Questo contenuto non è disponibile nella lingua selezionata.
Chapter 3. AMQ Streams deployment of Kafka
Apache Kafka components are provided for deployment to OpenShift with the AMQ Streams distribution. The Kafka components are generally run as clusters for availability.
A typical deployment incorporating Kafka components might include:
- Kafka cluster of broker nodes
- ZooKeeper cluster of replicated ZooKeeper instances
- Kafka Connect cluster for external data connections
- Kafka MirrorMaker cluster to mirror the Kafka cluster in a secondary cluster
- Kafka Exporter to extract additional Kafka metrics data for monitoring
- Kafka Bridge to make HTTP-based requests to the Kafka cluster
Not all of these components are mandatory, though you need Kafka and ZooKeeper as a minimum. Some components can be deployed without Kafka, such as MirrorMaker or Kafka Connect.
3.1. Kafka component architecture
A cluster of Kafka brokers is main part of the Apache Kafka project responsible for delivering messages.
A broker uses Apache ZooKeeper for storing configuration data and for cluster coordination. Before running Apache Kafka, an Apache ZooKeeper cluster has to be ready.
Each of the other Kafka components interact with the Kafka cluster to perform specific roles.
Kafka component interaction
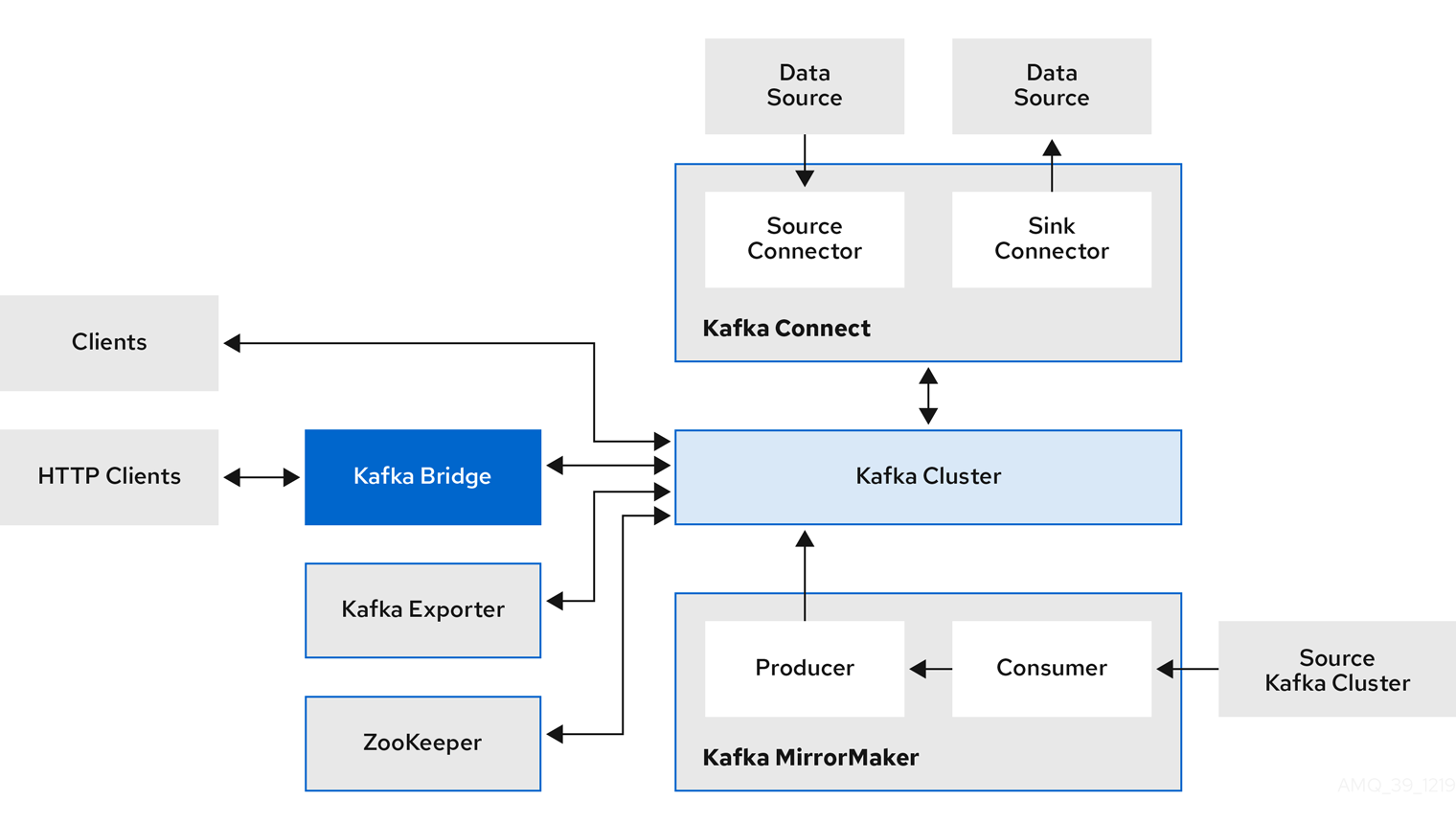
- Apache ZooKeeper
- Apache ZooKeeper is a core dependency for Kafka as it provides a cluster coordination service, storing and tracking the status of brokers and consumers. ZooKeeper is also used for leader election of partitions.
- Kafka Connect
Kafka Connect is an integration toolkit for streaming data between Kafka brokers and other systems using Connector plugins. Kafka Connect provides a framework for integrating Kafka with an external data source or target, such as a database, for import or export of data using connectors. Connectors are plugins that provide the connection configuration needed.
- A source connector pushes external data into Kafka.
A sink connector extracts data out of Kafka
External data is translated and transformed into the appropriate format.
You can deploy Kafka Connect with Source2Image support, which provides a convenient way to include connectors.
- Kafka MirrorMaker
Kafka MirrorMaker replicates data between two Kafka clusters, within or across data centers.
MirrorMaker takes messages from a source Kafka cluster and writes them to a target Kafka cluster.
- Kafka Bridge
- Kafka Bridge provides an API for integrating HTTP-based clients with a Kafka cluster.
- Kafka Exporter
- Kafka Exporter extracts data for analysis as Prometheus metrics, primarily data relating to offsets, consumer groups, consumer lag and topics. Consumer lag is the delay between the last message written to a partition and the message currently being picked up from that partition by a consumer
3.2. Kafka Bridge interface
The Kafka Bridge provides a RESTful interface that allows HTTP-based clients to interact with a Kafka cluster. It offers the advantages of a web API connection to AMQ Streams, without the need for client applications to interpret the Kafka protocol.
The API has two main resources — consumers and topics — that are exposed and made accessible through endpoints to interact with consumers and producers in your Kafka cluster. The resources relate only to the Kafka Bridge, not the consumers and producers connected directly to Kafka.
3.2.1. HTTP requests
The Kafka Bridge supports HTTP requests to a Kafka cluster, with methods to:
- Send messages to a topic.
- Retrieve messages from topics.
- Retrieve a list of partitions for a topic.
- Create and delete consumers.
- Subscribe consumers to topics, so that they start receiving messages from those topics.
- Retrieve a list of topics that a consumer is subscribed to.
- Unsubscribe consumers from topics.
- Assign partitions to consumers.
- Commit a list of consumer offsets.
- Seek on a partition, so that a consumer starts receiving messages from the first or last offset position, or a given offset position.
The methods provide JSON responses and HTTP response code error handling. Messages can be sent in JSON or binary formats.
Clients can produce and consume messages without the requirement to use the native Kafka protocol.
Additional resources
- To view the API documentation, including example requests and responses, see the Kafka Bridge API reference.
3.2.2. Supported clients for the Kafka Bridge
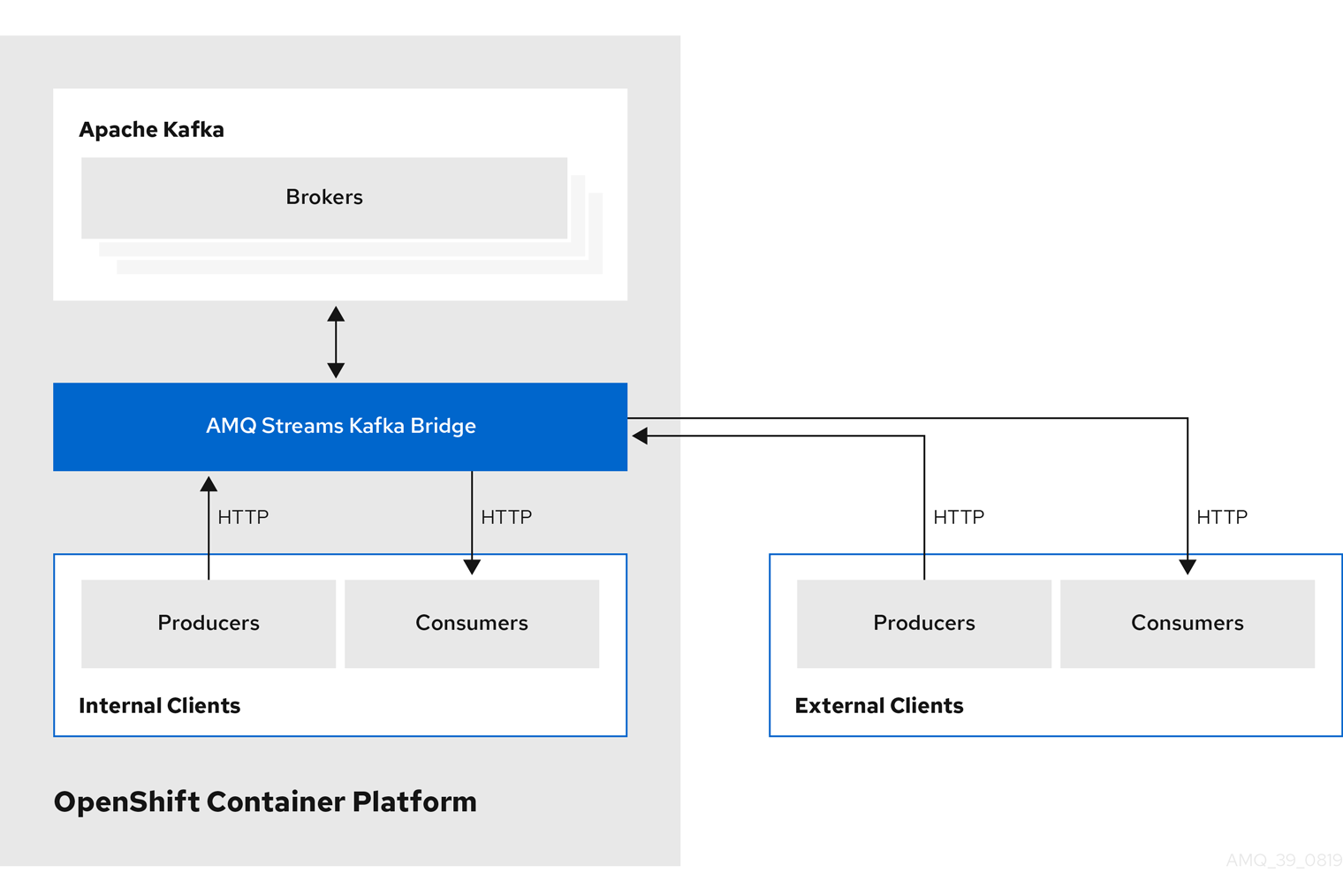
You can use the Kafka Bridge to integrate both internal and external HTTP client applications with your Kafka cluster.
- Internal clients
-
Internal clients are container-based HTTP clients running in the same OpenShift cluster as the Kafka Bridge itself. Internal clients can access the Kafka Bridge on the host and port defined in the
KafkaBridgecustom resource. - External clients
- External clients are HTTP clients running outside the OpenShift cluster in which the Kafka Bridge is deployed and running. External clients can access the Kafka Bridge through an OpenShift Route, a loadbalancer service, or using an Ingress.
HTTP internal and external client integration