Configuration post-installation
Opérations du jour 2 pour OpenShift Container Platform
Résumé
Chapitre 1. Aperçu de la configuration post-installation
Après avoir installé OpenShift Container Platform, un administrateur de cluster peut configurer et personnaliser les composants suivants :
- Machine
- Métal nu
- Groupement d'entreprises
- Nœud
- Réseau
- Stockage
- Utilisateurs
- Alertes et notifications
1.1. Tâches de configuration à effectuer après l'installation
Les administrateurs de clusters peuvent effectuer les tâches de configuration post-installation suivantes :
Configurer les caractéristiques du système d'exploitation: Machine Config Operator (MCO) gère les objets
MachineConfig. En utilisant MCO, vous pouvez effectuer les tâches suivantes sur un cluster OpenShift Container Platform :-
Configurer les nœuds à l'aide des objets
MachineConfig - Configurer les ressources personnalisées liées au MCO
-
Configurer les nœuds à l'aide des objets
Configurer les nœuds de métal nu: Le Bare Metal Operator (BMO) met en œuvre une API Kubernetes pour gérer les hôtes bare metal. Il maintient un inventaire des hôtes bare metal disponibles en tant qu'instances de la définition de ressource personnalisée (CRD) BareMetalHost. Le Bare Metal Operator peut :
- Inspecter les détails matériels de l'hôte et les rapporter sur le BareMetalHost correspondant. Cela inclut des informations sur les processeurs, la mémoire vive, les disques, les cartes réseau, etc.
- Inspecter le micrologiciel de l'hôte et configurer les paramètres du BIOS.
- Fournir aux hôtes l'image souhaitée.
- Nettoyer le contenu du disque d'un hôte avant ou après le provisionnement.
Configurer les fonctionnalités du cluster: En tant qu'administrateur de cluster, vous pouvez modifier les ressources de configuration des principales fonctionnalités d'un cluster OpenShift Container Platform. Ces fonctionnalités sont les suivantes :
- Registre des images
- Configuration du réseau
- Comportement de construction de l'image
- Fournisseur d'identité
- La configuration de etcd
- Création d'un ensemble de machines pour gérer les charges de travail
- Gestion des informations d'identification des fournisseurs de services en nuage
Configurer les composants du cluster pour qu'ils soient privés: Par défaut, le programme d'installation provisionne OpenShift Container Platform en utilisant un DNS et des points d'extrémité accessibles au public. Si vous souhaitez que votre cluster ne soit accessible qu'à partir d'un réseau interne, configurez les composants suivants pour qu'ils soient privés :
- DNS
- Contrôleur d'entrée
- Serveur API
Effectuer des opérations sur les nœuds: Par défaut, OpenShift Container Platform utilise des machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS). En tant qu'administrateur de cluster, vous pouvez effectuer les opérations suivantes avec les machines de votre cluster OpenShift Container Platform :
- Ajouter et supprimer des machines de calcul
- Ajouter et supprimer des taches et des tolérances aux nœuds
- Configurer le nombre maximum de pods par nœud
- Activer le gestionnaire de périphériques
Configurer le réseau: Après avoir installé OpenShift Container Platform, vous pouvez configurer les éléments suivants :
- Trafic d'entrée du cluster
- Port du nœud Plage de service
- Politique des réseaux
- Activation du proxy à l'échelle du cluster
Configurer le stockage: Par défaut, les conteneurs fonctionnent avec un stockage éphémère ou un stockage local transitoire. Le stockage éphémère a une durée de vie limitée. Pour stocker les données pendant une longue période, vous devez configurer le stockage persistant. Vous pouvez configurer le stockage en utilisant l'une des méthodes suivantes :
- Dynamic provisioning: Vous pouvez approvisionner dynamiquement le stockage à la demande en définissant et en créant des classes de stockage qui contrôlent différents niveaux de stockage, y compris l'accès au stockage.
- Static provisioning: Vous pouvez utiliser les volumes persistants Kubernetes pour mettre le stockage existant à la disposition d'un cluster. Le provisionnement statique peut prendre en charge diverses configurations de périphériques et options de montage.
- Configurer les utilisateurs: Les jetons d'accès OAuth permettent aux utilisateurs de s'authentifier auprès de l'API. En tant qu'administrateur de cluster, vous pouvez configurer OAuth pour effectuer les tâches suivantes :
- Spécifier un fournisseur d'identité
- Utiliser le contrôle d'accès basé sur les rôles pour définir et fournir des autorisations aux utilisateurs
- Installer un opérateur à partir d'OperatorHub
- Gérer les alertes et les notifications: Par défaut, les alertes de tir sont affichées sur l'interface utilisateur d'alerte de la console web. Vous pouvez également configurer OpenShift Container Platform pour envoyer des notifications d'alerte à des systèmes externes.
Chapitre 2. Configuration d'un cluster privé
Après avoir installé un cluster OpenShift Container Platform version 4.12, vous pouvez configurer certains de ses composants principaux pour qu'ils soient privés.
2.1. A propos des clusters privés
Par défaut, OpenShift Container Platform est provisionné en utilisant des DNS et des points de terminaison accessibles au public. Vous pouvez définir le DNS, le contrôleur d'entrée et le serveur API comme privés après avoir déployé votre cluster privé.
If the cluster has any public subnets, load balancer services created by administrators might be publicly accessible. To ensure cluster security, verify that these services are explicitly annotated as private.
DNS
Si vous installez OpenShift Container Platform sur une infrastructure fournie par l'installateur, le programme d'installation crée des enregistrements dans une zone publique préexistante et, si possible, crée une zone privée pour la propre résolution DNS du cluster. Dans la zone publique et la zone privée, le programme d'installation ou le cluster crée des entrées DNS pour *.apps, pour l'objet Ingress, et api, pour le serveur API.
Les enregistrements *.apps de la zone publique et de la zone privée sont identiques. Ainsi, lorsque vous supprimez la zone publique, la zone privée assure de manière transparente toutes les résolutions DNS pour le cluster.
Contrôleur d'entrée
Comme l'objet Ingress par défaut est créé en tant que public, l'équilibreur de charge est orienté vers l'internet et se trouve dans les sous-réseaux publics. Vous pouvez remplacer le contrôleur d'entrée par défaut par un contrôleur interne.
Serveur API
Par défaut, le programme d'installation crée des équilibreurs de charge réseau appropriés que le serveur API doit utiliser pour le trafic interne et externe.
Sur Amazon Web Services (AWS), des répartiteurs de charge publics et privés sont créés. Les équilibreurs de charge sont identiques, à l'exception d'un port supplémentaire disponible sur l'équilibreur interne pour une utilisation au sein du cluster. Bien que le programme d'installation crée ou détruise automatiquement l'équilibreur de charge en fonction des besoins du serveur API, le cluster ne les gère ni ne les maintient. Tant que vous préservez l'accès du cluster au serveur API, vous pouvez modifier ou déplacer manuellement les équilibreurs de charge. Pour l'équilibreur de charge public, le port 6443 est ouvert et le contrôle de santé est configuré pour HTTPS par rapport au chemin d'accès /readyz.
Sur Google Cloud Platform, un seul équilibreur de charge est créé pour gérer le trafic API interne et externe, vous n'avez donc pas besoin de modifier l'équilibreur de charge.
Sur Microsoft Azure, des équilibreurs de charge publics et privés sont créés. Cependant, en raison des limitations de l'implémentation actuelle, il suffit de conserver les deux équilibreurs de charge dans un cluster privé.
2.2. Régler le DNS sur privé
Après avoir déployé un cluster, vous pouvez modifier son DNS pour n'utiliser qu'une zone privée.
Procédure
Consultez la ressource personnalisée
DNSpour votre cluster :$ oc get dnses.config.openshift.io/cluster -o yamlExemple de sortie
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>: owned publicZone: id: Z2XXXXXXXXXXA4 status: {}Notez que la section
speccontient à la fois une zone privée et une zone publique.Modifier la ressource personnalisée
DNSpour supprimer la zone publique :$ oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}' dns.config.openshift.io/cluster patchedÉtant donné que le contrôleur d'entrée consulte la définition
DNSlorsqu'il crée des objetsIngress, lorsque vous créez ou modifiez des objetsIngress, seuls des enregistrements privés sont créés.ImportantLes enregistrements DNS des objets Ingress existants ne sont pas modifiés lorsque vous supprimez la zone publique.
Facultatif : Consultez la ressource personnalisée
DNSpour votre cluster et confirmez que la zone publique a été supprimée :$ oc get dnses.config.openshift.io/cluster -o yamlExemple de sortie
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>-wfpg4: owned status: {}
2.3. Configurer le contrôleur d'entrée comme étant privé
Après avoir déployé un cluster, vous pouvez modifier son contrôleur d'entrée pour qu'il n'utilise qu'une zone privée.
Procédure
Modifier le contrôleur d'entrée par défaut pour n'utiliser qu'un point d'extrémité interne :
$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOFExemple de sortie
ingresscontroller.operator.openshift.io "default" deleted ingresscontroller.operator.openshift.io/default replacedL'entrée DNS publique est supprimée et l'entrée de la zone privée est mise à jour.
2.4. Limiter le serveur API au domaine privé
Après avoir déployé un cluster sur Amazon Web Services (AWS) ou Microsoft Azure, vous pouvez reconfigurer le serveur API pour qu'il n'utilise que la zone privée.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Avoir accès à la console web en tant qu'utilisateur avec les privilèges
admin.
Procédure
Dans le portail web ou la console de votre fournisseur de cloud, effectuez les actions suivantes :
Localisez et supprimez le composant d'équilibreur de charge approprié :
- Pour AWS, supprimez l'équilibreur de charge externe. L'entrée API DNS dans la zone privée pointe déjà vers l'équilibreur de charge interne, qui utilise une configuration identique, de sorte qu'il n'est pas nécessaire de modifier l'équilibreur de charge interne.
-
Pour Azure, supprimez la règle
api-internalpour l'équilibreur de charge.
-
Supprimez l'entrée DNS
api.$clustername.$yourdomaindans la zone publique.
Supprimer les équilibreurs de charge externes :
ImportantVous ne pouvez exécuter les étapes suivantes que pour un cluster d'infrastructure fournie par l'installateur (IPI). Pour un cluster d'infrastructure fourni par l'utilisateur (UPI), vous devez supprimer ou désactiver manuellement les équilibreurs de charge externes.
Si votre cluster utilise un jeu de machines du plan de contrôle, supprimez les lignes suivantes dans la ressource personnalisée du jeu de machines du plan de contrôle :
providerSpec: value: loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: networkSi votre cluster n'utilise pas d'ensemble de machines du plan de contrôle, vous devez supprimer les équilibreurs de charge externes de chaque machine du plan de contrôle.
Depuis votre terminal, listez les machines du cluster en exécutant la commande suivante :
$ oc get machine -n openshift-machine-apiExemple de sortie
NAME STATE TYPE REGION ZONE AGE lk4pj-master-0 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-master-1 running m4.xlarge us-east-1 us-east-1b 17m lk4pj-master-2 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-worker-us-east-1a-5fzfj running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1a-vbghs running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1b-zgpzg running m4.xlarge us-east-1 us-east-1b 15mLes machines du plan de contrôle contiennent
masterdans leur nom.Supprimez l'équilibreur de charge externe de chaque machine du plan de contrôle :
Modifiez un objet machine du plan de contrôle en exécutant la commande suivante :
$ oc edit machines -n openshift-machine-api <control_plane_name>1 - 1
- Indiquez le nom de l'objet machine du plan de contrôle à modifier.
Supprimez les lignes qui décrivent l'équilibreur de charge externe, qui sont marquées dans l'exemple suivant :
providerSpec: value: loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: network- Enregistrez vos modifications et quittez la spécification d'objet.
- Répétez ce processus pour chacune des machines du plan de contrôle.
2.4.1. Configuration de l'étendue de la publication du contrôleur d'entrée sur Interne
Lorsqu'un administrateur de cluster installe un nouveau cluster sans spécifier qu'il s'agit d'un cluster privé, le contrôleur d'entrée par défaut est créé avec un scope défini sur External. Les administrateurs de clusters peuvent modifier un contrôleur d'entrée à portée External en Internal.
Conditions préalables
-
Vous avez installé le CLI
oc.
Procédure
Pour modifier un contrôleur d'entrée à portée de
ExternalenInternal, entrez la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"scope":"Internal"}}}}'Pour vérifier l'état du contrôleur d'entrée, entrez la commande suivante :
$ oc -n openshift-ingress-operator get ingresscontrollers/default -o yamlLa condition d'état
Progressingindique si vous devez prendre d'autres mesures. Par exemple, la condition d'état peut indiquer que vous devez supprimer le service en entrant la commande suivante :$ oc -n openshift-ingress delete services/router-defaultSi vous supprimez le service, l'opérateur d'entrée le recrée en tant que
Internal.
Chapitre 3. Configuration "bare metal" (métal nu)
Lors du déploiement d'OpenShift Container Platform sur des hôtes bare metal, il est parfois nécessaire d'apporter des modifications à l'hôte avant ou après le provisionnement. Il peut s'agir d'inspecter le matériel, le micrologiciel et les détails du micrologiciel de l'hôte. Il peut également s'agir de formater les disques ou de modifier les paramètres modifiables du firmware.
3.1. À propos de l'opérateur Bare Metal
Utilisez Bare Metal Operator (BMO) pour provisionner, gérer et inspecter les hôtes bare-metal de votre cluster.
La BMO utilise trois ressources pour accomplir ces tâches :
-
BareMetalHost -
HostFirmwareSettings -
FirmwareSchema
Le BMO maintient un inventaire des hôtes physiques dans le cluster en mappant chaque hôte bare-metal à une instance de la définition de ressource personnalisée BareMetalHost. Chaque ressource BareMetalHost contient des informations sur le matériel, les logiciels et les microprogrammes. Le BMO inspecte continuellement les hôtes nus de la grappe pour s'assurer que chaque ressource BareMetalHost détaille avec précision les composants de l'hôte correspondant.
Le BMO utilise également les ressources HostFirmwareSettings et FirmwareSchema pour détailler les spécifications des microprogrammes pour l'hôte nu.
L'interface BMO avec les machines nues de la grappe utilise le service API Ironic. Le service Ironic utilise le contrôleur de gestion de carte de base (BMC) de l'hôte pour s'interfacer avec la machine.
Voici quelques-unes des tâches courantes que vous pouvez effectuer à l'aide du BMO :
- Fournir des hôtes bare-metal à la grappe avec une image spécifique
- Formater le contenu du disque d'un hôte avant le provisionnement ou après le déprovisionnement
- Activer ou désactiver un hôte
- Modifier les paramètres du micrologiciel
- Afficher les détails du matériel de l'hôte
3.1.1. Architecture de l'opérateur Bare Metal
Le Bare Metal Operator (BMO) utilise trois ressources pour approvisionner, gérer et inspecter les hôtes bare-metal de votre cluster. Le diagramme suivant illustre l'architecture de ces ressources :
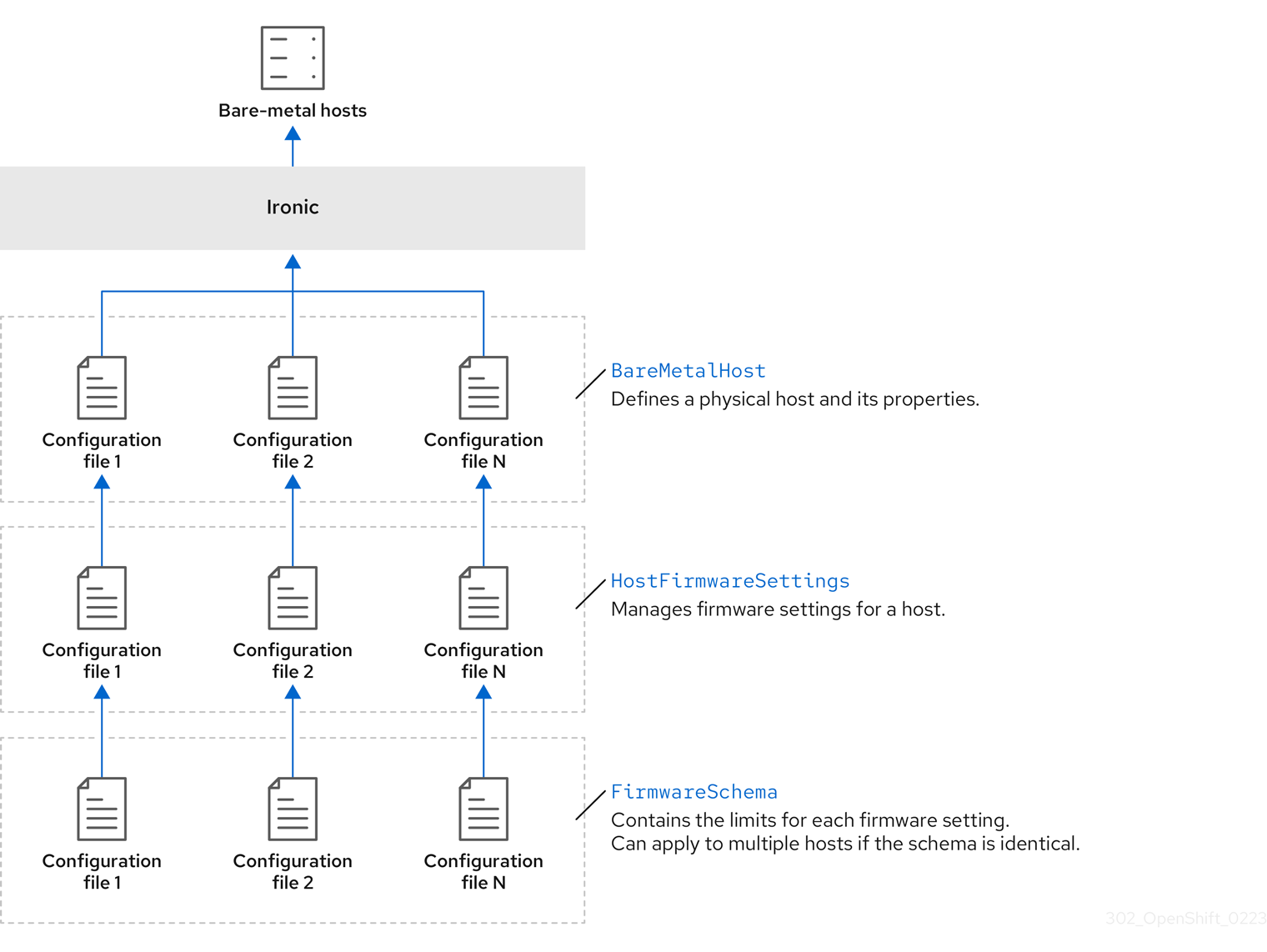
BareMetalHost
La ressource BareMetalHost définit un hôte physique et ses propriétés. Lorsque vous fournissez un hôte bare-metal au cluster, vous devez définir une ressource BareMetalHost pour cet hôte. Pour une gestion continue de l'hôte, vous pouvez inspecter les informations contenues dans la ressource BareMetalHost ou les mettre à jour.
La ressource BareMetalHost contient des informations de provisionnement telles que les suivantes :
- Spécifications de déploiement telles que l'image de démarrage du système d'exploitation ou le disque RAM personnalisé
- État de provisionnement
- Adresse du contrôleur de gestion de la carte de base (BMC)
- État de puissance souhaité
La ressource BareMetalHost contient des informations sur le matériel, telles que les suivantes :
- Nombre de CPU
- Adresse MAC d'un NIC
- Taille du périphérique de stockage de l'hôte
- État actuel de la puissance
Paramètres du micrologiciel hôte
Vous pouvez utiliser la ressource HostFirmwareSettings pour récupérer et gérer les paramètres du micrologiciel d'un hôte. Lorsqu'un hôte passe à l'état Available, le service Ironic lit les paramètres du micrologiciel de l'hôte et crée la ressource HostFirmwareSettings. Il existe une correspondance univoque entre la ressource BareMetalHost et la ressource HostFirmwareSettings.
Vous pouvez utiliser la ressource HostFirmwareSettings pour vérifier les spécifications du micrologiciel d'un hôte ou pour mettre à jour les spécifications du micrologiciel d'un hôte.
Vous devez respecter le schéma propre au micrologiciel du fournisseur lorsque vous modifiez le champ spec de la ressource HostFirmwareSettings. Ce schéma est défini dans la ressource en lecture seule FirmwareSchema.
FirmwareSchema
Les paramètres des microprogrammes varient selon les fournisseurs de matériel et les modèles d'hôtes. La ressource FirmwareSchema est une ressource en lecture seule qui contient les types et les limites de chaque paramètre de microprogramme pour chaque modèle d'hôte. Les données proviennent directement de la BMC en utilisant le service Ironic. La ressource FirmwareSchema vous permet d'identifier les valeurs valides que vous pouvez spécifier dans le champ spec de la ressource HostFirmwareSettings.
Une ressource FirmwareSchema peut s'appliquer à plusieurs ressources BareMetalHost si le schéma est le même.
3.2. À propos de la ressource BareMetalHost
Metal3 introduit le concept de ressource BareMetalHost, qui définit un hôte physique et ses propriétés. La ressource BareMetalHost contient deux sections :
-
La spécification
BareMetalHost -
Le statut
BareMetalHost
3.2.1. La spécification BareMetalHost
La section spec de la ressource BareMetalHost définit l'état souhaité de l'hôte.
| Parameters | Description |
|---|---|
|
|
Interface permettant d'activer ou de désactiver le nettoyage automatique pendant l'approvisionnement et le déprovisionnement. Si la valeur est |
|
Le paramètre de configuration
|
|
| L'adresse MAC de la carte réseau utilisée pour le provisionnement de l'hôte. |
|
|
Le mode de démarrage de l'hôte. Il est défini par défaut sur |
|
|
Une référence à une autre ressource qui utilise l'hôte. Elle peut être vide si une autre ressource n'utilise pas actuellement l'hôte. Par exemple, une ressource |
|
| Chaîne de caractères fournie par l'homme pour aider à identifier l'hôte. |
|
| Un booléen indiquant si le provisionnement et le déprovisionnement de l'hôte sont gérés en externe. Lorsqu'il est défini :
|
|
|
Contient des informations sur la configuration du BIOS des hôtes bare metal. Actuellement,
|
|
Le paramètre de configuration
|
|
| Une référence au secret contenant les données de configuration du réseau et son espace de noms, afin qu'il puisse être attaché à l'hôte avant que celui-ci ne démarre pour configurer le réseau. |
|
|
Un booléen indiquant si l'hôte doit être mis sous tension ( |
| (Facultatif) Contient les informations relatives à la configuration RAID pour les hôtes métalliques nus. Si elle n'est pas spécifiée, elle conserve la configuration actuelle. Note OpenShift Container Platform 4.12 prend en charge le RAID matériel pour les BMC utilisant le protocole iRMC uniquement. OpenShift Container Platform 4.12 ne prend pas en charge le RAID logiciel. Voir les paramètres de configuration suivants :
Vous pouvez définir le site
Si vous recevez un message d'erreur indiquant que le pilote ne prend pas en charge le RAID, attribuez la valeur nil à |
|
Le paramètre
|
3.2.2. L'état de BareMetalHost
L'état BareMetalHost représente l'état actuel de l'hôte et comprend les informations d'identification testées, les détails du matériel actuel et d'autres informations.
| Parameters | Description |
|---|---|
|
| Référence au secret et à son espace de noms contenant le dernier jeu d'informations d'identification du contrôleur de gestion de carte de base (BMC) que le système a pu valider comme étant fonctionnel. |
|
| Détails de la dernière erreur signalée par le backend de provisionnement, le cas échéant. |
|
| Indique la classe du problème qui a fait entrer l'hôte dans un état d'erreur. Les types d'erreur sont les suivants :
|
|
Le champ
|
| Contient des informations sur le micrologiciel du BIOS. Par exemple, le fournisseur et la version du matériel. |
|
Le champ
|
| La quantité de mémoire de l'hôte en Mebibytes (MiB). |
|
Le champ
|
|
Contient des informations sur les sites |
|
| Date de la dernière mise à jour de l'état de l'hôte. |
|
| L'état du serveur. L'état est l'un des suivants :
|
|
| Booléen indiquant si l'hôte est sous tension. |
|
Le champ
|
|
| Une référence au secret et à son espace de noms contenant le dernier ensemble d'informations d'identification BMC qui ont été envoyées au backend de provisionnement. |
3.3. Obtenir la ressource BareMetalHost
La ressource BareMetalHost contient les propriétés d'un hôte physique. Vous devez obtenir la ressource BareMetalHost pour un hôte physique afin d'examiner ses propriétés.
Procédure
Obtenir la liste des ressources
BareMetalHost:$ oc get bmh -n openshift-machine-api -o yamlNoteVous pouvez utiliser
baremetalhostcomme forme longue debmhavec la commandeoc get.Obtenir la liste des hôtes :
$ oc get bmh -n openshift-machine-apiObtenir la ressource
BareMetalHostpour un hôte spécifique :oc get bmh <host_name> -n openshift-machine-api -o yamlOù
<host_name>est le nom de l'hôte.Exemple de sortie
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: creationTimestamp: "2022-06-16T10:48:33Z" finalizers: - baremetalhost.metal3.io generation: 2 name: openshift-worker-0 namespace: openshift-machine-api resourceVersion: "30099" uid: 1513ae9b-e092-409d-be1b-ad08edeb1271 spec: automatedCleaningMode: metadata bmc: address: redfish://10.46.61.19:443/redfish/v1/Systems/1 credentialsName: openshift-worker-0-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:c7:f7:b0 bootMode: UEFI consumerRef: apiVersion: machine.openshift.io/v1beta1 kind: Machine name: ocp-edge-958fk-worker-0-nrfcg namespace: openshift-machine-api customDeploy: method: install_coreos hardwareProfile: unknown online: true rootDeviceHints: deviceName: /dev/sda userData: name: worker-user-data-managed namespace: openshift-machine-api status: errorCount: 0 errorMessage: "" goodCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120" hardware: cpu: arch: x86_64 clockMegahertz: 2300 count: 64 flags: - 3dnowprefetch - abm - acpi - adx - aes model: Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz firmware: bios: date: 10/26/2020 vendor: HPE version: U30 hostname: openshift-worker-0 nics: - mac: 48:df:37:c7:f7:b3 model: 0x8086 0x1572 name: ens1f3 ramMebibytes: 262144 storage: - hctl: "0:0:0:0" model: VK000960GWTTB name: /dev/sda sizeBytes: 960197124096 type: SSD vendor: ATA systemVendor: manufacturer: HPE productName: ProLiant DL380 Gen10 (868703-B21) serialNumber: CZ200606M3 hardwareProfile: unknown lastUpdated: "2022-06-16T11:41:42Z" operationalStatus: OK poweredOn: true provisioning: ID: 217baa14-cfcf-4196-b764-744e184a3413 bootMode: UEFI customDeploy: method: install_coreos image: url: "" raid: hardwareRAIDVolumes: null softwareRAIDVolumes: [] rootDeviceHints: deviceName: /dev/sda state: provisioned triedCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120"
3.4. À propos de la ressource HostFirmwareSettings
Vous pouvez utiliser la ressource HostFirmwareSettings pour récupérer et gérer les paramètres BIOS d'un hôte. Lorsqu'un hôte passe à l'état Available, Ironic lit les paramètres BIOS de l'hôte et crée la ressource HostFirmwareSettings. Cette ressource contient la configuration complète du BIOS renvoyée par le contrôleur de gestion de la carte de base (BMC). Alors que le champ firmware de la ressource BareMetalHost renvoie trois champs indépendants du fournisseur, la ressource HostFirmwareSettings comprend généralement de nombreux paramètres BIOS de champs spécifiques au fournisseur par hôte.
La ressource HostFirmwareSettings contient deux sections :
-
Le site
HostFirmwareSettingsspec. -
Le statut
HostFirmwareSettings.
3.4.1. La spécification HostFirmwareSettings
La section spec de la ressource HostFirmwareSettings définit l'état souhaité du BIOS de l'hôte, et elle est vide par défaut. Ironic utilise les paramètres de la section spec.settings pour mettre à jour le contrôleur de gestion de la carte de base (BMC) lorsque l'hôte est dans l'état Preparing. Utilisez la ressource FirmwareSchema pour vous assurer que vous n'envoyez pas de paires nom/valeur invalides aux hôtes. Voir "About the FirmwareSchema resource" pour plus de détails.
Exemple :
spec:
settings:
ProcTurboMode: Disabled- 1
- Dans l'exemple précédent, la section
spec.settingscontient une paire nom/valeur qui définira le paramètre BIOSProcTurboModesurDisabled.
Les paramètres entiers énumérés dans la section status apparaissent sous forme de chaînes de caractères. Par exemple, "1". Lorsque vous définissez des nombres entiers dans la section spec.settings, les valeurs doivent être définies comme des nombres entiers sans guillemets. Par exemple, 1.
3.4.2. Le statut HostFirmwareSettings
Le site status représente l'état actuel du BIOS de l'hôte.
| Parameters | Description |
|---|---|
|
Le champ
|
|
Le site
|
|
Le champ |
3.5. Obtention de la ressource HostFirmwareSettings
La ressource HostFirmwareSettings contient les propriétés BIOS spécifiques d'un hôte physique. Vous devez obtenir la ressource HostFirmwareSettings pour un hôte physique afin de consulter ses propriétés BIOS.
Procédure
Obtenez la liste détaillée des ressources
HostFirmwareSettings:$ oc get hfs -n openshift-machine-api -o yamlNoteVous pouvez utiliser
hostfirmwaresettingscomme forme longue dehfsavec la commandeoc get.Obtenir la liste des ressources
HostFirmwareSettings:$ oc get hfs -n openshift-machine-apiObtenir la ressource
HostFirmwareSettingspour un hôte particulier$ oc get hfs <host_name> -n openshift-machine-api -o yamlOù
<host_name>est le nom de l'hôte.
3.6. Modification de la ressource HostFirmwareSettings
Vous pouvez éditer le site HostFirmwareSettings des hôtes provisionnés.
Vous ne pouvez modifier les hôtes que lorsqu'ils sont dans l'état provisioned, à l'exception des valeurs en lecture seule. Vous ne pouvez pas modifier les hôtes dans l'état externally provisioned.
Procédure
Obtenir la liste des ressources
HostFirmwareSettings:$ oc get hfs -n openshift-machine-apiModifier la ressource
HostFirmwareSettingsd'un hôte :$ oc edit hfs <host_name> -n openshift-machine-apiOù
<host_name>est le nom d'un hôte provisionné. La ressourceHostFirmwareSettingss'ouvrira dans l'éditeur par défaut de votre terminal.Ajouter des paires nom/valeur à la section
spec.settings:Exemple :
spec: settings: name: value1 - 1
- Utilisez la ressource
FirmwareSchemapour identifier les paramètres disponibles pour l'hôte. Vous ne pouvez pas définir de valeurs en lecture seule.
- Enregistrez les modifications et quittez l'éditeur.
Obtenir le nom de la machine de l'hôte :
$ oc get bmh <host_name> -n openshift-machine nameOù
<host_name>est le nom de l'hôte. Le nom de la machine apparaît sous le champCONSUMER.Annoter la machine pour la supprimer du jeu de machines :
$ oc annotate machine <nom_de_la_machine> machine.openshift.io/delete-machine=true -n openshift-machine-apiOù
<machine_name>est le nom de la machine à supprimer.Obtenir une liste de nœuds et compter le nombre de nœuds de travail :
$ oc get nodesObtenir le jeu de machines :
$ oc get machinesets -n openshift-machine-apiMettre à l'échelle le jeu de machines :
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>Où
<machineset_name>est le nom du jeu de machines et<n-1>est le nombre décrémenté de nœuds de travail.Lorsque l'hôte entre dans l'état
Available, augmentez la taille de l'ensemble de machines pour que les changements de ressourcesHostFirmwareSettingsprennent effet :$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>Où
<machineset_name>est le nom du jeu de machines et<n>est le nombre de nœuds de travail.
3.7. Vérification de la validité de la ressource HostFirmware Settings
Lorsque l'utilisateur édite la section spec.settings pour apporter une modification à la ressource HostFirmwareSetting(HFS), le Bare Metal Operator (BMO) valide la modification par rapport à la ressource FimwareSchema, qui est une ressource en lecture seule. Si le paramètre n'est pas valide, le BMO définit la valeur Type du paramètre status.Condition sur False et génère également un événement qu'il stocke dans la ressource HFS. Utilisez la procédure suivante pour vérifier que la ressource est valide.
Procédure
Obtenir une liste des ressources
HostFirmwareSetting:$ oc get hfs -n openshift-machine-apiVérifiez que la ressource
HostFirmwareSettingsd'un hôte particulier est valide :$ oc describe hfs <nom_d'hôte> -n openshift-machine-apiOù
<host_name>est le nom de l'hôte.Exemple de sortie
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ValidationFailed 2m49s metal3-hostfirmwaresettings-controller Invalid BIOS setting: Setting ProcTurboMode is invalid, unknown enumeration value - FooImportantSi la réponse renvoie
ValidationFailed, il y a une erreur dans la configuration de la ressource et vous devez mettre à jour les valeurs pour qu'elles soient conformes à la ressourceFirmwareSchema.
3.8. À propos de la ressource FirmwareSchema
Les paramètres du BIOS varient selon les fournisseurs de matériel et les modèles d'hôtes. Une ressource FirmwareSchema est une ressource en lecture seule qui contient les types et les limites de chaque paramètre du BIOS pour chaque modèle d'hôte. Les données proviennent directement du BMC par l'intermédiaire d'Ironic. La ressource FirmwareSchema vous permet d'identifier les valeurs valides que vous pouvez spécifier dans le champ spec de la ressource HostFirmwareSettings. La ressource FirmwareSchema a un identifiant unique dérivé de ses paramètres et de ses limites. Les modèles d'hôtes identiques utilisent le même identifiant FirmwareSchema. Il est probable que plusieurs instances de HostFirmwareSettings utilisent le même FirmwareSchema.
| Parameters | Description |
|---|---|
|
Le site
|
3.9. Obtenir la ressource FirmwareSchema
Chaque modèle d'hôte de chaque fournisseur a des paramètres BIOS différents. Lorsque vous modifiez la section spec de la ressource HostFirmwareSettings, les paires nom/valeur que vous définissez doivent être conformes au schéma du micrologiciel de cet hôte. Pour vous assurer que vous définissez des paires nom/valeur valides, récupérez le site FirmwareSchema de l'hôte et consultez-le.
Procédure
Pour obtenir une liste des instances de ressources
FirmwareSchema, exécutez la procédure suivante :$ oc get firmwareschema -n openshift-machine-apiPour obtenir une instance particulière de
FirmwareSchema, exécutez :$ oc get firmwareschema <instance_name> -n openshift-machine-api -o yamlOù
<instance_name>est le nom de l'instance de schéma indiquée dans la ressourceHostFirmwareSettings(voir tableau 3).
Chapitre 4. Configurer des machines de calcul multi-architectures sur un cluster OpenShift Container Platform
Un cluster OpenShift Container Platform avec des machines de calcul multi-architecture est un cluster qui prend en charge des machines de calcul avec différentes architectures. Vous pouvez déployer un cluster avec des machines de calcul multi-architecture en créant un cluster provisionné par l'installateur Azure à l'aide du binaire d'installation multi-architecture. Pour l'installation sur Azure, voir Installation d'un cluster sur Azure avec personnalisations.
La fonction d'aperçu technologique des machines de calcul multi-architectures est peu utilisable pour l'installation, la mise à niveau et l'exécution de charges utiles.
Les procédures suivantes expliquent comment générer une image de démarrage arm64 et créer un ensemble de machines de calcul Azure avec l'image de démarrage arm64. Cela permet d'ajouter arm64 nœuds de calcul à votre cluster et de déployer la quantité souhaitée de arm64 machines virtuelles (VM). Cette section explique également comment mettre à niveau votre cluster existant vers un cluster prenant en charge les machines de calcul multi-architectures. Les clusters avec machines de calcul multi-architecture ne sont disponibles que sur les infrastructures Azure provisionnées par l'installateur avec des machines de plan de contrôle x86_64.
Les clusters OpenShift Container Platform avec des machines de calcul multi-architecture sur des installations d'infrastructure provisionnées par l'installateur Azure est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
4.1. Création d'une image de démarrage arm64 à l'aide de la galerie d'images Azure
Pour configurer votre cluster avec des machines de calcul multi-architectures, vous devez créer une image de démarrage arm64 et l'ajouter à votre ensemble de machines de calcul Azure. La procédure suivante décrit comment générer manuellement une image de démarrage arm64.
Conditions préalables
-
Vous avez installé le CLI Azure (
az). - Vous avez créé un cluster à architecture unique provisionné par le programme d'installation Azure avec le binaire d'installation multi-architecture.
Procédure
Connectez-vous à votre compte Azure :
$ az loginCréez un compte de stockage et téléchargez le disque dur virtuel (VHD)
arm64sur votre compte de stockage. Le programme d'installation d'OpenShift Container Platform crée un groupe de ressources, mais l'image de démarrage peut également être téléchargée dans un groupe de ressources personnalisé :$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 - 1
- L'objet
westusest un exemple de région.
Créez un conteneur de stockage en utilisant le compte de stockage que vous avez créé :
$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}Vous devez utiliser le fichier JSON du programme d'installation d'OpenShift Container Platform pour extraire l'URL et le nom du VHD
arch64:Extrayez le champ
URLet attribuez-lui le nom de fichierRHCOS_VHD_ORIGIN_URLen exécutant la commande suivante :$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".url')Extrayez le nom du VHD
aarch64et définissez-le àBLOB_NAMEcomme nom de fichier en exécutant la commande suivante :$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".release')-azure.aarch64.vhd
Générer un jeton de signature d'accès partagé (SAS). Utilisez ce jeton pour télécharger le VHD RHCOS dans votre conteneur de stockage à l'aide des commandes suivantes :
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`Copiez le VHD RHCOS dans le conteneur de stockage :
$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}Vous pouvez vérifier l'état du processus de copie à l'aide de la commande suivante :
$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copyExemple de sortie
{ "completionTime": null, "destinationSnapshot": null, "id": "1fd97630-03ca-489a-8c4e-cfe839c9627d", "incrementalCopy": null, "progress": "17179869696/17179869696", "source": "https://rhcos.blob.core.windows.net/imagebucket/rhcos-411.86.202207130959-0-azure.aarch64.vhd", "status": "success",1 "statusDescription": null }- 1
- Si le paramètre d'état affiche l'objet
success, le processus de copie est terminé.
Créez une galerie d'images à l'aide de la commande suivante :
$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}Utilisez la galerie d'images pour créer une définition d'image. Dans l'exemple de commande suivant,
rhcos-arm64est le nom de la définition d'image.$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --publisher RedHat --offer arm --sku arm64 --os-type linux --architecture Arm64 --hyper-v-generation V2Pour obtenir l'URL du VHD et lui attribuer le nom de fichier
RHCOS_VHD_URL, exécutez la commande suivante :$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)Utilisez le fichier
RHCOS_VHD_URL, votre compte de stockage, votre groupe de ressources et votre galerie d'images pour créer une version d'image. Dans l'exemple suivant,1.0.0est la version de l'image.$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}Votre image de démarrage
arm64est maintenant générée. Vous pouvez accéder à l'ID de votre image avec la commande suivante :$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-arm64 -e 1.0.0L'exemple suivant d'ID d'image est utilisé dans le paramètre
recourseIDde l'ensemble de machines de calcul :Exemple
resourceID/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.0
4.2. Ajouter un ensemble de machines de calcul multi-architecture à votre cluster en utilisant l'image de démarrage arm64
Pour ajouter des nœuds de calcul arm64 à votre cluster, vous devez créer un ensemble de machines de calcul Azure qui utilise l'image de démarrage arm64. Pour créer votre propre ensemble de machines de calcul personnalisé sur Azure, voir "Creating a compute machine set on Azure" (Création d'un ensemble de machines de calcul sur Azure).
Conditions préalables
-
You installed the OpenShift CLI (
oc).
Procédure
Créez un ensemble de machines de calcul et modifiez les paramètres
resourceIDetvmSizeà l'aide de la commande suivante. Cet ensemble de machines de calcul contrôlera les nœuds de travailarm64dans votre cluster :$ oc create -f arm64-machine-set-0.yamlExemple d'ensemble de machines de calcul YAML avec l'image de démarrage
arm64apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: <infrastructure_id>-arm64-machine-set-0 namespace: openshift-machine-api spec: replicas: 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-arm64-machine-set-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: <infrastructure_id>-arm64-machine-set-0 spec: lifecycleHooks: {} metadata: {} providerSpec: value: acceleratedNetworking: true apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: azure-cloud-credentials namespace: openshift-machine-api image: offer: "" publisher: "" resourceID: /resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.01 sku: "" version: "" kind: AzureMachineProviderSpec location: <region> managedIdentity: <infrastructure_id>-identity networkResourceGroup: <infrastructure_id>-rg osDisk: diskSettings: {} diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS osType: Linux publicIP: false publicLoadBalancer: <infrastructure_id> resourceGroup: <infrastructure_id>-rg subnet: <infrastructure_id>-worker-subnet userDataSecret: name: worker-user-data vmSize: Standard_D4ps_v52 vnet: <infrastructure_id>-vnet zone: "<zone>"
Vérification
Vérifiez que les nouvelles machines ARM64 fonctionnent en entrant la commande suivante :
$ oc get machineset -n openshift-machine-apiExemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-arm64-machine-set-0 2 2 2 2 10mVous pouvez vérifier que les nœuds sont prêts et programmables à l'aide de la commande suivante :
$ oc get nodes
4.3. Mise à niveau d'un cluster avec des machines de calcul à architecture multiple
Pour mettre à niveau votre cluster avec des machines de calcul à architecture multiple, utilisez le canal de mise à jour candidate-4.12. Pour plus d'informations, voir "Comprendre les canaux de mise à niveau".
Seuls les clusters OpenShift Container Platform qui utilisent déjà une charge utile multi-architecture peuvent être mis à jour avec le canal candidate-4.12.
Si vous souhaitez mettre à niveau un cluster existant pour prendre en charge des machines de calcul multi-architectures, vous pouvez exécuter une commande de mise à niveau explicite, comme indiqué dans la procédure suivante. Cette commande met à jour votre grappe à architecture unique actuelle vers une grappe qui utilise la charge utile multi-architecture.
Conditions préalables
-
You installed the OpenShift CLI (
oc).
Procédure
Pour mettre à niveau manuellement votre cluster, utilisez la commande suivante :
$ oc adm upgrade --allow-explicit-upgrade --to-image <image-pullspec>1 - 1
- Vous pouvez accéder à l'objet
image-pullspecà partir de la page des miroirs d'architecture mixte dans le fichierrelease.txt.
4.4. Importation de listes de manifestes dans des flux d'images sur vos machines de calcul multi-architectures
Sur un cluster OpenShift Container Platform 4.12 avec des machines de calcul multi-architecture, les flux d'images dans le cluster n'importent pas automatiquement les listes de manifestes. Vous devez remplacer manuellement l'option par défaut importMode par l'option PreserveOriginal afin d'importer la liste de manifestes.
Le champ referencePolicy.type de votre objet ImageStream doit être défini sur le type Source pour que cette procédure soit exécutée avec succès.
referencePolicy:
type: SourceConditions préalables
-
Vous avez installé le CLI OpenShift Container Platform (
oc).
Procédure
L'exemple de commande suivant montre comment corriger le fichier
ImageStreamcli-artifacts pour que la balisecli-artifacts:latestimage stream soit importée en tant que liste de manifestes.oc patch is/cli-artifacts -n openshift -p '{"spec":{"tags":[{"name":"latest","importPolicy":{"importMode":"PreserveOriginal"}}]}}'
Vérification
Vous pouvez vérifier que les listes de manifestes ont été importées correctement en inspectant la balise de flux d'images. La commande suivante permet d'obtenir la liste des manifestes d'architecture individuels pour une balise donnée.
oc get istag cli-artifacts:latest -n openshift -oyamlSi l'objet
dockerImageManifestsest présent, l'importation de la liste des manifestes a réussi.Exemple de sortie de l'objet
dockerImageManifestsdockerImageManifests: - architecture: amd64 digest: sha256:16d4c96c52923a9968fbfa69425ec703aff711f1db822e4e9788bf5d2bee5d77 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: arm64 digest: sha256:6ec8ad0d897bcdf727531f7d0b716931728999492709d19d8b09f0d90d57f626 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: ppc64le digest: sha256:65949e3a80349cdc42acd8c5b34cde6ebc3241eae8daaeea458498fedb359a6a manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: s390x digest: sha256:75f4fa21224b5d5d511bea8f92dfa8e1c00231e5c81ab95e83c3013d245d1719 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux
Chapitre 5. Tâches de configuration de la machine après l'installation
Il arrive que vous deviez apporter des modifications aux systèmes d'exploitation fonctionnant sur les nœuds d'OpenShift Container Platform. Il peut s'agir de modifier les paramètres du service de temps réseau, d'ajouter des arguments de noyau ou de configurer la journalisation d'une manière spécifique.
Hormis quelques fonctionnalités spécialisées, la plupart des modifications apportées aux systèmes d'exploitation sur les nœuds d'OpenShift Container Platform peuvent être effectuées en créant ce que l'on appelle des objets MachineConfig qui sont gérés par l'opérateur de configuration de la machine.
Les tâches de cette section décrivent comment utiliser les fonctionnalités de l'opérateur Machine Config pour configurer les fonctionnalités du système d'exploitation sur les nœuds d'OpenShift Container Platform.
5.1. Comprendre l'opérateur de configuration de la machine
5.1.1. Machine Config Operator
Objectif
L'opérateur de configuration des machines gère et applique la configuration et les mises à jour du système d'exploitation de base et de l'exécution des conteneurs, y compris tout ce qui se trouve entre le noyau et le kubelet.
Il y a quatre composantes :
-
machine-config-server: Fournit la configuration d'Ignition aux nouvelles machines qui rejoignent le cluster. -
machine-config-controller: Coordonne la mise à niveau des machines vers les configurations souhaitées définies par un objetMachineConfig. Des options sont fournies pour contrôler la mise à niveau d'ensembles de machines individuellement. -
machine-config-daemon: Applique la nouvelle configuration de la machine pendant la mise à jour. Valide et vérifie l'état de la machine par rapport à la configuration demandée. -
machine-config: Fournit une source complète de configuration de la machine lors de l'installation, du premier démarrage et des mises à jour d'une machine.
Currently, there is no supported way to block or restrict the machine config server endpoint. The machine config server must be exposed to the network so that newly-provisioned machines, which have no existing configuration or state, are able to fetch their configuration. In this model, the root of trust is the certificate signing requests (CSR) endpoint, which is where the kubelet sends its certificate signing request for approval to join the cluster. Because of this, machine configs should not be used to distribute sensitive information, such as secrets and certificates.
To ensure that the machine config server endpoints, ports 22623 and 22624, are secured in bare metal scenarios, customers must configure proper network policies.
Ressources supplémentaires
Projet
5.1.2. Aperçu de la configuration de la machine
Le Machine Config Operator (MCO) gère les mises à jour de systemd, CRI-O et Kubelet, le noyau, le Network Manager et d'autres fonctionnalités du système. Il offre également un CRD MachineConfig qui peut écrire des fichiers de configuration sur l'hôte (voir machine-config-operator). Comprendre ce que fait MCO et comment il interagit avec d'autres composants est essentiel pour effectuer des changements avancés au niveau du système dans un cluster OpenShift Container Platform. Voici quelques éléments à connaître sur le MCO, les configurations de machine et leur utilisation :
- Une machine config peut apporter une modification spécifique à un fichier ou à un service sur le système d'exploitation de chaque système représentant un pool de nœuds OpenShift Container Platform.
MCO applique des changements aux systèmes d'exploitation dans les pools de machines. Tous les clusters OpenShift Container Platform démarrent avec des pools de nœuds de plan de travail et de plan de contrôle. En ajoutant d'autres étiquettes de rôle, vous pouvez configurer des pools de nœuds personnalisés. Par exemple, vous pouvez configurer un pool personnalisé de nœuds de travailleur qui inclut des caractéristiques matérielles particulières nécessaires à une application. Toutefois, les exemples de cette section se concentrent sur les modifications apportées aux types de pools par défaut.
ImportantUn nœud peut avoir plusieurs étiquettes qui indiquent son type, comme
masterouworker, mais il ne peut être membre que d'un pool de configuration de machines single.-
Après un changement de configuration de machine, le MCO met à jour les nœuds concernés par ordre alphabétique de zone, sur la base de l'étiquette
topology.kubernetes.io/zone. Si une zone comporte plusieurs nœuds, les nœuds les plus anciens sont mis à jour en premier. Pour les nœuds qui n'utilisent pas de zones, comme dans les déploiements bare metal, les nœuds sont mis à jour par âge, les nœuds les plus anciens étant mis à jour en premier. Le MCO met à jour le nombre de nœuds spécifié par le champmaxUnavailabledu pool de configuration de la machine à la fois. - Une certaine configuration de la machine doit être en place avant l'installation d'OpenShift Container Platform sur le disque. Dans la plupart des cas, cela peut être accompli en créant une configuration de machine qui est injectée directement dans le processus d'installation d'OpenShift Container Platform, au lieu de fonctionner comme une configuration de machine post-installation. Dans d'autres cas, vous pourriez avoir besoin de faire une installation bare metal où vous passez des arguments de noyau au démarrage de l'installateur d'OpenShift Container Platform, pour faire des choses comme la définition d'adresses IP individuelles par nœud ou le partitionnement avancé du disque.
- MCO gère les éléments définis dans les configurations des machines. Les modifications manuelles que vous apportez à vos systèmes ne seront pas écrasées par MCO, à moins qu'il ne soit explicitement demandé à MCO de gérer un fichier conflictuel. En d'autres termes, MCO n'effectue que les mises à jour spécifiques que vous demandez, il ne revendique pas le contrôle de l'ensemble du nœud.
- Il est fortement déconseillé d'apporter des modifications manuelles aux nœuds. Si vous devez déclasser un nœud et en démarrer un nouveau, ces modifications directes seront perdues.
-
Le MCO n'est pris en charge que pour l'écriture de fichiers dans les répertoires
/etcet/var, bien qu'il existe des liens symboliques vers certains répertoires qui peuvent être accessibles en écriture en étant symboliquement liés à l'une de ces zones. Les répertoires/optet/usr/localen sont des exemples. - Ignition est le format de configuration utilisé dans MachineConfigs. Voir la spécification de configuration Ignition v3.2.0 pour plus de détails.
- Bien que les paramètres de configuration d'Ignition puissent être livrés directement au moment de l'installation d'OpenShift Container Platform, et qu'ils soient formatés de la même manière que les configurations d'Ignition livrées par MCO, MCO n'a aucun moyen de voir ce que sont ces configurations d'Ignition d'origine. Par conséquent, vous devez envelopper les paramètres de configuration Ignition dans une configuration de machine avant de les déployer.
-
Lorsqu'un fichier géré par le MCO est modifié en dehors du MCO, le Machine Config Daemon (MCD) définit le nœud comme
degraded. Il n'écrase cependant pas le fichier incriminé et doit continuer à fonctionner dans l'étatdegraded. -
L'une des principales raisons d'utiliser une configuration de machine est qu'elle sera appliquée lorsque vous démarrez de nouveaux nœuds pour un pool dans votre cluster OpenShift Container Platform. Le site
machine-api-operatorprovisionne une nouvelle machine et MCO la configure.
MCO utilise Ignition comme format de configuration. OpenShift Container Platform 4.6 est passé de la version 2 de la spécification de configuration Ignition à la version 3.
5.1.2.1. Que pouvez-vous changer dans la configuration des machines ?
Les types de composants que le MCO peut modifier sont les suivants :
config: Créer des objets de configuration Ignition (voir la spécification de configuration Ignition) pour faire des choses comme modifier des fichiers, des services systemd et d'autres fonctionnalités sur les machines OpenShift Container Platform, y compris :
-
Configuration files: Créer ou écraser des fichiers dans le répertoire
/varou/etc. - systemd units: Créer et définir l'état d'un service systemd ou ajouter des paramètres supplémentaires à un service systemd existant.
- users and groups: Modifier les clés SSH dans la section passwd après l'installation.
-
Configuration files: Créer ou écraser des fichiers dans le répertoire
La modification des clés SSH via la configuration des machines n'est possible que pour l'utilisateur core.
- kernelArguments: Ajout d'arguments à la ligne de commande du noyau lors du démarrage des nœuds d'OpenShift Container Platform.
-
kernelType: Identifier éventuellement un noyau non standard à utiliser à la place du noyau standard. Utilisez
realtimepour utiliser le noyau RT (pour RAN). Cette option n'est prise en charge que sur certaines plates-formes. - fips: Activer le mode FIPS. Le mode FIPS doit être défini au moment de l'installation et non lors d'une procédure post-installation.
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the x86_64 architecture.
- extensions: Étendre les fonctionnalités de RHCOS en ajoutant des logiciels pré-packagés sélectionnés. Pour cette fonctionnalité, les extensions disponibles comprennent usbguard et les modules du noyau.
-
Custom resources (for
ContainerRuntimeandKubelet): En dehors des configurations de machines, MCO gère deux ressources spéciales personnalisées pour modifier les paramètres d'exécution des conteneurs CRI-O (ContainerRuntimeCR) et le service Kubelet (KubeletCR).
Le MCO n'est pas le seul opérateur à pouvoir modifier les composants du système d'exploitation sur les nœuds d'OpenShift Container Platform. D'autres opérateurs peuvent également modifier les fonctionnalités du système d'exploitation. Un exemple est l'opérateur Node Tuning, qui vous permet d'effectuer des réglages au niveau du nœud par le biais de profils de démon Tuned.
Les tâches de configuration du MCO qui peuvent être effectuées après l'installation sont incluses dans les procédures suivantes. Voir les descriptions de l'installation RHCOS bare metal pour les tâches de configuration du système qui doivent être effectuées pendant ou avant l'installation d'OpenShift Container Platform.
Il peut arriver que la configuration d'un nœud ne corresponde pas entièrement à ce que la configuration de la machine actuellement appliquée spécifie. Cet état est appelé configuration drift. Le Machine Config Daemon (MCD) vérifie régulièrement que les nœuds ne présentent pas de dérive de configuration. Si le MCD détecte une dérive de la configuration, le MCO marque le nœud degraded jusqu'à ce qu'un administrateur corrige la configuration du nœud. Un nœud dégradé est en ligne et opérationnel, mais il ne peut pas être mis à jour. Pour plus d'informations sur la dérive de configuration, voir Understanding configuration drift detection.
5.1.2.2. Projet
Voir le site GitHub openshift-machine-config-operator pour plus de détails.
5.1.3. Comprendre la détection des dérives de configuration
Il peut arriver que l'état du disque d'un nœud diffère de ce qui est configuré dans la configuration de la machine. C'est ce que l'on appelle configuration drift. Par exemple, un administrateur de cluster peut modifier manuellement un fichier, un fichier d'unité systemd ou une autorisation de fichier qui a été configurée dans la configuration de la machine. Cela entraîne une dérive de la configuration. La dérive de la configuration peut causer des problèmes entre les nœuds d'un pool de configuration machine ou lorsque les configurations machine sont mises à jour.
Le Machine Config Operator (MCO) utilise le Machine Config Daemon (MCD) pour vérifier régulièrement que les nœuds ne présentent pas de dérive de configuration. En cas de détection, le MCO configure le nœud et le pool de configuration de la machine (MCP) sur Degraded et signale l'erreur. Un nœud dégradé est en ligne et opérationnel, mais il ne peut pas être mis à jour.
Le MCD détecte les dérives de configuration dans chacune des conditions suivantes :
- Lorsqu'un nœud démarre.
- Après que l'un des fichiers (fichiers Ignition et unités drop-in systemd) spécifiés dans la configuration de la machine a été modifié en dehors de la configuration de la machine.
Avant d'appliquer une nouvelle configuration de machine.
NoteSi vous appliquez une nouvelle configuration de machine aux nœuds, le MCD interrompt temporairement la détection des dérives de configuration. Cet arrêt est nécessaire car la nouvelle configuration de la machine diffère nécessairement de la configuration de la machine sur les nœuds. Une fois la nouvelle configuration machine appliquée, le MCD recommence à détecter les dérives de configuration à l'aide de la nouvelle configuration machine.
Lors de la détection des dérives de configuration, le MCD vérifie que le contenu et les autorisations des fichiers correspondent bien à ce que la configuration de la machine actuellement appliquée spécifie. En règle générale, le MCD détecte les dérives de configuration en moins d'une seconde après le déclenchement de la détection.
Si le MCD détecte une dérive de la configuration, il exécute les tâches suivantes :
- Émet une erreur dans les journaux de la console
- Emet un événement Kubernetes
- Arrêt de la détection sur le nœud
-
Définit le nœud et le PCM à
degraded
Vous pouvez vérifier si vous avez un nœud dégradé en dressant la liste des MCP :
$ oc get mcp worker
Si vous avez un MCP dégradé, le champ DEGRADEDMACHINECOUNT est non nul, comme dans le cas suivant :
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
worker rendered-worker-404caf3180818d8ac1f50c32f14b57c3 False True True 2 1 1 1 5h51mVous pouvez déterminer si le problème est dû à une dérive de la configuration en examinant le pool de configuration de la machine :
$ oc describe mcp workerExemple de sortie
...
Last Transition Time: 2021-12-20T18:54:00Z
Message: Node ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4 is reporting: "content mismatch for file \"/etc/mco-test-file\""
Reason: 1 nodes are reporting degraded status on sync
Status: True
Type: NodeDegraded
...Ou, si vous savez quel nœud est dégradé, examinez ce nœud :
$ oc describe node/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4Exemple de sortie
...
Annotations: cloud.network.openshift.io/egress-ipconfig: [{"interface":"nic0","ifaddr":{"ipv4":"10.0.128.0/17"},"capacity":{"ip":10}}]
csi.volume.kubernetes.io/nodeid:
{"pd.csi.storage.gke.io":"projects/openshift-gce-devel-ci/zones/us-central1-a/instances/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4"}
machine.openshift.io/machine: openshift-machine-api/ci-ln-j4h8nkb-72292-pxqxz-worker-a-fjks4
machineconfiguration.openshift.io/controlPlaneTopology: HighlyAvailable
machineconfiguration.openshift.io/currentConfig: rendered-worker-67bd55d0b02b0f659aef33680693a9f9
machineconfiguration.openshift.io/desiredConfig: rendered-worker-67bd55d0b02b0f659aef33680693a9f9
machineconfiguration.openshift.io/reason: content mismatch for file "/etc/mco-test-file"
machineconfiguration.openshift.io/state: Degraded
...- 1
- Le message d'erreur indique qu'une dérive de configuration a été détectée entre le nœud et la machine config listée. Ici, le message d'erreur indique que le contenu de
/etc/mco-test-file, qui a été ajouté par la machine config, a changé en dehors de la machine config. - 2
- L'état du nœud est
Degraded.
Vous pouvez corriger la dérive de la configuration et ramener le nœud à l'état Ready en effectuant l'une des opérations suivantes :
- Assurez-vous que le contenu et les autorisations des fichiers sur le nœud correspondent à ce qui est configuré dans la configuration de la machine. Vous pouvez réécrire manuellement le contenu des fichiers ou modifier leurs autorisations.
Générer un fichier de force sur le nœud dégradé. Le fichier de force permet au MCD de contourner la détection habituelle de dérive de la configuration et de réappliquer la configuration actuelle de la machine.
NoteLa génération d'un fichier de force sur un nœud entraîne le redémarrage de ce nœud.
5.1.4. Vérification de l'état du pool de configuration de la machine
Pour connaître l'état de l'opérateur de configuration de la machine (MCO), de ses sous-composants et des ressources qu'il gère, utilisez les commandes suivantes : oc:
Procédure
Pour connaître le nombre de nœuds gérés par MCO disponibles sur votre cluster pour chaque pool de configuration de machines (MCP), exécutez la commande suivante :
$ oc get machineconfigpoolExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-06c9c4… True False False 3 3 3 0 4h42m worker rendered-worker-f4b64… False True False 3 2 2 0 4h42moù :
- MISE À JOUR
-
L'état
Trueindique que le MCO a appliqué la configuration actuelle de la machine aux nœuds de ce MCP. La configuration actuelle de la machine est spécifiée dans le champSTATUSde la sortieoc get mcp. L'étatFalseindique qu'un nœud du MCP est en cours de mise à jour. - MISE À JOUR
-
L'état
Trueindique que le MCO applique la configuration machine souhaitée, telle que spécifiée dans la ressource personnaliséeMachineConfigPool, à au moins un des nœuds de ce MCP. La configuration machine souhaitée est la nouvelle configuration machine éditée. Les nœuds en cours de mise à jour peuvent ne pas être disponibles pour la planification. Le statutFalseindique que tous les nœuds du MCP sont mis à jour. - DEGRADE
-
L'état
Trueindique que le MCO ne peut pas appliquer la configuration actuelle ou souhaitée de la machine à au moins un des nœuds de ce MCP, ou que la configuration échoue. Les nœuds dégradés peuvent ne pas être disponibles pour la programmation. L'étatFalseindique que tous les nœuds du MCP sont prêts. - MACHINECOUNT
- Indique le nombre total de machines dans ce GPE.
- READYMACHINECOUNT
- Indique le nombre total de machines de ce GPE qui sont prêtes à être programmées.
- COMPTEMACHINE MIS À JOUR
- Indique le nombre total de machines dans ce MCP qui ont la configuration de machine actuelle.
- COMPTEMACHINEDÉGRADÉ
- Indique le nombre total de machines de ce GPE qui sont marquées comme étant dégradées ou inconciliables.
Dans la sortie précédente, il y a trois nœuds de plan de contrôle (maître) et trois nœuds de travailleur. Le MCP du plan de contrôle et les nœuds associés sont mis à jour avec la configuration actuelle de la machine. Les nœuds du MCP de l'employé sont mis à jour en fonction de la configuration souhaitée de la machine. Deux des nœuds du MCP ouvrier sont mis à jour et un autre est encore en cours de mise à jour, comme l'indique le site
UPDATEDMACHINECOUNT(2). Il n'y a pas de problème, comme l'indiquent les adressesDEGRADEDMACHINECOUNT(0) etDEGRADED(False).Pendant que les nœuds du MCP sont mis à jour, la configuration de la machine répertoriée sous
CONFIGest la configuration de la machine actuelle, à partir de laquelle le MCP est mis à jour. Lorsque la mise à jour est terminée, la configuration de machine répertoriée est la configuration de machine souhaitée, vers laquelle le MCP a été mis à jour.NoteSi un nœud est en cours de cordonage, ce nœud n'est pas inclus dans le
READYMACHINECOUNT, mais il est inclus dans leMACHINECOUNT. De plus, le statut MCP est défini surUPDATING. Comme le nœud a la configuration de la machine actuelle, il est compté dans le totalUPDATEDMACHINECOUNT:Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-06c9c4… True False False 3 3 3 0 4h42m worker rendered-worker-c1b41a… False True False 3 2 3 0 4h42mPour vérifier l'état des nœuds d'un MCP en examinant la ressource personnalisée
MachineConfigPool, exécutez la commande suivante : :$ oc describe mcp workerExemple de sortie
... Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 2 Ready Machine Count: 3 Unavailable Machine Count: 0 Updated Machine Count: 3 Events: <none>NoteSi un nœud fait l'objet d'un cordon, il n'est pas inclus dans le site
Ready Machine Count. Il est inclus dans le siteUnavailable Machine Count:Exemple de sortie
... Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 2 Ready Machine Count: 2 Unavailable Machine Count: 1 Updated Machine Count: 3Pour voir chaque objet
MachineConfigexistant, exécutez la commande suivante :$ oc get machineconfigsExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 00-worker 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 01-master-container-runtime 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m 01-master-kubelet 2c9371fbb673b97a6fe8b1c52… 3.2.0 5h18m ... rendered-master-dde... 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18m rendered-worker-fde... 2c9371fbb673b97a6fe8b1c52... 3.2.0 5h18mNotez que les objets
MachineConfigrépertoriés commerenderedne sont pas destinés à être modifiés ou supprimés.Pour afficher le contenu d'une configuration de machine particulière (dans ce cas,
01-master-kubelet), exécutez la commande suivante :$ oc describe machineconfigs 01-master-kubeletLa sortie de la commande montre que cet objet
MachineConfigcontient à la fois des fichiers de configuration (cloud.confetkubelet.conf) et un service systemd (Kubernetes Kubelet) :Exemple de sortie
Name: 01-master-kubelet ... Spec: Config: Ignition: Version: 3.2.0 Storage: Files: Contents: Source: data:, Mode: 420 Overwrite: true Path: /etc/kubernetes/cloud.conf Contents: Source: data:,kind%3A%20KubeletConfiguration%0AapiVersion%3A%20kubelet.config.k8s.io%2Fv1beta1%0Aauthentication%3A%0A%20%20x509%3A%0A%20%20%20%20clientCAFile%3A%20%2Fetc%2Fkubernetes%2Fkubelet-ca.crt%0A%20%20anonymous... Mode: 420 Overwrite: true Path: /etc/kubernetes/kubelet.conf Systemd: Units: Contents: [Unit] Description=Kubernetes Kubelet Wants=rpc-statd.service network-online.target crio.service After=network-online.target crio.service ExecStart=/usr/bin/hyperkube \ kubelet \ --config=/etc/kubernetes/kubelet.conf \ ...
Si quelque chose ne va pas avec une configuration de machine que vous appliquez, vous pouvez toujours revenir en arrière. Par exemple, si vous avez exécuté oc create -f ./myconfig.yaml pour appliquer une configuration de machine, vous pouvez supprimer cette configuration de machine en exécutant la commande suivante :
$ oc delete -f ./myconfig.yamlSi c'était le seul problème, les nœuds du pool concerné devraient revenir à un état non dégradé. En réalité, cela entraîne le retour de la configuration rendue à son état précédent.
Si vous ajoutez vos propres configurations de machines à votre cluster, vous pouvez utiliser les commandes présentées dans l'exemple précédent pour vérifier leur état et l'état connexe du pool auquel elles sont appliquées.
5.2. Utilisation des objets MachineConfig pour configurer les nœuds
Vous pouvez utiliser les tâches de cette section pour créer des objets MachineConfig qui modifient les fichiers, les fichiers d'unité systemd et d'autres fonctionnalités du système d'exploitation s'exécutant sur les nœuds d'OpenShift Container Platform. Pour plus d'idées sur le travail avec les configurations de machine, voir le contenu lié à la mise à jour des clés autorisées SSH, à la vérification des signatures d'image, à l'activation de SCTP et à la configuration des noms d'initiateur iSCSI pour OpenShift Container Platform.
OpenShift Container Platform supporte la version 3.2 de la spécification Ignition. Toutes les nouvelles configurations de machines que vous créerez à l'avenir devront être basées sur la version 3.2 de la spécification Ignition. Si vous mettez à jour votre cluster OpenShift Container Platform, toutes les configurations de machines Ignition version 2.x existantes seront automatiquement traduites en version 3.2.
Il peut arriver que la configuration d'un nœud ne corresponde pas entièrement à ce que la configuration de la machine actuellement appliquée spécifie. Cet état est appelé configuration drift. Le Machine Config Daemon (MCD) vérifie régulièrement que les nœuds ne présentent pas de dérive de configuration. Si le MCD détecte une dérive de la configuration, le MCO marque le nœud degraded jusqu'à ce qu'un administrateur corrige la configuration du nœud. Un nœud dégradé est en ligne et opérationnel, mais il ne peut pas être mis à jour. Pour plus d'informations sur la dérive de la configuration, voir Comprendre la détection de la dérive de la configuration.
Utilisez la procédure suivante "Configuring chrony time service" comme modèle pour ajouter d'autres fichiers de configuration aux nœuds d'OpenShift Container Platform.
5.2.1. Configuring chrony time service
You can set the time server and related settings used by the chrony time service (chronyd) by modifying the contents of the chrony.conf file and passing those contents to your nodes as a machine config.
Procédure
Create a Butane config including the contents of the
chrony.conffile. For example, to configure chrony on worker nodes, create a99-worker-chrony.bufile.NoteSee "Creating machine configs with Butane" for information about Butane.
variant: openshift version: 4.12.0 metadata: name: 99-worker-chrony1 labels: machineconfiguration.openshift.io/role: worker2 storage: files: - path: /etc/chrony.conf mode: 06443 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst4 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony- 1 2
- On control plane nodes, substitute
masterforworkerin both of these locations. - 3
- Specify an octal value mode for the
modefield in the machine config file. After creating the file and applying the changes, themodeis converted to a decimal value. You can check the YAML file with the commandoc get mc <mc-name> -o yaml. - 4
- Specify any valid, reachable time source, such as the one provided by your DHCP server. Alternately, you can specify any of the following NTP servers:
1.rhel.pool.ntp.org,2.rhel.pool.ntp.org, or3.rhel.pool.ntp.org.
Use Butane to generate a
MachineConfigobject file,99-worker-chrony.yaml, containing the configuration to be delivered to the nodes:$ butane 99-worker-chrony.bu -o 99-worker-chrony.yamlApply the configurations in one of two ways:
-
If the cluster is not running yet, after you generate manifest files, add the
MachineConfigobject file to the<installation_directory>/openshiftdirectory, and then continue to create the cluster. If the cluster is already running, apply the file:
$ oc apply -f ./99-worker-chrony.yaml
-
If the cluster is not running yet, after you generate manifest files, add the
5.2.2. Désactivation du service chronologique
Vous pouvez désactiver le service chronologique (chronyd) pour les nœuds ayant un rôle spécifique en utilisant une ressource personnalisée (CR) MachineConfig.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez le CR
MachineConfigqui désactivechronydpour le rôle de nœud spécifié.Enregistrez le YAML suivant dans le fichier
disable-chronyd.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: <node_role>1 name: disable-chronyd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=NTP client/server Documentation=man:chronyd(8) man:chrony.conf(5) After=ntpdate.service sntp.service ntpd.service Conflicts=ntpd.service systemd-timesyncd.service ConditionCapability=CAP_SYS_TIME [Service] Type=forking PIDFile=/run/chrony/chronyd.pid EnvironmentFile=-/etc/sysconfig/chronyd ExecStart=/usr/sbin/chronyd $OPTIONS ExecStartPost=/usr/libexec/chrony-helper update-daemon PrivateTmp=yes ProtectHome=yes ProtectSystem=full [Install] WantedBy=multi-user.target enabled: false name: "chronyd.service"- 1
- Rôle du nœud dans lequel vous souhaitez désactiver
chronyd, par exemple,master.
Créez le CR
MachineConfigen exécutant la commande suivante :$ oc create -f disable-chronyd.yaml
5.2.3. Ajout d'arguments de noyau aux nœuds
Dans certains cas particuliers, vous pouvez ajouter des arguments de noyau à un ensemble de nœuds de votre cluster. Cela ne doit être fait qu'avec prudence et en comprenant bien les implications des arguments que vous définissez.
Une mauvaise utilisation des arguments du noyau peut rendre vos systèmes non amorçables.
Voici quelques exemples d'arguments de noyau que vous pouvez définir :
- enforcing=0: Configure Security Enhanced Linux (SELinux) pour qu'il fonctionne en mode permissif. En mode permissif, le système agit comme si SELinux appliquait la politique de sécurité chargée, notamment en étiquetant les objets et en émettant des entrées de refus d'accès dans les journaux, mais il ne refuse en fait aucune opération. Bien qu'il ne soit pas pris en charge par les systèmes de production, le mode permissif peut s'avérer utile pour le débogage.
-
nosmt: Désactive le multithreading symétrique (SMT) dans le noyau. Le multithreading permet d'avoir plusieurs threads logiques pour chaque unité centrale. Vous pouvez envisager d'utiliser
nosmtdans les environnements multi-locataires afin de réduire les risques d'attaques croisées. En désactivant le SMT, vous choisissez essentiellement la sécurité au détriment des performances. systemd.unified_cgroup_hierarchy: Active le groupe de contrôle Linux version 2 (cgroup v2). cgroup v2 est la prochaine version du groupe de contrôle du noyau et offre de nombreuses améliorations.
ImportantOpenShift Container Platform cgroups version 2 support is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Voir Kernel.org kernel parameters pour une liste et une description des arguments du noyau.
Dans la procédure suivante, vous créez un objet MachineConfig qui identifie :
- Ensemble de machines auxquelles vous souhaitez ajouter l'argument du noyau. Dans ce cas, il s'agit des machines ayant un rôle de travailleur.
- Arguments du noyau qui sont ajoutés à la fin des arguments du noyau existants.
- Une étiquette qui indique à quel endroit de la liste des configurations de machines la modification est appliquée.
Conditions préalables
- Disposer de privilèges administratifs sur un cluster OpenShift Container Platform opérationnel.
Procédure
Listez les objets
MachineConfigexistants pour votre cluster OpenShift Container Platform afin de déterminer comment étiqueter votre machine config :$ oc get MachineConfigExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33mCréer un fichier objet
MachineConfigqui identifie l'argument du noyau (par exemple,05-worker-kernelarg-selinuxpermissive.yaml)apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 05-worker-kernelarg-selinuxpermissive2 spec: kernelArguments: - enforcing=03 Créer la nouvelle configuration de la machine :
$ oc create -f 05-worker-kernelarg-selinuxpermissive.yamlVérifiez les configurations de la machine pour voir si le nouveau a été ajouté :
$ oc get MachineConfigExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 05-worker-kernelarg-selinuxpermissive 3.2.0 105s 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33mVérifier les nœuds :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-136-161.ec2.internal Ready worker 28m v1.25.0 ip-10-0-136-243.ec2.internal Ready master 34m v1.25.0 ip-10-0-141-105.ec2.internal Ready,SchedulingDisabled worker 28m v1.25.0 ip-10-0-142-249.ec2.internal Ready master 34m v1.25.0 ip-10-0-153-11.ec2.internal Ready worker 28m v1.25.0 ip-10-0-153-150.ec2.internal Ready master 34m v1.25.0Vous pouvez voir que la planification sur chaque nœud de travailleur est désactivée pendant que la modification est appliquée.
Vérifiez que l'argument du noyau a fonctionné en vous rendant sur l'un des nœuds de travail et en listant les arguments de la ligne de commande du noyau (dans
/proc/cmdlinesur l'hôte) :$ oc debug node/ip-10-0-141-105.ec2.internalExemple de sortie
Starting pod/ip-10-0-141-105ec2internal-debug ... To use host binaries, run `chroot /host` sh-4.2# cat /host/proc/cmdline BOOT_IMAGE=/ostree/rhcos-... console=tty0 console=ttyS0,115200n8 rootflags=defaults,prjquota rw root=UUID=fd0... ostree=/ostree/boot.0/rhcos/16... coreos.oem.id=qemu coreos.oem.id=ec2 ignition.platform.id=ec2 enforcing=0 sh-4.2# exitVous devriez voir l'argument
enforcing=0ajouté aux autres arguments du noyau.
5.2.4. Enabling multipathing with kernel arguments on RHCOS
Red Hat Enterprise Linux CoreOS (RHCOS) prend en charge le multipathing sur le disque primaire, permettant une meilleure résilience aux pannes matérielles afin d'atteindre une plus grande disponibilité de l'hôte. La prise en charge post-installation est disponible en activant le multipathing via la configuration de la machine.
L'activation du multipathing lors de l'installation est prise en charge et recommandée pour les nœuds provisionnés dans OpenShift Container Platform 4.8 ou supérieur. Dans les configurations où toute E/S vers des chemins non optimisés entraîne des erreurs de système d'E/S, vous devez activer le multipathing au moment de l'installation. Pour plus d'informations sur l'activation du multipathing lors de l'installation, voir "Enabling multipathing with kernel arguments on RHCOS" dans la documentation Installing on bare metal.
On IBM zSystems and IBM® LinuxONE, you can enable multipathing only if you configured your cluster for it during installation. For more information, see "Installing RHCOS and starting the OpenShift Container Platform bootstrap process" in Installing a cluster with z/VM on IBM zSystems and IBM® LinuxONE.
Conditions préalables
- Vous disposez d'un cluster OpenShift Container Platform en cours d'exécution qui utilise la version 4.7 ou une version ultérieure.
- You are logged in to the cluster as a user with administrative privileges.
- Vous avez confirmé que le disque est activé pour le multipathing. Le multipathing n'est pris en charge que sur les hôtes connectés à un SAN via un adaptateur HBA.
Procédure
Pour activer le multipathing après l'installation sur les nœuds du plan de contrôle :
Créez un fichier de configuration de machine, tel que
99-master-kargs-mpath.yaml, qui demande au cluster d'ajouter l'étiquettemasteret qui identifie l'argument du noyau multipath, par exemple :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "master" name: 99-master-kargs-mpath spec: kernelArguments: - 'rd.multipath=default' - 'root=/dev/disk/by-label/dm-mpath-root'
Pour activer le multipathing après l'installation sur les nœuds de travail :
Créez un fichier de configuration de machine, tel que
99-worker-kargs-mpath.yaml, qui demande au cluster d'ajouter l'étiquetteworkeret qui identifie l'argument du noyau multipath, par exemple :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "worker" name: 99-worker-kargs-mpath spec: kernelArguments: - 'rd.multipath=default' - 'root=/dev/disk/by-label/dm-mpath-root'
Créez la nouvelle configuration de la machine en utilisant le fichier YAML du maître ou du travailleur que vous avez créé précédemment :
$ oc create -f ./99-worker-kargs-mpath.yamlVérifiez les configurations de la machine pour voir si le nouveau a été ajouté :
$ oc get MachineConfigExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-kargs-mpath 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 105s 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33mVérifier les nœuds :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-136-161.ec2.internal Ready worker 28m v1.25.0 ip-10-0-136-243.ec2.internal Ready master 34m v1.25.0 ip-10-0-141-105.ec2.internal Ready,SchedulingDisabled worker 28m v1.25.0 ip-10-0-142-249.ec2.internal Ready master 34m v1.25.0 ip-10-0-153-11.ec2.internal Ready worker 28m v1.25.0 ip-10-0-153-150.ec2.internal Ready master 34m v1.25.0Vous pouvez voir que la planification sur chaque nœud de travailleur est désactivée pendant que la modification est appliquée.
Vérifiez que l'argument du noyau a fonctionné en vous rendant sur l'un des nœuds de travail et en listant les arguments de la ligne de commande du noyau (dans
/proc/cmdlinesur l'hôte) :$ oc debug node/ip-10-0-141-105.ec2.internalExemple de sortie
Starting pod/ip-10-0-141-105ec2internal-debug ... To use host binaries, run `chroot /host` sh-4.2# cat /host/proc/cmdline ... rd.multipath=default root=/dev/disk/by-label/dm-mpath-root ... sh-4.2# exitYou should see the added kernel arguments.
5.2.5. Ajout d'un noyau en temps réel aux nœuds
Certaines charges de travail d'OpenShift Container Platform nécessitent un degré élevé de déterminisme.Bien que Linux ne soit pas un système d'exploitation en temps réel, le noyau Linux en temps réel comprend un planificateur préemptif qui fournit au système d'exploitation des caractéristiques en temps réel.
Si vos charges de travail OpenShift Container Platform nécessitent ces caractéristiques de temps réel, vous pouvez basculer vos machines vers le noyau temps réel Linux. Pour OpenShift Container Platform, 4.12, vous pouvez effectuer ce changement en utilisant un objet MachineConfig. Bien que le changement soit aussi simple que de changer un paramètre de configuration de machine kernelType en realtime, il y a quelques autres considérations à prendre en compte avant d'effectuer le changement :
- Actuellement, le noyau en temps réel n'est pris en charge que sur les nœuds de travail, et uniquement pour l'utilisation du réseau d'accès radio (RAN).
- La procédure suivante est entièrement prise en charge par les installations bare metal qui utilisent des systèmes certifiés pour Red Hat Enterprise Linux for Real Time 8.
- La prise en charge en temps réel dans OpenShift Container Platform est limitée à des abonnements spécifiques.
- La procédure suivante est également prise en charge pour une utilisation avec Google Cloud Platform.
Conditions préalables
- Disposer d'un cluster OpenShift Container Platform en cours d'exécution (version 4.4 ou ultérieure).
- Connectez-vous au cluster en tant qu'utilisateur disposant de privilèges administratifs.
Procédure
Créer une configuration de machine pour le noyau temps réel : Créez un fichier YAML (par exemple,
99-worker-realtime.yaml) qui contient un objetMachineConfigpour le type de noyaurealtime. Cet exemple indique au cluster d'utiliser un noyau en temps réel pour tous les nœuds de travail :$ cat << EOF > 99-worker-realtime.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "worker" name: 99-worker-realtime spec: kernelType: realtime EOFAjoutez la configuration de la machine au cluster. Tapez ce qui suit pour ajouter la configuration de la machine à la grappe :
$ oc create -f 99-worker-realtime.yamlVérifiez le noyau en temps réel : Une fois que chaque nœud impacté a redémarré, connectez-vous au cluster et exécutez les commandes suivantes pour vous assurer que le noyau en temps réel a remplacé le noyau normal pour l'ensemble des nœuds que vous avez configurés :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-143-147.us-east-2.compute.internal Ready worker 103m v1.25.0 ip-10-0-146-92.us-east-2.compute.internal Ready worker 101m v1.25.0 ip-10-0-169-2.us-east-2.compute.internal Ready worker 102m v1.25.0$ oc debug node/ip-10-0-143-147.us-east-2.compute.internalExemple de sortie
Starting pod/ip-10-0-143-147us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` sh-4.4# uname -a Linux <worker_node> 4.18.0-147.3.1.rt24.96.el8_1.x86_64 #1 SMP PREEMPT RT Wed Nov 27 18:29:55 UTC 2019 x86_64 x86_64 x86_64 GNU/LinuxLe nom du noyau contient
rtet le texte "PREEMPT RT" indique qu'il s'agit d'un noyau temps réel.Pour revenir au noyau normal, supprimez l'objet
MachineConfig:$ oc delete -f 99-worker-realtime.yaml
5.2.6. Configuration des paramètres de journald
Si vous devez configurer les paramètres du service journald sur les nœuds d'OpenShift Container Platform, vous pouvez le faire en modifiant le fichier de configuration approprié et en transmettant le fichier au pool de nœuds approprié en tant que machine config.
Cette procédure décrit comment modifier les paramètres de limitation du débit de journald dans le fichier /etc/systemd/journald.conf et les appliquer aux nœuds de travail. Voir la page de manuel journald.conf pour plus d'informations sur l'utilisation de ce fichier.
Conditions préalables
- Disposer d'un cluster OpenShift Container Platform en cours d'exécution.
- Connectez-vous au cluster en tant qu'utilisateur disposant de privilèges administratifs.
Procédure
Créez un fichier de configuration Butane,
40-worker-custom-journald.bu, qui inclut un fichier/etc/systemd/journald.confavec les paramètres requis.NoteSee "Creating machine configs with Butane" for information about Butane.
variant: openshift version: 4.12.0 metadata: name: 40-worker-custom-journald labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/systemd/journald.conf mode: 0644 overwrite: true contents: inline: | # Disable rate limiting RateLimitInterval=1s RateLimitBurst=10000 Storage=volatile Compress=no MaxRetentionSec=30sUtilisez Butane pour générer un fichier objet
MachineConfig,40-worker-custom-journald.yaml, contenant la configuration à fournir aux nœuds de travail :$ butane 40-worker-custom-journald.bu -o 40-worker-custom-journald.yamlAppliquer la configuration de la machine au pool :
$ oc apply -f 40-worker-custom-journald.yamlVérifiez que la nouvelle configuration de la machine est appliquée et que les nœuds ne sont pas dans un état dégradé. Cela peut prendre quelques minutes. Le worker pool affichera les mises à jour en cours, au fur et à mesure que chaque nœud aura appliqué avec succès la nouvelle configuration de la machine :
$ oc get machineconfigpool NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-35 True False False 3 3 3 0 34m worker rendered-worker-d8 False True False 3 1 1 0 34mPour vérifier que la modification a été appliquée, vous pouvez vous connecter à un nœud de travail :
$ oc get node | grep worker ip-10-0-0-1.us-east-2.compute.internal Ready worker 39m v0.0.0-master+$Format:%h$ $ oc debug node/ip-10-0-0-1.us-east-2.compute.internal Starting pod/ip-10-0-141-142us-east-2computeinternal-debug ... ... sh-4.2# chroot /host sh-4.4# cat /etc/systemd/journald.conf # Disable rate limiting RateLimitInterval=1s RateLimitBurst=10000 Storage=volatile Compress=no MaxRetentionSec=30s sh-4.4# exit
5.2.7. Ajout d'extensions au RHCOS
RHCOS est un système d'exploitation RHEL minimal orienté conteneur, conçu pour fournir un ensemble commun de fonctionnalités aux clusters OpenShift Container Platform sur toutes les plateformes. Bien que l'ajout de progiciels aux systèmes RHCOS soit généralement déconseillé, le MCO fournit une fonctionnalité extensions que vous pouvez utiliser pour ajouter un ensemble minimal de fonctionnalités aux nœuds RHCOS.
Les extensions suivantes sont actuellement disponibles :
-
usbguard: L'ajout de l'extension
usbguardprotège les systèmes RHCOS contre les attaques de périphériques USB intrusifs. Voir USBGuard pour plus de détails. -
kerberos: L'ajout de l'extension
kerberosfournit un mécanisme qui permet aux utilisateurs et aux machines de s'identifier sur le réseau pour recevoir un accès défini et limité aux zones et aux services qu'un administrateur a configurés. Voir Utilisation de Kerberos pour plus de détails, y compris la configuration d'un client Kerberos et le montage d'un partage NFS Kerberisé.
La procédure suivante décrit comment utiliser une configuration de machine pour ajouter une ou plusieurs extensions à vos nœuds RHCOS.
Conditions préalables
- Disposer d'un cluster OpenShift Container Platform en cours d'exécution (version 4.6 ou ultérieure).
- Connectez-vous au cluster en tant qu'utilisateur disposant de privilèges administratifs.
Procédure
Créer une configuration de machine pour les extensions : Créez un fichier YAML (par exemple,
80-extensions.yaml) qui contient un objetMachineConfigextensions. Cet exemple indique au cluster d'ajouter l'extensionusbguard.$ cat << EOF > 80-extensions.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 80-worker-extensions spec: config: ignition: version: 3.2.0 extensions: - usbguard EOFAjoutez la configuration de la machine au cluster. Tapez ce qui suit pour ajouter la configuration de la machine à la grappe :
$ oc create -f 80-extensions.yamlCela permet d'installer les paquets rpm pour
usbguardsur tous les nœuds de travail.Vérifier que les extensions ont été appliquées :
$ oc get machineconfig 80-worker-extensionsExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 80-worker-extensions 3.2.0 57sVérifiez que la nouvelle configuration de la machine est maintenant appliquée et que les nœuds ne sont pas dans un état dégradé. Cela peut prendre quelques minutes. Le worker pool affichera les mises à jour en cours, au fur et à mesure que la nouvelle configuration de chaque machine sera appliquée avec succès :
$ oc get machineconfigpoolExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-35 True False False 3 3 3 0 34m worker rendered-worker-d8 False True False 3 1 1 0 34mVérifiez les extensions. Pour vérifier que l'extension a été appliquée, exécutez :
$ oc get node | grep workerExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-169-2.us-east-2.compute.internal Ready worker 102m v1.25.0$ oc debug node/ip-10-0-169-2.us-east-2.compute.internalExemple de sortie
... To use host binaries, run `chroot /host` sh-4.4# chroot /host sh-4.4# rpm -q usbguard usbguard-0.7.4-4.el8.x86_64.rpm
5.2.8. Chargement de blobs de firmware personnalisés dans le manifeste de configuration de la machine
L'emplacement par défaut des blobs de firmware dans /usr/lib étant en lecture seule, vous pouvez localiser un blob de firmware personnalisé en mettant à jour le chemin de recherche. Cela vous permet de charger des blobs de firmware locaux dans le manifeste de configuration de la machine lorsque les blobs ne sont pas gérés par RHCOS.
Procédure
Créez un fichier de configuration Butane,
98-worker-firmware-blob.bu, qui met à jour le chemin de recherche de manière à ce qu'il soit détenu par la racine et accessible en écriture au stockage local. L'exemple suivant place le fichier blob personnalisé de votre station de travail locale sur les nœuds sous/var/lib/firmware.NoteSee "Creating machine configs with Butane" for information about Butane.
Fichier de configuration Butane pour le blob de firmware personnalisé
variant: openshift version: 4.12.0 metadata: labels: machineconfiguration.openshift.io/role: worker name: 98-worker-firmware-blob storage: files: - path: /var/lib/firmware/<package_name>1 contents: local: <package_name>2 mode: 06443 openshift: kernel_arguments: - 'firmware_class.path=/var/lib/firmware'4 - 1
- Définit le chemin d'accès au nœud où le paquet de microprogrammes est copié.
- 2
- Spécifie un fichier dont le contenu est lu à partir d'un répertoire de fichiers locaux sur le système où s'exécute Butane. Le chemin du fichier local est relatif à un répertoire
files-dir, qui doit être spécifié en utilisant l'option--files-diravec Butane à l'étape suivante. - 3
- Définit les autorisations pour le fichier sur le nœud RHCOS. Il est recommandé de définir les permissions sur
0644. - 4
- Le paramètre
firmware_class.pathpersonnalise le chemin de recherche du noyau pour savoir où chercher le blob de micrologiciel personnalisé qui a été copié depuis votre station de travail locale sur le système de fichiers racine du nœud. Cet exemple utilise/var/lib/firmwarecomme chemin personnalisé.
Exécutez Butane pour générer un fichier objet
MachineConfigqui utilise une copie du blob firmware sur votre station de travail locale nommée98-worker-firmware-blob.yaml. Le blob firmware contient la configuration à fournir aux nœuds. L'exemple suivant utilise l'option--files-dirpour spécifier le répertoire de votre station de travail où se trouvent le ou les fichiers locaux :$ butane 98-worker-firmware-blob.bu -o 98-worker-firmware-blob.yaml --files-dir <directory_including_package_name>Appliquez les configurations aux nœuds de l'une des deux manières suivantes :
-
If the cluster is not running yet, after you generate manifest files, add the
MachineConfigobject file to the<installation_directory>/openshiftdirectory, and then continue to create the cluster. If the cluster is already running, apply the file:
$ oc apply -f 98-worker-firmware-blob.yamlA
MachineConfigobject YAML file is created for you to finish configuring your machines.
-
If the cluster is not running yet, after you generate manifest files, add the
-
Save the Butane config in case you need to update the
MachineConfigobject in the future.
5.3. Configuration des ressources personnalisées liées au MCO
Outre la gestion des objets MachineConfig, le MCO gère deux ressources personnalisées (CR) : KubeletConfig et ContainerRuntimeConfig. Ces CR vous permettent de modifier les paramètres au niveau du nœud ayant un impact sur le comportement des services d'exécution des conteneurs Kubelet et CRI-O.
5.3.1. Création d'un CRD KubeletConfig pour éditer les paramètres des kubelets
La configuration du kubelet est actuellement sérialisée comme une configuration Ignition, elle peut donc être directement éditée. Cependant, une nouvelle adresse kubelet-config-controller a été ajoutée au contrôleur de configuration de la machine (MCC). Cela vous permet d'utiliser une ressource personnalisée (CR) KubeletConfig pour modifier les paramètres du kubelet.
Comme les champs de l'objet kubeletConfig sont transmis directement au kubelet par Kubernetes en amont, le kubelet valide ces valeurs directement. Des valeurs non valides dans l'objet kubeletConfig peuvent entraîner l'indisponibilité des nœuds du cluster. Pour connaître les valeurs valides, consultez la documentation de Kubernetes.
Examinez les conseils suivants :
-
Créez un CR
KubeletConfigpour chaque pool de configuration de machine avec toutes les modifications de configuration que vous souhaitez pour ce pool. Si vous appliquez le même contenu à tous les pools, vous n'avez besoin que d'un seul CRKubeletConfigpour tous les pools. -
Modifiez un CR
KubeletConfigexistant pour modifier les paramètres existants ou en ajouter de nouveaux, au lieu de créer un CR pour chaque changement. Il est recommandé de ne créer un CR que pour modifier un pool de configuration de machine différent, ou pour des changements qui sont censés être temporaires, afin de pouvoir revenir sur les modifications. -
Si nécessaire, créez plusieurs CR
KubeletConfigdans la limite de 10 par cluster. Pour le premier CRKubeletConfig, l'opérateur de configuration de machine (MCO) crée une configuration de machine avec l'extensionkubelet. Pour chaque CR suivant, le contrôleur crée une autre configuration machinekubeletavec un suffixe numérique. Par exemple, si vous avez une configuration machinekubeletavec un suffixe-2, la configuration machinekubeletsuivante est complétée par-3.
Si vous souhaitez supprimer les configurations de machine, supprimez-les dans l'ordre inverse pour éviter de dépasser la limite. Par exemple, vous supprimez la configuration de la machine kubelet-3 avant de supprimer la configuration de la machine kubelet-2.
Si vous avez une configuration de machine avec un suffixe kubelet-9 et que vous créez une autre CR KubeletConfig, une nouvelle configuration de machine n'est pas créée, même s'il y a moins de 10 configurations de machine kubelet.
Exemple KubeletConfig CR
$ oc get kubeletconfigNAME AGE
set-max-pods 15mExemple de configuration d'une machine KubeletConfig
$ oc get mc | grep kubelet...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
...La procédure suivante est un exemple qui montre comment configurer le nombre maximum de pods par nœud sur les nœuds de travail.
Conditions préalables
Obtenez l'étiquette associée au CR statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer. Effectuez l'une des opérations suivantes :Voir le pool de configuration de la machine :
oc describe machineconfigpool <name> $ oc describe machineconfigpool <name>Par exemple :
$ oc describe machineconfigpool workerExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods1 - 1
- Si un label a été ajouté, il apparaît sous
labels.
Si l'étiquette n'est pas présente, ajoutez une paire clé/valeur :
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
Procédure
Affichez les objets de configuration de la machine disponibles que vous pouvez sélectionner :
$ oc get machineconfigPar défaut, les deux configurations liées à kubelet sont
01-master-kubeletet01-worker-kubelet.Vérifier la valeur actuelle du nombre maximum de pods par nœud :
oc describe node <node_name>Par exemple :
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Cherchez
value: pods: <value>dans la stropheAllocatable:Exemple de sortie
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250Définissez le nombre maximum de pods par nœud sur les nœuds de travail en créant un fichier de ressources personnalisé qui contient la configuration du kubelet :
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods1 kubeletConfig: maxPods: 5002 NoteLe taux auquel le kubelet parle au serveur API dépend des requêtes par seconde (QPS) et des valeurs de rafale. Les valeurs par défaut,
50pourkubeAPIQPSet100pourkubeAPIBurst, sont suffisantes si le nombre de pods fonctionnant sur chaque nœud est limité. Il est recommandé de mettre à jour les taux de QPS et de burst du kubelet s'il y a suffisamment de ressources de CPU et de mémoire sur le nœud.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>Mettre à jour le pool de configuration des machines pour les travailleurs avec le label :
$ oc label machineconfigpool worker custom-kubelet=set-max-podsCréer l'objet
KubeletConfig:$ oc create -f change-maxPods-cr.yamlVérifiez que l'objet
KubeletConfigest créé :$ oc get kubeletconfigExemple de sortie
NAME AGE set-max-pods 15mEn fonction du nombre de nœuds de travail dans la grappe, attendez que les nœuds de travail soient redémarrés un par un. Pour une grappe de 3 nœuds de travail, cela peut prendre de 10 à 15 minutes.
Vérifiez que les modifications sont appliquées au nœud :
Vérifier sur un nœud de travail que la valeur de
maxPodsa changé :oc describe node <node_name>Repérez la strophe
Allocatable:... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 5001 ...- 1
- Dans cet exemple, le paramètre
podsdoit indiquer la valeur que vous avez définie dans l'objetKubeletConfig.
Vérifiez la modification de l'objet
KubeletConfig:$ oc get kubeletconfigs set-max-pods -o yamlL'état de
Trueettype:Successdevrait apparaître, comme le montre l'exemple suivant :spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
5.3.2. Création d'un CR ContainerRuntimeConfig pour modifier les paramètres CRI-O
Vous pouvez modifier certains paramètres associés au runtime CRI-O d'OpenShift Container Platform pour les nœuds associés à un pool de configuration machine (MCP) spécifique. En utilisant une ressource personnalisée (CR) ContainerRuntimeConfig, vous définissez les valeurs de configuration et ajoutez un label correspondant au MCP. Le MCO reconstruit ensuite les fichiers de configuration crio.conf et storage.conf sur les nœuds associés avec les valeurs mises à jour.
Pour annuler les modifications apportées par l'utilisation d'un CR ContainerRuntimeConfig, vous devez supprimer le CR. La suppression de l'étiquette du pool de configuration de la machine n'annule pas les modifications.
Vous pouvez modifier les paramètres suivants à l'aide d'un CR ContainerRuntimeConfig:
PIDs limit: La définition de la limite des PIDs sur le site
ContainerRuntimeConfigdevrait être obsolète. Si des limites de PIDs sont nécessaires, il est recommandé d'utiliser le champpodPidsLimitdans le CRKubeletConfig. La valeur par défaut du champpodPidsLimitest4096.NoteLe drapeau CRI-O est appliqué sur le cgroup du conteneur, tandis que le drapeau Kubelet est défini sur le cgroup du pod. Veuillez ajuster la limite des PIDs en conséquence.
-
Log level: Le paramètre
logLeveldéfinit le paramètre CRI-Olog_level, qui est le niveau de verbosité des messages de journalisation. La valeur par défaut estinfo(log_level = info). Les autres options sontfatal,panic,error,warn,debugettrace. -
Overlay size: Le paramètre
overlaySizedéfinit le paramètre du pilote de stockage de CRI-O Overlaysize, qui est la taille maximale d'une image de conteneur. -
Maximum log size: La définition de la taille maximale du journal dans le champ
ContainerRuntimeConfigdevrait être obsolète. Si une taille maximale de journal est requise, il est recommandé d'utiliser le champcontainerLogMaxSizedans le CRKubeletConfig. -
Container runtime: Le paramètre
defaultRuntimedéfinit la durée d'exécution du conteneur surruncoucrun. La valeur par défaut estrunc.
La prise en charge du moteur d'exécution de conteneur crun est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Vous devez avoir un CR ContainerRuntimeConfig pour chaque pool de configuration de machine avec toutes les modifications de configuration que vous souhaitez pour ce pool. Si vous appliquez le même contenu à tous les pools, vous n'avez besoin que d'un seul CR ContainerRuntimeConfig pour tous les pools.
Vous devez éditer un CR ContainerRuntimeConfig existant pour modifier les paramètres existants ou en ajouter de nouveaux au lieu de créer un nouveau CR pour chaque changement. Il est recommandé de créer un nouveau CR ContainerRuntimeConfig uniquement pour modifier un pool de configuration machine différent, ou pour des changements qui sont censés être temporaires afin que vous puissiez revenir sur les modifications.
Vous pouvez créer plusieurs ContainerRuntimeConfig CR, selon vos besoins, dans la limite de 10 par cluster. Pour le premier CR ContainerRuntimeConfig, le MCO crée une configuration de machine avec l'extension containerruntime. Pour chaque CR suivant, le contrôleur crée une nouvelle configuration machine containerruntime avec un suffixe numérique. Par exemple, si vous avez une configuration de machine containerruntime avec un suffixe -2, la prochaine configuration de machine containerruntime est complétée par -3.
Si vous souhaitez supprimer les configurations de machine, vous devez les supprimer dans l'ordre inverse pour éviter de dépasser la limite. Par exemple, vous devez supprimer la configuration de la machine containerruntime-3 avant de supprimer la configuration de la machine containerruntime-2.
Si vous avez une configuration de machine avec un suffixe containerruntime-9 et que vous créez une autre CR ContainerRuntimeConfig, une nouvelle configuration de machine n'est pas créée, même s'il y a moins de 10 configurations de machine containerruntime.
Exemple montrant plusieurs CR ContainerRuntimeConfig
$ oc get ctrcfgExemple de sortie
NAME AGE
ctr-pid 24m
ctr-overlay 15m
ctr-level 5m45sExemple de configuration de plusieurs machines containerruntime
$ oc get mc | grep containerExemple de sortie
...
01-master-container-runtime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 57m
...
01-worker-container-runtime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 57m
...
99-worker-generated-containerruntime b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
99-worker-generated-containerruntime-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 17m
99-worker-generated-containerruntime-2 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 7m26s
...
L'exemple suivant augmente la valeur de pids_limit à 2048, définit la valeur de log_level à debug, définit la taille de la superposition à 8 Go et définit la valeur de log_size_max à illimité :
Exemple ContainerRuntimeConfig CR
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: overlay-size
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ''
containerRuntimeConfig:
pidsLimit: 2048
logLevel: debug
overlaySize: 8G
logSizeMax: "-1"
defaultRuntime: "crun" - 1
- Spécifie l'étiquette du pool de configuration de la machine.
- 2
- Facultatif : Spécifie le nombre maximum de processus autorisés dans un conteneur.
- 3
- Facultatif : Spécifie le niveau de verbosité des messages du journal.
- 4
- Facultatif : Spécifie la taille maximale d'une image de conteneur.
- 5
- Facultatif : Spécifie la taille maximale autorisée pour le fichier journal du conteneur. S'il s'agit d'un nombre positif, il doit être au moins égal à 8192.
- 6
- Facultatif : Spécifie l'exécution du conteneur à déployer dans les nouveaux conteneurs. La valeur par défaut est
runc.
Prérequis
Pour activer crun, vous devez activer le jeu de fonctionnalités
TechPreviewNoUpgrade.NoteL'activation de l'ensemble de fonctionnalités
TechPreviewNoUpgradene peut être annulée et empêche les mises à jour mineures de la version. Ces jeux de fonctionnalités ne sont pas recommandés sur les clusters de production.
Procédure
Pour modifier les paramètres CRI-O à l'aide de ContainerRuntimeConfig CR :
Créer un fichier YAML pour le CR
ContainerRuntimeConfig:apiVersion: machineconfiguration.openshift.io/v1 kind: ContainerRuntimeConfig metadata: name: overlay-size spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ''1 containerRuntimeConfig:2 pidsLimit: 2048 logLevel: debug overlaySize: 8G logSizeMax: "-1"Créer le CR
ContainerRuntimeConfig:oc create -f <nom_du_fichier>.yamlVérifiez que la CR est créée :
$ oc get ContainerRuntimeConfigExemple de sortie
NAME AGE overlay-size 3m19sVérifier qu'une nouvelle configuration de la machine
containerruntimeest créée :$ oc get machineconfigs | grep containerrunExemple de sortie
99-worker-generated-containerruntime 2c9371fbb673b97a6fe8b1c52691999ed3a1bfc2 3.2.0 31sSurveillez le pool de configuration des machines jusqu'à ce qu'elles soient toutes prêtes :
$ oc get mcp workerExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-169 False True False 3 1 1 0 9hVérifier que les réglages ont été appliqués en CRI-O :
Ouvrez une session
oc debugsur un nœud du pool de configuration de la machine et exécutezchroot /host.oc debug node/<node_name>sh-4.4# chroot /hostVérifiez les changements dans le fichier
crio.conf:sh-4.4# crio config | egrep 'log_level|pids_limit|log_size_max'Exemple de sortie
pids_limit = 2048 log_size_max = -1 log_level = "debug"Vérifiez les changements dans le fichier `storage.conf` :
sh-4.4# head -n 7 /etc/containers/storage.confExemple de sortie
[storage] driver = "overlay" runroot = "/var/run/containers/storage" graphroot = "/var/lib/containers/storage" [storage.options] additionalimagestores = [] size = "8G"
5.3.3. Définition de la taille maximale par défaut de la partition racine du conteneur pour l'incrustation avec CRI-O
La partition racine de chaque conteneur affiche tout l'espace disque disponible de l'hôte sous-jacent. Suivez ces instructions pour définir une taille de partition maximale pour le disque racine de tous les conteneurs.
Pour configurer la taille maximale de la superposition, ainsi que d'autres options de CRI-O telles que le niveau de journalisation et la limite de PID, vous pouvez créer la définition de ressource personnalisée (CRD) suivante : ContainerRuntimeConfig:
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: overlay-size
spec:
machineConfigPoolSelector:
matchLabels:
custom-crio: overlay-size
containerRuntimeConfig:
pidsLimit: 2048
logLevel: debug
overlaySize: 8GProcédure
Créer l'objet de configuration :
$ oc apply -f overlaysize.ymlPour appliquer la nouvelle configuration CRI-O à vos nœuds de travail, modifiez le pool de configuration de la machine de travail :
$ oc edit machineconfigpool workerAjoutez l'étiquette
custom-crioen fonction du nommatchLabelsque vous avez défini dans le CRDContainerRuntimeConfig:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2020-07-09T15:46:34Z" generation: 3 labels: custom-crio: overlay-size machineconfiguration.openshift.io/mco-built-in: ""Enregistrez les modifications, puis affichez les configurations de la machine :
$ oc get machineconfigsDe nouveaux objets
99-worker-generated-containerruntimeetrendered-worker-xyzsont créés :Exemple de sortie
99-worker-generated-containerruntime 4173030d89fbf4a7a0976d1665491a4d9a6e54f1 3.2.0 7m42s rendered-worker-xyz 4173030d89fbf4a7a0976d1665491a4d9a6e54f1 3.2.0 7m36sUne fois ces objets créés, surveillez le pool de configuration de la machine pour que les modifications soient appliquées :
$ oc get mcp workerLes nœuds ouvriers affichent
UPDATINGsous la formeTrue, ainsi que le nombre de machines, le nombre de mises à jour et d'autres détails :Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-xyz False True False 3 2 2 0 20hUne fois l'opération terminée, les nœuds de travail reviennent à
UPDATINGen tant queFalse, et le numéro deUPDATEDMACHINECOUNTcorrespond à celui deMACHINECOUNT:Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE worker rendered-worker-xyz True False False 3 3 3 0 20hEn examinant une machine de travail, vous constatez que la nouvelle configuration de taille maximale de 8 Go est appliquée à toutes les machines de travail :
Exemple de sortie
head -n 7 /etc/containers/storage.conf [storage] driver = "overlay" runroot = "/var/run/containers/storage" graphroot = "/var/lib/containers/storage" [storage.options] additionalimagestores = [] size = "8G"En regardant à l'intérieur d'un conteneur, vous constatez que la partition racine est maintenant de 8 Go :
Exemple de sortie
~ $ df -h Filesystem Size Used Available Use% Mounted on overlay 8.0G 8.0K 8.0G 0% /
Chapitre 6. Tâches post-installation du cluster
Après avoir installé OpenShift Container Platform, vous pouvez étendre et personnaliser votre cluster en fonction de vos besoins.
6.1. Personnalisations disponibles pour les clusters
La majeure partie de la configuration et de la personnalisation du cluster est réalisée après le déploiement du cluster OpenShift Container Platform. Un certain nombre de sites configuration resources sont disponibles.
Si vous installez votre cluster sur des systèmes IBM z, toutes les caractéristiques et fonctions ne sont pas disponibles.
Vous modifiez les ressources de configuration pour configurer les principales fonctionnalités du cluster, telles que le registre d'images, la configuration du réseau, le comportement de construction des images et le fournisseur d'identité.
Pour obtenir la documentation actuelle des paramètres que vous contrôlez en utilisant ces ressources, utilisez la commande oc explain, par exemple oc explain builds --api-version=config.openshift.io/v1
6.1.1. Ressources de configuration du cluster
Toutes les ressources de configuration des clusters ont une portée globale (pas d'espace de noms) et sont nommées cluster.
| Nom de la ressource | Description |
|---|---|
|
| Fournit la configuration du serveur API, comme les certificats et les autorités de certification. |
|
| Contrôle le fournisseur d'identité et la configuration de l'authentification pour le cluster. |
|
| Contrôle la configuration par défaut et la configuration forcée pour toutes les constructions sur le cluster. |
|
| Configure le comportement de l'interface de la console web, y compris le comportement de déconnexion. |
|
| Active les FeatureGates afin que vous puissiez utiliser les fonctionnalités de la Tech Preview. |
|
| Configure la manière dont des registres d'images spécifiques doivent être traités (autorisés, non autorisés, non sécurisés, détails CA). |
|
| Détails de configuration liés au routage, tels que le domaine par défaut pour les itinéraires. |
|
| Configure les fournisseurs d'identité et d'autres comportements liés aux flux internes du serveur OAuth. |
|
| Configure la façon dont les projets sont créés, y compris le modèle de projet. |
|
| Définit les proxys à utiliser par les composants qui ont besoin d'un accès au réseau externe. Remarque : tous les composants ne consomment pas actuellement cette valeur. |
|
| Configure le comportement de l'ordonnanceur tel que les profils et les sélecteurs de nœuds par défaut. |
6.1.2. Ressources de configuration de l'opérateur
Ces ressources de configuration sont des instances à l'échelle du cluster, appelées cluster, qui contrôlent le comportement d'un composant spécifique appartenant à un opérateur particulier.
| Nom de la ressource | Description |
|---|---|
|
| Contrôle l'apparence de la console, comme la personnalisation de la marque |
|
| Configure les paramètres du registre d'images OpenShift tels que le routage public, les niveaux de journalisation, les paramètres de proxy, les contraintes de ressources, le nombre de répliques et le type de stockage. |
|
| Configure l'opérateur d'échantillons pour contrôler les flux d'images d'exemple et les modèles qui sont installés sur le cluster. |
6.1.3. Ressources de configuration supplémentaires
Ces ressources de configuration représentent une instance unique d'un composant particulier. Dans certains cas, vous pouvez demander plusieurs instances en créant plusieurs instances de la ressource. Dans d'autres cas, l'opérateur ne peut utiliser qu'un nom d'instance de ressource spécifique dans un espace de noms spécifique. Reportez-vous à la documentation spécifique au composant pour savoir quand et comment vous pouvez créer des instances de ressources supplémentaires.
| Nom de la ressource | Nom de l'instance | Espace de noms | Description |
|---|---|---|---|
|
|
|
| Contrôle les paramètres de déploiement de l'Alertmanager. |
|
|
|
| Configure le comportement de l'opérateur d'entrée tel que le domaine, le nombre de répliques, les certificats et le placement des contrôleurs. |
6.1.4. Ressources d'information
Ces ressources permettent de récupérer des informations sur le cluster. Certaines configurations peuvent nécessiter la modification directe de ces ressources.
| Nom de la ressource | Nom de l'instance | Description |
|---|---|---|
|
|
|
Dans OpenShift Container Platform 4.12, vous ne devez pas personnaliser la ressource |
|
|
| Vous ne pouvez pas modifier les paramètres DNS de votre cluster. Vous pouvez consulter l'état de l'opérateur DNS. |
|
|
| Détails de configuration permettant au cluster d'interagir avec son fournisseur de cloud. |
|
|
| Vous ne pouvez pas modifier la mise en réseau de votre cluster après l'installation. Pour personnaliser votre réseau, suivez la procédure de personnalisation de la mise en réseau lors de l'installation. |
6.2. Mise à jour du secret d'extraction du cluster global
Vous pouvez mettre à jour le secret d'extraction global pour votre cluster en remplaçant le secret d'extraction actuel ou en ajoutant un nouveau secret d'extraction.
Cette procédure est nécessaire lorsque les utilisateurs utilisent, pour stocker les images, un registre différent de celui utilisé lors de l'installation.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Facultatif : Pour ajouter un nouveau secret d'extraction au secret d'extraction existant, procédez comme suit :
Entrez la commande suivante pour télécharger le secret d'extraction :
$ oc get secret/pull-secret -n openshift-config --template='{{index .data ".dockerconfigjson" | base64decode}}' ><pull_secret_location>1 - 1
- Indiquer le chemin d'accès au fichier de secret d'extraction.
Entrez la commande suivante pour ajouter le nouveau secret d'extraction :
$ oc registry login --registry="<registry>" \1 --auth-basic="<username>:<password>" \2 --to=<pull_secret_location>3 Vous pouvez également procéder à une mise à jour manuelle du fichier "pull secret".
Entrez la commande suivante pour mettre à jour le secret d'extraction global pour votre cluster :
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
- Indiquez le chemin d'accès au nouveau fichier de secret d'extraction.
Cette mise à jour est déployée sur tous les nœuds, ce qui peut prendre un certain temps en fonction de la taille de votre cluster.
NoteDepuis OpenShift Container Platform 4.7.4, les modifications apportées au secret de tirage global ne déclenchent plus la vidange ou le redémarrage d'un nœud.
6.3. Ajout de nœuds de travail
Après avoir déployé votre cluster OpenShift Container Platform, vous pouvez ajouter des nœuds de travail pour mettre à l'échelle les ressources du cluster. Il existe différentes façons d'ajouter des nœuds de travail en fonction de la méthode d'installation et de l'environnement de votre cluster.
6.3.1. Ajout de nœuds de travail aux grappes d'infrastructures provisionnées par l'installateur
Pour les clusters d'infrastructure provisionnés par l'installateur, vous pouvez faire évoluer manuellement ou automatiquement l'objet MachineSet pour qu'il corresponde au nombre d'hôtes nus disponibles.
Pour ajouter un hôte bare-metal, vous devez configurer toutes les conditions préalables du réseau, configurer un objet baremetalhost associé, puis intégrer le nœud de travail au cluster. Vous pouvez ajouter un hôte bare-metal manuellement ou en utilisant la console web.
6.3.2. Ajout de nœuds de travail à des grappes d'infrastructures fournies par l'utilisateur
Pour les clusters d'infrastructure fournis par l'utilisateur, vous pouvez ajouter des nœuds de travailleur en utilisant une image ISO RHEL ou RHCOS et en la connectant à votre cluster à l'aide de fichiers de configuration Ignition cluster. Pour les nœuds de travail RHEL, l'exemple suivant utilise les playbooks Ansible pour ajouter des nœuds de travail au cluster. Pour les nœuds de travail RHCOS, l'exemple suivant utilise une image ISO et un démarrage en réseau pour ajouter des nœuds de travail au cluster.
6.3.3. Ajout de nœuds de travail aux clusters gérés par l'installateur assisté
Pour les clusters gérés par l'installateur assisté, vous pouvez ajouter des nœuds de travail en utilisant la console Red Hat OpenShift Cluster Manager, l'API REST de l'installateur assisté ou vous pouvez ajouter manuellement des nœuds de travail à l'aide d'une image ISO et des fichiers de configuration Ignition du cluster.
6.3.4. Ajouter des nœuds de travail aux clusters gérés par le moteur multicluster pour Kubernetes
Pour les clusters gérés par le moteur multicluster pour Kubernetes, vous pouvez ajouter des nœuds de travail en utilisant la console dédiée au moteur multicluster.
6.4. Ajuster les nœuds de travail
Si vous avez mal dimensionné les nœuds de travail lors du déploiement, ajustez-les en créant un ou plusieurs nouveaux ensembles de machines de calcul, augmentez-les, puis réduisez l'ensemble de machines de calcul d'origine avant de les supprimer.
6.4.1. Comprendre la différence entre les ensembles de machines de calcul et le pool de configuration des machines
MachineSet décrivent les nœuds d'OpenShift Container Platform par rapport au fournisseur de nuages ou de machines.
L'objet MachineConfigPool permet aux composants MachineConfigController de définir et de fournir l'état des machines dans le contexte des mises à niveau.
L'objet MachineConfigPool permet aux utilisateurs de configurer la manière dont les mises à niveau sont déployées sur les nœuds OpenShift Container Platform dans le pool de configuration de la machine.
L'objet NodeSelector peut être remplacé par une référence à l'objet MachineSet.
6.4.2. Mise à l'échelle manuelle d'un ensemble de machines de calcul
Pour ajouter ou supprimer une instance d'une machine dans un ensemble de machines de calcul, vous pouvez mettre à l'échelle manuellement l'ensemble de machines de calcul.
Ce guide s'applique aux installations d'infrastructure entièrement automatisées et fournies par l'installateur. Les installations d'infrastructure personnalisées et fournies par l'utilisateur n'ont pas d'ensembles de machines de calcul.
Conditions préalables
-
Installer un cluster OpenShift Container Platform et la ligne de commande
oc. -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Affichez les ensembles de machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machinesets -n openshift-machine-apiLes ensembles de machines de calcul sont répertoriés sous la forme de
<clusterid>-worker-<aws-region-az>.Affichez les machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machine -n openshift-machine-apiDéfinissez l'annotation sur la machine de calcul que vous souhaitez supprimer en exécutant la commande suivante :
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"Mettez à l'échelle l'ensemble de machines de calcul en exécutant l'une des commandes suivantes :
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiOu bien :
$ oc edit machineset <machineset> -n openshift-machine-apiAstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2Vous pouvez augmenter ou diminuer le nombre de machines de calcul. Il faut quelques minutes pour que les nouvelles machines soient disponibles.
ImportantPar défaut, le contrôleur de machine tente de drainer le nœud soutenu par la machine jusqu'à ce qu'il y parvienne. Dans certaines situations, comme dans le cas d'un budget de perturbation de pods mal configuré, l'opération de vidange peut ne pas aboutir. Si l'opération de vidange échoue, le contrôleur de machine ne peut pas procéder au retrait de la machine.
Vous pouvez éviter de vider le nœud en annotant
machine.openshift.io/exclude-node-drainingdans une machine spécifique.
Vérification
Vérifiez la suppression de la machine prévue en exécutant la commande suivante :
$ oc get machines
6.4.3. Politique de suppression des ensembles de machines de calcul
Random, Newest, et Oldest sont les trois options de suppression prises en charge. La valeur par défaut est Random, ce qui signifie que des machines aléatoires sont choisies et supprimées lorsque des machines de calcul à échelle réduite sont mises hors service. La politique de suppression peut être définie en fonction du cas d'utilisation en modifiant l'ensemble particulier de machines de calcul :
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
Des machines spécifiques peuvent également être supprimées en priorité en ajoutant l'annotation machine.openshift.io/delete-machine=true à la machine concernée, quelle que soit la politique de suppression.
Par défaut, les pods de routeur de OpenShift Container Platform sont déployés sur des workers. Comme le routeur est nécessaire pour accéder à certaines ressources du cluster, notamment la console Web, ne mettez pas à l'échelle l'ensemble de machines de calcul de l'ouvrier à l'adresse 0 à moins de déplacer d'abord les pods de routeur.
Les ensembles de machines de calcul personnalisés peuvent être utilisés pour des cas d'utilisation exigeant que des services s'exécutent sur des nœuds spécifiques et que ces services soient ignorés par le contrôleur lorsque les ensembles de machines de calcul travailleurs sont réduits. Cela permet d'éviter les interruptions de service.
6.4.4. Création de sélecteurs de nœuds par défaut pour l'ensemble du cluster
Vous pouvez utiliser des sélecteurs de nœuds par défaut à l'échelle du cluster sur les pods ainsi que des étiquettes sur les nœuds pour contraindre tous les pods créés dans un cluster à des nœuds spécifiques.
Avec des sélecteurs de nœuds à l'échelle du cluster, lorsque vous créez un pod dans ce cluster, OpenShift Container Platform ajoute les sélecteurs de nœuds par défaut au pod et planifie le pod sur des nœuds avec des étiquettes correspondantes.
Vous configurez les sélecteurs de nœuds à l'échelle du cluster en modifiant la ressource personnalisée (CR) de l'opérateur d'ordonnancement. Vous ajoutez des étiquettes à un nœud, à un ensemble de machines de calcul ou à une configuration de machine. L'ajout de l'étiquette à l'ensemble de machines de calcul garantit que si le nœud ou la machine tombe en panne, les nouveaux nœuds disposent de l'étiquette. Les étiquettes ajoutées à un nœud ou à une configuration de machine ne persistent pas si le nœud ou la machine tombe en panne.
Vous pouvez ajouter des paires clé/valeur supplémentaires à un pod. Mais vous ne pouvez pas ajouter une valeur différente pour une clé par défaut.
Procédure
Pour ajouter un sélecteur de nœuds par défaut à l'échelle du cluster :
Modifiez le CR de l'opérateur d'ordonnancement pour ajouter les sélecteurs de nœuds par défaut à l'échelle du cluster :
$ oc edit scheduler clusterExemple d'opérateur d'ordonnancement CR avec un sélecteur de nœuds
apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster ... spec: defaultNodeSelector: type=user-node,region=east1 mastersSchedulable: false- 1
- Ajouter un sélecteur de nœud avec les paires
<key>:<value>appropriées.
Après avoir effectué cette modification, attendez que les pods du projet
openshift-kube-apiserversoient redéployés. Cela peut prendre plusieurs minutes. Le sélecteur de nœuds par défaut à l'échelle du cluster ne prend pas effet tant que les pods ne sont pas redéployés.Ajoutez des étiquettes à un nœud en utilisant un ensemble de machines de calcul ou en éditant le nœud directement :
Utiliser un ensemble de machines de calcul pour ajouter des étiquettes aux nœuds gérés par l'ensemble de machines de calcul lors de la création d'un nœud :
Exécutez la commande suivante pour ajouter des étiquettes à un objet
MachineSet:$ oc patch MachineSet <name> --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"<key>"="<value>","<key>"="<value>"}}]' -n openshift-machine-api1 - 1
- Ajouter une paire
<key>/<value>pour chaque étiquette.
Par exemple :
$ oc patch MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"type":"user-node","region":"east"}}]' -n openshift-machine-apiAstuceVous pouvez également appliquer le YAML suivant pour ajouter des étiquettes à un ensemble de machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: template: spec: metadata: labels: region: "east" type: "user-node"Vérifiez que les étiquettes sont ajoutées à l'objet
MachineSeten utilisant la commandeoc edit:Par exemple :
$ oc edit MachineSet abc612-msrtw-worker-us-east-1c -n openshift-machine-apiExemple d'objet
MachineSetapiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... spec: ... template: metadata: ... spec: metadata: labels: region: east type: user-node ...Redéployez les nœuds associés à cet ensemble de machines de calcul en réduisant l'échelle à
0et en augmentant l'échelle des nœuds :Par exemple :
$ oc scale --replicas=0 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api$ oc scale --replicas=1 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-apiLorsque les nœuds sont prêts et disponibles, vérifiez que l'étiquette a été ajoutée aux nœuds à l'aide de la commande
oc get:$ oc get nodes -l <key>=<value>Par exemple :
$ oc get nodes -l type=user-nodeExemple de sortie
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-c-vmqzp Ready worker 61s v1.25.0
Ajouter des étiquettes directement à un nœud :
Modifiez l'objet
Nodepour le nœud :$ oc label nodes <name> <key>=<value>Par exemple, pour étiqueter un nœud :
$ oc label nodes ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 type=user-node region=eastAstuceVous pouvez également appliquer le langage YAML suivant pour ajouter des étiquettes à un nœud :
kind: Node apiVersion: v1 metadata: name: <node_name> labels: type: "user-node" region: "east"Vérifiez que les étiquettes sont ajoutées au nœud à l'aide de la commande
oc get:$ oc get nodes -l <key>=<value>,<key>=<valeur>Par exemple :
$ oc get nodes -l type=user-node,region=eastExemple de sortie
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 Ready worker 17m v1.25.0
6.4.5. Création de charges de travail utilisateur dans les zones locales AWS
After you create an Amazon Web Service (AWS) Local Zone environment, and you deploy your cluster, you can use edge worker nodes to create user workloads in Local Zone subnets.
Une fois que openshift-installer a créé le cluster, le programme d'installation spécifie automatiquement un effet d'altération de NoSchedule pour chaque nœud de travailleur périphérique. Cela signifie qu'un ordonnanceur n'ajoute pas de nouveau module ou déploiement à un nœud si le module ne correspond pas aux tolérances spécifiées pour un effet d'altération. Vous pouvez modifier l'altération pour mieux contrôler la manière dont chaque nœud crée une charge de travail dans chaque sous-réseau de la zone locale.
Le site openshift-installer crée le fichier manifests de l'ensemble de machines de calcul avec les étiquettes node-role.kubernetes.io/edge et node-role.kubernetes.io/worker appliquées à chaque nœud de travailleur périphérique situé dans un sous-réseau de la zone locale.
Conditions préalables
-
Vous avez accès au CLI OpenShift (
oc). - Vous avez déployé votre cluster dans un nuage privé virtuel (VPC) avec des sous-réseaux de zone locale définis.
-
Vous vous êtes assuré que l'ensemble de machines de calcul pour les travailleurs périphériques sur les sous-réseaux de la zone locale spécifie les taints pour
node-role.kubernetes.io/edge.
Procédure
Créez un fichier YAML de ressource
deploymentpour un exemple d'application à déployer dans le nœud de travailleur frontal qui opère dans un sous-réseau de la zone locale. Veillez à spécifier les tolérances correctes qui correspondent aux taints du nœud de travailleur frontal.Exemple de ressource
deploymentconfigurée pour un nœud de travailleur frontal opérant dans un sous-réseau de la zone localekind: Namespace apiVersion: v1 metadata: name: <local_zone_application_namespace> --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: <pvc_name> namespace: <local_zone_application_namespace> spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: gp2-csi1 volumeMode: Filesystem --- apiVersion: apps/v1 kind: Deployment2 metadata: name: <local_zone_application>3 namespace: <local_zone_application_namespace>4 spec: selector: matchLabels: app: <local_zone_application> replicas: 1 template: metadata: labels: app: <local_zone_application> zone-group: ${ZONE_GROUP_NAME}5 spec: securityContext: seccompProfile: type: RuntimeDefault nodeSelector:6 machine.openshift.io/zone-group: ${ZONE_GROUP_NAME} tolerations:7 - key: "node-role.kubernetes.io/edge" operator: "Equal" value: "" effect: "NoSchedule" containers: - image: openshift/origin-node command: - "/bin/socat" args: - TCP4-LISTEN:8080,reuseaddr,fork - EXEC:'/bin/bash -c \"printf \\\"HTTP/1.0 200 OK\r\n\r\n\\\"; sed -e \\\"/^\r/q\\\"\"' imagePullPolicy: Always name: echoserver ports: - containerPort: 8080 volumeMounts: - mountPath: "/mnt/storage" name: data volumes: - name: data persistentVolumeClaim: claimName: <pvc_name>- 1
storageClassName: Pour la configuration de la zone locale, vous devez spécifiergp2-csi.- 2
kind: Définit la ressourcedeployment.- 3
name: Spécifie le nom de l'application de la zone locale. Par exemple,local-zone-demo-app-nyc-1.- 4
namespace:Définit l'espace de noms de la zone locale AWS dans laquelle vous souhaitez exécuter la charge de travail de l'utilisateur. Par exemple :local-zone-app-nyc-1a.- 5
zone-group: Définit le groupe auquel une zone appartient. Par exemple,us-east-1-iah-1.- 6
nodeSelector: Cible les nœuds de travailleur d'arête qui correspondent aux étiquettes spécifiées.- 7
tolerations: Définit les valeurs qui correspondent àtaintsdéfinies dans le manifesteMachineSetpour le nœud de la zone locale.
Créez un fichier YAML de ressource
servicepour le nœud. Cette ressource expose un pod d'un nœud de travailleur périphérique ciblé aux services qui s'exécutent à l'intérieur de votre réseau de zone locale.Exemple de ressource
serviceconfigurée pour un nœud de travailleur frontal opérant dans un sous-réseau de la zone localeapiVersion: v1 kind: Service1 metadata: name: <local_zone_application> namespace: <local_zone_application_namespace> spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector:2 app: <local_zone_application>
Prochaines étapes
- Facultatif : Utilisez l'opérateur AWS Load Balancer (ALB) pour exposer un pod d'un nœud de travail périphérique ciblé aux services qui s'exécutent dans un sous-réseau de la zone locale à partir d'un réseau public. Voir Installation de l'opérateur AWS Load Balancer.
6.5. Amélioration de la stabilité des grappes dans les environnements à forte latence à l'aide de profils de latence des travailleurs
Tous les nœuds envoient des battements de cœur à l'opérateur du contrôleur Kubernetes (kube controller) dans le cluster OpenShift Container Platform toutes les 10 secondes, par défaut. Si le cluster ne reçoit pas de battements de cœur d'un nœud, OpenShift Container Platform répond à l'aide de plusieurs mécanismes par défaut.
Par exemple, si l'opérateur du gestionnaire de contrôleur Kubernetes perd le contact avec un nœud après une période configurée :
-
Le contrôleur de nœuds sur le plan de contrôle met à jour l'état du nœud à
Unhealthyet marque l'état du nœudReadycommeUnknown. - En réponse, l'ordonnanceur arrête de programmer des pods sur ce nœud.
-
Le contrôleur de nœuds sur site ajoute au nœud une tare
node.kubernetes.io/unreachableavec un effetNoExecuteet planifie l'éviction de tous les pods du nœud après cinq minutes, par défaut.
Ce comportement peut poser des problèmes si votre réseau est sujet à des problèmes de latence, en particulier si vous avez des nœuds à la périphérie du réseau. Dans certains cas, l'opérateur du gestionnaire de contrôleur Kubernetes peut ne pas recevoir de mise à jour d'un nœud sain en raison de la latence du réseau. L'opérateur du gestionnaire de contrôleur Kubernetes expulserait alors les pods du nœud, même si celui-ci est sain. Pour éviter ce problème, vous pouvez utiliser worker latency profiles pour ajuster la fréquence à laquelle le kubelet et le Kubernetes Controller Manager Operator attendent les mises à jour d'état avant d'agir. Ces ajustements permettent de s'assurer que votre cluster fonctionne correctement dans le cas où la latence du réseau entre le plan de contrôle et les nœuds de travail n'est pas optimale.
Ces profils de latence des travailleurs sont trois ensembles de paramètres prédéfinis avec des valeurs soigneusement ajustées qui vous permettent de contrôler la réaction du cluster aux problèmes de latence sans avoir à déterminer les meilleures valeurs manuellement.
6.5.1. Comprendre les profils de latence des travailleurs
Les profils de latence des travailleurs sont des ensembles multiples de valeurs soigneusement ajustées pour les paramètres node-status-update-frequency, node-monitor-grace-period, default-not-ready-toleration-seconds et default-unreachable-toleration-seconds. Ces paramètres vous permettent de contrôler la réaction du cluster aux problèmes de latence sans avoir à déterminer manuellement les meilleures valeurs.
Tous les profils de latence des travailleurs configurent les paramètres suivants :
-
node-status-update-frequency. Spécifie le temps en secondes pendant lequel un kubelet met à jour son statut auprès de l'opérateur du gestionnaire de contrôleur Kubernetes. -
node-monitor-grace-period. Spécifie la durée en secondes pendant laquelle l'opérateur Kubernetes Controller Manager attend une mise à jour d'un kubelet avant de marquer le nœud comme étant malsain et d'ajouter l'erreurnode.kubernetes.io/not-readyounode.kubernetes.io/unreachableau nœud. -
default-not-ready-toleration-seconds. Spécifie la durée en secondes après le marquage d'un nœud insalubre que l'opérateur Kubernetes Controller Manager attend avant d'expulser les pods de ce nœud. -
default-unreachable-toleration-seconds. Spécifie la durée en secondes pendant laquelle l'opérateur du gestionnaire de contrôle Kubernetes attend qu'un nœud soit marqué comme inaccessible avant d'expulser les pods de ce nœud.
La modification manuelle du paramètre node-monitor-grace-period n'est pas possible.
Les opérateurs suivants surveillent les modifications apportées aux profils de latence des travailleurs et réagissent en conséquence :
-
L'opérateur de configuration de la machine (MCO) met à jour le paramètre
node-status-update-frequencysur les nœuds de travail. -
L'opérateur du gestionnaire de contrôleur Kubernetes met à jour le paramètre
node-monitor-grace-periodsur les nœuds du plan de contrôle. -
L'opérateur du serveur API Kubernetes met à jour les paramètres
default-not-ready-toleration-secondsetdefault-unreachable-toleration-secondssur les nœuds de la plance de contrôle.
Bien que la configuration par défaut fonctionne dans la plupart des cas, OpenShift Container Platform propose deux autres profils de latence du travailleur pour les situations où le réseau connaît une latence plus élevée que d'habitude. Les trois profils de latence des travailleurs sont décrits dans les sections suivantes :
- Profil de latence du travailleur par défaut
Avec le profil
Default, chaque kubelet signale l'état de son nœud au Kubelet Controller Manager Operator (kube controller) toutes les 10 secondes. L'opérateur du gestionnaire du contrôleur de kubelet vérifie l'état du kubelet toutes les 5 secondes.L'opérateur du gestionnaire de contrôle Kubernetes attend 40 secondes pour une mise à jour de l'état avant de considérer ce nœud comme malsain. Il marque le nœud avec la taint
node.kubernetes.io/not-readyounode.kubernetes.io/unreachableet expulse les pods sur ce nœud. Si un pod sur ce nœud a la toléranceNoExecute, le pod est expulsé en 300 secondes. Si le pod a le paramètretolerationSeconds, l'expulsion attend la période spécifiée par ce paramètre.Expand Profile Composant Paramètres Valeur Défaut
kubelet
node-status-update-frequency10s
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period40s
Serveur API Kubernetes
default-not-ready-toleration-seconds300s
Serveur API Kubernetes
default-unreachable-toleration-seconds300s
- Profil de latence du travailleur moyen
Utilisez le profil
MediumUpdateAverageReactionsi la latence du réseau est légèrement plus élevée que d'habitude.Le profil
MediumUpdateAverageReactionréduit la fréquence des mises à jour des kubelets à 20 secondes et modifie la période d'attente de ces mises à jour par l'opérateur du contrôleur Kubernetes à 2 minutes. La période d'éviction d'un pod sur ce nœud est réduite à 60 secondes. Si le pod a le paramètretolerationSeconds, l'éviction attend la période spécifiée par ce paramètre.L'opérateur Kubernetes Controller Manager attend 2 minutes pour considérer qu'un nœud n'est pas sain. Une minute plus tard, le processus d'expulsion commence.
Expand Profile Composant Paramètres Valeur Moyenne des mises à jour
kubelet
node-status-update-frequency20s
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period2m
Serveur API Kubernetes
default-not-ready-toleration-seconds60s
Serveur API Kubernetes
default-unreachable-toleration-seconds60s
- Profil de latence faible pour les travailleurs
Utilisez le profil
LowUpdateSlowReactionsi la latence du réseau est extrêmement élevée.Le profil
LowUpdateSlowReactionréduit la fréquence des mises à jour des kubelets à 1 minute et modifie la période d'attente de ces mises à jour par l'opérateur du contrôleur Kubernetes à 5 minutes. La période d'éviction d'un pod sur ce nœud est réduite à 60 secondes. Si le pod a le paramètretolerationSeconds, l'éviction attend la période spécifiée par ce paramètre.L'opérateur Kubernetes Controller Manager attend 5 minutes pour considérer qu'un nœud n'est pas sain. Dans une minute, le processus d'expulsion commence.
Expand Profile Composant Paramètres Valeur Faible mise à jourRéaction lente
kubelet
node-status-update-frequency1m
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period5m
Serveur API Kubernetes
default-not-ready-toleration-seconds60s
Serveur API Kubernetes
default-unreachable-toleration-seconds60s
6.5.2. Utilisation des profils de latence des travailleurs
Pour mettre en œuvre un profil de latence du travailleur afin de gérer la latence du réseau, modifiez l'objet node.config pour ajouter le nom du profil. Vous pouvez modifier le profil à tout moment lorsque la latence augmente ou diminue.
Vous devez déplacer un profil de latence de travailleur à la fois. Par exemple, vous ne pouvez pas passer directement du profil Default au profil LowUpdateSlowReaction. Vous devez d'abord passer du profil default au profil MediumUpdateAverageReaction, puis à LowUpdateSlowReaction. De même, lorsque vous revenez au profil par défaut, vous devez d'abord passer du profil bas au profil moyen, puis au profil par défaut.
Vous pouvez également configurer les profils de latence des travailleurs lors de l'installation d'un cluster OpenShift Container Platform.
Procédure
Pour quitter le profil de latence par défaut du travailleur :
Passer au profil de latence du travailleur moyen :
Modifiez l'objet
node.config:$ oc edit nodes.config/clusterAjouter
spec.workerLatencyProfile: MediumUpdateAverageReaction:Exemple d'objet
node.configapiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction1 ...- 1
- Spécifie la politique de latence du travailleur moyen.
La programmation sur chaque nœud de travailleur est désactivée au fur et à mesure de l'application de la modification.
Lorsque tous les nœuds reviennent à l'état
Ready, vous pouvez utiliser la commande suivante pour vérifier dans le Kubernetes Controller Manager qu'elle a bien été appliquée :$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5Exemple de sortie
... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z"1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" ...- 1
- Spécifie que le profil est appliqué et actif.
Optionnel : Passez au profil de faible latence du travailleur :
Modifiez l'objet
node.config:$ oc edit nodes.config/clusterModifiez la valeur de
spec.workerLatencyProfileenLowUpdateSlowReaction:Exemple d'objet
node.configapiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction1 ...- 1
- Spécifie l'utilisation de la politique de faible latence du travailleur.
La programmation sur chaque nœud de travailleur est désactivée au fur et à mesure de l'application de la modification.
Pour transformer le profil bas en profil moyen ou le profil moyen en profil bas, modifiez l'objet node.config et réglez le paramètre spec.workerLatencyProfile sur la valeur appropriée.
6.6. Gestion des machines du plan de contrôle
Les ensembles de machines de plan de contrôle fournissent des capacités de gestion pour les machines de plan de contrôle qui sont similaires à ce que les ensembles de machines de calcul fournissent pour les machines de calcul. La disponibilité et l'état initial des jeux de machines de plan de contrôle sur votre cluster dépendent de votre fournisseur de cloud et de la version d'OpenShift Container Platform que vous avez installée. Pour plus d'informations, voir Démarrer avec les jeux de machines du plan de contrôle.
6.7. Création de jeux de machines d'infrastructure pour les environnements de production
Vous pouvez créer un ensemble de machines de calcul pour créer des machines qui hébergent uniquement des composants d'infrastructure, tels que le routeur par défaut, le registre intégré d'images de conteneurs et les composants pour les mesures et la surveillance des clusters. Ces machines d'infrastructure ne sont pas comptabilisées dans le nombre total d'abonnements requis pour faire fonctionner l'environnement.
Dans un déploiement de production, il est recommandé de déployer au moins trois ensembles de machines de calcul pour contenir les composants de l'infrastructure. OpenShift Logging et Red Hat OpenShift Service Mesh déploient tous deux Elasticsearch, qui nécessite l'installation de trois instances sur différents nœuds. Chacun de ces nœuds peut être déployé dans différentes zones de disponibilité pour une haute disponibilité. Une telle configuration nécessite trois ensembles de machines de calcul différents, un pour chaque zone de disponibilité. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de machines de calcul pour garantir une haute disponibilité.
Pour plus d'informations sur les nœuds d'infrastructure et sur les composants qui peuvent être exécutés sur ces nœuds, voir Création de jeux de machines d'infrastructure.
Pour créer un nœud d'infrastructure, vous pouvez utiliser un jeu de machines, attribuer une étiquette aux nœuds ou utiliser un pool de configuration de machines.
Pour des exemples de jeux de machines que vous pouvez utiliser avec ces procédures, voir Création de jeux de machines pour différents nuages.
En appliquant un sélecteur de nœud spécifique à tous les composants de l'infrastructure, OpenShift Container Platform planifie ces charges de travail sur les nœuds portant ce label.
6.7.1. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-apiExemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55mPour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yamlExemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-apiExemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55mLorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
6.7.2. Création d'un nœud d'infrastructure
Voir Création de jeux de machines d'infrastructure pour les environnements d'infrastructure fournis par l'installateur ou pour tout cluster dont les nœuds du plan de contrôle sont gérés par l'API des machines.
Les exigences du cluster imposent le provisionnement de l'infrastructure, également appelée infra nodes. Le programme d'installation ne fournit des provisions que pour le plan de contrôle et les nœuds de travail. Les nœuds de travail peuvent être désignés comme nœuds d'infrastructure ou nœuds d'application, également appelés app, par le biais de l'étiquetage.
Procédure
Ajoutez une étiquette au nœud de travailleur que vous voulez utiliser comme nœud d'application :
$ oc label node <node-name> node-role.kubernetes.io/app=""Ajoutez une étiquette aux nœuds de travailleur que vous souhaitez utiliser comme nœuds d'infrastructure :
$ oc label node <node-name> node-role.kubernetes.io/infra=""Vérifiez si les nœuds concernés ont désormais les rôles
infraetapp:$ oc get nodesCréer un sélecteur de nœuds par défaut pour l'ensemble du cluster. Le sélecteur de nœuds par défaut est appliqué aux modules créés dans tous les espaces de noms. Cela crée une intersection avec tous les sélecteurs de nœuds existants sur un pod, ce qui contraint davantage le sélecteur du pod.
ImportantSi la clé du sélecteur de nœuds par défaut est en conflit avec la clé de l'étiquette d'un pod, le sélecteur de nœuds par défaut n'est pas appliqué.
Cependant, ne définissez pas un sélecteur de nœud par défaut qui pourrait rendre un module non ordonnançable. Par exemple, si le sélecteur de nœud par défaut est défini sur un rôle de nœud spécifique, tel que
node-role.kubernetes.io/infra="", alors que l'étiquette d'un module est définie sur un rôle de nœud différent, tel quenode-role.kubernetes.io/master="", le module risque de ne plus être ordonnançable. C'est pourquoi il convient d'être prudent lorsque l'on définit le sélecteur de nœuds par défaut sur des rôles de nœuds spécifiques.Vous pouvez également utiliser un sélecteur de nœud de projet pour éviter les conflits de clés de sélecteur de nœud à l'échelle du cluster.
Modifiez l'objet
Scheduler:$ oc edit scheduler clusterAjoutez le champ
defaultNodeSelectoravec le sélecteur de nœud approprié :apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster ... spec: defaultNodeSelector: topology.kubernetes.io/region=us-east-11 ...- 1
- Cet exemple de sélecteur de nœuds déploie par défaut les pods sur les nœuds de la région
us-east-1.
- Enregistrez le fichier pour appliquer les modifications.
Vous pouvez maintenant déplacer les ressources d'infrastructure vers les nœuds infra nouvellement étiquetés.
6.7.3. Création d'un pool de configuration pour les machines d'infrastructure
Si vous avez besoin que les machines d'infrastructure aient des configurations dédiées, vous devez créer un pool d'infrastructure.
Procédure
Ajoutez une étiquette au nœud que vous souhaitez affecter comme nœud infra avec une étiquette spécifique :
$ oc label node <node_name> <label>$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=Créez un pool de configuration de machine qui contient à la fois le rôle de travailleur et votre rôle personnalisé en tant que sélecteur de configuration de machine :
$ cat infra.mcp.yamlExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: ""2 NoteLes pools de configuration machine personnalisés héritent des configurations machine du pool de travail. Les pools personnalisés utilisent n'importe quelle configuration de machine ciblée pour le pool de travailleur, mais ajoutent la possibilité de déployer également des changements qui sont ciblés uniquement sur le pool personnalisé. Étant donné qu'un pool personnalisé hérite des ressources du pool de travail, toute modification apportée au pool de travail affecte également le pool personnalisé.
Après avoir obtenu le fichier YAML, vous pouvez créer le pool de configuration de la machine :
$ oc create -f infra.mcp.yamlVérifier les configurations des machines pour s'assurer que la configuration de l'infrastructure a été rendue avec succès :
$ oc get machineconfigExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13dVous devriez voir une nouvelle configuration de machine, avec le préfixe
rendered-infra-*.Facultatif : Pour déployer les modifications apportées à un pool personnalisé, créez une configuration de machine qui utilise le nom du pool personnalisé comme étiquette, par exemple
infra. Notez que cette opération n'est pas obligatoire et qu'elle n'est présentée qu'à des fins didactiques. De cette manière, vous pouvez appliquer toutes les configurations personnalisées spécifiques à vos nœuds infra.NoteAprès avoir créé le nouveau pool de configuration machine, le MCO génère une nouvelle configuration rendue pour ce pool, et les nœuds associés à ce pool redémarrent pour appliquer la nouvelle configuration.
Créer une configuration de machine :
$ cat infra.mc.yamlExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- Ajoutez l'étiquette que vous avez ajoutée au nœud en tant que
nodeSelector.
Appliquer la configuration de la machine aux nœuds infra-étiquetés :
$ oc create -f infra.mc.yaml
Confirmez que le pool de configuration de votre nouvelle machine est disponible :
$ oc get mcpExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91mDans cet exemple, un nœud de travailleur a été transformé en nœud d'infrastructure.
6.8. Affectation des ressources de l'ensemble de machines aux nœuds d'infrastructure
Après avoir créé un jeu de machines d'infrastructure, les rôles worker et infra sont appliqués aux nouveaux nœuds d'infrastructure. Les nœuds dotés du rôle infra ne sont pas pris en compte dans le nombre total d'abonnements nécessaires à l'exécution de l'environnement, même si le rôle worker est également appliqué.
Cependant, lorsqu'un nœud infra se voit attribuer le rôle de travailleur, il est possible que les charges de travail des utilisateurs soient affectées par inadvertance au nœud infra. Pour éviter cela, vous pouvez appliquer une taint au nœud infra et des tolérances pour les pods que vous souhaitez contrôler.
6.8.1. Lier les charges de travail des nœuds d'infrastructure à l'aide de taches et de tolérances
Si vous disposez d'un nœud infra auquel les rôles infra et worker ont été attribués, vous devez configurer le nœud de manière à ce que les charges de travail utilisateur ne lui soient pas affectées.
Il est recommandé de conserver le double label infra,worker créé pour les nœuds infra et d'utiliser les taints et les tolérances pour gérer les nœuds sur lesquels les charges de travail des utilisateurs sont planifiées. Si vous supprimez le label worker du nœud, vous devez créer un pool personnalisé pour le gérer. Un nœud doté d'une étiquette autre que master ou worker n'est pas reconnu par le MCO sans pool personnalisé. Le maintien de l'étiquette worker permet au nœud d'être géré par le pool de configuration de la machine de travail par défaut, s'il n'existe aucun pool personnalisé qui sélectionne l'étiquette personnalisée. Le label infra indique au cluster qu'il ne compte pas dans le nombre total d'abonnements.
Conditions préalables
-
Configurez des objets
MachineSetsupplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Ajouter une tare au nœud infra pour empêcher la programmation des charges de travail des utilisateurs sur ce nœud :
Déterminer si le nœud est contaminé :
oc describe nodes <node_name>Exemple de sortie
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra:NoSchedule ...Cet exemple montre que le nœud a une tare. Vous pouvez procéder à l'ajout d'une tolérance à votre pod à l'étape suivante.
Si vous n'avez pas configuré une taint pour empêcher la planification des charges de travail des utilisateurs sur cette taint :
$ oc adm taint nodes <node_name> <key>=<value>:<effect>Par exemple :
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoExecuteAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'altération :
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoExecute value: reserved ...Cet exemple place une taint sur
node1qui a la clénode-role.kubernetes.io/infraet l'effet de taintNoSchedule. Les nœuds avec l'effetNoSchedulene planifient que les pods qui tolèrent l'altération, mais permettent aux pods existants de rester planifiés sur le nœud.NoteSi un planificateur est utilisé, les pods violant les taints de nœuds peuvent être expulsés du cluster.
Ajoutez des tolérances pour les configurations de pods que vous souhaitez planifier sur le nœud infra, comme le routeur, le registre et les charges de travail de surveillance. Ajoutez le code suivant à la spécification de l'objet
Pod:tolerations: - effect: NoExecute1 key: node-role.kubernetes.io/infra2 operator: Exists3 value: reserved4 - 1
- Spécifiez l'effet que vous avez ajouté au nœud.
- 2
- Spécifiez la clé que vous avez ajoutée au nœud.
- 3
- Spécifiez l'opérateur
Existspour exiger la présence d'une taint avec la clénode-role.kubernetes.io/infrasur le nœud. - 4
- Spécifiez la valeur de la paire clé-valeur taint que vous avez ajoutée au nœud.
Cette tolérance correspond à l'altération créée par la commande
oc adm taint. Un pod avec cette tolérance peut être programmé sur le nœud infra.NoteIl n'est pas toujours possible de déplacer les modules d'un opérateur installé via OLM vers un nœud infra. La possibilité de déplacer les pods d'un opérateur dépend de la configuration de chaque opérateur.
- Programmer le pod sur le nœud infra à l'aide d'un planificateur. Voir la documentation de Controlling pod placement onto nodes pour plus de détails.
6.9. Déplacement de ressources vers des ensembles de machines d'infrastructure
Certaines ressources d'infrastructure sont déployées par défaut dans votre cluster. Vous pouvez les déplacer vers les ensembles de machines d'infrastructure que vous avez créés.
6.9.1. Déplacement du routeur
Vous pouvez déployer le module de routeur sur un ensemble de machines de calcul différent. Par défaut, le module est déployé sur un nœud de travail.
Conditions préalables
- Configurez des ensembles de machines de calcul supplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Voir la ressource personnalisée
IngressControllerpour l'opérateur de routeur :$ oc get ingresscontroller default -n openshift-ingress-operator -o yamlLa sortie de la commande ressemble au texte suivant :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultModifiez la ressource
ingresscontrolleret changez la ressourcenodeSelectorpour qu'elle utilise l'étiquetteinfra:$ oc edit ingresscontroller default -n openshift-ingress-operatorspec: nodePlacement: nodeSelector:1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectorau format indiqué ou des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une taint au nœud d'infrastructure, ajoutez également une tolérance correspondante.
Confirmez que le pod routeur est en cours d'exécution sur le nœud
infra.Affichez la liste des modules de routeur et notez le nom du nœud du module en cours d'exécution :
$ oc get pod -n openshift-ingress -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>Dans cet exemple, le pod en cours d'exécution se trouve sur le nœud
ip-10-0-217-226.ec2.internal.Visualiser l'état du nœud du pod en cours d'exécution :
oc get node <node_name>1 - 1
- Spécifiez l'adresse
<node_name>que vous avez obtenue à partir de la liste des pods.
Exemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.25.0Comme la liste des rôles comprend
infra, le pod est exécuté sur le bon nœud.
6.9.2. Déplacement du registre par défaut
Vous configurez l'opérateur de registre pour qu'il déploie ses pods sur différents nœuds.
Conditions préalables
- Configurez des ensembles de machines de calcul supplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Voir l'objet
config/instance:$ oc get configs.imageregistry.operator.openshift.io/cluster -o yamlExemple de sortie
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...Modifiez l'objet
config/instance:$ oc edit configs.imageregistry.operator.openshift.io/clusterspec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Vérifiez que le pod de registre a été déplacé vers le nœud d'infrastructure.
Exécutez la commande suivante pour identifier le nœud où se trouve le module de registre :
$ oc get pods -o wide -n openshift-image-registryConfirmez que le nœud a l'étiquette que vous avez spécifiée :
oc describe node <node_name>Examinez la sortie de la commande et confirmez que
node-role.kubernetes.io/infrafigure dans la listeLABELS.
6.9.3. Déplacement de la solution de surveillance
La pile de surveillance comprend plusieurs composants, notamment Prometheus, Thanos Querier et Alertmanager. L'opérateur de surveillance des clusters gère cette pile. Pour redéployer la pile de surveillance sur les nœuds d'infrastructure, vous pouvez créer et appliquer une carte de configuration personnalisée.
Procédure
Modifiez la carte de configuration
cluster-monitoring-configet changez la cartenodeSelectorpour qu'elle utilise le labelinfra:$ oc edit configmap cluster-monitoring-config -n openshift-monitoringapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Observez le déplacement des modules de surveillance vers les nouvelles machines :
$ watch 'oc get pod -n openshift-monitoring -o wide'Si un composant n'a pas été déplacé vers le nœud
infra, supprimez le pod contenant ce composant :oc delete pod -n openshift-monitoring <pod>Le composant du module supprimé est recréé sur le nœud
infra.
6.9.4. Déplacer les ressources de journalisation d'OpenShift
Vous pouvez configurer le Cluster Logging Operator pour déployer les pods des composants du sous-système de journalisation, tels qu'Elasticsearch et Kibana, sur différents nœuds. Vous ne pouvez pas déplacer le pod Cluster Logging Operator de son emplacement d'installation.
Par exemple, vous pouvez déplacer les pods Elasticsearch vers un nœud distinct en raison des exigences élevées en matière de CPU, de mémoire et de disque.
Conditions préalables
- Les opérateurs Red Hat OpenShift Logging et Elasticsearch doivent être installés. Ces fonctionnalités ne sont pas installées par défaut.
Procédure
Modifiez la ressource personnalisée (CR)
ClusterLoggingdans le projetopenshift-logging:$ oc edit ClusterLogging instanceapiVersion: logging.openshift.io/v1 kind: ClusterLogging ... spec: collection: logs: fluentd: resources: null type: fluentd logStore: elasticsearch: nodeCount: 3 nodeSelector:1 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved redundancyPolicy: SingleRedundancy resources: limits: cpu: 500m memory: 16Gi requests: cpu: 500m memory: 16Gi storage: {} type: elasticsearch managementState: Managed visualization: kibana: nodeSelector:2 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved proxy: resources: null replicas: 1 resources: null type: kibana ...- 1 2
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Vérification
Pour vérifier qu'un composant a été déplacé, vous pouvez utiliser la commande oc get pod -o wide.
Par exemple :
Vous souhaitez déplacer le pod Kibana du nœud
ip-10-0-147-79.us-east-2.compute.internal:$ oc get pod kibana-5b8bdf44f9-ccpq9 -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-5b8bdf44f9-ccpq9 2/2 Running 0 27s 10.129.2.18 ip-10-0-147-79.us-east-2.compute.internal <none> <none>Vous souhaitez déplacer le pod Kibana vers le nœud
ip-10-0-139-48.us-east-2.compute.internal, un nœud d'infrastructure dédié :$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-133-216.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-146.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-192.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-139-241.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-147-79.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-152-241.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-48.us-east-2.compute.internal Ready infra 51m v1.25.0Notez que le nœud a une étiquette
node-role.kubernetes.io/infra: '':$ oc get node ip-10-0-139-48.us-east-2.compute.internal -o yamlExemple de sortie
kind: Node apiVersion: v1 metadata: name: ip-10-0-139-48.us-east-2.compute.internal selfLink: /api/v1/nodes/ip-10-0-139-48.us-east-2.compute.internal uid: 62038aa9-661f-41d7-ba93-b5f1b6ef8751 resourceVersion: '39083' creationTimestamp: '2020-04-13T19:07:55Z' labels: node-role.kubernetes.io/infra: '' ...Pour déplacer le pod Kibana, modifiez le CR
ClusterLoggingpour ajouter un sélecteur de nœud :apiVersion: logging.openshift.io/v1 kind: ClusterLogging ... spec: ... visualization: kibana: nodeSelector:1 node-role.kubernetes.io/infra: '' proxy: resources: null replicas: 1 resources: null type: kibana- 1
- Ajouter un sélecteur de nœud correspondant à l'étiquette de la spécification du nœud.
Après avoir sauvegardé le CR, le pod Kibana actuel est terminé et le nouveau pod est déployé :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 29m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 28m fluentd-42dzz 1/1 Running 0 28m fluentd-d74rq 1/1 Running 0 28m fluentd-m5vr9 1/1 Running 0 28m fluentd-nkxl7 1/1 Running 0 28m fluentd-pdvqb 1/1 Running 0 28m fluentd-tflh6 1/1 Running 0 28m kibana-5b8bdf44f9-ccpq9 2/2 Terminating 0 4m11s kibana-7d85dcffc8-bfpfp 2/2 Running 0 33sLe nouveau pod se trouve sur le nœud
ip-10-0-139-48.us-east-2.compute.internal:$ oc get pod kibana-7d85dcffc8-bfpfp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-7d85dcffc8-bfpfp 2/2 Running 0 43s 10.131.0.22 ip-10-0-139-48.us-east-2.compute.internal <none> <none>Après quelques instants, le pod Kibana original est retiré.
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 30m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 29m fluentd-42dzz 1/1 Running 0 29m fluentd-d74rq 1/1 Running 0 29m fluentd-m5vr9 1/1 Running 0 29m fluentd-nkxl7 1/1 Running 0 29m fluentd-pdvqb 1/1 Running 0 29m fluentd-tflh6 1/1 Running 0 29m kibana-7d85dcffc8-bfpfp 2/2 Running 0 62s
6.10. À propos de l'autoscaler de cluster
L'autoscaler de cluster ajuste la taille d'un cluster OpenShift Container Platform pour répondre à ses besoins de déploiement actuels. Il utilise des arguments déclaratifs, de type Kubernetes, pour fournir une gestion de l'infrastructure qui ne repose pas sur des objets d'un fournisseur de cloud spécifique. L'autoscaler de cluster a une portée de cluster et n'est pas associé à un espace de noms particulier.
L'autoscaler de cluster augmente la taille du cluster lorsque des pods ne parviennent pas à être planifiés sur l'un des nœuds de travail actuels en raison de ressources insuffisantes ou lorsqu'un autre nœud est nécessaire pour répondre aux besoins de déploiement. L'autoscaler de cluster n'augmente pas les ressources du cluster au-delà des limites que vous avez spécifiées.
L'autoscaler de cluster calcule la mémoire totale, le CPU et le GPU sur tous les nœuds du cluster, même s'il ne gère pas les nœuds du plan de contrôle. Ces valeurs ne sont pas axées sur une seule machine. Il s'agit d'une agrégation de toutes les ressources de l'ensemble de la grappe. Par exemple, si vous définissez la limite maximale des ressources mémoire, l'autoscaler de la grappe inclut tous les nœuds de la grappe lors du calcul de l'utilisation actuelle de la mémoire. Ce calcul est ensuite utilisé pour déterminer si l'autoscaler de cluster a la capacité d'ajouter des ressources de travailleur supplémentaires.
Assurez-vous que la valeur maxNodesTotal dans la définition de la ressource ClusterAutoscaler que vous créez est suffisamment grande pour tenir compte du nombre total possible de machines dans votre cluster. Cette valeur doit englober le nombre de machines du plan de contrôle et le nombre possible de machines de calcul vers lesquelles vous pourriez évoluer.
Toutes les 10 secondes, l'autoscaler de cluster vérifie quels sont les nœuds inutiles dans le cluster et les supprime. L'autoscaler de cluster considère qu'un nœud doit être supprimé si les conditions suivantes sont remplies :
-
L'utilisation du nœud est inférieure au seuil node utilization level pour la grappe. Le niveau d'utilisation du nœud est la somme des ressources demandées divisée par les ressources allouées au nœud. Si vous ne spécifiez pas de valeur dans la ressource personnalisée
ClusterAutoscaler, l'autoscaler de cluster utilise une valeur par défaut de0.5, ce qui correspond à une utilisation de 50 %. - L'autoscaler de cluster peut déplacer tous les pods en cours d'exécution sur le nœud vers les autres nœuds. Le planificateur Kubernetes est responsable de la planification des pods sur les nœuds.
- L'autoscaler de cluster n'a pas d'annotation de réduction d'échelle désactivée.
Si les types de pods suivants sont présents sur un nœud, l'autoscaler de cluster ne supprimera pas le nœud :
- Les pods dont les budgets de perturbation des pods (PDB) sont restrictifs.
- Les pods du système Kube qui ne s'exécutent pas par défaut sur le nœud.
- Les pods du système Kube qui n'ont pas de PDB ou qui ont un PDB trop restrictif.
- Pods qui ne sont pas soutenus par un objet contrôleur tel qu'un déploiement, un ensemble de répliques ou un ensemble avec état.
- Pods avec stockage local.
- Pods qui ne peuvent pas être déplacés ailleurs en raison d'un manque de ressources, de sélecteurs de nœuds ou d'affinités incompatibles, d'anti-affinités correspondantes, etc.
-
À moins qu'ils n'aient également une annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true", les pods qui ont une annotation"cluster-autoscaler.kubernetes.io/safe-to-evict": "false".
Par exemple, vous fixez la limite maximale de l'unité centrale à 64 cœurs et configurez l'autoscaler de cluster pour qu'il ne crée que des machines dotées de 8 cœurs chacune. Si votre cluster commence avec 30 cœurs, l'autoscaler de cluster peut ajouter jusqu'à 4 nœuds supplémentaires avec 32 cœurs, pour un total de 62.
Si vous configurez l'autoscaler de cluster, des restrictions d'utilisation supplémentaires s'appliquent :
- Ne modifiez pas directement les nœuds faisant partie de groupes de nœuds à mise à l'échelle automatique. Tous les nœuds d'un même groupe de nœuds ont la même capacité et les mêmes étiquettes et exécutent les mêmes pods système.
- Spécifiez les requêtes pour vos pods.
- Si vous devez éviter que des pods soient supprimés trop rapidement, configurez des PDB appropriés.
- Confirmez que le quota de votre fournisseur de cloud est suffisamment important pour prendre en charge les pools de nœuds maximums que vous configurez.
- N'exécutez pas d'autoscalers de groupes de nœuds supplémentaires, en particulier ceux proposés par votre fournisseur de cloud.
L'autoscaler de pods horizontaux (HPA) et l'autoscaler de clusters modifient les ressources du cluster de différentes manières. Le HPA modifie le nombre de répliques du déploiement ou de l'ensemble de répliques en fonction de la charge CPU actuelle. Si la charge augmente, le HPA crée de nouvelles répliques, quelle que soit la quantité de ressources disponibles pour la grappe. S'il n'y a pas assez de ressources, l'autoscaler du cluster ajoute des ressources pour que les pods créés par l'HPA puissent fonctionner. Si la charge diminue, l'APH arrête certaines répliques. Si cette action entraîne une sous-utilisation ou un vide complet de certains nœuds, l'autoscaler de cluster supprime les nœuds inutiles.
L'autoscaler de cluster prend en compte les priorités des pods. La fonction de priorité et de préemption des pods permet de planifier les pods en fonction des priorités si le cluster ne dispose pas de suffisamment de ressources, mais l'autoscaler de cluster garantit que le cluster dispose des ressources nécessaires pour faire fonctionner tous les pods. Pour respecter l'intention des deux fonctionnalités, l'autoscaler de cluster inclut une fonction de coupure de priorité. Vous pouvez utiliser cette coupure pour planifier les pods "best-effort", qui n'entraînent pas l'augmentation des ressources par l'autoscaler de cluster, mais qui s'exécutent uniquement lorsque des ressources sont disponibles.
Les modules dont la priorité est inférieure à la valeur limite n'entraînent pas l'augmentation de la taille du cluster et n'empêchent pas la réduction de la taille du cluster. Aucun nouveau nœud n'est ajouté pour exécuter les pods, et les nœuds exécutant ces pods peuvent être supprimés pour libérer des ressources.
La mise à l'échelle automatique du cluster est prise en charge pour les plates-formes qui disposent d'une API machine.
6.10.1. Définition de la ressource ClusterAutoscaler
Cette définition de ressource ClusterAutoscaler montre les paramètres et les valeurs d'exemple pour l'autoscaler de cluster.
apiVersion: "autoscaling.openshift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
podPriorityThreshold: -10
resourceLimits:
maxNodesTotal: 24
cores:
min: 8
max: 128
memory:
min: 4
max: 256
gpus:
- type: nvidia.com/gpu
min: 0
max: 16
- type: amd.com/gpu
min: 0
max: 4
logVerbosity: 4
scaleDown:
enabled: true
delayAfterAdd: 10m
delayAfterDelete: 5m
delayAfterFailure: 30s
unneededTime: 5m
utilizationThreshold: "0.4" - 1
- Spécifiez la priorité qu'un pod doit dépasser pour que l'autoscaler de cluster déploie des nœuds supplémentaires. Entrez une valeur entière de 32 bits. La valeur
podPriorityThresholdest comparée à la valeurPriorityClassque vous attribuez à chaque module. - 2
- Indiquez le nombre maximal de nœuds à déployer. Cette valeur correspond au nombre total de machines déployées dans votre cluster, et pas seulement à celles que l'autoscaler contrôle. Veillez à ce que cette valeur soit suffisamment importante pour prendre en compte toutes les machines de calcul et du plan de contrôle, ainsi que le nombre total de répliques spécifié dans les ressources
MachineAutoscaler. - 3
- Spécifiez le nombre minimum de cœurs à déployer dans le cluster.
- 4
- Spécifiez le nombre maximum de cœurs à déployer dans le cluster.
- 5
- Spécifiez la quantité minimale de mémoire, en GiB, dans le cluster.
- 6
- Spécifiez la quantité maximale de mémoire, en GiB, dans le cluster.
- 7
- Facultatif : Spécifiez le type de nœud GPU à déployer. Seuls
nvidia.com/gpuetamd.com/gpusont des types valides. - 8
- Spécifiez le nombre minimum de GPU à déployer dans le cluster.
- 9
- Spécifiez le nombre maximum de GPU à déployer dans le cluster.
- 10
- Spécifiez le niveau de verbosité de la journalisation entre
0et10. Les seuils de niveau de journalisation suivants sont fournis à titre indicatif :-
1(par défaut) Informations de base sur les modifications. -
4: Verbosité au niveau du débogage pour résoudre les problèmes typiques. -
9: Informations de débogage étendues au niveau du protocole.
Si vous ne spécifiez pas de valeur, la valeur par défaut de
1est utilisée. -
- 11
- Dans cette section, vous pouvez spécifier la période d'attente pour chaque action en utilisant n'importe quel intervalle ParseDuration valide, y compris
ns,us,ms,s,m, eth. - 12
- Indiquez si l'autoscaler de cluster peut supprimer les nœuds inutiles.
- 13
- Facultatif : Spécifiez le délai d'attente avant la suppression d'un nœud après qu'un nœud ait été récemment added. Si vous ne spécifiez pas de valeur, la valeur par défaut de
10mest utilisée. - 14
- Facultatif : Spécifiez le délai d'attente avant la suppression d'un nœud après qu'un nœud ait été récemment deleted. Si vous ne spécifiez pas de valeur, la valeur par défaut de
0sest utilisée. - 15
- Facultatif : Indiquez le délai d'attente avant la suppression d'un nœud après un échec de mise à l'échelle. Si vous n'indiquez pas de valeur, la valeur par défaut de
3mest utilisée. - 16
- Facultatif : Spécifiez la période avant qu'un nœud inutile ne soit éligible à la suppression. Si vous ne spécifiez pas de valeur, la valeur par défaut de
10mest utilisée.<17> Facultatif : Indiquez l'adresse node utilization level en dessous de laquelle un nœud inutile peut être supprimé. Le niveau d'utilisation du nœud correspond à la somme des ressources demandées divisée par les ressources allouées au nœud et doit être supérieur à"0"et inférieur à"1". Si vous n'indiquez pas de valeur, l'autoscaler de cluster utilise la valeur par défaut"0.5", qui correspond à une utilisation de 50 %. Cette valeur doit être exprimée sous la forme d'une chaîne de caractères.
Lors d'une opération de mise à l'échelle, l'autoscaler de cluster reste dans les plages définies dans la définition de la ressource ClusterAutoscaler, comme le nombre minimum et maximum de cœurs à déployer ou la quantité de mémoire dans le cluster. Cependant, l'autoscaler de cluster ne corrige pas les valeurs actuelles de votre cluster pour qu'elles soient comprises dans ces plages.
Les valeurs minimales et maximales des CPU, de la mémoire et des GPU sont déterminées en calculant ces ressources sur tous les nœuds de la grappe, même si l'autoscaler de grappe ne gère pas les nœuds. Par exemple, les nœuds du plan de contrôle sont pris en compte dans la mémoire totale de la grappe, même si l'autoscaler de la grappe ne gère pas les nœuds du plan de contrôle.
6.10.2. Déploiement du cluster autoscaler
Pour déployer le cluster autoscaler, vous créez une instance de la ressource ClusterAutoscaler.
Procédure
-
Créer un fichier YAML pour la ressource
ClusterAutoscalerqui contient la définition de la ressource personnalisée. Créer la ressource dans le cluster :
$ oc create -f <filename>.yaml1 - 1
<filename>est le nom du fichier de ressources que vous avez personnalisé.
6.11. À propos de l'autoscaler de la machine
L'autoscaler de machines ajuste le nombre de machines dans les ensembles de machines de calcul que vous déployez dans un cluster OpenShift Container Platform. Vous pouvez mettre à l'échelle à la fois l'ensemble de machines de calcul par défaut worker et tout autre ensemble de machines de calcul que vous créez. L'autoscaler de machines crée plus de machines lorsque le cluster manque de ressources pour prendre en charge plus de déploiements. Toute modification des valeurs dans les ressources MachineAutoscaler, telles que le nombre minimum ou maximum d'instances, est immédiatement appliquée à l'ensemble de machines de calcul qu'elle cible.
Vous devez déployer un autoscaler de machines pour que l'autoscaler de clusters puisse mettre à l'échelle vos machines. L'autoscaler de cluster utilise les annotations sur les ensembles de machines de calcul que l'autoscaler de machine définit pour déterminer les ressources qu'il peut mettre à l'échelle. Si vous définissez un autoscaler de cluster sans définir également des autoscalers de machines, l'autoscaler de cluster ne mettra jamais votre cluster à l'échelle.
6.11.1. Définition de la ressource MachineAutoscaler
Cette définition de la ressource MachineAutoscaler montre les paramètres et les valeurs d'exemple pour l'autoscaler de la machine.
apiVersion: "autoscaling.openshift.io/v1beta1"
kind: "MachineAutoscaler"
metadata:
name: "worker-us-east-1a"
namespace: "openshift-machine-api"
spec:
minReplicas: 1
maxReplicas: 12
scaleTargetRef:
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
name: worker-us-east-1a - 1
- Spécifiez le nom de l'autoscaler de machine. Pour faciliter l'identification de l'ensemble de machines de calcul que cet autoscaler de machine met à l'échelle, spécifiez ou incluez le nom de l'ensemble de machines de calcul à mettre à l'échelle. Le nom de l'ensemble de machines de calcul prend la forme suivante :
<clusterid>-<machineset>-<region>. - 2
- Indiquez le nombre minimum de machines du type spécifié qui doivent rester dans la zone spécifiée après que l'autoscaler de cluster a initié la mise à l'échelle du cluster. En cas d'exécution sur AWS, GCP, Azure, RHOSP ou vSphere, cette valeur peut être définie sur
0. Pour les autres fournisseurs, ne définissez pas cette valeur sur0.Vous pouvez réaliser des économies en définissant cette valeur sur
0pour des cas d'utilisation tels que l'exécution de matériel coûteux ou à usage limité utilisé pour des charges de travail spécialisées, ou en mettant à l'échelle un ensemble de machines de calcul avec des machines de très grande taille. L'autoscaler de cluster réduit l'ensemble de machines de calcul à zéro si les machines ne sont pas utilisées.ImportantNe définissez pas la valeur
spec.minReplicassur0pour les trois ensembles de machines de calcul qui sont créés pendant le processus d'installation d'OpenShift Container Platform pour une infrastructure provisionnée par l'installateur. - 3
- Indiquez le nombre maximum de machines du type spécifié que l'autoscaler de cluster peut déployer dans la zone spécifiée après avoir initié la mise à l'échelle du cluster. Assurez-vous que la valeur
maxNodesTotaldans la définition de la ressourceClusterAutoscalerest suffisamment grande pour permettre à l'autoscaler de machines de déployer ce nombre de machines. - 4
- Dans cette section, indiquez les valeurs qui décrivent l'ensemble des machines de calcul existantes à mettre à l'échelle.
- 5
- La valeur du paramètre
kindest toujoursMachineSet. - 6
- La valeur
namedoit correspondre au nom d'un ensemble de machines de calcul existant, comme indiqué dans la valeur du paramètremetadata.name.
6.11.2. Déploiement de la machine autoscaler
Pour déployer la machine autoscaler, vous créez une instance de la ressource MachineAutoscaler.
Procédure
-
Créer un fichier YAML pour la ressource
MachineAutoscalerqui contient la définition de la ressource personnalisée. Créer la ressource dans le cluster :
$ oc create -f <filename>.yaml1 - 1
<filename>est le nom du fichier de ressources que vous avez personnalisé.
6.12. Configuration de Linux cgroup v2
You can enable Linux control group version 2 (cgroup v2) in your cluster by editing the node.config object. Enabling cgroup v2 in OpenShift Container Platform disables all cgroups version 1 controllers and hierarchies in your cluster. cgroup v1 is enabled by default.
cgroup v2 is the next version of the Linux cgroup API. cgroup v2 offers several improvements over cgroup v1, including a unified hierarchy, safer sub-tree delegation, new features such as Pressure Stall Information, and enhanced resource management and isolation.
OpenShift Container Platform cgroups version 2 support is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
Conditions préalables
- Vous avez un cluster OpenShift Container Platform en cours d'exécution qui utilise la version 4.12 ou une version ultérieure.
- You are logged in to the cluster as a user with administrative privileges.
-
Vous avez activé l'ensemble de fonctions
TechPreviewNoUpgradeen utilisant les portes de fonctions.
Procédure
Activer le cgroup v2 sur les nœuds :
Modifiez l'objet
node.config:$ oc edit nodes.config/clusterAjouter
spec.cgroupMode: "v2":Exemple d'objet
node.configapiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: cgroupMode: "v2"1 ...- 1
- Active le cgroup v2.
Vérification
Vérifiez les configurations de la machine pour voir si les nouvelles configurations de la machine ont été ajoutées :
$ oc get mcExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 97-master-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 3m1 99-worker-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 3m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m worker-enable-cgroups-v2 3.2.0 10s- 1
- De nouvelles configurations de machines sont créées, comme prévu.
Vérifier que les nouvelles
kernelArgumentsont été ajoutées aux nouvelles configurations des machines :$ oc describe mc <name>Exemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-selinuxpermissive spec: kernelArguments: - systemd_unified_cgroup_hierarchy=11 - cgroup_no_v1="all"2 - psi=13 Vérifiez que la planification sur les nœuds est désactivée. Cela indique que la modification est en cours d'application :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ci-ln-fm1qnwt-72292-99kt6-master-0 Ready master 58m v1.25.0 ci-ln-fm1qnwt-72292-99kt6-master-1 Ready master 58m v1.25.0 ci-ln-fm1qnwt-72292-99kt6-master-2 Ready master 58m v1.25.0 ci-ln-fm1qnwt-72292-99kt6-worker-a-h5gt4 Ready,SchedulingDisabled worker 48m v1.25.0 ci-ln-fm1qnwt-72292-99kt6-worker-b-7vtmd Ready worker 48m v1.25.0 ci-ln-fm1qnwt-72292-99kt6-worker-c-rhzkv Ready worker 48m v1.25.0Une fois qu'un nœud est revenu à l'état
Ready, démarrez une session de débogage pour ce nœud :oc debug node/<node_name>Définir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /hostVérifiez que le fichier
sys/fs/cgroup/cgroup2fsest présent sur vos nœuds. Ce fichier est créé par le cgroup v2 :$ stat -c %T -f /sys/fs/cgroupExemple de sortie
cgroup2fs
6.13. Activation des fonctionnalités de l'aperçu technologique à l'aide des FeatureGates
Vous pouvez activer un sous-ensemble des fonctionnalités actuelles de l'aperçu technologique pour tous les nœuds du cluster en modifiant la ressource personnalisée (CR) FeatureGate.
6.13.1. Comprendre les "feature gates
Vous pouvez utiliser la ressource personnalisée (CR) FeatureGate pour activer des ensembles de fonctionnalités spécifiques dans votre cluster. Un ensemble de fonctionnalités est une collection de fonctionnalités d'OpenShift Container Platform qui ne sont pas activées par défaut.
Vous pouvez activer l'ensemble des fonctions suivantes en utilisant le CR FeatureGate:
TechPreviewNoUpgrade. Cet ensemble de fonctionnalités est un sous-ensemble des fonctionnalités de l'aperçu technologique actuel. Cet ensemble de fonctionnalités vous permet d'activer ces fonctionnalités d'aperçu technologique sur des clusters de test, où vous pouvez les tester entièrement, tout en laissant les fonctionnalités désactivées sur les clusters de production.AvertissementL'activation de l'ensemble de fonctionnalités
TechPreviewNoUpgradesur votre cluster ne peut pas être annulée et empêche les mises à jour mineures de la version. Vous ne devez pas activer ce jeu de fonctionnalités sur les clusters de production.Les fonctionnalités suivantes de l'aperçu technologique sont activées par cet ensemble de fonctionnalités :
Migration automatique CSI. Permet la migration automatique des plugins de volume in-tree pris en charge vers leurs pilotes CSI (Container Storage Interface) équivalents. Pris en charge pour :
-
Fichier Azure (
CSIMigrationAzureFile) -
VMware vSphere (
CSIMigrationvSphere)
-
Fichier Azure (
-
Shared Resources CSI Driver and Build CSI Volumes in OpenShift Builds. Active l'interface de stockage de conteneurs (CSI). (
CSIDriverSharedResource) -
Volumes CSI. Active la prise en charge des volumes CSI pour le système de construction de la plateforme OpenShift Container. (
BuildCSIVolumes) -
Mémoire d'échange sur les nœuds. Active l'utilisation de la mémoire d'échange pour les charges de travail de la plateforme OpenShift Container sur une base par nœud. (
NodeSwap) -
cgroups v2. Active cgroup v2, la prochaine version de l'API cgroup de Linux. (
CGroupsV2) -
crun. Active l'exécution du conteneur crun. (
Crun) -
Insights Operator. Active l'opérateur Insights, qui rassemble les données de configuration d'OpenShift Container Platform et les envoie à Red Hat. (
InsightsConfigAPI) -
Fournisseurs de clouds externes. Permet la prise en charge des fournisseurs de cloud externes pour les clusters sur vSphere, AWS, Azure et GCP. La prise en charge d'OpenStack est de type GA. (
ExternalCloudProvider) -
Contraintes d'étalement de la topologie du pod. Active le paramètre
matchLabelKeyspour les contraintes de topologie des pods. Le paramètre est une liste de clés d'étiquettes de pods permettant de sélectionner les pods sur lesquels l'étalement sera calculé. (MatchLabelKeysInPodTopologySpread) Application de l'admission à la sécurité des pods. Active l'application restreinte de l'admission à la sécurité des pods. Au lieu d'enregistrer un simple avertissement, les pods sont rejetés s'ils ne respectent pas les normes de sécurité des pods. (
OpenShiftPodSecurityAdmission)NoteL'application restreinte de l'admission à la sécurité des pods n'est activée que si vous activez l'ensemble de fonctionnalités
TechPreviewNoUpgradeaprès l'installation de votre cluster OpenShift Container Platform. Elle n'est pas activée si vous activez l'ensemble de fonctionnalitésTechPreviewNoUpgradependant l'installation du cluster.
6.13.2. Activation des jeux de fonctionnalités à l'aide de la console web
Vous pouvez utiliser la console Web d'OpenShift Container Platform pour activer les jeux de fonctionnalités pour tous les nœuds d'un cluster en modifiant la ressource personnalisée (CR) FeatureGate.
Procédure
Pour activer les jeux de fonctionnalités :
- Dans la console web d'OpenShift Container Platform, passez à la page Administration → Custom Resource Definitions.
- Sur la page Custom Resource Definitions, cliquez sur FeatureGate.
- Sur la page Custom Resource Definition Details, cliquez sur l'onglet Instances.
- Cliquez sur le portail de fonctionnalités cluster, puis sur l'onglet YAML.
Modifier l'instance cluster pour ajouter des ensembles de fonctionnalités spécifiques :
AvertissementL'activation de l'ensemble de fonctionnalités
TechPreviewNoUpgradesur votre cluster ne peut pas être annulée et empêche les mises à jour mineures de la version. Vous ne devez pas activer ce jeu de fonctionnalités sur les clusters de production.Exemple de ressource personnalisée Feature Gate
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 .... spec: featureSet: TechPreviewNoUpgrade2 Après avoir enregistré les modifications, de nouvelles configurations de machines sont créées, les pools de configurations de machines sont mis à jour et la planification sur chaque nœud est désactivée pendant l'application de la modification.
Vérification
Vous pouvez vérifier que les portes de fonctionnalités sont activées en consultant le fichier kubelet.conf d'un nœud après le retour des nœuds à l'état prêt.
- Depuis la perspective Administrator dans la console web, naviguez vers Compute → Nodes.
- Sélectionnez un nœud.
- Dans la page Node details, cliquez sur Terminal.
Dans la fenêtre du terminal, changez votre répertoire racine en
/host:sh-4.2# chroot /hostConsulter le fichier
kubelet.conf:sh-4.2# cat /etc/kubernetes/kubelet.confExemple de sortie
... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false ...Les fonctionnalités répertoriées à l'adresse
truesont activées sur votre cluster.NoteLes fonctionnalités listées varient en fonction de la version d'OpenShift Container Platform.
6.13.3. Activation des jeux de fonctionnalités à l'aide de l'interface de ligne de commande
Vous pouvez utiliser la CLI OpenShift (oc) pour activer les jeux de fonctionnalités pour tous les nœuds d'un cluster en modifiant la ressource personnalisée (CR) FeatureGate.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Pour activer les jeux de fonctionnalités :
Modifier le CR
FeatureGatenommécluster:$ oc edit featuregate clusterAvertissementL'activation de l'ensemble de fonctionnalités
TechPreviewNoUpgradesur votre cluster ne peut pas être annulée et empêche les mises à jour mineures de la version. Vous ne devez pas activer ce jeu de fonctionnalités sur les clusters de production.Exemple de ressource personnalisée FeatureGate
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 spec: featureSet: TechPreviewNoUpgrade2 Après avoir enregistré les modifications, de nouvelles configurations de machines sont créées, les pools de configurations de machines sont mis à jour et la planification sur chaque nœud est désactivée pendant l'application de la modification.
Vérification
Vous pouvez vérifier que les portes de fonctionnalités sont activées en consultant le fichier kubelet.conf d'un nœud après le retour des nœuds à l'état prêt.
- Depuis la perspective Administrator dans la console web, naviguez vers Compute → Nodes.
- Sélectionnez un nœud.
- Dans la page Node details, cliquez sur Terminal.
Dans la fenêtre du terminal, changez votre répertoire racine en
/host:sh-4.2# chroot /hostConsulter le fichier
kubelet.conf:sh-4.2# cat /etc/kubernetes/kubelet.confExemple de sortie
... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false ...Les fonctionnalités répertoriées à l'adresse
truesont activées sur votre cluster.NoteLes fonctionnalités listées varient en fonction de la version d'OpenShift Container Platform.
6.14. tâches etcd
Sauvegarder etcd, activer ou désactiver le cryptage etcd, ou défragmenter les données etcd.
6.14.1. À propos du chiffrement d'etcd
Par défaut, les données etcd ne sont pas cryptées dans OpenShift Container Platform. Vous pouvez activer le chiffrement etcd pour votre cluster afin de fournir une couche supplémentaire de sécurité des données. Par exemple, cela peut aider à protéger la perte de données sensibles si une sauvegarde etcd est exposée à des parties incorrectes.
Lorsque vous activez le chiffrement etcd, les ressources suivantes du serveur API OpenShift et du serveur API Kubernetes sont chiffrées :
- Secrets
- Cartes de configuration
- Routes
- Jetons d'accès OAuth
- Jetons d'autorisation OAuth
Lorsque vous activez le chiffrement etcd, des clés de chiffrement sont créées. Ces clés font l'objet d'une rotation hebdomadaire. Vous devez disposer de ces clés pour restaurer une sauvegarde etcd.
Le cryptage Etcd ne crypte que les valeurs, pas les clés. Les types de ressources, les espaces de noms et les noms d'objets ne sont pas chiffrés.
Si le chiffrement etcd est activé pendant une sauvegarde, le fichier static_kuberesources_<datetimestamp>.tar.gz contient les clés de chiffrement de l'instantané etcd. Pour des raisons de sécurité, ce fichier doit être stocké séparément de l'instantané etcd. Cependant, ce fichier est nécessaire pour restaurer un état antérieur de etcd à partir de l'instantané etcd correspondant.
6.14.2. Activation du chiffrement d'etcd
Vous pouvez activer le chiffrement etcd pour chiffrer les ressources sensibles de votre cluster.
Ne sauvegardez pas les ressources etcd tant que le processus de cryptage initial n'est pas terminé. Si le processus de chiffrement n'est pas terminé, la sauvegarde risque de n'être que partiellement chiffrée.
Après avoir activé le chiffrement d'etcd, plusieurs changements peuvent survenir :
- Le chiffrement d'etcd peut affecter la consommation de mémoire de quelques ressources.
- Il se peut que vous remarquiez un effet transitoire sur les performances de la sauvegarde, car le leader doit servir la sauvegarde.
- Une entrée/sortie de disque peut affecter le nœud qui reçoit l'état de sauvegarde.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier l'objet
APIServer:$ oc edit apiserverDéfinissez le type de champ
encryptionsuraescbc:spec: encryption: type: aescbc1 - 1
- Le type
aescbcsignifie que le chiffrement est effectué par AES-CBC avec un remplissage PKCS#7 et une clé de 32 octets.
Enregistrez le fichier pour appliquer les modifications.
Le processus de cryptage démarre. Ce processus peut durer 20 minutes ou plus, en fonction de la taille de votre cluster.
Vérifiez que le chiffrement d'etcd a réussi.
Examinez la condition d'état
Encryptedpour le serveur OpenShift API afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: routes.route.openshift.ioSi la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.Consultez la condition d'état
Encryptedpour le serveur API Kubernetes afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: secrets, configmapsSi la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.Examinez l'état
Encryptedpour le serveur OpenShift OAuth API afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.ioSi la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.
6.14.3. Désactiver le chiffrement d'etcd
Vous pouvez désactiver le chiffrement des données etcd dans votre cluster.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier l'objet
APIServer:$ oc edit apiserverDéfinissez le type de champ
encryptionsuridentity:spec: encryption: type: identity1 - 1
- Le type
identityest la valeur par défaut et signifie qu'aucun cryptage n'est effectué.
Enregistrez le fichier pour appliquer les modifications.
Le processus de décryptage démarre. Ce processus peut durer 20 minutes ou plus, en fonction de la taille de votre cluster.
Vérifier que le décryptage d'etcd a été effectué avec succès.
Examinez la condition d'état
Encryptedpour le serveur OpenShift API afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decryptedSi la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.Consultez la condition d'état
Encryptedpour le serveur API Kubernetes afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decryptedSi la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.Examinez l'état
Encryptedpour le serveur OpenShift OAuth API afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decryptedSi la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.
6.14.4. Sauvegarde des données etcd
Suivez ces étapes pour sauvegarder les données etcd en créant un instantané etcd et en sauvegardant les ressources des pods statiques. Cette sauvegarde peut être enregistrée et utilisée ultérieurement si vous avez besoin de restaurer etcd.
N'effectuez une sauvegarde qu'à partir d'un seul hôte de plan de contrôle. N'effectuez pas de sauvegarde à partir de chaque hôte de plan de contrôle du cluster.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. Vous avez vérifié si le proxy à l'échelle du cluster est activé.
AstuceVous pouvez vérifier si le proxy est activé en examinant la sortie de
oc get proxy cluster -o yaml. Le proxy est activé si les champshttpProxy,httpsProxyetnoProxyont des valeurs définies.
Procédure
Démarrer une session de débogage pour un nœud de plan de contrôle :
oc debug node/<node_name>Changez votre répertoire racine en
/host:sh-4.2# chroot /host-
Si le proxy à l'échelle du cluster est activé, assurez-vous que vous avez exporté les variables d'environnement
NO_PROXY,HTTP_PROXY, etHTTPS_PROXY. Exécutez le script
cluster-backup.shet indiquez l'emplacement où sauvegarder la sauvegarde.AstuceLe script
cluster-backup.shest maintenu en tant que composant de l'opérateur de cluster etcd et est une enveloppe autour de la commandeetcdctl snapshot save.sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backupExemple de sortie de script
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backupDans cet exemple, deux fichiers sont créés dans le répertoire
/home/core/assets/backup/sur l'hôte du plan de contrôle :-
snapshot_<datetimestamp>.db: Ce fichier est le snapshot etcd. Le scriptcluster-backup.shconfirme sa validité. static_kuberesources_<datetimestamp>.tar.gz: Ce fichier contient les ressources pour les pods statiques. Si le chiffrement etcd est activé, il contient également les clés de chiffrement pour l'instantané etcd.NoteSi le cryptage etcd est activé, il est recommandé de stocker ce deuxième fichier séparément de l'instantané etcd pour des raisons de sécurité. Toutefois, ce fichier est nécessaire pour restaurer à partir de l'instantané etcd.
Gardez à l'esprit que le chiffrement etcd ne chiffre que les valeurs, pas les clés. Cela signifie que les types de ressources, les espaces de noms et les noms d'objets ne sont pas chiffrés.
-
6.14.5. Défragmentation des données etcd
Pour les clusters importants et denses, etcd peut souffrir de mauvaises performances si l'espace-clé devient trop grand et dépasse le quota d'espace. Maintenez et défragmentez périodiquement etcd pour libérer de l'espace dans le magasin de données. Surveillez les métriques etcd dans Prometheus et défragmentez-le si nécessaire ; sinon, etcd peut déclencher une alarme à l'échelle de la grappe qui la met en mode de maintenance n'acceptant que les lectures et les suppressions de clés.
Surveillez ces paramètres clés :
-
etcd_server_quota_backend_bytesce qui correspond à la limite actuelle du quota -
etcd_mvcc_db_total_size_in_use_in_bytesqui indique l'utilisation réelle de la base de données après un compactage de l'historique -
etcd_mvcc_db_total_size_in_bytesqui indique la taille de la base de données, y compris l'espace libre en attente de défragmentation
Défragmenter les données etcd pour récupérer de l'espace disque après des événements qui provoquent la fragmentation du disque, comme le compactage de l'historique etcd.
Le compactage de l'historique est effectué automatiquement toutes les cinq minutes et laisse des trous dans la base de données back-end. Cet espace fragmenté peut être utilisé par etcd, mais n'est pas disponible pour le système de fichiers hôte. Vous devez défragmenter etcd pour rendre cet espace disponible au système de fichiers hôte.
La défragmentation se produit automatiquement, mais vous pouvez également la déclencher manuellement.
La défragmentation automatique est une bonne chose dans la plupart des cas, car l'opérateur etcd utilise les informations sur les clusters pour déterminer l'opération la plus efficace pour l'utilisateur.
6.14.5.1. Défragmentation automatique
L'opérateur etcd défragmente automatiquement les disques. Aucune intervention manuelle n'est nécessaire.
Vérifiez que le processus de défragmentation s'est déroulé correctement en consultant l'un de ces journaux :
- journaux etcd
- cluster-etcd-operator pod
- statut de l'opérateur journal des erreurs
La défragmentation automatique peut provoquer une défaillance de l'élection du leader dans divers composants de base d'OpenShift, tels que le gestionnaire de contrôleur Kubernetes, ce qui déclenche un redémarrage du composant défaillant. Le redémarrage est inoffensif et déclenche le basculement vers la prochaine instance en cours d'exécution ou le composant reprend le travail après le redémarrage.
Exemple de sortie de journal pour une défragmentation réussie
le membre etcd a été défragmenté : <member_name>, memberID : <member_id>Exemple de sortie de journal pour une défragmentation infructueuse
échec de la défragmentation sur le membre : <member_name>, memberID : <member_id>: <error_message>6.14.5.2. Défragmentation manuelle
Une alerte Prometheus vous indique si vous devez utiliser la défragmentation manuelle. L'alerte s'affiche dans deux cas :
- Lorsque etcd utilise plus de 50 % de son espace disponible pendant plus de 10 minutes
- Lorsque etcd utilise activement moins de 50 % de la taille totale de sa base de données pendant plus de 10 minutes
Vous pouvez également déterminer si une défragmentation est nécessaire en vérifiant la taille de la base de données etcd en Mo qui sera libérée par la défragmentation avec l'expression PromQL : (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes)/1024/1024
La défragmentation de etcd est une action bloquante. Le membre etcd ne répondra pas tant que la défragmentation ne sera pas terminée. Pour cette raison, attendez au moins une minute entre les actions de défragmentation sur chacun des pods pour permettre au cluster de récupérer.
Suivez cette procédure pour défragmenter les données etcd sur chaque membre etcd.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Déterminer quel membre etcd est le leader, car le leader doit être défragmenté en dernier.
Obtenir la liste des pods etcd :
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wideExemple de sortie
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>Choisissez un pod et exécutez la commande suivante pour déterminer quel membre etcd est le leader :
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w tableExemple de sortie
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+D'après la colonne
IS LEADERde cette sortie, le point d'extrémitéhttps://10.0.199.170:2379est le leader. En faisant correspondre ce point d'extrémité avec la sortie de l'étape précédente, le nom de pod du leader estetcd-ip-10-0-199-170.example.redhat.com.
Défragmenter un membre etcd.
Se connecter au conteneur etcd en cours d'exécution, en indiquant le nom d'un pod qui est not le leader :
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.comDésactivez la variable d'environnement
ETCDCTL_ENDPOINTS:sh-4.4# unset ETCDCTL_ENDPOINTSDéfragmenter le membre etcd :
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defragExemple de sortie
Finished defragmenting etcd member[https://localhost:2379]En cas d'erreur de temporisation, augmentez la valeur de
--command-timeoutjusqu'à ce que la commande réussisse.Vérifiez que la taille de la base de données a été réduite :
sh-4.4# etcdctl endpoint status -w table --clusterExemple de sortie
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 41 MB | false | false | 7 | 91624 | 91624 | |1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+Cet exemple montre que la taille de la base de données pour ce membre etcd est maintenant de 41 Mo, alors qu'elle était de 104 Mo au départ.
Répétez ces étapes pour vous connecter à chacun des autres membres etcd et les défragmenter. Défragmentez toujours le leader en dernier.
Attendez au moins une minute entre les actions de défragmentation pour permettre au pod etcd de se rétablir. Tant que le pod etcd n'est pas rétabli, le membre etcd ne répond pas.
Si des alarmes
NOSPACEont été déclenchées en raison du dépassement du quota d'espace, effacez-les.Vérifiez s'il y a des alarmes sur
NOSPACE:sh-4.4# etcdctl alarm listExemple de sortie
memberID:12345678912345678912 alarm:NOSPACEEffacer les alarmes :
sh-4.4# etcdctl alarm disarm
Prochaines étapes
Après la défragmentation, si etcd utilise toujours plus de 50 % de son espace disponible, envisagez d'augmenter le quota de disque pour etcd.
6.14.6. Rétablissement d'un état antérieur de la grappe
Vous pouvez utiliser une sauvegarde etcd enregistrée pour restaurer un état antérieur du cluster ou restaurer un cluster qui a perdu la majorité des hôtes du plan de contrôle.
Si votre cluster utilise un jeu de machines de plan de contrôle, voir "Dépannage du jeu de machines de plan de contrôle" pour une procédure de récupération etcd plus simple.
Lorsque vous restaurez votre cluster, vous devez utiliser une sauvegarde etcd provenant de la même version de z-stream. Par exemple, un cluster OpenShift Container Platform 4.7.2 doit utiliser une sauvegarde etcd provenant de la version 4.7.2.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Un hôte de plan de contrôle sain à utiliser comme hôte de reprise.
- Accès SSH aux hôtes du plan de contrôle.
-
Un répertoire de sauvegarde contenant à la fois l'instantané etcd et les ressources pour les pods statiques, qui proviennent de la même sauvegarde. Les noms de fichiers dans le répertoire doivent être dans les formats suivants :
snapshot_<datetimestamp>.dbetstatic_kuberesources_<datetimestamp>.tar.gz.
Pour les nœuds de plan de contrôle sans récupération, il n'est pas nécessaire d'établir une connectivité SSH ou d'arrêter les pods statiques. Vous pouvez supprimer et recréer d'autres machines de plan de contrôle sans récupération, une par une.
Procédure
- Sélectionnez un hôte du plan de contrôle à utiliser comme hôte de restauration. Il s'agit de l'hôte sur lequel vous exécuterez l'opération de restauration.
Établir une connectivité SSH avec chacun des nœuds du plan de contrôle, y compris l'hôte de reprise.
Le serveur API Kubernetes devient inaccessible après le démarrage du processus de restauration, de sorte que vous ne pouvez pas accéder aux nœuds du plan de contrôle. Pour cette raison, il est recommandé d'établir une connectivité SSH à chaque hôte du plan de contrôle dans un terminal séparé.
ImportantSi vous n'effectuez pas cette étape, vous ne pourrez pas accéder aux hôtes du plan de contrôle pour terminer la procédure de restauration, et vous ne pourrez pas récupérer votre cluster à partir de cet état.
Copiez le répertoire de sauvegarde etcd sur l'hôte du plan de contrôle de reprise.
Cette procédure suppose que vous avez copié le répertoire
backupcontenant le snapshot etcd et les ressources pour les pods statiques dans le répertoire/home/core/de votre hôte de plan de contrôle de récupération.Arrêtez les pods statiques sur tous les autres nœuds du plan de contrôle.
NoteIl n'est pas nécessaire d'arrêter manuellement les pods sur l'hôte de récupération. Le script de récupération arrêtera les pods sur l'hôte de récupération.
- Accéder à un hôte du plan de contrôle qui n'est pas l'hôte de reprise.
Déplacer le fichier pod etcd existant hors du répertoire kubelet manifest :
$ sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmpVérifiez que les pods etcd sont arrêtés.
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"La sortie de cette commande doit être vide. Si ce n'est pas le cas, attendez quelques minutes et vérifiez à nouveau.
Déplacez le fichier pod du serveur API Kubernetes existant hors du répertoire kubelet manifest :
$ sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpVérifiez que les pods du serveur API Kubernetes sont arrêtés.
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"La sortie de cette commande doit être vide. Si ce n'est pas le cas, attendez quelques minutes et vérifiez à nouveau.
Déplacez le répertoire de données etcd vers un autre emplacement :
$ sudo mv /var/lib/etcd/ /tmp- Répétez cette étape sur chacun des autres hôtes du plan de contrôle qui n'est pas l'hôte de reprise.
- Accéder à l'hôte du plan de contrôle de récupération.
Si le proxy à l'échelle du cluster est activé, assurez-vous que vous avez exporté les variables d'environnement
NO_PROXY,HTTP_PROXY, etHTTPS_PROXY.AstuceVous pouvez vérifier si le proxy est activé en examinant la sortie de
oc get proxy cluster -o yaml. Le proxy est activé si les champshttpProxy,httpsProxyetnoProxyont des valeurs définies.Exécutez le script de restauration sur l'hôte du plan de contrôle de récupération et indiquez le chemin d'accès au répertoire de sauvegarde etcd :
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/backupExemple de sortie de script
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yamlNoteLe processus de restauration peut entraîner l'entrée des nœuds dans l'état
NotReadysi les certificats des nœuds ont été mis à jour après la dernière sauvegarde etcd.Vérifiez que les nœuds sont dans l'état
Ready.Exécutez la commande suivante :
$ oc get nodes -wExemple de sortie
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.25.0 host-172-25-75-38 Ready infra,worker 3d20h v1.25.0 host-172-25-75-40 Ready master 3d20h v1.25.0 host-172-25-75-65 Ready master 3d20h v1.25.0 host-172-25-75-74 Ready infra,worker 3d20h v1.25.0 host-172-25-75-79 Ready worker 3d20h v1.25.0 host-172-25-75-86 Ready worker 3d20h v1.25.0 host-172-25-75-98 Ready infra,worker 3d20h v1.25.0Il peut s'écouler plusieurs minutes avant que tous les nœuds ne communiquent leur état.
Si des nœuds sont dans l'état
NotReady, connectez-vous aux nœuds et supprimez tous les fichiers PEM du répertoire/var/lib/kubelet/pkisur chaque nœud. Vous pouvez vous connecter aux nœuds par SSH ou utiliser la fenêtre de terminal de la console web.$ ssh -i <ssh-key-path> core@<master-hostname>Exemple de répertoire
pkish-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
Redémarrer le service kubelet sur tous les hôtes du plan de contrôle.
À partir de l'hôte de récupération, exécutez la commande suivante :
$ sudo systemctl restart kubelet.service- Répétez cette étape sur tous les autres hôtes du plan de contrôle.
Approuver les RSC en attente :
NoteLes clusters sans nœuds de travail, tels que les clusters à un seul nœud ou les clusters composés de trois nœuds de plan de contrôle ordonnançables, n'auront pas de CSR en attente à approuver. Dans ce cas, vous pouvez ignorer cette étape.
Obtenir la liste des CSR actuels :
$ oc get csrExemple de sortie
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...Examinez les détails d'un CSR pour vérifier qu'il est valide :
oc describe csr <csr_name>1 - 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
Approuver chaque CSR
node-bootstrappervalide :$ oc adm certificate approve <csr_name>Pour les installations fournies par l'utilisateur, approuver chaque CSR de service kubelet valide :
$ oc adm certificate approve <csr_name>
Vérifiez que le plan de contrôle à membre unique a bien démarré.
Depuis l'hôte de récupération, vérifiez que le conteneur etcd est en cours d'exécution.
$ sudo crictl ps | grep etcd | grep -v operatorExemple de sortie
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0Depuis l'hôte de récupération, vérifiez que le pod etcd est en cours d'exécution.
$ oc -n openshift-etcd get pods -l k8s-app=etcdNoteSi vous essayez d'exécuter
oc loginavant d'exécuter cette commande et que vous recevez l'erreur suivante, attendez quelques instants pour que les contrôleurs d'authentification démarrent et réessayez.Unable to connect to the server: EOFExemple de sortie
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sSi l'état est
Pending, ou si la sortie indique plus d'un pod etcd en cours d'exécution, attendez quelques minutes et vérifiez à nouveau.
NoteN'effectuez l'étape suivante que si vous utilisez le plugin réseau
OVNKubernetes.Supprimer les objets nœuds associés aux hôtes du plan de contrôle qui ne sont pas l'hôte du plan de contrôle de reprise.
oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>Vérifier que le Cluster Network Operator (CNO) redéploie le plan de contrôle OVN-Kubernetes et qu'il ne référence plus les mauvaises adresses IP des contrôleurs. Pour vérifier ce résultat, vérifiez régulièrement la sortie de la commande suivante. Attendez qu'elle renvoie un résultat vide avant de passer à l'étape suivante.
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<wrong_master_ip_1>|<wrong_master_ip_2>'NoteCela peut prendre au moins 5 à 10 minutes pour que le plan de contrôle OVN-Kubernetes soit redéployé et que la commande précédente renvoie une sortie vide.
Désactivez la garde du quorum en entrant la commande suivante :
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'Cette commande permet de s'assurer que vous pouvez recréer les secrets et déployer les pods statiques avec succès.
Redémarrez les pods Kubernetes d'Open Virtual Network (OVN) sur tous les hôtes.
NoteLes webhooks de validation et de mutation des admissions peuvent rejeter les pods. Si vous ajoutez d'autres webhooks dont l'adresse
failurePolicyestFail, ils peuvent rejeter des pods et le processus de restauration peut échouer. Vous pouvez éviter cela en sauvegardant et en supprimant les webhooks lors de la restauration de l'état de la grappe. Une fois l'état du cluster restauré avec succès, vous pouvez réactiver les webhooks.Vous pouvez également définir temporairement
failurePolicysurIgnorependant la restauration de l'état de la grappe. Une fois l'état de la grappe restauré avec succès, vous pouvez définirfailurePolicysurFail.Supprimez la base de données en direction du nord (nbdb) et la base de données en direction du sud (sbdb). Accédez à l'hôte de reprise et aux nœuds de plan de contrôle restants à l'aide de Secure Shell (SSH) et exécutez la commande suivante :
$ sudo rm -f /var/lib/ovn/etc/*.dbSupprimez tous les pods du plan de contrôle OVN-Kubernetes en exécutant la commande suivante :
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetesAssurez-vous que tous les pods du plan de contrôle OVN-Kubernetes sont à nouveau déployés et sont dans un état
Runningen exécutant la commande suivante :$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetesExemple de sortie
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s ovnkube-master-rm8kw 4/4 Running 0 47s ovnkube-master-zbqnh 4/4 Running 0 56sSupprimez tous les pods
ovnkube-nodeen exécutant la commande suivante :$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; doneAssurez-vous que tous les pods
ovnkube-nodesont à nouveau déployés et sont dans un étatRunningen exécutant la commande suivante :$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
Supprimer et recréer les autres machines du plan de contrôle qui ne sont pas des machines de récupération, une par une. Une fois les machines recréées, une nouvelle révision est forcée et etcd passe automatiquement à l'échelle supérieure.
Si vous utilisez une installation bare metal fournie par l'utilisateur, vous pouvez recréer une machine de plan de contrôle en utilisant la même méthode que celle utilisée pour la créer à l'origine. Pour plus d'informations, voir "Installation d'un cluster fourni par l'utilisateur sur bare metal".
AvertissementNe supprimez pas et ne recréez pas la machine pour l'hôte de récupération.
Si vous utilisez une infrastructure fournie par l'installateur ou si vous avez utilisé l'API Machine pour créer vos machines, procédez comme suit :
AvertissementNe supprimez pas et ne recréez pas la machine pour l'hôte de récupération.
Pour les installations bare metal sur une infrastructure fournie par l'installateur, les machines du plan de contrôle ne sont pas recréées. Pour plus d'informations, voir "Remplacement d'un nœud de plan de contrôle bare-metal".
Obtenir la machine de l'un des hôtes du plan de contrôle perdus.
Dans un terminal ayant accès au cluster en tant qu'utilisateur cluster-admin, exécutez la commande suivante :
$ oc get machines -n openshift-machine-api -o wideExemple de sortie :
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- Il s'agit de la machine du plan de contrôle de l'hôte du plan de contrôle perdu,
ip-10-0-131-183.ec2.internal.
Enregistrez la configuration de la machine dans un fichier sur votre système de fichiers :
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- Indiquez le nom de la machine du plan de contrôle pour l'hôte du plan de contrôle perdu.
Modifiez le fichier
new-master-machine.yamlcréé à l'étape précédente pour lui attribuer un nouveau nom et supprimer les champs inutiles.Retirer toute la section
status:status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatusChangez le nom du champ
metadata.name.Il est recommandé de conserver le même nom de base que l'ancienne machine et de remplacer le numéro de fin par le prochain numéro disponible. Dans cet exemple,
clustername-8qw5l-master-0est remplacé parclustername-8qw5l-master-3:apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...Supprimer le champ
spec.providerID:providerID: aws:///us-east-1a/i-0fdb85790d76d0c3fSupprimer les champs
metadata.annotationsetmetadata.generation:annotations: machine.openshift.io/instance-state: running ... generation: 2Supprimer les champs
metadata.resourceVersionetmetadata.uid:resourceVersion: "13291" uid: a282eb70-40a2-4e89-8009-d05dd420d31a
Supprimer la machine de l'hôte du plan de contrôle perdu :
oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- Indiquez le nom de la machine du plan de contrôle pour l'hôte du plan de contrôle perdu.
Vérifiez que la machine a été supprimée :
$ oc get machines -n openshift-machine-api -o wideExemple de sortie :
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a runningCréez une machine en utilisant le fichier
new-master-machine.yaml:$ oc apply -f new-master-machine.yamlVérifiez que la nouvelle machine a été créée :
$ oc get machines -n openshift-machine-api -o wideExemple de sortie :
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- La nouvelle machine,
clustername-8qw5l-master-3, est en cours de création et sera prête après le changement de phase deProvisioningàRunning.
La création de la nouvelle machine peut prendre quelques minutes. L'opérateur du cluster etcd se synchronisera automatiquement lorsque la machine ou le nœud reviendra à un état sain.
- Répétez ces étapes pour chaque hôte du plan de contrôle perdu qui n'est pas l'hôte de récupération.
Dans une fenêtre de terminal séparée, connectez-vous au cluster en tant qu'utilisateur ayant le rôle
cluster-adminen entrant la commande suivante :$ oc login -u <cluster_admin>1 - 1
- Pour
<cluster_admin>, indiquez un nom d'utilisateur avec le rôlecluster-admin.
Forcer le redéploiement de etcd.
Dans un terminal ayant accès au cluster en tant qu'utilisateur
cluster-admin, exécutez la commande suivante :$ oc patch etcd cluster -p='{"spec" : {\i1}"forceRedeploymentReason" : \N-"recovery-'\N"$( date --rfc-3339=ns )'\N'\N"}'' -type=merge} --type=merge1 - 1
- La valeur
forceRedeploymentReasondoit être unique, c'est pourquoi un horodatage est ajouté.
Lorsque l'opérateur du cluster etcd effectue un redéploiement, les nœuds existants sont démarrés avec de nouveaux pods, comme lors de la mise à l'échelle initiale.
Réactivez la garde du quorum en entrant la commande suivante :
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'Vous pouvez vérifier que la section
unsupportedConfigOverridesest supprimée de l'objet en entrant cette commande :$ oc get etcd/cluster -oyamlVérifier que tous les nœuds sont mis à jour avec la dernière révision.
Dans un terminal ayant accès au cluster en tant qu'utilisateur
cluster-admin, exécutez la commande suivante :$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez la condition d'état
NodeInstallerProgressingpour etcd afin de vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- Dans cet exemple, le dernier numéro de révision est
7.
Si le résultat comprend plusieurs numéros de révision, tels que
2 nodes are at revision 6; 1 nodes are at revision 7, cela signifie que la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.Une fois etcd redéployé, forcez de nouveaux déploiements pour le plan de contrôle. Le serveur API Kubernetes se réinstallera sur les autres nœuds car le kubelet est connecté aux serveurs API à l'aide d'un équilibreur de charge interne.
Dans un terminal ayant accès au cluster en tant qu'utilisateur
cluster-admin, exécutez les commandes suivantes.Forcer un nouveau déploiement pour le serveur API Kubernetes :
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVérifier que tous les nœuds sont mis à jour avec la dernière révision.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez l'état de
NodeInstallerProgressingpour vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- Dans cet exemple, le dernier numéro de révision est
7.
Si le résultat comprend plusieurs numéros de révision, tels que
2 nodes are at revision 6; 1 nodes are at revision 7, cela signifie que la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.Forcer un nouveau déploiement pour le gestionnaire de contrôleur Kubernetes :
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVérifier que tous les nœuds sont mis à jour avec la dernière révision.
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez l'état de
NodeInstallerProgressingpour vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- Dans cet exemple, le dernier numéro de révision est
7.
Si le résultat comprend plusieurs numéros de révision, tels que
2 nodes are at revision 6; 1 nodes are at revision 7, cela signifie que la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.Forcer un nouveau déploiement pour le planificateur Kubernetes :
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVérifier que tous les nœuds sont mis à jour avec la dernière révision.
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez l'état de
NodeInstallerProgressingpour vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- Dans cet exemple, le dernier numéro de révision est
7.
Si le résultat comprend plusieurs numéros de révision, tels que
2 nodes are at revision 6; 1 nodes are at revision 7, cela signifie que la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.
Vérifiez que tous les hôtes du plan de contrôle ont démarré et rejoint le cluster.
Dans un terminal ayant accès au cluster en tant qu'utilisateur
cluster-admin, exécutez la commande suivante :$ oc -n openshift-etcd get pods -l k8s-app=etcdExemple de sortie
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
Pour s'assurer que toutes les charges de travail reviennent à un fonctionnement normal à la suite d'une procédure de récupération, redémarrez chaque pod qui stocke les informations de l'API Kubernetes. Cela inclut les composants d'OpenShift Container Platform tels que les routeurs, les opérateurs et les composants tiers.
Notez que la restauration de tous les services peut prendre plusieurs minutes après l'exécution de cette procédure. Par exemple, l'authentification à l'aide de oc login peut ne pas fonctionner immédiatement jusqu'à ce que les pods du serveur OAuth soient redémarrés.
6.14.7. Problèmes et solutions de contournement pour la restauration d'un état de stockage persistant
Si votre cluster OpenShift Container Platform utilise un stockage persistant sous quelque forme que ce soit, un état du cluster est généralement stocké en dehors d'etcd. Il peut s'agir d'un cluster Elasticsearch fonctionnant dans un pod ou d'une base de données fonctionnant dans un objet StatefulSet. Lorsque vous restaurez à partir d'une sauvegarde etcd, l'état des charges de travail dans OpenShift Container Platform est également restauré. Cependant, si le snapshot etcd est ancien, l'état peut être invalide ou obsolète.
Le contenu des volumes persistants (PV) ne fait jamais partie de l'instantané etcd. Lorsque vous restaurez un cluster OpenShift Container Platform à partir d'un instantané etcd, les charges de travail non critiques peuvent avoir accès aux données critiques, et vice-versa.
Voici quelques exemples de scénarios qui produisent un état périmé :
- La base de données MySQL s'exécute dans un pod sauvegardé par un objet PV. La restauration d'OpenShift Container Platform à partir d'un snapshot etcd ne rétablit pas le volume sur le fournisseur de stockage et ne produit pas de pod MySQL en cours d'exécution, malgré les tentatives répétées de démarrage du pod. Vous devez restaurer manuellement ce pod en restaurant le volume sur le fournisseur de stockage, puis en modifiant le PV pour qu'il pointe vers le nouveau volume.
- Le pod P1 utilise le volume A, qui est attaché au nœud X. Si l'instantané etcd est pris alors qu'un autre pod utilise le même volume sur le nœud Y, alors lorsque la restauration etcd est effectuée, le pod P1 pourrait ne pas être en mesure de démarrer correctement en raison du fait que le volume est toujours attaché au nœud Y. OpenShift Container Platform n'est pas conscient de l'attachement et ne le détache pas automatiquement. Lorsque cela se produit, le volume doit être détaché manuellement du nœud Y afin que le volume puisse s'attacher au nœud X, puis le pod P1 peut démarrer.
- Les informations d'identification du fournisseur de cloud ou du fournisseur de stockage ont été mises à jour après que l'instantané etcd a été pris. Par conséquent, les pilotes ou opérateurs CSI qui dépendent de ces informations d'identification ne fonctionnent pas. Il se peut que vous deviez mettre à jour manuellement les informations d'identification requises par ces pilotes ou opérateurs.
Un périphérique est supprimé ou renommé à partir des nœuds OpenShift Container Platform après que l'instantané etcd a été pris. L'opérateur de stockage local crée des liens symboliques pour chaque PV qu'il gère à partir des répertoires
/dev/disk/by-idou/dev. Cette situation peut amener les PV locaux à faire référence à des périphériques qui n'existent plus.Pour résoudre ce problème, l'administrateur doit
- Supprimer manuellement les PV dont les dispositifs ne sont pas valides.
- Supprimer les liens symboliques des nœuds respectifs.
-
Supprimer les objets
LocalVolumeouLocalVolumeSet(voir Storage → Configuring persistent storage → Persistent storage using local volumes → Deleting the Local Storage Operator Resources).
6.15. Budgets pour les perturbations des gousses
Comprendre et configurer les budgets de perturbation des pods.
6.15.1. Comprendre comment utiliser les budgets de perturbation des pods pour spécifier le nombre de pods qui doivent être opérationnels
Un pod disruption budget fait partie de l'API Kubernetes, qui peut être géré avec des commandes oc comme d'autres types d'objets. Ils permettent de spécifier des contraintes de sécurité sur les pods pendant les opérations, comme la vidange d'un nœud pour la maintenance.
PodDisruptionBudget est un objet API qui spécifie le nombre ou le pourcentage minimum de répliques qui doivent être en service à un moment donné. La définition de ces valeurs dans les projets peut être utile lors de la maintenance des nœuds (par exemple, lors de la réduction ou de la mise à niveau d'un cluster) et n'est honorée qu'en cas d'éviction volontaire (et non en cas de défaillance d'un nœud).
La configuration d'un objet PodDisruptionBudget se compose des éléments clés suivants :
- Un sélecteur d'étiquettes, qui est une requête d'étiquettes sur un ensemble de pods.
Un niveau de disponibilité, qui spécifie le nombre minimum de pods qui doivent être disponibles simultanément, soit :
-
minAvailableest le nombre de pods qui doivent toujours être disponibles, même en cas d'interruption. -
maxUnavailableest le nombre de pods qui peuvent être indisponibles lors d'une perturbation.
-
Un maxUnavailable de 0% ou 0 ou un minAvailable de 100% ou égal au nombre de répliques est autorisé mais peut bloquer la vidange des nœuds.
Vous pouvez vérifier les budgets de perturbation des pods dans tous les projets en procédant comme suit :
$ oc get poddisruptionbudget --all-namespacesExemple de sortie
NAMESPACE NAME MIN-AVAILABLE SELECTOR
another-project another-pdb 4 bar=foo
test-project my-pdb 2 foo=bar
Le site PodDisruptionBudget est considéré comme sain lorsqu'il y a au moins minAvailable pods en cours d'exécution dans le système. Chaque pod dépassant cette limite peut être expulsé.
En fonction des paramètres de priorité et de préemption des pods, les pods de moindre priorité peuvent être supprimés en dépit de leurs exigences en matière de budget de perturbation des pods.
6.15.2. Spécification du nombre de pods qui doivent être opérationnels avec des budgets de perturbation de pods
Vous pouvez utiliser un objet PodDisruptionBudget pour spécifier le nombre ou le pourcentage minimum de répliques qui doivent être opérationnelles à un moment donné.
Procédure
Pour configurer un budget de perturbation de pods :
Créez un fichier YAML avec une définition d'objet similaire à la suivante :
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 22 selector:3 matchLabels: foo: bar- 1
PodDisruptionBudgetfait partie du groupepolicy/v1API.- 2
- Le nombre minimum de pods qui doivent être disponibles simultanément. Il peut s'agir d'un nombre entier ou d'une chaîne de caractères spécifiant un pourcentage, par exemple
20%. - 3
- Une requête d'étiquette sur un ensemble de ressources. Les résultats de
matchLabelsetmatchExpressionssont logiquement joints. Laissez ce paramètre vide, par exempleselector {}, pour sélectionner tous les pods du projet.
Ou bien :
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: maxUnavailable: 25%2 selector:3 matchLabels: foo: bar- 1
PodDisruptionBudgetfait partie du groupepolicy/v1API.- 2
- Le nombre maximum de pods qui peuvent être indisponibles simultanément. Il peut s'agir d'un nombre entier ou d'une chaîne de caractères spécifiant un pourcentage, par exemple
20%. - 3
- Une requête d'étiquette sur un ensemble de ressources. Les résultats de
matchLabelsetmatchExpressionssont logiquement joints. Laissez ce paramètre vide, par exempleselector {}, pour sélectionner tous les pods du projet.
Exécutez la commande suivante pour ajouter l'objet au projet :
$ oc create -f </path/to/file> -n <project_name>
6.16. Rotation ou suppression des informations d'identification des fournisseurs de services en nuage
Après l'installation d'OpenShift Container Platform, certaines organisations exigent la rotation ou la suppression des informations d'identification du fournisseur de cloud qui ont été utilisées lors de l'installation initiale.
Pour permettre au cluster d'utiliser les nouvelles informations d'identification, vous devez mettre à jour les secrets utilisés par le CCO (Cloud Credential Operator) pour gérer les informations d'identification des fournisseurs de cloud.
6.16.1. Rotation des informations d'identification des fournisseurs de nuages à l'aide de l'utilitaire Cloud Credential Operator
L'utilitaire Cloud Credential Operator (CCO) ccoctl prend en charge la mise à jour des secrets pour les clusters installés sur IBM Cloud.
6.16.1.1. Rotation des clés API pour IBM Cloud
Vous pouvez changer les clés API pour vos identifiants de service existants et mettre à jour les secrets correspondants.
Conditions préalables
-
You have configured the
ccoctlbinary. - Vous avez des identifiants de service existants dans un cluster OpenShift Container Platform installé sur IBM Cloud.
Procédure
Utilisez l'utilitaire
ccoctlpour faire pivoter vos clés API pour les identifiants de service et mettre à jour les secrets :$ ccoctl ibmcloud refresh-keys \ --kubeconfig <openshift_kubeconfig_file> \1 --credentials-requests-dir <path_to_credential_requests_directory> \2 --name <name>3 NoteSi votre cluster utilise des fonctionnalités d'aperçu technologique activées par l'ensemble de fonctionnalités
TechPreviewNoUpgrade, vous devez inclure le paramètre--enable-tech-preview.
6.16.2. Rotation manuelle des informations d'identification des fournisseurs de services en nuage
Si les informations d'identification de votre fournisseur de cloud sont modifiées pour une raison quelconque, vous devez mettre à jour manuellement le secret utilisé par le CCO (Cloud Credential Operator) pour gérer les informations d'identification du fournisseur de cloud.
Le processus de rotation des informations d'identification du nuage dépend du mode utilisé par l'OCC. Après avoir effectué la rotation des informations d'identification pour un cluster utilisant le mode menthe, vous devez supprimer manuellement les informations d'identification du composant qui ont été créées par l'information d'identification supprimée.
Conditions préalables
Votre cluster est installé sur une plateforme qui prend en charge la rotation manuelle des identifiants cloud avec le mode CCO que vous utilisez :
- Pour le mode menthe, Amazon Web Services (AWS) et Google Cloud Platform (GCP) sont pris en charge.
- Pour le mode passthrough, Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Red Hat OpenStack Platform (RHOSP), Red Hat Virtualization (RHV) et VMware vSphere sont pris en charge.
- Vous avez modifié les informations d'identification utilisées pour l'interface avec votre fournisseur de services en nuage.
- Les nouvelles informations d'identification ont des autorisations suffisantes pour le mode que CCO est configuré pour utiliser dans votre cluster.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
Dans le tableau de la page Secrets, recherchez le secret racine de votre fournisseur de cloud.
Expand Plate-forme Nom secret AWS
aws-credsL'azur
azure-credentialsPCG
gcp-credentialsRHOSP
openstack-credentialsRHV
ovirt-credentialsVMware vSphere
vsphere-creds-
Cliquez sur le menu Options
 sur la même ligne que le secret et sélectionnez Edit Secret.
sur la même ligne que le secret et sélectionnez Edit Secret.
- Enregistrez le contenu du ou des champs Value. Vous pouvez utiliser ces informations pour vérifier que la valeur est différente après la mise à jour des informations d'identification.
- Mettez à jour le texte du ou des champs Value avec les nouvelles informations d'authentification de votre fournisseur de cloud, puis cliquez sur Save.
Si vous mettez à jour les informations d'identification pour un cluster vSphere qui n'a pas activé vSphere CSI Driver Operator, vous devez forcer un déploiement du gestionnaire de contrôleur Kubernetes pour appliquer les informations d'identification mises à jour.
NoteSi le vSphere CSI Driver Operator est activé, cette étape n'est pas nécessaire.
Pour appliquer les informations d'identification vSphere mises à jour, connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-adminet exécutez la commande suivante :$ oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=mergePendant que les informations d'identification sont diffusées, l'état de l'opérateur du contrôleur Kubernetes Controller Manager est indiqué à l'adresse
Progressing=true. Pour afficher l'état, exécutez la commande suivante :$ oc get co kube-controller-managerSi l'OCC de votre cluster est configuré pour utiliser le mode menthe, supprimez chaque secret de composant référencé par les objets individuels
CredentialsRequest.-
Connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. Obtenir les noms et les espaces de noms de tous les secrets de composants référencés :
$ oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'où
<provider_spec>est la valeur correspondante pour votre fournisseur de services en nuage :-
AWS :
AWSProviderSpec -
GCP :
GCPProviderSpec
Exemple partiel de sortie pour AWS
{ "name": "ebs-cloud-credentials", "namespace": "openshift-cluster-csi-drivers" } { "name": "cloud-credential-operator-iam-ro-creds", "namespace": "openshift-cloud-credential-operator" }-
AWS :
Supprimer chacun des secrets des composants référencés :
$ oc delete secret <secret_name> \1 -n <secret_namespace>2 Exemple de suppression d'un secret AWS
$ oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-driversIl n'est pas nécessaire de supprimer manuellement les informations d'identification à partir de la console du fournisseur. En supprimant les secrets des composants référencés, le CCO supprimera les informations d'identification existantes de la plateforme et en créera de nouvelles.
-
Connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
Vérification
Pour vérifier que les informations d'identification ont changé :
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
- Vérifiez que le contenu du ou des champs Value a été modifié.
6.16.3. Suppression des informations d'identification du fournisseur de services en nuage
Après avoir installé un cluster OpenShift Container Platform avec le Cloud Credential Operator (CCO) en mode mineur, vous pouvez supprimer le secret d'authentification de niveau administrateur de l'espace de noms kube-system dans le cluster. Le justificatif d'identité de niveau administrateur n'est requis que pour les modifications nécessitant des autorisations élevées, telles que les mises à niveau.
Avant une mise à niveau sans z-stream, vous devez rétablir le secret d'authentification avec l'authentification de niveau administrateur. Si l'identifiant n'est pas présent, la mise à niveau risque d'être bloquée.
Conditions préalables
- Votre cluster est installé sur une plateforme qui prend en charge la suppression des informations d'identification du nuage à partir du CCO. Les plateformes prises en charge sont AWS et GCP.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
Dans le tableau de la page Secrets, recherchez le secret racine de votre fournisseur de cloud.
Expand Plate-forme Nom secret AWS
aws-credsPCG
gcp-credentials-
Cliquez sur le menu Options
sur la même ligne que le secret et sélectionnez Delete Secret.
6.17. Configuration des flux d'images pour un cluster déconnecté
Après avoir installé OpenShift Container Platform dans un environnement déconnecté, configurez les flux d'images pour le Cluster Samples Operator et le flux d'images must-gather.
6.17.1. Échantillons de grappes Assistance de l'opérateur pour la mise en miroir
Lors de l'installation, OpenShift Container Platform crée une carte de configuration nommée imagestreamtag-to-image dans l'espace de noms openshift-cluster-samples-operator. La carte de configuration imagestreamtag-to-image contient une entrée, l'image de remplissage, pour chaque balise de flux d'images.
Le format de la clé pour chaque entrée dans le champ de données de la carte de configuration est <image_stream_name>_<image_stream_tag_name>.
Lors d'une installation déconnectée d'OpenShift Container Platform, le statut de l'opérateur Cluster Samples est défini sur Removed. Si vous choisissez de le changer en Managed, il installe les échantillons.
L'utilisation d'échantillons dans un environnement à réseau restreint ou interrompu peut nécessiter l'accès à des services externes à votre réseau. Voici quelques exemples de services : Github, Maven Central, npm, RubyGems, PyPi et autres. Il peut y avoir des étapes supplémentaires à franchir pour permettre aux objets des opérateurs d'échantillons de grappes d'accéder aux services dont ils ont besoin.
Vous pouvez utiliser cette carte de configuration comme référence pour savoir quelles images doivent être mises en miroir pour que vos flux d'images soient importés.
-
Lorsque l'opérateur d'échantillonnage de cluster est défini sur
Removed, vous pouvez créer votre registre en miroir ou déterminer le registre en miroir existant que vous souhaitez utiliser. - Mettez en miroir les échantillons que vous souhaitez dans le registre mis en miroir en utilisant la nouvelle carte de configuration comme guide.
-
Ajoutez tous les flux d'images que vous n'avez pas mis en miroir à la liste
skippedImagestreamsde l'objet de configuration Cluster Samples Operator. -
Définir
samplesRegistryde l'objet de configuration Cluster Samples Operator sur le registre en miroir. -
Définissez ensuite l'opérateur d'échantillonnage de cluster sur
Managedpour installer les flux d'images que vous avez mis en miroir.
6.17.2. Utilisation des flux d'images de Cluster Samples Operator avec des registres alternatifs ou en miroir
La plupart des flux d'images dans l'espace de noms openshift géré par le Cluster Samples Operator pointent vers des images situées dans le registre Red Hat à l'adresse registry .redhat.io. La mise en miroir ne s'appliquera pas à ces flux d'images.
Les flux d'images cli, installer, must-gather et tests, bien qu'ils fassent partie de la charge utile de l'installation, ne sont pas gérés par l'opérateur d'échantillonnage en grappe. Ils ne sont pas abordés dans cette procédure.
Le Cluster Samples Operator doit être défini sur Managed dans un environnement déconnecté. Pour installer les flux d'images, vous devez disposer d'un registre miroir.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Créez un secret d'extraction pour votre registre miroir.
Procédure
Accéder aux images d'un flux d'images spécifique à mettre en miroir, par exemple :
$ oc get is <imagestream> -n openshift -o json | jq .spec.tags[].from.name | grep registry.redhat.ioMettez en miroir les images de registry.redhat.io associées aux flux d'images dont vous avez besoin dans l'environnement réseau restreint dans l'un des miroirs définis, par exemple :
$ oc image mirror registry.redhat.io/rhscl/ruby-25-rhel7:latest ${MIRROR_ADDR}/rhscl/ruby-25-rhel7:latestCréer l'objet de configuration de l'image du cluster :
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configAjoutez les autorités de certification de confiance requises pour le miroir dans l'objet de configuration de l'image du cluster :
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=mergeMettez à jour le champ
samplesRegistrydans l'objet de configuration Cluster Samples Operator pour qu'il contienne la partiehostnamede l'emplacement du miroir défini dans la configuration du miroir :$ oc edit configs.samples.operator.openshift.io -n openshift-cluster-samples-operatorNoteCeci est nécessaire car le processus d'importation de flux d'images n'utilise pas le mécanisme de miroir ou de recherche pour le moment.
Ajoutez tous les flux d'images qui ne sont pas en miroir dans le champ
skippedImagestreamsde l'objet de configuration Cluster Samples Operator. Ou si vous ne souhaitez pas prendre en charge les flux d'images échantillonnés, définissez l'opérateur d'échantillonnage de cluster surRemoveddans l'objet de configuration de l'opérateur d'échantillonnage de cluster.NoteLe Cluster Samples Operator émet des alertes si les importations de flux d'images échouent mais que le Cluster Samples Operator les relance périodiquement ou ne semble pas les relancer.
De nombreux modèles de l'espace de noms
openshiftfont référence aux flux d'images. L'utilisation deRemovedpour purger à la fois les flux d'images et les modèles éliminera les tentatives d'utilisation de ces derniers s'ils ne sont pas fonctionnels en raison de l'absence de flux d'images.
6.17.3. Préparer votre cluster à la collecte de données de soutien
Les clusters utilisant un réseau restreint doivent importer l'image must-gather par défaut afin de collecter des données de débogage pour le support de Red Hat. L'image must-gather n'est pas importée par défaut, et les clusters sur un réseau restreint n'ont pas accès à Internet pour extraire la dernière image d'un dépôt distant.
Procédure
Si vous n'avez pas ajouté l'autorité de certification approuvée de votre registre miroir à l'objet de configuration de l'image de votre cluster dans le cadre de la configuration de l'opérateur d'échantillons de cluster, procédez comme suit :
Créer l'objet de configuration de l'image du cluster :
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configAjoutez les autorités de certification de confiance requises pour le miroir dans l'objet de configuration de l'image du cluster :
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
Importer l'image par défaut de la collecte obligatoire à partir de la charge utile de l'installation :
$ oc import-image is/must-gather -n openshift
Lorsque vous exécutez la commande oc adm must-gather, utilisez l'indicateur --image et indiquez l'image de la charge utile, comme dans l'exemple suivant :
$ oc adm must-gather --image=$(oc adm release info --image-for must-gather)6.18. Configuration de l'importation périodique des balises de flux d'images de Cluster Sample Operator
Vous pouvez vous assurer que vous avez toujours accès aux dernières versions des images de l'opérateur d'échantillonnage de cluster en important périodiquement les balises de flux d'images lorsque de nouvelles versions sont disponibles.
Procédure
Récupérez tous les flux d'images dans l'espace de noms
openshiften exécutant la commande suivante :oc get imagestreams -nopenshiftRécupérez les balises de chaque flux d'images dans l'espace de noms
openshiften exécutant la commande suivante :$ oc get is <image-stream-name> -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -nopenshiftPar exemple :
$ oc get is ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -nopenshiftExemple de sortie
1.11 registry.access.redhat.com/ubi8/openjdk-17:1.11 1.12 registry.access.redhat.com/ubi8/openjdk-17:1.12Planifiez l'importation périodique d'images pour chaque balise présente dans le flux d'images en exécutant la commande suivante :
$ oc tag <repository/image> <image-stream-name:tag> --scheduled -nopenshiftPar exemple :
$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.11 ubi8-openjdk-17:1.11 --scheduled -nopenshift $ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.12 ubi8-openjdk-17:1.12 --scheduled -nopenshiftCette commande permet à OpenShift Container Platform de mettre à jour périodiquement cette balise de flux d'images. Cette période est un paramètre à l'échelle du cluster, fixé par défaut à 15 minutes.
Vérifiez l'état de la planification de l'importation périodique en exécutant la commande suivante :
oc get imagestream <image-stream-name> -o jsonpath="{range .spec.tags[*]}Tag : {.name}{'\t'}Scheduled : {.importPolicy.scheduled}{'\n'}{end}\N-" -nopenshiftPar exemple :
oc get imagestream ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}Tag : {.name}{'\t'}Scheduled : {.importPolicy.scheduled}{'\n'}{end}\N-" -nopenshiftExemple de sortie
Tag: 1.11 Scheduled: true Tag: 1.12 Scheduled: true
Chapitre 7. Tâches du nœud post-installation
Après avoir installé OpenShift Container Platform, vous pouvez étendre et personnaliser votre cluster en fonction de vos besoins grâce à certaines tâches de nœuds.
7.1. Ajouter des machines de calcul RHEL à un cluster OpenShift Container Platform
Comprendre et travailler avec les nœuds de calcul RHEL.
7.1.1. À propos de l'ajout de nœuds de calcul RHEL à un cluster
Dans OpenShift Container Platform 4.12, vous avez la possibilité d'utiliser des machines Red Hat Enterprise Linux (RHEL) comme machines de calcul dans votre cluster si vous utilisez une installation d'infrastructure fournie par l'utilisateur sur l'architecture x86_64. Vous devez utiliser des machines Red Hat Enterprise Linux CoreOS (RHCOS) pour les machines du plan de contrôle dans votre cluster.
Si vous choisissez d'utiliser des machines de calcul RHEL dans votre cluster, vous êtes responsable de la gestion et de la maintenance de l'ensemble du cycle de vie du système d'exploitation. Vous devez effectuer les mises à jour du système, appliquer les correctifs et effectuer toutes les autres tâches requises.
- Étant donné que la suppression d'OpenShift Container Platform d'une machine du cluster nécessite la destruction du système d'exploitation, vous devez utiliser du matériel dédié pour toutes les machines RHEL que vous ajoutez au cluster.
- La mémoire swap est désactivée sur toutes les machines RHEL que vous ajoutez à votre cluster OpenShift Container Platform. Vous ne pouvez pas activer la mémoire swap sur ces machines.
Vous devez ajouter toutes les machines de calcul RHEL au cluster après avoir initialisé le plan de contrôle.
7.1.2. Configuration requise pour les nœuds de calcul RHEL
Les machines de calcul Red Hat Enterprise Linux (RHEL) hôtes de votre environnement OpenShift Container Platform doivent répondre aux spécifications matérielles minimales et aux exigences de niveau système suivantes :
- Vous devez avoir un abonnement OpenShift Container Platform actif sur votre compte Red Hat. Si ce n'est pas le cas, contactez votre représentant commercial pour plus d'informations.
- Les environnements de production doivent fournir des machines de calcul pour prendre en charge les charges de travail prévues. En tant qu'administrateur de cluster, vous devez calculer la charge de travail prévue et ajouter environ 10 % de frais généraux. Pour les environnements de production, allouez suffisamment de ressources pour que la défaillance d'un hôte de nœud n'affecte pas votre capacité maximale.
Chaque système doit répondre aux exigences matérielles suivantes :
- Système physique ou virtuel, ou instance fonctionnant sur un IaaS public ou privé.
Système d'exploitation de base : RHEL 8.6 ou 8.7 avec l'option d'installation "Minimal".
ImportantL'ajout de machines de calcul RHEL 7 à un cluster OpenShift Container Platform n'est pas pris en charge.
Si vous disposez de machines de calcul RHEL 7 qui étaient prises en charge dans une version antérieure d'OpenShift Container Platform, vous ne pouvez pas les mettre à niveau vers RHEL 8. Vous devez déployer de nouveaux hôtes RHEL 8, et les anciens hôtes RHEL 7 doivent être supprimés. Voir la section "Suppression des nœuds" pour plus d'informations.
Pour obtenir la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, consultez la section Deprecated and removed features des notes de version d'OpenShift Container Platform.
- Si vous avez déployé OpenShift Container Platform en mode FIPS, vous devez activer FIPS sur la machine RHEL avant de la démarrer. Voir Installation d'un système RHEL 8 avec le mode FIPS activé dans la documentation RHEL 8.
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the x86_64 architecture.
- NetworkManager 1.0 ou version ultérieure.
- 1 vCPU.
- Minimum 8 Go de RAM.
-
Minimum 15 Go d'espace sur le disque dur pour le système de fichiers contenant
/var/. -
Minimum 1 Go d'espace sur le disque dur pour le système de fichiers contenant
/usr/local/bin/. Au moins 1 Go d'espace sur le disque dur pour le système de fichiers contenant son répertoire temporaire. Le répertoire temporaire du système est déterminé selon les règles définies dans le module tempfile de la bibliothèque standard Python.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
disk.enableUUID=truedoit être défini. - Chaque système doit pouvoir accéder aux points d'extrémité de l'API du cluster en utilisant des noms d'hôtes résolubles dans le DNS. Tout contrôle d'accès à la sécurité du réseau en place doit permettre l'accès du système aux points d'extrémité du service API de la grappe.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
7.1.2.1. Certificate signing requests management
Because your cluster has limited access to automatic machine management when you use infrastructure that you provision, you must provide a mechanism for approving cluster certificate signing requests (CSRs) after installation. The kube-controller-manager only approves the kubelet client CSRs. The machine-approver cannot guarantee the validity of a serving certificate that is requested by using kubelet credentials because it cannot confirm that the correct machine issued the request. You must determine and implement a method of verifying the validity of the kubelet serving certificate requests and approving them.
7.1.3. Préparation de la machine pour l'exécution du cahier de jeu
Avant d'ajouter des machines de calcul qui utilisent Red Hat Enterprise Linux (RHEL) comme système d'exploitation à un cluster OpenShift Container Platform 4.12, vous devez préparer une machine RHEL 8 pour exécuter un playbook Ansible qui ajoute le nouveau nœud au cluster. Cette machine ne fait pas partie du cluster mais doit pouvoir y accéder.
Conditions préalables
-
Installez le CLI OpenShift (
oc) sur la machine sur laquelle vous exécutez le playbook. -
Connectez-vous en tant qu'utilisateur disposant de l'autorisation
cluster-admin.
Procédure
-
Assurez-vous que le fichier
kubeconfigpour le cluster et le programme d'installation que vous avez utilisé pour installer le cluster se trouvent sur l'ordinateur RHEL 8. Pour ce faire, vous pouvez utiliser la même machine que celle que vous avez utilisée pour installer le cluster. - Configurez la machine pour accéder à tous les hôtes RHEL que vous prévoyez d'utiliser comme machines de calcul. Vous pouvez utiliser n'importe quelle méthode autorisée par votre entreprise, y compris un bastion avec un proxy SSH ou un VPN.
Configurez un utilisateur sur la machine sur laquelle vous exécutez le playbook et qui dispose d'un accès SSH à tous les hôtes RHEL.
ImportantSi vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH.
Si ce n'est pas déjà fait, enregistrez la machine auprès du RHSM et associez-lui un pool avec un abonnement
OpenShift:Enregistrer la machine auprès du RHSM :
# subscription-manager register --username=<user_name> --password=<password>Tirer les dernières données d'abonnement du RHSM :
# subscription-manager refreshListe des abonnements disponibles :
# subscription-manager list --available --matches '*OpenShift*'Dans la sortie de la commande précédente, trouvez l'ID du pool pour un abonnement à OpenShift Container Platform et attachez-le :
# subscription-manager attach --pool=<pool_id>
Activer les dépôts requis par OpenShift Container Platform 4.12 :
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.12-for-rhel-8-x86_64-rpms"Installez les paquets nécessaires, y compris
openshift-ansible:# yum install openshift-ansible openshift-clients jqLe paquet
openshift-ansiblefournit des utilitaires de programme d'installation et attire d'autres paquets dont vous avez besoin pour ajouter un nœud de calcul RHEL à votre cluster, tels qu'Ansible, les playbooks et les fichiers de configuration associés. Le paquetopenshift-clientsfournit la CLIoc, et le paquetjqaméliore l'affichage de la sortie JSON sur votre ligne de commande.
7.1.4. Préparation d'un nœud de calcul RHEL
Avant d'ajouter une machine Red Hat Enterprise Linux (RHEL) à votre cluster OpenShift Container Platform, vous devez enregistrer chaque hôte auprès du gestionnaire d'abonnements Red Hat (RHSM), attacher un abonnement OpenShift Container Platform actif et activer les référentiels requis.
Sur chaque hôte, s'enregistrer auprès du RHSM :
# subscription-manager register --username=<user_name> --password=<password>Tirer les dernières données d'abonnement du RHSM :
# subscription-manager refreshListe des abonnements disponibles :
# subscription-manager list --available --matches '*OpenShift*'Dans la sortie de la commande précédente, trouvez l'ID du pool pour un abonnement à OpenShift Container Platform et attachez-le :
# subscription-manager attach --pool=<pool_id>Désactiver tous les dépôts yum :
Désactiver tous les dépôts RHSM activés :
# subscription-manager repos --disable="*"Dressez la liste des dépôts yum restants et notez leur nom sous
repo id, le cas échéant :# yum repolistUtilisez
yum-config-managerpour désactiver les autres dépôts yum :# yum-config-manager --disable <repo_id>Vous pouvez également désactiver tous les dépôts :
# yum-config-manager --disable \*Notez que cette opération peut prendre quelques minutes si vous avez un grand nombre de référentiels disponibles
Activez uniquement les dépôts requis par OpenShift Container Platform 4.12 :
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.12-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"Arrêtez et désactivez firewalld sur l'hôte :
# systemctl disable --now firewalld.serviceNoteVous ne devez pas activer firewalld par la suite. Si vous le faites, vous ne pourrez pas accéder aux logs de OpenShift Container Platform sur le worker.
7.1.5. Ajout d'une machine de calcul RHEL à votre cluster
Vous pouvez ajouter des machines de calcul qui utilisent Red Hat Enterprise Linux comme système d'exploitation à un cluster OpenShift Container Platform 4.12.
Conditions préalables
- Vous avez installé les paquets requis et effectué la configuration nécessaire sur la machine sur laquelle vous exécutez le playbook.
- Vous avez préparé les hôtes RHEL pour l'installation.
Procédure
Effectuez les étapes suivantes sur la machine que vous avez préparée pour exécuter le manuel de jeu :
Créez un fichier d'inventaire Ansible nommé
/<path>/inventory/hostsqui définit les hôtes de votre machine de calcul et les variables requises :[all:vars] ansible_user=root1 #ansible_become=True2 openshift_kubeconfig_path="~/.kube/config"3 [new_workers]4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com- 1
- Indiquez le nom de l'utilisateur qui exécute les tâches Ansible sur les ordinateurs distants.
- 2
- Si vous ne spécifiez pas
rootpouransible_user, vous devez définiransible_becomepourTrueet attribuer à l'utilisateur les autorisations sudo. - 3
- Indiquez le chemin et le nom du fichier
kubeconfigpour votre cluster. - 4
- Dressez la liste de chaque machine RHEL à ajouter à votre cluster. Vous devez fournir le nom de domaine complet pour chaque hôte. Ce nom est le nom d'hôte que le cluster utilise pour accéder à la machine. Définissez donc le nom public ou privé correct pour accéder à la machine.
Naviguez jusqu'au répertoire du playbook Ansible :
$ cd /usr/share/ansible/openshift-ansibleExécutez le manuel de jeu :
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
- Pour
<path>, indiquez le chemin d'accès au fichier d'inventaire Ansible que vous avez créé.
7.1.6. Paramètres requis pour le fichier hosts d'Ansible
Vous devez définir les paramètres suivants dans le fichier hosts Ansible avant d'ajouter des machines de calcul Red Hat Enterprise Linux (RHEL) à votre cluster.
| Paramètres | Description | Valeurs |
|---|---|---|
|
| L'utilisateur SSH qui permet une authentification basée sur SSH sans mot de passe. Si vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH. |
Un nom d'utilisateur sur le système. La valeur par défaut est |
|
|
Si les valeurs de |
|
|
|
Spécifie un chemin et un nom de fichier vers un répertoire local qui contient le fichier | Le chemin et le nom du fichier de configuration. |
7.1.7. Optionnel : Suppression des machines de calcul RHCOS d'un cluster
Après avoir ajouté les machines de calcul Red Hat Enterprise Linux (RHEL) à votre cluster, vous pouvez éventuellement supprimer les machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) afin de libérer des ressources.
Conditions préalables
- Vous avez ajouté des machines de calcul RHEL à votre cluster.
Procédure
Affichez la liste des machines et enregistrez les noms des nœuds des machines de calcul RHCOS :
$ oc get nodes -o widePour chaque machine de calcul RHCOS, supprimer le nœud :
Marquez le nœud comme non ordonnançable en exécutant la commande
oc adm cordon:$ oc adm cordon <node_name>1 - 1
- Indiquez le nom du nœud de l'une des machines de calcul RHCOS.
Égoutter toutes les gousses du nœud :
oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 - 1
- Indiquez le nom du nœud de la machine de calcul RHCOS que vous avez isolée.
Supprimer le nœud :
oc delete nodes <node_name> $ oc delete nodes <node_name>1 - 1
- Indiquez le nom du nœud de la machine de calcul RHCOS que vous avez drainée.
Examinez la liste des machines de calcul pour vous assurer que seuls les nœuds RHEL sont conservés :
$ oc get nodes -o wide- Supprimez les machines RHCOS de l'équilibreur de charge pour les machines de calcul de votre cluster. Vous pouvez supprimer les machines virtuelles ou réimager le matériel physique des machines de calcul RHCOS.
7.2. Ajouter des machines de calcul RHCOS à un cluster OpenShift Container Platform
Vous pouvez ajouter des machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) à votre cluster OpenShift Container Platform sur du métal nu.
Avant d'ajouter des machines de calcul à un cluster installé sur une infrastructure bare metal, vous devez créer des machines RHCOS à utiliser. Vous pouvez utiliser une image ISO ou un démarrage PXE en réseau pour créer les machines.
7.2.1. Conditions préalables
- Vous avez installé un cluster sur du métal nu.
- Vous disposez des supports d'installation et des images Red Hat Enterprise Linux CoreOS (RHCOS) que vous avez utilisés pour créer votre cluster. Si vous ne disposez pas de ces fichiers, vous devez les obtenir en suivant les instructions de la procédure d'installation.
7.2.2. Création d'autres machines RHCOS à l'aide d'une image ISO
Vous pouvez créer davantage de machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) pour votre cluster bare metal en utilisant une image ISO pour créer les machines.
Conditions préalables
- Obtenez l'URL du fichier de configuration Ignition pour les machines de calcul de votre cluster. Vous avez téléchargé ce fichier sur votre serveur HTTP lors de l'installation.
Procédure
Utilisez le fichier ISO pour installer RHCOS sur d'autres machines de calcul. Utilisez la même méthode que lorsque vous avez créé des machines avant d'installer le cluster :
- Burn the ISO image to a disk and boot it directly.
- Utiliser la redirection ISO avec une interface LOM.
Démarrer l'image ISO RHCOS sans spécifier d'options ni interrompre la séquence de démarrage en direct. Attendez que le programme d'installation démarre à l'invite de l'interpréteur de commandes dans l'environnement réel RHCOS.
NoteVous pouvez interrompre le processus de démarrage de l'installation RHCOS pour ajouter des arguments au noyau. Cependant, pour cette procédure ISO, vous devez utiliser la commande
coreos-installercomme indiqué dans les étapes suivantes, au lieu d'ajouter des arguments au noyau.Run the
coreos-installercommand and specify the options that meet your installation requirements. At a minimum, you must specify the URL that points to the Ignition config file for the node type, and the device that you are installing to:$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 - 1
- You must run the
coreos-installercommand by usingsudo, because thecoreuser does not have the required root privileges to perform the installation. - 2
- The
--ignition-hashoption is required when the Ignition config file is obtained through an HTTP URL to validate the authenticity of the Ignition config file on the cluster node.<digest>is the Ignition config file SHA512 digest obtained in a preceding step.
NoteIf you want to provide your Ignition config files through an HTTPS server that uses TLS, you can add the internal certificate authority (CA) to the system trust store before running
coreos-installer.The following example initializes a bootstrap node installation to the
/dev/sdadevice. The Ignition config file for the bootstrap node is obtained from an HTTP web server with the IP address 192.168.1.2:$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bMonitor the progress of the RHCOS installation on the console of the machine.
ImportantAssurez-vous que l'installation est réussie sur chaque nœud avant de commencer l'installation d'OpenShift Container Platform. L'observation du processus d'installation peut également aider à déterminer la cause des problèmes d'installation du RHCOS qui pourraient survenir.
- Continue to create more compute machines for your cluster.
7.2.3. Création d'autres machines RHCOS par démarrage PXE ou iPXE
Vous pouvez créer davantage de machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) pour votre cluster bare metal en utilisant le démarrage PXE ou iPXE.
Conditions préalables
- Obtenez l'URL du fichier de configuration Ignition pour les machines de calcul de votre cluster. Vous avez téléchargé ce fichier sur votre serveur HTTP lors de l'installation.
-
Obtenez les URL de l'image ISO RHCOS, du BIOS métallique compressé, de
kernelet deinitramfsque vous avez téléchargés sur votre serveur HTTP lors de l'installation du cluster. - Vous avez accès à l'infrastructure de démarrage PXE que vous avez utilisée pour créer les machines de votre cluster OpenShift Container Platform lors de l'installation. Les machines doivent démarrer à partir de leurs disques locaux après l'installation de RHCOS.
-
Si vous utilisez l'UEFI, vous avez accès au fichier
grub.confque vous avez modifié lors de l'installation d'OpenShift Container Platform.
Procédure
Confirmez que votre installation PXE ou iPXE pour les images RHCOS est correcte.
Pour PXE :
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- Indiquez l'emplacement du fichier live
kernelque vous avez téléchargé sur votre serveur HTTP. - 2
- Indiquez l'emplacement des fichiers RHCOS que vous avez téléchargés sur votre serveur HTTP. La valeur du paramètre
initrdcorrespond à l'emplacement du fichierinitramfs, la valeur du paramètrecoreos.inst.ignition_urlcorrespond à l'emplacement du fichier de configuration Ignition et la valeur du paramètrecoreos.live.rootfs_urlcorrespond à l'emplacement du fichierrootfs. Les paramètrescoreos.inst.ignition_urletcoreos.live.rootfs_urlne prennent en charge que HTTP et HTTPS.
Cette configuration ne permet pas l'accès à la console série sur les machines dotées d'une console graphique. Pour configurer une console différente, ajoutez un ou plusieurs arguments console= à la ligne APPEND. Par exemple, ajoutez console=tty0 console=ttyS0 pour définir le premier port série du PC comme console primaire et la console graphique comme console secondaire. Pour plus d'informations, reportez-vous à Comment configurer un terminal série et/ou une console dans Red Hat Enterprise Linux ?
Pour iPXE :
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img1 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img2 - 1
- Spécifiez l'emplacement des fichiers RHCOS que vous avez téléchargés sur votre serveur HTTP. La valeur du paramètre
kernelcorrespond à l'emplacement du fichierkernel, l'argumentinitrd=mainest nécessaire pour le démarrage sur les systèmes UEFI, la valeur du paramètrecoreos.inst.ignition_urlcorrespond à l'emplacement du fichier de configuration Ignition worker et la valeur du paramètrecoreos.live.rootfs_urlcorrespond à l'emplacement du fichierrootfslive. Les paramètrescoreos.inst.ignition_urletcoreos.live.rootfs_urlne prennent en charge que les protocoles HTTP et HTTPS. - 2
- Specify the location of the
initramfsfile that you uploaded to your HTTP server.
Cette configuration ne permet pas l'accès à la console série sur les machines dotées d'une console graphique. Pour configurer une console différente, ajoutez un ou plusieurs arguments console= à la ligne kernel. Par exemple, ajoutez console=tty0 console=ttyS0 pour définir le premier port série du PC comme console primaire et la console graphique comme console secondaire. Pour plus d'informations, reportez-vous à Comment configurer un terminal série et/ou une console dans Red Hat Enterprise Linux ?
- Utilisez l'infrastructure PXE ou iPXE pour créer les machines de calcul nécessaires à votre cluster.
7.2.4. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csrExemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csrExemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
7.2.5. Ajout d'un nouveau nœud de travail RHCOS avec une partition personnalisée /var dans AWS
OpenShift Container Platform prend en charge le partitionnement des périphériques pendant l'installation en utilisant les configurations de machine qui sont traitées pendant le bootstrap. Cependant, si vous utilisez le partitionnement /var, le nom du périphérique doit être déterminé lors de l'installation et ne peut pas être modifié. Vous ne pouvez pas ajouter différents types d'instance en tant que nœuds s'ils ont un schéma de dénomination de périphérique différent. Par exemple, si vous avez configuré la partition /var avec le nom de périphérique AWS par défaut pour les instances m4.large, dev/xvdb, vous ne pouvez pas ajouter directement une instance AWS m5.large, car les instances m5.large utilisent un périphérique /dev/nvme1n1 par défaut. Le périphérique risque de ne pas être partitionné en raison de la différence de schéma de dénomination.
La procédure de cette section montre comment ajouter un nouveau nœud de calcul Red Hat Enterprise Linux CoreOS (RHCOS) avec une instance qui utilise un nom de périphérique différent de celui qui a été configuré lors de l'installation. Vous créez un secret de données utilisateur personnalisé et configurez un nouvel ensemble de machines de calcul. Ces étapes sont spécifiques à un cluster AWS. Les principes s'appliquent également à d'autres déploiements dans le nuage. Cependant, le schéma de dénomination des périphériques est différent pour d'autres déploiements et doit être déterminé au cas par cas.
Procédure
Sur une ligne de commande, passez à l'espace de noms
openshift-machine-api:$ oc project openshift-machine-apiCréer un nouveau secret à partir du secret
worker-user-data:Exporter la section
userDatadu secret dans un fichier texte :$ oc get secret worker-user-data --template='{{index .data.userData | base64decode}}' | jq > userData.txtModifiez le fichier texte pour ajouter les strophes
storage,filesystems, etsystemdpour les partitions que vous souhaitez utiliser pour le nouveau nœud. Vous pouvez spécifier tous les paramètres de configuration d'Ignition si nécessaire.NoteNe modifiez pas les valeurs de la strophe
ignition.{ "ignition": { "config": { "merge": [ { "source": "https:...." } ] }, "security": { "tls": { "certificateAuthorities": [ { "source": "data:text/plain;charset=utf-8;base64,.....==" } ] } }, "version": "3.2.0" }, "storage": { "disks": [ { "device": "/dev/nvme1n1",1 "partitions": [ { "label": "var", "sizeMiB": 50000,2 "startMiB": 03 } ] } ], "filesystems": [ { "device": "/dev/disk/by-partlabel/var",4 "format": "xfs",5 "path": "/var"6 } ] }, "systemd": { "units": [7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var\nWhat=/dev/disk/by-partlabel/var\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n", "enabled": true, "name": "var.mount" } ] } }- 1
- Spécifie un chemin d'accès absolu au périphérique de bloc AWS.
- 2
- Spécifie la taille de la partition de données en méga-octets.
- 3
- Spécifie le début de la partition en Mebibytes. Lors de l'ajout d'une partition de données au disque de démarrage, il est recommandé d'utiliser une valeur minimale de 25 000 Mo (Mebibytes). Le système de fichiers racine est automatiquement redimensionné pour remplir tout l'espace disponible jusqu'au décalage spécifié. Si aucune valeur n'est spécifiée, ou si la valeur spécifiée est inférieure au minimum recommandé, le système de fichiers racine résultant sera trop petit, et les réinstallations futures de RHCOS risquent d'écraser le début de la partition de données.
- 4
- Spécifie un chemin d'accès absolu à la partition
/var. - 5
- Spécifie le format du système de fichiers.
- 6
- Spécifie le point de montage du système de fichiers lorsque Ignition est en cours d'exécution, par rapport à l'endroit où le système de fichiers racine sera monté. Ce n'est pas nécessairement la même chose que l'endroit où il devrait être monté dans la racine réelle, mais il est encouragé de le faire.
- 7
- Définit une unité de montage systemd qui monte le périphérique
/dev/disk/by-partlabel/varsur la partition/var.
Extraire la section
disableTemplatingdu secretwork-user-datadans un fichier texte :$ oc get secret worker-user-data --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txtCréez le nouveau fichier de données utilisateur secrètes à partir des deux fichiers texte. Ce fichier secret transmet au nœud nouvellement créé les informations supplémentaires relatives à la partition du nœud contenues dans le fichier
userData.txt.$ oc create secret generic worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txt
Créez un nouvel ensemble de machines de calcul pour le nouveau nœud :
Créez un nouveau fichier YAML d'ensemble de machine de calcul, similaire au suivant, qui est configuré pour AWS. Ajoutez les partitions requises et le secret des données de l'utilisateur nouvellement créé :
AstuceUtilisez un ensemble de machines de calcul existant comme modèle et modifiez les paramètres selon les besoins pour le nouveau nœud.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 name: worker-us-east-2-nvme1n11 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b template: metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b spec: metadata: {} providerSpec: value: ami: id: ami-0c2dbd95931a apiVersion: awsproviderconfig.openshift.io/v1beta1 blockDevices: - DeviceName: /dev/nvme1n12 ebs: encrypted: true iops: 0 volumeSize: 120 volumeType: gp2 - DeviceName: /dev/nvme1n23 ebs: encrypted: true iops: 0 volumeSize: 50 volumeType: gp2 credentialsSecret: name: aws-cloud-credentials deviceIndex: 0 iamInstanceProfile: id: auto-52-92tf4-worker-profile instanceType: m6i.large kind: AWSMachineProviderConfig metadata: creationTimestamp: null placement: availabilityZone: us-east-2b region: us-east-2 securityGroups: - filters: - name: tag:Name values: - auto-52-92tf4-worker-sg subnet: id: subnet-07a90e5db1 tags: - name: kubernetes.io/cluster/auto-52-92tf4 value: owned userDataSecret: name: worker-user-data-x54 Créer l'ensemble de machines de calcul :
oc create -f <nom-de-fichier>.yamlLes machines peuvent prendre quelques instants avant d'être disponibles.
Vérifiez que la nouvelle partition et les nouveaux nœuds sont créés :
Vérifiez que l'ensemble de machines de calcul est créé :
$ oc get machinesetExemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m worker-us-east-2-nvme1n1 1 1 1 1 2m35s1 - 1
- Il s'agit du nouvel ensemble de machines de calcul.
Vérifiez que le nouveau nœud est créé :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-128-78.ec2.internal Ready worker 117m v1.25.0 ip-10-0-146-113.ec2.internal Ready master 127m v1.25.0 ip-10-0-153-35.ec2.internal Ready worker 118m v1.25.0 ip-10-0-176-58.ec2.internal Ready master 126m v1.25.0 ip-10-0-217-135.ec2.internal Ready worker 2m57s v1.25.01 ip-10-0-225-248.ec2.internal Ready master 127m v1.25.0 ip-10-0-245-59.ec2.internal Ready worker 116m v1.25.0- 1
- Il s'agit d'un nouveau nœud.
Vérifiez que la partition personnalisée
/varest créée sur le nouveau nœud :$ oc debug node/<node-name> -- chroot /host lsblkPar exemple :
$ oc debug node/ip-10-0-217-135.ec2.internal -- chroot /host lsblkExemple de sortie
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 202:0 0 120G 0 disk |-nvme0n1p1 202:1 0 1M 0 part |-nvme0n1p2 202:2 0 127M 0 part |-nvme0n1p3 202:3 0 384M 0 part /boot `-nvme0n1p4 202:4 0 119.5G 0 part /sysroot nvme1n1 202:16 0 50G 0 disk `-nvme1n1p1 202:17 0 48.8G 0 part /var1 - 1
- Le périphérique
nvme1n1est monté sur la partition/var.
7.3. Déploiement des contrôles de santé des machines
Comprendre et déployer les contrôles de santé des machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'7.3.1. À propos des contrôles de santé des machines
Vous ne pouvez appliquer un contrôle de l'état des machines qu'aux machines du plan de contrôle des clusters qui utilisent des jeux de machines du plan de contrôle.
Pour surveiller l'état des machines, créez une ressource afin de définir la configuration d'un contrôleur. Définissez une condition à vérifier, telle que le maintien de l'état NotReady pendant cinq minutes ou l'affichage d'une condition permanente dans le détecteur de problèmes de nœuds, ainsi qu'une étiquette pour l'ensemble des machines à surveiller.
Le contrôleur qui observe une ressource MachineHealthCheck vérifie la condition définie. Si une machine échoue au contrôle de santé, elle est automatiquement supprimée et une autre est créée pour la remplacer. Lorsqu'une machine est supprimée, un événement machine deleted s'affiche.
Pour limiter l'impact perturbateur de la suppression des machines, le contrôleur ne draine et ne supprime qu'un seul nœud à la fois. S'il y a plus de machines malsaines que le seuil maxUnhealthy ne le permet dans le groupe de machines ciblées, la remédiation s'arrête et permet donc une intervention manuelle.
Les délais d'attente doivent être étudiés avec soin, en tenant compte de la charge de travail et des besoins.
- Les délais d'attente prolongés peuvent entraîner de longues périodes d'indisponibilité de la charge de travail sur la machine en état d'insalubrité.
-
Des délais trop courts peuvent entraîner une boucle de remédiation. Par exemple, le délai de vérification de l'état de
NotReadydoit être suffisamment long pour permettre à la machine de terminer le processus de démarrage.
Pour arrêter le contrôle, retirez la ressource.
7.3.1.1. Limitations lors du déploiement des contrôles de santé des machines
Il y a des limites à prendre en compte avant de déployer un bilan de santé machine :
- Seules les machines appartenant à un jeu de machines sont remédiées par un bilan de santé de la machine.
- Si le nœud d'une machine est supprimé du cluster, un contrôle de santé de la machine considère que la machine n'est pas en bonne santé et y remédie immédiatement.
-
Si le nœud correspondant à une machine ne rejoint pas le cluster après le
nodeStartupTimeout, la machine est remédiée. -
Une machine est remédiée immédiatement si la phase de ressource
MachineestFailed.
7.3.2. Exemple de ressource MachineHealthCheck
La ressource MachineHealthCheck pour tous les types d'installation basés sur le cloud, et autre que bare metal, ressemble au fichier YAML suivant :
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- Indiquez le nom du bilan de santé de la machine à déployer.
- 2 3
- Spécifiez une étiquette pour le pool de machines que vous souhaitez vérifier.
- 4
- Indiquez le jeu de machines à suivre au format
<cluster_name>-<label>-<zone>. Par exemple,prod-node-us-east-1a. - 5 6
- Spécifiez la durée du délai d'attente pour une condition de nœud. Si une condition est remplie pendant la durée du délai, la machine sera remédiée. Les délais d'attente prolongés peuvent entraîner de longues périodes d'indisponibilité pour une charge de travail sur une machine en mauvais état.
- 7
- Spécifiez le nombre de machines autorisées à être assainies simultanément dans le pool ciblé. Il peut s'agir d'un pourcentage ou d'un nombre entier. Si le nombre de machines malsaines dépasse la limite fixée par
maxUnhealthy, la remédiation n'est pas effectuée. - 8
- Spécifiez le délai d'attente pour qu'un contrôle de l'état de santé d'une machine attende qu'un nœud rejoigne la grappe avant qu'une machine ne soit considérée comme étant en mauvais état.
Le site matchLabels n'est qu'un exemple ; vous devez définir vos groupes de machines en fonction de vos besoins spécifiques.
7.3.2.1. Court-circuitage du contrôle de santé de la machine remédiation
Le court-circuitage garantit que les contrôles de santé des machines ne remédient aux machines que lorsque le cluster est sain. Le court-circuitage est configuré via le champ maxUnhealthy de la ressource MachineHealthCheck.
Si l'utilisateur définit une valeur pour le champ maxUnhealthy, avant de remédier à des machines, MachineHealthCheck compare la valeur de maxUnhealthy avec le nombre de machines dans son pool cible qu'il a déterminé comme n'étant pas en bonne santé. La remédiation n'est pas effectuée si le nombre de machines malsaines dépasse la limite fixée par maxUnhealthy.
Si maxUnhealthy n'est pas défini, la valeur par défaut est 100% et les machines sont remédiées quel que soit l'état du cluster.
La valeur appropriée de maxUnhealthy dépend de l'échelle du cluster que vous déployez et du nombre de machines couvertes par MachineHealthCheck. Par exemple, vous pouvez utiliser la valeur maxUnhealthy pour couvrir plusieurs ensembles de machines de calcul dans plusieurs zones de disponibilité, de sorte que si vous perdez une zone entière, votre paramètre maxUnhealthy empêche toute autre remédiation au sein du cluster. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de disponibilité pour assurer une haute disponibilité.
Si vous configurez une ressource MachineHealthCheck pour le plan de contrôle, définissez la valeur de maxUnhealthy sur 1.
Cette configuration garantit que le contrôle de l'état des machines ne prend aucune mesure lorsque plusieurs machines du plan de contrôle semblent être en mauvaise santé. Plusieurs machines de plan de contrôle malsaines peuvent indiquer que le cluster etcd est dégradé ou qu'une opération de mise à l'échelle visant à remplacer une machine défaillante est en cours.
Si le cluster etcd est dégradé, une intervention manuelle peut être nécessaire. Si une opération de mise à l'échelle est en cours, le bilan de santé de la machine doit permettre de la terminer.
Le champ maxUnhealthy peut être défini comme un nombre entier ou un pourcentage. Il existe différentes implémentations de remédiation en fonction de la valeur de maxUnhealthy.
7.3.2.1.1. Réglage de l'insalubrité maximale par l'utilisation d'une valeur absolue
Si maxUnhealthy est défini sur 2:
- La remédiation sera effectuée si 2 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 3 nœuds ou plus sont malsains
Ces valeurs sont indépendantes du nombre de machines contrôlées par le bilan de santé.
7.3.2.1.2. Fixation de l'insalubrité maximale à l'aide de pourcentages
Si maxUnhealthy est défini sur 40% et qu'il y a 25 machines en cours de vérification :
- La remédiation sera effectuée si 10 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 11 nœuds ou plus sont malsains
Si maxUnhealthy est défini sur 40% et qu'il y a 6 machines en cours de contrôle :
- La remédiation sera effectuée si 2 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 3 nœuds ou plus sont malsains
Le nombre de machines autorisé est arrondi à la baisse lorsque le pourcentage de machines maxUnhealthy contrôlées n'est pas un nombre entier.
7.3.3. Création d'une ressource pour le bilan de santé d'une machine
Vous pouvez créer une ressource MachineHealthCheck pour les ensembles de machines de votre cluster.
Vous ne pouvez appliquer un contrôle de l'état des machines qu'aux machines du plan de contrôle des clusters qui utilisent des jeux de machines du plan de contrôle.
Conditions préalables
-
Installer l'interface de ligne de commande
oc.
Procédure
-
Créez un fichier
healthcheck.ymlqui contient la définition du contrôle de l'état de santé de votre machine. Appliquez le fichier
healthcheck.ymlà votre cluster :$ oc apply -f healthcheck.yml
7.3.4. Mise à l'échelle manuelle d'un ensemble de machines de calcul
Pour ajouter ou supprimer une instance d'une machine dans un ensemble de machines de calcul, vous pouvez mettre à l'échelle manuellement l'ensemble de machines de calcul.
Ce guide s'applique aux installations d'infrastructure entièrement automatisées et fournies par l'installateur. Les installations d'infrastructure personnalisées et fournies par l'utilisateur n'ont pas d'ensembles de machines de calcul.
Conditions préalables
-
Installer un cluster OpenShift Container Platform et la ligne de commande
oc. -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Affichez les ensembles de machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machinesets -n openshift-machine-apiLes ensembles de machines de calcul sont répertoriés sous la forme de
<clusterid>-worker-<aws-region-az>.Affichez les machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machine -n openshift-machine-apiDéfinissez l'annotation sur la machine de calcul que vous souhaitez supprimer en exécutant la commande suivante :
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"Mettez à l'échelle l'ensemble de machines de calcul en exécutant l'une des commandes suivantes :
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiOu bien :
$ oc edit machineset <machineset> -n openshift-machine-apiAstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2Vous pouvez augmenter ou diminuer le nombre de machines de calcul. Il faut quelques minutes pour que les nouvelles machines soient disponibles.
ImportantPar défaut, le contrôleur de machine tente de drainer le nœud soutenu par la machine jusqu'à ce qu'il y parvienne. Dans certaines situations, comme dans le cas d'un budget de perturbation de pods mal configuré, l'opération de vidange peut ne pas aboutir. Si l'opération de vidange échoue, le contrôleur de machine ne peut pas procéder au retrait de la machine.
Vous pouvez éviter de vider le nœud en annotant
machine.openshift.io/exclude-node-drainingdans une machine spécifique.
Vérification
Vérifiez la suppression de la machine prévue en exécutant la commande suivante :
$ oc get machines
7.3.5. Comprendre la différence entre les ensembles de machines de calcul et le pool de configuration des machines
MachineSet décrivent les nœuds d'OpenShift Container Platform par rapport au fournisseur de nuages ou de machines.
L'objet MachineConfigPool permet aux composants MachineConfigController de définir et de fournir l'état des machines dans le contexte des mises à niveau.
L'objet MachineConfigPool permet aux utilisateurs de configurer la manière dont les mises à niveau sont déployées sur les nœuds OpenShift Container Platform dans le pool de configuration de la machine.
L'objet NodeSelector peut être remplacé par une référence à l'objet MachineSet.
7.4. Pratiques recommandées pour les hôtes de nœuds
Le fichier de configuration des nœuds d'OpenShift Container Platform contient des options importantes. Par exemple, deux paramètres contrôlent le nombre maximum de pods qui peuvent être planifiés sur un nœud : podsPerCore et maxPods.
Lorsque les deux options sont utilisées, la plus faible des deux valeurs limite le nombre de pods sur un nœud. Le dépassement de ces valeurs peut avoir les conséquences suivantes
- Augmentation de l'utilisation de l'unité centrale.
- Lenteur de la programmation des pods.
- Scénarios potentiels de dépassement de mémoire, en fonction de la quantité de mémoire dans le nœud.
- Epuisement de la réserve d'adresses IP.
- Surcharge des ressources, entraînant de mauvaises performances pour les applications utilisateur.
Dans Kubernetes, un pod qui contient un seul conteneur utilise en réalité deux conteneurs. Le deuxième conteneur est utilisé pour mettre en place le réseau avant le démarrage du conteneur proprement dit. Par conséquent, un système exécutant 10 pods aura en réalité 20 conteneurs en cours d'exécution.
La limitation des IOPS disque par le fournisseur de cloud peut avoir un impact sur CRI-O et kubelet. Ils peuvent être surchargés lorsqu'un grand nombre de pods à forte intensité d'E/S s'exécutent sur les nœuds. Il est recommandé de surveiller les E/S disque sur les nœuds et d'utiliser des volumes avec un débit suffisant pour la charge de travail.
podsPerCore définit le nombre de modules que le nœud peut exécuter en fonction du nombre de cœurs de processeur du nœud. Par exemple, si podsPerCore est défini sur 10 sur un nœud avec 4 cœurs de processeur, le nombre maximum de modules autorisés sur le nœud sera 40.
kubeletConfig:
podsPerCore: 10
Le fait de régler podsPerCore sur 0 désactive cette limite. La valeur par défaut est 0. podsPerCore ne peut pas dépasser maxPods.
maxPods fixe le nombre de pods que le nœud peut exécuter à une valeur fixe, quelles que soient les propriétés du nœud.
kubeletConfig:
maxPods: 2507.4.1. Création d'un CRD KubeletConfig pour éditer les paramètres des kubelets
La configuration du kubelet est actuellement sérialisée comme une configuration Ignition, elle peut donc être directement éditée. Cependant, une nouvelle adresse kubelet-config-controller a été ajoutée au contrôleur de configuration de la machine (MCC). Cela vous permet d'utiliser une ressource personnalisée (CR) KubeletConfig pour modifier les paramètres du kubelet.
Comme les champs de l'objet kubeletConfig sont transmis directement au kubelet par Kubernetes en amont, le kubelet valide ces valeurs directement. Des valeurs non valides dans l'objet kubeletConfig peuvent entraîner l'indisponibilité des nœuds du cluster. Pour connaître les valeurs valides, consultez la documentation de Kubernetes.
Examinez les conseils suivants :
-
Créez un CR
KubeletConfigpour chaque pool de configuration de machine avec toutes les modifications de configuration que vous souhaitez pour ce pool. Si vous appliquez le même contenu à tous les pools, vous n'avez besoin que d'un seul CRKubeletConfigpour tous les pools. -
Modifiez un CR
KubeletConfigexistant pour modifier les paramètres existants ou en ajouter de nouveaux, au lieu de créer un CR pour chaque changement. Il est recommandé de ne créer un CR que pour modifier un pool de configuration de machine différent, ou pour des changements qui sont censés être temporaires, afin de pouvoir revenir sur les modifications. -
Si nécessaire, créez plusieurs CR
KubeletConfigdans la limite de 10 par cluster. Pour le premier CRKubeletConfig, l'opérateur de configuration de machine (MCO) crée une configuration de machine avec l'extensionkubelet. Pour chaque CR suivant, le contrôleur crée une autre configuration machinekubeletavec un suffixe numérique. Par exemple, si vous avez une configuration machinekubeletavec un suffixe-2, la configuration machinekubeletsuivante est complétée par-3.
Si vous souhaitez supprimer les configurations de machine, supprimez-les dans l'ordre inverse pour éviter de dépasser la limite. Par exemple, vous supprimez la configuration de la machine kubelet-3 avant de supprimer la configuration de la machine kubelet-2.
Si vous avez une configuration de machine avec un suffixe kubelet-9 et que vous créez une autre CR KubeletConfig, une nouvelle configuration de machine n'est pas créée, même s'il y a moins de 10 configurations de machine kubelet.
Exemple KubeletConfig CR
$ oc get kubeletconfigNAME AGE
set-max-pods 15mExemple de configuration d'une machine KubeletConfig
$ oc get mc | grep kubelet...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m
...La procédure suivante est un exemple qui montre comment configurer le nombre maximum de pods par nœud sur les nœuds de travail.
Conditions préalables
Obtenez l'étiquette associée au CR statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer. Effectuez l'une des opérations suivantes :Voir le pool de configuration de la machine :
oc describe machineconfigpool <name> $ oc describe machineconfigpool <name>Par exemple :
$ oc describe machineconfigpool workerExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods1 - 1
- Si un label a été ajouté, il apparaît sous
labels.
Si l'étiquette n'est pas présente, ajoutez une paire clé/valeur :
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
Procédure
Affichez les objets de configuration de la machine disponibles que vous pouvez sélectionner :
$ oc get machineconfigPar défaut, les deux configurations liées à kubelet sont
01-master-kubeletet01-worker-kubelet.Vérifier la valeur actuelle du nombre maximum de pods par nœud :
oc describe node <node_name>Par exemple :
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Cherchez
value: pods: <value>dans la stropheAllocatable:Exemple de sortie
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250Définissez le nombre maximum de pods par nœud sur les nœuds de travail en créant un fichier de ressources personnalisé qui contient la configuration du kubelet :
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods1 kubeletConfig: maxPods: 5002 NoteLe taux auquel le kubelet parle au serveur API dépend des requêtes par seconde (QPS) et des valeurs de rafale. Les valeurs par défaut,
50pourkubeAPIQPSet100pourkubeAPIBurst, sont suffisantes si le nombre de pods fonctionnant sur chaque nœud est limité. Il est recommandé de mettre à jour les taux de QPS et de burst du kubelet s'il y a suffisamment de ressources de CPU et de mémoire sur le nœud.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>Mettre à jour le pool de configuration des machines pour les travailleurs avec le label :
$ oc label machineconfigpool worker custom-kubelet=set-max-podsCréer l'objet
KubeletConfig:$ oc create -f change-maxPods-cr.yamlVérifiez que l'objet
KubeletConfigest créé :$ oc get kubeletconfigExemple de sortie
NAME AGE set-max-pods 15mEn fonction du nombre de nœuds de travail dans la grappe, attendez que les nœuds de travail soient redémarrés un par un. Pour une grappe de 3 nœuds de travail, cela peut prendre de 10 à 15 minutes.
Vérifiez que les modifications sont appliquées au nœud :
Vérifier sur un nœud de travail que la valeur de
maxPodsa changé :oc describe node <node_name>Repérez la strophe
Allocatable:... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 5001 ...- 1
- Dans cet exemple, le paramètre
podsdoit indiquer la valeur que vous avez définie dans l'objetKubeletConfig.
Vérifiez la modification de l'objet
KubeletConfig:$ oc get kubeletconfigs set-max-pods -o yamlL'état de
Trueettype:Successdevrait apparaître, comme le montre l'exemple suivant :spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
7.4.3. Dimensionnement des nœuds du plan de contrôle
Les besoins en ressources des nœuds du plan de contrôle dépendent du nombre et du type de nœuds et d'objets dans le cluster. Les recommandations suivantes concernant la taille des nœuds du plan de contrôle sont basées sur les résultats d'un test focalisé sur la densité du plan de contrôle, ou Cluster-density. Ce test crée les objets suivants dans un nombre donné d'espaces de noms :
- 1 flux d'images
- 1 construire
-
5 déploiements, avec 2 répliques de pods à l'état
sleep, montant chacun 4 secrets, 4 cartes de configuration et 1 volume d'API descendant - 5 services, chacun pointant vers les ports TCP/8080 et TCP/8443 d'un des déploiements précédents
- 1 itinéraire menant au premier des services précédents
- 10 secrets contenant 2048 caractères aléatoires
- 10 cartes de configuration contenant 2048 caractères aléatoires
| Number of worker nodes | Densité de la grappe (espaces nominatifs) | Cœurs de l'unité centrale | Mémoire (GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16, mais 24 si l'on utilise le plug-in réseau OVN-Kubernetes | 64, mais 128 si l'on utilise le plug-in réseau OVN-Kubernetes |
| 501, mais non testé avec le plug-in réseau OVN-Kubernetes | 4000 | 16 | 96 |
Les données du tableau ci-dessus sont basées sur une plateforme de conteneurs OpenShift fonctionnant au-dessus d'AWS, utilisant des instances r5.4xlarge comme nœuds de plan de contrôle et des instances m5.2xlarge comme nœuds de travail.
Dans un grand cluster dense comprenant trois nœuds de plan de contrôle, l'utilisation du processeur et de la mémoire augmente lorsque l'un des nœuds est arrêté, redémarré ou tombe en panne. Les pannes peuvent être dues à des problèmes inattendus d'alimentation, de réseau, d'infrastructure sous-jacente, ou à des cas intentionnels où le cluster est redémarré après avoir été arrêté pour réduire les coûts. Les deux nœuds restants du plan de contrôle doivent gérer la charge afin d'être hautement disponibles, ce qui entraîne une augmentation de l'utilisation des ressources. Ce phénomène se produit également lors des mises à niveau, car les nœuds du plan de contrôle sont isolés, vidés et redémarrés en série pour appliquer les mises à jour du système d'exploitation, ainsi que la mise à jour des opérateurs du plan de contrôle. Pour éviter les défaillances en cascade, maintenez l'utilisation globale des ressources CPU et mémoire sur les nœuds du plan de contrôle à un maximum de 60 % de la capacité disponible afin de gérer les pics d'utilisation des ressources. Augmentez l'UC et la mémoire des nœuds du plan de contrôle en conséquence pour éviter les temps d'arrêt potentiels dus au manque de ressources.
Le dimensionnement des nœuds varie en fonction du nombre de nœuds et d'objets dans la grappe. Il dépend également de la création active d'objets sur la grappe. Pendant la création des objets, le plan de contrôle est plus actif en termes d'utilisation des ressources que lorsque les objets sont dans la phase running.
Operator Lifecycle Manager (OLM) s'exécute sur les nœuds du plan de contrôle et son empreinte mémoire dépend du nombre d'espaces de noms et d'opérateurs installés par l'utilisateur qu'OLM doit gérer sur la grappe. Les nœuds du plan de contrôle doivent être dimensionnés en conséquence afin d'éviter les pertes de mémoire (OOM kills). Les points de données suivants sont basés sur les résultats des tests de maximisation des grappes.
| Nombre d'espaces de noms | Mémoire OLM au repos (GB) | Mémoire OLM avec 5 opérateurs utilisateurs installés (GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
Vous pouvez modifier la taille des nœuds du plan de contrôle dans un cluster OpenShift Container Platform 4.12 en cours d'exécution pour les configurations suivantes uniquement :
- Clusters installés avec une méthode d'installation fournie par l'utilisateur.
- Clusters AWS installés avec une méthode d'installation d'infrastructure fournie par l'installateur.
- Les clusters qui utilisent un jeu de machines du plan de contrôle pour gérer les machines du plan de contrôle.
Pour toutes les autres configurations, vous devez estimer le nombre total de nœuds et utiliser la taille de nœud suggérée pour le plan de contrôle lors de l'installation.
Les recommandations sont basées sur les points de données capturés sur les clusters OpenShift Container Platform avec OpenShift SDN comme plugin réseau.
Dans OpenShift Container Platform 4.12, la moitié d'un cœur de CPU (500 millicores) est désormais réservée par le système par défaut par rapport à OpenShift Container Platform 3.11 et aux versions précédentes. Les tailles sont déterminées en tenant compte de cela.
7.4.4. Configuration du gestionnaire de CPU
Procédure
Facultatif : Étiqueter un nœud :
# oc label node perf-node.example.com cpumanager=trueModifiez le site
MachineConfigPooldes nœuds pour lesquels le gestionnaire de CPU doit être activé. Dans cet exemple, tous les travailleurs ont activé le gestionnaire de CPU :# oc edit machineconfigpool workerAjouter une étiquette au pool de configuration de la machine de travail :
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledCréez une ressource personnalisée (CR)
KubeletConfig,cpumanager-kubeletconfig.yaml. Référez-vous à l'étiquette créée à l'étape précédente pour que les nœuds corrects soient mis à jour avec la nouvelle configuration du kubelet. Voir la sectionmachineConfigPoolSelector:apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 - 1
- Spécifier une politique :
-
none. Cette politique active explicitement le schéma d'affinité CPU par défaut existant, ne fournissant aucune affinité au-delà de ce que le planificateur fait automatiquement. Il s'agit de la stratégie par défaut. -
static. Cette politique autorise les conteneurs dans les pods garantis avec des demandes de CPU entières. Elle limite également l'accès aux CPU exclusifs sur le nœud. Sistatic, vous devez utiliser une minuscules.
-
- 2
- Facultatif. Indiquez la fréquence de rapprochement du gestionnaire de CPU. La valeur par défaut est
5s.
Créer la configuration dynamique du kubelet :
# oc create -f cpumanager-kubeletconfig.yamlCela ajoute la fonction CPU Manager à la configuration du kubelet et, si nécessaire, le Machine Config Operator (MCO) redémarre le nœud. Pour activer le gestionnaire de CPU, un redémarrage n'est pas nécessaire.
Vérifier la configuration du kubelet fusionné :
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7Exemple de sortie
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]Consultez le travailleur pour obtenir la mise à jour de
kubelet.conf:# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManagerExemple de sortie
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 Créer un pod qui demande un ou plusieurs cœurs. Les limites et les demandes doivent avoir une valeur CPU égale à un entier. Il s'agit du nombre de cœurs qui seront dédiés à ce module :
# cat cpumanager-pod.yamlExemple de sortie
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Créer la capsule :
# oc create -f cpumanager-pod.yamlVérifiez que le pod est planifié sur le nœud que vous avez étiqueté :
# oc describe pod cpumanagerExemple de sortie
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=trueVérifiez que l'adresse
cgroupsest correctement configurée. Obtenir l'ID du processus (PID) du processuspause:# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pauseLes pods du niveau de qualité de service (QoS)
Guaranteedsont placés à l'intérieur du sitekubepods.slice. Les pods des autres niveaux de QoS se retrouvent dans les enfantscgroupsdekubepods:# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; doneExemple de sortie
cpuset.cpus 1 tasks 32706Vérifiez la liste des unités centrales autorisées pour la tâche :
# grep ^Cpus_allowed_list /proc/32706/statusExemple de sortie
Cpus_allowed_list: 1Vérifiez qu'un autre pod (dans ce cas, le pod du niveau de qualité de service
burstable) sur le système ne peut pas fonctionner sur le cœur alloué au podGuaranteed:# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.comExemple de sortie
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)Cette VM dispose de deux cœurs de processeur. Le paramètre
system-reservedréserve 500 millicores, ce qui signifie que la moitié d'un cœur est soustraite de la capacité totale du nœud pour obtenir la quantitéNode Allocatable. Vous pouvez voir queAllocatable CPUest de 1500 millicores. Cela signifie que vous pouvez exécuter l'un des pods du gestionnaire de CPU, puisque chacun d'entre eux prendra un cœur entier. Un cœur entier est équivalent à 1000 millicores. Si vous essayez de planifier un deuxième module, le système acceptera le module, mais il ne sera jamais planifié :NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
7.5. Grandes pages
Comprendre et configurer les grandes pages.
7.5.1. Ce que font les grandes pages
La mémoire est gérée par blocs appelés pages. Sur la plupart des systèmes, une page correspond à 4Ki. 1Mi de mémoire équivaut à 256 pages ; 1Gi de mémoire équivaut à 256 000 pages, et ainsi de suite. Les unités centrales de traitement disposent d'une unité de gestion de la mémoire intégrée qui gère une liste de ces pages au niveau matériel. Le Translation Lookaside Buffer (TLB) est une petite mémoire cache matérielle des correspondances entre les pages virtuelles et les pages physiques. Si l'adresse virtuelle transmise dans une instruction matérielle peut être trouvée dans le TLB, la correspondance peut être déterminée rapidement. Si ce n'est pas le cas, la TLB est manquée et le système revient à une traduction d'adresse plus lente, basée sur le logiciel, ce qui entraîne des problèmes de performance. La taille de la TLB étant fixe, le seul moyen de réduire le risque d'erreur de la TLB est d'augmenter la taille de la page.
Une page énorme est une page de mémoire dont la taille est supérieure à 4Ki. Sur les architectures x86_64, il existe deux tailles courantes de pages énormes : 2Mi et 1Gi. Les tailles varient sur les autres architectures. Pour utiliser les pages énormes, le code doit être écrit de manière à ce que les applications en soient conscientes. Les pages énormes transparentes (THP) tentent d'automatiser la gestion des pages énormes sans que l'application en ait connaissance, mais elles ont des limites. En particulier, elles sont limitées à des tailles de page de 2Mi. Les THP peuvent entraîner une dégradation des performances sur les nœuds à forte utilisation ou fragmentation de la mémoire en raison des efforts de défragmentation des THP, qui peuvent bloquer les pages de mémoire. Pour cette raison, certaines applications peuvent être conçues pour (ou recommander) l'utilisation d'énormes pages pré-allouées au lieu de THP.
7.5.2. Comment les pages volumineuses sont consommées par les applications
Les nœuds doivent pré-allouer des pages volumineuses pour que le nœud puisse indiquer sa capacité de pages volumineuses. Un nœud ne peut pré-allouer des pages volumineuses que pour une seule taille.
Les pages volumineuses peuvent être consommées par le biais des exigences de ressources au niveau du conteneur en utilisant le nom de la ressource hugepages-<size>, où la taille est la notation binaire la plus compacte utilisant des valeurs entières prises en charge par un nœud particulier. Par exemple, si un nœud prend en charge des tailles de page de 2048 Ko, il expose une ressource planifiable hugepages-2Mi. Contrairement à l'unité centrale ou à la mémoire, les pages volumineuses ne permettent pas le surengagement.
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- Spécifiez la quantité de mémoire pour
hugepagescomme étant la quantité exacte à allouer. Ne spécifiez pas cette valeur comme étant la quantité de mémoire pourhugepagesmultipliée par la taille de la page. Par exemple, compte tenu d'une taille de page énorme de 2 Mo, si vous souhaitez utiliser 100 Mo de RAM soutenue par des pages énormes pour votre application, vous devez allouer 50 pages énormes. OpenShift Container Platform fait le calcul pour vous. Comme dans l'exemple ci-dessus, vous pouvez spécifier100MBdirectement.
Allocating huge pages of a specific size
Certaines plates-formes prennent en charge plusieurs tailles de pages volumineuses. Pour allouer des pages volumineuses d'une taille spécifique, faites précéder les paramètres de la commande d'amorçage des pages volumineuses d'un paramètre de sélection de la taille des pages volumineuses hugepagesz=<size>. La valeur de <size> doit être spécifiée en octets avec un suffixe d'échelle facultatif [kKmMgG]. La taille par défaut des pages énormes peut être définie à l'aide du paramètre d'amorçage default_hugepagesz=<size>.
Huge page requirements
- Les demandes de pages volumineuses doivent être égales aux limites. Il s'agit de la valeur par défaut si des limites sont spécifiées, mais que les demandes ne le sont pas.
- Les pages volumineuses sont isolées au niveau du pod. L'isolation des conteneurs est prévue dans une prochaine itération.
-
EmptyDirles volumes soutenus par des pages volumineuses ne doivent pas consommer plus de mémoire de page volumineuse que la demande de pod. -
Les applications qui consomment des pages volumineuses via
shmget()avecSHM_HUGETLBdoivent fonctionner avec un groupe supplémentaire qui correspond à proc/sys/vm/hugetlb_shm_group.
7.5.3. Configuration de pages volumineuses
Les nœuds doivent pré-allouer les pages volumineuses utilisées dans un cluster OpenShift Container Platform. Il existe deux façons de réserver des pages volumineuses : au démarrage et à l'exécution. La réservation au démarrage augmente les chances de succès car la mémoire n'a pas encore été fragmentée de manière significative. Le Node Tuning Operator prend actuellement en charge l'allocation de pages volumineuses au moment du démarrage sur des nœuds spécifiques.
7.5.3.1. Au moment du démarrage
Procédure
Pour minimiser les redémarrages de nœuds, l'ordre des étapes ci-dessous doit être respecté :
Étiqueter tous les nœuds qui ont besoin du même réglage de pages énormes par une étiquette.
oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp= $ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=Créez un fichier avec le contenu suivant et nommez-le
hugepages-tuned-boottime.yaml:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages1 namespace: openshift-cluster-node-tuning-operator spec: profile:2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=503 name: openshift-node-hugepages recommend: - machineConfigLabels:4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages- 1
- Réglez le site
namede la ressource accordée surhugepages. - 2
- Définir la section
profilepour allouer des pages volumineuses. - 3
- L'ordre des paramètres est important, car certaines plates-formes prennent en charge des pages volumineuses de différentes tailles.
- 4
- Activer la correspondance basée sur le pool de configuration de la machine.
Créer l'objet Tuned
hugepages$ oc create -f hugepages-tuned-boottime.yamlCréez un fichier avec le contenu suivant et nommez-le
hugepages-mcp.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""Créer le pool de configuration de la machine :
$ oc create -f hugepages-mcp.yaml
Avec suffisamment de mémoire non fragmentée, tous les nœuds du pool de configuration de la machine worker-hp devraient maintenant avoir 50 pages énormes de 2Mi allouées.
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiLe plugin TuneD bootloader est actuellement pris en charge sur les nœuds de travail Red Hat Enterprise Linux CoreOS (RHCOS) 8.x. Pour les nœuds de travail Red Hat Enterprise Linux (RHEL) 7.x, le plugin de chargeur de démarrage TuneD n'est actuellement pas pris en charge.
7.6. Comprendre les plugins d'appareils
Le plugin device fournit une solution cohérente et portable pour consommer des périphériques matériels à travers les clusters. Le plugin device fournit un support pour ces dispositifs à travers un mécanisme d'extension, qui rend ces dispositifs disponibles pour les conteneurs, fournit des contrôles de santé de ces dispositifs, et les partage de manière sécurisée.
OpenShift Container Platform prend en charge l'API du plugin de périphérique, mais les conteneurs de plugin de périphérique sont pris en charge par des fournisseurs individuels.
Un plugin de périphérique est un service gRPC fonctionnant sur les nœuds (en dehors du site kubelet) et chargé de gérer des ressources matérielles spécifiques. Tout plugin de périphérique doit prendre en charge les appels de procédure à distance (RPC) suivants :
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plug-in can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartcontainer is called, if indicated by Device Plug-in during
// registration phase, before each container start. Device plug-in
// can run device specific operations such as reseting the device
// before making devices available to the container
rpc PreStartcontainer(PreStartcontainerRequest) returns (PreStartcontainerResponse) {}
}Exemples de plugins d'appareils
Pour faciliter la mise en œuvre de la référence du plugin de périphérique, il existe un plugin de périphérique fictif dans le code du gestionnaire de périphériques : vendor/k8s.io/kubernetes/pkg/kubelet/cm/deviceplugin/device_plugin_stub.go.
7.6.1. Méthodes de déploiement d'un module d'extension de dispositif
- Les ensembles de démons constituent l'approche recommandée pour les déploiements de plugins de périphériques.
- Au démarrage, le plugin de périphérique essaiera de créer un socket de domaine UNIX à l'adresse /var/lib/kubelet/device-plugin/ sur le nœud pour servir les RPC du gestionnaire de périphériques.
- Comme les plugins de périphérique doivent gérer les ressources matérielles, l'accès au système de fichiers de l'hôte, ainsi que la création de sockets, ils doivent être exécutés dans un contexte de sécurité privilégié.
- Des détails plus spécifiques concernant les étapes de déploiement peuvent être trouvés avec chaque implémentation de plugin d'appareil.
7.6.2. Comprendre le gestionnaire de périphériques
Device Manager fournit un mécanisme pour annoncer les ressources matérielles spécialisées des nœuds à l'aide de plugins connus sous le nom de "device plugins".
Vous pouvez annoncer du matériel spécialisé sans avoir à modifier le code en amont.
OpenShift Container Platform prend en charge l'API du plugin de périphérique, mais les conteneurs de plugin de périphérique sont pris en charge par des fournisseurs individuels.
Le gestionnaire de dispositifs annonce les dispositifs en tant que Extended Resources. Les pods utilisateurs peuvent consommer les dispositifs annoncés par le Device Manager en utilisant le même mécanisme Limit/Request que celui utilisé pour demander n'importe quel autre Extended Resource.
Au démarrage, le plugin de périphérique s'enregistre auprès du gestionnaire de périphériques en invoquant Register sur l'adresse /var/lib/kubelet/device-plugins/kubelet.sock et lance un service gRPC à l'adresse /var/lib/kubelet/device-plugins/<plugin>.sock pour répondre aux demandes du gestionnaire d'appareils.
Lors du traitement d'une nouvelle demande d'enregistrement, le gestionnaire de périphérique invoque l'appel de procédure à distance (RPC) ListAndWatch auprès du service d'extension de périphérique. En réponse, le gestionnaire de périphérique obtient une liste d'objets Device du plugin via un flux gRPC. Le gestionnaire de périphérique surveillera le flux pour les nouvelles mises à jour du module d'extension. Du côté du plugin, le plugin gardera également le flux ouvert et chaque fois qu'il y a un changement dans l'état de l'un des appareils, une nouvelle liste d'appareils est envoyée au gestionnaire de périphériques via la même connexion de flux.
Lors du traitement d'une nouvelle demande d'admission d'un pod, Kubelet transmet la demande Extended Resources au Device Manager pour l'attribution d'un dispositif. Le gestionnaire de périphériques vérifie dans sa base de données si un plugin correspondant existe ou non. Si le plugin existe et qu'il y a des dispositifs allouables libres ainsi que dans le cache local, Allocate RPC est invoqué au niveau de ce plugin de dispositif particulier.
En outre, les plugins d'appareil peuvent également effectuer plusieurs autres opérations spécifiques à l'appareil, telles que l'installation du pilote, l'initialisation de l'appareil et la réinitialisation de l'appareil. Ces fonctionnalités varient d'une implémentation à l'autre.
7.6.3. Activation du gestionnaire de périphériques
Permettre au gestionnaire de périphériques de mettre en œuvre un plugin de périphérique pour annoncer du matériel spécialisé sans aucune modification du code en amont.
Device Manager fournit un mécanisme pour annoncer les ressources matérielles spécialisées des nœuds à l'aide de plugins connus sous le nom de "device plugins".
Obtenez l'étiquette associée au CRD statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer en entrant la commande suivante. Effectuez l'une des étapes suivantes :Voir la configuration de la machine :
# oc describe machineconfig <name>Par exemple :
# oc describe machineconfig 00-workerExemple de sortie
Name: 00-worker Namespace: Labels: machineconfiguration.openshift.io/role=worker1 - 1
- Étiquette requise pour le gestionnaire de périphériques.
Procédure
Créez une ressource personnalisée (CR) pour votre changement de configuration.
Exemple de configuration pour un gestionnaire de périphérique CR
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: devicemgr1 spec: machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io: devicemgr2 kubeletConfig: feature-gates: - DevicePlugins=true3 Créer le gestionnaire de périphériques :
$ oc create -f devicemgr.yamlExemple de sortie
kubeletconfig.machineconfiguration.openshift.io/devicemgr created- Assurez-vous que le gestionnaire de périphériques a bien été activé en confirmant que l'option /var/lib/kubelet/device-plugins/kubelet.sock est créé sur le nœud. Il s'agit du socket de domaine UNIX sur lequel le serveur gRPC du Device Manager écoute les nouveaux enregistrements de plugins. Ce fichier sock est créé au démarrage de la Kubelet uniquement si Device Manager est activé.
7.7. Taches et tolérances
Comprendre et travailler avec les taches et les tolérances.
7.7.1. Comprendre les taches et les tolérances
Un taint permet à un nœud de refuser qu'un module soit programmé à moins que ce module n'ait un toleration correspondant.
Vous appliquez des taches à un nœud par le biais de la spécification Node (NodeSpec) et vous appliquez des tolérances à un pod par le biais de la spécification Pod (PodSpec). Lorsque vous appliquez une tare à un nœud, l'ordonnanceur ne peut pas placer un module sur ce nœud à moins que le module ne puisse tolérer la tare.
Exemple d'altération dans la spécification d'un nœud
spec:
taints:
- effect: NoExecute
key: key1
value: value1
....Exemple de tolérance dans une spécification Pod
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
....Les plaintes et les tolérances se composent d'une clé, d'une valeur et d'un effet.
| Paramètres | Description | ||||||
|---|---|---|---|---|---|---|---|
|
|
Le site | ||||||
|
|
Le site | ||||||
|
| L'effet est l'un des suivants :
| ||||||
|
|
|
Si vous ajoutez une erreur
NoScheduleà un nœud du plan de contrôle, le nœud doit avoir l'erreurnode-role.kubernetes.io/master=:NoSchedule, qui est ajoutée par défaut.Par exemple :
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c ... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master ...
Une tolérance correspond à une souillure :
Si le paramètre
operatorest réglé surEqual:-
les paramètres de
keysont les mêmes ; -
les paramètres de
valuesont les mêmes ; -
les paramètres de
effectsont les mêmes.
-
les paramètres de
Si le paramètre
operatorest réglé surExists:-
les paramètres de
keysont les mêmes ; -
les paramètres de
effectsont les mêmes.
-
les paramètres de
Les plaintes suivantes sont intégrées à OpenShift Container Platform :
-
node.kubernetes.io/not-ready: Le nœud n'est pas prêt. Cela correspond à la condition du nœudReady=False. -
node.kubernetes.io/unreachable: Le nœud est inaccessible depuis le contrôleur de nœud. Cela correspond à l'état du nœudReady=Unknown. -
node.kubernetes.io/memory-pressure: Le nœud a des problèmes de pression de mémoire. Cela correspond à la condition du nœudMemoryPressure=True. -
node.kubernetes.io/disk-pressure: Le nœud a des problèmes de pression de disque. Cela correspond à l'état du nœudDiskPressure=True. -
node.kubernetes.io/network-unavailable: Le réseau du nœud est indisponible. -
node.kubernetes.io/unschedulable: Le nœud n'est pas ordonnançable. -
node.cloudprovider.kubernetes.io/uninitialized: Lorsque le contrôleur de nœuds est démarré avec un fournisseur de nuage externe, cette altération est définie sur un nœud pour le marquer comme inutilisable. Après qu'un contrôleur du cloud-controller-manager initialise ce nœud, le kubelet supprime cette taint. node.kubernetes.io/pid-pressure: Le nœud a un pid de pression. Cela correspond à la condition du nœudPIDPressure=True.ImportantOpenShift Container Platform ne définit pas de pid par défaut.available
evictionHard.
7.7.1.1. Comprendre comment utiliser les secondes de tolérance pour retarder les expulsions de nacelles
Vous pouvez spécifier la durée pendant laquelle un pod peut rester lié à un nœud avant d'être expulsé en spécifiant le paramètre tolerationSeconds dans la spécification Pod ou l'objet MachineSet. Si une altération ayant l'effet NoExecute est ajoutée à un nœud, un module qui tolère l'altération, qui a le paramètre tolerationSeconds, le module n'est pas expulsé avant l'expiration de ce délai.
Exemple de sortie
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600Ici, si ce pod est en cours d'exécution mais n'a pas de tolérance correspondante, le pod reste lié au nœud pendant 3 600 secondes avant d'être expulsé. Si l'altération est supprimée avant ce délai, le module n'est pas expulsé.
7.7.1.2. Comprendre comment utiliser des teintes multiples
Vous pouvez placer plusieurs taints sur le même nœud et plusieurs tolérances sur le même pod. OpenShift Container Platform traite les plaintes et tolérances multiples de la manière suivante :
- Traiter les plaintes pour lesquelles le pod a une tolérance correspondante.
Les autres souillures non appariées ont les effets indiqués sur la cosse :
-
S'il y a au moins une taint non appariée avec l'effet
NoSchedule, OpenShift Container Platform ne peut pas planifier un pod sur ce nœud. -
S'il n'y a pas de taint non apparié avec l'effet
NoSchedulemais qu'il y a au moins un taint non apparié avec l'effetPreferNoSchedule, OpenShift Container Platform essaie de ne pas planifier le pod sur le nœud. S'il y a au moins une taint non appariée avec l'effet
NoExecute, OpenShift Container Platform expulse le pod du nœud s'il est déjà en cours d'exécution sur le nœud, ou le pod n'est pas planifié sur le nœud s'il n'est pas encore en cours d'exécution sur le nœud.- Les pods qui ne tolèrent pas la souillure sont immédiatement expulsés.
-
Les pods qui tolèrent l'altération sans spécifier
tolerationSecondsdans leur spécificationPodrestent liés pour toujours. -
Les pods qui tolèrent l'altération à l'aide d'une adresse
tolerationSecondsspécifiée restent liés pendant la durée spécifiée.
-
S'il y a au moins une taint non appariée avec l'effet
Par exemple :
Ajoutez au nœud les taches suivantes :
$ oc adm taint nodes node1 key1=value1:NoSchedule$ oc adm taint nodes node1 key1=value1:NoExecute$ oc adm taint nodes node1 key2=value2:NoScheduleLes tolérances suivantes s'appliquent à la nacelle :
spec: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule" - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute"
Dans ce cas, le module ne peut pas être programmé sur le nœud, car il n'y a pas de tolérance correspondant à la troisième tare. Le module continue de fonctionner s'il est déjà en cours d'exécution sur le nœud lorsque la tare est ajoutée, car la troisième tare est la seule des trois qui n'est pas tolérée par le module.
7.7.1.3. Comprendre l'ordonnancement des pods et les conditions des nœuds (taint node by condition)
La fonction d'altération des nœuds par condition, activée par défaut, altère automatiquement les nœuds qui signalent des conditions telles que la pression de la mémoire et la pression du disque. Lorsqu'un nœud signale une condition, une erreur est ajoutée jusqu'à ce que la condition disparaisse. Les taches ont l'effet NoSchedule, ce qui signifie qu'aucun pod ne peut être planifié sur le nœud à moins que le pod n'ait une tolérance correspondante.
L'ordonnanceur vérifie la présence de ces anomalies sur les nœuds avant de planifier les modules. Si l'erreur est présente, le module est planifié sur un nœud différent. Comme l'ordonnanceur vérifie les anomalies et non les conditions réelles des nœuds, vous pouvez configurer l'ordonnanceur pour qu'il ignore certaines de ces conditions en ajoutant des tolérances appropriées pour les nœuds.
Pour assurer la compatibilité ascendante, le contrôleur de jeu de démons ajoute automatiquement les tolérances suivantes à tous les démons :
- node.kubernetes.io/memory-pressure
- node.kubernetes.io/disk-pressure
- node.kubernetes.io/unschedulable (1.10 ou ultérieur)
- node.kubernetes.io/network-unavailable (réseau hôte uniquement)
Vous pouvez également ajouter des tolérances arbitraires aux ensembles de démons.
Le plan de contrôle ajoute également la tolérance node.kubernetes.io/memory-pressure sur les pods qui ont une classe QoS. En effet, Kubernetes gère les pods dans les classes de QoS Guaranteed ou Burstable. Les nouveaux pods BestEffort ne sont pas planifiés sur le nœud affecté.
7.7.1.4. Comprendre l'éviction des pods par condition (évictions basées sur les taches)
La fonction Taint-Based Evictions, qui est activée par défaut, expulse les pods d'un nœud qui présente des conditions spécifiques, telles que not-ready et unreachable. Lorsqu'un nœud est confronté à l'une de ces conditions, OpenShift Container Platform ajoute automatiquement des taints au nœud et commence à expulser et à replanifier les pods sur différents nœuds.
Les évictions basées sur l'altération ont un effet NoExecute, où tout pod qui ne tolère pas l'altération est évincé immédiatement et tout pod qui tolère l'altération ne sera jamais évincé, à moins que le pod n'utilise le paramètre tolerationSeconds.
Le paramètre tolerationSeconds vous permet de spécifier la durée pendant laquelle un pod reste lié à un nœud qui a une condition de nœud. Si la condition existe toujours après la période tolerationSeconds, l'altération reste sur le nœud et les pods avec une tolérance correspondante sont expulsés. Si la condition disparaît avant la période tolerationSeconds, les pods avec les tolérances correspondantes ne sont pas supprimés.
Si vous utilisez le paramètre tolerationSeconds sans valeur, les pods ne sont jamais expulsés en raison des conditions "not ready" et "unreachable node".
OpenShift Container Platform évince les pods de manière limitée afin d'éviter les évictions massives de pods dans des scénarios tels que la partition du maître par rapport aux nœuds.
Par défaut, si plus de 55 % des nœuds d'une zone donnée sont malsains, le contrôleur du cycle de vie des nœuds fait passer l'état de cette zone à PartialDisruption et le taux d'expulsion des pods est réduit. Pour les petits clusters (par défaut, 50 nœuds ou moins) dans cet état, les nœuds de cette zone ne sont pas altérés et les expulsions sont arrêtées.
Pour plus d'informations, voir Rate limits on eviction dans la documentation Kubernetes.
OpenShift Container Platform ajoute automatiquement une tolérance pour node.kubernetes.io/not-ready et node.kubernetes.io/unreachable avec tolerationSeconds=300, à moins que la configuration Pod ne spécifie l'une ou l'autre tolérance.
spec:
tolerations:
- key: node.kubernetes.io/not-ready
operator: Exists
effect: NoExecute
tolerationSeconds: 300
- key: node.kubernetes.io/unreachable
operator: Exists
effect: NoExecute
tolerationSeconds: 300- 1
- Ces tolérances garantissent que le comportement par défaut du pod est de rester lié pendant cinq minutes après la détection d'un de ces problèmes de conditions de nœuds.
Vous pouvez configurer ces tolérances selon vos besoins. Par exemple, si vous avez une application avec beaucoup d'état local, vous pourriez vouloir garder les pods liés au nœud plus longtemps en cas de partition du réseau, ce qui permettrait à la partition de se rétablir et d'éviter l'éviction des pods.
Les pods générés par un ensemble de démons sont créés avec des tolérances de NoExecute pour les taches suivantes, sans tolerationSeconds:
-
node.kubernetes.io/unreachable -
node.kubernetes.io/not-ready
Par conséquent, les pods de l'ensemble des démons ne sont jamais expulsés en raison de ces conditions de nœuds.
7.7.1.5. Tolérer toutes les tares
Vous pouvez configurer un pod pour qu'il tolère toutes les plaintes en ajoutant une tolérance operator: "Exists" sans paramètres key et value. Les pods ayant cette tolérance ne sont pas retirés d'un nœud qui a des taches.
Pod spécification pour la tolérance de toutes les taches
spec:
tolerations:
- operator: "Exists"7.7.2. Ajout de taches et de tolérances
Vous ajoutez des tolérances aux modules et des taches aux nœuds pour permettre au nœud de contrôler les modules qui doivent ou ne doivent pas être planifiés sur eux. Pour les pods et les nœuds existants, vous devez d'abord ajouter la tolérance au pod, puis ajouter la taint au nœud afin d'éviter que les pods ne soient retirés du nœud avant que vous ne puissiez ajouter la tolérance.
Procédure
Ajouter une tolérance à un pod en modifiant la spécification
Podpour y inclure une strophetolerations:Exemple de fichier de configuration d'un pod avec un opérateur Equal
spec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 Par exemple :
Exemple de fichier de configuration d'un pod avec un opérateur Exists
spec: tolerations: - key: "key1" operator: "Exists"1 effect: "NoExecute" tolerationSeconds: 3600- 1
- L'opérateur
Existsne prend pas devalue.
Cet exemple place une tare sur
node1qui a la clékey1, la valeurvalue1, et l'effet de tareNoExecute.Ajoutez une tare à un nœud en utilisant la commande suivante avec les paramètres décrits dans le tableau Taint and toleration components:
$ oc adm taint nodes <node_name> <key>=<value>:<effect>Par exemple :
$ oc adm taint nodes node1 key1=value1:NoExecuteCette commande place une tare sur
node1qui a pour clékey1, pour valeurvalue1, et pour effetNoExecute.NoteSi vous ajoutez une erreur
NoScheduleà un nœud du plan de contrôle, le nœud doit avoir l'erreurnode-role.kubernetes.io/master=:NoSchedule, qui est ajoutée par défaut.Par exemple :
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c ... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master ...Les tolérances du module correspondent à l'altération du nœud. Un pod avec l'une ou l'autre des tolérances peut être programmé sur
node1.
7.7.3. Ajout de taches et de tolérances à l'aide d'un ensemble de machines de calcul
Vous pouvez ajouter des taches aux nœuds à l'aide d'un ensemble de machines de calcul. Tous les nœuds associés à l'objet MachineSet sont mis à jour avec l'erreur. Les tolérances réagissent aux taches ajoutées par un ensemble de machines de calcul de la même manière que les taches ajoutées directement aux nœuds.
Procédure
Ajouter une tolérance à un pod en modifiant la spécification
Podpour y inclure une strophetolerations:Exemple de fichier de configuration d'un pod avec l'opérateur
Equalspec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 Par exemple :
Exemple de fichier de configuration d'un pod avec l'opérateur
Existsspec: tolerations: - key: "key1" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600Ajouter l'altération à l'objet
MachineSet:Modifiez le fichier YAML de
MachineSetpour les nœuds que vous souhaitez altérer ou créez un nouvel objetMachineSet:$ oc edit machineset <machineset>Ajoutez la souillure à la section
spec.template.spec:Exemple d'altération dans la spécification d'un ensemble de machines de calcul
spec: .... template: .... spec: taints: - effect: NoExecute key: key1 value: value1 ....Cet exemple place une taint qui a la clé
key1, la valeurvalue1, et l'effet de taintNoExecutesur les nœuds.Réduire l'échelle de la machine de calcul à 0 :
$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-apiAstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0Attendez que les machines soient retirées.
Augmenter l'ensemble des machines de calcul en fonction des besoins :
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiOu bien :
$ oc edit machineset <machineset> -n openshift-machine-apiAttendez que les machines démarrent. L'altération est ajoutée aux nœuds associés à l'objet
MachineSet.
7.7.4. Lier un utilisateur à un nœud à l'aide de taches et de tolérances
Si vous souhaitez réserver un ensemble de nœuds à l'usage exclusif d'un groupe particulier d'utilisateurs, ajoutez une tolérance à leurs pods. Ajoutez ensuite une altération correspondante à ces nœuds. Les pods avec les tolérances sont autorisés à utiliser les nœuds altérés ou tout autre nœud du cluster.
Si vous voulez vous assurer que les pods sont programmés uniquement sur les nœuds altérés, ajoutez également une étiquette au même ensemble de nœuds et ajoutez une affinité de nœud aux pods de sorte que les pods ne puissent être programmés que sur des nœuds avec cette étiquette.
Procédure
Pour configurer un nœud de manière à ce que les utilisateurs ne puissent utiliser que ce nœud :
Ajouter une tare correspondante à ces nœuds :
Par exemple :
$ oc adm taint nodes node1 dedicated=groupName:NoScheduleAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'altération :
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: dedicated value: groupName effect: NoSchedule- Ajoutez une tolérance aux pods en écrivant un contrôleur d'admission personnalisé.
7.7.5. Contrôle des nœuds avec du matériel spécial à l'aide de taches et de tolérances
Dans un cluster où un petit sous-ensemble de nœuds dispose d'un matériel spécialisé, vous pouvez utiliser les taints et les tolérances pour empêcher les pods qui n'ont pas besoin de ce matériel spécialisé d'utiliser ces nœuds, laissant ainsi les nœuds aux pods qui ont besoin de ce matériel spécialisé. Vous pouvez également exiger que les modules qui ont besoin d'un matériel spécialisé utilisent des nœuds spécifiques.
Vous pouvez y parvenir en ajoutant une tolérance aux pods qui ont besoin d'un matériel spécial et en altérant les nœuds qui disposent de ce matériel.
Procédure
Pour s'assurer que les nœuds dotés d'un matériel spécialisé sont réservés à des modules spécifiques :
Ajouter une tolérance aux nacelles qui ont besoin d'un matériel spécial.
Par exemple :
spec: tolerations: - key: "disktype" value: "ssd" operator: "Equal" effect: "NoSchedule" tolerationSeconds: 3600Attaquez les nœuds dotés du matériel spécialisé à l'aide de l'une des commandes suivantes :
oc adm taint nodes <node-name> disktype=ssd:NoScheduleOu bien :
oc adm taint nodes <node-name> disktype=ssd:PreferNoScheduleAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'altération :
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: disktype value: ssd effect: PreferNoSchedule
7.7.6. Supprimer les tares et les tolérances
Vous pouvez supprimer les tares des nœuds et les tolérances des nacelles si nécessaire. Vous devez d'abord ajouter la tolérance au module, puis ajouter l'altération au nœud afin d'éviter que des modules soient retirés du nœud avant que vous ne puissiez ajouter la tolérance.
Procédure
Éliminer les tares et les tolérances :
Pour supprimer une tare d'un nœud :
$ oc adm taint nodes <node-name> <key>-Par exemple :
$ oc adm taint nodes ip-10-0-132-248.ec2.internal key1-Exemple de sortie
node/ip-10-0-132-248.ec2.internal untaintedPour supprimer une tolérance d'un pod, modifiez la spécification de
Podpour supprimer la tolérance :spec: tolerations: - key: "key2" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600
7.8. Gestionnaire de topologie
Comprendre et utiliser le gestionnaire de topologie.
7.8.1. Politiques du gestionnaire de topologie
Topology Manager aligne les ressources Pod de toutes les classes de qualité de service (QoS) en recueillant des indices topologiques auprès des fournisseurs d'indices, tels que CPU Manager et Device Manager, et en utilisant les indices recueillis pour aligner les ressources Pod.
Topology Manager prend en charge quatre politiques d'allocation, que vous attribuez dans la ressource personnalisée (CR) cpumanager-enabled:
nonepolitique- Il s'agit de la stratégie par défaut, qui n'effectue aucun alignement topologique.
best-effortpolitique-
Pour chaque conteneur d'un module avec la politique de gestion de la topologie
best-effort, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie enregistre l'affinité préférée du nœud NUMA pour ce conteneur. Si l'affinité n'est pas préférée, le gestionnaire de topologie le stocke et admet le pod au nœud. restrictedpolitique-
Pour chaque conteneur d'un module avec la politique de gestion de la topologie
restricted, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie enregistre l'affinité préférée du nœud NUMA pour ce conteneur. Si l'affinité n'est pas préférée, le gestionnaire de topologie rejette ce pod du nœud, ce qui se traduit par un pod dans l'étatTerminatedavec un échec d'admission de pod. single-numa-nodepolitique-
Pour chaque conteneur d'un pod avec la politique de gestion de la topologie
single-numa-node, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie détermine si une affinité avec un seul nœud NUMA est possible. Si c'est le cas, le pod est admis dans le nœud. Si une affinité de nœud NUMA unique n'est pas possible, le gestionnaire de topologie rejette le module du nœud. Le résultat est un pod en état Terminé avec un échec d'admission de pod.
7.8.2. Configuration du gestionnaire de topologie
Pour utiliser le gestionnaire de topologie, vous devez configurer une politique d'allocation dans la ressource personnalisée (CR) cpumanager-enabled. Ce fichier peut exister si vous avez configuré le Gestionnaire de CPU. Si le fichier n'existe pas, vous pouvez le créer.
Prequisites
-
Configurez la politique du gestionnaire de CPU pour qu'elle soit
static.
Procédure
Pour activer Topololgy Manager :
Configurer la politique d'allocation du gestionnaire de topologie dans la ressource personnalisée (CR)
cpumanager-enabled.$ oc edit KubeletConfig cpumanager-enabledapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node2
7.8.3. Interactions des pods avec les politiques de Topology Manager
Les exemples de spécifications Pod ci-dessous permettent d'illustrer les interactions entre les pods et Topology Manager.
Le pod suivant s'exécute dans la classe de qualité de service BestEffort car aucune demande ou limite de ressources n'est spécifiée.
spec:
containers:
- name: nginx
image: nginx
Le pod suivant fonctionne dans la classe de qualité de service Burstable car les demandes sont inférieures aux limites.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Si la politique sélectionnée est autre que none, Topology Manager ne tiendra compte d'aucune de ces spécifications Pod.
Le dernier exemple de pod ci-dessous s'exécute dans la classe de qualité de service garantie parce que les demandes sont égales aux limites.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"Le gestionnaire de topologie prend en compte ce module. Le gestionnaire de topologie consulte les fournisseurs d'indices, à savoir le gestionnaire de CPU et le gestionnaire de périphériques, afin d'obtenir des indices topologiques pour le module.
Le gestionnaire de topologie utilisera ces informations pour stocker la meilleure topologie pour ce conteneur. Dans le cas de ce module, le gestionnaire de CPU et le gestionnaire de périphériques utiliseront ces informations stockées lors de la phase d'allocation des ressources.
7.9. Demandes de ressources et surengagement
Pour chaque ressource informatique, un conteneur peut spécifier une demande de ressource et une limite. Les décisions d'ordonnancement sont prises en fonction de la demande afin de s'assurer qu'un nœud dispose d'une capacité suffisante pour répondre à la valeur demandée. Si un conteneur spécifie des limites, mais omet des demandes, les demandes sont définies par défaut en fonction des limites. Un conteneur ne peut pas dépasser la limite spécifiée sur le nœud.
L'application des limites dépend du type de ressource de calcul. Si un conteneur ne formule aucune demande ou limite, il est programmé sur un nœud sans garantie de ressources. En pratique, le conteneur est capable de consommer autant de ressources spécifiées qu'il est disponible avec la priorité locale la plus basse. Dans les situations où les ressources sont faibles, les conteneurs qui ne formulent aucune demande de ressources bénéficient de la qualité de service la plus faible.
L'ordonnancement est basé sur les ressources demandées, tandis que les quotas et les limites strictes font référence aux limites de ressources, qui peuvent être plus élevées que les ressources demandées. La différence entre la demande et la limite détermine le niveau de surengagement ; par exemple, si un conteneur reçoit une demande de mémoire de 1Gi et une limite de mémoire de 2Gi, il est ordonnancé sur la base de la demande de 1Gi disponible sur le nœud, mais pourrait utiliser jusqu'à 2Gi ; il est donc surengagé à 200%.
7.10. Surengagement au niveau du cluster à l'aide de l'opérateur d'annulation des ressources du cluster
Le Cluster Resource Override Operator est un webhook d'admission qui vous permet de contrôler le niveau d'overcommit et de gérer la densité des conteneurs sur tous les nœuds de votre cluster. L'opérateur contrôle la façon dont les nœuds de projets spécifiques peuvent dépasser les limites de mémoire et de CPU définies.
Vous devez installer le Cluster Resource Override Operator à l'aide de la console OpenShift Container Platform ou du CLI, comme indiqué dans les sections suivantes. Lors de l'installation, vous créez une ressource personnalisée (CR) ClusterResourceOverride, dans laquelle vous définissez le niveau de surengagement, comme le montre l'exemple suivant :
apiVersion: operator.autoscaling.openshift.io/v1
kind: ClusterResourceOverride
metadata:
name: cluster
spec:
podResourceOverride:
spec:
memoryRequestToLimitPercent: 50
cpuRequestToLimitPercent: 25
limitCPUToMemoryPercent: 200 - 1
- Le nom doit être
cluster. - 2
- Facultatif. Si une limite de mémoire de conteneur a été spécifiée ou définie par défaut, la demande de mémoire est remplacée par ce pourcentage de la limite, compris entre 1 et 100. La valeur par défaut est 50.
- 3
- Facultatif. Si une limite de CPU pour le conteneur a été spécifiée ou définie par défaut, la demande de CPU est remplacée par ce pourcentage de la limite, compris entre 1 et 100. La valeur par défaut est 25.
- 4
- Facultatif. Si une limite de mémoire de conteneur a été spécifiée ou définie par défaut, la limite de CPU est remplacée par un pourcentage de la limite de mémoire, si elle est spécifiée. La mise à l'échelle de 1Gi de RAM à 100 % équivaut à 1 cœur de CPU. Cette opération est effectuée avant de passer outre la demande de CPU (si elle est configurée). La valeur par défaut est 200.
Les dérogations de l'opérateur de dérogations des ressources du cluster n'ont aucun effet si des limites n'ont pas été définies pour les conteneurs. Créez un objet LimitRange avec des limites par défaut pour chaque projet ou configurez des limites dans les spécifications Pod pour que les dérogations s'appliquent.
Lorsqu'elles sont configurées, les dérogations peuvent être activées par projet en appliquant l'étiquette suivante à l'objet Namespace pour chaque projet :
apiVersion: v1
kind: Namespace
metadata:
....
labels:
clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"
....
L'opérateur guette le CR ClusterResourceOverride et s'assure que le webhook d'admission ClusterResourceOverride est installé dans le même espace de noms que l'opérateur.
7.10.1. Installation de l'opérateur de remplacement des ressources de cluster à l'aide de la console web
Vous pouvez utiliser la console web d'OpenShift Container Platform pour installer le Cluster Resource Override Operator afin de contrôler l'overcommit dans votre cluster.
Conditions préalables
-
L'opérateur d'annulation des ressources de cluster n'a aucun effet si des limites n'ont pas été définies pour les conteneurs. Vous devez spécifier des limites par défaut pour un projet à l'aide d'un objet
LimitRangeou configurer des limites dans les spécificationsPodpour que les surcharges s'appliquent.
Procédure
Pour installer le Cluster Resource Override Operator à l'aide de la console web d'OpenShift Container Platform :
Dans la console web d'OpenShift Container Platform, naviguez vers Home → Projects
- Cliquez sur Create Project.
-
Spécifiez
clusterresourceoverride-operatorcomme nom du projet. - Cliquez sur Create.
Naviguez jusqu'à Operators → OperatorHub.
- Choisissez ClusterResourceOverride Operator dans la liste des opérateurs disponibles et cliquez sur Install.
- Sur la page Install Operator, assurez-vous que A specific Namespace on the cluster est sélectionné pour Installation Mode.
- Assurez-vous que clusterresourceoverride-operator est sélectionné pour Installed Namespace.
- Sélectionnez une adresse Update Channel et Approval Strategy.
- Cliquez sur Install.
Sur la page Installed Operators, cliquez sur ClusterResourceOverride.
- Sur la page de détails ClusterResourceOverride Operator, cliquez sur Create Instance.
Sur la page Create ClusterResourceOverride, modifiez le modèle YAML pour définir les valeurs de surengagement selon les besoins :
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 - 1
- Le nom doit être
cluster. - 2
- Facultatif. Indiquez le pourcentage de dépassement de la limite de mémoire du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 50.
- 3
- Facultatif. Spécifiez le pourcentage de dépassement de la limite de CPU du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 25.
- 4
- Facultatif. Indiquez le pourcentage qui doit remplacer la limite de mémoire du conteneur, si elle est utilisée. La mise à l'échelle de 1Gi de RAM à 100 % équivaut à 1 cœur de CPU. Ceci est traité avant d'outrepasser la demande de CPU, si elle est configurée. La valeur par défaut est 200.
- Cliquez sur Create.
Vérifier l'état actuel du webhook d'admission en vérifiant l'état de la ressource personnalisée cluster :
- Sur la page ClusterResourceOverride Operator, cliquez sur cluster.
Sur la page ClusterResourceOverride Details, cliquez sur YAML. La section
mutatingWebhookConfigurationRefs'affiche lorsque le webhook est appelé.apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: .... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1beta1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 ....- 1
- Référence au webhook d'admission
ClusterResourceOverride.
7.10.2. Installation de l'opérateur de remplacement des ressources de cluster à l'aide de l'interface de ligne de commande (CLI)
Vous pouvez utiliser le CLI d'OpenShift Container Platform pour installer le Cluster Resource Override Operator afin de contrôler l'overcommit dans votre cluster.
Conditions préalables
-
L'opérateur d'annulation des ressources de cluster n'a aucun effet si des limites n'ont pas été définies pour les conteneurs. Vous devez spécifier des limites par défaut pour un projet à l'aide d'un objet
LimitRangeou configurer des limites dans les spécificationsPodpour que les surcharges s'appliquent.
Procédure
Pour installer l'opérateur de remplacement des ressources de cluster à l'aide de l'interface de ligne de commande :
Créez un espace de noms pour l'opérateur de remplacement des ressources de cluster :
Créez un fichier YAML de l'objet
Namespace(par exemple,cro-namespace.yaml) pour l'opérateur de remplacement des ressources du cluster :apiVersion: v1 kind: Namespace metadata: name: clusterresourceoverride-operatorCréer l'espace de noms :
oc create -f <nom-de-fichier>.yamlPar exemple :
$ oc create -f cro-namespace.yaml
Créer un groupe d'opérateurs :
Créez un fichier YAML de l'objet
OperatorGroup(par exemple, cro-og.yaml) pour l'opérateur de remplacement des ressources de cluster :apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: clusterresourceoverride-operator namespace: clusterresourceoverride-operator spec: targetNamespaces: - clusterresourceoverride-operatorCréer le groupe d'opérateurs :
oc create -f <nom-de-fichier>.yamlPar exemple :
$ oc create -f cro-og.yaml
Créer un abonnement :
Créez un fichier YAML de l'objet
Subscription(par exemple, cro-sub.yaml) pour l'opérateur de remplacement des ressources du cluster :apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: clusterresourceoverride namespace: clusterresourceoverride-operator spec: channel: "4.12" name: clusterresourceoverride source: redhat-operators sourceNamespace: openshift-marketplaceCréer l'abonnement :
oc create -f <nom-de-fichier>.yamlPar exemple :
$ oc create -f cro-sub.yaml
Créer un objet ressource personnalisée (CR)
ClusterResourceOverridedans l'espace de nomsclusterresourceoverride-operator:Passage à l'espace de noms
clusterresourceoverride-operator.$ oc project clusterresourceoverride-operatorCréez un fichier YAML de l'objet
ClusterResourceOverride(par exemple, cro-cr.yaml) pour l'opérateur de remplacement des ressources de cluster :apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 - 1
- Le nom doit être
cluster. - 2
- Facultatif. Indiquez le pourcentage de dépassement de la limite de mémoire du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 50.
- 3
- Facultatif. Spécifiez le pourcentage de dépassement de la limite de CPU du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 25.
- 4
- Facultatif. Indiquez le pourcentage qui doit remplacer la limite de mémoire du conteneur, si elle est utilisée. La mise à l'échelle de 1Gi de RAM à 100 % équivaut à 1 cœur de CPU. Ceci est traité avant d'outrepasser la demande de CPU, si elle est configurée. La valeur par défaut est 200.
Créer l'objet
ClusterResourceOverride:oc create -f <nom-de-fichier>.yamlPar exemple :
$ oc create -f cro-cr.yaml
Vérifiez l'état actuel du webhook d'admission en contrôlant l'état de la ressource personnalisée cluster.
$ oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yamlLa section
mutatingWebhookConfigurationRefs'affiche lorsque le webhook est appelé.Exemple de sortie
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: .... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1beta1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 ....- 1
- Référence au webhook d'admission
ClusterResourceOverride.
7.10.3. Configuration de l'overcommit au niveau du cluster
L'opérateur d'annulation des ressources de cluster a besoin d'une ressource personnalisée (CR) ClusterResourceOverride et d'un libellé pour chaque projet sur lequel vous souhaitez que l'opérateur contrôle le surengagement.
Conditions préalables
-
L'opérateur d'annulation des ressources de cluster n'a aucun effet si des limites n'ont pas été définies pour les conteneurs. Vous devez spécifier des limites par défaut pour un projet à l'aide d'un objet
LimitRangeou configurer des limites dans les spécificationsPodpour que les surcharges s'appliquent.
Procédure
Pour modifier l'overcommit au niveau du cluster :
Modifier le CR
ClusterResourceOverride:apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster spec: podResourceOverride: spec: memoryRequestToLimitPercent: 501 cpuRequestToLimitPercent: 252 limitCPUToMemoryPercent: 2003 - 1
- Facultatif. Indiquez le pourcentage de dépassement de la limite de mémoire du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 50.
- 2
- Facultatif. Spécifiez le pourcentage de dépassement de la limite de CPU du conteneur, s'il est utilisé, entre 1 et 100. La valeur par défaut est 25.
- 3
- Facultatif. Indiquez le pourcentage qui doit remplacer la limite de mémoire du conteneur, si elle est utilisée. La mise à l'échelle de 1Gi de RAM à 100 % équivaut à 1 cœur de CPU. Ceci est traité avant d'outrepasser la demande de CPU, si elle est configurée. La valeur par défaut est 200.
Assurez-vous que l'étiquette suivante a été ajoutée à l'objet Namespace pour chaque projet dans lequel vous souhaitez que l'opérateur de remplacement des ressources de cluster contrôle le surengagement :
apiVersion: v1 kind: Namespace metadata: ... labels: clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"1 ...- 1
- Ajoutez cette étiquette à chaque projet.
7.11. Sur-engagement au niveau du nœud
Vous pouvez utiliser différents moyens pour contrôler le surengagement sur des nœuds spécifiques, tels que les garanties de qualité de service (QOS), les limites de CPU ou les ressources de réserve. Vous pouvez également désactiver le surengagement pour des nœuds et des projets spécifiques.
7.11.1. Comprendre les ressources informatiques et les conteneurs
Le comportement renforcé par le nœud pour les ressources de calcul est spécifique au type de ressource.
7.11.1.1. Comprendre les demandes d'unité centrale des conteneurs
Un conteneur se voit garantir la quantité de CPU qu'il demande et peut en outre consommer le surplus de CPU disponible sur le nœud, jusqu'à une limite spécifiée par le conteneur. Si plusieurs conteneurs tentent d'utiliser l'unité centrale excédentaire, le temps d'utilisation de l'unité centrale est réparti en fonction de la quantité d'unité centrale demandée par chaque conteneur.
Par exemple, si un conteneur demande 500 m de temps CPU et qu'un autre conteneur demande 250 m de temps CPU, le temps CPU supplémentaire disponible sur le nœud est réparti entre les conteneurs dans un rapport de 2:1. Si un conteneur a spécifié une limite, il sera limité pour ne pas utiliser plus de CPU que la limite spécifiée. Les demandes de CPU sont appliquées en utilisant le support des parts CFS dans le noyau Linux. Par défaut, les limites de CPU sont appliquées en utilisant le support des quotas CFS dans le noyau Linux sur un intervalle de mesure de 100ms, bien que cela puisse être désactivé.
7.11.1.2. Comprendre les demandes de mémoire des conteneurs
Un conteneur se voit garantir la quantité de mémoire qu'il demande. Un conteneur peut utiliser plus de mémoire que celle demandée, mais une fois qu'il dépasse la quantité demandée, il peut être interrompu en cas de manque de mémoire sur le nœud. Si un conteneur utilise moins de mémoire que la quantité demandée, il ne sera pas interrompu, sauf si des tâches ou des démons du système ont besoin de plus de mémoire que ce qui a été pris en compte dans la réservation des ressources du nœud. Si un conteneur spécifie une limite de mémoire, il est immédiatement interrompu s'il dépasse cette limite.
7.11.2. Comprendre le surengagement et les classes de qualité de service
Un nœud est overcommitted lorsqu'un pod programmé n'effectue aucune demande ou lorsque la somme des limites de tous les pods sur ce nœud dépasse la capacité disponible de la machine.
Dans un environnement surengagé, il est possible que les pods sur le nœud tentent d'utiliser plus de ressources de calcul que celles disponibles à un moment donné. Dans ce cas, le nœud doit donner la priorité à un module plutôt qu'à un autre. La fonction utilisée pour prendre cette décision est appelée classe de qualité de service (QoS).
Un pod est désigné comme l'une des trois classes de qualité de service, par ordre de priorité décroissant :
| Priorité | Nom de la classe | Description |
|---|---|---|
| 1 (le plus élevé) | Guaranteed | Si des limites et, éventuellement, des demandes sont fixées (et non égales à 0) pour toutes les ressources et qu'elles sont égales, le pod est classé comme Guaranteed. |
| 2 | Burstable | Si des demandes et éventuellement des limites sont définies (différentes de 0) pour toutes les ressources, et qu'elles ne sont pas égales, le pod est classé comme Burstable. |
| 3 (le plus bas) | BestEffort | Si les demandes et les limites ne sont définies pour aucune des ressources, le pod est classé comme BestEffort. |
La mémoire étant une ressource incompressible, dans les situations où la mémoire est faible, les conteneurs qui ont la priorité la plus basse sont terminés en premier :
- Guaranteed sont considérés comme prioritaires et ne seront interrompus que s'ils dépassent leurs limites ou si le système est sous pression de mémoire et qu'il n'y a pas de conteneurs de moindre priorité pouvant être expulsés.
- Burstable les conteneurs soumis à la pression de la mémoire du système sont plus susceptibles d'être interrompus lorsqu'ils dépassent leurs demandes et qu'il n'existe pas d'autres conteneurs BestEffort.
- BestEffort sont traités avec la priorité la plus basse. Les processus de ces conteneurs sont les premiers à être interrompus si le système manque de mémoire.
7.11.2.1. Comprendre comment réserver de la mémoire entre les différents niveaux de qualité de service
Vous pouvez utiliser le paramètre qos-reserved pour spécifier un pourcentage de mémoire à réserver par un module dans un niveau de qualité de service particulier. Cette fonctionnalité tente de réserver les ressources demandées afin d'empêcher les pods des classes de qualité de service inférieures d'utiliser les ressources demandées par les pods des classes de qualité de service supérieures.
OpenShift Container Platform utilise le paramètre qos-reserved comme suit :
-
Une valeur de
qos-reserved=memory=100%empêchera les classes de qualité de serviceBurstableetBestEffortde consommer la mémoire demandée par une classe de qualité de service supérieure. Cela augmente le risque d'induire des OOM sur les charges de travailBestEffortetBurstableen faveur d'une augmentation des garanties de ressources mémoire pour les charges de travailGuaranteedetBurstable. -
Une valeur de
qos-reserved=memory=50%permet aux classes de qualité de serviceBurstableetBestEffortde consommer la moitié de la mémoire demandée par une classe de qualité de service supérieure. -
Une valeur de
qos-reserved=memory=0%permet aux classes de qualité de serviceBurstableetBestEffortde consommer la totalité de la quantité allouable au nœud si elle est disponible, mais augmente le risque qu'une charge de travailGuaranteedn'ait pas accès à la mémoire demandée. Cette condition désactive effectivement cette fonctionnalité.
7.11.3. Comprendre la mémoire d'échange et le QOS
Vous pouvez désactiver le swap par défaut sur vos nœuds afin de préserver les garanties de qualité de service (QOS). Dans le cas contraire, les ressources physiques d'un nœud peuvent se surinscrire, ce qui affecte les garanties de ressources que le planificateur Kubernetes apporte lors du placement des pods.
Par exemple, si deux modules garantis ont atteint leur limite de mémoire, chaque conteneur peut commencer à utiliser la mémoire d'échange. Finalement, s'il n'y a pas assez d'espace d'échange, les processus dans les modules peuvent être interrompus parce que le système est sursouscrit.
Si l'échange n'est pas désactivé, les nœuds ne reconnaissent pas qu'ils sont confrontés à MemoryPressure, ce qui fait que les modules ne reçoivent pas la mémoire qu'ils ont demandée dans leur requête de planification. En conséquence, des modules supplémentaires sont placés sur le nœud, ce qui augmente encore la pression sur la mémoire et, en fin de compte, le risque d'une panne de mémoire du système (OOM).
Si la permutation est activée, les seuils d'éviction de la mémoire disponible pour la gestion des ressources ne fonctionneront pas comme prévu. Tirez parti de la gestion des ressources manquantes pour permettre aux pods d'être expulsés d'un nœud lorsqu'il est soumis à une pression de mémoire, et replanifiés sur un autre nœud qui n'est pas soumis à une telle pression.
7.11.4. Comprendre le surengagement des nœuds
Dans un environnement surchargé, il est important de configurer correctement votre nœud afin d'obtenir le meilleur comportement possible du système.
Lorsque le nœud démarre, il s'assure que les drapeaux ajustables du noyau pour la gestion de la mémoire sont correctement définis. Le noyau ne devrait jamais échouer dans l'allocation de la mémoire à moins qu'il ne soit à court de mémoire physique.
Pour garantir ce comportement, OpenShift Container Platform configure le noyau pour qu'il surengage toujours de la mémoire en définissant le paramètre vm.overcommit_memory sur 1, ce qui annule le paramètre par défaut du système d'exploitation.
OpenShift Container Platform configure également le noyau pour qu'il ne panique pas lorsqu'il manque de mémoire en définissant le paramètre vm.panic_on_oom sur 0. Un paramètre de 0 indique au noyau d'appeler oom_killer dans une condition de manque de mémoire (OOM), ce qui tue les processus en fonction de leur priorité
Vous pouvez afficher le paramètre actuel en exécutant les commandes suivantes sur vos nœuds :
$ sysctl -a |grep commitExemple de sortie
vm.overcommit_memory = 1$ sysctl -a |grep panicExemple de sortie
vm.panic_on_oom = 0Les drapeaux ci-dessus devraient déjà être activés sur les nœuds, et aucune autre action n'est nécessaire.
Vous pouvez également effectuer les configurations suivantes pour chaque nœud :
- Désactiver ou appliquer les limites de l'unité centrale à l'aide des quotas CFS de l'unité centrale
- Réserver des ressources pour les processus du système
- Réserve de mémoire pour les différents niveaux de qualité de service
7.11.5. Désactivation ou application des limites de l'unité centrale à l'aide des quotas CFS de l'unité centrale
Les nœuds appliquent par défaut les limites de CPU spécifiées en utilisant la prise en charge des quotas CFS (Completely Fair Scheduler) dans le noyau Linux.
Si vous désactivez l'application de la limite du CPU, il est important de comprendre l'impact sur votre nœud :
- Si un conteneur a une demande d'unité centrale, la demande continue d'être exécutée par les parts CFS dans le noyau Linux.
- Si un conteneur n'a pas de demande de CPU, mais a une limite de CPU, la demande de CPU est fixée par défaut à la limite de CPU spécifiée, et est appliquée par les parts CFS dans le noyau Linux.
- Si un conteneur a à la fois une demande et une limite de CPU, la demande de CPU est appliquée par les parts CFS dans le noyau Linux, et la limite de CPU n'a pas d'impact sur le nœud.
Conditions préalables
Obtenez l'étiquette associée au CRD statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer en entrant la commande suivante :oc edit machineconfigpool <name> $ oc edit machineconfigpool <name>Par exemple :
$ oc edit machineconfigpool workerExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker- 1
- L'étiquette apparaît sous Étiquettes.
AstuceSi l'étiquette n'est pas présente, ajoutez une paire clé/valeur comme par exemple :
$ oc label machineconfigpool worker custom-kubelet=small-pods
Procédure
Créez une ressource personnalisée (CR) pour votre changement de configuration.
Exemple de configuration pour la désactivation des limites de l'unité centrale
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: disable-cpu-units1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: cpuCfsQuota:3 - "true"Exécutez la commande suivante pour créer le CR :
oc create -f <nom_du_fichier>.yaml
7.11.6. Réserver des ressources pour les processus du système
Pour assurer une planification plus fiable et minimiser le surengagement des ressources des nœuds, chaque nœud peut réserver une partie de ses ressources aux démons du système qui doivent être exécutés sur le nœud pour que la grappe fonctionne. Il est notamment recommandé de réserver des ressources incompressibles telles que la mémoire.
Procédure
Pour réserver explicitement des ressources aux processus qui ne sont pas des nœuds, allouez des ressources aux nœuds en spécifiant les ressources disponibles pour l'ordonnancement. Pour plus de détails, voir Allocation de ressources pour les nœuds.
7.11.7. Désactivation du surengagement pour un nœud
Lorsqu'il est activé, le surengagement peut être désactivé sur chaque nœud.
Procédure
Pour désactiver le surengagement dans un nœud, exécutez la commande suivante sur ce nœud :
$ sysctl -w vm.overcommit_memory=07.12. Limites au niveau du projet
Pour contrôler l'overcommit, vous pouvez définir des plages de limites de ressources par projet, en spécifiant des limites de mémoire et de CPU et des valeurs par défaut pour un projet que l'overcommit ne peut pas dépasser.
Pour plus d'informations sur les limites de ressources au niveau du projet, voir Ressources supplémentaires.
Vous pouvez également désactiver le surengagement pour des projets spécifiques.
7.12.1. Désactiver le surengagement pour un projet
Lorsqu'il est activé, le surengagement peut être désactivé par projet. Par exemple, vous pouvez autoriser la configuration des composants d'infrastructure indépendamment du surengagement.
Procédure
Pour désactiver le surengagement dans un projet :
- Modifier le fichier de l'élément de projet
Ajouter l'annotation suivante :
quota.openshift.io/cluster-resource-override-enabled: "false"Créer l'élément de projet :
oc create -f <nom-de-fichier>.yaml
7.13. Libérer les ressources des nœuds à l'aide du ramassage des ordures
Comprendre et utiliser le ramassage des ordures.
7.13.1. Comprendre comment les conteneurs terminés sont supprimés par le ramasse-miettes (garbage collection)
Le ramassage des ordures du conteneur peut être effectué à l'aide de seuils d'éviction.
Lorsque des seuils d'éviction sont définis pour le ramassage des ordures, le nœud tente de conserver tout conteneur pour tout module accessible à partir de l'API. Si le module a été supprimé, les conteneurs le seront également. Les conteneurs sont conservés tant que le module n'est pas supprimé et que le seuil d'éviction n'est pas atteint. Si le nœud est soumis à une pression de disque, il supprimera les conteneurs et leurs journaux ne seront plus accessibles à l'aide de oc logs.
- eviction-soft - Un seuil d'expulsion souple associe un seuil d'expulsion à un délai de grâce spécifié par l'administrateur.
- eviction-hard - Un seuil d'éviction dur n'a pas de période de grâce, et s'il est observé, OpenShift Container Platform prend des mesures immédiates.
Le tableau suivant énumère les seuils d'éviction :
| État du nœud | Signal d'expulsion | Description |
|---|---|---|
| MémoirePression |
| Mémoire disponible sur le nœud. |
| Pression du disque |
|
L'espace disque ou les inodes disponibles sur le système de fichiers racine du nœud, |
Pour evictionHard, vous devez spécifier tous ces paramètres. Si vous ne les spécifiez pas tous, seuls les paramètres spécifiés seront appliqués et le ramassage des ordures ne fonctionnera pas correctement.
Si un nœud oscille au-dessus et au-dessous d'un seuil d'éviction souple, mais sans dépasser le délai de grâce qui lui est associé, le nœud correspondant oscille constamment entre true et false. En conséquence, l'ordonnanceur pourrait prendre de mauvaises décisions en matière d'ordonnancement.
Pour se protéger contre cette oscillation, utilisez le drapeau eviction-pressure-transition-period pour contrôler la durée pendant laquelle OpenShift Container Platform doit attendre avant de sortir d'une condition de pression. OpenShift Container Platform ne définira pas un seuil d'éviction comme étant atteint pour la condition de pression spécifiée pendant la période spécifiée avant de basculer la condition sur false.
7.13.2. Comprendre comment les images sont supprimées par le ramassage des ordures
La collecte d'images s'appuie sur l'utilisation du disque telle qu'elle est rapportée par cAdvisor sur le nœud pour décider quelles images doivent être supprimées du nœud.
La politique de collecte des images est basée sur deux conditions :
- Le pourcentage d'utilisation du disque (exprimé sous forme d'un nombre entier) qui déclenche le ramassage des images. La valeur par défaut est 85.
- Pourcentage d'utilisation du disque (exprimé sous forme d'un nombre entier) que le ramasse-miettes tente de libérer. La valeur par défaut est 80.
Pour le ramassage des images, vous pouvez modifier l'une des variables suivantes à l'aide d'une ressource personnalisée.
| Paramètres | Description |
|---|---|
|
| L'âge minimum d'une image inutilisée avant qu'elle ne soit supprimée par le ramasse-miettes. La valeur par défaut est 2m. |
|
| Le pourcentage d'utilisation du disque, exprimé sous la forme d'un entier, qui déclenche le ramassage des images. La valeur par défaut est 85. |
|
| Le pourcentage d'utilisation du disque, exprimé sous forme d'un nombre entier, que le ramasse-miettes tente de libérer. La valeur par défaut est 80. |
Deux listes d'images sont récupérées à chaque passage de l'éboueur :
- Liste des images en cours d'exécution dans au moins un module.
- Liste des images disponibles sur un hôte.
Au fur et à mesure que de nouveaux conteneurs sont lancés, de nouvelles images apparaissent. Toutes les images sont marquées d'un horodatage. Si l'image est en cours d'exécution (première liste ci-dessus) ou nouvellement détectée (deuxième liste ci-dessus), elle est marquée avec l'heure actuelle. Les autres images sont déjà marquées lors des tours précédents. Toutes les images sont ensuite triées en fonction de l'horodatage.
Une fois la collecte commencée, les images les plus anciennes sont supprimées en premier jusqu'à ce que le critère d'arrêt soit rempli.
7.13.3. Configuration du ramassage des ordures pour les conteneurs et les images
En tant qu'administrateur, vous pouvez configurer la façon dont OpenShift Container Platform effectue la collecte des ordures en créant un objet kubeletConfig pour chaque pool de configuration de machine.
OpenShift Container Platform ne prend en charge qu'un seul objet kubeletConfig pour chaque pool de configuration de machine.
Vous pouvez configurer une combinaison des éléments suivants :
- Expulsion douce pour les conteneurs
- Expulsion dure pour les conteneurs
- Expulsion pour des images
Conditions préalables
Obtenez l'étiquette associée au CRD statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer en entrant la commande suivante :oc edit machineconfigpool <name> $ oc edit machineconfigpool <name>Par exemple :
$ oc edit machineconfigpool workerExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker- 1
- L'étiquette apparaît sous Étiquettes.
AstuceSi l'étiquette n'est pas présente, ajoutez une paire clé/valeur comme par exemple :
$ oc label machineconfigpool worker custom-kubelet=small-pods
Procédure
Créez une ressource personnalisée (CR) pour votre changement de configuration.
ImportantS'il n'y a qu'un seul système de fichiers, ou si
/var/lib/kubeletet/var/lib/containers/se trouvent dans le même système de fichiers, ce sont les paramètres ayant les valeurs les plus élevées qui déclenchent les expulsions, car ils sont respectés en premier. C'est le système de fichiers qui déclenche l'expulsion.Exemple de configuration pour un conteneur de collecte de déchets CR :
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: worker-kubeconfig1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: evictionSoft:3 memory.available: "500Mi"4 nodefs.available: "10%" nodefs.inodesFree: "5%" imagefs.available: "15%" imagefs.inodesFree: "10%" evictionSoftGracePeriod:5 memory.available: "1m30s" nodefs.available: "1m30s" nodefs.inodesFree: "1m30s" imagefs.available: "1m30s" imagefs.inodesFree: "1m30s" evictionHard:6 memory.available: "200Mi" nodefs.available: "5%" nodefs.inodesFree: "4%" imagefs.available: "10%" imagefs.inodesFree: "5%" evictionPressureTransitionPeriod: 0s7 imageMinimumGCAge: 5m8 imageGCHighThresholdPercent: 809 imageGCLowThresholdPercent: 7510 - 1
- Nom de l'objet.
- 2
- Spécifiez l'étiquette du pool de configuration de la machine.
- 3
- Type d'expulsion :
evictionSoftouevictionHard. - 4
- Seuils d'expulsion basés sur un signal de déclenchement d'expulsion spécifique.
- 5
- Délais de grâce pour l'expulsion douce. Ce paramètre ne s'applique pas à
eviction-hard. - 6
- Seuils d'éviction basés sur un signal de déclenchement d'éviction spécifique. Pour
evictionHard, vous devez spécifier tous ces paramètres. Si vous ne les spécifiez pas tous, seuls les paramètres spécifiés seront appliqués et le ramassage des ordures ne fonctionnera pas correctement. - 7
- Durée d'attente avant de sortir d'une condition de pression d'expulsion.
- 8
- L'âge minimum d'une image inutilisée avant qu'elle ne soit supprimée par le ramasse-miettes.
- 9
- Pourcentage d'utilisation du disque (exprimé sous forme d'un nombre entier) qui déclenche le ramassage des images.
- 10
- Pourcentage de l'utilisation du disque (exprimé sous forme d'un entier) que le système de collecte des images tente de libérer.
Exécutez la commande suivante pour créer le CR :
oc create -f <nom_du_fichier>.yamlPar exemple :
$ oc create -f gc-container.yamlExemple de sortie
kubeletconfig.machineconfiguration.openshift.io/gc-container created
Vérification
Vérifiez que le ramassage des ordures est actif en entrant la commande suivante. Le pool de configuration de la machine que vous avez spécifié dans la ressource personnalisée apparaît avec
UPDATINGcomme 'true' jusqu'à ce que le changement soit complètement implémenté :$ oc get machineconfigpoolExemple de sortie
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False True
7.14. Utilisation de l'opérateur Node Tuning
Comprendre et utiliser l'opérateur Node Tuning.
L'opérateur d'optimisation des nœuds vous aide à gérer l'optimisation au niveau des nœuds en orchestrant le démon TuneD et à obtenir des performances à faible latence en utilisant le contrôleur de profil de performance. La majorité des applications à hautes performances nécessitent un certain niveau de réglage du noyau. Le Node Tuning Operator offre une interface de gestion unifiée aux utilisateurs de sysctls au niveau des nœuds et plus de flexibilité pour ajouter des réglages personnalisés en fonction des besoins de l'utilisateur.
L'opérateur gère le démon TuneD conteneurisé pour OpenShift Container Platform en tant qu'ensemble de démons Kubernetes. Il s'assure que la spécification de réglage personnalisé est transmise à tous les démons TuneD conteneurisés s'exécutant dans le cluster dans le format que les démons comprennent. Les démons s'exécutent sur tous les nœuds du cluster, un par nœud.
Les paramètres de niveau nœud appliqués par le démon TuneD conteneurisé sont annulés lors d'un événement qui déclenche un changement de profil ou lorsque le démon TuneD conteneurisé se termine de manière élégante en recevant et en gérant un signal de fin.
L'opérateur de réglage des nœuds utilise le contrôleur de profil de performance pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift Container Platform. L'administrateur du cluster configure un profil de performance pour définir des paramètres au niveau du nœud, tels que les suivants :
- Mise à jour du noyau vers kernel-rt.
- Choix des unités centrales de traitement pour l'entretien ménager.
- Choix des unités centrales pour l'exécution des charges de travail.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
L'opérateur Node Tuning fait partie de l'installation standard d'OpenShift Container Platform à partir de la version 4.1.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
7.14.1. Accéder à un exemple de spécification de l'opérateur Node Tuning
Cette procédure permet d'accéder à un exemple de spécification de l'opérateur de réglage des nœuds.
Procédure
Exécutez la commande suivante pour accéder à un exemple de spécification de l'opérateur Node Tuning :
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
Le CR par défaut est destiné à fournir un réglage standard au niveau du nœud pour la plateforme OpenShift Container Platform et il ne peut être modifié que pour définir l'état de gestion de l'opérateur. Toute autre modification personnalisée de la CR par défaut sera écrasée par l'opérateur. Pour un réglage personnalisé, créez vos propres CR réglés. Les CR nouvellement créés seront combinés avec le CR par défaut et les réglages personnalisés appliqués aux nœuds d'OpenShift Container Platform en fonction des étiquettes de nœuds ou de pods et des priorités de profil.
Bien que dans certaines situations, la prise en charge des étiquettes de pods puisse être un moyen pratique de fournir automatiquement les réglages nécessaires, cette pratique est déconseillée et fortement déconseillée, en particulier dans les clusters à grande échelle. Le CR Tuned par défaut est livré sans correspondance d'étiquettes de pods. Si un profil personnalisé est créé avec la correspondance des étiquettes de pods, alors la fonctionnalité sera activée à ce moment-là. La fonctionnalité d'étiquetage de pods sera obsolète dans les versions futures de l'opérateur de tuning de nœuds.
7.14.2. Spécification de réglage personnalisé
La ressource personnalisée (CR) de l'opérateur comporte deux sections principales. La première section, profile:, est une liste de profils TuneD et de leurs noms. La seconde, recommend:, définit la logique de sélection des profils.
Plusieurs spécifications de réglage personnalisées peuvent coexister en tant que CR multiples dans l'espace de noms de l'opérateur. L'existence de nouveaux CR ou la suppression d'anciens CR est détectée par l'Opérateur. Toutes les spécifications de réglage personnalisées existantes sont fusionnées et les objets appropriés pour les démons TuneD conteneurisés sont mis à jour.
Management state
L'état de gestion de l'opérateur est défini en ajustant le CR accordé par défaut. Par défaut, l'opérateur est en état de gestion et le champ spec.managementState n'est pas présent dans le CR accordé par défaut. Les valeurs valides pour l'état de gestion de l'opérateur sont les suivantes :
- Géré : l'opérateur met à jour ses opérandes au fur et à mesure que les ressources de configuration sont mises à jour
- Non géré : l'opérateur ignore les changements apportés aux ressources de configuration
- Retiré : l'opérateur retire ses opérandes et les ressources qu'il a fournies
Profile data
La section profile: dresse la liste des profils TuneD et de leurs noms.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settingsRecommended profiles
La logique de sélection de profile: est définie par la section recommend: du CR. La section recommend: est une liste d'éléments permettant de recommander les profils sur la base d'un critère de sélection.
recommend:
<recommend-item-1>
# ...
<recommend-item-n>Les différents éléments de la liste :
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
tunedConfig:
reapply_sysctl: <bool> - 1
- En option.
- 2
- Un dictionnaire d'étiquettes clé/valeur
MachineConfig. Les clés doivent être uniques. - 3
- En cas d'omission, la correspondance des profils est présumée, sauf si un profil ayant une priorité plus élevée correspond en premier ou si
machineConfigLabelsest défini. - 4
- Une liste facultative.
- 5
- Ordre de priorité des profils. Les chiffres les plus bas signifient une priorité plus élevée (
0est la priorité la plus élevée). - 6
- Un profil TuneD à appliquer sur un match. Par exemple
tuned_profile_1. - 7
- Configuration facultative de l'opérande.
- 8
- Active ou désactive le débogage du démon TuneD. Les options sont
truepour on oufalsepour off. La valeur par défaut estfalse. - 9
- Active ou désactive la fonctionnalité
reapply_sysctlpour le démon TuneD. Les options sonttruepour on etfalsepour off.
<match> est une liste optionnelle définie récursivement comme suit :
- label: <label_name>
value: <label_value>
type: <label_type>
<match> - 1
- Nom de l'étiquette du nœud ou du pod.
- 2
- Valeur facultative de l'étiquette du nœud ou du pod. Si elle est omise, la présence de
<label_name>suffit à établir une correspondance. - 3
- Type d'objet facultatif (
nodeoupod). En cas d'omission,nodeest considéré comme tel. - 4
- Une liste facultative
<match>.
Si <match> n'est pas omis, toutes les sections imbriquées <match> doivent également être évaluées à true. Sinon, false est supposé et le profil avec la section <match> correspondante ne sera pas appliqué ou recommandé. Par conséquent, l'imbrication (sections <match> enfant) fonctionne comme un opérateur logique ET. Inversement, si un élément de la liste <match> correspond, toute la liste <match> est évaluée à true. La liste agit donc comme un opérateur logique OU.
Si machineConfigLabels est défini, la correspondance basée sur le pool de configuration de la machine est activée pour l'élément de liste recommend: donné. <mcLabels> spécifie les étiquettes d'une configuration de la machine. La configuration de la machine est créée automatiquement pour appliquer les paramètres de l'hôte, tels que les paramètres de démarrage du noyau, pour le profil <tuned_profile_name>. Il s'agit de trouver tous les pools de configuration de machine dont le sélecteur de configuration de machine correspond à <mcLabels> et de définir le profil <tuned_profile_name> sur tous les nœuds auxquels sont attribués les pools de configuration de machine trouvés. Pour cibler les nœuds qui ont à la fois un rôle de maître et de travailleur, vous devez utiliser le rôle de maître.
Les éléments de la liste match et machineConfigLabels sont reliés par l'opérateur logique OR. L'élément match est évalué en premier, en court-circuit. Par conséquent, s'il est évalué à true, l'élément machineConfigLabels n'est pas pris en compte.
Lors de l'utilisation de la correspondance basée sur le pool de configuration machine, il est conseillé de regrouper les nœuds ayant la même configuration matérielle dans le même pool de configuration machine. Si cette pratique n'est pas respectée, les opérandes TuneD peuvent calculer des paramètres de noyau contradictoires pour deux nœuds ou plus partageant le même pool de configuration de machine.
Exemple : correspondance basée sur l'étiquette d'un nœud ou d'un pod
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
Le CR ci-dessus est traduit pour le démon TuneD conteneurisé dans son fichier recommend.conf en fonction des priorités du profil. Le profil ayant la priorité la plus élevée (10) est openshift-control-plane-es et, par conséquent, il est considéré en premier. Le démon TuneD conteneurisé fonctionnant sur un nœud donné vérifie s'il existe un pod fonctionnant sur le même nœud avec l'étiquette tuned.openshift.io/elasticsearch définie. Si ce n'est pas le cas, toute la section <match> est évaluée comme false. S'il existe un pod avec le label, pour que la section <match> soit évaluée comme true, le label du nœud doit également être node-role.kubernetes.io/master ou node-role.kubernetes.io/infra.
Si les étiquettes du profil ayant la priorité 10 correspondent, le profil openshift-control-plane-es est appliqué et aucun autre profil n'est pris en considération. Si la combinaison d'étiquettes nœud/pod ne correspond pas, le deuxième profil le plus prioritaire (openshift-control-plane) est pris en compte. Ce profil est appliqué si le pod TuneD conteneurisé fonctionne sur un nœud avec les étiquettes node-role.kubernetes.io/master ou node-role.kubernetes.io/infra.
Enfin, le profil openshift-node a la priorité la plus basse de 30. Il ne contient pas la section <match> et, par conséquent, correspondra toujours. Il sert de profil fourre-tout pour définir le profil openshift-node si aucun autre profil ayant une priorité plus élevée ne correspond à un nœud donné.
Exemple : correspondance basée sur le pool de configuration de la machine
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-customPour minimiser les redémarrages de nœuds, il faut étiqueter les nœuds cibles avec une étiquette que le sélecteur de nœuds du pool de configuration de la machine fera correspondre, puis créer le Tuned CR ci-dessus et enfin créer le pool de configuration de la machine personnalisé lui-même.
Cloud provider-specific TuneD profiles
Avec cette fonctionnalité, tous les nœuds spécifiques à un fournisseur de Cloud peuvent commodément se voir attribuer un profil TuneD spécifiquement adapté à un fournisseur de Cloud donné sur un cluster OpenShift Container Platform. Cela peut être accompli sans ajouter d'étiquettes de nœuds supplémentaires ou regrouper les nœuds dans des pools de configuration de machines.
Cette fonctionnalité tire parti des valeurs de l'objet de nœud spec.providerID sous la forme de <cloud-provider>://<cloud-provider-specific-id> et écrit le fichier /var/lib/tuned/provider avec la valeur <cloud-provider> dans les conteneurs d'opérandes NTO. Le contenu de ce fichier est ensuite utilisé par TuneD pour charger le profil provider-<cloud-provider> s'il existe.
Le profil openshift dont les profils openshift-control-plane et openshift-node héritent des paramètres est maintenant mis à jour pour utiliser cette fonctionnalité grâce à l'utilisation du chargement conditionnel de profil. Ni NTO ni TuneD ne fournissent actuellement de profils spécifiques aux fournisseurs de Cloud. Cependant, il est possible de créer un profil personnalisé provider-<cloud-provider> qui sera appliqué à tous les nœuds de cluster spécifiques au fournisseur de cloud.
Exemple de profil de fournisseur GCE Cloud
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
En raison de l'héritage des profils, tout paramètre spécifié dans le profil provider-<cloud-provider> sera remplacé par le profil openshift et ses profils enfants.
7.14.3. Profils par défaut définis sur un cluster
Les profils par défaut définis sur un cluster sont les suivants.
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
Depuis OpenShift Container Platform 4.9, tous les profils OpenShift TuneD sont livrés avec le package TuneD. Vous pouvez utiliser la commande oc exec pour voir le contenu de ces profils :
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;7.14.4. Plugins de démon TuneD pris en charge
À l'exception de la section [main], les plugins TuneD suivants sont pris en charge lors de l'utilisation des profils personnalisés définis dans la section profile: du CR Tuned :
- audio
- cpu
- disque
- eeepc_she
- modules
- montures
- net
- planificateur
- scsi_host
- selinux
- sysctl
- sysfs
- uSB
- vidéo
- vm
- chargeur de démarrage
Certains de ces plugins offrent une fonctionnalité d'accord dynamique qui n'est pas prise en charge. Les plugins TuneD suivants ne sont actuellement pas pris en charge :
- scénario
- systemd
Le plugin TuneD bootloader est actuellement pris en charge sur les nœuds de travail Red Hat Enterprise Linux CoreOS (RHCOS) 8.x. Pour les nœuds de travail Red Hat Enterprise Linux (RHEL) 7.x, le plugin de chargeur de démarrage TuneD n'est actuellement pas pris en charge.
Voir Plugins TuneD disponibles et Démarrer avec TuneD pour plus d'informations.
7.15. Configurer le nombre maximum de pods par nœud
Deux paramètres contrôlent le nombre maximal de modules qui peuvent être planifiés sur un nœud : podsPerCore et maxPods. Si vous utilisez les deux options, la moins élevée des deux limite le nombre de modules sur un nœud.
Par exemple, si podsPerCore est défini sur 10 sur un nœud avec 4 cœurs de processeur, le nombre maximum de pods autorisé sur le nœud sera de 40.
Conditions préalables
Obtenez l'étiquette associée au CRD statique
MachineConfigPoolpour le type de nœud que vous souhaitez configurer en entrant la commande suivante :oc edit machineconfigpool <name> $ oc edit machineconfigpool <name>Par exemple :
$ oc edit machineconfigpool workerExemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker- 1
- L'étiquette apparaît sous Étiquettes.
AstuceSi l'étiquette n'est pas présente, ajoutez une paire clé/valeur comme par exemple :
$ oc label machineconfigpool worker custom-kubelet=small-pods
Procédure
Créez une ressource personnalisée (CR) pour votre changement de configuration.
Exemple de configuration pour un CR
max-podsapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: podsPerCore: 103 maxPods: 2504 - 1
- Attribuer un nom au CR.
- 2
- Spécifiez l'étiquette du pool de configuration de la machine.
- 3
- Indiquez le nombre de modules que le nœud peut exécuter en fonction du nombre de cœurs de processeur du nœud.
- 4
- Spécifie le nombre de pods que le nœud peut exécuter à une valeur fixe, indépendamment des propriétés du nœud.
NoteLe fait de régler
podsPerCoresur0désactive cette limite.Dans l'exemple ci-dessus, la valeur par défaut pour
podsPerCoreest10et la valeur par défaut pourmaxPodsest250. Cela signifie qu'à moins que le nœud ne dispose de 25 cœurs ou plus, par défaut,podsPerCoresera le facteur limitant.Exécutez la commande suivante pour créer le CR :
oc create -f <nom_du_fichier>.yaml
Vérification
Lister les CRDs
MachineConfigPoolpour voir si le changement est appliqué. La colonneUPDATINGindiqueTruesi la modification est prise en compte par le contrôleur de configuration de la machine :$ oc get machineconfigpoolsExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False False False worker worker-8cecd1236b33ee3f8a5e False True FalseUne fois la modification effectuée, la colonne
UPDATEDindiqueTrue.$ oc get machineconfigpoolsExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False True False worker worker-8cecd1236b33ee3f8a5e True False False
Chapitre 8. Configuration du réseau après l'installation
Après avoir installé OpenShift Container Platform, vous pouvez étendre et personnaliser votre réseau en fonction de vos besoins.
8.1. Cluster Network Operator configuration
The configuration for the cluster network is specified as part of the Cluster Network Operator (CNO) configuration and stored in a custom resource (CR) object that is named cluster. The CR specifies the fields for the Network API in the operator.openshift.io API group.
The CNO configuration inherits the following fields during cluster installation from the Network API in the Network.config.openshift.io API group and these fields cannot be changed:
clusterNetwork- IP address pools from which pod IP addresses are allocated.
serviceNetwork- IP address pool for services.
defaultNetwork.type- Cluster network plugin, such as OpenShift SDN or OVN-Kubernetes.
Après l'installation du cluster, vous ne pouvez pas modifier les champs énumérés dans la section précédente.
8.2. Activation du proxy à l'échelle du cluster
L'objet Proxy est utilisé pour gérer le proxy egress à l'échelle de la grappe. Lorsqu'un cluster est installé ou mis à niveau sans que le proxy soit configuré, un objet Proxy est toujours généré, mais il aura une valeur nulle spec. Par exemple :
apiVersion: config.openshift.io/v1
kind: Proxy
metadata:
name: cluster
spec:
trustedCA:
name: ""
status:
Un administrateur de cluster peut configurer le proxy pour OpenShift Container Platform en modifiant cet objet cluster Proxy .
Only the Proxy object named cluster is supported, and no additional proxies can be created.
Conditions préalables
- Autorisations de l'administrateur du cluster
-
L'outil CLI d'OpenShift Container Platform
ocest installé
Procédure
Créez une carte de configuration contenant tous les certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS.
NoteVous pouvez sauter cette étape si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
Créez un fichier appelé
user-ca-bundle.yamlavec le contenu suivant, et fournissez les valeurs de vos certificats encodés PEM :apiVersion: v1 data: ca-bundle.crt: |1 <MY_PEM_ENCODED_CERTS>2 kind: ConfigMap metadata: name: user-ca-bundle3 namespace: openshift-config4 - 1
- Cette clé de données doit être nommée
ca-bundle.crt. - 2
- Un ou plusieurs certificats X.509 encodés PEM utilisés pour signer le certificat d'identité du proxy.
- 3
- Le nom de la carte de configuration qui sera référencée dans l'objet
Proxy. - 4
- La carte de configuration doit se trouver dans l'espace de noms
openshift-config.
Créez la carte de configuration à partir de ce fichier :
$ oc create -f user-ca-bundle.yaml
Utilisez la commande
oc editpour modifier l'objetProxy:$ oc edit proxy/clusterConfigurez les champs nécessaires pour le proxy :
apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: httpProxy: http://<username>:<pswd>@<ip>:<port>1 httpsProxy: https://<username>:<pswd>@<ip>:<port>2 noProxy: example.com3 readinessEndpoints: - http://www.google.com4 - https://www.google.com trustedCA: name: user-ca-bundle5 - 1
- A proxy URL to use for creating HTTP connections outside the cluster. The URL scheme must be
http. - 2
- URL du proxy à utiliser pour créer des connexions HTTPS en dehors du cluster. Le schéma d'URL doit être
httpouhttps. Spécifiez une URL pour le proxy qui prend en charge le schéma d'URL. Par exemple, la plupart des mandataires signaleront une erreur s'ils sont configurés pour utiliserhttpsalors qu'ils ne prennent en charge quehttp. Ce message d'erreur peut ne pas se propager dans les journaux et peut apparaître comme une défaillance de la connexion réseau. Si vous utilisez un proxy qui écoute les connexionshttpsdu cluster, vous devrez peut-être configurer le cluster pour qu'il accepte les autorités de certification et les certificats utilisés par le proxy. - 3
- Une liste de noms de domaines de destination, de domaines, d'adresses IP ou d'autres CIDR de réseau, séparés par des virgules, pour exclure le proxys.
Faites précéder un domaine du signe
.pour ne faire correspondre que les sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour ignorer le proxy pour toutes les destinations. Si vous mettez à l’échelle des workers qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrà partir de la configuration d’installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si les champs
httpProxyethttpsProxyne sont pas renseignés. - 4
- Une ou plusieurs URL externes au cluster à utiliser pour effectuer un contrôle de disponibilité avant d'écrire les valeurs
httpProxyethttpsProxydans l'état. - 5
- Une référence à la carte de configuration dans l'espace de noms
openshift-configqui contient des certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS par proxy. Notez que la carte de configuration doit déjà exister avant d'être référencée ici. Ce champ est obligatoire sauf si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
- Enregistrez le fichier pour appliquer les modifications.
8.3. Régler le DNS sur privé
Après avoir déployé un cluster, vous pouvez modifier son DNS pour n'utiliser qu'une zone privée.
Procédure
Consultez la ressource personnalisée
DNSpour votre cluster :$ oc get dnses.config.openshift.io/cluster -o yamlExemple de sortie
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>: owned publicZone: id: Z2XXXXXXXXXXA4 status: {}Notez que la section
speccontient à la fois une zone privée et une zone publique.Modifier la ressource personnalisée
DNSpour supprimer la zone publique :$ oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}' dns.config.openshift.io/cluster patchedÉtant donné que le contrôleur d'entrée consulte la définition
DNSlorsqu'il crée des objetsIngress, lorsque vous créez ou modifiez des objetsIngress, seuls des enregistrements privés sont créés.ImportantLes enregistrements DNS des objets Ingress existants ne sont pas modifiés lorsque vous supprimez la zone publique.
Facultatif : Consultez la ressource personnalisée
DNSpour votre cluster et confirmez que la zone publique a été supprimée :$ oc get dnses.config.openshift.io/cluster -o yamlExemple de sortie
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>-wfpg4: owned status: {}
8.4. Configuration du trafic entrant dans le cluster
OpenShift Container Platform propose les méthodes suivantes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster :
- Si vous disposez de HTTP/HTTPS, utilisez un contrôleur d'entrée.
- Si vous utilisez un protocole TLS crypté autre que HTTPS, tel que TLS avec l'en-tête SNI, utilisez un contrôleur d'entrée.
- Sinon, utilisez un équilibreur de charge, une adresse IP externe ou un port de nœud.
| Méthode | Objectif |
|---|---|
| Permet d'accéder au trafic HTTP/HTTPS et aux protocoles cryptés TLS autres que HTTPS, tels que TLS avec l'en-tête SNI. | |
| Attribuer automatiquement une IP externe en utilisant un service d'équilibrage de charge | Autorise le trafic vers les ports non standard via une adresse IP attribuée à partir d'un pool. |
| Autorise le trafic vers des ports non standard via une adresse IP spécifique. | |
| Exposer un service sur tous les nœuds de la grappe. |
8.5. Configuration de la plage de service du port de nœud
En tant qu'administrateur de grappe, vous pouvez étendre la plage de ports de nœuds disponibles. Si votre grappe utilise un grand nombre de ports de nœuds, vous devrez peut-être augmenter le nombre de ports disponibles.
La plage de ports par défaut est 30000-32767. Vous ne pouvez jamais réduire la plage de ports, même si vous l'étendez d'abord au-delà de la plage par défaut.
8.5.1. Conditions préalables
-
Votre infrastructure de cluster doit autoriser l'accès aux ports que vous spécifiez dans la plage étendue. Par exemple, si vous étendez la plage de ports du nœud à
30000-32900, la plage de ports inclusive de32768-32900doit être autorisée par votre pare-feu ou votre configuration de filtrage de paquets.
8.5.1.1. Extension de la plage de ports du nœud
Vous pouvez étendre la plage de ports du nœud pour le cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour étendre la plage de ports du nœud, entrez la commande suivante. Remplacez
<port>par le plus grand numéro de port de la nouvelle plage.$ oc patch network.config.openshift.io cluster --type=merge -p \ '{ "spec": { "serviceNodePortRange": "30000-<port>" } }'AstuceVous pouvez également appliquer le fichier YAML suivant pour mettre à jour la plage de ports du nœud :
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNodePortRange: "30000-<port>"Exemple de sortie
network.config.openshift.io/cluster patchedPour confirmer que la configuration est active, entrez la commande suivante. L'application de la mise à jour peut prendre plusieurs minutes.
$ oc get configmaps -n openshift-kube-apiserver config \ -o jsonpath="{.data['config\.yaml']}" | \ grep -Eo '"service-node-port-range":["[[:digit:]]+-[[:digit:]]+"]'Exemple de sortie
"service-node-port-range":["30000-33000"]
8.6. Configuration du cryptage IPsec
Lorsque IPsec est activé, tout le trafic réseau entre les nœuds du plugin OVN-Kubernetes passe par un tunnel crypté.
IPsec est désactivé par défaut.
8.6.1. Conditions préalables
- Votre cluster doit utiliser le plugin réseau OVN-Kubernetes.
8.6.1.1. Activation du cryptage IPsec
En tant qu'administrateur de cluster, vous pouvez activer le cryptage IPsec après l'installation du cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin. -
Vous avez réduit la taille du MTU de votre cluster de
46octets pour tenir compte de la surcharge de l'en-tête IPsec ESP.
Procédure
Pour activer le cryptage IPsec, entrez la commande suivante :
$ oc patch networks.operator.openshift.io cluster --type=merge \ -p '{"spec":{"defaultNetwork":{"ovnKubernetesConfig":{"ipsecConfig":{ }}}}}'
8.6.1.2. Vérification de l'activation d'IPsec
En tant qu'administrateur de cluster, vous pouvez vérifier que le protocole IPsec est activé.
Vérification
Pour trouver les noms des pods du plan de contrôle OVN-Kubernetes, entrez la commande suivante :
$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-masterExemple de sortie
ovnkube-master-4496s 1/1 Running 0 6h39m ovnkube-master-d6cht 1/1 Running 0 6h42m ovnkube-master-skblc 1/1 Running 0 6h51m ovnkube-master-vf8rf 1/1 Running 0 6h51m ovnkube-master-w7hjr 1/1 Running 0 6h51m ovnkube-master-zsk7x 1/1 Running 0 6h42mVérifiez que le protocole IPsec est activé sur votre cluster :
$ oc -n openshift-ovn-kubernetes -c nbdb rsh ovnkube-master-<XXXXX> \ ovn-nbctl --no-leader-only get nb_global . ipsecoù :
<XXXXX>- Spécifie la séquence aléatoire de lettres pour un pod de l'étape précédente.
Exemple de sortie
true
8.7. Configuration de la politique de réseau
En tant qu'administrateur de cluster ou de projet, vous pouvez configurer des politiques de réseau pour un projet.
8.7.1. A propos de la politique de réseau
Dans un cluster utilisant un plugin réseau qui prend en charge la politique réseau de Kubernetes, l'isolation du réseau est entièrement contrôlée par les objets NetworkPolicy. Dans OpenShift Container Platform 4.12, OpenShift SDN prend en charge l'utilisation de la politique réseau dans son mode d'isolation réseau par défaut.
La politique de réseau ne s'applique pas à l'espace de noms du réseau hôte. Les pods dont le réseau d'hôtes est activé ne sont pas affectés par les règles de la politique de réseau.
Par défaut, tous les modules d'un projet sont accessibles aux autres modules et aux points d'extrémité du réseau. Pour isoler un ou plusieurs pods dans un projet, vous pouvez créer des objets NetworkPolicy dans ce projet pour indiquer les connexions entrantes autorisées. Les administrateurs de projet peuvent créer et supprimer des objets NetworkPolicy dans leur propre projet.
Si un pod est associé à des sélecteurs dans un ou plusieurs objets NetworkPolicy, il n'acceptera que les connexions autorisées par au moins un de ces objets NetworkPolicy. Un module qui n'est sélectionné par aucun objet NetworkPolicy est entièrement accessible.
Les exemples suivants d'objets NetworkPolicy illustrent la prise en charge de différents scénarios :
Refuser tout le trafic :
Pour qu'un projet soit refusé par défaut, ajoutez un objet
NetworkPolicyqui correspond à tous les pods mais n'accepte aucun trafic :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} ingress: []N'autoriser que les connexions provenant du contrôleur d'entrée de la plate-forme OpenShift Container :
Pour qu'un projet n'autorise que les connexions provenant du contrôleur d'ingestion de la plate-forme OpenShift Container, ajoutez l'objet
NetworkPolicysuivant.apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - IngressN'accepte que les connexions provenant de pods au sein d'un projet :
Pour que les pods acceptent les connexions d'autres pods du même projet, mais rejettent toutes les autres connexions de pods d'autres projets, ajoutez l'objet suivant
NetworkPolicy:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {}N'autoriser le trafic HTTP et HTTPS qu'en fonction des étiquettes de pods :
Pour permettre uniquement l'accès HTTP et HTTPS aux pods avec un label spécifique (
role=frontenddans l'exemple suivant), ajoutez un objetNetworkPolicysimilaire à ce qui suit :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443Accepter les connexions en utilisant des sélecteurs d'espace de noms et de pods :
Pour faire correspondre le trafic réseau en combinant les sélecteurs d'espace de noms et de pods, vous pouvez utiliser un objet
NetworkPolicysimilaire à ce qui suit :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-pod-and-namespace-both spec: podSelector: matchLabels: name: test-pods ingress: - from: - namespaceSelector: matchLabels: project: project_name podSelector: matchLabels: name: test-pods
NetworkPolicy sont additifs, ce qui signifie que vous pouvez combiner plusieurs objets NetworkPolicy pour répondre à des exigences complexes en matière de réseau.
Par exemple, pour les objets NetworkPolicy définis dans les exemples précédents, vous pouvez définir les politiques allow-same-namespace et allow-http-and-https dans le même projet. Cela permet aux pods portant l'étiquette role=frontend d'accepter toutes les connexions autorisées par chaque politique. C'est-à-dire des connexions sur n'importe quel port à partir de pods dans le même espace de noms, et des connexions sur les ports 80 et 443 à partir de pods dans n'importe quel espace de noms.
8.7.1.1. Utilisation de la stratégie réseau allow-from-router
Utilisez l'adresse NetworkPolicy pour autoriser le trafic externe quelle que soit la configuration du routeur :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-router
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/ingress:""
podSelector: {}
policyTypes:
- Ingress- 1
policy-group.network.openshift.io/ingress:""prend en charge à la fois Openshift-SDN et OVN-Kubernetes.
8.7.1.2. Utilisation de la stratégie réseau allow-from-hostnetwork
Ajoutez l'objet suivant allow-from-hostnetwork NetworkPolicy pour diriger le trafic des pods du réseau hôte :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-hostnetwork
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/host-network:""
podSelector: {}
policyTypes:
- Ingress8.7.2. Exemple d'objet NetworkPolicy
Un exemple d'objet NetworkPolicy est annoté ci-dessous :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l'objet NetworkPolicy.
- 2
- Un sélecteur qui décrit les pods auxquels la politique s'applique. L'objet de politique ne peut sélectionner que des pods dans le projet qui définit l'objet NetworkPolicy.
- 3
- Un sélecteur qui correspond aux pods à partir desquels l'objet de politique autorise le trafic entrant. Le sélecteur correspond aux pods situés dans le même espace de noms que la NetworkPolicy.
- 4
- Liste d'un ou plusieurs ports de destination sur lesquels le trafic doit être accepté.
8.7.3. Création d'une politique de réseau à l'aide de l'interface de ligne de commande
Pour définir des règles granulaires décrivant le trafic réseau entrant ou sortant autorisé pour les espaces de noms de votre cluster, vous pouvez créer une stratégie réseau.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créer une règle de politique :
Créer un fichier
<policy_name>.yaml:$ touch <policy_name>.yamloù :
<policy_name>- Spécifie le nom du fichier de stratégie réseau.
Définissez une politique de réseau dans le fichier que vous venez de créer, comme dans les exemples suivants :
Refuser l'entrée de tous les pods dans tous les espaces de noms
Il s'agit d'une politique fondamentale, qui bloque tout réseau inter-pods autre que le trafic inter-pods autorisé par la configuration d'autres politiques de réseau.
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: ingress: []Autoriser l'entrée de tous les pods dans le même espace de noms
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}Autoriser le trafic entrant vers un pod à partir d'un espace de noms particulier
Cette politique autorise le trafic vers les pods étiquetés
pod-aà partir des pods fonctionnant surnamespace-y.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-traffic-pod spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-y
Pour créer l'objet de stratégie de réseau, entrez la commande suivante :
oc apply -f <policy_name>.yaml -n <namespace>où :
<policy_name>- Spécifie le nom du fichier de stratégie réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Exemple de sortie
networkpolicy.networking.k8s.io/deny-by-default created
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix de créer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir d'un formulaire dans la console web.
8.7.4. Configuration de l'isolation des multitenants à l'aide d'une stratégie de réseau
Vous pouvez configurer votre projet pour l'isoler des pods et des services dans d'autres espaces de noms de projets.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
You installed the OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin.
Procédure
Créez les objets
NetworkPolicysuivants :Une police nommée
allow-from-openshift-ingress.$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress EOFNotepolicy-group.network.openshift.io/ingress: ""est l'étiquette de sélecteur d'espace de noms préférée pour OpenShift SDN. Vous pouvez utiliser l'étiquette de sélecteur d'espace de nomsnetwork.openshift.io/policy-group: ingress, mais il s'agit d'une étiquette héritée.Une police nommée
allow-from-openshift-monitoring:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: monitoring podSelector: {} policyTypes: - Ingress EOFUne police nommée
allow-same-namespace:$ cat << EOF| oc create -f - kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {} EOFUne police nommée
allow-from-kube-apiserver-operator:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress EOFPour plus de détails, voir Nouveau contrôleur de webhook
kube-apiserver-operatorvalidant l'état de santé du webhook.
Facultatif : Pour confirmer que les politiques de réseau existent dans votre projet actuel, entrez la commande suivante :
$ oc describe networkpolicyExemple de sortie
Name: allow-from-openshift-ingress Namespace: example1 Created on: 2020-06-09 00:28:17 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: ingress Not affecting egress traffic Policy Types: Ingress Name: allow-from-openshift-monitoring Namespace: example1 Created on: 2020-06-09 00:29:57 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: monitoring Not affecting egress traffic Policy Types: Ingress
8.7.5. Créer des politiques de réseau par défaut pour un nouveau projet
En tant qu'administrateur de cluster, vous pouvez modifier le modèle de nouveau projet pour inclure automatiquement les objets NetworkPolicy lorsque vous créez un nouveau projet.
8.7.6. Modifier le modèle pour les nouveaux projets
En tant qu'administrateur de cluster, vous pouvez modifier le modèle de projet par défaut afin que les nouveaux projets soient créés en fonction de vos besoins.
Pour créer votre propre modèle de projet personnalisé :
Procédure
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. Générer le modèle de projet par défaut :
oc adm create-bootstrap-project-template -o yaml > template.yaml-
Utilisez un éditeur de texte pour modifier le fichier
template.yamlgénéré en ajoutant des objets ou en modifiant des objets existants. Le modèle de projet doit être créé dans l'espace de noms
openshift-config. Chargez votre modèle modifié :$ oc create -f template.yaml -n openshift-configModifiez la ressource de configuration du projet à l'aide de la console Web ou de la CLI.
En utilisant la console web :
- Naviguez jusqu'à la page Administration → Cluster Settings.
- Cliquez sur Configuration pour afficher toutes les ressources de configuration.
- Trouvez l'entrée pour Project et cliquez sur Edit YAML.
Utilisation de la CLI :
Modifier la ressource
project.config.openshift.io/cluster:$ oc edit project.config.openshift.io/cluster
Mettez à jour la section
specpour inclure les paramètresprojectRequestTemplateetname, et définissez le nom de votre modèle de projet téléchargé. Le nom par défaut estproject-request.Ressource de configuration de projet avec modèle de projet personnalisé
apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestTemplate: name: <template_name>- Après avoir enregistré vos modifications, créez un nouveau projet pour vérifier que vos modifications ont bien été appliquées.
8.7.6.1. Ajouter des politiques de réseau au nouveau modèle de projet
En tant qu'administrateur de cluster, vous pouvez ajouter des politiques de réseau au modèle par défaut pour les nouveaux projets. OpenShift Container Platform créera automatiquement tous les objets NetworkPolicy spécifiés dans le modèle du projet.
Conditions préalables
-
Votre cluster utilise un fournisseur de réseau CNI par défaut qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avec l'optionmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
You installed the OpenShift CLI (
oc). -
Vous devez vous connecter au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous devez avoir créé un modèle de projet personnalisé par défaut pour les nouveaux projets.
Procédure
Modifiez le modèle par défaut pour un nouveau projet en exécutant la commande suivante :
$ oc edit template <project_template> -n openshift-configRemplacez
<project_template>par le nom du modèle par défaut que vous avez configuré pour votre cluster. Le nom du modèle par défaut estproject-request.Dans le modèle, ajoutez chaque objet
NetworkPolicyen tant qu'élément du paramètreobjects. Le paramètreobjectsaccepte une collection d'un ou plusieurs objets.Dans l'exemple suivant, la collection de paramètres
objectscomprend plusieurs objetsNetworkPolicy.objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...Facultatif : Créez un nouveau projet pour confirmer que vos objets de stratégie de réseau ont été créés avec succès en exécutant les commandes suivantes :
Créer un nouveau projet :
oc new-project <projet> $ oc new-project <projet>1 - 1
- Remplacez
<project>par le nom du projet que vous créez.
Confirmez que les objets de stratégie de réseau du nouveau modèle de projet existent dans le nouveau projet :
$ oc get networkpolicy NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
8.8. Configurations prises en charge
Les configurations suivantes sont prises en charge pour la version actuelle de Red Hat OpenShift Service Mesh.
8.8.1. Plates-formes prises en charge
L'opérateur Red Hat OpenShift Service Mesh prend en charge plusieurs versions de la ressource ServiceMeshControlPlane. Les plans de contrôle Service Mesh de la version 2.3 sont pris en charge sur les versions de plateforme suivantes :
- Red Hat OpenShift Container Platform version 4.9 ou ultérieure.
- Red Hat OpenShift Dedicated version 4.
- Azure Red Hat OpenShift (ARO) version 4.
- Red Hat OpenShift Service on AWS (ROSA).
8.8.2. Configurations non prises en charge
Les cas explicitement non pris en charge sont les suivants :
- OpenShift Online n'est pas pris en charge pour Red Hat OpenShift Service Mesh.
- Red Hat OpenShift Service Mesh ne prend pas en charge la gestion des microservices en dehors du cluster où Service Mesh est exécuté.
8.8.3. Configurations réseau prises en charge
Red Hat OpenShift Service Mesh prend en charge les configurations réseau suivantes.
- OpenShift-SDN
- OVN-Kubernetes est pris en charge sur OpenShift Container Platform 4.7.32 , OpenShift Container Platform 4.8.12 , et OpenShift Container Platform 4.9 .
- Plugins CNI (Container Network Interface) tiers qui ont été certifiés sur OpenShift Container Platform et qui ont passé les tests de conformité Service Mesh. Voir Plugins CNI OpenShift certifiés pour plus d'informations.
8.8.4. Configurations prises en charge pour Service Mesh
Cette version de Red Hat OpenShift Service Mesh est uniquement disponible sur OpenShift Container Platform x86_64, IBM zSystems et IBM Power.
- IBM zSystems n'est pris en charge que sur OpenShift Container Platform 4.6 et plus.
- IBM Power n'est pris en charge que sur OpenShift Container Platform 4.6 et plus.
- Configurations dans lesquelles tous les composants Service Mesh sont contenus dans un seul cluster OpenShift Container Platform.
- Configurations qui n'intègrent pas de services externes tels que des machines virtuelles.
-
Red Hat OpenShift Service Mesh ne prend pas en charge la configuration
EnvoyFilter, sauf lorsqu'elle est explicitement documentée.
8.8.5. Configurations prises en charge pour Kiali
- La console Kiali n'est compatible qu'avec les deux versions les plus récentes des navigateurs Chrome, Edge, Firefox ou Safari.
8.8.6. Configurations prises en charge pour le traçage distribué
- L'agent Jaeger en tant que sidecar est la seule configuration supportée pour Jaeger. Jaeger en tant que daemonset n'est pas pris en charge pour les installations multitenant ou OpenShift Dedicated.
8.8.7. Module WebAssembly pris en charge
- 3scale WebAssembly est le seul module WebAssembly fourni. Vous pouvez créer des modules WebAssembly personnalisés.
8.8.8. Vue d'ensemble de l'opérateur
Red Hat OpenShift Service Mesh nécessite les quatre opérateurs suivants :
- OpenShift Elasticsearch - (Facultatif) Fournit un stockage de base de données pour le traçage et la journalisation avec la plateforme de traçage distribuée. Il est basé sur le projet open source Elasticsearch.
- Red Hat OpenShift distributed tracing platform - Fournit un traçage distribué pour surveiller et dépanner les transactions dans les systèmes distribués complexes. Il est basé sur le projet open source Jaeger.
- Kiali - Fournit une observabilité pour votre maillage de services. Il vous permet de visualiser les configurations, de surveiller le trafic et d'analyser les traces dans une console unique. Il est basé sur le projet open source Kiali.
-
Red Hat OpenShift Service Mesh - Il vous permet de connecter, de sécuriser, de contrôler et d'observer les microservices qui composent vos applications. Le Service Mesh Operator définit et surveille les ressources
ServiceMeshControlPlanequi gèrent le déploiement, la mise à jour et la suppression des composants du Service Mesh. Il est basé sur le projet open source Istio.
Prochaines étapes
- Installez Red Hat OpenShift Service Mesh dans votre environnement OpenShift Container Platform.
8.9. Optimisation de l'acheminement
Le routeur HAProxy d'OpenShift Container Platform peut être dimensionné ou configuré pour optimiser les performances.
8.9.1. Performances de base du contrôleur d'entrée (routeur)
Le contrôleur d'entrée de la plateforme OpenShift Container, ou routeur, est le point d'entrée du trafic d'entrée pour les applications et les services qui sont configurés à l'aide de routes et d'entrées.
Lorsque l'on évalue les performances d'un routeur HAProxy unique en termes de requêtes HTTP traitées par seconde, les performances varient en fonction de nombreux facteurs. En particulier :
- Mode de maintien/fermeture HTTP
- Type d'itinéraire
- Prise en charge du client de reprise de session TLS
- Nombre de connexions simultanées par route cible
- Nombre de routes cibles
- Taille des pages du serveur dorsal
- Infrastructure sous-jacente (solution réseau/SDN, CPU, etc.)
Bien que les performances dans votre environnement spécifique varient, les tests du laboratoire Red Hat sur une instance de cloud public de taille 4 vCPU/16GB RAM. Un routeur HAProxy unique gérant 100 routes terminées par des backends servant des pages statiques de 1kB est capable de gérer le nombre suivant de transactions par seconde.
Dans les scénarios du mode "keep-alive" de HTTP :
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| aucun | 21515 | 29622 |
| bord | 16743 | 22913 |
| traversée | 36786 | 53295 |
| ré-encrypter | 21583 | 25198 |
Dans les scénarios de fermeture HTTP (pas de keep-alive) :
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| aucun | 5719 | 8273 |
| bord | 2729 | 4069 |
| traversée | 4121 | 5344 |
| ré-encrypter | 2320 | 2941 |
La configuration par défaut du contrôleur d'entrée a été utilisée avec le champ spec.tuningOptions.threadCount défini sur 4. Deux stratégies différentes de publication des points finaux ont été testées : Load Balancer Service et Host Network. La reprise de session TLS a été utilisée pour les itinéraires cryptés. Avec HTTP keep-alive, un seul routeur HAProxy est capable de saturer un NIC de 1 Gbit avec des pages d'une taille aussi petite que 8 kB.
Lorsque le système est exécuté sur du métal nu avec des processeurs modernes, vous pouvez vous attendre à des performances environ deux fois supérieures à celles de l'instance de nuage public ci-dessus. Cette surcharge est introduite par la couche de virtualisation en place sur les nuages publics et s'applique également à la virtualisation basée sur les nuages privés. Le tableau suivant indique le nombre d'applications à utiliser derrière le routeur :
| Number of applications | Application type |
|---|---|
| 5-10 | fichier statique/serveur web ou proxy de mise en cache |
| 100-1000 | les applications générant un contenu dynamique |
En général, HAProxy peut prendre en charge des routes pour un maximum de 1 000 applications, en fonction de la technologie utilisée. Les performances du contrôleur d'entrée peuvent être limitées par les capacités et les performances des applications qui se trouvent derrière lui, comme la langue ou le contenu statique par rapport au contenu dynamique.
La mise en commun des entrées, ou routeurs, devrait être utilisée pour servir davantage de routes vers les applications et contribuer à la mise à l'échelle horizontale du niveau de routage.
8.9.2. Configuration des sondes de disponibilité, de préparation et de démarrage du contrôleur d'entrée
Les administrateurs de cluster peuvent configurer les valeurs de délai d'attente pour les sondes de disponibilité, de préparation et de démarrage du kubelet pour les déploiements de routeurs qui sont gérés par le contrôleur d'entrée de la plateforme OpenShift Container (routeur). Les sondes de disponibilité et de préparation du routeur utilisent la valeur de temporisation par défaut de 1 seconde, qui est trop courte lorsque les performances du réseau ou de l'exécution sont gravement dégradées. Les délais d'attente des sondes peuvent entraîner des redémarrages intempestifs du routeur qui interrompent les connexions des applications. La possibilité de définir des valeurs de délai plus importantes peut réduire le risque de redémarrages inutiles et non désirés.
Vous pouvez mettre à jour la valeur timeoutSeconds dans les paramètres livenessProbe, readinessProbe et startupProbe du conteneur de routeur.
| Paramètres | Description |
|---|---|
|
|
Le site |
|
|
Le site |
|
|
Le site |
L'option de configuration du délai d'attente est une technique de réglage avancée qui peut être utilisée pour contourner les problèmes. Cependant, ces problèmes doivent être diagnostiqués et éventuellement faire l'objet d'un dossier d'assistance ou d'une question Jira pour tout problème entraînant un dépassement du délai d'attente des sondes.
L'exemple suivant montre comment vous pouvez corriger directement le déploiement du routeur par défaut pour définir un délai d'attente de 5 secondes pour les sondes de disponibilité et d'état de préparation :
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'Vérification
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=38.9.3. Configuration de l'intervalle de recharge de HAProxy
Lorsque vous mettez à jour une route ou un point d'extrémité associé à une route, le routeur OpenShift Container Platform met à jour la configuration de HAProxy. Ensuite, HAProxy recharge la configuration mise à jour pour que ces modifications prennent effet. Lorsque HAProxy se recharge, il génère un nouveau processus qui gère les nouvelles connexions à l'aide de la configuration mise à jour.
HAProxy maintient l'ancien processus en cours d'exécution pour gérer les connexions existantes jusqu'à ce qu'elles soient toutes fermées. Lorsque d'anciens processus ont des connexions de longue durée, ils peuvent accumuler et consommer des ressources.
L'intervalle minimum de rechargement de HAProxy par défaut est de cinq secondes. Vous pouvez configurer un contrôleur d'entrée à l'aide de son champ spec.tuningOptions.reloadInterval pour définir un intervalle de recharge minimum plus long.
La définition d'une valeur élevée pour l'intervalle minimum de rechargement de HAProxy peut entraîner une latence dans l'observation des mises à jour des itinéraires et de leurs points d'extrémité. Pour réduire ce risque, évitez de définir une valeur supérieure à la latence tolérable pour les mises à jour.
Procédure
Modifiez l'intervalle minimum de rechargement de HAProxy du contrôleur d'entrée par défaut pour le porter à 15 secondes en exécutant la commande suivante :
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'
8.10. Configuration du réseau RHOSP après l'installation
Vous pouvez configurer certains aspects d'un cluster OpenShift Container Platform on Red Hat OpenStack Platform (RHOSP) après l'installation.
8.10.1. Configuration de l'accès aux applications avec des adresses IP flottantes
Après avoir installé OpenShift Container Platform, configurez Red Hat OpenStack Platform (RHOSP) pour autoriser le trafic réseau des applications.
Vous n'avez pas besoin d'effectuer cette procédure si vous avez fourni des valeurs pour platform.openstack.apiFloatingIP et platform.openstack.ingressFloatingIP dans le fichier install-config.yaml, ou os_api_fip et os_ingress_fip dans le playbook inventory.yaml, lors de l'installation. Les adresses IP flottantes sont déjà définies.
Conditions préalables
- Le cluster OpenShift Container Platform doit être installé
- Les adresses IP flottantes sont activées comme décrit dans la documentation d'installation d'OpenShift Container Platform on RHOSP.
Procédure
Après avoir installé le cluster OpenShift Container Platform, attachez une adresse IP flottante au port d'entrée :
Afficher le port :
openstack port show <cluster_name>-<cluster_ID>-ingress-portAttachez le port à l'adresse IP :
$ openstack floating ip set --port <ingress_port_ID> <apps_FIP>Ajoutez un enregistrement
Apour*apps.à votre fichier DNS :*.apps.<cluster_name>.<base_domain> IN A <apps_FIP>
Si vous ne contrôlez pas le serveur DNS mais que vous souhaitez autoriser l'accès à l'application à des fins de non-production, vous pouvez ajouter ces noms d'hôtes à /etc/hosts:
<apps_FIP> console-openshift-console.apps.<cluster name>.<base domain>
<apps_FIP> integrated-oauth-server-openshift-authentication.apps.<cluster name>.<base domain>
<apps_FIP> oauth-openshift.apps.<cluster name>.<base domain>
<apps_FIP> prometheus-k8s-openshift-monitoring.apps.<cluster name>.<base domain>
<apps_FIP> <app name>.apps.<cluster name>.<base domain>8.10.2. Kuryr ports pools
A Kuryr ports pool maintains a number of ports on standby for pod creation.
Keeping ports on standby minimizes pod creation time. Without ports pools, Kuryr must explicitly request port creation or deletion whenever a pod is created or deleted.
The Neutron ports that Kuryr uses are created in subnets that are tied to namespaces. These pod ports are also added as subports to the primary port of OpenShift Container Platform cluster nodes.
Because Kuryr keeps each namespace in a separate subnet, a separate ports pool is maintained for each namespace-worker pair.
Prior to installing a cluster, you can set the following parameters in the cluster-network-03-config.yml manifest file to configure ports pool behavior:
-
The
enablePortPoolsPrepopulationparameter controls pool prepopulation, which forces Kuryr to add Neutron ports to the pools when the first pod that is configured to use the dedicated network for pods is created in a namespace. The default value isfalse. -
The
poolMinPortsparameter is the minimum number of free ports that are kept in the pool. The default value is1. The
poolMaxPortsparameter is the maximum number of free ports that are kept in the pool. A value of0disables that upper bound. This is the default setting.If your OpenStack port quota is low, or you have a limited number of IP addresses on the pod network, consider setting this option to ensure that unneeded ports are deleted.
-
The
poolBatchPortsparameter defines the maximum number of Neutron ports that can be created at once. The default value is3.
8.10.3. Ajustement des paramètres du pool de ports Kuryr dans les déploiements actifs sur RHOSP
Vous pouvez utiliser une ressource personnalisée (CR) pour configurer la façon dont Kuryr gère les ports Neutron de Red Hat OpenStack Platform (RHOSP) afin de contrôler la vitesse et l'efficacité de la création de pods sur un cluster déployé.
Procédure
À partir d'une ligne de commande, ouvrez le CR Cluster Network Operator (CNO) pour l'éditer :
$ oc edit networks.operator.openshift.io clusterEdit the settings to meet your requirements. The following file is provided as an example:
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 serviceNetwork: - 172.30.0.0/16 defaultNetwork: type: Kuryr kuryrConfig: enablePortPoolsPrepopulation: false1 poolMinPorts: 12 poolBatchPorts: 33 poolMaxPorts: 54 - 1
- Définissez
enablePortPoolsPrepopulationàtruepour que Kuryr crée des ports Neutron lorsque le premier pod configuré pour utiliser le réseau dédié aux pods est créé dans un espace de noms. Ce paramètre augmente le quota de ports Neutron mais peut réduire le temps nécessaire à la création de pods. La valeur par défaut estfalse. - 2
- Kuryr creates new ports for a pool if the number of free ports in that pool is lower than the value of
poolMinPorts. The default value is1. - 3
poolBatchPortscontrols the number of new ports that are created if the number of free ports is lower than the value ofpoolMinPorts. The default value is3.- 4
- Si le nombre de ports libres dans un pool est supérieur à la valeur de
poolMaxPorts, Kuryr les supprime jusqu'à ce que leur nombre corresponde à cette valeur. La valeur0désactive cette limite supérieure, ce qui empêche les pools de se réduire. La valeur par défaut est0.
- Enregistrez vos modifications et quittez l'éditeur de texte pour valider vos modifications.
La modification de ces options sur un cluster en fonctionnement oblige les pods kuryr-controller et kuryr-cni à redémarrer. Par conséquent, la création de nouveaux pods et services sera retardée.
8.10.4. Activation du délestage du matériel OVS
Pour les clusters qui s'exécutent sur Red Hat OpenStack Platform (RHOSP), vous pouvez activer le déchargement matériel d'Open vSwitch (OVS).
OVS est un commutateur virtuel multicouche qui permet la virtualisation de réseaux multiserveurs à grande échelle.
Conditions préalables
- Vous avez installé un cluster sur RHOSP qui est configuré pour la virtualisation des entrées/sorties à racine unique (SR-IOV).
- Vous avez installé l'opérateur de réseau SR-IOV sur votre cluster.
-
Vous avez créé deux interfaces de fonction virtuelle (VF) de type
hw-offloadsur votre cluster.
Procédure
Créez une politique
SriovNetworkNodePolicypour les deux interfaceshw-offloadtype VF qui se trouvent sur votre cluster :La première interface de fonction virtuelle
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy1 metadata: name: "hwoffload9" namespace: openshift-sriov-network-operator spec: deviceType: netdevice isRdma: true nicSelector: pfNames:2 - ens6 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: 'true' numVfs: 1 priority: 99 resourceName: "hwoffload9"La deuxième interface de fonction virtuelle
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy1 metadata: name: "hwoffload10" namespace: openshift-sriov-network-operator spec: deviceType: netdevice isRdma: true nicSelector: pfNames:2 - ens5 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: 'true' numVfs: 1 priority: 99 resourceName: "hwoffload10"Créer des ressources
NetworkAttachmentDefinitionpour les deux interfaces :Une ressource
NetworkAttachmentDefinitionpour la première interfaceapiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: annotations: k8s.v1.cni.cncf.io/resourceName: openshift.io/hwoffload9 name: hwoffload9 namespace: default spec: config: '{ "cniVersion":"0.3.1", "name":"hwoffload9","type":"host-device","device":"ens6" }'Une ressource
NetworkAttachmentDefinitionpour la deuxième interfaceapiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: annotations: k8s.v1.cni.cncf.io/resourceName: openshift.io/hwoffload10 name: hwoffload10 namespace: default spec: config: '{ "cniVersion":"0.3.1", "name":"hwoffload10","type":"host-device","device":"ens5" }'Utilisez les interfaces que vous avez créées avec un pod. Par exemple :
Un pod qui utilise les deux interfaces de déchargement OVS
apiVersion: v1 kind: Pod metadata: name: dpdk-testpmd namespace: default annotations: irq-load-balancing.crio.io: disable cpu-quota.crio.io: disable k8s.v1.cni.cncf.io/resourceName: openshift.io/hwoffload9 k8s.v1.cni.cncf.io/resourceName: openshift.io/hwoffload10 spec: restartPolicy: Never containers: - name: dpdk-testpmd image: quay.io/krister/centos8_nfv-container-dpdk-testpmd:latest
8.10.5. Attachement d'un réseau de délestage matériel OVS
Vous pouvez attacher un réseau de déchargement matériel Open vSwitch (OVS) à votre cluster.
Conditions préalables
- Votre cluster est installé et fonctionne.
- Vous avez provisionné un réseau de déchargement matériel OVS sur Red Hat OpenStack Platform (RHOSP) pour l'utiliser avec votre cluster.
Procédure
Créez un fichier nommé
network.yamlà partir du modèle suivant :spec: additionalNetworks: - name: hwoffload1 namespace: cnf rawCNIConfig: '{ "cniVersion": "0.3.1", "name": "hwoffload1", "type": "host-device","pciBusId": "0000:00:05.0", "ipam": {}}'1 type: Rawoù :
pciBusIdSpécifie l'appareil connecté au réseau de délestage. Si vous ne l'avez pas, vous pouvez trouver cette valeur en exécutant la commande suivante :
$ oc describe SriovNetworkNodeState -n openshift-sriov-network-operator
A partir d'une ligne de commande, entrez la commande suivante pour patcher votre cluster avec le fichier :
$ oc apply -f network.yaml
8.10.6. Activation de la connectivité IPv6 aux pods sur RHOSP
Pour permettre la connectivité IPv6 entre les modules qui ont des réseaux supplémentaires sur des nœuds différents, désactivez la sécurité des ports pour le port IPv6 du serveur. La désactivation de la sécurité des ports évite de devoir créer des paires d'adresses autorisées pour chaque adresse IPv6 attribuée aux modules et permet le trafic sur le groupe de sécurité.
Seules les configurations réseau supplémentaires IPv6 suivantes sont prises en charge :
- SLAAC et dispositif hôte
- SLAAC et MACVLAN
- DHCP stateless et host-device
- DHCP sans état et MACVLAN
Procédure
Sur une ligne de commande, entrez la commande suivante :
openstack port set --no-security-group --disable-port-security <compute_ipv6_port>ImportantCette commande supprime les groupes de sécurité du port et désactive la sécurité du port. Les restrictions de trafic sont entièrement supprimées du port.
où :
- <compute_ipv6_port>
- Spécifie le port IPv6 du serveur de calcul.
8.10.7. Ajouter la connectivité IPv6 aux pods sur RHOSP
Après avoir activé la connectivité IPv6 dans les pods, ajoutez-y une connectivité en utilisant une configuration CNI (Container Network Interface).
Procédure
Pour modifier l'opérateur de réseau de cluster (CNO), entrez la commande suivante :
$ oc edit networks.operator.openshift.io clusterSpécifiez votre configuration CNI dans le champ
spec. Par exemple, la configuration suivante utilise un mode d'adresse SLAAC avec MACVLAN :... spec: additionalNetworks: - name: ipv6 namespace: ipv61 rawCNIConfig: '{ "cniVersion": "0.3.1", "name": "ipv6", "type": "macvlan", "master": "ens4"}'2 type: RawNoteSi vous utilisez le mode d'adressage avec état, incluez la gestion des adresses IP (IPAM) dans la configuration de CNI.
DHCPv6 n'est pas pris en charge par Multus.
- Enregistrez vos modifications et quittez l'éditeur de texte pour valider vos modifications.
Vérification
Sur une ligne de commande, entrez la commande suivante :
$ oc get network-attachment-definitions -AExemple de sortie
NAMESPACE NAME AGE ipv6 ipv6 21h
Vous pouvez maintenant créer des pods qui ont des connexions IPv6 secondaires.
8.10.8. Créer des pods qui ont une connectivité IPv6 sur RHOSP
Après avoir activé la connectivité IPv6 pour les modules et l'avoir ajoutée à ces derniers, créez des modules dotés de connexions IPv6 secondaires.
Procédure
Définissez des pods qui utilisent votre espace de noms IPv6 et l'annotation
k8s.v1.cni.cncf.io/networks: <additional_network_name>, où<additional_network_nameest le nom du réseau supplémentaire. Par exemple, dans le cadre d'un objetDeployment:apiVersion: apps/v1 kind: Deployment metadata: name: hello-openshift namespace: ipv6 spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - hello-openshift replicas: 2 selector: matchLabels: app: hello-openshift template: metadata: labels: app: hello-openshift annotations: k8s.v1.cni.cncf.io/networks: ipv6 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: hello-openshift securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL image: quay.io/openshift/origin-hello-openshift ports: - containerPort: 8080Créez le pod. Par exemple, sur une ligne de commande, entrez la commande suivante :
oc create -f <ipv6_enabled_resource>
où :
- <ipv6_enabled_resource>
- Indique le fichier qui contient la définition de la ressource.
Chapitre 9. Configuration du stockage après l'installation
Après avoir installé OpenShift Container Platform, vous pouvez étendre et personnaliser votre cluster en fonction de vos besoins, y compris la configuration du stockage.
9.1. Provisionnement dynamique
9.1.1. À propos du provisionnement dynamique
L'objet ressource StorageClass décrit et classifie le stockage qui peut être demandé, et fournit un moyen de transmettre des paramètres pour le stockage dynamique à la demande. Les objets StorageClass peuvent également servir de mécanisme de gestion pour contrôler les différents niveaux de stockage et l'accès au stockage. Les administrateurs de grappes (cluster-admin) ou les administrateurs de stockage (storage-admin) définissent et créent les objets StorageClass que les utilisateurs peuvent demander sans avoir besoin d'une connaissance détaillée des sources de volume de stockage sous-jacentes.
Le cadre de volume persistant d'OpenShift Container Platform permet cette fonctionnalité et permet aux administrateurs de provisionner un cluster avec un stockage persistant. Ce cadre permet également aux utilisateurs de demander ces ressources sans avoir aucune connaissance de l'infrastructure sous-jacente.
De nombreux types de stockage sont disponibles pour une utilisation en tant que volumes persistants dans OpenShift Container Platform. Alors qu'ils peuvent tous être provisionnés statiquement par un administrateur, certains types de stockage sont créés dynamiquement à l'aide du fournisseur intégré et des API de plugin.
9.1.2. Plugins de provisionnement dynamique disponibles
OpenShift Container Platform fournit les plugins de provisionnement suivants, qui ont des implémentations génériques pour le provisionnement dynamique qui utilisent l'API du fournisseur configuré du cluster pour créer de nouvelles ressources de stockage :
| Type de stockage | Nom du plugin Provisioner | Notes |
|---|---|---|
| Red Hat OpenStack Platform (RHOSP) Cinder |
| |
| Interface de stockage de conteneurs (CSI) de RHOSP Manille |
| Une fois installés, l'OpenStack Manila CSI Driver Operator et ManilaDriver créent automatiquement les classes de stockage requises pour tous les types de partage Manila disponibles nécessaires au provisionnement dynamique. |
| AWS Elastic Block Store (EBS) |
|
Pour le provisionnement dynamique lors de l'utilisation de plusieurs clusters dans différentes zones, marquez chaque nœud avec |
| Disque Azure |
| |
| Fichier Azure |
|
Le compte de service |
| Disque persistant de la CME (gcePD) |
| Dans les configurations multizones, il est conseillé d'exécuter un cluster OpenShift Container Platform par projet GCE afin d'éviter que des PV ne soient créés dans des zones où aucun nœud du cluster actuel n'existe. |
|
|
Tout plugin de provisionnement choisi nécessite également une configuration pour le nuage, l'hôte ou le fournisseur tiers concerné, conformément à la documentation correspondante.
9.2. Définition d'une classe de stockage
StorageClass sont actuellement des objets à portée globale et doivent être créés par les utilisateurs cluster-admin ou storage-admin.
L'opérateur de stockage en cluster peut installer une classe de stockage par défaut en fonction de la plate-forme utilisée. Cette classe de stockage est détenue et contrôlée par l'opérateur. Elle ne peut pas être supprimée ou modifiée au-delà de la définition des annotations et des étiquettes. Si vous souhaitez un comportement différent, vous devez définir une classe de stockage personnalisée.
Les sections suivantes décrivent la définition de base d'un objet StorageClass et des exemples spécifiques pour chacun des types de plugins pris en charge.
9.2.1. Définition de base de l'objet StorageClass
La ressource suivante présente les paramètres et les valeurs par défaut que vous utilisez pour configurer une classe de stockage. Cet exemple utilise la définition de l'objet AWS ElasticBlockStore (EBS).
Exemple de définition StorageClass
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: <storage-class-name>
annotations:
storageclass.kubernetes.io/is-default-class: 'true'
...
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
...- 1
- (obligatoire) Le type d'objet de l'API.
- 2
- (obligatoire) Version actuelle de l'api.
- 3
- (obligatoire) Nom de la classe de stockage.
- 4
- (facultatif) Annotations pour la classe de stockage.
- 5
- (obligatoire) Le type de provisionneur associé à cette classe de stockage.
- 6
- (optionnel) Les paramètres requis pour le provisionneur spécifique, cela changera d'un plugin à l'autre.
9.2.2. Annotations de la classe de stockage
Pour définir une classe de stockage comme étant la classe par défaut à l'échelle du cluster, ajoutez l'annotation suivante aux métadonnées de votre classe de stockage :
storageclass.kubernetes.io/is-default-class: "true"Par exemple :
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true"
...Cela permet à toute demande de volume persistant (PVC) qui ne spécifie pas de classe de stockage spécifique d'être automatiquement approvisionnée par la classe de stockage par défaut. Cependant, votre cluster peut avoir plus d'une classe de stockage, mais une seule d'entre elles peut être la classe de stockage par défaut.
La version bêta de l'annotation storageclass.beta.kubernetes.io/is-default-class fonctionne toujours, mais elle sera supprimée dans une prochaine version.
Pour définir la description d'une classe de stockage, ajoutez l'annotation suivante aux métadonnées de votre classe de stockage :
kubernetes.io/description: My Storage Class DescriptionPar exemple :
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
kubernetes.io/description: My Storage Class Description
...9.2.3. Définition de l'objet RHOSP Cinder
cinder-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: <storage-class-name>
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
fsType: ext4 - 1
- Nom de la classe de stockage. La revendication de volume persistant utilise cette classe de stockage pour provisionner les volumes persistants associés.
- 2
- Type de volume créé dans Cinder. La valeur par défaut est vide.
- 3
- Zone de disponibilité. S'ils ne sont pas spécifiés, les volumes sont généralement arrondis dans toutes les zones actives où le cluster OpenShift Container Platform a un nœud.
- 4
- Système de fichiers créé sur les volumes provisionnés dynamiquement. Cette valeur est copiée dans le champ
fsTypedes volumes persistants provisionnés dynamiquement et le système de fichiers est créé lorsque le volume est monté pour la première fois. La valeur par défaut estext4.
9.2.4. Définition de l'objet AWS Elastic Block Store (EBS)
aws-ebs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: <storage-class-name>
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "10"
encrypted: "true"
kmsKeyId: keyvalue
fsType: ext4 - 1
- (obligatoire) Nom de la classe de stockage. La revendication de volume persistant utilise cette classe de stockage pour le provisionnement des volumes persistants associés.
- 2
- (obligatoire) Choisissez parmi
io1,gp3,sc1,st1. La valeur par défaut estgp3. Voir la documentation AWS pour les valeurs valides de l'Amazon Resource Name (ARN). - 3
- Optionnel : Uniquement pour les volumes io1. Opérations d'E/S par seconde et par gigaoctet. Le plugin de volume AWS multiplie cette valeur avec la taille du volume demandé pour calculer les IOPS du volume. La valeur maximale est de 20 000 IOPS, ce qui correspond au maximum supporté par AWS. Voir la documentation AWS pour plus de détails.
- 4
- Facultatif : Indique s'il faut crypter le volume EBS. Les valeurs valides sont
trueoufalse. - 5
- Facultatif : L'ARN complet de la clé à utiliser pour le chiffrement du volume. Si aucune valeur n'est fournie, mais que
encyptedest défini surtrue, AWS génère une clé. Voir la documentation AWS pour une valeur ARN valide. - 6
- Facultatif : Système de fichiers créé sur les volumes approvisionnés dynamiquement. Cette valeur est copiée dans le champ
fsTypedes volumes persistants provisionnés dynamiquement et le système de fichiers est créé lorsque le volume est monté pour la première fois. La valeur par défaut estext4.
9.2.5. Définition de l'objet Azure Disk
azure-advanced-disk-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: <storage-class-name>
provisioner: kubernetes.io/azure-disk
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
parameters:
kind: Managed
storageaccounttype: Premium_LRS
reclaimPolicy: Delete- 1
- Nom de la classe de stockage. La revendication de volume persistant utilise cette classe de stockage pour provisionner les volumes persistants associés.
- 2
- L'utilisation de
WaitForFirstConsumerest fortement recommandée. Cela permet de provisionner le volume tout en laissant suffisamment de stockage pour planifier le pod sur un nœud de travail libre à partir d'une zone disponible. - 3
- Les valeurs possibles sont
Shared(par défaut),ManagedetDedicated.ImportantRed Hat ne prend en charge que l'utilisation de
kind: Manageddans la classe de stockage.Avec
SharedetDedicated, Azure crée des disques non gérés, tandis qu'OpenShift Container Platform crée un disque géré pour les disques du système d'exploitation de la machine (racine). Mais comme Azure Disk ne permet pas l'utilisation de disques gérés et non gérés sur un nœud, les disques non gérés créés avecSharedouDedicatedne peuvent pas être attachés aux nœuds d'OpenShift Container Platform. - 4
- Niveau SKU du compte de stockage Azure. La valeur par défaut est vide. Notez que les VM Premium peuvent attacher les disques
Standard_LRSetPremium_LRS, les VM Standard ne peuvent attacher que les disquesStandard_LRS, les VM gérées ne peuvent attacher que les disques gérés, et les VM non gérées ne peuvent attacher que les disques non gérés.-
Si
kindest défini surShared, Azure crée tous les disques non gérés dans quelques comptes de stockage partagé dans le même groupe de ressources que le cluster. -
Si
kindest défini surManaged, Azure crée de nouveaux disques gérés. Si
kindest défini surDedicatedet qu'unstorageAccountest spécifié, Azure utilise le compte de stockage spécifié pour le nouveau disque non géré dans le même groupe de ressources que le cluster. Pour que cela fonctionne :- Le compte de stockage spécifié doit se trouver dans la même région.
- Azure Cloud Provider doit avoir un accès en écriture au compte de stockage.
-
Si
kindest défini surDedicatedet questorageAccountn'est pas spécifié, Azure crée un nouveau compte de stockage dédié pour le nouveau disque non géré dans le même groupe de ressources que le cluster.
-
Si
9.2.6. Définition de l'objet Azure File
La classe de stockage Azure File utilise des secrets pour stocker le nom et la clé du compte de stockage Azure nécessaires à la création d'un partage Azure Files. Ces autorisations sont créées dans le cadre de la procédure suivante.
Procédure
Définir un objet
ClusterRolequi permet de créer et de consulter des secrets :apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: # name: system:azure-cloud-provider name: <persistent-volume-binder-role>1 rules: - apiGroups: [''] resources: ['secrets'] verbs: ['get','create']- 1
- Nom du rôle de cluster permettant de visualiser et de créer des secrets.
Ajouter le rôle de cluster au compte de service :
oc adm policy add-cluster-role-to-user <persistent-volume-binder-role> system:serviceaccount:kube-system:persistent-volume-binderCréez l'objet Azure File
StorageClass:kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: <azure-file>1 provisioner: kubernetes.io/azure-file parameters: location: eastus2 skuName: Standard_LRS3 storageAccount: <storage-account>4 reclaimPolicy: Delete volumeBindingMode: Immediate- 1
- Nom de la classe de stockage. La revendication de volume persistant utilise cette classe de stockage pour provisionner les volumes persistants associés.
- 2
- Emplacement du compte de stockage Azure, tel que
eastus. La valeur par défaut est vide, ce qui signifie qu'un nouveau compte de stockage Azure sera créé à l'emplacement du cluster OpenShift Container Platform. - 3
- Niveau SKU du compte de stockage Azure, par exemple
Standard_LRS. La valeur par défaut est vide, ce qui signifie qu'un nouveau compte de stockage Azure sera créé avec l'UGSStandard_LRS. - 4
- Nom du compte de stockage Azure. Si un compte de stockage est fourni, les adresses
skuNameetlocationsont ignorées. Si aucun compte de stockage n'est fourni, la classe de stockage recherche tout compte de stockage associé au groupe de ressources pour tout compte correspondant aux valeurs définiesskuNameetlocation.
9.2.6.1. Points à prendre en compte lors de l'utilisation d'Azure File
Les fonctionnalités suivantes du système de fichiers ne sont pas prises en charge par la classe de stockage Azure File par défaut :
- Liens symboliques
- Liens directs
- Attributs étendus
- Fichiers épars
- Tuyaux nommés
De plus, l'identifiant de l'utilisateur propriétaire (UID) du répertoire monté Azure File est différent de l'UID du processus du conteneur. L'option uid mount peut être spécifiée dans l'objet StorageClass pour définir un identifiant utilisateur spécifique à utiliser pour le répertoire monté.
L'objet StorageClass suivant montre comment modifier l'identifiant de l'utilisateur et du groupe, et comment activer les liens symboliques pour le répertoire monté.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azure-file
mountOptions:
- uid=1500
- gid=1500
- mfsymlinks
provisioner: kubernetes.io/azure-file
parameters:
location: eastus
skuName: Standard_LRS
reclaimPolicy: Delete
volumeBindingMode: Immediate9.2.7. Définition de l'objet GCE PersistentDisk (gcePD)
gce-pd-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: <storage-class-name>
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
replication-type: none
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
reclaimPolicy: Delete9.2.8. Définition de l'objet VMware vSphere
vsphere-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: <storage-class-name>
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: thin - 1
- Nom de la classe de stockage. La revendication de volume persistant utilise cette classe de stockage pour provisionner les volumes persistants associés.
- 2
- Pour plus d'informations sur l'utilisation de VMware vSphere avec OpenShift Container Platform, consultez la documentation de VMware vSphere.
- 3
diskformat:thin,zeroedthicketeagerzeroedthicksont tous des formats de disque valides. Voir la documentation vSphere pour plus de détails sur les types de format de disque. La valeur par défaut estthin.
9.2.9. Définition de l'objet Red Hat Virtualization (RHV)
OpenShift Container Platform crée un objet par défaut de type StorageClass nommé ovirt-csi-sc qui est utilisé pour créer des volumes persistants provisionnés dynamiquement.
Pour créer des classes de stockage supplémentaires pour différentes configurations, créez et enregistrez un fichier avec l'objet StorageClass décrit par l'exemple YAML suivant :
ovirt-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: <storage_class_name>
annotations:
storageclass.kubernetes.io/is-default-class: "<boolean>"
provisioner: csi.ovirt.org
allowVolumeExpansion: <boolean>
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
storageDomainName: <rhv-storage-domain-name>
thinProvisioning: "<boolean>"
csi.storage.k8s.io/fstype: <file_system_type> - 1
- Nom de la classe de stockage.
- 2
- Défini à
falsesi la classe de stockage est la classe de stockage par défaut dans le cluster. Si la valeur esttrue, la classe de stockage par défaut existante doit être modifiée et définie surfalse. - 3
truepermet une expansion dynamique du volume, tandis quefalsel'empêche.trueest recommandé.- 4
- Les volumes persistants provisionnés dynamiquement de cette classe de stockage sont créés avec cette politique de récupération. Cette politique par défaut est
Delete. - 5
- Indique comment provisionner et lier
PersistentVolumeClaims. S'il n'est pas défini, c'estVolumeBindingImmediatequi est utilisé. Ce champ ne s'applique qu'aux serveurs qui activent la fonctionVolumeScheduling. - 6
- Le nom du domaine de stockage RHV à utiliser.
- 7
- Si
true, le disque est en mode "thin provisioned". Sifalse, le disque est pré-alloué. Le provisionnement fin est recommandé. - 8
- Facultatif : Type de système de fichiers à créer. Valeurs possibles :
ext4(par défaut) ouxfs.
9.3. Modification de la classe de stockage par défaut
Cette procédure permet de modifier la classe de stockage par défaut. Par exemple, vous avez deux classes de stockage définies, gp3 et standard, et vous souhaitez modifier la classe de stockage par défaut de gp3 à standard.
Procédure
Dressez la liste des classes de stockage :
$ oc get storageclassExemple de sortie
NAME TYPE gp3 (default) kubernetes.io/aws-ebs1 standard kubernetes.io/aws-ebs- 1
(default)indique la classe de stockage par défaut.
Changer la valeur de l'annotation
storageclass.kubernetes.io/is-default-classenfalsepour la classe de stockage par défaut :$ oc patch storageclass gp3 -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "false"}}}'Faites d'une autre classe de stockage la classe par défaut en définissant l'annotation
storageclass.kubernetes.io/is-default-classsurtrue:$ oc patch storageclass standard -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'Vérifiez les modifications :
$ oc get storageclassExemple de sortie
NAME TYPE gp3 kubernetes.io/aws-ebs standard (default) kubernetes.io/aws-ebs
9.4. Optimiser le stockage
L'optimisation du stockage permet de minimiser l'utilisation du stockage sur l'ensemble des ressources. En optimisant le stockage, les administrateurs s'assurent que les ressources de stockage existantes fonctionnent de manière efficace.
9.5. Options de stockage permanent disponibles
Comprenez vos options de stockage persistant afin d'optimiser votre environnement OpenShift Container Platform.
| Type de stockage | Description | Examples |
|---|---|---|
| Bloc |
| AWS EBS et VMware vSphere prennent en charge le provisionnement dynamique de volumes persistants (PV) de manière native dans OpenShift Container Platform. |
| Fichier |
| RHEL NFS, NetApp NFS [1] et Vendor NFS |
| Objet |
| AWS S3 |
- NetApp NFS prend en charge le provisionnement dynamique des PV lors de l'utilisation du plugin Trident.
Actuellement, CNS n'est pas pris en charge dans OpenShift Container Platform 4.12.
9.6. Technologie de stockage configurable recommandée
Le tableau suivant résume les technologies de stockage recommandées et configurables pour l'application de cluster OpenShift Container Platform donnée.
| Type de stockage | ROX1 | RWX2 | Registre | Registre échelonné | Métriques3 | Enregistrement | Applications |
|---|---|---|---|---|---|---|---|
|
1
2 3 Prometheus est la technologie sous-jacente utilisée pour les mesures. 4 Cela ne s'applique pas au disque physique, au disque physique de la VM, au VMDK, au loopback sur NFS, à AWS EBS et à Azure Disk.
5 Pour les mesures, l'utilisation du stockage de fichiers avec le mode d'accès 6 Pour la journalisation, consultez la solution de stockage recommandée dans la section Configuration d'un stockage persistant pour le magasin de journaux. L'utilisation du stockage NFS en tant que volume persistant ou via NAS, tel que Gluster, peut corrompre les données. Par conséquent, NFS n'est pas pris en charge pour le stockage Elasticsearch et le magasin de journaux LokiStack dans OpenShift Container Platform Logging. Vous devez utiliser un seul type de volume persistant par magasin de journaux. 7 Le stockage d'objets n'est pas consommé par les PV ou PVC d'OpenShift Container Platform. Les applications doivent s'intégrer à l'API REST de stockage d'objets. | |||||||
| Bloc | Oui4 | Non | Configurable | Non configurable | Recommandé | Recommandé | Recommandé |
| Fichier | Oui4 | Oui | Configurable | Configurable | Configurable5 | Configurable6 | Recommandé |
| Objet | Oui | Oui | Recommandé | Recommandé | Non configurable | Non configurable | Non configurable7 |
Un registre mis à l'échelle est un registre d'images OpenShift dans lequel deux répliques de pods ou plus sont en cours d'exécution.
9.6.1. Recommandations spécifiques pour le stockage des applications
Les tests montrent des problèmes avec l'utilisation du serveur NFS sur Red Hat Enterprise Linux (RHEL) comme backend de stockage pour les services principaux. Cela inclut OpenShift Container Registry et Quay, Prometheus pour la surveillance du stockage, et Elasticsearch pour la journalisation du stockage. Par conséquent, l'utilisation de RHEL NFS pour sauvegarder les PV utilisés par les services principaux n'est pas recommandée.
D'autres implémentations NFS sur le marché peuvent ne pas avoir ces problèmes. Contactez le vendeur de l'implémentation NFS pour plus d'informations sur les tests qui ont pu être réalisés avec ces composants de base d'OpenShift Container Platform.
9.6.1.1. Registre
Dans un déploiement de cluster de registre d'images OpenShift non échelonné/haute disponibilité (HA) :
- La technologie de stockage ne doit pas nécessairement prendre en charge le mode d'accès RWX.
- La technologie de stockage doit garantir la cohérence lecture-écriture.
- La technologie de stockage privilégiée est le stockage d'objets, suivi du stockage de blocs.
- Le stockage de fichiers n'est pas recommandé pour le déploiement d'un cluster de registres d'images OpenShift avec des charges de travail de production.
9.6.1.2. Registre échelonné
Dans un déploiement de cluster de registre d'images OpenShift scaled/HA :
- La technologie de stockage doit prendre en charge le mode d'accès RWX.
- La technologie de stockage doit garantir la cohérence lecture-écriture.
- La technologie de stockage privilégiée est le stockage d'objets.
- Red Hat OpenShift Data Foundation (ODF), Amazon Simple Storage Service (Amazon S3), Google Cloud Storage (GCS), Microsoft Azure Blob Storage et OpenStack Swift sont pris en charge.
- Le stockage d'objets doit être conforme aux normes S3 ou Swift.
- Pour les plateformes non cloud, telles que vSphere et les installations bare metal, la seule technologie configurable est le stockage de fichiers.
- Le stockage en bloc n'est pas configurable.
9.6.1.3. Metrics
Dans un déploiement de cluster de métriques hébergé par OpenShift Container Platform :
- La technologie de stockage privilégiée est le stockage par blocs.
- Le stockage d'objets n'est pas configurable.
Il n'est pas recommandé d'utiliser le stockage de fichiers pour le déploiement d'un cluster de métriques hébergé avec des charges de travail de production.
9.6.1.4. Enregistrement
Dans un déploiement de cluster de journalisation hébergé par OpenShift Container Platform :
- La technologie de stockage privilégiée est le stockage par blocs.
- Le stockage d'objets n'est pas configurable.
9.6.1.5. Applications
Les cas d'utilisation varient d'une application à l'autre, comme le montrent les exemples suivants :
- Les technologies de stockage qui prennent en charge l'approvisionnement dynamique en PV ont des temps de latence de montage faibles et ne sont pas liées aux nœuds, ce qui permet de maintenir une grappe saine.
- Il incombe aux développeurs d'applications de connaître et de comprendre les exigences de leur application en matière de stockage, ainsi que la manière dont elle fonctionne avec le stockage fourni, afin de s'assurer que des problèmes ne surviennent pas lorsqu'une application évolue ou interagit avec la couche de stockage.
9.6.2. Autres recommandations spécifiques en matière de stockage des applications
Il n'est pas recommandé d'utiliser des configurations RAID pour les charges de travail intensives Write, telles que etcd. Si vous utilisez etcd avec une configuration RAID, vous risquez de rencontrer des problèmes de performance avec vos charges de travail.
- Red Hat OpenStack Platform (RHOSP) Cinder : RHOSP Cinder tend à être compétent dans les cas d'utilisation du mode d'accès ROX.
- Bases de données : Les bases de données (SGBDR, bases de données NoSQL, etc.) ont tendance à mieux fonctionner avec un stockage en bloc dédié.
- La base de données etcd doit disposer d'une capacité de stockage et de performances suffisante pour permettre la mise en place d'un grand cluster. Des informations sur les outils de surveillance et d'analyse comparative permettant d'établir une capacité de stockage suffisante et un environnement performant sont décrites à l'adresse suivante : Recommended etcd practices.
9.7. Déployer Red Hat OpenShift Data Foundation
Red Hat OpenShift Data Foundation est un fournisseur de stockage persistant agnostique pour OpenShift Container Platform prenant en charge le stockage de fichiers, de blocs et d'objets, que ce soit en interne ou dans des clouds hybrides. En tant que solution de stockage Red Hat, Red Hat OpenShift Data Foundation est complètement intégré à OpenShift Container Platform pour le déploiement, la gestion et la surveillance.
| Si vous cherchez des informations sur Red Hat OpenShift Data Foundation.. | Consultez la documentation suivante de Red Hat OpenShift Data Foundation : |
|---|---|
| Nouveautés, problèmes connus, corrections de bogues importants et aperçus technologiques | |
| Charges de travail prises en charge, configurations, exigences matérielles et logicielles, recommandations en matière de dimensionnement et de mise à l'échelle | |
| Instructions sur le déploiement d'OpenShift Data Foundation pour utiliser un cluster externe Red Hat Ceph Storage | |
| Instructions sur le déploiement d'OpenShift Data Foundation vers un stockage local sur une infrastructure bare metal | Déployer OpenShift Data Foundation 4.12 en utilisant une infrastructure bare metal |
| Instructions sur le déploiement d'OpenShift Data Foundation sur les clusters VMware vSphere de Red Hat OpenShift Container Platform | |
| Instructions sur le déploiement d'OpenShift Data Foundation à l'aide d'Amazon Web Services pour le stockage local ou dans le nuage | Déployer OpenShift Data Foundation 4.12 avec Amazon Web Services |
| Instructions sur le déploiement et la gestion d'OpenShift Data Foundation sur les clusters Red Hat OpenShift Container Platform Google Cloud existants | Déployer et gérer OpenShift Data Foundation 4.12 avec Google Cloud |
| Instructions sur le déploiement et la gestion d'OpenShift Data Foundation sur les clusters Azure existants de Red Hat OpenShift Container Platform | Déployer et gérer OpenShift Data Foundation 4.12 avec Microsoft Azure |
| Instructions sur le déploiement d'OpenShift Data Foundation pour utiliser le stockage local sur l'infrastructure IBM Power | |
| Instructions sur le déploiement d'OpenShift Data Foundation pour utiliser le stockage local sur l'infrastructure IBM Z | Déployer OpenShift Data Foundation sur une infrastructure IBM Z |
| Allocation de stockage aux services centraux et aux applications hébergées dans Red Hat OpenShift Data Foundation, y compris snapshot et clone | |
| Gérer les ressources de stockage dans un environnement hybride ou multicloud à l'aide de la passerelle Multicloud Object Gateway (NooBaa) | |
| Remplacer en toute sécurité les périphériques de stockage pour Red Hat OpenShift Data Foundation | |
| Remplacer en toute sécurité un nœud dans un cluster Red Hat OpenShift Data Foundation | |
| Opérations de mise à l'échelle dans Red Hat OpenShift Data Foundation | |
| Surveillance d'un cluster Red Hat OpenShift Data Foundation 4.12 | |
| Résoudre les problèmes rencontrés au cours des opérations | |
| Migrer votre cluster OpenShift Container Platform de la version 3 à la version 4 |
Chapitre 10. Préparation des utilisateurs
Après avoir installé OpenShift Container Platform, vous pouvez développer et personnaliser votre cluster en fonction de vos besoins, notamment en prenant des mesures pour préparer les utilisateurs.
10.1. Comprendre la configuration du fournisseur d'identité
Le plan de contrôle d'OpenShift Container Platform comprend un serveur OAuth intégré. Les développeurs et les administrateurs obtiennent des jetons d'accès OAuth pour s'authentifier auprès de l'API.
En tant qu'administrateur, vous pouvez configurer OAuth pour qu'il spécifie un fournisseur d'identité après l'installation de votre cluster.
10.1.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
10.1.2. Fournisseurs d'identité pris en charge
Vous pouvez configurer les types de fournisseurs d'identité suivants :
| Fournisseur d'identité | Description |
|---|---|
|
Configurer le fournisseur d'identité | |
|
Configurez le fournisseur d'identité | |
|
Configurer le fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurez un fournisseur d'identité | |
|
Configurez un fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurer un fournisseur d'identité |
Après avoir défini un fournisseur d'identité, vous pouvez utiliser RBAC pour définir et appliquer des autorisations.
10.1.3. Paramètres du fournisseur d'identité
Les paramètres suivants sont communs à tous les fournisseurs d'identité :
| Paramètres | Description |
|---|---|
|
| Le nom du fournisseur est préfixé aux noms des utilisateurs du fournisseur pour former un nom d'identité. |
|
| Définit la manière dont les nouvelles identités sont associées aux utilisateurs lorsqu'ils se connectent. Entrez l'une des valeurs suivantes :
|
Lorsque vous ajoutez ou modifiez des fournisseurs d'identité, vous pouvez faire correspondre les identités du nouveau fournisseur aux utilisateurs existants en définissant le paramètre mappingMethod sur add.
10.1.4. Exemple de CR de fournisseur d'identité
La ressource personnalisée (CR) suivante montre les paramètres et les valeurs par défaut que vous utilisez pour configurer un fournisseur d'identité. Cet exemple utilise le fournisseur d'identité htpasswd.
Exemple de CR de fournisseur d'identité
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_identity_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret 10.2. Utilisation de RBAC pour définir et appliquer des autorisations
Comprendre et appliquer le contrôle d'accès basé sur les rôles.
10.2.1. Vue d'ensemble de RBAC
Les objets de contrôle d'accès basé sur les rôles (RBAC) déterminent si un utilisateur est autorisé à effectuer une action donnée au sein d'un projet.
Les administrateurs de cluster peuvent utiliser les rôles de cluster et les bindings pour contrôler qui a différents niveaux d'accès à la plateforme OpenShift Container Platform elle-même et à tous les projets.
Les développeurs peuvent utiliser des rôles et des liens locaux pour contrôler qui a accès à leurs projets. Notez que l'autorisation est une étape distincte de l'authentification, qui consiste plutôt à déterminer l'identité de la personne qui effectue l'action.
L'autorisation est gérée à l'aide de :
| Objet d'autorisation | Description |
|---|---|
| Règles |
Ensemble de verbes autorisés sur un ensemble d'objets. Par exemple, si un compte d'utilisateur ou de service peut |
| Rôles | Collections de règles. Vous pouvez associer, ou lier, des utilisateurs et des groupes à plusieurs rôles. |
| Fixations | Associations entre des utilisateurs et/ou des groupes ayant un rôle. |
Il existe deux niveaux de rôles et de liaisons RBAC qui contrôlent l'autorisation :
| Niveau RBAC | Description |
|---|---|
| Cluster RBAC | Rôles et liaisons applicables à tous les projets. Cluster roles existe à l'échelle du cluster, et cluster role bindings ne peut faire référence qu'à des rôles du cluster. |
| RBAC local | Rôles et liaisons qui sont liés à un projet donné. Alors que local roles n'existe que dans un seul projet, les liaisons de rôles locaux peuvent faire référence à both et aux rôles locaux. |
Un lien de rôle de cluster est un lien qui existe au niveau du cluster. Un lien de rôle existe au niveau du projet. Le rôle de cluster view doit être lié à un utilisateur à l'aide d'une liaison de rôle locale pour que cet utilisateur puisse consulter le projet. Ne créez des rôles locaux que si un rôle de cluster ne fournit pas l'ensemble des autorisations nécessaires dans une situation particulière.
Cette hiérarchie à deux niveaux permet la réutilisation dans plusieurs projets grâce aux rôles de groupe, tout en permettant la personnalisation au sein des projets individuels grâce aux rôles locaux.
Lors de l'évaluation, on utilise à la fois les liaisons de rôles de la grappe et les liaisons de rôles locales. Par exemple :
- Les règles d'autorisation à l'échelle du groupe sont vérifiées.
- Les règles locales d'autorisation sont vérifiées.
- Refusé par défaut.
10.2.1.1. Rôles par défaut des clusters
OpenShift Container Platform inclut un ensemble de rôles de cluster par défaut que vous pouvez lier à des utilisateurs et des groupes à l'échelle du cluster ou localement.
Il n'est pas recommandé de modifier manuellement les rôles par défaut des clusters. La modification de ces rôles système peut empêcher le bon fonctionnement d'un cluster.
| Rôle de la grappe par défaut | Description |
|---|---|
|
|
Un chef de projet. S'il est utilisé dans un lien local, un |
|
| Un utilisateur qui peut obtenir des informations de base sur les projets et les utilisateurs. |
|
| Un super-utilisateur qui peut effectuer n'importe quelle action dans n'importe quel projet. Lorsqu'il est lié à un utilisateur avec un lien local, il a le contrôle total des quotas et de toutes les actions sur toutes les ressources du projet. |
|
| Un utilisateur qui peut obtenir des informations de base sur l'état de la grappe. |
|
| Un utilisateur qui peut obtenir ou visualiser la plupart des objets mais ne peut pas les modifier. |
|
| Un utilisateur qui peut modifier la plupart des objets d'un projet mais qui n'a pas le pouvoir de visualiser ou de modifier les rôles ou les liaisons. |
|
| Un utilisateur qui peut créer ses propres projets. |
|
| Un utilisateur qui ne peut effectuer aucune modification, mais qui peut voir la plupart des objets d'un projet. Il ne peut pas voir ou modifier les rôles ou les liaisons. |
Soyez attentif à la différence entre les liaisons locales et les liaisons de grappe. Par exemple, si vous liez le rôle cluster-admin à un utilisateur à l'aide d'une liaison de rôle locale, il peut sembler que cet utilisateur dispose des privilèges d'un administrateur de cluster. Ce n'est pas le cas. La liaison du rôle cluster-admin à un utilisateur dans un projet accorde à l'utilisateur des privilèges de super administrateur pour ce projet uniquement. Cet utilisateur dispose des autorisations du rôle de cluster admin, ainsi que de quelques autorisations supplémentaires, comme la possibilité de modifier les limites de taux, pour ce projet. Cette liaison peut être déroutante via l'interface utilisateur de la console Web, qui ne répertorie pas les liaisons de rôles de cluster qui sont liées à de véritables administrateurs de cluster. Cependant, elle répertorie les liaisons de rôles locaux que vous pouvez utiliser pour lier localement cluster-admin.
Les relations entre les rôles de grappe, les rôles locaux, les liaisons de rôles de grappe, les liaisons de rôles locaux, les utilisateurs, les groupes et les comptes de service sont illustrées ci-dessous.
Les règles get pods/exec, get pods/* et get * accordent des privilèges d'exécution lorsqu'elles sont appliquées à un rôle. Appliquez le principe du moindre privilège et n'attribuez que les droits RBAC minimaux requis pour les utilisateurs et les agents. Pour plus d'informations, voir Règles RBAC autorisant les privilèges d'exécution.
10.2.1.2. Évaluation de l'autorisation
OpenShift Container Platform évalue l'autorisation en utilisant :
- Identité
- Le nom de l'utilisateur et la liste des groupes auxquels il appartient.
- Action
L'action que vous effectuez. Dans la plupart des cas, il s'agit de
- Project: Le projet auquel vous accédez. Un projet est un espace de noms Kubernetes avec des annotations supplémentaires qui permet à une communauté d'utilisateurs d'organiser et de gérer leur contenu de manière isolée par rapport à d'autres communautés.
-
Verb: L'action elle-même :
get,list,create,update,delete,deletecollection, ouwatch. - Resource name: Le point de terminaison de l'API auquel vous accédez.
- Fixations
- La liste complète des liens, les associations entre les utilisateurs ou les groupes avec un rôle.
OpenShift Container Platform évalue l'autorisation en utilisant les étapes suivantes :
- L'identité et l'action à l'échelle du projet sont utilisées pour trouver toutes les liaisons qui s'appliquent à l'utilisateur ou à ses groupes.
- Les liaisons sont utilisées pour localiser tous les rôles qui s'appliquent.
- Les rôles sont utilisés pour trouver toutes les règles qui s'appliquent.
- L'action est comparée à chaque règle pour trouver une correspondance.
- Si aucune règle correspondante n'est trouvée, l'action est alors refusée par défaut.
N'oubliez pas que les utilisateurs et les groupes peuvent être associés ou liés à plusieurs rôles à la fois.
Les administrateurs de projet peuvent utiliser l'interface de programmation pour visualiser les rôles locaux et les liaisons, y compris une matrice des verbes et des ressources associés à chacun d'entre eux.
Le rôle de cluster lié à l'administrateur de projet est limité dans un projet par un lien local. Il n'est pas lié à l'ensemble du cluster comme les rôles de cluster accordés à cluster-admin ou system:admin.
Les rôles de cluster sont des rôles définis au niveau du cluster, mais qui peuvent être liés soit au niveau du cluster, soit au niveau du projet.
10.2.1.2.1. Agrégation des rôles des clusters
Les rôles de cluster par défaut admin, edit, view et cluster-reader prennent en charge l'agrégation des rôles de cluster, où les règles de cluster pour chaque rôle sont mises à jour dynamiquement au fur et à mesure que de nouvelles règles sont créées. Cette fonctionnalité n'est pertinente que si vous étendez l'API Kubernetes en créant des ressources personnalisées.
10.2.2. Projets et espaces de noms
Un espace de noms Kubernetes namespace fournit un mécanisme permettant de délimiter les ressources dans un cluster. La documentation de Kubernetes contient plus d'informations sur les espaces de noms.
Les espaces de noms fournissent un champ d'application unique pour les :
- Ressources nommées pour éviter les collisions de noms de base.
- Délégation de l'autorité de gestion à des utilisateurs de confiance.
- La possibilité de limiter la consommation des ressources communautaires.
La plupart des objets du système sont délimités par l'espace de noms, mais certains sont exclus et n'ont pas d'espace de noms, notamment les nœuds et les utilisateurs.
Un project est un espace de noms Kubernetes avec des annotations supplémentaires et est le véhicule central par lequel l'accès aux ressources pour les utilisateurs réguliers est géré. Un projet permet à une communauté d'utilisateurs d'organiser et de gérer son contenu indépendamment des autres communautés. Les utilisateurs doivent se voir accorder l'accès aux projets par les administrateurs ou, s'ils sont autorisés à créer des projets, ont automatiquement accès à leurs propres projets.
Les projets peuvent avoir des name, displayName et description distincts.
-
Le nom obligatoire
nameest un identifiant unique pour le projet et est le plus visible lors de l'utilisation des outils CLI ou de l'API. La longueur maximale du nom est de 63 caractères. -
L'option
displayNameindique comment le projet est affiché dans la console web (la valeur par défaut estname). -
Le site optionnel
descriptionpeut être une description plus détaillée du projet et est également visible dans la console web.
Chaque projet a son propre ensemble d'objectifs :
| Objet | Description |
|---|---|
|
| Pods, services, contrôleurs de réplication, etc. |
|
| Règles selon lesquelles les utilisateurs peuvent ou ne peuvent pas effectuer des actions sur les objets. |
|
| Quotas pour chaque type d'objet pouvant être limité. |
|
| Les comptes de service agissent automatiquement avec un accès désigné aux objets du projet. |
Les administrateurs de clusters peuvent créer des projets et déléguer les droits d'administration du projet à n'importe quel membre de la communauté des utilisateurs. Les administrateurs de clusters peuvent également autoriser les développeurs à créer leurs propres projets.
Les développeurs et les administrateurs peuvent interagir avec les projets en utilisant le CLI ou la console web.
10.2.3. Projets par défaut
OpenShift Container Platform est livré avec un certain nombre de projets par défaut, et les projets commençant par openshift- sont les plus essentiels pour les utilisateurs. Ces projets hébergent des composants maîtres qui s'exécutent sous forme de pods et d'autres composants d'infrastructure. Les pods créés dans ces espaces de noms qui ont une annotation de pod critique sont considérés comme critiques, et leur admission est garantie par kubelet. Les pods créés pour les composants maîtres dans ces espaces de noms sont déjà marqués comme critiques.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
10.2.4. Visualisation des rôles et des liaisons des clusters
Vous pouvez utiliser l'interface CLI de oc pour visualiser les rôles et les liaisons des clusters à l'aide de la commande oc describe.
Conditions préalables
-
Installez le CLI
oc. - Obtenir l'autorisation de visualiser les rôles et les liaisons du cluster.
Les utilisateurs ayant le rôle de cluster par défaut cluster-admin lié à l'ensemble du cluster peuvent effectuer n'importe quelle action sur n'importe quelle ressource, y compris la visualisation des rôles de cluster et des liaisons.
Procédure
Pour afficher les rôles de la grappe et les ensembles de règles qui leur sont associés :
$ oc describe clusterrole.rbacExemple de sortie
Name: admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- .packages.apps.redhat.com [] [] [* create update patch delete get list watch] imagestreams [] [] [create delete deletecollection get list patch update watch create get list watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch create get list watch] secrets [] [] [create delete deletecollection get list patch update watch get list watch create delete deletecollection patch update] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates [] [] [create delete deletecollection get list patch update watch get list watch] routes [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances [] [] [create delete deletecollection get list patch update watch get list watch] templates [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate create delete deletecollection patch update get list watch] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] networkpolicies.extensions [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] networkpolicies.networking.k8s.io [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] configmaps [] [] [create delete deletecollection patch update get list watch] endpoints [] [] [create delete deletecollection patch update get list watch] persistentvolumeclaims [] [] [create delete deletecollection patch update get list watch] pods [] [] [create delete deletecollection patch update get list watch] replicationcontrollers/scale [] [] [create delete deletecollection patch update get list watch] replicationcontrollers [] [] [create delete deletecollection patch update get list watch] services [] [] [create delete deletecollection patch update get list watch] daemonsets.apps [] [] [create delete deletecollection patch update get list watch] deployments.apps/scale [] [] [create delete deletecollection patch update get list watch] deployments.apps [] [] [create delete deletecollection patch update get list watch] replicasets.apps/scale [] [] [create delete deletecollection patch update get list watch] replicasets.apps [] [] [create delete deletecollection patch update get list watch] statefulsets.apps/scale [] [] [create delete deletecollection patch update get list watch] statefulsets.apps [] [] [create delete deletecollection patch update get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection patch update get list watch] cronjobs.batch [] [] [create delete deletecollection patch update get list watch] jobs.batch [] [] [create delete deletecollection patch update get list watch] daemonsets.extensions [] [] [create delete deletecollection patch update get list watch] deployments.extensions/scale [] [] [create delete deletecollection patch update get list watch] deployments.extensions [] [] [create delete deletecollection patch update get list watch] ingresses.extensions [] [] [create delete deletecollection patch update get list watch] replicasets.extensions/scale [] [] [create delete deletecollection patch update get list watch] replicasets.extensions [] [] [create delete deletecollection patch update get list watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection patch update get list watch] poddisruptionbudgets.policy [] [] [create delete deletecollection patch update get list watch] deployments.apps/rollback [] [] [create delete deletecollection patch update] deployments.extensions/rollback [] [] [create delete deletecollection patch update] catalogsources.operators.coreos.com [] [] [create update patch delete get list watch] clusterserviceversions.operators.coreos.com [] [] [create update patch delete get list watch] installplans.operators.coreos.com [] [] [create update patch delete get list watch] packagemanifests.operators.coreos.com [] [] [create update patch delete get list watch] subscriptions.operators.coreos.com [] [] [create update patch delete get list watch] buildconfigs/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] builds/clone [] [] [create] deploymentconfigrollbacks [] [] [create] deploymentconfigs/instantiate [] [] [create] deploymentconfigs/rollback [] [] [create] imagestreamimports [] [] [create] localresourceaccessreviews [] [] [create] localsubjectaccessreviews [] [] [create] podsecuritypolicyreviews [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicysubjectreviews [] [] [create] resourceaccessreviews [] [] [create] routes/custom-host [] [] [create] subjectaccessreviews [] [] [create] subjectrulesreviews [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] builds.build.openshift.io/clone [] [] [create] imagestreamimports.image.openshift.io [] [] [create] routes.route.openshift.io/custom-host [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] jenkins.build.openshift.io [] [] [edit view view admin edit view] builds [] [] [get create delete deletecollection get list patch update watch get list watch] builds.build.openshift.io [] [] [get create delete deletecollection get list patch update watch get list watch] projects [] [] [get delete get delete get patch update] projects.project.openshift.io [] [] [get delete get delete get patch update] namespaces [] [] [get get list watch] pods/attach [] [] [get list watch create delete deletecollection patch update] pods/exec [] [] [get list watch create delete deletecollection patch update] pods/portforward [] [] [get list watch create delete deletecollection patch update] pods/proxy [] [] [get list watch create delete deletecollection patch update] services/proxy [] [] [get list watch create delete deletecollection patch update] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] appliedclusterresourcequotas [] [] [get list watch] bindings [] [] [get list watch] builds/log [] [] [get list watch] deploymentconfigs/log [] [] [get list watch] deploymentconfigs/status [] [] [get list watch] events [] [] [get list watch] imagestreams/status [] [] [get list watch] limitranges [] [] [get list watch] namespaces/status [] [] [get list watch] pods/log [] [] [get list watch] pods/status [] [] [get list watch] replicationcontrollers/status [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotas [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] controllerrevisions.apps [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] imagestreams/layers [] [] [get update get] imagestreams.image.openshift.io/layers [] [] [get update get] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] Name: basic-user Labels: <none> Annotations: openshift.io/description: A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- selfsubjectrulesreviews [] [] [create] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- *.* [] [] [*] [*] [] [*] ...Pour afficher l'ensemble actuel des liaisons de rôles de cluster, qui montre les utilisateurs et les groupes liés à divers rôles :
$ oc describe clusterrolebinding.rbacExemple de sortie
Name: alertmanager-main Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: alertmanager-main Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount alertmanager-main openshift-monitoring Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cloud-credential-operator-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cloud-credential-operator-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-cloud-credential-operator Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-api-manager-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cluster-api-manager-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-machine-api ...
10.2.5. Visualisation des rôles et des liens locaux
Vous pouvez utiliser l'interface de gestion de oc pour afficher les rôles et les liens locaux à l'aide de la commande oc describe.
Conditions préalables
-
Installez le CLI
oc. Obtenir l'autorisation de visualiser les rôles et les liens locaux :
-
Les utilisateurs ayant le rôle de cluster par défaut
cluster-admin, lié à l'ensemble du cluster, peuvent effectuer n'importe quelle action sur n'importe quelle ressource, y compris la visualisation des rôles locaux et des liaisons. -
Les utilisateurs ayant le rôle de cluster par défaut
adminlié localement peuvent voir et gérer les rôles et les liaisons dans ce projet.
-
Les utilisateurs ayant le rôle de cluster par défaut
Procédure
Pour afficher l'ensemble actuel des liaisons de rôle locales, qui montrent les utilisateurs et les groupes liés à divers rôles pour le projet en cours :
$ oc describe rolebinding.rbacPour afficher les rôles locaux d'un autre projet, ajoutez le drapeau
-nà la commande :$ oc describe rolebinding.rbac -n joe-projectExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
10.2.6. Ajouter des rôles aux utilisateurs
Vous pouvez utiliser le CLI de l'administrateur oc adm pour gérer les rôles et les liaisons.
Le fait de lier ou d'ajouter un rôle à des utilisateurs ou à des groupes donne à l'utilisateur ou au groupe l'accès accordé par le rôle. Vous pouvez ajouter et supprimer des rôles à des utilisateurs et à des groupes à l'aide des commandes oc adm policy.
Vous pouvez lier n'importe lequel des rôles de cluster par défaut à des utilisateurs ou groupes locaux dans votre projet.
Procédure
Ajouter un rôle à un utilisateur dans un projet spécifique :
$ oc adm policy add-role-to-user <role> <user> -n <project>Par exemple, vous pouvez ajouter le rôle
adminà l'utilisateuralicedans le projetjoeen exécutant :$ oc adm policy add-role-to-user admin alice -n joeAstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle à l'utilisateur :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: admin-0 namespace: joe roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: aliceAffichez les liaisons de rôle locales et vérifiez l'ajout dans la sortie :
$ oc describe rolebinding.rbac -n <projet>Par exemple, pour afficher les attributions de rôles locaux pour le projet
joe:$ oc describe rolebinding.rbac -n joeExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: admin-0 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice1 Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe- 1
- L'utilisateur
alicea été ajouté à l'utilisateuradminsRoleBinding.
10.2.7. Création d'un rôle local
Vous pouvez créer un rôle local pour un projet et le lier à un utilisateur.
Procédure
Pour créer un rôle local pour un projet, exécutez la commande suivante :
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>Dans cette commande, spécifiez :
-
<name>le nom du rôle local -
<verb>une liste de verbes à appliquer au rôle, séparés par des virgules -
<resource>les ressources auxquelles le rôle s'applique -
<project>, le nom du projet
Par exemple, pour créer un rôle local permettant à un utilisateur de visualiser les pods du projet
blue, exécutez la commande suivante :$ oc create role podview --verb=get --resource=pod -n blue-
Pour lier le nouveau rôle à un utilisateur, exécutez la commande suivante :
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
10.2.8. Création d'un rôle de cluster
Vous pouvez créer un rôle de cluster.
Procédure
Pour créer un rôle de cluster, exécutez la commande suivante :
oc create clusterrole <name> --verb=<verb> --resource=<resource> $ oc create clustersrole <name> --verb=<verb>Dans cette commande, spécifiez :
-
<name>le nom du rôle local -
<verb>une liste de verbes à appliquer au rôle, séparés par des virgules -
<resource>les ressources auxquelles le rôle s'applique
Par exemple, pour créer un rôle de cluster permettant à un utilisateur de visualiser les pods, exécutez la commande suivante :
$ oc create clusterrole podviewonly --verb=get --resource=pod-
10.2.9. Commandes de liaison des rôles locaux
Lorsque vous gérez les rôles associés à un utilisateur ou à un groupe pour les liaisons de rôles locales à l'aide des opérations suivantes, un projet peut être spécifié à l'aide de l'indicateur -n. S'il n'est pas spécifié, c'est le projet actuel qui est utilisé.
Vous pouvez utiliser les commandes suivantes pour la gestion locale de RBAC.
| Commandement | Description |
|---|---|
|
| Indique quels utilisateurs peuvent effectuer une action sur une ressource. |
|
| Associe un rôle spécifique à des utilisateurs spécifiques dans le projet en cours. |
|
| Supprime un rôle donné aux utilisateurs spécifiés dans le projet en cours. |
|
| Supprime les utilisateurs spécifiés et tous leurs rôles dans le projet en cours. |
|
| Relie un rôle donné aux groupes spécifiés dans le projet en cours. |
|
| Supprime un rôle donné des groupes spécifiés dans le projet en cours. |
|
| Supprime les groupes spécifiés et tous leurs rôles dans le projet en cours. |
10.2.10. Commandes de liaison des rôles de cluster
Vous pouvez également gérer les liaisons de rôles de cluster à l'aide des opérations suivantes. L'indicateur -n n'est pas utilisé pour ces opérations car les liaisons de rôles de cluster utilisent des ressources non espacées.
| Commandement | Description |
|---|---|
|
| Lie un rôle donné aux utilisateurs spécifiés pour tous les projets du cluster. |
|
| Supprime un rôle donné aux utilisateurs spécifiés pour tous les projets du cluster. |
|
| Lie un rôle donné aux groupes spécifiés pour tous les projets du cluster. |
|
| Supprime un rôle donné des groupes spécifiés pour tous les projets du cluster. |
10.2.11. Création d'un administrateur de cluster
Le rôle cluster-admin est nécessaire pour effectuer des tâches de niveau administrateur sur le cluster OpenShift Container Platform, telles que la modification des ressources du cluster.
Conditions préalables
- Vous devez avoir créé un utilisateur à définir comme administrateur du cluster.
Procédure
Définir l'utilisateur comme administrateur de cluster :
$ oc adm policy add-cluster-role-to-user cluster-admin <user>
10.3. L'utilisateur kubeadmin
OpenShift Container Platform crée un administrateur de cluster, kubeadmin, une fois le processus d'installation terminé.
Cet utilisateur a le rôle cluster-admin automatiquement appliqué et est traité comme l'utilisateur racine pour le cluster. Le mot de passe est généré dynamiquement et unique à votre environnement OpenShift Container Platform. Une fois l'installation terminée, le mot de passe est fourni dans la sortie du programme d'installation. Par exemple, le mot de passe est généré dynamiquement et est unique à votre environnement OpenShift Container Platform :
INFO Install complete!
INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI.
INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes).
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com
INFO Login to the console with user: kubeadmin, password: <provided>10.3.1. Suppression de l'utilisateur kubeadmin
Après avoir défini un fournisseur d'identité et créé un nouvel utilisateur cluster-admin, vous pouvez supprimer le site kubeadmin pour améliorer la sécurité du cluster.
Si vous suivez cette procédure avant qu'un autre utilisateur ne soit cluster-admin, OpenShift Container Platform doit être réinstallé. Il n'est pas possible d'annuler cette commande.
Conditions préalables
- Vous devez avoir configuré au moins un fournisseur d'identité.
-
Vous devez avoir ajouté le rôle
cluster-adminà un utilisateur. - Vous devez être connecté en tant qu'administrateur.
Procédure
Supprimez les secrets de
kubeadmin:$ oc delete secrets kubeadmin -n kube-system
10.4. Configuration de l'image
Comprendre et configurer les paramètres du registre des images.
10.4.1. Paramètres de configuration du contrôleur d'images
La ressource image.config.openshift.io/cluster contient des informations à l'échelle du cluster sur la manière de gérer les images. Le nom canonique, et le seul valide, est cluster. La ressource spec offre les paramètres de configuration suivants.
Les paramètres tels que DisableScheduledImport, MaxImagesBulkImportedPerRepository, MaxScheduledImportsPerMinute, ScheduledImageImportMinimumIntervalSeconds, InternalRegistryHostname ne sont pas configurables.
| Paramètres | Description |
|---|---|
|
|
Limite les registres d'images de conteneurs à partir desquels les utilisateurs normaux peuvent importer des images. Définissez cette liste en fonction des registres dont vous pensez qu'ils contiennent des images valides et à partir desquels vous souhaitez que les applications puissent importer des images. Les utilisateurs autorisés à créer des images ou Chaque élément de cette liste contient un emplacement du registre spécifié par le nom de domaine du registre.
|
|
|
Une référence à une carte de configuration contenant des autorités de certification supplémentaires qui doivent être approuvées pendant
L'espace de noms de cette carte de configuration est |
|
|
Fournit les noms d'hôtes pour le registre d'images externe par défaut. Le nom d'hôte externe ne doit être défini que lorsque le registre d'images est exposé à l'extérieur. La première valeur est utilisée dans le champ |
|
| Contient la configuration qui détermine comment le runtime du conteneur doit traiter les registres individuels lors de l'accès aux images pour les builds et les pods. Par exemple, l'autorisation ou non d'un accès non sécurisé. Il ne contient pas de configuration pour le registre interne du cluster.
Il est possible de définir soit |
Lorsque le paramètre allowedRegistries est défini, tous les registres, y compris les registres registry.redhat.io et quay.io et le registre d'image OpenShift par défaut, sont bloqués sauf s'ils sont explicitement listés. Lors de l'utilisation du paramètre, pour éviter un échec du pod, ajoutez tous les registres, y compris les registres registry.redhat.io et quay.io et la liste internalRegistryHostname à allowedRegistries, car ils sont requis par les images de charge utile dans votre environnement. Pour les clusters déconnectés, les registres miroirs doivent également être ajoutés.
Le champ status de la ressource image.config.openshift.io/cluster contient les valeurs observées de la grappe.
| Paramètres | Description |
|---|---|
|
|
Défini par l'opérateur de registre d'images, qui contrôle le registre d'images |
|
|
Défini par l'opérateur du registre d'images, il fournit les noms d'hôtes externes pour le registre d'images lorsqu'il est exposé à l'extérieur. La première valeur est utilisée dans le champ |
10.4.2. Configuration des paramètres du registre des images
Vous pouvez configurer les paramètres du registre d'images en modifiant la ressource personnalisée (CR) image.config.openshift.io/cluster. Lorsque les modifications apportées au registre sont appliquées à la CR image.config.openshift.io/cluster, l'opérateur de configuration de la machine (MCO) effectue les actions séquentielles suivantes :
- Cordons du nœud
- Applique les modifications en redémarrant CRI-O
Uncordons le nœud
NoteLe MCO ne redémarre pas les nœuds lorsqu'il détecte des changements.
Procédure
Modifiez la ressource personnalisée
image.config.openshift.io/cluster:$ oc edit image.config.openshift.io/clusterVoici un exemple de
image.config.openshift.io/clusterCR :apiVersion: config.openshift.io/v1 kind: Image1 metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2019-05-17T13:44:26Z" generation: 1 name: cluster resourceVersion: "8302" selfLink: /apis/config.openshift.io/v1/images/cluster uid: e34555da-78a9-11e9-b92b-06d6c7da38dc spec: allowedRegistriesForImport:2 - domainName: quay.io insecure: false additionalTrustedCA:3 name: myconfigmap registrySources:4 allowedRegistries: - example.com - quay.io - registry.redhat.io - image-registry.openshift-image-registry.svc:5000 - reg1.io/myrepo/myapp:latest insecureRegistries: - insecure.com status: internalRegistryHostname: image-registry.openshift-image-registry.svc:5000- 1
Image: Contient des informations à l'échelle du cluster sur la manière de gérer les images. Le nom canonique, et le seul valide, estcluster.- 2
allowedRegistriesForImport: Limite les registres d'images de conteneurs à partir desquels les utilisateurs normaux peuvent importer des images. Définissez cette liste en fonction des registres dont vous pensez qu'ils contiennent des images valides et à partir desquels vous souhaitez que les applications puissent importer des images. Les utilisateurs autorisés à créer des images ouImageStreamMappingsà partir de l'API ne sont pas concernés par cette politique. En général, seuls les administrateurs de clusters disposent des autorisations appropriées.- 3
additionalTrustedCA: Une référence à une carte de configuration contenant des autorités de certification (AC) supplémentaires qui sont approuvées lors de l'importation de flux d'images, de l'extraction d'images de pods, de l'extraction deopenshift-image-registryet des constructions. L'espace de noms pour cette carte de configuration estopenshift-config. Le format de la carte de configuration consiste à utiliser le nom d'hôte du registre comme clé et le certificat PEM comme valeur, pour chaque autorité de certification de registre supplémentaire à laquelle il faut faire confiance.- 4
registrySources: Contient la configuration qui détermine si le runtime du conteneur autorise ou bloque les registres individuels lors de l'accès aux images pour les builds et les pods. Le paramètreallowedRegistriesou le paramètreblockedRegistriespeut être défini, mais pas les deux. Vous pouvez également définir s'il faut ou non autoriser l'accès aux registres non sécurisés ou aux registres qui autorisent les registres utilisant des noms courts d'images. Cet exemple utilise le paramètreallowedRegistries, qui définit les registres dont l'utilisation est autorisée. Le registre non sécuriséinsecure.comest également autorisé. Le paramètreregistrySourcesne contient pas de configuration pour le registre interne du cluster.
NoteLorsque le paramètre
allowedRegistriesest défini, tous les registres, y compris les registres registry.redhat.io et quay.io et le registre d'image OpenShift par défaut, sont bloqués sauf s'ils sont explicitement répertoriés. Si vous utilisez ce paramètre, pour éviter une défaillance du pod, vous devez ajouter les registresregistry.redhat.ioetquay.ioet la listeinternalRegistryHostnameàallowedRegistries, car ils sont requis par les images de charge utile dans votre environnement. N'ajoutez pas les registresregistry.redhat.ioetquay.ioà la listeblockedRegistries.En utilisant les paramètres
allowedRegistries,blockedRegistriesouinsecureRegistries, vous pouvez spécifier un référentiel individuel au sein d'un registre. Par exemple :reg1.io/myrepo/myapp:latest.Les registres externes non sécurisés doivent être évités afin de réduire les risques éventuels pour la sécurité.
Pour vérifier que les modifications ont été appliquées, dressez la liste de vos nœuds :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-137-182.us-east-2.compute.internal Ready,SchedulingDisabled worker 65m v1.25.4+77bec7a ip-10-0-139-120.us-east-2.compute.internal Ready,SchedulingDisabled control-plane 74m v1.25.4+77bec7a ip-10-0-176-102.us-east-2.compute.internal Ready control-plane 75m v1.25.4+77bec7a ip-10-0-188-96.us-east-2.compute.internal Ready worker 65m v1.25.4+77bec7a ip-10-0-200-59.us-east-2.compute.internal Ready worker 63m v1.25.4+77bec7a ip-10-0-223-123.us-east-2.compute.internal Ready control-plane 73m v1.25.4+77bec7a
Pour plus d'informations sur les paramètres de registre autorisés, bloqués et non sécurisés, voir Configuration des paramètres du registre des images.
10.4.2.1. Configuration de magasins de confiance supplémentaires pour l'accès au registre d'images
La ressource personnalisée image.config.openshift.io/cluster peut contenir une référence à une carte de configuration qui contient des autorités de certification supplémentaires à approuver lors de l'accès au registre d'images.
Conditions préalables
- Les autorités de certification (CA) doivent être codées en PEM.
Procédure
Vous pouvez créer une carte de configuration dans l'espace de noms openshift-config et utiliser son nom dans AdditionalTrustedCA dans la ressource personnalisée image.config.openshift.io pour fournir des autorités de certification supplémentaires qui doivent être approuvées lorsqu'elles contactent des registres externes.
La clé de configuration est le nom d'hôte d'un registre avec le port pour lequel cette autorité de certification doit être approuvée, et le contenu du certificat PEM est la valeur, pour chaque autorité de certification de registre supplémentaire à approuver.
Registre d'images Exemple de carte de configuration de l'autorité de certification
apiVersion: v1
kind: ConfigMap
metadata:
name: my-registry-ca
data:
registry.example.com: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
registry-with-port.example.com..5000: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE------ 1
- Si le registre comporte le port, tel que
registry-with-port.example.com:5000,:doit être remplacé par...
Vous pouvez configurer des autorités de certification supplémentaires en suivant la procédure suivante.
Pour configurer une autorité de certification supplémentaire :
$ oc create configmap registry-config --from-file=<external_registry_address>=ca.crt -n openshift-config$ oc edit image.config.openshift.io clusterspec: additionalTrustedCA: name: registry-config
10.4.2.2. Configuration de la mise en miroir du référentiel du registre d'images
La configuration de la mise en miroir du référentiel du registre des conteneurs vous permet d'effectuer les opérations suivantes :
- Configurez votre cluster OpenShift Container Platform pour rediriger les demandes d'extraction d'images à partir d'un dépôt sur un registre d'images source et les faire résoudre par un dépôt sur un registre d'images miroir.
- Identifier plusieurs référentiels miroirs pour chaque référentiel cible, afin de s'assurer que si un miroir est en panne, un autre peut être utilisé.
Les attributs de la mise en miroir de référentiel dans OpenShift Container Platform sont les suivants :
- Les extractions d'images résistent aux interruptions du registre.
- Les clusters situés dans des environnements déconnectés peuvent extraire des images de sites critiques, tels que quay.io, et demander aux registres situés derrière le pare-feu de l'entreprise de fournir les images demandées.
- Un ordre particulier de registres est essayé lorsqu'une demande d'extraction d'image est faite, le registre permanent étant généralement le dernier essayé.
-
Les informations sur le miroir que vous saisissez sont ajoutées au fichier
/etc/containers/registries.confsur chaque nœud du cluster OpenShift Container Platform. - Lorsqu'un nœud demande une image à partir du référentiel source, il essaie chaque référentiel miroir à tour de rôle jusqu'à ce qu'il trouve le contenu demandé. Si tous les miroirs échouent, le cluster essaie le référentiel source. En cas de succès, l'image est transférée au nœud.
La configuration de la mise en miroir du référentiel peut se faire de la manière suivante :
A l'installation d'OpenShift Container Platform :
En extrayant les images de conteneurs nécessaires à OpenShift Container Platform, puis en amenant ces images derrière le pare-feu de votre entreprise, vous pouvez installer OpenShift Container Platform dans un centre de données qui se trouve dans un environnement déconnecté.
Après l'installation d'OpenShift Container Platform :
Même si vous ne configurez pas la mise en miroir lors de l'installation d'OpenShift Container Platform, vous pouvez le faire plus tard en utilisant l'objet
ImageContentSourcePolicy.
La procédure suivante fournit une configuration miroir post-installation, dans laquelle vous créez un objet ImageContentSourcePolicy qui identifie :
- La source du référentiel d'images de conteneurs que vous souhaitez mettre en miroir.
- Une entrée distincte pour chaque référentiel miroir dans lequel vous souhaitez proposer le contenu demandé au référentiel source.
Vous ne pouvez configurer des secrets de tirage globaux que pour les clusters qui ont un objet ImageContentSourcePolicy. Vous ne pouvez pas ajouter un secret d'extraction à un projet.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Configurer les référentiels miroirs, en utilisant l'un ou l'autre :
- La configuration d'un référentiel miroir avec Red Hat Quay, comme décrit dans Red Hat Quay Repository Mirroring. L'utilisation de Red Hat Quay vous permet de copier des images d'un référentiel vers un autre et de synchroniser automatiquement ces référentiels de manière répétée au fil du temps.
Utilisation d'un outil tel que
skopeopour copier manuellement les images du répertoire source vers le référentiel miroir.Par exemple, après avoir installé le paquetage RPM skopeo sur un système Red Hat Enterprise Linux (RHEL) 7 ou RHEL 8, utilisez la commande
skopeocomme indiqué dans cet exemple :$ skopeo copy \ docker://registry.access.redhat.com/ubi8/ubi-minimal@sha256:5cfbaf45ca96806917830c183e9f37df2e913b187adb32e89fd83fa455ebaa6 \ docker://example.io/example/ubi-minimalDans cet exemple, vous avez un registre d'images de conteneurs nommé
example.ioavec un dépôt d'images nomméexampledans lequel vous voulez copier l'imageubi8/ubi-minimalà partir deregistry.access.redhat.com. Après avoir créé le registre, vous pouvez configurer votre cluster OpenShift Container Platform pour rediriger les requêtes faites sur le dépôt source vers le dépôt miroir.
- Connectez-vous à votre cluster OpenShift Container Platform.
Créez un fichier
ImageContentSourcePolicy(par exemple,registryrepomirror.yaml), en remplaçant la source et les miroirs par vos propres paires et images de registres et de référentiels :apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: ubi8repo spec: repositoryDigestMirrors: - mirrors: - example.io/example/ubi-minimal1 - example.com/example/ubi-minimal2 source: registry.access.redhat.com/ubi8/ubi-minimal3 - mirrors: - mirror.example.com/redhat source: registry.redhat.io/openshift44 - mirrors: - mirror.example.com source: registry.redhat.io5 - mirrors: - mirror.example.net/image source: registry.example.com/example/myimage6 - mirrors: - mirror.example.net source: registry.example.com/example7 - mirrors: - mirror.example.net/registry-example-com source: registry.example.com8 - 1
- Indique le nom du registre d'images et du référentiel.
- 2
- Indique plusieurs référentiels miroirs pour chaque référentiel cible. Si un miroir est hors service, le référentiel cible peut utiliser un autre miroir.
- 3
- Indique le registre et le référentiel contenant le contenu qui est mis en miroir.
- 4
- Vous pouvez configurer un espace de noms à l'intérieur d'un registre pour utiliser n'importe quelle image dans cet espace de noms. Si vous utilisez un domaine de registre comme source, la ressource
ImageContentSourcePolicyest appliquée à tous les référentiels du registre. - 5
- Si vous configurez le nom du registre, la ressource
ImageContentSourcePolicyest appliquée à tous les référentiels, du registre source au registre miroir. - 6
- Tire l'image
mirror.example.net/image@sha256:…. - 7
- Extrait l'image
myimagedans l'espace de noms du registre source à partir du miroirmirror.example.net/myimage@sha256:…. - 8
- Extrait l'image
registry.example.com/example/myimagedu registre miroirmirror.example.net/registry-example-com/example/myimage@sha256:…. La ressourceImageContentSourcePolicyest appliquée à tous les référentiels d'un registre source à un registre miroirmirror.example.net/registry-example-com.
Créer le nouvel objet
ImageContentSourcePolicy:$ oc create -f registryrepomirror.yamlUne fois l'objet
ImageContentSourcePolicycréé, les nouveaux paramètres sont déployés sur chaque nœud et le cluster commence à utiliser le référentiel miroir pour les requêtes vers le référentiel source.Pour vérifier que les paramètres de configuration en miroir sont appliqués, procédez comme suit sur l'un des nœuds.
Dressez la liste de vos nœuds :
$ oc get nodeExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-137-44.ec2.internal Ready worker 7m v1.25.0 ip-10-0-138-148.ec2.internal Ready master 11m v1.25.0 ip-10-0-139-122.ec2.internal Ready master 11m v1.25.0 ip-10-0-147-35.ec2.internal Ready worker 7m v1.25.0 ip-10-0-153-12.ec2.internal Ready worker 7m v1.25.0 ip-10-0-154-10.ec2.internal Ready master 11m v1.25.0La ressource
Imagecontentsourcepolicyne redémarre pas les nœuds.Lancez le processus de débogage pour accéder au nœud :
$ oc debug node/ip-10-0-147-35.ec2.internalExemple de sortie
Starting pod/ip-10-0-147-35ec2internal-debug ... To use host binaries, run `chroot /host`Changez votre répertoire racine en
/host:sh-4.2# chroot /hostVérifiez le fichier
/etc/containers/registries.confpour vous assurer que les changements ont bien été effectués :sh-4.2# cat /etc/containers/registries.confExemple de sortie
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] short-name-mode = "" [[registry]] prefix = "" location = "registry.access.redhat.com/ubi8/ubi-minimal" mirror-by-digest-only = true [[registry.mirror]] location = "example.io/example/ubi-minimal" [[registry.mirror]] location = "example.com/example/ubi-minimal" [[registry]] prefix = "" location = "registry.example.com" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net/registry-example-com" [[registry]] prefix = "" location = "registry.example.com/example" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net" [[registry]] prefix = "" location = "registry.example.com/example/myimage" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net/image" [[registry]] prefix = "" location = "registry.redhat.io" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.com" [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.com/redhat"Transmet un condensé d'image au nœud à partir de la source et vérifie s'il est résolu par le miroir. Les objets
ImageContentSourcePolicyne prennent en charge que les condensés d'image, et non les balises d'image.sh-4.2# podman pull --log-level=debug registry.access.redhat.com/ubi8/ubi-minimal@sha256:5cfbaf45ca96806917830c183e9f37df2e913b187adb32e89fd83fa455ebaa6
Dépannage de la mise en miroir du référentiel
Si la procédure de mise en miroir du référentiel ne fonctionne pas comme décrit, utilisez les informations suivantes sur le fonctionnement de la mise en miroir du référentiel pour résoudre le problème.
- Le premier miroir de travail est utilisé pour fournir l'image tirée.
- Le registre principal n'est utilisé que si aucun autre miroir ne fonctionne.
-
Dans le contexte du système, les drapeaux
Insecuresont utilisés comme solution de repli. -
Le format du fichier
/etc/containers/registries.confa récemment changé. Il s'agit désormais de la version 2 et du format TOML.
10.5. Alimentation d'OperatorHub à partir de catalogues d'opérateurs miroirs
Si vous avez mis en miroir des catalogues d'opérateurs pour les utiliser avec des clusters déconnectés, vous pouvez remplir OperatorHub avec les opérateurs de vos catalogues mis en miroir. Vous pouvez utiliser les manifestes générés par le processus de mise en miroir pour créer les objets ImageContentSourcePolicy et CatalogSource requis.
10.5.1. Conditions préalables
10.5.2. Création de l'objet ImageContentSourcePolicy
Après avoir mis en miroir le contenu du catalogue de l'opérateur dans votre registre miroir, créez l'objet ImageContentSourcePolicy (ICSP) requis. L'objet ICSP configure les nœuds pour traduire les références d'images stockées dans les manifestes Operator et le registre miroir.
Procédure
Sur un hôte ayant accès au cluster déconnecté, créez l'ICSP en exécutant la commande suivante pour spécifier le fichier
imageContentSourcePolicy.yamldans votre répertoire manifests :oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yamloù
<path/to/manifests/dir>est le chemin d'accès au répertoire des manifestes de votre contenu en miroir.Vous pouvez maintenant créer un objet
CatalogSourcepour référencer l'image de l'index reflété et le contenu de l'opérateur.
10.5.3. Ajout d'une source de catalogue à un cluster
L'ajout d'une source de catalogue à un cluster OpenShift Container Platform permet la découverte et l'installation d'opérateurs pour les utilisateurs. Les administrateurs de cluster peuvent créer un objet CatalogSource qui référence une image d'index. OperatorHub utilise des sources de catalogue pour remplir l'interface utilisateur.
Conditions préalables
- Une image d'index est construite et poussée vers un registre.
Procédure
Créez un objet
CatalogSourcequi fait référence à votre image d'index. Si vous avez utilisé la commandeoc adm catalog mirrorpour mettre en miroir votre catalogue vers un registre cible, vous pouvez utiliser le fichiercatalogSource.yamlgénéré dans votre répertoire manifests comme point de départ.Modifiez le texte suivant selon vos spécifications et sauvegardez-le sous forme de fichier
catalogSource.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog1 namespace: openshift-marketplace2 spec: sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>3 image: <registry>/<namespace>/redhat-operator-index:v4.124 displayName: My Operator Catalog publisher: <publisher_name>5 updateStrategy: registryPoll:6 interval: 30m- 1
- Si vous avez mis en miroir le contenu dans des fichiers locaux avant de le télécharger dans un registre, supprimez tous les caractères backslash (
/) du champmetadata.nameafin d'éviter une erreur "invalid resource name" (nom de ressource non valide) lors de la création de l'objet. - 2
- Si vous souhaitez que la source du catalogue soit disponible globalement pour les utilisateurs de tous les espaces de noms, spécifiez l'espace de noms
openshift-marketplace. Sinon, vous pouvez spécifier un espace de noms différent pour que le catalogue soit délimité et disponible uniquement pour cet espace de noms. - 3
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy. - 4
- Spécifiez votre image d'index. Si vous spécifiez une balise après le nom de l'image, par exemple
:v4.12, le pod source du catalogue utilise une politique d'extraction d'image deAlways, ce qui signifie que le pod extrait toujours l'image avant de démarrer le conteneur. Si vous spécifiez un condensé, par exemple@sha256:<id>, la politique d'extraction d'image estIfNotPresent, ce qui signifie que le module n'extrait l'image que si elle n'existe pas déjà sur le nœud. - 5
- Indiquez votre nom ou le nom d'une organisation qui publie le catalogue.
- 6
- Les sources du catalogue peuvent automatiquement vérifier la présence de nouvelles versions pour rester à jour.
Utilisez le fichier pour créer l'objet
CatalogSource:$ oc apply -f catalogSource.yaml
Vérifiez que les ressources suivantes ont bien été créées.
Vérifier les gousses :
$ oc get pods -n openshift-marketplaceExemple de sortie
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26hVérifier la source du catalogue :
$ oc get catalogsource -n openshift-marketplaceExemple de sortie
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5sVérifier le manifeste du paquet :
$ oc get packagemanifest -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
Vous pouvez maintenant installer les opérateurs à partir de la page OperatorHub de votre console web OpenShift Container Platform.
10.6. A propos de l'installation de l'opérateur avec OperatorHub
OperatorHub est une interface utilisateur permettant de découvrir les opérateurs ; il fonctionne en conjonction avec Operator Lifecycle Manager (OLM), qui installe et gère les opérateurs sur un cluster.
En tant qu'administrateur de cluster, vous pouvez installer un Operator depuis OperatorHub en utilisant la console web ou le CLI d'OpenShift Container Platform. L'abonnement d'un opérateur à un ou plusieurs espaces de noms met l'opérateur à la disposition des développeurs de votre cluster.
Lors de l'installation, vous devez déterminer les paramètres initiaux suivants pour l'opérateur :
- Mode d'installation
- Choisissez All namespaces on the cluster (default) pour que l'opérateur soit installé sur tous les espaces de noms ou choisissez des espaces de noms individuels, le cas échéant, pour n'installer l'opérateur que sur les espaces de noms sélectionnés. Cet exemple choisit All namespaces… pour mettre l'opérateur à la disposition de tous les utilisateurs et de tous les projets.
- Canal de mise à jour
- Si un opérateur est disponible sur plusieurs canaux, vous pouvez choisir le canal auquel vous souhaitez vous abonner. Par exemple, pour déployer à partir du canal stable, s'il est disponible, sélectionnez-le dans la liste.
- Stratégie d'approbation
Vous pouvez choisir des mises à jour automatiques ou manuelles.
Si vous choisissez les mises à jour automatiques pour un opérateur installé, lorsqu'une nouvelle version de cet opérateur est disponible dans le canal sélectionné, Operator Lifecycle Manager (OLM) met automatiquement à jour l'instance en cours d'exécution de votre opérateur sans intervention humaine.
Si vous sélectionnez les mises à jour manuelles, lorsqu'une version plus récente d'un opérateur est disponible, OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement cette demande de mise à jour pour que l'opérateur soit mis à jour avec la nouvelle version.
10.6.1. Installation à partir d'OperatorHub en utilisant la console web
Vous pouvez installer et vous abonner à un opérateur à partir d'OperatorHub en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin.
Procédure
- Naviguez dans la console web jusqu'à la page Operators → OperatorHub.
Faites défiler ou tapez un mot-clé dans la case Filter by keyword pour trouver l'opérateur que vous souhaitez. Par exemple, tapez
jaegerpour trouver l'opérateur Jaeger.Vous pouvez également filtrer les options par Infrastructure Features. Par exemple, sélectionnez Disconnected si vous voulez voir les opérateurs qui travaillent dans des environnements déconnectés, également connus sous le nom d'environnements réseau restreints.
Sélectionnez l'opérateur pour afficher des informations supplémentaires.
NoteLe choix d'un Opérateur communautaire vous avertit que Red Hat ne certifie pas les Opérateurs communautaires ; vous devez accuser réception de cet avertissement avant de continuer.
- Lisez les informations sur l'opérateur et cliquez sur Install.
Sur la page Install Operator:
Sélectionnez l'un des éléments suivants :
-
All namespaces on the cluster (default) installe l'opérateur dans l'espace de noms par défaut
openshift-operatorspour qu'il soit surveillé et mis à la disposition de tous les espaces de noms du cluster. Cette option n'est pas toujours disponible. - A specific namespace on the cluster vous permet de choisir un seul espace de noms spécifique dans lequel installer l'opérateur. L'opérateur ne surveillera et ne pourra être utilisé que dans ce seul espace de noms.
-
All namespaces on the cluster (default) installe l'opérateur dans l'espace de noms par défaut
- Sélectionnez une adresse Update Channel (si plusieurs sont disponibles).
- Sélectionnez la stratégie d'approbation Automatic ou Manual, comme décrit précédemment.
Cliquez sur Install pour rendre l'opérateur disponible pour les espaces de noms sélectionnés sur ce cluster OpenShift Container Platform.
Si vous avez sélectionné une stratégie d'approbation Manual, le statut de mise à niveau de l'abonnement reste Upgrading jusqu'à ce que vous examiniez et approuviez le plan d'installation.
Après approbation sur la page Install Plan, le statut de la mise à niveau de l'abonnement passe à Up to date.
- Si vous avez sélectionné une stratégie d'approbation Automatic, le statut du surclassement devrait être résolu à Up to date sans intervention.
Une fois que l'état de mise à niveau de l'abonnement est Up to date, sélectionnez Operators → Installed Operators pour vérifier que la version du service de cluster (CSV) de l'opérateur installé s'affiche finalement. L'adresse Status devrait finalement se résoudre en InstallSucceeded dans l'espace de noms concerné.
NotePour le mode d'installation All namespaces…, le statut se résout en InstallSucceeded dans l'espace de noms
openshift-operators, mais le statut est Copied si vous vérifiez dans d'autres espaces de noms.Si ce n'est pas le cas :
-
Vérifiez les journaux de tous les pods du projet
openshift-operators(ou d'un autre espace de noms pertinent si le mode d'installation A specific namespace… a été sélectionné) sur la page Workloads → Pods qui signalent des problèmes afin de les résoudre.
-
Vérifiez les journaux de tous les pods du projet
10.6.2. Installation à partir d'OperatorHub en utilisant le CLI
Au lieu d'utiliser la console web de OpenShift Container Platform, vous pouvez installer un Operator depuis OperatorHub en utilisant le CLI. Utilisez la commande oc pour créer ou mettre à jour un objet Subscription.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. -
Installez la commande
ocsur votre système local.
Procédure
Voir la liste des opérateurs disponibles pour la grappe à partir d'OperatorHub :
$ oc get packagemanifests -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...Notez le catalogue de l'opérateur souhaité.
Inspectez l'opérateur de votre choix pour vérifier les modes d'installation pris en charge et les canaux disponibles :
oc describe packagemanifests <operator_name> -n openshift-marketplaceUn groupe d'opérateurs, défini par un objet
OperatorGroup, sélectionne des espaces de noms cibles dans lesquels générer l'accès RBAC requis pour tous les opérateurs dans le même espace de noms que le groupe d'opérateurs.L'espace de noms auquel vous abonnez l'opérateur doit avoir un groupe d'opérateurs qui correspond au mode d'installation de l'opérateur, soit le mode
AllNamespacesouSingleNamespace. Si l'opérateur que vous avez l'intention d'installer utilise le modeAllNamespaces, l'espace de nomsopenshift-operatorsdispose déjà d'un groupe d'opérateurs approprié.Cependant, si l'opérateur utilise le mode
SingleNamespaceet que vous n'avez pas déjà un groupe d'opérateurs approprié en place, vous devez en créer un.NoteLa version console web de cette procédure gère la création des objets
OperatorGroupetSubscriptionautomatiquement dans les coulisses lorsque vous choisissez le modeSingleNamespace.Créez un fichier YAML de l'objet
OperatorGroup, par exempleoperatorgroup.yaml:Exemple d'objet
OperatorGroupapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>Créer l'objet
OperatorGroup:$ oc apply -f operatorgroup.yaml
Créez un fichier YAML de l'objet
Subscriptionpour abonner un espace de noms à un opérateur, par exemplesub.yaml:Exemple d'objet
SubscriptionapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
- Pour l'utilisation du mode d'installation
AllNamespaces, indiquez l'espace de nomsopenshift-operators. Sinon, indiquez l'espace de noms unique correspondant à l'utilisation du mode d'installationSingleNamespace. - 2
- Nom du canal auquel s'abonner.
- 3
- Nom de l'opérateur auquel s'abonner.
- 4
- Nom de la source du catalogue qui fournit l'opérateur.
- 5
- Espace de noms de la source de catalogue. Utilisez
openshift-marketplacepour les sources de catalogue par défaut d'OperatorHub. - 6
- Le paramètre
envdéfinit une liste de variables d'environnement qui doivent exister dans tous les conteneurs du module créé par OLM. - 7
- Le paramètre
envFromdéfinit une liste de sources pour alimenter les variables d'environnement dans le conteneur. - 8
- Le paramètre
volumesdéfinit une liste de volumes qui doivent exister sur le pod créé par OLM. - 9
- Le paramètre
volumeMountsdéfinit une liste de VolumeMounts qui doivent exister dans tous les conteneurs du pod créé par OLM. Si unvolumeMountfait référence à unvolumequi n'existe pas, OLM ne parvient pas à déployer l'opérateur. - 10
- Le paramètre
tolerationsdéfinit une liste de tolérances pour le module créé par OLM. - 11
- Le paramètre
resourcesdéfinit les contraintes de ressources pour tous les conteneurs du module créé par OLM. - 12
- Le paramètre
nodeSelectordéfinit unNodeSelectorpour le module créé par OLM.
Créer l'objet
Subscription:$ oc apply -f sub.yamlA ce stade, OLM connaît l'opérateur sélectionné. Une version de service de cluster (CSV) pour l'opérateur devrait apparaître dans l'espace de noms cible, et les API fournies par l'opérateur devraient être disponibles pour la création.
Chapitre 11. Configuration des notifications d'alerte
Dans OpenShift Container Platform, une alerte est déclenchée lorsque les conditions définies dans une règle d'alerte sont vraies. Une alerte fournit une notification qu'un ensemble de circonstances sont apparentes au sein d'un cluster. Les alertes déclenchées peuvent être visualisées dans l'interface utilisateur d'alerte de la console web d'OpenShift Container Platform par défaut. Après une installation, vous pouvez configurer OpenShift Container Platform pour envoyer des notifications d'alerte à des systèmes externes.
11.1. Envoi de notifications à des systèmes externes
Dans OpenShift Container Platform 4.12, les alertes de tir peuvent être visualisées dans l'interface d'alerte. Les alertes ne sont pas configurées par défaut pour être envoyées à des systèmes de notification. Vous pouvez configurer OpenShift Container Platform pour envoyer des alertes aux types de récepteurs suivants :
- PagerDuty
- Crochet Web
- Courriel
- Slack
L'acheminement des alertes vers des récepteurs vous permet d'envoyer des notifications en temps voulu aux équipes appropriées lorsque des défaillances se produisent. Par exemple, les alertes critiques requièrent une attention immédiate et sont généralement envoyées à une personne ou à une équipe d'intervention critique. Les alertes qui fournissent des notifications d'avertissement non critiques peuvent être acheminées vers un système de billetterie pour un examen non immédiat.
Vérifier que l'alerte est opérationnelle en utilisant le chien de garde d'alerte
La surveillance d'OpenShift Container Platform comprend une alerte de chien de garde qui se déclenche en permanence. Alertmanager envoie de manière répétée des notifications d'alertes de chien de garde aux fournisseurs de notifications configurés. Le fournisseur est généralement configuré pour notifier un administrateur lorsqu'il ne reçoit plus l'alerte du chien de garde. Ce mécanisme permet d'identifier rapidement les problèmes de communication entre Alertmanager et le fournisseur de notification.
11.1.1. Configuration des récepteurs d'alerte
Vous pouvez configurer des récepteurs d'alerte pour vous assurer d'être informé des problèmes importants de votre cluster.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Dans la perspective Administrator, naviguez vers Administration → Cluster Settings → Configuration → Alertmanager.
NoteVous pouvez également accéder à la même page via le tiroir de notification. Sélectionnez l'icône de cloche en haut à droite de la console web OpenShift Container Platform et choisissez Configure dans l'alerte AlertmanagerReceiverNotConfigured.
- Sélectionnez Create Receiver dans la section Receivers de la page.
- Dans le formulaire Create Receiver, ajoutez un Receiver Name et choisissez un Receiver Type dans la liste.
Modifier la configuration du récepteur :
Pour les récepteurs PagerDuty :
- Choisissez un type d'intégration et ajoutez une clé d'intégration PagerDuty.
- Ajoutez l'URL de votre installation PagerDuty.
- Sélectionnez Show advanced configuration si vous souhaitez modifier les détails du client et de l'incident ou la spécification de gravité.
Pour les récepteurs webhook :
- Ajoutez le point de terminaison auquel envoyer des requêtes HTTP POST.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut d'envoi des alertes résolues au destinataire.
Pour les destinataires du courrier électronique :
- Ajouter l'adresse électronique à laquelle envoyer les notifications.
- Ajoutez les détails de la configuration SMTP, y compris l'adresse à partir de laquelle les notifications sont envoyées, le smarthost et le numéro de port utilisés pour l'envoi des courriels, le nom d'hôte du serveur SMTP et les détails d'authentification.
- Choisissez si TLS est nécessaire.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut consistant à ne pas envoyer d'alertes résolues au destinataire ou modifier le corps de la configuration des notifications par courrier électronique.
Pour les destinataires de Slack :
- Ajoutez l'URL du webhook Slack.
- Ajoutez le canal Slack ou le nom d'utilisateur auquel envoyer les notifications.
- Sélectionnez Show advanced configuration si vous souhaitez modifier l'option par défaut consistant à ne pas envoyer d'alertes résolues au destinataire ou modifier la configuration de l'icône et du nom d'utilisateur. Vous pouvez également choisir de rechercher et de lier les noms de canaux et les noms d'utilisateurs.
Par défaut, les alertes de déclenchement dont les étiquettes correspondent à tous les sélecteurs sont envoyées au destinataire. Si vous souhaitez que les valeurs des étiquettes des alertes de déclenchement correspondent exactement avant qu'elles ne soient envoyées au destinataire :
- Ajoutez les noms et valeurs des étiquettes de routage dans la section Routing Labels du formulaire.
- Sélectionnez Regular Expression si vous souhaitez utiliser une expression régulière.
- Sélectionnez Add Label pour ajouter d'autres étiquettes de routage.
- Sélectionnez Create pour créer le récepteur.
Chapitre 12. Conversion d'un cluster connecté en cluster déconnecté
Il peut arriver que vous ayez besoin de convertir votre cluster OpenShift Container Platform d'un cluster connecté à un cluster déconnecté.
Un cluster déconnecté, également connu sous le nom de cluster restreint, n'a pas de connexion active à l'internet. Vous devez donc créer un miroir du contenu de vos registres et de vos supports d'installation. Vous pouvez créer ce registre miroir sur un hôte qui peut accéder à la fois à Internet et à votre réseau fermé, ou copier des images sur un périphérique que vous pouvez déplacer au-delà des limites du réseau.
Cette rubrique décrit le processus général de conversion d'une grappe connectée existante en une grappe déconnectée.
12.1. À propos du registre miroir
Vous pouvez mettre en miroir les images requises pour l'installation d'OpenShift Container Platform et les mises à jour ultérieures du produit dans un registre de miroirs de conteneurs tel que Red Hat Quay, JFrog Artifactory, Sonatype Nexus Repository, ou Harbor. Si vous n'avez pas accès à un registre de conteneurs à grande échelle, vous pouvez utiliser mirror registry for Red Hat OpenShift, un registre de conteneurs à petite échelle inclus dans les abonnements à OpenShift Container Platform.
Vous pouvez utiliser n'importe quel registre de conteneurs prenant en charge Docker v2-2, tel que Red Hat Quay, mirror registry for Red Hat OpenShift, Artifactory, Sonatype Nexus Repository ou Harbor. Quel que soit le registre choisi, la procédure de mise en miroir du contenu des sites hébergés par Red Hat sur Internet vers un registre d'images isolé est la même. Après avoir mis en miroir le contenu, vous configurez chaque cluster pour qu'il récupère ce contenu à partir de votre registre miroir.
Le registre d'images OpenShift ne peut pas être utilisé comme registre cible car il ne prend pas en charge la poussée sans balise, ce qui est nécessaire pendant le processus de mise en miroir.
Si vous choisissez un registre de conteneurs qui n'est pas mirror registry for Red Hat OpenShift, il doit être accessible par chaque machine des clusters que vous provisionnez. Si le registre est inaccessible, l'installation, la mise à jour ou les opérations normales telles que la relocalisation de la charge de travail risquent d'échouer. Pour cette raison, vous devez exécuter les registres miroirs de manière hautement disponible, et les registres miroirs doivent au moins correspondre à la disponibilité de production de vos clusters OpenShift Container Platform.
Lorsque vous remplissez votre registre miroir avec des images OpenShift Container Platform, vous pouvez suivre deux scénarios. Si vous avez un hôte qui peut accéder à la fois à Internet et à votre registre miroir, mais pas à vos nœuds de cluster, vous pouvez directement mettre en miroir le contenu à partir de cette machine. Ce processus est appelé connected mirroring. Si vous ne disposez pas d'un tel hôte, vous devez mettre en miroir les images sur un système de fichiers, puis amener cet hôte ou ce support amovible dans votre environnement restreint. Ce processus est appelé disconnected mirroring.
Dans le cas des registres en miroir, pour connaître la source des images extraites, vous devez consulter l'entrée de journal Trying to access dans les journaux CRI-O. Les autres méthodes permettant d'afficher la source d'extraction des images, telles que la commande crictl images sur un nœud, affichent le nom de l'image non miroitée, même si l'image est extraite de l'emplacement miroitant.
Red Hat ne teste pas les registres tiers avec OpenShift Container Platform.
12.2. Conditions préalables
-
Le client
ocest installé. - Une grappe en cours d'exécution.
Un registre miroir installé, c'est-à-dire un registre d'images de conteneurs qui prend en charge Docker v2-2 à l'emplacement qui hébergera le cluster OpenShift Container Platform, tel que l'un des registres suivants :
Si vous avez un abonnement à Red Hat Quay, consultez la documentation sur le déploiement de Red Hat Quay à des fins de validation de concept ou en utilisant l'opérateur Quay.
- Le référentiel miroir doit être configuré pour partager des images. Par exemple, un référentiel Red Hat Quay nécessite des Organisations afin de pouvoir partager des images.
- Accès à l'internet pour obtenir les images de conteneurs nécessaires.
12.3. Préparation de la grappe pour la mise en miroir
Avant de déconnecter votre cluster, vous devez mettre en miroir, ou copier, les images sur un registre miroir accessible à chaque nœud de votre cluster déconnecté. Pour mettre en miroir les images, vous devez préparer votre grappe en procédant comme suit :
- Ajout des certificats du registre des miroirs à la liste des autorités de certification de confiance de votre hôte.
-
Création d'un fichier
.dockerconfigjsoncontenant le secret d'extraction de l'image, qui provient du jetoncloud.openshift.com.
Procédure
Configuration des informations d'identification permettant la mise en miroir des images :
Ajoutez le certificat de l'autorité de certification du registre miroir, au format simple PEM ou DER, à la liste des autorités de certification approuvées. Par exemple, le certificat de l'autorité de certification du registre miroir est ajouté à la liste des autorités de certification de confiance :
$ cp </path/to/cert.crt> /usr/share/pki/ca-trust-source/anchors/- où,
</path/to/cert.crt> - Indique le chemin d'accès au certificat sur votre système de fichiers local.
- où,
Mettre à jour la confiance de l'autorité de certification. Par exemple, sous Linux :
$ update-ca-trustExtraire le fichier
.dockerconfigjsondu secret d'extraction global :$ oc extract secret/pull-secret -n openshift-config --confirm --to=.Exemple de sortie
.dockerconfigjsonModifiez le fichier
.dockerconfigjsonpour ajouter le registre du miroir et les informations d'authentification, puis enregistrez-le dans un nouveau fichier :{\i1}"auths":{\i1}"<local_registry>" : {\i1}"auth" : \N- "<credentials>\N",\N "email\N" : "you@example.com"}}},"<registry>:<port>/<namespace>/":{"auth":"<token>"}}}où :
<local_registry>- Spécifie le nom de domaine du registre, et éventuellement le port, que votre registre miroir utilise pour servir le contenu.
auth- Spécifie le nom d'utilisateur et le mot de passe encodés en base64 pour votre registre miroir.
<registry>:<port>/<namespace>- Spécifie les détails du registre du miroir.
<token>Spécifie l'adresse
username:passwordencodée en base64 pour votre registre miroir.Par exemple :
$ {"auths":{"cloud.openshift.com":{"auth":"b3BlbnNoaWZ0Y3UjhGOVZPT0lOMEFaUjdPUzRGTA==","email":"user@example.com"}, "quay.io":{"auth":"b3BlbnNoaWZ0LXJlbGVhc2UtZGOVZPT0lOMEFaUGSTd4VGVGVUjdPUzRGTA==","email":"user@example.com"}, "registry.connect.redhat.com"{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VHkxOSTd4VGVGVU1MdTpleUpoYkdjaUailA==","email":"user@example.com"}, "registry.redhat.io":{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VH3BGSTd4VGVGVU1MdTpleUpoYkdjaU9fZw==","email":"user@example.com"}, "registry.svc.ci.openshift.org":{"auth":"dXNlcjpyWjAwWVFjSEJiT2RKVW1pSmg4dW92dGp1SXRxQ3RGN1pwajJhN1ZXeTRV"},"my-registry:5000/my-namespace/":{"auth":"dXNlcm5hbWU6cGFzc3dvcmQ="}}}
12.4. Miroir des images
Une fois le cluster correctement configuré, vous pouvez mettre en miroir les images de vos référentiels externes vers le référentiel miroir.
Procédure
Mettez en miroir les images de l'Operator Lifecycle Manager (OLM) :
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v{product-version} <mirror_registry>:<port>/olm -a <reg_creds>où :
product-version-
Spécifie la balise qui correspond à la version d'OpenShift Container Platform à installer, par exemple
4.8. mirror_registry-
Spécifie le nom de domaine pleinement qualifié (FQDN) du registre et de l'espace de noms cibles vers lesquels le contenu de l'opérateur doit être mis en miroir, où
<namespace>est un espace de noms existant dans le registre. reg_creds-
Spécifie l'emplacement de votre fichier
.dockerconfigjsonmodifié.
Par exemple :
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'Miroir du contenu pour tout autre opérateur fourni par Red Hat :
$ oc adm catalog mirror <index_image> <mirror_registry>:<port>/<namespace> -a <reg_creds>où :
index_image-
Spécifie l'image d'index pour le catalogue que vous souhaitez mettre en miroir. Par exemple, il peut s'agir d'une image d'index élaguée que vous avez créée précédemment ou de l'une des images d'index source pour les catalogues par défaut, comme
{index-image-pullspec}. mirror_registry-
Spécifie le FQDN du registre et de l'espace de noms cibles vers lesquels le contenu de l'opérateur doit être mis en miroir, où
<namespace>est un espace de noms existant dans le registre. reg_creds- Facultatif : Spécifie l'emplacement du fichier d'informations d'identification du registre, le cas échéant.
Par exemple :
$ oc adm catalog mirror registry.redhat.io/redhat/community-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'Miroir du dépôt d'images OpenShift Container Platform :
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release :v<version-produit>-<architecture> --to=<local_registry>/<local_repository> --to-release-image=<local_registry>/<local_repository> :v<product-version>-<architecture> : v<product-version>-<architecture> :où :
product-version-
Spécifie la balise qui correspond à la version d'OpenShift Container Platform à installer, par exemple
4.8.15-x86_64. architecture-
Spécifie le type d'architecture de votre serveur, par exemple
x86_64. local_registry- Spécifie le nom de domaine du registre pour votre référentiel miroir.
local_repository-
Spécifie le nom du référentiel à créer dans votre registre, par exemple
ocp4/openshift4.
Par exemple :
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:4.8.15-x86_64 --to=mirror.registry.com:443/ocp/release --to-release-image=mirror.registry.com:443/ocp/release:4.8.15-x86_64Exemple de sortie
info: Mirroring 109 images to mirror.registry.com/ocp/release ... mirror.registry.com:443/ ocp/release manifests: sha256:086224cadce475029065a0efc5244923f43fb9bb3bb47637e0aaf1f32b9cad47 -> 4.8.15-x86_64-thanos sha256:0a214f12737cb1cfbec473cc301aa2c289d4837224c9603e99d1e90fc00328db -> 4.8.15-x86_64-kuryr-controller sha256:0cf5fd36ac4b95f9de506623b902118a90ff17a07b663aad5d57c425ca44038c -> 4.8.15-x86_64-pod sha256:0d1c356c26d6e5945a488ab2b050b75a8b838fc948a75c0fa13a9084974680cb -> 4.8.15-x86_64-kube-client-agent ….. sha256:66e37d2532607e6c91eedf23b9600b4db904ce68e92b43c43d5b417ca6c8e63c mirror.registry.com:443/ocp/release:4.5.41-multus-admission-controller sha256:d36efdbf8d5b2cbc4dcdbd64297107d88a31ef6b0ec4a39695915c10db4973f1 mirror.registry.com:443/ocp/release:4.5.41-cluster-kube-scheduler-operator sha256:bd1baa5c8239b23ecdf76819ddb63cd1cd6091119fecdbf1a0db1fb3760321a2 mirror.registry.com:443/ocp/release:4.5.41-aws-machine-controllers info: Mirroring completed in 2.02s (0B/s) Success Update image: mirror.registry.com:443/ocp/release:4.5.41-x86_64 Mirror prefix: mirror.registry.com:443/ocp/releaseMettez en miroir tous les autres registres, si nécessaire :
$ oc image mirror <online_registry>/my/image:latest <mirror_registry>
Informations complémentaires
- Pour plus d'informations sur la mise en miroir des catalogues d'opérateurs, voir Mise en miroir d'un catalogue d'opérateurs.
-
Pour plus d'informations sur la commande
oc adm catalog mirror, voir la référence des commandes de l'administrateur OpenShift CLI.
12.5. Configuration du cluster pour le registre miroir
Après avoir créé et mis en miroir les images dans le registre miroir, vous devez modifier votre cluster pour que les pods puissent extraire des images du registre miroir.
Vous devez :
- Ajoutez les informations d'identification du registre du miroir au secret d'extraction global.
- Ajoutez le certificat du serveur de registre miroir au cluster.
Créer une ressource personnalisée
ImageContentSourcePolicy(ICSP), qui associe le registre miroir au registre source.Ajouter l'identifiant du registre des miroirs au secret d'extraction global du cluster :
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
- Indiquez le chemin d'accès au nouveau fichier de secret d'extraction.
Par exemple :
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=.mirrorsecretconfigjsonAjoutez le certificat du serveur de registre miroir signé par l'autorité de certification aux nœuds du cluster :
Créer une carte de configuration qui inclut le certificat du serveur pour le registre miroir
$ oc create configmap <config_map_name> --from-file=<mirror_address_host>..<port>=$path/ca.crt -n openshift-configPar exemple :
S oc create configmap registry-config --from-file=mirror.registry.com..443=/root/certs/ca-chain.cert.pem -n openshift-configUtilisez la carte de configuration pour mettre à jour la ressource personnalisée (CR)
image.config.openshift.io/cluster. OpenShift Container Platform applique les modifications de cette CR à tous les nœuds du cluster :$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"<config_map_name>"}}}' --type=mergePar exemple :
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
Créer un ICSP pour rediriger les demandes de retrait de conteneurs des registres en ligne vers le registre miroir :
Créer la ressource personnalisée
ImageContentSourcePolicy:apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: mirror-ocp spec: repositoryDigestMirrors: - mirrors: - mirror.registry.com:443/ocp/release1 source: quay.io/openshift-release-dev/ocp-release2 - mirrors: - mirror.registry.com:443/ocp/release source: quay.io/openshift-release-dev/ocp-v4.0-art-devCréer l'objet ICSP :
$ oc create -f registryrepomirror.yamlExemple de sortie
imagecontentsourcepolicy.operator.openshift.io/mirror-ocp createdOpenShift Container Platform applique les modifications de ce CR à tous les nœuds du cluster.
Vérifiez que les informations d'identification, l'autorité de certification et l'ICSP pour le registre miroir ont été ajoutés :
Se connecter à un nœud :
oc debug node/<node_name>Définir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /hostVérifiez les informations d'identification dans le fichier
config.json:sh-4.4# cat /var/lib/kubelet/config.jsonExemple de sortie
{"auths":{"brew.registry.redhat.io":{"xx=="},"brewregistry.stage.redhat.io":{"auth":"xxx=="},"mirror.registry.com:443":{"auth":"xx="}}}1 - 1
- Assurez-vous que le registre du miroir et les informations d'identification sont présents.
Se rendre dans le répertoire
certs.dsh-4.4# cd /etc/docker/certs.d/Liste des certificats dans le répertoire
certs.d:sh-4.4# lsExemple de sortie
image-registry.openshift-image-registry.svc.cluster.local:5000 image-registry.openshift-image-registry.svc:5000 mirror.registry.com:4431 - 1
- Assurez-vous que le registre miroir figure dans la liste.
Vérifiez que l'ICSP a ajouté le registre miroir au fichier
registries.conf:sh-4.4# cat /etc/containers/registries.confExemple de sortie
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-release" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release" [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-v4.0-art-dev" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release"Les paramètres
registry.mirrorindiquent que le registre miroir est recherché avant le registre original.Quitter le nœud.
sh-4.4# exit
12.6. Veiller à ce que les applications continuent de fonctionner
Avant de déconnecter le cluster du réseau, assurez-vous que votre cluster fonctionne comme prévu et que toutes vos applications fonctionnent comme prévu.
Procédure
Utilisez les commandes suivantes pour vérifier l'état de votre cluster :
Assurez-vous que vos pods fonctionnent :
$ oc get pods --all-namespacesExemple de sortie
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-0 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-1 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-2 1/1 Running 0 39m openshift-apiserver-operator openshift-apiserver-operator-79c7c646fd-5rvr5 1/1 Running 3 45m openshift-apiserver apiserver-b944c4645-q694g 2/2 Running 0 29m openshift-apiserver apiserver-b944c4645-shdxb 2/2 Running 0 31m openshift-apiserver apiserver-b944c4645-x7rf2 2/2 Running 0 33m ...Assurez-vous que vos nœuds sont dans l'état READY :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ci-ln-47ltxtb-f76d1-mrffg-master-0 Ready master 42m v1.25.0 ci-ln-47ltxtb-f76d1-mrffg-master-1 Ready master 42m v1.25.0 ci-ln-47ltxtb-f76d1-mrffg-master-2 Ready master 42m v1.25.0 ci-ln-47ltxtb-f76d1-mrffg-worker-a-gsxbz Ready worker 35m v1.25.0 ci-ln-47ltxtb-f76d1-mrffg-worker-b-5qqdx Ready worker 35m v1.25.0 ci-ln-47ltxtb-f76d1-mrffg-worker-c-rjkpq Ready worker 34m v1.25.0
12.7. Déconnecter le cluster du réseau
Après avoir mis en miroir tous les référentiels nécessaires et configuré votre cluster pour qu'il fonctionne comme un cluster déconnecté, vous pouvez déconnecter le cluster du réseau.
L'opérateur Insights se dégrade lorsque le cluster perd sa connexion Internet. Vous pouvez éviter ce problème en désactivant temporairement l 'opérateur Insights jusqu'à ce que vous puissiez le rétablir.
12.8. Restauration d'un opérateur Insights dégradé
La déconnexion du cluster du réseau entraîne nécessairement la perte de la connexion Internet du cluster. L'opérateur Insights est dégradé car il nécessite l'accès à Red Hat Insights.
Cette rubrique décrit comment récupérer un opérateur Insights dégradé.
Procédure
Modifiez votre fichier
.dockerconfigjsonpour supprimer l'entréecloud.openshift.com, par exemple :\N- "cloud.openshift.com":{\i1}"auth":\N"<hash>",\N "email":\N "user@example.com"}- Enregistrer le fichier.
Mettre à jour le secret de la grappe avec le fichier
.dockerconfigjsonmodifié :$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=./.dockerconfigjsonVérifiez que l'opérateur Insights n'est plus dégradé :
$ oc get co insightsExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE insights 4.5.41 True False False 3d
12.9. Restauration du réseau
Si vous souhaitez reconnecter un cluster déconnecté et extraire des images de registres en ligne, supprimez les objets ImageContentSourcePolicy (ICSP) du cluster. Sans ICSP, les demandes d'extraction vers des registres externes ne sont plus redirigées vers le registre miroir.
Procédure
Affichez les objets ICSP de votre cluster :
$ oc get imagecontentsourcepolicyExemple de sortie
NAME AGE mirror-ocp 6d20h ocp4-index-0 6d18h qe45-index-0 6d15hSupprimez tous les objets ICSP que vous avez créés lors de la déconnexion de votre cluster :
oc delete imagecontentsourcepolicy <icsp_name> <icsp_name> <icsp_name> <icsp_name>Par exemple :
$ oc delete imagecontentsourcepolicy mirror-ocp ocp4-index-0 qe45-index-0Exemple de sortie
imagecontentsourcepolicy.operator.openshift.io "mirror-ocp" deleted imagecontentsourcepolicy.operator.openshift.io "ocp4-index-0" deleted imagecontentsourcepolicy.operator.openshift.io "qe45-index-0" deletedAttendez que tous les nœuds redémarrent et reviennent à l'état READY et vérifiez que le fichier
registries.confpointe vers les registres d'origine et non vers les registres miroirs :Se connecter à un nœud :
oc debug node/<node_name>Définir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /hostExaminez le fichier
registries.conf:sh-4.4# cat /etc/containers/registries.confExemple de sortie
unqualified-search-registries = [\N- "registry.access.redhat.com", \N- "docker.io"]1 - 1
- Les entrées
registryetregistry.mirrorcréées par les ICSP que vous avez supprimées sont supprimées.
Chapitre 13. Activation des capacités des clusters
Les administrateurs de clusters peuvent activer des fonctionnalités de clusters qui étaient désactivées avant l'installation.
Cluster administrators cannot disable a cluster capability after it is enabled.
13.1. Visualisation des capacités de la grappe
En tant qu'administrateur de cluster, vous pouvez visualiser les capacités en utilisant le statut de la ressource clusterversion.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Pour afficher l'état des capacités de la grappe, exécutez la commande suivante :
$ oc get clusterversion version -o jsonpath='{.spec.capabilities}{"\n"}{.status.capabilities}{"\n"}'Exemple de sortie
{"additionalEnabledCapabilities":["openshift-samples"],"baselineCapabilitySet":"None"} {"enabledCapabilities":["openshift-samples"],"knownCapabilities":["CSISnapshot","Console","Insights","Storage","baremetal","marketplace","openshift-samples"]}
13.2. Activation des capacités de la grappe en définissant l'ensemble des capacités de base
En tant qu'administrateur de cluster, vous pouvez activer les capacités en définissant baselineCapabilitySet.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Pour définir le site
baselineCapabilitySet, exécutez la commande suivante :$ oc patch clusterversion version --type merge -p '{"spec":{"capabilities":{"baselineCapabilitySet":"vCurrent"}}}''1 - 1
- Pour
baselineCapabilitySet, vous pouvez spécifiervCurrent,v4.11,v4.12, ouNone.
The following table describes the baselineCapabilitySet values.
| Valeur | Description |
|---|---|
|
| Specify when you want to automatically add new capabilities as they become recommended. |
|
|
Specify when you want the capabilities recommended in OpenShift Container Platform 4.11 and not automatically enable capabilities, which might be introduced in later versions. The capabilities recommended in OpenShift Container Platform 4.11 are |
|
|
Specify when you want the capabilities recommended in OpenShift Container Platform 4.12 and not automatically enable capabilities, which might be introduced in later versions. The capabilities recommended in OpenShift Container Platform 4.12 are |
|
|
Specify when the other sets are too large, and you do not need any capabilities or want to fine-tune via |
13.3. Activation des capacités du cluster en définissant des capacités supplémentaires activées
En tant qu'administrateur de cluster, vous pouvez activer les capacités du cluster en définissant additionalEnabledCapabilities.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Affichez les capacités supplémentaires activées en exécutant la commande suivante :
$ oc get clusterversion version -o jsonpath='{.spec.capabilities.additionalEnabledCapabilities}{"\n"}'Exemple de sortie
["openshift-samples"]Pour définir le site
additionalEnabledCapabilities, exécutez la commande suivante :$ oc patch clusterversion/version --type merge -p '{"spec":{"capabilities":{"additionalEnabledCapabilities":["openshift-samples", "marketplace"]}}}'
Il n'est pas possible de désactiver une capacité déjà activée dans un cluster. L'opérateur de version de cluster (CVO) continue à réconcilier la capacité qui est déjà activée dans le cluster.
Si vous essayez de désactiver une capacité, l'OVE affiche les spécifications divergentes :
$ oc get clusterversion version -o jsonpath='{.status.conditions[?(@.type=="ImplicitlyEnabledCapabilities")]}{"\n"}'Exemple de sortie
{"lastTransitionTime":"2022-07-22T03:14:35Z","message":"The following capabilities could not be disabled: openshift-samples","reason":"CapabilitiesImplicitlyEnabled","status":"True","type":"ImplicitlyEnabledCapabilities"}
Lors des mises à jour de la grappe, il est possible qu'une capacité donnée soit implicitement activée. Si une ressource fonctionnait déjà sur le cluster avant la mise à niveau, toutes les capacités qui font partie de la ressource seront activées. Par exemple, lors d'une mise à niveau du cluster, une ressource déjà en cours d'exécution sur le cluster a été modifiée par le système pour faire partie de la capacité marketplace. Même si un administrateur de cluster n'a pas explicitement activé la fonctionnalité marketplace, elle est implicitement activée par le système.
Chapitre 14. Configuration de périphériques supplémentaires dans un environnement IBM zSystems ou IBM(R) LinuxONE
Après avoir installé OpenShift Container Platform, vous pouvez configurer des périphériques supplémentaires pour votre cluster dans un environnement IBM zSystems ou IBM® LinuxONE, qui est installé avec z/VM. Les périphériques suivants peuvent être configurés :
- Hôte du protocole Fibre Channel (FCP)
- FCP LUN
- DASD
- qeth
Vous pouvez configurer les périphériques en ajoutant des règles udev à l'aide du MCO (Machine Config Operator) ou vous pouvez configurer les périphériques manuellement.
Les procédures décrites ici s'appliquent uniquement aux installations z/VM. Si vous avez installé votre cluster avec RHEL KVM sur une infrastructure IBM zSystems ou IBM® LinuxONE, aucune configuration supplémentaire n'est nécessaire à l'intérieur de l'invité KVM après l'ajout des périphériques aux invités KVM. Cependant, tant dans les environnements z/VM que RHEL KVM, les étapes suivantes pour configurer l'opérateur de stockage local et l'opérateur NMState de Kubernetes doivent être appliquées.
14.1. Configuration d'appareils supplémentaires à l'aide du MCO (Machine Config Operator)
Les tâches de cette section décrivent comment utiliser les fonctionnalités de Machine Config Operator (MCO) pour configurer des périphériques supplémentaires dans un environnement IBM zSystems ou IBM® LinuxONE. La configuration des périphériques avec le MCO est persistante mais ne permet que des configurations spécifiques pour les nœuds de calcul. Le MCO ne permet pas aux nœuds du plan de contrôle d'avoir des configurations différentes.
Conditions préalables
- You are logged in to the cluster as a user with administrative privileges.
- Le périphérique doit être disponible pour l'invité z/VM.
- L'appareil est déjà fixé.
-
Le périphérique n'est pas inclus dans la liste
cio_ignore, qui peut être définie dans les paramètres du noyau. Vous avez créé un fichier objet
MachineConfigavec le YAML suivant :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker0 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker0]} nodeSelector: matchLabels: node-role.kubernetes.io/worker0: ""
14.1.1. Configuration d'un hôte Fibre Channel Protocol (FCP)
L'exemple suivant montre comment configurer un adaptateur hôte FCP avec la virtualisation de l'identificateur de port N (NPIV) en ajoutant une règle udev.
Procédure
Prenons l'exemple suivant : règle udev
441-zfcp-host-0.0.8000.rules:ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.8000", DRIVER=="zfcp", GOTO="cfg_zfcp_host_0.0.8000" ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="zfcp", TEST=="[ccw/0.0.8000]", GOTO="cfg_zfcp_host_0.0.8000" GOTO="end_zfcp_host_0.0.8000" LABEL="cfg_zfcp_host_0.0.8000" ATTR{[ccw/0.0.8000]online}="1" LABEL="end_zfcp_host_0.0.8000"Convertissez la règle en code Base64 en exécutant la commande suivante :
$ base64 /path/to/file/Copiez l'exemple de profil MCO suivant dans un fichier YAML :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-zfcp-host-0.0.8000.rules3
14.1.2. Configuration d'un LUN FCP
L'exemple suivant montre comment configurer un LUN FCP en ajoutant une règle udev. Vous pouvez ajouter de nouveaux LUN FCP ou des chemins d'accès supplémentaires à des LUN déjà configurés avec le multipathing.
Procédure
Prenons l'exemple suivant : règle udev
41-zfcp-lun-0.0.8000:0x500507680d760026:0x00bc000000000000.rules:ACTION=="add", SUBSYSTEMS=="ccw", KERNELS=="0.0.8000", GOTO="start_zfcp_lun_0.0.8207" GOTO="end_zfcp_lun_0.0.8000" LABEL="start_zfcp_lun_0.0.8000" SUBSYSTEM=="fc_remote_ports", ATTR{port_name}=="0x500507680d760026", GOTO="cfg_fc_0.0.8000_0x500507680d760026" GOTO="end_zfcp_lun_0.0.8000" LABEL="cfg_fc_0.0.8000_0x500507680d760026" ATTR{[ccw/0.0.8000]0x500507680d760026/unit_add}="0x00bc000000000000" GOTO="end_zfcp_lun_0.0.8000" LABEL="end_zfcp_lun_0.0.8000"Convertissez la règle en code Base64 en exécutant la commande suivante :
$ base64 /path/to/file/Copiez l'exemple de profil MCO suivant dans un fichier YAML :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-zfcp-lun-0.0.8000:0x500507680d760026:0x00bc000000000000.rules3
14.1.3. Configuration du DASD
L'exemple suivant montre comment configurer un périphérique DASD en ajoutant une règle udev.
Procédure
Prenons l'exemple suivant : règle udev
41-dasd-eckd-0.0.4444.rules:ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.4444", DRIVER=="dasd-eckd", GOTO="cfg_dasd_eckd_0.0.4444" ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="dasd-eckd", TEST=="[ccw/0.0.4444]", GOTO="cfg_dasd_eckd_0.0.4444" GOTO="end_dasd_eckd_0.0.4444" LABEL="cfg_dasd_eckd_0.0.4444" ATTR{[ccw/0.0.4444]online}="1" LABEL="end_dasd_eckd_0.0.4444"Convertissez la règle en code Base64 en exécutant la commande suivante :
$ base64 /path/to/file/Copiez l'exemple de profil MCO suivant dans un fichier YAML :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-dasd-eckd-0.0.4444.rules3
14.1.4. Configuration de qeth
Voici un exemple de configuration d'un périphérique qeth par l'ajout d'une règle udev.
Procédure
Prenons l'exemple suivant : règle udev
41-qeth-0.0.1000.rules:ACTION=="add", SUBSYSTEM=="drivers", KERNEL=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1000", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1001", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccw", KERNEL=="0.0.1002", DRIVER=="qeth", GOTO="group_qeth_0.0.1000" ACTION=="add", SUBSYSTEM=="ccwgroup", KERNEL=="0.0.1000", DRIVER=="qeth", GOTO="cfg_qeth_0.0.1000" GOTO="end_qeth_0.0.1000" LABEL="group_qeth_0.0.1000" TEST=="[ccwgroup/0.0.1000]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1000]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1001]", GOTO="end_qeth_0.0.1000" TEST!="[ccw/0.0.1002]", GOTO="end_qeth_0.0.1000" ATTR{[drivers/ccwgroup:qeth]group}="0.0.1000,0.0.1001,0.0.1002" GOTO="end_qeth_0.0.1000" LABEL="cfg_qeth_0.0.1000" ATTR{[ccwgroup/0.0.1000]online}="1" LABEL="end_qeth_0.0.1000"Convertissez la règle en code Base64 en exécutant la commande suivante :
$ base64 /path/to/file/Copiez l'exemple de profil MCO suivant dans un fichier YAML :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker01 name: 99-worker0-devices spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,<encoded_base64_string>2 filesystem: root mode: 420 path: /etc/udev/rules.d/41-dasd-eckd-0.0.4444.rules3
14.2. Configuration manuelle d'appareils supplémentaires
Les tâches de cette section décrivent comment configurer manuellement des périphériques supplémentaires dans un environnement IBM zSystems ou IBM® LinuxONE. Cette méthode de configuration est persistante lors des redémarrages de nœuds, mais elle n'est pas native pour OpenShift Container Platform et vous devez refaire les étapes si vous remplacez le nœud.
Conditions préalables
- You are logged in to the cluster as a user with administrative privileges.
- Le dispositif doit être disponible pour le nœud.
- Dans un environnement z/VM, le périphérique doit être attaché à l'invité z/VM.
Procédure
Connectez-vous au nœud via SSH en exécutant la commande suivante :
$ ssh <user>@<node_ip_address>Vous pouvez également lancer une session de débogage sur le nœud en exécutant la commande suivante :
oc debug node/<node_name>Pour activer les périphériques à l'aide de la commande
chzdev, entrez la commande suivante :$ sudo chzdev -e 0.0.8000 sudo chzdev -e 1000-1002 sude chzdev -e 4444 sudo chzdev -e 0.0.8000:0x500507680d760026:0x00bc000000000000
14.3. Cartes réseau RoCE
Les cartes réseau RoCE (RDMA over Converged Ethernet) n'ont pas besoin d'être activées et leurs interfaces peuvent être configurées avec l'opérateur NMState de Kubernetes dès lors qu'elles sont disponibles dans le nœud. Par exemple, les cartes réseau RoCE sont disponibles si elles sont attachées dans un environnement z/VM ou si elles passent dans un environnement KVM RHEL.
14.4. Activation du multipathing pour les LUN FCP
Les tâches de cette section décrivent comment configurer manuellement des périphériques supplémentaires dans un environnement IBM zSystems ou IBM® LinuxONE. Cette méthode de configuration est persistante lors des redémarrages de nœuds, mais elle n'est pas native pour OpenShift Container Platform et vous devez refaire les étapes si vous remplacez le nœud.
On IBM zSystems and IBM® LinuxONE, you can enable multipathing only if you configured your cluster for it during installation. For more information, see "Installing RHCOS and starting the OpenShift Container Platform bootstrap process" in Installing a cluster with z/VM on IBM zSystems and IBM® LinuxONE.
Conditions préalables
- You are logged in to the cluster as a user with administrative privileges.
- Vous avez configuré plusieurs chemins d'accès à un LUN avec l'une ou l'autre des méthodes expliquées ci-dessus.
Procédure
Connectez-vous au nœud via SSH en exécutant la commande suivante :
$ ssh <user>@<node_ip_address>Vous pouvez également lancer une session de débogage sur le nœud en exécutant la commande suivante :
oc debug node/<node_name>Pour activer le multipathing, exécutez la commande suivante :
$ sudo /sbin/mpathconf --enablePour démarrer le démon
multipathd, exécutez la commande suivante :$ sudo multipathFacultatif : Pour formater votre périphérique multipath avec fdisk, exécutez la commande suivante :
$ sudo fdisk /dev/mapper/mpatha
Vérification
Pour vérifier que les appareils ont été regroupés, exécutez la commande suivante :
$ sudo multipath -IIExemple de sortie
mpatha (20017380030290197) dm-1 IBM,2810XIV size=512G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw -+- policy='service-time 0' prio=50 status=enabled |- 1:0:0:6 sde 68:16 active ready running |- 1:0:1:6 sdf 69:24 active ready running |- 0:0:0:6 sdg 8:80 active ready running `- 0:0:1:6 sdh 66:48 active ready running
Chapitre 15. Superposition d'images RHCOS
La superposition d'images de Red Hat Enterprise Linux CoreOS (RHCOS) vous permet d'étendre facilement les fonctionnalités de votre image RHCOS de base en layering ajoutant des images supplémentaires à l'image de base. Cette stratification ne modifie pas l'image RHCOS de base. Au lieu de cela, elle crée un site custom layered image qui inclut toutes les fonctionnalités de RHCOS et ajoute des fonctionnalités supplémentaires à des nœuds spécifiques de la grappe.
Vous créez une image en couches personnalisée à l'aide d'un fichier Container et vous l'appliquez aux nœuds à l'aide d'un objet MachineConfig. L'opérateur de configuration de la machine remplace l'image RHCOS de base, telle que spécifiée par la valeur osImageURL dans la configuration de la machine associée, et démarre la nouvelle image. Vous pouvez supprimer l'image personnalisée en couches en supprimant la configuration de la machine. L'opérateur de configuration de la machine redémarre les nœuds avec l'image RHCOS de base.
Avec la superposition d'images RHCOS, vous pouvez installer des RPM dans votre image de base, et votre contenu personnalisé sera démarré en même temps que RHCOS. Le MCO (Machine Config Operator) peut déployer ces images personnalisées et surveiller ces conteneurs personnalisés de la même manière qu'il le fait pour l'image RHCOS par défaut. La superposition d'images RHCOS vous offre une plus grande flexibilité dans la gestion de vos nœuds RHCOS.
Il n'est pas recommandé d'installer le noyau en temps réel et les RPM d'extension en tant que contenu personnalisé en couches. En effet, ces RPM peuvent entrer en conflit avec les RPM installés à l'aide d'une configuration de machine. En cas de conflit, le MCO entre dans l'état degraded lorsqu'il tente d'installer le RPM de la configuration de la machine. Vous devez supprimer l'extension en conflit de votre configuration de machine avant de continuer.
Dès que vous appliquez l'image en couches personnalisée à votre cluster, vous avez effectivement take ownership de vos images en couches personnalisées et de ces nœuds. Alors que Red Hat reste responsable de la maintenance et de la mise à jour de l'image RHCOS de base sur les nœuds standard, vous êtes responsable de la maintenance et de la mise à jour des images sur les nœuds qui utilisent une image en couches personnalisée. Vous assumez la responsabilité du paquetage que vous avez appliqué avec l'image en couches personnalisée et de tout problème qui pourrait survenir avec le paquetage.
La superposition d'images est une fonctionnalité de l'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Actuellement, la superposition d'images RHCOS vous permet de travailler avec Customer Experience and Engagement (CEE) pour obtenir et appliquer des paquets Hotfix sur votre image RHCOS. Dans certains cas, vous pouvez avoir besoin d'une correction de bogue ou d'une amélioration avant qu'elle ne soit incluse dans une version officielle d'OpenShift Container Platform. La superposition d'images RHCOS vous permet d'ajouter facilement le correctif avant sa publication officielle et de le supprimer lorsque l'image RHCOS sous-jacente intègre le correctif.
Certains correctifs nécessitent une exception de support Red Hat et sont en dehors de la portée normale de la couverture de support d'OpenShift Container Platform ou des politiques de cycle de vie.
Si vous souhaitez un correctif, il vous sera fourni conformément à la politique de Red Hat en matière de correctifs. Appliquez-le sur l'image de base et testez cette nouvelle image en couches personnalisée dans un environnement de non-production. Lorsque vous êtes convaincu que l'image en couches personnalisée peut être utilisée en toute sécurité dans la production, vous pouvez la déployer selon votre propre calendrier dans des pools de nœuds spécifiques. Pour quelque raison que ce soit, vous pouvez facilement annuler l'image en couches personnalisée et revenir à l'utilisation du RHCOS par défaut.
Il est prévu, dans les prochaines versions, que vous puissiez utiliser la superposition d'images RHCOS pour intégrer des logiciels tiers tels que libreswan ou numactl.
Pour appliquer une image en couches personnalisée, vous créez un Containerfile qui référence une image OpenShift Container Platform et le Hotfix que vous souhaitez appliquer. Par exemple :
Exemple de fichier conteneur pour appliquer un correctif
# Using a 4.12.0 image
FROM quay.io/openshift-release-dev/ocp-release@sha256:6499bc69a0707fcad481c3cb73225b867d
#Install hotfix rpm
RUN rpm-ostree override replace https://example.com/myrepo/haproxy-1.0.16-5.el8.src.rpm && \
rpm-ostree cleanup -m && \
ostree container commit
Utilisez la même image RHCOS de base que celle installée sur le reste de votre cluster. Utilisez la commande oc adm release info --image-for rhel-coreos-8 pour obtenir l'image de base utilisée dans votre cluster.
Pousser l'image en couches personnalisée résultante vers un registre d'images. Dans un cluster OpenShift Container Platform non productif, créez un objet MachineConfig pour le pool de nœuds ciblé qui pointe vers la nouvelle image.
Le MCO (Machine Config Operator) met à jour le système d'exploitation avec le contenu fourni dans la configuration de la machine. Cela crée une image en couches personnalisée qui remplace l'image RHCOS de base sur ces nœuds.
Après avoir créé la configuration de la machine, le MCO :
- Rend une nouvelle configuration de machine pour le ou les pools spécifiés.
- Effectue des opérations de bouclage et de vidange sur les nœuds du ou des pools.
- Écrit le reste des paramètres de configuration de la machine sur les nœuds.
- Applique l'image personnalisée au nœud.
- Redémarre le nœud en utilisant la nouvelle image.
Il est fortement recommandé de tester vos images en dehors de votre environnement de production avant de les déployer dans votre cluster.
15.1. Application d'une image en couches personnalisée RHCOS
Vous pouvez facilement configurer la superposition d'images Red Hat Enterprise Linux CoreOS (RHCOS) sur les nœuds dans des pools de configuration de machines spécifiques. L'opérateur de configuration de machine (MCO) redémarre ces nœuds avec la nouvelle image personnalisée, en remplaçant l'image de base de Red Hat Enterprise Linux CoreOS (RHCOS).
Pour appliquer une image en couches personnalisée à votre cluster, vous devez avoir l'image en couches personnalisée dans un référentiel auquel votre cluster peut accéder. Créez ensuite un objet MachineConfig qui pointe vers l'image en couches personnalisée. Vous devez créer un objet MachineConfig distinct pour chaque pool de configuration de machine que vous souhaitez configurer.
Lorsque vous configurez une image en couches personnalisée, OpenShift Container Platform ne met plus automatiquement à jour les nœuds qui utilisent l'image en couches personnalisée. Vous devenez responsable de la mise à jour manuelle de vos nœuds, le cas échéant. Si vous annulez la couche personnalisée, OpenShift Container Platform mettra à nouveau à jour automatiquement le nœud. Consultez la section Ressources supplémentaires ci-dessous pour obtenir des informations importantes sur la mise à jour des nœuds qui utilisent une image en couches personnalisée.
Conditions préalables
Vous devez créer une image en couches personnalisée basée sur un condensé d'image OpenShift Container Platform, et non sur une balise.
NoteVous devez utiliser la même image RHCOS de base que celle installée sur le reste de votre cluster. Utilisez la commande
oc adm release info --image-for rhel-coreos-8pour obtenir l'image de base utilisée dans votre cluster.Par exemple, le fichier Containerfile suivant crée une image en couches personnalisée à partir d'une image OpenShift Container Platform 4.12 et d'un paquet Hotfix :
Exemple de fichier conteneur pour une image de couche personnalisée
# Using a 4.12.0 image FROM quay.io/openshift-release/ocp-release@sha256:6499bc69a0707fcad481c3cb73225b867d1 #Install hotfix rpm RUN rpm-ostree override replace https://example.com/hotfixes/haproxy-1.0.16-5.el8.src.rpm && \2 rpm-ostree cleanup -m && \ ostree container commitNoteLes instructions relatives à la création d'un fichier conteneur dépassent le cadre de cette documentation.
- Vous devez pousser l'image en couches personnalisée vers un référentiel auquel votre cluster peut accéder.
Procédure
Créer un fichier de configuration de la machine.
Créez un fichier YAML similaire au suivant :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: os-layer-hotfix spec: osImageURL: quay.io/my-registry/custom-image@sha256:306b606615dcf8f0e5e7d87fee32 Créer l'objet
MachineConfig:oc create -f <nom_du_fichier>.yamlImportantIl est fortement recommandé de tester vos images en dehors de votre environnement de production avant de les déployer dans votre cluster.
Vérification
Vous pouvez vérifier que l'image en couches personnalisée est appliquée en effectuant l'une des vérifications suivantes :
Vérifier que le pool de configuration de la machine de travail a été déployé avec la nouvelle configuration de la machine :
Vérifiez que la nouvelle configuration de la machine est créée :
$ oc get mcExemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 00-worker 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-master-container-runtime 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-master-kubelet 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-worker-container-runtime 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 01-worker-kubelet 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-master-generated-registries 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-master-ssh 3.2.0 98m 99-worker-generated-registries 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m 99-worker-ssh 3.2.0 98m os-layer-hotfix 10s1 rendered-master-15961f1da260f7be141006404d17d39b 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m rendered-worker-5aff604cb1381a4fe07feaf1595a797e 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 95m rendered-worker-5de4837625b1cbc237de6b22bc0bc873 5bdb57489b720096ef912f738b46330a8f577803 3.2.0 4s2 Vérifiez que la valeur
osImageURLdans la configuration de la nouvelle machine pointe vers l'image attendue :$ oc describe mc rendered-master-4e8be63aef68b843b546827b6ebe0913Exemple de sortie
Name: rendered-master-4e8be63aef68b843b546827b6ebe0913 Namespace: Labels: <none> Annotations: machineconfiguration.openshift.io/generated-by-controller-version: 8276d9c1f574481043d3661a1ace1f36cd8c3b62 machineconfiguration.openshift.io/release-image-version: 4.12.0-ec.3 API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig ... Os Image URL: quay.io/my-registry/custom-image@sha256:306b606615dcf8f0e5e7d87fee3Vérifier que le pool de configuration machine associé est mis à jour avec la nouvelle configuration machine :
$ oc get mcpExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-6faecdfa1b25c114a58cf178fbaa45e2 True False False 3 3 3 0 39m worker rendered-worker-6b000dbc31aaee63c6a2d56d04cd4c1b False True False 3 0 0 0 39m1 - 1
- Lorsque le champ
UPDATINGestTrue, le pool de configuration de la machine est mis à jour avec la nouvelle configuration de la machine. Lorsque le champ devientFalse, le pool de configuration de la machine du travailleur est passé à la nouvelle configuration de la machine.
Vérifiez que la planification sur les nœuds est désactivée. Cela indique que la modification est en cours d'application :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-148-79.us-west-1.compute.internal Ready worker 32m v1.25.0+3ef6ef3 ip-10-0-155-125.us-west-1.compute.internal Ready,SchedulingDisabled worker 35m v1.25.0+3ef6ef3 ip-10-0-170-47.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-174-77.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-211-49.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-218-151.us-west-1.compute.internal Ready worker 31m v1.25.0+3ef6ef3
Lorsque le nœud est revenu à l'état
Ready, vérifiez qu'il utilise l'image en couches personnalisée :Ouvrez une session
oc debugvers le nœud. Par exemple :$ oc debug node/ip-10-0-155-125.us-west-1.compute.internalDéfinir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /hostExécutez la commande
rpm-ostree statuspour vérifier que l'image en couches personnalisée est utilisée :sh-4.4# sudo rpm-ostree statusExemple de sortie
State: idle Deployments: * ostree-unverified-registry:quay.io/my-registry/custom-image@sha256:306b606615dcf8f0e5e7d87fee3 Digest: sha256:306b606615dcf8f0e5e7d87fee3
Ressources supplémentaires
15.2. Suppression d'une image en couches personnalisée RHCOS
Vous pouvez facilement inverser la superposition d'images Red Hat Enterprise Linux CoreOS (RHCOS) à partir des nœuds dans des pools de configuration de machines spécifiques. L'opérateur de configuration de machine (MCO) redémarre ces nœuds avec l'image Red Hat Enterprise Linux CoreOS (RHCOS) de base du cluster, en remplaçant l'image en couches personnalisée.
Pour supprimer une image personnalisée de Red Hat Enterprise Linux CoreOS (RHCOS) de votre cluster, vous devez supprimer la configuration de la machine qui a appliqué l'image.
Procédure
Supprimer la configuration de la machine qui a appliqué l'image en couches personnalisée.
$ oc delete mc os-layer-hotfixAprès avoir supprimé la configuration de la machine, les nœuds redémarrent.
Vérification
Vous pouvez vérifier que l'image en couches personnalisée a été supprimée en effectuant l'une des vérifications suivantes :
Vérifier que le pool de configuration de la machine travailleuse est mis à jour avec la configuration de la machine précédente :
$ oc get mcpExemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-6faecdfa1b25c114a58cf178fbaa45e2 True False False 3 3 3 0 39m worker rendered-worker-6b000dbc31aaee63c6a2d56d04cd4c1b False True False 3 0 0 0 39m1 - 1
- Lorsque le champ
UPDATINGestTrue, le pool de configuration de la machine est mis à jour avec la configuration de la machine précédente. Lorsque le champ devientFalse, le pool de configuration de la machine du travailleur est passé à la configuration de la machine précédente.
Vérifiez que la planification sur les nœuds est désactivée. Cela indique que la modification est en cours d'application :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-148-79.us-west-1.compute.internal Ready worker 32m v1.25.0+3ef6ef3 ip-10-0-155-125.us-west-1.compute.internal Ready,SchedulingDisabled worker 35m v1.25.0+3ef6ef3 ip-10-0-170-47.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-174-77.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-211-49.us-west-1.compute.internal Ready control-plane,master 42m v1.25.0+3ef6ef3 ip-10-0-218-151.us-west-1.compute.internal Ready worker 31m v1.25.0+3ef6ef3Lorsque le nœud est revenu à l'état
Ready, vérifiez qu'il utilise l'image de base :Ouvrez une session
oc debugvers le nœud. Par exemple :$ oc debug node/ip-10-0-155-125.us-west-1.compute.internalDéfinir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /hostExécutez la commande
rpm-ostree statuspour vérifier que l'image en couches personnalisée est utilisée :sh-4.4# sudo rpm-ostree statusExemple de sortie
State: idle Deployments: * ostree-unverified-registry:podman pull quay.io/openshift-release-dev/ocp-release@sha256:e2044c3cfebe0ff3a99fc207ac5efe6e07878ad59fd4ad5e41f88cb016dacd73 Digest: sha256:e2044c3cfebe0ff3a99fc207ac5efe6e07878ad59fd4ad5e41f88cb016dacd73
15.3. Mise à jour avec une image en couches personnalisée RHCOS
Lorsque vous configurez la superposition d'images Red Hat Enterprise Linux CoreOS (RHCOS), OpenShift Container Platform ne met plus automatiquement à jour le pool de nœuds qui utilise l'image superposée personnalisée. Vous devenez responsable de la mise à jour manuelle de vos nœuds, le cas échéant.
Pour mettre à jour un nœud qui utilise une image en couches personnalisée, suivez les étapes générales suivantes :
- Le cluster passe automatiquement à la version x.y.z 1, sauf pour les nœuds qui utilisent l'image en couches personnalisée.
- Vous pouvez alors créer un nouveau fichier de conteneur qui fait référence à l'image mise à jour d'OpenShift Container Platform et au RPM que vous avez appliqué précédemment.
- Créez une nouvelle configuration de machine qui pointe vers l'image en couches personnalisée mise à jour.
La mise à jour d'un nœud avec une image en couche personnalisée n'est pas nécessaire. Cependant, si ce nœud est trop éloigné de la version actuelle d'OpenShift Container Platform, vous pourriez obtenir des résultats inattendus.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.