Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 5. Erasure code pools overview
Ceph uses replicated pools by default, meaning that Ceph copies every object from a primary OSD node to one or more secondary OSDs. The erasure-coded pools reduce the amount of disk space required to ensure data durability but it is computationally a bit more expensive than replication.
Ceph storage strategies involve defining data durability requirements. Data durability means the ability to sustain the loss of one or more OSDs without losing data.
Ceph stores data in pools and there are two types of the pools:
- replicated
- erasure-coded
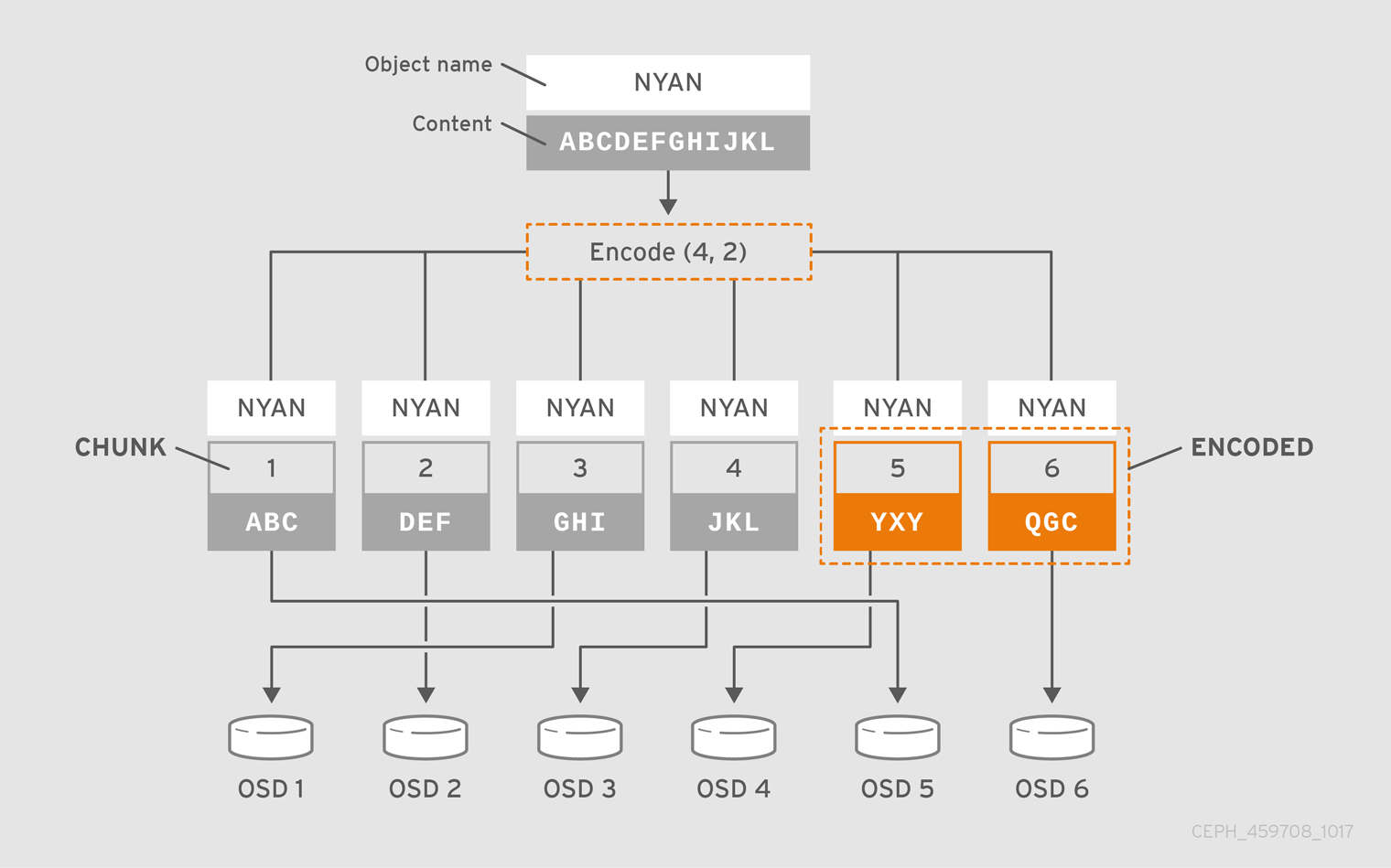
Erasure coding is a method of storing an object in the Ceph storage cluster durably where the erasure code algorithm breaks the object into data chunks (k) and coding chunks (m), and stores those chunks in different OSDs.
In the event of the failure of an OSD, Ceph retrieves the remaining data (k) and coding (m) chunks from the other OSDs and the erasure code algorithm restores the object from those chunks.
Red Hat recommends min_size for erasure-coded pools to be K+1 or more to prevent loss of writes and data.
Erasure coding uses storage capacity more efficiently than replication. The n-replication approach maintains n copies of an object (3x by default in Ceph), whereas erasure coding maintains only k + m chunks. For example, 3 data and 2 coding chunks use 1.5x the storage space of the original object.
While erasure coding uses less storage overhead than replication, the erasure code algorithm uses more RAM and CPU than replication when it accesses or recovers objects. Erasure coding is advantageous when data storage must be durable and fault tolerant, but do not require fast read performance (for example, cold storage, historical records, and so on).
For the mathematical and detailed explanation on how erasure code works in Ceph, see the Ceph Erasure Coding section in the Architecture Guide for Red Hat Ceph Storage 7.
Ceph creates a default erasure code profile when initializing a cluster with k=2 and m=2, This mean that Ceph will spread the object data over three OSDs (k+m == 4) and Ceph can lose one of those OSDs without losing data. To know more about erasure code profiling see the Erasure Code Profiles section.
Configure only the .rgw.buckets pool as erasure-coded and all other Ceph Object Gateway pools as replicated, otherwise an attempt to create a new bucket fails with the following error:
set_req_state_err err_no=95 resorting to 500
The reason for this is that erasure-coded pools do not support the omap operations and certain Ceph Object Gateway metadata pools require the omap support.
5.1. Creating a sample erasure-coded pool
Create an erasure-coded pool and specify the placement groups. The ceph osd pool create command creates an erasure-coded pool with the default profile, unless another profile is specified. Profiles define the redundancy of data by setting two parameters, k, and m. These parameters define the number of chunks a piece of data is split and the number of coding chunks are created.
The simplest erasure coded pool is equivalent to RAID5 and requires at least four hosts. You can create an erasure-coded pool with 2+2 profile.
Procedure
Set the following configuration for an erasure-coded pool on four nodes with 2+2 configuration.
Syntax
ceph config set mon mon_osd_down_out_subtree_limit host ceph config set osd osd_async_recovery_min_cost 1099511627776
ImportantThis is not needed for an erasure-coded pool in general.
ImportantThe async recovery cost is the number of PG log entries behind on the replica and the number of missing objects. The
osd_target_pg_log_entries_per_osdis30000. Hence, an OSD with a single PG could have30000entries. Since theosd_async_recovery_min_costis a 64-bit integer, set the value ofosd_async_recovery_min_costto1099511627776for an EC pool with 2+2 configuration.NoteFor an EC cluster with four nodes, the value of K+M is 2+2. If a node fails completely, it does not recover as four chunks and only three nodes are available. When you set the value of
mon_osd_down_out_subtree_limittohost, during a host down scenario, it prevents the OSDs from marked out, so as to prevent the data from re balancing and the waits until the node is up again.For an erasure-coded pool with a 2+2 configuration, set the profile.
Syntax
ceph osd erasure-code-profile set ec22 k=2 m=2 crush-failure-domain=host
Example
[ceph: root@host01 /]# ceph osd erasure-code-profile set ec22 k=2 m=2 crush-failure-domain=host Pool : ceph osd pool create test-ec-22 erasure ec22
Create an erasure-coded pool.
Example
[ceph: root@host01 /]# ceph osd pool create ecpool 32 32 erasure pool 'ecpool' created $ echo ABCDEFGHI | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHI
32 is the number of placement groups.
5.2. Erasure code profiles
Ceph defines an erasure-coded pool with a profile. Ceph uses a profile when creating an erasure-coded pool and the associated CRUSH rule.
Ceph creates a default erasure code profile when initializing a cluster and it provides the same level of redundancy as two copies in a replicated pool. This default profile defines k=2 and m=2, meaning Ceph spreads the object data over four OSDs (k+m=4) and Ceph can lose one of those OSDs without losing data. EC2+2 requires a minimum deployment footprint of 4 nodes (5 nodes recommended) and can cope with the temporary loss of 1 OSD node.
To display the default profile use the following command:
$ ceph osd erasure-code-profile get default k=2 m=2 plugin=jerasure technique=reed_sol_van
You can create a new profile to improve redundancy without increasing raw storage requirements. For instance, a profile with k=8 and m=4 can sustain the loss of four (m=4) OSDs by distributing an object on 12 (k+m=12) OSDs. Ceph divides the object into 8 chunks and computes 4 coding chunks for recovery. For example, if the object size is 8 MB, each data chunk is 1 MB and each coding chunk has the same size as the data chunk, that is also 1 MB. The object is not lost even if four OSDs fail simultaneously.
The most important parameters of the profile are k, m and crush-failure-domain, because they define the storage overhead and the data durability.
Choosing the correct profile is important because you cannot change the profile after you create the pool. To modify a profile, you must create a new pool with a different profile and migrate the objects from the old pool to the new pool.
For instance, if the desired architecture must sustain the loss of two racks with a storage overhead of 40% overhead, the following profile can be defined:
$ ceph osd erasure-code-profile set myprofile \ k=4 \ m=2 \ crush-failure-domain=rack $ ceph osd pool create ecpool 12 12 erasure *myprofile* $ echo ABCDEFGHIJKL | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHIJKL
The primary OSD will divide the NYAN object into four (k=4) data chunks and create two additional chunks (m=2). The value of m defines how many OSDs can be lost simultaneously without losing any data. The crush-failure-domain=rack will create a CRUSH rule that ensures no two chunks are stored in the same rack.
Red Hat supports the following jerasure coding values for k, and m:
- k=8 m=3
- k=8 m=4
- k=4 m=2
If the number of OSDs lost equals the number of coding chunks (m), some placement groups in the erasure coding pool will go into incomplete state. If the number of OSDs lost is less than m, no placement groups will go into incomplete state. In either situation, no data loss will occur. If placement groups are in incomplete state, temporarily reducing min_size of an erasure coded pool will allow recovery.
5.2.1. Setting OSD erasure-code-profile
To create a new erasure code profile:
Syntax
ceph osd erasure-code-profile set NAME \ [<directory=DIRECTORY>] \ [<plugin=PLUGIN>] \ [<stripe_unit=STRIPE_UNIT>] \ [<_CRUSH_DEVICE_CLASS_>]\ [<_CRUSH_FAILURE_DOMAIN_>]\ [<key=value> ...] \ [--force]
Where:
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- plugin
- Description
- Use the erasure code plug-in to compute coding chunks and recover missing chunks. See the Erasure Code Plug-ins section for details.
- Type
- String
- Required
- No.
- Default
-
jerasure
- stripe_unit
- Description
-
The amount of data in a data chunk, per stripe. For example, a profile with 2 data chunks and
stripe_unit=4Kwould put the range 0-4K in chunk 0, 4K-8K in chunk 1, then 8K-12K in chunk 0 again. This should be a multiple of 4K for best performance. The default value is taken from the monitor config optionosd_pool_erasure_code_stripe_unitwhen a pool is created. The stripe_width of a pool using this profile will be the number of data chunks multiplied by thisstripe_unit. - Type
- String
- Required
- No.
- Default
-
4K
- crush-device-class
- Description
-
The device class, such as
hddorssd. - Type
- String
- Required
- No
- Default
-
none, meaning CRUSH uses all devices regardless of class.
- crush-failure-domain
- Description
-
The failure domain, such as
hostorrack. - Type
- String
- Required
- No
- Default
-
host
- key
- Description
- The semantic of the remaining key-value pairs is defined by the erasure code plug-in.
- Type
- String
- Required
- No.
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.2.2. Removing OSD erasure-code-profile
To remove an erasure code profile:
Syntax
ceph osd erasure-code-profile rm RULE_NAME
If the profile is referenced by a pool, the deletion fails.
Removing an erasure code profile using osd erasure-code-profile rm command does not automatically delete the associated CRUSH rule associated with the erasure code profile. Red Hat recommends to manually remove the associated CRUSH rule using ceph osd crush rule remove RULE_NAME command to avoid unexpected behavior.
5.2.3. Getting OSD erasure-code-profile
To display an erasure code profile:
Syntax
ceph osd erasure-code-profile get NAME
5.2.4. Listing OSD erasure-code-profile
To list the names of all erasure code profiles:
Syntax
ceph osd erasure-code-profile ls
5.3. Erasure Coding with Overwrites
By default, erasure coded pools only work with the Ceph Object Gateway, which performs full object writes and appends.
Using erasure coded pools with overwrites allows Ceph Block Devices and CephFS store their data in an erasure coded pool:
Syntax
ceph osd pool set ERASURE_CODED_POOL_NAME allow_ec_overwrites true
Example
[ceph: root@host01 /]# ceph osd pool set ec_pool allow_ec_overwrites true
Enabling erasure coded pools with overwrites can only reside in a pool using BlueStore OSDs. Since BlueStore’s checksumming is used to detect bit rot or other corruption during deep scrubs.
Erasure coded pools do not support omap. To use erasure coded pools with Ceph Block Devices and CephFS, store the data in an erasure coded pool, and the metadata in a replicated pool.
For Ceph Block Devices, use the --data-pool option during image creation:
Syntax
rbd create --size IMAGE_SIZE_M|G|T --data-pool _ERASURE_CODED_POOL_NAME REPLICATED_POOL_NAME/IMAGE_NAME
Example
[ceph: root@host01 /]# rbd create --size 1G --data-pool ec_pool rep_pool/image01
If using erasure coded pools for CephFS, then setting the overwrites must be done in a file layout.
5.4. Erasure Code Plugins
Ceph supports erasure coding with a plug-in architecture, which means you can create erasure coded pools using different types of algorithms. Ceph supports Jerasure.
5.4.1. Creating a new erasure code profile using jerasure erasure code plugin
The jerasure plug-in is the most generic and flexible plug-in. It is also the default for Ceph erasure coded pools.
The jerasure plug-in encapsulates the JerasureH library. For detailed information about the parameters, see the jerasure documentation.
To create a new erasure code profile using the jerasure plug-in, run the following command:
Syntax
ceph osd erasure-code-profile set NAME \ plugin=jerasure \ k=DATA_CHUNKS \ m=DATA_CHUNKS \ technique=TECHNIQUE \ [crush-root=ROOT] \ [crush-failure-domain=BUCKET_TYPE] \ [directory=DIRECTORY] \ [--force]
Where:
- k
- Description
- Each object is split in data-chunks parts, each stored on a different OSD.
- Type
- Integer
- Required
- Yes.
- Example
-
4
- m
- Description
- Compute coding chunks for each object and store them on different OSDs. The number of coding chunks is also the number of OSDs that can be down without losing data.
- Type
- Integer
- Required
- Yes.
- Example
- 2
- technique
- Description
- The more flexible technique is reed_sol_van; it is enough to set k and m. The cauchy_good technique can be faster but you need to choose the packetsize carefully. All of reed_sol_r6_op, liberation, blaum_roth, liber8tion are RAID6 equivalents in the sense that they can only be configured with m=2.
- Type
- String
- Required
- No.
- Valid Settings
-
reed_sol_vanreed_sol_r6_opcauchy_origcauchy_goodliberationblaum_rothliber8tion - Default
-
reed_sol_van
- packetsize
- Description
- The encoding will be done on packets of bytes size at a time. Choosing the correct packet size is difficult. The jerasure documentation contains extensive information on this topic.
- Type
- Integer
- Required
- No.
- Default
-
2048
- crush-root
- Description
- The name of the CRUSH bucket used for the first step of the rule. For instance step take default.
- Type
- String
- Required
- No.
- Default
- default
- crush-failure-domain
- Description
- Ensure that no two chunks are in a bucket with the same failure domain. For instance, if the failure domain is host no two chunks will be stored on the same host. It is used to create a rule step such as step chooseleaf host.
- Type
- String
- Required
- No.
- Default
-
host
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.4.2. Controlling CRUSH Placement
The default CRUSH rule provides OSDs that are on different hosts. For instance:
chunk nr 01234567 step 1 _cDD_cDD step 2 cDDD____ step 3 ____cDDD
needs exactly 8 OSDs, one for each chunk. If the hosts are in two adjacent racks, the first four chunks can be placed in the first rack and the last four in the second rack. Recovering from the loss of a single OSD does not require using bandwidth between the two racks.
For instance:
crush-steps='[ [ "choose", "rack", 2 ], [ "chooseleaf", "host", 4 ] ]'
creates a rule that selects two CRUSH buckets of type rack and for each of them choose four OSDs, each of them located in a different bucket of type host.
The rule can also be created manually for finer control.