Questo contenuto non è disponibile nella lingua selezionata.
Chapter 4. Ceph erasure coding
Ceph can load one of many erasure code algorithms. The earliest and most commonly used is the Reed-Solomon algorithm. An erasure code is actually a forward error correction (FEC) code. FEC code transforms a message of K chunks into a longer message called a 'code word' of N chunks, such that Ceph can recover the original message from a subset of the N chunks.
More specifically, N = K+M where the variable K is the original amount of data chunks. The variable M stands for the extra or redundant chunks that the erasure code algorithm adds to provide protection from failures. The variable N is the total number of chunks created after the erasure coding process. The value of M is simply N-K which means that the algorithm computes N-K redundant chunks from K original data chunks. This approach guarantees that Ceph can access all the original data. The system is resilient to arbitrary N-K failures. For instance, in a 10 K of 16 N configuration, or erasure coding 10/16, the erasure code algorithm adds six extra chunks to the 10 base chunks K. For example, in a M = K-N or 16-10 = 6 configuration, Ceph will spread the 16 chunks N across 16 OSDs. The original file could be reconstructed from the 10 verified N chunks even if 6 OSDs fail—ensuring that the Red Hat Ceph Storage cluster will not lose data, and thereby ensures a very high level of fault tolerance.
Like replicated pools, in an erasure-coded pool the primary OSD in the up set receives all write operations. In replicated pools, Ceph makes a deep copy of each object in the placement group on the secondary OSDs in the set. For erasure coding, the process is a bit different. An erasure coded pool stores each object as K+M chunks. It is divided into K data chunks and M coding chunks. The pool is configured to have a size of K+M so that Ceph stores each chunk in an OSD in the acting set. Ceph stores the rank of the chunk as an attribute of the object. The primary OSD is responsible for encoding the payload into K+M chunks and sends them to the other OSDs. The primary OSD is also responsible for maintaining an authoritative version of the placement group logs.
For example, in a typical configuration a system administrator creates an erasure coded pool to use six OSDs and sustain the loss of two of them. That is, (K+M = 6) such that (M = 2).
When Ceph writes the object NYAN containing ABCDEFGHIJKL to the pool, the erasure encoding algorithm splits the content into four data chunks by simply dividing the content into four parts: ABC, DEF, GHI, and JKL. The algorithm will pad the content if the content length is not a multiple of K. The function also creates two coding chunks: the fifth with YXY and the sixth with QGC. Ceph stores each chunk on an OSD in the acting set, where it stores the chunks in objects that have the same name, NYAN, but reside on different OSDs. The algorithm must preserve the order in which it created the chunks as an attribute of the object shard_t, in addition to its name. For example, Chunk 1 contains ABC and Ceph stores it on OSD5 while chunk 5 contains YXY and Ceph stores it on OSD4.
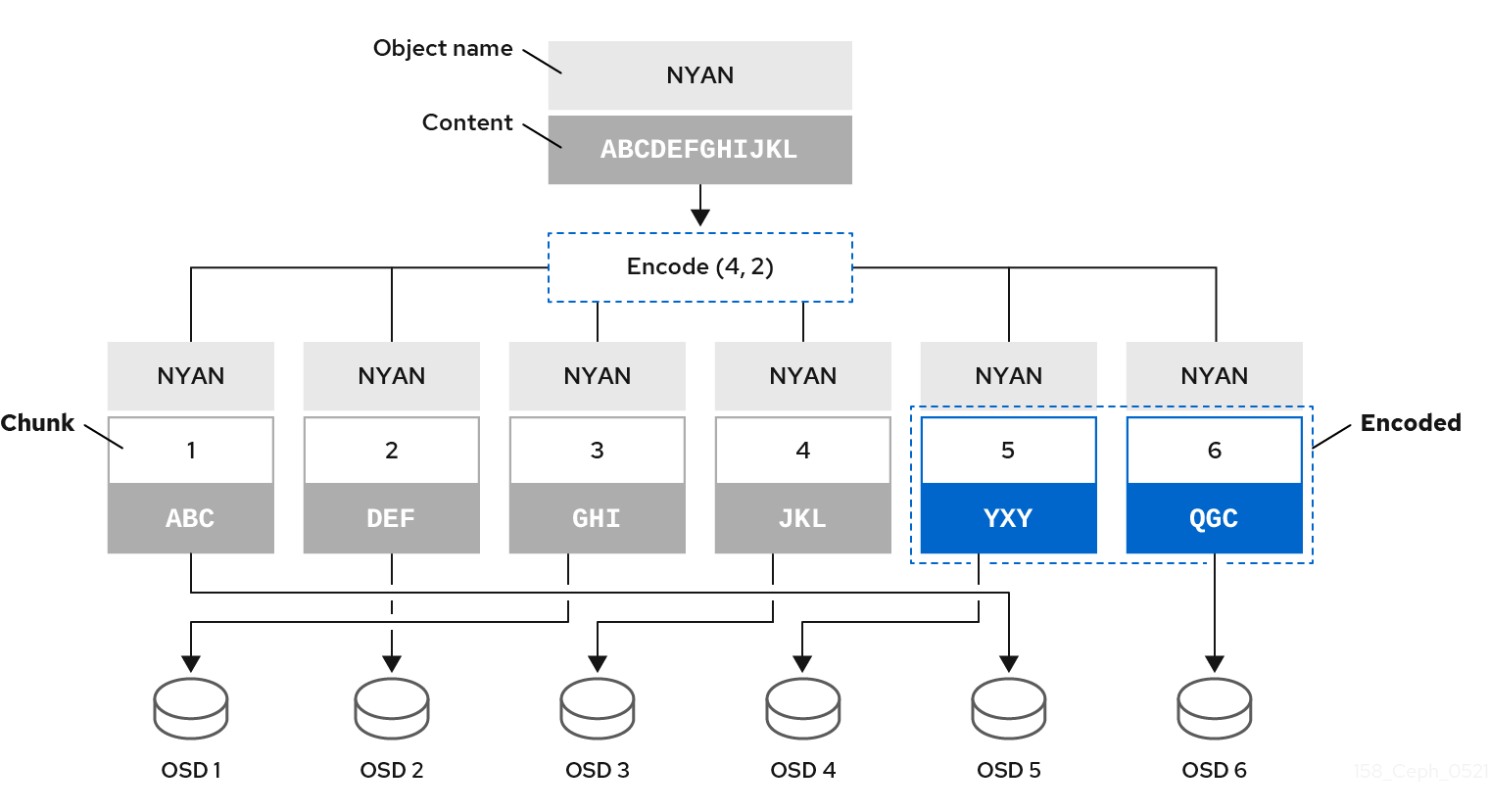
In a recovery scenario, the client attempts to read the object NYAN from the erasure-coded pool by reading chunks 1 through 6. The OSD informs the algorithm that chunks 2 and 6 are missing. These missing chunks are called 'erasures'. For example, the primary OSD could not read chunk 6 because the OSD6 is out, and could not read chunk 2, because OSD2 was the slowest and its chunk was not taken into account. However, as soon as the algorithm has four chunks, it reads the four chunks: chunk 1 containing ABC, chunk 3 containing GHI, chunk 4 containing JKL, and chunk 5 containing YXY. Then, it rebuilds the original content of the object ABCDEFGHIJKL, and original content of chunk 6, which contained QGC.
Splitting data into chunks is independent from object placement. The CRUSH ruleset along with the erasure-coded pool profile determines the placement of chunks on the OSDs. For instance, using the Locally Repairable Code (lrc) plugin in the erasure code profile creates additional chunks and requires fewer OSDs to recover from. For example, in an lrc profile configuration K=4 M=2 L=3, the algorithm creates six chunks (K+M), just as the jerasure plugin would, but the locality value (L=3) requires that the algorithm create 2 more chunks locally. The algorithm creates the additional chunks as such, (K+M)/L. If the OSD containing chunk 0 fails, this chunk can be recovered by using chunks 1, 2 and the first local chunk. In this case, the algorithm only requires 3 chunks for recovery instead of 5.
Using erasure-coded pools disables Object Map.
For an erasure-coded pool with 2+2 configuration, replace the input string from ABCDEFGHIJKL to ABCDEF and replace the coding chunks from 4 to 2.
MSR is abbreviation for "Multi-Step Retry (MSR)". It is a kind of CRUSH rule in Ceph cluster, that defines how data is distributed across storage devices, ensuring efficient data retrieval, balancing, and fault tolerance.
Additional Resources
- For more information about CRUSH, the erasure-coding profiles, and plugins, see the Storage Strategies Guide for Red Hat Ceph Storage 8.
- For more details on Object Map, see the Ceph client object map section.