1.2. Comprendre la pile de surveillance
La pile de surveillance comprend les composants suivants:
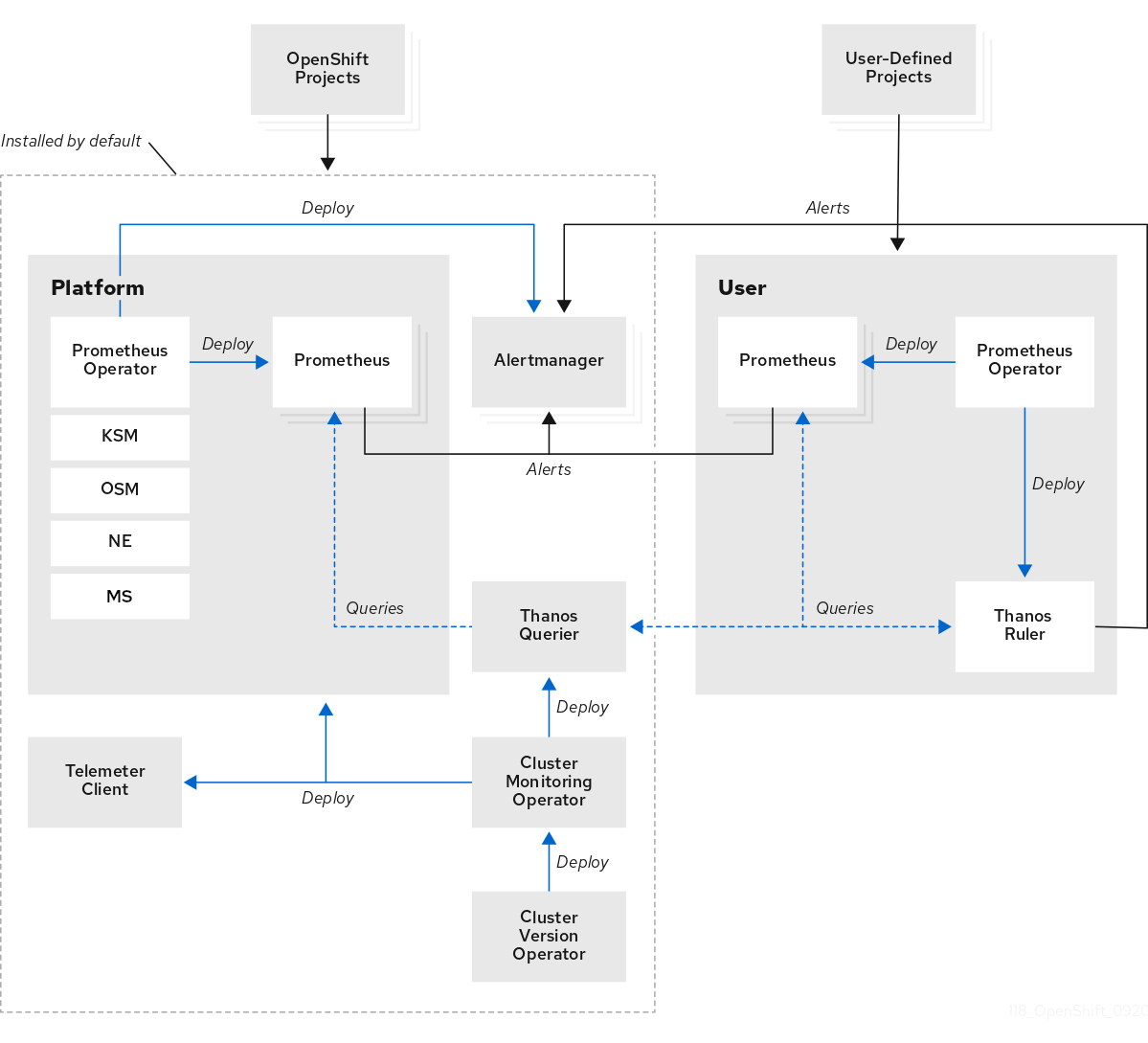
Composants de surveillance de plate-forme par défaut. Lors d’une installation dédiée à OpenShift, un ensemble de composants de surveillance de plate-forme sont installés par défaut dans le projet de surveillance openshift. Les ingénieurs de fiabilité du site Red Hat (SRE) utilisent ces composants pour surveiller les composants principaux des clusters, y compris les services Kubernetes. Cela inclut des métriques critiques, telles que CPU et mémoire, collectées à partir de toutes les charges de travail dans chaque espace de noms.
Ces composants sont illustrés dans la section Installé par défaut dans le diagramme suivant.
- Composants pour le suivi des projets définis par l’utilisateur. Dans le cadre d’une installation dédiée à OpenShift, un ensemble de composants de surveillance de projet définis par l’utilisateur sont installés par défaut dans le cadre d’un projet de surveillance de la charge de travail ouvert par l’utilisateur. Ces composants peuvent être utilisés pour surveiller les services et les pods dans les projets définis par l’utilisateur. Ces composants sont illustrés dans la section Utilisateur dans le diagramme suivant.
1.2.1. Cibles de surveillance par défaut
Ce qui suit sont des exemples de cibles surveillées par Red Hat Site Reliability Engineers (SRE) dans votre cluster OpenShift dédié:
- CoreDNS
- etc.
- HAProxy
- Enregistrement d’images
- Kubelets
- Kubernetes serveur API
- Gestionnaire de contrôleur Kubernetes
- Kubernetes planificateur
- Le serveur d’API OpenShift
- Gestionnaire de contrôleur OpenShift
- Gestionnaire du cycle de vie de l’opérateur (OLM)
La liste exacte des cibles peut varier en fonction des capacités de votre cluster et des composants installés.
1.2.2. Composants pour le suivi des projets définis par l’utilisateur
Le logiciel OpenShift Dedicated inclut une amélioration optionnelle de la pile de surveillance qui vous permet de surveiller les services et les pods dans les projets définis par l’utilisateur. Cette fonctionnalité comprend les composants suivants:
| Composante | Description |
|---|---|
| L’opérateur Prometheus | L’opérateur Prometheus (PO) dans le projet openshift-user-workload-monitoring crée, configure et gère les instances Prometheus et Thanos Ruler dans le même projet. |
| Le Prométhée | Le Prometheus est le système de surveillance par lequel la surveillance est assurée pour les projets définis par l’utilisateur. Le Prometheus envoie des alertes à Alertmanager pour le traitement. |
| Le chef de Thanos | Le Thanos Ruler est un moteur d’évaluation de règles pour Prometheus qui est déployé en tant que processus séparé. Dans OpenShift Dedicated , Thanos Ruler fournit une évaluation des règles et des alertes pour le suivi des projets définis par l’utilisateur. |
| Alertmanager | Le service Alertmanager gère les alertes reçues de Prometheus et Thanos Ruler. Alertmanager est également responsable de l’envoi d’alertes définies par l’utilisateur aux systèmes de notification externes. Le déploiement de ce service est facultatif. |
L’ensemble de ces composants sont surveillés par la pile et sont automatiquement mis à jour lorsque OpenShift Dedicated est mis à jour.
1.2.3. Cibles de suivi pour les projets définis par l’utilisateur
La surveillance est activée par défaut pour les projets définis par l’utilisateur OpenShift. Il est possible de surveiller:
- Les métriques fournies par l’intermédiaire de points de terminaison de service dans les projets définis par l’utilisateur.
- Des pods s’exécutant dans des projets définis par l’utilisateur.
1.2.4. La pile de surveillance dans les clusters à haute disponibilité
Dans les clusters multi-nœuds par défaut, les composants suivants s’exécutent en mode haute disponibilité (HA) pour éviter la perte de données et l’interruption de service:
- Le Prométhée
- Alertmanager
- Le chef de Thanos
Le composant est reproduit sur deux pods, chacun fonctionnant sur un nœud séparé. Cela signifie que la pile de surveillance peut tolérer la perte d’une gousse.
- Le Prométhée en mode HA
- Les deux répliques grattent indépendamment les mêmes cibles et évaluent les mêmes règles.
- Les répliques ne communiquent pas entre elles. Les données peuvent donc différer entre les pods.
- Alertmanager en mode HA
- Les deux répliques synchronisent les états de notification et de silence les uns avec les autres. Cela garantit que chaque notification est envoyée au moins une fois.
- Lorsque les répliques ne parviennent pas à communiquer ou s’il y a un problème du côté de la réception, des notifications sont toujours envoyées, mais elles peuvent être dupliquées.
Les Prometheus, Alertmanager et Thanos Ruler sont des composants d’état. Afin d’assurer une disponibilité élevée, vous devez les configurer avec un stockage persistant.