ネットワークの設定および管理
ネットワークインターフェイス、ファイアウォール、および高度なネットワーク機能の管理
概要
- ボンディング、VLAN、ブリッジ、トンネル、およびその他のネットワークタイプを設定して、ホストをネットワークに接続できます。
- ローカルホストとネットワーク全体に対して、パフォーマンスが重要なファイアウォールを構築できます。REHL には、
firewalldサービス、nftablesフレームワーク、Express Data Path (XDP) などのパケットフィルタリングソフトウェアが含まれています。 - RHEL は、ポリシーベースのルーティングや Multipath TCP (MPTCP) などの高度なネットワーク機能もサポートします。
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
第1章 一貫したネットワークインターフェイス命名の実装
udev デバイスマネージャーは、Red Hat Enterprise Linux で一貫したデバイス命名を実装します。デバイスマネージャーは、さまざまな命名スキームをサポートしています。デフォルトでは、ファームウェア、トポロジー、および場所の情報に基づいて固定名を割り当てます。
一貫したデバイス命名を使用しない場合、Linux カーネルは固定の接頭辞とインデックスを組み合わせて名前をネットワークインターフェイスに割り当てます。カーネルがネットワークデバイスを初期化すると、インデックスが増加します。たとえば、eth0 は、起動時にプローブされる最初のイーサネットデバイスを表します。別のネットワークインターフェイスコントローラーをシステムに追加すると、再起動後にデバイスが異なる順序で初期化される可能性があるため、カーネルデバイス名の割り当てが一定でなくなります。その場合、カーネルはデバイスに別の名前を付けることがあります。
この問題を解決するために、udev は一貫したデバイス名を割り当てます。これには、次の利点があります。
- 再起動してもデバイス名が変わりません。
- ハードウェアを追加または削除しても、デバイス名が固定されたままになります。
- 不具合のあるハードウェアをシームレスに交換できます。
- ネットワークの命名はステートレスであり、明示的な設定ファイルは必要ありません。
通常、Red Hat は、一貫したデバイス命名が無効になっているシステムはサポートしていません。例外は、Red Hat ナレッジベースのソリューション記事 Is it safe to set net.ifnames=0 を参照してください。
1.1. udev デバイスマネージャーによるネットワークインターフェイスの名前変更の仕組み
ネットワークインターフェイスの一貫した命名スキームを実装するために、udev デバイスマネージャーは次のルールファイルを記載されている順番どおりに処理します。
オプション:
/usr/lib/udev/rules.d/60-net.rules/usr/lib/udev/rules.d/60-net.rulesファイルは、非推奨の/usr/lib/udev/rename_deviceヘルパーユーティリティーが/etc/sysconfig/network-scripts/ifcfg-*ファイルのHWADDRパラメーターを検索することを定義します。変数に設定した値がインターフェイスの MAC アドレスに一致すると、ヘルパーユーティリティーは、インターフェイスの名前を、ifcfgファイルのDEVICEパラメーターに設定した名前に変更します。システムがキーファイル形式の NetworkManager 接続プロファイルのみを使用する場合、
udevはこの手順をスキップします。Dell システムのみ:
/usr/lib/udev/rules.d/71-biosdevname.rulesこのファイルは、
biosdevnameパッケージがインストールされている場合にのみ存在します。このルールファイルは、前の手順でインターフェイスの名前が変更されていない場合に、biosdevnameユーティリティーが命名ポリシーに従ってインターフェイスの名前を変更することを定義します。注記biosdevnameは Dell システムにのみインストールして使用してください。/usr/lib/udev/rules.d/75-net-description.rulesこのファイルは、
udevがネットワークインターフェイスを検査し、udevの内部変数にプロパティーを設定する方法を定義します。これらの変数は、次のステップで/usr/lib/udev/rules.d/80-net-setup-link.rulesファイルによって処理されます。一部のプロパティーは未定義である場合があります。/usr/lib/udev/rules.d/80-net-setup-link.rulesこのファイルは
udevサービスのnet_setup_linkビルトインを呼び出します。udevは/usr/lib/systemd/network/99-default.linkファイルのNamePolicyパラメーターのポリシーの順序に基づいてインターフェイスの名前を変更します。詳細は、ネットワークインターフェイスの命名ポリシー を参照してください。どのポリシーも適用されない場合、
udevはインターフェイスの名前を変更しません。
1.2. ネットワークインターフェイスの命名ポリシー
デフォルトでは、udev デバイスマネージャーは /usr/lib/systemd/network/99-default.link ファイルを使用して、インターフェイスの名前を変更するときに適用するデバイス命名ポリシーを決定します。このファイルの NamePolicy パラメーターは、udev がどのポリシーをどの順序で使用するかを定義します。
NamePolicy=kernel database onboard slot path
次の表では、NamePolicy パラメーターで指定された最初に一致するポリシーに基づく、udev のさまざまなアクションを説明します。
| ポリシー | 説明 | 名前の例 |
|---|---|---|
| kernel |
デバイス名が予測可能であるとカーネルが通知した場合、 |
|
| database |
このポリシーは、 |
|
| onboard | デバイス名には、ファームウェアまたは BIOS が提供するオンボードデバイスのインデックス番号が含まれます。 |
|
| slot | デバイス名には、ファームウェアまたは BIOS が提供する PCI Express (PCIe) ホットプラグのスロットインデックス番号が含まれます。 |
|
| path | デバイス名には、ハードウェアのコネクターの物理的な場所が含まれます。 |
|
| mac | デバイス名には MAC アドレスが含まれます。デフォルトでは、Red Hat Enterprise Linux はこのポリシーを使用しませんが、管理者はこのポリシーを有効にすることができます。 |
|
1.3. ネットワークインターフェイスの命名スキーム
udev デバイスマネージャーは、デバイスドライバーが提供する一定のインターフェイス属性を使用して、一貫したデバイス名を生成します。
新しいバージョンの udev によってサービスが特定のインターフェイス名を作成する方法が変更された場合、Red Hat は、新しいスキームバージョンを追加し、システム上の systemd.net-naming-scheme(7) man ページに詳細を記載します。デフォルトでは、Red Hat Enterprise Linux (RHEL) 10 は、ユーザーが RHEL のそれ以降のマイナーバージョンをインストールまたは更新した場合でも、rhel-10.0 命名スキームを使用します。
デフォルト以外のスキームを使用する場合は、ネットワークインターフェイスの命名スキームを切り替える ことができます。
さまざまなデバイスタイプおよびプラットフォームの命名スキームの詳細は、システム上の systemd.net-naming-scheme(7) man ページを参照してください。
1.4. 別のネットワークインターフェイス命名スキームへの切り替え
デフォルトでは、Red Hat Enterprise Linux (RHEL) 10 は、ユーザーが RHEL のそれ以降のマイナーバージョンをインストールまたは更新した場合でも、rhel-10.0 命名スキームを使用します。デフォルトの命名スキームはほとんどの状況に適していますが、次のような理由で別のスキームバージョンに切り替える必要がある場合もあります。
- 新しいスキームによりインターフェイス名にスロット番号などの追加属性を追加すると、デバイスをより適切に識別できるようになります。
-
新しいスキームにより、カーネルによって割り当てられたデバイス名 (
eth*) にudevがフォールバックするのを防ぐことができます。これは、ドライバーが 2 つ以上のインターフェイスに対して一意の名前を生成するのに十分な一意の属性を提供していない場合に発生します。
前提条件
- サーバーのコンソールにアクセスできる。
手順
ネットワークインターフェイスをリスト表示します。
# ip link show 2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...インターフェイスの MAC アドレスを記録します。
オプション: ネットワークインターフェイスの
ID_NET_NAMING_SCHEMEプロパティーを表示して、RHEL が現在使用している命名スキームを特定します。# udevadm info --query=property /sys/class/net/eno1 | grep "ID_NET_NAMING_SCHEME" ID_NET_NAMING_SCHEME=rhel-8.0このプロパティーは
loループバックデバイスでは使用できないことに注意してください。インストールされているすべてのカーネルのコマンドラインに
net.naming-scheme=<scheme>オプションを追加します。次に例を示します。# grubby --update-kernel=ALL --args=net.naming-scheme=rhel-8.4システムを再起動します。
# reboot記録した MAC アドレスに基づいて、命名スキームの変更により変更されたネットワークインターフェイスの新しい名前を特定します。
# ip link show 2: eno1np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...スキームを切り替えた後、
udevによって、指定された MAC アドレスを持つデバイスにeno1np0という名前が付けられます。これは以前はeno1という名前でした。以前の名前を持つインターフェイスを使用する NetworkManager 接続プロファイルを特定します。
# nmcli -f device,name connection show DEVICE NAME eno1 example_profile ...接続プロファイルの
connection.interface-nameプロパティーを新しいインターフェイス名に設定します。# nmcli connection modify example_profile connection.interface-name "eno1np0"接続プロファイルを再アクティブ化します。
# nmcli connection up example_profile
検証
ネットワークインターフェイスの
ID_NET_NAMING_SCHEMEプロパティーを表示して、RHEL が現在使用している命名スキームを特定します。# udevadm info --query=property /sys/class/net/eno1np0 | grep "ID_NET_NAMING_SCHEME" ID_NET_NAMING_SCHEME=_rhel-8.4
1.5. IBM Z プラットフォームでの予測可能な RoCE デバイス名の決定
Red Hat Enterprise Linux (RHEL) 8.7 以降では、udev デバイスマネージャーは IBM Z 上の RoCE インターフェイスの名前を次のように設定します。
-
ホストがデバイスに一意の識別子 (UID) を強制する場合、
udevはUID に基づく一貫したデバイス名 (例:eno<UID_in_decmal>) を割り当てます。 ホストがデバイスに UID を強制しない場合、設定によって動作が異なります。
-
デフォルトでは、
udevは予測できない名前をデバイスに使用します。 -
net.naming-scheme=rhel-8.7カーネルコマンドラインオプションを設定すると、udevはデバイスの機能識別子 (FID) に基づく一貫したデバイス名 (例:ens<FID_in_decmal>) を割り当てます。
-
デフォルトでは、
次の場合は、IBM Z 上の RoCE インターフェイスに、予測可能なデバイス名を手動で設定します。
ホストが RHEL 8.6 以前を実行しており、デバイスに UID を強制している。RHEL 8.7 以降のバージョンに更新する予定である。
RHEL 8.7 以降のバージョンに更新した後は、
udevは一貫したインターフェイス名を使用します。ただし、更新前に予測できないデバイス名を使用していた場合、NetworkManager 接続プロファイルは引き続きそれらの名前を使用し、影響を受けるプロファイルを更新するまでアクティベートできません。- ホストが RHEL 8.7 以降を実行しており、UID を強制していない。RHEL 9 にアップグレードする予定である。
udev ルールまたは systemd リンクファイルを使用してインターフェイスの名前を手動で変更する前に、予測可能なデバイス名を決定する必要があります。
前提条件
- RoCE コントローラーがシステムにインストールされている。
-
sysfsutilsパッケージがインストールされている。
手順
利用可能なネットワークデバイスを表示し、RoCE デバイスの名前を確認します。
# ip link show ... 2: enP5165p0s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 .../sys/ファイルシステム内のデバイスパスを表示します。# systool -c net -p Class = "net" Class Device = "enP5165p0s0" Class Device path = "/sys/devices/pci142d:00/142d:00:00.0/net/enP5165p0s0" Device = "142d:00:00.0" Device path = "/sys/devices/pci142d:00/142d:00:00.0"次の手順では、
Device pathフィールドに表示されているパスを使用します。<device_path>/uid_id_uniqueファイルの値を表示します。以下に例を示します。# cat /sys/devices/pci142d:00/142d:00:00.0/uid_id_unique表示された値は、UID の一意性が強制されるかどうかを示します。この値は後の手順で必要になります。
一意の識別子を決定します。
UID の一意性が強制されている場合 (
1)、<device_path>/uidファイルに保存されている UID を表示します。以下に例を示します。# cat /sys/devices/pci142d:00/142d:00:00.0/uidUID の一意性が強制されていない場合 (
0)、<device_path>/function_idファイルに保存されている FID を表示します。以下に例を示します。# cat /sys/devices/pci142d:00/142d:00:00.0/function_id
コマンドの出力には、UID 値と FID 値が 16 進数で表示されます。
16 進数の識別子を 10 進数に変換します。以下に例を示します。
# printf "%d\n" 0x00001402 5122予測可能なデバイス名を決定するには、UID の一意性が強制されるかどうかに基づいて、対応する接頭辞に 10 進数の形式の識別子を追加します。
-
UID の一意性が強制される場合は、
eno接頭辞に識別子を追加します (例:eno5122)。 -
UID の一意性が強制されない場合は、
ens接頭辞に識別子を追加します (例:ens5122)。
-
UID の一意性が強制される場合は、
1.6. インストール時のイーサネットインターフェイスの接頭辞のカスタマイズ
イーサネットインターフェイスにデフォルトのデバイス命名ポリシーを使用しない場合は、Red Hat Enterprise Linux (RHEL) のインストール時にカスタムデバイス接頭辞を設定できます。
Red Hat は、RHEL のインストール時に接頭辞を設定した場合にのみ、カスタマイズされたイーサネット接頭辞を持つシステムをサポートします。すでにデプロイされているシステムでの prefixdevname ユーティリティーの使用はサポートされていません。
インストール時にデバイス接頭辞を設定した場合、udev サービスはインストール後にイーサネットインターフェイスに <prefix><index> という形式を使用します。たとえば、接頭辞 net を設定すると、サービスはイーサネットインターフェイスに net0、net1 などの名前を割り当てます。
udev サービスはカスタム接頭辞にインデックスを追加し、既知のイーサネットインターフェイスのインデックス値を保存します。インターフェイスを追加すると、udev は、以前に割り当てたインデックス値より 1 大きいインデックス値を新しいインターフェイスに割り当てます。
前提条件
- 接頭辞が ASCII 文字で構成されている。
- 接頭辞が英数字の文字列である。
- 接頭辞が 16 文字未満である。
-
接頭辞が、
eth、eno、ens、emなどの他の既知のネットワークインターフェイス接頭辞と競合しない。
手順
- Red Hat Enterprise Linux インストールメディアを起動します。
ブートマネージャーで、次の手順を実行します。
-
Install Red Hat Enterprise Linux <version>エントリーを選択します。 - Tab を押してエントリーを編集します。
-
net.ifnames.prefix=<prefix>をカーネルオプションに追加します。 - Enter を押してインストールプログラムを起動します。
-
- Red Hat Enterprise Linux をインストールします。
検証
インターフェイス名を確認するには、ネットワークインターフェイスを表示します。
# ip link show ... 2: net0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...
1.7. udev ルールを使用したユーザー定義のネットワークインターフェイス名の設定
udev ルールを使用して、組織の要件を反映したカスタムネットワークインターフェイス名を実装できます。
手順
名前を変更するネットワークインターフェイスを特定します。
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...インターフェイスの MAC アドレスを記録します。
インターフェイスのデバイスタイプ ID を表示します。
# cat /sys/class/net/enp1s0/type 1/etc/udev/rules.d/70-persistent-net.rulesファイルを作成し、名前を変更する各インターフェイスのルールを追加します。SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="<MAC_address>",ATTR{type}=="<device_type_id>",NAME="<new_interface_name>"重要ブートプロセス中に一貫したデバイス名が必要な場合は、ファイル名として
70-persistent-net.rulesのみを使用してください。RAM ディスクイメージを再生成すると、dracutユーティリティーはこの名前のファイルをinitrdイメージに追加します。たとえば、次のルールを使用して、MAC アドレス
00:00:5e:00:53:1aのインターフェイスの名前をprovider0に変更します。SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="00:00:5e:00:53:1a",ATTR{type}=="1",NAME="provider0"オプション:
initrdRAM ディスクイメージを再生成します。# dracut -fこの手順は、RAM ディスクにネットワーク機能が必要な場合にのみ必要です。たとえば、ルートファイルシステムが iSCSI などのネットワークデバイスに保存されている場合がこれに当てはまります。
名前を変更するインターフェイスを使用する NetworkManager 接続プロファイルを特定します。
# nmcli -f device,name connection show DEVICE NAME enp1s0 example_profile ...接続プロファイルの
connection.interface-nameプロパティーの設定を解除します。# nmcli connection modify example_profile connection.interface-name ""一時的に、新しいインターフェイス名と以前のインターフェイス名の両方に一致するように接続プロファイルを設定します。
# nmcli connection modify example_profile match.interface-name "provider0 enp1s0"システムを再起動します。
# rebootリンクファイルで指定した MAC アドレスを持つデバイスの名前が
Provider0に変更されていることを確認します。# ip link show provider0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...新しいインターフェイス名のみと一致するように接続プロファイルを設定します。
# nmcli connection modify example_profile match.interface-name "provider0"これで、接続プロファイルから古いインターフェイス名が削除されました。
接続プロファイルを再アクティブ化します。
# nmcli connection up example_profile
1.8. systemd リンクファイルを使用したユーザー定義のネットワークインターフェイス名の設定
systemd リンクファイルを使用して、組織の要件を反映したカスタムネットワークインターフェイス名を実装できます。
前提条件
- NetworkManager がこのインターフェイスを管理していない。または、対応する接続プロファイルが キーファイル形式 を使用している。
手順
名前を変更するネットワークインターフェイスを特定します。
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...インターフェイスの MAC アドレスを記録します。
/etc/systemd/network/ディレクトリーがない場合は作成します。# mkdir -p /etc/systemd/network/名前を変更するインターフェイスごとに、次の内容を含む
70-*.linkファイルを/etc/systemd/network/ディレクトリーに作成します。[Match] MACAddress=<MAC_address> [Link] Name=<new_interface_name>重要udevのルールベースのソリューションとファイル名の一貫性を保つために、接頭辞70-を付けたファイル名を使用してください。たとえば、MAC アドレス
00:00:5e:00:53:1aのインターフェイスの名前をprovider0に変更するには、次の内容を含む/etc/systemd/network/70-provider0.linkファイルを作成します。[Match] MACAddress=00:00:5e:00:53:1a [Link] Name=provider0オプション:
initrdRAM ディスクイメージを再生成します。# dracut -fこの手順は、RAM ディスクにネットワーク機能が必要な場合にのみ必要です。たとえば、ルートファイルシステムが iSCSI などのネットワークデバイスに保存されている場合がこれに当てはまります。
名前を変更するインターフェイスを使用する NetworkManager 接続プロファイルを特定します。
# nmcli -f device,name connection show DEVICE NAME enp1s0 example_profile ...接続プロファイルの
connection.interface-nameプロパティーの設定を解除します。# nmcli connection modify example_profile connection.interface-name ""一時的に、新しいインターフェイス名と以前のインターフェイス名の両方に一致するように接続プロファイルを設定します。
# nmcli connection modify example_profile match.interface-name "provider0 enp1s0"システムを再起動します。
# rebootリンクファイルで指定した MAC アドレスを持つデバイスの名前が
Provider0に変更されていることを確認します。# ip link show provider0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...新しいインターフェイス名のみと一致するように接続プロファイルを設定します。
# nmcli connection modify example_profile match.interface-name "provider0"これで、接続プロファイルから古いインターフェイス名が削除されました。
接続プロファイルを再度アクティベートします。
# nmcli connection up example_profile
1.9. systemd リンクファイルを使用したネットワークインターフェイスへの代替名の割り当て
代替インターフェイス名の命名を使用すると、カーネルはネットワークインターフェイスに追加の名前を割り当てることができます。この代替名は、ネットワークインターフェイス名を必要とするコマンドで通常のインターフェイス名と同じように使用できます。
前提条件
- 代替名に ASCII 文字が使用されている。
- 代替名が 128 文字未満である。
手順
ネットワークインターフェイス名とその MAC アドレスを表示します。
# ip link show ... enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff ...代替名を割り当てるインターフェイスの MAC アドレスを記録します。
/etc/systemd/network/ディレクトリーがない場合は作成します。# mkdir -p /etc/systemd/network/代替名が必要なインターフェイスごとに、
/etc/systemd/network/ディレクトリーに、一意の名前と.link接尾辞を持つ/usr/lib/systemd/network/99-default.linkファイルのコピーを作成します。次に例を示します。# cp /usr/lib/systemd/network/99-default.link /etc/systemd/network/98-lan.link前のステップで作成したファイルを変更します。
[Match]セクションを次のように書き換え、AlternativeNameエントリーを[Link]セクションに追加します。[Match] MACAddress=<MAC_address> [Link] ... AlternativeName=<alternative_interface_name_1> AlternativeName=<alternative_interface_name_2> AlternativeName=<alternative_interface_name_n>たとえば、次の内容を含む
/etc/systemd/network/70-altname.linkファイルを作成して、MAC アドレス00:00:5e:00:53:1aのインターフェイスに代替名としてproviderを割り当てます。[Match] MACAddress=00:00:5e:00:53:1a [Link] NamePolicy=kernel database onboard slot path AlternativeNamesPolicy=database onboard slot path MACAddressPolicy=persistent AlternativeName=providerinitrdRAM ディスクイメージを再生成します。# dracut -fシステムを再起動します。
# reboot
検証
代替インターフェイス名を使用します。たとえば、代替名
providerを使用してデバイスの IP アドレス設定を表示します。# ip address show provider 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:00:5e:00:53:1a brd ff:ff:ff:ff:ff:ff altname provider ...
第2章 イーサネット接続の設定
NetworkManager は、ホストにインストールされている各イーサネットアダプターの接続プロファイルを作成します。デフォルトでは、このプロファイルは IPv4 接続と IPv6 接続の両方に DHCP を使用します。次の場合は、この自動作成されたプロファイルを変更するか、新しいプロファイルを追加してください。
- ネットワークに、静的 IP アドレス設定などのカスタム設定が必要な場合
- ホストが異なるネットワーク間をローミングするため、複数のプロファイルが必要な場合
Red Hat Enterprise Linux は、イーサネット接続を設定するためのさまざまなオプションを管理者に提供します。以下に例を示します。
-
nmcliを使用して、コマンドラインで接続を設定します。 -
nmtuiを使用して、テキストベースのユーザーインターフェイスで接続を設定します。 -
GNOME Settings メニューまたは
nm-connection-editorアプリケーションを使用して、グラフィカルインターフェイスで接続を設定します。 - nmstatectl を使用して、Nmstate API を介して接続を設定する。
- RHEL システムロールを使用して、1 つまたは複数のホストで接続の設定を自動化します。
Microsoft Azure クラウドで実行しているホストでイーサネット接続を手動で設定する場合は、cloud-init サービスを無効にするか、クラウド環境から取得したネットワーク設定を無視するように設定します。それ以外の場合は、cloud-init は、手動で設定したネットワーク設定を次回の再起動時に上書きされます。
2.1. nmcli を使用したイーサネット接続の設定
イーサネット経由でホストをネットワークに接続する場合は、nmcli ユーティリティーを使用してコマンドラインで接続の設定を管理できます。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
手順
NetworkManager 接続プロファイルをリストします。
# nmcli connection show NAME UUID TYPE DEVICE Wired connection 1 a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0デフォルトでは、NetworkManager はホスト内の各 NIC のプロファイルを作成します。この NIC を特定のネットワークにのみ接続する予定がある場合は、自動作成されたプロファイルを調整してください。この NIC をさまざまな設定のネットワークに接続する予定がある場合は、ネットワークごとに個別のプロファイルを作成してください。
追加の接続プロファイルを作成する場合は、次のように実行します。
# nmcli connection add con-name <connection-name> ifname <device-name> type ethernet既存のプロファイルを変更するには、この手順をスキップしてください。
オプション: 接続プロファイルの名前を変更します。
# nmcli connection modify "Wired connection 1" connection.id "Internal-LAN"ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
接続プロファイルの現在の設定を表示します。
# nmcli connection show Internal-LAN ... connection.interface-name: enp1s0 connection.autoconnect: yes ipv4.method: auto ipv6.method: auto ...IPv4 を設定します。
DHCP を使用するには、次のように実行します。
# nmcli connection modify Internal-LAN ipv4.method autoipv4.methodがすでにauto(デフォルト) に設定されている場合は、この手順をスキップしてください。静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、次のように実行します。
# nmcli connection modify Internal-LAN ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv4.gateway 192.0.2.254 ipv4.dns 192.0.2.200 ipv4.dns-search example.com
IPv6 設定を行います。
ステートレスアドレス自動設定 (SLAAC) を使用するには、次のように実行します。
# nmcli connection modify Internal-LAN ipv6.method autoipv6.methodがすでにauto(デフォルト) に設定されている場合は、この手順をスキップしてください。静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、次のように実行します。
# nmcli connection modify Internal-LAN ipv6.method manual ipv6.addresses 2001:db8:1::fffe/64 ipv6.gateway 2001:db8:1::fffe ipv6.dns 2001:db8:1::ffbb ipv6.dns-search example.com
プロファイルの他の設定をカスタマイズするには、次のコマンドを使用します。
# nmcli connection modify <connection-name> <setting> <value>値はスペースまたはセミコロンで引用符で囲みます。
プロファイルをアクティブ化します。
# nmcli connection up Internal-LAN
検証
NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
トラブルシューティング
- ネットワークケーブルがホストとスイッチに差し込まれていることを確認します。
- リンク障害がこのホストだけに存在するか、同じスイッチに接続された他のホストにも存在するかを確認します。
- ネットワークケーブルとネットワークインターフェイスが予想どおりに機能していることを確認します。ハードウェア診断手順を実行し、不具合のあるケーブルとネットワークインターフェイスカードを交換します。
- ディスクの設定がデバイスの設定と一致しない場合は、NetworkManager を起動するか再起動して、インメモリー接続を作成することで、デバイスの設定を反映します。この問題の詳細と回避方法は、Red Hat ナレッジベースソリューション NetworkManager duplicates a connection after restart of NetworkManager service を参照してください。
2.2. nmcli インタラクティブエディターを使用したイーサネット接続の設定
イーサネット経由でホストをネットワークに接続する場合は、nmcli ユーティリティーを使用してコマンドラインで接続の設定を管理できます。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
手順
NetworkManager 接続プロファイルをリストします。
# nmcli connection show NAME UUID TYPE DEVICE Wired connection 1 a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0デフォルトでは、NetworkManager はホスト内の各 NIC のプロファイルを作成します。この NIC を特定のネットワークにのみ接続する予定がある場合は、自動作成されたプロファイルを調整してください。この NIC をさまざまな設定のネットワークに接続する予定がある場合は、ネットワークごとに個別のプロファイルを作成してください。
nmcliインタラクティブモードで起動します。追加の接続プロファイルを作成するには、次のように実行します。
# nmcli connection edit type ethernet con-name "<connection-name>"既存の接続プロファイルを変更するには、次のように実行します。
# nmcli connection edit con-name "<connection-name>"
オプション: 接続プロファイルの名前を変更します。
nmcli> set connection.id Internal-LANホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
nmcliが引用符を名前の一部としてしまうことを避けるため、スペースを含む ID を設定する場合は引用符を使用しないでください。たとえば、Example Connectionを ID として設定するには、set connection.id Example Connectionと入力します。接続プロファイルの現在の設定を表示します。
nmcli> print ... connection.interface-name: enp1s0 connection.autoconnect: yes ipv4.method: auto ipv6.method: auto ...新しい接続プロファイルを作成する場合は、ネットワークインターフェイスを設定します。
nmcli> set connection.interface-name enp1s0IPv4 を設定します。
DHCP を使用するには、次のように実行します。
nmcli> set ipv4.method autoipv4.methodがすでにauto(デフォルト) に設定されている場合は、この手順をスキップしてください。静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、次のように実行します。
nmcli> ipv4.addresses 192.0.2.1/24 Do you also want to set 'ipv4.method' to 'manual'? [yes]: yes nmcli> ipv4.gateway 192.0.2.254 nmcli> ipv4.dns 192.0.2.200 nmcli> ipv4.dns-search example.com
IPv6 設定を行います。
ステートレスアドレス自動設定 (SLAAC) を使用するには、次のように実行します。
nmcli> set ipv6.method autoipv6.methodがすでにauto(デフォルト) に設定されている場合は、この手順をスキップしてください。静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、次のように実行します。
nmcli> ipv6.addresses 2001:db8:1::fffe/64 Do you also want to set 'ipv6.method' to 'manual'? [yes]: yes nmcli> ipv6.gateway 2001:db8:1::fffe nmcli> ipv6.dns 2001:db8:1::ffbb nmcli> ipv6.dns-search example.com
接続をアクティベートして保存します。
nmcli> save persistentインタラクティブモードを終了します。
nmcli> quit
検証
NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
トラブルシューティング
- ネットワークケーブルがホストとスイッチに差し込まれていることを確認します。
- リンク障害がこのホストだけに存在するか、同じスイッチに接続された他のホストにも存在するかを確認します。
- ネットワークケーブルとネットワークインターフェイスが予想どおりに機能していることを確認します。ハードウェア診断手順を実行し、不具合のあるケーブルとネットワークインターフェイスカードを交換します。
- ディスクの設定がデバイスの設定と一致しない場合は、NetworkManager を起動するか再起動して、インメモリー接続を作成することで、デバイスの設定を反映します。この問題の詳細と回避方法は、Red Hat ナレッジベースソリューション NetworkManager duplicates a connection after restart of NetworkManager service を参照してください。
2.3. nmtui を使用したイーサネット接続の設定
イーサネット経由でホストをネットワークに接続する場合は、nmtui アプリケーションを使用して、テキストベースのユーザーインターフェイスで接続の設定を管理できます。nmtui では、グラフィカルインターフェイスを使用せずに、新しいプロファイルの作成や、ホスト上の既存のプロファイルの更新を行います。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
手順
接続に使用するネットワークデバイス名がわからない場合は、使用可能なデバイスを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unavailable -- ...nmtuiを開始します。# nmtui- Edit a connection 選択し、Enter を押します。
新しい接続プロファイルを追加するか、既存の接続プロファイルを変更するかを選択します。
新しいプロファイルを作成するには、以下を実行します。
- Add を押します。
- ネットワークタイプのリストから Ethernet を選択し、Enter を押します。
- 既存のプロファイルを変更するには、リストからプロファイルを選択し、Enter を押します。
オプション: 接続プロファイルの名前を更新します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
- 新しい接続プロファイルを作成する場合は、ネットワークデバイス名を connection フィールドに入力します。
環境に応じて、
IPv4 configurationおよびIPv6 configuration領域に IP アドレス設定を設定します。これを行うには、これらの領域の横にあるボタンを押して、次を選択します。- この接続に IP アドレスが必要ない場合は、Disabled にします。
- DHCP サーバーが IP アドレスをこの NIC に動的に割り当てる場合は、Automatic にします。
ネットワークで静的 IP アドレス設定が必要な場合は、Manual にします。この場合、さらにフィールドに入力する必要があります。
- 設定するプロトコルの横にある Show を押して、追加のフィールドを表示します。
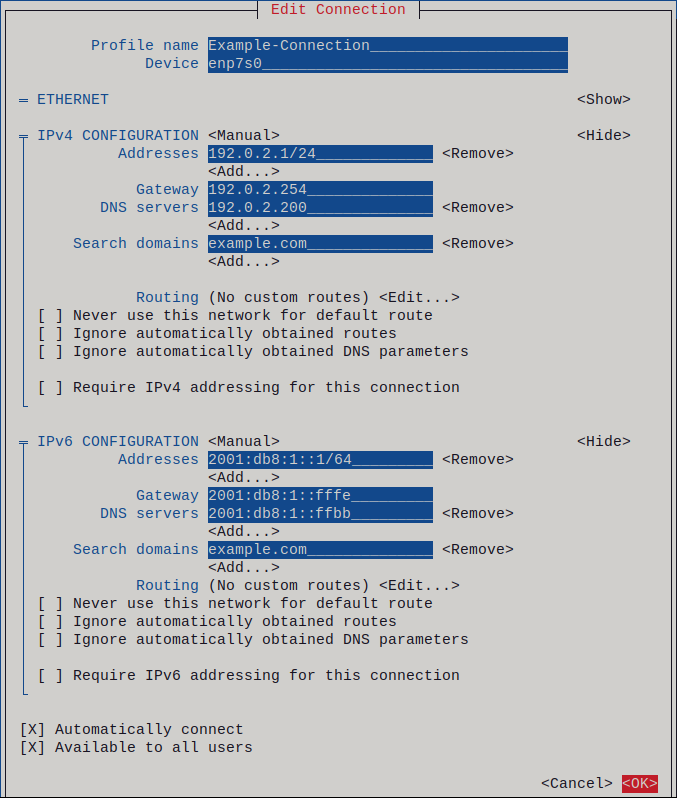
Addresses の横にある Add を押して、IP アドレスとサブネットマスクを Classless Inter-Domain Routing (CIDR) 形式で入力します。
サブネットマスクを指定しない場合、NetworkManager は IPv4 アドレスに
/32サブネットマスクを設定し、IPv6 アドレスに/64サブネットマスクを設定します。- デフォルトゲートウェイのアドレスを入力します。
- DNS servers の横にある Add を押して、DNS サーバーのアドレスを入力します。
- Search domains の横にある Add を押して、DNS 検索ドメインを入力します。
図2.1 静的 IP アドレス設定によるイーサネット接続の例
- OK を押すと、新しい接続が作成され、自動的にアクティブ化されます。
- Back を押してメインメニューに戻ります。
-
Quit を選択し、Enter キーを押して
nmtuiアプリケーションを閉じます。
検証
NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
トラブルシューティング
- ネットワークケーブルがホストとスイッチに差し込まれていることを確認します。
- リンク障害がこのホストだけに存在するか、同じスイッチに接続された他のホストにも存在するかを確認します。
- ネットワークケーブルとネットワークインターフェイスが予想どおりに機能していることを確認します。ハードウェア診断手順を実行し、不具合のあるケーブルとネットワークインターフェイスカードを交換します。
- ディスクの設定がデバイスの設定と一致しない場合は、NetworkManager を起動するか再起動して、インメモリー接続を作成することで、デバイスの設定を反映します。この問題の詳細と回避方法は、Red Hat ナレッジベースソリューション NetworkManager duplicates a connection after restart of NetworkManager service を参照してください。
2.4. control-center によるイーサネット接続の設定
イーサネット経由でホストをネットワークに接続する場合は、GNOME 設定メニューを使用して、グラフィカルインターフェイスで接続の設定を管理できます。
control-center は、nm-connection-editor アプリケーションまたは nmcli ユーティリティーほど多くの設定オプションに対応していないことに注意してください。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
- GNOME がインストールされている。
手順
-
Super キーを押して
Settingsを入力し、Enter を押します。 - 左側のナビゲーションにある Network を選択します。
新しい接続プロファイルを追加するか、既存の接続プロファイルを変更するかを選択します。
- 新しいプロファイルを作成するには、Ethernet エントリーの横にある ボタンをクリックします。
- 既存のプロファイルを変更するには、プロファイルエントリーの横にある歯車アイコンをクリックします。
オプション: Identity タブで、接続プロファイルの名前を更新します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
環境に応じて、IPv4 タブと IPv6 タブで IP アドレス設定を設定します。
-
DHCP または IPv6 ステートレスアドレス自動設定 (SLAAC) を使用するには、方法として
Automatic (DHCP)を選択します (デフォルト)。 静的 IP アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、方法として
Manualを選択し、タブのフィールドに入力します。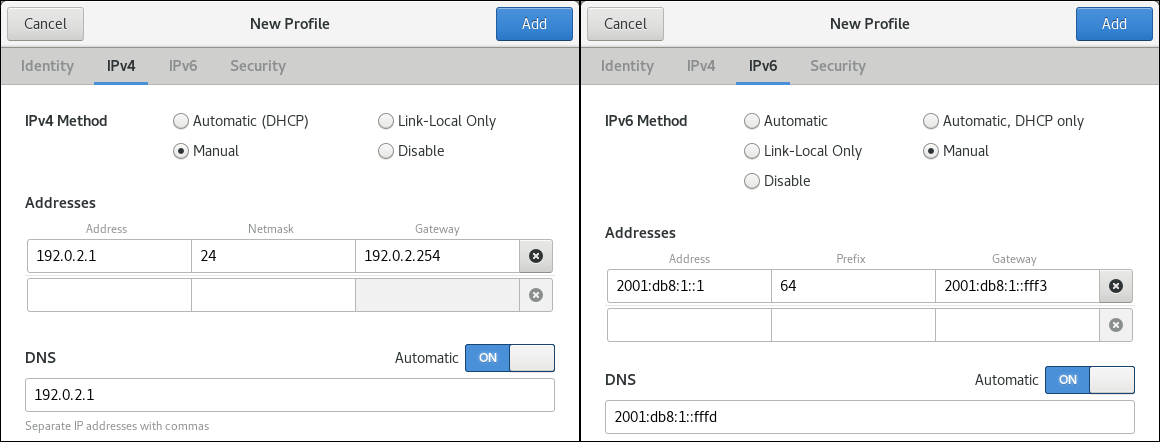
-
DHCP または IPv6 ステートレスアドレス自動設定 (SLAAC) を使用するには、方法として
接続プロファイルを追加するか変更するかに応じて、 または ボタンをクリックして接続を保存します。
GNOME の
control-centerは、接続を自動的にアクティブにします。
検証
NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
トラブルシューティングの手順
- ネットワークケーブルがホストとスイッチに差し込まれていることを確認します。
- リンク障害がこのホストだけに存在するか、同じスイッチに接続された他のホストにも存在するかを確認します。
- ネットワークケーブルとネットワークインターフェイスが予想どおりに機能していることを確認します。ハードウェア診断手順を実行し、不具合のあるケーブルとネットワークインターフェイスカードを交換します。
- ディスクの設定がデバイスの設定と一致しない場合は、NetworkManager を起動するか再起動して、インメモリー接続を作成することで、デバイスの設定を反映します。この問題の詳細と回避方法は、Red Hat ナレッジベースソリューション NetworkManager duplicates a connection after restart of NetworkManager service を参照してください。
2.5. nm-connection-editor を使用したイーサネット接続の設定
イーサネット経由でホストをネットワークに接続する場合は、nm-connection-editor アプリケーションを使用して、グラフィカルインターフェイスで接続の設定を管理できます。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
- GNOME がインストールされている。
手順
ターミナルを開き、次のコマンドを入力します。
$ nm-connection-editor新しい接続プロファイルを追加するか、既存の接続プロファイルを変更するかを選択します。
新しいプロファイルを作成するには、以下を実行します。
- ボタンをクリックします。
- 接続タイプとして Ethernet を選択し、 をクリックします。
- 既存のプロファイルを変更するには、プロファイルエントリーをダブルクリックします。
オプション: Connection フィールドでプロファイルの名前を更新します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
新しいプロファイルを作成する場合は、
Ethernetタブでデバイスを選択します。
環境に応じて、IPv4 Settings タブと IPv6 Settings タブで IP アドレス設定を設定します。
-
DHCP または IPv6 ステートレスアドレス自動設定 (SLAAC) を使用するには、方法として
Automatic (DHCP)を選択します (デフォルト)。 静的 IP アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および検索ドメインを設定するには、方法として
Manualを選択し、タブのフィールドに入力します。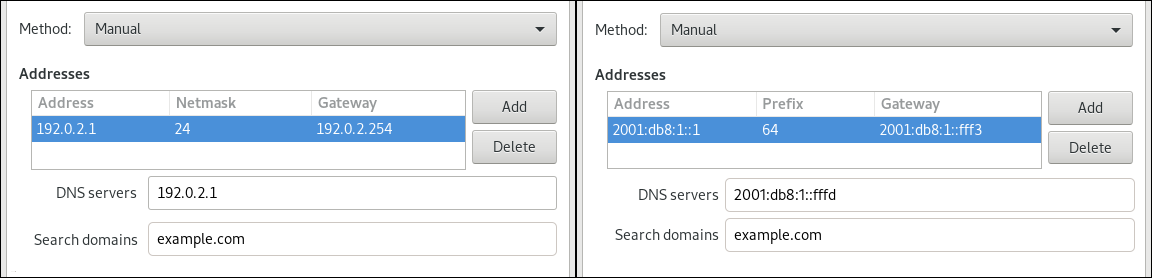
-
DHCP または IPv6 ステートレスアドレス自動設定 (SLAAC) を使用するには、方法として
- をクリックします。
- nm-connection-editor を閉じます。
検証
NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
トラブルシューティングの手順
- ネットワークケーブルがホストとスイッチに差し込まれていることを確認します。
- リンク障害がこのホストだけに存在するか、同じスイッチに接続された他のホストにも存在するかを確認します。
- ネットワークケーブルとネットワークインターフェイスが予想どおりに機能していることを確認します。ハードウェア診断手順を実行し、不具合のあるケーブルとネットワークインターフェイスカードを交換します。
- ディスクの設定がデバイスの設定と一致しない場合は、NetworkManager を起動するか再起動して、インメモリー接続を作成することで、デバイスの設定を反映します。この問題の詳細と回避方法は、Red Hat ナレッジベースソリューション NetworkManager duplicates a connection after restart of NetworkManager service を参照してください。
2.6. nmstatectl でインターフェイス名を指定して静的 IP アドレスによるイーサネット接続を設定する
nmstatectl ユーティリティーを使用して、Nmstate API を介してイーサネット接続を設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
Nmstate を使用すると、静的 IP アドレス、ゲートウェイ、および DNS 設定を使用してイーサネット接続を設定し、それらを指定のインターフェイス名に割り当てることができます。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
-
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイル (例:
~/create-ethernet-profile.yml) を作成します。--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: enp1s0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: enp1s0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbこれらの設定では、次の設定を使用して
enp1s0デバイスのイーサネット接続プロファイルを定義します。-
静的 IPv4 アドレス:
192.0.2.1(サブネットマスクが/24) -
静的 IPv6 アドレス:
2001:db8:1::1(サブネットマスクが/64) -
IPv4 デフォルトゲートウェイ -
192.0.2.254 -
IPv6 デフォルトゲートウェイ -
2001:db8:1::fffe -
IPv4 DNS サーバー -
192.0.2.200 -
IPv6 DNS サーバー -
2001:db8:1::ffbb -
DNS 検索ドメイン -
example.com
-
静的 IPv4 アドレス:
設定をシステムに適用します。
# nmstatectl apply ~/create-ethernet-profile.yml
検証
現在の状態を YAML 形式で表示します。
# nmstatectl show enp1s0NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
2.7. network RHEL システムロールとインターフェイス名を使用した静的 IP アドレスでのイーサネット接続の設定
Red Hat Enterprise Linux ホストをイーサネットネットワークに接続するには、ネットワークデバイスの NetworkManager 接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用すると、静的 IP アドレス、ゲートウェイ、および DNS 設定を使用してイーサネット接続を設定し、それらを指定のインターフェイス名に割り当てることができます。
通常、管理者は Playbook を再利用します。Ansible が静的 IP アドレスを割り当てるホストごとに、個別の Playbook を管理することはありません。そうすることにより、Playbook 内の変数を使用し、外部ファイルで設定を維持できます。その結果、複数のホストに個別の設定を動的に割り当てるために必要な Playbook が 1 つだけになります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーの構成に物理または仮想イーサネットデバイスが存在する。
- 管理対象ノードが NetworkManager を使用してネットワークを設定している。
手順
~/inventoryファイルを編集し、ホストエントリーにホスト固有の設定を追加します。managed-node-01.example.com interface=enp1s0 ip_v4=192.0.2.1/24 ip_v6=2001:db8:1::1/64 gateway_v4=192.0.2.254 gateway_v6=2001:db8:1::fffe managed-node-02.example.com interface=enp1s0 ip_v4=192.0.2.2/24 ip_v6=2001:db8:1::2/64 gateway_v4=192.0.2.254 gateway_v6=2001:db8:1::fffe次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com,managed-node-02.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: "{{ interface }}" interface_name: "{{ interface }}" type: ethernet autoconnect: yes ip: address: - "{{ ip_v4 }}" - "{{ ip_v6 }}" gateway4: "{{ gateway_v4 }}" gateway6: "{{ gateway_v6 }}" dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com state: upこの Playbook は、インベントリーファイルから各ホストの特定の値を動的に読み取り、すべてのホストで同じ設定に対して Playbook 内の静的な値を使用します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、アクティブなネットワーク設定を確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.8. network RHEL システムロールとデバイスパスを使用した静的 IP アドレスでのイーサネット接続の設定
Red Hat Enterprise Linux ホストをイーサネットネットワークに接続するには、ネットワークデバイスの NetworkManager 接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用すると、静的 IP アドレス、ゲートウェイ、および DNS 設定を使用してイーサネット接続を設定し、それらを名前ではなくパスに基づいてデバイスに割り当てることができます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーの構成に物理または仮想イーサネットデバイスが存在する。
- 管理対象ノードが NetworkManager を使用してネットワークを設定している。
-
デバイスのパスがわかっている。
udevadm info /sys/class/net/<device_name> | grep ID_PATH=コマンドを使用すると、デバイスパスを表示できます。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: example match: path: - pci-0000:00:0[1-3].0 - '&!pci-0000:00:02.0' type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com state: upサンプル Playbook で指定されている設定は次のとおりです。
match-
設定を適用するために満たす必要がある条件を定義します。この変数は
pathオプションでのみ使用できます。 path-
デバイスの永続パスを定義します。固定パスまたは式の形式で設定できます。値には修飾子とワイルドカードを含めることができます。この例では、PCI ID
0000:00:0[1-3].0に一致するデバイスには設定を適用しますが、0000:00:02.0に一致するデバイスには適用しません。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、アクティブなネットワーク設定を確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.9. nmstatectl でインターフェイス名を指定して動的 IP アドレスによる Ethernet 接続を設定する
nmstatectl ユーティリティーを使用して、Nmstate API を介してイーサネット接続を設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
Nmstate を使用すると、DHCP サーバーおよび IPv6 ステートレスアドレス自動設定 (SLAAC) から IP アドレス、ゲートウェイ、および DNS 設定を取得するイーサネット接続を設定できます。指定したインターフェイス名に接続プロファイルを割り当てることができます。
前提条件
- サーバーの構成に物理または仮想イーサネットネットワークインターフェイスコントローラー (NIC) が存在する。
- DHCP サーバーをネットワークで使用できる。
-
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイル (例:
~/create-ethernet-profile.yml) を作成します。--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true auto-dns: true auto-gateway: true auto-routes: true dhcp: true ipv6: enabled: true auto-dns: true auto-gateway: true auto-routes: true autoconf: true dhcp: trueこれらの設定では、
enp1s0デバイスのイーサネット接続プロファイルを定義します。接続では、DHCP サーバーと IPv6 ステートレスアドレス自動設定 (SLAAC) から、IPv4 アドレス、IPv6 アドレス、デフォルトゲートウェイ、ルート、DNS サーバー、および検索ドメインを取得します。設定をシステムに適用します。
# nmstatectl apply ~/create-ethernet-profile.yml
検証
現在の状態を YAML 形式で表示します。
# nmstatectl show enp1s0NIC の IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:17:b8:b6 brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft forever inet6 2001:db8:1::fffe/64 scope global noprefixroute valid_lft forever preferred_lft foreverIPv4 デフォルトゲートウェイを表示します。
# ip route show default default via 192.0.2.254 dev enp1s0 proto static metric 102IPv6 デフォルトゲートウェイを表示します。
# ip -6 route show default default via 2001:db8:1::fffe dev enp1s0 proto static metric 102 pref mediumDNS 設定を表示します。
# cat /etc/resolv.conf search example.com nameserver 192.0.2.200 nameserver 2001:db8:1::ffbb複数の接続プロファイルが同時にアクティブな場合、
nameserverエントリーの順序は、これらのプロファイルの DNS 優先度の値と接続タイプによって異なります。pingユーティリティーを使用して、このホストがパケットを他のホストに送信できることを確認します。# ping <host-name-or-IP-address>
2.10. network RHEL システムロールとインターフェイス名を使用した動的 IP アドレスでのイーサネット接続の設定
Red Hat Enterprise Linux ホストをイーサネットネットワークに接続するには、ネットワークデバイスの NetworkManager 接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用すると、DHCP サーバーおよび IPv6 ステートレスアドレス自動設定 (SLAAC) から IP アドレス、ゲートウェイ、および DNS 設定を取得するイーサネット接続を設定できます。このロールを使用すると、指定のインターフェイス名に接続プロファイルを割り当てることができます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーの構成に物理または仮想イーサネットデバイスが存在する。
- ネットワーク内で DHCP サーバーと SLAAC が利用できる。
- 管理対象ノードが NetworkManager サービスを使用してネットワークを設定している。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 interface_name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes state: upサンプル Playbook で指定されている設定は次のとおりです。
dhcp4: yes- DHCP、PPP、または同様のサービスからの自動 IPv4 アドレス割り当てを有効にします。
auto6: yes-
IPv6 自動設定を有効にします。デフォルトでは、NetworkManager はルーター広告を使用します。ルーターが
managedフラグを通知すると、NetworkManager は DHCPv6 サーバーに IPv6 アドレスと接頭辞を要求します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、インターフェイスが IP アドレスと DNS 設定を受信したことを確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.11. network RHEL システムロールとデバイスパスを使用した動的 IP アドレスでのイーサネット接続の設定
Red Hat Enterprise Linux ホストをイーサネットネットワークに接続するには、ネットワークデバイスの NetworkManager 接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用すると、DHCP サーバーおよび IPv6 ステートレスアドレス自動設定 (SLAAC) から IP アドレス、ゲートウェイ、および DNS 設定を取得するイーサネット接続を設定できます。このロールにより、インターフェイス名ではなくパスに基づいてデバイスに接続プロファイルを割り当てることができます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーの構成に物理または仮想イーサネットデバイスが存在する。
- ネットワーク内で DHCP サーバーと SLAAC が利用できる。
- 管理対象ホストは、NetworkManager を使用してネットワークを設定します。
-
デバイスのパスがわかっている。
udevadm info /sys/class/net/<device_name> | grep ID_PATH=コマンドを使用すると、デバイスパスを表示できます。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: example match: path: - pci-0000:00:0[1-3].0 - '&!pci-0000:00:02.0' type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes state: upサンプル Playbook で指定されている設定は次のとおりです。
match: path-
設定を適用するために満たす必要がある条件を定義します。この変数は
pathオプションでのみ使用できます。 path: <path_and_expressions>-
デバイスの永続パスを定義します。固定パスまたは式の形式で設定できます。値には修飾子とワイルドカードを含めることができます。この例では、PCI ID
0000:00:0[1-3].0に一致するデバイスには設定を適用しますが、0000:00:02.0に一致するデバイスには適用しません。 dhcp4: yes- DHCP、PPP、または同様のサービスからの自動 IPv4 アドレス割り当てを有効にします。
auto6: yes-
IPv6 自動設定を有効にします。デフォルトでは、NetworkManager はルーター広告を使用します。ルーターが
managedフラグを通知すると、NetworkManager は DHCPv6 サーバーに IPv6 アドレスと接頭辞を要求します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、インターフェイスが IP アドレスと DNS 設定を受信したことを確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { "address": "192.0.2.1", "alias": "enp1s0", "broadcast": "192.0.2.255", "gateway": "192.0.2.254", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "netmask": "255.255.255.0", "network": "192.0.2.0", "prefix": "24", "type": "ether" }, "ansible_default_ipv6": { "address": "2001:db8:1::1", "gateway": "2001:db8:1::fffe", "interface": "enp1s0", "macaddress": "52:54:00:17:b8:b6", "mtu": 1500, "prefix": "64", "scope": "global", "type": "ether" }, ... "ansible_dns": { "nameservers": [ "192.0.2.1", "2001:db8:1::ffbb" ], "search": [ "example.com" ] }, ...
2.12. インターフェイス名による単一の接続プロファイルを使用した複数のイーサネットインターフェイスの設定
ほとんどの場合、1 つの接続プロファイルには 1 つのネットワークデバイスの設定が含まれています。ただし、接続プロファイルでインターフェイス名を設定する場合、NetworkManager はワイルドカードもサポートします。ホストが動的 IP アドレス割り当てを使用してイーサネットネットワーク間をローミングする場合、この機能を使用して、複数のイーサネットインターフェイスに使用できる単一の接続プロファイルを作成できます。
前提条件
- サーバーの構成に物理または仮想イーサネットデバイスが複数存在する。
- DHCP サーバーをネットワークで使用できる。
- ホストに接続プロファイルが存在しません。
手順
enpで始まるすべてのインターフェイス名に適用される接続プロファイルを追加します。# nmcli connection add con-name "Wired connection 1" connection.multi-connect multiple match.interface-name enp* type ethernet
検証
単一接続プロファイルのすべての設定を表示します。
# nmcli connection show "Wired connection 1" connection.id: Wired connection 1 ... connection.multi-connect: 3 (multiple) match.interface-name: enp* ...3は、インターフェイスが特定の瞬間に複数回アクティブになる可能性があることを示します。接続プロファイルは、match.interface-nameパラメーターのパターンに一致するすべてのデバイスを使用するため、接続プロファイルには同じ Universally Unique Identifier (UUID) があります。接続のステータスを表示します。
# nmcli connection show NAME UUID TYPE DEVICE ... Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp7s0 Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp8s0 Wired connection 1 6f22402e-c0cc-49cf-b702-eaf0cd5ea7d1 ethernet enp9s0
2.13. PCI ID を使用した複数のイーサネットインターフェイスの単一接続プロファイルの設定
PCI ID は、システムに接続されているデバイスの一意の識別子です。接続プロファイルは、PCI ID のリストに基づいてインターフェイスを照合することにより、複数のデバイスを追加します。この手順を使用して、複数のデバイス PCI ID を単一の接続プロファイルに接続できます。
前提条件
- サーバーの構成に物理または仮想イーサネットデバイスが複数存在する。
- DHCP サーバーをネットワークで使用できる。
- ホストに接続プロファイルが存在しません。
手順
デバイスパスを特定します。たとえば、
enpで始まるすべてのインターフェイスのデバイスパスを表示するには、次のように実行します。# udevadm info /sys/class/net/enp* | grep ID_PATH= ... E: ID_PATH=pci-0000:07:00.0 E: ID_PATH=pci-0000:08:00.00000:00:0[7-8].0式に一致するすべての PCI ID に適用される接続プロファイルを追加します。# nmcli connection add type ethernet connection.multi-connect multiple match.path "pci-0000:07:00.0 pci-0000:08:00.0" con-name "Wired connection 1"
検証
接続のステータスを表示します。
# nmcli connection show NAME UUID TYPE DEVICE Wired connection 1 9cee0958-512f-4203-9d3d-b57af1d88466 ethernet enp7s0 Wired connection 1 9cee0958-512f-4203-9d3d-b57af1d88466 ethernet enp8s0 ...接続プロファイルのすべての設定を表示するには、次のコマンドを実行します。
# nmcli connection show "Wired connection 1" connection.id: Wired connection 1 ... connection.multi-connect: 3 (multiple) match.path: pci-0000:07:00.0,pci-0000:08:00.0 ...この接続プロファイルは、
match.pathパラメーターのパターンに一致する PCI ID を持つすべてのデバイスを使用するため、接続プロファイルには同じ Universally Unique Identifier (UUID) があります。
第3章 ネットワークボンディングの設定
ネットワークボンディングは、物理ネットワークインターフェイスと仮想ネットワークインターフェイスを組み合わせるか集約して、より高いスループットまたは冗長性を備えた論理インターフェイスを提供する方法です。ボンディングでは、カーネルがすべての操作を排他的に処理します。イーサネットデバイスや VLAN など、さまざまなタイプのデバイスでネットワークボンディングを作成できます。
Red Hat Enterprise Linux は、ボンディングデバイスを設定するためのさまざまなオプションを管理者に提供します。以下に例を示します。
-
nmcliを使用し、コマンドラインを使用してボンディング接続を設定します。 - RHEL Web コンソールを使用し、Web ブラウザーを使用してボンディング接続を設定します。
-
nmtuiを使用して、テキストベースのユーザーインターフェイスでボンディング接続を設定します。 -
nm-connection-editorアプリケーションを使用して、グラフィカルインターフェイスでボンディング接続を設定します。 -
nmstatectlを使用して、Nmstate API を介してボンディング接続を設定します。 - RHEL システムロールを使用して、1 つまたは複数のホストでボンディング設定を自動化します。
3.1. コントローラーおよびポートインターフェイスのデフォルト動作の理解
NetworkManager サービスを使用してチームまたはボンディングのポートインターフェイスを管理またはトラブルシューティングする場合は、以下のデフォルトの動作を考慮してください。
- コントローラーインターフェイスを起動しても、ポートインターフェイスは自動的に起動しない。
- ポートインターフェイスを起動すると、コントローラーインターフェイスは毎回、起動する。
- コントローラーインターフェイスを停止すると、ポートインターフェイスも停止する。
- ポートのないコントローラーは、静的 IP 接続を開始できる。
- コントローラーにポートがない場合は、DHCP 接続の開始時にポートを待つ。
- DHCP 接続でポートを待機中のコントローラーは、キャリアを伴うポートの追加時に完了する。
- DHCP 接続でポートを待機中のコントローラーは、キャリアを伴わないポートを追加する時に待機を継続する。
3.2. ボンディングモードに応じたアップストリームのスイッチ設定
使用するボンディングモードに応じて、スイッチでポートを設定する必要があります。
| ボンディングモード | スイッチの設定 |
|---|---|
|
| Link Aggregation Control Protocol (LACP) ネゴシエーションによるものではなく、静的な EtherChannel を有効にする必要があります。 |
|
| このスイッチで必要な設定は必要ありません。 |
|
| LACP ネゴシエーションによるものではなく、静的な EtherChannel を有効にする必要があります。 |
|
| LACP ネゴシエーションによるものではなく、静的な EtherChannel を有効にする必要があります。 |
|
| LACP ネゴシエーションにより設定された EtherChannel が有効になっている必要があります。 |
|
| このスイッチで必要な設定は必要ありません。 |
|
| このスイッチで必要な設定は必要ありません。 |
スイッチの設定方法の詳細は、スイッチのドキュメントを参照してください。
特定のネットワークボンディング機能 (例: fail-over メカニズム) は、ネットワークスイッチなしでのダイレクトケーブル接続に対応していません。詳細は、Red Hat ナレッジベースのソリューション記事 Is bonding supported with direct connection using crossover cables を参照してください。
3.3. nmcli を使用したネットワークボンディングの設定
コマンドラインでネットワークボンディングを設定するには、nmcli ユーティリティーを使用します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ボンディングのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスがサーバーにインストールされている。
ボンディングのポートにチーム、ブリッジ、または VLAN デバイスを使用するには、ボンディングの作成時にこれらのデバイスを作成するか、次の説明に従って事前にデバイスを作成することができます。
手順
ボンドインターフェイスを作成します。
# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup"このコマンドは、
active-backupモードを使用するbond0という名前のボンディングを作成します。Media Independent Interface (MII) 監視間隔も設定する場合は、
miimon=intervalオプションをbond.optionsプロパティーに追加します。次に例を示します。# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup,miimon=1000"ネットワークインターフェイスを表示して、ボンドに追加する予定のインターフェイス名を書き留めます。
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet disconnected -- enp8s0 ethernet disconnected -- bridge0 bridge connected bridge0 bridge1 bridge connected bridge1 ...この例では、以下のように設定されています。
-
enp7s0およびenp8s0は設定されません。これらのデバイスをポートとして使用するには、次のステップに接続プロファイルを追加します。 -
bridge0およびbridge1には既存の接続プロファイルがあります。これらのデバイスをポートとして使用するには、次の手順でプロファイルを変更します。
-
インターフェイスをボンディングに割り当てます。
ボンディングに割り当てるインターフェイスが設定されていない場合は、インターフェイス用に新しい接続プロファイルを作成します。
# nmcli connection add type ethernet slave-type bond con-name bond0-port1 ifname enp7s0 master bond0 # nmcli connection add type ethernet slave-type bond con-name bond0-port2 ifname enp8s0 master bond0これらのコマンドは、
enp7s0およびenp8s0のプロファイルを作成し、bond0接続に追加します。既存の接続プロファイルをボンディングに割り当てるには、以下を実行します。
これらの接続の
masterパラメーターをbond0に設定します。# nmcli connection modify bridge0 master bond0 # nmcli connection modify bridge1 master bond0これらのコマンドは、
bridge0およびbridge1という名前の既存の接続プロファイルをbond0接続に割り当てます。接続を再度アクティブにします。
# nmcli connection up bridge0 # nmcli connection up bridge1
IPv4 を設定します。
静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
bond0接続に設定するには、次のように実行します。# nmcli connection modify bond0 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.dns-search 'example.com' ipv4.method manual- DHCP を使用するために必要な操作はありません。
- このボンディングデバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
IPv6 設定を行います。
静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
bond0接続に設定するには、次のように実行します。# nmcli connection modify bond0 ipv6.addresses '2001:db8:1::1/64' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.dns-search 'example.com' ipv6.method manual- ステートレスアドレス自動設定 (SLAAC) を使用する場合、アクションは必要ありません。
- このボンディングデバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
オプション: ボンディングポートにパラメーターを設定する場合は、次のコマンドを使用します。
# nmcli connection modify bond0-port1 bond-port.<parameter> <value>接続をアクティベートします。
# nmcli connection up bond0ポートが接続されており、
CONNECTIONコラムがポートの接続名を表示していることを確認します。# nmcli device DEVICE TYPE STATE CONNECTION ... enp7s0 ethernet connected bond0-port1 enp8s0 ethernet connected bond0-port2接続のいずれかのポートをアクティブにすると、NetworkManager はボンディングもアクティブにしますが、他のポートはアクティブにしません。ボンディングが有効な場合に、Red Hat Enterprise Linux がすべてのポートを自動的に有効にするように設定できます。
ボンディングの接続で
connection.autoconnect-slavesパラメーターを有効にします。# nmcli connection modify bond0 connection.autoconnect-slaves 1ブリッジを再度アクティブにします。
# nmcli connection up bond0
検証
ネットワークデバイスの 1 つからネットワークケーブルを一時的に取り外し、ボンディング内の他のデバイスがトラフィックを処理しているかどうかを確認します。
ソフトウェアユーティリティーを使用して、リンク障害イベントを適切にテストする方法がないことに注意してください。
nmcliなどの接続を非アクティブにするツールでは、ポート設定の変更を処理するボンディングドライバーの機能のみが表示され、実際のリンク障害イベントは表示されません。ボンドのステータスを表示します。
# cat /proc/net/bonding/bond0
3.4. RHEL Web コンソールを使用したネットワークボンディングの設定
Web ブラウザーベースのインターフェイスを使用してネットワーク設定を管理する場合は、RHEL Web コンソールを使用してネットワークボンディングを設定します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ボンディングのメンバーとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスがサーバーにインストールされている。
チーム、ブリッジ、または VLAN デバイスを結合のメンバーとして使用するには、次の説明に従って事前に作成します。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- 画面左側のナビゲーションで Networking タブを選択します。
- Interfaces セクションで をクリックします。
- 作成するボンドデバイスの名前を入力します。
- 結合のメンバーにするインターフェイスを選択します。
結合のモードを選択します。
Active backup を選択すると、Web コンソールに追加フィールド Primary が表示され、ここで優先するアクティブデバイスを選択できます。
-
リンクモニタリング監視モードを設定します。たとえば、Adaptive load balancing モードを使用する場合は、
ARPに設定します。 オプション: モニター間隔、リンクアップ遅延、およびリンクダウン遅延の設定を調整します。通常、トラブルシューティングの目的でのみデフォルトを変更します。
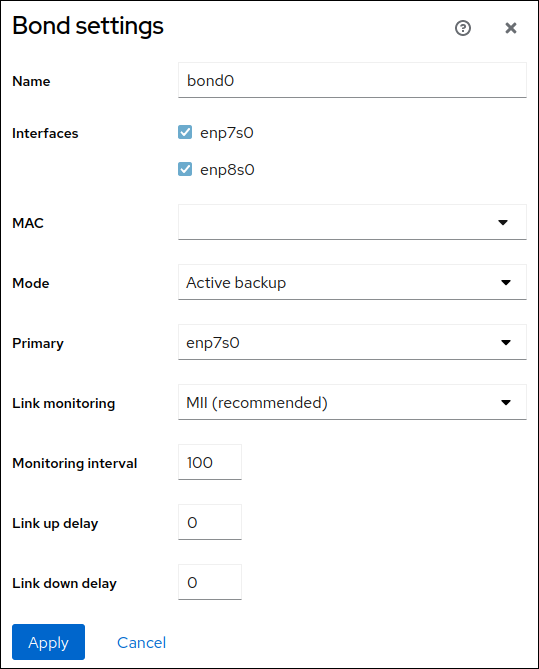
- をクリックします。
デフォルトでは、ボンドは動的 IP アドレスを使用します。静的 IP アドレスを設定する場合:
- Interfaces セクションでボンドの名前をクリックします。
- 設定するプロトコルの横にある Edit をクリックします。
- Addresses の横にある Manual を選択し、IP アドレス、接頭辞、およびデフォルトゲートウェイを入力します。
- DNS セクションで ボタンをクリックし、DNS サーバーの IP アドレスを入力します。複数の DNS サーバーを設定するには、この手順を繰り返します。
- DNS search domains セクションで、 ボタンをクリックし、検索ドメインを入力します。
インターフェイスにスタティックルートが必要な場合は、Routes セクションで設定します。
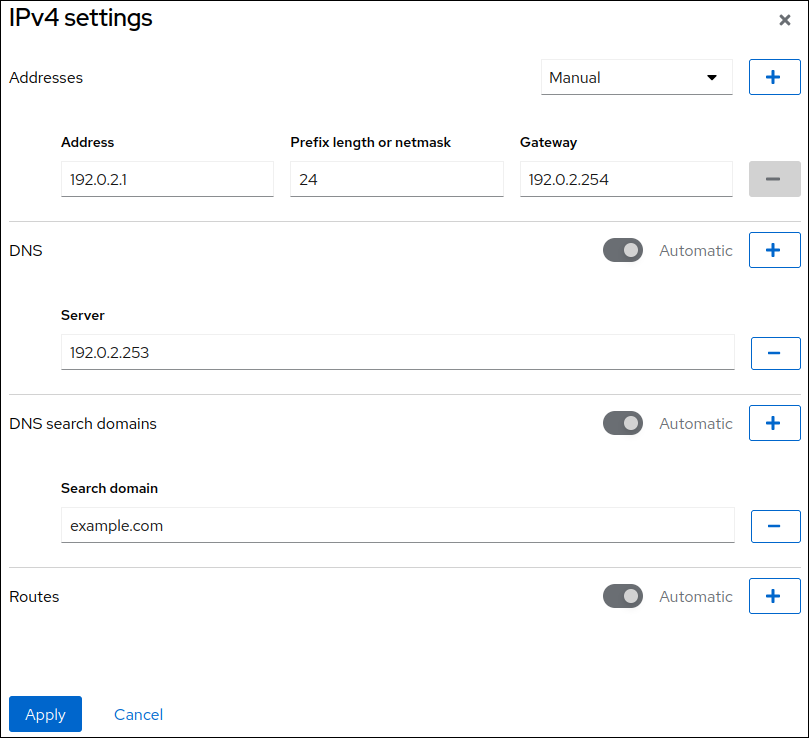
- をクリックします。
検証
画面左側のナビゲーションで Networking タブを選択し、インターフェイスに着信および発信トラフィックがあるか確認します。
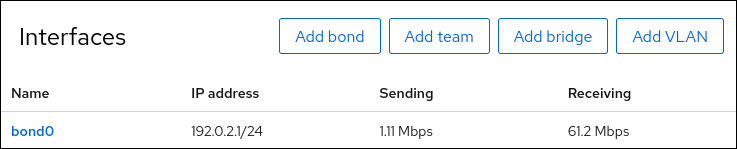
ネットワークデバイスの 1 つからネットワークケーブルを一時的に取り外し、ボンディング内の他のデバイスがトラフィックを処理しているかどうかを確認します。
ソフトウェアユーティリティーを使用して、リンク障害イベントを適切にテストする方法がないことに注意してください。Web コンソールなどの接続を非アクティブ化するツールは、実際のリンク障害イベントではなく、メンバー設定の変更を処理するボンディングドライバーの機能のみを示します。
ボンドのステータスを表示します。
# cat /proc/net/bonding/bond0
3.5. nmtui を使用したネットワークボンディングの設定
nmtui アプリケーションは、NetworkManager 用のテキストベースのユーザーインターフェイスを提供します。nmtui を使用して、グラフィカルインターフェイスを使用せずにホスト上でネットワークボンドを設定できます。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- イーサネットデバイスをボンディングのポートとして使用するために、物理または仮想イーサネットデバイスがサーバーにインストールされている。
手順
ネットワークボンドを設定するネットワークデバイス名がわからない場合は、使用可能なデバイスを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet unavailable -- enp8s0 ethernet unavailable -- ...nmtuiを開始します。# nmtui- Edit a connection 選択し、Enter を押します。
- Add を押します。
- ネットワークタイプのリストから Bond を選択し、Enter を押します。
オプション: 作成する NetworkManager プロファイルの名前を入力します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
- 作成するボンドデバイス名を Device フィールドに入力します。
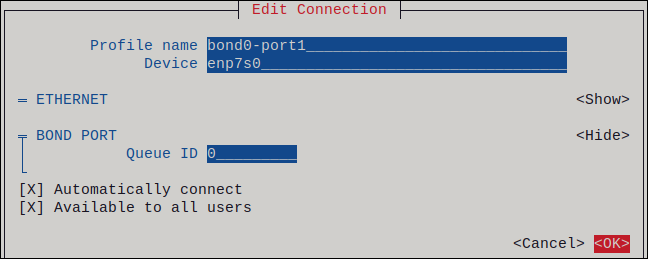
作成するボンドにポートを追加します。
- Slaves リストの横にある Add を押します。
- ボンドにポートとして追加するインターフェイスのタイプ (例: Ethernet) を選択します。
- オプション: このボンドポート用に作成する NetworkManager プロファイルの名前を入力します。
- ポートのデバイス名を Device フィールドに入力します。
OK を押して、ボンディング設定のウィンドウに戻ります。
図3.1 イーサネットデバイスをポートとしてボンドに追加する
- ボンドにさらにポートを追加するには、これらの手順を繰り返します。
-
ボンディングモードを設定します。設定した値に応じて、
nmtuiは、選択したモードに関連する設定の追加フィールドを表示します。 環境に応じて、IPv4 configuration および IPv6 configuration 領域に IP アドレス設定を設定します。これを行うには、これらの領域の横にあるボタンを押して、次を選択します。
-
ボンドが IP アドレスを必要としない場合は
Disabledにします。 -
DHCP サーバーまたはステートレスアドレス自動設定 (SLAAC) が IP アドレスをボンディングに動的に割り当てる場合は、
Automaticにします。 ネットワークで静的 IP アドレス設定が必要な場合は、
Manualにします。この場合、さらにフィールドに入力する必要があります。- 設定するプロトコルの横にある Show を押して、追加のフィールドを表示します。
Addresses の横にある Add を押して、IP アドレスとサブネットマスクを Classless Inter-Domain Routing (CIDR) 形式で入力します。
サブネットマスクを指定しない場合、NetworkManager は IPv4 アドレスに
/32サブネットマスクを設定し、IPv6 アドレスに/64サブネットマスクを設定します。- デフォルトゲートウェイのアドレスを入力します。
- DNS servers の横にある Add を押して、DNS サーバーのアドレスを入力します。
- Search domains の横にある Add を押して、DNS 検索ドメインを入力します。
図3.2 静的 IP アドレス設定によるボンド接続例
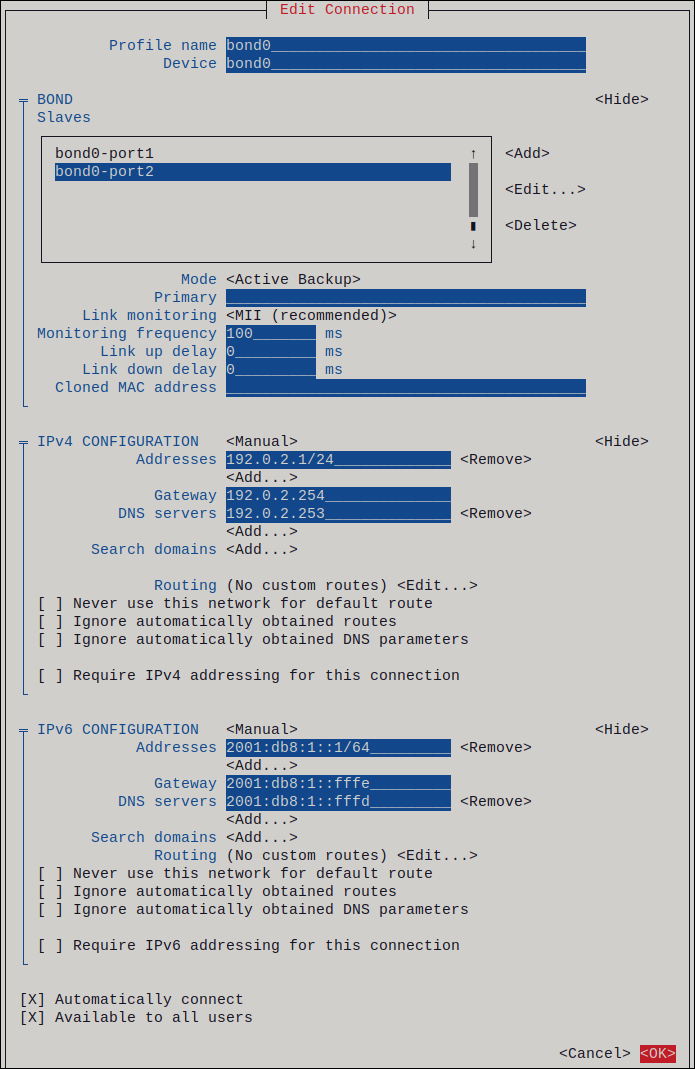
-
ボンドが IP アドレスを必要としない場合は
- OK を押すと、新しい接続が作成され、自動的にアクティブ化されます。
- Back を押してメインメニューに戻ります。
-
Quit を選択し、Enter キーを押して
nmtuiアプリケーションを閉じます。
検証
ネットワークデバイスの 1 つからネットワークケーブルを一時的に取り外し、ボンディング内の他のデバイスがトラフィックを処理しているかどうかを確認します。
ソフトウェアユーティリティーを使用して、リンク障害イベントを適切にテストする方法がないことに注意してください。
nmcliなどの接続を非アクティブにするツールでは、ポート設定の変更を処理するボンディングドライバーの機能のみが表示され、実際のリンク障害イベントは表示されません。ボンドのステータスを表示します。
# cat /proc/net/bonding/bond0
3.6. nm-connection-editor を使用したネットワークボンディングの設定
グラフィカルインターフェイスで Red Hat Enterprise Linux を使用する場合は、nm-connection-editor アプリケーションを使用してネットワークボンディングを設定できます。
nm-connection-editor は、新しいポートだけをボンドに追加できることに注意してください。既存の接続プロファイルをポートとして使用するには、nmcli を使用したネットワークボンディングの設定 の説明に従って nmcli ユーティリティーを使用してボンディングを作成します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ボンディングのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスがサーバーにインストールされている。
- ボンディングのポートとしてチーム、ボンディング、または VLAN デバイスを使用するには、これらのデバイスがまだ設定されていないことを確認してください。
手順
ターミナルを開き、
nm-connection-editorと入力します。$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
- 接続タイプ Bond を選択し、 をクリックします。
Bond タブで、以下を行います。
- 必要に応じて、Interface name フィールドにボンドインターフェイスの名前を設定します。
ボタンをクリックして、ネットワークインターフェイスをポートとしてボンドに追加します。
- インターフェイスの接続タイプを選択します。たとえば、有線接続に Ethernet を選択します。
- 必要に応じて、ポートの接続名を設定します。
- イーサネットデバイスの接続プロファイルを作成する場合は、Ethernet タブを開き、Device フィールドでポートとしてボンディングに追加するネットワークインターフェイスを選択します。別のデバイスタイプを選択した場合は、それに応じて設定します。イーサネットインターフェイスは、設定されていないボンディングでのみ使用できることに注意してください。
- をクリックします。
ボンディングに追加する各インターフェイスで直前の手順を繰り返します。
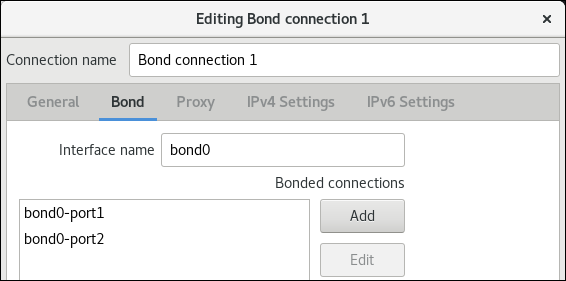
- 必要に応じて、Media Independent Interface (MII) の監視間隔などの他のオプションを設定します。
IPv4 Settings タブと IPv6 Settings タブの両方で IP アドレス設定を設定します。
- このブリッジデバイスを他のデバイスのポートとして使用する場合は、Method フィールドを Disabled に設定します。
- DHCP を使用するには、Method フィールドをデフォルトの Automatic (DHCP) のままにします。
静的 IP 設定を使用するには、Method フィールドを Manual に設定し、それに応じてフィールドに値を入力します。

- をクリックします。
-
nm-connection-editorを閉じます。
検証
ネットワークデバイスの 1 つからネットワークケーブルを一時的に取り外し、ボンディング内の他のデバイスがトラフィックを処理しているかどうかを確認します。
ソフトウェアユーティリティーを使用して、リンク障害イベントを適切にテストする方法がないことに注意してください。
nmcliなどの接続を非アクティブにするツールでは、ポート設定の変更を処理するボンディングドライバーの機能のみが表示され、実際のリンク障害イベントは表示されません。ボンドのステータスを表示します。
# cat /proc/net/bonding/bond0
3.7. nmstatectl を使用したネットワークボンディングの設定
nmstatectl ユーティリティーを使用して、Nmstate API を介してネットワークボンディングを設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
環境に応じて、YAML ファイルを適宜調整します。たとえば、ボンディングでイーサネットアダプターとは異なるデバイスを使用するには、ボンディングで使用するポートの Base-iface 属性と type 属性を調整します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- 物理または仮想のイーサネットデバイスをサーバーにインストールしてボンディングでポートとしてイーサネットデバイスを使用する。
-
ポートリストでインターフェイス名を設定し、対応するインターフェイスを定義して、ボンディングのポートとしてチーム、ブリッジ、または VLAN デバイスを使用する。 -
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイルを作成します (例:
~/create-bond.yml)。--- interfaces: - name: bond0 type: bond state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false link-aggregation: mode: active-backup port: - enp1s0 - enp7s0 - name: enp1s0 type: ethernet state: up - name: enp7s0 type: ethernet state: up routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: bond0 metric: 300 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: bond0 metric: 300 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbこれらの設定では、次の設定を使用してネットワークボンディングを定義します。
-
ボンドのネットワークインターフェイス:
enp1s0およびenp7s0 -
モード:
active-backup -
静的 IPv4 アドレス: サブネットマスクが
/24の192.0.2.1 -
静的 IPv6 アドレス:
2001:db8:1::1(/64サブネットマスクあり) -
IPv4 デフォルトゲートウェイ:
192.0.2.254 -
IPv6 デフォルトゲートウェイ:
2001:db8:1::fffe -
IPv4 DNS サーバー:
192.0.2.200 -
IPv6 DNS サーバー:
2001:db8:1::ffbb -
DNS 検索ドメイン:
example.com
-
ボンドのネットワークインターフェイス:
設定をシステムに適用します。
# nmstatectl apply ~/create-bond.yml
検証
デバイスおよび接続の状態を表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION bond0 bond connected bond0接続プロファイルのすべての設定を表示します。
# nmcli connection show bond0 connection.id: bond0 connection.uuid: 79cbc3bd-302e-4b1f-ad89-f12533b818ee connection.stable-id: -- connection.type: bond connection.interface-name: bond0 ...接続設定を YAML 形式で表示します。
# nmstatectl show bond0
3.8. network RHEL システムロールを使用したネットワークボンディングの設定
ネットワークインターフェイスをボンディングで組み合わせると、より高いスループットまたは冗長性を備えた論理インターフェイスを提供できます。ボンディングを設定するには、NetworkManager 接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用してネットワークボンディングを設定できます。ボンディングの親デバイスの接続プロファイルが存在しない場合は、このロールによって作成することもできます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Bond connection profile with two Ethernet ports ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: # Bond profile - name: bond0 type: bond interface_name: bond0 ip: dhcp4: yes auto6: yes bond: mode: active-backup state: up # Port profile for the 1st Ethernet device - name: bond0-port1 interface_name: enp7s0 type: ethernet controller: bond0 state: up # Port profile for the 2nd Ethernet device - name: bond0-port2 interface_name: enp8s0 type: ethernet controller: bond0 state: upサンプル Playbook で指定されている設定は次のとおりです。
type: <profile_type>- 作成するプロファイルのタイプを設定します。このサンプル Playbook では、3 つの接続プロファイルを作成します。1 つはボンディング用、2 つはイーサネットデバイス用です。
dhcp4: yes- DHCP、PPP、または同様のサービスからの自動 IPv4 アドレス割り当てを有効にします。
auto6: yes-
IPv6 自動設定を有効にします。デフォルトでは、NetworkManager はルーター広告を使用します。ルーターが
managedフラグを通知すると、NetworkManager は DHCPv6 サーバーに IPv6 アドレスと接頭辞を要求します。 mode: <bond_mode>ボンディングモードを設定します。可能な値は次のとおりです。
-
balance-rr(デフォルト) -
active-backup -
balance-xor -
broadcast -
802.3ad -
balance-tlb -
balance-alb
設定したモードに応じて、Playbook で追加の変数を設定する必要があります。
-
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
ネットワークデバイスの 1 つからネットワークケーブルを一時的に取り外し、ボンディング内の他のデバイスがトラフィックを処理しているかどうかを確認します。
ソフトウェアユーティリティーを使用して、リンク障害イベントを適切にテストする方法がないことに注意してください。
nmcliなどの接続を非アクティブにするツールでは、ポート設定の変更を処理するボンディングドライバーの機能のみが表示され、実際のリンク障害イベントは表示されません。
3.9. VPN を中断せずにイーサネットとワイヤレス接続間の切り替えを可能にするネットワークボンディングの作成
ワークステーションを会社のネットワークに接続する RHEL ユーザーは、通常、リモートリソースにアクセスするのに VPN を使用します。ただし、イーサネット接続と Wi-Fi 接続間のワークステーションスイッチ (たとえば、イーサネット接続のあるドッキングステーションからラップトップを解放した場合など) は、VPN 接続が中断されます。この問題を回避するには、active-backup モードでイーサネット接続および Wi-Fi 接続を使用するネットワークボンディングを作成します。
前提条件
- ホストに、イーサネットデバイスと Wi-Fi デバイスが含まれている。
イーサネットおよび Wi-Fi NetworkManager 接続プロファイルが作成され、両方の接続が独立して機能します。
この手順では、以下の接続プロファイルを使用して
bond0という名前のネットワークボンディングを作成します。-
enp11s0u1イーサネットデバイスに関連付けられたDocking_station -
wlp1s0Wi-Fi デバイスに関連付けられたWi-Fi
-
手順
active-backupモードでボンドインターフェイスを作成します。# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup"このコマンドは、インターフェイスおよび接続プロファイル
bond0の両方に名前を付けます。ボンディングの IPv4 設定を設定します。
- ネットワークの DHCP サーバーが IPv4 アドレスをホストに割り当てる場合は、何もする必要はありません。
ローカルネットワークに静的 IPv4 アドレスが必要な場合は、アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および DNS 検索ドメインを
bond0接続に設定します。# nmcli connection modify bond0 ipv4.addresses '192.0.2.1/24' # nmcli connection modify bond0 ipv4.gateway '192.0.2.254' # nmcli connection modify bond0 ipv4.dns '192.0.2.253' # nmcli connection modify bond0 ipv4.dns-search 'example.com' # nmcli connection modify bond0 ipv4.method manual
ボンディングの IPv6 設定を設定します。
- ネットワークのルーターまたは DHCP サーバーが IPv6 アドレスをホストに割り当てる場合、アクションは必要ありません。
ローカルネットワークに静的 IPv6 アドレスが必要な場合は、アドレス、ネットワークマスク、デフォルトゲートウェイ、DNS サーバー、および DNS 検索ドメインを
bond0接続に設定します。# nmcli connection modify bond0 ipv6.addresses '2001:db8:1::1/64' # nmcli connection modify bond0 ipv6.gateway '2001:db8:1::fffe' # nmcli connection modify bond0 ipv6.dns '2001:db8:1::fffd' # nmcli connection modify bond0 ipv6.dns-search 'example.com' # nmcli connection modify bond0 ipv6.method manual
接続プロファイルを表示します。
# nmcli connection show NAME UUID TYPE DEVICE Docking_station 256dd073-fecc-339d-91ae-9834a00407f9 ethernet enp11s0u1 Wi-Fi 1f1531c7-8737-4c60-91af-2d21164417e8 wifi wlp1s0 ...次のステップでは、接続プロファイルとイーサネットデバイス名が必要です。
イーサネット接続の接続プロファイルをボンドに割り当てます。
# nmcli connection modify Docking_station master bond0Wi-Fi 接続の接続プロファイルをボンディングに割り当てます。
# nmcli connection modify Wi-Fi master bond0Wi-Fi ネットワークが MAC フィルタリングを使用して、許可リストの MAC アドレスのみがネットワークにアクセスできるようにするには、NetworkManager がアクティブなポートの MAC アドレスをボンドに動的に割り当てるように設定します。
# nmcli connection modify bond0 +bond.options fail_over_mac=1この設定では、イーサネットデバイスと Wi-Fi デバイスの両方の MAC アドレスの代わりに、Wi-Fi デバイスの MAC アドレスのみを許可リストに設定する必要があります。
イーサネット接続に関連付けられたデバイスを、ボンドのプライマリーデバイスとして設定します。
# nmcli con modify bond0 +bond.options "primary=enp11s0u1"この設定では、ボンディングが利用可能な場合は、イーサネット接続を常に使用します。
bond0デバイスがアクティブになると、NetworkManager がポートを自動的にアクティブになるように設定します。# nmcli connection modify bond0 connection.autoconnect-slaves 1bond0接続をアクティベートします。# nmcli connection up bond0
検証
現在アクティブなデバイス、ボンドおよびそのポートのステータスを表示します。
# cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: fault-tolerance (active-backup) (fail_over_mac active) Primary Slave: enp11s0u1 (primary_reselect always) Currently Active Slave: enp11s0u1 MII Status: up MII Polling Interval (ms): 1 Up Delay (ms): 0 Down Delay (ms): 0 Peer Notification Delay (ms): 0 Slave Interface: enp11s0u1 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:53:00:59:da:b7 Slave queue ID: 0 Slave Interface: wlp1s0 MII Status: up Speed: Unknown Duplex: Unknown Link Failure Count: 2 Permanent HW addr: 00:53:00:b3:22:ba Slave queue ID: 0
3.10. 異なるネットワークボンディングモード
Linux ボンディングドライバーは、リンクアグリゲーションを提供します。ボンディングは、複数のネットワークインターフェイスを並行して集約して、単一の論理結合インターフェイスを提供するプロセスです。ボンディングされたインターフェイスのアクションは、モードとも呼ばれるボンディングポリシーによって異なります。さまざまなモードが、ロードバランシングサービスまたはホットスタンバイサービスのいずれかを提供します。
Linux ボンディングドライバーは、次のモードをサポートしています。
- Balance-rr (モード 0)
Balance-rrは、使用可能な最初のポートから最後のポートへとパケットを順次送信するラウンドロビンアルゴリズムを使用します。このモードは、ロードバランシングとフォールトトレランスを提供します。このモードでは、EtherChannel または同様ポートのグループ化とも呼ばれるポートアグリゲーショングループのスイッチ設定が必要です。EtherChannel は、複数の物理イーサネットリンクを 1 つの論理イーサネットリンクにグループ化するポートリンクアグリゲーションテクノロジーです。
このモードの欠点は、負荷の高いワークロードや、TCP スループットと順序付けられたパケット配信が不可欠な場合には適していないことです。
- Active-backup (Mode 1)
Active-backupは、結合内でアクティブなポートが 1 つだけであることを決定するポリシーを使用します。このモードはフォールトトレランスを提供し、スイッチ設定は必要ありません。アクティブポートに障害が発生すると、代替ポートがアクティブになります。ボンディングは、Gratuitous Address Resolution Protocol (ARP) 応答をネットワークに送信します。Gratuitous ARP は、ARP フレームの受信者に転送テーブルの更新を強制します。
Active-backupモードは、Gratuitous ARP を送信して、ホストの接続を維持するための新しいパスを通知します。primaryオプションは、ボンディングインターフェイスの優先ポートを定義します。- Balance-xor (Mode 2)
Balance-xorは、選択された送信ハッシュポリシーを使用してパケットを送信します。このモードは、ロードバランシングとフォールトトレランスを提供し、Etherchannel または同様のポートグループをセットアップするためのスイッチ設定を必要とします。パケット送信を変更して送信のバランスを取るために、このモードでは
xmit_hash_policyオプションを使用します。インターフェイス上のトラフィックの送信元または宛先に応じて、インターフェイスには追加の負荷分散設定が必要です。xmit_hash_policy bonding parameter の説明を参照してください。- Broadcast (Mode 3)
Broadcastは、すべてのインターフェイスですべてのパケットを送信するポリシーを使用します。このモードは、フォールトトレランスを提供し、EtherChannel または同様のポートグループをセットアップするためのスイッチ設定を必要とします。このモードの欠点は、負荷の高いワークロードや、TCP スループットと順序付けられたパケット配信が不可欠な場合には適していないことです。
- 802.3ad (Mode 4)
802.3adは、同じ名前の IEEE 標準の動的リンクアグリゲーションポリシーを使用します。このモードはフォールトトレランスを提供します。このモードでは、Link Aggregation Control Protocol (LACP) ポートグループを設定するためのスイッチ設定が必要です。このモードは、同じ速度とデュプレックス設定を共有するアグリゲーショングループを作成し、アクティブなアグリゲーターのすべてのポートを利用します。インターフェイス上のトラフィックの送信元または宛先に応じて、モードには追加の負荷分散設定が必要です。
デフォルトでは、発信トラフィックのポート選択は送信ハッシュポリシーに依存します。送信ハッシュポリシーの
xmit_hash_policyオプションを使用して、ポートの選択を変更し、送信を分散します。802.3adとBalance-xorの違いはコンプライアンスです。802.3adポリシーは、ポートアグリゲーショングループ間で LACP をネゴシエートします。xmit_hash_policy bonding parameter の説明を参照してください。- Balance-tlb (Mode 5)
Balance-tlbは、送信負荷分散ポリシーを使用します。このモードは、フォールトトレランスと負荷分散を提供し、スイッチサポートを必要としないチャネルボンディングを確立します。アクティブポートは着信トラフィックを受信します。アクティブポートに障害が発生した場合、別のポートが障害ポートの MAC アドレスを引き継ぎます。発信トラフィックを処理するインターフェイスを決定するには、次のいずれかのモードを使用します。
-
値が
0: ハッシュ分散ポリシーを使用して、負荷分散なしでトラフィックを配分します 値が
1: 負荷分散を使用してトラフィックを各ポートに配分しますボンディングオプション
tlb_dynamic_lb=0を使用すると、このボンディングモードはxmit_hash_policyボンディングオプションを使用して送信を分散します。primaryオプションは、ボンディングインターフェイスの優先ポートを定義します。
xmit_hash_policy bonding parameter の説明を参照してください。
-
値が
- Balance-alb (Mode 6)
Balance-albは、適応負荷分散ポリシーを使用します。このモードは、フォールトトレランスとロードバランシングを提供し、特別なスイッチサポートを必要としません。このモードには、IPv4 および IPv6 トラフィックのバランス型送信負荷分散 (
balance-tlb) と受信負荷分散が含まれています。ボンディングは、ローカルシステムから送信された ARP 応答を傍受し、ボンディング内のポートの 1 つの送信元ハードウェアアドレスを上書きします。ARP ネゴシエーションは、受信負荷分散を管理します。したがって、異なるポートは、サーバーに対して異なるハードウェアアドレスを使用します。primaryオプションは、ボンディングインターフェイスの優先ポートを定義します。ボンディングオプションtlb_dynamic_lb=0を使用すると、このボンディングモードはxmit_hash_policyボンディングオプションを使用して送信を分散します。xmit_hash_policy bonding parameter の説明を参照してください。
3.11. xmit_hash_policy ボンディングパラメーター
xmit_hash_policy 負荷分散パラメーターは、balance-xor、802.3ad、balance-alb、および balance-tlb モードでのノード選択の送信ハッシュポリシーを選択します。tlb_dynamic_lb parameter is 0 の場合、モード 5 および 6 にのみ適用されます。このパラメーターで使用できる値は、layer2、layer2+3、layer3+4、encap2+3、encap3+4、および vlan+srcmac です。
詳細は、次の表を参照してください。
| ポリシー層またはネットワーク層 | Layer2 | Layer2+3 | Layer3+4 | encap2+3 | encap3+4 | VLAN+srcmac |
| 用途 | 送信元および宛先の MAC アドレスとイーサネットプロトコルタイプの XOR | 送信元および宛先の MAC アドレスと IP アドレスの XOR | 送信元および宛先のポートと IP アドレスの XOR |
サポートされているトンネル内の送信元と宛先の MAC アドレスと IP アドレスの XOR (仮想拡張 LAN (VXLAN) など)。このモードは、 |
サポートされているトンネル内の送信元ポートと宛先ポートおよび IP アドレスの XOR (VXLAN など)。このモードは、 | VLAN ID、送信元 MAC ベンダー、送信元 MAC デバイスの XOR |
| トラフィックの配置 | 基盤となる同一ネットワークインターフェイス上にある特定のネットワークピアに向かうすべてのトラフィック | 基盤となる同一ネットワークインターフェイス上の特定の IP アドレスに向かうすべてのトラフィック | 基盤となる同一ネットワークインターフェイス上の特定の IP アドレスとポートに向かうすべてのトラフィック | |||
| プライマリーの選択 | このシステムと、同じブロードキャストドメイン内の他の複数システムとの間でネットワークトラフィックが発生している場合 | このシステムと他の複数システム間のネットワークトラフィックがデフォルトゲートウェイを通過する場合 | このシステムと別のシステムの間のネットワークトラフィックが同じ IP アドレスを使用しているが、複数のポートを通過する場合 | カプセル化されたトラフィックが、ソースシステムと、複数の IP アドレスを使用する他の複数システムとの間に発生している場合 | カプセル化されたトラフィックが、ソースシステムと、複数のポート番号を使用する他のシステムとの間で発生している場合 | ボンディングが、ブリッジネットワークなどの外部ネットワークに MAC アドレスを直接公開する複数のコンテナーまたは仮想マシン (VM) からのネットワークトラフィックを伝送し、スイッチをモード 2 またはモード 4 に設定できない場合 |
| セカンダリーの選択 | ネットワークトラフィックの大部分が、このシステムとデフォルトゲートウェイの背後にある複数の他のシステムとの間で発生する場合 | ネットワークトラフィックの大部分がこのシステムと別のシステムとの間で発生する場合 | ||||
| Compliant | 802.3ad | 802.3ad | 802.3ad 以外 | |||
| デフォルトポリシー | 設定されていない場合、これがデフォルトポリシー |
非 IP トラフィックの場合、式は |
非 IP トラフィックの場合、式は |
第4章 NIC チームの設定
ネットワークインターフェイスコントローラー (NIC) チーミングは、物理ネットワークインターフェイスと仮想ネットワークインターフェイスを結合または集約して、より高いスループットまたは冗長性を備えた論理インターフェイスを提供する方法です。NIC チーミングでは、小さなカーネルモジュールを使用して、パケットフローの高速処理と他のタスク用のユーザー空間サービスを実装します。このように、NIC チーミングは、負荷分散と冗長性の要件に応じて簡単に拡張できるスケーラブルなソリューションです。
Red Hat Enterprise Linux は、チームデバイスを設定するためのさまざまなオプションを管理者に提供します。以下に例を示します。
-
nmcliを使用し、コマンドラインを使用してチーム接続を設定します。 - RHEL Web コンソールを使用し、Web ブラウザーを使用してチーム接続を設定します。
-
nm-connection-editorアプリケーションを使用して、グラフィカルインターフェイスでチーム接続を設定します。
NIC チーミングは Red Hat Enterprise Linux 9 では非推奨です。サーバーを将来バージョンの RHEL にアップグレードする予定がある場合は、代替手段としてカーネルボンディングドライバーの使用を検討してください。詳細は、ネットワークボンディングの設定 を参照してください。
4.1. コントローラーおよびポートインターフェイスのデフォルト動作の理解
NetworkManager サービスを使用してチームまたはボンディングのポートインターフェイスを管理またはトラブルシューティングする場合は、以下のデフォルトの動作を考慮してください。
- コントローラーインターフェイスを起動しても、ポートインターフェイスは自動的に起動しない。
- ポートインターフェイスを起動すると、コントローラーインターフェイスは毎回、起動する。
- コントローラーインターフェイスを停止すると、ポートインターフェイスも停止する。
- ポートのないコントローラーは、静的 IP 接続を開始できる。
- コントローラーにポートがない場合は、DHCP 接続の開始時にポートを待つ。
- DHCP 接続でポートを待機中のコントローラーは、キャリアを伴うポートの追加時に完了する。
- DHCP 接続でポートを待機中のコントローラーは、キャリアを伴わないポートを追加する時に待機を継続する。
4.2. teamd サービス、ランナー、およびリンク監視の理解
チームサービス teamd は、チームドライバーのインスタンスを制御します。このドライバーのインスタンスは、ハードウェアデバイスドライバーのインスタンスを追加して、ネットワークインターフェイスのチームを形成します。チームドライバーは、ネットワークインターフェイス (team0 など) をカーネルに提示します。
teamd サービスは、チーミングのすべてのメソッドに共通のロジックを実装します。この関数は、ラウンドロビンなどの異なる負荷分散とバックアップメソッドに一意で、ランナー と呼ばれる別のコードのユニットにより実装されます。管理者は、JSON (JavaScript Object Notation) 形式でランナーを指定します。インスタンスの作成時に、JSON コードが teamd のインスタンスにコンパイルされます。または、NetworkManager を使用する場合は、team.runner パラメーターにランナーを設定でき、対応する JSON コードを NetworkManager が自動的に作成します。
以下のランナーが利用できます。
-
broadcast- すべてのポートでデータを送信します。 -
roundrobin- 次に、すべてのポートでデータを送信します。 -
activebackup- 1 つのポートにデータを送信します。もう 1 つのポートはバックアップとして維持されます。 -
loadbalance- アクティブな Tx 負荷分散と Berkeley Packet Filter (BPF) ベースの Tx ポートセレクターを持つすべてのポートでデータを送信します。 -
random- 無作為に選択されたポートでデータを送信します。 -
lacp- 802.3ad リンクアグリゲーション制御プロトコル (LACP) を実装します。
teamd サービスはリンク監視を使用して、下位デバイスの状態を監視します。さらに、以下のリンク監視が利用可能です。
-
ethtool-libteamライブラリーは、ethtoolユーティリティーを使用してリンク状態の変更を監視します。これはデフォルトのリンク監視です。 -
arp_ping-libteamライブラリーは、arp_pingユーティリティーでアドレス解決プロトコル (ARP) を使用して、遠端のハードウェアアドレスの存在を監視します。 -
nsna_ping- IPv6 接続では、libteamライブラリーが IPv6 neighbor Discovery プロトコルの Neighbor Advertisement 機能と Neighbor Solicitation 機能を使用して、近くのインターフェイスの存在を監視します。
各ランナーは、lacp を除くリンク監視を使用できます。このランナーは、ethtool リンク監視のみを使用できます。
4.3. nmcli を使用した NIC チームの設定
コマンドラインでネットワークインターフェイスコントローラー (NIC) チームを設定するには、nmcli ユーティリティーを使用します。
NIC チーミングは Red Hat Enterprise Linux 9 では非推奨です。サーバーを将来バージョンの RHEL にアップグレードする予定がある場合は、代替手段としてカーネルボンディングドライバーの使用を検討してください。詳細は、ネットワークボンディングの設定 を参照してください。
前提条件
-
teamdおよびNetworkManager-teamパッケージがインストールされている。 - サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- チームのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスがサーバーにインストールされ、スイッチに接続されている必要があります。
チームのポートにボンディング、ブリッジ、または VLAN デバイスを使用するには、チームの作成時にこれらのデバイスを作成するか、次の説明に従って事前にデバイスを作成することができます。
手順
チームインターフェイスを作成します。
# nmcli connection add type team con-name team0 ifname team0 team.runner activebackupこのコマンドは、
activebackupランナーを使用するteam0という名前の NIC チームを作成します。オプション: リンクウォッチャーを設定します。たとえば、
team0接続プロファイルでethtoolリンク監視を設定するには、次のコマンドを実行します。# nmcli connection modify team0 team.link-watchers "name=ethtool"リンク監視は、さまざまなパラメーターに対応します。リンク監視にパラメーターを設定するには、
nameプロパティーでスペースで区切って指定します。name プロパティーは引用符で囲む必要があることに注意してください。たとえば、ethtoolリンク監視を使用し、delay-upパラメーターを2500ミリ秒 (2.5 秒) で設定するには、次のコマンドを実行します。# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2500"複数のリンク監視および各リンク監視を、特定のパラメーターで設定するには、リンク監視をコンマで区切る必要があります。以下の例では、
delay-upパラメーターでethtoolリンク監視を設定します。arp_pingリンク監視は、source-hostパラメーターおよびtarget-hostパラメーターで設定します。# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2, name=arp_ping source-host=192.0.2.1 target-host=192.0.2.2"ネットワークインターフェイスを表示し、次のステップでチームに追加するインターフェイスの名前を書き留めておきます。
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet disconnected -- enp8s0 ethernet disconnected -- bond0 bond connected bond0 bond1 bond connected bond1 ...この例では、以下のように設定されています。
-
enp7s0およびenp8s0は設定されません。これらのデバイスをポートとして使用するには、次のステップに接続プロファイルを追加します。いずれの接続にも割り当てられていないチームのイーサネットインターフェイスのみを使用できる点に注意してください。 -
bond0およびbond1には既存の接続プロファイルがあります。これらのデバイスをポートとして使用するには、次の手順でプロファイルを変更します。
-
ポートインターフェイスをチームに割り当てます。
チームに割り当てるインターフェイスが設定されていない場合は、それらの接続プロファイルを新たに作成します。
# nmcli connection add type ethernet slave-type team con-name team0-port1 ifname enp7s0 master team0 # nmcli connection add type ethernet slave--type team con-name team0-port2 ifname enp8s0 master team0これらのコマンドは、
enp7s0およびenp8s0にプロファイルを作成し、team0接続に追加します。既存の接続プロファイルをチームに割り当てるには、以下を実行します。
これらの接続の
masterパラメーターをteam0に設定します。# nmcli connection modify bond0 master team0 # nmcli connection modify bond1 master team0これらのコマンドは、
bond0およびbond1という名前の既存の接続プロファイルをteam0接続に割り当てます。接続を再度アクティブにします。
# nmcli connection up bond0 # nmcli connection up bond1
IPv4 を設定します。
静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
team0接続に設定するには、次のように実行します。# nmcli connection modify team0 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.dns-search 'example.com' ipv4.method manual- DHCP を使用するために必要な操作はありません。
- このチームデバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
IPv6 設定を行います。
静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
team0接続に設定するには、次のように実行します。# nmcli connection modify team0 ipv6.addresses '2001:db8:1::1/64' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.dns-search 'example.com' ipv6.method manual- このチームデバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
- ステートレスアドレス自動設定 (SLAAC) を使用する場合、アクションは必要ありません。
接続をアクティベートします。
# nmcli connection up team0
検証
チームのステータスを表示します。
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0この例では、両方のポートが起動しています。
4.4. RHEL Web コンソールを使用した NIC チームの設定
Web ブラウザーベースのインターフェイスを使用してネットワーク設定を管理する場合は、RHEL Web コンソールを使用してネットワークインターフェイスコントローラー (NIC) チームを設定します。
NIC チーミングは Red Hat Enterprise Linux 9 では非推奨です。サーバーを将来バージョンの RHEL にアップグレードする予定がある場合は、代替手段としてカーネルボンディングドライバーの使用を検討してください。詳細は、ネットワークボンディングの設定 を参照してください。
前提条件
-
teamdおよびNetworkManager-teamパッケージがインストールされている。 - サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- チームのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスがサーバーにインストールされ、スイッチに接続されている必要があります。
ボンド、ブリッジ、または VLAN デバイスをチームのポートとして使用するには、次の説明に従って事前に作成します。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
-
画面左側のナビゲーションで
Networkingタブを選択します。 -
Interfacesセクションで をクリックします。 - 作成するチームデバイスの名前を入力します。
- チームのポートにするインターフェイスを選択します。
チームのランナーを選択します。
Load balancingまたは802.3ad LACPを選択すると、Web コンソールに追加のフィールドBalancerが表示されます。リンクウォッチャーを設定します。
-
Ethtoolを選択した場合は、さらに、リンクアップおよびリンクダウンの遅延を設定します。 -
ARP pingまたはNSNA pingを選択し、さらに ping の間隔と ping ターゲットを設定します。
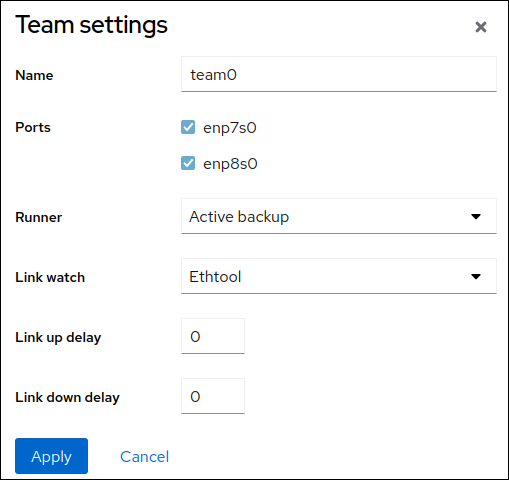
-
- をクリックします。
デフォルトでは、チームは動的 IP アドレスを使用します。静的 IP アドレスを設定する場合:
-
Interfacesセクションでチームの名前をクリックします。 -
設定するプロトコルの横にある
Editをクリックします。 -
Addressesの横にあるManualを選択し、IP アドレス、接頭辞、およびデフォルトゲートウェイを入力します。 -
DNSセクションで ボタンをクリックし、DNS サーバーの IP アドレスを入力します。複数の DNS サーバーを設定するには、この手順を繰り返します。 -
DNS search domainsセクションで、 ボタンをクリックし、検索ドメインを入力します。 インターフェイスにスタティックルートが必要な場合は、
Routesセクションで設定します。
- をクリックします。
-
検証
画面左側のナビゲーションで
Networkingタブを選択し、インターフェイスに着信および発信トラフィックがあるかどうかを確認します。
チームのステータスを表示します。
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0この例では、両方のポートが起動しています。
4.5. nm-connection-editor を使用した NIC チームを設定
グラフィカルインターフェイスを備えた Red Hat Enterprise Linux を使用している場合は、nm-connection-editor アプリケーションを使用してネットワークインターフェイスコントローラー (NIC) チームを設定できます。
nm-connection-editor は、新しいポートだけをチームに追加できることに注意してください。既存の接続プロファイルをポートとして使用するには、nmcli を使用した NIC チームの設定 の説明に従って、nmcli ユーティリティーを使用してチームを作成します。
NIC チーミングは Red Hat Enterprise Linux 9 では非推奨です。サーバーを将来バージョンの RHEL にアップグレードする予定がある場合は、代替手段としてカーネルボンディングドライバーの使用を検討してください。詳細は、ネットワークボンディングの設定 を参照してください。
前提条件
-
teamdおよびNetworkManager-teamパッケージがインストールされている。 - サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- 物理または仮想のイーサネットデバイスをサーバーにインストールし、チームのポートとしてイーサネットデバイスを使用する。
- チーム、ボンディング、または VLAN デバイスをチームのポートとして使用するには、これらのデバイスがまだ設定されていないことを確認してください。
手順
ターミナルを開き、
nm-connection-editorと入力します。$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
- 接続タイプ Team を選択し、 をクリックします。
Team タブで、以下を行います。
- 必要に応じて、Interface name フィールドにチームインターフェイスの名前を設定します。
ボタンをクリックして、ネットワークインターフェイスの新しい接続プロファイルを追加し、プロファイルをポートとしてチームに追加します。
- インターフェイスの接続タイプを選択します。たとえば、有線接続に Ethernet を選択します。
- 必要に応じて、ポートの接続名を設定します。
- イーサネットデバイスの接続プロファイルを作成する場合は、Ethernet タブを開き、Device フィールドでポートとしてチームに追加するネットワークインターフェイスを選択します。別のデバイスタイプを選択した場合は、それに応じて設定します。いずれの接続にも割り当てられていないチームのイーサネットインターフェイスのみを使用できる点に注意してください。
- をクリックします。
チームに追加する各インターフェイスに直前の手順を繰り返します。
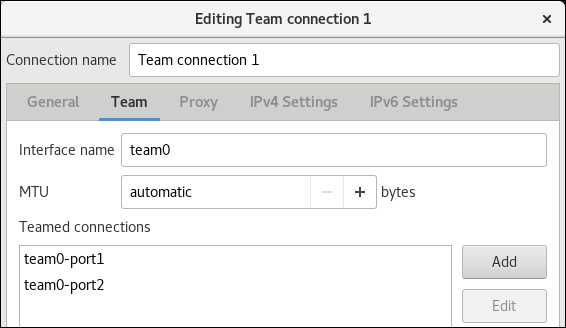
ボタンをクリックして、チーム接続に高度なオプションを設定します。
- Runner タブで、ランナーを選択します。
- Link Watcher タブで、リンク監視とそのオプションを設定します。
- をクリックします。
IPv4 Settings タブと IPv6 Settings タブの両方で IP アドレス設定を設定します。
- このブリッジデバイスを他のデバイスのポートとして使用する場合は、Method フィールドを Disabled に設定します。
- DHCP を使用するには、Method フィールドをデフォルトの Automatic (DHCP) のままにします。
静的 IP 設定を使用するには、Method フィールドを Manual に設定し、それに応じてフィールドに値を入力します。
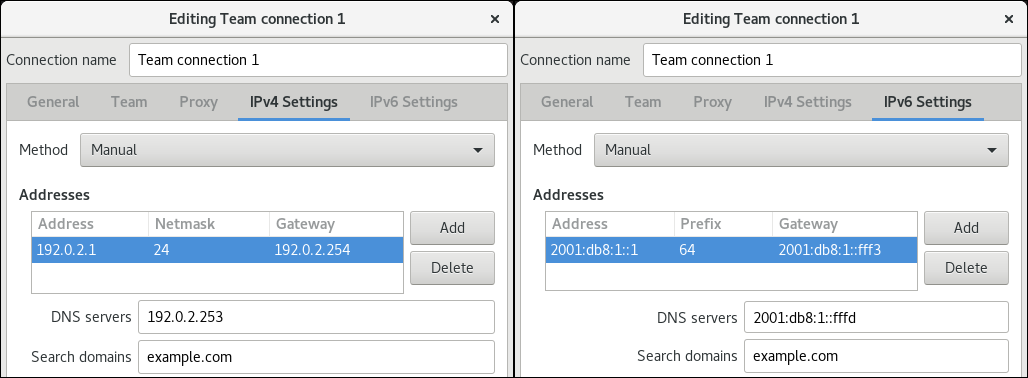
- をクリックします。
-
nm-connection-editorを閉じます。
検証
チームのステータスを表示します。
# teamdctl team0 state setup: runner: activebackup ports: enp7s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 enp8s0 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: enp7s0
第5章 VLAN タグの設定
仮想ローカルエリアネットワーク (VLAN) は、物理ネットワーク内の論理ネットワークです。VLAN インターフェイスは、インターフェイスを通過する際に VLAN ID でパケットをタグ付けし、返信パケットのタグを削除します。VLAN インターフェイスを、イーサネット、ボンド、チーム、ブリッジデバイスなどの別のインターフェイスに作成します。これらのインターフェイスは parent interface と呼ばれます。
Red Hat Enterprise Linux は、VLAN デバイスを設定するためのさまざまなオプションを管理者に提供します。以下に例を示します。
-
nmcliを使用し、コマンドラインを使用して VLAN のタグ付けを設定します。 - RHEL Web コンソールを使用し、Web ブラウザーを使用して VLAN のタグ付けを設定します。
-
nmtuiを使用し、テキストベースのユーザーインターフェイスで VLAN のタグ付けを設定します。 -
nm-connection-editorアプリケーションを使用して、グラフィカルインターフェイスで接続を設定します。 -
nmstatectlを使用して、Nmstate API を介して接続を設定します。 - RHEL システムロールを使用して、1 つまたは複数のホストで VLAN 設定を自動化します。
5.1. nmcli を使用した VLAN タグ付けの設定
nmcli ユーティリティーを使用して、コマンドラインで仮想ローカルエリアネットワーク (VLAN) のタグ付けを設定できます。
前提条件
- 仮想 VLAN インターフェイスに対する親として使用するインターフェイスが VLAN タグに対応している。
ボンドインターフェイスに VLAN を設定する場合は、以下のようになります。
- ボンディングのポートが起動している。
-
ボンドが、
fail_over_mac=followオプションで設定されていない。VLAN 仮想デバイスは、親の新規 MAC アドレスに一致する MAC アドレスを変更できません。このような場合、トラフィックは間違ったソースの MAC アドレスで送信されます。 -
ボンドは通常、DHCP サーバーまたは IPv6 自動設定から IP アドレスを取得することは想定されていません。ボンディングの作成時に
ipv4.method=disableオプションおよびipv6.method=ignoreオプションを設定してこれを確認します。そうしないと、DHCP または IPv6 の自動設定がしばらくして失敗した場合に、インターフェイスがダウンする可能性があります。
- ホストが接続するスイッチは、VLAN タグに対応するように設定されています。詳細は、スイッチのドキュメントを参照してください。
手順
ネットワークインターフェイスを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet disconnected enp1s0 bridge0 bridge connected bridge0 bond0 bond connected bond0 ...VLAN インターフェイスを作成します。たとえば、VLAN インターフェイス
vlan10を作成し、enp1s0を親インターフェイスとして使用し、VLAN ID10のタグパケットを作成するには、次のコマンドを実行します。# nmcli connection add type vlan con-name vlan10 ifname vlan10 vlan.parent enp1s0 vlan.id 10VLAN は、
0から4094の範囲内に存在する必要があります。デフォルトでは、VLAN 接続は、親インターフェイスから最大伝送単位 (MTU) を継承します。必要に応じて、別の MTU 値を設定します。
# nmcli connection modify vlan10 ethernet.mtu 2000IPv4 を設定します。
静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
vlan10接続に設定するには、次のように実行します。# nmcli connection modify vlan10 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.method manual- DHCP を使用するために必要な操作はありません。
- この VLAN デバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
IPv6 設定を行います。
静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
vlan10接続に設定するには、次のように実行します。# nmcli connection modify vlan10 ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.method manual- ステートレスアドレス自動設定 (SLAAC) を使用する場合、アクションは必要ありません。
- この VLAN デバイスを他のデバイスのポートとして使用する予定の場合は、何もする必要はありません。
接続をアクティベートします。
# nmcli connection up vlan10
検証
設定を確認します。
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.2. RHEL Web コンソールを使用した VLAN タグ付けの設定
RHEL Web コンソールで Web ブラウザーベースのインターフェイスを使用してネットワーク設定を管理する場合は、VLAN タグ付けを設定できます。
前提条件
- 仮想 VLAN インターフェイスに対する親として使用するインターフェイスが VLAN タグに対応している。
ボンドインターフェイスに VLAN を設定する場合は、以下のようになります。
- ボンディングのポートが起動している。
-
ボンドが、
fail_over_mac=followオプションで設定されていない。VLAN 仮想デバイスは、親の新規 MAC アドレスに一致する MAC アドレスを変更できません。このような場合、トラフィックは間違ったソースの MAC アドレスで送信されます。 - ボンドは通常、DHCP サーバーまたは IPv6 自動設定から IP アドレスを取得することは想定されていません。結合を作成する IPv4 および IPv6 プロトコルを無効にして、これを確認します。そうしないと、DHCP または IPv6 の自動設定がしばらくして失敗した場合に、インターフェイスがダウンする可能性があります。
- ホストが接続するスイッチは、VLAN タグに対応するように設定されています。詳細は、スイッチのドキュメントを参照してください。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
-
画面左側のナビゲーションで
Networkingタブを選択します。 -
Interfacesセクションで をクリックします。 - 親デバイスを選択します。
- VLAN ID を入力します。
VLAN デバイスの名前を入力するか、自動生成された名前のままにします。

- をクリックします。
デフォルトでは、VLAN デバイスは動的 IP アドレスを使用します。静的 IP アドレスを設定する場合:
-
Interfacesセクションで VLAN デバイスの名前をクリックします。 -
設定するプロトコルの横にある
Editをクリックします。 -
Addressesの横にあるManualを選択し、IP アドレス、接頭辞、およびデフォルトゲートウェイを入力します。 -
DNSセクションで ボタンをクリックし、DNS サーバーの IP アドレスを入力します。複数の DNS サーバーを設定するには、この手順を繰り返します。 -
DNS search domainsセクションで、 ボタンをクリックし、検索ドメインを入力します。 インターフェイスにスタティックルートが必要な場合は、
Routesセクションで設定します。
- をクリックします。
-
検証
画面左側のナビゲーションで
Networkingタブを選択し、インターフェイスに着信および発信トラフィックがあるか確認します。
5.3. nmtui を使用した VLAN タグ付けの設定
nmtui アプリケーションは、NetworkManager 用のテキストベースのユーザーインターフェイスを提供します。nmtui を使用して、グラフィカルインターフェイスを使用せずにホスト上で VLAN タグ付けを設定できます。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
前提条件
- 仮想 VLAN インターフェイスに対する親として使用するインターフェイスが VLAN タグに対応している。
ボンドインターフェイスに VLAN を設定する場合は、以下のようになります。
- ボンディングのポートが起動している。
-
ボンドが、
fail_over_mac=followオプションで設定されていない。VLAN 仮想デバイスは、親の新規 MAC アドレスに一致する MAC アドレスを変更できません。このような場合、トラフィックは間違ったソースの MAC アドレスで送信されます。 -
ボンドは通常、DHCP サーバーまたは IPv6 自動設定から IP アドレスを取得することは想定されていません。ボンディングの作成時に
ipv4.method=disableオプションおよびipv6.method=ignoreオプションを設定してこれを確認します。そうしないと、DHCP または IPv6 の自動設定がしばらくして失敗した場合に、インターフェイスがダウンする可能性があります。
- ホストが接続するスイッチは、VLAN タグに対応するように設定されています。詳細は、スイッチのドキュメントを参照してください。
手順
VLAN タグ付けを設定するネットワークデバイス名がわからない場合は、使用可能なデバイスを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unavailable -- ...nmtuiを開始します。# nmtui- Edit a connection 選択し、Enter を押します。
- Add を押します。
- ネットワークタイプのリストから VLAN を選択し、Enter を押します。
オプション: 作成する NetworkManager プロファイルの名前を入力します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
- 作成する VLAN デバイス名を Device フィールドに入力します。
- VLAN タグ付けを設定するデバイスの名前を Parent フィールドに入力します。
-
VLAN ID を入力します。ID は
0から4094の範囲内である必要があります。 環境に応じて、IPv4 configuration および IPv6 configuration 領域に IP アドレス設定を設定します。これを行うには、これらの領域の横にあるボタンを押して、次を選択します。
-
この VLAN デバイスが IP アドレスを必要としない場合、または他のデバイスのポートとして使用する場合は、
Disabledにします。 -
DHCP サーバーまたはステートレスアドレス自動設定 (SLAAC) が IP アドレスを VLAN デバイスに動的に割り当てる場合は、
Automaticにします。 ネットワークで静的 IP アドレス設定が必要な場合は、
Manualにします。この場合、さらにフィールドに入力する必要があります。- 設定するプロトコルの横にある Show を押して、追加のフィールドを表示します。
Addresses の横にある Add を押して、IP アドレスとサブネットマスクを Classless Inter-Domain Routing (CIDR) 形式で入力します。
サブネットマスクを指定しない場合、NetworkManager は IPv4 アドレスに
/32サブネットマスクを設定し、IPv6 アドレスに/64サブネットマスクを設定します。- デフォルトゲートウェイのアドレスを入力します。
- DNS servers の横にある Add を押して、DNS サーバーのアドレスを入力します。
- Search domains の横にある Add を押して、DNS 検索ドメインを入力します。
図5.1 静的 IP アドレス設定による VLAN 接続例

-
この VLAN デバイスが IP アドレスを必要としない場合、または他のデバイスのポートとして使用する場合は、
- OK を押すと、新しい接続が作成され、自動的にアクティブ化されます。
- Back を押してメインメニューに戻ります。
-
Quit を選択し、Enter キーを押して
nmtuiアプリケーションを閉じます。
検証
設定を確認します。
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.4. nm-connection-editor を使用した VLAN タグ付けの設定
nm-connection-editor アプリケーションを使用して、グラフィカルインターフェイスで仮想ローカルエリアネットワーク (VLAN) のタグ付けを設定できます。
前提条件
- 仮想 VLAN インターフェイスに対する親として使用するインターフェイスが VLAN タグに対応している。
ボンドインターフェイスに VLAN を設定する場合は、以下のようになります。
- ボンディングのポートが起動している。
-
ボンドが、
fail_over_mac=followオプションで設定されていない。VLAN 仮想デバイスは、親の新規 MAC アドレスに一致する MAC アドレスを変更できません。このような場合、トラフィックは間違ったソースの MAC アドレスで送信されます。
- ホストが接続するスイッチは、VLAN タグに対応するように設定されています。詳細は、スイッチのドキュメントを参照してください。
手順
ターミナルを開き、
nm-connection-editorと入力します。$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
- VLAN 接続タイプを選択し、 をクリックします。
VLAN タブで、以下を行います。
- 親インターフェイスを選択します。
- VLAN id を選択します。VLAN は、0 から 4094 の範囲内に存在する必要があります。
- デフォルトでは、VLAN 接続は、親インターフェイスから最大伝送単位 (MTU) を継承します。必要に応じて、別の MTU 値を設定します。
オプション: VLAN インターフェイスの名前および VLAN 固有のオプションを設定します。
IPv4 Settings タブと IPv6 Settings タブの両方で IP アドレス設定を設定します。
- このブリッジデバイスを他のデバイスのポートとして使用する場合は、Method フィールドを Disabled に設定します。
- DHCP を使用するには、Method フィールドをデフォルトの Automatic (DHCP) のままにします。
静的 IP 設定を使用するには、Method フィールドを Manual に設定し、それに応じてフィールドに値を入力します。
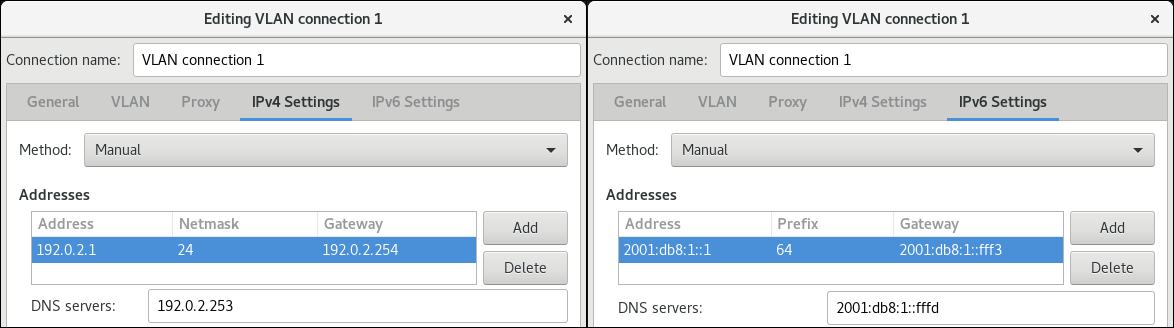
- をクリックします。
-
nm-connection-editorを閉じます。
検証
設定を確認します。
# ip -d addr show vlan10 4: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:d5:e0:fb brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10 valid_lft forever preferred_lft forever inet6 2001:db8:1::1/32 scope global noprefixroute valid_lft forever preferred_lft forever inet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroute valid_lft forever preferred_lft forever
5.5. nmstatectl を使用した VLAN タグ付けの設定
nmstatectl ユーティリティーを使用して、Nmstate API を介して仮想ローカルエリアネットワーク VLAN を設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
環境に応じて、YAML ファイルを適宜調整します。たとえば、VLAN でイーサネットアダプターとは異なるデバイスを使用するには、VLAN で使用するポートの Base-iface 属性と type 属性を調整します。
前提条件
- イーサネットデバイスを VLAN のポートとして使用するために、物理または仮想イーサネットデバイスがサーバーにインストールされている。
-
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイル (例:
~/create-vlan.yml) を作成します。--- interfaces: - name: vlan10 type: vlan state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false vlan: base-iface: enp1s0 id: 10 - name: enp1s0 type: ethernet state: up routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: vlan10 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: vlan10 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbこれらの設定では、
enp1s0デバイスを使用する ID 10 の VLAN を定義します。子デバイスの VLAN 接続の設定は以下のようになります。-
静的 IPv4 アドレス:
192.0.2.1(サブネットマスクが/24) -
静的 IPv6 アドレス:
2001:db8:1::1(サブネットマスクが/64) -
IPv4 デフォルトゲートウェイ -
192.0.2.254 -
IPv6 デフォルトゲートウェイ -
2001:db8:1::fffe -
IPv4 DNS サーバー -
192.0.2.200 -
IPv6 DNS サーバー -
2001:db8:1::ffbb -
DNS 検索ドメイン -
example.com
-
静的 IPv4 アドレス:
設定をシステムに適用します。
# nmstatectl apply ~/create-vlan.yml
検証
デバイスおよび接続の状態を表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION vlan10 vlan connected vlan10接続プロファイルのすべての設定を表示します。
# nmcli connection show vlan10 connection.id: vlan10 connection.uuid: 1722970f-788e-4f81-bd7d-a86bf21c9df5 connection.stable-id: -- connection.type: vlan connection.interface-name: vlan10 ...接続設定を YAML 形式で表示します。
# nmstatectl show vlan10
5.6. network RHEL システムロールを使用した VLAN タグ付けの設定
ネットワークで仮想ローカルエリアネットワーク (VLAN) を使用してネットワークトラフィックを論理ネットワークに分離する場合は、NetworkManager 接続プロファイルを作成して VLAN タグ付けを設定します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して VLAN タグ付けを設定できます。VLAN の親デバイスの接続プロファイルが存在しない場合は、このロールによって作成することもできます。
VLAN デバイスに IP アドレス、デフォルトゲートウェイ、および DNS 設定が必要な場合は、親デバイスではなく VLAN デバイスで設定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: VLAN connection profile with Ethernet port ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: # Ethernet profile - name: enp1s0 type: ethernet interface_name: enp1s0 autoconnect: yes state: up ip: dhcp4: no auto6: no # VLAN profile - name: enp1s0.10 type: vlan vlan: id: 10 ip: dhcp4: yes auto6: yes parent: enp1s0 state: upサンプル Playbook で指定されている設定は次のとおりです。
type: <profile_type>- 作成するプロファイルのタイプを設定します。このサンプル Playbook では、2 つの接続プロファイルを作成します。1 つは親イーサネットデバイス用、もう 1 つは VLAN デバイス用です。
dhcp4: <value>-
yesに設定すると、DHCP、PPP、または同様のサービスからの自動 IPv4 アドレス割り当てが有効になります。親デバイスの IP アドレス設定を無効にします。 auto6: <value>-
yesに設定すると、IPv6 自動設定が有効になります。この場合、デフォルトで NetworkManager がルーター広告を使用します。ルーターがmanagedフラグを通知すると、NetworkManager は DHCPv6 サーバーから IPv6 アドレスと接頭辞を要求します。親デバイスの IP アドレス設定を無効にします。 parent: <parent_device>- VLAN 接続プロファイルの親デバイスを設定します。この例では、親はイーサネットインターフェイスです。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
VLAN 設定を確認します。
# ansible managed-node-01.example.com -m command -a 'ip -d addr show enp1s0.10' managed-node-01.example.com | CHANGED | rc=0 >> 4: vlan10@enp1s0.10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:72:2f:6e brd ff:ff:ff:ff:ff:ff promiscuity 0 vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 ...
第6章 ネットワークブリッジの設定
ネットワークブリッジは、MAC アドレスのテーブルに基づいてネットワーク間のトラフィックを転送するリンク層デバイスです。ブリッジは、ネットワークトラフィックをリッスンし、どのホストが各ネットワークに接続しているかを把握して、MAC アドレステーブルを構築します。たとえば、Red Hat Enterprise Linux ホストのソフトウェアブリッジを使用して、ハードウェアブリッジまたは仮想環境をエミュレートし、仮想マシンをホストと同じネットワークに統合できます。
ブリッジには、ブリッジが接続する必要がある各ネットワークにネットワークデバイスが必要です。ブリッジを設定する場合には、ブリッジは コントローラー と呼ばれ、ポート を使用するデバイスです。
以下のように、さまざまなタイプのデバイスにブリッジを作成できます。
- 物理および仮想イーサネットデバイス
- ネットワークボンド
- ネットワークチーム
- VLAN デバイス
Wi-Fi で効率的に使用するために、Wi-Fi で 3-address フレームの使用を指定する IEEE 802.11 規格により、Ad-Hoc モードまたは Infrastructure モードで稼働している Wi-Fi ネットワークにはブリッジを設定できません。
6.1. nmcli を使用したネットワークブリッジの設定
コマンドラインでネットワークブリッジを設定するには、nmcli ユーティリティーを使用します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ブリッジのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスをサーバーにインストールする必要があります。
ブリッジのポートにチーム、ボンディング、または VLAN デバイスを使用するには、ブリッジの作成時にこれらのデバイスを作成するか、次の説明に従って事前にデバイスを作成することができます。
手順
ブリッジインターフェイスを作成します。
# nmcli connection add type bridge con-name bridge0 ifname bridge0このコマンドにより
bridge0という名前のブリッジが作成されます。ネットワークインターフェイスを表示し、ブリッジに追加するインターフェイスの名前を書き留めます。
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet disconnected -- enp8s0 ethernet disconnected -- bond0 bond connected bond0 bond1 bond connected bond1 ...この例では、以下のように設定されています。
-
enp7s0およびenp8s0は設定されません。これらのデバイスをポートとして使用するには、次のステップに接続プロファイルを追加します。 -
bond0およびbond1には既存の接続プロファイルがあります。これらのデバイスをポートとして使用するには、次の手順でプロファイルを変更します。
-
インターフェイスをブリッジに割り当てます。
ブリッジに割り当てるインターフェイスが設定されていない場合は、それらのブリッジに新しい接続プロファイルを作成します。
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp7s0 master bridge0 # nmcli connection add type ethernet slave-type bridge con-name bridge0-port2 ifname enp8s0 master bridge0これらのコマンドにより、
enp7s0およびenp8s0のプロファイルが作成され、それらをbridge0接続に追加します。既存の接続プロファイルをブリッジに割り当てるには、以下を実行します。
これらの接続の
masterパラメーターをbridge0に設定します。# nmcli connection modify bond0 master bridge0 # nmcli connection modify bond1 master bridge0これらのコマンドは、
bond0およびbond1という名前の既存の接続プロファイルをbridge0接続に割り当てます。接続を再度アクティブにします。
# nmcli connection up bond0 # nmcli connection up bond1
IPv4 を設定します。
静的 IPv4 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
bridge0接続に設定するには、次のように実行します。# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253' ipv4.dns-search 'example.com' ipv4.method manual- DHCP を使用するために必要な操作はありません。
- このブリッジデバイスを他のデバイスのポートとして使用する予定の場合は、特に必要な操作はありません。
IPv6 設定を行います。
静的 IPv6 アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーを
bridge0接続に設定するには、次のように実行します。# nmcli connection modify bridge0 ipv6.addresses '2001:db8:1::1/64' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd' ipv6.dns-search 'example.com' ipv6.method manual- ステートレスアドレス自動設定 (SLAAC) を使用する場合、アクションは必要ありません。
- このブリッジデバイスを他のデバイスのポートとして使用する予定の場合は、特に必要な操作はありません。
必要に応じて、ブリッジのその他のプロパティーを設定します。たとえば、
bridge0の STP (Spanning Tree Protocol) の優先度を16384に設定するには、次のコマンドを実行します。# nmcli connection modify bridge0 bridge.priority '16384'デフォルトでは STP が有効になっています。
接続をアクティベートします。
# nmcli connection up bridge0ポートが接続されており、
CONNECTIONコラムがポートの接続名を表示していることを確認します。# nmcli device DEVICE TYPE STATE CONNECTION ... enp7s0 ethernet connected bridge0-port1 enp8s0 ethernet connected bridge0-port2接続のいずれかのポートをアクティブにすると、NetworkManager はブリッジもアクティブにしますが、他のポートはアクティブにしません。ブリッジが有効な場合には、Red Hat Enterprise Linux がすべてのポートを自動的に有効にするように設定できます。
ブリッジ接続の
connection.autoconnect-slavesパラメーターを有効にします。# nmcli connection modify bridge0 connection.autoconnect-slaves 1ブリッジを再度アクティブにします。
# nmcli connection up bridge0
検証
ipユーティリティーを使用して、特定のブリッジのポートであるイーサネットデバイスのリンクステータスを表示します。# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffbridgeユーティリティーを使用して、任意のブリッジデバイスのポートであるイーサネットデバイスの状態を表示します。# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 5: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 100 6: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100 ...特定のイーサネットデバイスのステータスを表示するには、
bridge link show dev <ethernet_device_name>コマンドを使用します。
6.2. RHEL Web コンソールを使用したネットワークブリッジの設定
Web ブラウザーベースのインターフェイスを使用してネットワーク設定を管理する場合は、RHEL Web コンソールを使用してネットワークブリッジを設定します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ブリッジのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスをサーバーにインストールする必要があります。
ブリッジのポートにチーム、ボンディング、または VLAN デバイスを使用するには、ブリッジの作成時にこれらのデバイスを作成するか、次の説明に従って事前にデバイスを作成することができます。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- 画面左側のナビゲーションで Networking タブを選択します。
- Interfaces セクションで をクリックします。
- 作成するブリッジデバイスの名前を入力します。
- ブリッジのポートにするインターフェイスを選択します。
オプション: Spanning tree protocol (STP) 機能を有効にして、ブリッジループとブロードキャストの過剰拡散を回避します。
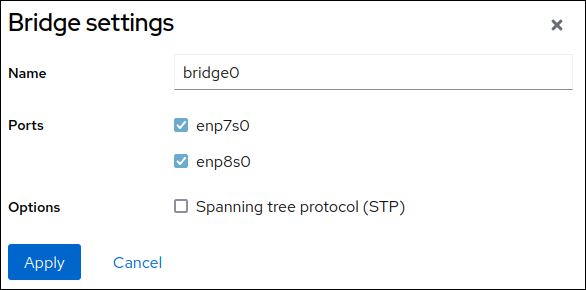
- をクリックします。
デフォルトでは、ブリッジは動的 IP アドレスを使用します。静的 IP アドレスを設定する場合:
- Interfaces セクションでブリッジの名前をクリックします。
- 設定するプロトコルの横にある Edit をクリックします。
- Addresses の横にある Manual を選択し、IP アドレス、接頭辞、およびデフォルトゲートウェイを入力します。
- DNS セクションで ボタンをクリックし、DNS サーバーの IP アドレスを入力します。複数の DNS サーバーを設定するには、この手順を繰り返します。
- DNS search domains セクションで、 ボタンをクリックし、検索ドメインを入力します。
インターフェイスにスタティックルートが必要な場合は、Routes セクションで設定します。
- をクリックします。
検証
画面左側のナビゲーションで Networking タブを選択し、インターフェイスに着信および発信トラフィックがあるか確認します。
6.3. nmtui を使用したネットワークブリッジの設定
nmtui アプリケーションは、NetworkManager 用のテキストベースのユーザーインターフェイスを提供します。nmtui を使用して、グラフィカルインターフェイスを使用せずにホスト上でネットワークブリッジを設定できます。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- イーサネットデバイスをブリッジのポートとして使用するために、物理または仮想イーサネットデバイスがサーバーにインストールされている。
手順
ネットワークブリッジを設定するネットワークデバイス名がわからない場合は、使用可能なデバイスを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp7s0 ethernet unavailable -- enp8s0 ethernet unavailable -- ...nmtuiを開始します。# nmtui-
Edit a connection選択し、Enter を押します。 -
Addを押します。 -
ネットワークタイプのリストから
Bridgeを選択し、Enter を押します。 オプション: 作成する NetworkManager プロファイルの名前を入力します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
-
作成するブリッジデバイス名を
Deviceフィールドに入力します。 作成するブリッジにポートを追加します。
-
Slavesリストの横にあるAddを押します。 -
ブリッジにポートとして追加するインターフェイスのタイプ (例:
Ethernet) を選択します。 - オプション: このブリッジポート用に作成する NetworkManager プロファイルの名前を入力します。
-
ポートのデバイス名を
Deviceフィールドに入力します。 OKを押して、ブリッジ設定のウィンドウに戻ります。図6.1 イーサネットデバイスをポートとしてブリッジに追加する

- ブリッジにさらにポートを追加するには、これらの手順を繰り返します。
-
環境に応じて、
IPv4 configurationおよびIPv6 configuration領域に IP アドレス設定を設定します。これを行うには、これらの領域の横にあるボタンを押して、次を選択します。-
ブリッジが IP アドレスを必要としない場合は
Disabledにします。 -
DHCP サーバーまたはステートレスアドレス自動設定 (SLAAC) が IP アドレスをブリッジに動的に割り当てる場合は、
Automaticにします。 ネットワークで静的 IP アドレス設定が必要な場合は、
Manualにします。この場合、さらにフィールドに入力する必要があります。-
設定するプロトコルの横にある
Showを押して、追加のフィールドを表示します。 Addressesの横にあるAddを押して、IP アドレスとサブネットマスクを Classless Inter-Domain Routing (CIDR) 形式で入力します。サブネットマスクを指定しない場合、NetworkManager は IPv4 アドレスに
/32サブネットマスクを設定し、IPv6 アドレスに/64サブネットマスクを設定します。- デフォルトゲートウェイのアドレスを入力します。
-
DNS serversの横にあるAddを押して、DNS サーバーのアドレスを入力します。 -
Search domainsの横にあるAddを押して、DNS 検索ドメインを入力します。
-
設定するプロトコルの横にある
図6.2 IP アドレス設定なしのブリッジ接続例
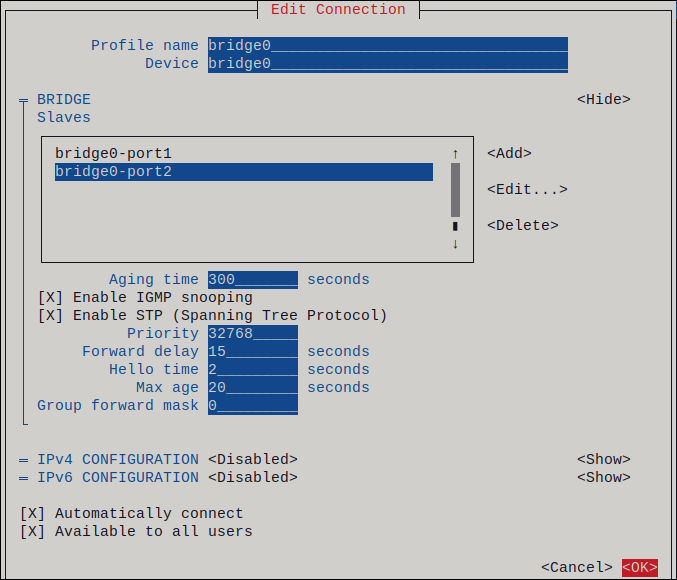
-
ブリッジが IP アドレスを必要としない場合は
-
OKを押すと、新しい接続が作成され、自動的にアクティブ化されます。 -
Backを押してメインメニューに戻ります。 -
Quitを選択し、Enter キーを押してnmtuiアプリケーションを閉じます。
検証
ipユーティリティーを使用して、特定のブリッジのポートであるイーサネットデバイスのリンクステータスを表示します。# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffbridgeユーティリティーを使用して、任意のブリッジデバイスのポートであるイーサネットデバイスの状態を表示します。# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 ...特定のイーサネットデバイスのステータスを表示するには、
bridge link show dev <ethernet_device_name>コマンドを使用します。
6.4. nm-connection-editor を使用したネットワークブリッジの設定
グラフィカルインターフェイスで Red Hat Enterprise Linux を使用する場合は、nm-connection-editor アプリケーションを使用してネットワークブリッジを設定できます。
nm-connection-editor は、新しいポートだけをブリッジに追加できることに注意してください。既存の接続プロファイルをポートとして使用するには、nmcli を使用したネットワークブリッジの設定 の説明に従って、nmcli ユーティリティーを使用してブリッジを作成します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- ブリッジのポートとしてイーサネットデバイスを使用するには、物理または仮想のイーサネットデバイスをサーバーにインストールする必要があります。
- ブリッジのポートとしてチーム、ボンディング、または VLAN デバイスを使用するには、これらのデバイスがまだ設定されていないことを確認してください。
手順
ターミナルを開き、
nm-connection-editorと入力します。$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
- 接続タイプ Bridge を選択し、 をクリックします。
Bridge タブで以下を行います。
- 必要に応じて、Interface name フィールドにブリッジインターフェイスの名前を設定します。
ボタンをクリックして、ネットワークインターフェイスの新しい接続プロファイルを作成し、プロファイルをポートとしてブリッジに追加します。
- インターフェイスの接続タイプを選択します。たとえば、有線接続に Ethernet を選択します。
- オプション: ポートデバイスの接続名を設定します。
- イーサネットデバイスの接続プロファイルを作成する場合は、Ethernet タブを開き、Device フィールドで選択し、ポートとしてブリッジに追加するネットワークインターフェイスを選択します。別のデバイスタイプを選択した場合は、それに応じて設定します。
- をクリックします。
ブリッジに追加する各インターフェイスに、直前の手順を繰り返します。
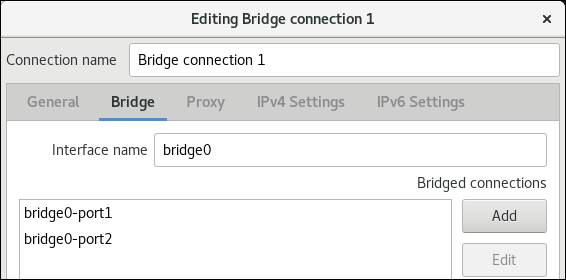
- 必要に応じて、スパニングツリープロトコル (STP) オプションなどの追加のブリッジ設定を行います。
IPv4 Settings タブと IPv6 Settings タブの両方で IP アドレス設定を設定します。
- このブリッジデバイスを他のデバイスのポートとして使用する場合は、Method フィールドを Disabled に設定します。
- DHCP を使用するには、Method フィールドをデフォルトの Automatic (DHCP) のままにします。
静的 IP 設定を使用するには、Method フィールドを Manual に設定し、それに応じてフィールドに値を入力します。
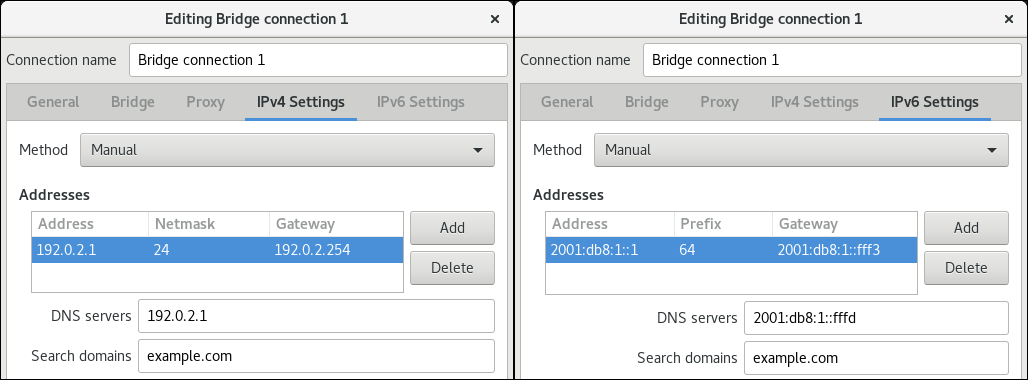
- をクリックします。
-
nm-connection-editorを閉じます。
検証
ipユーティリティーを使用して、特定のブリッジのポートであるイーサネットデバイスのリンクステータスを表示します。# ip link show master bridge0 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffbridgeユーティリティーを使用して、任意のブリッジデバイスのポートであるイーサネットデバイスの状態を表示します。# bridge link show 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100 5: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 100 6: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100 ...特定のイーサネットデバイスのステータスを表示するには、
bridge link show dev ethernet_device_nameコマンドを使用します。
6.5. nmstatectl を使用したネットワークブリッジの設定
nmstatectl ユーティリティーを使用して、Nmstate API を介してネットワークブリッジを設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
環境に応じて、YAML ファイルを適宜調整します。たとえば、ブリッジでイーサネットアダプターとは異なるデバイスを使用するには、ブリッジで使用するポートの Base-iface 属性と type 属性を調整します。
前提条件
- サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
- 物理または仮想のイーサネットデバイスをサーバーにインストールし、ブリッジでイーサネットデバイスをポートとして使用する。
-
ポートリストでインターフェイス名を設定し、対応するインターフェイスを定義して、ブリッジのポートとしてチーム、ボンディング、または VLAN デバイスを使用する。 -
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイル (例:
~/create-bridge.yml) を作成します。--- interfaces: - name: bridge0 type: linux-bridge state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false bridge: options: stp: enabled: true port: - name: enp1s0 - name: enp7s0 - name: enp1s0 type: ethernet state: up - name: enp7s0 type: ethernet state: up routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: bridge0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: bridge0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbこれらの設定では、次の設定でネットワークブリッジを定義します。
-
ブリッジのネットワークインターフェイス:
enp1s0およびenp7s0 - スパニングツリープロトコル (STP): 有効化
-
静的 IPv4 アドレス:
192.0.2.1(サブネットマスクが/24) -
静的 IPv6 アドレス:
2001:db8:1::1(サブネットマスクが/64) -
IPv4 デフォルトゲートウェイ:
192.0.2.254 -
IPv6 デフォルトゲートウェイ:
2001:db8:1::fffe -
IPv4 DNS サーバー:
192.0.2.200 -
IPv6 DNS サーバー:
2001:db8:1::ffbb -
DNS 検索ドメイン:
example.com
-
ブリッジのネットワークインターフェイス:
設定をシステムに適用します。
# nmstatectl apply ~/create-bridge.yml
検証
デバイスおよび接続の状態を表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION bridge0 bridge connected bridge0接続プロファイルのすべての設定を表示します。
# nmcli connection show bridge0 connection.id: bridge0_ connection.uuid: e2cc9206-75a2-4622-89cf-1252926060a9 connection.stable-id: -- connection.type: bridge connection.interface-name: bridge0 ...接続設定を YAML 形式で表示します。
# nmstatectl show bridge0
6.6. network RHEL システムロールを使用したネットワークブリッジの設定
ネットワークブリッジを作成することにより、Open Systems Interconnection (OSI) モデルのレイヤー 2 で複数のネットワークを接続できます。ブリッジを設定するには、NetworkManager で接続プロファイルを作成します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用してブリッジを設定できます。ブリッジの親デバイスの接続プロファイルが存在しない場合は、このロールによって作成することもできます。
IP アドレス、ゲートウェイ、DNS 設定をブリッジに割り当てる場合は、ポートではなくブリッジで設定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - サーバーに、2 つ以上の物理ネットワークデバイスまたは仮想ネットワークデバイスがインストールされている。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Bridge connection profile with two Ethernet ports ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: # Bridge profile - name: bridge0 type: bridge interface_name: bridge0 ip: dhcp4: yes auto6: yes state: up # Port profile for the 1st Ethernet device - name: bridge0-port1 interface_name: enp7s0 type: ethernet controller: bridge0 port_type: bridge state: up # Port profile for the 2nd Ethernet device - name: bridge0-port2 interface_name: enp8s0 type: ethernet controller: bridge0 port_type: bridge state: upサンプル Playbook で指定されている設定は次のとおりです。
type: <profile_type>- 作成するプロファイルのタイプを設定します。このサンプル Playbook では、3 つの接続プロファイルを作成します。1 つはブリッジ用、2 つはイーサネットデバイス用です。
dhcp4: yes- DHCP、PPP、または同様のサービスからの自動 IPv4 アドレス割り当てを有効にします。
auto6: yes-
IPv6 自動設定を有効にします。デフォルトでは、NetworkManager はルーター広告を使用します。ルーターが
managedフラグを通知すると、NetworkManager は DHCPv6 サーバーに IPv6 アドレスと接頭辞を要求します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
特定のブリッジのポートであるイーサネットデバイスのリンクステータスを表示します。
# ansible managed-node-01.example.com -m command -a 'ip link show master bridge0' managed-node-01.example.com | CHANGED | rc=0 >> 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ffブリッジデバイスのポートであるイーサネットデバイスのステータスを表示します。
# ansible managed-node-01.example.com -m command -a 'bridge link show' managed-node-01.example.com | CHANGED | rc=0 >> 3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 100 4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 100
第7章 IPsec VPN のセットアップ
仮想プライベートネットワーク (VPN) は、インターネット経由でローカルネットワークに接続する方法です。Libreswan により提供される IPsec は、VPN を作成するための望ましい方法です。Libreswan は、VPN のユーザー空間 IPsec 実装です。VPN は、インターネットなどの中間ネットワークにトンネルを設定して、使用中の LAN と別のリモート LAN との間の通信を可能にします。セキュリティー上の理由から、VPN トンネルは常に認証と暗号化を使用します。暗号化操作では、Libreswan は NSS ライブラリーを使用します。
7.1. IPsec VPN 実装としての Libreswan
RHEL では、IPsec プロトコルを使用して仮想プライベートネットワーク (VPN) を設定できます。これは、Libreswan アプリケーションによりサポートされます。Libreswan は、Openswan アプリケーションの延長であり、Openswan ドキュメントの多くの例は Libreswan でも利用できます。
VPN の IPsec プロトコルは、IKE (Internet Key Exchange) プロトコルを使用して設定されます。IPsec と IKE は同義語です。IPsec VPN は、IKE VPN、IKEv2 VPN、XAUTH VPN、Cisco VPN、または IKE/IPsec VPN とも呼ばれます。Layer 2 Tunneling Protocol (L2TP) も使用する IPsec VPN のバリアントは、通常、L2TP/IPsec VPN と呼ばれ、optional のリポジトリーによって提供される xl2tpd パッケージが必要です。
Libreswan は、オープンソースのユーザー空間の IKE 実装です。IKE v1 および v2 は、ユーザーレベルのデーモンとして実装されます。IKE プロトコルも暗号化されています。IPsec プロトコルは Linux カーネルで実装され、Libreswan は、VPN トンネル設定を追加および削除するようにカーネルを設定します。
IKE プロトコルは、UDP ポート 500 および 4500 を使用します。IPsec プロトコルは、以下の 2 つのプロトコルで構成されます。
- 暗号セキュリティーペイロード (ESP) (プロトコル番号が 50)
- 認証ヘッダー (AH) (プロトコル番号 51)
AH プロトコルの使用は推奨されていません。AH のユーザーは、null 暗号化で ESP に移行することが推奨されます。
IPsec プロトコルは、以下の 2 つの操作モードを提供します。
- トンネルモード (デフォルト)
- トランスポートモード
IKE を使用せずに IPsec を使用してカーネルを設定できます。これは、手動キーリング と呼ばれます。また、ip xfrm コマンドを使用して手動キーを設定できますが、これはセキュリティー上の理由からは強く推奨されません。Libreswan は、Netlink インターフェイスを使用して Linux カーネルと通信します。カーネルはパケットの暗号化と復号化を実行します。
Libreswan は、ネットワークセキュリティーサービス (NSS) 暗号化ライブラリーを使用します。NSS は、連邦情報処理標準 (FIPS) の公開文書 140-2 での使用が認定されています。
Libreswan および Linux カーネルが実装する IKE/IPsec の VPN は、RHEL で使用することが推奨される唯一の VPN 技術です。その他の VPN 技術は、そのリスクを理解せずに使用しないでください。
RHEL では、Libreswan はデフォルトで システム全体の暗号化ポリシー に従います。これにより、Libreswan は、デフォルトのプロトコルとして IKEv2 を含む現在の脅威モデルに対して安全な設定を使用するようになります。詳細は、Using system-wide crypto policies を参照してください。
IKE/IPsec はピアツーピアプロトコルであるため、Libreswan では、"ソース" および "宛先"、または "サーバー" および "クライアント" という用語を使用しません。終了点 (ホスト) を参照する場合は、代わりに "左" と "右" という用語を使用します。これにより、ほとんどの場合、両方の終了点で同じ設定も使用できます。ただし、管理者は通常、ローカルホストに "左" を使用し、リモートホストに "右" を使用します。
leftid と rightid オプションは、認証プロセス内の各ホストの識別として機能します。詳細は、man ページの ipsec.conf(5) を参照してください。
7.2. Libreswan の認証方法
Libreswan は複数の認証方法をサポートしますが、それぞれは異なるシナリオとなっています。
事前共有キー (PSK)
事前共有キー (PSK) は、最も簡単な認証メソッドです。セキュリティー上の理由から、PSK は 64 文字未満は使用しないでください。FIPS モードでは、PSK は、使用される整合性アルゴリズムに応じて、最低強度の要件に準拠する必要があります。authby=secret 接続を使用して PSK を設定できます。
Raw RSA 鍵
Raw RSA 鍵 は、静的なホスト間またはサブネット間の IPsec 設定で一般的に使用されます。各ホストは、他のすべてのホストのパブリック RSA 鍵を使用して手動で設定され、Libreswan はホストの各ペア間で IPsec トンネルを設定します。この方法は、多数のホストでは適切にスケーリングされません。
ipsec newhostkey コマンドを使用して、ホストで Raw RSA 鍵を生成できます。ipsec showhostkey コマンドを使用して、生成された鍵をリスト表示できます。leftrsasigkey= の行は、CKA ID キーを使用する接続設定に必要です。Raw RSA 鍵に authby=rsasig 接続オプションを使用します。
X.509 証明書
X.509 証明書 は、共通の IPsec ゲートウェイに接続するホストが含まれる大規模なデプロイメントに一般的に使用されます。中央の 認証局 (CA) は、ホストまたはユーザーの RSA 証明書に署名します。この中央 CA は、個別のホストまたはユーザーの取り消しを含む、信頼のリレーを行います。
たとえば、openssl コマンドおよび NSS certutil コマンドを使用して X.509 証明書を生成できます。Libreswan は、leftcert= 設定オプションの証明書のニックネームを使用して NSS データベースからユーザー証明書を読み取るため、証明書の作成時にニックネームを指定します。
カスタム CA 証明書を使用する場合は、これを Network Security Services(NSS) データベースにインポートする必要があります。ipsec import コマンドを使用して、PKCS #12 形式の証明書を Libreswan NSS データベースにインポートできます。
Libreswan は、section 3.1 of RFC 4945 で説明されているように、すべてのピア証明書のサブジェクト代替名 (SAN) としてインターネット鍵 Exchange(IKE) ピア ID を必要とします。require-id-on-certificate=no 接続オプションを設定してこのチェックを無効にすると、システムが中間者攻撃に対して脆弱になる可能性があります。
SHA-1 および SHA-2 で RSA を使用した X.509 証明書に基づく認証に authby=rsasig 接続オプションを使用します。authby= を ecdsa に設定し、authby=rsa-sha2 を介した SHA-2 による RSA Probabilistic Signature Scheme (RSASSA-PSS) デジタル署名ベースの認証を設定することにより、SHA-2 を使用する ECDSA デジタル署名に対してさらに制限することができます。デフォルト値は authby=rsasig,ecdsa です。
証明書と authby= 署名メソッドが一致する必要があります。これにより、相互運用性が向上し、1 つのデジタル署名システムでの認証が維持されます。
NULL 認証
NULL 認証 は、認証なしでメッシュ暗号化を実現するために使用されます。これは、パッシブ攻撃は防ぎますが、アクティブ攻撃は防ぎません。ただし、IKEv2 は非対称認証メソッドを許可するため、NULL 認証はインターネットスケールのオポチュニスティック IPsec にも使用できます。このモデルでは、クライアントはサーバーを認証しますが、サーバーはクライアントを認証しません。このモデルは、TLS を使用して Web サイトのセキュリティーを保護するのと似ています。NULL 認証に authby=null を使用します。
量子コンピューターに対する保護
上記の認証方法に加えて、Post-quantum Pre-shared Key (PPK) メソッドを使用して、量子コンピューターによる潜在的な攻撃から保護することができます。個々のクライアントまたはクライアントグループは、帯域外で設定された事前共有鍵に対応する PPK ID を指定することにより、独自の PPK を使用できます。
事前共有キーで IKEv1 を使用すると、量子攻撃者から保護されます。IKEv2 の再設計は、この保護をネイティブに提供しません。Libreswan は、Post-quantum Pre-shared Key (PPK) を使用して、量子攻撃から IKEv2 接続を保護します。
任意の PPK 対応を有効にする場合は、接続定義に ppk=yes を追加します。PPK が必要な場合は ppk=insist を追加します。次に、各クライアントには、帯域外で通信する (および可能であれば量子攻撃に対して安全な) シークレット値を持つ PPK ID を付与できます。PPK はランダム性において非常に強力で、辞書の単語に基づいていません。PPK ID と PPK データは、次のように ipsec.secrets ファイルに保存されます。
@west @east : PPKS "user1" "thestringismeanttobearandomstr"
PPKS オプションは、静的な PPK を参照します。実験的な関数は、ワンタイムパッドに基づいた動的 PPK を使用します。各接続では、ワンタイムパッドの新しい部分が PPK として使用されます。これを使用すると、ファイル内の動的な PPK の部分がゼロで上書きされ、再利用を防ぐことができます。複数のタイムパッドマテリアルが残っていないと、接続は失敗します。詳細は、man ページの ipsec.secrets(5) を参照してください。
動的 PPK の実装はサポート対象外のテクノロジープレビューとして提供されます。注意して使用してください。
7.3. Libreswan のインストール
Libreswan IPsec/IKE 実装を通じて VPN を設定する前に、対応するパッケージをインストールし、ipsec サービスを開始して、ファイアウォールでサービスを許可する必要があります。
前提条件
-
AppStreamリポジトリーが有効になっている。
手順
libreswanパッケージをインストールします。# yum install libreswanLibreswan を再インストールする場合は、古いデータベースファイルを削除し、新しいデータベースを作成します。
# systemctl stop ipsec # rm /etc/ipsec.d/*db # ipsec initnssipsecサービスを開始して有効にし、システムの起動時にサービスを自動的に開始できるようにします。# systemctl enable ipsec --nowファイアウォールで、
ipsecサービスを追加して、IKE プロトコル、ESP プロトコル、および AH プロトコルの 500/UDP ポートおよび 4500/UDP ポートを許可するように設定します。# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanent
7.4. ホスト間の VPN の作成
raw RSA キーによる認証を使用して、左 および 右 と呼ばれる 2 つのホスト間に、ホストツーホスト IPsec VPN を作成するように Libreswan を設定できます。
前提条件
-
Libreswan がインストールされ、
ipsecサービスが各ノードで開始している。
手順
各ホストで Raw RSA 鍵ペアを生成します。
# ipsec newhostkey前の手順で生成した鍵の
ckaidを返します。左 で次のコマンドを実行して、そのckaidを使用します。以下に例を示します。# ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857d上のコマンドの出力により、設定に必要な
leftrsasigkey=行が生成されます。次のホスト (右) でも同じ操作を行います。# ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03/etc/ipsec.d/ディレクトリーで、新しいmy_host-to-host.confファイルを作成します。上の手順のipsec showhostkeyコマンドの出力から、RSA ホストの鍵を新規ファイルに書き込みます。以下に例を示します。conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig鍵をインポートしたら、
ipsecサービスを再起動します。# systemctl restart ipsec接続を読み込みます。
# ipsec auto --add mytunnelトンネルを確立します。
# ipsec auto --up mytunnelipsecサービスの開始時に自動的にトンネルを開始するには、以下の行を接続定義に追加します。auto=start- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
7.5. サイト間 VPN の設定
2 つのネットワークを結合してサイト間の IPsec VPN を作成する場合は、その 2 つのホスト間の IPsec トンネルが作成されます。これにより、ホストは終了点として動作し、1 つまたは複数のサブネットからのトラフィックが通過できるように設定されます。したがって、ホストを、ネットワークのリモート部分にゲートウェイとして見なすことができます。
サイト間の VPN の設定は、設定ファイル内で複数のネットワークまたはサブネットを指定する必要がある点のみが、ホスト間の VPN とは異なります。
前提条件
- ホスト間の VPN が設定されている。
手順
ホスト間の VPN の設定が含まれるファイルを、新規ファイルにコピーします。以下に例を示します。
# cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.conf上の手順で作成したファイルに、サブネット設定を追加します。以下に例を示します。
conn mysubnet also=mytunnel leftsubnet=192.0.1.0/24 rightsubnet=192.0.2.0/24 auto=start conn mysubnet6 also=mytunnel leftsubnet=2001:db8:0:1::/64 rightsubnet=2001:db8:0:2::/64 auto=start # the following part of the configuration file is the same for both host-to-host and site-to-site connections: conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
7.6. リモートアクセスの VPN の設定
ロードウォーリアーとは、モバイルクライアントと動的に割り当てられた IP アドレスを使用する移動するユーザーのことです。モバイルクライアントは、X.509 証明書を使用して認証します。
以下の例では、IKEv2 の設定を示しています。IKEv1 XAUTH プロトコルは使用していません。
サーバー上では以下の設定になります。
conn roadwarriors
ikev2=insist
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
fragmentation=yes
left=1.2.3.4
# if access to the LAN is given, enable this, otherwise use 0.0.0.0/0
# leftsubnet=10.10.0.0/16
leftsubnet=0.0.0.0/0
leftcert=gw.example.com
leftid=%fromcert
leftxauthserver=yes
leftmodecfgserver=yes
right=%any
# trust our own Certificate Agency
rightca=%same
# pick an IP address pool to assign to remote users
# 100.64.0.0/16 prevents RFC1918 clashes when remote users are behind NAT
rightaddresspool=100.64.13.100-100.64.13.254
# if you want remote clients to use some local DNS zones and servers
modecfgdns="1.2.3.4, 5.6.7.8"
modecfgdomains="internal.company.com, corp"
rightxauthclient=yes
rightmodecfgclient=yes
authby=rsasig
# optionally, run the client X.509 ID through pam to allow or deny client
# pam-authorize=yes
# load connection, do not initiate
auto=add
# kill vanished roadwarriors
dpddelay=1m
dpdtimeout=5m
dpdaction=clearロードウォーリアーのデバイスであるモバイルクライアントでは、上記の設定に多少変更を加えて使用します。
conn to-vpn-server
ikev2=insist
# pick up our dynamic IP
left=%defaultroute
leftsubnet=0.0.0.0/0
leftcert=myname.example.com
leftid=%fromcert
leftmodecfgclient=yes
# right can also be a DNS hostname
right=1.2.3.4
# if access to the remote LAN is required, enable this, otherwise use 0.0.0.0/0
# rightsubnet=10.10.0.0/16
rightsubnet=0.0.0.0/0
fragmentation=yes
# trust our own Certificate Agency
rightca=%same
authby=rsasig
# allow narrowing to the server’s suggested assigned IP and remote subnet
narrowing=yes
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
# initiate connection
auto=startDHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
7.7. メッシュ VPN の設定
any-to-any VPN とも呼ばれるメッシュ VPN ネットワークは、全ノードが IPsec を使用して通信するネットワークです。この設定では、IPsec を使用できないノードの例外が許可されます。メッシュの VPN ネットワークは、以下のいずれかの方法で設定できます。
- IPSec を必要とする。
- IPsec を優先するが、平文通信へのフォールバックを可能にする。
ノード間の認証は、X.509 証明書または DNSSEC (DNS Security Extensions) を基にできます。
これらの接続は通常の Libreswan 設定であるため、オポチュニスティック IPsec に通常の IKEv2 認証方法を使用できます。ただし、right=%opportunisticgroup エントリーで定義されるオポチュニスティック IPsec を除きます。一般的な認証方法は、一般に共有される認証局 (CA) を使用して、X.509 証明書に基づいてホストを相互に認証させる方法です。クラウドデプロイメントでは通常、標準の手順の一部として、クラウド内の各ノードに証明書を発行します。
1 つのホストが侵害されると、グループの PSK シークレットも侵害されるため、PreSharedKey (PSK) 認証は使用しないでください。
NULL 認証を使用すると、認証なしでノード間に暗号化をデプロイできます。これを使用した場合、受動的な攻撃者からのみ保護されます。
以下の手順では、X.509 証明書を使用します。この証明書は、Dogtag Certificate System などの任意の種類の CA 管理システムを使用して生成できます。Dogtag は、各ノードの証明書が PKCS #12 形式 (.p12 ファイル) で利用可能であることを前提としています。これには、秘密鍵、ノード証明書、およびその他のノードの X.509 証明書を検証するのに使用されるルート CA 証明書が含まれます。
各ノードでは、その X.509 証明書を除いて、同じ設定を使用します。これにより、ネットワーク内で既存ノードを再設定せずに、新規ノードを追加できます。PKCS #12 ファイルには "分かりやすい名前" が必要であるため、名前には "node" を使用します。これにより、すべてのノードに対して、この名前を参照する設定ファイルが同一になります。
前提条件
-
Libreswan がインストールされ、
ipsecサービスが各ノードで開始している。 新しい NSS データベースが初期化されている。
すでに古い NSS データベースがある場合は、古いデータベースファイルを削除します。
# systemctl stop ipsec # rm /etc/ipsec.d/*db次のコマンドを使用して、新しいデータベースを初期化できます。
# ipsec initnss
手順
各ノードで PKCS #12 ファイルをインポートします。この手順では、PKCS #12 ファイルの生成に使用するパスワードが必要になります。
# ipsec import nodeXXX.p12IPsec required(private)、IPsec optional(private-or-clear)、およびNo IPsec(clear) プロファイルに、以下のような 3 つの接続定義を作成します。# cat /etc/ipsec.d/mesh.conf conn clear auto=ondemand1 type=passthrough authby=never left=%defaultroute right=%group conn private auto=ondemand type=transport authby=rsasig failureshunt=drop negotiationshunt=drop ikev2=insist left=%defaultroute leftcert=nodeXXXX leftid=%fromcert2 rightid=%fromcert right=%opportunisticgroup conn private-or-clear auto=ondemand type=transport authby=rsasig failureshunt=passthrough negotiationshunt=passthrough # left left=%defaultroute leftcert=nodeXXXX3 leftid=%fromcert leftrsasigkey=%cert # right rightrsasigkey=%cert rightid=%fromcert right=%opportunisticgroup- 1
auto変数にはいくつかのオプションがあります。ondemand接続オプションは、IPsec 接続を開始するオポチュニスティック IPsec や、常にアクティブにする必要のない明示的に設定した接続に使用できます。このオプションは、カーネル内にトラップ XFRM ポリシーを設定し、そのポリシーに一致する最初のパケットを受信したときに IPsec 接続を開始できるようにします。オポチュニスティック IPsec を使用する場合も、明示的に設定した接続を使用する場合も、次のオプションを使用すると、IPsec 接続を効果的に設定および管理できます。
addオプション-
接続設定をロードし、リモート開始に応答できるように準備します。ただし、接続はローカル側から自動的に開始されません。コマンド
ipsec auto --upを使用して、IPsec 接続を手動で開始できます。 startオプション- 接続設定をロードし、リモート開始に応答できるように準備します。さらに、リモートピアへの接続を即座に開始します。このオプションは、永続的かつ常にアクティブな接続に使用できます。
- 2
leftid変数とrightid変数は、IPsec トンネル接続の右チャネルと左チャネルを指定します。これらの変数を使用して、ローカル IP アドレスの値、またはローカル証明書のサブジェクト DN を取得できます (設定している場合)。- 3
leftcert変数は、使用する NSS データベースのニックネームを定義します。
ネットワークの IP アドレスを対応するカテゴリーに追加します。たとえば、すべてのノードが
10.15.0.0/16ネットワーク内に存在し、すべてのノードで IPsec 暗号化を使用する必要がある場合は、次のコマンドを実行します。# echo "10.15.0.0/16" >> /etc/ipsec.d/policies/private特定のノード (
10.15.34.0/24など) を IPsec の有無にかかわらず機能させるには、そのノードを private-or-clear グループに追加します。# echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clearホストを、
10.15.1.2など、IPsec の機能がない clear グループに定義する場合は、次のコマンドを実行します。# echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clear/etc/ipsec.d/policiesディレクトリーのファイルは、各新規ノードのテンプレートから作成することも、Puppet または Ansible を使用してプロビジョニングすることもできます。すべてのノードでは、例外のリストが同じか、異なるトラフィックフローが期待される点に注意してください。したがって、あるノードで IPsec が必要になり、別のノードで IPsec を使用できないために、ノード間の通信ができない場合もあります。
ノードを再起動して、設定したメッシュに追加します。
# systemctl restart ipsec- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
検証
pingコマンドを使用して IPsec トンネルを開きます。# ping <nodeYYY>インポートされた証明書を含む NSS データベースを表示します。
# certutil -L -d sql:/etc/ipsec.d Certificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI west u,u,u ca CT,,ノード上の開いているトンネルを確認します。
# ipsec trafficstatus 006 #2: "private#10.15.0.0/16"[1] ...<nodeYYY>, type=ESP, add_time=1691399301, inBytes=512, outBytes=512, maxBytes=2^63B, id='C=US, ST=NC, O=Example Organization, CN=east'
7.8. FIPS 準拠の IPsec VPN のデプロイ
Libreswan を使用して、FIPS 準拠の IPsec VPN ソリューションをデプロイできます。これを行うには、FIPS モードの Libreswan で使用できる暗号化アルゴリズムと無効になっている暗号化アルゴリズムを特定します。
前提条件
-
AppStreamリポジトリーが有効になっている。
手順
libreswanパッケージをインストールします。# yum install libreswanLibreswan を再インストールする場合は、古い NSS データベースを削除します。
# systemctl stop ipsec # rm /etc/ipsec.d/*dbipsecサービスを開始して有効にし、システムの起動時にサービスを自動的に開始できるようにします。# systemctl enable ipsec --nowファイアウォールで、
ipsecサービスを追加して、IKE プロトコル、ESP プロトコル、および AH プロトコルの500および4500UDP ポートを許可するように設定します。# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentシステムを FIPS モードに切り替えます。
# fips-mode-setup --enableシステムを再起動して、カーネルを FIPS モードに切り替えます。
# reboot
検証
Libreswan が FIPS モードで実行されていることを確認します。
# ipsec whack --fipsstatus 000 FIPS mode enabledまたは、
systemdジャーナルでipsecユニットのエントリーを確認します。$ journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YESFIPS モードで使用可能なアルゴリズムを表示するには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | head -11 FIPS Product: YES FIPS Kernel: YES FIPS Mode: YES NSS DB directory: sql:/etc/ipsec.d Initializing NSS Opening NSS database "sql:/etc/ipsec.d" read-only NSS initialized NSS crypto library initialized FIPS HMAC integrity support [enabled] FIPS mode enabled for pluto daemon NSS library is running in FIPS mode FIPS HMAC integrity verification self-test passedFIPS モードで無効化されたアルゴリズムをクエリーするには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | grep disabled Encryption algorithm CAMELLIA_CTR disabled; not FIPS compliant Encryption algorithm CAMELLIA_CBC disabled; not FIPS compliant Encryption algorithm SERPENT_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_SSH disabled; not FIPS compliant Encryption algorithm NULL disabled; not FIPS compliant Encryption algorithm CHACHA20_POLY1305 disabled; not FIPS compliant Hash algorithm MD5 disabled; not FIPS compliant PRF algorithm HMAC_MD5 disabled; not FIPS compliant PRF algorithm AES_XCBC disabled; not FIPS compliant Integrity algorithm HMAC_MD5_96 disabled; not FIPS compliant Integrity algorithm HMAC_SHA2_256_TRUNCBUG disabled; not FIPS compliant Integrity algorithm AES_XCBC_96 disabled; not FIPS compliant DH algorithm MODP1024 disabled; not FIPS compliant DH algorithm MODP1536 disabled; not FIPS compliant DH algorithm DH31 disabled; not FIPS compliantFIPS モードで許可されているすべてのアルゴリズムと暗号のリストを表示するには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | grep ESP | grep FIPS | sed "s/^.*FIPS//" {256,192,*128} aes_ccm, aes_ccm_c {256,192,*128} aes_ccm_b {256,192,*128} aes_ccm_a [*192] 3des {256,192,*128} aes_gcm, aes_gcm_c {256,192,*128} aes_gcm_b {256,192,*128} aes_gcm_a {256,192,*128} aesctr {256,192,*128} aes {256,192,*128} aes_gmac sha, sha1, sha1_96, hmac_sha1 sha512, sha2_512, sha2_512_256, hmac_sha2_512 sha384, sha2_384, sha2_384_192, hmac_sha2_384 sha2, sha256, sha2_256, sha2_256_128, hmac_sha2_256 aes_cmac null null, dh0 dh14 dh15 dh16 dh17 dh18 ecp_256, ecp256 ecp_384, ecp384 ecp_521, ecp521
7.9. パスワードによる IPsec NSS データベースの保護
デフォルトでは、IPsec サービスは、初回起動時に空のパスワードを使用して Network Security Services (NSS) データベースを作成します。セキュリティーを強化するために、パスワード保護を追加できます。
以前の RHEL 6.6 リリースでは、NSS 暗号化ライブラリーが FIPS 140-2 Level 2 標準で認定されているため、FIPS 140-2 要件を満たすパスワードで IPsec NSS データベースを保護する必要がありました。RHEL 8 では、この規格の NIST 認定 NSS がこの規格のレベル 1 に認定されており、このステータスではデータベースのパスワード保護は必要ありません。
前提条件
-
/etc/ipsec.d/ディレクトリーに NSS データベースファイルが含まれます。
手順
Libreswan の
NSSデータベースのパスワード保護を有効にします。# certutil -N -d sql:/etc/ipsec.d Enter Password or Pin for "NSS Certificate DB": Enter a password which will be used to encrypt your keys. The password should be at least 8 characters long, and should contain at least one non-alphabetic character. Enter new password:前の手順で設定したパスワードを含む
/etc/ipsec.d/nsspasswordファイルを作成します。以下はその例です。# cat /etc/ipsec.d/nsspassword NSS Certificate DB:_<password>_nsspasswordファイルは次の構文を使用します。<token_1>:<password1> <token_2>:<password2>デフォルトの NSS ソフトウェアトークンは
NSS Certificate DBです。システムが FIPS モードで実行し場合は、トークンの名前がNSS FIPS 140-2 Certificate DBになります。選択したシナリオに応じて、
nsspasswordファイルの完了後にipsecサービスを起動または再起動します。# systemctl restart ipsec
検証
NSS データベースに空でないパスワードを追加した後に、
ipsecサービスが実行中であることを確認します。# systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...Journalログに初期化が成功したことを確認するエントリーが含まれていることを確認します。# journalctl -u ipsec ... pluto[6214]: Initializing NSS using read-write database "sql:/etc/ipsec.d" pluto[6214]: NSS Password from file "/etc/ipsec.d/nsspassword" for token "NSS Certificate DB" with length 20 passed to NSS pluto[6214]: NSS crypto library initialized ...
7.10. TCP を使用するように IPsec VPN を設定
Libreswan は、RFC 8229 で説明されているように、IKE パケットおよび IPsec パケットの TCP カプセル化に対応します。この機能により、UDP 経由でトラフィックが転送されないように、IPsec VPN をネットワークに確立し、セキュリティーのペイロード (ESP) を強化できます。フォールバックまたはメインの VPN トランスポートプロトコルとして TCP を使用するように VPN サーバーおよびクライアントを設定できます。TCP カプセル化にはパフォーマンスコストが大きくなるため、UDP がシナリオで永続的にブロックされている場合に限り、TCP を主な VPN プロトコルとして使用してください。
前提条件
- リモートアクセス VPN が設定されている。
手順
config setupセクションの/etc/ipsec.confファイルに以下のオプションを追加します。listen-tcp=yesUDP で最初の試行に失敗した場合に TCP カプセル化をフォールバックオプションとして使用するには、クライアントの接続定義に以下の 2 つのオプションを追加します。
enable-tcp=fallback tcp-remoteport=4500または、UDP を永続的にブロックしている場合は、クライアントの接続設定で以下のオプションを使用します。
enable-tcp=yes tcp-remoteport=4500
7.11. IPsec 接続を高速化するために、ESP ハードウェアオフロードの自動検出と使用を設定
Encapsulating Security Payload (ESP) をハードウェアにオフロードすると、Ethernet で IPsec 接続が加速します。デフォルトでは、Libreswan は、ハードウェアがこの機能に対応しているかどうかを検出するため、ESP ハードウェアのオフロードを有効にします。機能が無効になっているか、明示的に有効になっている場合は、自動検出に戻すことができます。
前提条件
- ネットワークカードは、ESP ハードウェアオフロードに対応します。
- ネットワークドライバーは、ESP ハードウェアのオフロードに対応します。
- IPsec 接続が設定され、動作する。
手順
-
ESP ハードウェアオフロードサポートの自動検出を使用する接続の
/etc/ipsec.d/ディレクトリーにある Libreswan 設定ファイルを編集します。 -
接続の設定で
nic-offloadパラメーターが設定されていないことを確認します。 nic-offloadを削除した場合は、ipsecを再起動します。# systemctl restart ipsec
検証
IPsec 接続が使用するイーサネットデバイスの
tx_ipsecおよびrx_ipsecカウンターを表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10IPsec トンネルを介してトラフィックを送信します。たとえば、リモート IP アドレスに ping します。
# ping -c 5 remote_ip_addressイーサネットデバイスの
tx_ipsecおよびrx_ipsecカウンターを再度表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15カウンターの値が増えると、ESP ハードウェアオフロードが動作します。
7.12. IPsec 接続を加速化するためにボンディングでの ESP ハードウェアオフロードの設定
Encapsulating Security Payload (ESP) をハードウェアにオフロードすると、IPsec 接続が加速します。フェイルオーバーの理由でネットワークボンディングを使用する場合、ESP ハードウェアオフロードを設定する要件と手順は、通常のイーサーネットデバイスを使用する要件と手順とは異なります。たとえば、このシナリオでは、ボンディングでオフロードサポートを有効にし、カーネルはボンディングのポートに設定を適用します。
前提条件
-
ボンディングのすべてのネットワークカードが、ESP ハードウェアオフロードをサポートしている。各ボンディングポートがこの機能をサポートしているかどうかを確認するには、
ethtool -k <interface_name> | grep "esp-hw-offload"コマンドを使用します。 - ボンディングが設定されており動作する。
-
ボンディングで
active-backupモードを使用している。ボンディングドライバーは、この機能の他のモードはサポートしていません。 - IPsec 接続が設定され、動作する。
手順
ネットワークボンディングで ESP ハードウェアオフロードのサポートを有効にします。
# nmcli connection modify bond0 ethtool.feature-esp-hw-offload onこのコマンドにより、
bond0接続での ESP ハードウェアオフロードのサポートが有効になります。bond0接続を再度アクティブにします。# nmcli connection up bond0ESP ハードウェアオフロードに使用すべき接続の
/etc/ipsec.d/ディレクトリーにある Libreswan 設定ファイルを編集し、nic-offload=yesステートメントを接続エントリーに追加します。conn example ... nic-offload=yesipsecサービスを再起動します。# systemctl restart ipsec
検証
検証方法は、カーネルのバージョンやドライバーなど、さまざまな要素によって異なります。たとえば、一部のドライバーはカウンターを備えていますが、その名前はさまざまです。詳細は、お使いのネットワークドライバーのドキュメントを参照してください。
次の検証手順は、Red Hat Enterprise Linux 8 上の ixgbe ドライバーに対して使用できます。
ボンディングのアクティブなポートを表示します。
# grep "Currently Active Slave" /proc/net/bonding/bond0 Currently Active Slave: enp1s0アクティブなポートの
tx_ipsecカウンターおよびrx_ipsecカウンターを表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10IPsec トンネルを介してトラフィックを送信します。たとえば、リモート IP アドレスに ping します。
# ping -c 5 remote_ip_addressアクティブなポートの
tx_ipsecカウンターおよびrx_ipsecカウンターを再度表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15カウンターの値が増えると、ESP ハードウェアオフロードが動作します。
7.13. RHEL システムロールを使用して IPsec VPN 接続を設定する
仮想プライベートネットワーク (VPN) を使用すると、インターネットなどの信頼できないネットワーク上で、セキュアで暗号化されたトンネルを確立できます。このようなトンネルにより、転送中のデータの機密性と整合性が確保されます。一般的なユースケースとしては、支社と本社を接続することなどが挙げられます。
vpn RHEL システムロールを使用すると、Libreswan IPsec VPN 設定の作成プロセスを自動化できます。
vpn RHEL システムロールで作成できるのは、事前共有鍵 (PSK) または証明書を使用してピアを相互に認証する VPN 設定だけです。
7.13.1. vpn RHEL システムロールを使用して PSK 認証による IPsec ホスト間 VPN を設定する
ホスト間 VPN は、2 つのデバイス間に直接的で安全な暗号化された接続を確立し、アプリケーションがインターネットなどの安全でないネットワーク経由で安全に通信できるようにします。
認証の場合、事前共有鍵 (PSK) は、2 つのピアのみが知っている単一の共有秘密を使用する簡単な方法です。このアプローチは設定が簡単で、デプロイメントの容易さが優先される基本的なセットアップに最適です。ただし、キーは厳重に秘密にしておく必要があります。キーにアクセスできる攻撃者は接続を危険にさらす可能性があります。
vpn RHEL システムロールを使用すると、PSK 認証による IPsec ホスト間接続を作成するプロセスを自動化できます。デフォルトでは、このロールはトンネルベースの VPN を作成します。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - hosts: managed-node-01.example.com: managed-node-02.example.com: auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
hosts: <list>VPN を設定するピアを含む YAML ディクショナリーを定義します。エントリーが Ansible 管理対象ノードでない場合は、
hostnameパラメーターに完全修飾ドメイン名 (FQDN) または IP アドレスを指定する必要があります。次に例を示します。... - hosts: ... external-host.example.com: hostname: 192.0.2.1このロールは、各管理対象ノード上の VPN 接続を設定します。接続の名前は
<peer_A>-to-<peer_B>です (例:managed-node-01.example.com-to-managed-node-02.example.com)。このロールは、外部 (管理対象外) ノード上で Libreswan を設定することはできないことに注意してください。そのようなピアでは手動で設定を作成する必要があります。auth_method: psk-
ピア間の PSK 認証を有効にします。ロールはコントロールノードで
opensslを使用して PSK を作成します。 auto: <startup_method>-
接続の起動方法を指定します。有効な値は
add、ondemand、start、およびignoreです。詳細は、Libreswan がインストールされているシステム上のipsec.conf(5)man ページを参照してください。この変数のデフォルト値は null です。この値は自動起動操作を実行しないことを示します。 vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
接続が正常に開始されたことを確認します。次に例を示します。
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'このコマンドは、VPN 接続がアクティブでないと成功しないことに注意してください。Playbook 内の
auto変数をstart以外の値に設定する場合は、まず管理対象ノードで接続を手動でアクティブ化する必要がある場合があります。
7.13.2. vpn RHEL システムロールを使用して、個別のデータプレーンとコントロールプレーンおよび PSK 認証による IPsec ホスト間 VPN を設定する
ホスト間 VPN は、2 つのデバイス間に直接的で安全な暗号化された接続を確立し、アプリケーションがインターネットなどの安全でないネットワーク経由で安全に通信できるようにします。
認証の場合、事前共有鍵 (PSK) は、2 つのピアのみが知っている単一の共有秘密を使用する簡単な方法です。このアプローチは設定が簡単で、デプロイメントの容易さが優先される基本的なセットアップに最適です。ただし、キーは厳重に秘密にしておく必要があります。キーにアクセスできる攻撃者は接続を危険にさらす可能性があります。
たとえば、制御メッセージが傍受されたり妨害されたりするリスクを最小限に抑えてセキュリティーを強化するために、データトラフィックと制御トラフィックの両方に個別の接続を設定できます。vpn RHEL システムロールを使用すると、個別のデータプレーンとコントロールプレーンおよび PSK 認証を使用して IPsec ホスト間接続を作成するプロセスを自動化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - name: control_plane_vpn hosts: managed-node-01.example.com: hostname: 203.0.113.1 # IP address for the control plane managed-node-02.example.com: hostname: 198.51.100.2 # IP address for the control plane auth_method: psk auto: start - name: data_plane_vpn hosts: managed-node-01.example.com: hostname: 10.0.0.1 # IP address for the data plane managed-node-02.example.com: hostname: 172.16.0.2 # IP address for the data plane auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
hosts: <list>VPN を設定するホストを含む YAML ディクショナリーを定義します。接続の名前は
<name>-<IP_address_A>-to-<IP_address_B>です (例:control_plane_vpn-203.0.113.1-to-198.51.100.2)。このロールは、各管理対象ノード上の VPN 接続を設定します。このロールは、外部 (管理対象外) ノード上で Libreswan を設定することはできないことに注意してください。そのようなホストでは手動で設定を作成する必要があります。
auth_method: psk-
ホスト間の PSK 認証を有効にします。ロールはコントロールノードで
opensslを使用して事前共有鍵を作成します。 auto: <startup_method>-
接続の起動方法を指定します。有効な値は
add、ondemand、start、およびignoreです。詳細は、Libreswan がインストールされているシステム上のipsec.conf(5)man ページを参照してください。この変数のデフォルト値は null です。この値は自動起動操作を実行しないことを示します。 vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
接続が正常に開始されたことを確認します。次に例を示します。
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "control_plane_vpn-203.0.113.1-to-198.51.100.2"' ... 006 #3: "control_plane_vpn-203.0.113.1-to-198.51.100.2", type=ESP, add_time=1741860073, inBytes=0, outBytes=0, maxBytes=2^63B, id='198.51.100.2'このコマンドは、VPN 接続がアクティブでないと成功しないことに注意してください。Playbook 内の
auto変数をstart以外の値に設定する場合は、まず管理対象ノードで接続を手動でアクティブ化する必要がある場合があります。
7.13.3. RHEL システムロール vpn を使用して PSK 認証による IPsec サイト間 VPN を設定する
サイト間 VPN は、2 つの異なるネットワーク間に安全な暗号化トンネルを確立し、インターネットなどの安全でないパブリックネットワークを介してそれらをシームレスにリンクします。たとえば、これにより、支社のデバイスはすべて同じローカルネットワークの一部であるかのように、企業本社のリソースにアクセスできるようになります。
認証の場合、事前共有鍵 (PSK) は、2 つのピアのみが知っている単一の共有秘密を使用する簡単な方法です。このアプローチは設定が簡単で、デプロイメントの容易さが優先される基本的なセットアップに最適です。ただし、キーは厳重に秘密にしておく必要があります。キーにアクセスできる攻撃者は接続を危険にさらす可能性があります。
vpn RHEL システムロールを使用すると、PSK 認証による IPsec サイト間接続の作成プロセスを自動化できます。デフォルトでは、このロールはトンネルベースの VPN を作成します。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - hosts: managed-node-01.example.com: subnets: - 192.0.2.0/24 managed-node-02.example.com: subnets: - 198.51.100.0/24 - 203.0.113.0/24 auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
hosts: <list>VPN を設定するゲートウェイを含む YAML 辞書を定義します。エントリーが Ansible 管理ノードでない場合は、
ホスト名パラメーターにその完全修飾ドメイン名 (FQDN) または IP アドレスを指定する必要があります。次に例を示します。... - hosts: ... external-host.example.com: hostname: 192.0.2.1このロールは、各管理対象ノード上の VPN 接続を設定します。接続の名前は
<gateway_A> -to- <gateway_B>です (例:managed-node-01.example.com-to-managed-node-02.example.com)。このロールは、外部 (管理対象外) ノード上で Libreswan を設定することはできないことに注意してください。そのようなピアでは手動で設定を作成する必要があります。subnets: <yaml_list_of_subnets>- トンネルを介して接続されるサブネットを Classless Inter-Domain Routing (CIDR) 形式で定義します。
auth_method: psk-
ピア間の PSK 認証を有効にします。ロールはコントロールノードで
opensslを使用して PSK を作成します。 auto: <startup_method>-
接続の起動方法を指定します。有効な値は
add、ondemand、start、およびignoreです。詳細は、Libreswan がインストールされているシステム上のipsec.conf(5)man ページを参照してください。この変数のデフォルト値は null です。この値は自動起動操作を実行しないことを示します。 vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
接続が正常に開始されたことを確認します。次に例を示します。
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'このコマンドは、VPN 接続がアクティブでないと成功しないことに注意してください。Playbook 内の
auto変数をstart以外の値に設定する場合は、まず管理対象ノードで接続を手動でアクティブ化する必要がある場合があります。
7.13.4. vpn RHEL システムロールを使用して証明書ベースの認証による IPsec メッシュ VPN を設定する
IPsec メッシュは、すべてのサーバーが他のすべてのサーバーと安全かつ直接通信できる、完全に相互接続されたネットワークを作成します。これは、複数のデータセンターやクラウドプロバイダーにまたがる分散データベースクラスターや高可用性環境に最適です。各サーバーペア間に直接暗号化されたトンネルを確立することで、中央のボトルネックのない安全な通信が保証されます。
認証には、認証局 (CA) によって管理されるデジタル証明書を使用すると、非常に安全でスケーラブルなソリューションが提供されます。メッシュ内の各ホストは、信頼できる CA によって署名された証明書を提示します。この方法は、強力で検証可能な認証を提供し、ユーザー管理を簡素化します。アクセスは CA で集中的に許可または取り消すことができ、Libreswan は各証明書を証明書失効リスト (CRL) と照合してこれを強制し、リストに証明書がある場合はアクセスを拒否します。
vpn RHEL システムロールを使用すると、証明書ベースの認証による管理対象ノード間の VPN メッシュの設定を自動化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 各管理対象ノード用に PKCS #12 ファイルを用意した。
各ファイルには次のものを含めます。
- サーバーの秘密鍵
- サーバー証明書
- CA 証明書
- 中間証明書 (必要な場合)
-
ファイル名は
<managed_node_name_as_in_the_inventory>.p12とします。 - ファイルは Playbook と同じディレクトリーに保存します。
サーバー証明書には次のフィールドを含めます。
-
Extended Key Usage (EKU) を
TLS Web Server Authenticationに設定します。 - コモンネーム (CN) またはサブジェクト代替名 (SAN) を、ホストの完全修飾ドメイン名 (FQDN) に設定します。
- X509v3 CRL 配布ポイントには、証明書失効リスト (CRL) への URL が含まれています。
-
Extended Key Usage (EKU) を
手順
~/inventoryファイルを編集し、cert_name変数を追加します。managed-node-01.example.com cert_name=managed-node-01.example.com managed-node-02.example.com cert_name=managed-node-02.example.com managed-node-03.example.com cert_name=managed-node-03.example.comcert_name変数は、各ホストの証明書で使用されるコモンネーム (CN) フィールドの値に設定します。通常、CN フィールドは完全修飾ドメイン名 (FQDN) に設定します。機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。pkcs12_pwd: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。- name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com, managed-node-03.example.com vars_files: - ~/vault.yml tasks: - name: Install LibreSwan ansible.builtin.package: name: libreswan state: present - name: Identify the path to IPsec NSS database ansible.builtin.set_fact: nss_db_dir: "{{ '/etc/ipsec.d/' if ansible_distribution in ['CentOS', 'RedHat'] and ansible_distribution_major_version is version('8', '=') else '/var/lib/ipsec/nss/' }}" - name: Locate IPsec NSS database files ansible.builtin.find: paths: "{{ nss_db_dir }}" patterns: "*.db" register: db_files - name: Initialize IPsec NSS database if not initialized ansible.builtin.command: cmd: ipsec initnss when: db_files.matched == 0 - name: Copy PKCS #12 file to the managed node ansible.builtin.copy: src: "~/{{ inventory_hostname }}.p12" dest: "/etc/ipsec.d/{{ inventory_hostname }}.p12" mode: 0600 - name: Import PKCS #12 file in IPsec NSS database ansible.builtin.shell: cmd: 'pk12util -d {{ nss_db_dir }} -i /etc/ipsec.d/{{ inventory_hostname }}.p12 -W "{{ pkcs12_pwd }}"' - name: Remove PKCS #12 file ansible.builtin.file: path: "/etc/ipsec.d/{{ inventory_hostname }}.p12" state: absent - name: Opportunistic mesh IPsec VPN with certificate-based authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - opportunistic: true auth_method: cert policies: - policy: private cidr: default - policy: private cidr: 192.0.2.0/24 - policy: clear cidr: 192.0.2.1/32 vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
opportunistic: true-
複数ホスト間のオポチュニスティックメッシュを有効にします。
ポリシー変数は、どのサブネットとホストのトラフィックを暗号化する必要があるか、または暗号化できるか、またどのサブネットとホストでプレーンテキスト接続を引き続き使用する必要があるかを定義します。 auth_method: cert- 証明書ベースの認証を有効にします。これを行うには、インベントリーで各管理対象ノードの証明書のニックネームを指定する必要があります。
policies: <list_of_policies>Libreswan ポリシーを YAML リスト形式で定義します。
デフォルトのポリシーは
private-or-clearです。これをprivateに変更するには、上記の Playbook に、デフォルトのcidrエントリーに応じた適切なポリシーを含めます。Ansible コントロールノードが管理対象ノードと同じ IP サブネットにある場合は、Playbook の実行中に SSH 接続が失われるのを防ぐために、コントロールノードの IP アドレスに
clearポリシーを追加します。たとえば、メッシュを192.0.2.0/24サブネット用に設定する必要があり、コントロールノードが IP アドレス192.0.2.1を使用する場合、Playbook に示されているように、192.0.2.1/32のclearポリシーが必要です。ポリシーの詳細は、Libreswan がインストールされているシステム上の
ipsec.conf(5)man ページを参照してください。vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
メッシュ内のノードで、別のノードに ping を送信して接続をアクティブ化します。
[root@managed-node-01]# ping managed-node-02.example.com接続がアクティブであることを確認します。
[root@managed-node-01]# ipsec trafficstatus 006 #2: "private#192.0.2.0/24"[1] ...192.0.2.2, type=ESP, add_time=1741938929, inBytes=372408, outBytes=545728, maxBytes=2^63B, id='CN=managed-node-02.example.com'
7.14. システム全体の暗号化ポリシーをオプトアウトする IPsec 接続の設定
接続向けのシステム全体の暗号化ポリシーのオーバーライド
RHEL のシステム全体の暗号化ポリシーでは、%default と呼ばれる特別な接続が作成されます。この接続には、ikev2 オプション、esp オプション、および ike オプションのデフォルト値が含まれます。ただし、接続設定ファイルに上記のオプションを指定すると、デフォルト値を上書きできます。
たとえば、次の設定では、AES および SHA-1 または SHA-2 で IKEv1 を使用し、AES-GCM または AES-CBC で IPsec (ESP) を使用する接続が可能です。
conn MyExample
...
ikev2=never
ike=aes-sha2,aes-sha1;modp2048
esp=aes_gcm,aes-sha2,aes-sha1
...AES-GCM は IPsec (ESP) および IKEv2 で利用できますが、IKEv1 では利用できません。
全接続向けのシステム全体の暗号化ポリシーの無効化
すべての IPsec 接続のシステム全体の暗号化ポリシーを無効にするには、/etc/ipsec.conf ファイルで次の行をコメントアウトします。
include /etc/crypto-policies/back-ends/libreswan.config
次に、接続設定ファイルに ikev2=never オプションを追加してください。
7.15. IPsec VPN 設定のトラブルシューティング
IPsec VPN 設定に関連する問題は主に、一般的な理由が原因で発生する可能性が高くなっています。このような問題が発生した場合は、問題の原因が以下のシナリオのいずれかに該当するかを確認して、対応するソリューションを適用します。
基本的な接続のトラブルシューティング
VPN 接続関連の問題の多くは、管理者が不適当な設定オプションを指定してエンドポイントを設定した新しいデプロイメントで発生します。また、互換性のない値が新たに実装された場合に、機能していた設定が突然動作が停止する可能性があります。管理者が設定を変更した場合など、このような結果になることがあります。また、管理者が暗号化アルゴリズムなど、特定のオプションに異なるデフォルト値を使用して、ファームウェアまたはパッケージの更新をインストールした場合などです。
IPsec VPN 接続が確立されていることを確認するには、次のコマンドを実行します。
# ipsec trafficstatus
006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=100.64.13.5/32出力が空の場合や、エントリーで接続名が表示されない場合など、トンネルが破損します。
接続に問題があることを確認するには、以下を実行します。
vpn.example.com 接続をもう一度読み込みます。
# ipsec auto --add vpn.example.com 002 added connection description "vpn.example.com"次に、VPN 接続を開始します。
# ipsec auto --up vpn.example.com
ファイアウォール関連の問題
最も一般的な問題は、IPSec エンドポイントの 1 つ、またはエンドポイント間にあるルーターにあるファイアウォールで Internet Key Exchange (IKE) パケットがドロップされるという点が挙げられます。
IKEv2 の場合には、以下の例のような出力は、ファイアウォールに問題があることを示しています。
# ipsec auto --up vpn.example.com 181 "vpn.example.com"[1] 192.0.2.2 #15: initiating IKEv2 IKE SA 181 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: sent v2I1, expected v2R1 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 2 seconds for ...IKEv1 の場合は、最初のコマンドの出力は以下のようになります。
# ipsec auto --up vpn.example.com 002 "vpn.example.com" #9: initiating Main Mode 102 "vpn.example.com" #9: STATE_MAIN_I1: sent MI1, expecting MR1 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 2 seconds for response ...
IPsec の設定に使用される IKE プロトコルは暗号化されているため、tcpdump ツールを使用して、トラブルシューティングできるサブセットは一部のみです。ファイアウォールが IKE パケットまたは IPsec パケットをドロップしている場合は、tcpdump ユーティリティーを使用して原因を見つけることができます。ただし、tcpdump は IPsec VPN 接続に関する他の問題を診断できません。
eth0インターフェイスで VPN および暗号化データすべてのネゴシエーションを取得するには、次のコマンドを実行します。# tcpdump -i eth0 -n -n esp or udp port 500 or udp port 4500 or tcp port 4500
アルゴリズム、プロトコル、およびポリシーが一致しない場合
VPN 接続では、エンドポイントが IKE アルゴリズム、IPsec アルゴリズム、および IP アドレス範囲に一致する必要があります。不一致が発生した場合には接続は失敗します。以下の方法のいずれかを使用して不一致を特定した場合は、アルゴリズム、プロトコル、またはポリシーを調整して修正します。
リモートエンドポイントが IKE/IPsec を実行していない場合は、そのパケットを示す ICMP パケットが表示されます。以下に例を示します。
# ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)] ...IKE アルゴリズムが一致しない例:
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,NiIPsec アルゴリズムが一致しない例:
# ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSENまた、IKE バージョンが一致しないと、リモートエンドポイントが応答なしの状態でリクエストをドロップする可能性がありました。これは、すべての IKE パケットをドロップするファイアウォールと同じです。
IKEv2 (Traffic Selectors - TS) の IP アドレス範囲が一致しない例:
# ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLEIKEv1 の IP アドレス範囲で一致しない例:
# ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposalIKEv1 で PreSharedKeys (PSK) を使用する場合には、どちらでも同じ PSK に配置されなければ、IKE メッセージ全体の読み込みができなくなります。
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500IKEv2 では、mismatched-PSK エラーが原因で AUTHENTICATION_FAILED メッセージが表示されます。
# ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILED
最大伝送単位
ファイアウォールが IKE または IPSec パケットをブロックする以外で、ネットワークの問題の原因として、暗号化パケットのパケットサイズの増加が最も一般的です。ネットワークハードウェアは、最大伝送単位 (MTU) を超えるパケットを 1500 バイトなどのサイズに断片化します。多くの場合、断片化されたパケットは失われ、パケットの再アセンブルに失敗します。これにより、小さいサイズのパケットを使用する ping テスト時には機能し、他のトラフィックでは失敗するなど、断続的な問題が発生します。このような場合に、SSH セッションを確立できますが、リモートホストに 'ls -al /usr' コマンドに入力した場合など、すぐにターミナルがフリーズします。
この問題を回避するには、トンネル設定ファイルに mtu=1400 のオプションを追加して、MTU サイズを縮小します。
または、TCP 接続の場合は、MSS 値を変更する iptables ルールを有効にします。
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
各シナリオで上記のコマンドを使用して問題が解決されない場合は、set-mss パラメーターで直接サイズを指定します。
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1380ネットワークアドレス変換 (NAT)
IPsec ホストが NAT ルーターとしても機能すると、誤ってパケットが再マッピングされる可能性があります。以下の設定例はこの問題を示しています。
conn myvpn
left=172.16.0.1
leftsubnet=10.0.2.0/24
right=172.16.0.2
rightsubnet=192.168.0.0/16
…アドレスが 172.16.0.1 のシステムには NAT ルールが 1 つあります。
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADEアドレスが 10.0.2.33 のシステムがパケットを 192.168.0.1 に送信する場合に、ルーターは IPsec 暗号化を適用する前にソースを 10.0.2.33 から 172.16.0.1 に変換します。
次に、ソースアドレスが 10.0.2.33 のパケットは conn myvpn 設定と一致しなくなるので、IPsec ではこのパケットが暗号化されません。
この問題を解決するには、ルーターのターゲット IPsec サブネット範囲の NAT を除外するルールを挿入します。以下に例を示します。
iptables -t nat -I POSTROUTING -s 10.0.2.0/24 -d 192.168.0.0/16 -j RETURNカーネル IPsec サブシステムのバグ
たとえば、バグが原因で IKE ユーザー空間と IPsec カーネルの同期が解除される場合など、カーネル IPsec サブシステムに問題が発生する可能性があります。このような問題がないかを確認するには、以下を実行します。
$ cat /proc/net/xfrm_stat
XfrmInError 0
XfrmInBufferError 0
...上記のコマンドの出力でゼロ以外の値が表示されると、問題があることを示しています。この問題が発生した場合は、新しい サポートケース を作成し、1 つ前のコマンドの出力と対応する IKE ログを添付してください。
Libreswan のログ
デフォルトでは、Libreswan は syslog プロトコルを使用してログに記録します。journalctl コマンドを使用して、IPsec に関連するログエントリーを検索できます。ログへの対応するエントリーは pluto IKE デーモンにより送信されるため、以下のように、キーワード "pluto" を検索します。
$ journalctl -b | grep pluto
ipsec サービスのライブログを表示するには、次のコマンドを実行します。
$ journalctl -f -u ipsec
ロギングのデフォルトレベルで設定問題が解決しない場合は、/etc/ipsec.conf ファイルの config setup セクションに plutodebug=all オプションを追加してデバッグログを有効にします。
デバッグロギングは多くのエントリーを生成し、journald サービスまたは syslogd サービスレートのいずれかが syslog メッセージを制限する可能性があることに注意してください。完全なログを取得するには、ロギングをファイルにリダイレクトします。/etc/ipsec.conf を編集し、config setup セクションに logfile=/var/log/pluto.log を追加します。
7.16. control-center による VPN 接続の確立
グラフィカルインターフェイスで Red Hat Enterprise Linux を使用する場合は、この VPN 接続を GNOME control-center で設定できます。
前提条件
-
NetworkManager-libreswan-gnomeパッケージがインストールされている。
手順
-
Super キーを押して
Settingsと入力し、Enter を押してcontrol-centerアプリケーションを開きます。 -
左側の
Networkエントリーを選択します。 - + アイコンをクリックします。
-
VPNを選択します。 Identityメニューエントリーを選択して、基本的な設定オプションを表示します。全般
Gateway- リモート VPN ゲートウェイの名前またはIPアドレスです。認証
Type-
IKEv2 (証明書)- クライアントは、証明書により認証されます。これはより安全です (デフォルト)。 IKEv1(XAUTH): クライアントは、ユーザー名とパスワード、または事前共有キー (PSK) で認証されます。Advancedセクションでは、以下の設定が可能です。図7.1 VPN 接続の詳細なオプション
 警告
警告gnome-control-centerアプリケーションを使用して IPsec ベースの VPN 接続を設定すると、Advancedダイアログには設定が表示されますが、変更することはできません。したがって、詳細な IPsec オプションを変更できません。nm-connection-editorツールまたはnmcliツールを使用して、詳細なプロパティーの設定を実行します。識別
Domain- 必要な場合は、ドメイン名を入力します。セキュリティー
-
Phase1 Algorithms- Libreswan パラメーターikeに対応します。暗号化チャネルの認証およびセットアップに使用するアルゴリズムを入力します。 Phase2 Algorithms- Libreswan パラメーターespに対応します。IPsecネゴシエーションに使用するアルゴリズムを入力します。Disable PFSフィールドで PFS (Perfect Forward Secrecy) を無効にし、PFS に対応していない古いサーバーとの互換性があることを確認します。-
Phase1 Lifetime- Libreswan パラメーターikelifetimeに対応します。このパラメーターは、トラフィックの暗号化に使用される鍵がどのぐらい有効であるかどうかを示します。 Phase2 Lifetime- Libreswan パラメーターsalifetimeに対応します。このパラメーターは、接続の特定インスタンスが期限切れになるまでの持続時間を指定します。セキュリティー上の理由から、暗号化キーは定期的に変更する必要があります。
Remote network- Libreswan パラメーターrightsubnetに対応します。このパラメーターは、VPN から到達できる宛先のプライベートリモートネットワークです。絞り込むことのできる
narrowingフィールドを確認します。これは IKEv2 ネゴシエーションの場合にのみ有効であることに注意してください。-
Enable fragmentation- Libreswan パラメーターのfragmentationに対応します。IKE 断片化を許可するかどうかを指定します。有効な値は、yes(デフォルト) またはnoです。 -
Enable Mobike- Libreswan パラメーターmobikeに対応します。最初から接続を再起動しなくても、接続がエンドポイントを移行することを Mobility and Multihoming Protocol (MOBIKE, RFC 4555) が許可するかどうかを設定します。これは、有線、無線、またはモバイルデータの接続の切り替えを行うモバイルデバイスで使用されます。値は、no(デフォルト) またはyesです。
-
メニューエントリーを選択します。
IPv4 Method
-
Automatic (DHCP)- 接続しているネットワークが動的IPアドレスの割り当てにDHCPサーバーを使用する場合は、このオプションを選択します。 -
Link-Local Only- 接続しているネットワークにDHCPサーバーがなく、IPアドレスを手動で割り当てない場合は、このオプションを選択します。接頭辞169.254/16付きのランダムなアドレスが、RFC 3927 に従って割り当てられます。 -
Manual-IPアドレスを手動で割り当てたい場合は、このオプションを選択します。 Disable- この接続ではIPv4は無効化されています。DNS
DNSセクションでは、AutomaticがONになっているときに、これをOFFに切り替えて、使用する DNS サーバーの IP アドレスを入力します。IP アドレスはコンマで区切ります。Routes
Routesセクションでは、AutomaticがONになっている場合は、DHCP からのルートが使用されますが、他の静的ルートを追加することもできることに注意してください。OFFの場合は、静的ルートだけが使用されます。-
Address- リモートネットワークまたはホストのIPアドレスを入力します。 -
Netmask- 上記で入力したIPアドレスのネットマスクまた接頭辞長。 -
Gateway- 上記で入力したリモートネットワーク、またはホストにつながるゲートウェイのIPアドレス。 Metric- このルートに与える優先値であるネットワークコスト。数値が低い方が優先されます。Use this connection only for resources on its network (この接続はネットワーク上のリソースのためだけに使用)
このチェックボックスを選択すると、この接続はデフォルトルートになりません。このオプションを選択すると、この接続で自動的に学習したルートを使用することが明確なトラフィックか、手動で入力したトラフィックのみがこの接続を経由します。
-
VPN接続のIPv6設定を設定するには、 メニューエントリーを選択します。IPv6 Method
-
Automatic-IPv6ステートレスアドレス自動設定 (SLAAC) を使用して、ハードウェアのアドレスとルーター通知 (RA) に基づくステートレスの自動設定を作成するには、このオプションを選択します。 -
Automatic, DHCP only- RA を使用しないで、DHCPv6からの情報を直接要求してステートフルな設定を作成する場合は、このオプションを選択します。 -
Link-Local Only- 接続しているネットワークにDHCPサーバーがなく、IPアドレスを手動で割り当てない場合は、このオプションを選択します。接頭辞FE80::0付きのランダムなアドレスが、RFC 4862 に従って割り当てられます。 -
Manual-IPアドレスを手動で割り当てたい場合は、このオプションを選択します。 Disable- この接続ではIPv6は無効化されています。DNS、Routes、Use this connection only for resources on its networkが、一般的なIPv4設定となることに注意してください。
-
-
VPN接続の編集が終了したら、 ボタンをクリックして設定をカスタマイズするか、 ボタンをクリックして、既存の接続に保存します。 -
プロファイルを
ONに切り替え、VPN接続をアクティブにします。 - DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
7.17. nm-connection-editor による VPN 接続の設定
Red Hat Enterprise Linux をグラフィカルインターフェイスで使用する場合は、nm-connection-editor アプリケーションを使用して VPN 接続を設定できます。
前提条件
-
NetworkManager-libreswan-gnomeパッケージがインストールされている。 インターネット鍵交換バージョン 2 (IKEv2) 接続を設定する場合は、以下のようになります。
- 証明書が、IPsec ネットワークセキュリティーサービス (NSS) データベースにインポートされている。
- NSS データベースの証明書のニックネームが知られている。
手順
ターミナルを開き、次のコマンドを入力します。
$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
-
IPsec ベースの VPN接続タイプを選択し、 をクリックします。 VPNタブで、以下を行います。Gatewayフィールドに VPN ゲートウェイのホスト名または IP アドレスを入力し、認証タイプを選択します。認証タイプに応じて、異なる追加情報を入力する必要があります。-
IKEv2 (Certifiate)は、証明書を使用してクライアントを認証します。これは、より安全です。この設定には、IPsec NSS データベースの証明書のニックネームが必要です。 IKEv1 (XAUTH)は、ユーザー名とパスワード (事前共有鍵) を使用してユーザーを認証します。この設定は、以下の値を入力する必要があります。- ユーザー名
- Password
- グループ名
- シークレット
-
リモートサーバーが IKE 交換のローカル識別子を指定する場合は、
Remote IDフィールドに正確な文字列を入力します。リモートサーバーで Libreswan を実行すると、この値はサーバーのleftidパラメーターに設定されます。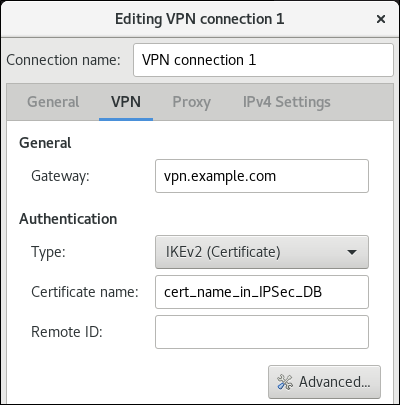
オプション: ボタンをクリックして、追加設定を行います。以下の設定を指定できます。
識別
-
Domain- 必要な場合は、ドメイン名を入力します。
-
セキュリティー
-
Phase1 アルゴリズムは、Libreswan パラメーターikeに対応します。暗号化チャンネルの認証および設定に使用するアルゴリズムを入力します。 Phase2 アルゴリズムは、Libreswan パラメーターespに対応します。IPsecネゴシエーションに使用するアルゴリズムを入力します。Disable PFSフィールドで PFS (Perfect Forward Secrecy) を無効にし、PFS に対応していない古いサーバーとの互換性があることを確認します。-
Phase1 ライフタイムは、Libreswan パラメーターikelifetimeに対応します。このパラメーターは、トラフィックの暗号化に使用される鍵が有効である期間を定義します。 -
Phase2 ライフタイムは、Libreswan パラメーターsalifetimeに対応します。このパラメーターは、セキュリティー関連が有効である期間を定義します。
-
接続性
リモートネットワークは、Libreswan パラメーターrightsubnetに対応し、VPN から到達できる宛先のプライベートリモートネットワークです。絞り込むことのできる
narrowingフィールドを確認します。これは IKEv2 ネゴシエーションの場合にのみ有効であることに注意してください。-
フラグメンテーションの有効化は、Libreswan パラメーターの断片化に対応します。IKE 断片化を許可するかどうかを指定します。有効な値は、yes(デフォルト) またはnoです。 -
Mobike の有効化は、Libreswan パラメーターmobikeに対応します。パラメーターは、最初から接続を再起動しなくても、接続がエンドポイントを移行することを Mobility and Multihoming Protocol (MOBIKE) (RFC 4555) が許可するかどうかを定義します。これは、有線、無線、またはモバイルデータの接続の切り替えを行うモバイルデバイスで使用されます。値は、no(デフォルト) またはyesです。
IPv4 設定タブで、IP 割り当て方法を選択し、必要に応じて、追加の静的アドレス、DNS サーバー、検索ドメイン、ルートを設定します。
- 接続を読み込みます。
-
nm-connection-editorを閉じます。 - DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
ボタンをクリックして新しい接続を追加する場合は、NetworkManager により、その接続用の新しい設定が作成され、既存の接続の編集に使用するのと同じダイアログが表示されます。このダイアログの違いは、既存の接続プロファイルに Details メニューエントリーがあることです。
7.18. 接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる
DHCP サーバーとステートレスアドレス自動設定 (SLAAC) はどちらも、クライアントのルーティングテーブルにルートを追加できます。悪意のある DHCP サーバーがこの機能を使用すると、たとえば、VPN 接続を使用するホストに対して、VPN トンネルではなく物理インターフェイス経由でトラフィックをリダイレクトするように強制できます。この脆弱性は TunnelVision とも呼ばれ、CVE-2024-3661 の脆弱性に関する記事で説明されています。
この脆弱性を軽減するために、VPN 接続を専用のルーティングテーブルに割り当てることができます。これを行うと、DHCP 設定または SLAAC が、VPN トンネル宛のネットワークパケットに関するルーティング決定を操作できなくなります。
次の条件が 1 つ以上環境に当てはまる場合は、この手順を実行してください。
- 少なくとも 1 つのネットワークインターフェイスが DHCP または SLAAC を使用している。
- ネットワークで、不正な DHCP サーバーを防ぐ DHCP スヌーピングなどのメカニズムが使用されていない。
トラフィック全体を VPN 経由でルーティングすると、ホストがローカルネットワークリソースにアクセスできなくなります。
前提条件
- NetworkManager 1.48.10-5 以降を使用している。
手順
- 使用するルーティングテーブルを決定します。次の手順ではテーブル 75 を使用します。デフォルトでは、RHEL はテーブル 1 - 254 を使用しないため、それらのテーブルのうちどれでも使用できます。
VPN ルートを専用のルーティングテーブルに割り当てるように VPN 接続プロファイルを設定します。
# nmcli connection modify <vpn_connection_profile> ipv4.route-table 75 ipv6.route-table 75上記のコマンドで使用したテーブルに低い優先度値を設定します。
# nmcli connection modify <vpn_connection_profile> ipv4.routing-rules "priority 32345 from all table 75" ipv6.routing-rules "priority 32345 from all table 75"優先度の値は 1 - 32766 の範囲で指定できます。値が低いほど、優先度が高くなります。
VPN 接続を再接続します。
# nmcli connection down <vpn_connection_profile> # nmcli connection up <vpn_connection_profile>
検証
テーブル 75 の IPv4 ルートを表示します。
# ip route show table 75 ... 192.0.2.0/24 via 192.0.2.254 dev vpn_device proto static metric 50 default dev vpn_device proto static scope link metric 50この出力から、リモートネットワークへのルートとデフォルトゲートウェイの両方がルーティングテーブル 75 に割り当てられており、すべてのトラフィックがトンネルを介してルーティングされることを確認できます。VPN 接続プロファイルで
ipv4.never-default trueを設定すると、デフォルトルートが作成されず、この出力には表示されません。テーブル 75 の IPv6 ルートを表示します。
# ip -6 route show table 75 ... 2001:db8:1::/64 dev vpn_device proto kernel metric 50 pref medium default dev vpn_device proto static metric 50 pref mediumこの出力から、リモートネットワークへのルートとデフォルトゲートウェイの両方がルーティングテーブル 75 に割り当てられており、すべてのトラフィックがトンネルを介してルーティングされることを確認できます。VPN 接続プロファイルで
ipv4.never-default trueを設定すると、デフォルトルートが作成されず、この出力には表示されません。
第8章 IP トンネルの設定
VPN と同様に、IP トンネルは、インターネットなどの 3 番目のネットワークを介して 2 つのネットワークを直接接続します。ただし、すべてのトンネルプロトコルが暗号化に対応しているわけではありません。
トンネルを確立する両方のネットワークのルーターには、最低でも 2 つのインターフェイスが必要です。
- ローカルネットワークに接続されているインターフェイス 1 つ
- トンネルが確立されたネットワークに接続されたインターフェイス 1 つ。
トンネルを確立するには、リモートサブネットから IP アドレスを使用して、両方のルーターに仮想インターフェイスを作成します。
NetworkManager は、以下の IP トンネルに対応します。
- GRE (Generic Routing Encapsulation)
- IP6GRE (Generic Routing Encapsulation over IPv6)
- GRETAP (Generic Routing Encapsulation Terminal Access Point)
- IP6GRETAP (Generic Routing Encapsulation Terminal Access Point over IPv6)
- IPIP (IPv4 over IPv4)
- IPIP6 (IPv4 over IPv6)
- IP6IP6 (IPv6 over IPv6)
- SIT (Simple Internet Transition)
このトンネルは、タイプに応じて、OSI (Open Systems Interconnection) モデルのレイヤー 2 または 3 で動作します。
8.1. IPv4 トラフィックを IPv4 パケットにカプセル化するための IPIP トンネルの設定
IP over IP (IPIP) トンネルは、RFC 2003 で説明されているように、OSI レイヤー 3 で動作し、IPv4 トラフィックを IPv4 パケットにカプセル化します。
IPIP トンネルを介して送信されるデータは暗号化されません。セキュリティー上の理由から、すでに暗号化されたデータにはトンネルを使用してください (HTTPS などの他のプロトコル)。
IPIP トンネルはユニキャストパケットのみをサポートすることに注意してください。マルチキャストをサポートする IPv4 トンネルが必要な場合は、レイヤー 3 トラフィックを IPv4 パケットにカプセル化するための GRE トンネルの設定 を参照してください。
たとえば、以下の図に示すように、2 つの RHEL ルーター間で IPIP トンネルを作成し、インターネット経由で 2 つの内部サブネットに接続できます。
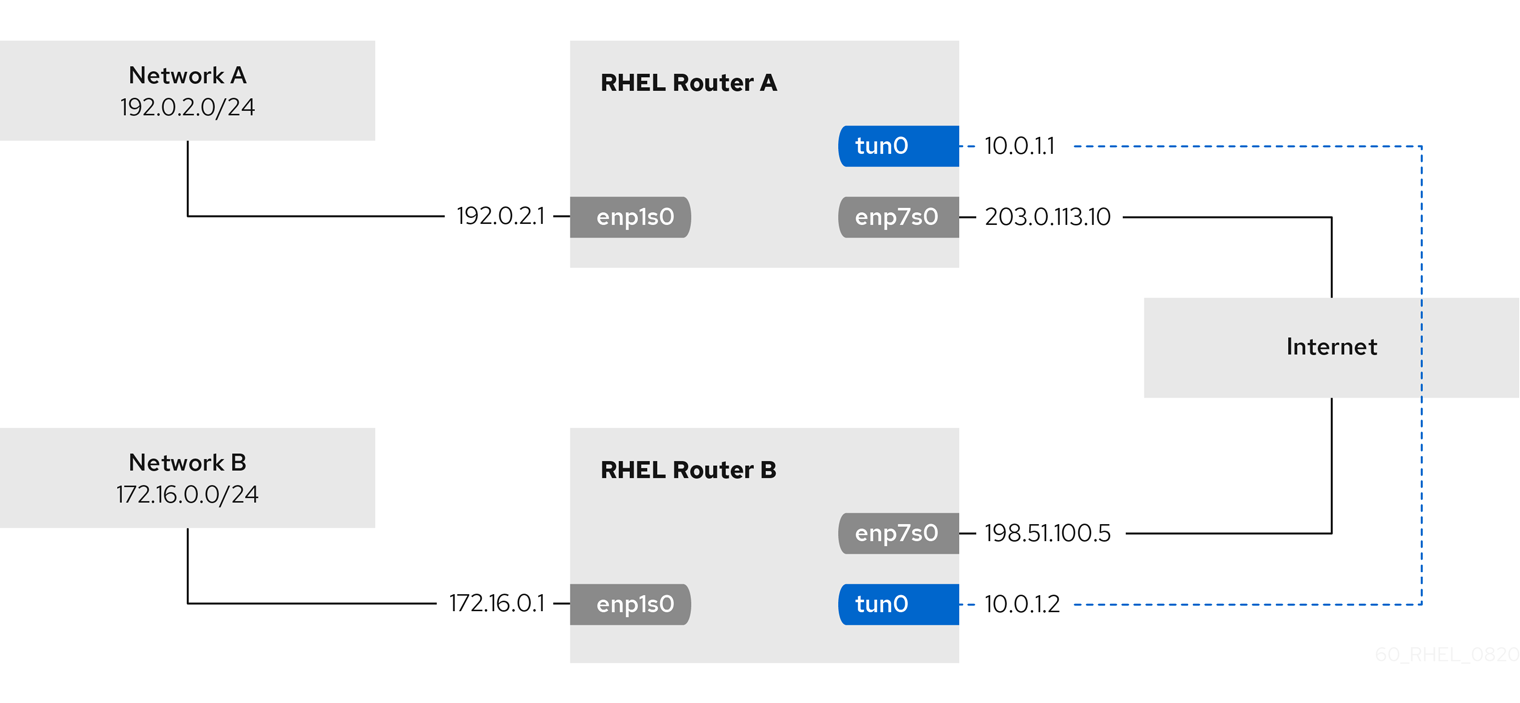
前提条件
- 各 RHEL ルーターには、ローカルサブネットに接続されているネットワークインターフェイスがあります。
- 各 RHEL ルーターには、インターネットに接続しているネットワークインターフェイスがあります。
- トンネル経由で送信するトラフィックは IPv4 ユニキャストです。
手順
ネットワーク A の RHEL ルーターで、次のコマンドを実行します。
tun0という名前の IPIP トンネルインターフェイスを作成します。# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 198.51.100.5 local 203.0.113.10remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。IPv4 アドレスを
tun0デバイスに設定します。# nmcli connection modify tun0 ipv4.addresses '10.0.1.1/30'トンネルには、2 つの使用可能な IP アドレスを持つ
/30サブネットで十分であることに注意してください。IPv4 設定を使用するように手動で
tun0接続を設定します。# nmcli connection modify tun0 ipv4.method manualトラフィックを
172.16.0.0/24ネットワークにルーティングする静的ルートをルーター B のトンネル IP に追加します。# nmcli connection modify tun0 +ipv4.routes "172.16.0.0/24 10.0.1.2"tun0接続を有効にします。# nmcli connection up tun0パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
ネットワーク B の RHEL ルーターで、次のコマンドを実行します。
tun0という名前の IPIP トンネルインターフェイスを作成します。# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 203.0.113.10 local 198.51.100.5remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。IPv4 アドレスを
tun0デバイスに設定します。# nmcli connection modify tun0 ipv4.addresses '10.0.1.2/30'IPv4 設定を使用するように手動で
tun0接続を設定します。# nmcli connection modify tun0 ipv4.method manualトラフィックを
192.0.2.0/24ネットワークにルーティングする静的ルートをルーター A のトンネル IP に追加します。# nmcli connection modify tun0 +ipv4.routes "192.0.2.0/24 10.0.1.1"tun0接続を有効にします。# nmcli connection up tun0パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
検証
各 RHEL ルーターから、他のルーターの内部インターフェイスの IP アドレスに ping します。
ルーター A で
172.16.0.1に ping します。# ping 172.16.0.1ルーター B で
192.0.2.1に ping します。# ping 192.0.2.1
8.2. レイヤー 3 トラフィックを IPv4 パケットにカプセル化するための GRE トンネルの設定
Generic Routing Encapsulation (GRE) トンネルは、RFC 2784 で説明されているように、レイヤー 3 トラフィックを IPv4 パケットにカプセル化します。GRE トンネルは、有効なイーサネットタイプで任意のレイヤー 3 プロトコルをカプセル化できます。
GRE トンネルを介して送信されるデータは暗号化されません。セキュリティー上の理由から、すでに暗号化されたデータにはトンネルを使用してください (HTTPS などの他のプロトコル)。
たとえば、以下の図に示すように、2 つの RHEL ルーター間で GRE トンネルを作成し、インターネット経由で 2 つの内部サブネットに接続できます。
前提条件
- 各 RHEL ルーターには、ローカルサブネットに接続されているネットワークインターフェイスがあります。
- 各 RHEL ルーターには、インターネットに接続しているネットワークインターフェイスがあります。
手順
ネットワーク A の RHEL ルーターで、次のコマンドを実行します。
gre1という名前の GRE トンネルインターフェイスを作成します。# nmcli connection add type ip-tunnel ip-tunnel.mode gre con-name gre1 ifname gre1 remote 198.51.100.5 local 203.0.113.10remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。重要gre0デバイス名は予約されています。デバイスにgre1または別の名前を使用します。IPv4 アドレスを
gre1デバイスに設定します。# nmcli connection modify gre1 ipv4.addresses '10.0.1.1/30'トンネルには、2 つの使用可能な IP アドレスを持つ
/30サブネットで十分であることに注意してください。手動の IPv4 設定を使用するように
gre1接続を設定します。# nmcli connection modify gre1 ipv4.method manualトラフィックを
172.16.0.0/24ネットワークにルーティングする静的ルートをルーター B のトンネル IP に追加します。# nmcli connection modify gre1 +ipv4.routes "172.16.0.0/24 10.0.1.2"gre1コネクションを有効にします。# nmcli connection up gre1パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
ネットワーク B の RHEL ルーターで、次のコマンドを実行します。
gre1という名前の GRE トンネルインターフェイスを作成します。# nmcli connection add type ip-tunnel ip-tunnel.mode gre con-name gre1 ifname gre1 remote 203.0.113.10 local 198.51.100.5remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。IPv4 アドレスを
gre1デバイスに設定します。# nmcli connection modify gre1 ipv4.addresses '10.0.1.2/30'手動の IPv4 設定を使用するように
gre1接続を設定します。# nmcli connection modify gre1 ipv4.method manualトラフィックを
192.0.2.0/24ネットワークにルーティングする静的ルートをルーター A のトンネル IP に追加します。# nmcli connection modify gre1 +ipv4.routes "192.0.2.0/24 10.0.1.1"gre1コネクションを有効にします。# nmcli connection up gre1パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
検証
各 RHEL ルーターから、他のルーターの内部インターフェイスの IP アドレスに ping します。
ルーター A で
172.16.0.1に ping します。# ping 172.16.0.1ルーター B で
192.0.2.1に ping します。# ping 192.0.2.1
8.3. IPv4 でイーサネットフレームを転送するための GRETAP トンネルの設定
GRETAP (Generic Routing Encapsulation Terminal Access Point) トンネルは OSI レベル 2 で動作し、RFC 2784 で説明されているように IPv4 パケットのイーサネットトラフィックをカプセル化します。
GRETAP トンネルを介して送信されるデータは暗号化されません。セキュリティー上の理由から、VPN または別の暗号化された接続にトンネルを確立します。
たとえば、以下の図に示すように、2 つの RHEL ルーター間で GRETAP トンネルを作成し、ブリッジを使用して 2 つのネットワークに接続します。
前提条件
- 各 RHEL ルーターには、ローカルネットワークに接続されたネットワークインターフェイスがあり、IP 設定は割り当てられません。
- 各 RHEL ルーターには、インターネットに接続しているネットワークインターフェイスがあります。
手順
ネットワーク A の RHEL ルーターで、次のコマンドを実行します。
bridge0という名前のブリッジインターフェイスを作成します。# nmcli connection add type bridge con-name bridge0 ifname bridge0ブリッジの IP 設定を設定します。
# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24' # nmcli connection modify bridge0 ipv4.method manualローカルネットワークに接続されたインターフェイス用の新しい接続プロファイルをブリッジに追加します。
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0GRETAP トンネルインターフェイスの新しい接続プロファイルをブリッジに追加します。
# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 198.51.100.5 local 203.0.113.10 master bridge0remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。重要gretap0デバイス名が予約されています。デバイスにgretap1または別の名前を使用します。必要に応じて、STP (Spanning Tree Protocol) を無効にする必要がない場合は、これを無効にします。
# nmcli connection modify bridge0 bridge.stp noデフォルトでは、STP は有効になり、接続を使用する前に遅延が生じます。
bridge0接続がアクティベートするように、ブリッジのポートが自動的にアクティブになるようにします。# nmcli connection modify bridge0 connection.autoconnect-slaves 1bridge0接続をアクティブにします。# nmcli connection up bridge0
ネットワーク B の RHEL ルーターで、次のコマンドを実行します。
bridge0という名前のブリッジインターフェイスを作成します。# nmcli connection add type bridge con-name bridge0 ifname bridge0ブリッジの IP 設定を設定します。
# nmcli connection modify bridge0 ipv4.addresses '192.0.2.2/24' # nmcli connection modify bridge0 ipv4.method manualローカルネットワークに接続されたインターフェイス用の新しい接続プロファイルをブリッジに追加します。
# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0GRETAP トンネルインターフェイスの新しい接続プロファイルをブリッジに追加します。
# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 203.0.113.10 local 198.51.100.5 master bridge0remoteパラメーターおよびlocalパラメーターは、リモートルーターおよびローカルルーターのパブリック IP アドレスを設定します。必要に応じて、STP (Spanning Tree Protocol) を無効にする必要がない場合は、これを無効にします。
# nmcli connection modify bridge0 bridge.stp nobridge0接続がアクティベートするように、ブリッジのポートが自動的にアクティブになるようにします。# nmcli connection modify bridge0 connection.autoconnect-slaves 1bridge0接続をアクティブにします。# nmcli connection up bridge0
検証
両方のルーターで、
enp1s0接続およびgretap1接続が接続され、CONNECTION列にポートの接続名が表示されていることを確認します。# nmcli device nmcli device DEVICE TYPE STATE CONNECTION ... bridge0 bridge connected bridge0 enp1s0 ethernet connected bridge0-port1 gretap1 iptunnel connected bridge0-port2各 RHEL ルーターから、他のルーターの内部インターフェイスの IP アドレスに ping します。
ルーター A で
192.0.2.2に ping します。# ping 192.0.2.2ルーター B で
192.0.2.1に ping します。# ping 192.0.2.1
第9章 VXLAN を使用した仮想マシンの仮想レイヤー 2 ドメインの作成
仮想拡張可能な LAN (VXLAN) は、UDP プロトコルを使用して IP ネットワーク経由でレイヤー 2 トラフィックをトンネルするネットワークプロトコルです。たとえば、別のホストで実行している特定の仮想マシンは、VXLAN トンネルを介して通信できます。ホストは、世界中の異なるサブネットやデータセンターに存在できます。仮想マシンの視点からは、同じ VXLAN 内のその他の仮想マシンは、同じレイヤー 2 ドメイン内にあります。
この例では、RHEL-host-A と RHEL-host-B は、ブリッジである br0 を使用して、VXLAN 名が vxlan10 である各ホストの仮想マシンの仮想ネットワークを接続します。この設定により、VXLAN は仮想マシンには表示されなくなり、仮想マシンに特別な設定は必要ありません。その後、別の仮想マシンを同じ仮想ネットワークに接続すると、仮想マシンは自動的に同じ仮想レイヤー 2 ドメインのメンバーになります。
通常のレイヤー 2 トラフィックと同様、VXLAN のデータは暗号化されません。セキュリティー上の理由から、VPN 経由で VXLAN を使用するか、その他のタイプの暗号化接続を使用します。
9.1. VXLAN の利点
仮想拡張可能 LAN (VXLAN) の主な利点は、以下のとおりです。
- VXLAN は 24 ビット ID を使用します。そのため、最大 16,777,216 の分離されたネットワークを作成できます。たとえば、仮想 LAN (VLAN) は 4,096 の分離されたネットワークのみをサポートします。
- VXLAN は IP プロトコルを使用します。これにより、トラフィックをルーティングし、仮想的に実行するシステムを、同じレイヤー 2 ドメイン内の異なるネットワークと場所に置くことができます。
- ほとんどのトンネルプロトコルとは異なり、VXLAN はポイントツーポイントネットワークだけではありません。VXLAN は、他のエンドポイントの IP アドレスを動的に学習するか、静的に設定された転送エントリーを使用できます。
- 特定のネットワークカードは、UDP トンネル関連のオフロード機能に対応します。
9.2. ホストでのイーサネットインターフェイスの設定
RHEL 仮想マシンホストをイーサネットに接続するには、ネットワーク接続プロファイルを作成し、IP 設定を設定して、プロファイルをアクティブにします。
両方の RHEL ホストでこの手順を実行し、IP アドレス設定を調整します。
前提条件
- ホストがイーサネットに接続されている。
手順
NetworkManager に新しいイーサネット接続プロファイルを追加します。
# nmcli connection add con-name Example ifname enp1s0 type ethernetIPv4 を設定します。
# nmcli connection modify Example ipv4.addresses 198.51.100.2/24 ipv4.method manual ipv4.gateway 198.51.100.254 ipv4.dns 198.51.100.200 ipv4.dns-search example.comネットワークが DHCP を使用する場合は、この手順をスキップします。
Exampleコネクションをアクティブにします。# nmcli connection up Example
検証
デバイスおよび接続の状態を表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet connected Exampleリモートネットワークでホストに ping を実行して、IP 設定を確認します。
# ping RHEL-host-B.example.comそのホストでネットワークを設定する前に、その他の仮想マシンホストに ping を実行することはできないことに注意してください。
9.3. VXLAN が接続されたネットワークブリッジの作成
仮想拡張可能な LAN (VXLAN) を仮想マシンに表示しないようにするには、ホストでブリッジを作成し、VXLAN をブリッジに割り当てます。NetworkManager を使用して、ブリッジと VXLAN の両方を作成します。仮想マシンのトラフィックアクセスポイント (TAP) デバイス (通常はホスト上の vnet*) をブリッジに追加することはありません。libvirtd は、仮想マシンの起動時に動的に追加します。
両方の RHEL ホストでこの手順を実行し、必要に応じて IP アドレスを調整します。
手順
ブリッジ
br0を作成します。# nmcli connection add type bridge con-name br0 ifname br0 ipv4.method disabled ipv6.method disabledこのコマンドは、ブリッジデバイスに IPv4 アドレスおよび IPv6 アドレスを設定しません。これは、このブリッジがレイヤー 2 で機能するためです。
VXLAN インターフェイスを作成し、
br0に割り当てます。# nmcli connection add type vxlan slave-type bridge con-name br0-vxlan10 ifname vxlan10 id 10 local 198.51.100.2 remote 203.0.113.1 master br0このコマンドは、次の設定を使用します。
-
id 10: VXLAN ID を設定します。 -
local 198.51.100.2: 送信パケットの送信元 IP アドレスを設定します。 -
remote 203.0.113.1: VXLAN デバイスフォワーディングデータベースで宛先リンク層アドレスが不明な場合に、送信パケットで使用するユニキャストまたはマルチキャストの IP アドレスを設定します。 -
master br0: この VXLAN 接続を、br0接続のポートとして作成するように設定します。 -
ipv4.method disabledおよびipv6.method disabled: ブリッジで IPv4 および IPv6 を無効にします。
初期設定では、NetworkManager は
8472を宛先ポートとして使用します。宛先ポートが異なる場合は、追加で、destination-port <port_number>オプションをコマンドに渡します。-
br0接続プロファイルを有効にします。# nmcli connection up br0ローカルファイアウォールで、着信 UDP 接続用にポート
8472を開くには、次のコマンドを実行します。# firewall-cmd --permanent --add-port=8472/udp # firewall-cmd --reload
検証
転送テーブルを表示します。
# bridge fdb show dev vxlan10 2a:53:bd:d5:b3:0a master br0 permanent 00:00:00:00:00:00 dst 203.0.113.1 self permanent ...
9.4. 既存のブリッジを使用した libvirt での仮想ネットワークの作成
仮想マシンが、接続した仮想拡張可能 LAN (VXLAN) で br0 ブリッジを使用できるようにするには、最初に、このブリッジを使用する libvirtd サービスに仮想ネットワークを追加します。
前提条件
-
libvirtをインストールした。 -
libvirtdを起動して有効にしている。 -
RHEL 上の VXLAN で
br0デバイスーを設定している。
手順
以下の内容で
~/vxlan10-bridge.xmlを作成します。<network> <name>vxlan10-bridge</name> <forward mode="bridge" /> <bridge name="br0" /> </network>~/vxlan10-bridge.xmlを使用して、libvirtに新しい仮想ネットワークを作成します。# virsh net-define ~/vxlan10-bridge.xml~/vxlan10-bridge.xmlを削除します。# rm ~/vxlan10-bridge.xmlvxlan10-bridge仮想ネットワークを起動します。# virsh net-start vxlan10-bridgelibvirtdの起動時に自動的に起動するようにvxlan10-bridge仮想ネットワークを設定します。# virsh net-autostart vxlan10-bridge
検証
仮想ネットワークのリストを表示します。
# virsh net-list Name State Autostart Persistent ---------------------------------------------------- vxlan10-bridge active yes yes ...
9.5. VXLAN を使用するように仮想マシンの設定
ホストで、接続されている仮想拡張 LAN (VXLAN) でブリッジデバイスを使用するように仮想マシンを設定するには、vxlan10-bridge 仮想ネットワークを使用する新しい仮想マシンを作成するか、このネットワークを使用する既存の仮想マシンの設定を更新します。
RHEL ホストでこの手順を実行します。
前提条件
-
libvirtdでvxlan10-bridge仮想ネットワークを設定している。
手順
新しい仮想マシンを作成し、
vxlan10-bridgeネットワークを使用するように設定するには、仮想マシンの作成時に、--network network:vxlan10-bridgeオプションをvirt-installに渡します。# virt-install ... --network network:vxlan10-bridge既存の仮想マシンのネットワーク設定を変更するには、次のコマンドを実行します。
仮想マシンのネットワークインターフェイスを、
vxlan10-bridge仮想ネットワークに接続します。# virt-xml VM_name --edit --network network=vxlan10-bridge仮想マシンをシャットダウンして、再起動します。
# virsh shutdown VM_name # virsh start VM_name
検証
ホストの仮想マシンの仮想ネットワークインターフェイスを表示します。
# virsh domiflist VM_name Interface Type Source Model MAC ------------------------------------------------------------------- vnet1 bridge vxlan10-bridge virtio 52:54:00:c5:98:1cvxlan10-bridgeブリッジに接続されているインターフェイスを表示します。# ip link show master vxlan10-bridge 18: vxlan10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 2a:53:bd:d5:b3:0a brd ff:ff:ff:ff:ff:ff 19: vnet1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 52:54:00:c5:98:1c brd ff:ff:ff:ff:ff:fflibvirtdは、ブリッジの設定を動的に更新することに注意してください。vxlan10-bridgeネットワークを使用する仮想マシンを起動すると、ホストの対応するvnet*デバイスがブリッジのポートとして表示されます。アドレス解決プロトコル (ARP) 要求を使用して、仮想マシンが同じ VXLAN にあるかどうかを確認します。
- 同じ VXLAN で、2 つ以上の仮想マシンを起動します。
仮想マシンから別の仮想マシンに ARP 要求を送信します。
# arping -c 1 192.0.2.2 ARPING 192.0.2.2 from 192.0.2.1 enp1s0 Unicast reply from 192.0.2.2 [52:54:00:c5:98:1c] 1.450ms Sent 1 probe(s) (0 broadcast(s)) Received 1 response(s) (0 request(s), 0 broadcast(s))コマンドが応答を示す場合、仮想マシンは同じレイヤー 2 ドメイン、およびこの場合は同じ VXLAN にあります。
arpingユーティリティーを使用するには、iputilsをインストールします。
第10章 wifi 接続の管理
RHEL には、Wi-Fi ネットワークを設定して接続するための複数のユーティリティーとアプリケーションが用意されています。次に例を示します。
-
nmcliユーティリティーを使用して、コマンドラインで接続を設定する。 -
nmtuiアプリケーションを使用して、テキストベースのユーザーインターフェイスで接続を設定する。 - GNOME システムメニューを使用すると、設定を必要としない Wi-Fi ネットワークにすばやく接続する。
-
GNOME Settingsアプリケーションを使用して、GNOME アプリケーションで接続を設定する。 -
nm-connection-editorアプリケーションを使用して、グラフィカルユーザーインターフェイスで接続を設定する。 -
networkRHEL システムロールを使用して、1 つまたは複数のホストでの接続の設定を自動化する。
10.1. サポートされている wifi セキュリティータイプ
wifi ネットワークがサポートするセキュリティータイプにより、データ送信の安全度は異なります。
暗号化を使用しない、または安全でない WEP または WPA 標準のみをサポートする wifi ネットワークには接続しないでください。
RHEL 8 は、次の Wi-Fi セキュリティータイプをサポートしています。
-
None: 暗号化は無効になり、ネットワーク経由でプレーンテキスト形式でデータが転送されます。 -
Enhanced Open: opportunistic wireless encryption (OWE) を使用すると、デバイスは一意のペアワイズマスターキー (PMK) をネゴシエートして、認証なしでワイヤレスネットワークの接続を暗号化します。 -
WEP 40/128 ビットキー (16 進数または ASCII): このモードの Wired Equivalent Privacy (WEP) プロトコルは、16 進数または ASCII 形式の事前共有キーのみを使用します。WEP は推奨されておらず、RHEL 9.1 で削除されます。 -
WEP 128 ビットパスフレーズ。このモードの WEP プロトコルは、パスフレーズの MD5 ハッシュを使用して WEP キーを取得します。WEP は推奨されておらず、RHEL 9.1 で削除されます。 -
動的 WEP (802.1x): 802.1X と EAP の組み合わせで、動的キーを使用する WEP プロトコルを使用します。WEP は推奨されておらず、RHEL 9.1 で削除されます。 -
LEAP: Cisco が開発した Lightweight Extensible Authentication Protocol は、拡張認証プロトコル (EAP) の独自バージョンです。 -
WPA & WPA2 Personal: パーソナルモードでは、Wi-Fi Protected Access (WPA) および Wi-Fi Protected Access 2 (WPA2) 認証方法で事前共有キーが使用されます。 -
WPA & WPA2 Enterprise: エンタープライズモードでは、WPA と WPA2 は EAP フレームワークを使用し、Remote Authentication Dial-In User Service (RADIUS) サーバーに対してユーザーを認証します。 -
WPA3 Personal: Wi-Fi Protected Access 3 (WPA3) Personal は、辞書攻撃を防ぐために pre-shared keys (PSK) の代わりに simultaneous authentication of equals (SAE) を使用します。WPA3 では、Perfect Forward Secrecy (PFS) が使用されます。
10.2. nmcli を使用した Wi-Fi ネットワークへの接続
nmcli ユーティリティーを使用して、Wi-Fi ネットワークに接続できます。初めてネットワークに接続しようとすると、ユーティリティーは NetworkManager 接続プロファイルを自動的に作成します。ネットワークに静的 IP アドレスなどの追加設定が必要な場合は、プロファイルが自動的に作成された後にプロファイルを変更できます。
前提条件
- ホストに Wi-Fi デバイスがインストールされている。
-
Wi-Fi デバイスが有効になっている。確認するには、
nmcli radioコマンドを使用します。
手順
NetworkManager で Wi-Fi 無線が無効になっている場合は、この機能を有効にします。
# nmcli radio wifi onオプション: 利用可能な Wi-Fi ネットワークを表示します。
# nmcli device wifi list IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY 00:53:00:2F:3B:08 Office Infra 44 270 Mbit/s 57 ▂▄▆_ WPA2 WPA3 00:53:00:15:03:BF -- Infra 1 130 Mbit/s 48 ▂▄__ WPA2 WPA3サービスセット識別子 (
SSID) 列には、ネットワークの名前が含まれています。列に--が表示されている場合、このネットワークのアクセスポイントは SSID をブロードキャストしていません。Wi-Fi ネットワークに接続します。
# nmcli device wifi connect Office --ask Password: wifi-password対話的に入力するのではなく、コマンドでパスワードを設定する場合は、コマンドで
--askの代わりにpassword <wifi_password>オプションを使用します。# nmcli device wifi connect Office password <wifi_password>ネットワークが静的 IP アドレスを必要とする場合、NetworkManager はこの時点で接続のアクティブ化に失敗することに注意してください。後の手順で IP アドレスを設定できます。
ネットワークに静的 IP アドレスが必要な場合:
IPv4 アドレス設定を設定します。次に例を示します。
# nmcli connection modify Office ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv4.gateway 192.0.2.254 ipv4.dns 192.0.2.200 ipv4.dns-search example.comIPv6 アドレス設定を設定します。次に例を示します。
# nmcli connection modify Office ipv6.method manual ipv6.addresses 2001:db8:1::1/64 ipv6.gateway 2001:db8:1::fffe ipv6.dns 2001:db8:1::ffbb ipv6.dns-search example.com
接続を再度有効にします。
# nmcli connection up Office
検証
アクティブな接続を表示します。
# nmcli connection show --active NAME ID TYPE DEVICE Office 2501eb7e-7b16-4dc6-97ef-7cc460139a58 wifi wlp0s20f3作成した Wi-Fi 接続が出力にリストされている場合、その接続はアクティブです。
ホスト名または IP アドレスに ping を実行します。
# ping -c 3 example.com
10.3. GNOME システムメニューを使用した Wi-Fi ネットワークへの接続
GNOME システムメニューを使用して、wifi ネットワークに接続できます。初めてネットワークに接続するとき、GNOME は NetworkManager 接続プロファイルを作成します。接続プロファイルを自動的に接続しないように設定した場合、GNOME システムメニューを用いて、既存の NetworkManager 接続プロファイルを使用して wifi ネットワークに手動で接続することもできます。
GNOME システムメニューを使用して初めて wifi ネットワークへの接続を確立する場合、一定の制限があります。たとえば、IP アドレス設定を設定することはできません。この場合、最初に接続を設定します。
前提条件
- ホストに Wi-Fi デバイスがインストールされている。
-
Wi-Fi デバイスが有効になっている。確認するには、
nmcli radioコマンドを使用します。
手順
- トップバーの右側にあるシステムメニューを開きます。
-
Wi-Fi Not Connectedエントリーを展開します。 Select Networkをクリックします。
- 接続する wifi ネットワークを選択します。
-
Connectをクリックします。 -
このネットワークに初めて接続する場合は、ネットワークのパスワードを入力し、
Connectをクリックします。
検証
トップバーの右側にあるシステムメニューを開き、Wi-Fi ネットワークが接続されていることを確認します。

ネットワークがリストに表示されていれば、接続されています。
ホスト名または IP アドレスに ping を実行します。
# ping -c 3 example.com
10.4. GNOME 設定を使用して Wi-Fi ネットワークに接続する
gnome-control-center とも呼ばれる GNOME 設定アプリケーションを使用して、Wi-Fi ネットワークに接続し、接続を設定することができます。初めてネットワークに接続するとき、GNOME は NetworkManager 接続プロファイルを作成します。
GNOME 設定では、RHEL がサポートするすべての Wi-Fi ネットワークセキュリティータイプの Wi-Fi 接続を設定できます。
前提条件
- ホストに Wi-Fi デバイスがインストールされている。
-
Wi-Fi デバイスが有効になっている。確認するには、
nmcli radioコマンドを使用します。
手順
-
Super キーを押し、
Wi-Fiと入力して Enter を押します。 - 接続したい Wi-Fi ネットワークの名前をクリックします。
-
ネットワークのパスワードを入力し、
Connectをクリックします。 静的 IP アドレスや WPA2 パーソナル以外のセキュリティータイプなど、ネットワークに追加の設定が必要な場合:
- ネットワーク名の横にある歯車のアイコンをクリックします。
オプション:
Detailsタブでネットワークプロファイルを設定して、自動的に接続しないようにします。この機能を無効にした場合は、GNOME 設定や GNOME システムメニューなどを使用して、常に手動でネットワークに接続する必要があります。
-
IPv4タブで IPv4 設定を設定し、IPv6タブで IPv6 設定を設定します。 Securityタブで、ネットワークの認証 (WPA3 Personalなど) を選択し、パスワードを入力します。選択したセキュリティーに応じて、アプリケーションは追加のフィールドを表示します。それに応じてそれらを埋めます。詳細は、Wi-Fi ネットワークの管理者におたずねください。
-
Applyをクリックします。
検証
トップバーの右側にあるシステムメニューを開き、Wi-Fi ネットワークが接続されていることを確認します。
ネットワークがリストに表示されていれば、接続されています。
ホスト名または IP アドレスに ping を実行します。
# ping -c 3 example.com
10.5. nmtui を使用した Wi-Fi 接続の設定
nmtui アプリケーションは、NetworkManager 用のテキストベースのユーザーインターフェイスを提供します。nmtui を使用して Wi-Fi ネットワークに接続できます。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
手順
nmtuiを開始します。# nmtui-
Edit a connection選択し、Enter を押します。 -
Addボタンを押します。 -
ネットワークタイプのリストから
Wi-Fiを選択し、Enter を押します。 オプション: 作成する NetworkManager プロファイルの名前を入力します。
ホストに複数のプロファイルがある場合は、わかりやすい名前を付けると、プロファイルの目的を識別しやすくなります。
-
Wi-Fi ネットワークの名前である Service Set Identifier (SSID) を
SSIDフィールドに入力します。 -
ModeフィールドはデフォルトのClientのままにします。 Securityフィールドを選択して Enter を押し、リストからネットワークの認証タイプを設定します。選択した認証タイプに応じて、
nmtuiは異なるフィールドを表示します。- 認証タイプ関連のフィールドに入力します。
Wi-Fi ネットワークに静的 IP アドレスが必要な場合:
-
プロトコルの横にある
Automaticボタンを押し、表示されたリストからManualを選択します。 -
設定するプロトコルの横にある
Showボタンを押して、追加のフィールドを表示し、それらに入力します。
-
プロトコルの横にある
OKボタンを押して、新しい接続を作成し、自動的にアクティブにします。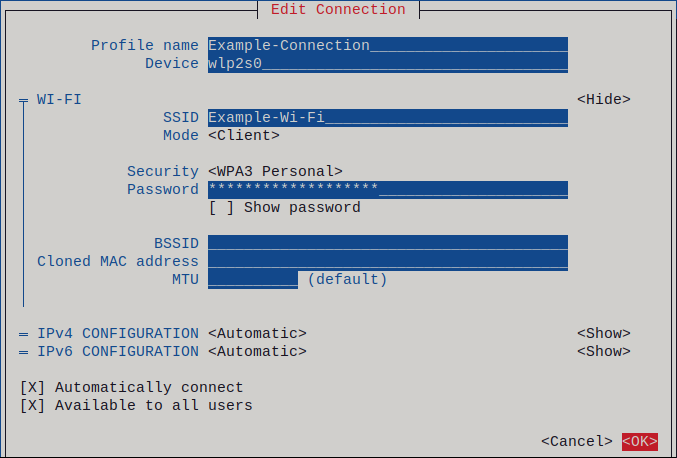
-
Backボタンを押してメインメニューに戻ります。 -
Quitを選択し、Enter キーを押してnmtuiアプリケーションを閉じます。
検証
アクティブな接続を表示します。
# nmcli connection show --active NAME ID TYPE DEVICE Office 2501eb7e-7b16-4dc6-97ef-7cc460139a58 wifi wlp0s20f3作成した Wi-Fi 接続が出力にリストされている場合、その接続はアクティブです。
ホスト名または IP アドレスに ping を実行します。
# ping -c 3 example.com
10.6. nm-connection-editor を使用した WiFi 接続の設定
nm-connection-editor アプリケーションを使用して、ワイヤレスネットワークの接続プロファイルを作成できます。このアプリケーションでは、RHEL がサポートするすべての wifi ネットワーク認証タイプを設定できます。
デフォルトでは、NetworkManager は接続プロファイルの自動接続機能を有効にし、保存されたネットワークが利用可能な場合は自動的に接続します。
前提条件
- ホストに Wi-Fi デバイスがインストールされている。
-
Wi-Fi デバイスが有効になっている。確認するには、
nmcli radioコマンドを使用します。
手順
ターミナルを開き、次のコマンドを入力します。
# nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
-
Wi-Fi接続タイプを選択し、 をクリックします。 - オプション: 接続プロファイルの名前を設定します。
オプション:
Generalタブでネットワークプロファイルを設定して、自動的に接続しないようにします。この機能を無効にした場合は、GNOME 設定や GNOME システムメニューなどを使用して、常に手動でネットワークに接続する必要があります。
-
Wi-Fiタブで、SSIDフィールドにサービスセット識別子 (SSID) を入力します。 Wi-Fi Securityタブで、ネットワークの認証タイプ (WPA3 Personalなど) を選択し、パスワードを入力します。選択したセキュリティーに応じて、アプリケーションは追加のフィールドを表示します。それに応じてそれらを埋めます。詳細は、wifi ネットワークの管理者におたずねください。
-
IPv4タブで IPv4 設定を設定し、IPv6タブで IPv6 設定を設定します。 -
Saveをクリックします。 -
Network Connectionsウィンドウを閉じます。
検証
トップバーの右側にあるシステムメニューを開き、Wi-Fi ネットワークが接続されていることを確認します。
ネットワークがリストに表示されていれば、接続されています。
ホスト名または IP アドレスに ping を実行します。
# ping -c 3 example.com
10.7. network RHEL システムロールを使用した 802.1X ネットワーク認証による Wi-Fi 接続の設定
ネットワークアクセス制御 (NAC) は、不正なクライアントからネットワークを保護します。クライアントがネットワークにアクセスできるようにするために、認証に必要な詳細を NetworkManager 接続プロファイルで指定できます。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
Ansible Playbook を使用して秘密鍵、証明書、および CA 証明書をクライアントにコピーしてから、network RHEL システムロールを使用して 802.1X ネットワーク認証による接続プロファイルを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - ネットワークは 802.1X ネットワーク認証をサポートしている。
-
マネージドノードに
wpa_supplicantパッケージをインストールしました。 - DHCP は、管理対象ノードのネットワークで使用できる。
TLS 認証に必要な以下のファイルがコントロールノードにある。
-
クライアントキーが
/srv/data/client.keyファイルに保存されている。 -
クライアント証明書が
/srv/data/client.crtファイルに保存されている。 -
CA 証明書は
/srv/data/ca.crtファイルに保存されます。
-
クライアントキーが
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。pwd: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure a wifi connection with 802.1X authentication hosts: managed-node-01.example.com tasks: - name: Copy client key for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.key" dest: "/etc/pki/tls/private/client.key" mode: 0400 - name: Copy client certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.crt" dest: "/etc/pki/tls/certs/client.crt" - name: Copy CA certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/ca.crt" dest: "/etc/pki/ca-trust/source/anchors/ca.crt" - name: Wifi connection profile with dynamic IP address settings and 802.1X ansible.builtin.import_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: Wifi connection profile with dynamic IP address settings and 802.1X interface_name: wlp1s0 state: up type: wireless autoconnect: yes ip: dhcp4: true auto6: true wireless: ssid: "Example-wifi" key_mgmt: "wpa-eap" ieee802_1x: identity: <user_name> eap: tls private_key: "/etc/pki/tls/client.key" private_key_password: "{{ pwd }}" private_key_password_flags: none client_cert: "/etc/pki/tls/client.pem" ca_cert: "/etc/pki/tls/cacert.pem" domain_suffix_match: "example.com"サンプル Playbook で指定されている設定は次のとおりです。
ieee802_1x- この変数には、802.1X 関連の設定を含めます。
eap: tls-
Extensible Authentication Protocol (EAP) に証明書ベースの
TLS認証方式を使用するようにプロファイルを設定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
10.8. nmcli を使用した既存のプロファイルでの 802.1X ネットワーク認証による Wi-Fi 接続の設定
nmcli ユーティリティーを使用して、クライアントがネットワークに対して自己認証するように設定できます。たとえば、wlp1s0 という名前の既存の NetworkManager wifi 接続プロファイルで、MSCHAPv2 (Microsoft Challenge-Handshake Authentication Protocol version 2) を使用する PEAP (Protected Extensible Authentication Protocol) 認証を設定します。
前提条件
- ネットワークには 802.1X ネットワーク認証が必要です。
- Wi-Fi 接続プロファイルが NetworkManager に存在し、有効な IP 設定があります。
-
クライアントがオーセンティケーターの証明書を検証する必要がある場合は、認証局 (CA) 証明書を
/etc/pki/ca-trust/source/anchors/ディレクトリーに保存する必要があります。 -
wpa_supplicantパッケージがインストールされている。
手順
Wi-Fi セキュリティーモードを
wpa-eapに設定し、Extensible Authentication Protocol (EAP) をpeapに設定し、内部認証プロトコルをmschapv2に設定し、ユーザー名を設定します。# nmcli connection modify wlp1s0 wireless-security.key-mgmt wpa-eap 802-1x.eap peap 802-1x.phase2-auth mschapv2 802-1x.identity user_name1 つのコマンドで
wireless-security.key-mgmtパラメーター、802-1x.eapパラメーター、802-1x.phase2-authパラメーター、および802-1x.identityパラメーターを設定する必要があります。オプション: 設定にパスワードを保存します。
# nmcli connection modify wlp1s0 802-1x.password password重要デフォルトでは、NetworkManager はパスワードをプレーンテキストで
/etc/sysconfig/network-scripts/keys-connection_nameファイルに保存します。このファイルはrootユーザーのみが読み取ることができます。ただし、設定ファイル内のプレーンテキストのパスワードは、セキュリティーリスクになる可能性があります。セキュリティーを強化するには、
802-1x.password-flagsパラメーターをagent-ownedに設定します。この設定では、GNOME デスクトップ環境またはnm-appletが実行中のサーバーで、NetworkManager は最初にキーリングのロックを解除してから、これらのサービスからパスワードを取得します。その他の場合は、NetworkManager によりパスワードの入力が求められます。クライアントがオーセンティケーターの証明書を検証する必要がある場合は、接続プロファイルの
802-1x.ca-certパラメーターを CA 証明書のパスに設定します。# nmcli connection modify wlp1s0 802-1x.ca-cert /etc/pki/ca-trust/source/anchors/ca.crt注記セキュリティー上の理由から、クライアントでオーセンティケーターの証明書を検証することを推奨します。
接続プロファイルをアクティベートします。
# nmcli connection up wlp1s0
検証
- ネットワーク認証が必要なネットワーク上のリソースにアクセスします。
10.9. ワイヤレス規制ドメインの手動設定
RHEL では、udev ルールが setregdomain ユーティリティーを実行してワイヤレス規制ドメインを設定します。次に、ユーティリティーはこの情報をカーネルに提供します。
デフォルトでは、setregdomain は国コードを自動的に決定しようとします。これが失敗する場合は、ワイヤレス規制ドメインの設定が間違っている可能性があります。この問題を回避するには、国コードを手動で設定します。
規制ドメインを手動で設定すると、自動検出が無効になります。そのため、後で別の国でコンピューターを使用すると、以前に設定された設定が正しくなくなる可能性があります。この場合、/etc/sysconfig/regdomain ファイルを削除して自動検出に戻すか、以下の手順を使用して規制ドメイン設定を手動で再度更新します。
前提条件
- Wi-Fi デバイスのドライバーが、規制ドメインの変更をサポートしている。
手順
オプション: 現在の規制ドメイン設定を表示します。
# iw reg get global country US: DFS-FCC ...次の内容で
/etc/sysconfig/regdomainファイルを作成します。COUNTRY=<country_code>COUNTRY変数を ISO 3166-1 alpha2 国コード (ドイツの場合はDE、アメリカ合衆国の場合はUSなど) に設定します。規制ドメインを設定します。
# setregdomain
検証
規制ドメインの設定を表示します。
# iw reg get global country DE: DFS-ETSI ...
第11章 RHEL を WPA2 または WPA3 パーソナルアクセスポイントとして設定する方法
Wi-Fi デバイスを備えたホストでは、NetworkManager を使用して、このホストをアクセスポイントとして設定できます。Wi-Fi Protected Access 2 (WPA2) および Wi-Fi Protected Access 3 (WPA3) Personal はセキュアな認証方法を提供します。ワイヤレスクライアントは事前共有キー (PSK) を使用してアクセスポイントに接続し、RHEL ホスト上およびネットワーク内のサービスを使用できます。
アクセスポイントを設定すると、NetworkManager は自動的に以下を行います。
-
クライアントに DHCP および DNS サービスを提供するように
dnsmasqサービスを設定します - IP 転送を有効にします
-
nftablesファイアウォールルールを追加して、wifi デバイスからのトラフィックをマスカレードし、IP 転送を設定します
前提条件
- Wi-Fi デバイスが、アクセスポイントモードでの実行をサポートしている
- Wi-Fi デバイスは使用していない
- ホストがインターネットにアクセスできる
手順
Wi-Fi デバイスを一覧表示して、アクセスポイントを提供するデバイスを特定します。
# nmcli device status | grep wifi wlp0s20f3 wifi disconnected --デバイスがアクセスポイントモードをサポートしていることを確認します。
# nmcli -f WIFI-PROPERTIES.AP device show wlp0s20f3 WIFI-PROPERTIES.AP: yesWi-Fi デバイスをアクセスポイントとして使用するには、デバイスがこの機能をサポートしている必要があります。
dnsmasqおよびNetworkManager-wifiパッケージをインストールします。# yum install dnsmasq NetworkManager-wifiNetworkManager は
dnsmasqサービスを使用して、アクセスポイントのクライアントに DHCP および DNS サービスを提供します。アクセスポイントの初期設定を作成します。
# nmcli device wifi hotspot ifname wlp0s20f3 con-name Example-Hotspot ssid Example-Hotspot password "password"このコマンドは、WPA2 および WPA3 Personal 認証を提供する
wlp0s20f3デバイス上のアクセスポイントの接続プロファイルを作成します。ワイヤレスネットワークの名前である Service Set Identifier (SSID) はExample-Hotspotで、事前共有キーのpasswordを使用します。オプション: WPA3 のみをサポートするようにアクセスポイントを設定します。
# nmcli connection modify Example-Hotspot 802-11-wireless-security.key-mgmt saeデフォルトでは、NetworkManager は wifi デバイスに IP アドレス
10.42.0.1を使用し、残りの10.42.0.0/24サブネットからの IP アドレスをクライアントに割り当てます。別のサブネットと IP アドレスを設定するには、次のように実行します。# nmcli connection modify Example-Hotspot ipv4.addresses 192.0.2.254/24設定した IP アドレス (この場合は
192.0.2.254) は、NetworkManager が wifi デバイスに割り当てるものです。クライアントは、この IP アドレスをデフォルトゲートウェイおよび DNS サーバーとして使用します。接続プロファイルをアクティベートします。
# nmcli connection up Example-Hotspot
検証
サーバー上では以下の設定になります。
NetworkManager が
dnsmasqサービスを開始し、そのサービスがポート 67 (DHCP) および 53 (DNS) でリッスンしていることを確認します。# ss -tulpn | grep -E ":53|:67" udp UNCONN 0 0 10.42.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=6)) udp UNCONN 0 0 0.0.0.0:67 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=4)) tcp LISTEN 0 32 10.42.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=55905,fd=7))nftablesルールセットを表示して、NetworkManager が10.42.0.0/24サブネットからのトラフィックの転送とマスカレードを有効にしていることを確認します。# nft list ruleset table ip nm-shared-wlp0s20f3 { chain nat_postrouting { type nat hook postrouting priority srcnat; policy accept; ip saddr 10.42.0.0/24 ip daddr != 10.42.0.0/24 masquerade } chain filter_forward { type filter hook forward priority filter; policy accept; ip daddr 10.42.0.0/24 oifname "wlp0s20f3" ct state { established, related } accept ip saddr 10.42.0.0/24 iifname "wlp0s20f3" accept iifname "wlp0s20f3" oifname "wlp0s20f3" accept iifname "wlp0s20f3" reject oifname "wlp0s20f3" reject } }
Wi-Fi アダプターを備えたクライアントの場合:
利用可能なネットワークのリストを表示します。
# nmcli device wifi IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY 00:53:00:88:29:04 Example-Hotspot Infra 11 130 Mbit/s 62 ▂▄▆_ WPA3 ...-
Example-Hotspotワイヤレスネットワークに接続します。Managing Wi-Fi connections を参照してください。 リモートネットワークまたはインターネット上のホストに ping を実行し、接続が機能していることを確認します。
# ping -c 3 www.redhat.com
第12章 MACsec を使用した同じ物理ネットワーク内のレイヤー 2 トラフィックの暗号化
MACsec を使用して、2 つのデバイス間の通信を (ポイントツーポイントで) セキュリティー保護できます。たとえば、ブランチオフィスがメトロイーサネット接続を介してセントラルオフィスに接続されている場合、オフィスを接続する 2 つのホストで MACsec を設定して、セキュリティーを強化できます。
12.1. MACsec がセキュリティーを強化する方法
Media Access Control Security (MACsec) は、イーサーネットリンクで異なるトラフィックタイプを保護するレイヤー 2 プロトコルです。これには以下が含まれます。
- Dynamic Host Configuration Protocol (DHCP)
- アドレス解決プロトコル (ARP)
- IPv4 および IPv6 トラフィック
- TCP や UDP などの IP 経由のトラフィック
MACsec はデフォルトで、LAN 内のすべてのトラフィックを GCM-AES-128 アルゴリズムで暗号化および認証し、事前共有キーを使用して参加者ホスト間の接続を確立します。事前共有キーを変更するには、MACsec を使用するすべてのネットワークホストで NM 設定を更新する必要があります。
MACsec 接続では、イーサネットネットワークカード、VLAN、トンネルデバイスなどのイーサネットデバイスを親として使用します。暗号化された接続のみを使用して他のホストと通信するように MACsec デバイスにのみ IP 設定を指定することも、親デバイスに IP 設定を設定することもできます。後者の場合、親デバイスを使用して、暗号化されていない接続と暗号化された接続用の MACsec デバイスで他のホストと通信できます。
MACsec には特別なハードウェアは必要ありません。たとえば、ホストとスイッチの間のトラフィックのみを暗号化する場合を除き、任意のスイッチを使用できます。このシナリオでは、スイッチが MACsec もサポートする必要があります。
つまり、次の 2 つの一般的なシナリオに合わせて MACsec を設定できます。
- ホストからホストへ
- ホストからスイッチへ、およびスイッチから他のホストへ
MACsec は、同じ物理 LAN または仮想 LAN 内にあるホスト間でのみ使用できます。
リンク層 (Open Systems Interconnection (OSI) モデルのレイヤー 2 とも呼ばれます) での通信を保護するために MACsec セキュリティー標準を使用すると、主に次のような利点が得られます。
- レイヤー 2 で暗号化することで、レイヤー 7 で個々のサービスを暗号化する必要がなくなります。これにより、各ホストの各エンドポイントで多数の証明書を管理することに関連するオーバーヘッドが削減されます。
- ルーターやスイッチなどの直接接続されたネットワークデバイス間のポイントツーポイントセキュリティー。
- アプリケーションや上位レイヤープロトコルに変更を加える必要がなくなります。
12.2. nmcli を使用した MACsec 接続の設定
nmcli ユーティリティーを使用して、MACsec を使用するようにイーサネットインターフェイスを設定できます。たとえば、イーサネット経由で接続された 2 つのホスト間に MACsec 接続を作成できます。
手順
MACsec を設定する最初のホストで:
事前共有鍵の接続アソシエーション鍵 (CAK) と接続アソシエーション鍵名 (CKN) を作成します。
16 バイトの 16 進 CAK を作成します。
# dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' 50b71a8ef0bd5751ea76de6d6c98c03a32 バイトの 16 進 CKN を作成します。
# dd if=/dev/urandom count=32 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550
- 両方のホストで、MACsec 接続を介して接続します。
MACsec 接続を作成します。
# nmcli connection add type macsec con-name macsec0 ifname macsec0 connection.autoconnect yes macsec.parent enp1s0 macsec.mode psk macsec.mka-cak 50b71a8ef0bd5751ea76de6d6c98c03a macsec.mka-ckn f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550前の手順で生成された CAK および CKN を
macsec.mka-cakおよびmacsec.mka-cknパラメーターで使用します。この値は、MACsec で保護されるネットワーク内のすべてのホストで同じである必要があります。MACsec 接続で IP を設定します。
IPv4設定を指定します。たとえば、静的IPv4アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーをmacsec0接続に設定するには、以下のコマンドを実行します。# nmcli connection modify macsec0 ipv4.method manual ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253'IPv6設定を指定しますたとえば、静的IPv6アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーをmacsec0接続に設定するには、以下のコマンドを実行します。# nmcli connection modify macsec0 ipv6.method manual ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd'
接続をアクティベートします。
# nmcli connection up macsec0
検証
トラフィックが暗号化されていることを確認します。
# tcpdump -nn -i enp1s0オプション: 暗号化されていないトラフィックを表示します。
# tcpdump -nn -i macsec0MACsec の統計を表示します。
# ip macsec showintegrity-only (encrypt off) および encryption (encrypt on) の各タイプの保護に対して個々のカウンターを表示します。
# ip -s macsec show
第13章 IPVLAN の使用
IPVLAN は、仮想ネットワークデバイス用のドライバーで、コンテナー環境でホストネットワークにアクセスするのに使用できます。IPVLAN は外部ネットワークに対し、ホストネットワーク内で作成された IPVLAN デバイスの数に関わらず、MAC アドレスを 1 つ公開します。つまり、ユーザーは複数コンテナーに複数の IPVLAN デバイスを持つことができますが、対応するスイッチは MAC アドレスを 1 つ読み込むということです。IPVLAN ドライバーは、ローカルスイッチで管理できる MAC アドレスの数に制限がある場合に役立ちます。
13.1. IPVLAN モード
IPVLAN では、次のモードが使用できます。
L2 モード
IPVLAN の L2 モード では、仮想デバイスはアドレス解決プロトコル (ARP) リクエストを受信して応答します。
netfilterフレームワークは、仮想デバイスを所有するコンテナー内でのみ動作します。デフォルトの名前空間では、コンテナー化されたトラフィックに対してnetfilterチェーンが実行されません。L2 モード を使用すると、パフォーマンスは向上しますが、ネットワークトラフィックに対する制御が少なくなります。L3 モード
L3 モード では、仮想デバイスは L3 以上のトラフィックのみを処理します。仮想デバイスは ARP リクエストに応答せず、関連するピアの IPVLAN IP アドレスは、隣接エントリーをユーザーが手動で設定する必要があります。関連するコンテナーの送信トラフィックはデフォルトの名前空間の
netfilterの POSTROUTING および OUTPUT チェーンに到達する一方、ingress トラフィックは L2 モード と同様にスレッド化されます。L3 モード を使用すると、制御性は高くなりますが、ネットワークトラフィックのパフォーマンスは低下します。L3S モード
L3S モード では、仮想デバイスは L3 モード と同様の処理をしますが、関連するコンテナーの egress トラフィックと ingress トラフィックの両方がデフォルトの名前空間の
netfilterチェーンに到達する点が異なります。L3S モード は、L3 モード と同様の動作をしますが、ネットワークの制御が強化されます。
IPVLAN 仮想デバイスは、L3 モードおよび L3S モードでは、ブロードキャストトラフィックおよびマルチキャストトラフィックを受信しません。
13.2. IPVLAN および MACVLAN の比較
以下の表は、MACVLAN と IPVLAN の主な相違点を示しています。
| MACVLAN | IPVLAN |
|---|---|
| 各 MACVLAN デバイスに対して、MAC アドレスを使用します。 スイッチが MAC テーブルに保存できる MAC アドレスの最大数に達すると、接続が失われる可能性があることに注意してください。 | IPVLAN デバイスの数を制限しない MAC アドレスを 1 つ使用します。 |
| グローバル名前空間の netfilter ルールは、子名前空間の MACVLAN デバイスとの間のトラフィックに影響を与えることはできません。 | L3 モード および L3S モード の IPVLAN デバイスとの間のトラフィックを制御できます。 |
IPVLAN と MACVLAN はどちらも、いかなるレベルのカプセル化も必要としません。
13.3. iproute2 を使用した IPVLAN デバイスの作成および設定
この手順では、iproute2 を使用して IPVLAN デバイスを設定する方法を説明します。
手順
IPVLAN デバイスを作成するには、次のコマンドを実行します。
# ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2ネットワークインターフェイスコントローラー (NIC) は、コンピューターをネットワークに接続するハードウェアコンポーネントです。
例13.1 IPVLAN デバイスの作成
# ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2 # ip link 47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ffIPv4アドレスまたはIPv6アドレスをインターフェイスに割り当てるには、次のコマンドを実行します。# ip addr add dev IPVLAN_device IP_address/subnet_mask_prefixL3 モード または L3S モード の IPVLAN デバイスを設定する場合は、以下の設定を行います。
リモートホストのリモートピアのネイバー設定を行います。
# ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_addressMAC_address は、IPVLAN デバイスのベースである実際の NIC の MAC アドレスになります。
L3 モード の IPVLAN デバイスを設定する場合は、次のコマンドを実行します。
# ip route add dev <real_NIC_device> <peer_IP_address/32>L3S モード の場合は、次のコマンドを実行します。
# ip route add dev real_NIC_device peer_IP_address/32IP アドレスは、リモートピアのアドレスを使用します。
IPVLAN デバイスをアクティブに設定するには、次のコマンドを実行します。
# ip link set dev IPVLAN_device upIPVLAN デバイスがアクティブであることを確認するには、リモートホストで次のコマンドを実行します。
# ping IP_addressIP_address には、IPVLAN デバイスの IP アドレスを使用します。
第14章 特定のデバイスを無視するように NetworkManager の設定
デフォルトでは、NetworkManager は /usr/lib/udev/rules.d/85-nm-unmanaged.rules ファイルに記述されているデバイスを除くすべてのデバイスを管理します。他の特定のデバイスを無視するには、NetworkManager でそのデバイスを unmanaged として設定できます。
14.1. NetworkManager でデバイスをマネージド外として永続的に設定
インターフェイス名、MAC アドレス、デバイスタイプなどのいくつかの基準に基づいてデバイスを unmanaged として設定できます。設定内のデバイスセクションを使用してデバイスを管理対象外として設定した場合、NetworkManager は接続プロファイルでそのデバイスの使用を開始するまでそのデバイスを管理しません。
手順
オプション: デバイスの一覧を表示して、
unmanagedに設定するデバイスまたは MAC アドレスを特定します。# ip link show ... 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:74:79:56 brd ff:ff:ff:ff:ff:ff ...-
/etc/NetworkManager/conf.d/ディレクトリーに*.confファイルを作成します (例:/etc/NetworkManager/conf.d/99-unmanaged-devices.conf)。 管理対象外として設定するデバイスごとに、一意の名前を持つセクションをファイルに追加します。
重要セクション名は
device-で始まる必要があります。特定のインターフェイスを管理対象外として設定するには、以下を追加します。
[device-enp1s0-unmanaged] match-device=interface-name:enp1s0 managed=0特定の MAC アドレスを管理対象外として設定するには、以下を追加します。
[device-mac525400747956-unmanaged] match-device=mac:52:54:00:74:79:56 managed=0特定のタイプのすべてのデバイスを管理対象外として設定するには、以下を追加します。
[device-ethernet-unmanaged] match-device=type:ethernet managed=0複数のデバイスを管理対象外に設定するには、
unmanaged-devicesパラメーターのエントリーをセミコロンで区切ります。以下に例を示します。[device-multiple-devices-unmanaged] match-device=interface-name:enp1s0;interface-name:enp7s0 managed=0または、このファイルにデバイスごとに個別のセクションを追加したり、
/etc/NetworkManager/conf.d/ディレクトリーに追加の*.confファイルを作成したりすることもできます。
ホストシステムを再起動します。
# reboot
検証
デバイスのリストを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unmanaged -- ...enp1s0デバイスの横のunmanaged状態は、NetworkManager がこのデバイスを管理していないことを示しています。
トラブルシューティング
nmcli device statusコマンドの出力にデバイスがunmanagedとしてリストされていない場合は、NetworkManager 設定を表示します。# NetworkManager --print-config ... [device-enp1s0-unmanaged] match-device=interface-name:enp1s0 managed=0 ...指定した設定と出力が一致しない場合は、より優先度が高い設定ファイルによって設定がオーバーライドされていないことを確認してください。NetworkManager が複数の設定ファイルをマージする方法の詳細は、システムの
NetworkManager.conf(5)man ページを参照してください。
14.2. NetworkManager でデバイスをマネージド外として一時的に設定
たとえばテスト目的で、デバイスを一時的に unmanaged として設定できます。この変更は、NetworkManager systemd サービスの再ロード後および再起動後も維持されますが、システムの再起動後は維持されません。
手順
必要に応じて、デバイスのリストを表示して、
マネージド外に設定するデバイスを特定します。# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet disconnected -- ...enp1s0デバイスをunmanagedの状態に設定します。# nmcli device set enp1s0 managed no
検証
デバイスのリストを表示します。
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet unmanaged -- ...enp1s0デバイスの横のunmanaged状態は、NetworkManager がこのデバイスを管理していないことを示しています。
第15章 nmcli を使用したループバックインターフェイスの設定
デフォルトでは、NetworkManager はループバック (lo) インターフェイスを管理しません。lo インターフェイスの接続プロファイルを作成した後、NetworkManager を使用してこのデバイスを設定できます。例としては次のようなものがあります。
-
loインターフェイスに追加の IP アドレスを割り当てる - DNS アドレスを定義する
-
loインターフェイスの最大伝送単位 (MTU) サイズを変更する
手順
タイプ
loopbackの新しい接続を作成します。# nmcli connection add con-name example-loopback type loopbackカスタム接続設定を設定します。次に例を示します。
追加の IP アドレスをインターフェイスに割り当てるには、次のように実行します。
# nmcli connection modify example-loopback +ipv4.addresses 192.0.2.1/24注記NetworkManager は、再起動後も持続する IP アドレス
127.0.0.1および::1を常に割り当てることで、loインターフェイスを管理します。127.0.0.1と::1を上書きすることはできません。ただし、追加の IP アドレスをインターフェイスに割り当てることができます。カスタムの最大伝送単位 (MTU) を設定するには、次のように実行します。
# nmcli con mod example-loopback loopback.mtu 16384DNS サーバーに IP アドレスを設定するには、次のように実行します。
# nmcli connection modify example-loopback ipv4.dns 192.0.2.0ループバック接続プロファイルで DNS サーバーを設定すると、このエントリーが
/etc/resolv.confファイルで常に使用可能になります。DNS サーバーのエントリーは、ホストが異なるネットワーク間をローミングするかどうかには関係ありません。
接続をアクティベートします。
# nmcli connection up example-loopback
検証
loインターフェイスの設定を表示します。# ip address show lo 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16384 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet 192.0.2.1/24 brd 192.0.2.255 scope global lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft foreverDNS アドレスを確認します。
# cat /etc/resolv.conf ... nameserver 192.0.2.0 ...
第16章 ダミーインターフェイスの作成
Red Hat Enterprise Linux ユーザーは、デバッグおよびテストの目的でダミーネットワークインターフェイスを作成および使用できます。ダミーインターフェイスは、実際には送信せずにパケットをルーティングするデバイスを提供します。NetworkManager が管理する追加のループバックのようなデバイスを作成し、非アクティブな SLIP (Serial Line Internet Protocol) アドレスをローカルプログラムの実アドレスのようにすることができます。
16.1. nmcli を使用して IPv4 アドレスと IPv6 アドレスの両方を使用したダミーインターフェイスを作成する
IPv4 アドレスや IPv6 アドレスなどのさまざまな設定でダミーインターフェイスを作成できます。ダミーインターフェイスを作成すると、NetworkManager により自動的にデフォルトの public firewalld ゾーンに割り当てられます。
手順
静的 IPv4 および IPv6 アドレスを使用して、
dummy0という名前のダミーインターフェイスを作成します。# nmcli connection add type dummy ifname dummy0 ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv6.method manual ipv6.addresses 2001:db8:2::1/64注記IPv4 および IPv6 アドレスなしでダミーインターフェイスを設定するには、
ipv4.methodおよびipv6.methodパラメーターの両方をdisabledに設定します。それ以外の場合は、IP 自動設定が失敗し、NetworkManager が接続を無効にしてデバイスを削除します。
検証
接続プロファイルを一覧表示します。
# nmcli connection show NAME UUID TYPE DEVICE dummy-dummy0 aaf6eb56-73e5-4746-9037-eed42caa8a65 dummy dummy0
第17章 NetworkManager で特定接続の IPv6 の無効化
NetworkManager を使用してネットワークインターフェイスを管理するシステムでは、ネットワークが IPv4 のみを使用している場合は、IPv6 プロトコルを無効にできます。IPv6 を無効にすると、NetworkManager はカーネルに対応する sysctl 値を自動的に設定します。
カーネルの設定項目またはカーネルブートパラメーターを使用して IPv6 を無効にする場合は、システム設定に追加で配慮が必要です。詳細は、Red Hat ナレッジベースのソリューション記事 How do I disable or enable the IPv6 protocol in RHEL を参照してください。
17.1. nmcli を使用して接続の IPv6 を無効にする
nmcli ユーティリティーを使用して、コマンドラインで IPv6 プロトコルを無効にすることができます。
前提条件
- システムは、NetworkManager を使用してネットワークインターフェイスを管理します。
手順
オプション: ネットワーク接続のリストを表示します。
# nmcli connection show NAME UUID TYPE DEVICE Example 7a7e0151-9c18-4e6f-89ee-65bb2d64d365 ethernet enp1s0 ...接続の
ipv6.methodパラメーターをdisabledに設定します。# nmcli connection modify Example ipv6.method "disabled"ネットワーク接続が再起動します。
# nmcli connection up Example
検証
デバイスの IP 設定を表示します。
# ip address show enp1s0 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:6b:74:be brd ff:ff:ff:ff:ff:ff inet 192.0.2.1/24 brd 192.10.2.255 scope global noprefixroute enp1s0 valid_lft forever preferred_lft foreverinet6エントリーが表示されない場合は、デバイスでIPv6が無効になります。/proc/sys/net/ipv6/conf/enp1s0/disable_ipv6ファイルに値1が含まれていることを確認します。# cat /proc/sys/net/ipv6/conf/enp1s0/disable_ipv6 1値が
1の場合は、デバイスに対してIPv6が無効になります。
第18章 ホスト名の変更
システムのホスト名は、システム自体の名前になります。RHEL のインストール時に名前を設定し、後で変更できます。
18.1. nmcli を使用したホスト名の変更
nmcli ユーティリティーを使用して、システムのホスト名を更新できます。その他のユーティリティーは、静的または永続的なホスト名などの別の用語を使用する可能性があることに注意してください。
手順
オプション: 現在のホスト名設定を表示します。
# nmcli general hostname old-hostname.example.com新しいホスト名を設定します。
# nmcli general hostname new-hostname.example.comNetworkManager は、
systemd-hostnamedを自動的に再起動して、新しい名前をアクティブにします。変更を有効にするには、ホストを再起動します。# rebootあるいは、そのホスト名を使用するサービスがわかっている場合は、次のようにします。
サービスの起動時にホスト名のみを読み取るすべてのサービスを再起動します。
# systemctl restart <service_name>- 変更を反映するには、アクティブなシェルユーザーを再ログインする必要があります。
検証
ホスト名を表示します。
# nmcli general hostname new-hostname.example.com
18.2. hostnamectl を使用したホスト名の変更
hostnamectl ユーティリティーを使用してホスト名を更新できます。デフォルトでは、このユーティリティーは以下のホスト名タイプを設定します。
-
静的ホスト名:
/etc/hostnameファイルに保存されます。通常、サービスはこの名前をホスト名として使用します。 -
Pretty hostname:
Proxy server in data center Aなどの説明的な名前。 - 一時的なホスト名: 通常ネットワーク設定から受信されるフォールバック値。
手順
オプション: 現在のホスト名設定を表示します。
# hostnamectl status --static old-hostname.example.com新しいホスト名を設定します。
# hostnamectl set-hostname new-hostname.example.comこのコマンドは、static と transient のホスト名を新しい値に設定します。特定のタイプのみを設定するには、
--staticオプション、--prettyオプション、または--transientオプションをコマンドに渡します。hostnamectlユーティリティーは、systemd-hostnamedを自動的に再起動して、新しい名前をアクティブにします。変更を有効にするには、ホストを再起動します。# rebootあるいは、そのホスト名を使用するサービスがわかっている場合は、次のようにします。
サービスの起動時にホスト名のみを読み取るすべてのサービスを再起動します。
# systemctl restart <service_name>- 変更を反映するには、アクティブなシェルユーザーを再ログインする必要があります。
検証
ホスト名を表示します。
# hostnamectl status --static new-hostname.example.com
第19章 NetworkManager の DHCP の設定
NetworkManager は、DHCP に関連するさまざまな設定オプションを提供します。たとえば、ビルトイン DHCP クライアント (デフォルト) または外部クライアントを使用するように NetworkManager を設定したり、個々のプロファイルの DHCP 設定に影響を与えることができます。
19.1. NetworkManager の DHCP クライアントの変更
デフォルトでは、NetworkManager は内部 DHCP クライアントを使用します。ただし、ビルトインクライアントが提供しない機能を備えた DHCP クライアントが必要な場合は、代わりに dhclient を使用するように NetworkManager を設定できます。
RHEL では dhcpcd が提供されていないため、NetworkManager はこのクライアントを使用できないことに注意してください。
手順
次のコンテンツで
/etc/NetworkManager/conf.d/dhcp-client.confファイルを作成します。[main] dhcp=dhclientdhcpパラメーターをinternal(デフォルト) またはdhclientに設定できます。dhcpパラメーターをdhclientに設定した場合は、dhcp-clientパッケージをインストールします。# yum install dhcp-clientNetworkManager を再起動します。
# systemctl restart NetworkManager再起動すると、すべてのネットワーク接続が一時的に中断されることに注意してください。
検証
/var/log/messagesログファイルで、次のようなエントリーを検索します。Apr 26 09:54:19 server NetworkManager[27748]: <info> [1650959659.8483] dhcp-init: Using DHCP client 'dhclient'このログエントリーは、NetworkManager が DHCP クライアントとして
dhclientを使用していることを確認します。
19.2. NetworkManager 接続の DHCP タイムアウト動作の設定
DHCP (Dynamic Host Configuration Protocol) クライアントは、クライアントがネットワークに接続するたびに、動的 IP アドレスと対応する設定情報を DHCP サーバーに要求します。
接続プロファイルで DHCP を有効にすると、NetworkManager はデフォルトでこの要求が完了するまで 45 秒間待機します。
前提条件
- DHCP を使用する接続がホストに設定されている。
手順
オプション:
ipv4.dhcp-timeoutプロパティーおよびipv6.dhcp-timeoutプロパティーを設定します。たとえば、両方のオプションを30秒に設定するには、次のコマンドを実行します。# nmcli connection modify <connection_name> ipv4.dhcp-timeout 30 ipv6.dhcp-timeout 30パラメーターを
infinityに設定すると、成功するまで NetworkManager が IP アドレスのリクエストおよび更新を停止しないようにします。必要に応じて、タイムアウト前に NetworkManager が IPv4 アドレスを受信しない場合にこの動作を設定します。
# nmcli connection modify <connection_name> ipv4.may-fail <value>ipv4.may-failオプションを以下のように設定します。yes、接続のステータスは IPv6 設定により異なります。- IPv6 設定が有効になり、成功すると、NetworkManager は IPv6 接続をアクティブにし、IPv4 接続のアクティブ化を試みなくなります。
- IPv6 設定が無効であるか設定されていないと、接続は失敗します。
いいえ、接続は非アクティブになります。この場合は、以下のようになります。-
接続の
autoconnectプロパティーが有効になっている場合、NetworkManager は、autoconnect-retriesプロパティーに設定された回数だけ、接続のアクティベーションを再試行します。デフォルト値は4です。 - それでも接続が DHCP アドレスを取得できないと、自動アクティベーションは失敗します。5 分後に自動接続プロセスが再開され、DHCP サーバーから IP アドレスを取得するようになりました。
-
接続の
必要に応じて、タイムアウト前に NetworkManager が IPv6 アドレスを受信しない場合にこの動作を設定します。
# nmcli connection modify <connection_name> ipv6.may-fail <value>
第20章 NetworkManager で dispatcher スクリプトを使用して dhclient の終了フックを実行する
NetworkManager の dispatcher スクリプトを使用して、dhclient の終了フックを実行できます。
20.1. NetworkManager の dispatcher スクリプトの概念
NetworkManager-dispatcher サービスは、ネットワークイベントが発生した場合に、ユーザーが提供したスクリプトをアルファベット順に実行します。通常、これらのスクリプトはシェルスクリプトですが、任意の実行可能スクリプトまたはアプリケーションにすることができます。たとえば、dispatcher スクリプトを使用して、NetworkManager では管理できないネットワーク関連の設定を調整できます。
dispatcher スクリプトは、以下のディレクトリーに保存できます。
-
/etc/NetworkManager/dispatcher.d/:rootユーザーが編集できるディスパッチャースクリプトの全般的な場所です。 -
/usr/lib/NetworkManager/dispatcher.d/: デプロイ済みの不変のディスパッチャースクリプト用。
セキュリティー上の理由から、NetworkManager-dispatcher では、以下の条件が満たされた場合にのみスクリプトを実行します。
-
このスクリプトは、
rootユーザーが所有します。 -
このスクリプトは、
rootでのみ読み取りと書き込みが可能です。 -
setuidビットはスクリプトに設定されていません。
NetworkManager-dispatcher サービスは、2 つの引数を指定して、それぞれのスクリプトを実行します。
- 操作が発生したデバイスのインターフェイス名。
-
インターフェイスがアクティブになったときの動作 (
upなど)。
NetworkManager(8) の man ページの Dispatcher scripts セクションには、スクリプトで使用できるアクションと環境変数の概要が記載されています。
NetworkManager-dispatcher サービスは、一度に 1 つのスクリプトを実行しますが、NetworkManager のメインプロセスとは非同期に実行します。スクリプトがキューに入れられている場合、後のイベントによってスクリプトが廃止された場合でも、サービスは常にスクリプトを実行することに注意してください。ただし、NetworkManager-dispatcher サービスは、以前のスクリプトの終了を待たずに、/etc/NetworkManager/dispatcher.d/no-wait.d/ 内のファイルを参照するシンボリックリンクであるスクリプトを即座に、そして並行して実行します。
20.2. dhclient の終了フックを実行する NetworkManager の dispatcher スクリプトの作成
DHCP サーバーが IPv4 アドレスを割り当てまたは更新すると、NetworkManager は /etc/dhcp/dhclient-exit-hooks.d/ ディレクトリーに保存されている dispatcher スクリプトを実行できます。この dispatcher スクリプトは、dhclient の終了フックなどを実行できます。
前提条件
-
dhclientの終了フックは、/etc/dhcp/dhclient-exit-hooks.d/ディレクトリーに保存されます。
手順
以下の内容で
/etc/NetworkManager/dispatcher.d/12-dhclient-downファイルを作成します。#!/bin/bash # Run dhclient.exit-hooks.d scripts if [ -n "$DHCP4_DHCP_LEASE_TIME" ] ; then if [ "$2" = "dhcp4-change" ] || [ "$2" = "up" ] ; then if [ -d /etc/dhcp/dhclient-exit-hooks.d ] ; then for f in /etc/dhcp/dhclient-exit-hooks.d/*.sh ; do if [ -x "${f}" ]; then . "${f}" fi done fi fi firootユーザーをファイルの所有者として設定します。# chown root:root /etc/NetworkManager/dispatcher.d/12-dhclient-down権限を設定して、root ユーザーのみが実行できるようにします。
# chmod 0700 /etc/NetworkManager/dispatcher.d/12-dhclient-downSELinux コンテキストを復元します。
# restorecon /etc/NetworkManager/dispatcher.d/12-dhclient-down
第21章 /etc/resolv.conf ファイルの手動設定
デフォルトでは、NetworkManager は、アクティブな NetworkManager 接続プロファイルの DNS 設定を使用して /etc/resolv.conf ファイルを動的に更新します。ただし、この動作を無効にし、/etc/resolv.conf で DNS 設定を手動で設定できます。
または、/etc/resolv.conf で特定の DNS サーバーの順序が必要な場合は、DNS サーバーの順序の設定 を参照してください。
21.1. NetworkManager 設定で DNS 処理の無効化
デフォルトでは、NetworkManager は /etc/resolv.conf ファイルで DNS 設定を管理し、DNS サーバーの順序を設定できます。または、/etc/resolv.conf で DNS 設定を手動で設定する場合は、NetworkManager で DNS 処理を無効にできます。
手順
root ユーザーとして、テキストエディターを使用して、以下の内容で
/etc/NetworkManager/conf.d/90-dns-none.confファイルを作成します。[main] dns=noneNetworkManagerサービスを再読み込みします。# systemctl reload NetworkManager注記サービスを再読み込みすると、NetworkManager は
/etc/resolv.confファイルを更新しなくなります。ただし、ファイルの最後の内容は保持されます。-
オプション: 混乱を避けるために、
Generated by NetworkManagerコメントを/etc/resolv.confから削除します。
検証
-
/etc/resolv.confファイルを編集し、設定を手動で更新します。 NetworkManagerサービスを再読み込みします。# systemctl reload NetworkManager/etc/resolv.confファイルを表示します。# cat /etc/resolv.confDNS 処理を無効にできた場合、NetworkManager は手動で設定した設定を上書きしませんでした。
トラブルシューティング
NetworkManager 設定を表示して、優先度の高い他の設定ファイルが設定をオーバーライドしていないことを確認します。
# NetworkManager --print-config ... dns=none ...
21.2. /etc/resolv.conf を、DNS 設定を手動で設定するシンボリックリンクに置き換え
デフォルトでは、NetworkManager は /etc/resolv.conf ファイルで DNS 設定を管理し、DNS サーバーの順序を設定できます。または、/etc/resolv.conf で DNS 設定を手動で設定する場合は、NetworkManager で DNS 処理を無効にできます。たとえば、/etc/resolv.conf がシンボリックリンクの場合、NetworkManager は DNS 設定を自動的に更新しません。
前提条件
-
NetworkManager
rc-manager設定オプションは、ファイルに設定されていません。検証には、NetworkManager --print-configコマンドを使用します。
手順
-
/etc/resolv.conf.manually-configuredなどのファイルを作成し、お使いの環境の DNS 設定を追加します。元の/etc/resolv.confと同じパラメーターと構文を使用します。 /etc/resolv.confファイルを削除します。# rm /etc/resolv.conf/etc/resolv.conf.manually-configuredを参照する/etc/resolv.confという名前のシンボリックリンクを作成します。# ln -s /etc/resolv.conf.manually-configured /etc/resolv.conf
第22章 DNS サーバーの順序の設定
ほとんどのアプリケーションは、glibc ライブラリーの getaddrinfo() 関数を使用して DNS で名前を解決します。デフォルトでは、glibc はすべての DNS 要求を、/etc/resolv.conf ファイルで指定された最初の DNS サーバーに送信します。このサーバーが応答しない場合、RHEL はこのファイル内にある他のすべてのネームサーバーを試します。NetworkManager を使用すると、/etc/resolv.conf 内の DNS サーバーの順序に影響を与えることができます。
22.1. NetworkManager が /etc/resolv.conf で DNS サーバーを順序付ける方法
NetworkManager は、以下のルールに基づいて /etc/resolv.conf ファイルの DNS サーバーの順序を付けます。
- 接続プロファイルが 1 つしか存在しない場合、NetworkManager は、その接続で指定された IPv4 および IPv6 の DNS サーバーの順序を使用します。
複数の接続プロファイルがアクティベートされると、NetworkManager は DNS の優先度の値に基づいて DNS サーバーを順序付けます。DNS の優先度を設定すると、NetworkManager の動作は、
dnsパラメーターに設定した値によって異なります。このパラメーターは、/etc/NetworkManager/NetworkManager.confファイルの[main]セクションで設定できます。dns=defaultまたはdnsパラメーターが設定されていないと、以下のようになります。NetworkManager は、各接続の
ipv4.dns-priorityパラメーターおよびipv6.dns-priorityパラメーターに基づいて、複数の接続から DNS サーバーを順序付けます。値を指定しない場合、または
ipv4.dns-priorityおよびipv6.dns-priorityを0に設定すると、NetworkManager はグローバルのデフォルト値を使用します。DNS 優先度パラメーターのデフォルト値 を参照してください。dns=dnsmasqまたはdns=systemd-resolved:この設定のいずれかを使用すると、NetworkManager は
dnsmasqの127.0.0.1に設定するか、127.0.0.53をnameserverエントリーとして/etc/resolv.confファイルに設定します。dnsmasqサービスとsystemd-resolvedサービスはどちらも、NetworkManager 接続で設定された検索ドメインのクエリーをその接続で指定された DNS サーバーに転送し、他のドメインへのクエリーをデフォルトルートを持つ接続に転送します。複数の接続に同じ検索ドメインが設定されている場合は、dnsmasqおよびsystemd-resolvedが、このドメインのクエリーを、優先度の値が最も低い接続に設定された DNS サーバーへ転送します。
DNS 優先度パラメーターのデフォルト値
NetworkManager は、接続に以下のデフォルト値を使用します。
-
VPN 接続の場合は
50 -
他の接続の場合は
100
有効な DNS 優先度の値:
グローバルのデフォルトおよび接続固有の ipv4.dns-priority パラメーターおよび ipv6.dns-priority パラメーターの両方を -2147483647 から 2147483647 までの値に設定できます。
- 値が小さいほど優先度が高くなります。
- 負の値は、値が大きい他の設定を除外する特別な効果があります。たとえば、優先度が負の値の接続が 1 つでも存在する場合は、NetworkManager が、優先度が最も低い接続プロファイルで指定された DNS サーバーのみを使用します。
複数の接続の DNS の優先度が同じ場合、NetworkManager は以下の順番で DNS の優先順位を決定します。
- VPN 接続。
- アクティブなデフォルトルートとの接続。アクティブなデフォルトルートは、メトリックスが最も低いデフォルトルートです。
22.2. NetworkManager 全体でデフォルトの DNS サーバー優先度の値の設定
NetworkManager は、接続に以下の DNS 優先度のデフォルト値を使用します。
-
VPN 接続の場合は
50 -
他の接続の場合は
100
これらのシステム全体のデフォルトは、IPv4 接続および IPv6 接続のカスタムデフォルト値で上書きできます。
手順
/etc/NetworkManager/NetworkManager.confファイルを編集します。[connection]セクションが存在しない場合は追加します。[connection][connection]セクションにカスタムのデフォルト値を追加します。たとえば、IPv4 と IPv6 の両方で新しいデフォルトを200に設定するには、以下を追加します。ipv4.dns-priority=200 ipv6.dns-priority=200パラメーターは、
-2147483647から2147483647までの値に設定できます。パラメーターを0に設定すると、組み込みのデフォルト (VPN 接続の場合は50、他の接続の場合は100) が有効になります。
NetworkManagerサービスを再読み込みします。# systemctl reload NetworkManager
22.3. NetworkManager 接続の DNS 優先度の設定
特定の DNS サーバーの順序が必要な場合は、接続プロファイルに優先度の値を設定できます。NetworkManager はこれらの値を使用して、サービスが /etc/resolv.conf ファイルを作成または更新する際にサーバーを順序付けます。
DNS 優先度の設定は、異なる DNS サーバーが設定された複数の接続がある場合にのみ有効であることに注意してください。複数の DNS サーバーが設定された接続が 1 つしかない場合は、接続プロファイルで DNS サーバーを優先順に手動で設定します。
前提条件
- システムに NetworkManager の接続が複数設定されている。
-
システムで、
/etc/NetworkManager/NetworkManager.confファイルにdnsパラメーターが設定されていないか、そのパラメーターがdefaultに設定されている。
手順
オプション: 利用可能な接続を表示します。
# nmcli connection show NAME UUID TYPE DEVICE Example_con_1 d17ee488-4665-4de2-b28a-48befab0cd43 ethernet enp1s0 Example_con_2 916e4f67-7145-3ffa-9f7b-e7cada8f6bf7 ethernet enp7s0 ...ipv4.dns-priorityパラメーターおよびipv6.dns-priorityパラメーターを設定します。たとえば、両方のパラメーターを10に設定するには、次のように実行します。# nmcli connection modify <connection_name> ipv4.dns-priority 10 ipv6.dns-priority 10- オプション: 他のコネクションに対しても 1 つ前の手順を繰り返します。
更新した接続を再度アクティブにします。
# nmcli connection up <connection_name>
検証
/etc/resolv.confファイルの内容を表示して、DNS サーバーの順序が正しいことを確認します。# cat /etc/resolv.conf
第23章 異なるドメインでの各種 DNS サーバーの使用
デフォルトでは、Red Hat Enterprise Linux (RHEL) は、すべての DNS リクエストを、/etc/resolv.conf ファイルで指定されている最初の DNS サーバーに送信します。このサーバーが応答しない場合、RHEL は動作するサーバーが見つかるまでこのファイル内の次のサーバーを試行します。ある DNS サーバーがすべてのドメインを解決できない環境では、管理者は、特定のドメインの DNS 要求を選択した DNS サーバーに送信するように RHEL を設定できます。
たとえば、サーバーを仮想プライベートネットワーク (VPN) に接続し、VPN 内のホストが example.com ドメインを使用するとします。この場合、次の方法で DNS クエリーを処理するように RHEL を設定できます。
-
example.comの DNS 要求のみを VPN ネットワーク内の DNS サーバーに送信します。 - 他のすべての要求は、デフォルトゲートウェイを使用して接続プロファイルで設定されている DNS サーバーに送信します。
23.1. NetworkManager で dnsmasq を使用して、特定のドメインの DNS リクエストを選択した DNS サーバーに送信する
dnsmasq のインスタンスを開始するように NetworkManager を設定できます。次に、この DNS キャッシュサーバーは、loopback デバイスのポート 53 をリッスンします。したがって、このサービスはローカルシステムからのみ到達でき、ネットワークからは到達できません。
この設定では、NetworkManager は nameserver 127.0.0.1 エントリーを /etc/resolv.conf ファイルに追加し、dnsmasq は DNS 要求を NetworkManager 接続プロファイルで指定された対応する DNS サーバーに動的にルーティングします。
前提条件
- システムに NetworkManager の接続が複数設定されている。
特定のドメインを解決する役割を担う接続に対して、DNS サーバーと検索ドメインが設定されている。
たとえば、VPN 接続で指定された DNS サーバーが
example.comドメインのクエリーを確実に解決できるようにするには、次の設定が必要です。-
example.comを解決できる DNS サーバー。DHCP サーバーによってこの情報を動的に提供することも、VPN 接続プロファイルでipv4.dnsおよびipv6.dnsパラメーターを設定することもできます。 -
example.comに設定された検索ドメイン。DHCP サーバーによってこの情報を動的に提供することも、VPN 接続プロファイルでipv4.dns-searchおよびipv6.dns-searchパラメーターを設定することもできます。
-
-
dnsmasqサービスが実行されていないか、localhostとは異なるインターフェイスでリッスンするように設定されています。
手順
dnsmasqパッケージをインストールします。# yum install dnsmasq/etc/NetworkManager/NetworkManager.confファイルを編集し、[main]セクションに以下のエントリーを設定します。dns=dnsmasqNetworkManagerサービスを再読み込みします。# systemctl reload NetworkManager
検証
NetworkManagerユニットのsystemdジャーナルで、サービスが別の DNS サーバーを使用しているドメインを検索します。# journalctl -xeu NetworkManager ... Jun 02 13:30:17 <client_hostname>_ dnsmasq[5298]: using nameserver 198.51.100.7#53 for domain example.com ...tcpdumpパケットスニファを使用して、DNS 要求の正しいルートを確認します。tcpdumpパッケージをインストールします。# yum install tcpdump1 つのターミナルで
tcpdumpを起動し、すべてのインターフェイスで DNS トラフィックを取得します。# tcpdump -i any port 53別のターミナルで、例外が存在するドメインと別のドメインのホスト名を解決します。次に例を示します。
# host -t A www.example.com # host -t A www.redhat.comtcpdump出力で、Red Hat Enterprise Linux がexample.comドメインの DNS クエリーのみを指定された DNS サーバーに、対応するインターフェイスを通じて送信していることを確認します。... 13:52:42.234533 IP server.43534 > 198.51.100.7.domain: 50121+ [1au] A? www.example.com. (33) ... 13:52:57.753235 IP server.40864 > 192.0.2.1.domain: 6906+ A? www.redhat.com. (33) ...Red Hat Enterprise Linux は、
www.example.comの DNS クエリーを198.51.100.7の DNS サーバーに送信し、www.redhat.comのクエリーを192.0.2.1に送信します。
トラブルシューティング
/etc/resolv.confファイルのnameserverエントリーが127.0.0.1を指していることを確認します。# cat /etc/resolv.conf nameserver 127.0.0.1エントリーがない場合は、
/etc/NetworkManager/NetworkManager.confファイルのdnsパラメーターを確認します。dnsmasqサービスがloopbackデバイスのポート53でリッスンしていることを確認します。# ss -tulpn | grep "127.0.0.1:53" udp UNCONN 0 0 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=7340,fd=18)) tcp LISTEN 0 32 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=7340,fd=19))サービスが
127.0.0.1:53をリッスンしていない場合は、NetworkManagerユニットのジャーナルエントリーを確認します。# journalctl -u NetworkManager
23.2. NetworkManager で systemd-resolved を使用して、特定のドメインの DNS 要求を選択した DNS サーバーに送信する
NetworkManager を設定して、systemd-resolved のインスタンスを開始することができます。次に、この DNS スタブリゾルバーは、IP アドレス 127.0.0.53 のポート 53 でリッスンします。したがって、このスタブリゾルバーはローカルシステムからのみ到達でき、ネットワークからは到達できません。
この設定では、NetworkManager は nameserver 127.0.0.53 エントリーを /etc/resolv.conf ファイルに追加し、systemd-resolved は、NetworkManager 接続プロファイルで指定された対応する DNS サーバーに DNS 要求を動的にルーティングします。
systemd-resolved サービスは、テクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) ではサポートされておらず、機能的に完全ではない可能性があるため、Red Hat では実稼働環境での使用を推奨していません。テクノロジープレビュー機能では、最新の製品機能をいち早く提供します。これにより、お客様は開発段階で機能をテストし、フィードバックを提供できます。
テクノロジープレビュー機能のサポート範囲は、Red Hat カスタマーポータルの テクノロジープレビュー機能のサポート範囲 を参照してください。
サポートされるソリューションは、Using dnsmasq in NetworkManager to send DNS requests for a specific domain to a selected DNS server を参照してください。
前提条件
- システムに NetworkManager の接続が複数設定されている。
特定のドメインを解決する役割を担う接続に対して、DNS サーバーと検索ドメインが設定されている。
たとえば、VPN 接続で指定された DNS サーバーが
example.comドメインのクエリーを確実に解決できるようにするには、次の設定が必要です。-
example.comを解決できる DNS サーバー。DHCP サーバーによってこの情報を動的に提供することも、VPN 接続プロファイルでipv4.dnsおよびipv6.dnsパラメーターを設定することもできます。 -
example.comに設定された検索ドメイン。DHCP サーバーによってこの情報を動的に提供することも、VPN 接続プロファイルでipv4.dns-searchおよびipv6.dns-searchパラメーターを設定することもできます。
-
手順
systemd-resolvedパッケージをインストールします。# dnf install systemd-resolvedsystemd-resolvedサービスを有効にして起動します。# systemctl --now enable systemd-resolved/etc/NetworkManager/NetworkManager.confファイルを編集し、[main]セクションに以下のエントリーを設定します。dns=systemd-resolvedNetworkManagerサービスを再読み込みします。# systemctl reload NetworkManager
検証
systemd-resolvedが使用する DNS サーバーと、サービスが別の DNS サーバーを使用するドメインを表示します。# resolvectl ... Link 2 (enp1s0) Current Scopes: DNS Protocols: +DefaultRoute ... Current DNS Server: 192.0.2.1 DNS Servers: 192.0.2.1 Link 3 (tun0) Current Scopes: DNS Protocols: -DefaultRoute ... Current DNS Server: 198.51.100.7 DNS Servers: 198.51.100.7 203.0.113.19 DNS Domain: example.comこの出力では、
systemd-resolvedがexample.comドメインに異なる DNS サーバーを使用していることを確認します。tcpdumpパケットスニファを使用して、DNS 要求の正しいルートを確認します。tcpdumpパッケージをインストールします。# yum install tcpdump1 つのターミナルで
tcpdumpを起動し、すべてのインターフェイスで DNS トラフィックを取得します。# tcpdump -i any port 53別のターミナルで、例外が存在するドメインと別のドメインのホスト名を解決します。次に例を示します。
# host -t A www.example.com # host -t A www.redhat.comtcpdump出力で、Red Hat Enterprise Linux がexample.comドメインの DNS クエリーのみを指定された DNS サーバーに、対応するインターフェイスを通じて送信していることを確認します。... 13:52:42.234533 IP server.43534 > 198.51.100.7.domain: 50121+ [1au] A? www.example.com. (33) ... 13:52:57.753235 IP server.40864 > 192.0.2.1.domain: 6906+ A? www.redhat.com. (33) ...Red Hat Enterprise Linux は、
www.example.comの DNS クエリーを198.51.100.7の DNS サーバーに送信し、www.redhat.comのクエリーを192.0.2.1に送信します。
トラブルシューティング
/etc/resolv.confファイルのnameserverエントリーが127.0.0.53を指していることを確認します。# cat /etc/resolv.conf nameserver 127.0.0.53エントリーがない場合は、
/etc/NetworkManager/NetworkManager.confファイルのdnsパラメーターを確認します。systemd-resolvedサービスがローカルの IP アドレス127.0.0.53の53ポートでリッスンしていることを確認します。# ss -tulpn | grep "127.0.0.53" udp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=1050,fd=12)) tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=1050,fd=13))サービスが
127.0.0.53:53をリッスンしない場合は、systemd-resolvedサービスが実行されているかどうかを確認します。
第24章 デフォルトのゲートウェイ設定の管理
デフォルトゲートウェイは、他のルートがパケットの宛先と一致する場合にネットワークパケットを転送するルーターです。ローカルネットワークでは、通常、デフォルトゲートウェイは、インターネットの近くの 1 ホップのホストです。
24.1. nmcli を使用して既存の接続にデフォルトゲートウェイを設定する
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、nmcli ユーティリティーを使用して、以前に作成した接続のデフォルトゲートウェイ設定を設定または更新することもできます。
前提条件
- デフォルトゲートウェイが設定されている接続で、静的 IP アドレスを少なくとも 1 つ設定している。
-
物理コンソールにログインしている場合は、十分な権限を有している。それ以外の場合は、
root権限が必要になります。
手順
デフォルトゲートウェイの IP アドレスを設定します。
IPv4 デフォルトゲートウェイを設定するには、次のように実行します。
# nmcli connection modify <connection_name> ipv4.gateway "<IPv4_gateway_address>"IPv6 デフォルトゲートウェイを設定するには、次のように実行します。
# nmcli connection modify <connection_name> ipv6.gateway "<IPv6_gateway_address>"ネットワーク接続を再起動して、変更を有効にします。
# nmcli connection up <connection_name>警告このネットワーク接続を現在使用しているすべての接続が、再起動時に一時的に中断されます。
検証
ルートがアクティブであることを確認します。
IPv4 デフォルトゲートウェイを表示するには、次のように実行します。
# ip -4 route default via 192.0.2.1 dev example proto static metric 100IPv6 デフォルトゲートウェイを表示するには、次のように実行します。
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.2. nmcli インタラクティブモードを使用して既存の接続にデフォルトゲートウェイを設定する
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、nmcli ユーティリティーのインタラクティブモードを使用して、以前に作成した接続のデフォルトゲートウェイ設定を設定または更新することもできます。
前提条件
- デフォルトゲートウェイが設定されている接続で、静的 IP アドレスを少なくとも 1 つ設定している。
-
物理コンソールにログインしている場合は、十分な権限を有している。それ以外の場合は、
root権限が必要になります。
手順
必要な接続に対して
nmcliインタラクティブモードを開きます。# nmcli connection edit <connection_name>デフォルトゲートウェイを設定します。
IPv4 デフォルトゲートウェイを設定するには、次のように実行します。
nmcli> set ipv4.gateway "<IPv4_gateway_address>"IPv6 デフォルトゲートウェイを設定するには、次のように実行します。
nmcli> set ipv6.gateway "<IPv6_gateway_address>"オプション: デフォルトゲートウェイが正しく設定されていることを確認します。
nmcli> print ... ipv4.gateway: <IPv4_gateway_address> ... ipv6.gateway: <IPv6_gateway_address> ...設定を保存します。
nmcli> save persistentネットワーク接続を再起動して、変更を有効にします。
nmcli> activate <connection_name>警告このネットワーク接続を現在使用しているすべての接続が、再起動時に一時的に中断されます。
nmcliインタラクティブモードを終了します。nmcli> quit
検証
ルートがアクティブであることを確認します。
IPv4 デフォルトゲートウェイを表示するには、次のように実行します。
# ip -4 route default via 192.0.2.1 dev example proto static metric 100IPv6 デフォルトゲートウェイを表示するには、次のように実行します。
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.3. nm-connection-editor を使用して既存の接続にデフォルトゲートウェイを設定する
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、nm-connection-editor アプリケーションを使用して、以前に作成した接続でデフォルトのゲートウェイを設定したり、更新したりすることもできます。
前提条件
- デフォルトゲートウェイが設定されている接続で、静的 IP アドレスを少なくとも 1 つ設定している。
手順
ターミナルを開き、
nm-connection-editorと入力します。# nm-connection-editor- 変更する接続を選択し、歯車のアイコンをクリックして、既存の接続を編集します。
IPv4 デフォルトゲートウェイを設定します。たとえば、その接続のデフォルトゲートウェイの IPv4 アドレスを
192.0.2.1に設定します。-
IPv4 Settingsタブを開きます。 そのゲートウェイのアドレスが含まれる IP アドレスの範囲の隣の
gatewayフィールドにアドレスを入力します。
-
IPv6 デフォルトゲートウェイを設定します。たとえば、接続のデフォルトゲートウェイの IPv6 アドレスを
2001:db8:1::1に設定するには、以下を行います。-
IPv6タブを開きます。 そのゲートウェイのアドレスが含まれる IP アドレスの範囲の隣の
gatewayフィールドにアドレスを入力します。
-
- をクリックします。
- をクリックします。
ネットワーク接続を再起動して、変更を有効にします。たとえば、コマンドラインで
example接続を再起動するには、次のコマンドを実行します。# nmcli connection up example警告このネットワーク接続を現在使用しているすべての接続が、再起動時に一時的に中断されます。
検証
ルートがアクティブであることを確認します。
IPv4 デフォルトゲートウェイを表示するには、次のコマンドを実行します。
# ip -4 route default via 192.0.2.1 dev example proto static metric 100IPv6 デフォルトゲートウェイを表示するには、次のコマンドを実行します。
# ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.4. control-center を使用して既存の接続にデフォルトゲートウェイを設定する
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、control-center アプリケーションを使用して、以前に作成した接続でデフォルトのゲートウェイを設定したり、更新したりできます。
前提条件
- デフォルトゲートウェイが設定されている接続で、静的 IP アドレスを少なくとも 1 つ設定している。
-
control-centerアプリケーションで、接続のネットワーク設定を開いている。
手順
IPv4 デフォルトゲートウェイを設定します。たとえば、その接続のデフォルトゲートウェイの IPv4 アドレスを
192.0.2.1に設定します。-
IPv4タブを開きます。 そのゲートウェイのアドレスが含まれる IP アドレスの範囲の隣の
gatewayフィールドにアドレスを入力します。
-
IPv6 デフォルトゲートウェイを設定します。たとえば、接続のデフォルトゲートウェイの IPv6 アドレスを
2001:db8:1::1に設定するには、以下を行います。-
IPv6タブを開きます。 そのゲートウェイのアドレスが含まれる IP アドレスの範囲の隣の
gatewayフィールドにアドレスを入力します。
-
- をクリックします。
Networkウィンドウに戻り、接続のボタンを に切り替えてから に戻して、接続を無効にして再度有効にし、変更を適用します。警告このネットワーク接続を現在使用しているすべての接続が、再起動時に一時的に中断されます。
検証
ルートがアクティブであることを確認します。
IPv4 デフォルトゲートウェイを表示するには、次のコマンドを実行します。
$ ip -4 route default via 192.0.2.1 dev example proto static metric 100IPv6 デフォルトゲートウェイを表示するには、次のコマンドを実行します。
$ ip -6 route default via 2001:db8:1::1 dev example proto static metric 100 pref medium
24.5. nmstatectl を使用して既存の接続にデフォルトゲートウェイを設定する
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、nmstatectl ユーティリティーを使用して、以前に作成した接続のデフォルトゲートウェイ設定を設定または更新することもできます。
nmstatectl ユーティリティーを使用して、Nmstate API を介してデフォルトゲートウェイを設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
前提条件
- デフォルトゲートウェイが設定されている接続で、静的 IP アドレスを少なくとも 1 つ設定している。
-
enp1s0インターフェイスが設定され、デフォルトゲートウェイの IP アドレスがこのインターフェイスの IP 設定のサブネット内にある。 -
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイル (例:
~/set-default-gateway.yml) を作成します。--- routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.1 next-hop-interface: enp1s0これらの設定では、
192.0.2.1をデフォルトゲートウェイとして定義します。デフォルトゲートウェイはenp1s0インターフェイス経由で到達可能です。設定をシステムに適用します。
# nmstatectl apply ~/set-default-gateway.yml
24.6. network RHEL システムロールを使用して既存の接続にデフォルトゲートウェイを設定する
パケットの宛先に、直接接続されたネットワーク経由でも、ホストに設定されたルート経由でも到達できない場合、ホストはネットワークパケットをデフォルトゲートウェイに転送します。ホストのデフォルトゲートウェイを設定するには、デフォルトゲートウェイと同じネットワークに接続されているインターフェイスの NetworkManager 接続プロファイルで、そのゲートウェイを設定します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、以前に作成した接続でデフォルトゲートウェイ設定を設定または更新することもできます。
network RHEL システムロールを使用して、既存接続プロファイル内の特定の値だけを更新することはできません。このロールは、接続プロファイルが Playbook の設定と正確に一致するようにします。同じ名前の接続プロファイルがすでに存在する場合、このロールは Playbook の設定を適用し、プロファイル内の他のすべての設定をデフォルトにリセットします。値がリセットされないようにするには、変更しない設定も含め、ネットワーク接続プロファイルの設定全体を Playbook に常に指定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: address: - 198.51.100.20/24 - 2001:db8:1::1/64 gateway4: 198.51.100.254 gateway6: 2001:db8:1::fffe dns: - 198.51.100.200 - 2001:db8:1::ffbb dns_search: - example.com state: upPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、アクティブなネットワーク設定を確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_default_ipv4": { ... "gateway": "198.51.100.254", "interface": "enp1s0", ... }, "ansible_default_ipv6": { ... "gateway": "2001:db8:1::fffe", "interface": "enp1s0", ... } ...
24.7. レガシーネットワークスクリプトの使用時に、既存の接続でデフォルトゲートウェイの設定
ほとんどの場合、管理者は接続を作成するときにデフォルトゲートウェイを設定します。ただし、従来のネットワークスクリプトを使用する際に、以前に作成した接続でデフォルトのゲートウェイを設定したり、更新したりすることもできます。
前提条件
-
NetworkManagerパッケージがインストールされていないか、NetworkManagerサービスが無効になります。 -
network-scriptsパッケージがインストールされている。
手順
/etc/sysconfig/network-scripts/ifcfg-enp1s0ファイルのGATEWAYパラメーターを192.0.2.1に設定します。GATEWAY=192.0.2.1/etc/sysconfig/network-scripts/route-enp0s1ファイルにデフォルトエントリーを追加します。default via 192.0.2.1ネットワークを再起動します。
# systemctl restart network
24.8. NetworkManager が複数のデフォルトゲートウェイを管理する方法
フォールバック上の理由で特定の状況では、ホストに複数のデフォルトゲートウェイを設定します。ただし、非同期ルーティングの問題を回避するために、同じプロトコルの各デフォルトゲートウェイには別のメトリック値が必要です。RHEL は、最も低いメトリックセットを持つデフォルトゲートウェイへの接続のみを使用することに注意してください。
以下のコマンドを使用して、接続の IPv4 ゲートウェイと IPv6 ゲートウェイの両方にメトリックを設定できます。
# nmcli connection modify <connection_name> ipv4.route-metric <value> ipv6.route-metric <value>ルーティングの問題を回避するために、複数の接続プロファイルで同じプロトコルに同じメトリック値を設定しないでください。
メトリック値なしでデフォルトのゲートウェイを設定すると、NetworkManager は、インターフェイスタイプに基づいてメトリック値を自動的に設定します。このため、NetworkManager は、アクティブな最初の接続に、このネットワークタイプのデフォルト値を割り当て、そのネットワークタイプがアクティベートされる順序で、同じタイプの他の接続にインクリメントした値を設定します。たとえば、デフォルトゲートウェイを持つ 2 つのイーサネット接続が存在する場合、NetworkManager は、ルートに 100 のメトリックを、最初にアクティブにしている接続のデフォルトゲートウェイに設定します。2 つ目の接続では、NetworkManager は 101 を設定します。
以下は、よく使用されるネットワークタイプと、そのデフォルトのメトリックの概要です。
| 接続タイプ | デフォルトのメトリック値 |
|---|---|
| VPN | 50 |
| イーサネット | 100 |
| MACsec | 125 |
| InfiniBand | 150 |
| Bond | 300 |
| team= | 350 |
| VLAN | 400 |
| ブリッジ | 425 |
| TUN | 450 |
| Wi-Fi | 600 |
| IP トンネル | 675 |
24.9. 特定のプロファイルでのデフォルトゲートウェイの指定を防ぐための NetworkManager の設定
NetworkManager が特定のプロファイルを使用してデフォルトゲートウェイを指定しないようにすることができます。デフォルトゲートウェイに接続されていない接続プロファイルには、以下の手順に従います。
前提条件
- デフォルトゲートウェイに接続されていない接続の NetworkManager 接続プロファイルが存在する。
手順
接続で動的 IP 設定を使用する場合は、NetworkManager が、対応する IP タイプのデフォルト接続としてこの接続を使用しないように設定します。つまり、NetworkManager がデフォルトのルートをこの接続に割り当てないようにします。
# nmcli connection modify <connection_name> ipv4.never-default yes ipv6.never-default yesipv4.never-defaultおよびipv6.never-defaultをyesに設定すると、対応するプロトコルのデフォルトのゲートウェイ IP アドレスが、接続プロファイルから削除されることに注意してください。接続をアクティベートします。
# nmcli connection up <connection_name>
検証
-
ip -4 routeコマンドおよびip -6 routeコマンドを使用して、RHEL が、IPv4 プロトコルおよび IPv6 プロトコルのデフォルトルートにネットワークインターフェイスを使用しないことを確認します。
24.10. 複数のデフォルトゲートウェイによる予期しないルーティング動作の修正
ホストに複数のデフォルトゲートウェイが必要となる状況は、Multipath TCP を使用する場合など、ごく限られています。多くの場合、ルーティングの動作や非同期ルーティングの問題を回避するために、1 つのデフォルトゲートウェイのみを設定します。
異なるインターネットプロバイダーにトラフィックをルーティングするには、複数のデフォルトゲートウェイの代わりにポリシーベースのルーティングを使用します。
前提条件
- ホストは NetworkManager を使用してネットワーク接続を管理します。これはデフォルトです。
- ホストには複数のネットワークインターフェイスがある。
- ホストには複数のデフォルトゲートウェイが設定されている。
手順
ルーティングテーブルを表示します。
IPv4 の場合は、次のコマンドを実行します。
# ip -4 route default via 192.0.2.1 dev enp1s0 proto dhcp metric 101 default via 198.51.100.1 dev enp7s0 proto dhcp metric 102 ...IPv6 の場合は、次のコマンドを実行します。
# ip -6 route default via 2001:db8:1::1 dev enp1s0 proto static ra 101 pref medium default via 2001:db8:2::1 dev enp7s0 proto static ra 102 pref medium ...
defaultで開始するエントリーはデフォルトのルートを示します。devの横に表示されるこれらのエントリーのインターフェイス名を書き留めます。以下のコマンドを使用して、前の手順で特定したインターフェイスを使用する NetworkManager 接続を表示します。
# nmcli -f GENERAL.CONNECTION,IP4.GATEWAY,IP6.GATEWAY device show enp1s0 GENERAL.CONNECTION: Corporate-LAN IP4.GATEWAY: 192.0.2.1 IP6.GATEWAY: 2001:db8:1::1 # nmcli -f GENERAL.CONNECTION,IP4.GATEWAY,IP6.GATEWAY device show enp7s0 GENERAL.CONNECTION: Internet-Provider IP4.GATEWAY: 198.51.100.1 IP6.GATEWAY: 2001:db8:2::1この例では、
Corporate-LANとInternet-Providerという名前のプロファイルにはデフォルトのゲートウェイが設定されています。これは、ローカルネットワークでは、通常、インターネット 1 ホップ近いホストがデフォルトゲートウェイであるため、この手順の残りの部分では、Corporate-LANのデフォルトゲートウェイが正しくないことを想定するためです。NetworkManager が、IPv4 および IPv6 接続のデフォルトルートとして
Corporate-LAN接続を使用しないように設定します。# nmcli connection modify Corporate-LAN ipv4.never-default yes ipv6.never-default yesipv4.never-defaultおよびipv6.never-defaultをyesに設定すると、対応するプロトコルのデフォルトのゲートウェイ IP アドレスが、接続プロファイルから削除されることに注意してください。Corporate-LAN接続をアクティブにします。# nmcli connection up Corporate-LAN
検証
IPv4 および IPv6 ルーティングテーブルを表示し、プロトコルごとに 1 つのデフォルトゲートウェイのみが利用可能であることを確認します。
IPv4 の場合は、次のコマンドを実行します。
# ip -4 route default via 198.51.100.1 dev enp7s0 proto dhcp metric 102 ...IPv6 の場合は、次のコマンドを実行します。
# ip -6 route default via 2001:db8:2::1 dev enp7s0 proto ra metric 102 pref medium ...
第25章 静的ルートの設定
ルーティングにより、相互に接続されたネットワーク間でトラフィックを送受信できるようになります。大規模な環境では、管理者は通常、ルーターが他のルーターについて動的に学習できるようにサービスを設定します。小規模な環境では、管理者は多くの場合、静的ルートを設定して、トラフィックが 1 つのネットワークから次のネットワークに確実に到達できるようにします。
次の条件がすべて当てはまる場合、複数のネットワーク間で機能する通信を実現するには、静的ルートが必要です。
- トラフィックは複数のネットワークを通過する必要があります。
- デフォルトゲートウェイを通過する排他的なトラフィックフローは十分ではありません。
静的ルートを必要とするネットワークの例 セクションで、静的ルートを設定しない場合のシナリオと、異なるネットワーク間でトラフィックがどのように流れるかを説明します。
25.1. 静的ルートを必要とするネットワークの例
すべての IP ネットワークが 1 つのルーターを介して直接接続されているわけではないため、この例では静的ルートが必要です。スタティックルートがないと、一部のネットワークは相互に通信できません。さらに、一部のネットワークからのトラフィックは一方向にしか流れません。
この例のネットワークトポロジーは人為的なものであり、静的ルーティングの概念を説明するためにのみ使用されています。これは、実稼働環境で推奨されるトポロジーではありません。
この例のすべてのネットワーク間で通信を機能させるには、Raleigh (198.51.100.0/24) への静的ルートを設定し、次のホップ Router 2 (203.0.113.10) を設定します。ネクストホップの IP アドレスは、データセンターネットワークのルーター 2 のものです (203.0.113.0/24)。
スタティックルートは次のように設定できます。
-
設定を簡素化するには、この静的ルートをルーター 1 だけに設定します。ただし、データセンター (
203.0.113.0/24) からのホストがトラフィックを Raleigh (198.51.100.0/24) に送信するため、常にルーター 1 を経由してルーター 2 に送信されるため、ルーター 1 のトラフィックが増加します。 -
より複雑な設定の場合、データセンター (
203.0.113.0/24) 内のすべてのホストでこの静的ルートを設定します。このサブネット内のすべてのホストは、Raleigh (198.51.100.0/24) に近いルーター 2 (203.0.113.10) にトラフィックを直接送信します。
どのネットワーク間でトラフィックが流れるかどうかの詳細は、図の下の説明を参照してください。

必要な静的経路が設定されていないときに、通信がうまくいく場合とうまくいかない場合を以下に示します。
ベルリンネットワークのホスト (
192.0.2.0/24):- 直接接続されているため、同じサブネット内の他のホストと通信できます。
-
Router 1 はベルリンネットワーク (
192.0.2.0/24) 内にあり、インターネットにつながるデフォルトゲートウェイがあるため、インターネットと通信できます。 -
ルーター 1 はベルリン (
192.0.2.0/24) とデータセンター (203.0.113.0/24) ネットワークの両方にインターフェイスを持っているため、データセンターネットワーク (203.0.113.0/24) と通信できます。 -
ローリーネットワーク (
198.51.100.0/24) と通信できません。これは、ルーター 1 がこのネットワークにインターフェイスを持たないためです。したがって、Router 1 はトラフィックを独自のデフォルトゲートウェイ (インターネット) に送信します。
データセンターネットワーク内のホスト (
203.0.113.0/24):- 直接接続されているため、同じサブネット内の他のホストと通信できます。
-
デフォルトゲートウェイがルーター 1 に設定されているため、インターネットと通信できます。ルーター 1 には、データセンター (
203.0.113.0/24) とインターネットの両方のネットワークにインターフェイスがあります。 -
デフォルトゲートウェイがルーター 1 に設定されているため、ベルリンネットワーク (
192.0.2.0/24) と通信でき、ルーター 1 にはデータセンター (203.0.113.0/24) とベルリン (192.0.2.0/24) の両方にインターフェイスがあります。) ネットワーク。 -
Raleigh ネットワーク (
198.51.100.0/24) と通信できません。これは、データセンターネットワークがこのネットワークにインターフェイスを持たないためです。したがって、データセンター (203.0.113.0/24) 内のホストは、トラフィックをデフォルトゲートウェイ (ルーター 1) に送信します。ルーター 1 も Raleigh ネットワーク (198.51.100.0/24) にインターフェイスを持たないため、ルーター 1 はこのトラフィックを独自のデフォルトゲートウェイ (インターネット) に送信します。
Raleigh ネットワーク内のホスト (
198.51.100.0/24):- 直接接続されているため、同じサブネット内の他のホストと通信できます。
-
インターネット上のホストと通信できません。デフォルトゲートウェイの設定により、ルーター 2 はトラフィックをルーター 1 に送信します。ルーター 1 の実際の動作は、リバースパスフィルター (
rp_filter) システム制御 (sysctl) の設定によって異なります。RHEL のデフォルトでは、Router 1 は送信トラフィックをインターネットにルーティングする代わりにドロップします。ただし、設定された動作に関係なく、スタティックルートがないと通信できません。 -
データセンターネットワーク (
203.0.113.0/24) と通信できません。デフォルトゲートウェイの設定により、発信トラフィックはルーター 2 を経由して宛先に到達します。ただし、データセンターネットワーク (203.0.113.0/24) 内のホストがデフォルトゲートウェイ (ルーター 1) に応答を送信するため、パケットへの応答は送信者に届きません。次に、Router 1 がトラフィックをインターネットに送信します。 -
ベルリンのネットワーク (
192.0.2.0/24) と通信できません。デフォルトゲートウェイの設定により、ルーター 2 はトラフィックをルーター 1 に送信します。ルーター 1 の実際の動作は、sysctl設定のrp_filterによって異なります。RHEL のデフォルトでは、Router 1 は発信トラフィックを Berlin ネットワーク (192.0.2.0/24) に送信する代わりにドロップします。ただし、設定された動作に関係なく、スタティックルートがないと通信できません。
静的ルートの設定に加え、両方のルーターで IP 転送を有効にする必要があります。
25.2. nmcli ユーティリティーを使用して静的ルートを設定する方法
静的ルートを設定するには、次の構文で nmcli ユーティリティーを使用します。
$ nmcli connection modify connection_name ipv4.routes "ip[/prefix] [next_hop] [metric] [attribute=value] [attribute=value] ..."このコマンドは、次のルート属性に対応します。
-
cwnd=n: パケット数で定義された輻輳ウィンドウ (CWND) サイズを設定します。 -
lock-cwnd=true|false: カーネルが CWND 値を更新できるかどうかを定義します。 -
lock-mtu=true|false: カーネルが MTU をパス MTU ディスカバリーに更新できるかどうかを定義します。 -
lock-window=true|false: カーネルが TCP パケットの最大ウィンドウサイズを更新できるかどうかを定義します。 -
mtu=<mtu_value>: 宛先へのパスに沿って使用する最大転送単位 (MTU) を設定します。 -
onlink=true|false: ネクストホップがどのインターフェイス接頭辞とも一致しない場合でも、このリンクに直接接続されるかどうかを定義します。 -
scope=<scope>: IPv4 ルートの場合、この属性は、ルート接頭辞によってカバーされる宛先の範囲を設定します。値を整数 (0〜255) として設定します。 -
src=<source_address>: ルート接頭辞の対象となる宛先にトラフィックを送信するときに優先する送信元アドレスを設定します。 -
table=<table_id>: ルートを追加するテーブルの ID を設定します。このパラメーターを省略すると、NetworkManager はmainテーブルを使用します。 -
tos=<type_of_service_key>: Type of Service (TOS) キーを設定します。値を整数 (0〜255) として設定します。 -
type=<route_type>: ルートタイプを設定します。NetworkManager は、unicast、local、blackhole、unreachable、prohibit、およびthrowルートタイプをサポートします。デフォルトはunicastです。 -
window=<window_size>: これらの宛先にアドバタイズする TCP の最大ウィンドウサイズをバイト単位で設定します。
先頭に + 記号を付けずに ipv4.routes オプションを使用すると、nmcli はこのパラメーターの現在の設定をすべてオーバーライドします。
追加のルートを作成するには、次のように実行します。
$ nmcli connection modify connection_name +ipv4.routes "<route>"特定のルートを削除するには、次のように実行します。
$ nmcli connection modify connection_name -ipv4.routes "<route>"
25.3. nmcli を使用した静的ルートの設定
nmcli connection modify コマンドを使用して、既存の NetworkManager 接続プロファイルに静的ルートを追加できます。
以下の手順では、次のルートを設定します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。IP アドレス192.0.2.10を持つ対応するゲートウェイは、LAN接続プロファイルを通じて到達可能です。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。IP アドレス2001:db8:1::10を持つ対応するゲートウェイは、LAN接続プロファイルを通じて到達可能です。
前提条件
-
LAN接続プロファイルが存在し、このホストがゲートウェイと同じ IP サブネットに存在するように設定されている。
手順
LAN接続プロファイルに静的 IPv4 ルートを追加します。# nmcli connection modify LAN +ipv4.routes "198.51.100.0/24 192.0.2.10"一度に複数のルートを設定するには、個々のルートをコンマで区切ってコマンドに渡します。
# nmcli connection modify <connection_profile> +ipv4.routes "<remote_network_1>/<subnet_mask_1> <gateway_1>, <remote_network_n>/<subnet_mask_n> <gateway_n>, ..."LAN接続プロファイルに静的 IPv6 ルートを追加します。# nmcli connection modify LAN +ipv6.routes "2001:db8:2::/64 2001:db8:1::10"接続を再度有効にします。
# nmcli connection up LAN
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.4. nmtui を使用した静的ルートの設定
nmtui アプリケーションは、NetworkManager 用のテキストベースのユーザーインターフェイスを提供します。nmtui を使用して、グラフィカルインターフェイスを使用せずにホスト上で静的ルートを設定できます。
たとえば、以下の手順では 198.51.100.1 で実行しているゲートウェイを使用する 192.0.2.0/24 ネットワークに経路を追加します。これは、既存の接続プロファイルから到達可能です。
nmtui で以下を行います。
- カーソルキーを使用してナビゲートします。
- ボタンを選択して Enter を押します。
- Space を使用してチェックボックスをオンまたはオフにします。
- 前の画面に戻るには、ESC を使用します。
前提条件
- ネットワークが設定されている。
- 静的ルートのゲートウェイが、インターフェイスで直接到達できる。
- 物理コンソールにログインしている場合は、十分な権限を有している。それ以外の場合は、コマンドに root 権限が必要になります。
手順
nmtuiを開始します。# nmtui- Edit a connection 選択し、Enter を押します。
- 宛先ネットワークへのネクストホップに到達できる接続プロファイルを選択し、Enter を押します。
- IPv4 ルートまたは IPv6 ルートに応じて、プロトコルの設定エリアの横にある Show ボタンを押します。
Routing の横にある Edit ボタンを押します。これにより、静的ルートを設定する新しいウィンドウが開きます。
Add ボタンを押して、次のように実行します。
- Classless Inter-Domain Routing (CIDR) 形式の接頭辞を含む宛先ネットワーク
- ネクストホップの IP アドレス
- 同じネットワークに複数のルートを追加し、効率によってルートに優先順位を付けたい場合のメトリック値
- 追加するルートごとに前の手順を繰り返し、この接続プロファイルを介して到達できます。
OK ボタンを押して、接続設定のウィンドウに戻ります。
図25.1 メトリックのない静的ルートの例
-
OK ボタンを押して
nmtuiメインメニューに戻ります。 - Activate a connection を選択し、Enter を押します。
編集した接続プロファイルを選択し、Enter キーを 2 回押して非アクティブ化し、再度アクティブ化します。
重要再アクティブ化する接続プロファイルを使用する SSH などのリモート接続で
nmtuiを実行する場合は、この手順をスキップしてください。この場合は、nmtuiで非アクティブ化すると、接続が切断されるため、再度アクティブ化することはできません。この問題を回避するには、上記のシナリオでnmcli connection <connection_profile> upコマンドを使用して接続を再アクティブ化します。- Back ボタンを押してメインメニューに戻ります。
-
Quit を選択し、Enter キーを押して
nmtuiアプリケーションを閉じます。
検証
ルートがアクティブであることを確認します。
$ ip route ... 192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
25.5. control-center を使用した静的ルートの設定
GNOME で control-center を使用して、ネットワーク接続の設定に静的ルートを追加します。
以下の手順では、次のルートを設定します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。対応するゲートウェイの IP アドレスは192.0.2.10です。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。対応するゲートウェイの IP アドレスは2001:db8:1::10です。
前提条件
- ネットワークが設定されている。
- このホストは、ゲートウェイと同じ IP サブネットにあります。
-
control-centerアプリケーションで接続のネットワーク設定が開いている。nm-connection-editor を使用したイーサネット接続の設定 を参照してください。
手順
IPv4タブで:-
オプション: 必要に応じて、
IPv4タブのRoutesセクションの ボタンをクリックして自動ルートを無効にし、静的ルートのみを使用します。自動ルートが有効になっている場合は、Red Hat Enterprise Linux が静的ルートと、DHCP サーバーから受け取ったルートを使用します。 IPv4 ルートのアドレス、ネットマスク、ゲートウェイ、およびオプションでメトリック値を入力します。

-
オプション: 必要に応じて、
IPv6タブで:-
オプション:
IPv4タブのRoutesセクションの ボタンをクリックして自動ルートを無効にし、静的ルートのみを使用します。 IPv6 ルートのアドレス、ネットマスク、ゲートウェイ、およびオプションでメトリック値を入力します。

-
オプション:
- をクリックします。
Networkウィンドウに戻り、接続のボタンを に切り替えてから に戻して、接続を無効にして再度有効にし、変更を適用します。警告接続を再起動すると、そのインターフェイスの接続が一時的に中断します。
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.6. nm-connection-editor を使用した静的ルートの設定
nm-connection-editor アプリケーションを使用して、ネットワーク接続の設定に静的ルートを追加できます。
以下の手順では、次のルートを設定します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。IP アドレス192.0.2.10を持つ対応するゲートウェイは、exampleの接続を介して到達可能です。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。IP アドレス2001:db8:1::10を持つ対応するゲートウェイは、exampleの接続を介して到達可能です。
前提条件
- ネットワークが設定されている。
- このホストは、ゲートウェイと同じ IP サブネットにあります。
手順
ターミナルを開き、
nm-connection-editorと入力します。$ nm-connection-editor-
example接続プロファイルを選択し、歯車アイコンをクリックして、既存の接続を変更します。 IPv4 Settingsタブで、以下を行います。- ボタンをクリックします。
ボタンをクリックして、アドレス、ネットマスク、ゲートウェイを入力します。必要に応じてメトリック値を入力します。
- をクリックします。
IPv6 Settingsタブで、以下を行います。- ボタンをクリックします。
ボタンをクリックして、アドレス、ネットマスク、ゲートウェイを入力します。必要に応じてメトリック値を入力します。
- をクリックします。
- をクリックします。
ネットワーク接続を再起動して、変更を有効にします。たとえば、コマンドラインで
example接続を再起動するには、次のコマンドを実行します。# nmcli connection up example
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.7. nmcli インタラクティブモードを使用した静的ルートの設定
nmcli ユーティリティーのインタラクティブモードを使用して、ネットワーク接続の設定に静的ルートを追加できます。
以下の手順では、次のルートを設定します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。IP アドレス192.0.2.10を持つ対応するゲートウェイは、exampleの接続を介して到達可能です。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。IP アドレス2001:db8:1::10を持つ対応するゲートウェイは、exampleの接続を介して到達可能です。
前提条件
-
exampleの接続プロファイルが存在し、このホストがゲートウェイと同じ IP サブネットになるように設定されています。
手順
example接続のnmcliインタラクティブモードを開きます。# nmcli connection edit example静的 IPv4 ルートを追加します。
nmcli> set ipv4.routes 198.51.100.0/24 192.0.2.10静的 IPv6 ルートを追加します。
nmcli> set ipv6.routes 2001:db8:2::/64 2001:db8:1::10オプション: ルートが設定に正しく追加されたことを確認します。
nmcli> print ... ipv4.routes: { ip = 198.51.100.0/24, nh = 192.0.2.10 } ... ipv6.routes: { ip = 2001:db8:2::/64, nh = 2001:db8:1::10 } ...ip属性には、転送するネットワークと、ゲートウェイのnh属性 (次のホップ) が表示されます。設定を保存します。
nmcli> save persistentネットワーク接続が再起動します。
nmcli> activate examplenmcliインタラクティブモードを終了します。nmcli> quit
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.8. nmstatectl を使用した静的ルートの設定
nmstatectl ユーティリティーを使用して、Nmstate API を介して静的ルートを設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
前提条件
-
enp1s0ネットワークインターフェイスが設定され、ゲートウェイと同じ IP サブネット内にあります。 -
nmstateパッケージがインストールされている。
手順
以下の内容を含む YAML ファイルを作成します (例:
~/add-static-route-to-enp1s0.yml)。--- routes: config: - destination: 198.51.100.0/24 next-hop-address: 192.0.2.10 next-hop-interface: enp1s0 - destination: 2001:db8:2::/64 next-hop-address: 2001:db8:1::10 next-hop-interface: enp1s0これらの設定では、次の静的ルートを定義します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。IP アドレス192.0.2.10の対応するゲートウェイは、enp1s0インターフェイスを介して到達できます。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。IP アドレス2001:db8:1::10の対応するゲートウェイは、enp1s0インターフェイスを介して到達できます。
-
リモート
設定をシステムに適用します。
# nmstatectl apply ~/add-static-route-to-enp1s0.yml
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
25.9. network RHEL システムロールを使用した静的ルートの設定
静的ルートを使用すると、デフォルトゲートウェイ経由では到達できない宛先にトラフィックを送信できるようになります。静的ルートは、ネクストホップと同じネットワークに接続されているインターフェイスの NetworkManager 接続プロファイルで設定します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して、既存接続プロファイル内の特定の値だけを更新することはできません。このロールは、接続プロファイルが Playbook の設定と正確に一致するようにします。同じ名前の接続プロファイルがすでに存在する場合、このロールは Playbook の設定を適用し、プロファイル内の他のすべての設定をデフォルトにリセットします。値がリセットされないようにするには、変更しない設定も含め、ネットワーク接続プロファイルの設定全体を Playbook に常に指定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with static IP address settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp7s0 type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com route: - network: 198.51.100.0 prefix: 24 gateway: 192.0.2.10 - network: '2001:db8:2::' prefix: 64 gateway: 2001:db8:1::10 state: upPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
IPv4 ルートを表示します。
# ansible managed-node-01.example.com -m command -a 'ip -4 route' managed-node-01.example.com | CHANGED | rc=0 >> ... 198.51.100.0/24 via 192.0.2.10 dev enp7s0IPv6 ルートを表示します。
# ansible managed-node-01.example.com -m command -a 'ip -6 route' managed-node-01.example.com | CHANGED | rc=0 >> ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp7s0 metric 1024 pref medium
25.10. レガシーネットワークスクリプトの使用時に key-value format に静的ルート設定ファイルを作成
従来のネットワークスクリプトは、キー値形式での静的ルートの設定をサポートしています。
以下の手順では、リモート 198.51.100.0/24 ネットワークへの IPv4 経路を設定します。IP アドレス 192.0.2.10 の対応するゲートウェイは、enp1s0 インターフェイスを介して到達できます。
従来のネットワークスクリプトは、静的 IPv4 ルートでのみ key-value format に対応します。IPv6 ルートの場合は、ip-command format を使用します。Creating static routes configuration files in ip-command format when using the legacy network scripts を参照してください。
前提条件
- 静的ルートのゲートウェイが、インターフェイスで直接到達できる。
-
NetworkManagerパッケージがインストールされていないか、NetworkManagerサービスが無効になります。 -
network-scriptsパッケージがインストールされている。 -
ネットワークサービスが有効になっています。
手順
静的 IPv4 ルートを
/etc/sysconfig/network-scripts/route-enp0s1ファイルに追加します。ADDRESS0=198.51.100.0 NETMASK0=255.255.255.0 GATEWAY0=192.0.2.10-
ADDRESS0変数は、最初のルーティングエントリーのネットワークを定義します。 -
NETMASK0変数は、最初のルーティングエントリーのネットマスクを定義します。 GATEWAY0変数は、最初のルーティングエントリーのリモートネットワークまたはホストへのゲートウェイの IP アドレスを定義します。複数の静的ルートを追加する場合は、変数名の数を増やします。各ルートの変数は順番に番号付けされる必要があることに注意してください。たとえば、
ADDRESS0、ADDRESS1、ADDRESS3などです。
-
ネットワークを再起動します。
# systemctl restart network
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0
トラブルシューティング
ネットワークユニットのジャーナルエントリーを表示します。# journalctl -u network考えられるエラーメッセージとその原因は次のとおりです。
-
Error: Nexthop has invalid gateway:route-enp1s0ファイルで、このルーターと同じサブネットにない IPv4 ゲートウェイアドレスを指定しました。 -
RTNETLINK answers: No route to host: このルーターと同じサブネットにない IPv6 ゲートウェイアドレスをroute6-enp1s0ファイルに指定しました。 -
Error: Invalid prefix for given prefix length: ネットワークアドレスではなく、リモートネットワーク内の IP アドレスを使用して、route-enp1s0ファイルでリモートネットワークを指定しました。
-
25.11. 従来のネットワークスクリプトの使用時に、ip-command format で静的ルート設定ファイルを作成
従来のネットワークスクリプトは、静的ルートの設定をサポートしています。
以下の手順では、以下の経路を設定します。
-
リモート
198.51.100.0/24ネットワークへの IPv4 ルート。IP アドレス192.0.2.10の対応するゲートウェイは、enp1s0インターフェイスを介して到達できます。 -
リモート
2001:db8:2::/64ネットワークへの IPv6 ルート。IP アドレス2001:db8:1::10の対応するゲートウェイは、enp1s0インターフェイスを介して到達できます。
ゲートウェイ (ネクストホップ) の IP アドレスは、静的ルートを設定するホストと同じ IP サブネット内にある必要があります。
この手順の例では、ip コマンド形式の設定エントリーを使用しています。
前提条件
- 静的ルートのゲートウェイが、インターフェイスで直接到達できる。
-
NetworkManagerパッケージがインストールされていないか、NetworkManagerサービスが無効になります。 -
network-scriptsパッケージがインストールされている。 -
ネットワークサービスが有効になっています。
手順
静的 IPv4 ルートを
/etc/sysconfig/network-scripts/route-enp1s0ファイルに追加します。198.51.100.0/24 via 192.0.2.10 dev enp1s0198.51.100.0など、常にリモートネットワークのネットワークアドレスを指定します。198.51.100.1などのリモートネットワーク内に IP アドレスを設定すると、ネットワークスクリプトがこのルートを追加できなくなります。静的 IPv6 ルートを
/etc/sysconfig/network-scripts/route6-enp1s0ファイルに追加します。2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0networkサービスを再起動します。# systemctl restart network
検証
IPv4 ルートを表示します。
# ip -4 route ... 198.51.100.0/24 via 192.0.2.10 dev enp1s0IPv6 ルートを表示します。
# ip -6 route ... 2001:db8:2::/64 via 2001:db8:1::10 dev enp1s0 metric 1024 pref medium
トラブルシューティング
ネットワークユニットのジャーナルエントリーを表示します。# journalctl -u network考えられるエラーメッセージとその原因は次のとおりです。
-
Error: Nexthop has invalid gateway:route-enp1s0ファイルで、このルーターと同じサブネットにない IPv4 ゲートウェイアドレスを指定しました。 -
RTNETLINK answers: No route to host: このルーターと同じサブネットにない IPv6 ゲートウェイアドレスをroute6-enp1s0ファイルに指定しました。 -
Error: Invalid prefix for given prefix length: ネットワークアドレスではなく、リモートネットワーク内の IP アドレスを使用して、route-enp1s0ファイルでリモートネットワークを指定しました。
-
第26章 代替ルートを定義するポリシーベースのルーティングの設定
デフォルトでは、RHEL のカーネルは、ルーティングテーブルを使用して宛先アドレスに基づいてネットワークパケットを転送する場所を決定します。ポリシーベースのルーティングにより、複雑なルーティングシナリオを設定できます。たとえば、送信元アドレス、パケットメタデータ、プロトコルなどのさまざまな基準に基づいてパケットをルーティングできます。
26.1. nmcli を使用して、特定のサブネットから別のデフォルトゲートウェイにトラフィックをルーティングする
ポリシーベースのルーティングを使用して、特定のサブネットからのトラフィックに対して別のデフォルトゲートウェイを設定できます。たとえば、RHEL をルーターとして設定し、デフォルトルートを使用してすべてのトラフィックをインターネットプロバイダー A にデフォルトでルーティングできます。ただし、内部ワークステーションサブネットから受信したトラフィックはプロバイダー B にルーティングされます。
この手順では、次のネットワークトポロジーを想定しています。
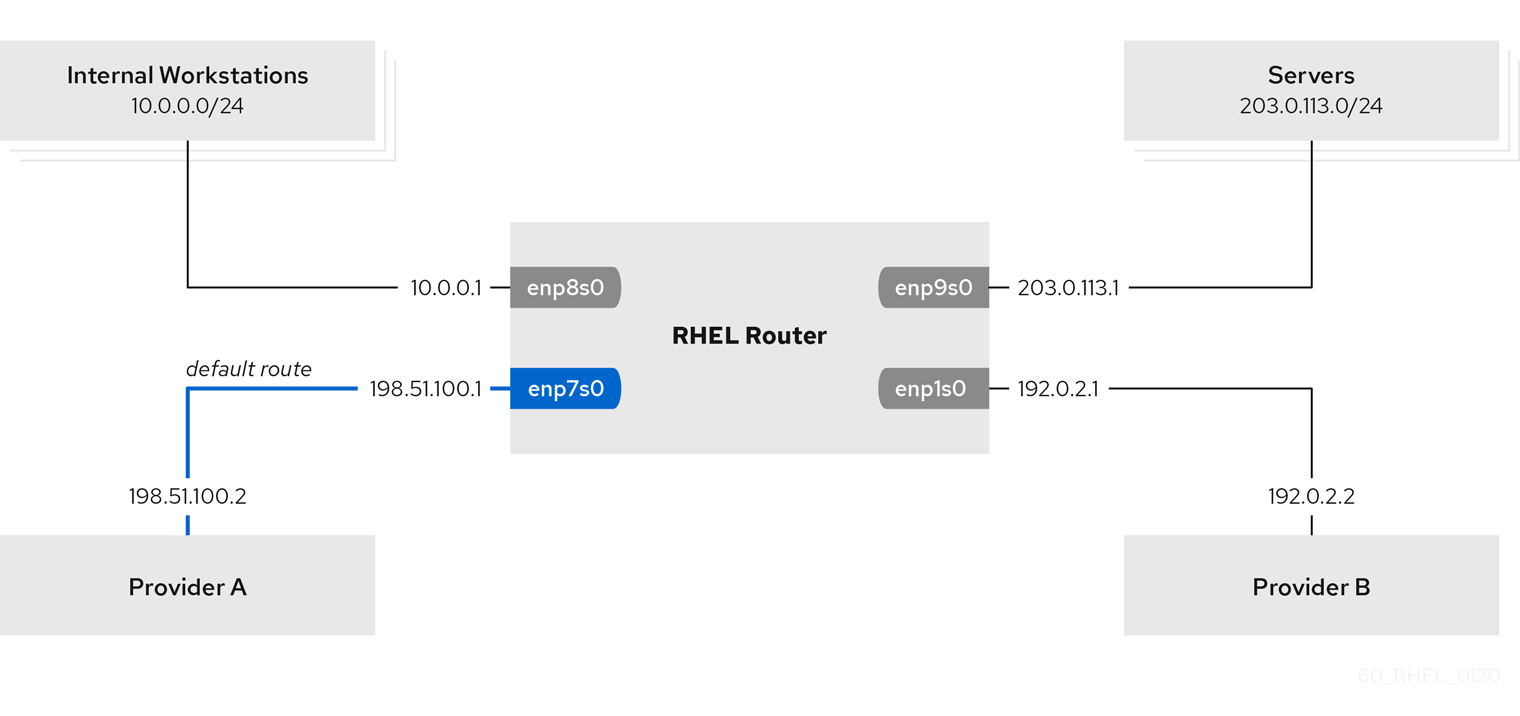
前提条件
-
システムは、
NetworkManagerを使用して、ネットワークを設定します (これがデフォルトです)。 この手順で設定する RHEL ルーターには、4 つのネットワークインターフェイスがあります。
-
enp7s0インターフェイスはプロバイダー A のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は198.51.100.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp1s0インターフェイスはプロバイダー B のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は192.0.2.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp8s0インターフェイスは、内部ワークステーションで10.0.0.0/24サブネットに接続されています。 -
enp9s0インターフェイスは、会社のサーバーで203.0.113.0/24サブネットに接続されています。
-
-
内部ワークステーションのサブネット内のホストは、デフォルトゲートウェイとして
10.0.0.1を使用します。この手順では、この IP アドレスをルーターのenp8s0ネットワークインターフェイスに割り当てます。 -
サーバーサブネット内のホストは、デフォルトゲートウェイとして
203.0.113.1を使用します。この手順では、この IP アドレスをルーターのenp9s0ネットワークインターフェイスに割り当てます。 -
デフォルトでは、
firewalldサービスは有効でアクティブになっています。
手順
プロバイダー A へのネットワークインターフェイスを設定します。
# nmcli connection add type ethernet con-name Provider-A ifname enp7s0 ipv4.method manual ipv4.addresses 198.51.100.1/30 ipv4.gateway 198.51.100.2 ipv4.dns 198.51.100.200 connection.zone externalnmcli connection addコマンドでは、NetworkManager 接続プロファイルが作成されます。このコマンドでは次のオプションを使用します。-
type ethernet: 接続タイプがイーサネットであることを定義します。 -
con-name <connection_name>: プロファイルの名前を設定します。混乱を避けるために、わかりやすい名前を使用してください。 -
ifname <network_device>: ネットワークインターフェイスを設定します。 -
ipv4.method manual: 静的 IP アドレスを設定できるようにします。 -
ipv4.addresses <IP_address>/<subnet_mask>: IPv4 アドレスとサブネットマスクを設定します。 -
ipv4.gateway <IP_address>: デフォルトゲートウェイアドレスを設定します。 -
ipv4.dns <IP_of_DNS_server>: DNS サーバーの IPv4 アドレスを設定します。 -
connection.zone <firewalld_zone>: 定義されたfirewalldゾーンにネットワークインターフェイスを割り当てます。firewalldは、外部ゾーンに割り当てられたマスカレードインターフェイスを自動的に有効にすることに注意してください。
-
プロバイダー B へのネットワークインターフェイスを設定します。
# nmcli connection add type ethernet con-name Provider-B ifname enp1s0 ipv4.method manual ipv4.addresses 192.0.2.1/30 ipv4.routes "0.0.0.0/0 192.0.2.2 table=5000" connection.zone externalこのコマンドは、デフォルトゲートウェイを設定する
ipv4.gatewayの代わりに、ipv4.routesパラメーターを使用します。これは、この接続のデフォルトゲートウェイを、デフォルトのルーティングテーブル (5000) に割り当てるために必要です。NetworkManager は、接続がアクティブになると、この新しいルーティングテーブルを自動的に作成します。内部ワークステーションサブネットへのネットワークインターフェイスを設定します。
# nmcli connection add type ethernet con-name Internal-Workstations ifname enp8s0 ipv4.method manual ipv4.addresses 10.0.0.1/24 ipv4.routes "10.0.0.0/24 table=5000" ipv4.routing-rules "priority 5 from 10.0.0.0/24 table 5000" connection.zone trustedこのコマンドは、
ipv4.routesパラメーターを使用して、ID が5000のルーティングテーブルに静的ルートを追加します。10.0.0.0/24サブネットのこの静的ルートは、ローカルネットワークインターフェイスの IP を使用してプロバイダー B (192.0.2.1) を次のホップとして使用します。また、このコマンドでは
ipv4.routing-rulesパラメーターを使用して、優先度5のルーティングルールを追加します。このルーティングルールは、トラフィックを10.0.0.0/24サブネットからテーブル5000へルーティングします。値が小さいほど優先度が高くなります。ipv4.routing-rulesパラメーターの構文はip rule addコマンドと同じですが、ipv4.routing-rulesは常に優先度を指定する必要があります。サーバーサブネットへのネットワークインターフェイスを設定します。
# nmcli connection add type ethernet con-name Servers ifname enp9s0 ipv4.method manual ipv4.addresses 203.0.113.1/24 connection.zone trusted
検証
内部ワークステーションサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...コマンドの出力には、ルーターがプロバイダー B のネットワークである
192.0.2.1経由でパケットを送信することが表示されます。
サーバーのサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...コマンドの出力には、ルーターがプロバイダー A のネットワークである
198.51.100.2経由でパケットを送信することが表示されます。
トラブルシューティングの手順
RHEL ルーターで以下を行います。
ルールのリストを表示します。
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultデフォルトでは、RHEL には、
localテーブル、mainテーブル、およびdefaultテーブルのルールが含まれます。テーブル
5000のルートを表示します。# ip route list table 5000 0.0.0.0/0 via 192.0.2.2 dev enp1s0 proto static metric 100 10.0.0.0/24 dev enp8s0 proto static scope link src 192.0.2.1 metric 102インターフェイスとファイアウォールゾーンを表示します。
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 trusted interfaces: enp8s0 enp9s0externalゾーンでマスカレードが有効になっていることを確認します。# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
26.2. network RHEL システムロールを使用して、特定のサブネットから別のデフォルトゲートウェイにトラフィックをルーティングする
ポリシーベースのルーティングを使用して、特定のサブネットからのトラフィックに対して別のデフォルトゲートウェイを設定できます。たとえば、RHEL をルーターとして設定し、デフォルトルートを使用してすべてのトラフィックをインターネットプロバイダー A にデフォルトでルーティングできます。一方、内部ワークステーションのサブネットから受信したトラフィックは、プロバイダー B にルーティングできます。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して、ルーティングテーブルやルールを含む接続プロファイルを設定できます。
この手順では、次のネットワークトポロジーを想定しています。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 -
管理対象ノードは、NetworkManager および
firewalldサービスを使用します。 設定する管理対象ノードには、次の 4 つのネットワークインターフェイスがあります。
-
enp7s0インターフェイスはプロバイダー A のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は198.51.100.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp1s0インターフェイスはプロバイダー B のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は192.0.2.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp8s0インターフェイスは、内部ワークステーションで10.0.0.0/24サブネットに接続されています。 -
enp9s0インターフェイスは、会社のサーバーで203.0.113.0/24サブネットに接続されています。
-
-
内部ワークステーションのサブネット内のホストは、デフォルトゲートウェイとして
10.0.0.1を使用します。この手順では、この IP アドレスをルーターのenp8s0ネットワークインターフェイスに割り当てます。 -
サーバーサブネット内のホストは、デフォルトゲートウェイとして
203.0.113.1を使用します。この手順では、この IP アドレスをルーターのenp9s0ネットワークインターフェイスに割り当てます。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring policy-based routing hosts: managed-node-01.example.com tasks: - name: Routing traffic from a specific subnet to a different default gateway ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: Provider-A interface_name: enp7s0 type: ethernet autoconnect: True ip: address: - 198.51.100.1/30 gateway4: 198.51.100.2 dns: - 198.51.100.200 state: up zone: external - name: Provider-B interface_name: enp1s0 type: ethernet autoconnect: True ip: address: - 192.0.2.1/30 route: - network: 0.0.0.0 prefix: 0 gateway: 192.0.2.2 table: 5000 state: up zone: external - name: Internal-Workstations interface_name: enp8s0 type: ethernet autoconnect: True ip: address: - 10.0.0.1/24 route: - network: 10.0.0.0 prefix: 24 table: 5000 routing_rule: - priority: 5 from: 10.0.0.0/24 table: 5000 state: up zone: trusted - name: Servers interface_name: enp9s0 type: ethernet autoconnect: True ip: address: - 203.0.113.1/24 state: up zone: trustedサンプル Playbook で指定されている設定は次のとおりです。
table: <value>-
table変数と同じリストエントリーのルートを、指定のルーティングテーブルに割り当てます。 routing_rule: <list>- 指定のルーティングルールの優先度と、接続プロファイルからルールの割り当て先のルーティングテーブルを定義します。
zone: <zone_name>-
接続プロファイルから指定の
firewalldゾーンにネットワークインターフェイスを割り当てます。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
内部ワークステーションサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...コマンドの出力には、ルーターがプロバイダー B のネットワークである
192.0.2.1経由でパケットを送信することが表示されます。
サーバーのサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...コマンドの出力には、ルーターがプロバイダー A のネットワークである
198.51.100.2経由でパケットを送信することが表示されます。
RHEL システムロールを使用して設定した RHEL ルーターで、次の手順を実行します。
ルールのリストを表示します。
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultデフォルトでは、RHEL には、
localテーブル、mainテーブル、およびdefaultテーブルのルールが含まれます。テーブル
5000のルートを表示します。# ip route list table 5000 0.0.0.0/0 via 192.0.2.2 dev enp1s0 proto static metric 100 10.0.0.0/24 dev enp8s0 proto static scope link src 192.0.2.1 metric 102インターフェイスとファイアウォールゾーンを表示します。
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 trusted interfaces: enp8s0 enp9s0externalゾーンでマスカレードが有効になっていることを確認します。# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
26.3. 従来のネットワークスクリプトを使用する場合のポリシーベースのルーティングに関連する設定ファイルの概要
NetworkManager の代わりに従来のネットワークスクリプトを使用してネットワークを設定する場合は、ポリシーベースのルーティングを設定することもできます。
network-scripts パッケージが提供する従来のネットワークスクリプトを使用したネットワークの設定は、RHEL 8 では非推奨になりました。NetworkManager を使用してポリシーベースのルーティングを設定します。たとえば、nmcli を使用した、特定のサブネットから別のデフォルトゲートウェイへのトラフィックのルーティング を参照してください。
レガシーネットワークスクリプトを使用する場合、次の設定ファイルがポリシーベースルーティングに含まれます。
/etc/sysconfig/network-scripts/route-interface- このファイルは IPv4 ルートを定義します。tableオプションを使用してルーティングテーブルを指定します。以下に例を示します。192.0.2.0/24 via 198.51.100.1 table 1 203.0.113.0/24 via 198.51.100.2 table 2-
/etc/sysconfig/network-scripts/route6-interface- このファイルは IPv6 ルートを定義します。 /etc/sysconfig/network-scripts/rule-interface- このファイルは、カーネルがトラフィックを特定のルーティングテーブルにルーティングする IPv4 ソースネットワークのルールを定義します。以下に例を示します。from 192.0.2.0/24 lookup 1 from 203.0.113.0/24 lookup 2-
/etc/sysconfig/network-scripts/rule6-interface- このファイルは、カーネルがトラフィックを特定のルーティングテーブルにルーティングする IPv6 ソースネットワークのルールを定義します。 /etc/iproute2/rt_tables- このファイルは、特定のルーティングテーブルを参照する数字の代わりに名前を使用する場合にマッピングを定義します。以下に例を示します。1 Provider_A 2 Provider_B
26.4. レガシーネットワークスクリプトを使用した特定のサブネットから別のデフォルトゲートウェイへのトラフィックのルーティング
ポリシーベースのルーティングを使用して、特定のサブネットからのトラフィックに対して別のデフォルトゲートウェイを設定できます。たとえば、RHEL をルーターとして設定し、デフォルトルートを使用してすべてのトラフィックをインターネットプロバイダー A にデフォルトでルーティングできます。ただし、内部ワークステーションサブネットから受信したトラフィックはプロバイダー B にルーティングされます。
network-scripts パッケージが提供する従来のネットワークスクリプトを使用したネットワークの設定は、RHEL 8 では非推奨になりました。この手順は、ホストで NetworkManager ではなく、レガシーネットワークスクリプトを使用している場合に限り行います。NetworkManager を使用してネットワーク設定を管理する場合は、 nmcli を使用した特定のサブネットから別のデフォルトゲートウェイへのトラフィックのルーティング を参照してください。
この手順では、次のネットワークトポロジーを想定しています。
従来のネットワークスクリプトは、設定ファイルをアルファベット順に処理します。したがって、他のインターフェイスのルールとルートで使用されるインターフェイスが、依存するインターフェイスが必要とするときに確実に稼働するように、設定ファイルに名前を付ける必要があります。正しい順序を達成するために、この手順では ifcfg-* ファイル、route-* ファイル、および rules-* ファイルの番号を使用します。
前提条件
-
NetworkManagerパッケージがインストールされていないか、NetworkManagerサービスが無効になります。 -
network-scriptsパッケージがインストールされている。 この手順で設定する RHEL ルーターには、4 つのネットワークインターフェイスがあります。
-
enp7s0インターフェイスはプロバイダー A のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は198.51.100.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp1s0インターフェイスはプロバイダー B のネットワークに接続されます。プロバイダーのネットワークのゲートウェイ IP は192.0.2.2で、ネットワークは/30ネットワークマスクを使用します。 -
enp8s0インターフェイスは、内部ワークステーションで10.0.0.0/24サブネットに接続されています。 -
enp9s0インターフェイスは、会社のサーバーで203.0.113.0/24サブネットに接続されています。
-
-
内部ワークステーションのサブネット内のホストは、デフォルトゲートウェイとして
10.0.0.1を使用します。この手順では、この IP アドレスをルーターのenp8s0ネットワークインターフェイスに割り当てます。 -
サーバーサブネット内のホストは、デフォルトゲートウェイとして
203.0.113.1を使用します。この手順では、この IP アドレスをルーターのenp9s0ネットワークインターフェイスに割り当てます。 -
デフォルトでは、
firewalldサービスは有効でアクティブになっています。
手順
以下の内容で
/etc/sysconfig/network-scripts/ifcfg-1_Provider-Aファイルを作成して、ネットワークインターフェイスの設定をプロバイダー A に追加します。TYPE=Ethernet IPADDR=198.51.100.1 PREFIX=30 GATEWAY=198.51.100.2 DNS1=198.51.100.200 DEFROUTE=yes NAME=1_Provider-A DEVICE=enp7s0 ONBOOT=yes ZONE=external設定ファイルは以下のパラメーターを使用します。
-
TYPE=Ethernet: 接続タイプがイーサネットであることを定義します。 -
IPADDR=IP_address- IPv4 アドレスを設定します。 -
PREFIX=subnet_mask- サブネットマスクを設定します。 -
GATEWAY=IP_address- デフォルトのゲートウェイアドレスを設定します。 -
DNS1=IP_of_DNS_server- DNS サーバーの IPv4 アドレスを設定します。 -
DEFROUTE=yes|no- 接続がデフォルトルートであるかどうかを定義します。 -
NAME=connection_name- 接続プロファイルの名前を設定します。混乱を避けるために、わかりやすい名前を使用してください。 -
DEVICE=network_device- ネットワークインターフェイスを設定します。 -
ONBOOT=yes- システムの起動時に RHEL がこの接続を開始することを定義します。 -
zone=firewalld_zone- 定義したfirewalldゾーンにネットワークインターフェイスを割り当てます。firewalldは、外部ゾーンに割り当てられたマスカレードインターフェイスを自動的に有効にすることに注意してください。
-
プロバイダー B にネットワークインターフェイスの設定を追加します。
以下の内容で
/etc/sysconfig/network-scripts/ifcfg-2_Provider-Bファイルを作成します。TYPE=Ethernet IPADDR=192.0.2.1 PREFIX=30 DEFROUTE=no NAME=2_Provider-B DEVICE=enp1s0 ONBOOT=yes ZONE=externalこのインターフェイスの設定ファイルには、デフォルトのゲートウェイ設定が含まれていないことに注意してください。
2_Provider-B接続のゲートウェイを別のルーティングテーブルに割り当てます。したがって、以下の内容で/etc/sysconfig/network-scripts/route-2_Provider-Bファイルを作成します。0.0.0.0/0 via 192.0.2.2 table 5000このエントリーは、このゲートウェイを経由するすべてのサブネットからのゲートウェイおよびトラフィックをテーブル
5000に割り当てます。
内部ワークステーションサブネットへのネットワークインターフェイスの設定を作成します。
以下の内容で
/etc/sysconfig/network-scripts/ifcfg-3_Internal-Workstationsファイルを作成します。TYPE=Ethernet IPADDR=10.0.0.1 PREFIX=24 DEFROUTE=no NAME=3_Internal-Workstations DEVICE=enp8s0 ONBOOT=yes ZONE=internal内部ワークステーションサブネットのルーティングルール設定を追加します。したがって、以下の内容で
/etc/sysconfig/network-scripts/rule-3_Internal-Workstationsファイルを作成します。pri 5 from 10.0.0.0/24 table 5000この設定では、優先度
5のルーティングルールを定義します。これは、すべてのトラフィックを10.0.0.0/24サブネットからテーブル5000にルーティングします。値が小さいほど優先度が高くなります。以下の内容を含む
/etc/sysconfig/network-scripts/route-3_Internal-Workstationsファイルを作成し、ID5000のルーティングテーブルに静的ルートを追加します。10.0.0.0/24 via 192.0.2.1 table 5000この静的ルートは、RHEL が、ローカルネットワークインターフェイスの IP への
10.0.0.0/24サブネットから、プロバイダー B (192.0.2.1) にトラフィックを送信することを定義します。このインターフェイスは、ルーティングテーブル5000に対するものであり、ネクストホップとして使用されます。
以下の内容で
/etc/sysconfig/network-scripts/ifcfg-4_Serversファイルを作成して、ネットワークインターフェイスの設定をサーバーのサブネットに追加します。TYPE=Ethernet IPADDR=203.0.113.1 PREFIX=24 DEFROUTE=no NAME=4_Servers DEVICE=enp9s0 ONBOOT=yes ZONE=internalネットワークを再起動します。
# systemctl restart network
検証
内部ワークステーションサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms 2 192.0.2.2 (192.0.2.2) 0.884 ms 1.066 ms 1.248 ms ...コマンドの出力には、ルーターがプロバイダー B のネットワークである
192.0.2.1経由でパケットを送信することが表示されます。
サーバーのサブネットの RHEL ホストで、以下を行います。
tracerouteパッケージをインストールします。# yum install traceroutetracerouteユーティリティーを使用して、インターネット上のホストへのルートを表示します。# traceroute redhat.com traceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets 1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms 2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms ...コマンドの出力には、ルーターがプロバイダー A のネットワークである
198.51.100.2経由でパケットを送信することが表示されます。
トラブルシューティングの手順
RHEL ルーターで以下を行います。
ルールのリストを表示します。
# ip rule list 0: from all lookup local 5: from 10.0.0.0/24 lookup 5000 32766: from all lookup main 32767: from all lookup defaultデフォルトでは、RHEL には、
localテーブル、mainテーブル、およびdefaultテーブルのルールが含まれます。テーブル
5000のルートを表示します。# ip route list table 5000 default via 192.0.2.2 dev enp1s0 10.0.0.0/24 via 192.0.2.1 dev enp1s0インターフェイスとファイアウォールゾーンを表示します。
# firewall-cmd --get-active-zones external interfaces: enp1s0 enp7s0 internal interfaces: enp8s0 enp9s0externalゾーンでマスカレードが有効になっていることを確認します。# firewall-cmd --info-zone=external external (active) target: default icmp-block-inversion: no interfaces: enp1s0 enp7s0 sources: services: ssh ports: protocols: masquerade: yes ...
第27章 異なるインターフェイスでの同じ IP アドレスの再利用
VRF (Virtual Routing and Forwarding) を使用すると、管理者は、同じホストで複数のルーティングテーブルを同時に使用できます。このため、VRF はレイヤー 3 でネットワークをパーティションで区切ります。これにより、管理者は、VRF ドメインごとに個別の独立したルートテーブルを使用してトラフィックを分離できるようになります。この技術は、レイヤー 2 でネットワークのパーティションを作成する仮想 LAN (VLAN) に類似しており、ここではオペレーティングシステムが異なる VLAN タグを使用して、同じ物理メディアを共有するトラフィックを分離させます。
レイヤー 2 のパーティションにある VRF の利点は、関与するピアの数に対して、ルーティングが適切にスケーリングすることです。
Red Hat Enterprise Linux は、各 VRF ドメインに仮想 vrt デバイスを使用し、既存のネットワークデバイスを VRF デバイスに追加して、VRF ドメインにルートを含めます。元のデバイスに接続していたアドレスとルートは、VRF ドメイン内に移動します。
各 VRF ドメインが互いに分離しているることに注意してください。
27.1. 別のインターフェイスで同じ IP アドレスを永続的に再利用する
VRF (Virtual Routing and Forwarding) 機能を使用して、1 台のサーバーの異なるインターフェイスで同じ IP アドレスを永続的に使用できます。
同じ IP アドレスを再利用しながら、リモートのピアが VRF インターフェイスの両方に接続するようにするには、ネットワークインターフェイスが異なるブロードキャストドメインに属する必要があります。ネットワークのブロードキャストドメインは、ノードのいずれかによって送信されたブロードキャストトラフィックを受信するノードセットです。ほとんどの設定では、同じスイッチに接続されているすべてのノードが、同じブロードキャストドメインに属するようになります。
前提条件
-
rootユーザーとしてログインしている。 - ネットワークインターフェイスが設定されていない。
手順
最初の VRF デバイスを作成して設定します。
VRF デバイスの接続を作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1001に割り当てられたvrf0という名前の VRF デバイスを作成するには、次のコマンドを実行します。# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabledvrf0デバイスを有効にします。# nmcli connection up vrf0上記で作成した VRF にネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp1s0をvrf0VRF デバイスに追加し、IP アドレスとサブネットマスクをenp1s0に割り当てるには、次のコマンドを実行します。# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24vrf.enp1s0接続をアクティベートします。# nmcli connection up vrf.enp1s0
次の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1002に割り当てられたvrf1という名前の VRF デバイスを作成するには、次のコマンドを実行します。# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabledvrf1デバイスをアクティベートします。# nmcli connection up vrf1上記で作成した VRF にネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp7s0をvrf1VRF デバイスに追加し、IP アドレスとサブネットマスクをenp7s0に割り当てるには、次のコマンドを実行します。# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24vrf.enp7s0デバイスをアクティベートします。# nmcli connection up vrf.enp7s0
27.2. 複数のインターフェイスで同じ IP アドレスを一時的に再利用
VRF (Virtual Routing and Forwarding) 機能を使用して、1 台のサーバーの異なるインターフェイスで同じ IP アドレスを一時的に使用できます。この手順は、システムの再起動後に設定が一時的で失われてしまうため、テスト目的にのみ使用します。
同じ IP アドレスを再利用しながら、リモートのピアが VRF インターフェイスの両方に接続するようにするには、ネットワークインターフェイスが異なるブロードキャストドメインに属する必要があります。ネットワークのブロードキャストドメインは、ノードのいずれかによって送信されたブロードキャストトラフィックを受信するノードセットです。ほとんどの設定では、同じスイッチに接続されているすべてのノードが、同じブロードキャストドメインに属するようになります。
前提条件
-
rootユーザーとしてログインしている。 - ネットワークインターフェイスが設定されていない。
手順
最初の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、
1001ルーティングテーブルに割り当てられたblueという名前の VRF デバイスを作成するには、次のコマンドを実行します。# ip link add dev blue type vrf table 1001blueデバイスを有効にします。# ip link set dev blue upVRF デバイスにネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp1s0を、VRF デバイスblueに追加するには、次のコマンドを実行します。# ip link set dev enp1s0 master blueenp1s0デバイスを有効にします。# ip link set dev enp1s0 upIP アドレスとサブネットマスクを
enp1s0デバイスに割り当てます。たとえば、192.0.2.1/24に設定するには、以下を実行します。# ip addr add dev enp1s0 192.0.2.1/24
次の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1002に割り当てられたredという名前の VRF デバイスを作成するには、次のコマンドを実行します。# ip link add dev red type vrf table 1002redデバイスを有効にします。# ip link set dev red upVRF デバイスにネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp7s0を、VRF デバイスredに追加するには、次のコマンドを実行します。# ip link set dev enp7s0 master redenp7s0デバイスを有効にします。# ip link set dev enp7s0 upVRF ドメイン
blueのenp1s0に使用したものと同じ IP アドレスとサブネットマスクをenp7s0デバイスに割り当てます。# ip addr add dev enp7s0 192.0.2.1/24
- オプション: 上記のとおりに、VRF デバイスをさらに作成します。
第28章 分離された VRF ネットワーク内でのサービスの開始
VRF (Virtual Routing and Forwarding) を使用すると、オペレーティングシステムのメインのルーティングテーブルとは異なるルーティングテーブルを使用して、分離したネットワークを作成できます。その後、サービスとアプリケーションを起動して、そのルーティングテーブルで定義されたネットワークにのみアクセスできるようにできます。
28.1. VRF デバイスの設定
VRF (Virtual Routing and Forwarding) を使用するには、VRF デバイスを作成し、物理ネットワークインターフェイスまたは仮想ネットワークインターフェイスを割り当て、そのデバイスにルーティング情報を提供します。
リモートでロックアウトを防ぐには、ローカルコンソール、または VRF デバイスに割り当てないネットワークインターフェイスを介してリモートでこの手順を実行します。
前提条件
- ローカルでログインしているか、VRF デバイスに割り当てるネットワークインターフェイスとは異なるネットワークインターフェイスを使用している。
手順
同じ名前の仮想デバイスで
vrf0接続を作成し、これをルーティングテーブル1000に割り当てます。# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1000 ipv4.method disabled ipv6.method disabledenp1s0デバイスーをvrf0接続に追加し、IP 設定を設定します。# nmcli connection add type ethernet con-name enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24 ipv4.gateway 192.0.2.254このコマンドは、
enp1s0接続を、vrf0接続のポートとして作成します。この設定により、ルーティング情報は、vrf0デバイスに関連付けられているルーティングテーブル1000に自動的に割り当てられます。分離したネットワークで静的ルートが必要な場合は、以下のコマンドを実行します。
静的ルートを追加します。
# nmcli connection modify enp1s0 +ipv4.routes "198.51.100.0/24 192.0.2.2"192.0.2.2をルーターとして使用する198.51.100.0/24ネットワークにルートを追加します。接続をアクティベートします。
# nmcli connection up enp1s0
検証
vrf0に関連付けられている機器の IP 設定を表示します。# ip -br addr show vrf vrf0 enp1s0 UP 192.0.2.1/24VRF デバイスと、その関連ルーティングテーブルを表示します。
# ip vrf show Name Table ----------------------- vrf0 1000メインのルーティングテーブルを表示します。
# ip route show default via 203.0.113.0/24 dev enp7s0 proto static metric 100メインルーティングテーブルには、
enp1s0デバイスまたは192.0.2.1/24サブネットに関連付けられたルートは記載されていません。ルーティングテーブルの
1000を表示します。# ip route show table 1000 default via 192.0.2.254 dev enp1s0 proto static metric 101 broadcast 192.0.2.0 dev enp1s0 proto kernel scope link src 192.0.2.1 192.0.2.0/24 dev enp1s0 proto kernel scope link src 192.0.2.1 metric 101 local 192.0.2.1 dev enp1s0 proto kernel scope host src 192.0.2.1 broadcast 192.0.2.255 dev enp1s0 proto kernel scope link src 192.0.2.1 198.51.100.0/24 via 192.0.2.2 dev enp1s0 proto static metric 101defaultエントリーは、このルーティングテーブルを使用するサービスでは、192.0.2.254をデフォルトゲートウェイとして使用し、メインルーティングテーブルのデフォルトゲートウェイは使用しないことを示しています。vrf0に関連付けられたネットワークでtracerouteユーティリティーを実行し、ユーティリティーがテーブル1000からのルートを使用することを確認します。# ip vrf exec vrf0 traceroute 203.0.113.1 traceroute to 203.0.113.1 (203.0.113.1), 30 hops max, 60 byte packets 1 192.0.2.254 (192.0.2.254) 0.516 ms 0.459 ms 0.430 ms ...最初のホップは、ルーティングテーブル
1000に割り当てられるデフォルトゲートウェイで、システムのメインルーティングテーブルのデフォルトゲートウェイではありません。
28.2. 分離された VRF ネットワーク内でのサービスの開始
Apache HTTP Server などのサービスを、分離された仮想ルーティングおよび転送 (VRF) ネットワーク内で開始するように設定できます。
サービスは、同じ VRF ネットワーク内にあるローカル IP アドレスにのみバインドできます。
前提条件
-
vrf0デバイスを設定している。 -
Apache HTTP Server が、
vrf0デバイスに関連付けられたインターフェイスに割り当てられた IP アドレスのみをリッスンするように設定している。
手順
httpdsystemd サービスの内容を表示します。# systemctl cat httpd ... [Service] ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ...分離された VRF ネットワーク内で同じコマンドを実行するには、後続の手順で
ExecStartパラメーターの内容を確認する必要があります。/etc/systemd/system/httpd.service.d/ディレクトリーを作成します。# mkdir /etc/systemd/system/httpd.service.d/以下の内容で
/etc/systemd/system/httpd.service.d/override.confファイルを作成します。[Service] ExecStart= ExecStart=/usr/sbin/ip vrf exec vrf0 /usr/sbin/httpd $OPTIONS -DFOREGROUNDExecStartパラメーターを上書きするには、まず設定を解除してから、以下のように新しい値を設定する必要があります。systemd を再ロードします。
# systemctl daemon-reloadhttpdサービスを再起動します。# systemctl restart httpd
検証
httpdプロセスのプロセス ID (PID) を表示します。# pidof -c httpd 1904 ...PID の VRF アソシエーションを表示します。以下に例を示します。
# ip vrf identify 1904 vrf0vrf0デバイスに関連付けられているすべての PID を表示します。# ip vrf pids vrf0 1904 httpd ...
第29章 NetworkManager 接続プロファイルでの ethtool 設定の実行
NetworkManager は、特定のネットワークドライバー設定とハードウェア設定を永続的に設定できます。ethtool ユーティリティーを使用してこれらの設定を管理する場合と比較して、これには再起動後に設定が失われないという利点があります。
NetworkManager 接続プロファイルでは、次の ethtool 設定を行うことができます。
- オフロード機能
- ネットワークインターフェイスコントローラーは、TCP オフロードエンジン (TOE) を使用して、特定の操作の処理をネットワークコントローラーにオフロードできます。これにより、ネットワークのスループットが向上します。
- 割り込み結合設定
- 割り込み結合を使用すると、システムはネットワークパケットを収集し、複数のパケットに対して割り込みを 1 つ生成します。これにより、1 つのハードウェア割り込みでカーネルに送信されたデータ量が増大し、割り込み負荷が減り、スループットを最大化します。
- リングバッファー
- これらのバッファーは、送受信ネットワークパケットを保存します。高いパケットドロップ率を下げるためにリングバッファーを増やすことができます。
29.1. nmcli を使用して ethtool オフロード機能を設定する
NetworkManager を使用して、接続プロファイルで ethtool オフロード機能を有効または無効にすることができます。
手順
たとえば、RX オフロード機能を有効にし、
enp1s0接続プロファイルで TX オフロードを無効にするには、次のコマンドを実行します。# nmcli con modify enp1s0 ethtool.feature-rx on ethtool.feature-tx offこのコマンドは、RX オフロードを明示的に有効にし、TX オフロードを無効にします。
以前に有効または無効にしたオフロード機能の設定を削除するには、機能のパラメーターを null 値に設定します。たとえば、TX オフロードの設定を削除するには、次のコマンドを実行します。
# nmcli con modify enp1s0 ethtool.feature-tx ""ネットワークプロファイルを再度アクティブにします。
# nmcli connection up enp1s0
検証
ethtool -kコマンドを使用して、ネットワークデバイスの現在のオフロード機能を表示します。# ethtool -k network_device
29.2. network RHEL システムロールを使用した ethtool オフロード機能の設定
ネットワークインターフェイスコントローラーは、TCP オフロードエンジン (TOE) を使用して、特定の操作の処理をネットワークコントローラーにオフロードできます。これにより、ネットワークのスループットが向上します。オフロード機能は、ネットワークインターフェイスの接続プロファイルで設定します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して、既存接続プロファイル内の特定の値だけを更新することはできません。このロールは、接続プロファイルが Playbook の設定と正確に一致するようにします。同じ名前の接続プロファイルがすでに存在する場合、このロールは Playbook の設定を適用し、プロファイル内の他のすべての設定をデフォルトにリセットします。値がリセットされないようにするには、変更しない設定も含め、ネットワーク接続プロファイルの設定全体を Playbook に常に指定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings and offload features ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: features: gro: no gso: yes tx_sctp_segmentation: no state: upサンプル Playbook で指定されている設定は次のとおりです。
gro: no- Generic Receive Offload (GRO) を無効にします。
gso: yes- Generic Segmentation Offload (GSO) を有効にします。
tx_sctp_segmentation: no- TX Stream Control Transmission Protocol (SCTP) セグメンテーションを無効にします。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードの Ansible fact をクエリーし、オフロード設定を確認します。
# ansible managed-node-01.example.com -m ansible.builtin.setup ... "ansible_enp1s0": { "active": true, "device": "enp1s0", "features": { ... "rx_gro_hw": "off, ... "tx_gso_list": "on, ... "tx_sctp_segmentation": "off", ... } ...
29.3. nmcli を使用した ethtool coalesce の設定
NetworkManager を使用して、接続プロファイルに ethtool coalesce を設定できます。
手順
たとえば、
enp1s0接続プロファイルで受信パケットの最大数を128に設定するには、次のコマンドを実行します。# nmcli connection modify enp1s0 ethtool.coalesce-rx-frames 128coalesce 設定を削除するには、null 値に設定します。たとえば、
ethtool.coalesce-rx-frames設定を削除するには、次のコマンドを実行します。# nmcli connection modify enp1s0 ethtool.coalesce-rx-frames ""ネットワークプロファイルを再度アクティブにするには、以下を実行します。
# nmcli connection up enp1s0
検証
ethtool -cコマンドを使用して、ネットワークデバイスの現在のオフロード機能を表示します。# ethtool -c network_device
29.4. network RHEL システムロールを使用した ethtool 結合の設定
割り込み結合を使用すると、システムはネットワークパケットを収集し、複数のパケットに対して割り込みを 1 つ生成します。これにより、1 つのハードウェア割り込みでカーネルに送信されたデータ量が増大し、割り込み負荷が減り、スループットを最大化します。結合設定は、ネットワークインターフェイスの接続プロファイルで設定します。Ansible と network RHEL ロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して、既存接続プロファイル内の特定の値だけを更新することはできません。このロールは、接続プロファイルが Playbook の設定と正確に一致するようにします。同じ名前の接続プロファイルがすでに存在する場合、このロールは Playbook の設定を適用し、プロファイル内の他のすべての設定をデフォルトにリセットします。値がリセットされないようにするには、変更しない設定も含め、ネットワーク接続プロファイルの設定全体を Playbook に常に指定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address settings and coalesce settings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: coalesce: rx_frames: 128 tx_frames: 128 state: upサンプル Playbook で指定されている設定は次のとおりです。
rx_frames: <value>- RX フレームの数を設定します。
gso: <value>- TX フレームの数を設定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
ネットワークデバイスの現在のオフロード機能を表示します。
# ansible managed-node-01.example.com -m command -a 'ethtool -c enp1s0' managed-node-01.example.com | CHANGED | rc=0 >> ... rx-frames: 128 ... tx-frames: 128 ...
29.5. nmcli を使用して、高いパケットドロップ率を減らすためにリングバッファーサイズを増やす
パケットドロップ率が原因でアプリケーションがデータの損失、タイムアウト、またはその他の問題を報告する場合は、イーサネットデバイスのリングバッファーのサイズを増やします。
受信リングバッファーは、デバイスドライバーとネットワークインターフェイスコントローラー (NIC) の間で共有されます。カードは、送信 (TX) および受信 (RX) リングバッファーを割り当てます。名前が示すように、リングバッファーは循環バッファーであり、オーバーフローによって既存のデータが上書きされます。NIC からカーネルにデータを移動するには、ハードウェア割り込みと、SoftIRQ とも呼ばれるソフトウェア割り込みの 2 つの方法があります。
カーネルは RX リングバッファーを使用して、デバイスドライバーが着信パケットを処理できるようになるまで着信パケットを格納します。デバイスドライバーは、通常は SoftIRQ を使用して RX リングをドレインします。これにより、着信パケットは sk_buff または skb と呼ばれるカーネルデータ構造に配置され、カーネルを経由して関連するソケットを所有するアプリケーションまでの移動を開始します。
カーネルは TX リングバッファーを使用して、ネットワークに送信する必要がある発信パケットを保持します。これらのリングバッファーはスタックの一番下にあり、パケットドロップが発生する重要なポイントであり、ネットワークパフォーマンスに悪影響を及ぼします。
手順
インターフェイスのパケットドロップ統計を表示します。
# ethtool -S enp1s0 ... rx_queue_0_drops: 97326 rx_queue_1_drops: 63783 ...コマンドの出力は、ネットワークカードとドライバーに依存することに注意してください。
discardまたはdropカウンターの値が高い場合は、カーネルがパケットを処理できるよりも速く、使用可能なバッファーがいっぱいになることを示します。リングバッファーを増やすと、このような損失を回避できます。最大リングバッファーサイズを表示します。
# ethtool -g enp1s0 Ring parameters for enp1s0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 16320 TX: 4096 Current hardware settings: RX: 255 RX Mini: 0 RX Jumbo: 0 TX: 255Pre-set maximumsセクションの値がCurrent hardware settingsセクションよりも高い場合は、次の手順で設定を変更できます。このインターフェイスを使用する NetworkManager 接続プロファイルを特定します。
# nmcli connection show NAME UUID TYPE DEVICE Example-Connection a5eb6490-cc20-3668-81f8-0314a27f3f75 ethernet enp1s0接続プロファイルを更新し、リングバッファーを増やします。
RX リングバッファーを増やすには、次のように実行します。
# nmcli connection modify Example-Connection ethtool.ring-rx 4096TX リングバッファーを増やすには、次のように実行します。
# nmcli connection modify Example-Connection ethtool.ring-tx 4096
NetworkManager 接続をリロードします。
# nmcli connection up Example-Connection重要NIC が使用するドライバーによっては、リングバッファーを変更すると、ネットワーク接続が短時間中断されることがあります。
29.6. network RHEL システムロールを使用して、高いパケットドロップ率を減らすためにリングバッファーサイズを増やす
パケットドロップ率が原因でアプリケーションがデータの損失、タイムアウト、またはその他の問題を報告する場合は、イーサネットデバイスのリングバッファーのサイズを増やします。
リングバッファーは循環バッファーであり、オーバーフローによって既存のデータが上書きされます。ネットワークカードは、送信 (TX) および受信 (RX) リングバッファーを割り当てます。受信リングバッファーは、デバイスドライバーとネットワークインターフェイスコントローラー (NIC) の間で共有されます。データは、ハードウェア割り込みまたは SoftIRQ とも呼ばれるソフトウェア割り込みによって NIC からカーネルに移動できます。
カーネルは RX リングバッファーを使用して、デバイスドライバーが着信パケットを処理できるようになるまで着信パケットを格納します。デバイスドライバーは、通常は SoftIRQ を使用して RX リングをドレインします。これにより、着信パケットは sk_buff または skb と呼ばれるカーネルデータ構造に配置され、カーネルを経由して関連するソケットを所有するアプリケーションまでの移動を開始します。
カーネルは TX リングバッファーを使用して、ネットワークに送信する必要がある発信パケットを保持します。これらのリングバッファーはスタックの一番下にあり、パケットドロップが発生する重要なポイントであり、ネットワークパフォーマンスに悪影響を及ぼします。
リングバッファー設定は、NetworkManager 接続プロファイルで設定します。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
network RHEL システムロールを使用して、既存接続プロファイル内の特定の値だけを更新することはできません。このロールは、接続プロファイルが Playbook の設定と正確に一致するようにします。同じ名前の接続プロファイルがすでに存在する場合、このロールは Playbook の設定を適用し、プロファイル内の他のすべての設定をデフォルトにリセットします。値がリセットされないようにするには、変更しない設定も含め、ネットワーク接続プロファイルの設定全体を Playbook に常に指定してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - デバイスがサポートする最大リングバッファーサイズを把握している。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure the network hosts: managed-node-01.example.com tasks: - name: Ethernet connection profile with dynamic IP address setting and increased ring buffer sizes ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: dhcp4: yes auto6: yes ethtool: ring: rx: 4096 tx: 4096 state: upサンプル Playbook で指定されている設定は次のとおりです。
rx: <value>- 受信するリングバッファーエントリーの最大数を設定します。
tx: <value>- 送信するリングバッファーエントリーの最大数を設定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
最大リングバッファーサイズを表示します。
# ansible managed-node-01.example.com -m command -a 'ethtool -g enp1s0' managed-node-01.example.com | CHANGED | rc=0 >> ... Current hardware settings: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096
第30章 NetworkManager のデバッグの概要
すべてのドメインまたは特定のドメインのログレベルを増やすと、NetworkManager が実行する操作の詳細をログに記録するのに役立ちます。この情報を使用して問題のトラブルシューティングを行うことができます。NetworkManager は、ロギング情報を生成するさまざまなレベルとドメインを提供します。/etc/NetworkManager/NetworkManager.conf ファイルは、NetworkManager の主な設定ファイルです。ログはジャーナルに保存されます。
30.1. NetworkManager の reapply メソッドの概要
NetworkManager サービスは、プロファイルを使用してデバイスの接続設定を管理します。Desktop Bus (D-Bus) API は、これらの接続設定を作成、変更、削除できます。プロファイルに変更があった場合、D-Bus API は既存の設定を変更された接続設定に複製します。複製はされるものの、変更された設定に変更は適用されません。これを反映するには、接続の既存の設定を再度アクティブにするか、reapply() メソッドを使用します。
reapply() メソッドには次の機能があります。
- ネットワークインターフェイスの非アクティブ化または再起動を行わずに、変更された接続設定を更新します。
-
変更された接続設定から保留中の変更を削除します。
NetworkManagerは、手動による変更を元に戻さないため、デバイスを再設定して外部パラメーターまたは手動パラメーターを元に戻すことができます。 - 既存の接続設定とは異なる、変更された接続設定を作成します。
また、reapply() メソッドは次の属性をサポートします。
-
bridge.ageing-time -
bridge.forward-delay -
bridge.group-address -
bridge.group-forward-mask -
bridge.hello-time -
bridge.max-age -
bridge.multicast-hash-max -
bridge.multicast-last-member-count -
bridge.multicast-last-member-interval -
bridge.multicast-membership-interval -
bridge.multicast-querier -
bridge.multicast-querier-interval -
bridge.multicast-query-interval -
bridge.multicast-query-response-interval -
bridge.multicast-query-use-ifaddr -
bridge.multicast-router -
bridge.multicast-snooping -
bridge.multicast-startup-query-count -
bridge.multicast-startup-query-interval -
bridge.priority -
bridge.stp -
bridge.VLAN-filtering -
bridge.VLAN-protocol -
bridge.VLANs -
802-3-ethernet.accept-all-mac-addresses -
802-3-ethernet.cloned-mac-address -
IPv4.addresses -
IPv4.dhcp-client-id -
IPv4.dhcp-iaid -
IPv4.dhcp-timeout -
IPv4.DNS -
IPv4.DNS-priority -
IPv4.DNS-search -
IPv4.gateway -
IPv4.ignore-auto-DNS -
IPv4.ignore-auto-routes -
IPv4.may-fail -
IPv4.method -
IPv4.never-default -
IPv4.route-table -
IPv4.routes -
IPv4.routing-rules -
IPv6.addr-gen-mode -
IPv6.addresses -
IPv6.dhcp-duid -
IPv6.dhcp-iaid -
IPv6.dhcp-timeout -
IPv6.DNS -
IPv6.DNS-priority -
IPv6.DNS-search -
IPv6.gateway -
IPv6.ignore-auto-DNS -
IPv6.may-fail -
IPv6.method -
IPv6.never-default -
IPv6.ra-timeout -
IPv6.route-metric -
IPv6.route-table -
IPv6.routes -
IPv6.routing-rules
30.2. NetworkManager ログレベルの設定
デフォルトでは、すべてのログドメインは INFO ログレベルを記録します。デバッグログを収集する前にレート制限を無効にします。帯域制限により、systemd-journald は、短時間にメッセージが多すぎる場合にメッセージを破棄します。これは、ログレベルが TRACE の場合に発生する可能性があります。
この手順では、レート制限を無効にし、すべての (ALL) ドメインのデバッグログの記録を有効にします。
手順
レート制限を無効にするには、
/etc/systemd/journald.confファイルを編集し、[Journal]セクションのRateLimitBurstパラメーターのコメントを解除し、その値を0に設定します。RateLimitBurst=0systemd-journaldサービスを再起動します。# systemctl restart systemd-journald以下の内容で
/etc/NetworkManager/conf.d/95-nm-debug.confファイルを作成します。[logging] domains=ALL:TRACEdomainsパラメーターには、複数のコンマ区切りのdomain:levelペアを含めることができます。NetworkManager サービスを再読み込みします。
# systemctl restart NetworkManager
検証
systemdジャーナルにクエリーを実行して、NetworkManagerユニットのジャーナルエントリーを表示します。# journalctl -u NetworkManager ... Jun 30 15:24:32 server NetworkManager[164187]: <debug> [1656595472.4939] active-connection[0x5565143c80a0]: update activation type from assume to managed Jun 30 15:24:32 server NetworkManager[164187]: <trace> [1656595472.4939] device[55b33c3bdb72840c] (enp1s0): sys-iface-state: assume -> managed Jun 30 15:24:32 server NetworkManager[164187]: <trace> [1656595472.4939] l3cfg[4281fdf43e356454,ifindex=3]: commit type register (type "update", source "device", existing a369f23014b9ede3) -> a369f23014b9ede3 Jun 30 15:24:32 server NetworkManager[164187]: <info> [1656595472.4940] manager: NetworkManager state is now CONNECTED_SITE ...
30.3. nmcli を使用してランタイム時にログレベルを一時的に設定する
nmcli を使用すると、ランタイム時にログレベルを変更できます。
手順
必要に応じて、現在のログ設定を表示します。
# nmcli general logging LEVEL DOMAINS INFO PLATFORM,RFKILL,ETHER,WIFI,BT,MB,DHCP4,DHCP6,PPP,WIFI_SCAN,IP4,IP6,A UTOIP4,DNS,VPN,SHARING,SUPPLICANT,AGENTS,SETTINGS,SUSPEND,CORE,DEVICE,OLPC, WIMAX,INFINIBAND,FIREWALL,ADSL,BOND,VLAN,BRIDGE,DBUS_PROPS,TEAM,CONCHECK,DC B,DISPATCHログレベルおよびドメインを変更するには、以下のオプションを使用します。
すべてのドメインのログレベルを同じ
LEVELに設定するには、次のコマンドを実行します。# nmcli general logging level LEVEL domains ALL特定のドメインのレベルを変更するには、以下を入力します。
# nmcli general logging level LEVEL domains DOMAINSこのコマンドを使用してログレベルを更新すると、他のすべてのドメインのログが無効になることに注意してください。
特定のドメインのレベルを変更し、他のすべてのドメインのレベルを保持するには、次のコマンドを実行します。
# nmcli general logging level KEEP domains DOMAIN:LEVEL,DOMAIN:LEVEL
30.4. NetworkManager ログの表示
トラブルシューティング用の NetworkManager ログを表示できます。
手順
ログを表示するには、以下を入力します。
# journalctl -u NetworkManager -b
30.5. デバッグレベルおよびドメイン
levels および domains パラメーターを使用して、NetworkManager のデバッグを管理できます。レベルは詳細レベルを定義しますが、ドメインは特定の重大度 (level) でログを記録するメッセージのカテゴリーを定義します。
| ログレベル | 説明 |
|---|---|
|
| NetworkManager に関するメッセージをログに記録しません。 |
|
| 重大なエラーのみのログ |
|
| 操作を反映できる警告をログに記録します。 |
|
| 状態および操作の追跡に役立つさまざまな情報メッセージをログに記録します。 |
|
| デバッグの目的で詳細なログを有効にします。 |
|
|
|
後続のレベルでは、以前のレベルのすべてのメッセージをログに記録することに注意してください。たとえば、ログレベルを INFO に設定すると、ERR および WARN ログレベルに含まれるメッセージをログに記録します。
第31章 LLDP を使用したネットワーク設定の問題のデバッグ
Link Layer Discovery Protocol (LLDP) を使用して、トポロジー内のネットワーク設定の問題をデバッグできます。つまり、LLDP は、他のホストまたはルーターやスイッチとの設定の不整合を報告できます。
31.1. LLDP 情報を使用した誤った VLAN 設定のデバッグ
特定の VLAN を使用するようにスイッチポートを設定し、ホストがこれらの VLAN パケットを受信しない場合は、Link Layer Discovery Protocol (LLDP) を使用して問題をデバッグできます。パケットを受信しないホストでこの手順を実行します。
前提条件
-
nmstateパッケージがインストールされている。 - スイッチは LLDP をサポートしています。
- LLDP は隣接デバイスで有効になっています。
手順
次のコンテンツで
~/enable-LLDP-enp1s0.ymlファイルを作成します。interfaces: - name: enp1s0 type: ethernet lldp: enabled: true~/enable-LLDP-enp1s0.ymlファイルを使用して、インターフェイスenp1s0で LLDP を有効にします。# nmstatectl apply ~/enable-LLDP-enp1s0.ymlLLDP 情報を表示します。
# nmstatectl show enp1s0 - name: enp1s0 type: ethernet state: up ipv4: enabled: false dhcp: false ipv6: enabled: false autoconf: false dhcp: false lldp: enabled: true neighbors: - - type: 5 system-name: Summit300-48 - type: 6 system-description: Summit300-48 - Version 7.4e.1 (Build 5) 05/27/05 04:53:11 - type: 7 system-capabilities: - MAC Bridge component - Router - type: 1 _description: MAC address chassis-id: 00:01:30:F9:AD:A0 chassis-id-type: 4 - type: 2 _description: Interface name port-id: 1/1 port-id-type: 5 - type: 127 ieee-802-1-vlans: - name: v2-0488-03-0505 vid: 488 oui: 00:80:c2 subtype: 3 - type: 127 ieee-802-3-mac-phy-conf: autoneg: true operational-mau-type: 16 pmd-autoneg-cap: 27648 oui: 00:12:0f subtype: 1 - type: 127 ieee-802-1-ppvids: - 0 oui: 00:80:c2 subtype: 2 - type: 8 management-addresses: - address: 00:01:30:F9:AD:A0 address-subtype: MAC interface-number: 1001 interface-number-subtype: 2 - type: 127 ieee-802-3-max-frame-size: 1522 oui: 00:12:0f subtype: 4 mac-address: 82:75:BE:6F:8C:7A mtu: 1500出力を確認して、想定される設定と一致していることを確認します。たとえば、スイッチに接続されているインターフェイスの LLDP 情報は、このホストが接続されているスイッチポートが VLAN ID
448を使用していることを示しています。- type: 127 ieee-802-1-vlans: - name: v2-0488-03-0505 vid: 488enp1s0インターフェイスのネットワーク設定で異なる VLAN ID を使用している場合は、それに応じて変更してください。
第32章 Linux トラフィックの制御
Linux は、パケットの送信を管理および操作するためのツールを提供します。Linux Traffic Control (TC) サブシステムは、ネットワークトラフィックの規制、分類、成熟、およびスケジューリングに役立ちます。また、TC はフィルターとアクションを使用して分類中にパケットコンテンツをマスリングします。TC サブシステムは、TC アーキテクチャーの基本要素であるキューイング規則 (qdisc) を使用してこれを実現します。
スケジューリングメカニズムは、異なるキューに入るか、終了する前にパケットを設定または再編成します。最も一般的なスケジューラーは First-In-First-Out (FIFO) スケジューラーです。qdiscs 操作は、tc ユーティリティーを使用して一時的に、NetworkManager を使用して永続的に実行できます。
Red Hat Enterprise Linux では、デフォルトのキューの規則をさまざまな方法で設定して、ネットワークインターフェイスのトラフィックを管理できます。
32.1. キュー規則の概要
グルーピング規則 (qdiscs) は、ネットワークインターフェイスによるトラフィックのスケジューリング、後でキューに役に立ちます。qdisc には 2 つの操作があります。
- パケットを後送信用にキューに入れるできるようにするキュー要求。
- キューに置かれたパケットのいずれかを即時に送信できるように要求を解除します。
各 qdisc には、ハンドル と呼ばれる 16 ビットの 16 進数の識別番号があり、1: や abcd: などのコロンが付けられています。この番号は qdisc メジャー番号と呼ばれます。qdisc にクラスがある場合、識別子はマイナー番号 (<major>:<minor>) の前にメジャー番号を持つ 2 つの数字のペア (abcd:1) として形成されます。マイナー番号の番号設定スキームは、qdisc タイプによって異なります。1 つ目のクラスには ID <major>:1、2 つ目の <major>:2 などが含まれる場合があります。一部の qdiscs では、クラスの作成時にクラスマイナー番号を任意に設定することができます。
- 分類的な
qdiscs ネットワークインターフェイスへのパケット転送には、さまざまな
qdiscsがあり、そのタイプの qdiscs が存在します。root、親、または子クラスを使用してqdiscsを設定できます。子を割り当て可能なポイントはクラスと呼ばれます。qdiscのクラスは柔軟性があり、常に複数の子クラス、または 1 つの子qdiscを含めることができます。これは、クラスフルなqdisc自体を含むクラスに対して禁止がないため、複雑なトラフィック制御シナリオが容易になります。分類的な
qdiscsはパケットを格納しません。代わりに、qdisc固有の基準に従って、子のいずれかに対してキューをキューに入れ、デキューします。最終的にこの再帰パケットが渡される場所は、パケットが格納される場所 (またはデキューの場合はから取得) となります。- クラスレス
qdiscs -
一部の
qdiscsには子クラスがなく、クラスレスqdiscsと呼ばれます。クラスレスqdiscsは、クラスフルqdiscsと比較してカスタマイズが少なくなります。通常、インターフェイスに割り当てるだけで十分です。
32.2. tc ユーティリティーを使用したネットワークインターフェイスの qdisc の検査
デフォルトでは、Red Hat Enterprise Linux システムは fq_codel qdisc を使用します。tc ユーティリティーを使用して qdisc カウンターを検査できます。
手順
オプション: 現在の
qdiscを表示します。# tc qdisc show dev enp0s1現在の
qdiscカウンターを検査します。# tc -s qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn Sent 1008193 bytes 5559 pkt (dropped 233, overlimits 55 requeues 77) backlog 0b 0p requeues 0-
dropped: すべてのキューが満杯であるため、パケットがドロップされる回数 -
overlimits: 設定されたリンク容量が一杯になる回数 -
sent: デキューの数
-
32.3. デフォルトの qdisc の更新
現在の qdisc でネットワークパケットの損失を確認する場合は、ネットワーク要件に基づいて qdisc を変更できます。
手順
現在のデフォルト
qdiscを表示します。# sysctl -a | grep qdisc net.core.default_qdisc = fq_codel現在のイーサネット接続の
qdiscを表示します。# tc -s qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 maxpacket 0 drop_overlimit 0 new_flow_count 0 ecn_mark 0 new_flows_len 0 old_flows_len 0既存の
qdiscを更新します。# sysctl -w net.core.default_qdisc=pfifo_fast変更を適用するには、ネットワークドライバーを再読み込みします。
# modprobe -r NETWORKDRIVERNAME # modprobe NETWORKDRIVERNAMEネットワークインターフェイスを起動します。
# ip link set enp0s1 up
検証
イーサネット接続の
qdiscを表示します。# tc -s qdisc show dev enp0s1 qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1 Sent 373186 bytes 5333 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 ....
32.4. tc ユーティリティーを使用してネットワークインターフェイスの現在の qdisc を一時的に設定する手順
デフォルトの qdisc を変更せずに、現在の qdisc を更新できます。
手順
オプション: 現在の
qdiscを表示します。# tc -s qdisc show dev enp0s1現在の
qdiscを更新します。# tc qdisc replace dev enp0s1 root htb
検証
更新された現在の
qdiscを表示します。# tc -s qdisc show dev enp0s1 qdisc htb 8001: root refcnt 2 r2q 10 default 0 direct_packets_stat 0 direct_qlen 1000 Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0
32.5. NetworkManager を使用してネットワークインターフェイスの現在の qdisc を永続的に設定する
NetworkManager 接続の現在の qdisc 値を更新できます。
手順
オプション: 現在の
qdiscを表示します。# tc qdisc show dev enp0s1 qdisc fq_codel 0: root refcnt 2現在の
qdiscを更新します。# nmcli connection modify enp0s1 tc.qdiscs 'root pfifo_fast'必要に応じて、既存の
qdiscに別のqdiscを追加するには、+tc.qdiscオプションを使用します。# nmcli connection modify enp0s1 +tc.qdisc 'ingress handle ffff:'変更を有効にします。
# nmcli connection up enp0s1
検証
ネットワークインターフェイスの現在の
qdiscを表示します。# tc qdisc show dev enp0s1 qdisc pfifo_fast 8001: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1 qdisc ingress ffff: parent ffff:fff1 ----------------
32.6. RHEL で利用できる qdiscs
各 qdisc は、ネットワーク関連の固有の問題に対応します。以下は、RHEL で利用可能な qdiscs のリストです。以下の qdisc を使用して、ネットワーク要件に基づいてネットワークトラフィックを形成できます。
qdisc 名 | 以下に含まれる | オフロードサポート |
|---|---|---|
| 非同期転送モード (ATM) |
| |
| クレジットカードベースのシェーパー |
| はい |
| 応答フローを選択するおよび Keep、応答しないフロー (CHOKE) の場合は CHOose および Kill |
| |
| Controlled Delay (CoDel) |
| |
| Enhanced Transmission Selection (ETS) |
| はい |
| Fair Queue (FQ) |
| |
| FQ_CODel (Fair Queuing Controlled Delay) |
| |
| GRED (Generalized Random Early Detection) |
| |
| 階層化されたサービス曲線 (HSFC) |
| |
| 負荷の高い永続フィルター (HHF) |
| |
| 階層型トークンバケット (HTB) |
| はい |
| INGRESS |
| はい |
| MQPRIO (Multi Queue Priority) |
| Yes |
| マルチキュー (MULTIQ) |
| Yes |
| ネットワークエミュレーター (NETEM) |
| |
| Proportional Integral-controller Enhanced (PIE) |
| |
| PLUG |
| |
| Quick Fair Queueing (QFQ) |
| |
| ランダム初期値検出 (RED) |
| はい |
| SFB (Stochastic Fair Blue) |
| |
| SFQ (Stochastic Fairness Queueing) |
| |
| トークンバケットフィルター (TBF) |
| はい |
| TEQL (Trivial Link Equalizer) |
|
qdisc オフロードには、NIC でハードウェアとドライバーのサポートが必要です。
第33章 ファイルシステムに保存されている証明書で 802.1X 標準を使用したネットワークへの RHEL クライアントの認証
管理者は、IEEE 802.1X 標準に基づいてポートベースのネットワークアクセス制御 (NAC) を使用して、承認されていない LAN および Wi-Fi クライアントからネットワークを保護します。ネットワークで Extensible Authentication Protocol Transport Layer Security (EAP-TLS) メカニズムを使用している場合は、このネットワークに対してクライアントを認証するための証明書が必要です。
33.1. nmcli を使用した既存のイーサネット接続での 802.1X ネットワーク認証の設定
nmcli ユーティリティーを使用して、コマンドラインで 802.1X ネットワーク認証によるイーサネット接続を設定できます。
前提条件
- ネットワークは 802.1X ネットワーク認証をサポートしている。
- イーサネット接続プロファイルが NetworkManager に存在し、有効な IP 設定があります。
TLS 認証に必要な以下のファイルがクライアントにある。
-
クライアント鍵が保存されているのは
/etc/pki/tls/private/client.keyファイルで、そのファイルは所有されており、rootユーザーのみが読み取り可能です。 -
クライアント証明書は
/etc/pki/tls/certs/client.crtに保存されます。 -
認証局 (CA) 証明書は、
/etc/pki/tls/certs/ca.crtファイルに保存されています。
-
クライアント鍵が保存されているのは
-
wpa_supplicantパッケージがインストールされている。
手順
EAP (Extensible Authentication Protocol) を
tlsに設定し、クライアント証明書およびキーファイルへのパスを設定します。# nmcli connection modify enp1s0 802-1x.eap tls 802-1x.client-cert /etc/pki/tls/certs/client.crt 802-1x.private-key /etc/pki/tls/certs/certs/client.key1 つのコマンドで、
802-1x.eapパラメーター、802-1x.client-certパラメーター、および802-1x.private-keyパラメーターを設定する必要があります。CA 証明書のパスを設定します。
# nmcli connection modify enp1s0 802-1x.ca-cert /etc/pki/tls/certs/ca.crt証明書で使用するユーザーの ID を設定します。
# nmcli connection modify enp1s0 802-1x.identity user@example.comオプション: 設定にパスワードを保存します。
# nmcli connection modify enp1s0 802-1x.private-key-password password重要デフォルトでは、NetworkManager はディスク上の接続プロファイルにパスワードをクリアテキストで保存します。このファイルを読み取ることができるのは
rootユーザーだけです。ただし、設定ファイルのクリアテキストパスワードはセキュリティーリスクとなる可能性があります。セキュリティーを強化するには、
802-1x.password-flagsパラメーターをagent-ownedに設定します。この設定では、GNOME デスクトップ環境またはnm-appletが実行中のサーバーで、NetworkManager はキーリングのロックを解除してから、これらのサービスからパスワードを取得します。その他の場合は、NetworkManager によりパスワードの入力が求められます。接続プロファイルをアクティベートします。
# nmcli connection up enp1s0
検証
- ネットワーク認証が必要なネットワーク上のリソースにアクセスします。
33.2. nmstatectl を使用した 802.1X ネットワーク認証による静的イーサネット接続の設定
nmstatectl ユーティリティーを使用して、Nmstate API を介して、802.1X ネットワーク認証によるイーサネット接続を設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
nmstate ライブラリーは、TLS Extensible Authentication Protocol (EAP) 方式のみをサポートします。
前提条件
- ネットワークは 802.1X ネットワーク認証をサポートしている。
- 管理ノードは NetworkManager を使用している。
TLS 認証に必要な以下のファイルがクライアントにある。
-
クライアント鍵が保存されているのは
/etc/pki/tls/private/client.keyファイルで、そのファイルは所有されており、rootユーザーのみが読み取り可能です。 -
クライアント証明書は
/etc/pki/tls/certs/client.crtに保存されます。 -
認証局 (CA) 証明書は、
/etc/pki/tls/certs/ca.crtファイルに保存されています。
-
クライアント鍵が保存されているのは
手順
以下の内容を含む YAML ファイル (例:
~/create-ethernet-profile.yml) を作成します。--- interfaces: - name: enp1s0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.0.2.1 prefix-length: 24 dhcp: false ipv6: enabled: true address: - ip: 2001:db8:1::1 prefix-length: 64 autoconf: false dhcp: false 802.1x: ca-cert: /etc/pki/tls/certs/ca.crt client-cert: /etc/pki/tls/certs/client.crt eap-methods: - tls identity: client.example.org private-key: /etc/pki/tls/private/client.key private-key-password: password routes: config: - destination: 0.0.0.0/0 next-hop-address: 192.0.2.254 next-hop-interface: enp1s0 - destination: ::/0 next-hop-address: 2001:db8:1::fffe next-hop-interface: enp1s0 dns-resolver: config: search: - example.com server: - 192.0.2.200 - 2001:db8:1::ffbbこれらの設定では、次の設定を使用して
enp1s0デバイスのイーサネット接続プロファイルを定義します。-
静的 IPv4 アドレス: サブネットマスクが
/24の192.0.2.1 -
静的 IPv6 アドレス -
2001:db8:1::1(/64サブネットマスクあり) -
IPv4 デフォルトゲートウェイ -
192.0.2.254 -
IPv6 デフォルトゲートウェイ -
2001:db8:1::fffe -
IPv4 DNS サーバー -
192.0.2.200 -
IPv6 DNS サーバー -
2001:db8:1::ffbb -
DNS 検索ドメイン -
example.com -
TLSEAP プロトコルを使用した 802.1X ネットワーク認証
-
静的 IPv4 アドレス: サブネットマスクが
設定をシステムに適用します。
# nmstatectl apply ~/create-ethernet-profile.yml
検証
- ネットワーク認証が必要なネットワーク上のリソースにアクセスします。
33.3. network RHEL システムロールを使用した 802.1X ネットワーク認証による静的イーサネット接続の設定
ネットワークアクセス制御 (NAC) は、不正なクライアントからネットワークを保護します。クライアントがネットワークにアクセスできるようにするために、認証に必要な詳細を NetworkManager 接続プロファイルで指定できます。Ansible と network RHEL システムロールを使用すると、このプロセスを自動化し、Playbook で定義されたホスト上の接続プロファイルをリモートで設定できます。
Ansible Playbook を使用して秘密鍵、証明書、および CA 証明書をクライアントにコピーしてから、network RHEL システムロールを使用して 802.1X ネットワーク認証による接続プロファイルを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - ネットワークは 802.1X ネットワーク認証をサポートしている。
- 管理対象ノードが NetworkManager を使用している。
TLS 認証に必要な次のファイルがコントロールノードに存在する。
-
クライアントキーが
/srv/data/client.keyファイルに保存されている。 -
クライアント証明書が
/srv/data/client.crtファイルに保存されている。 -
認証局 (CA) 証明書が
/srv/data/ca.crtファイルに保存されている。
-
クライアントキーが
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。pwd: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure an Ethernet connection with 802.1X authentication hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Copy client key for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.key" dest: "/etc/pki/tls/private/client.key" mode: 0600 - name: Copy client certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/client.crt" dest: "/etc/pki/tls/certs/client.crt" - name: Copy CA certificate for 802.1X authentication ansible.builtin.copy: src: "/srv/data/ca.crt" dest: "/etc/pki/ca-trust/source/anchors/ca.crt" - name: Ethernet connection profile with static IP address settings and 802.1X ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: network_connections: - name: enp1s0 type: ethernet autoconnect: yes ip: address: - 192.0.2.1/24 - 2001:db8:1::1/64 gateway4: 192.0.2.254 gateway6: 2001:db8:1::fffe dns: - 192.0.2.200 - 2001:db8:1::ffbb dns_search: - example.com ieee802_1x: identity: <user_name> eap: tls private_key: "/etc/pki/tls/private/client.key" private_key_password: "{{ pwd }}" client_cert: "/etc/pki/tls/certs/client.crt" ca_cert: "/etc/pki/ca-trust/source/anchors/ca.crt" domain_suffix_match: example.com state: upサンプル Playbook で指定されている設定は次のとおりです。
ieee802_1x- この変数には、802.1X 関連の設定を含めます。
eap: tls-
Extensible Authentication Protocol (EAP) に証明書ベースの
TLS認証方式を使用するようにプロファイルを設定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
- ネットワーク認証が必要なネットワーク上のリソースにアクセスします。
第34章 hostapd と FreeRADIUS バックエンドを使用した LAN クライアント用の 802.1x ネットワーク認証サービスのセットアップ
IEEE 802.1X 標準では、許可されていないクライアントからネットワークを保護するためのセキュアな認証および認可方法を定義しています。hostapd サービスと FreeRADIUS を使用すると、ネットワークにネットワークアクセス制御 (NAC) を提供できます。
Red Hat では、認証のバックエンドソースとして Red Hat Identity Management (IdM) を使用した FreeRADIUS のみをサポートしています。
このドキュメントでは、RHEL ホストは、さまざまなクライアントを既存のネットワークに接続するためのブリッジとして機能します。ただし、RHEL ホストは、認証されたクライアントのみにネットワークへのアクセスを許可します。
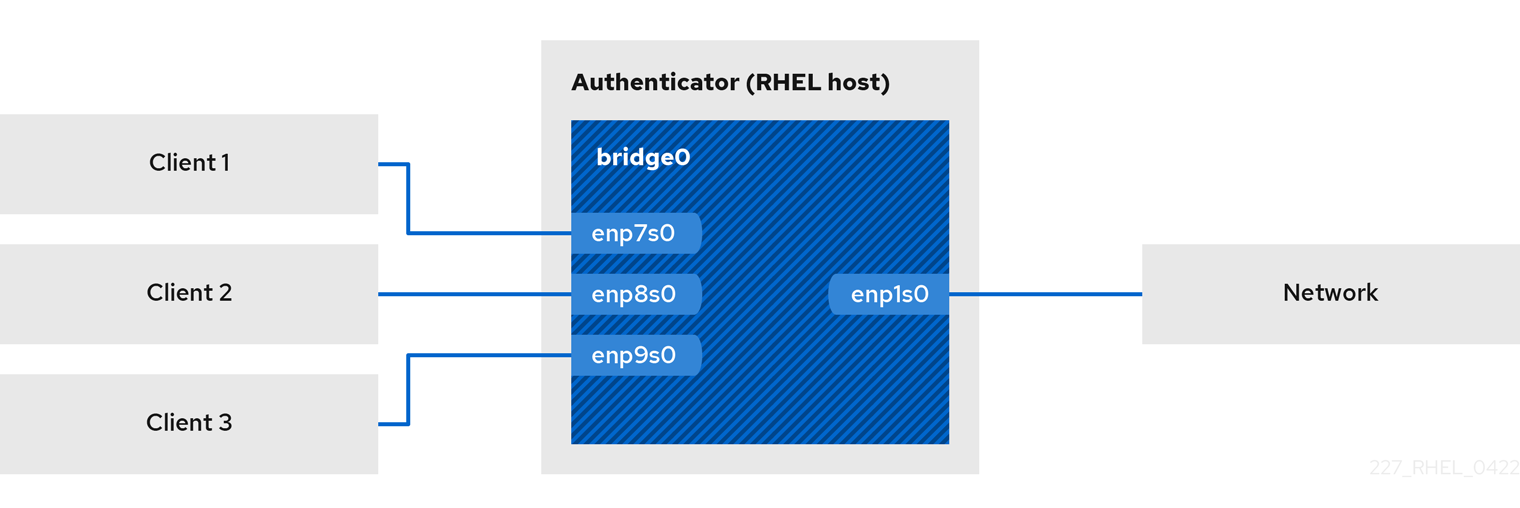
34.1. 前提条件
freeradiusおよびfreeradius-ldapパッケージのクリーンインストール。パッケージがすでにインストールされている場合は、
/etc/raddb/ディレクトリーを削除し、パッケージをアンインストールしてから再度インストールします。/etc/raddb/ディレクトリー内の権限とシンボリックリンクが異なるため、yum reinstallコマンドを使用してパッケージを再インストールしないでください。- FreeRADIUS を設定するホストが IdM ドメイン内のクライアント である。
34.2. オーセンティケーターにブリッジを設定する
ネットワークブリッジは、MAC アドレスのテーブルに基づいてホストとネットワーク間のトラフィックを転送するリンク層デバイスです。RHEL を 802.1X オーセンティケーターとして設定する場合は、認証を実行するインターフェイスと LAN インターフェイスの両方をブリッジに追加します。
前提条件
- サーバーには複数のイーサネットインターフェイスがあります。
手順
ブリッジインターフェイスが存在しない場合は、作成します。
# nmcli connection add type bridge con-name br0 ifname br0イーサネットインターフェイスをブリッジに割り当てます。
# nmcli connection add type ethernet slave-type bridge con-name br0-port1 ifname enp1s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port2 ifname enp7s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port3 ifname enp8s0 master br0 # nmcli connection add type ethernet slave-type bridge con-name br0-port4 ifname enp9s0 master br0ブリッジが拡張認証プロトコル over LAN (EAPOL) パケットを転送できるようにします。
# nmcli connection modify br0 group-forward-mask 8ブリッジデバイスで Spanning Tree Protocol (STP) を無効にします。
# *nmcli connection modify br0 stp off"ポートを自動的にアクティブ化するように接続を設定します。
# nmcli connection modify br0 connection.autoconnect-slaves 1接続をアクティベートします。
# nmcli connection up br0
検証
特定のブリッジのポートであるイーサネットデバイスのリンクステータスを表示します。
# ip link show master br0 3: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff ...EAPOL パケットの転送が
br0デバイスで有効になっているかどうかを確認します。# cat /sys/class/net/br0/bridge/group_fwd_mask 0x8コマンドが
0x8を返す場合、転送が有効になります。
34.3. ネットワーククライアントを安全に認証するための FreeRADIUS の設定 (EAP 使用)
FreeRADIUS は、Extensible Authentication Protocol (EAP) のさまざまな方式をサポートしています。しかし、サポートされるセキュアな状況では、EAP-TTLS (Tunneled Transport Layer Security) を使用してください。
EAP-TTLS では、クライアントが、トンネルを設定するための外部認証プロトコルとしてセキュアな TLS 接続を使用します。内部認証では、LDAP を使用して Identity Management に対して認証を行います。EAP-TTLS を使用するには、TLS サーバー証明書が必要です。
デフォルトの FreeRADIUS 設定ファイルはドキュメントとして機能し、すべてのパラメーターとディレクティブを記述します。特定の機能を無効にする場合は、設定ファイルの対応する部分を削除するのではなく、コメントアウトしてください。これにより、設定ファイルと含まれているドキュメントの構造を保持できます。
前提条件
-
freeradiusおよびfreeradius-ldapパッケージがインストールされている。 -
/etc/raddb/ディレクトリー内の設定ファイルが変更されておらず、freeradiusパッケージによって提供されるものである。 - ホストが Red Hat Enterprise Linux Identity Management (IdM) ドメインに登録されている。
手順
秘密鍵を作成し、IdM から証明書を要求します。
# ipa-getcert request -w -k /etc/pki/tls/private/radius.key -f /etc/pki/tls/certs/radius.pem -o "root:radiusd" -m 640 -O "root:radiusd" -M 640 -T caIPAserviceCert -C 'systemctl restart radiusd.service' -N freeradius.idm.example.com -D freeradius.idm.example.com -K radius/freeradius.idm.example.comcertmongerサービスが、秘密鍵を/etc/pki/tls/private/radius.keyファイルに保存し、証明書を/etc/pki/tls/certs/radius.pemファイルに保存して、セキュアな権限を設定します。さらに、certmongerは証明書を監視し、有効期限が切れる前に更新し、証明書の更新後にradiusdサービスを再起動します。CA が証明書を正常に発行したことを確認します。
# ipa-getcert list -f /etc/pki/tls/certs/radius.pem ... Number of certificates and requests being tracked: 1. Request ID '20240918142211': status: MONITORING stuck: no key pair storage: type=FILE,location='/etc/pki/tls/private/radius.key' certificate: type=FILE,location='/etc/pki/tls/certs/radius.crt' ...Diffie-Hellman (DH) パラメーターを使用して
/etc/raddb/certs/dhファイルを作成します。たとえば、2048 ビットの素数を持つ DH ファイルを作成するには、次のように実行します。# openssl dhparam -out /etc/raddb/certs/dh 2048セキュリティー上の理由から、素数が 2048 ビット未満の DH ファイルは使用しないでください。ビット数によっては、ファイルの作成に数分かかる場合があります。
/etc/raddb/mods-available/eapファイルを編集します。tls-config tls-commonディレクティブで TLS 関連の設定を指定します。eap { ... tls-config tls-common { ... private_key_file = /etc/pki/tls/private/radius.key certificate_file = /etc/pki/tls/certs/radius.pem ca_file = /etc/ipa/ca.crt ... } }eapディレクティブのdefault_eap_typeパラメーターをttlsに設定します。eap { ... default_eap_type = ttls ... }安全でない EAP-MD5 認証方式を無効にするには、
md5ディレクティブをコメントアウトします。eap { ... # md5 { # } ... }デフォルトの設定ファイルでは、他の安全でない EAP 認証方法がデフォルトでコメントアウトされていることに注意してください。
/etc/raddb/sites-available/defaultファイルを編集し、eap以外のすべての認証方法をコメントアウトします。authenticate { ... # Auth-Type PAP { # pap # } # Auth-Type CHAP { # chap # } # Auth-Type MS-CHAP { # mschap # } # mschap # digest ... }これにより、外部認証で EAP のみが有効になり、プレーンテキスト認証方法が無効になります。
/etc/raddb/sites-available/inner-tunnelファイルを編集し、次の変更を加えます。-ldapエントリーをコメントアウトし、ldapモジュール設定をauthorizeディレクティブに追加します。authorize { ... #-ldap ldap if ((ok || updated) && User-Password) { update { control:Auth-Type := ldap } } ... }authenticateディレクティブ内の LDAP 認証タイプのコメントを解除します。authenticate { Auth-Type LDAP { ldap } }
ldapモジュールを有効にします。# ln -s /etc/raddb/mods-available/ldap /etc/raddb/mods-enabled/ldap/etc/raddb/mods-available/ldapファイルを編集し、次の変更を加えます。ldapディレクティブで、IdM LDAP サーバーの URL とベース識別名 (DN) を設定します。ldap { ... server = 'ldaps://idm_server.idm.example.com' base_dn = 'cn=users,cn=accounts,dc=idm,dc=example,dc=com' ... }FreeRADIUS ホストと IdM サーバー間で TLS 暗号化接続を使用するには、サーバー URL に
ldapsプロトコルを指定します。ldapディレクティブで、IdM LDAP サーバーの TLS 証明書検証を有効にします。tls { ... require_cert = 'demand' ... }
/etc/raddb/clients.confファイルを編集します。localhostおよびlocalhost_ipv6クライアントディレクティブでセキュアなパスワードを設定します。client localhost { ipaddr = 127.0.0.1 ... secret = localhost_client_password ... } client localhost_ipv6 { ipv6addr = ::1 secret = localhost_client_password }ネットワークオーセンティケーターのクライアントディレクティブを追加します。
client hostapd.example.org { ipaddr = 192.0.2.2/32 secret = hostapd_client_password }オプション: 他のホストも FreeRADIUS サービスにアクセスできるようにするには、それらのホストにもクライアントディレクティブを追加します。以下に例を示します。
client <hostname_or_description> { ipaddr = <IP_address_or_range> secret = <client_password> }ipaddrパラメーターは IPv4 および IPv6 アドレスを受け入れ、オプションのクラスレスドメイン間ルーティング (CIDR) 表記を使用して範囲を指定できます。ただし、このパラメーターに設定できる値は 1 つだけです。たとえば、IPv4 アドレスと IPv6 アドレスの両方へのアクセスを許可するには、2 つのクライアントディレクティブを追加する必要があります。ホスト名や IP 範囲が使用される場所を説明する単語など、クライアントディレクティブのわかりやすい名前を使用します。
設定ファイルを確認します。
# radiusd -XC ... Configuration appears to be OKfirewalldサービスで RADIUS ポートを開きます。# firewall-cmd --permanent --add-service=radius # firewall-cmd --reloadradiusdサービスを有効にして開始します。# systemctl enable --now radiusd
トラブルシューティング
radiusdサービスの起動に失敗した場合は、IdM サーバーのホスト名を解決できることを確認します。# host -v idm_server.idm.example.comその他の問題が発生した場合は、
radiusdをデバッグモードで実行します。radiusdサービスを停止します。# systemctl stop radiusdデバッグモードでサービスを開始します。
# radiusd -X ... Ready to process requests-
Verificationセクションで参照されているように、FreeRADIUS ホストで認証テストを実行します。
次のステップ
- 不要になった認証方法や使用しないその他の機能を無効にします。
34.4. 有線ネットワークで hostapd をオーセンティケーターとして設定する
ホストアクセスポイントデーモン (hostapd) サービスは、有線ネットワークでオーセンティケーターとして機能し、802.1X 認証を提供できます。このため、hostapd サービスには、クライアントを認証する RADIUS サーバーが必要です。
hostapd サービスは、統合された RADIUS サーバーを提供します。ただし、統合 RADIUS サーバーはテスト目的でのみ使用してください。実稼働環境では、さまざまな認証方法やアクセス制御などの追加機能をサポートする FreeRADIUS サーバーを使用します。
hostapd サービスはトラフィックプレーンと相互作用しません。このサービスは、オーセンティケーターとしてのみ機能します。たとえば、hostapd 制御インターフェイスを使用するスクリプトまたはサービスを使用して、認証イベントの結果に基づいてトラフィックを許可または拒否します。
前提条件
-
hostapdパッケージをインストールしました。 - FreeRADIUS サーバーが設定され、クライアントを認証する準備が整いました。
手順
次のコンテンツで
/etc/hostapd/hostapd.confファイルを作成します。# General settings of hostapd # =========================== # Control interface settings ctrl_interface=/var/run/hostapd ctrl_interface_group=wheel # Enable logging for all modules logger_syslog=-1 logger_stdout=-1 # Log level logger_syslog_level=2 logger_stdout_level=2 # Wired 802.1X authentication # =========================== # Driver interface type driver=wired # Enable IEEE 802.1X authorization ieee8021x=1 # Use port access entry (PAE) group address # (01:80:c2:00:00:03) when sending EAPOL frames use_pae_group_addr=1 # Network interface for authentication requests interface=br0 # RADIUS client configuration # =========================== # Local IP address used as NAS-IP-Address own_ip_addr=192.0.2.2 # Unique NAS-Identifier within scope of RADIUS server nas_identifier=hostapd.example.org # RADIUS authentication server auth_server_addr=192.0.2.1 auth_server_port=1812 auth_server_shared_secret=hostapd_client_password # RADIUS accounting server acct_server_addr=192.0.2.1 acct_server_port=1813 acct_server_shared_secret=hostapd_client_passwordこの設定で使用されるパラメーターの詳細は、
/usr/share/doc/hostapd/hostapd.confサンプル設定ファイルの説明を参照してください。hostapdサービスを有効にして開始します。# systemctl enable --now hostapd
トラブルシューティング
hostapdサービスの起動に失敗した場合は、/etc/hostapd/hostapd.confファイルで使用するブリッジインターフェイスがシステム上に存在することを確認します。# ip link show br0その他の問題が発生した場合は、
hostapdをデバッグモードで実行します。hostapdサービスを停止します。# systemctl stop hostapdデバッグモードでサービスを開始します。
# hostapd -d /etc/hostapd/hostapd.conf-
Verificationセクションで参照されているように、FreeRADIUS ホストで認証テストを実行します。
34.5. FreeRADIUS サーバーまたはオーセンティケーターに対する EAP-TTLS 認証のテスト
Extensible Authentication Protocol - Tunneled Transport Layer Security (EAP-TTLS) を使用した認証が、期待どおりに機能するかテストするには、次の手順を実行します。
- FreeRADIUS サーバーをセットアップした後
-
hostapdサービスを 802.1X ネットワーク認証のオーセンティケーターとして設定した後。
この手順で使用されるテストユーティリティーの出力は、EAP 通信に関する追加情報を提供し、問題のデバッグに役立ちます。
前提条件
認証先が以下の場合:
FreeRADIUS サーバー:
-
hostapdパッケージによって提供されるeapol_testユーティリティーがインストールされている。 - この手順の実行対象のクライアントが、FreeRADIUS サーバーのクライアントデータベースで認可されている。
-
-
同じ名前のパッケージによって提供されるオーセンティケーターである
wpa_supplicantユーティリティーがインストールされている。
-
認証局 (CA) 証明書が
/etc/ipa/ca.certファイルに保存されている。
手順
オプション: Identity Management (IdM) でユーザーを作成します。
# ipa user-add --first "Test" --last "User" idm_user --password次のコンテンツで
/etc/wpa_supplicant/wpa_supplicant-TTLS.confファイルを作成します。ap_scan=0 network={ eap=TTLS eapol_flags=0 key_mgmt=IEEE8021X # Anonymous identity (sent in unencrypted phase 1) # Can be any string anonymous_identity="anonymous" # Inner authentication (sent in TLS-encrypted phase 2) phase2="auth=PAP" identity="idm_user" password="idm_user_password" # CA certificate to validate the RADIUS server's identity ca_cert="/etc/ipa/ca.crt" }認証するには:
FreeRADIUS サーバーには、次のように実行します。
# eapol_test -c /etc/wpa_supplicant/wpa_supplicant-TTLS.conf -a 192.0.2.1 -s <client_password> ... EAP: Status notification: remote certificate verification (param=success) ... CTRL-EVENT-EAP-SUCCESS EAP authentication completed successfully ... SUCCESS-aオプションは FreeRADIUS サーバーの IP アドレスを定義し、-sオプションは FreeRADIUS サーバーのクライアント設定でコマンドを実行するホストのパスワードを指定します。オーセンティケーター。次のように実行します。
# wpa_supplicant -c /etc/wpa_supplicant/wpa_supplicant-TTLS.conf -D wired -i enp0s31f6 ... enp0s31f6: CTRL-EVENT-EAP-SUCCESS EAP authentication completed successfully ...-iオプションは、wpa_supplicantが LAN(EAPOL) パケットを介して拡張認証プロトコルを送信するネットワークインターフェイス名を指定します。デバッグ情報の詳細は、コマンドに
-dオプションを渡してください。
34.6. hostapd 認証イベントに基づくトラフィックのブロックと許可
hostapd サービスはトラフィックプレーンと相互作用しません。このサービスは、オーセンティケーターとしてのみ機能します。ただし、認証イベントの結果に基づいてトラフィックを許可および拒否するスクリプトを作成できます。
この手順はサポートされておらず、エンタープライズ対応のソリューションではありません。hostapd_cli によって取得されたイベントを評価することにより、トラフィックをブロックまたは許可する方法のみを示しています。
802-1x-tr-mgmt systemd サービスが開始すると、RHEL は LAN(EAPOL) パケットを介した拡張認証プロトコルを除く hostapd のリッスンポート上のすべてのトラフィックをブロックし、hostapd_cli ユーティリティーを使用して hostapd 制御インターフェイスに接続します。次に、/usr/local/bin/802-1x-tr-mgmt スクリプトがイベントを評価します。hostapd_cli が受信するさまざまなイベントに応じて、スクリプトは MAC アドレスのトラフィックを許可またはブロックします。802-1x-tr-mgmt サービスが停止すると、すべてのトラフィックが自動的に再度許可されることに注意してください。
hostapd サーバーでこの手順を実行します。
前提条件
-
hostapdサービスが設定され、サービスはクライアントを認証する準備ができています。
手順
次のコンテンツで
/usr/local/bin/802-1x-tr-mgmtファイルを作成します。#!/bin/sh TABLE="tr-mgmt-${1}" read -r -d '' TABLE_DEF << EOF table bridge ${TABLE} { set allowed_macs { type ether_addr } chain accesscontrol { ether saddr @allowed_macs accept ether daddr @allowed_macs accept drop } chain forward { type filter hook forward priority 0; policy accept; meta ibrname "$1" jump accesscontrol } } EOF case ${2:-NOTANEVENT} in block_all) nft destroy table bridge "$TABLE" printf "$TABLE_DEF" | nft -f - echo "$1: All the bridge traffic blocked. Traffic for a client with a given MAC will be allowed after 802.1x authentication" ;; AP-STA-CONNECTED | CTRL-EVENT-EAP-SUCCESS | CTRL-EVENT-EAP-SUCCESS2) nft add element bridge tr-mgmt-br0 allowed_macs { $3 } echo "$1: Allowed traffic from $3" ;; AP-STA-DISCONNECTED | CTRL-EVENT-EAP-FAILURE) nft delete element bridge tr-mgmt-br0 allowed_macs { $3 } echo "$1: Denied traffic from $3" ;; allow_all) nft destroy table bridge "$TABLE" echo "$1: Allowed all bridge traffice again" ;; NOTANEVENT) echo "$0 was called incorrectly, usage: $0 interface event [mac_address]" ;; esac次のコンテンツで
/etc/systemd/system/802-1x-tr-mgmt@.serviceサービスファイルを作成します。[Unit] Description=Example 802.1x traffic management for hostapd After=hostapd.service After=sys-devices-virtual-net-%i.device [Service] Type=simple ExecStartPre=bash -c '/usr/sbin/hostapd_cli ping | grep PONG' ExecStartPre=/usr/local/bin/802-1x-tr-mgmt %i block_all ExecStart=/usr/sbin/hostapd_cli -i %i -a /usr/local/bin/802-1x-tr-mgmt ExecStopPost=/usr/local/bin/802-1x-tr-mgmt %i allow_all [Install] WantedBy=multi-user.targetsystemd を再ロードします。
# systemctl daemon-reloadhostapdがリッスンしているインターフェイス名で802-1x-tr-mgmtサービスを有効にして開始します。# systemctl enable --now 802-1x-tr-mgmt@br0.service
検証
- ネットワークに対してクライアントで認証します。FreeRADIUS サーバーまたはオーセンティケーターに対する EAP-TTLS 認証のテスト を参照してください。
第35章 Multipath TCP の使用
Transmission Control Protocol (TCP) は、インターネットを介したデータの信頼できる配信を保証し、ネットワーク負荷に応じて帯域幅を自動的に調整します。マルチパス TCP (MPTCP) は、元の TCP プロトコル (シングルパス) のエクステンションです。MPTCP は、トランスポート接続が複数のパスで同時に動作することを可能にし、ユーザーエンドポイントデバイスにネットワーク接続の冗長性をもたらします。
35.1. MPTCP について
マルチパス TCP (MPTCP) プロトコルを使用すると、接続エンドポイント間で複数のパスを同時に使用できます。プロトコル設計により、接続の安定性が向上し、シングルパス TCP と比較して他の利点ももたらされます。
MPTCP 用語では、リンクはパスと見なされます。
以下に、MPTCP を使用する利点の一部を示します。
- これにより、接続が複数のネットワークインターフェイスを同時に使用できるようになります。
- 接続がリンク速度にバインドされている場合は、複数のリンクを使用すると、接続スループットが向上します。接続が CPU にバインドされている場合は、複数のリンクを使用すると接続が遅くなることに注意してください。
- これは、リンク障害に対する耐障害性を高めます。
MPTCP の詳細は、関連情報 を参照してください。
35.2. MPTCP サポートを有効にするための RHEL の準備
デフォルトでは、RHEL で MPTCP サポートが無効になっています。この機能に対応するアプリケーションを使用できるように、MPTCP を有効にします。また、アプリケーションにデフォルトで TCP ソケットがある場合は、MPTCP ソケットを強制的に使用するように、ユーザー空間アプリケーションを設定する必要があります。
sysctl ユーティリティーを使用して MPTCP サポートを有効にし、SystemTap スクリプトを使用してアプリケーション全体で MPTCP を有効にする RHEL を準備することができます。
前提条件
以下のパッケージがインストールされている。
-
systemtap -
iperf3
手順
カーネルで MPTCP ソケットを有効にします。
# echo "net.mptcp.enabled=1" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.confMPTCP がカーネルで有効になっていることを確認します。
# sysctl -a | grep mptcp.enabled net.mptcp.enabled = 1以下の内容で
mptcp-app.stapファイルを作成します。#!/usr/bin/env stap %{ #include <linux/in.h> #include <linux/ip.h> %} /* RSI contains 'type' and RDX contains 'protocol'. */ function mptcpify () %{ if (CONTEXT->kregs->si == SOCK_STREAM && (CONTEXT->kregs->dx == IPPROTO_TCP || CONTEXT->kregs->dx == 0)) { CONTEXT->kregs->dx = IPPROTO_MPTCP; STAP_RETVALUE = 1; } else { STAP_RETVALUE = 0; } %} probe kernel.function("__sys_socket") { if (mptcpify() == 1) { printf("command %16s mptcpified\n", execname()); } }ユーザー空間のアプリケーションに、TCP ソケットの代わりに MPTCP ソケットを作成させるには、以下のコマンドを実行します。
# stap -vg mptcp-app.stap注意: この操作は、コマンドの後に開始するすべての TCP ソケットに影響します。アプリケーションは、上記のコマンドを Ctrl+C で中断した後も TCP ソケットを使用し続けます。
もしくは、MPTCP の使用を特定のアプリケーションのみに許可する場合は、以下の内容を使用して
mptcp-app.stapファイルを変更できます。#!/usr/bin/env stap %{ #include <linux/in.h> #include <linux/ip.h> %} /* according to [1], RSI contains 'type' and RDX * contains 'protocol'. * [1] https://github.com/torvalds/linux/blob/master/arch/x86/entry/entry_64.S#L79 */ function mptcpify () %{ if (CONTEXT->kregs->si == SOCK_STREAM && (CONTEXT->kregs->dx == IPPROTO_TCP || CONTEXT->kregs->dx == 0)) { CONTEXT->kregs->dx = IPPROTO_MPTCP; STAP_RETVALUE = 1; } else { STAP_RETVALUE = 0; } %} probe kernel.function("__sys_socket") { cur_proc = execname() if ((cur_proc == @1) && (mptcpify() == 1)) { printf("command %16s mptcpified\n", cur_proc); } }別の選択肢として、
iperf3ツールで TCP の代わりに MPTCP を強制的に使用する場合を想定します。起動するには、以下のコマンドを実行します。# stap -vg mptcp-app.stap iperf3mptcp-app.stapスクリプトがカーネルプローブをインストールすると、カーネルdmesgに次の警告が表示されます。# dmesg ... [ 1752.694072] Kprobes globally unoptimized [ 1752.730147] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module_layout: kernel tainted. [ 1752.732162] Disabling lock debugging due to kernel taint [ 1752.733468] stap_1ade3b3356f3e68765322e26dec00c3d_1476: loading out-of-tree module taints kernel. [ 1752.737219] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module verification failed: signature and/or required key missing - tainting kernel [ 1752.737219] stap_1ade3b3356f3e68765322e26dec00c3d_1476 (mptcp-app.stap): systemtap: 4.5/0.185, base: ffffffffc0550000, memory: 224data/32text/57ctx/65638net/367alloc kb, probes: 1iperf3サーバーを起動します。# iperf3 -s Server listening on 5201クライアントをサーバーに接続します。
# iperf3 -c 127.0.0.1 -t 3接続が確立されたら、
ss出力を確認し、サブフロー固有のステータスを確認します。# ss -nti '( dport :5201 )' State Recv-Q Send-Q Local Address:Port Peer Address:Port Process ESTAB 0 0 127.0.0.1:41842 127.0.0.1:5201 cubic wscale:7,7 rto:205 rtt:4.455/8.878 ato:40 mss:21888 pmtu:65535 rcvmss:536 advmss:65483 cwnd:10 bytes_sent:141 bytes_acked:142 bytes_received:4 segs_out:8 segs_in:7 data_segs_out:3 data_segs_in:3 send 393050505bps lastsnd:2813 lastrcv:2772 lastack:2772 pacing_rate 785946640bps delivery_rate 10944000000bps delivered:4 busy:41ms rcv_space:43690 rcv_ssthresh:43690 minrtt:0.008 tcp-ulp-mptcp flags:Mmec token:0000(id:0)/2ff053ec(id:0) seq:3e2cbea12d7673d4 sfseq:3 ssnoff:ad3d00f4 maplen:2MPTCP カウンターを確認します。
# nstat MPTcp* #kernel MPTcpExtMPCapableSYNRX 2 0.0 MPTcpExtMPCapableSYNTX 2 0.0 MPTcpExtMPCapableSYNACKRX 2 0.0 MPTcpExtMPCapableACKRX 2 0.0
35.3. iproute2 を使用した MPTCP アプリケーションの複数パスの一時的な設定と有効化
各 MPTCP 接続は、プレーンな TCP と似た 1 つのサブフローを使用します。MPTCP を活用するには、各 MPTCP 接続のサブフローの最大数に上限を指定します。次に、追加のエンドポイントを設定して、それらのサブフローを作成します。
この手順の設定は、マシンを再起動すると保持されません。
MPTCP は現在、同じソケットの IPv6 エンドポイントと IPv4 エンドポイントの組み合わせに対応していません。同じアドレスファミリーに属するエンドポイントを使用します。
前提条件
-
iperf3がインストールされている。 サーバーネットワークインターフェイスの設定:
-
enp4s0:
192.0.2.1/24 -
enp1s0:
198.51.100.1/24
-
enp4s0:
クライアントネットワークインターフェイスの設定:
-
enp4s0f0:
192.0.2.2/24 -
enp4s0f1:
198.51.100.2/24
-
enp4s0f0:
手順
サーバーによって提供される追加のリモートアドレスを最大 1 つ受け入れるようにクライアントを設定します。
# ip mptcp limits set add_addr_accepted 1IP アドレス
198.51.100.1を、サーバー上の新しい MPTCP エンドポイントとして追加します。# ip mptcp endpoint add 198.51.100.1 dev enp1s0 signalsignalオプションは、スリーウェイハンドシェイクの後にADD_ADDRパケットが送信されるようにします。iperf3サーバーを起動します。# iperf3 -s Server listening on 5201クライアントをサーバーに接続します。
# iperf3 -c 192.0.2.1 -t 3
検証
接続が確立されたことを確認します。
# ss -nti '( sport :5201 )'接続および IP アドレス制限を確認します。
# ip mptcp limit show新たに追加されたエンドポイントを確認します。
# ip mptcp endpoint showサーバーで
nstat MPTcp*コマンドを使用して MPTCP カウンターを確認します。# nstat MPTcp* #kernel MPTcpExtMPCapableSYNRX 2 0.0 MPTcpExtMPCapableACKRX 2 0.0 MPTcpExtMPJoinSynRx 2 0.0 MPTcpExtMPJoinAckRx 2 0.0 MPTcpExtEchoAdd 2 0.0
35.4. MPTCP アプリケーションの複数パスの永続的な設定
nmcli コマンドを使用して MultiPath TCP (MPTCP) を設定し、送信元システムと宛先システムの間に複数のサブフローを永続的に確立できます。サブフローは、さまざまなリソース、宛先へのさまざまなルート、さまざまなネットワークを使用できます。たとえばイーサネット、セルラー、Wi-Fi などです。その結果、接続が組み合わされ、ネットワークの回復力とスループットが向上します。
ここで使用した例では、サーバーは次のネットワークインターフェイスを使用します。
-
enp4s0:
192.0.2.1/24 -
enp1s0:
198.51.100.1/24 -
enp7s0:
192.0.2.3/24
ここで使用した例では、クライアントは次のネットワークインターフェイスを使用します。
-
enp4s0f0:
192.0.2.2/24 -
enp4s0f1:
198.51.100.2/24 -
enp6s0:
192.0.2.5/24
前提条件
- 関連するインターフェイスでデフォルトゲートウェイを設定している
手順
カーネルで MPTCP ソケットを有効にします。
# echo "net.mptcp.enabled=1" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.confオプション: RHEL カーネルのサブフロー制限のデフォルトは 2 です。不足する場合、以下を実行します。
次の内容で
/etc/systemd/system/set_mptcp_limit.serviceファイルを作成します。[Unit] Description=Set MPTCP subflow limit to 3 After=network.target [Service] ExecStart=ip mptcp limits set subflows 3 Type=oneshot [Install] WantedBy=multi-user.targetワンショット ユニットは、各ブートプロセス中にネットワーク (
network.target) が動作した後にip mptcp limits set subflows 3コマンドを実行します。ip mptcp limits set subflows 3コマンドは、各接続の 追加 サブフローの最大数を設定するため、合計が 4 になります。追加サブフローは最大 3 つです。set_mptcp_limitサービスを有効にします。# systemctl enable --now set_mptcp_limit
接続のアグリゲーションに使用するすべての接続プロファイルで MPTCP を有効にします。
# nmcli connection modify <profile_name> connection.mptcp-flags signal,subflow,also-without-default-routeconnection.mptcp-flagsパラメーターは、MPTCP エンドポイントと IP アドレスフラグを設定します。MPTCP が NetworkManager 接続プロファイルで有効になっている場合、設定により、関連するネットワークインターフェイスの IP アドレスが MPTCP エンドポイントとして設定されます。デフォルトでは、デフォルトゲートウェイがない場合、NetworkManager は MPTCP フラグを IP アドレスに追加しません。そのチェックをバイパスしたい場合は、
also-without-default-routeフラグも使用する必要があります。
検証
MPTCP カーネルパラメーターが有効になっていることを確認します。
# sysctl net.mptcp.enabled net.mptcp.enabled = 1デフォルトでは不足する場合に備えて、サブフロー制限を適切に設定していることを確認します。
# ip mptcp limit show add_addr_accepted 2 subflows 3アドレスごとの MPTCP 設定が正しく設定されていることを確認します。
# ip mptcp endpoint show 192.0.2.1 id 1 subflow dev enp4s0 198.51.100.1 id 2 subflow dev enp1s0 192.0.2.3 id 3 subflow dev enp7s0 192.0.2.4 id 4 subflow dev enp3s0 ...
35.5. MPTCP サブフローのモニタリング
マルチパス TCP (MPTCP) ソケットのライフサイクルは複雑です。主な MPTCP ソケットの作成、MPTCP パスの検証、1 つ以上のサブフローの作成を行い、最終的に削除されます。最後に、MPTCP ソケットが終了します。
MPTCP プロトコルを使用すると、iproute パッケージで提供される ip ユーティリティーを使用して、ソケットおよびサブフローの作成と削除に関連する MPTCP 固有のイベントをモニタリングできます。このユーティリティーは、netlink インターフェイスを使用して MPTCP イベントをモニターします。
この手順は、MPTCP イベントをモニターする方法を示しています。そのために、MPTCP サーバーアプリケーションをシミュレートし、クライアントがこのサービスに接続します。この例に関係するクライアントは、次のインターフェイスと IP アドレスを使用します。
-
サーバー:
192.0.2.1 -
クライアント (イーサネット接続):
192.0.2.2 -
クライアント (WiFi 接続):
192.0.2.3
この例を単純化するために、すべてのインターフェイスは同じサブネット内にあります。これは必須ではありません。ただし、ルーティングが正しく設定されており、クライアントが両方のインターフェイスを介してサーバーに到達できることが重要です。
前提条件
- イーサネットと WiFi を備えたラップトップなど、2 つのネットワークインターフェイスを備えた RHEL クライアント
- クライアントは両方のインターフェイスを介してサーバーに接続できます
- RHEL サーバー
- クライアントとサーバーの両方が RHEL 8.6 以降を実行しています
手順
クライアントとサーバーの両方で、接続ごとの追加のサブフロー制限を
1に設定します。# ip mptcp limits set add_addr_accepted 0 subflows 1サーバーで、MPTCP サーバーアプリケーションをシミュレートするには、TCP ソケットの代わりに強制された MPTCP ソケットを使用してリッスンモードで
netcat(nc) を開始します。# nc -l -k -p 12345-kオプションを指定すると、ncは、最初に受け入れられた接続の後でリスナーを閉じません。これは、サブフローのモニタリングを示すために必要です。クライアントで以下を実行します。
メトリックが最も低いインターフェイスを特定します。
# ip -4 route 192.0.2.0/24 dev enp1s0 proto kernel scope link src 192.0.2.2 metric 100 192.0.2.0/24 dev wlp1s0 proto kernel scope link src 192.0.2.3 metric 600enp1s0インターフェイスのメトリックは、wlp1s0よりも低くなります。したがって、RHEL はデフォルトでenp1s0を使用します。最初のターミナルで、モニタリングを開始します。
# ip mptcp monitor2 番目のターミナルで、サーバーへの MPTCP 接続を開始します。
# nc 192.0.2.1 12345RHEL は、
enp1s0インターフェイスとそれに関連する IP アドレスをこの接続のソースとして使用します。モニタリングターミナルで、
ip mptcp monitorコマンドが次のログを記録するようになりました。[ CREATED] token=63c070d2 remid=0 locid=0 saddr4=192.0.2.2 daddr4=192.0.2.1 sport=36444 dport=12345トークンは MPTCP ソケットを一意の ID として識別し、後で同じソケットで MPTCP イベントを相互に関連付けることができます。
サーバーへの
nc接続が実行されているターミナルで、Enter を押します。この最初のデータパケットは、接続を完全に確立します。データが送信されていない限り、接続は確立されないことに注意してください。モニタリングターミナルで、
ip mptcp monitorが次のログを記録するようになりました。[ ESTABLISHED] token=63c070d2 remid=0 locid=0 saddr4=192.0.2.2 daddr4=192.0.2.1 sport=36444 dport=12345オプション: サーバーのポート
12345への接続を表示します。# ss -taunp | grep ":12345" tcp ESTAB 0 0 192.0.2.2:36444 192.0.2.1:12345この時点で、サーバーへの接続は 1 つだけ確立されています。
3 番目のターミナルで、別のエンドポイントを作成します。
# ip mptcp endpoint add dev wlp1s0 192.0.2.3 subflowこのコマンドは、クライアントの WiFi インターフェイスの名前と IP アドレスを設定します。
モニタリングターミナルで、
ip mptcp monitorが次のログを記録するようになりました。[SF_ESTABLISHED] token=63c070d2 remid=0 locid=2 saddr4=192.0.2.3 daddr4=192.0.2.1 sport=53345 dport=12345 backup=0 ifindex=3locidフィールドには、新しいサブフローのローカルアドレス ID が表示され、接続でネットワークアドレス変換 (NAT) が使用されている場合でも、このサブフローが識別されます。saddr4フィールドは、ip mptcp endpoint addコマンドからのエンドポイントの IP アドレスと一致します。オプション: サーバーのポート
12345への接続を表示します。# ss -taunp | grep ":12345" tcp ESTAB 0 0 192.0.2.2:36444 192.0.2.1:12345 tcp ESTAB 0 0 192.0.2.3%wlp1s0:53345 192.0.2.1:12345このコマンドは、2 つの接続を表示します。
-
ソースアドレス
192.0.2.2との接続は、以前に確立した最初の MPTCP サブフローに対応します。 -
送信元アドレスが
192.0.2.3のwlp1s0インターフェイスを介したサブフローからの接続。
-
ソースアドレス
3 番目のターミナルで、エンドポイントを削除します。
# ip mptcp endpoint delete id 2ip mptcp monitor出力のlocidフィールドの ID を使用するか、ip mptcp endpoint showコマンドを使用してエンドポイント ID を取得します。モニタリングターミナルで、
ip mptcp monitorが次のログを記録するようになりました。[ SF_CLOSED] token=63c070d2 remid=0 locid=2 saddr4=192.0.2.3 daddr4=192.0.2.1 sport=53345 dport=12345 backup=0 ifindex=3ncクライアントを備えた最初のターミナルで、Ctrl+C を押してセッションを終了します。モニタリングターミナルで、
ip mptcp monitorが次のログを記録するようになりました。[ CLOSED] token=63c070d2
35.6. カーネルでの Multipath TCP の無効化
カーネルの MPTCP オプションを明示的に無効にできます。
手順
mptcp.enabledオプションを無効にします。# echo "net.mptcp.enabled=0" > /etc/sysctl.d/90-enable-MPTCP.conf # sysctl -p /etc/sysctl.d/90-enable-MPTCP.conf
検証
カーネルで
mptcp.enabledが無効になっているかどうかを確認します。# sysctl -a | grep mptcp.enabled net.mptcp.enabled = 0
第36章 RHEL における従来のネットワークスクリプトのサポート
デフォルトでは、RHEL は NetworkManager を使用してネットワーク接続を設定および管理し、/usr/sbin/ifup スクリプトおよび /usr/sbin/ifdown スクリプトは NetworkManager を使用して /etc/sysconfig/network-scripts/ ディレクトリー内の ifcfg ファイルを処理します。
レガシースクリプトは RHEL 8 で非推奨となり、RHEL の今後のメジャーバージョンで削除されます。以前のバージョンから RHEL 8 にアップグレードしたため、レガシーネットワークスクリプトを使用する場合は、設定を NetworkManager に移行することが推奨されます。
36.1. レガシーネットワークスクリプトのインストール
NetworkManager を使用せずにネットワーク設定を処理する非推奨のネットワークスクリプトが必要な場合は、それをインストールできます。この場合、/usr/sbin/ifup スクリプトおよび /usr/sbin/ifdown スクリプトは、ネットワーク設定を管理する非推奨のシェルスクリプトにリンクされます。
手順
network-scriptsパッケージをインストールします。# yum install network-scripts
第37章 ifcfg ファイルで IP ネットワークの設定
インターフェイス設定(ifcfg)ファイルは、個々のネットワークデバイスのソフトウェアインターフェイスを制御します。これは、システムの起動時に、このファイルを使用して、どのインターフェイスを起動するかと、どのように設定するかを決定します。これらのファイルの名前は ifcfg-name_pass です。接尾辞 name は、設定ファイルが制御するデバイスの名前を指します。通常、ifcfg ファイルの接尾辞は、設定ファイル自体の DEVICE ディレクティブが指定する文字列と同じです。
NetworkManager は、鍵ファイル形式で保存されたプロファイルに対応します。ただし、NetworkManager の API を使用してプロファイルを作成または更新する場合、NetworkManager はデフォルトで ifcfg 形式を使用します。
将来のメジャーリリースの RHEL では、鍵ファイル形式がデフォルトになります。設定ファイルを手動で作成して管理する場合は、鍵ファイル形式の使用を検討してください。詳細は、キーファイル形式の NetworkManager 接続プロファイル を参照してください。
37.1. ifcfg ファイルの静的ネットワーク設定でインタフェースの設定
NetworkManager ユーティリティーおよびアプリケーションを使用しない場合は、ifcfg ファイルを作成してネットワークインターフェイスを手動で設定できます。
手順
ifcfgファイルを使用して、静的ネットワークで、インターフェイスenp1s0を設定するには、/etc/sysconfig/network-scripts/ディレクトリー内に、以下のような内容でifcfg-enp1s0という名前のファイルを作成します。IPv4設定の場合は、以下のようになります。DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes PREFIX=24 IPADDR=192.0.2.1 GATEWAY=192.0.2.254IPv6設定の場合は、以下のようになります。DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64
37.2. ifcfg ファイルの動的ネットワーク設定でインタフェースの設定
NetworkManager ユーティリティーおよびアプリケーションを使用しない場合は、ifcfg ファイルを作成してネットワークインターフェイスを手動で設定できます。
手順
ifcfgファイルの動的ネットワークを使用して、インターフェイス em1 を設定するには、/etc/sysconfig/network-scripts/ディレクトリーに、以下のような内容で、ifcfg-em1という名前のファイルを作成します。DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yes送信するインターフェイスを設定するには、以下を行います。
DHCPサーバーに別のホスト名を追加し、ifcfgファイルに以下の行を追加します。DHCP_HOSTNAME=hostnameDHCPサーバーに、別の完全修飾ドメイン名 (FQDN) を追加し、ifcfgファイルに以下の行を追加します。DHCP_FQDN=fully.qualified.domain.name
注記この設定は、いずれか一方のみを使用できます。
DHCP_HOSTNAMEとDHCP_FQDNの両方を指定すると、DHCP_FQDNのみが使用されます。特定の
DNSサーバーを使用するようにインターフェイスを設定する場合は、ifcfgファイルに以下の行を追加します。PEERDNS=no DNS1=ip-address DNS2=ip-addressip-address は、
DNSサーバーのアドレスです。これにより、ネットワークサービスが、指定したDNSサーバーで/etc/resolv.confを更新します。DNSサーバーアドレスは、1 つだけ必要です。もう 1 つは任意です。
37.3. ifcfg ファイルでシステム全体およびプライベート接続プロファイルの管理
デフォルトでは、ホスト上のすべてのユーザーが ifcfg ファイルで定義された接続を使用できます。ifcfg ファイルに USERS パラメーターを追加すると、この動作を特定ユーザーに制限できます。
前提条件
-
ifcfgファイルがすでに存在します。
手順
特定のユーザーに制限する
/etc/sysconfig/network-scripts/ディレクトリーのifcfgファイルを編集し、以下を追加します。USERS="username1 username2 ..."接続をリアクティブにします。
# nmcli connection up connection_name
第38章 キーファイル形式の NetworkManager 接続プロファイル
NetworkManager は、デフォルトでは接続プロファイルを ifcfg 形式で保存しますが、キーファイル形式のプロファイルを使用することもできます。非推奨の ifcfg 形式とは異なり、キーファイル形式は NetworkManager が提供するすべての接続設定をサポートします。
Red Hat Enterprise Linux 9 では、キーファイル形式がデフォルトになります。
38.1. NetworkManager プロファイルのキーファイル形式
キーファイルの形式は INI 形式に似ています。たとえば、次はキーファイル形式のイーサネット接続プロファイルです。
[connection]
id=example_connection
uuid=82c6272d-1ff7-4d56-9c7c-0eb27c300029
type=ethernet
autoconnect=true
[ipv4]
method=auto
[ipv6]
method=auto
[ethernet]
mac-address=00:53:00:8f:fa:66パラメーターの入力や配置を誤ると、予期しない動作が発生する可能性があります。したがって、NetworkManager プロファイルを手動で編集または作成しないでください。
NetworkManager 接続を管理するには、nmcli ユーティリティー、network RHEL システムロール、または nmstate API を使用してください。たとえば、オフラインモードで nmcli ユーティリティー を使用して接続プロファイルを作成できます。
各セクションは、nm-settings(5) man ページで説明されている NetworkManager 設定名に対応しています。セクションの各 key-value-pair は、man ページの settings 仕様に記載されているプロパティーのいずれかになります。
NetworkManager キーファイルのほとんどの変数には、1 対 1 のマッピングがあります。つまり、NetworkManager プロパティーは、同じ名前と形式の変数としてキーファイルに保存されます。ただし、主にキーファイルの構文を読みやすくするために例外があります。この例外のリストは、システム上の nm-settings-keyfile(5) man ページを参照してください。
接続プロファイルには秘密鍵やパスフレーズなどの機密情報が含まれる可能性があるため、セキュリティー上の理由から、NetworkManager は root ユーザーが所有し、root のみが読み書きできる設定ファイルのみを使用します。
接続プロファイルを .nmconnection 接尾辞付きで /etc/NetworkManager/system-connections/ ディレクトリーに保存します。このディレクトリーには永続的なプロファイルが含まれています。NetworkManager API を使用して、永続プロファイルを変更すると、NetworkManager は、このディレクトリーにファイルを書き込み、上書きします。
NetworkManager は、ディスクからプロファイルを自動的に再読み込みしません。キーファイル形式で接続プロファイルを作成または更新する場合は、nmcli connection reload コマンドを使用して、変更を NetworkManager に通知します。
38.2. nmcli を使用したオフラインモードでのキーファイル接続プロファイルの作成
NetworkManager ユーティリティー (nmcli、network RHEL システムロール、NetworkManager 接続を管理するための nmstate API など) を使用して、設定ファイルを作成および更新します。ただし、nmcli --offline connection add コマンドを使用して、オフラインモードでキーファイル形式のさまざまな接続プロファイルを作成することもできます。
オフラインモードでは、nmcli が NetworkManager サービスなしで動作し、標準出力を介してキーファイル接続プロファイルを生成することが保証されます。この機能は、次の場合に役立ちます。
- どこかに事前に展開する必要がある接続プロファイルを作成する場合。たとえば、コンテナーイメージ内、または RPM パッケージとして作成する場合。
-
NetworkManagerサービスが利用できない環境で接続プロファイルを作成する場合 (chrootユーティリティーを使用する場合など)。または、Kickstart%postスクリプトを使用してインストールする RHEL システムのネットワーク設定を作成または変更する場合。
手順
キーファイル形式で新しい接続プロファイルを作成します。たとえば、DHCP を使用しないイーサネットデバイスの接続プロファイルの場合は、同様の
nmcliコマンドを実行します。# nmcli --offline connection add type ethernet con-name Example-Connection ipv4.addresses 192.0.2.1/24 ipv4.dns 192.0.2.200 ipv4.method manual > /etc/NetworkManager/system-connections/example.nmconnection注記con-nameキーで指定した接続名は、生成されたプロファイルのid変数に保存されます。後でnmcliコマンドを使用してこの接続を管理する場合は、次のように接続を指定します。-
id変数を省略しない場合は、Example-Connectionなどの接続名を使用します。 -
id変数を省略する場合は、outputのように.nmconnection接尾辞のないファイル名を使用します。
-
設定ファイルにパーミッションを設定して、
rootユーザーのみが読み取りおよび更新できるようにします。# chmod 600 /etc/NetworkManager/system-connections/example.nmconnection # chown root:root /etc/NetworkManager/system-connections/example.nmconnectionNetworkManagerサービスを開始します。# systemctl start NetworkManager.serviceプロファイルの
autoconnect変数をfalseに設定した場合は、コネクションをアクティブにします。# nmcli connection up Example-Connection
検証
NetworkManagerサービスが実行されていることを確認します。# systemctl status NetworkManager.service ● NetworkManager.service - Network Manager Loaded: loaded (/usr/lib/systemd/system/NetworkManager.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2022-08-03 13:08:32 CEST; 1min 40s ago ...NetworkManager が設定ファイルからプロファイルを読み込めることを確認します。
# nmcli -f TYPE,FILENAME,NAME connection TYPE FILENAME NAME ethernet /etc/NetworkManager/system-connections/examaple.nmconnection Example-Connection ethernet /etc/sysconfig/network-scripts/ifcfg-enp1s0 enp1s0 ...新しく作成された接続が出力に表示されない場合は、使用したキーファイルのパーミッションと構文が正しいことを確認してください。
接続プロファイルを表示します。
# nmcli connection show Example-Connection connection.id: Example-Connection connection.uuid: 232290ce-5225-422a-9228-cb83b22056b4 connection.stable-id: -- connection.type: 802-3-ethernet connection.interface-name: -- connection.autoconnect: yes ...
38.3. キーファイル形式での NetworkManager プロファイルの手動作成
NetworkManager 接続プロファイルは、キーファイル形式で手動で作成できます。
設定ファイルを手動で作成または更新すると、予期しないネットワーク設定や、機能しないネットワーク設定が発生する可能性があります。代わりに、オフラインモードで nmcli を使用できます。nmcli を使用したオフラインモードでのキーファイル接続プロファイルの作成 を参照してください。
手順
接続プロファイルを作成します。たとえば、DHCP を使用する
enp1s0イーサネットデバイスの接続プロファイルを作成する場合は、次の内容の/etc/NetworkManager/system-connections/example.nmconnectionファイルを作成します。[connection] id=Example-Connection type=ethernet autoconnect=true interface-name=enp1s0 [ipv4] method=auto [ipv6] method=auto注記ファイル名には、
.nmconnectionの接尾辞を付けた任意のファイル名を使用できます。ただし、後でnmcliコマンドを使用して接続を管理する場合は、この接続を参照する際に、idに設定した接続名を使用する必要があります。idを省略する場合は、.nmconnectionを使用せずにファイルネームを使用して、このコネクションを参照してください。設定ファイルにパーミッションを設定して、
rootのユーザーのみが読み取りおよび更新できるようにします。# chown root:root /etc/NetworkManager/system-connections/example.nmconnection # chmod 600 /etc/NetworkManager/system-connections/example.nmconnection接続プロファイルを再読み込みします。
# nmcli connection reloadNetworkManager が設定ファイルからプロファイルを読み込んでいることを確認します。
# nmcli -f NAME,UUID,FILENAME connection NAME UUID FILENAME Example-Connection 86da2486-068d-4d05-9ac7-957ec118afba /etc/NetworkManager/system-connections/example.nmconnection ...このコマンドで、新しく追加した接続が表示されない場合は、ファイルの権限と、ファイルで使用した構文が正しいことを確認します。
プロファイルの
autoconnect変数をfalseに設定した場合は、コネクションをアクティブにします。# nmcli connection up example_connection
検証
接続プロファイルを表示します。
# nmcli connection show example_connection
38.4. ifcfg およびキーファイル形式でのプロファイルを使用したインターフェイスの名前変更における違い
provider または lan などのカスタムネットワークインターフェイス名を定義して、インターフェイス名をよりわかりやすいものにすることができます。この場合、udev サービスはインターフェイスの名前を変更します。名前変更プロセスは、ifcfg またはキーファイル形式で接続プロファイルを使用するかどうかによって異なる動作をします。
ifcfg形式でプロファイルを使用する場合のインターフェイスの名前変更プロセス-
udevルールファイル/usr/lib/udev/rules.d/60-net.rulesが、/lib/udev/rename_deviceヘルパーユーティリティーを呼び出します。 -
ヘルパーユーティリティーは、
/etc/sysconfig/network-scripts/ifcfg-*ファイルのHWADDRパラメーターを検索します。 -
変数に設定した値がインターフェイスの MAC アドレスに一致すると、ヘルパーユーティリティーは、インターフェイスの名前を、ファイルの
DEVICEパラメーターに設定した名前に変更します。
-
- キーファイル形式でプロファイルを使用する場合のインターフェイスの名前変更プロセス
- インターフェイスの名前を変更する systemd リンクファイル または udev ルール を作成します。
-
NetworkManager 接続プロファイルの
interface-nameプロパティーで、カスタムインターフェイス名を使用します。
38.5. ifcfg からキーファイル形式への NetworkManager プロファイルの移行
ifcfg 形式の接続プロファイルを使用している場合は、接続プロファイルをキーファイル形式に変換して、すべてのプロファイルを推奨される形式で 1 つの場所に配置できます。
ifcfg ファイルに NM_CONTROLLED=no 設定が含まれる場合、NetworkManager は、このプロファイルを制御しないため、移行プロセスはそれを無視します。
前提条件
-
/etc/sysconfig/network-scripts/ディレクトリーにifcfg形式の接続プロファイルがある。 -
接続プロファイルに、
providerやlanなどのカスタムデバイス名に設定されているDEVICE変数が含まれている場合は、カスタムデバイス名ごとに systemd リンクファイル または udev ルール を作成している。
手順
接続プロファイルを移行します。
# nmcli connection migrate Connection 'enp1s0' (43ed18ab-f0c4-4934-af3d-2b3333948e45) successfully migrated. Connection 'enp2s0' (883333e8-1b87-4947-8ceb-1f8812a80a9b) successfully migrated. ...
検証
必要に応じて、すべての接続プロファイルが正常に移行されたことを確認できます。
# nmcli -f TYPE,FILENAME,NAME connection TYPE FILENAME NAME ethernet /etc/NetworkManager/system-connections/enp1s0.nmconnection enp1s0 ethernet /etc/NetworkManager/system-connections/enp2s0.nmconnection enp2s0 ...
第39章 systemd ネットワークターゲットおよびサービス
RHEL は、ネットワーク設定を適用する間に、network および network-online ターゲットと NetworkManager-wait-online サービスを使用します。また、systemd サービスがネットワークが稼働していることを前提としており、ネットワーク状態の変化に動的に反応できない場合は、ネットワークが完全に利用可能になった後にサービスが起動するように設定することもできます。
39.1. systemd ターゲット network と network-online の違い
Systemd は、ターゲットユニット network および network-online を維持します。NetworkManager-wait-online.service などの特殊ユニットは、WantedBy=network-online.target パラメーターおよび Before=network-online.target パラメーターを持ちます。有効にすると、このようなユニットは network-online.target で開始し、一部の形式のネットワーク接続が確立されるまでターゲットに到達させるよう遅延します。ネットワークが接続されるまで、network-online ターゲットが遅延します。
network-online ターゲットはサービスを開始します。これにより、実行の遅延が大幅に増加します。Systemd は、このターゲットユニットの Wants パラメーターおよび After パラメーターの依存関係を、$network ファシリティーを参照する Linux Standard Base (LSB) ヘッダーを持つすべての System V(SysV) init スクリプトサービスユニットに自動的に追加します。LSB ヘッダーは、init スクリプトのメタデータです。これを使用して依存関係を指定できます。これは systemd ターゲットに似ています。
network ターゲットは、起動プロセスの実行を大幅に遅らせません。network ターゲットに到達すると、ネットワークの設定を行うサービスが開始していることになります。ただし、ネットワークデバイスが設定されているわけではありません。このターゲットは、システムのシャットダウン時に重要です。たとえば、起動中に network ターゲットの後に順序付けされたサービスがあると、この依存関係はシャットダウン中に元に戻されます。サービスが停止するまで、ネットワークは切断されません。リモートネットワークファイルシステムのすべてのマウントユニットは、network-online ターゲットユニットを自動的に起動し、その後に自身を置きます。
network-online ターゲットユニットは、システムの起動時にのみ役に立ちます。システムの起動が完了すると、このターゲットがネットワークのオンライン状態を追跡しなくなります。したがって、network-online を使用してネットワーク接続を監視することはできません。このターゲットは、1 回限りのシステム起動の概念を提供します。
39.2. NetworkManager-wait-online の概要
NetworkManager-wait-online サービスは、起動が完了したことを NetworkManager が報告するまで、network-online ターゲットへの到達を遅らせます。NetworkManager は、起動時に connection.autoconnect パラメーターが yes に設定されたすべてのプロファイルをアクティブにします。ただし、NetworkManager プロファイルがアクティブ化状態である限り、プロファイルのアクティベーションは完了しません。アクティベーションに失敗すると、NetworkManager は connection.autoconnect-retries の値に応じてアクティベーションを再試行します。
デバイスがアクティブ状態に達するタイミングは、その設定により異なります。たとえば、プロファイルに IPv4 と IPv6 の両方の設定が含まれている場合、アドレスファミリーの 1 つだけ準備が完了していると、NetworkManager はデフォルトでデバイスが完全にアクティブ化されていると見なします。接続プロファイルの ipv4.may-fail および ipv6.may-fail パラメーターが、この動作を制御します。
イーサネットデバイスの場合、NetworkManager はタイムアウトでキャリアを待ちます。したがって、イーサネットケーブルが接続されていないと、NetworkManager-wait-online.service はさらに遅延します。
起動が完了すると、すべてのプロファイルが非接続状態になるか、正常にアクティブ化されます。プロファイルを自動接続するように設定できます。以下は、タイムアウトを設定したり、接続がアクティブとみなされるタイミングを定義するいくつかのパラメーター例です。
-
connection.wait-device-timeout: ドライバーがデバイスを検出するためのタイムアウトを設定します。 -
ipv4.may-failおよびipv6.may-fail: 1 つの IP アドレスファミリーの準備ができている状態でアクティベーションを設定します。または、特定のアドレスファミリーが設定を完了する必要があるかを設定します。 -
ipv4.gateway-ping-timeout: NetworkManager が IPv4 ゲートウェイから ping 応答を受信するまで、ネットワークのアクティブ化を遅延します。システムは、次の処理に進む前に、最大で指定された秒数だけ待機します。
39.3. ネットワークの開始後に systemd サービスが起動する設定
Red Hat Enterprise Linux は、systemd サービスファイルを /usr/lib/systemd/system/ ディレクトリーにインストールします。この手順では、/etc/systemd/system/<service_name>.service.d/ 内のサービスファイル用のドロップインスニペットを作成します。このスニペットは、ネットワークがオンラインになった後に特定のサービスを起動するために、/usr/lib/systemd/system/ 内のサービスファイルと一緒に使用します。ドロップインスニペットの設定が、/usr/lib/systemd/system/ 内のサービスファイルにある値と重複する場合は、優先度が高くなります。
手順
エディターでサービスファイルを開きます。
# systemctl edit <service_name>以下を入力し、変更を保存します。
[Unit] After=network-online.targetsystemdサービスを再読み込みします。# systemctl daemon-reload
第40章 Nmstate の概要
nmstate は宣言型のネットワークマネージャー API です。Nmstate を使用する場合、YAML または JSON 形式の命令を使用して想定されるネットワーク状態を記述します。
Nmstate には多くの利点があります。たとえば、以下のようになります。
- 安定性と拡張可能なインターフェイスを提供して RHEL ネットワーク機能を管理する。
- ホストおよびクラスターレベルでのアトミックおよびトランザクション操作をサポートする。
- ほとんどのプロパティーの部分編集をサポートし、この手順で指定されていない既存の設定を保持する。
- 管理者が独自のプラグインを使用できるようにプラグインサポートを提供する。
Nmstate は次のパッケージで構成されています。
| パッケージ | 内容 |
|---|---|
|
|
|
|
|
|
|
| Nmstate C ライブラリー |
|
| Nmstate C ライブラリーヘッダー |
40.1. Python アプリケーションでの libnmstate ライブラリーの使用
libnmstate Python ライブラリーを使用すると、開発者は独自のアプリケーションで Nmstate を使用できます。
ライブラリーを使用するには、ソースコードにインポートします。
import libnmstate
このライブラリーを使用するには、nmstate および python3-libnmstate パッケージをインストールする必要があることに注意してください。
例40.1 libnmstate ライブラリーを使用したネットワーク状態のクエリー
以下の Python コードは、libnmstate ライブラリーをインポートし、利用可能なネットワークインターフェイスとその状態を表示します。
import libnmstate
from libnmstate.schema import Interface
net_state = libnmstate.show()
for iface_state in net_state[Interface.KEY]:
print(iface_state[Interface.NAME] + ": "
+ iface_state[Interface.STATE])40.2. nmstatectl を使用した現在のネットワーク設定の更新
nmstatectl ユーティリティーを使用して、1 つまたはすべてのインターフェイスの現在のネットワーク設定をファイルに保存できます。このファイルを使用して、以下を行うことができます。
- 設定を変更し、同じシステムに適用します。
- 別のホストにファイルをコピーし、同じまたは変更された設定でホストを設定します。
たとえば、enp1s0 インターフェイスの設定をファイルにエクスポートして、設定を変更し、その設定をホストに適用することができます。
前提条件
-
nmstateパッケージがインストールされている。
手順
enp1s0インターフェイスの設定を~/network-config.ymlファイルにエクスポートします。# nmstatectl show enp1s0 > ~/network-config.ymlこのコマンドにより、
enp1s0の設定が YAML 形式で保存されます。JSON 形式で出力を保存するには、--jsonオプションをコマンドに渡します。インターフェイス名を指定しない場合、
nmstatectlはすべてのインターフェイスの設定をエクスポートします。-
テキストエディターで
~/network-config.ymlファイルを変更して、設定を更新します。 ~/network-config.ymlファイルからの設定を適用します。# nmstatectl apply ~/network-config.ymlJSON 形式で設定をエクスポートしている場合は、
--jsonオプションをコマンドに渡します。
40.3. network RHEL システムロールのネットワーク状態
network RHEL システムロールは、Playbook でデバイスを設定するための状態設定をサポートしています。これには、network_state 変数の後に状態設定を使用します。
Playbook で network_state 変数を使用する利点:
- 状態設定で宣言型の方法を使用すると、インターフェイスを設定でき、NetworkManager はこれらのインターフェイスのプロファイルをバックグラウンドで作成します。
-
network_state変数を使用すると、変更が必要なオプションを指定できます。他のすべてのオプションはそのまま残ります。ただし、network_connections変数を使用して、ネットワーク接続プロファイルを変更するには、すべての設定を指定する必要があります。
network_state では Nmstate YAML 命令のみを設定できます。この命令は、network_connections で設定できる変数とは異なります。
たとえば、動的 IP アドレス設定でイーサネット接続を作成するには、Playbook で次の vars ブロックを使用します。
| 状態設定を含む Playbook | 通常の Playbook |
|
|
たとえば、上記のように作成した動的 IP アドレス設定の接続ステータスのみを変更するには、Playbook で次の vars ブロックを使用します。
| 状態設定を含む Playbook | 通常の Playbook |
|
|
第41章 firewalld の使用および設定
ファイアウォールは、外部からの不要なトラフィックからマシンを保護する方法です。ファイアウォールルール セットを定義することで、ホストマシンへの着信ネットワークトラフィックを制御できます。このようなルールは、着信トラフィックを分類して、拒否または許可するために使用されます。
firewalld は、D-Bus インターフェイスを使用して、動的にカスタマイズできるファイアウォールを提供するファイアウォールサービスデーモンです。動的であるため、ルールが変更されるたびにファイアウォールデーモンを再起動する必要なく、ルールの作成、変更、削除が可能になります。
firewalld を使用して、一般的なケースの大部分で必要なパケットフィルタリングを設定できます。firewalld がシナリオをカバーしていない場合、またはルールを完全に制御したい場合は、nftables フレームワークを使用します。
firewalld は、ゾーン、ポリシー、サービスの概念を使用してトラフィック管理を単純化します。ゾーンはネットワークを論理的に分離します。ネットワークインターフェイスおよびソースをゾーンに割り当てることができます。ポリシーは、ゾーン間のトラフィックの流れを拒否または許可するために使用されます。ファイアウォールサービスは、特定のサービスに着信トラフィックを許可するのに必要なすべての設定を扱う事前定義のルールで、ゾーンに適用されます。
サービスは、ネットワーク接続に 1 つ以上のポートまたはアドレスを使用します。ファイアウォールは、ポートに基づいて接続のフィルターを設定します。サービスに対してネットワークトラフィックを許可するには、そのポートを解放する必要があります。firewalld は、明示的に解放されていないポートのトラフィックをすべてブロックします。trusted などのゾーンでは、デフォルトですべてのトラフィックを許可します。
firewalld は、ランタイム設定と永続設定を別々に維持します。そのため、ランタイムのみの変更が可能です。ランタイム設定は、firewalld の再読み込みまたは再起動後は保持されません。起動時に、永続的な設定から入力されます。
nftables バックエンドを使用した firewalld が、--direct オプションを使用して、カスタムの nftables ルールを firewalld に渡すことに対応していないことに注意してください。
41.1. firewalld、nftables、または iptables を使用する場合
RHEL 8 では、シナリオに応じて次のパケットフィルタリングユーティリティーを使用できます。
-
firewalld:firewalldユーティリティーは、一般的なユースケースのファイアウォール設定を簡素化します。 -
nftables:nftablesユーティリティーを使用して、ネットワーク全体など、複雑なパフォーマンスに関する重要なファイアウォールを設定します。 -
iptables: Red Hat Enterprise Linux のiptablesユーティリティーは、legacyバックエンドの代わりにnf_tablesカーネル API を使用します。nf_tablesAPI は、iptablesコマンドを使用するスクリプトが、Red Hat Enterprise Linux で引き続き動作するように、後方互換性を提供します。新しいファイアウォールスクリプトの場合は、nftablesを使用します。
さまざまなファイアウォール関連サービス (firewalld、nftables、または iptables) が相互に影響を与えないようにするには、RHEL ホストでそのうち 1 つだけを実行し、他のサービスを無効にします。
41.2. ファイアウォールゾーン
firewalld ユーティリティーを使用すると、ネットワーク内のインターフェイスおよびトラフィックに対する信頼レベルに応じて、ネットワークをさまざまなゾーンに分離できます。接続は 1 つのゾーンにしか指定できませんが、そのゾーンは多くのネットワーク接続に使用できます。
firewalld はゾーンに関して厳格な原則に従います。
- トラフィックは 1 つのゾーンのみに流入します。
- トラフィックは 1 つのゾーンのみから流出します。
- ゾーンは信頼のレベルを定義します。
- ゾーン内トラフィック (同じゾーン内) はデフォルトで許可されます。
- ゾーン間トラフィック (ゾーンからゾーン) はデフォルトで拒否されます。
原則 4 と 5 は原則 3 の結果です。
原則 4 は、ゾーンオプション --remove-forward を使用して設定できます。原則 5 は、新しいポリシーを追加することで設定できます。
NetworkManager は、firewalld にインターフェイスのゾーンを通知します。次のユーティリティーを使用して、ゾーンをインターフェイスに割り当てることができます。
-
NetworkManager -
firewall-configユーティリティー -
firewall-cmdユーティリティー - RHEL Web コンソール
RHEL Web コンソール、firewall-config、および firewall-cmd は、 適切な NetworkManager 設定ファイルのみを編集できます。Web コンソール、firewall-cmd または firewall-config を使用してインターフェイスのゾーンを変更する場合、リクエストは NetworkManager に転送され、firewalld では処理されません。
/usr/lib/firewalld/zones/ ディレクトリーには事前定義されたゾーンが保存されており、利用可能なネットワークインターフェイスに即座に適用できます。このファイルは、修正しないと /etc/firewalld/zones/ ディレクトリーにコピーされません。事前定義されたゾーンのデフォルト設定は次のとおりです。
block-
適している対象:
IPv4の場合は icmp-host-prohibited メッセージ、IPv6の場合は icmp6-adm-prohibited メッセージで、すべての着信ネットワーク接続を拒否する場合。 - 受け入れる接続: システム内から開始したネットワーク接続のみ。
-
適している対象:
dmz- 適している対象: パブリックにアクセス可能で、内部ネットワークへのアクセスが制限されている DMZ 内のコンピューター。
- 受け入れる接続: 選択した着信接続のみ。
drop適している対象: 着信ネットワークパケットを通知なしで破棄する場合。
- 受け入れる接続: 発信ネットワーク接続のみ。
external- 適している対象: マスカレードをルーター用に特別に有効にした外部ネットワーク。ネットワーク上の他のコンピューターを信頼できない状況。
- 受け入れる接続: 選択した着信接続のみ。
home- 適している対象: ネットワーク上の他のコンピューターをほぼ信頼できる自宅の環境。
- 受け入れる接続: 選択した着信接続のみ。
internal- 適している対象: ネットワーク上の他のコンピューターをほぼ信頼できる内部ネットワーク。
- 受け入れる接続: 選択した着信接続のみ。
public- 適している対象: ネットワーク上の他のコンピューターを信頼できないパブリックエリア。
- 受け入れる接続: 選択した着信接続のみ。
trusted- 受け入れる接続: すべてのネットワーク接続。
work適している対象: ネットワーク上の他のコンピューターをほぼ信頼できる職場の環境。
- 受け入れる接続: 選択した着信接続のみ。
このゾーンのいずれかを デフォルト ゾーンに設定できます。インターフェイス接続を NetworkManager に追加すると、デフォルトゾーンに割り当てられます。インストール時は、firewalld のデフォルトゾーンは public ゾーンです。デフォルトゾーンは変更できます。
ユーザーがすぐに理解できるように、ネットワークゾーン名は分かりやすい名前にしてください。
セキュリティー問題を回避するために、ニーズおよびリスク評価に合わせて、デフォルトゾーンの設定の見直しを行ったり、不要なサービスを無効にしてください。
41.3. ファイアウォールポリシー
ファイアウォールポリシーは、ネットワークの望ましいセキュリティー状態を指定します。これらのポリシーは、さまざまなタイプのトラフィックに対して実行するルールとアクションの概要を示します。通常、ポリシーには次のタイプのトラフィックに対するルールが含まれます。
- 着信トラフィック
- 送信トラフィック
- 転送トラフィック
- 特定のサービスとアプリケーション
- ネットワークアドレス変換 (NAT)
ファイアウォールポリシーは、ファイアウォールゾーンの概念を使用します。各ゾーンは、許可するトラフィックを決定する特定のファイアウォールルールのセットに関連付けられます。ポリシーは、ステートフルかつ一方向にファイアウォールルールを適用します。つまり、トラフィックの一方向のみを考慮します。firewalld のステートフルフィルタリングにより、トラフィックのリターンパスは暗黙的に許可されます。
ポリシーは、イングレスゾーンとエグレスゾーンに関連付けられます。イングレスゾーンは、トラフィックが発生する (受信される) 場所です。エグレスゾーンは、トラフィックが出る (送信される) 場所です。
ポリシーで定義されたファイアウォールのルールは、ファイアウォールゾーンを参照して、複数のネットワークインターフェイス全体に一貫した設定を適用できます。
41.4. ファイアウォールのルール
ファイアウォールのルールを使用して、ネットワークトラフィックを許可またはブロックする特定の設定を実装できます。その結果、ネットワークトラフィックのフローを制御して、システムをセキュリティーの脅威から保護できます。
ファイアウォールのルールは通常、さまざまな属性に基づいて特定の基準を定義します。属性は次のとおりです。
- ソース IP アドレス
- 宛先 IP アドレス
- 転送プロトコル (TCP、UDP、…)
- Ports
- ネットワークインターフェイス
firewalld ユーティリティーは、ファイアウォールのルールをゾーン (public、internal など) とポリシーに整理します。各ゾーンには、特定のゾーンに関連付けられたネットワークインターフェイスのトラフィック自由度のレベルを決定する独自のルールセットがあります。
41.5. ファイアウォールの直接ルール
firewalld サービスでは、次のような複数の方法でルールを設定できます。
- 通常ルール
- 直接ルール
これらの違いの 1 つは、それぞれの方法において基盤となるバックエンド (iptables または nftables) とどのように対話するかです。
直接ルールは、iptables との直接的なやり取りを可能にする高度な低レベルのルールです。これらは、firewalld の構造化されたゾーンベースの管理をバイパスして、より詳細な制御を可能にします。生の iptables 構文を使用して、firewall-cmd コマンドで直接ルールを手動で定義します。たとえば、firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -s 198.51.100.1 -j DROP です。このコマンドは、198.51.100.1 の送信元 IP アドレスからのトラフィックをドロップする iptables ルールを追加します。
ただし、直接ルールを使用すると欠点もあります。特に、nftables が 主要なファイアウォールバックエンドである場合に当てはまります。以下に例を示します。
-
直接ルールは維持が難しく、
nftablesベースのfirewalld設定と競合する可能性があります。 -
直接ルールは、生の式やステートフルオブジェクトなど、
nftablesにある高度な機能をサポートしません。 -
直接的なルールは将来に耐えられません。
iptablesコンポーネントは非推奨であり、最終的には RHEL から削除される予定です。
前述の理由により、firewalld の 直接ルールを nftables に置き換えることを検討してください。詳細は、ナレッジベースソリューション firewalld の直接ルールを nftables に置き換える方法 を参照してください。
41.6. 事前定義された firewalld サービス
事前定義された firewalld サービスは、低レベルのファイアウォールルール上に組み込みの抽象化レイヤーを提供します。これは、SSH や HTTP などの一般的に使用されるネットワークサービスを、対応するポートとプロトコルにマッピングすることで実現されます。これらを毎回手動で指定する代わりに、名前付きの定義済みサービスを参照できます。これにより、ファイアウォールの管理がよりシンプルになり、エラーが減り、より直感的になります。
利用可能な定義済みサービスを表示するには、以下を実行します。
# firewall-cmd --get-services RH-Satellite-6 RH-Satellite-6-capsule afp amanda-client amanda-k5-client amqp amqps apcupsd audit ausweisapp2 bacula bacula-client bareos-director bareos-filedaemon bareos-storage bb bgp bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc bittorrent-lsd ceph ceph-exporter ceph-mon cfengine checkmk-agent cockpit collectd condor-collector cratedb ctdb dds...特定の定義済みサービスをさらに調査するには、以下を実行します。
# sudo firewall-cmd --info-service=RH-Satellite-6 RH-Satellite-6 ports: 5000/tcp 5646-5647/tcp 5671/tcp 8000/tcp 8080/tcp 9090/tcp protocols: source-ports: modules: destination: includes: foreman helpers:出力例では、
RH-Satellite-6定義済みサービスがポート 5000/tcp、5646-5647/tcp、5671/tcp、8000/tcp、8080/tcp、9090/tcp をリッスンしていることが示されています。さらに、RH-Satellite-6は別の定義済みサービスからルールを継承します。この場合はforemanです。
定義済みの各サービスは、/usr/lib/firewalld/services/ ディレクトリーに同じ名前の XML ファイルとして保存されます。
41.7. ファイアウォールゾーンでの作業
ゾーンは、着信トラフィックをより透過的に管理する概念を表しています。ゾーンはネットワークインターフェイスに接続されているか、ソースアドレスの範囲に割り当てられます。各ゾーンは個別にファイアウォールルールを管理しますが、これにより、複雑なファイアウォール設定を定義してトラフィックに割り当てることができます。
41.7.1. 特定のゾーンのファイアウォール設定をカスタマイズすることによるセキュリティーの強化
ファイアウォール設定を変更し、特定のネットワークインターフェイスまたは接続を特定のファイアウォールゾーンに関連付けることで、ネットワークセキュリティーを強化できます。ゾーンの詳細なルールと制限を定義することで、意図したセキュリティーレベルに基づいて受信トラフィックと送信トラフィックを制御できます。
たとえば、次のような利点が得られます。
- 機密データの保護
- 不正アクセスの防止
- 潜在的なネットワーク脅威の軽減
前提条件
-
firewalldサービスが実行中である。
手順
利用可能なファイアウォールゾーンをリスト表示します。
# firewall-cmd --get-zonesfirewall-cmd --get-zonesコマンドは、システムで利用可能なすべてのゾーンを表示し、特定のゾーンの詳細は表示しません。すべてのゾーンの詳細情報を表示するには、firewall-cmd --list-all-zonesコマンドを使用します。- この設定に使用するゾーンを選択します。
選択したゾーンのファイアウォール設定を変更します。たとえば、
SSHサービスを許可し、ftpサービスを削除するには、次のようにします。# firewall-cmd --add-service=ssh --zone=<your_chosen_zone> # firewall-cmd --remove-service=ftp --zone=<same_chosen_zone>ネットワークインターフェイスをファイアウォールゾーンに割り当てます。
使用可能なネットワークインターフェイスをリスト表示します。
# firewall-cmd --get-active-zonesゾーンがアクティブかどうかは、その設定と一致するネットワークインターフェイスまたはソースアドレス範囲の存在によって決定します。デフォルトゾーンは、未分類のトラフィックに対してアクティブですが、ルールに一致するトラフィックがない場合は常にアクティブになるわけではありません。
選択したゾーンにネットワークインターフェイスを割り当てます。
# firewall-cmd --zone=<your_chosen_zone> --change-interface=<interface_name> --permanentネットワークインターフェイスをゾーンに割り当てることは、特定のインターフェイス (物理または仮想) 上のすべてのトラフィックに一貫したファイアウォール設定を適用する場合に適しています。
firewall-cmdコマンドを--permanentオプションとともに使用すると、多くの場合、NetworkManager 接続プロファイルが更新され、ファイアウォール設定に対する変更が永続化します。このfirewalldと NetworkManager の統合により、ネットワークとファイアウォールの設定に一貫性が確保されます。
検証
選択したゾーンの更新後の設定を表示します。
# firewall-cmd --zone=<your_chosen_zone> --list-allコマンド出力には、割り当てられたサービス、ネットワークインターフェイス、ネットワーク接続 (ソース) を含むすべてのゾーン設定が表示されます。
41.7.2. デフォルトゾーンの変更
システム管理者は、設定ファイルのネットワークインターフェイスにゾーンを割り当てます。特定のゾーンに割り当てられないインターフェイスは、デフォルトゾーンに割り当てられます。firewalld サービスを再起動するたびに、firewalld は、デフォルトゾーンの設定を読み込み、それをアクティブにします。他のすべてのゾーンの設定は保存され、すぐに使用できます。
通常、ゾーンは NetworkManager により、NetworkManager 接続プロファイルの connection.zone 設定に従って、インターフェイスに割り当てられます。また、再起動後、NetworkManager はこれらのゾーンを "アクティブ化" するための割り当てを管理します。
前提条件
-
firewalldサービスが実行中である。
手順
デフォルトゾーンを設定するには、以下を行います。
現在のデフォルトゾーンを表示します。
# firewall-cmd --get-default-zone新しいデフォルトゾーンを設定します。
# firewall-cmd --set-default-zone <zone_name>注記この手順では、
--permanentオプションを使用しなくても、設定は永続化します。
41.7.3. ゾーンへのネットワークインターフェイスの割り当て
複数のゾーンに複数のルールセットを定義して、使用されているインターフェイスのゾーンを変更することで、迅速に設定を変更できます。各インターフェイスに特定のゾーンを設定して、そのゾーンを通過するトラフィックを設定できます。
手順
特定インターフェイスにゾーンを割り当てるには、以下を行います。
アクティブゾーン、およびそのゾーンに割り当てられているインターフェイスをリスト表示します。
# firewall-cmd --get-active-zones別のゾーンにインターフェイスを割り当てます。
# firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
41.7.4. ソースの追加
着信トラフィックを特定のゾーンに転送する場合は、そのゾーンにソースを追加します。ソースは、CIDR (Classless Inter-domain Routing) 表記法の IP アドレスまたは IP マスクになります。
ネットワーク範囲が重複している複数のゾーンを追加する場合は、ゾーン名で順序付けされ、最初のゾーンのみが考慮されます。
現在のゾーンにソースを設定するには、次のコマンドを実行します。
# firewall-cmd --add-source=<source>特定ゾーンのソース IP アドレスを設定するには、次のコマンドを実行します。
# firewall-cmd --zone=zone-name --add-source=<source>
以下の手順は、信頼される ゾーンで 192.168.2.15 からのすべての着信トラフィックを許可します。
手順
利用可能なすべてのゾーンをリストします。
# firewall-cmd --get-zones永続化モードで、信頼ゾーンにソース IP を追加します。
# firewall-cmd --zone=trusted --add-source=192.168.2.15新しい設定を永続化します。
# firewall-cmd --runtime-to-permanent
41.7.5. ソースの削除
ゾーンからソースを削除すると、当該ソースに指定したルールは、そのソースから発信されたトラフィックに適用されなくなります。代わりに、トラフィックは、その発信元のインターフェイスに関連付けられたゾーンのルールと設定にフォールバックするか、デフォルトゾーンに移動します。
手順
必要なゾーンに対して許可されているソースのリストを表示します。
# firewall-cmd --zone=zone-name --list-sourcesゾーンからソースを永続的に削除します。
# firewall-cmd --zone=zone-name --remove-source=<source>新しい設定を永続化します。
# firewall-cmd --runtime-to-permanent
41.7.6. nmcli を使用して接続にゾーンを割り当て
nmcli ユーティリティーを使用して、firewalld ゾーンを NetworkManager 接続に追加できます。
手順
ゾーンを
NetworkManager接続プロファイルに割り当てます。# nmcli connection modify profile connection.zone zone_name接続をアクティベートします。
# nmcli connection up profile
41.7.7. ifcfg ファイルでゾーンをネットワーク接続に手動で割り当て
NetworkManager で接続を管理する場合は、NetworkManager が使用するゾーンを認識する必要があります。すべてのネットワーク接続プロファイルに対してゾーンを指定できるため、ポータブルデバイスを備えたコンピューターの場所に応じて、さまざまなファイアウォール設定を柔軟に行うことができます。したがって、ゾーンおよび設定には、会社または自宅など、様々な場所を指定できます。
手順
接続のゾーンを設定するには、
/etc/sysconfig/network-scripts/ifcfg-connection_nameファイルを変更して、この接続にゾーンを割り当てる行を追加します。ZONE=zone_name
41.7.8. 新しいゾーンの作成
カスタムゾーンを使用するには、新しいゾーンを作成したり、事前定義したゾーンなどを使用したりします。新しいゾーンには --permanent オプションが必要となり、このオプションがなければコマンドは動作しません。
前提条件
-
firewalldサービスが実行中である。
手順
新しいゾーンを作成します。
# firewall-cmd --permanent --new-zone=zone-name新しいゾーンを使用可能にします。
# firewall-cmd --reloadこのコマンドは、すでに実行中のネットワークサービスを中断することなく、最近の変更をファイアウォール設定に適用します。
検証
作成したゾーンが永続設定に追加されたかどうかを確認します。
# firewall-cmd --get-zones --permanent
41.7.9. Web コンソールを使用したゾーンの有効化
RHEL Web コンソールを使用して、事前定義された既存のファイアウォールゾーンを特定のインターフェイスまたは IP アドレスの範囲に適用できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。

ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
- Firewall セクションの Add new zone をクリックします。
ゾーンの追加 ダイアログボックスで、信頼レベル オプションからゾーンを選択します。
Web コンソールには、
firewalldサービスで事前定義されたすべてのゾーンが表示されます。- インターフェイス で、選択したゾーンが適用されるインターフェイスを選択します。
許可されたサービス で、ゾーンを適用するかどうかを選択できます。
- サブネット全体
または、以下の形式の IP アドレスの範囲
- 192.168.1.0
- 192.168.1.0/24
- 192.168.1.0/24, 192.168.1.0
ボタンをクリックします。

検証
Firewall セクションの設定を確認します。

41.7.10. Web コンソールを使用したゾーンの無効化
Web コンソールを使用して、ファイアウォール設定のファイアウォールゾーンを無効にできます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
削除するゾーンの オプションアイコン をクリックします。

- Delete をクリックします。
これでゾーンが無効になり、そのゾーンに設定されたオープンなサービスおよびポートがインターフェイスに含まれなくなります。
41.7.11. 着信トラフィックにデフォルトの動作を設定するゾーンターゲットの使用
すべてのゾーンに対して、特に指定されていない着信トラフィックを処理するデフォルト動作を設定できます。そのような動作は、ゾーンのターゲットを設定することで定義されます。4 つのオプションがあります。
-
ACCEPT: 指定したルールで許可されていないパケットを除いた、すべての着信パケットを許可します。 -
REJECT: 指定したルールで許可されているパケット以外の着信パケットをすべて拒否します。firewalldがパケットを拒否すると、送信元マシンに拒否が通知されます。 -
DROP: 指定したルールで許可されているパケット以外の着信パケットをすべて破棄します。firewalldがパケットを破棄すると、ソースマシンにパケット破棄の通知がされません。 -
default:REJECTと似ていますが、特定のシナリオで特別な意味を持ちます。
前提条件
-
firewalldサービスが実行中である。
手順
ゾーンにターゲットを設定するには、以下を行います。
特定ゾーンに対する情報をリスト表示して、デフォルトゾーンを確認します。
# firewall-cmd --zone=zone-name --list-allゾーンに新しいターゲットを設定します。
# firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>
41.7.12. IP セットを使用した許可リストの動的更新の設定
ほぼリアルタイムで更新を行うことで、予測不可能な状況でも IP セット内の特定の IP アドレスまたは IP アドレス範囲を柔軟に許可できます。これらの更新は、セキュリティー脅威の検出やネットワーク動作の変化など、さまざまなイベントによってトリガーされます。通常、このようなソリューションでは自動化を活用して手動処理を減らし、素早く状況に対応することでセキュリティーを向上させます。
前提条件
-
firewalldサービスが実行中である。
手順
分かりやすい名前で IP セットを作成します。
# firewall-cmd --permanent --new-ipset=allowlist --type=hash:ipこの
allowlistという新しい IP セットには、ファイアウォールで許可する IP アドレスが含まれています。IP セットに動的更新を追加します。
# firewall-cmd --permanent --ipset=allowlist --add-entry=198.51.100.10この設定により、新しく追加した、ネットワークトラフィックを渡すことがファイアウォールにより許可される IP アドレスで、
allowlistの IP セットが更新されます。先に作成した IP セットを参照するファイアウォールのルールを作成します。
# firewall-cmd --permanent --zone=public --add-source=ipset:allowlistこのルールがない場合、IP セットはネットワークトラフィックに影響を与えません。デフォルトのファイアウォールポリシーが優先されます。
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
すべての IP セットをリスト表示します。
# firewall-cmd --get-ipsets allowlistアクティブなルールをリスト表示します。
# firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: enp0s1 sources: ipset:allowlist services: cockpit dhcpv6-client ssh ports: protocols: ...コマンドライン出力の
sourcesセクションでは、どのトラフィックの発信元 (ホスト名、インターフェイス、IP セット、サブネットなど) が、特定のファイアウォールゾーンへのアクセスを許可または拒否されているかについて洞察が得られます。上記の場合、allowlistIP セットに含まれる IP アドレスが、publicゾーンのファイアウォールを通してトラフィックを渡すことが許可されています。IP セットの内容を調べます。
# cat /etc/firewalld/ipsets/allowlist.xml <?xml version="1.0" encoding="utf-8"?> <ipset type="hash:ip"> <entry>198.51.100.10</entry> </ipset>
次のステップ
-
スクリプトまたはセキュリティーユーティリティーを使用して脅威インテリジェンスのフィードを取得し、それに応じて
allowlistを自動的に更新します。
41.8. firewalld でネットワークトラフィックの制御
firewalld パッケージは、事前定義された多数のサービスファイルをインストールし、それらをさらに追加したり、カスタマイズしたりできます。さらに、これらのサービス定義を使用して、サービスが使用するプロトコルとポート番号を知らなくても、サービスのポートを開いたり閉じたりできます。
41.8.1. CLI を使用した事前定義サービスによるトラフィックの制御
トラフィックを制御する最も簡単な方法は、事前定義したサービスを firewalld に追加する方法です。これにより、必要なすべてのポートが開き、service definition file に従ってその他の設定が変更されます。
前提条件
-
firewalldサービスが実行中である。
手順
firewalldのサービスがまだ許可されていないことを確認します。# firewall-cmd --list-services ssh dhcpv6-clientこのコマンドは、デフォルトゾーンで有効になっているサービスをリスト表示します。
firewalldのすべての事前定義サービスをリスト表示します。# firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...このコマンドは、デフォルトゾーンで利用可能なサービスのリストを表示します。
firewalldが許可するサービスのリストにサービスを追加します。# firewall-cmd --add-service=<service_name>このコマンドは、指定したサービスをデフォルトゾーンに追加します。
新しい設定を永続化します。
# firewall-cmd --runtime-to-permanentこのコマンドは、これらのランタイムの変更をファイアウォールの永続的な設定に適用します。デフォルトでは、これらの変更はデフォルトゾーンの設定に適用されます。
検証
すべての永続的なファイアウォールのルールをリスト表示します。
# firewall-cmd --list-all --permanent public target: default icmp-block-inversion: no interfaces: sources: services: cockpit dhcpv6-client ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:このコマンドは、デフォルトのファイアウォールゾーン (
public) の永続的なファイアウォールのルールを含む完全な設定を表示します。firewalldサービスの永続的な設定の有効性を確認します。# firewall-cmd --check-config success永続的な設定が無効な場合、コマンドは詳細を含むエラーを返します。
# firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}永続的な設定ファイルを手動で検査して設定を確認することもできます。メインの設定ファイルは
/etc/firewalld/firewalld.confです。ゾーン固有の設定ファイルは/etc/firewalld/zones/ディレクトリーにあり、ポリシーは/etc/firewalld/policies/ディレクトリーにあります。
41.8.2. Web コンソールを使用したファイアウォールのサービスの有効化
デフォルトでは、サービスはデフォルトのファイアウォールゾーンに追加されます。他のネットワークインターフェイスで別のファイアウォールゾーンも使用する場合は、最初にゾーンを選択してから、そのサービスをポートとともに追加する必要があります。
RHEL 8 Web コンソールには、事前定義の firewalld サービスが表示され、それらをアクティブなファイアウォールゾーンに追加することができます。
RHEL 8 Web コンソールは、firewalld サービスを設定します。
また、Web コンソールは、Web コンソールに追加されていない一般的な firewalld ルールを許可しません。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
Firewall セクションで、サービスを追加するゾーンを選択し、Add Services をクリックします。

- サービスの追加 ダイアログボックスで、ファイアウォールで有効にするサービスを見つけます。
シナリオに応じてサービスを有効にします。

- Add Services をクリックします。
この時点で、RHEL 8 Web コンソールは、ゾーンの Services リストにサービスを表示します。
41.8.3. Web コンソールを使用したカスタムポートの設定
RHEL Web コンソールを使用して、サービスのカスタムポートを追加および設定できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
firewalldサービスが実行中である。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、Web コンソールに管理者権限でログインしてください。
ファイアウォール セクションで、カスタムポートを設定するゾーンを選択し、サービスの追加 をクリックします。
- サービスの追加 ダイアログボックスで、 ラジオボタンをクリックします。
TCP フィールドおよび UDP フィールドに、例に従ってポートを追加します。以下の形式でポートを追加できます。
- ポート番号 (22 など)
- ポート番号の範囲 (5900-5910 など)
- エイリアス (nfs、rsync など)
注記各フィールドには、複数の値を追加できます。値はコンマで区切り、スペースは使用しないでください (例:8080,8081,http)。
TCP filed、UDP filed、またはその両方にポート番号を追加した後、Name フィールドでサービス名を確認します。
名前 フィールドには、このポートを予約しているサービスの名前が表示されます。このポートが無料で、サーバーがこのポートで通信する必要がない場合は、名前を書き換えることができます。
- 名前 フィールドに、定義されたポートを含むサービスの名前を追加します。
ボタンをクリックします。

設定を確認するには、ファイアウォール ページに移動し、ゾーンの サービス リストでサービスを見つけます。
41.9. ゾーン間で転送されるトラフィックのフィルタリング
firewalld を使用すると、異なる firewalld ゾーン間のネットワークデータのフローを制御できます。ルールとポリシーを定義することで、これらのゾーン間を移動するトラフィックをどのように許可またはブロックするかを管理できます。
ポリシーオブジェクト機能は、firewalld で正引きフィルターと出力フィルターを提供します。firewalld を使用して、異なるゾーン間のトラフィックをフィルタリングし、ローカルでホストされている仮想マシンへのアクセスを許可して、ホストを接続できます。
41.9.1. ポリシーオブジェクトとゾーンの関係
ポリシーオブジェクトを使用すると、サービス、ポート、リッチルールなどの firewalld のプリミティブをポリシーに割り当てることができます。ポリシーオブジェクトは、ステートフルおよび一方向の方法でゾーン間を通過するトラフィックに適用することができます。
# firewall-cmd --permanent --new-policy myOutputPolicy
# firewall-cmd --permanent --policy myOutputPolicy --add-ingress-zone HOST
# firewall-cmd --permanent --policy myOutputPolicy --add-egress-zone ANY
HOST および ANY は、イングレスゾーンおよびエグレスゾーンのリストで使用されるシンボリックゾーンです。
-
HOSTシンボリックゾーンは、firewalld を実行しているホストから発信されるトラフィック、またはホストへの宛先を持つトラフィックのポリシーを許可します。 -
ANYシンボリックゾーンは、現行および将来のすべてのゾーンにポリシーを適用します。ANYシンボリックゾーンは、すべてのゾーンのワイルドカードとして機能します。
41.9.2. 優先度を使用したポリシーのソート
同じトラフィックセットに複数のポリシーを適用できるため、優先度を使用して、適用される可能性のあるポリシーの優先順位を作成する必要があります。
ポリシーをソートする優先度を設定するには、次のコマンドを実行します。
# firewall-cmd --permanent --policy mypolicy --set-priority -500この例では、-500 の優先度は低くなりますが、優先度は高くなります。したがって、-500 は、-100 より前に実行されます。
優先度の数値が小さいほど優先度が高く、最初に適用されます。
41.9.3. ポリシーオブジェクトを使用した、ローカルでホストされているコンテナーと、ホストに物理的に接続されているネットワークとの間でのトラフィックのフィルタリング
ポリシーオブジェクト機能を使用すると、ユーザーは Podman ゾーンと firewalld ゾーン間のトラフィックをフィルタリングできます。
Red Hat は、デフォルトではすべてのトラフィックをブロックし、Podman ユーティリティーに必要なサービスを選択して開くことを推奨します。
手順
新しいファイアウォールポリシーを作成します。
# firewall-cmd --permanent --new-policy podmanToAnyPodman から他のゾーンへのすべてのトラフィックをブロックし、Podman で必要なサービスのみを許可します。
# firewall-cmd --permanent --policy podmanToAny --set-target REJECT # firewall-cmd --permanent --policy podmanToAny --add-service dhcp # firewall-cmd --permanent --policy podmanToAny --add-service dns # firewall-cmd --permanent --policy podmanToAny --add-service https新しい Podman ゾーンを作成します。
# firewall-cmd --permanent --new-zone=podmanポリシーのイングレスゾーンを定義します。
# firewall-cmd --permanent --policy podmanToHost --add-ingress-zone podman他のすべてのゾーンのエグレスゾーンを定義します。
# firewall-cmd --permanent --policy podmanToHost --add-egress-zone ANYエグレスゾーンを ANY に設定すると、Podman と他のゾーンの間でフィルタリングすることになります。ホストに対してフィルタリングする場合は、エグレスゾーンを HOST に設定します。
firewalld サービスを再起動します。
# systemctl restart firewalld
検証
他のゾーンに対する Podman ファイアウォールポリシーを検証します。
# firewall-cmd --info-policy podmanToAny podmanToAny (active) ... target: REJECT ingress-zones: podman egress-zones: ANY services: dhcp dns https ...
41.9.4. ポリシーオブジェクトのデフォルトターゲットの設定
ポリシーには --set-target オプションを指定できます。以下のターゲットを使用できます。
-
ACCEPT- パケットを受け入れます -
DROP- 不要なパケットを破棄します -
REJECT- ICMP 応答で不要なパケットを拒否します CONTINUE(デフォルト) - パケットは、次のポリシーとゾーンのルールに従います。# firewall-cmd --permanent --policy mypolicy --set-target CONTINUE
検証
ポリシーに関する情報の確認
# firewall-cmd --info-policy mypolicy
41.10. firewalld を使用した NAT の設定
firewalld では、以下のネットワークアドレス変換 (NAT) タイプを設定できます。
- マスカレーディング
- 宛先 NAT (DNAT)
- リダイレクト
41.10.1. ネットワークアドレス変換のタイプ
以下は、ネットワークアドレス変換 (NAT) タイプになります。
- マスカレーディング
この NAT タイプのいずれかを使用して、パケットのソース IP アドレスを変更します。たとえば、インターネットサービスプロバイダー (ISP) は、プライベート IP 範囲 (
10.0.0.0/8など) をルーティングしません。ネットワークでプライベート IP 範囲を使用し、ユーザーがインターネット上のサーバーにアクセスできるようにする必要がある場合は、この範囲のパケットのソース IP アドレスをパブリック IP アドレスにマップします。マスカレードは、出力インターフェイスの IP アドレスを自動的に使用します。したがって、出力インターフェイスが動的 IP アドレスを使用する場合は、マスカレードを使用します。
- 宛先 NAT (DNAT)
- この NAT タイプを使用して、着信パケットの宛先アドレスとポートを書き換えます。たとえば、Web サーバーがプライベート IP 範囲の IP アドレスを使用しているため、インターネットから直接アクセスできない場合は、ルーターに DNAT ルールを設定し、着信トラフィックをこのサーバーにリダイレクトできます。
- リダイレクト
- このタイプは、パケットをローカルマシンの別のポートにリダイレクトする DNAT の特殊なケースです。たとえば、サービスが標準ポートとは異なるポートで実行する場合は、標準ポートからこの特定のポートに着信トラフィックをリダイレクトすることができます。
41.10.2. IP アドレスのマスカレードの設定
システムで IP マスカレードを有効にできます。IP マスカレードは、インターネットにアクセスする際にゲートウェイの向こう側にある個々のマシンを隠します。
手順
externalゾーンなどで IP マスカレーディングが有効かどうかを確認するには、rootで次のコマンドを実行します。# firewall-cmd --zone=external --query-masqueradeこのコマンドでは、有効な場合は
yesと出力され、終了ステータスは0になります。無効の場合はnoと出力され、終了ステータスは1になります。zoneを省略すると、デフォルトのゾーンが使用されます。IP マスカレードを有効にするには、
rootで次のコマンドを実行します。# firewall-cmd --zone=external --add-masquerade-
この設定を永続化するには、
--permanentオプションをコマンドに渡します。 IP マスカレードを無効にするには、
rootで次のコマンドを実行します。# firewall-cmd --zone=external --remove-masqueradeこの設定を永続化するには、
--permanentをコマンドラインに渡します。
41.10.3. DNAT を使用した着信 HTTP トラフィックの転送
宛先ネットワークアドレス変換 (DNAT) を使用して、着信トラフィックを 1 つの宛先アドレスおよびポートから別の宛先アドレスおよびポートに転送できます。通常、外部ネットワークインターフェイスからの着信リクエストを特定の内部サーバーまたはサービスにリダイレクトする場合に役立ちます。
前提条件
-
firewalldサービスが実行中である。
手順
着信 HTTP トラフィックを転送します。
# firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toaddr=198.51.100.10:toport=8080 --permanent上記のコマンドは、次の設定で DNAT ルールを定義します。
-
--zone=public- DNAT ルールを設定するファイアウォールゾーン。必要なゾーンに合わせて調整できます。 -
--add-forward-port- ポート転送ルールを追加することを示すオプション。 -
port=80- 外部宛先ポート。 -
proto=tcp- TCP トラフィックを転送することを示すプロトコル。 -
toaddr=198.51.100.10- 宛先 IP アドレス。 -
toport=8080- 内部サーバーの宛先ポート。 -
--permanent- 再起動後も DNAT ルールを永続化するオプション。
-
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
使用したファイアウォールゾーンの DNAT ルールを確認します。
# firewall-cmd --list-forward-ports --zone=public port=80:proto=tcp:toport=8080:toaddr=198.51.100.10あるいは、対応する XML 設定ファイルを表示します。
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="80" protocol="tcp" to-port="8080" to-addr="198.51.100.10"/> <forward/> </zone>
41.10.4. 非標準ポートからのトラフィックをリダイレクトして、標準ポートで Web サービスにアクセスできるようにする
リダイレクトメカニズムを使用すると、ユーザーが URL でポートを指定しなくても、非標準ポートで内部的に実行される Web サービスにアクセスできるようになります。その結果、URL はよりシンプルになり、ブラウジングエクスペリエンスが向上します。一方で、非標準ポートは依然として内部で、または特定の要件のために使用されます。
前提条件
-
firewalldサービスが実行中である。
手順
NAT リダイレクトルールを作成します。
# firewall-cmd --zone=public --add-forward-port=port=<standard_port>:proto=tcp:toport=<non_standard_port> --permanent上記のコマンドは、次の設定で NAT リダイレクトルールを定義します。
-
--zone=public- ルールを設定するファイアウォールゾーン。必要なゾーンに合わせて調整できます。 -
--add-forward-port=port=<non_standard_port>- 着信トラフィックを最初に受信するソースポートを使用したポート転送 (リダイレクト) ルールを追加することを示すオプション。 -
proto=tcp- TCP トラフィックをリダイレクトすることを示すプロトコル。 -
toport=<standard_port>- 着信トラフィックがソースポートで受信された後にリダイレクトされる宛先ポート。 -
--permanent- 再起動後もルールを永続化するオプション。
-
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
使用したファイアウォールゾーンのリダイレクトルールを確認します。
# firewall-cmd --list-forward-ports port=8080:proto=tcp:toport=80:toaddr=あるいは、対応する XML 設定ファイルを表示します。
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="8080" protocol="tcp" to-port="80"/> <forward/> </zone>
41.11. リッチルールの優先度設定
リッチルールを使用すると、ファイアウォールルールをより高度かつ柔軟な方法で定義できます。リッチルールは、サービスやポートなどでは複雑なファイアウォールルールを表現しきれない場合に特に役立ちます。
リッチルールの背後にある概念:
- 粒度と柔軟性
- より具体的な基準に基づき、ネットワークトラフィックの詳細な条件を定義できます。
- ルール構造
リッチルールは、ファミリー (IPv4 または IPv6) と、それに続く条件およびアクションで構成されます。
rule family="ipv4|ipv6" [conditions] [actions]- conditions
- 特定の基準が満たされた場合にのみ、リッチルールを適用できます。
- actions
- 条件に一致するネットワークトラフィックに何が起きるかを定義できます。
- combining multiple conditions
- より具体的かつ複雑なフィルタリングを作成できます。
- hierarchical control and reusability
- リッチルールを、ゾーンやサービスなどの他のファイアウォールメカニズムと組み合わせることができます。
デフォルトでは、リッチルールはルールアクションに基づいて設定されます。たとえば、許可 ルールよりも 拒否 ルールが優先されます。リッチルールで priority パラメーターを使用すると、管理者はリッチルールとその実行順序をきめ細かく制御できます。priority パラメーターを使用すると、ルールはまず優先度の値によって昇順にソートされます。多くのルールが同じ priority を持つ場合、ルールの順序はルールアクションによって決まります。アクションも同じである場合、順序は定義されない可能性があります。
41.11.1. priority パラメーターを異なるチェーンにルールを整理する方法
リッチルールの priority パラメーターは、-32768 から 32767 までの任意の数値に設定でき、数値が小さいほど優先度が高くなります。
firewalld サービスは、優先度の値に基づいて、ルールを異なるチェーンに整理します。
-
優先度が 0 未満 - ルールは
_pre接尾辞が付いたチェーンにリダイレクトされます。 -
優先度が 0 を超える - ルールは
_post接尾辞が付いたチェーンにリダイレクトされます。 -
優先度が 0 - アクションに基づいて、ルールは、
_log、_deny、または_allowのアクションを使用してチェーンにリダイレクトされます。
このサブチェーンでは、firewalld は優先度の値に基づいてルールを分類します。
41.11.2. リッチルールの優先度の設定
以下は、priority パラメーターを使用して、他のルールで許可または拒否されていないすべてのトラフィックをログに記録するリッチルールを作成する方法を示しています。このルールを使用して、予期しないトラフィックにフラグを付けることができます。
手順
優先度が非常に低いルールを追加して、他のルールと一致していないすべてのトラフィックをログに記録します。
# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'このコマンドでは、ログエントリーの数を、毎分
5に制限します。
検証
前の手順のコマンドで作成した
nftablesルールを表示します。# nft list chain inet firewalld filter_IN_public_post table inet firewalld { chain filter_IN_public_post { log prefix "UNEXPECTED: " limit rate 5/minute } }
41.12. firewalld ゾーン内の異なるインターフェイスまたはソース間でのトラフィック転送の有効化
ゾーン内転送は、firewalld ゾーン内のインターフェイスまたはソース間のトラフィック転送を可能にする firewalld 機能です。
41.12.1. ゾーン内転送と、デフォルトのターゲットが ACCEPT に設定されているゾーンの違い
ゾーン内転送を有効にすると、1 つの firewalld ゾーン内のトラフィックは、あるインターフェイスまたはソースから別のインターフェイスまたはソースに流れることができます。ゾーンは、インターフェイスおよびソースの信頼レベルを指定します。信頼レベルが同じ場合、トラフィックは同じゾーン内に留まります。
firewalld のデフォルトゾーンでゾーン内転送を有効にすると、現在のデフォルトゾーンに追加されたインターフェイスおよびソースにのみ適用されます。
firewalld は、異なるゾーンを使用して着信トラフィックと送信トラフィックを管理します。各ゾーンには独自のルールと動作のセットがあります。たとえば、trusted ゾーンでは、転送されたトラフィックがデフォルトですべて許可されます。
他のゾーンでは、異なるデフォルト動作を設定できます。標準ゾーンでは、ゾーンのターゲットが default に設定されている場合、転送されたトラフィックは通常デフォルトで破棄されます。
ゾーン内の異なるインターフェイスまたはソース間でトラフィックを転送する方法を制御するには、ゾーンのターゲットを理解し、それに応じてゾーンのターゲットを設定する必要があります。
41.12.2. ゾーン内転送を使用したイーサネットと Wi-Fi ネットワーク間でのトラフィックの転送
ゾーン内転送を使用して、同じ firewalld ゾーン内のインターフェイスとソース間のトラフィックを転送することができます。この機能には次の利点があります。
-
有線デバイスと無線デバイスの間のシームレスな接続性 (
enp1s0に接続されたイーサネットネットワークとwlp0s20に接続された Wi-Fi ネットワークの間でトラフィックを転送可能) - 柔軟な作業環境のサポート
- ネットワーク内の複数のデバイスまたはユーザーがアクセスして使用できる共有リソース (プリンター、データベース、ネットワーク接続ストレージなど)
- 効率的な内部ネットワーク (スムーズな通信、レイテンシーの短縮、リソースへのアクセス性など)
この機能は、個々の firewalld ゾーンに対して有効にすることができます。
手順
カーネルでパケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confゾーン内転送を有効にするインターフェイスが
internalゾーンにのみ割り当てられていることを確認します。# firewall-cmd --get-active-zones現在、インターフェイスが
internal以外のゾーンに割り当てられている場合は、以下のように再割り当てします。# firewall-cmd --zone=internal --change-interface=interface_name --permanentenp1s0およびwlp0s20インターフェイスをinternalゾーンに追加します。# firewall-cmd --zone=internal --add-interface=enp1s0 --add-interface=wlp0s20ゾーン内転送を有効にします。
# firewall-cmd --zone=internal --add-forward
検証
次の検証では、両方のホストに nmap-ncat パッケージがインストールされている必要があります。
-
ゾーン転送を有効にしたホストの
enp1s0インターフェイスと同じネットワーク上にあるホストにログインします。 ncatで echo サービスを起動し、接続をテストします。# ncat -e /usr/bin/cat -l 12345-
wlp0s20インターフェイスと同じネットワークにあるホストにログインします。 enp1s0と同じネットワークにあるホスト上で実行している echo サーバーに接続します。# ncat <other_host> 12345- 何かを入力して を押します。テキストが返送されることを確認します。
41.13. RHEL システムロールを使用した firewalld の設定
RHEL システムロールは、Ansible 自動化ユーティリティーのコンテンツセットです。このコンテンツを、Ansible Automation ユーティリティーと組み合わせることで、複数のシステムを同時にリモートで管理するための一貫した設定インターフェイスが実現します。
rhel-system-roles パッケージには、rhel-system-roles.firewall RHEL システムロールが含まれています。このロールは、firewalld サービスの自動設定のために導入されました。
firewall RHEL システムロールを使用すると、次のようなさまざまな firewalld パラメーターを設定できます。
- ゾーン
- パケットを許可すべきサービス
- ポートへのトラフィックアクセスの許可、拒否、またはドロップ
- ゾーンのポートまたはポート範囲の転送
41.13.1. firewall RHEL システムロールを使用した firewalld 設定のリセット
時間が経つにつれて、ファイアウォール設定の更新が累積し、予想外のセキュリティーリスクが発生する可能性があります。firewall RHEL システムロールを使用すると、firewalld 設定を自動的にデフォルト状態にリセットできます。これにより、意図しない、またはセキュアでないファイアウォールルールを効率的に削除し、管理を簡素化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Reset firewalld example hosts: managed-node-01.example.com tasks: - name: Reset firewalld ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - previous: replacedサンプル Playbook で指定されている設定は次のとおりです。
previous: replaced既存のユーザー定義設定をすべて削除し、
firewalld設定をデフォルトにリセットします。previous:replacedパラメーターを他の設定と組み合わせると、firewallロールは新しい設定を適用する前に既存の設定をすべて削除します。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードでこのコマンドを実行して、管理対象ノードのすべてのファイアウォール設定がデフォルト値にリセットされたことをリモートで確認します。
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-all-zones'
41.13.2. firewall RHEL システムロールを使用して、firewalld の着信トラフィックをあるローカルポートから別のローカルポートに転送する
firewall RHEL システムロールを使用して、あるローカルポートから別のローカルポートへの着信トラフィックの転送をリモートで設定できます。
たとえば、同じマシン上に複数のサービスが共存し、同じデフォルトポートが必要な環境の場合、ポートの競合が発生する可能性があります。この競合によりサービスが中断され、ダウンタイムが発生する可能性があります。firewall RHEL システムロールを使用すると、トラフィックを効率的に別のポートに転送して、サービスの設定を変更せずにサービスを同時に実行できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Forward incoming traffic on port 8080 to 443 ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - forward_port: 8080/tcp;443; state: enabled runtime: true permanent: trueサンプル Playbook で指定されている設定は次のとおりです。
forward_port: 8080/tcp;443- TCP プロトコルを使用してローカルポート 8080 に送信されるトラフィックが、ポート 443 に転送されます。
runtime: trueランタイム設定の変更を有効にします。デフォルトは
trueに設定されています。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードで次のコマンドを実行して、管理対象ノードの転送ポートをリモートで確認します。
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-forward-ports' managed-node-01.example.com | CHANGED | rc=0 >> port=8080:proto=tcp:toport=443:toaddr=
41.13.3. firewall RHEL システムロールを使用した firewalld DMZ ゾーンの設定
システム管理者は、firewall RHEL システムロールを使用して、enp1s0 インターフェイス上に dmz ゾーンを設定し、ゾーンへの HTTPS トラフィックを許可できます。これにより、外部ユーザーが Web サーバーにアクセスできるようにします。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Creating a DMZ with access to HTTPS port and masquerading for hosts in DMZ ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - zone: dmz interface: enp1s0 service: https state: enabled runtime: true permanent: truePlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードで次のコマンドを実行して、管理対象ノードの
dmzゾーンに関する情報をリモートで確認します。# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --zone=dmz --list-all' managed-node-01.example.com | CHANGED | rc=0 >> dmz (active) target: default icmp-block-inversion: no interfaces: enp1s0 sources: services: https ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks:
第42章 nftables の使用
firewalld で対処できる一般的なパケットフィルタリングのケースに当てはまらない場合、またはルールを完全に制御する必要がある場合は、nftables フレームワークを使用できます。
nftables フレームワークは、パケットを分類機能を提供し、iptables、ip6tables、arptables、ebtables、および ipset ユーティリティーの後継となります。利便性、機能、パフォーマンスにおいて、以前のパケットフィルタリングツールに多くの改良が追加されました。以下に例を示します。
- 線形処理の代わりに組み込みルックアップテーブルを使用
-
IPv4プロトコルおよびIPv6プロトコルに対する 1 つのフレームワーク - ルールセット全体を取得、更新、保存するのではなく、トランザクションを通じてカーネルルールセットをその場で更新する
-
ルールセットにおけるデバッグおよびトレースへの対応 (
nftrace) およびトレースイベントの監視 (nftツール) - より統一されたコンパクトな構文、プロトコル固有の拡張なし
- サードパーティーのアプリケーション用 Netlink API
nftables フレームワークは、テーブルを使用してチェーンを保存します。このチェーンには、アクションを実行する個々のルールが含まれます。nft ユーティリティーは、以前のパケットフィルタリングフレームワークのツールをすべて置き換えます。libnftnl ライブラリーを介して、nftables Netlink API との低レベルの対話に libnftables ライブラリーを使用できます。
ルールセット変更が適用されていることを表示するには、nft list ruleset コマンドを使用します。カーネルルールセットをクリアするには、nft flush ruleset コマンドを使用します。同じカーネルインフラストラクチャーを使用するため、iptables-nft コマンドでインストールされたルールセットにも影響する可能性があることに注意してください。
42.1. nftables テーブル、チェーン、およびルールの作成および管理
nftables ルールセットを表示して管理できます。
42.1.1. nftables テーブルの基本
nftables のテーブルは、チェーン、ルール、セットなどのオブジェクトを含む名前空間です。
各テーブルにはアドレスファミリーが割り当てられている必要があります。アドレスファミリーは、このテーブルが処理するパケットタイプを定義します。テーブルを作成する際に、以下のいずれかのアドレスファミリーを設定できます。
-
ip- IPv4 パケットのみと一致します。アドレスファミリーを指定しないと、これがデフォルトになります。 -
ip6- IPv6 パケットのみと一致します。 -
inet- IPv4 パケットと IPv6 パケットの両方と一致します。 -
arp: IPv4 アドレス解決プロトコル (ARP) パケットと一致します。 -
bridge: ブリッジデバイスを通過するパケットに一致します。 -
netdev: ingress からのパケットに一致します。
テーブルを追加する場合、使用する形式はファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { }シェルスクリプトで、以下を使用します。
nft add table <table_address_family> <table_name>
42.1.2. nftables チェーンの基本
テーブルは、ルールのコンテナーであるチェーンで構成されます。次の 2 つのルールタイプが存在します。
- ベースチェーン: ネットワークスタックからのパケットのエントリーポイントとしてベースチェーンを使用できます。
-
通常のチェーン:
jumpターゲットとして通常のチェーンを使用し、ルールをより適切に整理できます。
ベースチェーンをテーブルに追加する場合に使用する形式は、ファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> policy <policy> ; } }シェルスクリプトで、以下を使用します。
nft add chain <table_address_family> <table_name> <chain_name> { type <type> hook <hook> priority <priority> \; policy <policy> \; }シェルがセミコロンをコマンドの最後として解釈しないようにするには、セミコロンの前にエスケープ文字
\を配置します。
どちらの例でも、ベースチェーン を作成します。通常のチェーン を作成する場合、中括弧内にパラメーターを設定しないでください。
チェーンタイプ
チェーンタイプとそれらを使用できるアドレスファミリーとフックの概要を以下に示します。
| タイプ | アドレスファミリー | Hooks | 説明 |
|---|---|---|---|
|
| all | all | 標準のチェーンタイプ |
|
|
|
| このタイプのチェーンは、接続追跡エントリーに基づいてネイティブアドレス変換を実行します。最初のパケットのみがこのチェーンタイプをトラバースします。 |
|
|
|
| このチェーンタイプを通過する許可済みパケットは、IP ヘッダーの関連部分が変更された場合に、新しいルートルックアップを引き起こします。 |
チェーンの優先度
priority パラメーターは、パケットが同じフック値を持つチェーンを通過する順序を指定します。このパラメーターは、整数値に設定することも、標準の priority 名を使用することもできます。
以下のマトリックスは、標準的な priority 名とその数値の概要、それらを使用できるファミリーおよびフックの概要です。
| テキストの値 | 数値 | アドレスファミリー | Hooks |
|---|---|---|---|
|
|
|
| all |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
| all |
|
|
| all | |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
チェーンポリシー
チェーンポリシーは、このチェーンのルールでアクションが指定されていない場合に、nftables がパケットを受け入れるかドロップするかを定義します。チェーンには、以下のいずれかのポリシーを設定できます。
-
accept(デフォルト) -
drop
42.1.3. nftables ルールの基本
ルールは、このルールを含むチェーンを渡すパケットに対して実行するアクションを定義します。ルールに一致する式も含まれる場合、nftables は、以前の式がすべて適用されている場合にのみアクションを実行します。
チェーンにルールを追加する場合、使用する形式はファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> ; policy <policy> ; <rule> } }シェルスクリプトで、以下を使用します。
nft add rule <table_address_family> <table_name> <chain_name> <rule>このシェルコマンドは、チェーンの最後に新しいルールを追加します。チェーンの先頭にルールを追加する場合は、
nft addの代わりにnft insertコマンドを使用します。
42.1.4. nft コマンドを使用したテーブル、チェーン、ルールの管理
コマンドラインまたはシェルスクリプトで nftables ファイアウォールを管理するには、nft ユーティリティーを使用します。
この手順のコマンドは通常のワークフローを表しておらず、最適化されていません。この手順では、nft コマンドを使用して、一般的なテーブル、チェーン、およびルールを管理する方法を説明します。
手順
テーブルが IPv4 パケットと IPv6 パケットの両方を処理できるように、
inetアドレスファミリーを使用してnftables_svcという名前のテーブルを作成します。# nft add table inet nftables_svc受信ネットワークトラフィックを処理する
INPUTという名前のベースチェーンをinet nftables_svcテーブルに追加します。# nft add chain inet nftables_svc INPUT { type filter hook input priority filter \; policy accept \; }シェルがセミコロンをコマンドの最後として解釈しないようにするには、
\文字を使用してセミコロンをエスケープします。INPUTチェーンにルールを追加します。たとえば、INPUTチェーンの最後のルールとして、ポート 22 および 443 で着信 TCP トラフィックを許可し、他の着信トラフィックを、Internet Control Message Protocol (ICMP) ポートに到達できないというメッセージで拒否します。# nft add rule inet nftables_svc INPUT tcp dport 22 accept # nft add rule inet nftables_svc INPUT tcp dport 443 accept # nft add rule inet nftables_svc INPUT reject with icmpx type port-unreachableここで示されたように
nft add ruleコマンドを実行すると、nftはコマンド実行と同じ順序でルールをチェーンに追加します。ハンドルを含む現在のルールセットを表示します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 443 accept # handle 3 reject # handle 4 } }ハンドル 3 で既存ルールの前にルールを挿入します。たとえば、ポート 636 で TCP トラフィックを許可するルールを挿入するには、以下を入力します。
# nft insert rule inet nftables_svc INPUT position 3 tcp dport 636 acceptハンドル 3 で、既存ルールの後ろにルールを追加します。たとえば、ポート 80 で TCP トラフィックを許可するルールを追加するには、以下を入力します。
# nft add rule inet nftables_svc INPUT position 3 tcp dport 80 acceptハンドルでルールセットを再表示します。後で追加したルールが指定の位置に追加されていることを確認します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 tcp dport 80 accept # handle 6 reject # handle 4 } }ハンドル 6 でルールを削除します。
# nft delete rule inet nftables_svc INPUT handle 6ルールを削除するには、ハンドルを指定する必要があります。
ルールセットを表示し、削除されたルールがもう存在しないことを確認します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 reject # handle 4 } }INPUTチェーンから残りのルールをすべて削除します。# nft flush chain inet nftables_svc INPUTルールセットを表示し、
INPUTチェーンが空であることを確認します。# nft list table inet nftables_svc table inet nftables_svc { chain INPUT { type filter hook input priority filter; policy accept } }INPUTチェーンを削除します。# nft delete chain inet nftables_svc INPUTこのコマンドを使用して、まだルールが含まれているチェーンを削除することもできます。
ルールセットを表示し、
INPUTチェーンが削除されたことを確認します。# nft list table inet nftables_svc table inet nftables_svc { }nftables_svcテーブルを削除します。# nft delete table inet nftables_svcこのコマンドを使用して、まだルールが含まれているテーブルを削除することもできます。
注記ルールセット全体を削除するには、個別のコマンドですべてのルール、チェーン、およびテーブルを手動で削除するのではなく、
nft flush rulesetコマンドを使用します。
42.2. iptables から nftables への移行
ファイアウォール設定が依然として iptables ルールを使用している場合は、iptables ルールを nftables に移行できます。
42.2.1. firewalld、nftables、または iptables を使用する場合
RHEL 8 では、シナリオに応じて次のパケットフィルタリングユーティリティーを使用できます。
-
firewalld:firewalldユーティリティーは、一般的なユースケースのファイアウォール設定を簡素化します。 -
nftables:nftablesユーティリティーを使用して、ネットワーク全体など、複雑なパフォーマンスに関する重要なファイアウォールを設定します。 -
iptables: Red Hat Enterprise Linux のiptablesユーティリティーは、legacyバックエンドの代わりにnf_tablesカーネル API を使用します。nf_tablesAPI は、iptablesコマンドを使用するスクリプトが、Red Hat Enterprise Linux で引き続き動作するように、後方互換性を提供します。新しいファイアウォールスクリプトの場合は、nftablesを使用します。
さまざまなファイアウォール関連サービス (firewalld、nftables、または iptables) が相互に影響を与えないようにするには、RHEL ホストでそのうち 1 つだけを実行し、他のサービスを無効にします。
42.2.2. nftables フレームワークの概念
iptables フレームワークと比較すると、nftables はより最新で効率的かつ柔軟な代替手段を提供します。nftables フレームワークは、iptables よりも高度な機能と改善点を備えており、ルール管理を簡素化し、パフォーマンスを向上させます。そのため、nftables は高いパフォーマンスが求められる複雑なネットワーク環境向けの新しい選択肢となります。
- テーブルと名前空間
-
nftablesでは、テーブルは関連するファイアウォールチェーン、セット、フローテーブル、およびその他のオブジェクトをグループ化する組織単位または名前空間を表します。nftablesでは、テーブルにより、ファイアウォールルールと関連コンポーネントをより柔軟に構造化できます。一方、iptablesでは、テーブルは特定の目的に合わせてより厳密に定義されていました。 - テーブルファミリー
-
nftables内の各テーブルは、特定のファミリー (ip、ip6、inet、arp、bridge、またはnetdev) に関連付けられています。この関連付けによって、テーブルが処理できるパケットが決まります。たとえば、ipファミリーのテーブルは IPv4 パケットのみを処理します。一方、inetはテーブルファミリーの特殊なケースです。これは IPv4 パケットと IPv6 パケットの両方を処理できるため、複数のプロトコルに対応した統一的なアプローチを実現します。もう 1 つの特殊なテーブルファミリーの例はnetdevです。これは、ネットワークデバイスに直接適用されるルールに使用され、デバイスレベルでのフィルタリングを可能します。 - ベースチェーン
nftablesのベースチェーンは、パケット処理パイプライン内の高度に設定可能な項目です。これを使用すると、以下を指定できます。- チェーンのタイプ (例: "filter")
- パケット処理パスのフックポイント (例: "input"、"output"、"forward")
- チェーンの優先順位
この柔軟性により、パケットがネットワークスタックを通過するときにルールが適用されるタイミングと方法を正確に制御できます。チェーンの特殊なケースは
routeチェーンです。これは、パケットヘッダーに基づいてカーネルによって行われるルーティングの決定に影響を与えるために使用されます。- ルール処理用の仮想マシン
nftablesフレームワークは、ルールを処理するために内部仮想マシンを使用します。この仮想マシンは、アセンブリ言語の操作 (レジスターへのデータのロード、比較の実行など) に似た命令を実行します。このようなメカニズムにより、非常に柔軟かつ効率的なルール処理が可能になります。nftablesの機能拡張を、この仮想マシンの新しい命令として導入できます。これを行うには、通常、新しいカーネルモジュールと、libnftnlライブラリーおよびnftコマンドラインユーティリティーの更新が必要です。または、カーネルを変更することなく、既存の命令を新しい方法で組み合わせることで、新しい機能を導入することもできます。
nftablesルールの構文は、基盤となる仮想マシンの柔軟性を反映しています。たとえば、meta mark set tcp dport map { 22: 1, 80: 2 }というルールは、TCP 宛先ポートが 22 の場合にパケットのファイアウォールマークを 1 に設定し、ポートが 80 の場合に 2 に設定します。このように複雑なロジックを簡潔に表現できます。- 複雑なフィルタリングと決定マップ
nftablesフレームワークは、ipsetユーティリティーの機能を統合および拡張します。このユーティリティーは、iptablesにおいて IP アドレス、ポート、その他のデータタイプ、そして何よりもその組み合わせの一括マッチングに使用されるものです。この統合により、大規模で動的なデータセットをnftables内で直接管理することが容易になります。また、nftablesは、任意のデータ型の複数の値または範囲に基づいてパケットをマッチングすることをネイティブにサポートしています。これにより、複雑なフィルタリング要件を処理する機能が強化されています。nftablesを使用すると、パケット内の任意のフィールドを操作できます。nftablesでは、セットは名前付きまたは匿名のいずれかです。名前付きセットは複数のルールによって参照され、動的に変更できます。匿名セットはルール内でインラインで定義され、不変です。セットには、IP アドレスとポート番号のペアなど、異なるタイプの組み合わせである要素を含めることができます。この機能により、複雑な条件のマッチングにおける柔軟性が向上します。カーネルは、セットを管理するために、特定の要件 (パフォーマンス、メモリー効率など) に基づいて最も適切なバックエンドを選択できます。セットは、キーと値のペアを持つマップとしても機能できます。値の部分は、データポイント (パケットヘッダーに書き込む値) として、またはジャンプ先の決定やチェーンとして使用できます。これにより、"決定マップ" と呼ばれる複雑で動的なルール動作が可能になります。- 柔軟なルール形式
nftablesルールの構造はシンプルです。条件とアクションが左から右に順に適用されます。この直感的な形式により、ルールの作成とトラブルシューティングが簡素化されます。ルール内の条件は、論理的に (AND 演算子を使用して) 結合されます。そのため、ルールがマッチするには、すべての条件が "true" と評価される必要があります。いずれかの条件が失敗した場合、評価が次のルールに進みます。
nftables内のアクションは、dropやacceptなど、パケットのそれ以上のルール処理を停止する最終的なアクションにすることができます。counter log meta mark set 0x3などの非終端アクションは、特定のタスク (パケットのカウント、ロギング、マークの設定など) を実行しますが、後続のルールの評価を許可します。
42.2.3. 非推奨の iptables フレームワークの概念
積極的にメンテナンスされている nftables フレームワークと同様に、非推奨の iptables フレームワークを使用すると、さまざまなパケットフィルタリングタスク、ロギングと監査、NAT 関連の設定タスクなどを実行できます。
iptables フレームワークは複数のテーブルに構造化されています。各テーブルは特定の目的のために設計されています。
filter- デフォルトのテーブル。一般的なパケットフィルタリングを提供します。
nat- ネットワークアドレス変換 (NAT) 用。パケットの送信元アドレスと宛先アドレスの変更が含まれます。
mangle- 特定のパケット変更用。これを使用すると、高度なルーティング決定のためにパケットヘッダーを変更できます。
raw- 接続追跡の前に必要な設定。
これらのテーブルは、個別のカーネルモジュールとして実装されています。各テーブルは、INPUT、OUTPUT、FORWARD など、一定の組み込みチェーンのセットを提供します。チェーンは、パケットの評価基準となる一連のルールです。このチェーンは、カーネル内のパケット処理フローの特定のポイントにフックします。チェーンの名前は異なるテーブル間で同じですが、チェーンの実行順序はそれぞれのフックの優先順位によって決まります。ルールが正しい順序で適用されるように、優先順位はカーネルによって内部的に管理されます。
もともと、iptables は IPv4 トラフィックを処理するために設計されました。しかし、IPv6 プロトコルの登場に伴い、iptables と同等の機能を提供し、ユーザーが IPv6 パケットのファイアウォールルールを作成および管理できるようにするために、ip6tables ユーティリティーを導入する必要が生まれました。それと同じ理屈で、Address Resolution Protocol (ARP) を処理するために arptables ユーティリティーが作成され、イーサネットブリッジフレームを処理するために ebtables ユーティリティーが開発されました。これらのツールを使用すると、さまざまなネットワークプロトコルに iptables のパケットフィルタリング機能を適用し、包括的なネットワークカバレッジを実現できます。
iptables の機能を強化するために、機能拡張の開発が開始されました。通常、機能拡張は、ユーザー空間の動的共有オブジェクト (DSO) とペアになったカーネルモジュールとして実装されます。この拡張により、"マッチ" と "ターゲット" が導入されます。これらをファイアウォールルールで使用すると、より高度な操作を実行できます。この拡張は、複雑なマッチとターゲットを可能にするものです。たとえば、特定のレイヤー 4 プロトコルヘッダー値をマッチさせたり操作したり、レート制限を実行したり、クォータを適用したりすることができます。一部の拡張は、デフォルトの iptables 構文の制限に対処するように設計されています ("マルチポート" マッチ拡張など)。この拡張により、単一のルールを複数の非連続ポートにマッチさせることができるため、ルール定義が簡素化され、必要な個別のルールの数を減らすことができます。
ipset は、iptables に対する特別な種類の機能拡張です。これはカーネルレベルのデータ構造であり、パケットとマッチできる IP アドレス、ポート番号、その他のネットワーク関連要素のコレクションを作成するために、iptables と一緒に使用されます。これらのセットにより、ファイアウォールルールの作成と管理のプロセスが大幅に効率化、最適化、高速化されます。
42.2.4. iptables および ip6tables ルールセットの nftables への変換
iptables-restore-translate ユーティリティーおよび ip6tables-restore-translate ユーティリティーを使用して、iptables および ip6tables ルールセットを nftables に変換します。
前提条件
-
nftablesパッケージおよびiptablesパッケージがインストールされている。 -
システムに
iptablesルールおよびip6tablesルールが設定されている。
手順
iptablesルールおよびip6tablesルールをファイルに書き込みます。# iptables-save >/root/iptables.dump # ip6tables-save >/root/ip6tables.dumpダンプファイルを
nftables命令に変換します。# iptables-restore-translate -f /root/iptables.dump > /etc/nftables/ruleset-migrated-from-iptables.nft # ip6tables-restore-translate -f /root/ip6tables.dump > /etc/nftables/ruleset-migrated-from-ip6tables.nft-
必要に応じて、生成された
nftablesルールを手動で更新して、確認します。 nftablesサービスが生成されたファイルをロードできるようにするには、以下を/etc/sysconfig/nftables.confファイルに追加します。include "/etc/nftables/ruleset-migrated-from-iptables.nft" include "/etc/nftables/ruleset-migrated-from-ip6tables.nft"iptablesサービスを停止し、無効にします。# systemctl disable --now iptablesカスタムスクリプトを使用して
iptablesルールを読み込んだ場合は、スクリプトが自動的に開始されなくなったことを確認し、再起動してすべてのテーブルをフラッシュします。nftablesサービスを有効にして起動します。# systemctl enable --now nftables
検証
nftablesルールセットを表示します。# nft list ruleset
42.2.5. 単一の iptables および ip6tables ルールセットの nftables への変換
Red Hat Enterprise Linux は、iptables ルールまたは ip6tables ルールを、nftables で同等のルールに変換する iptables-translate ユーティリティーおよび ip6tables-translate ユーティリティーを提供します。
前提条件
-
nftablesパッケージがインストールされている。
手順
以下のように、
iptablesまたはip6tablesの代わりにiptables-translateユーティリティーまたはip6tables-translateユーティリティーを使用して、対応するnftablesルールを表示します。# iptables-translate -A INPUT -s 192.0.2.0/24 -j ACCEPT nft add rule ip filter INPUT ip saddr 192.0.2.0/24 counter accept拡張機能によっては変換機能がない場合もあります。このような場合には、ユーティリティーは、以下のように、前に
#記号が付いた未変換ルールを出力します。# iptables-translate -A INPUT -j CHECKSUM --checksum-fill nft # -A INPUT -j CHECKSUM --checksum-fill
42.2.6. 一般的な iptables コマンドと nftables コマンドの比較
以下は、一般的な iptables コマンドと nftables コマンドの比較です。
すべてのルールをリスト表示します。
Expand iptables nftables iptables-savenft list ruleset特定のテーブルおよびチェーンをリスト表示します。
Expand iptables nftables iptables -Lnft list table ip filteriptables -L INPUTnft list chain ip filter INPUTiptables -t nat -L PREROUTINGnft list chain ip nat PREROUTINGnftコマンドは、テーブルおよびチェーンを事前に作成しません。これらは、ユーザーが手動で作成した場合にのみ存在します。firewalld によって生成されたルールの一覧表示:
# nft list table inet firewalld # nft list table ip firewalld # nft list table ip6 firewalld
42.3. nftables を使用した NAT の設定
nftables を使用すると、以下のネットワークアドレス変換 (NAT) タイプを設定できます。
- マスカレーディング
- ソース NAT (SNAT)
- 宛先 NAT (DNAT)
- リダイレクト
iifname パラメーターおよび oifname パラメーターでは実インターフェイス名のみを使用でき、代替名 (altname) には対応していません。
42.3.1. NAT タイプ
以下は、ネットワークアドレス変換 (NAT) タイプになります。
- マスカレードおよびソースの NAT (SNAT)
この NAT タイプのいずれかを使用して、パケットのソース IP アドレスを変更します。たとえば、インターネットサービスプロバイダー (ISP) は、プライベート IP 範囲 (
10.0.0.0/8など) をルーティングしません。ネットワークでプライベート IP 範囲を使用し、ユーザーがインターネット上のサーバーにアクセスできるようにする必要がある場合は、この範囲のパケットのソース IP アドレスをパブリック IP アドレスにマップします。マスカレードと SNAT は互いに非常に似ています。相違点は次のとおりです。
- マスカレードは、出力インターフェイスの IP アドレスを自動的に使用します。したがって、出力インターフェイスが動的 IP アドレスを使用する場合は、マスカレードを使用します。
- SNAT は、パケットのソース IP アドレスを指定された IP に設定し、出力インターフェイスの IP アドレスを動的に検索しません。そのため、SNAT の方がマスカレードよりも高速です。出力インターフェイスが固定 IP アドレスを使用する場合は、SNAT を使用します。
- 宛先 NAT (DNAT)
- この NAT タイプを使用して、着信パケットの宛先アドレスとポートを書き換えます。たとえば、Web サーバーがプライベート IP 範囲の IP アドレスを使用しているため、インターネットから直接アクセスできない場合は、ルーターに DNAT ルールを設定し、着信トラフィックをこのサーバーにリダイレクトできます。
- リダイレクト
- このタイプは、チェーンフックに応じてパケットをローカルマシンにリダイレクトする DNAT の特殊なケースです。たとえば、サービスが標準ポートとは異なるポートで実行する場合は、標準ポートからこの特定のポートに着信トラフィックをリダイレクトすることができます。
42.3.2. nftables を使用したマスカレードの設定
マスカレードを使用すると、ルーターは、インターフェイスを介して送信されるパケットのソース IP を、インターフェイスの IP アドレスに動的に変更できます。これは、インターフェイスに新しい IP が割り当てられている場合に、nftables はソース IP の置き換え時に新しい IP を自動的に使用することを意味します。
ens3 インターフェイスを介してホストから出るパケットの送信元 IP を、ens3 で設定された IP に置き換えます。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要preroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、着信パケット返信に一致するようにこのチェーンが必要になります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。postroutingチェーンに、ens3インターフェイスの出力パケットに一致するルールを追加します。# nft add rule nat postrouting oifname "ens3" masquerade
42.3.3. nftables を使用したソース NAT の設定
ルーターでは、ソース NAT (SNAT) を使用して、インターフェイスを介して特定の IP アドレスに送信するパケットの IP を変更できます。次に、ルーターは送信パケットのソース IP を置き換えます。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要postroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、このチェーンが発信パケット返信に一致するようにする必要があります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。ens3を介した発信パケットのソース IP を192.0.2.1に置き換えるルールをpostroutingチェーンに追加します。# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
42.3.4. nftables を使用した宛先 NAT の設定
宛先 NAT (DNAT) を使用すると、ルーター上のトラフィックを、インターネットから直接アクセスできないホストにリダイレクトできます。
たとえば、DNAT を使用すると、ルーターはポート 80 および 443 に送信された受信トラフィックを、IP アドレス 192.0.2.1 の Web サーバーにリダイレクトします。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要postroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、このチェーンが発信パケット返信に一致するようにする必要があります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。preroutingチェーンに、ルーターのens3インターフェイスのポート80および443への受信トラフィックを、IP アドレス192.0.2.1の Web サーバーにリダイレクトするルールを追加します。# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1環境に応じて、SNAT ルールまたはマスカレードルールを追加して、Web サーバーから返されるパケットのソースアドレスを送信者に変更します。
ens3インターフェイスが動的 IP アドレスを使用している場合は、マスカレードルールを追加します。# nft add rule nat postrouting oifname "ens3" masqueradeens3インターフェイスが静的 IP アドレスを使用する場合は、SNAT ルールを追加します。たとえば、ens3が IP アドレス198.51.100.1を使用している場合は、以下のようになります。# nft add rule nat postrouting oifname "ens3" snat to 198.51.100.1
パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
42.3.5. nftables を使用したリダイレクトの設定
redirect 機能は、チェーンフックに応じてパケットをローカルマシンにリダイレクトする宛先ネットワークアドレス変換 (DNAT) の特殊なケースです。
たとえば、ローカルホストのポート 22 に送信された着信および転送されたトラフィックを 2222 ポートにリダイレクトすることができます。
手順
テーブルを作成します。
# nft add table natテーブルに
preroutingチェーンを追加します。# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。22ポートの着信トラフィックを2222ポートにリダイレクトするルールをpreroutingチェーンに追加します。# nft add rule nat prerouting tcp dport 22 redirect to 2222
42.4. nftables スクリプトの作成および実行
nftables フレームワークを使用する主な利点は、スクリプトの実行がアトミックであることです。つまり、システムがスクリプト全体を適用するか、エラーが発生した場合には実行を阻止することを意味します。これにより、ファイアウォールは常に一貫した状態になります。
さらに、nftables スクリプト環境を使用すると、次のことができます。
- コメントの追加
- 変数の定義
- 他のルールセットファイルの組み込み
nftables パッケージをインストールすると、Red Hat Enterprise Linux が自動的に *.nft スクリプトを /etc/nftables/ ディレクトリーに作成します。このスクリプトは、さまざまな目的でテーブルと空のチェーンを作成するコマンドが含まれます。
42.4.1. 対応している nftables スクリプトの形式
nftables スクリプト環境では、次の形式でスクリプトを記述できます。
nft list rulesetコマンドと同じ形式でルールセットが表示されます。#!/usr/sbin/nft -f # Flush the rule set flush ruleset table inet example_table { chain example_chain { # Chain for incoming packets that drops all packets that # are not explicitly allowed by any rule in this chain type filter hook input priority 0; policy drop; # Accept connections to port 22 (ssh) tcp dport ssh accept } }nftコマンドと同じ構文:#!/usr/sbin/nft -f # Flush the rule set flush ruleset # Create a table add table inet example_table # Create a chain for incoming packets that drops all packets # that are not explicitly allowed by any rule in this chain add chain inet example_table example_chain { type filter hook input priority 0 ; policy drop ; } # Add a rule that accepts connections to port 22 (ssh) add rule inet example_table example_chain tcp dport ssh accept
42.4.2. nftables スクリプトの実行
nftables スクリプトは、nft ユーティリティーに渡すか、スクリプトを直接実行することで実行できます。
手順
nftablesスクリプトをnftユーティリティーに渡して実行するには、次のコマンドを実行します。# nft -f /etc/nftables/<example_firewall_script>.nftnftablesスクリプトを直接実行するには、次のコマンドを実行します。1 回だけ実行する場合:
スクリプトが以下のシバンシーケンスで始まることを確認します。
#!/usr/sbin/nft -f重要-fパラメーターを指定しないと、nftユーティリティーはスクリプトを読み取らず、Error: syntax error, unexpected newline, expecting stringを表示します。必要に応じて、スクリプトの所有者を
rootに設定します。# chown root /etc/nftables/<example_firewall_script>.nft所有者のスクリプトを実行ファイルに変更します。
# chmod u+x /etc/nftables/<example_firewall_script>.nft
スクリプトを実行します。
# /etc/nftables/<example_firewall_script>.nft出力が表示されない場合は、システムがスクリプトを正常に実行します。
nft はスクリプトを正常に実行しますが、ルールの配置やパラメーター不足、またはスクリプト内のその他の問題により、ファイアウォールが期待通りの動作を起こさない可能性があります。
42.4.3. nftables スクリプトでコメントの使用
nftables スクリプト環境は、# 文字の右側から行末までのすべてをコメントとして解釈します。
コメントは、行の先頭またはコマンドの横から開始できます。
...
# Flush the rule set
flush ruleset
add table inet example_table # Create a table
...42.4.4. nftables スクリプトでの変数の使用
nftables スクリプトで変数を定義するには、define キーワードを使用します。シングル値および匿名セットを変数に保存できます。より複雑なシナリオの場合は、セットまたは決定マップを使用します。
- 値を 1 つ持つ変数
以下の例は、値が
enp1s0のINET_DEVという名前の変数を定義します。define INET_DEV = enp1s0スクリプトで変数を使用するには、
$記号と、それに続く変数名を指定します。... add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept ...- 匿名セットを含む変数
以下の例では、匿名セットを含む変数を定義します。
define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }スクリプトで変数を使用するには、
$記号と、それに続く変数名を指定します。add rule inet example_table example_chain ip daddr $DNS_SERVERS accept注記中括弧は、変数がセットを表していることを示すため、ルールで使用する場合は、特別なセマンティクスを持ちます。
42.4.5. nftables スクリプトへのファイルの追加
nftables スクリプト環境では、include ステートメントを使用して他のスクリプトを含めることができます。
絶対パスまたは相対パスのないファイル名のみを指定すると、nftables には、デフォルトの検索パスのファイルが含まれます。これは、Red Hat Enterprise Linux では /etc に設定されています。
例42.1 デフォルト検索ディレクトリーからのファイルを含む
デフォルトの検索ディレクトリーからファイルを指定するには、次のコマンドを実行します。
include "example.nft"例42.2 ディレクトリーの *.nft ファイルをすべて含む
*.nft で終わるすべてのファイルを /etc/nftables/rulesets/ ディレクトリーに保存するには、次のコマンドを実行します。
include "/etc/nftables/rulesets/*.nft"
include ステートメントは、ドットで始まるファイルに一致しないことに注意してください。
42.4.6. システムの起動時に nftables ルールの自動読み込み
systemd サービス nftables は、/etc/sysconfig/nftables.conf ファイルに含まれるファイアウォールスクリプトを読み込みます。
前提条件
-
nftablesスクリプトは、/etc/nftables/ディレクトリーに保存されます。
手順
/etc/sysconfig/nftables.confファイルを編集します。-
nftablesパッケージのインストールで/etc/nftables/に作成された*.nftスクリプトを変更した場合は、これらのスクリプトのincludeステートメントのコメントを解除します。 新しいスクリプトを作成した場合は、
includeステートメントを追加してこれらのスクリプトを含めます。たとえば、nftablesサービスの起動時に/etc/nftables/example.nftスクリプトを読み込むには、以下を追加します。include "/etc/nftables/_example_.nft"
-
オプション:
nftablesサービスを開始して、システムを再起動せずにファイアウォールルールを読み込みます。# systemctl start nftablesnftablesサービスを有効にします。# systemctl enable nftables
42.5. nftables コマンドでのセットの使用
nftables フレームワークは、セットをネイティブに対応します。たとえば、ルールが複数の IP アドレス、ポート番号、インターフェイス、またはその他の一致基準に一致する必要がある場合など、セットを使用できます。
42.5.1. nftables での匿名セットの使用
匿名セットには、ルールで直接使用する { 22, 80, 443 } などの中括弧で囲まれたコンマ区切りの値が含まれます。IP アドレスやその他の一致基準にも匿名セットを使用できます。
匿名セットの欠点は、セットを変更する場合はルールを置き換える必要があることです。動的なソリューションの場合は、nftables で名前付きセットの使用 で説明されているように名前付きセットを使用します。
前提条件
-
inetファミリーにexample_chainチェーンおよびexample_tableテーブルがある。
手順
たとえば、ポート
22、80、および443に着信トラフィックを許可するルールを、example_tableのexample_chainに追加するには、次のコマンドを実行します。# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } acceptオプション:
example_tableですべてのチェーンとそのルールを表示します。# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport { ssh, http, https } accept } }
42.5.2. nftables で名前付きセットの使用
nftables フレームワークは、変更可能な名前付きセットに対応します。名前付きセットは、テーブル内の複数のルールで使用できる要素のリストまたは範囲です。匿名セットに対する別の利点として、セットを使用するルールを置き換えることなく、名前付きセットを更新できます。
名前付きセットを作成する場合は、セットに含まれる要素のタイプを指定する必要があります。以下のタイプを設定できます。
-
192.0.2.1や192.0.2.0/24など、IPv4 アドレスまたは範囲を含むセットの場合はipv4_addr。 -
2001:db8:1::1や2001:db8:1::1/64など、IPv6 アドレスまたは範囲を含むセットの場合はipv6_addr。 -
52:54:00:6b:66:42など、メディアアクセス制御 (MAC) アドレスの一覧を含むセットの場合はether_addr。 -
tcpなど、インターネットプロトコルタイプの一覧が含まれるセットの場合はinet_proto。 -
sshなど、インターネットサービスの一覧を含むセットの場合はinet_service。 -
パケットマークの一覧を含むセットの場合は
mark。パケットマークは、任意の 32 ビットの正の整数値 (0から2147483647) にすることができます。
前提条件
-
example_chainチェーンとexample_tableテーブルが存在する。
手順
空のファイルを作成します。以下の例では、IPv4 アドレスのセットを作成します。
複数の IPv4 アドレスを格納することができるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; }IPv4 アドレス範囲を保存できるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }
重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
オプション: セットを使用するルールを作成します。たとえば、次のコマンドは、
example_setの IPv4 アドレスからのパケットをすべて破棄するルールを、example_tableのexample_chainに追加します。# nft add rule inet example_table example_chain ip saddr @example_set dropexample_setが空のままなので、ルールには現在影響がありません。IPv4 アドレスを
example_setに追加します。個々の IPv4 アドレスを保存するセットを作成する場合は、次のコマンドを実行します。
# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }IPv4 範囲を保存するセットを作成する場合は、次のコマンドを実行します。
# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }IP アドレス範囲を指定する場合は、上記の例の
192.0.2.0/24のように、CIDR (Classless Inter-Domain Routing) 表記を使用することもできます。
42.5.3. 動的セットを使用してパケットパスからエントリーを追加する
nftables フレームワークの動的セットを使用して、パケットデータから要素を自動的に追加できます。たとえば、IP アドレス、宛先ポート、MAC アドレスなどです。この機能を使用することで、これらの要素をリアルタイムで収集し、それらを使用して拒否リスト、禁止リストなどを作成し、セキュリティーの脅威に即座に対応できます。
前提条件
-
inetファミリーにexample_chainチェーンおよびexample_tableテーブルがある。
手順
空のファイルを作成します。以下の例では、IPv4 アドレスのセットを作成します。
複数の IPv4 アドレスを格納することができるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; }IPv4 アドレス範囲を保存できるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
着信パケットの送信元 IPv4 アドレスを
example_setセットに動的に追加するためのルールを作成します。# nft add rule inet example_table example_chain set add ip saddr @example_setこのコマンドは、
example_chainルールチェーンとexample_table内に新しいルールを作成し、パケットの送信元 IPv4 アドレスをexample_setに動的に追加します。
検証
ルールが追加されたことを確認します。
# nft list ruleset ... table ip example_table { set example_set { type ipv4_addr elements = { 192.0.2.250, 192.0.2.251 } } chain example_chain { type filter hook input priority 0 add @example_set { ip saddr } } }このコマンドは、現在
nftablesにロードされているルールセット全体を表示します。これは、IP がルールをアクティブにトリガーしており、example_setが適切なアドレスで更新されていることを示しています。
次のステップ
動的な IP セットを取得すると、さまざまなセキュリティー、フィルタリング、トラフィック制御のために使用できます。以下に例を示します。
- ネットワークトラフィックをブロック、制限、またはログに記録する
- 信頼済みユーザーを禁止しないように、許可リストと組み合わせて使用する
- 過剰なブロックを防ぐために自動タイムアウトを使用する
42.6. nftables コマンドにおける決定マップの使用
ディクショナリーとしても知られている決定マップにより、nft は一致基準をアクションにマッピングすることで、パケット情報に基づいてアクションを実行できます。
42.6.1. nftables での匿名マップの使用
匿名マップは、ルールで直接使用する { match_criteria : action } ステートメントです。ステートメントには、複数のコンマ区切りマッピングを含めることができます。
匿名マップの欠点は、マップを変更する場合には、ルールを置き換える必要があることです。動的なソリューションの場合は、nftables での名前付きマップの使用 で説明されているように名前付きマップを使用します。
たとえば、匿名マップを使用して、IPv4 プロトコルおよび IPv6 プロトコルの TCP パケットと UDP パケットの両方を異なるチェーンにルーティングし、着信 TCP パケットと UDP パケットを個別にカウントできます。
手順
新しいテーブルを作成します。
# nft add table inet example_tableexample_tableにtcp_packetsチェーンを作成します。# nft add chain inet example_table tcp_packetsこのチェーンのトラフィックをカウントする
tcp_packetsにルールを追加します。# nft add rule inet example_table tcp_packets counterexample_tableでudp_packetsチェーンを作成します。# nft add chain inet example_table udp_packetsこのチェーンのトラフィックをカウントする
udp_packetsにルールを追加します。# nft add rule inet example_table udp_packets counter着信トラフィックのチェーンを作成します。たとえば、
example_tableに、着信トラフィックをフィルタリングするincoming_trafficという名前のチェーンを作成するには、次のコマンドを実行します。# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }匿名マップを持つルールを
incoming_trafficに追加します。# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }匿名マップはパケットを区別し、プロトコルに基づいて別のカウンターチェーンに送信します。
トラフィックカウンターの一覧を表示する場合は、
example_tableを表示します。# nft list table inet example_table table inet example_table { chain tcp_packets { counter packets 36379 bytes 2103816 } chain udp_packets { counter packets 10 bytes 1559 } chain incoming_traffic { type filter hook input priority filter; policy accept; ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets } } }tcp_packetsチェーンおよびudp_packetsチェーンのカウンターは、受信パケットとバイトの両方を表示します。
42.6.2. nftables での名前付きマップの使用
nftables フレームワークは、名前付きマップに対応します。テーブルの複数のルールでこのマップを使用できます。匿名マップに対する別の利点は、名前付きマップを使用するルールを置き換えることなく、名前付きマップを更新できることです。
名前付きマップを作成する場合は、要素のタイプを指定する必要があります。
-
一致する部分に
192.0.2.1などの IPv4 アドレスが含まれるマップの場合はipv4_addr。 -
一致する部分に
2001:db8:1::1などの IPv6 アドレスが含まれるマップの場合はipv6_addr。 -
52:54:00:6b:66:42などのメディアアクセス制御 (MAC) アドレスを含むマップの場合はether_addr。 -
一致する部分に
tcpなどのインターネットプロトコルタイプが含まれるマップの場合はinet_proto。 -
一致する部分に
sshや22などのインターネットサービス名のポート番号が含まれるマップの場合はinet_service。 -
一致する部分にパケットマークが含まれるマップの場合は
mark。パケットマークは、任意の正の 32 ビットの整数値 (0~2147483647) にできます。 -
一致する部分にカウンターの値が含まれるマップの場合は
counter。カウンター値は、正の値の 64 ビットであれば任意の値にすることができます。 -
一致する部分にクォータ値が含まれるマップの場合は
quota。クォータの値は、64 ビットの整数値にできます。
たとえば、送信元 IP アドレスに基づいて着信パケットを許可または拒否できます。名前付きマップを使用すると、このシナリオを設定するのに必要なルールは 1 つだけで、IP アドレスとアクションがマップに動的に保存されます。
手順
テーブルを作成します。たとえば、IPv4 パケットを処理する
example_tableという名前のテーブルを作成するには、次のコマンドを実行します。# nft add table ip example_tableチェーンを作成します。たとえば、
example_tableに、example_chainという名前のチェーンを作成するには、次のコマンドを実行します。# nft add chain ip example_table example_chain { type filter hook input priority 0 \; }重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
空のマップを作成します。たとえば、IPv4 アドレスのマッピングを作成するには、次のコマンドを実行します。
# nft add map ip example_table example_map { type ipv4_addr : verdict \; }マップを使用するルールを作成します。たとえば、次のコマンドは、両方とも
example_mapで定義されている IPv4 アドレスにアクションを適用するルールを、example_tableのexample_chainに追加します。# nft add rule example_table example_chain ip saddr vmap @example_mapIPv4 アドレスと対応するアクションを
example_mapに追加します。# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }以下の例では、IPv4 アドレスのアクションへのマッピングを定義します。上記で作成したルールと組み合わせて、ファイアウォールは
192.0.2.1からのパケットを許可し、192.0.2.2からのパケットを破棄します。オプション: 別の IP アドレスおよび action ステートメントを追加してマップを拡張します。
# nft add element ip example_table example_map { 192.0.2.3 : accept }オプション: マップからエントリーを削除します。
# nft delete element ip example_table example_map { 192.0.2.1 }オプション: ルールセットを表示します。
# nft list ruleset table ip example_table { map example_map { type ipv4_addr : verdict elements = { 192.0.2.2 : drop, 192.0.2.3 : accept } } chain example_chain { type filter hook input priority filter; policy accept; ip saddr vmap @example_map } }
42.7. 例: nftables スクリプトを使用した LAN および DMZ の保護
RHEL ルーターで nftables フレームワークを使用して、内部 LAN 内のネットワーククライアントと DMZ の Web サーバーを、インターネットやその他のネットワークからの不正アクセスから保護するファイアウォールスクリプトを作成およびインストールします。
この例はデモ目的専用で、特定の要件があるシナリオを説明しています。
ファイアウォールスクリプトは、ネットワークインフラストラクチャーとセキュリティー要件に大きく依存します。この例を使用して、独自の環境用のスクリプトを作成する際に nftables ファイアウォールの概念を理解してください。
42.7.1. ネットワークの状態
この例のネットワークは、以下の条件下にあります。
ルーターは以下のネットワークに接続されています。
-
インターフェイス
enp1s0を介したインターネット -
インターフェイス
enp7s0を介した内部 LAN -
enp8s0までの DMZ
-
インターフェイス
-
ルーターのインターネットインターフェイスには、静的 IPv4 アドレス (
203.0.113.1) と IPv6 アドレス (2001:db8:a::1) の両方が割り当てられています。 -
内部 LAN のクライアントは
10.0.0.0/24の範囲のプライベート IPv4 アドレスのみを使用します。その結果、LAN からインターネットへのトラフィックには、送信元ネットワークアドレス変換 (SNAT) が必要です。 -
内部 LAN の管理者用 PC は、IP アドレス
10.0.0.100および10.0.0.200を使用します。 -
DMZ は、
198.51.100.0/24および2001:db8:b::/56の範囲のパブリック IP アドレスを使用します。 -
DMZ の Web サーバーは、IP アドレス
198.51.100.5および2001:db8:b::5を使用します。 - ルーターは、LAN および DMZ 内のホストのキャッシング DNS サーバーとして機能します。
42.7.2. ファイアウォールスクリプトのセキュリティー要件
以下は、サンプルネットワークにおける nftables ファイアウォールの要件です。
ルーターは以下を実行できる必要があります。
- DNS クエリーを再帰的に解決します。
- ループバックインターフェイスですべての接続を実行します。
内部 LAN のクライアントは以下を実行できる必要があります。
- ルーターで実行しているキャッシング DNS サーバーをクエリーします。
- DMZ の HTTPS サーバーにアクセスします。
- インターネット上の任意の HTTPS サーバーにアクセスします。
- 管理者用の PC は、SSH を使用してルーターと DMZ 内のすべてのサーバーにアクセスできる必要があります。
DMZ の Web サーバーは以下を実行できる必要があります。
- ルーターで実行しているキャッシング DNS サーバーをクエリーします。
- インターネット上の HTTPS サーバーにアクセスして更新をダウンロードします。
インターネット上のホストは以下を実行できる必要があります。
- DMZ の HTTPS サーバーにアクセスします。
さらに、以下のセキュリティー要件が存在します。
- 明示的に許可されていない接続の試行はドロップする必要があります。
- ドロップされたパケットはログに記録する必要があります。
42.7.3. ドロップされたパケットをファイルにロギングするための設定
デフォルトでは、systemd は、ドロップされたパケットなどのカーネルメッセージをジャーナルに記録します。さらに、このようなエントリーを別のファイルに記録するように rsyslog サービスを設定することもできます。ログファイルが無限に大きくならないようにするために、ローテーションポリシーを設定します。
前提条件
-
rsyslogパッケージがインストールされている。 -
rsyslogサービスが実行されている。
手順
以下の内容で
/etc/rsyslog.d/nftables.confファイルを作成します。:msg, startswith, "nft drop" -/var/log/nftables.log & stopこの設定を使用すると、
rsyslogサービスはドロップされたパケットを/var/log/messagesではなく/var/log/nftables.logファイルに記録します。rsyslogサービスを再起動します。# systemctl restart rsyslogサイズが 10 MB を超える場合は、以下の内容で
/etc/logrotate.d/nftablesファイルを作成し、/var/log/nftables.logをローテーションします。/var/log/nftables.log { size +10M maxage 30 sharedscripts postrotate /usr/bin/systemctl kill -s HUP rsyslog.service >/dev/null 2>&1 || true endscript }maxage 30設定は、次のローテーション操作中にlogrotateが 30 日経過したローテーション済みログを削除することを定義します。
42.7.4. nftables スクリプトの作成とアクティブ化
この例は、RHEL ルーターで実行され、DMZ の内部 LAN および Web サーバーのクライアントを保護する nftables ファイアウォールスクリプトです。この例で使用されているネットワークとファイアウォールの要件の詳細は、ファイアウォールスクリプトの ネットワークの状態 および ファイアウォールスクリプトのセキュリティー要件 を参照してください。
この nftables ファイアウォールスクリプトは、デモ専用です。お使いの環境やセキュリティー要件に適応させて使用してください。
前提条件
- ネットワークは、ネットワークの状態 で説明されているとおりに設定されます。
手順
以下の内容で
/etc/nftables/firewall.nftスクリプトを作成します。# Remove all rules flush ruleset # Table for both IPv4 and IPv6 rules table inet nftables_svc { # Define variables for the interface name define INET_DEV = enp1s0 define LAN_DEV = enp7s0 define DMZ_DEV = enp8s0 # Set with the IPv4 addresses of admin PCs set admin_pc_ipv4 { type ipv4_addr elements = { 10.0.0.100, 10.0.0.200 } } # Chain for incoming trafic. Default policy: drop chain INPUT { type filter hook input priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept incoming traffic on loopback interface iifname lo accept # Allow request from LAN and DMZ to local DNS server iifname { $LAN_DEV, $DMZ_DEV } meta l4proto { tcp, udp } th dport 53 accept # Allow admins PCs to access the router using SSH iifname $LAN_DEV ip saddr @admin_pc_ipv4 tcp dport 22 accept # Last action: Log blocked packets # (packets that were not accepted in previous rules in this chain) log prefix "nft drop IN : " } # Chain for outgoing traffic. Default policy: drop chain OUTPUT { type filter hook output priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept outgoing traffic on loopback interface oifname lo accept # Allow local DNS server to recursively resolve queries oifname $INET_DEV meta l4proto { tcp, udp } th dport 53 accept # Last action: Log blocked packets log prefix "nft drop OUT: " } # Chain for forwarding traffic. Default policy: drop chain FORWARD { type filter hook forward priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # IPv4 access from LAN and internet to the HTTPS server in the DMZ iifname { $LAN_DEV, $INET_DEV } oifname $DMZ_DEV ip daddr 198.51.100.5 tcp dport 443 accept # IPv6 access from internet to the HTTPS server in the DMZ iifname $INET_DEV oifname $DMZ_DEV ip6 daddr 2001:db8:b::5 tcp dport 443 accept # Access from LAN and DMZ to HTTPS servers on the internet iifname { $LAN_DEV, $DMZ_DEV } oifname $INET_DEV tcp dport 443 accept # Last action: Log blocked packets log prefix "nft drop FWD: " } # Postrouting chain to handle SNAT chain postrouting { type nat hook postrouting priority srcnat; policy accept; # SNAT for IPv4 traffic from LAN to internet iifname $LAN_DEV oifname $INET_DEV snat ip to 203.0.113.1 } }/etc/nftables/firewall.nftスクリプトを/etc/sysconfig/nftables.confファイルに追加します。include "/etc/nftables/firewall.nft"IPv4 転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confnftablesサービスを有効にして起動します。# systemctl enable --now nftables
検証
オプション:
nftablesルールセットを確認します。# nft list ruleset ...ファイアウォールが阻止するアクセスの実行を試みます。たとえば、DMZ から SSH を使用してルーターにアクセスします。
# ssh router.example.com ssh: connect to host router.example.com port 22: Network is unreachableロギング設定に応じて、以下を検索します。
ブロックされたパケットの
systemdジャーナル:# journalctl -k -g "nft drop" Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...ブロックされたパケットの
/var/log/nftables.logファイル:Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...
42.8. nftables を使用した接続の量の制限
nftables を使用して、接続の数を制限したり、一定の数の接続の確立を試みる IP アドレスをブロックして、システムリソースを過剰に使用されないようにします。
42.8.1. nftables を使用した接続数の制限
nft ユーティリティーの ct count パラメーターを使用すると、IP アドレスごとの同時接続数を制限できます。たとえば、この機能を使用すると、各送信元 IP アドレスがホストへの並列 SSH 接続を 2 つだけ確立できるように設定できます。
手順
inetアドレスファミリーを使用してfilterテーブルを作成します。# nft add table inet filterinputチェーンをinet filterテーブルに追加します。# nft add chain inet filter input { type filter hook input priority 0 \; }IPv4 アドレスの動的セットを作成します。
# nft add set inet filter limit-ssh { type ipv4_addr\; flags dynamic \;}IPv4 アドレスからの SSH ポート (22) への同時着信接続を 2 つだけ許可し、同じ IP からのそれ以降の接続をすべて拒否するルールを、
inputチェーンに追加します。# nft add rule inet filter input tcp dport ssh ct state new add @limit-ssh { ip saddr ct count over 2 } counter reject
検証
- 同じ IP アドレスからホストへの新しい同時 SSH 接続を 2 つ以上確立します。すでに 2 つの接続が確立されている場合、Nftables が SSH ポートへの接続を拒否します。
limit-ssh動的セットを表示します。# nft list set inet filter limit-ssh table inet filter { set limit-ssh { type ipv4_addr size 65535 flags dynamic elements = { 192.0.2.1 ct count over 2 , 192.0.2.2 ct count over 2 } } }elementsエントリーは、現時点でルールに一致するアドレスを表示します。この例では、elementsは、SSH ポートへのアクティブな接続がある IP アドレスを一覧表示します。出力には、アクティブな接続の数を表示しないため、接続が拒否された場合は表示されないことに注意してください。
42.8.2. 1 分以内に新しい着信 TCP 接続を 11 個以上試行する IP アドレスのブロック
1 分以内に 11 個以上の IPv4 TCP 接続を確立しているホストを一時的にブロックできます。
手順
ipアドレスファミリーを使用してfilterテーブルを作成します。# nft add table ip filterinputチェーンをfilterテーブルに追加します。# nft add chain ip filter input { type filter hook input priority 0 \; }1 分以内に 10 を超える TCP 接続を確立しようとするソースアドレスからのすべてのパケットを破棄するルールを追加します。
# nft add rule ip filter input ip protocol tcp ct state new, untracked meter ratemeter { ip saddr timeout 5m limit rate over 10/minute } droptimeout 5mパラメーターは、nftablesが、メーターが古いエントリーで一杯にならないように、5 分後にエントリーを自動的に削除することを定義します。
検証
メーターのコンテンツを表示するには、以下のコマンドを実行します。
# nft list meter ip filter ratemeter table ip filter { meter ratemeter { type ipv4_addr size 65535 flags dynamic,timeout elements = { 192.0.2.1 limit rate over 10/minute timeout 5m expires 4m58s224ms } } }
42.9. nftables ルールのデバッグ
nftables フレームワークは、管理者がルールをデバッグし、パケットがそれに一致するかどうかを確認するためのさまざまなオプションを提供します。
42.9.1. カウンターによるルールの作成
ルールが一致しているかどうかを確認するには、カウンターを使用できます。
- 既存のルールにカウンターを追加する手順の詳細は、Adding a counter to an existing rule を参照してください。
前提条件
- ルールを追加するチェーンが存在する。
手順
counterパラメーターで新しいルールをチェーンに追加します。以下の例では、ポート 22 で TCP トラフィックを許可し、このルールに一致するパケットとトラフィックをカウントするカウンターを使用するルールを追加します。# nft add rule inet example_table example_chain tcp dport 22 counter acceptカウンター値を表示するには、次のコマンドを実行します。
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
42.9.2. 既存のルールへのカウンターの追加
ルールが一致しているかどうかを確認するには、カウンターを使用できます。
- カウンターで新しいルールを追加する手順の詳細は、Creating a rule with the counter を参照してください。
前提条件
- カウンターを追加するルールがある。
手順
チェーンのルール (ハンドルを含む) を表示します。
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }ルールの代わりに、
counterパラメーターを使用してカウンターを追加します。以下の例は、前の手順で表示したルールの代わりに、カウンターを追加します。# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter acceptカウンター値を表示するには、次のコマンドを実行します。
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
42.9.3. 既存のルールに一致するパケットの監視
nftables のトレース機能と、nft monitor コマンドを組み合わせることにより、管理者はルールに一致するパケットを表示できます。このルールに一致するパケットを監視するために、ルールのトレースを有効にできます。
前提条件
- カウンターを追加するルールがある。
手順
チェーンのルール (ハンドルを含む) を表示します。
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }ルールを置き換えてトレース機能を追加しますが、
meta nftrace set 1パラメーターを使用します。以下の例は、前の手順で表示したルールの代わりに、トレースを有効にします。# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 acceptnft monitorコマンドを使用して、トレースを表示します。以下の例は、コマンドの出力をフィルタリングして、inet example_table example_chainが含まれるエントリーのみを表示します。# nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...警告nft monitorコマンドは、トレースが有効になっているルールの数と、一致するトラフィックの量に応じて、大量の出力を表示できます。grepなどのユーティリティーを使用して出力をフィルタリングします。
42.10. nftables ルールセットのバックアップおよび復元
nftables ルールをファイルにバックアップし、後で復元できます。また、管理者はルールが含まれるファイルを使用して、たとえばルールを別のサーバーに転送できます。
42.10.1. ファイルへの nftables ルールセットのバックアップ
nft ユーティリティーを使用して、nftables ルールセットをファイルにバックアップできます。
手順
nftablesルールのバックアップを作成するには、次のコマンドを実行します。nft list ruleset形式で生成された形式の場合:# nft list ruleset > file.nftJSON 形式の場合は、以下のようになります。
# nft -j list ruleset > file.json
42.10.2. ファイルからの nftables ルールセットの復元
ファイルから nftables ルールセットを復元できます。
手順
nftablesルールを復元するには、以下を行います。復元するファイルが、
nft list rulesetが生成した形式であるか、nftコマンドを直接含んでいる場合は、以下のコマンドを実行します。# nft -f file.nft復元するファイルが JSON 形式の場合は、次のコマンドを実行します。
# nft -j -f file.json
第43章 DDoS 攻撃を防ぐために、高パフォーマンストラフィックのフィルタリングで xdp-filter を使用
nftables と比べて、Express Data Path (XDP) は、パネットワークインターフェイスでネットワークパケットを処理して破棄します。したがって、XDP は、ファイアウォールやその他のアプリケーションに到達する前に、パッケージの次のステップを決定します。その結果、XDP フィルターは必要なリソースが少なく、DDoS (Distributed Denial of Service) 攻撃に備えるために、従来のパケットフィルターよりもはるかに高いレートでネットワークパケットを処理できます。たとえば、テスト時に、Red Hat は、1 つのコア上で 1 秒あたり 26 のネットワークパケットを破棄します。これは、同じハードウェアの nftables ドロップレートよりもはるかに高くなります。
xdp-filter ユーティリティーは、XDP を使用して着信ネットワークパケットを許可または破棄します。特定のトラフィックに対するトラフィックのフィルターを行うルールを作成できます。
- IP アドレス
- MAC アドレス
- ポート
xdp-filter にパケット処理速度が大幅に高くなりますが、nftables など、nftables は同じ機能がないことに注意してください。XDP を使用したパケットのフィルタリングを例示します。xdp-filter は、XDP を使用したパケットのフィルタリングを実証します。また、独自の XDP アプリケーションを作成する方法を理解するために、ユーティリティーのコードを使用できます。
AMD および Intel 64 ビット以外のアーキテクチャーでは、xdp-filter ユーティリティーはテクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) ではサポートされておらず、機能的に完全ではない可能性があるため、Red Hat では実稼働環境での使用を推奨していません。テクノロジープレビュー機能では、最新の製品機能をいち早く提供します。これにより、お客様は開発段階で機能をテストし、フィードバックを提供できます。
テクノロジープレビュー機能のサポート範囲は、Red Hat カスタマーポータルの テクノロジープレビュー機能のサポート範囲 を参照してください。
43.1. xdp-filter ルールに一致するネットワークパケットの削除
xdp-filter を使用して、ネットワークパケットをドロップできます。
- 特定の宛先ポートへの特定の宛先ポート
- 特定の IP アドレスの使用
- 特定の MAC アドレスの使用
xdp-filter の allow ポリシーは、すべてのトラフィックが許可され、フィルターが特定のルールに一致するネットワークパケットのみをドロップするように定義します。たとえば、ドロップするパケットのソース IP アドレスを知っている場合は、この方法を使用します。
前提条件
-
xdp-toolsパッケージがインストールされている。 - XDP プログラムをサポートするネットワークドライバー。
手順
xdp-filterを読み込み、enp1s0などの特定のインターフェイスの着信パケットを処理します。# xdp-filter load enp1s0デフォルトでは、
xdp-filterはallowポリシーを使用し、ユーティリティーはすべてのルールに一致するトラフィックのみを破棄します。オプションで、
-f featureオプションを使用して、tcp、ipv4、ethernetなどの特定の機能のみを有効にします。すべての機能をロードするのではなく、必要な機能のみをロードすることで、パケット処理の速度が向上します。複数の機能を有効にするには、コンマで区切ります。コマンドがエラーで失敗した場合、ネットワークドライバーは XDP プログラムをサポートしません。
ルールを追加して、それに一致するパケットをドロップします。以下に例を示します。
受信パケットをポート
22に破棄するには、次のコマンドを実行します。# xdp-filter port 22このコマンドは、TCP および UDP トラフィックに一致するルールを追加します。特定のプロトコルのみと一致する場合は、
-p protocolオプションを使用します。192.0.2.1から着信パケットを破棄するには、次のコマンドを実行します。# xdp-filter ip 192.0.2.1 -m srcxdp-filterは IP 範囲に対応していないことに注意してください。MAC アドレス
00:53:00:AA:07:BEから着信パケットを破棄するには、次のコマンドを実行します。# xdp-filter ether 00:53:00:AA:07:BE -m src
検証
以下のコマンドを使用して、破棄されたパケットおよび許可されるパケットに関する統計を表示します。
# xdp-filter status
43.2. xdp-filter ルールに一致するネットワークパケット以外のネットワークパケットをすべて削除
xdp-filter を使用して、ネットワークパケットのみを許可できます。
- 特定の宛先ポートから、あるいは指定された宛先ポートへ
- 特定の IP アドレスから、あるいは特定の IP アドレスへ
- 特定の MAC アドレスから、あるいは特定の MAC アドレスまで
これを行うには、特定のルールに一致するネットワークパケット以外のネットワークパケットをすべて破棄する xdp-filter の deny ポリシーを使用します。たとえば、ドロップするパケットのソース IP アドレスがわからない場合は、この方法を使用します。
インターフェイスで xdp-filter を読み込む際にデフォルトのポリシーを deny に設定すると、特定のトラフィックを許可するルールを作成するまで、カーネルはこのインターフェイスからのパケットをすべて直ちに破棄します。システムからロックアウトしないようにするには、ローカルにコマンドを入力するか、別のネットワークインターフェイスからホストに接続します。
前提条件
-
xdp-toolsパッケージがインストールされている。 - ホストにローカルにログインするか、トラフィックのフィルタリングを予定しないネットワークインターフェイスを使用してホストにログインします。
- XDP プログラムをサポートするネットワークドライバー。
手順
xdp-filterを読み込み、enp1s0などの特定のインターフェイスのパケットを処理します。# xdp-filter load enp1s0 -p denyオプションで、
-f featureオプションを使用して、tcp、ipv4、ethernetなどの特定の機能のみを有効にします。すべての機能をロードするのではなく、必要な機能のみをロードすることで、パケット処理の速度が向上します。複数の機能を有効にするには、コンマで区切ります。コマンドがエラーで失敗した場合、ネットワークドライバーは XDP プログラムをサポートしません。
ルールを追加して、一致するパケットを許可します。以下に例を示します。
パケットのポート
22を許可するには、以下のコマンドを実行します。# xdp-filter port 22このコマンドは、TCP および UDP トラフィックに一致するルールを追加します。特定のプロトコルのみと一致するように、
-p protocolオプションをコマンドに渡します。パケットの
192.0.2.1を許可するには、次のコマンドを実行します。# xdp-filter ip 192.0.2.1xdp-filterは IP 範囲に対応していないことに注意してください。MAC アドレス
00:53:00:AA:07:BEへのパケットを許可するには、次のコマンドを実行します。# xdp-filter ether 00:53:00:AA:07:BE
重要xdp-filterユーティリティーは、ステートフルパケットの検査に対応していません。これには、-m modeオプションでモードを設定せず、マシンが送信トラフィックに応答して受信トラフィックを許可する明示的なルールを追加する必要があります。
検証
以下のコマンドを使用して、破棄されたパケットおよび許可されるパケットに関する統計を表示します。
# xdp-filter status
第44章 ネットワークパケットのキャプチャー
ネットワークの問題と通信をデバッグするには、ネットワークパケットをキャプチャーできます。以下のセクションでは、ネットワークパケットのキャプチャーに関する手順と追加情報を提供します。
44.1. XDP プログラムがドロップしたパケットを含むネットワークパケットをキャプチャーするために xdpdump を使用
xdpdump ユーティリティーは、ネットワークパケットをキャプチャーします。tcpdump ユーティリティーとは異なり、xdpdump はこのタスクに extended Berkeley Packet Filter(eBPF) プログラムを使用します。これにより、xdpdump は Express Data Path (XDP) プログラムによりドロップされたパケットをキャプチャーできます。tcpdump などのユーザー空間ユーティリティーは、この削除されたパッケージや、XDP プログラムによって変更された元のパケットをキャプチャーできません。
xdpdump を使用して、インターフェイスにすでに割り当てられている XDP プログラムをデバッグすることができます。したがって、ユーティリティーは、XDP プログラムを起動し、終了する前にパケットをキャプチャーできます。後者の場合、xdpdump は XDP アクションもキャプチャーします。デフォルトでは、xdpdump は XDP プログラムのエントリーで着信パケットをキャプチャーします。
AMD および Intel 64 ビット以外のアーキテクチャーでは、xdpdump ユーティリティーはテクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) ではサポートされておらず、機能的に完全ではない可能性があるため、Red Hat では実稼働環境での使用を推奨していません。テクノロジープレビュー機能では、最新の製品機能をいち早く提供します。これにより、お客様は開発段階で機能をテストし、フィードバックを提供できます。
テクノロジープレビュー機能のサポート範囲は、Red Hat カスタマーポータルの テクノロジープレビュー機能のサポート範囲 を参照してください。
xdpdump には、パケットフィルターまたはデコード機能がないことに注意してください。ただし、パケットのデコードに tcpdump と組み合わせて使用できます。
前提条件
- XDP プログラムをサポートするネットワークドライバー。
-
XDP プログラムが
enp1s0インターフェイスに読み込まれている。プログラムが読み込まれていない場合は、xdpdumpが後方互換性としてtcpdumpと同様にパケットをキャプチャーします。
手順
enp1s0インターフェイスでパケットをキャプチャーして、/root/capture.pcapファイルに書き込むには、次のコマンドを実行します。# xdpdump -i enp1s0 -w /root/capture.pcap- パケットの取得を停止するには、Ctrl+C を押します。
第45章 RHEL 8 の eBPF ネットワーク機能について
eBPF (extended Berkeley Packet Filter) は、カーネル領域でのコード実行を可能にするカーネル内の仮想マシンです。このコードは、限られた一連の関数にのみアクセスできる制限付きサンドボックス環境で実行されます。
ネットワークでは、eBPF を使用してカーネルパケット処理を補完したり、置き換えることができます。使用するフックに応じて、eBPF プログラムには以下のような記述があります。
- パケットデータおよびメタデータへの読み取りおよび書き込みアクセス
- ソケットとルートを検索できる
- ソケットオプションを設定できる
- パケットをリダイレクト可能
45.1. RHEL 8 におけるネットワーク eBPF 機能の概要
eBPF (extended Berkeley Packet Filter) ネットワークプログラムは、RHEL の以下のフックに割り当てることができます。
- eXpress Data Path (XDP): カーネルネットワークスタックが受信したパケットを処理する前に、このパケットへの早期アクセスを提供します。
-
tceBPF 分類子 (direct-action フラグ): ingress および egress で強力なパケット処理を提供します。 - Control Groups version 2 (cgroup v2): コントロールグループ内のプログラムが実行するソケットベースの操作のフィルタリングおよび上書きを有効にします。
- ソケットフィルタリング: ソケットから受信したパケットのフィルタリングを有効にします。この機能は、従来の Berkeley Packet Filter (cBPF) でも利用できますが、eBPF プログラムに対応するために拡張されました。
- ストリームパーサー : 個別のメッセージへのストリームの分散、フィルタリング、ソケットへのリダイレクトを有効にします。
-
SO_REUSEPORTソケットの選択:reuseportソケットグループから受信したソケットをプログラム可能な選択を提供します。 - flow dissector: 特定の状況でカーネルがパケットヘッダーを解析する方法をオーバーライドします。
- TCP 輻輳制御コールバック: カスタム TCP 輻輳制御アルゴリズムの実装を有効にします。
- カプセル化によるルート: カスタムのトンネルカプセル化の作成を有効にします。
Red Hat は、RHEL で利用可能な eBPF 機能をすべてサポートせず、ここで説明するすべての eBPF 機能をサポートしているわけではないことに注意してください。詳細と、個別のフックのサポート状況は、RHEL 8 リリースノート と、次の概要を参照してください。
XDP
BPF_PROG_TYPE_XDP タイプのプログラムはネットワークインターフェイスに割り当てることができます。次にカーネルは、カーネルネットワークスタックが処理を開始する前に受信したパケットでプログラムを実行します。これにより、高速パケットドロップなど、特定の状況で高速なパケット転送が可能になり、負荷分散シナリオにおいて DDoS (Distributed Denial of Service) 攻撃や高速パケットリダイレクトを防ぐことができます。
さまざまな形式のパケット監視やサンプリングに XDP を使用することもできます。カーネルは、XDP プログラムはパケットを変更し、カーネルネットワークスタックへのさらなる処理を可能にします。
以下の XDP モードを使用できます。
- ネイティブ (ドライバー) XDP: カーネルは、パケット受信時に最速の可能点からプログラムを実行します。この時点で、カーネルはパケットを解析しなかったため、カーネルが提供するメタデータは利用できません。このモードでは、ネットワークインターフェイスドライバーが XDP をサポートしている必要がありますが、すべてのドライバーがこのネイティブモードをサポートするわけではありません。
- 汎用 XDP: カーネルネットワークスタックは、処理の初期段階で XDP プログラムを実行します。この時点で、カーネルデータ構造が割り当てられ、パケットを事前に処理しています。パケットをドロップまたはリダイレクトする必要がある場合は、ネイティブモードと比較して大きなオーバーヘッドが必要になります。ただし、汎用モードはネットワークインターフェイスドライバーのサポートを必要とせず、すべてのネットワークインターフェイスで機能します。
- オフロードされた XDP: カーネルは、ホストの CPU 上ではなく、ネットワークインターフェイスで XDP プログラムを実行します。これには特定のハードウェアが必要で、特定の eBPF 機能のみがこのモードで使用できることに注意してください。
RHEL で、libxdp ライブラリーを使用してすべての XDP プログラムを読み込みます。このライブラリーは、XDP のシステム制御を可能にします。
現在、XDP プログラムにはシステム設定に制限があります。たとえば、受信側インターフェイスで特定のハードウェアオフロード機能を無効にする必要があります。また、ネイティブモードをサポートするすべてのドライバーで利用可能なわけではありません。
Red Hat は、Red Hat 8.7 では、以下の条件がすべて適用されている場合に限り、XDP 機能をサポートします。
- AMD または Intel 64 ビットアーキテクチャーに XDP プログラムを読み込みます。
-
libxdpライブラリーを使用して、カーネルにプログラムを読み込む。 - XDP プログラムが XDP ハードウェアオフロードを使用しない
さらに、Red Hat は、サポート対象外のテクノロジープレビューとして以下の XDP の使用を提供します。
-
AMD および Intel 64 ビット以外のアーキテクチャーで XDP プログラムを読み込む。
libxdpライブラリーは、AMD および Intel 64 ビット以外のアーキテクチャーでは使用できません。 - XDP ハードウェアオフロード。
AF_XDP
指定した AF_XDP ソケットにパケットをフィルターしてリダイレクトする XDP プログラムを使用すると、AF_XDP プロトコルファミリーから 1 つ以上のソケットを使用して、カーネルからユーザー空間にパケットを速やかにコピーできます。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
トラフィック制御
Traffic Control (tc) サブシステムは、以下のタイプの eBPF プログラムを提供します。
-
BPF_PROG_TYPE_SCHED_CLS -
BPF_PROG_TYPE_SCHED_ACT
これらのタイプを使用すると、カスタム tc 分類子と tc アクションを eBPF に記述できます。これは、tc エコシステムの一部とともに、強力なパケット処理機能を提供します。また、複数のコンテナーネットワークオーケストレーションソリューションの中核となります。
多くの場合、direct-action フラグと同様に、eBPF 分類子は、同じ eBPF プログラムから直接アクションを実行できます。clsact Queueing Discipline (qdisc) は、Ingress 側でこれを有効にするように設計されています。
flow dissector の eBPF プログラムは、flower などのその他の qdiscs や tc 分類子の操作に影響を与える可能性があることに注意してください。
tc 機能の eBPF は、RHEL 8.2 以降で完全にサポートされています。
ソケットフィルター
複数のユーティリティーは、ソケットで受信されるパケットのフィルタリングに、従来の Berkeley Packet Filter (cBPF) を使用または使用しています。たとえば、tcpdump ユーティリティーを使用すると、ユーザーは、どの tcpdump を cBPF コードに変換するか、式を指定できます。
cBPF の代替として、カーネルは、同じ目的で BPF_PROG_TYPE_SOCKET_FILTER タイプの eBPF プログラムを許可します。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
コントロールグループ
RHEL では、cgroup に割り当てられる eBPF プログラムを複数使用できます。カーネルは、指定の cgroup のプログラムが操作を実行する際に、これらのプログラムを実行します。cgroups バージョン 2 のみを使用できます。
RHEL では、以下のネットワーク関連の cgroup eBPF プログラムが利用できます。
-
BPF_PROG_TYPE_SOCK_OPS- カーネルは、さまざまな TCP イベントでこのプログラムーを呼び出します。プログラムは、カスタム TCP ヘッダーオプションなどを含め、カーネル TCP スタックの動作を調整できます。 -
BPF_PROG_TYPE_CGROUP_SOCK_ADDR: カーネルは、connect、bind、sendto、recvmsg、getpeername、およびgetsocknameの操作中にこのプログラムを呼び出します。このプログラムは、IP アドレスとポートを変更できます。これは、ソケットベースのネットワークアドレス変換 (NAT) を eBPF に実装する場合に便利です。 -
BPF_PROG_TYPE_CGROUP_SOCKOPT: カーネルは、setsockoptおよびgetsockopt操作時にこのプログラムを呼び出して、オプションの変更を可能にします。 -
BPF_PROG_TYPE_CGROUP_SOCK: カーネルは、ソケットの作成時、ソケットの開放時、アドレスのバインド時にこのプログラムを呼び出します。これらのプログラムを使用して操作を許可または拒否するか、統計のソケット作成の検査のみを行います。 -
BPF_PROG_TYPE_CGROUP_SKB: このプログラムは ingress および egress の個別のパケットをフィルターし、パケットを受信または拒否できます。 -
BPF_CGROUP_INET4_GETPEERNAME、BPF_CGROUP_INET6_GETPEERNAME、BPF_CGROUP_INET4_GETSOCKNAMEおよびBPF_CGROUP_INET6_GETSOCKNAME: 上記のプログラムを使用して、getsocknameとgetpeernameのシステム呼び出しの結果を上書きします。これは、ソケットベースのネットワークアドレス変換 (NAT) を eBPF に実装する場合に便利です。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
ストリームパーサー
ストリームパーサーは、特別な eBPF マップに追加されるソケットのグループで動作します。次に、eBPF プログラムは、カーネルがこれらのソケットで受信または送信するパケットを処理します。
RHEL では、以下のストリームパーサー eBPF プログラムを利用できます。
-
BPF_PROG_TYPE_SK_SKB: eBPF プログラムは、ソケットから受信したパケットを個別のメッセージに解析したり、それらのメッセージをドロップしたり、グループ内の別のソケットに送信するようにカーネルに指示します。 -
BPF_PROG_TYPE_SK_MSG: このプログラムは egress メッセージをフィルタリングします。eBPF プログラムは、パケットを個別のメッセージを解析し、そのパケットを承認または拒否します。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
SO_REUSEPORT ソケットの選択
このソケットオプションを使用することで、複数のソケットを同じ IP アドレスとポートにバインドできます。eBPF がない場合、カーネルは接続ハッシュに基づいて受信ソケットを選択します。BPF_PROG_TYPE_SK_REUSEPORT プログラムを使用すると、受信ソケットの選択が完全にプログラム可能になります。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
Flow dissector
プロトコルの完全なデコードを待たずにカーネルがパケットヘッダーを処理する必要がある場合、これらは 破棄されます。たとえば、これは、tc サブシステム、ボンディングのルーティング、またはパケットのハッシュを計算する際に発生します。この場合、カーネルはパケットヘッダーを解析し、パケットヘッダーからの情報を使用して内部構造を埋めます。この内部解析は、BPF_PROG_TYPE_FLOW_DISSECTOR プログラムを使用して置き換えることができます。RHEL の eBPF では、TCP および UDP を IPv4 および IPv6 上でのみ破棄できます。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
TCP 輻輳制御
struct tcp_congestion_oops コールバックを実装する BPF_PROG_TYPE_STRUCT_OPS プログラムのグループを使用して、カスタム TCP 輻輳制御アルゴリズムを作成できます。この方法を実装するアルゴリズムは、ビルトインのカーネルアルゴリズムとともにシステムで利用できます。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
カプセル化によるルート
以下のいずれかの eBPF プログラムタイプは、トンネルのカプセル化属性として、ルーティングテーブルのルートに割り当てることができます。
-
BPF_PROG_TYPE_LWT_IN -
BPF_PROG_TYPE_LWT_OUT -
BPF_PROG_TYPE_LWT_XMIT
このような eBPF プログラムの機能は特定のトンネル設定に限定され、汎用のカプセル化またはデシリアライズソリューションの作成はできません。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
ソケットルックアップ
bind システムコールの制限を回避するには、BPF_PROG_TYPE_SK_LOOKUP タイプの eBPF プログラムを使用します。このようなプログラムは、新しい受信 TCP 接続のリスニングソケットまたは UDP パケットの非接続ソケットを選択できます。
Red Hat 8.7 では、この機能をサポート対象外のテクノロジープレビューとして提供していることに注意してください。
45.2. RHEL 8 におけるネットワークカードごとの XDP 機能の概要
以下は、XDP 対応ネットワークカードと、それらで使用できる XDP 機能の概要です。
| ネットワークカード | ドライバー | ベーシック | リダイレクト | ターゲット | HW オフロード | Zero-copy |
|---|---|---|---|---|---|---|
| Amazon Elastic Network Adapter |
| はい | はい | はい [a] | いいえ | いいえ |
| Broadcom NetXtreme-C/E 10/25/40/50 gigabit Ethernet |
| はい | はい | はい [a] | いいえ | いいえ |
| Cavium Thunder Virtual function |
| はい | いいえ | いいえ | いいえ | いいえ |
| Google Virtual NIC (gVNIC) のサポート |
| はい | はい | はい | いいえ | はい |
| Intel® 10GbE PCI Express Virtual Function Ethernet |
| はい | いいえ | いいえ | いいえ | いいえ |
| Intel® 10GbE PCI Express adapters |
| はい | はい | はい [a] | いいえ | はい |
| Intel® Ethernet Connection E800 Series |
| はい | はい | はい [a] | いいえ | はい |
| Intel® Ethernet Controller I225-LM/I225-V family |
| はい | はい | はい | いいえ | はい |
| Intel® Ethernet Controller XL710 Family |
| はい | はい | いいえ | はい | |
| Intel® PCI Express Gigabit adapters |
| はい | はい | はい [a] | いいえ | いいえ |
| Mellanox 5th generation network adapters (ConnectX series) |
| はい | はい | はい [b] | いいえ | はい |
| Mellanox Technologies 1/10/40Gbit Ethernet |
| はい | はい | いいえ | いいえ | いいえ |
| Microsoft Azure Network Adapter |
| はい | はい | はい | いいえ | いいえ |
| Microsoft Hyper-V virtual network |
| はい | はい | はい | いいえ | いいえ |
| Netronome® NFP4000/NFP6000 NIC |
| はい | いいえ | いいえ | はい | いいえ |
| QEMU Virtio network |
| はい | はい | はい [a] | いいえ | いいえ |
| QLogic QED 25/40/100Gb Ethernet NIC |
| はい | はい | はい | いいえ | いいえ |
| Solarflare SFC9000/SFC9100/EF100-family |
| はい | はい | はい [b] | いいえ | いいえ |
| Universal TUN/TAP device |
| はい | はい | はい | いいえ | いいえ |
| Virtual ethernet pair device |
| はい | はい | はい | いいえ | いいえ |
[a]
XDP プログラムがインターフェイスで読み込まれている場合にのみします。
[b]
最大の CPU インデックス以上の XDP TX キューを複数割り当てる必要があります。
| ||||||
説明:
-
Basic: 基本的な戻りコード (
DROP、PASS、ABORTED、およびTX) をサポートします。 -
redirect:
REDIRECTの戻りコードをサポートします。 -
target:
REDIRECTの戻りコードのターゲットにすることができます。 - HW オフロード: XDP ハードウェアオフロードをサポートします。
-
zero-copy:
AF_XDPプロトコルファミリーの zero-copy モードをサポートします。
第46章 BPF コンパイラーコレクションを使用したネットワークトレース
BPF コンパイラーコレクション (BCC) は、eBPF (extended Berkeley Packet Filter) プログラムの作成を容易にするライブラリーです。eBPF プログラムの主なユーティリティーは、オーバーヘッドやセキュリティー上の問題が発生することなく、オペレーティングシステムのパフォーマンスおよびネットワークパフォーマンスを分析することです。
BCC により、ユーザーは eBPF の技術詳細を把握する必要がなくなり、事前に作成した eBPF プログラムを含む bcc-tools パッケージなど、多くの標準スタートポイントを利用できます。
eBPF プログラムは、ディスク I/O、TCP 接続、プロセス作成などのイベントでトリガーされます。プログラムがカーネルのセーフ仮想マシンで実行するため、カーネルがクラッシュしたり、ループしたり、応答しなくなることはあまりありません。
46.1. bcc-tools パッケージのインストール
bcc-tools パッケージをインストールします。これにより、依存関係として BPF Compiler Collection (BCC) ライブラリーもインストールされます。
手順
bcc-toolsをインストールします。# yum install bcc-toolsBCC ツールは、
/usr/share/bcc/tools/ディレクトリーにインストールされます。
検証
インストールされたツールを検査します。
# ls -l /usr/share/bcc/tools/ ... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...リスト内の
docディレクトリーには、各ツールのドキュメントがあります。
46.2. カーネルの受け入れキューに追加された TCP 接続の表示
カーネルは、TCP 3 方向ハンドシェイクで ACK パケットを受け取ると、カーネルは接続の状態が ESTABLISHED に変更された後に SYN キューから accept キューに移動します。そのため、正常な TCP 接続だけがこのキューに表示されます。
tcpaccept ユーティリティーは、eBPF 機能を使用して、カーネルが accept キューに追加するすべての接続を表示します。このユーティリティーは、パケットをキャプチャーしてフィルタリングする代わりにカーネルの accept() 関数を追跡するため、軽量です。たとえば、一般的なトラブルシューティングには tcpaccept を使用して、サーバーが許可した新しい接続を表示します。
手順
次のコマンドを実行して、カーネルの
許可キューの追跡を開始します。# /usr/share/bcc/tools/tcpaccept PID COMM IP RADDR RPORT LADDR LPORT 843 sshd 4 192.0.2.17 50598 192.0.2.1 22 1107 ns-slapd 4 198.51.100.6 38772 192.0.2.1 389 1107 ns-slapd 4 203.0.113.85 38774 192.0.2.1 389 ...カーネルが接続を受け入れるたびに、
tcpacceptは接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.3. 発信 TCP 接続試行の追跡
tcpconnect ユーティリティーは、eBPF 機能を使用して発信 TCP 接続の試行を追跡します。ユーティリティーの出力には、失敗した接続も含まれます。
tcpconnect ユーティリティーは、パケットを取得してフィルタリングするのではなく、カーネルの connect() 関数などを追跡するため、軽量です。
手順
以下のコマンドを入力し、すべての発信接続を表示する追跡プロセスを開始します。
# /usr/share/bcc/tools/tcpconnect PID COMM IP SADDR DADDR DPORT 31346 curl 4 192.0.2.1 198.51.100.16 80 31348 telnet 4 192.0.2.1 203.0.113.231 23 31361 isc-worker00 4 192.0.2.1 192.0.2.254 53 ...カーネルが発信接続を処理するたびに、
tcpconnectは、接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.4. 発信 TCP 接続のレイテンシーの測定
TCP 接続のレイテンシーは、接続を確立するのにかかった時間です。通常、これには、アプリケーションのランタイムではなく、カーネル TCP/IP 処理およびネットワークのラウンドトリップタイムが含まれます。
tcpconnlat ユーティリティーは、eBPF 機能を使用して、送信した SYN パケットと受信した応答パケットの時間を測定します。
手順
発信接続のレイテンシーの測定を開始します。
# /usr/share/bcc/tools/tcpconnlat PID COMM IP SADDR DADDR DPORT LAT(ms) 32151 isc-worker00 4 192.0.2.1 192.0.2.254 53 0.60 32155 ssh 4 192.0.2.1 203.0.113.190 22 26.34 32319 curl 4 192.0.2.1 198.51.100.59 443 188.96 ...カーネルが発信接続を処理するたびに、
tcpconnlatは、カーネルが応答パケットを受信すると接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.5. カーネルによって破棄された TCP パケットおよびセグメントの詳細の表示
tcpdrop ユーティリティーを使用すると、管理者はカーネルによって破棄された TCP パケットおよびセグメントの詳細を表示できます。このユーティリティーを使用して、リモートシステムがタイマーベースの再送信を送信する可能性がある破棄されたパケットの高レートをデバッグします。ドロップされたパケットおよびセグメントの高レートは、サーバーのパフォーマンスに影響を与える可能性があります。
リソース集約型のパケットを取得およびフィルタリングする代わりに、tcpdrop ユーティリティーは eBPF 機能を使用してカーネルから直接情報を取得します。
手順
以下のコマンドを入力して、破棄された TCP パケットおよびセグメントの詳細表示を開始します。
# /usr/share/bcc/tools/tcpdrop TIME PID IP SADDR:SPORT > DADDR:DPORT STATE (FLAGS) 13:28:39 32253 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE_WAIT (FIN|ACK) b'tcp_drop+0x1' b'tcp_data_queue+0x2b9' ... 13:28:39 1 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE (ACK) b'tcp_drop+0x1' b'tcp_rcv_state_process+0xe2' ...カーネルが TCP パケットとセグメントを破棄するたびに、
tcpdropは、破棄されたパッケージにつながるカーネルスタックトレースを含む接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.6. TCP セッションのトレース
tcplife ユーティリティーは eBPF を使用して、開いて閉じる TCP セッションを追跡し、出力を 1 行で出力してそれぞれを要約します。管理者は tcplife を使用して、接続と転送されたトラフィック量を特定できます。
たとえば、ポート 22 (SSH) への接続を表示して、以下の情報を取得できます。
- ローカルプロセス ID (PID)
- ローカルプロセス名
- ローカルの IP アドレスおよびポート番号
- リモートの IP アドレスおよびポート番号
- 受信および送信トラフィックの量 (KB 単位)
- 接続がアクティブであった時間 (ミリ秒単位)
手順
次のコマンドを実行して、ローカルポート
22への接続の追跡を開始します。# /usr/share/bcc/tools/tcplife -L 22 PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS 19392 sshd 192.0.2.1 22 192.0.2.17 43892 53 52 6681.95 19431 sshd 192.0.2.1 22 192.0.2.245 43902 81 249381 7585.09 19487 sshd 192.0.2.1 22 192.0.2.121 43970 6998 7 16740.35 ...接続が閉じられるたびに、
tcplifeは接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.7. TCP 再送信の追跡
tcpretrans ユーティリティーは、ローカルおよびリモート IP アドレスおよびポート番号、再送信時の TCP 状態などの TCP 再送信の詳細を表示します。
このユーティリティーは eBPF 機能を使用するため、オーバーヘッドが非常に低くなります。
手順
以下のコマンドを使用して、TCP 再送信の詳細を表示します。
# /usr/share/bcc/tools/tcpretrans TIME PID IP LADDR:LPORT T> RADDR:RPORT STATE 00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED 00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED 00:45:43 0 4 192.0.2.1:22 R> 198.51.100.0:17634 ESTABLISHED ...カーネルが TCP 再送信関数を呼び出すたびに、
tcpretransは、接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.8. TCP 状態変更情報の表示
TCP セッション時に、TCP の状態が変わります。tcpstates ユーティリティーは、eBPF 関数を使用してこれらの状態の変更を追跡し、各状態の期間を含む詳細を出力します。たとえば、tcpstates を使用して、接続の初期化に時間がかかりすぎるかどうかを特定します。
手順
以下のコマンドを使用して、TCP 状態変更の追跡を開始します。
# /usr/share/bcc/tools/tcpstates SKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MS ffff9cd377b3af80 0 swapper/1 0.0.0.0 22 0.0.0.0 0 LISTEN -> SYN_RECV 0.000 ffff9cd377b3af80 0 swapper/1 192.0.2.1 22 192.0.2.45 53152 SYN_RECV -> ESTABLISHED 0.067 ffff9cd377b3af80 818 sssd_nss 192.0.2.1 22 192.0.2.45 53152 ESTABLISHED -> CLOSE_WAIT 65636.773 ffff9cd377b3af80 1432 sshd 192.0.2.1 22 192.0.2.45 53152 CLOSE_WAIT -> LAST_ACK 24.409 ffff9cd377b3af80 1267 pulseaudio 192.0.2.1 22 192.0.2.45 53152 LAST_ACK -> CLOSE 0.376 ...接続の状態が変更されるたびに、
tcpstatesは、更新された接続の詳細を含む新しい行を表示します。複数の接続が状態を同時に変更する場合は、最初の列 (
SKADDR) のソケットアドレスを使用して、同じ接続に属するエントリーを判断します。- Ctrl+C を押して、追跡プロセスを停止します。
46.9. 特定のサブネットに送信された TCP トラフィックの要約および集計
tcpsubnet ユーティリティーは、ローカルホストがサブネットに送信する IPv4 TCP トラフィックを要約し、固定の間隔で出力を表示します。このユーティリティーは、eBPF 機能を使用してデータを収集および要約して、オーバーヘッドを削減します。
デフォルトでは、tcpsubnet は以下のサブネットのトラフィックを要約します。
-
127.0.0.1/32 -
10.0.0.0/8 -
172.16.0.0/12 -
192.0.2.0/24/16 -
0.0.0.0/0
最後のサブネット (0.0.0.0/0) は catch-all オプションであることに注意してください。tcpsubnet ユーティリティーは、この catch-all エントリーの最初の 4 つとは異なるサブネットのトラフィックをすべてカウントします。
192.0.2.0/24 および 198.51.100.0/24 サブネットのトラフィックをカウントするには、以下の手順に従います。他のサブネットへのトラフィックは 0.0.0.0/0 catch-all subnet entry で追跡されます。
手順
192.0.2.0/24、198.51.100.0/24、および他のサブネットに送信するトラフィック量のモニタリングを開始します。# /usr/share/bcc/tools/tcpsubnet 192.0.2.0/24,198.51.100.0/24,0.0.0.0/0 Tracing... Output every 1 secs. Hit Ctrl-C to end [02/21/20 10:04:50] 192.0.2.0/24 856 198.51.100.0/24 7467 [02/21/20 10:04:51] 192.0.2.0/24 1200 198.51.100.0/24 8763 0.0.0.0/0 673 ...このコマンドは、指定したサブネットのトラフィックを 1 秒ごとに 1 回ずつバイト単位で表示します。
- Ctrl+C を押して、追跡プロセスを停止します。
46.10. IP アドレスとポートによるネットワークスループットの表示
tcptop ユーティリティーは、ホストがキロバイト単位で送受信する TCP トラフィックを表示します。レポートは自動的に更新され、アクティブな TCP 接続のみが含まれます。このユーティリティーは eBPF 機能を使用するため、オーバーヘッドは非常に低くなります。
手順
送受信トラフィックを監視するには、次のコマンドを実行します。
# /usr/share/bcc/tools/tcptop 13:46:29 loadavg: 0.10 0.03 0.01 1/215 3875 PID COMM LADDR RADDR RX_KB TX_KB 3853 3853 192.0.2.1:22 192.0.2.165:41838 32 102626 1285 sshd 192.0.2.1:22 192.0.2.45:39240 0 0 ...コマンドの出力には、アクティブな TCP 接続のみが含まれます。ローカルシステムまたはリモートシステムが接続を閉じると、接続が出力に表示されなくなります。
- Ctrl+C を押して、追跡プロセスを停止します。
46.11. 確立された TCP 接続の追跡
tcptracer ユーティリティーは、TCP 接続を接続、許可、および閉じるカーネル機能を追跡します。このユーティリティーは eBPF 機能を使用するため、オーバーヘッドが非常に低くなります。
手順
次のコマンドを実行して、トレースプロセスを開始します。
# /usr/share/bcc/tools/tcptracer Tracing TCP established connections. Ctrl-C to end. T PID COMM IP SADDR DADDR SPORT DPORT A 1088 ns-slapd 4 192.0.2.153 192.0.2.1 0 65535 A 845 sshd 4 192.0.2.1 192.0.2.67 22 42302 X 4502 sshd 4 192.0.2.1 192.0.2.67 22 42302 ...カーネルが接続を開始し、受け入れ、または閉じるたびに、
tcptracerは、接続の詳細を表示します。- Ctrl+C を押して、追跡プロセスを停止します。
46.12. IPv4 および IPv6 リッスン試行の追跡
solisten ユーティリティーは、すべての IPv4 および IPv6 のリッスン試行を追跡します。最終的に失敗するものや、接続を許可しないリスニングプログラムなど、試行を追跡します。このユーティリティーは、プログラムが TCP 接続をリッスンする場合にカーネルが呼び出す関数を追跡します。
手順
次のコマンドを実行して、リッスンする TCP 試行をすべて表示するトレースプロセスを開始します。
# /usr/share/bcc/tools/solisten PID COMM PROTO BACKLOG PORT ADDR 3643 nc TCPv4 1 4242 0.0.0.0 3659 nc TCPv6 1 4242 2001:db8:1::1 4221 redis-server TCPv6 128 6379 :: 4221 redis-server TCPv4 128 6379 0.0.0.0 ....- Ctrl+C を押して、追跡プロセスを停止します。
46.13. ソフト割り込みのサービス時間の要約
softirqs ユーティリティーは、ソフト割り込み (ソフト IRQ) に費やした時間を要約し、この時間を合計またはヒストグラムのディストリビューションとして表示します。このユーティリティーは、安定したトレースメカニズムであるカーネルトレースポイント irq:softirq_enter および irq:softirq_exit を使用します。
手順
以下のコマンドを実行して、
soft irqイベント時間を追跡します。# /usr/share/bcc/tools/softirqs Tracing soft irq event time... Hit Ctrl-C to end. ^C SOFTIRQ TOTAL_usecs tasklet 166 block 9152 net_rx 12829 rcu 53140 sched 182360 timer 306256- Ctrl+C を押して、追跡プロセスを停止します。
46.14. ネットワークインターフェイス上のパケットサイズとパケット数のまとめ
netqtop ユーティリティーは、特定のネットワークインターフェイスの各ネットワークキュー上の受信 (RX) パケットと送信 (TX) パケットの属性に関する統計情報を表示します。統計情報には次のものが含まれます。
- 1 秒あたりのバイト数 (BPS)
- 1 秒あたりのパケット数 (PPS)
- 平均パケットサイズ
- 総パケット数
これらの統計情報を生成するために、netqtop は、送信パケット net_dev_start_xmit および受信パケット netif_receive_skb のイベントを実行するカーネル関数をトレースします。
手順
2秒間のバイトサイズの範囲内に含まれるパケット数を表示します。# /usr/share/bcc/tools/netqtop -n enp1s0 -i 2 Fri Jan 31 18:08:55 2023 TX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 0 0 0 0 0 0 Total 0 0 0 0 0 0 RX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 38.0 1 0 0 0 0 Total 38.0 1 0 0 0 0 ----------------------------------------------------------------------------- Fri Jan 31 18:08:57 2023 TX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 0 0 0 0 0 0 Total 0 0 0 0 0 0 RX QueueID avg_size [0, 64) [64, 512) [512, 2K) [2K, 16K) [16K, 64K) 0 38.0 1 0 0 0 0 Total 38.0 1 0 0 0 0 ------------------------------------------------------------------------------
Ctrl+C を押して
netqtopを停止します。
第47章 すべての MAC アドレスからのトラフィックを受け入れるようにネットワークデバイスを設定
ネットワークデバイスは通常、コントローラーが受信するようにプログラムされているパケットを傍受して読み取ります。ネットワークデバイスを設定して、仮想スイッチまたはポートグループレベルのすべての MAC アドレスからのトラフィックを受け入れることができます。
このネットワークモードを使用すると、以下を行うことができます。
- ネットワーク接続の問題診断
- セキュリティー上の理由から、ネットワークアクティビティーの監視
- ネットワーク内のプライベートデータイントラントまたは侵入傍受
InfiniBand を除くあらゆる種類のネットワークデバイスに対してこのモードを有効にできます。
47.1. 全トラフィックを受け入れるようなデバイスの一時設定
ip ユーティリティーを使用して、MAC アドレスに関係なく、すべてのトラフィックを受け入れるようにネットワークデバイスを一時的に設定できます。
手順
必要に応じて、ネットワークインターフェイスを表示して、すべてのトラフィックを受信するインターフェイスを識別します。
# ip address show 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ff ...デバイスを変更して、このプロパティーを有効または無効にします。
enp1s0のaccept-all-mac-addressesモードを有効にするには、以下のコマンドを実行します。# ip link set enp1s0 promisc onenp1s0のaccept-all-mac-addressモードを有効にするには、以下のコマンドを実行します。# ip link set enp1s0 promisc off
検証
accept-all-mac-addressesモードが有効になっていることを確認します。# ip link show enp1s0 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,PROMISC,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ff機器の説明の
PROMISCフラグは、モードが有効であることを示しています。
47.2. nmcli を使用してすべてのトラフィックを受け入れるようにネットワークデバイスを永続的に設定する
nmcli ユーティリティーを使用して、MAC アドレスに関係なく、すべてのトラフィックを受け入れるようにネットワークデバイスを永続的に設定できます。
手順
必要に応じて、ネットワークインターフェイスを表示して、すべてのトラフィックを受信するインターフェイスを識別します。
# ip address show 1: enp1s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000 link/ether 98:fa:9b:a4:34:09 brd ff:ff:ff:ff:ff:ff ...接続がない場合は、新しい接続を作成できます。
ネットワークデバイスを変更して、このプロパティーを有効または無効にします。
enp1s0のethernet.accept-all-mac-addressesモードを有効にするには、以下のコマンドを実行します。# nmcli connection modify enp1s0 ethernet.accept-all-mac-addresses yesenp1s0のaccept-all-mac-addressモードを有効にするには、以下のコマンドを実行します。# nmcli connection modify enp1s0 ethernet.accept-all-mac-addresses no
変更を適用し、接続を再度アクティブにします。
# nmcli connection up enp1s0
検証
ethernet.accept-all-mac-addressesモードが有効になっていることを確認します。# nmcli connection show enp1s0 ... 802-3-ethernet.accept-all-mac-addresses:1 (true)この
802-3-ethernet.accept-all-mac-addresses: trueは、モードが有効であることを示しています。
47.3. nmstatectl を使用してすべてのトラフィックを受け入れるようにネットワークデバイスを永続的に設定する
nmstatectl ユーティリティーを使用して、Nmstate API を介して、MAC アドレスに関係なくすべてのトラフィックを受け入れるようにデバイスを設定します。Nmstate API は、設定を行った後、結果が設定ファイルと一致することを確認します。何らかの障害が発生した場合には、nmstatectl は自動的に変更をロールバックし、システムが不正な状態のままにならないようにします。
前提条件
-
nmstateパッケージがインストールされている。 -
デバイスの設定に使用した
enp1s0.ymlファイルが利用できます。
手順
enp1s0接続の既存のenp1s0.ymlファイルを編集し、以下の内容を追加します。--- interfaces: - name: enp1s0 type: ethernet state: up accept -all-mac-address: trueこれらの設定では、
enp1s0デバイスがすべてのトラフィックを受け入れるように設定します。ネットワーク設定を適用します。
# nmstatectl apply ~/enp1s0.yml
検証
802-3-ethernet.accept-all-mac-addressesモードが有効になっていることを確認します。# nmstatectl show enp1s0 interfaces: - name: enp1s0 type: ethernet state: up accept-all-mac-addresses: true ...この
802-3-ethernet.accept-all-mac-addresses: trueは、モードが有効であることを示しています。
第48章 nmcli を使用したネットワークインターフェイスのミラーリング
ネットワーク管理者は、ポートミラーリングを使用して、あるネットワークデバイスから別のネットワークデバイスに通信中の受信および送信トラフィックを複製できます。インターフェイスのトラフィックのミラーリングは、次の状況で役に立ちます。
- ネットワークの問題をデバッグしてネットワークフローを調整する
- ネットワークトラフィックを検査および分析する
- 侵入を検出する
前提条件
- ネットワークトラフィックをミラーリングするネットワークインターフェイス。
手順
ネットワークトラフィックをミラーリングするネットワーク接続プロファイルを追加します。
# nmcli connection add type ethernet ifname enp1s0 con-name enp1s0 autoconnect no10:handle を使用して、Egress (送信) トラフィック用に、タイプprioのqdiscをenp1s0にアタッチします。# nmcli connection modify enp1s0 +tc.qdisc "root prio handle 10:"子要素がない状態でアタッチされている、
prioに設定されたqdiscには、フィルターを割り当てることができます。ffff:handle を使用して、Ingress トラフィック用のqdiscを追加します。# nmcli connection modify enp1s0 +tc.qdisc "ingress handle ffff:"次のフィルターを追加して、入力および出力
qdiscsのパケットを照合し、それらをenp7s0にミラーリングします。# nmcli connection modify enp1s0 +tc.tfilter "parent ffff: matchall action mirred egress mirror dev enp7s0" # nmcli connection modify enp1s0 +tc.tfilter "parent 10: matchall action mirred egress mirror dev enp7s0"matchallフィルターは、すべてのパケットを照合し、mirredアクションではパケットを宛先にリダイレクトします。接続をアクティベートします。
# nmcli connection up enp1s0
検証
tcpdumpユーティリティーをインストールします。# yum install tcpdumpターゲットデバイス (
enp7s0) でミラーリングされたトラフィックを表示します。# tcpdump -i enp7s0
第49章 nmstate-autoconf を使用した LLDP を使用したネットワーク状態の自動設定
ネットワークデバイスは、LLDP (Link Layer Discovery Protocol) を使用して、LAN でその ID、機能、およびネイバーを通知できます。nmstate-autoconf ユーティリティーは、この情報を使用してローカルネットワークインターフェイスを自動的に設定できます。
nmstate-autoconf ユーティリティーは、テクノロジープレビューとしてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) ではサポートされておらず、機能的に完全ではない可能性があるため、Red Hat では実稼働環境での使用を推奨していません。テクノロジープレビュー機能では、最新の製品機能をいち早く提供します。これにより、お客様は開発段階で機能をテストし、フィードバックを提供できます。
テクノロジープレビュー機能のサポート範囲は、Red Hat カスタマーポータルの テクノロジープレビュー機能のサポート範囲 を参照してください。
49.1. nmstate-autoconf を使用したネットワークインターフェイスの自動設定
nmstate-autoconf ユーティリティーは、LLDP を使用して、スイッチに接続されているインターフェイスの VLAN 設定を識別し、ローカルデバイスを設定します。
この手順では、以下のシナリオで、スイッチが LLDP を使用して VLAN 設定をブロードキャストすることを前提としています。
-
RHEL サーバーの
enp1s0およびenp2s0インターフェイスは、VLAN ID100および VLAN 名prod-netで設定されたスイッチポートに接続されています。 -
RHEL サーバーの
enp3s0インターフェイスは、VLAN ID200および VLAN 名mgmt-netで設定されたスイッチポートに接続されています。
nmstate-autoconf ユーティリティーは、この情報を使用して、サーバーに以下のインターフェイスを作成します。
-
bond100-enp1s0とenp2s0がポートとして使用されるボンディングインターフェイス -
prod-net-bond100上の VLAN インターフェイスと VLAN ID100 -
mgmt-net-enp3s0上の VLAN インターフェイスと VLAN ID200
LLDP が同じ VLAN ID をブロードキャストする別のスイッチポートに複数のネットワークインターフェイスを接続する場合、nmstate-autoconf はこのインターフェイスでボンディングを作成し、さらにその上に共通 VLAN ID を設定します。
前提条件
-
nmstateパッケージがインストールされている。 - ネットワークスイッチで LLDP が有効になっている。
- イーサネットインターフェイスが稼働している。
手順
イーサネットインターフェイスで LLDP を有効にします。
以下の内容で、
~/enable-lldp.ymlなどのファイルを作成します。interfaces: - name: enp1s0 type: ethernet lldp: enabled: true - name: enp2s0 type: ethernet lldp: enabled: true - name: enp3s0 type: ethernet lldp: enabled: true設定をシステムに適用します。
# nmstatectl apply ~/enable-lldp.yml
LLDP を使用してネットワークインターフェイスを設定します。
必要に応じて、ドライランを起動して、
nmstate-autoconfが生成する YAML 設定を表示し、確認します。# nmstate-autoconf -d enp1s0,enp2s0,enp3s0 --- interfaces: - name: prod-net type: vlan state: up vlan: base-iface: bond100 id: 100 - name: mgmt-net type: vlan state: up vlan: base-iface: enp3s0 id: 200 - name: bond100 type: bond state: up link-aggregation: mode: balance-rr port: - enp1s0 - enp2s0nmstate-autoconfを使用して、LLDP から受信した情報に基づいて設定を生成し、その設定をシステムに適用します。# nmstate-autoconf enp1s0,enp2s0,enp3s0
次のステップ
ネットワークに、インターフェイスに IP 設定を提供する DHCP サーバーがない場合は、手動で設定します。詳細は、以下を参照してください。
検証
各インターフェイスの設定を表示します。
# nmstatectl show <interface_name>
第50章 802.3 リンク設定
オートネゴシエーションは、IEEE 802.3u ファストイーサネットプロトコルの機能です。これは、リンク経由で情報交換を行うために、速度、デュプレックスモード、およびフロー制御の最適なパフォーマンスを提供するデバイスポートを対象としています。オートネゴシエーションプロトコルを使用すると、イーサネット経由でデータ転送のパフォーマンスが最適化されます。
オートネゴシエーションのパフォーマンスを最大限に活用するには、リンクの両側で同じ設定を使用します。
50.1. nmcli ユーティリティーを使用した 802.3 リンクの設定
イーサネット接続の 802.3 リンクを設定するには、次の設定パラメーターを変更します。
-
802-3-ethernet.auto-negotiate -
802-3-ethernet.speed -
802-3-ethernet.duplex
手順
接続の現在の設定を表示します。
# nmcli connection show Example-connection ... 802-3-ethernet.speed: 0 802-3-ethernet.duplex: -- 802-3-ethernet.auto-negotiate: no ...問題が発生した場合にパラメーターをリセットする必要がある場合は、これらの値を使用できます。
速度とデュプレックスリンクの設定を行います。
# nmcli connection modify Example-connection 802-3-ethernet.auto-negotiate yes 802-3-ethernet.speed 10000 802-3-ethernet.duplex fullこのコマンドは、オートネゴシエーションを有効にし、接続の速度を
10000Mbit フルデュプレックスに設定します。接続を再度アクティベートします。
# nmcli connection up Example-connection
検証
ethtoolユーティリティーを使用して、イーサネットインターフェイスenp1s0の値を確認します。# ethtool enp1s0 Settings for enp1s0: ... Speed: 10000 Mb/s Duplex: Full Auto-negotiation: on ... Link detected: yes
第51章 DPDK の使用
データプレーン開発キット (DPDK) は、ユーザー空間でのパケット処理を高速化するためのライブラリーとネットワークドライバーを提供します。
管理者は、たとえば仮想マシンで、SR-IOV (Single Root I/O Virtualization) を使用して、レイテンシーを減らして I/O スループットを増やします。
Red Hat は、実験的な DPDK API に対応していません。
51.1. dpdk パッケージのインストール
DPDK を使用するには、dpdk パッケージをインストールします。
手順
yumユーティリティーを使用してdpdkパッケージをインストールします。# yum install dpdk
第52章 TIPC の使用
Transparent Inter-process Communication (TIPC) は、Cluster Domain Sockets とも呼ばれる、クラスター全体の操作に使用される Inter-process Communication (IPC) サービスです。
高可用性環境および動的クラスター環境で実行されているアプリケーションには、特別なニーズがあります。クラスター内のノード数は異なる可能性があります。また、ルーターに障害が発生する可能性があります。負荷分散に関する考慮事項により、クラスター内の異なるノードに機能が移行する可能性があります。TIPC は、アプリケーション開発者がこのような状況に対応する作業を最小限に抑え、適切かつ最適方法で処理される機会を最大化します。さらに、TIPC は TCP などの一般的なプロトコルよりも効率的で耐障害性のある通信を提供します。
52.1. TIPC のアーキテクチャー
TIPC は、TIPC とパケットトランスポートサービス (bearer) を使用してアプリケーション間のレイヤーで、トランスポート、ネットワーク、およびシグナル側のリンク層を結び付けます。しかし、TIPC は異なるトランスポートプロトコルをベアラーとして使用することができるため、たとえば TCP 接続は TIPC シグナルリンクのベアラーとして機能できます。
TIPC は以下のベアラーをサポートします。
- イーサネット
- InfiniBand
- UDP プロトコル
TIPC は、すべての TIPC 通信のエンドポイントである TIPC ポート間で、信頼できるメッセージの転送を提供します。
以下は TIPC アーキテクチャーの図です。
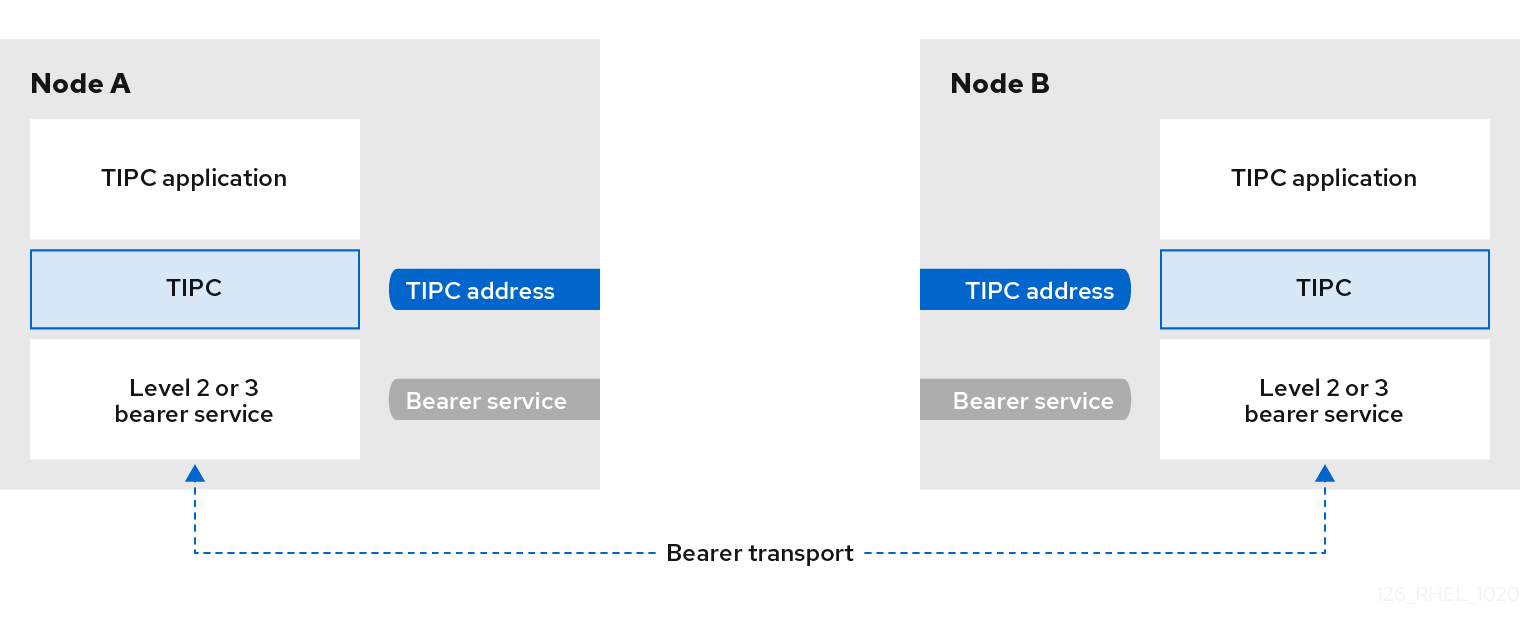
52.2. システム起動時の tipc モジュールのロード
TIPC プロトコルを使用するには、tipc カーネルモジュールをロードする必要があります。システムの起動時にこのカーネルモジュールを自動的にロードするように Red Hat Enterprise Linux を設定できます。
手順
以下の内容で
/etc/modules-load.d/tipc.confファイルを作成します。tipcsystemd-modules-loadサービスを再起動して、システムを再起動せずにモジュールを読み込みます。# systemctl start systemd-modules-load
検証
以下のコマンドを使用して、RHEL が
tipcモジュールをロードしていることを確認します。# lsmod | grep tipc tipc 311296 0このコマンドに、
tipcモジュールのエントリーが表示されない場合は、RHEL がそのモジュールの読み込みに失敗しました。
52.3. TIPC ネットワークの作成
TIPC ネットワークを作成するには、TIPC ネットワークに参加する各ホストでこの手順を実行します。
コマンドは、TIPC ネットワークを一時的に設定します。ノードに TIPC を永続的に設定するには、スクリプトでこの手順のコマンドを使用し、RHEL がシステムの起動時にそのスクリプトを実行するように設定します。
前提条件
-
tipcモジュールがロードされている。詳細は、システム起動時の tipc モジュールのロード を参照してください。
手順
オプション: UUID またはノードのホスト名などの一意のノード ID を設定します。
# tipc node set identity host_nameアイデンティティーには、最大 16 の文字と数字から成る一意の文字列を使用できます。
この手順の後に ID を設定または変更することはできません。
ベアラーを追加します。たとえば、イーサネットを media として、
enp0s1デバイスを物理ベアラーデバイスとして使用するには、次のコマンドを実行します。# tipc bearer enable media eth device enp1s0- 必要に応じて、冗長性とパフォーマンスを向上させるには、前の手順でコマンドを使用してさらにベアラーをアタッチします。最高 3 つのベアラーを設定できますが、同じメディアでは 2 つ以上のビギナーを設定することができます。
- TIPC ネットワークに参加する必要のある各ノードで直前の手順を繰り返します。
検証
クラスターメンバーのリンクステータスを表示します。
# tipc link list broadcast-link: up 5254006b74be:enp1s0-525400df55d1:enp1s0: upこの出力は、ノード
5254006b74beのベアラーenp1s0とノード525400df55d1のベアラーenp1s0間の接続がupになっていることを示します。TIPC 公開テーブルを表示します。
# tipc nametable show Type Lower Upper Scope Port Node 0 1795222054 1795222054 cluster 0 5254006b74be 0 3741353223 3741353223 cluster 0 525400df55d1 1 1 1 node 2399405586 5254006b74be 2 3741353223 3741353223 node 0 5254006b74be-
サービスタイプ
0の 2 つのエントリーは、2 つのノードがこのクラスターのメンバーであることを示しています。 -
サービスタイプ
1のエントリーは、組み込みのトポロジーサービス追跡サービスを表します。 -
サービスタイプ
2のエントリーには、発行したノードから表示されるリンクが表示されます。範囲の上限3741353223は、ピアエンドポイントのアドレス (ノード ID に基づく一意の 32 ビットハッシュ値) を 10 進数の形式で表します。
-
サービスタイプ
第53章 nm-cloud-setup を使用してパブリッククラウドのネットワークインターフェイスを自動的に設定する
通常、仮想マシン (VM) には、DHCP によって設定可能なインターフェイスが 1 つだけあります。しかし、DHCP は、インターフェイス、IP サブネット、IP アドレスなど、複数のネットワークエンティティーを使用して仮想マシンを設定することはできません。また、仮想マシンインスタンスの実行中は設定を適用できません。この実行時設定の問題を解決するために、nm-cloud-setup ユーティリティーはクラウドサービスプロバイダーのメタデータサーバーから設定情報を自動的に取得し、ホストのネットワーク設定を更新します。このユーティリティーは、複数のネットワークインターフェイス、複数の IP アドレス、または 1 つのインターフェイスの IP サブネットを自動的に取得し、実行中の仮想マシンインスタンスのネットワークを再設定するのに役立ちます。
53.1. nm-cloud-setup の設定と事前デプロイ
パブリッククラウドでネットワークインターフェイスを有効にして設定するには、nm-cloud-setup をタイマーおよびサービスとして実行します。
Red Hat Enterprise Linux On Demand および AWS ゴールデンイメージでは、nm-cloud-setup がすでに有効になっており、アクションは不要です。
前提条件
- ネットワーク接続が存在します。
接続は DHCP を使用します。
デフォルトでは、NetworkManager は DHCP を使用する接続プロファイルを作成します。
/etc/NetworkManager/NetworkManager.confでno-auto-defaultパラメーターを設定したためにプロファイルが作成されなかった場合は、この初期接続を手動で作成します。
手順
nm-cloud-setupパッケージをインストールします。# yum install NetworkManager-cloud-setupnm-cloud-setupサービスのスナップインファイルを作成して実行します。次のコマンドを使用して、スナップインファイルの編集を開始します。
# systemctl edit nm-cloud-setup.service設定を有効にするには、サービスを明示的に開始するか、システムを再起動することが重要です。
systemdスナップインファイルを使用して、nm-cloud-setupでクラウドプロバイダーを設定します。たとえば、Amazon EC2 を使用するには、次のように実行します。[Service] Environment=NM_CLOUD_SETUP_EC2=yes次の環境変数を設定して、クラウドが使用できるようにすることができます。
-
NM_CLOUD_SETUP_ALIYUNfor Alibaba Cloud (Aliyun) -
NM_CLOUD_SETUP_AZUREfor Microsoft Azure -
NM_CLOUD_SETUP_EC2for Amazon EC2 (AWS) -
NM_CLOUD_SETUP_GCPfor Google Cloud Platform(GCP)
-
- ファイルを保存して、エディターを終了します。
systemd設定をリロードします。# systemctl daemon-reloadnm-cloud-setupサービスを有効にして開始します。# systemctl enable --now nm-cloud-setup.servicenm-cloud-setupタイマーを有効にして開始します。# systemctl enable --now nm-cloud-setup.timer
53.2. RHEL EC2 インスタンスにおける IMDSv2 と nm-cloud-setup のロールについて
Amazon EC2 のインスタンスメタデータサービス (IMDS) を使用すると、実行中の Red Hat Enterprise Linux (RHEL) EC2 インスタンスのインスタンスメタデータにアクセスする権限を管理できます。RHEL EC2 インスタンスは、セッション指向の方式である IMDS バージョン 2 (IMDSv2) を使用します。nm-cloud-setup ユーティリティーを使用すると、管理者はネットワークを再設定し、実行中の RHEL EC2 インスタンスの設定を自動的に更新できます。nm-cloud-setup ユーティリティーは、ユーザーの介入なしで IMDSv2 トークンを使用して IMDSv2 API 呼び出しを処理します。
-
IMDS は、リンクローカルアドレス
169.254.169.254で実行され、RHEL EC2 インスタンス上のネイティブアプリケーションへのアクセスを提供します。 - アプリケーションおよびユーザー用の各 RHEL EC2 インスタンスに IMDSv2 を指定して設定すると、IMDSv1 にはアクセスできなくなります。
- IMDSv2 を使用することにより、RHEL EC2 インスタンスは、IAM ロールを介してアクセス可能な状態を維持しながら、IAM ロールを使用せずにメタデータを維持します。
-
RHEL EC2 インスタンスが起動すると、
nm-cloud-setupユーティリティーが自動的に実行され、RHEL EC2 インスタンス API を使用するための EC2 インスタンス API アクセストークンが取得されます。
IMDSv2 トークンを HTTP ヘッダーとして使用して EC2 環境の詳細を確認してください。