Configuración y gestión de clusters de alta disponibilidad
Configuración y gestión del complemento de alta disponibilidad de Red Hat
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Capítulo 1. Descripción del complemento de alta disponibilidad
El complemento de alta disponibilidad es un sistema en clúster que proporciona fiabilidad, escalabilidad y disponibilidad a los servicios de producción críticos.
Un clúster son dos o más ordenadores (llamados nodes o members) que trabajan juntos para realizar una tarea. Los clústeres pueden utilizarse para proporcionar servicios o recursos de alta disponibilidad. La redundancia de múltiples máquinas se utiliza para protegerse de fallos de muchos tipos.
Los clústeres de alta disponibilidad proporcionan servicios de alta disponibilidad eliminando los puntos únicos de fallo y pasando los servicios de un nodo del clúster a otro en caso de que un nodo quede inoperativo. Normalmente, los servicios de un clúster de alta disponibilidad leen y escriben datos (mediante sistemas de archivos montados de lectura y escritura). Por lo tanto, un cluster de alta disponibilidad debe mantener la integridad de los datos cuando un nodo del cluster toma el control de un servicio de otro nodo del cluster. Los fallos de los nodos de un clúster de alta disponibilidad no son visibles para los clientes externos al clúster. (Los clústeres de alta disponibilidad se denominan a veces clústeres de conmutación por error). El complemento de alta disponibilidad proporciona clústeres de alta disponibilidad a través de su componente de gestión de servicios de alta disponibilidad, Pacemaker.
1.1. Componentes del complemento de alta disponibilidad
El complemento de alta disponibilidad consta de los siguientes componentes principales:
- Infraestructura de clústeres
- Gestión de servicios de alta disponibilidad
- Herramientas de administración de clústeres
Puede complementar el complemento de alta disponibilidad con los siguientes componentes:
- Red Hat GFS2 (Global File System 2)
-
Demonio de bloqueo LVM (
lvmlockd) - Complemento del equilibrador de carga
1.2. Visión general del marcapasos
Pacemaker es un gestor de recursos de clúster. Consigue la máxima disponibilidad para los servicios y recursos de su clúster haciendo uso de las capacidades de mensajería y afiliación de la infraestructura del clúster para disuadir y recuperarse de los fallos a nivel de nodos y recursos.
1.2.1. Componentes de la arquitectura del marcapasos
Un clúster configurado con Pacemaker está compuesto por demonios de componentes separados que supervisan la pertenencia al clúster, scripts que gestionan los servicios y subsistemas de gestión de recursos que supervisan los distintos recursos.
Los siguientes componentes forman la arquitectura de Pacemaker:
- Base de información de clusters (CIB)
- El demonio de información de Pacemaker, que utiliza XML internamente para distribuir y sincronizar la configuración actual y la información de estado del Coordinador Designado (DC)
- Demonio de gestión de recursos del clúster (CRMd)
Las acciones de los recursos del cluster Pacemaker se enrutan a través de este demonio. Los recursos gestionados por CRMd pueden ser consultados por los sistemas cliente, movidos, instanciados y modificados cuando sea necesario.
Cada nodo del clúster también incluye un demonio gestor de recursos local (LRMd) que actúa como interfaz entre CRMd y los recursos. LRMd pasa comandos de CRMd a los agentes, como el arranque y la parada y la transmisión de información de estado.
- Disparar al otro nodo en la cabeza (STONITH)
- STONITH es la implementación de cercado de Pacemaker. Actúa como un recurso de clúster en Pacemaker que procesa las solicitudes de vallado, apagando a la fuerza los nodos y retirándolos del clúster para garantizar la integridad de los datos. STONITH está configurado en el CIB y puede ser monitorizado como un recurso de cluster normal. Para una visión general de la esgrima, ver Sección 1.3, “Visión general de la esgrima”.
- corosync
corosynces el componente - y un demonio del mismo nombre - que sirve a las necesidades centrales de membresía y comunicación de los miembros para los clusters de alta disponibilidad. Es necesario para que el complemento de alta disponibilidad funcione.Además de esas funciones de afiliación y mensajería,
corosynctambién:- Gestiona las normas de quórum y su determinación.
- Proporciona capacidades de mensajería para las aplicaciones que coordinan u operan a través de múltiples miembros del clúster y, por lo tanto, deben comunicar información de estado o de otro tipo entre las instancias.
-
Utiliza la librería
kronosnetcomo transporte de red para proporcionar múltiples enlaces redundantes y conmutación automática por error.
1.2.2. Herramientas de configuración y gestión
El complemento de alta disponibilidad cuenta con dos herramientas de configuración para el despliegue, la supervisión y la gestión del clúster.
pcsLa interfaz de línea de comandos
pcscontrola y configura Pacemaker y el demoniocorosyncheartbeat. Un programa basado en la línea de comandos,pcspuede realizar las siguientes tareas de gestión del clúster:- Crear y configurar un clúster Pacemaker/Corosync
- Modificar la configuración del clúster mientras se está ejecutando
- Configurar remotamente tanto Pacemaker como Corosync, así como iniciar, detener y mostrar la información de estado del clúster
pcsdWeb UI- Una interfaz gráfica de usuario para crear y configurar clusters Pacemaker/Corosync.
1.2.3. Los archivos de configuración del clúster y del marcapasos
Los archivos de configuración para el complemento de alta disponibilidad de Red Hat son corosync.conf y cib.xml.
El archivo corosync.conf proporciona los parámetros de cluster utilizados por corosync, el gestor de cluster en el que se basa Pacemaker. En general, no se debe editar el corosync.conf directamente sino, en su lugar, utilizar la interfaz pcs o pcsd.
El archivo cib.xml es un archivo XML que representa tanto la configuración del cluster como el estado actual de todos los recursos del cluster. Este archivo es utilizado por la Base de Información del Cluster (CIB) de Pacemaker. El contenido de la CIB se mantiene automáticamente sincronizado en todo el cluster. No edite el archivo cib.xml directamente; utilice la interfaz pcs o pcsd en su lugar.
1.3. Visión general de la esgrima
Si la comunicación con un solo nodo del clúster falla, los demás nodos del clúster deben ser capaces de restringir o liberar el acceso a los recursos a los que el nodo del clúster que ha fallado pueda tener acceso. Esto no puede lograrse contactando con el propio nodo del clúster, ya que éste puede no responder. En su lugar, debe proporcionar un método externo, que se denomina cercado con un agente de cercado. Un agente de valla es un dispositivo externo que puede ser utilizado por el clúster para restringir el acceso a los recursos compartidos por un nodo errante, o para emitir un reinicio duro en el nodo del clúster.
Sin un dispositivo de valla configurado, no tiene forma de saber que los recursos utilizados previamente por el nodo de clúster desconectado han sido liberados, y esto podría impedir que los servicios se ejecuten en cualquiera de los otros nodos de clúster. A la inversa, el sistema puede suponer erróneamente que el nodo del clúster ha liberado sus recursos y esto puede llevar a la corrupción y pérdida de datos. Sin un dispositivo de valla configurado no se puede garantizar la integridad de los datos y la configuración del clúster no será compatible.
Cuando el cercado está en curso, no se permite la ejecución de ninguna otra operación del clúster. El funcionamiento normal del clúster no se puede reanudar hasta que se haya completado el cercado o hasta que el nodo del clúster se reincorpore al clúster después de reiniciar el nodo del clúster.
Para más información sobre el cercado, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
1.4. Resumen del quórum
Para mantener la integridad y la disponibilidad del clúster, los sistemas de clúster utilizan un concepto conocido como quorum para evitar la corrupción y la pérdida de datos. Un clúster tiene quórum cuando más de la mitad de los nodos del clúster están en línea. Para mitigar la posibilidad de corrupción de datos debido a un fallo, Pacemaker detiene por defecto todos los recursos si el clúster no tiene quórum.
El quórum se establece mediante un sistema de votación. Cuando un nodo del clúster no funciona como debería o pierde la comunicación con el resto del clúster, la mayoría de los nodos que funcionan pueden votar para aislar y, si es necesario, cercar el nodo para su mantenimiento.
Por ejemplo, en un cluster de 6 nodos, el quórum se establece cuando al menos 4 nodos del cluster están funcionando. Si la mayoría de los nodos se desconectan o dejan de estar disponibles, el clúster deja de tener quórum y Pacemaker detiene los servicios en clúster.
Las características de quórum en Pacemaker previenen lo que también se conoce como split-brain, un fenómeno en el que el cluster se separa de la comunicación pero cada parte continúa trabajando como clusters separados, potencialmente escribiendo en los mismos datos y posiblemente causando corrupción o pérdida. Para más información sobre lo que significa estar en un estado de cerebro dividido, y sobre los conceptos de quórum en general, vea Explorando los conceptos de los clusters de alta disponibilidad de RHEL - Quórum.
Un cluster de Red Hat Enterprise Linux High Availability Add-On utiliza el servicio votequorum, en conjunto con fencing, para evitar situaciones de split brain. Se asigna un número de votos a cada sistema en el cluster, y las operaciones del cluster se permiten sólo cuando hay una mayoría de votos.
1.5. Resumen de recursos
Un cluster resource es una instancia de programa, datos o aplicación que debe ser gestionada por el servicio de cluster. Estos recursos se abstraen mediante agents que proporciona una interfaz estándar para gestionar el recurso en un entorno de clúster.
Para asegurarse de que los recursos se mantienen en buen estado, puede añadir una operación de supervisión a la definición de un recurso. Si no se especifica una operación de supervisión para un recurso, se añade una por defecto.
Puede determinar el comportamiento de un recurso en un cluster configurando constraints. Puede configurar las siguientes categorías de restricciones:
- limitaciones de ubicación
- restricciones de ordenación
- limitaciones de colocación
Uno de los elementos más comunes de un clúster es un conjunto de recursos que deben ubicarse juntos, iniciarse secuencialmente y detenerse en el orden inverso. Para simplificar esta configuración, Pacemaker admite el concepto de groups.
Capítulo 2. Cómo empezar con Pacemaker
Los siguientes procedimientos proporcionan una introducción a las herramientas y procesos que se utilizan para crear un cluster Pacemaker. Están destinados a los usuarios que están interesados en ver el aspecto del software de clúster y cómo se administra, sin necesidad de configurar un clúster en funcionamiento.
Estos procedimientos no crean un cluster Red Hat compatible, que requiere al menos dos nodos y la configuración de un dispositivo de cercado.
2.1. Aprender a usar el Marcapasos
Este ejemplo requiere un único nodo que ejecute RHEL 8 y requiere una dirección IP flotante que resida en la misma red que una de las direcciones IP asignadas estáticamente al nodo.
-
El nodo utilizado en este ejemplo es
z1.example.com. - La dirección IP flotante utilizada en este ejemplo es 192.168.122.120.
Asegúrese de que el nombre del nodo en el que se está ejecutando está en su archivo /etc/hosts.
Mediante este procedimiento, aprenderá a utilizar Pacemaker para configurar un clúster, a mostrar el estado del clúster y a configurar un servicio de clúster. Este ejemplo crea un servidor Apache HTTP como recurso de clúster y muestra cómo responde el clúster cuando el recurso falla.
Instale los paquetes de software de Red Hat High Availability Add-On desde el canal de Alta Disponibilidad, e inicie y habilite el servicio
pcsd.#
yum install pcs pacemaker fence-agents-all... #systemctl start pcsd.service#systemctl enable pcsd.serviceSi está ejecutando el demonio
firewalld, habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadEstablezca una contraseña para el usuario
haclusteren cada nodo del clúster y autentique el usuariohaclusterpara cada nodo del clúster en el nodo desde el que ejecutará los comandospcs. Este ejemplo está utilizando sólo un nodo, el nodo desde el cual está ejecutando los comandos, pero este paso se incluye aquí ya que es un paso necesario en la configuración de un cluster de alta disponibilidad de Red Hat soportado.#
passwd hacluster... #pcs host auth z1.example.comCrear un clúster llamado
my_clustercon un miembro y comprobar el estado del clúster. Este comando crea e inicia el clúster en un solo paso.#
pcs cluster setup my_cluster --start z1.example.com... #pcs cluster statusCluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 1 node configured 0 resources configured PCSD Status: z1.example.com: OnlineUn cluster de Alta Disponibilidad de Red Hat requiere que se configure el cercado para el cluster. Las razones de este requisito se describen en Esgrima en un cluster de alta disponibilidad de Red Hat. Para esta introducción, sin embargo, que pretende mostrar sólo cómo usar los comandos básicos de Pacemaker, desactive el cercado estableciendo la opción de cluster
stonith-enabledafalse.AvisoEl uso de
stonith-enabled=falsees completamente inapropiado para un cluster de producción. Le dice al clúster que simplemente finja que los nodos que fallan están cercados de forma segura.#
pcs property set stonith-enabled=falseConfigure un navegador web en su sistema y cree una página web para mostrar un simple mensaje de texto. Si está ejecutando el demonio
firewalld, habilite los puertos que requierehttpd.NotaNo utilice
systemctl enablepara habilitar cualquier servicio que vaya a ser gestionado por el clúster para que se inicie en el arranque del sistema.#
yum install -y httpd wget... #firewall-cmd --permanent --add-service=http#firewall-cmd --reload#cat <<-END >/var/www/html/index.html<html><body>My Test Site - $(hostname)</body></html>ENDPara que el agente de recursos de Apache obtenga el estado de Apache, cree la siguiente adición a la configuración existente para habilitar la URL del servidor de estado.
#
cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusOrder deny,allowDeny from allAllow from 127.0.0.1Allow from ::1</Location>ENDCree los recursos
IPaddr2yapachepara que el clúster los gestione. El recurso 'IPaddr2' es una dirección IP flotante que no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recurso 'IPaddr2', la IP flotante debe residir en la misma red que la dirección IP asignada estáticamente y utilizada por el nodo.Puede mostrar una lista de todos los tipos de recursos disponibles con el comando
pcs resource list. Puede utilizar el comandopcs resource describe resourcetypepara mostrar los parámetros que puede establecer para el tipo de recurso especificado. Por ejemplo, el siguiente comando muestra los parámetros que puede establecer para un recurso del tipoapache:#
pcs resource describe apache...En este ejemplo, el recurso dirección IP y el recurso apache están configurados como parte de un grupo llamado
apachegroup, lo que asegura que los recursos se mantienen juntos para ejecutarse en el mismo nodo cuando se configura un clúster multinodal en funcionamiento.#
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup#pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup#pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 1 node configured 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online ...Después de haber configurado un recurso de clúster, puede utilizar el comando
pcs resource configpara mostrar las opciones configuradas para ese recurso.#
pcs resource config WebSiteResource: WebSite (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: start interval=0s timeout=40s (WebSite-start-interval-0s) stop interval=0s timeout=60s (WebSite-stop-interval-0s) monitor interval=1min (WebSite-monitor-interval-1min)- Dirija su navegador al sitio web que ha creado utilizando la dirección IP flotante que ha configurado. Esto debería mostrar el mensaje de texto que definiste.
Detenga el servicio web de apache y compruebe el estado del clúster. El uso de
killall -9simula un fallo a nivel de aplicación.#
killall -9 httpdCompruebe el estado del clúster. Debería ver que la detención del servicio web provocó una acción fallida, pero que el software del clúster reinició el servicio y debería seguir pudiendo acceder al sitio web.
#
pcs statusCluster name: my_cluster ... Current DC: z1.example.com (version 1.1.13-10.el7-44eb2dd) - partition with quorum 1 node and 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=13, status=complete, exitreason='none', last-rc-change='Thu Oct 11 23:45:50 2016', queued=0ms, exec=0ms PCSD Status: z1.example.com: OnlinePuede borrar el estado de fallo en el recurso que ha fallado una vez que el servicio esté en funcionamiento de nuevo y el aviso de acción fallida ya no aparecerá cuando vea el estado del clúster.
#
pcs resource cleanup WebSiteCuando haya terminado de ver el clúster y el estado del mismo, detenga los servicios del clúster en el nodo. Aunque sólo haya iniciado los servicios en un nodo para esta introducción, se incluye el parámetro
--allya que detendría los servicios de clúster en todos los nodos de un clúster real de varios nodos.#
pcs cluster stop --all
2.2. Aprender a configurar la conmutación por error
Este procedimiento proporciona una introducción a la creación de un cluster Pacemaker que ejecuta un servicio que fallará de un nodo a otro cuando el nodo en el que se ejecuta el servicio deje de estar disponible. Mediante este procedimiento, podrá aprender a crear un servicio en un clúster de dos nodos y podrá observar lo que ocurre con ese servicio cuando falla en el nodo en el que se está ejecutando.
Este procedimiento de ejemplo configura un cluster Pacemaker de dos nodos que ejecuta un servidor HTTP Apache. A continuación, puede detener el servicio Apache en un nodo para ver cómo el servicio sigue estando disponible.
Este procedimiento requiere como prerrequisito que tenga dos nodos ejecutando Red Hat Enterprise Linux 8 que puedan comunicarse entre sí, y requiere una dirección IP flotante que resida en la misma red que una de las direcciones IP asignadas estáticamente del nodo.
-
Los nodos utilizados en este ejemplo son
z1.example.comyz2.example.com. - La dirección IP flotante utilizada en este ejemplo es 192.168.122.120.
Asegúrese de que los nombres de los nodos que está utilizando están en el archivo /etc/hosts en cada nodo.
En ambos nodos, instale los paquetes de software Red Hat High Availability Add-On desde el canal de Alta Disponibilidad, e inicie y habilite el servicio
pcsd.#
yum install pcs pacemaker fence-agents-all... #systemctl start pcsd.service#systemctl enable pcsd.serviceSi está ejecutando el demonio
firewalld, en ambos nodos habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadEn ambos nodos del clúster, establezca una contraseña para el usuario
hacluster.#
passwd haclusterAutentifique el usuario
haclusterpara cada nodo del clúster en el nodo desde el que va a ejecutar los comandospcs.#
pcs host auth z1.example.com z2.example.comCree un clúster llamado
my_clustercon ambos nodos como miembros del clúster. Este comando crea e inicia el cluster en un solo paso. Sólo es necesario ejecutarlo desde un nodo del clúster porque los comandos de configuración depcstienen efecto para todo el clúster.En un nodo del clúster, ejecute el siguiente comando.
#
pcs cluster setup my_cluster --start z1.example.com z2.example.comUn cluster de Alta Disponibilidad de Red Hat requiere que se configure el cercado para el cluster. Las razones de este requisito se describen en Esgrima en un cluster de alta disponibilidad de Red Hat. Para esta introducción, sin embargo, para mostrar solamente cómo funciona la conmutación por error en esta configuración, desactive el cercado estableciendo la opción de cluster
stonith-enabledafalseAvisoEl uso de
stonith-enabled=falsees completamente inapropiado para un cluster de producción. Le dice al clúster que simplemente finja que los nodos que fallan están cercados de forma segura.#
pcs property set stonith-enabled=falseDespués de crear un clúster y desactivar el cercado, compruebe el estado del clúster.
NotaCuando ejecute el comando
pcs cluster status, es posible que la salida difiera temporalmente de los ejemplos mientras se inician los componentes del sistema.#
pcs cluster statusCluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 2 nodes configured 0 resources configured PCSD Status: z1.example.com: Online z2.example.com: OnlineEn ambos nodos, configure un navegador web y cree una página web para mostrar un simple mensaje de texto. Si está ejecutando el demonio
firewalld, habilite los puertos que requierehttpd.NotaNo utilice
systemctl enablepara habilitar cualquier servicio que vaya a ser gestionado por el clúster para que se inicie en el arranque del sistema.#
yum install -y httpd wget... #firewall-cmd --permanent --add-service=http#firewall-cmd --reload#cat <<-END >/var/www/html/index.html<html><body>My Test Site - $(hostname)</body></html>ENDPara que el agente de recursos de Apache obtenga el estado de Apache, en cada nodo del clúster cree la siguiente adición a la configuración existente para habilitar la URL del servidor de estado.
#
cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusOrder deny,allowDeny from allAllow from 127.0.0.1Allow from ::1</Location>ENDCree los recursos
IPaddr2yapachepara que el clúster los gestione. El recurso 'IPaddr2' es una dirección IP flotante que no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recurso 'IPaddr2', la IP flotante debe residir en la misma red que la dirección IP asignada estáticamente y utilizada por el nodo.Puede mostrar una lista de todos los tipos de recursos disponibles con el comando
pcs resource list. Puede utilizar el comandopcs resource describe resourcetypepara mostrar los parámetros que puede establecer para el tipo de recurso especificado. Por ejemplo, el siguiente comando muestra los parámetros que puede establecer para un recurso del tipoapache:#
pcs resource describe apache...En este ejemplo, el recurso dirección IP y el recurso apache están configurados como parte de un grupo llamado
apachegroup, lo que asegura que los recursos se mantengan juntos para ejecutarse en el mismo nodo.Ejecute los siguientes comandos desde un nodo del clúster:
#
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup#pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup#pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online ...Tenga en cuenta que en este caso, el servicio
apachegroupse está ejecutando en el nodo z1.ejemplo.com.Acceda al sitio web que ha creado, detenga el servicio en el nodo en el que se está ejecutando y observe cómo el servicio falla en el segundo nodo.
- Dirija un navegador al sitio web que ha creado utilizando la dirección IP flotante que ha configurado. Esto debería mostrar el mensaje de texto que definió, mostrando el nombre del nodo en el que se está ejecutando el sitio web.
Detener el servicio web de apache. El uso de
killall -9simula un fallo a nivel de aplicación.#
killall -9 httpdCompruebe el estado del clúster. Debería ver que la detención del servicio web provocó una acción fallida, pero que el software del clúster reinició el servicio en el nodo en el que se había estado ejecutando y debería seguir pudiendo acceder al navegador web.
#
pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=31, status=complete, exitreason='none', last-rc-change='Fri Feb 5 21:01:41 2016', queued=0ms, exec=0msBorre el estado de fallo una vez que el servicio esté de nuevo en funcionamiento.
#
pcs resource cleanup WebSitePonga el nodo en el que se está ejecutando el servicio en modo de espera. Tenga en cuenta que, dado que hemos desactivado el cercado, no podemos simular eficazmente un fallo a nivel de nodo (como tirar de un cable de alimentación) porque el cercado es necesario para que el clúster se recupere de tales situaciones.
#
pcs node standby z1.example.comCompruebe el estado del clúster y anote dónde se está ejecutando el servicio.
#
pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Node z1.example.com: standby Online: [ z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z2.example.com WebSite (ocf::heartbeat:apache): Started z2.example.com- Acceda al sitio web. No debería haber pérdida de servicio, aunque el mensaje de la pantalla debería indicar el nodo en el que se está ejecutando el servicio.
Para restaurar los servicios del clúster en el primer nodo, saque el nodo del modo de espera. Esto no necesariamente moverá el servicio de nuevo a ese nodo.
#
pcs node unstandby z1.example.comPara la limpieza final, detenga los servicios del clúster en ambos nodos.
#
pcs cluster stop --all
Capítulo 3. La interfaz de línea de comandos de pcs
La interfaz de línea de comandos pcs controla y configura servicios de clúster como corosync, pacemaker,booth y sbd proporcionando una interfaz más sencilla para sus archivos de configuración.
Tenga en cuenta que no debe editar directamente el archivo de configuración cib.xml. En la mayoría de los casos, Pacemaker rechazará un archivo cib.xml modificado directamente.
3.1. pantalla de ayuda de pcs
Puede utilizar la opción -h de pcs para mostrar los parámetros de un comando pcs y una descripción de dichos parámetros. Por ejemplo, el siguiente comando muestra los parámetros del comando pcs resource. Sólo se muestra una parte de la salida.
# pcs resource -h3.2. Visualización de la configuración bruta del clúster
Aunque no debe editar el archivo de configuración del clúster directamente, puede ver la configuración del clúster en bruto con el comando pcs cluster cib.
Puede guardar la configuración bruta del clúster en un archivo específico con el comando pcs cluster cib filename comando. Si ha configurado previamente un clúster y ya hay un CIB activo, utilice el siguiente comando para guardar el archivo xml sin procesar.
pcs cluster cib filename
Por ejemplo, el siguiente comando guarda el xml crudo del CIB en un archivo llamado testfile.
pcs cluster cib testfile
3.3. Guardar un cambio de configuración en un archivo de trabajo
Al configurar un clúster, puede guardar los cambios de configuración en un archivo específico sin que ello afecte al CIB activo. Esto le permite especificar las actualizaciones de configuración sin actualizar inmediatamente la configuración del clúster que se está ejecutando actualmente con cada actualización individual.
Para obtener información sobre cómo guardar el CIB en un archivo, consulte Visualización de la configuración bruta del clúster. Una vez que haya creado ese archivo, puede guardar los cambios de configuración en ese archivo en lugar de en el CIB activo utilizando la opción -f del comando pcs. Cuando haya completado los cambios y esté listo para actualizar el archivo CIB activo, puede empujar esas actualizaciones del archivo con el comando pcs cluster cib-push.
El siguiente es el procedimiento recomendado para introducir cambios en el archivo CIB. Este procedimiento crea una copia del archivo CIB original guardado y realiza cambios en esa copia. Al transferir esos cambios al CIB activo, este procedimiento especifica la opción diff-against del comando pcs cluster cib-push para que sólo se transfieran al CIB los cambios entre el archivo original y el archivo actualizado. Esto permite a los usuarios realizar cambios en paralelo que no se sobrescriben entre sí, y reduce la carga de Pacemaker, que no necesita analizar todo el archivo de configuración.
Guardar el CIB activo en un archivo. Este ejemplo guarda el CIB en un archivo llamado
original.xml.#
pcs cluster cib original.xmlCopie el archivo guardado en el archivo de trabajo que utilizará para las actualizaciones de configuración.
#
cp original.xml updated.xmlActualice su configuración según sea necesario. El siguiente comando crea un recurso en el archivo
updated.xmlpero no añade ese recurso a la configuración del clúster que se está ejecutando actualmente.#
pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30sEmpuje el archivo actualizado al CIB activo, especificando que está empujando sólo los cambios que ha hecho en el archivo original.
#
pcs cluster cib-push updated.xml diff-against=original.xml
Alternativamente, puede empujar todo el contenido actual de un archivo CIB con el siguiente comando.
pcs cluster cib-push filename
Al empujar el archivo CIB completo, Pacemaker comprueba la versión y no permite empujar un archivo CIB que sea más antiguo que el que ya está en un cluster. Si necesita actualizar todo el archivo CIB con una versión más antigua que la que se encuentra actualmente en el clúster, puede utilizar la opción --config del comando pcs cluster cib-push.
pcs cluster cib-push --config filename3.4. Visualización del estado del clúster
Puede mostrar el estado del clúster y de los recursos del clúster con el siguiente comando.
estado de los pcs
Puede mostrar el estado de un componente concreto del clúster con el parámetro commands del comando pcs status, especificando resources, cluster, nodes o pcsd.
estado de los pcs commandsPor ejemplo, el siguiente comando muestra el estado de los recursos del cluster.
recursos del estado de los pcs
El siguiente comando muestra el estado del clúster, pero no los recursos del mismo.
estado del cluster pcs
3.5. Visualización de la configuración completa del clúster
Utilice el siguiente comando para mostrar la configuración completa del clúster actual.
pcs config
Capítulo 4. Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker
El siguiente procedimiento crea un cluster de alta disponibilidad de Red Hat de dos nodos utilizando pcs.
La configuración del cluster en este ejemplo requiere que su sistema incluya los siguientes componentes:
-
2 nodos, que se utilizarán para crear el cluster. En este ejemplo, los nodos utilizados son
z1.example.comyz2.example.com. - Conmutadores de red para la red privada. Recomendamos, pero no exigimos, una red privada para la comunicación entre los nodos del clúster y otro hardware del clúster, como los conmutadores de alimentación de red y los conmutadores de canal de fibra.
-
Un dispositivo de cercado para cada nodo del clúster. Este ejemplo utiliza dos puertos del conmutador de potencia APC con un nombre de host de
zapc.example.com.
4.1. Instalación del software del clúster
El siguiente procedimiento instala el software del clúster y configura su sistema para la creación del clúster.
En cada nodo del cluster, instale los paquetes de software Red Hat High Availability Add-On junto con todos los agentes de valla disponibles en el canal de Alta Disponibilidad.
#
yum install pcs pacemaker fence-agents-allAlternativamente, puede instalar los paquetes de software de Red Hat High Availability Add-On junto con sólo el agente de valla que necesite con el siguiente comando.
#
yum install pcs pacemaker fence-agents-modelEl siguiente comando muestra una lista de los agentes de la valla disponibles.
#
rpm -q -a | grep fencefence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...AvisoDespués de instalar los paquetes del complemento de alta disponibilidad de Red Hat, debe asegurarse de que sus preferencias de actualización de software estén configuradas para que no se instale nada automáticamente. La instalación en un cluster en funcionamiento puede causar comportamientos inesperados. Para obtener más información, consulte Prácticas recomendadas para aplicar actualizaciones de software a un cluster de alta disponibilidad o de almacenamiento resiliente de RHEL.
Si está ejecutando el demonio
firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.NotaPuede determinar si el demonio
firewalldestá instalado en su sistema con el comandorpm -q firewalld. Si está instalado, puede determinar si se está ejecutando con el comandofirewall-cmd --state.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityNotaLa configuración ideal del cortafuegos para los componentes del clúster depende del entorno local, en el que puede ser necesario tener en cuenta consideraciones como si los nodos tienen múltiples interfaces de red o si existe un cortafuegos fuera del host. El ejemplo que se presenta aquí, que abre los puertos que generalmente requiere un cluster Pacemaker, debe modificarse para adaptarse a las condiciones locales. Habilitación de puertos para el complemento de alta disponibilidad muestra los puertos que se deben habilitar para el complemento de alta disponibilidad de Red Hat y proporciona una explicación de para qué se utiliza cada puerto.
Para poder utilizar
pcspara configurar el cluster y comunicarse entre los nodos, debe establecer una contraseña en cada nodo para el usuariohacluster, que es la cuenta de administraciónpcs. Se recomienda que la contraseña del usuariohaclustersea la misma en cada nodo.#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Antes de poder configurar el cluster, el demonio
pcsddebe ser iniciado y habilitado para arrancar en cada nodo. Este demonio funciona con el comandopcspara gestionar la configuración en todos los nodos del clúster.En cada nodo del clúster, ejecute los siguientes comandos para iniciar el servicio
pcsdy para habilitarpcsdal inicio del sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
4.2. Instalación del paquete pcp-zeroconf (recomendado)
Cuando configure su cluster, se recomienda que instale el paquete pcp-zeroconf para la herramienta Performance Co-Pilot (PCP). PCP es la herramienta de monitorización de recursos recomendada por Red Hat para los sistemas RHEL. La instalación del paquete pcp-zeroconf le permite tener a PCP ejecutándose y recopilando datos de monitorización del rendimiento en beneficio de las investigaciones sobre cerramientos, fallos de recursos y otros eventos que perturban el cluster.
Los despliegues de clústeres en los que se habilita PCP necesitarán suficiente espacio disponible para los datos capturados por PCP en el sistema de archivos que contiene /var/log/pcp/. El uso típico de espacio por parte de PCP varía según las implementaciones, pero 10Gb suelen ser suficientes cuando se utiliza la configuración predeterminada de pcp-zeroconf, y algunos entornos pueden requerir menos. La supervisión del uso de este directorio durante un período de 14 días de actividad típica puede proporcionar una expectativa de uso más precisa.
Para instalar el paquete pcp-zeroconf, ejecute el siguiente comando.
# yum install pcp-zeroconf
Este paquete permite pmcd y establece la captura de datos a un intervalo de 10 segundos.
Para obtener información sobre la revisión de los datos del PCP, consulte ¿Por qué se ha reiniciado un nodo del cluster de alta disponibilidad de RHEL y cómo puedo evitar que vuelva a ocurrir? en el Portal del cliente de Red Hat.
4.3. Creación de un clúster de alta disponibilidad
Este procedimiento crea un cluster de Red Hat High Availability Add-On que consiste en los nodos z1.example.com y z2.example.com.
Autentifique el usuario
pcshaclusterpara cada nodo del clúster en el nodo desde el que va a ejecutarpcs.El siguiente comando autentifica al usuario
haclusterenz1.example.compara los dos nodos de un cluster de dos nodos que estará formado porz1.example.comyz2.example.com.[root@z1 ~]#
pcs host auth z1.example.com z2.example.comUsername:haclusterPassword: z1.example.com: Authorized z2.example.com: AuthorizedEjecute el siguiente comando desde
z1.example.compara crear el cluster de dos nodosmy_clusterque consta de los nodosz1.example.comyz2.example.com. Esto propagará los archivos de configuración del cluster a ambos nodos del cluster. Este comando incluye la opción--start, que iniciará los servicios de cluster en ambos nodos del cluster.[root@z1 ~]#
pcs cluster setup my_cluster --startz1.example.com z2.example.comHabilite los servicios del clúster para que se ejecuten en cada nodo del clúster cuando se inicie el nodo.
NotaPara su entorno particular, puede optar por dejar los servicios del clúster deshabilitados omitiendo este paso. Esto le permite asegurarse de que si un nodo se cae, cualquier problema con su clúster o sus recursos se resuelve antes de que el nodo se reincorpore al clúster. Si deja los servicios de clúster deshabilitados, tendrá que iniciar manualmente los servicios cuando reinicie un nodo ejecutando el comando
pcs cluster starten ese nodo.[root@z1 ~]#
pcs cluster enable --all
Puede mostrar el estado actual del clúster con el comando pcs cluster status. Debido a que puede haber un ligero retraso antes de que el clúster esté en funcionamiento cuando inicie los servicios del clúster con la opción --start del comando pcs cluster setup, debe asegurarse de que el clúster esté en funcionamiento antes de realizar cualquier acción posterior en el clúster y su configuración.
[root@z1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: z2.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum
Last updated: Thu Oct 11 16:11:18 2018
Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z2.example.com
2 Nodes configured
0 Resources configured
...4.4. Creación de un cluster de alta disponibilidad con múltiples enlaces
Puede utilizar el comando pcs cluster setup para crear un cluster de Alta Disponibilidad de Red Hat con múltiples enlaces especificando todos los enlaces para cada nodo.
El formato del comando para crear un cluster de dos nodos con dos enlaces es el siguiente.
pcs cluster setup cluster_name node1_name addr=node1_link0_address addr=node1_link1_address node2_name addr=node2_link0_address addr=node2_link1_address
Al crear un clúster con múltiples enlaces, debe tener en cuenta lo siguiente.
-
El orden de los
addr=addresses importante. La primera dirección especificada después de un nombre de nodo es paralink0, la segunda paralink1, y así sucesivamente. - Es posible especificar hasta ocho enlaces utilizando el protocolo de transporte knet, que es el protocolo de transporte por defecto.
-
Todos los nodos deben tener el mismo número de parámetros
addr=. -
A partir de RHEL 8.1, es posible añadir, eliminar y cambiar enlaces en un clúster existente utilizando los comandos
pcs cluster link add,pcs cluster link remove,pcs cluster link deleteypcs cluster link update. - Al igual que con los clusters de un solo enlace, no mezcles direcciones IPv4 e IPv6 en un enlace, aunque puedes tener un enlace ejecutando IPv4 y el otro ejecutando IPv6.
- Al igual que con los clústeres de un solo enlace, puede especificar las direcciones como direcciones IP o como nombres siempre que los nombres se resuelvan con direcciones IPv4 o IPv6 para las que no se mezclen direcciones IPv4 e IPv6 en un enlace.
El siguiente ejemplo crea un cluster de dos nodos llamado my_twolink_cluster con dos nodos, rh80-node1 y rh80-node2. rh80-node1 tiene dos interfaces, la dirección IP 192.168.122.201 como link0 y 192.168.123.201 como link1. rh80-node2 tiene dos interfaces, la dirección IP 192.168.122.202 como link0 y 192.168.123.202 como link1.
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202Para obtener información sobre cómo añadir nodos a un clúster existente con múltiples enlaces, consulte Añadir un nodo a un clúster con múltiples enlaces.
Para obtener información sobre la modificación de los enlaces en un clúster existente con múltiples enlaces, consulte Añadir y modificar enlaces en un clúster existente.
4.5. Configuración de las vallas
Debe configurar un dispositivo de cercado para cada nodo en el cluster. Para obtener información sobre los comandos y opciones de configuración de fencing, consulte Configuración de fencing en un cluster de Red Hat High Availability.
Para obtener información general sobre el cercado y su importancia en un cluster de alta disponibilidad de Red Hat, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
Al configurar un dispositivo de vallado, se debe prestar atención a si ese dispositivo comparte la energía con cualquier nodo o dispositivo del clúster. Si un nodo y su dispositivo de vallado comparten la alimentación, el clúster puede correr el riesgo de no poder vallar ese nodo si se pierde la alimentación de éste y de su dispositivo de vallado. Un clúster de este tipo debería tener fuentes de alimentación redundantes para los dispositivos de vallado y los nodos, o dispositivos de vallado redundantes que no compartan la energía. Los métodos alternativos de cercado, como el SBD o el cercado de almacenamiento, también pueden aportar redundancia en caso de pérdidas aisladas de energía.
Este ejemplo utiliza el conmutador de potencia APC con un nombre de host de zapc.example.com para cercar los nodos, y utiliza el agente de cercado fence_apc_snmp. Dado que ambos nodos serán cercados por el mismo agente de cercado, puede configurar ambos dispositivos de cercado como un único recurso, utilizando la opción pcmk_host_map.
Se crea un dispositivo de esgrima configurando el dispositivo como un recurso stonith con el comando pcs stonith create. El siguiente comando configura un recurso stonith llamado myapc que utiliza el agente de esgrima fence_apc_snmp para los nodos z1.example.com y z2.example.com. La opción pcmk_host_map asigna z1.example.com al puerto 1, y z2.example.com al puerto 2. El valor de inicio de sesión y la contraseña para el dispositivo APC son ambos apc. Por defecto, este dispositivo utilizará un intervalo de monitorización de sesenta segundos para cada nodo.
Tenga en cuenta que puede utilizar una dirección IP cuando especifique el nombre de host para los nodos.
[root@z1 ~]#pcs stonith create myapc fence_apc_snmp\ipaddr="zapc.example.com"\pcmk_host_map="z1.example.com:1;z2.example.com:2"\login="apc" passwd="apc"
El siguiente comando muestra los parámetros de un dispositivo STONITH existente.
[root@rh7-1 ~]# pcs stonith config myapc
Resource: myapc (class=stonith type=fence_apc_snmp)
Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc
Operations: monitor interval=60s (myapc-monitor-interval-60s)Después de configurar su dispositivo de valla, debe probar el dispositivo. Para obtener información sobre cómo probar un dispositivo de valla, consulte Probar un dispositivo de valla.
No pruebe su dispositivo de vallado desactivando la interfaz de red, ya que esto no probará correctamente el vallado.
Una vez que se ha configurado el cercado y se ha iniciado un clúster, un reinicio de la red desencadenará el cercado para el nodo que reinicie la red incluso cuando no se haya superado el tiempo de espera. Por este motivo, no reinicie el servicio de red mientras el servicio de clúster esté en funcionamiento, ya que activará el cercado involuntario en el nodo.
4.6. Copia de seguridad y restauración de la configuración de un clúster
Puede hacer una copia de seguridad de la configuración del clúster en un archivo tar con el siguiente comando. Si no especifica un nombre de archivo, se utilizará la salida estándar.
pcs config backup filename
El comando pcs config backup hace una copia de seguridad sólo de la configuración del clúster en sí, tal y como está configurada en el CIB; la configuración de los daemons de recursos está fuera del alcance de este comando. Por ejemplo, si ha configurado un recurso Apache en el clúster, se hará una copia de seguridad de la configuración del recurso (que está en el CIB), mientras que no se hará una copia de seguridad de la configuración del demonio Apache (como se establece en`/etc/httpd`) ni de los archivos que sirve. Del mismo modo, si hay un recurso de base de datos configurado en el clúster, la base de datos en sí no será respaldada, mientras que la configuración del recurso de base de datos (CIB) sí lo será.
Utilice el siguiente comando para restaurar los archivos de configuración del clúster en todos los nodos desde la copia de seguridad. Si no se especifica un nombre de archivo, se utilizará la entrada estándar. Si se especifica la opción --local, sólo se restaurarán los archivos del nodo actual.
pcs config restore [--local] [filename]4.7. Habilitación de puertos para el complemento de alta disponibilidad
La configuración ideal del cortafuegos para los componentes del clúster depende del entorno local, donde puede ser necesario tener en cuenta consideraciones tales como si los nodos tienen múltiples interfaces de red o si existe un cortafuegos fuera del host.
Si está ejecutando el demonio firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.
#firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availability
Es posible que tenga que modificar qué puertos están abiertos para adaptarse a las condiciones locales.
Puede determinar si el demonio firewalld está instalado en su sistema con el comando rpm -q firewalld. Si el demonio firewalld está instalado, puede determinar si se está ejecutando con el comando firewall-cmd --state.
Tabla 4.1, “Puertos a habilitar para el complemento de alta disponibilidad” muestra los puertos a habilitar para el Complemento de Alta Disponibilidad de Red Hat y proporciona una explicación de para qué se utiliza el puerto.
| Puerto | Cuando sea necesario |
|---|---|
| TCP 2224 |
Puerto por defecto
Es crucial abrir el puerto 2224 de forma que |
| TCP 3121 | Requerido en todos los nodos si el cluster tiene nodos Pacemaker Remote
El demonio |
| TCP 5403 |
Se requiere en el host del dispositivo de quórum cuando se utiliza un dispositivo de quórum con |
| UDP 5404-5412 |
Se requiere en los nodos corosync para facilitar la comunicación entre nodos. Es crucial abrir los puertos 5404-5412 de forma que |
| TCP 21064 |
Se requiere en todos los nodos si el cluster contiene algún recurso que requiera DLM (como |
| TCP 9929, UDP 9929 | Se requiere que esté abierto en todos los nodos del clúster y en los nodos del árbitro de la cabina para las conexiones desde cualquiera de esos mismos nodos cuando se utiliza el gestor de tickets de la cabina para establecer un clúster multisitio. |
Capítulo 5. Configuración de un servidor HTTP Apache activo/pasivo en un cluster de alta disponibilidad de Red Hat
El siguiente procedimiento configura un servidor HTTP Apache activo/pasivo en un cluster de dos nodos de Red Hat Enterprise Linux High Availability Add-On utilizando pcs para configurar los recursos del cluster. En este caso de uso, los clientes acceden al servidor Apache HTTP a través de una dirección IP flotante. El servidor web se ejecuta en uno de los dos nodos del cluster. Si el nodo en el que se ejecuta el servidor web queda inoperativo, el servidor web vuelve a arrancar en el segundo nodo del cluster con una mínima interrupción del servicio.
Figura 5.1, “Apache en un cluster de alta disponibilidad de dos nodos de Red Hat” muestra una visión general de alto nivel del clúster en el que El clúster es un clúster de alta disponibilidad de Red Hat de dos nodos que está configurado con un interruptor de alimentación de red y con almacenamiento compartido. Los nodos del cluster están conectados a una red pública, para el acceso de los clientes al servidor Apache HTTP a través de una IP virtual. El servidor Apache se ejecuta en el Nodo 1 o en el Nodo 2, cada uno de los cuales tiene acceso al almacenamiento en el que se guardan los datos de Apache. En esta ilustración, el servidor web se ejecuta en el Nodo 1, mientras que el Nodo 2 está disponible para ejecutar el servidor si el Nodo 1 queda inoperativo.
Figura 5.1. Apache en un cluster de alta disponibilidad de dos nodos de Red Hat
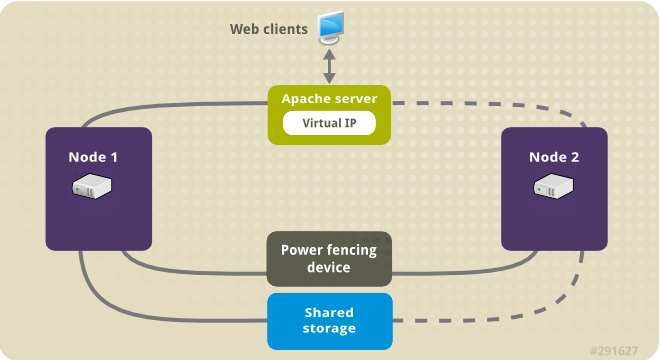
Este caso de uso requiere que su sistema incluya los siguientes componentes:
- Un clúster de alta disponibilidad de Red Hat de dos nodos con un cercado de energía configurado para cada nodo. Recomendamos pero no requerimos una red privada. Este procedimiento utiliza el ejemplo de cluster proporcionado en Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
- Una dirección IP virtual pública, necesaria para Apache.
- Almacenamiento compartido para los nodos del clúster, utilizando iSCSI, Fibre Channel u otro dispositivo de bloque de red compartido.
El clúster está configurado con un grupo de recursos Apache, que contiene los componentes del clúster que requiere el servidor web: un recurso LVM, un recurso de sistema de archivos, un recurso de dirección IP y un recurso de servidor web. Este grupo de recursos puede pasar de un nodo del clúster a otro, permitiendo que cualquiera de ellos ejecute el servidor web. Antes de crear el grupo de recursos para este clúster, usted realizará los siguientes procedimientos:
-
Configurar un sistema de archivos
ext4en el volumen lógicomy_lv. - Configurar un servidor web.
Después de realizar estos pasos, se crea el grupo de recursos y los recursos que contiene.
5.1. Configuración de un volumen LVM con un sistema de archivos ext4 en un cluster Pacemaker
Este caso de uso requiere que se cree un volumen lógico LVM en el almacenamiento que se comparte entre los nodos del clúster.
Los volúmenes LVM y las correspondientes particiones y dispositivos utilizados por los nodos del clúster deben estar conectados únicamente a los nodos del clúster.
El siguiente procedimiento crea un volumen lógico LVM y luego crea un sistema de archivos ext4 en ese volumen para utilizarlo en un cluster de Pacemaker. En este ejemplo, la partición compartida /dev/sdb1 se utiliza para almacenar el volumen físico LVM a partir del cual se creará el volumen lógico LVM.
En ambos nodos del clúster, realice los siguientes pasos para establecer el valor del ID del sistema LVM al valor del identificador
unamepara el sistema. El ID del sistema LVM se utilizará para garantizar que sólo el clúster sea capaz de activar el grupo de volúmenes.Establezca la opción de configuración
system_id_sourceen el archivo de configuración/etc/lvm/lvm.confcomouname.# Configuration option global/system_id_source. system_id_source = "uname"
Verifique que el ID del sistema LVM en el nodo coincide con el
unamepara el nodo.#
lvm systemidsystem ID: z1.example.com #uname -nz1.example.com
Cree el volumen LVM y cree un sistema de archivos ext4 en ese volumen. Como la partición
/dev/sdb1es un almacenamiento compartido, esta parte del procedimiento se realiza en un solo nodo.Crear un volumen físico LVM en la partición
/dev/sdb1.#
pvcreate /dev/sdb1Physical volume "/dev/sdb1" successfully createdCree el grupo de volúmenes
my_vgque consiste en el volumen físico/dev/sdb1.#
vgcreate my_vg /dev/sdb1Volume group "my_vg" successfully createdComprueba que el nuevo grupo de volúmenes tiene el ID del sistema del nodo en el que se está ejecutando y desde el que se creó el grupo de volúmenes.
#
vgs -o+systemidVG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCrear un volumen lógico utilizando el grupo de volumen
my_vg.#
lvcreate -L450 -n my_lv my_vgRounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdPuede utilizar el comando
lvspara mostrar el volumen lógico.#
lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Crear un sistema de archivos ext4 en el volumen lógico
my_lv.#
mkfs.ext4 /dev/my_vg/my_lvmke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
5.2. Configuración de un servidor HTTP Apache
El siguiente procedimiento configura un servidor HTTP Apache.
Asegúrese de que el servidor HTTP Apache está instalado en cada nodo del clúster. También necesita la herramienta
wgetinstalada en el clúster para poder comprobar el estado del servidor HTTP Apache.En cada nodo, ejecute el siguiente comando.
#
yum install -y httpd wgetSi está ejecutando el demonio
firewalld, en cada nodo del cluster habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadPara que el agente de recursos de Apache obtenga el estado del servidor HTTP Apache, asegúrese de que el siguiente texto está presente en el archivo
/etc/httpd/conf/httpd.confen cada nodo del clúster, y asegúrese de que no ha sido comentado. Si este texto no está ya presente, añádalo al final del archivo.<Location /server-status> SetHandler server-status Require local </Location>Cuando se utiliza el agente de recursos
apachepara gestionar Apache, no se utilizasystemd. Por ello, debe editar el scriptlogrotatesuministrado con Apache para que no utilicesystemctlpara recargar Apache.Elimine la siguiente línea en el archivo
/etc/logrotate.d/httpden cada nodo del clúster./bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
Sustituya la línea que ha eliminado por las tres líneas siguientes.
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \ -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
Cree una página web para que Apache la sirva. En un nodo del clúster, monte el sistema de archivos que creó en Configurar un volumen LVM con un sistema de archivos ext4, cree el archivo
index.htmlen ese sistema de archivos y luego desmonte el sistema de archivos.#
mount /dev/my_vg/my_lv /var/www/#mkdir /var/www/html#mkdir /var/www/cgi-bin#mkdir /var/www/error#restorecon -R /var/www#cat <<-END >/var/www/html/index.html<html><body>Hello</body></html>END#umount /var/www
5.3. Creación de los recursos y grupos de recursos
Este caso de uso requiere que se creen cuatro recursos de cluster. Para garantizar que todos estos recursos se ejecutan en el mismo nodo, se configuran como parte del grupo de recursos apachegroup. Los recursos a crear son los siguientes, listados en el orden en que se iniciarán.
-
Un recurso
LVMllamadomy_lvmque utiliza el grupo de volúmenes LVM que creó en Configuración de un volumen LVM con un sistema de archivos ext4. -
Un recurso
Filesystemllamadomy_fs, que utiliza el dispositivo del sistema de archivos/dev/my_vg/my_lvque creaste en Configuración de un volumen LVM con un sistema de archivos ext4. -
Un recurso
IPaddr2, que es una dirección IP flotante para el grupo de recursosapachegroup. La dirección IP no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recursoIPaddr2, la IP flotante debe residir en la misma red que una de las direcciones IP asignadas estáticamente del nodo, de lo contrario, el dispositivo NIC para asignar la dirección IP flotante no puede ser detectado correctamente. -
Un recurso
apachellamadoWebsiteque utiliza el archivoindex.htmly la configuración de Apache que definió en Configuración de un servidor HTTP Apache.
El siguiente procedimiento crea el grupo de recursos apachegroup y los recursos que contiene el grupo. Los recursos se iniciarán en el orden en que los añada al grupo y se detendrán en el orden inverso en que se añadan al grupo. Ejecute este procedimiento desde un solo nodo del clúster.
El siguiente comando crea el recurso
LVM-activatemy_lvm. Dado que el grupo de recursosapachegroupaún no existe, este comando crea el grupo de recursos.NotaNo configure más de un recurso
LVM-activateque utilice el mismo grupo de volúmenes LVM en una configuración de HA activa/pasiva, ya que esto podría causar la corrupción de los datos. Además, no configure un recursoLVM-activatecomo recurso clónico en una configuración de HA activa/pasiva.[root@z1 ~]#
pcs resource create my_lvm ocf:heartbeat:LVM-activatevgname=my_vgvg_access_mode=system_id --group apachegroupCuando se crea un recurso, éste se inicia automáticamente. Puede utilizar el siguiente comando para confirmar que el recurso se ha creado y se ha iniciado.
#
pcs resource statusResource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): StartedPuede detener e iniciar manualmente un recurso individual con los comandos
pcs resource disableypcs resource enable.Los siguientes comandos crean los recursos restantes para la configuración, añadiéndolos al grupo de recursos existente
apachegroup.[root@z1 ~]#
pcs resource create my_fs Filesystem\device="/dev/my_vg/my_lv" directory="/var/www" fstype="ext4"\--group apachegroup[root@z1 ~]#pcs resource create VirtualIP IPaddr2 ip=198.51.100.3\cidr_netmask=24 --group apachegroup[root@z1 ~]#pcs resource create Website apache\configfile="/etc/httpd/conf/httpd.conf"\statusurl="http://127.0.0.1/server-status" --group apachegroupDespués de crear los recursos y el grupo de recursos que los contiene, puede comprobar el estado del clúster. Observe que los cuatro recursos se ejecutan en el mismo nodo.
[root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Wed Jul 31 16:38:51 2013 Last change: Wed Jul 31 16:42:14 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com my_fs (ocf::heartbeat:Filesystem): Started z1.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z1.example.com Website (ocf::heartbeat:apache): Started z1.example.comTenga en cuenta que si no ha configurado un dispositivo de cercado para su clúster, por defecto los recursos no se inician.
Una vez que el clúster esté en funcionamiento, puede dirigir un navegador a la dirección IP que definió como recurso
IPaddr2para ver la pantalla de muestra, que consiste en la simple palabra "Hola".Hola
Si encuentra que los recursos que configuró no están funcionando, puede ejecutar el comando
pcs resource debug-start resourcepara probar la configuración de los recursos.
5.4. Probar la configuración de los recursos
En la pantalla de estado del clúster que se muestra en Creación de los recursos y grupos de recursos, todos los recursos se están ejecutando en el nodo z1.example.com. Puede probar si el grupo de recursos falla en el nodo z2.example.com utilizando el siguiente procedimiento para poner el primer nodo en modo standby, tras lo cual el nodo ya no podrá alojar recursos.
El siguiente comando pone el nodo
z1.example.comen modostandby.[root@z1 ~]#
pcs node standby z1.example.comDespués de poner el nodo
z1en modostandby, compruebe el estado del clúster. Observe que los recursos deberían estar ahora todos funcionando enz2.[root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Wed Jul 31 17:16:17 2013 Last change: Wed Jul 31 17:18:34 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Node z1.example.com (1): standby Online: [ z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com my_fs (ocf::heartbeat:Filesystem): Started z2.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z2.example.com Website (ocf::heartbeat:apache): Started z2.example.comEl sitio web en la dirección IP definida debería seguir mostrándose, sin interrupción.
Para eliminar
z1del modostandby, introduzca el siguiente comando.[root@z1 ~]#
pcs node unstandby z1.example.comNotaSacar un nodo del modo
standbyno provoca por sí mismo que los recursos vuelvan a fallar en ese nodo. Esto dependerá del valor deresource-stickinesspara los recursos. Para obtener información sobre el metaatributoresource-stickiness, consulte Configurar un recurso para que prefiera su nodo actual.
Capítulo 6. Configuración de un servidor NFS activo/pasivo en un cluster de Alta Disponibilidad de Red Hat
El siguiente procedimiento configura un servidor NFS activo/pasivo de alta disponibilidad en un cluster de dos nodos de Red Hat Enterprise Linux High Availability Add-On usando almacenamiento compartido. El procedimiento utiliza pcs para configurar los recursos del cluster Pacemaker. En este caso de uso, los clientes acceden al sistema de archivos NFS a través de una dirección IP flotante. El servidor NFS se ejecuta en uno de los dos nodos del clúster. Si el nodo en el que se ejecuta el servidor NFS deja de funcionar, el servidor NFS vuelve a arrancar en el segundo nodo del cluster con una mínima interrupción del servicio.
6.1. Requisitos previos
Este caso de uso requiere que su sistema incluya los siguientes componentes:
- Un clúster de alta disponibilidad de Red Hat de dos nodos con un cercado de energía configurado para cada nodo. Recomendamos pero no requerimos una red privada. Este procedimiento utiliza el ejemplo de cluster proporcionado en Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
- Una dirección IP virtual pública, necesaria para el servidor NFS.
- Almacenamiento compartido para los nodos del clúster, utilizando iSCSI, Fibre Channel u otro dispositivo de bloque de red compartido.
6.2. Resumen del procedimiento
La configuración de un servidor NFS activo/pasivo de alta disponibilidad en un cluster de alta disponibilidad de dos nodos de Red Hat Enterprise Linux requiere que realice los siguientes pasos:
-
Configure un sistema de archivos
ext4en el volumen lógico LVMmy_lven el almacenamiento compartido para los nodos del clúster. - Configure un recurso compartido NFS en el almacenamiento compartido en el volumen lógico LVM.
- Crear los recursos del clúster.
- Pruebe el servidor NFS que ha configurado.
6.3. Configuración de un volumen LVM con un sistema de archivos ext4 en un cluster Pacemaker
Este caso de uso requiere que se cree un volumen lógico LVM en el almacenamiento que se comparte entre los nodos del clúster.
Los volúmenes LVM y las correspondientes particiones y dispositivos utilizados por los nodos del clúster deben estar conectados únicamente a los nodos del clúster.
El siguiente procedimiento crea un volumen lógico LVM y luego crea un sistema de archivos ext4 en ese volumen para utilizarlo en un cluster de Pacemaker. En este ejemplo, la partición compartida /dev/sdb1 se utiliza para almacenar el volumen físico LVM a partir del cual se creará el volumen lógico LVM.
En ambos nodos del clúster, realice los siguientes pasos para establecer el valor del ID del sistema LVM al valor del identificador
unamepara el sistema. El ID del sistema LVM se utilizará para garantizar que sólo el clúster sea capaz de activar el grupo de volúmenes.Establezca la opción de configuración
system_id_sourceen el archivo de configuración/etc/lvm/lvm.confcomouname.# Configuration option global/system_id_source. system_id_source = "uname"
Verifique que el ID del sistema LVM en el nodo coincide con el
unamepara el nodo.#
lvm systemidsystem ID: z1.example.com #uname -nz1.example.com
Cree el volumen LVM y cree un sistema de archivos ext4 en ese volumen. Como la partición
/dev/sdb1es un almacenamiento compartido, esta parte del procedimiento se realiza en un solo nodo.Crear un volumen físico LVM en la partición
/dev/sdb1.#
pvcreate /dev/sdb1Physical volume "/dev/sdb1" successfully createdCree el grupo de volúmenes
my_vgque consiste en el volumen físico/dev/sdb1.#
vgcreate my_vg /dev/sdb1Volume group "my_vg" successfully createdComprueba que el nuevo grupo de volúmenes tiene el ID del sistema del nodo en el que se está ejecutando y desde el que se creó el grupo de volúmenes.
#
vgs -o+systemidVG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCrear un volumen lógico utilizando el grupo de volumen
my_vg.#
lvcreate -L450 -n my_lv my_vgRounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdPuede utilizar el comando
lvspara mostrar el volumen lógico.#
lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Crear un sistema de archivos ext4 en el volumen lógico
my_lv.#
mkfs.ext4 /dev/my_vg/my_lvmke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
6.5. Configuración de los recursos y del grupo de recursos para un servidor NFS en un clúster
Esta sección proporciona el procedimiento para configurar los recursos del clúster para este caso de uso.
Si no ha configurado un dispositivo de cercado para su clúster, por defecto los recursos no se inician.
Si encuentra que los recursos que configuró no están funcionando, puede ejecutar el comando pcs resource debug-start resource para probar la configuración de los recursos. Esto inicia el servicio fuera del control y conocimiento del cluster. En el momento en que los recursos configurados vuelvan a funcionar, ejecute pcs resource cleanup resource para que el clúster conozca las actualizaciones.
El siguiente procedimiento configura los recursos del sistema. Para garantizar que todos estos recursos se ejecutan en el mismo nodo, se configuran como parte del grupo de recursos nfsgroup. Los recursos se iniciarán en el orden en el que los añada al grupo, y se detendrán en el orden inverso en el que se añaden al grupo. Ejecute este procedimiento desde un solo nodo del clúster.
Crea el recurso LVM-activate llamado
my_lvm. Dado que el grupo de recursosnfsgroupaún no existe, este comando crea el grupo de recursos.AvisoNo configure más de un recurso
LVM-activateque utilice el mismo grupo de volúmenes LVM en una configuración de HA activa/pasiva, ya que se corre el riesgo de corromper los datos. Además, no configure un recursoLVM-activatecomo recurso clónico en una configuración de HA activa/pasiva.[root@z1 ~]#
pcs resource create my_lvm ocf:heartbeat:LVM-activatevgname=my_vgvg_access_mode=system_id --group nfsgroupCompruebe el estado del clúster para verificar que el recurso está en funcionamiento.
root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Thu Jan 8 11:13:17 2015 Last change: Thu Jan 8 11:13:08 2015 Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 3 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledConfigurar un recurso
Filesystempara el cluster.El siguiente comando configura un recurso ext4
Filesystemllamadonfssharecomo parte del grupo de recursosnfsgroup. Este sistema de archivos utiliza el grupo de volúmenes LVM y el sistema de archivos ext4 que creó en Configuración de un volumen LVM con un sistema de archivos ext4 y se montará en el directorio/nfsshareque creó en Configuración de un recurso compartido NFS.[root@z1 ~]#
pcs resource create nfsshare Filesystem\device=/dev/my_vg/my_lv directory=/nfsshare\fstype=ext4 --group nfsgroupPuede especificar las opciones de montaje como parte de la configuración de un recurso
Filesystemcon el parámetrooptions=optionsparámetro. Ejecute el comandopcs resource describe Filesystempara obtener las opciones de configuración completas.Compruebe que los recursos
my_lvmynfsshareestán en funcionamiento.[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com ...Cree el recurso
nfsserverdenominadonfs-daemoncomo parte del grupo de recursosnfsgroup.NotaEl recurso
nfsserverpermite especificar un parámetronfs_shared_infodir, que es un directorio que los servidores NFS utilizan para almacenar información de estado relacionada con NFS.Se recomienda que este atributo se establezca en un subdirectorio de uno de los recursos
Filesystemcreados en esta colección de exportaciones. Esto asegura que los servidores NFS están almacenando su información de estado en un dispositivo que estará disponible para otro nodo si este grupo de recursos necesita reubicarse. En este ejemplo;-
/nfssharees el directorio de almacenamiento compartido gestionado por el recursoFilesystem -
/nfsshare/exports/export1y/nfsshare/exports/export2son los directorios de exportación -
/nfsshare/nfsinfoes el directorio de información compartida del recursonfsserver
[root@z1 ~]#
pcs resource create nfs-daemon nfsserver\nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true\--group nfsgroup[root@z1 ~]#pcs status...-
Añada los recursos
exportfspara exportar el directorio/nfsshare/exports. Estos recursos forman parte del grupo de recursosnfsgroup. Esto construye un directorio virtual para los clientes NFSv4. Los clientes NFSv3 también pueden acceder a estas exportaciones.NotaLa opción
fsid=0sólo es necesaria si desea crear un directorio virtual para clientes NFSv4. Para más información, consulte ¿Cómo configuro la opción fsid en el archivo /etc/exports de un servidor NFS?[root@z1 ~]#
pcs resource create nfs-root exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash\directory=/nfsshare/exports\fsid=0 --group nfsgroup[root@z1 ~]# #pcs resource create nfs-export1 exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash directory=/nfsshare/exports/export1\fsid=1 --group nfsgroup[root@z1 ~]# #pcs resource create nfs-export2 exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash directory=/nfsshare/exports/export2\fsid=2 --group nfsgroupAñada el recurso de dirección IP flotante que los clientes NFS utilizarán para acceder al recurso compartido NFS. Este recurso forma parte del grupo de recursos
nfsgroup. Para esta implementación de ejemplo, estamos usando 192.168.122.200 como dirección IP flotante.[root@z1 ~]#
pcs resource create nfs_ip IPaddr2\ip=192.168.122.200 cidr_netmask=24 --group nfsgroupAñade un recurso
nfsnotifypara enviar notificaciones de reinicio de NFSv3 una vez que se haya inicializado todo el despliegue de NFS. Este recurso forma parte del grupo de recursosnfsgroup.NotaPara que la notificación NFS se procese correctamente, la dirección IP flotante debe tener un nombre de host asociado que sea consistente tanto en los servidores NFS como en el cliente NFS.
[root@z1 ~]#
pcs resource create nfs-notify nfsnotify\source_host=192.168.122.200 --group nfsgroupDespués de crear los recursos y las restricciones de recursos, puede comprobar el estado del clúster. Tenga en cuenta que todos los recursos se ejecutan en el mismo nodo.
[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...
6.6. Prueba de la configuración de los recursos NFS
Puede validar la configuración de su sistema con los siguientes procedimientos. Debería poder montar el sistema de archivos exportado con NFSv3 o NFSv4.
6.6.1. Prueba de la exportación NFS
En un nodo fuera del clúster, que resida en la misma red que el despliegue, verifique que el recurso compartido NFS puede ser visto montando el recurso compartido NFS. Para este ejemplo, estamos utilizando la red 192.168.122.0/24.
#
showmount -e 192.168.122.200Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0Para verificar que puede montar el recurso compartido NFS con NFSv4, monte el recurso compartido NFS en un directorio del nodo cliente. Tras el montaje, compruebe que el contenido de los directorios de exportación es visible. Desmonte el recurso compartido después de la prueba.
#
mkdir nfsshare#mount -o "vers=4" 192.168.122.200:export1 nfsshare#ls nfsshareclientdatafile1 #umount nfsshareCompruebe que puede montar el recurso compartido NFS con NFSv3. Tras el montaje, compruebe que el archivo de prueba
clientdatafile1es visible. A diferencia de NFSv4, como NFSv3 no utiliza el sistema de archivos virtual, debe montar una exportación específica. Desmonte el recurso compartido después de la prueba.#
mkdir nfsshare#mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare#ls nfsshareclientdatafile2 #umount nfsshare
6.6.2. Pruebas de conmutación por error
En un nodo fuera del clúster, monte el recurso compartido NFS y verifique el acceso a la dirección
clientdatafile1que creamos en Configuración de un recurso compartido NFS#
mkdir nfsshare#mount -o "vers=4" 192.168.122.200:export1 nfsshare#ls nfsshareclientdatafile1Desde un nodo del clúster, determine qué nodo del clúster está ejecutando
nfsgroup. En este ejemplo,nfsgroupse está ejecutando enz1.example.com.[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...Desde un nodo del clúster, ponga el nodo que está ejecutando
nfsgroupen modo de espera.[root@z1 ~]#
pcs node standby z1.example.comCompruebe que
nfsgroupse inicia con éxito en el otro nodo del clúster.[root@z1 ~]#
pcs status... Full list of resources: Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com nfsshare (ocf::heartbeat:Filesystem): Started z2.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z2.example.com nfs-root (ocf::heartbeat:exportfs): Started z2.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z2.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z2.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z2.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z2.example.com ...Desde el nodo externo al clúster en el que ha montado el recurso compartido NFS, verifique que este nodo externo sigue teniendo acceso al archivo de prueba dentro del montaje NFS.
#
ls nfsshareclientdatafile1El servicio se perderá brevemente para el cliente durante la conmutación por error, pero el cliente debería recuperarlo sin intervención del usuario. Por defecto, los clientes que utilizan NFSv4 pueden tardar hasta 90 segundos en recuperar el montaje; estos 90 segundos representan el periodo de gracia de arrendamiento de archivos NFSv4 que observa el servidor al iniciarse. Los clientes NFSv3 deberían recuperar el acceso al montaje en cuestión de pocos segundos.
Desde un nodo del clúster, retire del modo de espera el nodo que inicialmente estaba ejecutando
nfsgroup.NotaSacar un nodo del modo
standbyno provoca por sí mismo que los recursos vuelvan a fallar en ese nodo. Esto dependerá del valor deresource-stickinesspara los recursos. Para obtener información sobre el metaatributoresource-stickiness, consulte Configurar un recurso para que prefiera su nodo actual.[root@z1 ~]#
pcs node unstandby z1.example.com
Capítulo 7. Sistemas de archivos GFS2 en un clúster
Esta sección establece:
- Un procedimiento para configurar un clúster Pacemaker que incluya sistemas de archivos GFS2
- Un procedimiento para migrar volúmenes lógicos de RHEL 7 que contienen sistemas de archivos GFS2 a un clúster de RHEL 8
7.1. Configuración de un sistema de archivos GFS2 en un clúster
Este procedimiento es un resumen de los pasos necesarios para configurar un cluster Pacemaker que incluya sistemas de archivos GFS2. Este ejemplo crea tres sistemas de archivos GFS2 en tres volúmenes lógicos.
Como requisito previo a este procedimiento, debe instalar e iniciar el software de clúster en todos los nodos y crear un clúster básico de dos nodos. También debe configurar el cercado para el cluster. Para obtener información sobre la creación de un cluster Pacemaker y la configuración del cercado para el cluster, consulte Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
Procedimiento
En ambos nodos del clúster, instale los paquetes
lvm2-lockd,gfs2-utilsydlm. El paquetelvm2-lockdforma parte del canal AppStream y los paquetesgfs2-utilsydlmforman parte del canal Resilient Storage.#
yum install lvm2-lockd gfs2-utils dlmAjuste el parámetro global de Marcapasos
no_quorum_policyafreeze.NotaPor defecto, el valor de
no-quorum-policyse establece enstop, lo que indica que una vez que se pierde el quórum, todos los recursos de la partición restante se detendrán inmediatamente. Normalmente este valor por defecto es la opción más segura y óptima, pero a diferencia de la mayoría de los recursos, GFS2 requiere quórum para funcionar. Cuando se pierde el quórum, tanto las aplicaciones que utilizan los montajes de GFS2 como el propio montaje de GFS2 no pueden detenerse correctamente. Cualquier intento de detener estos recursos sin quórum fallará, lo que en última instancia provocará que todo el clúster quede vallado cada vez que se pierda el quórum.Para solucionar esta situación, configure
no-quorum-policyafreezecuando GFS2 esté en uso. Esto significa que cuando se pierde el quórum, la partición restante no hará nada hasta que se recupere el quórum.#
pcs property set no-quorum-policy=freezeConfigure un recurso
dlm. Esta es una dependencia necesaria para configurar un sistema de archivos GFS2 en un clúster. Este ejemplo crea el recursodlmcomo parte de un grupo de recursos llamadolocking.[root@z1 ~]#
pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fenceClone el grupo de recursos
lockingpara que el grupo de recursos pueda estar activo en ambos nodos del clúster.[root@z1 ~]#
pcs resource clone locking interleave=trueConfigure un recurso
lvmlockdcomo parte del grupolocking.[root@z1 ~]#
pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fenceCompruebe el estado del clúster para asegurarse de que el grupo de recursos
lockingse ha iniciado en ambos nodos del clúster.[root@z1 ~]#
pcs status --fullCluster name: my_cluster [...] Online: [ z1.example.com (1) z2.example.com (2) ] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Started: [ z1.example.com z2.example.com ]Compruebe que el demonio
lvmlockdse está ejecutando en ambos nodos del clúster.[root@z1 ~]#
ps -ef | grep lvmlockdroot 12257 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlm [root@z2 ~]#ps -ef | grep lvmlockdroot 12270 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlmEn un nodo del clúster, cree dos grupos de volúmenes compartidos. Un grupo de volumen contendrá dos sistemas de archivos GFS2 y el otro grupo de volumen contendrá un sistema de archivos GFS2.
El siguiente comando crea el grupo de volúmenes compartidos
shared_vg1en/dev/vdb.[root@z1 ~]#
vgcreate --shared shared_vg1 /dev/vdbPhysical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...El siguiente comando crea el grupo de volúmenes compartidos
shared_vg2en/dev/vdc.[root@z1 ~]#
vgcreate --shared shared_vg2 /dev/vdcPhysical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...En el segundo nodo del clúster, inicie el gestor de bloqueos para cada uno de los grupos de volúmenes compartidos.
[root@z2 ~]#
vgchange --lock-start shared_vg1VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready... [root@z2 ~]#vgchange --lock-start shared_vg2VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...En un nodo del clúster, cree los volúmenes lógicos compartidos y formatee los volúmenes con un sistema de archivos GFS2. Se necesita un diario para cada nodo que monte el sistema de archivos. Asegúrese de crear suficientes diarios para cada uno de los nodos del clúster.
[root@z1 ~]#
lvcreate --activate sy -L5G -n shared_lv1 shared_vg1Logical volume "shared_lv1" created. [root@z1 ~]#lvcreate --activate sy -L5G -n shared_lv2 shared_vg1Logical volume "shared_lv2" created. [root@z1 ~]#lvcreate --activate sy -L5G -n shared_lv1 shared_vg2Logical volume "shared_lv1" created. [root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo1 /dev/shared_vg1/shared_lv1[root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo2 /dev/shared_vg1/shared_lv2[root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo3 /dev/shared_vg2/shared_lv1Cree un recurso
LVM-activatepara cada volumen lógico para activar automáticamente ese volumen lógico en todos los nodos.Crea un recurso
LVM-activatellamadosharedlv1para el volumen lógicoshared_lv1en el grupo de volúmenesshared_vg1. Este comando también crea el grupo de recursosshared_vg1que incluye el recurso. En este ejemplo, el grupo de recursos tiene el mismo nombre que el grupo de volumen compartido que incluye el volumen lógico.[root@z1 ~]#
pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCrea un recurso
LVM-activatellamadosharedlv2para el volumen lógicoshared_lv2en el grupo de volúmenesshared_vg1. Este recurso también formará parte del grupo de recursosshared_vg1.[root@z1 ~]#
pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCrea un recurso
LVM-activatellamadosharedlv3para el volumen lógicoshared_lv1en el grupo de volúmenesshared_vg2. Este comando también crea el grupo de recursosshared_vg2que incluye el recurso.[root@z1 ~]#
pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockd
Clona los dos nuevos grupos de recursos.
[root@z1 ~]#
pcs resource clone shared_vg1 interleave=true[root@z1 ~]#pcs resource clone shared_vg2 interleave=trueConfigure las restricciones de ordenación para garantizar que el grupo de recursos
lockingque incluye los recursosdlmylvmlockdse inicie primero.[root@z1 ~]#
pcs constraint order start locking-clone then shared_vg1-cloneAdding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@z1 ~]#pcs constraint order start locking-clone then shared_vg2-cloneAdding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)Configure las restricciones de colocación para garantizar que los grupos de recursos
vg1yvg2se inicien en el mismo nodo que el grupo de recursoslocking.[root@z1 ~]#
pcs constraint colocation add shared_vg1-clone with locking-clone[root@z1 ~]#pcs constraint colocation add shared_vg2-clone with locking-cloneEn ambos nodos del clúster, verifique que los volúmenes lógicos estén activos. Puede haber un retraso de unos segundos.
[root@z1 ~]#
lvsLV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00g [root@z2 ~]#lvsLV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00gCree un recurso de sistema de archivos para montar automáticamente cada sistema de archivos GFS2 en todos los nodos.
No debe añadir el sistema de archivos al archivo
/etc/fstabporque se gestionará como un recurso de clúster de Pacemaker. Las opciones de montaje se pueden especificar como parte de la configuración del recurso conoptions=options. Ejecute el comandopcs resource describe Filesystempara obtener las opciones de configuración completas.Los siguientes comandos crean los recursos del sistema de archivos. Estos comandos añaden cada recurso al grupo de recursos que incluye el recurso de volumen lógico para ese sistema de archivos.
[root@z1 ~]#
pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence[root@z1 ~]#pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence[root@z1 ~]#pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fenceCompruebe que los sistemas de archivos GFS2 están montados en ambos nodos del clúster.
[root@z1 ~]#
mount | grep gfs2/dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel) [root@z2 ~]#mount | grep gfs2/dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel)Comprueba el estado del clúster.
[root@z1 ~]#
pcs status --fullCluster name: my_cluster [...1 Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg1-clone [shared_vg1] Resource Group: shared_vg1:0 sharedlv1 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z2.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg1:1 sharedlv1 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z1.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started example.co Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg2-clone [shared_vg2] Resource Group: shared_vg2:0 sharedlv3 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg2:1 sharedlv3 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [ z1.example.com z2.example.com ] ...
Recursos adicionales
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de Red Hat High Availability con Microsoft Azure Shared Disks, consulte Configuración del almacenamiento en bloque compartido.
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de Red Hat High Availability con volúmenes de Amazon EBS Multi-Attach, consulte Configuración del almacenamiento en bloque compartido.
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de alta disponibilidad de Red Hat en Alibaba Cloud, consulte Configuración del almacenamiento en bloque compartido para un clúster de alta disponibilidad de Red Hat en Alibaba Cloud.
7.2. Migración de un sistema de archivos GFS2 de RHEL7 a RHEL8
En Red Hat Enterprise Linux 8, LVM utiliza el demonio de bloqueo de LVM lvmlockd en lugar de clvmd para gestionar los dispositivos de almacenamiento compartido en un cluster activo/activo. Esto requiere que configure los volúmenes lógicos que su cluster activo/activo requerirá como volúmenes lógicos compartidos. Además, esto requiere que utilice el recurso LVM-activate para gestionar un volumen LVM y que utilice el agente de recursos lvmlockd para gestionar el demonio lvmlockd. Consulte Configuración de un sistema de archivos GFS2 en un clúster para conocer el procedimiento completo para configurar un clúster Pacemaker que incluya sistemas de archivos GFS2 mediante volúmenes lógicos compartidos.
Para utilizar sus volúmenes lógicos existentes de Red Hat Enterprise Linux 7 cuando configure un cluster RHEL8 que incluya sistemas de archivos GFS2, realice el siguiente procedimiento desde el cluster RHEL8. En este ejemplo, el volumen lógico RHEL 7 en cluster es parte del grupo de volúmenes upgrade_gfs_vg.
El clúster RHEL8 debe tener el mismo nombre que el clúster RHEL7 que incluye el sistema de archivos GFS2 para que el sistema de archivos existente sea válido.
- Asegúrese de que los volúmenes lógicos que contienen los sistemas de archivos GFS2 están actualmente inactivos. Este procedimiento sólo es seguro si todos los nodos han dejado de utilizar el grupo de volúmenes.
Desde un nodo del clúster, cambie a la fuerza el grupo de volúmenes para que sea local.
[root@rhel8-01 ~]#
vgchange --lock-type none --lock-opt force upgrade_gfs_vgForcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changedDesde un nodo del clúster, cambie el grupo de volumen local a un grupo de volumen compartido
[root@rhel8-01 ~]#
vgchange --lock-type dlm upgrade_gfs_vgVolume group "upgrade_gfs_vg" successfully changedEn cada nodo del clúster, inicie el bloqueo del grupo de volúmenes.
[root@rhel8-01 ~]#
vgchange --lock-start upgrade_gfs_vgVG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready... [root@rhel8-02 ~]#vgchange --lock-start upgrade_gfs_vgVG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready...
Después de realizar este procedimiento, puede crear un recurso LVM-activate para cada volumen lógico.
Capítulo 8. Introducción a la interfaz web de pcsd
La pcsd Web UI es una interfaz gráfica de usuario para crear y configurar clusters Pacemaker/Corosync.
8.1. Instalación del software del clúster
El siguiente procedimiento instala el software del clúster y configura su sistema para la creación del clúster.
En cada nodo del cluster, instale los paquetes de software Red Hat High Availability Add-On junto con todos los agentes de valla disponibles en el canal de Alta Disponibilidad.
#
yum install pcs pacemaker fence-agents-allAlternativamente, puede instalar los paquetes de software de Red Hat High Availability Add-On junto con sólo el agente de valla que necesite con el siguiente comando.
#
yum install pcs pacemaker fence-agents-modelEl siguiente comando muestra una lista de los agentes de la valla disponibles.
#
rpm -q -a | grep fencefence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...AvisoDespués de instalar los paquetes del complemento de alta disponibilidad de Red Hat, debe asegurarse de que sus preferencias de actualización de software estén configuradas para que no se instale nada automáticamente. La instalación en un cluster en funcionamiento puede causar comportamientos inesperados. Para obtener más información, consulte Prácticas recomendadas para aplicar actualizaciones de software a un cluster de alta disponibilidad o de almacenamiento resiliente de RHEL.
Si está ejecutando el demonio
firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.NotaPuede determinar si el demonio
firewalldestá instalado en su sistema con el comandorpm -q firewalld. Si está instalado, puede determinar si se está ejecutando con el comandofirewall-cmd --state.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityNotaLa configuración ideal del cortafuegos para los componentes del clúster depende del entorno local, en el que puede ser necesario tener en cuenta consideraciones como si los nodos tienen múltiples interfaces de red o si existe un cortafuegos fuera del host. El ejemplo que se presenta aquí, que abre los puertos que generalmente requiere un cluster Pacemaker, debe modificarse para adaptarse a las condiciones locales. Habilitación de puertos para el complemento de alta disponibilidad muestra los puertos que se deben habilitar para el complemento de alta disponibilidad de Red Hat y proporciona una explicación de para qué se utiliza cada puerto.
Para poder utilizar
pcspara configurar el cluster y comunicarse entre los nodos, debe establecer una contraseña en cada nodo para el usuariohacluster, que es la cuenta de administraciónpcs. Se recomienda que la contraseña del usuariohaclustersea la misma en cada nodo.#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Antes de poder configurar el cluster, el demonio
pcsddebe ser iniciado y habilitado para arrancar en cada nodo. Este demonio funciona con el comandopcspara gestionar la configuración en todos los nodos del clúster.En cada nodo del clúster, ejecute los siguientes comandos para iniciar el servicio
pcsdy para habilitarpcsdal inicio del sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
8.2. Configuración de la interfaz web de pcsd
Una vez que haya instalado las herramientas de configuración de Pacemaker y haya configurado su sistema para la configuración de clústeres, utilice el siguiente procedimiento para configurar su sistema y utilizar la interfaz web pcsd para configurar un clúster.
En cualquier sistema, abra un navegador a la siguiente URL, especificando uno de los nodos del clúster (tenga en cuenta que esto utiliza el protocolo
https). Aparecerá la pantalla de inicio de sesión depcsdWeb UI.https://nodename:2224Inicie sesión como usuario
hacluster. Esto hace que aparezca la páginaManage Clusterscomo se muestra en Figura 8.1, “Página de gestión de clusters”.Figura 8.1. Página de gestión de clusters
8.3. Creación de un clúster con la interfaz web de pcsd
Desde la página de Gestión de Clusters, puede crear un nuevo cluster, añadir un cluster existente a la Web UI, o eliminar un cluster de la Web UI.
-
Para crear un clúster, haga clic en
Create New. Introduzca el nombre del cluster a crear y los nodos que lo constituyen. Si no ha autenticado previamente el usuariohaclusterpara cada nodo del clúster, se le pedirá que autentique los nodos del clúster. -
Al crear el clúster, puede configurar las opciones avanzadas del clúster haciendo clic en
Go to advanced settingsen esta pantalla. Las configuraciones avanzadas del clúster que puede configurar se describen en Configuración de las opciones avanzadas de configuración del clúster con la UI web de pcsd. -
Para añadir un clúster existente a la interfaz web, haga clic en
Add Existinge introduzca el nombre de host o la dirección IP de un nodo del clúster que desee gestionar con la interfaz web.
Una vez que haya creado o añadido un clúster, el nombre del clúster se muestra en la página Gestionar clúster. Al seleccionar el clúster se muestra información sobre el mismo.
Cuando se utiliza la interfaz web pcsd para configurar un clúster, se puede pasar el ratón por encima del texto que describe muchas de las opciones para ver descripciones más largas de esas opciones en forma de pantalla tooltip.
8.3.1. Configuración de las opciones avanzadas de configuración del clúster con la interfaz web de pcsd
Al crear un clúster, puede configurar opciones adicionales del clúster haciendo clic en en la pantalla Crear clúster. Esto le permite modificar los ajustes configurables de los siguientes componentes del clúster:
- Configuración del transporte: Valores para el mecanismo de transporte utilizado para la comunicación del clúster
-
Opciones de quórum: Valores para las opciones de quórum del servicio
votequorum - Configuración de Totem: Valores para el protocolo Totem utilizado por Corosync
Al seleccionar estas opciones se muestran los ajustes que se pueden configurar. Para obtener información sobre cada uno de los ajustes, sitúe el puntero del ratón sobre la opción concreta.
8.3.2. Establecer los permisos de gestión del clúster
Hay dos conjuntos de permisos de clúster que puede conceder a los usuarios:
-
Permisos para gestionar el clúster con la interfaz web, que también concede permisos para ejecutar comandos de
pcsque se conectan a los nodos a través de una red. Esta sección describe cómo configurar esos permisos con la Web UI. - Permisos para los usuarios locales para permitir el acceso de sólo lectura o de lectura-escritura a la configuración del clúster, utilizando ACLs. La configuración de las ACL con la interfaz web se describe en Configuración de los componentes del clúster con la interfaz web de pcsd.
Puede conceder permiso a usuarios específicos que no sean el usuario hacluster para gestionar el clúster a través de la interfaz web y para ejecutar comandos pcs que se conectan a los nodos a través de una red, añadiéndolos al grupo haclient. A continuación, puede configurar los permisos establecidos para un miembro individual del grupo haclient haciendo clic en la pestaña Permisos de la página Gestionar clústeres y estableciendo los permisos en la pantalla resultante. Desde esta pantalla, también puedes configurar los permisos para los grupos.
Puede conceder los siguientes permisos:
- Permisos de lectura, para ver la configuración del clúster
- Permisos de escritura, para modificar la configuración del clúster (excepto los permisos y las ACL)
- Conceder permisos, para modificar los permisos del clúster y las ACL
- Permisos completos, para un acceso sin restricciones a un cluster, incluyendo la adición y eliminación de nodos, con acceso a claves y certificados
8.4. Configuración de los componentes del clúster con la interfaz web de pcsd
Para configurar los componentes y atributos de un clúster, haga clic en el nombre del clúster que aparece en la pantalla Manage Clusters. Esto hace que aparezca la página Nodes, como se describe en Sección 8.4.1, “Configuración de los nodos del clúster con la interfaz web de pcsd”. Esta página muestra un menú en la parte superior de la página con las siguientes entradas:
- Los nodos, como se describe en Sección 8.4.1, “Configuración de los nodos del clúster con la interfaz web de pcsd”
- Recursos, como se describe en Sección 8.4.2, “Configuración de los recursos del clúster con la interfaz web de pcsd”
- Dispositivos de vallas, como se describe en Sección 8.4.3, “Configuración de los dispositivos de la valla con la interfaz web de pcsd”
- ACL, como se describe en Sección 8.4.4, “Configuración de ACLs con la Web UI de pcsd”
- Propiedades del clúster, como se describe en Sección 8.4.5, “Configuración de las propiedades del clúster con la interfaz web de pcsd”
8.4.1. Configuración de los nodos del clúster con la interfaz web de pcsd
Al seleccionar la opción Nodes en el menú de la parte superior de la página de gestión de clústeres, se muestran los nodos actualmente configurados y el estado del nodo actualmente seleccionado, incluyendo los recursos que se están ejecutando en el nodo y las preferencias de ubicación de los recursos. Esta es la página por defecto que se muestra cuando se selecciona un clúster en la pantalla Manage Clusters.
Desde esta página puede añadir o eliminar nodos. También puede iniciar, detener, reiniciar o poner un nodo en modo de espera o de mantenimiento. Para obtener información sobre el modo de espera, consulte Poner un nodo en modo de espera. Para obtener información sobre el modo de mantenimiento, consulte Poner un clúster en modo de mantenimiento.
También puede configurar los dispositivos de valla directamente desde esta página, como se describe en seleccionando Configure Fencing. La configuración de los dispositivos de vallas se describe en Sección 8.4.3, “Configuración de los dispositivos de la valla con la interfaz web de pcsd”.
8.4.2. Configuración de los recursos del clúster con la interfaz web de pcsd
Al seleccionar la opción Resources en el menú de la parte superior de la página de gestión del clúster, se muestran los recursos actualmente configurados para el clúster, organizados según los grupos de recursos. Al seleccionar un grupo o un recurso se muestran los atributos de ese grupo o recurso.
Desde esta pantalla, puede añadir o eliminar recursos, puede editar la configuración de los recursos existentes y puede crear un grupo de recursos.
Para añadir un nuevo recurso al cluster:
-
Haga clic en
Add. Aparecerá la pantallaAdd Resource. -
Cuando selecciona un tipo de recurso en el menú desplegable
Type, los argumentos que debe especificar para ese recurso aparecen en el menú. -
Puede hacer clic en
Optional Argumentspara mostrar los argumentos adicionales que puede especificar para el recurso que está definiendo. -
Tras introducir los parámetros del recurso que está creando, haga clic en
Create Resource.
Al configurar los argumentos de un recurso, aparece una breve descripción del argumento en el menú. Si se desplaza el cursor al campo, se muestra una descripción de ayuda más larga de ese argumento.
Puede definir un recurso como un recurso clonado o como un recurso clonado promocionable. Para obtener información sobre estos tipos de recursos, consulte Creación de recursos de clúster activos en varios nodos (recursos clonados).
Una vez que haya creado al menos un recurso, puede crear un grupo de recursos. Para obtener información general sobre los grupos de recursos, consulte Configuración de grupos de recursos.
Para crear un grupo de recursos:
-
Seleccione los recursos que formarán parte del grupo en la pantalla
Resourcesy, a continuación, haga clic enCreate Group. Esto muestra la pantallaCreate Group. -
Desde la pantalla
Create Group, puede reorganizar el orden de los recursos en un grupo de recursos utilizando la función de arrastrar y soltar para desplazar la lista de los recursos. -
Introduzca un nombre de grupo y haga clic en
Create Group. Esto le devuelve a la pantallaResources, que ahora muestra el nombre del grupo y los recursos dentro de ese grupo.
Después de crear un grupo de recursos, puede indicar el nombre de ese grupo como parámetro de recurso cuando cree o modifique recursos adicionales.
8.4.3. Configuración de los dispositivos de la valla con la interfaz web de pcsd
Seleccionando la opción Fence Devices en el menú de la parte superior de la página de gestión del clúster se muestra la pantalla Fence Devices, que muestra los dispositivos de valla actualmente configurados.
Para añadir un nuevo dispositivo de valla al clúster:
-
Haga clic en
Add. Aparecerá la pantallaAdd Fence Device. -
Cuando selecciona un tipo de dispositivo de valla en el menú desplegable
Type, los argumentos que debe especificar para ese dispositivo de valla aparecen en el menú. -
Puede hacer clic en
Optional Argumentspara mostrar los argumentos adicionales que puede especificar para el dispositivo de valla que está definiendo. -
Tras introducir los parámetros del nuevo dispositivo de vallado, haga clic en
Create Fence Instance.
Para configurar un dispositivo de cercado SBD, haga clic en SBD en la pantalla Fence Devices. Esto llama a una pantalla que permite activar o desactivar el SBD en el clúster.
Para más información sobre los dispositivos de cercado, consulte Configuración de cercado en un cluster de Alta Disponibilidad de Red Hat.
8.4.4. Configuración de ACLs con la Web UI de pcsd
Al seleccionar la opción ACLS en el menú de la parte superior de la página de gestión del clúster, aparece una pantalla desde la que se pueden establecer permisos para los usuarios locales, permitiendo el acceso de sólo lectura o de lectura y escritura a la configuración del clúster mediante el uso de listas de control de acceso (ACL).
Para asignar permisos ACL, se crea un rol y se definen los permisos de acceso para ese rol. Cada rol puede tener un número ilimitado de permisos (lectura/escritura/denegación) aplicados a una consulta XPath o al ID de un elemento específico. Después de definir el rol, puede asignarlo a un usuario o grupo existente.
Para obtener más información sobre la asignación de permisos mediante ACL, consulte Configuración de permisos locales mediante ACL.
8.4.5. Configuración de las propiedades del clúster con la interfaz web de pcsd
Al seleccionar la opción Cluster Properties en el menú de la parte superior de la página de gestión del clúster, se muestran las propiedades del clúster y se pueden modificar sus valores predeterminados. Para obtener información sobre las propiedades del clúster de Pacemaker, consulte Propiedades del clúster de Pacemaker.
8.5. Configuración de una interfaz web de alta disponibilidad pcsd
Cuando se utiliza la interfaz web pcsd, se conecta a uno de los nodos del clúster para mostrar las páginas de gestión del mismo. Si el nodo al que se conecta se cae o deja de estar disponible, puede volver a conectarse al clúster abriendo el navegador a una URL que especifique un nodo diferente del clúster.
Sin embargo, es posible configurar la propia interfaz web pcsd para la alta disponibilidad, en cuyo caso se puede seguir gestionando el clúster sin necesidad de introducir una nueva URL.
Para configurar la interfaz web pcsd para una alta disponibilidad, realice los siguientes pasos.
-
Asegúrese de que los certificados de
pcsdestán sincronizados entre los nodos del clúster estableciendoPCSD_SSL_CERT_SYNC_ENABLEDatrueen el archivo de configuración/etc/sysconfig/pcsd. La activación de la sincronización de certificados hace quepcsdsincronice los certificados para los comandos de configuración del clúster y de adición de nodos. En RHEL 8,PCSD_SSL_CERT_SYNC_ENABLEDestá configurado comofalsepor defecto. -
Cree un recurso de clúster
IPaddr2, que es una dirección IP flotante que utilizará para conectarse a la interfaz webpcsd. La dirección IP no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recursoIPaddr2, la IP flotante debe residir en la misma red que una de las direcciones IP asignadas estáticamente del nodo, de lo contrario no se podrá detectar correctamente el dispositivo NIC que asignará la dirección IP flotante. Cree certificados SSL personalizados para utilizarlos con
pcsdy asegúrese de que son válidos para las direcciones de los nodos utilizados para conectarse a la interfaz webpcsd.- Para crear certificados SSL personalizados, puede utilizar certificados comodín o puede utilizar la extensión de certificado Subject Alternative Name. Para obtener información sobre Red Hat Certificate System, consulte el Manual de administración de Red Hat Certificate System.
-
Instale los certificados personalizados para
pcsdcon el comandopcs pcsd certkey. -
Sincronice los certificados de
pcsden todos los nodos del clúster con el comandopcs pcsd sync-certificates.
-
Conéctese a la interfaz web
pcsdutilizando la dirección IP flotante que configuró como recurso del clúster.
Aunque configure la interfaz web pcsd para una alta disponibilidad, se le pedirá que vuelva a conectarse cuando el nodo al que se está conectando se caiga.
Capítulo 9. Configuración del cercado en un cluster de alta disponibilidad de Red Hat
Un nodo que no responde puede seguir accediendo a los datos. La única manera de estar seguro de que sus datos están a salvo es cercar el nodo utilizando STONITH. STONITH es un acrónimo de "Shoot The Other Node In The Head" (dispara al otro nodo en la cabeza) y protege tus datos de ser corrompidos por nodos deshonestos o accesos concurrentes. Usando STONITH, puedes estar seguro de que un nodo está realmente desconectado antes de permitir que se acceda a los datos desde otro nodo.
STONITH también tiene un papel que desempeñar en el caso de que un servicio en clúster no pueda ser detenido. En este caso, el clúster utiliza STONITH para forzar la desconexión de todo el nodo, lo que hace que sea seguro iniciar el servicio en otro lugar.
Para una información general más completa sobre el cercado y su importancia en un cluster de alta disponibilidad de Red Hat, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
La implementación de STONITH en un clúster Pacemaker se realiza mediante la configuración de dispositivos de valla para los nodos del clúster.
9.1. Visualización de los agentes de la valla disponibles y sus opciones
Utilice el siguiente comando para ver la lista de todos los agentes STONITH disponibles. Cuando se especifica un filtro, este comando muestra sólo los agentes STONITH que coinciden con el filtro.
lista de pcs stonith [filter]Utilice el siguiente comando para ver las opciones del agente STONITH especificado.
pcs stonith describir stonith_agentPor ejemplo, el siguiente comando muestra las opciones del agente de la valla para APC sobre telnet/SSH.
# pcs stonith describe fence_apc
Stonith options for: fence_apc
ipaddr (required): IP Address or Hostname
login (required): Login Name
passwd: Login password or passphrase
passwd_script: Script to retrieve password
cmd_prompt: Force command prompt
secure: SSH connection
port (required): Physical plug number or name of virtual machine
identity_file: Identity file for ssh
switch: Physical switch number on device
inet4_only: Forces agent to use IPv4 addresses only
inet6_only: Forces agent to use IPv6 addresses only
ipport: TCP port to use for connection with device
action (required): Fencing Action
verbose: Verbose mode
debug: Write debug information to given file
version: Display version information and exit
help: Display help and exit
separator: Separator for CSV created by operation list
power_timeout: Test X seconds for status change after ON/OFF
shell_timeout: Wait X seconds for cmd prompt after issuing command
login_timeout: Wait X seconds for cmd prompt after login
power_wait: Wait X seconds after issuing ON/OFF
delay: Wait X seconds before fencing is started
retry_on: Count of attempts to retry power on
Para los agentes de la valla que proporcionan una opción method, un valor de cycle no es compatible y no debe ser especificado, ya que puede causar la corrupción de datos.
9.2. Creación de un dispositivo de vallas
El formato del comando para crear un dispositivo stonith es el siguiente. Para ver un listado de las opciones de creación de stoniths disponibles, consulte la pantalla pcs stonith -h.
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]
El siguiente comando crea un único dispositivo de esgrima para un solo nodo.
# pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30sAlgunos dispositivos de cercado sólo pueden cercar un único nodo, mientras que otros dispositivos pueden cercar varios nodos. Los parámetros que se especifican al crear un dispositivo de vallado dependen de lo que el dispositivo de vallado admita y requiera.
- Algunos dispositivos de vallado pueden determinar automáticamente los nodos que pueden vallar.
-
Puede utilizar el parámetro
pcmk_host_listal crear un dispositivo de cercado para especificar todas las máquinas que están controladas por ese dispositivo de cercado. -
Algunos dispositivos de vallado requieren una asignación de nombres de host a las especificaciones que el dispositivo de vallado entiende. Puede asignar nombres de host con el parámetro
pcmk_host_mapal crear un dispositivo de vallado.
Para obtener información sobre los parámetros pcmk_host_list y pcmk_host_map, consulte Propiedades generales de los dispositivos de cercado.
Después de configurar un dispositivo de valla, es imprescindible que pruebe el dispositivo para asegurarse de que funciona correctamente. Para obtener información sobre cómo probar un dispositivo de valla, consulte Probar un dispositivo de valla.
9.3. Propiedades generales de los dispositivos de cercado
Cualquier nodo del clúster puede cercar cualquier otro nodo del clúster con cualquier dispositivo de cercado, independientemente de si el recurso de cercado está iniciado o detenido. El hecho de que el recurso esté iniciado sólo controla el monitor recurrente para el dispositivo, no si se puede utilizar, con las siguientes excepciones:
-
Puede desactivar un dispositivo de esgrima ejecutando el comando
pcs stonith disable stonith_idcomando. Esto evitará que cualquier nodo utilice ese dispositivo. -
Para evitar que un nodo específico utilice un dispositivo de esgrima, puede configurar las restricciones de ubicación para el recurso de esgrima con el comando
pcs constraint location … avoids. -
La configuración de
stonith-enabled=falsedeshabilitará el cercado por completo. Tenga en cuenta, sin embargo, que Red Hat no soporta clusters cuando el fencing está deshabilitado, ya que no es adecuado para un entorno de producción.
enTabla 9.1, “Propiedades generales de los dispositivos de esgrima” se describen las propiedades generales que se pueden establecer para los dispositivos de cercado.
| Campo | Tipo | Por defecto | Descripción |
|---|---|---|---|
|
| cadena |
Un mapeo de nombres de host a números de puerto para dispositivos que no soportan nombres de host. Por ejemplo: | |
|
| cadena |
Una lista de máquinas controladas por este dispositivo (Opcional a menos que | |
|
| cadena |
*
* En caso contrario,
* En caso contrario,
*En caso contrario, |
Cómo determinar qué máquinas controla el dispositivo. Valores permitidos: |
9.4. Opciones avanzadas de configuración del cercado
Tabla 9.2, “Propiedades avanzadas de los dispositivos de esgrima” resume las propiedades adicionales que puede configurar para los dispositivos de cercado. Tenga en cuenta que estas propiedades son sólo para uso avanzado.
| Campo | Tipo | Por defecto | Descripción |
|---|---|---|---|
|
| cadena | puerto |
Un parámetro alternativo para suministrar en lugar del puerto. Algunos dispositivos no admiten el parámetro de puerto estándar o pueden proporcionar otros adicionales. Utilícelo para especificar un parámetro alternativo, específico del dispositivo, que debe indicar la máquina que se va a cercar. Un valor de |
|
| cadena | reiniciar |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo para utilizar en las acciones de reinicio en lugar de |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | fuera de |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo que se utilizará para las acciones de apagado en lugar de |
|
| entero | 2 | El número máximo de veces que se debe reintentar el comando de desconexión dentro del periodo de tiempo de espera. Algunos dispositivos no admiten conexiones múltiples. Las operaciones pueden fallar si el dispositivo está ocupado con otra tarea, por lo que Pacemaker reintentará automáticamente la operación, si queda tiempo. Utilice esta opción para modificar el número de veces que Pacemaker reintenta las acciones de desconexión antes de rendirse. |
|
| cadena | lista |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s | Especifique un tiempo de espera alternativo para usar en las acciones de la lista. Algunos dispositivos necesitan mucho más o mucho menos tiempo de lo normal para completarse. Utilice esta opción para especificar un tiempo de espera alternativo, específico del dispositivo, para las acciones de la lista. |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | monitor |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo que se utilizará para las acciones del monitor en lugar de |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | estado |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo para utilizar en las acciones de estado en lugar de |
|
| entero | 2 | El número máximo de veces para reintentar el comando de estado dentro del periodo de tiempo de espera. Algunos dispositivos no admiten conexiones múltiples. Las operaciones pueden fallar si el dispositivo está ocupado con otra tarea, por lo que Pacemaker reintentará automáticamente la operación, si queda tiempo. Utilice esta opción para modificar el número de veces que Pacemaker reintenta las acciones de estado antes de rendirse. |
|
| tiempo | 0s |
Habilite un retardo base para las acciones de stonith y especifique un valor de retardo base. En un clúster con un número par de nodos, configurar un retardo puede ayudar a evitar que los nodos se cerquen entre sí al mismo tiempo en una división uniforme. Un retardo aleatorio puede ser útil cuando se utiliza el mismo dispositivo de vallado para todos los nodos, y diferentes retardos estáticos pueden ser útiles en cada dispositivo de vallado cuando se utiliza un dispositivo independiente para cada nodo. El retardo global se deriva de un valor de retardo aleatorio añadiendo este retardo estático para que la suma se mantenga por debajo del retardo máximo. Si se establece
Algunos agentes de vallas individuales implementan un parámetro de "retraso", que es independiente de los retrasos configurados con una propiedad |
|
| tiempo | 0s |
Habilite un retardo aleatorio para las acciones de stonith y especifique el máximo de retardo aleatorio. En un clúster con un número par de nodos, configurar un retardo puede ayudar a evitar que los nodos se cerquen entre sí al mismo tiempo en una división uniforme. Un retardo aleatorio puede ser útil cuando se utiliza el mismo dispositivo de vallado para todos los nodos, y diferentes retardos estáticos pueden ser útiles en cada dispositivo de vallado cuando se utiliza un dispositivo separado para cada nodo. El retardo global se deriva de este valor de retardo aleatorio añadiendo un retardo estático para que la suma se mantenga por debajo del retardo máximo. Si se establece
Algunos agentes de vallas individuales implementan un parámetro de "retraso", que es independiente de los retrasos configurados con una propiedad |
|
| entero | 1 |
El número máximo de acciones que se pueden realizar en paralelo en este dispositivo. Es necesario configurar primero la propiedad de clúster |
|
| cadena | en |
Sólo para uso avanzado: Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Sólo para uso avanzado: Especifique un tiempo de espera alternativo que se utilizará para las acciones de |
|
| entero | 2 |
Sólo para uso avanzado: El número máximo de veces para reintentar el comando |
Además de las propiedades que puede establecer para los dispositivos de vallado individuales, también hay propiedades de cluster que puede establecer que determinan el comportamiento del vallado, como se describe en Tabla 9.3, “Propiedades de los racimos que determinan el comportamiento del cercado”.
| Opción | Por defecto | Descripción |
|---|---|---|
|
| verdadero |
Indica que los nodos fallidos y los nodos con recursos que no pueden ser detenidos deben ser cercados. La protección de los datos requiere que se configure esta opción
Si
Red Hat sólo admite clusters con este valor establecido en |
|
| reiniciar |
Acción a enviar al dispositivo STONITH. Valores permitidos: |
|
| 60s | Cuánto tiempo hay que esperar para que se complete una acción de STONITH. |
|
| 10 | Cuántas veces puede fallar el esgrima para un objetivo antes de que el clúster deje de reintentarlo inmediatamente. |
|
| El tiempo máximo de espera hasta que se pueda asumir que un nodo ha sido eliminado por el perro guardián del hardware. Se recomienda que este valor sea el doble del valor del tiempo de espera del perro guardián del hardware. Esta opción es necesaria sólo si se utiliza el SBD basado en watchdog para el fencing. | |
|
| true (RHEL 8.1 y posteriores) | Permitir que las operaciones de cercado se realicen en paralelo. |
|
| detener |
(Red Hat Enterprise Linux 8.2 y posterior) Determina cómo debe reaccionar un nodo del cluster si se le notifica su propio cercado. Un nodo de cluster puede recibir una notificación de su propio fencing si el fencing está mal configurado, o si el fabric fencing está en uso y no corta la comunicación del cluster. Los valores permitidos son
Aunque el valor por defecto para esta propiedad es |
Para obtener información sobre la configuración de las propiedades del clúster, consulte Configuración y eliminación de las propiedades del clúster.
9.5. Prueba de un dispositivo de valla
El cercado es una parte fundamental de la infraestructura de Red Hat Cluster y por lo tanto es importante validar o probar que el cercado funciona correctamente.
Utilice el siguiente procedimiento para probar un dispositivo de valla.
Utilice ssh, telnet, HTTP o cualquier protocolo remoto que se utilice para conectarse al dispositivo para iniciar sesión manualmente y probar el dispositivo de vallado o ver qué salida se da. Por ejemplo, si va a configurar el cercado para un dispositivo habilitado para IPMI, entonces intente iniciar la sesión de forma remota con
ipmitool. Tome nota de las opciones utilizadas al iniciar la sesión manualmente porque esas opciones podrían ser necesarias al utilizar el agente de cercado.Si no puede iniciar sesión en el dispositivo de vallado, verifique que el dispositivo es pingable, que no hay nada, como una configuración de cortafuegos, que esté impidiendo el acceso al dispositivo de vallado, que el acceso remoto está activado en el dispositivo de vallado y que las credenciales son correctas.
Ejecute el agente de vallas manualmente, utilizando el script del agente de vallas. Esto no requiere que los servicios del clúster se estén ejecutando, por lo que puede realizar este paso antes de que el dispositivo se configure en el clúster. Esto puede asegurar que el dispositivo de valla está respondiendo correctamente antes de proceder.
NotaLos ejemplos de esta sección utilizan el script
fence_ipmilanfence agent para un dispositivo iLO. El agente de valla real que utilizará y el comando que llama a ese agente dependerá del hardware de su servidor. Deberá consultar la página de manual del agente de vallas que esté utilizando para determinar qué opciones debe especificar. Normalmente necesitará conocer el nombre de usuario y la contraseña del dispositivo de valla y otra información relacionada con el dispositivo de valla.El siguiente ejemplo muestra el formato que se utilizaría para ejecutar el script del agente de vallado
fence_ipmilancon el parámetro-o statuspara comprobar el estado de la interfaz del dispositivo de vallado en otro nodo sin llegar a vallarlo. Esto le permite probar el dispositivo y hacerlo funcionar antes de intentar reiniciar el nodo. Cuando se ejecuta este comando, se especifica el nombre y la contraseña de un usuario iLO que tiene permisos de encendido y apagado para el dispositivo iLO.#
fence_ipmilan -a ipaddress -l username -p password -o statusEl siguiente ejemplo muestra el formato que se utilizaría para ejecutar el script del agente de la valla
fence_ipmilancon el parámetro-o reboot. La ejecución de este comando en un nodo reinicia el nodo gestionado por este dispositivo iLO.#
fence_ipmilan -a ipaddress -l username -p password -o rebootSi el agente de la valla no pudo realizar correctamente una acción de estado, apagado, encendido o reinicio, debe comprobar el hardware, la configuración del dispositivo de la valla y la sintaxis de sus comandos. Además, puede ejecutar el script del agente de valla con la salida de depuración activada. La salida de depuración es útil para algunos agentes de cercado para ver en qué parte de la secuencia de eventos el script del agente de cercado está fallando cuando se registra en el dispositivo de cercado.
#
fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debugAl diagnosticar un fallo que se ha producido, debe asegurarse de que las opciones que especificó al iniciar sesión manualmente en el dispositivo de valla son idénticas a las que pasó al agente de valla con el script del agente de valla.
En el caso de los agentes de valla que admiten una conexión encriptada, es posible que aparezca un error debido a que falla la validación del certificado, lo que requiere que confíe en el host o que utilice el parámetro
ssl-insecuredel agente de valla. Del mismo modo, si SSL/TLS está deshabilitado en el dispositivo de destino, es posible que deba tenerlo en cuenta al configurar los parámetros SSL para el agente de valla.NotaSi el agente de cercado que se está probando es un
fence_drac,fence_ilo, o algún otro agente de cercado para un dispositivo de gestión de sistemas que sigue fallando, entonces vuelva a intentarfence_ipmilan. La mayoría de las tarjetas de gestión de sistemas soportan el inicio de sesión remoto IPMI y el único agente de cercado soportado esfence_ipmilan.Una vez que se ha configurado el dispositivo de vallado en el cluster con las mismas opciones que funcionaron manualmente y se ha iniciado el cluster, pruebe el vallado con el comando
pcs stonith fencedesde cualquier nodo (o incluso varias veces desde diferentes nodos), como en el siguiente ejemplo. El comandopcs stonith fencelee la configuración del cluster desde el CIB y llama al agente de vallado tal y como está configurado para ejecutar la acción de vallado. Esto verifica que la configuración del cluster es correcta.#
pcs stonith fence node_nameSi el comando
pcs stonith fencefunciona correctamente, significa que la configuración de vallado del clúster debería funcionar cuando se produce un evento de vallado. Si el comando falla, significa que la administración del clúster no puede invocar el dispositivo de vallado a través de la configuración que ha recuperado. Compruebe los siguientes problemas y actualice la configuración del clúster según sea necesario.- Comprueba la configuración de tu valla. Por ejemplo, si ha utilizado un mapa de host, debe asegurarse de que el sistema puede encontrar el nodo utilizando el nombre de host que ha proporcionado.
- Comprueba si la contraseña y el nombre de usuario del dispositivo incluyen algún carácter especial que pueda ser malinterpretado por el shell bash. Asegurarse de introducir las contraseñas y los nombres de usuario entre comillas podría solucionar este problema.
-
Comprueba si puedes conectarte al dispositivo utilizando la dirección IP o el nombre de host exactos que has especificado en el comando
pcs stonith. Por ejemplo, si das el nombre de host en el comando stonith pero pruebas utilizando la dirección IP, esa no es una prueba válida. Si el protocolo que utiliza el dispositivo de la valla es accesible para usted, utilice ese protocolo para intentar conectarse al dispositivo. Por ejemplo, muchos agentes utilizan ssh o telnet. Debería intentar conectarse al dispositivo con las credenciales que proporcionó al configurar el dispositivo, para ver si obtiene un aviso válido y puede iniciar sesión en el dispositivo.
Si usted determina que todos sus parámetros son apropiados pero todavía tiene problemas para conectarse a su dispositivo de valla, puede comprobar el registro en el propio dispositivo de valla, si el dispositivo lo proporciona, que mostrará si el usuario se ha conectado y qué comando emitió el usuario. También puede buscar en el archivo
/var/log/messageslas instancias de stonith y error, que podrían dar alguna idea de lo que está ocurriendo, pero algunos agentes pueden proporcionar información adicional.
Una vez que las pruebas del dispositivo de la valla están funcionando y el clúster está en marcha, pruebe un fallo real. Para ello, realiza una acción en el clúster que debería iniciar una pérdida de tokens.
Desmontar una red. La forma de desmontar una red depende de su configuración específica. En muchos casos, puede sacar físicamente los cables de red o de alimentación del host. Para obtener información sobre la simulación de un fallo de red, consulte ¿Cuál es la forma adecuada de simular un fallo de red en un clúster RHEL?
NotaDesactivar la interfaz de red en el host local en lugar de desconectar físicamente los cables de red o de alimentación no se recomienda como prueba de cercado porque no simula con precisión un fallo típico del mundo real.
Bloquea el tráfico de corosync tanto de entrada como de salida utilizando el firewall local.
El siguiente ejemplo bloquea corosync, asumiendo que se utiliza el puerto por defecto de corosync,
firewalldse utiliza como firewall local, y la interfaz de red utilizada por corosync está en la zona de firewall por defecto:#
firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP#firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop'Simule un fallo y haga entrar en pánico a su máquina con
sysrq-trigger. Tenga en cuenta, sin embargo, que desencadenar un pánico del kernel puede causar la pérdida de datos; se recomienda que primero desactive los recursos de su clúster.#
echo c > /proc/sysrq-trigger
9.6. Configuración de los niveles de vallado
Pacemaker admite nodos de esgrima con múltiples dispositivos a través de una función denominada topologías de esgrima. Para implementar topologías, cree los dispositivos individuales como lo haría normalmente y luego defina uno o más niveles de esgrima en la sección de topología de esgrima en la configuración.
- Cada nivel se intenta en orden numérico ascendente, empezando por el 1.
- Si un dispositivo falla, el proceso termina para el nivel actual. No se ejercitan más dispositivos en ese nivel y se intenta el siguiente nivel en su lugar.
- Si todos los dispositivos son cercados con éxito, entonces ese nivel ha tenido éxito y no se intentan otros niveles.
- La operación finaliza cuando se ha superado un nivel (éxito), o se han intentado todos los niveles (fracaso).
Utilice el siguiente comando para añadir un nivel de cercado a un nodo. Los dispositivos se dan como una lista separada por comas de ids de stoniths, que se intentan para el nodo en ese nivel.
pcs stonith level add level node devices
El siguiente comando muestra todos los niveles de esgrima que están configurados actualmente.
pcs stonith level
En el siguiente ejemplo, hay dos dispositivos de valla configurados para el nodo rh7-2: un dispositivo de valla ilo llamado my_ilo y un dispositivo de valla apc llamado my_apc. Estos comandos configuran los niveles de vallado para que, si el dispositivo my_ilo falla y no puede vallar el nodo, Pacemaker intente utilizar el dispositivo my_apc. Este ejemplo también muestra la salida del comando pcs stonith level después de configurar los niveles.
#pcs stonith level add 1 rh7-2 my_ilo#pcs stonith level add 2 rh7-2 my_apc#pcs stonith levelNode: rh7-2 Level 1 - my_ilo Level 2 - my_apc
El siguiente comando elimina el nivel de valla para el nodo y los dispositivos especificados. Si no se especifica ningún nodo o dispositivo, el nivel de valla que se especifique se eliminará de todos los nodos.
pcs stonith level remove level [node_id] [stonith_id] ... [stonith_id]
El siguiente comando borra los niveles de valla en el nodo o id de piedra especificado. Si no se especifica un nodo o un id de stonith, se borran todos los niveles de valla.
pcs stonith level clear [node|stonith_id(s)]
Si especifica más de un id de stonith, deben estar separados por una coma y sin espacios, como en el siguiente ejemplo.
# pcs stonith level clear dev_a,dev_bEl siguiente comando verifica que todos los dispositivos y nodos especificados en los niveles de la valla existen.
pcs stonith level verify
Puede especificar nodos en la topología de vallado mediante una expresión regular aplicada a un nombre de nodo y mediante un atributo de nodo y su valor. Por ejemplo, los siguientes comandos configuran los nodos node1, node2, y `node3 para utilizar los dispositivos de vallado apc1 y `apc2, y los nodos `node4, node5, y `node6 para utilizar los dispositivos de vallado apc3 y `apc4.
pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2 pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4
Los siguientes comandos producen los mismos resultados utilizando la coincidencia de atributos de nodos.
pcs node attribute node1 rack=1 pcs node attribute node2 rack=1 pcs node attribute node3 rack=1 pcs node attribute node4 rack=2 pcs node attribute node5 rack=2 pcs node attribute node6 rack=2 pcs stonith level add 1 attrib%rack=1 apc1,apc2 pcs stonith level add 1 attrib%rack=2 apc3,apc4
9.7. Configurar el cercado para las fuentes de alimentación redundantes
Cuando se configura el cercado para las fuentes de alimentación redundantes, el clúster debe asegurarse de que cuando se intenta reiniciar un host, ambas fuentes de alimentación se apagan antes de que se vuelva a encender cualquiera de ellas.
Si el nodo nunca pierde completamente la energía, es posible que no libere sus recursos. Esto abre la posibilidad de que los nodos accedan a estos recursos simultáneamente y los corrompan.
Es necesario definir cada dispositivo sólo una vez y especificar que ambos son necesarios para cercar el nodo, como en el siguiente ejemplo.
#pcs stonith create apc1 fence_apc_snmp ipaddr=apc1.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"#pcs stonith create apc2 fence_apc_snmp ipaddr=apc2.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"#pcs stonith level add 1 node1.example.com apc1,apc2#pcs stonith level add 1 node2.example.com apc1,apc2
9.8. Visualización de los dispositivos de vallas configurados
El siguiente comando muestra todos los dispositivos de valla actualmente configurados. Si se especifica un stonith_id, el comando muestra las opciones de ese dispositivo stonith configurado solamente. Si se especifica la opción --full, se muestran todas las opciones de stonith configuradas.
pcs stonith config [stonith_id] [--full]9.9. Modificación y supresión de los dispositivos de la valla
Utilice el siguiente comando para modificar o añadir opciones a un dispositivo de cercado actualmente configurado.
pcs stonith update stonith_id [stonith_device_options]
Utilice el siguiente comando para eliminar un dispositivo de cercado de la configuración actual.
pcs stonith delete stonith_id9.10. Cercar manualmente un nodo del clúster
Puedes cercar un nodo manualmente con el siguiente comando. Si se especifica --off se utilizará la llamada de la API off a stonith que apagará el nodo en lugar de reiniciarlo.
pcs stonith fence node [--off]En una situación en la que ningún dispositivo stonith es capaz de cercar un nodo aunque ya no esté activo, es posible que el clúster no pueda recuperar los recursos del nodo. Si esto ocurre, después de asegurarse manualmente de que el nodo está apagado, puede introducir el siguiente comando para confirmar al clúster que el nodo está apagado y liberar sus recursos para su recuperación.
Si el nodo que especifica no está realmente apagado, sino que ejecuta el software del clúster o los servicios normalmente controlados por el clúster, se producirá una corrupción de datos/un fallo del clúster.
pcs stonith confirmar node9.11. Desactivación de un dispositivo de valla
Para desactivar un dispositivo/recurso de esgrima, se ejecuta el comando pcs stonith disable.
El siguiente comando desactiva el dispositivo de la valla myapc.
# pcs stonith disable myapc9.12. Impedir que un nodo utilice un dispositivo de valla
Para evitar que un nodo específico utilice un dispositivo de esgrima, puede configurar restricciones de ubicación para el recurso de esgrima.
El siguiente ejemplo evita que el dispositivo de valla node1-ipmi se ejecute en node1.
# pcs constraint location node1-ipmi avoids node19.13. Configuración de ACPI para su uso con dispositivos de valla integrados
Si su clúster utiliza dispositivos de cercado integrados, debe configurar ACPI (Advanced Configuration and Power Interface) para garantizar un cercado inmediato y completo.
Si un nodo del clúster está configurado para ser cercado por un dispositivo de cercado integrado, desactive el ACPI Soft-Off para ese nodo. La desactivación de ACPI Soft-Off permite que un dispositivo de valla integrado apague un nodo de forma inmediata y completa en lugar de intentar un apagado limpio (por ejemplo, shutdown -h now). De lo contrario, si el ACPI Soft-Off está habilitado, un dispositivo de barrera integrado puede tardar cuatro o más segundos en apagar un nodo (vea la nota que sigue). Además, si el ACPI Soft-Off está habilitado y un nodo entra en pánico o se congela durante el apagado, un dispositivo de cercado integrado puede no ser capaz de apagar el nodo. En esas circunstancias, el cercado se retrasa o no tiene éxito. En consecuencia, cuando un nodo está cercado con un dispositivo de cercado integrado y el ACPI Soft-Off está habilitado, un clúster se recupera lentamente o requiere la intervención administrativa para recuperarse.
El tiempo necesario para cercar un nodo depende del dispositivo de cercado integrado que se utilice. Algunos dispositivos de vallado integrados realizan el equivalente a pulsar y mantener el botón de encendido; por lo tanto, el dispositivo de vallado apaga el nodo en cuatro o cinco segundos. Otros dispositivos de valla integrados realizan el equivalente a pulsar el botón de encendido momentáneamente, confiando en el sistema operativo para apagar el nodo; por lo tanto, el dispositivo de valla apaga el nodo en un lapso de tiempo mucho mayor que cuatro o cinco segundos.
- La forma preferida de desactivar el ACPI Soft-Off es cambiar la configuración de la BIOS a "instant-off" o una configuración equivalente que apague el nodo sin demora, como se describe en Sección 9.13.1, “Desactivación de ACPI Soft-Off con la BIOS”.
La desactivación de ACPI Soft-Off con la BIOS puede no ser posible en algunos sistemas. Si la desactivación de ACPI con la BIOS no es satisfactoria para su clúster, puede desactivar ACPI Soft-Off con uno de los siguientes métodos alternativos:
-
Configurando
HandlePowerKey=ignoreen el archivo/etc/systemd/logind.confy verificando que el nodo se apague inmediatamente cuando sea cercado, como se describe en Sección 9.13.2, “Desactivación de ACPI Soft-Off en el archivo logind.conf”. Este es el primer método alternativo para desactivar el ACPI Soft-Off. Añadiendo
acpi=offa la línea de comandos de arranque del kernel, como se describe en Sección 9.13.3, “Desactivar completamente ACPI en el archivo GRUB 2”. Este es el segundo método alternativo para desactivar el ACPI Soft-Off, si el método preferido o el primer método alternativo no está disponible.ImportanteEste método desactiva completamente ACPI; algunos ordenadores no arrancan correctamente si ACPI está completamente desactivado. Utilice este método only si los otros métodos no son efectivos para su clúster.
9.13.1. Desactivación de ACPI Soft-Off con la BIOS
Puede desactivar el ACPI Soft-Off configurando la BIOS de cada nodo del cluster con el siguiente procedimiento.
El procedimiento para desactivar el ACPI Soft-Off con la BIOS puede variar entre los sistemas de servidor. Debe verificar este procedimiento con la documentación de su hardware.
-
Reinicie el nodo e inicie el programa
BIOS CMOS Setup Utility. - Navegue hasta el menú Power (o el menú de gestión de energía equivalente).
En el menú Power, ajuste la función
Soft-Off by PWR-BTTN(o su equivalente) aInstant-Off(o el ajuste equivalente que apague el nodo mediante el botón de encendido sin demora).BIOS CMOS Setup Utility: muestra un menú Power conACPI Functionajustado aEnabledySoft-Off by PWR-BTTNajustado aInstant-Off.NotaLos equivalentes a
ACPI Function,Soft-Off by PWR-BTTN, yInstant-Offpueden variar entre ordenadores. Sin embargo, el objetivo de este procedimiento es configurar la BIOS para que el ordenador se apague mediante el botón de encendido sin demora.-
Salga del programa
BIOS CMOS Setup Utility, guardando la configuración de la BIOS. - Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
BIOS CMOS Setup Utility:
`Soft-Off by PWR-BTTN` set to `Instant-Off`
+---------------------------------------------|-------------------+ | ACPI Function [Enabled] | Item Help | | ACPI Suspend Type [S1(POS)] |-------------------| | x Run VGABIOS if S3 Resume Auto | Menu Level * | | Suspend Mode [Disabled] | | | HDD Power Down [Disabled] | | | Soft-Off by PWR-BTTN [Instant-Off | | | CPU THRM-Throttling [50.0%] | | | Wake-Up by PCI card [Enabled] | | | Power On by Ring [Enabled] | | | Wake Up On LAN [Enabled] | | | x USB KB Wake-Up From S3 Disabled | | | Resume by Alarm [Disabled] | | | x Date(of Month) Alarm 0 | | | x Time(hh:mm:ss) Alarm 0 : 0 : | | | POWER ON Function [BUTTON ONLY | | | x KB Power ON Password Enter | | | x Hot Key Power ON Ctrl-F1 | | | | | | | | +---------------------------------------------|-------------------+
Este ejemplo muestra ACPI Function ajustado a Enabled, y Soft-Off by PWR-BTTN ajustado a Instant-Off.
9.13.2. Desactivación de ACPI Soft-Off en el archivo logind.conf
Para desactivar el manejo de la tecla de encendido en el archivo /etc/systemd/logind.conf, utilice el siguiente procedimiento.
Defina la siguiente configuración en el archivo
/etc/systemd/logind.conf:HandlePowerKey=ignorar
Reinicie el servicio
systemd-logind:#
systemctl restart systemd-logind.service- Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
9.13.3. Desactivar completamente ACPI en el archivo GRUB 2
Puede desactivar el ACPI Soft-Off añadiendo acpi=off a la entrada del menú GRUB para un kernel.
Este método desactiva completamente ACPI; algunos ordenadores no arrancan correctamente si ACPI está completamente desactivado. Utilice este método only si los otros métodos no son efectivos para su clúster.
Utilice el siguiente procedimiento para desactivar ACPI en el archivo GRUB 2:
Utilice la opción
--argsen combinación con la opción--update-kernelde la herramientagrubbypara cambiar el archivogrub.cfgde cada nodo del clúster de la siguiente manera:#
grubby --args=acpi=off --update-kernel=ALL- Reinicia el nodo.
- Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
Capítulo 10. Configuración de los recursos del clúster
El formato del comando para crear un recurso de cluster es el siguiente:
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options ]...] [meta meta_options...] [clone [clone_options] | master [master_options] | --group group_name [--before resource_id | --after resource_id] | [bundle bundle_id] [--disabled] [--wait[=n]]
Las principales opciones de creación de recursos de clúster son las siguientes:
-
Cuando se especifica la opción
--group, el recurso se añade al grupo de recursos nombrado. Si el grupo no existe, se crea el grupo y se añade este recurso al grupo.
-
Las opciones
--beforey--afterespecifican la posición del recurso añadido en relación con un recurso que ya existe en un grupo de recursos. -
Especificar la opción
--disabledindica que el recurso no se inicia automáticamente.
Puede determinar el comportamiento de un recurso en un clúster configurando restricciones para ese recurso.
Ejemplos de creación de recursos
El siguiente comando crea un recurso con el nombre VirtualIP de estándar ocf, proveedor heartbeat, y tipo IPaddr2. La dirección flotante de este recurso es 192.168.0.120, y el sistema comprobará si el recurso está funcionando cada 30 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
Alternativamente, puede omitir los campos standard y provider y utilizar el siguiente comando. De este modo, el estándar será ocf y el proveedor heartbeat.
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30sBorrar un recurso configurado
Utilice el siguiente comando para eliminar un recurso configurado.
supresión de recursos pcs resource_id
Por ejemplo, el siguiente comando elimina un recurso existente con un ID de recurso de VirtualIP.
# pcs resource delete VirtualIP10.1. Identificadores de agentes de recursos
Los identificadores que se definen para un recurso indican al clúster qué agente debe utilizar para el recurso, dónde encontrar ese agente y a qué estándares se ajusta. Tabla 10.1, “Identificadores de agentes de recursos”, describe estas propiedades.
| Campo | Descripción |
|---|---|
| estándar | La norma a la que se ajusta el agente. Valores permitidos y su significado:
*
*
*
*
* |
| tipo |
El nombre del agente de recursos que desea utilizar, por ejemplo |
| proveedor |
La especificación OCF permite que varios proveedores suministren el mismo agente de recursos. La mayoría de los agentes suministrados por Red Hat utilizan |
Tabla 10.2, “Comandos para mostrar las propiedades de los recursos” resume los comandos que muestran las propiedades de los recursos disponibles.
| comando de visualización de pcs | Salida |
|---|---|
|
| Muestra una lista de todos los recursos disponibles. |
|
| Muestra una lista de estándares de agentes de recursos disponibles. |
|
| Muestra una lista de proveedores de agentes de recursos disponibles. |
|
| Muestra una lista de recursos disponibles filtrados por la cadena especificada. Puede utilizar este comando para mostrar los recursos filtrados por el nombre de un estándar, un proveedor o un tipo. |
10.2. Visualización de los parámetros específicos de los recursos
Para cualquier recurso individual, puede utilizar el siguiente comando para mostrar una descripción del recurso, los parámetros que puede establecer para ese recurso y los valores por defecto que se establecen para el recurso.
pcs resource describe [standard:[provider:]]type
Por ejemplo, el siguiente comando muestra información de un recurso de tipo apache.
# pcs resource describe ocf:heartbeat:apache
This is the resource agent for the Apache Web server.
This resource agent operates both version 1.x and version 2.x Apache
servers.
...10.3. Configuración de las opciones meta de los recursos
Además de los parámetros específicos del recurso, puede configurar opciones adicionales para cualquier recurso. Estas opciones son utilizadas por el clúster para decidir cómo debe comportarse su recurso.
Tabla 10.3, “Meta opciones de recursos” describe las opciones meta de los recursos.
| Campo | Por defecto | Descripción |
|---|---|---|
|
|
| Si no todos los recursos pueden estar activos, el clúster detendrá los recursos de menor prioridad para mantener activos los de mayor prioridad. |
|
|
| ¿En qué estado debería el clúster intentar mantener este recurso? Valores permitidos: * Stopped - Forzar la detención del recurso * Started - Permitir que el recurso se inicie (y en el caso de los clones promocionables, que se promueva al rol de maestro si es apropiado) * Master - Permitir que el recurso se inicie y, en su caso, se promueva * Slave - Permite que el recurso se inicie, pero sólo en modo esclavo si el recurso es promocionable |
|
|
|
¿Tiene el clúster permiso para iniciar y detener el recurso? Valores permitidos: |
|
| 0 | Valor que indica cuánto prefiere el recurso quedarse donde está. |
|
| Calculado | Indica en qué condiciones se puede iniciar el recurso.
El valor por defecto es
*
*
*
* |
|
|
|
Cuántos fallos pueden ocurrir para este recurso en un nodo, antes de que este nodo sea marcado como inelegible para albergar este recurso. Un valor de 0 indica que esta característica está deshabilitada (el nodo nunca será marcado como no elegible); por el contrario, el cluster trata |
|
|
|
Utilizado junto con la opción |
|
|
| Qué debe hacer el cluster si alguna vez encuentra el recurso activo en más de un nodo. Valores permitidos:
*
*
* |
10.3.1. Cambiar el valor por defecto de una opción de recurso
A partir de Red Hat Enterprise Linux 8.3, puede cambiar el valor por defecto de una opción de recurso para todos los recursos con el comando pcs resource defaults update. El siguiente comando restablece el valor por defecto de resource-stickiness a 100.
# pcs resource defaults update resource-stickiness=100
El comando original pcs resource defaults name=value que establecía los valores predeterminados para todos los recursos en las versiones anteriores de RHEL 8, sigue siendo compatible a menos que haya más de un conjunto de valores predeterminados configurados. Sin embargo, pcs resource defaults update es ahora la versión preferida del comando.
10.3.2. Cambio del valor por defecto de una opción de recurso para conjuntos de recursos (RHEL 8.3 y posteriores)
A partir de Red Hat Enterprise Linux 8.3, puede crear múltiples conjuntos de recursos por defecto con el comando pcs resource defaults set create, que le permite especificar una regla que contenga expresiones resource. Sólo las expresiones resource, incluyendo and, or y paréntesis, están permitidas en las reglas que usted especifica con este comando.
Con el comando pcs resource defaults set create, puede configurar un valor de recurso por defecto para todos los recursos de un tipo determinado. Si, por ejemplo, está ejecutando bases de datos que tardan mucho en detenerse, puede aumentar el valor por defecto de resource-stickiness para todos los recursos del tipo de base de datos para evitar que esos recursos se trasladen a otros nodos con más frecuencia de la deseada.
El siguiente comando establece el valor por defecto de resource-stickiness a 100 para todos los recursos de tipo pqsql.
-
La opción
id, que nombra el conjunto de recursos por defecto, no es obligatoria. Si no se establece esta opción,pcsgenerará un ID automáticamente. Si establece este valor, podrá proporcionar un nombre más descriptivo. En este ejemplo,
::pgsqlsignifica un recurso de cualquier clase, cualquier proveedor, del tipopgsql.-
Especificar
ocf:heartbeat:pgsqlindicaría la claseocf, el proveedorheartbeat, el tipopgsql, -
Especificando
ocf:pacemaker:se indicarían todos los recursos de la claseocf, proveedorpacemaker, de cualquier tipo.
-
Especificar
# pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
Para cambiar los valores por defecto de un conjunto existente, utilice el comando pcs resource defaults set update.
10.3.3. Visualización de los valores predeterminados de los recursos configurados actualmente
El comando pcs resource defaults muestra una lista de los valores por defecto actualmente configurados para las opciones de recursos, incluyendo cualquier regla que haya especificado.
El siguiente ejemplo muestra la salida de este comando después de haber restablecido el valor por defecto de resource-stickiness a 100.
# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=100
El siguiente ejemplo muestra la salida de este comando después de haber restablecido el valor por defecto de resource-stickiness a 100 para todos los recursos de tipo pqsql y de haber establecido la opción id a id=pgsql-stickiness.
# pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql10.3.4. Configuración de las opciones meta en la creación de recursos
Tanto si se ha restablecido el valor por defecto de una metaopción de recurso como si no, se puede establecer una opción de recurso para un determinado recurso con un valor distinto al predeterminado cuando se crea el recurso. A continuación se muestra el formato del comando pcs resource create que se utiliza al especificar un valor para una metaopción de recurso.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
Por ejemplo, el siguiente comando crea un recurso con un valor resource-stickiness de 50.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50También se puede establecer el valor de una metaopción de recurso para un recurso existente, un grupo o un recurso clonado con el siguiente comando.
pcs resource meta resource_id | group_id | clone_id meta_options
En el siguiente ejemplo, hay un recurso existente llamado dummy_resource. Este comando establece la opción meta failure-timeout a 20 segundos, para que el recurso pueda intentar reiniciarse en el mismo nodo en 20 segundos.
# pcs resource meta dummy_resource failure-timeout=20s
Después de ejecutar este comando, puede visualizar los valores del recurso para verificar que failure-timeout=20s está configurado.
# pcs resource config dummy_resource
Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy)
Meta Attrs: failure-timeout=20s
...10.4. Configuración de los grupos de recursos
Uno de los elementos más comunes de un clúster es un conjunto de recursos que deben ubicarse juntos, iniciarse secuencialmente y detenerse en el orden inverso. Para simplificar esta configuración, Pacemaker admite el concepto de grupos de recursos.
10.4.1. Creación de un grupo de recursos
Se crea un grupo de recursos con el siguiente comando, especificando los recursos que se incluirán en el grupo. Si el grupo no existe, este comando crea el grupo. Si el grupo existe, este comando añade recursos adicionales al grupo. Los recursos se iniciarán en el orden que se especifique con este comando, y se detendrán en el orden inverso al de inicio.
pcs resource group add group_name resource_id [resource_id] ... [resource_id] [--before resource_id | --after resource_id]
Puede utilizar las opciones --before y --after de este comando para especificar la posición de los recursos añadidos en relación con un recurso que ya existe en el grupo.
También puede añadir un nuevo recurso a un grupo existente cuando crea el recurso, utilizando el siguiente comando. El recurso que se crea se añade al grupo denominado group_name. Si el grupo group_name no existe, se creará.
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options ] --group group_name
No hay límite en el número de recursos que puede contener un grupo. Las propiedades fundamentales de un grupo son las siguientes.
- Los recursos se colocan dentro de un grupo.
- Los recursos se inician en el orden en que se especifican. Si un recurso del grupo no puede ejecutarse en ningún sitio, ningún recurso especificado después de ese recurso podrá ejecutarse.
- Los recursos se detienen en el orden inverso al especificado.
El siguiente ejemplo crea un grupo de recursos denominado shortcut que contiene los recursos existentes IPaddr y Email.
# pcs resource group add shortcut IPaddr EmailEn este ejemplo:
-
Primero se pone en marcha el
IPaddry luego elEmail. -
Primero se detiene el recurso
Emaily luegoIPAddr. -
Si
IPaddrno puede correr en ningún sitio, tampocoEmail. -
Sin embargo, si
Emailno puede ejecutarse en ningún sitio, esto no afecta en absoluto aIPaddr.
10.4.2. Eliminar un grupo de recursos
Se elimina un recurso de un grupo con el siguiente comando. Si no quedan recursos en el grupo, este comando elimina el propio grupo.
pcs resource group remove group_name resource_id ...
10.4.3. Visualización de los grupos de recursos
El siguiente comando muestra todos los grupos de recursos configurados actualmente.
lista de grupos de recursos pcs
10.4.4. Opciones de grupo
Puede establecer las siguientes opciones para un grupo de recursos, y mantienen el mismo significado que cuando se establecen para un solo recurso: priority, target-role, is-managed. Para obtener información sobre las opciones meta de los recursos, consulte Configuración de las opciones meta de los recursos.
10.4.5. Adherencia al grupo
La pegajosidad, la medida de cuánto quiere un recurso quedarse donde está, es aditiva en los grupos. Cada recurso activo del grupo contribuirá con su valor de pegajosidad al total del grupo. Así, si el valor por defecto de resource-stickiness es 100, y un grupo tiene siete miembros, cinco de los cuales son activos, entonces el grupo en su conjunto preferirá su ubicación actual con una puntuación de 500.
10.5. Determinación del comportamiento de los recursos
Puede determinar el comportamiento de un recurso en un cluster configurando restricciones para ese recurso. Puede configurar las siguientes categorías de restricciones:
-
locationlimitaciones -
orderlimitaciones -
colocationlimitaciones
Pacemaker admite el concepto de grupos de recursos como una forma de abreviar la configuración de un conjunto de restricciones que ubicarán un conjunto de recursos juntos y garantizarán que los recursos se inicien de forma secuencial y se detengan en orden inverso. Una vez que haya creado un grupo de recursos, puede configurar las restricciones del propio grupo del mismo modo que configura las restricciones de los recursos individuales. Para obtener información sobre los grupos de recursos, consulte Configuración de grupos de recursos.
Capítulo 11. Determinación de los nodos en los que puede ejecutarse un recurso
Las restricciones de ubicación determinan en qué nodos puede ejecutarse un recurso. Puede configurar las restricciones de ubicación para determinar si un recurso preferirá o evitará un nodo específico.
Además de las restricciones de ubicación, el nodo en el que se ejecuta un recurso está influenciado por el valor resource-stickiness para ese recurso, que determina hasta qué punto un recurso prefiere permanecer en el nodo donde se está ejecutando actualmente. Para obtener información sobre la configuración del valor resource-stickiness, consulte Configuración de un recurso para que prefiera su nodo actual.
11.1. Configurar las restricciones de ubicación
Puede configurar una restricción de ubicación básica para especificar si un recurso prefiere o evita un nodo, con un valor opcional score para indicar el grado relativo de preferencia de la restricción.
El siguiente comando crea una restricción de ubicación para que un recurso prefiera el nodo o nodos especificados. Tenga en cuenta que es posible crear restricciones en un recurso concreto para más de un nodo con un solo comando.
pcs restricción ubicación rsc prefiere node[=score] [node[=score]] ...
El siguiente comando crea una restricción de ubicación para que un recurso evite el nodo o nodos especificados.
pcs restricción ubicación rsc evita node[=score] [node[=score]] ...
Tabla 11.1, “Opciones de restricción de ubicación” resume el significado de las opciones básicas para configurar las restricciones de ubicación.
| Campo | Descripción |
|---|---|
|
| Un nombre de recurso |
|
| El nombre de un nodo |
|
|
Valor entero positivo para indicar el grado de preferencia para que el recurso dado prefiera o evite el nodo dado.
Un valor de
Un valor de
Una puntuación numérica (es decir, no |
El siguiente comando crea una restricción de ubicación para especificar que el recurso Webserver prefiere el nodo node1.
pcs ubicación de la restricción El servidor web prefiere el nodo1
pcs admite expresiones regulares en las restricciones de ubicación en la línea de comandos. Estas restricciones se aplican a múltiples recursos basados en la expresión regular que coincide con el nombre del recurso. Esto le permite configurar múltiples restricciones de ubicación con una sola línea de comandos.
El siguiente comando crea una restricción de ubicación para especificar que los recursos dummy0 a dummy9 prefieren node1.
pcs ubicación de la restricción 'regexp mmy[0-9]' prefiere el nodo1
Dado que Pacemaker utiliza expresiones regulares extendidas de POSIX, como se documenta en http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04puede especificar la misma restricción con el siguiente comando.
pcs constraint location 'regexp mmy[[:digit:]]' prefiere el nodo1
11.2. Limitación del descubrimiento de recursos a un subconjunto de nodos
Antes de que Pacemaker inicie un recurso en cualquier lugar, primero ejecuta una operación de monitorización única (a menudo denominada "sondeo") en cada nodo, para saber si el recurso ya se está ejecutando. Este proceso de descubrimiento de recursos puede dar lugar a errores en los nodos que no pueden ejecutar el monitor.
Al configurar una restricción de ubicación en un nodo, puede utilizar la opción resource-discovery del comando pcs constraint location para indicar una preferencia sobre si Pacemaker debe realizar el descubrimiento de recursos en este nodo para el recurso especificado. Limitar el descubrimiento de recursos a un subconjunto de nodos en los que el recurso puede ejecutarse físicamente puede aumentar significativamente el rendimiento cuando hay un gran conjunto de nodos. Cuando pacemaker_remote está en uso para ampliar el número de nodos en el rango de cientos de nodos, esta opción debe ser considerada.
El siguiente comando muestra el formato para especificar la opción resource-discovery del comando pcs constraint location. En este comando, un valor positivo para score corresponde a una restricción de ubicación básica que configura un recurso para preferir un nodo, mientras que un valor negativo para score corresponde a una restricción de ubicación básica que configura un recurso para evitar un nodo. Al igual que con las restricciones de ubicación básicas, también puedes utilizar expresiones regulares para los recursos con estas restricciones.
pcs constraint location add id rsc node score [resource-discovery=option]
Tabla 11.2, “Parámetros de restricción de descubrimiento de recursos” resume los significados de los parámetros básicos para configurar las restricciones para el descubrimiento de recursos.
| Campo | Descripción |
|
| Un nombre elegido por el usuario para la propia restricción. |
|
| Un nombre de recurso |
|
| El nombre de un nodo |
|
| Valor entero para indicar el grado de preferencia para que el recurso dado prefiera o evite el nodo dado. Un valor positivo para la puntuación corresponde a una restricción de ubicación básica que configura un recurso para preferir un nodo, mientras que un valor negativo para la puntuación corresponde a una restricción de ubicación básica que configura un recurso para evitar un nodo.
Un valor de
Una puntuación numérica (es decir, no |
|
|
*
*
* |
Configurar resource-discovery como never o exclusive elimina la capacidad de Pacemaker de detectar y detener las instancias no deseadas de un servicio que se ejecuta donde no debe estar. Depende del administrador del sistema asegurarse de que el servicio nunca pueda estar activo en los nodos sin descubrimiento de recursos (por ejemplo, dejando desinstalado el software correspondiente).
11.3. Configurar una estrategia de restricción de ubicación
Cuando se utilizan restricciones de ubicación, se puede configurar una estrategia general para especificar en qué nodos puede ejecutarse un recurso:
- Agrupaciones Opt-In
- Agrupaciones Opt-Out
La elección de configurar su clúster como un clúster opt-in o opt-out depende tanto de sus preferencias personales como de la composición de su clúster. Si la mayoría de sus recursos pueden ejecutarse en la mayoría de los nodos, es probable que una disposición opt-out resulte en una configuración más sencilla. Por otro lado, si la mayoría de los recursos sólo pueden ejecutarse en un pequeño subconjunto de nodos, una configuración opt-in podría ser más sencilla.
11.3.1. Configuración de un clúster "Opt-In"
Para crear un clúster opcional, establezca la propiedad de clúster symmetric-cluster en false para evitar que los recursos se ejecuten en cualquier lugar por defecto.
# pcs property set symmetric-cluster=false
Habilitar nodos para recursos individuales. Los siguientes comandos configuran las restricciones de ubicación para que el recurso Webserver prefiera el nodo example-1, el recurso Database prefiera el nodo example-2, y ambos recursos puedan fallar en el nodo example-3 si su nodo preferido falla. Cuando se configuran las restricciones de ubicación para un cluster opt-in, establecer una puntuación de cero permite que un recurso se ejecute en un nodo sin indicar ninguna preferencia para preferir o evitar el nodo.
#pcs constraint location Webserver prefers example-1=200#pcs constraint location Webserver prefers example-3=0#pcs constraint location Database prefers example-2=200#pcs constraint location Database prefers example-3=0
11.3.2. Configuración de un clúster "Opt-Out"
Para crear un clúster de exclusión, establezca la propiedad de clúster symmetric-cluster en true para permitir que los recursos se ejecuten en todas partes por defecto. Esta es la configuración por defecto si symmetric-cluster no se establece explícitamente.
# pcs property set symmetric-cluster=true
Los siguientes comandos darán lugar a una configuración equivalente al ejemplo de Sección 11.3.1, “Configuración de un clúster "Opt-In"”. Ambos recursos pueden fallar al nodo example-3 si su nodo preferido falla, ya que cada nodo tiene una puntuación implícita de 0.
#pcs constraint location Webserver prefers example-1=200#pcs constraint location Webserver avoids example-2=INFINITY#pcs constraint location Database avoids example-1=INFINITY#pcs constraint location Database prefers example-2=200
Tenga en cuenta que no es necesario especificar una puntuación de INFINITO en estos comandos, ya que ese es el valor por defecto para la puntuación.
11.4. Configurar un recurso para que prefiera su nodo actual
Los recursos tienen un valor resource-stickiness que puedes establecer como un meta atributo cuando creas el recurso, como se describe en Configuración de las opciones meta de los recursos. El valor resource-stickiness determina cuánto quiere permanecer un recurso en el nodo donde se está ejecutando actualmente. Pacemaker tiene en cuenta el valor de resource-stickiness junto con otros ajustes (por ejemplo, los valores de puntuación de las restricciones de ubicación) para determinar si se debe mover un recurso a otro nodo o dejarlo en su lugar.
Por defecto, un recurso se crea con un valor resource-stickiness de 0. El comportamiento predeterminado de Pacemaker cuando resource-stickiness se establece en 0 y no hay restricciones de ubicación es mover los recursos para que se distribuyan uniformemente entre los nodos del clúster. Esto puede dar lugar a que los recursos sanos se muevan con más frecuencia de la deseada. Para evitar este comportamiento, puede establecer el valor predeterminado de resource-stickiness en 1. Este valor predeterminado se aplicará a todos los recursos del clúster. Este pequeño valor puede ser fácilmente anulado por otras restricciones que usted cree, pero es suficiente para evitar que Pacemaker mueva innecesariamente los recursos sanos por el cluster.
El siguiente comando establece el valor por defecto de resource-stickiness en 1.
# pcs resource defaults resource-stickiness=1
Si se establece el valor resource-stickiness, no se moverá ningún recurso a un nodo recién añadido. Si se desea equilibrar los recursos en ese momento, se puede volver a establecer temporalmente el valor resource-stickiness a 0.
Tenga en cuenta que si la puntuación de una restricción de ubicación es mayor que el valor de resource-stickiness, el clúster puede seguir moviendo un recurso sano al nodo donde apunta la restricción de ubicación.
Para obtener más información sobre cómo Pacemaker determina dónde colocar un recurso, consulte Configuración de una estrategia de colocación de nodos.
Capítulo 12. Determinación del orden de ejecución de los recursos del clúster
Para determinar el orden de ejecución de los recursos, se configura una restricción de orden.
A continuación se muestra el formato del comando para configurar una restricción de ordenación.
pcs constraint order [action] resource_id then [action] resource_id [options]
Tabla 12.1, “Propiedades de una restricción de orden”, resume las propiedades y opciones para configurar las restricciones de ordenación.
| Campo | Descripción |
|---|---|
| resource_id | El nombre de un recurso sobre el que se realiza una acción. |
| acción | La acción a realizar sobre un recurso. Los posibles valores de la propiedad action son los siguientes:
*
*
*
*
Si no se especifica ninguna acción, la acción por defecto es |
|
|
Cómo aplicar la restricción. Los posibles valores de la opción
*
*
* |
|
|
Si es verdadera, se aplica la inversa de la restricción para la acción opuesta (por ejemplo, si B comienza después de que A comience, entonces B se detiene antes Las restricciones de ordenación para las que |
Utilice el siguiente comando para eliminar los recursos de cualquier restricción de ordenación.
pcs constraint order remove resource1 [resourceN]...
12.1. Configuración de la ordenación obligatoria
Una restricción de orden obligatoria indica que la segunda acción no debe iniciarse para el segundo recurso a menos que y hasta que la primera acción se complete con éxito para el primer recurso. Las acciones que pueden ordenarse son stop, start, y adicionalmente para los clones promocionables, demote y promote. Por ejemplo, \ "A entonces B" (que equivale a "iniciar A y luego iniciar B") significa que B no se iniciará a menos que A se inicie con éxito. Una restricción de ordenación es obligatoria si la opción kind de la restricción se establece en Mandatory o se deja por defecto.
Si la opción symmetrical se establece en true o se deja por defecto, las acciones opuestas se ordenarán de forma inversa. Las acciones start y stop son opuestas, y demote y promote son opuestas. Por ejemplo, una ordenación simétrica \ "promocionar A y luego iniciar B" implica \ "detener B y luego degradar A", lo que significa que A no puede ser degradado hasta que y a menos que B se detenga con éxito. Un ordenamiento simétrico significa que los cambios en el estado de A pueden causar acciones que se programen para B. Por ejemplo, dado "A entonces B", si A se reinicia debido a una falla, B se detendrá primero, luego A se detendrá, luego A se iniciará, luego B se iniciará.
Tenga en cuenta que el clúster reacciona a cada cambio de estado. Si el primer recurso se reinicia y vuelve a estar en estado de inicio antes de que el segundo recurso inicie una operación de parada, no será necesario reiniciar el segundo recurso.
12.2. Configurar la ordenación de los avisos
Cuando se especifica la opción kind=Optional para una restricción de ordenación, la restricción se considera opcional y sólo se aplica si ambos recursos están ejecutando las acciones especificadas. Cualquier cambio de estado del primer recurso especificado no tendrá efecto en el segundo recurso especificado.
El siguiente comando configura una restricción de ordenación de asesoramiento para los recursos denominados VirtualIP y dummy_resource.
# pcs constraint order VirtualIP then dummy_resource kind=Optional12.3. Configuración de conjuntos de recursos ordenados
Una situación común es que un administrador cree una cadena de recursos ordenados, donde, por ejemplo, el recurso A se inicia antes que el recurso B, que se inicia antes que el recurso C. Si su configuración requiere que cree un conjunto de recursos que se coloquen y se inicien en orden, puede configurar un grupo de recursos que contenga esos recursos, como se describe en Configuración de grupos de recursos.
Sin embargo, hay algunas situaciones en las que no es adecuado configurar los recursos que deben iniciarse en un orden determinado como un grupo de recursos:
- Es posible que tenga que configurar los recursos para que se inicien en orden y que los recursos no estén necesariamente colocados.
- Puede tener un recurso C que debe iniciarse después de que se haya iniciado el recurso A o el B, pero no hay ninguna relación entre A y B.
- Puede tener recursos C y D que deben iniciarse después de que se hayan iniciado los recursos A y B, pero no hay ninguna relación entre A y B o entre C y D.
En estas situaciones, puede crear una restricción de ordenación en un conjunto o conjuntos de recursos con el comando pcs constraint order set.
Puede establecer las siguientes opciones para un conjunto de recursos con el comando pcs constraint order set.
sequential, que puede establecerse comotrueofalsepara indicar si el conjunto de recursos debe estar ordenado de forma relativa. El valor por defecto estrue.Si se establece
sequentialenfalse, se puede ordenar un conjunto en relación con otros conjuntos en la restricción de ordenación, sin que sus miembros se ordenen entre sí. Por lo tanto, esta opción sólo tiene sentido si hay varios conjuntos en la restricción; en caso contrario, la restricción no tiene ningún efecto.-
require-all, que puede establecerse entrueofalsepara indicar si todos los recursos del conjunto deben estar activos antes de continuar. Establecerrequire-allafalsesignifica que sólo un recurso del conjunto debe iniciarse antes de continuar con el siguiente conjunto. Establecerrequire-allafalseno tiene ningún efecto a menos que se utilice junto con conjuntos desordenados, que son conjuntos para los quesequentialse establece enfalse. El valor por defecto estrue. -
action, que puede establecerse enstart,promote,demoteostop, como se describe en Propiedades de una restricción de orden. -
role, que puede ajustarse aStopped,Started,MasteroSlave.
Puede establecer las siguientes opciones de restricción para un conjunto de recursos siguiendo el parámetro setoptions del comando pcs constraint order set.
-
id, para dar un nombre a la restricción que está definiendo. -
kind, que indica cómo hacer cumplir la restricción, como se describe en Propiedades de una restricción de orden. -
symmetrical, para establecer si la inversa de la restricción se aplica para la acción opuesta, como se describe en Propiedades de una restricción de orden.
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
Si tiene tres recursos llamados D1, D2, y D3, el siguiente comando los configura como un conjunto de recursos ordenados.
# pcs constraint order set D1 D2 D3
Si tiene seis recursos denominados A, B, C, D, E, y F, este ejemplo configura una restricción de ordenación para el conjunto de recursos que comenzará de la siguiente manera:
-
AyBse inician de forma independiente -
Cse inicia una vez que se ha iniciadoAoB -
Dse pone en marcha una vez que se ha iniciadoC -
EyFse inician de forma independiente una vez que se ha iniciadoD
La detención de los recursos no se ve influida por esta restricción, ya que se establece symmetrical=false.
# pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false12.4. Configuración del orden de inicio para las dependencias de recursos no gestionadas por Pacemaker
Es posible que un clúster incluya recursos con dependencias que no son gestionadas por el clúster. En este caso, debe asegurarse de que esas dependencias se inicien antes de iniciar Pacemaker y se detengan después de detenerlo.
Puede configurar su orden de inicio para tener en cuenta esta situación mediante el objetivo systemd resource-agents-deps . Puede crear una unidad de arranque systemd para este objetivo y Pacemaker se ordenará adecuadamente en relación con este objetivo.
Por ejemplo, si un clúster incluye un recurso que depende del servicio externo foo que no está gestionado por el clúster, realice el siguiente procedimiento.
Cree la unidad de entrega
/etc/systemd/system/resource-agents-deps.target.d/foo.confque contiene lo siguiente:[Unit] Requires=foo.service After=foo.service
-
Ejecute el comando
systemctl daemon-reload.
Una dependencia del clúster especificada de esta manera puede ser algo distinto a un servicio. Por ejemplo, puede tener una dependencia para montar un sistema de archivos en /srv, en cuyo caso realizaría el siguiente procedimiento:
-
Asegúrese de que
/srvaparece en el archivo/etc/fstab. Esto se convertirá automáticamente en el archivosystemdsrv.mounten el arranque cuando se recargue la configuración del administrador del sistema. Para más información, consulte las páginas de manualsystemd.mount(5) ysystemd-fstab-generator(8). Para asegurarse de que Pacemaker se inicie después de montar el disco, cree la unidad drop-in
/etc/systemd/system/resource-agents-deps.target.d/srv.confque contiene lo siguiente.[Unit] Requires=srv.mount After=srv.mount
-
Ejecute el comando
systemctl daemon-reload.
Capítulo 13. Colocación de los recursos del clúster
Para especificar que la ubicación de un recurso depende de la ubicación de otro recurso, se configura una restricción de colocación.
La creación de una restricción de colocación entre dos recursos tiene un efecto secundario importante: afecta al orden en que se asignan los recursos a un nodo. Esto se debe a que no se puede colocar el recurso A en relación con el recurso B a menos que se sepa dónde está el recurso B. Por lo tanto, cuando se crean restricciones de colocación, es importante considerar si se debe colocar el recurso A con el recurso B o el recurso B con el recurso A.
Otra cosa que hay que tener en cuenta al crear las restricciones de colocación es que, suponiendo que el recurso A esté colocado con el recurso B, el clúster también tendrá en cuenta las preferencias del recurso A a la hora de decidir qué nodo elegir para el recurso B.
El siguiente comando crea una restricción de colocación.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]
Tabla 13.1, “Propiedades de una restricción de colocación”, resume las propiedades y opciones para configurar las restricciones de colocación.
| Campo | Descripción |
|---|---|
| recurso_fuente | La fuente de colocación. Si la restricción no puede ser satisfecha, el clúster puede decidir no permitir que el recurso se ejecute en absoluto. |
| recurso_objetivo | El objetivo de colocación. El clúster decidirá dónde colocar este recurso primero y luego decidirá dónde colocar el recurso de origen. |
| puntuación |
Los valores positivos indican que el recurso debe ejecutarse en el mismo nodo. Los valores negativos indican que los recursos no deben ejecutarse en el mismo nodo. Un valor de |
13.1. Especificación de la ubicación obligatoria de los recursos
La colocación obligatoria se produce cada vez que la puntuación de la restricción es INFINITY o -INFINITY. En estos casos, si la restricción no puede satisfacerse, no se permite la ejecución de source_resource. En el caso de score=INFINITY, esto incluye los casos en los que el target_resource no está activo.
Si necesita que myresource1 se ejecute siempre en la misma máquina que myresource2, deberá añadir la siguiente restricción:
# pcs constraint colocation add myresource1 with myresource2 score=INFINITY
Como se ha utilizado INFINITY, si myresource2 no puede ejecutarse en ninguno de los nodos del clúster (por la razón que sea), entonces myresource1 no podrá ejecutarse.
Alternativamente, puede querer configurar lo contrario, un cluster en el que myresource1 no pueda ejecutarse en la misma máquina que myresource2. En este caso, utilice score=-INFINITY
# pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
De nuevo, al especificar -INFINITY, la restricción es vinculante. Así que si el único lugar que queda por ejecutar es donde ya está myresource2, entonces myresource1 no puede ejecutarse en ningún sitio.
13.2. Especificación de la colocación de los recursos con fines de asesoramiento
Si la colocación obligatoria se trata de \N "debe" y \N "no debe", entonces la colocación consultiva es la alternativa \N "preferiría si". Para las restricciones con puntuaciones superiores a -INFINITY e inferiores a INFINITY, el clúster intentará acomodar sus deseos pero puede ignorarlos si la alternativa es detener algunos de los recursos del clúster.
13.3. Colocación de conjuntos de recursos
Si su configuración requiere que cree un conjunto de recursos que se coloquen y se inicien en orden, puede configurar un grupo de recursos que contenga esos recursos, como se describe en Configuración de grupos de recursos. Sin embargo, hay algunas situaciones en las que no es apropiado configurar los recursos que deben colocarse como un grupo de recursos:
- Es posible que tenga que colocar un conjunto de recursos, pero los recursos no tienen que empezar necesariamente en orden.
- Puede tener un recurso C que debe estar colocado con el recurso A o B, pero no hay relación entre A y B.
- Es posible que haya recursos C y D que deban colocarse con los recursos A y B, pero no hay relación entre A y B ni entre C y D.
En estas situaciones, puede crear una restricción de colocación en un conjunto o conjuntos de recursos con el comando pcs constraint colocation set.
Puede establecer las siguientes opciones para un conjunto de recursos con el comando pcs constraint colocation set.
sequential, que puede establecerse comotrueofalsepara indicar si los miembros del conjunto deben estar colocados entre sí.Si se establece
sequentialenfalse, los miembros de este conjunto se colocan con otro conjunto que aparece más adelante en la restricción, independientemente de los miembros de este conjunto que estén activos. Por lo tanto, esta opción sólo tiene sentido si otro conjunto aparece después de éste en la restricción; de lo contrario, la restricción no tiene efecto.-
role, que puede ajustarse aStopped,Started,MasteroSlave.
Puede establecer la siguiente opción de restricción para un conjunto de recursos siguiendo el parámetro setoptions del comando pcs constraint colocation set.
-
id, para dar un nombre a la restricción que está definiendo. -
score, para indicar el grado de preferencia de esta restricción. Para obtener información sobre esta opción, consulte Opciones de restricción de ubicación.
Cuando se enumeran los miembros de un conjunto, cada miembro se coloca con el anterior. Por ejemplo, "conjunto A B" significa que "B está colocado con A". Sin embargo, cuando se enumeran varios conjuntos, cada conjunto se coloca con el que le sigue. Por ejemplo, "conjunto C D secuencial=falso conjunto A B" significa que "el conjunto C D (donde C y D no tienen relación entre sí) está colocado con el conjunto A B (donde B está colocado con A)".
El siguiente comando crea una restricción de colocación en un conjunto o conjuntos de recursos.
pcs constraint colocation set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
13.4. Eliminación de las restricciones de colocación
Utilice el siguiente comando para eliminar las restricciones de colocación con source_resource.
pcs constraint colocation remove source_resource target_resource
Capítulo 14. Visualización de las limitaciones de recursos
Hay varios comandos que se pueden utilizar para mostrar las restricciones que se han configurado.
14.1. Visualización de todas las restricciones configuradas
El siguiente comando muestra todas las restricciones de ubicación, orden y colocación actuales. Si se especifica la opción --full, muestra los ID de las restricciones internas.
pcs constraint [list|show] [--full]
A partir de RHEL 8.2, el listado de restricciones de recursos ya no muestra por defecto las restricciones caducadas. Para incluir las restricciones caducadas, utilice la opción --all del comando pcs constraint. Esto listará las restricciones expiradas, anotando las restricciones y sus reglas asociadas como (expired) en la pantalla.
14.2. Visualización de las restricciones de ubicación
El siguiente comando muestra todas las restricciones de ubicación actuales.
-
Si se especifica
resources, las restricciones de ubicación se muestran por recurso. Este es el comportamiento por defecto. -
Si se especifica
nodes, las restricciones de ubicación se muestran por nodo. - Si se especifican recursos o nodos concretos, sólo se mostrará información sobre esos recursos o nodos.
pcs constraint location [show [resources [resource...]] | [nodos [node...]]] [--full]
14.3. Visualización de las restricciones de ordenación
La siguiente orden enumera todas las restricciones de ordenación actuales.
pcs orden de restricción [mostrar]
14.4. Visualización de las restricciones de colocación
El siguiente comando muestra todas las restricciones de colocación actuales.
pcs constraint colocation [show]
14.5. Visualización de las restricciones específicas de los recursos
El siguiente comando enumera las restricciones que hacen referencia a recursos específicos.
pcs constraint ref resource...14.6. Visualización de las dependencias de recursos (Red Hat Enterprise Linux 8.2 y posteriores)
El siguiente comando muestra las relaciones entre los recursos del cluster en una estructura de árbol.
pcs resource relations resource [--full]
Si se utiliza la opción --full, el comando muestra información adicional, incluyendo los ID de las restricciones y los tipos de recursos.
En el siguiente ejemplo, hay 3 recursos configurados: C, D y E.
#pcs constraint order start C then start DAdding C D (kind: Mandatory) (Options: first-action=start then-action=start) #pcs constraint order start D then start EAdding D E (kind: Mandatory) (Options: first-action=start then-action=start) #pcs resource relations CC `- order | start C then start D `- D `- order | start D then start E `- E #pcs resource relations DD |- order | | start C then start D | `- C `- order | start D then start E `- E # pcsresource relations EE `- order | start D then start E `- D `- order | start C then start D `- C
En el siguiente ejemplo, hay 2 recursos configurados: A y B. Los recursos A y B forman parte del grupo de recursos G.
#pcs resource relations AA `- outer resource `- G `- inner resource(s) | members: A B `- B #pcs resource relations BB `- outer resource `- G `- inner resource(s) | members: A B `- A #pcs resource relations GG `- inner resource(s) | members: A B |- A `- B
Capítulo 15. Determinación de la ubicación de los recursos con reglas
Para restricciones de ubicación más complicadas, puede utilizar las reglas de Pacemaker para determinar la ubicación de un recurso.
15.1. Reglas del marcapasos
Las reglas pueden ser utilizadas para hacer su configuración más dinámica. Un uso de las reglas podría ser asignar máquinas a diferentes grupos de procesamiento (utilizando un atributo de nodo) en función del tiempo y luego utilizar ese atributo al crear restricciones de ubicación.
Cada regla puede contener varias expresiones, expresiones de fecha e incluso otras reglas. Los resultados de las expresiones se combinan basándose en el campo boolean-op de la regla para determinar si la regla se evalúa finalmente como true o false. Lo que ocurre a continuación depende del contexto en el que se utiliza la regla.
| Campo | Descripción |
|---|---|
|
|
Limita la regla para que se aplique sólo cuando el recurso está en ese rol. Valores permitidos: |
|
|
La puntuación a aplicar si la regla se evalúa como |
|
|
El atributo del nodo que se busca y se utiliza como puntuación si la regla se evalúa como |
|
|
Cómo combinar el resultado de varios objetos de expresión. Valores permitidos: |
15.1.1. Expresiones de atributos de los nodos
Las expresiones de atributos de nodo se utilizan para controlar un recurso en función de los atributos definidos por un nodo o nodos.
| Campo | Descripción |
|---|---|
|
| El atributo del nodo a probar |
|
|
Determina cómo se deben comprobar los valores. Valores permitidos: |
|
| La comparación a realizar. Valores permitidos:
*
*
*
*
*
*
*
* |
|
|
Valor suministrado por el usuario para la comparación (obligatorio a menos que |
Además de los atributos añadidos por el administrador, el clúster define atributos de nodo especiales e incorporados para cada nodo que también pueden utilizarse, como se describe en Tabla 15.3, “Atributos de los nodos incorporados”.
| Nombre | Descripción |
|---|---|
|
| Nombre del nodo |
|
| ID de nodo |
|
|
Tipo de nodo. Los valores posibles son |
|
|
|
|
|
El valor de la propiedad |
|
|
El valor del atributo del nodo |
|
| La función que el clon promocionable correspondiente tiene en este nodo. Válido sólo dentro de una regla para una restricción de ubicación para un clon promocionable. |
15.1.2. Expresiones basadas en la fecha y la hora
Las expresiones de fecha se utilizan para controlar un recurso o una opción del clúster en función de la fecha/hora actual. Pueden contener una especificación de fecha opcional.
| Campo | Descripción |
|---|---|
|
| Una fecha/hora conforme a la especificación ISO8601. |
|
| Una fecha/hora conforme a la especificación ISO8601. |
|
| Compara la fecha/hora actual con la fecha de inicio o de finalización o con ambas, dependiendo del contexto. Valores permitidos:
*
*
*
* |
15.1.3. Especificaciones de fecha
Las especificaciones de fecha se utilizan para crear expresiones tipo cron relacionadas con el tiempo. Cada campo puede contener un solo número o un solo rango. En lugar de ponerlo a cero por defecto, cualquier campo no suministrado se ignora.
Por ejemplo, monthdays="1" coincide con el primer día de cada mes y hours="09-17" con las horas comprendidas entre las 9 y las 17 horas (inclusive). Sin embargo, no se puede especificar weekdays="1,2" o weekdays="1-2,5-6" ya que contienen múltiples rangos.
| Campo | Descripción |
|---|---|
|
| Un nombre único para la fecha |
|
| Valores permitidos: 0-23 |
|
| Valores permitidos: 0-31 (según el mes y el año) |
|
| Valores permitidos: 1-7 (1=lunes, 7=domingos) |
|
| Valores permitidos: 1-366 (dependiendo del año) |
|
| Valores permitidos: 1-12 |
|
|
Valores permitidos: 1-53 (dependiendo de |
|
| Año según el calendario gregoriano |
|
|
Puede diferir de los años gregorianos; por ejemplo, |
|
| Valores permitidos: 0-7 (0 es luna nueva, 4 es luna llena). |
15.2. Configuración de una restricción de ubicación de marcapasos mediante reglas
Utilice el siguiente comando para configurar una restricción de Pacemaker que utilice reglas. Si se omite score, el valor por defecto es INFINITO. Si se omite resource-discovery, el valor predeterminado es always.
Para obtener información sobre la opción resource-discovery, consulte Limitar el descubrimiento de recursos a un subconjunto de nodos.
Al igual que con las restricciones de ubicación básicas, también puede utilizar expresiones regulares para los recursos con estas restricciones.
Cuando se utilizan reglas para configurar las restricciones de ubicación, el valor de score puede ser positivo o negativo, con un valor positivo que indica "prefiere" y un valor negativo que indica "evita".
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expression
La opción expression puede ser una de las siguientes, donde duration_options y date_spec_options son: horas, días del mes, días de la semana, días del año, meses, semanas, años, años de la semana, luna, como se describe en Propiedades de una especificación de fecha.
-
defined|not_defined attribute -
attribute lt|gt|lte|gte|eq|ne [string|integer|version] value -
date gt|lt date -
date in_range date to date -
date in_range date to duration duration_options … -
date-spec date_spec_options -
expression and|or expression -
(expression)
Tenga en cuenta que las duraciones son una forma alternativa de especificar un final para las operaciones de in_range mediante cálculos. Por ejemplo, puede especificar una duración de 19 meses.
La siguiente restricción de ubicación configura una expresión que es verdadera si ahora es cualquier momento del año 2018.
# pcs constraint location Webserver rule score=INFINITY date-spec years=2018El siguiente comando configura una expresión que es verdadera de 9 am a 5 pm, de lunes a viernes. Tenga en cuenta que el valor de horas de 16 coincide hasta las 16:59:59, ya que el valor numérico (hora) sigue coincidiendo.
# pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"El siguiente comando configura una expresión que es verdadera cuando hay luna llena el viernes trece.
# pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4Para eliminar una regla, utilice el siguiente comando. Si la regla que está eliminando es la última regla de su restricción, la restricción será eliminada.
regla de restricción pcs eliminar rule_idCapítulo 16. Gestión de los recursos del clúster
Esta sección describe varios comandos que puede utilizar para gestionar los recursos del clúster.
16.1. Visualización de los recursos configurados
Para mostrar una lista de todos los recursos configurados, utilice el siguiente comando.
estado de los recursos pcs
Por ejemplo, si su sistema está configurado con un recurso llamado VirtualIP y un recurso llamado WebSite, el comando pcs resource show produce la siguiente salida.
# pcs resource status
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started
Para mostrar una lista de todos los recursos configurados y los parámetros configurados para esos recursos, utilice la opción --full del comando pcs resource config, como en el siguiente ejemplo.
# pcs resource config
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s
Resource: WebSite (type=apache class=ocf provider=heartbeat)
Attributes: statusurl=http://localhost/server-status configfile=/etc/httpd/conf/httpd.conf
Operations: monitor interval=1minPara mostrar los parámetros configurados para un recurso, utilice el siguiente comando.
pcs resource config resource_id
Por ejemplo, el siguiente comando muestra los parámetros actualmente configurados para el recurso VirtualIP.
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s16.2. Modificación de los parámetros de los recursos
Para modificar los parámetros de un recurso configurado, utilice el siguiente comando.
pcs resource update resource_id [resource_options]
La siguiente secuencia de comandos muestra los valores iniciales de los parámetros configurados para el recurso VirtualIP, el comando para cambiar el valor del parámetro ip y los valores posteriores al comando de actualización.
#pcs resource config VirtualIPResource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat) Attributes: ip=192.168.0.120 cidr_netmask=24 Operations: monitor interval=30s #pcs resource update VirtualIP ip=192.169.0.120#pcs resource config VirtualIPResource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat) Attributes: ip=192.169.0.120 cidr_netmask=24 Operations: monitor interval=30s
Cuando se actualiza el funcionamiento de un recurso con el comando pcs resource update, cualquier opción que no se indique específicamente se restablece a sus valores por defecto.
16.3. Borrar el estado de fallo de los recursos del clúster
Si un recurso ha fallado, aparece un mensaje de fallo cuando se muestra el estado del cluster. Si resuelve ese recurso, puede borrar ese estado de fallo con el comando pcs resource cleanup. Este comando restablece el estado del recurso y failcount, indicando al clúster que olvide el historial de operaciones de un recurso y vuelva a detectar su estado actual.
El siguiente comando limpia el recurso especificado por resource_id.
limpieza de recursos pcs resource_id
Si no se especifica un resource_id, este comando restablece el estado del recurso y failcountpara todos los recursos.
El comando pcs resource cleanup sondea sólo los recursos que se muestran como una acción fallida. Para sondear todos los recursos en todos los nodos puede introducir el siguiente comando:
actualización de recursos pcs
Por defecto, el comando pcs resource refresh sondea sólo los nodos en los que se conoce el estado de un recurso. Para sondear todos los recursos aunque no se conozca su estado, introduzca el siguiente comando:
pcs resource refresh --full
16.4. Desplazamiento de recursos en un clúster
Pacemaker proporciona una variedad de mecanismos para configurar un recurso para que se mueva de un nodo a otro y para mover manualmente un recurso cuando sea necesario.
Puede mover manualmente los recursos de un clúster con los comandos pcs resource move y pcs resource relocate, como se describe en Mover manualmente los recursos del clúster.
Además de estos comandos, también puede controlar el comportamiento de los recursos del clúster habilitando, deshabilitando y prohibiendo recursos, como se describe en Habilitación, deshabilitación y prohibición de recursos del clúster.
Puedes configurar un recurso para que se mueva a un nuevo nodo después de un número definido de fallos, y puedes configurar un clúster para que mueva los recursos cuando se pierda la conectividad externa.
16.4.1. Desplazamiento de recursos por avería
Cuando creas un recurso, puedes configurar el recurso para que se mueva a un nuevo nodo después de un número definido de fallos, estableciendo la opción migration-threshold para ese recurso. Una vez alcanzado el umbral, este nodo ya no podrá ejecutar el recurso fallido hasta:
-
El administrador restablece manualmente el recurso
failcountmediante el comandopcs resource cleanup. -
Se alcanza el valor del recurso
failure-timeout.
El valor de migration-threshold se establece por defecto en INFINITY. INFINITY se define internamente como un número muy grande pero finito. Un valor de 0 desactiva la función migration-threshold.
Configurar un migration-threshold para un recurso no es lo mismo que configurar un recurso para la migración, en la que el recurso se mueve a otra ubicación sin pérdida de estado.
El siguiente ejemplo añade un umbral de migración de 10 al recurso llamado dummy_resource, que indica que el recurso se moverá a un nuevo nodo después de 10 fallos.
# pcs resource meta dummy_resource migration-threshold=10Puede añadir un umbral de migración a los valores predeterminados para todo el clúster con el siguiente comando.
# pcs resource defaults migration-threshold=10
Para determinar el estado actual de los fallos y los límites del recurso, utilice el comando pcs resource failcount show.
Hay dos excepciones al concepto de umbral de migración; ocurren cuando un recurso falla al arrancar o falla al parar. Si la propiedad del clúster start-failure-is-fatal se establece en true (que es el valor predeterminado), los fallos de arranque hacen que failcount se establezca en INFINITY y, por lo tanto, siempre hacen que el recurso se mueva inmediatamente.
Los fallos de parada son ligeramente diferentes y cruciales. Si un recurso falla al detenerse y STONITH está habilitado, entonces el cluster cercará el nodo para poder iniciar el recurso en otro lugar. Si STONITH no está habilitado, entonces el cluster no tiene forma de continuar y no intentará iniciar el recurso en otro lugar, sino que intentará detenerlo de nuevo después del tiempo de espera del fallo.
16.4.2. Desplazamiento de recursos por cambios de conectividad
Configurar el clúster para mover los recursos cuando se pierde la conectividad externa es un proceso de dos pasos.
-
Añade un recurso
pingal cluster. El recursopingutiliza la utilidad del sistema del mismo nombre para comprobar si una lista de máquinas (especificadas por el nombre de host DNS o la dirección IPv4/IPv6) son alcanzables y utiliza los resultados para mantener un atributo de nodo llamadopingd. - Configure una restricción de ubicación para el recurso que lo trasladará a un nodo diferente cuando se pierda la conectividad.
Tabla 10.1, “Identificadores de agentes de recursos” describe las propiedades que se pueden establecer para un recurso ping.
| Campo | Descripción |
|---|---|
|
| El tiempo de espera (dampening) para que se produzcan más cambios. Esto evita que un recurso rebote por el clúster cuando los nodos del clúster notan la pérdida de conectividad en momentos ligeramente diferentes. |
|
| El número de nodos de ping conectados se multiplica por este valor para obtener una puntuación. Es útil cuando hay varios nodos de ping configurados. |
|
| Las máquinas con las que hay que contactar para determinar el estado actual de la conectividad. Los valores permitidos incluyen nombres de host DNS resolubles y direcciones IPv4 e IPv6. Las entradas de la lista de hosts están separadas por espacios. |
El siguiente comando de ejemplo crea un recurso ping que verifica la conectividad con gateway.example.com. En la práctica, usted verificaría la conectividad con su puerta de enlace/enrutador de red. Configure el recurso ping como un clon para que el recurso se ejecute en todos los nodos del clúster.
# pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
El siguiente ejemplo configura una regla de restricción de ubicación para el recurso existente llamado Webserver. Esto hará que el recurso Webserver se mueva a un host que sea capaz de hacer ping a gateway.example.com si el host en el que se está ejecutando actualmente no puede hacer ping a gateway.example.com.
# pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingdModule included in the following assemblies: // // <List assemblies here, each on a new line> // rhel-8-docs/enterprise/assemblies/assembly_managing-cluster-resources.adoc
16.5. Desactivación de una operación de monitorización
La forma más fácil de detener un monitor recurrente es eliminarlo. Sin embargo, puede haber ocasiones en las que sólo quiera desactivarlo temporalmente. En estos casos, añada enabled="false" a la definición de la operación. Cuando quiera restablecer la operación de monitorización, ponga enabled="true" en la definición de la operación.
Cuando se actualiza la operación de un recurso con el comando pcs resource update, cualquier opción que no se indique específicamente se restablece a sus valores por defecto. Por ejemplo, si ha configurado una operación de monitorización con un valor de tiempo de espera personalizado de 600, la ejecución de los siguientes comandos restablecerá el valor de tiempo de espera al valor predeterminado de 20 (o al que haya establecido el valor predeterminado con el comando pcs resource ops default ).
#pcs resource update resourceXZY op monitor enabled=false#pcs resource update resourceXZY op monitor enabled=true
Para mantener el valor original de 600 para esta opción, al restablecer la operación de supervisión debe especificar ese valor, como en el siguiente ejemplo.
# pcs resource update resourceXZY op monitor timeout=600 enabled=true16.6. Configuración y gestión de las etiquetas de recursos del clúster (RHEL 8.3 y posterior)
A partir de Red Hat Enterprise Linux 8.3, puede utilizar el comando pcs para etiquetar los recursos del cluster. Esto le permite habilitar, deshabilitar, gestionar o desgestionar un conjunto específico de recursos con un solo comando.
16.6.1. Etiquetado de los recursos del clúster para su administración por categorías
El siguiente procedimiento etiqueta dos recursos con una etiqueta de recurso y desactiva los recursos etiquetados. En este ejemplo, los recursos existentes que se van a etiquetar se llaman d-01 y d-02.
Cree una etiqueta denominada
special-resourcespara los recursosd-01yd-02.[root@node-01]#
pcs tag create special-resources d-01 d-02Muestra la configuración de la etiqueta de recursos.
[root@node-01]#
pcs tag configspecial-resources d-01 d-02Desactivar todos los recursos etiquetados con la etiqueta
special-resources.[root@node-01]#
pcs resource disable special-resourcesMuestra el estado de los recursos para confirmar que los recursos
d-01yd-02están desactivados.[root@node-01]#
pcs resource* d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)
Además del comando pcs resource disable, los comandos pcs resource enable, pcs resource manage, y pcs resource unmanage apoyan la administración de recursos etiquetados.
Después de haber creado una etiqueta de recurso:
-
Puede eliminar una etiqueta de recurso con el comando
pcs tag delete. -
Puede modificar la configuración de una etiqueta de recurso existente con el comando
pcs tag update.
16.6.2. Eliminar un recurso de clúster etiquetado
No se puede eliminar un recurso de cluster etiquetado con el comando pcs. Para eliminar un recurso etiquetado, utilice el siguiente procedimiento.
Eliminar la etiqueta de recurso.
El siguiente comando elimina la etiqueta de recurso
special-resourcesde todos los recursos con esa etiqueta,[root@node-01]#
pcs tag remove special-resources[root@node-01]#pcs tagNo tags definedEl siguiente comando elimina la etiqueta de recurso
special-resourcessólo del recursod-01.[root@node-01]#
pcs tag update special-resources remove d-01
Eliminar el recurso.
[root@node-01]#
pcs resource delete d-01Attempting to stop: d-01... Stopped
Capítulo 17. Creación de recursos de cluster activos en varios nodos (recursos clonados)
Puede clonar un recurso de clúster para que el recurso pueda estar activo en varios nodos. Por ejemplo, puede utilizar los recursos clonados para configurar varias instancias de un recurso IP para distribuirlo en un clúster para el equilibrio de nodos. Puede clonar cualquier recurso siempre que el agente de recursos lo soporte. Un clon consiste en un recurso o un grupo de recursos.
Sólo los recursos que pueden estar activos en varios nodos al mismo tiempo son adecuados para la clonación. Por ejemplo, un recurso Filesystem que monte un sistema de archivos no agrupado como ext4 desde un dispositivo de memoria compartida no debe ser clonado. Dado que la partición ext4 no es consciente del clúster, este sistema de archivos no es adecuado para las operaciones de lectura/escritura que se producen desde varios nodos al mismo tiempo.
17.1. Creación y eliminación de un recurso clonado
Puedes crear un recurso y un clon de ese recurso al mismo tiempo con el siguiente comando.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
El nombre del clon será resource_id-clone.
No se puede crear un grupo de recursos y un clon de ese grupo de recursos en un solo comando.
Alternativamente, puede crear un clon de un recurso o grupo de recursos previamente creado con el siguiente comando.
pcs resource clone resource_id | group_name [clone options]...
El nombre del clon será resource_id-clone o group_name-clone.
Es necesario configurar los cambios de configuración de los recursos en un solo nodo.
Al configurar las restricciones, utilice siempre el nombre del grupo o del clon.
Cuando se crea un clon de un recurso, el clon toma el nombre del recurso con -clone añadido al nombre. Los siguientes comandos crean un recurso de tipo apache llamado webfarm y un clon de ese recurso llamado webfarm-clone.
# pcs resource create webfarm apache clone
Cuando se crea un clon de un recurso o grupo de recursos que se ordenará después de otro clon, casi siempre se debe establecer la opción interleave=true. Esto asegura que las copias del clon dependiente puedan detenerse o iniciarse cuando el clon del que depende se haya detenido o iniciado en el mismo nodo. Si no establece esta opción, si un recurso clonado B depende de un recurso clonado A y un nodo abandona el clúster, cuando el nodo regresa al clúster y el recurso A se inicia en ese nodo, entonces todas las copias del recurso B en todos los nodos se reiniciarán. Esto se debe a que cuando un recurso clonado dependiente no tiene la opción interleave establecida, todas las instancias de ese recurso dependen de cualquier instancia en ejecución del recurso del que depende.
Utilice el siguiente comando para eliminar un clon de un recurso o grupo de recursos. Esto no elimina el recurso o el grupo de recursos en sí.
pcs resource unclone resource_id | group_name
Tabla 17.1, “Opciones de clonación de recursos” describe las opciones que puede especificar para un recurso clonado.
| Campo | Descripción |
|---|---|
|
| Opciones heredadas del recurso que se está clonando, como se describe en Tabla 10.3, “Meta opciones de recursos”. |
|
| Cuántas copias del recurso se van a iniciar. Por defecto, el número de nodos del clúster. |
|
|
Cuántas copias del recurso pueden iniciarse en un solo nodo; el valor por defecto es |
|
|
Cuando se detiene o se inicia una copia del clon, se informa a todas las demás copias de antemano y cuando la acción ha tenido éxito. Valores permitidos: |
|
|
¿Cada copia del clon realiza una función diferente? Valores permitidos:
Si el valor de esta opción es
Si el valor de esta opción es |
|
|
Si las copias se inician en serie (en lugar de en paralelo). Valores permitidos: |
|
|
Cambia el comportamiento de las restricciones de ordenación (entre clones) para que las copias del primer clon puedan iniciarse o detenerse tan pronto como la copia en el mismo nodo del segundo clon se haya iniciado o detenido (en lugar de esperar hasta que cada instancia del segundo clon se haya iniciado o detenido). Valores permitidos: |
|
|
Si se especifica un valor, cualquier clon que se ordene después de este clon no podrá iniciarse hasta que se ejecute el número especificado de instancias del clon original, incluso si la opción |
Para lograr un patrón de asignación estable, los clones son ligeramente pegajosos por defecto, lo que indica que tienen una ligera preferencia por permanecer en el nodo donde se están ejecutando. Si no se proporciona ningún valor para resource-stickiness, el clon utilizará un valor de 1. Al ser un valor pequeño, causa una perturbación mínima en los cálculos de puntuación de otros recursos, pero es suficiente para evitar que Pacemaker mueva innecesariamente las copias por el clúster. Para obtener información sobre la configuración de la meta-opción de recursos resource-stickiness, consulte Configuración de meta-opciones de recursos.
17.2. Configurar las limitaciones de recursos de los clones
En la mayoría de los casos, un clon tendrá una sola copia en cada nodo activo del clúster. Sin embargo, puede establecer clone-max para el clon de recursos a un valor que sea menor que el número total de nodos en el clúster. Si este es el caso, puedes indicar a qué nodos debe asignar preferentemente las copias el clúster con restricciones de ubicación de recursos. Estas restricciones no se escriben de forma diferente a las de los recursos normales, salvo que se debe utilizar el id del clon.
El siguiente comando crea una restricción de ubicación para que el clúster asigne preferentemente el clon de recursos webfarm-clone a node1.
# pcs constraint location webfarm-clone prefers node1
Las restricciones de orden se comportan de forma ligeramente diferente para los clones. En el ejemplo siguiente, como la opción de clon de interleave se deja por defecto como false, ninguna instancia de webfarm-stats se iniciará hasta que todas las instancias de webfarm-clone que necesiten iniciarse lo hayan hecho. Sólo si no se puede iniciar ninguna copia de webfarm-clone, se impedirá que webfarm-stats se active. Además, webfarm-clone esperará a que webfarm-stats se detenga antes de detenerse.
# pcs constraint order start webfarm-clone then webfarm-statsLa colocación de un recurso regular (o de grupo) con un clon significa que el recurso puede ejecutarse en cualquier máquina con una copia activa del clon. El clúster elegirá una copia en función de dónde se ejecute el clon y de las preferencias de ubicación del propio recurso.
También es posible la colocación entre clones. En estos casos, el conjunto de ubicaciones permitidas para el clon se limita a los nodos en los que el clon está (o estará) activo. La asignación se realiza entonces de forma normal.
El siguiente comando crea una restricción de colocación para garantizar que el recurso webfarm-stats se ejecute en el mismo nodo que una copia activa de webfarm-clone.
# pcs constraint colocation add webfarm-stats with webfarm-clone17.3. Creación de recursos clonados promocionables
Los recursos clónicos promocionables son recursos clónicos con el meta atributo promotable establecido en true. Permiten que las instancias estén en uno de los dos modos de funcionamiento; éstos se denominan Master y Slave. Los nombres de los modos no tienen significados específicos, excepto por la limitación de que cuando una instancia se inicia, debe aparecer en el estado Slave.
17.3.1. Crear un recurso promocionable
Puede crear un recurso como clon promocionable con el siguiente comando único.
pcs resource create resource_id [standard:[provider:]]type [resource options] promocionable [clone options]
El nombre del clon promocionable será resource_id-clone.
Alternativamente, puede crear un recurso promocionable a partir de un recurso o grupo de recursos creado previamente con el siguiente comando. El nombre del clon promocionable será resource_id-clone o group_name-clone.
recurso pcs promocionable resource_id [clone options]
Tabla 17.2, “Opciones adicionales de clonación disponibles para los clones promocionables” describe las opciones adicionales de clonación que se pueden especificar para un recurso promocionable.
| Campo | Descripción |
|---|---|
|
| Cuántas copias del recurso se pueden promover; por defecto 1. |
|
| Cuántas copias del recurso pueden promoverse en un solo nodo; por defecto 1. |
17.3.2. Configuración de las limitaciones de los recursos promocionables
En la mayoría de los casos, un recurso promocionable tendrá una única copia en cada nodo activo del clúster. Si este no es el caso, puede indicar a qué nodos debe asignar preferentemente las copias el clúster con restricciones de ubicación de los recursos. Estas restricciones no se escriben de forma diferente a las de los recursos normales.
Puede crear una restricción de colocación que especifique si los recursos están operando en un rol de maestro o de esclavo. El siguiente comando crea una restricción de colocación de recursos.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]
Para obtener información sobre las restricciones de colocación, consulte Colocación de los recursos del clúster.
Al configurar una restricción de ordenación que incluya recursos promocionables, una de las acciones que puede especificar para los recursos es promote, que indica que el recurso sea promocionado del rol esclavo al rol maestro. Además, puede especificar una acción de demote, que indica que el recurso sea degradado de rol maestro a rol esclavo.
El comando para configurar una restricción de orden es el siguiente.
pcs constraint order [action] resource_id then [action] resource_id [options]
Para obtener información sobre las restricciones de orden de los recursos, consulte ifdef:: Determinación del orden de ejecución de los recursos del clúster.
17.4. Desplazamiento de un recurso promocionado en caso de fallo (RHEL 8.3 y posteriores)
Puede configurar un recurso promocionable para que cuando una acción de promote o monitor falle para ese recurso, o la partición en la que el recurso se está ejecutando pierda el quórum, el recurso se degradará pero no se detendrá completamente. Esto puede evitar la necesidad de una intervención manual en situaciones en las que sería necesario detener completamente el recurso.
Para configurar un recurso promocionable para que sea degradado cuando falle una acción de
promote, establezca la meta-opción de operaciónon-failademote, como en el siguiente ejemplo.#
pcs resource op add my-rsc promote on-fail="demote"Para configurar un recurso promocionable para que sea degradado cuando una acción de
monitorfalle, establezcaintervala un valor no nulo, establezca la meta-opción de operaciónon-failademote, y establezcaroleaMaster, como en el siguiente ejemplo.#
pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"-
Para configurar un clúster de manera que cuando una partición del clúster pierda el quórum cualquier recurso promovido sea degradado pero se deje en funcionamiento y todos los demás recursos se detengan, establezca la propiedad del clúster
no-quorum-policyendemote
La especificación de un metaatributo demote para una operación no afecta al modo en que se determina la promoción de un recurso. Si el nodo afectado sigue teniendo la mayor puntuación de promoción, será seleccionado para ser promovido de nuevo.
Capítulo 18. Gestión de los nodos del clúster
Las siguientes secciones describen los comandos que se utilizan para gestionar los nodos del clúster, incluidos los comandos para iniciar y detener los servicios del clúster y para añadir y eliminar nodos del clúster.
18.1. Detención de los servicios del clúster
El siguiente comando detiene los servicios de cluster en el nodo o nodos especificados. Al igual que con pcs cluster start, la opción --all detiene los servicios de clúster en todos los nodos y, si no se especifica ningún nodo, los servicios de clúster se detienen únicamente en el nodo local.
pcs cluster stop [--all | node] [...]
Puede forzar una parada de los servicios del clúster en el nodo local con el siguiente comando, que realiza un comando kill -9.
pcs cluster kill
18.2. Activación y desactivación de los servicios del clúster
Utilice el siguiente comando para habilitar los servicios del clúster, que configura los servicios del clúster para que se ejecuten al inicio en el nodo o nodos especificados. La habilitación permite que los nodos se reincorporen automáticamente al clúster después de que se hayan cercado, lo que minimiza el tiempo que el clúster está a menos de su capacidad. Si los servicios de clúster no están habilitados, un administrador puede investigar manualmente qué ha fallado antes de iniciar los servicios de clúster manualmente, de modo que, por ejemplo, no se permita que un nodo con problemas de hardware vuelva a entrar en el clúster cuando es probable que vuelva a fallar.
-
Si se especifica la opción
--all, el comando habilita los servicios de cluster en todos los nodos. - Si no se especifica ningún nodo, los servicios del clúster se activan sólo en el nodo local.
pcs cluster enable [--all | node] [...]Utilice el siguiente comando para configurar los servicios del clúster para que no se ejecuten al inicio en el nodo o nodos especificados.
-
Si se especifica la opción
--all, el comando desactiva los servicios de cluster en todos los nodos. - Si no se especifica ningún nodo, los servicios de cluster se desactivan sólo en el nodo local.
pcs cluster disable [--all | node] [...]18.3. Añadir nodos del clúster
Se recomienda encarecidamente añadir nodos a los clusters existentes sólo durante una ventana de mantenimiento de producción. Esto le permite realizar las pruebas de recursos y de despliegue adecuadas para el nuevo nodo y su configuración de cercado.
Utilice el siguiente procedimiento para añadir un nuevo nodo a un cluster existente. Este procedimiento añade nodos de clústeres estándar que ejecutan corosync. Para obtener información sobre la integración de nodos no corosync en un clúster, consulte Integración de nodos no corosync en un clúster: el servicio pacemaker_remote.
En este ejemplo, los nodos de cluster existentes son clusternode-01.example.com, clusternode-02.example.com, y clusternode-03.example.com. El nuevo nodo es newnode.example.com.
En el nuevo nodo a añadir al clúster, realice las siguientes tareas.
Instale los paquetes del clúster. Si el clúster utiliza SBD, el gestor de tickets de Booth o un dispositivo de quórum, debe instalar manualmente también los paquetes respectivos (
sbd,booth-site,corosync-qdevice) en el nuevo nodo.[root@newnode ~]#
yum install -y pcs fence-agents-allAdemás de los paquetes del cluster, también necesitará instalar y configurar todos los servicios que esté ejecutando en el cluster, que haya instalado en los nodos existentes del cluster. Por ejemplo, si está ejecutando un servidor Apache HTTP en un cluster de alta disponibilidad de Red Hat, necesitará instalar el servidor en el nodo que está añadiendo, así como la herramienta
wgetque comprueba el estado del servidor.Si está ejecutando el demonio
firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityEstablezca una contraseña para el ID de usuario
hacluster. Se recomienda utilizar la misma contraseña para cada nodo del clúster.[root@newnode ~]#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Ejecute los siguientes comandos para iniciar el servicio
pcsdy para habilitarpcsdal inicio del sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
En un nodo del clúster existente, realice las siguientes tareas.
Autenticar al usuario
haclusteren el nuevo nodo del clúster.[root@clusternode-01 ~]#
pcs host auth newnode.example.comUsername: hacluster Password: newnode.example.com: AuthorizedAñade el nuevo nodo al clúster existente. Este comando también sincroniza el archivo de configuración del clúster
corosync.confcon todos los nodos del clúster, incluido el nuevo nodo que está añadiendo.[root@clusternode-01 ~]#
pcs cluster node add newnode.example.com
En el nuevo nodo a añadir al clúster, realice las siguientes tareas.
Inicie y habilite los servicios del clúster en el nuevo nodo.
[root@newnode ~]#
pcs cluster startStarting Cluster... [root@newnode ~]#pcs cluster enable- Asegúrese de configurar y probar un dispositivo de cercado para el nuevo nodo del clúster.
18.4. Eliminación de los nodos del clúster
El siguiente comando apaga el nodo especificado y lo elimina del archivo de configuración del clúster, corosync.conf, en todos los demás nodos del clúster.
pcs cluster node remove node18.5. Añadir un nodo a un cluster con múltiples enlaces
Al añadir un nodo a un cluster con múltiples enlaces, debe especificar las direcciones para todos los enlaces. El siguiente ejemplo añade el nodo rh80-node3 a un cluster, especificando la dirección IP 192.168.122.203 para el primer enlace y 192.168.123.203 como segundo enlace.
# pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.20318.6. Añadir y modificar enlaces en un clúster existente (RHEL 8.1 y posterior)
En la mayoría de los casos, puede añadir o modificar los enlaces de un clúster existente sin reiniciar el clúster.
18.6.1. Añadir y eliminar enlaces en un clúster existente
Para añadir un nuevo enlace a un clúster en funcionamiento, utilice el comando pcs cluster link add.
- Al añadir un enlace, debe especificar una dirección para cada nodo.
- Añadir y eliminar un enlace sólo es posible cuando se utiliza el protocolo de transporte knet.
- Al menos un enlace del clúster debe estar definido en todo momento.
- El número máximo de enlaces en un cluster es de 8, numerados del 0 al 7. No importa qué enlaces se definan, así que, por ejemplo, puedes definir sólo los enlaces 3, 6 y 7.
-
Cuando se añade un enlace sin especificar su número de enlace,
pcsutiliza el enlace más bajo disponible. -
Los números de los enlaces actualmente configurados se encuentran en el archivo
corosync.conf. Para mostrar el archivocorosync.conf, ejecute el comandopcs cluster corosync.
El siguiente comando añade el enlace número 5 a un cluster de tres nodos.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
Para eliminar un enlace existente, utilice el comando pcs cluster link delete o pcs cluster link remove. Cualquiera de los siguientes comandos eliminará el enlace número 5 del clúster.
[root@node1 ~] #pcs cluster link delete 5[root@node1 ~] #pcs cluster link remove 5
18.6.2. Modificación de un enlace en un cluster con múltiples enlaces
Si hay varios enlaces en el cluster y quiere cambiar uno de ellos, realice el siguiente procedimiento.
Elimina el enlace que quieres cambiar.
[root@node1 ~] #
pcs cluster link remove 2Añade el enlace al clúster con las direcciones y opciones actualizadas.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
18.6.3. Modificación de las direcciones de enlace en un clúster con un solo enlace
Si su clúster utiliza un solo enlace y quiere modificar ese enlace para utilizar diferentes direcciones, realice el siguiente procedimiento. En este ejemplo, el enlace original es el enlace 1.
Añade un nuevo enlace con las nuevas direcciones y opciones.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2Quite el enlace original.
[root@node1 ~] #
pcs cluster link remove 1
Tenga en cuenta que no puede especificar direcciones que estén actualmente en uso al añadir enlaces a un clúster. Esto significa, por ejemplo, que si tienes un cluster de dos nodos con un enlace y quieres cambiar la dirección de un solo nodo, no puedes usar el procedimiento anterior para añadir un nuevo enlace que especifique una nueva dirección y una dirección existente. En su lugar, puede añadir un enlace temporal antes de eliminar el enlace existente y volver a añadirlo con la dirección actualizada, como en el siguiente ejemplo.
En este ejemplo:
- El enlace para el cluster existente es el enlace 1, que utiliza la dirección 10.0.5.11 para el nodo 1 y la dirección 10.0.5.12 para el nodo 2.
- Desea cambiar la dirección del nodo 2 a 10.0.5.31.
Para actualizar sólo una de las direcciones de un cluster de dos nodos con un único enlace, utilice el siguiente procedimiento.
Añade un nuevo enlace temporal al clúster existente, utilizando direcciones que no están actualmente en uso.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Quite el enlace original.
[root@node1 ~] #
pcs cluster link remove 1Añade el nuevo enlace modificado.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1Elimina el enlace temporal que has creado
[root@node1 ~] #
pcs cluster link remove 2
18.6.4. Modificación de las opciones de enlace para un enlace en un cluster con un solo enlace
Si su clúster utiliza sólo un enlace y quiere modificar las opciones de ese enlace pero no quiere cambiar la dirección a utilizar, puede añadir un enlace temporal antes de eliminar y actualizar el enlace a modificar.
En este ejemplo:
- El enlace para el cluster existente es el enlace 1, que utiliza la dirección 10.0.5.11 para el nodo 1 y la dirección 10.0.5.12 para el nodo 2.
-
Desea cambiar la opción de enlace
link_prioritya 11.
Utilice el siguiente procedimiento para modificar la opción de enlace en un cluster con un solo enlace.
Añade un nuevo enlace temporal al clúster existente, utilizando direcciones que no están actualmente en uso.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Quite el enlace original.
[root@node1 ~] #
pcs cluster link remove 1Vuelve a añadir el enlace original con las opciones actualizadas.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11Elimina el enlace temporal.
[root@node1 ~] #
pcs cluster link remove 2
18.6.5. No es posible modificar un enlace cuando se añade uno nuevo
Si por alguna razón no es posible añadir un nuevo enlace en su configuración y su única opción es modificar un enlace existente, puede utilizar el siguiente procedimiento, que requiere que apague su cluster.
El siguiente procedimiento de ejemplo actualiza el enlace número 1 en el cluster y establece la opción link_priority para el enlace a 11.
Detenga los servicios de cluster para el cluster.
[root@node1 ~] #
pcs cluster stop --allActualice las direcciones y opciones de los enlaces.
El comando
pcs cluster link updateno requiere que se especifiquen todas las direcciones y opciones de los nodos. En su lugar, puede especificar sólo las direcciones a modificar. Este ejemplo modifica las direcciones denode1ynode3y la opciónlink_prioritysolamente.[root@node1 ~] #
pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11Para eliminar una opción, puede establecer un valor nulo con el formato
option=formato.Reiniciar el clúster
[root@node1 ~] #
pcs cluster start --all
18.7. Configuración de un gran clúster con muchos recursos
Si el clúster que va a desplegar está formado por un gran número de nodos y muchos recursos, es posible que tenga que modificar los valores por defecto de los siguientes parámetros para su clúster.
- La propiedad del clúster
cluster-ipc-limit La propiedad de clúster
cluster-ipc-limites la máxima acumulación de mensajes IPC antes de que un demonio de clúster desconecte a otro. Cuando un gran número de recursos se limpian o modifican simultáneamente en un cluster grande, un gran número de actualizaciones CIB llegan a la vez. Esto podría hacer que los clientes más lentos sean desalojados si el servicio Pacemaker no tiene tiempo de procesar todas las actualizaciones de configuración antes de que se alcance el umbral de la cola de eventos CIB.El valor recomendado de
cluster-ipc-limitpara su uso en clusters grandes es el número de recursos en el cluster multiplicado por el número de nodos. Este valor puede aumentarse si se ven mensajes de "desalojo de clientes" para PIDs de demonio de clúster en los registros.Puede aumentar el valor de
cluster-ipc-limitdesde su valor por defecto de 500 con el comandopcs property set. Por ejemplo, para un clúster de diez nodos con 200 recursos, puede establecer el valor decluster-ipc-limiten 2000 con el siguiente comando.#
pcs property set cluster-ipc-limit=2000- El parámetro
PCMK_ipc_bufferMarcapasos En implementaciones muy grandes, los mensajes internos de Pacemaker pueden exceder el tamaño del búfer de mensajes. Cuando esto ocurra, verá un mensaje en los registros del sistema con el siguiente formato:
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higherCuando vea este mensaje, puede aumentar el valor de
PCMK_ipc_bufferen el archivo de configuración/etc/sysconfig/pacemakeren cada nodo. Por ejemplo, para aumentar el valor dePCMK_ipc_bufferde su valor predeterminado a 13396332 bytes, cambie el campo no comentadoPCMK_ipc_bufferen el archivo/etc/sysconfig/pacemakeren cada nodo del clúster de la siguiente manera.PCMK_ipc_buffer=13396332Para aplicar este cambio, ejecute el siguiente comando.
#
systemctl restart pacemaker
Capítulo 19. Configuración de los permisos de los usuarios para un clúster Pacemaker
Puede conceder permiso a usuarios específicos distintos del usuario hacluster para gestionar un cluster Pacemaker. Hay dos conjuntos de permisos que puede conceder a usuarios individuales:
-
Permisos que permiten a los usuarios individuales gestionar el clúster a través de la interfaz web y ejecutar los comandos de
pcsque se conectan a los nodos a través de una red. Los comandos que se conectan a los nodos a través de una red incluyen comandos para configurar un clúster, o para añadir o eliminar nodos de un clúster. - Permisos para los usuarios locales para permitir el acceso de sólo lectura o de lectura-escritura a la configuración del clúster. Los comandos que no requieren conectarse a través de una red incluyen comandos que editan la configuración del clúster, como los que crean recursos y configuran restricciones.
En las situaciones en las que se han asignado ambos conjuntos de permisos, se aplican primero los permisos para los comandos que se conectan a través de una red y luego se aplican los permisos para editar la configuración del clúster en el nodo local. La mayoría de los comandos de pcs no requieren acceso a la red y en esos casos no se aplicarán los permisos de red.
19.1. Establecer permisos para el acceso a los nodos a través de una red
Para conceder permiso a determinados usuarios para gestionar el clúster a través de la interfaz web y para ejecutar comandos de pcs que se conectan a los nodos a través de una red, añada esos usuarios al grupo haclient. Esto debe hacerse en cada nodo del clúster.
19.2. Establecimiento de permisos locales mediante ACLs
Puede utilizar el comando pcs acl para establecer los permisos de los usuarios locales para permitir el acceso de sólo lectura o de lectura-escritura a la configuración del clúster mediante el uso de listas de control de acceso (ACL).
Por defecto, las ACLs no están habilitadas. Cuando las ACLs no están habilitadas, el usuario root y cualquier usuario que sea miembro del grupo haclient en todos los nodos tiene acceso local completo de lectura/escritura a la configuración del cluster mientras que los usuarios que no son miembros de haclient no tienen acceso. Sin embargo, cuando las ACLs están activadas, incluso los usuarios que son miembros del grupo haclient tienen acceso sólo a lo que se le ha concedido a ese usuario por las ACLs.
El establecimiento de permisos para los usuarios locales es un proceso de dos pasos:
-
Ejecute el comando
pcs acl role create…para crear un role que defina los permisos para ese rol. -
Asigne el rol que creó a un usuario con el comando
pcs acl user create. Si asigna varios roles al mismo usuario, cualquier permiso dedenytiene prioridad, luegowrite, luegoread.
El siguiente procedimiento de ejemplo proporciona acceso de sólo lectura para una configuración de clúster a un usuario local llamado rouser. Tenga en cuenta que también es posible restringir el acceso sólo a determinadas partes de la configuración.
Es importante realizar este procedimiento como root o guardar todas las actualizaciones de la configuración en un archivo de trabajo que luego puede empujar a la CIB activa cuando haya terminado. De lo contrario, puede bloquearse a sí mismo para realizar más cambios. Para obtener información sobre cómo guardar las actualizaciones de configuración en un archivo de trabajo, consulte Guardar un cambio de configuración en un archivo de trabajo.
Este procedimiento requiere que el usuario
rouserexista en el sistema local y que el usuariorousersea miembro del grupohaclient.#
adduser rouser#usermod -a -G haclient rouserHabilite las ACL de Pacemaker con el comando
pcs acl enable.#
pcs acl enableCree un rol llamado
read-onlycon permisos de sólo lectura para el cib.#
pcs acl role create read-only description="Read access to cluster" read xpath /cibCree el usuario
rouseren el sistema pcs ACL y asigne a ese usuario el rolread-only.#
pcs acl user create rouser read-onlyVer las ACLs actuales.
#
pcs aclUser: rouser Roles: read-only Role: read-only Description: Read access to cluster Permission: read xpath /cib (read-only-read)
Capítulo 20. Operaciones de control de recursos
Para asegurarse de que los recursos se mantienen sanos, puede añadir una operación de monitorización a la definición de un recurso. Si no se especifica una operación de monitorización para un recurso, por defecto el comando pcs creará una operación de monitorización, con un intervalo determinado por el agente de recursos. Si el agente de recursos no proporciona un intervalo de monitorización por defecto, el comando pcs creará una operación de monitorización con un intervalo de 60 segundos.
Tabla 20.1, “Propiedades de una operación” resume las propiedades de una operación de supervisión de recursos.
| Campo | Descripción |
|---|---|
|
| Nombre único para la acción. El sistema lo asigna cuando se configura una operación. |
|
|
La acción a realizar. Valores comunes: |
|
|
Si se establece un valor distinto de cero, se crea una operación recurrente que se repite con esta frecuencia, en segundos. Un valor distinto de cero sólo tiene sentido cuando la acción
Si se establece en cero, que es el valor por defecto, este parámetro permite proporcionar los valores que se utilizarán para las operaciones creadas por el clúster. Por ejemplo, si el |
|
|
Si la operación no se completa en la cantidad de tiempo establecida por este parámetro, aborta la operación y la considera fallida. El valor por defecto es el valor de
El valor de |
|
| La acción a realizar si esta acción falla. Valores permitidos:
*
*
*
*
*
*
*
El valor por defecto de la operación |
|
|
Si |
20.1. Configuración de las operaciones de supervisión de recursos
Puede configurar las operaciones de supervisión cuando cree un recurso, utilizando el siguiente comando.
pcs resource create resource_id standard:provider:type|type [resource_options] [op operation_action operation_options [operation_type operation_options ]...]
Por ejemplo, el siguiente comando crea un recurso IPaddr2 con una operación de monitorización. El nuevo recurso se llama VirtualIP con una dirección IP de 192.168.0.99 y una máscara de red de 24 en eth2. Se realizará una operación de monitorización cada 30 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2 op monitor interval=30sAlternativamente, puede añadir una operación de supervisión a un recurso existente con el siguiente comando.
pcs resource op add resource_id operation_action [operation_properties]
Utilice el siguiente comando para eliminar una operación de recurso configurada.
pcs resource op remove resource_id operation_name operation_properties
Debe especificar las propiedades exactas de la operación para eliminar correctamente una operación existente.
Para cambiar los valores de una opción de monitorización, puede actualizar el recurso. Por ejemplo, puede crear un VirtualIP con el siguiente comando.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2Por defecto, este comando crea estas operaciones.
Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s)
stop interval=0s timeout=20s (VirtualIP-stop-timeout-20s)
monitor interval=10s timeout=20s (VirtualIP-monitor-interval-10s)Para cambiar la operación de parada del tiempo de espera, ejecute el siguiente comando.
#pcs resource update VirtualIP op stop interval=0s timeout=40s#pcs resource show VirtualIPResource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: ip=192.168.0.99 cidr_netmask=24 nic=eth2 Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s) monitor interval=10s timeout=20s (VirtualIP-monitor-interval-10s) stop interval=0s timeout=40s (VirtualIP-name-stop-interval-0s-timeout-40s)
20.2. Configuración de los valores predeterminados de las operaciones de recursos globales
A partir de Red Hat Enterprise Linux 8.3, puede cambiar el valor por defecto de una operación de recursos para todos los recursos con el comando pcs resource op defaults update. El siguiente comando establece un valor global por defecto de timeout de 240 segundos para todas las operaciones de monitoreo.
# pcs resource op defaults update timeout=240s
El comando original pcs resource op defaults name=value que establecía los valores predeterminados de funcionamiento de los recursos en las versiones anteriores de RHEL 8, sigue siendo compatible a menos que haya más de un conjunto de valores predeterminados configurados. Sin embargo, pcs resource op defaults update es ahora la versión preferida del comando.
20.2.1. Anulación de los valores de las operaciones específicas de los recursos
Tenga en cuenta que un recurso de clúster utilizará el valor global por defecto sólo cuando la opción no se especifique en la definición del recurso de clúster. Por defecto, los agentes de recursos definen la opción timeout para todas las operaciones. Para que se respete el valor global de tiempo de espera de la operación, debe crear el recurso de clúster sin la opción timeout explícitamente o debe eliminar la opción timeout actualizando el recurso de clúster, como en el siguiente comando.
# pcs resource update VirtualIP op monitor interval=10s
Por ejemplo, después de establecer un valor global por defecto de timeout de 240 segundos para todas las operaciones de monitorización y de actualizar el recurso de cluster VirtualIP para eliminar el valor de tiempo de espera para la operación monitor, el recurso VirtualIP tendrá entonces valores de tiempo de espera para las operaciones start, stop y monitor de 20s, 40s y 240s, respectivamente. El valor global por defecto para las operaciones de tiempo de espera se aplica aquí sólo en la operación monitor, donde la opción por defecto timeout fue eliminada por el comando anterior.
# pcs resource show VirtualIP
Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: ip=192.168.0.99 cidr_netmask=24 nic=eth2
Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s)
monitor interval=10s (VirtualIP-monitor-interval-10s)
stop interval=0s timeout=40s (VirtualIP-name-stop-interval-0s-timeout-40s)20.2.2. Cambio del valor por defecto de una operación de recursos para conjuntos de recursos (RHEL 8.3 y posteriores)
A partir de Red Hat Enterprise Linux 8.3, puede crear múltiples conjuntos de valores predeterminados de operaciones de recursos con el comando pcs resource op defaults set create, que le permite especificar una regla que contenga resource y expresiones de operación. Sólo resource y las expresiones de operación, incluyendo and, or y paréntesis, están permitidas en las reglas que usted especifica con este comando.
Con este comando, se puede configurar un valor de operación de recursos por defecto para todos los recursos de un tipo determinado. Por ejemplo, ahora es posible configurar los recursos implícitos de podman creados por Pacemaker cuando los paquetes están en uso.
El siguiente comando establece un valor de tiempo de espera por defecto de 90 para todas las operaciones de todos los recursos de podman. En este ejemplo, ::podman significa un recurso de cualquier clase, cualquier proveedor, de tipo podman.
La opción id, que nombra el conjunto de operaciones de recursos por defecto, no es obligatoria. Si no se establece esta opción, pcs generará un ID automáticamente. La configuración de este valor le permite proporcionar un nombre más descriptivo.
# pcs resource op defaults set create id=podman-timeout meta timeout=90s rule resource ::podman
El siguiente comando establece un valor de tiempo de espera por defecto de 120s para la operación stop para todos los recursos.
# pcs resource op defaults set create id=stop-timeout meta timeout=120s rule op stop
Es posible establecer el valor de tiempo de espera por defecto para una operación específica para todos los recursos de un tipo particular. El siguiente ejemplo establece un valor de tiempo de espera por defecto de 120s para la operación stop para todos los recursos podman.
# pcs resource op defaults set create id=podman-stop-timeout meta timeout=120s rule resource ::podman and op stop20.2.3. Visualización de los valores por defecto de las operaciones de los recursos actualmente configurados
El comando pcs resource op defaults muestra una lista de los valores por defecto actualmente configurados para las operaciones de recursos, incluyendo cualquier regla que haya especificado.
El siguiente comando muestra los valores de operación por defecto para un cluster que ha sido configurado con un valor de tiempo de espera por defecto de 90s para todas las operaciones de todos los recursos de podman, y para el cual se ha establecido un ID para el conjunto de valores por defecto de las operaciones de los recursos como podman-timeout.
# pcs resource op defaults
Meta Attrs: podman-timeout
timeout=90s
Rule: boolean-op=and score=INFINITY
Expression: resource ::podman
El siguiente comando muestra los valores de operación por defecto para un cluster que ha sido configurado con un valor de tiempo de espera por defecto de 120s para la operación stop para todos los recursos podman, y para el cual se ha establecido un ID para el conjunto de valores por defecto de operación de recursos como podman-stop-timeout.
# pcs resource op defaults
Meta Attrs: podman-stop-timeout
timeout=120s
Rule: boolean-op=and score=INFINITY
Expression: resource ::podman
Expression: op stop20.3. Configuración de múltiples operaciones de supervisión
Puede configurar un único recurso con tantas operaciones de monitorización como soporte tenga el agente de recursos. De este modo, puede hacer una comprobación de salud superficial cada minuto y otras progresivamente más intensas a intervalos mayores.
Cuando se configuran operaciones de monitorización múltiple, hay que asegurarse de que no se realizan dos operaciones en el mismo intervalo.
Para configurar operaciones de supervisión adicionales para un recurso que admita comprobaciones más exhaustivas a diferentes niveles, se añade una opción OCF_CHECK_LEVEL=n opción.
Por ejemplo, si se configura el siguiente recurso IPaddr2, por defecto se crea una operación de supervisión con un intervalo de 10 segundos y un valor de tiempo de espera de 20 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2Si la IP virtual admite una comprobación diferente con una profundidad de 10, el siguiente comando hace que Pacemaker realice la comprobación de supervisión más avanzada cada 60 segundos, además de la comprobación normal de la IP virtual cada 10 segundos. (Como se indica, no debe configurar la operación de supervisión adicional con un intervalo de 10 segundos también)
# pcs resource op add VirtualIP monitor interval=60s OCF_CHECK_LEVEL=10Capítulo 21. Propiedades de la agrupación de marcapasos
Las propiedades del clúster controlan cómo se comporta el clúster ante situaciones que pueden darse durante su funcionamiento.
21.1. Resumen de las propiedades y opciones del clúster
Tabla 21.1, “Propiedades del clúster” resume las propiedades del cluster Pacemaker, mostrando los valores por defecto de las propiedades y los posibles valores que puede establecer para esas propiedades.
Hay propiedades adicionales del clúster que determinan el comportamiento del cercado. Para obtener información sobre estas propiedades, consulte Opciones avanzadas de configuración de cercado.
Además de las propiedades descritas en esta tabla, existen otras propiedades del cluster que son expuestas por el software del cluster. Para estas propiedades, se recomienda no cambiar sus valores de los predeterminados.
| Opción | Por defecto | Descripción |
|---|---|---|
|
| 0 | El número de acciones de recursos que el clúster puede ejecutar en paralelo. El valor "correcto" dependerá de la velocidad y la carga de su red y de los nodos del clúster. El valor predeterminado de 0 significa que el clúster impondrá dinámicamente un límite cuando algún nodo tenga una carga elevada de CPU. |
|
| -1 (ilimitado) | El número de trabajos de migración que el clúster puede ejecutar en paralelo en un nodo. |
|
| detener | Qué hacer cuando el cluster no tiene quórum. Valores permitidos: * ignorar - continuar con la gestión de todos los recursos * congelar - continuar la gestión de los recursos, pero no recuperar los recursos de los nodos que no están en la partición afectada * detener - detener todos los recursos de la partición del clúster afectada * suicidio - valla todos los nodos de la partición del clúster afectado * degradar - si una partición del clúster pierde el quórum, degradar cualquier recurso promovido y detener todos los demás recursos |
|
| verdadero | Indica si los recursos pueden ejecutarse en cualquier nodo por defecto. |
|
| 60s | Retraso de ida y vuelta en la red (excluyendo la ejecución de la acción). El valor "correcto" dependerá de la velocidad y la carga de su red y de los nodos del clúster. |
|
| verdadero | Indica si los recursos eliminados deben ser detenidos. |
|
| verdadero | Indica si las acciones borradas deben ser canceladas. |
|
| verdadero |
Indica si un fallo en el arranque de un recurso en un nodo concreto impide nuevos intentos de arranque en ese nodo. Cuando se establece en
Si se establece |
|
| -1 (todos) | El número de entradas del programador que resultan en ERRORES para guardar. Se utiliza cuando se informa de los problemas. |
|
| -1 (todos) | El número de entradas del programador que resultan en ADVERTENCIAS para guardar. Se utiliza cuando se informa de los problemas. |
|
| -1 (todos) | El número de entradas "normales" del programador que hay que guardar. Se utiliza cuando se informa de los problemas. |
|
| La pila de mensajería en la que se está ejecutando actualmente Pacemaker. Se utiliza con fines informativos y de diagnóstico; no es configurable por el usuario. | |
|
| Versión de Pacemaker en el controlador designado (DC) del cluster. Se utiliza con fines de diagnóstico; no es configurable por el usuario. | |
|
| 15 minutos | Intervalo de sondeo para los cambios basados en el tiempo de las opciones, los parámetros de los recursos y las restricciones. Valores permitidos: Cero desactiva el sondeo, los valores positivos son un intervalo en segundos (a menos que se especifiquen otras unidades SI, como 5min). Tenga en cuenta que este valor es el tiempo máximo entre comprobaciones; si un evento del cluster ocurre antes del tiempo especificado por este valor, la comprobación se hará antes. |
|
| falso | El modo de mantenimiento indica al clúster que pase a un modo "sin manos" y que no inicie ni detenga ningún servicio hasta que se le indique lo contrario. Cuando el modo de mantenimiento se ha completado, el clúster realiza una comprobación del estado actual de los servicios y detiene o inicia los que lo necesiten. |
|
| 20min | El tiempo después del cual hay que renunciar a tratar de cerrar elegantemente y simplemente salir. Sólo para uso avanzado. |
|
| falso | En caso de que el clúster detenga todos los recursos. |
|
| falso |
Indica si el clúster puede utilizar listas de control de acceso, tal y como se establece con el comando |
|
|
| Indica si el clúster tendrá en cuenta los atributos de utilización a la hora de determinar la ubicación de los recursos en los nodos del clúster y cómo lo hará. |
|
| 0 (desactivado) | (RHEL 8.3 y posteriores) Permite configurar un clúster de dos nodos para que, en una situación de división del cerebro, el nodo con menos recursos en ejecución sea el que se cerque.
La propiedad
Por ejemplo, si se establece El nodo que ejecuta el rol de maestro de un clon promocionable obtiene 1 punto extra si se ha configurado una prioridad para ese clon.
Cualquier retardo establecido con la propiedad
Sólo el cercado programado por el propio Marcapasos observará |
21.2. Establecer y eliminar las propiedades del clúster
Para establecer el valor de una propiedad del clúster, utilice el siguiente pcs comando.
pcs property set property=value
Por ejemplo, para establecer el valor de symmetric-cluster en false, utilice el siguiente comando.
# pcs property set symmetric-cluster=falsePuede eliminar una propiedad del clúster de la configuración con el siguiente comando.
propiedad pcs unset property
Alternativamente, puede eliminar una propiedad del clúster de una configuración dejando en blanco el campo de valor del comando pcs property set. Esto restablece esa propiedad a su valor por defecto. Por ejemplo, si ha establecido previamente la propiedad symmetric-cluster a false, el siguiente comando elimina el valor que ha establecido de la configuración y restaura el valor de symmetric-cluster a true, que es su valor por defecto.
# pcs property set symmetic-cluster=21.3. Consulta de la configuración de las propiedades del clúster
En la mayoría de los casos, cuando se utiliza el comando pcs para mostrar los valores de los distintos componentes del cluster, se puede utilizar pcs list o pcs show indistintamente. En los siguientes ejemplos, pcs list es el formato utilizado para mostrar una lista completa de todos los ajustes de más de una propiedad, mientras que pcs show es el formato utilizado para mostrar los valores de una propiedad específica.
Para mostrar los valores de la configuración de las propiedades que se han establecido para el clúster, utilice el siguiente pcs comando.
lista de propiedades de pcs
Para mostrar todos los valores de las configuraciones de las propiedades del cluster, incluyendo los valores por defecto de las configuraciones de las propiedades que no se han establecido explícitamente, utilice el siguiente comando.
pcs property list --all
Para mostrar el valor actual de una propiedad específica del clúster, utilice el siguiente comando.
pcs property show property
Por ejemplo, para mostrar el valor actual de la propiedad cluster-infrastructure, ejecute el siguiente comando:
# pcs property show cluster-infrastructure
Cluster Properties:
cluster-infrastructure: cmanCon fines informativos, puede mostrar una lista de todos los valores por defecto de las propiedades, tanto si se han establecido como si no, utilizando el siguiente comando.
propiedad pcs [list|show] --defaults
Capítulo 22. Configurar los recursos para que permanezcan detenidos al apagar un nodo limpio (RHEL 8.2 y posteriores)
Cuando un nodo del clúster se apaga, la respuesta predeterminada de Pacemaker es detener todos los recursos que se ejecutan en ese nodo y recuperarlos en otro lugar, incluso si el apagado es limpio. A partir de RHEL 8.2, puede configurar Pacemaker para que, cuando un nodo se apague limpiamente, los recursos conectados al nodo queden bloqueados en él y no puedan arrancar en otro lugar hasta que vuelvan a arrancar cuando el nodo que se ha apagado se reincorpore al clúster. Esto permite apagar los nodos durante las ventanas de mantenimiento, cuando las interrupciones del servicio son aceptables, sin provocar que los recursos de ese nodo fallen en otros nodos del clúster.
22.1. Propiedades del clúster para configurar que los recursos permanezcan parados al apagar un nodo limpio
La capacidad de evitar que los recursos fallen en un cierre de nodo limpio se implementa por medio de las siguientes propiedades del clúster.
shutdown-lockCuando esta propiedad del clúster se establece en el valor predeterminado de
false, el clúster recuperará los recursos que estén activos en los nodos que se apaguen limpiamente. Cuando esta propiedad se establece entrue, los recursos que están activos en los nodos que se apagan limpiamente no pueden iniciarse en otro lugar hasta que se inicien en el nodo de nuevo después de que se reincorpore al clúster.La propiedad
shutdown-lockfuncionará tanto para los nodos del cluster como para los nodos remotos, pero no para los nodos invitados.Si
shutdown-lockestá configurado comotrue, puede eliminar el bloqueo de un recurso del clúster cuando un nodo está inactivo para que el recurso pueda iniciarse en otro lugar, realizando un refresco manual en el nodo con el siguiente comando.pcs resource refresh resource node=nodenameTen en cuenta que, una vez desbloqueados los recursos, el clúster es libre de moverlos a otro lugar. Puedes controlar la probabilidad de que esto ocurra utilizando valores de pegajosidad o preferencias de ubicación para el recurso.
NotaUna actualización manual sólo funcionará con nodos remotos si primero ejecuta los siguientes comandos:
-
Ejecute el comando
systemctl stop pacemaker_remoteen el nodo remoto para detener el nodo. -
Ejecute el
pcs resource disable remote-connection-resourcecomando.
A continuación, puede realizar una actualización manual en el nodo remoto.
-
Ejecute el comando
shutdown-lock-limitCuando esta propiedad del clúster se establece en un tiempo diferente al valor predeterminado de 0, los recursos estarán disponibles para la recuperación en otros nodos si el nodo no se reincorpora dentro del tiempo especificado desde que se inició el apagado.
NotaLa propiedad
shutdown-lock-limitfuncionará con nodos remotos sólo si primero ejecuta los siguientes comandos:-
Ejecute el comando
systemctl stop pacemaker_remoteen el nodo remoto para detener el nodo. -
Ejecute el
pcs resource disable remote-connection-resourcecomando.
Después de ejecutar estos comandos, los recursos que se habían estado ejecutando en el nodo remoto estarán disponibles para su recuperación en otros nodos cuando haya transcurrido la cantidad de tiempo especificada en
shutdown-lock-limit.-
Ejecute el comando
22.2. Establecimiento de la propiedad de cluster shutdown-lock
El siguiente ejemplo establece la propiedad de clúster shutdown-lock a true en un clúster de ejemplo y muestra el efecto que esto tiene cuando el nodo se apaga y se inicia de nuevo. Este clúster de ejemplo consta de tres nodos: z1.example.com, z2.example.com, y z3.example.com.
Establezca la propiedad
shutdown-lockentruey verifique su valor. En este ejemplo la propiedadshutdown-lock-limitmantiene su valor por defecto de 0.[root@z3.example.com ~]#
pcs property set shutdown-lock=true[root@z3.example.com ~]#pcs property list --all | grep shutdown-lockshutdown-lock: true shutdown-lock-limit: 0Compruebe el estado del clúster. En este ejemplo, los recursos
thirdyfifthse están ejecutando enz1.example.com.[root@z3.example.com ~]#
pcs status... Full List of Resources: ... * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Started z1.example.com * fourth (ocf::pacemaker:Dummy): Started z2.example.com * fifth (ocf::pacemaker:Dummy): Started z1.example.com ...Apagar
z1.example.com, lo que detendrá los recursos que se están ejecutando en ese nodo.[root@z3.example.com ~]
# pcs cluster stop z1.example.comStopping Cluster (pacemaker)... Stopping Cluster (corosync)...La ejecución del comando
pcs statusmuestra que el nodoz1.example.comestá fuera de línea y que los recursos que se habían estado ejecutando enz1.example.comsonLOCKEDmientras el nodo está fuera de línea.[root@z3.example.com ~]#
pcs status... Node List: * Online: [ z2.example.com z3.example.com ] * OFFLINE: [ z1.example.com ] Full List of Resources: ... * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Stopped z1.example.com (LOCKED) * fourth (ocf::pacemaker:Dummy): Started z3.example.com * fifth (ocf::pacemaker:Dummy): Stopped z1.example.com (LOCKED) ...Inicie de nuevo los servicios del clúster en
z1.example.compara que se reincorpore al clúster. Los recursos bloqueados deberían iniciarse en ese nodo, aunque una vez iniciados no necesariamente permanecerán en el mismo nodo.[root@z3.example.com ~]#
pcs cluster start z1.example.comStarting Cluster...En este ejemplo, los recursos
thirdyfifthse recuperan en el nodoz1.example.com.[root@z3.example.com ~]#
pcs status... Node List: * Online: [ z1.example.com z2.example.com z3.example.com ] Full List of Resources: .. * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Started z1.example.com * fourth (ocf::pacemaker:Dummy): Started z3.example.com * fifth (ocf::pacemaker:Dummy): Started z1.example.com ...
Capítulo 23. Configurar una estrategia de colocación de nodos
Pacemaker decide dónde colocar un recurso según las puntuaciones de asignación de recursos en cada nodo. El recurso se asignará al nodo en el que tenga la mayor puntuación. Esta puntuación de asignación se deriva de una combinación de factores, entre los que se incluyen las restricciones de recursos, la configuración de resource-stickiness, el historial de fallos anteriores de un recurso en cada nodo y la utilización de cada nodo.
Si las puntuaciones de asignación de recursos en todos los nodos son iguales, por la estrategia de colocación por defecto Pacemaker elegirá un nodo con el menor número de recursos asignados para equilibrar la carga. Si el número de recursos en cada nodo es igual, se elegirá el primer nodo elegible listado en el CIB para ejecutar el recurso.
Sin embargo, a menudo los diferentes recursos utilizan proporciones significativamente diferentes de las capacidades de un nodo (como la memoria o la E/S). No siempre se puede equilibrar la carga de forma ideal teniendo en cuenta sólo el número de recursos asignados a un nodo. Además, si los recursos se colocan de forma que sus requisitos combinados superen la capacidad proporcionada, es posible que no se inicien completamente o que funcionen con un rendimiento degradado. Para tener en cuenta estos factores, Pacemaker permite configurar los siguientes componentes:
- la capacidad que proporciona un nodo concreto
- la capacidad que requiere un determinado recurso
- una estrategia global de colocación de recursos
23.1. Atributos de utilización y estrategia de colocación
Para configurar la capacidad que proporciona un nodo o que requiere un recurso, puedes utilizar utilization attributes para nodos y recursos. Esto se hace estableciendo una variable de utilización para un recurso y asignando un valor a esa variable para indicar lo que el recurso requiere, y luego estableciendo esa misma variable de utilización para un nodo y asignando un valor a esa variable para indicar lo que ese nodo proporciona.
Puede nombrar los atributos de utilización según sus preferencias y definir tantos pares de nombre y valor como necesite su configuración. Los valores de los atributos de utilización deben ser enteros.
23.1.1. Configuración de la capacidad de nodos y recursos
El siguiente ejemplo configura un atributo de utilización de la capacidad de la CPU para dos nodos, estableciendo este atributo como la variable cpu. También configura un atributo de utilización de la capacidad de RAM, estableciendo este atributo como la variable memory. En este ejemplo:
- El nodo 1 se define por tener una capacidad de CPU de dos y una capacidad de RAM de 2048
- El nodo 2 se define por ofrecer una capacidad de CPU de cuatro y una capacidad de RAM de 2048
#pcs node utilization node1 cpu=2 memory=2048#pcs node utilization node2 cpu=4 memory=2048
El siguiente ejemplo especifica los mismos atributos de utilización que requieren tres recursos diferentes. En este ejemplo:
-
recurso
dummy-smallrequiere una capacidad de CPU de 1 y una capacidad de RAM de 1024 -
recurso
dummy-mediumrequiere una capacidad de CPU de 2 y una capacidad de RAM de 2048 -
recurso
dummy-largerequiere una capacidad de CPU de 1 y una capacidad de RAM de 3072
#pcs resource utilization dummy-small cpu=1 memory=1024#pcs resource utilization dummy-medium cpu=2 memory=2048#pcs resource utilization dummy-large cpu=3 memory=3072
Se considera que un nodo es elegible para un recurso si tiene suficiente capacidad libre para satisfacer los requisitos del recurso, definidos por los atributos de utilización.
23.1.2. Configuración de la estrategia de colocación
Después de haber configurado las capacidades que proporcionan sus nodos y las capacidades que requieren sus recursos, es necesario establecer la propiedad del clúster placement-strategy, de lo contrario las configuraciones de capacidad no tienen ningún efecto.
Hay cuatro valores disponibles para la propiedad placement-strategy cluster:
-
default -
utilization -
balanced -
minimal
El siguiente comando de ejemplo establece el valor de placement-strategy en balanced. Después de ejecutar este comando, Pacemaker se asegurará de que la carga de sus recursos se distribuya uniformemente por todo el clúster, sin necesidad de complicados conjuntos de restricciones de colocación.
# pcs property set placement-strategy=balanced23.2. Asignación de recursos del marcapasos
Las siguientes subsecciones resumen cómo Pacemaker asigna los recursos.
23.2.1. Preferencia de nodo
Pacemaker determina qué nodo tiene preferencia a la hora de asignar recursos según la siguiente estrategia.
- El nodo con el mayor peso de nodo se consume primero. El peso del nodo es una puntuación mantenida por el clúster para representar la salud del nodo.
Si varios nodos tienen el mismo peso de nodo:
Si la propiedad del cluster
placement-strategyesdefaultoutilization:- El nodo que tiene el menor número de recursos asignados se consume primero.
- Si el número de recursos asignados es igual, el primer nodo elegible que aparece en la CIB se consume primero.
Si la propiedad del cluster
placement-strategyesbalanced:- El nodo que tiene más capacidad libre se consume primero.
- Si las capacidades libres de los nodos son iguales, el nodo que tiene el menor número de recursos asignados se consume primero.
- Si las capacidades libres de los nodos son iguales y el número de recursos asignados es igual, el primer nodo elegible que aparece en el CIB se consume primero.
-
Si la propiedad del cluster
placement-strategyesminimal, el primer nodo elegible listado en el CIB se consume primero.
23.2.2. Capacidad del nodo
Pacemaker determina qué nodo tiene más capacidad libre según la siguiente estrategia.
- Si sólo se ha definido un tipo de atributo de utilización, la capacidad libre es una simple comparación numérica.
Si se han definido varios tipos de atributos de utilización, entonces el nodo que es numéricamente más alto en la mayoría de los tipos de atributos tiene la mayor capacidad libre. Por ejemplo:
- Si el NodoA tiene más CPUs libres, y el NodoB tiene más memoria libre, entonces sus capacidades libres son iguales.
- Si el NodoA tiene más CPUs libres, mientras que el NodoB tiene más memoria y almacenamiento libres, entonces el NodoB tiene más capacidad libre.
23.2.3. Preferencia de asignación de recursos
Pacemaker determina qué recurso se asigna primero según la siguiente estrategia.
- El recurso que tiene la mayor prioridad se asigna primero. Puede establecer la prioridad de un recurso cuando lo crea.
- Si las prioridades de los recursos son iguales, el recurso que tiene la puntuación más alta en el nodo en el que se está ejecutando se asigna primero, para evitar que se barajen los recursos.
- Si las puntuaciones de los recursos en los nodos donde se ejecutan los recursos son iguales o los recursos no se ejecutan, el recurso que tiene la puntuación más alta en el nodo preferido se asigna primero. Si las puntuaciones de los recursos en el nodo preferido son iguales en este caso, se asigna primero el primer recurso ejecutable listado en el CIB.
23.3. Directrices de la estrategia de colocación de recursos
Para garantizar que la estrategia de colocación de recursos de Pacemaker funcione de la manera más eficaz, debe tener en cuenta las siguientes consideraciones al configurar su sistema.
Asegúrate de que tienes suficiente capacidad física.
Si la capacidad física de sus nodos se está utilizando casi al máximo en condiciones normales, podrían producirse problemas durante la conmutación por error. Incluso sin la función de utilización, puede empezar a experimentar tiempos de espera y fallos secundarios.
Incorpore un poco de amortiguación en las capacidades que configure para los nodos.
Anuncie ligeramente más recursos de nodo de los que tiene físicamente, asumiendo que un recurso de Pacemaker no utilizará el 100% de la cantidad configurada de CPU, memoria, etc. todo el tiempo. Esta práctica se denomina a veces overcommit.
Especificar las prioridades de los recursos.
Si el clúster va a sacrificar servicios, deberían ser los que menos te importan. Asegúrate de que las prioridades de los recursos están bien configuradas para que tus recursos más importantes se programen primero.
23.4. El agente de recursos NodeUtilization
El agente NodeUtilization puede detectar los parámetros del sistema de la CPU disponible, la disponibilidad de la memoria del host y la disponibilidad de la memoria del hipervisor y añadir estos parámetros en el CIB. Puede ejecutar el agente como un recurso clonado para que rellene automáticamente estos parámetros en cada nodo.
Para obtener información sobre el agente de recursos NodeUtilization y las opciones de recursos para este agente, ejecute el comando pcs resource describe NodeUtilization.
Capítulo 24. Configuración de un dominio virtual como recurso
Puede configurar un dominio virtual gestionado por el marco de virtualización libvirt como recurso de clúster con el comando pcs resource create, especificando VirtualDomain como tipo de recurso.
Al configurar un dominio virtual como recurso, tenga en cuenta las siguientes consideraciones:
- Un dominio virtual debe ser detenido antes de configurarlo como recurso de cluster.
- Una vez que un dominio virtual es un recurso del clúster, no debe iniciarse, detenerse o migrar, excepto a través de las herramientas del clúster.
- No configure un dominio virtual que haya configurado como recurso de cluster para que se inicie cuando su host arranque.
- Todos los nodos autorizados a ejecutar un dominio virtual deben tener acceso a los archivos de configuración y dispositivos de almacenamiento necesarios para ese dominio virtual.
Si desea que el clúster gestione servicios dentro del propio dominio virtual, puede configurar el dominio virtual como nodo invitado.
24.1. Opciones de recursos del dominio virtual
Tabla 24.1, “Opciones de recursos para los recursos del dominio virtual” describe las opciones de recursos que puede configurar para un recurso VirtualDomain.
| Campo | Por defecto | Descripción |
|---|---|---|
|
|
(obligatorio) Ruta absoluta al archivo de configuración | |
|
| Depende del sistema |
URI del hipervisor al que conectarse. Puede determinar la URI por defecto del sistema ejecutando el comando |
|
|
|
Siempre se apaga a la fuerza (\ "destruir") el dominio al detenerse. El comportamiento por defecto es recurrir a un apagado forzado sólo después de que un intento de apagado gracioso haya fallado. Debe establecer esta opción en |
|
| Depende del sistema |
Transporte utilizado para conectarse al hipervisor remoto durante la migración. Si se omite este parámetro, el recurso utilizará el transporte predeterminado de |
|
| Utilizar una red de migración dedicada. La URI de migración se compone añadiendo el valor de este parámetro al final del nombre del nodo. Si el nombre del nodo es un nombre de dominio completo (FQDN), inserte el sufijo inmediatamente antes del primer punto (.) en el FQDN. Asegúrese de que este nombre de host compuesto se puede resolver localmente y que la dirección IP asociada es accesible a través de la red favorecida. | |
|
|
Para supervisar adicionalmente los servicios dentro del dominio virtual, añada este parámetro con una lista de scripts a supervisar. Note: Cuando se utilizan scripts de supervisión, las operaciones | |
|
|
|
Si se establece en |
|
|
|
Si se establece como verdadero, el agente detectará el número de |
|
| puerto alto aleatorio |
Este puerto se utilizará en el URI de migración de |
|
|
Ruta al directorio de instantáneas donde se almacenará la imagen de la máquina virtual. Cuando se establece este parámetro, el estado RAM de la máquina virtual se guardará en un archivo en el directorio de instantáneas cuando se detenga. Si al iniciarse hay un archivo de estado para el dominio, éste se restaurará al mismo estado en el que estaba justo antes de detenerse por última vez. Esta opción es incompatible con la opción |
Además de las opciones del recurso VirtualDomain, puede configurar la opción de metadatos allow-migrate para permitir la migración en vivo del recurso a otro nodo. Cuando esta opción se establece en true, el recurso puede ser migrado sin pérdida de estado. Cuando esta opción se establece en false, que es el estado por defecto, el dominio virtual se apagará en el primer nodo y luego se reiniciará en el segundo nodo cuando se mueva de un nodo a otro.
24.2. Creación del recurso de dominio virtual
Utilice el siguiente procedimiento para crear un recurso VirtualDomain en un clúster para una máquina virtual que haya creado previamente:
Para crear el agente de recursos
VirtualDomainpara la gestión de la máquina virtual, Pacemaker requiere que el archivo de configuraciónxmlde la máquina virtual se vuelque a un archivo en el disco. Por ejemplo, si creó una máquina virtual llamadaguest1, vuelque el archivoxmla un archivo en algún lugar de uno de los nodos del clúster que podrá ejecutar el huésped. Puede utilizar un nombre de archivo de su elección; este ejemplo utiliza/etc/pacemaker/guest1.xml.#
virsh dumpxml guest1 > /etc/pacemaker/guest1.xml-
Copie el archivo de configuración
xmlde la máquina virtual a todos los demás nodos del clúster que podrán ejecutar el invitado, en la misma ubicación de cada nodo. - Asegúrese de que todos los nodos autorizados a ejecutar el dominio virtual tienen acceso a los dispositivos de almacenamiento necesarios para ese dominio virtual.
- Compruebe por separado que el dominio virtual puede iniciarse y detenerse en cada nodo que ejecutará el dominio virtual.
- Si se está ejecutando, apague el nodo invitado. Pacemaker iniciará el nodo cuando esté configurado en el cluster. La máquina virtual no debe configurarse para que se inicie automáticamente al arrancar el host.
Configure el recurso
VirtualDomaincon el comandopcs resource create. Por ejemplo, el siguiente comando configura un recursoVirtualDomainllamadoVM. Dado que la opciónallow-migrateestá configurada comotrueunpcs move VM nodeXcomando se haría como una migración en vivo.En este ejemplo
migration_transportestá configurado comossh. Tenga en cuenta que para que la migración SSH funcione correctamente, el registro sin clave debe funcionar entre nodos.#
pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=true
Capítulo 25. Quórum del clúster
Un cluster de Red Hat Enterprise Linux High Availability Add-On utiliza el servicio votequorum, en conjunto con fencing, para evitar situaciones de split brain. Se asigna un número de votos a cada sistema en el cluster y las operaciones del cluster se permiten sólo cuando hay una mayoría de votos. El servicio debe cargarse en todos los nodos o en ninguno; si se carga en un subconjunto de nodos del clúster, los resultados serán imprevisibles. Para obtener información sobre la configuración y el funcionamiento del servicio votequorum, consulte la página de manual votequorum(5).
25.1. Configuración de las opciones de quórum
Hay algunas características especiales de la configuración del quórum que puede establecer cuando crea un clúster con el comando pcs cluster setup. Tabla 25.1, “Opciones de quórum” resume estas opciones.
| Opción | Descripción |
|---|---|
|
|
Cuando se activa, el clúster puede sufrir hasta el 50% de los nodos que fallan al mismo tiempo, de forma determinista. La partición del clúster, o el conjunto de nodos que aún están en contacto con el
La opción
La opción |
|
| Cuando se habilita, el clúster será quórum por primera vez sólo después de que todos los nodos hayan sido visibles al menos una vez al mismo tiempo.
La opción
La opción |
|
|
Cuando se activa, el clúster puede recalcular dinámicamente |
|
|
El tiempo, en milisegundos, que se debe esperar antes de recalcular |
Para más información sobre la configuración y el uso de estas opciones, consulte la página de manual votequorum(5).
25.2. Modificación de las opciones de quórum
Puede modificar las opciones generales de quórum de su clúster con el comando pcs quorum update. La ejecución de este comando requiere que el clúster esté detenido. Para obtener información sobre las opciones de quórum, consulte la página de manual votequorum(5).
El formato del comando pcs quorum update es el siguiente.
pcs actualización del quórum [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
La siguiente serie de comandos modifica la opción de quórum wait_for_all y muestra el estado actualizado de la opción. Tenga en cuenta que el sistema no permite ejecutar este comando mientras el clúster está en funcionamiento.
[root@node1:~]#pcs quorum update wait_for_all=1Checking corosync is not running on nodes... Error: node1: corosync is running Error: node2: corosync is running [root@node1:~]#pcs cluster stop --allnode2: Stopping Cluster (pacemaker)... node1: Stopping Cluster (pacemaker)... node1: Stopping Cluster (corosync)... node2: Stopping Cluster (corosync)... [root@node1:~]#pcs quorum update wait_for_all=1Checking corosync is not running on nodes... node2: corosync is not running node1: corosync is not running Sending updated corosync.conf to nodes... node1: Succeeded node2: Succeeded [root@node1:~]#pcs quorum configOptions: wait_for_all: 1
25.3. Visualización de la configuración y el estado del quórum
Una vez que el clúster está funcionando, puede introducir los siguientes comandos de quórum del clúster.
El siguiente comando muestra la configuración del quórum.
pcs quorum [config]
El siguiente comando muestra el estado de ejecución del quórum.
estado del quórum del pcs
25.4. Ejecución de clústeres inquemados
Si retira nodos de un clúster durante un largo período de tiempo y la pérdida de esos nodos provocaría la pérdida de quórum, puede cambiar el valor del parámetro expected_votes para el clúster en vivo con el comando pcs quorum expected-votes. Esto permite que el clúster siga funcionando cuando no tiene quórum.
El cambio de los votos esperados en un clúster en vivo debe hacerse con extrema precaución. Si menos del 50% del clúster se está ejecutando porque has cambiado manualmente los votos esperados, entonces los otros nodos del clúster podrían iniciarse por separado y ejecutar los servicios del clúster, causando corrupción de datos y otros resultados inesperados. Si cambia este valor, debe asegurarse de que el parámetro wait_for_all está activado.
El siguiente comando establece los votos esperados en el cluster en vivo al valor especificado. Esto afecta sólo al clúster en vivo y no cambia el archivo de configuración; el valor de expected_votes se restablece al valor del archivo de configuración en caso de recarga.
pcs quórum esperado-votos votes
En una situación en la que usted sabe que el clúster está inerme pero quiere que el clúster proceda a la gestión de recursos, puede utilizar el comando pcs quorum unblock para evitar que el clúster espere a todos los nodos al establecer el quórum.
Este comando debe utilizarse con extrema precaución. Antes de emitir este comando, es imprescindible asegurarse de que los nodos que no están actualmente en el clúster están apagados y no tienen acceso a los recursos compartidos.
# pcs quorum unblock25.5. Dispositivos de quórum
Puede permitir que un clúster soporte más fallos de nodo de los que permiten las reglas de quórum estándar configurando un dispositivo de quórum independiente que actúe como dispositivo de arbitraje de terceros para el clúster. Se recomienda un dispositivo de quórum para clusters con un número par de nodos. Con clusters de dos nodos, el uso de un dispositivo de quórum puede determinar mejor qué nodo sobrevive en una situación de cerebro dividido.
Al configurar un dispositivo de quórum hay que tener en cuenta lo siguiente.
- Se recomienda que un dispositivo de quórum se ejecute en una red física diferente en el mismo sitio que el clúster que utiliza el dispositivo de quórum. Lo ideal es que el host del dispositivo de quórum esté en un rack distinto al del clúster principal, o al menos en una fuente de alimentación distinta y no en el mismo segmento de red que el anillo o anillos de corosync.
- No se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo.
-
Aunque no se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo, un único dispositivo de quórum puede ser utilizado por varios clústeres al mismo tiempo. Cada clúster que utilice ese dispositivo de quórum puede utilizar diferentes algoritmos y opciones de quórum, ya que éstos se almacenan en los propios nodos del clúster. Por ejemplo, un único dispositivo de quórum puede ser utilizado por un cluster con un algoritmo
ffsplit(fifty/fifty split) y por un segundo cluster con un algoritmolms(last man standing). - Un dispositivo de quórum no debe ejecutarse en un nodo de clúster existente.
25.5.1. Instalación de paquetes de dispositivos de quórum
La configuración de un dispositivo de quórum para un clúster requiere la instalación de los siguientes paquetes:
Instale
corosync-qdeviceen los nodos de un clúster existente.[root@node1:~]#
yum install corosync-qdevice[root@node2:~]#yum install corosync-qdeviceInstale
pcsycorosync-qnetden el host del dispositivo de quórum.[root@qdevice:~]#
yum install pcs corosync-qnetdInicie el servicio
pcsdy habilitepcsdal iniciar el sistema en el host del dispositivo de quórum.[root@qdevice:~]#
systemctl start pcsd.service[root@qdevice:~]#systemctl enable pcsd.service
25.5.2. Configuración de un dispositivo de quórum
El siguiente procedimiento configura un dispositivo de quórum y lo añade al clúster. En este ejemplo:
-
El nodo utilizado para un dispositivo de quórum es
qdevice. El modelo de dispositivo de quórum es
net, que es actualmente el único modelo soportado. El modelonetadmite los siguientes algoritmos:-
ffsplit: división al cincuenta por ciento. Esto proporciona exactamente un voto a la partición con el mayor número de nodos activos. lms: último hombre en pie. Si el nodo es el único que queda en el clúster que puede ver el servidorqnetd, entonces devuelve un voto.AvisoEl algoritmo LMS permite que el clúster siga siendo quórum incluso con un solo nodo restante, pero también significa que el poder de voto del dispositivo de quórum es grande, ya que es igual al número_de_nodos - 1. Perder la conexión con el dispositivo de quórum significa perder el número_de_nodos - 1 de votos, lo que significa que sólo un clúster con todos los nodos activos puede seguir siendo quórum (sobrevotando al dispositivo de quórum); cualquier otro clúster se convierte en no quórum.
Para obtener información más detallada sobre la implementación de estos algoritmos, consulte la página de manual
corosync-qdevice(8).
-
-
Los nodos del clúster son
node1ynode2.
El siguiente procedimiento configura un dispositivo de quórum y añade ese dispositivo de quórum a un clúster.
En el nodo que utilizará para alojar su dispositivo de quórum, configure el dispositivo de quórum con el siguiente comando. Este comando configura e inicia el modelo de dispositivo de quórum
nety configura el dispositivo para que se inicie al arrancar.[root@qdevice:~]#
pcs qdevice setup model net --enable --startQuorum device 'net' initialized quorum device enabled Starting quorum device... quorum device startedDespués de configurar el dispositivo de quórum, puedes comprobar su estado. Esto debería mostrar que el demonio
corosync-qnetdse está ejecutando y, en este momento, no hay clientes conectados a él. La opción del comando--fullproporciona una salida detallada.[root@qdevice:~]#
pcs qdevice status net --fullQNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytesHabilite los puertos del cortafuegos necesarios para el demonio
pcsdy el dispositivo de quórumnethabilitando el serviciohigh-availabilityenfirewalldcon los siguientes comandos.[root@qdevice:~]#
firewall-cmd --permanent --add-service=high-availability[root@qdevice:~]#firewall-cmd --add-service=high-availabilityDesde uno de los nodos del clúster existente, autentique al usuario
haclusteren el nodo que aloja el dispositivo de quórum. Esto permite quepcsen el clúster se conecte apcsen el hostqdevice, pero no permite quepcsen el hostqdevicese conecte apcsen el clúster.[root@node1:~] #
pcs host auth qdeviceUsername: hacluster Password: qdevice: AuthorizedAñade el dispositivo de quórum al clúster.
Antes de añadir el dispositivo de quórum, puede comprobar la configuración actual y el estado del dispositivo de quórum para su posterior comparación. La salida de estos comandos indica que el clúster aún no está utilizando un dispositivo de quórum, y el estado de pertenencia a
Qdevicepara cada nodo esNR(No registrado).[root@node1:~]#
pcs quorum configOptions:[root@node1:~]#
pcs quorum statusQuorum information ------------------ Date: Wed Jun 29 13:15:36 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 2 Highest expected: 2 Total votes: 2 Quorum: 1 Flags: 2Node Quorate Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 NR node1 (local) 2 1 NR node2El siguiente comando añade al clúster el dispositivo de quórum que ha creado previamente. No se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo. Sin embargo, un dispositivo de quórum puede ser utilizado por varios clústeres al mismo tiempo. Este comando de ejemplo configura el dispositivo de quórum para utilizar el algoritmo
ffsplit. Para obtener información sobre las opciones de configuración del dispositivo de quórum, consulte la página de manualcorosync-qdevice(8).[root@node1:~]#
pcs quorum device add model net host=qdevice\algorithm=ffsplitSetting up qdevice certificates on nodes... node2: Succeeded node1: Succeeded Enabling corosync-qdevice... node1: corosync-qdevice enabled node2: corosync-qdevice enabled Sending updated corosync.conf to nodes... node1: Succeeded node2: Succeeded Corosync configuration reloaded Starting corosync-qdevice... node1: corosync-qdevice started node2: corosync-qdevice startedCompruebe el estado de configuración del dispositivo de quórum.
Desde el lado del clúster, puede ejecutar los siguientes comandos para ver cómo ha cambiado la configuración.
En
pcs quorum configse muestra el dispositivo de quórum que se ha configurado.[root@node1:~]#
pcs quorum configOptions: Device: Model: net algorithm: ffsplit host: qdeviceEl comando
pcs quorum statusmuestra el estado de ejecución del quórum, indicando que el dispositivo de quórum está en uso. Los significados de los valores de estado de la información de membresía deQdevicepara cada nodo del clúster son los siguientes:-
A/NA -
V/NV MW/NMW[root@node1:~]#
pcs quorum statusQuorum information ------------------ Date: Wed Jun 29 13:17:02 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW node1 (local) 2 1 A,V,NMW node2 0 1 QdeviceLa página
pcs quorum device statusmuestra el estado de ejecución del dispositivo de quórum.[root@node1:~]#
pcs quorum device statusQdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mycluster QNetd host: qdevice:5403 Algorithm: ffsplit Tie-breaker: Node with lowest node ID State: ConnectedDesde el lado del dispositivo de quórum, puede ejecutar el siguiente comando de estado, que muestra el estado del demonio
corosync-qnetd.[root@qdevice:~]#
pcs qdevice status net --fullQNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 2 Connected clusters: 1 Maximum send/receive size: 32768/32768 bytes Cluster "mycluster": Algorithm: ffsplit Tie-breaker: Node with lowest node ID Node ID 2: Client address: ::ffff:192.168.122.122:50028 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK) Node ID 1: Client address: ::ffff:192.168.122.121:48786 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK)
-
25.5.3. Gestión del servicio de dispositivos de quórum
PCS proporciona la capacidad de gestionar el servicio de dispositivo de quórum en el host local (corosync-qnetd), como se muestra en los siguientes comandos de ejemplo. Tenga en cuenta que estos comandos sólo afectan al servicio corosync-qnetd.
[root@qdevice:~]#pcs qdevice start net[root@qdevice:~]#pcs qdevice stop net[root@qdevice:~]#pcs qdevice enable net[root@qdevice:~]#pcs qdevice disable net[root@qdevice:~]#pcs qdevice kill net
25.5.4. Gestión de la configuración del dispositivo de quórum en un clúster
Las siguientes secciones describen los comandos PCS que puede utilizar para gestionar la configuración de los dispositivos de quórum en un clúster.
25.5.4.1. Cambiar la configuración del dispositivo de quórum
Puede cambiar la configuración de un dispositivo de quórum con el comando pcs quorum device update.
Para cambiar la opción host del modelo de dispositivo de quórum net, utilice los comandos pcs quorum device remove y pcs quorum device add para establecer la configuración correctamente, a menos que el host antiguo y el nuevo sean la misma máquina.
El siguiente comando cambia el algoritmo del dispositivo de quórum a lms.
[root@node1:~]# pcs quorum device update model algorithm=lms
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Reloading qdevice configuration on nodes...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
node1: corosync-qdevice started
node2: corosync-qdevice started25.5.4.2. Eliminación de un dispositivo de quórum
Utilice el siguiente comando para eliminar un dispositivo de quórum configurado en un nodo del clúster.
[root@node1:~]# pcs quorum device remove
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Disabling corosync-qdevice...
node1: corosync-qdevice disabled
node2: corosync-qdevice disabled
Stopping corosync-qdevice...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
Removing qdevice certificates from nodes...
node1: Succeeded
node2: SucceededDespués de haber eliminado un dispositivo de quórum, debería ver el siguiente mensaje de error al mostrar el estado del dispositivo de quórum.
[root@node1:~]# pcs quorum device status
Error: Unable to get quorum status: corosync-qdevice-tool: Can't connect to QDevice socket (is QDevice running?): No such file or directory25.5.4.3. Destrucción de un dispositivo de quórum
Para desactivar y detener un dispositivo de quórum en el host del dispositivo de quórum y eliminar todos sus archivos de configuración, utilice el siguiente comando.
[root@qdevice:~]# pcs qdevice destroy net
Stopping quorum device...
quorum device stopped
quorum device disabled
Quorum device 'net' configuration files removedCapítulo 26. Scripts de activación de eventos de cluster
Un clúster Pacemaker es un sistema impulsado por eventos, en el que un evento puede ser un fallo de un recurso o nodo, un cambio de configuración o el inicio o la detención de un recurso. Puede configurar las alertas de clúster de Pacemaker para que realicen alguna acción externa cuando se produzca un evento de clúster mediante agentes de alerta, que son programas externos a los que el clúster llama de la misma manera que el clúster llama a los agentes de recursos para gestionar la configuración y el funcionamiento de los recursos.
El clúster pasa información sobre el evento al agente mediante variables de entorno. Los agentes pueden hacer cualquier cosa con esta información, como enviar un mensaje de correo electrónico o registrar en un archivo o actualizar un sistema de monitorización.
-
Pacemaker proporciona varios agentes de alerta de muestra, que se instalan en
/usr/share/pacemaker/alertspor defecto. Estos scripts de muestra pueden copiarse y utilizarse tal cual, o bien pueden utilizarse como plantillas que pueden editarse para adaptarse a sus propósitos. Consulte el código fuente de los agentes de muestra para conocer el conjunto completo de atributos que admiten. - Si los agentes de alerta de muestra no satisfacen sus necesidades, puede escribir sus propios agentes de alerta para que llame una alerta de Marcapasos.
26.1. Instalación y configuración de agentes de alerta de muestra
Cuando utilice uno de los agentes de alerta de muestra, deberá revisar el script para asegurarse de que se adapta a sus necesidades. Estos agentes de muestra se proporcionan como punto de partida para scripts personalizados para entornos de cluster específicos. Tenga en cuenta que mientras Red Hat soporta las interfaces que los scripts de agentes de alerta utilizan para comunicarse con Pacemaker, Red Hat no proporciona soporte para los agentes personalizados en sí mismos.
Para utilizar uno de los agentes de alerta de ejemplo, debe instalar el agente en cada nodo del clúster. Por ejemplo, el siguiente comando instala el script alert_file.sh.sample como alert_file.sh.
# install --mode=0755 /usr/share/pacemaker/alerts/alert_file.sh.sample /var/lib/pacemaker/alert_file.shUna vez instalado el script, puede crear una alerta que utilice el script.
El siguiente ejemplo configura una alerta que utiliza el agente de alerta instalado alert_file.sh para registrar eventos en un archivo. Los agentes de alerta se ejecutan como el usuario hacluster, que tiene un conjunto mínimo de permisos.
Este ejemplo crea el archivo de registro pcmk_alert_file.log que se utilizará para registrar los eventos. A continuación, crea el agente de alerta y añade la ruta del archivo de registro como su destinatario.
#touch /var/log/pcmk_alert_file.log#chown hacluster:haclient /var/log/pcmk_alert_file.log#chmod 600 /var/log/pcmk_alert_file.log#pcs alert create id=alert_file description="Log events to a file." path=/var/lib/pacemaker/alert_file.sh#pcs alert recipient add alert_file id=my-alert_logfile value=/var/log/pcmk_alert_file.log
El siguiente ejemplo instala el script alert_snmp.sh.sample como alert_snmp.sh y configura una alerta que utiliza el agente de alerta instalado alert_snmp.sh para enviar los eventos del cluster como traps SNMP. Por defecto, el script enviará todos los eventos excepto las llamadas de monitorización exitosas al servidor SNMP. Este ejemplo configura el formato de marca de tiempo como una opción meta. Después de configurar la alerta, este ejemplo configura un destinatario para la alerta y muestra la configuración de la alerta.
#install --mode=0755 /usr/share/pacemaker/alerts/alert_snmp.sh.sample /var/lib/pacemaker/alert_snmp.sh#pcs alert create id=snmp_alert path=/var/lib/pacemaker/alert_snmp.sh meta timestamp-format="%Y-%m-%d,%H:%M:%S.%01N"#pcs alert recipient add snmp_alert value=192.168.1.2#pcs alertAlerts: Alert: snmp_alert (path=/var/lib/pacemaker/alert_snmp.sh) Meta options: timestamp-format=%Y-%m-%d,%H:%M:%S.%01N. Recipients: Recipient: snmp_alert-recipient (value=192.168.1.2)
El siguiente ejemplo instala el agente alert_smtp.sh y luego configura una alerta que utiliza el agente de alertas instalado para enviar los eventos del clúster como mensajes de correo electrónico. Después de configurar la alerta, este ejemplo configura un destinatario y muestra la configuración de la alerta.
#install --mode=0755 /usr/share/pacemaker/alerts/alert_smtp.sh.sample /var/lib/pacemaker/alert_smtp.sh#pcs alert create id=smtp_alert path=/var/lib/pacemaker/alert_smtp.sh options email_sender=donotreply@example.com#pcs alert recipient add smtp_alert value=admin@example.com#pcs alertAlerts: Alert: smtp_alert (path=/var/lib/pacemaker/alert_smtp.sh) Options: email_sender=donotreply@example.com Recipients: Recipient: smtp_alert-recipient (value=admin@example.com)
26.2. Creación de una alerta de clúster
El siguiente comando crea una alerta de cluster. Las opciones que se configuran son valores de configuración específicos del agente que se pasan al script del agente de alertas en la ruta que se especifica como variables de entorno adicionales. Si no especifica un valor para id, se generará uno.
pcs alert create path=path [id=alert-id] [description=description] [options [option=value]...] [meta [meta-option=value]...]
Se pueden configurar varios agentes de alerta; el clúster los llamará a todos para cada evento. Los agentes de alerta serán llamados sólo en los nodos del cluster. Serán llamados para eventos que involucren nodos Pacemaker Remote, pero nunca serán llamados en esos nodos.
El siguiente ejemplo crea una simple alerta que llamará a myscript.sh para cada evento.
# pcs alert create id=my_alert path=/path/to/myscript.sh26.3. Visualización, modificación y eliminación de alertas de cluster
El siguiente comando muestra todas las alertas configuradas junto con los valores de las opciones configuradas.
pcs alert [config|show]
El siguiente comando actualiza una alerta existente con el valor especificado en alert-id.
pcs alert update alert-id [path=path] [description=description] [options [option=value]...] [meta [meta-option=value]...]
El siguiente comando elimina una alerta con el valor especificado alert-id.
pcs alerta eliminar alert-id
Alternativamente, puede ejecutar el comando pcs alert delete, que es idéntico al comando pcs alert remove. Tanto el comando pcs alert delete como el pcs alert remove permiten especificar más de una alerta para ser eliminada.
26.4. Configurar los destinatarios de las alertas
Normalmente las alertas se dirigen a un destinatario. Así, cada alerta puede configurarse adicionalmente con uno o varios destinatarios. El clúster llamará al agente por separado para cada destinatario.
El destinatario puede ser cualquier cosa que el agente de alertas pueda reconocer: una dirección IP, una dirección de correo electrónico, un nombre de archivo o cualquier cosa que el agente en particular admita.
El siguiente comando añade un nuevo destinatario a la alerta especificada.
pcs alert recipient add alert-id value=recipient-value [id=recipient-id] [description=description] [options [option=value]...] [meta [meta-option=value]...]
El siguiente comando actualiza un destinatario de alerta existente.
pcs alert recipient update recipient-id [value=recipient-value] [description=description] [options [option=value]...] [meta [meta-option=value]...]
El siguiente comando elimina el destinatario de la alerta especificado.
pcs alerta receptor eliminar recipient-id
Alternativamente, puede ejecutar el comando pcs alert recipient delete, que es idéntico al comando pcs alert recipient remove. Tanto el comando pcs alert recipient remove como el pcs alert recipient delete le permiten eliminar más de un destinatario de alerta.
El siguiente comando de ejemplo añade el destinatario de la alerta my-alert-recipient con un ID de destinatario de my-recipient-id a la alerta my-alert. Esto configurará el cluster para llamar al script de alerta que ha sido configurado para my-alert para cada evento, pasando el destinatario some-address como una variable de entorno.
# pcs alert recipient add my-alert value=my-alert-recipient id=my-recipient-id options value=some-address26.5. Opciones de meta-alerta
Al igual que en el caso de los agentes de recursos, las opciones meta pueden configurarse para los agentes de alerta para afectar a la forma en que Pacemaker los llama. Tabla 26.1, “Meta Opciones de Alerta” describe las opciones meta de las alertas. Las opciones meta pueden configurarse por agente de alerta así como por destinatario.
| Meta-atributo | Por defecto | Descripción |
|---|---|---|
|
| %H:%M:%S.N |
Formato que utilizará el clúster al enviar la marca de tiempo del evento al agente. Se trata de una cadena como la que se utiliza con el comando |
|
| 30s | Si el agente de alerta no se completa dentro de este tiempo, se terminará. |
El siguiente ejemplo configura una alerta que llama al script myscript.sh y luego añade dos destinatarios a la alerta. El primer destinatario tiene un ID de my-alert-recipient1 y el segundo tiene un ID de my-alert-recipient2. El script será llamado dos veces para cada evento, con cada llamada usando un tiempo de espera de 15 segundos. Una llamada se pasará al destinatario someuser@example.com con una marca de tiempo en el formato %H:%M, mientras que la otra llamada se pasará al destinatario otheruser@example.com con una marca de tiempo en el formato
#pcs alert create id=my-alert path=/path/to/myscript.sh meta timeout=15s#pcs alert recipient add my-alert value=someuser@example.com id=my-alert-recipient1 meta timestamp-format="%D %H:%M"#pcs alert recipient add my-alert value=otheruser@example.com id=my-alert-recipient2 meta timestamp-format="%c"
26.6. Ejemplos de comandos de configuración de alertas
Los siguientes ejemplos secuenciales muestran algunos comandos básicos de configuración de alertas para mostrar el formato a utilizar para crear alertas, añadir destinatarios y mostrar las alertas configuradas.
Tenga en cuenta que, si bien debe instalar los agentes de alerta en sí en cada nodo de un clúster, sólo debe ejecutar los comandos de pcs una vez.
Los siguientes comandos crean una alerta simple, añaden dos destinatarios a la alerta y muestran los valores configurados.
-
Como no se especifica ningún valor de ID de alerta, el sistema crea un valor de ID de alerta de
alert. -
El primer comando de creación de destinatarios especifica un destinatario de
rec_value. Como este comando no especifica un ID de destinatario, se utiliza el valor dealert-recipientcomo ID de destinatario. -
El segundo comando de creación de destinatario especifica un destinatario de
rec_value2. Este comando especifica un ID de destinatario demy-recipientpara el destinatario.
#pcs alert create path=/my/path#pcs alert recipient add alert value=rec_value#pcs alert recipient add alert value=rec_value2 id=my-recipient#pcs alert configAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2)
Los siguientes comandos añaden una segunda alerta y un destinatario para esa alerta. El ID de la segunda alerta es my-alert y el valor del destinatario es my-other-recipient. Como no se especifica ningún ID de destinatario, el sistema proporciona un ID de destinatario de my-alert-recipient.
#pcs alert create id=my-alert path=/path/to/script description=alert_description options option1=value1 opt=val meta timeout=50s timestamp-format="%H%B%S"#pcs alert recipient add my-alert value=my-other-recipient#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=value1 Meta options: timestamp-format=%H%B%S timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient)
Los siguientes comandos modifican los valores de la alerta my-alert y del destinatario my-alert-recipient.
#pcs alert update my-alert options option1=newvalue1 meta timestamp-format="%H%M%S"#pcs alert recipient update my-alert-recipient options option1=new meta timeout=60s#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=newvalue1 Meta options: timestamp-format=%H%M%S timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient) Options: option1=new Meta options: timeout=60s
El siguiente comando elimina el destinatario my-alert-recipient de alert.
#pcs alert recipient remove my-recipient#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=newvalue1 Meta options: timestamp-format="%M%B%S" timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient) Options: option1=new Meta options: timeout=60s
El siguiente comando elimina myalert de la configuración.
#pcs alert remove myalert#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value)
26.7. Escribir un agente de alerta
Hay tres tipos de alertas de Pacemaker: alertas de nodo, alertas de cercado y alertas de recursos. Las variables de entorno que se pasan a los agentes de alerta pueden variar, dependiendo del tipo de alerta. Tabla 26.2, “Variables de entorno transmitidas a los agentes de alerta” describe las variables de entorno que se pasan a los agentes de alerta y especifica cuándo la variable de entorno está asociada a un tipo de alerta específico.
| Variable de entorno | Descripción |
|---|---|
|
| El tipo de alerta (nodo, cercado o recurso) |
|
| La versión de Pacemaker que envía la alerta |
|
| El destinatario configurado |
|
| Un número de secuencia que se incrementa cada vez que se emite una alerta en el nodo local, que puede utilizarse para referenciar el orden en el que Pacemaker ha emitido las alertas. Una alerta para un evento que ocurrió más tarde en el tiempo tiene confiablemente un número de secuencia más alto que las alertas para eventos anteriores. Tenga en cuenta que este número no tiene ningún significado en todo el clúster. |
|
|
Una marca de tiempo creada antes de ejecutar el agente, en el formato especificado por la opción meta |
|
| Nombre del nodo afectado |
|
|
Detalle del evento. Para las alertas de nodo, es el estado actual del nodo (miembro o perdido). Para las alertas de esgrima, es un resumen de la operación de esgrima solicitada, incluyendo el origen, el objetivo y el código de error de la operación de esgrima, si lo hay. Para las alertas de recursos, se trata de una cadena legible equivalente a |
|
| ID del nodo cuyo estado ha cambiado (sólo se proporciona con las alertas de nodo) |
|
| La operación de cercado o de recursos solicitada (sólo se proporciona con las alertas de cercado y de recursos) |
|
| El código numérico de retorno de la operación de esgrima o de recursos (sólo se proporciona con las alertas de esgrima y de recursos) |
|
| El nombre del recurso afectado (sólo alertas de recursos) |
|
| El intervalo de la operación de recursos (sólo alertas de recursos) |
|
| El código de retorno numérico esperado de la operación (sólo alertas de recursos) |
|
| Un código numérico utilizado por Pacemaker para representar el resultado de la operación (sólo alertas de recursos) |
A la hora de redactar un agente de alerta, hay que tener en cuenta los siguientes aspectos.
- Los agentes de alerta pueden ser llamados sin destinatario (si no está configurado ninguno), por lo que el agente debe ser capaz de manejar esta situación, aunque sólo salga en ese caso. Los usuarios pueden modificar la configuración por etapas, y añadir un destinatario más tarde.
- Si se configura más de un destinatario para una alerta, el agente de alerta será llamado una vez por cada destinatario. Si un agente no puede ejecutarse simultáneamente, debe configurarse con un solo destinatario. Sin embargo, el agente es libre de interpretar el destinatario como una lista.
- Cuando se produce un evento de cluster, todas las alertas se disparan al mismo tiempo como procesos separados. Dependiendo de cuántas alertas y destinatarios se configuren y de lo que se haga dentro de los agentes de alertas, puede producirse una explosión de carga significativa. El agente podría escribirse para tener esto en cuenta, por ejemplo, poniendo en cola las acciones que consumen muchos recursos en alguna otra instancia, en lugar de ejecutarlas directamente.
-
Los agentes de alerta se ejecutan como el usuario
hacluster, que tiene un conjunto mínimo de permisos. Si un agente requiere privilegios adicionales, se recomienda configurarsudopara permitir que el agente ejecute los comandos necesarios como otro usuario con los privilegios adecuados. -
Tenga cuidado de validar y sanear los parámetros configurados por el usuario, como
CRM_alert_timestamp(cuyo contenido está especificado por el usuariotimestamp-format),CRM_alert_recipient, y todas las opciones de alerta. Esto es necesario para protegerse de los errores de configuración. Además, si algún usuario puede modificar el CIB sin tenerhacluster-nivel de acceso a los nodos del clúster, esto es una preocupación potencial de seguridad también, y usted debe evitar la posibilidad de inyección de código. -
Si un clúster contiene recursos con operaciones para las que el parámetro
on-failestá configurado comofence, habrá múltiples notificaciones de valla en caso de fallo, una por cada recurso para el que esté configurado este parámetro más una notificación adicional. Tantopacemaker-fencedcomopacemaker-controldenviarán notificaciones. Sin embargo, Pacemaker sólo realiza una operación de valla real en este caso, sin importar cuántas notificaciones se envíen.
La interfaz de alertas está diseñada para ser compatible con la interfaz de scripts externos utilizada por el recurso ocf:pacemaker:ClusterMon. Para preservar esta compatibilidad, las variables de entorno que se pasan a los agentes de alertas están disponibles precedidas de CRM_notify_ así como de CRM_alert_. Una ruptura en la compatibilidad es que el recurso ClusterMon ejecutaba los scripts externos como el usuario root, mientras que los agentes de alerta se ejecutan como el usuario hacluster.
Capítulo 27. Configuración de clusters multisitio con Pacemaker
Cuando un clúster abarca más de un sitio, los problemas de conectividad de red entre los sitios pueden llevar a situaciones de cerebro dividido. Cuando la conectividad se cae, no hay manera de que un nodo en un sitio determine si un nodo en otro sitio ha fallado o sigue funcionando con un interlink de sitio fallado. Además, puede ser problemático proporcionar servicios de alta disponibilidad en dos sitios que están demasiado alejados para mantener la sincronización.
Para solucionar estos problemas, Pacemaker ofrece una compatibilidad total con la capacidad de configurar clústeres de alta disponibilidad que abarcan varios sitios mediante el uso de un gestor de tickets de clústeres de Booth.
27.1. Visión general del gestor de tickets del clúster Booth
El Booth ticket manager es un servicio distribuido que está pensado para ejecutarse en una red física diferente a las redes que conectan los nodos del clúster en sitios concretos. Produce otro clúster suelto, un Booth formation, que se sitúa encima de los clústeres regulares de los sitios. Esta capa de comunicación agregada facilita los procesos de decisión basados en el consenso para las entradas individuales de Booth.
Una cabina ticket es un singleton en la formación de la cabina y representa una unidad de autorización temporal y móvil. Los recursos pueden configurarse para que requieran un determinado ticket para ejecutarse. Esto puede garantizar que los recursos se ejecuten sólo en un sitio a la vez, para el que se ha concedido un ticket o tickets.
Se puede pensar en una formación Booth como un clúster superpuesto que consiste en clústeres que se ejecutan en diferentes sitios, donde todos los clústeres originales son independientes entre sí. Es el servicio Booth el que comunica a los clusters si se les ha concedido un ticket, y es Pacemaker el que determina si se ejecutan recursos en un cluster basándose en una restricción de ticket de Pacemaker. Esto significa que cuando se utiliza el gestor de tickets, cada uno de los clusters puede ejecutar sus propios recursos, así como los recursos compartidos. Por ejemplo, puede haber recursos A, B y C que se ejecuten sólo en un clúster, recursos D, E y F que se ejecuten sólo en el otro clúster, y recursos G y H que se ejecuten en cualquiera de los dos clústeres según lo determine un ticket. También es posible tener un recurso adicional J que podría ejecutarse en cualquiera de los dos clústeres según lo determinado por un ticket separado.
27.2. Configuración de clusters multisitio con Pacemaker
El siguiente procedimiento proporciona un resumen de los pasos que se siguen para configurar una configuración multisitio que utiliza el gestor de tickets de Booth.
Estos comandos de ejemplo utilizan la siguiente disposición:
-
El clúster 1 está formado por los nodos
cluster1-node1ycluster1-node2 - El cluster 1 tiene asignada una dirección IP flotante de 192.168.11.100
-
El grupo 2 está formado por
cluster2-node1ycluster2-node2 - El clúster 2 tiene asignada una dirección IP flotante de 192.168.22.100
-
El nodo árbitro es
arbitrator-nodecon una dirección ip de 192.168.99.100 -
El nombre del ticket de Booth que utiliza esta configuración es
apacheticket
Estos comandos de ejemplo asumen que los recursos de cluster para un servicio Apache han sido configurados como parte del grupo de recursos apachegroup para cada cluster. No es necesario que los recursos y los grupos de recursos sean los mismos en cada clúster para configurar una restricción de tickets para esos recursos, ya que la instancia de Pacemaker para cada clúster es independiente, pero ese es un escenario común de conmutación por error.
Tenga en cuenta que en cualquier momento del procedimiento de configuración puede introducir el comando pcs booth config para mostrar la configuración de booth para el nodo o clúster actual o el comando pcs booth status para mostrar el estado actual de booth en el nodo local.
Instale el paquete
booth-siteBooth ticket manager en cada nodo de ambos clusters.[root@cluster1-node1 ~]#
yum install -y booth-site[root@cluster1-node2 ~]#yum install -y booth-site[root@cluster2-node1 ~]#yum install -y booth-site[root@cluster2-node2 ~]#yum install -y booth-siteInstale los paquetes
pcs,booth-core, ybooth-arbitratoren el nodo árbitro.[root@arbitrator-node ~]#
yum install -y pcs booth-core booth-arbitratorSi está ejecutando el demonio
firewalld, ejecute los siguientes comandos en todos los nodos de ambos clústeres así como en el nodo árbitro para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.#
firewall-cmd --permanent --add-service=high-availability` #firewall-cmd --add-service=high-availability`Es posible que tenga que modificar los puertos que están abiertos para adaptarse a las condiciones locales. Para más información sobre los puertos requeridos por el complemento de alta disponibilidad de Red Hat, consulte Habilitación de puertos para el complemento de alta disponibilidad.
Cree una configuración de Booth en un nodo de un cluster. Las direcciones que especifique para cada clúster y para el árbitro deben ser direcciones IP. Para cada clúster, se especifica una dirección IP flotante.
[cluster1-node1 ~] #
pcs booth setup sites 192.168.11.100 192.168.22.100 arbitrators 192.168.99.100Este comando crea los archivos de configuración
/etc/booth/booth.confy/etc/booth/booth.keyen el nodo desde el que se ejecuta.Cree un ticket para la configuración de Booth. Este es el ticket que utilizará para definir la restricción de recursos que permitirá que los recursos se ejecuten solo cuando este ticket se haya concedido al clúster.
Este procedimiento básico de configuración de la conmutación por error utiliza sólo un ticket, pero puede crear tickets adicionales para escenarios más complicados en los que cada ticket esté asociado a un recurso o recursos diferentes.
[cluster1-node1 ~] #
pcs booth ticket add apacheticketSincronizar la configuración de Booth en todos los nodos del clúster actual.
[cluster1-node1 ~] #
pcs booth syncDesde el nodo del árbitro, extraiga la configuración de Booth al árbitro. Si no lo ha hecho previamente, debe autenticar primero
pcsen el nodo desde el que está extrayendo la configuración.[arbitrator-node ~] #
pcs host auth cluster1-node1[arbitrator-node ~] #pcs booth pull cluster1-node1Extraiga la configuración de Booth al otro clúster y sincronice a todos los nodos de ese clúster. Al igual que con el nodo árbitro, si no lo ha hecho previamente, debe autenticar primero
pcsen el nodo del que está tirando la configuración.[cluster2-node1 ~] #
pcs host auth cluster1-node1[cluster2-node1 ~] #pcs booth pull cluster1-node1[cluster2-node1 ~] #pcs booth syncIniciar y habilitar Booth en el árbitro.
NotaNo debe iniciar o habilitar manualmente Booth en ninguno de los nodos de los clusters, ya que Booth se ejecuta como un recurso de Pacemaker en esos clusters.
[arbitrator-node ~] #
pcs booth start[arbitrator-node ~] #pcs booth enableConfigure Booth para que se ejecute como un recurso de clúster en ambos sitios de clúster. Esto crea un grupo de recursos con
booth-ipybooth-servicecomo miembros de ese grupo.[cluster1-node1 ~] #
pcs booth create ip 192.168.11.100[cluster2-node1 ~] #pcs booth create ip 192.168.22.100Añade una restricción de ticket al grupo de recursos que has definido para cada clúster.
[cluster1-node1 ~] #
pcs constraint ticket add apacheticket apachegroup[cluster2-node1 ~] #pcs constraint ticket add apacheticket apachegroupPuede introducir el siguiente comando para mostrar las restricciones de billetes actualmente configuradas.
pcs constraint ticket [show]
Conceda el ticket que creó para esta configuración al primer clúster.
Tenga en cuenta que no es necesario haber definido las restricciones de los tickets antes de concederlos. Una vez que haya concedido inicialmente un ticket a un clúster, Booth se encarga de la gestión de los tickets a menos que lo anule manualmente con el comando
pcs booth ticket revoke. Para obtener información sobre los comandos de administración depcs booth, consulte la pantalla de ayuda de PCS para el comandopcs booth.[cluster1-node1 ~] #
pcs booth ticket grant apacheticket
Es posible añadir o eliminar tickets en cualquier momento, incluso después de completar este procedimiento. Sin embargo, después de añadir o eliminar un ticket, debe sincronizar los archivos de configuración con los otros nodos y clústeres, así como con el árbitro, y conceder el ticket como se muestra en este procedimiento.
Para obtener información sobre otros comandos de administración de Booth que puede utilizar para limpiar y eliminar archivos de configuración, tickets y recursos de Booth, consulte la pantalla de ayuda de PCS para el comando pcs booth.
Capítulo 28. Integración de nodos no sincronizados en un clúster: el servicio pacemaker_remote
El servicio pacemaker_remote permite que los nodos que no ejecutan corosync se integren en el clúster y que éste gestione sus recursos como si fueran nodos reales del clúster.
Entre las capacidades que ofrece el servicio pacemaker_remote se encuentran las siguientes:
-
El servicio
pacemaker_remotele permite escalar más allá del límite de soporte de Red Hat de 32 nodos para RHEL 8.1. -
El servicio
pacemaker_remotepermite gestionar un entorno virtual como recurso de cluster y también gestionar servicios individuales dentro del entorno virtual como recursos de cluster.
Los siguientes términos se utilizan para describir el servicio pacemaker_remote.
- cluster node
- remote node
- guest node
- pacemaker_remote
Un cluster Pacemaker que ejecuta el servicio pacemaker_remote tiene las siguientes características.
-
Los nodos remotos y los nodos invitados ejecutan el servicio
pacemaker_remote(con muy poca configuración necesaria en el lado de la máquina virtual). -
La pila del clúster (
pacemakerycorosync), que se ejecuta en los nodos del clúster, se conecta al serviciopacemaker_remoteen los nodos remotos, lo que les permite integrarse en el clúster. -
La pila del clúster (
pacemakerycorosync), que se ejecuta en los nodos del clúster, lanza los nodos invitados y se conecta inmediatamente al serviciopacemaker_remoteen los nodos invitados, permitiéndoles integrarse en el clúster.
La diferencia clave entre los nodos del clúster y los nodos remotos e invitados que gestionan los nodos del clúster es que los nodos remotos e invitados no están ejecutando la pila del clúster. Esto significa que los nodos remotos e invitados tienen las siguientes limitaciones:
- no tienen lugar en el quórum
- no ejecutan las acciones del dispositivo de esgrima
- no son elegibles para ser el controlador designado (DC) de la agrupación
-
no ejecutan por sí mismos toda la gama de comandos de
pcs
Por otro lado, los nodos remotos y los nodos invitados no están sujetos a los límites de escalabilidad asociados a la pila del clúster.
Aparte de estas limitaciones, los nodos remotos e invitados se comportan igual que los nodos del clúster en lo que respecta a la gestión de recursos, y los propios nodos remotos e invitados pueden ser cercados. El clúster es totalmente capaz de gestionar y supervisar los recursos de cada nodo remoto e invitado: Puede crear restricciones contra ellos, ponerlos en espera o realizar cualquier otra acción que realice en los nodos del clúster con los comandos pcs. Los nodos remotos e invitados aparecen en la salida del estado del clúster igual que los nodos del clúster.
28.1. Autenticación de host y guest de los nodos pacemaker_remote
La conexión entre los nodos del clúster y pacemaker_remote está asegurada mediante Transport Layer Security (TLS) con cifrado de clave precompartida (PSK) y autenticación a través de TCP (utilizando el puerto 3121 por defecto). Esto significa que tanto el nodo del clúster como el nodo que ejecuta pacemaker_remote deben compartir la misma clave privada. Por defecto, esta clave debe colocarse en /etc/pacemaker/authkey tanto en los nodos del clúster como en los nodos remotos.
El comando pcs cluster node add-guest configura el authkey para los nodos invitados y el comando pcs cluster node add-remote configura el authkey para los nodos remotos.
28.2. Configuración de los nodos invitados KVM
Un nodo invitado de Pacemaker es un nodo invitado virtual que ejecuta el servicio pacemaker_remote. El nodo invitado virtual es gestionado por el clúster.
28.2.1. Opciones de recursos del nodo invitado
Al configurar una máquina virtual para que actúe como nodo invitado, se crea un recurso VirtualDomain, que gestiona la máquina virtual. Para ver las descripciones de las opciones que puede establecer para un recurso VirtualDomain, consulte Tabla 24.1, “Opciones de recursos para los recursos del dominio virtual”.
Además de las opciones del recurso VirtualDomain, las opciones de metadatos definen el recurso como nodo invitado y definen los parámetros de conexión. Estas opciones de recursos se establecen con el comando pcs cluster node add-guest. Tabla 28.1, “Opciones de metadatos para configurar recursos KVM como nodos remotos” describe estas opciones de metadatos.
| Campo | Por defecto | Descripción |
|---|---|---|
|
| <one> | El nombre del nodo invitado que define este recurso. Esto habilita el recurso como nodo invitado y define el nombre único utilizado para identificar el nodo invitado. WARNING: Este valor no puede solaparse con ningún recurso o ID de nodo. |
|
| 3121 |
Configura un puerto personalizado para utilizar la conexión de invitados a |
|
|
La dirección proporcionada en el comando | La dirección IP o el nombre de host al que conectarse |
|
| 60s | Cantidad de tiempo antes de que se agote el tiempo de una conexión pendiente de invitados |
28.2.2. Integración de una máquina virtual como nodo invitado
El siguiente procedimiento es un resumen de alto nivel de los pasos a realizar para que Pacemaker lance una máquina virtual e integre esa máquina como nodo invitado, utilizando libvirt y los invitados virtuales KVM.
-
Configure los recursos de
VirtualDomain. Introduzca los siguientes comandos en cada máquina virtual para instalar los paquetes de
pacemaker_remote, iniciar el serviciopcsdy permitir que se ejecute al inicio, y permitir el puerto TCP 3121 a través del cortafuegos.#
yum install pacemaker-remote resource-agents pcs#systemctl start pcsd.service#systemctl enable pcsd.service#firewall-cmd --add-port 3121/tcp --permanent#firewall-cmd --add-port 2224/tcp --permanent#firewall-cmd --reload- Dé a cada máquina virtual una dirección de red estática y un nombre de host único, que debe ser conocido por todos los nodos. Para obtener información sobre la configuración de una dirección IP estática para la máquina virtual invitada, consulte la sección Virtualization Deployment and Administration Guide.
Si aún no lo has hecho, autentifica
pcsen el nodo que vas a integrar como nodo de búsqueda.#
pcs host auth nodenameUtilice el siguiente comando para convertir un recurso existente de
VirtualDomainen un nodo invitado. Este comando debe ejecutarse en un nodo del clúster y no en el nodo invitado que se está añadiendo. Además de convertir el recurso, este comando copia el/etc/pacemaker/authkeyal nodo invitado e inicia y habilita el demoniopacemaker_remoteen el nodo invitado. El nombre del nodo invitado, que se puede definir de forma arbitraria, puede diferir del nombre del host del nodo.#
pcs cluster node add-guest nodename resource_id[options]Después de crear el recurso
VirtualDomain, puede tratar el nodo invitado como trataría cualquier otro nodo del clúster. Por ejemplo, puede crear un recurso y colocar una restricción de recursos para que se ejecute en el nodo invitado, como en los siguientes comandos, que se ejecutan desde un nodo del clúster. Puede incluir nodos invitados en grupos, lo que le permite agrupar un dispositivo de almacenamiento, un sistema de archivos y una máquina virtual.#
pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s#pcs constraint location webserver prefersnodename
28.3. Configuración de los nodos remotos de Pacemaker
Un nodo remoto se define como un recurso de cluster con ocf:pacemaker:remote como agente de recursos. Este recurso se crea con el comando pcs cluster node add-remote.
28.3.1. Opciones de recursos del nodo remoto
Tabla 28.2, “Opciones de recursos para nodos remotos” describe las opciones de recursos que puede configurar para un recurso remote.
| Campo | Por defecto | Descripción |
|---|---|---|
|
| 0 | Tiempo en segundos para esperar antes de intentar reconectarse a un nodo remoto después de que se haya cortado una conexión activa con el nodo remoto. Esta espera es recurrente. Si la reconexión falla después del período de espera, se realizará un nuevo intento de reconexión después de observar el tiempo de espera. Cuando se utiliza esta opción, Pacemaker seguirá intentando alcanzar y conectar con el nodo remoto indefinidamente después de cada intervalo de espera. |
|
|
Dirección especificada con el comando | Servidor al que conectarse. Puede ser una dirección IP o un nombre de host. |
|
| Puerto TCP al que conectarse. |
28.3.2. Resumen de la configuración del nodo remoto
Esta sección proporciona un resumen de alto nivel de los pasos a realizar para configurar un nodo Pacemaker Remote e integrar ese nodo en un entorno de cluster Pacemaker existente.
En el nodo que va a configurar como nodo remoto, permita los servicios relacionados con el cluster a través del firewall local.
#
firewall-cmd --permanent --add-service=high-availabilitysuccess #firewall-cmd --reloadsuccessNotaSi está usando
iptablesdirectamente, o alguna otra solución de firewall además defirewalld, simplemente abra los siguientes puertos: Puertos TCP 2224 y 3121.Instale el demonio
pacemaker_remoteen el nodo remoto.#
yum install -y pacemaker-remote resource-agents pcsInicie y habilite
pcsden el nodo remoto.#
systemctl start pcsd.service#systemctl enable pcsd.serviceSi aún no lo ha hecho, autentique
pcsen el nodo que va a añadir como nodo remoto.#
pcs host auth remote1Añade el recurso del nodo remoto al clúster con el siguiente comando. Este comando también sincroniza todos los archivos de configuración relevantes con el nuevo nodo, arranca el nodo y lo configura para iniciar
pacemaker_remoteen el arranque. Este comando debe ejecutarse en un nodo del clúster y no en el nodo remoto que se está añadiendo.#
pcs cluster node add-remote remote1Después de añadir el recurso
remoteal clúster, puede tratar el nodo remoto igual que trataría cualquier otro nodo del clúster. Por ejemplo, puede crear un recurso y colocar una restricción de recursos para que se ejecute en el nodo remoto, como en los siguientes comandos, que se ejecutan desde un nodo del clúster.#
pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s#pcs constraint location webserver prefers remote1AvisoNunca incluya un recurso de conexión de nodo remoto en un grupo de recursos, restricción de colocación o restricción de orden.
- Configure los recursos de cercado para el nodo remoto. Los nodos remotos se cercan de la misma manera que los nodos de cluster. Configure los recursos de esgrima para su uso con los nodos remotos de la misma manera que lo haría con los nodos del clúster. Sin embargo, tenga en cuenta que los nodos remotos nunca pueden iniciar una acción de esgrima. Sólo los nodos del clúster son capaces de ejecutar una operación de cercado contra otro nodo.
28.4. Cambiar la ubicación del puerto por defecto
Si necesita cambiar la ubicación del puerto por defecto para Pacemaker o pacemaker_remote, puede establecer la variable de entorno PCMK_remote_port que afecta a ambos demonios. Esta variable de entorno se puede habilitar colocándola en el archivo /etc/sysconfig/pacemaker de la siguiente manera.
====# Pacemaker Remote
...
#
# Specify a custom port for Pacemaker Remote connections
PCMK_remote_port=3121
Cuando se cambia el puerto por defecto utilizado por un nodo invitado o un nodo remoto en particular, la variable PCMK_remote_port debe establecerse en el archivo /etc/sysconfig/pacemaker de ese nodo, y el recurso del clúster que crea la conexión del nodo invitado o del nodo remoto también debe configurarse con el mismo número de puerto (utilizando la opción de metadatos remote-port para los nodos invitados, o la opción port para los nodos remotos).
28.5. Actualización de sistemas con nodos pacemaker_remote
Si el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, el clúster migrará con gracia los recursos del nodo antes de detenerlo. Esto le permite realizar actualizaciones de software y otros procedimientos de mantenimiento rutinarios sin retirar el nodo del clúster. Sin embargo, una vez que se apague pacemaker_remote, el clúster intentará reconectarse inmediatamente. Si pacemaker_remote no se reinicia dentro del tiempo de espera de monitorización del recurso, el clúster considerará la operación de monitorización como fallida.
Si desea evitar fallos de monitorización cuando el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, puede utilizar el siguiente procedimiento para sacar el nodo del clúster antes de realizar cualquier administración del sistema que pueda detener pacemaker_remote
-
Detenga el recurso de conexión del nodo con el botón
pcs resource disable resourcenameque moverá todos los servicios fuera del nodo. Para los nodos invitados, esto también detendrá la VM, por lo que la VM debe iniciarse fuera del clúster (por ejemplo, utilizandovirsh) para realizar cualquier mantenimiento. - Realice el mantenimiento necesario.
-
Cuando esté listo para devolver el nodo al clúster, vuelva a habilitar el recurso con el botón
pcs resource enable.
Capítulo 29. Realizar el mantenimiento del clúster
Para realizar el mantenimiento de los nodos de su clúster, es posible que tenga que detener o mover los recursos y servicios que se ejecutan en ese clúster. O puede que tenga que detener el software del clúster dejando los servicios intactos. Pacemaker proporciona una variedad de métodos para realizar el mantenimiento del sistema.
- Si necesita detener un nodo de un clúster mientras continúa proporcionando los servicios que se ejecutan en ese clúster en otro nodo, puede poner el nodo del clúster en modo de espera. Un nodo que está en modo de espera ya no puede alojar recursos. Cualquier recurso actualmente activo en el nodo se moverá a otro nodo, o se detendrá si ningún otro nodo es elegible para ejecutar el recurso. Para obtener información sobre el modo de espera, consulte Poner un nodo en modo de espera.
Si necesita mover un recurso individual fuera del nodo en el que se está ejecutando actualmente sin detener ese recurso, puede utilizar el comando
pcs resource movepara mover el recurso a un nodo diferente. Para obtener información sobre el comandopcs resource move, consulte Mover manualmente los recursos del clúster.Cuando se ejecuta el comando
pcs resource move, se añade una restricción al recurso para evitar que se ejecute en el nodo en el que se está ejecutando actualmente. Cuando esté listo para volver a mover el recurso, puede ejecutar el comandopcs resource clearopcs constraint deletepara eliminar la restricción. Sin embargo, esto no necesariamente mueve los recursos de vuelta al nodo original, ya que el lugar donde los recursos pueden ejecutarse en ese momento depende de cómo hayas configurado tus recursos inicialmente. Puede reubicar un recurso en su nodo preferido con el comandopcs resource relocate run, como se describe en Mover un recurso a su nodo preferido.-
Si necesita detener un recurso en ejecución por completo y evitar que el clúster lo vuelva a iniciar, puede utilizar el comando
pcs resource disable. Para obtener información sobre el comandopcs resource disable, consulte Activación, desactivación y prohibición de recursos del clúster. -
Si desea evitar que Pacemaker realice alguna acción para un recurso (por ejemplo, si desea desactivar las acciones de recuperación mientras se realiza el mantenimiento del recurso, o si necesita recargar la configuración de
/etc/sysconfig/pacemaker), utilice el comandopcs resource unmanage, como se describe en Cómo poner un recurso en modo no gestionado. Los recursos de conexión de Pacemaker Remote nunca deben estar sin gestionar. -
Si necesita poner el clúster en un estado en el que no se inicie ni se detenga ningún servicio, puede establecer la propiedad de clúster
maintenance-mode. Al poner el clúster en modo de mantenimiento, se deshabilitan automáticamente todos los recursos. Para obtener información sobre cómo poner el clúster en modo de mantenimiento, consulte Poner un clúster en modo de mantenimiento. - Si necesita actualizar los paquetes que componen los complementos RHEL High Availability y Resilient Storage, puede actualizar los paquetes en un nodo a la vez o en todo el cluster como un todo, como se resume en Actualización de un cluster de alta disponibilidad de Red Hat Enterprise Linux.
- Si necesita realizar tareas de mantenimiento en un nodo remoto de Pacemaker, puede eliminar ese nodo del clúster desactivando el recurso del nodo remoto, como se describe en Actualización de nodos remotos y nodos invitados.
29.1. Poner un nodo en modo de espera
Cuando un nodo del clúster está en modo de espera, el nodo ya no puede albergar recursos. Cualquier recurso actualmente activo en el nodo será trasladado a otro nodo.
El siguiente comando pone el nodo especificado en modo de espera. Si se especifica el --all, este comando pone todos los nodos en modo de espera.
Puedes utilizar este comando cuando actualices los paquetes de un recurso. También se puede utilizar este comando al probar una configuración, para simular la recuperación sin apagar realmente un nodo.
pcs nodo standby node | --all
El siguiente comando elimina el nodo especificado del modo de espera. Después de ejecutar este comando, el nodo especificado podrá alojar recursos. Si se especifica el --all, este comando elimina todos los nodos del modo de espera.
pcs node unstandby node | --all
Tenga en cuenta que cuando ejecuta el comando pcs node standby, esto impide que los recursos se ejecuten en el nodo indicado. Cuando se ejecuta el comando pcs node unstandby, se permite que los recursos se ejecuten en el nodo indicado. Esto no mueve necesariamente los recursos de vuelta al nodo indicado; dónde pueden ejecutarse los recursos en ese momento depende de cómo hayas configurado tus recursos inicialmente.
29.2. Mover manualmente los recursos del clúster
Puede anular el clúster y forzar que los recursos se muevan de su ubicación actual. Hay dos ocasiones en las que querrás hacer esto:
- Cuando un nodo está en mantenimiento, y necesita mover todos los recursos que se ejecutan en ese nodo a un nodo diferente
- Cuando hay que mover recursos especificados individualmente
Para trasladar todos los recursos que se ejecutan en un nodo a otro nodo, se pone el nodo en modo de espera.
Puede mover los recursos especificados individualmente de cualquiera de las siguientes maneras.
-
Puede utilizar el comando
pcs resource movepara mover un recurso fuera de un nodo en el que se está ejecutando actualmente. -
Puede utilizar el comando
pcs resource relocate runpara mover un recurso a su nodo preferido, según el estado actual del clúster, las restricciones, la ubicación de los recursos y otras configuraciones.
29.2.1. Mover un recurso de su nodo actual
Para mover un recurso fuera del nodo en el que se está ejecutando actualmente, utilice el siguiente comando, especificando el resource_id del recurso tal y como está definido. Especifique la dirección destination_node si desea indicar en qué nodo debe ejecutarse el recurso que está moviendo.
pcs resource move resource_id [destination_node] [--master] [lifetime=lifetime]
Cuando se ejecuta el comando pcs resource move, se añade una restricción al recurso para evitar que se ejecute en el nodo en el que se está ejecutando actualmente. Puede ejecutar el comando pcs resource clear o pcs constraint delete para eliminar la restricción. Esto no necesariamente mueve los recursos de vuelta al nodo original; dónde pueden ejecutarse los recursos en ese momento depende de cómo hayas configurado tus recursos inicialmente.
Si especifica el parámetro --master del comando pcs resource move, el alcance de la restricción se limita al rol maestro y debe especificar master_id en lugar de resource_id.
Opcionalmente, puede configurar un parámetro lifetime para el comando pcs resource move para indicar un período de tiempo que la restricción debe permanecer. Las unidades de un parámetro lifetime se especifican según el formato definido en la norma ISO 8601, que requiere que se especifique la unidad como una letra mayúscula como Y (para años), M (para meses), W (para semanas), D (para días), H (para horas), M (para minutos) y S (para segundos).
Para distinguir una unidad de minutos(M) de una unidad de meses(M), debe especificar PT antes de indicar el valor en minutos. Por ejemplo, un parámetro lifetime de 5M indica un intervalo de cinco meses, mientras que un parámetro lifetime de PT5M indica un intervalo de cinco minutos.
El parámetro lifetime se comprueba a intervalos definidos por la propiedad de cluster cluster-recheck-interval. Por defecto este valor es de 15 minutos. Si su configuración requiere que compruebe este parámetro con más frecuencia, puede restablecer este valor con el siguiente comando.
pcs property set cluster-recheck-interval=value
Opcionalmente se puede configurar un parámetro --wait[=n] para el comando pcs resource move para indicar el número de segundos que se debe esperar para que el recurso se inicie en el nodo de destino antes de devolver 0 si el recurso se ha iniciado o 1 si el recurso aún no se ha iniciado. Si no se especifica n, se utilizará el tiempo de espera del recurso por defecto.
El siguiente comando mueve el recurso resource1 al nodo example-node2 y evita que vuelva al nodo en el que se estaba ejecutando originalmente durante una hora y treinta minutos.
pcs resource move resource1 example-node2 lifetime=PT1H30M
El siguiente comando mueve el recurso resource1 al nodo example-node2 y evita que vuelva al nodo en el que se estaba ejecutando originalmente durante treinta minutos.
pcs resource move resource1 example-node2 lifetime=PT30M
29.2.2. Mover un recurso a su nodo preferido
Después de que un recurso se haya movido, ya sea debido a una conmutación por error o a que un administrador haya movido manualmente el nodo, no necesariamente se moverá de nuevo a su nodo original incluso después de que las circunstancias que causaron la conmutación por error se hayan corregido. Para reubicar los recursos en su nodo preferido, utilice el siguiente comando. El nodo preferido está determinado por el estado actual del clúster, las restricciones, la ubicación de los recursos y otras configuraciones, y puede cambiar con el tiempo.
pcs resource relocate run [resource1] [resource2] ...
Si no se especifica ningún recurso, todos los recursos se reubican en sus nodos preferidos.
Este comando calcula el nodo preferido para cada recurso sin tener en cuenta la rigidez de los recursos. Después de calcular el nodo preferido, crea restricciones de ubicación que harán que los recursos se muevan a sus nodos preferidos. Una vez que los recursos se han movido, las restricciones se eliminan automáticamente. Para eliminar todas las restricciones creadas por el comando pcs resource relocate run, puede introducir el comando pcs resource relocate clear. Para mostrar el estado actual de los recursos y su nodo óptimo ignorando la adherencia de los recursos, introduzca el comando pcs resource relocate show.
29.3. Desactivación, activación y prohibición de los recursos del clúster
Además de los comandos pcs resource move y pcs resource relocate, hay una variedad de otros comandos que puede utilizar para controlar el comportamiento de los recursos del clúster.
Desactivación de un recurso del clúster
Puede detener manualmente un recurso en ejecución y evitar que el clúster lo inicie de nuevo con el siguiente comando. Dependiendo del resto de la configuración (restricciones, opciones, fallos, etc.), el recurso puede permanecer iniciado. Si se especifica la opción --wait, pcs esperará hasta 'n' segundos para que el recurso se detenga y luego devolverá 0 si el recurso está detenido o 1 si el recurso no se ha detenido. Si no se especifica 'n', el valor por defecto es de 60 minutos.
pcs resource disable resource_id [--wait[=n]]
A partir de Red Hat Enterprise Linux 8.2, puede especificar que un recurso sea desactivado sólo si la desactivación del recurso no tendría un efecto sobre otros recursos. Asegurar que este sea el caso puede ser imposible de hacer a mano cuando se establecen relaciones complejas de recursos.
-
El comando
pcs resource disable --simulatemuestra los efectos de desactivar un recurso sin cambiar la configuración del cluster. -
El comando
pcs resource disable --safedeshabilita un recurso sólo si no hay otros recursos que se vean afectados de alguna manera, como por ejemplo, si se migra de un nodo a otro. El comandopcs resource safe-disablees un alias del comandopcs resource disable --safe. -
El comando
pcs resource disable --safe --no-strictdesactiva un recurso sólo si no se detienen o degradan otros recursos
Habilitación de un recurso de clúster
Utilice el siguiente comando para permitir que el clúster inicie un recurso. Dependiendo del resto de la configuración, el recurso puede permanecer detenido. Si especifica la opción --wait, pcs esperará hasta 'n' segundos para que el recurso se inicie y luego devolverá 0 si el recurso se ha iniciado o 1 si el recurso no se ha iniciado. Si no se especifica 'n', el valor por defecto es de 60 minutos.
pcs resource enable resource_id [--wait[=n]]
Impedir que un recurso se ejecute en un nodo concreto
Utilice el siguiente comando para evitar que un recurso se ejecute en un nodo especificado, o en el nodo actual si no se especifica ningún nodo.
pcs resource ban resource_id [node] [--master] [lifetime=lifetime] [--wait[=n]]
Tenga en cuenta que cuando ejecuta el comando pcs resource ban, éste añade una restricción de ubicación -INFINITY al recurso para evitar que se ejecute en el nodo indicado. Puede ejecutar el comando pcs resource clear o pcs constraint delete para eliminar la restricción. Esto no necesariamente mueve los recursos de vuelta al nodo indicado; dónde pueden ejecutarse los recursos en ese momento depende de cómo haya configurado sus recursos inicialmente.
Si especifica el parámetro --master del comando pcs resource ban, el alcance de la restricción se limita al rol maestro y debe especificar master_id en lugar de resource_id.
Opcionalmente, puede configurar un parámetro lifetime para el comando pcs resource ban para indicar un período de tiempo que la restricción debe permanecer.
Opcionalmente se puede configurar un parámetro --wait[=n] para el comando pcs resource ban para indicar el número de segundos que se debe esperar para que el recurso se inicie en el nodo de destino antes de devolver 0 si el recurso se ha iniciado o 1 si el recurso aún no se ha iniciado. Si no se especifica n, se utilizará el tiempo de espera del recurso por defecto.
Forzar el inicio de un recurso en el nodo actual
Utilice el parámetro debug-start del comando pcs resource para forzar el inicio de un recurso especificado en el nodo actual, ignorando las recomendaciones del clúster e imprimiendo la salida del inicio del recurso. Esto se utiliza principalmente para depurar recursos; el arranque de recursos en un cluster se realiza (casi) siempre por Pacemaker y no directamente con un comando pcs. Si su recurso no se inicia, normalmente se debe a una mala configuración del recurso (que se depura en el registro del sistema), a restricciones que impiden que el recurso se inicie o a que el recurso está deshabilitado. Puede utilizar este comando para probar la configuración de los recursos, pero normalmente no debería utilizarse para iniciar recursos en un clúster.
El formato del comando debug-start es el siguiente.
pcs resource debug-start resource_id29.4. Poner un recurso en modo no gestionado
Cuando un recurso está en modo unmanaged, el recurso sigue en la configuración pero Pacemaker no gestiona el recurso.
El siguiente comando establece los recursos indicados en el modo unmanaged.
pcs resource unmanage resource1 [resource2] ...
El siguiente comando pone los recursos en modo managed, que es el estado por defecto.
pcs resource manage resource1 [resource2] ...
Puede especificar el nombre de un grupo de recursos con el comando pcs resource manage o pcs resource unmanage. El comando actuará sobre todos los recursos del grupo, de modo que puede poner todos los recursos de un grupo en modo managed o unmanaged con un solo comando y luego gestionar los recursos contenidos individualmente.
29.5. Poner un clúster en modo de mantenimiento
Cuando un clúster está en modo de mantenimiento, el clúster no inicia ni detiene ningún servicio hasta que se le indique lo contrario. Cuando el modo de mantenimiento finaliza, el clúster realiza una comprobación del estado actual de los servicios y, a continuación, detiene o inicia los que lo necesiten.
Para poner un clúster en modo de mantenimiento, utilice el siguiente comando para establecer la propiedad del clúster maintenance-mode en true.
# pcs property set maintenance-mode=true
Para eliminar un clúster del modo de mantenimiento, utilice el siguiente comando para establecer la propiedad del clúster maintenance-mode en false.
# pcs property set maintenance-mode=falsePuede eliminar una propiedad del clúster de la configuración con el siguiente comando.
propiedad pcs unset property
Alternativamente, puede eliminar una propiedad del clúster de una configuración dejando en blanco el campo de valor del comando pcs property set. Esto restablece esa propiedad a su valor por defecto. Por ejemplo, si ha establecido previamente la propiedad symmetric-cluster a false, el siguiente comando elimina el valor que ha establecido de la configuración y restaura el valor de symmetric-cluster a true, que es su valor por defecto.
# pcs property set symmetric-cluster=29.6. Actualización de un clúster de alta disponibilidad RHEL
La actualización de los paquetes que componen los complementos RHEL High Availability y Resilient Storage, ya sea de forma individual o en su conjunto, puede realizarse de dos formas generales:
- Rolling Updates: Retirar del servicio un nodo a la vez, actualizar su software y volver a integrarlo en el clúster. Esto permite que el clúster siga prestando servicio y gestionando recursos mientras se actualiza cada nodo.
- Entire Cluster Update: Detenga todo el clúster, aplique las actualizaciones a todos los nodos y vuelva a iniciar el clúster.
Es crítico que cuando se realicen procedimientos de actualización de software para los clusters de Red Hat Enterprise LInux High Availability y Resilient Storage, se asegure de que cualquier nodo que vaya a sufrir actualizaciones no sea un miembro activo del cluster antes de que se inicien dichas actualizaciones.
Para obtener una descripción completa de cada uno de estos métodos y los procedimientos a seguir para las actualizaciones, consulte Prácticas recomendadas para aplicar actualizaciones de software a un clúster de alta disponibilidad o de almacenamiento resistente de RHEL.
29.7. Actualización de nodos remotos y nodos invitados
Si el servicio pacemaker_remote se detiene en un nodo remoto activo o en un nodo invitado, el clúster migrará con gracia los recursos del nodo antes de detenerlo. Esto permite realizar actualizaciones de software y otros procedimientos de mantenimiento rutinarios sin necesidad de retirar el nodo del clúster. Sin embargo, una vez que se apague pacemaker_remote, el clúster intentará reconectarse inmediatamente. Si pacemaker_remote no se reinicia dentro del tiempo de espera de monitorización del recurso, el clúster considerará la operación de monitorización como fallida.
Si desea evitar fallos de monitorización cuando el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, puede utilizar el siguiente procedimiento para sacar el nodo del clúster antes de realizar cualquier administración del sistema que pueda detener pacemaker_remote
-
Detenga el recurso de conexión del nodo con el botón
pcs resource disable resourcenameque moverá todos los servicios fuera del nodo. Para los nodos invitados, esto también detendrá la VM, por lo que la VM debe iniciarse fuera del clúster (por ejemplo, utilizandovirsh) para realizar cualquier mantenimiento. - Realice el mantenimiento necesario.
-
Cuando esté listo para devolver el nodo al clúster, vuelva a habilitar el recurso con el botón
pcs resource enable.
29.8. Migración de máquinas virtuales en un clúster RHEL
La información sobre las políticas de soporte para los clusters de alta disponibilidad de RHEL con miembros de clusters virtualizados se puede encontrar en Políticas de soporte para clusters de alta disponibilidad de RHEL - Condiciones generales con miembros de clusters virtualizados. Como se ha indicado, Red Hat no soporta la migración en vivo de nodos de cluster activos entre hipervisores o hosts. Si necesita realizar una migración en vivo, primero tendrá que detener los servicios de cluster en la VM para eliminar el nodo del cluster, y luego volver a iniciar el cluster después de realizar la migración. Los siguientes pasos describen el procedimiento para eliminar una máquina virtual de un clúster, migrar la máquina virtual y restaurar la máquina virtual en el clúster.
Este procedimiento se aplica a las máquinas virtuales que se utilizan como nodos de clúster completos, no a las máquinas virtuales gestionadas como recursos de clúster (incluidas las máquinas virtuales utilizadas como nodos invitados) que pueden migrarse en vivo sin precauciones especiales. Para obtener información general sobre el procedimiento más completo necesario para actualizar los paquetes que componen los complementos RHEL High Availability y Resilient Storage, ya sea individualmente o en conjunto, consulte Prácticas recomendadas para aplicar actualizaciones de software a un clúster RHEL High Availability o Resilient Storage.
Antes de realizar este procedimiento, considere el efecto que tiene la eliminación de un nodo del clúster sobre el quórum del mismo. Por ejemplo, si tiene un clúster de tres nodos y elimina un nodo, su clúster sólo puede soportar el fallo de un nodo más. Si un nodo de un clúster de tres nodos ya está caído, al eliminar un segundo nodo se perderá el quórum.
- Si es necesario realizar alguna preparación antes de detener o mover los recursos o el software que se ejecuta en la VM para migrar, realice esos pasos.
Ejecute el siguiente comando en la VM para detener el software de cluster en la VM.
#
pcs cluster stop- Realice la migración en vivo de la VM.
Inicie los servicios de cluster en la VM.
#
pcs cluster start
Capítulo 30. Configuración de clusters de recuperación de desastres
Un método para proporcionar recuperación de desastres para un clúster de alta disponibilidad es configurar dos clústeres. Puede configurar un clúster como su clúster de sitio primario, y el segundo clúster como su clúster de recuperación de desastres.
En circunstancias normales, el clúster primario está ejecutando los recursos en modo de producción. El clúster de recuperación de desastres también tiene todos los recursos configurados y los ejecuta en modo degradado o no los ejecuta en absoluto. Por ejemplo, puede haber una base de datos que se ejecute en el clúster primario en modo promocionado y que se ejecute en el clúster de recuperación de desastres en modo degradado. La base de datos en esta configuración estaría configurada para que los datos se sincronicen desde el sitio primario al de recuperación de desastres. Esto se hace a través de la propia configuración de la base de datos y no a través de la interfaz de comandos pcs.
Cuando el clúster primario se cae, los usuarios pueden utilizar la interfaz de comandos pcs para transferir manualmente los recursos al sitio de recuperación de desastres. A continuación, pueden iniciar sesión en el sitio de desastre y promover e iniciar los recursos allí. Una vez que el clúster primario se haya recuperado, los usuarios pueden utilizar la interfaz de comandos pcs para trasladar manualmente los recursos de vuelta al sitio primario.
A partir de Red Hat Enterprise Linux 8.2, puede utilizar el comando pcs para mostrar el estado del cluster del sitio primario y del de recuperación de desastres desde un solo nodo en cualquiera de los dos sitios.
30.1. Consideraciones sobre los clusters de recuperación de desastres
Cuando planifique y configure un sitio de recuperación de desastres que gestionará y supervisará con la interfaz de comandos pcs, tenga en cuenta las siguientes consideraciones.
- El sitio de recuperación de desastres debe ser un clúster. Esto permite configurarlo con las mismas herramientas y procedimientos similares a los del sitio primario.
-
Los clústeres primario y de recuperación de desastres se crean mediante comandos independientes de
pcs cluster setup. - Los clusters y sus recursos deben estar configurados para que los datos estén sincronizados y sea posible la conmutación por error.
- Los nodos del cluster en el sitio de recuperación no pueden tener los mismos nombres que los nodos del sitio primario.
-
El usuario pcs
haclusterdebe estar autenticado para cada nodo en ambos clusters en el nodo desde el que se ejecutarán los comandos depcs.
30.2. Visualización del estado de los clusters de recuperación (RHEL 8.2 y posteriores)
Para configurar un clúster primario y uno de recuperación de desastres de manera que pueda visualizar el estado de ambos clústeres, realice el siguiente procedimiento.
La configuración de un clúster de recuperación de desastres no configura automáticamente los recursos ni replica los datos. Esos elementos deben ser configurados manualmente por el usuario.
En este ejemplo:
-
El cluster primario se llamará
PrimarySitey estará formado por los nodosz1.example.com. yz2.example.com. -
El clúster del sitio de recuperación de desastres se llamará
DRsitey estará formado por los nodosz3.example.comyz4.example.com.
Este ejemplo configura un clúster básico sin recursos ni cercas configuradas.
Autenticar todos los nodos que se utilizarán para ambos clústeres.
[root@z1 ~]#
pcs host auth z1.example.com z2.example.com z3.example.com z4.example.com -u hacluster -p passwordz1.example.com: Authorized z2.example.com: Authorized z3.example.com: Authorized z4.example.com: AuthorizedCree el clúster que se utilizará como clúster primario e inicie los servicios de clúster para el clúster.
[root@z1 ~]#
pcs cluster setup PrimarySite z1.example.com z2.example.com --start{...} Cluster has been successfully set up. Starting cluster on hosts: 'z1.example.com', 'z2.example.com'...Cree el clúster que se utilizará como clúster de recuperación de desastres e inicie los servicios de clúster para el clúster.
[root@z1 ~]#
pcs cluster setup DRSite z3.example.com z4.example.com --start{...} Cluster has been successfully set up. Starting cluster on hosts: 'z3.example.com', 'z4.example.com'...Desde un nodo del clúster primario, configure el segundo clúster como sitio de recuperación. El sitio de recuperación se define con el nombre de uno de sus nodos.
[root@z1 ~]#
pcs dr set-recovery-site z3.example.comSending 'disaster-recovery config' to 'z3.example.com', 'z4.example.com' z3.example.com: successful distribution of the file 'disaster-recovery config' z4.example.com: successful distribution of the file 'disaster-recovery config' Sending 'disaster-recovery config' to 'z1.example.com', 'z2.example.com' z1.example.com: successful distribution of the file 'disaster-recovery config' z2.example.com: successful distribution of the file 'disaster-recovery config'Compruebe la configuración de la recuperación de desastres.
[root@z1 ~]#
pcs dr configLocal site: Role: Primary Remote site: Role: Recovery Nodes: z1.example.com z2.example.comCompruebe el estado del clúster primario y del clúster de recuperación de desastres desde un nodo del clúster primario.
[root@z1 ~]#
pcs dr status--- Local cluster - Primary site --- Cluster name: PrimarySite WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: z2.example.com (version 2.0.3-2.el8-2c9cea563e) - partition with quorum * Last updated: Mon Dec 9 04:10:31 2019 * Last change: Mon Dec 9 04:06:10 2019 by hacluster via crmd on z2.example.com * 2 nodes configured * 0 resource instances configured Node List: * Online: [ z1.example.com z2.example.com ] Full List of Resources: * No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled --- Remote cluster - Recovery site --- Cluster name: DRSite WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: z4.example.com (version 2.0.3-2.el8-2c9cea563e) - partition with quorum * Last updated: Mon Dec 9 04:10:34 2019 * Last change: Mon Dec 9 04:09:55 2019 by hacluster via crmd on z4.example.com * 2 nodes configured * 0 resource instances configured Node List: * Online: [ z3.example.com z4.example.com ] Full List of Resources: * No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Para conocer otras opciones de visualización de una configuración de recuperación de desastres, consulte la pantalla de ayuda del comando pcs dr.