このコンテンツは選択した言語では利用できません。
Chapter 3. Deployment configuration
This chapter describes how to configure different aspects of the supported deployments:
- Kafka clusters
- Kafka Connect clusters
- Kafka Connect clusters with Source2Image support
- Kafka Mirror Maker
- Kafka Bridge
- OAuth 2.0 token based authentication
3.1. Kafka cluster configuration
The full schema of the Kafka resource is described in the Section C.1, “Kafka schema reference”. All labels that are applied to the desired Kafka resource will also be applied to the OpenShift resources making up the Kafka cluster. This provides a convenient mechanism for resources to be labeled as required.
3.1.1. Sample Kafka YAML configuration
For help in understanding the configuration options available for your Kafka deployment, refer to sample YAML file provided here.
The sample shows only some of the possible configuration options, but those that are particularly important include:
- Resource requests (CPU / Memory)
- JVM options for maximum and minimum memory allocation
- Listeners (and authentication)
- Authentication
- Storage
- Rack awareness
- Metrics
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 3
version: 1.3
resources:
requests:
memory: 64Gi
cpu: "8"
limits:
memory: 64Gi
cpu: "12"
jvmOptions:
-Xms: 8192m
-Xmx: 8192m
listeners:
tls:
authentication:
type: tls
external:
type: route
authentication:
type: tls
authorization:
type: simple
config:
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
storage:
type: persistent-claim
size: 10000Gi
rack:
topologyKey: failure-domain.beta.kubernetes.io/zone
metrics:
lowercaseOutputName: true
rules:
# Special cases and very specific rules
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
# ...
zookeeper:
replicas: 3
resources:
requests:
memory: 8Gi
cpu: "2"
limits:
memory: 8Gi
cpu: "2"
jvmOptions:
-Xms: 4096m
-Xmx: 4096m
storage:
type: persistent-claim
size: 1000Gi
metrics:
# ...
entityOperator:
topicOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
userOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
kafkaExporter:
# ...- 1
- Replicas specifies the number of broker nodes.
- 2
- Kafka version, which can be changed by following the upgrade procedure.
- 3
- Resource requests specify the resources to reserve for a given container.
- 4
- Resource limits specify the maximum resources that can be consumed by a container.
- 5
- 6
- Listeners configure how clients connect to the Kafka cluster via bootstrap addresses. Listeners are configured as
plain(without encryption),tlsorexternal. - 7
- Listener authentication mechanisms may be configured for each listener, and specified as mutual TLS or SCRAM-SHA.
- 8
- External listener configuration specifies how the Kafka cluster is exposed outside OpenShift, such as through a
route,loadbalancerornodeport. - 9
- 10
- Config specifies the broker configuration. Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by AMQ Streams.
- 11
- 12
- Storage size for persistent volumes may be increased and additional volumes may be added to JBOD storage.
- 13
- Persistent storage has additional configuration options, such as a storage
idandclassfor dynamic volume provisioning. - 14
- Rack awareness is configured to spread replicas across different racks. A
topologykey must match the label of a cluster node. - 15
- 16
- Kafka rules for exporting metrics to a Grafana dashboard through the JMX Exporter. A set of rules provided with AMQ Streams may be copied to your Kafka resource configuration.
- 17
- Zookeeper-specific configuration, which contains properties similar to the Kafka configuration.
- 18
- Entity Operator configuration, which specifies the configuration for the Topic Operator and User Operator.
- 19
- Kafka Exporter configuration, which is used to expose data as Prometheus metrics.
3.1.2. Data storage considerations
An efficient data storage infrastructure is essential to the optimal performance of AMQ Streams.
AMQ Streams requires block storage and is designed to work optimally with cloud-based block storage solutions, including Amazon Elastic Block Store (EBS). The use of file storage (for example, NFS) is not recommended.
Choose local storage (local persistent volumes) when possible. If local storage is not available, you can use a Storage Area Network (SAN) accessed by a protocol such as Fibre Channel or iSCSI.
3.1.2.1. Apache Kafka and Zookeeper storage
Use separate disks for Apache Kafka and Zookeeper.
Three types of data storage are supported:
- Ephemeral (Recommended for development only)
- Persistent
- JBOD (Just a Bunch of Disks, suitable for Kafka only)
For more information, see Kafka and Zookeeper storage.
Solid-state drives (SSDs), though not essential, can improve the performance of Kafka in large clusters where data is sent to and received from multiple topics asynchronously. SSDs are particularly effective with Zookeeper, which requires fast, low latency data access.
You do not need to provision replicated storage because Kafka and Zookeeper both have built-in data replication.
3.1.2.2. File systems
It is recommended that you configure your storage system to use the XFS file system. AMQ Streams is also compatible with the ext4 file system, but this might require additional configuration for best results.
3.1.3. Kafka and Zookeeper storage types
As stateful applications, Kafka and Zookeeper need to store data on disk. AMQ Streams supports three storage types for this data:
- Ephemeral
- Persistent
- JBOD storage
JBOD storage is supported only for Kafka, not for Zookeeper.
When configuring a Kafka resource, you can specify the type of storage used by the Kafka broker and its corresponding Zookeeper node. You configure the storage type using the storage property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper
The storage type is configured in the type field.
The storage type cannot be changed after a Kafka cluster is deployed.
Additional resources
- For more information about ephemeral storage, see ephemeral storage schema reference.
- For more information about persistent storage, see persistent storage schema reference.
- For more information about JBOD storage, see JBOD schema reference.
-
For more information about the schema for
Kafka, seeKafkaschema reference.
3.1.3.1. Ephemeral storage
Ephemeral storage uses the `emptyDir` volumes to store data. To use ephemeral storage, the type field should be set to ephemeral.
EmptyDir volumes are not persistent and the data stored in them will be lost when the Pod is restarted. After the new pod is started, it has to recover all data from other nodes of the cluster. Ephemeral storage is not suitable for use with single node Zookeeper clusters and for Kafka topics with replication factor 1, because it will lead to data loss.
An example of Ephemeral storage
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: ephemeral
# ...
zookeeper:
# ...
storage:
type: ephemeral
# ...3.1.3.1.1. Log directories
The ephemeral volume will be used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-log_idx_-
Where
idxis the Kafka broker pod index. For example/var/lib/kafka/data/kafka-log0.
3.1.3.2. Persistent storage
Persistent storage uses Persistent Volume Claims to provision persistent volumes for storing data. Persistent Volume Claims can be used to provision volumes of many different types, depending on the Storage Class which will provision the volume. The data types which can be used with persistent volume claims include many types of SAN storage as well as Local persistent volumes.
To use persistent storage, the type has to be set to persistent-claim. Persistent storage supports additional configuration options:
id(optional)-
Storage identification number. This option is mandatory for storage volumes defined in a JBOD storage declaration. Default is
0. size(required)- Defines the size of the persistent volume claim, for example, "1000Gi".
class(optional)- The OpenShift Storage Class to use for dynamic volume provisioning.
selector(optional)- Allows selecting a specific persistent volume to use. It contains key:value pairs representing labels for selecting such a volume.
deleteClaim(optional)-
Boolean value which specifies if the Persistent Volume Claim has to be deleted when the cluster is undeployed. Default is
false.
Increasing the size of persistent volumes in an existing AMQ Streams cluster is only supported in OpenShift versions that support persistent volume resizing. The persistent volume to be resized must use a storage class that supports volume expansion. For other versions of OpenShift and storage classes which do not support volume expansion, you must decide the necessary storage size before deploying the cluster. Decreasing the size of existing persistent volumes is not possible.
Example fragment of persistent storage configuration with 1000Gi size
# ...
storage:
type: persistent-claim
size: 1000Gi
# ...The following example demonstrates the use of a storage class.
Example fragment of persistent storage configuration with specific Storage Class
# ...
storage:
type: persistent-claim
size: 1Gi
class: my-storage-class
# ...
Finally, a selector can be used to select a specific labeled persistent volume to provide needed features such as an SSD.
Example fragment of persistent storage configuration with selector
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
hdd-type: ssd
deleteClaim: true
# ...3.1.3.2.1. Storage class overrides
You can specify a different storage class for one or more Kafka brokers, instead of using the default storage class. This is useful if, for example, storage classes are restricted to different availability zones or data centers. You can use the overrides field for this purpose.
In this example, the default storage class is named my-storage-class:
Example AMQ Streams cluster using storage class overrides
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
labels:
app: my-cluster
name: my-cluster
namespace: myproject
spec:
# ...
kafka:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
As a result of the configured overrides property, the broker volumes use the following storage classes:
-
The persistent volumes of broker 0 will use
my-storage-class-zone-1a. -
The persistent volumes of broker 1 will use
my-storage-class-zone-1b. -
The persistent volumes of broker 2 will use
my-storage-class-zone-1c.
The overrides property is currently used only to override storage class configurations. Overriding other storage configuration fields is not currently supported. Other fields from the storage configuration are currently not supported.
3.1.3.2.2. Persistent Volume Claim naming
When persistent storage is used, it creates Persistent Volume Claims with the following names:
data-cluster-name-kafka-idx-
Persistent Volume Claim for the volume used for storing data for the Kafka broker pod
idx. data-cluster-name-zookeeper-idx-
Persistent Volume Claim for the volume used for storing data for the Zookeeper node pod
idx.
3.1.3.2.3. Log directories
The persistent volume will be used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-log_idx_-
Where
idxis the Kafka broker pod index. For example/var/lib/kafka/data/kafka-log0.
3.1.3.3. Resizing persistent volumes
You can provision increased storage capacity by increasing the size of the persistent volumes used by an existing AMQ Streams cluster. Resizing persistent volumes is supported in clusters that use either a single persistent volume or multiple persistent volumes in a JBOD storage configuration.
You can increase but not decrease the size of persistent volumes. Decreasing the size of persistent volumes is not currently supported in OpenShift.
Prerequisites
- An OpenShift cluster with support for volume resizing.
- The Cluster Operator is running.
- A Kafka cluster using persistent volumes created using a storage class that supports volume expansion.
Procedure
In a
Kafkaresource, increase the size of the persistent volume allocated to the Kafka cluster, the Zookeeper cluster, or both.-
To increase the volume size allocated to the Kafka cluster, edit the
spec.kafka.storageproperty. To increase the volume size allocated to the Zookeeper cluster, edit the
spec.zookeeper.storageproperty.For example, to increase the volume size from
1000Gito2000Gi:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: persistent-claim size: 2000Gi class: my-storage-class # ... zookeeper: # ...
-
To increase the volume size allocated to the Kafka cluster, edit the
Create or update the resource.
Use
oc apply:oc apply -f your-fileOpenShift increases the capacity of the selected persistent volumes in response to a request from the Cluster Operator. When the resizing is complete, the Cluster Operator restarts all pods that use the resized persistent volumes. This happens automatically.
Additional resources
For more information about resizing persistent volumes in OpenShift, see Resizing Persistent Volumes using Kubernetes.
3.1.3.4. JBOD storage overview
You can configure AMQ Streams to use JBOD, a data storage configuration of multiple disks or volumes. JBOD is one approach to providing increased data storage for Kafka brokers. It can also improve performance.
A JBOD configuration is described by one or more volumes, each of which can be either ephemeral or persistent. The rules and constraints for JBOD volume declarations are the same as those for ephemeral and persistent storage. For example, you cannot change the size of a persistent storage volume after it has been provisioned.
3.1.3.4.1. JBOD configuration
To use JBOD with AMQ Streams, the storage type must be set to jbod. The volumes property allows you to describe the disks that make up your JBOD storage array or configuration. The following fragment shows an example JBOD configuration:
# ...
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...The ids cannot be changed once the JBOD volumes are created.
Users can add or remove volumes from the JBOD configuration.
3.1.3.4.2. JBOD and Persistent Volume Claims
When persistent storage is used to declare JBOD volumes, the naming scheme of the resulting Persistent Volume Claims is as follows:
data-id-cluster-name-kafka-idx-
Where
idis the ID of the volume used for storing data for Kafka broker podidx.
3.1.3.4.3. Log directories
The JBOD volumes will be used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data-id/kafka-log_idx_-
Where
idis the ID of the volume used for storing data for Kafka broker podidx. For example/var/lib/kafka/data-0/kafka-log0.
3.1.3.5. Adding volumes to JBOD storage
This procedure describes how to add volumes to a Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type.
When adding a new volume under an id which was already used in the past and removed, you have to make sure that the previously used PersistentVolumeClaims have been deleted.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage
Procedure
Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Add the new volumes to thevolumesarray. For example, add the new volume with id2:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false - id: 1 type: persistent-claim size: 100Gi deleteClaim: false - id: 2 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file- Create new topics or reassign existing partitions to the new disks.
Additional resources
For more information about reassigning topics, see Section 3.1.24.2, “Partition reassignment”.
3.1.3.6. Removing volumes from JBOD storage
This procedure describes how to remove volumes from Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type. The JBOD storage always has to contain at least one volume.
To avoid data loss, you have to move all partitions before removing the volumes.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage with two or more volumes
Procedure
- Reassign all partitions from the disks which are you going to remove. Any data in partitions still assigned to the disks which are going to be removed might be lost.
Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Remove one or more volumes from thevolumesarray. For example, remove the volumes with ids1and2:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
For more information about reassigning topics, see Section 3.1.24.2, “Partition reassignment”.
3.1.4. Kafka broker replicas
A Kafka cluster can run with many brokers. You can configure the number of brokers used for the Kafka cluster in Kafka.spec.kafka.replicas. The best number of brokers for your cluster has to be determined based on your specific use case.
3.1.4.1. Configuring the number of broker nodes
This procedure describes how to configure the number of Kafka broker nodes in a new cluster. It only applies to new clusters with no partitions. If your cluster already has topics defined, see Section 3.1.24, “Scaling clusters”.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with no topics defined yet
Procedure
Edit the
replicasproperty in theKafkaresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... replicas: 3 # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
If your cluster already has topics defined, see Section 3.1.24, “Scaling clusters”.
3.1.5. Kafka broker configuration
AMQ Streams allows you to customize the configuration of the Kafka brokers in your Kafka cluster. You can specify and configure most of the options listed in the "Broker Configs" section of the Apache Kafka documentation. You cannot configure options that are related to the following areas:
- Security (Encryption, Authentication, and Authorization)
- Listener configuration
- Broker ID configuration
- Configuration of log data directories
- Inter-broker communication
- Zookeeper connectivity
These options are automatically configured by AMQ Streams.
3.1.5.1. Kafka broker configuration
The config property in Kafka.spec.kafka contains Kafka broker configuration options as keys with values in one of the following JSON types:
- String
- Number
- Boolean
You can specify and configure all of the options in the "Broker Configs" section of the Apache Kafka documentation apart from those managed directly by AMQ Streams. Specifically, you are prevented from modifying all configuration options with keys equal to or starting with one of the following strings:
-
listeners -
advertised. -
broker. -
listener. -
host.name -
port -
inter.broker.listener.name -
sasl. -
ssl. -
security. -
password. -
principal.builder.class -
log.dir -
zookeeper.connect -
zookeeper.set.acl -
authorizer. -
super.user
If the config property specifies a restricted option, it is ignored and a warning message is printed to the Cluster Operator log file. All other supported options are passed to Kafka.
An example Kafka broker configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
config:
num.partitions: 1
num.recovery.threads.per.data.dir: 1
default.replication.factor: 3
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 1
log.retention.hours: 168
log.segment.bytes: 1073741824
log.retention.check.interval.ms: 300000
num.network.threads: 3
num.io.threads: 8
socket.send.buffer.bytes: 102400
socket.receive.buffer.bytes: 102400
socket.request.max.bytes: 104857600
group.initial.rebalance.delay.ms: 0
# ...3.1.5.2. Configuring Kafka brokers
You can configure an existing Kafka broker, or create a new Kafka broker with a specified configuration.
Prerequisites
- An OpenShift cluster is available.
- The Cluster Operator is running.
Procedure
-
Open the YAML configuration file that contains the
Kafkaresource specifying the cluster deployment. In the
spec.kafka.configproperty in theKafkaresource, enter one or more Kafka configuration settings. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... config: default.replication.factor: 3 offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 1 # ... zookeeper: # ...Apply the new configuration to create or update the resource.
Use
oc apply:oc apply -f kafka.yamlwhere
kafka.yamlis the YAML configuration file for the resource that you want to configure; for example,kafka-persistent.yaml.
3.1.6. Kafka broker listeners
You can configure the listeners enabled in Kafka brokers. The following types of listener are supported:
- Plain listener on port 9092 (without encryption)
- TLS listener on port 9093 (with encryption)
- External listener on port 9094 for access from outside of OpenShift
OAuth 2.0
If you are using OAuth 2.0 token based authentication, you can configure the listeners to connect to your authorization server. For more information, see Using OAuth 2.0 token based authentication.
3.1.6.1. Kafka listeners
You can configure Kafka broker listeners using the listeners property in the Kafka.spec.kafka resource. The listeners property contains three sub-properties:
-
plain -
tls -
external
Each listener will only be defined when the listeners object has the given property.
An example of listeners property with all listeners enabled
# ...
listeners:
plain: {}
tls: {}
external:
type: loadbalancer
# ...An example of listeners property with only the plain listener enabled
# ...
listeners:
plain: {}
# ...3.1.6.2. Configuring Kafka listeners
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
listenersproperty in theKafka.spec.kafkaresource.An example configuration of the plain (unencrypted) listener without authentication:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: plain: {} # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see
KafkaListenersschema reference.
3.1.6.3. Listener authentication
The listener authentication property is used to specify an authentication mechanism specific to that listener:
- Mutual TLS authentication (only on the listeners with TLS encryption)
- SCRAM-SHA authentication
If no authentication property is specified then the listener does not authenticate clients which connect through that listener.
Authentication must be configured when using the User Operator to manage KafkaUsers.
3.1.6.3.1. Authentication configuration for a listener
The following example shows:
-
A
plainlistener configured for SCRAM-SHA authentication -
A
tlslistener with mutual TLS authentication -
An
externallistener with mutual TLS authentication
An example showing listener authentication configuration
# ...
listeners:
plain:
authentication:
type: scram-sha-512
tls:
authentication:
type: tls
external:
type: loadbalancer
tls: true
authentication:
type: tls
# ...3.1.6.3.2. Mutual TLS authentication
Mutual TLS authentication is always used for the communication between Kafka brokers and Zookeeper pods.
Mutual authentication or two-way authentication is when both the server and the client present certificates. AMQ Streams can configure Kafka to use TLS (Transport Layer Security) to provide encrypted communication between Kafka brokers and clients either with or without mutual authentication. When you configure mutual authentication, the broker authenticates the client and the client authenticates the broker.
TLS authentication is more commonly one-way, with one party authenticating the identity of another. For example, when HTTPS is used between a web browser and a web server, the server obtains proof of the identity of the browser.
3.1.6.3.2.1. When to use mutual TLS authentication for clients
Mutual TLS authentication is recommended for authenticating Kafka clients when:
- The client supports authentication using mutual TLS authentication
- It is necessary to use the TLS certificates rather than passwords
- You can reconfigure and restart client applications periodically so that they do not use expired certificates.
3.1.6.3.3. SCRAM-SHA authentication
SCRAM (Salted Challenge Response Authentication Mechanism) is an authentication protocol that can establish mutual authentication using passwords. AMQ Streams can configure Kafka to use SASL (Simple Authentication and Security Layer) SCRAM-SHA-512 to provide authentication on both unencrypted and TLS-encrypted client connections. TLS authentication is always used internally between Kafka brokers and Zookeeper nodes. When used with a TLS client connection, the TLS protocol provides encryption, but is not used for authentication.
The following properties of SCRAM make it safe to use SCRAM-SHA even on unencrypted connections:
- The passwords are not sent in the clear over the communication channel. Instead the client and the server are each challenged by the other to offer proof that they know the password of the authenticating user.
- The server and client each generate a new challenge for each authentication exchange. This means that the exchange is resilient against replay attacks.
3.1.6.3.3.1. Supported SCRAM credentials
AMQ Streams supports SCRAM-SHA-512 only. When a KafkaUser.spec.authentication.type is configured with scram-sha-512 the User Operator will generate a random 12 character password consisting of upper and lowercase ASCII letters and numbers.
3.1.6.3.3.2. When to use SCRAM-SHA authentication for clients
SCRAM-SHA is recommended for authenticating Kafka clients when:
- The client supports authentication using SCRAM-SHA-512
- It is necessary to use passwords rather than the TLS certificates
- Authentication for unencrypted communication is required
3.1.6.4. External listeners
Use an external listener to expose your AMQ Streams Kafka cluster to a client outside an OpenShift environment.
Additional resources
3.1.6.4.1. Customizing advertised addresses on external listeners
By default, AMQ Streams tries to automatically determine the hostnames and ports that your Kafka cluster advertises to its clients. This is not sufficient in all situations, because the infrastructure on which AMQ Streams is running might not provide the right hostname or port through which Kafka can be accessed. You can customize the advertised hostname and port in the overrides property of the external listener. AMQ Streams will then automatically configure the advertised address in the Kafka brokers and add it to the broker certificates so it can be used for TLS hostname verification. Overriding the advertised host and ports is available for all types of external listeners.
Example of an external listener configured with overrides for advertised addresses
# ...
listeners:
external:
type: route
authentication:
type: tls
overrides:
brokers:
- broker: 0
advertisedHost: example.hostname.0
advertisedPort: 12340
- broker: 1
advertisedHost: example.hostname.1
advertisedPort: 12341
- broker: 2
advertisedHost: example.hostname.2
advertisedPort: 12342
# ...Additionally, you can specify the name of the bootstrap service. This name will be added to the broker certificates and can be used for TLS hostname verification. Adding the additional bootstrap address is available for all types of external listeners.
Example of an external listener configured with an additional bootstrap address
# ...
listeners:
external:
type: route
authentication:
type: tls
overrides:
bootstrap:
address: example.hostname
# ...3.1.6.4.2. Route external listeners
An external listener of type route exposes Kafka using OpenShift Routes and the HAProxy router.
route is only supported on OpenShift
3.1.6.4.2.1. Exposing Kafka using OpenShift Routes
When exposing Kafka using OpenShift Routes and the HAProxy router, a dedicated Route is created for every Kafka broker pod. An additional Route is created to serve as a Kafka bootstrap address. Kafka clients can use these Routes to connect to Kafka on port 443.
TLS encryption is always used with Routes.
By default, the route hosts are automatically assigned by OpenShift. However, you can override the assigned route hosts by specifying the requested hosts in the overrides property. AMQ Streams will not perform any validation that the requested hosts are available; you must ensure that they are free and can be used.
Example of an external listener of type routes configured with overrides for OpenShift route hosts
# ...
listeners:
external:
type: route
authentication:
type: tls
overrides:
bootstrap:
host: bootstrap.myrouter.com
brokers:
- broker: 0
host: broker-0.myrouter.com
- broker: 1
host: broker-1.myrouter.com
- broker: 2
host: broker-2.myrouter.com
# ...
For more information on using Routes to access Kafka, see Section 3.1.6.4.2.2, “Accessing Kafka using OpenShift routes”.
3.1.6.4.2.2. Accessing Kafka using OpenShift routes
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Deploy Kafka cluster with an external listener enabled and configured to the type
route.An example configuration with an external listener configured to use
Routes:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: external: type: route # ... # ... zookeeper: # ...Create or update the resource.
oc apply -f your-fileFind the address of the bootstrap
Route.oc get routes _cluster-name_-kafka-bootstrap -o=jsonpath='{.status.ingress[0].host}{"\n"}'Use the address together with port 443 in your Kafka client as the bootstrap address.
Extract the public certificate of the broker certification authority
oc get secret _<cluster-name>_-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtUse the extracted certificate in your Kafka client to configure TLS connection. If you enabled any authentication, you will also need to configure SASL or TLS authentication.
Additional resources
-
For more information about the schema, see
KafkaListenersschema reference.
3.1.6.4.3. Loadbalancer external listeners
External listeners of type loadbalancer expose Kafka by using Loadbalancer type Services.
3.1.6.4.3.1. Exposing Kafka using loadbalancers
When exposing Kafka using Loadbalancer type Services, a new loadbalancer service is created for every Kafka broker pod. An additional loadbalancer is created to serve as a Kafka bootstrap address. Loadbalancers listen to connections on port 9094.
By default, TLS encryption is enabled. To disable it, set the tls field to false.
Example of an external listener of type loadbalancer
# ...
listeners:
external:
type: loadbalancer
authentication:
type: tls
# ...For more information on using loadbalancers to access Kafka, see Section 3.1.6.4.3.4, “Accessing Kafka using loadbalancers”.
3.1.6.4.3.2. Customizing the DNS names of external loadbalancer listeners
On loadbalancer listeners, you can use the dnsAnnotations property to add additional annotations to the loadbalancer services. You can use these annotations to instrument DNS tooling such as External DNS, which automatically assigns DNS names to the loadbalancer services.
Example of an external listener of type loadbalancer using dnsAnnotations
# ...
listeners:
external:
type: loadbalancer
authentication:
type: tls
overrides:
bootstrap:
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-bootstrap.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
brokers:
- broker: 0
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-0.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 1
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-1.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 2
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-2.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
# ...3.1.6.4.3.3. Customizing the loadbalancer IP addresses
On loadbalancer listeners, you can use the loadBalancerIP property to request a specific IP address when creating a loadbalancer. Use this property when you need to use a loadbalancer with a specific IP address. The loadBalancerIP field is ignored if the cloud provider does not support the feature.
Example of an external listener of type loadbalancer with specific loadbalancer IP address requests
# ...
listeners:
external:
type: loadbalancer
authentication:
type: tls
overrides:
bootstrap:
loadBalancerIP: 172.29.3.10
brokers:
- broker: 0
loadBalancerIP: 172.29.3.1
- broker: 1
loadBalancerIP: 172.29.3.2
- broker: 2
loadBalancerIP: 172.29.3.3
# ...3.1.6.4.3.4. Accessing Kafka using loadbalancers
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Deploy Kafka cluster with an external listener enabled and configured to the type
loadbalancer.An example configuration with an external listener configured to use loadbalancers:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: external: type: loadbalancer authentication: type: tls # ... # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-fileFind the hostname of the bootstrap loadbalancer.
This can be done using
oc get:oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].hostname}{"\n"}'If no hostname was found (nothing was returned by the command), use the loadbalancer IP address.
This can be done using
oc get:oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].ip}{"\n"}'Use the hostname or IP address together with port 9094 in your Kafka client as the bootstrap address.
Unless TLS encryption was disabled, extract the public certificate of the broker certification authority.
This can be done using
oc get:oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtUse the extracted certificate in your Kafka client to configure TLS connection. If you enabled any authentication, you will also need to configure SASL or TLS authentication.
Additional resources
-
For more information about the schema, see
KafkaListenersschema reference.
3.1.6.4.4. Node Port external listeners
External listeners of type nodeport expose Kafka by using NodePort type Services.
3.1.6.4.4.1. Exposing Kafka using node ports
When exposing Kafka using NodePort type Services, Kafka clients connect directly to the nodes of OpenShift. You must enable access to the ports on the OpenShift nodes for each client (for example, in firewalls or security groups). Each Kafka broker pod is then accessible on a separate port. Additional NodePort type Service is created to serve as a Kafka bootstrap address.
When configuring the advertised addresses for the Kafka broker pods, AMQ Streams uses the address of the node on which the given pod is running. When selecting the node address, the different address types are used with the following priority:
- ExternalDNS
- ExternalIP
- Hostname
- InternalDNS
- InternalIP
By default, TLS encryption is enabled. To disable it, set the tls field to false.
TLS hostname verification is not currently supported when exposing Kafka clusters using node ports.
By default, the port numbers used for the bootstrap and broker services are automatically assigned by OpenShift. However, you can override the assigned node ports by specifying the requested port numbers in the overrides property. AMQ Streams does not perform any validation on the requested ports; you must ensure that they are free and available for use.
Example of an external listener configured with overrides for node ports
# ...
listeners:
external:
type: nodeport
tls: true
authentication:
type: tls
overrides:
bootstrap:
nodePort: 32100
brokers:
- broker: 0
nodePort: 32000
- broker: 1
nodePort: 32001
- broker: 2
nodePort: 32002
# ...For more information on using node ports to access Kafka, see Section 3.1.6.4.4.3, “Accessing Kafka using node ports”.
3.1.6.4.4.2. Customizing the DNS names of external node port listeners
On nodeport listeners, you can use the dnsAnnotations property to add additional annotations to the nodeport services. You can use these annotations to instrument DNS tooling such as External DNS, which automatically assigns DNS names to the cluster nodes.
Example of an external listener of type nodeport using dnsAnnotations
# ...
listeners:
external:
type: nodeport
tls: true
authentication:
type: tls
overrides:
bootstrap:
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-bootstrap.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
brokers:
- broker: 0
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-0.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 1
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-1.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 2
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-2.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
# ...3.1.6.4.4.3. Accessing Kafka using node ports
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Deploy Kafka cluster with an external listener enabled and configured to the type
nodeport.An example configuration with an external listener configured to use node ports:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: external: type: nodeport tls: true # ... # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-fileFind the port number of the bootstrap service.
This can be done using
oc get:oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.spec.ports[0].nodePort}{"\n"}'The port should be used in the Kafka bootstrap address.
Find the address of the OpenShift node.
This can be done using
oc get:oc get node node-name -o=jsonpath='{range .status.addresses[*]}{.type}{"\t"}{.address}{"\n"}'If several different addresses are returned, select the address type you want based on the following order:
- ExternalDNS
- ExternalIP
- Hostname
- InternalDNS
InternalIP
Use the address with the port found in the previous step in the Kafka bootstrap address.
Unless TLS encryption was disabled, extract the public certificate of the broker certification authority.
This can be done using
oc get:oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtUse the extracted certificate in your Kafka client to configure TLS connection. If you enabled any authentication, you will also need to configure SASL or TLS authentication.
Additional resources
-
For more information about the schema, see
KafkaListenersschema reference.
3.1.6.4.5. OpenShift Ingress external listeners
External listeners of type ingress exposes Kafka by using Kubernetes Ingress and the NGINX Ingress Controller for Kubernetes.
3.1.6.4.5.1. Exposing Kafka using Kubernetes Ingress
When exposing Kafka using using Kubernetes Ingress and the NGINX Ingress Controller for Kubernetes, a dedicated Ingress resource is created for every Kafka broker pod. An additional Ingress resource is created to serve as a Kafka bootstrap address. Kafka clients can use these Ingress resources to connect to Kafka on port 443.
External listeners using Ingress have been currently tested only with the NGINX Ingress Controller for Kubernetes.
AMQ Streams uses the TLS passthrough feature of the NGINX Ingress Controller for Kubernetes. Make sure TLS passthrough is enabled in your NGINX Ingress Controller for Kubernetes deployment. For more information about enabling TLS passthrough see TLS passthrough documentation. Because it is using the TLS passthrough functionality, TLS encryption cannot be disabled when exposing Kafka using Ingress.
The Ingress controller does not assign any hostnames automatically. You have to specify the hostnames which should be used by the bootstrap and per-broker services in the spec.kafka.listeners.external.configuration section. You also have to make sure that the hostnames resolve to the Ingress endpoints. AMQ Streams will not perform any validation that the requested hosts are available and properly routed to the Ingress endpoints.
Example of an external listener of type ingress
# ...
listeners:
external:
type: ingress
authentication:
type: tls
configuration:
bootstrap:
host: bootstrap.myingress.com
brokers:
- broker: 0
host: broker-0.myingress.com
- broker: 1
host: broker-1.myingress.com
- broker: 2
host: broker-2.myingress.com
# ...
For more information on using Ingress to access Kafka, see Section 3.1.6.4.5.4, “Accessing Kafka using ingress”.
3.1.6.4.5.2. Configuring the Ingress class
By default, the Ingress class is set to nginx. You can change the Ingress class using the class property.
Example of an external listener of type ingress using Ingress class nginx-internal
# ...
listeners:
external:
type: ingress
class: nginx-internal
# ...
# ...3.1.6.4.5.3. Customizing the DNS names of external ingress listeners
On ingress listeners, you can use the dnsAnnotations property to add additional annotations to the ingress resources. You can use these annotations to instrument DNS tooling such as External DNS, which automatically assigns DNS names to the ingress resources.
Example of an external listener of type ingress using dnsAnnotations
# ...
listeners:
external:
type: ingress
authentication:
type: tls
configuration:
bootstrap:
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: bootstrap.myingress.com.
external-dns.alpha.kubernetes.io/ttl: "60"
host: bootstrap.myingress.com
brokers:
- broker: 0
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: broker-0.myingress.com.
external-dns.alpha.kubernetes.io/ttl: "60"
host: broker-0.myingress.com
- broker: 1
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: broker-1.myingress.com.
external-dns.alpha.kubernetes.io/ttl: "60"
host: broker-1.myingress.com
- broker: 2
dnsAnnotations:
external-dns.alpha.kubernetes.io/hostname: broker-2.myingress.com.
external-dns.alpha.kubernetes.io/ttl: "60"
host: broker-2.myingress.com
# ...3.1.6.4.5.4. Accessing Kafka using ingress
This procedure shows how to access AMQ Streams Kafka clusters from outside of OpenShift using Ingress.
Prerequisites
- An OpenShift cluster
- Deployed NGINX Ingress Controller for Kubernetes with TLS passthrough enabled
- A running Cluster Operator
Procedure
Deploy Kafka cluster with an external listener enabled and configured to the type
ingress.An example configuration with an external listener configured to use
Ingress:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: external: type: ingress authentication: type: tls configuration: bootstrap: host: bootstrap.myingress.com brokers: - broker: 0 host: broker-0.myingress.com - broker: 1 host: broker-1.myingress.com - broker: 2 host: broker-2.myingress.com # ... zookeeper: # ...-
Make sure the hosts in the
configurationsection properly resolve to the Ingress endpoints. Create or update the resource.
oc apply -f your-fileExtract the public certificate of the broker certificate authority
oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt- Use the extracted certificate in your Kafka client to configure the TLS connection. If you enabled any authentication, you will also need to configure SASL or TLS authentication. Connect with your client to the host you specified in the configuration on port 443.
Additional resources
-
For more information about the schema, see
KafkaListenersschema reference.
3.1.6.5. Network policies
AMQ Streams automatically creates a NetworkPolicy resource for every listener that is enabled on a Kafka broker. By default, a NetworkPolicy grants access to a listener to all applications and namespaces.
If you want to restrict access to a listener at the network level to only selected applications or namespaces, use the networkPolicyPeers field.
Use network policies in conjunction with authentication and authorization.
Each listener can have a different networkPolicyPeers configuration.
3.1.6.5.1. Network policy configuration for a listener
The following example shows a networkPolicyPeers configuration for a plain and a tls listener:
# ...
listeners:
plain:
authentication:
type: scram-sha-512
networkPolicyPeers:
- podSelector:
matchLabels:
app: kafka-sasl-consumer
- podSelector:
matchLabels:
app: kafka-sasl-producer
tls:
authentication:
type: tls
networkPolicyPeers:
- namespaceSelector:
matchLabels:
project: myproject
- namespaceSelector:
matchLabels:
project: myproject2
# ...In the example:
-
Only application pods matching the labels
app: kafka-sasl-consumerandapp: kafka-sasl-producercan connect to theplainlistener. The application pods must be running in the same namespace as the Kafka broker. -
Only application pods running in namespaces matching the labels
project: myprojectandproject: myproject2can connect to thetlslistener.
The syntax of the networkPolicyPeers field is the same as the from field in NetworkPolicy resources. For more information about the schema, see NetworkPolicyPeer API reference and the KafkaListeners schema reference.
Your configuration of OpenShift must support ingress NetworkPolicies in order to use network policies in AMQ Streams.
3.1.6.5.2. Restricting access to Kafka listeners using networkPolicyPeers
You can restrict access to a listener to only selected applications by using the networkPolicyPeers field.
Prerequisites
- An OpenShift cluster with support for Ingress NetworkPolicies.
- The Cluster Operator is running.
Procedure
-
Open the
Kafkaresource. In the
networkPolicyPeersfield, define the application pods or namespaces that will be allowed to access the Kafka cluster.For example, to configure a
tlslistener to allow connections only from application pods with the labelappset tokafka-client:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: tls: networkPolicyPeers: - podSelector: matchLabels: app: kafka-client # ... zookeeper: # ...Create or update the resource.
Use
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see NetworkPolicyPeer API reference and the
KafkaListenersschema reference.
3.1.7. Authentication and Authorization
AMQ Streams supports authentication and authorization. Authentication can be configured independently for each listener. Authorization is always configured for the whole Kafka cluster.
3.1.7.1. Authentication
Authentication is configured as part of the listener configuration in the authentication property. The authentication mechanism is defined by the type field.
When the authentication property is missing, no authentication is enabled on a given listener. The listener will accept all connections without authentication.
Supported authentication mechanisms:
- TLS client authentication
- SASL SCRAM-SHA-512
- OAuth 2.0 token based authentication
3.1.7.1.1. TLS client authentication
TLS Client authentication is enabled by specifying the type as tls. The TLS client authentication is supported only on the tls listener.
An example of authentication with type tls
# ...
authentication:
type: tls
# ...3.1.7.2. Configuring authentication in Kafka brokers
Prerequisites
- An OpenShift cluster is available.
- The Cluster Operator is running.
Procedure
-
Open the YAML configuration file that contains the
Kafkaresource specifying the cluster deployment. In the
spec.kafka.listenersproperty in theKafkaresource, add theauthenticationfield to the listeners for which you want to enable authentication. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: tls: authentication: type: tls # ... zookeeper: # ...Apply the new configuration to create or update the resource.
Use
oc apply:oc apply -f kafka.yamlwhere
kafka.yamlis the YAML configuration file for the resource that you want to configure; for example,kafka-persistent.yaml.
Additional resources
- For more information about the supported authentication mechanisms, see authentication reference.
-
For more information about the schema for
Kafka, seeKafkaschema reference.
3.1.7.3. Authorization
You configure authorization for Kafka brokers using the authorization property in the Kafka.spec.kafka resource. If the authorization property is missing, no authorization is enabled. When enabled, authorization is applied to all enabled listeners. The authorization method is defined in the type field; only Simple authorization is currently supported.
You can optionally designate a list of super users in the superUsers field.
3.1.7.3.1. Simple authorization
Simple authorization in AMQ Streams uses the SimpleAclAuthorizer plugin, the default Access Control Lists (ACLs) authorization plugin provided with Apache Kafka. ACLs allow you to define which users have access to which resources at a granular level. To enable simple authorization, set the type field to simple.
An example of Simple authorization
# ...
authorization:
type: simple
# ...3.1.7.3.2. Super users
Super users can access all resources in your Kafka cluster regardless of any access restrictions defined in ACLs. To designate super users for a Kafka cluster, enter a list of user principles in the superUsers field. If a user uses TLS Client Authentication, the username will be the common name from their certificate subject prefixed with CN=.
An example of designating super users
# ...
authorization:
type: simple
superUsers:
- CN=fred
- sam
- CN=edward
# ...
The super.user configuration option in the config property in Kafka.spec.kafka is ignored. Designate super users in the authorization property instead. For more information, see Kafka broker configuration.
3.1.7.4. Configuring authorization in Kafka brokers
Configure authorization and designate super users for a particular Kafka broker.
Prerequisites
- An OpenShift cluster
- The Cluster Operator is running
Procedure
Add or edit the
authorizationproperty in theKafka.spec.kafkaresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... authorization: type: simple superUsers: - CN=fred - sam - CN=edward # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
- For more information about the supported authorization methods, see authorization reference.
-
For more information about the schema for
Kafka, seeKafkaschema reference. - For more information about configuring user authentication, see Kafka User resource.
3.1.8. Zookeeper replicas
Zookeeper clusters or ensembles usually run with an odd number of nodes, typically three, five, or seven.
The majority of nodes must be available in order to maintain an effective quorum. If the Zookeeper cluster loses its quorum, it will stop responding to clients and the Kafka brokers will stop working. Having a stable and highly available Zookeeper cluster is crucial for AMQ Streams.
- Three-node cluster
- A three-node Zookeeper cluster requires at least two nodes to be up and running in order to maintain the quorum. It can tolerate only one node being unavailable.
- Five-node cluster
- A five-node Zookeeper cluster requires at least three nodes to be up and running in order to maintain the quorum. It can tolerate two nodes being unavailable.
- Seven-node cluster
- A seven-node Zookeeper cluster requires at least four nodes to be up and running in order to maintain the quorum. It can tolerate three nodes being unavailable.
For development purposes, it is also possible to run Zookeeper with a single node.
Having more nodes does not necessarily mean better performance, as the costs to maintain the quorum will rise with the number of nodes in the cluster. Depending on your availability requirements, you can decide for the number of nodes to use.
3.1.8.1. Number of Zookeeper nodes
The number of Zookeeper nodes can be configured using the replicas property in Kafka.spec.zookeeper.
An example showing replicas configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
replicas: 3
# ...3.1.8.2. Changing the number of Zookeeper replicas
Prerequisites
- An OpenShift cluster is available.
- The Cluster Operator is running.
Procedure
-
Open the YAML configuration file that contains the
Kafkaresource specifying the cluster deployment. In the
spec.zookeeper.replicasproperty in theKafkaresource, enter the number of replicated Zookeeper servers. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... replicas: 3 # ...Apply the new configuration to create or update the resource.
Use
oc apply:oc apply -f kafka.yamlwhere
kafka.yamlis the YAML configuration file for the resource that you want to configure; for example,kafka-persistent.yaml.
3.1.9. Zookeeper configuration
AMQ Streams allows you to customize the configuration of Apache Zookeeper nodes. You can specify and configure most of the options listed in the Zookeeper documentation.
Options which cannot be configured are those related to the following areas:
- Security (Encryption, Authentication, and Authorization)
- Listener configuration
- Configuration of data directories
- Zookeeper cluster composition
These options are automatically configured by AMQ Streams.
3.1.9.1. Zookeeper configuration
Zookeeper nodes are configured using the config property in Kafka.spec.zookeeper. This property contains the Zookeeper configuration options as keys. The values can be described using one of the following JSON types:
- String
- Number
- Boolean
Users can specify and configure the options listed in Zookeeper documentation with the exception of those options which are managed directly by AMQ Streams. Specifically, all configuration options with keys equal to or starting with one of the following strings are forbidden:
-
server. -
dataDir -
dataLogDir -
clientPort -
authProvider -
quorum.auth -
requireClientAuthScheme
When one of the forbidden options is present in the config property, it is ignored and a warning message is printed to the Custer Operator log file. All other options are passed to Zookeeper.
The Cluster Operator does not validate keys or values in the provided config object. When invalid configuration is provided, the Zookeeper cluster might not start or might become unstable. In such cases, the configuration in the Kafka.spec.zookeeper.config object should be fixed and the Cluster Operator will roll out the new configuration to all Zookeeper nodes.
Selected options have default values:
-
timeTickwith default value2000 -
initLimitwith default value5 -
syncLimitwith default value2 -
autopurge.purgeIntervalwith default value1
These options will be automatically configured when they are not present in the Kafka.spec.zookeeper.config property.
An example showing Zookeeper configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
# ...
zookeeper:
# ...
config:
autopurge.snapRetainCount: 3
autopurge.purgeInterval: 1
# ...3.1.9.2. Configuring Zookeeper
Prerequisites
- An OpenShift cluster is available.
- The Cluster Operator is running.
Procedure
-
Open the YAML configuration file that contains the
Kafkaresource specifying the cluster deployment. In the
spec.zookeeper.configproperty in theKafkaresource, enter one or more Zookeeper configuration settings. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... zookeeper: # ... config: autopurge.snapRetainCount: 3 autopurge.purgeInterval: 1 # ...Apply the new configuration to create or update the resource.
Use
oc apply:oc apply -f kafka.yamlwhere
kafka.yamlis the YAML configuration file for the resource that you want to configure; for example,kafka-persistent.yaml.
3.1.10. Zookeeper connection
Zookeeper services are secured with encryption and authentication and are not intended to be used by external applications that are not part of AMQ Streams.
However, if you want to use Kafka CLI tools that require a connection to Zookeeper, such as the kafka-topics tool, you can use a terminal inside a Kafka container and connect to the local end of the TLS tunnel to Zookeeper by using localhost:2181 as the Zookeeper address.
3.1.10.1. Connecting to Zookeeper from a terminal
Open a terminal inside a Kafka container to use Kafka CLI tools that require a Zookeeper connection.
Prerequisites
- An OpenShift cluster is available.
- A kafka cluster is running.
- The Cluster Operator is running.
Procedure
Open the terminal using the OpenShift console or run the
execcommand from your CLI.For example:
oc exec -ti my-cluster-kafka-0 -- bin/kafka-topics.sh --list --zookeeper localhost:2181Be sure to use
localhost:2181.You can now run Kafka commands to Zookeeper.
3.1.11. Entity Operator
The Entity Operator is responsible for managing Kafka-related entities in a running Kafka cluster.
The Entity Operator comprises the:
- Topic Operator to manage Kafka topics
- User Operator to manage Kafka users
Through Kafka resource configuration, the Cluster Operator can deploy the Entity Operator, including one or both operators, when deploying a Kafka cluster.
When deployed, the Entity Operator contains the operators according to the deployment configuration.
The operators are automatically configured to manage the topics and users of the Kafka cluster.
3.1.11.1. Configuration
The Entity Operator can be configured using the entityOperator property in Kafka.spec
The entityOperator property supports several sub-properties:
-
tlsSidecar -
topicOperator -
userOperator -
template
The tlsSidecar property can be used to configure the TLS sidecar container which is used to communicate with Zookeeper. For more details about configuring the TLS sidecar, see Section 3.1.19, “TLS sidecar”.
The template property can be used to configure details of the Entity Operator pod, such as labels, annotations, affinity, tolerations and so on.
The topicOperator property contains the configuration of the Topic Operator. When this option is missing, the Entity Operator is deployed without the Topic Operator.
The userOperator property contains the configuration of the User Operator. When this option is missing, the Entity Operator is deployed without the User Operator.
Example of basic configuration enabling both operators
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
When both topicOperator and userOperator properties are missing, the Entity Operator will be not deployed.
3.1.11.1.1. Topic Operator
Topic Operator deployment can be configured using additional options inside the topicOperator object. The following options are supported:
watchedNamespace-
The OpenShift namespace in which the topic operator watches for
KafkaTopics. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
90. zookeeperSessionTimeoutSeconds-
The Zookeeper session timeout in seconds. Default
20. topicMetadataMaxAttempts-
The number of attempts at getting topic metadata from Kafka. The time between each attempt is defined as an exponential back-off. Consider increasing this value when topic creation could take more time due to the number of partitions or replicas. Default
6. image-
The
imageproperty can be used to configure the container image which will be used. For more details about configuring custom container images, see Section 3.1.18, “Container images”. resources-
The
resourcesproperty configures the amount of resources allocated to the Topic Operator. For more details about resource request and limit configuration, see Section 3.1.12, “CPU and memory resources”. loggingThe
loggingproperty configures the logging of the Topic Operator.The Topic Operator has its own configurable logger:
-
rootLogger.level
-
Example of Topic Operator configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
# ...3.1.11.1.2. User Operator
User Operator deployment can be configured using additional options inside the userOperator object. The following options are supported:
watchedNamespace-
The OpenShift namespace in which the topic operator watches for
KafkaUsers. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
120. zookeeperSessionTimeoutSeconds-
The Zookeeper session timeout in seconds. Default
6. image-
The
imageproperty can be used to configure the container image which will be used. For more details about configuring custom container images, see Section 3.1.18, “Container images”. resources-
The
resourcesproperty configures the amount of resources allocated to the User Operator. For more details about resource request and limit configuration, see Section 3.1.12, “CPU and memory resources”. loggingThe
loggingproperty configures the logging of the User Operator.The User Operator has its own configurable logger:
-
rootLogger.level
-
Example of Topic Operator configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-user-namespace
reconciliationIntervalSeconds: 60
# ...3.1.11.2. Configuring Entity Operator
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
entityOperatorproperty in theKafkaresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... entityOperator: topicOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 userOperator: watchedNamespace: my-user-namespace reconciliationIntervalSeconds: 60Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.12. CPU and memory resources
For every deployed container, AMQ Streams allows you to request specific resources and define the maximum consumption of those resources.
AMQ Streams supports two types of resources:
- CPU
- Memory
AMQ Streams uses the OpenShift syntax for specifying CPU and memory resources.
3.1.12.1. Resource limits and requests
Resource limits and requests are configured using the resources property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
Additional resources
- For more information about managing computing resources on OpenShift, see Managing Compute Resources for Containers.
3.1.12.1.1. Resource requests
Requests specify the resources to reserve for a given container. Reserving the resources ensures that they are always available.
If the resource request is for more than the available free resources in the OpenShift cluster, the pod is not scheduled.
Resources requests are specified in the requests property. Resources requests currently supported by AMQ Streams:
-
cpu -
memory
A request may be configured for one or more supported resources.
Example resource request configuration with all resources
# ...
resources:
requests:
cpu: 12
memory: 64Gi
# ...3.1.12.1.2. Resource limits
Limits specify the maximum resources that can be consumed by a given container. The limit is not reserved and might not always be available. A container can use the resources up to the limit only when they are available. Resource limits should be always higher than the resource requests.
Resource limits are specified in the limits property. Resource limits currently supported by AMQ Streams:
-
cpu -
memory
A resource may be configured for one or more supported limits.
Example resource limits configuration
# ...
resources:
limits:
cpu: 12
memory: 64Gi
# ...3.1.12.1.3. Supported CPU formats
CPU requests and limits are supported in the following formats:
-
Number of CPU cores as integer (
5CPU core) or decimal (2.5CPU core). -
Number or millicpus / millicores (
100m) where 1000 millicores is the same1CPU core.
Example CPU units
# ...
resources:
requests:
cpu: 500m
limits:
cpu: 2.5
# ...The computing power of 1 CPU core may differ depending on the platform where OpenShift is deployed.
Additional resources
- For more information on CPU specification, see the Meaning of CPU.
3.1.12.1.4. Supported memory formats
Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes.
-
To specify memory in megabytes, use the
Msuffix. For example1000M. -
To specify memory in gigabytes, use the
Gsuffix. For example1G. -
To specify memory in mebibytes, use the
Misuffix. For example1000Mi. -
To specify memory in gibibytes, use the
Gisuffix. For example1Gi.
An example of using different memory units
# ...
resources:
requests:
memory: 512Mi
limits:
memory: 2Gi
# ...Additional resources
- For more details about memory specification and additional supported units, see Meaning of memory.
3.1.12.2. Configuring resource requests and limits
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
resourcesproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... resources: requests: cpu: "8" memory: 64Gi limits: cpu: "12" memory: 128Gi # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see
Resourcesschema reference.
3.1.13. Logging
This section provides information on loggers and how to configure log levels.
You can set the log levels by specifying the loggers and their levels directly (inline) or use a custom (external) config map.
3.1.13.1. Kafka and Zookeeper loggers
Kafka has its own configurable loggers:
-
kafka.root.logger.level -
log4j.logger.org.I0Itec.zkclient.ZkClient -
log4j.logger.org.apache.zookeeper -
log4j.logger.kafka -
log4j.logger.org.apache.kafka -
log4j.logger.kafka.request.logger -
log4j.logger.kafka.network.Processor -
log4j.logger.kafka.server.KafkaApis -
log4j.logger.kafka.network.RequestChannel$ -
log4j.logger.kafka.controller -
log4j.logger.kafka.log.LogCleaner -
log4j.logger.state.change.logger -
log4j.logger.kafka.authorizer.logger
Zookeeper has its own logger as well:
-
zookeeper.root.logger
3.1.13.2. Specifying inline logging
Procedure
Edit the YAML file to specify the loggers and logging level for the required components.
For example, the logging level here is set to INFO:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... logging: type: inline loggers: logger.name: "INFO" # ... zookeeper: # ... logging: type: inline loggers: logger.name: "INFO" # ... entityOperator: # ... topicOperator: # ... logging: type: inline loggers: logger.name: "INFO" # ... # ... userOperator: # ... logging: type: inline loggers: logger.name: "INFO" # ...You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF.
For more information about the log levels, see the log4j manual.
Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
3.1.13.3. Specifying an external ConfigMap for logging
Procedure
Edit the YAML file to specify the name of the
ConfigMapto use for the required components. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... logging: type: external name: customConfigMap # ...Remember to place your custom ConfigMap under the
log4j.propertiesorlog4j2.propertieskey.Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
Garbage collector (GC) logging can also be enabled (or disabled). For more information on GC, see Section 3.1.17.1, “JVM configuration”
3.1.14. Kafka rack awareness
The rack awareness feature in AMQ Streams helps to spread the Kafka broker pods and Kafka topic replicas across different racks. Enabling rack awareness helps to improve availability of Kafka brokers and the topics they are hosting.
"Rack" might represent an availability zone, data center, or an actual rack in your data center.
3.1.14.1. Configuring rack awareness in Kafka brokers
Kafka rack awareness can be configured in the rack property of Kafka.spec.kafka. The rack object has one mandatory field named topologyKey. This key needs to match one of the labels assigned to the OpenShift cluster nodes. The label is used by OpenShift when scheduling the Kafka broker pods to nodes. If the OpenShift cluster is running on a cloud provider platform, that label should represent the availability zone where the node is running. Usually, the nodes are labeled with failure-domain.beta.kubernetes.io/zone that can be easily used as the topologyKey value. This has the effect of spreading the broker pods across zones, and also setting the brokers' broker.rack configuration parameter inside Kafka broker.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Consult your OpenShift administrator regarding the node label that represents the zone / rack into which the node is deployed.
Edit the
rackproperty in theKafkaresource using the label as the topology key.apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... rack: topologyKey: failure-domain.beta.kubernetes.io/zone # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
- For information about Configuring init container image for Kafka rack awareness, see Section 3.1.18, “Container images”.
3.1.15. Healthchecks
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, OpenShift assumes that the application is not healthy and attempts to fix it.
OpenShift supports two types of Healthcheck probes:
- Liveness probes
- Readiness probes
For more details about the probes, see Configure Liveness and Readiness Probes. Both types of probes are used in AMQ Streams components.
Users can configure selected options for liveness and readiness probes.
3.1.15.1. Healthcheck configurations
Liveness and readiness probes can be configured using the livenessProbe and readinessProbe properties in following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
For more information about the livenessProbe and readinessProbe options, see Section C.34, “Probe schema reference”.
An example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...3.1.15.2. Configuring healthchecks
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
livenessProbeorreadinessProbeproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.16. Prometheus metrics
AMQ Streams supports Prometheus metrics using Prometheus JMX exporter to convert the JMX metrics supported by Apache Kafka and Zookeeper to Prometheus metrics. When metrics are enabled, they are exposed on port 9404.
For more information about configuring Prometheus and Grafana, see Metrics.
3.1.16.1. Metrics configuration
Prometheus metrics are enabled by configuring the metrics property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
When the metrics property is not defined in the resource, the Prometheus metrics will be disabled. To enable Prometheus metrics export without any further configuration, you can set it to an empty object ({}).
Example of enabling metrics without any further configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics: {}
# ...
zookeeper:
# ...
The metrics property might contain additional configuration for the Prometheus JMX exporter.
Example of enabling metrics with additional Prometheus JMX Exporter configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics:
lowercaseOutputName: true
rules:
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count"
name: "kafka_server_$1_$2_total"
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count"
name: "kafka_server_$1_$2_total"
labels:
topic: "$3"
# ...
zookeeper:
# ...3.1.16.2. Configuring Prometheus metrics
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
metricsproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... metrics: lowercaseOutputName: true # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.17. JVM Options
The following components of AMQ Streams run inside a Virtual Machine (VM):
- Apache Kafka
- Apache Zookeeper
- Apache Kafka Connect
- Apache Kafka Mirror Maker
- AMQ Streams Kafka Bridge
JVM configuration options optimize the performance for different platforms and architectures. AMQ Streams allows you to configure some of these options.
3.1.17.1. JVM configuration
JVM options can be configured using the jvmOptions property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Only a selected subset of available JVM options can be configured. The following options are supported:
-Xms and -Xmx
-Xms configures the minimum initial allocation heap size when the JVM starts. -Xmx configures the maximum heap size.
The units accepted by JVM settings such as -Xmx and -Xms are those accepted by the JDK java binary in the corresponding image. Accordingly, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit suffix. This is in contrast to the units used for memory requests and limits, which follow the OpenShift convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes
The default values used for -Xms and -Xmx depends on whether there is a memory request limit configured for the container:
- If there is a memory limit then the JVM’s minimum and maximum memory will be set to a value corresponding to the limit.
-
If there is no memory limit then the JVM’s minimum memory will be set to
128Mand the JVM’s maximum memory will not be defined. This allows for the JVM’s memory to grow as-needed, which is ideal for single node environments in test and development.
Setting -Xmx explicitly requires some care:
-
The JVM’s overall memory usage will be approximately 4 × the maximum heap, as configured by
-Xmx. -
If
-Xmxis set without also setting an appropriate OpenShift memory limit, it is possible that the container will be killed should the OpenShift node experience memory pressure (from other Pods running on it). -
If
-Xmxis set without also setting an appropriate OpenShift memory request, it is possible that the container will be scheduled to a node with insufficient memory. In this case, the container will not start but crash (immediately if-Xmsis set to-Xmx, or some later time if not).
When setting -Xmx explicitly, it is recommended to:
- set the memory request and the memory limit to the same value,
-
use a memory request that is at least 4.5 × the
-Xmx, -
consider setting
-Xmsto the same value as-Xmx.
Containers doing lots of disk I/O (such as Kafka broker containers) will need to leave some memory available for use as operating system page cache. On such containers, the requested memory should be significantly higher than the memory used by the JVM.
Example fragment configuring -Xmx and -Xms
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...In the above example, the JVM will use 2 GiB (=2,147,483,648 bytes) for its heap. Its total memory usage will be approximately 8GiB.
Setting the same value for initial (-Xms) and maximum (-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed. For Kafka and Zookeeper pods such allocation could cause unwanted latency. For Kafka Connect avoiding over allocation may be the most important concern, especially in distributed mode where the effects of over-allocation will be multiplied by the number of consumers.
-server
-server enables the server JVM. This option can be set to true or false.
Example fragment configuring -server
# ...
jvmOptions:
"-server": true
# ...
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
-XX
-XX object can be used for configuring advanced runtime options of a JVM. The -server and -XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Example showing the use of the -XX object
jvmOptions:
"-XX":
"UseG1GC": true
"MaxGCPauseMillis": 20
"InitiatingHeapOccupancyPercent": 35
"ExplicitGCInvokesConcurrent": true
"UseParNewGC": falseThe example configuration above will result in the following JVM options:
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
3.1.17.1.1. Garbage collector logging
The jvmOptions section also allows you to enable and disable garbage collector (GC) logging. GC logging is enabled by default. To disable it, set the gcLoggingEnabled property as follows:
Example of disabling GC logging
# ...
jvmOptions:
gcLoggingEnabled: false
# ...3.1.17.2. Configuring JVM options
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
jvmOptionsproperty in theKafka,KafkaConnect,KafkaConnectS2I,KafkaMirrorMaker, orKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... jvmOptions: "-Xmx": "8g" "-Xms": "8g" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.18. Container images
AMQ Streams allows you to configure container images which will be used for its components. Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such a case, you should either copy the AMQ Streams images or build them from the source. If the configured image is not compatible with AMQ Streams images, it might not work properly.
3.1.18.1. Container image configurations
Container image which should be used for given components can be specified using the image property in:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.1.18.1.1. Configuring the Kafka.spec.kafka.image property
The Kafka.spec.kafka.image property functions differently from the others, because AMQ Streams supports multiple versions of Kafka, each requiring the own image. The STRIMZI_KAFKA_IMAGES environment variable of the Cluster Operator configuration is used to provide a mapping between Kafka versions and the corresponding images. This is used in combination with the Kafka.spec.kafka.image and Kafka.spec.kafka.version properties as follows:
-
If neither
Kafka.spec.kafka.imagenorKafka.spec.kafka.versionare given in the custom resource then theversionwill default to the Cluster Operator’s default Kafka version, and the image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
If
Kafka.spec.kafka.imageis given butKafka.spec.kafka.versionis not then the given image will be used and theversionwill be assumed to be the Cluster Operator’s default Kafka version. -
If
Kafka.spec.kafka.versionis given butKafka.spec.kafka.imageis not then image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
Both
Kafka.spec.kafka.versionandKafka.spec.kafka.imageare given the given image will be used, and it will be assumed to contain a Kafka broker with the given version.
It is best to provide just Kafka.spec.kafka.version and leave the Kafka.spec.kafka.image property unspecified. This reduces the chances of making a mistake in configuring the Kafka resource. If you need to change the images used for different versions of Kafka, it is better to configure the Cluster Operator’s STRIMZI_KAFKA_IMAGES environment variable.
3.1.18.1.2. Configuring the image property in other resources
For the image property in the other custom resources, the given value will be used during deployment. If the image property is missing, the image specified in the Cluster Operator configuration will be used. If the image name is not defined in the Cluster Operator configuration, then the default value will be used.
For Kafka broker TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper nodes:
-
Container image specified in the
STRIMZI_DEFAULT_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper node TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Topic Operator:
-
Container image specified in the
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For User Operator:
-
Container image specified in the
STRIMZI_DEFAULT_USER_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For Entity Operator TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect with Source2image support:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such case, you should either copy the AMQ Streams images or build them from source. In case the configured image is not compatible with AMQ Streams images, it might not work properly.
Example of container image configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...
zookeeper:
# ...3.1.18.2. Configuring container images
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
imageproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... image: my-org/my-image:latest # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.19. TLS sidecar
A sidecar is a container that runs in a pod but serves a supporting purpose. In AMQ Streams, the TLS sidecar uses TLS to encrypt and decrypt all communication between the various components and Zookeeper. Zookeeper does not have native TLS support.
The TLS sidecar is used in:
- Kafka brokers
- Zookeeper nodes
- Entity Operator
3.1.19.1. TLS sidecar configuration
The TLS sidecar can be configured using the tlsSidecar property in:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator
The TLS sidecar supports the following additional options:
-
image -
resources -
logLevel -
readinessProbe -
livenessProbe
The resources property can be used to specify the memory and CPU resources allocated for the TLS sidecar.
The image property can be used to configure the container image which will be used. For more details about configuring custom container images, see Section 3.1.18, “Container images”.
The logLevel property is used to specify the logging level. Following logging levels are supported:
- emerg
- alert
- crit
- err
- warning
- notice
- info
- debug
The default value is notice.
For more information about configuring the readinessProbe and livenessProbe properties for the healthchecks, see Section 3.1.15.1, “Healthcheck configurations”.
Example of TLS sidecar configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
tlsSidecar:
image: my-org/my-image:latest
resources:
requests:
cpu: 200m
memory: 64Mi
limits:
cpu: 500m
memory: 128Mi
logLevel: debug
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...
zookeeper:
# ...3.1.19.2. Configuring TLS sidecar
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
tlsSidecarproperty in theKafkaresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... tlsSidecar: resources: requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.20. Configuring pod scheduling
When two applications are scheduled to the same OpenShift node, both applications might use the same resources like disk I/O and impact performance. That can lead to performance degradation. Scheduling Kafka pods in a way that avoids sharing nodes with other critical workloads, using the right nodes or dedicated a set of nodes only for Kafka are the best ways how to avoid such problems.
3.1.20.1. Scheduling pods based on other applications
3.1.20.1.1. Avoid critical applications to share the node
Pod anti-affinity can be used to ensure that critical applications are never scheduled on the same disk. When running Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share the nodes with other workloads like databases.
3.1.20.1.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.1.20.1.3. Configuring pod anti-affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.20.2. Scheduling pods to specific nodes
3.1.20.2.1. Node scheduling
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of AMQ Streams components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
3.1.20.2.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.1.20.2.3. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where AMQ Streams components should be scheduled.
This can be done using
oc label:oc label node your-node node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.20.3. Using dedicated nodes
3.1.20.3.1. Dedicated nodes
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Taints can be used to create dedicated nodes. Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
To schedule Kafka pods on the dedicated nodes, configure node affinity and tolerations.
3.1.20.3.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.1.20.3.3. Tolerations
Tolerations can be configured using the tolerations property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The format of the tolerations property follows the OpenShift specification. For more details, see the Kubernetes taints and tolerations.
3.1.20.3.4. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node your-node dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node your-node dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.1.21. Kafka Exporter
You can configure the Kafka resource to automatically deploy Kafka Exporter in your cluster.
Kafka Exporter extracts data for analysis as Prometheus metrics, primarily data relating to offsets, consumer groups, consumer lag and topics.
For information on Kafka Exporter and why it is important to monitor consumer lag for performance, see Kafka Exporter.
3.1.21.1. Configuring Kafka Exporter
Configure Kafka Exporter in the Kafka resource through KafkaExporter properties.
Refer to the sample Kafka YAML configuration for an overview of the Kafka resource and its properties.
The properties relevant to the Kafka Exporter configuration are shown in this procedure.
You can configure these properties as part of a deployment or redeployment of the Kafka cluster.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
KafkaExporterproperties for theKafkaresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: # ... kafkaExporter: image: my-org/my-image:latest1 groupRegex: ".*"2 topicRegex: ".*"3 resources:4 requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi logging: debug5 enableSaramaLogging: true6 template:7 pod: metadata: labels: label1: value1 imagePullSecrets: - name: my-docker-credentials securityContext: runAsUser: 1000001 fsGroup: 0 terminationGracePeriodSeconds: 120 readinessProbe:8 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe:9 initialDelaySeconds: 15 timeoutSeconds: 5 # ...- 1
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 2
- A regular expression to specify the consumer groups to include in the metrics.
- 3
- A regular expression to specify the topics to include in the metrics.
- 4
- 5
- Logging configuration, to log messages with a given severity (debug, info, warn, error, fatal) or above.
- 6
- Boolean to enable Sarama logging, a Go client library used by Kafka Exporter.
- 7
- 8
- 9
Create or update the resource:
oc apply -f kafka.yaml
What to do next
After configuring and deploying Kafka Exporter, you can enable Grafana to present the Kafka Exporter dashboards.
Additional resources
3.1.22. Performing a rolling update of a Kafka cluster
This procedure describes how to manually trigger a rolling update of an existing Kafka cluster by using an OpenShift annotation.
Prerequisites
- A running Kafka cluster.
- A running Cluster Operator.
Procedure
Find the name of the
StatefulSetthat controls the Kafka pods you want to manually update.For example, if your Kafka cluster is named my-cluster, the corresponding
StatefulSetis named my-cluster-kafka.Annotate the
StatefulSetresource in OpenShift. For example, usingoc annotate:oc annotate statefulset cluster-name-kafka strimzi.io/manual-rolling-update=true-
Wait for the next reconciliation to occur (every two minutes by default). A rolling update of all pods within the annotated
StatefulSetis triggered, as long as the annotation was detected by the reconciliation process. When the rolling update of all the pods is complete, the annotation is removed from theStatefulSet.
Additional resources
- For more information about deploying the Cluster Operator, see Section 2.3, “Cluster Operator”.
- For more information about deploying the Kafka cluster, see Section 2.4.1, “Deploying the Kafka cluster”.
3.1.23. Performing a rolling update of a Zookeeper cluster
This procedure describes how to manually trigger a rolling update of an existing Zookeeper cluster by using an OpenShift annotation.
Prerequisites
- A running Zookeeper cluster.
- A running Cluster Operator.
Procedure
Find the name of the
StatefulSetthat controls the Zookeeper pods you want to manually update.For example, if your Kafka cluster is named my-cluster, the corresponding
StatefulSetis named my-cluster-zookeeper.Annotate the
StatefulSetresource in OpenShift. For example, usingoc annotate:oc annotate statefulset cluster-name-zookeeper strimzi.io/manual-rolling-update=true-
Wait for the next reconciliation to occur (every two minutes by default). A rolling update of all pods within the annotated
StatefulSetis triggered, as long as the annotation was detected by the reconciliation process. When the rolling update of all the pods is complete, the annotation is removed from theStatefulSet.
Additional resources
- For more information about deploying the Cluster Operator, see Section 2.3, “Cluster Operator”.
- For more information about deploying the Zookeeper cluster, see Section 2.4.1, “Deploying the Kafka cluster”.
3.1.24. Scaling clusters
3.1.24.1. Scaling Kafka clusters
3.1.24.1.1. Adding brokers to a cluster
The primary way of increasing throughput for a topic is to increase the number of partitions for that topic. That works because the extra partitions allow the load of the topic to be shared between the different brokers in the cluster. However, in situations where every broker is constrained by a particular resource (typically I/O) using more partitions will not result in increased throughput. Instead, you need to add brokers to the cluster.
When you add an extra broker to the cluster, Kafka does not assign any partitions to it automatically. You must decide which partitions to move from the existing brokers to the new broker.
Once the partitions have been redistributed between all the brokers, the resource utilization of each broker should be reduced.
3.1.24.1.2. Removing brokers from a cluster
Because AMQ Streams uses StatefulSets to manage broker pods, you cannot remove any pod from the cluster. You can only remove one or more of the highest numbered pods from the cluster. For example, in a cluster of 12 brokers the pods are named cluster-name-kafka-0 up to cluster-name-kafka-11. If you decide to scale down by one broker, the cluster-name-kafka-11 will be removed.
Before you remove a broker from a cluster, ensure that it is not assigned to any partitions. You should also decide which of the remaining brokers will be responsible for each of the partitions on the broker being decommissioned. Once the broker has no assigned partitions, you can scale the cluster down safely.
3.1.24.2. Partition reassignment
The Topic Operator does not currently support reassigning replicas to different brokers, so it is necessary to connect directly to broker pods to reassign replicas to brokers.
Within a broker pod, the kafka-reassign-partitions.sh utility allows you to reassign partitions to different brokers.
It has three different modes:
--generate- Takes a set of topics and brokers and generates a reassignment JSON file which will result in the partitions of those topics being assigned to those brokers. Because this operates on whole topics, it cannot be used when you just need to reassign some of the partitions of some topics.
--execute- Takes a reassignment JSON file and applies it to the partitions and brokers in the cluster. Brokers that gain partitions as a result become followers of the partition leader. For a given partition, once the new broker has caught up and joined the ISR (in-sync replicas) the old broker will stop being a follower and will delete its replica.
--verify-
Using the same reassignment JSON file as the
--executestep,--verifychecks whether all of the partitions in the file have been moved to their intended brokers. If the reassignment is complete, --verify also removes any throttles that are in effect. Unless removed, throttles will continue to affect the cluster even after the reassignment has finished.
It is only possible to have one reassignment running in a cluster at any given time, and it is not possible to cancel a running reassignment. If you need to cancel a reassignment, wait for it to complete and then perform another reassignment to revert the effects of the first reassignment. The kafka-reassign-partitions.sh will print the reassignment JSON for this reversion as part of its output. Very large reassignments should be broken down into a number of smaller reassignments in case there is a need to stop in-progress reassignment.
3.1.24.2.1. Reassignment JSON file
The reassignment JSON file has a specific structure:
{
"version": 1,
"partitions": [
<PartitionObjects>
]
}Where <PartitionObjects> is a comma-separated list of objects like:
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
Although Kafka also supports a "log_dirs" property this should not be used in Red Hat AMQ Streams.
The following is an example reassignment JSON file that assigns topic topic-a, partition 4 to brokers 2, 4 and 7, and topic topic-b partition 2 to brokers 1, 5 and 7:
{
"version": 1,
"partitions": [
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7]
},
{
"topic": "topic-b",
"partition": 2,
"replicas": [1,5,7]
}
]
}Partitions not included in the JSON are not changed.
3.1.24.2.2. Reassigning partitions between JBOD volumes
When using JBOD storage in your Kafka cluster, you can choose to reassign the partitions between specific volumes and their log directories (each volume has a single log directory). To reassign a partition to a specific volume, add the log_dirs option to <PartitionObjects> in the reassignment JSON file.
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ],
"log_dirs": [ <AssignedLogDirs> ]
}
The log_dirs object should contain the same number of log directories as the number of replicas specified in the replicas object. The value should be either an absolute path to the log directory, or the any keyword.
For example:
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7].
"log_dirs": [ "/var/lib/kafka/data-0/kafka-log2", "/var/lib/kafka/data-0/kafka-log4", "/var/lib/kafka/data-0/kafka-log7" ]
}3.1.24.3. Generating reassignment JSON files
This procedure describes how to generate a reassignment JSON file that reassigns all the partitions for a given set of topics using the kafka-reassign-partitions.sh tool.
Prerequisites
- A running Cluster Operator
-
A
Kafkaresource - A set of topics to reassign the partitions of
Procedure
Prepare a JSON file named
topics.jsonthat lists the topics to move. It must have the following structure:{ "version": 1, "topics": [ <TopicObjects> ] }where <TopicObjects> is a comma-separated list of objects like:
{ "topic": <TopicName> }For example if you want to reassign all the partitions of
topic-aandtopic-b, you would need to prepare atopics.jsonfile like this:{ "version": 1, "topics": [ { "topic": "topic-a"}, { "topic": "topic-b"} ] }Copy the
topics.jsonfile to one of the broker pods:cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'Use the
kafka-reassign-partitions.sh`command to generate the reassignment JSON.oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generateFor example, to move all the partitions of
topic-aandtopic-bto brokers4and7oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generate
3.1.24.4. Creating reassignment JSON files manually
You can manually create the reassignment JSON file if you want to move specific partitions.
3.1.24.5. Reassignment throttles
Partition reassignment can be a slow process because it involves transferring large amounts of data between brokers. To avoid a detrimental impact on clients, you can throttle the reassignment process. This might cause the reassignment to take longer to complete.
- If the throttle is too low then the newly assigned brokers will not be able to keep up with records being published and the reassignment will never complete.
- If the throttle is too high then clients will be impacted.
For example, for producers, this could manifest as higher than normal latency waiting for acknowledgement. For consumers, this could manifest as a drop in throughput caused by higher latency between polls.
3.1.24.6. Scaling up a Kafka cluster
This procedure describes how to increase the number of brokers in a Kafka cluster.
Prerequisites
- An existing Kafka cluster.
-
A reassignment JSON file named
reassignment.jsonthat describes how partitions should be reassigned to brokers in the enlarged cluster.
Procedure
-
Add as many new brokers as you need by increasing the
Kafka.spec.kafka.replicasconfiguration option. - Verify that the new broker pods have started.
Copy the
reassignment.jsonfile to the broker pod on which you will later execute the commands:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'For example:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Execute the partition reassignment using the
kafka-reassign-partitions.shcommand line tool from the same broker pod.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --executeIf you are going to throttle replication you can also pass the
--throttleoption with an inter-broker throttled rate in bytes per second. For example:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeThis command will print out two reassignment JSON objects. The first records the current assignment for the partitions being moved. You should save this to a local file (not a file in the pod) in case you need to revert the reassignment later on. The second JSON object is the target reassignment you have passed in your reassignment JSON file.
If you need to change the throttle during reassignment you can use the same command line with a different throttled rate. For example:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executePeriodically verify whether the reassignment has completed using the
kafka-reassign-partitions.shcommand line tool from any of the broker pods. This is the same command as the previous step but with the--verifyoption instead of the--executeoption.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyFor example,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
The reassignment has finished when the
--verifycommand reports each of the partitions being moved as completed successfully. This final--verifywill also have the effect of removing any reassignment throttles. You can now delete the revert file if you saved the JSON for reverting the assignment to their original brokers.
3.1.24.7. Scaling down a Kafka cluster
Additional resources
This procedure describes how to decrease the number of brokers in a Kafka cluster.
Prerequisites
- An existing Kafka cluster.
-
A reassignment JSON file named
reassignment.jsondescribing how partitions should be reassigned to brokers in the cluster once the broker(s) in the highest numberedPod(s)have been removed.
Procedure
Copy the
reassignment.jsonfile to the broker pod on which you will later execute the commands:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'For example:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Execute the partition reassignment using the
kafka-reassign-partitions.shcommand line tool from the same broker pod.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --executeIf you are going to throttle replication you can also pass the
--throttleoption with an inter-broker throttled rate in bytes per second. For example:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeThis command will print out two reassignment JSON objects. The first records the current assignment for the partitions being moved. You should save this to a local file (not a file in the pod) in case you need to revert the reassignment later on. The second JSON object is the target reassignment you have passed in your reassignment JSON file.
If you need to change the throttle during reassignment you can use the same command line with a different throttled rate. For example:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executePeriodically verify whether the reassignment has completed using the
kafka-reassign-partitions.shcommand line tool from any of the broker pods. This is the same command as the previous step but with the--verifyoption instead of the--executeoption.oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyFor example,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
The reassignment has finished when the
--verifycommand reports each of the partitions being moved as completed successfully. This final--verifywill also have the effect of removing any reassignment throttles. You can now delete the revert file if you saved the JSON for reverting the assignment to their original brokers. Once all the partition reassignments have finished, the broker(s) being removed should not have responsibility for any of the partitions in the cluster. You can verify this by checking that the broker’s data log directory does not contain any live partition logs. If the log directory on the broker contains a directory that does not match the extended regular expression
\.[a-z0-9]-delete$then the broker still has live partitions and it should not be stopped.You can check this by executing the command:
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"where N is the number of the
Pod(s)being deleted.If the above command prints any output then the broker still has live partitions. In this case, either the reassignment has not finished, or the reassignment JSON file was incorrect.
-
Once you have confirmed that the broker has no live partitions you can edit the
Kafka.spec.kafka.replicasof yourKafkaresource, which will scale down theStatefulSet, deleting the highest numbered brokerPod(s).
3.1.25. Deleting Kafka nodes manually
Additional resources
This procedure describes how to delete an existing Kafka node by using an OpenShift annotation. Deleting a Kafka node consists of deleting both the Pod on which the Kafka broker is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
- A running Kafka cluster.
- A running Cluster Operator.
Procedure
Find the name of the
Podthat you want to delete.For example, if the cluster is named cluster-name, the pods are named cluster-name-kafka-index, where index starts at zero and ends at the total number of replicas.
Annotate the
Podresource in OpenShift.Use
oc annotate:oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=true- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
Additional resources
- For more information about deploying the Cluster Operator, see Section 2.3, “Cluster Operator”.
- For more information about deploying the Kafka cluster, see Section 2.4.1, “Deploying the Kafka cluster”.
3.1.26. Deleting Zookeeper nodes manually
This procedure describes how to delete an existing Zookeeper node by using an OpenShift annotation. Deleting a Zookeeper node consists of deleting both the Pod on which Zookeeper is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
- A running Zookeeper cluster.
- A running Cluster Operator.
Procedure
Find the name of the
Podthat you want to delete.For example, if the cluster is named cluster-name, the pods are named cluster-name-zookeeper-index, where index starts at zero and ends at the total number of replicas.
Annotate the
Podresource in OpenShift.Use
oc annotate:oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=true- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
Additional resources
- For more information about deploying the Cluster Operator, see Section 2.3, “Cluster Operator”.
- For more information about deploying the Zookeeper cluster, see Section 2.4.1, “Deploying the Kafka cluster”.
3.1.27. Maintenance time windows for rolling updates
Maintenance time windows allow you to schedule certain rolling updates of your Kafka and Zookeeper clusters to start at a convenient time.
3.1.27.1. Maintenance time windows overview
In most cases, the Cluster Operator only updates your Kafka or Zookeeper clusters in response to changes to the corresponding Kafka resource. This enables you to plan when to apply changes to a Kafka resource to minimize the impact on Kafka client applications.
However, some updates to your Kafka and Zookeeper clusters can happen without any corresponding change to the Kafka resource. For example, the Cluster Operator will need to perform a rolling restart if a CA (Certificate Authority) certificate that it manages is close to expiry.
While a rolling restart of the pods should not affect availability of the service (assuming correct broker and topic configurations), it could affect performance of the Kafka client applications. Maintenance time windows allow you to schedule such spontaneous rolling updates of your Kafka and Zookeeper clusters to start at a convenient time. If maintenance time windows are not configured for a cluster then it is possible that such spontaneous rolling updates will happen at an inconvenient time, such as during a predictable period of high load.
3.1.27.2. Maintenance time window definition
You configure maintenance time windows by entering an array of strings in the Kafka.spec.maintenanceTimeWindows property. Each string is a cron expression interpreted as being in UTC (Coordinated Universal Time, which for practical purposes is the same as Greenwich Mean Time).
The following example configures a single maintenance time window that starts at midnight and ends at 01:59am (UTC), on Sundays, Mondays, Tuesdays, Wednesdays, and Thursdays:
# ...
maintenanceTimeWindows:
- "* * 0-1 ? * SUN,MON,TUE,WED,THU *"
# ...
In practice, maintenance windows should be set in conjunction with the Kafka.spec.clusterCa.renewalDays and Kafka.spec.clientsCa.renewalDays properties of the Kafka resource, to ensure that the necessary CA certificate renewal can be completed in the configured maintenance time windows.
AMQ Streams does not schedule maintenance operations exactly according to the given windows. Instead, for each reconciliation, it checks whether a maintenance window is currently "open". This means that the start of maintenance operations within a given time window can be delayed by up to the Cluster Operator reconciliation interval. Maintenance time windows must therefore be at least this long.
Additional resources
- For more information about the Cluster Operator configuration, see Section 4.1.7, “Cluster Operator Configuration”.
3.1.27.3. Configuring a maintenance time window
You can configure a maintenance time window for rolling updates triggered by supported processes.
Prerequisites
- An OpenShift cluster.
- The Cluster Operator is running.
Procedure
Add or edit the
maintenanceTimeWindowsproperty in theKafkaresource. For example to allow maintenance between 0800 and 1059 and between 1400 and 1559 you would set themaintenanceTimeWindowsas shown below:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... maintenanceTimeWindows: - "* * 8-10 * * ?" - "* * 14-15 * * ?"Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
- Performing a rolling update of a Kafka cluster, see Section 3.1.22, “Performing a rolling update of a Kafka cluster”
- Performing a rolling update of a Zookeeper cluster, see Section 3.1.23, “Performing a rolling update of a Zookeeper cluster”
3.1.28. Renewing CA certificates manually
Unless the Kafka.spec.clusterCa.generateCertificateAuthority and Kafka.spec.clientsCa.generateCertificateAuthority objects are set to false, the cluster and clients CA certificates will auto-renew at the start of their respective certificate renewal periods. You can manually renew one or both of these certificates before the certificate renewal period starts, if required for security reasons. A renewed certificate uses the same private key as the old certificate.
Prerequisites
- The Cluster Operator is running.
- A Kafka cluster in which CA certificates and private keys are installed.
Procedure
Apply the
strimzi.io/force-renewannotation to theSecretthat contains the CA certificate that you want to renew.Expand Certificate Secret Annotate command Cluster CA
<cluster-name>-cluster-ca-cert
oc annotate secret <cluster-name>-cluster-ca-cert strimzi.io/force-renew=trueClients CA
<cluster-name>-clients-ca-cert
oc annotate secret <cluster-name>-clients-ca-cert strimzi.io/force-renew=true
At the next reconciliation the Cluster Operator will generate a new CA certificate for the Secret that you annotated. If maintenance time windows are configured, the Cluster Operator will generate the new CA certificate at the first reconciliation within the next maintenance time window.
Client applications must reload the cluster and clients CA certificates that were renewed by the Cluster Operator.
3.1.29. Replacing private keys
You can replace the private keys used by the cluster CA and clients CA certificates. When a private key is replaced, the Cluster Operator generates a new CA certificate for the new private key.
Prerequisites
- The Cluster Operator is running.
- A Kafka cluster in which CA certificates and private keys are installed.
Procedure
Apply the
strimzi.io/force-replaceannotation to theSecretthat contains the private key that you want to renew.Expand Private key for Secret Annotate command Cluster CA
<cluster-name>-cluster-ca
oc annotate secret <cluster-name>-cluster-ca strimzi.io/force-replace=trueClients CA
<cluster-name>-clients-ca
oc annotate secret <cluster-name>-clients-ca strimzi.io/force-replace=true
At the next reconciliation the Cluster Operator will:
-
Generate a new private key for the
Secretthat you annotated - Generate a new CA certificate
If maintenance time windows are configured, the Cluster Operator will generate the new private key and CA certificate at the first reconciliation within the next maintenance time window.
Client applications must reload the cluster and clients CA certificates that were renewed by the Cluster Operator.
3.1.30. List of resources created as part of Kafka cluster
The following resources will created by the Cluster Operator in the OpenShift cluster:
cluster-name-kafka- StatefulSet which is in charge of managing the Kafka broker pods.
cluster-name-kafka-brokers- Service needed to have DNS resolve the Kafka broker pods IP addresses directly.
cluster-name-kafka-bootstrap- Service can be used as bootstrap servers for Kafka clients.
cluster-name-kafka-external-bootstrap- Bootstrap service for clients connecting from outside of the OpenShift cluster. This resource will be created only when external listener is enabled.
cluster-name-kafka-pod-id- Service used to route traffic from outside of the OpenShift cluster to individual pods. This resource will be created only when external listener is enabled.
cluster-name-kafka-external-bootstrap-
Bootstrap route for clients connecting from outside of the OpenShift cluster. This resource will be created only when external listener is enabled and set to type
route. cluster-name-kafka-pod-id-
Route for traffic from outside of the OpenShift cluster to individual pods. This resource will be created only when external listener is enabled and set to type
route. cluster-name-kafka-config- ConfigMap which contains the Kafka ancillary configuration and is mounted as a volume by the Kafka broker pods.
cluster-name-kafka-brokers- Secret with Kafka broker keys.
cluster-name-kafka- Service account used by the Kafka brokers.
cluster-name-kafka- Pod Disruption Budget configured for the Kafka brokers.
strimzi-namespace-name-cluster-name-kafka-init- Cluster role binding used by the Kafka brokers.
cluster-name-zookeeper- StatefulSet which is in charge of managing the Zookeeper node pods.
cluster-name-zookeeper-nodes- Service needed to have DNS resolve the Zookeeper pods IP addresses directly.
cluster-name-zookeeper-client- Service used by Kafka brokers to connect to Zookeeper nodes as clients.
cluster-name-zookeeper-config- ConfigMap which contains the Zookeeper ancillary configuration and is mounted as a volume by the Zookeeper node pods.
cluster-name-zookeeper-nodes- Secret with Zookeeper node keys.
cluster-name-zookeeper- Pod Disruption Budget configured for the Zookeeper nodes.
cluster-name-entity-operator- Deployment with Topic and User Operators. This resource will be created only if Cluster Operator deployed Entity Operator.
cluster-name-entity-topic-operator-config- Configmap with ancillary configuration for Topic Operators. This resource will be created only if Cluster Operator deployed Entity Operator.
cluster-name-entity-user-operator-config- Configmap with ancillary configuration for User Operators. This resource will be created only if Cluster Operator deployed Entity Operator.
cluster-name-entity-operator-certs- Secret with Entitiy operators keys for communication with Kafka and Zookeeper. This resource will be created only if Cluster Operator deployed Entity Operator.
cluster-name-entity-operator- Service account used by the Entity Operator.
strimzi-cluster-name-topic-operator- Role binding used by the Entity Operator.
strimzi-cluster-name-user-operator- Role binding used by the Entity Operator.
cluster-name-cluster-ca- Secret with the Cluster CA used to encrypt the cluster communication.
cluster-name-cluster-ca-cert- Secret with the Cluster CA public key. This key can be used to verify the identity of the Kafka brokers.
cluster-name-clients-ca- Secret with the Clients CA used to encrypt the communication between Kafka brokers and Kafka clients.
cluster-name-clients-ca-cert- Secret with the Clients CA public key. This key can be used to verify the identity of the Kafka brokers.
cluster-name-cluster-operator-certs- Secret with Cluster operators keys for communication with Kafka and Zookeeper.
data-cluster-name-kafka-idx-
Persistent Volume Claim for the volume used for storing data for the Kafka broker pod
idx. This resource will be created only if persistent storage is selected for provisioning persistent volumes to store data. data-id-cluster-name-kafka-idx-
Persistent Volume Claim for the volume
idused for storing data for the Kafka broker podidx. This resource is only created if persistent storage is selected for JBOD volumes when provisioning persistent volumes to store data. data-cluster-name-zookeeper-idx-
Persistent Volume Claim for the volume used for storing data for the Zookeeper node pod
idx. This resource will be created only if persistent storage is selected for provisioning persistent volumes to store data.
3.2. Kafka Connect cluster configuration
The full schema of the KafkaConnect resource is described in the Section C.62, “KafkaConnect schema reference”. All labels that are applied to the desired KafkaConnect resource will also be applied to the OpenShift resources making up the Kafka Connect cluster. This provides a convenient mechanism for resources to be labeled as required.
3.2.1. Replicas
Kafka Connect clusters can run multiple of nodes. The number of nodes is defined in the KafkaConnect and KafkaConnectS2I resources. Running a Kafka Connect cluster with multiple nodes can provide better availability and scalability. However, when running Kafka Connect on OpenShift it is not absolutely necessary to run multiple nodes of Kafka Connect for high availability. If a node where Kafka Connect is deployed to crashes, OpenShift will automatically reschedule the Kafka Connect pod to a different node. However, running Kafka Connect with multiple nodes can provide faster failover times, because the other nodes will be up and running already.
3.2.1.1. Configuring the number of nodes
The number of Kafka Connect nodes is configured using the replicas property in KafkaConnect.spec and KafkaConnectS2I.spec.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
replicasproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnectS2I metadata: name: my-cluster spec: # ... replicas: 3 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.2. Bootstrap servers
A Kafka Connect cluster always works in combination with a Kafka cluster. A Kafka cluster is specified as a list of bootstrap servers. On OpenShift, the list must ideally contain the Kafka cluster bootstrap service named cluster-name-kafka-bootstrap, and a port of 9092 for plain traffic or 9093 for encrypted traffic.
The list of bootstrap servers is configured in the bootstrapServers property in KafkaConnect.spec and KafkaConnectS2I.spec. The servers must be defined as a comma-separated list specifying one or more Kafka brokers, or a service pointing to Kafka brokers specified as a hostname:_port_ pairs.
When using Kafka Connect with a Kafka cluster not managed by AMQ Streams, you can specify the bootstrap servers list according to the configuration of the cluster.
3.2.2.1. Configuring bootstrap servers
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
bootstrapServersproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-cluster spec: # ... bootstrapServers: my-cluster-kafka-bootstrap:9092 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.3. Connecting to Kafka brokers using TLS
By default, Kafka Connect tries to connect to Kafka brokers using a plain text connection. If you prefer to use TLS, additional configuration is required.
3.2.3.1. TLS support in Kafka Connect
TLS support is configured in the tls property in KafkaConnect.spec and KafkaConnectS2I.spec. The tls property contains a list of secrets with key names under which the certificates are stored. The certificates must be stored in X509 format.
An example showing TLS configuration with multiple certificates
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-other-secret
certificate: certificate.crt
# ...When multiple certificates are stored in the same secret, it can be listed multiple times.
An example showing TLS configuration with multiple certificates from the same secret
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnectS2I
metadata:
name: my-cluster
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-secret
certificate: ca2.crt
# ...3.2.3.2. Configuring TLS in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretfor the certificate used for TLS Server Authentication, and the key under which the certificate is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the TLS certificate used in authentication in a file and create a
Secret.NoteThe secrets created by the Cluster Operator for Kafka cluster may be used directly.
This can be done using
oc create:oc create secret generic my-secret --from-file=my-file.crtEdit the
tlsproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... tls: trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.4. Connecting to Kafka brokers with Authentication
By default, Kafka Connect will try to connect to Kafka brokers without authentication. Authentication is enabled through the KafkaConnect and KafkaConnectS2I resources.
3.2.4.1. Authentication support in Kafka Connect
Authentication is configured through the authentication property in KafkaConnect.spec and KafkaConnectS2I.spec. The authentication property specifies the type of the authentication mechanisms which should be used and additional configuration details depending on the mechanism. The supported authentication types are:
- TLS client authentication
- SASL-based authentication using the SCRAM-SHA-512 mechanism
- SASL-based authentication using the PLAIN mechanism
- OAuth 2.0 token based authentication
3.2.4.1.1. TLS Client Authentication
To use TLS client authentication, set the type property to the value tls. TLS client authentication uses a TLS certificate to authenticate. The certificate is specified in the certificateAndKey property and is always loaded from an OpenShift secret. In the secret, the certificate must be stored in X509 format under two different keys: public and private.
TLS client authentication can be used only with TLS connections. For more details about TLS configuration in Kafka Connect see Section 3.2.3, “Connecting to Kafka brokers using TLS”.
An example TLS client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: tls
certificateAndKey:
secretName: my-secret
certificate: public.crt
key: private.key
# ...3.2.4.1.2. SASL based SCRAM-SHA-512 authentication
To configure Kafka Connect to use SASL-based SCRAM-SHA-512 authentication, set the type property to scram-sha-512. This authentication mechanism requires a username and password.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name of theSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example SASL based SCRAM-SHA-512 client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: scram-sha-512
username: my-connect-user
passwordSecret:
secretName: my-connect-user
password: my-connect-password-key
# ...3.2.4.1.3. SASL based PLAIN authentication
To configure Kafka Connect to use SASL-based PLAIN authentication, set the type property to plain. This authentication mechanism requires a username and password.
The SASL PLAIN mechanism will transfer the username and password across the network in cleartext. Only use SASL PLAIN authentication if TLS encryption is enabled.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name of such aSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example showing SASL based PLAIN client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: plain
username: my-connect-user
passwordSecret:
secretName: my-connect-user
password: my-connect-password-key
# ...3.2.4.2. Configuring TLS client authentication in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretwith the public and private keys used for TLS Client Authentication, and the keys under which they are stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the keys used for authentication in a file and create the
Secret.NoteSecrets created by the User Operator may be used.
This can be done using
oc create:oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyEdit the
authenticationproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... authentication: type: tls certificateAndKey: secretName: my-secret certificate: my-public.crt key: my-private.key # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.4.3. Configuring SCRAM-SHA-512 authentication in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- Username of the user which should be used for authentication
-
If they exist, the name of the
Secretwith the password used for authentication and the key under which the password is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare a file with the password used in authentication and create the
Secret.NoteSecrets created by the User Operator may be used.
This can be done using
oc create:echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Edit the
authenticationproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... authentication: type: scram-sha-512 username: _<my-username>_ passwordSecret: secretName: _<my-secret>_ password: _<my-password.txt>_ # ...Create or update the resource.
On OpenShift this can be done using
oc apply:oc apply -f your-file
3.2.5. Kafka Connect configuration
AMQ Streams allows you to customize the configuration of Apache Kafka Connect nodes by editing certain options listed in Apache Kafka documentation.
Configuration options that cannot be configured relate to:
- Kafka cluster bootstrap address
- Security (Encryption, Authentication, and Authorization)
- Listener / REST interface configuration
- Plugin path configuration
These options are automatically configured by AMQ Streams.
3.2.5.1. Kafka Connect configuration
Kafka Connect is configured using the config property in KafkaConnect.spec and KafkaConnectS2I.spec. This property contains the Kafka Connect configuration options as keys. The values can be one of the following JSON types:
- String
- Number
- Boolean
You can specify and configure the options listed in the Apache Kafka documentation with the exception of those options that are managed directly by AMQ Streams. Specifically, configuration options with keys equal to or starting with one of the following strings are forbidden:
-
ssl. -
sasl. -
security. -
listeners -
plugin.path -
rest. -
bootstrap.servers
When a forbidden option is present in the config property, it is ignored and a warning message is printed to the Custer Operator log file. All other options are passed to Kafka Connect.
The Cluster Operator does not validate keys or values in the config object provided. When an invalid configuration is provided, the Kafka Connect cluster might not start or might become unstable. In this circumstance, fix the configuration in the KafkaConnect.spec.config or KafkaConnectS2I.spec.config object, then the Cluster Operator can roll out the new configuration to all Kafka Connect nodes.
Certain options have default values:
-
group.idwith default valueconnect-cluster -
offset.storage.topicwith default valueconnect-cluster-offsets -
config.storage.topicwith default valueconnect-cluster-configs -
status.storage.topicwith default valueconnect-cluster-status -
key.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
value.converterwith default valueorg.apache.kafka.connect.json.JsonConverter
These options are automatically configured in case they are not present in the KafkaConnect.spec.config or KafkaConnectS2I.spec.config properties.
Example Kafka Connect configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
# ...3.2.5.2. Kafka Connect configuration for multiple instances
If you are running multiple instances of Kafka Connect, pay attention to the default configuration of the following properties:
# ...
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# ...
Values for the three topics must be the same for all Kafka Connect instances with the same group.id.
Unless you change the default settings, each Kafka Connect instance connecting to the same Kafka cluster is deployed with the same values. What happens, in effect, is all instances are coupled to run in a cluster and use the same topics.
If multiple Kafka Connect clusters try to use the same topics, Kafka Connect will not work as expected and generate errors.
If you wish to run multiple Kafka Connect instances, change the values of these properties for each instance.
3.2.5.3. Configuring Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
configproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... config: group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.6. CPU and memory resources
For every deployed container, AMQ Streams allows you to request specific resources and define the maximum consumption of those resources.
AMQ Streams supports two types of resources:
- CPU
- Memory
AMQ Streams uses the OpenShift syntax for specifying CPU and memory resources.
3.2.6.1. Resource limits and requests
Resource limits and requests are configured using the resources property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
Additional resources
- For more information about managing computing resources on OpenShift, see Managing Compute Resources for Containers.
3.2.6.1.1. Resource requests
Requests specify the resources to reserve for a given container. Reserving the resources ensures that they are always available.
If the resource request is for more than the available free resources in the OpenShift cluster, the pod is not scheduled.
Resources requests are specified in the requests property. Resources requests currently supported by AMQ Streams:
-
cpu -
memory
A request may be configured for one or more supported resources.
Example resource request configuration with all resources
# ...
resources:
requests:
cpu: 12
memory: 64Gi
# ...3.2.6.1.2. Resource limits
Limits specify the maximum resources that can be consumed by a given container. The limit is not reserved and might not always be available. A container can use the resources up to the limit only when they are available. Resource limits should be always higher than the resource requests.
Resource limits are specified in the limits property. Resource limits currently supported by AMQ Streams:
-
cpu -
memory
A resource may be configured for one or more supported limits.
Example resource limits configuration
# ...
resources:
limits:
cpu: 12
memory: 64Gi
# ...3.2.6.1.3. Supported CPU formats
CPU requests and limits are supported in the following formats:
-
Number of CPU cores as integer (
5CPU core) or decimal (2.5CPU core). -
Number or millicpus / millicores (
100m) where 1000 millicores is the same1CPU core.
Example CPU units
# ...
resources:
requests:
cpu: 500m
limits:
cpu: 2.5
# ...The computing power of 1 CPU core may differ depending on the platform where OpenShift is deployed.
Additional resources
- For more information on CPU specification, see the Meaning of CPU.
3.2.6.1.4. Supported memory formats
Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes.
-
To specify memory in megabytes, use the
Msuffix. For example1000M. -
To specify memory in gigabytes, use the
Gsuffix. For example1G. -
To specify memory in mebibytes, use the
Misuffix. For example1000Mi. -
To specify memory in gibibytes, use the
Gisuffix. For example1Gi.
An example of using different memory units
# ...
resources:
requests:
memory: 512Mi
limits:
memory: 2Gi
# ...Additional resources
- For more details about memory specification and additional supported units, see Meaning of memory.
3.2.6.2. Configuring resource requests and limits
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
resourcesproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... resources: requests: cpu: "8" memory: 64Gi limits: cpu: "12" memory: 128Gi # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see
Resourcesschema reference.
3.2.7. Logging
This section provides information on loggers and how to configure log levels.
You can set the log levels by specifying the loggers and their levels directly (inline) or use a custom (external) config map.
3.2.7.1. Kafka Connect loggers
Kafka Connect has its own configurable loggers:
-
connect.root.logger.level -
log4j.logger.org.apache.zookeeper -
log4j.logger.org.I0Itec.zkclient -
log4j.logger.org.reflections
3.2.7.2. Specifying inline logging
Procedure
Edit the YAML file to specify the loggers and logging level for the required components.
For example, the logging level here is set to INFO:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect spec: # ... logging: type: inline loggers: logger.name: "INFO" # ...You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF.
For more information about the log levels, see the log4j manual.
Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
3.2.7.3. Specifying an external ConfigMap for logging
Procedure
Edit the YAML file to specify the name of the
ConfigMapto use for the required components. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect spec: # ... logging: type: external name: customConfigMap # ...Remember to place your custom ConfigMap under the
log4j.propertiesorlog4j2.propertieskey.Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
Garbage collector (GC) logging can also be enabled (or disabled). For more information on GC, see Section 3.1.17.1, “JVM configuration”
3.2.8. Healthchecks
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, OpenShift assumes that the application is not healthy and attempts to fix it.
OpenShift supports two types of Healthcheck probes:
- Liveness probes
- Readiness probes
For more details about the probes, see Configure Liveness and Readiness Probes. Both types of probes are used in AMQ Streams components.
Users can configure selected options for liveness and readiness probes.
3.2.8.1. Healthcheck configurations
Liveness and readiness probes can be configured using the livenessProbe and readinessProbe properties in following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
For more information about the livenessProbe and readinessProbe options, see Section C.34, “Probe schema reference”.
An example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...3.2.8.2. Configuring healthchecks
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
livenessProbeorreadinessProbeproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.9. Prometheus metrics
AMQ Streams supports Prometheus metrics using Prometheus JMX exporter to convert the JMX metrics supported by Apache Kafka and Zookeeper to Prometheus metrics. When metrics are enabled, they are exposed on port 9404.
For more information about configuring Prometheus and Grafana, see Metrics.
3.2.9.1. Metrics configuration
Prometheus metrics are enabled by configuring the metrics property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
When the metrics property is not defined in the resource, the Prometheus metrics will be disabled. To enable Prometheus metrics export without any further configuration, you can set it to an empty object ({}).
Example of enabling metrics without any further configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics: {}
# ...
zookeeper:
# ...
The metrics property might contain additional configuration for the Prometheus JMX exporter.
Example of enabling metrics with additional Prometheus JMX Exporter configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics:
lowercaseOutputName: true
rules:
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count"
name: "kafka_server_$1_$2_total"
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count"
name: "kafka_server_$1_$2_total"
labels:
topic: "$3"
# ...
zookeeper:
# ...3.2.9.2. Configuring Prometheus metrics
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
metricsproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... metrics: lowercaseOutputName: true # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.10. JVM Options
The following components of AMQ Streams run inside a Virtual Machine (VM):
- Apache Kafka
- Apache Zookeeper
- Apache Kafka Connect
- Apache Kafka Mirror Maker
- AMQ Streams Kafka Bridge
JVM configuration options optimize the performance for different platforms and architectures. AMQ Streams allows you to configure some of these options.
3.2.10.1. JVM configuration
JVM options can be configured using the jvmOptions property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Only a selected subset of available JVM options can be configured. The following options are supported:
-Xms and -Xmx
-Xms configures the minimum initial allocation heap size when the JVM starts. -Xmx configures the maximum heap size.
The units accepted by JVM settings such as -Xmx and -Xms are those accepted by the JDK java binary in the corresponding image. Accordingly, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit suffix. This is in contrast to the units used for memory requests and limits, which follow the OpenShift convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes
The default values used for -Xms and -Xmx depends on whether there is a memory request limit configured for the container:
- If there is a memory limit then the JVM’s minimum and maximum memory will be set to a value corresponding to the limit.
-
If there is no memory limit then the JVM’s minimum memory will be set to
128Mand the JVM’s maximum memory will not be defined. This allows for the JVM’s memory to grow as-needed, which is ideal for single node environments in test and development.
Setting -Xmx explicitly requires some care:
-
The JVM’s overall memory usage will be approximately 4 × the maximum heap, as configured by
-Xmx. -
If
-Xmxis set without also setting an appropriate OpenShift memory limit, it is possible that the container will be killed should the OpenShift node experience memory pressure (from other Pods running on it). -
If
-Xmxis set without also setting an appropriate OpenShift memory request, it is possible that the container will be scheduled to a node with insufficient memory. In this case, the container will not start but crash (immediately if-Xmsis set to-Xmx, or some later time if not).
When setting -Xmx explicitly, it is recommended to:
- set the memory request and the memory limit to the same value,
-
use a memory request that is at least 4.5 × the
-Xmx, -
consider setting
-Xmsto the same value as-Xmx.
Containers doing lots of disk I/O (such as Kafka broker containers) will need to leave some memory available for use as operating system page cache. On such containers, the requested memory should be significantly higher than the memory used by the JVM.
Example fragment configuring -Xmx and -Xms
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...In the above example, the JVM will use 2 GiB (=2,147,483,648 bytes) for its heap. Its total memory usage will be approximately 8GiB.
Setting the same value for initial (-Xms) and maximum (-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed. For Kafka and Zookeeper pods such allocation could cause unwanted latency. For Kafka Connect avoiding over allocation may be the most important concern, especially in distributed mode where the effects of over-allocation will be multiplied by the number of consumers.
-server
-server enables the server JVM. This option can be set to true or false.
Example fragment configuring -server
# ...
jvmOptions:
"-server": true
# ...
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
-XX
-XX object can be used for configuring advanced runtime options of a JVM. The -server and -XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Example showing the use of the -XX object
jvmOptions:
"-XX":
"UseG1GC": true
"MaxGCPauseMillis": 20
"InitiatingHeapOccupancyPercent": 35
"ExplicitGCInvokesConcurrent": true
"UseParNewGC": falseThe example configuration above will result in the following JVM options:
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
3.2.10.1.1. Garbage collector logging
The jvmOptions section also allows you to enable and disable garbage collector (GC) logging. GC logging is enabled by default. To disable it, set the gcLoggingEnabled property as follows:
Example of disabling GC logging
# ...
jvmOptions:
gcLoggingEnabled: false
# ...3.2.10.2. Configuring JVM options
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
jvmOptionsproperty in theKafka,KafkaConnect,KafkaConnectS2I,KafkaMirrorMaker, orKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... jvmOptions: "-Xmx": "8g" "-Xms": "8g" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.11. Container images
AMQ Streams allows you to configure container images which will be used for its components. Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such a case, you should either copy the AMQ Streams images or build them from the source. If the configured image is not compatible with AMQ Streams images, it might not work properly.
3.2.11.1. Container image configurations
Container image which should be used for given components can be specified using the image property in:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.2.11.1.1. Configuring the Kafka.spec.kafka.image property
The Kafka.spec.kafka.image property functions differently from the others, because AMQ Streams supports multiple versions of Kafka, each requiring the own image. The STRIMZI_KAFKA_IMAGES environment variable of the Cluster Operator configuration is used to provide a mapping between Kafka versions and the corresponding images. This is used in combination with the Kafka.spec.kafka.image and Kafka.spec.kafka.version properties as follows:
-
If neither
Kafka.spec.kafka.imagenorKafka.spec.kafka.versionare given in the custom resource then theversionwill default to the Cluster Operator’s default Kafka version, and the image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
If
Kafka.spec.kafka.imageis given butKafka.spec.kafka.versionis not then the given image will be used and theversionwill be assumed to be the Cluster Operator’s default Kafka version. -
If
Kafka.spec.kafka.versionis given butKafka.spec.kafka.imageis not then image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
Both
Kafka.spec.kafka.versionandKafka.spec.kafka.imageare given the given image will be used, and it will be assumed to contain a Kafka broker with the given version.
It is best to provide just Kafka.spec.kafka.version and leave the Kafka.spec.kafka.image property unspecified. This reduces the chances of making a mistake in configuring the Kafka resource. If you need to change the images used for different versions of Kafka, it is better to configure the Cluster Operator’s STRIMZI_KAFKA_IMAGES environment variable.
3.2.11.1.2. Configuring the image property in other resources
For the image property in the other custom resources, the given value will be used during deployment. If the image property is missing, the image specified in the Cluster Operator configuration will be used. If the image name is not defined in the Cluster Operator configuration, then the default value will be used.
For Kafka broker TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper nodes:
-
Container image specified in the
STRIMZI_DEFAULT_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper node TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Topic Operator:
-
Container image specified in the
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For User Operator:
-
Container image specified in the
STRIMZI_DEFAULT_USER_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For Entity Operator TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect with Source2image support:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such case, you should either copy the AMQ Streams images or build them from source. In case the configured image is not compatible with AMQ Streams images, it might not work properly.
Example of container image configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...
zookeeper:
# ...3.2.11.2. Configuring container images
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
imageproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... image: my-org/my-image:latest # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.12. Configuring pod scheduling
When two applications are scheduled to the same OpenShift node, both applications might use the same resources like disk I/O and impact performance. That can lead to performance degradation. Scheduling Kafka pods in a way that avoids sharing nodes with other critical workloads, using the right nodes or dedicated a set of nodes only for Kafka are the best ways how to avoid such problems.
3.2.12.1. Scheduling pods based on other applications
3.2.12.1.1. Avoid critical applications to share the node
Pod anti-affinity can be used to ensure that critical applications are never scheduled on the same disk. When running Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share the nodes with other workloads like databases.
3.2.12.1.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.2.12.1.3. Configuring pod anti-affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.12.2. Scheduling pods to specific nodes
3.2.12.2.1. Node scheduling
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of AMQ Streams components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
3.2.12.2.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.2.12.2.3. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where AMQ Streams components should be scheduled.
This can be done using
oc label:oc label node your-node node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.12.3. Using dedicated nodes
3.2.12.3.1. Dedicated nodes
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Taints can be used to create dedicated nodes. Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
To schedule Kafka pods on the dedicated nodes, configure node affinity and tolerations.
3.2.12.3.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.2.12.3.3. Tolerations
Tolerations can be configured using the tolerations property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The format of the tolerations property follows the OpenShift specification. For more details, see the Kubernetes taints and tolerations.
3.2.12.3.4. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node your-node dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node your-node dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.2.13. Using external configuration and secrets
Kafka Connect connectors are configured using an HTTP REST interface. The connector configuration is passed to Kafka Connect as part of an HTTP request and stored within Kafka itself.
Some parts of the configuration of a Kafka Connect connector can be externalized using ConfigMaps or Secrets. You can then reference the configuration values in HTTP REST commands (this keeps the configuration separate and more secure, if needed). This method applies especially to confidential data, such as usernames, passwords, or certificates.
ConfigMaps and Secrets are standard OpenShift resources used for storing of configurations and confidential data.
3.2.13.1. Storing connector configurations externally
You can mount ConfigMaps or Secrets into a Kafka Connect pod as volumes or environment variables. Volumes and environment variables are configured in the externalConfiguration property in KafkaConnect.spec and KafkaConnectS2I.spec.
3.2.13.1.1. External configuration as environment variables
The env property is used to specify one or more environment variables. These variables can contain a value from either a ConfigMap or a Secret.
The names of user-defined environment variables cannot start with KAFKA_ or STRIMZI_.
To mount a value from a Secret to an environment variable, use the valueFrom property and the secretKeyRef as shown in the following example.
Example of an environment variable set to a value from a Secret
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
secretKeyRef:
name: my-secret
key: my-key
A common use case for mounting Secrets to environment variables is when your connector needs to communicate with Amazon AWS and needs to read the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables with credentials.
To mount a value from a ConfigMap to an environment variable, use configMapKeyRef in the valueFrom property as shown in the following example.
Example of an environment variable set to a value from a ConfigMap
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-key3.2.13.1.2. External configuration as volumes
You can also mount ConfigMaps or Secrets to a Kafka Connect pod as volumes. Using volumes instead of environment variables is useful in the following scenarios:
- Mounting truststores or keystores with TLS certificates
- Mounting a properties file that is used to configure Kafka Connect connectors
In the volumes property of the externalConfiguration resource, list the ConfigMaps or Secrets that will be mounted as volumes. Each volume must specify a name in the name property and a reference to ConfigMap or Secret.
Example of volumes with external configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
volumes:
- name: connector1
configMap:
name: connector1-configuration
- name: connector1-certificates
secret:
secretName: connector1-certificates
The volumes will be mounted inside the Kafka Connect containers in the path /opt/kafka/external-configuration/<volume-name>. For example, the files from a volume named connector1 would appear in the directory /opt/kafka/external-configuration/connector1.
The FileConfigProvider has to be used to read the values from the mounted properties files in connector configurations.
3.2.13.2. Mounting Secrets as environment variables
You can create an OpenShift Secret and mount it to Kafka Connect as an environment variable.
Prerequisites
- A running Cluster Operator.
Procedure
Create a secret containing the information that will be mounted as an environment variable. For example:
apiVersion: v1 kind: Secret metadata: name: aws-creds type: Opaque data: awsAccessKey: QUtJQVhYWFhYWFhYWFhYWFg= awsSecretAccessKey: Ylhsd1lYTnpkMjl5WkE=Create or edit the Kafka Connect resource. Configure the
externalConfigurationsection of theKafkaConnectorKafkaConnectS2Icustom resource to reference the secret. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... externalConfiguration: env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKeyApply the changes to your Kafka Connect deployment.
Use
oc apply:oc apply -f your-file
The environment variables are now available for use when developing your connectors.
Additional resources
-
For more information about external configuration in Kafka Connect, see Section C.72, “
ExternalConfigurationschema reference”.
3.2.13.3. Mounting Secrets as volumes
You can create an OpenShift Secret, mount it as a volume to Kafka Connect, and then use it to configure a Kafka Connect connector.
Prerequisites
- A running Cluster Operator.
Procedure
Create a secret containing a properties file that defines the configuration options for your connector configuration. For example:
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque stringData: connector.properties: |- dbUsername: my-user dbPassword: my-passwordCreate or edit the Kafka Connect resource. Configure the
FileConfigProviderin theconfigsection and theexternalConfigurationsection of theKafkaConnectorKafkaConnectS2Icustom resource to reference the secret. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... config: config.providers: file config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider #... externalConfiguration: volumes: - name: connector-config secret: secretName: mysecretApply the changes to your Kafka Connect deployment.
Use
oc apply:oc apply -f your-fileUse the values from the mounted properties file in your JSON payload with connector configuration. For example:
{ "name":"my-connector", "config":{ "connector.class":"MyDbConnector", "tasks.max":"3", "database": "my-postgresql:5432" "username":"${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbUsername}", "password":"${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbPassword}", # ... } }
Additional resources
-
For more information about external configuration in Kafka Connect, see Section C.72, “
ExternalConfigurationschema reference”.
3.2.14. List of resources created as part of Kafka Connect cluster
The following resources will created by the Cluster Operator in the OpenShift cluster:
- connect-cluster-name-connect
- Deployment which is in charge to create the Kafka Connect worker node pods.
- connect-cluster-name-connect-api
- Service which exposes the REST interface for managing the Kafka Connect cluster.
- connect-cluster-name-config
- ConfigMap which contains the Kafka Connect ancillary configuration and is mounted as a volume by the Kafka broker pods.
- connect-cluster-name-connect
- Pod Disruption Budget configured for the Kafka Connect worker nodes.
3.3. Kafka Connect cluster with Source2Image support
The full schema of the KafkaConnectS2I resource is described in the Section C.78, “KafkaConnectS2I schema reference”. All labels that are applied to the desired KafkaConnectS2I resource will also be applied to the OpenShift resources making up the Kafka Connect cluster with Source2Image support. This provides a convenient mechanism for resources to be labeled as required.
3.3.1. Replicas
Kafka Connect clusters can run multiple of nodes. The number of nodes is defined in the KafkaConnect and KafkaConnectS2I resources. Running a Kafka Connect cluster with multiple nodes can provide better availability and scalability. However, when running Kafka Connect on OpenShift it is not absolutely necessary to run multiple nodes of Kafka Connect for high availability. If a node where Kafka Connect is deployed to crashes, OpenShift will automatically reschedule the Kafka Connect pod to a different node. However, running Kafka Connect with multiple nodes can provide faster failover times, because the other nodes will be up and running already.
3.3.1.1. Configuring the number of nodes
The number of Kafka Connect nodes is configured using the replicas property in KafkaConnect.spec and KafkaConnectS2I.spec.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
replicasproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnectS2I metadata: name: my-cluster spec: # ... replicas: 3 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.2. Bootstrap servers
A Kafka Connect cluster always works in combination with a Kafka cluster. A Kafka cluster is specified as a list of bootstrap servers. On OpenShift, the list must ideally contain the Kafka cluster bootstrap service named cluster-name-kafka-bootstrap, and a port of 9092 for plain traffic or 9093 for encrypted traffic.
The list of bootstrap servers is configured in the bootstrapServers property in KafkaConnect.spec and KafkaConnectS2I.spec. The servers must be defined as a comma-separated list specifying one or more Kafka brokers, or a service pointing to Kafka brokers specified as a hostname:_port_ pairs.
When using Kafka Connect with a Kafka cluster not managed by AMQ Streams, you can specify the bootstrap servers list according to the configuration of the cluster.
3.3.2.1. Configuring bootstrap servers
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
bootstrapServersproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-cluster spec: # ... bootstrapServers: my-cluster-kafka-bootstrap:9092 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.3. Connecting to Kafka brokers using TLS
By default, Kafka Connect tries to connect to Kafka brokers using a plain text connection. If you prefer to use TLS, additional configuration is required.
3.3.3.1. TLS support in Kafka Connect
TLS support is configured in the tls property in KafkaConnect.spec and KafkaConnectS2I.spec. The tls property contains a list of secrets with key names under which the certificates are stored. The certificates must be stored in X509 format.
An example showing TLS configuration with multiple certificates
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-other-secret
certificate: certificate.crt
# ...When multiple certificates are stored in the same secret, it can be listed multiple times.
An example showing TLS configuration with multiple certificates from the same secret
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnectS2I
metadata:
name: my-cluster
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-secret
certificate: ca2.crt
# ...3.3.3.2. Configuring TLS in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretfor the certificate used for TLS Server Authentication, and the key under which the certificate is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the TLS certificate used in authentication in a file and create a
Secret.NoteThe secrets created by the Cluster Operator for Kafka cluster may be used directly.
This can be done using
oc create:oc create secret generic my-secret --from-file=my-file.crtEdit the
tlsproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... tls: trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.4. Connecting to Kafka brokers with Authentication
By default, Kafka Connect will try to connect to Kafka brokers without authentication. Authentication is enabled through the KafkaConnect and KafkaConnectS2I resources.
3.3.4.1. Authentication support in Kafka Connect
Authentication is configured through the authentication property in KafkaConnect.spec and KafkaConnectS2I.spec. The authentication property specifies the type of the authentication mechanisms which should be used and additional configuration details depending on the mechanism. The supported authentication types are:
- TLS client authentication
- SASL-based authentication using the SCRAM-SHA-512 mechanism
- SASL-based authentication using the PLAIN mechanism
- OAuth 2.0 token based authentication
3.3.4.1.1. TLS Client Authentication
To use TLS client authentication, set the type property to the value tls. TLS client authentication uses a TLS certificate to authenticate. The certificate is specified in the certificateAndKey property and is always loaded from an OpenShift secret. In the secret, the certificate must be stored in X509 format under two different keys: public and private.
TLS client authentication can be used only with TLS connections. For more details about TLS configuration in Kafka Connect see Section 3.3.3, “Connecting to Kafka brokers using TLS”.
An example TLS client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: tls
certificateAndKey:
secretName: my-secret
certificate: public.crt
key: private.key
# ...3.3.4.1.2. SASL based SCRAM-SHA-512 authentication
To configure Kafka Connect to use SASL-based SCRAM-SHA-512 authentication, set the type property to scram-sha-512. This authentication mechanism requires a username and password.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name of theSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example SASL based SCRAM-SHA-512 client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: scram-sha-512
username: my-connect-user
passwordSecret:
secretName: my-connect-user
password: my-connect-password-key
# ...3.3.4.1.3. SASL based PLAIN authentication
To configure Kafka Connect to use SASL-based PLAIN authentication, set the type property to plain. This authentication mechanism requires a username and password.
The SASL PLAIN mechanism will transfer the username and password across the network in cleartext. Only use SASL PLAIN authentication if TLS encryption is enabled.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name of such aSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example showing SASL based PLAIN client authentication configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
authentication:
type: plain
username: my-connect-user
passwordSecret:
secretName: my-connect-user
password: my-connect-password-key
# ...3.3.4.2. Configuring TLS client authentication in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretwith the public and private keys used for TLS Client Authentication, and the keys under which they are stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the keys used for authentication in a file and create the
Secret.NoteSecrets created by the User Operator may be used.
This can be done using
oc create:oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyEdit the
authenticationproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... authentication: type: tls certificateAndKey: secretName: my-secret certificate: my-public.crt key: my-private.key # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.4.3. Configuring SCRAM-SHA-512 authentication in Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- Username of the user which should be used for authentication
-
If they exist, the name of the
Secretwith the password used for authentication and the key under which the password is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare a file with the password used in authentication and create the
Secret.NoteSecrets created by the User Operator may be used.
This can be done using
oc create:echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Edit the
authenticationproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... authentication: type: scram-sha-512 username: _<my-username>_ passwordSecret: secretName: _<my-secret>_ password: _<my-password.txt>_ # ...Create or update the resource.
On OpenShift this can be done using
oc apply:oc apply -f your-file
3.3.5. Kafka Connect configuration
AMQ Streams allows you to customize the configuration of Apache Kafka Connect nodes by editing certain options listed in Apache Kafka documentation.
Configuration options that cannot be configured relate to:
- Kafka cluster bootstrap address
- Security (Encryption, Authentication, and Authorization)
- Listener / REST interface configuration
- Plugin path configuration
These options are automatically configured by AMQ Streams.
3.3.5.1. Kafka Connect configuration
Kafka Connect is configured using the config property in KafkaConnect.spec and KafkaConnectS2I.spec. This property contains the Kafka Connect configuration options as keys. The values can be one of the following JSON types:
- String
- Number
- Boolean
You can specify and configure the options listed in the Apache Kafka documentation with the exception of those options that are managed directly by AMQ Streams. Specifically, configuration options with keys equal to or starting with one of the following strings are forbidden:
-
ssl. -
sasl. -
security. -
listeners -
plugin.path -
rest. -
bootstrap.servers
When a forbidden option is present in the config property, it is ignored and a warning message is printed to the Custer Operator log file. All other options are passed to Kafka Connect.
The Cluster Operator does not validate keys or values in the config object provided. When an invalid configuration is provided, the Kafka Connect cluster might not start or might become unstable. In this circumstance, fix the configuration in the KafkaConnect.spec.config or KafkaConnectS2I.spec.config object, then the Cluster Operator can roll out the new configuration to all Kafka Connect nodes.
Certain options have default values:
-
group.idwith default valueconnect-cluster -
offset.storage.topicwith default valueconnect-cluster-offsets -
config.storage.topicwith default valueconnect-cluster-configs -
status.storage.topicwith default valueconnect-cluster-status -
key.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
value.converterwith default valueorg.apache.kafka.connect.json.JsonConverter
These options are automatically configured in case they are not present in the KafkaConnect.spec.config or KafkaConnectS2I.spec.config properties.
Example Kafka Connect configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
# ...3.3.5.2. Kafka Connect configuration for multiple instances
If you are running multiple instances of Kafka Connect, pay attention to the default configuration of the following properties:
# ...
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# ...
Values for the three topics must be the same for all Kafka Connect instances with the same group.id.
Unless you change the default settings, each Kafka Connect instance connecting to the same Kafka cluster is deployed with the same values. What happens, in effect, is all instances are coupled to run in a cluster and use the same topics.
If multiple Kafka Connect clusters try to use the same topics, Kafka Connect will not work as expected and generate errors.
If you wish to run multiple Kafka Connect instances, change the values of these properties for each instance.
3.3.5.3. Configuring Kafka Connect
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
configproperty in theKafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... config: group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.6. CPU and memory resources
For every deployed container, AMQ Streams allows you to request specific resources and define the maximum consumption of those resources.
AMQ Streams supports two types of resources:
- CPU
- Memory
AMQ Streams uses the OpenShift syntax for specifying CPU and memory resources.
3.3.6.1. Resource limits and requests
Resource limits and requests are configured using the resources property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
Additional resources
- For more information about managing computing resources on OpenShift, see Managing Compute Resources for Containers.
3.3.6.1.1. Resource requests
Requests specify the resources to reserve for a given container. Reserving the resources ensures that they are always available.
If the resource request is for more than the available free resources in the OpenShift cluster, the pod is not scheduled.
Resources requests are specified in the requests property. Resources requests currently supported by AMQ Streams:
-
cpu -
memory
A request may be configured for one or more supported resources.
Example resource request configuration with all resources
# ...
resources:
requests:
cpu: 12
memory: 64Gi
# ...3.3.6.1.2. Resource limits
Limits specify the maximum resources that can be consumed by a given container. The limit is not reserved and might not always be available. A container can use the resources up to the limit only when they are available. Resource limits should be always higher than the resource requests.
Resource limits are specified in the limits property. Resource limits currently supported by AMQ Streams:
-
cpu -
memory
A resource may be configured for one or more supported limits.
Example resource limits configuration
# ...
resources:
limits:
cpu: 12
memory: 64Gi
# ...3.3.6.1.3. Supported CPU formats
CPU requests and limits are supported in the following formats:
-
Number of CPU cores as integer (
5CPU core) or decimal (2.5CPU core). -
Number or millicpus / millicores (
100m) where 1000 millicores is the same1CPU core.
Example CPU units
# ...
resources:
requests:
cpu: 500m
limits:
cpu: 2.5
# ...The computing power of 1 CPU core may differ depending on the platform where OpenShift is deployed.
Additional resources
- For more information on CPU specification, see the Meaning of CPU.
3.3.6.1.4. Supported memory formats
Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes.
-
To specify memory in megabytes, use the
Msuffix. For example1000M. -
To specify memory in gigabytes, use the
Gsuffix. For example1G. -
To specify memory in mebibytes, use the
Misuffix. For example1000Mi. -
To specify memory in gibibytes, use the
Gisuffix. For example1Gi.
An example of using different memory units
# ...
resources:
requests:
memory: 512Mi
limits:
memory: 2Gi
# ...Additional resources
- For more details about memory specification and additional supported units, see Meaning of memory.
3.3.6.2. Configuring resource requests and limits
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
resourcesproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... resources: requests: cpu: "8" memory: 64Gi limits: cpu: "12" memory: 128Gi # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see
Resourcesschema reference.
3.3.7. Logging
This section provides information on loggers and how to configure log levels.
You can set the log levels by specifying the loggers and their levels directly (inline) or use a custom (external) config map.
3.3.7.1. Kafka Connect with Source2Image loggers
Kafka Connect with Source2Image support has its own configurable loggers:
-
connect.root.logger.level -
log4j.logger.org.apache.zookeeper -
log4j.logger.org.I0Itec.zkclient -
log4j.logger.org.reflections
3.3.7.2. Specifying inline logging
Procedure
Edit the YAML file to specify the loggers and logging level for the required components.
For example, the logging level here is set to INFO:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnectS2I spec: # ... logging: type: inline loggers: logger.name: "INFO" # ...You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF.
For more information about the log levels, see the log4j manual.
Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
3.3.7.3. Specifying an external ConfigMap for logging
Procedure
Edit the YAML file to specify the name of the
ConfigMapto use for the required components. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnectS2I spec: # ... logging: type: external name: customConfigMap # ...Remember to place your custom ConfigMap under the
log4j.propertiesorlog4j2.propertieskey.Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
Garbage collector (GC) logging can also be enabled (or disabled). For more information on GC, see Section 3.1.17.1, “JVM configuration”
3.3.8. Healthchecks
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, OpenShift assumes that the application is not healthy and attempts to fix it.
OpenShift supports two types of Healthcheck probes:
- Liveness probes
- Readiness probes
For more details about the probes, see Configure Liveness and Readiness Probes. Both types of probes are used in AMQ Streams components.
Users can configure selected options for liveness and readiness probes.
3.3.8.1. Healthcheck configurations
Liveness and readiness probes can be configured using the livenessProbe and readinessProbe properties in following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
For more information about the livenessProbe and readinessProbe options, see Section C.34, “Probe schema reference”.
An example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...3.3.8.2. Configuring healthchecks
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
livenessProbeorreadinessProbeproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.9. Prometheus metrics
AMQ Streams supports Prometheus metrics using Prometheus JMX exporter to convert the JMX metrics supported by Apache Kafka and Zookeeper to Prometheus metrics. When metrics are enabled, they are exposed on port 9404.
For more information about configuring Prometheus and Grafana, see Metrics.
3.3.9.1. Metrics configuration
Prometheus metrics are enabled by configuring the metrics property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
When the metrics property is not defined in the resource, the Prometheus metrics will be disabled. To enable Prometheus metrics export without any further configuration, you can set it to an empty object ({}).
Example of enabling metrics without any further configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics: {}
# ...
zookeeper:
# ...
The metrics property might contain additional configuration for the Prometheus JMX exporter.
Example of enabling metrics with additional Prometheus JMX Exporter configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics:
lowercaseOutputName: true
rules:
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count"
name: "kafka_server_$1_$2_total"
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count"
name: "kafka_server_$1_$2_total"
labels:
topic: "$3"
# ...
zookeeper:
# ...3.3.9.2. Configuring Prometheus metrics
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
metricsproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... metrics: lowercaseOutputName: true # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.10. JVM Options
The following components of AMQ Streams run inside a Virtual Machine (VM):
- Apache Kafka
- Apache Zookeeper
- Apache Kafka Connect
- Apache Kafka Mirror Maker
- AMQ Streams Kafka Bridge
JVM configuration options optimize the performance for different platforms and architectures. AMQ Streams allows you to configure some of these options.
3.3.10.1. JVM configuration
JVM options can be configured using the jvmOptions property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Only a selected subset of available JVM options can be configured. The following options are supported:
-Xms and -Xmx
-Xms configures the minimum initial allocation heap size when the JVM starts. -Xmx configures the maximum heap size.
The units accepted by JVM settings such as -Xmx and -Xms are those accepted by the JDK java binary in the corresponding image. Accordingly, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit suffix. This is in contrast to the units used for memory requests and limits, which follow the OpenShift convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes
The default values used for -Xms and -Xmx depends on whether there is a memory request limit configured for the container:
- If there is a memory limit then the JVM’s minimum and maximum memory will be set to a value corresponding to the limit.
-
If there is no memory limit then the JVM’s minimum memory will be set to
128Mand the JVM’s maximum memory will not be defined. This allows for the JVM’s memory to grow as-needed, which is ideal for single node environments in test and development.
Setting -Xmx explicitly requires some care:
-
The JVM’s overall memory usage will be approximately 4 × the maximum heap, as configured by
-Xmx. -
If
-Xmxis set without also setting an appropriate OpenShift memory limit, it is possible that the container will be killed should the OpenShift node experience memory pressure (from other Pods running on it). -
If
-Xmxis set without also setting an appropriate OpenShift memory request, it is possible that the container will be scheduled to a node with insufficient memory. In this case, the container will not start but crash (immediately if-Xmsis set to-Xmx, or some later time if not).
When setting -Xmx explicitly, it is recommended to:
- set the memory request and the memory limit to the same value,
-
use a memory request that is at least 4.5 × the
-Xmx, -
consider setting
-Xmsto the same value as-Xmx.
Containers doing lots of disk I/O (such as Kafka broker containers) will need to leave some memory available for use as operating system page cache. On such containers, the requested memory should be significantly higher than the memory used by the JVM.
Example fragment configuring -Xmx and -Xms
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...In the above example, the JVM will use 2 GiB (=2,147,483,648 bytes) for its heap. Its total memory usage will be approximately 8GiB.
Setting the same value for initial (-Xms) and maximum (-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed. For Kafka and Zookeeper pods such allocation could cause unwanted latency. For Kafka Connect avoiding over allocation may be the most important concern, especially in distributed mode where the effects of over-allocation will be multiplied by the number of consumers.
-server
-server enables the server JVM. This option can be set to true or false.
Example fragment configuring -server
# ...
jvmOptions:
"-server": true
# ...
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
-XX
-XX object can be used for configuring advanced runtime options of a JVM. The -server and -XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Example showing the use of the -XX object
jvmOptions:
"-XX":
"UseG1GC": true
"MaxGCPauseMillis": 20
"InitiatingHeapOccupancyPercent": 35
"ExplicitGCInvokesConcurrent": true
"UseParNewGC": falseThe example configuration above will result in the following JVM options:
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
3.3.10.1.1. Garbage collector logging
The jvmOptions section also allows you to enable and disable garbage collector (GC) logging. GC logging is enabled by default. To disable it, set the gcLoggingEnabled property as follows:
Example of disabling GC logging
# ...
jvmOptions:
gcLoggingEnabled: false
# ...3.3.10.2. Configuring JVM options
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
jvmOptionsproperty in theKafka,KafkaConnect,KafkaConnectS2I,KafkaMirrorMaker, orKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... jvmOptions: "-Xmx": "8g" "-Xms": "8g" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.11. Container images
AMQ Streams allows you to configure container images which will be used for its components. Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such a case, you should either copy the AMQ Streams images or build them from the source. If the configured image is not compatible with AMQ Streams images, it might not work properly.
3.3.11.1. Container image configurations
Container image which should be used for given components can be specified using the image property in:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.3.11.1.1. Configuring the Kafka.spec.kafka.image property
The Kafka.spec.kafka.image property functions differently from the others, because AMQ Streams supports multiple versions of Kafka, each requiring the own image. The STRIMZI_KAFKA_IMAGES environment variable of the Cluster Operator configuration is used to provide a mapping between Kafka versions and the corresponding images. This is used in combination with the Kafka.spec.kafka.image and Kafka.spec.kafka.version properties as follows:
-
If neither
Kafka.spec.kafka.imagenorKafka.spec.kafka.versionare given in the custom resource then theversionwill default to the Cluster Operator’s default Kafka version, and the image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
If
Kafka.spec.kafka.imageis given butKafka.spec.kafka.versionis not then the given image will be used and theversionwill be assumed to be the Cluster Operator’s default Kafka version. -
If
Kafka.spec.kafka.versionis given butKafka.spec.kafka.imageis not then image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
Both
Kafka.spec.kafka.versionandKafka.spec.kafka.imageare given the given image will be used, and it will be assumed to contain a Kafka broker with the given version.
It is best to provide just Kafka.spec.kafka.version and leave the Kafka.spec.kafka.image property unspecified. This reduces the chances of making a mistake in configuring the Kafka resource. If you need to change the images used for different versions of Kafka, it is better to configure the Cluster Operator’s STRIMZI_KAFKA_IMAGES environment variable.
3.3.11.1.2. Configuring the image property in other resources
For the image property in the other custom resources, the given value will be used during deployment. If the image property is missing, the image specified in the Cluster Operator configuration will be used. If the image name is not defined in the Cluster Operator configuration, then the default value will be used.
For Kafka broker TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper nodes:
-
Container image specified in the
STRIMZI_DEFAULT_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper node TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Topic Operator:
-
Container image specified in the
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For User Operator:
-
Container image specified in the
STRIMZI_DEFAULT_USER_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For Entity Operator TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect with Source2image support:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such case, you should either copy the AMQ Streams images or build them from source. In case the configured image is not compatible with AMQ Streams images, it might not work properly.
Example of container image configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...
zookeeper:
# ...3.3.11.2. Configuring container images
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
imageproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... image: my-org/my-image:latest # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.12. Configuring pod scheduling
When two applications are scheduled to the same OpenShift node, both applications might use the same resources like disk I/O and impact performance. That can lead to performance degradation. Scheduling Kafka pods in a way that avoids sharing nodes with other critical workloads, using the right nodes or dedicated a set of nodes only for Kafka are the best ways how to avoid such problems.
3.3.12.1. Scheduling pods based on other applications
3.3.12.1.1. Avoid critical applications to share the node
Pod anti-affinity can be used to ensure that critical applications are never scheduled on the same disk. When running Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share the nodes with other workloads like databases.
3.3.12.1.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.3.12.1.3. Configuring pod anti-affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.12.2. Scheduling pods to specific nodes
3.3.12.2.1. Node scheduling
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of AMQ Streams components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
3.3.12.2.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.3.12.2.3. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where AMQ Streams components should be scheduled.
This can be done using
oc label:oc label node your-node node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.12.3. Using dedicated nodes
3.3.12.3.1. Dedicated nodes
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Taints can be used to create dedicated nodes. Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
To schedule Kafka pods on the dedicated nodes, configure node affinity and tolerations.
3.3.12.3.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.3.12.3.3. Tolerations
Tolerations can be configured using the tolerations property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The format of the tolerations property follows the OpenShift specification. For more details, see the Kubernetes taints and tolerations.
3.3.12.3.4. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node your-node dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node your-node dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.3.13. Using external configuration and secrets
Kafka Connect connectors are configured using an HTTP REST interface. The connector configuration is passed to Kafka Connect as part of an HTTP request and stored within Kafka itself.
Some parts of the configuration of a Kafka Connect connector can be externalized using ConfigMaps or Secrets. You can then reference the configuration values in HTTP REST commands (this keeps the configuration separate and more secure, if needed). This method applies especially to confidential data, such as usernames, passwords, or certificates.
ConfigMaps and Secrets are standard OpenShift resources used for storing of configurations and confidential data.
3.3.13.1. Storing connector configurations externally
You can mount ConfigMaps or Secrets into a Kafka Connect pod as volumes or environment variables. Volumes and environment variables are configured in the externalConfiguration property in KafkaConnect.spec and KafkaConnectS2I.spec.
3.3.13.1.1. External configuration as environment variables
The env property is used to specify one or more environment variables. These variables can contain a value from either a ConfigMap or a Secret.
The names of user-defined environment variables cannot start with KAFKA_ or STRIMZI_.
To mount a value from a Secret to an environment variable, use the valueFrom property and the secretKeyRef as shown in the following example.
Example of an environment variable set to a value from a Secret
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
secretKeyRef:
name: my-secret
key: my-key
A common use case for mounting Secrets to environment variables is when your connector needs to communicate with Amazon AWS and needs to read the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables with credentials.
To mount a value from a ConfigMap to an environment variable, use configMapKeyRef in the valueFrom property as shown in the following example.
Example of an environment variable set to a value from a ConfigMap
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-key3.3.13.1.2. External configuration as volumes
You can also mount ConfigMaps or Secrets to a Kafka Connect pod as volumes. Using volumes instead of environment variables is useful in the following scenarios:
- Mounting truststores or keystores with TLS certificates
- Mounting a properties file that is used to configure Kafka Connect connectors
In the volumes property of the externalConfiguration resource, list the ConfigMaps or Secrets that will be mounted as volumes. Each volume must specify a name in the name property and a reference to ConfigMap or Secret.
Example of volumes with external configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
volumes:
- name: connector1
configMap:
name: connector1-configuration
- name: connector1-certificates
secret:
secretName: connector1-certificates
The volumes will be mounted inside the Kafka Connect containers in the path /opt/kafka/external-configuration/<volume-name>. For example, the files from a volume named connector1 would appear in the directory /opt/kafka/external-configuration/connector1.
The FileConfigProvider has to be used to read the values from the mounted properties files in connector configurations.
3.3.13.2. Mounting Secrets as environment variables
You can create an OpenShift Secret and mount it to Kafka Connect as an environment variable.
Prerequisites
- A running Cluster Operator.
Procedure
Create a secret containing the information that will be mounted as an environment variable. For example:
apiVersion: v1 kind: Secret metadata: name: aws-creds type: Opaque data: awsAccessKey: QUtJQVhYWFhYWFhYWFhYWFg= awsSecretAccessKey: Ylhsd1lYTnpkMjl5WkE=Create or edit the Kafka Connect resource. Configure the
externalConfigurationsection of theKafkaConnectorKafkaConnectS2Icustom resource to reference the secret. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... externalConfiguration: env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKeyApply the changes to your Kafka Connect deployment.
Use
oc apply:oc apply -f your-file
The environment variables are now available for use when developing your connectors.
Additional resources
-
For more information about external configuration in Kafka Connect, see Section C.72, “
ExternalConfigurationschema reference”.
3.3.13.3. Mounting Secrets as volumes
You can create an OpenShift Secret, mount it as a volume to Kafka Connect, and then use it to configure a Kafka Connect connector.
Prerequisites
- A running Cluster Operator.
Procedure
Create a secret containing a properties file that defines the configuration options for your connector configuration. For example:
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque stringData: connector.properties: |- dbUsername: my-user dbPassword: my-passwordCreate or edit the Kafka Connect resource. Configure the
FileConfigProviderin theconfigsection and theexternalConfigurationsection of theKafkaConnectorKafkaConnectS2Icustom resource to reference the secret. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect spec: # ... config: config.providers: file config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider #... externalConfiguration: volumes: - name: connector-config secret: secretName: mysecretApply the changes to your Kafka Connect deployment.
Use
oc apply:oc apply -f your-fileUse the values from the mounted properties file in your JSON payload with connector configuration. For example:
{ "name":"my-connector", "config":{ "connector.class":"MyDbConnector", "tasks.max":"3", "database": "my-postgresql:5432" "username":"${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbUsername}", "password":"${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbPassword}", # ... } }
Additional resources
-
For more information about external configuration in Kafka Connect, see Section C.72, “
ExternalConfigurationschema reference”.
3.3.14. List of resources created as part of Kafka Connect cluster with Source2Image support
The following resources will created by the Cluster Operator in the OpenShift cluster:
- connect-cluster-name-connect-source
- ImageStream which is used as the base image for the newly-built Docker images.
- connect-cluster-name-connect
- BuildConfig which is responsible for building the new Kafka Connect Docker images.
- connect-cluster-name-connect
- ImageStream where the newly built Docker images will be pushed.
- connect-cluster-name-connect
- DeploymentConfig which is in charge of creating the Kafka Connect worker node pods.
- connect-cluster-name-connect-api
- Service which exposes the REST interface for managing the Kafka Connect cluster.
- connect-cluster-name-config
- ConfigMap which contains the Kafka Connect ancillary configuration and is mounted as a volume by the Kafka broker pods.
- connect-cluster-name-connect
- Pod Disruption Budget configured for the Kafka Connect worker nodes.
3.3.15. Creating a container image using OpenShift builds and Source-to-Image
You can use OpenShift builds and the Source-to-Image (S2I) framework to create new container images. An OpenShift build takes a builder image with S2I support, together with source code and binaries provided by the user, and uses them to build a new container image. Once built, container images are stored in OpenShift’s local container image repository and are available for use in deployments.
A Kafka Connect builder image with S2I support is provided on the Red Hat Container Catalog as part of the registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0 image. This S2I image takes your binaries (with plug-ins and connectors) and stores them in the /tmp/kafka-plugins/s2i directory. It creates a new Kafka Connect image from this directory, which can then be used with the Kafka Connect deployment. When started using the enhanced image, Kafka Connect loads any third-party plug-ins from the /tmp/kafka-plugins/s2i directory.
Procedure
On the command line, use the
oc applycommand to create and deploy a Kafka Connect S2I cluster:oc apply -f examples/kafka-connect/kafka-connect-s2i.yamlCreate a directory with Kafka Connect plug-ins:
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.mdUse the
oc start-buildcommand to start a new build of the image using the prepared directory:oc start-build my-connect-cluster-connect --from-dir ./my-plugins/NoteThe name of the build is the same as the name of the deployed Kafka Connect cluster.
- Once the build has finished, the new image is used automatically by the Kafka Connect deployment.
3.4. Kafka Mirror Maker configuration
This chapter describes how to configure the KafkaMirrorMaker resource to support a Kafka Mirror Maker deployment in your cluster.
The following procedures show how the resource is configured:
Supported properties are also described in more detail for your reference:
The full schema of the KafkaMirrorMaker resource is described in the KafkaMirrorMaker schema reference.
Labels applied to a KafkaMirrorMaker resource are also applied to the OpenShift resources comprising Kafka Mirror Maker. This provides a convenient mechanism for resources to be labeled as required.
3.4.1. Configuring Kafka Mirror Maker
Use the properties of the KafkaMirrorMaker resource to configure your Kafka Mirror Maker deployment.
You can configure access control for producers and consumers using TLS or SASL authentication. This procedure shows a configuration that uses TLS encryption and authentication on the consumer and producer side.
Prerequisites
- AMQ Streams and Kafka is deployed
- Source and target Kafka clusters are available
Procedure
Edit the
specproperties for theKafkaMirrorMakerresource.The properties you can configure are shown in this example configuration:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: replicas: 31 consumer: bootstrapServers: my-source-cluster-kafka-bootstrap:90922 groupId: "my-group"3 numStreams: 24 offsetCommitInterval: 1200005 tls:6 trustedCertificates: - secretName: my-source-cluster-ca-cert certificate: ca.crt authentication:7 type: tls certificateAndKey: secretName: my-source-secret certificate: public.crt key: private.key config:8 max.poll.records: 100 receive.buffer.bytes: 32768 producer: bootstrapServers: my-target-cluster-kafka-bootstrap:9092 abortOnSendFailure: false9 tls: trustedCertificates: - secretName: my-target-cluster-ca-cert certificate: ca.crt authentication: type: tls certificateAndKey: secretName: my-target-secret certificate: public.crt key: private.key config: compression.type: gzip batch.size: 8192 whitelist: "my-topic|other-topic"10 resources:11 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:12 type: inline loggers: mirrormaker.root.logger: "INFO" readinessProbe:13 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metrics:14 lowercaseOutputName: true rules: - pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count" name: "kafka_server_$1_$2_total" - pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count" name: "kafka_server_$1_$2_total" labels: topic: "$3" jvmOptions:15 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest16 template:17 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname"- 1
- The number of replica nodes.
- 2
- Bootstrap servers for consumer and producer.
- 3
- Group ID for the consumer.
- 4
- The number of consumer streams.
- 5
- The offset auto-commit interval in milliseconds.
- 6
- TLS encryption with key names under which TLS certificates are stored in X.509 format for consumer or producer. For more details see
KafkaMirrorMakerTlsschema reference. - 7
- Authentication for consumer or producer, using the TLS mechanism, as shown here, using OAuth bearer tokens, or a SASL-based SCRAM-SHA-512 or PLAIN mechanism.
- 8
- Kafka configuration options for consumer and producer.
- 9
- If set to
true, Kafka Mirror Maker will exit and the container will restart following a send failure for a message. - 10
- Topics mirrored from source to target Kafka cluster.
- 11
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 12
- Specified loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom ConfigMap must be placed under thelog4j.propertiesorlog4j2.propertieskey. Mirror Maker has a single logger calledmirrormaker.root.logger. You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 13
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 14
- Prometheus metrics, which are enabled with configuration for the Prometheus JMX exporter in this example. You can enable metrics without further configuration using
metrics: {}. - 15
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka Mirror Maker.
- 16
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 17
- Template customization. Here a pod is scheduled based with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
WarningWith the
abortOnSendFailureproperty set tofalse, the producer attempts to send the next message in a topic. The original message might be lost, as there is no attempt to resend a failed message.Create or update the resource:
oc apply -f <your-file>
3.4.2. Kafka Mirror Maker configuration properties
Use the spec configuration properties of the KafkaMirrorMaker resource to set up your Mirror Maker deployment.
Supported properties are described here for your reference.
3.4.2.1. Replicas
Use the replicas property to configure replicas.
You can run multiple Mirror Maker replicas to provide better availability and scalability. When running Kafka Mirror Maker on OpenShift it is not absolutely necessary to run multiple replicas of the Kafka Mirror Maker for high availability. When the node where the Kafka Mirror Maker has deployed crashes, OpenShift will automatically reschedule the Kafka Mirror Maker pod to a different node. However, running Kafka Mirror Maker with multiple replicas can provide faster failover times as the other nodes will be up and running.
3.4.2.2. Bootstrap servers
Use the consumer.bootstrapServers and producer.bootstrapServers properties to configure lists of bootstrap servers for the consumer and producer.
Kafka Mirror Maker always works together with two Kafka clusters (source and target). The source and the target Kafka clusters are specified in the form of two lists of comma-separated list of <hostname>:<port> pairs. Each comma-separated list contains one or more Kafka brokers or a Service pointing to Kafka brokers specified as a <hostname>:<port> pairs.
The bootstrap server lists can refer to Kafka clusters that do not need to be deployed in the same OpenShift cluster. They can even refer to a Kafka cluster not deployed by AMQ Streams, or deployed by AMQ Streams but on a different OpenShift cluster accessible outside.
If on the same OpenShift cluster, each list must ideally contain the Kafka cluster bootstrap service which is named <cluster-name>-kafka-bootstrap and a port of 9092 for plain traffic or 9093 for encrypted traffic. If deployed by AMQ Streams but on different OpenShift clusters, the list content depends on the approach used for exposing the clusters (routes, nodeports or loadbalancers).
When using Kafka Mirror Maker with a Kafka cluster not managed by AMQ Streams, you can specify the bootstrap servers list according to the configuration of the given cluster.
3.4.2.3. Whitelist
Use the whitelist property to configure a list of topics that Kafka Mirror Maker mirrors from the source to the target Kafka cluster.
The property allows any regular expression from the simplest case with a single topic name to complex patterns. For example, you can mirror topics A and B using "A|B" or all topics using "*". You can also pass multiple regular expressions separated by commas to the Kafka Mirror Maker.
3.4.2.4. Consumer group identifier
Use the consumer.groupId property to configure a consumer group identifier for the consumer.
Kafka Mirror Maker uses a Kafka consumer to consume messages, behaving like any other Kafka consumer client. Messages consumed from the source Kafka cluster are mirrored to a target Kafka cluster. A group identifier is required, as the consumer needs to be part of a consumer group for the assignment of partitions.
3.4.2.5. Consumer streams
Use the consumer.numStreams property to configure the number of streams for the consumer.
You can increase the throughput in mirroring topics by increasing the number of consumer threads. Consumer threads belong to the consumer group specified for Kafka Mirror Maker. Topic partitions are assigned across the consumer threads, which consume messages in parallel.
3.4.2.6. Offset auto-commit interval
Use the consumer.offsetCommitInterval property to configure an offset auto-commit interval for the consumer.
You can specify the regular time interval at which an offset is committed after Kafka Mirror Maker has consumed data from the source Kafka cluster. The time interval is set in milliseconds, with a default value of 60,000.
3.4.2.7. Abort on message send failure
Use the producer.abortOnSendFailure property to configure how to handle message send failure from the producer.
By default, if an error occurs when sending a message from Kafka Mirror Maker to a Kafka cluster:
- The Kafka Mirror Maker container is terminated in OpenShift.
- The container is then recreated.
If the abortOnSendFailure option is set to false, message sending errors are ignored.
3.4.2.8. Kafka producer and consumer
Use the consumer.config and producer.config properties to configure Kafka options for the consumer and producer.
The config property contains the Kafka Mirror Maker consumer and producer configuration options as keys, with values set in one of the following JSON types:
- String
- Number
- Boolean
Exceptions
You can specify and configure standard Kafka consumer and producer options:
However, there are exceptions for options automatically configured and managed directly by AMQ Streams related to:
- Kafka cluster bootstrap address
- Security (encryption, authentication, and authorization)
- Consumer group identifier
Specifically, all configuration options with keys equal to or starting with one of the following strings are forbidden:
-
ssl. -
sasl. -
security. -
bootstrap.servers -
group.id
When a forbidden option is present in the config property, it is ignored and a warning message is printed to the Custer Operator log file. All other options are passed to Kafka Mirror Maker.
The Cluster Operator does not validate keys or values in the provided config object. When an invalid configuration is provided, the Kafka Mirror Maker might not start or might become unstable. In such cases, the configuration in the KafkaMirrorMaker.spec.consumer.config or KafkaMirrorMaker.spec.producer.config object should be fixed and the Cluster Operator will roll out the new configuration for Kafka Mirror Maker.
3.4.2.9. CPU and memory resources
Use the reources.requests and resources.limits properties to configure resource requests and limits.
For every deployed container, AMQ Streams allows you to request specific resources and define the maximum consumption of those resources.
AMQ Streams supports requests and limits for the following types of resources:
-
cpu -
memory
AMQ Streams uses the OpenShift syntax for specifying these resources.
For more information about managing computing resources on OpenShift, see Managing Compute Resources for Containers.
Resource requests
Requests specify the resources to reserve for a given container. Reserving the resources ensures that they are always available.
If the resource request is for more than the available free resources in the OpenShift cluster, the pod is not scheduled.
A request may be configured for one or more supported resources.
Resource limits
Limits specify the maximum resources that can be consumed by a given container. The limit is not reserved and might not always be available. A container can use the resources up to the limit only when they are available. Resource limits should be always higher than the resource requests.
A resource may be configured for one or more supported limits.
Supported CPU formats
CPU requests and limits are supported in the following formats:
-
Number of CPU cores as integer (
5CPU core) or decimal (2.5CPU core). -
Number or millicpus / millicores (
100m) where 1000 millicores is the same1CPU core.
The computing power of 1 CPU core may differ depending on the platform where OpenShift is deployed.
For more information on CPU specification, see the Meaning of CPU.
Supported memory formats
Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes.
-
To specify memory in megabytes, use the
Msuffix. For example1000M. -
To specify memory in gigabytes, use the
Gsuffix. For example1G. -
To specify memory in mebibytes, use the
Misuffix. For example1000Mi. -
To specify memory in gibibytes, use the
Gisuffix. For example1Gi.
For more details about memory specification and additional supported units, see Meaning of memory.
3.4.2.10. Kafka Mirror Maker loggers
Kafka Mirror Maker has its own configurable logger:
-
mirrormaker.root.logger
Use the logging property to configure loggers and logger levels.
You can set the log levels by specifying the logger and level directly (inline) or use a custom (external) ConfigMap.
Here we see examples of inline and external logging:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaMirrorMaker
spec:
# ...
logging:
type: inline
loggers:
mirrormaker.root.logger: "INFO"
# ...apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaMirrorMaker
spec:
# ...
logging:
type: external
name: customConfigMap
# ...Additional resources
- Garbage collector (GC) logging can also be enabled (or disabled). For more information on GC, see Section 3.1.17.1, “JVM configuration”
- For more information about log levels, see the log4j manual.
3.4.2.11. Healthchecks
Use the livenessProbe and readinessProbe properties to configure healthcheck probes supported in AMQ Streams.
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, OpenShift assumes that the application is not healthy and attempts to fix it.
For more details about the probes, see Configure Liveness and Readiness Probes.
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
An example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...
For more information about the livenessProbe and readinessProbe options, see Probe schema reference.
3.4.2.12. Prometheus metrics
Use the metrics property to enable and configure Prometheus metrics.
The metrics property can also contain additional configuration for the Prometheus JMX exporter. AMQ Streams supports Prometheus metrics using Prometheus JMX exporter to convert the JMX metrics supported by Apache Kafka and Zookeeper to Prometheus metrics.
To enable Prometheus metrics export without any further configuration, you can set it to an empty object ({}).
When metrics are enabled, they are exposed on port 9404.
When the metrics property is not defined in the resource, the Prometheus metrics are disabled.
For more information about configuring Prometheus and Grafana, see Metrics.
3.4.2.13. JVM Options
Use the jvmOptions property to configure supported options for the JVM on which the component is running.
Supported JVM options help to optimize performance for different platforms and architectures.
For more information on the supported options, see JVM configuration.
3.4.2.14. Container images
Use the image property to configure the container image used by the component.
Overriding container images is recommended only in special situations where you need to use a different container registry or a customized image.
For example, if your network does not allow access to the container repository used by AMQ Streams, you can copy the AMQ Streams images or build them from the source. However, if the configured image is not compatible with AMQ Streams images, it might not work properly.
A copy of the container image might also be customized and used for debugging.
For more information see Container image configurations.
3.4.3. List of resources created as part of Kafka Mirror Maker
The following resources are created by the Cluster Operator in the OpenShift cluster:
- <mirror-maker-name>-mirror-maker
- Deployment which is responsible for creating the Kafka Mirror Maker pods.
- <mirror-maker-name>-config
- ConfigMap which contains ancillary configuration for the the Kafka Mirror Maker, and is mounted as a volume by the Kafka broker pods.
- <mirror-maker-name>-mirror-maker
- Pod Disruption Budget configured for the Kafka Mirror Maker worker nodes.
3.5. Kafka Bridge configuration
The full schema of the KafkaBridge resource is described in the Section C.102, “KafkaBridge schema reference”. All labels that are applied to the desired KafkaBridge resource will also be applied to the OpenShift resources making up the Kafka Bridge cluster. This provides a convenient mechanism for resources to be labeled as required.
3.5.1. Replicas
Kafka Bridge can run multiple nodes. The number of nodes is defined in the KafkaBridge resource. Running a Kafka Bridge with multiple nodes can provide better availability and scalability. However, when running Kafka Bridge on OpenShift it is not absolutely necessary to run multiple nodes of Kafka Bridge for high availability.
If a node where Kafka Bridge is deployed to crashes, OpenShift will automatically reschedule the Kafka Bridge pod to a different node. In order to prevent issues arising when client consumer requests are processed by different Kafka Bridge instances, addressed-based routing must be employed to ensure that requests are routed to the right Kafka Bridge instance. Additionally, each independent Kafka Bridge instance must have a replica. A Kafka Bridge instance has its own state which is not shared with another instances.
3.5.1.1. Configuring the number of nodes
The number of Kafka Bridge nodes is configured using the replicas property in KafkaBridge.spec.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
replicasproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... replicas: 3 # ...Create or update the resource.
oc apply -f your-file
3.5.2. Bootstrap servers
A Kafka Bridge always works in combination with a Kafka cluster. A Kafka cluster is specified as a list of bootstrap servers. On OpenShift, the list must ideally contain the Kafka cluster bootstrap service named cluster-name-kafka-bootstrap, and a port of 9092 for plain traffic or 9093 for encrypted traffic.
The list of bootstrap servers is configured in the bootstrapServers property in KafkaBridge.kafka.spec. The servers must be defined as a comma-separated list specifying one or more Kafka brokers, or a service pointing to Kafka brokers specified as a hostname:_port_ pairs.
When using Kafka Bridge with a Kafka cluster not managed by AMQ Streams, you can specify the bootstrap servers list according to the configuration of the cluster.
3.5.2.1. Configuring bootstrap servers
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
bootstrapServersproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... bootstrapServers: my-cluster-kafka-bootstrap:9092 # ...Create or update the resource.
oc apply -f your-file
3.5.3. Connecting to Kafka brokers using TLS
By default, Kafka Bridge tries to connect to Kafka brokers using a plain text connection. If you prefer to use TLS, additional configuration is required.
3.5.3.1. TLS support for Kafka connection to the Kafka Bridge
TLS support for Kafka connection is configured in the tls property in KafkaBridge.spec.kafka. The tls property contains a list of secrets with key names under which the certificates are stored. The certificates must be stored in X509 format.
An example showing TLS configuration with multiple certificates
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-other-secret
certificate: certificate.crt
# ...When multiple certificates are stored in the same secret, it can be listed multiple times.
An example showing TLS configuration with multiple certificates from the same secret
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
tls:
trustedCertificates:
- secretName: my-secret
certificate: ca.crt
- secretName: my-secret
certificate: ca2.crt
# ...3.5.3.2. Configuring TLS in Kafka Bridge
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretfor the certificate used for TLS Server Authentication, and the key under which the certificate is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the TLS certificate used in authentication in a file and create a
Secret.NoteThe secrets created by the Cluster Operator for Kafka cluster may be used directly.
oc create secret generic my-secret --from-file=my-file.crtEdit the
tlsproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... tls: trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt # ...Create or update the resource.
oc apply -f your-file
3.5.4. Connecting to Kafka brokers with Authentication
By default, Kafka Bridge will try to connect to Kafka brokers without authentication. Authentication is enabled through the KafkaBridge resources.
3.5.4.1. Authentication support in Kafka Bridge
Authentication is configured through the authentication property in KafkaBridge.spec.kafka. The authentication property specifies the type of the authentication mechanisms which should be used and additional configuration details depending on the mechanism. The currently supported authentication types are:
- TLS client authentication
- SASL-based authentication using the SCRAM-SHA-512 mechanism
- SASL-based authentication using the PLAIN mechanism
- OAuth 2.0 token based authentication
3.5.4.1.1. TLS Client Authentication
To use TLS client authentication, set the type property to the value tls. TLS client authentication uses a TLS certificate to authenticate. The certificate is specified in the certificateAndKey property and is always loaded from an OpenShift secret. In the secret, the certificate must be stored in X509 format under two different keys: public and private.
TLS client authentication can be used only with TLS connections. For more details about TLS configuration in Kafka Bridge see Section 3.5.3, “Connecting to Kafka brokers using TLS”.
An example TLS client authentication configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
authentication:
type: tls
certificateAndKey:
secretName: my-secret
certificate: public.crt
key: private.key
# ...3.5.4.1.2. SCRAM-SHA-512 authentication
To configure Kafka Bridge to use SASL-based SCRAM-SHA-512 authentication, set the type property to scram-sha-512. This authentication mechanism requires a username and password.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name of theSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example SASL based SCRAM-SHA-512 client authentication configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
authentication:
type: scram-sha-512
username: my-bridge-user
passwordSecret:
secretName: my-bridge-user
password: my-bridge-password-key
# ...3.5.4.1.3. SASL-based PLAIN authentication
To configure Kafka Bridge to use SASL-based PLAIN authentication, set the type property to plain. This authentication mechanism requires a username and password.
The SASL PLAIN mechanism will transfer the username and password across the network in cleartext. Only use SASL PLAIN authentication if TLS encryption is enabled.
-
Specify the username in the
usernameproperty. -
In the
passwordSecretproperty, specify a link to aSecretcontaining the password. ThesecretNameproperty contains the name theSecretand thepasswordproperty contains the name of the key under which the password is stored inside theSecret.
Do not specify the actual password in the password field.
An example showing SASL based PLAIN client authentication configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
authentication:
type: plain
username: my-bridge-user
passwordSecret:
secretName: my-bridge-user
password: my-bridge-password-key
# ...3.5.4.2. Configuring TLS client authentication in Kafka Bridge
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
-
If they exist, the name of the
Secretwith the public and private keys used for TLS Client Authentication, and the keys under which they are stored in theSecret
Procedure
(Optional) If they do not already exist, prepare the keys used for authentication in a file and create the
Secret.NoteSecrets created by the User Operator may be used.
oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyEdit the
authenticationproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... authentication: type: tls certificateAndKey: secretName: my-secret certificate: my-public.crt key: my-private.key # ...Create or update the resource.
oc apply -f your-file
3.5.4.3. Configuring SCRAM-SHA-512 authentication in Kafka Bridge
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- Username of the user which should be used for authentication
-
If they exist, the name of the
Secretwith the password used for authentication and the key under which the password is stored in theSecret
Procedure
(Optional) If they do not already exist, prepare a file with the password used in authentication and create the
Secret.NoteSecrets created by the User Operator may be used.
echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Edit the
authenticationproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... authentication: type: scram-sha-512 username: _<my-username>_ passwordSecret: secretName: _<my-secret>_ password: _<my-password.txt>_ # ...Create or update the resource.
oc apply -f your-file
3.5.5. Kafka Bridge configuration
AMQ Streams allows you to customize the configuration of Apache Kafka Bridge nodes by editing certain options listed in Apache Kafka configuration documentation for consumers and Apache Kafka configuration documentation for producers.
Configuration options that can be configured relate to:
- Kafka cluster bootstrap address
- Security (Encryption, Authentication, and Authorization)
- Consumer configuration
- Producer configuration
- HTTP configuration
3.5.5.1. Kafka Bridge Consumer configuration
Kafka Bridge consumer is configured using the properties in KafkaBridge.spec.consumer. This property contains the Kafka Bridge consumer configuration options as keys. The values can be one of the following JSON types:
- String
- Number
- Boolean
Users can specify and configure the options listed in the Apache Kafka configuration documentation for consumers with the exception of those options which are managed directly by AMQ Streams. Specifically, all configuration options with keys equal to or starting with one of the following strings are forbidden:
-
ssl. -
sasl. -
security. -
bootstrap.servers -
group.id
When one of the forbidden options is present in the config property, it will be ignored and a warning message will be printed to the Custer Operator log file. All other options will be passed to Kafka
The Cluster Operator does not validate keys or values in the config object provided. When an invalid configuration is provided, the Kafka Bridge cluster might not start or might become unstable. In this circumstance, fix the configuration in the KafkaBridge.spec.consumer.config object, then the Cluster Operator can roll out the new configuration to all Kafka Bridge nodes.
Example Kafka Bridge consumer configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
consumer:
config:
auto.offset.reset: earliest
enable.auto.commit: true
# ...3.5.5.2. Kafka Bridge Producer configuration
Kafka Bridge producer is configured using the properties in KafkaBridge.spec.producer. This property contains the Kafka Bridge producer configuration options as keys. The values can be one of the following JSON types:
- String
- Number
- Boolean
Users can specify and configure the options listed in the Apache Kafka configuration documentation for producers with the exception of those options which are managed directly by AMQ Streams. Specifically, all configuration options with keys equal to or starting with one of the following strings are forbidden:
-
ssl. -
sasl. -
security. -
bootstrap.servers
The Cluster Operator does not validate keys or values in the config object provided. When an invalid configuration is provided, the Kafka Bridge cluster might not start or might become unstable. In this circumstance, fix the configuration in the KafkaBridge.spec.producer.config object, then the Cluster Operator can roll out the new configuration to all Kafka Bridge nodes.
Example Kafka Bridge producer configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
producer:
config:
acks: 1
delivery.timeout.ms: 300000
# ...3.5.5.3. Kafka Bridge HTTP configuration
Kafka Bridge HTTP configuration is set using the properties in KafkaBridge.spec.http. This property contains the Kafka Bridge HTTP configuration options.
-
port
Example Kafka Bridge HTTP configuration
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
http:
port: 8080
# ...3.5.5.4. Configuring Kafka Bridge
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
kafka,http,consumerorproducerproperty in theKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: # ... bootstrapServers: my-cluster-kafka:9092 http: port: 8080 consumer: config: auto.offset.reset: earliest producer: config: delivery.timeout.ms: 300000 # ...Create or update the resource.
oc apply -f your-file
3.5.6. CPU and memory resources
For every deployed container, AMQ Streams allows you to request specific resources and define the maximum consumption of those resources.
AMQ Streams supports two types of resources:
- CPU
- Memory
AMQ Streams uses the OpenShift syntax for specifying CPU and memory resources.
3.5.6.1. Resource limits and requests
Resource limits and requests are configured using the resources property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
Additional resources
- For more information about managing computing resources on OpenShift, see Managing Compute Resources for Containers.
3.5.6.1.1. Resource requests
Requests specify the resources to reserve for a given container. Reserving the resources ensures that they are always available.
If the resource request is for more than the available free resources in the OpenShift cluster, the pod is not scheduled.
Resources requests are specified in the requests property. Resources requests currently supported by AMQ Streams:
-
cpu -
memory
A request may be configured for one or more supported resources.
Example resource request configuration with all resources
# ...
resources:
requests:
cpu: 12
memory: 64Gi
# ...3.5.6.1.2. Resource limits
Limits specify the maximum resources that can be consumed by a given container. The limit is not reserved and might not always be available. A container can use the resources up to the limit only when they are available. Resource limits should be always higher than the resource requests.
Resource limits are specified in the limits property. Resource limits currently supported by AMQ Streams:
-
cpu -
memory
A resource may be configured for one or more supported limits.
Example resource limits configuration
# ...
resources:
limits:
cpu: 12
memory: 64Gi
# ...3.5.6.1.3. Supported CPU formats
CPU requests and limits are supported in the following formats:
-
Number of CPU cores as integer (
5CPU core) or decimal (2.5CPU core). -
Number or millicpus / millicores (
100m) where 1000 millicores is the same1CPU core.
Example CPU units
# ...
resources:
requests:
cpu: 500m
limits:
cpu: 2.5
# ...The computing power of 1 CPU core may differ depending on the platform where OpenShift is deployed.
Additional resources
- For more information on CPU specification, see the Meaning of CPU.
3.5.6.1.4. Supported memory formats
Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes.
-
To specify memory in megabytes, use the
Msuffix. For example1000M. -
To specify memory in gigabytes, use the
Gsuffix. For example1G. -
To specify memory in mebibytes, use the
Misuffix. For example1000Mi. -
To specify memory in gibibytes, use the
Gisuffix. For example1Gi.
An example of using different memory units
# ...
resources:
requests:
memory: 512Mi
limits:
memory: 2Gi
# ...Additional resources
- For more details about memory specification and additional supported units, see Meaning of memory.
3.5.6.2. Configuring resource requests and limits
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
resourcesproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... resources: requests: cpu: "8" memory: 64Gi limits: cpu: "12" memory: 128Gi # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
Additional resources
-
For more information about the schema, see
Resourcesschema reference.
3.5.7. Logging
This section provides information on loggers and how to configure log levels.
You can set the log levels by specifying the loggers and their levels directly (inline) or use a custom (external) config map.
3.5.7.1. Kafka Bridge loggers
Kafka Bridge has configurable loggers for each OpenAPI operation: Loggers are formatted as follows:
log4j.logger.http.openapi.operation.<operation-id>
Where <operation-id> is the identifier of the specific operation. Following is the list of operations defined by the OpenAPI specification:
-
createConsumer -
deleteConsumer -
subscribe -
unsubscribe -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
seek -
healthy -
ready -
openapi
3.5.7.2. Specifying inline logging
Procedure
Edit the YAML file to specify the loggers and logging level for the required components.
For example, the logging level here is set to INFO:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaBridge spec: # ... logging: type: inline loggers: logger.name: "INFO" # ...You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF.
For more information about the log levels, see the log4j manual.
Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
3.5.7.3. Specifying an external ConfigMap for logging
Procedure
Edit the YAML file to specify the name of the
ConfigMapto use for the required components. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaBridge spec: # ... logging: type: external name: customConfigMap # ...Remember to place your custom ConfigMap under the
log4j.propertiesorlog4j2.propertieskey.Create or update the Kafka resource in OpenShift.
This can be done using
oc apply:oc apply -f your-file
Garbage collector (GC) logging can also be enabled (or disabled). For more information on GC, see Section 3.1.17.1, “JVM configuration”
3.5.8. JVM Options
The following components of AMQ Streams run inside a Virtual Machine (VM):
- Apache Kafka
- Apache Zookeeper
- Apache Kafka Connect
- Apache Kafka Mirror Maker
- AMQ Streams Kafka Bridge
JVM configuration options optimize the performance for different platforms and architectures. AMQ Streams allows you to configure some of these options.
3.5.8.1. JVM configuration
JVM options can be configured using the jvmOptions property in following resources:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Only a selected subset of available JVM options can be configured. The following options are supported:
-Xms and -Xmx
-Xms configures the minimum initial allocation heap size when the JVM starts. -Xmx configures the maximum heap size.
The units accepted by JVM settings such as -Xmx and -Xms are those accepted by the JDK java binary in the corresponding image. Accordingly, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit suffix. This is in contrast to the units used for memory requests and limits, which follow the OpenShift convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes
The default values used for -Xms and -Xmx depends on whether there is a memory request limit configured for the container:
- If there is a memory limit then the JVM’s minimum and maximum memory will be set to a value corresponding to the limit.
-
If there is no memory limit then the JVM’s minimum memory will be set to
128Mand the JVM’s maximum memory will not be defined. This allows for the JVM’s memory to grow as-needed, which is ideal for single node environments in test and development.
Setting -Xmx explicitly requires some care:
-
The JVM’s overall memory usage will be approximately 4 × the maximum heap, as configured by
-Xmx. -
If
-Xmxis set without also setting an appropriate OpenShift memory limit, it is possible that the container will be killed should the OpenShift node experience memory pressure (from other Pods running on it). -
If
-Xmxis set without also setting an appropriate OpenShift memory request, it is possible that the container will be scheduled to a node with insufficient memory. In this case, the container will not start but crash (immediately if-Xmsis set to-Xmx, or some later time if not).
When setting -Xmx explicitly, it is recommended to:
- set the memory request and the memory limit to the same value,
-
use a memory request that is at least 4.5 × the
-Xmx, -
consider setting
-Xmsto the same value as-Xmx.
Containers doing lots of disk I/O (such as Kafka broker containers) will need to leave some memory available for use as operating system page cache. On such containers, the requested memory should be significantly higher than the memory used by the JVM.
Example fragment configuring -Xmx and -Xms
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...In the above example, the JVM will use 2 GiB (=2,147,483,648 bytes) for its heap. Its total memory usage will be approximately 8GiB.
Setting the same value for initial (-Xms) and maximum (-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed. For Kafka and Zookeeper pods such allocation could cause unwanted latency. For Kafka Connect avoiding over allocation may be the most important concern, especially in distributed mode where the effects of over-allocation will be multiplied by the number of consumers.
-server
-server enables the server JVM. This option can be set to true or false.
Example fragment configuring -server
# ...
jvmOptions:
"-server": true
# ...
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
-XX
-XX object can be used for configuring advanced runtime options of a JVM. The -server and -XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Example showing the use of the -XX object
jvmOptions:
"-XX":
"UseG1GC": true
"MaxGCPauseMillis": 20
"InitiatingHeapOccupancyPercent": 35
"ExplicitGCInvokesConcurrent": true
"UseParNewGC": falseThe example configuration above will result in the following JVM options:
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
When neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
3.5.8.1.1. Garbage collector logging
The jvmOptions section also allows you to enable and disable garbage collector (GC) logging. GC logging is enabled by default. To disable it, set the gcLoggingEnabled property as follows:
Example of disabling GC logging
# ...
jvmOptions:
gcLoggingEnabled: false
# ...3.5.8.2. Configuring JVM options
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
jvmOptionsproperty in theKafka,KafkaConnect,KafkaConnectS2I,KafkaMirrorMaker, orKafkaBridgeresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... jvmOptions: "-Xmx": "8g" "-Xms": "8g" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.9. Healthchecks
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, OpenShift assumes that the application is not healthy and attempts to fix it.
OpenShift supports two types of Healthcheck probes:
- Liveness probes
- Readiness probes
For more details about the probes, see Configure Liveness and Readiness Probes. Both types of probes are used in AMQ Streams components.
Users can configure selected options for liveness and readiness probes.
3.5.9.1. Healthcheck configurations
Liveness and readiness probes can be configured using the livenessProbe and readinessProbe properties in following resources:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
For more information about the livenessProbe and readinessProbe options, see Section C.34, “Probe schema reference”.
An example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...3.5.9.2. Configuring healthchecks
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
livenessProbeorreadinessProbeproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.10. Container images
AMQ Streams allows you to configure container images which will be used for its components. Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such a case, you should either copy the AMQ Streams images or build them from the source. If the configured image is not compatible with AMQ Streams images, it might not work properly.
3.5.10.1. Container image configurations
Container image which should be used for given components can be specified using the image property in:
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.5.10.1.1. Configuring the Kafka.spec.kafka.image property
The Kafka.spec.kafka.image property functions differently from the others, because AMQ Streams supports multiple versions of Kafka, each requiring the own image. The STRIMZI_KAFKA_IMAGES environment variable of the Cluster Operator configuration is used to provide a mapping between Kafka versions and the corresponding images. This is used in combination with the Kafka.spec.kafka.image and Kafka.spec.kafka.version properties as follows:
-
If neither
Kafka.spec.kafka.imagenorKafka.spec.kafka.versionare given in the custom resource then theversionwill default to the Cluster Operator’s default Kafka version, and the image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
If
Kafka.spec.kafka.imageis given butKafka.spec.kafka.versionis not then the given image will be used and theversionwill be assumed to be the Cluster Operator’s default Kafka version. -
If
Kafka.spec.kafka.versionis given butKafka.spec.kafka.imageis not then image will be the one corresponding to this version in theSTRIMZI_KAFKA_IMAGES. -
Both
Kafka.spec.kafka.versionandKafka.spec.kafka.imageare given the given image will be used, and it will be assumed to contain a Kafka broker with the given version.
It is best to provide just Kafka.spec.kafka.version and leave the Kafka.spec.kafka.image property unspecified. This reduces the chances of making a mistake in configuring the Kafka resource. If you need to change the images used for different versions of Kafka, it is better to configure the Cluster Operator’s STRIMZI_KAFKA_IMAGES environment variable.
3.5.10.1.2. Configuring the image property in other resources
For the image property in the other custom resources, the given value will be used during deployment. If the image property is missing, the image specified in the Cluster Operator configuration will be used. If the image name is not defined in the Cluster Operator configuration, then the default value will be used.
For Kafka broker TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper nodes:
-
Container image specified in the
STRIMZI_DEFAULT_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Zookeeper node TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Topic Operator:
-
Container image specified in the
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For User Operator:
-
Container image specified in the
STRIMZI_DEFAULT_USER_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-operator:1.3.0container image.
-
Container image specified in the
For Entity Operator TLS sidecar:
-
Container image specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
For Kafka Connect with Source2image support:
-
Container image specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGEenvironment variable from the Cluster Operator configuration. -
registry.redhat.io/amq7/amq-streams-kafka-23:1.3.0container image.
-
Container image specified in the
Overriding container images is recommended only in special situations, where you need to use a different container registry. For example, because your network does not allow access to the container repository used by AMQ Streams. In such case, you should either copy the AMQ Streams images or build them from source. In case the configured image is not compatible with AMQ Streams images, it might not work properly.
Example of container image configuration
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...
zookeeper:
# ...3.5.10.2. Configuring container images
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
imageproperty in theKafka,KafkaConnectorKafkaConnectS2Iresource. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... image: my-org/my-image:latest # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.11. Configuring pod scheduling
When two applications are scheduled to the same OpenShift node, both applications might use the same resources like disk I/O and impact performance. That can lead to performance degradation. Scheduling Kafka pods in a way that avoids sharing nodes with other critical workloads, using the right nodes or dedicated a set of nodes only for Kafka are the best ways how to avoid such problems.
3.5.11.1. Scheduling pods based on other applications
3.5.11.1.1. Avoid critical applications to share the node
Pod anti-affinity can be used to ensure that critical applications are never scheduled on the same disk. When running Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share the nodes with other workloads like databases.
3.5.11.1.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.5.11.1.3. Configuring pod anti-affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.11.2. Scheduling pods to specific nodes
3.5.11.2.1. Node scheduling
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of AMQ Streams components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
3.5.11.2.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.5.11.2.3. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where AMQ Streams components should be scheduled.
This can be done using
oc label:oc label node your-node node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.11.3. Using dedicated nodes
3.5.11.3.1. Dedicated nodes
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Taints can be used to create dedicated nodes. Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
To schedule Kafka pods on the dedicated nodes, configure node affinity and tolerations.
3.5.11.3.2. Affinity
Affinity can be configured using the affinity property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
The format of the affinity property follows the OpenShift specification. For more details, see the Kubernetes node and pod affinity documentation.
3.5.11.3.3. Tolerations
Tolerations can be configured using the tolerations property in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
The format of the tolerations property follows the OpenShift specification. For more details, see the Kubernetes taints and tolerations.
3.5.11.3.4. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node your-node dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node your-node dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f your-file
3.5.12. List of resources created as part of Kafka Bridge cluster
The following resources are created by the Cluster Operator in the OpenShift cluster:
- bridge-cluster-name-bridge
- Deployment which is in charge to create the Kafka Bridge worker node pods.
- bridge-cluster-name-bridge-service
- Service which exposes the REST interface of the Kafka Bridge cluster.
- bridge-cluster-name-bridge-config
- ConfigMap which contains the Kafka Bridge ancillary configuration and is mounted as a volume by the Kafka broker pods.
- bridge-cluster-name-bridge
- Pod Disruption Budget configured for the Kafka Bridge worker nodes.
3.6. Using OAuth 2.0 token based authentication
AMQ Streams supports the use of OAuth 2.0 authentication using the SASL OAUTHBEARER mechanism.
OAuth 2.0 enables standardized token based authentication and authorization between applications, using a central authorization server to issue tokens that grant limited access to resources.
OAuth 2.0 is currently only supported for authentication, with no authorization support. However, OAuth 2.0 authentication can be used in conjunction with ACL-based Kafka authorization.
Using OAuth 2.0 token based authentication, application clients can access resources on application servers (called ‘resource servers’) without exposing account credentials. The client passes an access token as a means of authenticating, which application servers can also use to find more information about the level of access granted. The authorization server handles the granting of access and inquiries about access.
In the context of AMQ Streams:
- Kafka brokers act as resource servers
- Kafka clients act as resource clients
The brokers and clients communicate with the OAuth 2.0 authorization server, as necessary, to obtain or validate access tokens.
For a deployment of AMQ Streams, OAuth 2.0 integration provides:
- Server-side OAuth 2.0 support for Kafka brokers
- Client-side OAuth 2.0 support for Kafka Mirror Maker, Kafka Connect and the Kafka Bridge
Additional resources
3.6.1. OAuth 2.0 authentication mechanism
Support for OAuth 2.0 is based on the Kafka SASL OAUTHBEARER mechanism, which is used to establish authenticated sessions with a Kafka broker.
A Kafka client initiates a session with the Kafka broker using the SASL OAUTHBEARER mechanism for credentials exchange, where credentials take the form of an access token.
Kafka brokers and clients need to be configured to use OAuth 2.0.
Kafka broker configuration
The Kafka broker must be configured to validate the token received during session initiation. The recommended approach is to create a client definition in an authorization server with:
-
Client ID of
kafka-broker - Client ID and secret as the authentication mechanism
Kafka client configuration
A Kafka client is configured with either:
- Credentials required to obtain a valid access token from an authorization server
- A valid long-lived access token, obtained using tools provided by an authorization server
Credentials are never sent to the Kafka broker. The only information ever sent to the Kafka broker is an access token. When a client obtains an access token, no further communication with the authorization server is needed.
The simplest mechanism, which requires no additional usage of authorization server tools, is authentication with a client ID and secret. Using a long-lived access token, or a long-lived refresh token, is more complex.
If you are using long-lived access tokens, you can set policy in the authorization server to increase the maximum lifetime of the token.
If the Kafka client is not configured with an access token directly, the client exchanges credentials for an access token during Kafka session initiation by contacting the authorization server. The Kafka client uses one of two mechanisms:
- Client id and secret
- Client id, refresh token, and (optionally) a secret
3.6.2. OAuth 2.0 client authentication flow
In this section, we explain and visualize the communication flow between Kafka client, Kafka broker, and authorization server during Kafka session initiation. The flow depends on the client and server configuration.
When a Kafka client sends an access token as credentials to a Kafka broker, the token needs to be validated.
Depending on the authorization server used, and the configuration options available, you may prefer to use:
- Fast local token validation based on JWT signature checking and local token introspection, without contacting the authorization server
- An OAuth 2.0 introspection endpoint provided by the authorization server
Using fast local token validation requires the authorization server to provide a JWKS endpoint with public certificates that are used to validate signatures on the tokens.
An authorization server might only allow the use of opaque access tokens, which means that local token validation is not possible.
Another option is to use an OAuth 2.0 introspection endpoint on the authorization server. Each time a Kafka broker connection is established, the broker sends the access token it receives to the authorization server, and a response confirming whether or not the token is valid is returned.
Kafka client credentials can also be configured for:
- Direct local access using a previously generated long-lived access token
- Contact with the authorization server for a new access token to be issued and sent to the Kafka broker
3.6.2.1. Example client authentication flows
Here you can see the communication flows, for different configurations of Kafka clients and brokers, during Kafka session authentication.
- Client using client ID and secret, with broker delegating validation to authorization server
- Client using client ID and secret, with broker performing fast local token validation
- Client using long-lived access token, with broker delegating validation to authorization server
- Client using long-lived access token, with broker performing fast local validation
Client using client ID and secret, with broker delegating validation to authorization server
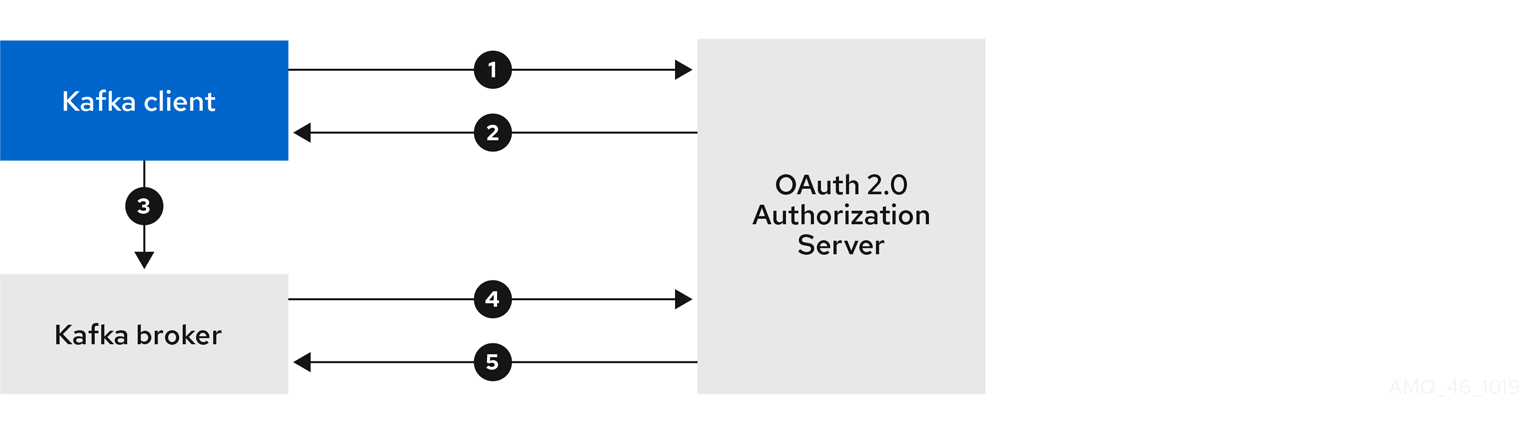
- Kafka client requests access token from authorization server, using client ID and secret, and optionally a refresh token.
- Authorization server generates a new access token.
- Kafka client authenticates with the Kafka broker using the SASL OAUTHBEARER mechanism to pass the access token.
- Kafka broker validates the access token by calling a token introspection endpoint on authorization server, using its own client ID and secret.
- Kafka client session is established if the token is valid.
Client using client ID and secret, with broker performing fast local token validation
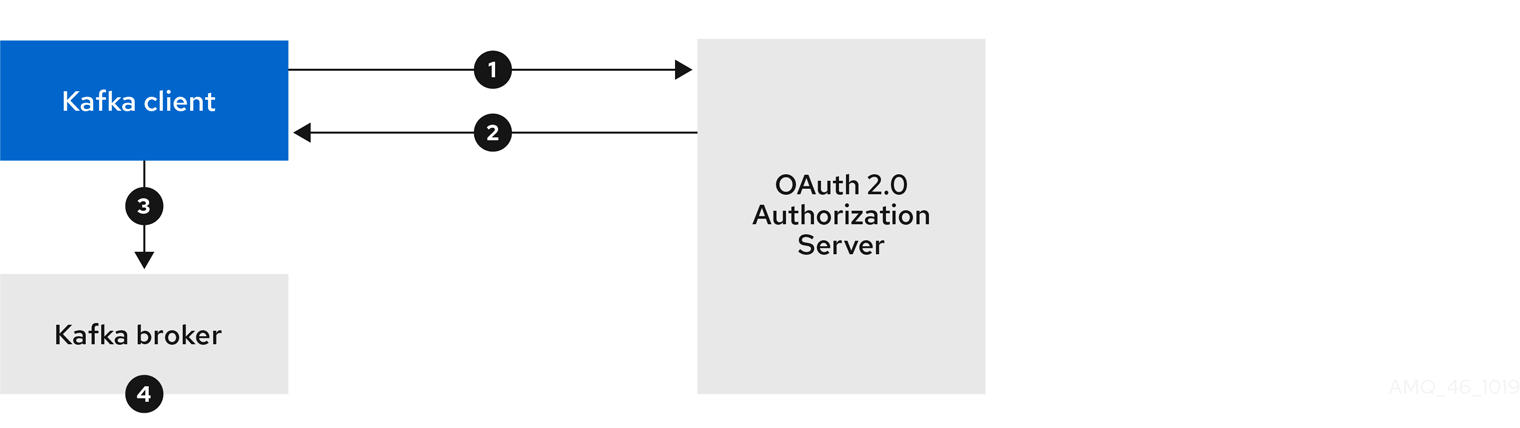
- Kafka client authenticates with authorization server from the token endpoint, using a client ID and secret, and optionally a refresh token.
- Authorization server generates a new access token.
- Kafka client authenticates with the Kafka broker using the SASL OAUTHBEARER mechanism to pass the access token.
- Kafka broker validates the access token locally using a JWT token signature check, and local token introspection.
Client using long-lived access token, with broker delegating validation to authorization server
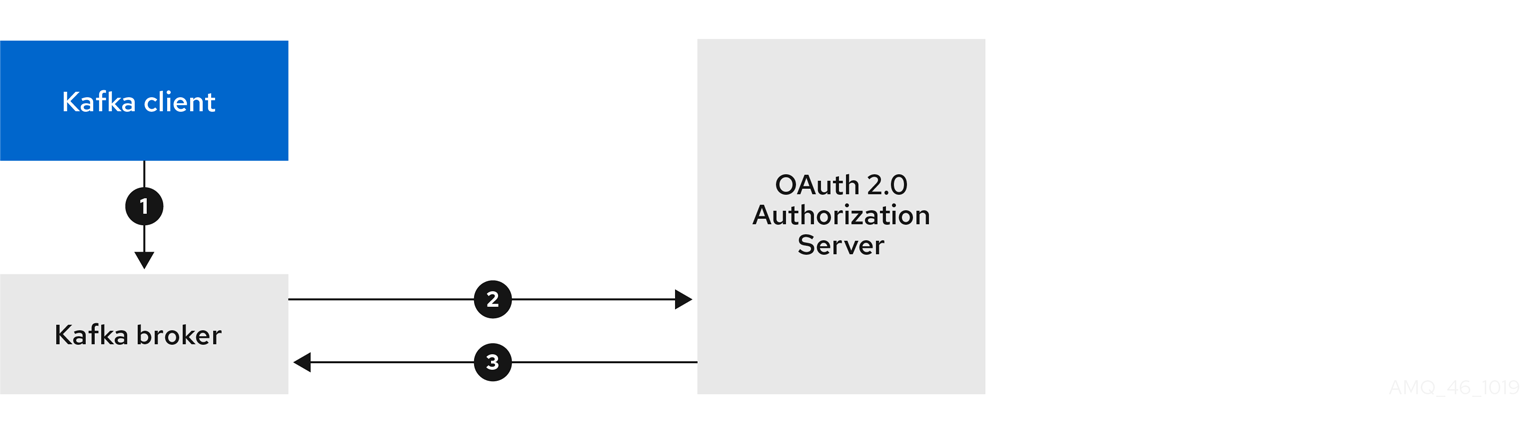
- Kafka client authenticates with the Kafka broker using the SASL OAUTHBEARER mechanism to pass the long-lived access token.
- Kafka broker validates the access token by calling a token introspection endpoint on authorization server, using its own client ID and secret.
- Kafka client session is established if the token is valid.
Client using long-lived access token, with broker performing fast local validation

- Kafka client authenticates with the Kafka broker using the SASL OAUTHBEARER mechanism to pass the long-lived access token.
- Kafka broker validates the access token locally using JWT token signature check, and local token introspection.
Fast local JWT token signature validation is suitable only for short-lived tokens as there is no check with the authorization server if a token has been revoked. Token expiration is written into the token, but revocation can happen at any time, so cannot be accounted for without contacting the authorization server. Any issued token would be considered valid until it expires.
3.6.3. Configuring OAuth 2.0 authentication
OAuth 2.0 is used for interaction between Kafka clients and AMQ Streams components.
In order to use OAuth 2.0 for AMQ Streams, you must:
3.6.3.1. Configuring Red Hat Single Sign-On as an OAuth 2.0 authorization server
This procedure describes how to deploy Red Hat Single Sign-On as an authorization server and configure it for integration with AMQ Streams.
The authorization server provides a central point for authentication and authorization, and management of users, clients, and permissions. Red Hat Single Sign-On has a concept of realms where a realm represents a separate set of users, clients, permissions, and other configuration. You can use a default master realm, or create a new one. Each realm exposes its own OAuth 2.0 endpoints, which means that application clients and application servers all need to use the same realm.
To use OAuth 2.0 with AMQ Streams, you use a deployment of Red Hat Single Sign-On to create and manage authentication realms.
If you already have Red Hat Single Sign-On deployed, you can skip the deployment step and use your current deployment.
Before you begin
You will need to be familiar with using Red Hat Single Sign-On.
For deployment and administration instructions, see:
Prerequisites
- AMQ Streams and Kafka is running
For the Red Hat Single Sign-On deployment:
- Check the Red Hat Single Sign-On Supported Configurations
- Installation requires a user with a cluster-admin role, such as system:admin
Procedure
Deploy Red Hat Single Sign-On to your OpenShift cluster.
Check the progress of the deployment in your OpenShift web console.
Log in to the Red Hat Single Sign-On Admin Console to create the OAuth 2.0 policies for AMQ Streams.
Login details are provided when you deploy Red Hat Single Sign-On.
Create and enable a realm.
You can use an existing master realm.
- Adjust the session and token timeouts for the realm, if required.
-
Create a client called
kafka-broker. From the tab, set:
-
Access Type to
Confidential -
Standard Flow Enabled to
OFFto disable web login for this client -
Service Accounts Enabled to
ONto allow this client to authenticate in its own name
-
Access Type to
- Click Save before continuing.
- From the tab, take a note of the secret for using in your AMQ Streams Kafka cluster configuration.
Repeat the client creation steps for any application client that will connect to your Kafka brokers.
Create a definition for each new client.
You will use the names as client IDs in your configuration.
What to do next
After deploying and configuring the authorization server, configure the Kafka brokers to use OAuth 2.0.
3.6.3.2. Configuring OAuth 2.0 support for Kafka brokers
This procedure describes how to configure Kafka brokers so that the broker listeners are enabled to use OAuth 2.0 authentication using an authorization server.
If the authorization server is using certificates signed by the trusted CA and matching the OAuth 2.0 server hostname, TLS connection works using the default settings. Otherwise, you have two connection options for your external listener configuration when delegating token validation to the authorization server:
- TLS connection to the authorization server with trusted certificates
- Direct connection using an introspection endpoint configuration
Both options are described in this procedure.
Before you start
For more information on the configuration and authentication of Kafka broker listeners, see:
Prerequisites
- AMQ Streams and Kafka are running
- An OAuth 2.0 authorization server is deployed
Procedure
Update the Kafka broker configuration (
Kafka.spec.kafka) of yourKafkaresource in an editor.oc edit kafka my-clusterConfigure the Kafka broker
listenersconfiguration.The configuration for each type of listener does not have to be the same, as they are independent.
For example:
#... authentication: type: oauth1 validIssuerUri: <https://<authorization-server-address>/auth/realms/master>2 jwksEndpointUri: <https://<authorization-server-address>/auth/realms/master/protocol/openid-connect/certs>3 userNameClaim: preferred_username4 #external configuration external: type: loadbalancer //Option 1 authentication:5 type: oauth validIssuerUri: <https://<authorization-server-address>/auth/realms/external> jwksEndpointUri: <https://<authorization-server-address>/auth/realms/external/protocol/openid-connect/certs> userNameClaim: preferred_username tlsTrustedCertificates:6 - secretName: oauth-server-cert certificate: ca.crt disableTlsHostnameVerification: true7 //Option 2 authentication:8 type: oauth validIssuerUri: <https://<authorization-server-address>/auth/realms/external> introspectionEndpointUri: <https://<authorization-server-address>/auth/realms/external/protocol/openid-connect/token/introspect> clientId: kafka-broker clientSecret: secretName: my-cluster-oauth key: clientSecret- 1
- Listener type set to
oauth. - 2
- URI of the token issuer used for authentication.
- 3
- URI of the JWKS certificate endpoint used for local JWT validation.
- 4
- The user name profile claim (or key) that contains the actual user name in the token. The user name is the principal used to identify the user. The
userNameClaimvalue will depend on the authentication flow and the authorization server used. - 5
- OPTION 1: TLS connection to the authorization server.
- 6
- (Optional) Trusted certificates for TLS connection to the authorization server.
- 7
- Enable TLS hostname verification. Default is
false. - 8
- OPTION 2: Introspection endpoint to connect directly to the authorization server.
- Save and exit the editor, then wait for rolling updates to complete.
Check the update in the logs or by watching the pod state transitions:
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get po -wThe rolling update configures the brokers to use OAuth 2.0 authentication.
What to do next
3.6.3.3. Configuring Kafka Java clients to use OAuth 2.0
This procedure describes how to configure Kafka producer and consumer APIs to use OAuth 2.0 for interaction with Kafka brokers.
Add a client callback plugin to your pom.xml file, and configure the system properties.
Prerequisites
- AMQ Streams and Kafka are running
- An OAuth 2.0 authorization server is deployed and configured for OAuth access to Kafka brokers
- Kafka brokers are configured for OAuth 2.0
Procedure
Add the client library with OAuth 2.0 support to the
pom.xmlfile for the Kafka client:<dependency> <groupId>io.strimzi</groupId> <artifactId>kafka-oauth-client</artifactId> <version>0.1.0.redhat-00002</version> </dependency>Configure the system properties for the callback:
For example:
System.setProperty(ClientConfig.OAUTH_TOKEN_ENDPOINT_URI, “https://<authorization-server-address>/auth/realms/master/protocol/openid-connect/token”);1 System.setProperty(ClientConfig.OAUTH_CLIENT_ID, "<client-name>");2 System.setProperty(ClientConfig.OAUTH_CLIENT_SECRET, "<client-secret>");3 Enable the SASL OAUTHBEARER mechanism on a TLS encrypted connection in the Kafka client configuration:
For example:
props.put("sasl.jaas.config", "org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required;"); props.put("security.protocol", "SASL_SSL");1 props.put("sasl.mechanism", "OAUTHBEARER"); props.put("sasl.login.callback.handler.class", "io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler");- 1
- Here we use
SASL_SSLfor use over TLS connections. UseSASL_PLAINTEXTover unencrypted connections.
- Verify that the Kafka client can access the Kafka brokers.
What to do next
3.6.3.4. Configuring OAuth for Kafka components
This procedure describes how to configure Kafka components to use OAuth 2.0 authentication using an authorization server.
You can configure authentication for:
- Kafka Connect
- Kafka Mirror Maker
- Kafka Bridge
In this scenario, the Kafka component and the authorization server are running in the same cluster.
Prerequisites
- AMQ Streams and Kafka are running
- An OAuth 2.0 authorization server is deployed and configured for OAuth access to Kafka brokers
- Kafka brokers are configured for OAuth 2.0
Procedure
Create a client secret and mount it to the component as an environment variable.
For example, here we are creating a client
Secretfor the Kafka Bridge:apiVersion: kafka.strimzi.io/v1beta1 kind: Secret metadata: name: my-bridge-oauth type: Opaque data: clientSecret: MGQ1OTRmMzYtZTllZS00MDY2LWI5OGEtMTM5MzM2NjdlZjQw1 - 1
- The
clientSecretkey must be in base64 format.
Create or edit the resource for the Kafka component so that OAuth 2.0 authentication is configured for the authentication property.
For example, here OAuth 2.0 is assigned to the Kafka Bridge client:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaBridge metadata: name: my-bridge spec: # ... authentication: type: oauth1 tokenEndpointUri: https://<authorization-server-address>/auth/realms/master/protocol/openid-connect/token2 clientId: kafka-bridge clientSecret: secretName: my-bridge-oauth key: clientSecret tlsTrustedCertificates:3 - secretName: oauth-server-cert certificate: tls.crtApply the changes to the deployment of your Kafka resource.
oc apply -f your-fileCheck the update in the logs or by watching the pod state transitions:
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get pod -wThe rolling updates configure the component for interaction with Kafka brokers using OAuth 2.0 authentication.
3.7. Customizing deployments
AMQ Streams creates several OpenShift resources, such as Deployments, StatefulSets, Pods, and Services, which are managed by OpenShift operators. Only the operator that is responsible for managing a particular OpenShift resource can change that resource. If you try to manually change an operator-managed OpenShift resource, the operator will revert your changes back.
However, changing an operator-managed OpenShift resource can be useful if you want to perform certain tasks, such as:
-
Adding custom labels or annotations that control how
Podsare treated by Istio or other services; -
Managing how
Loadbalancer-type Services are created by the cluster.
You can make these types of changes using the template property in the AMQ Streams custom resources.
3.7.1. Template properties
You can use the template property to configure aspects of the resource creation process. You can include it in the following resources and properties:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator -
Kafka.spec.kafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMakerSpec -
KafkaBridge.spec
In the following example, the template property is used to modify the labels in a Kafka broker’s StatefulSet:
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
labels:
app: my-cluster
spec:
kafka:
# ...
template:
statefulset:
metadata:
labels:
mylabel: myvalue
# ...3.7.1.1. Supported template properties for a Kafka cluster
statefulset-
Configures the
StatefulSetused by the Kafka broker. pod-
Configures the Kafka broker
Podscreated by theStatefulSet. bootstrapService- Configures the bootstrap service used by clients running within OpenShift to connect to the Kafka broker.
brokersService- Configures the headless service.
externalBootstrapService- Configures the bootstrap service used by clients connecting to Kafka brokers from outside of OpenShift.
perPodService- Configures the per-Pod services used by clients connecting to the Kafka broker from outside OpenShift to access individual brokers.
externalBootstrapRoute-
Configures the bootstrap route used by clients connecting to the Kafka brokers from outside of OpenShift using OpenShift
Routes. perPodRoute-
Configures the per-Pod routes used by clients connecting to the Kafka broker from outside OpenShift to access individual brokers using OpenShift
Routes. podDisruptionBudget-
Configures the Pod Disruption Budget for Kafka broker
StatefulSet. kafkaContainer- Configures the container used to run the Kafka broker, including custom environment variables.
tlsSidecarContainer- Configures the TLS sidecar container, including custom environment variables.
initContainer- Configures the container used to initialize the brokers.
persistentVolumeClaim-
Configures the metadata of the Kafka
PersistentVolumeClaims.
Additional resources
3.7.1.2. Supported template properties for a Zookeeper cluster
statefulset-
Configures the Zookeeper
StatefulSet. pod-
Configures the Zookeeper
Podscreated by theStatefulSet. clientsService- Configures the service used by clients to access Zookeeper.
nodesService- Configures the headless service.
podDisruptionBudget-
Configures the Pod Disruption Budget for Zookeeper
StatefulSet. zookeeperContainer- Configures the container used to run the Zookeeper Node, including custom environment variables.
tlsSidecarContainer- Configures the TLS sidecar container, including custom environment variables.
persistentVolumeClaim-
Configures the metadata of the Zookeeper
PersistentVolumeClaims.
Additional resources
3.7.1.3. Supported template properties for Entity Operator
deployment- Configures the Deployment used by the Entity Operator.
pod-
Configures the Entity Operator
Podcreated by theDeployment. topicOperatorContainer- Configures the container used to run the Topic Operator, including custom environment variables.
userOperatorContainer- Configures the container used to run the User Operator, including custom environment variables.
tlsSidecarContainer- Configures the TLS sidecar container, including custom environment variables.
Additional resources
3.7.1.4. Supported template properties for Kafka Exporter
deployment- Configures the Deployment used by Kafka Exporter.
pod-
Configures the Kafka Exporter
Podcreated by theDeployment. services- Configures the Kafka Exporter services.
container- Configures the container used to run Kafka Exporter, including custom environment variables.
Additional resources
3.7.1.5. Supported template properties for Kafka Connect and Kafka Connect with Source2Image support
deployment-
Configures the Kafka Connect
Deployment. pod-
Configures the Kafka Connect
Podscreated by theDeployment. apiService- Configures the service used by the Kafka Connect REST API.
podDisruptionBudget-
Configures the Pod Disruption Budget for Kafka Connect
Deployment. connectContainer- Configures the container used to run Kafka Connect, including custom environment variables.
Additional resources
3.7.1.6. Supported template properties for Kafka Mirror Maker
deployment-
Configures the Kafka Mirror Maker
Deployment. pod-
Configures the Kafka Mirror Maker
Podscreated by theDeployment. podDisruptionBudget-
Configures the Pod Disruption Budget for Kafka Mirror Maker
Deployment. mirrorMakerContainer- Configures the container used to run Kafka Mirror Maker, including custom environment variables.
Additional resources
3.7.2. Labels and Annotations
For every resource, you can configure additional Labels and Annotations. Labels and Annotations are used to identify and organize resources, and are configured in the metadata property.
For example:
# ...
template:
statefulset:
metadata:
labels:
label1: value1
label2: value2
annotations:
annotation1: value1
annotation2: value2
# ...
The labels and annotations fields can contain any labels or annotations that do not contain the reserved string strimzi.io. Labels and annotations containing strimzi.io are used internally by AMQ Streams and cannot be configured.
The metadata property is not applicable to container templates, such as the kafkaContainer.
3.7.3. Customizing Pods
In addition to Labels and Annotations, you can customize some other fields on Pods. These fields are described in the following table and affect how the Pod is created.
| Field | Description |
|---|---|
|
|
Defines the period of time, in seconds, by which the Pod must have terminated gracefully. After the grace period, the Pod and its containers are forcefully terminated (killed). The default value is NOTE: You might need to increase the grace period for very large Kafka clusters, so that the Kafka brokers have enough time to transfer their work to another broker before they are terminated. |
|
| Defines a list of references to OpenShift Secrets that can be used for pulling container images from private repositories. For more information about how to create a Secret with the credentials, see Pull an Image from a Private Registry.
NOTE: When the |
|
| Configures pod-level security attributes for containers running as part of a given Pod. For more information about configuring SecurityContext, see Configure a Security Context for a Pod or Container. |
|
| Configures the name of the Priority Class which will be used for given a Pod. For more information about Priority Classes, see Pod Priority and Preemption. |
These fields are effective on each type of cluster (Kafka and Zookeeper; Kafka Connect and Kafka Connect with S2I support; and Kafka Mirror Maker).
The following example shows these customized fields on a template property:
# ...
template:
pod:
metadata:
labels:
label1: value1
imagePullSecrets:
- name: my-docker-credentials
securityContext:
runAsUser: 1000001
fsGroup: 0
terminationGracePeriodSeconds: 120
# ...Additional resources
-
For more information, see Section C.43, “
PodTemplateschema reference”.
3.7.4. Customizing containers with environment variables
You can set custom environment variables for a container by using the relevant template container property. The following table lists the AMQ Streams containers and the relevant template configuration property (defined under spec) for each custom resource.
| AMQ Streams Element | Container | Configuration property |
|---|---|---|
| Kafka | Kafka Broker |
|
| Kafka | Kafka Broker TLS Sidecar |
|
| Kafka | Kafka Initialization |
|
| Kafka | Zookeeper Node |
|
| Kafka | Zookeeper TLS Sidecar |
|
| Kafka | Topic Operator |
|
| Kafka | User Operator |
|
| Kafka | Entity Operator TLS Sidecar |
|
| KafkaConnect | Connect and ConnectS2I |
|
| KafkaMirrorMaker | Mirror Maker |
|
| KafkaBridge | Bridge |
|
The environment variables are defined under the env property as a list of objects with name and value fields. The following example shows two custom environment variables set for the Kafka broker containers:
# ...
kind: Kafka
spec:
kafka:
template:
kafkaContainer:
env:
- name: TEST_ENV_1
value: test.env.one
- name: TEST_ENV_2
value: test.env.two
# ...
Environment variables prefixed with KAFKA_ are internal to AMQ Streams and should be avoided. If you set a custom environment variable that is already in use by AMQ Streams, it is ignored and a warning is recorded in the log.
Additional resources
-
For more information, see Section C.45, “
ContainerTemplateschema reference”.
3.7.5. Customizing the image pull policy
AMQ Streams allows you to customize the image pull policy for containers in all pods deployed by the Cluster Operator. The image pull policy is configured using the environment variable STRIMZI_IMAGE_PULL_POLICY in the Cluster Operator deployment. The STRIMZI_IMAGE_PULL_POLICY environment variable can be set to three different values:
Always- Container images are pulled from the registry every time the pod is started or restarted.
IfNotPresent- Container images are pulled from the registry only when they were not pulled before.
Never- Container images are never pulled from the registry.
The image pull policy can be currently customized only for all Kafka, Kafka Connect, and Kafka Mirror Maker clusters at once. Changing the policy will result in a rolling update of all your Kafka, Kafka Connect, and Kafka Mirror Maker clusters.
Additional resources
- For more information about Cluster Operator configuration, see Section 4.1, “Cluster Operator”.
- For more information about Image Pull Policies, see Disruptions.
3.7.6. Customizing Pod Disruption Budgets
AMQ Streams creates a pod disruption budget for every new StatefulSet or Deployment. By default, these pod disruption budgets only allow a single pod to be unavailable at a given time by setting the maxUnavailable value in the`PodDisruptionBudget.spec` resource to 1. You can change the amount of unavailable pods allowed by changing the default value of maxUnavailable in the pod disruption budget template. This template applies to each type of cluster (Kafka and Zookeeper; Kafka Connect and Kafka Connect with S2I support; and Kafka Mirror Maker).
The following example shows customized podDisruptionBudget fields on a template property:
# ...
template:
podDisruptionBudget:
metadata:
labels:
key1: label1
key2: label2
annotations:
key1: label1
key2: label2
maxUnavailable: 1
# ...Additional resources
-
For more information, see Section C.44, “
PodDisruptionBudgetTemplateschema reference”. - The Disruptions chapter of the OpenShift documentation.
3.7.7. Customizing deployments
This procedure describes how to customize Labels of a Kafka cluster.
Prerequisites
- An OpenShift cluster.
- A running Cluster Operator.
Procedure
Edit the
templateproperty in theKafka,KafkaConnect,KafkaConnectS2I, orKafkaMirrorMakerresource. For example, to modify the labels for the Kafka brokerStatefulSet, use:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster labels: app: my-cluster spec: kafka: # ... template: statefulset: metadata: labels: mylabel: myvalue # ...Create or update the resource.
Use
oc apply:oc apply -f your-fileAlternatively, use
oc edit:oc edit Resource ClusterName