Contrôle
Configurer et utiliser la pile de surveillance dans OpenShift Container Platform
Résumé
Chapitre 1. Aperçu de la surveillance
1.1. À propos de la surveillance de la plateforme OpenShift Container
OpenShift Container Platform inclut une pile de surveillance préconfigurée, préinstallée et auto-mise à jour qui fournit une surveillance pour les composants de base de la plate-forme. Vous avez également la possibilité d'activer la surveillance pour des projets définis par l'utilisateur.
Un administrateur de cluster peut configurer la pile de surveillance avec les configurations prises en charge. OpenShift Container Platform offre les meilleures pratiques de surveillance dès sa sortie de l'emballage.
Un ensemble d'alertes est inclus par défaut et permet d'informer immédiatement les administrateurs des problèmes rencontrés par un cluster. Les tableaux de bord par défaut de la console web d'OpenShift Container Platform incluent des représentations visuelles des métriques du cluster pour vous aider à comprendre rapidement l'état de votre cluster. Avec la console web d'OpenShift Container Platform, vous pouvez voir et gérer les métriques, les alertes et examiner les tableaux de bord de surveillance.
Dans la section Observe de la console web d'OpenShift Container Platform, vous pouvez accéder et gérer les fonctionnalités de surveillance telles que les métriques, les alertes, les tableaux de bord de surveillance et les cibles de métriques.
Après l'installation d'OpenShift Container Platform, les administrateurs de clusters peuvent optionnellement activer la surveillance pour les projets définis par l'utilisateur. Grâce à cette fonctionnalité, les administrateurs de clusters, les développeurs et les autres utilisateurs peuvent spécifier comment les services et les pods sont surveillés dans leurs propres projets. En tant qu'administrateur de cluster, vous pouvez trouver des réponses à des problèmes courants tels que l'indisponibilité des métriques utilisateur et la consommation élevée d'espace disque par Prometheus dans Dépannage des problèmes de surveillance.
1.2. Comprendre la pile de surveillance
La pile de surveillance d'OpenShift Container Platform est basée sur le projet open source Prometheus et son écosystème élargi. La pile de surveillance comprend les éléments suivants :
-
Default platform monitoring components. Un ensemble de composants de surveillance de la plateforme est installé par défaut dans le projet
openshift-monitoringlors de l'installation d'OpenShift Container Platform. Cela permet de surveiller les composants principaux d'OpenShift Container Platform, y compris les services Kubernetes. La pile de surveillance par défaut permet également de surveiller l'état des clusters à distance. Ces composants sont illustrés dans la section Installed by default dans le diagramme suivant. -
Components for monitoring user-defined projects. Après l'activation optionnelle du contrôle pour les projets définis par l'utilisateur, des composants de contrôle supplémentaires sont installés dans le projet
openshift-user-workload-monitoring. Cela permet de surveiller les projets définis par l'utilisateur. Ces composants sont illustrés dans la section User dans le diagramme suivant.
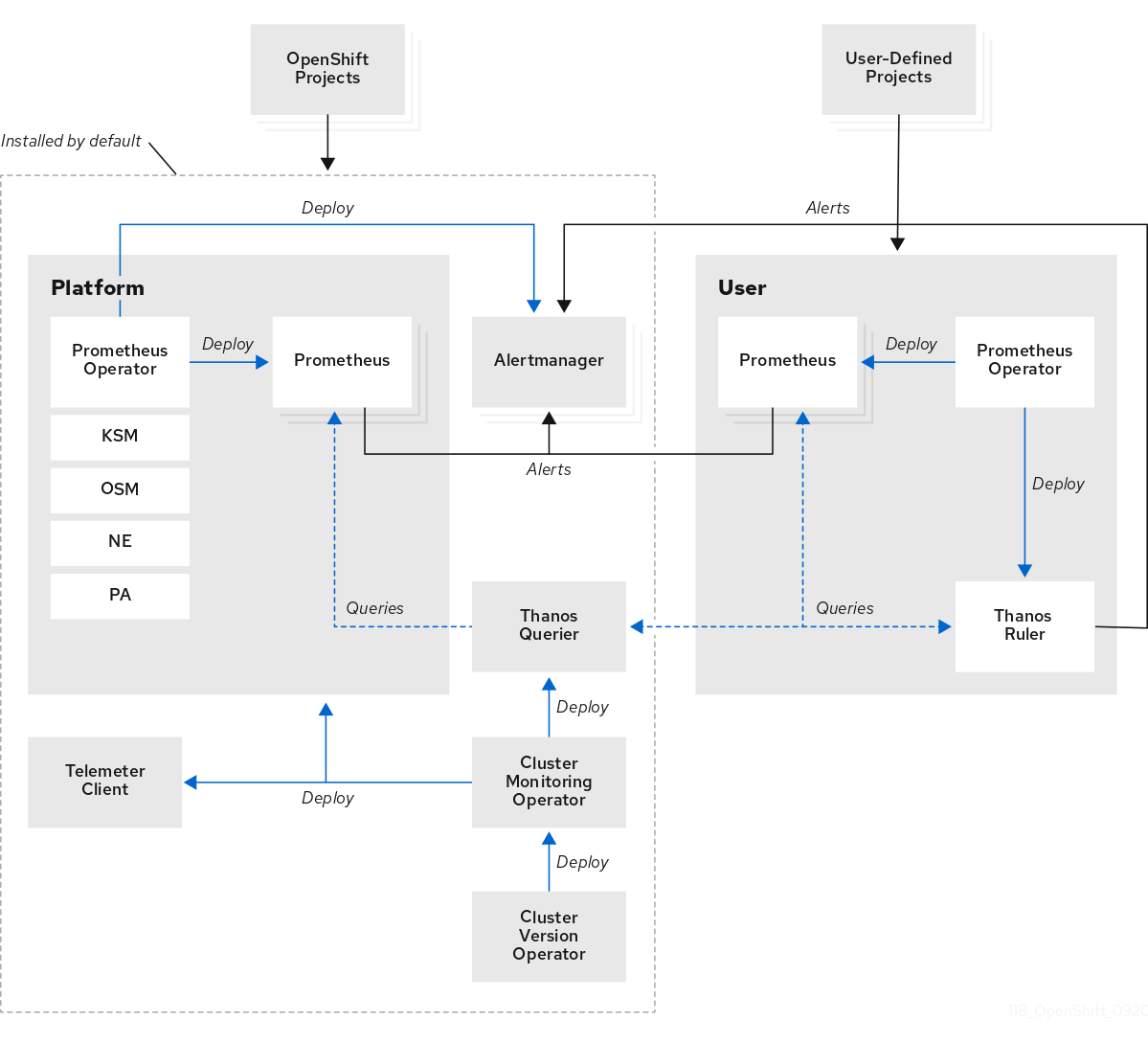
1.2.1. Composants de surveillance par défaut
Par défaut, la pile de surveillance d'OpenShift Container Platform 4.12 inclut ces composants :
| Composant | Description |
|---|---|
| Opérateur de suivi de groupe | L'opérateur de surveillance de cluster (CMO) est un composant central de la pile de surveillance. Il déploie, gère et met automatiquement à jour les instances de Prometheus et d'Alertmanager, l'interrogateur Thanos, le client Telemeter et les cibles de mesure. Le CMO est déployé par l'opérateur de version de cluster (CVO). |
| Opérateur Prométhée |
L'opérateur Prometheus (PO) du projet |
| Prometheus | Prometheus est le système de surveillance sur lequel repose la pile de surveillance d'OpenShift Container Platform. Prometheus est une base de données de séries temporelles et un moteur d'évaluation de règles pour les métriques. Prometheus envoie des alertes à Alertmanager pour traitement. |
| Adaptateur Prométhée |
L'adaptateur Prometheus (PA dans le diagramme précédent) traduit les requêtes de nœuds et de pods Kubernetes pour les utiliser dans Prometheus. Les métriques de ressources traduites comprennent les métriques d'utilisation du processeur et de la mémoire. L'adaptateur Prometheus expose l'API de métriques de ressources de cluster pour l'autoscaling horizontal de pods. L'adaptateur Prometheus est également utilisé par les commandes |
| Gestionnaire d'alerte | Le service Alertmanager gère les alertes reçues de Prometheus. Alertmanager est également responsable de l'envoi des alertes aux systèmes de notification externes. |
|
|
L'agent exportateur |
|
|
L'exportateur |
|
|
L'agent |
| Enquêteur Thanos | Thanos Querier agrège et éventuellement déduplique les métriques de base d'OpenShift Container Platform et les métriques pour les projets définis par l'utilisateur dans une interface unique et multi-tenant. |
| Client Télémètre | Telemeter Client envoie une sous-section des données des instances Prometheus de la plate-forme à Red Hat pour faciliter la surveillance à distance de la santé des grappes. |
Tous les composants de la pile de surveillance sont surveillés par la pile et sont automatiquement mis à jour lorsque OpenShift Container Platform est mis à jour.
Tous les composants de la pile de surveillance utilisent les paramètres de profil de sécurité TLS qui sont configurés de manière centralisée par un administrateur de cluster. Si vous configurez un composant de la pile de surveillance qui utilise des paramètres de sécurité TLS, le composant utilise les paramètres de profil de sécurité TLS qui existent déjà dans le champ tlsSecurityProfile de la ressource globale OpenShift Container Platform apiservers.config.openshift.io/cluster.
1.2.2. Objectifs de surveillance par défaut
Outre les composants de la pile elle-même, la pile de surveillance par défaut assure la surveillance :
- CoreDNS
- Elasticsearch (si la journalisation est installée)
- etcd
- Fluentd (si la journalisation est installée)
- HAProxy
- Registre des images
- Kubelets
- Serveur API Kubernetes
- Gestionnaire de contrôleur Kubernetes
- Ordonnanceur Kubernetes
- Serveur API OpenShift
- Gestionnaire de contrôleur OpenShift
- Gestionnaire du cycle de vie des opérateurs (OLM)
Chaque composant d'OpenShift Container Platform est responsable de sa configuration de surveillance. Pour les problèmes liés à la surveillance d'un composant d'OpenShift Container Platform, ouvrez une question Jira sur ce composant, et non sur le composant de surveillance général.
D'autres composants du framework OpenShift Container Platform peuvent également exposer des métriques. Pour plus de détails, consultez leur documentation respective.
1.2.3. Composants pour le suivi de projets définis par l'utilisateur
OpenShift Container Platform 4.12 inclut une amélioration optionnelle de la pile de surveillance qui vous permet de surveiller les services et les pods dans des projets définis par l'utilisateur. Cette fonctionnalité comprend les composants suivants :
| Composant | Description |
|---|---|
| Opérateur Prométhée |
L'opérateur Prometheus (PO) du projet |
| Prometheus | Prometheus est le système de surveillance qui permet de surveiller les projets définis par l'utilisateur. Prometheus envoie des alertes à Alertmanager pour traitement. |
| Règle de Thanos | Thanos Ruler est un moteur d'évaluation des règles pour Prometheus qui est déployé en tant que processus distinct. Dans OpenShift Container Platform 4.12, Thanos Ruler fournit une évaluation des règles et des alertes pour la surveillance des projets définis par l'utilisateur. |
| Gestionnaire d'alerte | Le service Alertmanager gère les alertes reçues de Prometheus et de Thanos Ruler. Alertmanager est également chargé d'envoyer des alertes définies par l'utilisateur à des systèmes de notification externes. Le déploiement de ce service est facultatif. |
Les composants du tableau précédent sont déployés après l'activation de la surveillance pour les projets définis par l'utilisateur.
Tous les composants de la pile de surveillance sont surveillés par la pile et sont automatiquement mis à jour lorsque OpenShift Container Platform est mis à jour.
1.2.4. Suivi des objectifs pour les projets définis par l'utilisateur
Lorsque la surveillance est activée pour les projets définis par l'utilisateur, vous pouvez surveiller :
- Les mesures sont fournies par des points d'extrémité de service dans des projets définis par l'utilisateur.
- Pods fonctionnant dans des projets définis par l'utilisateur.
1.3. Glossaire des termes courants pour la surveillance de OpenShift Container Platform
Ce glossaire définit les termes communs utilisés dans l'architecture d'OpenShift Container Platform.
- Gestionnaire d'alerte
- Alertmanager traite les alertes reçues de Prometheus. Alertmanager est également responsable de l'envoi des alertes aux systèmes de notification externes.
- Règles d'alerte
- Les règles d'alerte contiennent un ensemble de conditions qui définissent un état particulier au sein d'un cluster. Les alertes sont déclenchées lorsque ces conditions sont remplies. Une règle d'alerte peut se voir attribuer une gravité qui définit la manière dont les alertes sont acheminées.
- Opérateur de suivi de groupe
- L'opérateur de surveillance de cluster (CMO) est un composant central de la pile de surveillance. Il déploie et gère les instances Prometheus telles que le Thanos Querier, le Telemeter Client et les cibles de métriques pour s'assurer qu'elles sont à jour. Le CMO est déployé par l'opérateur de version de cluster (CVO).
- Opérateur de version de cluster
- Le Cluster Version Operator (CVO) gère le cycle de vie des Cluster Operators, dont beaucoup sont installés par défaut dans OpenShift Container Platform.
- carte de configuration
-
Une carte de configuration permet d'injecter des données de configuration dans les pods. Vous pouvez référencer les données stockées dans une carte de configuration dans un volume de type
ConfigMap. Les applications fonctionnant dans un pod peuvent utiliser ces données. - Conteneur
- Un conteneur est une image légère et exécutable qui comprend un logiciel et toutes ses dépendances. Les conteneurs virtualisent le système d'exploitation. Par conséquent, vous pouvez exécuter des conteneurs n'importe où, d'un centre de données à un nuage public ou privé, en passant par l'ordinateur portable d'un développeur.
- ressource personnalisée (CR)
- Un CR est une extension de l'API Kubernetes. Vous pouvez créer des ressources personnalisées.
- etcd
- etcd est le magasin clé-valeur d'OpenShift Container Platform, qui stocke l'état de tous les objets de ressources.
- Fluentd
- Fluentd recueille les journaux des nœuds et les transmet à Elasticsearch.
- Kubelets
- S'exécute sur les nœuds et lit les manifestes des conteneurs. S'assure que les conteneurs définis ont démarré et sont en cours d'exécution.
- Serveur API Kubernetes
- Le serveur API Kubernetes valide et configure les données pour les objets API.
- Gestionnaire de contrôleur Kubernetes
- Le gestionnaire de contrôleur Kubernetes régit l'état du cluster.
- Ordonnanceur Kubernetes
- Le planificateur Kubernetes alloue les pods aux nœuds.
- étiquettes
- Les étiquettes sont des paires clé-valeur que vous pouvez utiliser pour organiser et sélectionner des sous-ensembles d'objets tels qu'un pod.
- nœud
- Une machine de travail dans le cluster OpenShift Container Platform. Un nœud est soit une machine virtuelle (VM), soit une machine physique.
- Opérateur
- La méthode préférée pour empaqueter, déployer et gérer une application Kubernetes dans un cluster OpenShift Container Platform. Un opérateur prend les connaissances opérationnelles humaines et les encode dans un logiciel qui est emballé et partagé avec les clients.
- Gestionnaire du cycle de vie des opérateurs (OLM)
- OLM vous aide à installer, mettre à jour et gérer le cycle de vie des applications natives Kubernetes. OLM est une boîte à outils open source conçue pour gérer les opérateurs de manière efficace, automatisée et évolutive.
- Stockage permanent
- Stocke les données même après l'arrêt de l'appareil. Kubernetes utilise des volumes persistants pour stocker les données de l'application.
- Réclamation de volume persistante (PVC)
- Vous pouvez utiliser un PVC pour monter un PersistentVolume dans un Pod. Vous pouvez accéder au stockage sans connaître les détails de l'environnement en nuage.
- nacelle
- Le pod est la plus petite unité logique de Kubernetes. Un pod est composé d'un ou plusieurs conteneurs à exécuter dans un worker node.
- Prometheus
- Prometheus est le système de surveillance sur lequel repose la pile de surveillance d'OpenShift Container Platform. Prometheus est une base de données de séries temporelles et un moteur d'évaluation de règles pour les métriques. Prometheus envoie des alertes à Alertmanager pour traitement.
- Adaptateur Prométhée
- L'adaptateur Prometheus traduit les requêtes de nœuds et de pods Kubernetes pour les utiliser dans Prometheus. Les mesures de ressources traduites comprennent l'utilisation du processeur et de la mémoire. L'adaptateur Prometheus expose l'API de métriques de ressources de cluster pour l'autoscaling horizontal de pods.
- Opérateur Prométhée
-
L'opérateur Prometheus (PO) du projet
openshift-monitoringcrée, configure et gère les instances Prometheus et Alertmanager de la plateforme. Il génère également automatiquement des configurations de cibles de surveillance basées sur des requêtes d'étiquettes Kubernetes. - Silences
- Un silence peut être appliqué à une alerte pour empêcher l'envoi de notifications lorsque les conditions de l'alerte sont remplies. Vous pouvez mettre une alerte en sourdine après la notification initiale, pendant que vous travaillez à la résolution du problème sous-jacent.
- stockage
- OpenShift Container Platform prend en charge de nombreux types de stockage, à la fois pour les fournisseurs sur site et dans le nuage. Vous pouvez gérer le stockage des conteneurs pour les données persistantes et non persistantes dans un cluster OpenShift Container Platform.
- Règle de Thanos
- Thanos Ruler est un moteur d'évaluation des règles pour Prometheus qui est déployé en tant que processus distinct. Dans OpenShift Container Platform, Thanos Ruler fournit une évaluation des règles et des alertes pour la surveillance des projets définis par l'utilisateur.
- console web
- Une interface utilisateur (UI) pour gérer OpenShift Container Platform.
1.5. Prochaines étapes
Chapitre 2. Configuration de la pile de surveillance
Le programme d'installation d'OpenShift Container Platform 4 ne propose qu'un faible nombre d'options de configuration avant l'installation. La configuration de la plupart des composants du framework OpenShift Container Platform, y compris la pile de surveillance des clusters, se fait après l'installation.
Cette section explique quelle configuration est prise en charge, montre comment configurer la pile de surveillance et présente plusieurs scénarios de configuration courants.
2.1. Conditions préalables
- La pile de surveillance impose des exigences supplémentaires en matière de ressources. Consultez les recommandations relatives aux ressources informatiques dans le document Scaling the Cluster Monitoring Operator et vérifiez que vous disposez de ressources suffisantes.
2.2. Maintenance et soutien pour la surveillance
La manière prise en charge de configurer la surveillance de OpenShift Container Platform consiste à la configurer à l'aide des options décrites dans ce document. Do not use other configurations, as they are unsupported. Les paradigmes de configuration peuvent changer entre les versions de Prometheus, et de tels cas ne peuvent être gérés de manière gracieuse que si toutes les possibilités de configuration sont contrôlées. Si vous utilisez des configurations autres que celles décrites dans cette section, vos modifications disparaîtront car le site cluster-monitoring-operator réconcilie toutes les différences. L'Opérateur réinitialise tout à l'état défini par défaut et par conception.
2.2.1. Considérations relatives au soutien pour le suivi
Les modifications suivantes ne sont explicitement pas prises en charge :
-
Creating additional
ServiceMonitor,PodMonitor, andPrometheusRuleobjects in theopenshift-*andkube-*projects. Modifying any resources or objects deployed in the
openshift-monitoringoropenshift-user-workload-monitoringprojects. Les ressources créées par la pile de surveillance de OpenShift Container Platform ne sont pas destinées à être utilisées par d'autres ressources, car il n'y a aucune garantie quant à leur compatibilité ascendante.NoteLa configuration Alertmanager est déployée en tant que ressource secrète dans l'espace de noms
openshift-monitoring. Si vous avez activé une instance distincte d'Alertmanager pour le routage des alertes définies par l'utilisateur, une configuration d'Alertmanager est également déployée en tant que ressource secrète dans l'espace de nomsopenshift-user-workload-monitoring. Pour configurer des routes supplémentaires pour n'importe quelle instance d'Alertmanager, vous devez décoder, modifier et ensuite encoder ce secret. Cette procédure est une exception supportée à la déclaration précédente.- Modifying resources of the stack. La pile de surveillance d'OpenShift Container Platform s'assure que ses ressources sont toujours dans l'état qu'elle attend d'elles. Si elles sont modifiées, la pile les réinitialise.
-
Deploying user-defined workloads to
openshift-*, andkube-*projects. Ces projets sont réservés aux composants fournis par Red Hat et ne doivent pas être utilisés pour des charges de travail définies par l'utilisateur. - Installing custom Prometheus instances on OpenShift Container Platform. Une instance personnalisée est une ressource personnalisée Prometheus (CR) gérée par l'opérateur Prometheus.
-
Enabling symptom based monitoring by using the
Probecustom resource definition (CRD) in Prometheus Operator.
La rétrocompatibilité des métriques, des règles d'enregistrement ou des règles d'alerte n'est pas garantie.
2.2.2. Politique de soutien au suivi des opérateurs
Les opérateurs de surveillance garantissent que les ressources de surveillance d'OpenShift Container Platform fonctionnent comme prévu et testé. Si le contrôle de l'opérateur de version de cluster (CVO) d'un opérateur est outrepassé, l'opérateur ne répond pas aux changements de configuration, ne réconcilie pas l'état prévu des objets du cluster et ne reçoit pas de mises à jour.
Bien qu'il puisse être utile de remplacer le contrôle de l'OVE pour un opérateur lors du débogage, cette opération n'est pas prise en charge et l'administrateur du cluster assume le contrôle total des configurations et des mises à niveau des composants individuels.
Remplacement de l'opérateur de version du cluster
Le paramètre spec.overrides peut être ajouté à la configuration de l'OVC pour permettre aux administrateurs de fournir une liste de dérogations au comportement de l'OVC pour un composant. La définition du paramètre spec.overrides[].unmanaged à true pour un composant bloque les mises à niveau du cluster et alerte l'administrateur lorsqu'une dérogation CVO a été définie :
Disabling ownership via cluster version overrides prevents upgrades. Please remove overrides before continuing.La définition d'une dérogation CVO place l'ensemble du cluster dans un état non pris en charge et empêche la pile de surveillance d'être réconciliée avec l'état prévu. Cela a un impact sur les fonctions de fiabilité intégrées aux opérateurs et empêche la réception des mises à jour. Les problèmes signalés doivent être reproduits après la suppression de toute dérogation pour que l'assistance puisse avoir lieu.
2.3. Préparation de la configuration de la pile de surveillance
Vous pouvez configurer la pile de surveillance en créant et en mettant à jour des cartes de configuration de la surveillance.
2.3.1. Création d'une carte de configuration pour la surveillance des clusters
Pour configurer les composants de surveillance de base d'OpenShift Container Platform, vous devez créer l'objet cluster-monitoring-config ConfigMap dans le projet openshift-monitoring.
Lorsque vous enregistrez vos modifications dans l'objet cluster-monitoring-config ConfigMap , certains ou tous les pods du projet openshift-monitoring peuvent être redéployés. Le redéploiement de ces composants peut parfois prendre un certain temps.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Vérifier si l'objet
cluster-monitoring-configConfigMapexiste :$ oc -n openshift-monitoring get configmap cluster-monitoring-configSi l'objet
ConfigMapn'existe pas :Créez le manifeste YAML suivant. Dans cet exemple, le fichier s'appelle
cluster-monitoring-config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |Appliquer la configuration pour créer l'objet
ConfigMap:$ oc apply -f cluster-monitoring-config.yaml
2.3.2. Création d'une carte de configuration de surveillance de la charge de travail définie par l'utilisateur
Pour configurer les composants qui contrôlent les projets définis par l'utilisateur, vous devez créer l'objet user-workload-monitoring-config ConfigMap dans le projet openshift-user-workload-monitoring.
Lorsque vous enregistrez vos modifications dans l'objet user-workload-monitoring-config ConfigMap , certains ou tous les pods du projet openshift-user-workload-monitoring peuvent être redéployés. Le redéploiement de ces composants peut parfois prendre un certain temps. Vous pouvez créer et configurer la carte de configuration avant d'activer pour la première fois la surveillance des projets définis par l'utilisateur, afin d'éviter d'avoir à redéployer souvent les pods.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Vérifier si l'objet
user-workload-monitoring-configConfigMapexiste :$ oc -n openshift-user-workload-monitoring get configmap user-workload-monitoring-configSi l'objet
user-workload-monitoring-configConfigMapn'existe pas :Créez le manifeste YAML suivant. Dans cet exemple, le fichier s'appelle
user-workload-monitoring-config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |Appliquer la configuration pour créer l'objet
ConfigMap:$ oc apply -f user-workload-monitoring-config.yamlNoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.
2.4. Configuration de la pile de surveillance
Dans OpenShift Container Platform 4.12, vous pouvez configurer la pile de surveillance à l'aide des objets cluster-monitoring-config ou user-workload-monitoring-config ConfigMap . Les cartes de configuration configurent l'opérateur de surveillance de cluster (CMO), qui configure à son tour les composants de la pile.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap.To configure core OpenShift Container Platform monitoring components:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez votre configuration sous
data/config.yamlsous la forme d'une paire clé-valeur<component_name>: <component_configuration>:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: <configuration_for_the_component>Remplacer
<component>et<configuration_for_the_component>en conséquence.L'exemple d'objet
ConfigMapsuivant configure une revendication de volume persistant (PVC) pour Prometheus. Cela concerne uniquement l'instance Prometheus qui surveille les composants de base d'OpenShift Container Platform :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s:1 volumeClaimTemplate: spec: storageClassName: fast volumeMode: Filesystem resources: requests: storage: 40Gi- 1
- Définit le composant Prometheus et les lignes suivantes définissent sa configuration.
To configure components that monitor user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez votre configuration sous
data/config.yamlsous la forme d'une paire clé-valeur<component_name>: <component_configuration>:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: <configuration_for_the_component>Remplacer
<component>et<configuration_for_the_component>en conséquence.L'exemple suivant d'objet
ConfigMapconfigure une période de rétention des données et des demandes minimales de ressources de conteneur pour Prometheus. Cela concerne l'instance Prometheus qui surveille uniquement les projets définis par l'utilisateur :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus:1 retention: 24h2 resources: requests: cpu: 200m3 memory: 2Gi4 - 1
- Définit le composant Prometheus et les lignes suivantes définissent sa configuration.
- 2
- Configure une période de rétention des données de 24 heures pour l'instance Prometheus qui surveille les projets définis par l'utilisateur.
- 3
- Définit une demande de ressources minimale de 200 millicores pour le conteneur Prometheus.
- 4
- Définit une demande de ressource pod minimale de 2 GiB de mémoire pour le conteneur Prometheus.
NoteLe composant Prometheus config map est appelé
prometheusK8sdans l'objetcluster-monitoring-configConfigMapetprometheusdans l'objetuser-workload-monitoring-configConfigMap.
Enregistrez le fichier pour appliquer les modifications à l'objet
ConfigMap. Les pods concernés par la nouvelle configuration sont redémarrés automatiquement.NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
2.5. Composants de surveillance configurables
Ce tableau présente les composants de surveillance que vous pouvez configurer et les clés utilisées pour spécifier les composants dans les objets cluster-monitoring-config et user-workload-monitoring-config ConfigMap :
| Composant | cluster-monitoring-config config map key | user-workload-monitoring-config config map key |
|---|---|---|
| Opérateur Prométhée |
|
|
| Prometheus |
|
|
| Gestionnaire d'alerte |
|
|
| kube-state-metrics |
| |
| openshift-state-metrics |
| |
| Client Télémètre |
| |
| Adaptateur Prométhée |
| |
| Enquêteur Thanos |
| |
| Règle de Thanos |
|
La clé Prometheus est appelée prometheusK8s dans l'objet cluster-monitoring-config ConfigMap et prometheus dans l'objet user-workload-monitoring-config ConfigMap .
2.6. Déplacement des composants de surveillance vers différents nœuds
Vous pouvez déplacer n'importe quel composant de la pile de surveillance vers des nœuds spécifiques.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap:To move a component that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configSpécifiez la contrainte
nodeSelectorpour le composant sousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: nodeSelector: <node_key>: <node_value> <node_key>: <node_value> <...>Remplacez
<component>en conséquence et remplacez<node_key>: <node_value>par la carte de paires clé-valeur qui spécifie un groupe de nœuds de destination. Souvent, une seule paire clé-valeur est utilisée.Le composant ne peut être exécuté que sur les nœuds dont les étiquettes sont constituées de chacune des paires clé-valeur spécifiées. Les nœuds peuvent également avoir des étiquettes supplémentaires.
ImportantDe nombreux composants de surveillance sont déployés en utilisant plusieurs pods sur différents nœuds du cluster afin de maintenir une haute disponibilité. Lorsque vous déplacez des composants de surveillance vers des nœuds étiquetés, assurez-vous que suffisamment de nœuds correspondants sont disponibles pour maintenir la résilience du composant. Si une seule étiquette est spécifiée, assurez-vous que suffisamment de nœuds contiennent cette étiquette pour distribuer tous les pods du composant sur des nœuds distincts. Vous pouvez également spécifier plusieurs étiquettes, chacune se rapportant à des nœuds individuels.
NoteSi les composants de surveillance restent dans l'état
Pendingaprès avoir configuré la contraintenodeSelector, vérifiez dans les journaux du pod les erreurs relatives aux taches et aux tolérances.Par exemple, pour déplacer les composants de surveillance des projets principaux d'OpenShift Container Platform vers des nœuds spécifiques étiquetés
nodename: controlplane1,nodename: worker1,nodename: worker2, etnodename: worker2, utilisez :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusOperator: nodeSelector: nodename: controlplane1 prometheusK8s: nodeSelector: nodename: worker1 nodename: worker2 alertmanagerMain: nodeSelector: nodename: worker1 nodename: worker2 kubeStateMetrics: nodeSelector: nodename: worker1 telemeterClient: nodeSelector: nodename: worker1 k8sPrometheusAdapter: nodeSelector: nodename: worker1 nodename: worker2 openshiftStateMetrics: nodeSelector: nodename: worker1 thanosQuerier: nodeSelector: nodename: worker1 nodename: worker2
To move a component that monitors user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configSpécifiez la contrainte
nodeSelectorpour le composant sousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: nodeSelector: <node_key>: <node_value> <node_key>: <node_value> <...>Remplacez
<component>en conséquence et remplacez<node_key>: <node_value>par la carte des paires clé-valeur qui spécifie les nœuds de destination. Souvent, une seule paire clé-valeur est utilisée.Le composant ne peut être exécuté que sur les nœuds dont les étiquettes sont constituées de chacune des paires clé-valeur spécifiées. Les nœuds peuvent également avoir des étiquettes supplémentaires.
ImportantDe nombreux composants de surveillance sont déployés en utilisant plusieurs pods sur différents nœuds du cluster afin de maintenir une haute disponibilité. Lorsque vous déplacez des composants de surveillance vers des nœuds étiquetés, assurez-vous que suffisamment de nœuds correspondants sont disponibles pour maintenir la résilience du composant. Si une seule étiquette est spécifiée, assurez-vous que suffisamment de nœuds contiennent cette étiquette pour distribuer tous les pods du composant sur des nœuds distincts. Vous pouvez également spécifier plusieurs étiquettes, chacune se rapportant à des nœuds individuels.
NoteSi les composants de surveillance restent dans l'état
Pendingaprès avoir configuré la contraintenodeSelector, vérifiez dans les journaux du pod les erreurs relatives aux taches et aux tolérances.Par exemple, pour déplacer les composants de surveillance des projets définis par l'utilisateur vers des nœuds de travail spécifiques étiquetés
nodename: worker1,nodename: worker2, etnodename: worker2, utilisez :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheusOperator: nodeSelector: nodename: worker1 prometheus: nodeSelector: nodename: worker1 nodename: worker2 thanosRuler: nodeSelector: nodename: worker1 nodename: worker2
Enregistrez le fichier pour appliquer les modifications. Les composants concernés par la nouvelle configuration sont automatiquement déplacés vers les nouveaux nœuds.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
2.7. Attribution de tolérances aux composants de surveillance
Vous pouvez assigner des tolérances à n'importe quel composant de la pile de surveillance afin de pouvoir les déplacer vers des nœuds altérés.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap:To assign tolerations to a component that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configSpécifiez
tolerationspour le composant :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification>Remplacer
<component>et<toleration_specification>en conséquence.Par exemple,
oc adm taint nodes node1 key1=value1:NoScheduleajoute une taint ànode1avec la clékey1et la valeurvalue1. Cela empêche les composants de surveillance de déployer des pods surnode1à moins qu'une tolérance ne soit configurée pour cette anomalie. L'exemple suivant configure le composantalertmanagerMainpour qu'il tolère l'altération de l'exemple :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
To assign tolerations to a component that monitors user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configSpécifiez
tolerationspour le composant :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification>Remplacer
<component>et<toleration_specification>en conséquence.Par exemple,
oc adm taint nodes node1 key1=value1:NoScheduleajoute une taint ànode1avec la clékey1et la valeurvalue1. Cela empêche les composants de surveillance de déployer des pods surnode1à moins qu'une tolérance ne soit configurée pour cette anomalie. L'exemple suivant configure le composantthanosRulerpour qu'il tolère l'altération de l'exemple :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
Enregistrez le fichier pour appliquer les modifications. La nouvelle configuration de placement des composants est appliquée automatiquement.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
2.8. Définition de la taille limite du corps pour le raclage des métriques
Par défaut, aucune limite n'est fixée pour la taille du corps non compressé des données renvoyées par les cibles de métriques analysées. Vous pouvez définir une limite pour la taille du corps afin d'éviter que Prometheus ne consomme une quantité excessive de mémoire lorsque les cibles raclées renvoient une réponse contenant une grande quantité de données. En outre, en définissant une limite de taille de corps, vous pouvez réduire l'impact qu'une cible malveillante peut avoir sur Prometheus et sur le cluster dans son ensemble.
Après avoir défini une valeur pour enforcedBodySizeLimit, l'alerte PrometheusScrapeBodySizeLimitHit se déclenche lorsqu'au moins une cible de balayage Prometheus répond avec un corps de réponse supérieur à la valeur configurée.
Si les données métriques extraites d'une cible ont une taille de corps non compressée supérieure à la limite de taille configurée, l'extraction échoue. Prometheus considère alors que cette cible est en panne et définit sa valeur métrique up sur 0, ce qui peut déclencher l'alerte TargetDown.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
cluster-monitoring-configConfigMapdans l'espace de nomsopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter une valeur pour
enforcedBodySizeLimitàdata/config.yaml/prometheusK8safin de limiter la taille du corps qui peut être acceptée par raclage ciblé :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |- prometheusK8s: enforcedBodySizeLimit: 40MB1 - 1
- Spécifier la taille maximale du corps des cibles de métriques scrappées. L'exemple suivant (
enforcedBodySizeLimit) limite la taille non compressée de chaque cible scrappée à 40 mégaoctets. Les valeurs numériques valides utilisent le format de taille des données Prometheus : B (octets), KB (kilooctets), MB (mégaoctets), GB (gigaoctets), TB (téraoctets), PB (pétaoctets) et EB (exaoctets). La valeur par défaut est0, ce qui signifie qu'il n'y a pas de limite. Vous pouvez également définir la valeurautomaticpour calculer automatiquement la limite en fonction de la capacité de la grappe.
Enregistrez le fichier pour appliquer automatiquement les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à une carte de configuration
cluster-monitoring-config, les pods et autres ressources du projetopenshift-monitoringpeuvent être redéployés. Les processus de surveillance en cours d'exécution dans ce projet peuvent également redémarrer.
2.9. Configuration du stockage persistant
L'exécution de la surveillance des clusters avec un stockage persistant signifie que vos mesures sont stockées dans un volume persistant (PV) et peuvent survivre au redémarrage ou à la recréation d'un pod. Cette solution est idéale si vous souhaitez que vos données de mesure ou d'alerte soient protégées contre la perte de données. Pour les environnements de production, il est fortement recommandé de configurer le stockage persistant. En raison des exigences élevées en matière d'entrées-sorties, il est préférable d'utiliser le stockage local.
2.9.1. Conditions préalables au stockage permanent
- Consacrez suffisamment d'espace de stockage persistant local pour éviter que le disque ne soit saturé. La quantité de stockage nécessaire dépend du nombre de modules.
- Vérifiez que vous disposez d'un volume persistant (PV) prêt à être réclamé par la réclamation de volume persistant (PVC), un PV pour chaque réplique. Prometheus et Alertmanager ayant tous deux deux répliques, vous avez besoin de quatre PV pour prendre en charge l'ensemble de la pile de surveillance. Les PV sont disponibles auprès de l'opérateur de stockage local, mais pas si vous avez activé le stockage à provisionnement dynamique.
Utilisez
Filesystemcomme valeur de type de stockage pour le paramètrevolumeModelorsque vous configurez le volume persistant.NoteSi vous utilisez un volume local pour le stockage persistant, n'utilisez pas de volume de bloc brut, qui est décrit avec
volumeMode: Blockdans l'objetLocalVolume. Prometheus ne peut pas utiliser de volumes de blocs bruts.
2.9.2. Configuration d'une revendication de volume persistant local
Pour que les composants de surveillance utilisent un volume persistant (PV), vous devez configurer une réclamation de volume persistant (PVC).
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap:To configure a PVC for a component that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez votre configuration PVC pour le composant sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: volumeClaimTemplate: spec: storageClassName: <storage_class> resources: requests: storage: <amount_of_storage>Voir la documentation Kubernetes sur PersistentVolumeClaims pour plus d'informations sur la façon de spécifier
volumeClaimTemplate.L'exemple suivant configure un PVC qui réclame un stockage persistant local pour l'instance Prometheus qui surveille les composants principaux d'OpenShift Container Platform :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40GiDans l'exemple ci-dessus, la classe de stockage créée par l'Opérateur de stockage local s'appelle
local-storage.L'exemple suivant configure un PVC qui demande un stockage persistant local pour Alertmanager :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 10Gi
To configure a PVC for a component that monitors user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez votre configuration PVC pour le composant sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: volumeClaimTemplate: spec: storageClassName: <storage_class> resources: requests: storage: <amount_of_storage>Voir la documentation Kubernetes sur PersistentVolumeClaims pour plus d'informations sur la façon de spécifier
volumeClaimTemplate.L'exemple suivant configure un PVC qui réclame un stockage persistant local pour l'instance Prometheus qui surveille les projets définis par l'utilisateur :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40GiDans l'exemple ci-dessus, la classe de stockage créée par l'Opérateur de stockage local s'appelle
local-storage.L'exemple suivant configure un PVC qui réclame un stockage persistant local pour Thanos Ruler :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 10GiNoteLes besoins en stockage du composant
thanosRulerdépendent du nombre de règles évaluées et du nombre d'échantillons générés par chaque règle.
Enregistrez le fichier pour appliquer les modifications. Les pods concernés par la nouvelle configuration sont redémarrés automatiquement et la nouvelle configuration de stockage est appliquée.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
2.9.3. Redimensionnement d'un volume de stockage persistant
OpenShift Container Platform ne prend pas en charge le redimensionnement d'un volume de stockage persistant existant utilisé par des ressources StatefulSet, même si la ressource sous-jacente StorageClass utilisée prend en charge le dimensionnement du volume persistant. Par conséquent, même si vous mettez à jour le champ storage pour une réclamation de volume persistant (PVC) existante avec une taille plus grande, ce paramètre ne sera pas propagé au volume persistant (PV) associé.
Cependant, le redimensionnement d'un PV est toujours possible en utilisant un processus manuel. Si vous souhaitez redimensionner un PV pour un composant de surveillance tel que Prometheus, Thanos Ruler ou Alertmanager, vous pouvez mettre à jour la carte de configuration appropriée dans laquelle le composant est configuré. Ensuite, corrigez le PVC, puis supprimez et rendez les pods orphelins. Le fait de rendre les pods orphelins recrée immédiatement la ressource StatefulSet et met automatiquement à jour la taille des volumes montés dans les pods avec les nouveaux paramètres du PVC. Aucune interruption de service ne se produit au cours de ce processus.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap. - Vous avez configuré au moins un PVC pour les composants de surveillance de base d'OpenShift Container Platform.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap. - Vous avez configuré au moins un PVC pour les composants qui surveillent les projets définis par l'utilisateur.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
Procédure
Modifiez l'objet
ConfigMap:To resize a PVC for a component that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter une nouvelle taille de stockage pour la configuration PVC du composant sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 L'exemple suivant configure un PVC qui définit le stockage persistant local à 100 gigaoctets pour l'instance Prometheus qui surveille les composants principaux d'OpenShift Container Platform :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 100GiL'exemple suivant configure un PVC qui définit le stockage persistant local pour Alertmanager à 40 gigaoctets :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40Gi
To resize a PVC for a component that monitors user-defined projects:
NoteVous pouvez redimensionner les volumes des instances Thanos Ruler et Prometheus qui surveillent les projets définis par l'utilisateur.
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configMettre à jour la configuration du PVC pour le composant de surveillance sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 L'exemple suivant configure la taille du PVC à 100 gigaoctets pour l'instance Prometheus qui surveille les projets définis par l'utilisateur :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 100GiL'exemple suivant définit la taille du PVC à 20 gigaoctets pour Thanos Ruler :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 20GiNoteLes besoins en stockage du composant
thanosRulerdépendent du nombre de règles évaluées et du nombre d'échantillons générés par chaque règle.
Enregistrez le fichier pour appliquer les modifications. Les pods concernés par la nouvelle configuration redémarrent automatiquement.
AvertissementLorsque vous enregistrez les modifications apportées à une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours d'exécution dans ce projet peuvent également être redémarrés.
Patch manuel de chaque PVC avec la demande de stockage mise à jour. L'exemple suivant redéfinit la taille du stockage pour le composant Prometheus dans l'espace de noms
openshift-monitoringà 100Gi :$ for p in $(oc -n openshift-monitoring get pvc -l app.kubernetes.io/name=prometheus -o jsonpath='{range .items[*]}{.metadata.name} {end}'); do \ oc -n openshift-monitoring patch pvc/${p} --patch '{"spec": {"resources": {"requests": {"storage":"100Gi"}}}}'; \ doneSupprime le StatefulSet sous-jacent avec le paramètre
--cascade=orphan:$ oc delete statefulset -l app.kubernetes.io/name=prometheus --cascade=orphan
2.9.4. Modification de la durée et de la taille de rétention des données de métrologie Prometheus
Par défaut, Prometheus conserve automatiquement les données de mesure pendant 15 jours. Vous pouvez modifier la durée de conservation pour changer le délai de suppression des données en spécifiant une valeur de temps dans le champ retention. Vous pouvez également configurer la quantité maximale d'espace disque utilisée par les données de mesure conservées en spécifiant une valeur de taille dans le champ retentionSize. Si les données atteignent cette limite de taille, Prometheus supprime d'abord les données les plus anciennes jusqu'à ce que l'espace disque utilisé soit à nouveau inférieur à la limite.
Notez les comportements suivants de ces paramètres de conservation des données :
-
La politique de conservation basée sur la taille s'applique à tous les répertoires de blocs de données du répertoire
/prometheus, y compris les blocs persistants, les données WAL (write-ahead log) et les blocs m-mappés. -
Les données des répertoires
/walet/head_chunkssont prises en compte dans la limite de taille de rétention, mais Prometheus ne purge jamais les données de ces répertoires sur la base de politiques de rétention basées sur la taille ou le temps. Ainsi, si vous définissez une limite de taille de rétention inférieure à la taille maximale définie pour les répertoires/walet/head_chunks, vous avez configuré le système pour qu'il ne conserve aucun bloc de données dans les répertoires de données/prometheus. - La politique de conservation basée sur la taille n'est appliquée que lorsque Prometheus coupe un nouveau bloc de données, ce qui se produit toutes les deux heures lorsque le WAL contient au moins trois heures de données.
-
Si vous ne définissez pas explicitement de valeurs pour
retentionouretentionSize, la durée de conservation est fixée par défaut à 15 jours et la taille de la conservation n'est pas définie. -
Si vous définissez des valeurs pour
retentionetretentionSize, les deux valeurs s'appliquent. Si des blocs de données dépassent la durée de conservation définie ou la limite de taille définie, Prometheus purge ces blocs de données. -
Si vous définissez une valeur pour
retentionSizeet que vous ne définissez pasretention, seule la valeurretentionSizes'applique. -
Si vous ne définissez pas de valeur pour
retentionSizeet que vous ne définissez qu'une valeur pourretention, seule la valeurretentions'applique.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
- Un administrateur de cluster a activé la surveillance des projets définis par l'utilisateur.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez installé l'OpenShift CLI (
oc).
L'enregistrement des modifications apportées à une carte de configuration de surveillance peut redémarrer les processus de surveillance et redéployer les pods et autres ressources dans le projet concerné. Les processus de surveillance en cours dans ce projet peuvent également redémarrer.
Procédure
Modifiez l'objet
ConfigMap:To modify the retention time and size for the Prometheus instance that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez la configuration du temps de rétention et de la taille sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time_specification>1 retentionSize: <size_specification>2 - 1
- Le temps de rétention : un nombre directement suivi de
ms(millisecondes),s(secondes),m(minutes),h(heures),d(jours),w(semaines) ouy(années). Vous pouvez également combiner des valeurs temporelles pour des périodes spécifiques, comme1h30m15s. - 2
- La taille de rétention : un nombre directement suivi de
B(octets),KB(kilo-octets),MB(méga-octets),GB(giga-octets),TB(téra-octets),PB(péta-octets) etEB(exa-octets).
L'exemple suivant définit la durée de rétention à 24 heures et la taille de rétention à 10 gigaoctets pour l'instance Prometheus qui surveille les composants principaux d'OpenShift Container Platform :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: 24h retentionSize: 10GB
To modify the retention time and size for the Prometheus instance that monitors user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez la configuration du temps de rétention et de la taille sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: <time_specification>1 retentionSize: <size_specification>2 - 1
- Le temps de rétention : un nombre directement suivi de
ms(millisecondes),s(secondes),m(minutes),h(heures),d(jours),w(semaines) ouy(années). Vous pouvez également combiner des valeurs temporelles pour des périodes spécifiques, comme1h30m15s. - 2
- La taille de rétention : un nombre directement suivi de
B(octets),KB(kilo-octets),MB(méga-octets),GB(giga-octets),TB(téra-octets),PB(péta-octets) ouEB(exa-octets).
L'exemple suivant définit la durée de conservation à 24 heures et la taille de conservation à 10 gigaoctets pour l'instance Prometheus qui surveille les projets définis par l'utilisateur :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: 24h retentionSize: 10GB
- Enregistrez le fichier pour appliquer les modifications. Les pods concernés par la nouvelle configuration redémarrent automatiquement.
2.9.5. Modifier le temps de rétention des données de métriques de la règle de Thanos
Par défaut, pour les projets définis par l'utilisateur, Thanos Ruler conserve automatiquement les données de mesure pendant 24 heures. Vous pouvez modifier la durée de conservation des données en spécifiant une valeur de temps dans la carte de configuration user-workload-monitoring-config, dans l'espace de noms openshift-user-workload-monitoring.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Un administrateur de cluster a activé la surveillance des projets définis par l'utilisateur.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-adminou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
L'enregistrement des modifications apportées à une carte de configuration de surveillance peut redémarrer les processus de surveillance et redéployer les pods et autres ressources dans le projet concerné. Les processus de surveillance en cours dans ce projet peuvent également redémarrer.
Procédure
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez la configuration du temps de rétention sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: retention: <time_specification>1 - 1
- Spécifiez la durée de rétention au format suivant : un nombre directement suivi de
ms(millisecondes),s(secondes),m(minutes),h(heures),d(jours),w(semaines) ouy(années). Vous pouvez également combiner des valeurs temporelles pour des heures spécifiques, comme1h30m15s. La valeur par défaut est24h.
L'exemple suivant fixe la durée de conservation à 10 jours pour les données de Thanos Ruler :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: retention: 10d- Enregistrez le fichier pour appliquer les modifications. Les pods concernés par la nouvelle configuration redémarrent automatiquement.
2.10. Configuration du stockage en écriture à distance
Vous pouvez configurer le stockage en écriture à distance pour permettre à Prometheus d'envoyer les métriques ingérées à des systèmes distants pour un stockage à long terme. Cette opération n'a aucune incidence sur la manière dont Prometheus stocke les métriques, ni sur la durée de ce stockage.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-adminou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez configuré un point d'extrémité compatible avec l'écriture à distance (tel que Thanos) et vous connaissez l'URL du point d'extrémité. Consultez la documentation sur les points d'extrémité et le stockage à distance de Prometheus pour obtenir des informations sur les points d'extrémité compatibles avec la fonction d'écriture à distance.
Vous avez configuré les informations d'authentification dans un objet
Secretpour le point de terminaison d'écriture à distance. Vous devez créer le secret dans le même espace de noms que l'objet Prometheus pour lequel vous configurez l'écriture à distance : l'espace de nomsopenshift-monitoringpour la surveillance de la plate-forme par défaut ou l'espace de nomsopenshift-user-workload-monitoringpour la surveillance de la charge de travail de l'utilisateur.ImportantPour réduire les risques de sécurité, utilisez HTTPS et l'authentification pour envoyer des mesures à un point final.
Procédure
Suivez ces étapes pour configurer l'écriture à distance pour la surveillance de la plate-forme par défaut dans la carte de configuration cluster-monitoring-config de l'espace de noms openshift-monitoring.
Si vous configurez l'écriture à distance pour l'instance Prometheus qui surveille les projets définis par l'utilisateur, apportez des modifications similaires à la carte de configuration user-workload-monitoring-config dans l'espace de noms openshift-user-workload-monitoring. Notez que le composant de carte de configuration Prometheus est appelé prometheus dans l'objet user-workload-monitoring-config ConfigMap et non prometheusK8s, comme c'est le cas dans l'objet cluster-monitoring-config ConfigMap .
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-config-
Ajouter une section
remoteWrite:sousdata/config.yaml/prometheusK8s. Ajoutez une URL de point final et des informations d'authentification dans cette section :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com"1 <endpoint_authentication_credentials>2 - 1
- L'URL du point de terminaison d'écriture à distance.
- 2
- La méthode d'authentification et les informations d'identification pour le point de terminaison. Les méthodes d'authentification actuellement prises en charge sont AWS Signature Version 4, l'authentification par HTTP et l'en-tête de requête
Authorization, l'authentification de base, OAuth 2.0 et le client TLS. Voir Supported remote write authentication settings ci-dessous pour des exemples de configuration des méthodes d'authentification prises en charge.
Ajouter des valeurs de configuration après les informations d'authentification :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> <write_relabel_configs>1 - 1
- Les paramètres de configuration du relabel d'écriture.
Pour
<write_relabel_configs>, substituez une liste de configurations d'étiquetage en écriture pour les mesures que vous souhaitez envoyer au point de terminaison distant.L'exemple suivant montre comment transmettre une métrique unique appelée
my_metric:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: [__name__] regex: 'my_metric' action: keepVoir la documentation Prometheus relabel_config pour plus d'informations sur les options de configuration de write relabel.
Enregistrez le fichier pour appliquer les modifications à l'objet
ConfigMap. Les pods concernés par la nouvelle configuration redémarrent automatiquement.NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementL'enregistrement des modifications apportées à un objet de surveillance
ConfigMappeut entraîner le redéploiement des pods et d'autres ressources dans le projet concerné. L'enregistrement des modifications peut également redémarrer les processus de surveillance en cours dans ce projet.
2.10.1. Paramètres d'authentification de l'écriture à distance pris en charge
Vous pouvez utiliser différentes méthodes pour vous authentifier auprès d'un point de terminaison d'écriture distant. Les méthodes d'authentification actuellement prises en charge sont AWS Signature Version 4, l'authentification de base, l'autorisation, OAuth 2.0 et le client TLS. Le tableau suivant fournit des détails sur les méthodes d'authentification prises en charge pour l'écriture à distance.
| Méthode d'authentification | Champ de la carte de configuration | Description |
|---|---|---|
| Signature AWS version 4 |
| Cette méthode utilise l'authentification AWS Signature Version 4 pour signer les demandes. Vous ne pouvez pas utiliser cette méthode simultanément avec l'autorisation, OAuth 2.0 ou l'authentification de base. |
| authentification de base |
| L'authentification de base définit l'en-tête d'autorisation sur chaque demande d'écriture à distance avec le nom d'utilisateur et le mot de passe configurés. |
| autorisation |
|
L'autorisation définit l'en-tête |
| OAuth 2.0 |
|
Une configuration OAuth 2.0 utilise le type de subvention des informations d'identification du client. Prometheus récupère un jeton d'accès sur |
| Client TLS |
| Une configuration client TLS spécifie le certificat de l'autorité de certification, le certificat du client et les informations du fichier clé du client utilisés pour s'authentifier avec le serveur de point d'accès en écriture distant à l'aide de TLS. L'exemple de configuration suppose que vous avez déjà créé un fichier de certificat CA, un fichier de certificat client et un fichier de clé client. |
2.10.1.1. Emplacement de la carte de configuration pour les paramètres d'authentification
La figure suivante montre l'emplacement de la configuration de l'authentification dans l'objet ConfigMap pour la surveillance de la plate-forme par défaut.
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
<endpoint_authentication_details> - 1
- L'URL du point de terminaison d'écriture à distance.
- 2
- Détails de la configuration requise pour la méthode d'authentification du point de terminaison. Les méthodes d'authentification actuellement prises en charge sont Amazon Web Services (AWS) Signature Version 4, autorisation, authentification de base, OAuth 2.0 et client TLS.
Si vous configurez l'écriture à distance pour l'instance Prometheus qui surveille les projets définis par l'utilisateur, modifiez la carte de configuration user-workload-monitoring-config dans l'espace de noms openshift-user-workload-monitoring. Notez que le composant de la carte de configuration Prometheus est appelé prometheus dans l'objet user-workload-monitoring-config ConfigMap et non prometheusK8s, comme c'est le cas dans l'objet cluster-monitoring-config ConfigMap .
2.10.1.2. Exemple de paramètres d'authentification de l'écriture à distance
Les exemples suivants montrent différents paramètres d'authentification que vous pouvez utiliser pour vous connecter à un point final d'écriture à distance. Chaque exemple montre également comment configurer un objet Secret correspondant qui contient les informations d'authentification et d'autres paramètres pertinents. Chaque exemple configure l'authentification pour une utilisation avec la surveillance de la plate-forme par défaut dans l'espace de noms openshift-monitoring.
Exemple de YAML pour l'authentification AWS Signature Version 4
L'exemple suivant montre les paramètres d'un secret sigv4 nommé sigv4-credentials dans l'espace de noms openshift-monitoring.
apiVersion: v1
kind: Secret
metadata:
name: sigv4-credentials
namespace: openshift-monitoring
stringData:
accessKey: <AWS_access_key>
secretKey: <AWS_secret_key>
type: Opaque
Les exemples suivants montrent des paramètres d'authentification d'écriture à distance AWS Signature Version 4 qui utilisent un objet Secret nommé sigv4-credentials dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://authorization.example.com/api/write"
sigv4:
region: <AWS_region>
accessKey:
name: sigv4-credentials
key: accessKey
secretKey:
name: sigv4-credentials
key: secretKey
profile: <AWS_profile_name>
roleArn: <AWS_role_arn> - 1
- La région AWS.
- 2 4
- Le nom de l'objet
Secretcontenant les identifiants d'accès à l'API AWS. - 3
- La clé qui contient la clé d'accès à l'API AWS dans l'objet
Secretspécifié. - 5
- La clé qui contient la clé secrète de l'API AWS dans l'objet
Secretspécifié. - 6
- Le nom du profil AWS utilisé pour l'authentification.
- 7
- L'identifiant unique de l'Amazon Resource Name (ARN) attribué à votre rôle.
Exemple de YAML pour l'authentification de base
L'exemple suivant montre des paramètres d'authentification de base pour un objet Secret nommé rw-basic-auth dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: Secret
metadata:
name: rw-basic-auth
namespace: openshift-monitoring
stringData:
user: <basic_username>
password: <basic_password>
type: Opaque
L'exemple suivant montre une configuration d'écriture à distance basicAuth qui utilise un objet Secret nommé rw-basic-auth dans l'espace de noms openshift-monitoring. Il suppose que vous avez déjà configuré les informations d'authentification pour le point final.
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://basicauth.example.com/api/write"
basicAuth:
username:
name: rw-basic-auth
key: user
password:
name: rw-basic-auth
key: password Exemple de YAML pour l'authentification avec un jeton de porteur à l'aide d'un objet Secret
L'exemple suivant montre les paramètres du jeton de support pour un objet Secret nommé rw-bearer-auth dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: Secret
metadata:
name: rw-bearer-auth
namespace: openshift-monitoring
stringData:
token: <authentication_token>
type: Opaque- 1
- Le jeton d'authentification.
Les exemples suivants montrent des paramètres de carte de configuration de jetons de support qui utilisent un objet Secret nommé rw-bearer-auth dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
enableUserWorkload: true
prometheusK8s:
remoteWrite:
- url: "https://authorization.example.com/api/write"
authorization:
type: Bearer
credentials:
name: rw-bearer-auth
key: token Exemple de YAML pour l'authentification OAuth 2.0
L'exemple suivant montre des paramètres OAuth 2.0 pour un objet Secret nommé oauth2-credentials dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: Secret
metadata:
name: oauth2-credentials
namespace: openshift-monitoring
stringData:
id: <oauth2_id>
secret: <oauth2_secret>
token: <oauth2_authentication_token>
type: Opaque
La figure suivante présente un exemple de configuration de l'authentification d'écriture à distance oauth2 qui utilise un objet Secret nommé oauth2-credentials dans l'espace de noms openshift-monitoring:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://test.example.com/api/write"
oauth2:
clientId:
secret:
name: oauth2-credentials
key: id
clientSecret:
name: oauth2-credentials
key: secret
tokenUrl: https://example.com/oauth2/token
scopes:
- <scope_1>
- <scope_2>
endpointParams:
param1: <parameter_1>
param2: <parameter_2>- 1 3
- Le nom de l'objet
Secretcorrespondant. Notez queClientIdpeut également faire référence à un objetConfigMap, bien queclientSecretdoive faire référence à un objetSecret. - 2 4
- La clé qui contient les informations d'identification OAuth 2.0 dans l'objet
Secretspécifié. - 5
- L'URL utilisée pour obtenir un jeton avec les adresses
clientIdetclientSecret. - 6
- Les champs d'application OAuth 2.0 pour la demande d'autorisation. Ces champs d'application limitent les données auxquelles les jetons peuvent accéder.
- 7
- Les paramètres de la demande d'autorisation OAuth 2.0 requis pour le serveur d'autorisation.
Exemple de YAML pour l'authentification du client TLS
L'exemple suivant montre des exemples de paramètres client TLS pour un objet tls Secret nommé mtls-bundle dans l'espace de noms openshift-monitoring.
apiVersion: v1
kind: Secret
metadata:
name: mtls-bundle
namespace: openshift-monitoring
data:
ca.crt: <ca_cert>
client.crt: <client_cert>
client.key: <client_key>
type: tls
L'exemple suivant montre une configuration d'authentification d'écriture à distance tlsConfig qui utilise un objet TLS Secret nommé mtls-bundle.
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
tlsConfig:
ca:
secret:
name: mtls-bundle
key: ca.crt
cert:
secret:
name: mtls-bundle
key: client.crt
keySecret:
name: mtls-bundle
key: client.key - 1 3 5
- Le nom de l'objet
Secretcorrespondant qui contient les informations d'authentification TLS. Notez quecaetcertpeuvent alternativement faire référence à un objetConfigMap, bien quekeySecretdoive faire référence à un objetSecret. - 2
- La clé de l'objet
Secretspécifié qui contient le certificat de l'autorité de certification pour le point d'extrémité. - 4
- La clé de l'objet
Secretspécifié qui contient le certificat du client pour le point d'extrémité. - 6
- La clé de l'objet
Secretspécifié qui contient le secret de la clé du client.
2.11. Ajout d'étiquettes d'identification des clusters aux métriques
Si vous gérez plusieurs clusters OpenShift Container Platform et que vous utilisez la fonction d'écriture à distance pour envoyer des données de métriques de ces clusters vers un emplacement de stockage externe, vous pouvez ajouter des étiquettes d'ID de cluster pour identifier les données de métriques provenant de différents clusters. Vous pouvez ensuite interroger ces étiquettes pour identifier le cluster source d'une métrique et distinguer ces données de données de métriques similaires envoyées par d'autres clusters.
Ainsi, si vous gérez de nombreux clusters pour plusieurs clients et que vous envoyez des données de mesure à un système de stockage centralisé unique, vous pouvez utiliser des étiquettes d'identification de cluster pour interroger les mesures d'un cluster ou d'un client particulier.
La création et l'utilisation d'étiquettes d'identification de grappes comportent trois étapes générales :
- Configuration des paramètres d'étiquetage en écriture pour le stockage en écriture à distance.
- Ajout d'étiquettes d'identification des clusters aux métriques.
- L'interrogation de ces étiquettes permet d'identifier la grappe ou le client source d'une mesure.
2.11.1. Création d'étiquettes d'identification des clusters pour les métriques
Vous pouvez créer des étiquettes d'ID de cluster pour les métriques destinées à la surveillance de la plate-forme par défaut et à la surveillance de la charge de travail de l'utilisateur.
Pour la surveillance de la plate-forme par défaut, vous ajoutez des étiquettes d'ID de cluster pour les métriques dans les paramètres write_relabel pour le stockage en écriture à distance dans la carte de configuration cluster-monitoring-config dans l'espace de noms openshift-monitoring.
Pour la surveillance de la charge de travail de l'utilisateur, vous modifiez les paramètres de la carte de configuration user-workload-monitoring-config dans l'espace de noms openshift-user-workload-monitoring.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez configuré le stockage en écriture à distance.
If you are configuring default platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-adminou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
Procédure
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configNoteSi vous configurez des étiquettes d'ID de cluster pour les mesures de l'instance Prometheus qui surveille les projets définis par l'utilisateur, modifiez la carte de configuration
user-workload-monitoring-configdans l'espace de nomsopenshift-user-workload-monitoring. Notez que le composant Prometheus est appeléprometheusdans cette carte de configuration et nonprometheusK8s, qui est le nom utilisé dans la carte de configurationcluster-monitoring-config.Dans la section
writeRelabelConfigs:, sousdata/config.yaml/prometheusK8s/remoteWrite, ajoutez les valeurs de configuration de l'identifiant de cluster (cluster ID) :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> writeRelabelConfigs:1 - <relabel_config>2 L'exemple suivant montre comment transmettre une métrique avec l'étiquette d'ID de cluster
cluster_iddans la surveillance de la plate-forme par défaut :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: - __tmp_openshift_cluster_id__1 targetLabel: cluster_id2 action: replace3 - 1
- Le système applique initialement une étiquette source d'ID de cluster temporaire nommée
__tmp_openshift_cluster_id__. Cette étiquette temporaire est remplacée par le nom de l'étiquette d'ID de cluster que vous spécifiez. - 2
- Indiquez le nom de l'étiquette d'identification du cluster pour les mesures envoyées au stockage en écriture à distance. Si vous utilisez un nom d'étiquette qui existe déjà pour une mesure, cette valeur est remplacée par le nom de cette étiquette d'ID de cluster. N'utilisez pas
__tmp_openshift_cluster_id__pour le nom de l'étiquette. L'étape finale de réétiquetage supprime les étiquettes qui utilisent ce nom. - 3
- L'action
replacewrite relabel remplace l'étiquette temporaire par l'étiquette cible pour les métriques sortantes. Cette action est la valeur par défaut et est appliquée si aucune action n'est spécifiée.
Enregistrez le fichier pour appliquer les modifications à l'objet
ConfigMap. Les pods concernés par la configuration mise à jour redémarrent automatiquement.AvertissementL'enregistrement des modifications apportées à un objet de surveillance
ConfigMappeut entraîner le redéploiement des pods et d'autres ressources dans le projet concerné. L'enregistrement des modifications peut également redémarrer les processus de surveillance en cours dans ce projet.
2.12. Contrôler l'impact des attributs de métriques non liés dans les projets définis par l'utilisateur
Les développeurs peuvent créer des étiquettes pour définir les attributs des métriques sous la forme de paires clé-valeur. Le nombre de paires clé-valeur potentielles correspond au nombre de valeurs possibles pour un attribut. Un attribut dont le nombre de valeurs potentielles est illimité est appelé attribut non lié. Par exemple, un attribut customer_id est non consolidé car il possède un nombre infini de valeurs possibles.
Chaque paire clé-valeur attribuée possède une série temporelle unique. L'utilisation de nombreux attributs non liés dans les étiquettes peut créer un nombre exponentiel de séries temporelles, ce qui peut avoir un impact sur les performances de Prometheus et l'espace disque disponible.
Les administrateurs de cluster peuvent utiliser les mesures suivantes pour contrôler l'impact des attributs de métriques non liés dans les projets définis par l'utilisateur :
- Limiter le nombre d'échantillons qui peuvent être acceptés pour chaque analyse de la cible dans les projets définis par l'utilisateur
- Limiter le nombre d'étiquettes scannées, la longueur des noms d'étiquettes et la longueur des valeurs d'étiquettes.
- Créer des alertes qui se déclenchent lorsqu'un seuil d'échantillonnage est atteint ou lorsque la cible ne peut pas être scrappée
Pour éviter les problèmes liés à l'ajout de nombreux attributs non liés, limitez le nombre d'échantillons, de noms d'étiquettes et d'attributs non liés que vous définissez pour les métriques. Réduisez également le nombre de combinaisons potentielles de paires clé-valeur en utilisant des attributs liés à un ensemble limité de valeurs possibles.
2.12.1. Définition des limites d'échantillons et d'étiquettes pour les projets définis par l'utilisateur
Vous pouvez limiter le nombre d'échantillons qui peuvent être acceptés par balayage cible dans des projets définis par l'utilisateur. Vous pouvez également limiter le nombre d'étiquettes scrappées, la longueur des noms d'étiquettes et la longueur des valeurs d'étiquettes.
Si vous définissez des limites d'échantillons ou d'étiquettes, aucune autre donnée d'échantillon n'est ingérée pour ce balayage cible une fois la limite atteinte.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. - Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez la configuration
enforcedSampleLimitàdata/config.yamlpour limiter le nombre d'échantillons qui peuvent être acceptés par balayage de cible dans les projets définis par l'utilisateur :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: enforcedSampleLimit: 500001 - 1
- Une valeur est requise si ce paramètre est spécifié. Cet exemple
enforcedSampleLimitlimite à 50 000 le nombre d'échantillons pouvant être acceptés par target scrape dans les projets définis par l'utilisateur.
Ajoutez les configurations
enforcedLabelLimit,enforcedLabelNameLengthLimit, etenforcedLabelValueLengthLimitàdata/config.yamlpour limiter le nombre d'étiquettes scrappées, la longueur des noms d'étiquettes et la longueur des valeurs d'étiquettes dans les projets définis par l'utilisateur :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: enforcedLabelLimit: 5001 enforcedLabelNameLengthLimit: 502 enforcedLabelValueLengthLimit: 6003 - 1
- Indique le nombre maximal d'étiquettes par balayage. La valeur par défaut est
0, ce qui signifie qu'il n'y a pas de limite. - 2
- Spécifie la longueur maximale en caractères d'un nom d'étiquette. La valeur par défaut est
0, ce qui signifie qu'il n'y a pas de limite. - 3
- Spécifie la longueur maximale en caractères d'une valeur d'étiquette. La valeur par défaut est
0, ce qui signifie qu'il n'y a pas de limite.
Enregistrez le fichier pour appliquer les modifications. Les limites sont appliquées automatiquement.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque les modifications sont enregistrées dans l'objet
user-workload-monitoring-configConfigMap, les pods et autres ressources du projetopenshift-user-workload-monitoringpeuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
2.12.2. Création d'alertes d'échantillons scrape
Vous pouvez créer des alertes qui vous préviennent lorsque :
-
La cible ne peut pas être scannée ou n'est pas disponible pour la durée spécifiée
for -
Un seuil d'échantillonnage par raclage est atteint ou dépassé pendant la durée spécifiée
for
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. - Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous avez créé l'objet
user-workload-monitoring-configConfigMap. -
Vous avez limité le nombre d'échantillons qui peuvent être acceptés par target scrape dans les projets définis par l'utilisateur, en utilisant
enforcedSampleLimit. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Créez un fichier YAML avec des alertes qui vous informent lorsque les cibles sont en panne et lorsque la limite d'échantillons imposée approche. Le fichier de cet exemple s'appelle
monitoring-stack-alerts.yaml:apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: k8s role: alert-rules name: monitoring-stack-alerts1 namespace: ns12 spec: groups: - name: general.rules rules: - alert: TargetDown3 annotations: message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.'4 expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 for: 10m5 labels: severity: warning6 - alert: ApproachingEnforcedSamplesLimit7 annotations: message: '{{ $labels.container }} container of the {{ $labels.pod }} pod in the {{ $labels.namespace }} namespace consumes {{ $value | humanizePercentage }} of the samples limit budget.'8 expr: scrape_samples_scraped/50000 > 0.89 for: 10m10 labels: severity: warning11 - 1
- Définit le nom de la règle d'alerte.
- 2
- Spécifie le projet défini par l'utilisateur dans lequel la règle d'alerte sera déployée.
- 3
- L'alerte
TargetDownest déclenchée si la cible ne peut pas être grattée ou si elle n'est pas disponible pendant la durée de l'alertefor. - 4
- Le message qui sera affiché lorsque l'alerte
TargetDownse déclenchera. - 5
- Les conditions de l'alerte
TargetDowndoivent être vraies pendant cette durée avant que l'alerte ne soit déclenchée. - 6
- Définit la gravité de l'alerte
TargetDown. - 7
- L'alerte
ApproachingEnforcedSamplesLimitest déclenchée lorsque le seuil d'échantillonnage défini est atteint ou dépassé pendant la durée spécifiéefor. - 8
- Le message qui sera affiché lorsque l'alerte
ApproachingEnforcedSamplesLimitse déclenchera. - 9
- Le seuil de l'alerte
ApproachingEnforcedSamplesLimit. Dans cet exemple, l'alerte est déclenchée lorsque le nombre d'échantillons par balayage cible a dépassé 80 % de la limite d'échantillons imposée de50000. La durée defordoit également s'être écoulée avant que l'alerte ne soit déclenchée. La valeur<number>de l'expressionscrape_samples_scraped/<number> > <threshold>doit correspondre à la valeurenforcedSampleLimitdéfinie dans l'objetuser-workload-monitoring-configConfigMap. - 10
- Les conditions de l'alerte
ApproachingEnforcedSamplesLimitdoivent être vraies pendant cette durée avant que l'alerte ne soit déclenchée. - 11
- Définit la gravité de l'alerte
ApproachingEnforcedSamplesLimit.
Appliquer la configuration au projet défini par l'utilisateur :
$ oc apply -f monitoring-stack-alerts.yaml
Chapitre 3. Configuration des instances externes du gestionnaire d'alerte
La pile de surveillance d'OpenShift Container Platform comprend une instance locale d'Alertmanager qui achemine les alertes de Prometheus. Vous pouvez ajouter des instances Alertmanager externes en configurant la carte de configuration cluster-monitoring-config dans le projet openshift-monitoring ou le projet user-workload-monitoring-config.
Si vous ajoutez la même configuration Alertmanager externe pour plusieurs clusters et désactivez l'instance locale pour chaque cluster, vous pouvez alors gérer le routage des alertes pour plusieurs clusters en utilisant une seule instance Alertmanager externe.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). If you are configuring core OpenShift Container Platform monitoring components in the
openshift-monitoringproject:-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé la carte de configuration
cluster-monitoring-config.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé la carte de configuration
user-workload-monitoring-config.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
Procédure
Modifiez l'objet
ConfigMap.To configure additional Alertmanagers for routing alerts from core OpenShift Container Platform projects:
Modifiez la carte de configuration
cluster-monitoring-configdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-config-
Ajouter une section
additionalAlertmanagerConfigs:sousdata/config.yaml/prometheusK8s. Ajoutez les détails de configuration pour les gestionnaires d'alerte supplémentaires dans cette section :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - <alertmanager_specification>Pour
<alertmanager_specification>, remplacez l'authentification et les autres détails de configuration pour les instances supplémentaires d'Alertmanager. Les méthodes d'authentification actuellement prises en charge sont le jeton de porteur (bearerToken) et l'authentification TLS du client (tlsConfig). L'exemple de carte de configuration suivant configure un Alertmanager supplémentaire en utilisant un jeton de porteur avec une authentification TLS du client :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.com
To configure additional Alertmanager instances for routing alerts from user-defined projects:
Modifiez la carte de configuration
user-workload-monitoring-configdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config-
Ajouter une section
<component>/additionalAlertmanagerConfigs:sousdata/config.yaml/. Ajoutez les détails de configuration pour les gestionnaires d'alerte supplémentaires dans cette section :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: additionalAlertmanagerConfigs: - <alertmanager_specification>Remplacez
<component>par l'un des deux composants externes supportés par Alertmanager :prometheusouthanosRuler.Pour
<alertmanager_specification>, remplacez l'authentification et les autres détails de configuration pour les instances supplémentaires d'Alertmanager. Les méthodes d'authentification actuellement prises en charge sont le jeton de porteur (bearerToken) et le client TLS (tlsConfig). L'exemple de carte de configuration suivant configure un Alertmanager supplémentaire utilisant Thanos Ruler avec un jeton de porteur et une authentification TLS du client :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.comNoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.
-
Enregistrez le fichier pour appliquer les modifications à l'objet
ConfigMap. La nouvelle configuration de placement des composants est appliquée automatiquement.
3.1. Attacher des étiquettes supplémentaires à vos séries temporelles et à vos alertes
Grâce à la fonction d'étiquettes externes de Prometheus, vous pouvez attacher des étiquettes personnalisées à toutes les séries temporelles et alertes qui quittent Prometheus.
Conditions préalables
If you are configuring core OpenShift Container Platform monitoring components:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are configuring components that monitor user-defined projects:
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap:To attach custom labels to all time series and alerts leaving the Prometheus instance that monitors core OpenShift Container Platform projects:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configDéfinissez une carte des étiquettes que vous souhaitez ajouter pour chaque métrique sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: <key>: <value>1 - 1
- Remplacer
<key>: <value>par une carte de paires clé-valeur où<key>est un nom unique pour le nouveau label et<value>sa valeur.
AvertissementN'utilisez pas
prometheusouprometheus_replicacomme noms de clés, car ils sont réservés et seront écrasés.Par exemple, pour ajouter des métadonnées sur la région et l'environnement à toutes les séries temporelles et alertes, utilisez :
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: region: eu environment: prod
To attach custom labels to all time series and alerts leaving the Prometheus instance that monitors user-defined projects:
Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configDéfinissez une carte des étiquettes que vous souhaitez ajouter pour chaque métrique sous
data/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: <key>: <value>1 - 1
- Remplacer
<key>: <value>par une carte de paires clé-valeur où<key>est un nom unique pour le nouveau label et<value>sa valeur.
AvertissementN'utilisez pas
prometheusouprometheus_replicacomme noms de clés, car ils sont réservés et seront écrasés.NoteDans le projet
openshift-user-workload-monitoring, Prometheus gère les mesures et Thanos Ruler les règles d'alerte et d'enregistrement. En remplaçantprometheusparexternalLabelsdans l'objetuser-workload-monitoring-configConfigMap, vous ne configurerez les étiquettes externes que pour les mesures et non pour les règles.Par exemple, pour ajouter des métadonnées sur la région et l'environnement à toutes les séries temporelles et alertes liées à des projets définis par l'utilisateur, utilisez :
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: region: eu environment: prod
Enregistrez le fichier pour appliquer les modifications. La nouvelle configuration est appliquée automatiquement.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Chapitre 4. Configuration des contraintes d'étalement de la topologie des pods pour la surveillance
Vous pouvez utiliser les contraintes de répartition de la topologie des pods pour contrôler la répartition des pods Prometheus, Thanos Ruler et Alertmanager sur une topologie de réseau lorsque les pods OpenShift Container Platform sont déployés dans plusieurs zones de disponibilité.
Les contraintes de répartition de la topologie des pods permettent de contrôler la planification des pods dans des topologies hiérarchiques dans lesquelles les nœuds sont répartis sur différents niveaux d'infrastructure, tels que les régions et les zones au sein de ces régions. En outre, la possibilité de planifier des pods dans différentes zones permet d'améliorer la latence du réseau dans certains scénarios.
4.1. Configuration des contraintes d'étalement de la topologie des pods pour Prometheus
Pour la surveillance de la plateforme OpenShift Container Platform, vous pouvez configurer des contraintes d'étalement de la topologie des pods pour Prometheus afin d'affiner la planification des répliques de pods sur les nœuds dans les différentes zones. Cela permet de s'assurer que les pods Prometheus sont hautement disponibles et s'exécutent plus efficacement, car les charges de travail sont réparties sur des nœuds dans différents centres de données ou zones d'infrastructure hiérarchiques.
Vous configurez les contraintes d'étalement de la topologie des pods pour Prometheus dans la carte de configuration cluster-monitoring-config.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
Procédure
Modifiez l'objet
cluster-monitoring-configConfigMapdans l'espace de nomsopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez des valeurs pour les paramètres suivants sous
data/config.yaml/prometheusK8spour configurer les contraintes d'étalement de la topologie des pods :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: topologySpreadConstraints: - maxSkew: 11 topologyKey: monitoring2 whenUnsatisfiable: DoNotSchedule3 labelSelector: matchLabels:4 app.kubernetes.io/name: prometheus- 1
- Indiquez une valeur numérique pour
maxSkew, qui définit le degré d'inégalité de la répartition des cosses. Ce champ est obligatoire et la valeur doit être supérieure à zéro. La valeur spécifiée a un effet différent selon la valeur spécifiée pourwhenUnsatisfiable. - 2
- Spécifiez une clé d'étiquettes de nœuds pour
topologyKey. Ce champ est obligatoire. Les nœuds qui ont une étiquette avec cette clé et des valeurs identiques sont considérés comme étant dans la même topologie. Le planificateur essaiera de placer un nombre équilibré de pods dans chaque domaine. - 3
- Indiquez une valeur pour
whenUnsatisfiable. Ce champ est obligatoire. Les options disponibles sontDoNotScheduleetScheduleAnyway. IndiquezDoNotSchedulesi vous souhaitez que la valeurmaxSkewdéfinisse la différence maximale autorisée entre le nombre de modules correspondants dans la topologie cible et le minimum global. IndiquezScheduleAnywaysi vous souhaitez que le planificateur planifie toujours le module, mais qu'il accorde une priorité plus élevée aux nœuds susceptibles de réduire l'asymétrie. - 4
- Spécifiez une valeur pour
matchLabels. Cette valeur est utilisée pour identifier l'ensemble des pods correspondants auxquels appliquer les contraintes.
Enregistrez le fichier pour appliquer automatiquement les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à la carte de configuration
cluster-monitoring-config, les pods et autres ressources du projetopenshift-monitoringpeuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également redémarrer.
4.2. Configuration des contraintes d'étalement de la topologie des pods pour Alertmanager
Pour la surveillance de la plateforme OpenShift Container Platform, vous pouvez configurer des contraintes d'étalement de la topologie des pods pour Alertmanager afin d'affiner la planification des répliques de pods sur les nœuds dans les différentes zones. Cela permet de s'assurer que les pods Alertmanager sont hautement disponibles et s'exécutent plus efficacement, car les charges de travail sont réparties sur des nœuds dans différents centres de données ou zones d'infrastructure hiérarchiques.
Vous configurez les contraintes d'étalement de la topologie des pods pour Alertmanager dans la carte de configuration cluster-monitoring-config.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
Procédure
Modifiez l'objet
cluster-monitoring-configConfigMapdans l'espace de nomsopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez des valeurs pour les paramètres suivants sous
data/config.yaml/alertmanagermainpour configurer les contraintes d'étalement de la topologie des pods :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: topologySpreadConstraints: - maxSkew: 11 topologyKey: monitoring2 whenUnsatisfiable: DoNotSchedule3 labelSelector: matchLabels:4 app.kubernetes.io/name: alertmanager- 1
- Indiquez une valeur numérique pour
maxSkew, qui définit le degré d'inégalité de la répartition des cosses. Ce champ est obligatoire et la valeur doit être supérieure à zéro. La valeur spécifiée a un effet différent selon la valeur spécifiée pourwhenUnsatisfiable. - 2
- Spécifiez une clé d'étiquettes de nœuds pour
topologyKey. Ce champ est obligatoire. Les nœuds qui ont une étiquette avec cette clé et des valeurs identiques sont considérés comme étant dans la même topologie. Le planificateur essaiera de placer un nombre équilibré de pods dans chaque domaine. - 3
- Indiquez une valeur pour
whenUnsatisfiable. Ce champ est obligatoire. Les options disponibles sontDoNotScheduleetScheduleAnyway. IndiquezDoNotSchedulesi vous souhaitez que la valeurmaxSkewdéfinisse la différence maximale autorisée entre le nombre de modules correspondants dans la topologie cible et le minimum global. IndiquezScheduleAnywaysi vous souhaitez que le planificateur planifie toujours le module, mais qu'il accorde une priorité plus élevée aux nœuds susceptibles de réduire l'asymétrie. - 4
- Spécifiez une valeur pour
matchLabels. Cette valeur est utilisée pour identifier l'ensemble des pods correspondants auxquels appliquer les contraintes.
Enregistrez le fichier pour appliquer automatiquement les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à la carte de configuration
cluster-monitoring-config, les pods et autres ressources du projetopenshift-monitoringpeuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également redémarrer.
4.3. Mise en place des contraintes d'étalement de la topologie des pods pour Thanos Ruler
Pour la surveillance définie par l'utilisateur, vous pouvez définir des contraintes d'étalement de la topologie des pods pour Thanos Ruler afin d'affiner la manière dont les répliques de pods sont planifiées sur les nœuds des différentes zones. Cela permet de s'assurer que les pods Thanos Ruler sont hautement disponibles et s'exécutent plus efficacement, car les charges de travail sont réparties sur des nœuds situés dans différents centres de données ou zones d'infrastructure hiérarchique.
Vous configurez les contraintes d'étalement de la topologie des pods pour Thanos Ruler dans la carte de configuration user-workload-monitoring-config.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Un administrateur de cluster a activé la surveillance des projets définis par l'utilisateur.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
Procédure
Modifiez la carte de configuration
user-workload-monitoring-configdans l'espace de nomsopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjoutez des valeurs pour les paramètres suivants sous
data/config.yaml/thanosRulerpour configurer les contraintes d'étalement de la topologie des pods :apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: topologySpreadConstraints: - maxSkew: 11 topologyKey: monitoring2 whenUnsatisfiable: ScheduleAnyway3 labelSelector: matchLabels:4 app.kubernetes.io/name: thanos-ruler- 1
- Indiquez une valeur numérique pour
maxSkew, qui définit le degré d'inégalité de la répartition des cosses. Ce champ est obligatoire et la valeur doit être supérieure à zéro. La valeur spécifiée a un effet différent selon la valeur spécifiée pourwhenUnsatisfiable. - 2
- Spécifiez une clé d'étiquettes de nœuds pour
topologyKey. Ce champ est obligatoire. Les nœuds qui ont une étiquette avec cette clé et des valeurs identiques sont considérés comme étant dans la même topologie. Le planificateur essaiera de placer un nombre équilibré de pods dans chaque domaine. - 3
- Indiquez une valeur pour
whenUnsatisfiable. Ce champ est obligatoire. Les options disponibles sontDoNotScheduleetScheduleAnyway. IndiquezDoNotSchedulesi vous souhaitez que la valeurmaxSkewdéfinisse la différence maximale autorisée entre le nombre de modules correspondants dans la topologie cible et le minimum global. IndiquezScheduleAnywaysi vous souhaitez que le planificateur planifie toujours le module, mais qu'il accorde une priorité plus élevée aux nœuds susceptibles de réduire l'asymétrie. - 4
- Spécifiez une valeur pour
matchLabels. Cette valeur est utilisée pour identifier l'ensemble des pods correspondants auxquels appliquer les contraintes.
Enregistrez le fichier pour appliquer automatiquement les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à la carte de configuration
user-workload-monitoring-config, les pods et autres ressources du projetopenshift-user-workload-monitoringpeuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également redémarrer.
4.4. Définition des niveaux de journalisation pour les composants de surveillance
Vous pouvez configurer le niveau de journalisation pour Alertmanager, Prometheus Operator, Prometheus, Thanos Querier et Thanos Ruler.
Les niveaux de journalisation suivants peuvent être appliqués au composant concerné dans les objets cluster-monitoring-config et user-workload-monitoring-config ConfigMap :
-
debug. Enregistrer les messages de débogage, d'information, d'avertissement et d'erreur. -
info. Enregistrer les messages d'information, d'avertissement et d'erreur. -
warn. Enregistrer uniquement les messages d'avertissement et d'erreur. -
error. Enregistrer uniquement les messages d'erreur.
Le niveau de journalisation par défaut est info.
Conditions préalables
If you are setting a log level for Alertmanager, Prometheus Operator, Prometheus, or Thanos Querier in the
openshift-monitoringproject:-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are setting a log level for Prometheus Operator, Prometheus, or Thanos Ruler in the
openshift-user-workload-monitoringproject:-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez l'objet
ConfigMap:To set a log level for a component in the
openshift-monitoringproject:Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
logLevel: <log_level>pour un composant sousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2 - 1
- Le composant de la pile de surveillance pour lequel vous définissez un niveau de journalisation. Pour la surveillance de la plate-forme par défaut, les valeurs disponibles sont
prometheusK8s,alertmanagerMain,prometheusOperatoretthanosQuerier. - 2
- Le niveau de journalisation à définir pour le composant. Les valeurs disponibles sont
error,warn,info, etdebug. La valeur par défaut estinfo.
To set a log level for a component in the
openshift-user-workload-monitoringproject:Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjouter
logLevel: <log_level>pour un composant sousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2 - 1
- Le composant de la pile de surveillance pour lequel vous définissez un niveau de journalisation. Pour la surveillance de la charge de travail de l'utilisateur, les valeurs disponibles sont
prometheus,prometheusOperator, etthanosRuler. - 2
- Le niveau de journalisation à définir pour le composant. Les valeurs disponibles sont
error,warn,info, etdebug. La valeur par défaut estinfo.
Enregistrez le fichier pour appliquer les modifications. Les pods du composant redémarrent automatiquement lorsque vous appliquez la modification du niveau de journalisation.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Confirmez que le niveau de journalisation a été appliqué en examinant la configuration du déploiement ou du pod dans le projet concerné. L'exemple suivant vérifie le niveau de journalisation dans le déploiement
prometheus-operatordu projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring get deploy prometheus-operator -o yaml | grep "log-level"Exemple de sortie
- --log-level=debugVérifiez que les pods du composant sont en cours d'exécution. L'exemple suivant répertorie l'état des modules dans le projet
openshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring get podsNoteSi une valeur
loglevelnon reconnue est incluse dans l'objetConfigMap, les pods du composant risquent de ne pas redémarrer avec succès.
4.5. Activation du fichier journal des requêtes pour Prometheus
Vous pouvez configurer Prometheus pour qu'il écrive toutes les requêtes exécutées par le moteur dans un fichier journal. Vous pouvez le faire pour la surveillance de la plate-forme par défaut et pour la surveillance de la charge de travail définie par l'utilisateur.
La rotation des journaux n'étant pas prise en charge, n'activez cette fonctionnalité que temporairement, lorsque vous devez résoudre un problème. Une fois le dépannage terminé, désactivez la journalisation des requêtes en annulant les modifications apportées à l'objet ConfigMap pour activer la fonctionnalité.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). If you are enabling the query log file feature for Prometheus in the
openshift-monitoringproject:-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
If you are enabling the query log file feature for Prometheus in the
openshift-user-workload-monitoringproject:-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin, ou en tant qu'utilisateur ayant le rôleuser-workload-monitoring-config-editdans le projetopenshift-user-workload-monitoring. -
Vous avez créé l'objet
user-workload-monitoring-configConfigMap.
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
Procédure
To set the query log file for Prometheus in the
openshift-monitoringproject:Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
queryLogFile: <path>pourprometheusK8ssousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: queryLogFile: <path>1 - 1
- Le chemin complet vers le fichier dans lequel les requêtes seront enregistrées.
Enregistrez le fichier pour appliquer les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Vérifiez que les pods du composant sont en cours d'exécution. L'exemple de commande suivant répertorie l'état des modules dans le projet
openshift-monitoring:$ oc -n openshift-monitoring get podsLire le journal des requêtes :
oc -n openshift-monitoring exec prometheus-k8s-0 -- cat <path>ImportantRétablissez le paramètre dans la carte de configuration après avoir examiné les informations de requête consignées.
To set the query log file for Prometheus in the
openshift-user-workload-monitoringproject:Modifiez l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjouter
queryLogFile: <path>pourprometheussousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: queryLogFile: <path>1 - 1
- Le chemin complet vers le fichier dans lequel les requêtes seront enregistrées.
Enregistrez le fichier pour appliquer les modifications.
NoteLes configurations appliquées à l'objet
user-workload-monitoring-configConfigMapne sont pas activées à moins qu'un administrateur de cluster n'ait activé la surveillance pour les projets définis par l'utilisateur.AvertissementLorsque vous enregistrez les modifications apportées à une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Vérifiez que les pods du composant sont en cours d'exécution. L'exemple de commande suivant répertorie l'état des modules dans le projet
openshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring get podsLire le journal des requêtes :
oc -n openshift-user-workload-monitoring exec prometheus-user-workload-0 -- cat <path>ImportantRétablissez le paramètre dans la carte de configuration après avoir examiné les informations de requête consignées.
4.6. Activation de la journalisation des requêtes pour Thanos Querier
Pour la surveillance de la plate-forme par défaut dans le projet openshift-monitoring, vous pouvez activer l'opérateur de surveillance du cluster pour enregistrer toutes les requêtes exécutées par Thanos Querier.
La rotation des journaux n'étant pas prise en charge, n'activez cette fonctionnalité que temporairement, lorsque vous devez résoudre un problème. Une fois le dépannage terminé, désactivez la journalisation des requêtes en annulant les modifications apportées à l'objet ConfigMap pour activer la fonctionnalité.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
Procédure
Vous pouvez activer la journalisation des requêtes pour Thanos Querier dans le projet openshift-monitoring:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjoutez une section
thanosQueriersousdata/config.yamlet ajoutez des valeurs comme indiqué dans l'exemple suivant :apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | thanosQuerier: enableRequestLogging: <value>1 logLevel: <value>2 Enregistrez le fichier pour appliquer les modifications.
AvertissementLorsque vous enregistrez les modifications apportées à une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Vérification
Vérifiez que les pods Thanos Querier sont en cours d'exécution. L'exemple de commande suivant répertorie l'état des modules dans le projet
openshift-monitoring:$ oc -n openshift-monitoring get podsExécutez une requête de test en utilisant les exemples de commandes suivants comme modèle :
$ token=`oc create token prometheus-k8s -n openshift-monitoring` $ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -k -H "Authorization: Bearer $token" 'https://thanos-querier.openshift-monitoring.svc:9091/api/v1/query?query=cluster_version'Exécutez la commande suivante pour lire le journal des requêtes :
oc -n openshift-monitoring logs <thanos_querier_pod_name> -c thanos-queryNoteLes pods
thanos-querierétant des pods hautement disponibles (HA), il se peut que vous ne puissiez voir les journaux que dans un seul pod.-
Après avoir examiné les informations de requête consignées, désactivez la consignation des requêtes en remplaçant la valeur
enableRequestLoggingparfalsedans la carte de configuration.
Chapitre 5. Définition des niveaux de journal d'audit pour l'adaptateur Prometheus
Dans la surveillance de la plate-forme par défaut, vous pouvez configurer le niveau du journal d'audit pour l'adaptateur Prometheus.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé l'objet
cluster-monitoring-configConfigMap.
Procédure
Vous pouvez définir un niveau de journal d'audit pour l'adaptateur Prometheus dans le projet par défaut openshift-monitoring:
Modifiez l'objet
cluster-monitoring-configConfigMapdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
profile:dans la sectionk8sPrometheusAdapter/auditsousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | k8sPrometheusAdapter: audit: profile: <audit_log_level>1 - 1
- Le niveau du journal d'audit à appliquer à l'adaptateur Prometheus.
Définissez le niveau du journal d'audit en utilisant l'une des valeurs suivantes pour le paramètre
profile::-
None: Ne pas enregistrer les événements. -
Metadata: Enregistrer uniquement les métadonnées de la demande, telles que l'utilisateur, l'horodatage, etc. Ne pas enregistrer le texte de la demande et le texte de la réponse.Metadataest le niveau par défaut du journal d'audit. -
Request: Enregistrer uniquement les métadonnées et le texte de la demande, mais pas le texte de la réponse. Cette option ne s'applique pas aux demandes ne portant pas sur des ressources. -
RequestResponse: Métadonnées de l'événement, texte de la demande et texte de la réponse. Cette option ne s'applique pas aux demandes ne portant pas sur des ressources.
-
Enregistrez le fichier pour appliquer les modifications. Les pods de l'adaptateur Prometheus redémarrent automatiquement lorsque vous appliquez la modification.
AvertissementLorsque des modifications sont enregistrées dans une carte de configuration de surveillance, les pods et autres ressources du projet concerné peuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.
Vérification
-
Dans la carte de configuration, sous
k8sPrometheusAdapter/audit/profile, réglez le niveau de journalisation surRequestet enregistrez le fichier. Confirmez que les pods de l'adaptateur Prometheus sont en cours d'exécution. L'exemple suivant répertorie l'état des modules dans le projet
openshift-monitoring:$ oc -n openshift-monitoring get podsConfirmez que le niveau du journal d'audit et le chemin d'accès au fichier du journal d'audit sont correctement configurés :
$ oc -n openshift-monitoring get deploy prometheus-adapter -o yamlExemple de sortie
... - --audit-policy-file=/etc/audit/request-profile.yaml - --audit-log-path=/var/log/adapter/audit.logConfirmez que le niveau de journalisation correct a été appliqué dans le déploiement de
prometheus-adapterdans le projetopenshift-monitoring:$ oc -n openshift-monitoring exec deploy/prometheus-adapter -c prometheus-adapter -- cat /etc/audit/request-profile.yamlExemple de sortie
"apiVersion": "audit.k8s.io/v1" "kind": "Policy" "metadata": "name": "Request" "omitStages": - "RequestReceived" "rules": - "level": "Request"NoteSi vous saisissez une valeur
profilenon reconnue pour l'adaptateur Prometheus dans l'objetConfigMap, aucune modification n'est apportée à l'adaptateur Prometheus et une erreur est consignée par l'opérateur de surveillance des clusters.Examinez le journal d'audit de l'adaptateur Prometheus :
oc -n openshift-monitoring exec -c <prometheus_adapter_pod_name> -- cat /var/log/adapter/audit.log
5.1. Désactivation de l'Alertmanager local
Un Alertmanager local qui achemine les alertes des instances Prometheus est activé par défaut dans le projet openshift-monitoring de la pile de surveillance OpenShift Container Platform.
Si vous n'avez pas besoin de l'Alertmanager local, vous pouvez le désactiver en configurant la carte de configuration cluster-monitoring-config dans le projet openshift-monitoring.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé la carte de configuration
cluster-monitoring-config. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifiez la carte de configuration
cluster-monitoring-configdans le projetopenshift-monitoring:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
enabled: falsepour le composantalertmanagerMainsousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enabled: false- Enregistrez le fichier pour appliquer les modifications. L'instance de l'Alertmanager est automatiquement désactivée lorsque vous appliquez la modification.
5.2. Prochaines étapes
- Permettre le suivi de projets définis par l'utilisateur
- Renseignez-vous sur les rapports de santé à distance et, le cas échéant, refusez-les.
Chapitre 6. Permettre le suivi de projets définis par l'utilisateur
Dans OpenShift Container Platform 4.12, vous pouvez activer la surveillance des projets définis par l'utilisateur en plus de la surveillance par défaut de la plateforme. Vous pouvez surveiller vos propres projets dans OpenShift Container Platform sans avoir besoin d'une solution de surveillance supplémentaire. L'utilisation de cette fonctionnalité centralise la surveillance des composants centraux de la plateforme et des projets définis par l'utilisateur.
Les versions de Prometheus Operator installées à l'aide d'Operator Lifecycle Manager (OLM) ne sont pas compatibles avec la surveillance définie par l'utilisateur. Par conséquent, les instances Prometheus personnalisées installées en tant que ressource personnalisée Prometheus (CR) gérée par l'opérateur Prometheus OLM ne sont pas prises en charge dans OpenShift Container Platform.
6.1. Permettre le suivi de projets définis par l'utilisateur
Les administrateurs de clusters peuvent activer la surveillance des projets définis par l'utilisateur en définissant le champ enableUserWorkload: true dans l'objet de surveillance des clusters ConfigMap.
Dans OpenShift Container Platform 4.12, vous devez supprimer toutes les instances Prometheus personnalisées avant d'activer la surveillance des projets définis par l'utilisateur.
Vous devez avoir accès au cluster en tant qu'utilisateur avec le rôle cluster-admin pour activer la surveillance des projets définis par l'utilisateur dans OpenShift Container Platform. Les administrateurs de cluster peuvent ensuite, de manière facultative, accorder aux utilisateurs l'autorisation de configurer les composants responsables de la surveillance des projets définis par l'utilisateur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez créé l'objet
cluster-monitoring-configConfigMap. Vous avez éventuellement créé et configuré l'objet
user-workload-monitoring-configConfigMapdans le projetopenshift-user-workload-monitoring. Vous pouvez ajouter des options de configuration à cet objetConfigMappour les composants qui surveillent les projets définis par l'utilisateur.NoteChaque fois que vous enregistrez des modifications de configuration dans l'objet
user-workload-monitoring-configConfigMap, les pods du projetopenshift-user-workload-monitoringsont redéployés. Le redéploiement de ces composants peut parfois prendre un certain temps. Vous pouvez créer et configurer l'objetConfigMapavant d'activer pour la première fois la surveillance des projets définis par l'utilisateur, afin d'éviter de devoir redéployer souvent les pods.
Procédure
Modifier l'objet
cluster-monitoring-configConfigMap:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
enableUserWorkload: truesousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
- Lorsqu'il est défini sur
true, le paramètreenableUserWorkloadpermet la surveillance de projets définis par l'utilisateur dans un cluster.
Enregistrez le fichier pour appliquer les modifications. La surveillance des projets définis par l'utilisateur est alors automatiquement activée.
AvertissementLorsque les modifications sont enregistrées dans l'objet
cluster-monitoring-configConfigMap, les pods et autres ressources du projetopenshift-monitoringpeuvent être redéployés. Les processus de surveillance en cours dans ce projet peuvent également être redémarrés.Vérifiez que les pods
prometheus-operator,prometheus-user-workloadetthanos-ruler-user-workloadsont en cours d'exécution dans le projetopenshift-user-workload-monitoring. Le démarrage des pods peut prendre un certain temps :$ oc -n openshift-user-workload-monitoring get podExemple de sortie
NAME READY STATUS RESTARTS AGE prometheus-operator-6f7b748d5b-t7nbg 2/2 Running 0 3h prometheus-user-workload-0 4/4 Running 1 3h prometheus-user-workload-1 4/4 Running 1 3h thanos-ruler-user-workload-0 3/3 Running 0 3h thanos-ruler-user-workload-1 3/3 Running 0 3h
6.2. Autoriser les utilisateurs à suivre des projets définis par l'utilisateur
Les administrateurs de clusters peuvent surveiller tous les projets principaux d'OpenShift Container Platform et les projets définis par l'utilisateur.
Les administrateurs de clusters peuvent accorder aux développeurs et à d'autres utilisateurs l'autorisation de surveiller leurs propres projets. Les privilèges sont accordés en attribuant l'un des rôles de surveillance suivants :
-
Le rôle monitoring-rules-view permet d'accéder en lecture aux ressources personnalisées
PrometheusRuled'un projet. -
Le rôle monitoring-rules-edit permet à un utilisateur de créer, modifier et supprimer des ressources personnalisées
PrometheusRulepour un projet. -
Le rôle monitoring-edit accorde les mêmes privilèges que le rôle
monitoring-rules-edit. En outre, il permet à un utilisateur de créer de nouvelles cibles de scrape pour les services ou les pods. Avec ce rôle, vous pouvez également créer, modifier et supprimer les ressourcesServiceMonitoretPodMonitor.
Vous pouvez également autoriser les utilisateurs à configurer les composants responsables de la surveillance des projets définis par l'utilisateur :
-
Le rôle user-workload-monitoring-config-edit dans le projet
openshift-user-workload-monitoringvous permet de modifier l'objetuser-workload-monitoring-configConfigMap. Avec ce rôle, vous pouvez modifier l'objetConfigMappour configurer Prometheus, Prometheus Operator et Thanos Ruler pour la surveillance de la charge de travail définie par l'utilisateur.
Vous pouvez également autoriser les utilisateurs à configurer le routage des alertes pour des projets définis par l'utilisateur :
-
Le rôle alert-routing-edit permet à un utilisateur de créer, mettre à jour et supprimer les ressources personnalisées
AlertmanagerConfigpour un projet.
Cette section fournit des détails sur la façon d'attribuer ces rôles en utilisant la console web de OpenShift Container Platform ou la CLI.
6.2.1. Octroi de permissions aux utilisateurs à l'aide de la console web
Vous pouvez accorder aux utilisateurs des permissions pour surveiller leurs propres projets, en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Le compte utilisateur auquel vous attribuez le rôle existe déjà.
Procédure
- Dans la perspective Administrator au sein de la console web OpenShift Container Platform, naviguez vers User Management → Role Bindings → Create Binding.
- Dans la section Binding Type, sélectionnez le type "Namespace Role Binding".
- Dans le champ Name, saisissez un nom pour la liaison de rôle.
Dans le champ Namespace, sélectionnez le projet défini par l'utilisateur auquel vous souhaitez accorder l'accès.
ImportantLe rôle de surveillance sera lié au projet que vous avez indiqué dans le champ Namespace. Les autorisations que vous accordez à un utilisateur en suivant cette procédure ne s'appliquent qu'au projet sélectionné.
-
Sélectionnez
monitoring-rules-view,monitoring-rules-editoumonitoring-editdans la liste Role Name. - Dans la section Subject, sélectionnez User.
- Dans le champ Subject Name, saisissez le nom de l'utilisateur.
- Sélectionnez Create pour appliquer la liaison de rôle.
6.2.2. Octroi de permissions aux utilisateurs à l'aide de l'interface de programmation
Vous pouvez accorder aux utilisateurs des permissions pour surveiller leurs propres projets, en utilisant l'OpenShift CLI (oc).
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Le compte utilisateur auquel vous attribuez le rôle existe déjà.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Attribuer un rôle de surveillance à un utilisateur pour un projet :
$ oc policy add-role-to-user <role> <user> -n <namespace>1 - 1
- Remplacez
<role>parmonitoring-rules-view,monitoring-rules-edit, oumonitoring-edit.
ImportantQuel que soit le rôle choisi, vous devez le lier à un projet spécifique en tant qu'administrateur de cluster.
Par exemple, remplacez
<role>parmonitoring-edit,<user>parjohnsmith, et<namespace>parns1. L'utilisateurjohnsmithest ainsi autorisé à mettre en place la collecte de métriques et à créer des règles d'alerte dans l'espace de nomsns1.
6.3. Autoriser les utilisateurs à configurer la surveillance pour des projets définis par l'utilisateur
Vous pouvez autoriser les utilisateurs à configurer la surveillance pour des projets définis par l'utilisateur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Le compte utilisateur auquel vous attribuez le rôle existe déjà.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Attribuer le rôle
user-workload-monitoring-config-edità un utilisateur du projetopenshift-user-workload-monitoring:$ oc -n openshift-user-workload-monitoring adm policy add-role-to-user \ user-workload-monitoring-config-edit <user> \ --role-namespace openshift-user-workload-monitoring
6.4. Accès aux métriques depuis l'extérieur du cluster pour des applications personnalisées
Apprenez à interroger les statistiques Prometheus à partir de la ligne de commande lorsque vous surveillez vos propres services. Vous pouvez accéder aux données de surveillance depuis l'extérieur du cluster grâce à la route thanos-querier.
Conditions préalables
- Vous avez déployé votre propre service en suivant la procédure Enabling monitoring for user-defined projects.
Procédure
Extraire un jeton pour se connecter à Prometheus :
$ SECRET=`oc get secret -n openshift-user-workload-monitoring | grep prometheus-user-workload-token | head -n 1 | awk '{print $1 }'`$ TOKEN=`echo $(oc get secret $SECRET -n openshift-user-workload-monitoring -o json | jq -r '.data.token') | base64 -d`Extrayez votre hôte de route :
$ THANOS_QUERIER_HOST=`oc get route thanos-querier -n openshift-monitoring -o json | jq -r '.spec.host'`Interrogez les métriques de vos propres services en ligne de commande. Par exemple :
$ NAMESPACE=ns1$ curl -X GET -kG "https://$THANOS_QUERIER_HOST/api/v1/query?" --data-urlencode "query=up{namespace='$NAMESPACE'}" -H "Authorization: Bearer $TOKEN"Le résultat vous indiquera la durée pendant laquelle vos pods d'application ont été activés.
Exemple de sortie
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"up","endpoint":"web","instance":"10.129.0.46:8080","job":"prometheus-example-app","namespace":"ns1","pod":"prometheus-example-app-68d47c4fb6-jztp2","service":"prometheus-example-app"},"value":[1591881154.748,"1"]}]}}
6.5. Exclusion d'un projet défini par l'utilisateur de la surveillance
Les projets individuels définis par l'utilisateur peuvent être exclus de la surveillance de la charge de travail de l'utilisateur. Pour ce faire, il suffit d'ajouter l'étiquette openshift.io/user-monitoring à l'espace de noms du projet avec la valeur false.
Procédure
Ajouter l'étiquette à l'espace de noms du projet :
$ oc label namespace my-project 'openshift.io/user-monitoring=false'Pour réactiver la surveillance, retirez l'étiquette de l'espace de noms :
$ oc label namespace my-project 'openshift.io/user-monitoring-'NoteS'il existe des cibles de surveillance actives pour le projet, Prometheus peut prendre quelques minutes pour arrêter de les gratter après l'ajout de l'étiquette.
6.6. Désactivation de la surveillance pour les projets définis par l'utilisateur
Après avoir activé la surveillance des projets définis par l'utilisateur, vous pouvez la désactiver à nouveau en définissant enableUserWorkload: false dans l'objet de surveillance des clusters ConfigMap.
Vous pouvez également supprimer enableUserWorkload: true pour désactiver la surveillance des projets définis par l'utilisateur.
Procédure
Modifier l'objet
cluster-monitoring-configConfigMap:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configDéfinissez
enableUserWorkload:àfalsesousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: false
- Enregistrez le fichier pour appliquer les modifications. La surveillance des projets définis par l'utilisateur est alors automatiquement désactivée.
Vérifiez que les pods
prometheus-operator,prometheus-user-workloadetthanos-ruler-user-workloadsont terminés dans le projetopenshift-user-workload-monitoring. Cela peut prendre un peu de temps :$ oc -n openshift-user-workload-monitoring get podExemple de sortie
No resources found in openshift-user-workload-monitoring project.
L'objet user-workload-monitoring-config ConfigMap du projet openshift-user-workload-monitoring n'est pas automatiquement supprimé lorsque la surveillance des projets définis par l'utilisateur est désactivée. Cela permet de préserver les configurations personnalisées que vous avez pu créer dans l'objet ConfigMap.
6.7. Prochaines étapes
Chapitre 7. Activation de l'acheminement des alertes pour les projets définis par l'utilisateur
Dans OpenShift Container Platform 4.12, un administrateur de cluster peut activer le routage des alertes pour des projets définis par l'utilisateur. Ce processus se compose de deux étapes générales :
- Activer le routage des alertes pour les projets définis par l'utilisateur afin d'utiliser l'instance Alertmanager de la plate-forme par défaut ou, en option, une instance Alertmanager distincte uniquement pour les projets définis par l'utilisateur.
- Autoriser les utilisateurs à configurer l'acheminement des alertes pour des projets définis par l'utilisateur.
Une fois ces étapes terminées, les développeurs et autres utilisateurs peuvent configurer des alertes personnalisées et leur acheminement pour leurs projets définis par l'utilisateur.
7.1. Comprendre le routage des alertes pour les projets définis par l'utilisateur
En tant qu'administrateur de cluster, vous pouvez activer le routage des alertes pour les projets définis par l'utilisateur. Cette fonctionnalité permet aux utilisateurs ayant le rôle alert-routing-edit de configurer l'acheminement et les récepteurs des notifications d'alerte pour les projets définis par l'utilisateur. Ces notifications sont acheminées par l'instance Alertmanager par défaut ou, si elle est activée, par une instance Alertmanager optionnelle dédiée à la surveillance définie par l'utilisateur.
Les utilisateurs peuvent alors créer et configurer le routage d'alertes défini par l'utilisateur en créant ou en modifiant les objets AlertmanagerConfig pour leurs projets définis par l'utilisateur, sans l'aide d'un administrateur.
Une fois que l'utilisateur a défini l'acheminement des alertes pour un projet défini par l'utilisateur, les notifications d'alerte définies par l'utilisateur sont acheminées comme suit :
-
Vers les pods
alertmanager-maindans l'espace de nomsopenshift-monitoringsi vous utilisez l'instance Alertmanager de la plate-forme par défaut. -
Vers les pods
alertmanager-user-workloaddans l'espace de nomsopenshift-user-workload-monitoringsi vous avez activé une instance distincte d'Alertmanager pour les projets définis par l'utilisateur.
Les limitations de l'acheminement des alertes pour les projets définis par l'utilisateur sont les suivantes :
-
Pour les règles d'alerte définies par l'utilisateur, le routage défini par l'utilisateur est limité à l'espace de noms dans lequel la ressource est définie. Par exemple, une configuration de routage dans l'espace de noms
ns1ne s'applique qu'aux ressourcesPrometheusRulesdu même espace de noms. -
Lorsqu'un espace de noms est exclu de la surveillance définie par l'utilisateur, les ressources
AlertmanagerConfigde l'espace de noms ne font plus partie de la configuration de l'Alertmanager.
7.2. Activation de l'instance Alertmanager de la plate-forme pour l'acheminement des alertes définies par l'utilisateur
Vous pouvez autoriser les utilisateurs à créer des configurations d'acheminement des alertes définies par l'utilisateur qui utilisent l'instance principale de la plate-forme Alertmanager.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifier l'objet
cluster-monitoring-configConfigMap:$ oc -n openshift-monitoring edit configmap cluster-monitoring-configAjouter
enableUserAlertmanagerConfig: truedans la sectionalertmanagerMainsousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enableUserAlertmanagerConfig: true1 - 1
- Définissez la valeur
enableUserAlertmanagerConfigsurtruepour permettre aux utilisateurs de créer des configurations d'acheminement des alertes définies par l'utilisateur qui utilisent l'instance de la plate-forme principale de l'Alertmanager.
- Enregistrez le fichier pour appliquer les modifications.
7.3. Activation d'une instance distincte d'Alertmanager pour l'acheminement des alertes définies par l'utilisateur
Dans certains clusters, vous pourriez vouloir déployer une instance Alertmanager dédiée aux projets définis par l'utilisateur, ce qui peut aider à réduire la charge sur l'instance Alertmanager de la plate-forme par défaut et peut mieux séparer les alertes définies par l'utilisateur des alertes de la plate-forme par défaut. Dans ce cas, vous pouvez optionnellement activer une instance distincte d'Alertmanager pour envoyer des alertes uniquement pour les projets définis par l'utilisateur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez activé la surveillance pour les projets définis par l'utilisateur dans la carte de configuration
cluster-monitoring-configpour l'espace de nomsopenshift-monitoring. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Modifier l'objet
user-workload-monitoring-configConfigMap:$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configAjouter
enabled: trueetenableAlertmanagerConfig: truedans la sectionalertmanagersousdata/config.yaml:apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | alertmanager: enabled: true1 enableAlertmanagerConfig: true2 - 1
- Fixez la valeur de
enabledàtruepour activer une instance dédiée de l'Alertmanager pour les projets définis par l'utilisateur dans un cluster. Fixez la valeur àfalseou omettez la clé pour désactiver l'Alertmanager pour les projets définis par l'utilisateur. Si vous définissez cette valeur surfalseou si la clé est omise, les alertes définies par l'utilisateur sont acheminées vers l'instance Alertmanager de la plate-forme par défaut. - 2
- Définissez la valeur
enableAlertmanagerConfigsurtruepour permettre aux utilisateurs de définir leurs propres configurations de routage des alertes avec les objetsAlertmanagerConfig.
- Sauvegardez le fichier pour appliquer les changements. L'instance dédiée de l'Alertmanager pour les projets définis par l'utilisateur démarre automatiquement.
Vérification
Vérifiez que l'instance de
user-workloadAlertmanager a démarré :# oc -n openshift-user-workload-monitoring get alertmanagerExemple de sortie
NAME VERSION REPLICAS AGE user-workload 0.24.0 2 100s
7.4. Autoriser les utilisateurs à configurer l'acheminement des alertes pour des projets définis par l'utilisateur
Vous pouvez autoriser les utilisateurs à configurer le routage des alertes pour des projets définis par l'utilisateur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Le compte utilisateur auquel vous attribuez le rôle existe déjà.
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez activé la surveillance pour les projets définis par l'utilisateur.
Procédure
Attribuer le rôle
alert-routing-edità un utilisateur dans le projet défini par l'utilisateur :oc -n <namespace> adm policy add-role-to-user alert-routing-edit <user>1 - 1
- Pour
<namespace>, remplacez l'espace de noms du projet défini par l'utilisateur, par exemplens1. Pour<user>, remplacez le nom d'utilisateur par le compte auquel vous souhaitez attribuer le rôle.
7.5. Prochaines étapes
Chapitre 8. Gestion des indicateurs
Vous pouvez collecter des métriques pour surveiller les performances des composants de la grappe et de vos propres charges de travail.
8.1. Comprendre les indicateurs
Dans OpenShift Container Platform 4.12, les composants du cluster sont surveillés en récupérant les métriques exposées via les points de terminaison des services. Vous pouvez également configurer la collecte de métriques pour des projets définis par l'utilisateur.
Vous pouvez définir les mesures que vous souhaitez fournir pour vos propres charges de travail en utilisant les bibliothèques client Prometheus au niveau de l'application.
Dans OpenShift Container Platform, les mesures sont exposées par le biais d'un point d'extrémité de service HTTP sous le nom canonique /metrics. Vous pouvez répertorier toutes les mesures disponibles pour un service en exécutant une requête curl sur http://<endpoint>/metrics. Par exemple, vous pouvez exposer une route vers le service d'exemple prometheus-example-app et exécuter ce qui suit pour afficher toutes les mesures disponibles :
$ curl http://<example_app_endpoint>/metricsExemple de sortie
# HELP http_requests_total Count of all HTTP requests
# TYPE http_requests_total counter
http_requests_total{code="200",method="get"} 4
http_requests_total{code="404",method="get"} 2
# HELP version Version information about this binary
# TYPE version gauge
version{version="v0.1.0"} 18.2. Mise en place de la collecte de métriques pour des projets définis par l'utilisateur
Vous pouvez créer une ressource ServiceMonitor pour extraire des métriques d'un point d'extrémité de service dans un projet défini par l'utilisateur. Cela suppose que votre application utilise une bibliothèque client Prometheus pour exposer les métriques au nom canonique /metrics.
Cette section décrit comment déployer un exemple de service dans un projet défini par l'utilisateur, puis créer une ressource ServiceMonitor qui définit comment ce service doit être contrôlé.
8.2.1. Déploiement d'un exemple de service
Pour tester la surveillance d'un service dans un projet défini par l'utilisateur, vous pouvez déployer un exemple de service.
Procédure
-
Créez un fichier YAML pour la configuration du service. Dans cet exemple, il s'appelle
prometheus-example-app.yaml. Ajoutez au fichier les détails de déploiement et de configuration des services suivants :
apiVersion: v1 kind: Namespace metadata: name: ns1 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: replicas: 1 selector: matchLabels: app: prometheus-example-app template: metadata: labels: app: prometheus-example-app spec: containers: - image: ghcr.io/rhobs/prometheus-example-app:0.4.1 imagePullPolicy: IfNotPresent name: prometheus-example-app --- apiVersion: v1 kind: Service metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: ports: - port: 8080 protocol: TCP targetPort: 8080 name: web selector: app: prometheus-example-app type: ClusterIPCette configuration déploie un service nommé
prometheus-example-appdans le projetns1défini par l'utilisateur. Ce service expose la métrique personnaliséeversion.Appliquer la configuration au cluster :
$ oc apply -f prometheus-example-app.yamlLe déploiement du service prend un certain temps.
Vous pouvez vérifier que le pod fonctionne :
$ oc -n ns1 get podExemple de sortie
NAME READY STATUS RESTARTS AGE prometheus-example-app-7857545cb7-sbgwq 1/1 Running 0 81m
8.2.2. Spécifier comment un service est contrôlé
Pour utiliser les métriques exposées par votre service, vous devez configurer la surveillance de OpenShift Container Platform pour récupérer les métriques à partir du point de terminaison /metrics. Vous pouvez le faire en utilisant une définition de ressource personnalisée (CRD) ServiceMonitor qui spécifie comment un service doit être surveillé, ou une CRD PodMonitor qui spécifie comment un pod doit être surveillé. La première nécessite un objet Service, tandis que la seconde n'en nécessite pas, ce qui permet à Prometheus de récupérer directement des métriques à partir du point de terminaison de métriques exposé par un pod.
Cette procédure vous montre comment créer une ressource ServiceMonitor pour un service dans un projet défini par l'utilisateur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-adminoumonitoring-edit. - Vous avez activé la surveillance pour les projets définis par l'utilisateur.
Pour cet exemple, vous avez déployé le service exemple
prometheus-example-appdans le projetns1.NoteL'exemple de service
prometheus-example-appne prend pas en charge l'authentification TLS.
Procédure
-
Créez un fichier YAML pour la configuration de la ressource
ServiceMonitor. Dans cet exemple, le fichier s'appelleexample-app-service-monitor.yaml. Ajoutez les détails de configuration de la ressource
ServiceMonitorsuivants :apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: prometheus-example-monitor name: prometheus-example-monitor namespace: ns1 spec: endpoints: - interval: 30s port: web scheme: http selector: matchLabels: app: prometheus-example-appCeci définit une ressource
ServiceMonitorqui récupère les métriques exposées par le service d'échantillonnageprometheus-example-app, qui inclut la métriqueversion.NoteUne ressource
ServiceMonitordans un espace de noms défini par l'utilisateur ne peut découvrir que des services dans le même espace de noms. En d'autres termes, le champnamespaceSelectorde la ressourceServiceMonitorest toujours ignoré.Appliquer la configuration au cluster :
$ oc apply -f example-app-service-monitor.yamlLe déploiement de la ressource
ServiceMonitorprend un certain temps.Vous pouvez vérifier que la ressource
ServiceMonitorest en cours d'exécution :$ oc -n ns1 get servicemonitorExemple de sortie
NAME AGE prometheus-example-monitor 81m
8.3. Affichage d'une liste des mesures disponibles
En tant qu'administrateur d'un cluster ou en tant qu'utilisateur disposant d'autorisations de visualisation pour tous les projets, vous pouvez afficher une liste des métriques disponibles dans un cluster et produire cette liste au format JSON.
Conditions préalables
-
Vous avez installé le CLI OpenShift Container Platform (
oc). - Vous avez obtenu la route API OpenShift Container Platform pour Thanos Querier.
Vous êtes un administrateur de cluster ou vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-monitoring-view.NoteVous ne pouvez utiliser que l'authentification par jeton de porteur pour accéder à la route API Thanos Querier.
Procédure
Si vous n'avez pas obtenu la route API OpenShift Container Platform pour Thanos Querier, exécutez la commande suivante :
$ oc get routes -n openshift-monitoring thanos-querier -o jsonpath='{.status.ingress[0].host}'Récupérez une liste de métriques au format JSON à partir de la route API Thanos Querier en exécutant la commande suivante. Cette commande utilise
ocpour s'authentifier avec un jeton de porteur.$ curl -k -H \N "Authorization : Bearer $(oc whoami -t)" https://<thanos_querier_route>/api/v1/metadata1 - 1
- Remplacez
<thanos_querier_route>par la route de l'API OpenShift Container Platform pour Thanos Querier.
8.4. Prochaines étapes
Chapitre 9. Interroger les métriques
Vous pouvez interroger les métriques pour afficher des données sur les performances des composants de la grappe et de vos propres charges de travail.
9.1. A propos de l'interrogation des métriques
Le tableau de bord de surveillance d'OpenShift Container Platform vous permet d'exécuter des requêtes Prometheus Query Language (PromQL) pour examiner les mesures visualisées sur un graphique. Cette fonctionnalité fournit des informations sur l'état d'un cluster et de toute charge de travail définie par l'utilisateur que vous surveillez.
En tant que cluster administrator, vous pouvez interroger les métriques pour tous les projets principaux d'OpenShift Container Platform et les projets définis par l'utilisateur.
En tant que developer, vous devez spécifier un nom de projet lorsque vous interrogez les métriques. Vous devez disposer des privilèges requis pour afficher les métriques du projet sélectionné.
9.1.1. Interroger les métriques de tous les projets en tant qu'administrateur de cluster
En tant qu'administrateur de cluster ou en tant qu'utilisateur disposant de permissions de visualisation pour tous les projets, vous pouvez accéder aux métriques pour tous les projets par défaut d'OpenShift Container Platform et les projets définis par l'utilisateur dans l'interface utilisateur des métriques.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur avec le rôle
cluster-adminou avec des permissions de visualisation pour tous les projets. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
- Sélectionnez la perspective Administrator dans la console web de OpenShift Container Platform.
- Sélectionnez Observe → Metrics.
- Sélectionnez Insert Metric at Cursor pour afficher une liste de requêtes prédéfinies.
Pour créer une requête personnalisée, ajoutez votre requête Prometheus Query Language (PromQL) au champ Expression.
NoteLorsque vous saisissez une expression PromQL, des suggestions d'autocomplétion apparaissent dans une liste déroulante. Ces suggestions incluent des fonctions, des métriques, des étiquettes et des jetons de temps. Vous pouvez utiliser les flèches du clavier pour sélectionner l'un des éléments suggérés, puis appuyer sur Entrée pour l'ajouter à votre expression. Vous pouvez également déplacer le pointeur de votre souris sur un élément suggéré pour afficher une brève description de cet élément.
- Pour ajouter plusieurs requêtes, sélectionnez Add Query.
-
Pour dupliquer une requête existante, sélectionnez
 à côté de la requête, puis choisissez Duplicate query.
à côté de la requête, puis choisissez Duplicate query.
-
Pour supprimer une requête, sélectionnez
à côté de la requête, puis choisissez Delete query.
-
Pour empêcher l'exécution d'une requête, sélectionnez
à côté de la requête et choisissez Disable query.
Pour exécuter les requêtes que vous avez créées, sélectionnez Run Queries. Les métriques des requêtes sont visualisées sur le graphique. Si une requête n'est pas valide, l'interface utilisateur affiche un message d'erreur.
NoteLes requêtes qui portent sur de grandes quantités de données peuvent dépasser le temps imparti ou surcharger le navigateur lors de l'affichage de graphiques de séries temporelles. Pour éviter cela, sélectionnez Hide graph et calibrez votre requête en utilisant uniquement le tableau des métriques. Ensuite, après avoir trouvé une requête réalisable, activez le tracé pour dessiner les graphiques.
- Facultatif : L'URL de la page contient maintenant les requêtes que vous avez exécutées. Pour réutiliser cet ensemble de requêtes à l'avenir, enregistrez cette URL.
9.1.2. Interroger les métriques pour des projets définis par l'utilisateur en tant que développeur
Vous pouvez accéder aux métriques d'un projet défini par l'utilisateur en tant que développeur ou en tant qu'utilisateur disposant d'autorisations de visualisation du projet.
Dans la perspective Developer, l'interface utilisateur Metrics comprend des requêtes prédéfinies sur l'unité centrale, la mémoire, la bande passante et les paquets réseau pour le projet sélectionné. Vous pouvez également exécuter des requêtes Prometheus Query Language (PromQL) personnalisées pour l'unité centrale, la mémoire, la bande passante, les paquets réseau et les métriques d'application pour le projet.
Les développeurs ne peuvent utiliser que la perspective Developer et non la perspective Administrator. En tant que développeur, vous ne pouvez interroger les métriques que pour un seul projet à la fois dans la page Observe -→ Metrics de la console web pour votre projet défini par l'utilisateur.
Conditions préalables
- Vous avez accès au cluster en tant que développeur ou en tant qu'utilisateur disposant d'autorisations de visualisation pour le projet dont vous consultez les métriques.
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
- Vous avez déployé un service dans un projet défini par l'utilisateur.
-
Vous avez créé une définition de ressource personnalisée (CRD)
ServiceMonitorpour le service afin de définir la manière dont le service est surveillé.
Procédure
- Sélectionnez la perspective Developer dans la console web de OpenShift Container Platform.
- Sélectionnez Observe → Metrics.
- Dans la liste Project:, sélectionnez le projet pour lequel vous souhaitez afficher les mesures.
- Sélectionnez une requête dans la liste Select query ou créez une requête PromQL personnalisée basée sur la requête sélectionnée en sélectionnant Show PromQL.
Optionnel : Sélectionnez Custom query dans la liste Select query pour saisir une nouvelle requête. Au fur et à mesure de la saisie, des suggestions d'autocomplétion apparaissent dans une liste déroulante. Ces suggestions comprennent des fonctions et des mesures. Cliquez sur un élément suggéré pour le sélectionner.
NoteDans la perspective Developer, vous ne pouvez exécuter qu'une seule requête à la fois.
9.1.3. Exploration des métriques visualisées
Après l'exécution des requêtes, les mesures sont affichées sur un graphique interactif. L'axe X du graphique représente le temps et l'axe Y représente les valeurs des mesures. Chaque mesure est représentée par une ligne colorée sur le graphique. Vous pouvez manipuler le graphique de manière interactive et explorer les mesures.
Procédure
Dans la perspective de Administrator:
Initialement, toutes les mesures de toutes les requêtes activées sont affichées sur le graphique. Vous pouvez sélectionner les mesures à afficher.
NotePar défaut, le tableau des requêtes affiche une vue développée qui répertorie chaque mesure et sa valeur actuelle. Vous pouvez sélectionner ˅ pour réduire la vue développée d'une requête.
-
Pour masquer toutes les mesures d'une requête, cliquez sur
pour la requête et cliquez sur Hide all series.
- Pour masquer une mesure spécifique, allez dans le tableau de la requête et cliquez sur le carré coloré près du nom de la mesure.
-
Pour masquer toutes les mesures d'une requête, cliquez sur
Pour effectuer un zoom sur le graphique et modifier l'intervalle de temps, procédez de l'une des manières suivantes :
- Sélectionnez visuellement l'intervalle de temps en cliquant et en faisant glisser horizontalement le tracé.
- Utilisez le menu dans le coin supérieur gauche pour sélectionner l'intervalle de temps.
- Pour réinitialiser l'intervalle de temps, sélectionnez Reset Zoom.
- Pour afficher les résultats de toutes les requêtes à un moment précis, maintenez le curseur de la souris sur le graphique à ce moment-là. Les résultats de la requête apparaissent dans une fenêtre contextuelle.
- Pour masquer le tracé, sélectionnez Hide Graph.
Dans la perspective de Developer:
Pour effectuer un zoom sur le graphique et modifier l'intervalle de temps, procédez de l'une des manières suivantes :
- Sélectionnez visuellement l'intervalle de temps en cliquant et en faisant glisser horizontalement le tracé.
- Utilisez le menu dans le coin supérieur gauche pour sélectionner l'intervalle de temps.
- Pour réinitialiser l'intervalle de temps, sélectionnez Reset Zoom.
- Pour afficher les résultats de toutes les requêtes à un moment précis, maintenez le curseur de la souris sur le graphique à ce moment-là. Les résultats de la requête apparaissent dans une fenêtre contextuelle.
9.2. Prochaines étapes
Chapitre 10. Gestion des objectifs de mesure
OpenShift Container Platform Monitoring collecte des métriques à partir de composants de cluster ciblés en récupérant des données à partir de points d'extrémité de services exposés.
Dans la perspective Administrator de la console web OpenShift Container Platform, vous pouvez utiliser la page Metrics Targets pour afficher, rechercher et filtrer les points d'extrémité qui sont actuellement ciblés pour le scraping, ce qui vous aide à identifier et à résoudre les problèmes. Par exemple, vous pouvez afficher l'état actuel des points de terminaison ciblés pour voir quand OpenShift Container Platform Monitoring n'est pas en mesure de récupérer les métriques d'un composant ciblé.
La page Metrics Targets affiche des cibles pour les projets OpenShift Container Platform par défaut et pour les projets définis par l'utilisateur.
10.1. Accès à la page Cibles de mesure dans la perspective de l'administrateur
Vous pouvez voir la page Metrics Targets dans la perspective Administrator dans la console web de OpenShift Container Platform.
Conditions préalables
- Vous avez accès au cluster en tant qu'administrateur du projet pour lequel vous souhaitez consulter les objectifs de mesure.
Procédure
- Dans la perspective Administrator, sélectionnez Observe → Targets. La page Metrics Targets s'ouvre sur une liste de toutes les cibles d'extrémité de service dont les métriques sont recherchées.
10.2. Recherche et filtrage des cibles de métriques
La liste des objectifs de mesure peut être longue. Vous pouvez filtrer et rechercher ces objectifs en fonction de différents critères.
Dans la perspective Administrator, la page Metrics Targets fournit des détails sur les cibles pour OpenShift Container Platform par défaut et les projets définis par l'utilisateur. Cette page répertorie les informations suivantes pour chaque cible :
- l'URL du point de terminaison du service qui fait l'objet de la recherche
- le composant ServiceMonitor surveillé
- l'état de la cible à la hausse ou à la baisse
- l'espace nominatif
- le dernier temps de grattage
- la durée du dernier raclage
Vous pouvez filtrer la liste des cibles par statut et par source. Les options de filtrage suivantes sont disponibles :
Status des filtres :
- Up. La cible est actuellement en place et fait l'objet d'une recherche active de métriques.
- Down. L'objectif est actuellement en panne et ne fait pas l'objet d'une recherche de métriques.
Source des filtres :
- Platform. Les cibles au niveau de la plateforme ne concernent que les projets par défaut d'OpenShift Container Platform. Ces projets fournissent les fonctionnalités de base d'OpenShift Container Platform.
- User. Les cibles utilisateur se rapportent à des projets définis par l'utilisateur. Ces projets sont créés par l'utilisateur et peuvent être personnalisés.
Vous pouvez également utiliser le champ de recherche pour trouver une cible par son nom ou son étiquette. Sélectionnez Text ou Label dans le menu de la boîte de recherche pour limiter votre recherche.
10.3. Obtenir des informations détaillées sur une cible
Sur la page Target details, vous pouvez consulter des informations détaillées sur un objectif métrique.
Conditions préalables
- Vous avez accès au cluster en tant qu'administrateur du projet pour lequel vous souhaitez consulter les objectifs de mesure.
Procédure
To view detailed information about a target in the Administrator perspective:
- Ouvrez la console web d'OpenShift Container Platform et naviguez vers Observe → Targets.
- Facultatif : Filtrez les cibles par statut et par source en sélectionnant des filtres dans la liste Filter.
- Facultatif : Recherchez une cible par nom ou par étiquette en utilisant le champ Text ou Label à côté du champ de recherche.
- Facultatif : Triez les cibles en cliquant sur un ou plusieurs des en-têtes de colonne Endpoint, Status, Namespace, Last Scrape, et Scrape Duration.
Cliquez sur l'URL d'une cible dans la colonne Endpoint pour accéder à sa page Target details. Cette page fournit des informations sur la cible, notamment :
- L'URL du point de terminaison qui fait l'objet d'une recherche de métriques
- Le statut actuel Up ou Down de la cible
- Un lien vers l'espace de noms
- Un lien vers les détails du ServiceMonitor
- Étiquettes attachées à la cible
- La date la plus récente à laquelle la cible a été scrappée pour les métriques
10.4. Prochaines étapes
Chapitre 11. Gestion des alertes
Dans OpenShift Container Platform 4.12, l'interface d'alerte vous permet de gérer les alertes, les silences et les règles d'alerte.
- Alerting rules. Les règles d'alerte contiennent un ensemble de conditions qui définissent un état particulier au sein d'un cluster. Les alertes sont déclenchées lorsque ces conditions sont remplies. Une règle d'alerte peut se voir attribuer une gravité qui définit la manière dont les alertes sont acheminées.
- Alerts. Une alerte est déclenchée lorsque les conditions définies dans une règle d'alerte sont remplies. Les alertes fournissent une notification qu'un ensemble de circonstances sont apparentes au sein d'un cluster OpenShift Container Platform.
- Silences. Un silence peut être appliqué à une alerte pour empêcher l'envoi de notifications lorsque les conditions de l'alerte sont remplies. Vous pouvez mettre une alerte en sourdine après la notification initiale, pendant que vous travaillez à la résolution du problème sous-jacent.
Les alertes, les silences et les règles d'alerte disponibles dans l'interface utilisateur d'alerte sont liés aux projets auxquels vous avez accès. Par exemple, si vous êtes connecté avec les privilèges cluster-admin, vous pouvez accéder à toutes les alertes, tous les silences et toutes les règles d'alerte.
Si vous n'êtes pas administrateur, vous pouvez créer des alertes et les rendre silencieuses si les rôles d'utilisateur suivants vous sont attribués :
-
Le rôle
cluster-monitoring-view, qui permet d'accéder à Alertmanager -
Le rôle
monitoring-alertmanager-edit, qui vous permet de créer et de rendre silencieuses des alertes dans la perspective Administrator de la console web -
Le rôle
monitoring-rules-edit, qui vous permet de créer et de rendre silencieuses des alertes dans la perspective Developer de la console web
11.1. Accès à l'interface utilisateur des alertes dans les perspectives de l'administrateur et du développeur
L'interface utilisateur d'alerte est accessible via la perspective de l'administrateur et la perspective du développeur dans la console web de OpenShift Container Platform.
- Dans la perspective Administrator, sélectionnez Observe → Alerting. Les trois pages principales de l'interface utilisateur d'alerte dans cette perspective sont les pages Alerts, Silences et Alerting Rules.
- Dans la perspective Developer, sélectionnez Observe → <project_name> → Alerts. Dans cette perspective, les alertes, les silences et les règles d'alerte sont tous gérés à partir de la page Alerts. Les résultats affichés sur la page Alerts sont spécifiques au projet sélectionné.
Dans la perspective du développeur, vous pouvez sélectionner des projets OpenShift Container Platform et des projets définis par l'utilisateur auxquels vous avez accès dans la liste Project:. Cependant, les alertes, les silences et les règles d'alerte relatifs aux projets de la plate-forme OpenShift Container ne sont pas affichés si vous n'avez pas les privilèges cluster-admin.
11.2. Recherche et filtrage des alertes, des silences et des règles d'alerte
Vous pouvez filtrer les alertes, les silences et les règles d'alerte affichés dans l'interface utilisateur des alertes. Cette section décrit chacune des options de filtrage disponibles.
Comprendre les filtres d'alerte
Dans la perspective Administrator, la page Alerts de l'interface utilisateur d'alerte fournit des détails sur les alertes relatives à la plate-forme OpenShift Container par défaut et aux projets définis par l'utilisateur. La page comprend un résumé de la gravité, de l'état et de la source de chaque alerte. L'heure à laquelle une alerte a atteint son état actuel est également indiquée.
Vous pouvez filtrer les alertes en fonction de leur état, de leur gravité et de leur source. Par défaut, seules les alertes Platform qui sont Firing sont affichées. Les paragraphes suivants décrivent chaque option de filtrage des alertes :
Alert State des filtres :
-
Firing. L'alerte est déclenchée parce que la condition d'alerte est vraie et que la durée optionnelle
fors'est écoulée. L'alerte continuera à se déclencher tant que la condition restera vraie. - Pending. L'alerte est active mais attend la durée spécifiée dans la règle d'alerte avant de se déclencher.
- Silenced. L'alerte est maintenant réduite au silence pour une période de temps définie. Les silences mettent temporairement les alertes en sourdine en fonction d'un ensemble de sélecteurs d'étiquettes que vous définissez. Les notifications ne seront pas envoyées pour les alertes qui correspondent à toutes les valeurs ou expressions régulières répertoriées.
-
Firing. L'alerte est déclenchée parce que la condition d'alerte est vraie et que la durée optionnelle
Severity des filtres :
- Critical. L'état qui a déclenché l'alerte peut avoir un impact critique. L'alerte nécessite une attention immédiate lorsqu'elle est déclenchée et est généralement transmise par téléavertisseur à une personne ou à une équipe d'intervention critique.
- Warning. L'alerte fournit une notification d'avertissement sur quelque chose qui pourrait nécessiter une attention particulière afin d'éviter qu'un problème ne se produise. Les alertes sont généralement acheminées vers un système de billetterie pour un examen non immédiat.
- Info. L'alerte est fournie à titre d'information uniquement.
- None. L'alerte n'a pas de gravité définie.
- Vous pouvez également créer des définitions de gravité personnalisées pour les alertes relatives à des projets définis par l'utilisateur.
Source des filtres :
- Platform. Les alertes au niveau de la plateforme ne concernent que les projets par défaut d'OpenShift Container Platform. Ces projets fournissent les fonctionnalités de base d'OpenShift Container Platform.
- User. Les alertes utilisateur concernent des projets définis par l'utilisateur. Ces alertes sont créées par l'utilisateur et peuvent être personnalisées. La surveillance des charges de travail définies par l'utilisateur peut être activée après l'installation afin de permettre l'observation de vos propres charges de travail.
Comprendre les filtres de silence
Dans la perspective Administrator, la page Silences de l'interface utilisateur d'alerte fournit des détails sur les silences appliqués aux alertes dans la plate-forme OpenShift Container par défaut et les projets définis par l'utilisateur. La page comprend un résumé de l'état de chaque silence et l'heure à laquelle un silence se termine.
Vous pouvez filtrer par état de silence. Par défaut, seuls les silences Active et Pending sont affichés. Les paragraphes suivants décrivent chaque option de filtrage par état de silence :
Silence State des filtres :
- Active. Le silence est actif et l'alerte est mise en sourdine jusqu'à l'expiration du silence.
- Pending. Le silence a été programmé et n'est pas encore actif.
- Expired. Le silence a expiré et des notifications seront envoyées si les conditions d'une alerte sont réunies.
Comprendre les filtres des règles d'alerte
Dans la perspective Administrator, la page Alerting Rules de l'interface utilisateur d'alerte fournit des détails sur les règles d'alerte relatives à la plate-forme OpenShift Container par défaut et aux projets définis par l'utilisateur. La page comprend un résumé de l'état, de la gravité et de la source pour chaque règle d'alerte.
Vous pouvez filtrer les règles d'alerte en fonction de l'état, de la gravité et de la source de l'alerte. Par défaut, seules les règles d'alerte Platform sont affichées. Les paragraphes suivants décrivent chaque option de filtrage des règles d'alerte :
Alert State des filtres :
-
Firing. L'alerte est déclenchée parce que la condition d'alerte est vraie et que la durée optionnelle
fors'est écoulée. L'alerte continuera à se déclencher tant que la condition restera vraie. - Pending. L'alerte est active mais attend la durée spécifiée dans la règle d'alerte avant de se déclencher.
- Silenced. L'alerte est maintenant réduite au silence pour une période de temps définie. Les silences mettent temporairement les alertes en sourdine en fonction d'un ensemble de sélecteurs d'étiquettes que vous définissez. Les notifications ne seront pas envoyées pour les alertes qui correspondent à toutes les valeurs ou expressions régulières répertoriées.
- Not Firing. L'alerte n'est pas déclenchée.
-
Firing. L'alerte est déclenchée parce que la condition d'alerte est vraie et que la durée optionnelle
Severity des filtres :
- Critical. Les conditions définies dans la règle d'alerte peuvent avoir un impact critique. Lorsqu'elles sont avérées, ces conditions requièrent une attention immédiate. Les alertes relatives à la règle sont généralement envoyées par téléavertisseur à une personne ou à une équipe d'intervention critique.
- Warning. Les conditions définies dans la règle d'alerte peuvent nécessiter une attention particulière afin d'éviter qu'un problème ne se produise. Les alertes relatives à la règle sont généralement acheminées vers un système de billetterie pour un examen non immédiat.
- Info. La règle d'alerte ne fournit que des alertes informatives.
- None. La règle d'alerte n'a pas de gravité définie.
- Vous pouvez également créer des définitions de gravité personnalisées pour les règles d'alerte relatives aux projets définis par l'utilisateur.
Source des filtres :
- Platform. Les règles d'alerte au niveau de la plateforme ne concernent que les projets par défaut d'OpenShift Container Platform. Ces projets fournissent les fonctionnalités de base d'OpenShift Container Platform.
- User. Les règles d'alerte relatives à la charge de travail définies par l'utilisateur se rapportent à des projets définis par l'utilisateur. Ces règles d'alerte sont créées par l'utilisateur et peuvent être personnalisées. La surveillance de la charge de travail définie par l'utilisateur peut être activée après l'installation afin de permettre l'observation de vos propres charges de travail.
Recherche et filtrage des alertes, des silences et des règles d'alerte dans la perspective du développeur
Dans la perspective Developer, la page Alertes de l'interface utilisateur Alertes fournit une vue combinée des alertes et des silences relatifs au projet sélectionné. Un lien vers la règle d'alerte applicable est fourni pour chaque alerte affichée.
Dans cette vue, vous pouvez filtrer par état et gravité de l'alerte. Par défaut, toutes les alertes du projet sélectionné sont affichées si vous avez le droit d'accéder au projet. Ces filtres sont les mêmes que ceux décrits pour la perspective Administrator.
11.3. Obtenir des informations sur les alertes, les silences et les règles d'alerte
L'interface utilisateur des alertes fournit des informations détaillées sur les alertes ainsi que sur les règles d'alerte et les silences qui les régissent.
Conditions préalables
- Vous avez accès au cluster en tant que développeur ou en tant qu'utilisateur disposant d'autorisations de visualisation pour le projet dont vous consultez les métriques.
Procédure
To obtain information about alerts in the Administrator perspective:
- Ouvrez la console web OpenShift Container Platform et naviguez jusqu'à la page Observe → Alerting → Alerts.
- Facultatif : Recherchez les alertes par nom en utilisant le champ Name dans la liste de recherche.
- Facultatif : Filtrez les alertes par état, gravité et source en sélectionnant des filtres dans la liste Filter.
- Facultatif : Triez les alertes en cliquant sur un ou plusieurs des en-têtes de colonne Name, Severity, State, et Source.
Sélectionnez le nom d'une alerte pour accéder à sa page Alert Details. La page comprend un graphique qui illustre les données chronologiques de l'alerte. Elle fournit également des informations sur l'alerte, notamment
- Une description de l'alerte
- Messages associés aux alertes
- Étiquettes jointes au signalement
- Un lien vers la règle d'alerte qui la régit
- Silences pour l'alerte, s'il y en a
To obtain information about silences in the Administrator perspective:
- Naviguez jusqu'à la page Observe → Alerting → Silences.
- Facultatif : Filtrez les silences par nom en utilisant le champ Search by name.
- Facultatif : Filtrez les silences par État en sélectionnant des filtres dans la liste Filter. Par défaut, les filtres Active et Pending sont appliqués.
- Facultatif : Triez les silences en cliquant sur un ou plusieurs des en-têtes de colonne Name, Firing Alerts, et State.
Sélectionnez le nom d'un silence pour accéder à sa page Silence Details. La page contient les informations suivantes :
- Spécification d'alerte
- Heure de début
- Heure de fin
- État de silence
- Nombre et liste des avis de tir
To obtain information about alerting rules in the Administrator perspective:
- Naviguez jusqu'à la page Observe → Alerting → Alerting Rules.
- Facultatif : Filtrez les règles d'alerte par état, gravité et source en sélectionnant des filtres dans la liste Filter.
- Facultatif : Triez les règles d'alerte en cliquant sur un ou plusieurs des en-têtes de colonne Name, Severity, Alert State, et Source.
Sélectionnez le nom d'une règle d'alerte pour accéder à sa page Alerting Rule Details. La page fournit les détails suivants sur la règle d'alerte :
- Nom, gravité et description de la règle d'alerte
- L'expression qui définit la condition de déclenchement de l'alerte
- Durée pendant laquelle la condition doit être remplie pour qu'une alerte soit déclenchée
- Un graphique pour chaque alerte régie par la règle d'alerte, indiquant la valeur avec laquelle l'alerte est déclenchée
- Un tableau de toutes les alertes régies par la règle d'alerte
To obtain information about alerts, silences, and alerting rules in the Developer perspective:
- Naviguez jusqu'à la page Observe → <project_name> → Alerts.
Afficher les détails d'une alerte, d'un silence ou d'une règle d'alerte :
- Alert Details peut être consultée en sélectionnant > à gauche du nom d'une alerte, puis en sélectionnant l'alerte dans la liste.
Silence Details peuvent être consultés en sélectionnant un silence dans la section Silenced By de la page Alert Details. La page Silence Details contient les informations suivantes :
- Spécification d'alerte
- Heure de début
- Heure de fin
- État de silence
- Nombre et liste des avis de tir
-
Alerting Rule Details peut être consultée en sélectionnant View Alerting Rule dans le
à droite d'une alerte sur la page Alerts.
Seules les alertes, les silences et les règles d'alerte relatifs au projet sélectionné sont affichés dans la perspective Developer.
11.4. Gérer les silences
Vous pouvez créer une mise en silence pour ne plus recevoir de notifications concernant une alerte lorsqu'elle est déclenchée. Il peut être utile de faire taire une alerte après avoir été notifiée pour la première fois, pendant que vous résolvez le problème sous-jacent.
Lors de la création d'un silence, vous devez préciser s'il devient actif immédiatement ou à un moment ultérieur. Vous devez également définir une période de temps après laquelle le silence expire.
Vous pouvez consulter, modifier et supprimer les silences existants.
11.4.1. Silence sur les alertes
Vous pouvez soit faire taire une alerte spécifique, soit faire taire les alertes qui correspondent à une spécification que vous définissez.
Conditions préalables
-
Vous êtes un administrateur de cluster et avez accès au cluster en tant qu'utilisateur ayant le rôle de cluster
cluster-admin. Vous êtes un utilisateur non administrateur et vous avez accès au cluster en tant qu'utilisateur ayant les rôles suivants :
-
Le rôle du cluster
cluster-monitoring-view, qui vous permet d'accéder à Alertmanager. -
Le rôle
monitoring-alertmanager-edit, qui vous permet de créer et de rendre silencieuses des alertes dans la perspective Administrator de la console web. -
Le rôle
monitoring-rules-edit, qui vous permet de créer et de rendre silencieuses des alertes dans la perspective Developer de la console web.
-
Le rôle du cluster
Procédure
Pour faire taire une alerte spécifique :
Dans la perspective de Administrator:
- Naviguez jusqu'à la page Observe → Alerting → Alerts de la console web OpenShift Container Platform.
-
Pour l'alerte que vous souhaitez faire taire, sélectionnez le bouton
dans la colonne de droite et sélectionnez Silence Alert. Le formulaire Silence Alert s'affichera avec une spécification pré-remplie pour l'alerte choisie.
- En option : Modifier le silence.
- Vous devez ajouter un commentaire avant de créer le silence.
- Pour créer le silence, sélectionnez Silence.
Dans la perspective de Developer:
- Naviguez jusqu'à la page Observe → <project_name> → Alerts dans la console web d'OpenShift Container Platform.
- Développez les détails d'une alerte en sélectionnant > à gauche du nom de l'alerte. Sélectionnez le nom de l'alerte dans la vue développée pour ouvrir la page Alert Details de l'alerte.
- Sélectionnez Silence Alert. Le formulaire Silence Alert s'affiche avec une spécification préremplie pour l'alerte choisie.
- En option : Modifier le silence.
- Vous devez ajouter un commentaire avant de créer le silence.
- Pour créer le silence, sélectionnez Silence.
Pour faire taire un ensemble d'alertes en créant une spécification d'alerte dans la perspective Administrator:
- Naviguez jusqu'à la page Observe → Alerting → Silences dans la console web d'OpenShift Container Platform.
- Sélectionnez Create Silence.
- Définissez l'horaire, la durée et les détails de l'étiquette d'une alerte dans le formulaire Create Silence. Vous devez également ajouter un commentaire pour le silence.
- Pour créer des silences pour les alertes qui correspondent aux secteurs d'étiquetage que vous avez saisis à l'étape précédente, sélectionnez Silence.
11.4.2. Editer les silences
Vous pouvez modifier un silence, ce qui aura pour effet d'expirer le silence existant et d'en créer un nouveau avec la configuration modifiée.
Procédure
Pour modifier un silence dans la perspective Administrator:
- Naviguez jusqu'à la page Observe → Alerting → Silences.
Pour le silence que vous souhaitez modifier, sélectionnez le bouton
dans la dernière colonne et choisissez Edit silence.
Vous pouvez également sélectionner Actions → Edit Silence dans la page Silence Details pour obtenir un silence.
- Dans la page Edit Silence, entrez vos modifications et sélectionnez Silence. Le silence existant expirera et un nouveau silence sera créé avec la configuration choisie.
Pour modifier un silence dans la perspective Developer:
- Naviguez jusqu'à la page Observe → <project_name> → Alerts.
- Développez les détails d'une alerte en sélectionnant > à gauche du nom de l'alerte. Sélectionnez le nom de l'alerte dans la vue développée pour ouvrir la page Alert Details de l'alerte.
- Sélectionnez le nom d'un silence dans la section Silenced By de cette page pour naviguer vers la page Silence Details correspondant à ce silence.
- Sélectionnez le nom d'un silence pour accéder à sa page Silence Details.
- Sélectionnez Actions → Edit Silence dans la page Silence Details pour obtenir un silence.
- Dans la page Edit Silence, entrez vos modifications et sélectionnez Silence. Le silence existant expirera et un nouveau silence sera créé avec la configuration choisie.
11.4.3. Silences expirants
Vous pouvez faire expirer un silence. L'expiration d'un silence le désactive définitivement.
Procédure
Expirer un silence dans la perspective Administrator:
- Naviguez jusqu'à la page Observe → Alerting → Silences.
Pour le silence que vous souhaitez modifier, sélectionnez le bouton
dans la dernière colonne et choisissez Expire silence.
Vous pouvez également sélectionner Actions → Expire Silence dans la page Silence Details pour obtenir un silence.
Expirer un silence dans la perspective Developer:
- Naviguez jusqu'à la page Observe → <project_name> → Alerts.
- Développez les détails d'une alerte en sélectionnant > à gauche du nom de l'alerte. Sélectionnez le nom de l'alerte dans la vue développée pour ouvrir la page Alert Details de l'alerte.
- Sélectionnez le nom d'un silence dans la section Silenced By de cette page pour naviguer vers la page Silence Details correspondant à ce silence.
- Sélectionnez le nom d'un silence pour accéder à sa page Silence Details.
- Sélectionnez Actions → Expire Silence dans la page Silence Details pour obtenir un silence.
11.5. Gestion des règles d'alerte pour les projets définis par l'utilisateur
La surveillance d'OpenShift Container Platform est livrée avec un ensemble de règles d'alerte par défaut. En tant qu'administrateur de cluster, vous pouvez afficher les règles d'alerte par défaut.
Dans OpenShift Container Platform 4.12, vous pouvez créer, afficher, modifier et supprimer des règles d'alerte dans des projets définis par l'utilisateur.
Considérations sur les règles d'alerte
- Les règles d'alerte par défaut sont utilisées spécifiquement pour le cluster OpenShift Container Platform.
- Certaines règles d'alerte portent intentionnellement des noms identiques. Elles envoient des alertes sur le même événement avec des seuils différents, une gravité différente, ou les deux.
- Les règles d'inhibition empêchent les notifications pour les alertes de moindre gravité qui se déclenchent lorsqu'une alerte de plus grande gravité se déclenche également.
11.5.1. Optimisation des alertes pour les projets définis par l'utilisateur
Vous pouvez optimiser les alertes pour vos propres projets en tenant compte des recommandations suivantes lors de la création de règles d'alerte :
- Minimize the number of alerting rules that you create for your project. Créez des règles d'alerte qui vous informent des conditions qui vous concernent. Il est plus difficile de remarquer les alertes pertinentes si vous générez de nombreuses alertes pour des conditions qui n'ont pas d'impact sur vous.
- Create alerting rules for symptoms instead of causes. Créez des règles d'alerte qui vous informent des conditions, quelle que soit la cause sous-jacente. La cause peut alors être examinée. Vous aurez besoin de beaucoup plus de règles d'alerte si chacune d'entre elles ne concerne qu'une cause spécifique. Certaines causes risquent alors d'être ignorées.
- Plan before you write your alerting rules. Déterminez les symptômes qui sont importants pour vous et les actions que vous souhaitez entreprendre s'ils se produisent. Élaborez ensuite une règle d'alerte pour chaque symptôme.
- Provide clear alert messaging. Indiquer le symptôme et les actions recommandées dans le message d'alerte.
- Include severity levels in your alerting rules. La gravité d'une alerte dépend de la manière dont vous devez réagir si le symptôme signalé se produit. Par exemple, une alerte critique doit être déclenchée si un symptôme nécessite une attention immédiate de la part d'une personne ou d'une équipe d'intervention critique.
Optimize alert routing. Déployer une règle d'alerte directement sur l'instance Prometheus dans le projet
openshift-user-workload-monitoringsi la règle n'interroge pas les métriques par défaut d'OpenShift Container Platform. Cela réduit la latence pour les règles d'alerte et minimise la charge sur les composants de surveillance.AvertissementLes métriques par défaut de OpenShift Container Platform pour les projets définis par l'utilisateur fournissent des informations sur l'utilisation du processeur et de la mémoire, des statistiques sur la bande passante et des informations sur le débit de paquets. Ces métriques ne peuvent pas être incluses dans une règle d'alerte si vous acheminez la règle directement vers l'instance Prometheus dans le projet
openshift-user-workload-monitoring. L'optimisation des règles d'alerte ne doit être utilisée que si vous avez lu la documentation et que vous comprenez parfaitement l'architecture de surveillance.
11.5.2. Création de règles d'alerte pour des projets définis par l'utilisateur
Vous pouvez créer des règles d'alerte pour des projets définis par l'utilisateur. Ces règles d'alerte déclenchent des alertes en fonction des valeurs des indicateurs choisis.
Conditions préalables
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
monitoring-rules-editpour le projet dans lequel vous souhaitez créer une règle d'alerte. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
-
Créez un fichier YAML pour les règles d'alerte. Dans cet exemple, il s'appelle
example-app-alerting-rule.yaml. Ajoutez une configuration de règle d'alerte au fichier YAML. Par exemple :
NoteLorsque vous créez une règle d'alerte, une étiquette de projet lui est imposée si une règle portant le même nom existe dans un autre projet.
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 spec: groups: - name: example rules: - alert: VersionAlert expr: version{job="prometheus-example-app"} == 0Cette configuration crée une règle d'alerte nommée
example-alert. La règle d'alerte déclenche une alerte lorsque la métriqueversionexposée par le service exemple devient0.ImportantUne règle d'alerte définie par l'utilisateur peut inclure des mesures pour son propre projet et des mesures de cluster. Vous ne pouvez pas inclure les métriques d'un autre projet défini par l'utilisateur.
Par exemple, une règle d'alerte pour le projet défini par l'utilisateur
ns1peut contenir des métriques provenant dens1et des métriques de cluster, telles que les métriques de CPU et de mémoire. Cependant, la règle ne peut pas inclure les métriques dens2.De plus, vous ne pouvez pas créer de règles d'alerte pour les projets
openshift-*core OpenShift Container Platform. La surveillance d'OpenShift Container Platform fournit par défaut un ensemble de règles d'alerte pour ces projets.Appliquer le fichier de configuration au cluster :
$ oc apply -f example-app-alerting-rule.yamlLa création de la règle d'alerte prend un certain temps.
11.5.3. Réduction de la latence pour les règles d'alerte qui n'interrogent pas les métriques de la plate-forme
Si une règle d'alerte pour un projet défini par l'utilisateur n'interroge pas les métriques de cluster par défaut, vous pouvez déployer la règle directement sur l'instance Prometheus dans le projet openshift-user-workload-monitoring. Cela permet de réduire la latence des règles d'alerte en contournant Thanos Ruler lorsqu'il n'est pas nécessaire. Cela permet également de minimiser la charge globale sur les composants de surveillance.
Les métriques OpenShift Container Platform par défaut pour les projets définis par l'utilisateur fournissent des informations sur l'utilisation du processeur et de la mémoire, des statistiques sur la bande passante et des informations sur le débit de paquets. Ces métriques ne peuvent pas être incluses dans une règle d'alerte si vous déployez la règle directement sur l'instance Prometheus dans le projet openshift-user-workload-monitoring. La procédure décrite dans cette section ne doit être utilisée que si vous avez lu la documentation et que vous comprenez parfaitement l'architecture de surveillance.
Conditions préalables
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
monitoring-rules-editpour le projet dans lequel vous souhaitez créer une règle d'alerte. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
-
Créez un fichier YAML pour les règles d'alerte. Dans cet exemple, il s'appelle
example-app-alerting-rule.yaml. Ajoutez une configuration de règle d'alerte au fichier YAML qui inclut une étiquette avec la clé
openshift.io/prometheus-rule-evaluation-scopeet la valeurleaf-prometheus. Par exemple :apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 labels: openshift.io/prometheus-rule-evaluation-scope: leaf-prometheus spec: groups: - name: example rules: - alert: VersionAlert expr: version{job="prometheus-example-app"} == 0
Si cette étiquette est présente, la règle d'alerte est déployée sur l'instance Prometheus dans le projet openshift-user-workload-monitoring. Si l'étiquette n'est pas présente, la règle d'alerte est déployée sur Thanos Ruler.
Appliquer le fichier de configuration au cluster :
$ oc apply -f example-app-alerting-rule.yamlLa création de la règle d'alerte prend un certain temps.
- Voir Monitoring overview pour plus de détails sur l'architecture de surveillance d'OpenShift Container Platform 4.12.
11.5.4. Accès aux règles d'alerte pour les projets définis par l'utilisateur
Pour répertorier les règles d'alerte d'un projet défini par l'utilisateur, le rôle monitoring-rules-view doit vous avoir été attribué pour ce projet.
Conditions préalables
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
monitoring-rules-viewpour votre projet. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Vous pouvez dresser la liste des règles d'alerte sur
<project>:oc -n <projet> get prometheusrulePour répertorier la configuration d'une règle d'alerte, procédez comme suit :
$ oc -n <projet> get prometheusrule <rule> -o yaml
11.5.5. Liste des règles d'alerte pour tous les projets dans une vue unique
En tant qu'administrateur de cluster, vous pouvez répertorier les règles d'alerte pour le cœur d'OpenShift Container Platform et les projets définis par l'utilisateur dans une seule vue.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
- Dans la perspective Administrator, naviguez vers Observe → Alerting → Alerting Rules.
Sélectionnez les sources Platform et User dans le menu déroulant Filter.
NoteLa source Platform est sélectionnée par défaut.
11.5.6. Suppression des règles d'alerte pour les projets définis par l'utilisateur
Vous pouvez supprimer les règles d'alerte pour les projets définis par l'utilisateur.
Conditions préalables
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
monitoring-rules-editpour le projet dans lequel vous souhaitez créer une règle d'alerte. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Pour supprimer la règle
<foo>dans<namespace>, exécutez la procédure suivante :oc -n <namespace> delete prometheusrule <foo>
11.6. Gestion des règles d'alerte pour la surveillance de la plate-forme centrale
La création et la modification des règles d'alerte pour la surveillance de la plate-forme principale est une fonctionnalité de l'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
La surveillance d'OpenShift Container Platform 4.12 est livrée avec un large ensemble de règles d'alerte par défaut pour les métriques de la plateforme. En tant qu'administrateur de cluster, vous pouvez personnaliser cet ensemble de règles de deux manières :
-
Modifiez les paramètres des règles d'alerte de la plate-forme existante en ajustant les seuils ou en ajoutant et en modifiant les étiquettes. Par exemple, vous pouvez modifier l'étiquette
severityd'une alerte dewarningàcriticalpour vous aider à acheminer et à trier les problèmes signalés par une alerte. -
Définissez et ajoutez de nouvelles règles d'alerte personnalisées en construisant une expression de requête basée sur les mesures de la plate-forme de base dans l'espace de noms
openshift-monitoring.
Considérations relatives aux règles d'alerte de la plate-forme principale
- Les nouvelles règles d'alerte doivent être basées sur les métriques de surveillance par défaut d'OpenShift Container Platform.
- Vous pouvez uniquement ajouter et modifier des règles d'alerte. Vous ne pouvez pas créer de nouvelles règles d'enregistrement ni modifier des règles d'enregistrement existantes.
-
Si vous modifiez les règles d'alerte existantes de la plateforme en utilisant un objet
AlertRelabelConfig, vos modifications ne sont pas reflétées dans l'API d'alertes Prometheus. Par conséquent, les alertes supprimées apparaissent toujours dans la console Web d'OpenShift Container Platform, même si elles ne sont plus transmises à Alertmanager. En outre, toute modification apportée aux alertes, telle qu'une modification de l'étiquetteseverity, n'apparaît pas dans la console Web.
11.6.1. Modifier les règles d'alerte de la plate-forme centrale
En tant qu'administrateur de cluster, vous pouvez modifier les alertes de la plate-forme centrale avant qu'Alertmanager ne les transmette à un récepteur. Par exemple, vous pouvez modifier l'étiquette de gravité d'une alerte, ajouter une étiquette personnalisée ou exclure une alerte de l'envoi à Alertmanager.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc). - Vous avez activé les fonctionnalités de l'aperçu technologique et tous les nœuds du cluster sont prêts.
Procédure
-
Créer un nouveau fichier de configuration YAML nommé
example-modified-alerting-rule.yamldans l'espace de nomsopenshift-monitoring. Ajoutez une ressource
AlertRelabelConfigau fichier YAML. L'exemple suivant modifie le paramètreseverityencriticalpour la règle d'alertewatchdogde la plate-forme par défaut :apiVersion: monitoring.openshift.io/v1alpha1 kind: AlertRelabelConfig metadata: name: watchdog namespace: openshift-monitoring spec: configs: - sourceLabels: [alertname,severity]1 regex: "Watchdog;none"2 targetLabel: severity3 replacement: critical4 action: Replace5 - 1
- Les étiquettes sources des valeurs que vous souhaitez modifier.
- 2
- Expression régulière à laquelle la valeur de
sourceLabelsest comparée. - 3
- L'étiquette cible de la valeur à modifier.
- 4
- La nouvelle valeur qui remplacera l'étiquette cible.
- 5
- L'action relabel qui remplace l'ancienne valeur sur la base d'une correspondance regex. L'action par défaut est
Replace. Les autres valeurs possibles sontKeep,Drop,HashMod,LabelMap,LabelDrop, etLabelKeep.
Appliquer le fichier de configuration au cluster :
$ oc apply -f example-modified-alerting-rule.yaml
11.6.2. Création de nouvelles règles d'alerte
En tant qu'administrateur de cluster, vous pouvez créer de nouvelles règles d'alerte basées sur les métriques de la plateforme. Ces règles d'alerte déclenchent des alertes en fonction des valeurs des paramètres choisis.
Si vous créez une ressource personnalisée AlertingRule basée sur une règle d'alerte de plate-forme existante, mettez l'alerte d'origine en sourdine pour éviter de recevoir des alertes contradictoires.
Conditions préalables
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc). - Vous avez activé les fonctionnalités de l'aperçu technologique et tous les nœuds du cluster sont prêts.
Procédure
-
Créer un nouveau fichier de configuration YAML nommé
example-alerting-rule.yamldans l'espace de nomsopenshift-monitoring. Ajoutez une ressource
AlertingRuleau fichier YAML. L'exemple suivant crée une nouvelle règle d'alerte nomméeexample, similaire à l'alerte par défautwatchdog:apiVersion: monitoring.openshift.io/v1alpha1 kind: AlertingRule metadata: name: example namespace: openshift-monitoring spec: groups: - name: example-rules rules: - alert: ExampleAlert1 expr: vector(1)2 Appliquer le fichier de configuration au cluster :
$ oc apply -f example-alerting-rule.yaml
11.7. Envoi de notifications à des systèmes externes
Dans OpenShift Container Platform 4.12, les alertes de tir peuvent être visualisées dans l'interface d'alerte. Les alertes ne sont pas configurées par défaut pour être envoyées à des systèmes de notification. Vous pouvez configurer OpenShift Container Platform pour envoyer des alertes aux types de récepteurs suivants :
- PagerDuty
- Crochet Web
- Courriel
- Slack
L'acheminement des alertes vers des récepteurs vous permet d'envoyer des notifications en temps voulu aux équipes appropriées lorsque des défaillances se produisent. Par exemple, les alertes critiques requièrent une attention immédiate et sont généralement envoyées à une personne ou à une équipe d'intervention critique. Les alertes qui fournissent des notifications d'avertissement non critiques peuvent être acheminées vers un système de billetterie pour un examen non immédiat.
Vérifier que l'alerte est opérationnelle en utilisant le chien de garde d'alerte
La surveillance d'OpenShift Container Platform comprend une alerte de chien de garde qui se déclenche en permanence. Alertmanager envoie de manière répétée des notifications d'alertes de chien de garde aux fournisseurs de notifications configurés. Le fournisseur est généralement configuré pour notifier un administrateur lorsqu'il ne reçoit plus l'alerte du chien de garde. Ce mécanisme permet d'identifier rapidement les problèmes de communication entre Alertmanager et le fournisseur de notification.
11.7.1. Configuration des récepteurs d'alerte
Vous pouvez configurer des récepteurs d'alerte pour vous assurer d'être informé des problèmes importants de votre cluster.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Dans la perspective Administrator, naviguez vers Administration → Cluster Settings → Configuration → Alertmanager.
NoteVous pouvez également accéder à la même page via le tiroir de notification. Sélectionnez l'icône de cloche en haut à droite de la console web OpenShift Container Platform et choisissez Configure dans l'alerte AlertmanagerReceiverNotConfigured.
- Sélectionnez Create Receiver dans la section Receivers de la page.
- Dans le formulaire Create Receiver, ajoutez un Receiver Name et choisissez un Receiver Type dans la liste.
Modifier la configuration du récepteur :
Pour les récepteurs PagerDuty :
- Choisissez un type d'intégration et ajoutez une clé d'intégration PagerDuty.
- Ajoutez l'URL de votre installation PagerDuty.
- Sélectionnez Show advanced configuration si vous souhaitez modifier les détails du client et de l'incident ou la spécification de gravité.
Pour les récepteurs webhook :
- Ajoutez le point de terminaison auquel envoyer des requêtes HTTP POST.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut d'envoi des alertes résolues au destinataire.
Pour les destinataires du courrier électronique :
- Ajouter l'adresse électronique à laquelle envoyer les notifications.
- Ajoutez les détails de la configuration SMTP, y compris l'adresse à partir de laquelle les notifications sont envoyées, le smarthost et le numéro de port utilisés pour l'envoi des courriels, le nom d'hôte du serveur SMTP et les détails d'authentification.
- Choisissez si TLS est nécessaire.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut consistant à ne pas envoyer d'alertes résolues au destinataire ou modifier le corps de la configuration des notifications par courrier électronique.
Pour les destinataires de Slack :
- Ajoutez l'URL du webhook Slack.
- Ajoutez le canal Slack ou le nom d'utilisateur auquel envoyer les notifications.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut consistant à ne pas envoyer d'alertes résolues au destinataire ou modifier la configuration de l'icône et du nom d'utilisateur. Vous pouvez également choisir de rechercher et de lier les noms de canaux et les noms d'utilisateurs.
Par défaut, les alertes de déclenchement dont les étiquettes correspondent à tous les sélecteurs sont envoyées au destinataire. Si vous souhaitez que les valeurs des étiquettes des alertes de déclenchement correspondent exactement avant qu'elles ne soient envoyées au destinataire :
- Ajoutez les noms et valeurs des étiquettes de routage dans la section Routing Labels du formulaire.
- Sélectionnez Regular Expression si vous souhaitez utiliser une expression régulière.
- Sélectionnez Add Label pour ajouter d'autres étiquettes de routage.
- Sélectionnez Create pour créer le récepteur.
11.7.2. Création d'un routage d'alertes pour des projets définis par l'utilisateur
Si vous n'êtes pas un administrateur et que vous avez reçu le rôle alert-routing-edit, vous pouvez créer ou modifier le routage des alertes pour des projets définis par l'utilisateur.
Conditions préalables
- Un administrateur de cluster a activé la surveillance des projets définis par l'utilisateur.
- Un administrateur de cluster a activé le routage des alertes pour les projets définis par l'utilisateur.
-
Vous êtes connecté en tant qu'utilisateur ayant le rôle
alert-routing-editpour le projet pour lequel vous voulez créer un routage d'alerte. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
-
Créez un fichier YAML pour le routage des alertes. L'exemple de cette procédure utilise un fichier appelé
example-app-alert-routing.yaml. Ajoutez une définition YAML
AlertmanagerConfigau fichier. Par exemple :apiVersion: monitoring.coreos.com/v1beta1 kind: AlertmanagerConfig metadata: name: example-routing namespace: ns1 spec: route: receiver: default groupBy: [job] receivers: - name: default webhookConfigs: - url: https://example.org/postNotePour les règles d'alerte définies par l'utilisateur, le routage défini par l'utilisateur est limité à l'espace de noms dans lequel la ressource est définie. Par exemple, une configuration de routage définie dans l'objet
AlertmanagerConfigpour l'espace de nomsns1ne s'applique qu'aux ressourcesPrometheusRulesdu même espace de noms.- Enregistrer le fichier.
Appliquer la ressource au cluster :
$ oc apply -f example-app-alert-routing.yamlLa configuration est automatiquement appliquée aux pods Alertmanager.
11.8. Application d'une configuration personnalisée de l'Alertmanager
Vous pouvez écraser la configuration par défaut d'Alertmanager en modifiant le secret alertmanager-main dans l'espace de noms openshift-monitoring pour l'instance de plateforme d'Alertmanager.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Pour modifier la configuration de l'Alertmanager à partir du CLI :
Imprimer la configuration active de l'Alertmanager dans le fichier
alertmanager.yaml:$ oc -n openshift-monitoring get secret alertmanager-main --template='{{ index .data "alertmanager.yaml" }}' | base64 --decode > alertmanager.yamlModifiez la configuration sur
alertmanager.yaml:global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 5m receiver: watchdog - matchers: - "service=<your_service>"1 routes: - matchers: - <your_matching_rules>2 receiver: <receiver>3 receivers: - name: default - name: watchdog - name: <receiver> # <receiver_configuration>NoteUtilisez le nom de clé
matcherspour indiquer les critères de correspondance qu'une alerte doit remplir pour correspondre au nœud. N'utilisez pas les noms de clésmatchoumatch_re, qui sont tous deux obsolètes et dont la suppression est prévue dans une prochaine version.En outre, si vous définissez des règles d'inhibition, utilisez le nom de clé
target_matcherspour indiquer les correspondants cibles et le nom de clésource_matcherspour indiquer les correspondants sources. N'utilisez pas les noms de cléstarget_match,target_match_re,source_matchousource_match_re, qui sont obsolètes et dont la suppression est prévue dans une prochaine version.L'exemple de configuration suivant de l'Alertmanager configure PagerDuty en tant que récepteur d'alertes :
global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 5m receiver: watchdog - matchers: - "service=example-app" routes: - matchers: - "severity=critical" receiver: team-frontend-page receivers: - name: default - name: watchdog - name: team-frontend-page pagerduty_configs: - service_key: "your-key"Avec cette configuration, les alertes de gravité
criticaldéclenchées par le serviceexample-appsont envoyées à l'aide du récepteurteam-frontend-page. En règle générale, ces types d'alertes sont envoyés à une personne ou à une équipe d'intervention critique.Appliquer la nouvelle configuration dans le fichier :
$ oc -n openshift-monitoring create secret generic alertmanager-main --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-monitoring replace secret --filename=-
Pour modifier la configuration de l'Alertmanager à partir de la console web d'OpenShift Container Platform :
- Naviguez jusqu'à la page Administration → Cluster Settings → Configuration → Alertmanager → YAML de la console web.
- Modifier le fichier de configuration YAML.
- Sélectionnez Save.
11.9. Application d'une configuration personnalisée à Alertmanager pour l'acheminement des alertes définies par l'utilisateur
Si vous avez activé une instance distincte d'Alertmanager dédiée au routage des alertes définies par l'utilisateur, vous pouvez écraser la configuration de cette instance d'Alertmanager en modifiant le secret alertmanager-user-workload dans l'espace de noms openshift-user-workload-monitoring.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Imprimer la configuration active de l'Alertmanager dans le fichier
alertmanager.yaml:$ oc -n openshift-user-workload-monitoring get secret alertmanager-user-workload --template='{{ index .data "alertmanager.yaml"\N-) }}' | base64 --decode > alertmanager.yamlModifiez la configuration sur
alertmanager.yaml:route: receiver: Default group_by: - name: Default routes: - matchers: - "service = prometheus-example-monitor"1 receiver: <receiver>2 receivers: - name: Default - name: <receiver> # <receiver_configuration>Appliquer la nouvelle configuration dans le fichier :
$ oc -n openshift-user-workload-monitoring create secret generic alertmanager-user-workload --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-user-workload-monitoring replace secret --filename=-
11.10. Prochaines étapes
Chapitre 12. Examen des tableaux de bord de suivi
OpenShift Container Platform 4.12 fournit un ensemble complet de tableaux de bord de surveillance qui vous aident à comprendre l'état des composants du cluster et des charges de travail définies par l'utilisateur.
Utilisez la perspective Administrator pour accéder aux tableaux de bord des composants principaux d'OpenShift Container Platform, y compris les éléments suivants :
- Performance de l'API
- etcd
- Kubernetes compute resources
- Kubernetes network resources
- Prometheus
- Tableaux de bord de la méthode USE relatifs à la performance des clusters et des nœuds
Figure 12.1. Exemple de tableau de bord dans la perspective de l'administrateur
Utilisez la perspective Developer pour accéder aux tableaux de bord des ressources de calcul Kubernetes qui fournissent les mesures d'application suivantes pour un projet sélectionné :
- Utilisation de l'unité centrale
- Utilisation de la mémoire
- Informations sur la largeur de bande
- Informations sur le débit des paquets
Figure 12.2. Exemple de tableau de bord dans la perspective du développeur
Dans la perspective Developer, vous pouvez consulter les tableaux de bord d'un seul projet à la fois.
12.1. Examen des tableaux de bord de surveillance en tant qu'administrateur de cluster
Dans la perspective Administrator, vous pouvez consulter des tableaux de bord relatifs aux composants principaux du cluster OpenShift Container Platform.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
- In the Administrator perspective in the OpenShift Container Platform web console, navigate to Observe → Dashboards.
- Choisissez un tableau de bord dans la liste Dashboard. Certains tableaux de bord, tels que les tableaux de bord etcd et Prometheus, produisent des sous-menus supplémentaires lorsqu'ils sont sélectionnés.
Optional: Select a time range for the graphs in the Time Range list.
- Select a pre-defined time period.
Set a custom time range by selecting Custom time range in the Time Range list.
- Input or select the From and To dates and times.
- Click Save to save the custom time range.
- Optional: Select a Refresh Interval.
- Hover over each of the graphs within a dashboard to display detailed information about specific items.
12.2. Examiner les tableaux de bord de surveillance en tant que développeur
Utilisez la perspective Développeur pour afficher les tableaux de bord des ressources de calcul Kubernetes d'un projet sélectionné.
Conditions préalables
- Vous avez accès au cluster en tant que développeur ou en tant qu'utilisateur.
- Vous avez des droits de visualisation pour le projet dont vous consultez le tableau de bord.
Procédure
- Dans la perspective développeur de la console web OpenShift Container Platform, naviguez vers Observe → Dashboard.
- Sélectionnez un projet dans la liste déroulante Project:.
Sélectionnez un tableau de bord dans la liste déroulante Dashboard pour afficher les mesures filtrées.
NoteTous les tableaux de bord produisent des sous-menus supplémentaires lorsqu'ils sont sélectionnés, à l'exception de Kubernetes / Compute Resources / Namespace (Pods).
Optional: Select a time range for the graphs in the Time Range list.
- Select a pre-defined time period.
Set a custom time range by selecting Custom time range in the Time Range list.
- Input or select the From and To dates and times.
- Click Save to save the custom time range.
- Optional: Select a Refresh Interval.
- Hover over each of the graphs within a dashboard to display detailed information about specific items.
12.3. Prochaines étapes
Chapitre 13. Tableau de bord d'administration du GPU NVIDIA
13.1. Introduction
Le plugin OpenShift Console NVIDIA GPU est un tableau de bord d'administration dédié à la visualisation de l'utilisation des GPU NVIDIA dans la console OpenShift Container Platform (OCP). Les visualisations du tableau de bord d'administration fournissent des conseils sur la manière d'optimiser au mieux les ressources GPU dans les clusters, par exemple lorsqu'un GPU est sous-utilisé ou sur-utilisé.
Le plugin OpenShift Console NVIDIA GPU fonctionne comme un bundle distant pour la console OCP. Pour exécuter le plugin, la console OCP doit être en cours d'exécution.
13.2. Installation du tableau de bord d'administration des GPU NVIDIA
Installez le plugin NVIDIA GPU en utilisant Helm sur la console OpenShift Container Platform (OCP) pour ajouter des capacités GPU.
Le plugin OpenShift Console NVIDIA GPU fonctionne comme un bundle distant pour la console OCP. Pour exécuter le plugin OpenShift Console NVIDIA GPU, une instance de la console OCP doit être en cours d'exécution.
Conditions préalables
- Red Hat OpenShift 4.11
- Opérateur GPU NVIDIA
- Tige
Procédure
Utilisez la procédure suivante pour installer le plugin NVIDIA GPU d'OpenShift Console.
Ajouter le dépôt Helm :
$ helm repo add rh-ecosystem-edge https://rh-ecosystem-edge.github.io/console-plugin-nvidia-gpu$ helm repo updateInstallez la carte Helm dans l'espace de noms par défaut de l'opérateur NVIDIA GPU :
$ helm install -n nvidia-gpu-operator console-plugin-nvidia-gpu rh-ecosystem-edge/console-plugin-nvidia-gpuExemple de sortie
NAME: console-plugin-nvidia-gpu LAST DEPLOYED: Tue Aug 23 15:37:35 2022 NAMESPACE: nvidia-gpu-operator STATUS: deployed REVISION: 1 NOTES: View the Console Plugin NVIDIA GPU deployed resources by running the following command: $ oc -n {{ .Release.Namespace }} get all -l app.kubernetes.io/name=console-plugin-nvidia-gpu Enable the plugin by running the following command: # Check if a plugins field is specified $ oc get consoles.operator.openshift.io cluster --output=jsonpath="{.spec.plugins}" # if not, then run the following command to enable the plugin $ oc patch consoles.operator.openshift.io cluster --patch '{ "spec": { "plugins": ["console-plugin-nvidia-gpu"] } }' --type=merge # if yes, then run the following command to enable the plugin $ oc patch consoles.operator.openshift.io cluster --patch '[{"op": "add", "path": "/spec/plugins/-", "value": "console-plugin-nvidia-gpu" }]' --type=json # add the required DCGM Exporter metrics ConfigMap to the existing NVIDIA operator ClusterPolicy CR: oc patch clusterpolicies.nvidia.com gpu-cluster-policy --patch '{ "spec": { "dcgmExporter": { "config": { "name": "console-plugin-nvidia-gpu" } } } }' --type=mergeLe tableau de bord s'appuie principalement sur les métriques Prometheus exposées par l'exportateur NVIDIA DCGM, mais les métriques exposées par défaut ne sont pas suffisantes pour que le tableau de bord rende les jauges nécessaires. C'est pourquoi l'exportateur DGCM est configuré pour exposer un ensemble personnalisé de mesures, comme indiqué ici.
apiVersion: v1 data: dcgm-metrics.csv: | DCGM_FI_PROF_GR_ENGINE_ACTIVE, gauge, gpu utilization. DCGM_FI_DEV_MEM_COPY_UTIL, gauge, mem utilization. DCGM_FI_DEV_ENC_UTIL, gauge, enc utilization. DCGM_FI_DEV_DEC_UTIL, gauge, dec utilization. DCGM_FI_DEV_POWER_USAGE, gauge, power usage. DCGM_FI_DEV_POWER_MGMT_LIMIT_MAX, gauge, power mgmt limit. DCGM_FI_DEV_GPU_TEMP, gauge, gpu temp. DCGM_FI_DEV_SM_CLOCK, gauge, sm clock. DCGM_FI_DEV_MAX_SM_CLOCK, gauge, max sm clock. DCGM_FI_DEV_MEM_CLOCK, gauge, mem clock. DCGM_FI_DEV_MAX_MEM_CLOCK, gauge, max mem clock. kind: ConfigMap metadata: annotations: meta.helm.sh/release-name: console-plugin-nvidia-gpu meta.helm.sh/release-namespace: nvidia-gpu-operator creationTimestamp: "2022-10-26T19:46:41Z" labels: app.kubernetes.io/component: console-plugin-nvidia-gpu app.kubernetes.io/instance: console-plugin-nvidia-gpu app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: console-plugin-nvidia-gpu app.kubernetes.io/part-of: console-plugin-nvidia-gpu app.kubernetes.io/version: latest helm.sh/chart: console-plugin-nvidia-gpu-0.2.3 name: console-plugin-nvidia-gpu namespace: nvidia-gpu-operator resourceVersion: "19096623" uid: 96cdf700-dd27-437b-897d-5cbb1c255068Installez le ConfigMap et modifiez le CR de la politique de cluster de l'opérateur NVIDIA pour ajouter ce ConfigMap à la configuration de l'exportateur DCGM. L'installation du ConfigMap est effectuée par la nouvelle version du plugin de console NVIDIA GPU Helm Chart, mais l'édition du CR ClusterPolicy est effectuée par l'utilisateur.
Voir les ressources déployées :
$ oc -n nvidia-gpu-operator get all -l app.kubernetes.io/name=console-plugin-nvidia-gpuExemple de sortie
NAME READY STATUS RESTARTS AGE pod/console-plugin-nvidia-gpu-7dc9cfb5df-ztksx 1/1 Running 0 2m6s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/console-plugin-nvidia-gpu ClusterIP 172.30.240.138 <none> 9443/TCP 2m6s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/console-plugin-nvidia-gpu 1/1 1 1 2m6s NAME DESIRED CURRENT READY AGE replicaset.apps/console-plugin-nvidia-gpu-7dc9cfb5df 1 1 1 2m6s
13.3. Utilisation du tableau de bord d'administration du GPU NVIDIA
Après avoir déployé le plugin NVIDIA GPU de l'OpenShift Console, connectez-vous à la console web de l'OpenShift Container Platform en utilisant vos identifiants de connexion pour accéder à la perspective Administrator.
Pour voir les changements, vous devez rafraîchir la console pour voir l'onglet GPUs sous Compute.
13.3.1. Visualisation de la vue d'ensemble du GPU de la grappe
Vous pouvez consulter l'état des GPU de votre cluster sur la page de présentation en sélectionnant Présentation dans la section Accueil.
La page Vue d'ensemble fournit des informations sur les GPU de la grappe, notamment :
- Détails sur les fournisseurs de GPU
- Statut des GPU
- Utilisation de la grappe de GPU
13.3.2. Affichage du tableau de bord des GPU
Vous pouvez afficher le tableau de bord d'administration des GPU NVIDIA en sélectionnant GPU dans la section Compute de la console OpenShift.
Les graphiques du tableau de bord des GPU sont les suivants :
-
GPU utilization: Indique le ratio de temps pendant lequel le moteur graphique est actif et est basé sur la métrique
DCGM_FI_PROF_GR_ENGINE_ACTIVE. -
Memory utilization: Indique la mémoire utilisée par le GPU et est basée sur la métrique
DCGM_FI_DEV_MEM_COPY_UTIL. -
Encoder utilization: Indique le taux d'utilisation de l'encodeur vidéo et est basé sur la métrique
DCGM_FI_DEV_ENC_UTIL. -
Decoder utilization: Encoder utilization: Indique le taux d'utilisation du décodeur vidéo et est basé sur la métrique
DCGM_FI_DEV_DEC_UTIL. -
Power consumption: Indique la consommation moyenne d'énergie du GPU en watts et se base sur la métrique
DCGM_FI_DEV_POWER_USAGE. -
GPU temperature: Affiche la température actuelle du GPU et se base sur la métrique
DCGM_FI_DEV_GPU_TEMP. Le maximum est fixé à110, qui est un nombre empirique, car le nombre réel n'est pas exposé par le biais d'une métrique. -
GPU clock speed: Indique la vitesse d'horloge moyenne utilisée par le GPU et est basée sur la métrique
DCGM_FI_DEV_SM_CLOCK. -
Memory clock speed: Indique la vitesse d'horloge moyenne utilisée par la mémoire et est basée sur la métrique
DCGM_FI_DEV_MEM_CLOCK.
13.3.3. Visualisation des mesures du GPU
Vous pouvez visualiser les métriques des GPU en sélectionnant la métrique en bas de chaque GPU pour afficher la page des métriques.
Sur la page Métriques, vous pouvez
- Spécifier un taux de rafraîchissement pour les métriques
- Ajouter, exécuter, désactiver et supprimer des requêtes
- Insérer des métriques
- Réinitialiser l'affichage du zoom
Chapitre 14. Surveillance des événements bare-metal avec Bare Metal Event Relay
Bare Metal Event Relay est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
14.1. À propos des événements "bare-metal
Utilisez le relais d'événements Bare Metal pour abonner les applications qui s'exécutent dans votre cluster OpenShift Container Platform aux événements générés sur l'hôte bare-metal sous-jacent. Le service Redfish publie des événements sur un nœud et les transmet sur une file d'attente de messages avancée aux applications abonnées.
Les événements "bare-metal" sont basés sur la norme ouverte Redfish, développée sous l'égide de la Distributed Management Task Force (DMTF). Redfish fournit un protocole industriel standard sécurisé avec une API REST. Le protocole est utilisé pour la gestion de ressources et d'infrastructures distribuées, convergentes ou définies par logiciel.
Les événements liés au matériel publiés par Redfish sont les suivants :
- Dépassement des limites de température
- État du serveur
- Statut du ventilateur
Commencez à utiliser les événements bare-metal en déployant l'opérateur de relais d'événements bare-metal et en abonnant votre application au service. L'opérateur de relais d'événements bare metal installe et gère le cycle de vie du service d'événements bare metal Redfish.
Le relais d'événements Bare Metal ne fonctionne qu'avec des dispositifs compatibles Redfish sur des clusters à nœud unique fournis sur une infrastructure Bare Metal.
14.2. Fonctionnement des événements "bare-metal
Le relais d'événements Bare Metal permet aux applications fonctionnant sur des clusters bare-metal de répondre rapidement aux changements et aux défaillances du matériel Redfish, tels que les dépassements de seuils de température, les pannes de ventilateur, les pertes de disque, les coupures de courant et les pannes de mémoire. Ces événements matériels sont transmis via un canal de transport fiable à faible latence basé sur le protocole AMQP (Advanced Message Queuing Protocol). Le temps de latence du service de messagerie est compris entre 10 et 20 millisecondes.
Le Bare Metal Event Relay fournit un service de publication et d'abonnement pour les événements matériels, où plusieurs applications peuvent utiliser les API REST pour s'abonner et consommer les événements. Le Bare Metal Event Relay prend en charge le matériel conforme à Redfish OpenAPI v1.8 ou supérieur.
14.2.1. Flux de données du relais d'événements Bare Metal
La figure suivante illustre un exemple de flux de données d'événements bare-metal :
Figure 14.1. Flux de données du relais d'événements Bare Metal

14.2.1.1. Nacelle gérée par l'opérateur
L'opérateur utilise des ressources personnalisées pour gérer le pod contenant le Bare Metal Event Relay et ses composants à l'aide du CR HardwareEvent.
14.2.1.2. Relais d'événements Bare Metal
Au démarrage, le Bare Metal Event Relay interroge l'API Redfish et télécharge tous les registres de messages, y compris les registres personnalisés. Le Bare Metal Event Relay commence alors à recevoir les événements souscrits du matériel Redfish.
Le relais d'événements Bare Metal permet aux applications fonctionnant sur des clusters bare-metal de répondre rapidement aux changements et aux défaillances du matériel Redfish, tels que les dépassements de seuils de température, les pannes de ventilateur, les pertes de disque, les coupures de courant et les pannes de mémoire. Les événements sont signalés à l'aide de HardwareEvent CR.
14.2.1.3. Événement "cloud native
Cloud native events (CNE) est une spécification d'API REST pour définir le format des données d'événements.
14.2.1.4. CNCF CloudEvents
CloudEvents est une spécification neutre développée par la Cloud Native Computing Foundation (CNCF) pour définir le format des données d'événements.
14.2.1.5. Routeur de distribution AMQP
Le routeur de distribution est responsable du service de livraison des messages entre l'éditeur et l'abonné. AMQP 1.0 qpid est une norme ouverte qui prend en charge une messagerie fiable, performante et entièrement symétrique sur l'internet.
14.2.1.6. Sidecar de proxy d'événement cloud
L'image du conteneur sidecar du proxy d'événements en nuage est basée sur la spécification de l'API ORAN et fournit un cadre d'événements de publication et d'abonnement pour les événements matériels.
14.2.2. Service d'analyse de messages Redfish
Outre le traitement des événements Redfish, le Bare Metal Event Relay assure l'analyse des messages pour les événements sans propriété Message. Le proxy télécharge tous les registres de messages Redfish, y compris les registres spécifiques aux fournisseurs, à partir du matériel lorsqu'il démarre. Si un événement ne contient pas de propriété Message, le proxy utilise les registres de messages Redfish pour construire les propriétés Message et Resolution et les ajouter à l'événement avant de le transmettre au cadre d'événements en nuage. Ce service permet aux événements Redfish d'avoir une taille de message plus petite et une latence de transmission plus faible.
14.2.3. Installation de Bare Metal Event Relay à l'aide de l'interface de programmation (CLI)
En tant qu'administrateur de cluster, vous pouvez installer Bare Metal Event Relay Operator à l'aide de la CLI.
Conditions préalables
- Cluster installé sur du matériel bare-metal avec des nœuds dotés d'un contrôleur de gestion de carte de base (BMC) compatible avec RedFish.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un espace de noms pour le relais d'événements Bare Metal.
Enregistrez le YAML suivant dans le fichier
bare-metal-events-namespace.yaml:apiVersion: v1 kind: Namespace metadata: name: openshift-bare-metal-events labels: name: openshift-bare-metal-events openshift.io/cluster-monitoring: "true"Créer le CR
Namespace:$ oc create -f bare-metal-events-namespace.yaml
Créez un groupe d'opérateurs pour l'opérateur de relais d'événements Bare Metal.
Enregistrez le YAML suivant dans le fichier
bare-metal-events-operatorgroup.yaml:apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: bare-metal-event-relay-group namespace: openshift-bare-metal-events spec: targetNamespaces: - openshift-bare-metal-eventsCréer le CR
OperatorGroup:$ oc create -f bare-metal-events-operatorgroup.yaml
S'abonner au relais d'événements Bare Metal.
Enregistrez le YAML suivant dans le fichier
bare-metal-events-sub.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: bare-metal-event-relay-subscription namespace: openshift-bare-metal-events spec: channel: "stable" name: bare-metal-event-relay source: redhat-operators sourceNamespace: openshift-marketplaceCréer le CR
Subscription:$ oc create -f bare-metal-events-sub.yaml
Vérification
Pour vérifier que Bare Metal Event Relay Operator est installé, exécutez la commande suivante :
$ oc get csv -n openshift-bare-metal-events -o custom-columns=Name:.metadata.name,Phase:.status.phaseExemple de sortie
Name Phase
bare-metal-event-relay.4.12.0-xxxxxxxxxxxx Succeeded14.2.4. Installation de Bare Metal Event Relay à l'aide de la console web
En tant qu'administrateur de cluster, vous pouvez installer Bare Metal Event Relay Operator à l'aide de la console web.
Conditions préalables
- Cluster installé sur du matériel bare-metal avec des nœuds dotés d'un contrôleur de gestion de carte de base (BMC) compatible avec RedFish.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Installez le Bare Metal Event Relay à l'aide de la console web d'OpenShift Container Platform :
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Choisissez Bare Metal Event Relay dans la liste des opérateurs disponibles, puis cliquez sur Install.
- Sur la page Install Operator, sélectionnez ou créez un Namespace, sélectionnez openshift-bare-metal-events, puis cliquez sur Install.
Vérification
Facultatif : vous pouvez vérifier que l'installation de l'opérateur s'est déroulée correctement en effectuant le contrôle suivant :
- Passez à la page Operators → Installed Operators.
Assurez-vous que Bare Metal Event Relay est listé dans le projet avec un Status de InstallSucceeded.
NotePendant l'installation, un opérateur peut afficher un état Failed. Si l'installation réussit par la suite avec un message InstallSucceeded, vous pouvez ignorer le message Failed.
Si l'opérateur n'apparaît pas tel qu'il a été installé, il convient de poursuivre le dépannage :
- Allez à la page Operators → Installed Operators et inspectez les onglets Operator Subscriptions et Install Plans pour voir s'il y a des défaillances ou des erreurs sous Status.
- Allez sur la page Workloads → Pods et vérifiez les journaux pour les pods dans l'espace de noms du projet.
14.3. Installation du bus de messagerie AMQ
Pour transmettre les notifications d'événements Redfish bare-metal entre l'éditeur et l'abonné sur un nœud, vous devez installer et configurer un bus de messagerie AMQ à exécuter localement sur le nœud. Pour ce faire, vous devez installer l'opérateur d'interconnexion AMQ à utiliser dans le cluster.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
-
Installez l'opérateur d'interconnexion AMQ dans son propre espace de noms
amq-interconnect. Voir Installation de l'opérateur d'interconnexion AMQ.
Vérification
Vérifiez que l'opérateur d'interconnexion AMQ est disponible et que les pods requis sont en cours d'exécution :
$ oc get pods -n amq-interconnectExemple de sortie
NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23hVérifiez que le pod de production d'événements bare-metal
bare-metal-event-relayrequis est en cours d'exécution dans l'espace de nomsopenshift-bare-metal-events:$ oc get pods -n openshift-bare-metal-eventsExemple de sortie
NAME READY STATUS RESTARTS AGE hw-event-proxy-operator-controller-manager-74d5649b7c-dzgtl 2/2 Running 0 25s
14.4. Abonnement aux événements Redfish BMC bare-metal pour un nœud de cluster
En tant qu'administrateur de cluster, vous pouvez vous abonner aux événements Redfish BMC générés sur un nœud de votre cluster en créant une ressource personnalisée (CR) BMCEventSubscription pour le nœud, en créant une CR HardwareEvent pour l'événement et une CR Secret pour la BMC.
14.4.1. S'abonner aux événements "bare-metal
Vous pouvez configurer le contrôleur de gestion de la carte de base (BMC) pour qu'il envoie des événements bare-metal aux applications abonnées s'exécutant dans un cluster OpenShift Container Platform. Parmi les exemples d'événements Redfish bare-metal, citons l'augmentation de la température d'un périphérique ou le retrait d'un périphérique. Vous abonnez les applications aux événements bare-metal à l'aide d'une API REST.
Vous ne pouvez créer une ressource personnalisée (CR) BMCEventSubscription que pour le matériel physique qui prend en charge Redfish et dont l'interface fournisseur est définie sur redfish ou idrac-redfish.
Utilisez le CR BMCEventSubscription pour vous abonner à des événements Redfish prédéfinis. La norme Redfish ne permet pas de créer des alertes et des seuils spécifiques. Par exemple, pour recevoir un événement d'alerte lorsque la température d'un boîtier dépasse 40° Celsius, vous devez configurer manuellement l'événement conformément aux recommandations du fournisseur.
Effectuez la procédure suivante pour vous abonner aux événements bare-metal pour le nœud à l'aide d'un CR BMCEventSubscription.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Obtenir le nom d'utilisateur et le mot de passe du BMC.
Déployez un nœud de métal nu avec un contrôleur de gestion de carte de base (BMC) compatible avec Redfish dans votre cluster, et activez les événements Redfish sur le BMC.
NoteL'activation des événements Redfish sur un matériel spécifique n'entre pas dans le cadre de ces informations. Pour plus d'informations sur l'activation des événements Redfish pour votre matériel spécifique, consultez la documentation du fabricant de BMC.
Procédure
Confirmez que le matériel du nœud a activé Redfish
EventServiceen exécutant la commandecurlsuivante :curl https://<bmc_ip_address>/redfish/v1/EventService --insecure -H 'Content-Type : application/json' -u "<bmc_username>:<password>"où :
- adresse IP bmc
- est l'adresse IP du BMC où les événements Redfish sont générés.
Exemple de sortie
{ "@odata.context": "/redfish/v1/$metadata#EventService.EventService", "@odata.id": "/redfish/v1/EventService", "@odata.type": "#EventService.v1_0_2.EventService", "Actions": { "#EventService.SubmitTestEvent": { "EventType@Redfish.AllowableValues": ["StatusChange", "ResourceUpdated", "ResourceAdded", "ResourceRemoved", "Alert"], "target": "/redfish/v1/EventService/Actions/EventService.SubmitTestEvent" } }, "DeliveryRetryAttempts": 3, "DeliveryRetryIntervalSeconds": 30, "Description": "Event Service represents the properties for the service", "EventTypesForSubscription": ["StatusChange", "ResourceUpdated", "ResourceAdded", "ResourceRemoved", "Alert"], "EventTypesForSubscription@odata.count": 5, "Id": "EventService", "Name": "Event Service", "ServiceEnabled": true, "Status": { "Health": "OK", "HealthRollup": "OK", "State": "Enabled" }, "Subscriptions": { "@odata.id": "/redfish/v1/EventService/Subscriptions" } }Obtenez l'itinéraire du service Bare Metal Event Relay pour le cluster en exécutant la commande suivante :
$ oc get route -n openshift-bare-metal-eventsExemple de sortie
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hw-event-proxy hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com hw-event-proxy-service 9087 edge NoneCréer une ressource
BMCEventSubscriptionpour s'abonner aux événements Redfish :Enregistrez le YAML suivant dans le fichier
bmc_sub.yaml:apiVersion: metal3.io/v1alpha1 kind: BMCEventSubscription metadata: name: sub-01 namespace: openshift-machine-api spec: hostName: <hostname>1 destination: <proxy_service_url>2 context: ''- 1
- Spécifie le nom ou l'UUID du nœud de travail où les événements Redfish sont générés.
- 2
- Spécifie le service proxy d'événements pour le métal nu, par exemple,
https://hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com/webhook.
Créer le CR
BMCEventSubscription:$ oc create -f bmc_sub.yaml
Facultatif : Pour supprimer l'abonnement aux événements BMC, exécutez la commande suivante :
$ oc delete -f bmc_sub.yamlFacultatif : Pour créer manuellement un abonnement aux événements Redfish sans créer de CR
BMCEventSubscription, exécutez la commandecurlsuivante, en spécifiant le nom d'utilisateur et le mot de passe de la BMC.$ curl -i -k -X POST -H "Content-Type: application/json" -d '{"Destination": "https://<proxy_service_url>", "Protocol" : "Redfish", "EventTypes": ["Alert"], "Context": "root"}' -u <bmc_username>:<password> 'https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions' –voù :
- proxy_service_url
-
est le service de proxy d'événements à l'état brut, par exemple,
https://hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com/webhook.
- adresse IP bmc
- est l'adresse IP du BMC où les événements Redfish sont générés.
Exemple de sortie
HTTP/1.1 201 Created Server: AMI MegaRAC Redfish Service Location: /redfish/v1/EventService/Subscriptions/1 Allow: GET, POST Access-Control-Allow-Origin: * Access-Control-Expose-Headers: X-Auth-Token Access-Control-Allow-Headers: X-Auth-Token Access-Control-Allow-Credentials: true Cache-Control: no-cache, must-revalidate Link: <http://redfish.dmtf.org/schemas/v1/EventDestination.v1_6_0.json>; rel=describedby Link: <http://redfish.dmtf.org/schemas/v1/EventDestination.v1_6_0.json> Link: </redfish/v1/EventService/Subscriptions>; path= ETag: "1651135676" Content-Type: application/json; charset=UTF-8 OData-Version: 4.0 Content-Length: 614 Date: Thu, 28 Apr 2022 08:47:57 GMT
14.4.2. Interroger les abonnements aux événements Redfish bare-metal avec curl
Certains fournisseurs de matériel limitent le nombre d'abonnements aux événements matériels Redfish. Vous pouvez demander le nombre d'abonnements aux événements Redfish en utilisant curl.
Conditions préalables
- Obtenir le nom d'utilisateur et le mot de passe du BMC.
- Déployez un nœud bare-metal avec un contrôleur de gestion de carte de base (BMC) compatible avec Redfish dans votre cluster, et activez les événements matériels Redfish sur le BMC.
Procédure
Vérifiez les abonnements actuels de la BMC en exécutant la commande suivante :
curl:$ curl --globoff -H "Content-Type : application/json" -k -X GET --user <bmc_username>:<password> https://<bmc_ip_address>/redfish/v1/EventService/Subscriptionsoù :
- adresse IP bmc
- est l'adresse IP du BMC où les événements Redfish sont générés.
Exemple de sortie
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 435 100 435 0 0 399 0 0:00:01 0:00:01 --:--:-- 399 { "@odata.context": "/redfish/v1/$metadata#EventDestinationCollection.EventDestinationCollection", "@odata.etag": "" 1651137375 "", "@odata.id": "/redfish/v1/EventService/Subscriptions", "@odata.type": "#EventDestinationCollection.EventDestinationCollection", "Description": "Collection for Event Subscriptions", "Members": [ { "@odata.id": "/redfish/v1/EventService/Subscriptions/1" }], "Members@odata.count": 1, "Name": "Event Subscriptions Collection" }Dans cet exemple, un seul abonnement est configuré :
/redfish/v1/EventService/Subscriptions/1.Facultatif : Pour supprimer l'abonnement à
/redfish/v1/EventService/Subscriptions/1aveccurl, exécutez la commande suivante en spécifiant le nom d'utilisateur et le mot de passe de la BMC :$ curl --globoff -L -w "%{http_code} %{url_effective}\n\n" -k -u <bmc_username>:<password >-H "Content-Type : application/json" -d '{}' -X DELETE https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions/1où :
- adresse IP bmc
- est l'adresse IP du BMC où les événements Redfish sont générés.
14.4.3. Création de l'événement bare-metal et des CR secrètes
Pour commencer à utiliser les événements bare-metal, créez la ressource personnalisée (CR) HardwareEvent pour l'hôte où se trouve le matériel Redfish. Les événements matériels et les pannes sont signalés dans les journaux de hw-event-proxy.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer le relais d'événements Bare Metal.
-
Créez un CR
BMCEventSubscriptionpour le matériel BMC Redfish.
Les ressources multiples HardwareEvent ne sont pas autorisées.
Procédure
Créer la ressource personnalisée (CR)
HardwareEvent:Enregistrez le YAML suivant dans le fichier
hw-event.yaml:apiVersion: "event.redhat-cne.org/v1alpha1" kind: "HardwareEvent" metadata: name: "hardware-event" spec: nodeSelector: node-role.kubernetes.io/hw-event: ""1 transportHost: "amqp://amq-router-service-name.amq-namespace.svc.cluster.local"2 logLevel: "debug"3 msgParserTimeout: "10"4 - 1
- Obligatoire. Utilisez le champ
nodeSelectorpour cibler les nœuds portant l'étiquette spécifiée, par exemplenode-role.kubernetes.io/hw-event: "". - 2
- Nécessaire. Hôte AMQP qui délivre les événements au niveau de la couche transport à l'aide du protocole AMQP.
- 3
- Facultatif. La valeur par défaut est
debug. Définit le niveau de journalisation dans les journauxhw-event-proxy. Les niveaux de journalisation suivants sont disponibles :fatal,error,warning,info,debug,trace. - 4
- Facultatif. Définit la valeur du délai d'attente en millisecondes pour l'analyseur de messages. Si une demande d'analyse de message ne reçoit pas de réponse dans le délai imparti, le message d'événement matériel d'origine est transmis au cadre d'événements natif du nuage. La valeur par défaut est 10.
Créer le CR
HardwareEvent:$ oc create -f hardware-event.yaml
Créez un nom d'utilisateur et un mot de passe BMC
SecretCR qui permet au proxy d'événements matériels d'accéder au registre de messages Redfish pour l'hôte bare-metal.Enregistrez le YAML suivant dans le fichier
hw-event-bmc-secret.yaml:apiVersion: v1 kind: Secret metadata: name: redfish-basic-auth type: Opaque stringData:1 username: <bmc_username> password: <bmc_password> # BMC host DNS or IP address hostaddr: <bmc_host_ip_address>- 1
- Saisissez des valeurs en texte clair pour les différents postes sous
stringData.
Créer le CR
Secret:$ oc create -f hw-event-bmc-secret.yaml
14.5. Abonnement des applications aux événements bare-metal Référence de l'API REST
Utilisez l'API REST des événements bare-metal pour abonner une application aux événements bare-metal générés sur le nœud parent.
Abonnez-vous aux événements Redfish en utilisant l'adresse de ressource /cluster/node/<node_name>/redfish/event, où <node_name> est le nœud de cluster qui exécute l'application.
Déployez votre conteneur d'application cloud-event-consumer et votre conteneur sidecar cloud-event-proxy dans un pod d'application séparé. L'application cloud-event-consumer s'abonne au conteneur cloud-event-proxy dans le module d'application.
Utilisez les points d'extrémité API suivants pour abonner l'application cloud-event-consumer aux événements Redfish publiés par le conteneur cloud-event-proxy à http://localhost:8089/api/ocloudNotifications/v1/ dans le pod d'application :
/api/ocloudNotifications/v1/subscriptions-
POST: Crée un nouvel abonnement -
GET: Récupère une liste d'abonnements
-
/api/ocloudNotifications/v1/subscriptions/<subscription_id>-
GET: Renvoie les détails de l'identifiant d'abonnement spécifié
-
api/ocloudNotifications/v1/subscriptions/status/<subscription_id>-
PUT: Crée une nouvelle demande de ping d'état pour l'identifiant d'abonnement spécifié
-
/api/ocloudNotifications/v1/health-
GET: Renvoie l'état de santé deocloudNotificationsAPI
-
9089 est le port par défaut du conteneur cloud-event-consumer déployé dans le pod d'application. Vous pouvez configurer un port différent pour votre application si nécessaire.
api/ocloudNotifications/v1/subscriptions
Méthode HTTP
GET api/ocloudNotifications/v1/subscriptions
Description
Renvoie une liste d'abonnements. Si des abonnements existent, un code d'état 200 OK est renvoyé avec la liste des abonnements.
Exemple de réponse API
[
{
"id": "ca11ab76-86f9-428c-8d3a-666c24e34d32",
"endpointUri": "http://localhost:9089/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/ca11ab76-86f9-428c-8d3a-666c24e34d32",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
]Méthode HTTP
POST api/ocloudNotifications/v1/subscriptions
Description
Crée un nouvel abonnement. Si un abonnement est créé avec succès, ou s'il existe déjà, un code d'état 201 Created est renvoyé.
| Paramètres | Type |
|---|---|
| abonnement | données |
Exemple de charge utile
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}api/ocloudNotifications/v1/abonnements/<subscription_id>
Méthode HTTP
GET api/ocloudNotifications/v1/subscriptions/<subscription_id>
Description
Renvoie les détails de l'abonnement avec l'ID <subscription_id>
| Paramètres | Type |
|---|---|
|
| chaîne de caractères |
Exemple de réponse API
{
"id":"ca11ab76-86f9-428c-8d3a-666c24e34d32",
"endpointUri":"http://localhost:9089/api/ocloudNotifications/v1/dummy",
"uriLocation":"http://localhost:8089/api/ocloudNotifications/v1/subscriptions/ca11ab76-86f9-428c-8d3a-666c24e34d32",
"resource":"/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}api/ocloudNotifications/v1/abonnements/status/<subscription_id>
Méthode HTTP
PUT api/ocloudNotifications/v1/subscriptions/status/<subscription_id>
Description
Crée une nouvelle demande de ping d'état pour l'abonnement avec l'ID <subscription_id>. Si un abonnement est présent, la demande d'état est réussie et le code d'état 202 Accepted est renvoyé.
| Paramètres | Type |
|---|---|
|
| chaîne de caractères |
Exemple de réponse API
{"status":"ping sent"}api/ocloudNotifications/v1/santé/
Méthode HTTP
GET api/ocloudNotifications/v1/health/
Description
Renvoie l'état de santé de l'API REST ocloudNotifications.
Exemple de réponse API
OKChapitre 15. Accès aux API de surveillance de tiers
Dans OpenShift Container Platform 4.12, vous pouvez accéder aux API de services web pour certains composants de surveillance tiers à partir de l'interface de ligne de commande (CLI).
15.1. Accès aux API de services web de surveillance de tiers
Vous pouvez accéder directement aux API de services web tiers à partir de la ligne de commande pour les composants de la pile de surveillance suivants : Prometheus, Alertmanager, Thanos Ruler et Thanos Querier.
L'exemple de commande suivant montre comment interroger les récepteurs de l'API de service pour Alertmanager. Cet exemple exige que le compte d'utilisateur associé soit lié au rôle monitoring-alertmanager-edit dans l'espace de noms openshift-monitoring et que le compte ait le privilège d'afficher l'itinéraire. Cet accès ne prend en charge que l'utilisation d'un jeton de support pour l'authentification.
$ oc login -u <nom d'utilisateur> -p <mot de passe>$ host=$(oc -n openshift-monitoring get route alertmanager-main -ojsonpath={.spec.host})$ token=$(oc whoami -t)$ curl -H "Authorization: Bearer $token" -k "https://$host/api/v2/receivers"
Pour accéder aux API des services Thanos Ruler et Thanos Querier, le compte demandeur doit avoir l'autorisation get sur la ressource namespaces, ce qui peut être fait en accordant le rôle de cluster cluster-monitoring-view au compte.
15.2. Interroger les métriques en utilisant le point de terminaison de la fédération pour Prometheus
Vous pouvez utiliser le point d'extrémité de fédération pour récupérer des métriques de plate-forme et des métriques définies par l'utilisateur à partir d'un emplacement réseau en dehors du cluster. Pour ce faire, accédez au point d'extrémité Prometheus /federate pour le cluster via une route OpenShift Container Platform.
L'utilisation de la fédération entraîne un retard dans la récupération des données de mesure. Ce délai peut affecter la précision et l'actualité des métriques récupérées.
L'utilisation du point de terminaison de la fédération peut également dégrader les performances et l'évolutivité de votre cluster, en particulier si vous utilisez le point de terminaison de la fédération pour récupérer de grandes quantités de données de métriques. Pour éviter ces problèmes, suivez les recommandations suivantes :
- N'essayez pas de récupérer toutes les données de métrologie via le point de terminaison de la fédération. Ne l'interrogez que si vous souhaitez récupérer un ensemble de données limité et agrégé. Par exemple, l'extraction de moins de 1 000 échantillons par requête permet de minimiser le risque de dégradation des performances.
- Évitez d'interroger fréquemment le point de terminaison de la fédération. Limitez les requêtes à un maximum d'une toutes les 30 secondes.
Si vous devez transmettre de grandes quantités de données en dehors du cluster, utilisez plutôt l'écriture à distance. Pour plus d'informations, voir la section Configuring remote write storage.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez obtenu l'URL de l'hôte pour la route OpenShift Container Platform.
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-monitoring-viewou vous avez obtenu un jeton de porteur avec la permissiongetsur la ressourcenamespaces.NoteVous ne pouvez utiliser que l'authentification par jeton porteur pour accéder au point de terminaison de la fédération.
Procédure
Récupérer le jeton du porteur :
$ token=`oc whoami -t`Interroger les métriques de la route
/federate. L'exemple suivant interroge les métriques deup:$ curl -G -s -k -H "Authorization: Bearer $token" \ 'https:/<federation_host>/federate' \1 --data-urlencode 'match[]=up'- 1
- Pour <federation_host>, remplacez l'URL de l'hôte pour la route de la fédération.
Exemple de sortie
# TYPE up untyped up{apiserver="kube-apiserver",endpoint="https",instance="10.0.143.148:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035322214 up{apiserver="kube-apiserver",endpoint="https",instance="10.0.148.166:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035338597 up{apiserver="kube-apiserver",endpoint="https",instance="10.0.173.16:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035343834 ...
Chapitre 16. Dépannage des problèmes de surveillance
16.2. Déterminer pourquoi Prometheus consomme beaucoup d'espace disque
Les développeurs peuvent créer des étiquettes pour définir les attributs des métriques sous la forme de paires clé-valeur. Le nombre de paires clé-valeur potentielles correspond au nombre de valeurs possibles pour un attribut. Un attribut dont le nombre de valeurs potentielles est illimité est appelé attribut non lié. Par exemple, un attribut customer_id est non consolidé car il possède un nombre infini de valeurs possibles.
Chaque paire clé-valeur attribuée a une série chronologique unique. L'utilisation de nombreux attributs non liés dans les étiquettes peut entraîner une augmentation exponentielle du nombre de séries temporelles créées. Cela peut avoir un impact sur les performances de Prometheus et consommer beaucoup d'espace disque.
Vous pouvez utiliser les mesures suivantes lorsque Prometheus consomme beaucoup de disque :
- Check the number of scrape samples qui sont collectés.
- Check the time series database (TSDB) status using the Prometheus HTTP API pour plus d'informations sur les étiquettes qui créent le plus de séries temporelles. Cette opération nécessite des privilèges d'administrateur de cluster.
Reduce the number of unique time series that are created en réduisant le nombre d'attributs non liés attribués aux mesures définies par l'utilisateur.
NoteL'utilisation d'attributs liés à un ensemble limité de valeurs possibles réduit le nombre de combinaisons potentielles de paires clé-valeur.
- Enforce limits on the number of samples that can be scraped dans des projets définis par l'utilisateur. Cette opération nécessite des privilèges d'administrateur de cluster.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
- Dans la perspective Administrator, naviguez vers Observe → Metrics.
Exécutez la requête Prometheus Query Language (PromQL) suivante dans le champ Expression. Cette requête renvoie les dix métriques qui ont le plus grand nombre d'échantillons de scrape :
topk(10,count by (job)({__name__=~".+"}))Étudier le nombre de valeurs d'étiquettes non liées attribuées à des mesures dont le nombre d'échantillons raclés est plus élevé que prévu.
- If the metrics relate to a user-defined projectdans le cas d'une charge de travail, passez en revue les paires clé-valeur de métriques attribuées à votre charge de travail. Celles-ci sont mises en œuvre par les bibliothèques client Prometheus au niveau de l'application. Essayez de limiter le nombre d'attributs non liés référencés dans vos étiquettes.
- If the metrics relate to a core OpenShift Container Platform projectcréez un dossier d'assistance Red Hat sur le portail client Red Hat.
Examinez l'état de la TSDB à l'aide de l'API HTTP Prometheus en exécutant les commandes suivantes en tant qu'administrateur de cluster :
$ oc login -u <nom d'utilisateur> -p <mot de passe>$ host=$(oc -n openshift-monitoring get route prometheus-k8s -ojsonpath={.spec.host})$ token=$(oc whoami -t)$ curl -H "Authorization: Bearer $token" -k "https://$host/api/v1/status/tsdb"Exemple de sortie
"status": "success",
Chapitre 17. Référence de la carte de configuration pour l'opérateur de surveillance des clusters
17.1. Référence de configuration de l'opérateur de surveillance des clusters
Certaines parties de la surveillance des clusters d'OpenShift Container Platform sont configurables. L'API est accessible en définissant des paramètres dans diverses cartes de configuration.
-
Pour configurer les composants de surveillance, modifiez l'objet
ConfigMapnommécluster-monitoring-configdans l'espace de nomsopenshift-monitoring. Ces configurations sont définies par ClusterMonitoringConfiguration. -
Pour configurer les composants de surveillance qui surveillent les projets définis par l'utilisateur, modifiez l'objet
ConfigMapnomméuser-workload-monitoring-configdans l'espace de nomsopenshift-user-workload-monitoring. Ces configurations sont définies par UserWorkloadConfiguration.
Le fichier de configuration est toujours défini sous la clé config.yaml dans les données de la carte de configuration.
- Tous les paramètres de configuration ne sont pas exposés.
- La configuration de la surveillance des clusters est facultative.
- Si une configuration n'existe pas ou est vide, les valeurs par défaut sont utilisées.
-
Si la configuration est constituée de données YAML non valides, l'opérateur de surveillance des clusters cesse de réconcilier les ressources et signale
Degraded=Truedans les conditions d'état de l'opérateur.
17.2. AdditionalAlertmanagerConfig
17.2.1. Description
La ressource AdditionalAlertmanagerConfig définit les paramètres de communication d'un composant avec d'autres instances d'Alertmanager.
17.2.2. Exigée
-
apiVersion
Apparaît dans : PrometheusK8sConfig, PrometheusRestrictedConfig, ThanosRulerConfig
| Propriété | Type | Description |
|---|---|---|
| apiVersion | chaîne de caractères |
Définit la version de l'API de Alertmanager. Les valeurs possibles sont |
| bearerToken | *v1.SecretKeySelector | Définit la référence de la clé secrète contenant le jeton du porteur à utiliser lors de l'authentification auprès de l'Alertmanager. |
| préfixe du chemin | chaîne de caractères | Définit le préfixe du chemin à ajouter devant le chemin du point d'arrivée de la poussée. |
| schéma | chaîne de caractères |
Définit le schéma d'URL à utiliser pour communiquer avec les instances de l'Alertmanager. Les valeurs possibles sont |
| statiqueConfigs | []chaîne |
Une liste de points d'extrémité Alertmanager configurés statiquement sous la forme de |
| délai d'attente | *chaîne de caractères | Définit la valeur du délai d'attente utilisé lors de l'envoi d'alertes. |
| tlsConfig | Définit les paramètres TLS à utiliser pour les connexions Alertmanager. |
17.3. AlertmanagerMainConfig
17.3.1. Description
La ressource AlertmanagerMainConfig définit les paramètres du composant Alertmanager dans l'espace de noms openshift-monitoring.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| activée | *bool |
Indicateur booléen qui active ou désactive l'instance principale d'Alertmanager dans l'espace de noms |
| enableUserAlertmanagerConfig | bool |
Indicateur booléen qui active ou désactive la sélection des espaces de noms définis par l'utilisateur pour les recherches sur le site |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation de l'Alertmanager. Les valeurs possibles sont les suivantes : |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont planifiés. |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes et les limites de ressources pour le conteneur Alertmanager. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Définit les contraintes d'étalement de la topologie d'un pod. |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Définit le stockage persistant pour Alertmanager. Ce paramètre permet de configurer la demande de volume persistant, y compris la classe de stockage, la taille du volume et le nom. |
17.4. AlertmanagerUserWorkloadConfig
17.4.1. Description
La ressource AlertmanagerUserWorkloadConfig définit les paramètres de l'instance Alertmanager utilisée pour les projets définis par l'utilisateur.
Apparaît dans : UserWorkloadConfiguration
| Propriété | Type | Description |
|---|---|---|
| activée | bool |
Indicateur booléen qui active ou désactive une instance dédiée d'Alertmanager pour les alertes définies par l'utilisateur dans l'espace de noms |
| enableAlertmanagerConfig | bool |
Indicateur booléen permettant d'activer ou de désactiver la sélection d'espaces de noms définis par l'utilisateur pour la recherche sur |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation de l'Alertmanager pour la surveillance de la charge de travail de l'utilisateur. Les valeurs possibles sont |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes et les limites de ressources pour le conteneur Alertmanager. |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Définit le stockage persistant pour Alertmanager. Ce paramètre permet de configurer la demande de volume persistant, y compris la classe de stockage, la taille du volume et le nom. |
17.5. ClusterMonitoringConfiguration
17.5.1. Description
La ressource ClusterMonitoringConfiguration définit les paramètres qui personnalisent la pile de surveillance de la plate-forme par défaut via la carte de configuration cluster-monitoring-config dans l'espace de noms openshift-monitoring.
| Propriété | Type | Description |
|---|---|---|
| alertmanagerMain |
| |
| activer le chargement de travail de l'utilisateur (enableUserWorkload) | *bool |
|
| k8sPrometheusAdapter |
| |
| kubeStateMetrics |
| |
| prometheusK8s |
| |
| prometheusOperator |
| |
| openshiftStateMetrics |
| |
| telemeterClient |
| |
| thanosQuerier |
|
17.6. Moniteurs de services dédiés
17.6.1. Description
Vous pouvez utiliser la ressource DedicatedServiceMonitors pour configurer des moniteurs de service dédiés à l'adaptateur Prometheus
Apparaît dans : K8sPrometheusAdapter
| Propriété | Type | Description |
|---|---|---|
| activée | bool |
Lorsque |
17.7. K8sPrometheusAdapter
17.7.1. Description
La ressource K8sPrometheusAdapter définit les paramètres du composant Prometheus Adapter.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| audit | *Audit |
Définit la configuration d'audit utilisée par l'instance de Prometheus Adapter. Les valeurs de profil possibles sont les suivantes : |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| moniteurs de services dédiés | Définit les moniteurs de services dédiés. |
17.8. KubeStateMetricsConfig
17.8.1. Description
La ressource KubeStateMetricsConfig définit les paramètres de l'agent kube-state-metrics.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
17.9. OpenShiftStateMetricsConfig
17.9.1. Description
La ressource OpenShiftStateMetricsConfig définit les paramètres de l'agent openshift-state-metrics.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
17.10. PrometheusK8sConfig
17.10.1. Description
La ressource PrometheusK8sConfig définit les paramètres du composant Prometheus.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| additionalAlertmanagerConfigs | Configure des instances Alertmanager supplémentaires qui reçoivent des alertes du composant Prometheus. Par défaut, aucune instance Alertmanager supplémentaire n'est configurée. | |
| limite de taille du corps imposée | chaîne de caractères |
Applique une limite de taille de corps pour les métriques scrappées par Prometheus. Si le corps de la réponse d'une cible scrappée est plus grand que la limite, le scrape échouera. Les valeurs suivantes sont valides : une valeur vide pour spécifier aucune limite, une valeur numérique au format Prometheus (telle que |
| étiquettes externes | map[string]string | Définit les étiquettes à ajouter aux séries temporelles ou aux alertes lors de la communication avec des systèmes externes tels que la fédération, le stockage à distance et l'Alertmanager. Par défaut, aucune étiquette n'est ajoutée. |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation pour Prometheus. Les valeurs possibles sont les suivantes : |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| queryLogFile | chaîne de caractères |
Spécifie le fichier dans lequel les requêtes PromQL sont enregistrées. Ce paramètre peut être un nom de fichier, auquel cas les requêtes sont enregistrées sur un volume |
| écriture à distance | Définit la configuration de l'écriture à distance, y compris les paramètres d'URL, d'authentification et de réétiquetage. | |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes et les limites de ressources pour le conteneur Prometheus. |
| rétention | chaîne de caractères |
Définit la durée pendant laquelle Prometheus conserve les données. Cette définition doit être spécifiée à l'aide du modèle d'expression régulière suivant : |
| taille de la rétention | chaîne de caractères |
Définit la quantité maximale d'espace disque utilisée par les blocs de données et le journal d'écriture (WAL). Les valeurs prises en charge sont |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Définit les contraintes d'étalement de la topologie du pod. |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Définit le stockage persistant pour Prometheus. Ce paramètre permet de configurer la demande de volume persistant, y compris la classe de stockage, la taille du volume et le nom. |
17.11. PrometheusOperatorConfig
17.11.1. Description
La ressource PrometheusOperatorConfig définit les paramètres du composant Prometheus Operator.
Apparaît dans : ClusterMonitoringConfiguration, UserWorkloadConfiguration
| Propriété | Type | Description |
|---|---|---|
| niveau du journal | chaîne de caractères |
Définit les paramètres du niveau de journalisation pour Prometheus Operator. Les valeurs possibles sont |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
17.12. PrometheusRestrictedConfig
17.12.1. Description
La ressource PrometheusRestrictedConfig définit les paramètres du composant Prometheus qui surveille les projets définis par l'utilisateur.
Apparaît dans : UserWorkloadConfiguration
| Propriété | Type | Description |
|---|---|---|
| additionalAlertmanagerConfigs | Configure des instances Alertmanager supplémentaires qui reçoivent des alertes du composant Prometheus. Par défaut, aucune instance Alertmanager supplémentaire n'est configurée. | |
| enforcedLabelLimit | *uint64 |
Spécifie une limite par raclage sur le nombre d'étiquettes acceptées pour un échantillon. Si le nombre d'étiquettes dépasse cette limite après le réétiquetage métrique, l'ensemble du prélèvement est considéré comme ayant échoué. La valeur par défaut est |
| enforcedLabelNameLengthLimit | *uint64 |
Spécifie une limite de longueur du nom de l'étiquette pour un échantillon. Si la longueur d'un nom d'étiquette dépasse cette limite après le réétiquetage métrique, l'ensemble du prélèvement est considéré comme ayant échoué. La valeur par défaut est |
| enforcedLabelValueLengthLimit | *uint64 |
Spécifie la limite de longueur d'une valeur d'étiquette pour un échantillon. Si la longueur d'une valeur d'étiquette dépasse cette limite après le réétiquetage métrique, l'ensemble du prélèvement est considéré comme ayant échoué. La valeur par défaut est |
| enforcedSampleLimit | *uint64 |
Spécifie une limite globale sur le nombre d'échantillons récupérés qui seront acceptés. Ce paramètre remplace la valeur |
| enforcedTargetLimit | *uint64 |
Spécifie une limite globale sur le nombre de cibles scannées. Ce paramètre remplace la valeur |
| étiquettes externes | map[string]string | Définit les étiquettes à ajouter aux séries temporelles ou aux alertes lors de la communication avec des systèmes externes tels que la fédération, le stockage à distance et l'Alertmanager. Par défaut, aucune étiquette n'est ajoutée. |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation pour Prometheus. Les valeurs possibles sont |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| queryLogFile | chaîne de caractères |
Spécifie le fichier dans lequel les requêtes PromQL sont enregistrées. Ce paramètre peut être un nom de fichier, auquel cas les requêtes sont enregistrées sur un volume |
| écriture à distance | Définit la configuration de l'écriture à distance, y compris les paramètres d'URL, d'authentification et de réétiquetage. | |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes et les limites de ressources pour le conteneur Prometheus. |
| rétention | chaîne de caractères |
Définit la durée pendant laquelle Prometheus conserve les données. Cette définition doit être spécifiée à l'aide du modèle d'expression régulière suivant : |
| taille de la rétention | chaîne de caractères |
Définit la quantité maximale d'espace disque utilisée par les blocs de données et le journal d'écriture (WAL). Les valeurs prises en charge sont |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Définit le stockage persistant pour Prometheus. Ce paramètre permet de configurer la classe de stockage et la taille d'un volume. |
17.13. Spécification d'écriture à distance
17.13.1. Description
La ressource RemoteWriteSpec définit les paramètres du stockage en écriture à distance.
17.13.2. Exigée
-
url
Apparaît dans : PrometheusK8sConfig, PrometheusRestrictedConfig
| Propriété | Type | Description |
|---|---|---|
| autorisation | *monv1.SafeAuthorization | Définit les paramètres d'autorisation pour le stockage en écriture à distance. |
| basicAuth | *monv1.BasicAuth | Définit les paramètres d'authentification de base pour l'URL du point de terminaison d'écriture à distance. |
| bearerTokenFile | chaîne de caractères | Définit le fichier qui contient le jeton du porteur pour le point de terminaison d'écriture à distance. Cependant, comme il n'est pas possible de monter des secrets dans un pod, en pratique, vous ne pouvez faire référence qu'au jeton du compte de service. |
| en-têtes | map[string]string | Spécifie les en-têtes HTTP personnalisés à envoyer avec chaque demande d'écriture à distance. Les en-têtes définis par Prometheus ne peuvent pas être remplacés. |
| metadataConfig | *monv1.MetadataConfig | Définit les paramètres pour l'envoi des métadonnées de la série au stockage d'écriture à distance. |
| nom | chaîne de caractères | Définit le nom de la file d'attente d'écriture distante. Ce nom est utilisé dans les métriques et la journalisation pour différencier les files d'attente. S'il est spécifié, ce nom doit être unique. |
| oauth2 | *monv1.OAuth2 | Définit les paramètres d'authentification OAuth2 pour le point de terminaison d'écriture à distance. |
| proxyUrl | chaîne de caractères | Définit une URL de proxy optionnelle. |
| queueConfig | *monv1.QueueConfig | Permet de configurer les paramètres de la file d'attente d'écriture à distance. |
| délai d'attente à distance | chaîne de caractères | Définit la valeur du délai d'attente pour les requêtes adressées au point final d'écriture à distance. |
| sigv4 | *monv1.Sigv4 | Définit les paramètres d'authentification de la signature AWS version 4. |
| tlsConfig | *monv1.SafeTLSConfig | Définit les paramètres d'authentification TLS pour le point de terminaison d'écriture à distance. |
| url | chaîne de caractères | Définit l'URL du point de terminaison d'écriture à distance vers lequel les échantillons seront envoyés. |
| writeRelabelConfigs | []monv1.RelabelConfig | Définit la liste des configurations de relabel d'écriture à distance. |
17.14. TelemeterClientConfig
17.14.1. Description
La ressource TelemeterClientConfig définit les paramètres du composant telemeter-client.
17.14.2. Exigée
-
nodeSelector -
tolerations
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
17.15. ThanosQuerierConfig
17.15.1. Description
La ressource ThanosQuerierConfig définit les paramètres du composant Thanos Querier.
Apparaît dans : ClusterMonitoringConfiguration
| Propriété | Type | Description |
|---|---|---|
| enableRequestLogging | bool |
Indicateur booléen qui active ou désactive l'enregistrement des demandes. La valeur par défaut est |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation pour Thanos Querier. Les valeurs possibles sont |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont programmés. |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes de ressources et les limites pour le conteneur Thanos Querier. |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
17.16. ThanosRulerConfig
17.16.1. Description
La ressource ThanosRulerConfig définit la configuration de l'instance de Thanos Ruler pour les projets définis par l'utilisateur.
Apparaît dans : UserWorkloadConfiguration
| Propriété | Type | Description |
|---|---|---|
| additionalAlertmanagerConfigs |
Configure la façon dont le composant Thanos Ruler communique avec les instances supplémentaires d'Alertmanager. La valeur par défaut est | |
| niveau du journal | chaîne de caractères |
Définit le niveau de journalisation pour Thanos Ruler. Les valeurs possibles sont |
| nodeSelector | map[string]string | Définit les nœuds sur lesquels les pods sont planifiés. |
| ressources | *v1.Exigences en matière de ressources | Définit les demandes et les limites de ressources pour le conteneur Alertmanager. |
| rétention | chaîne de caractères |
Définit la durée pendant laquelle Prometheus conserve les données. Cette définition doit être spécifiée à l'aide du modèle d'expression régulière suivant : |
| tolérances | []v1.Tolérance | Définit les tolérances pour les pods. |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Définit les contraintes d'étalement de la topologie pour les pods. |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Définit le stockage persistant pour Thanos Ruler. Ce paramètre permet de configurer la classe de stockage et la taille d'un volume. |
17.17. TLSConfig
17.17.1. Description
La ressource TLSConfig configure les paramètres des connexions TLS.
17.17.2. Exigée
-
insecureSkipVerify
Apparaît dans : AdditionalAlertmanagerConfig
| Propriété | Type | Description |
|---|---|---|
| ca | *v1.SecretKeySelector | Définit la référence de la clé secrète contenant l'autorité de certification (CA) à utiliser pour l'hôte distant. |
| certitude | *v1.SecretKeySelector | Définit la référence de la clé secrète contenant le certificat public à utiliser pour l'hôte distant. |
| clé | *v1.SecretKeySelector | Définit la référence de la clé secrète contenant la clé privée à utiliser pour l'hôte distant. |
| nom du serveur | chaîne de caractères | Utilisé pour vérifier le nom d'hôte sur le certificat renvoyé. |
| insecureSkipVerify | bool |
Lorsqu'il vaut |
17.18. UserWorkloadConfiguration
17.18.1. Description
La ressource UserWorkloadConfiguration définit les paramètres responsables des projets définis par l'utilisateur dans la carte de configuration user-workload-monitoring-config de l'espace de noms openshift-user-workload-monitoring. Vous ne pouvez activer UserWorkloadConfiguration qu'après avoir configuré enableUserWorkload en true dans la carte de configuration cluster-monitoring-config de l'espace de noms openshift-monitoring.
| Propriété | Type | Description |
|---|---|---|
| gestionnaire d'alerte | Définit les paramètres du composant Alertmanager dans le cadre de la surveillance de la charge de travail de l'utilisateur. | |
| prometheus | Définit les paramètres du composant Prometheus pour la surveillance de la charge de travail de l'utilisateur. | |
| prometheusOperator | Définit les paramètres du composant Prometheus Operator dans la surveillance de la charge de travail de l'utilisateur. | |
| thanosRuler | Définit les paramètres du composant Thanos Ruler dans la surveillance de la charge de travail de l'utilisateur. |
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.