Este contenido no está disponible en el idioma seleccionado.
Chapter 3. The Ceph client components
Ceph clients differ materially in how they present data storage interfaces. A Ceph block device presents block storage that mounts just like a physical storage drive. A Ceph gateway presents an object storage service with S3-compliant and Swift-compliant RESTful interfaces with its own user management. However, all Ceph clients use the Reliable Autonomic Distributed Object Store (RADOS) protocol to interact with the Red Hat Ceph Storage cluster.
They all have the same basic needs:
- The Ceph configuration file, and the Ceph monitor address.
- The pool name.
- The user name and the path to the secret key.
Ceph clients tend to follow some similar patterns, such as object-watch-notify and striping. The following sections describe a little bit more about RADOS, librados and common patterns used in Ceph clients.
Prerequisites
- A basic understanding of distributed storage systems.
3.1. Ceph client native protocol
Modern applications need a simple object storage interface with asynchronous communication capability. The Ceph Storage Cluster provides a simple object storage interface with asynchronous communication capability. The interface provides direct, parallel access to objects throughout the cluster.
- Pool Operations
- Snapshots
Read/Write Objects
- Create or Remove
- Entire Object or Byte Range
- Append or Truncate
- Create/Set/Get/Remove XATTRs
- Create/Set/Get/Remove Key/Value Pairs
- Compound operations and dual-ack semantics
3.2. Ceph client object watch and notify
A Ceph client can register a persistent interest with an object and keep a session to the primary OSD open. The client can send a notification message and payload to all watchers and receive notification when the watchers receive the notification. This enables a client to use any object as a synchronization/communication channel.
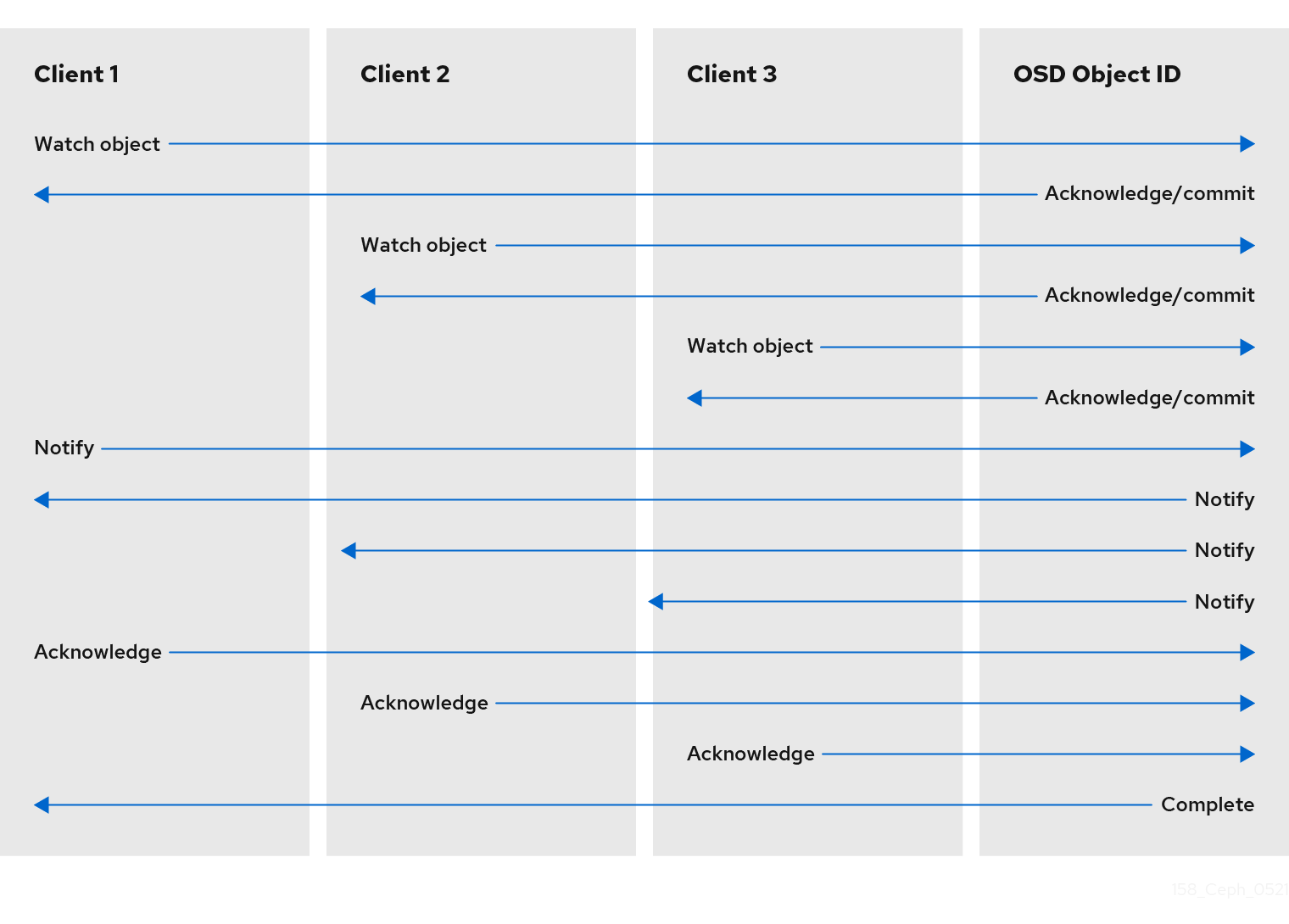
3.3. Ceph client Mandatory Exclusive Locks
Mandatory Exclusive Locks is a feature that locks an RBD to a single client, if multiple mounts are in place. This helps address the write conflict situation when multiple mounted clients try to write to the same object. This feature is built on object-watch-notify explained in the previous section. So, when writing, if one client first establishes an exclusive lock on an object, another mounted client will first check to see if a peer has placed a lock on the object before writing.
With this feature enabled, only one client can modify an RBD device at a time, especially when changing internal RBD structures during operations like snapshot create/delete. It also provides some protection for failed clients. For instance, if a virtual machine seems to be unresponsive and you start a copy of it with the same disk elsewhere, the first one will be blacklisted in Ceph and unable to corrupt the new one.
Mandatory Exclusive Locks are not enabled by default. You have to explicitly enable it with --image-feature parameter when creating an image.
Example
[root@mon ~]# rbd create --size 102400 mypool/myimage --image-feature 5
Here, the numeral 5 is a summation of 1 and 4 where 1 enables layering support and 4 enables exclusive locking support. So, the above command will create a 100 GB rbd image, enable layering and exclusive lock.
Mandatory Exclusive Locks is also a prerequisite for object map. Without enabling exclusive locking support, object map support cannot be enabled.
Mandatory Exclusive Locks also does some ground work for mirroring.
3.4. Ceph client object map
Object map is a feature that tracks the presence of backing RADOS objects when a client writes to an rbd image. When a write occurs, that write is translated to an offset within a backing RADOS object. When the object map feature is enabled, the presence of these RADOS objects is tracked. So, we can know if the objects actually exist. Object map is kept in-memory on the librbd client so it can avoid querying the OSDs for objects that it knows don’t exist. In other words, object map is an index of the objects that actually exist.
Object map is beneficial for certain operations, viz:
- Resize
- Export
- Copy
- Flatten
- Delete
- Read
A shrink resize operation is like a partial delete where the trailing objects are deleted.
An export operation knows which objects are to be requested from RADOS.
A copy operation knows which objects exist and need to be copied. It does not have to iterate over potentially hundreds and thousands of possible objects.
A flatten operation performs a copy-up for all parent objects to the clone so that the clone can be detached from the parent i.e, the reference from the child clone to the parent snapshot can be removed. So, instead of all potential objects, copy-up is done only for the objects that exist.
A delete operation deletes only the objects that exist in the image.
A read operation skips the read for objects it knows doesn’t exist.
So, for operations like resize, shrinking only, exporting, copying, flattening, and deleting, these operations would need to issue an operation for all potentially affected RADOS objects, whether they exist or not. With object map enabled, if the object doesn’t exist, the operation need not be issued.
For example, if we have a 1 TB sparse RBD image, it can have hundreds and thousands of backing RADOS objects. A delete operation without object map enabled would need to issue a remove object operation for each potential object in the image. But if object map is enabled, it only needs to issue remove object operations for the objects that exist.
Object map is valuable against clones that don’t have actual objects but get objects from parents. When there is a cloned image, the clone initially has no objects and all reads are redirected to the parent. So, object map can improve reads as without the object map, first it needs to issue a read operation to the OSD for the clone, when that fails, it issues another read to the parent — with object map enabled. It skips the read for objects it knows doesn’t exist.
Object map is not enabled by default. You have to explicitly enable it with --image-features parameter when creating an image. Also, Mandatory Exclusive Locks is a prerequisite for object map. Without enabling exclusive locking support, object map support cannot be enabled. To enable object map support when creating a image, execute:
[root@mon ~]# rbd -p mypool create myimage --size 102400 --image-features 13
Here, the numeral 13 is a summation of 1, 4 and 8 where 1 enables layering support, 4 enables exclusive locking support and 8 enables object map support. So, the above command will create a 100 GB rbd image, enable layering, exclusive lock and object map.
3.5. Ceph client data stripping
Storage devices have throughput limitations, which impact performance and scalability. So storage systems often support striping—storing sequential pieces of information across multiple storage devices—to increase throughput and performance. The most common form of data striping comes from RAID. The RAID type most similar to Ceph’s striping is RAID 0, or a 'striped volume.' Ceph’s striping offers the throughput of RAID 0 striping, the reliability of n-way RAID mirroring and faster recovery.
Ceph provides three types of clients: Ceph Block Device, Ceph Filesystem, and Ceph Object Storage. A Ceph Client converts its data from the representation format it provides to its users, such as a block device image, RESTful objects, CephFS filesystem directories, into objects for storage in the Ceph Storage Cluster.
The objects Ceph stores in the Ceph Storage Cluster are not striped. Ceph Object Storage, Ceph Block Device, and the Ceph Filesystem stripe their data over multiple Ceph Storage Cluster objects. Ceph Clients that write directly to the Ceph storage cluster using librados must perform the striping, and parallel I/O for themselves to obtain these benefits.
The simplest Ceph striping format involves a stripe count of 1 object. Ceph Clients write stripe units to a Ceph Storage Cluster object until the object is at its maximum capacity, and then create another object for additional stripes of data. The simplest form of striping may be sufficient for small block device images, S3 or Swift objects. However, this simple form doesn’t take maximum advantage of Ceph’s ability to distribute data across placement groups, and consequently doesn’t improve performance very much. The following diagram depicts the simplest form of striping:
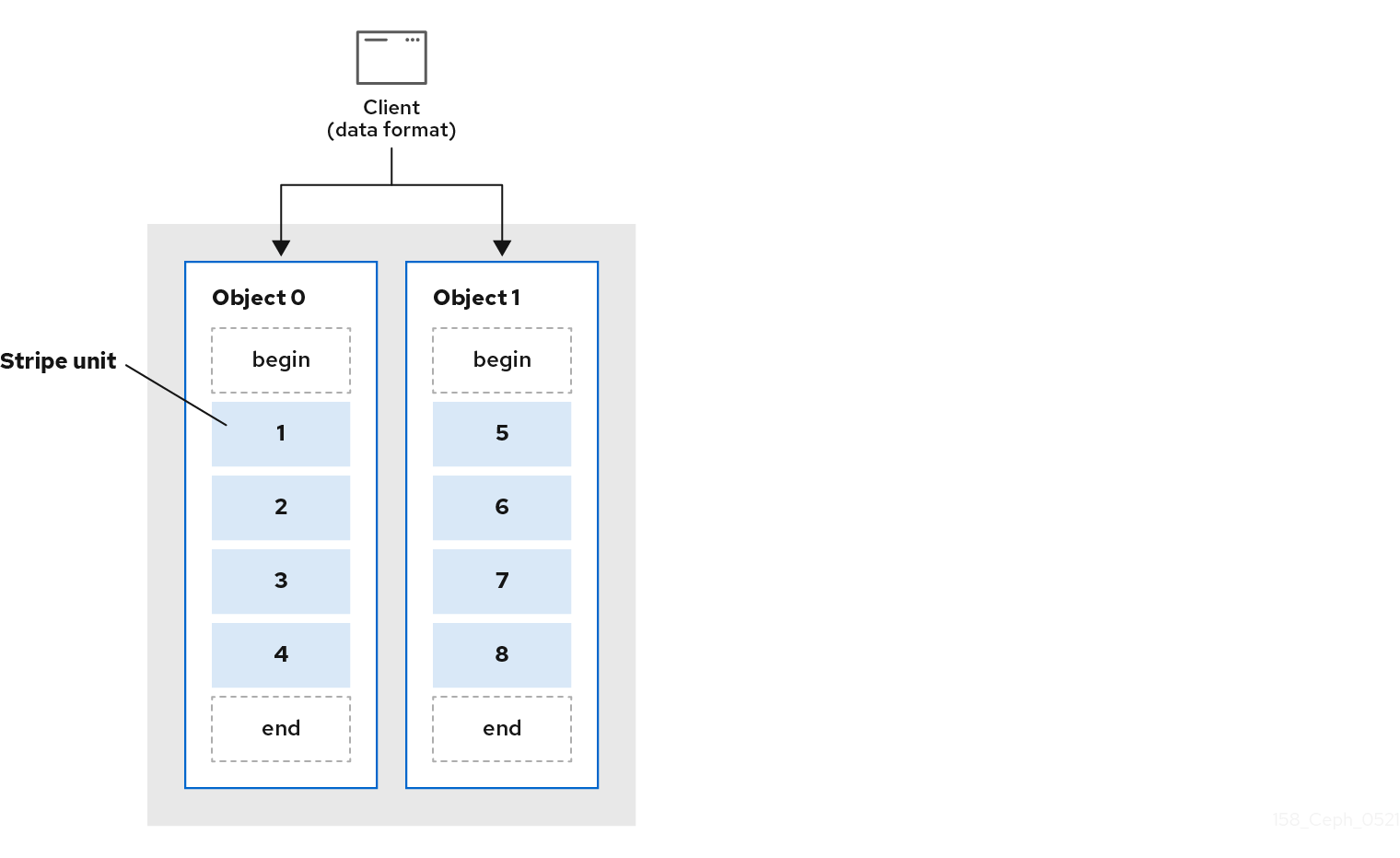
If you anticipate large images sizes, large S3 or Swift objects for example, video, you may see considerable read/write performance improvements by striping client data over multiple objects within an object set. Significant write performance occurs when the client writes the stripe units to their corresponding objects in parallel. Since objects get mapped to different placement groups and further mapped to different OSDs, each write occurs in parallel at the maximum write speed. A write to a single disk would be limited by the head movement for example, 6ms per seek and bandwidth of that one device for example, 100MB/s. By spreading that write over multiple objects, which map to different placement groups and OSDs, Ceph can reduce the number of seeks per drive and combine the throughput of multiple drives to achieve much faster write or read speeds.
Striping is independent of object replicas. Since CRUSH replicates objects across OSDs, stripes get replicated automatically.
In the following diagram, client data gets striped across an object set (object set 1 in the following diagram) consisting of 4 objects, where the first stripe unit is stripe unit 0 in object 0, and the fourth stripe unit is stripe unit 3 in object 3. After writing the fourth stripe, the client determines if the object set is full. If the object set is not full, the client begins writing a stripe to the first object again, see object 0 in the following diagram. If the object set is full, the client creates a new object set, see object set 2 in the following diagram, and begins writing to the first stripe, with a stripe unit of 16, in the first object in the new object set, see object 4 in the diagram below.
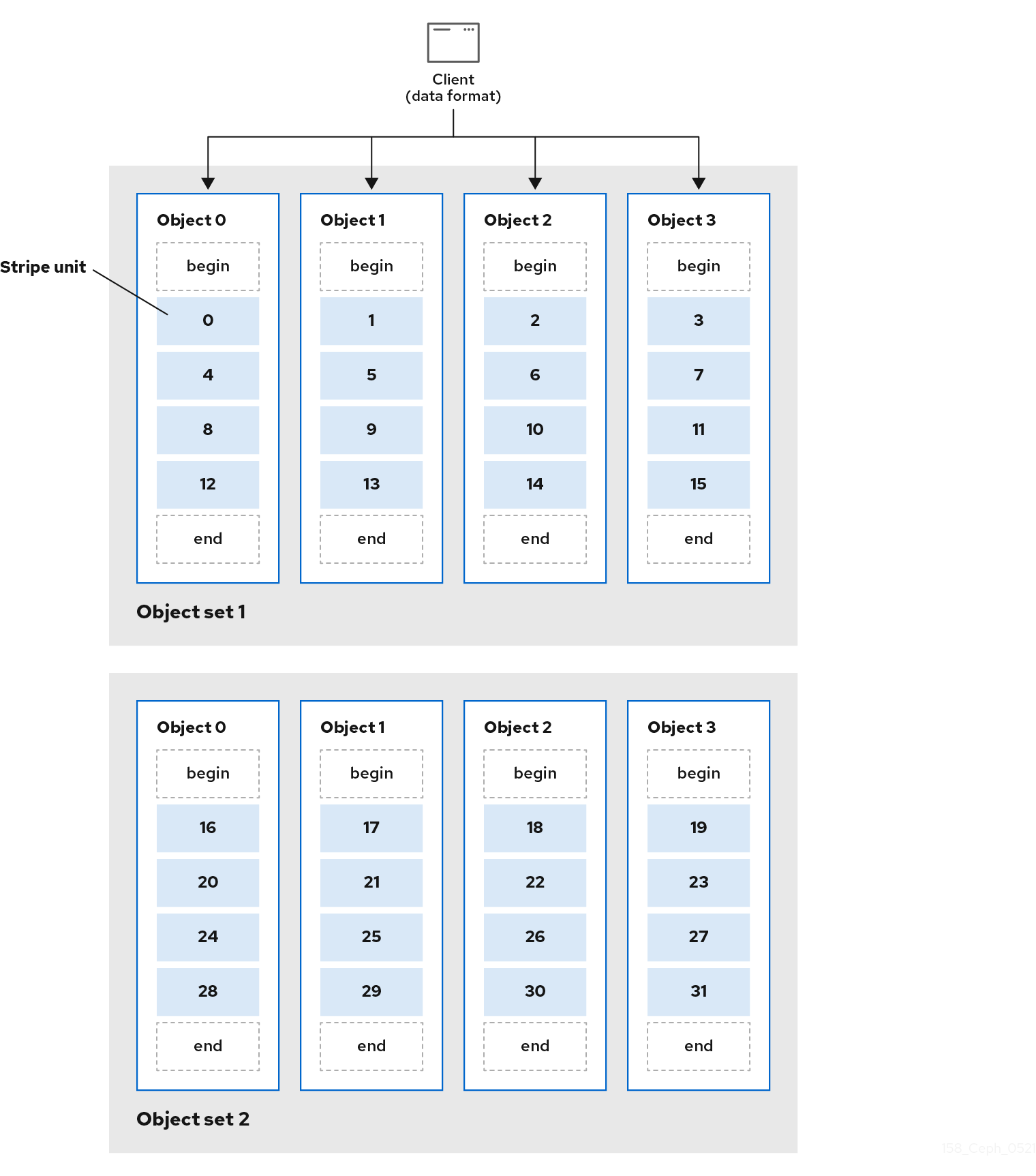
Three important variables determine how Ceph stripes data:
Object Size: Objects in the Ceph Storage Cluster have a maximum configurable size, such as 2 MB, or 4 MB. The object size should be large enough to accommodate many stripe units, and should be a multiple of the stripe unit.
ImportantRed Hat recommends a safe maximum value of 16 MB.
- Stripe Width: Stripes have a configurable unit size, for example 64 KB. The Ceph Client divides the data it will write to objects into equally sized stripe units, except for the last stripe unit. A stripe width should be a fraction of the Object Size so that an object may contain many stripe units.
- Stripe Count: The Ceph Client writes a sequence of stripe units over a series of objects determined by the stripe count. The series of objects is called an object set. After the Ceph Client writes to the last object in the object set, it returns to the first object in the object set.
Test the performance of your striping configuration before putting your cluster into production. You CANNOT change these striping parameters after you stripe the data and write it to objects.
Once the Ceph Client has striped data to stripe units and mapped the stripe units to objects, Ceph’s CRUSH algorithm maps the objects to placement groups, and the placement groups to Ceph OSD Daemons before the objects are stored as files on a storage disk.
Since a client writes to a single pool, all data striped into objects get mapped to placement groups in the same pool. So they use the same CRUSH map and the same access controls.
3.6. Ceph on-wire encryption
You can enable encryption for all Ceph traffic over the network with the messenger version 2 protocol. The secure mode setting for messenger v2 encrypts communication between Ceph daemons and Ceph clients, giving you end-to-end encryption.
The second version of Ceph’s on-wire protocol, msgr2, includes several new features:
- A secure mode encrypting all data moving through the network.
- Encapsulation improvement of authentication payloads.
- Improvements to feature advertisement and negotiation.
The Ceph daemons bind to multiple ports allowing both the legacy, v1-compatible, and the new, v2-compatible, Ceph clients to connect to the same storage cluster. Ceph clients or other Ceph daemons connecting to the Ceph Monitor daemon will try to use the v2 protocol first, if possible, but if not, then the legacy v1 protocol will be used. By default, both messenger protocols, v1 and v2, are enabled. The new v2 port is 3300, and the legacy v1 port is 6789, by default.
The messenger v2 protocol has two configuration options that control whether the v1 or the v2 protocol is used:
-
ms_bind_msgr1- This option controls whether a daemon binds to a port speaking the v1 protocol; it istrueby default. -
ms_bind_msgr2- This option controls whether a daemon binds to a port speaking the v2 protocol; it istrueby default.
Similarly, two options control based on IPv4 and IPv6 addresses used:
-
ms_bind_ipv4- This option controls whether a daemon binds to an IPv4 address; it istrueby default. -
ms_bind_ipv6- This option controls whether a daemon binds to an IPv6 address; it istrueby default.
The msgr2 protocol supports two connection modes:
crc-
Provides strong initial authentication when a connection is established with
cephx. -
Provides a
crc32cintegrity check to protect against bit flips. - Does not provide protection against a malicious man-in-the-middle attack.
- Does not prevent an eavesdropper from seeing all post-authentication traffic.
-
Provides strong initial authentication when a connection is established with
secure-
Provides strong initial authentication when a connection is established with
cephx. - Provides full encryption of all post-authentication traffic.
- Provides a cryptographic integrity check.
-
Provides strong initial authentication when a connection is established with
The default mode is crc.
Ensure that you consider cluster CPU requirements when you plan the Red Hat Ceph Storage cluster, to include encryption overhead.
Using secure mode is currently supported by Ceph kernel clients, such as CephFS and krbd on Red Hat Enterprise Linux. Using secure mode is supported by Ceph clients using librbd, such as OpenStack Nova, Glance, and Cinder.
Address Changes
For both versions of the messenger protocol to coexist in the same storage cluster, the address formatting has changed:
-
Old address format was,
IP_ADDR:PORT/CLIENT_ID, for example,1.2.3.4:5678/91011. -
New address format is,
PROTOCOL_VERSION:IP_ADDR:PORT/CLIENT_ID, for example,v2:1.2.3.4:5678/91011, where PROTOCOL_VERSION can be eitherv1orv2.
Because the Ceph daemons now bind to multiple ports, the daemons display multiple addresses instead of a single address. Here is an example from a dump of the monitor map:
epoch 1
fsid 50fcf227-be32-4bcb-8b41-34ca8370bd17
last_changed 2021-12-12 11:10:46.700821
created 2021-12-12 11:10:46.700821
min_mon_release 14 (nautilus)
0: [v2:10.0.0.10:3300/0,v1:10.0.0.10:6789/0] mon.a
1: [v2:10.0.0.11:3300/0,v1:10.0.0.11:6789/0] mon.b
2: [v2:10.0.0.12:3300/0,v1:10.0.0.12:6789/0] mon.c
Also, the mon_host configuration option and specifying addresses on the command line, using -m, supports the new address format.
Connection Phases
There are four phases for making an encrypted connection:
- Banner
-
On connection, both the client and the server send a banner. Currently, the Ceph banner is
ceph 0 0n. - Authentication Exchange
- All data, sent or received, is contained in a frame for the duration of the connection. The server decides if authentication has completed, and what the connection mode will be. The frame format is fixed, and can be in three different forms depending on the authentication flags being used.
- Message Flow Handshake Exchange
- The peers identify each other and establish a session. The client sends the first message, and the server will reply with the same message. The server can close connections if the client talks to the wrong daemon. For new sessions, the client and server proceed to exchanging messages. Client cookies are used to identify a session, and can reconnect to an existing session.
- Message Exchange
- The client and server start exchanging messages, until the connection is closed.