Le réseautage
Configuration du réseau dédié OpenShift
Résumé
Chapitre 1. À propos du réseautage
Le Red Hat OpenShift Networking est un écosystème de fonctionnalités, de plugins et de fonctionnalités de réseau avancées qui améliorent le réseau Kubernetes avec des fonctionnalités liées au réseau avancées dont votre cluster a besoin pour gérer le trafic réseau pour un ou plusieurs clusters hybrides. Cet écosystème de capacités de mise en réseau intègre l’entrée, la sortie, l’équilibrage de charge, le débit haute performance, la sécurité et la gestion du trafic inter et intra-cluster. L’écosystème Red Hat OpenShift Networking fournit également des outils d’observabilité basés sur les rôles pour réduire ses complexités naturelles.
Ce qui suit sont quelques-unes des fonctionnalités de réseau Red Hat OpenShift les plus couramment utilisées disponibles sur votre cluster:
- Cluster Network Operator pour la gestion des plugins réseau
Le réseau de cluster primaire fourni par l’un des plugins d’interface réseau de conteneurs (CNI) suivants:
- Le plugin réseau OVN-Kubernetes, qui est le plugin CNI par défaut.
- Le plugin réseau OpenShift SDN, qui a été déprécié dans OpenShift 4.16 et supprimé dans OpenShift 4.17.
Avant de mettre à niveau OpenShift Dedicated clusters configurés avec le plugin réseau OpenShift SDN vers la version 4.17, vous devez migrer vers le plugin réseau OVN-Kubernetes. Cliquez ici pour plus d’informations sur la migration du plugin réseau OpenShift SDN vers le plugin réseau OVN-Kubernetes dans la section Ressources supplémentaires.
Ressources supplémentaires
Chapitre 2. Opérateurs de réseautage
2.1. L’opérateur DNS dans OpenShift dédié
Dans OpenShift Dedicated, l’opérateur DNS déploie et gère une instance CoreDNS pour fournir un service de résolution de noms aux pods à l’intérieur du cluster, permet la découverte de Kubernetes Service basé sur DNS et résout les noms internes cluster.local.
2.1.1. Contrôle de l’état de l’opérateur DNS
L’opérateur DNS implémente l’API dns du groupe d’API operator.openshift.io. L’opérateur déploie CoreDNS à l’aide d’un jeu de démons, crée un service pour l’ensemble de démons et configure le kubelet pour demander aux pods d’utiliser l’adresse IP du service CoreDNS pour la résolution de nom.
Procédure
L’opérateur DNS est déployé lors de l’installation avec un objet de déploiement.
La commande oc get permet d’afficher l’état du déploiement:
$ oc get -n openshift-dns-operator deployment/dns-operatorExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23hLa commande oc get permet d’afficher l’état de l’opérateur DNS:
$ oc get clusteroperator/dnsExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE dns 4.1.15-0.11 True False False 92mAVAILABLE, PROGRESSING et DEGRADED fournissent des informations sur le statut de l’Opérateur. AVAILABLE est vrai quand au moins 1 pod du jeu de démon CoreDNS signale une condition d’état disponible, et le service DNS a une adresse IP en cluster.
2.1.2. Afficher le DNS par défaut
Chaque nouvelle installation OpenShift Dedicated a un dns.operator nommé par défaut.
Procédure
La commande oc described permet d’afficher les dns par défaut:
$ oc describe dns.operator/defaultExemple de sortie
Name: default Namespace: Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: DNS ... Status: Cluster Domain: cluster.local1 Cluster IP: 172.30.0.102 ...
2.1.3. En utilisant le transfert DNS
Le transfert DNS vous permet de remplacer la configuration de transfert par défaut dans le fichier /etc/resolv.conf de la manière suivante:
Indiquez les serveurs de noms (spec.servers) pour chaque zone. Lorsque la zone transférée est le domaine d’entrée géré par OpenShift Dedicated, le serveur de noms en amont doit être autorisé pour le domaine.
ImportantIl faut spécifier au moins une zone. Dans le cas contraire, votre cluster peut perdre des fonctionnalités.
- Fournir une liste de serveurs DNS en amont (spec.upstreamResolvers).
- Changez la stratégie de transfert par défaut.
La configuration de transfert DNS pour le domaine par défaut peut avoir à la fois les serveurs par défaut spécifiés dans le fichier /etc/resolv.conf et les serveurs DNS en amont.
Procédure
La modification de l’objet DNS Operator nommé par défaut:
$ oc edit dns.operator/defaultAprès avoir émis la commande précédente, l’opérateur crée et met à jour la carte de configuration nommée dns-default avec des blocs de configuration de serveur supplémentaires basés sur spec.servers.
ImportantLorsque vous spécifiez des valeurs pour le paramètre zones, assurez-vous que vous ne transmettez que des zones spécifiques, telles que votre intranet. Il faut spécifier au moins une zone. Dans le cas contraire, votre cluster peut perdre des fonctionnalités.
Dans le cas où aucun des serveurs n’a une zone correspondant à la requête, la résolution de nom revient aux serveurs DNS en amont.
Configuration du transfert DNS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: negativeTTL: 0s positiveTTL: 0s logLevel: Normal nodePlacement: {} operatorLogLevel: Normal servers: - name: example-server1 zones: - example.com2 forwardPlugin: policy: Random3 upstreams:4 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers:5 policy: Random6 protocolStrategy: ""7 transportConfig: {}8 upstreams: - type: SystemResolvConf9 - type: Network address: 1.2.3.410 port: 5311 status: clusterDomain: cluster.local clusterIP: x.y.z.10 conditions: ...- 1
- Doit se conformer à la syntaxe du nom de service rfc6335.
- 2
- Doit être conforme à la définition d’un sous-domaine dans la syntaxe du nom de service rfc1123. Le domaine cluster, cluster.local, est un sous-domaine invalide pour le champ zones.
- 3
- Définit la stratégie pour sélectionner les résolveurs en amont listés dans le forwardPlugin. La valeur par défaut est aléatoire. Il est également possible d’utiliser les valeurs RoundRobin et Sequential.
- 4
- Au maximum 15 amonts sont permis par forwardPlugin.
- 5
- Il est possible d’utiliser upstreamResolvers pour remplacer la stratégie de transfert par défaut et transférer la résolution DNS vers les résolveurs DNS spécifiés (résolutionurs en amont) pour le domaine par défaut. Dans le cas où vous ne fournissez pas de résolveurs en amont, les requêtes de nom DNS vont aux serveurs déclarés dans /etc/resolv.conf.
- 6
- Détermine l’ordre dans lequel les serveurs en amont listés en amont sont sélectionnés pour la requête. Il est possible de spécifier l’une de ces valeurs : aléatoire, RoundRobin ou séquentiel. La valeur par défaut est séquentielle.
- 7
- Lorsqu’elle est omise, la plate-forme choisit un défaut, normalement le protocole de la demande du client d’origine. Définissez sur TCP pour spécifier que la plate-forme doit utiliser TCP pour toutes les requêtes DNS en amont, même si la demande client utilise UDP.
- 8
- Il est utilisé pour configurer le type de transport, le nom du serveur et le paquet CA personnalisé optionnel à utiliser lors du transfert de requêtes DNS à un résolveur en amont.
- 9
- Il est possible de spécifier deux types d’amont : SystemResolvConf ou Network. Le SystemResolvConf configure l’amont pour utiliser /etc/resolv.conf et Network définit un Networkresolver. Il est possible d’en spécifier un ou les deux.
- 10
- Dans le cas où le type spécifié est Network, vous devez fournir une adresse IP. Le champ d’adresse doit être une adresse IPv4 ou IPv6 valide.
- 11
- Dans le cas où le type spécifié est Network, vous pouvez éventuellement fournir un port. Le champ port doit avoir une valeur comprise entre 1 et 65535. Dans le cas où vous ne spécifiez pas un port pour l’amont, le port par défaut est 853.
2.1.4. Contrôle de l’état de l’opérateur DNS
Il est possible d’inspecter l’état et d’afficher les détails de l’opérateur DNS à l’aide de la commande oc described.
Procédure
Afficher l’état de l’opérateur DNS:
$ oc describe clusteroperators/dnsBien que les messages et l’orthographe puissent varier dans une version spécifique, la sortie d’état attendue ressemble à:
Status: Conditions: Last Transition Time: <date> Message: DNS "default" is available. Reason: AsExpected Status: True Type: Available Last Transition Time: <date> Message: Desired and current number of DNSes are equal Reason: AsExpected Status: False Type: Progressing Last Transition Time: <date> Reason: DNSNotDegraded Status: False Type: Degraded Last Transition Time: <date> Message: DNS default is upgradeable: DNS Operator can be upgraded Reason: DNSUpgradeable Status: True Type: Upgradeable
2.1.5. Affichage des journaux de l’opérateur DNS
En utilisant la commande oc logs, vous pouvez afficher les journaux DNS Operator.
Procédure
Consultez les journaux de l’opérateur DNS:
$ oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operator
2.1.6. Définition du niveau de journal CoreDNS
Les niveaux de log pour CoreDNS et l’opérateur CoreDNS sont définis en utilisant différentes méthodes. Il est possible de configurer le niveau de journal CoreDNS pour déterminer la quantité de détails dans les messages d’erreur enregistrés. Les valeurs valides pour le niveau de journal CoreDNS sont Normal, Debug et Trace. Le logLevel par défaut est normal.
Le niveau de journal des erreurs CoreDNS est toujours activé. Les paramètres de niveau de journal suivants rapportent différentes réponses d’erreur:
- LogLevel: Normal active la classe "erreurs": log . { erreur de classe }.
- LogLevel: Debug active la classe "denial": log . { erreur de déni de classe }.
- LogLevel: Trace permet la classe "all": log . {classe tout }.
Procédure
Afin de définir logLevel sur Debug, entrez la commande suivante:
$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=mergeAfin de définir logLevel sur Trace, entrez la commande suivante:
$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=merge
La vérification
Afin de s’assurer que le niveau de journal souhaité a été défini, vérifiez la carte de configuration:
$ oc get configmap/dns-default -n openshift-dns -o yamlÀ titre d’exemple, après avoir configuré le logLevel sur Trace, vous devriez voir cette strophe dans chaque bloc de serveur:
errors log . { class all }
2.1.7. Définition du niveau de journal de l’opérateur CoreDNS
Les niveaux de log pour CoreDNS et CoreDNS Operator sont définis en utilisant différentes méthodes. Les administrateurs de clusters peuvent configurer le niveau de journal de l’opérateur pour suivre plus rapidement les problèmes DNS OpenShift. Les valeurs valides pour operatorLogLevel sont Normal, Debug et Trace. La trace a les informations les plus détaillées. L’opérateurloglogLevel par défaut est normal. Il y a sept niveaux de journalisation pour les problèmes d’opérateur: Trace, Debug, Info, Avertissement, Erreur, Fatal et Panic. Après que le niveau de journalisation est défini, les entrées de journal avec cette sévérité ou quoi que ce soit au-dessus, il sera enregistré.
- OperatorLogLevel: "Normal" set logrus.SetLogLevel("Info").
- OperatorLogLevel: "Debug" définit logrus.SetLogLevel("Debug").
- OperatorLogLevel: "Trace" définit logrus.SetLogLevel("Trace").
Procédure
Afin de définir operatorLogLevel sur Debug, entrez la commande suivante:
$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=mergeAfin de définir operatorLogLevel sur Trace, entrez la commande suivante:
$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=merge
La vérification
Afin d’examiner le changement qui en résulte, entrez la commande suivante:
$ oc get dnses.operator -A -oyamlIl faut voir deux entrées de niveau de journal. L’opérateur operatorLogLevel s’applique aux problèmes d’opérateur DNS OpenShift, et le logLevel s’applique au daemonset des pods CoreDNS:
logLevel: Trace operatorLogLevel: DebugAfin d’examiner les journaux du daemonset, entrez la commande suivante:
$ oc logs -n openshift-dns ds/dns-default
2.1.8. Réglage du cache CoreDNS
Dans le cas de CoreDNS, vous pouvez configurer la durée maximale de mise en cache réussie ou infructueuse, également connue respectivement sous le nom de mise en cache positive ou négative. Le réglage de la durée du cache des réponses de requête DNS peut réduire la charge pour tous les résolveurs DNS en amont.
La définition des champs TTL à des valeurs basses pourrait entraîner une charge accrue sur le cluster, tous les résolveurs en amont, ou les deux.
Procédure
Éditez l’objet DNS Operator nommé par défaut en exécutant la commande suivante:
$ oc edit dns.operator.openshift.io/defaultDe modifier les valeurs de mise en cache en temps-à-vie (TTL):
Configuration de la mise en cache DNS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: positiveTTL: 1h1 negativeTTL: 0.5h10m2 - 1
- La valeur de la chaîne 1h est convertie en son nombre respectif de secondes par CoreDNS. En cas d’omission de ce champ, la valeur est supposée être 0s et le cluster utilise la valeur par défaut interne de 900s comme repli.
- 2
- La valeur de la chaîne peut être une combinaison d’unités telles que 0.5h10m et est convertie en son nombre respectif de secondes par CoreDNS. En cas d’omission de ce champ, la valeur est supposée être 0s et le cluster utilise la valeur par défaut interne de 30s comme un repli.
La vérification
Afin d’examiner la modification, regardez à nouveau la carte de configuration en exécutant la commande suivante:
oc get configmap/dns-default -n openshift-dns -o yamlAssurez-vous que vous voyez des entrées qui ressemblent à l’exemple suivant:
cache 3600 { denial 9984 2400 }
2.1.9. Des tâches avancées
2.1.9.1. Changer l’état de gestion de l’opérateur DNS
L’opérateur DNS gère le composant CoreDNS pour fournir un service de résolution de noms pour les pods et les services dans le cluster. L’état de gestion de l’opérateur DNS est défini sur Gestion par défaut, ce qui signifie que l’opérateur DNS gère activement ses ressources. Il est possible de le changer en Ungaged, ce qui signifie que l’opérateur DNS ne gère pas ses ressources.
Les cas suivants sont des cas d’utilisation pour changer l’état de gestion de l’opérateur DNS:
- Il s’agit d’un développeur et vous souhaitez tester une modification de configuration pour voir s’il corrige un problème dans CoreDNS. Il est possible d’empêcher l’opérateur DNS d’écraser la modification de configuration en définissant l’état de gestion sur Ungaged.
- Il s’agit d’un administrateur de cluster et vous avez signalé un problème avec CoreDNS, mais vous devez appliquer une solution de contournement jusqu’à ce que le problème soit résolu. Le champ État de gestion de l’opérateur DNS peut être défini sur Ungaged pour appliquer la solution de contournement.
Procédure
Change managementState to Ungaged dans l’opérateur DNS:
oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'État de l’opérateur DNS utilisant la ligne de commande jsonpath JSON parser:
$ oc get dns.operator.openshift.io default -ojsonpath='{.spec.managementState}'Exemple de sortie
"Unmanaged"
Il n’est pas possible de mettre à niveau l’état de gestion sur Ungaged.
2.1.9.2. Contrôle du positionnement des pod DNS
L’opérateur DNS a deux ensembles de démons: un pour CoreDNS appelé dns-default et un pour la gestion du fichier /etc/hosts appelé node-resolver.
Les pods CoreDNS peuvent être attribués et exécutés sur des nœuds spécifiés. Ainsi, si l’administrateur du cluster a configuré des stratégies de sécurité qui interdisent la communication entre paires de nœuds, vous pouvez configurer des pods CoreDNS pour s’exécuter sur un ensemble restreint de nœuds.
Le service DNS est disponible pour tous les pods si les circonstances suivantes sont vraies:
- Les gousses DNS s’exécutent sur certains nœuds dans le cluster.
- Les nœuds sur lesquels les pods DNS ne s’exécutent pas ont une connectivité réseau aux nœuds sur lesquels les pod DNS s’exécutent,
Le jeu de démons de résolution de nœuds doit s’exécuter sur chaque hôte de nœuds, car il ajoute une entrée pour le registre d’images de cluster pour prendre en charge les images en tirant. Les pods node-resolver n’ont qu’un seul travail : rechercher l’adresse IP du cluster du service image-registry.openshift-image-registry.svc et l’ajouter à /etc/hosts sur l’hôte du nœud afin que le temps d’exécution du conteneur puisse résoudre le nom du service.
En tant qu’administrateur de cluster, vous pouvez utiliser un sélecteur de nœuds personnalisé pour configurer le jeu de démon pour que CoreDNS s’exécute ou ne s’exécute pas sur certains nœuds.
Conditions préalables
- C’est toi qui as installé le CLI.
- En tant qu’utilisateur, vous êtes connecté au cluster avec des privilèges cluster-admin.
- L’état de gestion de votre opérateur DNS est configuré sur Managed.
Procédure
Afin de permettre au jeu de démon pour CoreDNS de s’exécuter sur certains nœuds, configurez une tainte et une tolérance:
Définissez une tainte sur les nœuds que vous souhaitez contrôler le placement des pod DNS en entrant la commande suivante:
$ oc adm taint nodes <node_name> dns-only=abc:NoExecute1 - 1
- <node_name> par le nom réel du nœud.
De modifier l’objet DNS Operator nommé par défaut pour inclure la tolérance correspondante en entrant la commande suivante:
$ oc edit dns.operator/defaultIndiquez une touche tainte et une tolérance pour la tainte. La tolérance suivante correspond à la tainte définie sur les nœuds.
spec: nodePlacement: tolerations: - effect: NoExecute key: "dns-only"1 operator: Equal value: abc tolerationSeconds: 36002 Facultatif: Pour spécifier le placement des nœuds à l’aide d’un sélecteur de nœuds, modifiez l’opérateur DNS par défaut:
Éditer l’objet DNS Operator nommé par défaut pour inclure un sélecteur de nœuds:
spec: nodePlacement: nodeSelector:1 node-role.kubernetes.io/control-plane: ""- 1
- Ce sélecteur de nœuds garantit que les gousses CoreDNS s’exécutent uniquement sur les nœuds de plan de contrôle.
2.1.9.3. Configuration du transfert DNS avec TLS
Lorsque vous travaillez dans un environnement hautement réglementé, vous pourriez avoir besoin de la possibilité de sécuriser le trafic DNS lorsque vous transmettez des demandes à des résolveurs en amont afin que vous puissiez assurer un trafic DNS supplémentaire et la confidentialité des données.
Gardez à l’esprit que CoreDNS met en cache les connexions transférées pendant 10 secondes. CoreDNS tiendra une connexion TCP ouverte pendant ces 10 secondes si aucune demande n’est émise. Avec de grands clusters, assurez-vous que votre serveur DNS est conscient qu’il pourrait obtenir de nombreuses nouvelles connexions à tenir ouvert parce que vous pouvez lancer une connexion par nœud. Configurez votre hiérarchie DNS en conséquence pour éviter les problèmes de performance.
Lorsque vous spécifiez des valeurs pour le paramètre zones, assurez-vous que vous ne transmettez que des zones spécifiques, telles que votre intranet. Il faut spécifier au moins une zone. Dans le cas contraire, votre cluster peut perdre des fonctionnalités.
Procédure
La modification de l’objet DNS Operator nommé par défaut:
$ oc edit dns.operator/defaultLes administrateurs de clusters peuvent configurer la sécurité des couches de transport (TLS) pour les requêtes DNS transmises.
Configuration du transfert DNS avec TLS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example-server1 zones: - example.com2 forwardPlugin: transportConfig: transport: TLS3 tls: caBundle: name: mycacert serverName: dnstls.example.com4 policy: Random5 upstreams:6 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers:7 transportConfig: transport: TLS tls: caBundle: name: mycacert serverName: dnstls.example.com upstreams: - type: Network8 address: 1.2.3.49 port: 5310 - 1
- Doit se conformer à la syntaxe du nom de service rfc6335.
- 2
- Doit être conforme à la définition d’un sous-domaine dans la syntaxe du nom de service rfc1123. Le domaine cluster, cluster.local, est un sous-domaine invalide pour le champ zones. Le domaine cluster, cluster.local, est un sous-domaine invalide pour les zones.
- 3
- Lorsque vous configurez TLS pour les requêtes DNS transmises, définissez le champ de transport pour avoir la valeur TLS.
- 4
- Lors de la configuration de TLS pour les requêtes DNS transmises, il s’agit d’un nom de serveur obligatoire utilisé dans le cadre de l’indication de nom de serveur (SNI) pour valider le certificat de serveur TLS en amont.
- 5
- Définit la stratégie pour sélectionner les résolveurs en amont. La valeur par défaut est aléatoire. Il est également possible d’utiliser les valeurs RoundRobin et Sequential.
- 6
- C’est nécessaire. L’utiliser pour fournir des résolveurs en amont. Au maximum 15 entrées en amont sont autorisées par entrée forwardPlugin.
- 7
- En option. Il peut être utilisé pour remplacer la stratégie par défaut et transférer la résolution DNS vers les résolveurs DNS spécifiés (résolutionurs en amont) pour le domaine par défaut. Dans le cas où vous ne fournissez pas de résolveurs en amont, les requêtes de nom DNS vont aux serveurs de /etc/resolv.conf.
- 8
- Le type réseau est uniquement autorisé lors de l’utilisation de TLS et vous devez fournir une adresse IP. Le type de réseau indique que ce résolveur en amont doit gérer les demandes transmises séparément des résolveurs en amont listés dans /etc/resolv.conf.
- 9
- Le champ d’adresse doit être une adresse IPv4 ou IPv6 valide.
- 10
- En option, vous pouvez fournir un port. Le port doit avoir une valeur comprise entre 1 et 65535. Dans le cas où vous ne spécifiez pas un port pour l’amont, le port par défaut est 853.
NoteLorsque les serveurs sont indéfinis ou invalides, la carte de configuration ne contient que le serveur par défaut.
La vérification
Afficher la carte de configuration:
$ oc get configmap/dns-default -n openshift-dns -o yamlExemple de DNS ConfigMap basé sur l’exemple de transfert TLS
apiVersion: v1 data: Corefile: | example.com:5353 { forward . 1.1.1.1 2.2.2.2:5353 } bar.com:5353 example.com:5353 { forward . 3.3.3.3 4.4.4.4:54541 } .:5353 { errors health kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure upstream fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf 1.2.3.4:53 { policy Random } cache 30 reload } kind: ConfigMap metadata: labels: dns.operator.openshift.io/owning-dns: default name: dns-default namespace: openshift-dns- 1
- Les modifications apportées à forwardPlugin déclenchent une mise à jour continue du jeu de démon CoreDNS.
2.2. L’opérateur d’entrée dans OpenShift dédié
L’opérateur Ingress implémente l’API IngressController et est le composant responsable de l’accès externe aux services de cluster dédiés OpenShift.
2.2.1. Opérateur d’ingénieur dédié OpenShift
Lorsque vous créez votre cluster dédié OpenShift, les pods et les services s’exécutant sur le cluster reçoivent chacun leurs propres adresses IP. Les adresses IP sont accessibles à d’autres pods et services en cours d’exécution à proximité, mais ne sont pas accessibles aux clients externes.
L’opérateur Ingress permet aux clients externes d’accéder à votre service en déployant et en gérant un ou plusieurs contrôleurs Ingress basés sur HAProxy pour gérer le routage. Les ingénieurs de fiabilité du site Red Hat (SRE) gèrent l’opérateur Ingress pour les clusters dédiés à OpenShift. Bien que vous ne puissiez pas modifier les paramètres de l’opérateur Ingress, vous pouvez afficher les configurations, l’état et les journaux par défaut du contrôleur Ingress, ainsi que l’état de l’opérateur Ingress.
2.2.2. L’actif de configuration Ingress
Le programme d’installation génère une ressource Ingress dans le groupe API config.openshift.io, cluster-ingress-02-config.yml.
Définition YAML de la ressource Ingress
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
spec:
domain: apps.openshiftdemos.comLe programme d’installation stocke cette ressource dans le fichier cluster-ingress-02-config.yml dans le répertoire manifestes. Cette ressource Ingress définit la configuration à l’échelle du cluster pour Ingress. Cette configuration Ingress est utilisée comme suit:
- L’opérateur Ingress utilise le domaine à partir de la configuration du cluster Ingress comme domaine pour le contrôleur Ingress par défaut.
- L’opérateur de serveur d’API OpenShift utilise le domaine à partir de la configuration du cluster Ingress. Ce domaine est également utilisé lors de la génération d’un hôte par défaut pour une ressource Route qui ne spécifie pas un hôte explicite.
2.2.3. Ingress Paramètres de configuration du contrôleur
La ressource personnalisée IngressController (CR) inclut des paramètres de configuration optionnels que vous pouvez configurer pour répondre aux besoins spécifiques de votre organisation.
| Le paramètre | Description |
|---|---|
|
| domaine est un nom DNS desservi par le contrôleur Ingress et est utilisé pour configurer plusieurs fonctionnalités:
La valeur de domaine doit être unique parmi tous les contrôleurs Ingress et ne peut pas être mise à jour. En cas de vide, la valeur par défaut est ingress.config.openshift.io/cluster .spec.domain. |
|
| les répliques sont le nombre de répliques du contrôleur Ingress. Dans le cas contraire, la valeur par défaut est 2. |
|
| endpointPublishingStrategy est utilisé pour publier les points de terminaison Ingress Controller sur d’autres réseaux, activer l’intégration de l’équilibreur de charge et fournir l’accès à d’autres systèmes. Dans les environnements cloud, utilisez le champ loadBalancer pour configurer la stratégie de publication des points de terminaison pour votre contrôleur Ingress. Les champs endpointPublishingStrategy suivants peuvent être configurés:
Dans le cas contraire, la valeur par défaut est basée sur infrastructure.config.openshift.io/cluster .status.platform:
Dans la plupart des plateformes, la valeur endpointPublishingStrategy peut être mise à jour. Dans GCP, vous pouvez configurer les champs de fin suivantsPublishingStrategy:
Lorsque vous avez besoin de mettre à jour la valeur endpointPublishingStrategy après le déploiement de votre cluster, vous pouvez configurer les champs endpointPublishingStrategy suivants:
|
|
| La valeur defaultCertificate est une référence à un secret qui contient le certificat par défaut qui est servi par le contrôleur Ingress. Lorsque les Routes ne spécifient pas leur propre certificat, le certificat par défaut est utilisé. Le secret doit contenir les clés et données suivantes: * tls.crt: contenu du fichier de certificat * tls.key: contenu du fichier clé Dans le cas contraire, un certificat wildcard est automatiquement généré et utilisé. Le certificat est valable pour le domaine et les sous-domaines Ingress Controller, et l’AC du certificat généré est automatiquement intégrée au magasin de confiance du cluster. Le certificat en service, qu’il soit généré ou spécifié par l’utilisateur, est automatiquement intégré au serveur OAuth intégré OpenShift Dedicated. |
|
| le namespaceSelector est utilisé pour filtrer l’ensemble d’espaces de noms desservis par le contrôleur Ingress. Ceci est utile pour la mise en œuvre de fragments. |
|
| RouteSelector est utilisé pour filtrer l’ensemble de Routes desservies par le contrôleur Ingress. Ceci est utile pour la mise en œuvre de fragments. |
|
| le nodePlacement permet un contrôle explicite sur la planification du contrôleur d’Ingress. Dans le cas contraire, les valeurs par défaut sont utilisées. Note Le paramètre nodePlacement comprend deux parties, nodeSelector et tolérances. À titre d’exemple: |
|
| le fichier tlsSecurityProfile spécifie les paramètres des connexions TLS pour les contrôleurs Ingress. Dans le cas contraire, la valeur par défaut est basée sur la ressource apiservers.config.openshift.io/cluster. Lors de l’utilisation des types de profils anciens, intermédiaires et modernes, la configuration efficace du profil est sujette à changement entre les versions. À titre d’exemple, compte tenu d’une spécification pour utiliser le profil intermédiaire déployé sur la version X.Y.Z.Z, une mise à niveau pour libérer X.Y.Z+1 peut entraîner l’application d’une nouvelle configuration de profil sur le contrôleur Ingress, ce qui entraîne un déploiement. La version TLS minimale pour les contrôleurs Ingress est 1.1, et la version TLS maximum est 1.3. Note Les chiffrements et la version TLS minimale du profil de sécurité configuré sont reflétés dans le statut TLSProfile. Important L’opérateur Ingress convertit le TLS 1.0 d’un profil Old ou Custom en 1.1. |
|
| clientTLS authentifie l’accès du client au cluster et aux services; par conséquent, l’authentification TLS mutuelle est activée. Dans le cas contraire, le client TLS n’est pas activé. clientTLS a les sous-champs requis, spec.clientTLS.clientCertificatePolicy et spec.clientTLS.ClientCA. Le sous-champ ClientCertificatePolicy accepte l’une des deux valeurs requises ou facultatives. Le sous-champ ClientCA spécifie une carte de configuration qui se trouve dans l’espace de noms openshift-config. La carte de configuration doit contenir un paquet de certificats CA. AllowedSubjectPatterns est une valeur optionnelle qui spécifie une liste d’expressions régulières, qui sont appariées avec le nom distingué sur un certificat client valide pour filtrer les requêtes. Les expressions régulières doivent utiliser la syntaxe PCRE. Au moins un modèle doit correspondre au nom distingué d’un certificat client; sinon, le contrôleur Ingress rejette le certificat et nie la connexion. Dans le cas contraire, le Contrôleur Ingress ne rejette pas les certificats basés sur le nom distingué. |
|
| RouteAdmission définit une politique pour traiter de nouvelles revendications d’itinéraire, telles que l’autorisation ou le refus de revendications dans les espaces de noms. le nom de namespaceOwnership décrit comment les revendications des noms d’hôte doivent être traitées dans les espaces de noms. La valeur par défaut est Strict.
WildcardPolicy décrit comment les routes avec les stratégies de wildcard sont gérées par le contrôleur d’Ingress.
|
|
| la journalisation définit les paramètres de ce qui est enregistré où. Lorsque ce champ est vide, les journaux opérationnels sont activés mais les journaux d’accès sont désactivés.
|
|
| httpHeaders définit la stratégie pour les en-têtes HTTP. En définissant l’en-tête HTTP d’IngressControllerHTTPHeaders, vous spécifiez quand et comment le contrôleur d’ingénierie définit les en-têtes HTTP Forwarded, X-Forwarded-Forwarded-Host, X-Forwarded-Port, X-Forwarded-Proto et X-Forwarded-Proto-Version. La stratégie par défaut est définie à l’annexe.
En définissant l’en-têteNameCaseAdjustments, vous pouvez spécifier les ajustements de cas qui peuvent être appliqués aux noms d’en-tête HTTP. Chaque ajustement est spécifié comme un nom d’en-tête HTTP avec la capitalisation souhaitée. Ainsi, spécifier X-Forwarded-For indique que l’en-tête x-forwarded-for HTTP doit être ajusté pour avoir la capitalisation spécifiée. Ces ajustements ne sont appliqués qu’aux routes de texte clair, terminées par bord et recryptées, et uniquement lorsque vous utilisez HTTP/1. En ce qui concerne les en-têtes de requête, ces ajustements sont appliqués uniquement pour les itinéraires qui ont l’annotation réelle haproxy.router.openshift.io/h1-adjust-case=true. Dans le cas des en-têtes de réponse, ces ajustements sont appliqués à toutes les réponses HTTP. Dans le cas où ce champ est vide, aucun en-tête de requête n’est ajusté. actions spécifie les options pour effectuer certaines actions sur les en-têtes. Les en-têtes ne peuvent pas être réglés ou supprimés pour les connexions de passage TLS. Le champ actions a des sous-champs supplémentaires spec.httpHeader.actions.response et spec.httpHeader.actions.request:
|
|
| httpCompression définit la stratégie de compression du trafic HTTP.
|
|
| httpErrorCodePages spécifie les pages personnalisées de réponse au code d’erreur HTTP. IngressController utilise par défaut des pages d’erreur intégrées dans l’image IngressController. |
|
| httpCaptureCookies spécifie les cookies HTTP que vous souhaitez capturer dans les journaux d’accès. Lorsque le champ httpCaptureCookies est vide, les journaux d’accès ne capturent pas les cookies. Dans tout cookie que vous souhaitez capturer, les paramètres suivants doivent être dans votre configuration IngressController:
À titre d’exemple: |
|
| httpCaptureHeaders spécifie les en-têtes HTTP que vous souhaitez capturer dans les journaux d’accès. Lorsque le champ httpCaptureHeaders est vide, les journaux d’accès ne capturent pas les en-têtes. httpCaptureHeaders contient deux listes d’en-têtes à capturer dans les journaux d’accès. Les deux listes de champs d’en-tête sont requête et réponse. Dans les deux listes, le champ nom doit spécifier le nom de l’en-tête et le champ de longueur max doit spécifier la longueur maximale de l’en-tête. À titre d’exemple: |
|
| LogningOptions spécifie les options pour régler les performances des pods Ingress Controller.
|
|
| logEmptyRequests spécifie les connexions pour lesquelles aucune demande n’est reçue et enregistrée. Ces requêtes vides proviennent de sondes de santé d’équilibreur de charge ou de connexions spéculatives du navigateur Web (préconnection) et l’enregistrement de ces demandes peut être indésirable. Cependant, ces requêtes peuvent être causées par des erreurs réseau, auquel cas la journalisation des requêtes vides peut être utile pour diagnostiquer les erreurs. Ces requêtes peuvent être causées par des scans de ports, et l’enregistrement des requêtes vides peut aider à détecter les tentatives d’intrusion. Les valeurs autorisées pour ce champ sont Log et Ignore. La valeur par défaut est Log. Le type LoggingPolicy accepte l’une ou l’autre des deux valeurs:
|
|
| HTTPEmptyRequestsPolicy décrit comment les connexions HTTP sont gérées si les temps de connexion sont écoulés avant la réception d’une demande. Les valeurs autorisées pour ce champ sont Répondre et Ignorer. La valeur par défaut est Répondre. Le type HTTPEmptyRequestsPolicy accepte l’une ou l’autre des deux valeurs:
Ces connexions proviennent de sondes de santé d’équilibreur de charge ou de connexions spéculatives par navigateur Web (préconnection) et peuvent être ignorées en toute sécurité. Cependant, ces demandes peuvent être causées par des erreurs de réseau, de sorte que le réglage de ce champ à Ignore peut entraver la détection et le diagnostic des problèmes. Ces requêtes peuvent être causées par des scans de ports, auquel cas l’enregistrement des requêtes vides peut aider à détecter les tentatives d’intrusion. |
2.2.3.1. Ingress Controller TLS Profils de sécurité
Les profils de sécurité TLS offrent aux serveurs un moyen de réguler les chiffrements qu’un client de connexion peut utiliser lors de la connexion au serveur.
2.2.3.1.1. Comprendre les profils de sécurité TLS
Il est possible d’utiliser un profil de sécurité TLS (Transport Layer Security) pour définir quels chiffrements TLS sont requis par divers composants dédiés à OpenShift. Les profils de sécurité TLS dédiés OpenShift sont basés sur les configurations recommandées par Mozilla.
Il est possible de spécifier l’un des profils de sécurité TLS suivants pour chaque composant:
| Le profil | Description |
|---|---|
|
| Ce profil est destiné à être utilisé avec des clients ou des bibliothèques hérités. Le profil est basé sur la configuration recommandée par l’ancienne compatibilité rétrograde. L’ancien profil nécessite une version TLS minimale de 1.0. Note Dans le cas du contrôleur Ingress, la version TLS minimale est convertie de 1.0 à 1.1. |
|
| Ce profil est la configuration recommandée pour la majorité des clients. C’est le profil de sécurité TLS par défaut pour le contrôleur Ingress, le kubelet et le plan de contrôle. Le profil est basé sur la configuration de compatibilité intermédiaire recommandée. Le profil intermédiaire nécessite une version TLS minimale de 1.2. |
|
| Ce profil est destiné à une utilisation avec des clients modernes qui n’ont pas besoin de rétrocompatibilité. Ce profil est basé sur la configuration de compatibilité moderne recommandée. Le profil Moderne nécessite une version TLS minimale de 1.3. |
|
| Ce profil vous permet de définir la version TLS et les chiffrements à utiliser. Avertissement Faites preuve de prudence lors de l’utilisation d’un profil personnalisé, car les configurations invalides peuvent causer des problèmes. |
Lors de l’utilisation de l’un des types de profil prédéfinis, la configuration de profil efficace est sujette à changement entre les versions. À titre d’exemple, compte tenu d’une spécification pour utiliser le profil intermédiaire déployé sur la version X.Y.Z.Z, une mise à niveau pour libérer X.Y.Z+1 pourrait entraîner l’application d’une nouvelle configuration de profil, entraînant un déploiement.
2.2.3.1.2. Configuration du profil de sécurité TLS pour le contrôleur Ingress
Afin de configurer un profil de sécurité TLS pour un contrôleur Ingress, modifiez la ressource personnalisée IngressController (CR) pour spécifier un profil de sécurité TLS prédéfini ou personnalisé. Lorsqu’un profil de sécurité TLS n’est pas configuré, la valeur par défaut est basée sur le profil de sécurité TLS défini pour le serveur API.
Exemple IngressController CR qui configure l’ancien profil de sécurité TLS
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...Le profil de sécurité TLS définit la version minimale de TLS et les chiffrements TLS pour les connexions TLS pour les contrôleurs d’Ingress.
Les chiffrements et la version TLS minimale du profil de sécurité TLS configuré dans la ressource personnalisée IngressController (CR) sous Profil Status.Tls et le profil de sécurité TLS configuré sous Profil de sécurité Spec.Tls. Dans le cas du profil de sécurité TLS personnalisé, les chiffrements spécifiques et la version TLS minimale sont listés sous les deux paramètres.
L’image HAProxy Ingress Controller prend en charge TLS 1.3 et le profil Modern.
L’opérateur Ingress convertit également le TLS 1.0 d’un profil Old ou Custom en 1.1.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
Procédure
Editez le CR IngressController CR dans le projet openshift-ingress-operator pour configurer le profil de sécurité TLS:
$ oc edit IngressController default -n openshift-ingress-operatorAjouter le champ spec.tlsSecurityProfile:
Exemple IngressController CR pour un profil personnalisé
apiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 1
- Indiquez le type de profil de sécurité TLS (ancien, intermédiaire ou personnalisé). La valeur par défaut est intermédiaire.
- 2
- Indiquez le champ approprié pour le type sélectionné:
-
ancien: {} -
intermédiaire: {} -
coutume:
-
- 3
- Dans le cas du type personnalisé, spécifiez une liste de chiffrements TLS et une version minimale acceptée de TLS.
- Enregistrez le fichier pour appliquer les modifications.
La vérification
Assurez-vous que le profil est défini dans IngressController CR:
$ oc describe IngressController default -n openshift-ingress-operatorExemple de sortie
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
2.2.3.1.3. Configuration de l’authentification TLS mutuelle
Il est possible de configurer le contrôleur Ingress pour activer l’authentification mutuelle TLS (mTLS) en définissant une valeur spec.clientTLS. La valeur clientTLS configure le contrôleur Ingress pour vérifier les certificats clients. Cette configuration inclut la définition d’une valeur clientCA, qui est une référence à une carte de configuration. La carte de configuration contient le paquet de certificats CA codé par PEM qui est utilisé pour vérifier le certificat d’un client. En option, vous pouvez également configurer une liste de filtres sujets de certificat.
Lorsque la valeur clientCA spécifie un point de distribution de liste de révocation de certificat X509v3 (CRL), l’opérateur Ingress télécharge et gère une carte de configuration CRL basée sur le point de distribution HTTP URI X509v3 CRL spécifié dans chaque certificat fourni. Le contrôleur Ingress utilise cette carte de configuration lors de la négociation mTLS/TLS. Les demandes qui ne fournissent pas de certificats valides sont rejetées.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
- Il y a un paquet de certificats CA codé par PEM.
Dans le cas où votre groupe CA fait référence à un point de distribution de LCR, vous devez également inclure le certificat d’entité finale ou de feuille au paquet CA client. Ce certificat doit avoir inclus un URI HTTP sous les points de distribution CRL, comme décrit dans la RFC 5280. À titre d’exemple:
Issuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crl
Procédure
Dans l’espace de noms openshift-config, créez une carte de configuration à partir de votre paquet CA:
$ oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \1 -n openshift-config- 1
- La clé de données cartographique de configuration doit être ca-bundle.pem, et la valeur des données doit être un certificat CA au format PEM.
Éditer la ressource IngressController dans le projet openshift-ingress-operator:
$ oc edit IngressController default -n openshift-ingress-operatorAjoutez le champ spec.clientTLS et les sous-champs pour configurer le TLS mutuel:
Exemple IngressController CR pour un profil clientTLS qui spécifie les modèles de filtrage
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: clientTLS: clientCertificatePolicy: Required clientCA: name: router-ca-certs-default allowedSubjectPatterns: - "^/CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift$"- En option, obtenez le Nom Distinguished (DN) pour AuthorSubjectPatterns en entrant la commande suivante.
$ openssl x509 -in custom-cert.pem -noout -subject
subject= /CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift2.2.4. Afficher le contrôleur Ingress par défaut
L’opérateur Ingress est une caractéristique centrale d’OpenShift Dedicated et est activé hors de la boîte.
Chaque nouvelle installation OpenShift Dedicated a un ingresscontroller nommé par défaut. Il peut être complété par des contrôleurs Ingress supplémentaires. En cas de suppression de l’ingresscontroller par défaut, l’opérateur Ingress le recréera automatiquement en une minute.
Procédure
Afficher le contrôleur Ingress par défaut:
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/default
2.2.5. Afficher le statut de l’opérateur Ingress
Consultez et inspectez l’état de votre opérateur Ingress.
Procédure
Consultez le statut de votre opérateur Ingress:
$ oc describe clusteroperators/ingress
2.2.6. Afficher les journaux du contrôleur Ingress
Consultez les journaux de vos contrôleurs Ingress.
Procédure
Consultez vos journaux Ingress Controller:
$ oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
2.2.7. Afficher l’état Ingress Controller
Il est possible d’afficher l’état d’un contrôleur d’Ingress particulier.
Procédure
Afficher l’état d’un contrôleur Ingress:
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
2.2.8. Création d’un contrôleur Ingress personnalisé
En tant qu’administrateur de cluster, vous pouvez créer un nouveau contrôleur d’Ingress personnalisé. Étant donné que le contrôleur Ingress par défaut peut changer lors des mises à jour dédiées d’OpenShift, la création d’un contrôleur Ingress personnalisé peut être utile lors de la maintenance manuelle d’une configuration qui persiste entre les mises à jour de cluster.
Cet exemple fournit une spécification minimale pour un contrôleur d’Ingress personnalisé. Afin de personnaliser davantage votre contrôleur Ingress personnalisé, voir "Configuring the Ingress Controller".
Conditions préalables
- Installez le OpenShift CLI (oc).
- Connectez-vous en tant qu’utilisateur avec des privilèges cluster-admin.
Procédure
Créez un fichier YAML qui définit l’objet IngressController personnalisé:
Exemple de fichier custom-ingress-controller.yaml
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: <custom_name>1 namespace: openshift-ingress-operator spec: defaultCertificate: name: <custom-ingress-custom-certs>2 replicas: 13 domain: <custom_domain>4 - 1
- Indiquez le nom personnalisé de l’objet IngressController.
- 2
- Indiquez le nom du secret avec le certificat de wildcard personnalisé.
- 3
- La réplique minimale doit être UNE
- 4
- Indiquez le domaine à votre nom de domaine. Le domaine spécifié sur l’objet IngressController et le domaine utilisé pour le certificat doivent correspondre. À titre d’exemple, si la valeur de domaine est "custom_domain.mycompany.com", le certificat doit avoir SAN *.custom_domain.mycompany.com (avec le *. ajouté au domaine).
Créez l’objet en exécutant la commande suivante:
$ oc create -f custom-ingress-controller.yaml
2.2.9. Configuration du contrôleur Ingress
2.2.9.1. Définition d’un certificat par défaut personnalisé
En tant qu’administrateur, vous pouvez configurer un contrôleur Ingress pour utiliser un certificat personnalisé en créant une ressource secrète et en modifiant la ressource personnalisée IngressController (CR).
Conditions préalables
- Il faut avoir une paire de certificats/clés dans des fichiers codés PEM, où le certificat est signé par une autorité de certification de confiance ou par une autorité de certification privée de confiance que vous avez configurée dans un PKI personnalisé.
Le certificat répond aux exigences suivantes:
- Le certificat est valable pour le domaine d’entrée.
- Le certificat utilise l’extension subjectAltName pour spécifier un domaine wildcard, tel que *.apps.ocp4.example.com.
Il faut avoir un IngressController CR. Il est possible d’utiliser la valeur par défaut:
$ oc --namespace openshift-ingress-operator get ingresscontrollersExemple de sortie
NAME AGE default 10m
Lorsque vous avez des certificats intermédiaires, ils doivent être inclus dans le fichier tls.crt du secret contenant un certificat par défaut personnalisé. La commande est importante lorsque vous spécifiez un certificat; énumérez votre(s) certificat(s) intermédiaire(s) après tout certificat(s) serveur(s).
Procédure
Ce qui suit suppose que le certificat personnalisé et la paire de clés sont dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Les noms de chemin réels sont remplacés par tls.crt et tls.key. Il est également possible de remplacer un autre nom par défaut lors de la création de la ressource Secret et de la référencer dans IngressController CR.
Cette action entraînera le redéploiement du contrôleur Ingress, en utilisant une stratégie de déploiement mobile.
Créez une ressource Secret contenant le certificat personnalisé dans l’espace de noms openshift-ingress à l’aide des fichiers tls.crt et tls.key.
$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.keyActualisez l’IngressController CR pour faire référence au nouveau secret de certificat:
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'La mise à jour a été efficace:
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddatelà où:
<domaine>- Indique le nom de domaine de base de votre cluster.
Exemple de sortie
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GMAstuceAlternativement, vous pouvez appliquer le YAML suivant pour définir un certificat par défaut personnalisé:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-defaultLe nom secret du certificat doit correspondre à la valeur utilisée pour mettre à jour le CR.
Lorsque l’IngressController CR a été modifié, l’opérateur Ingress met à jour le déploiement du contrôleur Ingress pour utiliser le certificat personnalisé.
2.2.9.2. La suppression d’un certificat par défaut personnalisé
En tant qu’administrateur, vous pouvez supprimer un certificat personnalisé que vous avez configuré un contrôleur Ingress à utiliser.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
- L’OpenShift CLI (oc) a été installé.
- Auparavant, vous avez configuré un certificat par défaut personnalisé pour le contrôleur Ingress.
Procédure
Afin de supprimer le certificat personnalisé et de restaurer le certificat qui est livré avec OpenShift Dedicated, entrez la commande suivante:
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'Il peut y avoir un retard pendant que le cluster réconcilie la nouvelle configuration du certificat.
La vérification
Afin de confirmer que le certificat de cluster original est restauré, entrez la commande suivante:
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddatelà où:
<domaine>- Indique le nom de domaine de base de votre cluster.
Exemple de sortie
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
2.2.9.3. Auto-échelle d’un contrôleur Ingress
Il est possible d’adapter automatiquement un contrôleur Ingress pour répondre de manière dynamique aux exigences de performance ou de disponibilité de routage, telles que l’exigence d’augmenter le débit.
La procédure suivante fournit un exemple pour la mise à l’échelle du contrôleur Ingress par défaut.
Conditions préalables
- L’OpenShift CLI (oc) est installé.
- En tant qu’utilisateur, vous avez accès à un cluster OpenShift dédié avec le rôle cluster-admin.
Le Custom Metrics Autoscaler Operator et un contrôleur KEDA associé ont été installés.
- Il est possible d’installer l’opérateur en utilisant OperatorHub sur la console Web. Après avoir installé l’opérateur, vous pouvez créer une instance de KedaController.
Procédure
Créez un compte de service à authentifier avec Thanos en exécutant la commande suivante:
$ oc create -n openshift-ingress-operator serviceaccount thanos && oc describe -n openshift-ingress-operator serviceaccount thanosExemple de sortie
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-kfvf2 Mountable secrets: thanos-dockercfg-kfvf2 Tokens: <none> Events: <none>Créez manuellement le jeton secret de compte de service avec la commande suivante:
$ oc apply -f - <<EOF apiVersion: v1 kind: Secret metadata: name: thanos-token namespace: openshift-ingress-operator annotations: kubernetes.io/service-account.name: thanos type: kubernetes.io/service-account-token EOFDéfinissez un objet TriggerAuthentication dans l’espace de noms openshift-ingress-operator en utilisant le jeton du compte de service.
Créez l’objet TriggerAuthentication et passez la valeur de la variable secrète au paramètre TOKEN:
$ oc apply -f - <<EOF apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus namespace: openshift-ingress-operator spec: secretTargetRef: - parameter: bearerToken name: thanos-token key: token - parameter: ca name: thanos-token key: ca.crt EOF
Créer et appliquer un rôle pour la lecture des métriques à partir de Thanos:
Créez un nouveau rôle, thanos-metrics-reader.yaml, qui lit des métriques à partir de pods et de nœuds:
à propos de Thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader namespace: openshift-ingress-operator rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - getAppliquez le nouveau rôle en exécutant la commande suivante:
$ oc apply -f thanos-metrics-reader.yaml
Ajoutez le nouveau rôle au compte de service en entrant les commandes suivantes:
$ oc adm policy -n openshift-ingress-operator add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operator$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanosNoteL’argument add-cluster-role-to-user n’est requis que si vous utilisez des requêtes cross-namespace. L’étape suivante utilise une requête de l’espace de noms kube-metrics qui nécessite cet argument.
Créez un nouveau fichier ScaledObject YAML, ingress-autoscaler.yaml, qui cible le déploiement par défaut du contrôleur Ingress:
Exemple ScaledObject Définition
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler namespace: openshift-ingress-operator spec: scaleTargetRef:1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 202 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:90913 namespace: openshift-ingress-operator4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})'5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus- 1
- La ressource personnalisée que vous ciblez. Dans ce cas, le contrôleur Ingress.
- 2
- Facultatif: Le nombre maximum de répliques. En cas d’omission de ce champ, le maximum par défaut est défini à 100 répliques.
- 3
- Le point d’extrémité du service Thanos dans l’espace de noms de surveillance openshift.
- 4
- L’espace de noms Ingress Operator.
- 5
- Cette expression évalue cependant de nombreux nœuds de travail sont présents dans le cluster déployé.
ImportantLorsque vous utilisez des requêtes cross-namespace, vous devez cibler le port 9091 et non le port 9092 dans le champ serverAddress. Il faut aussi avoir des privilèges élevés pour lire les métriques à partir de ce port.
Appliquez la définition de ressource personnalisée en exécutant la commande suivante:
$ oc apply -f ingress-autoscaler.yaml
La vérification
Assurez-vous que le contrôleur Ingress par défaut est mis à l’échelle pour correspondre à la valeur retournée par la requête kube-state-metrics en exécutant les commandes suivantes:
La commande grep permet de rechercher dans le fichier Ingress Controller YAML des répliques:
$ oc get -n openshift-ingress-operator ingresscontroller/default -o yaml | grep replicas:Exemple de sortie
replicas: 3Faites entrer les gousses dans le projet openshift-ingress:
$ oc get pods -n openshift-ingressExemple de sortie
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
2.2.9.4. Evoluation d’un contrôleur Ingress
Adaptez manuellement un contrôleur Ingress pour répondre aux exigences de performance de routage ou de disponibilité telles que l’exigence d’augmenter le débit. les commandes OC sont utilisées pour mettre à l’échelle la ressource IngressController. La procédure suivante fournit un exemple pour la mise à l’échelle de l’IngreressController par défaut.
La mise à l’échelle n’est pas une action immédiate, car il faut du temps pour créer le nombre désiré de répliques.
Procédure
Afficher le nombre actuel de répliques disponibles pour le logiciel IngressController par défaut:
$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
2Adaptez le logiciel IngressController par défaut au nombre de répliques souhaité à l’aide de la commande oc patch. L’exemple suivant met à l’échelle le IngressController par défaut à 3 répliques:
$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=mergeExemple de sortie
ingresscontroller.operator.openshift.io/default patchedAssurez-vous que l’IngreressController par défaut a mis à l’échelle le nombre de répliques que vous avez spécifiées:
$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
3AstuceAlternativement, vous pouvez appliquer le YAML suivant pour mettre à l’échelle un contrôleur Ingress en trois répliques:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 31 - 1
- Lorsque vous avez besoin d’une quantité différente de répliques, modifiez la valeur des répliques.
2.2.9.5. Configuration de la journalisation des accès Ingress
Il est possible de configurer le contrôleur Ingress pour activer les journaux d’accès. Lorsque vous avez des clusters qui ne reçoivent pas beaucoup de trafic, vous pouvez vous connecter à un sidecar. Lorsque vous avez des clusters de trafic élevés, afin d’éviter de dépasser la capacité de la pile de journalisation ou de vous intégrer à une infrastructure de journalisation en dehors d’OpenShift Dedicated, vous pouvez transférer les journaux à un point de terminaison syslog personnalisé. Il est également possible de spécifier le format des journaux d’accès.
L’enregistrement des conteneurs est utile pour activer les journaux d’accès sur les clusters à faible trafic lorsqu’il n’y a pas d’infrastructure de journalisation Syslog existante, ou pour une utilisation à court terme lors du diagnostic des problèmes avec le contrôleur Ingress.
Le syslog est nécessaire pour les clusters à fort trafic où les journaux d’accès pourraient dépasser la capacité de la pile OpenShift Logging, ou pour les environnements où toute solution de journalisation doit s’intégrer à une infrastructure de journalisation Syslog existante. Les cas d’utilisation Syslog peuvent se chevaucher.
Conditions préalables
- Connectez-vous en tant qu’utilisateur avec des privilèges cluster-admin.
Procédure
Configurer la connexion d’accès Ingress à un sidecar.
Afin de configurer la journalisation des accès Ingress, vous devez spécifier une destination à l’aide de spec.logging.access.destination. Afin de spécifier l’enregistrement à un conteneur sidecar, vous devez spécifier Container spec.logging.access.destination.type. L’exemple suivant est une définition Ingress Controller qui se connecte à une destination Container:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: ContainerLorsque vous configurez le contrôleur Ingress pour se connecter à un sidecar, l’opérateur crée un conteneur nommé logs à l’intérieur du Pod de contrôleur Ingress:
$ oc -n openshift-ingress logs deployment.apps/router-default -c logsExemple de sortie
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
Configurer la journalisation des accès Ingress à un point de terminaison Syslog.
Afin de configurer la journalisation des accès Ingress, vous devez spécifier une destination à l’aide de spec.logging.access.destination. Afin de spécifier la connexion à une destination de point de terminaison Syslog, vous devez spécifier Syslog pour spec.logging.access.destination.type. Dans le cas où le type de destination est Syslog, vous devez également spécifier un point d’extrémité de destination en utilisant spec.logging.access.destination.syslog.address et vous pouvez spécifier une installation en utilisant spec.logging.access.destination.syslog.facility. L’exemple suivant est une définition Ingress Controller qui se connecte à une destination Syslog:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514NoteLe port de destination syslog doit être UDP.
L’adresse de destination syslog doit être une adresse IP. Il ne prend pas en charge le nom d’hôte DNS.
Configurer la journalisation des accès Ingress avec un format de journal spécifique.
Il est possible de spécifier spec.logging.access.httpLogFormat pour personnaliser le format du journal. L’exemple suivant est une définition du contrôleur Ingress qui se connecte à un point de terminaison syslog avec l’adresse IP 1.2.3.4 et le port 10514:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514 httpLogFormat: '%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV'
Désactiver l’enregistrement des accès Ingress.
Afin de désactiver la journalisation des accès Ingress, laissez spec.logging ou spec.logging.access vide:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: null
Autoriser le contrôleur Ingress à modifier la longueur du journal HAProxy lors de l’utilisation d’un sidecar.
Employez spec.logging.access.destination.syslog.maxLength si vous utilisez spec.logging.access.destination.type: Syslog.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 maxLength: 4096 port: 10514Employez spec.logging.access.destination.container.maxLength si vous utilisez spec.logging.access.destination.type: Container.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Container container: maxLength: 8192
2.2.9.6. Configuration du nombre de threads Ingress Controller
L’administrateur de cluster peut définir le nombre de threads pour augmenter le nombre de connexions entrantes qu’un cluster peut gérer. Il est possible de corriger un contrôleur Ingress existant pour augmenter la quantité de threads.
Conditions préalables
- Ce qui suit suppose que vous avez déjà créé un contrôleur Ingress.
Procédure
Actualisez le contrôleur Ingress pour augmenter le nombre de threads:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'NoteLorsque vous avez un nœud capable d’exécuter de grandes quantités de ressources, vous pouvez configurer spec.nodePlacement.nodeSelector avec des étiquettes correspondant à la capacité du nœud prévu, et configurer spec.tuningOptions.threadCount à une valeur appropriée.
2.2.9.7. Configuration d’un contrôleur Ingress pour utiliser un équilibreur de charge interne
Lors de la création d’un contrôleur Ingress sur les plates-formes cloud, le contrôleur Ingress est publié par défaut par un équilibreur de charge dans le cloud public. En tant qu’administrateur, vous pouvez créer un contrôleur Ingress qui utilise un équilibreur de charge dans le cloud interne.
Lorsque vous souhaitez modifier la portée d’un IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Figure 2.1. Diagramme de LoadBalancer
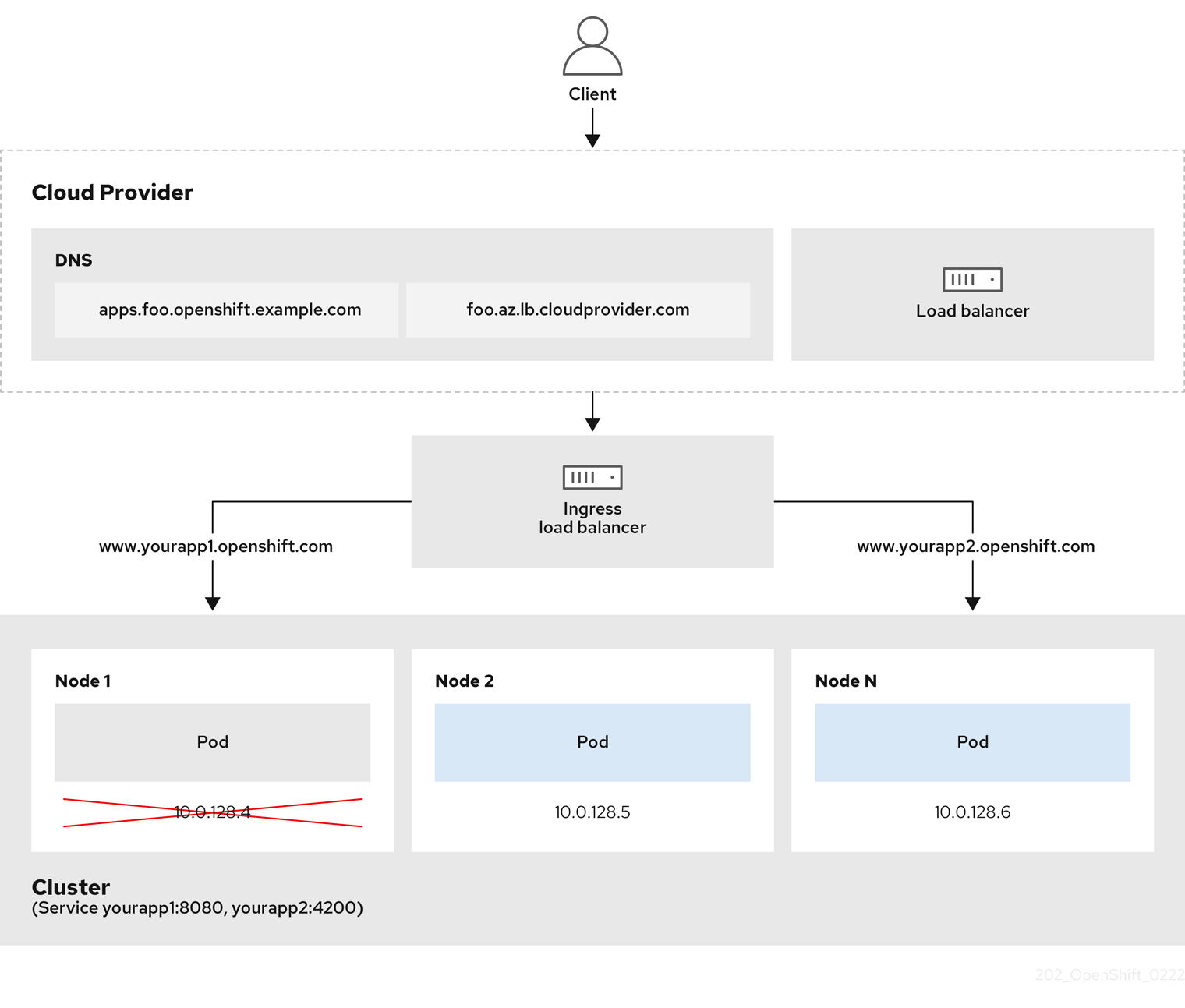
Le graphique précédent montre les concepts suivants relatifs à OpenShift Dedicated Ingress LoadBalancerService endpoint:
- Il est possible de charger l’équilibre externe, à l’aide de l’équilibreur de charge du fournisseur de cloud, ou en interne, à l’aide de l’équilibreur de charge OpenShift Ingress Controller.
- Il est possible d’utiliser l’adresse IP unique de l’équilibreur de charge et les ports plus familiers, tels que 8080 et 4200, comme indiqué sur le cluster représenté dans le graphique.
- Le trafic de l’équilibreur de charge externe est dirigé vers les pods, et géré par l’équilibreur de charge, comme indiqué dans le cas d’un nœud vers le bas. Consultez la documentation de Kubernetes Services pour plus de détails sur la mise en œuvre.
Conditions préalables
- Installez le OpenShift CLI (oc).
- Connectez-vous en tant qu’utilisateur avec des privilèges cluster-admin.
Procédure
Créez une ressource personnalisée IngressController (CR) dans un fichier nommé <name>-ingress-controller.yaml, comme dans l’exemple suivant:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal3 Créez le contrôleur Ingress défini à l’étape précédente en exécutant la commande suivante:
$ oc create -f <name>-ingress-controller.yaml1 - 1
- <name> par le nom de l’objet IngressController.
Facultatif: Confirmer que le contrôleur Ingress a été créé en exécutant la commande suivante:
$ oc --all-namespaces=true get ingresscontrollers
2.2.9.8. Définir l’intervalle de contrôle de santé Ingress Controller
L’administrateur du cluster peut définir l’intervalle de contrôle de santé pour définir combien de temps le routeur attend entre deux contrôles de santé consécutifs. Cette valeur est appliquée globalement par défaut pour tous les itinéraires. La valeur par défaut est de 5 secondes.
Conditions préalables
- Ce qui suit suppose que vous avez déjà créé un contrôleur Ingress.
Procédure
Actualisez le contrôleur Ingress pour modifier l’intervalle entre les contrôles de santé arrière:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'NoteAfin de remplacer l’intervale healthCheckInterval pour une seule route, utilisez l’itinéraire annotation router.openshift.io/haproxy.health.check.interval
2.2.9.9. Configuration du contrôleur Ingress par défaut pour que votre cluster soit interne
Il est possible de configurer le contrôleur Ingress par défaut pour que votre cluster soit interne en le supprimant et en le recréant.
Lorsque vous souhaitez modifier la portée d’un IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Conditions préalables
- Installez le OpenShift CLI (oc).
- Connectez-vous en tant qu’utilisateur avec des privilèges cluster-admin.
Procédure
Configurez le contrôleur Ingress par défaut pour que votre cluster soit interne en le supprimant et en le recréant.
$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
2.2.9.10. Configuration de la politique d’admission d’itinéraire
Les administrateurs et les développeurs d’applications peuvent exécuter des applications dans plusieurs espaces de noms avec le même nom de domaine. C’est pour les organisations où plusieurs équipes développent des microservices qui sont exposés sur le même nom d’hôte.
Autoriser les réclamations dans les espaces de noms ne devrait être activé que pour les clusters ayant confiance entre les espaces de noms, sinon un utilisateur malveillant pourrait prendre en charge un nom d’hôte. C’est pourquoi la politique d’admission par défaut interdit les revendications de nom d’hôte dans les espaces de noms.
Conditions préalables
- Les privilèges d’administrateur de cluster.
Procédure
Éditez le champ .spec.routeAdmission de la variable ressource ingresscontroller à l’aide de la commande suivante:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeExemple de configuration du contrôleur Ingress
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...AstuceAlternativement, vous pouvez appliquer les YAML suivants pour configurer la politique d’admission d’itinéraire:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
2.2.9.11. En utilisant des routes wildcard
Le contrôleur HAProxy Ingress a pris en charge les routes wildcard. L’opérateur Ingress utilise wildcardPolicy pour configurer la variable d’environnement ROUTER_ALLOW_WILDCARD_ROUTES du contrôleur Ingress.
Le comportement par défaut du contrôleur Ingress est d’admettre des itinéraires avec une stratégie de carte sauvage de None, qui est rétrocompatible avec les ressources existantes IngressController.
Procédure
Configurez la stratégie de wildcard.
À l’aide de la commande suivante pour modifier la ressource IngressController:
$ oc edit IngressControllerDans la section Spécification, définissez le champ wildcardPolicy sur WildcardsDisallowed ou WildcardsAllowed:
spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
2.2.9.12. Configuration d’en-tête HTTP
Le logiciel OpenShift Dedicated fournit différentes méthodes pour travailler avec les en-têtes HTTP. Lorsque vous configurez ou supprimez des en-têtes, vous pouvez utiliser des champs spécifiques dans le contrôleur d’Ingress ou un itinéraire individuel pour modifier les en-têtes de requête et de réponse. Il est également possible de définir certains en-têtes en utilisant des annotations d’itinéraire. Les différentes façons de configurer les en-têtes peuvent présenter des défis lorsque vous travaillez ensemble.
Il est possible de définir ou de supprimer uniquement des en-têtes au sein d’un IngressController ou Route CR, vous ne pouvez pas les ajouter. Lorsqu’un en-tête HTTP est défini avec une valeur, cette valeur doit être complète et ne pas nécessiter d’ajouter à l’avenir. Dans les situations où il est logique d’ajouter un en-tête, comme l’en-tête X-Forwarded-Forwarded, utilisez le champ spec.httpHeaders.forwardedHeaderPolicy, au lieu de spec.httpHeaders.actions.
2.2.9.12.1. Ordre de préséance
Lorsque le même en-tête HTTP est modifié à la fois dans le contrôleur Ingress et dans un itinéraire, HAProxy priorise les actions de certaines manières selon qu’il s’agit d’une requête ou d’un en-tête de réponse.
- Dans le cas des en-têtes de réponse HTTP, les actions spécifiées dans le contrôleur Ingress sont exécutées après les actions spécifiées dans un itinéraire. Cela signifie que les actions spécifiées dans le Contrôleur Ingress ont préséance.
- Dans le cas des en-têtes de requête HTTP, les actions spécifiées dans une route sont exécutées après les actions spécifiées dans le contrôleur Ingress. Cela signifie que les actions spécifiées dans l’itinéraire ont préséance.
À titre d’exemple, un administrateur de cluster définit l’en-tête de réponse X-Frame-Options avec la valeur DENY dans le contrôleur Ingress en utilisant la configuration suivante:
Exemple IngressController spec
apiVersion: operator.openshift.io/v1
kind: IngressController
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: DENYLe propriétaire de route définit le même en-tête de réponse que l’administrateur du cluster défini dans le contrôleur Ingress, mais avec la valeur SAMEORIGIN en utilisant la configuration suivante:
Exemple de route Spécification
apiVersion: route.openshift.io/v1
kind: Route
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: SAMEORIGINLorsque les spécifications IngressController et Route configurent l’en-tête de réponse X-Frame-Options, alors la valeur définie pour cet en-tête au niveau global dans le contrôleur Ingress a préséance, même si un itinéraire spécifique permet des cadres. Dans le cas d’un en-tête de requête, la valeur spec de Route remplace la valeur spec d’IngressController.
Cette priorisation se produit parce que le fichier haproxy.config utilise la logique suivante, où le contrôleur Ingress est considéré comme l’extrémité avant et les itinéraires individuels sont considérés comme l’arrière-plan. La valeur d’en-tête DENY appliquée aux configurations d’extrémité avant remplace le même en-tête avec la valeur SAMEORIGIN définie dans l’arrière:
frontend public
http-response set-header X-Frame-Options 'DENY'
frontend fe_sni
http-response set-header X-Frame-Options 'DENY'
frontend fe_no_sni
http-response set-header X-Frame-Options 'DENY'
backend be_secure:openshift-monitoring:alertmanager-main
http-response set-header X-Frame-Options 'SAMEORIGIN'En outre, toutes les actions définies dans le contrôleur d’Ingress ou dans une route remplacent les valeurs définies à l’aide d’annotations d’itinéraire.
2.2.9.12.2. En-têtes de cas spéciaux
Les en-têtes suivants sont soit empêchés entièrement d’être réglés ou supprimés, soit autorisés dans des circonstances spécifiques:
| Le nom de l’en-tête | Configurable en utilisant IngressController spec | Configurable à l’aide de Route spec | La raison de l’exclusion | Configurable en utilisant une autre méthode |
|---|---|---|---|---|
|
| C) Non | C) Non | L’en-tête de requête HTTP proxy peut être utilisé pour exploiter les applications CGI vulnérables en injectant la valeur d’en-tête dans la variable d’environnement HTTP_PROXY. L’en-tête de requête HTTP proxy est également non standard et sujet à une erreur lors de la configuration. | C) Non |
|
| C) Non | ♪ oui ♪ | Lorsque l’en-tête de requête HTTP hôte est défini à l’aide de l’IngressController CR, HAProxy peut échouer lors de la recherche de la bonne route. | C) Non |
|
| C) Non | C) Non | L’en-tête de réponse HTTP strict-transport-sécurité est déjà géré à l’aide d’annotations de route et n’a pas besoin d’une implémentation séparée. | L’annotation de route haproxy.router.openshift.io/hsts_header |
| cookie et set-cookie | C) Non | C) Non | Les cookies que HAProxy définit sont utilisés pour le suivi de session pour cartographier les connexions client à des serveurs back-end particuliers. La mise en place de ces en-têtes pourrait interférer avec l’affinité de la session de HAProxy et restreindre la propriété d’un cookie par HAProxy. | C’est oui:
|
2.2.9.13. Configurer ou supprimer les en-têtes de requête et de réponse HTTP dans un contrôleur Ingress
Il est possible de définir ou de supprimer certains en-têtes de requête et de réponse HTTP à des fins de conformité ou pour d’autres raisons. Ces en-têtes peuvent être définis ou supprimés soit pour tous les itinéraires desservis par un contrôleur d’Ingress, soit pour des itinéraires spécifiques.
À titre d’exemple, vous voudrez peut-être migrer une application s’exécutant sur votre cluster pour utiliser TLS mutuel, ce qui nécessite que votre application vérifie un en-tête de requête X-Forwarded-Client-Cert, mais le contrôleur d’ingrédient par défaut OpenShift Dedicated fournit un en-tête de requête X-SSL-Client-Der.
La procédure suivante modifie le contrôleur d’ingrédient pour définir l’en-tête de requête X-Forwarded-Client-Cert, et supprimer l’en-tête de requête X-SSL-Client-Der.
Conditions préalables
- L’OpenShift CLI (oc) a été installé.
- En tant qu’utilisateur, vous avez accès à un cluster OpenShift dédié avec le rôle cluster-admin.
Procédure
Éditer la ressource Ingress Controller:
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultDe remplacer l’en-tête de requête HTTP X-SSL-Client-Der par l’en-tête de requête HTTP X-Forwarded-Client-Cert:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: actions:1 request:2 - name: X-Forwarded-Client-Cert3 action: type: Set4 set: value: "%{+Q}[ssl_c_der,base64]"5 - name: X-SSL-Client-Der action: type: Delete- 1
- La liste des actions que vous souhaitez effectuer sur les en-têtes HTTP.
- 2
- Le type d’en-tête que vous voulez changer. Dans ce cas, un en-tête de demande.
- 3
- Le nom de l’en-tête que vous voulez changer. Dans le cas d’une liste d’en-têtes disponibles que vous pouvez définir ou supprimer, voir la configuration d’en-tête HTTP.
- 4
- Le type d’action en cours sur l’en-tête. Ce champ peut avoir la valeur Set ou Supprimer.
- 5
- Lorsque vous définissez des en-têtes HTTP, vous devez fournir une valeur. La valeur peut être une chaîne à partir d’une liste de directives disponibles pour cet en-tête, par exemple DENY, ou il peut s’agir d’une valeur dynamique qui sera interprétée à l’aide de la syntaxe de valeur dynamique de HAProxy. Dans ce cas, une valeur dynamique est ajoutée.
NoteLes valeurs d’en-tête dynamiques pour les réponses HTTP sont ré.hdr et ssl_c_der. Les valeurs d’en-tête dynamiques pour les requêtes HTTP sont req.hdr et ssl_c_der. Les valeurs dynamiques de requête et de réponse peuvent utiliser les convertisseurs inférieur et base64.
- Enregistrez le fichier pour appliquer les modifications.
2.2.9.14. En utilisant des en-têtes X-Forwarded
Configurez le contrôleur HAProxy Ingress pour spécifier une stratégie pour gérer les en-têtes HTTP, y compris Forwarded et X-Forwarded-For. L’opérateur Ingress utilise le champ HTTPHeaders pour configurer la variable d’environnement ROUTER_SET_FORWARDED_HEADERS de la variable Ingress Controller.
Procédure
Configurez le champ HTTPHeaders pour le contrôleur Ingress.
À l’aide de la commande suivante pour modifier la ressource IngressController:
$ oc edit IngressControllerDans la section Spécification, définissez le champ de stratégie HTTPHeaders pour ajouter, remplacer, IfNone ou jamais:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
Exemples de cas d’utilisation
En tant qu’administrateur de cluster, vous pouvez:
Configurez un proxy externe qui injecte l’en-tête X-Forwarded-For dans chaque requête avant de le transmettre à un contrôleur Ingress.
Afin de configurer le contrôleur Ingress pour passer l’en-tête sans modification, vous spécifiez la stratégie jamais. Le contrôleur Ingress ne définit alors jamais les en-têtes, et les applications ne reçoivent que les en-têtes fournis par le proxy externe.
Configurez le contrôleur Ingress pour passer l’en-tête X-Forwarded-For que votre proxy externe définit sur les requêtes de cluster externe via un module non modifié.
Afin de configurer le contrôleur Ingress pour définir l’en-tête X-Forwarded-For sur les requêtes de cluster interne, qui ne passent pas par le proxy externe, spécifiez la stratégie if-none. Lorsqu’une requête HTTP a déjà l’en-tête défini par le proxy externe, le contrôleur Ingress le conserve. En cas d’absence de l’en-tête parce que la requête n’est pas passée par le proxy, le contrôleur d’intruss ajoute l’en-tête.
En tant que développeur d’applications, vous pouvez:
Configurez un proxy externe spécifique à l’application qui injecte l’en-tête X-Forwarded-Forwarded.
Afin de configurer un contrôleur d’Ingress pour passer l’en-tête à travers non modifié pour la Route d’une application, sans affecter la politique d’autres Routes, ajouter une annotation haproxy.router.openshift.openshift.io/set-forwarded-headers: if-none ou haproxy.router.openshift.io/set-forwarded-headers: jamais sur la Route pour l’application.
NoteL’annotation de haproxy.router.openshift.io/set-forwarded-headers peut être définie sur une base par route, indépendamment de la valeur globale définie pour le contrôleur Ingress.
2.2.9.15. Activer ou désactiver HTTP/2 sur les contrôleurs Ingress
Activer ou désactiver la connectivité HTTP/2 transparente de bout en bout dans HAProxy. Les propriétaires d’applications peuvent utiliser les capacités du protocole HTTP/2, y compris la connexion unique, la compression d’en-tête, les flux binaires, et plus encore.
Activer ou désactiver la connectivité HTTP/2 pour un contrôleur d’Ingress individuel ou pour l’ensemble du cluster.
Lorsque vous activez ou désactivez la connectivité HTTP/2 pour un contrôleur Ingress individuel et pour l’ensemble du cluster, la configuration HTTP/2 pour le contrôleur Ingress prime sur la configuration HTTP/2 pour le cluster.
Afin d’activer l’utilisation de HTTP/2 pour une connexion du client à une instance HAProxy, une route doit spécifier un certificat personnalisé. L’itinéraire qui utilise le certificat par défaut ne peut pas utiliser HTTP/2. Cette restriction est nécessaire pour éviter les problèmes de fusion de connexion, où le client réutilise une connexion pour différents itinéraires utilisant le même certificat.
Considérez les cas d’utilisation suivants pour une connexion HTTP/2 pour chaque type d’itinéraire:
- Dans le cas d’une route de recryptage, la connexion de HAProxy au pod d’application peut utiliser HTTP/2 si l’application prend en charge l’utilisation de la Négociation du protocole Application-Level (ALPN) pour négocier HTTP/2 avec HAProxy. Il est impossible d’utiliser HTTP/2 avec une route recryptée à moins que le contrôleur Ingress n’ait activé HTTP/2.
- Dans le cas d’un parcours de passage, la connexion peut utiliser HTTP/2 si l’application prend en charge l’utilisation d’ALPN pour négocier HTTP/2 avec le client. Il est possible d’utiliser HTTP/2 avec un parcours de passage si le contrôleur Ingress a activé ou désactivé HTTP/2.
- La connexion utilise HTTP/2 si le service spécifie uniquement appProtocol: kubernetes.io/h2c. Il est possible d’utiliser HTTP/2 avec une route sécurisée à durée limite si le contrôleur Ingress est activé ou désactivé par HTTP/2.
- Dans le cas d’un itinéraire non sécurisé, la connexion utilise HTTP/2 si le service spécifie uniquement appProtocol: kubernetes.io/h2c. Il est possible d’utiliser HTTP/2 avec une route non sécurisée si le contrôleur Ingress a activé ou désactivé HTTP/2.
En ce qui concerne les routes non-passées, le Contrôleur Ingress négocie sa connexion à l’application indépendamment de la connexion du client. Cela signifie qu’un client peut se connecter au contrôleur Ingress et négocier HTTP/1.1. Le contrôleur d’Ingress peut alors se connecter à l’application, négocier HTTP/2 et transmettre la demande de la connexion HTTP/1.1 client en utilisant la connexion HTTP/2 à l’application.
Cette séquence d’événements provoque un problème si le client tente par la suite de mettre à niveau sa connexion à partir de HTTP/1.1 vers le protocole WebSocket. Considérez que si vous avez une application qui a l’intention d’accepter des connexions WebSocket, et que l’application tente de permettre la négociation de protocole HTTP/2, le client échoue toute tentative de mise à niveau vers le protocole WebSocket.
2.2.9.15.1. Activer HTTP/2
Activer HTTP/2 sur un contrôleur Ingress spécifique, ou activer HTTP/2 pour l’ensemble du cluster.
Procédure
Afin d’activer HTTP/2 sur un contrôleur Ingress spécifique, entrez la commande oc annotate:
$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true1 - 1
- <ingresscontroller_name> par le nom d’un contrôleur Ingress pour activer HTTP/2.
Afin d’activer HTTP/2 pour l’ensemble du cluster, entrez la commande oc annotate:
$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
Alternativement, vous pouvez appliquer le code YAML suivant pour activer HTTP/2:
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "true"2.2.9.15.2. Désactiver HTTP/2
Il est possible de désactiver HTTP/2 sur un contrôleur Ingress spécifique, ou de désactiver HTTP/2 pour l’ensemble du cluster.
Procédure
Afin de désactiver HTTP/2 sur un contrôleur Ingress spécifique, entrez la commande oc annotate:
$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=false1 - 1
- <ingresscontroller_name> par le nom d’un contrôleur Ingress pour désactiver HTTP/2.
Afin de désactiver HTTP/2 pour l’ensemble du cluster, entrez la commande oc annotate:
$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=false
Alternativement, vous pouvez appliquer le code YAML suivant pour désactiver HTTP/2:
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "false"2.2.9.16. Configuration du protocole PROXY pour un contrôleur Ingress
L’administrateur de cluster peut configurer le protocole PROXY lorsqu’un contrôleur Ingress utilise soit les types de stratégie de publication HostNetwork, NodePortService ou Private Endpoint. Le protocole PROXY permet à l’équilibreur de charge de préserver les adresses client d’origine pour les connexions que le contrôleur Ingress reçoit. Les adresses clientes d’origine sont utiles pour enregistrer, filtrer et injecter des en-têtes HTTP. Dans la configuration par défaut, les connexions que le contrôleur Ingress reçoit ne contiennent que l’adresse source associée à l’équilibreur de charge.
Le contrôleur Ingress par défaut avec des clusters fournis par l’installateur sur des plates-formes non cloud utilisant une IP virtuelle d’Ingress (VIP) Keepalived ne prend pas en charge le protocole PROXY.
Le protocole PROXY permet à l’équilibreur de charge de préserver les adresses client d’origine pour les connexions que le contrôleur Ingress reçoit. Les adresses clientes d’origine sont utiles pour enregistrer, filtrer et injecter des en-têtes HTTP. Dans la configuration par défaut, les connexions que le contrôleur Ingress reçoit ne contiennent que l’adresse IP source associée à l’équilibreur de charge.
Dans le cas d’une configuration d’itinéraire de passage, les serveurs des clusters dédiés OpenShift ne peuvent pas observer l’adresse IP source du client d’origine. Lorsque vous devez connaître l’adresse IP source du client d’origine, configurez la journalisation des accès Ingress pour votre contrôleur Ingress afin que vous puissiez afficher les adresses IP source du client.
Le routeur dédié OpenShift définit les en-têtes Forwarded et X-Forwarded-Forwarded-Forwarded-Forwarded afin que les charges de travail de l’application vérifient l’adresse IP source du client.
En savoir plus sur l’enregistrement des accès Ingress, voir « Configuring Ingress access logging ».
La configuration du protocole PROXY pour un contrôleur Ingress n’est pas prise en charge lors de l’utilisation du type de stratégie de publication du point de terminaison LoadBalancerService. Cette restriction est parce que lorsque OpenShift Dedicated s’exécute dans une plate-forme cloud, et qu’un contrôleur Ingress spécifie qu’un équilibreur de charge de service doit être utilisé, l’opérateur Ingress configure le service d’équilibreur de charge et active le protocole PROXY en fonction de l’exigence de la plate-forme pour préserver les adresses source.
Il faut configurer OpenShift Dedicated et l’équilibreur de charge externe pour utiliser le protocole PROXY ou TCP.
Cette fonctionnalité n’est pas prise en charge dans les déploiements cloud. Cette restriction est parce que lorsque OpenShift Dedicated s’exécute dans une plate-forme cloud, et qu’un contrôleur Ingress spécifie qu’un équilibreur de charge de service doit être utilisé, l’opérateur Ingress configure le service d’équilibreur de charge et active le protocole PROXY en fonction de l’exigence de la plate-forme pour préserver les adresses source.
Il faut configurer OpenShift Dedicated et l’équilibreur de charge externe pour utiliser le protocole PROXY ou utiliser le protocole de contrôle de transmission (TCP).
Conditions préalables
- C’est vous qui avez créé un contrôleur Ingress.
Procédure
Modifiez la ressource Ingress Controller en entrant la commande suivante dans votre CLI:
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultDéfinir la configuration PROXY:
Lorsque votre contrôleur Ingress utilise le type de stratégie de publication du point de terminaison HostNetwork, définissez le sous-champ spec.endpointPublishingStrategy.hostNetwork.protocol sur PROXY:
Exemple de configuration hostNetwork à PROXY
# ... spec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetwork # ...Lorsque votre contrôleur Ingress utilise le type de stratégie de publication NodePortService, définissez le sous-champ spec.endpointPublishingStrategy.nodePort.protocol sur PROXY:
Exemple de configuration nodePort à PROXY
# ... spec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService # ...Dans le cas où votre contrôleur Ingress utilise le type de stratégie de publication de points de terminaison privés, définissez le sous-champ spec.endpointPublishingStrategy.priv.protocol sur PROXY:
Exemple de configuration privée à PROXY
# ... spec: endpointPublishingStrategy: private: protocol: PROXY type: Private # ...
2.2.9.17. Définir un domaine de cluster alternatif à l’aide de l’option appsDomain
En tant qu’administrateur de cluster, vous pouvez spécifier une alternative au domaine du cluster par défaut pour les itinéraires créés par l’utilisateur en configurant le champ appsDomain. Le champ appsDomain est un domaine facultatif pour OpenShift Dedicated à utiliser au lieu de la valeur par défaut, qui est spécifiée dans le champ de domaine. Lorsque vous spécifiez un domaine alternatif, il remplace le domaine du cluster par défaut dans le but de déterminer l’hôte par défaut pour une nouvelle route.
À titre d’exemple, vous pouvez utiliser le domaine DNS pour votre entreprise comme domaine par défaut pour les routes et les entrées pour les applications s’exécutant sur votre cluster.
Conditions préalables
- Déploiement d’un cluster OpenShift dédié.
- L’interface de ligne de commande oc a été installée.
Procédure
Configurez le champ appsDomain en spécifiant un domaine par défaut alternatif pour les itinéraires créés par l’utilisateur.
Éditer la ressource du cluster d’entrée:
$ oc edit ingresses.config/cluster -o yamlÉditer le fichier YAML:
Exemple d’applicationsConfiguration de la main pour tester.example.com
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com1 appsDomain: <test.example.com>2 - 1
- Indique le domaine par défaut. Après l’installation, vous ne pouvez pas modifier le domaine par défaut.
- 2
- En option: Domaine pour OpenShift Infrastructure dédiée à utiliser pour les itinéraires d’application. Au lieu du préfixe par défaut, les applications, vous pouvez utiliser un préfixe alternatif comme le test.
Assurez-vous qu’une route existante contient le nom de domaine spécifié dans le champ appsDomain en exposant l’itinéraire et en vérifiant le changement de domaine d’itinéraire:
NoteAttendez que l’apiserver ouvert termine les mises à jour de roulement avant d’exposer l’itinéraire.
Exposer l’itinéraire:
$ oc expose service hello-openshift route.route.openshift.io/hello-openshift exposedExemple de sortie
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
2.2.9.18. Conversion de la coque d’en-tête HTTP
HAProxy minuscules les noms d’en-tête HTTP par défaut; par exemple, changer Host: xyz.com pour héberger: xyz.com. Lorsque les applications héritées sont sensibles à la capitalisation des noms d’en-tête HTTP, utilisez le champ API Ingress Controller spec.httpHeaders.headerNameCaseAdjustements pour une solution permettant d’adapter les applications héritées jusqu’à ce qu’elles puissent être corrigées.
L’OpenShift Dedicated inclut HAProxy 2.8. Lorsque vous souhaitez mettre à jour cette version de l’équilibreur de charge basé sur le Web, assurez-vous d’ajouter la section spec.httpHeaders.headerNameCaseAdjustments au fichier de configuration de votre cluster.
En tant qu’administrateur de cluster, vous pouvez convertir le cas d’en-tête HTTP en entrant la commande patch oc ou en définissant le champ HeaderNameCaseAdjustments dans le fichier Ingress Controller YAML.
Conditions préalables
- L’OpenShift CLI (oc) a été installé.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
Procédure
Capitalisez un en-tête HTTP en utilisant la commande oc patch.
Changez l’en-tête HTTP de l’hôte à l’hôte en exécutant la commande suivante:
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'Créez un fichier YAML ressource Route afin que l’annotation puisse être appliquée à l’application.
Exemple d’un itinéraire nommé my-application
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: <application_name> namespace: <application_name> # ...- 1
- Définissez haproxy.router.openshift.io/h1-adjust-case afin que le contrôleur Ingress puisse ajuster l’en-tête de requête hôte comme spécifié.
Indiquez les ajustements en configurant le champ HeaderNameCaseAdjustments dans le fichier de configuration du contrôleur d’Ingress YAML.
L’exemple suivant de fichier Ingress Controller YAML ajuste l’en-tête hôte à Host pour les requêtes HTTP/1 aux itinéraires annotés de manière appropriée:
Exemple Contrôleur d’Ingress YAML
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - HostL’exemple suivant permet des ajustements de cas d’en-tête de réponse HTTP en utilisant l’annotation de cas haproxy.router.openshift.io/h1-adjust-case:
Exemple d’itinéraire YAML
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
- Définissez haproxy.router.openshift.io/h1-adjust-case sur true.
2.2.9.19. Compression de routeur
Configurez le contrôleur HAProxy Ingress pour spécifier la compression du routeur à l’échelle mondiale pour des types MIME spécifiques. La variable mimeTypes permet de définir les formats des types MIME auxquels la compression est appliquée. Les types sont: application, image, message, multipartie, texte, vidéo, ou un type personnalisé préfacé par "X-". Afin de voir la notation complète pour les types et sous-types MIME, voir la RFC1341.
La mémoire allouée à la compression peut affecter les connexions maximales. En outre, la compression de grands tampons peut provoquer une latence, comme le regex lourd ou de longues listes de regex.
Les types MIME ne bénéficient pas tous de la compression, mais HAProxy utilise toujours des ressources pour essayer de compresser si vous en avez besoin. Généralement, les formats de texte, tels que html, css et js, les formats bénéficient de compression, mais les formats qui sont déjà compressés, tels que l’image, l’audio et la vidéo, profitent peu en échange du temps et des ressources consacrées à la compression.
Procédure
Configurez le champ httpCompression pour le contrôleur Ingress.
À l’aide de la commande suivante pour modifier la ressource IngressController:
$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultDans spec, définissez le champ de stratégie httpCompression sur mimeTypes et spécifiez une liste de types MIME qui devraient avoir une compression appliquée:
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
2.2.9.20. Exposer les métriques du routeur
Il est possible d’exposer les métriques de routeur HAProxy par défaut au format Prometheus sur le port de statistiques par défaut, 1936. Les systèmes de collecte et d’agrégation des métriques externes tels que Prometheus peuvent accéder aux métriques de routeur HAProxy. Les métriques de routeur HAProxy sont affichées dans un navigateur au format HTML et virgule (CSV).
Conditions préalables
- J’ai configuré votre pare-feu pour accéder au port de statistiques par défaut, 1936.
Procédure
Obtenez le nom de la pod de routeur en exécutant la commande suivante:
$ oc get pods -n openshift-ingressExemple de sortie
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11hAccédez au nom d’utilisateur et au mot de passe du routeur, que le routeur stocke dans les fichiers /var/lib/haproxy/conf/metrics-auth/statsUsername et /var/lib/haproxy/conf/metrics-auth/statsword:
Obtenez le nom d’utilisateur en exécutant la commande suivante:
$ oc rsh <router_pod_name> cat metrics-auth/statsUsernameAccédez au mot de passe en exécutant la commande suivante:
$ oc rsh <router_pod_name> cat metrics-auth/statsPassword
Obtenez les certificats IP et métriques du routeur en exécutant la commande suivante:
$ oc describe pod <router_pod>Bénéficiez des statistiques brutes au format Prometheus en exécutant la commande suivante:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsAccédez aux métriques en toute sécurité en exécutant la commande suivante:
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -kAccédez au port de statistiques par défaut, 1936, en exécutant la commande suivante:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsExemple 2.1. Exemple de sortie
... # HELP haproxy_backend_connections_total Total number of connections. # TYPE haproxy_backend_connections_total gauge haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0 ... # HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value. # TYPE haproxy_exporter_server_threshold gauge haproxy_exporter_server_threshold{type="current"} 11 haproxy_exporter_server_threshold{type="limit"} 500 ... # HELP haproxy_frontend_bytes_in_total Current total of incoming bytes. # TYPE haproxy_frontend_bytes_in_total gauge haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0 haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0 haproxy_frontend_bytes_in_total{frontend="public"} 119070 ... # HELP haproxy_server_bytes_in_total Current total of incoming bytes. # TYPE haproxy_server_bytes_in_total gauge haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0 haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0 ...Lancez la fenêtre de statistiques en entrant l’URL suivante dans un navigateur:
http://<user>:<password>@<router_IP>:<stats_port>Facultatif: Obtenez les statistiques au format CSV en entrant l’URL suivante dans un navigateur:
http://<user>:<password>@<router_ip>:1936/metrics;csv
2.2.9.21. Personnalisation des pages de réponse au code d’erreur HAProxy
En tant qu’administrateur de cluster, vous pouvez spécifier une page de réponse de code d’erreur personnalisée pour 503, 404, ou les deux pages d’erreur. Le routeur HAProxy sert une page d’erreur 503 lorsque le pod d’application n’est pas en cours d’exécution ou une page d’erreur 404 lorsque l’URL demandée n’existe pas. Ainsi, si vous personnalisez la page de réponse du code d’erreur 503, la page est servie lorsque le pod d’application n’est pas en cours d’exécution, et la page de réponse HTTP par défaut du code d’erreur 404 est desservie par le routeur HAProxy pour une route incorrecte ou une route non existante.
Les pages de réponse de code d’erreur personnalisées sont spécifiées dans une carte de configuration puis corrigées sur le contrôleur d’Ingress. Les touches map de configuration ont deux noms de fichiers disponibles comme suit: error-page-503.http et error-page-404.http.
Les pages personnalisées de réponse au code d’erreur HTTP doivent suivre les directives de configuration de la page d’erreur HAProxy HTTP. Ci-dessous un exemple de la page de réponse par défaut du code d’erreur OpenShift Dedicated HAProxy http 503. Le contenu par défaut peut être utilisé comme modèle pour créer votre propre page personnalisée.
Le routeur HAProxy ne sert par défaut qu’une page d’erreur 503 lorsque l’application n’est pas en cours d’exécution ou lorsque l’itinéraire est incorrect ou inexistant. Ce comportement par défaut est le même que le comportement sur OpenShift Dedicated 4.8 et antérieur. Lorsqu’une carte de configuration pour la personnalisation d’une réponse au code d’erreur HTTP n’est pas fournie et que vous utilisez une page de réponse au code d’erreur HTTP personnalisée, le routeur sert une page de réponse au code d’erreur 404 ou 503 par défaut.
Lorsque vous utilisez la page de code d’erreur 503 par défaut d’OpenShift comme modèle pour vos personnalisations, les en-têtes du fichier nécessitent un éditeur qui peut utiliser les terminaisons de ligne CRLF.
Procédure
Créer une carte de configuration nommée my-custom-error-code-pages dans l’espace de noms openshift-config:
$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.httpImportantLorsque vous ne spécifiez pas le format correct pour la page de réponse du code d’erreur personnalisé, une panne de pod de routeur se produit. Afin de résoudre cette panne, vous devez supprimer ou corriger la carte de configuration et supprimer les pods de routeurs concernés afin qu’ils puissent être recréés avec les informations correctes.
Corrigez le contrôleur Ingress pour référencer les pages de code my-custom-error-config map par nom:
$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeL’opérateur Ingress copie la carte my-custom-error-code-pages de configuration de l’espace de noms openshift-config vers l’espace de noms openshift-ingress. L’opérateur nomme la carte de configuration en fonction du modèle, <your_ingresscontroller_name>-errorpages, dans l’espace de noms openshift-ingress.
Afficher la copie:
$ oc get cm default-errorpages -n openshift-ingressExemple de sortie
NAME DATA AGE default-errorpages 2 25s1 - 1
- L’exemple de nom de la carte de configuration est des pages d’erreur par défaut parce que la ressource personnalisée (CR) par défaut du contrôleur Ingress a été corrigée.
Confirmez que la carte de configuration contenant la page de réponse d’erreur personnalisée monte sur le volume du routeur où la clé map de configuration est le nom de fichier qui a la réponse de code d’erreur HTTP personnalisée:
503 réponse de code d’erreur personnalisée HTTP personnalisée:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.http404 réponse de code d’erreur personnalisée HTTP personnalisée:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
La vérification
Contrôlez votre code d’erreur personnalisé en réponse HTTP:
Créer un projet de test et une application:
$ oc new-project test-ingress$ oc new-app django-psql-example503 réponse de code d’erreur http personnalisée:
- Arrêtez toutes les gousses pour l’application.
Exécutez la commande curl suivante ou visitez le nom d’hôte de route dans le navigateur:
$ curl -vk <route_hostname>
404 réponse d’erreur http personnalisée:
- Consultez un itinéraire inexistant ou un itinéraire incorrect.
Exécutez la commande curl suivante ou visitez le nom d’hôte de route dans le navigateur:
$ curl -vk <route_hostname>
Cochez si l’attribut errorfile est correctement dans le fichier haproxy.config:
$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
2.2.9.22. Configuration des connexions maximales du contrôleur Ingress
L’administrateur de cluster peut définir le nombre maximum de connexions simultanées pour les déploiements de routeurs OpenShift. Il est possible de corriger un contrôleur Ingress existant pour augmenter le nombre maximum de connexions.
Conditions préalables
- Ce qui suit suppose que vous avez déjà créé un contrôleur Ingress
Procédure
Actualisez le contrôleur Ingress pour modifier le nombre maximum de connexions pour HAProxy:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'AvertissementLorsque vous définissez la valeur spec.tuningOptions.maxConnections supérieure à la limite actuelle du système d’exploitation, le processus HAProxy ne démarre pas. Consultez le tableau dans la section « Paramètres de configuration du contrôleur d’entrée » pour plus d’informations sur ce paramètre.
2.2.10. Configurations d’opérateurs d’ingénieurs dédiés à OpenShift
Le tableau suivant détaille les composants de l’opérateur Ingress et si Red Hat Site Fiability Engineers (SRE) maintient ce composant sur OpenShift Dedicated clusters.
| Composant d’entrée | Géré par | Configuration par défaut? |
|---|---|---|
| Contrôleur d’Ingress de mise à l’échelle | DE SRE | ♪ oui ♪ |
| Compte de fil d’opérateur d’entrée | DE SRE | ♪ oui ♪ |
| Enregistrement d’accès au contrôleur d’entrée | DE SRE | ♪ oui ♪ |
| Ingress Controller sharding | DE SRE | ♪ oui ♪ |
| Ingress Controller Politique d’admission d’itinéraire | DE SRE | ♪ oui ♪ |
| Ingress Controller itinéraires de wildcard | DE SRE | ♪ oui ♪ |
| Contrôleur d’entrée X-Forwarded en-têtes | DE SRE | ♪ oui ♪ |
| Compression d’itinéraire du contrôleur d’entrée | DE SRE | ♪ oui ♪ |
Chapitre 3. La vérification du réseau pour OpenShift clusters dédiés
Les vérifications réseau s’exécutent automatiquement lorsque vous déployez un cluster dédié OpenShift dans un cloud privé virtuel (VPC) existant ou créez un pool de machines supplémentaire avec un sous-réseau qui est nouveau à votre cluster. Les vérifications valident votre configuration réseau et mettent en évidence les erreurs, vous permettant de résoudre les problèmes de configuration avant le déploiement.
Il est également possible d’exécuter manuellement les vérifications réseau pour valider la configuration d’un cluster existant.
3.1. Comprendre la vérification du réseau pour OpenShift clusters dédiés
Lorsque vous déployez un cluster dédié OpenShift dans un cloud privé virtuel (VPC) existant ou créez un pool de machines supplémentaire avec un sous-réseau qui est nouveau à votre cluster, la vérification réseau s’exécute automatiquement. Cela vous aide à identifier et à résoudre les problèmes de configuration avant le déploiement.
Lorsque vous vous préparez à installer votre cluster en utilisant Red Hat OpenShift Cluster Manager, les vérifications automatiques s’exécutent après avoir entré un sous-réseau dans un champ ID de sous-réseau sur la page de paramètres de sous-réseau Virtual Private Cloud (VPC).
Lorsque vous ajoutez un pool de machines avec un sous-réseau qui est nouveau à votre cluster, la vérification automatique du réseau vérifie le sous-réseau pour s’assurer que la connectivité réseau est disponible avant que le pool de machines ne soit mis en place.
Après la vérification automatique du réseau, un enregistrement est envoyé au journal de service. L’enregistrement fournit les résultats de la vérification, y compris les erreurs de configuration du réseau. Avant un déploiement, vous pouvez résoudre les problèmes identifiés et le déploiement a une plus grande chance de succès.
Il est également possible d’exécuter la vérification du réseau manuellement pour un cluster existant. Cela vous permet de vérifier la configuration du réseau pour votre cluster après avoir apporté des modifications de configuration. En ce qui concerne les étapes permettant d’exécuter manuellement les vérifications du réseau, voir Exécution manuelle de la vérification du réseau.
3.2. Champ d’application des contrôles de vérification du réseau
La vérification du réseau comprend des vérifications pour chacune des exigences suivantes:
- Le cloud privé virtuel (VPC) de parent existe.
- Les sous-réseaux spécifiés appartiennent au VPC.
- Le VPC a activéDnsSupport.
- Le VPC a activéDnsHostnames activé.
- Egress est disponible pour les combinaisons de domaines et de ports requises qui sont spécifiées dans la section prérequis du pare-feu AWS.
3.3. Contournement automatique de la vérification réseau
Il est possible de contourner la vérification automatique du réseau si vous souhaitez déployer un cluster OpenShift Dedicated avec des problèmes de configuration réseau connus dans un cloud privé virtuel (VPC) existant.
Lorsque vous contournez la vérification du réseau lorsque vous créez un cluster, le cluster a un statut de support limité. Après l’installation, vous pouvez résoudre les problèmes, puis exécuter manuellement la vérification du réseau. Le statut de support limité est supprimé après le succès de la vérification.
Lorsque vous installez un cluster dans un VPC existant en utilisant Red Hat OpenShift Cluster Manager, vous pouvez contourner la vérification automatique en sélectionnant la vérification réseau Bypass sur la page de paramètres de sous-réseau Virtual Private Cloud (VPC).
3.4. Exécuter la vérification du réseau manuellement
En utilisant Red Hat OpenShift Cluster Manager, vous pouvez exécuter manuellement les vérifications réseau d’un cluster dédié OpenShift existant.
Conditions préalables
- Il y a un cluster dédié OpenShift existant.
- C’est vous qui êtes le propriétaire du cluster ou vous avez le rôle d’éditeur de cluster.
Procédure
- Accédez à OpenShift Cluster Manager et sélectionnez votre cluster.
- Choisissez Vérifier la mise en réseau dans le menu déroulant Actions.
Chapitre 4. Configuration d’un proxy à l’échelle du cluster
Lorsque vous utilisez un cloud privé virtuel (VPC), vous pouvez configurer un proxy à l’échelle du cluster lors d’une installation de cluster dédié OpenShift ou après l’installation du cluster. Lorsque vous activez un proxy, les composants du cluster de base se voient refuser un accès direct à Internet, mais le proxy n’affecte pas les charges de travail des utilisateurs.
Le trafic de sortie du système de cluster est proxié, y compris les appels vers l’API fournisseur de cloud.
Il est possible d’activer un proxy uniquement pour les clusters dédiés OpenShift utilisant le modèle Customer Cloud Subscription (CCS).
Lorsque vous utilisez un proxy à l’échelle du cluster, vous êtes responsable de maintenir la disponibilité du proxy au cluster. Lorsque le proxy devient indisponible, il pourrait avoir une incidence sur la santé et la solidité du cluster.
4.1. Conditions préalables à la configuration d’un proxy à l’échelle du cluster
Afin de configurer un proxy à l’échelle du cluster, vous devez répondre aux exigences suivantes. Ces exigences sont valables lorsque vous configurez un proxy pendant l’installation ou la postinstallation.
Exigences générales
- C’est vous qui êtes le propriétaire du cluster.
- Les privilèges de votre compte sont suffisants.
- Il existe un cloud privé virtuel (VPC) existant pour votre cluster.
- Le modèle d’abonnement au cloud client (CCS) est utilisé pour votre cluster.
- Le proxy peut accéder au VPC pour le cluster et les sous-réseaux privés du VPC. Le proxy est également accessible depuis le VPC pour le cluster et depuis les sous-réseaux privés du VPC.
Les points de terminaison suivants ont été ajoutés à votre point de terminaison VPC:
-
ec2.<aws_region>.amazonaws.com -
élastique d’équilibrage.<aws_region>.amazonaws.com .<aws_region>.amazonaws.comCes points de terminaison sont nécessaires pour remplir les demandes des nœuds vers l’API AWS EC2. Étant donné que le proxy fonctionne au niveau du conteneur et non au niveau des nœuds, vous devez acheminer ces demandes vers l’API AWS EC2 via le réseau privé AWS. Ajouter l’adresse IP publique de l’API EC2 à votre liste d’autorisations dans votre serveur proxy ne suffit pas.
ImportantLorsque vous utilisez un proxy à l’échelle du cluster, vous devez configurer le point de terminaison s3.<aws_region>.amazonaws.com en tant que point de terminaison de type Gateway.
-
Exigences du réseau
Lorsque votre proxy recrypte le trafic de sortie, vous devez créer des exclusions aux combinaisons de domaines et de ports. Le tableau suivant donne des indications sur ces exceptions.
Le proxy doit exclure le recryptage des URL OpenShift suivantes:
Expand Adresse Le Protocole/Port Fonction le site Observatorium-mst.api.openshift.comHTTPS/443
C’est nécessaire. Utilisé pour la télémétrie spécifique à OpenShift gérée.
à propos de SSO.redhat.comHTTPS/443
Le site https://cloud.redhat.com/openshift utilise l’authentification de sso.redhat.com pour télécharger le cluster pull secret et utiliser les solutions Red Hat SaaS pour faciliter la surveillance de vos abonnements, de l’inventaire des clusters et des rapports de rétrofacturation.
4.2. Les responsabilités pour des ensembles de confiance supplémentaires
Lorsque vous fournissez un forfait de confiance supplémentaire, vous êtes responsable des exigences suivantes:
- Faire en sorte que le contenu du paquet de confiance supplémentaire soit valide
- Garantir que les certificats, y compris les certificats intermédiaires, contenus dans le groupe de fiducie supplémentaire n’ont pas expiré
- Le suivi de l’expiration et l’exécution des renouvellements nécessaires pour les certificats contenus dans le groupe de fiducie supplémentaire
- La mise à jour de la configuration du cluster avec le paquet de confiance supplémentaire mis à jour
4.3. Configuration d’un proxy pendant l’installation
Il est possible de configurer un proxy HTTP ou HTTPS lorsque vous installez un cluster OpenShift Dedicated with Customer Cloud Subscription (CCS) dans un cloud privé virtuel (VPC) existant. Lors de l’installation, vous pouvez configurer le proxy en utilisant Red Hat OpenShift Cluster Manager.
4.4. Configuration d’un proxy pendant l’installation à l’aide d’OpenShift Cluster Manager
Lorsque vous installez un cluster dédié OpenShift dans un cloud privé virtuel existant (VPC), vous pouvez utiliser Red Hat OpenShift Cluster Manager pour activer un proxy HTTP ou HTTPS à l’échelle du cluster pendant l’installation. Il est possible d’activer un proxy uniquement pour les clusters utilisant le modèle Customer Cloud Subscription (CCS).
Avant l’installation, vous devez vérifier que le proxy est accessible depuis le VPC dans lequel le cluster est installé. Le proxy doit également être accessible depuis les sous-réseaux privés du VPC.
Des étapes détaillées pour configurer un proxy à l’échelle du cluster pendant l’installation en utilisant OpenShift Cluster Manager, voir Créer un cluster sur AWS ou Créer un cluster sur GCP.
4.5. Configuration d’un proxy après l’installation
Il est possible de configurer un proxy HTTP ou HTTPS après avoir installé un cluster OpenShift Dedicated with Customer Cloud Subscription (CCS) dans un cloud privé virtuel (VPC) existant. Après l’installation, vous pouvez configurer le proxy en utilisant Red Hat OpenShift Cluster Manager.
4.6. Configuration d’un proxy après l’installation à l’aide d’OpenShift Cluster Manager
Il est possible d’utiliser Red Hat OpenShift Cluster Manager pour ajouter une configuration proxy à l’échelle du cluster à un cluster dédié OpenShift existant dans un cloud privé virtuel (VPC). Il est possible d’activer un proxy uniquement pour les clusters utilisant le modèle Customer Cloud Subscription (CCS).
Il est également possible d’utiliser OpenShift Cluster Manager pour mettre à jour une configuration proxy existante à l’échelle du cluster. À titre d’exemple, vous devrez peut-être mettre à jour l’adresse réseau du proxy ou remplacer le groupe de confiance supplémentaire si l’une des autorités de certification du proxy expire.
Le cluster applique la configuration proxy au plan de contrôle et calcule les nœuds. Lors de l’application de la configuration, chaque nœud de cluster est temporairement placé dans un état imprévu et vidé de ses charges de travail. Chaque nœud est redémarré dans le cadre du processus.
Conditions préalables
- Il existe un cluster dédié OpenShift qui utilise le modèle d’abonnement au cloud client (CCS).
- Le cluster est déployé dans un VPC.
Procédure
- Accédez à OpenShift Cluster Manager et sélectionnez votre cluster.
- Dans la section Virtual Private Cloud (VPC) de la page de mise en réseau, cliquez sur Modifier le proxy à l’échelle du cluster.
Dans la page proxy Edit cluster, fournissez les détails de la configuration de votre proxy:
Entrez une valeur dans au moins un des champs suivants:
- Indiquez une URL proxy HTTP valide.
- Indiquez une URL proxy HTTPS valide.
- Dans le champ Autres paquets de confiance, fournissez un paquet de certificats X.509 codé PEM. Lorsque vous remplacez un fichier de groupe de confiance existant, sélectionnez Remplacer le fichier pour afficher le champ. Le paquet est ajouté au magasin de certificats de confiance pour les nœuds de cluster. Il est nécessaire d’obtenir un fichier de groupe de confiance supplémentaire si vous utilisez un proxy d’inspection TLS à moins que le certificat d’identité du proxy ne soit signé par une autorité du groupe de confiance Red Hat Enterprise Linux CoreOS (RHCOS). Cette exigence s’applique indépendamment du fait que le proxy soit transparent ou nécessite une configuration explicite en utilisant les arguments http-proxy et https-proxy.
- Cliquez sur Confirmer.
La vérification
- Dans la section Virtual Private Cloud (VPC) de la page de mise en réseau, vérifiez que la configuration proxy de votre cluster est comme prévu.
Chapitre 5. Définitions de la gamme CIDR
Dans le cas où votre cluster utilise OVN-Kubernetes, vous devez spécifier des plages de sous-réseau non superposées (CIDR).
Dans OpenShift Dedicated 4.17 et versions ultérieures, les clusters utilisent 169.254.0.0/17 pour IPv4 et fd69::/112 pour IPv6 comme sous-réseau masqué par défaut. Ces gammes devraient également être évitées par les utilisateurs. Dans le cas des clusters mis à niveau, il n’y a pas de changement au sous-réseau masqué par défaut.
Les types de sous-réseau suivants et sont obligatoires pour un cluster qui utilise OVN-Kubernetes:
- Joint: Utilise un commutateur de joint pour connecter les routeurs de passerelle aux routeurs distribués. Le commutateur de joint réduit le nombre d’adresses IP pour un routeur distribué. Dans le cas d’un cluster utilisant le plugin OVN-Kubernetes, une adresse IP à partir d’un sous-réseau dédié est attribuée à tout port logique qui se fixe au commutateur de joint.
- Empêche les collisions pour les adresses IP de source et de destination identiques qui sont envoyées d’un nœud comme trafic d’épingle à cheveux au même nœud après qu’un balanceur de charge prenne une décision de routage.
- Transit : Un commutateur de transit est un type de commutateur distribué qui s’étend sur tous les nœuds du cluster. L’interrupteur de transit relie le trafic entre différentes zones. Dans le cas d’un cluster utilisant le plugin OVN-Kubernetes, une adresse IP d’un sous-réseau dédié est attribuée à tout port logique qui se fixe au commutateur de transit.
En tant que tâche post-installation, vous pouvez modifier les gammes CIDR de jointure, de mascarade et de transit pour votre cluster.
Lorsque vous spécifiez les plages CIDR de sous-réseau, assurez-vous que la plage CIDR de sous-réseau se trouve dans le CIDR de machine défini. Il faut vérifier que les plages CIDR de sous-réseau permettent suffisamment d’adresses IP pour toutes les charges de travail prévues en fonction de la plate-forme hébergée par le cluster.
En interne, OVN-Kubernetes, le fournisseur de réseau par défaut dans OpenShift Dedicated 4.14 et versions ultérieures, utilise en interne les plages de sous-réseau d’adresse IP suivantes:
- Ajouter au panier V4JoinSubnet: 100.64.0.0/16
- Ajouter au panier V6JoinSubnet: fd98::/64
- Caractéristiques de V4TransitSwitchSubnet: 100.88.0.0/16
- Informations sur V6TransitSwitchSubnet: fd97::/64
- defaultV4MasqueradeSubnet: 169.254.0.0/17
- defaultV6MasqueradeSubnet: fd69::/112
La liste précédente comprend les sous-réseaux d’adresses IPv4 et IPv6 masqués. Lorsque votre cluster utilise OVN-Kubernetes, n’incluez aucune de ces gammes d’adresses IP dans les autres définitions CIDR de votre cluster ou de votre infrastructure.
5.1. CIDR machine
Dans le champ de routage interdomaine sans classe de machine (CIDR), vous devez spécifier la plage d’adresses IP pour les machines ou les nœuds de cluster.
Les plages CIDR de machine ne peuvent pas être modifiées après la création de votre cluster.
Cette gamme doit englober toutes les gammes d’adresses CIDR pour vos sous-réseaux virtuels de cloud privé (VPC). Les sous-réseaux doivent être contigus. La plage d’adresses IP minimale de 128 adresses, utilisant le préfixe de sous-réseau /25, est prise en charge pour les déploiements de zones de disponibilité uniques. La plage d’adresse minimale de 256 adresses, à l’aide du préfixe de sous-réseau /24, est prise en charge pour les déploiements utilisant plusieurs zones de disponibilité.
La valeur par défaut est 10.0.0.0/16. Cette gamme ne doit pas entrer en conflit avec les réseaux connectés.
5.2. CIDR de service
Dans le champ Service CIDR, vous devez spécifier la plage d’adresses IP pour les services. Il est recommandé, mais pas nécessaire, que le bloc d’adresse soit le même entre les clusters. Cela ne créera pas de conflits d’adresse IP. La gamme doit être suffisamment grande pour s’adapter à votre charge de travail. Le bloc d’adresse ne doit pas se chevaucher avec un service externe accessible depuis le cluster. La valeur par défaut est 172.30.0.0/16.
5.3. Gousse CIDR
Dans le champ Pod CIDR, vous devez spécifier la plage d’adresse IP pour les pods.
Il est recommandé, mais pas nécessaire, que le bloc d’adresse soit le même entre les clusters. Cela ne créera pas de conflits d’adresse IP. La gamme doit être suffisamment grande pour s’adapter à votre charge de travail. Le bloc d’adresse ne doit pas se chevaucher avec un service externe accessible depuis le cluster. La valeur par défaut est 10.128.0.0/14.
5.4. Hôte Préfixe
Dans le champ Préfixe hôte, vous devez spécifier la longueur du préfixe de sous-réseau assignée aux pods programmés aux machines individuelles. Le préfixe hôte détermine le pool d’adresses IP pod pour chaque machine.
Ainsi, si le préfixe hôte est réglé sur /23, chaque machine se voit attribuer un sous-réseau /23 à partir de la plage d’adresses CIDR pod. La valeur par défaut est /23, permettant 512 nœuds de cluster, et 512 pods par nœud (dont les deux sont au-delà de notre maximum supporté).
Chapitre 6. La sécurité du réseau
6.1. Comprendre les API de stratégie réseau
Kubernetes offre deux fonctionnalités que les utilisateurs peuvent utiliser pour renforcer la sécurité du réseau. L’API NetworkPolicy est conçue principalement pour les développeurs d’applications et les locataires de l’espace de noms afin de protéger leurs espaces de noms en créant des stratégies basées sur l’espace de noms.
La deuxième fonctionnalité est AdminNetworkPolicy qui se compose de deux API: l’API AdminNetworkPolicy (ANP) et l’API BaselineAdminNetworkPolicy (BANP). ANP et BANP sont conçus pour les administrateurs de cluster et de réseau afin de protéger l’ensemble de leur cluster en créant des stratégies axées sur les clusters. Les administrateurs de clusters peuvent utiliser des ANP pour appliquer des stratégies non-surpassables qui ont préséance sur les objets NetworkPolicy. Les administrateurs peuvent utiliser BANP pour configurer et appliquer des règles optionnelles de stratégie réseau à portée de cluster qui sont subdivisées par les utilisateurs en utilisant des objets NetworkPolicy lorsque cela est nécessaire. Lorsqu’ils sont utilisés ensemble, ANP, BANP et la politique de réseau peuvent atteindre l’isolement multi-locataires complet que les administrateurs peuvent utiliser pour sécuriser leur cluster.
Le CNI d’OVN-Kubernetes dans OpenShift Dedicated met en œuvre ces politiques de réseau à l’aide des Tiers de la Liste de contrôle d’accès (ACL) pour les évaluer et les appliquer. Les ACL sont évaluées dans l’ordre décroissant du niveau 1 au niveau 3.
Le niveau 1 évalue les objets AdminNetworkPolicy (ANP). Le niveau 2 évalue les objets de NetworkPolicy. Le niveau 3 évalue les objets BaselineAdminNetworkPolicy (BANP).

Les PAN sont évalués en premier. Lorsque la correspondance est une règle d’autorisation ou de refus de l’ANP, tous les objets existants de NetworkPolicy et BaselineAdminNetworkPolicy (BANP) dans le cluster sont ignorés de l’évaluation. Lorsque la correspondance est une règle de passage ANP, l’évaluation passe du niveau 1 de l’ACL au niveau 2 où la politique de NetworkPolicy est évaluée. En l’absence de NetworkPolicy, l’évaluation passe du niveau 2 aux ACL de niveau 3 où le BANP est évalué.
6.1.1. Différences clés entre AdminNetworkPolicy et NetworkPolicy ressources personnalisées
Le tableau suivant explique les principales différences entre l’API AdminNetworkPolicy et l’API NetworkPolicy.
| Éléments de politique générale | AdminNetworkPlicy | La politique de réseau |
|---|---|---|
| L’utilisateur applicable | Administrateur de cluster ou équivalent | Les propriétaires d’espace de noms |
| Champ d’application | Groupe de travail | Espace de nom |
| Laisser tomber le trafic | Il est pris en charge avec une action de Deny explicite définie en règle générale. | Prise en charge par l’isolement implicite de Deny au moment de la création de la politique. |
| Déléguer le trafic | En règle générale, pris en charge avec une action Pass. | Inapplicable |
| Autoriser le trafic | Compatible avec une action explicite Autoriser en règle générale. | L’action par défaut pour toutes les règles est d’autoriser. |
| La préséance de la règle dans le cadre de la politique | Dépend de l’ordre dans lequel ils apparaissent dans un ANP. La position de la règle est élevée, plus la préséance est élevée. | Les règles sont additives |
| A) Priorité des politiques | Au sein des PAN, le champ prioritaire fixe l’ordre d’évaluation. Le nombre de priorité est inférieur à celui de la politique. | Il n’y a pas d’ordre politique entre les politiques. |
| La préséance des caractéristiques | Évalué en premier par l’ACL de niveau 1 et le BANP est évalué en dernier via l’ACL de niveau 3. | Appliquées après l’ANP et avant le BANP, elles sont évaluées au niveau 2 de l’ACL. |
| Assortiment de la sélection de pod | Il peut appliquer différentes règles dans les espaces de noms. | Il peut appliquer différentes règles entre les pods dans un espace de noms unique. |
| Le trafic d’égressivité de cluster | Supporté via des nœuds et des réseaux pairs | Compatible avec le champ ipBlock ainsi que la syntaxe CIDR acceptée. |
| Le trafic d’entrée de cluster | Ce n’est pas pris en charge | Ce n’est pas pris en charge |
| Le support par les pairs de noms de domaine entièrement qualifiés (FQDN) | Ce n’est pas pris en charge | Ce n’est pas pris en charge |
| Les sélecteurs d’espace de noms | Compatible avec la sélection avancée de Namespaces avec l’utilisation du champ namespaces.matchLabels | Prend en charge la sélection de l’espace de noms basé sur l’étiquette avec l’utilisation du champ namespaceSelector |
6.2. La politique de réseau
6.2.1. À propos de la politique de réseau
En tant que développeur, vous pouvez définir des stratégies réseau qui limitent le trafic aux pods dans votre cluster.
6.2.1.1. À propos de la politique de réseau
Par défaut, tous les pods d’un projet sont accessibles à partir d’autres gousses et points de terminaison réseau. Afin d’isoler un ou plusieurs pods dans un projet, vous pouvez créer des objets NetworkPolicy dans ce projet pour indiquer les connexions entrantes autorisées. Les administrateurs de projet peuvent créer et supprimer des objets NetworkPolicy dans leur propre projet.
Lorsqu’une pod est appariée par des sélecteurs dans un ou plusieurs objets NetworkPolicy, la pod n’acceptera que des connexions autorisées par au moins un de ces objets NetworkPolicy. La pod qui n’est pas sélectionnée par aucun objet NetworkPolicy est entièrement accessible.
La politique réseau ne s’applique qu’aux protocoles TCP, UDP, ICMP et SCTP. D’autres protocoles ne sont pas affectés.
La stratégie réseau ne s’applique pas à l’espace de noms du réseau hôte. Les pods avec le réseau hôte activé ne sont pas affectés par les règles de stratégie réseau. Cependant, les pods se connectant aux pods en réseau d’hôte pourraient être affectés par les règles de politique du réseau.
Les stratégies réseau ne peuvent pas bloquer le trafic de l’hôte local ou de leurs nœuds résidents.
L’exemple suivant d’objets NetworkPolicy démontre la prise en charge de différents scénarios:
Refuser tout trafic:
Afin de rendre un projet refusé par défaut, ajoutez un objet NetworkPolicy qui correspond à tous les pods mais n’accepte aucun trafic:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} ingress: []Autoriser uniquement les connexions à partir du contrôleur d’Ingress dédié OpenShift:
Afin de faire un projet, n’autorisez que les connexions à partir du contrôleur d’ingénierie dédié OpenShift, ajoutez l’objet NetworkPolicy suivant.
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - IngressAccepter uniquement les connexions des pods au sein d’un projet:
ImportantAfin d’autoriser les connexions entrantes à partir des pods hostNetwork dans le même espace de noms, vous devez appliquer la politique d’autorisation de l’hôte avec la politique d’autorisation-même-namespace.
Afin de faire accepter les connexions d’autres pods dans le même projet, mais rejeter toutes les autres connexions de pods dans d’autres projets, ajouter l’objet NetworkPolicy suivant:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {}Autoriser uniquement le trafic HTTP et HTTPS basé sur les étiquettes de pod:
Afin d’activer uniquement l’accès HTTP et HTTPS aux pods avec une étiquette spécifique (rôle=frontend dans l’exemple suivant), ajoutez un objet NetworkPolicy similaire à ce qui suit:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443Accepter les connexions en utilisant à la fois namespace et pod sélecteurs:
Afin de faire correspondre le trafic réseau en combinant l’espace de noms et les sélecteurs de pod, vous pouvez utiliser un objet NetworkPolicy similaire à ce qui suit:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-pod-and-namespace-both spec: podSelector: matchLabels: name: test-pods ingress: - from: - namespaceSelector: matchLabels: project: project_name podSelector: matchLabels: name: test-pods
Les objets NetworkPolicy sont additifs, ce qui signifie que vous pouvez combiner plusieurs objets NetworkPolicy pour répondre à des exigences réseau complexes.
À titre d’exemple, pour les objets NetworkPolicy définis dans les échantillons précédents, vous pouvez définir à la fois des stratégies d’autorisation-même-namespace et d’autorisation-http-and-https au sein d’un même projet. Ainsi, permettant aux pods avec le label role=frontend, d’accepter toute connexion autorisée par chaque politique. Autrement dit, les connexions sur n’importe quel port à partir de pods dans le même espace de noms, et les connexions sur les ports 80 et 443 à partir de pods dans n’importe quel espace de noms.
6.2.1.1.1. En utilisant la politique de réseau d’autorisation-de-routeur
Utilisez la NetworkPolicy suivante pour autoriser le trafic externe quelle que soit la configuration du routeur:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-router
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/ingress: ""
podSelector: {}
policyTypes:
- Ingress- 1
- le label policy-group.network.openshift.io/ingress:" prend en charge OVN-Kubernetes.
6.2.1.1.2. À l’aide de la politique de réseau d’autorisation-de-hôte
Ajoutez l’objet Permis-from-hostnetwork NetworkPolicy suivant pour diriger le trafic à partir des pods réseau hôte.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-hostnetwork
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/host-network: ""
podSelector: {}
policyTypes:
- Ingress6.2.1.2. Des optimisations pour la stratégie réseau avec le plugin réseau OVN-Kubernetes
Lors de la conception de votre politique de réseau, consultez les lignes directrices suivantes:
- Dans le cas des stratégies réseau avec la même spécification spec.podSelector, il est plus efficace d’utiliser une stratégie réseau avec plusieurs règles d’entrée ou de sortie, que plusieurs stratégies réseau avec des sous-ensembles de règles d’entrée ou de sortie.
Chaque règle d’entrée ou de sortie basée sur la spécification podSelector ou namespaceSelector génère le nombre de flux OVS proportionnels au nombre de pods sélectionnés par stratégie réseau + nombre de pods sélectionnés par la règle d’entrée ou de sortie. Il est donc préférable d’utiliser la spécification podSelector ou namespaceSelector qui peut sélectionner autant de pods que vous en avez besoin en une seule règle, au lieu de créer des règles individuelles pour chaque pod.
À titre d’exemple, la politique suivante contient deux règles:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchLabels: role: frontend - from: - podSelector: matchLabels: role: backendLa politique suivante exprime ces deux mêmes règles qu’une:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchExpressions: - {key: role, operator: In, values: [frontend, backend]}La même ligne directrice s’applique à la spécification spec.podSelector. Lorsque vous avez les mêmes règles d’entrée ou de sortie pour différentes politiques de réseau, il pourrait être plus efficace de créer une politique réseau avec une spécification spec.podSelector commune. À titre d’exemple, les deux politiques suivantes ont des règles différentes:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy1 spec: podSelector: matchLabels: role: db ingress: - from: - podSelector: matchLabels: role: frontend --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy2 spec: podSelector: matchLabels: role: client ingress: - from: - podSelector: matchLabels: role: frontendLa politique de réseau suivante exprime ces deux mêmes règles qu’une:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy3 spec: podSelector: matchExpressions: - {key: role, operator: In, values: [db, client]} ingress: - from: - podSelector: matchLabels: role: frontendCette optimisation peut être appliquée lorsque seulement plusieurs sélecteurs sont exprimés en un seul. Dans les cas où les sélecteurs sont basés sur différentes étiquettes, il peut être impossible d’appliquer cette optimisation. Dans ces cas, envisagez d’appliquer de nouvelles étiquettes pour l’optimisation des politiques réseau spécifiquement.
6.2.1.3. Les prochaines étapes
6.2.2. Créer une politique de réseau
En tant qu’utilisateur avec le rôle d’administrateur, vous pouvez créer une stratégie réseau pour un espace de noms.
6.2.2.1. Exemple d’objet NetworkPolicy
Ce qui suit annote un exemple d’objet NetworkPolicy:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l’objet NetworkPolicy.
- 2
- C) un sélecteur qui décrit les pods auxquels la politique s’applique. L’objet de stratégie ne peut sélectionner que des pods dans le projet qui définit l’objet NetworkPolicy.
- 3
- D’un sélecteur qui correspond aux pods à partir desquels l’objet de stratégie permet le trafic d’entrée. Le sélecteur correspond aux pods dans le même espace de noms que NetworkPolicy.
- 4
- Liste d’un ou de plusieurs ports de destination sur lesquels accepter le trafic.
6.2.2.2. Création d’une stratégie réseau à l’aide du CLI
Afin de définir des règles granulaires décrivant le trafic réseau d’entrée ou de sortie autorisé pour les espaces de noms de votre cluster, vous pouvez créer une stratégie réseau.
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez créer une stratégie réseau dans n’importe quel espace de noms du cluster.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- C’est vous qui travaillez dans l’espace de noms auquel s’applique la stratégie réseau.
Procédure
Créer une règle de politique:
Créer un fichier <policy_name>.yaml:
$ touch <policy_name>.yamllà où:
<policy_name>- Indique le nom du fichier de stratégie réseau.
Définissez une stratégie réseau dans le fichier que vous venez de créer, comme dans les exemples suivants:
Dénier l’entrée de tous les pods dans tous les espaces de noms
Il s’agit d’une politique fondamentale, bloquant tout réseau interpod autre que le trafic interpod autorisé par la configuration d’autres stratégies réseau.
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} policyTypes: - Ingress ingress: []Autoriser l’entrée de tous les pods dans le même espace de noms
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}Autoriser le trafic d’entrée vers un pod à partir d’un espace de noms particulier
Cette politique permet au trafic de pods étiquetés pod-a à partir de pods fonctionnant dans namespace-y.
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-traffic-pod spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-y
Afin de créer l’objet de stratégie réseau, entrez la commande suivante:
$ oc apply -f <policy_name>.yaml -n <namespace>là où:
<policy_name>- Indique le nom du fichier de stratégie réseau.
<namespace>- Facultatif : Spécifie l’espace de noms si l’objet est défini dans un espace de noms différent de celui de l’espace de noms actuel.
Exemple de sortie
networkpolicy.networking.k8s.io/deny-by-default created
Lorsque vous vous connectez à la console Web avec des privilèges cluster-admin, vous avez le choix de créer une stratégie réseau dans n’importe quel espace de noms du cluster directement dans YAML ou à partir d’un formulaire dans la console Web.
6.2.2.3. Création d’une stratégie de réseau par défaut
Il s’agit d’une politique fondamentale, bloquant tout réseau interpod autre que le trafic réseau autorisé par la configuration d’autres stratégies réseau déployées. Cette procédure applique une politique de refus par défaut.
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez créer une stratégie réseau dans n’importe quel espace de noms du cluster.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- C’est vous qui travaillez dans l’espace de noms auquel s’applique la stratégie réseau.
Procédure
Créez le YAML suivant qui définit une politique de déni par défaut pour refuser l’entrée de tous les pods dans tous les espaces de noms. Enregistrez le YAML dans le fichier deny-by-default.yaml:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: default1 spec: podSelector: {}2 ingress: []3 - 1
- namespace: par défaut déploie cette stratégie dans l’espace de noms par défaut.
- 2
- le podSelector: est vide, cela signifie qu’il correspond à tous les gousses. La politique s’applique donc à tous les pods dans l’espace de noms par défaut.
- 3
- Il n’y a pas de règles d’entrée spécifiées. Cela provoque la chute du trafic entrant vers toutes les gousses.
Appliquer la politique en entrant la commande suivante:
$ oc apply -f deny-by-default.yamlExemple de sortie
networkpolicy.networking.k8s.io/deny-by-default created
6.2.2.4. Création d’une stratégie réseau pour permettre le trafic de clients externes
Avec la stratégie de refus par défaut en place, vous pouvez procéder à la configuration d’une stratégie qui permet le trafic des clients externes vers un pod avec l’app=web d’étiquette.
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez créer une stratégie réseau dans n’importe quel espace de noms du cluster.
Cette procédure permet de configurer une politique qui permet au service externe de l’Internet public directement ou en utilisant un Balanceur de charge d’accéder au pod. Le trafic n’est autorisé qu’à un pod avec l’étiquette app=web.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- C’est vous qui travaillez dans l’espace de noms auquel s’applique la stratégie réseau.
Procédure
Créez une politique qui permet le trafic depuis l’Internet public directement ou en utilisant un balanceur de charge pour accéder au pod. Enregistrez le YAML dans le fichier web-allow-external.yaml:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-external namespace: default spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}Appliquer la politique en entrant la commande suivante:
$ oc apply -f web-allow-external.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-external createdCette politique permet le trafic à partir de toutes les ressources, y compris le trafic externe comme illustré dans le diagramme suivant:

6.2.2.5. Création d’une stratégie réseau permettant le trafic vers une application à partir de tous les espaces de noms
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez créer une stratégie réseau dans n’importe quel espace de noms du cluster.
Cette procédure permet de configurer une stratégie qui permet le trafic de tous les pods dans tous les espaces de noms à une application particulière.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- C’est vous qui travaillez dans l’espace de noms auquel s’applique la stratégie réseau.
Procédure
Créez une stratégie qui permet le trafic de tous les pods dans tous les espaces de noms vers une application particulière. Enregistrez le YAML dans le fichier web-allow-all-namespaces.yaml:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-all-namespaces namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {}2 NotePar défaut, si vous omet de spécifier un namespaceSelector, il ne sélectionne pas d’espaces de noms, ce qui signifie que la stratégie autorise le trafic uniquement à partir de l’espace de noms vers lequel la stratégie réseau est déployée.
Appliquer la politique en entrant la commande suivante:
$ oc apply -f web-allow-all-namespaces.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-all-namespaces created
La vérification
Démarrez un service Web dans l’espace de noms par défaut en entrant la commande suivante:
$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour déployer une image alpine dans l’espace de noms secondaire et démarrer un shell:
$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- shExécutez la commande suivante dans le shell et observez que la requête est autorisée:
# wget -qO- --timeout=2 http://web.defaultA) Produit attendu
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
6.2.2.6. Création d’une stratégie réseau permettant le trafic vers une application à partir d’un espace de noms
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez créer une stratégie réseau dans n’importe quel espace de noms du cluster.
Cette procédure permet de configurer une stratégie qui permet le trafic vers un pod avec l’étiquette app=web à partir d’un espace de noms particulier. Il se peut que vous vouliez faire ceci pour:
- Limitez le trafic à une base de données de production uniquement aux espaces de noms où des charges de travail de production sont déployées.
- Activer les outils de surveillance déployés dans un espace de noms particulier pour gratter des métriques à partir de l’espace de noms actuel.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- C’est vous qui travaillez dans l’espace de noms auquel s’applique la stratégie réseau.
Procédure
Créez une stratégie qui permet le trafic de tous les pods dans un espace de noms particulier avec un but d’étiquette=production. Enregistrez le YAML dans le fichier web-allow-prod.yaml:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production2 Appliquer la politique en entrant la commande suivante:
$ oc apply -f web-allow-prod.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-prod created
La vérification
Démarrez un service Web dans l’espace de noms par défaut en entrant la commande suivante:
$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour créer l’espace de noms prod:
$ oc create namespace prodExécutez la commande suivante pour étiqueter l’espace de noms prod:
$ oc label namespace/prod purpose=productionExécutez la commande suivante pour créer l’espace de noms dev:
$ oc create namespace devExécutez la commande suivante pour étiqueter l’espace de noms dev:
$ oc label namespace/dev purpose=testingExécutez la commande suivante pour déployer une image alpine dans l’espace de noms de dev et démarrer un shell:
$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- shExécutez la commande suivante dans le shell et observez que la requête est bloquée:
# wget -qO- --timeout=2 http://web.defaultA) Produit attendu
wget: download timed outExécutez la commande suivante pour déployer une image alpine dans l’espace de noms prod et démarrer un shell:
$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- shExécutez la commande suivante dans le shell et observez que la requête est autorisée:
# wget -qO- --timeout=2 http://web.defaultA) Produit attendu
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
6.2.2.7. Création d’une stratégie réseau à l’aide d’OpenShift Cluster Manager
Afin de définir des règles granulaires décrivant le trafic réseau d’entrée ou de sortie autorisé pour les espaces de noms de votre cluster, vous pouvez créer une stratégie réseau.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- Configuration d’un fournisseur d’identité pour votre cluster.
- Ajout de votre compte utilisateur au fournisseur d’identité configuré.
- Dans votre cluster dédié OpenShift, vous avez créé un projet.
Procédure
- À partir d’OpenShift Cluster Manager, cliquez sur le cluster auquel vous souhaitez accéder.
- Cliquez sur Ouvrir la console pour accéder à la console Web OpenShift.
- Cliquez sur votre fournisseur d’identité et fournissez vos informations d’identification pour vous connecter au cluster.
- Du point de vue administrateur, sous Networking, cliquez sur NetworkPolicies.
- Cliquez sur Créer NetworkPolicy.
- Indiquez un nom pour la politique dans le champ Nom de la politique.
- Facultatif: Vous pouvez fournir l’étiquette et le sélecteur pour un pod spécifique si cette politique ne s’applique qu’à un ou plusieurs gousses spécifiques. Dans le cas où vous ne sélectionnez pas un pod spécifique, cette politique s’appliquera à tous les pods du cluster.
- Facultatif: Vous pouvez bloquer tous les trafics d’entrée et de sortie en utilisant le Deny tous les trafics entrants ou Deny toutes les cases à cocher du trafic sortant.
- En outre, vous pouvez ajouter n’importe quelle combinaison de règles d’entrée et de sortie, vous permettant de spécifier le port, l’espace de noms ou les blocs IP que vous souhaitez approuver.
Ajoutez des règles d’entrée à votre politique:
Cliquez sur Ajouter une règle d’entrée pour configurer une nouvelle règle. Cette action crée une nouvelle ligne de règles Ingress avec un menu déroulant Ajouter la source autorisée qui vous permet de spécifier la façon dont vous souhaitez limiter le trafic entrant. Le menu déroulant offre trois options pour limiter votre trafic d’entrée:
- Autoriser les pods du même espace de noms limite le trafic aux pods dans le même espace de noms. Dans un espace de noms, vous pouvez spécifier les pods, mais laisser cette option en blanc permet tout le trafic à partir des pods dans l’espace de noms.
- Autoriser les pods de l’intérieur du cluster limite le trafic à des pods dans le même cluster que la politique. Il est possible de spécifier les espaces de noms et les pods à partir desquels vous souhaitez autoriser le trafic entrant. Laisser cette option vide permet le trafic entrant à partir de tous les espaces de noms et les pods dans ce cluster.
- Autoriser les pairs par le blocage IP limite le trafic à partir d’un bloc IP de routage interdomain (CIDR) spécifié. Il est possible de bloquer certaines adresses IP avec l’option exception. Laisser le champ CIDR vide permet tout le trafic entrant de toutes les sources externes.
- Il est possible de limiter tout votre trafic entrant à un port. Dans le cas où vous n’y ajoutez pas de ports, tous les ports sont accessibles au trafic.
Ajoutez des règles de sortie à votre politique de réseau:
Cliquez sur Ajouter une règle de sortie pour configurer une nouvelle règle. Cette action crée une nouvelle ligne de règles Egress avec un menu déroulant Ajouter la destination autorisée* qui vous permet de spécifier la façon dont vous souhaitez limiter le trafic sortant. Le menu déroulant offre trois options pour limiter votre trafic de sortie:
- Autoriser les pods du même espace de noms limite le trafic sortant aux pods dans le même espace de noms. Dans un espace de noms, vous pouvez spécifier les pods, mais laisser cette option en blanc permet tout le trafic à partir des pods dans l’espace de noms.
- Autoriser les pods de l’intérieur du cluster limite le trafic à des pods dans le même cluster que la politique. Il est possible de spécifier les espaces de noms et les pods à partir desquels vous souhaitez autoriser le trafic sortant. Laisser cette option vide permet le trafic sortant de tous les espaces de noms et pods au sein de ce cluster.
- Autoriser les pairs par le blocage IP limite le trafic à partir d’un bloc IP CIDR spécifié. Il est possible de bloquer certaines adresses IP avec l’option exception. Laisser le champ CIDR vide permet tout le trafic sortant de toutes les sources externes.
- Il est possible de limiter tout votre trafic sortant à un port. Dans le cas où vous n’y ajoutez pas de ports, tous les ports sont accessibles au trafic.
6.2.3. Affichage d’une politique de réseau
En tant qu’utilisateur avec le rôle d’administrateur, vous pouvez afficher une stratégie réseau pour un espace de noms.
6.2.3.1. Exemple d’objet NetworkPolicy
Ce qui suit annote un exemple d’objet NetworkPolicy:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l’objet NetworkPolicy.
- 2
- C) un sélecteur qui décrit les pods auxquels la politique s’applique. L’objet de stratégie ne peut sélectionner que des pods dans le projet qui définit l’objet NetworkPolicy.
- 3
- D’un sélecteur qui correspond aux pods à partir desquels l’objet de stratégie permet le trafic d’entrée. Le sélecteur correspond aux pods dans le même espace de noms que NetworkPolicy.
- 4
- Liste d’un ou de plusieurs ports de destination sur lesquels accepter le trafic.
6.2.3.2. Consulter les stratégies de réseau à l’aide du CLI
Il est possible d’examiner les stratégies réseau dans un espace de noms.
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez afficher n’importe quelle stratégie réseau dans le cluster.
Conditions préalables
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- Dans l’espace de noms où existe la stratégie réseau, vous travaillez.
Procédure
Liste des stratégies réseau dans un espace de noms:
Afin d’afficher les objets de stratégie réseau définis dans un espace de noms, entrez la commande suivante:
$ oc get networkpolicyFacultatif: Pour examiner une stratégie réseau spécifique, entrez la commande suivante:
$ oc describe networkpolicy <policy_name> -n <namespace>là où:
<policy_name>- Indique le nom de la politique de réseau à inspecter.
<namespace>- Facultatif : Spécifie l’espace de noms si l’objet est défini dans un espace de noms différent de celui de l’espace de noms actuel.
À titre d’exemple:
$ oc describe networkpolicy allow-same-namespaceLa sortie pour oc décrit la commande
Name: allow-same-namespace Namespace: ns1 Created on: 2021-05-24 22:28:56 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: PodSelector: <none> Not affecting egress traffic Policy Types: Ingress
Lorsque vous vous connectez à la console Web avec des privilèges d’administration de cluster, vous avez le choix de visualiser une stratégie réseau dans n’importe quel espace de noms du cluster directement dans YAML ou à partir d’un formulaire dans la console Web.
6.2.3.3. Affichage des stratégies de réseau à l’aide d’OpenShift Cluster Manager
Consultez les détails de configuration de votre stratégie réseau dans Red Hat OpenShift Cluster Manager.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- Configuration d’un fournisseur d’identité pour votre cluster.
- Ajout de votre compte utilisateur au fournisseur d’identité configuré.
- C’est vous qui avez créé une stratégie de réseau.
Procédure
- Du point de vue administrateur dans la console Web OpenShift Cluster Manager, sous Networking, cliquez sur NetworkPolicies.
- Choisissez la politique de réseau souhaitée à afficher.
- Dans la page Détails de la stratégie réseau, vous pouvez consulter toutes les règles d’entrée et de sortie associées.
Choisissez YAML sur les détails de la stratégie réseau pour afficher la configuration de la stratégie au format YAML.
NoteIl est possible de consulter uniquement les détails de ces politiques. Il est impossible d’éditer ces politiques.
6.2.4. La suppression d’une politique de réseau
En tant qu’utilisateur avec le rôle d’administrateur, vous pouvez supprimer une stratégie réseau d’un espace de noms.
6.2.4.1. La suppression d’une politique de réseau à l’aide du CLI
Il est possible de supprimer une stratégie réseau dans un espace de noms.
Lorsque vous vous connectez avec un utilisateur avec le rôle cluster-admin, vous pouvez supprimer n’importe quelle stratégie réseau dans le cluster.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
- Dans l’espace de noms où existe la stratégie réseau, vous travaillez.
Procédure
Afin de supprimer un objet de stratégie réseau, entrez la commande suivante:
$ oc delete networkpolicy <policy_name> -n <namespace>là où:
<policy_name>- Indique le nom de la stratégie réseau.
<namespace>- Facultatif : Spécifie l’espace de noms si l’objet est défini dans un espace de noms différent de celui de l’espace de noms actuel.
Exemple de sortie
networkpolicy.networking.k8s.io/default-deny deleted
Lorsque vous vous connectez à la console Web avec des privilèges cluster-admin, vous avez le choix de supprimer une stratégie réseau dans n’importe quel espace de noms du cluster directement dans YAML ou à partir de la stratégie de la console Web via le menu Actions.
6.2.4.2. La suppression d’une stratégie réseau à l’aide d’OpenShift Cluster Manager
Il est possible de supprimer une stratégie réseau dans un espace de noms.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- Configuration d’un fournisseur d’identité pour votre cluster.
- Ajout de votre compte utilisateur au fournisseur d’identité configuré.
Procédure
- Du point de vue administrateur dans la console Web OpenShift Cluster Manager, sous Networking, cliquez sur NetworkPolicies.
Employez l’une des méthodes suivantes pour supprimer votre politique de réseau:
Effacer la politique du tableau des politiques de réseau:
- Dans la table Politiques réseau, sélectionnez le menu de pile de la ligne de la stratégie réseau que vous souhaitez supprimer, puis cliquez sur Supprimer NetworkPolicy.
Supprimez la stratégie à l’aide du menu déroulant Actions des détails de la stratégie réseau:
- Cliquez sur Actions menu déroulant pour votre stratégie de réseau.
- Choisissez Supprimer NetworkPolicy dans le menu.
6.2.5. Configuration de l’isolement multilocataire avec la stratégie réseau
En tant qu’administrateur de clusters, vous pouvez configurer vos stratégies réseau pour fournir une isolation réseau multilocataire.
La configuration des stratégies réseau comme décrit dans cette section fournit une isolation réseau similaire au mode multilocataires d’OpenShift SDN dans les versions précédentes d’OpenShift Dedicated.
6.2.5.1. Configuration de l’isolement multilocataire en utilisant la stratégie réseau
Configurez votre projet pour l’isoler des pods et services dans d’autres espaces de noms de projet.
Conditions préalables
- Le cluster utilise un plugin réseau qui prend en charge les objets NetworkPolicy, tels que le plugin réseau OVN-Kubernetes, avec mode: NetworkPolicy set.
- Installation de l’OpenShift CLI (oc).
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur.
Procédure
Créez les objets de NetworkPolicy suivants:
D’une politique nommée Autor-from-openshift-ingress.
$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress EOFNotele label policy-group.network.openshift.io/ingress: "" est l’étiquette de sélecteur d’espace de noms préférée pour OVN-Kubernetes.
D’une politique nommée Autorisation- from-openshift-monitoring:
$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: monitoring podSelector: {} policyTypes: - Ingress EOFD’une politique nommée allow-same-namespace:
$ cat << EOF| oc create -f - kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {} EOFD’une politique nommée Author-from-kube-apiserver-operator:
$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress EOFConsultez le nouveau contrôleur kube-apiserver-operator webhook pour valider la santé du webhook.
Facultatif : Pour confirmer que les stratégies réseau existent dans votre projet actuel, entrez la commande suivante:
$ oc describe networkpolicyExemple de sortie
Name: allow-from-openshift-ingress Namespace: example1 Created on: 2020-06-09 00:28:17 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: ingress Not affecting egress traffic Policy Types: Ingress Name: allow-from-openshift-monitoring Namespace: example1 Created on: 2020-06-09 00:29:57 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: monitoring Not affecting egress traffic Policy Types: Ingress
Chapitre 7. Plugin réseau OVN-Kubernetes
7.1. À propos du plugin réseau OVN-Kubernetes
Le cluster OpenShift Dedicated utilise un réseau virtualisé pour les réseaux de pod et de service.
Faisant partie de Red Hat OpenShift Networking, le plugin réseau OVN-Kubernetes est le fournisseur réseau par défaut d’OpenShift Dedicated. Le réseau OVN-Kubernetes est basé sur un réseau virtuel ouvert (OVN) et fournit une implémentation de réseau basée sur la superposition. Le cluster qui utilise le plugin OVN-Kubernetes exécute également Open vSwitch (OVS) sur chaque nœud. L’OVN configure OVS sur chaque nœud pour implémenter la configuration réseau déclarée.
L’OVN-Kubernetes est la solution de mise en réseau par défaut pour les déploiements OpenShift Dedicated et un seul nœud OpenShift.
Le projet OVN-Kubernetes, issu du projet OVS, utilise plusieurs des mêmes constructions, telles que les règles de flux ouvert, pour déterminer comment les paquets circulent à travers le réseau. Consultez le site Web Open Virtual Network pour plus d’informations.
L’OVN-Kubernetes est une série de démons pour OVS qui traduisent les configurations réseau virtuelles en règles OpenFlow. L’OpenFlow est un protocole pour communiquer avec les commutateurs et les routeurs réseau, fournissant un moyen de contrôler à distance le flux de trafic réseau sur un périphérique réseau afin que les administrateurs réseau puissent configurer, gérer et surveiller le flux du trafic réseau.
L’OVN-Kubernetes fournit une plus grande partie des fonctionnalités avancées qui ne sont pas disponibles avec OpenFlow. L’OVN prend en charge le routage virtuel distribué, les commutateurs logiques distribués, le contrôle d’accès, le protocole de configuration de l’hôte dynamique (DHCP) et le DNS. L’OVN implémente le routage virtuel distribué dans des flux logiques équivalents à des flux ouverts. Ainsi, si vous avez un pod qui envoie une requête DHCP au serveur DHCP sur le réseau, une règle de flux logique dans la requête aide les OVN-Kubernetes à gérer le paquet afin que le serveur puisse répondre avec la passerelle, le serveur DNS, l’adresse IP et d’autres informations.
Les OVN-Kubernetes exécutent un démon sur chaque nœud. Il existe des ensembles de démons pour les bases de données et pour le contrôleur OVN qui s’exécutent sur chaque nœud. Le contrôleur OVN programme le démon Open vSwitch sur les nœuds pour prendre en charge les fonctionnalités du fournisseur de réseau: IP de sortie, pare-feu, routeurs, réseau hybride, chiffrement IPSEC, IPv6, stratégie réseau, journaux de stratégie réseau, déchargement matériel et multidiffusion.
7.1.1. But OVN-Kubernetes
Le plugin réseau OVN-Kubernetes est un plugin CNI Kubernetes open source et entièrement équipé qui utilise Open Virtual Network (OVN) pour gérer les flux de trafic réseau. La société OVN est une solution de virtualisation réseau agnostique développée par la communauté. Le plugin réseau OVN-Kubernetes utilise les technologies suivantes:
- L’OVN pour gérer les flux de trafic réseau.
- Kubernetes supporte les politiques de réseau et les journaux, y compris les règles d’entrée et de sortie.
- Le protocole Générique Network Virtualization Encapsulation (Geneve), plutôt que Virtual Extensible LAN (VXLAN), pour créer un réseau de superposition entre les nœuds.
Le plugin réseau OVN-Kubernetes prend en charge les fonctionnalités suivantes:
- Des clusters hybrides qui peuvent exécuter à la fois des charges de travail Linux et Microsoft Windows. Cet environnement est connu sous le nom de réseau hybride.
- Déchargement du traitement des données réseau de l’unité centrale hôte (CPU) vers des cartes réseau compatibles et des unités de traitement de données (DPU). Ceci est connu sous le nom de déchargement de matériel.
- IPv4-primary double pile réseau sur les plates-formes en métal nu, VMware vSphere, IBM Power®, IBM Z® et Red Hat OpenStack Platform (RHOSP).
- IPv6 mise en réseau unique sur les plates-formes RHOSP et métal nu.
- IPv6-primary double pile réseau pour un cluster s’exécutant sur un métal nu, un VMware vSphere, ou une plate-forme RHOSP.
- Egress les dispositifs de pare-feu et les adresses IP sortantes.
- Egress les périphériques de routeur qui fonctionnent en mode redirection.
- Cryptage IPsec des communications intracluster.
7.1.2. Limites OVN-Kubernetes IPv6 et double pile
Le plugin réseau OVN-Kubernetes présente les limites suivantes:
Dans le cas des clusters configurés pour le réseau à double pile, les trafics IPv4 et IPv6 doivent utiliser la même interface réseau que la passerelle par défaut. En cas de non-respect de cette exigence, les pods sur l’hôte dans le jeu de démon ovnkube-node entrent dans l’état CrashLoopBackOff. Lorsque vous affichez un pod avec une commande telle que oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml, le champ d’état contient plus d’un message sur la passerelle par défaut, comme indiqué dans la sortie suivante:
I1006 16:09:50.985852 60651 helper_linux.go:73] Found default gateway interface br-ex 192.168.127.1 I1006 16:09:50.985923 60651 helper_linux.go:73] Found default gateway interface ens4 fe80::5054:ff:febe:bcd4 F1006 16:09:50.985939 60651 ovnkube.go:130] multiple gateway interfaces detected: br-ex ens4La seule résolution est de reconfigurer le réseau hôte afin que les deux familles IP utilisent la même interface réseau pour la passerelle par défaut.
Dans le cas des clusters configurés pour le réseau à double pile, les tables de routage IPv4 et IPv6 doivent contenir la passerelle par défaut. En cas de non-respect de cette exigence, les pods sur l’hôte dans le jeu de démon ovnkube-node entrent dans l’état CrashLoopBackOff. Lorsque vous affichez un pod avec une commande telle que oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml, le champ d’état contient plus d’un message sur la passerelle par défaut, comme indiqué dans la sortie suivante:
I0512 19:07:17.589083 108432 helper_linux.go:74] Found default gateway interface br-ex 192.168.123.1 F0512 19:07:17.589141 108432 ovnkube.go:133] failed to get default gateway interfaceLa seule résolution est de reconfigurer le réseau hôte afin que les deux familles IP contiennent la passerelle par défaut.
7.1.3. Affinité de session
Affinité de session est une fonctionnalité qui s’applique aux objets Kubernetes Service. Il est possible d’utiliser l’affinité de session si vous voulez vous assurer que chaque fois que vous vous connectez à un <service_VIP>:<Port>, le trafic est toujours équilibré vers le même back end. De plus amples informations, y compris la façon de définir l’affinité de session en fonction de l’adresse IP d’un client, consultez l’affinité de session.
Délai d’adhérence pour l’affinité de la session
Le plugin réseau OVN-Kubernetes pour OpenShift Dedicated calcule le délai d’adhérence d’une session à partir d’un client basé sur le dernier paquet. À titre d’exemple, si vous exécutez une commande curl 10 fois, le minuteur de session collant commence à partir du dixième paquet et non le premier. En conséquence, si le client contacte continuellement le service, la session ne s’arrête jamais. Le délai d’attente commence lorsque le service n’a pas reçu de paquet pour la quantité de temps définie par le paramètre TimeoutSeconds.
7.2. La migration du plugin réseau OpenShift SDN vers le plugin réseau OVN-Kubernetes
En tant qu’administrateur de cluster dédié OpenShift, vous pouvez lancer la migration du plugin réseau OpenShift SDN vers le plugin réseau OVN-Kubernetes et vérifier l’état de migration à l’aide du CLI OCM.
Avant de commencer l’initiation à la migration, certaines considérations sont les suivantes:
- La version du cluster doit être 4.16.24 et ci-dessus.
- Le processus de migration ne peut pas être interrompu.
- La migration vers le plugin réseau SDN n’est pas possible.
- Les nœuds de cluster seront redémarrés pendant la migration.
- Il n’y aura aucun impact sur les charges de travail résilientes aux perturbations des nœuds.
- Le temps de migration peut varier entre plusieurs minutes et heures, en fonction de la taille du cluster et des configurations de charge de travail.
7.2.1. Démarrage de la migration à l’aide de l’interface de ligne de commande (ocm) de l’API OpenShift Cluster Manager
Il est possible d’initier la migration uniquement sur des clusters qui sont la version 4.16.24 et ci-dessus.
Conditions préalables
- L’interface de ligne de commande de l’API OpenShift Cluster Manager (ocm) a été installée.
L’interface de ligne de commande de l’API OpenShift Cluster Manager (ocm) est uniquement une fonctionnalité de prévisualisation des développeurs. Afin d’obtenir de plus amples informations sur la portée du support des fonctionnalités Red Hat Developer Preview, consultez le champ d’application du support d’aperçu du développeur.
Procédure
Créez un fichier JSON avec le contenu suivant:
{ "type": "sdnToOvn" }Facultatif: Dans le fichier JSON, vous pouvez configurer des sous-réseaux internes en utilisant l’une ou l’autre des options jointes, masquées et transit, ainsi qu’un seul CIDR par option, comme indiqué dans l’exemple suivant:
{ "type": "sdnToOvn", "sdn_to_ovn": { "transit_ipv4": "192.168.255.0/24", "join_ipv4": "192.168.255.0/24", "masquerade_ipv4": "192.168.255.0/24" } }NoteL’OVN-Kubernetes réserve les plages d’adresse IP suivantes:
100.64.0.0/16. Cette plage d’adresses IP est utilisée pour le paramètre interneJoinSubnet d’OVN-Kubernetes par défaut.
100.88.0.0/16. Cette plage d’adresses IP est utilisée pour le paramètre interneTransSwitchSubnet d’OVN-Kubernetes par défaut.
Lorsque ces adresses IP ont été utilisées par OpenShift SDN ou par tout réseau externe susceptible de communiquer avec ce cluster, vous devez les corriger pour utiliser une plage d’adresses IP différente avant d’initier la migration en direct limitée. Consultez les plages d’adresses Patching OVN-Kubernetes dans la section Ressources supplémentaires.
Afin d’initier la migration, exécutez la demande de publication suivante dans une fenêtre terminale:
$ ocm post /api/clusters_mgmt/v1/clusters/{cluster_id}/migrations1 --body=myjsonfile.json2 Exemple de sortie
{ "kind": "ClusterMigration", "href": "/api/clusters_mgmt/v1/clusters/2gnts65ra30sclb114p8qdc26g5c8o3e/migrations/2gois8j244rs0qrfu9ti2o790jssgh9i", "id": "7sois8j244rs0qrhu9ti2o790jssgh9i", "cluster_id": "2gnts65ra30sclb114p8qdc26g5c8o3e", "type": "sdnToOvn", "state": { "value": "scheduled", "description": "" }, "sdn_to_ovn": { "transit_ipv4": "100.65.0.0/16", "join_ipv4": "100.66.0.0/16" }, "creation_timestamp": "2025-02-05T14:56:34.878467542Z", "updated_timestamp": "2025-02-05T14:56:34.878467542Z" }
La vérification
Afin de vérifier l’état de la migration, exécutez la commande suivante:
$ ocm get cluster $cluster_id/migration1 - 1
- Il faut remplacer $cluster_id par l’ID du cluster auquel la migration a été appliquée.
Ressources supplémentaires
Chapitre 8. Plugin réseau OpenShift SDN
8.1. Activer la multidiffusion pour un projet
8.1.1. À propos du multidiffusion
Avec le multidiffusion IP, les données sont diffusées simultanément à de nombreuses adresses IP.
- À l’heure actuelle, le multicast est le mieux utilisé pour la coordination à faible bande passante ou la découverte de services et non pour une solution à bande passante élevée.
- Les stratégies réseau affectent par défaut toutes les connexions dans un espace de noms. Cependant, la multidiffusion n’est pas affectée par les politiques de réseau. Lorsque la multidiffusion est activée dans le même espace de noms que vos stratégies réseau, elle est toujours autorisée, même s’il existe une stratégie réseau refusée. Les administrateurs de clusters devraient tenir compte des implications de l’exemption de la multidiffusion des politiques réseau avant de l’autoriser.
Le trafic multidiffusion entre les pods dédiés OpenShift est désactivé par défaut. En utilisant le plugin réseau OVN-Kubernetes, vous pouvez activer la multidiffusion par projet.
8.1.2. Activer la multidiffusion entre les pods
Il est possible d’activer le multicast entre les pods pour votre projet.
Conditions préalables
- Installez le OpenShift CLI (oc).
- Connectez-vous au cluster avec un utilisateur qui a le rôle cluster-admin ou dédié-admin.
Procédure
Exécutez la commande suivante pour activer le multicast pour un projet. <namespace> par l’espace de noms pour le projet pour lequel vous souhaitez activer le multicast.
$ oc annotate namespace <namespace> \ k8s.ovn.org/multicast-enabled=trueAstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter l’annotation:
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: "true"
La vérification
Afin de vérifier que la multidiffusion est activée pour un projet, complétez la procédure suivante:
Changez votre projet actuel au projet pour lequel vous avez activé le multicast. <project> par le nom du projet.
$ oc project <project>Créer un pod pour agir en tant que récepteur multicast:
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOFCréer un pod pour agir en tant qu’expéditeur multicast:
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOFDans une nouvelle fenêtre ou onglet terminal, démarrez l’auditeur multicast.
Accédez à l’adresse IP du Pod:
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')Démarrez l’auditeur multicast en entrant la commande suivante:
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
Démarrez l’émetteur multidiffusion.
Accédez à la plage d’adresse IP du réseau pod:
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')Afin d’envoyer un message multicast, entrez la commande suivante:
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"Lorsque le multicast fonctionne, la commande précédente renvoie la sortie suivante:
mlistener
Chapitre 9. Configuration des itinéraires
9.1. Configuration de l’itinéraire
9.1.1. Création d’une route HTTP
Créez un itinéraire pour héberger votre application à une URL publique. L’itinéraire peut être sécurisé ou non sécurisé, en fonction de la configuration de sécurité réseau de votre application. La route HTTP est une route non sécurisée qui utilise le protocole de routage HTTP de base et expose un service sur un port d’application non sécurisé.
La procédure suivante décrit comment créer une route HTTP simple vers une application Web, en utilisant l’application hello-openshift comme exemple.
Conditions préalables
- Installation de l’OpenShift CLI (oc).
- En tant qu’administrateur, vous êtes connecté.
- Il existe une application web qui expose un port et un point de terminaison TCP à l’écoute du trafic sur le port.
Procédure
Créez un projet appelé hello-openshift en exécutant la commande suivante:
$ oc new-project hello-openshiftCréez un pod dans le projet en exécutant la commande suivante:
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.jsonCréez un service appelé hello-openshift en exécutant la commande suivante:
$ oc expose pod/hello-openshiftCréez une route non sécurisée vers l’application hello-openshift en exécutant la commande suivante:
$ oc expose svc hello-openshift
La vérification
Afin de vérifier que la ressource d’itinéraire que vous avez créée exécute la commande suivante:
$ oc get routes -o yaml <name of resource>1 - 1
- Dans cet exemple, l’itinéraire est nommé hello-openshift.
Exemple de définition YAML de l’itinéraire non sécurisé créé
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: hello-openshift
spec:
host: www.example.com
port:
targetPort: 8080
to:
kind: Service
name: hello-openshift- 1
- Le champ hôte est un enregistrement DNS alias qui pointe vers le service. Ce champ peut être n’importe quel nom DNS valide, tel que www.example.com. Le nom DNS doit suivre les conventions de sous-domaine DNS952. Lorsqu’il n’est pas spécifié, un nom d’itinéraire est automatiquement généré.
- 2
- Le champ TargetPort est le port cible sur les pods qui est sélectionné par le service auquel cette route pointe.Note
Afin d’afficher votre domaine d’entrée par défaut, exécutez la commande suivante:
$ oc get ingresses.config/cluster -o jsonpath={.spec.domain}
9.1.2. Configuration des délais d’itinéraire
Il est possible de configurer les délais par défaut pour un itinéraire existant lorsque vous avez des services qui ont besoin d’un délai d’attente réduit, ce qui est nécessaire aux fins de la disponibilité de niveau de service (SLA), ou d’un délai d’attente élevé, pour les cas où le retard est lent.
Conditions préalables
- Il vous faut un contrôleur Ingress déployé sur un cluster en cours d’exécution.
Procédure
En utilisant la commande oc annotate, ajoutez le timeout à l’itinéraire:
$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit>1 - 1
- Les unités de temps prises en charge sont les microsecondes (nous), les millisecondes (ms), les secondes (s), les minutes (m), les heures (h) ou les jours (d).
L’exemple suivant définit un délai de deux secondes sur un itinéraire nommé myroute:
$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
9.1.3. HTTP Strict Transport Security
La stratégie HTTP Strict Transport Security (HSTS) est une amélioration de la sécurité, qui signale au client du navigateur que seul le trafic HTTPS est autorisé sur l’hôte de route. HSTS optimise également le trafic Web en signalant le transport HTTPS, sans utiliser de redirections HTTP. HSTS est utile pour accélérer les interactions avec les sites Web.
Lorsque la politique HSTS est appliquée, HSTS ajoute un en-tête Strict Transport Security aux réponses HTTP et HTTPS du site. Il est possible d’utiliser la valeur insecureEdgeTerminationPolicy dans un itinéraire pour rediriger HTTP vers HTTPS. Lorsque HSTS est appliqué, le client modifie toutes les requêtes de l’URL HTTP en HTTPS avant l’envoi de la requête, éliminant ainsi la nécessité d’une redirection.
Les administrateurs de clusters peuvent configurer HSTS pour faire ce qui suit:
- Activer le HSTS par route
- Désactiver le HSTS par route
- Appliquer HSTS par domaine, pour un ensemble de domaines, ou utiliser des étiquettes d’espace de noms en combinaison avec des domaines
HSTS ne fonctionne qu’avec des routes sécurisées, soit terminales soit recryptées. La configuration est inefficace sur les routes HTTP ou passthrough.
9.1.3.1. Activer HTTP Strict Transport Security par route
HTTP strict de sécurité de transport (HSTS) est implémenté dans le modèle HAProxy et appliqué à bord et recrypter les routes qui ont l’annotation haproxy.router.openshift.io/hsts_header.
Conditions préalables
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur pour le projet.
- Installation de l’OpenShift CLI (oc).
Procédure
Afin d’activer HSTS sur une route, ajoutez la valeur haproxy.router.openshift.io/hsts_header à la route terminale ou recryptée. Il est possible d’utiliser l’outil oc annotate pour le faire en exécutant la commande suivante. Afin d’exécuter correctement la commande, assurez-vous que le point-virgule (;) dans l’annotation de route haproxy.router.openshift.io/hsts_header est également entouré de guillemets doubles ("").
Exemple de commande annotée qui fixe l’âge maximum à 31536000 ms (environ 8,5 heures)
$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header=max-age=31536000;\ includeSubDomains;preload"Exemple d’itinéraire configuré avec une annotation
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=31536000;includeSubDomains;preload1 2 3 # ... spec: host: def.abc.com tls: termination: "reencrypt" ... wildcardPolicy: "Subdomain" # ...- 1
- C’est nécessaire. l’âge maximal mesure la durée, en secondes, que la politique sur le TVH est en vigueur. Lorsqu’il est défini à 0, il annule la politique.
- 2
- En option. Lorsqu’il est inclus, includeSubDomains indique au client que tous les sous-domaines de l’hôte doivent avoir la même politique HSTS que l’hôte.
- 3
- En option. Lorsque l’âge maximum est supérieur à 0, vous pouvez ajouter la précharge dans haproxy.router.openshift.io/hsts_header pour permettre aux services externes d’inclure ce site dans leurs listes de préchargement HSTS. À titre d’exemple, des sites tels que Google peuvent construire une liste de sites qui ont un préchargement défini. Les navigateurs peuvent ensuite utiliser ces listes pour déterminer les sites avec lesquels ils peuvent communiquer via HTTPS, avant même qu’ils n’aient interagi avec le site. En l’absence de préchargement, les navigateurs doivent avoir interagi avec le site via HTTPS, au moins une fois, pour obtenir l’en-tête.
9.1.3.2. Désactivation de HTTP Strict Transport Security par route
Afin de désactiver HTTP strict de sécurité de transport (HSTS) par route, vous pouvez définir la valeur d’âge maximum dans l’annotation de route à 0.
Conditions préalables
- Il est connecté au cluster avec un utilisateur avec des privilèges d’administrateur pour le projet.
- Installation de l’OpenShift CLI (oc).
Procédure
Afin de désactiver le HSTS, définissez la valeur d’âge max dans l’annotation de route à 0, en entrant la commande suivante:
$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"AstuceAlternativement, vous pouvez appliquer le YAML suivant pour créer la carte de configuration:
Exemple de désactivation du TVH par route
metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=0Afin de désactiver les HSTS pour chaque route dans un espace de noms, entrez la commande suivante:
$ oc annotate route --all -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"
La vérification
Afin d’interroger l’annotation pour tous les itinéraires, entrez la commande suivante:
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'Exemple de sortie
Name: routename HSTS: max-age=0
9.1.4. En utilisant des cookies pour garder l’état de route
L’OpenShift Dedicated fournit des sessions collantes, ce qui permet un trafic d’application étatique en veillant à ce que tous les trafics atteignent le même point de terminaison. Cependant, si le point d’extrémité se termine, que ce soit par redémarrage, mise à l’échelle, ou un changement de configuration, cet état d’état peut disparaître.
Le logiciel OpenShift Dedicated peut utiliser des cookies pour configurer la persistance des sessions. Le contrôleur d’entrée sélectionne un point de terminaison pour traiter les demandes de l’utilisateur et crée un cookie pour la session. Le cookie est réintégré dans la réponse à la demande et l’utilisateur renvoie le cookie avec la demande suivante dans la session. Le cookie indique au contrôleur d’entrée quel point de terminaison traite la session, s’assurant que les demandes du client utilisent le cookie afin qu’ils soient acheminés vers le même pod.
Les cookies ne peuvent pas être définis sur les routes de passage, car le trafic HTTP ne peut pas être vu. Au lieu de cela, un nombre est calculé en fonction de l’adresse IP source, qui détermine le backend.
En cas de changement de backend, le trafic peut être dirigé vers le mauvais serveur, ce qui le rend moins collant. Lorsque vous utilisez un balanceur de charge, qui cache l’IP source, le même nombre est défini pour toutes les connexions et le trafic est envoyé au même pod.
9.1.4.1. Annotation d’un itinéraire avec un cookie
Il est possible de définir un nom de cookie pour écraser le nom par défaut, généré automatiquement pour l’itinéraire. Cela permet à l’application recevant du trafic d’itinéraire de connaître le nom du cookie. La suppression du cookie peut forcer la prochaine demande à re-choisir un point de terminaison. Le résultat est que si un serveur est surchargé, ce serveur essaie de supprimer les requêtes du client et de les redistribuer.
Procédure
Annoter l’itinéraire avec le nom de cookie spécifié:
$ oc annotate route <route_name> router.openshift.io/cookie_name="<cookie_name>"là où:
<route_nom>- Indique le nom de l’itinéraire.
<cookie_name>- Indique le nom du cookie.
A titre d’exemple, annoter l’itinéraire my_route avec le nom de cookie my_cookie:
$ oc annotate route my_route router.openshift.io/cookie_name="my_cookie"Capturez le nom d’hôte de l’itinéraire dans une variable:
$ ROUTE_NAME=$(oc get route <route_name> -o jsonpath='{.spec.host}')là où:
<route_nom>- Indique le nom de l’itinéraire.
Enregistrez le cookie, puis accédez à l’itinéraire:
$ curl $ROUTE_NAME -k -c /tmp/cookie_jarLorsque vous vous connectez à l’itinéraire, utilisez le cookie enregistré par la commande précédente:
$ curl $ROUTE_NAME -k -b /tmp/cookie_jar
9.1.5. Itinéraires basés sur le chemin
Les routes basées sur le chemin spécifient un composant de chemin qui peut être comparé à une URL, ce qui nécessite que le trafic pour l’itinéraire soit basé sur HTTP. Ainsi, plusieurs itinéraires peuvent être desservis en utilisant le même nom d’hôte, chacun avec un chemin différent. Les routeurs doivent correspondre à des itinéraires basés sur le chemin le plus spécifique au moins.
Le tableau suivant présente des exemples d’itinéraires et leur accessibilité:
| Itinéraire | Lorsque comparé à | Accessible |
|---|---|---|
| www.example.com/test | www.example.com/test | ♪ oui ♪ |
| www.example.com | C) Non | |
| www.example.com/test et www.example.com | www.example.com/test | ♪ oui ♪ |
| www.example.com | ♪ oui ♪ | |
| www.example.com | www.example.com/text | (Matched par l’hôte, pas l’itinéraire) |
| www.example.com | ♪ oui ♪ |
Itinéraire non sécurisé avec un chemin
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: route-unsecured
spec:
host: www.example.com
path: "/test"
to:
kind: Service
name: service-name- 1
- Le chemin est le seul attribut ajouté pour une route basée sur le chemin.
Le routage basé sur le chemin n’est pas disponible lors de l’utilisation de TLS passthrough, car le routeur ne met pas fin à TLS dans ce cas et ne peut pas lire le contenu de la demande.
9.1.6. Configuration d’en-tête HTTP
Le logiciel OpenShift Dedicated fournit différentes méthodes pour travailler avec les en-têtes HTTP. Lorsque vous configurez ou supprimez des en-têtes, vous pouvez utiliser des champs spécifiques dans le contrôleur d’Ingress ou un itinéraire individuel pour modifier les en-têtes de requête et de réponse. Il est également possible de définir certains en-têtes en utilisant des annotations d’itinéraire. Les différentes façons de configurer les en-têtes peuvent présenter des défis lorsque vous travaillez ensemble.
Il est possible de définir ou de supprimer uniquement des en-têtes au sein d’un IngressController ou Route CR, vous ne pouvez pas les ajouter. Lorsqu’un en-tête HTTP est défini avec une valeur, cette valeur doit être complète et ne pas nécessiter d’ajouter à l’avenir. Dans les situations où il est logique d’ajouter un en-tête, comme l’en-tête X-Forwarded-Forwarded, utilisez le champ spec.httpHeaders.forwardedHeaderPolicy, au lieu de spec.httpHeaders.actions.
9.1.6.1. Ordre de préséance
Lorsque le même en-tête HTTP est modifié à la fois dans le contrôleur Ingress et dans un itinéraire, HAProxy priorise les actions de certaines manières selon qu’il s’agit d’une requête ou d’un en-tête de réponse.
- Dans le cas des en-têtes de réponse HTTP, les actions spécifiées dans le contrôleur Ingress sont exécutées après les actions spécifiées dans un itinéraire. Cela signifie que les actions spécifiées dans le Contrôleur Ingress ont préséance.
- Dans le cas des en-têtes de requête HTTP, les actions spécifiées dans une route sont exécutées après les actions spécifiées dans le contrôleur Ingress. Cela signifie que les actions spécifiées dans l’itinéraire ont préséance.
À titre d’exemple, un administrateur de cluster définit l’en-tête de réponse X-Frame-Options avec la valeur DENY dans le contrôleur Ingress en utilisant la configuration suivante:
Exemple IngressController spec
apiVersion: operator.openshift.io/v1
kind: IngressController
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: DENYLe propriétaire de route définit le même en-tête de réponse que l’administrateur du cluster défini dans le contrôleur Ingress, mais avec la valeur SAMEORIGIN en utilisant la configuration suivante:
Exemple de route Spécification
apiVersion: route.openshift.io/v1
kind: Route
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: SAMEORIGINLorsque les spécifications IngressController et Route configurent l’en-tête de réponse X-Frame-Options, alors la valeur définie pour cet en-tête au niveau global dans le contrôleur Ingress a préséance, même si un itinéraire spécifique permet des cadres. Dans le cas d’un en-tête de requête, la valeur spec de Route remplace la valeur spec d’IngressController.
Cette priorisation se produit parce que le fichier haproxy.config utilise la logique suivante, où le contrôleur Ingress est considéré comme l’extrémité avant et les itinéraires individuels sont considérés comme l’arrière-plan. La valeur d’en-tête DENY appliquée aux configurations d’extrémité avant remplace le même en-tête avec la valeur SAMEORIGIN définie dans l’arrière:
frontend public
http-response set-header X-Frame-Options 'DENY'
frontend fe_sni
http-response set-header X-Frame-Options 'DENY'
frontend fe_no_sni
http-response set-header X-Frame-Options 'DENY'
backend be_secure:openshift-monitoring:alertmanager-main
http-response set-header X-Frame-Options 'SAMEORIGIN'En outre, toutes les actions définies dans le contrôleur d’Ingress ou dans une route remplacent les valeurs définies à l’aide d’annotations d’itinéraire.
9.1.6.2. En-têtes de cas spéciaux
Les en-têtes suivants sont soit empêchés entièrement d’être réglés ou supprimés, soit autorisés dans des circonstances spécifiques:
| Le nom de l’en-tête | Configurable en utilisant IngressController spec | Configurable à l’aide de Route spec | La raison de l’exclusion | Configurable en utilisant une autre méthode |
|---|---|---|---|---|
|
| C) Non | C) Non | L’en-tête de requête HTTP proxy peut être utilisé pour exploiter les applications CGI vulnérables en injectant la valeur d’en-tête dans la variable d’environnement HTTP_PROXY. L’en-tête de requête HTTP proxy est également non standard et sujet à une erreur lors de la configuration. | C) Non |
|
| C) Non | ♪ oui ♪ | Lorsque l’en-tête de requête HTTP hôte est défini à l’aide de l’IngressController CR, HAProxy peut échouer lors de la recherche de la bonne route. | C) Non |
|
| C) Non | C) Non | L’en-tête de réponse HTTP strict-transport-sécurité est déjà géré à l’aide d’annotations de route et n’a pas besoin d’une implémentation séparée. | L’annotation de route haproxy.router.openshift.io/hsts_header |
| cookie et set-cookie | C) Non | C) Non | Les cookies que HAProxy définit sont utilisés pour le suivi de session pour cartographier les connexions client à des serveurs back-end particuliers. La mise en place de ces en-têtes pourrait interférer avec l’affinité de la session de HAProxy et restreindre la propriété d’un cookie par HAProxy. | C’est oui:
|
9.1.7. Définir ou supprimer les en-têtes de requête et de réponse HTTP dans un itinéraire
Il est possible de définir ou de supprimer certains en-têtes de requête et de réponse HTTP à des fins de conformité ou pour d’autres raisons. Ces en-têtes peuvent être définis ou supprimés soit pour tous les itinéraires desservis par un contrôleur d’Ingress, soit pour des itinéraires spécifiques.
À titre d’exemple, vous voudrez peut-être activer une application Web à servir du contenu dans d’autres endroits pour des itinéraires spécifiques si ce contenu est écrit en plusieurs langues, même s’il existe un emplacement global par défaut spécifié par le contrôleur Ingress desservant les routes.
La procédure suivante crée un itinéraire qui définit l’en-tête de requête HTTP Content-Location de sorte que l’URL associée à l’application, https://app.example.com, dirige vers l’emplacement https://app.example.com/lang/en-us. Diriger le trafic d’application vers cet emplacement signifie que toute personne utilisant cette route spécifique accède au contenu Web écrit en anglais américain.
Conditions préalables
- L’OpenShift CLI (oc) a été installé.
- En tant qu’administrateur de projet, vous êtes connecté à un cluster OpenShift Dedicated.
- Il existe une application Web qui expose un port et un point de terminaison HTTP ou TLS à l’écoute du trafic sur le port.
Procédure
Créez une définition d’itinéraire et enregistrez-la dans un fichier appelé app-example-route.yaml:
Définition YAML de l’itinéraire créé avec les directives d’en-tête HTTP
apiVersion: route.openshift.io/v1 kind: Route # ... spec: host: app.example.com tls: termination: edge to: kind: Service name: app-example httpHeaders: actions:1 response:2 - name: Content-Location3 action: type: Set4 set: value: /lang/en-us5 - 1
- La liste des actions que vous souhaitez effectuer sur les en-têtes HTTP.
- 2
- Le type d’en-tête que vous voulez changer. Dans ce cas, un en-tête de réponse.
- 3
- Le nom de l’en-tête que vous voulez changer. Dans le cas d’une liste d’en-têtes disponibles que vous pouvez définir ou supprimer, voir la configuration d’en-tête HTTP.
- 4
- Le type d’action en cours sur l’en-tête. Ce champ peut avoir la valeur Set ou Supprimer.
- 5
- Lorsque vous définissez des en-têtes HTTP, vous devez fournir une valeur. La valeur peut être une chaîne à partir d’une liste de directives disponibles pour cet en-tête, par exemple DENY, ou il peut s’agir d’une valeur dynamique qui sera interprétée à l’aide de la syntaxe de valeur dynamique de HAProxy. Dans ce cas, la valeur est définie à l’emplacement relatif du contenu.
Créez un itinéraire vers votre application Web existante en utilisant la définition de route nouvellement créée:
$ oc -n app-example create -f app-example-route.yaml
Dans le cas des en-têtes de requête HTTP, les actions spécifiées dans les définitions de route sont exécutées après toutes les actions effectuées sur les en-têtes de requête HTTP dans le contrôleur Ingress. Cela signifie que toutes les valeurs définies pour ces en-têtes de requête dans un itinéraire auront préséance sur celles définies dans le contrôleur Ingress. Consultez la configuration de l’en-tête HTTP pour plus d’informations sur l’ordre de traitement des en-têtes HTTP.
9.1.8. Annotations spécifiques à la route
Le contrôleur Ingress peut définir les options par défaut pour tous les itinéraires qu’il expose. L’itinéraire individuel peut remplacer certaines de ces valeurs par défaut en fournissant des configurations spécifiques dans ses annotations. Le Red Hat ne prend pas en charge l’ajout d’une annotation d’itinéraire à une route gérée par l’opérateur.
Afin de créer une liste d’autorisation avec plusieurs sources IP ou sous-réseaux, utilisez une liste délimitée dans l’espace. Dans tout autre type de délimiteur, la liste est ignorée sans message d’avertissement ou d’erreur.
| La variable | Description | La variable d’environnement utilisée par défaut |
|---|---|---|
|
| Définit l’algorithme d’équilibrage de charge. Les options disponibles sont aléatoires, source, rondrobine et leastconn. La valeur par défaut est source pour les routes de passage TLS. Dans tous les autres itinéraires, la valeur par défaut est aléatoire. | Le ROUTER_TCP_BALANCE_SCHEME pour les routes de passage. Dans le cas contraire, utilisez ROUTER_LOAD_BALANCE_ALGORITHM. |
|
| Désactive l’utilisation de cookies pour suivre les connexions connexes. Lorsqu’il est défini sur 'vrai' ou 'TRUE', l’algorithme d’équilibre est utilisé pour choisir quel back-end sert les connexions pour chaque requête HTTP entrante. | |
|
| Indique un cookie optionnel à utiliser pour cet itinéraire. Le nom doit être composé de toute combinaison de lettres majuscules et minuscules, chiffres, "_" et "-". La valeur par défaut est le nom de clé interne haché pour l’itinéraire. | |
|
|
Définit le nombre maximum de connexions autorisées à une gousse de support à partir d’un routeur. | |
|
|
La définition de 'vrai' ou 'TRUE' permet de limiter le taux de fonctionnalité qui est implémentée par le biais de stick-tables sur le backend spécifique par route. | |
|
|
Limite le nombre de connexions TCP simultanées effectuées via la même adresse IP source. Il accepte une valeur numérique. | |
|
|
Limite le taux auquel un client avec la même adresse IP source peut faire des requêtes HTTP. Il accepte une valeur numérique. | |
|
|
Limite le taux auquel un client avec la même adresse IP source peut effectuer des connexions TCP. Il accepte une valeur numérique. | |
|
| Définit un temps d’attente côté serveur pour l’itinéraire. (Unités temporelles) |
|
|
| Ce délai s’applique à une connexion tunnel, par exemple, WebSocket sur des routes de texte clair, bord, recryptage ou passthrough. Avec le texte clair, le bord ou le recryptage des types d’itinéraires, cette annotation est appliquée en tant que tunnel d’expiration avec la valeur de timeout existante. Dans le cas des types d’itinéraires de passage, l’annotation prime sur toute valeur de temps d’attente existante. |
|
|
| Il est possible de définir soit un IngressController, soit la configuration d’entrée. Cette annotation redéploie le routeur et configure le proxy HA pour émettre l’option haproxy hard-stop-après global, qui définit le temps maximum autorisé pour effectuer un arrêt souple propre. |
|
|
| Définit l’intervalle pour les contrôles de santé back-end. (Unités temporelles) |
|
|
| Définit une liste d’autorisations pour l’itinéraire. La liste d’autorisation est une liste séparée d’adresses IP et de gammes CIDR pour les adresses source approuvées. Les demandes d’adresses IP qui ne figurent pas dans la liste d’autorisation sont supprimées. Le nombre maximum d’adresses IP et de plages CIDR directement visibles dans le fichier haproxy.config est de 61. [1] | |
|
| Définit un en-tête Strict-Transport-Security pour la route terminée ou recryptée. | |
|
| Définit le chemin de réécriture de la requête sur le backend. | |
|
| Définit une valeur pour restreindre les cookies. Les valeurs sont: Lax: le navigateur n’envoie pas de cookies sur les requêtes croisées, mais envoie des cookies lorsque les utilisateurs naviguent sur le site d’origine à partir d’un site externe. Il s’agit du comportement du navigateur par défaut lorsque la valeur SameSite n’est pas spécifiée. Strict : le navigateur n’envoie des cookies que pour les demandes du même site. Aucun : le navigateur envoie des cookies à la fois pour les demandes intersites et les demandes de même site. Cette valeur s’applique uniquement aux itinéraires recryptés et bordés. Consultez la documentation sur les cookies SameSite pour plus d’informations. | |
|
| Définit la politique de gestion des en-têtes Forwarded et X-Forwarded-Forwarded par route. Les valeurs sont: ajouter: ajoute l’en-tête, en préservant tout en-tête existant. C’est la valeur par défaut. le remplacement : définit l’en-tête, en supprimant tout en en-tête existant. jamais : ne règlez jamais l’en-tête, mais préservent les en-têtes existants. if-none: définit l’en-tête s’il n’est pas déjà réglé. |
|
Lorsque le nombre d’adresses IP et de gammes CIDR dans une liste d’autorisation dépasse 61, ils sont écrits dans un fichier séparé qui est ensuite référencé à partir de haproxy.config. Ce fichier est stocké dans le dossier var/lib/haproxy/router/allowlists.
NoteAfin de s’assurer que les adresses sont écrites à la liste d’autorisation, vérifiez que la liste complète des plages CIDR est répertoriée dans le fichier de configuration Ingress Controller. La limite de taille de l’objet etcd limite la taille d’une annotation d’itinéraire. De ce fait, il crée un seuil pour le nombre maximum d’adresses IP et de plages CIDR que vous pouvez inclure dans une liste d’autorisations.
Les variables d’environnement ne peuvent pas être modifiées.
Les variables de timeout du routeur
Les unités de temps sont représentées par un nombre suivi par l’unité: nous *(microsecondes), ms (millisecondes, par défaut), s (secondes), m (minutes), h *(heures), d (jours).
L’expression régulière est: [1-9][0-9]*(us\|ms\|s\|h\|d).
| La variable | Défaut par défaut | Description |
|---|---|---|
|
|
| Durée entre les contrôles de vivacité ultérieurs sur les extrémités arrière. |
|
|
| Contrôle la période d’attente TCP FIN pour le client qui se connecte à l’itinéraire. Lorsque le FIN envoyé pour fermer la connexion ne répond pas dans le délai imparti, HAProxy ferme la connexion. Ceci est inoffensif s’il est défini à une valeur faible et utilise moins de ressources sur le routeur. |
|
|
| Durée du temps qu’un client doit reconnaître ou envoyer des données. |
|
|
| Le temps de connexion maximum. |
|
|
| Contrôle le temps d’attente TCP FIN du routeur jusqu’au pod qui soutient l’itinéraire. |
|
|
| Durée du temps qu’un serveur doit reconnaître ou envoyer des données. |
|
|
| Durée pour que les connexions TCP ou WebSocket restent ouvertes. Cette période d’expiration se réinitialise chaque fois que HAProxy se recharge. |
|
|
| Définissez le temps maximum pour attendre l’apparition d’une nouvelle requête HTTP. Lorsque cela est défini trop bas, il peut causer des problèmes avec les navigateurs et les applications ne s’attendant pas à une petite valeur de conservation. Certaines valeurs de timeout efficaces peuvent être la somme de certaines variables, plutôt que le délai d’attente prévu spécifique. À titre d’exemple, ROUTER_SLOWLORIS_HTTP_KEEPALIVE ajuste le délai d’attente http-mainep-alive. Il est réglé sur 300s par défaut, mais HAProxy attend également sur tcp-request inspect-delay, qui est réglé sur 5s. Dans ce cas, le délai d’attente global serait de 300s plus 5s. |
|
|
| Durée de la transmission d’une requête HTTP. |
|
|
| Autorise la fréquence minimale pour le routeur à recharger et accepter de nouveaux changements. |
|
|
| Délai de collecte des métriques HAProxy. |
La configuration d’un itinéraire chronométrage personnalisé
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/timeout: 5500ms
...- 1
- Indique le nouveau délai d’attente avec les unités prises en charge par HAProxy (nous, ms, s, m, h, d). Dans le cas où l’unité n’est pas fournie, ms est la valeur par défaut.
La définition d’une valeur de temps d’attente côté serveur pour les itinéraires de passage trop bas peut causer des connexions WebSocket fréquemment sur cette route.
Itinéraire qui n’autorise qu’une seule adresse IP spécifique
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.10Itinéraire qui permet plusieurs adresses IP
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.10 192.168.1.11 192.168.1.12Itinéraire permettant un réseau d’adresse IP CIDR
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.0/24Itinéraire permettant à la fois une adresse IP et des réseaux CIDR d’adresse IP
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 180.5.61.153 192.168.1.0/24 10.0.0.0/8Itinéraire spécifiant une cible de réécriture
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/rewrite-target: /
...- 1
- Définit / comme chemin de réécriture de la requête sur le backend.
La définition de l’annotation de cible haproxy.router.openshift.io/rewrite-target sur une route spécifie que le contrôleur Ingress devrait réécrire les chemins dans les requêtes HTTP en utilisant cette route avant de transmettre les requêtes à l’application backend. La partie du chemin de requête qui correspond au chemin spécifié dans spec.path est remplacée par la cible de réécriture spécifiée dans l’annotation.
Le tableau suivant fournit des exemples du comportement de réécriture de chemin pour diverses combinaisons de spec.path, de chemin de requête et de réécriture de cible.
| Itinéraire.spec.path | Demander le chemin | La réécriture de la cible | Chemin de demande transmis |
|---|---|---|---|
| /foo | /foo | / | / |
| /foo | /foo/ | / | / |
| /foo | /foo/bar | / | /bar |
| /foo | /foo/bar/ | / | /bar/ |
| /foo | /foo | /bar | /bar |
| /foo | /foo/ | /bar | /bar/ |
| /foo | /foo/bar | /Baz | /Baz/bar |
| /foo | /foo/bar/ | /Baz | /Baz/bar/ |
| /foo/ | /foo | / | Le chemin n/a (request path ne correspond pas au chemin d’itinéraire) |
| /foo/ | /foo/ | / | / |
| /foo/ | /foo/bar | / | /bar |
Certains caractères spéciaux de haproxy.router.openshift.io/rewrite-target nécessitent une manipulation spéciale car ils doivent être échappés correctement. Consultez le tableau suivant pour comprendre comment ces caractères sont traités.
| Caractère | À utiliser des caractères | Les notes |
|---|---|---|
| ♪ | \# | Evitez # parce qu’il met fin à l’expression de réécriture |
| % | % ou %% | Évitez les séquences étranges telles que %%% |
| '' | ♪ | Éviter ' parce qu’il est ignoré |
Les autres caractères URL valides peuvent être utilisés sans s’échapper.
9.1.9. Création d’un itinéraire à l’aide du certificat par défaut via un objet Ingress
Lorsque vous créez un objet Ingress sans spécifier une configuration TLS, OpenShift Dedicated génère une route non sécurisée. Afin de créer un objet Ingress qui génère une route sécurisée et terminée par bord à l’aide du certificat d’entrée par défaut, vous pouvez spécifier une configuration TLS vide comme suit.
Conditions préalables
- Il y a un service que vous voulez exposer.
- Accès à l’OpenShift CLI (oc).
Procédure
Créez un fichier YAML pour l’objet Ingress. Dans cet exemple, le fichier est appelé example-ingress.yaml:
Définition YAML d’un objet Ingress
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend ... spec: rules: ... tls: - {}1 - 1
- Employez cette syntaxe exacte pour spécifier TLS sans spécifier un certificat personnalisé.
Créez l’objet Ingress en exécutant la commande suivante:
$ oc create -f example-ingress.yaml
La vérification
Assurez-vous que OpenShift Dedicated a créé la route attendue pour l’objet Ingress en exécutant la commande suivante:
$ oc get routes -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-j9sdd1 ... spec: ... tls:2 insecureEdgeTerminationPolicy: Redirect termination: edge3 ...
9.1.10. Création d’un itinéraire à l’aide du certificat CA de destination dans l’annotation Ingress
L’annotation route.openshift.io/destination-ca-certificate-secret peut être utilisée sur un objet Ingress pour définir un itinéraire avec un certificat CA de destination personnalisé.
Conditions préalables
- Il se peut que vous ayez une paire de certificats / clé dans les fichiers encodés PEM, où le certificat est valide pour l’hôte de route.
- Il se peut que vous ayez un certificat CA distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Il faut avoir un certificat CA de destination distinct dans un fichier encodé PEM.
- Il faut avoir un service que vous voulez exposer.
Procédure
Créez un secret pour le certificat CA de destination en entrant la commande suivante:
$ oc create secret generic dest-ca-cert --from-file=tls.crt=<file_path>À titre d’exemple:
$ oc -n test-ns create secret generic dest-ca-cert --from-file=tls.crt=tls.crtExemple de sortie
secret/dest-ca-cert createdAjouter la route.openshift.io/destination-ca-certificate-secret aux annotations d’Ingress:
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt" route.openshift.io/destination-ca-certificate-secret: secret-ca-cert1 ...- 1
- L’annotation fait référence à un secret de kubernetes.
Le secret référencé dans cette annotation sera inséré dans la route générée.
Exemple de sortie
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend annotations: route.openshift.io/termination: reencrypt route.openshift.io/destination-ca-certificate-secret: secret-ca-cert spec: ... tls: insecureEdgeTerminationPolicy: Redirect termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- ...
9.2. Itinéraires sécurisés
Les itinéraires sécurisés permettent d’utiliser plusieurs types de terminaison TLS pour servir des certificats au client. Les sections suivantes décrivent comment créer des itinéraires de recryptage, de bord et de passage avec des certificats personnalisés.
Lorsque vous créez des itinéraires dans Microsoft Azure via des points de terminaison publics, les noms de ressource sont soumis à des restrictions. Il est impossible de créer des ressources qui utilisent certains termes. Dans la liste des termes qu’Azure restreint, consultez Résoudre les erreurs de nom de ressource réservées dans la documentation Azure.
9.2.1. Créer un itinéraire recrypté avec un certificat personnalisé
Il est possible de configurer un itinéraire sécurisé en recryptant la terminaison TLS avec un certificat personnalisé à l’aide de la commande oc create route.
Conditions préalables
- Il faut avoir une paire de certificats/clés dans les fichiers encodés PEM, où le certificat est valide pour l’hôte de route.
- Il se peut que vous ayez un certificat CA distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Il faut avoir un certificat CA de destination distinct dans un fichier encodé PEM.
- Il faut avoir un service que vous voulez exposer.
Les fichiers clés protégés par mot de passe ne sont pas pris en charge. Afin de supprimer une phrase de passe d’un fichier clé, utilisez la commande suivante:
$ openssl rsa -in password_protected_tls.key -out tls.keyProcédure
Cette procédure crée une ressource Route avec un certificat personnalisé et recrypte la terminaison TLS. Ce qui suit suppose que la paire certificat/clé est dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Il faut également spécifier un certificat CA de destination pour permettre au contrôleur Ingress de faire confiance au certificat du service. Il est également possible que vous spécifiiez un certificat CA si nécessaire pour compléter la chaîne de certificats. Les noms de chemin réels sont remplacés par tls.crt, tls.key, cacert.crt et (facultativement) ca.crt. Remplacez le nom de la ressource Service que vous souhaitez exposer pour frontend. Remplacez le nom d’hôte approprié à www.example.com.
Créez une ressource Route sécurisée en recryptant la terminaison TLS et un certificat personnalisé:
$ oc create route reencrypt --service=frontend --cert=tls.crt --key=tls.key --dest-ca-cert=destca.crt --ca-cert=ca.crt --hostname=www.example.comLorsque vous examinez la ressource de Route résultante, elle devrait ressembler à ce qui suit:
Définition YAML de la route sécurisée
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: reencrypt key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- destinationCACertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----Consultez oc create route reencrypt --help pour plus d’options.
9.2.2. Création d’un itinéraire bordé avec un certificat personnalisé
Il est possible de configurer un itinéraire sécurisé à l’aide d’un certificat personnalisé en utilisant la commande oc create route. Avec une route bordée, le contrôleur Ingress met fin au cryptage TLS avant de transférer du trafic vers le pod de destination. L’itinéraire spécifie le certificat TLS et la clé que le contrôleur Ingress utilise pour l’itinéraire.
Conditions préalables
- Il faut avoir une paire de certificats/clés dans les fichiers encodés PEM, où le certificat est valide pour l’hôte de route.
- Il se peut que vous ayez un certificat CA distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Il faut avoir un service que vous voulez exposer.
Les fichiers clés protégés par mot de passe ne sont pas pris en charge. Afin de supprimer une phrase de passe d’un fichier clé, utilisez la commande suivante:
$ openssl rsa -in password_protected_tls.key -out tls.keyProcédure
Cette procédure crée une ressource Route avec un certificat personnalisé et une terminaison TLS. Ce qui suit suppose que la paire certificat/clé est dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Il est également possible que vous spécifiiez un certificat CA si nécessaire pour compléter la chaîne de certificats. Les noms de chemin réels sont remplacés par tls.crt, tls.key et (facultativement) ca.crt. Remplacez le nom du service que vous souhaitez exposer pour frontend. Remplacez le nom d’hôte approprié à www.example.com.
Créez une ressource Route sécurisée à l’aide de terminaisons TLS et d’un certificat personnalisé.
$ oc create route edge --service=frontend --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=www.example.comLorsque vous examinez la ressource de Route résultante, elle devrait ressembler à ce qui suit:
Définition YAML de la route sécurisée
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: edge key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----Consultez oc créer le bord de route --aide pour plus d’options.
9.2.3. Création d’un parcours de passage
Il est possible de configurer un itinéraire sécurisé à l’aide de la commande oc create route. Avec la terminaison de passage, le trafic crypté est envoyé directement à la destination sans que le routeur ne fournisse la terminaison TLS. Aucune clé ou certificat n’est donc requis sur l’itinéraire.
Conditions préalables
- Il faut avoir un service que vous voulez exposer.
Procédure
Créer une ressource Route:
$ oc create route passthrough route-passthrough-secured --service=frontend --port=8080Lorsque vous examinez la ressource de Route résultante, elle devrait ressembler à ce qui suit:
La route sécurisée à l’aide de la terminaison de passage
apiVersion: route.openshift.io/v1 kind: Route metadata: name: route-passthrough-secured1 spec: host: www.example.com port: targetPort: 8080 tls: termination: passthrough2 insecureEdgeTerminationPolicy: None3 to: kind: Service name: frontendLe pod de destination est responsable du service des certificats pour le trafic au point de terminaison. C’est actuellement la seule méthode qui peut prendre en charge l’exigence de certificats clients, également connu sous le nom d’authentification bidirectionnelle.
9.2.4. Création d’un itinéraire avec certificat géré par l’externe
La sécurisation de l’itinéraire avec des certificats externes dans les secrets TLS n’est qu’une fonctionnalité d’aperçu technologique. Les fonctionnalités d’aperçu technologique ne sont pas prises en charge avec les accords de niveau de service de production de Red Hat (SLA) et pourraient ne pas être fonctionnellement complètes. Le Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès précoce aux fonctionnalités du produit à venir, permettant aux clients de tester les fonctionnalités et de fournir des commentaires pendant le processus de développement.
En savoir plus sur la portée du support des fonctionnalités de Red Hat Technology Preview, voir la portée du support des fonctionnalités d’aperçu de la technologie.
En utilisant le champ .spec.tls.externalCertificate de l’API de route, vous pouvez configurer OpenShift Dedicated avec des solutions de gestion de certificats tierces. Il est possible de faire référence à des certificats TLS gérés par l’extérieur via des secrets, éliminant ainsi la nécessité d’une gestion manuelle des certificats. L’utilisation du certificat géré par l’extérieur réduit les erreurs assurant un déploiement plus fluide des mises à jour des certificats, permettant au routeur OpenShift de servir rapidement les certificats renouvelés.
Cette fonctionnalité s’applique à la fois aux routes périphériques et au recryptage des routes.
Conditions préalables
- Il faut activer le portail RouteExternalCertificate.
- Il faut avoir les autorisations de création et de mise à jour sur les routes/hôte personnalisé.
- Il faut avoir un secret contenant une paire de certificats / clé valide au format PEM de type kubernetes.io/tls, qui comprend à la fois les touches tls.key et tls.crt.
- Il faut placer le secret référencé dans le même espace de noms que l’itinéraire que vous souhaitez sécuriser.
Procédure
Créez un rôle dans le même espace de noms que le secret pour permettre l’accès au compte de service routeur en exécutant la commande suivante:
$ oc create role secret-reader --verb=get,list,watch --resource=secrets --resource-name=<secret-name> \1 --namespace=<current-namespace>2 Créez une liaison de rôle dans le même espace de noms que le secret et liez le compte de service routeur au rôle nouvellement créé en exécutant la commande suivante:
$ oc create rolebinding secret-reader-binding --role=secret-reader --serviceaccount=openshift-ingress:router --namespace=<current-namespace>1 - 1
- Indiquez l’espace de noms où résident à la fois votre secret et votre itinéraire.
Créez un fichier YAML qui définit l’itinéraire et spécifie le secret contenant votre certificat à l’aide de l’exemple suivant.
Définition YAML de l’itinéraire sécurisé
apiVersion: route.openshift.io/v1 kind: Route metadata: name: myedge namespace: test spec: host: myedge-test.apps.example.com tls: externalCertificate: name: <secret-name>1 termination: edge [...] [...]- 1
- Indiquez le nom de votre secret.
Créez une ressource d’itinéraire en exécutant la commande suivante:
$ oc apply -f <route.yaml>1 - 1
- Indiquez le nom de fichier YAML généré.
En cas d’existence d’un secret et d’une paire de clés, le routeur servira le certificat généré si toutes les conditions préalables sont remplies.
Dans le cas où .spec.tls.externalCertificate n’est pas fourni, le routeur utilisera les certificats générés par défaut.
Il est impossible de fournir le champ .spec.tls.certificate ou le champ .spec.tls.key lorsque vous utilisez le champ .spec.tls.externalCertificate.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.