1.7. クラスターライフサイクルの概要
multicluster engine Operator は、OpenShift Container Platform および Red Hat Advanced Cluster Management ハブクラスターにクラスター管理機能を提供するクラスターライフサイクル Operator です。multicluster engine Operator は、クラスターフリートの管理を強化し、クラウドとデータセンター全体の OpenShift Container Platform クラスターライフサイクル管理を支援するソフトウェア Operator です。multicluster engine Operator は、Red Hat Advanced Cluster Management の有無にかかわらず使用できます。Red Hat Advanced Cluster Management は、multicluster engine Operator を自動的にインストールし、さらにマルチクラスター機能を提供します。
以下のドキュメントを参照してください。
- クラスターライフサイクルのアーキテクチャー
- 認証情報の管理の概要
- リリースイメージ
- クラスターの作成
- クラスターのインポート
- クラスターへのアクセス
- マネージドクラスターのスケーリング
- 作成されたクラスターの休止
- クラスターのアップグレード
- クラスタープロキシーアドオンの有効化
- マネージドクラスターで実行する Ansible Automation Platform タスクの設定
- ClusterClaims
- ManagedClusterSets
- Placement
- クラスタープールの管理 (テクノロジープレビュー)
- ManagedServiceAccount の有効化
- クラスターのライフサイクルの詳細設定
- 管理からのクラスターの削除
1.7.1. クラスターライフサイクルのアーキテクチャー
クラスターライフサイクルには、ハブクラスター と マネージドクラスター の 2 種類のクラスターが必要です。
ハブクラスターは、multicluster engine Operator が自動的にインストールされる OpenShift Container Platform (または Red Hat Advanced Cluster Management) のメインクラスターです。ハブクラスターを使用して他の Kubernetes クラスターの作成、管理、および監視を行うことができます。ハブクラスターを使用してクラスターを作成できますが、ハブクラスターが管理する既存のクラスターをインポートすることもできます。
マネージドクラスターを作成すると、クラスターは Red Hat OpenShift Container Platform クラスターインストーラーと Hive リソースを使用して作成されます。OpenShift Container Platform インストーラーを使用してクラスターをインストールするプロセスの詳細は、OpenShift Container Platform ドキュメントの OpenShift Container Platform インストールの概要 を参照してください。
次の図は、クラスター管理用の multicluster engine for Kubernetes Operator とともにインストールされるコンポーネントを示しています。
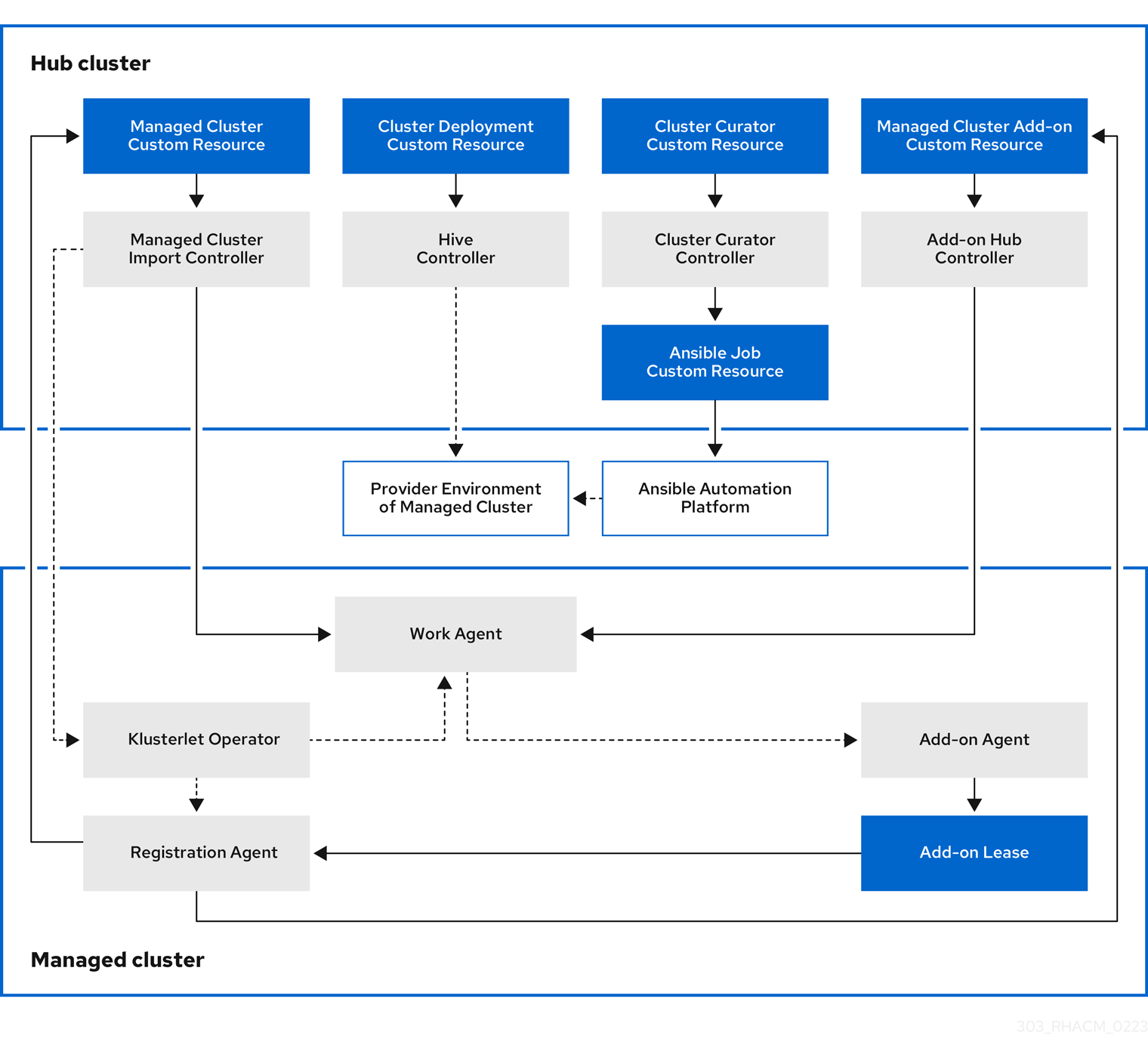
クラスターライフサイクル管理のアーキテクチャーのコンポーネントには、以下の項目が含まれます。
1.7.1.1. ハブクラスター
- マネージドクラスターのインポートコントローラー は、klusterlet Operator をマネージドクラスターにデプロイします。
- Hive コントローラー は、multicluster engine for Kubernetes Operator を使用して作成したクラスターをプロビジョニングします。また、Hive コントローラーは、multicluster engine for Kubernetes Operator によって作成されたマネージドクラスターを破棄します。
- クラスターキュレーターコントローラー は、マネージドクラスターの作成またはアップグレード時にクラスターインフラストラクチャー環境を設定するためのプレフックまたはポストフックとして Ansible ジョブを作成します。
- マネージドクラスターアドオンがハブクラスターで有効になると、その アドオンハブコントローラー がハブクラスターにデプロイされます。アドオンハブコントローラー は、アドオンエージェント をマネージドクラスターにデプロイします。
1.7.1.2. マネージドクラスター
- klusterlet Operator マネージドクラスターに登録およびワークコントローラーをデプロイします。
登録エージェント は、マネージドクラスターとマネージドクラスターアドオンをハブクラスターに登録します。また、登録エージェントは、マネージドクラスターとマネージドクラスターアドオンのステータスを維持します。次のアクセス許可が Clusterrole 内に自動的に作成され、マネージドクラスターがハブクラスターにアクセスできるようになります。
- エージェントは、ハブクラスターが管理する所有クラスターを取得または更新できます。
- エージェントが、ハブクラスターが管理する所有クラスターのステータスを更新できるようにします。
- エージェントが証明書をローテーションできるようにします。
-
エージェントが
coordination.k8s.ioリースをgetまたはupdateできるようにします。 -
エージェントがマネージドクラスターアドオンを
getできるようにします。 - エージェントがマネージドクラスターアドオンのステータスを更新できるようにします。
- ワークエージェント は、アドオンエージェントをマネージドクラスターに適用します。マネージドクラスターによるハブクラスターへのアクセスを許可する権限は、Clusterrole 内に自動的に作成され、エージェントはイベントをハブクラスターに送信できます。
クラスターの追加と管理を続行するには、クラスターライフサイクルの概要 を参照してください。
1.7.2. リリースイメージ
クラスターをビルドするときは、リリースイメージで指定されているバージョンの Red Hat OpenShift Container Platform を使用します。デフォルトでは、OpenShift Container Platform は clusterImageSets リソースを使用して、サポートされているリリースイメージのリストを取得します。
リリースイメージの詳細は、読み続けてください。
1.7.2.1. リリースイメージの指定
multicluster engine for Kubernetes Operator を使用してプロバイダー上にクラスターを作成する場合は、新しいクラスターに使用するリリースイメージを指定します。リリースイメージを指定するには、次のトピックを参照してください。
1.7.2.1.1. ClusterImageSets の検索
リリースイメージを参照する YAML ファイルは、acm-hive-openshift-releases GitHub リポジトリーに保持されます。これらのファイルは、コンソールで利用可能なリリースイメージのリストを作成します。これには、OpenShift Container Platform における最新の fast チャネルイメージが含まれます。
コンソールには、OpenShift Container Platform の 3 つの最新バージョンの最新リリースイメージのみが表示されます。たとえば、コンソールオプションに以下のリリースイメージが表示される可能性があります。
quay.io/openshift-release-dev/ocp-release:4.15.1-x86_64
コンソールには最新バージョンが表示され、最新のリリースイメージを使用してクラスターを作成するのに役立ちます。特定のバージョンのクラスターを作成する必要がある場合は、古いリリースイメージバージョンも利用できます。
注記: コンソールでクラスターを作成する場合は、visible: 'true' ラベルを持つイメージのみを選択できます。ClusterImageSet リソース内のこのラベルの例は、以下の内容で提供されます。4.x.1 は、製品の最新バージョンに置き換えます。
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.x.1-x86-64-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64追加のリリースイメージは保管されますが、コンソールには表示されません。利用可能なリリースイメージをすべて表示するには、次のコマンドを実行します。
oc get clusterimageset
リポジトリーには、clusterImageSets ディレクトリーがあります。これは、リリースイメージを操作するときに使用するディレクトリーです。clusterImageSets ディレクトリーには、次のディレクトリーがあります。
- Fast: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新バージョンを参照するファイルが含まれます。このフォルダー内のリリースイメージはテストされ、検証されており、サポートされます。
Releases: 各 OpenShift Container Platform バージョン (stable、fast、および candidate チャネル) のリリースイメージすべてを参照するファイルが含まれます。
注記: これらのリリースすべてがテストされおらず、安定版とみなされているわけではありません。
Stable: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新の安定版 2 つを参照するファイルが含まれます。
注記: デフォルトでは、リリースイメージの現在のリストは 1 時間ごとに更新されます。製品をアップグレードした後、リストに製品の新しいバージョンの推奨リリースイメージバージョンが反映されるまでに最大 1 時間かかる場合があります。
1.7.2.1.2. ClusterImageSets の設定
次のオプションを使用して ClusterImageSets を設定できます。
オプション 1: コンソールでクラスターを作成するには、使用する特定の
ClusterImageSetのイメージ参照を指定します。指定した新しいエントリーはそれぞれ保持され、将来のすべてのクラスタープロビジョニングで使用できます。次のエントリーの例を参照してください。quay.io/openshift-release-dev/ocp-release:4.6.8-x86_64-
オプション 2: GitHub リポジトリー
acm-hive-openshift-releasesから YAML ファイルClusterImageSetsを手動で作成し、適用します。 -
オプション 3: フォークされた GitHub リポジトリーから
ClusterImageSetsの自動更新を有効にするには、cluster-image-set-controller GitHub リポジトリーのREADME.mdに従います。
1.7.2.1.3. 別のアーキテクチャーにクラスターをデプロイするためのリリースイメージの作成
両方のアーキテクチャーのファイルを持つリリースイメージを手動で作成することで、ハブクラスターのアーキテクチャーとは異なるアーキテクチャーでクラスターを作成できます。
たとえば、ppc64le、aarch64、または s390x アーキテクチャーで実行されているハブクラスターから x86_64 クラスターを作成する必要があるとします。両方のファイルセットでリリースイメージを作成する場合に、新規のリリースイメージにより OpenShift Container Platform リリースレジストリーがマルチアーキテクチャーイメージマニフェストを提供できるので、クラスターの作成は成功します。
OpenShift Container Platform では、デフォルトで複数のアーキテクチャーがサポートされます。以下の clusterImageSet を使用してクラスターをプロビジョニングできます。4.x.0 は、現在サポートされているバージョンに置き換えます。
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.x.0-multi-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.0-multi複数のアーキテクチャーをサポートしない OpenShift Container Platform イメージのリリースイメージを作成するには、アーキテクチャータイプについて以下のような手順を実行します。
OpenShift Container Platform リリースレジストリー から、
x86_64、s390x、aarch64、およびppc64leリリースイメージを含む マニフェスト一覧 を作成します。以下のコマンド例を実行して、Quay リポジトリー から環境内の両方のアーキテクチャーのマニフェストリストをプルします。
4.x.1は、製品の最新バージョンに置き換えます。podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64 podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-ppc64le podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-s390x podman pull quay.io/openshift-release-dev/ocp-release:4.x.1-aarch64次のコマンドを実行して、イメージを管理するプライベートリポジトリーにログインします。
<private-repo>は、リポジトリーへのパスに置き換えます。podman login <private-repo>環境に適用される以下のコマンドを実行して、リリースイメージマニフェストをプライベートリポジトリーに追加します。
4.x.1は、製品の最新バージョンに置き換えます。<private-repo>は、リポジトリーへのパスに置き換えます。podman push quay.io/openshift-release-dev/ocp-release:4.x.1-x86_64 <private-repo>/ocp-release:4.x.1-x86_64 podman push quay.io/openshift-release-dev/ocp-release:4.x.1-ppc64le <private-repo>/ocp-release:4.x.1-ppc64le podman push quay.io/openshift-release-dev/ocp-release:4.x.1-s390x <private-repo>/ocp-release:4.x.1-s390x podman push quay.io/openshift-release-dev/ocp-release:4.x.1-aarch64 <private-repo>/ocp-release:4.x.1-aarch64次のコマンドを実行して、新しい情報のマニフェストを作成します。
podman manifest create mymanifest次のコマンドを実行して、両方のリリースイメージへの参照をマニフェストリストに追加します。
4.x.1は、製品の最新バージョンに置き換えます。<private-repo>は、リポジトリーへのパスに置き換えます。podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-x86_64 podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-ppc64le podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-s390x podman manifest add mymanifest <private-repo>/ocp-release:4.x.1-aarch64次のコマンドを実行して、マニフェストリスト内のリストを既存のマニフェストとマージします。
<private-repo>は、リポジトリーへのパスに置き換えます。4.x.1は、最新バージョンに置き換えます。podman manifest push mymanifest docker://<private-repo>/ocp-release:4.x.1
ハブクラスターで、リポジトリーのマニフェストを参照するリリースイメージを作成します。
以下の例のような情報を含む YAML ファイルを作成します。
<private-repo>は、リポジトリーへのパスに置き換えます。4.x.1は、最新バージョンに置き換えます。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: fast visible: "true" name: img4.x.1-appsub spec: releaseImage: <private-repo>/ocp-release:4.x.1ハブクラスターで以下のコマンドを実行し、変更を適用します。
<file-name>を、先の手順で作成した YAML ファイルの名前に置き換えます。oc apply -f <file-name>.yaml
- OpenShift Container Platform クラスターの作成時に新規リリースイメージを選択します。
- Red Hat Advanced Cluster Management コンソールを使用してマネージドクラスターをデプロイする場合は、クラスター作成プロセス時に Architecture フィールドにマネージドクラスターのアーキテクチャーを指定します。
作成プロセスでは、マージされたリリースイメージを使用してクラスターを作成します。
1.7.2.1.4. 関連情報
- リリースイメージを参照する YAML ファイルは、acm-hive-openshift-releases GitHub リポジトリーを参照してください。
-
フォークされた GitHub リポジトリーから
ClusterImageSetsの自動更新を有効にする方法は、cluster-image-set-controller GitHub リポジトリー を参照してください。
1.7.2.2. 接続環境におけるリリースイメージのカスタムリストの管理
すべてのクラスターに同じリリースイメージを使用することもできます。クラスターの作成時に利用可能なリリースイメージのカスタムリストを作成し、作業を簡素化します。利用可能なリリースイメージを管理するには、以下の手順を実行します。
- acm-hive-openshift-releases GitHub をフォークします。
-
クラスターの作成時に使用できるイメージの YAML ファイルを追加します。Git コンソールまたはターミナルを使用して、イメージを
./clusterImageSets/stable/または./clusterImageSets/fast/ディレクトリーに追加します。 -
cluster-image-set-git-repoという名前のmulticluster-enginenamespace にConfigMapを作成します。次の例を参照してください。ただし、2.xは 2.7 に置き換えてください。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-image-set-git-repo
namespace: multicluster-engine
data:
gitRepoUrl: <forked acm-hive-openshift-releases repository URL>
gitRepoBranch: backplane-<2.x>
gitRepoPath: clusterImageSets
channel: <fast or stable>次の手順でフォークされたリポジトリーに変更をマージすることで、メインリポジトリーから利用可能な YAML ファイルを取得できます。
- フォークしたリポジトリーに変更をコミットし、マージします。
-
acm-hive-openshift-releasesリポジトリーのクローンを作成した後に高速リリースイメージのリストを同期するには、cluster-image-set-git-repoConfigMapの channel フィールドの値をfastに更新します。 -
安定版リリースイメージを同期して表示するには、
cluster-image-set-git-repoConfigMapの channel フィールドの値をstableに更新します。
ConfigMap を更新すると、約 1 分以内に、利用可能な安定リリースイメージのリストが現在利用可能なイメージで更新されます。
以下のコマンドを使用して、利用可能ものを表示し、デフォルトの設定を削除します。
<clusterImageSet_NAME>を正しい名前に置き換えます。oc get clusterImageSets oc delete clusterImageSet <clusterImageSet_NAME>
クラスターの作成時に、コンソールで現在利用可能なリリースイメージの一覧を表示します。
ConfigMap を通じて利用できる他のフィールドは、cluster-image-set-controller GitHub リポジトリーの README を参照してください。
1.7.2.3. 非接続環境におけるリリースイメージのカスタムリストの管理
場合によっては、ハブクラスターにインターネット接続がないときに、リリースイメージのカスタムリストを管理する必要があります。リリースイメージの独自のカスタムリストを作成しておくと、クラスターの作成時にそのリストを使用できます。非接続環境で利用可能なリリースイメージを管理するには、次の手順を実行します。
- オンラインのシステムの場合は、acm-hive-openshift-releases GitHub リポジトリー に移動して、利用可能なクラスターイメージセットにアクセスします。
-
clusterImageSetsディレクトリーを、非接続の multicluster engine Operator クラスターにアクセスできるシステムにコピーします。 マネージドクラスターに合わせて次の手順を実行して、クラスターイメージセットを含むオフラインリポジトリーとマネージドクラスター間のマッピングを追加します。
-
OpenShift Container Platform マネージドクラスターの場合は、イメージレジストリーリポジトリーのミラーリングの設定 を参照し、
ImageContentSourcePolicyオブジェクトを使用してマッピングを完了する方法を確認します。 -
OpenShift Container Platform クラスターではないマネージドクラスターの場合は、
ManageClusterImageRegistryカスタムリソース定義を使用してイメージセットの場所を上書きします。マッピング用にクラスターを上書きする方法は、インポート用のマネージドクラスターでのレジストリーイメージの指定 を参照してください。
-
OpenShift Container Platform マネージドクラスターの場合は、イメージレジストリーリポジトリーのミラーリングの設定 を参照し、
-
コンソールまたは CLI を使用して、
clusterImageSetYAML コンテンツを手動で追加することにより、クラスターを作成するときに使用できるイメージの YAML ファイルを追加します。 残りの OpenShift Container Platform リリースイメージの
clusterImageSetYAML ファイルを、イメージの保存先の正しいオフラインリポジトリーを参照するように変更します。変更後は次の例のようになります。spec.releaseImageはリリースイメージのオフラインイメージレジストリーを使用します。リリースイメージはダイジェストによって参照されます。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: fast name: img<4.x.x>-x86-64-appsub spec: releaseImage: IMAGE_REGISTRY_IPADDRESS_or__DNSNAME/REPO_PATH/ocp-release@sha256:073a4e46289be25e2a05f5264c8f1d697410db66b960c9ceeddebd1c61e58717- YAML ファイルで参照されているオフラインイメージレジストリーにイメージがロードされていることを確認します。
次のコマンドを実行して、イメージダイジェストを取得します。
oc adm release info <tagged_openshift_release_image> | grep "Pull From"<tagged_openshift_release_image>は、サポートされている OpenShift Container Platform バージョンのタグ付きイメージに置き換えます。以下の出力例を参照してください。Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfeイメージタグとダイジェストの詳細は、イメージストリームでのイメージの参照 を参照してください。
各 YAML ファイルに以下のコマンドを入力して、各
clusterImageSetsを作成します。oc create -f <clusterImageSet_FILE>clusterImageSet_FILEを、クラスターイメージセットファイルの名前に置き換えます。以下に例を示します。oc create -f img4.11.9-x86_64.yaml追加するリソースごとにこのコマンドを実行すると、使用可能なリリースイメージのリストが表示されます。
-
または、クラスターの作成コンソールに直接イメージ URL を貼り付けることもできます。イメージ URL を追加すると、新しい
clusterImageSetsが存在しない場合に作成されます。 - クラスターの作成時に、コンソールで現在利用可能なリリースイメージの一覧を表示します。
1.7.2.4. 利用可能なリリースイメージの同期
MultiClusterHub Operator を使用してハブクラスターコンポーネントを管理、アップグレード、およびインストールする Red Hat Advanced Cluster Management ハブクラスターがある場合は、リリースイメージのリストを同期して、利用可能な最新バージョンを選択できるようします。リリースイメージは acm-hive-openshift-releases リポジトリーで入手でき、頻繁に更新されます。
1.7.2.4.1. 安定性レベル
リリースイメージの安定性には、次の表に示すように 3 つのレベルがあります。
| カテゴリー | 説明 |
|---|---|
| candidate | 最新のイメージ。テストされていないため、バグがある可能性があります。 |
| fast | 部分的にテストされたイメージですが、stable バージョンよりも安定性が低い可能性があります。 |
| stable | 完全にテストされたイメージ。これらのイメージは、クラスターを正しくインストールおよび構築できることが確認されています。 |
1.7.2.4.2. リリースイメージリストの更新
Linux または Mac オペレーティングシステムを使用してイメージのリストを更新および同期するには、次の手順を実行します。
-
インストーラーが管理する
acm-hive-openshift-releasesサブスクリプションが有効になっている場合は、MultiClusterHubリソースのdisableUpdateClusterImageSetsの値をtrueに設定してサブスクリプションを無効にします。 - acm-hive-openshift-releases の GitHub リポジトリーをクローンします。
次のコマンドを実行して、サブスクリプションを削除します。
oc delete -f subscribe/subscription-fastcandidateリリースイメージを同期して表示するには、Linux または Mac オペレーティングシステムを使用して次のコマンドを実行します。make subscribe-candidate約 1 分後に、
candidateリリースイメージの最新リストが利用可能になります。fastリリースイメージを同期して表示するには、以下のコマンドを実行します。make subscribe-fast約 1 分後に、
fastリリースイメージの最新リストが利用可能になります。stableリリースイメージに接続し、Red Hat Advanced Cluster Management ハブクラスターを同期します。Linux または Mac オペレーティングシステムを使用して次のコマンドを実行します。make subscribe-stable利用可能な
candidate、fast、およびstableリリースイメージのリストが、現在利用可能なイメージで約 1 分ほどで更新されます。- クラスターの作成時に、Red Hat Advanced Cluster Management コンソールで現在利用可能なリリースイメージの一覧を表示します。
更新の表示を停止するには、次のコマンドを実行して、これらのチャネルのいずれかから登録を解除します。
oc delete -f subscribe/subscription-fast
1.7.3. クラスターの作成
multicluster engine Operator を使用して、複数のクラウドプロバイダーに Red Hat OpenShift Container Platform クラスターを作成する方法を説明します。
multicluster engine Operator は、OpenShift Container Platform で提供される Hive Operator を使用して、オンプレミスクラスターと Hosted Control Plane を除くすべてのプロバイダーのクラスターをプロビジョニングします。オンプレミスクラスターをプロビジョニングする場合、multicluster engine Operator は OpenShift Container Platform で提供される Central Infrastructure Management および Assisted Installer 機能を使用します。Hosted Control Plane のホステッドクラスターは、HyperShift Operator を使用してプロビジョニングされます。
1.7.3.1. CLI を使用したクラスターの作成
Multicluster engine for Kubernetes Operator は、内部の Hive コンポーネントを使用して Red Hat OpenShift Container Platform クラスターを作成します。クラスターの作成方法は、以下の情報を参照してください。
1.7.3.1.1. 前提条件
クラスターを作成する前に、clusterImageSets リポジトリーのクローンを作成し、ハブクラスターに適用しておく。以下の手順を実行します。
クローンするには、次のコマンドを実行します。ただし、
2.xは、multicluster engine Operator のバージョンに置き換えます。git clone https://github.com/stolostron/acm-hive-openshift-releases.git cd acm-hive-openshift-releases git checkout origin/backplane-<2.x>- 次のコマンドを実行して、ハブクラスターに適用します。
find clusterImageSets/fast -type d -exec oc apply -f {} \; 2> /dev/nullクラスターを作成するときに、OpenShift Container Platform リリースイメージを選択します。
注記: Nutanix プラットフォームを使用する場合は、
ClusterImageSetリソースのreleaseImageにx86_64アーキテクチャーを使用し、visibleのラベル値を'true'に設定してください。以下の例を参照してください。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: stable visible: 'true' name: img4.x.47-x86-64-appsub spec: releaseImage: quay.io/openshift-release-dev/ocp-release:4.x.47-x86_64-
ハブクラスターの
KubeAPIServer証明書検証ストラテジーを確認し、デフォルトのUseAutoDetectedCABundleストラテジーが機能することを確認する。ストラテジーを手動で変更する必要がある場合は、ハブクラスターのKubeAPIServer検証ストラテジーの設定 を参照してください。
1.7.3.1.2. ClusterDeployment を使用してクラスターを作成する
ClusterDeployment は、クラスターのライフサイクルを制御するために使用される Hive カスタムリソースです。
Using Hive のドキュメントに従って ClusterDeployment カスタムリソースを作成し、個別のクラスターを作成します。
1.7.3.1.3. ClusterPool を使用してクラスターを作成
ClusterPool は、複数のクラスターを作成するために使用される Hive カスタムリソースでもあります。
Cluster Pools のドキュメントに従って、Hive ClusterPool API でクラスターを作成します。
1.7.3.2. クラスター作成時の追加のマニフェストの設定
追加の Kubernetes リソースマニフェストは、クラスター作成のインストールプロセス中に設定できます。これは、ネットワークの設定やロードバランサーの設定など、シナリオの追加マニフェストを設定する必要がある場合に役立ちます。
1.7.3.2.1. 前提条件
追加のリソースマニフェストが含まれる config map リソースを指定する ClusterDeployment リソースへの参照を追加する。
注記: ClusterDeployment リソースと config map は同じ namespace にある必要があります。
1.7.3.2.2. 例を使用してクラスター作成中に追加のマニフェストを設定する
リソースマニフェストを含む config map を使用して追加のマニフェストを設定する場合は、次の手順を実行します。
YAML ファイルを作成し、次のサンプルコンテンツを追加します。
kind: ConfigMap apiVersion: v1 metadata: name: <my-baremetal-cluster-install-manifests> namespace: <mynamespace> data: 99_metal3-config.yaml: | kind: ConfigMap apiVersion: v1 metadata: name: metal3-config namespace: openshift-machine-api data: http_port: "6180" provisioning_interface: "enp1s0" provisioning_ip: "172.00.0.3/24" dhcp_range: "172.00.0.10,172.00.0.100" deploy_kernel_url: "http://172.00.0.3:6180/images/ironic-python-agent.kernel" deploy_ramdisk_url: "http://172.00.0.3:6180/images/ironic-python-agent.initramfs" ironic_endpoint: "http://172.00.0.3:6385/v1/" ironic_inspector_endpoint: "http://172.00.0.3:5150/v1/" cache_url: "http://192.168.111.1/images" rhcos_image_url: "https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.201911192044.0/x86_64/rhcos-43.81.201911192044.0-openstack.x86_64.qcow2.gz"注記: サンプル
ConfigMapには、別のConfigMapリソースを含むマニフェストが含まれています。リソースマニフェストのConfigMapには、data.<resource_name>\.yamlというパターンでリソース設定を追加することにより、複数のキーを含めることができます。以下のコマンドを実行してこのファイルを適用します。
oc apply -f <filename>.yamlリソースマニフェストの
ConfigMapを参照してClusterDeploymentを使用して追加のマニフェストを設定する場合は、次の手順を実行します。YAML ファイルを作成し、次のサンプルコンテンツを追加します。リソースマニフェスト
ConfigMapはspec.provisioning.manifestsConfigMapRefで参照されます。apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <my-baremetal-cluster> namespace: <mynamespace> annotations: hive.openshift.io/try-install-once: "true" spec: baseDomain: test.example.com clusterName: <my-baremetal-cluster> controlPlaneConfig: servingCertificates: {} platform: baremetal: libvirtSSHPrivateKeySecretRef: name: provisioning-host-ssh-private-key provisioning: installConfigSecretRef: name: <my-baremetal-cluster-install-config> sshPrivateKeySecretRef: name: <my-baremetal-hosts-ssh-private-key> manifestsConfigMapRef: name: <my-baremetal-cluster-install-manifests> imageSetRef: name: <my-clusterimageset> sshKnownHosts: - "10.1.8.90 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXvVVVKUYVkuyvkuygkuyTCYTytfkufTYAAAAIbmlzdHAyNTYAAABBBKWjJRzeUVuZs4yxSy4eu45xiANFIIbwE3e1aPzGD58x/NX7Yf+S8eFKq4RrsfSaK2hVJyJjvVIhUsU9z2sBJP8=" pullSecretRef: name: <my-baremetal-cluster-pull-secret>以下のコマンドを実行してこのファイルを適用します。
oc apply -f <filename>.yaml
1.7.3.3. Amazon Web Services でのクラスターの作成
multicluster engine Operator コンソールを使用して、Amazon Web Services (AWS) 上に Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの AWS へのインストール でプロセスの詳細を確認してください。
1.7.3.3.1. 前提条件
AWS でクラスターを作成する前に、以下の前提条件を確認してください。
- ハブクラスターをデプロイしている。
- AWS 認証情報がある。詳細は、Amazon Web Services の認証情報の作成 を参照してください。
- AWS で設定されたドメインがある。ドメインの設定方法は、AWS アカウントの設定 を参照してください。
- ユーザー名、パスワード、アクセスキー ID およびシークレットアクセスキーなど、Amazon Web Services (AWS) のログイン認証情報がある。Understanding and Getting Your Security Credentials を参照してください。
OpenShift Container Platform イメージのプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、コンソールでクラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.7.3.3.2. AWS クラスターの作成
AWS クラスターの作成に関する次の重要な情報を参照してください。
-
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに
install-config.yamlファイルの内容を表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。 - クラスターを作成すると、コントローラーはクラスターとリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。
- クラスターを 破棄 すると、namespace とその中のすべてのリソースが削除されます。
-
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に
cluster-admin権限がない場合に、clusterset-admin権限があるクラスターセットを選択する必要があります。 -
指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの
clusterset-admin権限を受け取ってください。 -
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを
ManagedClusterSetに割り当てない場合は、デフォルトのマネージドクラスターセットに自動的に追加されます。 - AWS アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。この名前はクラスターのホスト名で使用されます。
- このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。利用可能なイメージのリストからイメージを選択します。使用したいイメージがない場合は、使用したいイメージの URL を入力します。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
- region: ノードプールが必要なリージョンを指定します。
- CPU アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- ゾーン: コントロールプレーンプールを実行する場所を指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ルートストレージ: クラスターに割り当てるルートストレージの量を指定します。
ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ゾーン: ワーカープールを実行する場所を指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: ワーカープールのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ノード数: ワーカープールのノード数を指定します。ワーカープールを定義する場合にこの設定は必須です。
- ルートストレージ: ワーカープールに割り当てるルートストレージの量を指定します。ワーカープールを定義する場合にこの設定は必須です。
- クラスターにはネットワークの詳細が必要であり、IPv6 を使用するには複数のネットワークが必要です。Add network をクリックして、追加のネットワークを追加できます。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシーサイトなし: プロキシーをバイパスする必要のあるサイトのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
-
HTTP プロキシー:
1.7.3.3.3. コンソールを使用したクラスターの作成
新しいクラスターを作成するには、次の手順を参照してください。代わりに既存のクラスターを インポート する場合は、クラスターのインポート を参照してください。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、multicluster engine Operator で管理されるように自動的に設定されます。
- Infrastructure > Clusters に移動します。
- Clusters ページで、以下を実行します。Cluster > Create cluster をクリックし、コンソールで手順を完了します。
- 任意: コンソールに情報を入力するときにコンテンツの更新を表示するには、YAML: On を選択します。
認証情報を作成する必要がある場合は、Amazon Web Services の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
1.7.3.3.4. 関連情報
- AWS プライベート設定情報は、AWS GovCloud クラスターの作成時に使用されます。その環境での クラスターの作成は、Amazon Web Services GovCloud でのクラスターの作成 を参照してください。
- 詳細は、AWS アカウントの設定 を参照してください。
- リリースイメージの詳細については、リリースイメージ を参照してください。
- サポートされているインスタントタイプの詳細は、AWS 汎用インスタンス などのクラウドプロバイダーのサイトにアクセスしてください。
1.7.3.4. Amazon Web Services GovCloud でのクラスターの作成
コンソールを使用して、Amazon Web Services (AWS) または AWS GovCloud で Red Hat OpenShift Container Platform クラスターを作成できます。この手順では、AWS GovCloud でクラスターを作成する方法を説明します。AWS でクラスターを作成する手順は、Amazon Web Services でのクラスターの作成 を参照してください。
AWS GovCloud は、政府のドキュメントをクラウドに保存するために必要な追加の要件を満たすクラウドサービスを提供します。AWS GovCloud でクラスターを作成する場合、環境を準備するために追加の手順を実行する必要があります。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの AWS の government リージョンへのクラスターのインストール を参照して、プロセスの詳細を確認してください。以下のセクションでは、AWS GovCloud でクラスターを作成する手順を説明します。
1.7.3.4.1. 前提条件
AWS GovCloud クラスターを作成する前に、以下の前提条件を満たす必要があります。
- ユーザー名、パスワード、アクセスキー ID、およびシークレットアクセスキーなどの AWS ログイン認証情報が必要です。Understanding and Getting Your Security Credentials を参照してください。
- AWS 認証情報がある。詳細は、Amazon Web Services の認証情報の作成 を参照してください。
- AWS で設定されたドメインがある。ドメインの設定方法は、AWS アカウントの設定 を参照してください。
- OpenShift Container Platform イメージのプルシークレットがある。イメージプルシークレットの使用 を参照してください。
- ハブクラスター用の既存の Red Hat OpenShift Container Platform クラスターを備えた Amazon Virtual Private Cloud (VPC) が必要です。この VPC は、マネージドクラスターリソースまたはマネージドクラスターサービスエンドポイントに使用される VPC とは異なる必要があります。
- マネージドクラスターリソースがデプロイされる VPC が必要です。これは、ハブクラスターまたはマネージドクラスターサービスエンドポイントに使用される VPC と同じにすることはできません。
- マネージドクラスターサービスエンドポイントを提供する 1 つ以上の VPC が必要です。これは、ハブクラスターまたはマネージドクラスターリソースに使用される VPC と同じにすることはできません。
- Classless Inter-Domain Routing (CIDR) によって指定される VPC の IP アドレスが重複しないようにしてください。
-
Hive namespace 内で認証情報を参照する
HiveConfigカスタムリソースが必要です。このカスタムリソースは、マネージドクラスターサービスエンドポイント用に作成した VPC でリソースを作成するためにアクセスできる必要があります。
注記: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、multicluster engine Operator コンソールでクラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.7.3.4.2. Hive を AWS GovCloud にデプロイするように設定します。
AWS GovCloud でのクラスターの作成は、標準の AWS でクラスターを作成することとほぼ同じですが、AWS GovCloud でクラスターの AWS PrivateLink を準備するために追加の手順を実行する必要があります。
1.7.3.4.2.1. リソースおよびエンドポイントの VPC の作成
前提条件に記載されているように、ハブクラスターが含まれる VPC に加えて、2 つの VPC が必要です。VPC を作成する具体的な手順は、Amazon Web Services ドキュメントの VPC の作成 を参照してください。
- プライベートサブネットを使用してマネージドクラスターの VPC を作成します。
- プライベートサブネットを使用して、マネージドクラスターサービスエンドポイントの 1 つ以上の VPC を作成します。リージョンの各 VPC には 255 VPC エンドポイントの制限があるため、そのリージョン内の 255 を超えるクラスターをサポートするには、複数の VPC が必要です。
各 VPC について、リージョンのサポートされるすべてのアベイラビリティーゾーンにサブネットを作成します。コントローラーの要件があるため、各サブネットには少なくとも 255 以上の使用可能な IP アドレスが必要です。
以下の例は、
us-gov-east-1リージョンに 6 つのアベイラビリティーゾーンを持つ VPC のサブネットを設定する方法を示しています。vpc-1 (us-gov-east-1) : 10.0.0.0/20 subnet-11 (us-gov-east-1a): 10.0.0.0/23 subnet-12 (us-gov-east-1b): 10.0.2.0/23 subnet-13 (us-gov-east-1c): 10.0.4.0/23 subnet-12 (us-gov-east-1d): 10.0.8.0/23 subnet-12 (us-gov-east-1e): 10.0.10.0/23 subnet-12 (us-gov-east-1f): 10.0.12.0/2vpc-2 (us-gov-east-1) : 10.0.16.0/20 subnet-21 (us-gov-east-1a): 10.0.16.0/23 subnet-22 (us-gov-east-1b): 10.0.18.0/23 subnet-23 (us-gov-east-1c): 10.0.20.0/23 subnet-24 (us-gov-east-1d): 10.0.22.0/23 subnet-25 (us-gov-east-1e): 10.0.24.0/23 subnet-26 (us-gov-east-1f): 10.0.28.0/23- すべてのハブクラスター (ハブクラスター VPC) に、ピアリング、転送ゲートウェイ、およびすべての DNS 設定が有効になっている VPC エンドポイント用に作成した VPC へのネットワーク接続があることを確認します。
- AWS GovCloud 接続に必要な AWS PrivateLink の DNS 設定を解決するために必要な VPC のリストを収集します。これには、少なくとも設定中の multicluster engine Operator インスタンスの VPC を含めます。さまざまな Hive コントローラーが存在するすべての VPC のリストを含めることもできます。
1.7.3.4.2.2. VPC エンドポイントのセキュリティーグループの設定
AWS の各 VPC エンドポイントには、エンドポイントへのアクセスを制御するためにセキュリティーグループが割り当てられます。Hive が VPC エンドポイントを作成する場合、セキュリティーグループは指定しません。VPC のデフォルトのセキュリティーグループは VPC エンドポイントに割り当てられます。VPC のデフォルトのセキュリティーグループには、VPC エンドポイントが Hive インストーラー Pod から作成されるトラフィックを許可するルールが必要です。詳細は、AWS ドキュメントの エンドポイントポリシーを使用した VPC エンドポイントへのアクセスの制御 を参照してください。
たとえば、Hive が hive-vpc (10.1.0.0/16) で実行されている場合は、VPC エンドポイントが作成される VPC のデフォルトセキュリティーグループに、10.1.0.0/16 からのイングレスを許可するルールが必要です。
1.7.3.4.2.3. AWS PrivateLink の権限の設定
AWS PrivateLink を設定するには、複数の認証情報が必要です。これらの認証情報に必要な権限は、認証情報のタイプによって異なります。
ClusterDeployment の認証情報には、以下の権限が必要です。
ec2:CreateVpcEndpointServiceConfiguration ec2:DescribeVpcEndpointServiceConfigurations ec2:ModifyVpcEndpointServiceConfiguration ec2:DescribeVpcEndpointServicePermissions ec2:ModifyVpcEndpointServicePermissions ec2:DeleteVpcEndpointServiceConfigurationsエンドポイント VPC アカウントの HiveConfig の認証情報
.spec.awsPrivateLink.credentialsSecretRefには、以下の権限が必要です。ec2:DescribeVpcEndpointServices ec2:DescribeVpcEndpoints ec2:CreateVpcEndpoint ec2:CreateTags ec2:DescribeNetworkInterfaces ec2:DescribeVPCs ec2:DeleteVpcEndpoints route53:CreateHostedZone route53:GetHostedZone route53:ListHostedZonesByVPC route53:AssociateVPCWithHostedZone route53:DisassociateVPCFromHostedZone route53:CreateVPCAssociationAuthorization route53:DeleteVPCAssociationAuthorization route53:ListResourceRecordSets route53:ChangeResourceRecordSets route53:DeleteHostedZoneVPC をプライベートホストゾーンに関連付けるために
HiveConfigカスタムリソースに指定された認証情報 (.spec.awsPrivateLink.associatedVPCs[$idx].credentialsSecretRef)。VPC が置かれているアカウントには、以下の権限が必要です。route53:AssociateVPCWithHostedZone route53:DisassociateVPCFromHostedZone ec2:DescribeVPCs
ハブクラスターの Hive namespace 内に認証情報シークレットがあることを確認します。
HiveConfig カスタムリソースは、特定の提供される VPC でリソースを作成する権限を持つ Hive namespace 内で認証情報を参照する必要があります。AWS GovCloud での AWS クラスターのプロビジョニングに使用する認証情報がすでに Hive namespace にある場合は、別の認証情報を作成する必要はありません。AWS GovCloud での AWS クラスターのプロビジョニングに使用する認証情報がまだ Hive namespace にない場合、現在の認証情報を置き換えるか、Hive namespace に追加の認証情報を作成できます。
HiveConfig カスタムリソースには、以下の内容が含まれている必要があります。
- 指定された VPC のリソースをプロビジョニングするために必要な権限を持つ AWS GovCloud 認証情報。
OpenShift Container Platform クラスターインストールの VPC のアドレス、およびマネージドクラスターのサービスエンドポイント。
ベストプラクティス: OpenShift Container Platform クラスターのインストールおよびサービスエンドポイントに異なる VPC を使用します。
以下の例は、認証情報の内容を示しています。
spec:
awsPrivateLink:
## The list of inventory of VPCs that can be used to create VPC
## endpoints by the controller.
endpointVPCInventory:
- region: us-east-1
vpcID: vpc-1
subnets:
- availabilityZone: us-east-1a
subnetID: subnet-11
- availabilityZone: us-east-1b
subnetID: subnet-12
- availabilityZone: us-east-1c
subnetID: subnet-13
- availabilityZone: us-east-1d
subnetID: subnet-14
- availabilityZone: us-east-1e
subnetID: subnet-15
- availabilityZone: us-east-1f
subnetID: subnet-16
- region: us-east-1
vpcID: vpc-2
subnets:
- availabilityZone: us-east-1a
subnetID: subnet-21
- availabilityZone: us-east-1b
subnetID: subnet-22
- availabilityZone: us-east-1c
subnetID: subnet-23
- availabilityZone: us-east-1d
subnetID: subnet-24
- availabilityZone: us-east-1e
subnetID: subnet-25
- availabilityZone: us-east-1f
subnetID: subnet-26
## The credentialsSecretRef references a secret with permissions to create.
## The resources in the account where the inventory of VPCs exist.
credentialsSecretRef:
name: <hub-account-credentials-secret-name>
## A list of VPC where various mce clusters exists.
associatedVPCs:
- region: region-mce1
vpcID: vpc-mce1
credentialsSecretRef:
name: <credentials-that-have-access-to-account-where-MCE1-VPC-exists>
- region: region-mce2
vpcID: vpc-mce2
credentialsSecretRef:
name: <credentials-that-have-access-to-account-where-MCE2-VPC-exists>
AWS PrivateLink が endpointVPCInventory 一覧でサポートされているすべてのリージョンから VPC を含めることができます。コントローラーは、ClusterDeployment の要件を満たす VPC を選択します。
詳細は、Hive ドキュメント を参照してください。
1.7.3.4.3. コンソールを使用したクラスターの作成
コンソールからクラスターを作成するには、Infrastructure > Clusters > Create cluster AWS > Standalone に移動して、コンソールで手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、クラスターのインポート でインポート手順を参照してください。
AWS GovCloud クラスターを作成する場合、選択する認証情報は AWS GovCloud リージョンのリソースにアクセスできる必要があります。クラスターをデプロイするために必要な権限を持つ場合は、Hive namespace にある AWS GovCloud シークレットを使用できます。コンソールに既存の認証情報が表示されます。認証情報を作成する必要がある場合は、Amazon Web Services の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
AWS または AWS GovCloud アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。この名前はクラスターのホスト名で使用されます。詳細は、AWS アカウントの設定 を参照してください。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
-
リージョン: クラスターリソースを作成するリージョン。AWS GovCloud プロバイダーでクラスターを作成する場合、ノードプールの AWS GovCloud リージョンを含める必要があります。たとえば、
us-gov-west-1です。 - CPU アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- ゾーン: コントロールプレーンプールを実行する場所を指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: コントロールプレーンノードのインスタンスタイプを指定します。これは、以前に指定した CPU アーキテクチャー と同じにする必要があります。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ルートストレージ: クラスターに割り当てるルートストレージの量を指定します。
ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- プール名: プールの一意の名前を指定します。
- ゾーン: ワーカープールを実行する場所を指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: ワーカープールのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ノード数: ワーカープールのノード数を指定します。ワーカープールを定義する場合にこの設定は必須です。
- ルートストレージ: ワーカープールに割り当てるルートストレージの量を指定します。ワーカープールを定義する場合にこの設定は必須です。
クラスターにはネットワークの詳細が必要であり、IPv6 を使用するには複数のネットワークが必要です。AWS GovCloud クラスターの場合は、Machine CIDR フィールドに Hive VPC のアドレスのブロックの値を入力します。Add network をクリックして、追加のネットワークを追加できます。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
AWS GovCloud クラスターを作成するか、プライベート環境を使用する場合は、AMI ID およびサブネット値を使用して、AWS プライベート設定 ページのフィールドに入力します。ClusterDeployment.yaml ファイルで spec:platform:aws:privateLink:enabled の値が true に設定されていることを確認します。これは、Use private configuration を選択すると自動的に設定されます。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに install-config.yaml ファイルの内容を表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、そのクラスターは multicluster engine for Kubernetes Operator の管理下で自動的に設定されます。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.5. Microsoft Azure でのクラスターの作成
multicluster engine Operator コンソールを使用して、Microsoft Azure または Microsoft Azure Government に Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの Azure へのインストール でプロセスの詳細を確認してください。
1.7.3.5.1. 前提条件
Azure でクラスターを作成する前に、以下の前提条件を確認してください。
- ハブクラスターをデプロイしている。
- Azure 認証情報がある。詳細は、Microsoft Azure の認証情報の作成 を参照してください。
- Azure または Azure Government に設定済みドメインがある。ドメイン設定の方法は、Configuring a custom domain name for an Azure cloud service を参照してください。
- ユーザー名とパスワードなどの Azure ログイン認証情報がある。Microsoft Azure Portal を参照してください。
-
clientId、clientSecretおよびtenantIdなどの Azure サービスプリンシパルがある。azure.microsoft.com を参照してください。 - OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、multicluster engine Operator のコンソールでクラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.7.3.5.2. コンソールを使用したクラスターの作成
multicluster engine Operator コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、クラスターのインポート でインポート手順を参照してください。
認証情報を作成する必要がある場合は、Microsoft Azure の認証情報の作成 に記載される詳細を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
Azure アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Configuring a custom domain name for an Azure cloud service を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。この情報には、次のオプションフィールドが含まれます。
- リージョン: ノードプールを実行するリージョンを指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- CPU アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
クラスターの作成後に、コントロールプレーンプールのタイプおよびルートストレージの割り当て (必須) を変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- ゾーン: ワーカープールを実行することを指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー:
HTTPトラフィックのプロキシーとして使用する URL。 -
HTTPS プロキシー:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシーなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、multicluster engine Operator で管理されるように自動的に設定されます。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.6. Google Cloud Platform でのクラスターの作成
Google Cloud Platform (GCP) で Red Hat OpenShift Container Platform クラスターを作成する手順に従います。GCP の詳細は、Google Cloud Platform を参照してください。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの GCP のインストール でプロセスの詳細を確認してください。
1.7.3.6.1. 前提条件
GCP でクラスターを作成する前に、次の前提条件を確認してください。
- ハブクラスターをデプロイしている。
- GCP 認証情報がある。詳細は、Google Cloud Platform の認証情報の作成 を参照してください。
- GCP に設定済みのドメインがある。ドメインの設定方法は、Setting up a custom domain を参照してください。
- ユーザー名とパスワードを含む GCP ログイン認証情報がある。
- OpenShift Container Platform イメージのプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、multicluster engine Operator のコンソールでクラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.7.3.6.2. コンソールを使用したクラスターの作成
multicluster engine Operator コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、クラスターのインポート でインポート手順を参照してください。
認証情報を作成する必要がある場合は、Google Cloud Platform の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。GCP クラスターの命名に適用される制限がいくつかあります。この制限には、名前を goog で開始しないことや、名前に google に類似する文字および数字のグループが含まれないことなどがあります。制限の完全な一覧は、Bucket naming guidelines を参照してください。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
選択した GCP アカウントの認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Setting up a custom domain を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
- リージョン: コントロールプレーンプールを実行するリージョンを指定します。リージョンが近くにある場合はパフォーマンスの速度が向上しますが、リージョンの距離が離れると、より分散されます。
- CPU アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
コントロールプレーンプールのインスタンスタイプを指定できます。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
- ノード数: ワーカープールを定義するときに必要な設定です。
ネットワークの詳細が必要であり、IPv6 アドレスを使用するには複数のネットワークが必要です。Add network をクリックして、追加のネットワークを追加できます。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー:
HTTPトラフィックのプロキシーとして使用する URL。 -
HTTPS プロキシー:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシーサイトなし: プロキシーをバイパスする必要のあるサイトのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに install-config.yaml ファイルの内容を表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、multicluster engine Operator で管理されるように自動的に設定されます。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.7. VMware vSphere でのクラスターの作成
multicluster engine Operator コンソールを使用して、VMware vSphere に Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの vSphere のインストール でプロセスの詳細を確認してください。
1.7.3.7.1. 前提条件
vSphere でクラスターを作成する前に、次の前提条件を確認してください。
- サポートされている OpenShift Container Platform バージョンにハブクラスターがデプロイされている。
- vSphere 認証情報がある。詳細は、VMware vSphere の認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
デプロイする VMware インスタンスについて、以下の情報がある。
- API および Ingress インスタンスに必要な静的 IP アドレス
以下の DNS レコード。
次の API ベースドメインは静的 API VIP を指す必要があります。
api.<cluster_name>.<base_domain>次のアプリケーションベースドメインは、Ingress VIP の静的 IP アドレスを指す必要があります。
*.apps.<cluster_name>.<base_domain>
1.7.3.7.2. コンソールを使用したクラスターの作成
multicluster engine Operator コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、クラスターのインポート でインポート手順を参照してください。
認証情報を作成する必要がある場合は、認証情報の作成の詳細について、VMware vSphere の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
vSphere アカウントで設定した、選択した認証情報に関連付けられているベースドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、カスタマイズによる vSphere へのクラスターのインストール を参照してください。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
注記: OpenShift Container Platform バージョン 4.15 以降のリリースイメージがサポートされています。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。この情報には、CPU アーキテクチャー フィールドが含まれます。次のフィールドの説明を表示します。
- CPU アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。この情報には、ソケットあたりのコア数、CPU、Memory_min MiB、GiB 単位の _Disk サイズ、および ノード数 が含まれます。
ネットワーク情報が必要です。IPv6 を使用するには、複数のネットワークが必要です。必要なネットワーク情報の一部は、次のフィールドに含まれています。
- vSphere ネットワーク名: VMware vSphere ネットワーク名を指定します。
API VIP: 内部 API 通信に使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシーサイトなし: プロキシーをバイパスする必要のあるサイトのコンマ区切りリストを指定します。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
非接続インストールを定義するには、Disconnected installation をクリックします。VMware vSphere プロバイダーと非接続インストールを使用してクラスターを作成する際に、ミラーレジストリーにアクセスするための証明書が必要な場合は、クラスターを作成する際の認証情報または Disconnected installation セクションを設定するときに、Configuration for disconnected installation セクションの Additional trust bundle フィールドにその証明書を入力する必要があります。
Add automation template をクリックしてテンプレートを作成できます。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、multicluster engine Operator で管理されるように自動的に設定されます。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.8. Red Hat OpenStack Platform でのクラスターの作成
multicluster engine Operator コンソールを使用して、Red Hat OpenStack Platform に Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順を完了した後、クラスターの作成について質問がある場合は、プロセスの詳細は、OpenShift Container Platform ドキュメントの OpenStack へのインストール を参照してください。
1.7.3.8.1. 前提条件
Red Hat OpenStack Platform でクラスターを作成する前に、以下の前提条件を確認してください。
- OpenShift Container Platform バージョン 4.6 以降にデプロイされたハブクラスターが必要です。
- Red Hat OpenStack Platform の認証情報がある。詳細は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
デプロイする Red Hat OpenStack Platform インスタンスに関する以下の情報がある。
-
コントロールプレーンとワーカーインスタンスのフレーバー名 (例:
m1.xlarge) - Floating IP アドレスを提供する外部ネットワークのネットワーク名
- API および Ingress インスタンスに必要な静的 IP アドレス
以下の DNS レコード。
次の API ベースドメインは、API のフローティング IP アドレスを指す必要があります。
api.<cluster_name>.<base_domain>次のアプリケーションベースドメインは、ingress:app-name のフローティング IP アドレスを指す必要があります。
*.apps.<cluster_name>.<base_domain>
-
コントロールプレーンとワーカーインスタンスのフレーバー名 (例:
1.7.3.8.2. コンソールを使用したクラスターの作成
multicluster engine Operator コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、クラスターのインポート でインポート手順を参照してください。
認証情報を作成する必要がある場合は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。名前には 15 文字以上指定できません。値は、認証情報の要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
Red Hat OpenStack Platform アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Red Hat OpenStack Platform ドキュメントの ドメインの管理 を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。OpenShift Container Platform バージョン 4.6.x 以降のリリースイメージのみがサポートされます。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
コントロールプレーンプールのインスタンスタイプを追加する必要がありますが、インスタンスの作成後にインスタンスのタイプとサイズを変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
- ノード数: ワーカープールのノード数を指定します。ワーカープールを定義する場合にこの設定は必須です。
クラスターにはネットワークの詳細が必要です。IPv4 ネットワーク用に 1 つ以上のネットワークの値を指定する必要があります。IPv6 ネットワークの場合は、複数のネットワークを定義する必要があります。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値が指定されていない場合、HTTP Proxyと同じ値がHTTPとHTTPSの両方に使用されます。 -
プロキシーなし: プロキシーをバイパスする必要のあるサイトのコンマ区切りリストを定義します。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加の信頼バンドル: HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書。
Disconnected installation をクリックして、オフラインインストールイメージを定義できます。Red Hat OpenStack Platform プロバイダーとオフラインインストールを使用してクラスターを作成する際に、ミラーレジストリーにアクセスするための証明書が必要な場合は、クラスターを作成する際の認証情報または Disconnected installation セクションを設定するときに、Configuration for disconnected installation セクションの Additional trust bundle フィールドにその証明書を入力する必要があります。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
内部認証局 (CA) を使用するクラスターを作成する場合、以下の手順を実行してクラスターの YAML ファイルをカスタマイズする必要があります。
レビューステップで YAML スイッチをオンにし、CA 証明書バンドルを使用してリストの上部に
Secretオブジェクトを挿入します。注記: Red Hat OpenStack Platform 環境が複数の機関によって署名された証明書を使用してサービスを提供する場合、バンドルには、必要なすべてのエンドポイントを検証するための証明書を含める必要があります。ocp3という名前のクラスターの追加は以下の例のようになります。apiVersion: v1 kind: Secret type: Opaque metadata: name: ocp3-openstack-trust namespace: ocp3 stringData: ca.crt: | -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----以下の例のように、Hive
ClusterDeploymentオブジェクトを変更して、spec.platform.openstackにcertificatesSecretRefの値を指定します。platform: openstack: certificatesSecretRef: name: ocp3-openstack-trust credentialsSecretRef: name: ocp3-openstack-creds cloud: openstack上記の例では、
clouds.yamlファイルのクラウド名がopenstackであることを前提としています。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
注記: クラスターのインポートには、クラスターの詳細で提示された oc コマンドを実行する必要はありません。クラスターを作成すると、multicluster engine Operator で管理されるように自動的に設定されます。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.9. オンプレミス環境でのクラスターの作成
コンソールを使用して、オンプレミスの Red Hat OpenShift Container Platform クラスターを作成できます。クラスターは、VMware vSphere、Red Hat OpenStack、Nutanix、またはベアメタル環境上のシングルノード OpenShift クラスター、マルチノードクラスター、およびコンパクトな 3 ノードクラスターにすることができます。
プラットフォームの値が platform=none に設定されているため、クラスターをインストールするプラットフォームとのプラットフォーム統合はありません。シングルノード OpenShift クラスターには、コントロールプレーンサービスとユーザーワークロードをホストするシングルノードのみが含まれます。この設定は、クラスターのリソースフットプリントを最小限に抑えたい場合に役立ちます。
Red Hat OpenShift Container Platform で利用できる機能であるゼロタッチプロビジョニング機能を使用して、エッジリソース上に複数のシングルノード OpenShift クラスターをプロビジョニングすることもできます。ゼロタッチプロビジョニングの詳細は、OpenShift Container Platform ドキュメントの ネットワークファーエッジのクラスター を参照してください。
1.7.3.9.1. 前提条件
オンプレミス環境にクラスターを作成する前に、以下の前提条件を確認してください。
- サポートされている OpenShift Container Platform バージョンにハブクラスターがデプロイされている。
- 設定済みホストのホストインベントリーを備えた設定済みインフラストラクチャー環境がある。
- クラスターの作成に必要なイメージを取得できるように、ハブクラスターにインターネットアクセスがある (接続環境) か、インターネットに接続されている内部レジストリーまたはミラーレジストリーへの接続がある (非接続環境)。
- オンプレミス認証情報が設定されている。
- OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
次の DNS レコードが必要です。
次の API ベースドメインは静的 API VIP を指す必要があります。
api.<cluster_name>.<base_domain>次のアプリケーションベースドメインは、Ingress VIP の静的 IP アドレスを指す必要があります。
*.apps.<cluster_name>.<base_domain>
-
ハブクラスターの
KubeAPIServer証明書検証ストラテジーを確認し、デフォルトのUseAutoDetectedCABundleストラテジーが機能することを確認する。ストラテジーを手動で変更する必要がある場合は、ハブクラスターのKubeAPIServer検証ストラテジーの設定 を参照してください。
1.7.3.9.2. コンソールを使用したクラスターの作成
コンソールからクラスターを作成するには、次の手順を実行します。
- Infrastructure > Clusters に移動します。
- Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
- クラスターのタイプとして Host inventory を選択します。
支援インストールでは、次のオプションを使用できます。
- 既存の検出されたホストを使用する: 既存のホストインベントリーにあるホストのリストからホストを選択します。
- 新規ホストの検出: 既存のインフラストラクチャー環境にないホストを検出します。インフラストラクチャー環境にあるものを使用するのではなく、独自のホストを検出します。
認証情報を作成する必要がある場合、詳細は オンプレミス環境の認証情報の作成 を参照してください。
クラスターの名前は、クラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
注記: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
プロバイダーアカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は上書きすると変更できますが、この設定はクラスターの作成後には変更できません。プロバイダーのベースドメインは、Red Hat OpenShift Container Platform クラスターコンポーネントへのルートの作成に使用されます。これは、クラスタープロバイダーの DNS で Start of Authority (SOA) レコードとして設定されます。
OpenShift version は、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。詳細は、リリースイメージ を参照してください。
サポート対象の OpenShift Container Platform バージョンを選択すると、Install single node OpenShift を選択するオプションが表示されます。シングルノード OpenShift クラスターには、コントロールプレーンサービスとユーザーワークロードをホストするシングルノードが含まれます。シングルノード OpenShift クラスターの作成後にノードを追加する方法の詳細は、インフラストラクチャー環境へのホストのスケーリング を参照してください。
クラスターをシングルノード OpenShift クラスターにする場合は、シングルノード OpenShift オプションを選択します。以下の手順を実行することで、シングルノードの OpenShift クラスターにワーカーを追加できます。
- コンソールから、Infrastructure > Clusters に移動し、作成したクラスターまたはアクセスするクラスターの名前を選択します。
- Actions > Add hosts を選択して、ワーカーを追加します。
注記: シングルノード OpenShift コントロールプレーンには 8 つの CPU コアが必要ですが、マルチノードコントロールプレーンクラスターのコントロールプレーンノードには 4 つの CPU コアしか必要ありません。
クラスターを確認して保存すると、クラスターはドラフトクラスターとして保存されます。Clusters ページでクラスター名を選択すると、作成プロセスを閉じてプロセスを終了することができます。
既存のホストを使用している場合は、ホストを独自に選択するか、自動的に選択するかどうかを選択します。ホストの数は、選択したノード数に基づいています。たとえば、シングルノード OpenShift クラスターではホストが 1 つだけ必要ですが、標準の 3 ノードクラスターには 3 つのホストが必要です。
このクラスターの要件を満たす利用可能なホストの場所は、ホストの場所 のリストに表示されます。ホストと高可用性設定の分散には、複数の場所を選択します。
既存のインフラストラクチャー環境がない新しいホストを検出する場合は、Discovery Image を使用したホストインベントリーへのホストの追加 の手順を実行します。
ホストがバインドされ、検証に合格したら、以下の IP アドレスを追加してクラスターのネットワーク情報を入力します。
API VIP: 内部 API 通信に使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。
Red Hat Advanced Cluster Management for Kubernetes を使用しており、マネージドクラスターの klusterlet を特定のノードで実行するように設定する場合は、オプション: 特定のノードで実行するように klusterlet を設定する で必要な手順を参照してください。
Clusters ナビゲーションページで、インストールのステータスを表示できます。
クラスターにアクセスする 手順は、クラスターへのアクセスに進みます。
1.7.3.9.3. コマンドラインを使用したクラスターの作成
Central Infrastructure Management 管理コンポーネント内のアシステッドインストーラー機能を使用して、コンソールを使用せずにクラスターを作成することもできます。この手順を完了したら、生成された検出イメージからホストを起動できます。通常、手順の順序は重要ではありませんが、順序が必要な場合は注意してください。
1.7.3.9.3.1. namespace を作成します。
リソースの namespace が必要です。すべてのリソースを共有 namespace に保持すると便利です。この例では、namespace の名前に sample-namespace を使用していますが、assisted-installer 以外の任意の名前を使用できます。次のファイルを作成して適用して namespace を作成します。
apiVersion: v1
kind: Namespace
metadata:
name: sample-namespace1.7.3.9.3.2. プルシークレットを namespace に追加する
以下のカスタムリソースを作成し、適用して プルシークレット を namespace に追加します。
apiVersion: v1
kind: Secret
type: kubernetes.io/dockerconfigjson
metadata:
name: <pull-secret>
namespace: sample-namespace
stringData:
.dockerconfigjson: 'your-pull-secret-json' 1.7.3.9.3.3. ClusterImageSet の生成
以下のカスタムリソースを作成して適用することで、CustomImageSet を生成してクラスターの OpenShift Container Platform のバージョンを指定します。
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
name: openshift-v4.15.0
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.15.0-rc.0-x86_64
注記: ハブクラスターとは異なるアーキテクチャーを持つマネージドクラスターをインストールする場合は、マルチアーキテクチャーの ClusterImageSet を作成する必要があります。詳細は、別のアーキテクチャーにクラスターをデプロイするためのリリースイメージの作成 を参照してください。
1.7.3.9.3.4. ClusterDeployment カスタムリソースを作成します。
ClusterDeployment カスタムリソース定義は、クラスターのライフサイクルを制御する API です。これは、クラスターリソースを定義する spec.ClusterInstallRef 設定で AgentClusterInstall カスタムリソースを参照します。
以下の例に基づいて ClusterDeployment カスタムリソースを作成して適用します。
apiVersion: hive.openshift.io/v1
kind: ClusterDeployment
metadata:
name: single-node
namespace: demo-worker4
spec:
baseDomain: hive.example.com
clusterInstallRef:
group: extensions.hive.openshift.io
kind: AgentClusterInstall
name: test-agent-cluster-install
version: v1beta1
clusterName: test-cluster
controlPlaneConfig:
servingCertificates: {}
platform:
agentBareMetal:
agentSelector:
matchLabels:
location: internal
pullSecretRef:
name: <pull-secret> - 1
AgentClusterInstallリソースの名前を使用します。- 2
- Add the pull secret to the namespace でダウンロードしたプルシークレットを使用します。
1.7.3.9.3.5. AgentClusterInstall カスタムリソースを作成します。
AgentClusterInstall カスタムリソースでは、クラスターの要件の多くを指定できます。たとえば、クラスターネットワーク設定、プラットフォーム、コントロールプレーンの数、およびワーカーノードを指定できます。
次の例のようなカスタムリソースを作成して追加します。
apiVersion: extensions.hive.openshift.io/v1beta1
kind: AgentClusterInstall
metadata:
name: test-agent-cluster-install
namespace: demo-worker4
spec:
platformType: BareMetal
clusterDeploymentRef:
name: single-node
imageSetRef:
name: openshift-v4.15.0
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 192.168.111.0/24
serviceNetwork:
- 172.30.0.0/16
provisionRequirements:
controlPlaneAgents: 1
sshPublicKey: ssh-rsa <your-public-key-here> - 1
- クラスターが作成される環境のプラットフォームタイプを指定します。有効な値は、
BareMetal、None、VSphere、Nutanix、またはExternalです。 - 2
ClusterDeploymentリソースに使用したものと同じ名前を使用します。- 3
- Generate a ClusterImageSet で生成した
ClusterImageSetを使用します。 - 4
- SSH 公開鍵を指定すると、インストール後にホストにアクセスできるようになります。
1.7.3.9.3.6. オプション: NMStateConfig カスタムリソースを作成する
NMStateConfig カスタムリソースは、静的 IP アドレスなどのホストレベルのネットワーク設定がある場合にのみ必要です。NMStateConfig カスタムリソースを作成する場合は、InfraEnv カスタムリソースを作成する前にこの手順を完了する必要があります。InfraEnv カスタムリソースの spec.nmStateConfigLabelSelector の値は、NMStateConfig カスタムリソースを参照します。
次の例のような NMStateConfig カスタムリソースを作成して適用します。必要に応じて値を置き換えます。
apiVersion: agent-install.openshift.io/v1beta1
kind: NMStateConfig
metadata:
name: <mynmstateconfig>
namespace: <demo-worker4>
labels:
demo-nmstate-label: <value>
spec:
config:
interfaces:
- name: eth0
type: ethernet
state: up
mac-address: 02:00:00:80:12:14
ipv4:
enabled: true
address:
- ip: 192.168.111.30
prefix-length: 24
dhcp: false
- name: eth1
type: ethernet
state: up
mac-address: 02:00:00:80:12:15
ipv4:
enabled: true
address:
- ip: 192.168.140.30
prefix-length: 24
dhcp: false
dns-resolver:
config:
server:
- 192.168.126.1
routes:
config:
- destination: 0.0.0.0/0
next-hop-address: 192.168.111.1
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
next-hop-address: 192.168.140.1
next-hop-interface: eth1
table-id: 254
interfaces:
- name: "eth0"
macAddress: "02:00:00:80:12:14"
- name: "eth1"
macAddress: "02:00:00:80:12:15"重要:
-
InfraEnvカスタムリソースのspec.nmStateConfigLabelSelector.matchLabelsフィールドに、demo-nmstate-labelのラベル名と値を含める必要があります。 - DHCP または静的ネットワークプロトコルを使用する場合は、MAC アドレスを追加する必要があります。
spec.config フィールドに追加できる NMState の追加の例は、OpenShift Container Platform Assisted Installer ドキュメントの 追加の NMState 設定例 を参照してください。
1.7.3.9.3.7. InfraEnv カスタムリソースを作成します。
InfraEnv カスタムリソースは、検出 ISO を作成する設定を提供します。このカスタムリソース内で、プロキシー設定、Ignition オーバーライドの値を特定し、NMState ラベルを指定します。このカスタムリソースの spec.nmStateConfigLabelSelector の値は、NMStateConfig カスタムリソースを参照します。
注: オプションの NMStateConfig カスタムリソースを含める場合は、InfraEnv カスタムリソースでそちらを参照する必要があります。NMStateConfig カスタムリソースを作成する前に InfraEnv カスタムリソースを作成した場合は、InfraEnv カスタムリソースを編集して NMStateConfig カスタムリソースを参照し、参照の追加後に ISO をダウンロードします。
以下のカスタムリソースを作成して適用します。
apiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
metadata:
name: myinfraenv
namespace: demo-worker4
spec:
clusterRef:
name: single-node
namespace: demo-worker4
pullSecretRef:
name: pull-secret
sshAuthorizedKey: <your_public_key_here>
nmStateConfigLabelSelector:
matchLabels:
demo-nmstate-label: value
proxy:
httpProxy: http://USERNAME:PASSWORD@proxy.example.com:PORT
httpsProxy: https://USERNAME:PASSWORD@proxy.example.com:PORT
noProxy: .example.com,172.22.0.0/24,10.10.0.0/24- 1
- Create the ClusterDeployment の
clusterDeploymentリソース名を置き換えます。 - 2
- ClusterDeployment の作成 の
clusterDeploymentリソース namespace を置き換えます。
1.7.3.9.3.7.1. InfraEnv のフィールドの表
| フィールド | 任意または必須 | 説明 |
|---|---|---|
|
| 任意 | SSH 公開鍵を指定できます。指定すると、検出 ISO イメージからホストを起動するときにホストにアクセスできるようになります。 |
|
| 任意 |
ホストの静的 IP、ブリッジ、ボンディングなどの高度なネットワーク設定を統合します。ホストネットワーク設定は、選択したラベルを持つ 1 つ以上の |
|
| 任意 | proxy セクションでは、検出中にホストに必要なプロキシー設定を指定できます。 |
注記: IPv6 を使用してプロビジョニングする場合、noProxy 設定で CIDR アドレスブロックを定義することはできません。各アドレスを個別に定義する必要があります。
1.7.3.9.3.8. 検出イメージからホストを起動します。
残りの手順では、前の手順で取得した検出 ISO イメージからホストを起動する方法を説明します。
次のコマンドを実行して、namespace から検出イメージをダウンロードします。
curl --insecure -o image.iso $(kubectl -n sample-namespace get infraenvs.agent-install.openshift.io myinfraenv -o=jsonpath="{.status.isoDownloadURL}")- 検出イメージを仮想メディア、USB ドライブ、または別の保管場所に移動し、ダウンロードしたディスカバリーイメージからホストを起動します。
Agentリソースは自動的に作成されます。これはクラスターに登録されており、検出イメージから起動したホストを表します。次のコマンドを実行して、Agentのカスタムリソースを承認し、インストールを開始します。oc -n sample-namespace patch agents.agent-install.openshift.io 07e80ea9-200c-4f82-aff4-4932acb773d4 -p '{"spec":{"approved":true}}' --type mergeエージェント名と UUID は、実際の値に置き換えます。
前のコマンドの出力に、
APPROVEDパラメーターの値がtrueであるターゲットクラスターのエントリーが含まれている場合、承認されたことを確認できます。
1.7.3.9.4. 関連情報
- CLI を使用して Nutanix プラットフォーム上にクラスターを作成するときに必要な追加の手順は、Red Hat OpenShift Container Platform ドキュメントの API を使用した Nutanix へのホストの追加 および Nutanix インストール後の設定 を参照してください。
- ゼロタッチプロビジョニングの詳細は、OpenShift Container Platform ドキュメントの ネットワーク遠端のクラスター を参照してください。
- イメージプルシークレットの使用 を参照してください。
- オンプレミス環境の認証情報の作成 を参照してください。
- リリースイメージ を参照してください。
- Discovery Image を使用したホストのホストインベントリーへの追加 を参照してください。
1.7.3.10. プロキシー環境でのクラスターの作成
ハブクラスターがプロキシーサーバー経由で接続されている場合は、Red Hat OpenShift Container Platform クラスターを作成できます。クラスターを正常に作成するには、以下のいずれかの状況に該当している必要があります。
- multicluster engine Operator に、作成するマネージドクラスターとのプライベートネットワーク接続があり、マネージドクラスターがプロキシーを使用してインターネットにアクセスできる。
- マネージドクラスターはインフラストラクチャープロバイダーにあるが、ファイアウォールポートを使用することでマネージドクラスターからハブクラスターへの通信が可能になる。
プロキシーで設定されたクラスターを作成するには、以下の手順を実行します。
シークレットに保存されている
install-configYAML に次の情報を追加して、ハブクラスターでcluster-wide-proxy設定を設定します。apiVersion: v1 kind: Proxy baseDomain: <domain> proxy: httpProxy: http://<username>:<password>@<proxy.example.com>:<port> httpsProxy: https://<username>:<password>@<proxy.example.com>:<port> noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR>usernameは、プロキシーサーバーのユーザー名に置き換えます。passwordは、プロキシーサーバーへのアクセス時に使用するパスワードに置き換えます。proxy.example.comは、プロキシーサーバーのパスに置き換えます。portは、プロキシーサーバーとの通信ポートに置き換えます。wildcard-of-domainは、プロキシーをバイパスするドメインのエントリーに置き換えます。provisioning-network/CIDRは、プロビジョニングネットワークの IP アドレスと割り当てられた IP アドレスの数 (CIDR 表記) に置き換えます。BMC-address-range/CIDRは、BMC アドレスおよびアドレス数 (CIDR 表記) に置き換えます。- クラスターの作成手順を実行してクラスターをプロビジョニングします。クラスターの作成 を参照してプロバイダーを選択します。
注: install-config YAML は、クラスターをデプロイする場合にのみ使用できます。クラスターをデプロイした後、install-config YAML に加えた新しい変更は適用されません。導入後に設定を更新するには、ポリシーを使用する必要があります。詳細は、Pod ポリシー を参照してください。
1.7.3.10.1. 関連情報
1.7.3.11. AgentClusterInstall プロキシーの設定
AgentClusterInstall プロキシーフィールドは、インストール中のプロキシー設定を決定し、作成されたクラスターにクラスター全体のプロキシーリソースを作成するために使用されます。
1.7.3.11.1. AgentClusterInstall の設定
AgentClusterInstall プロキシーを設定するには、プロキシー 設定を AgentClusterInstall リソースに追加します。httpProxy、httpsProxy、noProxy を使用した次の YAML サンプルを参照してください。
apiVersion: extensions.hive.openshift.io/v1beta1
kind: AgentClusterInstall
spec:
proxy:
httpProxy: http://<username>:<password>@<proxy.example.com>:<port>
httpsProxy: https://<username>:<password>@<proxy.example.com>:<port>
noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR> - 1
httpProxyは、HTTP リクエストのプロキシーの URL です。ユーザー名とパスワードの値は、プロキシーサーバーの認証情報に置き換えます。proxy.example.comは、プロキシーサーバーのパスに置き換えます。- 2
httpsProxyは、HTTPS リクエストのプロキシーの URL です。値を自分の認証情報に置き換えます。portは、プロキシーサーバーとの通信ポートに置き換えます。- 3
noProxyは、プロキシーを使用しないドメインと CIDR のコンマ区切りリストです。wildcard-of-domainは、プロキシーをバイパスするドメインのエントリーに置き換えます。provisioning-network/CIDRは、プロビジョニングネットワークの IP アドレスと割り当てられた IP アドレスの数 (CIDR 表記) に置き換えます。BMC-address-range/CIDRは、BMC アドレスおよびアドレス数 (CIDR 表記) に置き換えます。
1.7.3.11.2. 関連情報
1.7.4. クラスターのインポート
別の Kubernetes クラウドプロバイダーからクラスターをインポートできます。インポート後、ターゲットのクラスターが multicluster engine Operator ハブクラスターのマネージドクラスターになります。特に指定されていない限りは通常、ハブクラスターとターゲットのマネージドクラスターにアクセスできる場所で、インポートタスクを実行できます。
- ハブクラスターは 他 のハブクラスターの管理はできず、自己管理のみが可能です。ハブクラスターは、自動的にインポートして自己管理できるように設定されています。ハブクラスターは手動でインポートする必要はありません。
-
ハブクラスターを削除して再度インポートする場合は、
local-cluster:trueラベルをManagedClusterリソースに追加する必要があります。
重要: クラスターライフサイクルで、Cloud Native Computing Foundation (CNCF) Kubernetes Conformance Program を通じて認定されたすべてのプロバイダーがサポートされるようになりました。ハイブリッドクラウドマルチクラスター管理用に CNCF が認識するベンダーを選択します。
CNCF プロバイダーの使用については、以下の情報を参照してください。
- CNCF プロバイダーが Certified Kubernetes Conformance で認定されている方法を学習します。
- CNCF サードパーティープロバイダーに関する Red Hat サポート情報については、Red Hat サポート サードパーティーコンポーネント または Red Hat サポートへの問い合わせ を参照してください。
-
独自の CNCF 適合認定クラスターを用意する場合は、OpenShift Container Platform CLI
ocコマンドを Kubernetes CLI コマンドkubectlに変更する必要があります。
クラスターを管理できるようにクラスターをインポートする方法の詳細は、次のトピックを参照してください。
必要なユーザータイプまたはアクセスレベル: クラスター管理者
1.7.4.1. コンソールを使用したマネージドクラスターのインポート
multicluster engine for Kubernetes Operator をインストールしたら、クラスターをインポートして管理できるようになります。コンソールを使用してマネージドクラスターをインポートする方法は、以下を参照してください。
1.7.4.1.1. 前提条件
- デプロイされたハブクラスター。ベアメタルクラスターをインポートする場合、サポートされている Red Hat OpenShift Container Platform バージョンにハブクラスターがインストールされている。
- 管理するクラスター。
-
base64コマンドラインツール。 -
OpenShift Container Platform によって作成されていないクラスターをインポートする場合、定義された
multiclusterhub.spec.imagePullSecret。このシークレットは、multicluster engine for Kubernetes Operator のインストール時に作成済みである可能性があります。このシークレットを定義する方法の詳細は、カスタムイメージプルシークレット を参照してください。 -
ハブクラスターの
KubeAPIServer証明書検証ストラテジーを確認し、デフォルトのUseAutoDetectedCABundleストラテジーが機能することを確認する。ストラテジーを手動で変更する必要がある場合は、ハブクラスターのKubeAPIServer検証ストラテジーの設定 を参照してください。
Required user type or access level: クラスター管理者
1.7.4.1.2. 新規プルシークレットの作成
新しいプルシークレットを作成する必要がある場合は、以下の手順を実行します。
- cloud.redhat.com から Kubernetes プルシークレットをダウンロードします。
- プルシークレットをハブクラスターの namespace に追加します。
次のコマンドを実行して、
open-cluster-managementnamespace に新しいシークレットを作成します。oc create secret generic pull-secret -n <open-cluster-management> --from-file=.dockerconfigjson=<path-to-pull-secret> --type=kubernetes.io/dockerconfigjsonopen-cluster-managementをハブクラスターの namespace の名前に置き換えます。ハブクラスターのデフォルトの namespace はopen-cluster-managementです。path-to-pull-secretを、ダウンロードしたプルシークレットへのパスに置き換えます。シークレットは、インポート時にマネージドクラスターに自動的にコピーされます。
-
以前にインストールされたエージェントが、インポートするクラスターから削除されていることを確認します。エラーを回避するには、
open-cluster-management-agentおよびopen-cluster-management-agent-addonnamespace を削除する必要があります。 Red Hat OpenShift Dedicated 環境にインポートする場合には、以下の注意点を参照してください。
- ハブクラスターを Red Hat OpenShift Dedicated 環境にデプロイしている必要があります。
-
Red Hat OpenShift Dedicated のデフォルト権限は dedicated-admin ですが、namespace を作成するための権限がすべて含まれているわけではありません。multicluster engine Operator を使用してクラスターをインポートおよび管理するには、
cluster-admin権限が必要です。
-
以前にインストールされたエージェントが、インポートするクラスターから削除されていることを確認します。エラーを回避するには、
1.7.4.1.3. クラスターのインポート
利用可能なクラウドプロバイダーごとに、コンソールから既存のクラスターをインポートできます。
注記: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、自動的にインポートおよび自己管理するように設定されるため、ハブクラスターを手動でインポートして自己管理する必要はありません。
デフォルトでは、namespace がクラスター名と namespace に使用されますが、これは変更できます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの namespace を作成します。その namespace には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、namespace とその中のすべてのリソースが削除されます。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、クラスターは default マネージドクラスターセットに自動的に追加されます。
クラスターを別のクラスターセットに追加する場合は、クラスターセットへの clusterset-admin 権限が必要です。クラスターのインポート時に cluster-admin 権限がない場合は、clusterset-admin 権限を持つクラスターセットを選択する必要があります。指定されたクラスターセットに適切な権限がない場合、クラスターのインポートは失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへの clusterset-admin 権限を受け取ってください。
OpenShift Container Platform Dedicated クラスターをインポートし、vendor=OpenShiftDedicated のラベルを追加してベンダーを指定しない場合、vendor=auto-detect のラベルを追加すると、managed-by=platform ラベルがクラスターに自動的に追加されます。この追加されたラベルを使用して、クラスターを OpenShift Container Platform Dedicated クラスターとして識別し、OpenShift Container Platform Dedicated クラスターをグループとして取得できます。
以下の表は、クラスターをインポートする方法を指定する インポートモード で使用できるオプションを示しています。
| import コマンドの手動実行 | Red Hat Ansible Automation Platform テンプレートなど、コンソールで情報を完了および送信した後に、提供されたコマンドをターゲットクラスターで実行してクラスターをインポートします。 |
| 既存クラスターのサーバー URL および API トークンを入力します。 | インポートするクラスターのサーバー URL および API トークンを指定します。クラスターのアップグレード時に実行する Red Hat Ansible Automation Platform テンプレートを指定できます。 |
|
|
インポートするクラスターの |
注記: Ansible Automation Platform ジョブを作成して実行するには、OperatorHub から Red Hat Ansible Automation Platform Resource Operator をインストールし、実行する必要があります。
クラスター API アドレスを設定するには、任意: Configuring the cluster API address を参照してください。
マネージドクラスター klusterlet を特定のノードで実行するように設定するには、オプション: 特定のノードで実行するように klusterlet を設定する を参照してください。
1.7.4.1.3.1. オプション: クラスター API アドレスの設定
oc get managedcluster コマンドの実行時に表に表示される URL を設定して、クラスターの詳細ページにある Cluster API アドレス をオプションで設定します。
-
cluster-admin権限がある ID でハブクラスターにログインします。 -
ターゲットに設定されたマネージドクラスターの
kubeconfigファイルを設定します。 次のコマンドを実行して、インポートするクラスターのマネージドクラスターエントリーを編集します。
cluster -nameをマネージドクラスターの名前に置き換えます。oc edit managedcluster <cluster-name>以下の例のように、YAML ファイルの
ManagedCluster仕様にManagedClusterClientConfigsセクションを追加します。spec: hubAcceptsClient: true managedClusterClientConfigs: - url: <https://api.new-managed.dev.redhat.com>1 - 1
- URL の値を、インポートするマネージドクラスターへの外部アクセスを提供する URL に置き換えます。
1.7.4.1.3.2. オプション: 特定のノードで実行するように klusterlet を設定する
マネージドクラスターの nodeSelector と tolerations アノテーションを設定することで、マネージドクラスター klusterlet を実行するノードを指定できます。これらを設定するには、次の手順を実行します。
- コンソールのクラスターページから、更新するマネージドクラスターを選択します。
YAML コンテンツを表示するには、YAML スイッチを
Onに設定します。注記: YAML エディターは、クラスターをインポートまたは作成するときにのみ使用できます。インポートまたは作成後にマネージドクラスターの YAML 定義を編集するには、OpenShift Container Platform コマンドラインインターフェイスまたは Red Hat Advanced Cluster Management 検索機能を使用する必要があります。
-
nodeSelectorアノテーションをマネージドクラスターの YAML 定義に追加します。このアノテーションのキーは、open-cluster-management/nodeSelectorです。このアノテーションの値は、JSON 形式の文字列マップです。 tolerationsエントリーをマネージドクラスターの YAML 定義に追加します。このアノテーションのキーは、open-cluster-management/tolerationsです。このアノテーションの値は、JSON 形式の toleration リストを表します。結果の YAML は次の例のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: open-cluster-management/nodeSelector: '{"dedicated":"acm"}' open-cluster-management/tolerations: '[{"key":"dedicated","operator":"Equal","value":"acm","effect":"NoSchedule"}]'
KlusterletConfig を使用して、マネージドクラスターの nodeSelector と tolerations を設定することもできます。これらを設定するには、次の手順を実行します。
注: KlusterletConfig を使用する場合、マネージドクラスターは、マネージドクラスターのアノテーションの設定ではなく、KlusterletConfig 設定の構成を使用します。
次のサンプル YAML の内容を適用します。必要に応じて値を置き換えます。
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: <klusterletconfigName> spec: nodePlacement: nodeSelector: dedicated: acm tolerations: - key: dedicated operator: Equal value: acm effect: NoSchedule-
agent.open-cluster-management.io/klusterlet-config: `<klusterletconfigName>アノテーションをマネージドクラスターに追加し、<klusterletconfigName>をKlusterletConfigの名前に置き換えます。
1.7.4.1.4. インポートされたクラスターの削除
以下の手順を実行して、インポートされたクラスターと、マネージドクラスターで作成された open-cluster-management-agent-addon を削除します。
Clusters ページで、Actions > Detach cluster をクリックしてマネージメントからクラスターを削除します。
注記: local-cluster という名前のハブクラスターをデタッチしようとする場合は、デフォルトの disableHubSelfManagement 設定が false である点に注意してください。この設定が原因で、ハブクラスターがデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが完了するのを待たずにハブクラスターを再インポートする場合は、次のコマンドを実行して multiclusterhub-operator Pod を再起動し、再インポートを高速化できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
disableHubSelfManagement の値を true に指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。詳細は、disableHubSelfManagement のトピックを参照してください。
1.7.4.1.4.1. 関連情報
- カスタムイメージプルシークレット の定義方法の詳細は、カスタムイメージプルシークレットを参照してください。
- disableHubSelfManagement トピックを参照してください。
1.7.4.2. CLI を使用したマネージドクラスターのインポート
multicluster engine for Kubernetes Operator をインストールしたら、Red Hat OpenShift Container Platform CLI を使用して、クラスターをインポートおよび管理できるようになります。自動インポートシークレットを使用するか、man コマンドを使用して、CLI でマネージドクラスターをインポートする方法は、以下のトピックを参照してください。
重要: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、ローカルクラスター として自動的にインポートおよび管理されるようにセットアップされます。ハブクラスターは、手動でインポートして自己管理する必要はありません。ハブクラスターを削除して再度インポートする場合は、local-cluster:true ラベルを追加する必要があります。
1.7.4.2.1. 前提条件
- デプロイされたハブクラスター。ベアメタルクラスターをインポートする場合、サポートされている OpenShift Container Platform バージョンにハブクラスターがインストールされている。
- 管理する別のクラスター。
- OpenShift Container Platform CLI。OpenShift Container Platform CLI のインストールと設定については、OpenShift CLI の使用を開始する を参照してください。
-
OpenShift Container Platform によって作成されていないクラスターをインポートする場合、定義された
multiclusterhub.spec.imagePullSecret。このシークレットは、multicluster engine for Kubernetes Operator のインストール時に作成済みである可能性があります。このシークレットを定義する方法の詳細は、カスタムイメージプルシークレット を参照してください。 -
ハブクラスターの
KubeAPIServer証明書検証ストラテジーを確認し、デフォルトのUseAutoDetectedCABundleストラテジーが機能することを確認する。ストラテジーを手動で変更する必要がある場合は、ハブクラスターのKubeAPIServer検証ストラテジーの設定 を参照してください。
1.7.4.2.2. サポート対象のアーキテクチャー
- Linux (x86_64, s390x, ppc64le)
- macOS
1.7.4.2.3. クラスターインポートの準備
CLI を使用してマネージドクラスターをインポートする前に、以下の手順を実行する必要があります。
次のコマンドを実行して、ハブクラスターにログインします。
oc loginハブクラスターで次のコマンドを実行して、プロジェクトおよび namespace を作成します。
<cluster_name>で定義されているクラスター名は、YAML ファイルとコマンドでクラスター namespace としても使用されます。oc new-project <cluster_name>重要:
cluster.open-cluster-management.io/managedClusterラベルは、マネージドクラスターの namespace に対して自動的に追加および削除されます。手動でマネージドクラスター namespace に追加したり、削除したりしないでください。以下の内容例で
managed-cluster.yamlという名前のファイルを作成します。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> labels: cloud: auto-detect vendor: auto-detect spec: hubAcceptsClient: truecloudおよびvendorの値をauto-detectする場合、Red Hat Advanced Cluster Management はインポートしているクラスターからクラウドおよびベンダータイプを自動的に検出します。オプションで、auto-detectの値をクラスターのクラウドおよびベンダーの値に置き換えることができます。以下の例を参照してください。cloud: Amazon vendor: OpenShift以下のコマンドを実行して、YAML ファイルを
ManagedClusterリソースに適用します。oc apply -f managed-cluster.yaml
これで、自動インポートシークレットを使用してクラスターをインポートする か、手動でクラスターをインポートする のいずれかに進むことができます。
1.7.4.2.4. 自動インポートシークレットを使用したクラスターのインポート
自動インポートシークレットを使用してマネージドクラスターをインポートするには、クラスターの kubeconfig ファイルへの参照、またはクラスターの kube API サーバーとトークンのペアのいずれかの参照を含むシークレットを作成する必要があります。自動インポートシークレットを使用してクラスターをインポートするには、以下の手順を実行します。
-
インポートするマネージドクラスターの
kubeconfigファイル、または kube API サーバーおよびトークンを取得します。kubeconfigファイルまたは kube API サーバーおよびトークンの場所を特定する方法は、Kubernetes クラスターのドキュメントを参照してください。 ${CLUSTER_NAME} namespace に
auto-import-secret.yamlファイルを作成します。以下のテンプレートのようなコンテンツを使用して、
auto-import-secret.yamlという名前の YAML ファイルを作成します。apiVersion: v1 kind: Secret metadata: name: auto-import-secret namespace: <cluster_name> stringData: autoImportRetry: "5" # If you are using the kubeconfig file, add the following value for the kubeconfig file # that has the current context set to the cluster to import: kubeconfig: |- <kubeconfig_file> # If you are using the token/server pair, add the following two values instead of # the kubeconfig file: token: <Token to access the cluster> server: <cluster_api_url> type: Opaque以下のコマンドを実行して、<cluster_name> namespace に YAML ファイルを適用します。
oc apply -f auto-import-secret.yaml注記: デフォルトでは、自動インポートシークレットは 1 回使用され、インポートプロセスが完了すると削除されます。自動インポートシークレットを保持する場合は、
managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secretをシークレットに追加します。これを追加するには、以下のコマンドを実行します。oc -n <cluster_name> annotate secrets auto-import-secret managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secret=""
インポートしたクラスターのステータス (
JOINEDおよびAVAILABLE) を確認します。ハブクラスターから以下のコマンドを実行します。oc get managedcluster <cluster_name>クラスターで以下のコマンドを実行して、マネージドクラスターにログインします。
oc login以下のコマンドを実行して、インポートするクラスターの Pod ステータスを検証できます。
oc get pod -n open-cluster-management-agent
klusterlet アドオンのインポート に進むことができます。
1.7.4.2.5. クラスターの手動インポート
重要: import コマンドには、インポートされた各マネージドクラスターにコピーされるプルシークレット情報が含まれます。インポートしたクラスターにアクセスできるユーザーであれば誰でも、プルシークレット情報を表示することもできます。
マネージドクラスターを手動でインポートするには、以下の手順を実行します。
以下のコマンドを実行して、ハブクラスターでインポートコントローラーによって生成された
klusterlet-crd.yamlファイルを取得します。oc get secret <cluster_name>-import -n <cluster_name> -o jsonpath={.data.crds\\.yaml} | base64 --decode > klusterlet-crd.yaml以下のコマンドを実行して、ハブクラスターにインポートコントローラーによって生成された
import.yamlファイルを取得します。oc get secret <cluster_name>-import -n <cluster_name> -o jsonpath={.data.import\\.yaml} | base64 --decode > import.yamlインポートするクラスターで次の手順を実行します。
次のコマンドを入力して、インポートするマネージドクラスターにログインします。
oc login以下のコマンドを実行して、手順 1 で生成した
klusterlet-crd.yamlを適用します。oc apply -f klusterlet-crd.yaml以下のコマンドを実行して、以前に生成した
import.yamlファイルを適用します。oc apply -f import.yamlハブクラスターから次のコマンドを実行して、インポートするマネージドクラスターの
JOINEDおよびAVAILABLEステータスを検証できます。oc get managedcluster <cluster_name>
klusterlet アドオンのインポート に進むことができます。
1.7.4.2.6. klusterlet アドオンのインポート
KlusterletAddonConfig klusterlet アドオン設定を実装して、マネージドクラスターで他のアドオンを有効にします。次の手順を実行して、設定ファイルを作成して適用します。
以下の例のような YAML ファイルを作成します。
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: applicationManager: enabled: true certPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: true-
ファイルは
klusterlet-addon-config.yamlとして保存します。 以下のコマンドを実行して YAML を適用します。
oc apply -f klusterlet-addon-config.yamlアドオンは、インポートするマネージドクラスターのステータスが
AVAILABLEになると、インストールされます。以下のコマンドを実行して、インポートするクラスターのアドオンの Pod ステータスを検証できます。
oc get pod -n open-cluster-management-agent-addon
1.7.4.2.7. コマンドラインインターフェイスを使用したインポート済みクラスターの削除
コマンドラインインターフェイスを使用してマネージドクラスターを削除するには、以下のコマンドを実行します。
oc delete managedcluster <cluster_name>
<cluster_name> をクラスターの名前に置き換えます。
1.7.4.3. エージェント登録を使用したマネージドクラスターのインポート
multicluster engine for Kubernetes Operator をインストールしたら、エージェント登録エンドポイントを使用して、クラスターをインポートおよび管理できるようになります。エージェント登録エンドポイントを使用してマネージドクラスターをインポートする方法は、次のトピックをそのまま参照してください。
1.7.4.3.1. 前提条件
- デプロイされたハブクラスター。ベアメタルクラスターをインポートする場合、サポートされている OpenShift Container Platform バージョンにハブクラスターがインストールされている。
- 管理するクラスター。
-
base64コマンドラインツール。 OpenShift Container Platform によって作成されていないクラスターをインポートする場合、定義された
multiclusterhub.spec.imagePullSecret。このシークレットは、multicluster engine for Kubernetes Operator のインストール時に作成済みである可能性があります。このシークレットを定義する方法の詳細は、カスタムイメージプルシークレット を参照してください。新規シークレットを作成する必要がある場合は、新規プルシークレットの作成 を参照してください。
1.7.4.3.2. サポートされているアーキテクチャー
- Linux (x86_64, s390x, ppc64le)
- macOS
1.7.4.3.3. クラスターのインポート
エージェント登録エンドポイントを使用してマネージドクラスターをインポートするには、次の手順を実行します。
ハブクラスターで次のコマンドを実行して、エージェント登録サーバーの URL を取得します。
export agent_registration_host=$(oc get route -n multicluster-engine agent-registration -o=jsonpath="{.spec.host}")注: ハブクラスターがクラスター全体のプロキシーを使用している場合は、マネージドクラスターがアクセスできる URL を使用していることを確認してください。
次のコマンドを実行して、cacert を取得します。
oc get configmap -n kube-system kube-root-ca.crt -o=jsonpath="{.data['ca\.crt']}" > ca.crt_注記:
kube-root-ca発行エンドポイントを使用していない場合は、kube-root-caCA の代わりにパブリックagent-registrationAPI エンドポイント CA を使用してください。次の YAML コンテンツを適用して、エージェント登録サーバーが承認するトークンを取得します。
apiVersion: v1 kind: ServiceAccount metadata: name: managed-cluster-import-agent-registration-sa namespace: multicluster-engine --- apiVersion: v1 kind: Secret type: kubernetes.io/service-account-token metadata: name: managed-cluster-import-agent-registration-sa-token namespace: multicluster-engine annotations: kubernetes.io/service-account.name: "managed-cluster-import-agent-registration-sa" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: managedcluster-import-controller-agent-registration-client rules: - nonResourceURLs: ["/agent-registration/*"] verbs: ["get"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: managed-cluster-import-agent-registration roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: managedcluster-import-controller-agent-registration-client subjects: - kind: ServiceAccount name: managed-cluster-import-agent-registration-sa namespace: multicluster-engine以下のコマンドを実行してトークンをエクスポートします。
export token=$(oc get secret -n multicluster-engine managed-cluster-import-agent-registration-sa-token -o=jsonpath='{.data.token}' | base64 -d)次のコマンドを実行して、自動承認を有効にし、コンテンツを
cluster-managerにパッチを適用します。oc patch clustermanager cluster-manager --type=merge -p '{"spec":{"registrationConfiguration":{"featureGates":[ {"feature": "ManagedClusterAutoApproval", "mode": "Enable"}], "autoApproveUsers":["system:serviceaccount:multicluster-engine:agent-registration-bootstrap"]}}}'注: 自動承認を無効にして、マネージドクラスターからの証明書署名リクエストを手動で承認することもできます。
次のコマンドを実行して、マネージドクラスターに切り替え、cacert を取得します。
curl --cacert ca.crt -H "Authorization: Bearer $token" https://$agent_registration_host/agent-registration/crds/v1 | oc apply -f -次のコマンドを実行して、マネージドクラスターをハブクラスターにインポートします。
<clusterName>は、クラスターの名前に置き換えます。<duration>は、時間値に置き換えます。たとえば、4hなどに置き換えます。オプション:
<klusterletconfigName>は KlusterletConfig の名前に置き換えます。curl --cacert ca.crt -H "Authorization: Bearer $token" https://$agent_registration_host/agent-registration/manifests/<clusterName>?klusterletconfig=<klusterletconfigName>&duration=<duration> | oc apply -f -注記: 期間を設定しないと、klusterlet マニフェストの
kubeconfigブートストラップは期限切れになりません。
1.7.4.4. Central Infrastructure Management を使用してオンプレミスの Red Hat OpenShift Container Platform クラスターを手動でインポートする
multicluster engine for Kubernetes Operator をインストールしたら、管理するクラスターをインポートできるようになります。既存の OpenShift Container Platform クラスターをインポートして、ノードを追加できます。詳細は、次のトピックを引き続きお読みください。
1.7.4.4.1. 前提条件
- Central Infrastructure Management 機能を有効にします。
1.7.4.4.2. クラスターのインポート
静的ネットワークまたはベアメタルホストなしで OpenShift Container Platform クラスターを手動でインポートし、ノードを追加する準備をするには、以下の手順を実行します。
次の YAML コンテンツを適用して、インポートする OpenShift Container Platform クラスターの namespace を作成します。
apiVersion: v1 kind: Namespace metadata: name: managed-cluster以下の YAML コンテンツを適用して、インポートしている OpenShift Container Platform クラスターに一致する ClusterImageSet が存在することを確認します。
apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: openshift-v4.15 spec: releaseImage: quay.io/openshift-release-dev/ocp-release@sha256:22e149142517dfccb47be828f012659b1ccf71d26620e6f62468c264a7ce7863次の YAML コンテンツを適用して、イメージにアクセスするためのプルシークレットを追加します。
apiVersion: v1 kind: Secret type: kubernetes.io/dockerconfigjson metadata: name: pull-secret namespace: managed-cluster stringData: .dockerconfigjson: <pull-secret-json>1 - 1
- <pull-secret-json> をプルシークレット JSON に置き換えます。
kubeconfigを OpenShift Container Platform クラスターからハブクラスターにコピーします。次のコマンドを実行して、OpenShift Container Platform クラスターから
kubeconfigを取得します。kubeconfigがインポートされるクラスターとして設定されていることを確認します。oc get secret -n openshift-kube-apiserver node-kubeconfigs -ojson | jq '.data["lb-ext.kubeconfig"]' --raw-output | base64 -d > /tmp/kubeconfig.some-other-cluster注記: クラスター API にカスタムドメイン経由でアクセスする場合は、まずこの
kubeconfigを編集して、certificate-authority-dataフィールドにカスタム証明書を追加し、serverフィールドをカスタムドメインに合わせて変更する必要があります。次のコマンドを実行して、
kubeconfigをハブクラスターにコピーします。kubeconfigがハブクラスターとして設定されていることを確認します。oc -n managed-cluster create secret generic some-other-cluster-admin-kubeconfig --from-file=kubeconfig=/tmp/kubeconfig.some-other-cluster
次の YAML コンテンツを適用して、
AgentClusterInstallカスタムリソースを作成します。必要に応じて値を置き換えます。apiVersion: extensions.hive.openshift.io/v1beta1 kind: AgentClusterInstall metadata: name: <your-cluster-name>1 namespace: <managed-cluster> spec: networking: userManagedNetworking: true clusterDeploymentRef: name: <your-cluster> imageSetRef: name: openshift-v4.11.18 provisionRequirements: controlPlaneAgents:2 sshPublicKey: <"">3 次の YAML コンテンツを適用して、
ClusterDeploymentを作成します。必要に応じて値を置き換えます。apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <your-cluster-name>1 namespace: managed-cluster spec: baseDomain: <redhat.com>2 installed: <true>3 clusterMetadata: adminKubeconfigSecretRef: name: <your-cluster-name-admin-kubeconfig>4 clusterID: <"">5 infraID: <"">6 clusterInstallRef: group: extensions.hive.openshift.io kind: AgentClusterInstall name: your-cluster-name-install version: v1beta1 clusterName: your-cluster-name platform: agentBareMetal: pullSecretRef: name: pull-secret次の YAML コンテンツを適用することで、
InfraEnvカスタムリソースを追加して、クラスターに追加する新しいホストを検出します。必要に応じて値を置き換えます。注記: 静的 IP アドレスを使用していない場合、次の例では追加の設定が必要になる場合があります。
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: your-infraenv namespace: managed-cluster spec: clusterRef: name: your-cluster-name namespace: managed-cluster pullSecretRef: name: pull-secret sshAuthorizedKey: ""
| フィールド | 任意または必須 | 説明 |
|---|---|---|
|
| 任意 |
遅延バインディングを使用している場合、 |
|
| 任意 |
トラブルシューティングのためにノードにログインできるように、オプションの |
インポートに成功すると、ISO ファイルをダウンロードする URL が表示されます。次のコマンドを実行して ISO ファイルをダウンロードします。<url> は表示される URL に置き換えます。
注記: ベアメタルホストを使用すると、ホストの検出を自動化できます。
oc get infraenv -n managed-cluster some-other-infraenv -ojson | jq ".status.<url>" --raw-output | xargs curl -k -o /storage0/isos/some-other.iso-
オプション: OpenShift Container Platform クラスターで、ポリシーなどの Red Hat Advanced Cluster Management 機能を使用する場合は、
ManagedClusterリソースを作成します。ManagedClusterリソースの名前は、ClusterDeplpoymentリソースの名前と一致させてください。ManagedClusterリソースがない場合、コンソールではクラスターのステータスがdetachedになります。
1.7.4.4.3. クラスターリソースのインポート
OpenShift Container Platform マネージドクラスターを Assisted Installer によってインストールした場合、あるハブクラスターから別のハブクラスターにマネージドクラスターとそのリソースを移動できます。
元のリソースのコピーを保存し、それを新しいハブクラスターに適用し、元のリソースを削除することで、新しいハブクラスターからクラスターを管理できます。その後、新しいハブクラスターからマネージドクラスターをスケールダウンまたはスケールアップできます。
重要: インポートした OpenShift Container Platform マネージドクラスターは、Assisted Installer によってインストールされたものである場合にのみスケールダウンできます。
次のリソースをインポートできます。これらのリソースを使用してクラスターの管理を継続できます。
| リソース | 任意または必須 | 説明 |
|---|---|---|
|
| 必須 | |
|
| 任意 | フィルタークエリーを使用してエージェントを分類する場合は必須です。 |
|
| 必須 | |
|
| 任意 |
|
|
| 必須 | |
|
| 必須 | |
|
| 任意 | ホストにネットワーク設定を適用する場合は必須です。 |
|
| 必須 | |
|
| 必須 |
|
1.7.4.4.3.1. マネージドクラスターリソースの保存と適用
マネージドクラスターリソースのコピーを保存し、リソースを新しいハブクラスターに適用するには、次の手順を実行します。
次のコマンドを実行して、ソースハブクラスターからリソースを取得します。必要に応じて値を置き換えます。
oc –kubeconfig <source_hub_kubeconfig> -n <managed_cluster_name> get <resource_name> <cluster_provisioning_namespace> -oyaml > <resource_name>.yaml-
<resource_name>をリソースの名前に置き換えて、インポートするリソースごとにこのコマンドを繰り返し実行します。
-
次のコマンドを実行して、次のリソースから
ownerReferencesプロパティーを削除します。AgentClusterInstallyq --in-place -y 'del(.metadata.ownerReferences)' AgentClusterInstall.yamlSecret(admin-kubeconfig)yq --in-place -y 'del(.metadata.ownerReferences)' AdminKubeconfigSecret.yaml
次のコマンドを実行して、マネージドクラスターをソースハブクラスターからデタッチします。必要に応じて値を置き換えます。
oc –kubeconfig <target_hub_kubeconfig> delete ManagedCluster <cluster_name>- マネージドクラスターのターゲットハブクラスターに namespace を作成します。ソースハブクラスターと同様の名前を使用します。
次のコマンドを実行して、保存したリソースをターゲットハブクラスターに個別に適用します。必要に応じて値を置き換えます。
注記: すべてのリソースを個別ではなく一括で適用する場合は、
<resource_name>.yamlを.に置き換えてください。oc –kubeconfig <target_hub_kubeconfig> apply -f <resource_name>.yaml
1.7.4.4.3.2. ソースハブクラスターからのマネージドクラスターの削除
クラスターリソースをインポートした後、次の手順を実行して、ソースハブクラスターからマネージドクラスターを削除します。
-
ClusterDeploymentカスタムリソースでspec.preserveOnDeleteパラメーターをtrueに設定し、マネージドクラスターの破棄を防止します。 - 管理からのクラスターの削除 の手順を完了します。
1.7.4.5. インポート用のマネージドクラスターでのイメージレジストリーの指定
インポートしているマネージドクラスターのイメージレジストリーを上書きする必要がある場合があります。これには、ManagedClusterImageRegistry カスタムリソース定義を作成します。
ManagedClusterImageRegistry カスタムリソース定義は、namespace スコープのリソースです。
ManagedClusterImageRegistry カスタムリソース定義は、Placement が選択するマネージドクラスターのセットを指定しますが、カスタムイメージレジストリーとは異なるイメージが必要になります。マネージドクラスターが新規イメージで更新されると、識別用に各マネージドクラスターに、open-cluster-management.io/image-registry=<namespace>.<managedClusterImageRegistryName> のラベルが追加されます。
以下の例は、ManagedClusterImageRegistry カスタムリソース定義を示しています。
apiVersion: imageregistry.open-cluster-management.io/v1alpha1
kind: ManagedClusterImageRegistry
metadata:
name: <imageRegistryName>
namespace: <namespace>
spec:
placementRef:
group: cluster.open-cluster-management.io
resource: placements
name: <placementName>
pullSecret:
name: <pullSecretName>
registries:
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>- 1
- マネージドクラスターのセットを選択するのと同じ namespace 内の配置の名前に置き換えます。
- 2
- カスタムイメージレジストリーからイメージをプルするために使用されるプルシークレットの名前に置き換えます。
- 3
ソースおよびミラーレジストリーのそれぞれの値をリスト表示します。mirrored-image-registry-addressおよびimage-registry-addressは、レジストリーの各ミラーおよびソース値に置き換えます。-
例 1:
registry.redhat.io/rhacm2という名前のソースイメージレジストリーをlocalhost:5000/rhacm2に、registry.redhat.io/multicluster-engineをlocalhost:5000/multicluster-engineに置き換えるには、以下の例を使用します。
-
例 1:
registries:
- mirror: localhost:5000/rhacm2/
source: registry.redhat.io/rhacm2
- mirror: localhost:5000/multicluster-engine
source: registry.redhat.io/multicluster-engine例 2: ソースイメージ
registry.redhat.io/rhacm2/registration-rhel8-operatorをlocalhost:5000/rhacm2-registration-rhel8-operatorに置き換えるには、以下の例を使用します。registries: - mirror: localhost:5000/rhacm2-registration-rhel8-operator source: registry.redhat.io/rhacm2/registration-rhel8-operator
重要: エージェント登録を使用してマネージドクラスターをインポートする場合は、イメージレジストリーを含む KlusterletConfig を作成する必要があります。以下の例を参照してください。必要に応じて値を置き換えます。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: <klusterletconfigName>
spec:
pullSecret:
namespace: <pullSecretNamespace>
name: <pullSecretName>
registries:
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>詳細は、エージェント登録エンドポイントを使用したマネージドクラスターのインポート を参照してください。
1.7.4.5.1. ManagedClusterImageRegistry を持つクラスターのインポート
ManagedClusterImageRegistry カスタムリソース定義でカスタマイズされるクラスターをインポートするには、以下の手順を実行します。
クラスターをインポートする必要のある namespace にプルシークレットを作成します。これらの手順では、namespace は
myNamespaceです。$ kubectl create secret docker-registry myPullSecret \ --docker-server=<your-registry-server> \ --docker-username=<my-name> \ --docker-password=<my-password>作成した namespace に Placement を作成します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: myPlacement namespace: myNamespace spec: clusterSets: - myClusterSet tolerations: - key: "cluster.open-cluster-management.io/unreachable" operator: Exists注記: Placement がクラスターを選択できるようにするには、toleration を
unreachableに指定する必要があります。ManagedClusterSetリソースを作成し、これを namespace にバインドします。apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSet metadata: name: myClusterSet --- apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: name: myClusterSet namespace: myNamespace spec: clusterSet: myClusterSetnamespace に
ManagedClusterImageRegistryカスタムリソース定義を作成します。apiVersion: imageregistry.open-cluster-management.io/v1alpha1 kind: ManagedClusterImageRegistry metadata: name: myImageRegistry namespace: myNamespace spec: placementRef: group: cluster.open-cluster-management.io resource: placements name: myPlacement pullSecret: name: myPullSecret registry: myRegistryAddress- コンソールからマネージドクラスターをインポートし、マネージドクラスターセットに追加します。
-
open-cluster-management.io/image-registry=myNamespace.myImageRegistryラベルをマネージドクラスターに追加した後に、マネージドクラスターで import コマンドをコピーして実行します。
1.7.5. クラスターへのアクセス
作成され、管理されている Red Hat OpenShift Container Platform クラスターにアクセスするには、以下の手順を実行します。
- コンソールから、Infrastructure > Clusters に移動し、作成したクラスターまたはアクセスするクラスターの名前を選択します。
Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターにログインする際に使用するため、この値を書き留めてください。
注記: インポートしたクラスターでは、Reveal credentials オプションは利用できません。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.6. マネージドクラスターのスケーリング
作成したクラスターは、仮想マシンのサイズやノード数など、マネージドクラスターの仕様をカスタマイズおよびサイズ変更できます。インストーラーでプロビジョニングされたインフラストラクチャーをクラスターデプロイメントに使用している場合は、次のオプションを参照してください。
クラスターのデプロイメントに Central Infrastructure Management を使用している場合は、次のオプションを参照してください。
1.7.6.1. MachinePool によるスケーリング
multicluster engine Operator を使用してプロビジョニングするクラスターの場合、MachinePool リソースが自動的に作成されます。MachinePool を使用して、仮想マシンのサイズやノード数など、マネージドクラスターの仕様をさらにカスタマイズおよびサイズ変更できます。
-
MachinePoolリソースの使用は、ベアメタルクラスターではサポートされていません。 -
MachinePoolリソースは、ハブクラスター上の Kubernetes リソースで、MachineSetリソースをマネージドクラスターでグループ化します。 -
MachinePoolリソースは、ゾーンの設定、インスタンスタイプ、ルートストレージなど、マシンリソースのセットを均一に設定します。 -
MachinePoolでは、マネージドクラスターで、必要なノード数を手動で設定したり、ノードの自動スケーリングを設定したりするのに役立ちます。
1.7.6.1.1. 自動スケーリングの設定
自動スケーリングを設定すると、トラフィックが少ない場合にリソースをスケールダウンし、多くのリソースが必要な場合に十分にリソースを確保できるようにスケールアップするなど、必要に応じてクラスターに柔軟性を持たせることができます。
コンソールを使用して
MachinePoolリソースで自動スケーリングを有効にするには、以下の手順を実行します。- ナビゲーションで、Infrastructure > Clusters を選択します。
- ターゲットクラスターの名前をクリックし、Machine pools タブを選択します。
- マシンプールページのターゲットマシンプールの Options メニューから Enable autoscale を選択します。
マシンセットレプリカの最小数および最大数を選択します。マシンセットレプリカは、クラスターのノードに直接マップします。
Scale をクリックした後、変更がコンソールに反映されるまでに数分かかる場合があります。Machine pools タブの通知がある場合は、View machines をクリックしてスケーリング操作のステータスを表示できます。
コマンドラインを使用して
MachinePoolリソースで自動スケーリングを有効にするには、以下の手順を実行します。次のコマンドを入力して、マシンプールのリストを表示します。このとき、
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。oc get machinepools -n <managed-cluster-namespace>以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <MachinePool-resource-name> -n <managed-cluster-namespace>-
MachinePool-resource-nameはMachinePoolリソースの名前に置き換えます。 -
managed-cluster-namespaceはマネージドクラスターの namespace の名前に置き換えます。
-
-
YAML ファイルから
spec.replicasフィールドを削除します。 -
spec.autoscaling.minReplicas設定およびspec.autoscaling.maxReplicasフィールドをリソース YAML に追加します。 -
レプリカの最小数を
minReplicas設定に追加します。 -
レプリカの最大数を
maxReplicas設定に追加します。 - ファイルを保存して変更を送信します。
1.7.6.1.2. 自動スケーリングの無効化
コンソールまたはコマンドラインを使用して自動スケーリングを無効にできます。
コンソールを使用して自動スケーリングを無効にするには、次の手順を実行します。
- ナビゲーションで、Infrastructure > Clusters を選択します。
- ターゲットクラスターの名前をクリックし、Machine pools タブを選択します。
- マシンプールページから、ターゲットマシンプールの Options メニューから autoscale を無効にします。
必要なマシンセットのレプリカ数を選択します。マシンセットのレプリカは、クラスター上のノードを直接マップします。
Scale をクリックした後、表示されるまでに数分かかる場合があります。Machine pools タブの通知で View machines をクリックすると、スケーリングの状態を表示できます。
コマンドラインを使用して自動スケーリングを無効にするには、以下の手順を実行します。
以下のコマンドを実行して、マシンプールのリストを表示します。
oc get machinepools -n <managed-cluster-namespace>managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML ファイルから
spec.autoscalingフィールドを削除します。 -
spec.replicasフィールドをリソース YAML に追加します。 -
replicasの設定にレプリカ数を追加します。 - ファイルを保存して変更を送信します。
1.7.6.1.3. 手動スケーリングの有効化
コンソールおよびコマンドラインから手動でスケーリングできます。
1.7.6.1.3.1. コンソールでの手動スケーリングの有効化
コンソールを使用して MachinePool リソースをスケーリングするには、次の手順を実行します。
-
有効になっている場合は、
MachinePoolの自動スケーリングを無効にします。前の手順を参照してください。 - コンソールから、Infrastructure > Clusters をクリックします。
- ターゲットクラスターの名前をクリックし、Machine pools タブを選択します。
- マシンプールページで、対象のマシンプールの Options メニューから Scale machine pool を選択します。
- 必要なマシンセットのレプリカ数を選択します。マシンセットのレプリカは、クラスター上のノードを直接マップします。Scale をクリックした後、変更がコンソールに反映されるまでに数分かかる場合があります。マシンプールタブの通知から View machines をクリックすると、スケーリング操作の状態を表示できます。
1.7.6.1.3.2. コマンドラインでの手動スケーリングの有効化
コマンドラインを使用して MachinePool リソースをスケーリングするには、次の手順を実行します。
次のコマンドを入力して、マシンプールのリストを表示します。このとき、
<managed-cluster-namespace>は、ターゲットのマネージドクラスターの namespace に置き換えます。oc get machinepools.hive.openshift.io -n <managed-cluster-namespace>以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool.hive.openshift.io <MachinePool-resource-name> -n <managed-cluster-namespace>-
MachinePool-resource-nameはMachinePoolリソースの名前に置き換えます。 -
managed-cluster-namespaceはマネージドクラスターの namespace の名前に置き換えます。
-
-
YAML ファイルから
spec.autoscalingフィールドを削除します。 -
YAML ファイルの
spec.replicasフィールドを必要な数のレプリカに変更します。 - ファイルを保存して変更を送信します。
1.7.6.2. OpenShift Container Platform クラスターへのワーカーノードの追加
Central Infrastructure Management を使用している場合は、実稼働環境ノードを追加することで OpenShift Container Platform クラスターをカスタマイズできます。
必要なアクセス権限: 管理者
1.7.6.2.1. 前提条件
マネージドクラスター API を信頼するために必要な新しい CA 証明書が必要です。
1.7.6.2.2. 有効な kubeconfig の作成
実稼働環境のワーカーノードを OpenShift Container Platform クラスターに追加する前に、有効な kubeconfig があるかどうかを確認する必要があります。
マネージドクラスターの API 証明書が変更された場合は、次の手順を実行して、kubeconfig を新しい CA 証明書で更新します。
次のコマンドを実行して、
clusterDeploymentのkubeconfigが有効かどうかを確認します。<kubeconfig_name>を現在のkubeconfigの名前に置き換え、<cluster_name>をクラスターの名前に置き換えます。export <kubeconfig_name>=$(oc get cd $<cluster_name> -o "jsonpath={.spec.clusterMetadata.adminKubeconfigSecretRef.name}") oc extract secret/$<kubeconfig_name> --keys=kubeconfig --to=- > original-kubeconfig oc --kubeconfig=original-kubeconfig get node次のエラーメッセージが表示された場合は、
kubeconfigシークレットを更新する必要があります。エラーメッセージが表示されない場合は、ワーカーノードの追加 に進みます。Unable to connect to the server: tls: failed to verify certificate: x509: certificate signed by unknown authoritykubeconfigのcertificate-authority-dataフィールドからbase64でエンコードされた証明書バンドルを取得し、次のコマンドを実行してデコードします。echo <base64 encoded blob> | base64 --decode > decoded-existing-certs.pem元のファイルをコピーして、更新された
kubeconfigファイルを作成します。次のコマンドを実行し、<new_kubeconfig_name>を新しいkubeconfigファイルの名前に置き換えます。cp original-kubeconfig <new_kubeconfig_name>次のコマンドを実行して、デコードされた pem に新しい証明書を追加します。
cat decoded-existing-certs.pem new-ca-certificate.pem | openssl base64 -A-
テキストエディターを使用して、前のコマンドの
base64出力を新しいkubeconfigファイルのcertificate-authority-dataキーの値として追加します。 新しい
kubeconfigを使用して API をクエリーし、新しいkubeconfigが有効かどうかを確認します。以下のコマンドを実行します。<new_kubeconfig_name>を新しいkubeconfigファイルの名前に置き換えます。KUBECONFIG=<new_kubeconfig_name> oc get nodes成功した出力を受け取った場合、
kubeconfigは有効です。次のコマンドを実行して、Red Hat Advanced Cluster Management ハブクラスターの
kubeconfigシークレットを更新します。<new_kubeconfig_name>を新しいkubeconfigファイルの名前に置き換えます。oc patch secret $original-kubeconfig --type='json' -p="[{'op': 'replace', 'path': '/data/kubeconfig', 'value': '$(openssl base64 -A -in <new_kubeconfig_name>)'},{'op': 'replace', 'path': '/data/raw-kubeconfig', 'value': '$(openssl base64 -A -in <new_kubeconfig_name>)'}]"
1.7.6.2.3. ワーカーノードの追加
有効な kubeconfig がある場合は、以下の手順を実行して、実稼働環境のワーカーノードを OpenShift Container Platform クラスターに追加します。
ワーカーノードとして使用するマシンを、以前にダウンロードした ISO から起動します。
注記: ワーカーノードが OpenShift Container Platform ワーカーノードの要件を満たしていることを確認してください。
次のコマンドを実行した後、エージェントが登録されるまで待ちます。
watch -n 5 "oc get agent -n managed-cluster"エージェントの登録が成功すると、エージェントがリストされます。インストールのためにエージェントを承認します。これには数分かかる場合があります。
注記: エージェントがリストにない場合は、Ctrl キーと C キーを押して
watchコマンドを終了し、ワーカーノードにログインしてトラブルシューティングを行ってください。遅延バインディングを使用している場合は、次のコマンドを実行して、保留中のバインドされていないエージェントを OpenShift Container Platform クラスターに関連付けます。遅延バインディングを使用していない場合は、ステップ 5 に進みます。
oc get agent -n managed-cluster -ojson | jq -r '.items[] | select(.spec.approved==false) |select(.spec.clusterDeploymentName==null) | .metadata.name'| xargs oc -n managed-cluster patch -p '{"spec":{"clusterDeploymentName":{"name":"some-other-cluster","namespace":"managed-cluster"}}}' --type merge agent次のコマンドを実行して、保留中のエージェントのインストールを承認します。
oc get agent -n managed-cluster -ojson | jq -r '.items[] | select(.spec.approved==false) | .metadata.name'| xargs oc -n managed-cluster patch -p '{"spec":{"approved":true}}' --type merge agent
ワーカーノードのインストールを待ちます。ワーカーノードのインストールが完了すると、ワーカーノードは証明書署名要求 (CSR) を使用してマネージドクラスターに接続し、参加プロセスを開始します。CSR は自動的に署名されます。
1.7.6.3. マネージドクラスターへのコントロールプレーンノードの追加
問題のあるコントロールプレーンを置き換えるには、コントロールプレーンノードを正常または正常でないマネージドクラスターに追加します。
必要なアクセス権限: 管理者
1.7.6.3.1. 正常なマネージドクラスターへのコントロールプレーンノードの追加
以下の手順を実行して、コントロールプレーンノードを正常なマネージドクラスターに追加します。
- 新しいコントロールプレーンノードを追加するには、OpenShift Container Platform クラスターへのワーカーノードの追加 の手順を完了します。
Discovery ISO を使用してノードを追加する場合は、エージェントを承認する前にエージェントを
masterに設定します。以下のコマンドを実行します。oc patch agent <agent-name> -p '{"spec":{"role": "master"}}' --type=merge注記: 証明書署名要求 (CSR) は自動的に承認されません。
BareMetalHostを使用してノードを追加する場合は、BareMetalHostリソースの作成時に、BareMetalHostアノテーションに次の行を追加します。bmac.agent-install.openshift.io/role: master- OpenShift Container Platform の Assisted Installer ドキュメントの 正常なクラスター内のコントロールプレーンノードの置き換え の手順に従います。
1.7.6.3.2. API を使用して正常なマネージドクラスターにコントロールプレーンノードを追加する
API を使用して正常なマネージドクラスターにコントロールプレーンノードを追加するには、次の手順を実行します。
次のコマンドを実行して、ハブクラスターにログインします。クラスターの名前を追加します。
oc login --token=sha256~value--server=https://api.<cluster-name>.basedomain:6443コントロールプレーンノードとして使用するマシンを Discovery ISO から起動します。
注記: または、
BareMetalHostYAML を適用して、新しいホストをInfraEnvに適用します。エージェントの状態をチェックして、エージェントがクラスターに再度バインドする準備ができていることを確認します。次のコマンドを実行し、必要に応じて変数を置き換えます。
インベントリーを切り替えるには、次のコマンドを実行します。
<host-inventory-namespace>は自分の namespace に置き換えます。oc project <host-inventory-namespace>エージェントの状態を取得するには、次のコマンドを実行します。
<agent-name>は、エージェントの名前に置き換えます。oc get agent <agent-name> -oyaml | grep state-
出力で
stateInfo行をチェックして、ホストがクラスターにバインドする準備ができていることを確認します。
ホストのロールを
masterに設定します。Discovery ISO を使用してノードを追加する場合は、エージェントを承認し、ロールを
masterに設定します。以下のコマンドを実行します。oc patch agent <agent-name> -p '{"spec":{"approved":true,"role":"master"}}' --type=merge-
BareMetalHostを使用してノードを追加する場合は、BareMetalHostリソースの作成時に、BareMetalHostアノテーションに次の行を追加します。
bmac.agent-install.openshift.io/role: master次のコマンドを実行してパッチを検証します。
oc get agent出力で、
APPROVED列の各行がtrueであること、およびROLEがmasterであることを確認します。以下の例を参照してください。NAME CLUSTER APPROVED ROLE STAGE c6e00642-0e11-1689-a79d-0e131d2c6ecf true master次のコマンドを実行して、エージェントをクラスターに追加します。
oc patch agent <agent name> -p '{"spec":{"clusterDeploymentName":{"name":"<managed-cluster-name>","namespace":"<managed-cluster-namespace>"}}}' --type=merge次のコマンドを実行して、エージェントがクラスターにバインドされていることを確認します。
oc get agent以下の出力例を参照してください。
NAME CLUSTER APPROVED ROLE STAGE c6e00642-0e11-1689-a79d-0e131d2c6ecf hcpagent true master次のコマンドを実行してエージェントのステータスを確認します。エージェントがインストールされ、クラスターに参加している間、数分待つ必要がある場合があります。
oc get agent -w注記: 証明書署名要求 (CSR) は自動的に承認されません。
エージェントが
Rebootingの段階に達したら、CSR を手動で承認する必要があります。以下の手順を実行します。次のコマンドを実行して、マネージドクラスターの
kubeconfigファイルを取得します。kubeconfig_secret_name=$(oc -n ${cluster_name} get clusterdeployments ${cluster_name} -ojsonpath='{.spec.clusterMetadata.adminKubeconfigSecretRef.name}') oc -n ${cluster_name} get secret ${kubeconfig_secret_name} -ojsonpath={.data.kubeconfig} | base64 -d > managed-cluster.kubeconfig次のコマンドを実行して、マネージドクラスター上で保留中の CSR を見つけます。
oc --kubeconfig managed-cluster.kubeconfig get csr | grep Pendingマネージドクラスター内のエージェントの保留中の CSR を承認します。次のコマンドを実行し、
<csr-name>は CSR 名に置き換えます。oc --kubeconfig managed-cluster.kubeconfig adm certificate approve <csr-name>
STAGE に Done と表示されたら、ホストはインストールされています。次の出力例を参照してください。
NAME CLUSTER APPROVED ROLE STAGE
c6e00642-0e11-1689-a79d-0e131d2c6ecf hcpagent true master Done1.7.6.3.3. 正常でないマネージドクラスターへのコントロールプレーンノードの追加
以下の手順を実行して、コントロールプレーンノードを正常でないマネージドクラスターに追加します。
- 正常でないコントロールプレーンノードのエージェントを削除します。
- デプロイメントにゼロタッチプロビジョニングフローを使用した場合は、ベアメタルホストを削除します。
- 新規コントロールプレーンノードの OpenShift Container Platform クラスターへのワーカーノードの追加 の手順を実行します。
次のコマンドを実行して、エージェントを承認する前にエージェントを
masterに設定します。oc patch agent <AGENT-NAME> -p '{"spec":{"role": "master"}}' --type=merge注記: CSR は自動的に承認されません。
- OpenShift Container Platform のアシステッドインストーラードキュメント の 正常でないクラスターへのプライマリーコントロールプレーンノードのインストール の手順に従います。
1.7.7. 作成されたクラスターの休止
リソースを節約するために、multicluster engine Operator を使用して作成されたクラスターを休止状態にすることができます。休止状態のクラスターに必要となるリソースは、実行中のものより少なくなるので、クラスターを休止状態にしたり、休止状態を解除したりすることで、プロバイダーのコストを削減できる可能性があります。この機能は、次の環境の multicluster engine Operator によって作成されたクラスターにのみ適用されます。
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
1.7.7.1. コンソールを使用したクラスターの休止
コンソールを使用して、multicluster engine Operator によって作成されたクラスターを休止状態にするには、次の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。Manage clusters タブが選択されていることを確認します。
- そのクラスターの Options メニューから Hibernate cluster を選択します。注記: Hibernate cluster オプションが利用できない場合には、クラスターを休止状態にすることはできません。これは、クラスターがインポートされたものであり、multicluster engine Operator によって作成されたものでない場合に発生する可能性があります。
Clusters ページのクラスターのステータスは、プロセスが完了すると Hibernating になります。
ヒント: Clusters ページで休止するするクラスターを選択し、Actions > Hibernate clusters を選択して、複数のクラスターを休止できます。
選択したクラスターが休止状態になりました。
1.7.7.2. CLI を使用したクラスターの休止
CLI を使用して、multicluster engine Operator によって作成されたクラスターを休止状態にするには、次の手順を実行します。
以下のコマンドを入力して、休止するクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値はHibernatingに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yamlname-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターを休止するプロセスが完了すると、クラスターのタイプの値は
type=Hibernatingになります。
選択したクラスターが休止状態になりました。
1.7.7.3. コンソールを使用して休止中のクラスターの通常操作を再開する手順
コンソールを使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。Manage clusters タブが選択されていることを確認します。
- 再開するクラスターの Options メニューから Resume cluster を選択します。
プロセスを完了すると、Clusters ページのクラスターのステータスは Ready になります。
ヒント: Clusters ページで、再開するクラスターを選択し、Actions > Resume cluster の順に選択して、複数のクラスターを再開できます。
選択したクラスターで通常の操作が再開されました。
1.7.7.4. CLI を使用して休止中のクラスターの通常操作を再開する手順
CLI を使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
以下のコマンドを入力してクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値をRunningに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yamlname-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターの再開プロセスが完了すると、クラスターのタイプの値は
type=Runningになります。
選択したクラスターで通常の操作が再開されました。
1.7.8. クラスターのアップグレード
multicluster engine Operator で管理する Red Hat OpenShift Container Platform クラスターを作成した後、multicluster engine Operator コンソールを使用して、マネージドクラスターが使用するバージョンチャネルで利用できる最新のマイナーバージョンにこれらのクラスターをアップグレードできます。
接続された環境では、コンソールでアップグレードが必要な各クラスターに提供される通知によって、更新が自動的に識別されます。
1.7.8.1. 前提条件
そのバージョンにアップグレードするための前提条件をすべて満たしていることを確認する。コンソールでクラスターをアップグレードする前に、マネージドクラスターのバージョンチャネルを更新する必要があります。
注記: マネージドクラスターでバージョンチャネルを更新すると、multicluster engine Operator コンソールに、アップグレードに使用できる最新バージョンが表示されます。
- OpenShift Container Platform マネージドクラスターが、Ready 状態である。
重要: multicluster engine Operator コンソールを使用して、Red Hat OpenShift Dedicated 上の Red Hat OpenShift Kubernetes Service マネージドクラスターまたは OpenShift Container Platform マネージドクラスターをアップグレードすることはできません。
1.7.8.2. オンライン環境でのクラスターのアップグレード
オンライン環境でクラスターをアップグレードするには、以下の手順を実行します。
- ナビゲーションメニューから、Infrastructure > Clusters. に移動します。アップグレードが利用可能な場合は、Distribution version 列に表示されます。
- アップグレードする Ready 状態のクラスターを選択します。OpenShift Container Platform クラスターは、コンソールでのみアップグレードできます。
- Upgrade を選択します。
- 各クラスターの新しいバージョンを選択します。
- Upgrade を選択します。
クラスターのアップグレードに失敗すると、Operator は通常アップグレードを数回再試行し、停止し、コンポーネントに問題があるステータスを報告します。場合によっては、アップグレードプロセスは、プロセスの完了を繰り返し試行します。アップグレードに失敗した後にクラスターを以前のバージョンにロールバックすることはサポートされていません。クラスターのアップグレードに失敗した場合は、Red Hat サポートにお問い合わせください。
1.7.8.3. チャネルの選択
コンソールを使用して、OpenShift Container Platform でクラスターをアップグレードするためのチャネルを選択できます。チャネルを選択すると、エラータバージョンとリリースバージョンの両方で利用可能なクラスターアップグレードが自動的に通知されます。
クラスターのチャネルを選択するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters をクリックします。
- 変更するクラスターの名前を選択して、Cluster details ページを表示します。クラスターに別のチャネルが利用可能な場合は、編集アイコンが Channel フィールドに表示されます。
- Edit アイコンをクリックし、フィールドの設定を変更します。
- New channel フィールドでチャネルを選択します。
利用可能なチャネル更新のリマインダーは、クラスターの Cluster details ページで見つけることができます。
1.7.8.4. オフラインクラスターのアップグレード
multicluster engine Operator と OpenShift Update Service を使用し、オフライン環境でクラスターをアップグレードできます。
セキュリティー上の理由で、クラスターがインターネットに直接接続できない場合があります。このような場合は、アップグレードが利用可能なタイミングや、これらのアップグレードの処理方法を把握するのが困難になります。OpenShift Update Service を設定すると便利です。
OpenShift Update Service は、個別の Operator およびオペランドで、非接続環境で利用可能なマネージドクラスターを監視して、クラスターのアップグレードで利用できるようにします。OpenShift Update Service を設定すると、次の操作を実行できます。
- オフラインのクラスター向けにいつアップグレードが利用できるかを監視します。
- グラフデータファイルを使用してアップグレード用にどの更新がローカルサイトにミラーリングされているかを特定します。
- コンソールを使用して、クラスターのアップグレードが利用可能であることを通知します。
次のトピックでは、オフラインクラスターをアップグレードする手順を説明します。
1.7.8.4.1. 前提条件
OpenShift Update Service を使用して非接続クラスターをアップグレードするには、以下の前提条件を満たす必要があります。
制限付きの OLM が設定されたサポート対象の OpenShift Container Platform バージョンで実行されているデプロイ済みのハブクラスター。制限付きの OLM の設定方法については、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
Note: 制限付きの OLM の設定時に、カタログソースイメージをメモします。
- ハブクラスターによって管理される OpenShift Container Platform クラスター
クラスターイメージをミラーリング可能なローカルレジストリーにアクセスするための認証情報。このリポジトリーを作成する方法の詳細は、非接続インストールミラーリング を参照してください。
注記: アップグレードするクラスターの現行バージョンのイメージは、ミラーリングされたイメージの 1 つとして常に利用可能でなければなりません。アップグレードに失敗すると、クラスターはアップグレード試行時のクラスターのバージョンに戻ります。
1.7.8.4.2. 非接続ミラーレジストリーの準備
ローカルのミラーリングレジストリーに、アップグレード前の現行のイメージと、アップグレード後のイメージの療法をミラーリングする必要があります。イメージをミラーリングするには以下の手順を実行します。
以下の例のような内容を含むスクリプトファイルを作成します。
UPSTREAM_REGISTRY=quay.io PRODUCT_REPO=openshift-release-dev RELEASE_NAME=ocp-release OCP_RELEASE=4.12.2-x86_64 LOCAL_REGISTRY=$(hostname):5000 LOCAL_SECRET_JSON=/path/to/pull/secret1 oc adm -a ${LOCAL_SECRET_JSON} release mirror \ --from=${UPSTREAM_REGISTRY}/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE} \ --to=${LOCAL_REGISTRY}/ocp4 \ --to-release-image=${LOCAL_REGISTRY}/ocp4/release:${OCP_RELEASE}- 1
path-to-pull-secretは、OpenShift Container Platform のプルシークレットへのパスに置き換えます。
スクリプトを実行して、イメージのミラーリング、設定の設定、リリースイメージとリリースコンテンツの分離を行います。
ImageContentSourcePolicyの作成時に、このスクリプトの最後の行にある出力を使用できます。
1.7.8.4.3. OpenShift Update Service の Operator のデプロイ
OpenShift Container Platform 環境で OpenShift Update Service の Operator をデプロイするには、以下の手順を実行します。
- ハブクラスターで、OpenShift Container Platform Operator のハブにアクセスします。
-
OpenShift Update Service Operatorを選択して Operator をデプロイします。必要に応じてデフォルト値を更新します。Operator をデプロイすると、openshift-cincinnatiという名前の新規プロジェクトが作成されます。 Operator のインストールが完了するまで待ちます。
OpenShift Container Platform コマンドラインで
oc get podsコマンドを入力すると、インストールのステータスを確認できます。Operator の状態がrunningであることを確認します。
1.7.8.4.4. グラフデータの init コンテナーの構築
OpenShift Update Service はグラフデータ情報を使用して、利用可能なアップグレードを判別します。オンライン環境では、OpenShift Update Service は Cincinnati グラフデータの GitHub リポジトリー から直接利用可能なアップグレードがないか、グラフデータ情報をプルします。非接続環境を設定しているため、init container を使用してローカルリポジトリーでグラフデータを利用できるようにする必要があります。以下の手順を実行して、グラフデータの init container を作成します。
以下のコマンドを入力して、グラフデータ Git リポジトリーのクローンを作成します。
git clone https://github.com/openshift/cincinnati-graph-dataグラフデータの
initの情報が含まれるファイルを作成します。このサンプル Dockerfile は、cincinnati-operatorGitHub リポジトリーにあります。ファイルの内容は以下の例のようになります。FROM registry.access.redhat.com/ubi8/ubi:8.11 RUN curl -L -o cincinnati-graph-data.tar.gz https://github.com/openshift/cincinnati-graph-data/archive/master.tar.gz2 RUN mkdir -p /var/lib/cincinnati/graph-data/3 CMD exec /bin/bash -c "tar xvzf cincinnati-graph-data.tar.gz -C /var/lib/ cincinnati/graph-data/ --strip-components=1"4 この例では、以下のように設定されています。
以下のコマンドを実行して、
graph data init containerをビルドします。podman build -f <path_to_Dockerfile> -t <${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container>:latest1 2 podman push <${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container><2>:latest --authfile=</path/to/pull_secret>.json3 注記:
podmanがインストールされていない場合は、コマンドのpodmanをdockerに置き換えることもできます。
1.7.8.4.5. ミラーリングされたレジストリーの証明書の設定
セキュアな外部コンテナーレジストリーを使用してミラーリングされた OpenShift Container Platform リリースイメージを保存する場合は、アップグレードグラフをビルドするために OpenShift Update Service からこのレジストリーへのアクセス権が必要です。OpenShift Update Service Pod と連携するように CA 証明書を設定するには、以下の手順を実行します。
image.config.openshift.ioにある OpenShift Container Platform 外部レジストリー API を検索します。これは、外部レジストリーの CA 証明書の保存先です。詳細は、OpenShift Container Platform ドキュメントの イメージレジストリーアクセス用の追加のトラストストアの設定 を参照してください。
-
openshift-confignamespace に ConfigMap を作成します。 キー
updateservice-registryの下に CA 証明書を追加します。OpenShift Update Service はこの設定を使用して、証明書を特定します。apiVersion: v1 kind: ConfigMap metadata: name: trusted-ca data: updateservice-registry: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE-----image.config.openshift.ioAPI のclusterリソースを編集して、additionalTrustedCAフィールドを作成した ConfigMap 名に設定します。oc patch image.config.openshift.io cluster -p '{"spec":{"additionalTrustedCA":{"name":"trusted-ca"}}}' --type mergetrusted-caは、新しい ConfigMap へのパスに置き換えます。
OpenShift Update Service Operator は、変更がないか、image.config.openshift.io API と、openshift-config namespace に作成した ConfigMap を監視し、CA 証明書が変更された場合はデプロイメントを再起動します。
1.7.8.4.6. OpenShift Update Service インスタンスのデプロイ
ハブクラスターへの OpenShift Update Service インスタンスのデプロイが完了したら、このインスタンスは、クラスターのアップグレードのイメージをミラーリングして非接続マネージドクラスターに提供する場所に配置されます。インスタンスをデプロイするには、以下の手順を実行します。
デフォルトの Operator の namespace (
openshift-cincinnati) を使用しない場合は、お使いの OpenShift Update Service インスタンスの namespace を作成します。- OpenShift Container Platform ハブクラスターコンソールのナビゲーションメニューで、Administration > Namespaces を選択します。
- Create Namespace を選択します。
- namespace 名と、namespace のその他の情報を追加します。
- Create を選択して namespace を作成します。
- OpenShift Container Platform コンソールの Installed Operator セクションで、OpenShift Update Service Operator を選択します。
- メニューから Create Instance を選択します。
OpenShift Update Service インスタンスからコンテンツを貼り付けます。YAML ファイルは以下のマニフェストのようになります。
apiVersion: cincinnati.openshift.io/v1beta2 kind: Cincinnati metadata: name: openshift-update-service-instance namespace: openshift-cincinnati spec: registry: <registry_host_name>:<port>1 replicas: 1 repository: ${LOCAL_REGISTRY}/ocp4/release graphDataImage: '<host_name>:<port>/cincinnati-graph-data-container'2 - Create を選択してインスタンスを作成します。
-
ハブクラスター CLI で
oc get podsコマンドを入力し、インスタンス作成のステータスを表示します。時間がかかる場合がありますが、コマンド結果でインスタンスと Operator が実行中である旨が表示されたらプロセスは完了です。
1.7.8.4.7. デフォルトのレジストリーの上書き (オプション)
注記: このセクションの手順は、ミラーレジストリーにリリースをミラーリングした場合にのみ該当します。
OpenShift Container Platform にはイメージレジストリーのデフォルト値があり、この値でアップグレードパッケージの検索先を指定します。オフライン環境では、オーバーライドを作成して、その値をリリースイメージをミラーリングしたローカルイメージレジストリーへのパスに置き換えることができます。
デフォルトのレジストリーを上書きするには、次の手順を実行します。
次の内容のような、
mirror.yamlという名前の YAML ファイルを作成します。apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: <your-local-mirror-name>1 spec: repositoryDigestMirrors: - mirrors: - <your-registry>2 source: registry.redhat.io注記:
oc adm release mirrorコマンドを入力すると、ローカルミラーへのパスが分かります。マネージドクラスターのコマンドラインを使用して、次のコマンドを実行してデフォルトのレジストリーをオーバーライドします。
oc apply -f mirror.yaml
1.7.8.4.8. オフラインカタログソースのデプロイ
マネージドクラスターで、デフォルトのカタログソースをすべて無効にし、新しいカタログソースを作成します。デフォルトの場所を接続された場所からオフラインローカルレジストリーに変更するには、次の手順を実行します。
次の内容のような、
source.yamlという名前の YAML ファイルを作成します。apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: name: cluster spec: disableAllDefaultSources: true --- apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace spec: sourceType: grpc image: '<registry_host_name>:<port>/olm/redhat-operators:v1'1 displayName: My Operator Catalog publisher: grpc- 1
spec.imageの値を、ローカルの制約付きカタログソースイメージへのパスに置き換えます。
マネージドクラスターのコマンドラインで、次のコマンドを実行してカタログソースを変更します。
oc apply -f source.yaml
1.7.8.4.9. マネージドクラスターのパラメーターを変更する
マネージドクラスターの ClusterVersion リソース情報を更新して、アップグレードを取得するデフォルトの場所を変更します。
マネージドクラスターから、以下のコマンドを入力して
ClusterVersionアップストリームパラメーターがデフォルトの OpenShift Update Service オペランドであることを確認します。oc get clusterversion -o yamlサポートされているバージョンとして
4.xが設定されている場合、次のような内容が返されます。apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.x upstream: https://api.openshift.com/api/upgrades_info/v1/graphハブクラスターから、次のコマンドを入力して、OpenShift Update Service オペランドへのルート URL を特定します。
oc get routes後のステップのために戻り値に注意してください。
マネージドクラスターのコマンドラインで、次のコマンドを入力して
ClusterVersionリソースを編集します。oc edit clusterversion versionspec.channelの値を新しいバージョンに置き換えます。spec.upstreamの値は、ハブクラスター OpenShift Update Service オペランドへのパスに置き換えます。次の手順を実行して、オペランドへのパスを決定できます。ハブクラスターで以下のコマンドを実行してください。
oc get routes -A-
cincinnatiへのパスを見つけます。オペランドのパスは、HOST/PORTフィールドの値です。
マネージドクラスターのコマンドラインで、次のコマンドを入力して、
ClusterVersionのアップストリームパラメーターがローカルハブクラスターの OpenShift Update Service URL で更新されていることを確認します。oc get clusterversion -o yaml結果は次のような内容になります。
apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.x upstream: https://<hub-cincinnati-uri>/api/upgrades_info/v1/graph
1.7.8.4.10. 利用可能なアップグレードの表示
Cluster ページでは、オフラインレジストリーにアップグレードがある場合、クラスターの Distribution version に、利用可能なアップグレードがあることが示されます。クラスターを選択し、Actions メニューから Upgrade clusters を選択すると、利用可能なアップグレードを表示できます。オプションのアップグレードパスが利用可能な場合は、利用可能なアップグレードがリストされます。
注記: 現行バージョンがローカルのイメージリポジトリーにミラーリングされていないと、利用可能なアップグレードバージョンは表示されません。
1.7.8.4.11. チャネルの選択
コンソールを使用して、OpenShift Container Platform バージョン 4.6 以降でクラスターをアップグレードするためのチャネルを選択できます。これらのバージョンはミラーレジストリーで利用可能である必要があります。チャネルの選択 の手順を実行して、アップグレードチャネルを指定します。
1.7.8.4.12. クラスターのアップグレード
非接続レジストリーを設定すると、multicluster engine Operator と OpenShift Update Service が非接続レジストリーを使用して、アップグレードが利用可能かどうかを判断します。利用可能なアップグレードが表示されない場合は、クラスターの現行のリリースイメージと、1 つ後のイメージがローカルリポジトリーにミラーリングされていることを確認します。クラスターの現行バージョンのリリースイメージが利用できないと、アップグレードは利用できません。
Cluster ページでは、オフラインレジストリーにアップグレードがある場合、クラスターの Distribution version に、利用可能なアップグレードがあることが示されます。イメージをアップグレードするには、Upgrade available をクリックし、アップグレードするバージョンを選択します。
マネージドクラスターは、選択したバージョンに更新されます。
クラスターのアップグレードに失敗すると、Operator は通常アップグレードを数回再試行し、停止し、コンポーネントに問題があるステータスを報告します。場合によっては、アップグレードプロセスは、プロセスの完了を繰り返し試行します。アップグレードに失敗した後にクラスターを以前のバージョンにロールバックすることはサポートされていません。クラスターのアップグレードに失敗した場合は、Red Hat サポートにお問い合わせください。
1.7.9. クラスタープロキシーアドオンの使用
一部の環境では、マネージドクラスターはファイアウォールの背後にあり、ハブクラスターから直接アクセスすることはできません。アクセスを取得するには、プロキシーアドオンを設定してマネージドクラスターの kube-apiserver にアクセスし、よりセキュアな接続を提供できます。
重要: ハブクラスター上にクラスター全体のプロキシー設定を配置しないようにしてください。
必要なアクセス権限: 編集
ハブクラスターとマネージドクラスターのクラスタープロキシーアドオンを設定するには、次の手順を実行します。
次の手順を実行してマネージドクラスター
kube-apiserverにアクセスするようにkubeconfigファイルを設定します。マネージドクラスターに有効なアクセストークンを指定します。
注記: サービスアカウントの対応するトークンを使用できます。デフォルトの namespace にあるデフォルトのサービスアカウントを使用することもできます。
次のコマンドを実行して、マネージドクラスターの
kubeconfigファイルをエクスポートします。export KUBECONFIG=<managed-cluster-kubeconfig>次のコマンドを実行して、Pod へのアクセス権があるロールをサービスアカウントに追加します。
oc create role -n default test-role --verb=list,get --resource=pods oc create rolebinding -n default test-rolebinding --serviceaccount=default:default --role=test-role次のコマンドを実行して、サービスアカウントトークンのシークレットを見つけます。
oc get secret -n default | grep <default-token>default-tokenは、シークレット名に置き換えます。次のコマンドを実行して、トークンをコピーします。
export MANAGED_CLUSTER_TOKEN=$(kubectl -n default get secret <default-token> -o jsonpath={.data.token} | base64 -d)default-tokenは、シークレット名に置き換えます。
Red Hat Advanced Cluster Management ハブクラスターで
kubeconfigファイルを設定します。次のコマンドを実行して、ハブクラスター上の現在の
kubeconfigファイルをエクスポートします。oc config view --minify --raw=true > cluster-proxy.kubeconfigエディターで
serverファイルを変更します。この例では、sedの使用時にコマンドを使用します。OSX を使用している場合は、alias sed=gsedを実行します。export TARGET_MANAGED_CLUSTER=<managed-cluster-name> export NEW_SERVER=https://$(oc get route -n multicluster-engine cluster-proxy-addon-user -o=jsonpath='{.spec.host}')/$TARGET_MANAGED_CLUSTER sed -i'' -e '/server:/c\ server: '"$NEW_SERVER"'' cluster-proxy.kubeconfig export CADATA=$(oc get configmap -n openshift-service-ca kube-root-ca.crt -o=go-template='{{index .data "ca.crt"}}' | base64) sed -i'' -e '/certificate-authority-data:/c\ certificate-authority-data: '"$CADATA"'' cluster-proxy.kubeconfig次のコマンドを入力して、元のユーザー認証情報を削除します。
sed -i'' -e '/client-certificate-data/d' cluster-proxy.kubeconfig sed -i'' -e '/client-key-data/d' cluster-proxy.kubeconfig sed -i'' -e '/token/d' cluster-proxy.kubeconfigサービスアカウントのトークンを追加します。
sed -i'' -e '$a\ token: '"$MANAGED_CLUSTER_TOKEN"'' cluster-proxy.kubeconfig
次のコマンドを実行して、ターゲットマネージドクラスターのターゲット namespace にあるすべての Pod をリスト表示します。
oc get pods --kubeconfig=cluster-proxy.kubeconfig -n <default>defaultnamespace は、使用する namespace に置き換えます。マネージドクラスター上の他のサービスにアクセスします。この機能は、マネージドクラスターが Red Hat OpenShift Container Platform クラスターの場合に利用できます。サービスは
service-serving-certificateを使用してサーバー証明書を生成する必要があります。マネージドクラスターから、以下のサービスアカウントトークンを使用します。
export PROMETHEUS_TOKEN=$(kubectl get secret -n openshift-monitoring $(kubectl get serviceaccount -n openshift-monitoring prometheus-k8s -o=jsonpath='{.secrets[0].name}') -o=jsonpath='{.data.token}' | base64 -d)ハブクラスターから、以下のコマンドを実行して認証局をファイルに変換します。
oc get configmap kube-root-ca.crt -o=jsonpath='{.data.ca\.crt}' > hub-ca.crt
以下のコマンドを使用して、マネージドクラスターの Prometheus メトリックを取得します。
export SERVICE_NAMESPACE=openshift-monitoring export SERVICE_NAME=prometheus-k8s export SERVICE_PORT=9091 export SERVICE_PATH="api/v1/query?query=machine_cpu_sockets" curl --cacert hub-ca.crt $NEW_SERVER/api/v1/namespaces/$SERVICE_NAMESPACE/services/$SERVICE_NAME:$SERVICE_PORT/proxy-service/$SERVICE_PATH -H "Authorization: Bearer $PROMETHEUS_TOKEN"
1.7.9.1. クラスタープロキシーアドオンのプロキシー設定
マネージドクラスターが HTTP および HTTPS プロキシーサーバー経由でハブクラスターと通信できるように、クラスタープロキシーアドオンのプロキシー設定を指定できます。クラスタープロキシーアドオンエージェントがプロキシーサーバー経由でハブクラスターにアクセスする必要がある場合は、プロキシー設定が必要な可能性があります。
クラスタープロキシーアドオンのプロキシー設定を指定するには、次の手順を実行します。
ハブクラスターに
AddOnDeploymentConfigリソースを作成し、spec.proxyConfigパラメーターを追加します。以下の例を参照してください。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: <name>1 namespace: <namespace>2 spec: agentInstallNamespace: open-cluster-management-agent-addon proxyConfig: httpsProxy: "http://<username>:<password>@<ip>:<port>"3 noProxy: ".cluster.local,.svc,172.30.0.1"4 caBundle: <value>5 作成した
AddOnDeploymentConfigリソースを参照して、ManagedClusterAddOnリソースを更新します。以下の例を参照してください。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: cluster-proxy namespace: <namespace>1 spec: installNamespace: open-cluster-management-addon configs: group: addon.open-cluster-management.io resource: addondeploymentconfigs name: <name>2 namespace: <namespace>3
1.7.10. マネージドクラスターで実行する Ansible Automation Platform タスクの設定
multicluster engine Operator は Red Hat Ansible Automation Platform と統合されているため、クラスターの作成またはアップグレードの前後に実行される prehook および posthook Ansible ジョブインスタンスを作成できます。クラスター破棄の prehook および posthook ジョブの設定やクラスターのスケールアクションはサポートされません。
必要なアクセス権: クラスター管理者
1.7.10.1. 前提条件
クラスターで自動化テンプレートを実行するには、次の前提条件を満たす必要があります。
- OpenShift Container Platform をインストールする。
- Ansible Automation Platform Resource Operator をインストールして、Ansible ジョブを Git サブスクリプションのライフサイクルに接続している。自動化テンプレートを使用して Ansible Automation Platform ジョブを起動する場合に最良の結果を得るには、Ansible Automation Platform ジョブテンプレートを実行時にべき等にする必要があります。Ansible Automation Platform Resource Operator は、OpenShift Container Platform OperatorHub ページから検索できます。
-
Ansible Automation Platform Resource Operator をインストールするときに、
*-cluster-scopedチャネルを選択し、all namespaces インストールモードを選択する。
1.7.10.2. コンソールを使用して、クラスターで実行するように、自動化 テンプレートを設定する
クラスターの作成時、クラスターのインポート時、またはクラスターの作成後、クラスターに使用する自動化テンプレートを指定できます。
クラスターの作成時またはインポート時にテンプレートを指定するには、Automation の手順でクラスターに適用する Ansible テンプレートを選択します。自動化テンプレートがない場合は、Add automation template をクリックして作成します。
クラスターの作成後にテンプレートを指定するには、既存のクラスターのアクションメニューで Update automation template をクリックします。Update automation template オプションを使用して、既存の自動化テンプレートを更新することもできます。
1.7.10.3. 自動化テンプレートの作成
クラスターのインストールまたはアップグレードで Ansible ジョブを開始するには、自動化テンプレートを作成して、いつジョブを実行するかを指定する必要があります。これらは、クラスターのインストールまたはアップグレード前後に実行するように設定できます。
テンプレートの作成時に Ansible テンプレートの実行に関する詳細を指定するには、コンソールで以下の手順を実行します。
- ナビゲーションから Infrastructure > Automation を選択します。
状況に適したパスを選択します。
- 新規テンプレートを作成する場合には、Create Ansible template をクリックして手順 3 に進みます。
- 既存のテンプレートを変更する場合は、変更するテンプレートの Options メニューの Edit template をクリックして、手順 5 に進みます。
- 一意のテンプレート名を入力します。名前には小文字の英数字またはハイフン (-) を指定してください。
- 新規テンプレートの認証情報を選択します。
認証情報を選択した後、すべてのジョブに使用する Ansible インベントリーを選択できます。Ansible 認証情報を Ansible テンプレートにリンクするには、以下の手順を実行します。
- ナビゲーションから Automation を選択します。認証情報にリンクされていないテンプレートの一覧内のテンプレートには、テンプレートを既存の認証情報にリンクするために使用できるリンク 認証情報へのリンク アイコンが含まれています。テンプレートと同じ namespace の認証情報のみが表示されます。
- 選択できる認証情報がない場合や、既存の認証情報を使用しない場合は、リンクするテンプレートの Options メニューから Edit template を選択します。
- 認証情報を作成する場合は、Add credential をクリックして、Ansible Automation Platform の認証情報の作成 の手順を行います。
- テンプレートと同じ namespace に認証情報を作成したら、テンプレートの編集時に Ansible Automation Platform credential フィールドで認証情報を選択します。
- クラスターをインストールする前に、Ansible ジョブを開始する場合は、Pre-install Automation templates セクションの Add an Automation template を選択します。
表示されるモーダルで
Job templateまたはWorkflow job templateを選択します。job_tags、Skip_tags、およびワークフロータイプを追加することもできます。-
Extra variables フィールドを使用して、
キー=値ペアの形式でデータをAnsibleJobリソースに渡します。 -
特殊キーの
cluster_deploymentとinstall_configは、追加の変数として自動的に渡されます。こちらには、クラスターに関する一般情報とクラスターのインストール設定に関する詳細が含まれています。
-
Extra variables フィールドを使用して、
- クラスターのインストールまたはアップグレードに追加するプリフックおよびポストフックの Ansible ジョブの名前を選択します。
- 必要に応じて、Ansible ジョブをドラッグして、順番を変更します。
-
インストール後の自動化テンプレート セクション、アップグレード前の自動化テンプレート セクション、および アップグレード後の自動化テンプレート セクションでクラスターのインストール後に開始するすべての自動化テンプレートに手順 5 〜 7 を繰り返します。クラスターをアップグレードする場合、
Extra variablesフィールドを使用して、key=valueペアの形式でAnsibleJobリソースにデータを渡すことができます。cluster_deployment特殊キーおよびinstall_config特殊キーに加えて、cluster_info特殊キーも、ManagedClusterInfoリソースからのデータを含む追加変数として自動的に渡されます。
Ansible テンプレートは、指定のアクションが起こるタイミングで、このテンプレートを指定するクラスターで実行するように設定されます。
1.7.10.4. Ansible ジョブのステータスの表示
実行中の Ansible ジョブのステータスを表示して、起動し、正常に実行されていることを確認できます。実行中の Ansible ジョブの現在のステータスを表示するには、以下の手順を実行します。
- メニューで、Infrastructure > Clusters を選択して、Clusters ページにアクセスします。
- クラスターの名前を選択して、その詳細を表示します。
クラスター情報で Ansible ジョブの最後の実行ステータスを表示します。エントリーには、以下のステータスの 1 つが表示されます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
Failedと表示されます。 - アップグレード prehook または posthook ジョブが失敗すると、アップグレードに失敗した Distribution フィールドに警告が表示されます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
1.7.10.5. 失敗した Ansible ジョブを再度実行する
クラスターの prehook または posthook が失敗した場合は、Clusters ページからアップグレードを再試行できます。
時間を節約するために、クラスター自動化テンプレートの一部である失敗した Ansible ポストフックのみを実行できるようになりました。アップグレード全体を再試行せずに、ポストフックのみを再度実行するには、次の手順を実行します。
次のコンテンツを
ClusterCuratorリソースのルートに追加して、インストールポストフックを再度実行します。operation: retryPosthook: installPosthook次のコンテンツを
ClusterCuratorリソースのルートに追加して、アップグレードポストフックを再度実行します。operation: retryPosthook: upgradePosthook
コンテンツを追加すると、Ansible ポストフックを実行するための新しいジョブが作成されます。
1.7.10.6. すべてのジョブに使用する Ansible インベントリーの指定
ClusterCurator リソースを使用して、すべてのジョブに使用する Ansible インベントリーを指定できます。以下の例を参照してください。channel と desiredUpdate を ClusterCurator の正しい値に置き換えます。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: test-inno
namespace: test-inno
spec:
desiredCuration: upgrade
destroy: {}
install: {}
scale: {}
upgrade:
channel: stable-4.x
desiredUpdate: 4.x.1
monitorTimeout: 150
posthook:
- extra_vars: {}
clusterName: test-inno
type: post_check
name: ACM Upgrade Checks
prehook:
- extra_vars: {}
clusterName: test-inno
type: pre_check
name: ACM Upgrade Checks
towerAuthSecret: awx
inventory: Demo Inventory注記: サンプルリソースを使用するには、インベントリーが Ansible にすでに存在している必要があります。
コンソールから利用可能な Ansible インベントリーのリストを確認すると、インベントリーが作成されていることを確認できます。
1.7.10.7. ClusterCurator リソースから自動化ジョブ Pod へのカスタムラベルのプッシュ
ClusterCurator リソースを使用して、カスタムラベルを Cluster Curator によって作成された自動化ジョブ Pod にプッシュできます。カスタムラベルをすべてのキュレーションタイプにプッシュできます。以下の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: cluster1
{{{} namespace: cluster1
labels:
test1: test1
test2: test2
{}}}spec:
desiredCuration: install
install:
jobMonitorTimeout: 5
posthook:
- extra_vars: {}
name: Demo Job Template
type: Job
prehook:
- extra_vars: {}
name: Demo Job Template
type: Job
towerAuthSecret: toweraccess1.7.10.8. Extended Update Support (EUS) アップグレードに ClusterCurator を使用する
ClusterCurator リソースを使用すると、EUS リリース間のアップグレードをより簡単に自動で実行できます。
spec.upgrade.intermediateUpdateをClusterCuratorリソースに追加し、中間リリースの値を指定します。次のサンプルを参照してください。中間リリースは4.14.xで、desiredUpdateは4.15.xです。spec: desiredCuration: upgrade upgrade: intermediateUpdate: 4.14.x desiredUpdate: 4.15.x monitorTimeout: 120オプション:
machineconfigpoolsを一時停止すると、中間リリースをスキップしてアップグレードを迅速化できます。posthookジョブにUnpause machinepoolと入力し、prehookジョブにpause machinepoolと入力します。以下の例を参照してください。posthook: - extra_vars: {} name: Unpause machinepool type: Job prehook: - extra_vars: {} name: Pause machinepool type: Job
EUS から EUS にアップグレードするように設定された ClusterCurator の完全な例を次に示します。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
annotations:
cluster.open-cluster-management.io/upgrade-clusterversion-backoff-limit: "10"
name: your-name
namespace: your-namespace
spec:
desiredCuration: upgrade
upgrade:
intermediateUpdate: 4.14.x
desiredUpdate: 4.15.x
monitorTimeout: 120
posthook:
- extra_vars: {}
name: Unpause machinepool
type: Job
prehook:
- extra_vars: {}
name: Pause machinepool
type: Job1.7.11. Ansible Automation Platform ジョブをホステッドクラスター上で実行されるように設定
Red Hat Ansible Automation Platform は multicluster engine Operator と統合されているため、ホステッドクラスターの作成または更新の前後に実行される prehook および posthook Ansible Automation Platform ジョブインスタンスを作成できます。
必要なアクセス権: クラスター管理者
1.7.11.1. 前提条件
クラスターで自動化テンプレートを実行するには、次の前提条件を満たす必要があります。
- サポートされているバージョンの OpenShift Container Platform
- Ansible Automation Platform Resource Operator をインストールして、Ansible Automation Platform ジョブを Git サブスクリプションのライフサイクルに接続する。Automation テンプレートを使用して Ansible Automation Platform ジョブを開始する場合は、実行時に Ansible Automation Platform ジョブテンプレートが冪等である。Ansible Automation Platform Resource Operator は、OpenShift Container Platform OperatorHub ページから検索できます。
1.7.11.2. Ansible Automation Platform ジョブを実行してホステッドクラスターをインストールする
ホステッドクラスターをインストールする Ansible Automation Platform ジョブを開始するには、次の手順を実行します。
pausedUntil: trueフィールドを含むHostedClusterおよびNodePoolリソースを作成します。hcp create clusterコマンドラインインターフェイスコマンドを使用する場合は、--pausedUntil: trueフラグを指定できます。以下の例を参照してください。
apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: my-cluster namespace: clusters spec: pausedUntil: 'true'apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: my-cluster-us-east-2 namespace: clusters spec: pausedUntil: 'true'HostedClusterリソースと同じ名前とHostedClusterリソースと同じ namespace で、ClusterCuratorリソースを作成します。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ClusterCurator metadata: name: my-cluster namespace: clusters labels: open-cluster-management: curator spec: desiredCuration: install install: jobMonitorTimeout: 5 prehook: - name: Demo Job Template extra_vars: variable1: something-interesting variable2: 2 - name: Demo Job Template posthook: - name: Demo Job Template towerAuthSecret: toweraccessAnsible Automation Platform Tower で認証が必要な場合は、シークレットリソースを作成します。以下の例を参照してください。
apiVersion: v1 kind: Secret metadata: name: toweraccess namespace: clusters stringData: host: https://my-tower-domain.io token: ANSIBLE_TOKEN_FOR_admin
1.7.11.3. Ansible Automation Platform ジョブを実行してホステッドクラスターを更新する
ホステッドクラスターを更新する Ansible Automation Platform ジョブを実行するには、更新するホステッドクラスターの ClusterCurator リソースを編集します。以下の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: my-cluster
namespace: clusters
labels:
open-cluster-management: curator
spec:
desiredCuration: upgrade
upgrade:
desiredUpdate: 4.15.1
monitorTimeout: 120
prehook:
- name: Demo Job Template
extra_vars:
variable1: something-interesting
variable2: 2
- name: Demo Job Template
posthook:
- name: Demo Job Template
towerAuthSecret: toweraccess- 1
- サポート対象バージョンの詳細は、Hosted Control Plane を参照してください。
注: この方法でホステッドクラスターを更新すると、Hosted Control Plane とノードプールの両方が同じバージョンに更新されます。Hosted Control Plane とノードプールを別のバージョンに更新することはサポートされていません。
1.7.11.4. Ansible Automation Platform ジョブを実行してホステッドクラスターを削除する
ホステッドクラスターを削除する Ansible Automation Platform ジョブを実行するには、削除するホステッドクラスターの ClusterCurator リソースを編集します。以下の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: ClusterCurator
metadata:
name: my-cluster
namespace: clusters
labels:
open-cluster-management: curator
spec:
desiredCuration: destroy
destroy:
jobMonitorTimeout: 5
prehook:
- name: Demo Job Template
extra_vars:
variable1: something-interesting
variable2: 2
- name: Demo Job Template
posthook:
- name: Demo Job Template
towerAuthSecret: toweraccess注記: AWS 上のホステッドクラスターの削除はサポートされていません。
1.7.11.5. 関連情報
-
Hosted Control Plane コマンドラインインターフェイス (
hcp) の詳細は、Hosted Control Plane コマンドラインインターフェイスのインストール を参照してください。 - サポートされているバージョンなど、ホステッドクラスターの詳細は、Hosted Control Plane の概要 を参照してください。
1.7.12. ClusterClaims
ClusterClaim は、マネージドクラスター上のカスタムリソース定義 (CRD) です。ClusterClaim は、マネージドクラスターが要求する情報の一部を表します。ClusterClaim を使用して、ターゲットクラスター上のリソースの配置を決定できます。
次の例は、YAML ファイルで指定された ClusterClaim を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: ClusterClaim
metadata:
name: id.openshift.io
spec:
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
次の表は、multicluster engine Operator が管理するクラスターの定義済み ClusterClaim のリストを示しています。
| 要求名 | 予約 | 変更可能 | 説明 |
|---|---|---|---|
|
| true | false | アップストリームの提案で定義された ClusterID |
|
| true | true | Kubernetes バージョン |
|
| true | false | マネージドクラスターが実行されているプラットフォーム (AWS、GCE、Equinix Metal など) |
|
| true | false | 製品名 (OpenShift、Anthos、EKS、GKE など) |
|
| false | false | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform 外部 ID |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる管理コンソールの URL |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform バージョン |
マネージドクラスターで以前の要求が削除されるか、更新されると、自動的に復元またはロールバックされます。
マネージドクラスターがハブに参加すると、マネージドクラスターで作成された ClusterClaim が、ハブクラスター上の ManagedCluster リソースのステータスと同期されます。以下に示す ManagedCluster の clusterClaims の例を参照してください。4.x は、OpenShift Container Platform のサポートされているバージョンに置き換えます。
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
labels:
cloud: Amazon
clusterID: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
installer.name: multiclusterhub
installer.namespace: open-cluster-management
name: cluster1
vendor: OpenShift
name: cluster1
spec:
hubAcceptsClient: true
leaseDurationSeconds: 60
status:
allocatable:
cpu: '15'
memory: 65257Mi
capacity:
cpu: '18'
memory: 72001Mi
clusterClaims:
- name: id.k8s.io
value: cluster1
- name: kubeversion.open-cluster-management.io
value: v1.18.3+6c42de8
- name: platform.open-cluster-management.io
value: AWS
- name: product.open-cluster-management.io
value: OpenShift
- name: id.openshift.io
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
- name: consoleurl.openshift.io
value: 'https://console-openshift-console.apps.xxxx.dev04.red-chesterfield.com'
- name: version.openshift.io
value: '4.x'
conditions:
- lastTransitionTime: '2020-10-26T07:08:49Z'
message: Accepted by hub cluster admin
reason: HubClusterAdminAccepted
status: 'True'
type: HubAcceptedManagedCluster
- lastTransitionTime: '2020-10-26T07:09:18Z'
message: Managed cluster joined
reason: ManagedClusterJoined
status: 'True'
type: ManagedClusterJoined
- lastTransitionTime: '2020-10-30T07:20:20Z'
message: Managed cluster is available
reason: ManagedClusterAvailable
status: 'True'
type: ManagedClusterConditionAvailable
version:
kubernetes: v1.18.3+6c42de81.7.12.1. カスタム ClusterClaims の作成
カスタム名を持つ ClusterClaim リソースをマネージドクラスターに作成すると、リソースを識別しやすくなります。カスタムの ClusterClaim リソースは、ハブクラスター上の ManagedCluster リソースのステータスと同期されます。以下のコンテンツでは、カスタマイズされた ClusterClaim リソースの定義例を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: ClusterClaim
metadata:
name: <custom_claim_name>
spec:
value: <custom_claim_value>
spec.value フィールドの長さは 1024 以下である必要があります。ClusterClaim リソースを作成するには clusterclaims.cluster.open-cluster-management.io リソースの create 権限が必要です。
1.7.12.2. 既存の ClusterClaim の表示
kubectl コマンドを使用して、マネージドクラスターに適用される ClusterClaim をリスト表示すると、ClusterClaim をエラーメッセージと比較することができます。
注記: clusterclaims.cluster.open-cluster-management.io のリソースに list の権限があることを確認します。
以下のコマンドを実行して、マネージドクラスターにある既存の ClusterClaim のリストを表示します。
kubectl get clusterclaims.cluster.open-cluster-management.io1.7.13. ManagedClusterSets
ManagedClusterSet は、マネージドクラスターのグループです。マネージドクラスターセット。すべてのマネージドクラスターへのアクセスを管理するのに役立ちます。ManagedClusterSetBinding リソースを作成して ManagedClusterSet リソースを namespace にバインドすることもできます。
各クラスターは、マネージドクラスターセットのメンバーである必要があります。ハブクラスターをインストールすると、default という名前の ManagedClusterSet リソースが作成されます。マネージドクラスターセットに割り当てられていないすべてのクラスターは、default マネージドクラスターセットに自動的に割り当てられます。default マネージドクラスターセットを削除または更新することはできません。
マネージドクラスターセットの作成および管理方法の詳細は、以下を参照してください。
1.7.13.1. ManagedClusterSet の作成
マネージドクラスターセットにマネージドクラスターをグループ化して、マネージドクラスターでのユーザーのアクセス権限を制限できます。
必要なアクセス権: クラスター管理者
ManagedClusterSet は、クラスタースコープのリソースであるため、ManagedClusterSet の作成先となるクラスターで管理者権限が必要です。マネージドクラスターは、複数の ManagedClusterSet に追加できません。マネージドクラスターセットは、multicluster engine Operator コンソールまたは CLI から作成できます。
注記: マネージドクラスターセットに追加されていないクラスタープールは、デフォルトの ManagedClusterSet リソースに追加されません。クラスターがクラスタープールから要求されると、クラスターはデフォルトの ManagedClusterSet に追加されます。
マネージドクラスターを作成すると、管理を容易にするために次のものが自動的に作成されます。
-
globalと呼ばれるManagedClusterSet。 -
open-cluster-management-global-setという namespace。 globalと呼ばれるManagedClusterSetBindingは、globalManagedClusterSetをopen-cluster-management-global-setnamespace にバインドします。重要:
globalマネージドクラスターセットを削除、更新、または編集することはできません。globalマネージドクラスターセットには、すべてのマネージドクラスターが含まれます。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: name: global namespace: open-cluster-management-global-set spec: clusterSet: global
1.7.13.1.1. CLI を使用した ManagedClusterSet の作成
CLI を使用してマネージドクラスターセットの定義を YAML ファイルに追加し、マネージドクラスターセットを作成します。
apiVersion: cluster.open-cluster-management.io/v1beta2
kind: ManagedClusterSet
metadata:
name: <cluster_set>
<cluster_set> をマネージドクラスターセットの名前に置き換えます。
1.7.13.1.2. クラスターの ManagedClusterSet への追加
ManagedClusterSet の作成後に、コンソールまたは CLI を使用してクラスターをマネージドクラスターセットに追加できます。
1.7.13.1.3. CLI を使用したクラスターの ManagedClusterSet への追加
CLI を使用してクラスターをマネージドクラスターに追加するには、以下の手順を実行します。
managedclustersets/joinの仮想サブリソースに作成できるように、RBACClusterRoleエントリーが追加されていることを確認します。注記: この権限がないと、マネージドクラスターを
ManagedClusterSetに割り当てることはできません。このエントリーが存在しない場合は、YAML ファイルに追加します。以下の例を参照してください。kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/join"] resourceNames: ["<cluster_set>"] verbs: ["create"]<cluster_set>をManagedClusterSetの名前に置き換えます。注記: マネージドクラスターを別の
ManagedClusterSetに移動する場合には、両方のマネージドクラスターセットで権限の設定が必要です。YAML ファイルでマネージドクラスターの定義を検索します。以下の定義例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> spec: hubAcceptsClient: truecluster.open-cluster-management.io/clustersetパラメーターを追加し、ManagedClusterSetの名前を指定します。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> labels: cluster.open-cluster-management.io/clusterset: <cluster_set> spec: hubAcceptsClient: true
1.7.13.2. ManagedClusterSet への RBAC 権限の割り当て
ハブクラスターに設定したアイデンティティープロバイダーが提供するクラスターセットに、ユーザーまたはグループを割り当てることができます。
必要なアクセス権: クラスター管理者
ManagedClusterSet API RBAC 権限レベルは、以下の表を参照してください。
| クラスターセット | アクセス権限 | 権限の作成 |
|---|---|---|
|
| マネージドクラスターセットに割り当てられたすべてのクラスターおよびクラスタープールリソースへのフルアクセス権限。 | クラスターの作成、クラスターのインポート、クラスタープールの作成権限。権限は、作成時にマネージドクラスターセットに割り当てる必要があります。 |
|
|
| クラスターの作成、クラスターのインポート、またはクラスタープールの作成を実行する権限なし。 |
|
| マネージドクラスターセットに割り当てられたすべてのクラスターおよびクラスタープールリソースに対する読み取り専用権限。 | クラスターの作成、クラスターのインポート、またはクラスタープールの作成を実行する権限なし。 |
注記: グローバルクラスターセットにクラスターセットの admin 権限を適用することはできません。
コンソールからマネージドクラスターセットにユーザーまたはグループを割り当てるには、次の手順を実行します。
- OpenShift Container Platform コンソールから、Infrastructure > Clusters に移動します。
- Cluster sets タブを選択します。
- ターゲットクラスターセットを選択します。
- Access management タブを選択します。
- Add user or group を選択します。
- アクセス権を割り当てるユーザーまたはグループを検索して選択します。
- Cluster set admin または Cluster set view ロールを選択して、選択したユーザーまたはグループに付与します。詳細は、multicluster engine Operator のロールベースのアクセス制御 の ロールの概要 を参照してください。
- Add を選択して変更を送信します。
テーブルにユーザーまたはグループが表示されます。全マネージドクラスターセットリソースの権限の割り当てがユーザーまたはグループに伝播されるまでに数秒かかる場合があります。
placement 情報は、ManagedCusterSets からの ManagedClusters のフィルタリング を参照してください。
1.7.13.3. ManagedClusterSetBinding リソースの作成
ManagedClusterSetBinding リソースは、ManagedClusterSet リソースを namespace にバインドします。同じ namespace で作成されたアプリケーションおよびポリシーは、バインドされたマネージドクラスターセットリソースに含まれるクラスターにのみアクセスできます。
namespace へのアクセス権限は、その namespace にバインドされるマネージドクラスターセットに自動的に適用されます。その namespace へのアクセス権限を持つ場合、その namespace にバインドされるマネージドクラスターセットへのアクセス権限が自動的に付与されます。マネージドクラスターセットにアクセスする権限のみがある場合、namespace の他のマネージドクラスターセットにアクセスする権限は自動的に割り当てられません。
コンソールまたはコマンドラインを使用してマネージドクラスターセットバインドを作成できます。
1.7.13.3.1. コンソールを使用した ManagedClusterSetBinding の作成
コンソールを使用して ManagedClusterSetBinding を作成するには、以下の手順を実行します。
- OpenShift Container Platform コンソールから、Infrastructure > Clusters に移動し、Cluster sets タブを選択します。
- バインドを作成するクラスターセットの名前を選択します。
- Actions > Edit namespace bindings に移動します。
- Edit namespace bindings ページで、ドロップダウンメニューからクラスターセットをバインドする namespace を選択します。
1.7.13.3.2. CLI を使用した ManagedClusterSetBinding の作成
CLI を使用して ManagedClusterSetBinding を作成するには、以下の手順を実行します。
YAML ファイルに
ManagedClusterSetBindingリソースを作成します。注記: マネージドクラスターセットバインドを作成する場合、マネージドクラスターセットバインドの名前は、バインドするマネージドクラスターセットの名前と一致する必要があります。
ManagedClusterSetBindingリソースは、以下の情報のようになります。apiVersion: cluster.open-cluster-management.io/v1beta2 kind: ManagedClusterSetBinding metadata: namespace: <namespace> name: <cluster_set> spec: clusterSet: <cluster_set>ターゲットのマネージドクラスターセットでのバインド権限を割り当てておく必要があります。次の
ClusterRoleリソースの例を表示します。これには、ユーザーが<cluster_set>にバインドすることを許可するルールが含まれています。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <clusterrole> rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/bind"] resourceNames: ["<cluster_set>"] verbs: ["create"]
1.7.13.4. taint と toleration を使用したマネージドクラスターの配置
taint と toleration を使用して、マネージドクラスターまたはマネージドクラスターセットの placement を制御できます。taint と toleration は、特定の placement でマネージドクラスターが選択されないようにする方法を提供します。この制御は、特定のマネージドクラスターが一部の placement に含まれないようにする場合に役立ちます。taint をマネージドクラスターに、toleration を placement に追加できます。taint と toleration が一致しないと、マネージドクラスターはその placement に選択されません。
1.7.13.4.1. マネージドクラスターへの taint の追加
taint はマネージドクラスターのプロパティーで指定され、placement がマネージドクラスターまたはマネージドクラスターのセットを除外できます。
taint セクションが存在しない場合は、次の例のようなコマンドを実行して、マネージドクラスターに taint を追加できます。
oc patch managedcluster <managed_cluster_name> -p '{"spec":{"taints":[{"key": "key", "value": "value", "effect": "NoSelect"}]}}' --type=mergeまたは、次の例のようなコマンドを実行して、既存の taint に taint を追加することもできます。
oc patch managedcluster <managed_cluster_name> --type='json' -p='[{"op": "add", "path": "/spec/taints/-", "value": {"key": "key", "value": "value", "effect": "NoSelect"}}]'taint の仕様には以下のフィールドが含まれます。
-
(必須) Key: クラスターに適用される taint キー。この値は、その placement に追加される基準を満たすように、マネージドクラスターの toleration の値と一致させる必要があります。この値は確認できます。たとえば、この値は
barまたはfoo.example.com/barです。 -
(オプション) Value: taint キーの taint 値。この値は、その placement に追加される基準を満たすように、マネージドクラスターの toleration の値と一致させる必要があります。たとえば、この値は
valueとすることができます。 (必須) Effect: taint を許容しない placement における taint の効果、または placement の taint と toleration が一致しないときに何が起こるか。effect の値は、以下のいずれかの値である必要があります。
-
NoSelect: placement は、この taint を許容しない限り、クラスターを選択できません。taint の設定前に placement でクラスターが選択された場合は、クラスターは placement の決定から削除されます。 -
NoSelectIfNew: スケジューラーは、クラスターが新しい場合にそのクラスターを選択できません。プレイスメントは、taint を許容し、すでにクラスター決定にそのクラスターがある場合にのみ、そのクラスターを選択することができます。
-
-
(必須)
TimeAdded: taint を追加した時間。この値は自動的に設定されます。
1.7.13.4.2. マネージドクラスターのステータスを反映させる組み込み taint の特定
マネージドクラスターにアクセスできない場合には、クラスターを placement に追加しないでください。以下の taint は、アクセスできないマネージドクラスターに自動的に追加されます。
cluster.open-cluster-management.io/unavailable: この taint は、ステータスがFalseのManagedClusterConditionAvailableの条件がある場合にマネージドクラスターに追加されます。taint にはNoSelectと同じ効果があり、空の値を指定すると、利用不可のクラスターがスケジュールされないようにできます。この taint の例は、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unavailable timeAdded: '2022-02-21T08:11:54Z'cluster.open-cluster-management.io/unreachable-ManagedClusterConditionAvailableの条件のステータスがUnknownであるか、条件がない場合に、この taint はマネージドクラスターに追加されます。この taint にはNoSelectと同じ効果があり、空の値を指定すると、到達不可のクラスターがスケジュールされないようにできます。この taint の例は、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unreachable timeAdded: '2022-02-21T08:11:06Z'
1.7.13.4.3. toleration の placement への追加
toleration は placement に適用され、placement の toleration と taint が同じでないマネージドクラスターを placement から除外できます。toleration の仕様には以下のフィールドが含まれます。
- (任意) Key: キーは placement ができるように taint キーに一致します。
- (任意) Value: toleration の値は、placement を許可する toleration の taint の値と一致する必要があります。
(任意) Operator: 演算子はキーと値の関係を表します。有効な演算子は
equalとexistsです。デフォルト値はequalです。toleration は、キーが同じ場合、効果が同じ場合、さらび Operator が以下の値のいずれかである場合に、taint にマッチします。-
equal: Operator がequalで、値は taint および toleration と同じになります。 -
exists: 値のワイルドカード。これにより、placement は特定のカテゴリーのすべての taint を許容できます。
-
-
(任意) Effect: 一致する taint の効果。空のままにすると、すべての taint の効果と一致します。指定可能な値は、
NoSelectまたはNoSelectIfNewです。 -
(任意) TolerationSeconds: マネージドクラスターを新しい placement に移動する前に、taint を許容する時間の長さ (秒単位) です。effect 値が
NoSelectまたはPreferNoSelectでない場合は、このフィールドは無視されます。デフォルト値はnilで、時間制限がないことを示します。TolerationSecondsのカウント開始時刻は、クラスターのスケジュール時刻やTolerationSeconds加算時刻の値ではなく、自動的に taint のTimeAddedの値として記載されます。
以下の例は、taint が含まれるクラスターを許容する toleration を設定する方法を示しています。
この例のマネージドクラスターの taint:
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: gpu value: "true" timeAdded: '2022-02-21T08:11:06Z'taint を許容できる placement の toleration
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: default spec: tolerations: - key: gpu value: "true" operator: Equaltoleration の定義例では、
key: gpuとvalue: "true"が一致するため、placement でcluster1を選択できます。
注記: マネージドクラスターは、taint の toleration が含まれる placement に置かれる保証はありません。他の placement に同じ toleration が含まれる場合には、マネージドクラスターはそれらの placement のいずれかに置かれる可能性があります。
1.7.13.4.4. 一時的な toleration の指定
TolerationSeconds の値は、toleration が taint を許容する期間を指定します。この一時的な toleration は、マネージドクラスターがオフラインで、このクラスターにデプロイされているアプリケーションを、許容時間中に別のマネージドクラスターに転送できる場合に役立ちます。
たとえば、以下の taint を持つマネージドクラスターに到達できなくなります。
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
name: cluster1
spec:
hubAcceptsClient: true
taints:
- effect: NoSelect
key: cluster.open-cluster-management.io/unreachable
timeAdded: '2022-02-21T08:11:06Z'
以下の例のように、TolerationSeconds の値で placement を定義すると、ワークロードは 5 分後に利用可能な別のマネージドクラスターに転送されます。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: demo4
namespace: demo1
spec:
tolerations:
- key: cluster.open-cluster-management.io/unreachable
operator: Exists
tolerationSeconds: 300マネージドクラスターに到達できなくなると、アプリケーションが 5 分間別のマネージドクラスターに移動されます。
1.7.13.4.5. 関連情報
- taint と toleration の詳細は、OpenShift Container Platform ドキュメントの taint と toleration を使用したロギング Pod の配置制御 を参照してください。
-
oc patchの使用方法については、OpenShift Container Platform ドキュメントの oc patch を参照してください。
1.7.13.5. ManagedClusterSet からのマネージドクラスターの削除
マネージドクラスターセットからマネージドクラスターを削除して別のマネージドクラスターセットに移動するか、セットの管理設定から削除する必要がある場合があります。コンソールまたは CLI を使用して、マネージドクラスターセットからマネージドクラスターを削除できます。
注記:
-
マネージドクラスターはすべて、マネージドクラスターセットに割り当てる必要があります。
ManagedClusterSetからマネージドクラスターを削除し、別のManagedClusterSetに割り当てない場合は、そのクラスターはdefaultのマネージドクラスターセットに自動的に追加されます。 -
Submariner アドオンがマネージドクラスターにインストールされている場合は、アドオンをアンインストールしてから、マネージドクラスターを
ManagedClusterSetから削除する必要があります。
1.7.13.5.1. コンソールを使用した ManagedClusterSet からのクラスターの削除
コンソールを使用してマネージドクラスターセットからクラスターを削除するには、次の手順を実行します。
- Infrastructure > Clusters をクリックし、Cluster sets タブが選択されていることを確認します。
- マネージドクラスターセットから削除するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Manage resource assignments を選択します。
Manage resource assignments ページで、クラスターセットから削除するリソースのチェックボックスをオフにします。
この手順では、すでにクラスターセットのメンバーであるリソースを削除します。マネージドクラスターの詳細を表示して、リソースがすでにクラスターセットのメンバーであるかどうかを確認できます。
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合には、マネージドクラスターセット両方で RBAC 権限の設定が必要です。
1.7.13.5.2. CLI を使用した ManagedClusterSet からのクラスターの削除
コマンドラインを使用してマネージドクラスターセットからクラスターを削除するには、以下の手順を実行します。
以下のコマンドを実行して、マネージドクラスターセットでマネージドクラスターのリストを表示します。
oc get managedclusters -l cluster.open-cluster-management.io/clusterset=<cluster_set><cluster_set>をマネージドクラスターセットの名前に置き換えます。- 削除するクラスターのエントリーを見つけます。
削除するクラスターの YAML エントリーからラベルを削除します。ラベルの例は、以下のコードを参照してください。
labels: cluster.open-cluster-management.io/clusterset: clusterset1
注記: マネージドクラスターを別のクラスターセットに移動する場合は、マネージドクラスターセット両方で RBAC 権限の設定が必要です。
1.7.14. Placement
placement リソースは、placement namespace にバインドされている ManagedClusterSets から ManagedClusters のセットを選択するルールを定義する、namespace スコープのリソースです。
必要なアクセス権: クラスター管理者、クラスターセット管理者
プレースメントの使用方法の詳細は、読み続けてください。
1.7.14.1. Placement の概要
マネージドクラスターを使用した配置がどのように機能するかは、次の情報を参照してください。
-
Kubernetes クラスターは、cluster スコープの
ManagedClustersとしてハブクラスターに登録されます。 -
ManagedClustersは、クラスタースコープのManagedClusterSetsに編成されます。 -
ManagedClusterSetsはワークロード namespace にバインドされます。 -
namespace スコープの placement では、潜在的な
ManagedClustersの作業セットを選択するManagedClusterSetsの一部を指定します。 -
placement は、
labelSelectorとclaimSelectorを使用して、ManagedClusterSetsからManagedClustersをフィルター処理します。 -
ManagedClustersの placement は、taint と toleration を使用して制御できます。 -
placement は、
Prioritizersスコアによってクラスターを並べ替え、そのグループから上位n個のクラスターを選択します。nはnumberOfClustersで定義できます。 - 配置では、削除するマネージドクラスターは選択されません。
注記:
-
namespace に
ManagedClusterSetBindingを作成して、その namespace にManagedClusterSetを最低でも 1 つバインドする必要があります。 -
managedclustersets/bindの仮想サブリソースのCREATEに対してロールベースのアクセスが必要です。
1.7.14.1.1. 関連情報
- 詳細は、taint と toleration を使用したマネージドクラスターの配置 を参照してください。
-
API と
Prioritizersの詳細は、Placements API を参照してください。 - placement を伴う ManagedClusters の選択 に戻ります。
1.7.14.2. ManagedClusterSets から ManagedClusters を選択する
labelSelector または claimSelector を使用して、フィルタリングする ManagedClusters を選択できます。両方のフィルターの使用方法は、次の例を参照してください。
次の例では、
labelSelectorはラベルvendor: OpenShiftを持つクラスターのみを照合します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShift次の例では、
claimSelectorは、region.open-cluster-management.ioとus-west-1を持つクラスターのみを照合します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1また、
clusterSetsパラメーターを使用して、特定のクラスターセットからManagedClustersをフィルター処理することもできます。次の例では、claimSelectorはクラスターセットclusterset1およびclusterset2のみに一致します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: clusterSets: - clusterset1 - clusterset2 predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1
また、numberOfClusters パラメーターを使用して、フィルタリングする ManagedClusters の数を選択することもできます。以下の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement
namespace: ns1
spec:
numberOfClusters: 3
predicates:
- requiredClusterSelector:
labelSelector:
matchLabels:
vendor: OpenShift
claimSelector:
matchExpressions:
- key: region.open-cluster-management.io
operator: In
values:
- us-west-1- 1
- 選択する
ManagedClustersの数を指定します。前の例では3に設定されています。
1.7.14.2.1. placement を使用して toleration を定義することで ManagedClusters をフィルタリングする
一致するテイントを使用して ManagedClusters をフィルタリングする方法は、次の例を参照してください。
デフォルトでは、次の例では、placement で
cluster1を選択できません。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: gpu value: "true" timeAdded: '2022-02-21T08:11:06Z'cluster1を選択するには、許容範囲を定義する必要があります。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: tolerations: - key: gpu value: "true" operator: Equal
tolerationSeconds パラメーターを使用して、指定した期間、一致するテイントを持つ ManagedClusters を選択することもできます。tolerationSeconds は、許容がテイントにバインドされ続ける期間を定義します。tolerationSeconds は、指定された時間が経過すると、オフラインになったクラスターにデプロイされたアプリケーションを別のマネージドクラスターに自動的に転送できます。
次の例を見て、tolerationSeconds の使用方法を学習します。
次の例では、マネージドクラスターにアクセスできなくなります。
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unreachable timeAdded: '2022-02-21T08:11:06Z'tolerationSecondsを使用して配置を定義すると、ワークロードは別の使用可能なマネージドクラスターに転送されます。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: tolerations: - key: cluster.open-cluster-management.io/unreachable operator: Exists tolerationSeconds: 3001 - 1
- 何秒後にワークロードを転送するかを指定します。
1.7.14.2.2. アドオンのステータスに基づき ManagedClusters をフィルタリングする
デプロイされているアドオンのステータスに基づいて、プレースメント用のマネージドクラスターを選択することもできます。たとえば、マネージドクラスターで有効になっている特定のアドオンがある場合にのみ、placement にマネージドクラスターを選択できます。
placement を作成するときに、アドオンのラベルとそのステータスを指定できます。マネージドクラスターでアドオンが有効になっている場合、ラベルは ManagedCluster リソース上に自動的に作成されます。アドオンが無効になると、ラベルは自動的に削除されます。
各アドオンは、feature.open-cluster-management.io/addon-<addon_name>=<status_of_addon> の形式でラベルで表現します。
addon_name を選択したマネージドクラスターで有効にするアドオンの名前に置き換えます。
status_of_addon をマネージドクラスターが選択されている場合にアドオンに設定するステータスに置き換えます。
status_of_addon に指定できる値は、次の表を参照してください。
| 値 | 説明 |
|---|---|
|
| アドオンは有効化されており、利用可能です。 |
|
| アドオンは有効ですが、リースは継続的に更新されません。 |
|
| アドオンは有効ですが、そのアドオンのリースが見つかりません。これは、マネージドクラスターがオフライン時にも発生する可能性があります。 |
たとえば、使用可能な application-manager. アドオンは、マネージドクラスター上の次のようなラベルで表されます。
feature.open-cluster-management.io/addon-application-manager: availableアドオンとそのステータスに基づいて placement を作成する方法は、次の例を参照してください。
次の placement 例には、
application-managerが有効になっているすべてのマネージドクラスターが含まれています。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: Exists次の placement 例には、
application-managerがavailableステータスで有効になっているすべてのマネージドクラスターが含まれています。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: "feature.open-cluster-management.io/addon-application-manager": "available"次の placement 例には、
application-managerが無効になっているすべてのマネージドクラスターが含まれています。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement3 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: DoesNotExist
1.7.14.2.3. placement を使用して prioritizerPolicy を定義することで ManagedClusters の優先順位を付ける
次の例を参照して、prioritizerPolicy パラメーターと配置を使用して ManagedClusters に優先順位を付ける方法を学習します。
次の例では、割り当て可能なメモリーが最大のクラスターを選択します。
注記: Kubernetes Node Allocatable と同様に、'allocatable' は、各クラスターの Pod で利用可能なコンピュートリソースの量として定義されます。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableMemory次の例では、割り当て可能な最大の CPU とメモリーを持つクラスターを選択し、リソースの変更に敏感な配置を行います。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableCPU weight: 2 - scoreCoordinate: builtIn: ResourceAllocatableMemory weight: 2次の例では、
addOnスコアの CPU 比率が最も大きい 2 つのクラスターを選択し、配置の決定を固定します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement namespace: ns1 spec: numberOfClusters: 2 prioritizerPolicy: mode: Exact configurations: - scoreCoordinate: builtIn: Steady weight: 3 - scoreCoordinate: type: AddOn addOn: resourceName: default scoreName: cpuratio
1.7.14.2.4. 関連情報
- 詳細は、ノード割り当て可能 を参照してください。
- 他のトピックは Selecting ManagedClusters with placement に戻ります。
1.7.14.3. PlacementDecisions を使用して選択した ManagedClusters を確認する
ラベル cluster.open-cluster-management.io/placement={placement_name} を持つ 1 つ以上の PlacementDecision 種類が、プレースメントによって選択された ManagedClusters を表すために作成されます。
ManagedCluster を選択して PlacementDecision に追加すると、この placement を使用するコンポーネントがこの ManagedCluster にワークロードを適用する可能性があります。
ManagedCluster を選択せずに PlacementDecision から削除すると、この ManagedCluster に適用されているワークロードが削除されます。toleration を定義することで、ワークロードの削除を回避できます。
toleration の定義の詳細は、placement を使用して toleration を定義することで ManagedClusters をフィルタリングする を参照してください。
次の PlacementDecision の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/placement: placement1
name: placement1-kbc7q
namespace: ns1
ownerReferences:
- apiVersion: cluster.open-cluster-management.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: Placement
name: placement1
uid: 05441cf6-2543-4ecc-8389-1079b42fe63e
status:
decisions:
- clusterName: cluster1
reason: ''
- clusterName: cluster2
reason: ''
- clusterName: cluster3
reason: ''1.7.14.3.1. 関連情報
- API の詳細は、PlacementDecisions API を参照してください。
1.7.15. クラスタープールの管理 (テクノロジープレビュー)
クラスタープールは、Red Hat OpenShift Container Platform クラスターにオンデマンドで、スケーリングする場合に、迅速かつコスト効果を高く保ちながら、アクセスできるようにします。クラスタープールは、Amazon Web Services、Google Cloud Platform または Microsoft Azure で設定可能な数多くの OpenShift Container Platform クラスターをプロビジョニングします。このプールは、開発、継続統合、および実稼働のシナリオにおいてクラスター環境を提供したり、置き換えたりする場合に特に便利です。実行を継続するクラスターの数を指定して、すぐに要求できるようにすることができます。残りのクラスターは休止状態に保たれるため、数分以内に再開して要求できます。
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスター要求が作成されると、その要求にプールは実行中のクラスターを割り当てます。実行中のクラスターがない場合は、休止状態のクラスターを再開してクラスターを提供するか、新規クラスターをプロビジョニングします。クラスタープールは自動的に新しいクラスターを作成し、休止状態のクラスターを再開して、プール内で利用可能な実行中のクラスターの指定サイズおよび数を維持します。
クラスタープールを作成する手順は、クラスターの作成手順と似ています。クラスタープールのクラスターは、すぐ使用するために作成されるわけではありません。
1.7.15.1. クラスタープールの作成
クラスタープールを作成する手順は、クラスターの作成手順と似ています。クラスタープールのクラスターは、すぐ使用するために作成されるわけではありません。
必要なアクセス権限: 管理者
1.7.15.1.1. 前提条件
クラスタープールを作成する前に、次の前提条件を参照してください。
- multicluster engine Operator ハブクラスターをデプロイする必要があります。
- プロバイダー環境で Kubernetes クラスターを作成できるように、multicluster engine Operator ハブクラスターのインターネットアクセスが必要です。
- AWS、GCP、または Microsoft Azure プロバイダーのクレデンシャルが必要です。詳細は、認証情報の管理の概要 を参照してください。
- プロバイダー環境で設定済みのドメインが必要です。ドメインの設定方法は、プロバイダーのドキュメントを参照してください。
- プロバイダーのログイン認証情報が必要です。
- OpenShift Container Platform イメージプルシークレットが必要です。イメージプルシークレットの使用 を参照してください。
注記: この手順でクラスタープールを追加すると、プールからクラスターを要求するときに、multicluster engine Operator で管理するために、クラスターを自動的にインポートするようにクラスタープールが設定されます。クラスター要求を使用して管理するために、要求されたクラスターを自動的にインポートしないクラスタープールを作成する場合は、clusterClaim リソースに次のアノテーションを追加してください。
kind: ClusterClaim
metadata:
annotations:
cluster.open-cluster-management.io/createmanagedcluster: "false" - 1
- 文字列であることを示すには、
"false"という単語を引用符で囲む必要があります。
1.7.15.1.2. クラスタープールを作成する
クラスタープールを作成するには、ナビゲーションメニューで Infrastructure > Clusters を選択します。Cluster pools タブには、アクセス可能なクラスタープールがリスト表示されます。Create cluster pool を選択し、コンソールの手順を実行します。
クラスタープールに使用するインフラストラクチャー認証情報がない場合は、Add credential を選択して作成できます。
リストから既存の namespace を選択するか、作成する新規 namespace の名前を入力します。クラスタープールは、クラスターと同じ namespace に配置する必要はありません。
クラスタープールの RBAC ロールを使用して、既存クラスターセットのロール割り当てを共有する場合は、クラスターセット名を選択します。クラスタープールのクラスターセットは、クラスタープールの作成時にのみ設定できます。クラスタープールの作成後には、クラスタープールまたはクラスタープールのクラスターセットの関連付けを変更できません。クラスタープールから要求したクラスターは、クラスタープールと同じクラスターセットに自動的に追加されます。
注記: cluster admin の権限がない場合は、クラスターセットを選択する必要があります。この状況でクラスターセットの名前が含まれない場合は、禁止エラーで、クラスターセットの作成要求が拒否されます。選択できるクラスターセットがない場合は、クラスター管理者に連絡してクラスターセットを作成し、clusterset admin 権限を付与してもらいます。
cluster pool size は、クラスタープールにプロビジョニングするクラスターの数を指定し、クラスタープールの実行回数は、プールが実行を継続し、すぐに使用できるように要求できるクラスターの数を指定します。
この手順は、クラスターを作成する手順と非常に似ています。
プロバイダーに必要な固有の情報は、以下を参照してください。
1.7.15.2. クラスタープールからのクラスターの要求
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスターの稼働中で、クラスタープールで準備できると、要求が完了します。クラスタープールは、クラスタープールに指定された要件を維持するために、クラスタープールに新しい実行中およびハイバネートされたクラスターを自動的に作成します。
注記: クラスタープールから要求されたクラスターが不要になり、破棄されると、リソースは削除されます。クラスターはクラスタープールに戻りません。
必要なアクセス権限: 管理者
1.7.15.2.1. 前提条件
使用可能なクラスターの有無にかかわらず、クラスタープールが必要です。クラスタープールに利用可能なクラスターがある場合、利用可能なクラスターが要求されます。クラスタープールに利用可能なクラスターがない場合は、要求を満たすためにクラスターが作成されます。クラスタープールの作成方法は、クラスタープールの作成 を参照してください。
1.7.15.2.2. クラスタープールからのクラスターの要求
クラスター要求の作成時に、クラスタープールから新規クラスターを要求します。クラスターが利用可能になると、クラスターはプールからチェックアウトされます。自動インポートを無効にしていない限り、要求されたクラスターはマネージドクラスターの 1 つとして自動的にインポートされます。
以下の手順を実行してクラスターを要求します。
- ナビゲーションメニューから Infrastructure > Clusters をクリックし、Cluster pools タブを選択します。
- クラスターを要求するクラスタープールの名前を見つけ、Claim cluster を選択します。
クラスターが利用可能な場合には、クラスターが要求され、マネージドクラスター タブにすぐに表示されます。利用可能なクラスターがない場合は、休止状態のクラスターの再開や、新しいクラスターのプロビジョニングに数分かかる場合があります。この間、要求のステータスは pending です。クラスタープールをデプロイメントして、保留中の要求を表示または削除します。
要求されたクラスターは、クラスタープールにあった時に関連付けられたクラスターセットに所属します。要求時には、要求したクラスターのクラスターセットは変更できません。
注記: クラウドプロバイダー認証情報のプルシークレット、SSH キー、またはベースドメインへの変更は、元の認証情報を使用してすでにプロビジョニングされているため、クラスタープールから要求された既存のクラスターには反映されません。コンソールを使用してクラスタープール情報を編集することはできませんが、CLI インターフェイスを使用してその情報を更新することで更新できます。更新された情報を含む認証情報を使用して、新しいクラスタープールを作成することもできます。新しいプールで作成されるクラスターは、新しい認証情報で提供される設定を使用します。
1.7.15.3. クラスタープールリリースイメージの更新
クラスタープールのクラスターが一定期間、休止状態のままになると、クラスターの Red Hat OpenShift Container Platform リリースイメージがバックレベルになる可能性があります。このような場合は、クラスタープールにあるクラスターのリリースイメージのバージョンをアップグレードしてください。
必要なアクセス: 編集
クラスタープールにあるクラスターの OpenShift Container Platform リリースイメージを更新するには、以下の手順を実行します。
注記: この手順では、クラスタープールですでに要求されているクラスタープールからクラスターを更新しません。この手順を完了すると、リリースイメージの更新は、クラスタープールに関連する次のクラスターにのみ適用されます。
- この手順でリリースイメージを更新した後にクラスタープールによって作成されたクラスター。
- クラスタープールで休止状態になっているクラスター。古いリリースイメージを持つ既存の休止状態のクラスターは破棄され、新しいリリースイメージを持つ新しいクラスターがそれらを置き換えます。
- ナビゲーションメニューから Infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- クラスタープール の表で、更新するクラスタープールの名前を見つけます。
- 表の Cluster pools の Options メニューをクリックし、Update release image を選択します。
- このクラスタープールから今後、クラスターの作成に使用する新規リリースイメージを選択します。
クラスタープールのリリースイメージが更新されました。
ヒント: アクション 1 つで複数のクラスターのリリースイメージを更新するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールのリリースイメージを更新します。
1.7.15.4. Scaling cluster pools (Technology Preview)
クラスタープールのクラスター数は、クラスタープールサイズのクラスター数を増やしたり、減らしたりして変更できます。
必要なアクセス権限: クラスターの管理者
クラスタープールのクラスター数を変更するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- 変更するクラスタープールの Options メニューで、Scale cluster pool を選択します。
- プールサイズの値を変更します。
- オプションで、実行中のクラスターの数を更新して、要求時にすぐに利用可能なクラスター数を増減できます。
クラスタープールは、新しい値を反映するようにスケーリングされます。
1.7.15.5. クラスタープールの破棄
クラスタープールを作成し、不要になった場合は、そのクラスタープールを破棄できます。
重要: クラスター要求がないクラスタープールのみ破棄できます。
必要なアクセス権限: クラスターの管理者
クラスタープールを破棄するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
削除するクラスタープールの Options メニューで、確認ボックスに
confirmと入力して Destroy を選択します。注記:
- クラスタープールにクラスター要求がある場合、Destroy ボタンは無効になります。
- クラスタープールを含む namespace は削除されません。namespace を削除すると、これらのクラスターのクラスター要求リソースが同じ namespace で作成されるため、クラスタープールから要求されたクラスターが破棄されます。
ヒント: アクション 1 つで複数のクラスタープールを破棄するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールを破棄します。
1.7.16. ManagedServiceAccount アドオンの有効化
サポートされているバージョンの multicluster engine Operator をインストールすると、ManagedServiceAccount アドオンがデフォルトで有効になります。
重要: ハブクラスターを multicluster engine Operator バージョン 2.4 からアップグレードし、アップグレード前に ManagedServiceAccount アドオンを有効にしていなかった場合は、アドオンを手動で有効にする必要があります。
ManagedServiceAccount を使用すると、マネージドクラスターでサービスアカウントを作成または削除できます。
必要なアクセス権限: 編集
ManagedServiceAccount カスタムリソースがハブクラスターの <managed_cluster> namespace に作成されると、ServiceAccount がマネージドクラスターに作成されます。
TokenRequest は、マネージドクラスターの ServiceAccount を使用して、マネージドクラスターの Kubernetes API サーバーに対して行われます。トークンは、ハブクラスターの <target_managed_cluster> namespace の Secret に保存されます。
注記 トークンは期限切れになり、ローテーションされる可能性があります。トークンリクエストの詳細は、TokenRequest を参照してください。
1.7.16.1. 前提条件
- サポートされている Red Hat OpenShift Container Platform 環境がある。
- multicluster engine Operator がインストールされている。
1.7.16.2. ManagedServiceAccount の有効化
ハブクラスターとマネージドクラスターの ManagedServiceAccount アドオンを有効にするには、次の手順を実行します。
-
ハブクラスターで
ManagedServiceAccountアドオンを有効にします。詳細は、詳細設定 を参照してください。 ManagedServiceAccountアドオンをデプロイし、それをターゲットのマネージドクラスターに適用します。次の YAML ファイルを作成し、target_managed_clusterをManaged-ServiceAccountアドオンを適用するマネージドクラスターの名前に置き換えます。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: managed-serviceaccount namespace: <target_managed_cluster> spec: installNamespace: open-cluster-management-agent-addon次のコマンドを実行して、ファイルを適用します。
oc apply -f -これで、マネージドクラスターの
ManagedServiceAccountプラグインが有効になりました。ManagedServiceAccountを設定するには、次の手順を参照してください。次の YAML ソースを使用して
ManagedServiceAccountカスタムリソースを作成します。apiVersion: authentication.open-cluster-management.io/v1alpha1 kind: ManagedServiceAccount metadata: name: <managedserviceaccount_name> namespace: <target_managed_cluster> spec: rotation: {}-
managed_serviceaccount_nameをManagedServiceAccountの名前に置き換えます。 -
target_managed_clusterを、ManagedServiceAccountを適用するマネージドクラスターの名前に置き換えます。
-
確認するには、
ManagedServiceAccountオブジェクトのステータスでtokenSecretRef属性を表示して、シークレット名と namespace を見つけます。アカウントとクラスター名を使用して次のコマンドを実行します。oc get managedserviceaccount <managed_serviceaccount_name> -n <target_managed_cluster> -o yamlマネージドクラスターで作成された
ServiceAccountに接続されている取得されたトークンを含むSecretを表示します。以下のコマンドを実行します。oc get secret <managed_serviceaccount_name> -n <target_managed_cluster> -o yaml
1.7.17. クラスターのライフサイクルの詳細設定
一部のクラスター設定は、インストール中またはインストール後に設定できます。
1.7.17.1. API サーバー証明書のカスタマイズ
マネージドクラスターは、OpenShift Kube API サーバーの外部ロードバランサーとの相互接続を介してハブクラスターと通信します。デフォルトの OpenShift Kube API サーバー証明書は、OpenShift Container Platform のインストール時に内部 Red Hat OpenShift Container Platform クラスター認証局 (CA) によって発行されます。必要に応じて、証明書を追加または変更できます。
API サーバー証明書を変更すると、マネージドクラスターとハブクラスター間の通信に影響を与える可能性があります。製品をインストールする前に名前付き証明書を追加すると、マネージドクラスターがオフライン状態になる可能性がある問題を回避できます。
次のリストには、証明書の更新が必要となる場合の例がいくつか含まれています。
外部ロードバランサーのデフォルトの API サーバー証明書を独自の証明書に置き換える必要がある。OpenShift Container Platform ドキュメントの API サーバー証明書の追加 のガイダンスに従い、ホスト名
api.<cluster_name>.<base_domain>の名前付き証明書を追加して、外部ロードバランサーのデフォルトの API サーバー証明書を置き換えることができます。証明書を置き換えると、マネージドクラスターの一部がオフライン状態に移行する可能性があります。証明書のアップグレード後にクラスターがオフライン状態になった場合は、Troubleshooting imported clusters offline after certificate change のトラブルシューティング手順に従って問題を解決してください。注記: 製品をインストールする前に名前付き証明書を追加すると、クラスターがオフライン状態に移行するのを回避できます。
外部ロードバランサーの名前付き証明書の有効期限が切れているため、証明書を置き換える必要がある。中間証明書の数に関係なく、古い証明書と新しい証明書の両方が同じルート CA 証明書を共有する場合は、OpenShift Container Platform ドキュメントの API サーバー証明書の追加 のガイダンスに従って、新しい証明書の新しいシークレットを作成できます。次に、ホスト名
api.<cluster_name>.<base_domain>のサービス証明書参照をAPIServerカスタムリソース内の新しいシークレットに更新します。それ以外の場合、古い証明書と新しい証明書に異なるルート CA 証明書がある場合は、次の手順を実行して証明書を置き換えます。次の例のような
APIServerカスタムリソースを見つけます。apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: old-cert-secret次のコマンドを実行して、既存の証明書と新しい証明書の内容を含む新しいシークレットを
openshift-confignamespace に作成します。古い証明書を新しい証明書にコピーします。
cp old.crt combined.crt新しい証明書の内容を古い証明書のコピーに追加します。
cat new.crt >> combined.crt結合した証明書を適用してシークレットを作成します。
oc create secret tls combined-certs-secret --cert=combined.crt --key=old.key -n openshift-config
APIServerリソースを更新して、結合された証明書をservingCertificateとして参照します。apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: combined-cert-secret- 約 15 分後、新しい証明書と古い証明書の両方を含む CA バンドルがマネージドクラスターに伝播されます。
次のコマンドを入力して、新しい証明書情報のみを含む
new-cert-secretという名前の別のシークレットをopenshift-confignamespace に作成します。oc create secret tls new-cert-secret --cert=new.crt --key=new.key -n openshift-config {code}new-cert-secretを参照するようにservingCertificateの名前を変更して、APIServerリソースを更新します。リソースは以下の例のようになります。apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: audit: profile: Default servingCerts: namedCertificates: - names: - api.mycluster.example.com servingCertificate: name: new-cert-secret約 15 分後、古い証明書が CA バンドルから削除され、変更がマネージドクラスターに自動的に伝播されます。
注記: マネージドクラスターは、ホスト名 api.<cluster_name>.<base_domain> を使用してハブクラスターにアクセスする必要があります。他のホスト名で設定された名前付き証明書は使用できません。
1.7.17.2. ハブクラスターとマネージドクラスター間のプロキシーの設定
マネージドクラスターを multicluster engine for Kubernetes Operator に登録するには、マネージドクラスターを multicluster engine Operator ハブクラスターに転送する必要があります。場合によっては、マネージドクラスターが multicluster engine Operator ハブクラスターに直接アクセスできないことがあります。この例では、マネージドクラスターからの通信が HTTP または HTTPS プロキシーサーバー経由で multicluster engine Operator ハブクラスターにアクセスできるようにプロキシー設定を指定します。
たとえば、multicluster engine Operator ハブクラスターはパブリッククラウドにあり、マネージドクラスターはファイアウォールの背後にあるプライベートクラウド環境にあります。プライベートクラウドからの通信は、HTTP または HTTPS プロキシーサーバーのみを経由できます。
1.7.17.2.1. 前提条件
- HTTP トンネルをサポートする HTTP または HTTPS プロキシーサーバーが実行されている。(例: HTTP connect メソッド)
- HTTP または HTTPS プロキシーサーバーに到達できるマネージドクラスターがあり、プロキシーサーバーが multicluster engine Operator ハブクラスターにアクセスできる。
ハブクラスターとマネージドクラスターとの間でプロキシー設定を指定するには、以下の手順を実行します。
プロキシー設定を使用して
KlusterConfigリソースを作成します。以下の HTTP プロキシー設定を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: http-proxy spec: hubKubeAPIServerConfig: proxyURL: "http://<username>:<password>@<ip>:<port>"以下の HTTPS プロキシー設定を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: https-proxy spec: hubKubeAPIServerConfig: proxyURL: "https://<username>:<password>@<ip>:<port>" trustedCABundles: - name: "proxy-ca-bundle" caBundle: name: <configmap-name> namespace: <configmap-namespace>注記: HTTPS プロキシーには CA バンドルが必要です。CA バンドルとは、1 つまたは複数の CA 証明書を含む ConfigMap を指します。この ConfigMap は次のコマンドを実行すると作成できます。
oc create -n <configmap-namespace> configmap <configmap-name> --from-file=ca.crt=/path/to/ca/file
マネージドクラスターの作成時に、
KlusterletConfigリソースを参照するアノテーションを追加して、KlusterletConfigリソースを選択します。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: agent.open-cluster-management.io/klusterlet-config: <klusterlet-config-name> name:<managed-cluster-name> spec: hubAcceptsClient: true leaseDurationSeconds: 60注記:
-
multicluster engine Operator コンソールで操作する場合、YAML ビューを切り替えて、
ManagedClusterリソースにアノテーションを追加することが必要になる場合があります。 -
グローバルの
KlusterletConfigを使用して、バインドにアノテーションを使用せずにすべてのマネージドクラスターで設定を有効化できます。
-
multicluster engine Operator コンソールで操作する場合、YAML ビューを切り替えて、
1.7.17.2.2. ハブクラスターとマネージドクラスター間のプロキシーの無効化
開発が変更された場合は、HTTP または HTTPS プロキシーを無効にする必要がある場合があります。
-
ManagedClusterリソースに移動します。 -
agent.open-cluster-management.io/klusterlet-configアノテーションを削除します。
1.7.17.2.3. オプション: 特定のノードで実行するように klusterlet を設定する
Red Hat Advanced Cluster Management for Kubernetes を使用してクラスターを作成する場合、マネージドクラスターの nodeSelector および tolerations アノテーションを設定することで、マネージドクラスター klusterlet を実行するノードを指定できます。これらを設定するには、次の手順を実行します。
- コンソールのクラスターページから、更新するマネージドクラスターを選択します。
YAML コンテンツを表示するには、YAML スイッチを
Onに設定します。注記: YAML エディターは、クラスターをインポートまたは作成するときにのみ使用できます。インポートまたは作成後にマネージドクラスターの YAML 定義を編集するには、OpenShift Container Platform コマンドラインインターフェイスまたは Red Hat Advanced Cluster Management 検索機能を使用する必要があります。
-
nodeSelectorアノテーションをマネージドクラスターの YAML 定義に追加します。このアノテーションのキーは、open-cluster-management/nodeSelectorです。このアノテーションの値は、JSON 形式の文字列マップです。 tolerationsエントリーをマネージドクラスターの YAML 定義に追加します。このアノテーションのキーは、open-cluster-management/tolerationsです。このアノテーションの値は、JSON 形式の toleration リストを表します。結果の YAML は次の例のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: open-cluster-management/nodeSelector: '{"dedicated":"acm"}' open-cluster-management/tolerations: '[{"key":"dedicated","operator":"Equal","value":"acm","effect":"NoSchedule"}]'- コンテンツが正しいノードにデプロイされていることを確認するには、klusterlet アドオンの nodeSelectors と許容範囲の設定 の 手順を行います。
1.7.17.3. マネージドクラスターをインポートする際のハブクラスター API サーバーのサーバー URL と CA バンドルのカスタマイズ (テクノロジープレビュー)
マネージドクラスターとハブクラスターの間に中間コンポーネントが存在する場合、multicluster engine Operator ハブクラスターにマネージドクラスターを登録できない可能性があります。中間コンポーネントの例には、仮想 IP、ロードバランサー、リバースプロキシー、API ゲートウェイなどがあります。中間コンポーネントがある場合は、マネージドクラスターをインポートするときに、ハブクラスター API サーバーのカスタムサーバー URL と CA バンドルを使用する必要があります。
1.7.17.3.1. 前提条件
- マネージドクラスターからハブクラスター API サーバーにアクセスできるように、中間コンポーネントを設定する必要があります。
中間コンポーネントがマネージドクラスターとハブクラスター API サーバー間の SSL 接続を終端する場合は、SSL 接続をブリッジし、元のリクエストからの認証情報をハブクラスター API サーバーのバックエンドに渡す必要があります。Kubernetes API サーバーのユーザー偽装機能を使用すると、SSL 接続をブリッジできます。
中間コンポーネントは、元のリクエストからクライアント証明書を抽出し、証明書サブジェクトのコモンネーム (CN) と組織 (O) を偽装ヘッダーとして追加し、変更された偽装リクエストをハブクラスター API サーバーのバックエンドに転送します。
注記: SSL 接続をブリッジすると、クラスタープロキシーアドオンが機能しなくなります。
1.7.17.3.2. サーバー URL とハブクラスター CA バンドルのカスタマイズ
マネージドクラスターをインポートするときにカスタムハブ API サーバー URL と CA バンドルを使用するには、次の手順を実行します。
カスタムのハブクラスター API サーバー URL と CA バンドルを使用して
KlusterConfigリソースを作成します。以下の例を参照してください。apiVersion: config.open-cluster-management.io/v1alpha1 kind: KlusterletConfig metadata: name: <name>1 spec: hubKubeAPIServerConfig: url: "https://api.example.com:6443"2 serverVerificationStrategy: UseCustomCABundles trustedCABundles: - name: <custom-ca-bundle>3 caBundle: name: <custom-ca-bundle-configmap>4 namespace: <multicluster-engine>5 - 1
- klusterlet 設定名を追加します。
- 2
- カスタムサーバー URL を追加します。
- 3
- カスタム CA バンドル名を追加します。内部使用のために予約されている
auto-detected以外の任意の値を使用できます。 - 4
- CA バンドル ConfigMap の名前を追加します。ConfigMap を作成するには、コマンド
oc create -n <configmap-namespace> configmap <configmap-name> --from-file=ca.crt=/path/to/ca/fileを実行します。 - 5
- CA バンドル ConfigMap の namespace を追加します。
マネージドクラスターを作成するときに、リソースを参照するアノテーションを追加して
KlusterletConfigリソースを選択します。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: agent.open-cluster-management.io/klusterlet-config:1 name:2 spec: hubAcceptsClient: true leaseDurationSeconds: 60注記:
-
コンソールを使用する場合は、
ManagedClusterリソースにアノテーションを追加するために、YAML ビューを有効にする必要がある場合があります。 -
グローバルの
KlusterletConfigを使用して、バインドにアノテーションを使用せずにすべてのマネージドクラスターで設定を有効化できます。
-
コンソールを使用する場合は、
1.7.17.3.3. グローバル KlusterletConfig の設定
KlusterletConfig リソースを作成し、名前を global に設定すると、グローバル KlusterletConfig 内の設定が全マネージドクラスターに自動的に適用されます。
グローバルの KlusterletConfig がある環境では、agent.open-cluster-management.io/klusterlet-config: <klusterletconfig-name> アノテーションを ManagedCluster リソースに追加することで、クラスター固有の KlusterletConfig を作成し、それをマネージドクラスターにバインドすることもできます。同じフィールドに異なる値を設定した場合、クラスター固有の KlusterletConfig の値によってグローバルの KlusterletConfig の値がオーバーライドされます。
次の例では、hubKubeAPIServerURL フィールドに、KlusterletConfig とグローバル KlusterletConfig で異なる値が設定されています。"https://api.example.test.com:6443" 値によって "https://api.example.global.com:6443" 値がオーバーライドされます。
非推奨: hubKubeAPIServerURL フィールドは非推奨です。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: test
spec:
hubKubeAPIServerConfig:
url: "https://api.example.test.com:6443"
---
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: global
spec:
hubKubeAPIServerConfig:
url: "https://api.example.global.com:6443"
マネージドクラスターにバインドされたクラスター固有の KlusterletConfig がない場合、またはクラスター固有の KlusterletConfig に同じフィールドが存在しないか値がない場合には、グローバル KlusterletConfig の値が使用されます。
次の例を参照してください。ここでは、グローバル KlusterletConfig の hubKubeAPIServerURL フィールドの "example.global.com" 値が KlusterletConfig をオーバーライドします。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: test
spec:
hubKubeAPIServerURL: ""
—
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: global
spec:
hubKubeAPIServerURL: "example.global.com"
次の例を参照してください。ここでは、グローバル KlusterletConfig の hubKubeAPIServerURL フィールドの "example.global.com" 値が KlusterletConfig をオーバーライドします。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: test
—
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: global
spec:
hubKubeAPIServerURL: "example.global.com"1.7.17.4. ハブクラスターの KubeAPIServer 検証ストラテジーの設定
マネージドクラスターは、OpenShift Container Platform KubeAPIServer の外部ロードバランサーとの相互接続を介してハブクラスターと通信します。OpenShift Container Platform をインストールすると、内部の OpenShift Container Platform クラスター認証局 (CA) がデフォルトの OpenShift Container Platform KubeAPIServer 証明書を発行します。multicluster engine for Kubernetes Operator は、証明書を自動的に検出して bootstrap-kubeconfig-secret namespace 内のマネージドクラスターに追加します。
自動的に検出された証明書が機能しない場合は、KlusterletConfig リソースでストラテジー設定を手動で設定できます。ストラテジーを手動で設定すると、ハブクラスターの KubeAPIServer 証明書の検証方法を制御できます。
ストラテジーを手動で設定する方法は、次の 3 つのストラテジーのいずれかの例を参照してください。
1.7.17.4.1. UseAutoDetectedCABundle を使用したストラテジーの設定
デフォルトの設定ストラテジーは UseAutoDetectedCABundle です。multicluster engine Operator は、ハブクラスター上の証明書を自動的に検出し、trustedCABundles リストの config map 参照に設定されている証明書を実際の CA バンドル (存在する場合) にマージします。
次の例では、ハブクラスターから自動的に検出された証明書と、new-ocp-ca config map で設定した証明書をマージし、両方をマネージドクラスターに追加します。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: ca-strategy
spec:
hubKubeAPIServerConfig:
serverVerificationStrategy: UseAutoDetectedCABundle
trustedCABundles:
- name: new-ca
caBundle:
name: new-ocp-ca
namespace: default1.7.17.4.2. UseSystemTruststore を使用したストラテジーの設定
UseSystemTruststore を使用すると、multicluster engine Operator は証明書を検出せず、trustedCABundles パラメーターセクションで設定された証明書を無視します。この設定では、マネージドクラスターに証明書は渡されません。代わりに、マネージドクラスターは、マネージドクラスターのシステムトラストストアからの証明書を使用して、ハブクラスター API サーバーを検証します。これは、Let’s Encrypt などのパブリック CA がハブクラスター証明書を発行する場合に該当します。UseSystemTruststore を使用する次の例を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: ca-strategy
spec:
hubKubeAPIServerConfig:
serverVerificationStrategy: UseSystemTruststore1.7.17.4.3. UseCustomCABundles を使用したストラテジーの設定
ハブクラスター API サーバーの CA がわかっていて、multicluster engine Operator にそれを自動的に検出させない場合は、UseCustomCABundles を使用できます。このストラテジーでは、multicluster engine Operator が、設定された証明書を trustedCABundles パラメーターからマネージドクラスターに追加します。UseCustomCABundles の使用方法は、次の例を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: ca-strategy
spec:
hubKubeAPIServerConfig:
serverVerificationStrategy: UseCustomCABundles
trustedCABundles:
- name: ca
caBundle:
name: ocp-ca
namespace: default
通常、このポリシーは各マネージドクラスターで同じです。ハブクラスター管理者は、multicluster engine Operator をインストールするとき、またはハブクラスター証明書が変更されたときに、global という名前の KlusterletConfig を設定して、各マネージドクラスターのポリシーをアクティブ化できます。以下の例を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: global
spec:
hubKubeAPIServerConfig:
serverVerificationStrategy: UseSystemTruststore
マネージドクラスターで別のストラテジーを使用する必要がある場合は、別の KlusterletConfig を作成し、マネージドクラスターで agent.open-cluster-management.io/klusterlet-config アノテーションを使用して特定のストラテジーを指定することもできます。以下の例を参照してください。
apiVersion: config.open-cluster-management.io/v1alpha1
kind: KlusterletConfig
metadata:
name: test-ca
spec:
hubKubeAPIServerConfig:
serverVerificationStrategy: UseCustomCABundles
trustedCABundles:
- name: ca
caBundle:
name: ocp-ca
namespace: default
--
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
annotations:
agent.open-cluster-management.io/klusterlet-config: test-ca
name: cluster1
spec:
hubAcceptsClient: true
leaseDurationSeconds: 601.7.17.5. 関連情報
1.7.18. 管理からのクラスターの削除
multicluster engine Operator で作成された OpenShift Container Platform クラスターを管理から削除する場合は、クラスターを デタッチ または 破棄 することができます。クラスターをデタッチするとマネージメントから削除されますが、完全には削除されません。管理する場合には、もう一度インポートし直すことができます。このオプションは、クラスターが Ready 状態にある場合にだけ利用できます。
次の手順により、次のいずれかの状況でクラスターが管理から削除されます。
- すでにクラスターを削除しており、削除したクラスターを Red Hat Advanced Cluster Management から削除したいと考えています。
- クラスターを管理から削除したいが、クラスターを削除していない。
重要:
- クラスターを破棄すると、マネージメントから削除され、クラスターのコンポーネントが削除されます。
マネージドクラスターを接続解除または破棄すると、関連する namespace が自動的に削除されます。この namespace にカスタムリソースを配置しないでください。
1.7.18.1. コンソールを使用したクラスターの削除
ナビゲーションメニューから、Infrastructure > Clusters に移動し、管理から削除するクラスターの横にあるオプションメニューから Destroy cluster または Detach cluster を選択します。
ヒント: 複数のクラスターをデタッチまたは破棄するには、デタッチまたは破棄するクラスターのチェックボックスを選択して、Detach または Destroy を選択します。
注記: local-cluster と呼ばれる管理対象時にハブクラスターをデタッチしようとすると、disableHubSelfManagement のデフォルト設定が false かどうかを確認してください。この設定が原因で、ハブクラスターはデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。
プロセスが終了するのを待たずにハブクラスターを再インポートするには、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
ネットワーク接続時のオンラインインストール で説明されているように、disableHubSelfManagement の値を true に変更して、自動的にインポートされないようにハブクラスターの値を変更できます。
1.7.18.2. コマンドラインを使用したクラスターの削除
ハブクラスターのコマンドラインを使用してマネージドクラスターをデタッチするには、以下のコマンドを実行します。
oc delete managedcluster $CLUSTER_NAME切断後にマネージドクラスターを破棄するには、次のコマンドを実行します。
oc delete clusterdeployment <CLUSTER_NAME> -n $CLUSTER_NAME注記:
-
マネージドクラスターの破壊を防ぐには、
ClusterDeploymentカスタムリソースでspec.preserveOnDeleteパラメーターをtrueに設定します。 disableHubSelfManagementのデフォルト設定はfalseです。false`setting causes the hub cluster, also called `local-cluster切り離されたときに再インポートして管理し、MultiClusterHubコントローラーを調整します。切り離しと再インポートのプロセスには数時間かかる場合があり、ハブクラスターが完了するまでに数時間かかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して
multiclusterhub-operatorPod を再起動して、再インポートの時間を短縮できます。oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`disableHubSelfManagementの値をtrueに指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。ネットワーク接続時のオンラインインストール を参照してください。
1.7.18.3. クラスター削除後の残りのリソースの削除
削除したマネージドクラスターにリソースが残っている場合は、残りのすべてのコンポーネントを削除するための追加の手順が必要になります。これらの追加手順が必要な場合には、以下の例が含まれます。
-
マネージドクラスターは、完全に作成される前にデタッチされ、
klusterletなどのコンポーネントはマネージドクラスターに残ります。 - マネージドクラスターをデタッチする前に、クラスターを管理していたハブが失われたり、破棄されているため、ハブからマネージドクラスターをデタッチする方法はありません。
- マネージドクラスターは、デタッチ時にオンライン状態ではありませんでした。
これらの状況の 1 つがマネージドクラスターのデタッチの試行に該当する場合は、マネージドクラスターから削除できないリソースがいくつかあります。マネージドクラスターをデタッチするには、以下の手順を実行します。
-
ocコマンドラインインターフェイスが設定されていることを確認してください。 また、マネージドクラスターに
KUBECONFIGが設定されていることを確認してください。oc get ns | grep open-cluster-management-agentを実行すると、2 つの namespace が表示されるはずです。open-cluster-management-agent Active 10m open-cluster-management-agent-addon Active 10m次のコマンドを使用して、
klusterletカスタムリソースを削除します。oc get klusterlet | grep klusterlet | awk '{print $1}' | xargs oc patch klusterlet --type=merge -p '{"metadata":{"finalizers": []}}'次のコマンドを実行して、残りのリソースを削除します。
oc delete namespaces open-cluster-management-agent open-cluster-management-agent-addon --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc delete crds --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc patch crds --type=merge -p '{"metadata":{"finalizers": []}}'次のコマンドを実行して、namespaces と開いているすべてのクラスター管理
crdsの両方が削除されていることを確認します。oc get crds | grep open-cluster-management.io | awk '{print $1}' oc get ns | grep open-cluster-management-agent
1.7.18.4. クラスターの削除後の etcd データベースのデフラグ
マネージドクラスターが多数ある場合は、ハブクラスターの etcd データベースのサイズに影響を与える可能性があります。OpenShift Container Platform 4.8 では、マネージドクラスターを削除すると、ハブクラスターの etcd データベースのサイズは自動的に縮小されません。シナリオによっては、etcd データベースは領域不足になる可能性があります。etcdserver: mvcc: database space exceeded のエラーが表示されます。このエラーを修正するには、データベース履歴を圧縮し、etcd データベースのデフラグを実行して etcd データベースのサイズを縮小します。
注記: OpenShift Container Platform バージョン 4.9 以降では、etcd Operator はディスクを自動的にデフラグし、etcd 履歴を圧縮します。手動による介入は必要ありません。以下の手順は、OpenShift Container Platform 4.8 以前のバージョン向けです。
以下の手順を実行して、ハブクラスターで etcd 履歴を圧縮し、ハブクラスターで etcd データベースをデフラグします。
1.7.18.4.1. 前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
1.7.18.4.2. 手順
etcd履歴を圧縮します。次に、
etcdメンバーへのリモートシェルセッションを開きます。$ oc rsh -n openshift-etcd etcd-control-plane-0.example.com etcdctl endpoint status --cluster -w table以下のコマンドを実行して
etcd履歴を圧縮します。sh-4.4#etcdctl compact $(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*' -m1)出力例
$ compacted revision 158774421
-
etcdデータのデフラグの説明に従って、etcdデータベースをデフラグし、NOSPACEアラームをクリアします。