第5章 Kafka の設定
AMQ Streams を使用した Kafka コンポーネントの OpenShift クラスターへのデプロイメントは、カスタムリソースの適用により高度な設定が可能です。カスタムリソースは、OpenShift リソースを拡張するために CRD (カスタムリソース定義、Custom Resource Definition) によって追加される API のインスタンスとして作成されます。
CRD は、OpenShift クラスターでカスタムリソースを記述するための設定手順として機能し、デプロイメントで使用する Kafka コンポーネントごとに AMQ Streams で提供されます。CRD およびカスタムリソースは YAML ファイルとして定義されます。YAML ファイルのサンプルは AMQ Streams ディストリビューションに同梱されています。
また、CRD を使用すると、CLI へのアクセスや設定検証などのネイティブ OpenShift 機能を AMQ Streams リソースで活用することもできます。
本章では、カスタムリソースを使用して Kafka のコンポーネントを設定する方法を見ていきます。まず、一般的な設定のポイント、次にコンポーネント固有の重要な設定に関する考慮事項について説明します。
5.1. カスタムリソース
CRD をインストールして新規カスタムリソースタイプをクラスターに追加した後に、その仕様に基づいてリソースのインスタンスを作成できます。
AMQ Streams コンポーネントのカスタムリソースには、specで定義される共通の設定プロパティーがあります。
Kafka トピックカスタムリソースからのこの抜粋では、apiVersion および kind プロパティーを使用して、関連付けられた CRD を識別します。spec プロパティーは、トピックのパーティションおよびレプリカの数を定義する設定を示しています。
Kafka トピックカスタムリソース
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
# ...共通の設定、特定のコンポーネントに特有の設定など、他にも YAML 定義に組み込むことができる設定オプションが多数あります。
5.2. 共通の設定
複数のリソースに共通する設定オプションの一部が以下に記載されています。セキュリティー および メトリクスコレクション も採用できます (該当する場合)。
- ブートストラップサーバー
ブートストラップサーバーは、以下の Kafka クラスターに対するホスト/ポート接続に使用されます。
- Kafka Connect
- Kafka Bridge
- Kafka MirrorMaker プロデューサーおよびコンシューマー
- CPU およびメモリーリソース
コンポーネントの CPU およびメモリーリソースを要求します。制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。
Topic Operator および User Operator のリソース要求および制限は
Kafkaリソースに設定されます。- ロギング
- コンポーネントのロギングレベルを定義します。ロギングは直接 (インライン) または外部で Config Map を使用して定義できます。
- ヘルスチェック
- ヘルスチェックの設定では、liveness および readiness プローブが導入され、コンテナーを再起動するタイミング (liveliness) と、コンテナーがトラフィック (readiness) を受け入れるタイミングが分かります。
- JVM オプション
- JVM オプションでは、メモリー割り当ての最大と最小を指定し、実行するプラットフォームに応じてコンポーネントのパフォーマンスを最適化します。
- Pod のスケジューリング
- Pod スケジュールは アフィニティー/非アフィニティールール を使用して、どのような状況で Pod がノードにスケジューリングされるかを決定します。
共通設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
bootstrapServers: my-cluster-kafka-bootstrap:9092
resources:
requests:
cpu: 12
memory: 64Gi
limits:
cpu: 12
memory: 64Gi
logging:
type: inline
loggers:
connect.root.logger.level: "INFO"
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
template:
pod:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-type
operator: In
values:
- fast-network
# ...5.3. Kafka クラスターの設定
Kafka クラスターは、1 つまたは複数のブローカーで構成されます。プロデューサーおよびコンシューマーがブローカー内のトピックにアクセスできるようにするには、Kafka 設定でクラスターへのデータの保存方法、およびデータへのアクセス方法を定義する必要があります。ラック 全体で複数のブローカーノードを使用して Kafka クラスターを実行するように設定できます。
- ストレージ
Kafka および ZooKeeper は、ディスクにデータを格納します。
AMQ Streams は、
StorageClassでプロビジョニングされるブロックストレージが必要です。ストレージ用のファイルシステム形式は XFS または EXT4 である必要があります。3 種類のデータストレージがサポートされます。- 一時データストレージ (開発用のみで推奨されます)
- 一時ストレージは、インスタンスの有効期間についてのデータを格納します。インスタンスを再起動すると、データは失われます。
- 永続ストレージ
- 永続ストレージは、インスタンスのライフサイクルとは関係なく長期のデータストレージに関連付けられます。
- JBOD (Just a Bunch of Disks、Kafka のみに適しています)
- JBOD では、複数のディスクを使用して各ブローカーにコミットログを保存できます。
既存の Kafka クラスターが使用するディスク容量は、増やすことができます (インフラストラクチャーでサポートされる場合)。
- リスナー
リスナーは、クライアントが Kafka クラスターに接続する方法を設定します。
Kafka クラスター内の各リスナーに一意の名前とポートを指定することで、複数のリスナーを設定できます。
以下のタイプのリスナーがサポートされます。
- OpenShift 内でのアクセスに使用する 内部リスナー
- OpenShift 外からアクセスするときに使用する 外部リスナー
リスナーの TLS 暗号化を有効にし、認証 を設定できます。
内部リスナーは
internalタイプを使用して指定されます。外部リスナーは、外部用
typeを指定して Kafka を公開します。-
OpenShift ルートおよびデフォルトの HAProxy ルーターを使用する
route -
ロードバランサーサービスを使用する
loadbalancer -
OpenShift ノードのポートを使用する
nodeport -
OpenShift Ingress と NGINX Ingress Controller for Kubernetes を使用する
ingress
トークンベースの認証に OAuth 2.0 を使用している場合は、リスナーが承認サーバーを使用するように設定できます。
- ラックアウェアネス
- ラックアウェアネス (rack awareness) は、Kafka ブローカーの Pod とトピックレプリカを racks 全体に分散する設定機能です。ラックとは、データセンターまたは、データセンター内のラック、アベイラビリティーゾーンを表します。
Kafka 設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external1
port: 9094
type: route
tls: true
authentication:
type: tls
# ...
storage:
type: persistent-claim
size: 10000Gi
# ...
rack:
topologyKey: topology.kubernetes.io/zone
# ...5.4. Kafka MirrorMaker の設定
MirrorMaker を設定するには、ソースおよびターゲット (宛先) の Kafka クラスターが実行中である必要があります。
従来のバージョンの MirrorMaker のサポートも継続されますが、AMQ Streams で MirrorMaker 2.0 を使用することもできます。
MirrorMaker 2.0
MirrorMaker 2.0 は Kafka Connect フレームワークをベースとし、コネクターによってクラスター間のデータ転送が管理されます。
MirrorMaker 2.0 は以下を使用します。
- ソースクラスターからデータを消費するソースクラスターの設定。
- データをターゲットクラスターに出力するターゲットクラスターの設定。
クラスターの設定
active/passive または active/active クラスター設定で MirrorMaker 2.0 を使用できます。
- active/active 設定では、両方のクラスターがアクティブで、同じデータを同時に提供します。これは、地理的に異なる場所で同じデータをローカルで利用可能にする場合に便利です。
- active/passive 設定では、アクティブなクラスターからのデータはパッシブなクラスターで複製され、たとえば、システム障害時のデータ復旧などでスタンバイ状態を維持します。
KafkaMirrorMaker2 カスタムリソースを設定し、ソースおよびターゲットクラスターの接続詳細を含む Kafka Connect デプロイメントを定義します。次に、複数の MirrorMaker 2.0 コネクターを実行し、接続を確立します。
トピックの設定は、KafkaMirrorMaker2 カスタムリソースに定義されたトピックに従って、ソースクラスターとターゲットクラスターの間で自動的に同期化されます。設定の変更はリモートトピックに伝播されるため、新しいトピックおよびパーティションは削除および作成されます。トピックのレプリケーションは、トピックを許可または拒否するために、正規表現パターンを使用して定義されます。
以下の MirrorMaker 2.0 コネクターおよび関連する内部トピックは、クラスター間でのデータの転送および同期を管理するのに役立ちます。
- MirrorSourceConnector
- MirrorSourceConnector は、ソースクラスターからリモートトピックを作成します。
- MirrorCheckpointConnector
- MirrorCheckpointConnector は、オフセット同期 (offset sync) トピックと チェックポイント (checkpoint) トピックを使用して、指定のコンシューマーグループのオフセットを追跡し、マッピングします。オフセット同期トピックは、複製されたトピックパーティションのソースおよびターゲットオフセットをレコードメタデータからマッピングします。チェックポイントは、各ソースクラスターから生成され、チェックポイントトピックを介してターゲットクラスターでレプリケートされます。チェックポイントトピックは、各コンシューマーグループのレプリケートされたトピックパーティションのソースおよびターゲットクラスターで最後にコミットされたオフセットをマッピングします。
- MirrorHeartbeatConnector
- MirrorHeartbeatConnector は、クラスター間の接続を定期的に確認します。ハートビートは、ローカルクラスターで作成される ハートビート (heartbeat) トピックで、MirrorHeartbeatConnector によって毎秒作成されます。MirrorMaker 2.0 がリモートとローカルの両方にある場合、リモートで MirrorHeartbeatConnector によって生成されるハートビートはリモートトピックと同様に処理され、ローカルクラスターで MirrorSourceConnector によってミラーリングされます。ハートビートトピックによって、リモートクラスターが利用可能で、クラスターが接続されていることを簡単にチェックできます。障害が発生した場合、ハートビートトピックのオフセットポジションとタイムスタンプは復旧と診断に役立ちます。
図5.1 2 つのクラスターにおけるレプリケーション
2 つのクラスターにおける双方向レプリケーション
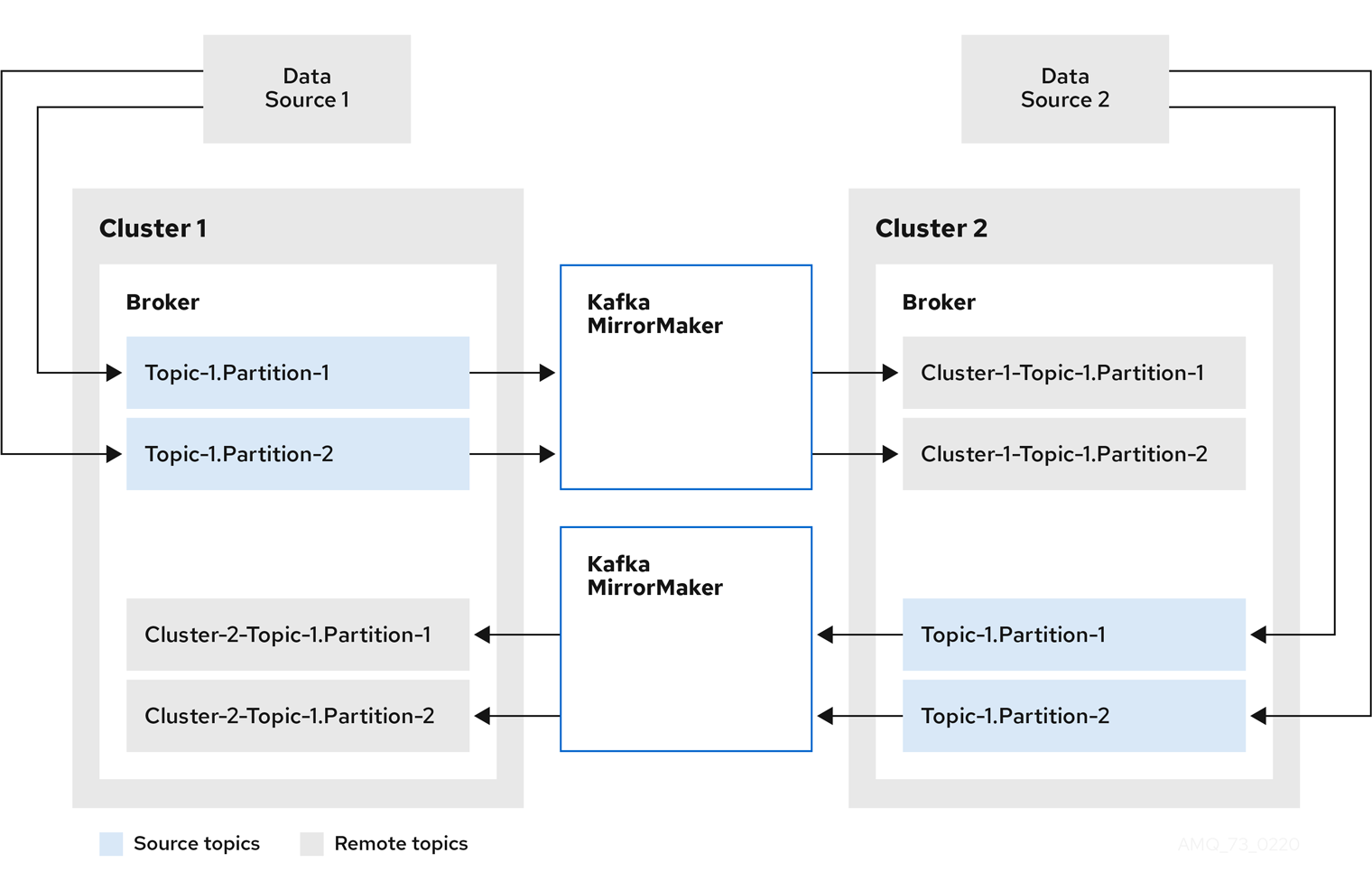
MirrorMaker 2.0 アーキテクチャーは、アクティブ/アクティブ クラスター設定で双方向レプリケーションをサポートするため、両方のクラスターがアクティブになり、同じデータを同時に提供します。MirrorMaker 2.0 クラスターは、ターゲット宛先ごとに必要です。
リモートトピックは、クラスター名をトピック名に追加する、自動名前変更によって区別されます。これは、同じデータを地理的に異なる場所でローカルで使用できるようにする場合に便利です。
ただし、active/passive クラスター設定でデータをバックアップまたは移行する場合は、トピックの元の名前を維持することが望ましい場合があります。その場合は、自動名前変更を無効にするように MirrorMaker 2.0 を設定できます。
図5.2 双方向レプリケーション
MirrorMaker 2.0 設定の YAML の例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.7.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}
topicsPattern: ".*"
groupsPattern: "group1|group2|group3"MirrorMaker
従来のバージョンの MirrorMaker では、プロデューサーとコンシューマーを使用して、クラスターにまたがってデータをレプリケートします。
MirrorMaker は以下を使用します。
- ソースクラスターからデータを使用するコンシューマーの設定。
- データをターゲットクラスターに出力するプロデューサーの設定。
コンシューマーおよびプロデューサー設定には、認証および暗号化設定が含まれます。
許可リスト (allowlist) では、ソースからターゲットクラスターにミラーリングするトピックを定義します。
主なコンシューマー設定
- コンシューマーグループ ID
- 使用するメッセージがコンシューマーグループに割り当てられるようにするための MirrorMaker コンシューマーのコンシューマーグループ ID。
- コンシューマーストリームの数
- メッセージを並行して使用するコンシューマーグループ内のコンシューマー数を決定する値。
- オフセットコミットの間隔
- メッセージの使用とメッセージのコミットの期間を設定するオフセットコミットの間隔。
キープロデューサーの設定
- 送信失敗のキャンセルオプション
- メッセージ送信の失敗を無視するか、または MirrorMaker を終了して再作成するかを定義できます。
MirrorMaker 設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker
metadata:
name: my-mirror-maker
spec:
# ...
consumer:
bootstrapServers: my-source-cluster-kafka-bootstrap:9092
groupId: "my-group"
numStreams: 2
offsetCommitInterval: 120000
# ...
producer:
# ...
abortOnSendFailure: false
# ...
whitelist: "my-topic|other-topic"
# ...5.5. Kafka Connect の設定
Kafka Connect の基本設定には、Kafka クラスターに接続するブートストラップアドレスと、暗号化および認証の詳細が必要です。
Kafka Connect インスタンスはデフォルトでは、以下が同じ値で設定されます。
- Kafka Connect クラスターのグループ ID
- コネクターオフセットを保存する Kafka トピック
- コネクターおよびタスクステータス設定を保存する Kafka トピック
- コネクターおよびタスクステータスの更新情報を保存する Kafka トピック
複数の異なる Kafka Connect インスタンスが使用されている場合には、上記の設定はインスタンスごとに反映する必要があります。
Kafka Connect 設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
# ...コネクター
コネクターは Kafka Connect とは別に設定されます。この設定では、Kafka Connect にフィードするソース入力データおよびターゲット出力データを記述します。外部ソースデータは、対象のメッセージを格納する特定のトピックを参照する必要があります。
Kafka には、以下のようにビルトインコネクターが 2 つあります。
-
FileStreamSourceConnectorは、外部システムから Kafka にデータをストリーミングし、入力ソースから行を読み取り、各行を Kafka トピックに送信します。 -
FileStreamSinkConnectorは、Kafka から外部システムにデータをストリーミングし、Kafka トピックからメッセージを読み取り、出力ファイルにメッセージごとに 1 行を作成します。
コネクタープラグインを使用して他のコネクターを追加できます。コネクタープラグインは、JAR ファイルまたは TGZ アーカイブのセットで、特定タイプの外部システムへの接続に必要な実装を定義します。
新しいコネクタープラグインを使用するカスタム Kafka Connect イメージを作成します。
イメージを作成するには、以下を使用します。
- AMQ Streams が新しいイメージを自動的に作成するための Kafka Connect の設定。
- ベースイメージとしての Red Hat Ecosystem Catalog の Kafka コンテナーイメージ
- 新規コンテナーイメージを作成する OpenShift ビルド と S2I (Source-to-Image) フレームワーク。
AMQ Streams で新しいイメージを自動的に作成するには、build 設定に、コンテナーイメージを格納するコンテナーレジストリーを参照する output プロパティーと、イメージに追加するコネクタープラグインとそれらのアーティファクトをリストする plugins プロパティーが必要です。
output プロパティーは、イメージのタイプおよび名前を記述し、任意でコンテナーレジストリーへのアクセスに必要なクレデンシャルが含まれる Secret の名前を記述します。plugins プロパティーは、アーティファクトのタイプとアーティファクトのダウンロード元となる URL を記述します。さらに、SHA-512 チェックサムを指定して、アーティファクトを展開する前に検証することもできます。
新しいイメージを自動的に作成する Kafka Connect の設定例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
# ...
build:
output:
type: docker
image: my-registry.io/my-org/my-connect-cluster:latest
pushSecret: my-registry-credentials
plugins:
- name: debezium-postgres-connector
artifacts:
- type: tgz
url: https://ARTIFACT-ADDRESS.tgz
sha512sum: HASH-NUMBER-TO-VERIFY-ARTIFACT
# ...
#...コネクターの管理
KafkaConnector リソースまたは Kafka Connect REST API を使用して、Kafka Connect クラスターでコネクターインスタンスを作成および管理できます。KafkaConnector リソースでは OpenShift ネイティブな方法が提供され、Cluster Operator によって管理されます。
KafkaConnector リソースの spec では、コネクタークラスと設定、およびデータを処理するコネクター タスク の最大数を指定します。
KafkaConnector 設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-source-connector
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.kafka.connect.file.FileStreamSourceConnector
tasksMax: 2
config:
file: "/opt/kafka/LICENSE"
topic: my-topic
# ...
アノテーションを KafkaConnect リソースに追加して、KafkaConnector を有効にします。KafkaConnector リソースは、リンク先の Kafka Connect クラスターと同じ namespace にデプロイする必要があります。
KafkaConnector を有効にするアノテーションの YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
annotations:
strimzi.io/use-connector-resources: "true"
# ...5.6. Kafka Bridge の設定
Kafka Bridge 設定には、接続先の Kafka クラスターのブートストラップサーバー仕様と、必須の暗号化および認証オプションが必要になります。
コンシューマーの Apache Kafka 設定ドキュメント およびプロデューサーの Apache Kafka 設定ドキュメント で説明されているように、Kafka Bridge コンシューマーおよびプロデューサー設定は標準です。
HTTP 関連の設定オプションでは、サーバーがリッスンするポート接続を設定します。
CORS
Kafka Bridge では、CORS (Cross-Origin Resource Sharing) の使用がサポートされます。CORS は、複数のオリジンから指定のリソースにブラウザーでアクセスできるようにする HTTP メカニズムです (たとえば、異なるドメイン上のリソースへのアクセス)。CORS を使用する場合、Kafka Bridge を通じた Kafka クラスターとの対話用に、許可されるリソースオリジンおよび HTTP メソッドのリストを定義できます。リストは、Kafka Bridge 設定の http 仕様で定義されます。
CORS では、異なるドメイン上のオリジンソース間での シンプルな リクエストおよび プリフライト リクエストが可能です。
- シンプルなリクエストは、そのヘッダーで許可されるオリジンを定義する必要のある HTTP リクエストです。
- プリフライトリクエストでは、オリジンとメソッドが許可されることを確認するために、実際のリクエストの前に初期 OPTIONS HTTP リクエストが送信されます。
Kafka ブリッジ設定の YAML 例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
bootstrapServers: my-cluster-kafka:9092
http:
port: 8080
cors:
allowedOrigins: "https://strimzi.io"
allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH"
consumer:
config:
auto.offset.reset: earliest
producer:
config:
delivery.timeout.ms: 300000
# ...その他のリソース
- Fetch CORS 仕様