Chapter 3. Monitoring
Once you have a running cluster, you may begin monitoring the storage cluster to ensure that the Ceph Monitor and OSD daemons are running, at a high-level. Ceph storage cluster clients must connect to a Ceph monitor and receive the latest version of the Ceph cluster map before they can read and write data to the Ceph pools of the storage cluster. So the monitor cluster must have agreement on the state of the cluster before Ceph clients can read and write data.
Ceph OSDs must peer the placement groups on the primary OSD with the copies of the placement groups on secondary OSDs. If faults arise, peering will reflect something other than the active + clean state.
3.1. High-level Monitoring
High level monitoring of a storage cluster typically involves checking the status of Ceph OSD and Monitor daemons to ensure that they are up and running. High level monitoring also involves checking the storage cluster capacity to ensure that the cluster doesn’t exceed its full ratio. The Calamari instance on the Ansible Tower or Red Hat Storage Console node is the most common way to conduct high-level monitoring. However, you may also use the command line, the admin socket or the Ceph API to monitor the storage cluster.
3.1.1. Interactive Mode
To run the ceph utility in interactive mode, type ceph at the command line with no arguments, for example:
# ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon_status3.1.2. Checking Cluster Health
After you start the Ceph storage cluster, and before you start reading and/or writing data, check the storage cluster’s health first. You can check on the health of the Ceph storage cluster with the following:
# ceph healthIf you specified non-default locations for the configuration or keyring, you may specify their locations:
# ceph -c /path/to/conf -k /path/to/keyring health
Upon starting the Ceph cluster, you will likely encounter a health warning such as HEALTH_WARN XXX num placement groups stale. Wait a few moments and check it again. When the storage cluster is ready, ceph health should return a message such as HEALTH_OK. At that point, it is okay to begin using the cluster.
3.1.3. Watching a Cluster
To watch the cluster’s ongoing events on the command line, open a new terminal. Then, enter:
# ceph -wCeph will print each event. For example, a tiny Ceph cluster consisting of one monitor and two OSDs may print the following:
cluster b370a29d-9287-4ca3-ab57-3d824f65e339
health HEALTH_OK
monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
osdmap e63: 2 osds: 2 up, 2 in
pgmap v41338: 952 pgs, 20 pools, 17130 MB data, 2199 objects
115 GB used, 167 GB / 297 GB avail
952 active+clean
2014-06-02 15:45:21.655871 osd.0 [INF] 17.71 deep-scrub ok
2014-06-02 15:45:47.880608 osd.1 [INF] 1.0 scrub ok
2014-06-02 15:45:48.865375 osd.1 [INF] 1.3 scrub ok
2014-06-02 15:45:50.866479 osd.1 [INF] 1.4 scrub ok
2014-06-02 15:45:01.345821 mon.0 [INF] pgmap v41339: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:05.718640 mon.0 [INF] pgmap v41340: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:53.997726 osd.1 [INF] 1.5 scrub ok
2014-06-02 15:45:06.734270 mon.0 [INF] pgmap v41341: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:15.722456 mon.0 [INF] pgmap v41342: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:46:06.836430 osd.0 [INF] 17.75 deep-scrub ok
2014-06-02 15:45:55.720929 mon.0 [INF] pgmap v41343: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB availThe output provides:
- Cluster ID
- Cluster health status
- The monitor map epoch and the status of the monitor quorum
- The OSD map epoch and the status of OSDs
- The placement group map version
- The number of placement groups and pools
- The notional amount of data stored and the number of objects stored
- The total amount of data stored
How Ceph Calculates Data Usage
The used value reflects the actual amount of raw storage used. The xxx GB / xxx GB value means the amount available, the lesser of the two numbers, of the overall storage capacity of the cluster. The notional number reflects the size of the stored data before it is replicated, cloned or snapshotted. Therefore, the amount of data actually stored typically exceeds the notional amount stored, because Ceph creates replicas of the data and may also use storage capacity for cloning and snapshotting.
3.1.4. Checking a Cluster’s Usage Statistics
To check a cluster’s data usage and data distribution among pools, you can use the df option. It is similar to Linux df. Execute the following:
# ceph dfThe GLOBAL section of the output provides an overview of the amount of storage the storage cluster uses for data.
- SIZE: The overall storage capacity of the storage cluster.
- AVAIL: The amount of free space available in the storage cluster.
- RAW USED: The amount of raw storage used.
-
% RAW USED: The percentage of raw storage used. Use this number in conjunction with the
full ratioandnear full ratioto ensure that you are not reaching the storage cluster’s capacity.
The POOLS section of the output provides a list of pools and the notional usage of each pool. The output from this section DOES NOT reflect replicas, clones or snapshots. For example, if you store an object with 1MB of data, the notional usage will be 1MB, but the actual usage may be 3MB or more depending on the number of replicas (e.g., size = 3, clones and snapshots.
- NAME: The name of the pool.
- ID: The pool ID.
- USED: The notional amount of data stored in kilobytes, unless the number appends M for megabytes or G for gigabytes.
- %USED: The notional percentage of storage used per pool.
- Objects: The notional number of objects stored per pool.
The numbers in the POOLS section are notional. They are not inclusive of the number of replicas, shapshots or clones. As a result, the sum of the USED and %USED amounts will not add up to the RAW USED and %RAW USED amounts in the GLOBAL section of the output. See How Ceph Calculates Data Usage for details.
3.1.5. Checking a Cluster’s Status
To check a cluster’s status, execute the following:
# ceph statusOr:
# ceph -s
In interactive mode, type status and press Enter. :
ceph> statusCeph will print the cluster status. For example, a tiny Ceph cluster consisting of one monitor, and two OSDs may print the following:
cluster b370a29d-9287-4ca3-ab57-3d824f65e339
health HEALTH_OK
monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
osdmap e63: 2 osds: 2 up, 2 in
pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects
115 GB used, 167 GB / 297 GB avail
1 active+clean+scrubbing+deep
951 active+clean3.1.6. Checking Monitor Status
If the storage cluster has multiple monitors, which is required for high availability for production Ceph storage clusters. You should check the Ceph Monitor quorum status after you start the Ceph storage cluster before reading and/or writing data. A quorum must be present when multiple monitors are running. You should also check Ceph Monitor status periodically to ensure that they are running. If there is a problem with the Monitor, that prevents an agreement on the state of the storage cluster, the fault may prevent Ceph clients from reading and writing data.
To display the monitor map, execute the following:
# ceph mon stator
# ceph mon dumpTo check the quorum status for the storage cluster, execute the following:
# ceph quorum_status -f json-prettyCeph will return the quorum status. For example, a Ceph storage cluster consisting of three monitors may return the following:
{ "election_epoch": 10, "quorum": [ 0, 1, 2], "monmap": { "epoch": 1, "fsid": "444b489c-4f16-4b75-83f0-cb8097468898", "modified": "2011-12-12 13:28:27.505520", "created": "2011-12-12 13:28:27.505520", "mons": [ { "rank": 0, "name": "a", "addr": "127.0.0.1:6789\/0"}, { "rank": 1, "name": "b", "addr": "127.0.0.1:6790\/0"}, { "rank": 2, "name": "c", "addr": "127.0.0.1:6791\/0"} ] } }
3.1.7. Using the Administration Socket
Use the administration socket to interact with a given daemon directly by using a UNIX socket file. For example, the socket enables you to:
- List the Ceph configuration at runtime
-
Set configuration values at runtime directly without relaying on Monitors. This is useful when Monitors are
down. - Dump historic operations
- Dump the operation priority queue state
- Dump operations without rebooting
- Dump performance counters
In addition, using the socket is helpful when troubleshooting problems related to Monitors or OSDs. For details, see the Troubleshooting Guide for Red Hat Ceph Storage 3.
To use the socket:
ceph daemon <type>.<id> <command>Replace:
-
<type>with the type of the Ceph daemon (mon,osd,mds). -
<id>with the daemon ID -
<command>with the command to run. Usehelpto list the available commands for a given daemon.
For example, to view a Monitor status of a Monitor named mon.0:
# ceph daemon mon.0 mon_statusAlternatively, specify the daemon by using its socket file.
ceph daemon /var/run/ceph/<socket-file> <command>
For example, to view the status of an OSD named osd.2:
# ceph daemon /var/run/ceph/ceph-osd.2.asok statusTo list all socket files for the Ceph processes:
$ ls /var/run/ceph3.1.8. Checking OSD Status
An OSD’s status is either in the cluster, in, or out of the cluster, out; and, it is either up and running, up, or it is down and not running, or down. If an OSD is up, it may be either in the storage cluster, which data can be read and written, or it is out of the storage cluster. If it was in the cluster and recently moved out of the cluster, Ceph will migrate placement groups to other OSDs. If an OSD is out of the cluster, CRUSH will not assign placement groups to the OSD. If an OSD is down, it should also be out.
If an OSD is down and in, there is a problem and the cluster will not be in a healthy state.

If you execute a command such as ceph health, ceph -s or ceph -w, you may notice that the cluster does not always echo back HEALTH OK. Don’t panic. With respect to OSDs, you should expect that the cluster will NOT echo HEALTH OK in a few expected circumstances:
- You haven’t started the cluster yet, it won’t respond.
- You have just started or restarted the cluster and it’s not ready yet, because the placement groups are getting created and the OSDs are in the process of peering.
- You just added or removed an OSD.
- You just have modified the cluster map.
An important aspect of monitoring OSDs is to ensure that when the cluster is up and running that all OSDs that are in the cluster are up and running, too. To see if all OSDs are running, execute:
# ceph osd stator
# ceph osd dump
The result should tell you the map epoch, eNNNN, the total number of OSDs, x, how many, y, are up, and how many, z, are in:
eNNNN: x osds: y up, z in
If the number of OSDs that are in the cluster is more than the number of OSDs that are up, execute the following command to identify the ceph-osd daemons that aren’t running:
# ceph osd treeExample output:
# id weight type name up/down reweight
-1 3 pool default
-3 3 rack mainrack
-2 3 host osd-host
0 1 osd.0 up 1
1 1 osd.1 up 1
2 1 osd.2 up 1The ability to search through a well-designed CRUSH hierarchy may help you troubleshoot the storage cluster by identifying the physical locations faster.
If an OSD is down, connect to the node and start it. You can use Red Hat Storage Console to restart the OSD node, or you can use the command line, for example:
# systemctl start ceph-osd@<osd_id>3.2. Low-level Monitoring
Lower-level monitoring typically involves ensuring that OSDs are peering. When faults occur, placement groups operate in a degraded state. This can be due to many things such as failed hardware, hung or crashed daemon, network latency or outage among other things.
3.2.1. Placement Group Sets
When CRUSH assigns placement groups to OSDs, it looks at the number of replicas for the pool and assigns the placement group to OSDs such that each replica of the placement group gets assigned to a different OSD. For example, if the pool requires three replicas of a placement group, CRUSH may assign them to osd.1, osd.2 and osd.3 respectively. CRUSH actually seeks a pseudo-random placement that will take into account failure domains you set in the CRUSH map, so you will rarely see placement groups assigned to nearest neighbor OSDs in a large cluster. We refer to the set of OSDs that should contain the replicas of a particular placement group as the Acting Set. In some cases, an OSD in the Acting Set is down or otherwise not able to service requests for objects in the placement group. When these situations arise, don’t panic. Common examples include:
- You added or removed an OSD. Then, CRUSH reassigned the placement group to other OSDs—thereby changing the composition of the Acting Set and spawning the migration of data with a "backfill" process.
-
An OSD was
down, was restarted and is nowrecovering. -
An OSD in the Acting Set is
downor unable to service requests, and another OSD has temporarily assumed its duties.
Ceph processes a client request using the Up Set, which is the set of OSDs that will actually handle the requests. In most cases, the Up Set and the Acting Set are virtually identical. When they are not, it may indicate that Ceph is migrating data, an OSD is recovering, or that there is a problem, that is, Ceph usually echoes a HEALTH WARN state with a "stuck stale" message in such scenarios.
To retrieve a list of placement groups:
# ceph pg dumpTo view which OSDs are in the Acting Set or in the Up Set for a given placement group:
# ceph pg map <pg-num>The result should tell you the osdmap epoch,
eNNN, the placement group number,<pg-num>, the OSDs in the Up Setup[], and the OSDs in the acting set,acting[]:osdmap eNNN pg <pg-num> -> up [0,1,2] acting [0,1,2]NoteIf the Up Set and Acting Set do not match, this may be an indicator that the cluster rebalancing itself or of a potential problem with the cluster.
3.2.2. Peering
Before you can write data to a placement group, it must be in an active state, and it should be in a clean state. For Ceph to determine the current state of a placement group, the primary OSD of the placement group (i.e., the first OSD in the acting set), peers with the secondary and tertiary OSDs to establish agreement on the current state of the placement group (assuming a pool with 3 replicas of the PG).
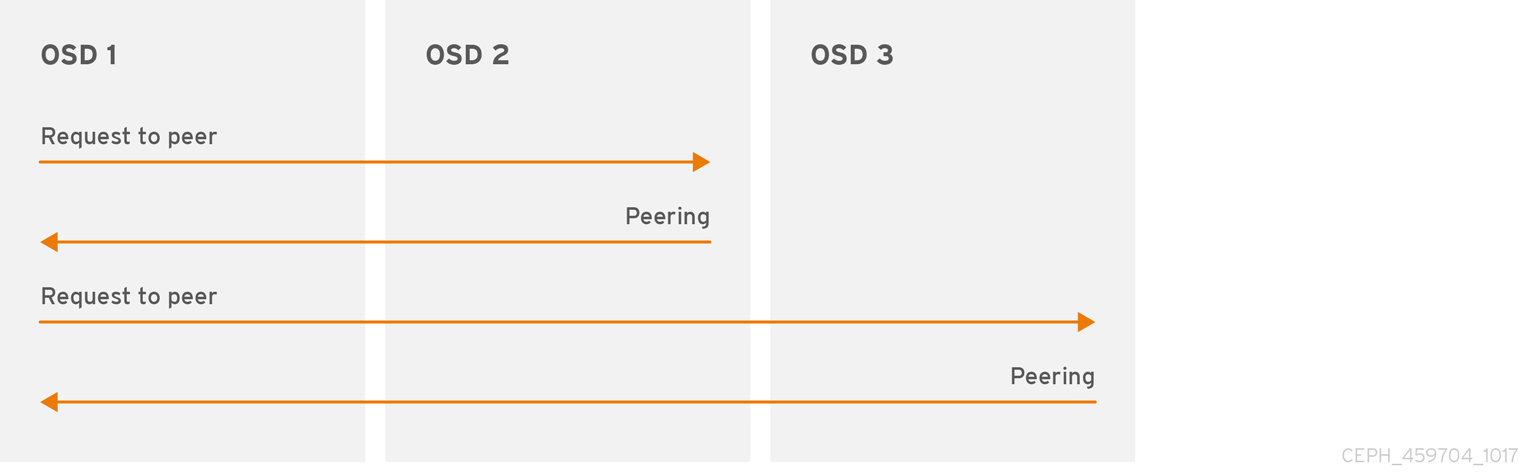
3.2.3. Monitoring Placement Group States
If you execute a command such as ceph health, ceph -s or ceph -w, you may notice that the cluster does not always echo back HEALTH OK. After you check to see if the OSDs are running, you should also check placement group states. You should expect that the cluster will NOT echo HEALTH OK in a number of placement group peering-related circumstances:
- You have just created a pool and placement groups haven’t peered yet.
- The placement groups are recovering.
- You have just added an OSD to or removed an OSD from the cluster.
- You have just modified the CRUSH map and the placement groups are migrating.
- There is inconsistent data in different replicas of a placement group.
- Ceph is scrubbing a placement group’s replicas.
- Ceph doesn’t have enough storage capacity to complete backfilling operations.
If one of the foregoing circumstances causes Ceph to echo HEALTH WARN, don’t panic. In many cases, the cluster will recover on its own. In some cases, you may need to take action. An important aspect of monitoring placement groups is to ensure that when the cluster is up and running that all placement groups are active, and preferably in the clean state. To see the status of all placement groups, execute:
# ceph pg stat
The result should tell you the placement group map version, vNNNNNN, the total number of placement groups, x, and how many placement groups, y, are in a particular state such as active+clean:
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availIt is common for Ceph to report multiple states for placement groups.
Snapshot Trimming PG States
When snapshots exist, two additional PG states will be reported.
-
snaptrim: The PGs are currently being trimmed -
snaptrim_wait: The PGs are waiting to be trimmed
Example Output:
244 active+clean+snaptrim_wait
32 active+clean+snaptrimSee the miscellaneous OSD settings in the Red Hat Ceph Storage 3 Configuration Guide for more details on the snapshot trimming settings.
In addition to the placement group states, Ceph will also echo back the amount of data used, aa, the amount of storage capacity remaining, bb, and the total storage capacity for the placement group. These numbers can be important in a few cases:
-
You are reaching the
near full ratioorfull ratio. - Your data isn’t getting distributed across the cluster due to an error in the CRUSH configuration.
Placement Group IDs
Placement group IDs consist of the pool number, and not the pool name, followed by a period (.) and the placement group ID—a hexadecimal number. You can view pool numbers and their names from the output of ceph osd lspools. The default pool names data, metadata and rbd correspond to pool numbers 0, 1 and 2 respectively. A fully qualified placement group ID has the following form:
<pool_num>.<pg_id>Example output:
0.1fTo retrieve a list of placement groups:
# ceph pg dumpTo format the output in JSON format and save it to a file:
# ceph pg dump -o <file_name> --format=jsonTo query a particular placement group:
# ceph pg <pool_num>.<pg_id> queryExample output in JSON format:
{ "state": "active+clean", "up": [ 1, 0 ], "acting": [ 1, 0 ], "info": { "pgid": "1.e", "last_update": "4'1", "last_complete": "4'1", "log_tail": "0'0", "last_backfill": "MAX", "purged_snaps": "[]", "history": { "epoch_created": 1, "last_epoch_started": 537, "last_epoch_clean": 537, "last_epoch_split": 534, "same_up_since": 536, "same_interval_since": 536, "same_primary_since": 536, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174" }, "stats": { "version": "4'1", "reported": "536'782", "state": "active+clean", "last_fresh": "2013-01-25 10:12:23.828271", "last_change": "2013-01-25 10:12:23.828271", "last_active": "2013-01-25 10:12:23.828271", "last_clean": "2013-01-25 10:12:23.828271", "last_unstale": "2013-01-25 10:12:23.828271", "mapping_epoch": 535, "log_start": "0'0", "ondisk_log_start": "0'0", "created": 1, "last_epoch_clean": 1, "parent": "0.0", "parent_split_bits": 0, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174", "log_size": 128, "ondisk_log_size": 128, "stat_sum": { "num_bytes": 205, "num_objects": 1, "num_object_clones": 0, "num_object_copies": 0, "num_objects_missing_on_primary": 0, "num_objects_degraded": 0, "num_objects_unfound": 0, "num_read": 1, "num_read_kb": 0, "num_write": 3, "num_write_kb": 1 }, "stat_cat_sum": { }, "up": [ 1, 0 ], "acting": [ 1, 0 ] }, "empty": 0, "dne": 0, "incomplete": 0 }, "recovery_state": [ { "name": "Started\/Primary\/Active", "enter_time": "2013-01-23 09:35:37.594691", "might_have_unfound": [ ], "scrub": { "scrub_epoch_start": "536", "scrub_active": 0, "scrub_block_writes": 0, "finalizing_scrub": 0, "scrub_waiting_on": 0, "scrub_waiting_on_whom": [ ] } }, { "name": "Started", "enter_time": "2013-01-23 09:35:31.581160" } ] }
The following subsections describe common states in greater detail.
3.2.3.1. Creating
When you create a pool, it will create the number of placement groups you specified. Ceph will echo creating when it is creating one or more placement groups. Once they are created, the OSDs that are part of a placement group’s Acting Set will peer. Once peering is complete, the placement group status should be active+clean, which means a Ceph client can begin writing to the placement group.
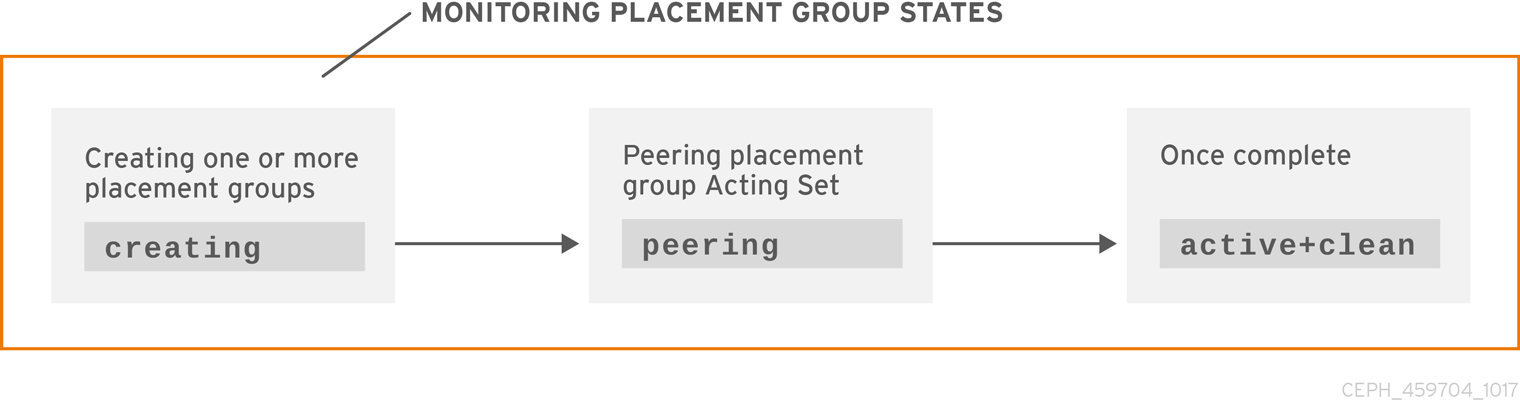
3.2.3.2. Peering
When Ceph is Peering a placement group, Ceph is bringing the OSDs that store the replicas of the placement group into agreement about the state of the objects and metadata in the placement group. When Ceph completes peering, this means that the OSDs that store the placement group agree about the current state of the placement group. However, completion of the peering process does NOT mean that each replica has the latest contents.
Authoritative History
Ceph will NOT acknowledge a write operation to a client, until all OSDs of the acting set persist the write operation. This practice ensures that at least one member of the acting set will have a record of every acknowledged write operation since the last successful peering operation.
With an accurate record of each acknowledged write operation, Ceph can construct and disseminate a new authoritative history of the placement group—a complete, and fully ordered set of operations that, if performed, would bring an OSD’s copy of a placement group up to date.
3.2.3.3. Active
Once Ceph completes the peering process, a placement group may become active. The active state means that the data in the placement group is generally available in the primary placement group and the replicas for read and write operations.
3.2.3.4. Clean
When a placement group is in the clean state, the primary OSD and the replica OSDs have successfully peered and there are no stray replicas for the placement group. Ceph replicated all objects in the placement group the correct number of times.
3.2.3.5. Degraded
When a client writes an object to the primary OSD, the primary OSD is responsible for writing the replicas to the replica OSDs. After the primary OSD writes the object to storage, the placement group will remain in a degraded state until the primary OSD has received an acknowledgement from the replica OSDs that Ceph created the replica objects successfully.
The reason a placement group can be active+degraded is that an OSD may be active even though it doesn’t hold all of the objects yet. If an OSD goes down, Ceph marks each placement group assigned to the OSD as degraded. The OSDs must peer again when the OSD comes back online. However, a client can still write a new object to a degraded placement group if it is active.
If an OSD is down and the degraded condition persists, Ceph may mark the down OSD as out of the cluster and remap the data from the down OSD to another OSD. The time between being marked down and being marked out is controlled by mon_osd_down_out_interval, which is set to 600 seconds by default.
A placement group can also be degraded, because Ceph cannot find one or more objects that Ceph thinks should be in the placement group. While you cannot read or write to unfound objects, you can still access all of the other objects in the degraded placement group.
Let’s say there are 9 OSDs with three copies of an object. If OSD number 9 goes down, the PGs assigned to OSD 9 go in a degraded state. If OSD 9 doesn’t recover, it goes out of the cluster and the cluster rebalances. In that scenario, the PGs are degraded and then recover to an active state.
3.2.3.6. Recovering
Ceph was designed for fault-tolerance at a scale where hardware and software problems are ongoing. When an OSD goes down, its contents may fall behind the current state of other replicas in the placement groups. When the OSD is back up, the contents of the placement groups must be updated to reflect the current state. During that time period, the OSD may reflect a recovering state.
Recovery isn’t always trivial, because a hardware failure might cause a cascading failure of multiple OSDs. For example, a network switch for a rack or cabinet may fail, which can cause the OSDs of a number of host machines to fall behind the current state of the cluster. Each one of the OSDs must recover once the fault is resolved.
Ceph provides a number of settings to balance the resource contention between new service requests and the need to recover data objects and restore the placement groups to the current state. The osd recovery delay start setting allows an OSD to restart, re-peer and even process some replay requests before starting the recovery process. The osd recovery threads setting limits the number of threads for the recovery process, by default one thread. The osd recovery thread timeout sets a thread timeout, because multiple OSDs may fail, restart and re-peer at staggered rates. The osd recovery max active setting limits the number of recovery requests an OSD will entertain simultaneously to prevent the OSD from failing to serve . The osd recovery max chunk setting limits the size of the recovered data chunks to prevent network congestion.
3.2.3.7. Backfilling
When a new OSD joins the cluster, CRUSH will reassign placement groups from OSDs in the cluster to the newly added OSD. Forcing the new OSD to accept the reassigned placement groups immediately can put excessive load on the new OSD. Backfilling the OSD with the placement groups allows this process to begin in the background. Once backfilling is complete, the new OSD will begin serving requests when it is ready.
During the backfill operations, you may see one of several states: backfill_wait indicates that a backfill operation is pending, but isn’t underway yet; backfill indicates that a backfill operation is underway; and, backfill_too_full indicates that a backfill operation was requested, but couldn’t be completed due to insufficient storage capacity. When a placement group cannot be backfilled, it may be considered incomplete.
Ceph provides a number of settings to manage the load spike associated with reassigning placement groups to an OSD, especially a new OSD. By default, osd_max_backfills sets the maximum number of concurrent backfills to or from an OSD to 10. The osd backfill full ratio enables an OSD to refuse a backfill request if the OSD is approaching its full ratio, by default 85%. If an OSD refuses a backfill request, the osd backfill retry interval enables an OSD to retry the request, by default after 10 seconds. OSDs can also set osd backfill scan min and osd backfill scan max to manage scan intervals, by default 64 and 512.
For some workloads, it is beneficial to avoid regular recovery entirely and use backfill instead. Since backfilling occurs in the background, this allows I/O to proceed on the objects in the OSD. To force backfill rather than recovery, set osd_min_pg_log_entries to 1, and set osd_max_pg_log_entries to 2. Contact your Red Hat Support account team for details on when this situation is appropriate for your workload.
3.2.3.8. Forcing the priority of recovery or backfill operations
You might encounter a situation where some placement groups (PGs) require recovery and/or backfill, and some of those placement groups contain more important data than do others. Use the pg force-recovery or pg force-backfill command to ensure that the PGs with the higher-priority data undergo recovery or backfill first.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to the node.
Procedure
Issue the
pg force-recoveryorpg force-backfillcommand and specify the order of priority for the PGs with the higher-priority data:Syntax
# ceph pg force-recovery PG1 [PG2] [PG3 ...] # ceph pg force-backfill PG1 [PG2] [PG3 ...]Example
[root@node]# ceph pg force-recovery group1 group2 [root@node]# ceph pg force-backfill group1 group2This command causes Red Hat Ceph Storage to perform recovery or backfill on specified placement groups (PGs) first, before processing other placement groups. Issuing the command does not interrupt backfill or recovery operations that are currently executing. After the currently running operations have finished, recovery or backfill takes place as soon as possible for the specified PGs.
3.2.3.9. Changing or canceling the priority of recovery or backfill operations
If you cancel a high-priority force-recovery or force-backfill operation on certain placement groups (PGs) in a storage cluster, operations for those PGs revert to the default recovery or backfill settings.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to the node.
Procedure
To change or cancel a recovery or backfill operation on specified placement groups:
Syntax
ceph pg cancel-force-recovery PG1 [PG2] [PG3 ...] ceph pg cancel-force-backfill PG1 [PG2] [PG3 ...]Example
[root@node]# ceph pg cancel-force-recovery group1 group2 [root@node]# ceph pg cancel-force-backfill group1 group2This cancels the
forceflag and processes the PGs in the default order.After recovery or backfill operations for the specified PGs have completed, processing order reverts to the default.
3.2.3.10. Forcing high-priority recovery or backfill operations for pools
If all of the placement groups in a pool require high-priority recovery or backfill, use the force-recovery or force-backfill options to initiate the operation.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to the node.
Procedure
To force high-priority recovery or backfill on all placement groups in a specified pool:
Syntax
ceph osd pool force-recovery POOL_NAME ceph osd pool force-backfill POOL_NAMEExample
[root@node]# ceph osd pool force-recovery pool1 [root@node]# ceph osd pool force-backfill pool1NoteUse the
force-recoveryandforce-backfillcommands with caution. Changing the priority of these operations might break the ordering of Ceph’s internal priority computations.
3.2.3.11. Canceling high-priority recovery or backfill operations for pools
If you cancel a high-priority force-recovery or force-backfill operation on all placement groups in a pool, operations for the PGs in that pool revert to the default recovery or backfill settings.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to the node.
Procedure
To cancel a high-priority recovery or backfill operation on all placement groups in a specified pool:
Syntax
ceph osd pool cancel-force-recovery POOL_NAME ceph osd pool cancel-force-backfill POOL_NAMEExample
[root@node]# ceph osd pool cancel-force-recovery pool1 [root@node]# ceph osd pool cancel-force-backfill pool1
3.2.3.12. Rearranging the priority of recovery and backfill operations for pools
If you have multiple pools that currently use the same underlying OSDs and some of the pools contain high-priority data, you can rearrange the order in which the operations execute. Use the recovery_priority option to assign a higher priority value to the pools with the higher-priority data. Those pools will execute before pools with lower priority values, or pools that are set to default priority.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to the node.
Procedure
To rearrange the recovery/backfill priority for the pools:
Syntax
ceph osd pool set POOL_NAME recovery_priority VALUEVALUE sets the order of priority. For example, if you have 10 pools, the pool with a priority value of 10 gets processed first, followed by the pool with priority 9, and so on. If only some pools have high priority, you can set priority values for just those pools. The pools without set priority values are processed in the default order.
Example
ceph osd pool set pool1 recovery_priority 10
3.2.3.13. Priority of placement group recovery in RADOS
This section describes the relative priority values for the recovery and backfilling of placement groups (PGs) in RADOS. Higher values are processed first. Inactive PGs receive higher priority values than active or degraded PGs.
| Operation | Value | Description |
|---|---|---|
| OSD_RECOVERY_PRIORITY_MIN | 0 | Minimum recovery value |
| OSD_BACKFILL_PRIORITY_BASE | 100 | Base backfill priority for MBackfillReserve |
| OSD_BACKFILL_DEGRADED_PRIORITY_BASE | 140 | Base backfill priority for MBackfillReserve (degraded PG) |
| OSD_RECOVERY_PRIORITY_BASE | 180 | Base recovery priority for MBackfillReserve |
| OSD_BACKFILL_INACTIVE_PRIORITY_BASE | 220 | Base backfill priority for MBackfillReserve (inactive PG) |
| OSD_RECOVERY_INACTIVE_PRIORITY_BASE | 220 | Base recovery priority for MRecoveryReserve (inactive PG) |
| OSD_RECOVERY_PRIORITY_MAX | 253 | Max manually/automatically set recovery priority for MBackfillReserve |
| OSD_BACKFILL_PRIORITY_FORCED | 254 | Backfill priority for MBackfillReserve, when forced manually |
| OSD_RECOVERY_PRIORITY_FORCED | 255 | Recovery priority for MRecoveryReserve, when forced manually |
| OSD_DELETE_PRIORITY_NORMAL | 179 | Priority for PG deletion when the OSD is not fullish |
| OSD_DELETE_PRIORITY_FULLISH | 219 | Priority for PG deletion when the OSD is approaching full |
| OSD_DELETE_PRIORITY_FULL | 255 | Priority for deletion when the OSD is full |
3.2.3.14. Remapped
When the Acting Set that services a placement group changes, the data migrates from the old acting set to the new acting set. It may take some time for a new primary OSD to service requests. So it may ask the old primary to continue to service requests until the placement group migration is complete. Once data migration completes, the mapping uses the primary OSD of the new acting set.
3.2.3.15. Stale
While Ceph uses heartbeats to ensure that hosts and daemons are running, the ceph-osd daemons may also get into a stuck state where they aren’t reporting statistics in a timely manner, for example, a temporary network fault. By default, OSD daemons report their placement group, up thru, boot and failure statistics every half second, that is, 0.5, which is more frequent than the heartbeat thresholds. If the Primary OSD of a placement group’s acting set fails to report to the monitor or if other OSDs have reported the primary OSD down, the monitors will mark the placement group stale.
When you start the storage cluster, it is common to see the stale state until the peering process completes. After the storage cluster has been running for awhile, seeing placement groups in the stale state indicates that the primary OSD for those placement groups is down or not reporting placement group statistics to the monitor.
3.2.3.16. Misplaced
There are some temporary backfilling scenarios where a PG gets mapped temporarily to an OSD. When that temporary situation should no longer be the case, the PGs might still reside in the temporary location and not in the proper location. In which case, they are said to be misplaced. That’s because the correct number of extra copies actually exist, but one or more copies is in the wrong place.
Lets say there are 3 OSDs: 0,1,2 and all PGs map to some permutation of those three. If you add another OSD (OSD 3), some PGs will now map to OSD 3 instead of one of the others. However, until OSD 3 is backfilled, the PG will have a temporary mapping allowing it to continue to serve I/O from the old mapping. During that time, the PG is misplaced, because it has a temporary mapping, but not degraded, since there are 3 copies.
Example
pg 1.5: up=acting: [0,1,2]
<add osd 3>
pg 1.5: up: [0,3,1] acting: [0,1,2]
Here, [0,1,2] is a temporary mapping, so the up set is not equal to the acting set and the PG is misplaced but not degraded since [0,1,2] is still three copies.
Example
pg 1.5: up=acting: [0,3,1]OSD 3 is now backfilled and the temporary mapping is removed, not degraded and not misplaced.
3.2.3.17. Incomplete
A PG goes into a incomplete state when there is incomplete content and peering fails, that is, when there are no complete OSDs which are current enough to perform recovery.
Lets say OSD 1, 2, and 3 are the acting OSD set and it switches to OSD 1, 4, and 3, then osd.1 will request a temporary acting set of OSD 1, 2, and 3 while backfilling 4. During this time, if OSD 1, 2, and 3 all go down, osd.4 will be the only one left which might not have fully backfilled all the data. At this time, the PG will go incomplete indicating that there are no complete OSDs which are current enough to perform recovery.
Alternately, if osd.4 is not involved and the acting set is simply OSD 1, 2, and 3 when OSD 1, 2, and 3 go down, the PG would likely go stale indicating that the mons have not heard anything on that PG since the acting set changed. The reason being there are no OSDs left to notify the new OSDs.
3.2.4. Identifying Troubled Placement Groups
As previously noted, a placement group isn’t necessarily problematic just because its state isn’t active+clean. Generally, Ceph’s ability to self repair may not be working when placement groups get stuck. The stuck states include:
- Unclean: Placement groups contain objects that are not replicated the desired number of times. They should be recovering.
-
Inactive: Placement groups cannot process reads or writes because they are waiting for an OSD with the most up-to-date data to come back
up. -
Stale: Placement groups are in an unknown state, because the OSDs that host them have not reported to the monitor cluster in a while, and can be configured with the
mon osd report timeoutsetting.
To identify stuck placement groups, execute the following:
# ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}3.2.5. Finding an Object Location
To store object data in the Ceph Object Store, a Ceph client must:
- Set an object name
- Specify a pool
The Ceph client retrieves the latest cluster map and the CRUSH algorithm calculates how to map the object to a placement group, and then calculates how to assign the placement group to an OSD dynamically. To find the object location, all you need is the object name and the pool name. For example:
# ceph osd map <pool_name> <object_name>3.3. Monitoring a Ceph storage cluster with the Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a monitoring dashboard to visualize the state of a Ceph Storage Cluster. Also, the Red Hat Ceph Storage Dashboard architecture provides a framework for additional modules to add functionality to the storage cluster.
- To learn about the Dashboard, see Section 3.3.1, “The Red Hat Ceph Storage Dashboard”.
- To install the Dashboard, see Section 3.3.2, “Installing the Red Hat Ceph Storage Dashboard”.
- To access the Dashboard, see Section 3.3.3, “Accessing the Red Hat Ceph Storage Dashboard”.
- To change the default password after installing the Dashboard, see Section 3.3.4, “Changing the default Red Hat Ceph Storage dashboard password”.
- To learn about the Prometheus plugin, see Section 3.3.5, “The Prometheus plugin for Red Hat Ceph Storage”.
- To learn about the Red Hat Ceph Storage Dashboard alerts and how to configure them, see Section 3.3.6, “The Red Hat Ceph Storage Dashboard alerts”.
Prerequisites
- A running Red Hat Ceph Storage cluster
3.3.1. The Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a monitoring dashboard for Ceph clusters to visualize the storage cluster state. The dashboard is accessible from a web browser and provides a number of metrics and graphs about the state of the cluster, Monitors, OSDs, Pools, or the network.
With the previous releases of Red Hat Ceph Storage, monitoring data was sourced through a collectd plugin, which sent the data to an instance of the Graphite monitoring utility. Starting with Red Hat Ceph Storage 3.3, monitoring data is sourced directly from the ceph-mgr daemon, using the ceph-mgr Prometheus plugin.
The introduction of Prometheus as the monitoring data source simplifies deployment and operational management of the Red Hat Ceph Storage Dashboard solution, along with reducing the overall hardware requirements. By sourcing the Ceph monitoring data directly, the Red Hat Ceph Storage Dashboard solution is better able to support Ceph clusters deployed in containers.
With this change in architecture, there is no migration path for monitoring data from Red Hat Ceph Storage 2.x and 3.0 to Red Hat Ceph Storage 3.3.
The Red Hat Ceph Storage Dashboard uses the following utilities:
- The Ansible automation application for deployment.
-
The embedded Prometheus
ceph-mgrplugin. -
The Prometheus
node-exporterdaemon, running on each node of the storage cluster. - The Grafana platform to provide a user interface and alerting.
The Red Hat Ceph Storage Dashboard supports the following features:
- General Features
- Support for Red Hat Ceph Storage 3.1 and higher
- SELinux support
- Support for FileStore and BlueStore OSD back ends
- Support for encrypted and non-encrypted OSDs
- Support for Monitor, OSD, the Ceph Object Gateway, and iSCSI roles
- Initial support for the Metadata Servers (MDS)
- Drill down and dashboard links
- 15 second granularity
- Support for Hard Disk Drives (HDD), Solid-state Drives (SSD), Non-volatile Memory Express (NVMe) interface, and Intel® Cache Acceleration Software (Intel® CAS)
- Node Metrics
- CPU and RAM usage
- Network load
- Configurable Alerts
- Out-of-Band (OOB) alerts and triggers
- Notification channel is automatically defined during the installation
The Ceph Health Summary dashboard created by default
See the Red Hat Ceph Storage Dashboard Alerts section for details.
- Cluster Summary
- OSD configuration summary
- OSD FileStore and BlueStore summary
- Cluster versions breakdown by role
- Disk size summary
- Host size by capacity and disk count
- Placement Groups (PGs) status breakdown
- Pool counts
- Device class summary, HDD vs. SSD
- Cluster Details
-
Cluster flags status (
noout,nodown, and others) -
OSD or Ceph Object Gateway hosts
upanddownstatus - Per pool capacity usage
- Raw capacity utilization
- Indicators for active scrub and recovery processes
- Growth tracking and forecast (raw capacity)
-
Information about OSDs that are
downornear full, including the OSD host and disk - Distribution of PGs per OSD
- OSDs by PG counts, highlighting the over or under utilized OSDs
-
Cluster flags status (
- OSD Performance
- Information about I/O operations per second (IOPS) and throughput by pool
- OSD performance indicators
- Disk statistics per OSD
- Cluster wide disk throughput
- Read/write ratio (client IOPS)
- Disk utilization heat map
- Network load by Ceph role
- The Ceph Object Gateway Details
- Aggregated load view
- Per host latency and throughput
- Workload breakdown by HTTP operations
- The Ceph iSCSI Gateway Details
- Aggregated views
- Configuration
- Performance
- Per Gateway resource utilization
- Per client load and configuration
- Per Ceph Block Device image performance
3.3.2. Installing the Red Hat Ceph Storage Dashboard
The Red Hat Ceph Storage Dashboard provides a visual dashboard to monitor various metrics in a running Ceph Storage Cluster.
For information on upgrading the Red Hat Ceph Storage Dashboard see Upgrading Red Hat Ceph Storage Dashboard in the Installation Guide for Red Hat Enterprise Linux.
Prerequisites
- The storage cluster nodes use Red Hat Enterprise Linux 7.
- A separate node, the Red Hat Ceph Storage Dashboard node, for receiving data from the cluster nodes and providing the Red Hat Ceph Storage Dashboard.
Prepare the Red Hat Ceph Storage Dashboard node:
Enable the Tools repository on all nodes.
For details, see the Enabling the Red Hat Ceph Storage Repositories section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux.
If using a firewall, then ensure that the following TCP ports are open:
Expand Table 3.1. TCP Port Requirements Port Use Where? 3000Grafana
The Red Hat Ceph Storage Dashboard node.
9090Basic Prometheus graphs
The Red Hat Ceph Storage Dashboard node.
9100Prometheus'
node-exporterdaemonAll storage cluster nodes.
9283Gathering Ceph data
All
ceph-mgrnodes.9287Ceph iSCSI gateway data
All Ceph iSCSI gateway nodes.
For more details see the Using Firewalls chapter in the Security Guide for Red Hat Enterprise Linux 7.
Procedure
Run the following commands on the Ansible administration node as the root user.
Install the
cephmetrics-ansiblepackage.[root@admin ~]# yum install cephmetrics-ansibleUsing the Ceph Ansible inventory as a base, add the Red Hat Ceph Storage Dashboard node under the
[ceph-grafana]section of the Ansible inventory file, by default located at/etc/ansible/hosts.[ceph-grafana] $HOST_NAMEReplace:
-
$HOST_NAMEwith the name of the Red Hat Ceph Storage Dashboard node
For example:
[ceph-grafana] node0-
Change to the
/usr/share/cephmetrics-ansible/directory.[root@admin ~]# cd /usr/share/cephmetrics-ansibleRun the Ansible playbook.
[root@admin cephmetrics-ansible]# ansible-playbook -v playbook.ymlImportantEvery time you update the cluster configuration, for example, you add or remove a MON or OSD node, you must re-run the
cephmetricsAnsible playbook.NoteThe
cephmetricsAnsible playbook does the following actions:-
Updates the
ceph-mgrinstance to enable the prometheus plugin and opens TCP port 9283. Deploys the Prometheus
node-exporterdaemon to each node in the storage cluster.- Opens TCP port 9100.
-
Starts the
node-exporterdaemon.
Deploys Grafana and Prometheus containers under Docker/systemd on the Red Hat Ceph Storage Dashboard node.
- Prometheus is configured to gather data from the ceph-mgr nodes and the node-exporters running on each ceph host
- Opens TCP port 3000.
- The dashboards, themes and user accounts are all created in Grafana.
- Outputs the URL of Grafana for the administrator.
-
Updates the
3.3.3. Accessing the Red Hat Ceph Storage Dashboard
Accessing the Red Hat Ceph Storage Dashboard gives you access to the web-based management tool for administrating Red Hat Ceph Storage clusters.
Prerequisites
- Install the Red Hat Ceph Storage Dashboard.
- Ensure that NTP is synchronizing clocks properly because a time lag can occur among the Ceph Storage Dashboard node, cluster nodes, and a browser when the nodes are not properly synced. See the Configuring the Network Time Protocol for Red Hat Ceph Storage section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux or Ubuntu.
Procedure
Enter the following URL to a web browser:
http://$HOST_NAME:3000Replace:
-
$HOST_NAMEwith the name of the Red Hat Ceph Storage Dashboard node
For example:
http://cephmetrics:3000-
Enter the password for the
adminuser. If you did not set the password during the installation, useadmin, which is the default password.Once logged in, you are automatically placed on the Ceph At a Glance dashboard. The Ceph At a Glance dashboard provides a high-level overviews of capacity, performance, and node-level performance information.
Example
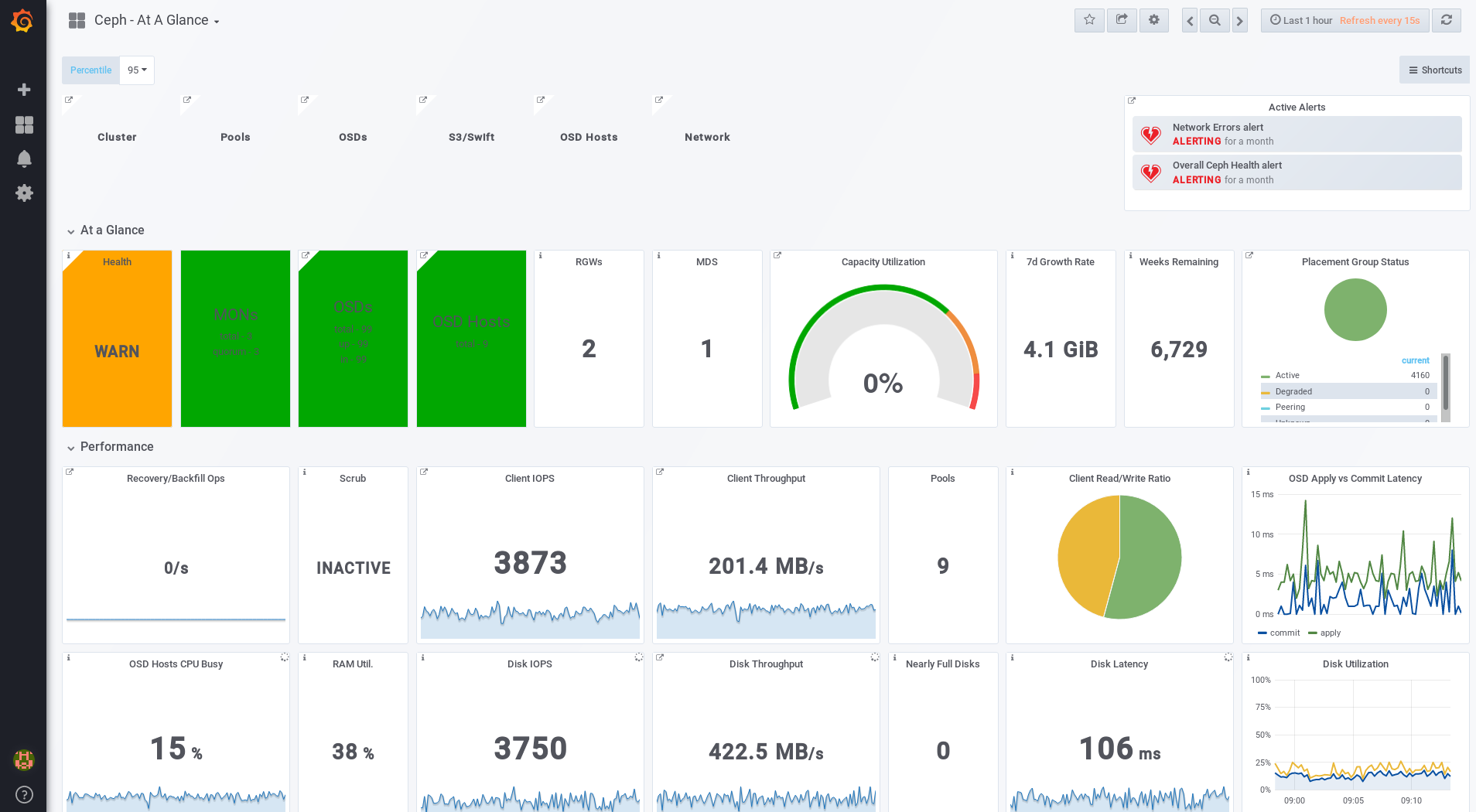
Additional Resources
- See the Changing the Default Red Hat Ceph Storage Dashboard Password section in the Red Hat Ceph Storage Administration Guide.
3.3.4. Changing the default Red Hat Ceph Storage dashboard password
The default user name and password for accessing the Red Hat Ceph Storage Dashboard is set to admin and admin. For security reasons, you might want to change the password after the installation.
To prevent the password from resetting to the default value, update the custom password in the /usr/share/cephmetrics-ansible/group_vars/all.yml file.
Prerequisites
Procedure
- Click the Grafana icon in the upper-left corner.
-
Hover over the user name you want to modify the password for. In this case
admin. -
Click
Profile. -
Click
Change Password. -
Enter the new password twice and click
Change Password.
Additional Resource
- If you forgot the password, follow the Reset admin password procedure on the Grafana web pages.
3.3.5. The Prometheus plugin for Red Hat Ceph Storage
As a storage administrator, you can gather performance data, export that data using the Prometheus plugin module for the Red Hat Ceph Storage Dashboard, and then perform queries on this data. The Prometheus module allows ceph-mgr to expose Ceph related state and performance data to a Prometheus server.
3.3.5.1. Prerequisites
- Running Red Hat Ceph Storage 3.1 or higher.
- Installation of the Red Hat Ceph Storage Dashboard.
3.3.5.2. The Prometheus plugin
The Prometheus plugin provides an exporter to pass on Ceph performance counters from the collection point in ceph-mgr. The Red Hat Ceph Storage Dashboard receives MMgrReport messages from all MgrClient processes, such as Ceph Monitors and OSDs. A circular buffer of the last number of samples contains the performance counter schema data and the actual counter data. This plugin creates an HTTP endpoint and retrieves the latest sample of every counter when polled. The HTTP path and query parameters are ignored; all extant counters for all reporting entities are returned in a text exposition format.
Additional Resources
- See the Prometheus documentation for more details on the text exposition format.
3.3.5.3. Managing the Prometheus environment
To monitor a Ceph storage cluster with Prometheus you can configure and enable the Prometheus exporter so the metadata information about the Ceph storage cluster can be collected.
Prerequisites
- A running Red Hat Ceph Storage 3.1 cluster
- Installation of the Red Hat Ceph Storage Dashboard
Procedure
As the
rootuser, open and edit the/etc/prometheus/prometheus.ymlfile.Under the
globalsection, set thescrape_intervalandevaluation_intervaloptions to 15 seconds.Example
global: scrape_interval: 15s evaluation_interval: 15sUnder the
scrape_configssection, add thehonor_labels: trueoption, and edit thetargets, andinstanceoptions for each of theceph-mgrnodes.Example
scrape_configs: - job_name: 'node' honor_labels: true static_configs: - targets: [ 'node1.example.com:9100' ] labels: instance: "node1.example.com" - targets: ['node2.example.com:9100'] labels: instance: "node2.example.com"NoteUsing the
honor_labelsoption enables Ceph to output properly-labelled data relating to any node in the Ceph storage cluster. This allows Ceph to export the properinstancelabel without Prometheus overwriting it.To add a new node, simply add the
targets, andinstanceoptions in the following format:Example
- targets: [ 'new-node.example.com:9100' ] labels: instance: "new-node"NoteThe
instancelabel has to match what appears in Ceph’s OSD metadatainstancefield, which is the short host name of the node. This helps to correlate Ceph stats with the node’s stats.
Add Ceph targets to the
/etc/prometheus/ceph_targets.ymlfile in the following format.Example
[ { "targets": [ "cephnode1.example.com:9283" ], "labels": {} } ]Enable the Prometheus module:
# ceph mgr module enable prometheus
3.3.5.4. Using the Prometheus expression browser
Use the builtin Prometheus expression browser to run queries against the collected data.
Prerequisites
- A running Red Hat Ceph Storage 3.1 cluster
- Installation of the Red Hat Ceph Storage Dashboard
Procedure
Enter the URL for the Prometh the web browser:
http://$DASHBOARD_SEVER_NAME:9090/graphReplace…
-
$DASHBOARD_SEVER_NAMEwith the name of the Red Hat Ceph Storage Dashboard server.
-
Click on Graph, then type in or paste the query into the query window and press the Execute button.
- View the results in the console window.
- Click on Graph to view the rendered data.
Additional Resources
- See the Prometheus expression browser documentation on the Prometheus web site for more information.
3.3.5.5. Working with the Prometheus data and queries
The statistic names are exactly as Ceph names them, with illegal characters translated to underscores, and ceph_ prefixed to all names. All Ceph daemon statistics have a ceph_daemon label that identifies the type and ID of the daemon they come from, for example: osd.123. Some statistics can come from different types of daemons, so when querying you will want to filter on Ceph daemons starting with osd to avoid mixing in the Ceph Monitor and RocksDB stats. The global Ceph storage cluster statistics have labels appropriate to what they report on. For example, metrics relating to pools have a pool_id label. The long running averages that represent the histograms from core Ceph are represented by a pair of sum and count performance metrics.
The following example queries can be used in the Prometheus expression browser:
Show the physical disk utilization of an OSD
(irate(node_disk_io_time_ms[1m]) /10) and on(device,instance) ceph_disk_occupation{ceph_daemon="osd.1"}Show the physical IOPS of an OSD as seen from the operating system
irate(node_disk_reads_completed[1m]) + irate(node_disk_writes_completed[1m]) and on (device, instance) ceph_disk_occupation{ceph_daemon="osd.1"}Pool and OSD metadata series
Special data series are output to enable the displaying and the querying on certain metadata fields. Pools have a ceph_pool_metadata field, for example:
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0
OSDs have a ceph_osd_metadata field, for example:
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.0Correlating drive statistics with node_exporter
The Prometheus output from Ceph is designed to be used in conjunction with the generic node monitoring from the Prometheus node exporter. Correlation of Ceph OSD statistics with the generic node monitoring drive statistics, special data series are output, for example:
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="node1"}
To get disk statistics by an OSD ID, use either the and operator or the asterisk (*) operator in the Prometheus query. All metadata metrics have the value of 1 so they act neutral with asterisk operator. Using asterisk operator allows to use group_left and group_right grouping modifiers, so that the resulting metric has additional labels from one side of the query. For example:
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}Using label_replace
The label_replace function can add a label to, or alter a label of, a metric within a query. To correlate an OSD and its disks write rate, the following query can be used:
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}Additional Resources
- See Prometheus querying basics for more information on constructing queries.
-
See Prometheus'
label_replacedocumentation for more information.
3.3.5.6. Additional Resources
3.3.6. The Red Hat Ceph Storage Dashboard alerts
This section includes information about alerting in the Red Hat Ceph Storage Dashboard.
- To learn about the Red Hat Ceph Storage Dashboard alerts, see Section 3.3.6.2, “About Alerts”.
- To view the alerts, see Section 3.3.6.3, “Accessing the Alert Status dashboard”.
- To configure the notification target, see Section 3.3.6.4, “Configuring the Notification Target”.
- To change the default alerts or add new ones, see Section 3.3.6.5, “Changing the Default Alerts and Adding New Ones”.
3.3.6.1. Prerequisites
3.3.6.2. About Alerts
The Red Hat Ceph Storage Dashboard supports alerting mechanism that is provided by the Grafana platform. You can configure the dashboard to send you a notification when a metric that you are interested in reaches certain value. Such metrics are in the Alert Status dashboard.
By default, Alert Status already includes certain metrics, such as Overall Ceph Health, OSDs Down, or Pool Capacity. You can add metrics that you are interested in to this dashboard or change their trigger values.
Here is a list of the pre-defined alerts that are included with Red Hat Ceph Storage Dashboard:
- Overall Ceph Health
- Disks Near Full (>85%)
- OSD Down
- OSD Host Down
- PG’s Stuck Inactive
- OSD Host Less - Free Capacity Check
- OSD’s With High Response Times
- Network Errors
- Pool Capacity High
- Monitors Down
- Overall Cluster Capacity Low
- OSDs With High PG Count
3.3.6.3. Accessing the Alert Status dashboard
Certain Red Hat Ceph Storage Dashboard alerts are configured by default in the Alert Status dashboard. This section shows two ways to access it.
Procedure
To access the dashboard:
- In the main At the Glance dashboard, click the Active Alerts panel in the upper-right corner.
Or..
- Click the dashboard menu from in the upper-left corner next to the Grafana icon. Select Alert Status.
3.3.6.4. Configuring the Notification Target
A notification channel called cephmetrics is automatically created during installation. All preconfigured alerts reference the cephmetrics channel but before you can receive the alerts, complete the notification channel definition by selecting the desired notification type. The Grafana platform supports a number of different notification types including email, Slack, and PagerDuty.
Procedure
- To configure the notification channel, follow the instructions in the Alert Notifications section on the Grafana web page.
3.3.6.5. Changing the Default Alerts and Adding New Ones
This section explains how to change the trigger value on already configured alerts and how to add new alerts to the Alert Status dashboard.
Procedure
To change the trigger value on alerts or to add new alerts, follow the Alerting Engine & Rules Guide on the Grafana web pages.
ImportantTo prevent overriding custom alerts, the Alert Status dashboard will not be updated when upgrading the Red Hat Ceph Storage Dashboard packages when you change the trigger values or add new alerts.
Additional Resources
- The Grafana web page
3.4. Using ceph-medic to diagnose a Ceph Storage Cluster
The ceph-medic utility performs checks against a running Ceph Storage Cluster to identify potential problems.
The ceph-medics utility for example checks:
- The correct ownership of files and directories
-
If the
fsidis the same for all nodes in the storage cluster - If the secret key in the keyring is different than other nodes in the storage cluster
3.4.1. Prerequisites
- A working Red Hat Ceph Storage cluster
-
SSH and
sudoaccess to storage nodes
3.4.2. Installing the ceph-medic Utility
Prerequisite
- Access to the Red Hat Ceph Storage 3 software repositories
Procedure
Do the following steps on the Ansible administration node, as the root user.
Install the
ceph-medicpackage:[root@admin ~]# yum install ceph-medicVerify the installation of
ceph-medic:[root@admin ~]# ceph-medic --help
Additional Resources
- The Enabling the Red Hat Ceph Storage Repositories section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux
3.4.3. Running a Diagnostic Check
A basic check for potential problems with a Ceph Storage Cluster.
Prerequisites
- A working Red Hat Ceph Storage cluster
-
SSH and
sudoaccess to storage nodes
Procedure
Do the following step from the Ansible administration node, as a normal user.
Use the
ceph-medic checkcommand:[admin@admin ~]$ ceph-medic check Host: mon0 connection: [connected ] Host: mon1 connection: [connected ] Host: mon2 connection: [connected ] Host: osd0 connection: [connected ] Host: osd1 connection: [connected ] Host: osd2 connection: [connected ] Collection completed! ======================= Starting remote check session ======================== Version: 1.0.2 Cluster Name: "example" Total hosts: [6] OSDs: 3 MONs: 3 Clients: 0 MDSs: 0 RGWs: 0 MGRs: 0 ================================================================================ ------------ osds ------------ osd0 osd1 osd2 ------------ mons ------------ mon0 mon1 mon2 17 passed, 0 errors, on 6 hosts
Additional Resources
-
Appendix A, Error Code Definitions for
ceph-medic - The Enabling Passwordless SSH for Ansible section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux
3.4.4. Using a Custom Inventory File
The ceph-medic utility must know the storage cluster topology. By default, ceph-medic uses the Ansible inventory file (/etc/ansible/hosts) to detect nodes.
Prerequisites
- A working Red Hat Ceph Storage cluster
-
SSH and
sudoaccess to storage nodes
Procedure
To use a custom inventory file, do the following steps on the Ansible administration node, as a user.
Create a custom
hostsfile:[admin@admin ~]$ touch ~/example/hostsOpen the
hostsfile for editing. Add the nodes in the storage cluster under the appropriate node group type. Theceph-medictool supports the following node group types:mons,osds,rgws,mdss,mgrsandclients.For example:
[mons] mon0 mon1 mon2 [osds] osd0 osd1 osd2When doing a diagnostic check, to specify a custom inventory file, use the
--inventoryoption:ceph-medic --inventory $PATH_TO_HOSTS_FILE check- Replace
$PATH_TO_HOSTS_FILEwith the full path to thehostsfile.For example:
[admin@admin ~]$ ceph-medic --inventory ~/example/hosts check
Additional Resources
-
Appendix A, Error Code Definitions for
ceph-medic - The Enabling Passwordless SSH for Ansible section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux
3.4.5. Configuring a Custom Logging Path
The ceph-medic log file contains more verbosity than the command output on the terminal. The ceph-medic tool by default writes logs to the current working directory.
Prerequisites
- A working Red Hat Ceph Storage cluster
-
SSH and
sudoaccess to storage nodes
Procedure
To change where these logs are written, do the following step on the Ansible administration node, as a normal user.
-
Open the
~/.cephmedic.conffile for editing. Change the
--log-pathoption, from a.to a custom log location.For example:
--log-path = /var/log/ceph-medic/
Additional Resources
-
Appendix A, Error Code Definitions for
ceph-medic - The Enabling Passwordless SSH for Ansible section in the Red Hat Ceph Storage 3 Installation Guide for Red Hat Enterprise Linux