Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 12. Human Tasks Management
12.1. Human Tasks
Human Tasks are tasks within a process that must be carried out by human actors. BRMS Business Process Management supports a human task node inside processes for modeling the interaction with human actors. The human task node allows process designers to define the properties related to the task that the human actor needs to execute; for example, the type of task, the actor, and the data associated with the task can be defined by the human task node. A back-end human task service manages the lifecycle of the tasks at runtime. The implementation of the human task service is based on the WS-HumanTask specification, and the implementation is fully pluggable; this means users can integrate their own human task solution if necessary. Human tasks nodes must be included inside the process model and the end users must interact with a human task client to request their tasks, claim and complete tasks.
12.2. Using User Tasks in Processes
Red Hat JBoss BPM Suite supports the use of human tasks inside processes using a special User Task node defined by the BPMN2 Specification. A User Task node represents an atomic task that is executed by a human actor.
Although Red Hat JBoss BPM Suite has a special user task node for including human tasks inside a process, human tasks are considered the same as any other kind of external service that is invoked and are therefore implemented as a domain-specific service.
You can edit the values of User Tasks variables in the Properties view of JBoss Developer Studio after selecting the User Task node.
A User Task node contains the following core properties:
-
Actors: The actors that are responsible for executing the human task. A list of actor id’s can be specified using a comma (,) as separator. -
Group: The group id that is responsible for executing the human task. A list of group id’s can be specified using a comma (,) as separator. -
Name: The display name of the node. -
TaskName: The name of the human task. This name is used to link the task to a Form. It also represent the internal name of the Task that can be used for other purposes. -
DataInputSet: all the input variables that the task will receive to work on. Usually you will be interested in copying variables from the scope of the process to the scope of the task. -
DataOutputSet: all the output variables that will be generated by the execution of the task. Here you specify all the name of the variables in the context of the task that you are interested to copy to the context of the process. -
Assignments: here you specify which process variable will be linked to each Data Input and Data Output mapping.
A User Task node contains the following extra properties:
-
Comment: A comment associated with the human task. Here you can use expressions. -
Content: The data associated with this task. -
Priority: An integer indicating the priority of the human task. -
Skippable: Specifies whether the human task can be skipped, that is, whether the actor may decide not to execute the task. -
On entry and on exit actions: Action scripts that are executed upon entry and exit of this node, respectively.
Apart from the above mentioned core and extra properties of user tasks, there are some additional generic user properties that are not exposed through the user interface. These properties are:
-
ActorId: The performer of the task to whom the task is assigned. -
GroupId: The group to which the task performer belongs. -
BusinessAdministratorId: The default business administrator responsible for the progress and the outcome of a task at the task definition level. -
BusinessAdministratorGroupId: The group to which the administrator belongs. -
ExcludedOwnerId: Anybody who has been excluded to perform the task and become an actual or potential owner. -
RecipientId: A person who is the recipient of notifications related to the task. A notification may have more than one recipients.
To override the default values of these generic user properties, you must define a data input with the name of the property, and then set the desired value in the assignment section.
12.3. Data Mapping
Human tasks typically present some data related to the task that needs to be performed to the actor that is executing the task. Human tasks usually also request the actor to provide some result data related to the execution of the task. Task forms are typically used to present this data to the actor and request results.
You must specify the data that is used by the task when you define the user task in our process. In order to do that, you need to define which data must be copied from the process context to the task context. Notice that the data is copied, so it can be modified inside the task context but it will not affect the process variables unless we decide to copy back the value from the task to the process context.
Most of the times forms are used to display data to the end user. This allows them to generate or create new data to propagate to the process context to be used by future activities. In order to decide how the information flow from the process to a particular task and from the task to the process, you need to define which pieces of information must be automatically copied by the process engine.
12.4. Task Lifecycle
A human task is created when a user task node is encountered during the execution. The process leaves the user task node only when the associated human task is completed or aborted. The human task itself has a complete life cycle as well. The following diagram describes the human task life cycle.
Figure 12.1. Human Task Life Cycle
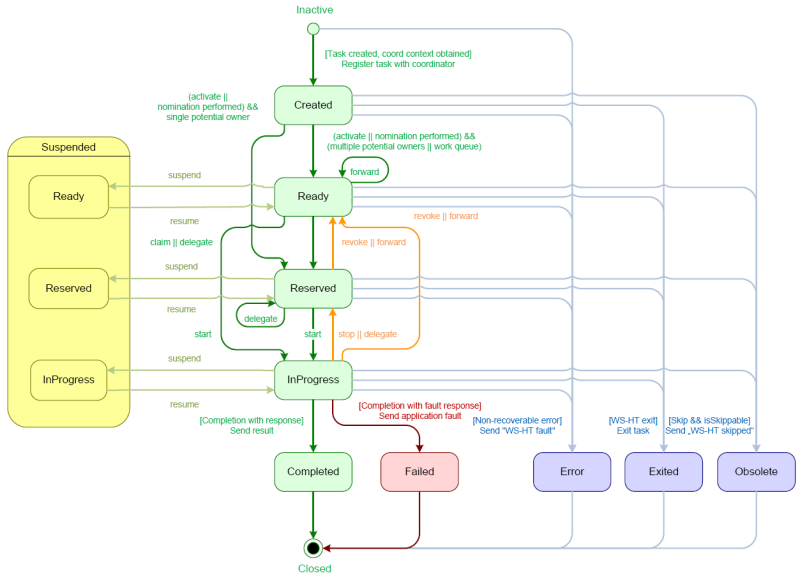
A newly created task starts in the Created stage. It then automatically comes into the Ready stage. The task then shows up on the task list of all the actors that are allowed to execute the task. The task stays in the Ready stage until one of these actors claims the task. When a user then eventually claims the task, the status changes to Reserved. Note that a task that only has one potential (specific) actor is automatically assigned to that actor upon creation of the task. When the user who has claimed the task starts executing it, the task status changes from Reserved to InProgress.
Once the user has performed and completed the task, the task status changes to Completed. In this step, the user can optionally specify the result data related to the task. If the task could not be completed, the user may indicate this by using a fault response, possibly including fault data, in which case the status changes to Failed.
While this life cycle explained above is the normal life cycle, the specification also describes a number of other life cycle methods, including:
- Delegating or forwarding a task, so that the task is assigned to another actor.
- Revoking a task, so that it is no longer claimed by one specific actor but is (re)available to all actors allowed to take it.
- Temporarily suspending and resuming a task.
- Stopping a task in progress.
- Skipping a task (if the task has been marked as skippable), in which case the task will not be executed.
12.5. Task Permissions
Only users associated with a specific task are allowed to modify or retrieve information about the task. This allows users to create a Red Hat JBoss BPM Suite workflow with multiple tasks and yet still be assured of both the confidentiality and integrity of the task status and information associated with a task.
Some task operations end up throwing a org.jbpm.services.task.exception.PermissionDeniedException when used with information about an unauthorized user. For example, when a user is trying to directly modify the task (for example, by trying to claim or complete the task), the PermissionDeniedException is thrown if that user does not have the correct role for that operation. Also, users are not able to view or retrieve tasks in Business Central that they are not involved with.
It is possible to allow an authenticated user to execute task operations on behalf of an unauthenticated user by setting the -Dorg.kie.task.insecure=true system property on the server side. For example, if you have a bot that executes task operations on behalf of other users, the bot can use a system account and does not need any credentials of the real users.
If you are using a remote Java client, you need to turn on insecure task operations on the client side as well. To do so, set the mentioned system property in your client or call the disableTaskSecurity method of the client builder.
12.5.1. Task Permissions Matrix
The task permissions matrix below summarizes the actions that specific user roles are allowed to do. The cells of the permissions matrix contain one of three possible characters, each of which indicate the user role permissions for that operation:
-
+indicates that the user role can do the specified operation. -
-indicates that the user role may not do the specified operation, or it is not an operation that matches the user’s role ("not applicable").
| Role | Description |
|---|---|
| Potential Owner | The user who can claim the task before it has been claimed, or after it has been released or forwarded. Only tasks that have the status Ready may be claimed. A potential owner becomes the actual owner of a task by claiming the task. |
| Actual Owner | The user who has claimed the task and will progress the task to completion or failure. |
| Business Administrator | A super user who may modify the status or progress of a task at any point in a task’s lifecycle. |
User roles are assigned to users by the definition of the task in the JBoss BPM Suite (BPMN2) process definition.
Permissions Matrices
The following matrix describes the authorizations for all operations which modify a task:
| Operation/Role | Potential Owner | Actual Owner | Business Administrator |
|---|---|---|---|
| activate | - | - | + |
| claim | + | - | + |
| complete | - | + | + |
| delegate | + | + | + |
| fail | - | + | + |
| forward | + | + | + |
| nominate | - | - | + |
| release | - | + | + |
| remove | - | - | + |
| resume | + | + | + |
| skip | + | + | + |
| start | + | + | + |
| stop | - | + | + |
| suspend | + | + | + |
12.6. Task Service
12.6.1. Task Service and Process Engine
Human tasks are similar to any other external service that are invoked and implemented as a domain-specific service. As a human task is an example of such a domain-specific service, the process itself only contains a high-level, abstract description of the human task to be executed and a work item handler that is responsible for binding this (abstract) task to a specific implementation.
You can plug in any human task service implementation, such as the one that is provided by JBoss BPM Suite, or may register your own implementation. The Red Hat JBoss BPM Suite provides a default implementation of a human task service based on the WS-HumanTask specification. If you do not need to integrate JBoss BPM Suite with another existing implementation of a human task service, you can use this service. The Red Hat JBoss BPM Suite implementation manages the life cycle of the tasks (such as creation, claiming, completion) and stores the state of all the tasks, task lists, and other associated information. It also supports features like internationalization, calendar integration, different types of assignments, delegation, escalation and deadlines. You can find the code for the implementation in the jbpm-human-task module. The Red Hat JBoss BPM Suite task service implementation is based on the WS-HumanTask (WS-HT) specification. This specification defines (in detail) the model of the tasks, the life cycle, and many other features.
12.6.2. Task Service API
The human task service exposes a Java API for managing the life cycle of tasks. This allows clients to integrate (at a low level) with the human task service. Note that, the end users should probably not interact with this low-level API directly, but use one of the more user-friendly task clients instead. These clients offer a graphical user interface to request task lists, claim and complete tasks, and manage tasks in general. The task clients listed below use the Java API to internally interact with the human task service. Of course, the low-level API is also available so that developers can use it in their code to interact with the human task service directly.
A task service (interface org.kie.api.task.TaskService) offers the following methods for managing the life cycle of human tasks:
...
void start( long taskId, String userId );
void stop( long taskId, String userId );
void release( long taskId, String userId );
void suspend( long taskId, String userId );
void resume( long taskId, String userId );
void skip( long taskId, String userId );
void delegate(long taskId, String userId, String targetUserId);
void complete( long taskId, String userId, Map<String, Object> results );
...The common arguments passed to these methods are:
-
taskId: The ID of the task that we are working with. This is usually extracted from the currently selected task in the user task list in the user interface. -
userId: The ID of the user that is executing the action. This is usually the id of the user that is logged in into the application.
To make use of the methods provided by the internal interface InternalTaskService, you need to manually cast to InternalTaskService. One method that can be useful from this interface is getTaskContent():
Map<String, Object> getTaskContent( long taskId );
This method saves you from the complexity of getting the ContentMarshallerContext to unmarshall the serialized version of the task content. If you only want to use the stable or public API’s, you can use the following method:
import java.util.Map;
import org.jbpm.services.task.utils.ContentMarshallerHelper;
import org.kie.api.task.model.Content;
import org.kie.api.task.model.Task;
import org.kie.internal.task.api.ContentMarshallerContext;
import org.kie.internal.task.api.TaskContentService;
import org.kie.internal.task.api.TaskQueryService;
...
Task taskById = taskQueryService.getTaskInstanceById(taskId);
Content contentById = taskContentService.getContentById
(taskById.getTaskData().getDocumentContentId());
ContentMarshallerContext context = getMarshallerContext(taskById);
Object unmarshalledObject = ContentMarshallerHelper.unmarshall
(contentById.getContent(), context.getEnvironment(), context.getClassloader());
if (!(unmarshalledObject instanceof Map)) {
throw new IllegalStateException
(" The Task Content Needs to be a Map in order to use this method and it was: "
+ unmarshalledObject.getClass());
}
Map<String, Object> content = (Map<String, Object>) unmarshalledObject;
return content;For a list of Maven dependencies, see example Embedded jBPM Engine Dependencies.
12.6.3. Interacting with the Task Service
In order to get access to the Task Service API, it is recommended to let the Runtime Manager ensure that everything is setup correctly. From the API perspective, if you use the following approach, there is no need to register the Task Service with the Process Engine:
import java.util.List;
import org.kie.api.runtime.KieSession;
import org.kie.api.runtime.manager.RuntimeEngine;
import org.kie.api.task.TaskService;
import org.kie.api.task.model.TaskSummary;
import org.kie.internal.runtime.manager.context.EmptyContext;
...
RuntimeEngine engine = runtimeManager.getRuntimeEngine(EmptyContext.get());
KieSession kieSession = engine.getKieSession();
// Start a process:
kieSession.startProcess("CustomersRelationship.customers", params);
// Do task operations:
TaskService taskService = engine.getTaskService();
List<TaskSummary> tasksAssignedAsPotentialOwner = taskService
.getTasksAssignedAsPotentialOwner("mary", "en-UK");
// Claim task:
taskService.claim(taskSummary.getId(), "mary");
// Start task:
taskService.start(taskSummary.getId(), "mary");
...For a list of Maven dependencies, see example Embedded jBPM Engine Dependencies.
The Runtime Manager registers the Task Service with the Process Engine automatically. If you do not use the Runtime Manager, you have to set the LocalHTWorkItemHandler in the session to get the Task Service notify the Process Engine once the task completes. In Red Hat JBoss BPM Suite, the Task Service runs locally to the Process and Rule Engine. This enables you to create multiple light clients for different Process and Rule Engine’s instances. All the clients can share the same database.
12.6.4. Accessing Task Variables Using TaskEventListener
Task variables can be accessed in the TaskEventListener for process instances.
Creating a CustomTaskEventListener
Create a
CustomTaskEventListenerclass using your preferred IDE, such as Red Hat JBoss Developer Studio.import org.jboss.logging.Logger; import org.jbpm.services.task.events.DefaultTaskEventListener; import org.kie.api.task.TaskEvent; public class CustomTaskEventListener extends DefaultTaskEventListener { private static final Logger LOGGER = Logger.getLogger(CustomTaskEventListener.class.getName()); @Override public void beforeTaskStartedEvent(TaskEvent event) { LOGGER.info("Starting task " + event.getTask().getId()); } }Registering the CustomTaskEventListener
The listener can be registered at
RuntimeManagerlevel:import java.util.List; import org.kie.internal.io.ResourceFactory; import org.kie.api.io.ResourceType; import org.kie.api.runtime.manager.RuntimeEnvironment; import org.kie.api.runtime.manager.RuntimeManagerFactory; import org.kie.api.task.TaskEvent; import org.kie.api.task.TaskLifeCycleEventListener; import org.jbpm.runtime.manager.impl.DefaultRegisterableItemsFactory; import org.jbpm.runtime.manager.impl.RuntimeEnvironmentBuilder; import org.jbpm.services.task.events.DefaultTaskEventListener; ... RuntimeEnvironment environment = RuntimeEnvironmentBuilder.getDefault() .persistence(true) .entityManagerFactory(emf) .userGroupCallback(userGroupCallback) .addAsset(ResourceFactory.newClassPathResource(process), ResourceType.BPMN2) .registerableItemsFactory(new DefaultRegisterableItemsFactory() { @Override public List<TaskLifeCycleEventListener> getTaskListeners() { List<TaskLifeCycleEventListener> listeners = super.getTaskListeners(); listeners.add(new DefaultTaskEventListener() { @Override public void afterTaskAddedEvent(TaskEvent event) { System.out.println("taskId = " + event.getTask().getId()); } }); return listeners; } }) .get(); return RuntimeManagerFactory.Factory.get().newPerProcessInstanceRuntimeManager(environment);Alternatively, it can be registered at
Task Servicelevel:import org.jbpm.services.task.events.DefaultTaskEventListener; import org.kie.api.task.TaskEvent; import org.kie.api.task.TaskLifeCycleEventListener; import org.kie.api.task.TaskService; import org.kie.internal.task.api.EventService; ... TaskService taskService = runtime.getTaskService(); ((EventService<TaskLifeCycleEventListener>)taskService).registerTaskEventListener(new DefaultTaskEventListener() { @Override public void afterTaskAddedEvent(TaskEvent event) { System.out.println("taskId = " + event.getTask().getId()); } });Loading Task Variables
The
TaskEventListenercan now obtain task variables using theloadTaskVariablesmethod to populate both input and output variables of a given task.event.getTaskContext().loadTaskVariables(event.getTask())This populates both Input and Output tasks, which can be retrieved using the following:
Input
task.getTaskData().getTaskInputVariables()Output
task.getTaskData().getTaskOutputVariables()To improve performance, task variables are automatically set when they are available, and are usually given by the caller on
Task Service. TheloadTaskVariablesmethod is "no op" where task variables are already set on a task. For example:-
When created, a task usually has input variables, which are then set on
Taskinstance. This applies tobeforeTaskAddedandafterTaskAddedevents handling. When
Taskis completed, it usually has output variables, which are set on a task.The
loadTaskVariablesmethod should be used to populate task variables in all other circumstances.NoteCalling the
loadTaskVariablesmethod of the listener once (such as inbeforeTask) makes it available to bothbeforeTaskandafterTaskmethods.
-
When created, a task usually has input variables, which are then set on
Configuring the TaskEventListener
At the project level,
TaskEventListenercan be configured using thekie-deployment-descriptor.xmlfile. To configureTaskEventListenerin Business Central, go to Deployment Descriptor Editor and add an entry underTask event listenerswith the classnameCustomProcessEventListener. TheTaskEventListenerappears inkie-deployment-descriptor.xmlas:<task-event-listeners> <task-event-listener> <resolver>reflection</resolver> <identifier>com.redhat.gss.sample.CustomTaskEventListener</identifier> </task-event-listener> </task-event-listeners>The
TaskEventListenercan also be registered inbusiness-central.war/WEB-INF/classes/META-INF/kie-wb-deployment-descriptor.xml. ThisTaskEventListeneris available for all projects that are deployed in Business Central.Adding Maven Dependencies
If you are using a Maven project, see example Embedded jBPM Engine Dependencies for a list of Maven dependencies.
12.6.5. Task Service Data Model
The task service data model is illustrated in the following image. In this section, each entity of the database model is described in detail.
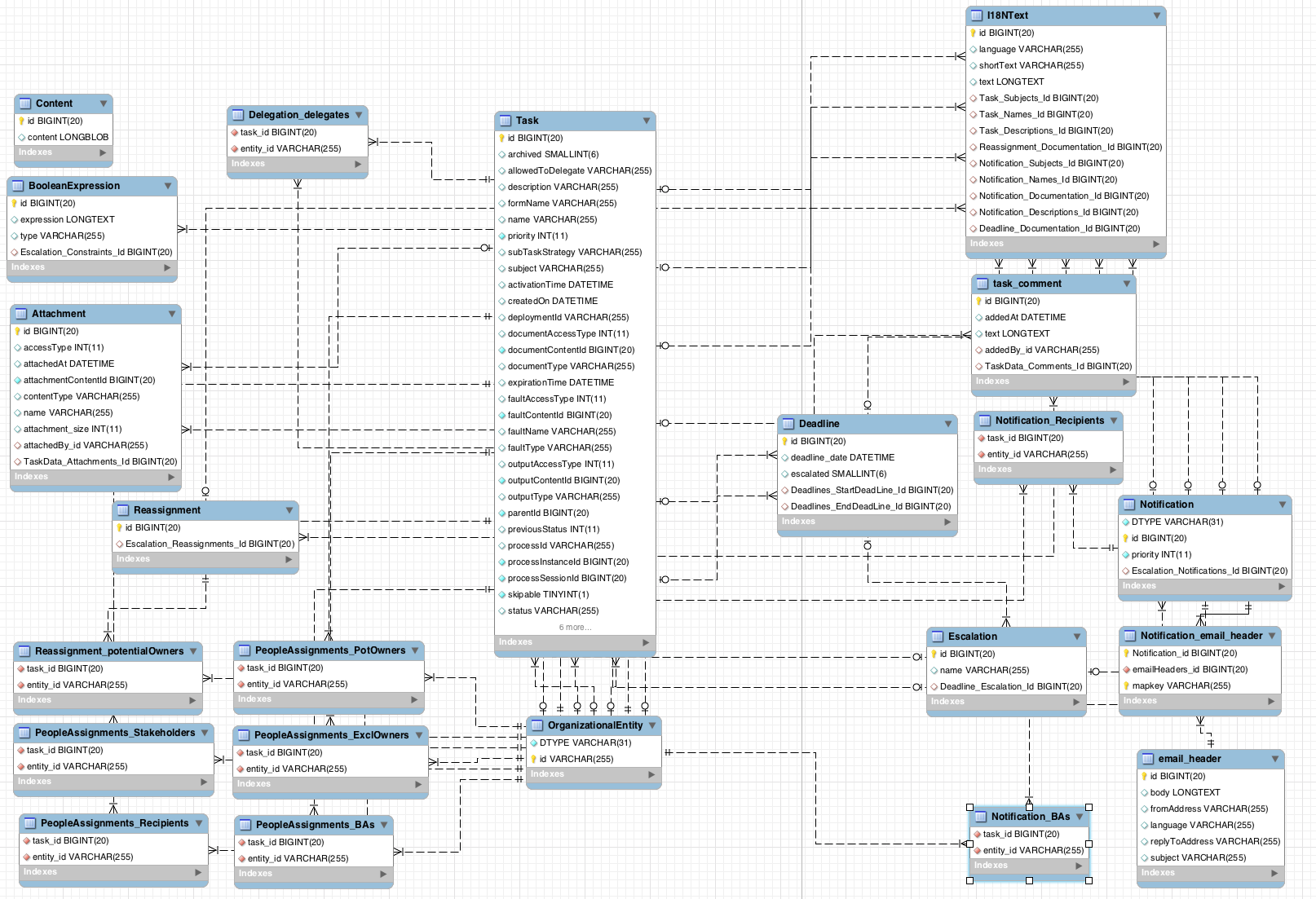
The I18NText table represents a text in a particular language. The language is stored in the language attribute, the unique ID of a text in the id attribute, the short attribute contains an abbreviated content and the text attribute contains the text itself.
Tasks
The Task table stores information about a particular task.
| Attribute | Description |
|---|---|
|
| The unique ID of a task. |
|
|
Determines whether a task is archived. The value can be |
|
| Determines whether a task can be delegated (assigned to another user). For more information about delegations, see the section called “Delegations”. |
|
| The description of a task. The maximum number of characters is 255. |
|
| The name of a form attached to a task. |
|
| The name of a task. |
|
|
The priority of a task. The value ranges from |
|
|
The default subtask strategy is
|
|
| The subject of a task. |
|
| The time when a task is assigned to a user or when a user claims a task. |
|
| The time when a process reaches a task and an instance of the task is created. The claim operation is either performed automatically or the task waits until it is assigned to a particular user. |
|
| The ID of a kJAR deployment in which a task was created. |
|
| The time until when a task is expected to be completed. |
|
|
The ID of a parent task. If a task does not have any parent (and at the same time can be a parent of other tasks), the value is |
|
|
The status of a task. Possible values are (in this order): |
|
|
The previous status of a task. The value is a number from |
|
| The ID of a process in which the task was created. |
|
| The ID of a process instance in which the task was created. |
|
| The ID of a process session in which the task was created. |
|
|
Determines whether a task can be skipped. Possible values are |
|
| The ID of a task work item. Each task can be a certain type of a work item. |
|
| The unique ID of the user who claimed a task. |
|
| The unique ID of the user who created a task. |
The Task table stores also the information about an input and output task content in the following attributes:
| INPUT | OUTPUT | Description |
|---|---|---|
|
|
|
The content access type: can be either inline (then the value of the attribute is |
|
|
|
A content ID is the unique ID of a content stored in the |
|
|
|
The type of a task content. If the access type is inline, then the content type is |
The faultAccessType, faultContentId, faultName, and faultType attributes follow the same logic as the attributes described in the previous table, with the difference that they are used by failed tasks. While the completed tasks have an output document assigned (which can be for example a HashMap), the failed tasks return a fail document.
Task comments are stored in the task_comment table. See a list of task_comment attributes below:
| Attribute | Description |
|---|---|
|
| The unique ID of a comment. |
|
| The time when a comment was added to a task. |
|
| The content of a comment. |
|
|
The unique ID of a user who created a comment. Based on the ID, you can find the user in the |
|
| The unique ID of a task to which a comment was added. |
For more information about task data model, see Section 13.2, “Audit Log”.
Entities and People Assignments
Information about particular users and groups are stored in the OrganizationalEntity table. The attribute DTYPE determines whether it is a user or a group and id is the name of a user (for example bpmsAdmin) or a group (for example Administrators).
See a list of different types of people assignments below. All the assignments have the following attributes: task_id, entity_id.
- PeopleAssignments_PotOwners
-
Potential owners are users or groups who can claim a task and start the task. The attribute
task_idis a unique ID of an assigned task andentity_iddetermines the unique ID of a user or a group. - PeopleAssignments_ExclOwners
-
Excluded owners are users excluded from a group that has a specific task assigned. You can assign a task to a group and specify excluded owners. These users then cannot claim the assigned task. The attribute
task_idis a unique ID of a task andentity_iddetermines the unique ID of an excluded user. - PeopleAssignments_BAs
-
Business administrators have the rights to manage tasks, delegate tasks and perform similar operations. The attribute
task_idis a unique ID of an assigned task andentity_iddetermines the unique ID of a user or a group. - PeopleAssignments_Stakeholders
- Not fully supported.
- PeopleAssignments_Recipients
- Not fully supported.
Reassignments
It is possible to set a reassignment time for each task. If the task has not started or has not been completed before the set time, it is reassigned to a particular user or a group.
The reassignments are stored in the Reassignment_potentialOwners table, where task_id is a unique ID of a task and entity_id is a user or a group to which a task is assigned after the deadline.
The Escalation table contains the unique ID of an escalation (id), the ID of a deadline (Deadline_Escalation_Id), and the deadline name (name) which is generated by default and cannot be changed.
The Deadline table stores deadline information: the unique ID of a deadline (id) and the time and date of a deadline (deadline_date). The escalated attribute determines whether the reassignment have been performed (the value can be either 1 or 0). If a task is reassigned after it has not started until the set deadline, the Deadlines_StartDeadLine_Id attribute will be nonempty. If a task is reassigned after it has not been completed until the set deadline, Deadlines_EndDeadLine_Id attribute will be nonempty.
The Reassignment table refers to the Escalation table: the Escalation_Reassignments_Id attribute in Reassignments is equivalent to the id attribute in Escalation.
Notifications
If a task has not started or has not been completed before the deadline, a notification is sent to a subscribed user or a group of users (recipients). These notification are stored in the Notification table: id is the unique ID of a notification, DTYPE is the type of a notification (currently only an email notifications are supported), priority is set to 0 by default, and Escalation_Notifications_Id refers to the Escalation table, which then refers to the Deadline table. For example, if a task has not been completed before the deadline, then the Deadlines_EndDeadLine_Id attribute is nonempty and a notification is sent.
Recipients of a notification are stored in the Notification_Recipients table, where task_id is the unique ID of a task and entity_id is the ID of a subscribed user or a group.
The Notification_email_header stores the ID of a notification in the Notification_id attribute and the ID of an email that is sent in the emailHeader_id attribute. The email_header table contains the unique ID of an email (id), content of an email (body), the name of a user who is sending an email (fromAddress), the language of an email (language), the email address to which it is possible to reply (replyToAddress), and the subject of an email (subject).
Attachments
You can attach an attachment with an arbitrary type and content to each task. These attachments are stored in the Attachment table.
| Attribute | Description |
|---|---|
|
| The unique ID of an attachment. |
|
| The way you can access an attachment. Can be either inline or a URL. |
|
| The time when an attachment was added to a task. |
|
|
Refers to the |
|
| The type of an attachment (MIME). |
|
| The name of an attachment. Different attachments can have the same name. |
|
| The size of an attachment. |
|
| The unique ID of a user who attached an attachment to a task. |
|
| The unique ID of a task that contains the attachment. |
The Content table stores the actual binary content of an attachment. The content type is defined in the Attachment table. The maximum size of an attachment is 2 GB.
Delegations
Each task defines whether it can be escalated to another user or a group in the allowedToDelegate attribute of the Task table. The Delegation_delegates table stores the tasks that can be escalated (in the task_id attribute) and the users to which the tasks are escalated (entity_id).
12.6.6. Connecting to Custom Directory Information Services
It is often necessary to establish a connection and transfer data from existing systems and services, such as LDAP, to get data on actors and groups for User Tasks. To do so, implement the UserGroupInfoProducer interface. This enables you to create your own implementation for user and group management, and then configure it using CDI for Business Central.
To implement and activate the interface:
Implement the
UserGroupInfoProducerinterface and provide a custom callback (see chapter Connecting to LDAP of the Red Hat JBoss BPM Suite User Guide) and user information implementations according to the needs from the producer.To enable Business Central to find the implementation, Annotate your implementation with the
@Selectablequalifier. See an example LDAP implementation:import javax.enterprise.context.ApplicationScoped; import javax.enterprise.inject.Alternative; import javax.enterprise.inject.Produces; import org.jbpm.services.task.identity.LDAPUserGroupCallbackImpl; import org.jbpm.services.task.identity.LDAPUserInfoImpl; import org.jbpm.shared.services.cdi.Selectable; import org.kie.api.task.UserGroupCallback; import org.kie.internal.task.api.UserInfo; @ApplicationScoped @Alternative @Selectable public class LDAPUserGroupInfoProducer implements UserGroupInfoProducer { private UserGroupCallback callback = new LDAPUserGroupCallbackImpl(true); private UserInfo userInfo = new LDAPUserInfoImpl(true); @Override @Produces public UserGroupCallback produceCallback() { return callback; } @Override @Produces public UserInfo produceUserInfo() { return userInfo; } }-
Package your custom implementations, that is the
LDAPUserGroupInfoProducer, theLDAPUserGroupCallbackImpland theLDAPUserInfoImplclasses from the example above, into a JAR archive. Create theMETA-INFdirectory and in it, create thebeans.xmlfile. This makes your implementation CDI enabled. Add the resulting JAR file tobusiness-central.war/WEB-INF/lib/. Modify
business-central.war/WEB-INF/beans.xmland add the implementation,LDAPUserGroupInfoProducerfrom the example above, as an alternative to be used by Business Central.<beans xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://docs.jboss.org/cdi/beans_1_0.xsd"> <alternatives> <class>com.test.services.producer.LDAPUserGroupInfoProducer</class> </alternatives> </beans>WarningThe use of a custom
UserGroupInfoProducerrequires internal APIs, which may change in future releases. Using a customUserGroupInfoProduceris not recommended or supported by Red Hat.- Restart your server. Your custom callback implementation should now be used by Business Central.
12.6.7. LDAP Connection
A dedicated UserGroupCallback implementation for LDAP servers is provided with the product to enable the User Task service to retrieve information about users, groups, and roles directly from an LDAP service. See LDAP Callback Connection Example for example configuration.
The LDAP UserGroupCallback implementation takes the following properties:
-
ldap.bind.user: a username used to connect to the LDAP server. The property is optional if LDAP server accepts anonymous access. -
ldap.bind.pwd: a password used to connect to the LDAP server. The property is optional if LDAP server accepts anonymous access. -
ldap.user.ctx: an LDAP context with user information. The property is mandatory. -
ldap.role.ctx: an LDAP context with group and role information. The property is mandatory. -
ldap.user.roles.ctx: an LDAP context with user group and role membership information. The property is optional; if not specified,ldap.role.ctxis used. -
ldap.user.filter: a search filter used for user information; usually contains substitution keys {0}, which are replaced with parameters. The property is mandatory. -
ldap.role.filter: a search filter used for group and role information; usually contains substitution keys {0}, which are replaced with parameters. The property is mandatory. -
ldap.user.roles.filter: a search filter used for user group and role membership information; usually contains substitution keys {0}, which are replaced with parameters. The property is mandatory. -
ldap.user.attr.id: an attribute name of the user ID in LDAP. This property is optional; if not specified,uidis used. -
ldap.roles.attr.id: an attribute name of the group and role ID in LDAP. This property is optional; if not specified,cnis used. -
ldap.user.id.dn: a user ID in a DN, instructs the callback to query for user DN before searching for roles. This property is optional, by defaultfalse. -
java.naming.factory.initial: initial context factory class name (by defaultcom.sun.jndi.ldap.LdapCtxFactory) -
java.naming.security.authentication: authentication type (possible values arenone,simple,strong; by defaultsimple) -
java.naming.security.protocol: security protocol to be used; for instancessl -
java.naming.provider.url: LDAP url (by defaultldap://localhost:389; if the protocol is set tosslthenldap://localhost:636)
12.6.7.1. Connecting to LDAP
To use the LDAP UserGroupCallback implementation, configure the respective LDAP properties as shown below. For more information, see Section 12.6.7, “LDAP Connection”.
Programatically: build a
Propertiesobject with the respective LDAPUserGroupCallbackImplproperties and createLDAPUserGroupCallbackImplwith thePropertiesobject as its parameter.import org.kie.api.PropertiesConfiguration; import org.kie.api.task.UserGroupCallback; ... Properties properties = new Properties(); properties.setProperty(LDAPUserGroupCallbackImpl.USER_CTX, "ou=People,dc=my-domain,dc=com"); properties.setProperty(LDAPUserGroupCallbackImpl.ROLE_CTX, "ou=Roles,dc=my-domain,dc=com"); properties.setProperty(LDAPUserGroupCallbackImpl.USER_ROLES_CTX, "ou=Roles,dc=my-domain,dc=com"); properties.setProperty(LDAPUserGroupCallbackImpl.USER_FILTER, "(uid={0})"); properties.setProperty(LDAPUserGroupCallbackImpl.ROLE_FILTER, "(cn={0})"); properties.setProperty(LDAPUserGroupCallbackImpl.USER_ROLES_FILTER, "(member={0})"); UserGroupCallback ldapUserGroupCallback = new LDAPUserGroupCallbackImpl(properties); UserGroupCallbackManager.getInstance().setCallback(ldapUserGroupCallback);Declaratively: create the
jbpm.usergroup.callback.propertiesfile in the root of your application or specify the file location as a system property:-Djbpm.usergroup.callback.properties=FILE_LOCATION_ON_CLASSPATH.Make sure to register the LDAP callback when starting the User Task server.
LDAP Callback Connection Example
#ldap.bind.user= #ldap.bind.pwd= ldap.user.ctx=ou\=People,dc\=my-domain,dc\=com ldap.role.ctx=ou\=Roles,dc\=my-domain,dc\=com ldap.user.roles.ctx=ou\=Roles,dc\=my-domain,dc\=com ldap.user.filter=(uid\={0}) ldap.role.filter=(cn\={0}) ldap.user.roles.filter=(member\={0}) #ldap.user.attr.id= #ldap.roles.attr.id=
12.7. Task Escalation and Notifications
For human tasks in business processes, you can define automatic task escalation and notification behavior if the tasks remain incomplete for a defined period of time. For example, if a user assigned to a task is unable to complete that task within the defined period of time, the engine can automatically reassign the task to another actor or group for completion and send an email notification to the relevant users.
You can set up automatic escalations and notifications for tasks that are in the following states:
-
not-started(tasks inREADYorRESERVEDstate) -
not-completed(tasks inIN_PROGRESSstate)
When an escalation occurs, users and groups defined in the task are assigned to the task as potential owners, replacing those who were previously assigned. If an actual owner is assigned to the task, the escalation is reset and the task is set to the READY state.
To define automatic task reassignment, follow these steps:
- Select the human task in the process designer.
In the Properties panel on the right side of the window, select the Reassignment property and add or edit the following reassignment details as needed:
-
Users: A comma-separated list of user IDs to which the task will be assigned after the Expires At period lapses. This attribute supports string values and the variable expression
#{user-id}. -
Groups: A comma-separated list of group IDs to which the task will be assigned after the Expires At period lapses. This attribute supports string values and the variable expression
#{group-id}. -
Expires At: The amount of time after which the task is reassigned to the defined users or groups (in the format
2m,4h,6d, and so on). This attribute supports string values and the variable expression#{expiresAt}. -
Type: The task state in which the task reassignment can occur (
not-startedornot-completed).
-
Users: A comma-separated list of user IDs to which the task will be assigned after the Expires At period lapses. This attribute supports string values and the variable expression
Figure 12.2. Defining automatic task reassignment
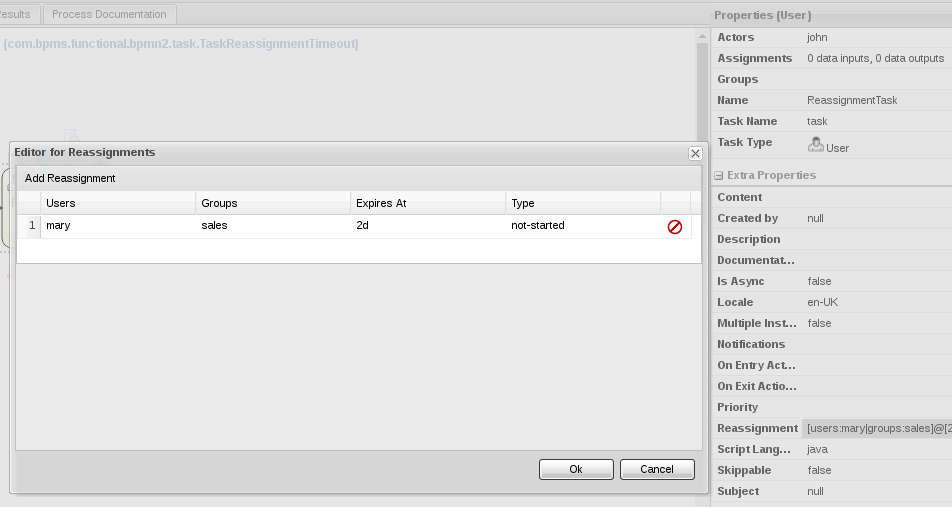
In this example, this task that is assigned to John will be reassigned to Mary in Sales if the task is still in a not-started state after two days.
To define automatic email notifications for a task escalation, follow these steps:
- Select the human task in the process designer.
In the Properties panel on the right side of the window, select the Notifications property and add or edit the following notification details as needed:
-
Type: The task state in which the notification can occur (
not-startedornot-completed). -
Expires At: The amount of time after which the email notification is sent (in the format
2m,4h,6d, and so on). Set this value to a period of time equal to or greater than the period you defined for the task Reassignment property. This attribute supports string values and the variable expression#{expiresAt}. -
From: An optional user or group ID that is used in the From field of the email notification. This attribute supports string values and the variable expressions
#{user-id}and#{group-id}. -
To Users: A comma-separated list of user IDs to which the email notification will be sent after the Expires At period lapses. This attribute supports string values and the variable expression
#{user-id}. -
To Groups: A comma-separated list of group IDs to which the email notification will be sent after the Expires At period lapses. This attribute supports string values and the variable expression
#{group-id}. -
Reply To: An optional user or group ID to which the recipients of the notification can reply. This attribute supports string values and the variable expressions
#{user-id}and#{group-id}. - Subject: The subject of the email notification. The subject supports string values and the variable expressions described in this list.
- Body: The message body of the email notification. The body supports string values and the variable expressions described in this list.
-
Type: The task state in which the notification can occur (
Figure 12.3. Defining automatic email notifications
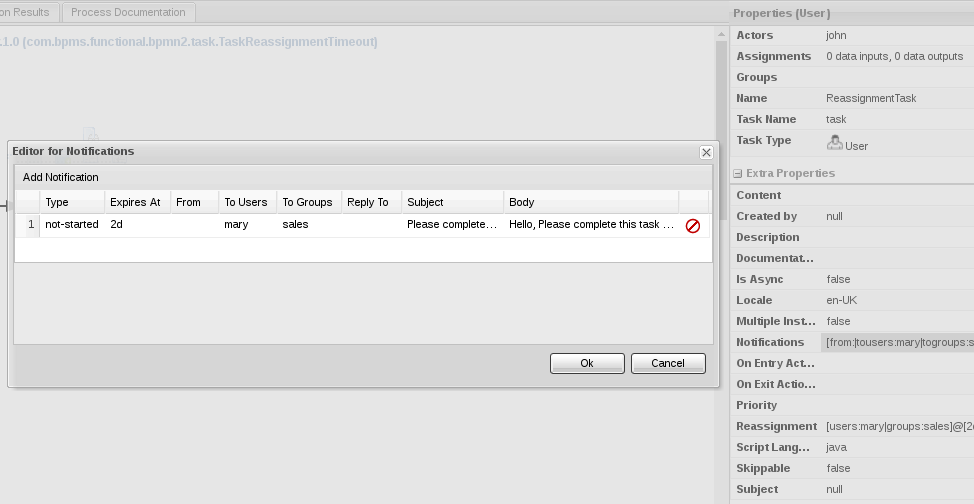
In this example, Mary in Sales will receive an email notification along with the reassigned task if the task is still in a not-started state after two days.
Notification messages also support process and task variables in the format ${variable}. Process variables resolve when the task is created and task variables resolve when the task notification is sent.
The following list contains several process and task variables that you can use in task notifications:
-
taskId: An internal ID of a task instance -
processInstanceId: An internal ID of a process instance that the task belongs to -
workItemId: An internal ID of a work item that created the task -
processSessionId: An internal ID of a runtime engine -
owners: A list of users or groups that are potential owners of the task -
doc: A map that contains regular task variables
The following example notification message illustrates how you can use process and task variables:
<html>
<body>
<b>${owners[0].id} you have been assigned to a task (task-id ${taskId})</b><br>
You can access it in your task
<a href="http://localhost:8080/jbpm-console/app.html#errai_ToolSet_Tasks;Group_Tasks.3">inbox</a><br/>
Important technical information that can be of use when working on it<br/>
- process instance id - ${processInstanceId}<br/>
- work item id - ${workItemId}<br/>
<hr/>
Here are some task variables available:
<ul>
<li>ActorId = ${doc['ActorId']}</li>
<li>GroupId = ${doc['GroupId']}</li>
<li>Comment = ${doc['Comment']}</li>
</ul>
<hr/>
Here are all potential owners for this task:
<ul>
$foreach{orgEntity : owners}
<li>Potential owner = ${orgEntity.id}</li>
$end{}
</ul>
<i>Regards</i>
</body>
</html>12.7.1. Configuring a Custom Implementation of Email Notification Events
You can use the NotificationListener interface to configure a custom implementation of the Email Notification Events in the Task Escalation service. A custom notification implementation provides greater flexibility for your existing task escalation configurations.
To configure a custom implementation of Email Notification Events, follow these steps:
-
Implement the
NotificationListenerinterface. -
Create an
org.jbpm.services.task.deadlines.NotificationListenertext file in theMETA-INF/services/directory. -
Add a Fully Qualified Name (FQN) for your custom listener implementation to the
org.jbpm.services.task.deadlines.NotificationListenertext file. -
Package all classes and files from the
META-INF/services/org.jbpm.services.task.deadlines.NotificationListenertext file into a JAR file. -
Deploy your JAR package by copying it and any required external dependencies into the
$SERVER_HOME/standalone/kie-server.war/WEB-INF/libor$SERVER_HOME/standalone/business-central.war/WEB-INF/libdirectory. - Restart your server.
After you restart your server, the Task Escalation Service triggers your custom Email Notification Event. This feature is based on notification broadcasting, which enables all the notification handlers to handle the event. You can specify the following identifying information in any calls that your application makes to the desired handlers:
- Task information, such as task ID, name, and description
- Process information, such as process instance ID, process ID, and deployment ID
12.8. Retrieving Process and Task Information
There are two services which can be used when building list-based user interfaces: the RuntimeDataService and TaskQueryService.
The RuntimeDataService interface can be used as the main source of information, as it provides an interface for retrieving data associated with the runtime. It can list process definitions, process instances, tasks for given users, node instance information and other. The service should provide all required information and still be as efficient as possible.
See the following examples:
Example 12.1. Get All Process Definitions
Returns every available process definition.
import java.util.Collection;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.RuntimeDataService;
...
Collection definitions = runtimeDataService.getProcesses(new QueryContext());Example 12.2. Get Active Process Instances
Returns a list of all active process instance descriptions.
import java.util.Collection;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.RuntimeDataService;
...
Collection<processInstanceDesc> activeInstances = runtimeDataService
.getProcessInstances(new QueryContext());Example 12.3. Get Active Nodes for Given Process Instance
Returns a trace of all active nodes for given process instance ID.
import java.util.Collection;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.RuntimeDataService;
...
Collection<nodeInstanceDesc> activeNodes = runtimeDataService
.getProcessInstanceHistoryActive(processInstanceId, new QueryContext());Example 12.4. Get Tasks Assigned to Given User
Returns a list of tasks the given user is eligible for.
import java.util.List;
import org.jbpm.services.api.RuntimeDataService;
import org.kie.api.task.model.TaskSummary;
import org.kie.internal.query.QueryFilter;
...
List<TaskSummary> TaskSummaries = runtimeDataService
.getTasksAssignedAsPotentialOwner("john", new QueryFilter(0, 10));Example 12.5. Get Tasks Assigned to Business Administrator
Returns a list of tasks assigned to the given business administrator user.
import java.util.List;
import org.jbpm.services.api.RuntimeDataService;
import org.kie.internal.query.QueryFilter;
List<TaskSummary> taskSummaries = runtimeDataService
.getTasksAssignedAsBusinessAdministrator("john", new QueryFilter(0, 10));For a list of Maven dependencies, see example Embedded jBPM Engine Dependencies.
The RuntimeDataService is mentioned also in Section 20.4, “CDI Integration”.
As you can notice, operations of the RuntimeDataService then support two important arguments:
-
QueryContext -
QueryFilter(which is an extension ofQueryContext)
These two classes provide capabilities for an efficient management and search results. The QueryContext allows you to set an offset (by using the offset argument), number of results (count), their order (orderBy) and ascending order (asc) as well.
Since the QueryFilter inherits all of the mentioned attributes, it provides the same features, as well as some others: for example, it is possible to set the language, single result, maximum number of results, or paging.
Moreover, additional filtering can be applied to the queries to provide more advanced options when searching for user tasks and processes.
12.9. Advanced Queries with QueryService
QueryService provides advanced search capabilities based on JBoss BPM Suite Dashbuilder datasets. You can retrieve data from the underlying data store by means of, for example, JPA entity tables, or custom database tables.
QueryService consists of two main parts:
Management operations, such as:
- Register query definition.
- Replace query definition.
- Remove query definition.
- Get query definition.
- Get all registered query definitions.
Runtime operations:
-
Simple, with
QueryParamas the filter provider. -
Advanced, with
QueryParamBuilderas the filter provider.
-
Simple, with
Following services are a part of QueryService:
-
QueryDefinition: represents dataset which consists of a unique name, SQL expression (the query), and source. QueryParam: represents theconditionquery parameter that consists of:- Column name
- Operator
- Expected value(s)
-
QueryResultMapper: responsible for mapping raw datasets (rows and columns) to objects. -
QueryParamBuilder: responsible for building query filters for the query invocation of the given query definition.
12.9.1. QueryResultMapper
QueryResultMapper maps data to an object. It is similar to other object-relational mapping (ORM) providers, such as hibernate, which maps tables to entities. Red Hat JBoss BPM Suite provides a number of mappers for various object types:
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper-
Registered with name
ProcessInstances.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithVarsQueryMapper-
Registered with name
ProcessInstancesWithVariables.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithCustomVarsQueryMapper-
Registered with name
ProcessInstancesWithCustomVariables.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceQueryMapper-
Registered with name
UserTasks.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithVarsQueryMapper-
Registered with name
UserTasksWithVariables.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithCustomVarsQueryMapper-
Registered with name
UserTasksWithCustomVariables.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.TaskSummaryQueryMapper-
Registered with name
TaskSummaries.
-
Registered with name
org.jbpm.kie.services.impl.query.mapper.RawListQueryMapper-
Registered with name
RawList.
-
Registered with name
Alternatively, you can build custom mappers. The name for each mapper serves as a reference that you can use instead of the class name. It is useful, for example, when you want to reduce the number of dependencies and you do not want to rely on implementation on the client side. To reference QueryResultMapper, use the mapper’s name, which is a part of jbpm-services-api. It acts as a (lazy) delegate as it will search for the mapper when the query is performed.
Following example references ProcessInstanceQueryMapper by name:
queryService.query("my query def", new NamedQueryMapper<Collection<ProcessInstanceDesc>>("ProcessInstances"), new QueryContext());12.9.2. QueryParamBuilder
When you use the QueryService query method which accepts QueryParam instances, all of the parameters are joined by logical conjunction (AND) by default. Alternatively, use QueryParamBuilder to create custom builder which provides filters when the query is issued.
You can use a predefined builder, which includes a number of QueryParam methods based on core functions. Core functions are SQL-based conditions and include following conditions:
-
IS_NULL -
NOT_NULL -
EQUALS_TO -
NOT_EQUALS_TO -
LIKE_TO -
GREATER_THAN -
GREATER_OR_EQUALS_TO -
LOWER_THAN -
LOWER_OR_EQUALS_TO -
BETWEEN -
IN -
NOT_IN
12.9.3. Implementing QueryParamBuilder
QueryParamBuilder is an interface that is invoked when its build method returns a non-null value before the query is performed. It allows you to build complex filter options that a QueryParam list cannot express.
Example 12.6. QueryParamBuilder Implementation Using DashBuilder Dataset API
import java.util.Map;
import org.dashbuilder.dataset.filter.ColumnFilter;
import org.dashbuilder.dataset.filter.FilterFactory;
import org.jbpm.services.api.query.QueryParamBuilder;
public class TestQueryParamBuilder implements QueryParamBuilder<ColumnFilter> {
private Map<String, Object> parameters;
private boolean built = false;
public TestQueryParamBuilder(Map<String, Object> parameters) {
this.parameters = parameters;
}
@Override
public ColumnFilter build() {
// Return NULL if it was already invoked:
if (built) {
return null;
}
String columnName = "processInstanceId";
ColumnFilter filter = FilterFactory.OR(
FilterFactory.greaterOrEqualsTo((Long)parameters.get("min")),
FilterFactory.lowerOrEqualsTo((Long)parameters.get("max")));
filter.setColumnId(columnName);
built = true;
return filter;
}
}For a list of Maven dependencies, see Embedded jBPM Engine Dependencies.
When you implement QueryParamBuilder, use its instance through QueryService:
import org.jbpm.services.api.query.QueryService;
...
queryService.query("my query def", ProcessInstanceQueryMapper.get(), new QueryContext(), paramBuilder);12.9.4. QueryService in Embedded Mode
QueryService is a part of the jBPM Services API, a cross-framework API built to simplify embedding Red Hat JBoss BPM Suite. You can also use advanced querying through the Intelligent Process Server, described in Section 12.9.5, “Advanced Queries Through Intelligent Process Server”. When you use QueryService in embedded mode, follow these steps:
Define the dataset you want to work with:
import org.jbpm.kie.services.impl.query.SqlQueryDefinition; ... SqlQueryDefinition query = new SqlQueryDefinition ("getAllProcessInstances", "java:jboss/datasources/ExampleDS"); query.setExpression("select * from processinstancelog");The constructor of this query definition requires:
- A unique name that serves as ID during runtime.
- JDNI name of a data source for the query.
The expression is an SQL statement that creates a view that will be filtered when performing queries.
Register the query definition:
import org.jbpm.services.api.query.QueryService; ... queryService.registerQuery(query);
You can now use the query definition. The following example does not use filtering:
import java.util.Collection;
import org.jbpm.services.api.model.ProcessInstanceDesc;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.query.QueryService;
import org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper;
...
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext());You can change the query context, that is paging and sorting of the query:
import java.util.Collection;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.model.ProcessInstanceDesc;
import org.jbpm.services.api.query.QueryService;
import org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper;
...
QueryContext ctx = new QueryContext(0, 100, "start_date", true);
Collection<ProcessInstanceDesc> instances = queryService.query
("getAllProcessInstances", ProcessInstanceQueryMapper.get(), ctx);You can also use filtering:
import java.util.Collection;
import org.jbpm.kie.services.impl.model.ProcessInstanceDesc;
import org.jbpm.services.api.query.QueryService;
import org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper;
import org.kie.api.runtime.query.QueryContext;
import org.jbpm.services.api.query.model.QueryParam;
...
// Single filter parameter:
Collection<ProcessInstanceDesc> instances = queryService.query
("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(),
QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"));
// Multiple filter parameters (AND):
Collection<ProcessInstanceDesc> instances = queryService.query
("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(),
QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"),
QueryParam.in(COLUMN_STATUS, 1, 3));For a list of Maven dependencies, see Embedded jBPM Engine Dependencies.
12.9.5. Advanced Queries Through Intelligent Process Server
To use advanced queries, you need to deploy the Intelligent Process Server. See chapter The Intelligent Process Server from Red Hat JBoss BPM Suite User Guide to learn more about the Intelligent Process Server. Also, for a list of endpoints you can use, view chapter Advanced Queries for the Intelligent Process Server from the Red Hat JBoss BPM Suite User Guide.
Through the Intelligent Process Server, users can:
- Register query definitions.
- Replace query definitions.
- Remove query definitions.
- Get a query or a list of queries.
Execute queries with:
- Paging and sorting.
- Filter parameters.
- Custom parameter builders and mappers.
To use advanced queries through the Intelligent Process Server, you need to build your Intelligent Process Server to use query services. For Maven projects, see Embedded jBPM Engine Dependencies. To build your Intelligent Process Server:
import java.util.Date;
import java.util.HashSet;
import java.util.Set;
import org.kie.server.api.marshalling.MarshallingFormat;
import org.kie.server.client.KieServicesClient;
import org.kie.server.client.KieServicesConfiguration;
import org.kie.server.client.KieServicesFactory;
import org.kie.server.client.QueryServicesClient;
...
KieServicesConfiguration configuration = KieServicesFactory
.newRestConfiguration(serverUrl, user, password);
Set<Class<?>> extraClasses = new HashSet<Class<?>>();
extraClasses.add(Date.class); // for JSON only to properly map dates
configuration.setMarshallingFormat(MarshallingFormat.JSON);
configuration.addJaxbClasses(extraClasses);
KieServicesClient kieServicesClient = KieServicesFactory
.newKieServicesClient(configuration);
QueryServicesClient queryClient = kieServicesClient
.getServicesClient(QueryServicesClient.class);
// Maven dependency list shown aboveYou can now list available queries on your system:
List<QueryDefinition> queryDefs = queryClient.getQueries(0, 10);
System.out.println(queryDefs);To use advanced queries, register a new query definition:
import org.jbpm.services.api.query.model.QueryDefinition;
...
QueryDefinition query = new QueryDefinition();
query.setName("getAllTaskInstancesWithCustomVariables");
query.setSource("java:jboss/datasources/ExampleDS");
query.setExpression("select ti.*,c.country,c.productCode,c.quantity,c.price,c.saleDate " +
"from AuditTaskImpl ti " +
"inner join (select mv.map_var_id, mv.taskid from MappedVariable mv) mv " +
"on (mv.taskid = ti.taskId) " +
"inner join ProductSale c " +
"on (c.id = mv.map_var_id)");
query.setTarget("Task");
queryClient.registerQuery(query);
// Maven dependency list shown above
Note that Target instructs QueryService to apply default filters. Alternatively, you can set filter parameters manually. Target has the following values:
public enum Target {
PROCESS,
TASK,
BA_TASK,
PO_TASK,
JOBS,
CUSTOM;
}Once registered, you can start with queries:
import java.util.List;
import org.kie.server.api.model.instance.TaskInstance;
//necessary for the queryClient object
import org.kie.server.client.QueryServicesClient;
List<TaskInstance> tasks = queryClient.query
("getAllTaskInstancesWithCustomVariables", "UserTasks", 0, 10, TaskInstance.class);
System.out.println(tasks);
// Maven dependency list shown above
This query returns task instances from the defined dataset, and does not use filtering or UserTasks mapper.
Following example uses advanced querying:
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import org.kie.server.api.model.definition.QueryFilterSpec;
import org.kie.server.api.model.instance.TaskInstance;
import org.kie.server.api.util.QueryFilterSpecBuilder;
//necessary for the queryClient object
import org.kie.server.client.QueryServicesClient;
...
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date from = sdf.parse("2016-02-01");
Date to = sdf.parse("2016-03-01");
QueryFilterSpec spec = new QueryFilterSpecBuilder()
.between("processInstanceId", 1000, 2000)
.greaterThan("price", 800)
.between("saleDate", from, to)
.in("productCode", Arrays.asList("EAP", "WILDFLY"))
.oderBy("saleDate, country", false)
.addColumnMapping("COUNTRY", "string")
.addColumnMapping("PRODUCTCODE", "string")
.addColumnMapping("QUANTITY", "integer")
.addColumnMapping("PRICE", "double")
.addColumnMapping("SALEDATE", "date")
.get();
List<TaskInstance> tasks = queryClient.query
("getAllTaskInstancesWithCustomVariables", "UserTasksWithCustomVariables",
spec, 0, 10, TaskInstance.class);
System.out.println(tasks);
// Maven dependency list shown aboveIt searches for tasks which have following attributes:
-
The
processInstanceIdis between 1000 and 2000. - Price is greater than 800.
- Sale date is between 2016-02-01 and 2016-03-01.
- Sold product is in groups EAP or Wildfly.
- The results will be ordered by sale date and country in descending order.
The query example uses QueryFilterSpec to specify query parameters and sorting options. It also allows to specify column mapping for custom elements to be set as variables, and combine it with default column mapping for task details. In the example, the UserTasksWithCustomVariables mapper was used.
When you use QueryFilterSpec, all the conditions are connected by logical conjunction (AND). You can build custom advanced filters with different behavior by implementing QueryParamBuilder. You need to include it in one of the following:
-
The Intelligent Process Server (for example, in
WEB-INF/lib). - Inside a project, that is in a project kJAR.
- As a project dependency.
To use QueryParamBuilder, you need to:
Implement
QueryParamBuilderby an object that produces a new instance every time you request it with a map of parameters:import java.util.Map; import org.dashbuilder.dataset.filter.ColumnFilter; import org.dashbuilder.dataset.filter.FilterFactory; import org.jbpm.services.api.query.QueryParamBuilder; ... public class TestQueryParamBuilder implements QueryParamBuilder<ColumnFilter> { private Map<String, Object> parameters; private boolean built = false; public TestQueryParamBuilder(Map<String, Object> parameters) { this.parameters = parameters; } @Override public ColumnFilter build() { // Return NULL if it was already invoked: if (built) { return null; } String columnName = "processInstanceId"; ColumnFilter filter = FilterFactory.OR( FilterFactory.greaterOrEqualsTo(((Number)parameters.get("min")).longValue()), FilterFactory.lowerOrEqualsTo(((Number)parameters.get("max")).longValue())); filter.setColumnId(columnName); built = true; return filter; } } // Maven dependency list shown aboveThis example will accept processInstanceId values that are either grater than
minvalue or lower thanmaxvalue.Implement
QueryParamBuilderFactory:import java.util.Map; import org.jbpm.services.api.query.QueryParamBuilder; import org.jbpm.services.api.query.QueryParamBuilderFactory; import org.jbpm.kie.services.test.objects.TestQueryParamBuilder; ... public class TestQueryParamBuilderFactory implements QueryParamBuilderFactory { @Override public boolean accept(String identifier) { if ("test".equalsIgnoreCase(identifier)) { return true; } return false; } @Override public QueryParamBuilder newInstance(Map<String, Object> parameters) { return new TestQueryParamBuilder(parameters); } } // Maven dependency list shown aboveThe factory interface returns new instances of the
QueryParamBuilderonly if the given identifier is accepted by the factory. The Identifier is a part of the query request. Only one query builder factory can be selected based on the identifier. In the example, usetestidentifier to use this factory, and theQueryParamBuilder.Add a service file into
META-INF/services/of the JAR that will package these implementations. In the service file, specify fully qualified class name of the factory, for example:org.jbpm.services.api.query.QueryParamBuilderFactory
You can now request your query builder:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.kie.server.api.model.instance.TaskInstance;
...
Map<String, Object> params = new HashMap<String, Object>();
params.put("min", 10);
params.put("max", 20);
List<TaskInstance> instances = queryClient.query
("getAllTaskInstancesWithCustomVariables", "UserTasksWithCustomVariables", "test",
params, 0, 10, TaskInstance.class);
// Maven dependencies shown aboveSimilarly, to create a custom mapper, follow these steps:
Implement the mapper interface:
public class ProductSaleQueryMapper extends UserTaskInstanceWithCustomVarsQueryMapper { private static final long serialVersionUID = 3299692663640707607L; public ProductSaleQueryMapper() { super(getVariableMapping()); } protected static Map<String, String> getVariableMapping() { Map<String, String> variablesMap = new HashMap<String, String>(); variablesMap.put("COUNTRY", "string"); variablesMap.put("PRODUCTCODE", "string"); variablesMap.put("QUANTITY", "integer"); variablesMap.put("PRICE", "double"); variablesMap.put("SALEDATE", "date"); return variablesMap; } @Override public String getName() { return "ProductSale"; } }Add appropriate service file into
META-INF/services/:org.jbpm.services.api.query.QueryResultMapperReference it by the name, for example:
List<TaskInstance> tasks = queryClient.query ("getAllTaskInstancesWithCustomVariables", "ProductSale", 0, 10, TaskInstance.class); System.out.println(tasks);
12.10. Process Instance Migration
Process instance migration is available only with Red Hat JBoss BPM Suite 6.4 and higher.
The ProcessInstanceMigrationService service is a utility used to migrate given process instances from one deployment to another. Process or task variables are not affected by the migration. The ProcessInstanceMigrationService service enables you to change the process definition for the process engine.
For process instance migrations, let active process instances finish and start new process instances in the new deployment. If this approach is not suitable to your needs, consider the following before starting process instance migration:
- Backward compatibility
- Data change
- Need for node mapping
You should create backward compatible processes whenever possible, such as extending process definitions. For example, removing specific nodes from the process definition breaks compatibility. In such case, you must provide new node mapping in case an active process instance is in a node that has been removed.
A node map contains source node IDs from the old process definition mapped to target node IDs in the new process definition. You can map nodes of the same type only, such as a user task to a user task.
Red Hat JBoss BPM Suite offers several implementations of the migration service:
public interface ProcessInstanceMigrationService {
/**
* Migrates given process instance that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instance (with node mapping) that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
/**
* Migrates given process instances that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instances (with node mapping) that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns list of migration reports one per each process instance
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
}To migrate process instances on the KIE Server, use the following implementations. These correspond with the implementations described in the previous code sample.
public interface ProcessAdminServicesClient {
MigrationReportInstance migrateProcessInstance(String containerId, Long processInstanceId, String targetContainerId, String targetProcessId);
MigrationReportInstance migrateProcessInstance(String containerId, Long processInstanceId, String targetContainerId, String targetProcessId, Map<String, String> nodeMapping);
List<MigrationReportInstance> migrateProcessInstances(String containerId, List<Long> processInstancesId, String targetContainerId, String targetProcessId);
List<MigrationReportInstance> migrateProcessInstances(String containerId, List<Long> processInstancesId, String targetContainerId, String targetProcessId, Map<String, String> nodeMapping);
}You can migrate a single process instance, or multiple process instances at once. If you migrate multiple process instances, each instance will be migrated in a separate transaction to ensure that the migrations do not affect each other.
After migration is done, the migrate method returns a MigrationReport object that contains the following information:
- Start and end dates of the migration.
- Migration outcome (success or failure).
-
Log entry as
INFO,WARN, orERRORtype. TheERRORmessage terminates the migration.
The following is an example process instance migration:
Example Process Instance Migration
import org.kie.server.api.model.admin.MigrationReportInstance;
import org.kie.server.api.marshalling.MarshallingFormat;
import org.kie.server.client.KieServicesClient;
import org.kie.server.client.KieServicesConfiguration;
public class ProcessInstanceMigrationTest{
private static final String SOURCE_CONTAINER = "com.redhat:MigrateMe:1.0";
private static final String SOURCE_PROCESS_ID = "MigrateMe.MigrateMev1";
private static final String TARGET_CONTAINER = "com.redhat:MigrateMe:2";
private static final String TARGET_PROCESS_ID = "MigrateMe.MigrateMeV2";
public static void main(String[] args) {
KieServicesConfiguration config = KieServicesFactory.newRestConfiguration("http://HOST:PORT/kie-server/services/rest/server", "USERNAME", "PASSWORD");
config.setMarshallingFormat(MarshallingFormat.JSON);
KieServicesClient client = KieServicesFactory.newKieServicesClient(config);
long sourcePid = client.getProcessClient().startProcess(SOURCE_CONTAINER, SOURCE_PROCESS_ID);
// Use the 'report' object to return migration results.
MigrationReportInstance report = client.getAdminClient().migrateProcessInstance(SOURCE_CONTAINER, sourcePid,TARGET_CONTAINER, TARGET_PROCESS_ID);
System.out.println("Was migration successful:" + report.isSuccessful());
client.getProcessClient().abortProcessInstance(TARGET_CONTAINER, sourcePid);
}
}Known Limitations
There are several limitations to the migration service:
- You can migrate process instances only, not their data.
- If you modify a task that is preceding the active task, the active task will not be affected by the change.
- You cannot remove a currently active human task. You can replace a human task by mapping it onto a different human task.
- You cannot add new branches parallel to the current active task. In such case, the new branch will not be activated and the workflow will not pass the AND gateway.
- Changes in the active recurring timer events will not be persisted in the database.
- You cannot update task inputs and outputs.
- Node mapping updates task node name and description only. Other task fields will not be mapped and migrated.