Chapter 1. Components
The Red Hat OpenStack Platform IaaS cloud is implemented as a collection of interacting services that control compute, storage, and networking resources. The cloud can be managed with a web-based dashboard or command-line clients, which allow administrators to control, provision, and automate OpenStack resources. OpenStack also has an extensive API, which is also available to all cloud users.
The following diagram provides a high-level overview of the OpenStack core services and their relationship with each other.
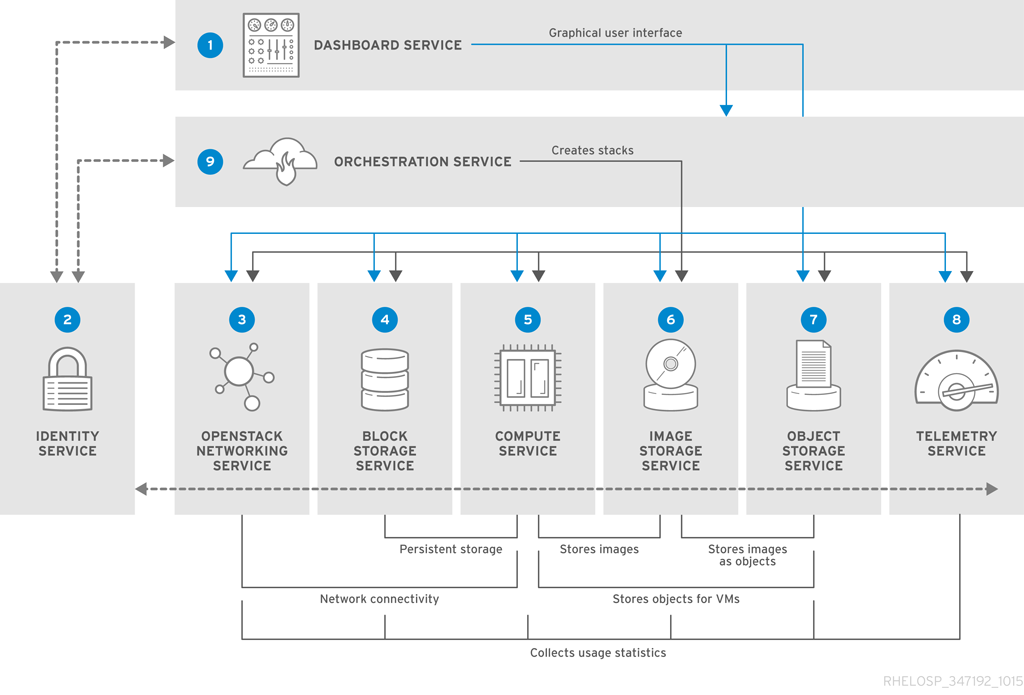
The following table describes each component shown in the diagram and provides links for the component documentation section.
| Service | Code | Description | Location | |
|---|---|---|---|---|
|
| Dashboard | horizon | Web browser-based dashboard that you use to manage OpenStack services. | |
|
| Identity | keystone | Centralized service for authentication and authorization of OpenStack services and for managing users, projects, and roles. | |
|
| OpenStack Networking | neutron | Provides connectivity between the interfaces of OpenStack services. | |
|
| Block Storage | cinder | Manages persistent block storage volumes for virtual machines. | |
|
| Compute | nova | Manages and provisions virtual machines running on hypervisor nodes. | |
|
| Image | glance | Registry service that you use to store resources such as virtual machine images and volume snapshots. | |
|
| Object Storage | swift | Allows users to store and retrieve files and arbitrary data. | |
|
| Telemetry | ceilometer | Provides measurements of cloud resources. | |
|
| Orchestration | heat | Template-based orchestration engine that supports automatic creation of resource stacks. |









Each OpenStack service contains a functional group of Linux services and other components. For example, the glance-api and glance-registry Linux services, together with a MariaDB database, implement the Image service. For information about third-party components included in OpenStack services, see Section 1.6.1, “Third-party Components”.
Additional services are:
- Section 1.3.2, “OpenStack Bare Metal Provisioning (ironic)” - Enables users to provision physical machines (bare metal) with a variety of hardware vendors.
- Section 1.3.5, “OpenStack Data Processing (sahara)” - Enables users to provision and manage Hadoop clusters on OpenStack.
1.1. Networking
1.1.1. OpenStack Networking (neutron)
OpenStack Networking handles creation and management of a virtual networking infrastructure in the OpenStack cloud. Infrastructure elements include networks, subnets, and routers. You can also deploy advanced services such as firewalls or virtual private networks (VPN).
OpenStack Networking provides cloud administrators with flexibility to decide which individual services to run on which physical systems. All service daemons can be run on a single physical host for evaluation purposes. Alternatively, each service can have a unique physical host or replicated across multiple hosts to provide redundancy.
Because OpenStack Networking is software-defined, it can react in real-time to changing network needs, such as creation and assignment of new IP addresses.
OpenStack Networking advantages include:
- Users can create networks, control traffic, and connect servers and devices to one or more networks.
- Flexible networking models can adapt to the network volume and tenancy.
- IP addresses can be dedicated or floating, where floating IPs can be used for dynamic traffic rerouting.
- If using VLAN networking, you can use a maximum of 4094 VLANs (4094 networks), where 4094 = 2^12 (minus 2 unusable) network addresses, which is imposed by the 12-bit header limitation.
- If using VXLAN tunnel-based networks, the VNI (Virtual Network Identifier) can use a 24-bit header, which will essentially allow around 16 million unique addresses/networks.
| Component | Description |
|---|---|
| Network agent | Service that runs on each OpenStack node to perform local networking configuration for the node virtual machines and for networking services such as Open vSwitch. |
| neutron-dhcp-agent | Agent that provides DHCP services to tenant networks. |
| neutron-ml2 | Plug-in that manages network drivers and provides routing and switching services for networking services such as Open vSwitch or Ryu networks. |
| neutron-server | Python daemon that manages user requests and exposes the Networking API. The default server configuration uses a plug-in with a specific set of networking mechanisms to implement the Networking API. Certain plug-ins, such as the openvswitch and linuxbridge plug-ins, use native Linux networking mechanisms, while other plug-ins interface with external devices or SDN controllers. |
| neutron | Command-line client to access the API. |
The placement of OpenStack Networking services and agents depends on the network requirements. The following diagram shows an example of a common deployment model without a controller. This model utilizes a dedicated OpenStack Networking node and tenant networks.
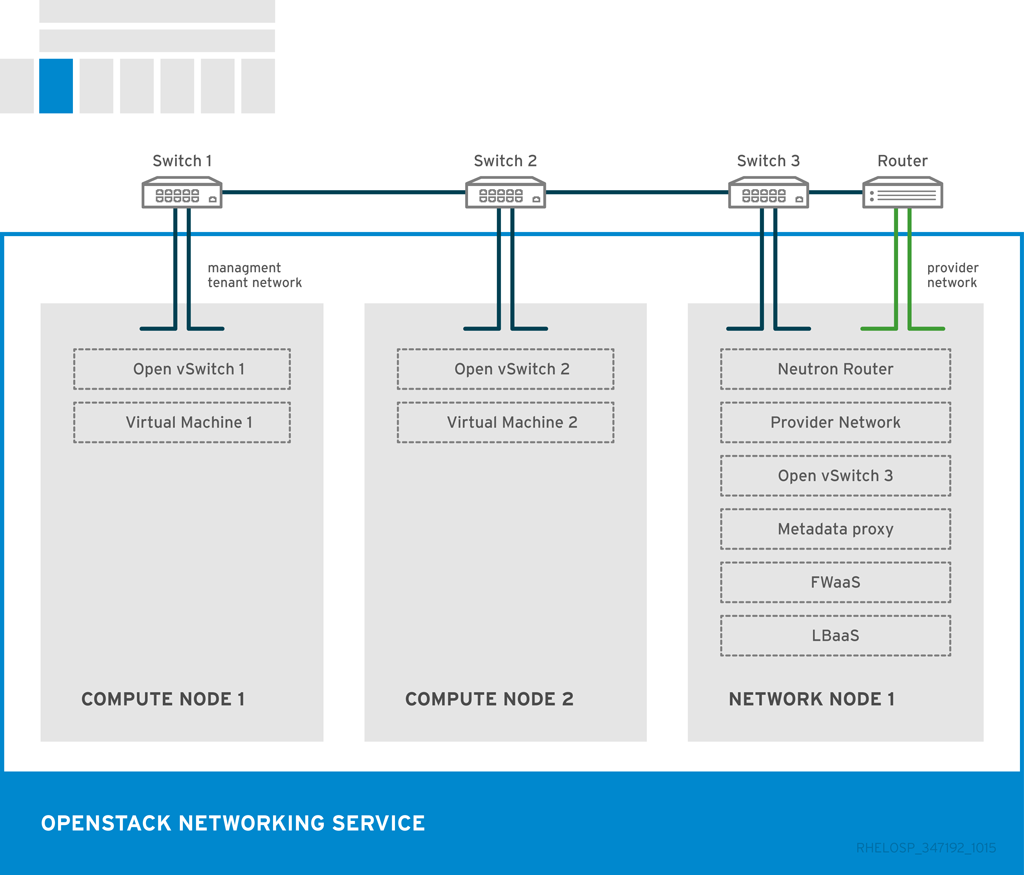
The example shows the following Networking service configuration:
Two Compute nodes run the Open vSwitch (ovs-agent), and one OpenStack Networking node performs the following network functions:
- L3 routing
- DHCP
- NAT including services such as FWaaS and LBaaS
- The compute nodes have two physical network cards each. One card handles tenant traffic, and the other card manages connectivity.
- The OpenStack Networking node has a third network card dedicated to provider traffic.
1.2. Storage
Section 1.2.1, “OpenStack Block Storage (cinder)”
Section 1.2.2, “OpenStack Object Storage (swift)”
1.2.1. OpenStack Block Storage (cinder)
OpenStack Block Storage provides persistent block storage management for virtual hard drives. Block Storage enables the user to create and delete block devices, and to manage attachment of block devices to servers.
The actual attachment and detachment of devices is handled through integration with the Compute service. You can use regions and zones to handle distributed block storage hosts.
You can use Block Storage in performance-sensitive scenarios, such as database storage or expandable file systems. You can also use it as a server with access to raw block-level storage. Additionally, you can take volume snapshots to restore data or to create new block storage volumes. Snapshots are dependent on driver support.
OpenStack Block Storage advantages include:
- Creating, listing and deleting volumes and snapshots.
- Attaching and detaching volumes to running virtual machines.
Although the main Block Storage services, such as volume, scheduler, API, can be co-located in a production environment, it is more common to deploy multiple instances of the volume service along one or more instances of the API and scheduler services to manage them.
| Component | Description |
|---|---|
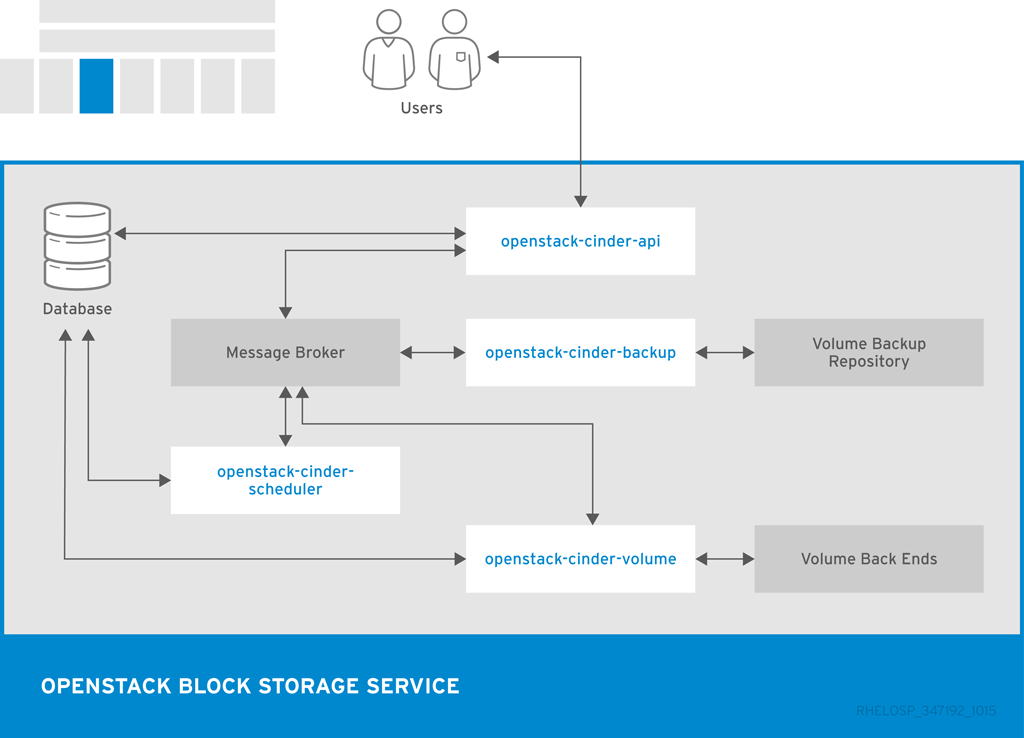
| openstack-cinder-api | Responds to requests and places them in the message queue. When a request is received, the API service verifies that identity requirements are met and translates the request into a message that includes the required block storage action. The message is then sent to the message broker for processing by the other Block Storage services. |
| openstack-cinder-backup | Backs up a Block Storage volume to an external storage repository. By default, OpenStack uses the Object Storage service to store the backup. You can also use Ceph or NFS back ends as storage repositories for backups. |
| openstack-cinder-scheduler | Assigns tasks to the queue and determines the provisioning volume server. The scheduler service reads requests from the message queue and determines on which block storage host to perform the requested action. The scheduler then communicates with the openstack-cinder-volume service on the selected host to process the request. |
| openstack-cinder-volume | Designates storage for virtual machines. The volume service manages the interaction with the block-storage devices. When requests arrive from the scheduler, the volume service can create, modify, or remove volumes. The volume service includes several drivers to interact with the block-storage devices, such as NFS, Red Hat Storage, or Dell EqualLogic. |
| cinder | Command-line client to access the Block Storage API. |
The following diagram shows the relationship between the Block Storage API, the scheduler, the volume services, and other OpenStack components.
1.2.2. OpenStack Object Storage (swift)
Object Storage provides an HTTP-accessible storage system for large amounts of data, including static entities such as videos, images, email messages, files, or VM images. Objects are stored as binaries on the underlying file system along with metadata stored in the extended attributes of each file.
The Object Storage distributed architecture supports horizontal scaling as well as failover redundancy with software-based data replication. Because the service supports asynchronous and eventual consistency replication, you can use it in a multiple data-center deployment.
OpenStack Object Storage advantages include:
- Storage replicas maintain the state of objects in case of outage. A minimum of three replicas is recommended.
- Storage zones host replicas. Zones ensure that each replica of a given object can be stored separately. A zone might represent an individual disk drive, an array, a server, a server rack, or even an entire data center.
- Storage regions can group zones by location. Regions can include servers or server farms that are usually located in the same geographical area. Regions have a separate API endpoint for each Object Storage service installation, which allows for a discrete separation of services.
Object Storage uses ring .gz files, which serve as database and configuration files. These files contain details of all the storage devices and mappings of stored entities to the physical location of each file. Therefore, you can use ring files to determine the location of specific data. Each object, account, and container server has a unique ring file.
The Object Storage service relies on other OpenStack services and components to perform actions. For example, the Identity Service (keystone), the rsync daemon, and a load balancer are all required.
| Component | Description |
|---|---|
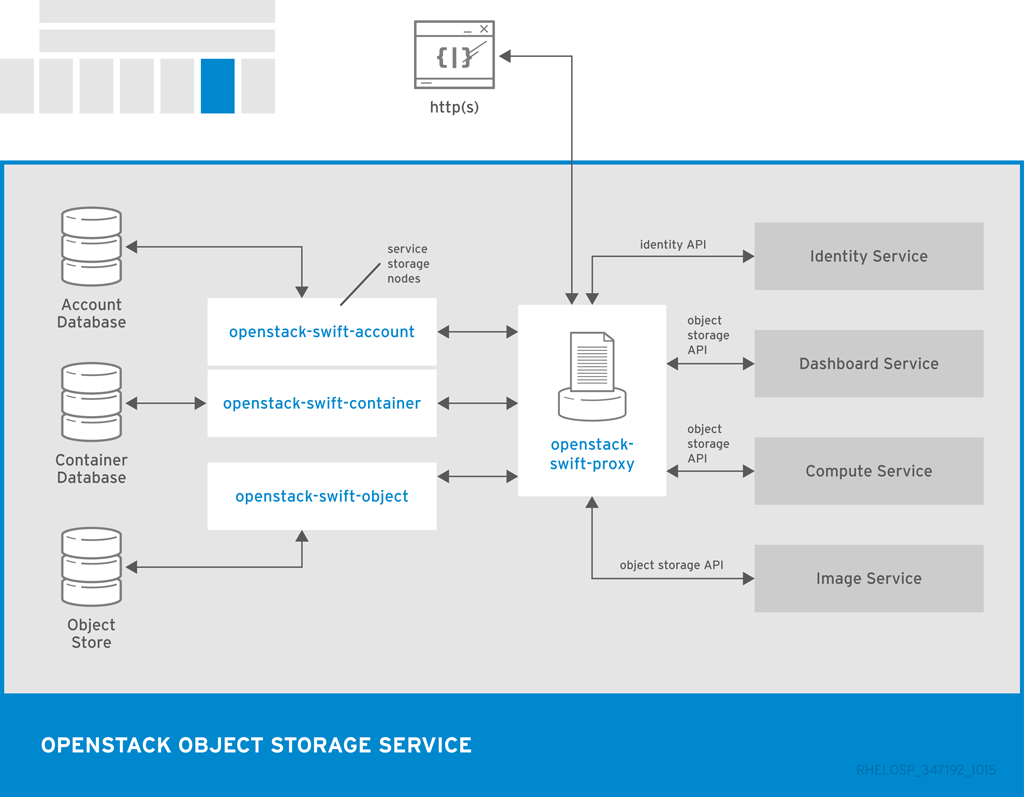
| openstack-swift-account | Handles listings of containers with the account database. |
| openstack-swift-container | Handles listings of objects that are included in a specific container with the container database. |
| openstack-swift-object | Stores, retrieves, and deletes objects. |
| openstack-swift-proxy | Exposes the public API, provides authentication, and routes requests. Objects are streamed through the proxy server to the user without spooling. |
| swift | Command-line client to access the Object Storage API. |
| Housekeeping | Components | Description |
|---|---|---|
| Auditing |
| Verifies the integrity of Object Storage accounts, containers, and objects, and helps to protect against data corruption. |
| Replication |
| Ensures consistent and available replication throughout the Object Storage cluster, including garbage collection. |
| Updating |
| Identifies and retries failed updates. |
The following diagram shows the main interfaces that the Object Storage uses to interact with other OpenStack services, databases, and brokers.
1.3. Virtual Machines, Images, and Templates
Section 1.3.1, “OpenStack Compute (nova)”
Section 1.3.2, “OpenStack Bare Metal Provisioning (ironic)”
Section 1.3.3, “OpenStack Image (glance)”
Section 1.3.4, “OpenStack Orchestration (heat)”
Section 1.3.5, “OpenStack Data Processing (sahara)”
1.3.1. OpenStack Compute (nova)
OpenStack Compute serves as the core of the OpenStack cloud by providing virtual machines on demand. Compute schedules virtual machines to run on a set of nodes by defining drivers that interact with underlying virtualization mechanisms, and by exposing the functionality to the other OpenStack components.
Compute supports the libvirt driver libvirtd that uses KVM as the hypervisor. The hypervisor creates virtual machines and enables live migration from node to node. To provision bare metal machines, you can also use Section 1.3.2, “OpenStack Bare Metal Provisioning (ironic)”.
Compute interacts with the Identity service to authenticate instance and database access, with the Image service to access images and launch instances, and with the dashboard service to provide user and administrative interface.
You can restrict access to images by project and by user, and specify project and user quota, such as the number of instances that can be created by a single user.
When you deploy a Red Hat OpenStack Platform cloud, you can break down the cloud according to different categories:
- Regions
Each service cataloged in the Identity service is identified by the service region, which typically represents a geographical location, and the service endpoint. In a cloud with multiple compute nodes, regions enable discrete separation of services.
You can also use regions to share infrastructure between Compute installations while maintaining a high degree of failure tolerance.
- Cells (Technology Preview)
The Compute hosts can be partitioned into groups called cells to handle large deployments or geographically separate installations. Cells are configured in a tree, where the top-level cell, called the API cell, runs the nova-api service but no nova-compute services.
Each child cell in the tree runs all other typical nova-* services but not the nova-api service. Each cell has a separate message queue and database service, and also runs the nova-cells service that manages the communication between the API cell and the child cells.
The benefits of cells include:
- You can use a single API server to control access to multiple Compute installations.
- An additional level of scheduling at the cell level is available that, unlike host scheduling, provides greater flexibility and control when you run virtual machines.
This feature is available in this release as a Technology Preview, and therefore is not fully supported by Red Hat. It should only be used for testing, and should not be deployed in a production environment. For more information about Technology Preview features, see Scope of Coverage Details.
- Host Aggregates and Availability Zones
A single Compute deployment can be partitioned into logical groups. You can create multiple groups of hosts that share common resources such as storage and network, or groups that share a special property such as trusted computing hardware.
To administrators, the group is presented as a Host Aggregate with assigned compute nodes and associated metadata. The Host Aggregate metadata is commonly used to provide information for openstack-nova-scheduler actions, such as limiting specific flavors or images to a subset of hosts.
To users, the group is presented as an Availability Zone. The user cannot view the group metadata or see the list of hosts in the zone.
The benefits of aggregates, or zones, include:
- Load balancing and instance distribution.
- Physical isolation and redundancy between zones, implemented with a separate power supply or network equipment.
- Labeling for groups of servers that have common attributes.
- Separation of different classes of hardware.
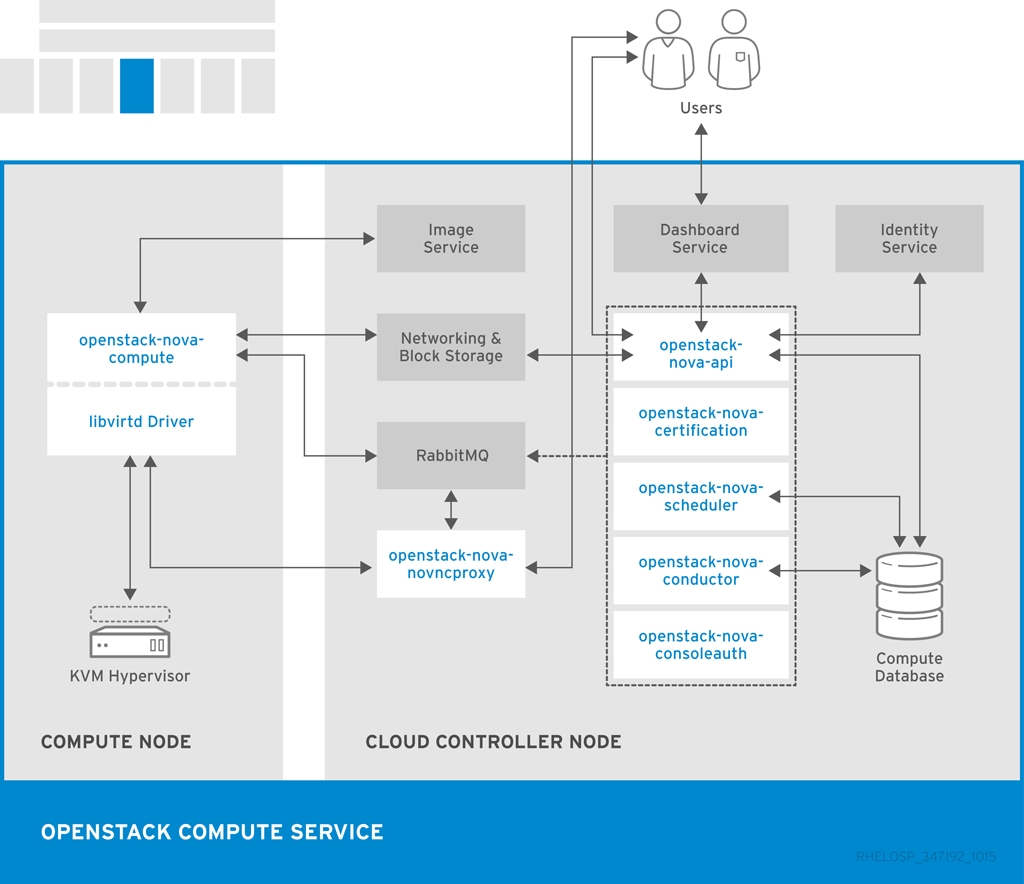
| Component | Description |
|---|---|
| openstack-nova-api | Handles requests and provides access to the Compute services, such as booting an instance. |
| openstack-nova-cert | Provides the certificate manager. |
| openstack-nova-compute | Runs on each node to create and terminate virtual instances. The compute service interacts with the hypervisor to launch new instances, and ensures that the instance state is maintained in the Compute database. |
| openstack-nova-conductor | Provides database-access support for compute nodes to reduce security risks. |
| openstack-nova-consoleauth | Handles console authentication. |
| openstack-nova-novncproxy | Provides a VNC proxy for browsers to enable VNC consoles to access virtual machines. |
| openstack-nova-scheduler | Dispatches requests for new virtual machines to the correct node based on configured weights and filters. |
| nova | Command-line client to access the Compute API. |
The following diagram shows the relationship between the Compute services and other OpenStack components.
1.3.2. OpenStack Bare Metal Provisioning (ironic)
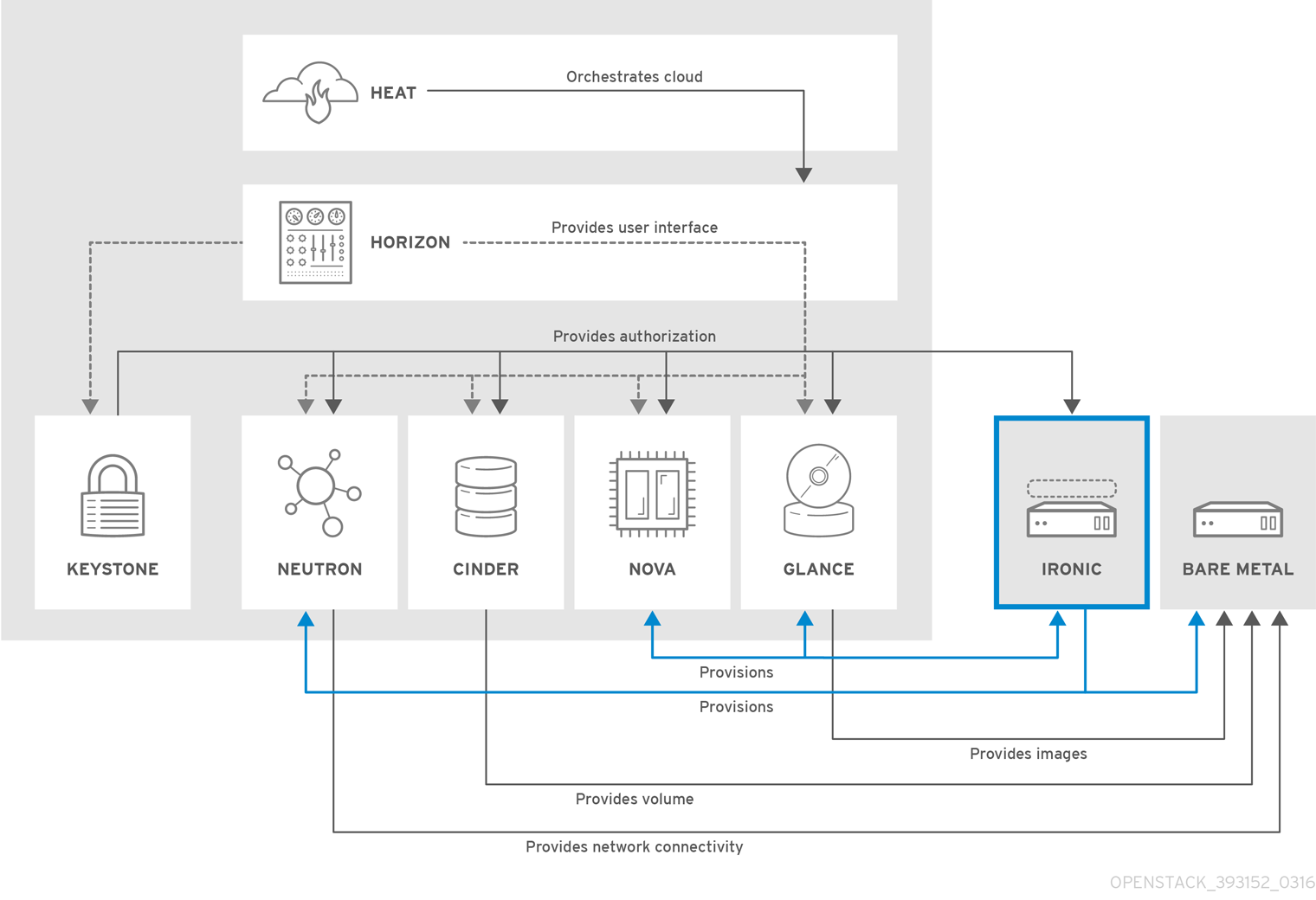
OpenStack Bare Metal Provisioning enables the user to provision physical, or bare metal machines, for a variety of hardware vendors with hardware-specific drivers. Bare Metal Provisioning integrates with the Compute service to provision the bare metal machines in the same way that virtual machines are provisioned, and provides a solution for the bare-metal-to-trusted-tenant use case.
OpenStack Baremetal Provisioning advantages include:
- Hadoop clusters can be deployed on bare metal machines.
- Hyperscale and high-performance computing (HPC) clusters can be deployed.
- Database hosting for applications that are sensitive to virtual machines can be used.
Bare Metal Provisioning uses the Compute service for scheduling and quota management, and uses the Identity service for authentication. Instance images must be configured to support Bare Metal Provisioning instead of KVM.
The following diagram shows how Ironic and the other OpenStack services interact when a physical server is being provisioned:
| Component | Description |
|---|---|
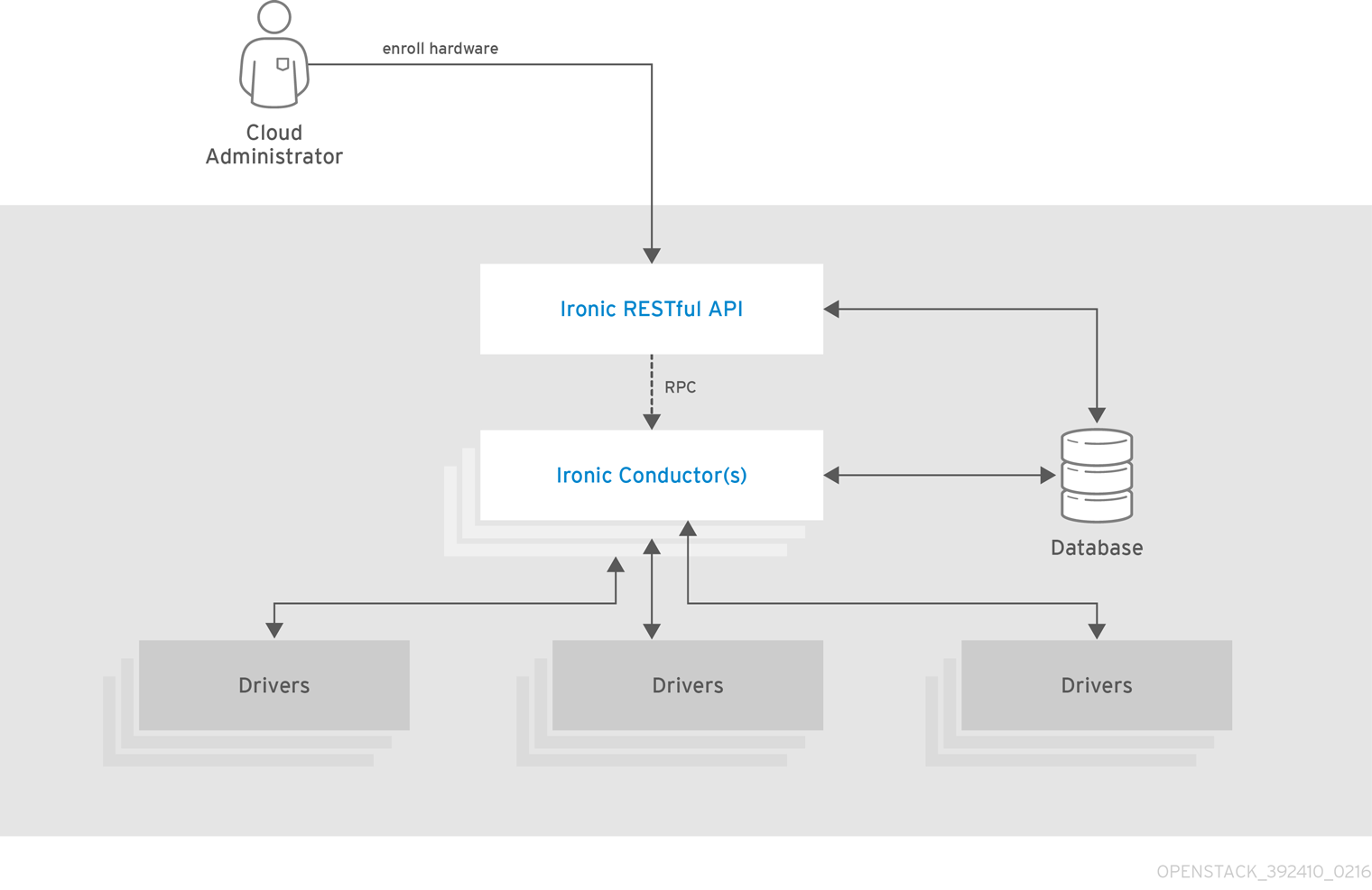
| openstack-ironic-api | Handles requests and provides access to Compute resources on the bare metal node. |
| openstack-ironic-conductor | Interacts directly with hardware and ironic databases, and handles requested and periodic actions. You can create multiple conductors to interact with different hardware drivers. |
| ironic | Command-line client to access the Bare Metal Provisioning API. |
The Ironic API is illustrated in following diagram:
1.3.3. OpenStack Image (glance)
OpenStack Image acts as a registry for virtual disk images. Users can add new images or take a snapshot of an existing server for immediate storage. You can use the snapshots for backup or as templates for new servers.
Registered images can be stored in the Object Storage service or in other locations, such as simple file systems or external Web servers.
The following image disk formats are supported:
- aki/ami/ari (Amazon kernel, ramdisk, or machine image)
- iso (archive format for optical discs, such as CDs)
- qcow2 (Qemu/KVM, supports Copy on Write)
- raw (unstructured format)
- vhd (Hyper-V, common for virtual machine monitors from vendors such as VMware, Xen, Microsoft, and VirtualBox)
- vdi (Qemu/VirtualBox)
- vmdk (VMware)
Container formats can also be registered by the Image service. The container format determines the type and detail level of the virtual machine metadata to store in the image.
The following container formats are supported:
- bare (no metadata)
- ova (OVA tar archive)
- ovf (OVF format)
- aki/ami/ari (Amazon kernel, ramdisk, or machine image)
| Component | Description |
|---|---|
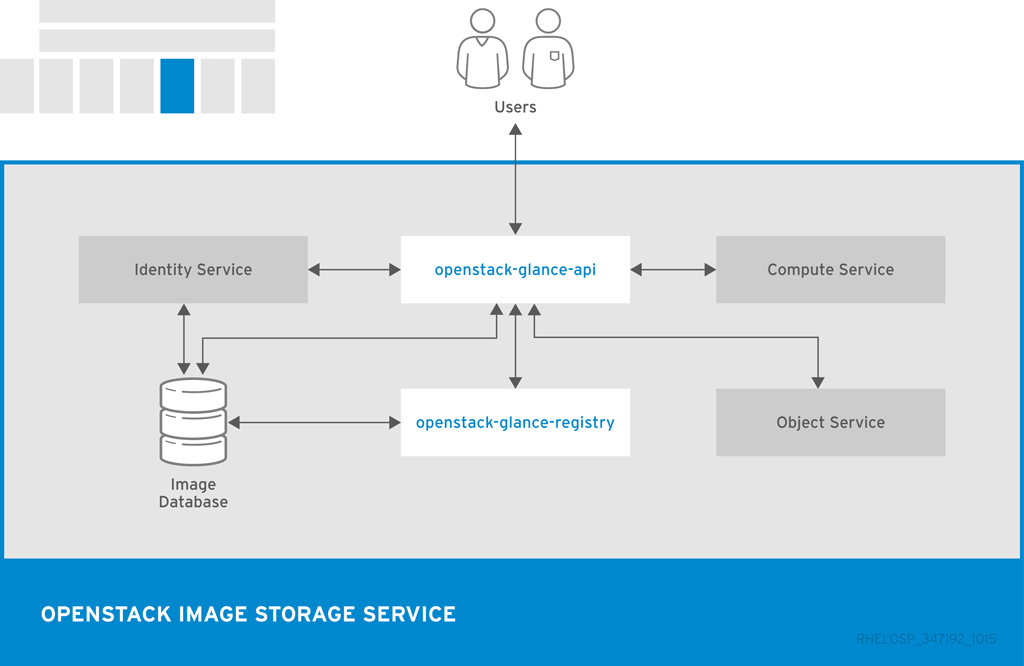
| openstack-glance-api | Interacts with storage back ends to handle requests for image retrieval and storage. The API uses openstack-glance-registry to retrieve image information. You must not access the registry service directly. |
| openstack-glance-registry | Manages all metadata for each image. |
| glance | Command-line client to access the Image API. |
The following diagram shows the main interfaces that the Image service uses to register and retrieve images from the Image database.
1.3.4. OpenStack Orchestration (heat)
OpenStack Orchestration provides templates to create and manage cloud resources such as storage, networking, instances, or applications. Templates are used to create stacks, which are collections of resources.
For example, you can create templates for instances, floating IPs, volumes, security groups, or users. Orchestration offers access to all OpenStack core services with a single modular template, as well as capabilities such as auto-scaling and basic high availability.
OpenStack Orchestration advantages include:
- A single template provides access to all underlying service APIs.
- Templates are modular and resource-oriented.
- Templates can be recursively defined and reusable, such as nested stacks. The cloud infrastructure can then be defined and reused in a modular way.
- Resource implementation is pluggable, which allows for custom resources.
- Resources can be auto-scaled, and therefore added or removed from the cluster based on usage.
- Basic high availability functionality is available.
| Component | Description |
|---|---|
| openstack-heat-api | OpenStack-native REST API that processes API requests by sending the requests to the openstack-heat-engine service over RPC. |
| openstack-heat-api-cfn | Optional AWS-Query API compatible with AWS CloudFormation that processes API requests by sending the requests to the openstack-heat-engine service over RPC. |
| openstack-heat-engine | Orchestrates template launch and generates events for the API consumer. |
| openstack-heat-cfntools | Package of helper scripts such as cfn-hup, which handle updates to metadata and execute custom hooks. |
| heat | Command-line tool that communicates with the Orchestration API to execute AWS CloudFormation APIs. |
The following diagram shows the main interfaces that the Orchestration service uses to create a new stack of two new instances and a local network.
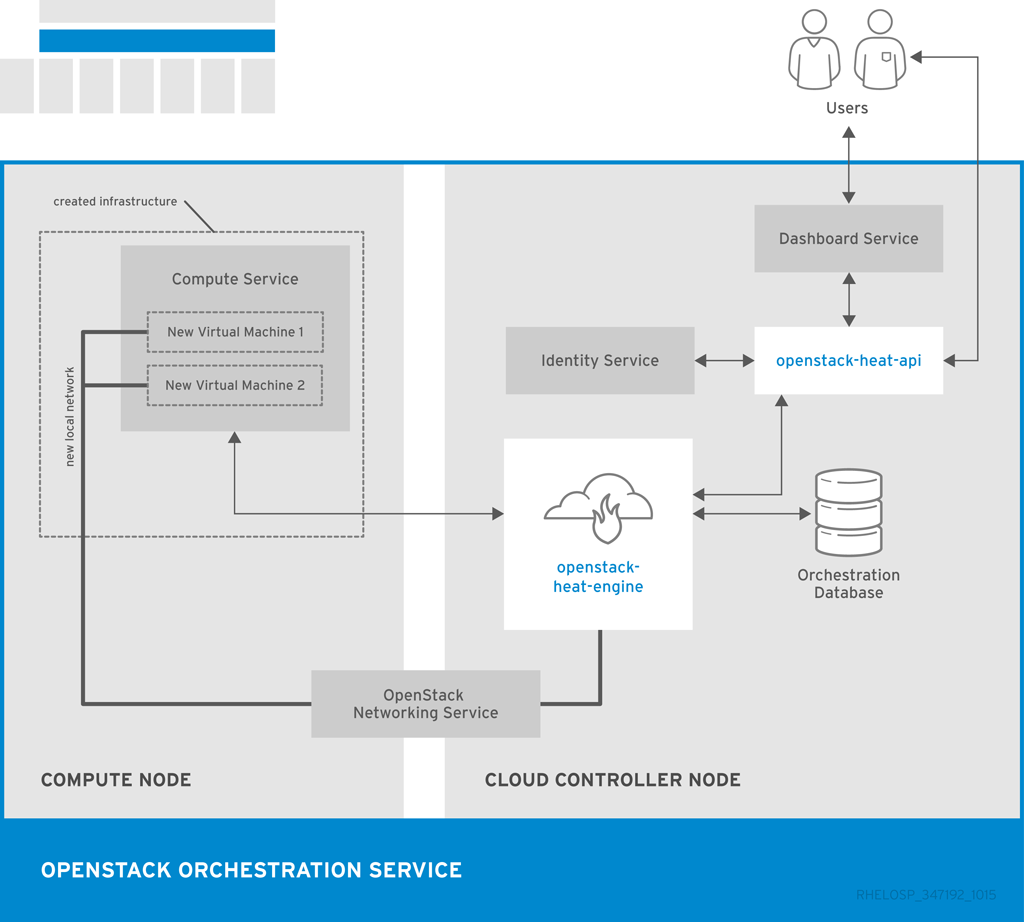
1.3.5. OpenStack Data Processing (sahara)
OpenStack Data Processing enables the provisioning and management of Hadoop clusters on OpenStack. Hadoop stores and analyze large amounts of unstructured and structured data in clusters.
Hadoop clusters are groups of servers that can act as storage servers running the Hadoop Distributed File System (HDFS), compute servers running Hadoop’s MapReduce (MR) framework, or both.
The servers in a Hadoop cluster need to reside in the same network, but they do not need to share memory or disks. Therefore, you can add or remove servers and clusters without affecting compatibility of the existing servers.
The Hadoop compute and storage servers are co-located, which enables high-speed analysis of stored data. All tasks are divided across the servers and utilizes the local server resources.
OpenStack Data Processing advantages include:
- Identity service can authenticate users and provide user security in the Hadoop cluster.
- Compute service can provision cluster instances.
- Image service can store cluster instances, where each instance contains an operating system and HDFS.
- Object Storage service can be used to store data that Hadoop jobs process.
- Templates can be used to create and configure clusters. Users can change configuration parameters by creating custom templates or overriding parameters during cluster creation. Nodes are grouped together using a Node Group template, and cluster templates combine Node Groups.
- Jobs can be used to execute tasks on Hadoop clusters. Job binaries store executable code, and data sources store input or output locations and any necessary credentials.
Data Processing supports the Cloudera (CDH) plug-in as well as vendor-specific management tools, such as Apache Ambari. You can use the OpenStack dashboard or the command-line tool to provision and manage clusters.
| Component | Description |
|---|---|
| openstack-sahara-all | Legacy package that handles API and engine services. |
| openstack-sahara-api | Handles API requests and provides access to the Data Processing services. |
| openstack-sahara-engine | Provisioning engine that handles cluster requests and data delivery. |
| sahara | Command-line client to access the Data Processing API. |
The following diagram shows the main interfaces that the Data Processing service uses to provision and manage a Hadoop cluster.
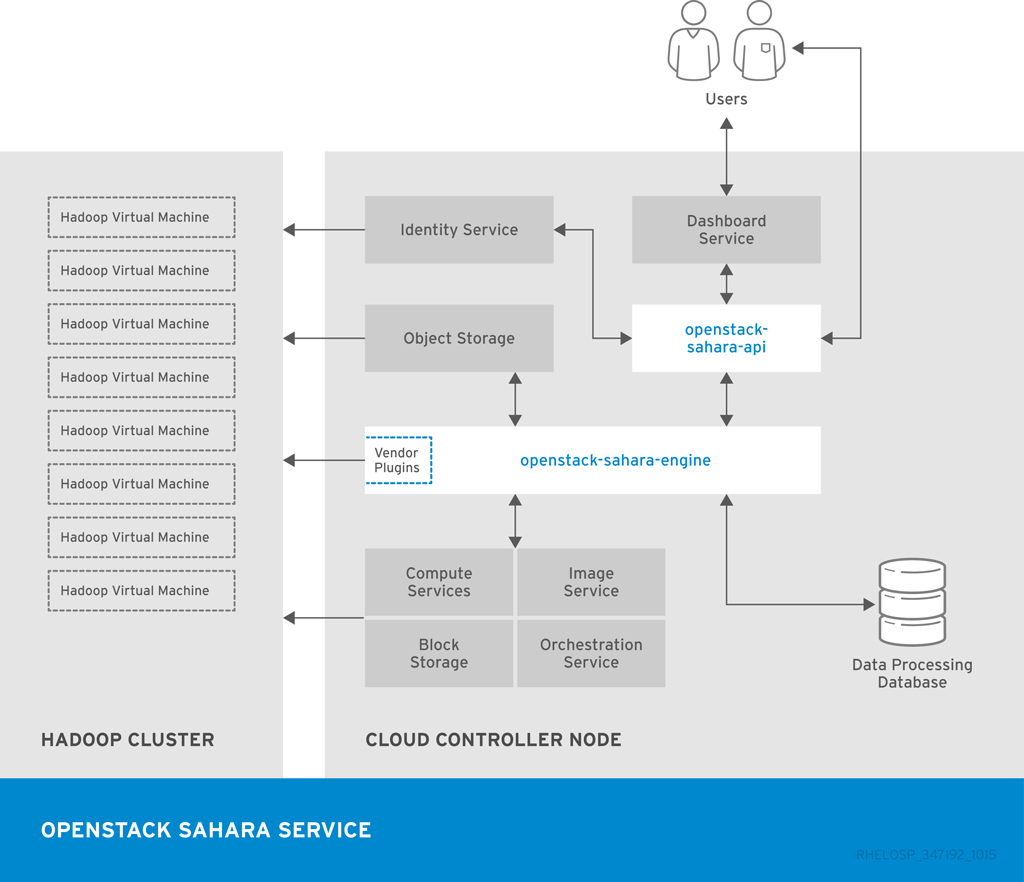
1.4. Identity Management
1.4.1. OpenStack Identity (keystone)
OpenStack Identity provides user authentication and authorization to all OpenStack components. Identity supports multiple authentication mechanisms, including user name and password credentials, token-based systems, and AWS-style log-ins.
By default, the Identity service uses a MariaDB back end for token, catalog, policy, and identity information. This back end is recommended for development environments or to authenticate smaller user sets. You can also use multiple identity back ends concurrently, such as LDAP and SQL. You can also use memcache or Redis for token persistence.
Identity supports Federation with SAML. Federated Identity establishes trust between Identity Providers (IdP) and the services that Identity provides to the end user.
Federated Identity and concurrent multiple back ends require Identity API v3 and Apache HTTPD deployment instead of Eventlet deployment.
OpenStack Identity advantages include:
- User account management, including associated information such as a name and password. In addition to custom users, a user must be defined for each cataloged service. For example, the glance user must be defined for the Image service.
- Tenant, or project, management. Tenants can be the user group, project, or organization.
- Role management. Roles determine the user permissions. For example, a role might differentiate between permissions for a sales rep and permissions for a manager.
- Domain management. Domains determine the administrative boundaries of Identity service entities, and support multi-tenancy, where a domain represents a grouping of users, groups, and tenants. A domain can have more than one tenant, and if you use multiple concurrent Identity providers, each provider has one domain.
| Component | Description |
|---|---|
| openstack-keystone | Provides Identity services, together with the administrative and public APIs. Both Identity API v2 and API v3 are supported. |
| keystone | Command-line client to access the Identity API. |
The following diagram shows the basic authentication flow that Identity uses to authenticate users with other OpenStack components.
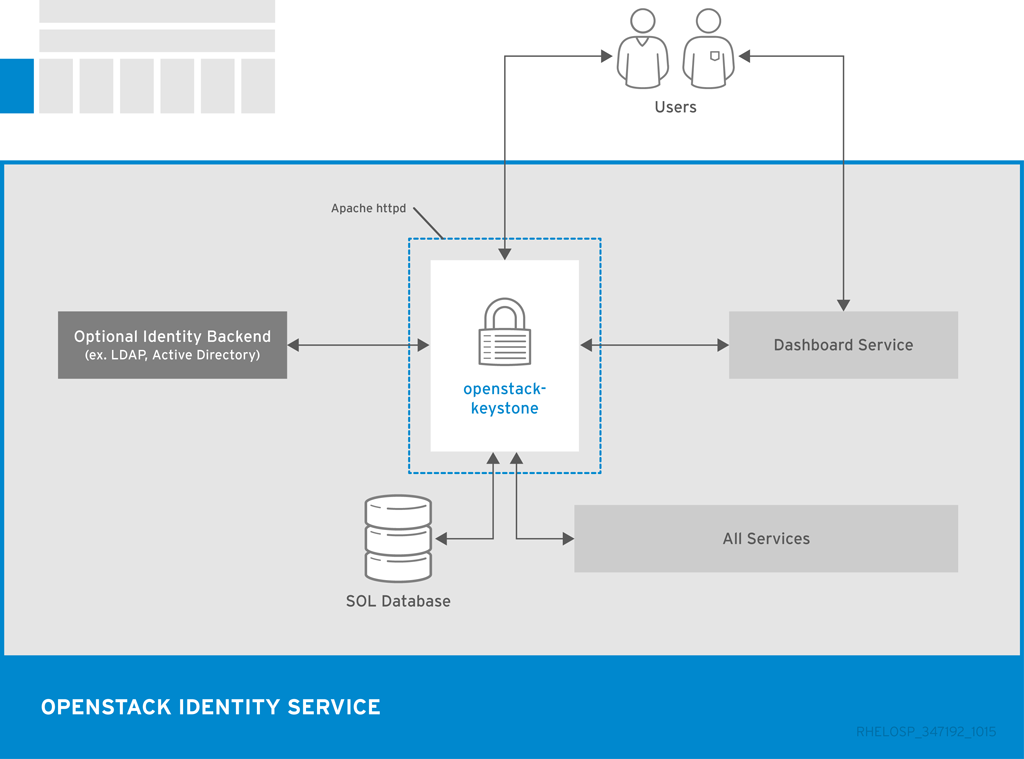
1.5. User Interfaces
Section 1.5.1, “OpenStack Dashboard (horizon)”
Section 1.5.2, “OpenStack Telemetry (ceilometer)”
1.5.1. OpenStack Dashboard (horizon)
OpenStack Dashboard provides a graphical user interface for users and administrators to perform operations such as creating and launching instances, managing networking, and setting access control.
The Dashboard service provides the Project, Admin, and Settings default dashboards. The modular design enables the dashboard to interface with other products such as billing, monitoring, and additional management tools.
The following image shows an example of the Compute panel in the Admin dashboard.
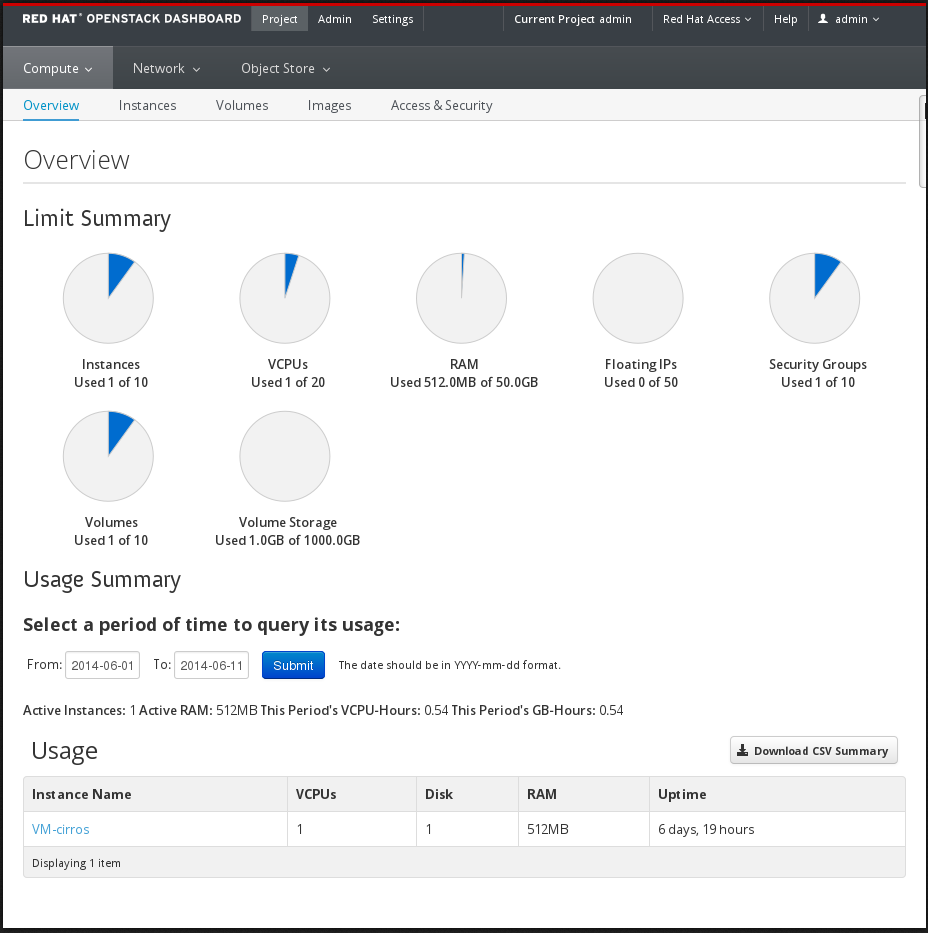
The role of the user that logs in to the dashboard determines which dashboards and panels are available.
| Component | Description |
|---|---|
| openstack-dashboard | Django Web application that provides access to the dashboard from any Web browser. |
| Apache HTTP server (httpd service) | Hosts the application. |
The following diagram shows an overview of the dashboard architecture.
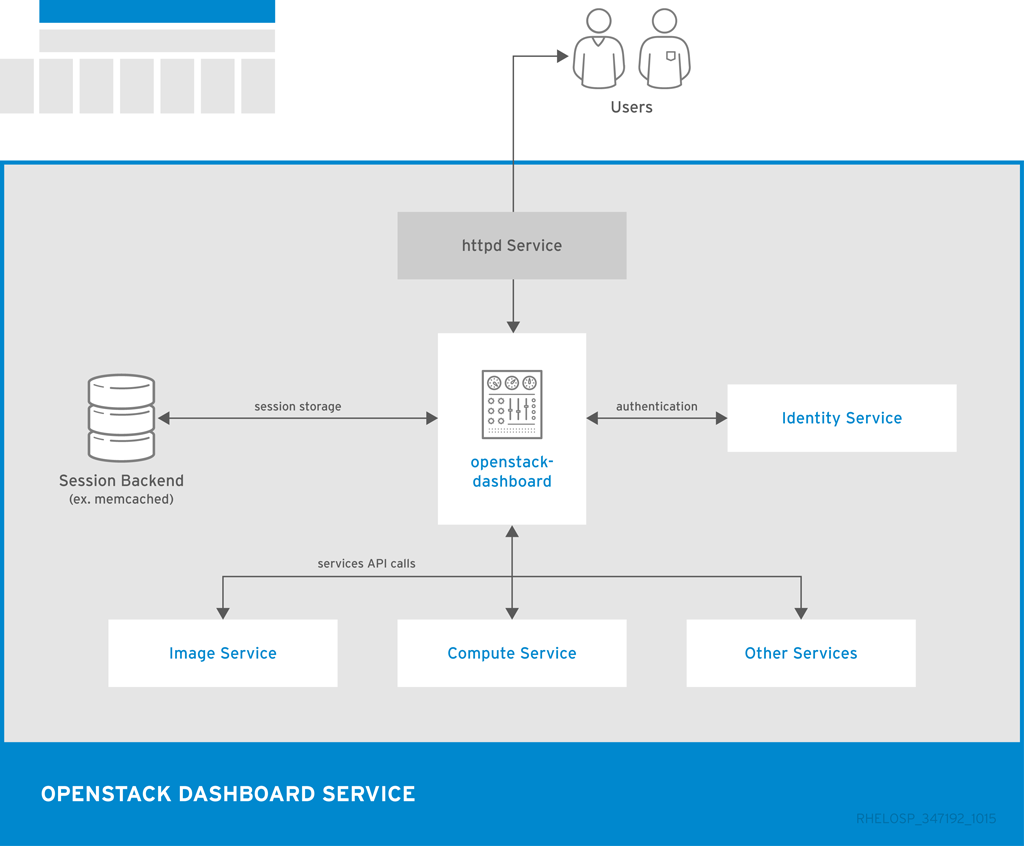
The example shows the following interaction:
- The OpenStack Identity service authenticates and authorizes users
- The session back end provides database services
- The httpd service hosts the Web application and all other OpenStack services for API calls
1.5.2. OpenStack Telemetry (ceilometer)
OpenStack Telemetry provides user-level usage data for OpenStack-based clouds. The data can be used for customer billing, system monitoring, or alerts. Telemetry can collect data from notifications sent by existing OpenStack components such as Compute usage events, or by polling OpenStack infrastructure resources such as libvirt.
Telemetry includes a storage daemon that communicates with authenticated agents through a trusted messaging system to collect and aggregate data. Additionally, the service uses a plug-in system that you can use to add new monitors. You can deploy the API Server, central agent, data store service, and collector agent on different hosts.
The service uses a MongoDB database to store collected data. Only the collector agents and the API server have access to the database.
The alarms and notifications are newly handled and controlled by the aodh service.
| Component | Description |
|---|---|
| openstack-aodh-api | Provides access to the alarm information stored in the data store. |
| openstack-aodh-alarm-evaluator | Determines when alarms fire due to the associated statistic trend crossing a threshold over a sliding time window. |
| openstack-aodh-alarm-notifier | Executes actions when alarms are triggered. |
| openstack-aodh-alarm-listener | Emits an alarm when a pre-defined event pattern occurs. |
| openstack-ceilometer-api | Runs on one or more central management servers to provide access to data in the database. |
| openstack-ceilometer-central | Runs on a central management server to poll for utilization statistics about resources independent from instances or Compute nodes. The agent cannot be horizontally scaled, so you can run only a single instance of this service at a time. |
| openstack-ceilometer-collector | Runs on one or more central management servers to monitor the message queues. Each collector processes and translates notification messages to Telemetry messages, and sends the messages back to the message bus with the relevant topic. Telemetry messages are written to the data store without modification. You can choose where to run these agents, because all intra-agent communication is based on AMQP or REST calls to the ceilometer-api service, similar to the ceilometer-alarm-evaluator service. |
| openstack-ceilometer-compute | Runs on each Compute node to poll for resource utilization statistics. Each nova-compute node must have a ceilometer-compute agent deployed and running. |
| openstack-ceilometer-notification | Pushes metrics to the collector service from various OpenStack services. |
| ceilometer | Command-line client to access the Telemetry API. |
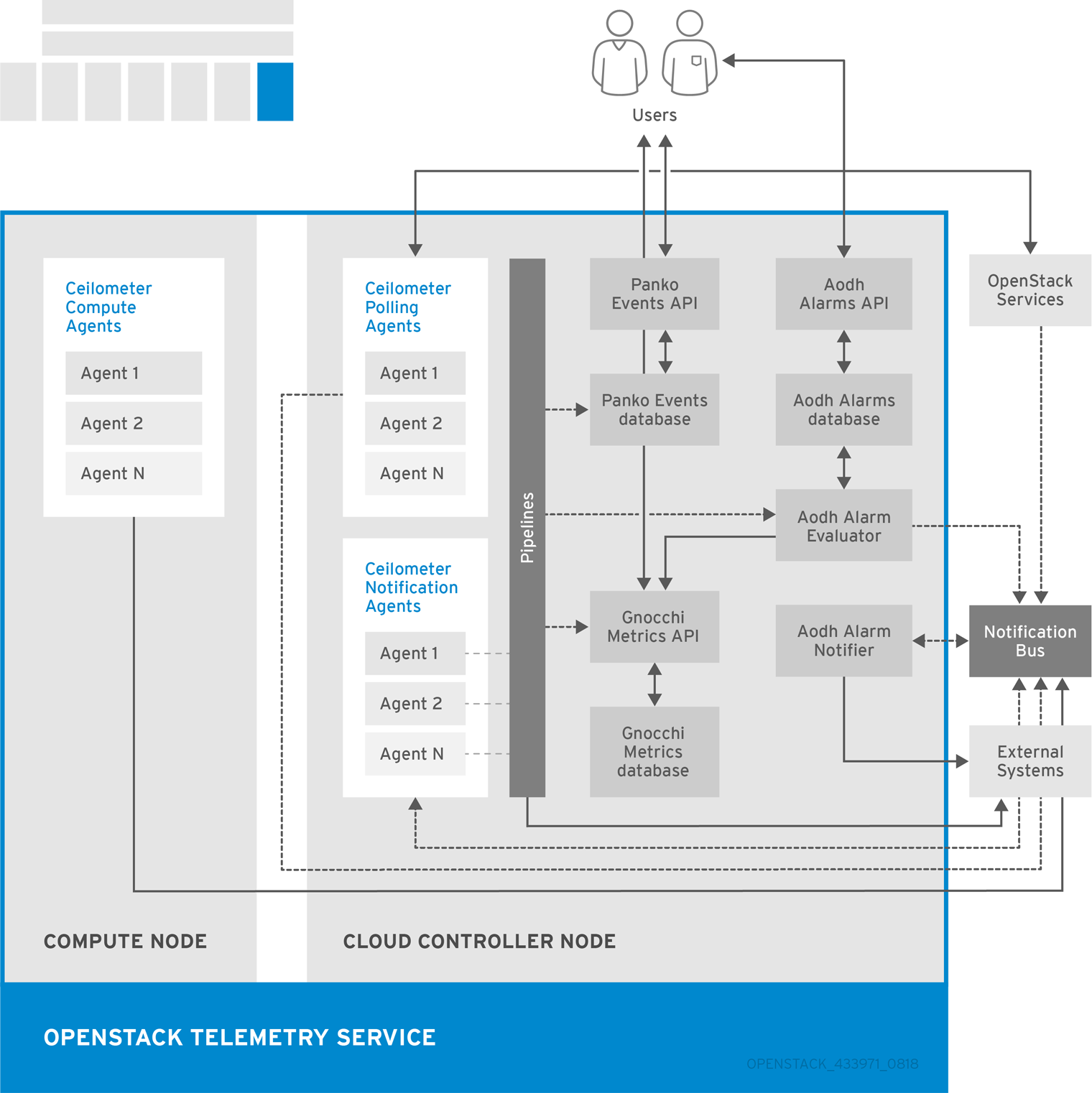
The following diagram shows the interfaces used by the Telemetry service.
1.6. Third-party Components
1.6.1. Third-party Components
Some Red Hat OpenStack Platform components use third-party databases, services, and tools.
1.6.1.1. Databases
- MariaDB is the default database that is shipped with Red Hat Enterprise Linux. MariaDB enables Red Hat to fully support open source community-developed software. Each OpenStack component except Telemetry requires a running MariaDB service. Therefore, you need to deploy MariaDB before you deploy a full OpenStack cloud service or before you install any standalone OpenStack component.
- The Telemetry service uses a MongoDB database to store collected usage data from collector agents. Only the collector agents and the API server have access to the database.
1.6.1.2. Messaging
RabbitMQ is a robust open-source messaging system based on the AMQP standard. RabbitMQ is a high-performance message broker used in many enterprise systems with widespread commercial support. In Red Hat OpenStack Platform, RabbitMQ is the default and recommended message broker.
RabbitMQ manages OpenStack transactions including queuing, distribution, security, management, clustering, and federation. It also serves a key role in high availability and clustering scenarios.
1.6.1.3. External Caching
External applications for caching, such as memcached or Redis, offer persistence and shared storage and speed up dynamic web applications by reducing the database load. External caching is used by various OpenStack components, for example:
- The Object Storage service uses memcached to cache authenticated clients, instead of requiring each client to re-authorize each interaction.
- By default, the dashboard uses memcached for session storage.
- The Identity service uses Redis or memcached for token persistence.