Este contenido no está disponible en el idioma seleccionado.
Chapter 3. Active-Passive Disaster Recovery
3.1. Active-Passive Overview
Red Hat Virtualization supports an active-passive disaster recovery solution that can span two sites. If the primary site becomes unavailable, the Red Hat Virtualization environment can be forced to fail over to the secondary (backup) site.
The failover is achieved by configuring a Red Hat Virtualization environment in the secondary site, which requires:
- An active Red Hat Virtualization Manager.
- A data center and clusters.
- Networks with the same general connectivity as the primary site.
- Active hosts capable of running critical virtual machines after failover.
You must ensure that the secondary environment has enough resources to run the failed over virtual machines, and that both the primary and secondary environments have identical Manager versions, data center and cluster compatibility levels, and PostgreSQL versions. The minimum supported compatibility level is 4.2.
Storage domains that contain virtual machine disks and templates in the primary site must be replicated. These replicated storage domains must not be attached to the secondary site.
The failover and failback process must be executed manually. To do this you must create Ansible playbooks to map entities between the sites, and to manage the failover and failback processes. The mapping file instructs the Red Hat Virtualization components where to fail over or fail back to on the target site.
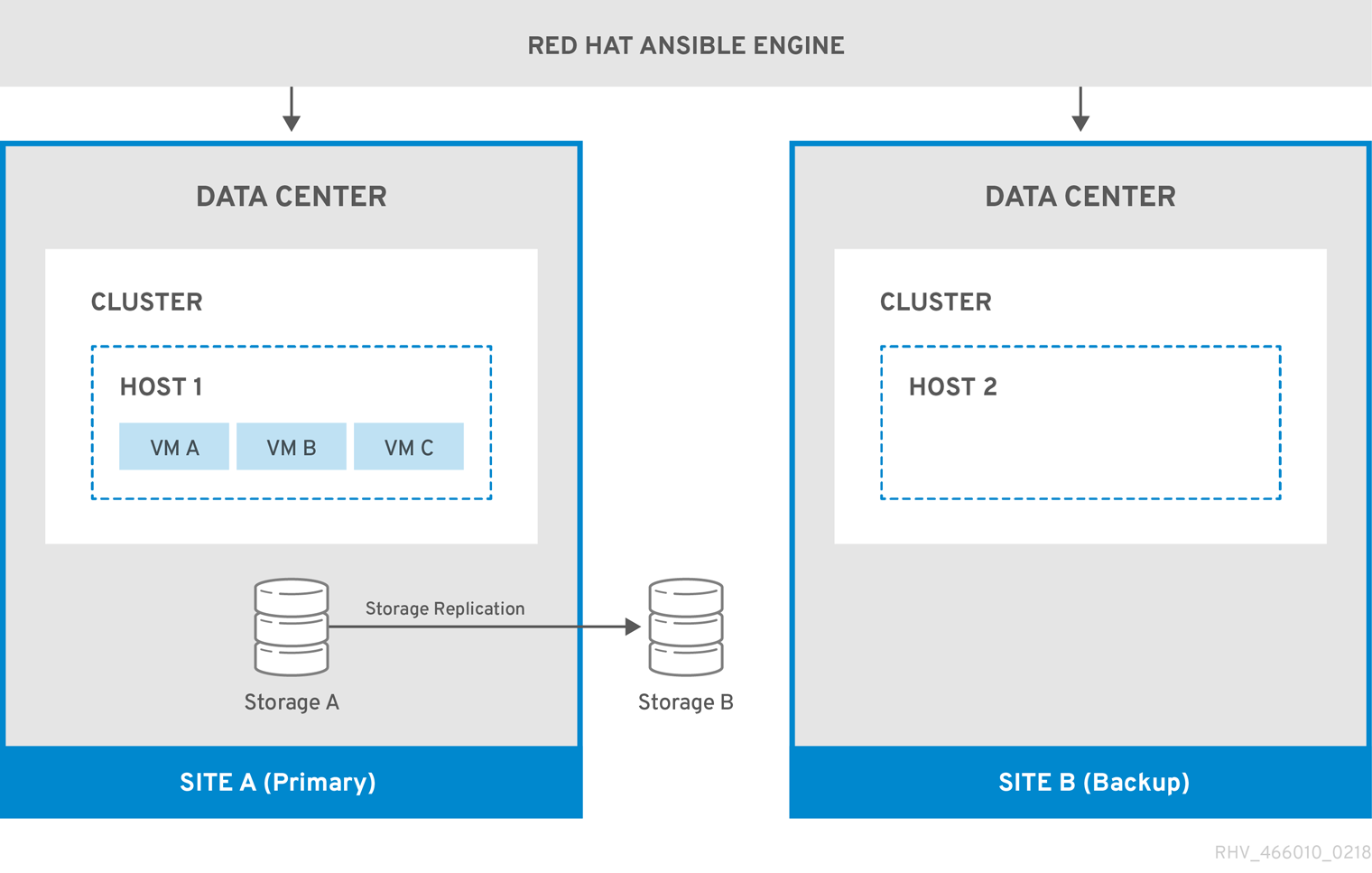
The following diagram describes an active-passive setup where the machine running Red Hat Ansible Engine is highly available, and has access to the oVirt.disaster-recovery Ansible role, configured playbooks, and mapping file. The storage domains that store the virtual machine disks in Site A is replicated. Site B has no virtual machines or attached storage domains.
Figure 3.1. Active-Passive Configuration
When the environment fails over to Site B, the storage domains are first attached and activated in Site B’s data center, and then the virtual machines are registered. Highly available virtual machines will fail over first.
Figure 3.2. Failover to Backup Site
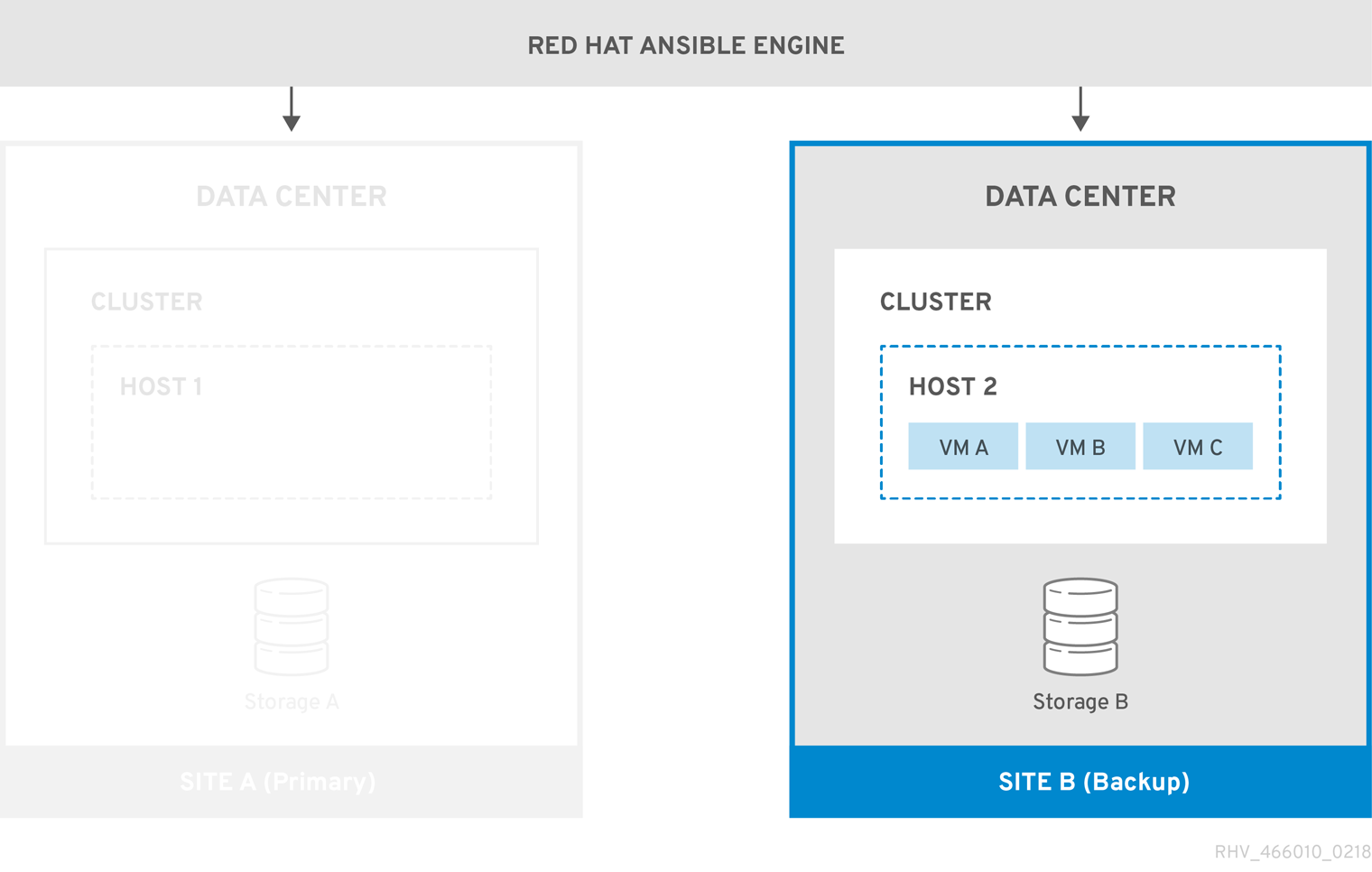
You must manually fail back to the primary site (Site A) when it is running again.
3.2. Network Considerations
You must ensure that the same general connectivity exists in the primary and secondary sites.
If you have multiple networks or multiple data centers then you must use an empty network mapping in the mapping file to ensure that all entities register on the target during failover. See Mapping File Attributes for more information.
3.3. Storage Considerations
The storage domain for Red Hat Virtualization can comprise either block devices (SAN - iSCSI or FCP) or a file system (NAS - NFS, GlusterFS, or other POSIX compliant file systems). For more information about Red Hat Virtualization storage see Storage in the Administration Guide.
GlusterFS Storage is deprecated, and will no longer be supported in future releases.
Local storage domains are unsupported for disaster recovery.
A primary and secondary storage replica is required. The primary storage domain’s block devices or shares that contain virtual machine disks or templates must be replicated. The secondary storage must not be attached to any data center, and will be added to the backup site’s data center during failover.
If you are implementing disaster recovery using a self-hosted engine, ensure that the storage domain used by the Manager virtual machine does not contain virtual machine disks because in such a case the storage domain will not be failed over.
All storage solutions that have replication options that are supported by Red Hat Enterprise Linux 7 and later can be used.
3.4. Create the Required Ansible Playbooks
Ansible is used to initiate and manage the disaster recovery failover and failback. So you must create Ansible playbooks to facilitate this. For more information about creating Ansible playbooks, see the Ansible documentation.
Prerequisites
- Fully functioning Red Hat Virtualization environment in the primary site.
A backup environment in the secondary site with the same data center and cluster compatibility level as the primary environment. The backup environment must have:
- A Red Hat Virtualization Manager.
- Active hosts capable of running the virtual machines and connecting to the replicated storage domains.
- A data center with clusters.
- Networks with the same general connectivity as the primary site.
Replicated storage. See Storage Considerations for more information.
NoteThe replicated storage that contains virtual machines and templates must not be attached to the secondary site.
-
The
oVirt.disaster-recoverypackage must be installed on the highly available Red Hat Ansible Engine machine that will automate the failover and failback. - The machine running Red Hat Ansible Engine must be able to use SSH to connect to the Manager in the primary and secondary site.
It is also recommended to create environment properties that exist in the primary site, such as affinity groups, affinity labels, users, on the secondary site.
The default behaviour of the Ansible playbooks can be configured in the /usr/share/ansible/roles/oVirt.disaster-recovery/defaults/main.yml file.
The following playbooks must be created:
- The playbook that creates the file to map entities on the primary and secondary site.
- The failover playbook.
- The failback playbook.
You can also create an optional playbook to clean the primary site before failing back.
Create the playbooks and associated files in /usr/share/ansible/roles/oVirt.disaster-recovery/ on the Ansible machine that is managing the failover and failback. If you have multiple Ansible machines that can manage it, ensure that you copy the files to all of them.
You can test the configuration using one or more of the testing procedures in Testing the Active-Passive Configuration.
3.4.1. The ovirt-dr Script for Ansible Tasks
The ovirt-dr script simplifies the following Ansible tasks:
-
Generating a
varmapping file of the primary and secondary sites for failover and fallback -
Validating the
varmapping file - Executing failover on a target site
- Executing failback from a target site to a source site
This script is located in /usr/share/ansible/roles/oVirt.disaster-recovery/files
Usage
# ./ovirt-dr generate/validate/failover/failback
[--conf-file=dr.conf]
[--log-file=ovirt-dr-log_number.log]
[--log-level=DEBUG/INFO/WARNING/ERROR]You can set the parameters for the script’s actions in the configuration file, /usr/share/ansible/roles/oVirt.disaster-recovery/files/dr.conf.
You can change the location of the configuration file with the --conf-file option.
You can set the location and level of logging detail with the --log-file and --log-level options.
3.4.2. Creating the Playbook to Generate the Mapping File
The Ansible playbook used to generate the mapping file will prepopulate the file with the target (primary) site’s entities. You then must manually add the backup site’s entities, such as IP addresses, cluster, affinity groups, affinity label, external LUN disks, authorization domains, roles, and vNIC profiles, to the file.
The mapping file generation will fail if you have any virtual machine disks on the self-hosted engine’s storage domain. Also, the mapping file will not contain an attribute for this storage domain because it must not be failed over.
In this example the Ansible playbook is named dr-rhv-setup.yml, and is executed on the Manager machine in the primary site.
Procedure
Create an Ansible playbook to generate the mapping file. For example:
--- - name: Generate mapping hosts: localhost connection: local vars: site: https://example.engine.redhat.com/ovirt-engine/api username: admin@internal password: my_password ca: /etc/pki/ovirt-engine/ca.pem var_file: disaster_recovery_vars.yml roles: - oVirt.disaster-recoveryNoteFor extra security, you can encrypt your Manager password in a
.ymlfile. See Using Ansible Roles to Configure Red Hat Virtualization in the Administration Guide for more information.Run the Ansible command to generate the mapping file. The primary site’s configuration will be prepopulated.
# ansible-playbook dr-rhv-setup.yml --tags "generate_mapping"-
Configure the mapping file (
disaster_recovery_vars.ymlin this case) with the backup site’s configuration. See Mapping File Attributes for more information about the mapping file’s attributes.
If you have multiple Ansible machines that can perform the failover and failback, then copy the mapping file to all relevant machines.
3.4.3. Create the Failover and Failback Playbooks
Ensure that you have the mapping file that you created and configured, in this case disaster_recovery_vars.yml, because this must be added to the playbooks.
You can define a password file (for example passwords.yml) to store the Manager passwords of the primary and secondary site. For example:
---
# This file is in plain text, if you want to
# encrypt this file, please execute following command:
#
# $ ansible-vault encrypt passwords.yml
#
# It will ask you for a password, which you must then pass to
# ansible interactively when executing the playbook.
#
# $ ansible-playbook myplaybook.yml --ask-vault-pass
#
dr_sites_primary_password: primary_password
dr_sites_secondary_password: secondary_password
For extra security you can encrypt the password file. However, you must use the --ask-vault-pass parameter when running the playbook. See Using Ansible Roles to Configure Red Hat Virtualization in the Administration Guide for more information.
In these examples the Ansible playbooks to fail over and fail back are named dr-rhv-failover.yml and dr-rhv-failback.yml.
Create the following Ansible playbook to failover the environment:
---
- name: Failover RHV
hosts: localhost
connection: local
vars:
dr_target_host: secondary
dr_source_map: primary
vars_files:
- disaster_recovery_vars.yml
- passwords.yml
roles:
- oVirt.disaster-recoveryCreate the following Ansible playbook to failback the environment:
---
- name: Failback RHV
hosts: localhost
connection: local
vars:
dr_target_host: primary
dr_source_map: secondary
vars_files:
- disaster_recovery_vars.yml
- passwords.yml
roles:
- oVirt.disaster-recovery3.4.4. Create the Playbook to Clean the Primary Site
Before you fail back to the primary site, you must ensure that the primary site is cleaned of all storage domains to be imported. You can do so manually on the Manager, or optionally you can create an Ansible playbook to do it for you.
The Ansible playbook to clean the primary site is named dr-cleanup.yml in this example, and it uses the mapping file generated by another Ansible playbook:
---
- name: clean RHV
hosts: localhost
connection: local
vars:
dr_source_map: primary
vars_files:
- disaster_recovery_vars.yml
roles:
- oVirt.disaster-recovery3.5. Executing a Failover
Prerequisites
- The Manager and hosts in the secondary site are running.
- Replicated storage domains are in read/write mode.
- No replicated storage domains are attached to the secondary site.
A machine running Red Hat Ansible Engine that can connect via SSH to the Manager in the primary and secondary site, with the required packages and files:
-
The
oVirt.disaster-recoverypackage. - The mapping file and required failover playbook.
-
The
Sanlock must release all storage locks from the replicated storage domains before the failover process starts. These locks should be released automatically approximately 80 seconds after the disaster occurs.
This example uses the dr-rhv-failover.yml playbook created earlier.
Procedure
Run the failover playbook with the following command:
# ansible-playbook dr-rhv-failover.yml --tags "fail_over"- When the primary site becomes active, ensure that you clean the environment before failing back. See Cleaning the Primary Site for more information.
3.6. Cleaning the Primary Site
After you fail over, you must clean the environment in the primary site before failing back to it:
- Reboot all hosts in the primary site.
- Ensure the secondary site’s storage domains are in read/write mode and the primary site’s storage domains are in read only mode.
- Synchronize the replication from the secondary site’s storage domains to the primary site’s storage domains.
- Clean the primary site of all storage domains to be imported. This can be done manually in the Manager, or by creating and running an Ansible playbook. See Detaching a Storage Domain in the Administration Guide for manual instructions, or Create the Playbook to Clean the Primary Site for information to create the Ansible playbook.
This example uses the dr-cleanup.yml playbook created earlier to clean the environment.
Procedure
Clean up the primary site with the following command:
# ansible-playbook dr-cleanup.yml --tags "clean_engine"- You can now failback the environment to the primary site. See Executing a Failback for more information.
3.7. Executing a Failback
Once you fail over, you can fail back to the primary site when it is active and you have performed the necessary steps to clean the environment.
Prerequisites
- The environment in the primary site is running and has been cleaned, see Cleaning the Primary Site for more information.
- The environment in the secondary site is running, and has active storage domains.
A machine running Red Hat Ansible Engine that can connect via SSH to the Manager in the primary and secondary site, with the required packages and files:
-
The
oVirt.disaster-recoverypackage. - The mapping file and required failback playbook.
-
The
This example uses the dr-rhv-failback.yml playbook created earlier.
Procedure
Run the failback playbook with the following command:
# ansible-playbook dr-rhv-failback.yml --tags "fail_back"- Enable replication from the primary storage domains to the secondary storage domains.