Este contenido no está disponible en el idioma seleccionado.
Chapter 1. Introduction to operational measurements
You can use observability components such as ceilometer, collectd, and the logging service to collect data from your Red Hat OpenStack Platform (RHOSP) environment. You can store the data that you collect in Gnocchi for the autoscaling use case or you can use metrics_qdr to forward the data to Service Telemetry Framework(STF).
For more information about autoscaling, see Auto Scaling for Instances
For more information about STF, see Service Telemetry Framework 1.5
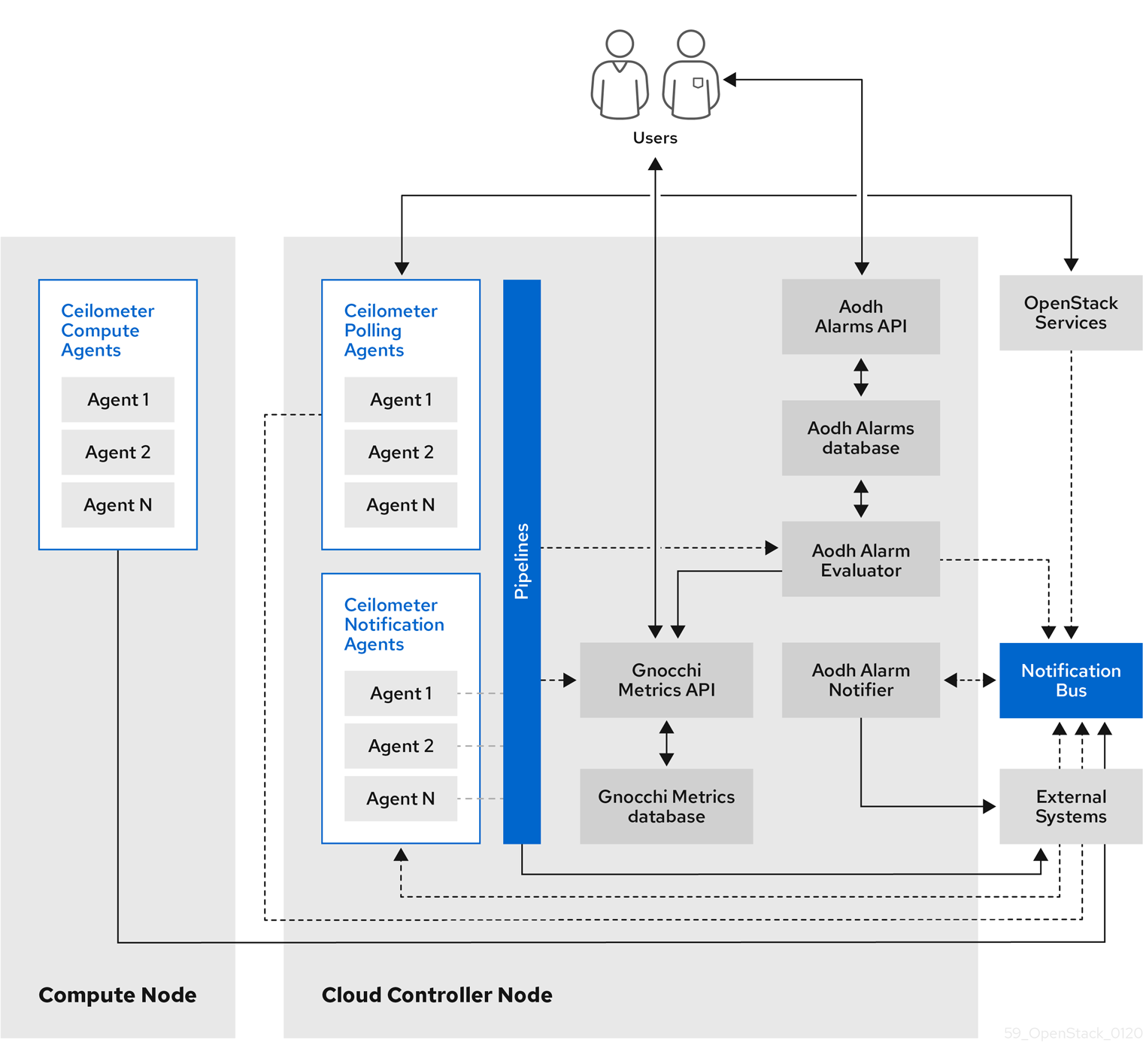
1.1. Observability architecture
Red Hat OpenStack Platform (RHOSP) Observability provides user-level usage data for OpenStack-based clouds. You can configure observability components to collect data from notifications sent by existing RHOSP components, such as Compute usage events, or by polling RHOSP infrastructure resources, such as libvirt. Ceilometer publishes collected data to various targets such as data stores and message queues, including Service Telemetry Framework(STF).
Observability consists of the following components:
- Data collection: Observability uses Ceilometer to gather metric and event data. For more information, see Section 1.2.1, “Ceilometer”.
- Storage: Observability stores metric data in Gnocchi. For more information, see Section 1.3, “Storage with Gnocchi”.
- Alarm service: Observability uses the Alarming service (Aodh) to trigger actions based on defined rules against metric or event data collected by Ceilometer.
After you collect the data, you can use a third-party tool to display and analyze metric data, and you can use the Alarming service to configure alarms for events.
Figure 1.1. Observability architecture
1.1.1. Support status of monitoring components
Use this table to view the support status of monitoring components in Red Hat OpenStack Platform (RHOSP).
| Component | Fully supported since | Deprecated in | Removed since | Note |
|---|---|---|---|---|
| Aodh | RHOSP 9 | RHOSP 15 | Supported for the autoscaling use case. | |
| Ceilometer | RHOSP 4 | Supported for collection of metrics and events for RHOSP in the autoscaling and Service Telemetry Framework (STF) use cases. | ||
| Collectd | RHOSP 11 | RHOSP 17.1 | Supported for collection of infrastructure metrics for STF. | |
| Gnocchi | RHOSP 9 | RHOSP 15 | Supported for storage of metrics for the autoscaling use case. | |
| Panko | RHOSP 11 | RHOSP 12, not installed by default since RHOSP 14 | RHOSP 17.0 | |
| QDR | RHOSP 13 | RHOSP 17.1 | Supported for transmission of metrics and events data from RHOSP to STF. |
1.2. Data collection in Red Hat OpenStack Platform
Red Hat OpenStack Platform (RHOSP) supports two types of data collection:
- Ceilometer for the RHOSP component-level monitoring. For more information, see Section 1.2.1, “Ceilometer”.
- collectd for infrastructure monitoring. For more information, see Section 1.2.2, “collectd”.
1.2.1. Ceilometer
Ceilometer is the default data collection component of Red Hat OpenStack Platform (RHOSP) that provides the ability to normalize and transform data across all of the current RHOSP core components. Ceilometer collects metering and event data relating to RHOSP services.
The Ceilometer service uses three agents to collect data from Red Hat OpenStack Platform (RHOSP) components:
-
A compute agent (ceilometer-agent-compute): Runs on each Compute node and polls for resource utilization statistics. This agent is the same as polling agent
ceilometer-pollingrunning with parameter--polling namespace-compute. -
A central agent (ceilometer-agent-central): Runs on a central management server to poll for resource utilization statistics for resources that are not tied to instances or Compute nodes. You can start multiple agents to scale services horizontally. This is the same as the polling agent
ceilometer-pollingthat operates with the parameter--polling namespace-central. - A notification agent (ceilometer-agent-notification): Runs on a central management server and consumes messages from the message queues to build event and metering data. Data publishes to defined targets. Gnocchi is the default target. These services use the RHOSP notification bus to communicate.
The Ceilometer agents use publishers to send data to the corresponding end points, for example Gnocchi or AMQP version 1 (QDR).
1.2.2. collectd
Collectd is another data collecting agent that you can use to provide infrastructure metrics. It repeatedly pulls data from configured sources. You can forward metrics to Service Telemetry Framework (STF) to store and visualize the data.
1.3. Storage with Gnocchi
Gnocchi is an open-source time-series database. You can use gnocchi to store and provide access to metrics and resources to operators and users. Gnocchi uses an archive policy to define which aggregations to compute and how many aggregates to retain; and an indexer driver to store the index of all resources, archive policies, and metrics.
The use of Gnocchi in Red Hat OpenStack Platform (RHOSP) is supported for the autoscaling use-case. For more information about autoscaling, see Auto Scaling for Instances
1.3.1. Archive policies: Storing both short and long-term data in a time-series database
An archive policy defines which aggregations to compute and how many aggregates to retain. Gnocchi supports different aggregation methods, such as minimum, maximum, average, Nth percentile, and standard deviation. These aggregations are computed over a period of time called granularity and retained for a specific timespan.
The archive policy defines how the metrics are aggregated and for how long they are stored. Each archive policy is defined as the number of points over a timespan.
For example, if your archive policy defines a policy of 10 points with a granularity of 1 second, the time-series archive keeps up to 10 seconds, each representing an aggregation over 1 second. This means that the time series, at a maximum, retains 10 seconds of data between the more recent point and the older point.
The archive policy also defines which aggregate methods are used. The default is set to the parameter default_aggregation_methods whose values by default are set to mean, min, max. sum, std, count. So, depending on the use case, the archive policy and the granularity vary.
Additional resources
- For more information about archive policies, see Section 2.3, “Planning and managing archive policies”.
1.3.2. Indexer driver
The indexer is responsible for storing the index of all resources, archive policies, and metrics along with their definitions, types, and properties. It is also responsible for linking resources with metrics. Red Hat OpenStack Platform director installs the indexer driver by default. You need a database to index all the resources and metrics that Gnocchi handles. The supported driver is MySQL.
1.3.3. Gnocchi terminology
This table contains definitions of the commonly used terms for Gnocchi features.
| Term | Definition |
|---|---|
| Aggregation method | A function used to aggregate multiple measures into an aggregate. For example, the min aggregation method aggregates the values of different measures to the minimum value of all the measures in the time range. |
| Aggregate | A data point tuple generated from several measures according to the archive policy. An aggregate is composed of a timestamp and a value. |
| Archive policy | An aggregate storage policy attached to a metric. An archive policy determines how long aggregates are kept in a metric and how aggregates are aggregated (the aggregation method). |
| Granularity | The time between two aggregates in an aggregated time series of a metric. |
| Measure | An incoming data point tuple sent to the Time series database by the API. A measure is composed of a timestamp and a value. |
| Metric | An entity storing aggregates identified by an UUID. A metric can be attached to a resource using a name. How a metric stores its aggregates is defined by the archive policy to which the metric is associated. |
| Resource | An entity representing anything in your infrastructure that you associate a metric with. A resource is identified by a unique ID and can contain attributes. |
| Time series | A list of aggregates ordered by time. |
| Timespan | The time period for which a metric keeps its aggregates. It is used in the context of archive policy. |