Este contenido no está disponible en el idioma seleccionado.
Chapter 4. Telco RAN DU reference design specification
The telco RAN DU reference design specifications (RDS) describes the configuration for clusters running on commodity hardware to host 5G workloads in the Radio Access Network (RAN). It captures the recommended, tested, and supported configurations to get reliable and repeatable performance for a cluster running the telco RAN DU profile.
Use the use model and system level information to plan telco RAN DU workloads, cluster resources, and minimum hardware specifications for managed single-node OpenShift clusters.
Specific limits, requirements, and engineering considerations for individual components are described in individual sections.
4.1. Reference design specifications for telco RAN DU 5G deployments
Red Hat and certified partners offer deep technical expertise and support for networking and operational capabilities required to run telco applications on OpenShift Container Platform 4.20 clusters.
Red Hat’s telco partners require a well-integrated, well-tested, and stable environment that can be replicated at scale for enterprise 5G solutions. The telco core and RAN DU reference design specifications (RDS) outline the recommended solution architecture based on a specific version of OpenShift Container Platform. Each RDS describes a tested and validated platform configuration for telco core and RAN DU use models. The RDS ensures an optimal experience when running your applications by defining the set of critical KPIs for telco 5G core and RAN DU. Following the RDS minimizes high severity escalations and improves application stability.
5G use cases are evolving and your workloads are continually changing. Red Hat is committed to iterating over the telco core and RAN DU RDS to support evolving requirements based on customer and partner feedback.
The reference configuration includes the configuration of the far edge clusters and hub cluster components.
The reference configurations in this document are deployed using a centrally managed hub cluster infrastructure as shown in the following image.
Figure 4.1. Telco RAN DU deployment architecture

4.1.1. Supported CPU architectures for RAN DU
| Architecture | Real-time Kernel | Non-Realtime Kernel |
|---|---|---|
| x86_64 | Yes | Yes |
| aarch64 | No | Yes |
4.2. Reference design scope
The telco core, telco RAN and telco hub reference design specifications (RDS) capture the recommended, tested, and supported configurations to get reliable and repeatable performance for clusters running the telco core and telco RAN profiles.
Each RDS includes the released features and supported configurations that are engineered and validated for clusters to run the individual profiles. The configurations provide a baseline OpenShift Container Platform installation that meets feature and KPI targets. Each RDS also describes expected variations for each individual configuration. Validation of each RDS includes many long duration and at-scale tests.
The validated reference configurations are updated for each major Y-stream release of OpenShift Container Platform. Z-stream patch releases are periodically re-tested against the reference configurations.
4.3. Deviations from the reference design
Deviating from the validated telco core, telco RAN DU, and telco hub reference design specifications (RDS) can have significant impact beyond the specific component or feature that you change. Deviations require analysis and engineering in the context of the complete solution.
All deviations from the RDS should be analyzed and documented with clear action tracking information. Due diligence is expected from partners to understand how to bring deviations into line with the reference design. This might require partners to provide additional resources to engage with Red Hat to work towards enabling their use case to achieve a best in class outcome with the platform. This is critical for the supportability of the solution and ensuring alignment across Red Hat and with partners.
Deviation from the RDS can have some or all of the following consequences:
- It can take longer to resolve issues.
- There is a risk of missing project service-level agreements (SLAs), project deadlines, end provider performance requirements, and so on.
Unapproved deviations may require escalation at executive levels.
NoteRed Hat prioritizes the servicing of requests for deviations based on partner engagement priorities.
4.4. Engineering considerations for the RAN DU use model
The RAN DU use model configures an OpenShift Container Platform cluster running on commodity hardware for hosting RAN distributed unit (DU) workloads. Model and system level considerations are described below. Specific limits, requirements and engineering considerations for individual components are detailed in later sections.
For details of the telco RAN DU RDS KPI test results, see the telco RAN DU 4.20 reference design specification KPI test results. This information is only available to customers and partners.
- Cluster topology
The recommended topology for RAN DU workloads is single-node OpenShift. DU workloads may be run on other cluster topologies such as 3-node compact cluster, high availability (3 control plane + n worker nodes), or SNO+1 as needed. Multiple SNO clusters, or a highly-available 3-node compact cluster, are recommended over the SNO+1 topology.
Under the standard cluster topology case (3+n), a mixed architecture cluster is allowed only if:
- All control plane nodes are x86_64.
- All worker nodes are aarch64.
Remote worker node (RWN) cluster topologies are not recommended or included under this reference design specification. For workloads with high service level agreement requirements such as RAN DU the following drawbacks exclude RWN from consideration:
- No support for Image Based Upgrades and the benefits offered by that feature, such as faster upgrades and rollback capability.
- Updates to Day 2 operators affect all RWNs simultaneously without the ability to perform a rolling update.
- Loss of the control plane (disaster scenario) would have a significantly higher impact on overall service availability due to the greater number of sites served by that control plane.
- Loss of network connectivity between the RWN and the control plane for a period exceeding the monitoring grace period and toleration timeouts might result in pod eviction and lead to a service outage.
- No support for container image pre-caching.
- Additional complexities in workload affinities.
- Supported cluster topologies for RAN DU
Expand Table 4.2. Supported cluster topologies for RAN DU Architecture SNO SNO+1 3-node Standard RWN x86_64
Yes
Yes
Yes
Yes
No
aarch64
Yes
No
No
No
No
mixed
N/A
No
No
Yes
No
- Workloads
- DU workloads are described in Telco RAN DU application workloads.
- DU worker nodes are Intel 3rd Generation Xeon (IceLake) 2.20 GHz or newer with host firmware tuned for maximum performance.
- Resources
- The maximum number of running pods in the system, inclusive of application workload and OpenShift Container Platform pods, is 160.
- Resource utilization
OpenShift Container Platform resource utilization varies depending on many factors such as the following application workload characteristics:
- Pod count
- Type and frequency of probes
- Messaging rates on the primary or secondary CNI with kernel networking
- API access rate
- Logging rates
- Storage IOPS
Resource utilization is measured for clusters configured as follows:
- The cluster is a single host with single-node OpenShift installed.
- The cluster runs the representative application workload described in "Reference application workload characteristics".
- The cluster is managed under the constraints detailed in "Hub cluster management characteristics".
- Components noted as "optional" in the use model configuration are not included.
NoteConfiguration outside the scope of the RAN DU RDS that do not meet these criteria requires additional analysis to determine the impact on resource utilization and ability to meet KPI targets. You might need to allocate additional cluster resources to meet these requirements.
- Reference application workload characteristics
- Uses 75 pods across 5 namespaces with 4 containers per pod for the vRAN application including its management and control functions
-
Creates 30
ConfigMapCRs and 30SecretCRs per namespace - Uses no exec probes
Uses a secondary network
NoteYou can extract CPU load can from the platform metrics. For example:
$ query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])- Application logs are not collected by the platform log collector.
- Aggregate traffic on the primary CNI is up to 30 Mbps and up to 5 Gbps on the secondary network
- Hub cluster management characteristics
RHACM is the recommended cluster management solution and is configured to these limits:
- Use a maximum of 10 RHACM configuration policies, comprising 5 Red Hat provided policies and up to 5 custom configuration policies with a compliant evaluation interval of not less than 10 minutes.
- Use a minimal number (up to 10) of managed cluster templates in cluster policies. Use hub-side templating.
-
Disable RHACM addons with the exception of the
policyControllerand configure observability with the default configuration.
The following table describes resource utilization under reference application load.
Expand Table 4.3. Resource utilization under reference application load Metric Limits Notes OpenShift platform CPU usage
Less than 4000mc – 2 cores (4HT)
Platform CPU is pinned to reserved cores, including both hyper-threads of each reserved core. The system is engineered to 3 CPUs (3000mc) at steady-state to allow for periodic system tasks and spikes.
OpenShift Platform memory
Less than 16G
4.5. Telco RAN DU application workloads
Develop RAN DU applications that are subject to the following requirements and limitations.
- Description and limits
- Develop cloud-native network functions (CNFs) that conform to the latest version of Red Hat best practices for Kubernetes.
- Use SR-IOV for high performance networking.
Use exec probes sparingly and only when no other suitable options are available.
-
Do not use exec probes if a CNF uses CPU pinning. Use other probe implementations, for example,
httpGetortcpSocket. When you need to use exec probes, limit the exec probe frequency and quantity. The maximum number of exec probes must be kept below 10, and frequency must not be set to less than 10 seconds. Exec probes cause much higher CPU usage on management cores compared to other probe types because they require process forking.
NoteStartup probes require minimal resources during steady-state operation. The limitation on exec probes applies primarily to liveness and readiness probes.
-
Do not use exec probes if a CNF uses CPU pinning. Use other probe implementations, for example,
NoteA test workload that conforms to the dimensions of the reference DU application workload described in this specification can be found at openshift-kni/du-test-workloads.
4.6. Telco RAN DU reference design components
The following sections describe the various OpenShift Container Platform components and configurations that you use to configure and deploy clusters to run RAN DU workloads.
Figure 4.2. Telco RAN DU reference design components
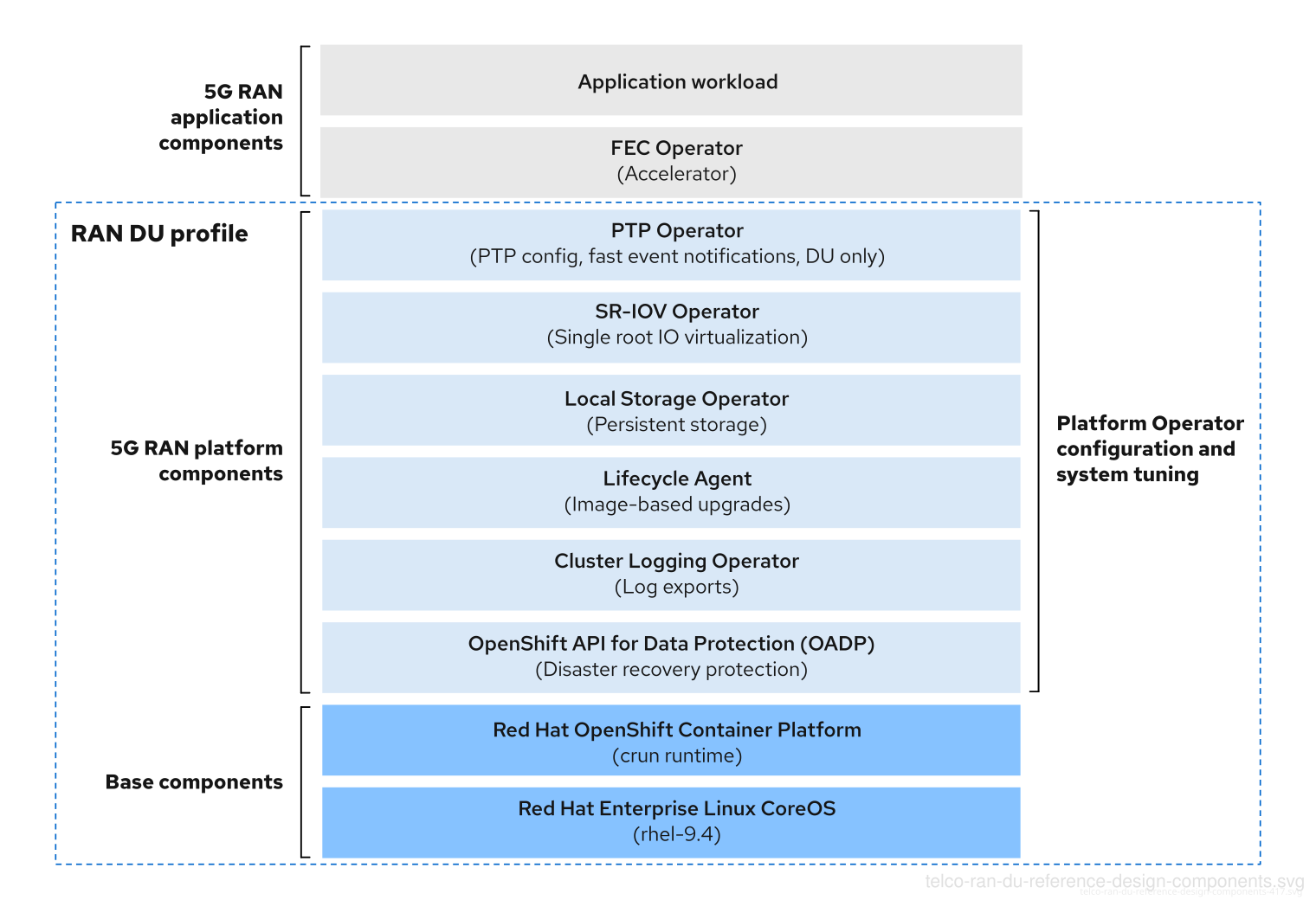
Ensure that additional components you include that are not specified in the telco RAN DU profile do not affect the CPU resources allocated to workload applications.
Out of tree drivers are not supported. 5G RAN application components are not included in the RAN DU profile and must be engineered against resources (CPU) allocated to applications.
4.6.1. Host firmware tuning
- New in this release
- No reference design updates in this release
- Description
Tune host firmware settings for optimal performance during initial cluster deployment. For more information, see "Recommended single-node OpenShift cluster configuration for vDU application workloads". Apply tuning settings in the host firmware during initial deployment. For more information, see "Managing host firmware settings with GitOps ZTP". The managed cluster host firmware settings are available on the hub cluster as individual
BareMetalHostcustom resources (CRs) that are created when you deploy the managed cluster with theClusterInstanceCR and GitOps ZTP.NoteCreate the
ClusterInstanceCR based on the provided referenceexample-sno.yamlCR.- Limits and requirements
- You must enable Hyper-Threading in the host firmware settings
- Engineering considerations
- Tune all firmware settings for maximum performance.
- All settings are expected to be for maximum performance unless tuned for power savings.
- You can tune host firmware for power savings at the expense of performance as required.
- Enable secure boot. When secure boot is enabled, only signed kernel modules are loaded by the kernel. Out-of-tree drivers are not supported.
4.6.2. Kubelet Settings
Some CNF workloads make use of sysctls which are not in the list of system-wide safe sysctls. Generally, network sysctls are namespaced and you can enable them using the kubeletconfig.experimental annotation in the PerformanceProfile Custom Resource (CR) as a string of JSON in the following form:
Example snippet showing allowedUnsafeSysctls
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: {{ .metadata.name }}
annotations:kubeletconfig.experimental: |
{"allowedUnsafeSysctls":["net.ipv6.conf.all.accept_ra"]}
# ...Although these sysctls are namespaced, they may allow a pod to consume memory or other resources beyond any limits specified in the pod description. You must ensure that these sysctls do not exhaust platform resources.
For more information, see "Using sysctls in containers".
4.6.3. CPU partitioning and performance tuning
- New in this release
The
PerformanceProfileandTunedPerformancePatchobjects have been updated to fully support the aarch64 architecture.-
If you have previously applied additional patches to the
TunedPerformancePatchobject, you must convert those patches to a new performance profile that includes theran-du-performanceprofile instead. See the "Engineering considerations" section.
-
If you have previously applied additional patches to the
- Description
-
The RAN DU use model includes cluster performance tuning using
PerformanceProfileCRs for low-latency performance, and aTunedPerformancePatchCR that adds additional RAN-specific tuning. A referencePerformanceProfileis provided for both x86_64 and aarch64 CPU architectures. The singleTunedPerformancePatchobject provided automatically detects the CPU architecture and performs the required additional tuning. The RAN DU use case requires the cluster to be tuned for low-latency performance. The Node Tuning Operator reconciles thePerformanceProfileandTunedPerformancePatchCRs.
For more information about node tuning with the PerformanceProfile CR, see "Tuning nodes for low latency with the performance profile".
- Limits and requirements
You must configure the following settings in the telco RAN DU profile
PerformanceProfileCR:Set a reserved
cpusetof 4 or more, equating to 4 hyper-threads (2 cores) on x86_64, or 4 cores on aarch64 for any of the following CPUs:- Intel 3rd Generation Xeon (IceLake) 2.20 GHz, or newer, CPUs with host firmware tuned for maximum performance
- AMD EPYC Zen 4 CPUs (Genoa, Bergamo)
ARM CPUs (Neoverse)
NoteIt is recommended to evaluate features, such as per-pod power management, to determine any potential impact on performance.
x86_64:
-
Set the reserved
cpusetto include both hyper-thread siblings for each included core. Unreserved cores are available as allocatable CPU for scheduling workloads. - Ensure that hyper-thread siblings are not split across reserved and isolated cores.
- Ensure that reserved and isolated CPUs include all the threads for all cores in the CPU.
- Include Core 0 for each NUMA node in the reserved CPU set.
- Set the hugepage size to 1G.
-
Set the reserved
aarch64:
- Use the first 4 cores for the reserved CPU set (or more).
- Set the hugepage size to 512M.
- Only pin OpenShift Container Platform pods that are by default configured as part of the management workload partition to reserved cores.
-
When recommended by the hardware vendor, set the maximum CPU frequency for reserved and isolated CPUs using the
hardwareTuningsection.
- Engineering considerations
RealTime (RT) kernel
Under x86_64, to reach the full performance metrics, you must use the RT kernel, which is the default in the
x86_64/PerformanceProfile.yamlconfiguration.- If required, you can select the non-RT kernel with corresponding impact to performance.
-
Under aarch64, only the 64k-pagesize non-RT kernel is recommended for RAN DU use cases, which is the default in the
aarch64/PerformanceProfile.yamlconfiguration.
- The number of hugepages you configure depends on application workload requirements. Variation in this parameter is expected and allowed.
- Variation is expected in the configuration of reserved and isolated CPU sets based on selected hardware and additional components in use on the system. The variation must still meet the specified limits.
- Hardware without IRQ affinity support affects isolated CPUs. To ensure that pods with guaranteed whole CPU QoS have full use of allocated CPUs, all hardware in the server must support IRQ affinity.
-
To enable workload partitioning, set
cpuPartitioningModetoAllNodesduring deployment, and then use thePerformanceProfileCR to allocate enough CPUs to support the operating system, interrupts, and OpenShift Container Platform pods. -
Under x86_64, the
PerformanceProfileCR includes additional kernel arguments settings forvfio_pci. These arguments are included for support of devices such as the FEC accelerator. You can omit them if they are not required for your workload. Under aarch64, the
PerformanceProfilemust be adjusted depending on the needs of the platform:For Grace Hopper systems, the following kernel commandline arguments are required:
-
acpi_power_meter.force_cap_on=y -
module_blacklist=nouveau -
pci=realloc=off -
pci=pcie_bus_safe
-
-
For other ARM platforms, you may need to enable
iommu.passthrough=1orpci=realloc
Extending and augmenting
TunedPerformancePatch.yaml:-
TunedPerformancePatch.yamlintroduces a default top-level tuned profile namedran-du-performanceand an architecture-aware RAN tuning profile namedran-du-performance-architecture-common, and additional archichitecture-specific child policies that are automatically selected by the common policy. -
By default, the
ran-du-performanceprofile is set toprioritylevel18, and it includes both the PerformanceProfile-created profileopenshift-node-performance-openshift-node-performance-profileandran-du-performance-architecture-common If you have customized the name of the
PerformanceProfileobject, you must create a new tuned object that includes the name change of the tuned profile created by thePerformanceProfileCR, as well as theran-du-performance-architecture-commonRAN tuning profile. This must have apriorityless than 18. For example, if the PerformanceProfile object is namedchange-this-name:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: custom-performance-profile-override namespace: openshift-cluster-node-tuning-operator spec: profile: - name: custom-performance-profile-x data: | [main] summary=Override of the default ran-du performance tuning to adjust for our renamed PerformanceProfile include=openshift-node-performance-change-this-name,ran-du-performance-architecture-common recommend: - machineConfigLabels: machineconfiguration.openshift.io/role: "master" priority: 15 profile: custom-performance-profile-x-
To further override, the optional
TunedPowerCustom.yamlconfig file exemplifies how to extend the providedTunedPerformancePatch.yamlwithout needing to overlay or edit it directly. Creating an additional tuned profile which includes the top-level tuned profile namedran-du-performanceand has a lowerprioritynumber in therecommendsection allows adding additional settings easily. - For additional information on the Node Tuning Operator, see "Using the Node Tuning Operator".
-
4.6.4. PTP Operator
- New in this release
- No reference design updates in this release
- Description
- Configure Precision Time Protocol (PTP) in cluster nodes. PTP ensures precise timing and reliability in the RAN environment, compared to other clock synchronization protocols, like NTP.
- Support includes
- Grandmaster clock (T-GM): use GPS to sync the local clock and provide time synchronization to other devices
- Boundary clock (T-BC): receive time from another PTP source and redistribute it to other devices
- Ordinary clock (T-TSC): synchronize the local clock from another PTP time provider
Configuration variations allow for multiple NIC configurations for greater time distribution and high availability (HA), and optional fast event notification over HTTP.
- Limits and requirements
Supports the PTP G.8275.1 profile for the following telco use-cases:
T-GM use-case:
- Limited to a maximum of 3 Westport channel NICs
- Requires GNSS input to one NIC card, with SMA connections to synchronize additional NICs
- HA support N/A
T-BC use-case:
- Limited to a maximum of 2 NICs
- System clock HA support is optional in 2-NIC configuration.
T-TSC use-case:
- Limited to single NIC only
- System clock HA support is optional in active/standby 2-port configuration.
-
Log reduction must be enabled with
trueorenhanced.
- Engineering considerations
* Example RAN DU RDS configurations are provided for:
- T-GM, T-BC, and T-TSC
- Variations with and without HA
-
PTP fast event notifications use
ConfigMapCRs to persist subscriber details. - Hierarchical event subscription as described in the O-RAN specification is not supported for PTP events.
- The PTP fast events REST API v1 is end of life.
4.6.5. SR-IOV Operator
- New in this release
- No reference design updates in this release
- Description
-
The SR-IOV Operator provisions and configures the SR-IOV CNI and device plugins. Both
netdevice(kernel VFs) andvfio(DPDK) devices are supported and applicable to the RAN DU use models. - Limits and requirements
- Use devices that are supported for OpenShift Container Platform. For more information, see "Supported devices".
- SR-IOV and IOMMU enablement in host firmware settings: The SR-IOV Network Operator automatically enables IOMMU on the kernel command line.
- SR-IOV VFs do not receive link state updates from the PF. If link down detection is required you must configure this at the protocol level.
- Engineering considerations
-
SR-IOV interfaces with the
vfiodriver type are typically used to enable additional secondary networks for applications that require high throughput or low latency. -
Customer variation on the configuration and number of
SriovNetworkandSriovNetworkNodePolicycustom resources (CRs) is expected. -
IOMMU kernel command line settings are applied with a
MachineConfigCR at install time. This ensures that theSriovOperatorCR does not cause a reboot of the node when adding them. - SR-IOV support for draining nodes in parallel is not applicable in a single-node OpenShift cluster.
-
You must include the
SriovOperatorConfigCR in your deployment; the CR is not created automatically. This CR is included in the reference configuration policies which are applied during initial deployment. - In scenarios where you pin or restrict workloads to specific nodes, the SR-IOV parallel node drain feature will not result in the rescheduling of pods. In these scenarios, the SR-IOV Operator disables the parallel node drain functionality.
- You must pre-configure NICs which do not support firmware updates under secure boot or kernel lockdown with sufficient virtual functions (VFs) to support the number of VFs needed by the application workload. For Mellanox NICs, you must disable the Mellanox vendor plugin in the SR-IOV Network Operator. For more information, see "Configuring the SR-IOV Network Operator on Mellanox cards when Secure Boot is enabled".
To change the MTU value of a virtual function after the pod has started, do not configure the MTU field in the
SriovNetworkNodePolicyCR. Instead, configure the Network Manager or use a customsystemdscript to set the MTU of the physical function to an appropriate value. For example:# ip link set dev <physical_function> mtu 9000
-
SR-IOV interfaces with the
4.6.6. Logging
- New in this release
- No reference design updates in this release
- Description
- Use logging to collect logs from the far edge node for remote analysis. The recommended log collector is Vector.
- Engineering considerations
- Handling logs beyond the infrastructure and audit logs, for example, from the application workload requires additional CPU and network bandwidth based on additional logging rate.
- As of OpenShift Container Platform 4.14, Vector is the reference log collector. Use of fluentd in the RAN use models is deprecated.
4.6.7. SRIOV-FEC Operator
- New in this release
- No reference design updates in this release
- Description
- SRIOV-FEC Operator is an optional 3rd party Certified Operator supporting FEC accelerator hardware.
- Limits and requirements
Starting with FEC Operator v2.7.0:
- Secure boot is supported
-
vfiodrivers for PFs require the usage of avfio-tokenthat is injected into the pods. Applications in the pod can pass the VF token to DPDK by using EAL parameter--vfio-vf-token.
- Engineering considerations
- The SRIOV-FEC Operator uses CPU cores from the isolated CPU set.
- You can validate FEC readiness as part of the pre-checks for application deployment, for example, by extending the validation policy.
4.6.8. Lifecycle Agent
- New in this release
- No reference design updates in this release
- Description
- The Lifecycle Agent provides local lifecycle management services for image-based upgrade of single-node OpenShift clusters. Image-based upgrade is the recommended upgrade method for single-node OpenShift clusters.
- Limits and requirements
- The Lifecycle Agent is not applicable in multi-node clusters or single-node OpenShift clusters with an additional worker.
- The Lifecycle Agent requires a persistent volume that you create when installing the cluster.
For more information about partition requirements, see "Configuring a shared container directory between ostree stateroots when using GitOps ZTP".
4.6.9. Local Storage Operator
- New in this release
- No reference design updates in this release
- Description
-
You can create persistent volumes that can be used as
PVCresources by applications with the Local Storage Operator. The number and type ofPVresources that you create depends on your requirements. - Engineering considerations
-
Create backing storage for
PVCRs before creating thePV. This can be a partition, a local volume, LVM volume, or full disk. -
Refer to the device listing in
LocalVolumeCRs by the hardware path used to access each device to ensure correct allocation of disks and partitions, for example,/dev/disk/by-path/<id>. Logical names (for example,/dev/sda) are not guaranteed to be consistent across node reboots.
-
Create backing storage for
4.6.10. Logical Volume Manager Storage
- New in this release
- No reference design updates in this release
- Description
-
Logical Volume Manager (LVM) Storage is an optional component. It provides dynamic provisioning of both block and file storage by creating logical volumes from local devices that can be consumed as persistent volume claim (PVC) resources by applications. Volume expansion and snapshots are also possible. An example configuration is provided in the RDS with the
StorageLVMCluster.yamlfile. - Limits and requirements
- In single-node OpenShift clusters, persistent storage must be provided by either LVM Storage or local storage, not both.
- Volume snapshots are excluded from the reference configuration.
- Engineering considerations
- LVM Storage can be used as the local storage implementation for the RAN DU use case. When LVM Storage is used as the storage solution, it replaces the Local Storage Operator, and the CPU required is assigned to the management partition as platform overhead. The reference configuration must include one of these storage solutions but not both.
- Ensure that sufficient disks or partitions are available for storage requirements.
4.6.11. Workload partitioning
- New in this release
- No reference design updates in this release
- Description
-
Workload partitioning pins OpenShift Container Platform and Day 2 Operator pods that are part of the DU profile to the reserved CPU set and removes the reserved CPU from node accounting. This leaves all unreserved CPU cores available for user workloads. This leaves all non-reserved CPU cores available for user workloads. Workload partitioning is enabled through a capability set in installation parameters:
cpuPartitioningMode: AllNodes. The set of management partition cores are set with the reserved CPU set that you configure in thePerformanceProfileCR. - Limits and requirements
-
NamespaceandPodCRs must be annotated to allow the pod to be applied to the management partition - Pods with CPU limits cannot be allocated to the partition. This is because mutation can change the pod QoS.
- For more information about the minimum number of CPUs that can be allocated to the management partition, see "Node Tuning Operator".
-
- Engineering considerations
- Workload partitioning pins all management pods to reserved cores. A sufficient number of cores must be allocated to the reserved set to account for operating system, management pods, and expected spikes in CPU use that occur when the workload starts, the node reboots, or other system events happen.
4.6.12. Cluster tuning
- New in this release
- No reference design updates in this release
- Description
- For a full list of components that you can disable using the cluster capabilities feature, see "Cluster capabilities".
- Limits and requirements
- Cluster capabilities are not available for installer-provisioned installation methods.
The following table lists the required platform tuning configurations:
| Feature | Description |
|---|---|
| Remove optional cluster capabilities | Reduce the OpenShift Container Platform footprint by disabling optional cluster Operators on single-node OpenShift clusters only.
|
| Configure cluster monitoring | Configure the monitoring stack for reduced footprint by doing the following:
|
| Disable networking diagnostics | Disable networking diagnostics for single-node OpenShift because they are not required. |
| Configure a single OperatorHub catalog source |
Configure the cluster to use a single catalog source that contains only the Operators required for a RAN DU deployment. Each catalog source increases the CPU use on the cluster. Using a single |
| Disable the Console Operator |
If the cluster was deployed with the console disabled, the |
- Engineering considerations
- As of OpenShift Container Platform 4.19, cgroup v1 is no longer supported and has been removed. All workloads must now be compatible with cgroup v2. For more information, see Red Hat Enterprise Linux 9 changes in the context of Red Hat OpenShift workloads.
4.6.13. Machine configuration
- New in this release
- No reference design updates in this release
- Limits and requirements
-
The CRI-O wipe disable
MachineConfigCR assumes that images on disk are static other than during scheduled maintenance in defined maintenance windows. To ensure the images are static, do not set the podimagePullPolicyfield toAlways. - The configuration CRs in this table are required components unless otherwise noted.
-
The CRI-O wipe disable
| Feature | Description |
|---|---|
| Container Runtime |
Sets the container runtime to |
| Kubelet config and container mount namespace hiding | Reduces the frequency of kubelet housekeeping and eviction monitoring, which reduces CPU usage |
| SCTP | Optional configuration (enabled by default) |
| Kdump | Optional configuration (enabled by default) Enables kdump to capture debug information when a kernel panic occurs. The reference CRs that enable kdump have an increased memory reservation based on the set of drivers and kernel modules included in the reference configuration. |
| CRI-O wipe disable | Disables automatic wiping of the CRI-O image cache after unclean shutdown |
| SR-IOV-related kernel arguments | Include additional SR-IOV-related arguments in the kernel command line |
| Set RCU Normal |
Systemd service that sets |
| One-shot time sync | Runs a one-time NTP system time synchronization job for control plane or worker nodes. |
4.7. Telco RAN DU deployment components
The following sections describe the various OpenShift Container Platform components and configurations that you use to configure the hub cluster with RHACM.
4.7.1. Red Hat Advanced Cluster Management
- New in this release
- No reference design updates in this release
- Description
RHACM provides Multi Cluster Engine (MCE) installation and ongoing lifecycle management functionality for deployed clusters. You manage cluster configuration and upgrades declaratively by applying
Policycustom resources (CRs) to clusters during maintenance windows.RHACM provides the following functionality:
- Zero touch provisioning (ZTP) of clusters using the MCE component in RHACM.
- Configuration, upgrades, and cluster status through the RHACM policy controller.
-
During managed cluster installation, RHACM can apply labels to individual nodes as configured through the
ClusterInstanceCR.
The recommended method for single-node OpenShift cluster installation is the image-based installation approach, available in MCE, using the
ClusterInstanceCR for cluster definition.Image-based upgrade is the recommended method for single-node OpenShift cluster upgrade.
- Limits and requirements
-
A single hub cluster supports up to 3500 deployed single-node OpenShift clusters with 5
PolicyCRs bound to each cluster.
-
A single hub cluster supports up to 3500 deployed single-node OpenShift clusters with 5
- Engineering considerations
- Use RHACM policy hub-side templating to better scale cluster configuration. You can significantly reduce the number of policies by using a single group policy or small number of general group policies where the group and per-cluster values are substituted into templates.
-
Cluster specific configuration: managed clusters typically have some number of configuration values that are specific to the individual cluster. These configurations should be managed using RHACM policy hub-side templating with values pulled from
ConfigMapCRs based on the cluster name. - To save CPU resources on managed clusters, policies that apply static configurations should be unbound from managed clusters after GitOps ZTP installation of the cluster.
4.7.2. SiteConfig Operator
- New in this release
- No reference design updates in this release
- Description
The SiteConfig Operator is a template-driven solution designed to provision clusters through various installation methods. It introduces the unified
ClusterInstanceAPI, which replaces the deprecatedSiteConfigAPI. By leveraging theClusterInstanceAPI, the SiteConfig Operator improves cluster provisioning by providing the following:- Better isolation of definitions from installation methods
- Unification of Git and non-Git workflows
- Consistent APIs across installation methods
- Enhanced scalability
- Increased flexibility with custom installation templates
- Valuable insights for troubleshooting deployment issues
The SiteConfig Operator provides validated default installation templates to facilitate cluster deployment through both the Assisted Installer and Image-based Installer provisioning methods:
- Assisted Installer automates the deployment of OpenShift Container Platform clusters by leveraging predefined configurations and validated host setups. It ensures that the target infrastructure meets OpenShift Container Platform requirements. The Assisted Installer streamlines the installation process while minimizing time and complexity compared to manual setup.
- Image-based Installer expedites the deployment of single-node OpenShift clusters by utilizing preconfigured and validated OpenShift Container Platform seed images. Seed images are preinstalled on target hosts, enabling rapid reconfiguration and deployment. The Image-based Installer is particularly well-suited for remote or disconnected environments because it simplifies the cluster creation process and significantly reduces deployment time.
- Limits and requirements
- A single hub cluster supports up to 3500 deployed single-node OpenShift clusters.
4.7.3. Topology Aware Lifecycle Manager
- New in this release
- No reference design updates in this release
- Description
TALM is an Operator that runs only on the hub cluster for managing how changes like cluster upgrades, Operator upgrades, and cluster configuration are rolled out to the network. TALM supports the following features:
- Progressive rollout of policy updates to fleets of clusters in user configurable batches.
-
Per-cluster actions add
ztp-donelabels or other user-configurable labels following configuration changes to managed clusters. Precaching of single-node OpenShift clusters images: TALM supports optional pre-caching of OpenShift, OLM Operator, and additional user images to single-node OpenShift clusters before initiating an upgrade. The precaching feature is not applicable when using the recommended image-based upgrade method for upgrading single-node OpenShift clusters.
-
Specifying optional pre-caching configurations with
PreCachingConfigCRs. Review the sample referencePreCachingConfigCR for more information. - Excluding unused images with configurable filtering.
- Enabling before and after pre-caching storage space validations with configurable space-required parameters.
-
Specifying optional pre-caching configurations with
- Limits and requirements
- Supports concurrent cluster deployment in batches of 400
- Pre-caching and backup are limited to single-node OpenShift clusters only
- Engineering considerations
-
The
PreCachingConfigCR is optional and does not need to be created if you only need to precache platform-related OpenShift and OLM Operator images. -
The
PreCachingConfigCR must be applied before referencing it in theClusterGroupUpgradeCR. -
Only policies with the
ran.openshift.io/ztp-deploy-waveannotation are automatically applied by TALM during cluster installation. -
Any policy can be remediated by TALM under control of a user created
ClusterGroupUpgradeCR.
-
The
4.7.4. GitOps Operator and GitOps ZTP
- New in this release
- No reference design updates in this release
- Description
GitOps Operator and GitOps ZTP provide a GitOps-based infrastructure for managing cluster deployment and configuration. Cluster definitions and configurations are maintained as a declarative state in Git. You can apply
ClusterInstanceCRs to the hub cluster where theSiteConfigOperator renders them as installation CRs. In earlier releases, a GitOps ZTP plugin supported the generation of installation CRs fromSiteConfigCRs. This plugin is now deprecated. A separate GitOps ZTP plugin is available to enable automatic wrapping of configuration CRs into policies based on thePolicyGeneratororPolicyGenTemplateCR.You can deploy and manage multiple versions of OpenShift Container Platform on managed clusters using the baseline reference configuration CRs. You can use custom CRs alongside the baseline CRs. To maintain multiple per-version policies simultaneously, use Git to manage the versions of the source and policy CRs by using
PolicyGeneratororPolicyGenTemplateCRs. RHACMPolicyGeneratoris the recommended generator plugin starting from OpenShift Container Platform 4.19 release.- Limits and requirements
-
1000
ClusterInstanceCRs per ArgoCD application. Multiple applications can be used to achieve the maximum number of clusters supported by a single hub cluster -
Content in the
source-crs/directory in Git overrides content provided in the ZTP plugin container, as Git takes precedence in the search path. -
The
source-crs/directory must be located in the same directory as thekustomization.yamlfile, which includesPolicyGeneratorCRs as a generator. Alternative locations for thesource-crs/directory are not supported in this context.
-
1000
- Engineering considerations
-
For multi-node cluster upgrades, you can pause
MachineConfigPool(MCP) CRs during maintenance windows by setting thepausedfield totrue. You can increase the number of simultaneously updated nodes perMCPCR by configuring themaxUnavailablesetting in theMCPCR. TheMaxUnavailablefield defines the percentage of nodes in the pool that can be simultaneously unavailable during aMachineConfigupdate. SetmaxUnavailableto the maximum tolerable value. This reduces the number of reboots in a cluster during upgrades which results in shorter upgrade times. When you finally unpause theMCPCR, all the changed configurations are applied with a single reboot. -
During cluster installation, you can pause custom MCP CRs by setting the paused field to true and setting
maxUnavailableto 100% to improve installation times. Keep reference CRs and custom CRs under different directories. Doing this allows you to patch and update the reference CRs by simple replacement of all directory contents without touching the custom CRs. When managing multiple versions, the following best practices are recommended:
- Keep all source CRs and policy creation CRs in Git repositories to ensure consistent generation of policies for each OpenShift Container Platform version based solely on the contents in Git.
- Keep reference source CRs in a separate directory from custom CRs. This facilitates easy update of reference CRs as required.
-
To avoid confusion or unintentional overwrites when updating content, it is highly recommended to use unique and distinguishable names for custom CRs in the
source-crs/directory and extra manifests in Git. -
Extra installation manifests are referenced in the
ClusterInstanceCR through aConfigMapCR. TheConfigMapCR should be stored alongside theClusterInstanceCR in Git, serving as the single source of truth for the cluster. If needed, you can use aConfigMapgenerator to create theConfigMapCR.
-
For multi-node cluster upgrades, you can pause
4.7.5. Agent-based installer
- New in this release
- No reference design updates in this release
- Description
- The optional Agent-based Installer component provides installation capabilities without centralized infrastructure. The installation program creates an ISO image that you mount to the server. When the server boots it installs OpenShift Container Platform and supplied extra manifests. The Agent-based Installer allows you to install OpenShift Container Platform without a hub cluster. A container image registry is required for cluster installation.
- Limits and requirements
- You can supply a limited set of additional manifests at installation time.
-
You must include
MachineConfigurationCRs that are required by the RAN DU use case.
- Engineering considerations
- The Agent-based Installer provides a baseline OpenShift Container Platform installation.
- You install Day 2 Operators and the remainder of the RAN DU use case configurations after installation.
4.8. Telco RAN DU reference configuration CRs
Use the following custom resources (CRs) to configure and deploy OpenShift Container Platform clusters with the telco RAN DU profile. Use the CRs to form the common baseline used in all the specific use models unless otherwise indicated.
You can extract the complete set of RAN DU CRs from the ztp-site-generate container image. See Preparing the GitOps ZTP site configuration repository for more information.
4.8.1. Cluster tuning reference CRs
| Component | Reference CR | Description | Optional |
|---|---|---|---|
| Cluster capabilities |
| Representative SiteConfig CR to install single-node OpenShift with the RAN DU profile | No |
| Console disable |
| Disables the Console Operator. | No |
| Disconnected registry |
| Defines a dedicated namespace for managing the OpenShift Operator Marketplace. | No |
| Disconnected registry |
| Configures the catalog source for the disconnected registry. | No |
| Disconnected registry |
| Disables performance profiling for OLM. | No |
| Disconnected registry |
| Configures disconnected registry image content source policy. | No |
| Disconnected registry |
| Optional, for multi-node clusters only. Configures the OperatorHub in OpenShift, disabling all default Operator sources. Not required for single-node OpenShift installs with marketplace capability disabled. | No |
| Monitoring configuration |
| Reduces the monitoring footprint by disabling Alertmanager and Telemeter, and sets Prometheus retention to 24 hours | No |
| Network diagnostics disable |
| Configures the cluster network settings to disable built-in network troubleshooting and diagnostic features. | No |
4.8.2. Day 2 Operators reference CRs
| Component | Reference CR | Description | Optional |
|---|---|---|---|
| Cluster Logging Operator |
| Configures log forwarding for the cluster. | No |
| Cluster Logging Operator |
| Configures the namespace for cluster logging. | No |
| Cluster Logging Operator |
| Configures Operator group for cluster logging. | No |
| Cluster Logging Operator |
| New in 4.18. Configures the cluster logging service account. | No |
| Cluster Logging Operator |
| New in 4.18. Configures the cluster logging service account. | No |
| Cluster Logging Operator |
| New in 4.18. Configures the cluster logging service account. | No |
| Cluster Logging Operator |
| Manages installation and updates for the Cluster Logging Operator. | No |
| Lifecycle Agent |
| Manage the image-based upgrade process in OpenShift. | Yes |
| Lifecycle Agent |
| Manages installation and updates for the LCA Operator. | Yes |
| Lifecycle Agent |
| Configures namespace for LCA subscription. | Yes |
| Lifecycle Agent |
| Configures the Operator group for the LCA subscription. | Yes |
| Local Storage Operator |
| Defines a storage class with a Delete reclaim policy and no dynamic provisioning in the cluster. | No |
| Local Storage Operator |
| Configures local storage devices for the example-storage-class in the openshift-local-storage namespace, specifying device paths and filesystem type. | No |
| Local Storage Operator |
| Creates the namespace with annotations for workload management and the deployment wave for the Local Storage Operator. | No |
| Local Storage Operator |
| Creates the Operator group for the Local Storage Operator. | No |
| Local Storage Operator |
| Creates the namespace for the Local Storage Operator with annotations for workload management and deployment wave. | No |
| LVM Operator |
| Verifies the installation or upgrade of the LVM Storage Operator. | Yes |
| LVM Operator |
| Defines an LVM cluster configuration, with placeholders for storage device classes and volume group settings. Optional substitute for the Local Storage Operator. | No |
| LVM Operator |
| Manages installation and updates of the LVMS Operator. Optional substitute for the Local Storage Operator. | No |
| LVM Operator |
| Creates the namespace for the LVMS Operator with labels and annotations for cluster monitoring and workload management. Optional substitute for the Local Storage Operator. | No |
| LVM Operator |
| Defines the target namespace for the LVMS Operator. Optional substitute for the Local Storage Operator. | No |
| Node Tuning Operator |
| Configures node performance settings in an OpenShift cluster, optimizing for low latency and real-time workloads for aarch64 CPUs. | No |
| Node Tuning Operator |
| Configures node performance settings in an OpenShift cluster, optimizing for low latency and real-time workloads for x86_64 CPUs. | No |
| Node Tuning Operator |
| Applies performance tuning settings, including scheduler groups and service configurations for nodes in the specific namespace. | No |
| Node Tuning Operator |
| Applies additional powersave mode tuning as an overlay on top of TunedPerformancePatch. | No |
| PTP fast event notifications |
| Configures PTP settings for PTP boundary clocks with additional options for event synchronization. Dependent on cluster role. | No |
| PTP fast event notifications |
| Configures PTP for highly available boundary clocks with additional PTP fast event settings. Dependent on cluster role. | No |
| PTP fast event notifications |
| Configures PTP for PTP grandmaster clocks with additional PTP fast event settings. Dependent on cluster role. | No |
| PTP fast event notifications |
| Configures PTP for PTP ordinary clocks with additional PTP fast event settings. Dependent on cluster role. | No |
| PTP fast event notifications |
| Overrides the default OperatorConfig. Configures the PTP Operator specifying node selection criteria for running PTP daemons in the openshift-ptp namespace. | No |
| PTP Operator |
| Configures PTP settings for PTP boundary clocks. Dependent on cluster role. | No |
| PTP Operator |
| Configures PTP grandmaster clock settings for hosts that have dual NICs. Dependent on cluster role. | No |
| PTP Operator |
| Configures PTP grandmaster clock settings for hosts that have 3 NICs. Dependent on cluster role. | No |
| PTP Operator |
| Configures PTP grandmaster clock settings for hosts that have a single NIC. Dependent on cluster role. | No |
| PTP Operator |
| Configures PTP settings for a PTP ordinary clock. Dependent on cluster role. | No |
| PTP Operator |
| Configures PTP settings for a PTP ordinary clock with 2 interfaces in an active/standby configuration. Dependent on cluster role. | No |
| PTP Operator |
| Configures the PTP Operator settings, specifying node selection criteria for running PTP daemons in the openshift-ptp namespace. | No |
| PTP Operator |
| Manages installation and updates of the PTP Operator in the openshift-ptp namespace. | No |
| PTP Operator |
| Configures the namespace for the PTP Operator. | No |
| PTP Operator |
| Configures the Operator group for the PTP Operator. | No |
| PTP Operator (high availability) |
| Configures PTP settings for highly available PTP boundary clocks. | No |
| PTP Operator (high availability) |
| Configures PTP settings for highly available PTP boundary clocks. | No |
| SR-IOV FEC Operator |
| Configures namespace for the VRAN Acceleration Operator. Optional part of application workload. | Yes |
| SR-IOV FEC Operator |
| Configures the Operator group for the VRAN Acceleration Operator. Optional part of application workload. | Yes |
| SR-IOV FEC Operator |
| Manages installation and updates for the VRAN Acceleration Operator. Optional part of application workload. | Yes |
| SR-IOV FEC Operator |
| Configures SR-IOV FPGA Ethernet Controller (FEC) settings for nodes, specifying drivers, VF amount, and node selection. | Yes |
| SR-IOV Operator |
| Defines an SR-IOV network configuration, with placeholders for various network settings. | No |
| SR-IOV Operator |
| Configures SR-IOV network settings for specific nodes, including device type, RDMA support, physical function names, and the number of virtual functions. | No |
| SR-IOV Operator |
| Configures SR-IOV Network Operator settings, including node selection, injector, and webhook options. | No |
| SR-IOV Operator |
| Configures the SR-IOV Network Operator settings for Single Node OpenShift (SNO), including node selection, injector, webhook options, and disabling node drain, in the openshift-sriov-network-operator namespace. | No |
| SR-IOV Operator |
| Manages the installation and updates of the SR-IOV Network Operator. | No |
| SR-IOV Operator |
| Creates the namespace for the SR-IOV Network Operator with specific annotations for workload management and deployment waves. | No |
| SR-IOV Operator |
| Defines the target namespace for the SR-IOV Network Operators, enabling their management and deployment within this namespace. | No |
4.8.3. Machine configuration reference CRs
| Component | Reference CR | Description | Optional |
|---|---|---|---|
| Container runtime (crun) |
| Configures the container runtime (crun) for control plane nodes. | No |
| Container runtime (crun) |
| Configures the container runtime (crun) for worker nodes. | No |
| CRI-O wipe disable |
| Disables automatic CRI-O cache wipe following a reboot for on control plane nodes. | No |
| CRI-O wipe disable |
| Disables automatic CRI-O cache wipe following a reboot for on worker nodes. | No |
| Kdump enable |
| Configures kdump crash reporting on master nodes. | No |
| Kdump enable |
| Configures kdump crash reporting on worker nodes. | No |
| Kubelet configuration and container mount hiding |
| Configures a mount namespace for sharing container-specific mounts between kubelet and CRI-O on control plane nodes. | No |
| Kubelet configuration and container mount hiding |
| Configures a mount namespace for sharing container-specific mounts between kubelet and CRI-O on worker nodes. | No |
| One-shot time sync |
| Synchronizes time once on master nodes. | No |
| One-shot time sync |
| Synchronizes time once on worker nodes. | No |
| SCTP |
| Loads the SCTP kernel module on master nodes. | Yes |
| SCTP |
| Loads the SCTP kernel module on worker nodes. | Yes |
| Set RCU normal |
| Disables rcu_expedited by setting rcu_normal after the control plane node has booted. | No |
| Set RCU normal |
| Disables rcu_expedited by setting rcu_normal after the worker node has booted. | No |
| SRIOV-related kernel arguments |
| Enables SR-IOV support on master nodes. | No |
| SRIOV-related kernel arguments |
| Enables SR-IOV support on worker nodes. | No |
4.9. Comparing a cluster with the telco RAN DU reference configuration
After you deploy a telco RAN DU cluster, you can use the cluster-compare plugin to assess the cluster’s compliance with the telco RAN DU reference design specifications (RDS). The cluster-compare plugin is an OpenShift CLI (oc) plugin. The plugin uses a telco RAN DU reference configuration to validate the cluster with the telco RAN DU custom resources (CRs).
The plugin-specific reference configuration for telco RAN DU is packaged in a container image with the telco RAN DU CRs.
For further information about the cluster-compare plugin, see "Understanding the cluster-compare plugin".
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have credentials to access the
registry.redhat.iocontainer image registry. -
You installed the
cluster-compareplugin.
Procedure
Log on to the container image registry with your credentials by running the following command:
$ podman login registry.redhat.ioExtract the content from the
ztp-site-generate-rhel8container image by running the following commands::$ podman pull registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.20$ mkdir -p ./out$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.20 extract /home/ztp --tar | tar x -C ./outCompare the configuration for your cluster to the reference configuration by running the following command:
$ oc cluster-compare -r out/reference/metadata.yamlExample output
... ********************************** Cluster CR: config.openshift.io/v1_OperatorHub_cluster1 Reference File: required/other/operator-hub.yaml2 Diff Output: diff -u -N /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster --- /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 +++ /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 @@ -1,6 +1,6 @@ apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: + annotations:3 + include.release.openshift.io/hypershift: "true" name: cluster -spec: - disableAllDefaultSources: true ********************************** Summary4 CRs with diffs: 11/125 CRs in reference missing from the cluster: 406 optional-image-registry: image-registry: Missing CRs:7 - optional/image-registry/ImageRegistryPV.yaml optional-ptp-config: ptp-config: One of the following is required: - optional/ptp-config/PtpConfigBoundary.yaml - optional/ptp-config/PtpConfigGmWpc.yaml - optional/ptp-config/PtpConfigDualCardGmWpc.yaml - optional/ptp-config/PtpConfigForHA.yaml - optional/ptp-config/PtpConfigMaster.yaml - optional/ptp-config/PtpConfigSlave.yaml - optional/ptp-config/PtpConfigSlaveForEvent.yaml - optional/ptp-config/PtpConfigForHAForEvent.yaml - optional/ptp-config/PtpConfigMasterForEvent.yaml - optional/ptp-config/PtpConfigBoundaryForEvent.yaml ptp-operator-config: One of the following is required: - optional/ptp-config/PtpOperatorConfig.yaml - optional/ptp-config/PtpOperatorConfigForEvent.yaml optional-storage: storage: Missing CRs: - optional/local-storage-operator/StorageLV.yaml ... No CRs are unmatched to reference CRs8 Metadata Hash: 09650c31212be9a44b99315ec14d2e7715ee194a5d68fb6d24f65fd5ddbe3c3c9 No patched CRs10 - 1
- The CR under comparison. The plugin displays each CR with a difference from the corresponding template.
- 2
- The template matching with the CR for comparison.
- 3
- The output in Linux diff format shows the difference between the template and the cluster CR.
- 4
- After the plugin reports the line diffs for each CR, the summary of differences are reported.
- 5
- The number of CRs in the comparison with differences from the corresponding templates.
- 6
- The number of CRs represented in the reference configuration, but missing from the live cluster.
- 7
- The list of CRs represented in the reference configuration, but missing from the live cluster.
- 8
- The CRs that did not match to a corresponding template in the reference configuration.
- 9
- The metadata hash identifies the reference configuration.
- 10
- The list of patched CRs.
4.10. Telco RAN DU 4.20 validated software components
The Red Hat telco RAN DU 4.20 solution has been validated using the following Red Hat software products for OpenShift Container Platform managed clusters.
| Component | Software version |
|---|---|
| Managed cluster version | 4.19 |
| Cluster Logging Operator | 6.2 |
| Local Storage Operator | 4.20 |
| OpenShift API for Data Protection (OADP) | 1.5 |
| PTP Operator | 4.20 |
| SR-IOV Operator | 4.20 |
| SRIOV-FEC Operator | 2.11 |
| Lifecycle Agent | 4.20 |