Este contenido no está disponible en el idioma seleccionado.
2.3. LVM Logical Volumes
In LVM, a volume group is divided up into logical volumes. The following sections describe the different types of logical volumes.
2.3.1. Linear Volumes
Copiar enlaceEnlace copiado en el portapapeles!
A linear volume aggregates space from one or more physical volumes into one logical volume. For example, if you have two 60GB disks, you can create a 120GB logical volume. The physical storage is concatenated.
Creating a linear volume assigns a range of physical extents to an area of a logical volume in order. For example, as shown in Figure 2.2, “Extent Mapping” logical extents 1 to 99 could map to one physical volume and logical extents 100 to 198 could map to a second physical volume. From the point of view of the application, there is one device that is 198 extents in size.

Figure 2.2. Extent Mapping
The physical volumes that make up a logical volume do not have to be the same size. Figure 2.3, “Linear Volume with Unequal Physical Volumes” shows volume group
VG1 with a physical extent size of 4MB. This volume group includes 2 physical volumes named PV1 and PV2. The physical volumes are divided into 4MB units, since that is the extent size. In this example, PV1 is 200 extents in size (800MB) and PV2 is 100 extents in size (400MB). You can create a linear volume any size between 1 and 300 extents (4MB to 1200MB). In this example, the linear volume named LV1 is 300 extents in size.
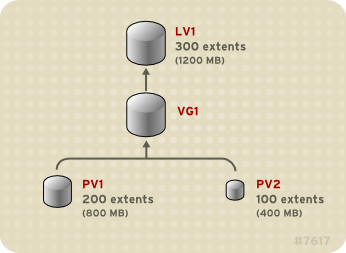
Figure 2.3. Linear Volume with Unequal Physical Volumes
You can configure more than one linear logical volume of whatever size you require from the pool of physical extents. Figure 2.4, “Multiple Logical Volumes” shows the same volume group as in Figure 2.3, “Linear Volume with Unequal Physical Volumes”, but in this case two logical volumes have been carved out of the volume group:
LV1, which is 250 extents in size (1000MB) and LV2 which is 50 extents in size (200MB).
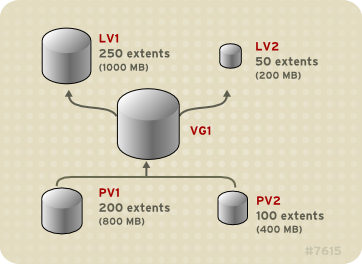
Figure 2.4. Multiple Logical Volumes
2.3.2. Striped Logical Volumes
Copiar enlaceEnlace copiado en el portapapeles!
When you write data to an LVM logical volume, the file system lays the data out across the underlying physical volumes. You can control the way the data is written to the physical volumes by creating a striped logical volume. For large sequential reads and writes, this can improve the efficiency of the data I/O.
Striping enhances performance by writing data to a predetermined number of physical volumes in round-robin fashion. With striping, I/O can be done in parallel. In some situations, this can result in near-linear performance gain for each additional physical volume in the stripe.
The following illustration shows data being striped across three physical volumes. In this figure:
- the first stripe of data is written to the first physical volume
- the second stripe of data is written to the second physical volume
- the third stripe of data is written to the third physical volume
- the fourth stripe of data is written to the first physical volume
In a striped logical volume, the size of the stripe cannot exceed the size of an extent.
Figure 2.5. Striping Data Across Three PVs
Striped logical volumes can be extended by concatenating another set of devices onto the end of the first set. In order to extend a striped logical volume, however, there must be enough free space on the set of underlying physical volumes that make up the volume group to support the stripe. For example, if you have a two-way stripe that uses up an entire volume group, adding a single physical volume to the volume group will not enable you to extend the stripe. Instead, you must add at least two physical volumes to the volume group. For more information on extending a striped volume, see Section 4.4.17, “Extending a Striped Volume”.
2.3.3. RAID Logical Volumes
Copiar enlaceEnlace copiado en el portapapeles!
LVM supports RAID0/1/4/5/6/10. An LVM RAID volume has the following characteristics:
- RAID logical volumes created and managed by means of LVM leverage the MD kernel drivers.
- RAID1 images can be temporarily split from the array and merged back into the array later.
- LVM RAID volumes support snapshots.
For information on creating RAID logical volumes, see Section 4.4.3, “RAID Logical Volumes”.
Note
RAID logical volumes are not cluster-aware. While RAID logical volumes can be created and activated exclusively on one machine, they cannot be activated simultaneously on more than one machine.
2.3.4. Thinly-Provisioned Logical Volumes (Thin Volumes)
Copiar enlaceEnlace copiado en el portapapeles!
Logical volumes can be thinly provisioned. This allows you to create logical volumes that are larger than the available extents. Using thin provisioning, you can manage a storage pool of free space, known as a thin pool, which can be allocated to an arbitrary number of devices when needed by applications. You can then create devices that can be bound to the thin pool for later allocation when an application actually writes to the logical volume. The thin pool can be expanded dynamically when needed for cost-effective allocation of storage space.
Note
Thin volumes are not supported across the nodes in a cluster. The thin pool and all its thin volumes must be exclusively activated on only one cluster node.
By using thin provisioning, a storage administrator can overcommit the physical storage, often avoiding the need to purchase additional storage. For example, if ten users each request a 100GB file system for their application, the storage administrator can create what appears to be a 100GB file system for each user but which is backed by less actual storage that is used only when needed.
Note
When using thin provisioning, it is important that the storage administrator monitor the storage pool and add more capacity if it starts to become full.
To make sure that all available space can be used, LVM supports data discard. This allows for re-use of the space that was formerly used by a discarded file or other block range.
For information on creating thin volumes, see Section 4.4.5, “Creating Thinly-Provisioned Logical Volumes”.
Thin volumes provide support for a new implementation of copy-on-write (COW) snapshot logical volumes, which allow many virtual devices to share the same data in the thin pool. For information on thin snapshot volumes, see Section 2.3.6, “Thinly-Provisioned Snapshot Volumes”.
2.3.5. Snapshot Volumes
Copiar enlaceEnlace copiado en el portapapeles!
The LVM snapshot feature provides the ability to create virtual images of a device at a particular instant without causing a service interruption. When a change is made to the original device (the origin) after a snapshot is taken, the snapshot feature makes a copy of the changed data area as it was prior to the change so that it can reconstruct the state of the device.
Note
LVM supports thinly-provisioned snapshots. For information on thinly provisioned snapshot volumes, see Section 2.3.6, “Thinly-Provisioned Snapshot Volumes”.
Note
LVM snapshots are not supported across the nodes in a cluster. You cannot create a snapshot volume in a clustered volume group.
Because a snapshot copies only the data areas that change after the snapshot is created, the snapshot feature requires a minimal amount of storage. For example, with a rarely updated origin, 3-5 % of the origin's capacity is sufficient to maintain the snapshot.
Note
Snapshot copies of a file system are virtual copies, not an actual media backup for a file system. Snapshots do not provide a substitute for a backup procedure.
The size of the snapshot governs the amount of space set aside for storing the changes to the origin volume. For example, if you made a snapshot and then completely overwrote the origin the snapshot would have to be at least as big as the origin volume to hold the changes. You need to dimension a snapshot according to the expected level of change. So for example a short-lived snapshot of a read-mostly volume, such as
/usr, would need less space than a long-lived snapshot of a volume that sees a greater number of writes, such as /home.
If a snapshot runs full, the snapshot becomes invalid, since it can no longer track changes on the origin volume. You should regularly monitor the size of the snapshot. Snapshots are fully resizable, however, so if you have the storage capacity you can increase the size of the snapshot volume to prevent it from getting dropped. Conversely, if you find that the snapshot volume is larger than you need, you can reduce the size of the volume to free up space that is needed by other logical volumes.
When you create a snapshot file system, full read and write access to the origin stays possible. If a chunk on a snapshot is changed, that chunk is marked and never gets copied from the original volume.
There are several uses for the snapshot feature:
- Most typically, a snapshot is taken when you need to perform a backup on a logical volume without halting the live system that is continuously updating the data.
- You can execute the
fsckcommand on a snapshot file system to check the file system integrity and determine whether the original file system requires file system repair. - Because the snapshot is read/write, you can test applications against production data by taking a snapshot and running tests against the snapshot, leaving the real data untouched.
- You can create LVM volumes for use with Red Hat Virtualization. LVM snapshots can be used to create snapshots of virtual guest images. These snapshots can provide a convenient way to modify existing guests or create new guests with minimal additional storage. For information on creating LVM-based storage pools with Red Hat Virtualization, see the Virtualization Administration Guide.
For information on creating snapshot volumes, see Section 4.4.6, “Creating Snapshot Volumes”.
You can use the
--merge option of the lvconvert command to merge a snapshot into its origin volume. One use for this feature is to perform system rollback if you have lost data or files or otherwise need to restore your system to a previous state. After you merge the snapshot volume, the resulting logical volume will have the origin volume's name, minor number, and UUID and the merged snapshot is removed. For information on using this option, see Section 4.4.9, “Merging Snapshot Volumes”.
2.3.6. Thinly-Provisioned Snapshot Volumes
Copiar enlaceEnlace copiado en el portapapeles!
Red Hat Enterprise Linux provides support for thinly-provisioned snapshot volumes. Thin snapshot volumes allow many virtual devices to be stored on the same data volume. This simplifies administration and allows for the sharing of data between snapshot volumes.
As for all LVM snapshot volumes, as well as all thin volumes, thin snapshot volumes are not supported across the nodes in a cluster. The snapshot volume must be exclusively activated on only one cluster node.
Thin snapshot volumes provide the following benefits:
- A thin snapshot volume can reduce disk usage when there are multiple snapshots of the same origin volume.
- If there are multiple snapshots of the same origin, then a write to the origin will cause one COW operation to preserve the data. Increasing the number of snapshots of the origin should yield no major slowdown.
- Thin snapshot volumes can be used as a logical volume origin for another snapshot. This allows for an arbitrary depth of recursive snapshots (snapshots of snapshots of snapshots...).
- A snapshot of a thin logical volume also creates a thin logical volume. This consumes no data space until a COW operation is required, or until the snapshot itself is written.
- A thin snapshot volume does not need to be activated with its origin, so a user may have only the origin active while there are many inactive snapshot volumes of the origin.
- When you delete the origin of a thinly-provisioned snapshot volume, each snapshot of that origin volume becomes an independent thinly-provisioned volume. This means that instead of merging a snapshot with its origin volume, you may choose to delete the origin volume and then create a new thinly-provisioned snapshot using that independent volume as the origin volume for the new snapshot.
Although there are many advantages to using thin snapshot volumes, there are some use cases for which the older LVM snapshot volume feature may be more appropriate to your needs:
- You cannot change the chunk size of a thin pool. If the thin pool has a large chunk size (for example, 1MB) and you require a short-living snapshot for which a chunk size that large is not efficient, you may elect to use the older snapshot feature.
- You cannot limit the size of a thin snapshot volume; the snapshot will use all of the space in the thin pool, if necessary. This may not be appropriate for your needs.
In general, you should consider the specific requirements of your site when deciding which snapshot format to use.
Note
When using thin provisioning, it is important that the storage administrator monitor the storage pool and add more capacity if it starts to become full. For information on configuring and displaying information on thinly-provisioned snapshot volumes, see Section 4.4.7, “Creating Thinly-Provisioned Snapshot Volumes”.
2.3.7. Cache Volumes
Copiar enlaceEnlace copiado en el portapapeles!
As of the Red Hat Enterprise Linux 7.1 release, LVM supports the use of fast block devices (such as SSD drives) as write-back or write-through caches for larger slower block devices. Users can create cache logical volumes to improve the performance of their existing logical volumes or create new cache logical volumes composed of a small and fast device coupled with a large and slow device.
For information on creating LVM cache volumes, see Section 4.4.8, “Creating LVM Cache Logical Volumes”.