このコンテンツは選択した言語では利用できません。
Chapter 13. Persistence and Transactions
13.1. Process Instance State
Red Hat JBoss BPM Suite allows persistent storage of information. For example, you can persistently store process runtime state to ensure that you will be able to resume your process instance in case of failure. While logs of current and previous process states are stored by default, you can store process definitions and logging information as well.
13.1.1. Runtime State
When you start a process, Red Hat JBoss BPM Suite creates a process instance, which represents the execution of the process in the specific context. For example, when you start a process that specifies how to process a sales order, Red Hat JBoss BPM Suite creates a process instance for each order. Process instances contain all the related information and minimal runtime state required to continue the execution at any time. However, it does not include process instance logs unless needed for execution of the process instance.
You can make the runtime state of an executing process persistent, for example, in a database. This allows you to restore the state of execution of all running processes in case of failure, or to temporarily remove running instances from memory and restore them later. Red Hat JBoss BPM Suite allows you to plug in different persistence strategies. Note that process instances are not persistent by default.
When you configure the Red Hat JBoss BPM Suite engine to use persistence, it automatically stores the runtime state in a database without further prompting. When you invoke the engine, it ensures that all changes are stored at the end of that invocation. If you encounter a failure and restore the engine from the database, do not manually resume the execution. Process instances automatically resume execution if they are triggered.
Inexperienced users should not directly access and modify database tables containing runtime persistence data. Changes in the runtime state of process instances which are not done by the engine may have unexpected results. If you require information about the current execution state of a process instance, use the history log.
13.1.2. Binary Persistence
Binary persistence, or marshaling, converts the state of the process instance into a binary dataset. Binary persistence is a mechanism used to store and retrieve information persistently. The same mechanism is also applied to the session state and work item states.
When you enable persistence of a process instance:
- Red Hat JBoss BPM Suite transforms the process instance information into binary data. Custom serialization is used instead of Java serialization for performance reasons.
- The binary data is stored together with other process instance metadata, such as process instance ID, process ID, and the process start date.
The session can also store other forms of state, such as the state of timer jobs, or data required for business rules evaluation. Session state is stored separately as a binary dataset along with the ID of the session and metadata. You can restore the session state by reloading a session with given ID. Use ksession.getId() to get the session ID.
13.1.3. Data Model Description
Each entity of the data model is described below.
Figure 13.1. Data Model
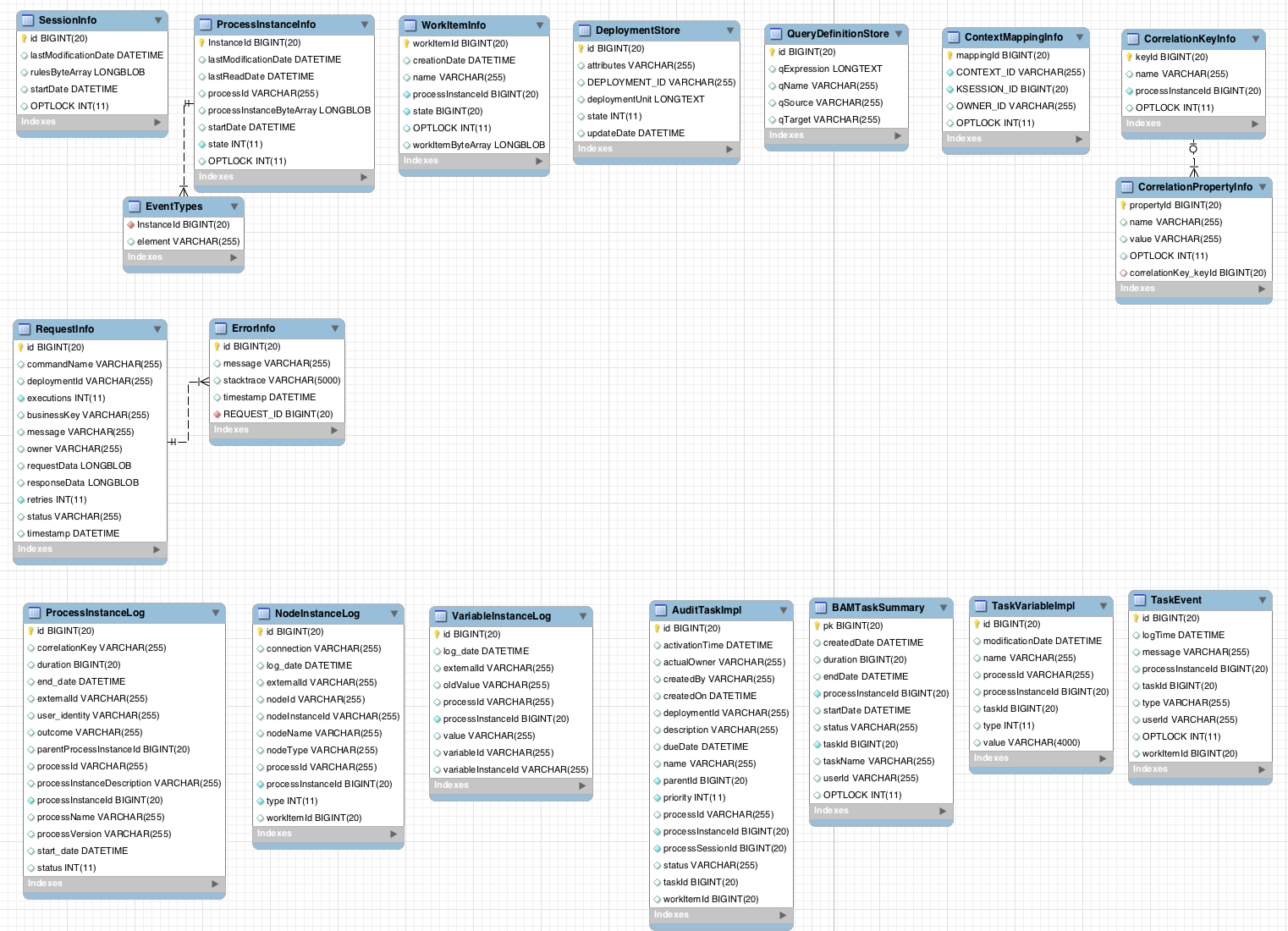
The SessionInfo entity contains the state of the (knowledge) session in which the process instance is running.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The last time that entity was saved to a database. | |
|
| The state of a session. | NOT NULL |
|
| The session start time. | |
|
| A version field containing a lock value. |
The ProcessInstanceInfo entity contains the state of the process instance.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The last time that the entity was saved to a database. | |
|
| The last time that the entity was retrieved from the database. | |
|
| The ID of the process. | |
|
| The state of a process instance in form of a binary dataset. | NOT NULL |
|
| The start time of the process. | |
|
| An integer representing the state of a process instance. | NOT NULL |
|
| A version field containing a lock value. |
The EventTypes entity contains information about events that a process instance will undergo or has undergone.
| Field | Description | Nullable |
|---|---|---|
|
|
A reference to the | NOT NULL |
|
| A finished event in the process. |
The WorkItemInfo entity contains the state of a work item.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The name of the work item. | |
|
| The (primary key) ID of the process. There is no foreign key constraint on this field. | NOT NULL |
|
| The state of a work item. | NOT NULL |
|
| A version field containing a lock value. | |
|
| The work item state in as a binary dataset. | NOT NULL |
The CorrelationKeyInfo entity contains information about correlation keys assigned to the given process instance. This table is optional. Use it only when you require correlation capabilities.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The assigned name of the correlation key. | |
|
| The ID of the process instance which is assigned to the correlation key. | NOT NULL |
|
| A version field containing a lock value. |
The CorrelationPropertyInfo entity contains information about correlation properties for a correlation key assigned the process instance.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The name of the property. | |
|
| The value of the property. | NOT NULL |
|
| A version field containing a lock value. | |
|
| A foreign key mapped to the correlation key. | NOT NULL |
The ContextMappingInfo entity contains information about the contextual information mapped to a KieSession. This is an internal part of RuntimeManager and can be considered optional when RuntimeManager is not used.
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The context identifier. | NOT NULL |
|
|
The | NOT NULL |
|
| A version field containing a lock value. |
13.1.4. Safe Points
During the process engine execution, the state of a process instance is stored in safe points. When you execute a process instance, the engine continues the execution until there are no more actions to be performed. That is, the process instance has been completed, aborted, or is in the wait state in all of its paths. At that point, the engine has reached the next safe state, and the state of the process instance (and all other process instances that it affected) is stored persistently.
13.2. Audit Log
Storing information about the execution of process instances can be useful when you need to, for example:
- Verify which actions have been executed in a particular process instance.
- Monitor and analyze the efficiency of a particular process.
However, storing history information in the runtime database can result in the database rapidly increasing in size. Additionally, monitoring and analysis queries might influence the performance of your runtime engine. This is why process execution history logs are stored separately.
13.2.1. Audit Data Model
The jbpm-audit module contains an event listener that stores process-related information in a database using Java Persistence API (JPA). The data model contains the following entities:
- The ProcessInstanceLog table contains the basic log information about a process instance.
- The NodeInstanceLog table contains information about which nodes were actually executed inside each process instance. Whenever a node instance is entered from one of its incoming connections or is exited through one of its outgoing connections, that information is stored in this table.
- The VariableInstanceLog table contains information about changes in variable instances. The execution engine generates log entries after a variable changes, by default. Alternatively, you can log entries before the variable value changes.
- The AuditTaskImpl table contains information about tasks that can be used for queries.
- The BAMTaskSummary table collects information about tasks. The Business Activity Monitor engine then uses the information to build charts and dashboards.
- The TaskVariableImpl table contains information about task variable instances.
- The TaskEvent table contains information about changes in task instances. It contains a timeline view of events (for example claim, start, or stop) for the given task.
13.2.2. Audit Data Model Description
All audit data model entities contain following elements:
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the null value. |
|
| The duration of a process instance since its start date. |
|
| The end date of a process instance when applicable. |
|
| An optional external identifier used to correlate various elements, for example deployment ID. |
|
| An optional identifier of the user who started the process instance. |
|
| The outcome of a process instance, for example the error code. |
|
| The process instance ID of the parent process instance. |
|
| The ID of the executed process. |
|
| The process instance ID. Cannot have the NULL value. |
|
| The name of the process. |
|
| The version of the process. |
|
| The start date of the process instance. |
|
| The status of process instance that maps to process instance state. |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the NULL value. |
|
| The identifier of the sequence flow that led to this node instance. |
|
| The event date. |
|
| An optional external identifier used to correlate various elements, for example deployment ID. |
|
| The node ID of the corresponding node in the process definition. |
|
| The instance ID of the node. |
|
| The name of the node. |
|
| The type of the node. |
|
| The ID of the executed process. |
|
| The process instance ID. |
|
| The type of the event (0 = enter, 1 = exit). Cannot have the NULL value. |
|
| An optional identifier of work items available only for certain node types. |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the NULL value. |
|
| An optional external identifier used to correlate various elements, for example deployment ID. |
|
| The date of the event. |
|
| The ID of the executed process. |
|
| The process instance ID. |
|
| The previous value of the variable at the time of recording of the log. |
|
| The value of the variable at the time of recording of the log. |
|
| The variable ID in the process definition. |
|
| The ID of the variable instance. |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. |
|
| The time of the task activation. |
|
| The actual owner assigned to this task. This field is set only when a user claims the task. |
|
| The user who created the task. |
|
| The date of the task creation. |
|
| The deployment ID to which this task belongs. |
|
| The task description. |
|
| The due date set on this task. |
|
| The name of the task. |
|
| The parent task ID. |
|
| The priority of the task. |
|
| The process definition ID to which this task belongs. |
|
| The process instance ID with which this task is associated. |
|
|
The |
|
| The current status of the task. |
|
| The identifier of task. |
|
| The work item ID assigned to this task ID (on process side). |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the null value. |
|
| The date of the task creation. |
|
| Duration since the task was created. |
|
| The date when the task reached an end state (that is: complete, exit, fail, or skip). |
|
| The process instance ID. |
|
| The date when the task was started. |
|
| The current status of the task. |
|
| The identifier of the task. |
|
| The name of the task. |
|
| The user ID assigned to the task. |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the null value. |
|
| The last time when the variable was modified. |
|
| The name of the task. |
|
| The ID of the process that the process instance is executing. |
|
| The process instance ID. |
|
| The identifier of the task. |
|
| The type of the variable, that is input or output of the task. |
|
| The value of a variable. |
| Field | Description |
|---|---|
|
| The primary key and ID of the log entity. Cannot have the null value. |
|
| The date when this event was saved. |
|
| The log event message. |
|
| The process instance ID. |
|
| The identifier of the task. |
|
| The type of the event, which corresponds to the life cycle phases of the task. |
|
| The user ID assigned to the task. |
|
| The identifier of the work item to which the task is assigned. |
13.2.3. Storing Process Events in a Database
To log process history in a database, register a logger in your session:
Modify persistence.xml to specify a database. You need to include audit log classes as well (ProcessInstanceLog, NodeInstanceLog, and VariableInstanceLog). See the example:
13.2.4. Storing Process Events in a JMS Queue
Synchronous storing of history logs and runtime data in one database may be undesirable due to performance reasons. In that case, you can use JMS logger to send data into a JMS queue instead of directly storing it in a database. You can also configure it to be transactional in order to avoid issues with inconsistent data, for example when the process engine transaction is reversed.
Example configuration of JMS queue:
13.2.5. Auditing Variables
Process and task variables are stored as string (similar to variable.toString()) in audit tables by default. This is not always efficient, for example, when you need to query by the process or task instance variables:
In this example, when you want to query all the people with certain age, querying becomes inefficient.
Thus, variable audit is based on VariableIndexer, which extracts relevant parts of the variables that will be stored in audit log:
The default indexer (that is indexer accepting toString()) produces a single audit entry for a single variable. However, you can create a custom indexer which indexes variables into separate audit entries:
This allows you to search all the process instances or tasks that contain the person instance of age 34 by querying for:
- Variable name: person.age
- Variable value: 34
13.2.6. Building and Registering Custom Indexers
You can build indexers for both process and task variables. They are supported by different interfaces because they produce different type of objects representing audit view of the variable. To create a custom indexer, follow these steps:
Implement following interfaces to build custom indexers:
-
Process variables:
org.kie.internal.process.ProcessVariableIndexer. -
Task variables:
org.kie.internal.task.api.TaskVariableIndexer.
-
Process variables:
Implement the following methods:
-
accept: indicates what types are handled by given indexer. Only one indexer can index any given variable. The first that accepts the variable will index it. -
index: the method for indexing the variable.
-
Package the implementation into a jar file, including following files:
-
For process variables:
META-INF/services/org.kie.internal.process.ProcessVariableIndexerwith list of fully qualified class names that represent the process variable indexers (single class name per line). -
For task variables:
META-INF/services/org.kie.internal.task.api.TaskVariableIndexerwith list of fully qualified class names that represent the task variable indexers (single class name per line).
-
For process variables:
The ServiceLoader service registers indexers. When you start indexing, all the registered indexers are examined. If no applicable indexer is found, the default indexer (toString() based) is used.
13.3. Transactions
Red Hat JBoss BPM Suite engine supports Java Transaction API (JTA). The engine executes any method you invoke in a separate transaction unless you set transaction boundaries. Transaction boundaries allow you to combine multiple commands into one transaction.
Register a transaction manager before using user-defined transactions. The following sample code uses Bitronix transaction manager. It also uses JTA to specify transaction boundaries:
If you use Bitronix as the transaction manager, you must provide jndi.properties in your root classpath to register the Bitronix transaction manager in JNDI.
-
If you use the
jbpm-testmodule,jndi.propertiesis included by default. If you are not using
jbpm-testmodule, createjndi.propertiesmanually with the following content:java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow
If you use a different JTA transaction manager, modify the transaction manager property in persistence.xml:
<property name = "hibernate.transaction.jta.platform" value = "org.hibernate.transaction.JBossTransactionManagerLookup" />
<property
name = "hibernate.transaction.jta.platform"
value = "org.hibernate.transaction.JBossTransactionManagerLookup"
/>
Using the (runtime manager) Singleton strategy with JTA transactions (UserTransaction or CMT) is not recommended because of a race condition. It can result in an IllegalStateException with a message similar to "Process instance X is disconnected".
Avoid this condition by explicitly synchronizing around the KieSession instance when invoking the transaction in the user application code:
13.4. Implementing Container Managed Transaction
You can embed Red Hat JBoss BPM Suite inside an application that executes in Container Managed Transaction (CMT) mode, such as Enterprise Java Beans (EJB).
To configure the transaction manager, follow these steps:
Implement the dedicated transaction manager:
org.jbpm.persistence.jta.ContainerManagedTransactionManager
org.jbpm.persistence.jta.ContainerManagedTransactionManagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow Insert the transaction manager and persistence context manager into the environment before you create or load your session:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure JPA provider (example Hibernate and WebSphere):
<property name="hibernate.transaction.factory_class" value="org.hibernate.transaction.CMTTransactionFactory"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.WebSphereJtaPlatform"/><property name="hibernate.transaction.factory_class" value="org.hibernate.transaction.CMTTransactionFactory"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.WebSphereJtaPlatform"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
To ensure that the container is aware of process instance execution exceptions, make sure that exceptions thrown by the engine are sent to the container to properly reverse the transaction.
Using the CMT Dispose KieSession Command
If you dispose of your KieSession directly when running in the CMT mode, you may generate exceptions, because Red Hat JBoss BPM Suite requires transaction synchronization. Use org.jbpm.persistence.jta.ContainerManagedTransactionDisposeCommand to dispose of your session.
13.5. Using Persistence
Red Hat JBoss BPM Suite engine does not save runtime data persistently by default. To use persistence, you need to:
- Add necessary dependencies.
- Configure a datasource.
- Configure the Red Hat JBoss BPM Suite engine.
13.5.1. Adding Dependencies
To use persistence, add necessary dependencies to the classpath of your application. If you are using Red Hat JBoss Development Studio with Red Hat JBoss BPM Suite runtime default configuration, all necessary dependencies are already present for the default persistence configuration. Otherwise, ensure that the necessary JAR files are added to your Red Hat JBoss BPM Suite runtime directory.
Following is a list of dependencies for the default combination with Hibernate as the JPA persistence provider, an H2 in-memory database, and Bitronix for JTA-based transaction management. Dependencies needed for your project will vary depending on your solution configuration.
jbpm-persistence-jpa.jar file is necessary for saving the runtime state. Therefore, always make sure it is available in your project.
-
jbpm-persistence-jpa(org.jbpm) -
drools-persistence-jpa(org.drools) -
persistence-api(javax.persistence) -
hibernate-entitymanager(org.hibernate) -
hibernate-annotations(org.hibernate) -
hibernate-commons-annotations(org.hibernate) -
hibernate-core(org.hibernate) -
commons-collections(commons-collections) -
dom4j(dom4j) -
jta(javax.transaction) -
btm(org.codehaus.btm) -
javassist(javassist) -
slf4j-api(org.slf4j) -
slf4j-jdk14(org.slf4j) -
h2(com.h2database)
13.5.2. Manually Configuring Red Hat JBoss BPM Suite Engine to Use Persistence
Use JPAKnowledgeService to create a knowledge session based on a knowledge base, a knowledge session configuration (if necessary), and the environment. Ensure that the environment contains a reference to your Entity Manager Factory. For example:
Additionally, you can use JPAKnowledgeService to recreate a session based on a specific session ID. For example:
// Recreate the session from database using the sessionId: ksession = JPAKnowledgeService.loadStatefulKnowledgeSession(sessionId, kbase, null, env);
// Recreate the session from database using the sessionId:
ksession = JPAKnowledgeService.loadStatefulKnowledgeSession(sessionId, kbase, null, env);Note that only the minimal state that is required to continue execution of the process instance is saved. You cannot retrieve information related to already executed nodes if that information is no longer necessary. To search for history-related information, use the history log.
Add persistence.xml to META-INF to configure JPA. Following example uses Hibernate and H2 database:
In this example, persistence.xml refers to a data source called jdbc/jbpm-ds. If you run your application in an application server, these containers typically allow you to use custom configure file for the data sources. See your application server documentation for further details.
Following example shows you how to set up a data source: