Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 15. High availability configuration for Knative Serving
15.1. High availability for Knative services
High availability (HA) is a standard feature of Kubernetes APIs that helps to ensure that APIs stay operational if a disruption occurs. In an HA deployment, if an active controller crashes or is deleted, another controller is readily available. This controller takes over processing of the APIs that were being serviced by the controller that is now unavailable.
HA in OpenShift Serverless is available through leader election, which is enabled by default after the Knative Serving or Eventing control plane is installed. When using a leader election HA pattern, instances of controllers are already scheduled and running inside the cluster before they are required. These controller instances compete to use a shared resource, known as the leader election lock. The instance of the controller that has access to the leader election lock resource at any given time is called the leader.
15.2. High availability for Knative deployments
High availability (HA) is available by default for the Knative Serving activator, autoscaler, autoscaler-hpa, controller, webhook, domain-mapping, domainmapping-webhook, kourier-control, and kourier-gateway components, which are configured to have two replicas each. You can change the number of replicas for these components by modifying the spec.high-availability.replicas value in the KnativeServing custom resource (CR).
15.2.1. Configuring high availability replicas for Knative Serving
To specify three minimum replicas for the eligible deployment resources, set the value of the field spec.high-availability.replicas in the custom resource to 3.
Prerequisites
- You have cluster administrator permissions on OpenShift Container Platform, or you have cluster or dedicated administrator permissions on Red Hat OpenShift Service on AWS or OpenShift Dedicated.
- The OpenShift Serverless Operator and Knative Serving are installed on your cluster.
Procedure
-
In the OpenShift Container Platform web console Administrator perspective, navigate to OperatorHub
Installed Operators. -
Select the
knative-servingnamespace. - Click Knative Serving in the list of Provided APIs for the OpenShift Serverless Operator to go to the Knative Serving tab.
Click knative-serving, then go to the YAML tab in the knative-serving page.
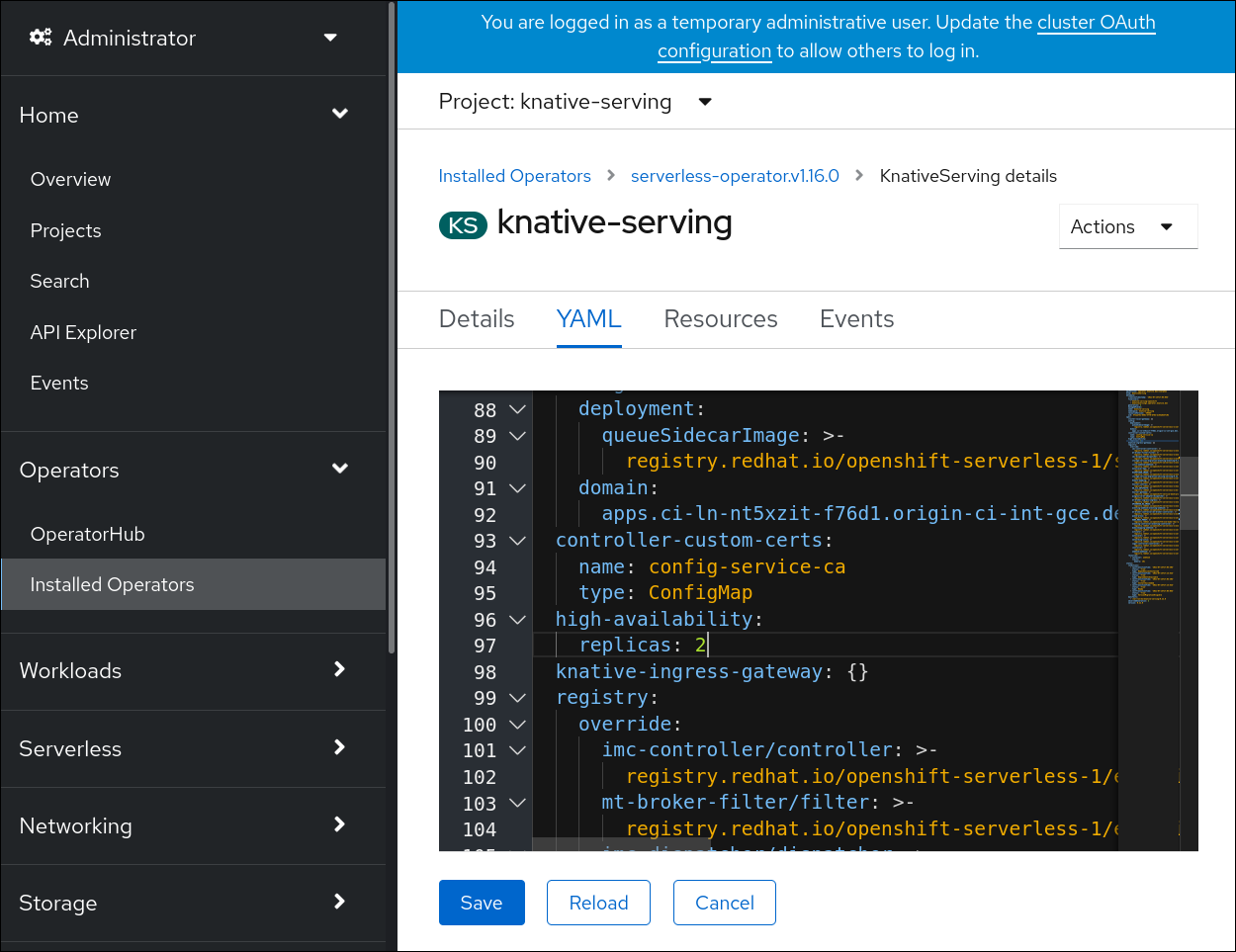
Modify the number of replicas in the
KnativeServingCR:Example YAML
apiVersion: operator.knative.dev/v1beta1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: high-availability: replicas: 3You can also specify the number of replicas for a specific workload.
NoteWorkload-specific configuration overrides the global setting for Knative Serving.
Example YAML
apiVersion: operator.knative.dev/v1beta1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: high-availability: replicas: 3 workloads: - name: webhook replicas: 4Verify that the high availability limits are respected:
Example command
$ oc get hpa -n knative-serving
Example output
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE activator Deployment/activator 0%/100% 3 22 3 2m24s webhook Deployment/webhook 2%/100% 4 8 4 2m23s
15.2.2. Overriding disruption budgets
A Pod Disruption Budget (PDB) is a standard feature of Kubernetes APIs that helps limit the disruption to an application when its pods need to be rescheduled for maintenance reasons.
Procedure
-
Override the default PDB for a specific resource by modifying the
minAvailableconfiguration value in theKnativeServingcustom resource (CR).
Example PDB with a minAvailable seting of 70%
apiVersion: operator.knative.dev/v1beta1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: podDisruptionBudgets: - name: activator-pdb minAvailable: 70%
If you disable high-availability, for example, by changing the high-availability.replicas value to 1, make sure you also update the corresponding PDB minAvailable value to 0. Otherwise, the pod disruption budget prevents automatic cluster or Operator updates.