Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 1. Kafka Bridge overview
Use the Streams for Apache Kafka Bridge to make HTTP requests to a Kafka cluster.
You can use the Kafka Bridge to integrate HTTP client applications with your Kafka cluster.
HTTP client integration
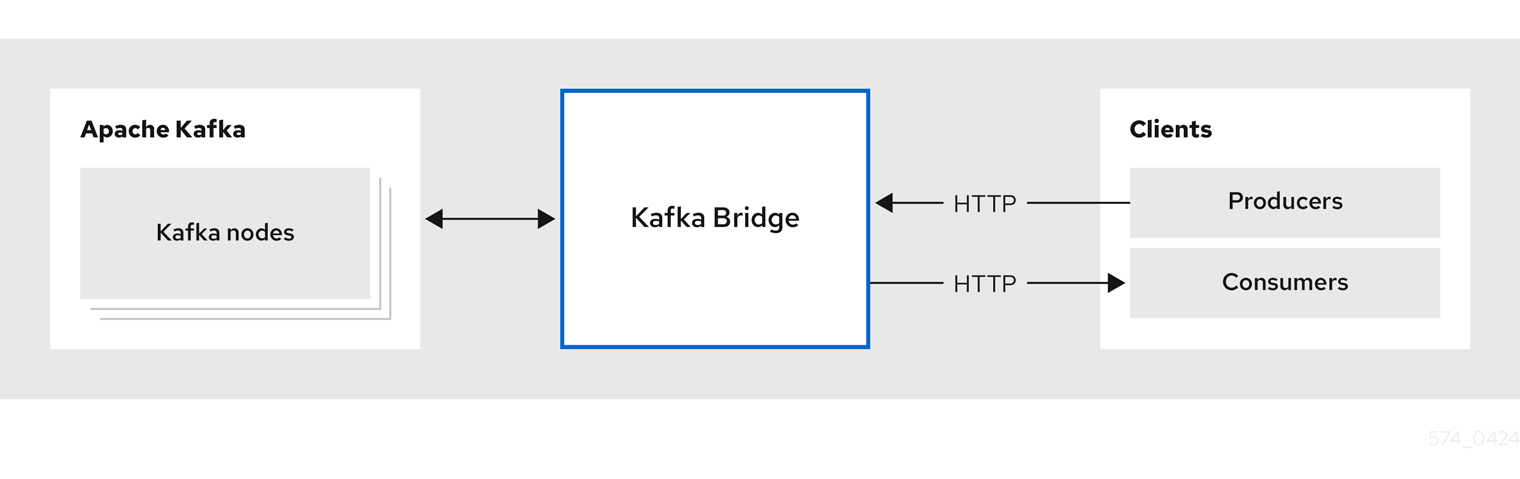
1.1. Running the Kafka Bridge
Install the Streams for Apache Kafka Bridge to run in the same environment as your Kafka cluster.
You can download and add the Kafka Bridge installation artifacts to your host machine. To try out the Kafka Bridge in your local environment, see the Kafka Bridge quickstart.
It’s important to note that each instance of the Kafka Bridge maintains its own set of in-memory consumers (and subscriptions) that connect to the Kafka Brokers on behalf of the HTTP clients. This means that each HTTP client must maintain affinity to the same Kafka Bridge instance in order to access any subscriptions that are created. Additionally, when an instance of the Kafka Bridge restarts, the in-memory consumers and subscriptions are lost. It is the responsibility of the HTTP client to recreate any consumers and subscriptions if the Kafka Bridge restarts.
1.1.1. Running the Kafka Bridge on OpenShift
If you deployed Streams for Apache Kafka on OpenShift, you can use the Streams for Apache Kafka Cluster Operator to deploy the Kafka Bridge to the OpenShift cluster. Configure and deploy the Kafka Bridge as a KafkaBridge resource. You’ll need a running Kafka cluster that was deployed by the Cluster Operator in an OpenShift namespace. You can configure your deployment to access the Kafka Bridge outside the OpenShift cluster.
HTTP clients must maintain affinity to the same instance of the Kafka Bridge to access any consumers or subscriptions that they create. Hence, running multiple replicas of the Kafka Bridge per OpenShift Deployment is not recommended. If the Kafka Bridge pod restarts (for instance, due to OpenShift relocating the workload to another node), the HTTP client must recreate any consumers or subscriptions.
For information on deploying and configuring the Kafka Bridge as a KafkaBridge resource, see the Streams for Apache Kafka documentation.
1.2. Kafka Bridge interface
The Kafka Bridge provides a RESTful interface that allows HTTP-based clients to interact with a Kafka cluster. It offers the advantages of a web API connection to Streams for Apache Kafka, without the need for client applications to interpret the Kafka protocol.
The API has two main resources — consumers and topics — that are exposed and made accessible through endpoints to interact with consumers and producers in your Kafka cluster. The resources relate only to the Kafka Bridge, not the consumers and producers connected directly to Kafka.
1.2.1. HTTP requests
The Kafka Bridge supports HTTP requests to a Kafka cluster, with methods to:
- Send messages to a topic.
- Retrieve messages from topics.
- Retrieve a list of partitions for a topic.
- Create and delete consumers.
- Subscribe consumers to topics, so that they start receiving messages from those topics.
- Retrieve a list of topics that a consumer is subscribed to.
- Unsubscribe consumers from topics.
- Assign partitions to consumers.
- Commit a list of consumer offsets.
- Seek on a partition, so that a consumer starts receiving messages from the first or last offset position, or a given offset position.
The methods provide JSON responses and HTTP response code error handling. Messages can be sent in JSON or binary formats.
Clients can produce and consume messages without the requirement to use the native Kafka protocol.
Additional resources
1.3. Kafka Bridge OpenAPI specification
Kafka Bridge APIs use the OpenAPI Specification (OAS). OAS provides a standard framework for describing and implementing HTTP APIs.
The Kafka Bridge OpenAPI specification is in JSON format. You can find the OpenAPI JSON files in the src/main/resources/ folder of the Kafka Bridge source download files. The download files are available from the Customer Portal.
You can also use the GET /openapi method to retrieve the OpenAPI v2 specification in JSON format.
Additional resources
1.4. Securing connectivity to the Kafka cluster
You can configure the following between the Kafka Bridge and your Kafka cluster:
- TLS or SASL-based authentication
- A TLS-encrypted connection
You configure the Kafka Bridge for authentication through its properties file.
You can also use ACLs in Kafka brokers to restrict the topics that can be consumed and produced using the Kafka Bridge.
Use the KafkaBridge resource to configure authentication when you are running the Kafka Bridge on OpenShift.
1.5. Securing the Kafka Bridge HTTP interface
Authentication and encryption between HTTP clients and the Kafka Bridge is not supported directly by the Kafka Bridge. Requests sent from clients to the Kafka Bridge are sent without authentication or encryption. Requests must use HTTP rather than HTTPS.
You can combine the Kafka Bridge with the following tools to secure it:
- Network policies and firewalls that define which pods can access the Kafka Bridge
- Reverse proxies (for example, OAuth 2.0)
- API gateways
1.6. Requests to the Kafka Bridge
Specify data formats and HTTP headers to ensure valid requests are submitted to the Kafka Bridge.
1.6.1. Content Type headers
API request and response bodies are always encoded as JSON.
When performing consumer operations,
POSTrequests must provide the followingContent-Typeheader if there is a non-empty body:Content-Type: application/vnd.kafka.v2+json
When performing producer operations,
POSTrequests must provideContent-Typeheaders specifying the embedded data format of the messages produced. This can be eitherjson,binaryortext.Embedded data format Content-Type header JSON
Content-Type: application/vnd.kafka.json.v2+jsonBinary
Content-Type: application/vnd.kafka.binary.v2+jsonText
Content-Type: application/vnd.kafka.text.v2+json
The embedded data format is set per consumer, as described in the next section.
The Content-Type must not be set if the POST request has an empty body. An empty body can be used to create a consumer with the default values.
1.6.2. Embedded data format
The embedded data format is the format of the Kafka messages that are transmitted, over HTTP, from a producer to a consumer using the Kafka Bridge. Three embedded data formats are supported: JSON, binary and text.
When creating a consumer using the /consumers/groupid endpoint, the POST request body must specify an embedded data format of either JSON, binary or text. This is specified in the format field, for example:
{
"name": "my-consumer",
"format": "binary", 1
# ...
}- 1
- A binary embedded data format.
The embedded data format specified when creating a consumer must match the data format of the Kafka messages it will consume.
If you choose to specify a binary embedded data format, subsequent producer requests must provide the binary data in the request body as Base64-encoded strings. For example, when sending messages using the /topics/topicname endpoint, records.value must be encoded in Base64:
{
"records": [
{
"key": "my-key",
"value": "ZWR3YXJkdGhldGhyZWVsZWdnZWRjYXQ="
},
]
}
Producer requests must also provide a Content-Type header that corresponds to the embedded data format, for example, Content-Type: application/vnd.kafka.binary.v2+json.
1.6.3. Message format
When sending messages using the /topics endpoint, you enter the message payload in the request body, in the records parameter.
The records parameter can contain any of these optional fields:
-
Message
headers -
Message
key -
Message
value -
Destination
partition
Example POST request to /topics
curl -X POST \
http://localhost:8080/topics/my-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001",
"partition": 2,
"headers": [
{
"key": "key1",
"value": "QXBhY2hlIEthZmthIGlzIHRoZSBib21iIQ==" 1
}
]
}
]
}'
- 1
- The header value in binary format and encoded as Base64.
Please note that if your consumer is configured to use the text embedded data format, the value and key field in the records parameter must be a string and not a JSON object.
1.6.4. Accept headers
After creating a consumer, all subsequent GET requests must provide an Accept header in the following format:
Accept: application/vnd.kafka.EMBEDDED-DATA-FORMAT.v2+json
The EMBEDDED-DATA-FORMAT is either json, binary or text.
For example, when retrieving records for a subscribed consumer using an embedded data format of JSON, include this Accept header:
Accept: application/vnd.kafka.json.v2+json
1.7. CORS
In general, it is not possible for an HTTP client to issue requests across different domains.
For example, suppose the Kafka Bridge you deployed alongside a Kafka cluster is accessible using the http://my-bridge.io domain. HTTP clients can use the URL to interact with the Kafka Bridge and exchange messages through the Kafka cluster. However, your client is running as a web application in the http://my-web-application.io domain. The client (source) domain is different from the Kafka Bridge (target) domain. Because of same-origin policy restrictions, requests from the client fail. You can avoid this situation by using Cross-Origin Resource Sharing (CORS).
CORS allows for simple and preflighted requests between origin sources on different domains.
Simple requests are suitable for standard requests using GET, HEAD, POST methods.
A preflighted request sends a HTTP OPTIONS request as an initial check that the actual request is safe to send. On confirmation, the actual request is sent. Preflight requests are suitable for methods that require greater safeguards, such as PUT and DELETE, and use non-standard headers.
All requests require an origins value in their header, which is the source of the HTTP request.
CORS allows you to specify allowed methods and originating URLs for accessing the Kafka cluster in your Kafka Bridge HTTP configuration.
Example CORS configuration for Kafka Bridge
# ... http.cors.enabled=true http.cors.allowedOrigins=http://my-web-application.io http.cors.allowedMethods=GET,POST,PUT,DELETE,OPTIONS,PATCH
1.7.1. Simple request
For example, this simple request header specifies the origin as http://my-web-application.io.
Origin: http://my-web-application.io
The header information is added to the request to consume records.
curl -v -X GET HTTP-BRIDGE-ADDRESS/consumers/my-group/instances/my-consumer/records \
-H 'Origin: http://my-web-application.io'\
-H 'content-type: application/vnd.kafka.v2+json'
In the response from the Kafka Bridge, an Access-Control-Allow-Origin header is returned. It contains the list of domains from where HTTP requests can be issued to the bridge.
HTTP/1.1 200 OK
Access-Control-Allow-Origin: * 1- 1
- Returning an asterisk (
*) shows the resource can be accessed by any domain.
1.7.2. Preflighted request
An initial preflight request is sent to Kafka Bridge using an OPTIONS method. The HTTP OPTIONS request sends header information to check that Kafka Bridge will allow the actual request.
Here the preflight request checks that a POST request is valid from http://my-web-application.io.
OPTIONS /my-group/instances/my-consumer/subscription HTTP/1.1 Origin: http://my-web-application.io Access-Control-Request-Method: POST 1 Access-Control-Request-Headers: Content-Type 2
OPTIONS is added to the header information of the preflight request.
curl -v -X OPTIONS -H 'Origin: http://my-web-application.io' \ -H 'Access-Control-Request-Method: POST' \ -H 'content-type: application/vnd.kafka.v2+json'
Kafka Bridge responds to the initial request to confirm that the request will be accepted. The response header returns allowed origins, methods and headers.
HTTP/1.1 200 OK Access-Control-Allow-Origin: http://my-web-application.io Access-Control-Allow-Methods: GET,POST,PUT,DELETE,OPTIONS,PATCH Access-Control-Allow-Headers: content-type
If the origin or method is rejected, an error message is returned.
The actual request does not require Access-Control-Request-Method header, as it was confirmed in the preflight request, but it does require the origin header.
curl -v -X POST HTTP-BRIDGE-ADDRESS/topics/bridge-topic \
-H 'Origin: http://my-web-application.io' \
-H 'content-type: application/vnd.kafka.v2+json'The response shows the originating URL is allowed.
HTTP/1.1 200 OK Access-Control-Allow-Origin: http://my-web-application.io
Additional resources
1.8. Configuring loggers for the Kafka Bridge
You can set a different log level for each operation that is defined by the Kafka Bridge OpenAPI specification.
Each operation has a corresponding API endpoint through which the bridge receives requests from HTTP clients. You can change the log level on each endpoint to produce more or less fine-grained logging information about the incoming and outgoing HTTP requests.
Loggers are defined in the log4j2.properties file, which has the following default configuration for healthy and ready endpoints:
logger.healthy.name = http.openapi.operation.healthy logger.healthy.level = WARN logger.ready.name = http.openapi.operation.ready logger.ready.level = WARN
The log level of all other operations is set to INFO by default. Loggers are formatted as follows:
logger.<operation_id>.name = http.openapi.operation.<operation_id> logger.<operation_id>_level = _<LOG_LEVEL>
Where <operation_id> is the identifier of the specific operation.
List of operations defined by the OpenAPI specification
-
createConsumer -
deleteConsumer -
subscribe -
unsubscribe -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
seek -
healthy -
ready -
openapi
Where <LOG_LEVEL> is the logging level as defined by log4j2 (i.e. INFO, DEBUG, …).