第1章 Data Grid のデプロイメントモデルとユースケース
Data Grid は、さまざまなユースケースをサポートする柔軟なデプロイメントモデルを提供します。
- Red Hat Build of Quarkus、Red Hat JBoss EAP、および Spring アプリケーションのパフォーマンスを大幅に改善します。
- サービスの可用性および継続性を確保します。
- 運用コストの削減。
1.1. Data Grid デプロイメントモデル
Data Grid には、キャッシュ用にリモートと組み込みの 2 つのデプロイメントモデルがあります。どちらの導入モデルでも、アプリケーションは、従来のデータベースシステムと比較して、読み取り操作の待ち時間を大幅に短縮し、書き込み操作のスループットを向上させてデータにアクセスできます。
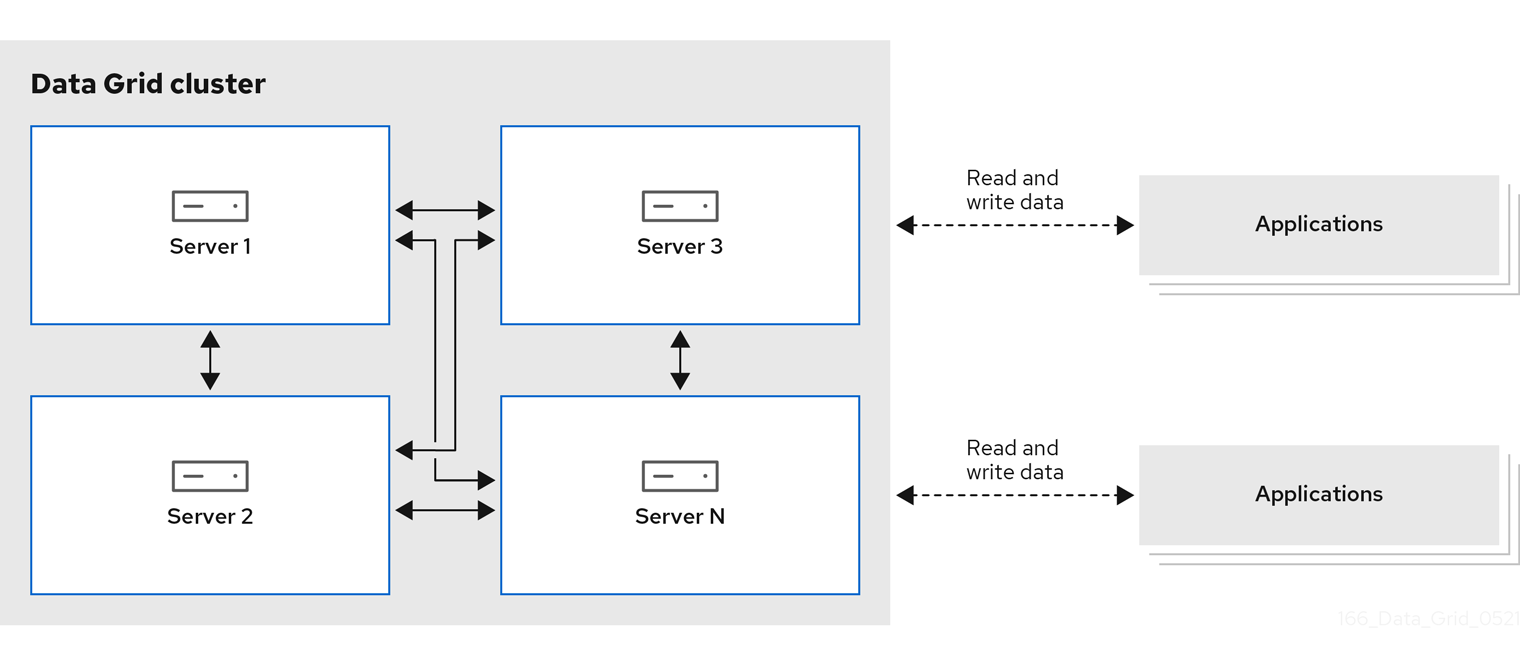
- リモートキャッシュ
- Data Grid Server ノードは、専用の Java 仮想マシン (JVM) で実行されます。クライアントは、Hot Rod、バイナリー TCP プロトコル、または REST over HTTP を使用してリモートキャッシュにアクセスします。
- 組み込みキャッシュ
- Data Grid は、Java アプリケーションと同じ JVM で実行されます。つまり、データはコードが実行されるメモリー領域に保存されます。
Red Hat は、ほとんどのデプロイメントにはサーバー/クライアントアーキテクチャーを推奨します。データレイヤーはビジネスロジックから分離されているため、リモートキャッシュでは、デプロイメントがより高速になります。Data Grid Server は、開発コストを削減できるように、監視および可観測性やその他の組み込み機能を提供します。
ニアキャッシュ
ニアキャッシング機能により、リモートクライアントはデータをローカルに保存できます。つまり、読み取りが集中するアプリケーションは、呼び出しごとにネットワークを横断する必要がありません。ニアキャッシュにより読み取り操作の速度が大幅に増大し、組み込みキャッシュと同じパフォーマンスを実現します。
図1.1 リモートキャッシュデプロイメントモデル
1.1.1. プラットフォームおよび自動化ツール
必要な QoS を実現すると、CPU および RAM リソースが最適な Data Grid を提供することになります。リソースの数が多すぎると、ホストリソースが過剰に使用されている間、Data Grid のパフォーマンスのダウングレードによりコストが迅速に増大します。
CPU または RAM の適切な割り当てを見つけるために Data Grid クラスターをベンチマークおよびチューニングしますが、クラスターをスケーリングし、リソースを効率的に管理するために適切な種類の自動化ツールを提供するホストプラットフォームも考慮する必要があります。
ベアメタルまたは仮想マシン
Red Hat Ansible と Data Grid の設定を管理し、サービスをポーリングして、可用性を確保し、リソースの使用が最適となるように、RHEL または Microsoft Windows を組み合わせます。
Automation Hub から入手できる Data Grid の Ansible コレクション は、クラスターのインストールを自動化し、Keycloak 統合とクロスサイトレプリケーションのオプションを含みます。
OpenShift
Kubernetes オーケストレーションを活用して、Pod を自動的にプロビジョニングし、リソースに制限を課し、ワークロードの需要に合わせて Data Grid クラスターを自動的にスケーリングします。