Questo contenuto non è disponibile nella lingua selezionata.
Chapter 12. Configuring Debezium connectors for your application
When the default Debezium connector behavior is not right for your application, you can use the following Debezium features to configure the behavior you need.
- Kafka Connect automatic topic creation
- Enables Connect to create topics at runtime, and apply configuration settings to those topics based on their names.
- Avro serialization
- Support for configuring Debezium PostgreSQL, MongoDB, or SQL Server connectors to use Avro to serialize message keys and value, making it easier for change event record consumers to adapt to a changing record schema.
- xref:configuring-notifications-to-report-connector-status
- Provides a mechanism to expose status information about a connector through a configurable set of channels.
- CloudEvents converter
- Enables a Debezium connector to emit change event records that conform to the CloudEvents specification.
- Sending signals to a Debezium connector
- Provides a way to modify the behavior of a connector, or trigger an action, such as initiating an ad hoc snapshot.
12.1. Customization of Kafka Connect automatic topic creation
Kafka provides two mechanisms for creating topics automatically. You can enable automatic topic creation for the Kafka broker, and, beginning with Kafka 2.6.0, you can also enable Kafka Connect to create topics. The Kafka broker uses the auto.create.topics.enable property to control automatic topic creation. In Kafka Connect, the topic.creation.enable property specifies whether Kafka Connect is permitted to create topics. In both cases, the default settings for the properties enables automatic topic creation.
When automatic topic creation is enabled, if a Debezium source connector emits a change event record for a table for which no target topic already exists, the topic is created at runtime as the event record is ingested into Kafka.
Differences between automatic topic creation at the broker and in Kafka Connect
Topics that the broker creates are limited to sharing a single default configuration. The broker cannot apply unique configurations to different topics or sets of topics. By contrast, Kafka Connect can apply any of several configurations when creating topics, setting the replication factor, number of partitions, and other topic-specific settings as specified in the Debezium connector configuration. The connector configuration defines a set of topic creation groups, and associates a set of topic configuration properties with each group.
The broker configuration and the Kafka Connect configuration are independent of each other. Kafka Connect can create topics regardless of whether you disable topic creation at the broker. If you enable automatic topic creation at both the broker and in Kafka Connect, the Connect configuration takes precedence, and the broker creates topics only if none of the settings in the Kafka Connect configuration apply.
See the following topics for more information:
- Section 12.1.1, “Disabling automatic topic creation for the Kafka broker”
- Section 12.1.2, “Configuring automatic topic creation in Kafka Connect”
- Section 12.1.3, “Configuration of automatically created topics”
- Section 12.1.3.1, “Topic creation groups”
- Section 12.1.3.2, “Topic creation group configuration properties”
- Section 12.1.3.3, “Specifying the configuration for the Debezium default topic creation group”
- Section 12.1.3.4, “Specifying the configuration for Debezium custom topic creation groups”
- Section 12.1.3.5, “Registering Debezium custom topic creation groups”
12.1.1. Disabling automatic topic creation for the Kafka broker
By default, the Kafka broker configuration enables the broker to create topics at runtime if the topics do not already exist. Topics created by the broker cannot be configured with custom properties. If you use a Kafka version earlier than 2.6.0, and you want to create topics with specific configurations, you must to disable automatic topic creation at the broker, and then explicitly create the topics, either manually, or through a custom deployment process.
Procedure
-
In the broker configuration, set the value of
auto.create.topics.enabletofalse.
12.1.2. Configuring automatic topic creation in Kafka Connect
Automatic topic creation in Kafka Connect is controlled by the topic.creation.enable property. The default value for the property is true, enabling automatic topic creation, as shown in the following example:
topic.creation.enable = true
topic.creation.enable = true
The setting for the topic.creation.enable property applies to all workers in the Connect cluster.
Kafka Connect automatic topic creation requires you to define the configuration properties that Kafka Connect applies when creating topics. You specify topic configuration properties in the Debezium connector configuration by defining topic groups, and then specifying the properties to apply to each group. The connector configuration defines a default topic creation group, and, optionally, one or more custom topic creation groups. Custom topic creation groups use lists of topic name patterns to specify the topics to which the group’s settings apply.
For details about how Kafka Connect matches topics to topic creation groups, see Topic creation groups. For more information about how configuration properties are assigned to groups, see Topic creation group configuration properties.
By default, topics that Kafka Connect creates are named based on the pattern server.schema.table, for example, dbserver.myschema.inventory.
Procedure
-
To prevent Kafka Connect from creating topics automatically, set the value of
topic.creation.enabletofalsein the Kafka Connect custom resource, as in the following example:
Kafka Connect automatic topic creation requires the replication.factor and partitions properties to be set for at least the default topic creation group. It is valid for groups to obtain the values for the required properties from the default values for the Kafka broker.
12.1.3. Configuration of automatically created topics
For Kafka Connect to create topics automatically, it requires information from the source connector about the configuration properties to apply when creating topics. You define the properties that control topic creation in the configuration for each Debezium connector. As Kafka Connect creates topics for event records that a connector emits, the resulting topics obtain their configuration from the applicable group. The configuration applies to event records emitted by that connector only.
12.1.3.1. Topic creation groups
A set of topic properties is associated with a topic creation group. Minimally, you must define a default topic creation group and specify its configuration properties. Beyond that you can optionally define one or more custom topic creation groups and specify unique properties for each.
When you create custom topic creation groups, you define the member topics for each group based on topic name patterns. You can specify naming patterns that describe the topics to include or exclude from each group. The include and exclude properties contain comma-separated lists of regular expressions that define topic name patterns. For example, if you want a group to include all topics that start with the string dbserver1.inventory, set the value of its topic.creation.inventory.include property to dbserver1\\.inventory\\.*.
If you specify both include and exclude properties for a custom topic group, the exclusion rules take precedence, and override the inclusion rules.
12.1.3.2. Topic creation group configuration properties
The default topic creation group and each custom group is associated with a unique set of configuration properties. You can configure a group to include any of the Kafka topic-level configuration properties. For example, you can specify the cleanup policy for old topic segments, retention time, or the topic compression type for a topic group. You must define at least a minimum set of properties to describe the configuration of the topics to be created.
If no custom groups are registered, or if the include patterns for any registered groups don’t match the names of any topics to be created, then Kafka Connect uses the configuration of the default group to create topics.
For general information about configuring topics, see Kafka topic creation recommendations in Installing Debezium on OpenShift.
12.1.3.3. Specifying the configuration for the Debezium default topic creation group
Before you can use Kafka Connect automatic topic creation, you must create a default topic creation group and define a configuration for it. The configuration for the default topic creation group is applied to any topics with names that do not match the include list pattern of a custom topic creation group.
Prerequisites
In the Kafka Connect custom resource, the
use-connector-resourcesvalue inmetadata.annotationsspecifies that the cluster Operator uses KafkaConnector custom resources to configure connectors in the cluster. For example:... metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" ...... metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Procedure
To define properties for the
topic.creation.defaultgroup, add them tospec.configin the connector custom resource, as shown in the following example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can include any Kafka topic-level configuration property in the configuration for the
defaultgroup.
| Item | Description |
|---|---|
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
Custom groups fall back to the default group settings only for the required replication.factor and partitions properties. If the configuration for a custom topic group leaves other properties undefined, the values specified in the default group are not applied.
12.1.3.4. Specifying the configuration for Debezium custom topic creation groups
You can define multiple custom topic groups, each with its own configuration.
Procedure
To define a custom topic group, add a
topic.creation.<group_name>.includeproperty tospec.configin the connector custom resource, followed by the configuration properties that you want to apply to topics in the custom group.The following example shows an excerpt of a custom resource that defines the custom topic creation groups
inventoryandapplicationlogs:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
| Item | Description |
|---|---|
| 1 |
Defines the configuration for the |
| 2 |
|
| 3 |
Defines the configuration for the |
| 4 |
|
| 5 |
|
12.1.3.5. Registering Debezium custom topic creation groups
After you specify the configuration for any custom topic creation groups, register the groups.
Procedure
Register custom groups by adding the
topic.creation.groupsproperty to the connector custom resource, and specifying a comma-separated list of custom topic creation groups.The following excerpt from a connector custom resource registers the custom topic creation groups
inventoryandapplicationlogs:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Completed configuration
The following example shows a completed configuration that includes the configuration for a default topic group, along with the configurations for an inventory and an applicationlogs custom topic creation group:
Example: Configuration for a default topic creation group and two custom groups
12.2. Configuring Debezium connectors to use Avro serialization
A Debezium connector works in the Kafka Connect framework to capture each row-level change in a database by generating a change event record. For each change event record, the Debezium connector completes the following actions:
- Applies configured transformations.
- Serializes the record key and value into a binary form by using the configured Kafka Connect converters.
- Writes the record to the correct Kafka topic.
You can specify converters for each individual Debezium connector instance. Kafka Connect provides a JSON converter that serializes the record keys and values into JSON documents. The default behavior is that the JSON converter includes the record’s message schema, which makes each record very verbose. The Getting Started with Debezium guide shows what the records look like when both payload and schemas are included. If you want records to be serialized with JSON, consider setting the following connector configuration properties to false:
-
key.converter.schemas.enable -
value.converter.schemas.enable
Setting these properties to false excludes the verbose schema information from each record.
Alternatively, you can serialize the record keys and values by using Apache Avro. The Avro binary format is compact and efficient. Avro schemas make it possible to ensure that each record has the correct structure. Avro’s schema evolution mechanism enables schemas to evolve. This is essential for Debezium connectors, which dynamically generate each record’s schema to match the structure of the database table that was changed. Over time, change event records written to the same Kafka topic might have different versions of the same schema. Avro serialization makes it easier for the consumers of change event records to adapt to a changing record schema.
To use Apache Avro serialization, you must deploy a schema registry that manages Avro message schemas and their versions. For information about setting up this registry, see the documentation for Installing and deploying Service Registry on OpenShift.
12.2.1. About the Service Registry
Service Registry
Service Registry provides the following components that work with Avro:
- An Avro converter that you can specify in Debezium connector configurations. This converter maps Kafka Connect schemas to Avro schemas. The converter then uses the Avro schemas to serialize the record keys and values into Avro’s compact binary form.
An API and schema registry that tracks:
- Avro schemas that are used in Kafka topics.
- Where the Avro converter sends the generated Avro schemas.
Because the Avro schemas are stored in this registry, each record needs to contain only a tiny schema identifier. This makes each record even smaller. For an I/O bound system like Kafka, this means more total throughput for producers and consumers.
- Avro Serdes (serializers and deserializers) for Kafka producers and consumers. Kafka consumer applications that you write to consume change event records can use Avro Serdes to deserialize the change event records.
To use the Service Registry with Debezium, add Service Registry converters and their dependencies to the Kafka Connect container image that you are using for running a Debezium connector.
The Service Registry project also provides a JSON converter. This converter combines the advantage of less verbose messages with human-readable JSON. Messages do not contain the schema information themselves, but only a schema ID.
To use converters provided by Service Registry you need to provide apicurio.registry.url.
12.2.2. Overview of deploying a Debezium connector that uses Avro serialization
To deploy a Debezium connector that uses Avro serialization, you must complete three main tasks:
- Deploy a Service Registry instance by following the instructions in Installing and deploying Service Registry on OpenShift.
- Install the Avro converter by downloading the Debezium Service Registry Kafka Connect zip file and extracting it into the Debezium connector’s directory.
Configure a Debezium connector instance to use Avro serialization by setting configuration properties as follows:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Internally, Kafka Connect always uses JSON key/value converters for storing configuration and offsets.
12.2.3. Deploying connectors that use Avro in Debezium containers
In your environment, you might want to use a provided Debezium container to deploy Debezium connectors that use Avro serialization. Complete the following procedure to build a custom Kafka Connect container image for Debezium, and configure the Debezium connector to use the Avro converter.
Prerequisites
- You have Docker installed and sufficient rights to create and manage containers.
- You downloaded the Debezium connector plug-in(s) that you want to deploy with Avro serialization.
Procedure
Deploy an instance of Service Registry. See Installing and deploying Service Registry on OpenShift, which provides instructions for:
- Installing Service Registry
- Installing AMQ Streams
- Setting up AMQ Streams storage
Extract the Debezium connector archives to create a directory structure for the connector plug-ins. If you downloaded and extracted the archives for multiple Debezium connectors, the resulting directory structure looks like the one in the following example:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the Avro converter to the directory that contains the Debezium connector that you want to configure to use Avro serialization:
- Go to the Red Hat Integration download site and download the Service Registry Kafka Connect zip file.
- Extract the archive into the desired Debezium connector directory.
To configure more than one type of Debezium connector to use Avro serialization, extract the archive into the directory for each relevant connector type. Although extracting the archive to each directory duplicates the files, by doing so you remove the possibility of conflicting dependencies.
Create and publish a custom image for running Debezium connectors that are configured to use the Avro converter:
Create a new
Dockerfileby usingregistry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0as the base image. In the following example, replace my-plugins with the name of your plug-ins directory:FROM registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001
FROM registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001Copy to Clipboard Copied! Toggle word wrap Toggle overflow Before Kafka Connect starts running the connector, Kafka Connect loads any third-party plug-ins that are in the
/opt/kafka/pluginsdirectory.Build the docker container image. For example, if you saved the docker file that you created in the previous step as
debezium-container-with-avro, then you would run the following command:docker build -t debezium-container-with-avro:latestPush your custom image to your container registry, for example:
docker push <myregistry.io>/debezium-container-with-avro:latestPoint to the new container image. Do one of the following:
Edit the
KafkaConnect.spec.imageproperty of theKafkaConnectcustom resource. If set, this property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator. For example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
In the
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlfile, edit theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable to point to the new container image and reinstall the Cluster Operator. If you edit this file you will need to apply it to your OpenShift cluster.
Deploy each Debezium connector that is configured to use the Avro converter. For each Debezium connector:
Create a Debezium connector instance. The following
inventory-connector.yamlfile example creates aKafkaConnectorcustom resource that defines a MySQL connector instance that is configured to use the Avro converter:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apply the connector instance, for example:
oc apply -f inventory-connector.yamlThis registers
inventory-connectorand the connector starts to run against theinventorydatabase.
Verify that the connector was created and has started to track changes in the specified database. You can verify the connector instance by watching the Kafka Connect log output as, for example,
inventory-connectorstarts.Display the Kafka Connect log output:
oc logs $(oc get pods -o name -l strimzi.io/name=my-connect-cluster-connect)
oc logs $(oc get pods -o name -l strimzi.io/name=my-connect-cluster-connect)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Review the log output to verify that the initial snapshot has been executed. You should see something like the following lines:
... 2020-02-21 17:57:30,801 INFO Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&connectTimeout=30000 with user 'debezium' with locking mode 'minimal' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,805 INFO Snapshot is using user 'debezium' with these MySQL grants: (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...
... 2020-02-21 17:57:30,801 INFO Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&connectTimeout=30000 with user 'debezium' with locking mode 'minimal' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,805 INFO Snapshot is using user 'debezium' with these MySQL grants: (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow Taking the snapshot involves a number of steps:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow After completing the snapshot, Debezium begins tracking changes in, for example, the
inventorydatabase’sbinlogfor change events:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.2.4. About Avro name requirements
As stated in the Avro documentation, names must adhere to the following rules:
-
Start with
[A-Za-z_] -
Subsequently contains only
[A-Za-z0-9_]characters
Debezium uses the column’s name as the basis for the corresponding Avro field. This can lead to problems during serialization if the column name does not also adhere to the Avro naming rules. Each Debezium connector provides a configuration property, field.name.adjustment.mode that you can set to avro if you have columns that do not adhere to Avro rules for names. Setting field.name.adjustment.mode to avro allows serialization of non-conformant fields without having to actually modify your schema.
12.3. Emitting Debezium change event records in CloudEvents format
CloudEvents is a specification for describing event data in a common way. Its aim is to provide interoperability across services, platforms and systems. Debezium enables you to configure a MongoDB, MySQL, PostgreSQL, or SQL Server connector to emit change event records that conform to the CloudEvents specification.
Emitting change event records in CloudEvents format is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
The CloudEvents specification defines:
- A set of standardized event attributes
- Rules for defining custom attributes
- Encoding rules for mapping event formats to serialized representations such as JSON or Avro
- Protocol bindings for transport layers such as Apache Kafka, HTTP or AMQP
To configure a Debezium connector to emit change event records that conform to the CloudEvents specification, Debezium provides the io.debezium.converters.CloudEventsConverter, which is a Kafka Connect message converter.
Currently, only structured mapping mode is supported. The CloudEvents change event envelope can be JSON or Avro and each envelope type supports JSON or Avro as the data format. It is expected that a future Debezium release will support binary mapping mode.
Information about emitting change events in CloudEvents format is organized as follows:
For information about using Avro, see:
12.3.1. Example Debezium change event records in CloudEvents format
The following example shows what a CloudEvents change event record emitted by a PostgreSQL connector looks like. In this example, the PostgreSQL connector is configured to use JSON as the CloudEvents format envelope and also as the data format.
- 1 1 1
- Unique ID that the connector generates for the change event based on the change event’s content.
- 2 2 2
- The source of the event, which is the logical name of the database as specified by the
topic.prefixproperty in the connector’s configuration. - 3 3 3
- The CloudEvents specification version.
- 4 4 4
- Connector type that generated the change event. The format of this field is
io.debezium.CONNECTOR_TYPE.datachangeevent. The value ofCONNECTOR_TYPEismongodb,mysql,postgresql, orsqlserver. - 5 5
- Time of the change in the source database.
- 6
- Describes the content type of the
dataattribute, which is JSON in this example. The only alternative is Avro. - 7
- An operation identifier. Possible values are
rfor read,cfor create,ufor update, ordfor delete. - 8
- All
sourceattributes that are known from Debezium change events are mapped to CloudEvents extension attributes by using theiodebeziumprefix for the attribute name. - 9
- When enabled in the connector, each
transactionattribute that is known from Debezium change events is mapped to a CloudEvents extension attribute by using theiodebeziumtxprefix for the attribute name. - 10
- The actual data change itself. Depending on the operation and the connector, the data might contain
before,afterand/orpatchfields.
The following example also shows what a CloudEvents change event record emitted by a PostgreSQL connector looks like. In this example, the PostgreSQL connector is again configured to use JSON as the CloudEvents format envelope, but this time the connector is configured to use Avro for the data format.
It is also possible to use Avro for the envelope as well as the data attribute.
12.3.2. Example of configuring Debezium CloudEvents converter
Configure io.debezium.converters.CloudEventsConverter in your Debezium connector configuration. The following example shows how to configure the CloudEvents converter to emit change event records that have the following characteristics:
- Use JSON as the envelope.
-
Use the schema registry at
http://my-registry/schemas/ids/1to serialize thedataattribute as binary Avro data.
- 1
- Specifying the
serializer.typeis optional, becausejsonis the default.
The CloudEvents converter converts Kafka record values. In the same connector configuration, you can specify key.converter if you want to operate on record keys. For example, you might specify StringConverter, LongConverter, JsonConverter, or AvroConverter.
12.3.3. Debezium CloudEvents converter configuration options
When you configure a Debezium connector to use the CloudEvent converter you can specify the following options.
| Option | Default | Description |
|
|
The encoding type to use for the CloudEvents envelope structure. The value can be | |
|
|
The encoding type to use for the | |
| N/A |
Any configuration options to be passed through to the underlying converter when using JSON. The | |
| N/A |
Any configuration options to be passed through to the underlying converter when using Avro. The | |
| none |
Specifies how schema names should be adjusted for compatibility with the message converter used by the connector. The value can be |
12.4. Configuring notifications to report connector status
Debezium notifications provide a mechanism to obtain status information about the connector. Notifications can be sent to the following channels:
- SinkNotificationChannel
- Sends notifications through the Connect API to a configured topic.
- LogNotificationChannel
- Notifications are appended to the log.
- JmxNotificationChannel
- Notifications are exposed as an attribute in a JMX bean.
- For details about Debezium notifications, see the following topics
12.4.1. Description of the format of Debezium notifications
Notification messages contain the following information:
| Property | Description |
|---|---|
| id |
A unique identifier that is assigned to the notification. For incremental snapshot notifications, the |
| aggregate_type | The data type of the aggregate root to which a notification is related. In domain-driven design, exported events should always refer to an aggregate. |
| type |
Provides status information about the event specified in the |
| additional_data | A Map<String,String> with detailed information about the notification. For an example, see Debezium notifications about the progress of incremental snapshots. |
12.4.2. Types of Debezium notifications
Debezium notifications deliver information about the progress of initial snapshots or incremental snapshots.
Debezium notifications about the status of an initial snapshot
The following example shows a typical notification that provides the status of an initial snapshot:
{
"id": "5563ae14-49f8-4579-9641-c1bbc2d76f99",
"aggregate_type": "Initial Snapshot",
"type": "COMPLETED"
}
{
"id": "5563ae14-49f8-4579-9641-c1bbc2d76f99",
"aggregate_type": "Initial Snapshot",
"type": "COMPLETED"
}- 1
- The type field can contain one of the following values:
-
COMPLETED -
ABORTED -
SKIPPED
-
12.4.2.1. Example: Debezium notifications that report on the progress of incremental snapshots
The following table shows examples of the different payloads that might be present in notifications that report the status of incremental snapshots:
| Status | Payload |
|---|---|
| Start |
|
| Paused |
|
| Resumed |
|
| Stopped |
|
| Processing chunk |
|
| Snapshot completed for a table |
|
| Completed |
|
12.4.3. Enabling Debezium to emit events to notification channels
To enable Debezium to emit notifications, specify a list of notification channels by setting the notification.enabled.channels configuration property. By default, the following notification channels are available:
-
sink -
log -
jmx
To use the sink notification channel, you must also set the notification.sink.topic.name configuration property to the name of the topic where you want Debezium to send notifications.
12.4.3.1. Enabling Debezium notifications to report events exposed through JMX beans
To enable Debezium to report events that are exposed through JMX beans, complete the following configuration steps:
- Enable the JMX MBean Server to expose the notification bean.
-
Add
jmxto thenotification.enabled.channelsproperty in the connector configuration. - Connect your preferred JMX client to the MBean Server.
Notifications are exposed through the Notifications attribute of a bean with the name debezium.<connector-type>.management.notifications.<server>.
The following image shows a notification that reports the start of an incremental snapshot:
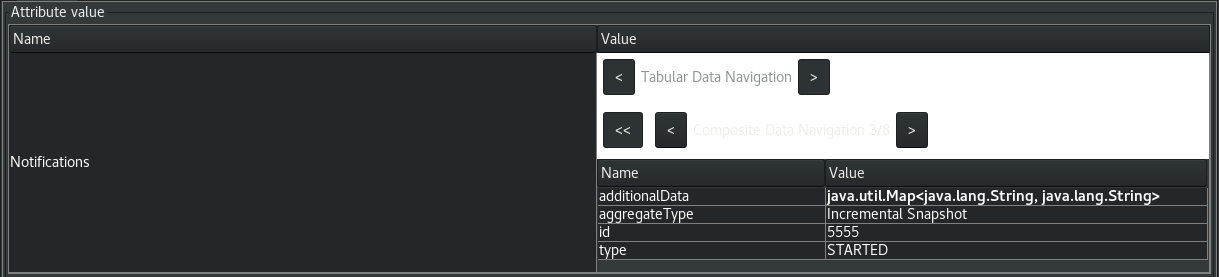
To discard a notification, call the reset operation on the bean.
The notifications are also exposed as a JMX notification with type debezium.notification. To enable an application to listen for the JMX notifications that an MBean emits, subscribe the application to the notifications.
12.5. Sending signals to a Debezium connector
The Debezium signaling mechanism provides a way to modify the behavior of a connector, or to trigger a one-time action, such as initiating an ad hoc snapshot of a table. To use signals to trigger a connector to perform a specified action, you can configure the connector to use one or more of the following channels:
- SourceSignalChannel
- You can issue a SQL command to add a signal message to a specialized signaling data collection. The signaling data collection, which you create on the source database, is designated exclusively for communicating with Debezium.
- KafkaSignalChannel
- You submit signal messages to a configurable Kafka topic.
- JmxSignalChannel
-
You submit signals through the JMX
signaloperation. When Debezium detects that a new logging record or ad hoc snapshot record is added to the channel, it reads the signal, and initiates the requested operation.
Signaling is available for use with the following Debezium connectors:
- Db2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
You can specify which channel is enabled by setting the signal.enabled.channels configuration property. The property lists the names of the channels that are enabled. By default, Debezium provides the following channels: source and kafka. The source channel is enabled by default, because it is required for incremental snapshot signals.
12.5.1. Enabling Debezium source signaling channel
By default, the Debezium source signaling channel is enabled.
You must explicitly configure signaling for each connector that you want to use it with.
Procedure
- On the source database, create a signaling data collection table for sending signals to the connector. For information about the required structure of the signaling data collection, see Structure of a signaling data collection.
- For source databases such as Db2 or SQL Server that implement a native change data capture (CDC) mechanism, enable CDC for the signaling table.
Add the name of the signaling data collection to the Debezium connector configuration.
In the connector configuration, add the propertysignal.data.collection, and set its value to the fully-qualified name of the signaling data collection that you created in Step 1.
For example,signal.data.collection = inventory.debezium_signals.
The format for the fully-qualified name of the signaling collection depends on the connector.
The following example shows the naming formats to use for each connector:- Db2
-
<schemaName>.<tableName> - MongoDB
-
<databaseName>.<collectionName> - MySQL
-
<databaseName>.<tableName> - Oracle
-
<databaseName>.<schemaName>.<tableName> - PostgreSQL
-
<schemaName>.<tableName> - SQL Server
-
<databaseName>.<schemaName>.<tableName>
For more information about setting thesignal.data.collectionproperty, see the table of configuration properties for your connector.
12.5.1.1. Required structure of a Debezium signaling data collection
A signaling data collection, or signaling table, stores signals that you send to a connector to trigger a specified operation. The structure of the signaling table must conform to the following standard format.
- Contains three fields (columns).
- Fields are arranged in a specific order, as shown in Table 1.
| Field | Type | Description |
|---|---|---|
|
|
|
An arbitrary unique string that identifies a signal instance. |
|
|
|
Specifies the type of signal to send. |
|
|
|
Specifies JSON-formatted parameters to pass to a signal action. |
The field names in a data collection are arbitrary. The preceding table provides suggested names. If you use a different naming convention, ensure that the values in each field are consistent with the expected content.
12.5.1.2. Creating a Debezium signaling data collection
You create a signaling table by submitting a standard SQL DDL query to the source database.
Prerequisites
- You have sufficient access privileges to create a table on the source database.
Procedure
-
Submit a SQL query to the source database to create a table that is consistent with the required structure, as shown in the following example:
CREATE TABLE <tableName> (id VARCHAR(<varcharValue>) PRIMARY KEY, type VARCHAR(<varcharValue>) NOT NULL, data VARCHAR(<varcharValue>) NULL);
The amount of space that you allocate to the VARCHAR parameter of the id variable must be sufficient to accommodate the size of the ID strings of signals sent to the signaling table.
If the size of an ID exceeds the available space, the connector cannot process the signal.
The following example shows a CREATE TABLE command that creates a three-column debezium_signal table:
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);12.5.2. Enabling the Debezium Kafka signaling channel
You can enable the Kafka signaling channel by adding it to the signal.enabled.channels configuration property, and then adding the name of the topic that receives signals to the signal.kafka.topic property. After you enable the signaling channel, a Kafka consumer is created to consume signals that are sent to the configured signal topic.
Additional configuration available for the consumer
- Db2 connector Kafka signal configuration properties
- MongoDB connector Kafka signal configuration properties
- MySQL connector Kafka signal configuration properties
- Oracle connector Kafka signal configuration properties
- PostgreSQL connector Kafka signal configuration properties
- SQL Server connector Kafka signal configuration properties
To use Kafka signaling to trigger ad hoc incremental snapshots for a connector, you must first enable a source signaling channel in the connector configuration. The source channel implements a watermarking mechanism to deduplicate events that might be captured by an incremental snapshot and then captured again after streaming resumes.
Message format
The key of the Kafka message must match the value of the topic.prefix connector configuration option.
The value is a JSON object with type and data fields.
When the signal type is set to execute-snapshot, the data field must include the fields that are listed in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
The type of the snapshot to run. Currently Debezium supports only the |
|
| N/A |
An array of comma-separated regular expressions that match the fully-qualified names of the tables to include in the snapshot. |
|
| N/A | An optional string that specifies a condition that the connector evaluates to designate a subset of records to include in a snapshot. |
The following example shows a typical execute-snapshot Kafka message:
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`12.5.3. Enabling the Debezium JMX signaling channel
You can enable the JMX signaling by adding jmx to the signal.enabled.channels property in the connector configuration, and then enabling the JMX MBean Server to expose the signaling bean.
Procedure
- Use your preferred JMX client (for example. JConsole or JDK Mission Control) to connect to the MBean server.
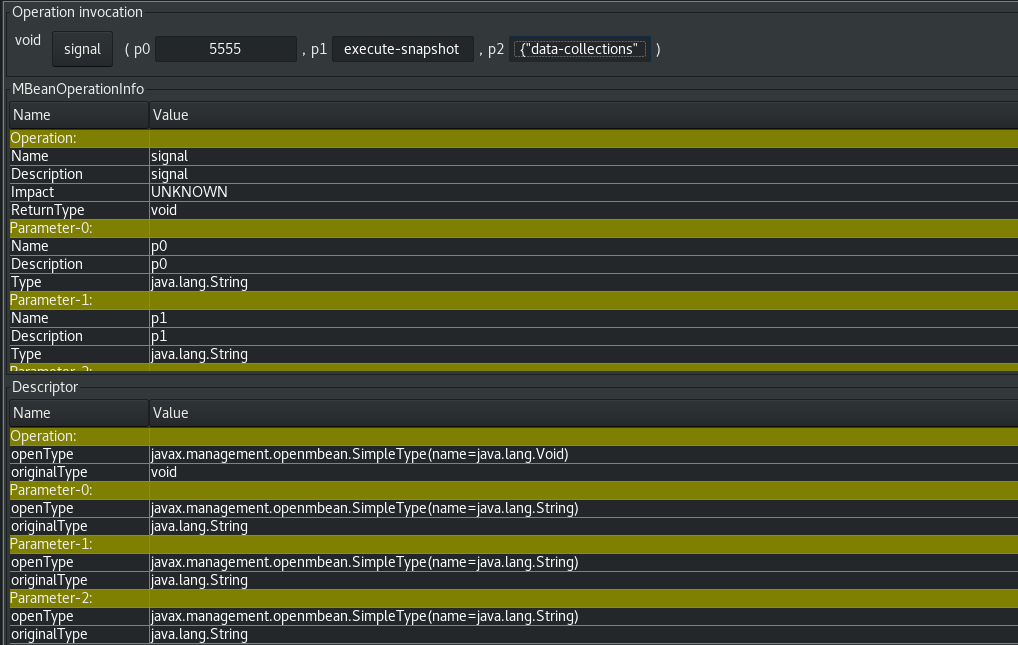
Search for the Mbean
debezium.<connector-type>.management.signals.<server>. The Mbean exposessignaloperations that accept the following input parameters:- p0
- The id of the signal.
- p1
-
The type of the signal, for example,
execute-snapshot. - p2
- A JSON data field that contains additional information about the specified signal type.
Send an
execute-snapshotsignal by providing value for the input parameters.
In the JSON data field, include the information that is listed in the following table:Expand Table 12.6. Execute snapshot data fields Field Default Value typeincrementalThe type of the snapshot to run. Currently Debezium supports only the
incrementaltype.data-collectionsN/A
An array of comma-separated regular expressions that match the fully-qualified names of the tables to include in the snapshot.
Specify the names by using the same format as is required for the signal.data.collection configuration option.additional-conditionN/A
An optional string that specifies a condition that the connector evaluates to designate a subset of records to include in a snapshot.
The following image shows an example of how to use JConsole to send a signal:
12.5.4. Types of Debezium signal actions
You can use signaling to initiate the following actions:
Some signals are not compatible with all connectors.
12.5.4.1. Logging signals
You can request a connector to add an entry to the log by creating a signaling table entry with the log signal type. After processing the signal, the connector prints the specified message to the log. Optionally, you can configure the signal so that the resulting message includes the streaming coordinates.
| Column | Value | Description |
|---|---|---|
| id |
| |
| type |
| The action type of the signal. |
| data |
|
The |
12.5.4.2. Ad hoc snapshot signals
You can request a connector to initiate an ad hoc snapshot by creating a signal with the execute-snapshot signal type. After processing the signal, the connector runs the requested snapshot operation.
Unlike the initial snapshot that a connector runs after it first starts, an ad hoc snapshot occurs during runtime, after the connector has already begun to stream change events from a database. You can initiate ad hoc snapshots at any time.
Ad hoc snapshots are available for the following Debezium connectors:
- Db2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| Column | Value |
|---|---|
| id |
|
| type |
|
| data |
|
| Key | Value |
|---|---|
| test_connector |
|
For more information about ad hoc snapshots, see the Snapshots topic in the documentation for your connector.
Additional resources
Ad hoc snapshot stop signals
You can request a connector to stop an in-progress ad hoc snapshot by creating a signal table entry with the stop-snapshot signal type. After processing the signal, the connector will stop the current in-progress snapshot operation.
You can stop ad hoc snapshots for the following Debezium connectors:
- Db2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| Column | Value |
|---|---|
| id |
|
| type |
|
| data |
|
You must specify the type of the signal. The data-collections field is optional. Leave the data-collections field blank to request the connector to stop all activity in the current snapshot. If you want the incremental snapshot to proceed, but you want to exclude specific collections from the snapshot, provide a comma-separated list of the names of the collections or regular expressions to exclude. After the connector processes the signal, the incremental snapshot proceeds, but it excludes data from the collections that you specify.
12.5.4.3. Incremental snapshots
Incremental snapshots are a specific type of ad hoc snapshot. In an incremental snapshot, the connector captures the baseline state of the tables that you specify, similar to an initial snapshot. However, unlike an initial snapshot, an incremental snapshot captures tables in chunks, rather than all at once. The connector uses a watermarking method to track the progress of the snapshot.
By capturing the initial state of the specified tables in chunks rather than in a single monolithic operation, incremental snapshots provide the following advantages over the initial snapshot process:
- While the connector captures the baseline state of the specified tables, streaming of near real-time events from the transaction log continues uninterrupted.
- If the incremental snapshot process is interrupted, it can be resumed from the point at which it stopped.
- You can initiate an incremental snapshot at any time.
Incremental snapshot pause signals
You can request a connector to pause an in-progress incremental snapshot by creating a signal table entry with the pause-snapshot signal type. After processing the signal, the connector will stop pause current in-progress snapshot operation. Therefor it’s not possible to specify the data collection as the snapshot processing will be paused in position where it is in time of processing of the signal.
You can pause incremental snapshots for the following Debezium connectors:
- Db2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| Column | Value |
|---|---|
| id |
|
| type |
|
You must specify the type of the signal. The data field is ignored.
Incremental snapshot resume signals
You can request a connector to resume a paused incremental snapshot by creating a signal table entry with the resume-snapshot signal type. After processing the signal, the connector will resume previously paused snapshot operation.
You can resume incremental snapshots for the following Debezium connectors:
- Db2
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| Column | Value |
|---|---|
| id |
|
| type |
|
You must specify the type of the signal. The data field is ignored.
For more information about incremental snapshots, see the Snapshots topic in the documentation for your connector.