第2章 Red Hat OpenShift Dev Spaces をスケーラブルに実行する
Kubernetes は、コンテナー化されたワークロードをスケーラブルにデプロイおよび管理するための強力な基盤として登場しましたが、特に数千の同時ワークスペースの範囲でクラウド開発環境 (CDE) によるスケーリングの実現は、大きな課題となります。
このような規模では、インフラストラクチャーに対する要求が高まり、システム全体のパフォーマンスと安定性に影響を及ぼす可能性のあるボトルネックが発生する可能性があります。これらの課題に対処するには、多数のユーザーにとってシームレスで効率的な開発エクスペリエンスを確保するために、綿密な計画、戦略的なアーキテクチャーの選択、監視、継続的な最適化が必要です。
CDE ワークロードのスケーリングが複雑になる主な理由は、Visual Studio Code - Open Source ("Code - OSS") または JetBrains Gateway などの基盤となる IDE ソリューションが、マルチテナントサービスではなく、シングルユーザーアプリケーションとして設計されていることです。
リソース量とオブジェクトの最大値
Kubernetes クラスター内のリソース数に厳密な制限はありませんが、大規模なクラスターでは考慮事項 がいくつかあります。
Kubernetes のスケーラビリティーに関する詳細は、"Scalability, with Wojciech Tyczynski" episode of Kubernetes Podcast を参照してください。
Kubernetes の認定ディストリビューションである OpenShift Container Platform では、さまざまなリソースのテスト済みの最大値のセットも提供されており、これは環境を計画するための最初のガイドラインとして役立ちます。
| Resource type | テスト済みの最大値 |
|---|---|
| ノード数 | 2000 |
| Pod 数 | 150000 |
| ノードあたりの Pod 数 | 2500 |
| namespace の数 | 10000 |
| サービス数 | 10000 |
| シークレットの数 | 80000 |
| config map の数 | 90000 |
表 1: OpenShift Container Platform のテスト済みのさまざまなリソースのクラスターの最大値。
OpenShift Container Platform のテスト済みオブジェクトの最大値の詳細は、公式ドキュメント を参照してください。
たとえば、パフォーマンスと管理のオーバーヘッドが発生する可能性があるため、通常は 10,000 を超える namespace を持つことは推奨されません。Red Hat OpenShift Dev Spaces では、各ユーザーに namespace が割り当てられます。ユーザーベースが大規模になると予想される場合は、ワークロードを複数の「用途別」クラスターに分散させ、必要に応じてマルチクラスターをオーケストレーションするためのソリューションを活用することも検討してください。
リソース要件
Kubernetes に Red Hat OpenShift Dev Spaces をデプロイする場合、リソース要件を正確に計算し、各 CDE のメモリーと CPU/GPU のニーズを決定して、クラスターの適切なサイズを決定することが重要です。一般に、CDE のサイズはワーカーノードのサイズによって制限され、それよりも大きくすることはできません。CDE のリソース要件は、特定のワークロードと設定によって大きく異なる場合があります。たとえば、単純な CDE では数百メガバイトのメモリーしか必要としませんが、より複雑な CDE では数ギガバイトのメモリーと複数の CPU コアが必要になります。
リソース要件の計算の詳細は、公式ドキュメント を参照してください。
etcd の使用
Kubernetes クラスターの設定と状態の主なデータストアは etcd です。ノード、Pod、サービス、カスタムリソースに関する情報を含む、クラスターの状態と設定が保持されます。分散型キーバリューストアである etcd は、特定のしきい値を超えてスケーリングできず、etcd のサイズが大きくなるにつれてクラスターの負荷も大きくなり、安定性が損なわれるリスクがあります。
デフォルトの etcd サイズは 2 GB で、推奨される最大値は 8 GB です。最大制限を超えると、Kubernetes クラスターが不安定になり、応答しなくなる可能性があります。
要因としてのオブジェクトサイズ
etcd に保存されるオブジェクトの総数だけでなくサイズも、パフォーマンスと安定性に大きな影響を与える重要な要素です。etcd に保存される各オブジェクトはスペースを消費し、オブジェクトの数が増えると、etcd の全体的なサイズも大きくなります。オブジェクトが大きくなればなるほど、etcd で占めるスペースも大きくなります。たとえば、etcd は、比較的大きな Kubernetes オブジェクトが数千個あるだけで過負荷になる可能性があります。
ConfigMap に保存されるデータは設計上 1 MiB を超えることはできませんが、比較的大きな ConfigMap オブジェクトが数千個あると、etcd ストレージが過負荷になる可能性があります。
Red Hat OpenShift Dev Spaces のコンテキストでは、Operator はデフォルトで、すべてのユーザー namespace で、認証局 (CA) バンドルを含む 'ca-certs-merged' ConfigMap を作成して管理します。クラスター内に大量の TLS 証明書がある場合、etcd の使用量がさらに増加します。
/etc/pki/ca-trust/extracted/pem パスの下の ConfigMap を使用して CA バンドルのマウントを無効にするには、disableWorkspaceCaBundleMount プロパティーを true に設定して CheCluster カスタムリソースを設定します。この設定では、カスタム証明書のみがパス /public-certs の下にマウントされます。
spec:
devEnvironments:
trustedCerts:
disableWorkspaceCaBundleMount: true
spec:
devEnvironments:
trustedCerts:
disableWorkspaceCaBundleMount: trueDev Workspace オブジェクト
大規模な Kubernetes デプロイメント、特に CDE を表す DevWorkspace オブジェクトなどの多数のカスタムリソースが含まれるデプロイメントでは、etcd が重大なパフォーマンスのボトルネックになる可能性があります。
6,000 個の DevWorkspace オブジェクトの負荷テストに基づくと、etcd のストレージ消費量は約 2.5 GB でした。
Dev Workspace Operator バージョン 0.34.0 以降では、一定期間使用されていない DevWorkspace オブジェクトを自動的にクリーンアップするプルーナーを設定できます。プルーナーをセットアップするには、DevWorkspaceOperatorConfig オブジェクトを次のように設定します。
OLMConfig
Operator が Operator Lifecycle Manager (OLM) によってインストールされると、Operator が監視するように設定されているすべての namespace に、その CSV の簡素化されたコピーが作成されます。これらの簡素化された CSV は「Copied CSV」と呼ばれ、特定の namespace でどのコントローラーがリソースイベントをアクティブに調整しているかをユーザーに伝えます。特に大規模なクラスターでは、namespace とインストールされた Operator の数が数百または数千になる傾向があり、Copied CSV は、OLM メモリー使用量、クラスター etcd 制限、ネットワークなど、持続不可能な量のリソースを消費します。すべての namespace にコピーされる CSV を削除するには、OLMConfig オブジェクトを適切に設定します。
disableCopiedCSVs 機能に関する追加情報は、オリジナルの 機能拡張提案 に記載されています。
etcd に対する disableCopiedCSVs プロパティーの主な影響は、リソースの消費に関連しています。多数の namespace と多くのクラスター全体の Operator を持つクラスターでは、多数の Copied CSV の作成と保守によって、etcd ストレージの使用量とメモリー消費量が増加する可能性があります。Copied CSV を無効にすると、etcd に保存されるデータ量が大幅に削減され、クラスター全体のパフォーマンスと安定性の向上に役立ちます。
これは、namespace と Operator の数が急増して大量のデータになる可能性がある大規模なクラスターにとって特に重要です。Copied CSV を無効にすると、etcd の負荷が軽減され、クラスターのパフォーマンスと応答性の向上につながります。さらに、OLM はこれらの追加リソースを維持および管理する必要がなくなるため、OLM のメモリーフットプリントの削減にも役立ちます。
「Copied CSV の無効化」の詳細は、公式ドキュメント を参照してください。
クラスターの自動スケーリング
クラスターの自動スケーリングは Kubernetes の強力な機能ですが、常にそれに頼れるわけではありません。環境上の負荷データを分析して毎日または毎週の使用パターンを検出することにより、常に予測スケーリングを検討する必要があります。ワークロードがパターンに従っており、1 日を通して急激なピークが発生する場合は、それに応じてワーカーノードをプロビジョニングすることを検討する必要があります。たとえば、ワークスペースの数が営業時間中に増加し、営業時間外に減少するという予測可能な負荷パターンがある場合、予測スケーリングを使用して、予想される負荷に基づいてワーカーノードの数を調整できます。これにより、オフピーク時のコストを最小限に抑えながら、ピーク負荷を処理するために十分なリソースを確保できるようになります。
ワーカーノードの設定とライフサイクル管理には、Karpenter などのオープンソースソリューションを活用することを検討してください。Karpenter は、ワークロードの特定の要件に基づいてワーカーノードを動的にプロビジョニングおよび最適化できるため、リソースの利用効率の向上とコストの削減に貢献します。
マルチクラスター
設計上、Red Hat OpenShift Dev Spaces はマルチクラスターに対応しておらず、クラスターごとに 1 つのインスタンスしか持つことができません。ただし、Red Hat OpenShift Dev Spaces を各クラスターにデプロイし、ロードバランサーまたは DNS ベースのルーティングを使用して、ユーザーの場所やその他の基準に基づいてトラフィックを適切なインスタンスに振り分けることで、Red Hat OpenShift Dev Spaces をマルチクラスター環境で実行できます。このアプローチは、ワークロードを複数のクラスターに分散し、クラスター障害が発生した場合に冗長性を提供することで、パフォーマンスと信頼性の向上に貢献できます。
図2.1 マルチクラスター環境のスキーム
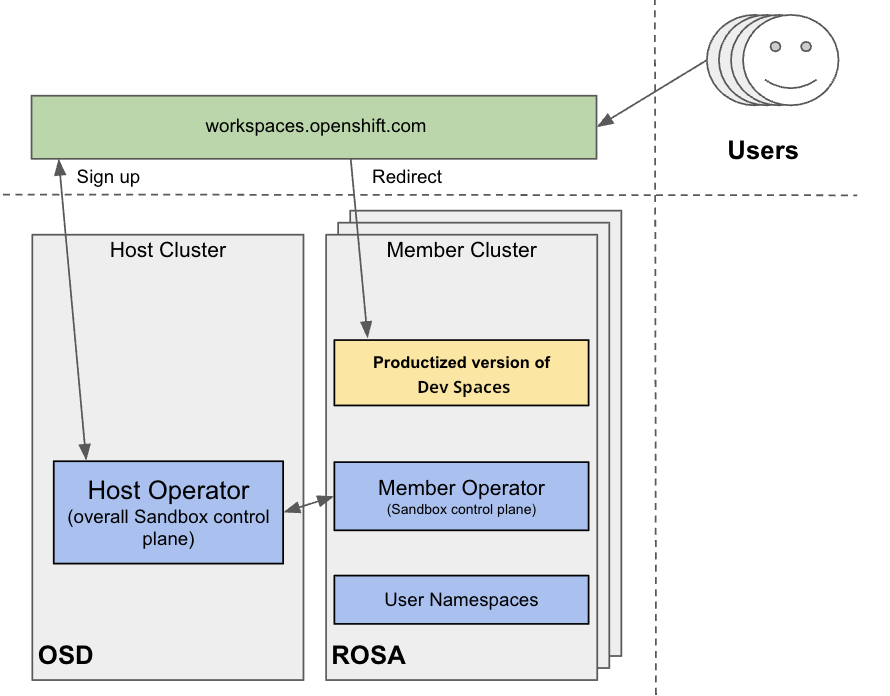
事前設定されたツールとサービスを備えた Red Hat の無料試用環境である Developer Sandbox を使用して、マルチクラスターで OpenShift Dev Spaces の実行をテストできます。インフラストラクチャーの観点から見ると、Developer Sandbox は複数の ROSA クラスターで構成されています。各クラスターでは、Argo CD を使用して、Red Hat OpenShift Dev Spaces の製品バージョンがインストールされ、設定されます。ユーザーベースは複数のクラスターに分散されているため、workspaces.openshift.com は、製品化された Red Hat OpenShift Dev Spaces インスタンスへの単一のエントリーポイントとして使用されます。マルチクラスターリダイレクターの実装の詳細は、次の GitHub リポジトリー を参照してください。
workspaces.openshift.com のマルチクラスターアーキテクチャーは、Developer Sandbox の一部です。これは Developer Sandbox 固有のソリューションであり、そのままでは他の環境で再利用できません。ただし、これをリファレンスとして使用して、特定のマルチクラスターのニーズに合わせてカスタマイズされた同様のソリューションを実装できます。