このコンテンツは選択した言語では利用できません。
Chapter 30. High Availability
High availability is the ability for the system to continue functioning after failure of one or more of the servers.
A part of high availability is failover which is the ability for client connections to migrate from one server to another in event of server failure so client applications can continue to operate.
Only persistent message data will survive failover. Any non persistent message data will not be available after failover.
30.1. Live / Backup Pairs
JBoss EAP 7 messaging allows servers to be linked together as live - backup pairs where each live server has a backup. Live servers receive messages from clients, while a backup server is not operational until failover occurs. A backup server can be owned by only one live server, and it will remain in passive mode, waiting to take over the live server’s work.
There is a one-to-one relation between a live server and a backup server. A live server can have only one backup server, and a backup server can be owned by only one live server.
When a live server crashes or is brought down in the correct mode, the backup server currently in passive mode will become the new live server. If the new live server is configured to allow automatic failback, it will detect the old live server coming back up and automatically stop, allowing the old live server to start receiving messages again.
If you deploy just one pair of live / backup servers, you cannot effectively use a load balancer in front of the pair because the backup instance is not actively processing messages. Moreover, services such as JNDI and the Undertow web server are not active on the backup server either. For these reasons, deploying JEE applications to an instance of JBoss EAP being used as a backup messaging server is not supported.
30.2. HA Policies
JBoss EAP messaging supports two different strategies for backing up a server: replication and shared store. Use the ha-policy attribute of the server configuration element to assign the policy of your choice to the given server. There are four valid values for ha-policy:
-
replication-master -
replication-slave -
shared-store-master -
shared-store-slave
As you can see, the value specifies whether the server uses a data replication or a shared store ha policy, and whether it takes the role of master or slave.
Use the management CLI console to add an ha-policy to the server of your choice.
The examples below assume you are running JBoss EAP using the standalone-full-ha configuration profile.
/subsystem=messaging-activemq/server=SERVER/ha-policy=POLICY:add
For example, use the following command to add the replication-master policy to the default server.
/subsystem=messaging-activemq/server=default/ha-policy=replication-master:add
The replication-master policy is configured with the default values. Values to override the default configuration can be included when you add the policy. The management CLI command to read the current configuration uses the following basic syntax.
/subsystem=messaging-activemq/server=SERVER/ha-policy=POLICY:read-resource
For example, use the following command to read the current configuration for the replication-master policy that was added above to the default server. The output is also is also included to highlight the default configuration.
/subsystem=messaging-activemq/server=default/ha-policy=replication-master:read-resource
{
"outcome" => "success",
"result" => {
"check-for-live-server" => true,
"cluster-name" => undefined,
"group-name" => undefined,
"initial-replication-sync-timeout" => 30000L
}
}See Data Replication and Shared Store for details on the configuration options available for each policy.
30.3. Data Replication
When using replication, the live and the backup server pairs do not share the same data directories, all data synchronization is done over the network. Therefore all (persistent) data received by the live server will be duplicated to the backup.
If the live server is cleanly shut down, the backup server will activate and clients will failover to backup. This behavior is pre-determined and is therefore not configurable when using data replication.
The backup server will first need to synchronize all existing data from the live server before replacing it. Unlike shared storage, therefore, a replicating backup will not be fully operational immediately after startup. The time it will take for the synchronization to happen depends on the amount of data to be synchronized and the network speed. Also note that clients are blocked for the duration of initial-replication-sync-timeout when the backup is started. After this timeout elapses, clients will be unblocked, even if synchronization is not completed.
After a successful failover, the backup’s journal will start holding newer data than the data on the live server. You can configure the original live server to perform a failback and become the live server once restarted. A failback will synchronize data between the backup and the live server before the live server comes back online.
In cases were both servers are shut down, the administrator will have to determine which server’s journal has the latest data. If the backup journal has the latest data, copy that journal to the live server. Otherwise, whenever it activates again, the backup will replicate the stale journal data from the live server and will delete its own journal data. If the live server’s data is the latest, no action is needed and the servers can be started normally.
Due to higher latencies and a potentially unreliable network between data centers, the configuration and use of replicated journals for high availability between data centers is neither recommended nor supported.
The replicating live and backup pair must be part of a cluster, and it is the cluster-connection configuration element that defines how a backup server will find its live pair. See Configuring Cluster Connections for details on how to configure a cluster connection. When configuring a cluster-connection, keep in mind the following:
- Both the live and backup server must be part of the same cluster. Notice that even a simple live/backup replicating pair will require a cluster configuration.
- Their cluster user and password must match.
Specify a pair of live / backup servers by configuring the group-name attribute in either the master or the slave element. A backup server will only connect to a live server that shares the same group-name.
As a simple example of using a group-name, suppose you have 2 live servers and 2 backup servers. Because each live server needs to pair with its own backup, you would assign names like so:
-
live1 and backup1 will both have a
group-nameofpair1. -
live2 and backup2 will both have a
group-nameofpair2.
In the above example, server backup1 with will search for the live server with the same group-name, pair1, which in this case is the server live1.
Much like in the shared store case, when the live server stops or crashes, its replicating, paired backup will become active and take over its duties. Specifically, the paired backup will become active when it loses connection to its live server. This can be problematic because this can also happen because of a temporary network problem. In order to address this issue, the paired backup will try to determine whether it still can connect to the other servers in the cluster. If it can connect to more than half the servers, it will become active. If it loses communication to its live server plus more than half the other servers in the cluster, the paired backup will wait and try reconnecting with the live server. This reduces the risk of a "split brain" situation where both the backup and live servers are processing messages without the other knowing it.
This is an important distinction from a shared store backup, where the backup will activate and start to serve client requests if it does not find a live server and the file lock on the journal was released. Note also that in replication the backup server does not know whether any data it might have is up to date, so it really cannot decide to activate automatically. To activate a replicating backup server using the data it has, the administrator must change its configuration to make it a live server by changing slave to master.
30.3.1. Configuring Data Replication
Below are two examples showing the basic configuration for both a live and a backup server residing in the cluster named my-cluster and in the backup group named group1.
The steps below use the management CLI to provide a basic configuration for both a live and a backup server residing in the cluster named my-cluster and in the backup group named group1.
The examples below assume you are running JBoss EAP using the standalone-full-ha configuration profile.
Management CLI Commands to Configure a Live Server for Data Replication
Add the
ha-policyto the Live Server/subsystem=messaging-activemq/server=default/ha-policy=replication-master:add(check-for-live-server=true,cluster-name=my-cluster,group-name=group1)The
check-for-live-serverattribute tells the live server to check to make sure that no other server has its given id within the cluster. The default value for this attribute wasfalsein JBoss EAP 7.0. In JBoss EAP 7.1 and later, the default value istrue.Add the
ha-policyto the Backup Server/subsystem=messaging-activemq/server=default/ha-policy=replication-slave:add(cluster-name=my-cluster,group-name=group1)Confirm a shared
cluster-connectionexists.Proper communication between the live and backup servers requires a
cluster-connection. Use the following management CLI command to confirm that the samecluster-connectionis configured on both the live and backup servers. The example uses the defaultcluster-connectionfound in thestandalone-full-haconfiguration profile, which should be sufficient for most use cases. See Configuring Cluster Connections for details on how to configure a cluster connection.Use the following management CLI command to confirm that both the live and backup server are using the same cluster-connection.
/subsystem=messaging-activemq/server=default/cluster-connection=my-cluster:read-resourceIf the
cluster-connectionexists, the output will provide the current configuration. Otherwise an error message will be displayed.
See All Replication Configuration for details on all configuration attributes.
30.3.2. All Replication Configuration
You can use the management CLI to add configuration to a policy after it has been added. The commands to do so follow the basic syntax below.
/subsystem=messaging-activemq/server=default/ha-policy=POLICY:write-attribute(name=ATTRIBUTE,value=VALUE)
For example, to set the value of the restart-backup attribute to true, use the following command.
/subsystem=messaging-activemq/server=default/ha-policy=replication-slave:write-attribute(name=restart-backup,value=true)
The following tables provide the HA configuration attributes for the replication-master node and replication-slave configuration elements.
| Attribute | Description |
|---|---|
| check-for-live-server |
Set to |
| cluster-name | Name of the cluster used for replication. |
| group-name |
If set, backup servers will only pair with live servers with the matching |
| initial-replication-sync-timeout |
How long to wait in milliseconds until the initiation replication is synchronized. Default is |
| Attribute | Description |
|---|---|
| allow-failback |
Whether this server will automatically stop when another places a request to take over its place. A typical use case is when live server requests to resume active processing after a restart or failure recovery. A backup server with |
| cluster-name | Name of the cluster used for replication. |
| group-name |
If set, backup servers will pair only with live servers with the matching |
| initial-replication-sync-timeout |
How long to wait in milliseconds until the initiation replication is synchronized. Default is |
| max-saved-replicated-journal-size |
Specifies how many times a replicated backup server can restart after moving its files on start. After reaching the maximum, the server will stop permanently after if fails back. Default is |
| restart-backup |
Set to |
30.3.3. Preventing Cluster Connection Timeouts
Each live and backup pair uses a cluster-connection to communicate. The call-timeout attribute of a cluster-connection sets the amount of a time a server will wait for a response after making a call to another server on the cluster. The default value for call-timeout is 30 seconds, which is sufficient for most use cases. However, there are situations where the backup server might be unable to process replication packets coming from the live server. This may happen, for example, when the initial pre-creation of journal files takes too much time, due to slow disk operations or to a large value for journal-min-files. If timeouts like this occur you will see a line in your logs similar to the one below.
AMQ222207: The backup server is not responding promptly introducing latency beyond the limit. Replication server being disconnected now.If a line like the one above appears in your logs that means that the replication process has stopped. You must restart the backup server to reinitiate replication.
To prevent cluster connection timeouts, consider the following options:
-
Increase the
call-timeoutof thecluster-connection. See Configuring Cluster Connections for more information. -
Decrease the value of
journal-min-files. See Configuring Persistence for more information.
30.3.4. Removing Old Journal Directories
A backup server will move its journals to a new location when it starts to synchronize with a live server. By default the journal directories are located in data/activemq directory under EAP_HOME/standalone. For domains, each server will have its own serverX/data/activemq directory located under EAP_HOME/domain/servers. The directories are named bindings, journal, largemessages and paging. See Configuring Persistence and Configuring Paging for more information about these directories.
Once moved, the new directories are renamed oldreplica.X, where X is a digit suffix. If another synchronization starts due to a new failover then the suffix for the "moved" directories will be increased by 1. For example, on the first synchronization the journal directories will be moved to oldreplica.1, on the second, oldreplica.2, and so on. The original directories will store the data synchronized from the live server.
By default a backup server is configured to manage two occurrences of failing over and failing back. After that a cleanup process triggers that removes the oldreplica.X directories. You can change the number of failover occurrences that trigger the cleanup process using the max-saved-replicated-journal-size attribute on the backup server.
Live servers will have max-saved-replicated-journal-size set to 2. This value cannot be changed
30.3.5. Updating Dedicated Live and Backup Servers
If the live and backup servers are deployed in a dedicated topology, where each server is running in its own instance of JBoss EAP, follow the steps below to ensure a smooth update and restart of the cluster.
- Cleanly shut down the backup servers.
- Cleanly shut down the live servers.
- Update the configuration of the live and backup servers.
- Start the live servers.
- Start the backup servers.
30.3.6. Limitations of Data Replication: Split Brain Processing
A "split brain" situation occurs when both a live server and its backup are active at the same time. Both servers can serve clients and process messages without the other knowing it. In this situation there is no longer any message replication between the live and backup servers. A split situation can happen if there is network failure between the two servers.
For example, if the connection between a live server and a network router is broken, the backup server will lose the connection to the live server. However, because the backup can still can connect to more than half the servers in the cluster, it becomes active. Recall that a backup will also activate if there is just one live-backup pair and the backup server loses connectivity to the live server. When both servers are active within the cluster, two undesired situations can happen:
- Remote clients fail over to the backup server, but local clients such as MDBs will use the live server. Both nodes will have completely different journals, resulting in split brain processing.
- The broken connection to the live server is fixed after remote clients have already failed over to the backup server. Any new clients will be connected to the live server while old clients continue to use the backup, which also results in a split brain scenario.
Customers should implement a reliable network between each pair of live and backup servers to reduce the risk of split brain processing when using data replication. For example, use duplicated Network Interface Cards and other network redundancies.
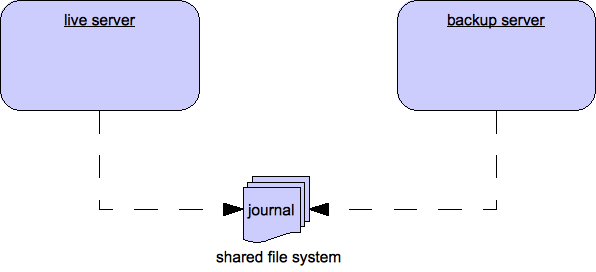
30.4. Shared Store
This style of high availability differs from data replication in that it requires a shared file system which is accessible by both the live and backup node. This means that the server pairs use the same location for their paging, message journal, bindings journal, and large messages in their configuration.
Using a shared store is not supported on Windows. It is supported on Red Hat Enterprise Linux when using Red Hat versions of GFS2 or NFSv4. In addition, GFS2 is supported only with an ASYNCIO journal type, while NFSv4 is supported with both ASYNCIO and NIO journal types.
Also, each participating server in the pair, live and backup, will need to have a cluster-connection defined, even if not part of a cluster, because the cluster-connection defines how the backup server announces its presence to its live server and any other nodes. See Configuring Cluster Connections for details on how this is done.
When failover occurs and a backup server takes over, it will need to load the persistent storage from the shared file system before clients can connect to it. This style of high availability differs from data replication in that it requires a shared file system which is accessible by both the live and backup pair. Typically this will be some kind of high performance Storage Area Network, or SAN. Red Hat does not recommend using Network Attached Storage, known as a NAS, for your storage solution.
The advantage of shared store high availability is that no replication occurs between the live and backup nodes, this means it does not suffer any performance penalties due to the overhead of replication during normal operation.
The disadvantage of shared store replication is that when the backup server activates it needs to load the journal from the shared store which can take some time depending on the amount of data in the store. Also, it requires a shared storage solution supported by JBoss EAP.
If you require the highest performance during normal operation, Red Hat recommends having access to a highly performant SAN and accept the slightly slower failover costs. Exact costs will depend on the amount of data.
30.5. Failing Back to a Live Server
After a live server has failed and a backup taken has taken over its duties, you may want to restart the live server and have clients fail back to it.
In case of a shared store, simply restart the original live server and kill the new live server by killing the process itself. Alternatively, you can set allow-fail-back to true on the slave which will force it to automatically stop once the master is back online. The management CLI command to set allow-fail-back looks like the following:
/subsystem=messaging-activemq/server=default/ha-policy=shared-store-slave:write-attribute(name=allow-fail-back,value=true)
In replication HA mode you need make sure the check-for-live-server attribute is set to true in the master configuration. This is now the default value in JBoss EAP 7.1.
/subsystem=messaging-activemq/server=default/ha-policy=replication-master:write-attribute(name=check-for-live-server,value=true)
If set to true, a live server will search the cluster during startup for another server using its nodeID. If it finds one, it will contact this server and try to "fail-back". Since this is a remote replication scenario, the original live server will have to synchronize its data with the backup running with its ID. Once they are in sync, it will request the backup server to shut down so it can take over active processing. This behavior allows the original live server to determine whether there was a fail-over, and if so whether the server that took its duties is still running or not.
Be aware that if you restart a live server after the failover to backup has occurred, then the check-for-live-server attribute must be set to true. If not, then the live server will start at once without checking that its backup server is running. This results in a situation in which the live and backup are running at the same time, causing the delivery of duplicate messages to all newly connected clients.
For shared stores, it is also possible to cause failover to occur on normal server shut down, to enable this set failover-on-server-shutdown to true in the HA configuration on either the master or slave like so:
/subsystem=messaging-activemq/server=default/ha-policy=shared-store-slave:write-attribute(name=failover-on-server-shutdown,value=true)
You can also force the running backup server to shut down when the original live server comes back up, allowing the original live server to take over automatically, by setting allow-failback to true.
/subsystem=messaging-activemq/server=default/ha-policy=shared-store-slave:write-attribute(name=allow-failback,value=true)30.6. Colocated Backup Servers
JBoss EAP also makes it possible to colocate backup messaging servers in the same JVM as another live server. Take for example a simple two node cluster of standalone servers where each live server colocates the backup for the other. You can use either a shared store or a replicated HA policy when colocating servers in this way. There are two important things to remember when configuring messaging servers for colocation.
First, each server element in the configuration will need its own remote-connector and remote-acceptor or http-connector and http-acceptor. For example, a live server with a remote-acceptor can be configured to listen on port 5445, while a remote-acceptor from a colocated backup uses port 5446. The ports are defined in socket-binding elements that must be added to the default socket-binding-group. In the case of http-acceptors, the live and colocated backup can share the same http-listener. Cluster-related configuration elements in each server configuration will use the remote-connector or http-connector used by the server. The relevant configuration is included in each of the examples that follow.
Second, remember to properly configure paths for journal related directories. For example, in a shared store colocated topology, both the live server and its backup, colocated on another live server, must be configured to share directory locations for the binding and message journals, for large messages, and for paging.
30.7. Failover Modes
JBoss EAP messaging defines two types of client failover:
- Automatic client failover
- Application-level client failover
JBoss EAP messaging also provides 100% transparent automatic reattachment of connections to the same server (e.g. in case of transient network problems). This is similar to failover, except it is reconnecting to the same server and is discussed in Client Reconnection and Session Reattachment.
During failover, if the client has consumers on any non persistent or temporary queues, those queues will be automatically recreated during failover on the backup node, since the backup node will not have any knowledge of non persistent queues.
30.7.1. Automatic Client Failover
JBoss EAP messaging clients can be configured to receive knowledge of all live and backup servers, so that in the event of a connection failure at the client - live server connection, the client will detect the failure and reconnect to the backup server. The backup server will then automatically recreate any sessions and consumers that existed on each connection before failover, thus saving the user from having to hand-code manual reconnection logic.
A JBoss EAP messaging client detects connection failure when it has not received packets from the server within the time given by client-failure-check-period as explained in Detecting Dead Connections.
If the client does not receive data in the allotted time, it will assume the connection has failed and attempt failover. If the socket is closed by the operating system, the server process might be killed rather than the server hardware itself crashing for example, the client will failover straight away.
JBoss EAP messaging clients can be configured to discover the list of live-backup server pairs in a number of different ways. They can be configured with explicit endpoints, for example, but the most common way is for the client to receive information about the cluster topology when it first connects to the cluster. See Server Discovery for more information.
The default HA configuration includes a cluster-connection that uses the recommended http-connector for cluster communication. This is the same http-connector that remote clients use when making connections to the server using the default RemoteConnectionFactory. While it is not recommended, you can use a different connector. If you use your own connector, make sure it is included as part of the configuration for both the connection-factory to be used by the remote client and the cluster-connection used by the cluster nodes. See Configuring the Messaging Transports and Cluster Connections for more information on connectors and cluster connections.
The connector defined in the connection-factory to be used by a JMS client must be the same one defined in the cluster-connection used by the cluster. Otherwise, the client will not be able to update its topology of the underlying live/backup pairs and therefore will not know the location of the backup server.
Use CLI commands to review the configuration for both the connection-factory and the cluster-connection. For example, to read the current configuration for the connection-factory named RemoteConnectionFactory use the following command.
/subsystem=messaging-activemq/server=default/connection-factory=RemoteConnectionFactory:read-resource
Likewise, the command below reads the configuration for the cluster-connection named my-cluster.
/subsystem=messaging-activemq/server=default/cluster-connection=my-cluster:read-resource
To enable automatic client failover, the client must be configured to allow non-zero reconnection attempts. See Client Reconnection and Session Reattachment for more information. By default, failover will occur only after at least one connection has been made to the live server. In other words, failover will not occur if the client fails to make an initial connection to the live server. If it does fail its initial attempt, a client would simply retry connecting to the live server according to the reconnect-attempts property and fail after the configured number of attempts.
/subsystem=messaging-activemq/server=default/connection-factory=RemoteConnectionFactory:write-attribute(name=reconnect-attempts,value=<NEW_VALUE>)
An exception to this rule is the case where there is only one pair of live - backup servers, and no other live server, and a remote MDB is connected to the live server when it is cleanly shut down. If the MDB has configured @ActivationConfigProperty(propertyName = "rebalanceConnections", propertyValue = "true"), it tries to rebalance its connection to another live server and will not failover to the backup.
Failing Over on the Initial Connection
Since the client does not learn about the full topology until after the first connection is made, there is a window of time where it does not know about the backup. If a failure happens at this point the client can only try reconnecting to the original live server. To configure how many attempts the client will make you can set the property initialConnectAttempts on the ClientSessionFactoryImpl or ActiveMQConnectionFactory.
Alternatively in the server configuration, you can set the initial-connect-attempts attribute of the connection factory used by the client. The default for this is 0, that is, try only once. Once the number of attempts has been made, an exception will be thrown.
/subsystem=messaging-activemq/server=default/connection-factory=RemoteConnectionFactory:write-attribute(name=initial-connect-attempts,value=<NEW_VALUE>)About Server Replication
JBoss EAP messaging does not replicate full server state between live and backup servers. When the new session is automatically recreated on the backup, it won’t have any knowledge of the messages already sent or acknowledged during that session. Any in-flight sends or acknowledgements at the time of failover may also be lost.
By replicating full server state, JBoss EAP messaging could theoretically provide a 100% transparent seamless failover, avoiding any lost messages or acknowledgements. However, doing so comes at a great cost: replicating the full server state, including the queues and session. This would require replication of the entire server state machine. That is, every operation on the live server would have to replicated on the replica servers in the exact same global order to ensure a consistent replica state. This is extremely hard to do in a performant and scalable way, especially considering that multiple threads are changing the live server state concurrently.
It is possible to provide full state machine replication using techniques such as virtual synchrony, but this does not scale well and effectively serializes all operations to a single thread, dramatically reducing concurrency. Other techniques for multi-threaded active replication exist such as replicating lock states or replicating thread scheduling, but this is very hard to achieve at a Java level.
Consequently, it was not worth reducing performance and concurrency for the sake of 100% transparent failover. Even without 100% transparent failover, it is simple to guarantee once and only once delivery, even in the case of failure, by using a combination of duplicate detection and retrying of transactions. However this is not 100% transparent to the client code.
30.7.1.1. Handling Blocking Calls During Failover
If the client code is in a blocking call to the server, i.e. it is waiting for a response to continue its execution, during a failover, the new session will not have any knowledge of the call that was in progress. The blocked call might otherwise hang forever, waiting for a response that will never come.
To prevent this, JBoss EAP messaging will unblock any blocking calls that were in progress at the time of failover by making them throw a javax.jms.JMSException, if using JMS, or an ActiveMQException with error code ActiveMQException.UNBLOCKED if using the core API. It is up to the client code to catch this exception and retry any operations if desired.
If the method being unblocked is a call to commit(), or prepare(), then the transaction will be automatically rolled back and JBoss EAP messaging will throw a javax.jms.TransactionRolledBackException, if using JMS, or a ActiveMQException with error code ActiveMQException.TRANSACTION_ROLLED_BACK if using the core API.
30.7.1.2. Handling Failover With Transactions
If the session is transactional and messages have already been sent or acknowledged in the current transaction, then the server cannot be sure whether messages or acknowledgements were lost during the failover.
Consequently the transaction will be marked as rollback-only, and any subsequent attempt to commit it will throw a javax.jms.TransactionRolledBackException,if using JMS. or a ActiveMQException with error code ActiveMQException.TRANSACTION_ROLLED_BACK if using the core API.
The caveat to this rule is when XA is used either via JMS or through the core API. If a two phase commit is used and prepare() has already been called then rolling back could cause a HeuristicMixedException. Because of this the commit will throw a XAException.XA_RETRY exception. This informs the Transaction Manager that it should retry the commit at some later point in time, a side effect of this is that any non persistent messages will be lost. To avoid this from happening, be sure to use persistent messages when using XA. With acknowledgements this is not an issue since they are flushed to the server before prepare() gets called.
It is up to the user to catch the exception and perform any client side local rollback code as necessary. There is no need to manually rollback the session since it is already rolled back. The user can then just retry the transactional operations again on the same session.
If failover occurs when a commit call is being executed, the server, as previously described, will unblock the call to prevent a hang, since no response will come back. In this case it is not easy for the client to determine whether the transaction commit was actually processed on the live server before failure occurred.
If XA is being used either via JMS or through the core API then an XAException.XA_RETRY is thrown. This is to inform Transaction Managers that a retry should occur at some point. At some later point in time the Transaction Manager will retry the commit. If the original commit has not occurred, it will still exist and be committed. If it does not exist, then it is assumed to have been committed, although the transaction manager may log a warning.
To remedy this, the client can enable duplicate detection in the transaction, and retry the transaction operations again after the call is unblocked. See Duplicate Message Detection for information on how detection is configured on the server. If the transaction had indeed been committed on the live server successfully before failover, duplicate detection will ensure that any durable messages resent in the transaction will be ignored on the server to prevent them getting sent more than once when the transaction is retried.
30.7.1.3. Getting Notified of Connection Failure
JMS provides a standard mechanism for sending asynchronously notifications of a connection failure: java.jms.ExceptionListener. Please consult the JMS javadoc for more information on this class. The core API also provides a similar feature in the form of the class org.apache.activemq.artemis.core.client.SessionFailureListener.
Any ExceptionListener or SessionFailureListener instance will always be called by JBoss EAP in case of a connection failure, whether the connection was successfully failed over, reconnected, or reattached. However, you can find out if the reconnect or reattach has happened by inspecting the value for the failedOver flag passed into connectionFailed() on SessionfailureListener or the error code on the javax.jms.JMSException which will be one of the following:
JMSException error codes
| Error code | Description |
|---|---|
| FAILOVER | Failover has occurred and we have successfully reattached or reconnected. |
| DISCONNECT | No failover has occurred and we are disconnected. |
30.7.2. Application-Level Failover
In some cases you may not want automatic client failover, and prefer to handle any connection failure yourself, and code your own manually reconnection logic in your own failure handler. We define this as application-level failover, since the failover is handled at the user application level.
To implement application-level failover if you’re using JMS set an ExceptionListener class on the JMS connection. The ExceptionListener will be called by JBoss EAP messaging in the event that connection failure is detected. In your ExceptionListener, you would close your old JMS connections, potentially look up new connection factory instances from JNDI and creating new connections.
If you are using the core API, then the procedure is very similar: you would set a FailureListener on the core ClientSession instances.
30.8. Detecting Dead Connections
This section discusses connection time to live (TTL) and explains how JBoss EAP messaging handles crashed clients and clients that have exited without cleanly closing their resources.
Cleaning up Dead Connection Resources on the Server
Before a JBoss EAP client application exits, it should close its resources in a controlled manner, using a finally block.
Below is an example of a core client appropriately closing its session and session factory in a finally block:
ServerLocator locator = null;
ClientSessionFactory sf = null;
ClientSession session = null;
try {
locator = ActiveMQClient.createServerLocatorWithoutHA(..);
sf = locator.createClientSessionFactory();;
session = sf.createSession(...);
... do some stuff with the session...
}
finally {
if (session != null) {
session.close();
}
if (sf != null) {
sf.close();
}
if(locator != null) {
locator.close();
}
}And here is an example of a well behaved JMS client application:
Connection jmsConnection = null;
try {
ConnectionFactory jmsConnectionFactory = ActiveMQJMSClient.createConnectionFactoryWithoutHA(...);
jmsConnection = jmsConnectionFactory.createConnection();
... do some stuff with the connection...
}
finally {
if (connection != null) {
connection.close();
}
}Unfortunately sometimes clients crash and do not have a chance to clean up their resources. If this occurs, it can leave server side resources hanging on the server. If these resources are not removed they would cause a resource leak on the server, and over time this likely would result in the server running out of memory or other resources.
When looking to clean up dead client resources, it is important to be aware of the fact that sometimes the network between the client and the server can fail and then come back, allowing the client to reconnect. Because JBoss EAP supports client reconnection, it is important that it not clean up "dead" server side resources too soon, or clients will be prevented any client from reconnecting and regaining their old sessions on the server.
JBoss EAP makes all of this configurable. For each ClientSessionFactory configured, a Time-To-Live, or TTL, property can be used to set how long the server will keep a connection alive in milliseconds in the absence of any data from the client. The client will automatically send "ping" packets periodically to prevent the server from closing its connection. If the server does not receive any packets on a connection for the length of the TTL time, it will automatically close all the sessions on the server that relate to that connection.
If you are using JMS, the connection TTL is defined by the ConnectionTTL attribute on a ActiveMQConnectionFactory instance, or if you are deploying JMS connection factory instances direct into JNDI on the server side, you can specify it in the xml config, using the parameter connectionTtl.
The default value for ConnectionTTL on an network-based connection, such as an http-connector, is 60000, i.e. 1 minute. The default value for connection TTL on a internal connection, e.g. an in-vm connection, is -1. A value of -1 for ConnectionTTL means the server will never time out the connection on the server side.
If you do not want clients to specify their own connection TTL, you can set a global value on the server side. This can be done by specifying the connection-ttl-override attribute in the server configuration. The default value for connection-ttl-override is -1 which means "do not override", i.e. let clients use their own values.
Closing Core Sessions or JMS Connections
It is important that all core client sessions and JMS connections are always closed explicitly in a finally block when you are finished using them.
If you fail to do so, JBoss EAP will detect this at garbage collection time. It will then close the connection and log a warning similar to the following:
[Finalizer] 20:14:43,244 WARNING [org.apache.activemq.artemis.core.client.impl.DelegatingSession] I'm closing a ClientSession you left open. Please make sure you close all ClientSessions explicitly before let
ting them go out of scope!
[Finalizer] 20:14:43,244 WARNING [org.apache.activemq.artemis.core.client.impl.DelegatingSession] The session you didn't close was created here:
java.lang.Exception
at org.apache.activemq.artemis.core.client.impl.DelegatingSession.<init>(DelegatingSession.java:83)
at org.acme.yourproject.YourClass (YourClass.java:666)Note that if you are using JMS the warning will involve a JMS connection, not a client session. Also, the log will tell you the exact line of code where the unclosed JMS connection or core client session was instantiated. This will enable you to pinpoint the error in your code and correct it appropriately.
Detecting Failure from the Client Side
As long as the client is receiving data from the server it will consider the connection to be alive. If the client does not receive any packets for client-failure-check-period milliseconds, it will consider the connection failed and will either initiate failover, or call any FailureListener instances, or ExceptionListener instances if you are using JMS, depending on how the client has been configured.
If you are using JMS the behavior is defined by the ClientFailureCheckPeriod attribute on a ActiveMQConnectionFactory instance.
The default value for client failure check period on a network connection, for example an HTTP connection, is 30000, or 30 seconds. The default value for client failure check period on an in-vm connection, is -1. A value of -1 means the client will never fail the connection on the client side if no data is received from the server. Whatever the type of connection, the check period is typically much lower than the value for connection TTL on the server so that clients can reconnect in case of transitory failure.
Configuring Asynchronous Connection Execution
Most packets received on the server side are executed on the remoting thread. These packets represent short-running operations and are always executed on the remoting thread for performance reasons.
However, by default some kinds of packets are executed using a thread from a thread pool so that the remoting thread is not tied up for too long. Please note that processing operations asynchronously on another thread adds a little more latency. These packets are:
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.RollbackMessage
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.SessionCloseMessage
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.SessionCommitMessage
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.SessionXACommitMessage
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.SessionXAPrepareMessage
org.apache.activemq.artemis.core.protocol.core.impl.wireformat.SessionXARollbackMessage
To disable asynchronous connection execution, set the parameter async-connection-execution-enabled to false. The default value is true.
30.9. Client Reconnection and Session Reattachment
JBoss EAP messaging clients can be configured to automatically reconnect or reattach to the server in the event that a failure is detected in the connection between the client and the server.
Transparent Session Reattachment
If the failure was due to some transient cause such as a temporary network outage, and the target server was not restarted, the sessions will still exist on the server, assuming the client has not been disconnected for more than the value of connection-ttl. See Detecting Dead Connections.
In this scenario, JBoss EAP will automatically reattach the client sessions to the server sessions when the re-connection is made. This is done 100% transparently and the client can continue exactly as if nothing had happened.
As JBoss EAP messaging clients send commands to their servers they store each sent command in an in-memory buffer. When a connection fails and the client subsequently attempts to reattach to the same server, as part of the reattachment protocol, the server gives the client the id of the last command it successfully received.
If the client has sent more commands than were received before failover it can replay any sent commands from its buffer so that the client and server can reconcile their states.
The size in bytes of this buffer is set by the confirmationWindowSize property. When the server has received confirmationWindowSize bytes of commands and processed them it will send back a command confirmation to the client, and the client can then free up space in the buffer.
If you are using the JMS service on the server to load your JMS connection factory instances into JNDI, then this property can be configured in the server configuration, by setting the confirmation-window-size attribute of the chosen connection-factory. If you are using JMS but not using JNDI then you can set these values directly on the ActiveMQConnectionFactory instance using the appropriate setter method, setConfirmationWindowSize. If you are using the core API, the ServerLocator instance has a setConfirmationWindowSize method exposed as well.
Setting confirmationWindowSize to -1, which is also the default, disables any buffering and prevents any reattachment from occurring, forcing a reconnect instead.
Session Reconnection
Alternatively, the server might have actually been restarted after crashing or it might have been stopped. In such a case any sessions will no longer exist on the server and it will not be possible to 100% transparently reattach to them.
In this case, JBoss EAP will automatically reconnect the connection and recreate any sessions and consumers on the server corresponding to the sessions and consumers on the client. This process is exactly the same as what happens when failing over to a backup server.
Client reconnection is also used internally by components such as core bridges to allow them to reconnect to their target servers.
See the section on Automatic Client Failover to get a full understanding of how transacted and non-transacted sessions are reconnected during a reconnect and what you need to do to maintain once and only once delivery guarantees.
Configuring Reconnection Attributes
Client reconnection is configured by setting the following properties:
-
retryInterval. This optional parameter sets the period in milliseconds between subsequent reconnection attempts, if the connection to the target server has failed. The default value is
2000milliseconds. retryIntervalMultiplier. This optional parameter sets a multiplier to apply to the time since the last retry to compute the time to the next retry. This allows you to implement an exponential backoff between retry attempts.
For example, if you set
retryIntervalto1000ms and set retryIntervalMultiplier to2.0, then, if the first reconnect attempt fails, the client will wait1000ms then2000ms then4000ms between subsequent reconnection attempts.The default value is
1.0meaning each reconnect attempt is spaced at equal intervals.-
maxRetryInterval. This optional parameter sets the maximum retry interval that will be used. When setting
retryIntervalMultiplierit would otherwise be possible that subsequent retries exponentially increase to ridiculously large values. By setting this parameter you can set an upper limit on that value. The default value is2000milliseconds. -
reconnectAttempts. This optional parameter sets the total number of reconnect attempts to make before giving up and shutting down. A value of
-1signifies an unlimited number of attempts. The default value is0.
If you are using JMS and JNDI on the client to look up your JMS connection factory instances then you can specify these parameters in the JNDI context environment. For example, your jndi.properties file might look like the following.
java.naming.factory.initial = ActiveMQInitialContextFactory
connection.ConnectionFactory=tcp://localhost:8080?retryInterval=1000&retryIntervalMultiplier=1.5&maxRetryInterval=60000&reconnectAttempts=1000
If you are using JMS, but instantiating your JMS connection factory directly, you can specify the parameters using the appropriate setter methods on the ActiveMQConnectionFactory immediately after creating it.
If you are using the core API and instantiating the ServerLocator instance directly you can also specify the parameters using the appropriate setter methods on the ServerLocator immediately after creating it.
If your client does manage to reconnect but the session is no longer available on the server, for instance if the server has been restarted or it has timed out, then the client will not be able to reattach, and any ExceptionListener or FailureListener instances registered on the connection or session will be called.
ExceptionListeners and SessionFailureListeners
Note that when a client reconnects or reattaches, any registered JMS ExceptionListener or core API SessionFailureListener will be called.