Este contenido no está disponible en el idioma seleccionado.
Chapter 2. Basic Principles of Route Building
Abstract
Apache Camel provides several processors and components that you can link together in a route. This chapter provides a basic orientation by explaining the principles of building a route using the provided building blocks.
2.1. Pipeline Processing
Overview
In Apache Camel, pipelining is the dominant paradigm for connecting nodes in a route definition. The pipeline concept is probably most familiar to users of the UNIX operating system, where it is used to join operating system commands. For example, ls | more is an example of a command that pipes a directory listing, ls, to the page-scrolling utility, more. The basic idea of a pipeline is that the output of one command is fed into the input of the next. The natural analogy in the case of a route is for the Out message from one processor to be copied to the In message of the next processor.
Processor nodes
Every node in a route, except for the initial endpoint, is a processor, in the sense that they inherit from the org.apache.camel.Processor interface. In other words, processors make up the basic building blocks of a DSL route. For example, DSL commands such as filter(), delayer(), setBody(), setHeader(), and to() all represent processors. When considering how processors connect together to build up a route, it is important to distinguish two different processing approaches.
The first approach is where the processor simply modifies the exchange’s In message, as shown in Figure 2.1, “Processor Modifying an In Message”. The exchange’s Out message remains null in this case.
Figure 2.1. Processor Modifying an In Message
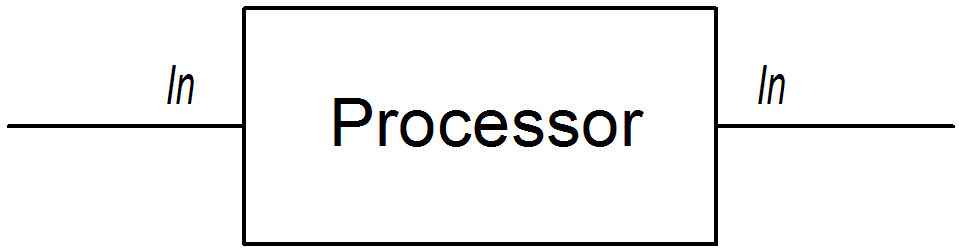
The following route shows a setHeader() command that modifies the current In message by adding (or modifying) the BillingSystem heading:
from("activemq:orderQueue")
.setHeader("BillingSystem", xpath("/order/billingSystem"))
.to("activemq:billingQueue");The second approach is where the processor creates an Out message to represent the result of the processing, as shown in Figure 2.2, “Processor Creating an Out Message”.
Figure 2.2. Processor Creating an Out Message
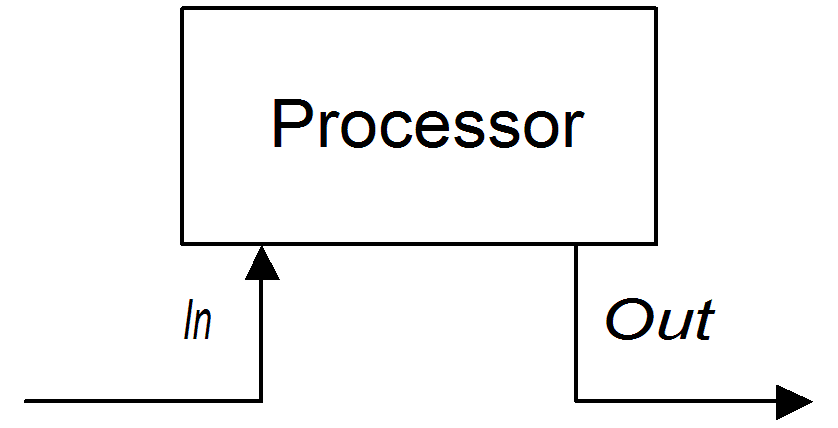
The following route shows a transform() command that creates an Out message with a message body containing the string, DummyBody:
from("activemq:orderQueue")
.transform(constant("DummyBody"))
.to("activemq:billingQueue");
where constant("DummyBody") represents a constant expression. You cannot pass the string, DummyBody, directly, because the argument to transform() must be an expression type.
Pipeline for InOnly exchanges
Figure 2.3, “Sample Pipeline for InOnly Exchanges” shows an example of a processor pipeline for InOnly exchanges. Processor A acts by modifying the In message, while processors B and C create an Out message. The route builder links the processors together as shown. In particular, processors B and C are linked together in the form of a pipeline: that is, processor B’s Out message is moved to the In message before feeding the exchange into processor C, and processor C’s Out message is moved to the In message before feeding the exchange into the producer endpoint. Thus the processors' outputs and inputs are joined into a continuous pipeline, as shown in Figure 2.3, “Sample Pipeline for InOnly Exchanges”.
Figure 2.3. Sample Pipeline for InOnly Exchanges

Apache Camel employs the pipeline pattern by default, so you do not need to use any special syntax to create a pipeline in your routes. For example, the following route pulls messages from a userdataQueue queue, pipes the message through a Velocity template (to produce a customer address in text format), and then sends the resulting text address to the queue, envelopeAddresses:
from("activemq:userdataQueue")
.to(ExchangePattern.InOut, "velocity:file:AdressTemplate.vm")
.to("activemq:envelopeAddresses");
Where the Velocity endpoint, velocity:file:AddressTemplate.vm, specifies the location of a Velocity template file, file:AddressTemplate.vm, in the file system. The to() command changes the exchange pattern to InOut before sending the exchange to the Velocity endpoint and then changes it back to InOnly afterwards. For more details of the Velocity endpoint, see Velocity in the Apache Camel Component Reference Guide.
Pipeline for InOut exchanges
Figure 2.4, “Sample Pipeline for InOut Exchanges” shows an example of a processor pipeline for InOut exchanges, which you typically use to support remote procedure call (RPC) semantics. Processors A, B, and C are linked together in the form of a pipeline, with the output of each processor being fed into the input of the next. The final Out message produced by the producer endpoint is sent all the way back to the consumer endpoint, where it provides the reply to the original request.
Figure 2.4. Sample Pipeline for InOut Exchanges
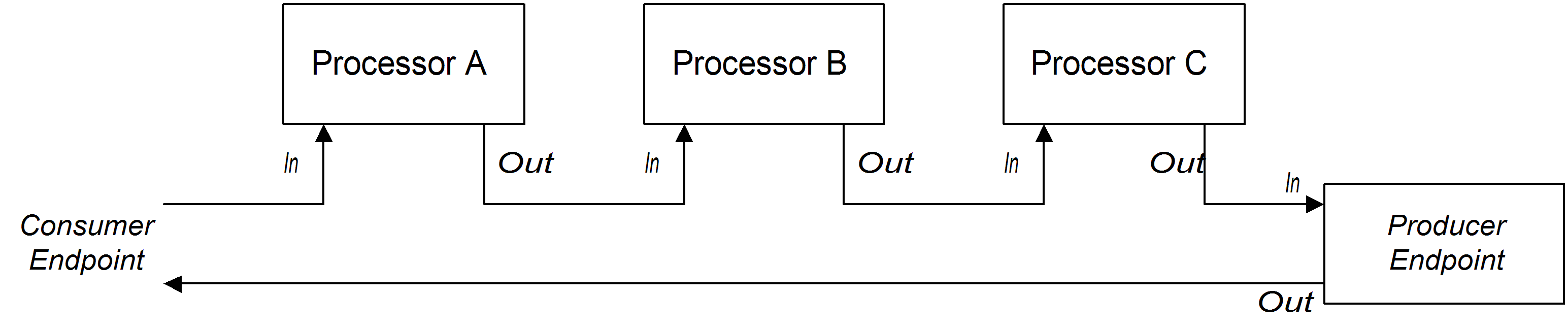
Note that in order to support the InOut exchange pattern, it is essential that the last node in the route (whether it is a producer endpoint or some other kind of processor) creates an Out message. Otherwise, any client that connects to the consumer endpoint would hang and wait indefinitely for a reply message. You should be aware that not all producer endpoints create Out messages.
Consider the following route that processes payment requests, by processing incoming HTTP requests:
from("jetty:http://localhost:8080/foo")
.to("cxf:bean:addAccountDetails")
.to("cxf:bean:getCreditRating")
.to("cxf:bean:processTransaction");
Where the incoming payment request is processed by passing it through a pipeline of Web services, cxf:bean:addAccountDetails, cxf:bean:getCreditRating, and cxf:bean:processTransaction. The final Web service, processTransaction, generates a response (Out message) that is sent back through the JETTY endpoint.
When the pipeline consists of just a sequence of endpoints, it is also possible to use the following alternative syntax:
from("jetty:http://localhost:8080/foo")
.pipeline("cxf:bean:addAccountDetails", "cxf:bean:getCreditRating", "cxf:bean:processTransaction");Pipeline for InOptionalOut exchanges
The pipeline for InOptionalOut exchanges is essentially the same as the pipeline in Figure 2.4, “Sample Pipeline for InOut Exchanges”. The difference between InOut and InOptionalOut is that an exchange with the InOptionalOut exchange pattern is allowed to have a null Out message as a reply. That is, in the case of an InOptionalOut exchange, a nullOut message is copied to the In message of the next node in the pipeline. By contrast, in the case of an InOut exchange, a nullOut message is discarded and the original In message from the current node would be copied to the In message of the next node instead.
2.2. Multiple Inputs
Overview
A standard route takes its input from just a single endpoint, using the from(EndpointURL) syntax in the Java DSL. But what if you need to define multiple inputs for your route? Apache Camel provides several alternatives for specifying multiple inputs to a route. The approach to take depends on whether you want the exchanges to be processed independently of each other or whether you want the exchanges from different inputs to be combined in some way (in which case, you should use the the section called “Content enricher pattern”).
Multiple independent inputs
The simplest way to specify multiple inputs is using the multi-argument form of the from() DSL command, for example:
from("URI1", "URI2", "URI3").to("DestinationUri");Or you can use the following equivalent syntax:
from("URI1").from("URI2").from("URI3").to("DestinationUri");In both of these examples, exchanges from each of the input endpoints, URI1, URI2, and URI3, are processed independently of each other and in separate threads. In fact, you can think of the preceding route as being equivalent to the following three separate routes:
from("URI1").to("DestinationUri");
from("URI2").to("DestinationUri");
from("URI3").to("DestinationUri");Segmented routes
For example, you might want to merge incoming messages from two different messaging systems and process them using the same route. In most cases, you can deal with multiple inputs by dividing your route into segments, as shown in Figure 2.5, “Processing Multiple Inputs with Segmented Routes”.
Figure 2.5. Processing Multiple Inputs with Segmented Routes

The initial segments of the route take their inputs from some external queues — for example, activemq:Nyse and activemq:Nasdaq — and send the incoming exchanges to an internal endpoint, InternalUrl. The second route segment merges the incoming exchanges, taking them from the internal endpoint and sending them to the destination queue, activemq:USTxn. The InternalUrl is the URL for an endpoint that is intended only for use within a router application. The following types of endpoints are suitable for internal use:
The main purpose of these endpoints is to enable you to glue together different segments of a route. They all provide an effective way of merging multiple inputs into a single route.
Direct endpoints
The direct component provides the simplest mechanism for linking together routes. The event model for the direct component is synchronous, so that subsequent segments of the route run in the same thread as the first segment. The general format of a direct URL is direct:EndpointID, where the endpoint ID, EndpointID, is simply a unique alphanumeric string that identifies the endpoint instance.
For example, if you want to take the input from two message queues, activemq:Nyse and activemq:Nasdaq, and merge them into a single message queue, activemq:USTxn, you can do this by defining the following set of routes:
from("activemq:Nyse").to("direct:mergeTxns");
from("activemq:Nasdaq").to("direct:mergeTxns");
from("direct:mergeTxns").to("activemq:USTxn");
Where the first two routes take the input from the message queues, Nyse and Nasdaq, and send them to the endpoint, direct:mergeTxns. The last queue combines the inputs from the previous two queues and sends the combined message stream to the activemq:USTxn queue.
The implementation of the direct endpoint behaves as follows: whenever an exchange arrives at a producer endpoint (for example, to("direct:mergeTxns")), the direct endpoint passes the exchange directly to all of the consumers endpoints that have the same endpoint ID (for example, from("direct:mergeTxns")). Direct endpoints can only be used to communicate between routes that belong to the same CamelContext in the same Java virtual machine (JVM) instance.
SEDA endpoints
The SEDA component provides an alternative mechanism for linking together routes. You can use it in a similar way to the direct component, but it has a different underlying event and threading model, as follows:
- Processing of a SEDA endpoint is not synchronous. That is, when you send an exchange to a SEDA producer endpoint, control immediately returns to the preceding processor in the route.
-
SEDA endpoints contain a queue buffer (of
java.util.concurrent.BlockingQueuetype), which stores all of the incoming exchanges prior to processing by the next route segment. - Each SEDA consumer endpoint creates a thread pool (the default size is 5) to process exchange objects from the blocking queue.
- The SEDA component supports the competing consumers pattern, which guarantees that each incoming exchange is processed only once, even if there are multiple consumers attached to a specific endpoint.
One of the main advantages of using a SEDA endpoint is that the routes can be more responsive, owing to the built-in consumer thread pool. The stock transactions example can be re-written to use SEDA endpoints instead of direct endpoints, as follows:
from("activemq:Nyse").to("seda:mergeTxns");
from("activemq:Nasdaq").to("seda:mergeTxns");
from("seda:mergeTxns").to("activemq:USTxn");
The main difference between this example and the direct example is that when using SEDA, the second route segment (from seda:mergeTxns to activemq:USTxn) is processed by a pool of five threads.
There is more to SEDA than simply pasting together route segments. The staged event-driven architecture (SEDA) encompasses a design philosophy for building more manageable multi-threaded applications. The purpose of the SEDA component in Apache Camel is simply to enable you to apply this design philosophy to your applications. For more details about SEDA, see http://www.eecs.harvard.edu/~mdw/proj/seda/.
VM endpoints
The VM component is very similar to the SEDA endpoint. The only difference is that, whereas the SEDA component is limited to linking together route segments from within the same CamelContext, the VM component enables you to link together routes from distinct Apache Camel applications, as long as they are running within the same Java virtual machine.
The stock transactions example can be re-written to use VM endpoints instead of SEDA endpoints, as follows:
from("activemq:Nyse").to("vm:mergeTxns");
from("activemq:Nasdaq").to("vm:mergeTxns");And in a separate router application (running in the same Java VM), you can define the second segment of the route as follows:
from("vm:mergeTxns").to("activemq:USTxn");Content enricher pattern
The content enricher pattern defines a fundamentally different way of dealing with multiple inputs to a route. When an exchange enters the enricher processor, the enricher contacts an external resource to retrieve information, which is then added to the original message. In this pattern, the external resource effectively represents a second input to the message.
For example, suppose you are writing an application that processes credit requests. Before processing a credit request, you need to augment it with the data that assigns a credit rating to the customer, where the ratings data is stored in a file in the directory, src/data/ratings. You can combine the incoming credit request with data from the ratings file using the pollEnrich() pattern and a GroupedExchangeAggregationStrategy aggregation strategy, as follows:
from("jms:queue:creditRequests")
.pollEnrich("file:src/data/ratings?noop=true", new GroupedExchangeAggregationStrategy())
.bean(new MergeCreditRequestAndRatings(), "merge")
.to("jms:queue:reformattedRequests");
Where the GroupedExchangeAggregationStrategy class is a standard aggregation strategy from the org.apache.camel.processor.aggregate package that adds each new exchange to a java.util.List instance and stores the resulting list in the Exchange.GROUPED_EXCHANGE exchange property. In this case, the list contains two elements: the original exchange (from the creditRequests JMS queue); and the enricher exchange (from the file endpoint).
To access the grouped exchange, you can use code like the following:
public class MergeCreditRequestAndRatings {
public void merge(Exchange ex) {
// Obtain the grouped exchange
List<Exchange> list = ex.getProperty(Exchange.GROUPED_EXCHANGE, List.class);
// Get the exchanges from the grouped exchange
Exchange originalEx = list.get(0);
Exchange ratingsEx = list.get(1);
// Merge the exchanges
...
}
}An alternative approach to this application would be to put the merge code directly into the implementation of the custom aggregation strategy class.
For more details about the content enricher pattern, see Section 10.1, “Content Enricher”.
2.3. Exception Handling
Abstract
Apache Camel provides several different mechanisms, which let you handle exceptions at different levels of granularity: you can handle exceptions within a route using doTry, doCatch, and doFinally; or you can specify what action to take for each exception type and apply this rule to all routes in a RouteBuilder using onException; or you can specify what action to take for all exception types and apply this rule to all routes in a RouteBuilder using errorHandler.
For more details about exception handling, see Section 6.3, “Dead Letter Channel”.
2.3.1. onException Clause
Overview
The onException clause is a powerful mechanism for trapping exceptions that occur in one or more routes: it is type-specific, enabling you to define distinct actions to handle different exception types; it allows you to define actions using essentially the same (actually, slightly extended) syntax as a route, giving you considerable flexibility in the way you handle exceptions; and it is based on a trapping model, which enables a single onException clause to deal with exceptions occurring at any node in any route.
Trapping exceptions using onException
The onException clause is a mechanism for trapping, rather than catching exceptions. That is, once you define an onException clause, it traps exceptions that occur at any point in a route. This contrasts with the Java try/catch mechanism, where an exception is caught, only if a particular code fragment is explicitly enclosed in a try block.
What really happens when you define an onException clause is that the Apache Camel runtime implicitly encloses each route node in a try block. This is why the onException clause is able to trap exceptions at any point in the route. But this wrapping is done for you automatically; it is not visible in the route definitions.
Java DSL example
In the following Java DSL example, the onException clause applies to all of the routes defined in the RouteBuilder class. If a ValidationException exception occurs while processing either of the routes (from("seda:inputA") or from("seda:inputB")), the onException clause traps the exception and redirects the current exchange to the validationFailed JMS queue (which serves as a deadletter queue).
// Java
public class MyRouteBuilder extends RouteBuilder {
public void configure() {
onException(ValidationException.class)
.to("activemq:validationFailed");
from("seda:inputA")
.to("validation:foo/bar.xsd", "activemq:someQueue");
from("seda:inputB").to("direct:foo")
.to("rnc:mySchema.rnc", "activemq:anotherQueue");
}
}XML DSL example
The preceding example can also be expressed in the XML DSL, using the onException element to define the exception clause, as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<onException>
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
<route>
<from uri="seda:inputA"/>
<to uri="validation:foo/bar.xsd"/>
<to uri="activemq:someQueue"/>
</route>
<route>
<from uri="seda:inputB"/>
<to uri="rnc:mySchema.rnc"/>
<to uri="activemq:anotherQueue"/>
</route>
</camelContext>
</beans>Trapping multiple exceptions
You can define multiple onException clauses to trap exceptions in a RouteBuilder scope. This enables you to take different actions in response to different exceptions. For example, the following series of onException clauses defined in the Java DSL define different deadletter destinations for ValidationException, IOException, and Exception:
onException(ValidationException.class).to("activemq:validationFailed");
onException(java.io.IOException.class).to("activemq:ioExceptions");
onException(Exception.class).to("activemq:exceptions");
You can define the same series of onException clauses in the XML DSL as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
<onException>
<exception>java.io.IOException</exception>
<to uri="activemq:ioExceptions"/>
</onException>
<onException>
<exception>java.lang.Exception</exception>
<to uri="activemq:exceptions"/>
</onException>
You can also group multiple exceptions together to be trapped by the same onException clause. In the Java DSL, you can group multiple exceptions as follows:
onException(ValidationException.class, BuesinessException.class)
.to("activemq:validationFailed");
In the XML DSL, you can group multiple exceptions together by defining more than one exception element inside the onException element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<exception>com.mycompany.BuesinessException</exception>
<to uri="activemq:validationFailed"/>
</onException>
When trapping multiple exceptions, the order of the onException clauses is significant. Apache Camel initially attempts to match the thrown exception against the first clause. If the first clause fails to match, the next onException clause is tried, and so on until a match is found. Each matching attempt is governed by the following algorithm:
If the thrown exception is a chained exception (that is, where an exception has been caught and rethrown as a different exception), the most nested exception type serves initially as the basis for matching. This exception is tested as follows:
-
If the exception-to-test has exactly the type specified in the
onExceptionclause (tested usinginstanceof), a match is triggered. -
If the exception-to-test is a sub-type of the type specified in the
onExceptionclause, a match is triggered.
-
If the exception-to-test has exactly the type specified in the
- If the most nested exception fails to yield a match, the next exception in the chain (the wrapping exception) is tested instead. The testing continues up the chain until either a match is triggered or the chain is exhausted.
The throwException EIP enables you to create a new exception instance from a simple language expression. You can make it dynamic, based on the available information from the current exchange. for example,
<throwException exceptionType="java.lang.IllegalArgumentException" message="${body}"/>Deadletter channel
The basic examples of onException usage have so far all exploited the deadletter channel pattern. That is, when an onException clause traps an exception, the current exchange is routed to a special destination (the deadletter channel). The deadletter channel serves as a holding area for failed messages that have not been processed. An administrator can inspect the messages at a later time and decide what action needs to be taken.
For more details about the deadletter channel pattern, see Section 6.3, “Dead Letter Channel”.
Use original message
By the time an exception is raised in the middle of a route, the message in the exchange could have been modified considerably (and might not even by readable by a human). Often, it is easier for an administrator to decide what corrective actions to take, if the messages visible in the deadletter queue are the original messages, as received at the start of the route. The useOriginalMessage option is false by default, but will be auto-enabled if it is configured on an error handler.
The useOriginalMessage option can result in unexpected behavior when applied to Camel routes that send messages to multiple endpoints, or split messages into parts. The original message might not be preserved in a Multicast, Splitter, or RecipientList route in which intermediate processing steps modify the original message.
In the Java DSL, you can replace the message in the exchange by the original message. Set the setAllowUseOriginalMessage() to true, then use the useOriginalMessage() DSL command, as follows:
onException(ValidationException.class)
.useOriginalMessage()
.to("activemq:validationFailed");
In the XML DSL, you can retrieve the original message by setting the useOriginalMessage attribute on the onException element, as follows:
<onException useOriginalMessage="true">
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
If the setAllowUseOriginalMessage() option is set to true, Camel makes a copy of the original message at the start of the route, which ensures that the original message is available when you call useOriginalMessage(). However, if the setAllowUseOriginalMessage() option is set to false (this is the default) on the Camel context, the original message will not be accessible and you cannot call useOriginalMessage().
A reasons to exploit the default behaviour is to optimize performance when processing large messages.
In Camel versions prior to 2.18, the default setting of allowUseOriginalMessage is true.
Redelivery policy
Instead of interrupting the processing of a message and giving up as soon as an exception is raised, Apache Camel gives you the option of attempting to redeliver the message at the point where the exception occurred. In networked systems, where timeouts can occur and temporary faults arise, it is often possible for failed messages to be processed successfully, if they are redelivered shortly after the original exception was raised.
The Apache Camel redelivery supports various strategies for redelivering messages after an exception occurs. Some of the most important options for configuring redelivery are as follows:
maximumRedeliveries()-
Specifies the maximum number of times redelivery can be attempted (default is
0). A negative value means redelivery is always attempted (equivalent to an infinite value). retryWhile()Specifies a predicate (of
Predicatetype), which determines whether Apache Camel ought to continue redelivering. If the predicate evaluates totrueon the current exchange, redelivery is attempted; otherwise, redelivery is stopped and no further redelivery attempts are made.This option takes precedence over the
maximumRedeliveries()option.
In the Java DSL, redelivery policy options are specified using DSL commands in the onException clause. For example, you can specify a maximum of six redeliveries, after which the exchange is sent to the validationFailed deadletter queue, as follows:
onException(ValidationException.class)
.maximumRedeliveries(6)
.retryAttemptedLogLevel(org.apache.camel.LogginLevel.WARN)
.to("activemq:validationFailed");
In the XML DSL, redelivery policy options are specified by setting attributes on the redeliveryPolicy element. For example, the preceding route can be expressed in XML DSL as follows:
<onException useOriginalMessage="true">
<exception>com.mycompany.ValidationException</exception>
<redeliveryPolicy maximumRedeliveries="6"/>
<to uri="activemq:validationFailed"/>
</onException>The latter part of the route — after the redelivery options are set — is not processed until after the last redelivery attempt has failed. For detailed descriptions of all the redelivery options, see Section 6.3, “Dead Letter Channel”.
Alternatively, you can specify redelivery policy options in a redeliveryPolicyProfile instance. You can then reference the redeliveryPolicyProfile instance using the onException element’s redeliverPolicyRef attribute. For example, the preceding route can be expressed as follows:
<redeliveryPolicyProfile id="redelivPolicy" maximumRedeliveries="6" retryAttemptedLogLevel="WARN"/>
<onException useOriginalMessage="true" redeliveryPolicyRef="redelivPolicy">
<exception>com.mycompany.ValidationException</exception>
<to uri="activemq:validationFailed"/>
</onException>
The approach using redeliveryPolicyProfile is useful, if you want to re-use the same redelivery policy in multiple onException clauses.
Conditional trapping
Exception trapping with onException can be made conditional by specifying the onWhen option. If you specify the onWhen option in an onException clause, a match is triggered only when the thrown exception matches the clause and the onWhen predicate evaluates to true on the current exchange.
For example, in the following Java DSL fragment,the first onException clause triggers, only if the thrown exception matches MyUserException and the user header is non-null in the current exchange:
// Java
// Here we define onException() to catch MyUserException when
// there is a header[user] on the exchange that is not null
onException(MyUserException.class)
.onWhen(header("user").isNotNull())
.maximumRedeliveries(2)
.to(ERROR_USER_QUEUE);
// Here we define onException to catch MyUserException as a kind
// of fallback when the above did not match.
// Noitce: The order how we have defined these onException is
// important as Camel will resolve in the same order as they
// have been defined
onException(MyUserException.class)
.maximumRedeliveries(2)
.to(ERROR_QUEUE);
The preceding onException clauses can be expressed in the XML DSL as follows:
<redeliveryPolicyProfile id="twoRedeliveries" maximumRedeliveries="2"/>
<onException redeliveryPolicyRef="twoRedeliveries">
<exception>com.mycompany.MyUserException</exception>
<onWhen>
<simple>${header.user} != null</simple>
</onWhen>
<to uri="activemq:error_user_queue"/>
</onException>
<onException redeliveryPolicyRef="twoRedeliveries">
<exception>com.mycompany.MyUserException</exception>
<to uri="activemq:error_queue"/>
</onException>Handling exceptions
By default, when an exception is raised in the middle of a route, processing of the current exchange is interrupted and the thrown exception is propagated back to the consumer endpoint at the start of the route. When an onException clause is triggered, the behavior is essentially the same, except that the onException clause performs some processing before the thrown exception is propagated back.
But this default behavior is not the only way to handle an exception. The onException provides various options to modify the exception handling behavior, as follows:
-
Suppressing exception rethrow — you have the option of suppressing the rethrown exception after the
onExceptionclause has completed. In other words, in this case the exception does not propagate back to the consumer endpoint at the start of the route. - Continuing processing — you have the option of resuming normal processing of the exchange from the point where the exception originally occurred. Implicitly, this approach also suppresses the rethrown exception.
- Sending a response — in the special case where the consumer endpoint at the start of the route expects a reply (that is, having an InOut MEP), you might prefer to construct a custom fault reply message, rather than propagating the exception back to the consumer endpoint.
Suppressing exception rethrow
To prevent the current exception from being rethrown and propagated back to the consumer endpoint, you can set the handled() option to true in the Java DSL, as follows:
onException(ValidationException.class)
.handled(true)
.to("activemq:validationFailed");
In the Java DSL, the argument to the handled() option can be of boolean type, of Predicate type, or of Expression type (where any non-boolean expression is interpreted as true, if it evaluates to a non-null value).
The same route can be configured to suppress the rethrown exception in the XML DSL, using the handled element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<handled>
<constant>true</constant>
</handled>
<to uri="activemq:validationFailed"/>
</onException>Continuing processing
To continue processing the current message from the point in the route where the exception was originally thrown, you can set the continued option to true in the Java DSL, as follows:
onException(ValidationException.class)
.continued(true);
In the Java DSL, the argument to the continued() option can be of boolean type, of Predicate type, or of Expression type (where any non-boolean expression is interpreted as true, if it evaluates to a non-null value).
The same route can be configured in the XML DSL, using the continued element, as follows:
<onException>
<exception>com.mycompany.ValidationException</exception>
<continued>
<constant>true</constant>
</continued>
</onException>Sending a response
When the consumer endpoint that starts a route expects a reply, you might prefer to construct a custom fault reply message, instead of simply letting the thrown exception propagate back to the consumer. There are two essential steps you need to follow in this case: suppress the rethrown exception using the handled option; and populate the exchange’s Out message slot with a custom fault message.
For example, the following Java DSL fragment shows how to send a reply message containing the text string, Sorry, whenever the MyFunctionalException exception occurs:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body as Sorry.
onException(MyFunctionalException.class)
.handled(true)
.transform().constant("Sorry");
If you are sending a fault response to the client, you will often want to incorporate the text of the exception message in the response. You can access the text of the current exception message using the exceptionMessage() builder method. For example, you can send a reply containing just the text of the exception message whenever the MyFunctionalException exception occurs, as follows:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body and return the exception message
onException(MyFunctionalException.class)
.handled(true)
.transform(exceptionMessage());
The exception message text is also accessible from the Simple language, through the exception.message variable. For example, you could embed the current exception text in a reply message, as follows:
// we catch MyFunctionalException and want to mark it as handled (= no failure returned to client)
// but we want to return a fixed text response, so we transform OUT body and return a nice message
// using the simple language where we want insert the exception message
onException(MyFunctionalException.class)
.handled(true)
.transform().simple("Error reported: ${exception.message} - cannot process this message.");
The preceding onException clause can be expressed in XML DSL as follows:
<onException>
<exception>com.mycompany.MyFunctionalException</exception>
<handled>
<constant>true</constant>
</handled>
<transform>
<simple>Error reported: ${exception.message} - cannot process this message.</simple>
</transform>
</onException>Exception thrown while handling an exception
An exception that gets thrown while handling an existing exception (in other words, one that gets thrown in the middle of processing an onException clause) is handled in a special way. Such an exception is handled by the special fallback exception handler, which handles the exception as follows:
- All existing exception handlers are ignored and processing fails immediately.
- The new exception is logged.
- The new exception is set on the exchange object.
The simple strategy avoids complex failure scenarios which could otherwise end up with an onException clause getting locked into an infinite loop.
Scopes
The onException clauses can be effective in either of the following scopes:
RouteBuilder scope —
onExceptionclauses defined as standalone statements inside aRouteBuilder.configure()method affect all of the routes defined in thatRouteBuilderinstance. On the other hand, theseonExceptionclauses have no effect whatsoever on routes defined inside any otherRouteBuilderinstance. TheonExceptionclauses must appear before the route definitions.All of the examples up to this point are defined using the
RouteBuilderscope.-
Route scope —
onExceptionclauses can also be embedded directly within a route. These onException clauses affect only the route in which they are defined.
Route scope
You can embed an onException clause anywhere inside a route definition, but you must terminate the embedded onException clause using the end() DSL command.
For example, you can define an embedded onException clause in the Java DSL, as follows:
// Java
from("direct:start")
.onException(OrderFailedException.class)
.maximumRedeliveries(1)
.handled(true)
.beanRef("orderService", "orderFailed")
.to("mock:error")
.end()
.beanRef("orderService", "handleOrder")
.to("mock:result");
You can define an embedded onException clause in the XML DSL, as follows:
<route errorHandlerRef="deadLetter">
<from uri="direct:start"/>
<onException>
<exception>com.mycompany.OrderFailedException</exception>
<redeliveryPolicy maximumRedeliveries="1"/>
<handled>
<constant>true</constant>
</handled>
<bean ref="orderService" method="orderFailed"/>
<to uri="mock:error"/>
</onException>
<bean ref="orderService" method="handleOrder"/>
<to uri="mock:result"/>
</route>2.3.2. Error Handler
Overview
The errorHandler() clause provides similar features to the onException clause, except that this mechanism is not able to discriminate between different exception types. The errorHandler() clause is the original exception handling mechanism provided by Apache Camel and was available before the onException clause was implemented.
Java DSL example
The errorHandler() clause is defined in a RouteBuilder class and applies to all of the routes in that RouteBuilder class. It is triggered whenever an exception of any kind occurs in one of the applicable routes. For example, to define an error handler that routes all failed exchanges to the ActiveMQ deadLetter queue, you can define a RouteBuilder as follows:
public class MyRouteBuilder extends RouteBuilder {
public void configure() {
errorHandler(deadLetterChannel("activemq:deadLetter"));
// The preceding error handler applies
// to all of the following routes:
from("activemq:orderQueue")
.to("pop3://fulfillment@acme.com");
from("file:src/data?noop=true")
.to("file:target/messages");
// ...
}
}Redirection to the dead letter channel will not occur, however, until all attempts at redelivery have been exhausted.
XML DSL example
In the XML DSL, you define an error handler within a camelContext scope using the errorHandler element. For example, to define an error handler that routes all failed exchanges to the ActiveMQ deadLetter queue, you can define an errorHandler element as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:camel="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<errorHandler type="DeadLetterChannel"
deadLetterUri="activemq:deadLetter"/>
<route>
<from uri="activemq:orderQueue"/>
<to uri="pop3://fulfillment@acme.com"/>
</route>
<route>
<from uri="file:src/data?noop=true"/>
<to uri="file:target/messages"/>
</route>
</camelContext>
</beans>Types of error handler
Table 2.1, “Error Handler Types” provides an overview of the different types of error handler you can define.
| Java DSL Builder | XML DSL Type Attribute | Description |
|---|---|---|
|
|
| Propagates exceptions back to the caller and supports the redelivery policy, but it does not support a dead letter queue. |
|
|
| Supports the same features as the default error handler and, in addition, supports a dead letter queue. |
|
|
| Logs the exception text whenever an exception occurs. |
|
|
| Dummy handler implementation that can be used to disable the error handler. |
|
| An error handler for transacted routes. A default transaction error handler instance is automatically used for a route that is marked as transacted. |
2.3.3. doTry, doCatch, and doFinally
Overview
To handle exceptions within a route, you can use a combination of the doTry, doCatch, and doFinally clauses, which handle exceptions in a similar way to Java’s try, catch, and finally blocks.
Similarities between doCatch and Java catch
In general, the doCatch() clause in a route definition behaves in an analogous way to the catch() statement in Java code. In particular, the following features are supported by the doCatch() clause:
Multiple doCatch clauses — you can have multiple
doCatchclauses within a singledoTryblock. ThedoCatchclauses are tested in the order they appear, just like Javacatch()statements. Apache Camel executes the firstdoCatchclause that matches the thrown exception.NoteThis algorithm is different from the exception matching algorithm used by the
onExceptionclause — see Section 2.3.1, “onException Clause” for details.-
Rethrowing exceptions — you can rethrow the current exception from within a
doCatchclause using constructs (see the section called “Rethrowing exceptions in doCatch”).
Special features of doCatch
There are some special features of the doCatch() clause, however, that have no analogue in the Java catch() statement. The following feature is specific to doCatch():
-
Conditional catching — you can catch an exception conditionally, by appending an
onWhensub-clause to thedoCatchclause (see the section called “Conditional exception catching using onWhen”).
Example
The following example shows how to write a doTry block in the Java DSL, where the doCatch() clause will be executed, if either the IOException exception or the IllegalStateException exception are raised, and the doFinally() clause is always executed, irrespective of whether an exception is raised or not.
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class, IllegalStateException.class)
.to("mock:catch")
.doFinally()
.to("mock:finally")
.end();Or equivalently, in Spring XML:
<route>
<from uri="direct:start"/>
<!-- here the try starts. its a try .. catch .. finally just as regular java code -->
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<!-- catch multiple exceptions -->
<exception>java.io.IOException</exception>
<exception>java.lang.IllegalStateException</exception>
<to uri="mock:catch"/>
</doCatch>
<doFinally>
<to uri="mock:finally"/>
</doFinally>
</doTry>
</route>Rethrowing exceptions in doCatch
It is possible to rethrow an exception in a doCatch() clause, using constructs, as follows:
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class)
.to("mock:io")
// Rethrow the exception using a construct instead of handled(false) which is deprecated in a doTry/doCatch clause.
.throwException(new IllegalArgumentException("Forced"))
.doCatch(Exception.class)
// Catch all other exceptions.
.to("mock:error")
.end();
You can also re-throw an exception using a processor instead of handled(false) which is deprecated in a doTry/doCatch clause:
.process(exchange -> {throw exchange.getProperty(Exchange.EXCEPTION_CAUGHT, Exception.class);})
In the preceding example, if the IOException is caught by doCatch(), the current exchange is sent to the mock:io endpoint, and then the IOException is rethrown. This gives the consumer endpoint at the start of the route (in the from() command) an opportunity to handle the exception as well.
The following example shows how to define the same route in Spring XML:
<route>
<from uri="direct:start"/>
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<to uri="mock:io"/>
<throwException message="Forced" exceptionType="java.lang.IllegalArgumentException"/>
</doCatch>
<doCatch>
<!-- Catch all other exceptions. -->
<exception>java.lang.Exception</exception>
<to uri="mock:error"/>
</doCatch>
</doTry>
</route>Conditional exception catching using onWhen
A special feature of the Apache Camel doCatch() clause is that you can conditionalize the catching of exceptions based on an expression that is evaluated at run time. In other words, if you catch an exception using a clause of the form, doCatch(ExceptionList).doWhen(Expression), an exception will only be caught, if the predicate expression, Expression, evaluates to true at run time.
For example, the following doTry block will catch the exceptions, IOException and IllegalStateException, only if the exception message contains the word, Severe:
from("direct:start")
.doTry()
.process(new ProcessorFail())
.to("mock:result")
.doCatch(IOException.class, IllegalStateException.class)
.onWhen(exceptionMessage().contains("Severe"))
.to("mock:catch")
.doCatch(CamelExchangeException.class)
.to("mock:catchCamel")
.doFinally()
.to("mock:finally")
.end();Or equivalently, in Spring XML:
<route>
<from uri="direct:start"/>
<doTry>
<process ref="processorFail"/>
<to uri="mock:result"/>
<doCatch>
<exception>java.io.IOException</exception>
<exception>java.lang.IllegalStateException</exception>
<onWhen>
<simple>${exception.message} contains 'Severe'</simple>
</onWhen>
<to uri="mock:catch"/>
</doCatch>
<doCatch>
<exception>org.apache.camel.CamelExchangeException</exception>
<to uri="mock:catchCamel"/>
</doCatch>
<doFinally>
<to uri="mock:finally"/>
</doFinally>
</doTry>
</route>Nested Conditions in doTry
There are various options available to add Camel exception handling to a JavaDSL route. dotry() creates a try or catch block for handling exceptions and is useful for route specific error handling.
If you want to catch the exception inside of ChoiceDefinition, you can use the following doTry blocks:
from("direct:wayne-get-token").setExchangePattern(ExchangePattern.InOut)
.doTry()
.to("https4://wayne-token-service")
.choice()
.when().simple("${header.CamelHttpResponseCode} == '200'")
.convertBodyTo(String.class)
.setHeader("wayne-token").groovy("body.replaceAll('\"','')")
.log(">> Wayne Token : ${header.wayne-token}")
.endChoice()
.doCatch(java.lang.Class (java.lang.Exception>)
.log(">> Exception")
.endDoTry();
from("direct:wayne-get-token").setExchangePattern(ExchangePattern.InOut)
.doTry()
.to("https4://wayne-token-service")
.doCatch(Exception.class)
.log(">> Exception")
.endDoTry();2.3.4. Propagating SOAP Exceptions
Overview
The Camel CXF component provides an integration with Apache CXF, enabling you to send and receive SOAP messages from Apache Camel endpoints. You can easily define Apache Camel endpoints in XML, which can then be referenced in a route using the endpoint’s bean ID. For more details, see CXF in the Apache Camel Component Reference Guide.
How to propagate stack trace information
It is possible to configure a CXF endpoint so that, when a Java exception is thrown on the server side, the stack trace for the exception is marshalled into a fault message and returned to the client. To enable this feaure, set the dataFormat to PAYLOAD and set the faultStackTraceEnabled property to true in the cxfEndpoint element, as follows:
<cxf:cxfEndpoint id="router" address="http://localhost:9002/TestMessage"
wsdlURL="ship.wsdl"
endpointName="s:TestSoapEndpoint"
serviceName="s:TestService"
xmlns:s="http://test">
<cxf:properties>
<!-- enable sending the stack trace back to client; the default value is false-->
<entry key="faultStackTraceEnabled" value="true" />
<entry key="dataFormat" value="PAYLOAD" />
</cxf:properties>
</cxf:cxfEndpoint>
For security reasons, the stack trace does not include the causing exception (that is, the part of a stack trace that follows Caused by). If you want to include the causing exception in the stack trace, set the exceptionMessageCauseEnabled property to true in the cxfEndpoint element, as follows:
<cxf:cxfEndpoint id="router" address="http://localhost:9002/TestMessage"
wsdlURL="ship.wsdl"
endpointName="s:TestSoapEndpoint"
serviceName="s:TestService"
xmlns:s="http://test">
<cxf:properties>
<!-- enable to show the cause exception message and the default value is false -->
<entry key="exceptionMessageCauseEnabled" value="true" />
<!-- enable to send the stack trace back to client, the default value is false-->
<entry key="faultStackTraceEnabled" value="true" />
<entry key="dataFormat" value="PAYLOAD" />
</cxf:properties>
</cxf:cxfEndpoint>
You should only enable the exceptionMessageCauseEnabled flag for testing and diagnostic purposes. It is normal practice for servers to conceal the original cause of an exception to make it harder for hostile users to probe the server.
2.4. Bean Integration
Overview
Bean integration provides a general purpose mechanism for processing messages using arbitrary Java objects. By inserting a bean reference into a route, you can call an arbitrary method on a Java object, which can then access and modify the incoming exchange. The mechanism that maps an exchange’s contents to the parameters and return values of a bean method is known as parameter binding. Parameter binding can use any combination of the following approaches in order to initialize a method’s parameters:
- Conventional method signatures — If the method signature conforms to certain conventions, the parameter binding can use Java reflection to determine what parameters to pass.
- Annotations and dependency injection — For a more flexible binding mechanism, employ Java annotations to specify what to inject into the method’s arguments. This dependency injection mechanism relies on Spring 2.5 component scanning. Normally, if you are deploying your Apache Camel application into a Spring container, the dependency injection mechanism will work automatically.
- Explicitly specified parameters — You can specify parameters explicitly (either as constants or using the Simple language), at the point where the bean is invoked.
Bean registry
Beans are made accessible through a bean registry, which is a service that enables you to look up beans using either the class name or the bean ID as a key. The way that you create an entry in the bean registry depends on the underlying framework — for example, plain Java, Spring, Guice, or Blueprint. Registry entries are usually created implicitly (for example, when you instantiate a Spring bean in a Spring XML file).
Registry plug-in strategy
Apache Camel implements a plug-in strategy for the bean registry, defining an integration layer for accessing beans which makes the underlying registry implementation transparent. Hence, it is possible to integrate Apache Camel applications with a variety of different bean registries, as shown in Table 2.2, “Registry Plug-Ins”.
| Registry Implementation | Camel Component with Registry Plug-In |
|---|---|
| Spring bean registry |
|
| Guice bean registry |
|
| Blueprint bean registry |
|
| OSGi service registry | deployed in OSGi container |
| JNDI registry |
Normally, you do not have to worry about configuring bean registries, because the relevant bean registry is automatically installed for you. For example, if you are using the Spring framework to define your routes, the Spring ApplicationContextRegistry plug-in is automatically installed in the current CamelContext instance.
Deployment in an OSGi container is a special case. When an Apache Camel route is deployed into the OSGi container, the CamelContext automatically sets up a registry chain for resolving bean instances: the registry chain consists of the OSGi registry, followed by the Blueprint (or Spring) registry.
Accessing a bean created in Java
To process exchange objects using a Java bean (which is a plain old Java object or POJO), use the bean() processor, which binds the inbound exchange to a method on the Java object. For example, to process inbound exchanges using the class, MyBeanProcessor, define a route like the following:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody")
.to("file:data/outbound");
Where the bean() processor creates an instance of MyBeanProcessor type and invokes the processBody() method to process inbound exchanges. This approach is adequate if you only want to access the MyBeanProcessor instance from a single route. However, if you want to access the same MyBeanProcessor instance from multiple routes, use the variant of bean() that takes the Object type as its first argument. For example:
MyBeanProcessor myBean = new MyBeanProcessor();
from("file:data/inbound")
.bean(myBean, "processBody")
.to("file:data/outbound");
from("activemq:inboundData")
.bean(myBean, "processBody")
.to("activemq:outboundData");Accessing overloaded bean methods
If a bean defines overloaded methods, you can choose which of the overloaded methods to invoke by specifying the method name along with its parameter types. For example, if the MyBeanBrocessor class has two overloaded methods, processBody(String) and processBody(String,String), you can invoke the latter overloaded method as follows:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(String,String)")
.to("file:data/outbound");
Alternatively, if you want to identify a method by the number of parameters it takes, rather than specifying the type of each parameter explicitly, you can use the wildcard character, *. For example, to invoke a method named processBody that takes two parameters, irrespective of the exact type of the parameters, invoke the bean() processor as follows:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(*,*)")
.to("file:data/outbound");
When specifying the method, you can use either a simple unqualified type name—for example, processBody(Exchange)—or a fully qualified type name—for example, processBody(org.apache.camel.Exchange).
In the current implementation, the specified type name must be an exact match of the parameter type. Type inheritance is not taken into account.
Specify parameters explicitly
You can specify parameter values explicitly, when you call the bean method. The following simple type values can be passed:
-
Boolean:
trueorfalse. -
Numeric:
123,7, and so on. -
String:
'In single quotes'or"In double quotes". -
Null object:
null.
The following example shows how you can mix explicit parameter values with type specifiers in the same method invocation:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBody(String, 'Sample string value', true, 7)")
.to("file:data/outbound");In the preceding example, the value of the first parameter would presumably be determined by a parameter binding annotation (see the section called “Basic annotations”).
In addition to the simple type values, you can also specify parameter values using the Simple language (Chapter 30, The Simple Language). This means that the full power of the Simple language is available when specifying parameter values. For example, to pass the message body and the value of the title header to a bean method:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBodyAndHeader(${body},${header.title})")
.to("file:data/outbound");
You can also pass the entire header hash map as a parameter. For example, in the following example, the second method parameter must be declared to be of type java.util.Map:
from("file:data/inbound")
.bean(MyBeanProcessor.class, "processBodyAndAllHeaders(${body},${header})")
.to("file:data/outbound");From Apache Camel 2.19 release, returning null from a bean method call now always ensures the message body has been set as a null value.
Basic method signatures
To bind exchanges to a bean method, you can define a method signature that conforms to certain conventions. In particular, there are two basic conventions for method signatures:
Method signature for processing message bodies
If you want to implement a bean method that accesses or modifies the incoming message body, you must define a method signature that takes a single String argument and returns a String value. For example:
// Java
package com.acme;
public class MyBeanProcessor {
public String processBody(String body) {
// Do whatever you like to 'body'...
return newBody;
}
}Method signature for processing exchanges
For greater flexibility, you can implement a bean method that accesses the incoming exchange. This enables you to access or modify all headers, bodies, and exchange properties. For processing exchanges, the method signature takes a single org.apache.camel.Exchange parameter and returns void. For example:
// Java
package com.acme;
public class MyBeanProcessor {
public void processExchange(Exchange exchange) {
// Do whatever you like to 'exchange'...
exchange.getIn().setBody("Here is a new message body!");
}
}Accessing a Spring bean from Spring XML
Instead of creating a bean instance in Java, you can create an instance using Spring XML. In fact, this is the only feasible approach if you are defining your routes in XML. To define a bean in XML, use the standard Spring bean element. The following example shows how to create an instance of MyBeanProcessor:
<beans ...>
...
<bean id="myBeanId" class="com.acme.MyBeanProcessor"/>
</beans>
It is also possible to pass data to the bean’s constructor arguments using Spring syntax. For full details of how to use the Spring bean element, see The IoC Container from the Spring reference guide.
When you create an object instance using the bean element, you can reference it later using the bean’s ID (the value of the bean element’s id attribute). For example, given the bean element with ID equal to myBeanId, you can reference the bean in a Java DSL route using the beanRef() processor, as follows:
from("file:data/inbound").beanRef("myBeanId", "processBody").to("file:data/outbound");
Where the beanRef() processor invokes the MyBeanProcessor.processBody() method on the specified bean instance.
You can also invoke the bean from within a Spring XML route, using the Camel schema’s bean element. For example:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="file:data/inbound"/>
<bean ref="myBeanId" method="processBody"/>
<to uri="file:data/outbound"/>
</route>
</camelContext>
For a slight efficiency gain, you can set the cache option to true, which avoids looking up the registry every time a bean is used. For example, to enable caching, you can set the cache attribute on the bean element as follows:
<bean ref="myBeanId" method="processBody" cache="true"/>Accessing a Spring bean from Java
When you create an object instance using the Spring bean element, you can reference it from Java using the bean’s ID (the value of the bean element’s id attribute). For example, given the bean element with ID equal to myBeanId, you can reference the bean in a Java DSL route using the beanRef() processor, as follows:
from("file:data/inbound").beanRef("myBeanId", "processBody").to("file:data/outbound");
Alternatively, you can reference the Spring bean by injection, using the @BeanInject annotation as follows:
// Java
import org.apache.camel.@BeanInject;
...
public class MyRouteBuilder extends RouteBuilder {
@BeanInject("myBeanId")
com.acme.MyBeanProcessor bean;
public void configure() throws Exception {
..
}
}
If you omit the bean ID from the @BeanInject annotation, Camel looks up the registry by type, but this only works if there is just a single bean of the given type. For example, to look up and inject the bean of com.acme.MyBeanProcessor type:
@BeanInject
com.acme.MyBeanProcessor bean;Bean shutdown order in Spring XML
For the beans used by a Camel context, the correct shutdown order is usually:
-
Shut down the
camelContextinstance, followed by; - Shut down the used beans.
If this shutdown order is reversed, then it could happen that the Camel context tries to access a bean that is already destroyed (either leading directly to an error; or the Camel context tries to create the missing bean while it is being destroyed, which also causes an error). The default shutdown order in Spring XML depends on the order in which the beans and the camelContext appear in the Spring XML file. In order to avoid random errors due to incorrect shutdown order, therefore, the camelContext is configured to shut down before any of the other beans in the Spring XML file. This is the default behaviour since Apache Camel 2.13.0.
If you need to change this behaviour (so that the Camel context is not forced to shut down before the other beans), you can set the shutdownEager attribute on the camelContext element to false. In this case, you could potentially exercise more fine-grained control over shutdown order using the Spring depends-on attribute.
Parameter binding annotations
The basic parameter bindings described in the section called “Basic method signatures” might not always be convenient to use. For example, if you have a legacy Java class that performs some data manipulation, you might want to extract data from an inbound exchange and map it to the arguments of an existing method signature. For this kind of parameter binding, Apache Camel provides the following kinds of Java annotation:
Basic annotations
Table 2.3, “Basic Bean Annotations” shows the annotations from the org.apache.camel Java package that you can use to inject message data into the arguments of a bean method.
| Annotation | Meaning | Parameter? |
|---|---|---|
|
| Binds to a list of attachments. | |
|
| Binds to an inbound message body. | |
|
| Binds to an inbound message header. | String name of the header. |
|
|
Binds to a | |
|
|
Binds to a | |
|
| Binds to a named exchange property. | String name of the property. |
|
|
Binds to a |
For example, the following class shows you how to use basic annotations to inject message data into the processExchange() method arguments.
// Java
import org.apache.camel.*;
public class MyBeanProcessor {
public void processExchange(
@Header(name="user") String user,
@Body String body,
Exchange exchange
) {
// Do whatever you like to 'exchange'...
exchange.getIn().setBody(body + "UserName = " + user);
}
}
Notice how you are able to mix the annotations with the default conventions. As well as injecting the annotated arguments, the parameter binding also automatically injects the exchange object into the org.apache.camel.Exchange argument.
Expression language annotations
The expression language annotations provide a powerful mechanism for injecting message data into a bean method’s arguments. Using these annotations, you can invoke an arbitrary script, written in the scripting language of your choice, to extract data from an inbound exchange and inject the data into a method argument. Table 2.4, “Expression Language Annotations” shows the annotations from the org.apache.camel.language package (and sub-packages, for the non-core annotations) that you can use to inject message data into the arguments of a bean method.
| Annotation | Description |
|---|---|
|
| Injects a Bean expression. |
|
| Injects a Constant expression |
|
| Injects an EL expression. |
|
| Injects a Groovy expression. |
|
| Injects a Header expression. |
|
| Injects a JavaScript expression. |
|
| Injects an OGNL expression. |
|
| Injects a PHP expression. |
|
| Injects a Python expression. |
|
| Injects a Ruby expression. |
|
| Injects a Simple expression. |
|
| Injects an XPath expression. |
|
| Injects an XQuery expression. |
For example, the following class shows you how to use the @XPath annotation to extract a username and a password from the body of an incoming message in XML format:
// Java
import org.apache.camel.language.*;
public class MyBeanProcessor {
public void checkCredentials(
@XPath("/credentials/username/text()") String user,
@XPath("/credentials/password/text()") String pass
) {
// Check the user/pass credentials...
...
}
}
The @Bean annotation is a special case, because it enables you to inject the result of invoking a registered bean. For example, to inject a correlation ID into a method argument, you can use the @Bean annotation to invoke an ID generator class, as follows:
// Java
import org.apache.camel.language.*;
public class MyBeanProcessor {
public void processCorrelatedMsg(
@Bean("myCorrIdGenerator") String corrId,
@Body String body
) {
// Check the user/pass credentials...
...
}
}
Where the string, myCorrIdGenerator, is the bean ID of the ID generator instance. The ID generator class can be instantiated using the spring bean element, as follows:
<beans ...>
...
<bean id="myCorrIdGenerator" class="com.acme.MyIdGenerator"/>
</beans>
Where the MyIdGenerator class could be defined as follows:
// Java
package com.acme;
public class MyIdGenerator {
private UserManager userManager;
public String generate(
@Header(name = "user") String user,
@Body String payload
) throws Exception {
User user = userManager.lookupUser(user);
String userId = user.getPrimaryId();
String id = userId + generateHashCodeForPayload(payload);
return id;
}
}
Notice that you can also use annotations in the referenced bean class, MyIdGenerator. The only restriction on the generate() method signature is that it must return the correct type to inject into the argument annotated by @Bean. Because the @Bean annotation does not let you specify a method name, the injection mechanism simply invokes the first method in the referenced bean that has the matching return type.
Some of the language annotations are available in the core component (@Bean, @Constant, @Simple, and @XPath). For non-core components, however, you will have to make sure that you load the relevant component. For example, to use the OGNL script, you must load the camel-ognl component.
Inherited annotations
Parameter binding annotations can be inherited from an interface or from a superclass. For example, if you define a Java interface with a Header annotation and a Body annotation, as follows:
// Java
import org.apache.camel.*;
public interface MyBeanProcessorIntf {
void processExchange(
@Header(name="user") String user,
@Body String body,
Exchange exchange
);
}
The overloaded methods defined in the implementation class, MyBeanProcessor, now inherit the annotations defined in the base interface, as follows:
// Java
import org.apache.camel.*;
public class MyBeanProcessor implements MyBeanProcessorIntf {
public void processExchange(
String user, // Inherits Header annotation
String body, // Inherits Body annotation
Exchange exchange
) {
...
}
}Interface implementations
The class that implements a Java interface is often protected, private or in package-only scope. If you try to invoke a method on an implementation class that is restricted in this way, the bean binding falls back to invoking the corresponding interface method, which is publicly accessible.
For example, consider the following public BeanIntf interface:
// Java
public interface BeanIntf {
void processBodyAndHeader(String body, String title);
}
Where the BeanIntf interface is implemented by the following protected BeanIntfImpl class:
// Java
protected class BeanIntfImpl implements BeanIntf {
void processBodyAndHeader(String body, String title) {
...
}
}
The following bean invocation would fall back to invoking the public BeanIntf.processBodyAndHeader method:
from("file:data/inbound")
.bean(BeanIntfImpl.class, "processBodyAndHeader(${body}, ${header.title})")
.to("file:data/outbound");Invoking static methods
Bean integration has the capability to invoke static methods without creating an instance of the associated class. For example, consider the following Java class that defines the static method, changeSomething():
// Java
...
public final class MyStaticClass {
private MyStaticClass() {
}
public static String changeSomething(String s) {
if ("Hello World".equals(s)) {
return "Bye World";
}
return null;
}
public void doSomething() {
// noop
}
}
You can use bean integration to invoke the static changeSomething method, as follows:
from("direct:a")
*.bean(MyStaticClass.class, "changeSomething")*
.to("mock:a");
Note that, although this syntax looks identical to the invocation of an ordinary function, bean integration exploits Java reflection to identify the method as static and proceeds to invoke the method without instantiating MyStaticClass.
Invoking an OSGi service
In the special case where a route is deployed into a Red Hat Fuse container, it is possible to invoke an OSGi service directly using bean integration. For example, assuming that one of the bundles in the OSGi container has exported the service, org.fusesource.example.HelloWorldOsgiService, you could invoke the sayHello method using the following bean integration code:
from("file:data/inbound")
.bean(org.fusesource.example.HelloWorldOsgiService.class, "sayHello")
.to("file:data/outbound");You could also invoke the OSGi service from within a Spring or blueprint XML file, using the bean component, as follows:
<to uri="bean:org.fusesource.example.HelloWorldOsgiService?method=sayHello"/>The way this works is that Apache Camel sets up a chain of registries when it is deployed in the OSGi container. First of all, it looks up the specified class name in the OSGi service registry; if this lookup fails, it then falls back to the local Spring DM or blueprint registry.
2.5. Creating Exchange Instances
Overview
When processing messages with Java code (for example, in a bean class or in a processor class), it is often necessary to create a fresh exchange instance. If you need to create an Exchange object, the easiest approach is to invoke the methods of the ExchangeBuilder class, as described here.
ExchangeBuilder class
The fully qualified name of the ExchangeBuilder class is as follows:
org.apache.camel.builder.ExchangeBuilder
The ExchangeBuilder exposes the static method, anExchange, which you can use to start building an exchange object.
Example
For example, the following code creates a new exchange object containing the message body string, Hello World!, and with headers containing username and password credentials:
// Java
import org.apache.camel.Exchange;
import org.apache.camel.builder.ExchangeBuilder;
...
Exchange exch = ExchangeBuilder.anExchange(camelCtx)
.withBody("Hello World!")
.withHeader("username", "jdoe")
.withHeader("password", "pass")
.build();ExchangeBuilder methods
The ExchangeBuilder class supports the following methods:
ExchangeBuilder anExchange(CamelContext context)- (static method) Initiate building an exchange object.
Exchange build()- Build the exchange.
ExchangeBuilder withBody(Object body)- Set the message body on the exchange (that is, sets the exchange’s In message body).
ExchangeBuilder withHeader(String key, Object value)- Set a header on the exchange (that is, sets a header on the exchange’s In message).
ExchangeBuilder withPattern(ExchangePattern pattern)- Sets the exchange pattern on the exchange.
ExchangeBuilder withProperty(String key, Object value)- Sets a property on the exchange.
2.6. Transforming Message Content
Abstract
Apache Camel supports a variety of approaches to transforming message content. In addition to a simple native API for modifying message content, Apache Camel supports integration with several different third-party libraries and transformation standards.
2.6.1. Simple Message Transformations
Overview
The Java DSL has a built-in API that enables you to perform simple transformations on incoming and outgoing messages. For example, the rule shown in Example 2.1, “Simple Transformation of Incoming Messages” appends the text, World!, to the end of the incoming message body.
Example 2.1. Simple Transformation of Incoming Messages
from("SourceURL").setBody(body().append(" World!")).to("TargetURL");
Where the setBody() command replaces the content of the incoming message’s body.
API for simple transformations
You can use the following API classes to perform simple transformations of the message content in a router rule:
-
org.apache.camel.model.ProcessorDefinition -
org.apache.camel.builder.Builder -
org.apache.camel.builder.ValueBuilder
ProcessorDefinition class
The org.apache.camel.model.ProcessorDefinition class defines the DSL commands you can insert directly into a router rule — for example, the setBody() command in Example 2.1, “Simple Transformation of Incoming Messages”. Table 2.5, “Transformation Methods from the ProcessorDefinition Class” shows the ProcessorDefinition methods that are relevant to transforming message content:
| Method | Description |
|---|---|
|
| Converts the IN message body to the specified type. |
|
| Adds a processor which removes the header on the FAULT message. |
|
| Adds a processor which removes the header on the IN message. |
|
| Adds a processor which removes the exchange property. |
|
| Adds a processor which sets the body on the IN message. |
|
| Adds a processor which sets the body on the FAULT message. |
|
| Adds a processor which sets the header on the FAULT message. |
|
| Adds a processor which sets the header on the IN message. |
|
| Adds a processor which sets the header on the IN message. |
|
| Adds a processor which sets the header on the OUT message. |
|
| Adds a processor which sets the header on the OUT message. |
|
| Adds a processor which sets the exchange property. |
|
| Adds a processor which sets the exchange property. |
|
| Adds a processor which sets the body on the OUT message. |
|
| Adds a processor which sets the body on the OUT message. |
Builder class
The org.apache.camel.builder.Builder class provides access to message content in contexts where expressions or predicates are expected. In other words, Builder methods are typically invoked in the arguments of DSL commands — for example, the body() command in Example 2.1, “Simple Transformation of Incoming Messages”. Table 2.6, “Methods from the Builder Class” summarizes the static methods available in the Builder class.
| Method | Description |
|---|---|
|
| Returns a predicate and value builder for the inbound body on an exchange. |
|
| Returns a predicate and value builder for the inbound message body as a specific type. |
|
| Returns a constant expression. |
|
| Returns a predicate and value builder for the fault body on an exchange. |
|
| Returns a predicate and value builder for the fault message body as a specific type. |
|
| Returns a predicate and value builder for headers on an exchange. |
|
| Returns a predicate and value builder for the outbound body on an exchange. |
|
| Returns a predicate and value builder for the outbound message body as a specific type. |
|
| Returns a predicate and value builder for properties on an exchange. |
|
| Returns an expression that replaces all occurrences of the regular expression with the given replacement. |
|
| Returns an expression that replaces all occurrences of the regular expression with the given replacement. |
|
| Returns an expression sending the exchange to the given endpoint uri. |
|
| Returns an expression for the given system property. |
|
| Returns an expression for the given system property. |
ValueBuilder class
The org.apache.camel.builder.ValueBuilder class enables you to modify values returned by the Builder methods. In other words, the methods in ValueBuilder provide a simple way of modifying message content. Table 2.7, “Modifier Methods from the ValueBuilder Class” summarizes the methods available in the ValueBuilder class. That is, the table shows only the methods that are used to modify the value they are invoked on (for full details, see the API Reference documentation).
| Method | Description |
|---|---|
|
| Appends the string evaluation of this expression with the given value. |
|
| Create a predicate that the left hand expression contains the value of the right hand expression. |
|
| Converts the current value to the given type using the registered type converters. |
|
| Converts the current value a String using the registered type converters. |
|
| |
|
| |
|
| |
|
| |
|
|
Returns true, if the current value is equal to the given |
|
|
Returns true, if the current value is greater than the given |
|
|
Returns true, if the current value is greater than or equal to the given |
|
| Returns true, if the current value is an instance of the given type. |
|
|
Returns true, if the current value is less than the given |
|
|
Returns true, if the current value is less than or equal to the given |
|
|
Returns true, if the current value is not equal to the given |
|
|
Returns true, if the current value is not |
|
|
Returns true, if the current value is |
|
| |
|
| Negates the predicate argument. |
|
| Prepends the string evaluation of this expression to the given value. |
|
| |
|
| Replaces all occurrencies of the regular expression with the given replacement. |
|
| Replaces all occurrencies of the regular expression with the given replacement. |
|
| Tokenizes the string conversion of this expression using the given regular expression. |
|
| Sorts the current value using the given comparator. |
|
|
Returns true, if the current value matches the string value of the |
|
| Tokenizes the string conversion of this expression using the comma token separator. |
|
| Tokenizes the string conversion of this expression using the given token separator. |
2.6.2. Marshalling and Unmarshalling
Java DSL commands
You can convert between low-level and high-level message formats using the following commands:
-
marshal()— Converts a high-level data format to a low-level data format. -
unmarshal()— Converts a low-level data format to a high-level data format.
Data formats
Apache Camel supports marshalling and unmarshalling of the following data formats:
- Java serialization
- JAXB
- XMLBeans
- XStream
Java serialization
Enables you to convert a Java object to a blob of binary data. For this data format, unmarshalling converts a binary blob to a Java object, and marshalling converts a Java object to a binary blob. For example, to read a serialized Java object from an endpoint, SourceURL, and convert it to a Java object, you use a rule like the following:
from("SourceURL").unmarshal().serialization()
.<FurtherProcessing>.to("TargetURL");Or alternatively, in Spring XML:
<camelContext id="serialization" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<serialization/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>JAXB
Provides a mapping between XML schema types and Java types (see https://jaxb.dev.java.net/). For JAXB, unmarshalling converts an XML data type to a Java object, and marshalling converts a Java object to an XML data type. Before you can use JAXB data formats, you must compile your XML schema using a JAXB compiler to generate the Java classes that represent the XML data types in the schema. This is called binding the schema. After the schema is bound, you define a rule to unmarshal XML data to a Java object, using code like the following:
org.apache.camel.spi.DataFormat jaxb = new org.apache.camel.converter.jaxb.JaxbDataFormat("GeneratedPackageName");
from("SourceURL").unmarshal(jaxb)
.<FurtherProcessing>.to("TargetURL");where GeneratedPackagename is the name of the Java package generated by the JAXB compiler, which contains the Java classes representing your XML schema.
Or alternatively, in Spring XML:
<camelContext id="jaxb" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<jaxb prettyPrint="true" contextPath="GeneratedPackageName"/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>XMLBeans
Provides an alternative mapping between XML schema types and Java types (see http://xmlbeans.apache.org/). For XMLBeans, unmarshalling converts an XML data type to a Java object and marshalling converts a Java object to an XML data type. For example, to unmarshal XML data to a Java object using XMLBeans, you use code like the following:
from("SourceURL").unmarshal().xmlBeans()
.<FurtherProcessing>.to("TargetURL");Or alternatively, in Spring XML:
<camelContext id="xmlBeans" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="SourceURL"/>
<unmarshal>
<xmlBeans prettyPrint="true"/>
</unmarshal>
<to uri="TargetURL"/>
</route>
</camelContext>XStream
Provides another mapping between XML types and Java types (see http://www.xml.com/pub/a/2004/08/18/xstream.html). XStream is a serialization library (like Java serialization), enabling you to convert any Java object to XML. For XStream, unmarshalling converts an XML data type to a Java object, and marshalling converts a Java object to an XML data type.
from("SourceURL").unmarshal().xstream()
.<FurtherProcessing>.to("TargetURL");The XStream data format is currently not supported in Spring XML.
2.6.3. Endpoint Bindings
What is a binding?
In Apache Camel, a binding is a way of wrapping an endpoint in a contract — for example, by applying a Data Format, a Content Enricher or a validation step. A condition or transformation is applied to the messages coming in, and a complementary condition or transformation is applied to the messages going out.
DataFormatBinding
The DataFormatBinding class is useful for the specific case where you want to define a binding that marshals and unmarshals a particular data format (see Section 2.6.2, “Marshalling and Unmarshalling”). In this case, all that you need to do to create a binding is to create a DataFormatBinding instance, passing a reference to the relevant data format in the constructor.
For example, the XML DSL snippet in Example 2.2, “JAXB Binding” shows a binding (with ID, jaxb) that is capable of marshalling and unmarshalling the JAXB data format when it is associated with an Apache Camel endpoint:
Example 2.2. JAXB Binding
<beans ... >
...
<bean id="jaxb" class="org.apache.camel.processor.binding.DataFormatBinding">
<constructor-arg ref="jaxbformat"/>
</bean>
<bean id="jaxbformat" class="org.apache.camel.model.dataformat.JaxbDataFormat">
<property name="prettyPrint" value="true"/>
<property name="contextPath" value="org.apache.camel.example"/>
</bean>
</beans>Associating a binding with an endpoint
The following alternatives are available for associating a binding with an endpoint:
Binding URI
To associate a binding with an endpoint, you can prefix the endpoint URI with binding:NameOfBinding, where NameOfBinding is the bean ID of the binding (for example, the ID of a binding bean created in Spring XML).
For example, the following example shows how to associate ActiveMQ endpoints with the JAXB binding defined in Example 2.2, “JAXB Binding”.
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="binding:jaxb:activemq:orderQueue"/>
<to uri="binding:jaxb:activemq:otherQueue"/>
</route>
</camelContext>
...
</beans>BindingComponent
Instead of using a prefix to associate a binding with an endpoint, you can make the association implicit, so that the binding does not need to appear in the URI. For existing endpoints that do not have an implicit binding, the easiest way to achieve this is to wrap the endpoint using the BindingComponent class.
For example, to associate the jaxb binding with activemq endpoints, you could define a new BindingComponent instance as follows:
<beans ... >
...
<bean id="jaxbmq" class="org.apache.camel.component.binding.BindingComponent">
<constructor-arg ref="jaxb"/>
<constructor-arg value="activemq:foo."/>
</bean>
<bean id="jaxb" class="org.apache.camel.processor.binding.DataFormatBinding">
<constructor-arg ref="jaxbformat"/>
</bean>
<bean id="jaxbformat" class="org.apache.camel.model.dataformat.JaxbDataFormat">
<property name="prettyPrint" value="true"/>
<property name="contextPath" value="org.apache.camel.example"/>
</bean>
</beans>
Where the (optional) second constructor argument to jaxbmq defines a URI prefix. You can now use the jaxbmq ID as the scheme for an endpoint URI. For example, you can define the following route using this binding component:
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="jaxbmq:firstQueue"/>
<to uri="jaxbmq:otherQueue"/>
</route>
</camelContext>
...
</beans>The preceding route is equivalent to the following route, which uses the binding URI approach:
<beans ...>
...
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="binding:jaxb:activemq:foo.firstQueue"/>
<to uri="binding:jaxb:activemq:foo.otherQueue"/>
</route>
</camelContext>
...
</beans>
For developers that implement a custom Apache Camel component, it is possible to achieve this by implementing an endpoint class that inherits from the org.apache.camel.spi.HasBinding interface.
BindingComponent constructors
The BindingComponent class supports the following constructors:
public BindingComponent()- No arguments form. Use property injection to configure the binding component instance.
public BindingComponent(Binding binding)-
Associate this binding component with the specified
Bindingobject,binding. public BindingComponent(Binding binding, String uriPrefix)-
Associate this binding component with the specified
Bindingobject,binding, and URI prefix,uriPrefix. This is the most commonly used constructor. public BindingComponent(Binding binding, String uriPrefix, String uriPostfix)-
This constructor supports the additional URI post-fix,
uriPostfix, argument, which is automatically appended to any URIs defined using this binding component.
Implementing a custom binding
In addition to the DataFormatBinding, which is used for marshalling and unmarshalling data formats, you can implement your own custom bindings. Define a custom binding as follows:
-
Implement an
org.apache.camel.Processorclass to perform a transformation on messages incoming to a consumer endpoint (appearing in afromelement). -
Implement a complementary
org.apache.camel.Processorclass to perform the reverse transformation on messages outgoing from a producer endpoint (appearing in atoelement). -
Implement the
org.apache.camel.spi.Bindinginterface, which acts as a factory for the processor instances.
Binding interface
Example 2.3, “The org.apache.camel.spi.Binding Interface” shows the definition of the org.apache.camel.spi.Binding interface, which you must implement to define a custom binding.
Example 2.3. The org.apache.camel.spi.Binding Interface
// Java
package org.apache.camel.spi;
import org.apache.camel.Processor;
/**
* Represents a <a href="http://camel.apache.org/binding.html">Binding</a> or contract
* which can be applied to an Endpoint; such as ensuring that a particular
* <a href="http://camel.apache.org/data-format.html">Data Format</a> is used on messages in and out of an endpoint.
*/
public interface Binding {
/**
* Returns a new {@link Processor} which is used by a producer on an endpoint to implement
* the producer side binding before the message is sent to the underlying endpoint.
*/
Processor createProduceProcessor();
/**
* Returns a new {@link Processor} which is used by a consumer on an endpoint to process the
* message with the binding before its passed to the endpoint consumer producer.
*/
Processor createConsumeProcessor();
}When to use bindings
Bindings are useful when you need to apply the same kind of transformation to many different kinds of endpoint.
2.7. Property Placeholders
Overview
The property placeholders feature can be used to substitute strings into various contexts (such as endpoint URIs and attributes in XML DSL elements), where the placeholder settings are stored in Java properties files. This feature can be useful, if you want to share settings between different Apache Camel applications or if you want to centralize certain configuration settings.
For example, the following route sends requests to a Web server, whose host and port are substituted by the placeholders, {{remote.host}} and {{remote.port}}:
from("direct:start").to("http://{{remote.host}}:{{remote.port}}");The placeholder values are defined in a Java properties file, as follows:
# Java properties file
remote.host=myserver.com
remote.port=8080
Property Placeholders support an encoding option that enables you to read the .properties file, using a specific character set such as UTF-8. However, by default, it implements the ISO-8859-1 character set.
Apache Camel using the PropertyPlaceholders support the following:
- Specify the default value together with the key to lookup.
-
No need to define the
PropertiesComponent, if all the placeholder keys consist of default values, which are to be used. Use third-party functions to lookup the property values. It enables you to implement your own logic.
NoteProvide three out of the box functions to lookup values from OS environmental variable, JVM system properties, or the service name idiom.
Property files
Property settings are stored in one or more Java properties files and must conform to the standard Java properties file format. Each property setting appears on its own line, in the format Key=Value. Lines with # or ! as the first non-blank character are treated as comments.
For example, a property file could have content as shown in Example 2.4, “Sample Property File”.
Example 2.4. Sample Property File
# Property placeholder settings
# (in Java properties file format)
cool.end=mock:result
cool.result=result
cool.concat=mock:{{cool.result}}
cool.start=direct:cool
cool.showid=true
cheese.end=mock:cheese
cheese.quote=Camel rocks
cheese.type=Gouda
bean.foo=foo
bean.bar=barResolving properties
The properties component must be configured with the locations of one or more property files before you can start using it in route definitions. You must provide the property values using one of the following resolvers:
classpath:PathName,PathName,…- (Default) Specifies locations on the classpath, where PathName is a file pathname delimited using forward slashes.
file:PathName,PathName,…- Specifies locations on the file system, where PathName is a file pathname delimited using forward slashes.
ref:BeanID-
Specifies the ID of a
java.util.Propertiesobject in the registry. blueprint:BeanID-
Specifies the ID of a
cm:property-placeholderbean, which is used in the context of an OSGi blueprint file to access properties defined in the OSGi Configuration Admin service. For details, see the section called “Integration with OSGi blueprint property placeholders”.
For example, to specify the com/fusesource/cheese.properties property file and the com/fusesource/bar.properties property file, both located on the classpath, you would use the following location string:
com/fusesource/cheese.properties,com/fusesource/bar.properties
You can omit the classpath: prefix in this example, because the classpath resolver is used by default.
Specifying locations using system properties and environment variables
You can embed Java system properties and O/S environment variables in a location PathName.
Java system properties can be embedded in a location resolver using the syntax, ${PropertyName}. For example, if the root directory of Red Hat Fuse is stored in the Java system property, karaf.home, you could embed that directory value in a file location, as follows:
file:${karaf.home}/etc/foo.properties
O/S environment variables can be embedded in a location resolver using the syntax, ${env:VarName}. For example, if the root directory of JBoss Fuse is stored in the environment variable, SMX_HOME, you could embed that directory value in a file location, as follows:
file:${env:SMX_HOME}/etc/foo.propertiesConfiguring the properties component
Before you can start using property placeholders, you must configure the properties component, specifying the locations of one or more property files.
In the Java DSL, you can configure the properties component with the property file locations, as follows:
// Java
import org.apache.camel.component.properties.PropertiesComponent;
...
PropertiesComponent pc = new PropertiesComponent();
pc.setLocation("com/fusesource/cheese.properties,com/fusesource/bar.properties");
context.addComponent("properties", pc);
As shown in the addComponent() call, the name of the properties component must be set to properties.
In the XML DSL, you can configure the properties component using the dedicated propertyPlacholder element, as follows:
<camelContext ...>
<propertyPlaceholder
id="properties"
location="com/fusesource/cheese.properties,com/fusesource/bar.properties"
/>
</camelContext>
If you want the properties component to ignore any missing .properties files when it is being initialized, you can set the ignoreMissingLocation option to true (normally, a missing .properties file would result in an error being raised).
Additionally, if you want the properties component to ignore any missing locations that are specified using Java system properties or O/S environment variables, you can set the ignoreMissingLocation option to true.
Placeholder syntax
After it is configured, the property component automatically substitutes placeholders (in the appropriate contexts). The syntax of a placeholder depends on the context, as follows:
-
In endpoint URIs and in Spring XML files — the placeholder is specified as
{{Key}}. When setting XML DSL attributes —
xs:stringattributes are set using the following syntax:AttributeName="{{Key}}"Other attribute types (for example,
xs:intorxs:boolean) must be set using the following syntax:prop:AttributeName="Key"Where
propis associated with thehttp://camel.apache.org/schema/placeholdernamespace.When setting Java DSL EIP options — to set an option on an Enterprise Integration Pattern (EIP) command in the Java DSL, add a
placeholder()clause like the following to the fluent DSL:.placeholder("OptionName", "Key")-
In Simple language expressions — the placeholder is specified as
${properties:Key}.
Substitution in endpoint URIs
Wherever an endpoint URI string appears in a route, the first step in parsing the endpoint URI is to apply the property placeholder parser. The placeholder parser automatically substitutes any property names appearing between double braces, {{Key}}. For example, given the property settings shown in Example 2.4, “Sample Property File”, you could define a route as follows:
from("{{cool.start}}")
.to("log:{{cool.start}}?showBodyType=false&showExchangeId={{cool.showid}}")
.to("mock:{{cool.result}}");
By default, the placeholder parser looks up the properties bean ID in the registry to find the properties component. If you prefer, you can explicitly specify the scheme in the endpoint URIs. For example, by prefixing properties: to each of the endpoint URIs, you can define the following equivalent route:
from("properties:{{cool.start}}")
.to("properties:log:{{cool.start}}?showBodyType=false&showExchangeId={{cool.showid}}")
.to("properties:mock:{{cool.result}}");
When specifying the scheme explicitly, you also have the option of specifying options to the properties component. For example, to override the property file location, you could set the location option as follows:
from("direct:start").to("properties:{{bar.end}}?location=com/mycompany/bar.properties");Substitution in Spring XML files
You can also use property placeholders in the XML DSL, for setting various attributes of the DSL elements. In this context, the placholder syntax also uses double braces, {{Key}}. For example, you could define a jmxAgent element using property placeholders, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties" location="org/apache/camel/spring/jmx.properties"/>
<!-- we can use property placeholders when we define the JMX agent -->
<jmxAgent id="agent" registryPort="{{myjmx.port}}"
usePlatformMBeanServer="{{myjmx.usePlatform}}"
createConnector="true"
statisticsLevel="RoutesOnly"
/>
<route>
<from uri="seda:start"/>
<to uri="mock:result"/>
</route>
</camelContext>Substitution of XML DSL attribute values
You can use the regular placeholder syntax for specifying attribute values of xs:string type — for example, <jmxAgent registryPort="{{myjmx.port}}" …>. But for attributes of any other type (for example, xs:int or xs:boolean), you must use the special syntax, prop:AttributeName="Key".
For example, given that a property file defines the stop.flag property to have the value, true, you can use this property to set the stopOnException boolean attribute, as follows:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:prop="http://camel.apache.org/schema/placeholder"
... >
<bean id="illegal" class="java.lang.IllegalArgumentException">
<constructor-arg index="0" value="Good grief!"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties"
location="classpath:org/apache/camel/component/properties/myprop.properties"
xmlns="http://camel.apache.org/schema/spring"/>
<route>
<from uri="direct:start"/>
<multicast prop:stopOnException="stop.flag">
<to uri="mock:a"/>
<throwException ref="damn"/>
<to uri="mock:b"/>
</multicast>
</route>
</camelContext>
</beans>
The prop prefix must be explicitly assigned to the http://camel.apache.org/schema/placeholder namespace in your Spring file, as shown in the beans element of the preceding example.
Substitution of Java DSL EIP options
When invoking an EIP command in the Java DSL, you can set any EIP option using the value of a property placeholder, by adding a sub-clause of the form, placeholder("OptionName", "Key").
For example, given that a property file defines the stop.flag property to have the value, true, you can use this property to set the stopOnException option of the multicast EIP, as follows:
from("direct:start")
.multicast().placeholder("stopOnException", "stop.flag")
.to("mock:a").throwException(new IllegalAccessException("Damn")).to("mock:b");Substitution in Simple language expressions
You can also substitute property placeholders in Simple language expressions, but in this case the syntax of the placeholder is ${properties:Key}. For example, you can substitute the cheese.quote placeholder inside a Simple expression, as follows:
from("direct:start")
.transform().simple("Hi ${body} do you think ${properties:cheese.quote}?");
You can specify a default value for the property, using the syntax, ${properties:Key:DefaultVal}. For example:
from("direct:start")
.transform().simple("Hi ${body} do you think ${properties:cheese.quote:cheese is good}?");
It is also possible to override the location of the property file using the syntax, ${properties-location:Location:Key}. For example, to substitute the bar.quote placeholder using the settings from the com/mycompany/bar.properties property file, you can define a Simple expression as follows:
from("direct:start")
.transform().simple("Hi ${body}. ${properties-location:com/mycompany/bar.properties:bar.quote}.");Using Property Placeholders in the XML DSL
In older releases, the xs:string type attributes were used to support placeholders in the XML DSL. For example, the timeout attribute would be a xs:int type. Therefore, you cannot set a string value as the placeholder key.
From Apache Camel 2.7 onwards, this is now possible by using a special placeholder namespace. The following example illustrates the prop prefix for the namespace. It enables you to use the prop prefix in the attributes in the XML DSLs.
In the Multicast, set the option stopOnException as the value of the placeholder with the key stop. Also, in the properties file, define the value as
stop=true<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:prop="http://camel.apache.org/schema/placeholder"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd
">
<!-- Notice in the declaration above, we have defined the prop prefix as the Camel placeholder namespace -->
<bean id="damn" class="java.lang.IllegalArgumentException">
<constructor-arg index="0" value="Damn"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<propertyPlaceholder id="properties"
location="classpath:org/apache/camel/component/properties/myprop.properties"
xmlns="http://camel.apache.org/schema/spring"/>
<route>
<from uri="direct:start"/>
<!-- use prop namespace, to define a property placeholder, which maps to
option stopOnException={{stop}} -->
<multicast prop:stopOnException="stop">
<to uri="mock:a"/>
<throwException ref="damn"/>
<to uri="mock:b"/>
</multicast>
</route>
</camelContext>
</beans>Integration with OSGi blueprint property placeholders
If you deploy your route into the Red Hat Fuse OSGi container, you can integrate the Apache Camel property placeholder mechanism with JBoss Fuse’s blueprint property placeholder mechanism (in fact, the integration is enabled by default). There are two basic approaches to setting up the integration, as follows:
Implicit blueprint integration
If you define a camelContext element inside an OSGi blueprint file, the Apache Camel property placeholder mechanism automatically integrates with the blueprint property placeholder mechanism. That is, placeholders obeying the Apache Camel syntax (for example, {{cool.end}}) that appear within the scope of camelContext are implicitly resolved by looking up the blueprint property placeholder mechanism.
For example, consider the following route defined in an OSGi blueprint file, where the last endpoint in the route is defined by the property placeholder, {{result}}:
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:cm="http://aries.apache.org/blueprint/xmlns/blueprint-cm/v1.0.0"
xsi:schemaLocation="
http://www.osgi.org/xmlns/blueprint/v1.0.0 https://www.osgi.org/xmlns/blueprint/v1.0.0/blueprint.xsd">
<!-- OSGI blueprint property placeholder -->
<cm:property-placeholder id="myblueprint.placeholder" persistent-id="camel.blueprint">
<!-- list some properties for this test -->
<cm:default-properties>
<cm:property name="result" value="mock:result"/>
</cm:default-properties>
</cm:property-placeholder>
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<!-- in the route we can use {{ }} placeholders which will look up in blueprint,
as Camel will auto detect the OSGi blueprint property placeholder and use it -->
<route>
<from uri="direct:start"/>
<to uri="mock:foo"/>
<to uri="{{result}}"/>
</route>
</camelContext>
</blueprint>
The blueprint property placeholder mechanism is initialized by creating a cm:property-placeholder bean. In the preceding example, the cm:property-placeholder bean is associated with the camel.blueprint persistent ID, where a persistent ID is the standard way of referencing a group of related properties from the OSGi Configuration Admin service. In other words, the cm:property-placeholder bean provides access to all of the properties defined under the camel.blueprint persistent ID. It is also possible to specify default values for some of the properties (using the nested cm:property elements).
In the context of blueprint, the Apache Camel placeholder mechanism searches for an instance of cm:property-placeholder in the bean registry. If it finds such an instance, it automatically integrates the Apache Camel placeholder mechanism, so that placeholders like, {{result}}, are resolved by looking up the key in the blueprint property placeholder mechanism (in this example, through the myblueprint.placeholder bean).
The default blueprint placeholder syntax (accessing the blueprint properties directly) is ${Key}. Hence, outside the scope of a camelContext element, the placeholder syntax you must use is ${Key}. Whereas, inside the scope of a camelContext element, the placeholder syntax you must use is {{Key}}.
Explicit blueprint integration
If you want to have more control over where the Apache Camel property placeholder mechanism finds its properties, you can define a propertyPlaceholder element and specify the resolver locations explicitly.
For example, consider the following blueprint configuration, which differs from the previous example in that it creates an explicit propertyPlaceholder instance:
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:cm="http://aries.apache.org/blueprint/xmlns/blueprint-cm/v1.0.0"
xsi:schemaLocation="
http://www.osgi.org/xmlns/blueprint/v1.0.0 ">https://www.osgi.org/xmlns/blueprint/v1.0.0/blueprint.xsd">
<!-- OSGI blueprint property placeholder -->
<cm:property-placeholder id="myblueprint.placeholder" persistent-id="camel.blueprint">
<!-- list some properties for this test -->
<cm:default-properties>
<cm:property name="result" value="mock:result"/>
</cm:default-properties>
</cm:property-placeholder>
<camelContext xmlns="http://camel.apache.org/schema/blueprint">
<!-- using Camel properties component and refer to the blueprint property placeholder by its id -->
<propertyPlaceholder id="properties" location="blueprint:myblueprint.placeholder"/>
<!-- in the route we can use {{ }} placeholders which will lookup in blueprint -->
<route>
<from uri="direct:start"/>
<to uri="mock:foo"/>
<to uri="{{result}}"/>
</route>
</camelContext>
</blueprint>
In the preceding example, the propertyPlaceholder element specifies explicitly which cm:property-placeholder bean to use by setting the location to blueprint:myblueprint.placeholder. That is, the blueprint: resolver explicitly references the ID, myblueprint.placeholder, of the cm:property-placeholder bean.
This style of configuration is useful, if there is more than one cm:property-placeholder bean defined in the blueprint file and you need to specify which one to use. It also makes it possible to source properties from multiple locations, by specifying a comma-separated list of locations. For example, if you wanted to look up properties both from the cm:property-placeholder bean and from the properties file, myproperties.properties, on the classpath, you could define the propertyPlaceholder element as follows:
<propertyPlaceholder id="properties"
location="blueprint:myblueprint.placeholder,classpath:myproperties.properties"/>Integration with Spring property placeholders
If you define your Apache Camel application using XML DSL in a Spring XML file, you can integrate the Apache Camel property placeholder mechanism with Spring property placeholder mechanism by declaring a Spring bean of type, org.apache.camel.spring.spi.BridgePropertyPlaceholderConfigurer.
Define a BridgePropertyPlaceholderConfigurer, which replaces both Apache Camel’s propertyPlaceholder element and Spring’s ctx:property-placeholder element in the Spring XML file. You can then refer to the configured properties using either the Spring ${PropName} syntax or the Apache Camel {{PropName}} syntax.
For example, defining a bridge property placeholder that reads its property settings from the cheese.properties file:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ctx="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- Bridge Spring property placeholder with Camel -->
<!-- Do not use <ctx:property-placeholder ... > at the same time -->
<bean id="bridgePropertyPlaceholder"
class="org.apache.camel.spring.spi.BridgePropertyPlaceholderConfigurer">
<property name="location"
value="classpath:org/apache/camel/component/properties/cheese.properties"/>
</bean>
<!-- A bean that uses Spring property placeholder -->
<!-- The ${hi} is a spring property placeholder -->
<bean id="hello" class="org.apache.camel.component.properties.HelloBean">
<property name="greeting" value="${hi}"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<!-- Use Camel's property placeholder {{ }} style -->
<route>
<from uri="direct:{{cool.bar}}"/>
<bean ref="hello"/>
<to uri="{{cool.end}}"/>
</route>
</camelContext>
</beans>
Alternatively, you can set the location attribute of the BridgePropertyPlaceholderConfigurer to point at a Spring properties file. The Spring properties file syntax is fully supported.
2.8. Threading Model
Java thread pool API
The Apache Camel threading model is based on the powerful Java concurrency API, Package java.util.concurrent, that first became available in Sun’s JDK 1.5. The key interface in this API is the ExecutorService interface, which represents a thread pool. Using the concurrency API, you can create many different kinds of thread pool, covering a wide range of scenarios.
Apache Camel thread pool API
The Apache Camel thread pool API builds on the Java concurrency API by providing a central factory (of org.apache.camel.spi.ExecutorServiceManager type) for all of the thread pools in your Apache Camel application. Centralising the creation of thread pools in this way provides several advantages, including:
- Simplified creation of thread pools, using utility classes.
- Integrating thread pools with graceful shutdown.
- Threads automatically given informative names, which is beneficial for logging and management.
Component threading model
Some Apache Camel components — such as SEDA, JMS, and Jetty — are inherently multi-threaded. These components have all been implemented using the Apache Camel threading model and thread pool API.
If you are planning to implement your own Apache Camel component, it is recommended that you integrate your threading code with the Apache Camel threading model. For example, if your component needs a thread pool, it is recommended that you create it using the CamelContext’s ExecutorServiceManager object.
Processor threading model
Some of the standard processors in Apache Camel create their own thread pool by default. These threading-aware processors are also integrated with the Apache Camel threading model and they provide various options that enable you to customize the thread pools that they use.
Table 2.8, “Processor Threading Options” shows the various options for controlling and setting thread pools on the threading-aware processors built-in to Apache Camel.
| Processor | Java DSL | XML DSL |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
threads DSL options
The threads processor is a general-purpose DSL command, which you can use to introduce a thread pool into a route. It supports the following options to customize the thread pool:
poolSize()- Minimum number of threads in the pool (and initial pool size).
maxPoolSize()- Maximum number of threads in the pool.
keepAliveTime()- If any threads are idle for longer than this period of time (specified in seconds), they are terminated.
timeUnit()-
Time unit for keep alive, specified using the
java.util.concurrent.TimeUnittype. maxQueueSize()- Maximum number of pending tasks that this thread pool can store in its incoming task queue.
rejectedPolicy()- Specifies what course of action to take, if the incoming task queue is full. See Table 2.10, “Thread Pool Builder Options”
The preceding thread pool options are not compatible with the executorServiceRef option (for example, you cannot use these options to override the settings in the thread pool referenced by an executorServiceRef option). Apache Camel validates the DSL to enforce this.
Creating a default thread pool
To create a default thread pool for one of the threading-aware processors, enable the parallelProcessing option, using the parallelProcessing() sub-clause, in the Java DSL, or the parallelProcessing attribute, in the XML DSL.
For example, in the Java DSL, you can invoke the multicast processor with a default thread pool (where the thread pool is used to process the multicast destinations concurrently) as follows:
from("direct:start")
.multicast().parallelProcessing()
.to("mock:first")
.to("mock:second")
.to("mock:third");You can define the same route in XML DSL as follows
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<multicast parallelProcessing="true">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Default thread pool profile settings
The default thread pools are automatically created by a thread factory that takes its settings from the default thread pool profile. The default thread pool profile has the settings shown in Table 2.9, “Default Thread Pool Profile Settings” (assuming that these settings have not been modified by the application code).
| Thread Option | Default Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Changing the default thread pool profile
It is possible to change the default thread pool profile settings, so that all subsequent default thread pools will be created with the custom settings. You can change the profile either in Java or in Spring XML.
For example, in the Java DSL, you can customize the poolSize option and the maxQueueSize option in the default thread pool profile, as follows:
// Java
import org.apache.camel.spi.ExecutorServiceManager;
import org.apache.camel.spi.ThreadPoolProfile;
...
ExecutorServiceManager manager = context.getExecutorServiceManager();
ThreadPoolProfile defaultProfile = manager.getDefaultThreadPoolProfile();
// Now, customize the profile settings.
defaultProfile.setPoolSize(3);
defaultProfile.setMaxQueueSize(100);
...In the XML DSL, you can customize the default thread pool profile, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile
id="changedProfile"
defaultProfile="true"
poolSize="3"
maxQueueSize="100"/>
...
</camelContext>
Note that it is essential to set the defaultProfile attribute to true in the preceding XML DSL example, otherwise the thread pool profile would be treated like a custom thread pool profile (see the section called “Creating a custom thread pool profile”), instead of replacing the default thread pool profile.
Customizing a processor’s thread pool
It is also possible to specify the thread pool for a threading-aware processor more directly, using either the executorService or executorServiceRef options (where these options are used instead of the parallelProcessing option). There are two approaches you can use to customize a processor’s thread pool, as follows:
-
Specify a custom thread pool — explicitly create an
ExecutorService(thread pool) instance and pass it to theexecutorServiceoption. -
Specify a custom thread pool profile — create and register a custom thread pool factory. When you reference this factory using the
executorServiceRefoption, the processor automatically uses the factory to create a custom thread pool instance.
When you pass a bean ID to the executorServiceRef option, the threading-aware processor first tries to find a custom thread pool with that ID in the registry. If no thread pool is registered with that ID, the processor then attempts to look up a custom thread pool profile in the registry and uses the custom thread pool profile to instantiate a custom thread pool.
Creating a custom thread pool
A custom thread pool can be any thread pool of java.util.concurrent.ExecutorService type. The following approaches to creating a thread pool instance are recommended in Apache Camel:
-
Use the
org.apache.camel.builder.ThreadPoolBuilderutility to build the thread pool class. -
Use the
org.apache.camel.spi.ExecutorServiceManagerinstance from the currentCamelContextto create the thread pool class.
Ultimately, there is not much difference between the two approaches, because the ThreadPoolBuilder is actually defined using the ExecutorServiceManager instance. Normally, the ThreadPoolBuilder is preferred, because it offers a simpler approach. But there is at least one kind of thread (the ScheduledExecutorService) that can only be created by accessing the ExecutorServiceManager instance directly.
Table 2.10, “Thread Pool Builder Options” shows the options supported by the ThreadPoolBuilder class, which you can set when defining a new custom thread pool.
| Builder Option | Description |
|---|---|
|
|
Sets the maximum number of pending tasks that this thread pool can store in its incoming task queue. A value of |
|
| Sets the minimum number of threads in the pool (this is also the initial pool size). Default value is taken from default thread pool profile. |
|
| Sets the maximum number of threads that can be in the pool. Default value is taken from default thread pool profile. |
|
| If any threads are idle for longer than this period of time (specified in seconds), they are terminated. This allows the thread pool to shrink when the load is light. Default value is taken from default thread pool profile. |
|
| Specifies what course of action to take, if the incoming task queue is full. You can specify four possible values:
|
|
|
Finishes building the custom thread pool and registers the new thread pool under the ID specified as the argument to |
In Java DSL, you can define a custom thread pool using the ThreadPoolBuilder, as follows:
// Java
import org.apache.camel.builder.ThreadPoolBuilder;
import java.util.concurrent.ExecutorService;
...
ThreadPoolBuilder poolBuilder = new ThreadPoolBuilder(context);
ExecutorService customPool = poolBuilder.poolSize(5).maxPoolSize(5).maxQueueSize(100).build("customPool");
...
from("direct:start")
.multicast().executorService(customPool)
.to("mock:first")
.to("mock:second")
.to("mock:third");
Instead of passing the object reference, customPool, directly to the executorService() option, you can look up the thread pool in the registry, by passing its bean ID to the executorServiceRef() option, as follows:
// Java
from("direct:start")
.multicast().executorServiceRef("customPool")
.to("mock:first")
.to("mock:second")
.to("mock:third");
In XML DSL, you access the ThreadPoolBuilder using the threadPool element. You can then reference the custom thread pool using the executorServiceRef attribute to look up the thread pool by ID in the Spring registry, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPool id="customPool"
poolSize="5"
maxPoolSize="5"
maxQueueSize="100" />
<route>
<from uri="direct:start"/>
<multicast executorServiceRef="customPool">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Creating a custom thread pool profile
If you have many custom thread pool instances to create, you might find it more convenient to define a custom thread pool profile, which acts as a factory for thread pools. Whenever you reference a thread pool profile from a threading-aware processor, the processor automatically uses the profile to create a new thread pool instance. You can define a custom thread pool profile either in Java DSL or in XML DSL.
For example, in Java DSL you can create a custom thread pool profile with the bean ID, customProfile, and reference it from within a route, as follows:
// Java
import org.apache.camel.spi.ThreadPoolProfile;
import org.apache.camel.impl.ThreadPoolProfileSupport;
...
// Create the custom thread pool profile
ThreadPoolProfile customProfile = new ThreadPoolProfileSupport("customProfile");
customProfile.setPoolSize(5);
customProfile.setMaxPoolSize(5);
customProfile.setMaxQueueSize(100);
context.getExecutorServiceManager().registerThreadPoolProfile(customProfile);
...
// Reference the custom thread pool profile in a route
from("direct:start")
.multicast().executorServiceRef("customProfile")
.to("mock:first")
.to("mock:second")
.to("mock:third");
In XML DSL, use the threadPoolProfile element to create a custom pool profile (where you let the defaultProfile option default to false, because this is not a default thread pool profile). You can create a custom thread pool profile with the bean ID, customProfile, and reference it from within a route, as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<threadPoolProfile
id="customProfile"
poolSize="5"
maxPoolSize="5"
maxQueueSize="100" />
<route>
<from uri="direct:start"/>
<multicast executorServiceRef="customProfile">
<to uri="mock:first"/>
<to uri="mock:second"/>
<to uri="mock:third"/>
</multicast>
</route>
</camelContext>Sharing a thread pool between components
Some of the standard poll-based components — such as File and FTP — allow you to specify the thread pool to use. This makes it possible for different components to share the same thread pool, reducing the overall number of threads in the JVM.
For example, the see File2 in the Apache Camel Component Reference Guide. and the Ftp2 in the Apache Camel Component Reference Guide both expose the scheduledExecutorService property, which you can use to specify the component’s ExecutorService object.
Customizing thread names
To make the application logs more readable, it is often a good idea to customize the thread names (which are used to identify threads in the log). To customize thread names, you can configure the thread name pattern by calling the setThreadNamePattern method on the ExecutorServiceStrategy class or the ExecutorServiceManager class. Alternatively, an easier way to set the thread name pattern is to set the threadNamePattern property on the CamelContext object.
The following placeholders can be used in a thread name pattern:
#camelId#-
The name of the current
CamelContext. #counter#- A unique thread identifier, implemented as an incrementing counter.
#name#- The regular Camel thread name.
#longName#- The long thread name — which can include endpoint parameters and so on.
The following is a typical example of a thread name pattern:
Camel (#camelId#) thread #counter# - #name#
The following example shows how to set the threadNamePattern attribute on a Camel context using XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring"
threadNamePattern="Riding the thread #counter#" >
<route>
<from uri="seda:start"/>
<to uri="log:result"/>
<to uri="mock:result"/>
</route>
</camelContext>2.9. Controlling Start-Up and Shutdown of Routes
Overview
By default, routes are automatically started when your Apache Camel application (as represented by the CamelContext instance) starts up and routes are automatically shut down when your Apache Camel application shuts down. For non-critical deployments, the details of the shutdown sequence are usually not very important. But in a production environment, it is often crucial that existing tasks should run to completion during shutdown, in order to avoid data loss. You typically also want to control the order in which routes shut down, so that dependencies are not violated (which would prevent existing tasks from running to completion).
For this reason, Apache Camel provides a set of features to support graceful shutdown of applications. Graceful shutdown gives you full control over the stopping and starting of routes, enabling you to control the shutdown order of routes and enabling current tasks to run to completion.
Setting the route ID
It is good practice to assign a route ID to each of your routes. As well as making logging messages and management features more informative, the use of route IDs enables you to apply greater control over the stopping and starting of routes.
For example, in the Java DSL, you can assign the route ID, myCustomerRouteId, to a route by invoking the routeId() command as follows:
from("SourceURI").routeId("myCustomRouteId").process(...).to(TargetURI);
In the XML DSL, set the route element’s id attribute, as follows:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route id="myCustomRouteId" >
<from uri="SourceURI"/>
<process ref="someProcessorId"/>
<to uri="TargetURI"/>
</route>
</camelContext>Disabling automatic start-up of routes
By default, all of the routes that the CamelContext knows about at start time will be started automatically. If you want to control the start-up of a particular route manually, however, you might prefer to disable automatic start-up for that route.
To control whether a Java DSL route starts up automatically, invoke the autoStartup command, either with a boolean argument (true or false) or a String argument (true or false). For example, you can disable automatic start-up of a route in the Java DSL, as follows:
from("SourceURI")
.routeId("nonAuto")
.autoStartup(false)
.to(TargetURI);
You can disable automatic start-up of a route in the XML DSL by setting the autoStartup attribute to false on the route element, as follows:
<camelContext id="CamelContextID" xmlns="http://camel.apache.org/schema/spring">
<route id="nonAuto" autoStartup="false">
<from uri="SourceURI"/>
<to uri="TargetURI"/>
</route>
</camelContext>Manually starting and stopping routes
You can manually start or stop a route at any time in Java by invoking the startRoute() and stopRoute() methods on the CamelContext instance. For example, to start the route having the route ID, nonAuto, invoke the startRoute() method on the CamelContext instance, context, as follows:
// Java
context.startRoute("nonAuto");
To stop the route having the route ID, nonAuto, invoke the stopRoute() method on the CamelContext instance, context, as follows:
// Java
context.stopRoute("nonAuto");Startup order of routes
By default, Apache Camel starts up routes in a non-deterministic order. In some applications, however, it can be important to control the startup order. To control the startup order in the Java DSL, use the startupOrder() command, which takes a positive integer value as its argument. The route with the lowest integer value starts first, followed by the routes with successively higher startup order values.
For example, the first two routes in the following example are linked together through the seda:buffer endpoint. You can ensure that the first route segment starts after the second route segment by assigning startup orders (2 and 1 respectively), as follows:
Example 2.5. Startup Order in Java DSL
from("jetty:http://fooserver:8080")
.routeId("first")
.startupOrder(2)
.to("seda:buffer");
from("seda:buffer")
.routeId("second")
.startupOrder(1)
.to("mock:result");
// This route's startup order is unspecified
from("jms:queue:foo").to("jms:queue:bar");
Or in Spring XML, you can achieve the same effect by setting the route element’s startupOrder attribute, as follows:
Example 2.6. Startup Order in XML DSL
<route id="first" startupOrder="2">
<from uri="jetty:http://fooserver:8080"/>
<to uri="seda:buffer"/>
</route>
<route id="second" startupOrder="1">
<from uri="seda:buffer"/>
<to uri="mock:result"/>
</route>
<!-- This route's startup order is unspecified -->
<route>
<from uri="jms:queue:foo"/>
<to uri="jms:queue:bar"/>
</route>Each route must be assigned a unique startup order value. You can choose any positive integer value that is less than 1000. Values of 1000 and over are reserved for Apache Camel, which automatically assigns these values to routes without an explicit startup value. For example, the last route in the preceding example would automatically be assigned the startup value, 1000 (so it starts up after the first two routes).
Shutdown sequence
When a CamelContext instance is shutting down, Apache Camel controls the shutdown sequence using a pluggable shutdown strategy. The default shutdown strategy implements the following shutdown sequence:
- Routes are shut down in the reverse of the start-up order.
- Normally, the shutdown strategy waits until the currently active exchanges have finshed processing. The treatment of running tasks is configurable, however.
- Overall, the shutdown sequence is bound by a timeout (default, 300 seconds). If the shutdown sequence exceeds this timeout, the shutdown strategy will force shutdown to occur, even if some tasks are still running.
Shutdown order of routes
Routes are shut down in the reverse of the start-up order. That is, when a start-up order is defined using the startupOrder() command (in Java DSL) or startupOrder attribute (in XML DSL), the first route to shut down is the route with the highest integer value assigned by the start-up order and the last route to shut down is the route with the lowest integer value assigned by the start-up order.
For example, in Example 2.5, “Startup Order in Java DSL”, the first route segment to be shut down is the route with the ID, first, and the second route segment to be shut down is the route with the ID, second. This example illustrates a general rule, which you should observe when shutting down routes: the routes that expose externally-accessible consumer endpoints should be shut down first, because this helps to throttle the flow of messages through the rest of the route graph.
Apache Camel also provides the option shutdownRoute(Defer), which enables you to specify that a route must be amongst the last routes to shut down (overriding the start-up order value). But you should rarely ever need this option. This option was mainly needed as a workaround for earlier versions of Apache Camel (prior to 2.3), for which routes would shut down in the same order as the start-up order.
Shutting down running tasks in a route
If a route is still processing messages when the shutdown starts, the shutdown strategy normally waits until the currently active exchange has finished processing before shutting down the route. This behavior can be configured on each route using the shutdownRunningTask option, which can take either of the following values:
ShutdownRunningTask.CompleteCurrentTaskOnly- (Default) Usually, a route operates on just a single message at a time, so you can safely shut down the route after the current task has completed.
ShutdownRunningTask.CompleteAllTasks- Specify this option in order to shut down batch consumers gracefully. Some consumer endpoints (for example, File, FTP, Mail, iBATIS, and JPA) operate on a batch of messages at a time. For these endpoints, it is more appropriate to wait until all of the messages in the current batch have completed.
For example, to shut down a File consumer endpoint gracefully, you should specify the CompleteAllTasks option, as shown in the following Java DSL fragment:
// Java
public void configure() throws Exception {
from("file:target/pending")
.routeId("first").startupOrder(2)
.shutdownRunningTask(ShutdownRunningTask.CompleteAllTasks)
.delay(1000).to("seda:foo");
from("seda:foo")
.routeId("second").startupOrder(1)
.to("mock:bar");
}The same route can be defined in the XML DSL as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<!-- let this route complete all its pending messages when asked to shut down -->
<route id="first"
startupOrder="2"
shutdownRunningTask="CompleteAllTasks">
<from uri="file:target/pending"/>
<delay><constant>1000</constant></delay>
<to uri="seda:foo"/>
</route>
<route id="second" startupOrder="1">
<from uri="seda:foo"/>
<to uri="mock:bar"/>
</route>
</camelContext>Shutdown timeout
The shutdown timeout has a default value of 300 seconds. You can change the value of the timeout by invoking the setTimeout() method on the shutdown strategy. For example, you can change the timeout value to 600 seconds, as follows:
// Java
// context = CamelContext instance
context.getShutdownStrategy().setTimeout(600);Integration with custom components
If you are implementing a custom Apache Camel component (which also inherits from the org.apache.camel.Service interface), you can ensure that your custom code receives a shutdown notification by implementing the org.apache.camel.spi.ShutdownPrepared interface. This gives the component an opportunity execute custom code in preparation for shutdown.
2.9.1. RouteIdFactory
Based on the consumer endpoints, you can add RouteIdFactory that can assign route ids with the logical names.
For example, when using the routes with seda or direct components as route inputs, then you may want to use their names as the route id, such as,
- direct:foo- foo
- seda:bar- bar
- jms:orders- orders
Instead of using auto-assigned names, you can use the NodeIdFactory that can assign logical names for routes. Also, you can use the context-path of route URL as the name. For example, execute the following to use the RouteIDFactory:
context.setNodeIdFactory(new RouteIdFactory());It is possible to get the custom route id from rest endpoints.
2.10. Scheduled Route Policy
2.10.1. Overview of Scheduled Route Policies
Overview
A scheduled route policy can be used to trigger events that affect a route at runtime. In particular, the implementations that are currently available enable you to start, stop, suspend, or resume a route at any time (or times) specified by the policy.
Scheduling tasks
The scheduled route policies are capable of triggering the following kinds of event:
- Start a route — start the route at the time (or times) specified. This event only has an effect, if the route is currently in a stopped state, awaiting activation.
- Stop a route — stop the route at the time (or times) specified. This event only has an effect, if the route is currently active.
-
Suspend a route — temporarily de-activate the consumer endpoint at the start of the route (as specified in
from()). The rest of the route is still active, but clients will not be able to send new messages into the route. - Resume a route — re-activate the consumer endpoint at the start of the route, returning the route to a fully active state.
Quartz component
The Quartz component is a timer component based on Terracotta’s Quartz, which is an open source implementation of a job scheduler. The Quartz component provides the underlying implementation for both the simple scheduled route policy and the cron scheduled route policy.
2.10.2. Simple Scheduled Route Policy
Overview
The simple scheduled route policy is a route policy that enables you to start, stop, suspend, and resume routes, where the timing of these events is defined by providing the time and date of an initial event and (optionally) by specifying a certain number of subsequent repititions. To define a simple scheduled route policy, create an instance of the following class:
org.apache.camel.routepolicy.quartz.SimpleScheduledRoutePolicyDependency
The simple scheduled route policy depends on the Quartz component, camel-quartz. For example, if you are using Maven as your build system, you would need to add a dependency on the camel-quartz artifact.
Java DSL example
Example 2.7, “Java DSL Example of Simple Scheduled Route” shows how to schedule a route to start up using the Java DSL. The initial start time, startTime, is defined to be 3 seconds after the current time. The policy is also configured to start the route a second time, 3 seconds after the initial start time, which is configured by setting routeStartRepeatCount to 1 and routeStartRepeatInterval to 3000 milliseconds.
In Java DSL, you attach the route policy to the route by calling the routePolicy() DSL command in the route.
Example 2.7. Java DSL Example of Simple Scheduled Route
// Java
SimpleScheduledRoutePolicy policy = new SimpleScheduledRoutePolicy();
long startTime = System.currentTimeMillis() + 3000L;
policy.setRouteStartDate(new Date(startTime));
policy.setRouteStartRepeatCount(1);
policy.setRouteStartRepeatInterval(3000);
from("direct:start")
.routeId("test")
.routePolicy(policy)
.to("mock:success");
You can specify multiple policies on the route by calling routePolicy() with multiple arguments.
XML DSL example
Example 2.8, “XML DSL Example of Simple Scheduled Route” shows how to schedule a route to start up using the XML DSL.
In XML DSL, you attach the route policy to the route by setting the routePolicyRef attribute on the route element.
Example 2.8. XML DSL Example of Simple Scheduled Route
<bean id="date" class="java.util.Data"/>
<bean id="startPolicy" class="org.apache.camel.routepolicy.quartz.SimpleScheduledRoutePolicy">
<property name="routeStartDate" ref="date"/>
<property name="routeStartRepeatCount" value="1"/>
<property name="routeStartRepeatInterval" value="3000"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route id="myroute" routePolicyRef="startPolicy">
<from uri="direct:start"/>
<to uri="mock:success"/>
</route>
</camelContext>
You can specify multiple policies on the route by setting the value of routePolicyRef as a comma-separated list of bean IDs.
Defining dates and times
The initial times of the triggers used in the simple scheduled route policy are specified using the java.util.Date type.The most flexible way to define a Date instance is through the java.util.GregorianCalendar class. Use the convenient constructors and methods of the GregorianCalendar class to define a date and then obtain a Date instance by calling GregorianCalendar.getTime().
For example, to define the time and date for January 1, 2011 at noon, call a GregorianCalendar constructor as follows:
// Java
import java.util.GregorianCalendar;
import java.util.Calendar;
...
GregorianCalendar gc = new GregorianCalendar(
2011,
Calendar.JANUARY,
1,
12, // hourOfDay
0, // minutes
0 // seconds
);
java.util.Date triggerDate = gc.getTime();
The GregorianCalendar class also supports the definition of times in different time zones. By default, it uses the local time zone on your computer.
Graceful shutdown
When you configure a simple scheduled route policy to stop a route, the route stopping algorithm is automatically integrated with the graceful shutdown procedure (see Section 2.9, “Controlling Start-Up and Shutdown of Routes”). This means that the task waits until the current exchange has finished processing before shutting down the route. You can set a timeout, however, that forces the route to stop after the specified time, irrespective of whether or not the route has finished processing the exchange.
Logging Inflight Exchanges on Timeout
If a graceful shutdown fails to shutdown cleanly within the given timeout period, then Apache Camel performs more aggressive shut down. It forces routes, threadpools etc to shutdown.
After the timeout, Apache Camel logs information about the current inflight exchanges. It logs the origin of the exchange and current route of exchange.
For example, the log below shows that there is one inflight exchange, that origins from route1 and is currently on the same route1 at the delay1 node.
During graceful shutdown, If you enable the DEBUG logging level on org.apache.camel.impl.DefaultShutdownStrategy, then it logs the same inflight exchange information.
2015-01-12 13:23:23,656 [- ShutdownTask] INFO DefaultShutdownStrategy - There are 1 inflight exchanges:
InflightExchange: [exchangeId=ID-davsclaus-air-62213-1421065401253-0-3, fromRouteId=route1, routeId=route1, nodeId=delay1, elapsed=2007, duration=2017]
If you do not want to see these logs, you can turn this off by setting the option logInflightExchangesOnTimeout to false.
context.getShutdownStrategegy().setLogInflightExchangesOnTimeout(false);Scheduling tasks
You can use a simple scheduled route policy to define one or more of the following scheduling tasks:
Starting a route
The following table lists the parameters for scheduling one or more route starts.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is started for the first time. |
|
|
|
| When set to a non-zero value, specifies how many times the route should be started. |
|
|
|
| Specifies the time interval between starts, in units of milliseconds. |
Stopping a route
The following table lists the parameters for scheduling one or more route stops.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is stopped for the first time. |
|
|
|
| When set to a non-zero value, specifies how many times the route should be stopped. |
|
|
|
| Specifies the time interval between stops, in units of milliseconds. |
|
|
|
| Specifies how long to wait for the current exchange to finish processing (grace period) before forcibly stopping the route. Set to 0 for an infinite grace period. |
|
|
|
| Specifies the time unit of the grace period. |
Suspending a route
The following table lists the parameters for scheduling the suspension of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is suspended for the first time. |
|
|
| 0 | When set to a non-zero value, specifies how many times the route should be suspended. |
|
|
| 0 | Specifies the time interval between suspends, in units of milliseconds. |
Resuming a route
The following table lists the parameters for scheduling the resumption of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies the date and time when the route is resumed for the first time. |
|
|
| 0 | When set to a non-zero value, specifies how many times the route should be resumed. |
|
|
| 0 | Specifies the time interval between resumes, in units of milliseconds. |
2.10.3. Cron Scheduled Route Policy
Overview
The cron scheduled route policy is a route policy that enables you to start, stop, suspend, and resume routes, where the timing of these events is specified using cron expressions. To define a cron scheduled route policy, create an instance of the following class:
org.apache.camel.routepolicy.quartz.CronScheduledRoutePolicyDependency
The simple scheduled route policy depends on the Quartz component, camel-quartz. For example, if you are using Maven as your build system, you would need to add a dependency on the camel-quartz artifact.
Java DSL example
Example 2.9, “Java DSL Example of a Cron Scheduled Route” shows how to schedule a route to start up using the Java DSL. The policy is configured with the cron expression, \*/3 * * * * ?, which triggers a start event every 3 seconds.
In Java DSL, you attach the route policy to the route by calling the routePolicy() DSL command in the route.
Example 2.9. Java DSL Example of a Cron Scheduled Route
// Java
CronScheduledRoutePolicy policy = new CronScheduledRoutePolicy();
policy.setRouteStartTime("*/3 * * * * ?");
from("direct:start")
.routeId("test")
.routePolicy(policy)
.to("mock:success");;
You can specify multiple policies on the route by calling routePolicy() with multiple arguments.
XML DSL example
Example 2.10, “XML DSL Example of a Cron Scheduled Route”shows how to schedule a route to start up using the XML DSL.
In XML DSL, you attach the route policy to the route by setting the routePolicyRef attribute on the route element.
Example 2.10. XML DSL Example of a Cron Scheduled Route
<bean id="date" class="org.apache.camel.routepolicy.quartz.SimpleDate"/>
<bean id="startPolicy" class="org.apache.camel.routepolicy.quartz.CronScheduledRoutePolicy">
<property name="routeStartTime" value="*/3 * * * * ?"/>
</bean>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route id="testRoute" routePolicyRef="startPolicy">
<from uri="direct:start"/>
<to uri="mock:success"/>
</route>
</camelContext>
You can specify multiple policies on the route by setting the value of routePolicyRef as a comma-separated list of bean IDs.
Defining cron expressions
The cron expression syntax has its origins in the UNIX cron utility, which schedules jobs to run in the background on a UNIX system. A cron expression is effectively a syntax for wildcarding dates and times that enables you to specify either a single event or multiple events that recur periodically.
A cron expression consists of 6 or 7 fields in the following order:
Seconds Minutes Hours DayOfMonth Month DayOfWeek [Year]
The Year field is optional and usually omitted, unless you want to define an event that occurs once and once only. Each field consists of a mixture of literals and special characters. For example, the following cron expression specifies an event that fires once every day at midnight:
0 0 24 * * ?
The * character is a wildcard that matches every value of a field. Hence, the preceding expression matches every day of every month. The ? character is a dummy placeholder that means *ignore this field*. It always appears either in the DayOfMonth field or in the DayOfWeek field, because it is not logically consistent to specify both of these fields at the same time. For example, if you want to schedule an event that fires once a day, but only from Monday to Friday, use the following cron expression:
0 0 24 ? * MON-FRI
Where the hyphen character specifies a range, MON-FRI. You can also use the forward slash character, /, to specify increments. For example, to specify that an event fires every 5 minutes, use the following cron expression:
0 0/5 * * * ?For a full explanation of the cron expression syntax, see the Wikipedia article on CRON expressions.
Scheduling tasks
You can use a cron scheduled route policy to define one or more of the following scheduling tasks:
Starting a route
The following table lists the parameters for scheduling one or more route starts.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route start events. |
Stopping a route
The following table lists the parameters for scheduling one or more route stops.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route stop events. |
|
|
|
| Specifies how long to wait for the current exchange to finish processing (grace period) before forcibly stopping the route. Set to 0 for an infinite grace period. |
|
|
|
| Specifies the time unit of the grace period. |
Suspending a route
The following table lists the parameters for scheduling the suspension of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route suspend events. |
Resuming a route
The following table lists the parameters for scheduling the resumption of a route one or more times.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| None | Specifies a cron expression that triggers one or more route resume events. |
2.10.4. Route Policy Factory
Using Route Policy Factory
Available as of Camel 2.14
If you want to use a route policy for every route, you can use a org.apache.camel.spi.RoutePolicyFactory as a factory for creating a RoutePolicy instance for each route. This can be used when you want to use the same kind of route policy for every route. Then you need to only configure the factory once, and every route created will have the policy assigned.
There is API on CamelContext to add a factory, as shown below:
context.addRoutePolicyFactory(new MyRoutePolicyFactory());
From XML DSL you only define a <bean> with the factory
<bean id="myRoutePolicyFactory" class="com.foo.MyRoutePolicyFactory"/>The factory contains the createRoutePolicy method for creating route policies.
/**
* Creates a new {@link org.apache.camel.spi.RoutePolicy} which will be assigned to the given route.
*
* @param camelContext the camel context
* @param routeId the route id
* @param route the route definition
* @return the created {@link org.apache.camel.spi.RoutePolicy}, or <tt>null</tt> to not use a policy for this route
*/
RoutePolicy createRoutePolicy(CamelContext camelContext, String routeId, RouteDefinition route);
Note you can have as many route policy factories as you want. Just call the addRoutePolicyFactory again, or declare the other factories as <bean> in XML.
2.11. Reloading Camel Routes
In Apache Camel 2.19 release, you can enable the live reload of your camel XML routes, which will trigger a reload, when you save the XML file from your editor. You can use this feature when using:
- Camel standalone with Camel Main class
- Camel Spring Boot
- From the camel:run maven plugin
However, you can also enable this manually, by setting a ReloadStrategy on the CamelContext and by providing your own custom strategies.
2.12. Camel Maven Plugin
The Camel Maven Plugin supports the following goals:
- camel:run - To run your Camel application
- camel:validate - To validate your source code for invalid Camel endpoint URIs
- camel:route-coverage - To report the coverage of your Camel routes after unit testing
2.12.1. camel:run
The camel:run goal of the Camel Maven Plugin is used to run your Camel Spring configurations in a forked JVM from Maven. A good example application to get you started is the Spring Example.
cd examples/camel-example-spring
mvn camel:run
This makes it very easy to spin up and test your routing rules without having to write a main(…) method; it also lets you create multiple jars to host different sets of routing rules and easily test them independently. The Camel Maven plugin compiles the source code in the maven project, then boots up a Spring ApplicationContext using the XML configuration files on the classpath at META-INF/spring/*.xml. If you want to boot up your Camel routes a little faster, you can try the camel:embedded instead.
2.12.1.1. Options
The Camel Maven plugin run goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| duration | -1 | Sets the time duration (seconds) that the application runs for before terminating. A value ⇐ 0 will run forever. |
| durationIdle | -1 | Sets the idle time duration (seconds) duration that the application can be idle for before terminating. A value ⇐ 0 will run forever. |
| durationMaxMessages | -1 | Sets the duration of maximum number of messages that the application processes before terminating. |
| logClasspath | false | Whether to log the classpath when starting |
2.12.1.2. Running OSGi Blueprint
The camel:run plugin also supports running a Blueprint application, and by default it scans for OSGi blueprint files in OSGI-INF/blueprint/*.xml. You would need to configure the camel:run plugin to use blueprint, by setting useBlueprint to true as shown below:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<useBlueprint>true</useBlueprint>
</configuration>
</plugin>
This allows you to boot up any Blueprint services you wish, regardless of whether they are Camel-related, or any other Blueprint. The camel:run goal can auto detect if camel-blueprint is on the classpath or there are blueprint XML files in the project, and therefore you no longer have to configure the useBlueprint option.
2.12.1.3. Using limited Blueprint container
We use the Felix Connector project as the blueprint container. This project is not a full fledged blueprint container. For that you can use Apache Karaf or Apache ServiceMix. You can use the applicationContextUri configuration to specify an explicit blueprint XML file, such as:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<useBlueprint>true</useBlueprint>
<applicationContextUri>myBlueprint.xml</applicationContextUri>
<!-- ConfigAdmin options which have been added since Camel 2.12.0 -->
<configAdminPid>test</configAdminPid>
<configAdminFileName>/user/test/etc/test.cfg</configAdminFileName>
</configuration>
</plugin>
The applicationContextUri loads the file from the classpath, so in the example above the myBlueprint.xml file must be in the root of the classpath. The configAdminPid is the pid name which will be used as the pid name for configuration admin service when loading the persistence properties file. The configAdminFileName is the file name which will be used to load the configuration admin service properties file.
2.12.1.4. Running CDI
The camel:run plugin also supports running a CDI application. This allows you to boot up any CDI services you wish, whether they are Camel-related, or any other CDI enabled services. You should add the CDI container of your choice (e.g. Weld or OpenWebBeans) to the dependencies of the camel-maven-plugin such as in this example. From the source of Camel you can run a CDI example as follows:
cd examples/camel-example-cdi
mvn compile camel:run2.12.1.5. Logging the classpath
You can configure whether the classpath should be logged when camel:run executes. You can enable this in the configuration using:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<logClasspath>true</logClasspath>
</configuration>
</plugin>2.12.1.6. Using live reload of XML files
You can configure the plugin to scan for XML file changes and trigger a reload of the Camel routes which are contained in those XML files.
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<configuration>
<fileWatcherDirectory>src/main/resources/META-INF/spring</fileWatcherDirectory>
</configuration>
</plugin>
Then the plugin watches this directory. This allows you to edit the source code from your editor and save the file, and have the running Camel application utilize those changes. Note that only the changes of Camel routes, for example, <routes>, or <route> which are supported. You cannot change Spring or OSGi Blueprint <bean> elements.
2.12.2. camel:validate
For source code validation of the following Camel features:
- endpoint URIs
- simple expressions or predicates
- duplicate route ids
Then you can run the camel:validate goal from the command line or from within your Java editor such as IDEA or Eclipse.
mvn camel:validateYou can also enable the plugin to automatic run as part of the build to catch these errors.
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<executions>
<execution>
<phase>process-classes</phase>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>
The phase determines when the plugin runs. In the sample above the phase is process-classes which runs after the compilation of the main source code. The maven plugin can also be configured to validate the test source code, which means that the phase should be changed accordingly to process-test-classes as shown below:
<plugin>
<groupId>org.jboss.redhat-fuse</groupId>
<artifactId>camel-maven-plugin</artifactId>
<executions>
<execution>
<configuration>
<includeTest>true</includeTest>
</configuration>
<phase>process-test-classes</phase>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>2.12.2.1. Running the goal on any Maven project
You can also run the validate goal on any Maven project without having to add the plugin to the pom.xml file. Doing so requires to specify the plugin using its fully qualified name. For example to run the goal on the camel-example-cdi from Apache Camel, you can run
$cd camel-example-cdi
$mvn org.apache.camel:camel-maven-plugin:2.20.0:validatewhich then runs and outputs the following:
[INFO] ------------------------------------------------------------------------
[INFO] Building Camel :: Example :: CDI 2.20.0
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- camel-maven-plugin:2.20.0:validate (default-cli) @ camel-example-cdi ---
[INFO] Endpoint validation success: (4 = passed, 0 = invalid, 0 = incapable, 0 = unknown components)
[INFO] Simple validation success: (0 = passed, 0 = invalid)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------The validation passed, and 4 endpoints was validated. Now suppose we made a typo in one of the Camel endpoint URIs in the source code, such as:
@Uri("timer:foo?period=5000")
is changed to include a typo error in the period option
@Uri("timer:foo?perid=5000")And when running the validate goal again reports the following:
[INFO] ------------------------------------------------------------------------
[INFO] Building Camel :: Example :: CDI 2.20.0
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- camel-maven-plugin:2.20.0:validate (default-cli) @ camel-example-cdi ---
[WARNING] Endpoint validation error at: org.apache.camel.example.cdi.MyRoutes(MyRoutes.java:32)
timer:foo?perid=5000
perid Unknown option. Did you mean: [period]
[WARNING] Endpoint validation error: (3 = passed, 1 = invalid, 0 = incapable, 0 = unknown components)
[INFO] Simple validation success: (0 = passed, 0 = invalid)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------2.12.2.2. Options
The Camel Maven plugin validate goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| downloadVersion | true | Whether to allow downloading Camel catalog version from the internet. This is needed if the project uses a different Camel version than this plugin is using by default. |
| failOnError | false | Whether to fail if invalid Camel endpoints were found. By default the plugin logs the errors at WARN level. |
| logUnparseable | false | Whether to log endpoint URI which was un-parsable and therefore not possible to validate. |
| includeJava | true | Whether to include Java files to be validated for invalid Camel endpoints. |
| includeXml | true | Whether to include XML files to be validated for invalid Camel endpoints. |
| includeTest | false | Whether to include test source code. |
| includes | To filter the names of java and xml files to only include files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| excludes | To filter the names of java and xml files to exclude files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| ignoreUnknownComponent | true | Whether to ignore unknown components. |
| ignoreIncapable | true | Whether to ignore incapable of parsing the endpoint URI or simple expression. |
| ignoreLenientProperties | true | Whether to ignore components that uses lenient properties. When this is true, then the URI validation is stricter but would fail on properties that are not part of the component but in the URI because of using lenient properties. For example using the HTTP components to provide query parameters in the endpoint URI. |
| ignoreDeprecated | true | Camel 2.23 Whether to ignore deprecated options being used in the endpoint URI. |
| duplicateRouteId | true | Camel 2.20 Whether to validate for duplicate route ids. Route ids should be unique and if there are duplicates then Camel will fail to startup. |
| directOrSedaPairCheck | true | Camel 2.23 Whether to validate direct/seda endpoints sending to non existing consumers. |
| showAll | false | Whether to show all endpoints and simple expressions (both invalid and valid). |
For example to turn off ignoring usage of deprecated options from the command line, you can run:
$mvn camel:validate -Dcamel.ignoreDeprecated=false
Note that you must prefix the -D command argument with camel., eg camel.ignoreDeprecated as the option name.
2.12.2.3. Validating Endpoints using include test
If you have a Maven project then you can run the plugin to validate the endpoints in the unit test source code as well. You can pass in the options using -D style as shown:
$cd myproject
$mvn org.apache.camel:camel-maven-plugin:2.20.0:validate -DincludeTest=true2.12.3. camel:route-coverage
For generating a report of the coverage of your Camel routes from unit testing. You can use this to know which parts of your Camel routes has been used or not.
2.12.3.1. Enabling route coverage
You can enable route coverage while running unit tests either by:
- setting global JVM system property enabling for all test classes
-
using
@EnableRouteCoverageannotation per test class if usingcamel-test-springmodule -
overriding
isDumpRouteCoveragemethod per test class if usingcamel-testmodule
2.12.3.2. Enabling Route Coverage by using JVM system property
You can turn on the JVM system property CamelTestRouteCoverage to enable route coverage for all tests cases. This can be done either in the configuration of the maven-surefire-plugin:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<systemPropertyVariables>
<CamelTestRouteCoverage>true</CamelTestRouteCoverage>
</systemPropertyVariables>
</configuration>
</plugin>Or from the command line when running tests:
mvn clean test -DCamelTestRouteCoverage=true2.12.3.3. Enabling via @EnableRouteCoverage annotation
You can enable route coverage in the unit tests classes by adding the @EnableRouteCoverage annotation to the test class if you are testing using camel-test-spring:
@RunWith(CamelSpringBootRunner.class)
@SpringBootTest(classes = SampleCamelApplication.class)
@EnableRouteCoverage
public class FooApplicationTest {2.12.3.4. Enabling via isDumpRouteCoverage method
However if you are using camel-test and your unit tests are extending CamelTestSupport then you can turn on route coverage as shown:
@Override
public boolean isDumpRouteCoverage() {
return true;
}
Routes that can be coveraged under RouteCoverage method must have an unique id assigned, in other words you cannot use anonymous routes. You do this using routeId in Java DSL:
from("jms:queue:cheese").routeId("cheesy")
.to("log:foo")
...And in XML DSL you just assign the route id via the id attribute
<route id="cheesy">
<from uri="jms:queue:cheese"/>
<to uri="log:foo"/>
...
</route>2.12.3.5. Generating route coverage report
TO generate the route coverage report, run the unit test with:
mvn testYou can then run the goal to report the route coverage as follows:
mvn camel:route-coverageThis reports which routes has missing route coverage with precise source code line reporting:
[INFO] --- camel-maven-plugin:2.21.0:route-coverage (default-cli) @ camel-example-spring-boot-xml ---
[INFO] Discovered 1 routes
[INFO] Route coverage summary:
File: src/main/resources/my-camel.xml
RouteId: hello
Line # Count Route
------ ----- -----
28 1 from
29 1 transform
32 1 filter
34 0 to
36 1 to
Coverage: 4 out of 5 (80.0%)
Here we can see that the 2nd last line with to has 0 in the count column, and therefore is not covered. We can also see that this is one line 34 in the source code file, which is in the my-camel.xml XML file.
2.12.3.6. Options
The Camel Maven plugin coverage goal supports the following options which can be configured from the command line (use -D syntax), or defined in the pom.xml file in the <configuration> tag.
| Parameter | Default Value | Description |
| failOnError | false | Whether to fail if any of the routes does not have 100% coverage. |
| includeTest | false | Whether to include test source code. |
| includes | To filter the names of java and xml files to only include files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| excludes | To filter the names of java and xml files to exclude files matching any of the given list of patterns (wildcard and regular expression). Multiple values can be separated by comma. | |
| anonymousRoutes | false | Whether to allow anonymous routes (routes without any route id assigned). By using route id’s then its safer to match the route cover data with the route source code. Anonymous routes are less safe to use for route coverage as its harder to know exactly which route that was tested corresponds to which of the routes from the source code. |
2.13. Running Apache Camel Standalone
When you run camel as a standalone application, it provides the Main class that you can use to run the application and keep it running until the JVM terminates. You can find the MainListener class within the org.apache.camel.main Java package.
Following are the components of the Main class:
-
camel-coreJAR in theorg.apache.camel.Mainclass -
camel-springJAR in theorg.apache.camel.spring.Mainclass
The following example shows how you can create and use the Main class from Camel:
public class MainExample {
private Main main;
public static void main(String[] args) throws Exception {
MainExample example = new MainExample();
example.boot();
}
public void boot() throws Exception {
// create a Main instance
main = new Main();
// bind MyBean into the registry
main.bind("foo", new MyBean());
// add routes
main.addRouteBuilder(new MyRouteBuilder());
// add event listener
main.addMainListener(new Events());
// set the properties from a file
main.setPropertyPlaceholderLocations("example.properties");
// run until you terminate the JVM
System.out.println("Starting Camel. Use ctrl + c to terminate the JVM.\n");
main.run();
}
private static class MyRouteBuilder extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:foo?delay={{millisecs}}")
.process(new Processor() {
public void process(Exchange exchange) throws Exception {
System.out.println("Invoked timer at " + new Date());
}
})
.bean("foo");
}
}
public static class MyBean {
public void callMe() {
System.out.println("MyBean.callMe method has been called");
}
}
public static class Events extends MainListenerSupport {
@Override
public void afterStart(MainSupport main) {
System.out.println("MainExample with Camel is now started!");
}
@Override
public void beforeStop(MainSupport main) {
System.out.println("MainExample with Camel is now being stopped!");
}
}
}2.14. OnCompletion
Overview
The OnCompletion DSL name is used to define an action that is to take place when a Unit of Work is completed. A Unit of Work is a Camel concept that encompasses an entire exchange. See Section 34.1, “Exchanges”. The onCompletion command has the following features:
-
The scope of the
OnCompletioncommand can be global or per route. A route scope overrides global scope. -
OnCompletioncan be configured to be triggered on success for failure. -
The
onWhenpredicate can be used to only trigger theonCompletionin certain situations. - You can define whether or not to use a thread pool, though the default is no thread pool.
Route Only Scope for onCompletion
When an onCompletion DSL is specified on an exchange, Camel spins off a new thread. This allows the original thread to continue without interference from the onCompletion task. A route will only support one onCompletion. In the following example, the onCompletion is triggered whether the exchange completes with success or failure. This is the default action.
from("direct:start")
.onCompletion()
// This route is invoked when the original route is complete.
// This is similar to a completion callback.
.to("log:sync")
.to("mock:sync")
// Must use end to denote the end of the onCompletion route.
.end()
// here the original route contiues
.process(new MyProcessor())
.to("mock:result");For XML the format is as follows:
<route>
<from uri="direct:start"/>
<!-- This onCompletion block is executed when the exchange is done being routed. -->
<!-- This callback is always triggered even if the exchange fails. -->
<onCompletion>
<!-- This is similar to an after completion callback. -->
<to uri="log:sync"/>
<to uri="mock:sync"/>
</onCompletion>
<process ref="myProcessor"/>
<to uri="mock:result"/>
</route>
To trigger the onCompletion on failure, the onFailureOnly parameter can be used. Similarly, to trigger the onCompletion on success, use the onCompleteOnly parameter.
from("direct:start")
// Here onCompletion is qualified to invoke only when the exchange fails (exception or FAULT body).
.onCompletion().onFailureOnly()
.to("log:sync")
.to("mock:sync")
// Must use end to denote the end of the onCompletion route.
.end()
// here the original route continues
.process(new MyProcessor())
.to("mock:result");
For XML, onFailureOnly and onCompleteOnly are expressed as booleans on the onCompletion tag:
<route>
<from uri="direct:start"/>
<!-- this onCompletion block will only be executed when the exchange is done being routed -->
<!-- this callback is only triggered when the exchange failed, as we have onFailure=true -->
<onCompletion onFailureOnly="true">
<to uri="log:sync"/>
<to uri="mock:sync"/>
</onCompletion>
<process ref="myProcessor"/>
<to uri="mock:result"/>
</route>Global Scope for onCompletion
To define onCompletion for more than just one route:
// define a global on completion that is invoked when the exchange is complete
onCompletion().to("log:global").to("mock:sync");
from("direct:start")
.process(new MyProcessor())
.to("mock:result");Using onWhen
To trigger the onCompletion under certain circumstances, use the onWhen predicate. The following example will trigger the onCompletion when the body of the message contains the word Hello:
/from("direct:start")
.onCompletion().onWhen(body().contains("Hello"))
// this route is only invoked when the original route is complete as a kind
// of completion callback. And also only if the onWhen predicate is true
.to("log:sync")
.to("mock:sync")
// must use end to denote the end of the onCompletion route
.end()
// here the original route contiues
.to("log:original")
.to("mock:result");Using onCompletion with or without a thread pool
As of Camel 2.14, onCompletion will not use a thread pool by default. To force the use of a thread pool, either set an executorService or set parallelProcessing to true. For example, in Java DSL, use the following format:
onCompletion().parallelProcessing()
.to("mock:before")
.delay(1000)
.setBody(simple("OnComplete:${body}"));For XML the format is:
<onCompletion parallelProcessing="true">
<to uri="before"/>
<delay><constant>1000</constant></delay>
<setBody><simple>OnComplete:${body}<simple></setBody>
</onCompletion>
Use the executorServiceRef option to refer to a specific thread pool:
<onCompletion executorServiceRef="myThreadPool"
<to uri="before"/>
<delay><constant>1000</constant></delay>
<setBody><simple>OnComplete:${body}</simple></setBody>
</onCompletion>>Run onCompletion before Consumer Sends Response
onCompletion can be run in two modes:
- AfterConsumer - The default mode which runs after the consumer is finished
-
BeforeConsumer - Runs before the consumer writes a response back to the callee. This allows
onCompletionto modify the Exchange, such as adding special headers, or to log the Exchange as a response logger.
For example, to add a created by header to the response, use modeBeforeConsumer() as shown below:
.onCompletion().modeBeforeConsumer()
.setHeader("createdBy", constant("Someone"))
.end()
For XML, set the mode attribute to BeforeConsumer:
<onCompletion mode="BeforeConsumer">
<setHeader headerName="createdBy">
<constant>Someone</constant>
</setHeader>
</onCompletion>2.15. Metrics
Overview
Available as of Camel 2.14
While Camel provides a lot of existing metrics integration with Codahale metrics has been added for Camel routes. This allows end users to seamless feed Camel routing information together with existing data they are gathering using Codahale metrics.
To use the Codahale metrics you will need to:
- Add camel-metrics component
- Enable route metrics in XML or Java code
Note that performance metrics are only usable if you have a way of displaying them; any kind of monitoring tooling which can integrate with JMX can be used, as the metrics are available over JMX. In addition, the actual data is 100% Codehale JSON.
Metrics Route Policy
Obtaining Codahale metrics for a single route can be accomplished by defining a MetricsRoutePolicy on a per route basis.
From Java create an instance of MetricsRoutePolicy to be assigned as the route’s policy. This is shown below:
from("file:src/data?noop=true").routePolicy(new MetricsRoutePolicy()).to("jms:incomingOrders");
From XML DSL you define a <bean> which is specified as the route’s policy; for example:
<bean id="policy" class="org.apache.camel.component.metrics.routepolicy.MetricsRoutePolicy"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route routePolicyRef="policy">
<from uri="file:src/data?noop=true"/>
[...]Metrics Route Policy Factory
This factory allows one to add a RoutePolicy for each route which exposes route utilization statistics using Codahale metrics. This factory can be used in Java and XML as the examples below demonstrate.
From Java you just add the factory to the CamelContext as shown below:
context.addRoutePolicyFactory(new MetricsRoutePolicyFactory());
And from XML DSL you define a <bean> as follows:
<!-- use camel-metrics route policy to gather metrics for all routes -->
<bean id="metricsRoutePolicyFactory" class="org.apache.camel.component.metrics.routepolicy.MetricsRoutePolicyFactory"/>
From Java code you can get hold of the com.codahale.metrics.MetricRegistry from the org.apache.camel.component.metrics.routepolicy.MetricsRegistryService as shown below:
MetricRegistryService registryService = context.hasService(MetricsRegistryService.class);
if (registryService != null) {
MetricsRegistry registry = registryService.getMetricsRegistry();
...
}Options
The MetricsRoutePolicyFactory and MetricsRoutePolicy supports the following options:
| Name | Default | Description |
|
|
| The unit to use for duration in the metrics reporter or when dumping the statistics as json. |
|
|
| The JXM domain name. |
|
|
Allow to use a shared | |
|
|
| Whether to use pretty print when outputting statistics in json format. |
|
|
| The unit to use for rate in the metrics reporter or when dumping the statistics as json. |
|
|
|
Whether to report fine grained statistics to JMX by using the
Notice that if JMX is enabled on CamelContext then a |
2.16. JMX Naming
Overview
Apache Camel allows you to customize the name of a CamelContext bean as it appears in JMX, by defining a management name pattern for it. For example, you can customize the name pattern of an XML CamelContext instance, as follows:
<camelContext id="myCamel" managementNamePattern="#name#">
...
</camelContext>
If you do not explicitly set a name pattern for the CamelContext bean, Apache Camel reverts to a default naming strategy.
Default naming strategy
By default, the JMX name of a CamelContext bean deployed in an OSGi bundle is equal to the OSGi symbolic name of the bundle. For example, if the OSGi symbolic name is MyCamelBundle, the JMX name would be MyCamelBundle. In cases where there is more than one CamelContext in the bundle, the JMX name is disambiguated by adding a counter value as a suffix. For example, if there are multiple Camel contexts in the MyCamelBundle bundle, the corresponding JMX MBeans are named as follows:
MyCamelBundle-1
MyCamelBundle-2
MyCamelBundle-3
...Customizing the JMX naming strategy
One drawback of the default naming strategy is that you cannot guarantee that a given CamelContext bean will have the same JMX name between runs. If you want to have greater consistency between runs, you can control the JMX name more precisely by defining a JMX name pattern for the CamelContext instances.
Specifying a name pattern in Java
To specify a name pattern on a CamelContext in Java, call the setNamePattern method, as follows:
// Java
context.getManagementNameStrategy().setNamePattern("#name#");Specifying a name pattern in XML
To specify a name pattern on a CamelContext in XML, set the managementNamePattern attribute on the camelContext element, as follows:
<camelContext id="myCamel" managementNamePattern="#name#">Name pattern tokens
You can construct a JMX name pattern by mixing literal text with any of the following tokens:
| Token | Description |
|---|---|
|
|
Value of the |
|
|
Same as |
|
|
An incrementing counter (starting at |
|
| The OSGi bundle ID of the deployed bundle (OSGi only). |
|
| The OSGi symbolic name (OSGi only). |
|
| The OSGi bundle version (OSGi only). |
Examples
Here are some examples of JMX name patterns you could define using the supported tokens:
<camelContext id="fooContext" managementNamePattern="FooApplication-#name#">
...
</camelContext>
<camelContext id="myCamel" managementNamePattern="#bundleID#-#symbolicName#-#name#">
...
</camelContext>Ambiguous names
Because the customised naming pattern overrides the default naming strategy, it is possible to define ambiguous JMX MBean names using this approach. For example:
<camelContext id="foo" managementNamePattern="SameOldSameOld"> ... </camelContext>
...
<camelContext id="bar" managementNamePattern="SameOldSameOld"> ... </camelContext>In this case, Apache Camel would fail on start-up and report an MBean already exists exception. You should, therefore, take extra care to ensure that you do not define ambiguous name patterns.
2.17. Performance and Optimization
Message copying
The allowUseOriginalMessage option default setting is false, to cut down on copies being made of the original message when they are not needed. To enable the allowUseOriginalMessage option use the following commands:
-
Set
useOriginalMessage=trueon any of the error handlers or on theonExceptionelement. -
In Java application code, set
AllowUseOriginalMessage=true, then use thegetOriginalMessagemethod.
In Camel versions prior to 2.18, the default setting of allowUseOriginalMessage is true.