Este contenido no está disponible en el idioma seleccionado.
Chapter 14. About Placement Groups
Tracking object placement on a per-object basis within a pool is computationally expensive at scale. To facilitate high performance at scale, Ceph subdivides a pool into placement groups, assigns each individual object to a placement group, and assigns the placement group to a primary OSD. If an OSD fails or the cluster re-balances, Ceph can move or replicate an entire placement group—i.e., all of the objects in the placement groups—without having to address each object individually. This allows a Ceph cluster to re-balance or recover efficiently.
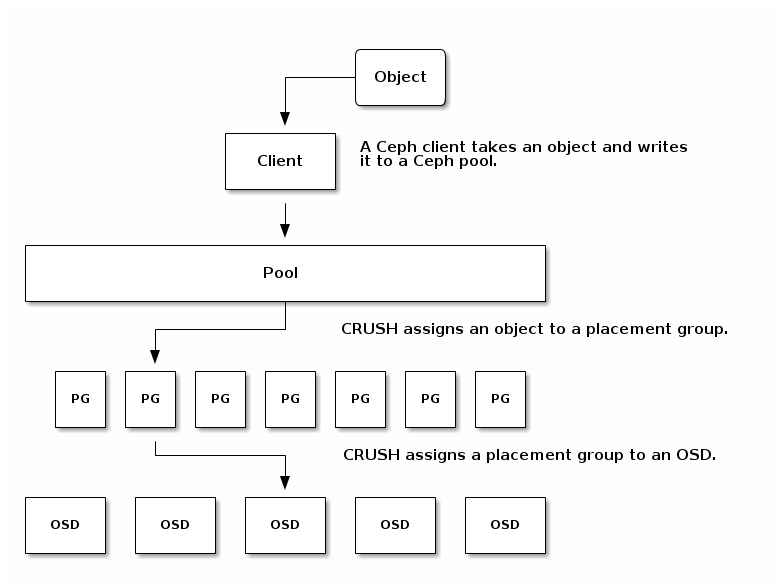
When CRUSH assigns a placement group to an OSD, it calculates a series of OSDs—the first being the primary. The osd_pool_default_size setting minus 1 for replicated pools, and the number of coding chunks M for erasure-coded pools determine the number of OSDs storing a placement group that can fail without losing data permanently. Primary OSDs use CRUSH to identify the secondary OSDs and copy the placement group’s contents to the secondary OSDs. For example, if CRUSH assigns an object to a placement group, and the placement group is assigned to OSD 5 as the primary OSD, if CRUSH calculates that OSD 1 and OSD 8 are secondary OSDs for the placement group, the primary OSD 1 will copy the data to OSDs 1 and 8. By copying data on behalf of clients, Ceph simplifies the client interface and reduces the client workload. The same process allows the Ceph cluster to recover and rebalance dynamically.
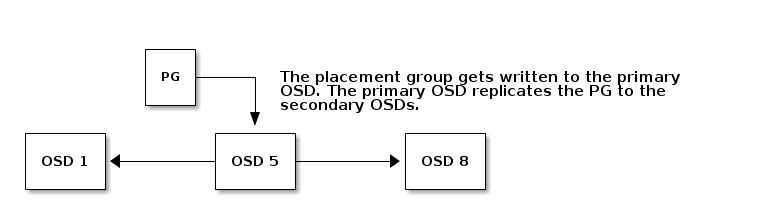
Should the primary OSD fail and get marked out of the cluster, CRUSH will assign the placement group to another OSD, which will will receive copies of objects in the placement group. Another OSD in the Up Set will assume the role of the primary OSD.
When you increase the number of object replicas or coding chunks, CRUSH will assign each placement group to additional OSDs as required.
PGs do not own OSDs. CRUSH assigns many placement groups to each OSD pseudo-randomly to ensure that data gets distributed evenly across the cluster.