Este contenido no está disponible en el idioma seleccionado.
Chapter 1. Using cost models and analyzing your usage
You can use cost models in cost management to apply a price to usage in your hybrid cloud environment, then distribute the costs to resources.
1.1. Understanding cost models
It can be difficult to determine the real cost of cloud-based IT systems. Different integrations provide a variety of cost data and metrics, which make it complicated to calculate and accurately distribute costs. A cost model is a framework that cost management uses to determine the calculations to apply to costs. With a cost model, you can associate a price to metrics provided by your integrations and charge for utilization of resources.
In some cases, costs are related to the raw costs of the infrastructure, while in other cases there is a price list that maps usage to costs. Your data must be normalized before you can add a markup to cover your overhead and distribute the charges to your resources or end customers. With a cost model, you can better align costs to utilization: customers that use a resource more will be charged more.
A cost model can have multiple different integrations assigned to it, but a single integration can be mapped to only one cost model.
1.2. Cost model concepts and terminology
The following terms are important for understanding the cost management cost model workflow:
- Cost model
- A cost model is a framework that defines the calculations that cost management uses for costs. Cost models use raw costs and metrics to help you with budgeting, accounting, visualization, and analysis. In cost management, cost models provide the basis for your cost information and enable you to record, categorize, and allocate costs to specific customers, business units, or projects.
- Count-based costs
- A charge applied per unit of a specific resource, such as persistent volume claims, nodes, or clusters. You are charged for each individual element identified. For example, if you charge $10 per node and your environment has 10 nodes, the final charge is $100.
- Distributed costs
- The costs calculated by the cost model that get distributed to higher level application concepts such as projects, accounts, and services. The cost type in the cost model, either infrastructure or supplementary, determines how costs are distributed.
- Effective usage
- The pod resources that are used or requested each hour, whichever value is higher
- Infrastructure raw cost
- The portion of a Hyperscaler’s cost that is matched to your OpenShift usage. This cost is identified by direct resource matching or special OpenShift tags.
- Markup
- The portion of cost that is calculated by applying markup or discount to infrastructure raw cost in cost management. For example, if you have a raw cost of $100 and a markup of 10%, the markup is $10 and the cost is $110.
- Monthly cost
- The portion of cost calculated by applying monthly price list rates to metrics that are returned as part of usage cost. Monthly cost can be configured for OpenShift nodes or clusters in a cost model to account for subscription costs and are displayed as part of the usage costs in the cost management API and interface. For example, for an OpenShift cluster with 10 nodes at a rate of $10,000 per node per month, the monthly cost is $100,000.
Monthly costs are distributed evenly throughout the billing period.
- Price list
- A list of rates used in a cost model to calculate the usage cost of resources
- Request
- The pod resources that were requested according to OpenShift
- Distributed costs
- The costs calculated by the cost model that get distributed to higher level application concepts such as projects, accounts, and services. The cost type in the cost model, either infrastructure or supplementary, determines how costs are distributed.
- Usage cost
- The portion of cost calculated by applying hourly or monthly price list rates to metrics. For example, if a metric has 100 core-hours and a rate of $1 per core-hour, the usage cost is $100.
1.3. Cost model metrics
There are hidden costs associated with running an OpenShift cluster. Many of these costs are from subscriptions related to CPU core metrics. To better capture these costs and distribute them to user projects, cost models have the following metrics:
| Metric | Definition | Example calculation |
|---|---|---|
| Cluster - Core-hour | The subscription cost that applies to the entire cluster based on total CPU core hours |
Formula: Example: 16 * 24 * 2 = $768 |
| Node - Core-hour | The hourly subscription models that apply to the node based on the total CPU core hours This metric can also be used with tag-based rates to differentiate Infra and Worker node costs. | Example one calculation: 4 * 24 * 2 = $192 Example two calculations: - Node 1: 4 * 24 * 2 = $192 - Node 2: 4 * 24 * 4 = $384 |
| Node - Core-month | The monthly subscription models that apply to the node based on the total CPU core hours This metric can also be used with tag-based rates to differentiate Infra and Worker node costs. This metric has a daily amortization schedule based on the number of days in a month. |
Formula: Monthly example: 2 * 100 = $200 Daily amortized example for March (31 days): 200/31 = $6.45 per day |
| Cluster - hour | The subscription cost that applies to a cluster based on running hours. It is not dependent on CPU cores. | A cluster has been running for one full day and has a user-defined rate of $10 per hour.
Formula: Example: 24 * 10 = $240 |
| VM - Core | To get more precise control over your billing, you can now bill Virtual Machines (VMs) based on the number of physical VM cores that are utilized. This new VM core metric enables you to bill either hourly or monthly. Your system must be running on Operator Release 4.0.0 or later. |
Monthly, where the rate is spread out evenly across all days in the month:
Hourly: |
1.4. The cost model workflow
The following diagram shows the cost model workflow that cost management uses to apply a price to metrics and inventory, normalize cost data from different integrations, apply a markup (or discount), then distribute the costs across the relevant resources.
The cost model also helps differentiate raw costs from the costs used in cost management.
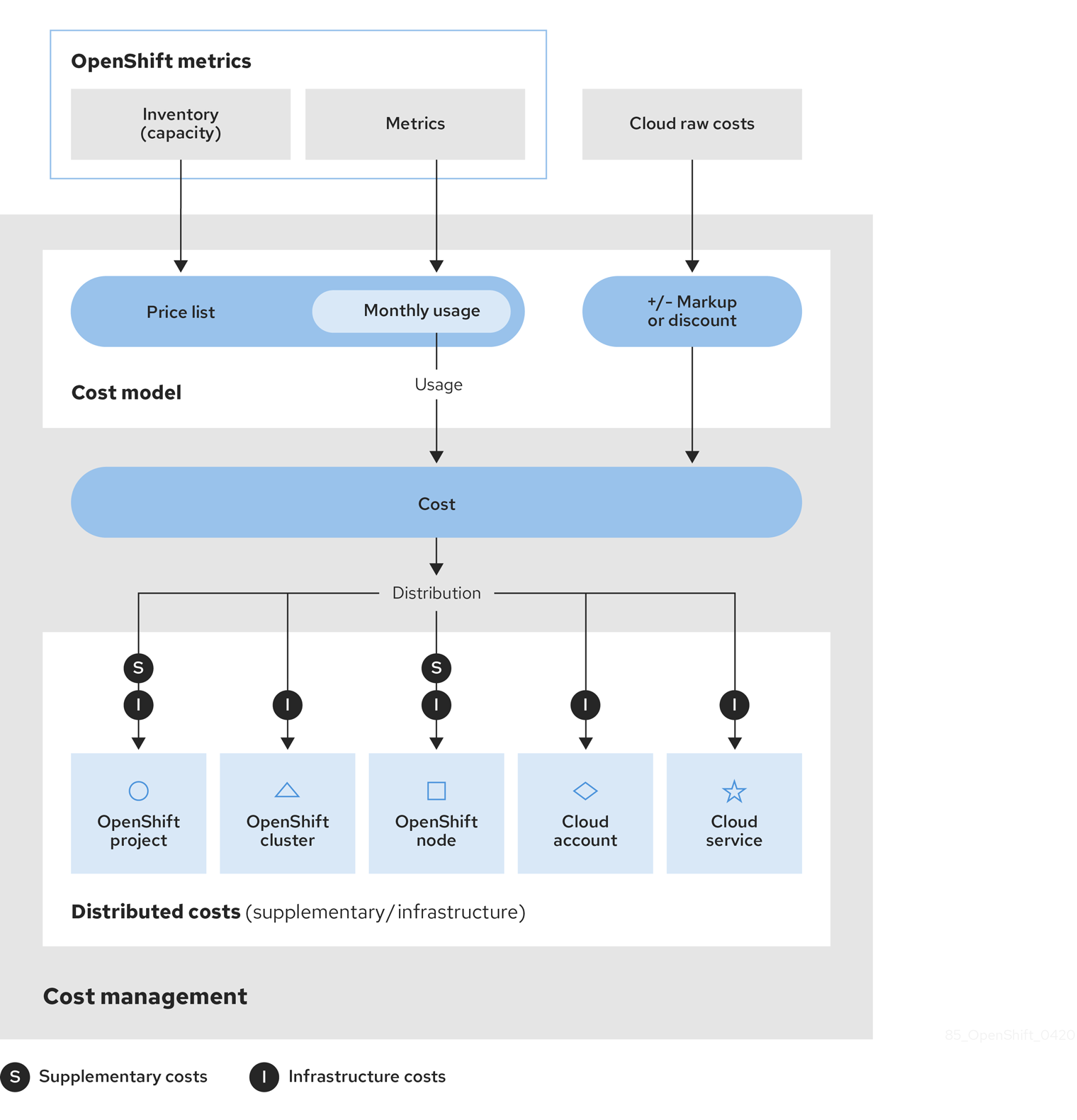
Cost management collects cost data from several integrations:
- Inventory - All the resources that have ever run in your integration, including those that are no longer in use. For example, if your OpenShift Container Platform environment contains a node that is not in use, that node still costs $x amount per month. There are several ways to collect inventory data into cost management: cost management can generate inventory from the AWS data export, Azure or Google Cloud export, or OpenShift Metering Operator reports.
- Metrics - A subset of the OpenShift inventory showing usage and consumption for each resource.
- Cloud raw costs - AWS, Azure, and Google Cloud provide regular reports to cost management listing consumption of resources and their costs, which cost management uses for calculations. As a result, configuring a custom price list is not necessary for cloud integrations.
The cost model allows you to apply a markup or discount of your choice to account for other costs and overhead, and provides options for assigning a cost layer (infrastructure or supplementary) to costs:
- For OpenShift Container Platform integrations - Since the metrics and inventory data do not have a price assigned to usage, you must create and assign a price list to your integrations to determine the usage cost of these resources. A price list includes rates for storage, memory, CPU usage and requests, and clusters and nodes.
- For AWS, Azure, and Google Cloud integrations - You can create cost models for these integrations to account for any extra costs or overhead in your environment by applying a markup percentage, or a negative percentage to calculate a discount.
- Costs from integrations are then collected together and allocated as infrastructure cost and supplementary cost.
- The cost is then distributed to resources across the environment. Depending on your organization, these resources may include OpenShift projects, nodes, or clusters, and cloud integration services or accounts. You can also use tagging to distribute the costs by team, project, or group within your organization.
For more information about configuring tagging for cost management, see Managing cost data using tagging.
1.5. Analyzing unused cluster and node capacity
You can analyze your cluster usage with cost management by examining the unrequested capacity and unused capacity of your cluster. The unrequested capacity identifies how much of the requested resources are being used in the cluster. When this value is high, there are nodes in your cluster that are requesting more resources than it uses. You can find the nodes that are responsible and adjust your requests to make your cluster usage more efficient. However, the usage can exceed the amount requested, so the unused capacity can help you to understand if you should adjust the overall capacity.
- Request
- The pod resources requested, which OpenShift reports.
- Unrequested capacity
- is the requests minus the usage.
- Effective usage
- The pod resources used or requested each hour, whichever is higher.
- Unused capacity
- is the capacity minus the effective usage.
For more information, see Section 1.2, “Cost model concepts and terminology”.
Prerequisites
- You created a integration on Red Hat Hybrid Cloud Console.
Procedure
- Log in to the Red Hat Hybrid Cloud Console.
-
From the Services menu, click
. To view unused cluster capacity and unrequested cluster capacity:
-
In the Global Navigation, click
. - On the OpenShift details page, in the Group By menu, select Cluster. Filter by Cluster, then select a cluster from the results.
- On the Cost overview tab, you can see your unused capacity and unrequested capacity in the CPU tile. If the unrequested capacity is higher than your unused capacity, or the unrequested core-hours are too high as a percentage of capacity, you can search for the nodes in your cluster that are responsible.
-
In the Global Navigation, click
To view unused node capacity and unrequested node capacity:
-
In the Global Navigation, click
. - On the OpenShift details page, in the Group By menu, select Node. Filter by Node, then select a node from the results.
-
In the Global Navigation, click
- If the unrequested capacity is higher than your unused capacity, or the unrequested core-hours are too high as a percentage of capacity for your node, you can adjust them in your cloud service provider to optimize your cloud spending.
1.6. Understanding cost distribution in cost management
Costs can belong to three different groups:
- Platform costs
-
Costs that incur from running the OpenShift Container Platform. Platform costs include the cost of all projects with the label Default. These namespaces and projects contain
openshift-orkube-in the name. These projects were not created by the user but are required for OpenShift to run. You can optionally add namespaces and projects to platform costs. For more information, see Section 1.6.3, “Adding OpenShift projects”. - Worker unallocated costs
- Costs that represent any unused part of your worker node’s usage and request capacity.
- Network unattributed costs
- Costs associated with ingress and egress network traffic for individual nodes.
- Storage unattributed costs
- The amount of storage on a cloud provider’s physical disk that is not being used. The cost model uses the the cloud provider’s cost report to determine the size of the physical disk. It then calculates how much of the disk is not being used by subtracting the disk size from the persistent volume claim’s capacity.
1.6.1. Distributing costs
To configure the distribution of platform and worker unallocated costs into your projects, you can set costs to Distribute or Do not distribute. When you create a cost model, the costs are set to Distribute by default. A value of zero is applied to the platform projects costs because the costs are distributed to user projects.
The costs distribute into your project costs according to the sum of the effective CPU or the Memory usage of your cost model. Most users use the default Distribute setting to track platform and worker unallocated costs for their organizations.
If you instead set the costs to Do not distribute, the costs of each Platform project are displayed individually instead of spread across all of the projects. The worker unallocated cost still is calculated, but it appears as an individual project in the OpenShift details page. With this option, you cannot see how the costs would distribute to user projects.
You can always distribute platform or worker unallocated costs independently of each other, or you can choose to distribute none of them.
1.6.2. Calculating costs
Cost management uses effective usage to calculate both platform and worker unallocated costs, in addition to project costs.
To distribute platform costs, cost management uses the following formula:
(individual user project effective usage) / (sum of usage for all user project's effective usage) * (platform cost)
To distribute worker unallocated costs, cost management uses the following formula:
(individual user project effective usage) / (sum of usage for all user project's effective usage) * (worker unallocated cost)
1.6.3. Adding OpenShift projects
In cost management, the Group named Platform has default projects that you cannot remove. These projects start with the prefixes openshift or kube and have a Default label in the OpenShift details page. You can add your own projects to the Platform group so that you have control over what is considered a platform cost. Any projects that have the cost of some Platform projects have the Overhead label.
For example, you might have a cost that you consider overhead and that you want to show up as a platform cost. You can add the cost to your Platform projects to distribute the costs according to your cost model.
Prerequisites
- You must have a cluster that has a cost model set to Distribute.
Procedure
To add OpenShift projects to the Platform group, complete the following steps:
- In Settings in cost management, click the Platform projects tab.
- Select a project to add to the Platform group.
- Click .
The project now has the label Platform, but not the label Default.
Verification
Complete the following steps to verify that your costs are distributing properly:
- In cost management, click to open the OpenShift Details page.
- Select the cluster whose project you edited in the previous steps.
The project should display a cost of $0 because you set the cost to distribute across all other projects. A project with the label Overhead includes the cost of that project plus the default project costs.