1.8. Serveur virtuel Linux
LVS (de l'anglais Linux Virtual Server) est un ensemble de composants logiciels intégrés permettant de répartir la charge IP à travers un ensemble de serveurs réels. LVS s'exécute sur une paire d'ordinateurs ayant la même configuration : un routeur LVS actif et un routeur LVS de sauvegarde. Le routeur LVS actif joue deux rôles :
- Il répartit la charge à travers les serveurs réels.
- Il vérifie l'intégrité des services sur chaque serveur réel.
Le routeur LVS de sauvegarde surveille le routeur LVS actif et prend le pas sur ce dernier s'il échoue.
Figure 1.19, « Components of a Running LVS Cluster » provides an overview of the LVS components and their interrelationship.
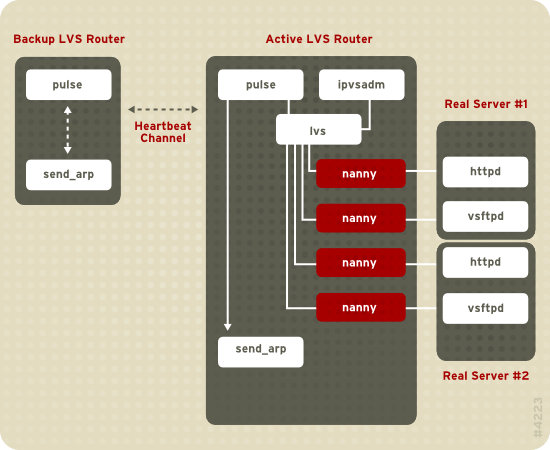
Figure 1.19. Components of a Running LVS Cluster
Le démon
pulse est exécuté sur les deux routeurs LVS actifs et passifs. Sur le routeur LVS de sauvegarde, pulse envoie un signal heartbeat à l'interface publique du routeur actif afin de s'assurer que le routeur LVS actif fonctionne correctement. Sur le routeur LVS actif, pulse démarre le démon lvs et répond aux requêtes heartbeat du routeur LVS de sauvegarde.
Une fois démarré, le démon
lvs appelle l'utilitaire ipvsadm afin de configurer et maintenir la table de routage IPVS (de l'anglais IP Virtual Server) dans le noyau et démarre un processus nanny pour chaque serveur virtuel configuré sur chaque serveur réel. Chaque processus nanny vérifie l'état d'un service configuré sur un serveur réel et indique au démon lvs si le service sur ce serveur réel ne fonctionne pas correctement. Si un dysfonctionnement est détecté, le démon lvs demande à l'utilitaire ipvsadm de supprimer ce serveur réel de la table de routage IPVS.
Si le routeur LVS de sauvegarde ne reçoit pas de réponse à partir du routeur LVS actif, il initie un failover en appelant
send_arp afin de réassigner toutes les adresses IP virtuelles aux adresses matérielles NIC (adresse MAC) du routeur LVS de sauvegarde. Il envoie également une commande au routeur LVS actif via les interfaces réseau publiques et privées afin d'arrêter le démon lvs sur le routeur LVS actif et démarre le démon lvs sur le routeur LVS de sauvegarde afin d'accepter les requêtes pour les serveurs virtuels configurés.
Pour un utilisateur externe accédant à un service hôte (tel qu'un site Web ou une application de base de données), LVS apparaît comme un serveur. Cependant, l'utilisateur accède aux serveurs réels derrière les routeurs LVS.
Parce qu'il n'y a pas de composant intégré dans LVS pour partager les données à travers les serveurs réels, vous disposez de deux options de base :
- Synchroniser les données à travers les serveurs réels.
- Ajouter une troisième couche à la topologie pour l'accès aux données partagées.
La première option est préférable pour les serveurs qui n'autorisent pas un grand nombre d'utilisateurs à télécharger ou changer des données sur les serveurs réels. Si les serveurs réels autorisent un grand nombre d'utilisateurs à modifier les données, par exemple un site Web de e-commerce, ajouter une troisième couche est préférable.
Il existe de nombreuses façons pour synchroniser les données entre les serveurs réels. Vous pouvez par exemple utiliser des scripts shell afin de poster simultanément des pages Web mises à jour sur les serveurs réels. Vous pouvez également utiliser des programmes comme
rsync pour répliquer les données modifiées à travers tous les noeuds à un intervalle défini. Toutefois, dans les environnements où les utilisateurs téléchargent fréquemment des fichiers ou émettent des transactions avec la base de données, l'utilisation de scripts ou de la commande rsync pour la synchronisation des données ne fonctionne pas de façon optimale. Par conséquent, pour les serveurs réels avec un nombre élevé de téléchargements, transactions de base de données, ou autre trafic similaire, une topologie trois tiers est plus appropriée pour la synchronisation des données.
1.8.1. Two-Tier LVS Topology
Copier lienLien copié sur presse-papiers!
Figure 1.20, « Two-Tier LVS Topology » shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. The LVS-router tier consists of one active LVS router and one backup LVS router. The real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In Figure 1.20, « Two-Tier LVS Topology », the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. The real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity.
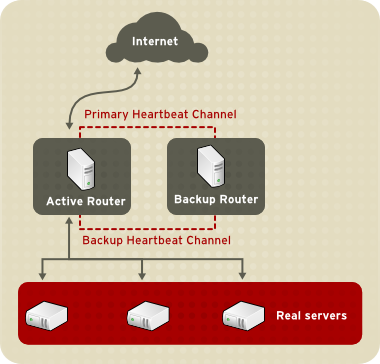
Figure 1.20. Two-Tier LVS Topology
Les requêtes de service arrivant au routeur LVS sont adressées à une adresse IP virtuelle (VIP de l'anglais Virtual IP). Il s'agit d'une adresse routable publiquement que l'administrateur du site associe à un nom de domaine pleinement qualifié, tel que www.exemple.com et qui est assignée à un ou plusieurs serveurs virtuels[1]. Notez qu'une adresse VIP migre d'un routeur LVS à l'autre durant le failover, ainsi cette adresse IP est toujours en présence d'un routeur (également appelée adresse IP flottante).
Les adresses VIP peuvent avoir un alias pour le même périphérique connectant le routeur LVS au réseau public. Par exemple, si eth0 est connecté à Internet, plusieurs serveurs virtuels peuvent être nommés
eth0:1. De façon alternative, chaque serveur virtuel peut être associé à un périphérique différent par service. Par exemple, le trafic HTTP peut être traité sur eth0:1 et le trafic FTP peut être traité sur eth0:2.
Seul un routeur LVS peut être actif à un moment donné. Le rôle du routeur LVS actif est de rediriger les requêtes de service, des adresses IP virtuelles vers les serveurs réels. La redirection est basée sur un de ces huit algorithmes de répartition de charge :
- Programmation Round-Robin — Distribue chaque requête consécutivement autour d'un pool de serveurs réels. En utilisant cet algorithme, tous les serveurs réels sont traités de la même manière, sans prendre en compte la capacité ou la charge.
- Programmation Weighted Round-Robin — Distribue chaque requête consécutivement autour d'un pool de serveurs réels mais donne plus de travail aux serveurs ayant une plus grande capacité. La capacité est indiquée par un facteur de poids assigné par l'utilisateur, qui est ensuite ajusté en fonction des informations de charge dynamiques. Cette option est préférée s'il y a des différences sensibles entre la capacité des serveurs réels d'un pool de serveurs. Cependant, si la charge des requêtes varie considérablement, un serveur très alourdi pourrait répondre à plus de requêtes qu'il ne devrait.
- Least-Connection — Distribue davantage de requêtes aux serveurs réels ayant moins de connexions actives. Ceci est un genre d'algorithme de programmation dynamique. C'est une bonne option s'il y a un degré de variation important au niveau de la charge des requêtes. Il s'agit de l'algorithme qui correspond le mieux à un pool de serveurs où chaque noeud du serveur a approximativement la même capacité. Si les serveurs réels ont des capacités différentes, la programmation weighted least-connection constitue un meilleur choix.
- Weighted Least-Connections (par défaut) — Distribue davantage de requêtes aux serveurs ayant moins de connexions actives en fonction de leurs capacités. La capacité est indiquée par un facteur de poids assigné par l'utilisateur, qui est ensuite ajusté en fonction des informations de charge dynamiques. L'ajout de poids rend l'algorithme idéal lorsque le pool de serveurs réels contient du matériel avec différentes capacités.
- Programmation Locality-Based Least-Connection — Distribue davantage de requêtes aux serveurs ayant moins de connexions actives en fonction de leur adresse IP de destination. Cet algorithme est dédié à une utilisation au sein d'un cluster de serveurs proxy-cache. Il achemine les paquets d'une adresse IP vers le serveur de cette adresse à moins que ce serveur soit au-delà de ses capacités, auquel cas il assigne l'adresse IP au serveur réel le moins chargé.
- Programmation Locality-Based Least-Connection avec programmation répliquée — Distribue davantage de paquets aux serveurs ayant moins de connexions actives en fonction de leur adresse IP de destination. Cet algorithme est également dédié à une utilisation au sein d'un cluster de serveurs proxy-cache. Il diffère de la programmation Locality-Based Least-Connection car il mappe l'adresse IP cible à un sous-groupe de noeuds de serveurs réels. Les requêtes sont ensuite routées vers le serveur de ce sous-groupe ayant le moins de connexions. Si tous les noeuds pour l'adresse IP de destination sont en-dessus de leurs capacités, il réplique un nouveau serveur pour cette adresse IP de destination en ajoutant le serveur réel ayant le moins de connexions à partir du pool entier de serveurs réels vers le sous-groupe de serveurs réels. Le noeud le plus chargé est ensuite retiré du sous-groupe de serveurs réels pour éviter les excès de réplication.
- Programmation Source Hash — Distribue les requêtes vers le pool de serveurs réels en cherchant l'adresse IP source dans une table de hachage statique. Cet algorithme est dédié aux routeurs LVS avec plusieurs pare-feu.
De plus, le routeur LVS contrôle dynamiquement la santé globale des services spécifiques sur les serveurs réels à travers de simples scripts send/expect. Pour aider à détecter la santé de services nécessitant des données dynamiques, tels que HTTPS ou SSL, vous pouvez également appeler des exécutables externes. Si le service d'un serveur réel ne fonctionne plus correctement, le routeur LVS actif arrête de lui envoyer des travaux jusqu'à ce qu'il fonctionne à nouveau.
Le routeur LVS de sauvegarde joue le rôle de système de secours. Régulièrement, les routeurs LVS échangent des messages "heartbeat" à travers l'interface publique externe primaire et, en cas d'échec, l'interface privée. Si le routeur LVS de sauvegarde ne reçoit pas de message "heartbeat" dans un intervalle défini, il initie un failover et endosse le rôle de routeur LVS actif. Durant le failover, le routeur LVS de sauvegarde récupère les adresses VIP desservies par le routeur ayant échoué en utilisant une technique appelée ARP spoofing — où le routeur LVS de sauvegarde s'annonce lui-même comme destinataire des paquets IP adressés au noeud défaillant. Lorsque le noeud ayant échoué fonctionne à nouveau, le routeur LVS de sauvegarde reprend son rôle de routeur de sauvegarde.
The simple, two-tier configuration in Figure 1.20, « Two-Tier LVS Topology » is suited best for clusters serving data that does not change very frequently — such as static web pages — because the individual real servers do not automatically synchronize data among themselves.
[1]
Un serveur virtuel est un service configuré pour écouter sur une adresse IP virtuelle spécifique.