クラスター
クラウドプロバイダー間でクラスターを作成、インポート、および管理する方法については、詳細をご覧ください。
概要
第1章 クラスターの管理
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用した、クラウドプロバイダー全体におけるクラスターの作成、インポート、管理の方法を説明します。
以下のトピックでは、クラウドプロバイダー全体でクラスターを管理する方法について説明します。
- サポート対象のクラウド
- クラスターのサイズ調整
- リリースイメージ
- ベアメタルアセットの作成および変更
- インフラストラクチャー環境の作成
- 認証情報の管理の概要
- クラスターの作成
- ハブクラスターへのターゲットのマネージドクラスターのインポート
- プロキシー環境でのクラスターの作成
- クラスタープロキシーアドオンの有効化
- 特定のクラスター管理ロールの設定
- クラスターラベルの管理
- ManagedClusterSets の管理 (テクノロジープレビュー)
- Placement での ManagedClustersSets の使用
- クラスタープールの管理 (テクノロジープレビュー)
- マネージドクラスターで実行する Ansible Tower タスクの設定
- クラスタープールからのクラスターの要求
- Discovery の概要 (テクノロジープレビュー)
- クラスターのアップグレード
- マネージメントからのクラスターの削除
- クラスターのバックアップおよび復元 Operator(テクノロジープレビュー)
- VolSync を使用した永続ボリュームの複製
1.1. クラスターライフサイクルのアーキテクチャー
Red Hat Advanced Cluster Management for Kubernetes には、ハブクラスター と マネージド クラスターの 2 つの主なクラスタータイプがあります。
ハブクラスターは、Red Hat Advanced Cluster Management for Kubernetes でインストールされたメインとなるクラスターのことです。ハブクラスターを使用して他の Kubernetes クラスターの作成、管理、および監視を行うことができます。
マネージドクラスターは、ハブクラスターが管理する Kubernetes クラスターです。Red Hat Advanced Cluster Management ハブクラスターを使用してクラスターを作成することもできますが、ハブクラスターで管理する既存のクラスターをインポートすることもできます。
Red Hat Advanced Cluster Management を使用してマネージドクラスターを作成する場合、クラスターは、Hive リソースを備えた Red Hat OpenShift Container Platform クラスターインストーラーを使用して作成されます。OpenShift Container Platform インストーラーでクラスターのインストールプロセスについての詳細は、OpenShift Container Platform ドキュメントの OpenShift Container Platform インストールの概要 を参照してください。
以下の図は、Red Hat Advanced Cluster Management for クラスター管理でインストールされるコンポーネントを示しています。
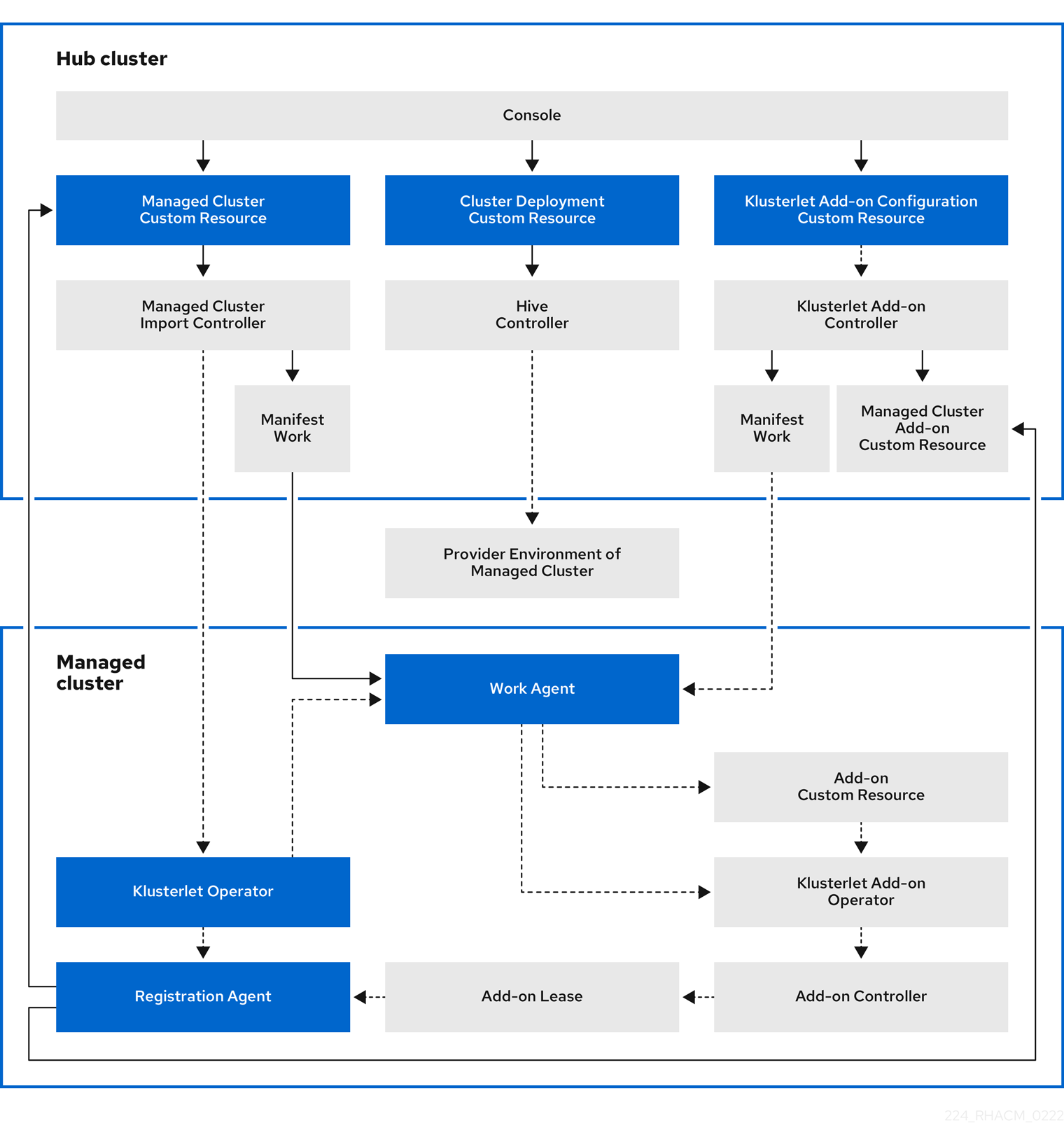
クラスターライフサイクル管理のアーキテクチャーのコンポーネントには、以下の項目が含まれます。
ハブクラスターのコンポーネント:
- コンソール: Red Hat Advanced Cluster Management マネージドクラスターのクラスターライフサイクルを管理する Web ベースのインターフェイスを提供します。
- Hive Controller: Red Hat Advanced Cluster Management で作成するクラスターをプロビジョニングします。Hive コントローラーは、Red Hat Advanced Cluster Management で作成されたマネージドクラスターをデタッチおよび破棄します。
- マネージドクラスターのインポートコントローラー: klusterlet Operator をマネージドクラスターにデプロイします。
- klusterlet アドオンコントローラー: klusterlet アドオン Operator をマネージドクラスターにデプロイします。
マネージドクラスター上のコンポーネント:
- klusterlet Operator: マネージドクラスターに登録およびワークコントローラーをデプロイします。
登録エージェント: ハブクラスターを使用してマネージドクラスターを登録します。マネージドクラスターがハブクラスターにアクセスできるように、以下のパーミッションが自動的に作成されます。
Clusterrole
- エージェントが証明書をローテーションできるようにします。
-
エージェントが、ハブクラスターが管理するクラスターを
取得/一覧表示/更新/監視できるようにします。 - ハブクラスターが管理するクラスターのステータスを、エージェントが更新できるようにします。
ハブクラスターのハブクラスター namespace で作成されたロール
-
マネージドクラスター登録エージェントが
coordination.k8s.ioリースを取得または更新できるようにします。 -
エージェントがマネージドクラスターアドオンを
取得/一覧表示/監視できるようにします。 - エージェントがマネージドクラスターアドオンのステータスを更新できるようにします。
-
マネージドクラスター登録エージェントが
ワークエージェント: マニフェストはマネージドクラスターで機能します。マネージドクラスターがハブクラスターにアクセスできるように、以下のパーミッションが自動的に作成されます。
ハブクラスターのハブクラスター namespace で作成されたロール
- ワークエージェントがイベントをハブクラスターに送信できるようにします。
-
エージェントが
manifestworksリソースを取得/一覧表示/監視/更新できるようにします。 -
エージェントが
manifestworksリソースのステータスを更新できるようにします。
- klusterlet アドオン Operator: アドオンコンポーネントをデプロイします。
1.2. サポート対象のクラウド
Red Hat Advanced Cluster Management for Kubernetes で利用可能なクラウドプロバイダーについて説明します。また、利用可能なマネージドプロバイダーに関するドキュメントも参照してください。サポート対象のクラウドの詳細は、サポートマトリックス を参照してください。
ベストプラクティス: マネージドクラスターのプロバイダーには、最新版の Kubernetes を使用してください。
1.2.1. サポート対象のハブクラスタープロバイダー
ハブクラスターとしてサポートされるのは、Red Hat OpenShift Container Platform 4.6.1 以降です。
- Amazon Web Services 上の Red Hat OpenShift Container Platform を参照してください。
- Red Hat OpenShift Container Platform on Microsoft Azure を参照してください。
- Red Hat OpenShift Container Platform on Google Cloud Platform を参照してください。
- Red Hat OpenShift Dedicated (OSD) を参照してください。
- IBM Cloud (ROKS) 上の Red Hat OpenShift Container Platform を参照してください。
- Azure for Red Hat OpenShift (ARO) を参照してください。
- Red Hat OpenShift Container Platform on VMware vSphere を参照してください。
- Red Hat OpenShift Container Platform on OpenStack を参照してください。
- OpenShift on Amazon Web Services (ROSA) を参照してください。
- IBM Power Systems 上の OpenShift Container Platform を参照してください。
- z/VM を使用した IBM Z および LinuxONE へのインストール を参照してください。
1.2.2. サポート対象のマネージドクラスタープロバイダー
マネージドクラスターとしてサポートされるのは、Red Hat OpenShift Container Platform 3.11.200 以降、4.6.1 以降です。
利用可能なマネージドクラスターのオプションおよびドキュメントは以下を参照してください。
- Amazon Web Services 上の Red Hat OpenShift Container Platform を参照してください。
- Red Hat OpenShift Container Platform on Microsoft Azure を参照してください。
- Red Hat OpenShift Container Platform on Google Cloud Platform を参照してください。
- Red Hat OpenShift Dedicated (OSD) を参照してください。
- IBM Cloud (ROKS) 上の Red Hat OpenShift Container Platform を参照してください。
- Azure Red Hat OpenShift (ARO) を参照してください。
- Red Hat OpenShift Container Platform on VMware vSphere を参照してください。
- Red Hat OpenShift Container Platform on OpenStack を参照してください。
- OpenShift on Amazon Web Services (ROSA) を参照してください。
- About Red Hat OpenShift Kubernetes Engine を参照してください。
- Amazon Elastic Kubernetes Service (Kubernetes 1.21 以降) を参照してください。
- Google Kubernetes Engine (Kubernetes 1.22.2 以降) を参照してください。
- IBM Cloud Kubernetes Service 概説 (Kubernetes 1.22.3 以降) を参照してください。
- Azure Kubernetes Service (Kubernetes 1.22.2 以降) を参照してください。
- Red Hat OpenShift Container Platform (4.6.1 以降) on IBM Z を参照してください。
- IBM Power Systems 上の OpenShift Container Platform を参照してください。
1.2.3. kubectl の設定
前述したベンダーのドキュメントを参照し、kubectl の設定方法を確認してください。マネージドクラスターをハブクラスターにインポートする場合には kubectl をインストールしておく必要があります。詳細は、ハブクラスターへのターゲットのマネージドクラスターのインポート を参照してください。
1.3. クラスターのサイズ変更 (テクノロジープレビュー)
仮想マシンのサイズやノード数などのマネージドクラスターの仕様をカスタマイズできます。
Red Hat Advanced Cluster Management for Kubernetes が管理するクラスターの多くは、Red Hat Advanced Cluster Management コンソールまたはコマンドライン、MachinePool リソースを使用してスケーリングできます。MachinePool リソースは、ハブクラスター上の Kubernetes リソースで、MachineSet リソースをマネージドクラスターでグループ化します。MachinePool リソースは、ゾーンの設定、インスタンスタイプ、ルートストレージなど、マシンリソースのセットを均一に設定します。また、マネージドクラスターで、必要なノード数を手動で設定したり、ノードの自動スケーリングを設定したりするのに役立ちます。
1.3.1. Red Hat Advanced Cluster Management で作成したマネージドクラスターのスケーリング
MachinePool リソースを使用して Red Hat Advanced Cluster Management で作成されたクラスターのスケーリングは、テクノロジープレビュー機能であり、Red Hat Advanced Cluster Management で作成されたベアメタルクラスターではサポートされません。
1.3.1.1. 自動スケーリング
自動スケーリングを設定すると、トラフィックが少ない場合にリソースをスケールダウンし、多くのリソースが必要な場合に十分にリソースを確保できるようにスケールアップするなど、必要に応じてクラスターに柔軟性を持たせることができます。
1.3.1.1.1. 自動スケーリングの有効化
Red Hat Advanced Cluster Management コンソールを使用して、
MachinePoolリソースで自動スケーリングを有効化するには、以下の手順を実行します。- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- ターゲットクラスターの名前をクリックし、クラスターの詳細を表示します。
- Machine pools タブを選択して、マシンプール情報を表示します。
- マシンプールページのターゲットマシンプールの Options メニューから Enable autoscale を選択します。
- マシンセットレプリカの最小数および最大数を選択します。マシンセットレプリカは、クラスターのノードに直接マップします。
Scale を選択して変更を送信します。
変更内容をコンソール De 反映するのに数分かかる場合があります。Machine pools タブの通知がある場合は、View machines をクリックしてスケーリング操作のステータスを表示できます。
コマンドラインを使用して
MachinePoolリソースで自動スケーリングを有効にするには、以下の手順を実行します。以下のコマンドを実行して、マシンプールの一覧を表示します。
oc get machinepools -n <managed-cluster-namespace>
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>
name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML ファイルから
spec.replicasフィールドを削除します。 -
spec.autoscaling.minReplicas設定およびspec.autoscaling.maxReplicasフィールドをリソース YAML に追加します。 -
レプリカの最小数を
minReplicas設定に追加します。 -
レプリカの最大数を
maxReplicas設定に追加します。 - ファイルを保存して変更を送信します。
マシンプールの自動スケーリングが有効になりました。
1.3.1.1.2. 自動スケーリングの無効化
コンソールまたはコマンドラインを使用して自動スケーリングを無効にできます。
Red Hat Advanced Cluster Management コンソールを使用して自動スケーリングを無効にするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- ターゲットクラスターの名前をクリックし、クラスターの詳細を表示します。
- Machine pools タブを選択して、マシンプール情報を表示します。
- マシンプールページから、ターゲットマシンプールの Options メニューから autoscale を無効にします。
- 必要なマシンセットのレプリカ数を選択します。マシンセットのレプリカは、クラスター上のノードを直接マップします。
- Scale を選択して変更を送信します。コンソールに表示されるまでに数分かかる場合があります。
- Machine pools タブの通知で View machine をクリックし、スケーリングのステータスを表示します。
コマンドラインを使用して自動スケーリングを無効にするには、以下の手順を実行します。
以下のコマンドを実行して、マシンプールの一覧を表示します。
oc get machinepools -n <managed-cluster-namespace>
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>
name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML ファイルから
spec.autoscalingフィールドを削除します。 -
spec.replicasフィールドをリソース YAML に追加します。 -
replicasの設定にレプリカ数を追加します。 - ファイルを保存して変更を送信します。
自動スケーリングが無効になりました。
1.3.1.2. クラスターの手動スケーリング
クラスターの自動スケーリングを有効にしない場合は、Red Hat Advanced Cluster Management コンソールまたはコマンドラインで、クラスターが管理するレプリカの静的数を変更できます。これにより、必要に応じてサイズを増減できます。
1.3.1.2.1. コンソールを使用した手作業でのクラスターのスケーリング
Red Hat Advanced Cluster Management コンソールを使用して MachinePool リソースをスケーリングするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- ターゲットクラスターの名前をクリックし、クラスターの詳細を表示します。
Machine pools タブを選択して、マシンプール情報を表示します。
注記: Autoscale フィールドの値が
Enabledになっている場合に、自動スケーリングの無効化 の手順を実行して自動スケーリング機能を無効にするようにしてください。- マシンプールの Options メニューから、Scale machine pool を選択します。
- マシンプールをスケーリングするようにマシンセットのレプリカ数を調整します。
- Scale を選択して変更を実装します。
1.3.1.2.2. コマンドラインを使用した手作業でのクラスターのスケーリング
コマンドラインを使用して MachinePool リソースをスケーリングするには、以下の手順を実行します。
以下のコマンドを実行して、マシンプールの一覧を表示します。
oc get machinepools -n <managed-cluster-namespace>
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>
name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML の
spec.replicas設定は、レプリカの数に更新します。 - ファイルを保存して変更を送信します。
クラスターが新しいサイズ設定を使用するようになりました。
1.3.2. インポートされたマネージドクラスターのスケーリング
インポートしたマネージドクラスターには、Red Hat Advanced Cluster Management で作成したクラスターと同じリソースがありません。そのため、クラスターのスケーリングの手順が異なります。プロバイダーのドキュメントには、インポートしたクラスターのスケーリング方法に関する情報が含まれます。
利用可能なプロバイダーごとの推奨設定は以下の一覧を参照してください。ただし、詳細な情報については、ドキュメントも参照してください。
1.3.2.1. OpenShift Container Platform クラスター
お使いのバージョンに該当する OpenShift Container Platform ドキュメントの クラスターのスケーリングに関する推奨プラクティス および MachineSet の手動によるスケーリング を参照してください。
1.3.2.2. Amazon Elastic Kubernetes Services
インポートした Amazon EKS クラスターにあるノード数を変更する場合は、Cluster autoscaler でクラスターのスケーリングに関する情報を参照してください。
1.3.2.3. Google Kubernetes Engine
インポートした Google Kubernetes Engine クラスターにあるノード数を変更する場合は、Resizing a cluster でクラスターのスケーリングに関する情報を参照してください。
1.3.2.4. Microsoft Azure Kubernetes Service
インポートした Azure Kubernetes Services クラスターにあるノード数を変更する場合は、Scaling a cluster でクラスターのスケーリングに関する情報を参照してください。
1.3.2.5. VMware vSphere
インポートした VMware vSphere クラスターにあるノード数を変更する場合は、Edit cluster settings でクラスターのスケーリングに関する情報を参照してください。
1.3.2.6. Red Hat OpenStack Platform
インポートした Red Hat OpenStack Platform クラスターにあるノード数を変更する場合は、Auto scaling for instances でクラスターのスケーリングに関する情報を参照してください。
1.3.2.7. ベアメタルクラスター
インポートしたベアメタルクラスターにあるノード数を変更する場合には、Expanding the cluster でクラスターのスケーリングに関する情報を参照してください。
注記: ベアメタルクラスターは、ハブクラスターが OpenShift Container Platform バージョン 4.6 以降である場合にのみサポートされます。
1.3.2.8. IBM Kubernetes Service
インポートした IBM Kubernetes Service クラスターにあるノード数を変更する場合は、Adding worker nodes and zones to clusters でクラスターのスケーリングに関する情報を参照してください。
1.3.2.9. IBM Power Systems
インポートした IBM Power Systems クラスターにあるノード数を変更する場合には、need link でクラスターのスケーリングに関する情報を参照してください。
1.3.2.10. IBM Z および LinuxONE
インポートした IBM Z および LinuxONE Systems クラスターにあるノード数を変更する場合には、need link でクラスターのスケーリングに関する情報を参照してください。
1.4. リリースイメージ
Red Hat Advanced Cluster Management for Kubernetes を使用してプロバイダーでクラスターを作成する場合は、新規クラスターに使用するリリースイメージを指定する必要があります。リリースイメージでは、クラスターのビルドに使用する Red Hat OpenShift Container Platform のバージョンを指定します。
acm-hive-openshift-releases GitHub リポジトリーの YAML ファイルを使用して、リリースイメージを参照します。Red Hat Advanced Cluster Management はこれらのファイルを使用して、コンソールで利用可能なリリースイメージの一覧を作成します。これには、OpenShift Container Platform における最新の fast チャネルイメージが含まれます。コンソールには、OpenShift Container Platform の 3 つの最新バージョンの最新リリースイメージのみが表示されます。たとえば、コンソールオプションに以下のリリースイメージが表示される可能性があります。
- quay.io/openshift-release-dev/ocp-release:4.6.23-x86_64
- quay.io/openshift-release-dev/ocp-release:4.9.0-x86_64
注記: コンソールでクラスターの作成時に選択できるのは、visible: 'true' のラベルが付いたリリースイメージのみです。ClusterImageSet リソースのこのラベルの例は以下の内容で提供されます。
apiVersion: config.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.9.8-x86-64-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.9.8-x86_64
追加のリリースイメージは保管されますが、コンソールには表示されません。利用可能なすべてのリリースイメージを表示するには、CLI で kubectl get clusterimageset を実行します。最新のリリースイメージでクラスターを作成することが推奨されるため、コンソールには最新バージョンのみがあります。特定バージョンのクラスター作成が必要となる場合があります。そのため、古いバージョンが利用可能となっています。Red Hat Advanced Cluster Management はこれらのファイルを使用して、コンソールで利用可能なリリースイメージの一覧を作成します。これには、OpenShift Container Platform における最新の fast チャネルイメージが含まれます。
リポジトリーには、clusterImageSets ディレクトリーおよび subscription ディレクトリーが含まれます。これらのディレクトリーは、リリースイメージの操作時に使用します。
リポジトリーには、clusterImageSets ディレクトリーおよび subscription ディレクトリーが含まれます。これらのディレクトリーは、リリースイメージの操作時に使用します。
clusterImageSets ディレクトリーには以下のディレクトリーが含まれます。
- Fast: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新バージョンを参照するファイルが含まれます。このフォルダー内のリリースイメージはテストされ、検証されており、サポートされます。
- Releases: 各 OpenShift Container Platform バージョン (stable、fast、および candidate チャネル) のリリースイメージをすべて参照するファイルが含まれます。注記: このリリースはすべてテストされ、安定していると判別されているわけではありません。
- Stable: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新の安定版 2 つを参照するファイルが含まれます。
注記: デフォルトでは、リリースイメージの現在の一覧は 1 時間ごとに更新されます。製品をアップグレードした後、リストに製品の新しいバージョンの推奨リリースイメージバージョンが反映されるまでに最大 1 時間かかる場合があります。
独自の ClusterImageSets は以下の 3 つの方法でキュレートできます。
3 つの方法のいずれかの最初のステップは、最新の fast チャンネルイメージを自動的に更新する付属のサブスクリプションを無効にすることです。最新の fast の ClusterImageSets の自動キュレーションを無効にするには、multiclusterhub リソースでインストーラーパラメーターを使用します。spec.disableUpdateClusterImageSets パラメーターを true と false の間で切り替えることにより、Red Hat Advanced Cluster Management でインストールしたサブスクリプションが、それぞれ無効または有効になります。独自のイメージをキューレートする場合は、spec.disableUpdateClusterImageSets を true に設定してサブスクリプションを無効にします。
オプション 1: クラスターの作成時にコンソールで使用する特定の ClusterImageSet のイメージ参照を指定します。指定する新規エントリーはそれぞれ保持され、将来のすべてのクラスタープロビジョニングで利用できます。たとえば、エントリーは quay.io/openshift-release-dev/ocp-release:4.6.8-x86_64 のようになります。
オプション 2: GitHub リポジトリー acm-hive-openshift-releases から YAML ファイル ClusterImageSets を手動で作成し、適用します。
オプション 3: GitHub リポジトリー acm-hive-openshift-releases の README.md に従って、フォークした GitHub リポジトリーから ClusterImageSets の自動更新を有効にします。
subscription ディレクトリーには、リリースイメージの一覧がプルされる場所を指定するファイルが含まれます。
Red Hat Advanced Cluster Management のデフォルトのリリースイメージは、Quay.io デフォルトで提供されます。
このイメージは、acm-hive-openshift-releases GitHub repository for release 2.4 のファイルで参照されます。
1.4.1. 利用可能なリリースイメージの同期
リリースイメージは頻繁に更新されるため、リリースイメージの一覧を同期して、利用可能な最新バージョンを選択できるようにする必要があります。リリースイメージは、リリース 2.4 の acm-hive-openshift-releases の GitHub リポジトリーから入手できます。
リリースイメージの安定性には、以下の 3 つのレベルがあります。
| カテゴリー | 説明 |
| stable | 完全にテストされたイメージで、クラスターを正常にインストールしてビルドできることが確認されています。 |
| fast | 部分的にテスト済みですが、stable バージョンよりも安定性が低い可能性があります。 |
| candidate | テストはしていませんが、最新のイメージです。バグがある可能性もあります。 |
一覧を更新するには、以下の手順を実行します。
-
インストーラーが管理する
acm-hive-openshift-releasesサブスクリプションが有効になっている場合は、multiclusterhubリソースのdisableUpdateClusterImageSetsの値をtrueに設定してサブスクリプションを無効にします。 - リリース 2.4 の acm-hive-openshift-releases GitHub リポジトリーのクローンを作成します。
以下のコマンドのようなコマンドを入力して、サブスクリプションを削除します。
oc delete -f subscribe/subscription-fast
以下のコマンドを入力して、stable リリースイメージに接続し、Red Hat Advanced Cluster Management for Kubernetes のハブクラスターに同期します。
make subscribe-stable
注記: この
makeコマンドは、Linux または MacOS のオペレーティングシステムを使用している場合のみ実行できます。約 1 分後に、
安定版のリリースイメージの最新の一覧が利用可能になります。Fast リリースイメージを同期して表示するには、以下のコマンドを実行します。
make subscribe-fast
注記: この
makeコマンドは、Linux または MacOS のオペレーティングシステムを使用している場合のみ実行できます。このコマンド実行の約 1 分後に、利用可能な
stableとfastのリリースイメージの一覧が、現在利用可能なイメージに更新されます。candidateリリースイメージを同期して表示するには、以下のコマンドを実行します。make subscribe-candidate
注記: この
makeコマンドは、Linux または MacOS のオペレーティングシステムを使用している場合のみ実行できます。このコマンド実行の約 1 分後に、利用可能な
stable、fast、およびcandidateのリリースイメージの一覧が、現在利用可能なイメージに更新されます。
- クラスターの作成時に、Red Hat Advanced Cluster Management コンソールで現在利用可能なリリースイメージの一覧を表示します。
以下の形式でコマンドを入力して、これらのチャネルのサブスクライブを解除して更新の表示を停止することができます。
oc delete -f subscribe/subscription-fast
1.4.1.1. 接続時におけるリリースイメージのカスタム一覧の管理
すべてのクラスターに同じリリースイメージが使用されるようにします。クラスターの作成時に利用可能なリリースイメージのカスタム一覧を作成し、作業を簡素化します。利用可能なリリースイメージを管理するには、以下の手順を実行します。
-
インストーラーが管理する
acm-hive-openshift-releasesサブスクリプションが有効になっている場合は、multiclusterhubリソースのdisableUpdateClusterImageSetsの値をtrueに設定して無効にします。 - acm-hive-openshift-releases GitHub repository 2.4 branch をフォークします。
./subscribe/channel.yamlファイルを更新して、stolostronではなく、フォークしたリポジトリーの GitHub 名にアクセスするようにspec: pathnameを変更します。この手順では、ハブクラスターによるリリースイメージの取得先を指定します。更新後の内容は以下の例のようになります。spec: type: Git pathname: https://github.com/<forked_content>/acm-hive-openshift-releases.git
forked_contentはフォークしたリポジトリーのへのパスに置き換えます。- Red Hat Advanced Cluster Management for Kubernetes を使用してクラスターを作成する時に利用できるようにイメージの YAML ファイルを ./clusterImageSets/stable/ または ./clusterImageSets/fast/* ディレクトリーに追加します。*ヒント: フォークしたリポジトリーに変更をマージすることで、利用可能な YAML ファイルはメインのリポジトリーから取得できます。
- フォークしたリポジトリーに変更をコミットし、マージします。
acm-hive-openshift-releasesリポジトリーをクローンした後に fast リリースイメージの一覧を同期するには、以下のコマンドを入力して fast イメージを更新します。make subscribe-fast
注記: この
makeコマンドは、Linux または MacOS のオペレーティングシステムを使用している場合のみ実行できます。このコマンドを実行後に、利用可能な fast リリースイメージの一覧が、現在利用可能なイメージに約 1 分ほどで更新されます。
デフォルトでは、fast イメージのみが一覧表示されます。stable リリースイメージを同期して表示するには、以下のコマンドを実行します。
make subscribe-stable
注記: この
makeコマンドは、Linux または MacOS のオペレーティングシステムを使用している場合のみ実行できます。このコマンドを実行後に、利用可能な安定版のリリースイメージの一覧が、現在利用可能なイメージに約 1 分ほどで更新されます。
デフォルトでは、Red Hat Advanced Cluster Management は、複数の ClusterImageSets を事前に読み込みます。以下のコマンドを使用して、利用可能ものを表示し、デフォルトの設定を削除します。
oc get clusterImageSets oc delete clusterImageSet <clusterImageSet_NAME>
注記:
multiclusterhubのdisableUpdateClusterImageSetsの値をtrueに設定して、インストーラー管理のClusterImageSetsの自動更新をまだ無効にしていない場合は、削除するイメージが自動的に再作成されます。- クラスターの作成時に、Red Hat Advanced Cluster Management コンソールで現在利用可能なリリースイメージの一覧を表示します。
1.4.1.2. 非接続時におけるリリースイメージのカスタム一覧の管理
ハブクラスターにインターネット接続がない場合は、リリースイメージのカスタムリストを管理しないといけない場合があります。クラスターの作成時に利用可能なリリースイメージのカスタム一覧を作成します。非接続時に、利用可能なリリースイメージを管理するには、以下の手順を実行します。
- オンラインシステムを使用している場合は、GitHub リポジトリー acm-hive-openshift-releases に移動し、バージョン 2.4 で利用可能なクラスターイメージセットにアクセスします。
-
clusterImageSetsディレクトリーを、非接続の Red Hat Advanced Cluster Management for Kubernetes ハブクラスターにアクセス可能なシステムにコピーします。 管理対象クラスターに適合する次の手順を実行して、管理対象クラスターと切断されたリポジトリーの間にクラスターイメージセットを含むマッピングを追加します。
-
OpenShift Container Platform マネージドクラスターの場合は、
ImageContentSourcePolicyオブジェクトを使用してマッピングを完了する方法についての詳細は、イメージレジストリーリポジトリーのミラーリングの設定 を参照してください。 -
OpenShift Container Platform クラスターではないマネージドクラスターの場合は、
ManageClusterImageRegistryCRD を使用してイメージセットの場所を上書きします。マッピング用にクラスターを上書きする方法については、カスタム ManagedClusterImageRegistry CRD を使用したクラスターのインポート を参照してください。
-
OpenShift Container Platform マネージドクラスターの場合は、
-
clusterImageSetYAML を手作業で追加し、Red Hat Advanced Cluster Management for Kubernetes コンソールを使用してクラスターを作成する時に利用できるようにイメージの YAML ファイルを追加します。 残りの OpenShift Container Platform リリースイメージの
clusterImageSetYAML ファイルを、イメージの保存先の正しいオフラインリポジトリーを参照するように変更します。更新は次の例のようになります。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: img4.4.0-rc.6-x86-64 spec: releaseImage: IMAGE_REGISTRY_IPADDRESS_or_DNSNAME/REPO_PATH/ocp-release:4.4.0-rc.6-x86_64YAML ファイルで参照されているオフラインイメージレジストリーにイメージがロードされていることを確認します。
各 YAML ファイルに以下のコマンドを入力して、各
clusterImageSetsを作成します。oc create -f <clusterImageSet_FILE>
clusterImageSet_FILEを、クラスターイメージセットファイルの名前に置き換えます。以下は例になります。oc create -f img4.9.9-x86_64.yaml
追加するリソースごとにこのコマンドを実行すると、利用可能なリリースイメージの一覧が使用できるようになります。
- または Red Hat Advanced Cluster Management のクラスター作成のコンソールに直接イメージの URL を貼り付けることもできます。イメージ URL が存在しない場合は、イメージ URL を追加すると新しい clusterImageSets が作成されます。
- クラスターの作成時に、Red Hat Advanced Cluster Management コンソールで現在利用可能なリリースイメージの一覧を表示します。
1.5. ベアメタルアセットの作成および変更
ベアメタルアセットとは、OpenShift Container Platform クラスターで実行されるように設定する仮想サーバーまたは物理サーバーです。Red Hat Advanced Cluster Management for Kubernetes は管理者が作成するベアメタルアセットに接続できます。ベアメタルアセットはマネージドクラスターにデプロイできます。
ハブクラスターのインベントリーコントローラーは、ベアメタルのアセットのインベントリーレコードを保持する BareMetalAsset というカスタムリソース定義 (CRD) を定義します。マネージドクラスターをプロビジョニングする場合、インベントリーコントローラーは、マネージドクラスター内にある対応する BareMetalHost リソースと、BareMetalAsset インベントリーレコードを調整します。
Red Hat Advanced Cluster Management は BareMetalAsset CR を使用して、設定管理データベース (CMDB) または同様のシステムで入力したレコードに基づいてクラスターハードウェアをプロビジョニングします。外部ツールまたは自動化は CMDB をポーリングし、Red Hat Advanced Cluster Management API を使用して、マネージドクラスターでの後続のデプロイメントに備え、対応する BareMetalAsset と Secret リソースをハブクラスターに作成します。
以下の手順を使用して、Red Hat Advanced Cluster Management が管理するクラスターのベアメタルアセットを作成して管理します。
1.5.1. 前提条件
ベアメタルアセットを作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.6 以降に、Red Hat Advanced Cluster Management ハブクラスターをデプロイしている。
- Red Hat Advanced Cluster Management ハブクラスターがベアメタルアセットに接続できるようにアクセスを設定している。
ベアメタルアセット、およびベアメタルアセットへのログインまたは管理に必要なパーミッションを指定したログイン認証情報を設定している。
注記: ベアメタルアセットの認証情報には、管理者が提供するアセットの項目 (ユーザー名、パスワード、 Baseboard Management Controller (BMC) アドレス の起動 NIC MAC アドレス) が含まれます。
1.5.2. コンソールを使用したベアメタルアセットの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用してベアメタルアセットを作成するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Bare metal assets に移動します。
- Bare metal assets ページで Create bare metal asset をクリックします。
- クラスターの作成時に識別できるようにアセット名を入力します。
ベアメタルアセットを作成する namespace を入力します。
注記: ベアメタルアセット、ベアメタルのマネージドクラスター、および関連シークレットは同じ namespace に配置する必要があります。
この namespace にアクセスできるユーザーは、クラスターの作成時にこのアセットをクラスターに関連付けることができます。
BMC アドレスを入力します。このコントローラーで、ホストとの通信が可能になります。以下のプロトコルがサポートされます。
- IPMI。詳細は、IPMI 2.0 Specification を参照してください。
- iDRAC。詳細は、Support for Integrated Dell Remote Access Controller 9 (iDRAC9) を参照してください。
- iRMC。詳細は、Data Sheet: FUJITSU Software ServerView Suite integrated Remote Management Controller - iRMC S5 を参照してください。
- Redfish。詳細は、Redfish specification を参照してください。
- ベアメタルアセットのユーザー名とパスワードを入力します。
- ベアメタルアセットのブート NIC MAC アドレスを追加します。これは、ネットワーク接続されたホストの NIC の MAC アドレスで、ベアメタルアセットにホストをプロビジョニングする時に使用します。
ベアメタルでのクラスターの作成 に進んでください。
1.5.3. CLI を使用したベアメタルアセットの作成
BareMetalAsset CR を使用して、クラスター内の特定の namespace のベアメタルアセットを作成します。各 BareMetalAsset には、同じ namespace に対応の Secret があり、そこには BMC (Baseboard Management Controller) 認証情報およびシークレット名が含まれます。
1.5.3.1. 前提条件
- ハブクラスターに Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをインストールしている。
- Red Hat OpenShift CLI (oc) をインストールしている。
-
cluster-admin権限を持つユーザーとしてログインしている。
1.5.3.2. ベアメタルノードの作成
- 環境にベアメタルアセットをインストールしてプロビジョニングします。
- BMC の電源をオンにし、ハードウェアの IPMI または Redfish BMC アドレスおよび MAC アドレスを書き留めます。
以下の
BareMetalAssetおよびSecretCR を作成し、ファイルをbaremetalasset-cr.yamlとして保存します。apiVersion: inventory.open-cluster-management.io/v1alpha1 kind: BareMetalAsset metadata: name: <baremetalasset-machine> namespace: <baremetalasset-namespace> spec: bmc: address: ipmi://<out_of_band_ip>:<port> credentialsName: baremetalasset-machine-secret bootMACAddress: "00:1B:44:11:3A:B7" hardwareProfile: "hardwareProfile" role: "<role>" clusterName: "<cluster name>" --- apiVersion: v1 kind: Secret metadata: name: baremetalasset-machine-secret type: Opaque data: username: <username> password: <password>-
baremetalasset-machineは、ベアメタルアセットが置かれているマシンの名前に置き換えます。作成時に、マネージドクラスターのBareMetalHostは、ハブクラスター上の対応するBareMetalAssetと同じ名前を取得します。BareMetalHost名は常に対応するBareMetalAsset名と一致している必要があります。 -
baremetalasset-namespaceは、ベアメタルアセットが作成されるクラスター namespace に置き換えます。 -
out_of_band_ipおよびportは、ベアメタルアセットのアドレスおよびポートに置き換えます。Redfish アドレス設定には、redfish://<out-of-band-ip>/redfish/v1/Systems/1のアドレス形式を使用します。 -
roleは、workerか、masterに置き換えるか、またはマシンのロールの種類に応じて空のままにします。role設定を使用して、クラスター内の固有のマシンロールタイプに、ベアメタルアセットを一致させます。指定のマシンロールタイプのBareMetalAssetリソースは、別のロールを満たすためには使用しないでください。roleの値は、キーがinventory.open-cluster-management.io/roleのラベル値として使用されます。これにより、クラスター管理アプリケーションまたはユーザーは、特定のロール向けに用意されたインベントリーについてクエリーできます。 -
cluster_nameは、クラスターの名前に置き換えます。この名前は、クラスター管理アプリケーションまたはユーザーが、特定のクラスターに関連付けられたインベントリーのクエリーに使用します。クラスターデプロイメントに追加せずにベアメタルアセットを作成するには、この値を空欄のままにします。 -
usernameは、シークレットのユーザー名に置き換えます。 -
passwordは、シークレットのパスワードに置き換えます。
-
以下のコマンドを実行して
BareMetalAssetCR を作成します。$ oc create -f baremetalasset-cr.yaml
BareMetalAssetが正常に作成されていることを確認します。$ oc get baremetalassets -A
出力例
NAMESPACE NAME AGE ocp-example-bm baremetalasset-machine 2m ocp-example-bm csv-f24-h27-000-r630-master-1-1 4d21h
1.5.4. コンソールを使用したベアメタルアセットの一括インポート
CSV 形式の一覧を使用して、Red Hat Advanced Cluster Management for Kubernetes コンソールでベアメタルアセットを一括インポートできます。
1.5.4.1. 前提条件
- 1 つ以上のスポーククラスターを管理するハブクラスターに Red Hat Advanced Cluster Management をインストールしている。
- OpenShift Container Platform CLI (oc) をインストールしている。
-
cluster-admin権限を持つユーザーとしてログインしている。
1.5.4.2. アセットのインポート
ベアメタルアセットをインポートするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management コンソールのナビゲーションメニューで Cluster management > Bare metal assets を選択します。
Import assets を選択し、ベアメタルアセットのデータを含む CSV ファイルをインポートします。CSV ファイルには、以下のヘッダーコラムが必要です。
hostName, hostNamespace, bmcAddress, macAddress, role (optional), username, password
1.5.5. ベアメタルアセットの変更
ベアメタルアセットの設定を変更する必要がある場合は、以下の手順を実行します。
- Red Hat Advanced Cluster Management for Kubernetes コンソールのナビゲーションで、Infrastructure > Bare metal assets を選択します。
- テーブルで変更するアセットのオプションメニューを選択します。
- Edit asset を選択します。
1.5.6. ベアメタルアセットの削除
ベアメタルアセットがどのクラスターにも使用されなくなった場合は、利用可能なベアメタルアセット一覧から削除できます。使用されていないアセットを削除することで、利用可能なアセット一覧が簡素化されて、対象のアセットが誤って選択されないようにします。
コンソールでベアメタルアセットを削除するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management for Kubernetes コンソールのナビゲーションで、Infrastructure > Bare metal assets を選択します。
- テーブルで削除するアセットのオプションメニューを選択します。
- Delete asset を選択します。
1.5.7. REST API を使用したベアメタルアセットの作成
OpenShift Container Platform REST API を使用して、Red Hat Advanced Cluster Management クラスターで使用するベアメタルアセットを管理できます。これは、お使いの環境でベアメタルアセットを管理するために別の CMDB アプリケーションまたはデータベースがある場合に役立ちます。
1.5.7.1. 前提条件
- ハブクラスターに Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをインストールしている。
- OpenShift Container Platform CLI (oc) をインストールしている。
-
cluster-admin権限を持つユーザーとしてログインしている。
1.5.7.2. ベアメタルノードの作成
REST API を使用してベアメタルアセットを作成するには、以下を実行します。
ハブクラスターのログイントークンを取得して、コマンドラインでクラスターにログインします。以下は例になります。
$ oc login --token=<login_token> --server=https://<hub_cluster_api_url>:6443
以下の curl コマンドを、クラスターに追加するベアメタルアセットの詳細を使用して変更し、コマンドを実行します。
$ curl --location --request POST '<hub_cluster_api_url>:6443/apis/inventory.open-cluster-management.io/v1alpha1/namespaces/<bare_metal_asset_namespace>/baremetalassets?fieldManager=kubectl-create' \ --header 'Authorization: Bearer <login_token>' \ --header 'Content-Type: application/json' \ --data-raw '{ "apiVersion": "inventory.open-cluster-management.io/v1alpha1", "kind": "BareMetalAsset", "metadata": { "name": "<baremetalasset_name>", "namespace": "<bare_metal_asset_namespace>" }, "spec": { "bmc": { "address": "ipmi://<ipmi_address>", "credentialsName": "<credentials-secret>" }, "bootMACAddress": "<boot_mac_address>", "clusterName": "<cluster_name>", "hardwareProfile": "hardwareProfile", "role": "worker" } }'-
baremetalasset-nameは、ベアメタルアセットの名前に置き換えます。作成時に、マネージドクラスターのBareMetalHostは、ハブクラスター上の対応するBareMetalAssetと同じ名前を取得します。BareMetalHost名は常に対応するBareMetalAsset名と一致している必要があります。 -
baremetalasset-namespaceは、ベアメタルアセットが作成されるクラスター namespace に置き換えます。 -
out_of_band_ipおよびportは、ベアメタルアセットのアドレスおよびポートに置き換えます。Redfish アドレス設定には、redfish://<out-of-band-ip>/redfish/v1/Systems/1のアドレス形式を使用します。 -
roleは、workerか、masterに置き換えるか、またはマシンのロールの種類に応じて空のままにします。role設定を使用して、クラスター内の固有のマシンロールタイプに、ベアメタルアセットを一致させます。指定のマシンロールタイプのBareMetalAssetリソースは、別のロールを満たすためには使用しないでください。roleの値は、キーがinventory.open-cluster-management.io/roleのラベル値として使用されます。これにより、クラスター管理アプリケーションまたはユーザーは、特定のロール向けに用意されたインベントリーについてクエリーできます。 cluster_nameは、クラスターの名前に置き換えます。この名前は、クラスター管理アプリケーションまたはユーザーが、特定のクラスターに関連付けられたインベントリーのクエリーに使用します。クラスターデプロイメントに追加せずにベアメタルアセットを作成するには、この値を空欄のままにします。注記: 以前の curl コマンドでは、API サーバーが HTTPS 経由で提供され、安全にアクセスされることを前提としています。開発またはテスト環境では、
--insecureパラメーターを指定できます。
-
ヒント: --v=9 を oc コマンドに追加して、結果となるアクションの出力を未加工で表示できます。これは、oc コマンドの REST API ルートの認定に役立ちます。
1.6. インフラストラクチャー環境の作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、インフラストラクチャー環境を作成して、ホストを管理し、それらのホストでクラスターを作成できます。
インフラストラクチャー環境は、次の機能をサポートしています。
- クラスターのゼロタッチプロビジョニング: スクリプトを使用してクラスターを展開します。詳細は、Red Hat OpenShift Container Platform ドキュメントの Deploying distributed units at scale in a disconnected environment を参照してください。
- レイトバインディング: インフラストラクチャー管理者がホストを起動できるようにします。クラスター作成者は、後でクラスターをそのホストにバインドできます。レイトバインディングを使用する場合、クラスター作成者はインフラストラクチャーに対する管理者権限を持っている必要はありません。
-
デュアルスタック: IPv4 と IPv6 の両方のアドレスを持つクラスターをデプロイします。デュアルスタックは、
OVN-Kubernetesネットワーク実装を使用して、複数のサブネットをサポートします。 - リモートワーカーノードの追加: リモートワーカーノードを作成して実行した後、クラスターに追加します。これにより、バックアップ目的で他の場所にノードを追加する柔軟性が提供されます。
- NMState を使用した静的 IP: NMState API を使用して、環境の静的 IP アドレスを定義します。
- Red Hat Advanced Cluster Management バージョン 2.3 を Assisted Installer 静的 IP アドレス指定を使用して Red Hat Advanced Cluster Management 2.4 にアップグレードします。ハブクラスター上の Red Hat Advanced Cluster Management をバージョン 2.3 から 2.4 にアップグレードすると、ハブクラスター上のインフラストラクチャー Operator およびインフラストラクチャーオペランド、または支援付きのサービスがバージョン 2.3 から 2.4 バンドル版にアップグレードされます。管理対象クラスターは自動的にアップグレードされません。
1.6.1. 前提条件
インフラストラクチャー観葉を作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.9 以降に、Red Hat Advanced Cluster Management ハブクラスターをデプロイしておく。
- クラスターを作成するために必要なイメージを取得するための、Red Hat Advanced Cluster Management ハブクラスターへのインターネットアクセス (接続済み)、あるいはインターネットへの接続がある内部またはミラーレジストリーへの接続 (非接続) がある。
- ハブクラスター上にある設定済みの Central Infrastructure Management(CIM) 機能のインスタンス。手順は Configuring the Central Infrastructure Management service を参照してください。
- OpenShift Container Platform プルシークレット。詳細は、イメージプルシークレットの使用 を参照してください。
-
デフォルトで
~/.ssh/id_rsa.pubファイルにある SSH キーです。 - 設定されたストレージクラス。
- 非接続環境のみ: OpenShift Container Platform ドキュメントの 非接続環境の準備 の手順を実行します。
1.6.2. Central Infrastructure Management サービスの有効化
CIM サービスは、Red Hat Advanced Cluster Management で提供され、OpenShift Container Platform クラスターをデプロイします。Red Hat Advanced Cluster Management ハブクラスターで MultiClusterHub Operator が有効になっているときにデプロイされますが、必ず有効化しておく必要があります。
CIM サービスを有効にするには、以下の手順を実行します。
Red Hat Advanced Cluster Management バージョン 2.4.0 のみ。Red Hat Advanced Cluster Management バージョン 2.4.1 以降を実行している場合は、この手順を省略します。以下のコマンドを実行して、
HiveConfigリソースを変更して CIM サービスの機能ゲートを有効にします。oc patch hiveconfig hive --type merge -p '{"spec":{"targetNamespace":"hive","logLevel":"debug","featureGates":{"custom":{"enabled":["AlphaAgentInstallStrategy"]},"featureSet":"Custom"}}}'provisioningリソースを変更し、以下のコマンドを実行してベアメタル Operator がすべての namespace を監視できるようにします。oc patch provisioning provisioning-configuration --type merge -p '{"spec":{"watchAllNamespaces": true }}'以下の手順を実行して
AgentServiceConfigCR を作成します。以下の
YAMLコンテンツをagent_service_config.yamlファイルに保存します。apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: databaseStorage: accessModes: - ReadWriteOnce resources: requests: storage: <db_volume_size> filesystemStorage: accessModes: - ReadWriteOnce resources: requests: storage: <fs_volume_size> osImages: - openshiftVersion: "<ocp_version>" version: "<ocp_release_version>" url: "<iso_url>" rootFSUrl: "<root_fs_url>" cpuArchitecture: "x86_64"db_volume_sizeはdatabaseStorageフィールドのボリュームサイズに置き換えます (例:50M)。この値は、クラスターのデータベーステーブルやデータベースビューなどのファイルを格納するために割り当てられるストレージの量を指定します。クラスターが多い場合は、より高い値を使用する必要がある場合があります。fs_volume_sizeを、filesystemStorageフィールドのボリュームのサイズ (例:50M) に置き換えます。この値は、クラスターのログ、マニフェスト、およびkubeconfigファイルを保存するために割り当てられるストレージのサイズを指定します。クラスターが多い場合は、より高い値を使用する必要がある場合があります。ocp_versionは、インストールする OpenShift Container Platform バージョンに置き換えます (例:4.9)。ocp_release_versionは、特定のインストールバージョン (例:49.83.2021032516400) に置き換えます。iso_urlは、 ISO URL に置き換えます (例:https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/rhcos-4.10.3-x86_64-live.x86_64.iso)。他の値は https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/ にあります。root_fs_urlは、ルート FS イメージの URL に置き換えます (例:https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/rhcos-4.10.3-x86_64-live-rootfs.x86_64.img)。他の値は https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/ にあります。以下のコマンドを実行して AgentServiceConfig CR を作成します。
oc create -f agent_service_config.yaml
出力は次の例のような内容になります。
agentserviceconfig.agent-install.openshift.io/agent created
CIM サービスが設定されました。assisted-service と assisted-image-service デプロイメントをチェックして、Pod の準備ができ、実行されていることを確認して、正常性を検証できます。コンソールを使用したインフラストラクチャー環境の作成 に進んでください。
1.6.3. コンソールを使用したインフラストラクチャー環境の作成
Red Hat Advanced Cluster Management コンソールからインフラストラクチャー環境を作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
- インフラストラクチャー環境 ページで、Create infrastructure environment をクリックします。
お使いのインフラストラクチャー環境設定に以下の情報を追加します。
Name: お使いの環境の一意の名前。
重要: クラスターの削除時にこのインフラストラクチャー環境が誤って削除されないようにするために、このインフラストラクチャー環境の名前は環境内のクラスターの名前と同じにすることはできません。
- ネットワークタイプ: 環境に追加可能なホストのタイプを指定できます。ベアメタルホストを使用している場合には、静的 IP オプションのみを使用できます。
- Location: ホストの地理的な場所を指定します。地理的な場所を使用すると、クラスターの作成時に、クラスター上のデータの保存場所を簡単に判断できます。
- Labels: インフラストラクチャー環境にラベルを追加できる任意のフィールド。これにより、検索がかんたんになり、特徴がよく似た他の環境とグループ化できます。ネットワークタイプと場所に対して行った選択は、自動的にラベルの一覧に追加されます。
- プルシークレット: OpenShift Container Platform リソースへのアクセスを可能にする OpenShift Container Platform プルシークレット。
-
SSH 公開鍵: ホストとのセキュアな通信を可能にする SSH キー。これは通常
~/.ssh/id_rsa.pubファイルにあります。 すべてのクラスターでプロキシー設定を有効にする必要がある場合は、有効にする設定を選択します。この設定は、以下の情報を入力する必要があります。
- HTTP Proxy URL: 検出サービスへのアクセス時に使用する必要のある URL。
-
HTTPS Proxy URL: 検出サービスへのアクセス時に使用する必要のあるセキュアなプロキシー URL。
httpsはまだサポートされていないため、形式はhttpである必要があります。 - プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。(*) を追加し、すべての宛先のプロキシーをバイパスします。
ホストをインフラストラクチャー環境に追加して、続行できるようになりました。
1.6.4. インフラストラクチャー環境へのアクセス
インフラストラクチャー環境にアクセスするには、Red Hat Advanced Cluster Management コンソールでInfrastructure > Infrastructure environments を選択します。一覧からインフラストラクチャー環境を選択し、そのインフラストラクチャー環境の詳細とホストを表示します。
1.6.5. インフラストラクチャー環境へのホストの追加
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用してインフラストラクチャー環境にホストを追加します。ホストを追加すると、クラスターの作成時に設定済みホストを簡単に選択できます。
以下の手順を実行して、新規スポットを追加します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Infrastructure environments に移動します。
- ホストを追加するインフラストラクチャー環境を選択して、その設定を表示します。
- ホスト タブを選択して、その環境にすでに追加されているホストを表示します。利用可能なホストが表に表示されるまでに数分かかる場合があります。
- ホストを追加 を選択して、ホストをインフラストラクチャー環境に追加します。
- Discovery ISO または Baseboard Management Controller(BMC) を選択して、ホストの情報を入力します。
Discovery ISO オプションを選択した場合は、以下の手順を実行します。
- コンソールで提供されるコマンドをコピーして ISO をダウンロードするか、Download Discovery ISO を選択します。
- ブート可能なデバイスで以下のコマンドを実行し、各ホストを起動します。
- セキュリティーを強化する場合は、検出された各ホストに対して Approve host を選択する必要があります。この追加手順では、ISO ファイルが変更されたり、アクセス権のないユーザーにより実行された場合に備えて保護します。
-
localhostに指定されたホスト名を一意の名前に変更します。
Baseboard Management Controller(BMC) オプションを選択した場合は、以下の手順を実行します。
注記: ホストを追加する BMC オプションは、ハブクラスターがベアメタルプラットフォームで実行されている場合にのみ使用できます。
- ホストの BMC の接続詳細を追加します。
ホストの追加 を選択して、ブートプロセスを開始します。ホストは、検出 ISO イメージを使用して自動的に起動され、起動時にホストの一覧に追加されます。
BMC オプションを使用してホストを追加すると、ホストは自動的に承認されます。
このインフラストラクチャー環境にオンプレミスクラスターを作成できるようになりました。クラスター作成の詳細は、Creating a cluster in an on-premises environment を参照してください。
1.7. クラスターの作成
Red Hat Advanced Cluster Management for Kubernetes を使用した、クラウドプロバイダー全体にクラスターを作成する方法を説明します。
1.7.1. クラスター作成時の追加のマニフェストの設定
追加の Kubernetes リソースマニフェストは、クラスター作成のインストールプロセス中に設定できます。これは、ネットワークの設定やロードバランサーの設定など、シナリオの追加マニフェストを設定する必要がある場合に役立ちます。
クラスターを作成する前に、追加のリソースマニフェストが含まれる ConfigMap を指定する ClusterDeployment リソースへの参照を追加する必要があります。
注記: ClusterDeployment リソースと ConfigMap は同じ namespace にある必要があります。以下の例で、どのような内容かを紹介しています。
リソースマニフェストを含む ConfigMap
ConfigMapリソースが別のマニフェストが含まれるConfigMap。リソースマニフェストのConfigMapには、data.<resource_name>\.yamlパターンに追加されたリソース設定が指定されたキーを複数含めることができます。kind: ConfigMap apiVersion: v1 metadata: name: <my-baremetal-cluster-install-manifests> namespace: <mynamespace> data: 99_metal3-config.yaml: | kind: ConfigMap apiVersion: v1 metadata: name: metal3-config namespace: openshift-machine-api data: http_port: "6180" provisioning_interface: "enp1s0" provisioning_ip: "172.00.0.3/24" dhcp_range: "172.00.0.10,172.00.0.100" deploy_kernel_url: "http://172.00.0.3:6180/images/ironic-python-agent.kernel" deploy_ramdisk_url: "http://172.00.0.3:6180/images/ironic-python-agent.initramfs" ironic_endpoint: "http://172.00.0.3:6385/v1/" ironic_inspector_endpoint: "http://172.00.0.3:5150/v1/" cache_url: "http://192.168.111.1/images" rhcos_image_url: "https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.201911192044.0/x86_64/rhcos-43.81.201911192044.0-openstack.x86_64.qcow2.gz"リソースマニフェスト
ConfigMapが参照される ClusterDeploymentリソースマニフェスト
ConfigMapはspec.provisioning.manifestsConfigMapRefで参照されます。apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <my-baremetal-cluster> namespace: <mynamespace> annotations: hive.openshift.io/try-install-once: "true" spec: baseDomain: test.example.com clusterName: <my-baremetal-cluster> controlPlaneConfig: servingCertificates: {} platform: baremetal: libvirtSSHPrivateKeySecretRef: name: provisioning-host-ssh-private-key provisioning: installConfigSecretRef: name: <my-baremetal-cluster-install-config> sshPrivateKeySecretRef: name: <my-baremetal-hosts-ssh-private-key> manifestsConfigMapRef: name: <my-baremetal-cluster-install-manifests> imageSetRef: name: <my-clusterimageset> sshKnownHosts: - "10.1.8.90 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXvVVVKUYVkuyvkuygkuyTCYTytfkufTYAAAAIbmlzdHAyNTYAAABBBKWjJRzeUVuZs4yxSy4eu45xiANFIIbwE3e1aPzGD58x/NX7Yf+S8eFKq4RrsfSaK2hVJyJjvVIhUsU9z2sBJP8=" pullSecretRef: name: <my-baremetal-cluster-pull-secret>
1.7.2. Amazon Web Services でのクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、Amazon Web Services (AWS) で Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの AWS へのインストール を参照してください。
1.7.2.1. 前提条件
AWS でクラスターを作成する前に、以下の前提条件を満たす必要があります。
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイしている。
- Amazon Web Services で Kubernetes クラスターを作成できるようにする Red Hat Advanced Cluster Management for Kubernetes ハブクラスターにインターネットアクセスがある。
- AWS 認証情報。詳細は、Amazon Web Services の認証情報の作成 を参照してください。
- AWS で設定されたドメイン。ドメインの設定方法は、AWS アカウントの設定 を参照してください。
- ユーザー名、パスワード、アクセスキー ID およびシークレットアクセスキーなど、Amazon Web Services (AWS) のログイン認証情報。Understanding and getting your AWS credentials を参照してください。
- OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーのアクセスキーを変更する場合は、プロビジョニングしたクラスターアクセスキーを手動で更新する必要があります。詳細は、既知の問題の プロビジョニングしたクラスターのシークレットの自動更新はサポートされない を参照してください。
1.7.2.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create cluster をクリックします。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダー用の Kubernetes ディストリビューションおよび Amazon Web Services を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報から、お使いのインフラストラクチャープロバイダーの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、Amazon Web Services の認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。この名前はクラスターのホスト名で使用されます。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - AWS アカウントに設定した Base DNS domain 情報を指定します。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は、上書きすると変更できます。詳細は、AWS アカウントの設定 を参照してください。この名前はクラスターのホスト名で使用されます。
- クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージへの url を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
コントロールプレーンプールに関する詳細を入力します。コントロールプレーンプールには、クラスター向けに作成されたコントロールプレーンノードが 3 つあります。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。オプションの情報には以下のフィールドが含まれます。
- コントロールプレーンプールを実行する ゾーン を指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は mx5.xlarge - 4 vCPU, 16 GiB RAM - General Purpose です。
- Root ストレージ の割り当てを入力します。デフォルト値は、ルートストレージ 100 GiB です。
ワーカープールに関する情報を入力します。ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ワーカープールの名前を追加します。
- ワーカープールを実行する ゾーン を指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- ワーカープールの インスタンスタイプ を指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は mx5.xlarge - 4 vCPU, 16 GiB RAM - General Purpose です。
- ワーカープールの Node count を入力します。ワーカープールを定義する場合にこの設定は必須です。
Root ストレージ の割り当てを入力します。デフォルト値は、ルートストレージ 100 GiB です。ワーカープールを定義する場合にこの設定は必須です。
Add worker pool をクリックして追加のワーカープールを定義できます。
クラスターのネットワーク情報を入力します。この情報は必須です。IPv6 を使用するには、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
OpenShiftSDNです。IPv6 を使用するには、OVNKubernetes の設定は必須です。 -
Cluster network CIDR を選択します。これは、Pod IP アドレスに使用できる IP アドレスの数およびリストです。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.128.0.0/14です。 -
ネットワークホストの接頭辞 を指定します。これにより、各ノードにサブネット接頭辞の長さを設定します。デフォルト値は
23です。 -
サービスネットワーク CIDR でサービスの IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
172.30.0.0/16です。 マシン CIDR で OpenShift Container Platform ホストで使用される IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.0.0.0/16です。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.2.3. クラスターへのアクセス
Red Hat Advanced Cluster Management for Kubernetes で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターにログインする際に使用するため、この値を書き留めてください。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.3. Microsoft Azure でのクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、Microsoft Azure または Microsoft Azure Government で Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの Azure へのインストール を参照してください。
1.7.3.1. 前提条件
Azure でクラスターを作成する前に、以下の前提条件を満たす必要があります。
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイしている。
- Azure または Azure Government で Kubernetes クラスターを作成できるようにする Red Hat Advanced Cluster Management for Kubernetes ハブクラスターでのインターネットアクセスがある。
Azure 認証情報。
詳細は、Microsoft Azure の認証情報の作成 を参照してください。
Azure または Azure Government で設定されたドメイン。
ドメイン設定の方法は、Configuring a custom domain name for an Azure cloud service を参照してください。
- ユーザー名とパスワードなどの Azure ログイン認証情報。Microsoft Azure Portal を参照してください。
clientId、clientSecret、tenantIdなどの Azure サービスプリンシパル。azure.microsoft.com を参照してください。
OpenShift Container Platform イメージプルシークレット。
イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーのアクセスキーを変更する場合は、プロビジョニングしたクラスターアクセスキーを手動で更新する必要があります。詳細は、既知の問題の プロビジョニングしたクラスターのシークレットの自動更新はサポートされない を参照してください。
1.7.3.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create cluster をクリックします。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダーに Kubernetes ディストリビューションおよび Microsoft Azure を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報から、お使いのインフラストラクチャープロバイダーの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、Microsoft Azure の認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。この名前はクラスターのホスト名で使用されます。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - Azure アカウントに設定した Base DNS domain 情報を指定します。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は、上書きすると変更できます。詳細は、Configuring a custom domain name for an Azure cloud service を参照してください。この名前はクラスターのホスト名で使用されます。
- クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
コントロールプレーンプールに関する詳細を入力します。コントロールプレーンプールには、クラスター向けに作成されたコントロールプレーンノードが 3 つあります。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。オプションの情報には以下のフィールドが含まれます。
- コントロールプレーンプールを実行する リージョン を指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は、Standard_D4s_v3 - 4 vCPU, 16 GiB RAM - General Purpose です。
- Root ストレージ の割り当てを入力します。デフォルト値は、ルートストレージ 128 GiB です。
ワーカープールに関する情報を入力します。ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ワーカープールの名前を追加します。
- ワーカープールを実行する ゾーン を指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- ワーカープールの インスタンスタイプ を指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は Standard_D2s_v3 - 2 vCPU, 8 GiB - General Purpose です。
- ワーカープールの Node count を入力します。ワーカープールを定義する場合にこの設定は必須です。
Root ストレージ の割り当てを入力します。デフォルト値は、ルートストレージ 128 GiB です。ワーカープールを定義する場合にこの設定は必須です。
Add worker pool をクリックして追加のワーカープールを定義できます。
クラスターのネットワーク情報を入力します。この情報は必須です。IPv6 を使用するには、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
OpenShiftSDNです。IPv6 を使用するには、OVNKubernetes の設定は必須です。 -
Cluster network CIDR を選択します。これは、Pod IP アドレスに使用できる IP アドレスの数およびリストです。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.128.0.0/14です。 -
ネットワークホストの接頭辞 を指定します。これにより、各ノードにサブネット接頭辞の長さを設定します。デフォルト値は
23です。 -
サービスネットワーク CIDR でサービスの IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
172.30.0.0/16です。 マシン CIDR で OpenShift Container Platform ホストで使用される IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.0.0.0/16です。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.3.3. クラスターへのアクセス
Red Hat Advanced Cluster Management for Kubernetes で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management for Kubernetes ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターにログインする際に使用するため、この値を書き留めてください。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.4. Google Cloud Platform でのクラスターの作成
Google Cloud Platform (GCP) で Red Hat OpenShift Container Platform クラスターを作成する手順に従います。Google Cloud Platform の詳細は、Google Cloud Platform を参照してください。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの GCP へのインストール を参照してください。
1.7.4.1. 前提条件
GCP でクラスターを作成する前に、以下の前提条件を満たす必要があります。
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイしている。
- GCP で Kubernetes クラスターを作成できるようにする Red Hat Advanced Cluster Management for Kubernetes ハブクラスターでのインターネットアクセスがある。
- GCP 認証情報。詳細は、Google Cloud Platform の認証情報の作成 を参照してください。
- GCP に設定されたドメイン。ドメインの設定方法は、Setting up a custom domain を参照してください。
- ユーザー名とパスワードなどの GCP ログイン認証情報。
- OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
注記: クラウドプロバイダーのアクセスキーを変更する場合は、プロビジョニングしたクラスターアクセスキーを手動で更新する必要があります。詳細は、既知の問題の プロビジョニングしたクラスターのシークレットの自動更新はサポートされない を参照してください。
1.7.4.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create Cluster タブを選択します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダーに、Kubernetes ディストリビューションおよび Google Cloud を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報からお使いの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、Google Cloud Platform の認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。この名前はクラスターのホスト名で使用されます。GCP クラスターの命名に適用される制限がいくつかあります。この制限には、名前を
googで開始しないことや、名前にgoogleに類似する文字および数字のグループが含まれないことなどがあります。制限の完全な一覧は、Bucket naming guidelines を参照してください。ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - GCP アカウントに設定した Base DNS domain 情報を指定します。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は、上書きすると変更できます。この名前はクラスターのホスト名で使用されます。詳細は、Setting up a custom domain を参照してください。
- クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージへの url を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
コントロールプレーンプールに関する詳細を入力します。コントロールプレーンプールには、クラスター向けに作成されたコントロールプレーンノードが 3 つあります。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。オプションの情報には以下のフィールドが含まれます。
- コントロールプレーンプールを実行する リージョン を指定します。リージョンが近くにある場合はパフォーマンスの速度が向上しますが、リージョンの距離が離れると、より分散されます。
- コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は、n1-standard-1 - n1-standard-1 1 vCPU - General Purpose です。
ワーカープールに関する情報を入力します。ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ワーカープールの名前を追加します。
- ワーカープールの インスタンスタイプ を指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は、n1-standard-4 - 4 vCPU 15 GiB RAM - General Purpose です。
ワーカープールの Node count を入力します。ワーカープールを定義する場合にこの設定は必須です。
Add worker pool をクリックして追加のワーカープールを定義できます。
クラスターのネットワーク情報を入力します。この情報は必須です。IPv6 を使用するには、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
OpenShiftSDNです。IPv6 を使用するには、OVNKubernetes の設定は必須です。 -
Cluster network CIDR を選択します。これは、Pod IP アドレスに使用できる IP アドレスの数およびリストです。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.128.0.0/14です。 -
ネットワークホストの接頭辞 を指定します。これにより、各ノードにサブネット接頭辞の長さを設定します。デフォルト値は
23です。 -
サービスネットワーク CIDR でサービスの IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
172.30.0.0/16です。 マシン CIDR で OpenShift Container Platform ホストで使用される IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.0.0.0/16です。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
-
ネットワークタイプ を選択します。デフォルト値は
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.4.3. クラスターへのアクセス
Red Hat Advanced Cluster Management for Kubernetes で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management for Kubernetes ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターにログインする際に使用するため、この値を書き留めてください。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.5. VMware vSphere でのクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、VMware vSphere で Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの vSphere へのインストール を参照してください。
1.7.5.1. 前提条件
vSphere でクラスターを作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.6 以降に Red Hat Advanced Cluster Management ハブクラスターをデプロイしている。
- vSphere で Kubernetes クラスターを作成できるように Red Hat Advanced Cluster Management ハブクラスターでのインターネットアクセスがある。
- vSphere 認証情報。詳細は、VMware vSphere での認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
デプロイする VMware インスタンスについての以下の情報。
- API および Ingress インスタンスに必要な静的 IP アドレス。
以下の DNS レコード。
-
api.<cluster_name>.<base_domain>。静的 API VIP を参照する必要があります。 -
*.apps.<cluster_name>.<base_domain>。Ingress VIP の静的 IP アドレスを参照する必要があります。
-
1.7.5.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create cluster をクリックします。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダーに Kubernetes ディストリビューションおよび VMware vSphere を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報から、お使いのインフラストラクチャープロバイダーの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、VMware vSphere の認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。値は、認証情報の要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。この名前はクラスターのホスト名で使用されます。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - VMware vSphere アカウントに設定した Base DNS domain 情報を指定します。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。この名前はクラスターのホスト名で使用されます。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は、上書きすると変更できます。詳細は、AWS アカウントの設定 を参照してください。この名前はクラスターのホスト名で使用されます。
クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージへの url を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
注記: OpenShift Container Platform バージョン 4.5.x 以降のリリースイメージのみがサポートされます。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
コントロールプレーンプールに関する詳細を入力します。コントロールプレーンプールには、クラスター向けに作成されたコントロールプレーンノードが 3 つあります。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。必要な情報には以下のフィールドが含まれます。
- クラスターに割り当てる ソケットごとにコア を 1 つ以上指定します。
- コントロールプレーンノードに割り当てる CPU の数を指定します。
- 割り当てる メモリー サイズを MB 単位で指定します。
- コントロールプレーンノード用に作成するディスクサイズを追加します。
ワーカープールに関する情報を入力します。ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- ワーカープールの名前を追加します。
- クラスターに割り当てる ソケットごとにコア を 1 つ以上指定します。
- 割り当てる CPU の数を指定します。
- 割り当てる メモリー サイズを MB 単位で指定します。
- 作成する ディスクのサイズ (GiB 単位) を追加します。
ノード数 を追加し、クラスター内のワーカーノードの数を指定します。
Add worker pool をクリックして追加のワーカープールを定義できます。
クラスターネットワークオプションを設定します。この情報は必須です。IPv6 を使用するには、複数のネットワークが必要です。
- vSphere ネットワーク名: VMware vSphere ネットワーク名
API VIP: 内部 API 通信に使用する IP アドレス
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレス
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.5.3. クラスターへのアクセス
Red Hat Advanced Cluster Management で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターへのログイン時にこの値を使用します。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.6. Red Hat OpenStack Platform でのクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、Red Hat OpenStack Platform で Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの OpenStack へのインストール を参照してください。
1.7.6.1. 前提条件
Red Hat OpenStack Platform でクラスターを作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.6 以降に Red Hat Advanced Cluster Management ハブクラスターをデプロイしている。
- Red Hat OpenStack Platform で Kubernetes クラスターを作成できるように Red Hat Advanced Cluster Management ハブクラスターでのインターネットアクセスがある。
- Red Hat OpenStack Platform の認証情報。詳細は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
デプロイする Red Hat OpenStack Platform インスタンスについての以下の情報。
- コントロールプレーンとワーカーインスタンスのフレーバー名。たとえば、m1.xlarge です。
- Floating IP アドレスを提供する外部ネットワークのネットワーク名。
- API および Ingress インスタンスに必要な静的 IP アドレス。
以下の DNS レコード。
-
api.<cluster_name>.<base_domain>。API の Floating IP アドレスを参照する必要があります。 -
*.apps.<cluster_name>.<base_domain>。Ingreess の Floating IP アドレスを参照する必要があります。
-
1.7.6.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create cluster をクリックします。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダーに Kubernetes ディストリビューションおよび Red Hat OpenStack を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報から、お使いのインフラストラクチャープロバイダーの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。この名前はクラスターのホスト名で使用されます。名前には 15 文字以上指定できません。
注記: 値は、認証情報の要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 Red Hat OpenStack Platform アカウントに設定した Base DNS domain 情報を指定します。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は、上書きすると変更できます。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。
詳細は、Red Hat OpenStack Platform ドキュメントの ドメインの管理 を参照してください。この名前はクラスターのホスト名で使用されます。
クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージへの url を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
注記: OpenShift Container Platform バージョン 4.6.x 以降のリリースイメージのみがサポートされます。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
コントロールプレーンノードの詳細を入力します。コントロールプレーンプールには、クラスター向けに作成されたコントロールプレーンノードが 3 つあります。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。オプションの情報には以下のフィールドが含まれます。
- コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は m1.xlarge です。
ワーカープールに関する情報を入力します。ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ワーカープールの名前を追加します。
- ワーカープールの インスタンスタイプ を指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。デフォルト値は m1.xlarge です。
ワーカープールの Node count を入力します。ワーカープールを定義する場合にこの設定は必須です。
Add worker pool をクリックして追加のワーカープールを定義できます。
クラスターのネットワーク情報を入力します。IPv4 ネットワーク用に 1 つ以上のネットワークの値を指定する必要があります。IPv6 ネットワークの場合は、複数のネットワークを定義する必要があります。
- External network name に Red Hat OpenStack Platform の外部ネットワーク名を追加します。
- API Floating IP アドレス を追加します。既存の Floating IP アドレスは、OpenShift Container Platform API の外部ネットワーク用です。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。
- Ingress Floating IP アドレスを追加します。既存の Floating IP アドレスは、Ingress ポートの外部ネットワーク上にあります。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。既存の Floating IP アドレスは、Ingress ポートの外部ネットワーク上にあります。
- プライベートネットワークの名前解決をサポートする External DNS IP addresses を追加します。
-
デプロイする Pod ネットワークプロバイダープラグインを指定する ネットワークタイプ を指定します。使用できる値は
OVNKubernetesまたはOpenShiftSDNです。デフォルト値はOpenShiftSDNです。IPv6 を使用するには、OVNKubernetes の設定は必須です。 -
Cluster network CIDR を選択します。クラスターで使用するために予約される IP アドレスのグループです。クラスターに十分な数値を指定し、その範囲に他のクラスターの IP アドレスを追加しないようにします。デフォルト値は
10.128.0.0/14です。 -
Network host prefix を指定して、それぞれの個別ノードに割り当てるサブネット接頭辞の長さを設定します。デフォルト値は
23です。 -
サービスネットワーク CIDR でサービスの IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
172.30.0.0/16です。 マシン CIDR で OpenShift Container Platform ホストで使用される IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.0.0.0/16です。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.6.3. クラスターへのアクセス
Red Hat Advanced Cluster Management で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターへのログイン時にこの値を使用します。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.7. ベアメタルでのクラスターの作成
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、ベアメタル環境で Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの ベアメタルへのインストール を参照してください。
1.7.7.1. 前提条件
ベアメタル環境にクラスターを作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.6 以降に、Red Hat Advanced Cluster Management for Kubernetes ハブクラスターをデプロイしている。
- クラスターを作成するために必要なイメージを取得するための、Red Hat Advanced Cluster Management for Kubernetes ハブクラスターへのインターネットアクセス (接続済み)、あるいはインターネットへの接続がある内部またはミラーレジストリーへの接続 (非接続) がある。
- Hive クラスターの作成に使用されるブートストラップ仮想マシンを実行する一時的な外部 KVM ホスト。詳細は、プロビジョナーホストの準備 を参照してください。
- デプロイされた Red Hat Advanced Cluster Management for Kubernetes ハブクラスターが、プロビジョニングネットワークにルーティングできる。
- ベアメタルサーバーのログイン資格情報。これには、前の項目のブートストラップ仮想マシンからの libvirt URI、SSH 秘密鍵、および SSH の既知のホストのリストが含まれます。詳細は、OpenShift インストール環境の設定 について参照してください。
- 設定済みのベアメタルクレデンシャル。詳細は ベアメタルのクレデンシャルの作成 を参照してください。
- ユーザー名、パスワード、ベースボード管理コントローラー (BMC) アドレスなどのベアメタル環境のログイン認証情報。
- ベアメタルアセットが証明書の検証を有効にしている場合は、ベアメタルアセットを設定します。詳細は、ベアメタルアセットの作成および変更 を参照してください。
OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
注記:
- ベアメタルアセット、ベアメタルのマネージドクラスター、および関連シークレットは同じ namespace に配置する必要があります。
- クラウドプロバイダーのアクセスキーを変更する場合は、プロビジョニングしたクラスターアクセスキーを手動で更新する必要があります。詳細は、既知の問題の プロビジョニングしたクラスターのシークレットの自動更新はサポートされない を参照してください。
1.7.7.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
Clusters ページで、Create cluster をクリックします。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合は、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
- インフラストラクチャープロバイダーに Kubernetes ディストリビューションおよび Bare Metal を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報からお使いの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、ベアメタルの認証情報の作成 を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。ベアメタルクラスターの場合は、名前を任意で指定できません。この名前は、クラスター URL に関連付けられています。使用するクラスター名が DNS およびネットワーク設定と一致していることを確認します。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - ベアメタルプロバイダーアカウントに設定した Base DNS domain 情報を指定します。プロバイダーのベースドメインは、Red Hat OpenShift Container Platform クラスターコンポーネントへのルートの作成に使用されます。これは、クラスタープロバイダーの DNS で Start of Authority (SOA) レコードとして設定されます。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は上書きすると変更できますが、この設定はクラスターの作成後には変更できません。詳細は、OpenShift Container Platform ドキュメントの ベアメタルへのインストール を参照してください。この名前はクラスターのホスト名で使用されます。
- クラスターに使用する リリースイメージ を指定します。このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
認証情報に関連付けられたホスト一覧から、お使いのホストを選択します。ハイパーバイザーと同じブリッジネットワークにあるベアメタルアセットを 3 つ以上選択します。
ホストの一覧は、既存のベアメタルアセットからコンパイルされます。ベアメタルホストで最新のファームウェアを実行していることを確認してください。実行していないと、プロビジョニングが失敗する可能性があります。ベアメタルアセットを作成していない場合は、作成プロセスを続行する前に Import assets を選択して作成またはインポートを行うことができます。ベアメタルアセットの詳細は、ベアメタルアセットの作成および変更 を参照してください。Disable certificate verification を選択して要件を無視することができます。
クラスターネットワークオプションを設定します。以下の表では、ネットワークオプションとその説明をまとめています。
パラメーター 説明 必須またはオプション プロビジョニングネットワーク CIDR
プロビジョニングに使用するネットワークの CIDR。このサンプル形式は 172.30.0.0/16 です。
必須
プロビジョニングネットワークインターフェイス
プロビジョニングネットワークに接続されたコントロールプレーンノード上のネットワークインターフェイス名。
必須
プロビジョニングネットワークブリッジ
プロビジョニングネットワークに接続されているハイパーバイザーのブリッジ名。
必須
外部ネットワークブリッジ
外部ネットワークに接続されているハイパーバイザーのブリッジ名。
必須
API VIP
内部 API 通信に使用する仮想 IP。
api.<cluster_name>.<Base DNS domain>パスが正しく解決されるように、DNS は A/AAAA または CNAME レコードで事前設定する必要があります。必須
Ingress VIP
Ingress トラフィックに使用する仮想 IP。
*.apps.<cluster_name>.<Base DNS domain>パスが正しく解決されるように、DNS は A/AAAA または CNAME レコードで事前設定する必要があります。オプション
ネットワークタイプ
デプロイする Pod ネットワークプロバイダープラグイン。OpenShift Container Platform 4.3 でサポートされるのは、OpenShiftSDN プラグインのみです。OVNKubernetes プラグインは、OpenShift Container Platform 4.3、4.4、および 4.5 でテクノロジープレビューとしてご利用いただけます。通常、これは OpenShift Container Platform バージョン 4.6 以降で利用できます。OVNKubernetes は IPv6 と共に使用する必要があります。デフォルト値は
OpenShiftSDNです。必須
クラスターのネットワーク CIDR
Pod IP アドレスの割り当てに使用する IP アドレスのブロック。OpenShiftSDN ネットワークプラグインは複数のクラスターネットワークをサポートします。複数のクラスターネットワークのアドレスブロックには重複が許可されません。予想されるワークロードに適したサイズのアドレスプールを選択してください。デフォルト値は 10.128.0.0/14 です。
必須
ネットワークホストの接頭辞
それぞれの個別ノードに割り当てるサブネット接頭辞の長さ。たとえば、hostPrefix が 23 に設定される場合は、各ノードに指定の cidr から /23 サブネットが割り当てられます (510 (2^(32 - 23) - 2) Pod IP アドレスが許可されます)。デフォルトは 23 です。
必須
サービスネットワーク CIDR
サービスの IP アドレスのブロック。OpenShiftSDN が許可するのは serviceNetwork ブロック 1 つだけです。このアドレスは他のネットワークブロックと重複できません。デフォルト値は 172.30.0.0/16 です。
必須
マシン CIDR
OpenShift Container Platform ホストで使用される IP アドレスのブロック。このアドレスブロックは他のネットワークブロックと重複できません。デフォルト値は 10.0.0.0/16 です。
必須
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
- プロキシーを有効にする場合は、プロキシー情報を追加します。
クラスターのインストールまたはアップグレードの前後に実行する Ansible Automation template (任意) を追加します。
Add automation template をクリックしてテンプレートを作成できます。
情報を確認し、必要に応じてカスタマイズします。
-
YAML スライダーを On にクリックし、パネルに
install-config.yamlファイルの内容を表示します。 - YAML ファイルをカスタム設定で編集します。
-
YAML スライダーを On にクリックし、パネルに
Create を選択してクラスターを作成します。
注記: クラスターのインポートには、クラスターの詳細で提示された
kubectlコマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されます。
1.7.7.3. クラスターへのアクセス
Red Hat Advanced Cluster Management for Kubernetes で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management for Kubernetes ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。クラスターにログインする際に使用するため、この値を書き留めてください。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.8. オンプレミス環境でのクラスターの作成 (テクノロジープレビュー)
Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、オンプレミスの Red Hat OpenShift Container Platform クラスターを作成できます。
注記: Red Hat Advanced Cluster Management のオンプレミスデプロイメントはテクノロジープレビュー機能ですが、OpenShift Container Platform バージョン 4.9 では、結果として生成される単一ノードの OpenShift(SNO) クラスターは、ベアメタルのデプロイメントに対してのみ完全にサポートされています。
1.7.8.1. 前提条件
オンプレミスの環境にクラスターを作成する前に、以下の前提条件を満たす必要があります。
- OpenShift Container Platform バージョン 4.9 以降に、Red Hat Advanced Cluster Management ハブクラスターをデプロイしておく。
- 設定済みのインフラストラクチャー環境に、設定済みホストを指定しておく。
- クラスターを作成するために必要なイメージを取得するための、Red Hat Advanced Cluster Management for Kubernetes ハブクラスターへのインターネットアクセス (接続済み)、あるいはインターネットへの接続がある内部またはミラーレジストリーへの接続 (非接続) がある。
- オンプレミス認証情報が設定されている。詳細は、Creating a credential for an on-premises environment を参照してください。
- OpenShift Container Platform イメージプルシークレット。イメージプルシークレットの使用 を参照してください。
1.7.8.2. コンソールを使用したクラスターの作成
Red Hat Advanced Cluster Management コンソールからクラスターを作成するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
- Clusters ページで、Create cluster をクリックします。
- インフラストラクチャープロバイダーに On-premises を選択します。残りの手順は、選択した内容により異なります。
- 一覧で利用可能な認証情報からお使いの認証情報を選択します。設定されていない場合や、新たに設定する場合は、Add credential を参照してください。認証情報の作成に関する詳細は、Creating a credential for an on-premises environment を参照してください。
クラスターの詳細を追加します。
クラスターの名前を入力します。
ヒント: コンソールに情報を入力する時に
yamlコンテンツの更新内容を表示するには、YAML を ON に切り替えるように設定します。-
クラスターセットを既存のクラスターセットに追加する場合は、クラスターセット を 1 つ指定します。クラスターの作成時に
cluster-admin権限がない場合は、クラスターを作成するclusterset-adminパーミッションがあるクラスターセットを選択する必要があります。クラスターセットを選択しないと、クラスターの作成には失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへのclusterset-adminパーミッションを受け取ってください。 - プロバイダーアカウントに設定した Base DNS domain 情報を指定します。プロバイダーのベースドメインは、Red Hat OpenShift Container Platform クラスターコンポーネントへのルートの作成に使用されます。これは、クラスタープロバイダーの DNS で Start of Authority (SOA) レコードとして設定されます。選択した認証情報にベースドメインが紐付けされている場合は、その値がこのフィールドに設定されます。値は上書きすると変更できますが、この設定はクラスターの作成後には変更できません。
- クラスターを SNO クラスターに指定する場合は、SNO オプションを選択します。SNO クラスターは、標準クラスターが作成する 3 つのノードではなく、1 つのノードだけを作成します。
- クラスターに関連付ける 追加のラベル を追加します。これらのラベルは、クラスターを特定し、検索結果を絞り込むのに役立ちます。
- クラスターの作成またはアップグレード時に実行する Automation テンプレートを設定します。
クラスターを確認し、保存します。
ヒント: この時点でクラスターを確認し、保存した後に、クラスターはドラフトクラスターとして保存されます。Clusters ページでクラスター名を選択すると、作成プロセスを閉じてプロセスを終了することができます。
独自にホストを選択するかどうか、またはそれらのホストを自動的に選択するかを選びます。ホストの数は、選択したノード数に基づいています。たとえば、SNO クラスターではホストが 1 つだけ必要ですが、標準の 3 ノードクラスターには 3 つのホストが必要です。
このクラスターの要件を満たす利用可能なホストの場所は、ホストの場所 の一覧に表示されます。ホストと高可用性設定の分散については、複数の場所を選択します。
-
ホストがバインディングを終了して
Boundステータスを表示したら、バインドされたホストのオプションの一覧からクラスターのサブネットを選択します。 以下の IP アドレスを追加します。
API VIP: 内部 API 通信に使用する IP アドレス
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレス
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。
- 情報を確認します。
- Create を選択してクラスターを作成します。
クラスターがインストールされています。Clusters ナビゲーションページで、インストールのステータスを表示できます。
1.7.8.3. クラスターへのアクセス
Red Hat Advanced Cluster Management で管理されるクラスターにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。
- 作成したクラスターまたはアクセスするクラスターの名前を選択します。クラスターの詳細が表示されます。
- Reveal credentials を選択し、クラスターのユーザー名およびパスワードを表示します。これらの値をコピーして、クラスターにログイン時に使用します。
- クラスターにリンクする Console URL を選択します。
- 手順 3 で確認したユーザー ID およびパスワードを使用して、クラスターにログインします。
1.7.9. 作成されたクラスターの休止 (テクノロジープレビュー)
Red Hat Advanced Cluster Management for Kubernetes を使用して作成されたクラスターを休止し、リソースを節約できます。休止状態のクラスターに必要となるリソースは、実行中のものより少なくなるので、クラスターを休止状態にしたり、休止状態を解除したりすることで、プロバイダーのコストを削減できる可能性があります。この機能は、以下の環境の Red Hat Advanced Cluster Management で作成したクラスターにのみ該当します。
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
1.7.9.1. コンソールを使用したクラスターの休止
Red Hat Advanced Cluster Management コンソールを使用して、Red Hat Advanced Cluster Management で作成したクラスターを休止するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。Manage clusters タブが選択されていることを確認します。
- 休止するクラスターを特定します。
- そのクラスターの Options メニューから Hibernate cluster を選択します。注記: Hibernate cluster オプションが利用できない場合には、クラスターを休止状態にすることはできません。これは、クラスターがインポートされており、Red Hat Advanced Cluster Management で作成されていない場合に、発生する可能性があります。
- 確認ダイアログボックスの Hibernate を選択して、クラスターを休止します。
Clusters ページのクラスターのステータスは、プロセスが完了すると Hibernating になります。
ヒント: Clusters ページで休止するするクラスターを選択し、Actions > Hibernate cluster を選択して、複数のクラスターを休止できます。
選択したクラスターが休止状態になりました。
1.7.9.2. CLI を使用したクラスターの休止
CLI を使用して、Red Hat Advanced Cluster Management が作成したクラスターを休止するには、以下の手順を実行します。
以下のコマンドを入力して、休止するクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値はHibernatingに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yaml
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターを休止するプロセスが完了すると、クラスターのタイプの値は
type=Hibernatingになります。
選択したクラスターが休止状態になりました。
1.7.9.3. コンソールを使用して休止中のクラスターの通常操作を再開する手順
Red Hat Advanced Cluster Management コンソールを使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動します。Manage clusters タブが選択されていることを確認します。
- 休止状態で、再開させるクラスターを見つけます。
- クラスターの Options メニューから Resume cluster を選択します。
- 確認ダイアログボックスの Resume を選択して、クラスターの機能を再開します。
プロセスを完了すると、Clusters ページのクラスターのステータスは Ready になります。
ヒント: Clusters ページで、再開するクラスターを選択し、Actions > Resume cluster の順に選択して、複数のクラスターを再開できます。
選択したクラスターで通常の操作が再開されました。
1.7.9.4. CLI を使用して休止中のクラスターの通常操作を再開する手順
CLI を使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
以下のコマンドを入力してクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値をRunningに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yaml
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターの再開プロセスが完了すると、クラスターのタイプの値は
type=Runningになります。
選択したクラスターで通常の操作が再開されました。
1.8. ハブクラスターへのターゲットのマネージドクラスターのインポート
別の Kubernetes クラウドプロバイダーからクラスターをインポートできます。インポートすると、ターゲットクラスターは Red Hat Advanced Cluster Management for Kubernetes ハブクラスターのマネージドクラスターになります。指定されていない場合は、ハブクラスターとターゲットのマネージドクラスターにアクセスできる場所で、インポートタスクを実行します。
ハブクラスターは 他 のハブクラスターの管理はできず、自己管理のみが可能です。ハブクラスターは、自動的にインポートして自己管理できるように設定されています。ハブクラスターは手動でインポートする必要はありません。
ただし、ハブクラスターを削除して、もう一度インポートする場合は、local-cluster:true ラベルを追加する必要があります。
コンソールまたは CLI からのマネージドクラスターの設定は、以下の手順から選択します。
必要なユーザータイプまたはアクセスレベル: クラスター管理者
1.8.1. コンソールを使用した既存クラスターのインポート
Red Hat Advanced Cluster Management for Kubernetes をインストールすると、管理するクラスターをインポートする準備が整います。コンソールと CLI の両方からインポートできます。コンソールからインポートするには、以下の手順に従います。この手順では、認証用にターミナルが必要です。
1.8.1.1. 前提条件
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイしている。ベアメタルクラスターをインポートする場合は、ハブクラスターを Red Hat OpenShift Container Platform バージョン 4.6 以降にインストールする必要があります。
- 管理するクラスターとインターネット接続が必要である。
-
kubectlをインストールしておく必要がある。kubectlのインストール手順は、Kubernetes ドキュメント の Install and Set Up kubectl を参照してください。 - 管理するクラスターとインターネット接続が必要である。
-
Base64コマンドラインツールが必要である。 -
Red Hat OpenShift Container Platform によって作成されていないクラスターをインポートする場合は、
multiclusterhub.spec.imagePullSecretを定義する必要があります。このシークレットは、Red Hat Advanced Cluster Management for Kubernetes のインストール時に作成されている場合もあります。シークレットの定義の詳細は OperatorHub からのインストール を参照してください。 -
インポートするクラスターでエージェントが削除されていることを確認します。
open-cluster-management-agentおよびopen-cluster-management-agent-addonnamespace は存在させないでください。 Red Hat OpenShift Dedicated 環境にインポートする場合には、以下を実行しておく。
- ハブクラスターを Red Hat OpenShift Dedicated 環境にデプロイしている必要があります。
-
Red Hat OpenShift Dedicated のデフォルトパーミッションは dedicated-admin ですが、namespace を作成するためのパーミッションがすべて含まれているわけではありません。Red Hat Advanced Cluster Management for Kubernetes でクラスターをインポートして管理するには
cluster-adminパーミッションが必要です。
必要なユーザータイプまたはアクセスレベル: クラスター管理者
1.8.1.2. クラスターのインポート
利用可能なクラウドプロバイダーごとに、Red Hat Advanced Cluster Management for Kubernetes コンソールから既存のクラスターをインポートできます。
注記: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、自動的にインポートおよび自己管理するように設定されるため、ハブクラスターを手動でインポートして自己管理する必要はありません。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。
- Add cluster をクリックします。
- Import an existing cluster をクリックします。
- クラスターの名前を指定します。デフォルトで、namespace はクラスター名と namespace に使用されます。
オプション: ラベル を追加します。
注記: Red Hat OpenShift Dedicated クラスターをインポートし、
vendor=OpenShiftDedicatedのラベルを追加してベンダーが指定されないようにする場合、またはvendor=auto-detectのラベルを追加する場合は、managed-by=platformラベルがクラスターに自動的に追加されます。この追加ラベルを使用して、クラスターを Red Hat OpenShift Dedicated クラスターとして識別し、Red Hat OpenShift Dedicated クラスターをグループとして取得できます。以下のオプションからインポートするクラスター特定に使用する インポートモード を選択します。
import コマンドを手動で実行する: 指定した情報に基づいてコピーして実行できるインポートコマンドを生成します。Save import and generate code をクリックし、
open-cluster-management-agent-addonのデプロイに使用するコマンドを生成します。確認メッセージが表示されます。Import an existing cluster ウィンドウで Copy command を選択し、生成されたコマンドおよびトークンをクリップボードにコピーします。
重要: コマンドには、インポートした各クラスターにコピーされるプルシークレット情報が含まれます。インポートしたクラスターにアクセスできるユーザーであれば誰でも、プルシークレット情報を表示することもできます。https://cloud.redhat.com/ で 2 つ目のプルシークレットを作成することを検討するか、サービスアカウントを作成して個人の認証情報を保護してください。プルシークレットの詳細は、イメージプルシークレットの使用 または サービスアカウントの概要および作成 を参照してください。
- インポートするマネージドクラスターにログインします。
Red Hat OpenShift Dedicated 環境のみ対象 : 以下の手順を実行します。
-
マネージドクラスターで
open-cluster-management-agentおよびopen-cluster-managementnamespace またはプロジェクトを作成します。 - OpenShift Container Platform カタログで klusterlet Operator を検索します。
作成した
open-cluster-managementnamespace またはプロジェクトにインストールします。重要:
open-cluster-management-agentnamespace に Operator をインストールしないでください。以下の手順を実行して、import コマンドからブートストラップシークレットを展開します。
import コマンドを生成します。
- Red Hat Advanced Cluster Management コンソールで、Infrastructure > Clusters を選択します。
- Add a cluster > Import an existing cluster を選択します。
- クラスター情報を追加し、Save import and generate code を選択します。
- import コマンドをコピーします。
-
import-commandという名前で作成したファイルに、import コマンドを貼り付けます。 以下のコマンドを実行して、新しいファイルにコンテンツを挿入します。
cat import-command | awk '{split($0,a,"&&"); print a[3]}' | awk '{split($0,a,"|"); print a[1]}' | sed -e "s/^ echo //" | base64 -d-
出力で
bootstrap-hub-kubeconfigという名前のシークレットを見つけ、コピーします。 -
シークレットをマネージドクラスターの
open-cluster-management-agentnamespace に適用します。 インストールした Operator の例を使用して klusterlet リソースを作成します。clusterName は、インポート中に設定されたクラスター名と同じ名前に変更する必要があります。
注記:
managedclusterリソースがハブに正しく登録されると、2 つの klusterlet Operator がインストールされます。klusterlet Operator の 1 つはopen-cluster-managementnamespace に、もう 1 つはopen-cluster-management-agentnamespace にあります。Operator が複数あっても klusterlet の機能には影響はありません。
-
マネージドクラスターで
Red Hat OpenShift Dedicated 環境に含まれていないクラスターのインポート: 以下の手順を実行します。
必要な場合は、マネージドクラスターの
kubectlコマンドを設定します。kubectlコマンドラインインターフェイスの設定方法は、サポート対象のクラウド を参照してください。-
マネージドクラスターに
open-cluster-management-agent-addonをデプロイするには、コピーしたトークンでコマンドを実行します。
- View cluster をクリックして Overview ページのクラスターの概要を表示します。
- 既存のクラスターのサーバー URL および API トークンを入力する: インポートするクラスターの サーバー URL および API トークンを指定します。
-
kubeconfig: インポートしているクラスターの
kubeconfigファイルの内容をコピーし、貼り付けます。
オプション:
oc get managedclusterコマンドを実行する際に、テーブルに表示される URL を設定して、クラスターの詳細ページにある Cluster API アドレス を設定します。-
cluster-adminパーミッションがある ID でハブクラスターにログインします。 ターゲットのマネージドクラスターの
kubectlを設定します。kubectlの設定方法は、サポート対象のクラウド を参照してください。以下のコマンドを入力して、インポートしているクラスターのマネージドクラスターエントリーを編集します。
oc edit managedcluster <cluster-name>
cluster-nameは、マネージドクラスターの名前に置き換えます。以下の例のように、YAML ファイルの
ManagedCluster仕様にmanageClusterClientConfigsセクションを追加します。spec: hubAcceptsClient: true managedClusterClientConfigs: - url: https://multicloud-console.apps.new-managed.dev.redhat.com
URL の値を、インポートするマネージドクラスターへの外部アクセスを提供する URL に置き換えます。
-
クラスターがインポートされました。Import another を選択すると、さらにインポートできます。
1.8.1.3. インポートされたクラスターの削除
以下の手順を実行して、インポートされたクラスターと、マネージドクラスターで作成された open-cluster-management-agent-addon を削除します。
- Clusters ページの表から、インポートされたクラスターを見つけます。
- Actions > Detach cluster をクリックしてマネージメントからクラスターを削除します。
注記: local-cluster という名前のハブクラスターをデタッチしようとする場合は、デフォルトの disableHubSelfManagement 設定が false である点に注意してください。この設定が原因で、ハブクラスターがデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
disableHubSelfManagement の値を true に指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。詳細は、disableHubSelfManagement トピックを参照してください。
1.8.2. CLI を使用したマネージドクラスターのインポート
Red Hat Advanced Cluster Management for Kubernetes をインストールすると、Red Hat OpenShift Container Platform CLI を使用して管理するクラスターをインポートする準備が整います。インポートしているクラスターの kubeconfig ファイルを使用してクラスターをインポートするか、インポートしているクラスターで import コマンドを手動で実行できます。どちらの手順も文書化されています。
重要: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、自動でインポートおよび自己管理するように設定されます。ハブクラスターは、手動でインポートして自己管理する必要はありません。
ただし、ハブクラスターを削除して、もう一度インポートする場合は、local-cluster:true ラベルを追加する必要があります。
1.8.2.1. 前提条件
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイしている。ベアメタルクラスターをインポートする場合は、ハブクラスターを Red Hat OpenShift Container Platform バージョン 4.6 以降にインストールする必要があります。
- インターネットに接続できる、管理する別のクラスターが必要です。
-
ocコマンドを実行するには、Red Hat OpenShift Container Platform の CLI バージョン 4.6 以降が必要である。Red Hat OpenShift Container Platform CLI (oc) のインストールおよび設定の詳細は、Getting started with the OpenShift CLI を参照してください。 Kubernetes CLI (
kubectl) をインストールする必要がある。kubectlのインストール手順は、Kubernetes ドキュメント の Install and Set Up kubectl を参照してください。注記: コンソールから CLI ツールのインストールファイルをダウンロードします。
-
OpenShift Container Platform によって作成されていないクラスターをインポートする場合は、
multiclusterhub.spec.imagePullSecretを定義する必要があります。このシークレットは、Red Hat Advanced Cluster Management for Kubernetes のインストール時に作成されている場合もあります。シークレットの定義の詳細は OperatorHub からのインストール を参照してください。
1.8.2.2. サポートされているアーキテクチャー
- Linux (x86_64, s390x, ppc64le)
- macOS
1.8.2.3. インポートの準備
以下のコマンドを実行して ハブクラスター にログインします。
oc login
ハブクラスターで以下のコマンドを実行し、プロジェクトおよび namespace を作成します。注記:
CLUSTER_NAMEで定義したクラスター名は、YAML ファイルおよびコマンドでクラスターの namespace としても使用します。oc new-project ${CLUSTER_NAME} oc label namespace ${CLUSTER_NAME} cluster.open-cluster-management.io/managedCluster=${CLUSTER_NAME}以下の内容例で
managed-cluster.yamlという名前のファイルを作成します。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: ${CLUSTER_NAME} labels: cloud: auto-detect vendor: auto-detect spec: hubAcceptsClient: truecloudおよびvendorの値をauto-detectする場合、Red Hat Advanced Cluster Management はインポートしているクラスターからクラウドおよびベンダータイプを自動的に検出します。オプションで、auto-detectの値をクラスターのクラウドおよびベンダーの値に置き換えることができます。以下の例を参照してください。cloud: Amazon vendor: OpenShift
以下のコマンドを入力して、YAML ファイルを
ManagedClusterリソースに適用します。oc apply -f managed-cluster.yaml
自動インポートシークレットを使用したクラスターのインポート または 手動コマンドを使用したクラスターのインポート に進みます。
1.8.2.4. 自動インポートシークレットを使用したクラスターのインポート
自動インポートシークレットでインポートするには、クラスターの kubeconfig ファイルを参照するか、またはクラスターの kube API サーバーおよびトークンのペアのいずれかの参照を含むシークレットを作成する必要があります。
-
インポートしているクラスターの
kubeconfigファイルまたは kube API サーバーおよびトークンを取得します。kubeconfigファイルまたは kube API サーバーおよびトークンの場所を特定する方法については、Kubernetes クラスターのドキュメントを参照してください。 ${CLUSTER_NAME} namespace に
auto-import-secret.yamlファイルを作成します。以下のテンプレートのようなコンテンツが含まれる
auto-import-secret.yamlという名前の YAML ファイルを作成します。apiVersion: v1 kind: Secret metadata: name: auto-import-secret namespace: <cluster_name> stringData: autoImportRetry: "5" # If you are using the kubeconfig file, add the following value for the kubeconfig file # that has the current context set to the cluster to import: kubeconfig: |- <kubeconfig_file> # If you are using the token/server pair, add the following two values instead of # the kubeconfig file: token: <Token to access the cluster> server: <cluster_api_url> type: Opaque
次のコマンドを使用して、${CLUSTER_NAME} 名前空間の YAML ファイルを適用します。
oc apply -f auto-import-secret.yaml
注記: デフォルトでは、自動インポートシークレットは 1 回使用され、インポートプロセスの完了時に削除されます。自動インポートシークレットを保持する場合は、
managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secretをシークレットに追加します。これを追加するには、以下のコマンドを実行します。
インポートしたクラスターのステータス (
JOINEDおよびAVAILABLE) を確認します。ハブクラスターから以下のコマンドを実行します。oc get managedcluster ${CLUSTER_NAME}管理対象クラスターで次のコマンドを実行して、管理対象クラスターにログインします。
oc login
次のコマンドを実行して、インポートするクラスターの Pod ステータスを検証します。
oc get pod -n open-cluster-management-agent
klusterlet のインポート を進めます。
1.8.2.5. 手動コマンドを使用したクラスターのインポート
重要: import コマンドには、インポートした各クラスターにコピーされるプルシークレット情報が含まれます。インポートしたクラスターにアクセスできるユーザーであれば誰でも、プルシークレット情報を表示することもできます。
以下のコマンドを実行して、ハブクラスターでインポートコントローラーによって生成された
klusterlet-crd.yamlファイルを取得します。oc get secret ${CLUSTER_NAME}-import -n ${CLUSTER_NAME} -o jsonpath={.data.crds\\.yaml} | base64 --decode > klusterlet-crd.yaml以下のコマンドを実行して、ハブクラスターにインポートコントローラーによって生成された
import.yamlファイルを取得します。oc get secret ${CLUSTER_NAME}-import -n ${CLUSTER_NAME} -o jsonpath={.data.import\\.yaml} | base64 --decode > import.yamlインポートするクラスターで次の手順を実行します。
次のコマンドを入力して、インポートする管理対象クラスターにログインします。
oc login
以下のコマンドを実行して、手順 1 で生成した
klusterlet-crd.yamlを適用します。oc apply -f klusterlet-crd.yaml
以下のコマンドを実行して、以前に生成した
import.yamlファイルを適用します。oc apply -f import.yaml
インポートしているクラスターの
JOINEDおよびAVAILABLEのステータスを検証します。ハブクラスターから以下のコマンドを実行します。oc get managedcluster ${CLUSTER_NAME}
klusterlet のインポート を進めます。
1.8.2.6. klusterlet のインポート
以下の手順を実行して、klusterlet アドオン設定ファイルを作成および適用できます。
以下の例のような YAML ファイルを作成します。
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: true-
ファイルは
klusterlet-addon-config.yamlとして保存します。 以下のコマンドを実行して YAML を適用します。
oc apply -f klusterlet-addon-config.yaml
ManagedCluster-Import-Controller は
${CLUSTER_NAME}-importという名前のシークレットを生成します。${CLUSTER_NAME}-importシークレットには、import.yamlが含まれており、このファイルをユーザーがマネージドクラスターに適用して klusterlet をインストールします。アドオンは、インポートするクラスターの
AVAILABLEの後にインストールされます。次のコマンドを実行して、インポートするクラスター上のアドオンの Pod ステータスを検証します。
oc get pod -n open-cluster-management-agent-addon
クラスターがインポートされました。
1.8.2.7. CLI でのインポートされたクラスターの削除
クラスターを削除するには、以下のコマンドを実行します。
oc delete managedcluster ${CLUSTER_NAME}
cluster_name は、クラスターの名前に置き換えます。
これでクラスターが削除されます。
1.8.3. カスタム ManagedClusterImageRegistry CRD を使用したクラスターのインポート
インポートしているマネージドクラスターのレジストリーイメージを上書きする必要がある場合があります。この方法は、ManagedClusterImageRegistry カスタムリソース定義 (CRD) を作成して実行できます。
ManagedClusterImageRegistry CRD は namespace スコープのリソースです。
ManagedClusterImageRegistry CRD は、配置が選択するマネージドクラスターのセットを指定しますが、カスタムイメージレジストリーとは異なるイメージが必要になります。マネージドクラスターが新規イメージで更新されると、識別用に各マネージドクラスターに、open-cluster-management.io/image-registry=<namespace>.<managedClusterImageRegistryName> のラベルが追加されます。
以下の例は、ManagedClusterImageRegistry CRD を示しています。
apiVersion: imageregistry.open-cluster-management.io/v1alpha1
kind: ManagedClusterImageRegistry
metadata:
name: <imageRegistryName>
namespace: <namespace>
spec:
placementRef:
group: cluster.open-cluster-management.io
resource: placements
name: <placementName>
pullSecret:
name: <pullSecretName>
registry: <registryAddress>
spec セクション:
-
placementRefは、マネージドクラスターのセットを選択する同じ namespace の Placement に置き換えます。 -
pullSecretは、カスタムイメージレジストリーからイメージをプルするために使用されるプルシークレットの名前に置き換えます。 -
registryは、カスタムレジストリーアドレスに置き換えます。
1.8.3.1. ManagedClusterImageRegistry CRD を使用したクラスターのインポート
ManagedClusterImageRegistry CRD でクラスターをインポートするには、以下の手順を実行します。
クラスターをインポートする必要のある namespace にプルシークレットを作成します。これらの手順では、これは
myNamespaceです。$ kubectl create secret docker-registry myPullSecret \ --docker-server=<your-registry-server> \ --docker-username=<my-name> \ --docker-password=<my-password>
作成した namespace に Placement を作成します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: myPlacement namespace: myNamespace spec: clusterSets: - myClusterSet
ManagedClusterSetリソースを作成し、これを namespace にバインドします。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSet metadata: name: myClusterSet --- apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSetBinding metadata: name: myClusterSet namespace: myNamespace spec: clusterSet: myClusterSet
namespace に
ManagedClusterImageRegistryCRD を作成します。apiVersion: imageregistry.open-cluster-management.io/v1alpha1 kind: ManagedClusterImageRegistry metadata: name: myImageRegistry namespace: myNamespace spec: placementRef: group: cluster.open-cluster-management.io resource: placements name: myPlacement pullSecret: name: myPullSecret registry: myRegistryAddress- Red Hat Advanced Cluster Management コンソールからマネージドクラスターをインポートして、マネージドクラスターセットに追加します。
-
open-cluster-management.io/image-registry=myNamespace.myImageRegistryラベルをマネージドクラスターに追加した後に、マネージドクラスターで import コマンドをコピーして実行します。
1.8.4. クラスターの klusterlet アドオン設定の変更
ハブクラスターを使用して設定を変更するには、KlusterletAddonConfig の設定を変更します。
KlusterletAddonConfig コントローラーは、klusterletaddonconfigs.agent.open-cluster-management.io Kubernetes リソースの設定に合わせて有効化/無効化される機能を管理します。以下で KlusterletAddonConfig を参照してください。
apiVersion: agent.open-cluster-management.io/v1
kind: KlusterletAddonConfig
metadata:
name: <cluster-name>
namespace: <cluster-name>
spec:
clusterName: <cluster-name>
clusterNamespace: <cluster-name>
clusterLabels:
cloud: auto-detect
vendor: auto-detect
applicationManager:
enabled: true
certPolicyController:
enabled: true
iamPolicyController:
enabled: true
policyController:
enabled: true
searchCollector:
enabled: false
version: 2.4.01.8.4.1. klusterlet アドオン設定の説明
以下の設定は、klusterletaddonconfigs.agent.open-cluster-management.io の Kubernetes リソースで更新できます。
| 設定名 | 値 | 説明 |
|---|---|---|
| applicationmanager |
| このコントローラーは、マネージドクラスターでアプリケーションのサブスクリプションライフサイクルを管理します。 |
| certPolicyController |
| このコントローラーは、マネージドクラスターで証明書ベースのポリシーを有効にします。 |
| iamPolicyController |
| このコントローラーは、マネージドクラスターで IAM ベースのポリシーライフサイクルを有効にします。 |
| policyController |
| このコントローラーは、マネージドクラスターの他の全ポリシールールを有効にします。 |
| searchCollector |
| このコントローラーを使用して、リソースインデックスデータをハブクラスターに定期的に戻します。 |
1.8.4.2. ハブクラスターのコンソールを使用した変更
ハブクラスターを使用して、klusterletaddonconfigs.agent.open-cluster-management.io リソースの設定を変更できます。設定の変更には、以下の手順を実行します。
- ハブクラスターの Red Hat Advanced Cluster Management for Kubernetes コンソールにログインします。
- ハブクラスターコンソールのヘッダーメニューから Search アイコンを選択します。
-
検索パラメーターに、
kind:klusterletaddonconfigsの値を入力します。 - 更新するエンドポイントリソースを選択します。
-
specセクションから、Edit を選択してコンテンツを編集します。 - 設定を変更します。
- Save を選択して変更を適用します。
1.8.4.3. ハブクラスターのコマンドラインを使用した変更
ハブクラスターを使用して設定を変更するには、cluster-name namespace へのアクセス権が必要です。以下の手順を実行します。
- ハブクラスターにログインします。
以下のコマンドを入力してリソースを編集します。
kubectl edit klusterletaddonconfigs.agent.open-cluster-management.io <cluster-name> -n <cluster-name>
-
specセクションを検索します。 - 必要に応じて設定を変更します。
1.9. プロキシー環境でのクラスターの作成
ハブクラスターがプロキシーサーバー経由で接続されている場合は、Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターの作成を成功させるには、以下のいずれかの状況が true である必要があります。
- Red Hat Advanced Cluster Management for Kubernetes には、作成しているマネージドクラスターを使用したプライベートネットワーク接続がありますが、Red Hat Advanced Cluster Management およびマネージドクラスターは、プロキシーを使用してインターネットにアクセスします。
- マネージドクラスターはインフラストラクチャープロバイダーにありますが、ファイアウォールポートを使用することでマネージドクラスターからハブクラスターへの通信を有効にします。
プロキシーで設定されたクラスターを作成するには、以下の手順を実行します。
以下の情報を
install-config.yamlファイルに追加して、ハブクラスターに cluster-wide-proxy 設定を指定します。apiVersion: v1 kind: Proxy baseDomain: <domain> proxy: httpProxy: http://<username>:<password>@<proxy.example.com>:<port> httpsProxy: https://<username>:<password>@<proxy.example.com>:<port> noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR>
usernameは、プロキシーサーバーのユーザー名に置き換えます。passwordは、プロキシーサーバーへのアクセス時に使用するパスワードに置き換えます。proxy.example.comは、プロキシーサーバーのパスに置き換えます。portは、プロキシーサーバーとの通信ポートに置き換えます。wildcard-of-domainは、プロキシーをバイパスするドメインのエントリーに置き換えます。provisioning-network/CIDRは、プロビジョニングネットワークの IP アドレスと割り当てられた IP アドレスの数 (CIDR 表記) に置き換えます。BMC-address-range/CIDRは、BMC アドレスおよびアドレス数 (CIDR 表記) に置き換えます。以前の値を追加すると、設定はクラスターに適用されます。
- クラスターの作成手順を実行してクラスターをプロビジョニングします。クラスターの作成 を参照してプロバイダーを選択します。
1.9.1. 既存のクラスターアドオンでクラスター全体のプロキシーを有効にする
クラスター namespace で KlusterletAddonConfig を設定して、ハブクラスターが管理する Red Hat OpenShift Container Platform クラスターのすべての klusterlet アドオン Pod にプロキシー環境変数を追加できます。
KlusterletAddonConfig が 3 つの環境変数を klusterlet アドオンの Pod に追加するように設定するには、以下の手順を実行します。
-
プロキシーを追加する必要のあるクラスターの namespace にある
KlusterletAddonConfigファイルを開きます。 ファイルの
.spec.proxyConfigセクションを編集して、以下の例のようにします。spec proxyConfig: httpProxy: "<proxy_not_secure>" httpsProxy: "<proxy_secure>" noProxy: "<no_proxy>"proxy_not_secureは、http要求のプロキシーサーバーのアドレスに置き換えます。(例:http://192.168.123.145:3128)。proxy_secureは、https要求のプロキシーサーバーのアドレスに置き換えます。例:https://192.168.123.145:3128no_proxyは、トラフィックがプロキシー経由でルーティングされない IP アドレス、ホスト名、およびドメイン名のコンマ区切りの一覧に置き換えます。(例:.cluster.local,.svc,10.128.0.0/14,example.com)。spec.proxyConfigは任意のセクションです。OpenShift Container Platform クラスターが Red Hat Advanced Cluster Management ハブクラスターでクラスターワイドプロキシーを設定して作成されている場合は、以下の条件が満たされると、クラスターワイドプロキシー設定値が環境変数として klusterlet アドオンの Pod に追加されます。-
addonセクションの.spec.policyController.proxyPolicyが有効になり、OCPGlobalProxyに設定されます。 .spec.applicationManager.proxyPolocyが有効になり、CustomProxyに設定されます。注記:
addonセクションのproxyPolicyのデフォルト値はDisabledです。以下の例を参照してください。
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: clusterName namespace: clusterName spec: proxyConfig: httpProxy: http://pxuser:12345@10.0.81.15:3128 httpsProxy: http://pxuser:12345@10.0.81.15:3128 noProxy: .cluster.local,.svc,10.128.0.0/14, example.com applicationManager: enabled: true proxyPolicy: CustomProxy policyController: enabled: true proxyPolicy: OCPGlobalProxy searchCollector: enabled: true proxyPolicy: Disabled certPolicyController: enabled: true proxyPolicy: Disabled iamPolicyController: enabled: true proxyPolicy: Disabled
-
プロキシーはクラスターアドオンで設定されます。
重要: グローバルプロキシー設定は、アラートの転送には影響しません。クラスター全体のプロキシーを使用して Red Hat Advanced Cluster Management ハブクラスターのアラート転送を設定する場合は、その詳細について アラートの転送 を参照してください。
1.10. クラスタープロキシーアドオンの有効化
一部の環境では、マネージドクラスターはファイアウォールの背後にあり、ハブクラスターから直接アクセスすることはできません。アクセスするには、プロキシーアドオンを設定して、より安全な接続を提供する、マネージドクラスターの kube-api サーバーにアクセスします。
必要なアクセス: 編集
ハブクラスターとマネージドクラスターのクラスタープロキシーアドオンを設定するには、次の手順を実行します。
次のコマンドを入力して、
multiclusterhub.yamlファイルにtrueの値を指定してenableClusterProxyAddonエントリーを追加し、Red Hat Advanced Cluster Management for Kubernetes ハブクラスターでクラスタープロキシーアドオンを有効にします。oc patch -n open-cluster-management multiclusterhub multiclusterhub --type merge -p '{"spec":{"enableClusterProxyAddon":true}}'コマンドで示されているように、このファイルは
open-cluster-managementnamespace にあります。次のコマンドを入力して、クラスタープロキシーアドオンをターゲットのマネージドクラスターに適用して、クラスタープロキシーアドオンをターゲットマネージドクラスターにデプロイします。
cat <<EOF | oc apply -f - apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: cluster-proxy namespace: <target_managed_cluster> spec: installNamespace: open-cluster-management-agent-addon EOF
target_managed_clusterは、クラスタープロキシーアドオンを適用するマネージドクラスターの名前に置き換えます。次の手順を実行してマネージドクラスター
kube-apiserverにアクセスするようにkubeconfigファイルを設定します。マネージドクラスターに有効なアクセストークンを指定します。デフォルトのサービスアカウントがデフォルトの namespace にある場合には、サービスアカウントに対応するトークンを使用できます。
-
マネージドクラスターのコンテキストを使用していることを確認してください。
managed-cluster.kubeconfigという名前のファイルがマネージドクラスターのkubeconfigファイルであると想定します。ヒント:--kubeconfig=managed-cluster.kubeconfigを指定したコマンドはマネージドクラスターで実行されます。また、この手順で使用するコマンドはすべて、その同じコンソールで実行する必要があります。別のコンソールでコマンドを実行しないでください。 次のコマンドを実行して、Pod へのアクセス権があるロールをサービスアカウントに追加します。
oc create role -n default test-role --verb=list,get --resource=pods --kubeconfig=managed-cluster.kubeconfig oc create rolebinding -n default test-rolebinding --serviceaccount=default:default --role=test-role --kubeconfig=managed-cluster.kubeconfig
次のコマンドを実行して、サービスアカウントトークンのシークレットを見つけます。
oc get secret -n default --kubeconfig=managed-cluster.kubeconfig | grep default-token
次のコマンドを実行して、トークンをコピーします。
export MANAGED_CLUSTER_TOKEN=$(kubectl --kubeconfig=managed-cluster.kubeconfig -n default get secret <default-token> -o jsonpath={.data.token} | base64 -d)default-tokenは、シークレット名に置き換えます。
-
マネージドクラスターのコンテキストを使用していることを確認してください。
Red Hat Advanced Cluster Management ハブクラスターで
kubeconfigファイルを設定します。次のコマンドを実行して、ハブクラスター上の現在の
kubeconfigファイルをエクスポートします。oc config view --minify --raw=true > cluster-proxy.kubeconfig
エディターで
serverファイルを変更します。この例では、sedの使用時にコマンドを使用します。OSX を使用している場合は、alias sed=gsedを実行します。export TARGET_MANAGE_CLUSTER=<cluster1> export NEW_SERVER=https://$(oc get route -n open-cluster-management cluster-proxy-addon-user -o=jsonpath='{.spec.host}')/$TARGET_MANAGE_CLUSTER sed -i'' -e '/server:/c\ server: '"$NEW_SERVER"'' cluster-proxy.kubeconfigcluster1は、アクセスするマネージドクラスター名に置き換えます。次のコマンドを入力して、元のユーザー認証情報を削除します。
sed -i'' -e '/client-certificate-data/d' cluster-proxy.kubeconfig sed -i'' -e '/client-key-data/d' cluster-proxy.kubeconfig sed -i'' -e '/token/d' cluster-proxy.kubeconfig
サービスアカウントのトークンを追加します。
sed -i'' -e '$a\ token: '"$MANAGED_CLUSTER_TOKEN"'' cluster-proxy.kubeconfig
次のコマンドを実行して、ターゲットマネージドクラスターのターゲット namespace にあるすべての Pod を一覧表示します。
oc get pods --kubeconfig=cluster-proxy.kubeconfig -n <default>
defaultnamespace は、使用する namespace に置き換えます。
これで、ハブクラスターはマネージドクラスターの kube-api と通信するようになりました。
1.11. 特定のクラスター管理ロールの設定
Red Hat Advanced Cluster Management for Kubernetes をインストールすると、デフォルト設定で Red Hat Advanced Cluster Management ハブクラスターに cluster-admin ロールが提供されます。このパーミッションを使用すると、ハブクラスターでマネージドクラスターを作成、管理、およびインポートできます。状況によっては、ハブクラスターのすべてのマネージドクラスターへのアクセスを提供するのではなく、ハブクラスターが管理する特定のマネージドクラスターへのアクセスを制限する必要がある場合があります。
クラスターロールを定義し、ユーザーまたはグループに適用することで、特定のマネージドクラスターへのアクセスを制限できます。ロールを設定して適用するには、以下の手順を実行します。
以下の内容を含む YAML ファイルを作成してクラスターロールを定義します。
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <clusterrole-name> rules: - apiGroups: - cluster.open-cluster-management.io resources: - managedclusters resourceNames: - <managed-cluster-name> verbs: - get - list - watch - update - delete - deletecollection - patch - apiGroups: - cluster.open-cluster-management.io resources: - managedclusters verbs: - create - apiGroups: - "" resources: - namespaces resourceNames: - <managed-cluster-name> verbs: - create - get - list - watch - update - delete - deletecollection - patch - apiGroups: - register.open-cluster-management.io resources: - managedclusters/accept resourceNames: - <managed-cluster-name> verbs: - update
clusterrole-nameは、作成するクラスターロールの名前に置き換えます。managed-cluster-nameは、ユーザーにアクセスを許可するマネージドクラスターの名前に置き換えます。以下のコマンドを入力して
clusterrole定義を適用します。oc apply <filename>
filenameを、先の手順で作成した YAML ファイルの名前に置き換えます。以下のコマンドを入力して、
clusterroleを指定されたユーザーまたはグループにバインドします。oc adm policy add-cluster-role-to-user <clusterrole-name> <username>
clusterrole-nameを、直前の手順で適用したクラスターロールの名前に置き換えます。usernameを、クラスターロールをバインドするユーザー名に置き換えます。
1.12. クラスターラベルの管理
クラスターにラベルを追加してグループリソースを選択します。詳細は、Labels and Selectors を参照してください。
クラスターの新規ラベルの追加、既存ラベルの削除、既存ラベルの編集が可能です。ラベルを管理するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Clusters テーブルでクラスターを探します。
- Options をクリックし、メニューのオプションを表示します。
- Edit labels を選択します。
-
Edit labels ダイアログボックスで、ラベルを入力します。入力内容は
Key=Valueのようになります。 - Enter を押してコンマを追加するか、スペースを追加して別のラベルを追加します。
- 最後の項目を入力したら、Save をクリックします。Save をクリックしてからでないと、ラベルは保存されません。
完了したら、ラベルの編集ペインを閉じます。
- 既存のラベルを削除するには、一覧から削除するラベルの Remove アイコンをクリックします。
-
既存のラベルを更新する場合は、同じキーに別の値を使用して、新規ラベルを追加すると、新しい値にキーを再割り当てすることができます。たとえば、
Key=Valueを変更するには、Key=NewValueを入力してKeyの値を更新します。
ヒント: クラスターの詳細ページからクラスターラベルを編集することもできます。ナビゲーションメニューから Infrastructure > Clusters をクリックします。Clusters ページで、クラスターの名前をクリックしてクラスターの詳細ページにアクセスします。Labels セクションの Edit アイコンをクリックします。Edit labels ダイアログボックスが表示されます。
1.13. マネージドクラスターで実行する Ansible Tower タスクの設定
Red Hat Advanced Cluster Management は、Ansible Tower 自動化と統合し、クラスターの作成またはアップグレード前後に、prehook および posthook AnsibleJob インスタンスを作成できるようにします。クラスター破棄の prehook および posthook ジョブの設定やクラスターのスケールアクションはサポートされません。
必要なアクセス権限: クラスターの管理者
1.13.1. 前提条件
Red Hat Advanced Cluster Management クラスターで Ansible テンプレートを実行するには、以下の前提条件を満たす必要があります。
- OpenShift Container Platform 4.6 以降
- Ansible Automation Platform Resource Operator をインストールして、Ansible ジョブを Git サブスクリプションのライフサイクルに接続している。AnsibleJob を使用した Ansible Tower ジョブの実行時に最善の結果を得るには、実行時に Ansible Tower ジョブテンプレートが冪等でなければなりません。Ansible Automation Platform Resource Operator は、Red Hat OpenShift Container Platform OperatorHub ページから検索できます。
Ansible Tower 自動化のインストールおよび設定に関する詳細は、Ansible タスクの設定 (テクノロジープレビュー) を参照してください。
1.13.2. コンソールでを使用したクラスターでの実行用の AnsibleJob テンプレート設定
クラスターの作成時にクラスターに使用する Ansible ジョブテンプレートを指定する必要があります。クラスターの作成時にテンプレートを指定するには、Automation の手順でクラスターに適用する Ansible テンプレートを選択します。Ansible テンプレートがない場合は、Add automation template をクリックして作成します。
1.13.3. AnsibleJob テンプレートの作成
クラスターのインストールまたはアップグレードで Ansible ジョブを開始するには、ジョブ実行のタイミングを指定する Ansible ジョブテンプレートを作成する必要があります。これらは、クラスターのインストールまたはアップグレード前後に実行するように設定できます。
テンプレートの作成時に Ansible テンプレートの実行に関する詳細を指定するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Automation に移動します。既存の Ansible テンプレートが表示されます。
状況に適したパスを選択します。
- 新規テンプレートを作成する場合には、Create Ansible template をクリックして手順 3 に進みます。
- 既存のテンプレートを変更する場合は、変更するテンプレートの Options メニューの Edit template をクリックして、手順 5 に進みます。
- テンプレートの名前を入力します。小文字、英数字、ハイフン (-) が含まれる一意の名前を指定する必要があります。
新規テンプレートの認証情報を選択します。Ansible 認証情報を Ansible テンプレートにリンクするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Automation を選択します。認証情報にリンクされていないテンプレートの一覧内のテンプレートには、テンプレートを既存の認証情報にリンクするために使用できるリンク 認証情報へのリンク アイコンが含まれています。
- Link to credential を選択して、既存の認証情報を検索し、リンクします。
- Ansible Automation Platform credential フィールドにあるメニューから、利用可能な認証情報を選択します。テンプレートと同じ namespace の認証情報のみが表示されます。
- 選択できる認証情報がない場合や、既存の認証情報を使用しない場合は、リンクするテンプレートの Options メニューから Edit template を選択します。
- Add credential をクリックして、テンプレートの認証情報を作成します。
- 認証情報を作成する場合は、Ansible Automation Platform の認証情報の作成 の手順を行います。
- テンプレートと同じ namespace に認証情報を作成したら、テンプレートの編集時に Ansible Automation Platform credential フィールドで認証情報を選択します。
- Save をクリックして、認証情報とテンプレート間のリンクをコミットします。
- クラスターをインストールする前に Ansible ジョブを開始する場合は、Pre-install Ansible job templates セクションで Add an Ansible job template を選択します。
prehook および posthook Ansible ジョブを選択するか、名前を入力して、クラスターのインストールまたはアップグレードに追加します。
注記: Ansible job template name は、Ansible Tower の Ansible ジョブの名前と一致している必要があります。
- Ansible Tower ジョブで必要な 追加変数 (ある場合) を入力します。
- 必要に応じて、Ansible ジョブをドラッグして、順番を変更します。
- Save をクリックして情報をコミットします。
- Post-install Ansible job templates セクションでクラスターのインストールを完了したら、開始する Ansible ジョブテンプレートごとに手順 5 ~ 9 を繰り返します。
- Save をクリックして情報をコミットします。
- Next をクリックし、アップグレード の開始に使用する Ansible ジョブの指定を開始します。
- Pre-install Ansible job templates セクションでクラスターのアップグレード前に、開始する Ansible ジョブテンプレートごとに手順 5 ~ 9 を繰り返します。
- Save をクリックして情報をコミットします。
- Post-install Ansible job templates セクションでクラスターのアップグレード後に、開始する Ansible ジョブテンプレートごとに手順 5 ~ 9 を繰り返します。
- Save をクリックして情報をコミットします。
- Next をクリックして、追加した Ansible ジョブを確認します。
- Add を選択して、Ansible ジョブの設定情報をテンプレートに追加します。
Ansible テンプレートは、指定のアクションが起こるタイミングで、このテンプレートを指定するクラスターで実行するように設定されます。
1.13.4. ラベルを使用したマネージドクラスターでの実行用の AnsibleJob テンプレート設定
Red Hat Advanced Cluster Management for Kubernetes でクラスターを作成した場合、または Red Hat Advanced Cluster Management で管理するためにラベルを使用してインポートした場合は、AnsibleJob を作成してクラスターにバインドできます。
以下の手順を実行して、Ansible ジョブを作成し、Red Hat Advanced Cluster Management でまだ管理されていないクラスターを使用して設定します。
アプリケーション機能でサポートされるチャネルのいずれかで、Ansible ジョブの定義ファイルを作成します。Git チャネルのみがサポートされます。
AnsibleJobは、定義のkindの値として使用します。定義ファイルの内容は以下の例のようになります。
apiVersion: apiVersion: tower.ansible.com/v1alpha1 kind: AnsibleJob metadata: name: hive-cluster-gitrepo spec: tower_auth_secret: my-toweraccess job_template_name: my-tower-template-name extra_vars: variable1: value1 variable2: value2ファイルを prehook ディレクトリーまたは posthook ディレクトリーに保存すると、配置ルールと一致するクラスター名の一覧が作成されます。クラスター名の一覧は、
extra_varsの値としてAnsibleJobkindリソースに渡すことができます。この値がAnsibleJobリソースに渡されると、Ansible ジョブで、新しいクラスター名が判別され、自動化での使用が可能になります。- Red Hat Advanced Cluster Management ハブクラスターにログインします。
Red Hat Advanced Cluster Management コンソールを使用して、先程作成した定義ファイルの保存先のチャネルを参照する Git サブスクリプションでアプリケーションを作成します。アプリケーションおよびサブスクリプションの作成に関する詳細は、アプリケーションリソースの管理 を参照してください。
サブスクリプションの作成時に、ラベルを指定して、クラスターとこのサブスクリプションを連携させるために作成またはインポートするクラスターに追加できます。このラベルは、
vendor=OpenShiftなどの既存のものでも、一意のラベルを作成、定義することも可能です。注記: すでに使用中のラベルを選択すると、Ansible ジョブは自動的に実行されます。prehook または posthook の一部ではないアプリケーションに、リソースを追加することがベストプラクティスです。
デフォルトの配置ルールでは、
AnsibleJobのラベルと一致するラベルの付いたクラスターが検出されると、ジョブが実行されます。ハブクラスターが管理する実行中のすべてのクラスターで、自動化を実行するには、以下の内容を配置ルールに追加します。clusterConditions: - type: ManagedClusterConditionAvailable status: "True"これを配置ルールの YAML コンテンツに貼り付けるか、Red Hat Advanced Cluster Management コンソールの Application create ページで Deploy to all online cluster and local cluster オプションを選択します。
クラスターの作成 または ハブクラスターへのターゲットのマネージドクラスターのインポート の手順に従って、クラスターを作成またはインポートします。
クラスターの作成またはインポート時には、サブスクリプションの作成時に使用したラベルと同じラベルを使用すると、
AnsibleJobはクラスター上で自動的に実行されるように設定されます。
Red Hat Advanced Cluster Management は、クラスター名を AnsibleJob.extra_vars.target_clusters パスに自動的に挿入します。クラスター名を定義に動的に挿入できます。以下の手順を実行して、AnsibleJob を作成し、Red Hat Advanced Cluster Management で管理しているクラスターを使用して設定します。
Git チャネルの prehook ディレクトリーまたは posthook ディレクトリーに、AnsibleJob の定義ファイルを作成します。
AnsibleJobは、定義のkindの値として使用します。定義ファイルの内容は以下の例のようになります。
apiVersion: tower.ansible.com/v1alpha1 kind: AnsibleJob metadata: name: hive-cluster-gitrepo spec: tower_auth_secret: my-toweraccess job_template_name: my-tower-template-name extra_vars: variable1: value1 variable2: value2my-toweraccessは、Ansible Tower にアクセスするための認証シークレットに置き換えます。my-tower-template-nameは、Ansible Tower のテンプレート名に置き換えます。
Ansible ジョブが制御するクラスターが削除されるか、追加されるたびに、AnsibleJob は自動的に extra_vars.target_clusters 変数を実行して更新します。この更新により、特定の自動化でクラスター名を指定したり、クラスターのグループに自動化を適用したりできるようになりました。
1.13.5. Ansible ジョブのステータスの表示
実行中の Ansible ジョブのステータスを表示して、起動し、正常に実行されていることを確認できます。実行中の Ansible ジョブの現在のステータスを表示するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションメニューで Infrastructure > Clusters に移動して、Clusters ページにアクセスします。
- クラスターの名前を選択して、その詳細を表示します。
クラスター情報で Ansible ジョブの最後の実行ステータスを表示します。エントリーには、以下のステータスの 1 つが表示されます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
Failedと表示されます。 アップグレード prehook または posthook ジョブが失敗すると、アップグレードに失敗した Distribution フィールドに警告が表示されます。
ヒント: クラスターの prehook または posthook が失敗した場合は、Clusters ページからアップグレードを再試行できます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
1.14. ManagedClusterSets の管理 (テクノロジープレビュー)
ManagedClusterSet は、マネージドクラスターのグループです。マネージドクラスターセットでは、グループ内の全マネージドクラスターに対するアクセス権を管理できます。ManagedClusterSetBinding リソースを作成して ManagedClusterSet リソースを namespace にバインドすることもできます。
1.14.1. ManagedClusterSet の作成
マネージドクラスターセットにマネージドクラスターをグループ化して、マネージドクラスターでのユーザーのアクセス権限を制限できます。
必要なアクセス権限: クラスターの管理者
ManagedClusterSet は、クラスタースコープのリソースであるため、ManagedClusterSet の作成先となるクラスターで管理者権限が必要です。マネージドクラスターは、複数の ManagedClusterSet に追加できません。Red Hat Advanced Cluster Management for Kubernetes コンソールまたはコマンドラインインターフェイスから、マネージドクラスターセットを作成できます。
1.14.1.1. コンソールを使用した ManagedClusterSet の作成
Red Hat Advanced Cluster Management コンソールを使用して、マネージドクラスターセットを作成するには、以下の手順を実行します。
- メインコンソールナビゲーションで、Infrastructure > Clusters を選択します。
- Cluster sets タブを選択します。
- Create cluster set を選択します。
- 作成するクラスターセットの名前を入力します。
- Create を選択して、クラスターセットリソースを作成します。
1.14.1.2. コマンドラインを使用した ManagedClusterSet の作成
コマンドラインを使用して yaml ファイルに以下のマネージドクラスターセットの定義を追加し、マネージドクラスターセットを作成します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSet metadata: name: <clusterset1>
clusterset1 はマネージドクラスターセットの名前に置き換えます。
1.14.2. ManagedClusterSet に対するユーザーまたはグループのロールベースのアクセス制御パーミッションの割り当て
ハブクラスターに設定したアイデンティティープロバイダーが提供するクラスターセットに、ユーザーまたはグループを割り当てることができます。
必要なアクセス権限: クラスターの管理者
ManagedClusterSet API が提供する RBAC パーミッションにはレベルが 2 つあります。
クラスターセット
admin- マネージドクラスターセットに割り当てられた、すべてのクラスターおよびクラスタープールリソースに対する完全なアクセス権限。
- クラスターの作成、クラスターのインポート、クラスタープールの作成権限。パーミッションは、マネージドクラスターセットの作成時に設定したマネージドクラスターに割り当てる必要があります。
クラスターセット
view- マネージドクラスターセットに割り当てられた、すべてのクラスターおよびクラスタープールリソースに対する読み取り専用の権限。
- クラスターの作成、クラスターのインポート、またはクラスタープールの作成を実行する権限なし。
Red Hat Advanced Cluster Management コンソールからマネージドクラスターセットにユーザーまたはグループを割り当てるには、以下の手順を実行します。
- コンソールのメインナビゲーションメニューで、Infrastructure > Clusters を選択します。
- Cluster sets タブを選択します。
- ターゲットクラスターセットを選択します。
- Access management タブを選択します。
- Add user or group を選択します。
- アクセス権を割り当てるユーザーまたはグループを検索して選択します。
- Cluster set admin または Cluster set view ロールを選択して、選択したユーザーまたはグループに付与します。ロールのパーミッションについての詳細は、ロールの概要 を参照してください。
- Add を選択して変更を送信します。
テーブルにユーザーまたはグループが表示されます。全マネージドクラスターセットリソースのパーミッションの割り当てがユーザーまたはグループに伝播されるまでに数秒かかる場合があります。
ロールアクションの詳細は、ロールベースのアクセス制御 を参照してください。
配置の詳細については、Placement での ManagedClustersSets の使用 を参照してください。
1.14.2.1. ManagedClusterSetBinding リソースの作成
ManagedClusterSetBinding リソースを作成して ManagedClusterSet リソースを namespace にバインドします。同じ namespace で作成されたアプリケーションおよびポリシーがアクセスできるのは、バインドされたマネージドクラスターセットリソースに含まれるマネージドクラスターだけです。
namespace へのアクセスパーミッションは、その namespace にバインドされるマネージドクラスターセットに自動的に適用されます。マネージドクラスターセットがバインドされる namespace へのアクセス権限がある場合は、その namespace にバインドされているマネージドクラスターセットにアクセス権限が自動的に付与されます。ただし、マネージドクラスターセットへのアクセス権限のみがある場合は、対象の namespace にある他のマネージドクラスターセットにアクセスする権限は自動的に割り当てられません。マネージドクラスターセットが表示されない場合は、表示に必要なパーミッションがない可能性があります。
コンソールまたはコマンドラインを使用してマネージドクラスターセットバインディングを作成できます。
1.14.2.1.1. コンソールを使用した ManagedClusterSetBinding の作成
Red Hat Advanced Cluster Management コンソールを使用して、マネージドクラスターセットからクラスターを削除するには、以下の手順を実行します。
- メインのナビゲーションで Infrastructure > Clusters を選択して、クラスターページにアクセスします。
- Cluster sets タブを選択して、利用可能なクラスターセットを表示します。
- バインディングを作成するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Edit namespace bindings を選択します。
- Edit namespace bindings ページで、ドロップダウンメニューからクラスターセットをバインドする namespace を選択します。このクラスターセットにバインディングされている既存の namespace は選択してあります。
- Save を選択して変更を送信します。
1.14.2.1.2. コマンドラインを使用した ManagedClusterSetBinding の作成
コマンドラインを使用してマネージドクラスターセットバインディングを作成するには、以下の手順を実行します。
yamlファイルにManagedClusterSetBindingリソースを作成します。クラスターセットバインディングの作成時には、クラスターセットバインディング名と、バインドするマネージドクラスターセット名を一致させる必要があります。ManagedClusterSetBindingリソースは、以下の情報のようになります。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSetBinding metadata: namespace: project1 name: clusterset1 spec: clusterSet: clusterset1
ターゲットのマネージドクラスターセットでのバインド権限を割り当てておく必要があります。以下の
ClusterRoleリソースの例を確認してください。この例には、ユーザーがclusterset1にバインドできるように、複数のルールが含まれています。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/bind"] resourceNames: ["clusterset1"] verbs: ["create"]
1.14.3. クラスターの ManagedClusterSet への追加
ManagedClusterSet の作成後に、1 つ以上のマネージドクラスターを追加する必要があります。コンソールまたはコマンドラインのいずれかを使用して、マネージドクラスターをマネージドクラスターセットに追加できます。
1.14.3.1. コンソールを使用したクラスターの ManagedClusterSet への追加
Red Hat Advanced Cluster Management コンソールを使用してマネージドクラスターセットにクラスターを追加するには、以下の手順を実行します。
- マネージドクラスターセットを作成している場合は、Manage resource assignments を選択して、Manage resource assignments ページに直接移動します。この手順のステップ 6 に進みます。
- クラスターがすでに存在する場合は、メインのナビゲーションで Infrastructure > Clusters を選択してクラスターページにアクセスします。
- Cluster sets タブを選択して、利用可能なクラスターセットを表示します。
- マネージドクラスターセットに追加するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Manage resource assignments を選択します。
- Manage resource assignments ページで、クラスターセットに追加するリソースのチェックボックスを選択します。
- Review を選択して変更を確認します。
Save を選択して変更を保存します。
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合は、マネージドクラスター両方で RBAC パーミッションの設定が必要です。
1.14.3.2. コマンドラインを使用した ManagedClusterSet へのクラスターの追加
コマンドラインを使用してクラスターをマネージドクラスターに追加するには、以下の手順を実行します。
managedclustersets/joinの仮想サブリソースに作成できるように、RBACClusterRoleエントリーが追加されていることを確認します。このパーミッションがない場合は、マネージドクラスターをManagedClusterSetに割り当てることはできません。このエントリーが存在しない場合は、
yamlファイルに追加します。サンプルエントリーは以下の内容のようになります。kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/join"] resourceNames: ["<clusterset1>"] verbs: ["create"]clusterset1はManagedClusterSetの名前に置き換えます。注記: マネージドクラスターを別の
ManagedClusterSetに移動する場合には、マネージドクラスターセット両方でパーミッションの設定が必要です。yamlファイルでマネージドクラスターの定義を検索します。ラベルの追加先のマネージドクラスター定義のセクションは、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true
この例では、
cluster1はマネージドクラスターの名前です。ManagedClusterSetの名前をcluster.open-cluster-management.io/clusterset: clusterset1形式で指定してラベルを追加します。コードは以下の例のようになります。
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 labels: cluster.open-cluster-management.io/clusterset: clusterset1 spec: hubAcceptsClient: trueこの例では、
cluster1は、clusterset1のマネージドクラスターセット名に追加するクラスターです。注記: マネージドクラスターが削除済みのマネージドクラスターセットにこれまでに割り当てられていた場合は、すでに存在しないクラスターが指定されたマネージドクラスターセットがマネージドクラスターに設定されている可能性があります。その場合は、名前を新しい名前に置き換えます。
1.14.4. ManagedClusterSet からのマネージドクラスターの削除
マネージドクラスターセットからマネージドクラスターを削除して別のマネージドクラスターセットに移動するか、セットの管理設定から削除する必要がある場合があります。コンソールまたはコマンドラインインターフェイスを使用して、マネージドクラスターセットからマネージドクラスターを削除できます。
1.14.4.1. コンソールを使用した ManagedClusterSet からのマネージドクラスターの削除
Red Hat Advanced Cluster Management コンソールを使用して、マネージドクラスターセットからクラスターを削除するには、以下の手順を実行します。
- マネージドクラスターセットを作成している場合は、Manage resource assignments を選択して、Manage resource assignments ページに直接移動します。この手順のステップ 6 に進みます。
- クラスターがすでに存在する場合は、メインのナビゲーションで Infrastructure > Clusters を選択してクラスターページにアクセスします。
- Cluster sets タブを選択して、利用可能なクラスターセットを表示します。
- マネージドクラスターセットから削除するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Manage resource assignments を選択します。
Manage resource assignments ページで、クラスターセットから削除するリソースのチェックボックスを選択します。
この手順では、クラスターセットのメンバーであるリソースを削除するか、クラスターセットのメンバーでないリソースを追加します。マネージドクラスターの詳細を表示して、リソースがすでにクラスターセットのメンバーであるかどうかを確認できます。
-
Reviewを選択して変更を確認し、Saveを選択します。
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合には、マネージドクラスターセット両方で RBAC パーミッションの設定が必要です。
1.14.4.2. コマンドラインを使用した ManagedClusterSet からのクラスターの削除
マネージドクラスターセットからマネージドクラスターを削除するには、以下の手順を実行します。
以下のコマンドを実行して、マネージドクラスターセットでマネージドクラスターのリストを表示します。
oc get managedclusters -l cluster.open-cluster-management.io/clusterset=<clusterset1>
clusterset1はマネージドクラスターセットの名前を置き換えます。- 削除するクラスターのエントリーを見つけます。
削除するクラスターの
yamlエントリーからラベルを削除します。ラベルの例については、以下のコードを参照してください。labels: cluster.open-cluster-management.io/clusterset: clusterset1
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合には、マネージドクラスターセット両方で RBAC パーミッションの設定が必要です。
1.14.5. Placement での ManagedClusterSets の使用
Placement リソースは、namespace レベルのリソースで、placement namespace にバインドされる ManagedClusterSets から ManagedClusters セットを選択するルールを定義します。
必要なアクセス権限: クラスター管理者またはクラスターセット管理者。
1.14.5.1. 配置の概要
マネージドクラスターによる配置の仕組みについては、以下を参照してください。
-
Kubernetes クラスターは、cluster スコープの
ManagedClustersとしてハブクラスターに登録されます。 -
managedclusterは、クラスタースコープのManagedClusterSetsに編成されます。 -
ManagedClusterSetsはワークロード namespace にバインドされます。 -
namespace スコープの
Placementsは、ManagedClusterSetsの一部を指定して、ManagedClusters候補の作業セットを選択します。 Placementsは、ラベルと要求セレクターを使用して作業セットから選択します。重要:
Placementでは、placement namespace にManagedClusterSetがバインドされていない場合、ManagedClusterは選択されません。
Placement 仕様には以下のフィールドが含まれます。
ClusterSetsは、ManagedClustersの選択元のManagedClusterSetsを表します。-
指定されていない場合は、Placement namespace にバインドされる
ManagedClusterSetsからManagedClustersが選択されます。 -
指定されている場合は、
ManagedClustersがこのセットの交差部分から選択され、ManagedClusterSetsは Placement namespace にバインドされます。
-
指定されていない場合は、Placement namespace にバインドされる
NumberOfClustersは、配置要件を満たすManagedClustersの中から選択する数を表します。指定されていない場合は、配置要件を満たすすべての
ManagedClustersが選択されます。-
Predicatesは、ラベルおよび要求セレクターでManagedClustersを選択する述語のスライスを表します。述語は ORed です。 prioritizerPolicyは優先順位のポリシーを表します。モードはExact、Additive、または""のいずれかになります。ここで""はデフォルトで Additive になります。-
Additiveモードでは、設定値が特に指定されていない Prioritizer はデフォルト設定で有効になっています。現在のデフォルト設定では、Steady と Balance の重みは 1 で、他の Prioritizer は 0 になります。デフォルトの設定は、今後変更される可能性があるので、優先順位が変更される可能性があります。Additiveモードでは、すべての Prioritizer を設定する必要はありません。 -
Exactモードでは、設定値で特に指定されていない Prioritizer の重みがゼロになります。Exactモードでは、必要な Prioritizer の完全なセットを入力する必要がありますが、リリースごとに動作が変わることはありません。
-
設定とは、Prioritizer の設定を表します。Nameは、Prioritizer の名前です。Prioritizer の有効な名前のリストを参照してください。-
Balance: クラスター間の決定を分散します。 -
Steady: 既存のデシジョンが安定していることを確認します。 -
ResourceAllocatableCPU&ResourceAllocatableMemory: 割り当て可能なリソースに基づいてクラスターを分類します。
-
-
weightは Prioritizer の重みを定義します。値は [0,10] の範囲に指定する必要があります。それぞれの prioritizer は、[-100, 100] の範囲でクラスターの整数スコアを計算します。クラスターの最後のスコアは、以下の式sum(weight * prioritizer_score)で決定されます。重みが大きい場合は、Prioritizer はクラスターの選択で重みの高いものを受け取ることを意味し、一方、重みが 0 の場合は Prioritizer が無効であることを示します。
1.14.5.2. 配置の例
namespace に ManagedClusterSetBinding を作成して、その namespace に ManagedClusterSet を最低でも 1 つバインドする必要があります。注記: managedclustersets/bind の仮想サブリソースの CREATE に対してロールベースのアクセスが必要です。以下の例を参照してください。
labelSelectorでManagedClustersを選択します。以下の例では、labelSelectorはラベルvendor: OpenShiftのクラスターだけに一致します。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShiftclaimSelectorでManagedClustersを選択します。以下の例では、claimSelectorはregion.open-cluster-management.ioがus-west-1のクラスターだけに一致します。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1clusterSetsからManagedClustersを選択します。以下の例では、claimSelectorはclusterSets:clusterset1clusterset2だけに一致します。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement3 namespace: ns1 spec: clusterSets: - clusterset1 - clusterset2 predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1任意の数の
ManagedClustersを選択します。以下の例は、numberOfClustersが3の場合です。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement4 namespace: ns1 spec: numberOfClusters: 3 predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShift claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1割り当て可能なメモリーが最大のクラスターを選択します。
注記: Kubernetes Node Allocatable と同様に、ここでの allocatable は、各クラスターの Pod で利用可能なコンピュートリソースの量として定義されます。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement6 namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - name: ResourceAllocatableMemory割り当て可能な CPU およびメモリーが最大のクラスターを選択し、配置がリソースの変更に厳密に対応するように設定します。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement7 namespace: ns1 spec: numberOfClusters: 2 prioritizerPolicy: configurations: - name: ResourceAllocatableCPU weight: 2 - name: ResourceAllocatableMemory weight: 2割り当て可能なメモリーが最大となっているクラスターを選択し、placementdecisions を固定します。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement8 namespace: ns1 spec: numberOfClusters: 4 prioritizerPolicy: mode: Exact configurations: - name: ResourceAllocatableMemory - name: Steady weight: 3
1.14.5.3. 配置のデシジョン
ラベルが cluster.open-cluster-management.io/placement={placement name} の PlacementDecisions が 1 つまたは複数作成され、Placement で選択された ManagedClusters を表します。
ManagedCluster が選択され、PlacementDecision に追加されると、この Placement を使用するコンポーネントは、ManagedCluster でワークロードを適用する可能性があります。ManagedCluster が選択されなくなり、PlacementDecisions から削除されると、この ManagedCluster に適用されるワークロードも随時削除する必要があります。
以下の PlacementDecision の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/placement: placement1
name: placement1-kbc7q
namespace: ns1
ownerReferences:
- apiVersion: cluster.open-cluster-management.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Placement
name: placement1
uid: 05441cf6-2543-4ecc-8389-1079b42fe63e
status:
decisions:
- clusterName: cluster1
reason: ''
- clusterName: cluster2
reason: ''
- clusterName: cluster3
reason: ''1.14.5.4. アドオンのステータス
デプロイ先のアドオンのステータスに合わせて、配置用のマネージドクラスターを選択できます。たとえば、クラスターで有効になっている特定のアドオンがある場合にのみ、配置のマネージドクラスターを選択します。
これは、アドオンのラベルと、必要に応じてそのステータスを指定して実行できます。クラスターでアドオンが有効になっている場合、ラベルは ManagedCluster リソースで自動的に作成されます。アドオンが無効になると、ラベルは自動的に削除されます。
各アドオンは、feature.open-cluster-management.io/addon-<addon_name>=<status_of_addon> の形式でラベルで表現します。
addon_name は、選択するマネージドクラスターで有効にする必要があるアドオンの名前に置き換えます。
status_of_addon は、クラスターが選択されている場合にアドオンに指定すべきステータスに置き換えます。status_of_addon の使用可能な値は以下の一覧のとおりです。
-
Available: アドオンが有効で利用可能である。 -
unhealthy: アドオンは有効になっているが、リースは継続的に更新されない。 -
unreachable: アドオンは有効になっているが、リースが見つからない。これは、マネージドクラスターがオフライン時にも発生する可能性があります。
たとえば、利用可能な application-manager アドオンは、以下を読み取るマネージドクラスターのラベルで表されます。
feature.open-cluster-management.io/addon-application-manager: available
アドオンおよびそれらのステータスに基づいて配置を作成する以下の例を参照してください。
以下の YAML コンテンツを追加して、
application-managerを有効化したマネージドクラスターすべてを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: Exists以下の YAML コンテンツを追加して、
application-managerがavailableのステータスで有効化されているすべてのマネージドクラスターを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: "feature.open-cluster-management.io/addon-application-manager": "available"以下の YAML コンテンツを追加して、
application-managerが無効にされているマネージドクラスターすべてを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: Placement metadata: name: placement3 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: DoesNotExist
1.15. クラスタープールの管理 (テクノロジープレビュー)
クラスタープールは、Red Hat OpenShift Container Platform クラスターにオンデマンドで、スケーリングする場合に、迅速かつコスト効果を高く保ちながら、アクセスできるようにします。クラスタープールは、Amazon Web Services、Google Cloud Platform、または Microsoft Azure で設定可能な数多くの OpenShift Container Platform クラスターを維持します。このプールは、開発、継続統合、および実稼働のシナリオにおいてクラスター環境を提供したり、置き換えたりする場合に特に便利です。
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスターがクラスタープールからチェックアウトされると、チェックされたクラスターは再開されて、Ready 状態に切り替わります。クラスタープールは、クラスタープールに休止状態のクラスターを自動的に作成して要求されたクラスターと置き換えます。
注記: クラスタープールから要求されたクラスターが不要になり、破棄されると、リソースは削除されます。クラスターはクラスタープールに戻りません。
必要なアクセス権限: 管理者
クラスタープールを作成する手順は、クラスターの作成手順と似ています。クラスタープールのクラスターは、すぐ使用するために作成されるわけではありません。
1.15.1. 前提条件
クラスタープールを作成する前に、次の前提条件を参照してください。
- Red Hat Advanced Cluster Management for Kubernetes のハブクラスターをデプロイする必要があります。
- プロバイダー環境で Kubernetes クラスターを作成できるようにする Red Hat Advanced Cluster Management for Kubernetes ハブクラスターでのインターネットアクセスが必要です。
- AWS、GCP、または Microsoft Azure プロバイダーのクレデンシャルが必要です。詳細は、認証情報の管理 を参照してください。
- プロバイダー環境で設定済みのドメインが必要です。ドメインの設定方法は、プロバイダーのドキュメントを参照してください。
- プロバイダーのログイン認証情報が必要です。
- OpenShift Container Platform イメージプルシークレットが必要です。イメージプルシークレットの使用 を参照してください。
注記: この手順でクラスタープールを追加すると、プールからのクラスター要求時に、Red Hat Advanced Cluster Management が管理するクラスターが自動的にインポートされます。クラスター要求で管理用に、要求されたクラスターを自動的にインポートしないようにクラスタープールを作成する場合には、clusterClaim 理 s−すを以下ののテーションに追加します。
kind: ClusterClaim
metadata:
annotations:
cluster.open-cluster-management.io/createmanagedcluster: "false"
文字列であることを示すには、"false" という単語を引用符で囲む必要があります。
1.15.2. クラスタープールの作成
クラスタープールを作成するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択して、アクセス可能なクラスタープールを表示します。
- Create cluster pool を選択します。
- クラスタープールのインフラストラクチャープロバイダーを選択します。
- クラスタープールに使用するインフラストラクチャーの認証情報を選択します。一覧にない場合は、Add credential を選択して作成します。
- Next を選択して、クラスタープールの詳細に進みます。
- クラスタープールの名前を入力します。
クラスタープールを作成する namespace を入力します。一覧から既存の namespace を選択するか、作成する新規 namespace の名前を入力します。クラスタープールは、クラスターと同じ namespace に配置する必要はありません。
クラスターセットでクラスタープールを作成すると、クラスタープールの追加先の namespace の
clusterset adminパーミッションがある全ユーザーに、namespace adminパーミッションが適用されます。同様に、namespace viewパーミッションはclusterset viewパーミッションのあるユーザーに適用されます。オプション: クラスタープールの RBAC ロールを使用して、既存クラスターセットのロール割り当てを共有する場合は、クラスターセット名を選択します。クラスタープールのクラスターセットは、クラスタープールの作成時にのみ設定できます。クラスタープールの作成後には、クラスタープールまたはクラスタープールのクラスターセットの関連付けを変更できません。クラスタープールから要求したクラスターは、クラスタープールと同じクラスターセットに自動的に追加されます。
注記:
cluster adminのパーミッションがない場合は、クラスターセットを選択する必要があります。この状況でクラスターセットの名前が含まれない場合は、禁止エラーで、クラスターセットの作成要求が拒否されます。選択できるクラスターセットがない場合は、クラスター管理者に連絡してクラスターセットを作成し、clusterset adminパーミッションを付与してもらいます。- クラスタープールのサイズに、クラスタープールで利用可能にするクラスターの数を追加して、入力します。
- Next を選択します。
残りの手順で必要な情報を入力して、クラスタープールをプロビジョニングします。以下の手順は、クラスターを作成する手順と同じです。
プロバイダーに必要な固有の情報は、以下を参照してください。
- すべての情報を入力したら、Create を選択してクラスタープールを作成します。1 つ以上のクラスターがプールで利用可能になると、Claim cluster ボタンが表示されます。
1.15.3. クラスタープールからのクラスターの要求
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスターがクラスタープールからチェックアウトされると、チェックされたクラスターは Ready 状態に切り替わります。クラスタープールは、クラスタープールに休止状態のクラスターを新たに自動作成し、要求されたクラスターと置き換えます。
注記: クラスタープールから要求されたクラスターが不要になり、破棄されると、リソースは削除されます。クラスターはクラスタープールに戻りません。
必要なアクセス権限: 管理者
1.15.3.1. 前提条件
クラスタープールからクラスターを要求する前に、以下を利用意する必要があります。
要求可能なクラスターが含まれるクラスタープール。クラスタープールの作成方法については、クラスタープールの作成 を参照してください。要求可能なクラスターがない場合は、Claim Cluster ボタンは表示されません。
1.15.3.2. クラスタープールからのクラスターの要求
クラスタープールからクラスターをチェックアウトするには、クラスターを再開し、マネージドクラスターの 1 つとして要求します。以下の手順を実行してクラスターを要求します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- クラスターを要求するクラスタープールの名前を見つけ、Claim cluster を選択します。
- クラスターの特定に役立つクラスターの要求名を入力します。
- Claim を選択します。
クラスターは要求されると、休止状態を終了して、Resuming のステータスで Managed Cluster タブに表示されます。クラスターのステータスが Ready になると、クラスターは使用できます。
要求されたクラスターは、クラスタープールにあった時に関連付けられたクラスターセットに所属します。要求時には、要求したクラスターのクラスターセットは変更できません。
1.15.4. クラスタープールのスケーリング
クラスタープールのサイズを変更するには、クラスタープール内の休止状態のクラスターの数を増減できます。
必要なアクセス権限: クラスターの管理者
クラスタープールのクラスター数を変更するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- Cluster pools の表でクラスタープールの名前を見つけます。
- 変更するクラスタープールの Options メニューで、Scale cluster pool を選択します。
- プールサイズの値を変更して、プールサイズを増減します。
- Scale を選択して変更をコミットします。
クラスタープールは、新しい値を反映するようにスケーリングされます。
1.15.5. クラスタープールリリースイメージの更新
クラスタープールのクラスターが一定期間、休止状態のままになると、クラスターの Red Hat OpenShift Container Platform リリースイメージがバックレベルになる可能性があります。このような場合は、クラスタープールにあるクラスターのリリースイメージのバージョンをアップグレードしてください。
必要なアクセス: 編集
クラスタープールにあるクラスターの OpenShift Container Platform リリースイメージを更新するには、以下の手順を実行します。
注記: この手順では、クラスタープールですでに要求されているクラスタープールからクラスターを更新しません。この手順を完了すると、リリースイメージの更新は、クラスタープールに関連する次のクラスターにのみ適用されます。
- この手順でリリースイメージを更新した後にクラスタープールによって作成されたクラスター。
- クラスタープールで休止状態になっているクラスター。古いリリースイメージを持つ既存の休止状態のクラスターは破棄され、新しいリリースイメージを持つ新しいクラスターがそれらを置き換えます。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- クラスタープール の表で、更新するクラスタープールの名前を見つけます。
- Options メニューをクリックして、利用可能なオプションを表示します。
- Update release image を選択します。
- このクラスタープールから今後、クラスターの作成に使用する新規リリースイメージを選択します。
- Update を選択して、選択したリリースイメージを適用します。
- クラスタープールのリリースイメージが更新されました。
ヒント: アクション 1 つで複数のクラスターのリリースイメージを更新するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールのリリースイメージを更新します。
1.15.6. クラスタープールの破棄
クラスタープールを作成し、不要になった場合は、そのクラスタープールを破棄できます。クラスタープールを破棄する時に、要求されていない休止状態のクラスターはすべて破棄され、そのリソースは解放されます。
必要なアクセス権限: クラスターの管理者
クラスタープールを破棄するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- Cluster pools の表でクラスタープールの名前を見つけます。
- Options メニューをクリックし、クラスタープールのオプションを表示します。
- Destroy cluster pool を選択します。
- クラスターの名前を入力して確定します。
Destroy を選択して、クラスタープールを削除します。クラスタープールで要求されていないクラスターは破棄されます。すべてのリソースが削除されるまでに時間がかかる場合があります。また、クラスタープールは、すべてのリソースが削除されるまでコンソールに表示されたままになります。
ClusterPool が含まれる namespace は削除されません。namespace を削除すると、これらのクラスターの ClusterClaim リソースは同じ namespace で作成されるため、ClusterPool から要求されたクラスターがすべて破棄されます。
ヒント: アクション 1 つで複数のクラスタープールを破棄するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールを破棄します。
クラスタープールが削除されました。
1.16. ClusterClaims
ClusterClaim は、マネージドクラスター上のカスタムリソース定義 (CRD) です。ClusterClaim は、マネージドクラスターが要求する情報の一部を表します。以下の例は、YAML ファイルで特定される要求を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: ClusterClaim metadata: name: id.openshift.io spec: value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
以下の表は、Red Hat Advanced Cluster Management for Kubernetes が管理するクラスターにある、定義済みの ClusterClaim を示しています。
| 要求名 | 予約 | 変更可能 | 説明 |
|---|---|---|---|
|
| true | false | アップストリームの提案で定義された ClusterID |
|
| true | true | Kubernetes バージョン |
|
| true | false | AWS、GCE、Equinix Metal など、マネージドクラスターが稼働しているプラットフォーム |
|
| true | false | OpenShift、Anthos、EKS、および GKE などの製品名 |
|
| false | false | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform 外部 ID |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる管理コンソールの URL |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform バージョン |
マネージドクラスターで以前の要求が削除されるか、または更新されると、自動的に復元またはロールバックされます。
マネージドクラスターがハブに参加すると、マネージドクラスターで作成された ClusterClaim は、ハブの ManagedCluster リソースのステータスと同期されます。ClusterClaims のマネージドクラスターは、以下の例のようになります。
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
labels:
cloud: Amazon
clusterID: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
installer.name: multiclusterhub
installer.namespace: open-cluster-management
name: cluster1
vendor: OpenShift
name: cluster1
spec:
hubAcceptsClient: true
leaseDurationSeconds: 60
status:
allocatable:
cpu: '15'
memory: 65257Mi
capacity:
cpu: '18'
memory: 72001Mi
clusterClaims:
- name: id.k8s.io
value: cluster1
- name: kubeversion.open-cluster-management.io
value: v1.18.3+6c42de8
- name: platform.open-cluster-management.io
value: AWS
- name: product.open-cluster-management.io
value: OpenShift
- name: id.openshift.io
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
- name: consoleurl.openshift.io
value: 'https://console-openshift-console.apps.xxxx.dev04.red-chesterfield.com'
- name: version.openshift.io
value: '4.5'
conditions:
- lastTransitionTime: '2020-10-26T07:08:49Z'
message: Accepted by hub cluster admin
reason: HubClusterAdminAccepted
status: 'True'
type: HubAcceptedManagedCluster
- lastTransitionTime: '2020-10-26T07:09:18Z'
message: Managed cluster joined
reason: ManagedClusterJoined
status: 'True'
type: ManagedClusterJoined
- lastTransitionTime: '2020-10-30T07:20:20Z'
message: Managed cluster is available
reason: ManagedClusterAvailable
status: 'True'
type: ManagedClusterConditionAvailable
version:
kubernetes: v1.18.3+6c42de81.16.1. 既存の ClusterClaim の表示
kubectl コマンドを使用して、マネージドクラスターに適用される ClusterClaim を一覧表示できます。これは、ClusterClaim をエラーメッセージと比較する場合に便利です。
注記: clusterclaims.cluster.open-cluster-management.io のリソースに list のパーミッションがあることを確認します。
以下のコマンドを実行して、マネージドクラスターにある既存の ClusterClaim の一覧を表示します。
kubectl get clusterclaims.cluster.open-cluster-management.io
1.16.2. カスタム ClusterClaims の作成
ClusterClaim は、マネージドクラスターでカスタム名を使用して作成できるため、簡単に識別できます。カスタム ClusterClaim は、ハブクラスターの ManagedCluster リソースのステータスと同期されます。以下のコンテンツでは、カスタマイズされた ClusterClaim の定義例を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: ClusterClaim metadata: name: <custom_claim_name> spec: value: <custom_claim_value>
spec.value フィールドの最大長は 1024 です。ClusterClaim を作成するには clusterclaims.cluster.open-cluster-management.io リソースの create パーミッションが必要です。
1.17. Discovery サービスの概要 (テクノロジープレビュー)
OpenShift Cluster Manager で利用可能な OpenShift 4 クラスターを検出できます。検出後に、クラスターをインポートして管理できます。Discovery サービスは、バックエンドおよびコンソールでの用途に Discover Operator を使用します。
OpenShift Cluster Manager 認証情報が必要になります。認証情報を作成する必要がある場合は、Red Hat OpenShift Cluster Manager の認証情報の作成 を参照してください。
必要なアクセス権限: 管理者
1.17.1. コンソールでの検出の設定 (テクノロジープレビュー)
製品のコンソールを使用して検出を有効にします。
必要なアクセス権: 認証情報が作成される namespace へのアクセス権。
1.17.1.1. 前提条件
- 認証情報が必要です。OpenShift Cluster Manager に接続するには、Red Hat OpenShift Cluster Manager の認証情報の作成 を参照してください。
1.17.1.2. 検出の設定
コンソールで検出を設定し、クラスターを検索します。個別の認証情報を使用して複数の DiscoveryConfig リソースを作成できます。
検出を初めて使用する場合は、以下の手順を参照してください。
- コンソールナビゲーションで Clusters をクリックします。
- Configure Discovery をクリックして検出設定を指定します。
namespace および認証情報を選択します。
- 認証情報を含む namespace を選択します。
- その namespace 内での認証情報を選択します。
フィルターを設定して、関連するクラスターを検出します。
- 有効な最新のクラスターのフィルターを選択します。たとえば、7 日を選択した場合は、直前の 7 日間にアクティブなクラスターを検索します。
- Red Hat OpenShift バージョンを選択します。
- Add をクリックします。
- Clusters ページから、コンソールで検出されたクラスターを表示します。
- オプション: Create discovery settings をクリックして、他のクラスターを作成します。
- オプション: Configure discovery settings をクリックして、検出設定を変更したり、削除したりします。
1.17.2. CLI を使用した検出の有効化 (テクノロジープレビュー)
CLI を使用して検出を有効にし、Red Hat OpenShift Cluster Manager (リンク) が入手できるクラスターを見つけます。
必要なアクセス権限: 管理者
1.17.2.1. 前提条件
- Red Hat OpenShift Cluster Manager に接続するための認証情報を作成している。
1.17.2.2. 検出の設定とプロセス
注記: DiscoveryConfig は discovery という名前に指定し、選択した credential と同じ namespace に作成する必要があります。以下の DiscoveryConfig のサンプルを参照してください。
apiVersion: discovery.open-cluster-management.io/v1alpha1
kind: DiscoveryConfig
metadata:
name: discovery
namespace: <NAMESPACE_NAME>
spec:
credential: <SECRET_NAME>
filters:
lastActive: 7
openshiftVersions:
- "4.8"
- "4.7"
- "4.6"
- "4.5"-
SECRET_NAMEは、以前に設定した認証情報に置き換えます。 -
NAMESPACE_NAMEはSECRET_NAMEの namespace に置き換えます。 -
クラスターの最後のアクティビティー (日数) からの最大時間を入力します。たとえば、
lastActive: 7は、過去 7 日間にアクティブなクラスターのみ検出します。 -
Red Hat OpenShift クラスターのバージョンを入力して、文字列の一覧として検出します。注記:
openshiftVersions一覧に含まれるエントリーはすべて、OpenShift のメジャーバージョンとマイナーバージョンを指定します。たとえば、"4.7"には OpenShift バージョン4.7(4.7.1、4.7.2など) のパッチリリースすべてが含まれます。
1.17.2.3. 検出されたクラスターの表示
検出されたクラスターを表示するには、oc get discoveredclusters -n <namespace> を実行して、namespace は検出認証情報が存在する namespace に置き換えます。
1.17.2.3.1. DiscoveredClusters
オブジェクトは Discovery コントローラーにより作成されます。このような DiscoveredClusters は、 DiscoveryConfig discoveredclusters.discovery.open-cluster-management.io API で指定したフィルターと認証情報を使用して OpenShift Cluster Manager で検出されたクラスターを表します。name の値はクラスターの外部 ID です。
apiVersion: discovery.open-cluster-management.io/v1alpha1
kind: DiscoveredCluster
metadata:
name: fd51aafa-95a8-41f7-a992-6fb95eed3c8e
namespace: <NAMESPACE_NAME>
spec:
activity_timestamp: "2021-04-19T21:06:14Z"
cloudProvider: vsphere
console: https://console-openshift-console.apps.qe1-vmware-pkt.dev02.red-chesterfield.com
creation_timestamp: "2021-04-19T16:29:53Z"
credential:
apiVersion: v1
kind: Secret
name: <SECRET_NAME>
namespace: <NAMESPACE_NAME>
display_name: qe1-vmware-pkt.dev02.red-chesterfield.com
name: fd51aafa-95a8-41f7-a992-6fb95eed3c8e
openshiftVersion: 4.6.22
status: Stale1.17.3. 検出したクラスターの表示 (テクノロジープレビュー)
認証情報を設定してインポートするクラスターを検出した後に、コンソールで表示できます。
- Cluster > Discovered clusters の順にクリックします。
以下の情報が投入された表を確認してください。
- name は、OpenShift Cluster Manager で指定された表示名です。クラスターに表示名がない場合は、クラスターコンソール URL をもとに生成された名前が表示されます。OpenShift Cluster Manager でコンソール URL がない場合や手動で変更された場合には、クラスターの外部 ID が表示されます。
- Namespace は、認証情報および検出クラスターを作成した namespace です。
- type は検出されたクラスターの Red Hat OpenShift タイプです。
- distribution version は、検出されたクラスターの Red Hat OpenShift バージョンです。
- infrastrcture provider は検出されたクラスターのクラウドプロバイダーです。
- Last active は、検出されたクラスターが最後にアクティブであった時間です。
- Created は検出クラスターが作成された時間です。
- Discovered は検出クラスターが検出された時間です。
- 表の中にある情報はどれでも検索できます。たとえば、特定の namespace で Discovered clusters のみを表示するには、その namespace を検索します。
- Import cluster をクリックすると、マネージドクラスターを作成できます。検出クラスターのインポート を参照してください。
1.17.4. 検出クラスターのインポート (テクノロジープレビュー)
クラスターの検出後に、コンソールの Discovered clusters に表示されるクラスターをインポートできます。
1.17.4.1. 前提条件
検出の設定に使用した namespace へのアクセス権が必要である。
1.17.4.2. 検出クラスターのインポート
- 既存の Clusters ページに移動し、 Discovered clusters タブをクリックします。
- Discovered Clusters の表から、インポートするクラスターを見つけます。
- オプションメニューから Import cluster を選択します。
- 検出クラスターの場合は、本書を使用して手動でインポートしたり、Import cluster を自動的に選択したりできます。
- 認証情報または Kubeconfig ファイルを使用して自動でインポートするには、コンテンツをコピーして貼り付けます。
- Import をクリックします。
1.18. クラスターのアップグレード
Red Hat Advanced Cluster Management for Kubernetes で管理する Red Hat OpenShift Container Platform クラスターを作成したら、Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、マネージドクラスターが使用するバージョンチャネルで利用可能な最新のマイナーバージョンに、これらのクラスターをアップグレードできます。
オンライン環境では、Red Hat Advanced Cluster Management コンソールでアップグレードが必要なクラスターごとに送信される通知を使用して、更新が自動識別されます。
重要: オフライン環境のクラスターをアップグレードするプロセスでは、必要なリリースイメージを設定してミラーリングする手順が追加で必要になります。この手順では、Red Hat OpenShift Update Service の Operator を使用してアップグレードを特定します。オフライン環境を使用している場合の必要な手順については、非接続クラスターのアップグレード を参照してください。
注記:
メジャーバージョンへのアップグレードには、そのバージョンへのアップグレードの前提条件をすべて満たしていることを確認する必要があります。コンソールでクラスターをアップグレードする前に、マネージドクラスターのバージョンチャネルを更新する必要があります。
マネージドクラスターのバージョンチャネルを更新後に、Red Hat Advanced Cluster Management for Kubernetes コンソールに、アップグレードに利用可能な最新版が表示されます。
このアップグレードの手法は、ステータスが Ready の OpenShift Container Platform のマネージドクラスタークラスターでだけ使用できます。
重要: Red Hat Advanced Cluster Management for Kubernetes コンソールを使用して、Red Hat OpenShift Dedicated で Red Hat OpenShift Kubernetes Service マネージドクラスターまたは OpenShift Container Platform マネージドクラスターをアップグレードできません。
オンライン環境でクラスターをアップグレードするには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。アップグレードが利用可能な場合には、Distribution version の列に表示されます。
- アップグレードする Ready 状態のクラスターを選択します。コンソールでアップグレードするには、クラスターが andcluster である必要があります。
- Upgrade を選択します。
- 各クラスターの新しいバージョンを選択します。
- Upgrade を選択します。
クラスターのアップグレードに失敗すると、Operator は通常アップグレードを数回再試行し、停止し、コンポーネントに問題があるステータスを報告します。場合によっては、アップグレードプロセスは、プロセスの完了を繰り返し試行します。アップグレードに失敗した後にクラスターを以前のバージョンにロールバックすることはサポートされていません。クラスターのアップグレードに失敗した場合は、Red Hat サポートにお問い合わせください。
1.18.1. チャネルの選択
Red Hat Advanced Cluster Management コンソールを使用して、OpenShift Container Platform バージョン 4.6 以降でクラスターのアップグレードのチャネルを選択できます。チャネルを選択すると、エラータバージョン (4.8.1> 4.8.2> 4.8.3 など) とリリースバージョン (4.8> 4.9 など) の両方で使用できるクラスターアップグレードが自動的に通知されます。
クラスターのチャネルを選択するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- 変更するクラスターの名前を選択して、Cluster details ページを表示します。クラスターに別のチャネルが利用可能な場合は、編集アイコンが Channel フィールドに表示されます。
- 編集アイコンをクリックして、フィールドの設定を変更します。
- New channel フィールドでチャネルを選択します。
- Save をクリックして変更をコミットします。
利用可能なチャネル更新のリマインダーは、クラスターの Cluster details ページで見つけることができます。
1.18.2. 非接続クラスターのアップグレード
Red Hat OpenShift Update Service を Red Hat Advanced Cluster Management for Kubernetes で使用すると、非接続環境でクラスターをアップグレードできます。
セキュリティー上の理由で、クラスターがインターネットに直接接続できない場合があります。このような場合は、アップグレードが利用可能なタイミングや、これらのアップグレードの処理方法を把握するのが困難になります。OpenShift Update Service を設定すると便利です。
OpenShift Update Service は、個別の Operator および オペランドで、非接続環境で利用可能なマネージドクラスターを監視して、クラスターのアップグレードで利用できるようにします。OpenShift Update Service の設定後に、以下のアクションを実行できます。
- オフラインのクラスター向けにいつアップグレードが利用できるかを監視します。
- グラフデータファイルを使用してアップグレード用にどの更新がローカルサイトにミラーリングされているかを特定します。
Red Hat Advanced Cluster Management コンソールを使用して、クラスターのアップグレードが利用可能であることを通知します。
1.18.2.1. 前提条件
OpenShift Update Service を使用して非接続クラスターをアップグレードするには、以下の前提条件を満たす必要があります。
Red Hat OpenShift Container Platform 4.6 以降に、制限付きの OLM を設定して Red Hat Advanced Cluster Management ハブクラスターをデプロイしている。制限付きの OLM の設定方法については、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
ヒント: 制限付きの OLM の設定時に、カタログソースイメージをメモします。
- Red Hat Advanced Cluster Management ハブクラスターが管理する OpenShift Container Platform クラスター。
クラスターイメージをミラーリング可能なローカルレジストリーにアクセスするための認証情報。このリポジトリーの作成方法は、非接続インストールのイメージのミラーリング を参照してください。
注記: アップグレードするクラスターの現行バージョンのイメージは、ミラーリングされたイメージの 1 つとして常に利用可能でなければなりません。アップグレードに失敗すると、クラスターはアップグレード試行時のクラスターのバージョンに戻ります。
1.18.2.2. 非接続ミラーレジストリーの準備
ローカルのミラーリングレジストリーに、アップグレード前の現行のイメージと、アップグレード後のイメージの療法をミラーリングする必要があります。イメージをミラーリングするには以下の手順を実行します。
以下の例のような内容を含むスクリプトファイルを作成します。
UPSTREAM_REGISTRY=quay.io PRODUCT_REPO=openshift-release-dev RELEASE_NAME=ocp-release OCP_RELEASE=4.5.2-x86_64 LOCAL_REGISTRY=$(hostname):5000 LOCAL_SECRET_JSON=/path/to/pull/secret oc adm -a ${LOCAL_SECRET_JSON} release mirror \ --from=${UPSTREAM_REGISTRY}/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE} \ --to=${LOCAL_REGISTRY}/ocp4 \ --to-release-image=${LOCAL_REGISTRY}/ocp4/release:${OCP_RELEASE}path-to-pull-secretは、OpenShift Container Platform のプルシークレットへのパスに置き換えます。- スクリプトを実行して、イメージのミラーリング、設定の設定、リリースイメージとリリースコンテンツの分離を行います。
ヒント: ImageContentSourcePolicy の作成時に、このスクリプトの最後の行にある出力を使用できます。
1.18.2.3. OpenShift Update Service の Operator のデプロイ
OpenShift Container Platform 環境で OpenShift Update Service の Operator をデプロイするには、以下の手順を実行します。
- ハブクラスターで、OpenShift Container Platform Operator のハブにアクセスします。
-
Red Hat OpenShift Update Service Operatorを選択して Operator をデプロイします。必要に応じてデフォルト値を更新します。Operator をデプロイすると、openshift-cincinnatiという名前の新規プロジェクトが作成されます。 Operator のインストールが完了するまで待ちます。
ヒント: OpenShift Container Platform コマンドラインで
oc get podsコマンドを入力して、インストールのステータスを確認できます。Operator の状態がrunningであることを確認します。
1.18.2.4. グラフデータの init コンテナーの構築
OpenShift Update Service はグラフデータ情報を使用して、利用可能なアップグレードを判別します。オンライン環境では、OpenShift Update Service は Cincinnati グラフデータの GitHub リポジトリー から直接利用可能なアップグレードがないか、グラフデータ情報をプルします。非接続環境を設定しているため、init container を使用してローカルリポジトリーでグラフデータを利用できるようにする必要があります。以下の手順を実行して、グラフデータの init container を作成します。
以下のコマンドを入力して、グラフデータ Git リポジトリーのクローンを作成します。
git clone https://github.com/openshift/cincinnati-graph-data
グラフデータの
initの情報が含まれるファイルを作成します。このサンプル Dockerfile は、cincinnati-operatorGitHub リポジトリーにあります。ファイルの内容は以下の例のようになります。FROM registry.access.redhat.com/ubi8/ubi:8.1 RUN curl -L -o cincinnati-graph-data.tar.gz https://github.com/openshift/cincinnati-graph-data/archive/master.tar.gz RUN mkdir -p /var/lib/cincinnati/graph-data/ CMD exec /bin/bash -c "tar xvzf cincinnati-graph-data.tar.gz -C /var/lib/ cincinnati/graph-data/ --strip-components=1"
この例では、以下のように設定されています。
-
FROM値は、OpenShift Update Service がイメージを検索する先の外部レジストリーに置き換えます。 -
RUNコマンドはディレクトリーを作成し、アップグレードファイルをパッケージ化します。 -
CMDコマンドは、パッケージファイルをローカルリポジトリーにコピーして、ファイルを展開してアップグレードします。
-
以下のコマンドを実行して、
graph data init containerをビルドします。podman build -f <path_to_Dockerfile> -t ${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container:latest podman push ${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container:latest --authfile=/path/to/pull_secret.jsonpath_to_Dockerfile は、直前の手順で作成したファイルへのパスに置き換えます。
${DISCONNECTED_REGISTRY}/cincinnati/cincinnati-graph-data-container は、ローカルグラフデータ init container へのパスに置き換えます。
/path/to/pull_secret は、プルシークレットへのパスに置き換えます。
注記:
podmanがインストールされていない場合は、コマンドのpodmanをdockerに置き換えることもできます。
1.18.2.5. ミラーリングされたレジストリーの証明書の設定
セキュアな外部コンテナーレジストリーを使用してミラーリングされた OpenShift Container Platform リリースイメージを保存する場合は、アップグレードグラフをビルドするために OpenShift Update Service からこのレジストリーへのアクセス権が必要です。OpenShift Update Service Pod と連携するように CA 証明書を設定するには、以下の手順を実行します。
image.config.openshift.ioにある OpenShift Container Platform 外部レジストリー API を検索します。これは、外部レジストリーの CA 証明書の保存先です。詳細は、OpenShift Container Platform ドキュメントの イメージレジストリーアクセス用の追加のトラストストアの設定 を参照してください。
-
openshift-confignamespace に ConfigMap を作成します。 キー
updateservice-registryの下に CA 証明書を追加します。OpenShift Update Service はこの設定を使用して、証明書を特定します。apiVersion: v1 kind: ConfigMap metadata: name: trusted-ca data: updateservice-registry: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE-----image.config.openshift.ioAPI のclusterリソースを編集して、additionalTrustedCAフィールドを作成した ConfigMap 名に設定します。oc patch image.config.openshift.io cluster -p '{"spec":{"additionalTrustedCA":{"name":"trusted-ca"}}}' --type mergetrusted-caは、新しい ConfigMap へのパスに置き換えます。
OpenShift Update Service Operator は、変更がないか、image.config.openshift.io API と、openshift-config namespace に作成した ConfigMap を監視し、CA 証明書が変更された場合はデプロイメントを再起動します。
1.18.2.6. OpenShift Update Service インスタンスのデプロイ
ハブクラスターへの OpenShift Update Service インスタンスのデプロイが完了したら、このインスタンスは、クラスターのアップグレードのイメージをミラーリングして非接続マネージドクラスターに提供する場所に配置されます。インスタンスをデプロイするには、以下の手順を実行します。
デフォルトの Operator の namespace (
openshift-cincinnati) を使用しない場合は、お使いの OpenShift Update Service インスタンスの namespace を作成します。- OpenShift Container Platform ハブクラスターコンソールのナビゲーションメニューで、Administration > Namespaces を選択します。
- Create Namespace を選択します。
- namespace 名と、namespace のその他の情報を追加します。
- Create を選択して namespace を作成します。
- OpenShift Container Platform コンソールの Installed Operators セクションで、Red Hat OpenShift Update Service Operator を選択します。
- メニューから Create Instance を選択します。
OpenShift Update Service インスタンスからコンテンツを貼り付けます。YAML ファイルは以下のマニフェストのようになります。
apiVersion: cincinnati.openshift.io/v1beta2 kind: Cincinnati metadata: name: openshift-update-service-instance namespace: openshift-cincinnati spec: registry: <registry_host_name>:<port> replicas: 1 repository: ${LOCAL_REGISTRY}/ocp4/release graphDataImage: '<host_name>:<port>/cincinnati-graph-data-container'spec.registryの値は、イメージの非接続環境にあるローカルレジストリーへのパスに置き換えます。spec.graphDataImageの値は、グラフデータ init container へのパスに置き換えます。ヒント: これは、podman pushコマンドを使用して、グラフデータ init container をプッシュする時に使用した値と同じです。- Create を選択してインスタンスを作成します。
-
ハブクラスター CLI で
oc get podsコマンドを入力し、インスタンス作成のステータスを表示します。時間がかかる場合がありますが、コマンド結果でインスタンスと Operator が実行中である旨が表示されたらプロセスは完了です。
1.18.2.7. デフォルトレジストリーを上書きするためのポリシーのデプロイ (任意)
注記: 本セクションの手順は、ミラーレジストリーにリリースをミラーリングした場合にのみ該当します。
OpenShift Container Platform にはイメージレジストリーのデフォルト値があり、この値でアップグレードパッケージの検索先を指定します。非接続環境では、リリースイメージをミラーリングするローカルイメージレジストリーへのパスに値を置き換えるポリシーを作成してください。
これらの手順では、ポリシーの名前に ImageContentSourcePolicy を指定します。ポリシーを作成するには、以下の手順を実行します。
- ハブクラスターの OpenShift Container Platform 環境にログインします。
- OpenShift Container Platform ナビゲーションから Administration > Custom Resource Definitions を選択します。
- Instances タブを選択します。
- コンテンツが表示されるように非接続 OLM を設定する時に作成した ImageContentSourcePolicy の名前を選択します。
-
YAML タブを選択して、
YAML形式でコンテンツを表示します。 - ImageContentSourcePolicy の内容全体をコピーします。
- Red Hat Advanced Cluster Management コンソールで、Governance > Create policy を選択します。
-
YAMLスイッチを On に設定して、ポリシーの YAML バージョンを表示します。 -
YAMLコードのコンテンツをすべて削除します。 以下の
YAMLコンテンツをウィンドウに貼り付け、カスタムポリシーを作成します。apiVersion: policy.open-cluster-management.io/v1 kind: Policy metadata: name: policy-pod namespace: default annotations: policy.open-cluster-management.io/standards: policy.open-cluster-management.io/categories: policy.open-cluster-management.io/controls: spec: disabled: false policy-templates: - objectDefinition: apiVersion: policy.open-cluster-management.io/v1 kind: ConfigurationPolicy metadata: name: policy-pod-sample-nginx-pod spec: object-templates: - complianceType: musthave objectDefinition: apiVersion: v1 kind: Pod metadata: name: sample-nginx-pod namespace: default status: phase: Running remediationAction: inform severity: low remediationAction: enforce --- apiVersion: policy.open-cluster-management.io/v1 kind: PlacementBinding metadata: name: binding-policy-pod namespace: default placementRef: name: placement-policy-pod kind: PlacementRule apiGroup: apps.open-cluster-management.io subjects: - name: policy-pod kind: Policy apiGroup: policy.open-cluster-management.io --- apiVersion: apps.open-cluster-management.io/v1 kind: PlacementRule metadata: name: placement-policy-pod namespace: default spec: clusterConditions: - status: "True" type: ManagedClusterConditionAvailable clusterSelector: matchExpressions: [] # selects all clusters if not specifiedテンプレートの
objectDefinitionセクション内のコンテンツは、ImageContentSourcePolicy の設定を追加する以下の内容に置き換えます。apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: <your-local-mirror-name> spec: repositoryDigestMirrors: - mirrors: - <your-registry> source: registry.redhat.io-
your-local-mirr-nameをローカルミラーリポジトリーの名前に置き換えます。 your-registryをローカルミラーリポジトリーへのパスに置き換えます。ヒント:
oc adm release mirrorコマンドを入力すると、ローカルミラーへのパスが分かります。
-
- Enforce if supported のボックスを選択します。
- Create を選択してポリシーを作成します。
1.18.2.8. 非接続カタログソースをデプロイするためのポリシーのデプロイ
マネージドクラスターに Catalogsource ポリシーをプッシュして、接続環境がある場所から非接続のローカルレジストリーにデフォルトの場所を変更します。
- Red Hat Advanced Cluster Management コンソールで Infrastructure > Clusters を選択します。
- クラスター一覧でポリシーを受信するマネージドクラスターを検索します。
-
マネージドクラスターの
nameラベルの値をメモします。ラベルの形式はname=managed-cluster-nameです。この値は、ポリシーのプッシュ時に使用します。 - Red Hat Advanced Cluster Management コンソールメニューで、Governance > Create policy を選択します。
- YAML スイッチを On に設定して、ポリシーの YAML バージョンを表示します。
- YAML コードのコンテンツをすべて削除します。
以下の YAML コンテンツをウィンドウに貼り付け、カスタムポリシーを作成します。
apiVersion: policy.open-cluster-management.io/v1 kind: Policy metadata: name: policy-pod namespace: default annotations: policy.open-cluster-management.io/standards: policy.open-cluster-management.io/categories: policy.open-cluster-management.io/controls: spec: disabled: false policy-templates: - objectDefinition: apiVersion: policy.open-cluster-management.io/v1 kind: ConfigurationPolicy metadata: name: policy-pod-sample-nginx-pod spec: object-templates: - complianceType: musthave objectDefinition: apiVersion: v1 kind: Pod metadata: name: sample-nginx-pod namespace: default status: phase: Running remediationAction: inform severity: low remediationAction: enforce --- apiVersion: policy.open-cluster-management.io/v1 kind: PlacementBinding metadata: name: binding-policy-pod namespace: default placementRef: name: placement-policy-pod kind: PlacementRule apiGroup: apps.open-cluster-management.io subjects: - name: policy-pod kind: Policy apiGroup: policy.open-cluster-management.io --- apiVersion: apps.open-cluster-management.io/v1 kind: PlacementRule metadata: name: placement-policy-pod namespace: default spec: clusterConditions: - status: "True" type: ManagedClusterConditionAvailable clusterSelector: matchExpressions: [] # selects all clusters if not specified以下の内容をポリシーに追加します。
apiVersion: config.openshift.io/vi kind: OperatorHub metadata: name: cluster spec: disableAllDefaultSources: true
以下の内容を追加します。
apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace spec: sourceType: grpc image: <registry_host_name>:<port>/olm/redhat-operators:v1 displayName: My Operator Catalog publisher: grpc
spec.image の値は、ローカルの制約付きのカタログソースイメージへのパスに置き換えます。
-
Red Hat Advanced Cluster Management コンソールのナビゲーションで、Infrastructure > Clusters を選択して、マネージドクラスターのステータスを確認します。ポリシーが適用されると、クラスターのステータスは
Readyになります。
1.18.2.9. マネージドクラスターのパラメーターを変更するためのポリシーのデプロイ
ClusterVersion ポリシーをマネージドクラスターにプッシュし、アップグレード取得先のデフォルトの場所を変更します。
マネージドクラスターから、以下のコマンドを入力して ClusterVersion アップストリームパラメーターがデフォルトの OpenShift Update Service オペランドであることを確認します。
oc get clusterversion -o yaml
返される内容は以下のようになります。
apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.4 upstream: https://api.openshift.com/api/upgrades_info/v1/graphハブクラスターから、
oc get routesというコマンドを入力して OpenShift Update Service オペランドへのルート URL を特定します。ヒント: 今後の手順で使用できるようにこの値をメモします。
- ハブクラスターの Red Hat Advanced Cluster Management コンソールメニューで、Governance > Create a policy を選択します。
-
YAMLスイッチを On に設定して、ポリシーの YAML バージョンを表示します。 -
YAMLコードのコンテンツをすべて削除します。 以下の YAML コンテンツをウィンドウに貼り付け、カスタムポリシーを作成します。
apiVersion: policy.open-cluster-management.io/v1 kind: Policy metadata: name: policy-pod namespace: default annotations: policy.open-cluster-management.io/standards: policy.open-cluster-management.io/categories: policy.open-cluster-management.io/controls: spec: disabled: false policy-templates: - objectDefinition: apiVersion: policy.open-cluster-management.io/v1 kind: ConfigurationPolicy metadata: name: policy-pod-sample-nginx-pod spec: object-templates: - complianceType: musthave objectDefinition: apiVersion: v1 kind: Pod metadata: name: sample-nginx-pod namespace: default status: phase: Running remediationAction: inform severity: low remediationAction: enforce --- apiVersion: policy.open-cluster-management.io/v1 kind: PlacementBinding metadata: name: binding-policy-pod namespace: default placementRef: name: placement-policy-pod kind: PlacementRule apiGroup: apps.open-cluster-management.io subjects: - name: policy-pod kind: Policy apiGroup: policy.open-cluster-management.io --- apiVersion: apps.open-cluster-management.io/v1 kind: PlacementRule metadata: name: placement-policy-pod namespace: default spec: clusterConditions: - status: "True" type: ManagedClusterConditionAvailable clusterSelector: matchExpressions: [] # selects all clusters if not specifiedpolicy セクションの
policy.specに以下の内容を追加します。apiVersion: config.openshift.io/v1 kind: ClusterVersion metadata: name: version spec: channel: stable-4.4 upstream: https://example-cincinnati-policy-engine-uri/api/upgrades_info/v1/graphspec.upstream の値は、ハブクラスター OpenShift Update Service オペランドへのパスに置き換えます。
ヒント: 以下の手順を実行すると、オペランドへのパスを確認できます。
-
ハブクラスターで
oc get routes -Aコマンドを実行します。 -
cincinnatiへのルートを見つけます。+ オペランドへのパスは、HOST/PORTフィールドの値です。
-
ハブクラスターで
マネージドクラスター CLI で、
ClusterVersionのアップストリームパラメーターがローカルハブクラスター OpenShift Update Service URL に更新されていることを確認します。これには以下のコマンドを入力します。oc get clusterversion -o yaml
結果は、以下の内容のようになります。
apiVersion: v1 items: - apiVersion: config.openshift.io/v1 kind: ClusterVersion [..] spec: channel: stable-4.4 upstream: https://<hub-cincinnati-uri>/api/upgrades_info/v1/graph
1.18.2.10. 利用可能なアップグレードの表示
以下の手順を実行して、マネージドクラスターで利用可能なアップグレード一覧を確認します。
- Red Hat Advanced Cluster Management コンソールにログインします。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。
- 状態が Ready のクラスターを選択します。
- Actions メニューから Upgrade cluster を選択します。
オプションのアップグレードパスが利用可能であることを確認します。
注記: 現行バージョンがローカルのイメージリポジトリーにミラーリングされていないと、利用可能なアップグレードバージョンは表示されません。
1.18.2.11. チャネルの選択
Red Hat Advanced Cluster Management コンソールを使用して、OpenShift Container Platform バージョン 4.6 以降でクラスターのアップグレードのチャネルを選択できます。これらのバージョンはミラーレジストリーで利用可能である必要があります。Selecting a channel の手順を実行して、アップグレードチャネルを指定します。
1.18.2.12. クラスターのアップグレード
非接続レジストリーの設定後に、Red Hat Advanced Cluster Management および OpenShift Update Service は非接続レジストリーを使用して、アップグレードが利用可能かどうかを判断します。利用可能なアップグレードが表示されない場合は、クラスターの現行のリリースイメージと、1 つ後のイメージがローカルリポジトリーにミラーリングされていることを確認します。クラスターの現行バージョンのリリースイメージが利用できないと、アップグレードは利用できません。
以下の手順を実行してアップグレードします。
- Red Hat Advanced Cluster Management コンソールで Infrastructure > Clusters を選択します。
- そのクラスターの内、利用可能なアップグレードがあるかどうかを判断するクラスターを特定します。
- 利用可能なアップグレードがある場合は、クラスターの Distribution version コラムで、アップグレードが利用可能であることが表示されます。
- クラスターの Options メニュー、Upgrade cluster の順に選択します。
- アップグレードのターゲットバージョン、Upgrade の順に選択します。
マネージドクラスターは、選択したバージョンに更新されます。
クラスターのアップグレードに失敗すると、Operator は通常アップグレードを数回再試行し、停止し、コンポーネントに問題があるステータスを報告します。場合によっては、アップグレードプロセスは、プロセスの完了を繰り返し試行します。アップグレードに失敗した後にクラスターを以前のバージョンにロールバックすることはサポートされていません。クラスターのアップグレードに失敗した場合は、Red Hat サポートにお問い合わせください。
1.19. マネージメントからのクラスターの削除
Red Hat Advanced Cluster Management for Kubernetes で作成したマネージメントから、OpenShift Container Platform クラスターを削除すると、このクラスターをデタッチ するか、破棄 できます。
クラスターをデタッチするとマネージメントから削除されますが、完全には削除されません。管理する場合には、もう一度インポートし直すことができます。このオプションは、クラスターが Ready 状態にある場合にだけ利用できます。
これらの手順により、次のいずれかの状況でクラスターが管理から削除されます。
- すでにクラスターを削除しており、削除したクラスターを Red Hat Advanced Cluster Management から削除したいと考えています。
- クラスターを管理から削除したいが、クラスターを削除していない。
重要:
- クラスターを破棄すると、マネージメントから削除され、クラスターのコンポーネントが削除されます。
管理対象クラスターを切り離すと、関連するネームスペースが自動的に削除されます。この名前空間にカスタムリソースを配置しないでください。
1.19.1. コンソールを使用したクラスターの削除
- ナビゲーションメニューから Infrastructure > Clusters に移動します。
- マネージメントから削除するクラスターの横にあるオプションメニューを選択します。
Destroy cluster または Detach cluster を選択します。
ヒント: 複数のクラスターをデタッチまたは破棄するには、デタッチまたは破棄するクラスターのチェックボックスを選択します。次に、Detach または Destroy を選択します。
注記: local-cluster と呼ばれる管理対象時にハブクラスターをデタッチしようとすると、disableHubSelfManagement のデフォルト設定が false かどうかを確認してください。この設定が原因で、ハブクラスターはデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
ネットワーク接続時のオンラインインストール で説明されているように、disableHubSelfManagement の値を true に指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。
1.19.2. コマンドラインを使用したクラスターの削除
ハブクラスターのコマンドラインを使用してマネージドクラスターをデタッチするには、以下のコマンドを実行します。
oc delete managedcluster $CLUSTER_NAME
デタッチ後にマネージドクラスターを削除するには、次のコマンドを実行します。
oc delete clusterdeployment <CLUSTER_NAME> -n $CLUSTER_NAME
注記: local-cluster という名前のハブクラスターをデタッチしようとする場合は、デフォルトの disableHubSelfManagement 設定が false である点に注意してください。この設定が原因で、ハブクラスターがデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
ネットワーク接続時のオンラインインストール で説明されているように、disableHubSelfManagement の値を true に指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。
1.19.3. クラスター削除後の残りのリソースの削除
削除したマネージドクラスターにリソースが残っている場合は、残りのすべてのコンポーネントを削除するための追加の手順が必要になります。これらの追加手順が必要な場合には、以下の例が含まれます。
-
マネージドクラスターは、完全に作成される前にデタッチされ、
klusterletなどのコンポーネントはマネージドクラスターに残ります。 - マネージドクラスターをデタッチする前に、クラスターを管理していたハブが失われたり、破棄されているため、ハブからマネージドクラスターをデタッチする方法はありません。
- マネージドクラスターは、デタッチ時にオンライン状態ではありませんでした。
これらの状況の 1 つがマネージドクラスターのデタッチの試行に該当する場合は、マネージドクラスターから削除できないリソースがいくつかあります。マネージドクラスターをデタッチするには、以下の手順を実行します。
-
ocコマンドラインインターフェイスが設定されていることを確認してください。 また、マネージドクラスターに
KUBECONFIGが設定されていることを確認してください。oc get ns | grep open-cluster-management-agentを実行すると、2 つの namespace が表示されるはずです。open-cluster-management-agent Active 10m open-cluster-management-agent-addon Active 10m
次のコマンドを実行して、残りのリソースを削除します。
oc delete namespaces open-cluster-management-agent open-cluster-management-agent-addon --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc delete crds --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc patch crds --type=merge -p '{"metadata":{"finalizers": []}}'次のコマンドを実行して、namespaces と開いているすべてのクラスター管理
crdsの両方が削除されていることを確認します。oc get crds | grep open-cluster-management.io | awk '{print $1}' oc get ns | grep open-cluster-management-agent
1.19.4. クラスターの削除後の etcd データベースのデフラグ
マネージドクラスターが多数ある場合は、ハブクラスターの etcd データベースのサイズに影響を与える可能性があります。OpenShift Container Platform 4.8 では、マネージドクラスターを削除すると、ハブクラスターの etcd データベースのサイズは自動的に縮小されません。シナリオによっては、etcd データベースは領域不足になる可能性があります。etcdserver: mvcc: database space exceeded のエラーが表示されます。このエラーを修正するには、データベース履歴を圧縮し、etcd データベースのデフラグを実行して etcd データベースのサイズを縮小します。
注記: OpenShift Container Platform バージョン 4.9 以降では、etcd Operator はディスクを自動的にデフラグし、etcd 履歴を圧縮します。手動による介入は必要ありません。以下の手順は、OpenShift Container Platform 4.8 以前のバージョン向けです。
以下の手順を実行して、ハブクラスターで etcd 履歴を圧縮し、ハブクラスターで etcd データベースをデフラグします。
1.19.4.1. 前提条件
-
OpenShift CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。
1.19.4.2. 手順
etcd履歴を圧縮します。次に、
etcdメンバーへのリモートシェルセッションを開きます。$ oc rsh -n openshift-etcd etcd-control-plane-0.example.com etcdctl endpoint status --cluster -w table
以下のコマンドを実行して
etcd履歴を圧縮します。sh-4.4#etcdctl compact $(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*' -m1)
出力例
$ compacted revision 158774421
-
Defragmenting
etcddata で説明されているように、etcdデータベースを デフラグし、NOSPACEアラームを消去します。
1.20. クラスターのバックアップおよび復元 Operator(テクノロジープレビュー)
クラスターのバックアップと復元 Operator はハブクラスターで実行され、OADP Operator に依存して Red Hat Advanced Cluster Management for Kubernetes ハブクラスターに Velero をインストールします。Velero を使用して、Red Hat Advanced Cluster Management ハブクラスターをバックアップおよび復元します。
Velero のサポートされるストレージプロバイダーの一覧は、S3-Compatible オブジェクトストアプロバイダー を参照してください。
1.20.1. 前提条件
- 最新バージョンの OADP オペレーターをインストールする必要があります。Install OADP Operator using OperatorHub ドキュメントを参照してください。
- バックアップの保存先となるクラウドストレージの 認証情報シークレットの作成 手順を必ず実行します。
- 次に、Velero カスタムリソースの作成 時に作成されたシークレットを使用します。
注: クラスターのバックアップおよび復元 Operator のリソースは、OADP Operato がインストールされている、同じ namespace に作成する必要があります。
1.20.2. Operator アーキテクチャーのバックアップと復元
Operator は、プロセスに使用されている backupSchedule.cluster.open-cluster-management.io リソース (Red Hat Advanced Cluster Management のバックアップスケジュールの設定に使用) と restore.cluster.open-cluster-management.io リソース (バックアップの処理と復元に使用) を定義します。Operator は、対応する Velero リソースを作成し、リモートクラスターと、復元を必要とする他のハブクラスターリソースのバックアップに必要なオプションを定義します。次の図を表示します。

1.20.3. クラスターバックアップのスケジュール
backupschedule.cluster.open-cluster-management.io リソースを作成した後に、次のコマンドを実行して、スケジュールされたクラスターバックアップのステータス (oc get bsch -n <oadp-operator-ns>) を取得できます。<oadp-operator-ns> は、 BackupSchedule の作成先の namespace で、OADP Operator がインストールされている namespace と同じである必要があります。
backupSchedule.cluster.open-cluster-management.io リソースは、次の 3 つの schedule.velero.io リソースを作成します。
acm-managed-clusters-schedule: このリソースは、マネージドクラスター、クラスタープール、クラスターセットなど、マネージドクラスターリソースのバックアップのスケジュールに使用されます。注記:
-
バックアップが別のハブクラスターに復元されると、
hiveAPI を使用して作成されたマネージドクラスターのみが自動的にインポートされます。他のすべてのマネージドクラスターはPending Importとして表示され、新しいハブクラスターに手動でインポートし直す必要があります。 - 新しいハブクラスターにバックアップを復元する場合には、バックアップを作成した、前のバブクラスターがシャットダウンされていることを確認します。実行中の場合には、前のハブクラスターは、マネージドクラスターの調整機能により、マネージドクラスターが使用できなくなったことが検出されるとすぐに、マネージドクラスターの再インポートが試行されます。
このバックアップでは、次のリソースが取得されています。これらは、新しいハブクラスターで全マネージドクラスター情報を復元するのに必要です。
-
hiveおよびopenshift-operator-lifecycle-managernamespaces、およびハブクラスターで作成されたすべてのManagedClusters resourcesnamespaces からのシークレットと ConfigMap。 -
クラスターレベルの
ManagedClusterリソース。 -
ServiceAccount、ManagedClusterInfo、ManagedClusterSet、ManagedClusterSetBindings、KlusterletAddonConfig、ManagedClusterView、ClusterPool、ClusterProvision、ClusterDeployment、ClusterSyncLease、ClusterSync、ClusterCuratorなど、マネージドクラスターの詳細の復元に使用されるその他の namespace 内のリソース。
-
-
バックアップが別のハブクラスターに復元されると、
acm-credentials-schedule: このリソースは、ユーザーが作成した認証情報とそのコピーのバックアップをスケジュールするのに使用されます。これらの資格情報は、cluster.open-cluster-management.io/typeラベルセレクターで識別されます。ラベルセレクターを定義するすべてのシークレットがバックアップに含まれます。注: ユーザー定義のプライベートチャネルがある場合に、
cluster.open-cluster-management.io/typeラベルセレクターをこのシークレットに設定すると、資格情報のバックアップにチャネルシークレットを含めることができます。cluster.open-cluster-management.io/typeラベルセレクターがないと、チャネルのシークレットはacm-credentials-scheduleバックアップで識別されず、復元されたクラスターで手動で再作成する必要があります。acm-resources-schedule: このリソースは、以下のような必須リソースなど、ApplicationsとPolicyリソースのバックアップのスケジュールに使用されます。Applications:Channels、Subscriptions、DeployablesおよびPlacementRulesPolicy:PlacementBindings、Placement、およびPlacementDecisionslocal-clusterまたはopen-cluster-managementnamespace から収集されたリソースはありません。
1.20.4. バックアップの復元
障害のシナリオでは、バックアップが実行されるハブクラスターが利用できなくなり、バックアップデータを新しいハブクラスターに移動する必要があります。これには、新しいハブクラスターでクラスター復元操作を実行します。この場合、復元操作はバックアップが作成される場所とは異なるハブクラスターで実行します。
また、以前のスナップショットからのデータを復元できるように、バックアップデータを取得したハブクラスターでデータを復元するケースもあります。この場合、復元とバックアップ操作の両方が同じハブクラスターで実行されます。
ハブクラスターで restore.cluster.open-cluster-management.io リソースを作成した後に、oc get restore -n <oadp-operator-ns> のコマンドを実行して復元操作のステータスを取得できます。また、バックアップファイルに含まれるバックアップのリソースが作成されていることを確認できる必要があります。
注記: restore.cluster.open-cluster-management.io リソースは 1 回実行されます。復元操作の完了後に同じ復元操作を再度実行する場合は、同じ spec オプションで新しい restore.cluster.open-cluster-management.io リソースを作成する必要があります。
復元操作を使用して、バックアップ操作で作成される全バックアップタイプ 3 つを復元します。ただし、特定の種類のバックアップ (マネージドクラスターのみ、ユーザー資格情報のみ、またはハブクラスターリソースのみ) のみをインストールするように選択できます。
復元では、以下の 3 つの必要な spec プロパティーを定義します。ここでは、バックアップしたファイルのタイプに対して復元ロジックが定義されます。
-
veleroManagedClustersBackupNameは、マネージドクラスターの復元オプションの定義に使用されます。 -
veleroCredentialsBackupNameは、ユーザーの認証情報の復元オプションを定義するために使用されます。 veleroResourcesBackupNameは、ハブクラスターリソース (ApplicationsとPolicy) の復元オプションを定義するために使用されます。前述のプロパティーの有効な値は次のとおりです。
-
latest: このプロパティーは、このタイプのバックアップで使用可能な、最後のバックアップファイルを復元します。 -
skip:このプロパティーは、現在の復元操作でこのタイプのバックアップの復元は試行ません。 -
<backup_name>: このプロパティーは、名前で参照する指定のバックアップを復元します。
-
restore.cluster.open-cluster-management.io で作成された restore.velero.io リソースの名前は、<restore.cluster.open-cluster-management.io name>-<velero-backup-resource-name> のテンプレートルールを使用して生成されます。以下の説明を参照してください。
-
restore.cluster.open-cluster-management.ioは、復元を開始する現在のrestore.cluster.open-cluster-management.ioリソースの名前です。 Velero-backup-resource-nameは、データの復元に使用される Velero バックアップファイルの名前です。たとえば、restore.cluster.open-cluster-management.ioリソースrestore-acmはrestore.velero.io復元リソースを作成します。フォーマットについては、以下の例を参照してください。-
restore-acm-acm-managed-clusters-schedule-20210902205438は、マネージドクラスターのバックアップの復元に使用されます。このサンプルでは、リソースの復元に使用されるbackup.velero.ioバックアップ名はacm-managed-clusters-schedule-20210902205438です。 -
restore-acm-acm-credentials-schedule-20210902206789は、認証情報バックアップの復元に使用されます。このサンプルでは、リソースの復元に使用されるbackup.velero.ioバックアップ名はacm-managed-clusters-schedule-20210902206789です。 restore-acm-acm-resources-schedule-20210902201234は、アプリケーションおよびポリシーバックアップの復元に使用されます。このサンプルでは、リソースの復元に使用されるbackup.velero.ioバックアップ名はacm-managed-clusters-schedule-20210902201234です。注記:
skipがバックアップタイプに使用されている場合は、restore.velero.ioは作成されません。
-
以下の YAML サンプルで、クラスターの リストア リソースを参照してください。この例では、利用可能な最新のバックアップファイルを使用して、3 つのタイプのバックアップファイルがすべて復元されています。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Restore metadata: name: restore-acm spec: veleroManagedClustersBackupName: latest veleroCredentialsBackupName: latest veleroResourcesBackupName: latest
クラスターのバックアップおよび復元 Operator を有効にして管理する方法は、バックアップと復元のオペレーターの有効化 を参照してください。
1.20.5. バックアップおよび復元 Operator の有効化 (テクノロジープレビュー)
クラスターのバックアップおよび復元 Operator を有効にして、クラスターリソースのバックアップおよび復元をスケジュールできます。Red Hat Advanced Cluster Management for Kubernetes は、クラスターのバックアップ Operator をテクノロジープレビューとして提供します。この機能はデフォルトでは無効になっています。
必要なアクセス権限: クラスターの管理者
1.20.5.1. 前提条件
- 最新バージョンの OADP オペレーターをインストールする必要があります。Install OADP Operator using OperatorHub ドキュメントを参照してください。
注記: OADP Operator のインストール手順に従って Velero リソースを作成し、バックアップが保存されるバックアップストレージの場所への有効な接続を作成してください。oadp-operator リポジトリーから インストールと設定手順 を表示します。
1.20.5.2. バックアップおよびリストア Operator の有効化
クラスターのバックアップおよび復元 Operator は、MultiClusterHub リソースの初回作成時に有効にできます。OpenShift Container Platform コンソールから、Enable Cluster Backup switch を選択して Operator を有効にします。enableClusterBackup パラメーターは true に設定します。Operator を有効にすると、Operator リソースがインストールされます。
MultiClusterHub リソースがすでに作成されている場合には、MultiClusterHub リソースを編集して、クラスターバックアップ Operator をインストールまたはアンインストールできます。クラスターバックアップ Operator をアンインストールする場合は、enableClusterBackup を false に設定します。
バックアップおよび復元 Operator が有効にされている場合には、MultiClusterHub リソースは以下の YAML ファイルのようになります。
apiVersion: operator.open-cluster-management.io/v1
kind: MultiClusterHub
metadata:
name: multiclusterhub
namespace: open-cluster-management
spec:
availabilityConfig: High
enableClusterBackup: true <-----
imagePullSecret: multiclusterhub-operator-pull-secret
ingress:
sslCiphers:
- ECDHE-ECDSA-AES256-GCM-SHA384
- ECDHE-RSA-AES256-GCM-SHA384
- ECDHE-ECDSA-AES128-GCM-SHA256
- ECDHE-RSA-AES128-GCM-SHA256
separateCertificateManagement: false1.20.5.3. バックアップおよびリストア Operator の使用
バックアップをスケジュールおよび復元するには、以下の手順を実行します。
バックアップおよび復元 Operator、
backupschedule.cluster.open-cluster-management.ioおよびrestore.cluster.open-cluster-management.ioリソースを使用して、cluster_v1beta1_backupschedule.yamlサンプルファイルで、backupschedule.cluster.open-cluster-management.ioリソースを作成します。cluster-backup-operatorサンプル を参照してください。以下のコマンドを実行し、cluster_v1beta1_backupschedule.yamlサンプルファイルを使用して、backupschedule.cluster.open-cluster-management.ioリソースを作成します。kubectl create -n <oadp-operator-ns> -f config/samples/cluster_v1beta1_backupschedule.yaml
リソースは以下のファイルのようになります。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: BackupSchedule metadata: name: schedule-acm spec: maxBackups: 10 # maximum number of backups after which old backups should be removed veleroSchedule: 0 */6 * * * # Create a backup every 6 hours veleroTtl: 72h # deletes scheduled backups after 72h; optional, if not specified, the maximum default value set by velero is used - 720h
backupschedule.cluster.open-cluster-management.iospecプロパティーに関する以下の説明を確認してください。-
maxBackupは必須プロパティーであり、以前のバックアップの削除後のバックアップの最大数を表します。 -
veleroScheduleは必須のプロパティーで、バックアップをスケジュールする cron ジョブを定義します。 -
veleroTtlは任意のプロパティーで、スケジュールされているバックアップリソースの有効期限を定義します。指定されていない場合には、Velero で設定された最大デフォルト値 (720h) が使用されます。
-
backupschedule.cluster.open-cluster-management.ioリソースの状態をチェックします。3 つのschedule.velero.ioリソースの定義が表示されます。以下のコマンドを実行します。oc get bsch -n <oadp-operator-ns>
注意: 復元操作は、復元シナリオ向けに別のハブクラスターで実行します。復元操作を開始するには、バックアップを復元するハブクラスターに
restore.cluster.open-cluster-management.ioリソースを作成します。クラスターのバックアップおよび復元 Operator、backup
schedule.cluster.open-cluster-management.ioおよびrestore.cluster.open-cluster-management.ioリソースを使用して、バックアップまたは復元リソースを作成できます。cluster-backup-operatorサンプル を参照してください。以下のコマンドを実行して、
cluster_v1beta1_restore.yamlサンプルファイルを使用してrestore.cluster.open-cluster-management.ioリソースを作成します。oadp-operator-nsは、OADP Operator のインストールに使用される namespace 名に置き換えます。OADP Operator インストール namespace のデフォルト値はoadp-operatorです。kubectl create -n <oadp-operator-ns> -f config/samples/cluster_v1beta1_restore.yaml
リソースは以下のファイルのようになります。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Restore metadata: name: restore-acm spec: veleroManagedClustersBackupName: latest veleroCredentialsBackupName: latest veleroResourcesBackupName: latest
restore.cluster.open-cluster-management.ioの 3 つの必要なspecプロパティーの説明は次のとおりです。-
veleroManagedClustersBackupNameは、マネージドクラスターの復元オプションの定義に使用されます。 -
veleroCredentialsBackupNameは、ユーザーの認証情報の復元オプションを定義するために使用されます。 veleroResourcesBackupNameは、ハブクラスターリソース (ApplicationsとPolicy) の復元オプションを定義するために使用されます。前述のプロパティーの有効な値は次のとおりです。
-
latest: このプロパティーは、このタイプのバックアップで使用可能な、最後のバックアップファイルを復元します。 -
skip:このプロパティーは、現在の復元操作でこのタイプのバックアップの復元は試行ません。 -
backup_name: このプロパティーは、名前を参照することで、指定したバックアップを復元します。
-
以下のコマンドを実行して Velero
Restoreリソースを表示します。oc get restore.velero.io -n <oadp-operator-ns>
以下の YAML の例を参照して、さまざまなタイプのバックアップファイルを復元します。
3 種類のバックアップリソースをすべて復元します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Restore metadata: name: restore-acm spec: veleroManagedClustersBackupSchedule: latest veleroCredentialsBackupSchedule: latest veleroResourcesBackupSchedule: latest
マネージドクラスターリソースのみを復元します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Restore metadata: name: restore-acm spec: veleroManagedClustersBackupName: latest veleroCredentialsBackupName: skip veleroResourcesBackupName: skip
acm-managed-clusters-schedule-20210902205438バックアップを使用して、マネージドクラスターのリソースのみを復元します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Restore metadata: name: restore-acm spec: veleroManagedClustersBackupName: acm-managed-clusters-schedule-20210902205438 veleroCredentialsBackupName: skip veleroResourcesBackupName: skip
必要な仕様プロパティーと有効なオプションの説明は、バックアップのリストア を参照してください。注記: restore.cluster.open-cluster-management.io リソースは 1 回実行されます。復元操作が完了したら、オプションで同じハブクラスターで別の復元操作を実行できます。新しい復元操作を実行するには、restore.cluster.open-cluster-management.io リソースを新規作成する必要があります。
1.21. VolSync を使用した永続ボリュームの複製
VolSync は、レプリケーションの互換性がないストレージタイプがしていされたクラスター全体、または 1 つのクラスター内の永続ボリュームの非同期レプリケーションを有効にする Kubernetes Operator です。これは Container Storage Interface (CSI) を使用して互換性の制限を解消します。VolSync オペレーターを環境にデプロイした後、それを活用して永続データのコピーを作成および保守できます。
注記: VolSync は FIPS 標準の要件に対応していません。
VolSync 使用時に、複製に使用できる方法は 3 つあります。これは、所有する同期の場所の数により異なります。この例では、Rsync メソッドが使用されます。他の方法や Rsync の詳細情報は、VolSync ドキュメントの 使用方法 を参照してください。
rsync レプリケーションは永続ボリュームの 1 対 1 レプリケーションであり、最も一般的に使用される可能性が高くなります。これは、リモートサイトにデータを複製するために使用されます。
1.21.1. 前提条件
クラスターに VolSync をインストールする前に、以下の要件が必要です。
- Red Hat Advanced Cluster Management バージョン 2.4 以降のハブクラスターで実行中で、設定済みの OpenShift Container Platform 環境。
- 同じ Red Hat Advanced Cluster Management ハブクラスターが管理する 2 つ以上のクラスター。
-
VolSync で設定しているクラスター間のネットワーク接続。クラスターが同じネットワーク上にない場合は、Submariner ネットワークサービス を設定し、
ServiceTypeのClusterIP値を使用してクラスターをネットワーク化するか、ServiceTypeのLoadBalancer値でロードバランサーを使用できます。 - ソース永続ボリュームに使用するストレージドライバーは、CSI 互換であり、スナップショットをサポートできる必要があります。
1.21.2. マネージドクラスターへの VolSync のインストール
環境内の 2 つのクラスターで VolSync を有効にするには、ソースクラスターとターゲットのマネージドクラスターの両方にインストールする必要があります。Red Hat Advanced Cluster Management のポリシーテンプレートを使用して VolSync をインストールします。
GitHub リポジトリーから policy-persistent-data-management ポリシーテンプレートをダウンロードします。このポリシーは、現在の形式で、ハブクラスターの VolSync のインストールを開始します。ハブクラスターにインストールすると、ハブのすべての管理対象クラスターに必要な VolSync コンポーネントが自動的にインストールされます。
注記: Red Hat Advanced Cluster Management バージョン 2.4.2 の前にこのポリシーをダウンロードして使用した場合は、ファイルを再度ダウンロードします。ファイルとその参照の一部のパスが変更されました。
ポリシーファイルの以下のセクションを変更して、VolSync がインストールされているクラスターの識別に別のラベルを指定できます。
spec: clusterSelector: matchLabels: vendor: OpenShift注記:
local-clusterに適用されるファイルのclusterSelectorの内容は変更しないでください。以下のコマンドを入力して、ハブクラスターにログインした状態でポリシーを適用します。
oc -n <namespace> apply -f ./policy-persistent-data-management.yaml
namespaceはお使いのハブクラスター namespace 名に置き換えます。
1.21.3. 管理対象クラスター間での Rsync レプリケーションの設定
Rsync ベースのレプリケーションの場合は、ソースクラスターおよび宛先クラスターでカスタムリソースを設定します。カスタムリソースは、address 値を使用してソースを宛先に接続し、sshKeys を使用して転送されたデータがセキュアであることを確認します。
注記: address および sshKeys の値を宛先からソースにコピーし、ソースを設定する前に宛先を設定する必要があります。
この例では、source-ns namespace の source クラスターの永続ボリューム要求から destination-ns namespace の destination クラスターの永続ボリューム要求に Rsync レプリケーションを設定する手順を説明します。必要に応じて、これらの値を他の値に置き換えることができます。
宛先クラスターを設定します。
宛先クラスターで次のコマンドを実行して、ネームスペースを作成します。
$ kubectl create ns <destination-ns>
destination-nsを、オンサイトのボリューム要求ごとに宛先が含まれる namespace の名前に置き換えます。以下の YAML コンテンツをコピーし、
replication_destination.yamlという名前の新規ファイルを作成します。--- apiVersion: volsync.backube/v1alpha1 kind: ReplicationDestination metadata: name: <destination> namespace: <destination-ns> spec: rsync: serviceType: LoadBalancer copyMethod: Snapshot capacity: 2Gi accessModes: [ReadWriteOnce] storageClassName: gp2-csi volumeSnapshotClassName: csi-aws-vsc注記:
capacityの値は、レプリケートされる永続ボリューム要求 (PVC) の容量と一致する必要があります。destinationは、宛先 CR の名前に置き換えます。destination-nsは、宛先の namespace の名前に置き換えます。この例では、
LoadBalancerのServiceType値が使用されます。ロードバランサーサービスはソースクラスターによって作成され、ソースマネージドクラスターが別の宛先マネージドクラスターに情報を転送できるようにします。ソースと宛先が同じクラスター上にある場合、または Submariner ネットワークサービスが設定されている場合は、サービスタイプとしてClusterIPを使用できます。ソースクラスターを設定するときに参照するシークレットのアドレスと名前をメモします。storageClassNameおよびvolumeSnapshotClassNameは任意のパラメーターです。特に、環境のデフォルト値とは異なるストレージクラスおよびボリュームスナップショットクラス名を使用している場合は、環境の値を指定してください。宛先クラスターで以下のコマンドを実行し、
replicationdestinationリソースを作成します。$ kubectl create -n <destination-ns> -f replication_destination.yaml
destination-nsは、宛先の namespace の名前に置き換えます。replicationdestinationリソースが作成されると、以下のパラメーターおよび値がリソースに追加されます。パラメーター 値 .status.rsync.address送信元クラスターと宛先クラスターが通信できるようにするために使用される宛先クラスターの IP アドレス。
.status.rsync.sshKeysソースクラスターから宛先クラスターへの安全なデータ転送を可能にする SSH キーファイルの名前。
以下のコマンドを実行して、ソースクラスターで使用する
.status.rsync.addressの値をコピーします。$ ADDRESS=`kubectl get replicationdestination <destination> -n <destination-ns> --template={{.status.rsync.address}}` $ echo $ADDRESSdestinationは、宛先 CR の名前に置き換えます。destination-nsは、宛先の namespace の名前に置き換えます。出力は、Amazon Web Services 環境の次の出力のように表示されます。
a831264645yhrjrjyer6f9e4a02eb2-5592c0b3d94dd376.elb.us-east-1.amazonaws.com
以下のコマンドを実行して、シークレットの名前および
.status.rsync.sshKeysの値として提供されるシークレットの内容をコピーします。$ SSHKEYS=`kubectl get replicationdestination <destination> -n <destination-ns> --template={{.status.rsync.sshKeys}}` $ echo $SSHKEYSdestinationは、宛先 CR の名前に置き換えます。destination-nsは、宛先の namespace の名前に置き換えます。ソースの設定時に、ソースクラスターで入力する必要があります。出力は、SSH キーシークレットファイルの名前である必要があります。これは、次の名前のようになります。
volsync-rsync-dst-src-destination-name
複製するソース永続ボリュームクレームを特定します。
注記: ソース永続ボリューム要求は CSI ストレージクラスにある必要があります。
ReplicationSourceアイテムを作成します。以下の YAML コンテンツをコピーして、ソースクラスターに
replication_source.yamlという名前の新規ファイルを作成します。--- apiVersion: volsync.backube/v1alpha1 kind: ReplicationSource metadata: name: <source> namespace: <source-ns> spec: sourcePVC: <persistent_volume_claim> trigger: schedule: "*/3 * * * *" rsync: sshKeys: <mysshkeys> address: <my.host.com> copyMethod: Snapshot storageClassName: gp2-csi volumeSnapshotClassName: csi-aws-vscsourceは、レプリケーションソース CR の名前に置き換えます。これを自動的に置き換える方法については、この手順のステップ 3-vi を参照してください。source-nsを、ソースが置かれている Persistent Volume Claim(永続ボリューム要求、PVC) の namespace に置き換えます。これを自動的に置き換える方法については、この手順のステップ 3-vi を参照してください。persistent_volume_claimは、ソース永続ボリューム要求の名前に置き換えます。mysshkeysは、設定時にReplicationDestinationの.status.rsync.sshKeysフィールドからコピーしたキーに置き換えます。my.host.comは、設定時にReplicationDestinationの.status.rsync.addressフィールドからコピーしたホストアドレスに置き換えます。ストレージドライバーがクローン作成をサポートする場合は、
copyMethodの値にCloneを使用すると、レプリケーションのより効率的なプロセスになる可能性があります。storageClassNameおよびvolumeSnapshotClassNameはオプションのパラメーターです。ご使用の環境のデフォルトとは異なるストレージクラスおよびボリュームスナップショットクラス名を使用している場合は、それらの値を指定してください。永続ボリュームの同期方法を設定できるようになりました。
宛先クラスターに対して次のコマンドを入力して、宛先クラスターから SSH シークレットをコピーします。
$ kubectl get secret -n <destination-ns> $SSHKEYS -o yaml > /tmp/secret.yaml
destination-nsを、宛先が置かれている永続ボリューム要求の namespace に置き換えます。以下のコマンドを入力して、
viエディターでシークレットファイルを開きます。$ vi /tmp/secret.yaml
宛先クラスターのオープンシークレットファイルで、次の変更を行います。
-
名前空間をソースクラスターの名前空間に変更します。この例では、
source-nsです。 -
所有者の参照を削除します (
.metadata.ownerReferences)。
-
名前空間をソースクラスターの名前空間に変更します。この例では、
ソースクラスターで、ソースクラスターで次のコマンドを入力してシークレットファイルを作成します。
$ kubectl create -f /tmp/secret.yaml
ソースクラスターで、以下のコマンドを入力して
ReplicationSourceオブジェクトのaddressおよびsshKeysの値を、宛先クラスターから書き留めた値に置き換えてreplication_source.yamlファイルを変更します。$ sed -i "s/<my.host.com>/$ADDRESS/g" replication_source.yaml $ sed -i "s/<mysshkeys>/$SSHKEYS/g" replication_source.yaml $ kubectl create -n <source> -f replication_source.yaml
my.host.comは、設定時にReplicationDestinationの.status.rsync.addressフィールドからコピーしたホストアドレスに置き換えます。mysshkeysは、設定時にReplicationDestinationの.status.rsync.sshKeysフィールドからコピーしたキーに置き換えます。sourceを、ソース が置かれている永続ボリューム要求の名前に置き換えます。注記: 複製する永続ボリューム要求と同じ namespace にファイルを作成する必要があります。
ReplicationSourceオブジェクトで以下のコマンドを実行して、レプリケーションが完了したことを確認します。$ kubectl describe ReplicationSource -n <source-ns> <source>
source-nsを、ソースが置かれている Persistent Volume Claim の namespace に置き換えます。sourceは、レプリケーションソース CR の名前に置き換えます。レプリケーションが成功した場合、出力は次の例のようになります。
Status: Conditions: Last Transition Time: 2021-10-14T20:48:00Z Message: Synchronization in-progress Reason: SyncInProgress Status: True Type: Synchronizing Last Transition Time: 2021-10-14T20:41:41Z Message: Reconcile complete Reason: ReconcileComplete Status: True Type: Reconciled Last Sync Duration: 5m20.764642395s Last Sync Time: 2021-10-14T20:47:01Z Next Sync Time: 2021-10-14T20:48:00ZLast Sync Timeに時間がリストされていない場合、レプリケーションは完了しません。
1.21.4. 複製されたイメージを使用可能な永続的なボリュームクレームに変換する
複製されたイメージを使用してデータを回復したり、永続ボリュームクレームの新しいインスタンスを作成したりする必要がある場合があります。イメージのコピーは、使用する前に永続的なボリュームクレームに変換する必要があります。複製されたイメージを永続的なボリュームクレームに変換するには、次の手順を実行します。
レプリケーションが完了したら、以下のコマンドを入力して
ReplicationDestinationオブジェクトから最新のスナップショットを特定します。$ kubectl get replicationdestination <destination> -n <destination-ns> --template={{.status.latestImage.name}}永続的なボリュームクレームを作成するときの最新のスナップショットの値に注意してください。
destinationは、レプリケーション先の名前に置き換えます。destination-nsは、宛先の namespace に置き換えます。以下の例のような
pvc.yamlファイルを作成します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: <pvc-name> namespace: <destination-ns> spec: accessModes: - ReadWriteOnce dataSource: kind: VolumeSnapshot apiGroup: snapshot.storage.k8s.io name: <snapshot_to_replace> resources: requests: storage: 2Gipvc-nameは、新規の永続ボリューム要求 (PVC) の名前に置き換えます。destination-nsを、永続ボリューム要求 (PVC) が置かれている namespace に置き換えます。snapshot_to_replaceを、直前の手順で確認したVolumeSnapshot名に置き換えます。resources.requests.storageは異なる値で更新できますが、値が初期ソース永続ボリューム要求と同じサイズである場合には、ベストプラクティスとして推奨されます。次のコマンドを入力して、永続ボリュームクレームが環境で実行されていることを確認します。
$ kubectl get pvc -n <destination-ns>
1.21.5. 同期のスケジューリング
レプリケーションの開始方法、スケジュール、または手動での実行方法を決定する際に選択すべきオプションがいくつかあります。レプリケーションのスケジューリングは、通常選択されているオプションです。
スケジュール オプションは、スケジュール時にレプリケーションを実行します。スケジュールは cronspec で定義されるため、スケジュールを時間間隔または特定の時間として設定できます。スケジュールの値の順序は次のとおりです。
"minute (0-59) hour (0-23) day-of-month (1-31) month (1-12) day-of-week (0-6)"
レプリケーションはスケジュールされた時間に開始されます。このレプリケーションオプションの設定は、以下の内容のようになります。
spec:
trigger:
schedule: "*/6 * * * *"これらの方法のいずれかを有効にしたら、設定した方法に従って同期スケジュールが実行されます。
追加情報およびオプションについては、VolSync のドキュメントを参照してください。