네트워크 관찰성
OpenShift 컨테이너 플랫폼에서 네트워크 관찰 연산자 구성 및 사용
초록
1장. 네트워크 관찰 운영자 릴리스 노트
Network Observability Operator의 새로운 기능, 개선 사항, 수정된 문제 및 알려진 문제를 검토합니다. 이 릴리스 노트에서는 최신 Operator 릴리스에서 변경 사항 및 보안 권고를 이해하는 데 도움이 되는 정보를 제공합니다.
네트워크 관찰 연산자를 통해 관리자는 OpenShift Container Platform 클러스터의 네트워크 트래픽 흐름을 관찰하고 분석할 수 있습니다.
이 릴리스 노트는 OpenShift 컨테이너 플랫폼의 네트워크 관찰 연산자 개발 과정을 추적합니다.
1.1. Network Observability Operator 1.11.2 권고
Network Observability Operator 1.11.2 릴리스에 대한 권고를 검토할 수 있습니다.
1.2. Network Observability Operator 1.11.1 권고
Network Observability Operator 1.11.1 릴리스에 대한 권고를 검토할 수 있습니다.
1.3. Network Observability Operator 1.11.1 문제 해결
Network Observability Operator 1.11.1 릴리스에는 eBPF 에이전트 성능 및 OpenShift Container Platform 웹 콘솔의 사용자 환경을 개선하는 몇 가지 수정된 문제가 포함되어 있습니다.
- eBPF 에이전트 메모리 사용 최적화
이번 업데이트 이전에는 eBPF 에이전트의 회귀 문제로 인해 비활성화된 기능에 대해 커널 메모리가 의도치 않게 예약되었습니다. 이로 인해 에이전트에 대한 메모리 사용량보다 많은 메모리 사용량이 증가했습니다.
이번 업데이트를 통해 eBPF 에이전트는 기능이 비활성화될 때 예약된 커널 메모리가 최소로 유지되도록 합니다. 결과적으로 에이전트의 메모리 공간이 줄어들고 리소스 할당이 향상됩니다.
- Prometheus 전용 모드에서 DNS 그래프 가용성 개선
이번 업데이트 이전에는 Loki가 비활성화되고 DNS 추적이 활성화되면 OpenShift Container Platform 콘솔 플러그인에서 DNS 그래프를 표시하지 못했습니다. 대신 유효한 Prometheus 데이터가 있는 그래프에도 Prometheus 지표를 사용하여 요청을 수행할 수 없다는 오류가 표시되었습니다.
이번 업데이트를 통해 구성된 메트릭이 없는 특정 그래프에만 오류가 표시됩니다. 결과적으로 모든 유효한 DNS 그래프가 이제 웹 콘솔에 올바르게 표시됩니다.
- 토폴로지 보기에서 오류 처리 개선
이번 업데이트 이전에는 Loki가 없는 설치에서 Topology 뷰에 특정 쿼리로 인해 누락된 Prometheus 지표로 인해 오류가 발생할 수 있었습니다. 이러한 오류는 브라우저 캐시를 삭제할 때까지 유지되는 경우가 있습니다.
이번 업데이트를 통해 콘솔에서 누락된 메트릭으로 인한 잘못된 범위가 표시되지 않습니다. 또한 콘솔의 오류 처리가 업데이트되어 더 많은 실행 가능한 정보를 제공하도록 업데이트되어 이러한 시나리오에서 수동 캐시 지우기가 필요하지 않습니다.
1.4. Network Observability Operator 1.11 권고
Network Observability Operator 1.11 릴리스에 대한 권고를 검토할 수 있습니다.
1.5. Network Observability Operator 1.11 새로운 기능 및 개선 사항
FlowCollectorSlice 리소스의 계층 거버넌스, 새로운 서비스 배포 모델 및 상태 규칙의 일반 가용성을 포함하여 Network Observability Operator 1.11 릴리스의 새로운 기능 및 개선 사항에 대해 알아보십시오.
- FlowCollectorSlice 리소스를 사용한 테넌트별 계층 거버넌스
이번 릴리스에서는
FlowCollectorSliceAPI가 도입되어 계층 거버넌스를 지원하므로 프로젝트 관리자가 특정 네임스페이스에 대한 샘플링 및 서브넷 레이블을 독립적으로 관리할 수 있습니다.이 기능은 글로벌 처리 오버헤드를 줄이고 클러스터 전체 구성 변경 없이 개별 팀에 셀프 서비스 가시성이 필요한 대규모 환경에서 테넌트 자동성을 제공하기 위해 구현되었습니다. 따라서 조직은 중앙 클러스터 제어를 유지하면서 선택적으로 트래픽을 수집하고 데이터 강화 작업을 프로젝트 수준에 위임할 수 있습니다.
FlowCollector리소스에 대한 새로운 서비스 배포 모델이번 릴리스에서는
FlowCollector사용자 지정 리소스에 새로운서비스배포 모델이 도입되었습니다. 이 모델은Direct및Kafka모델 간의 중간 옵션을 제공합니다.서비스모델에서 eBPF 에이전트는데몬세트로 배포되고flowlogs-pipeline구성 요소는 확장 가능한 서비스로 배포됩니다.이 모델은 구성 요소 인스턴스의 캐시 중복을 줄임으로써 대규모 클러스터에서 성능이 향상됩니다.
- 일반적으로 건강 규칙을 사용할 수 있습니다.
이전 버전에서 기술 프리뷰 기능으로 도입된 상태 경고 기능은 Network Observability Operator 1.11 릴리스에서 상태 규칙으로 완전히 지원됩니다.
중요네트워크 Observability 상태 규칙은 OpenShift Container Platform 4.16 이상에서 사용할 수 있습니다.
이 eBPF 기반 시스템은 네트워크 메트릭과 인프라 메타데이터의 상관관계를 제공하여 트래픽 급증 또는 대기 시간 추세와 같은 클러스터 상태에 대한 사전 예방적 알림 및 자동화된 인사이트를 제공합니다. 결과적으로 OpenShift Container Platform 웹 콘솔에서 Network Health 대시보드를 사용하여 분류된 경고를 관리하고 임계값을 사용자 지정하고, 시각화 성능을 개선하기 위한 기록 규칙을 생성할 수 있습니다.
- 네트워크 트래픽 시각화 및 필터링 강화
이번 릴리스에서는 OpenShift Container Platform 웹 콘솔에서 향상된 시각화 및 필터링 도구가 도입되었습니다.
- 인라인 필터 편집: 필터 입력 필드 내에서 직접 필터 칩을 편집할 수 있습니다. 이번 개선된 기능을 통해 이전에 잘린 긴 필터 값을 수정하기 위한 보다 효율적인 방법을 제공하여 수동으로 값을 복사하고 붙여넣을 필요가 없습니다. 이번 업데이트에서는 저장 필터 기능과 일치하는 인라인 편집 규칙을 채택합니다.
- 외부 트래픽 빠른 필터: 새로운 빠른 필터를 사용하면 외부 수신 및 송신 트래픽을 적극적으로 모니터링할 수 있습니다. 이번 개선된 기능을 통해 네트워크 관리가 간소화되어 외부 네트워크 통신과 관련된 문제를 신속하게 식별하고 해결할 수 있습니다.
- 직관적인 리소스 아이콘: OpenShift Container Platform 콘솔은 이제 Kubernetes 종류, 그룹 및 필터에 특정 아이콘을 사용합니다. 이러한 아이콘은 보다 직관적이고 시각적으로 일관된 환경을 제공하여 네트워크 토폴로지를 탐색하고 적용된 필터를 한 눈에 쉽게 식별할 수 있습니다.
- DNS 확인 분석
이 릴리스에는 도메인 이름으로 네트워크 흐름 레코드를 보강하기 위해 eBPF 기반 DNS 추적이 포함되어 있습니다.
이 기능은 관리자가
NXDOMAIN오류와 같은 네트워크 라우팅 실패와 서비스 검색 문제를 즉시 구분할 수 있도록 하여 식별(MTTI)이라는 평균 시간을 줄이기 위해 구현되었습니다.- 게이트웨이 API와 통합
이번 릴리스에서는
GatewayClass리소스가 생성될 때 Network Observability Operator와 Gateway API 간의 자동 통합이 도입되었습니다. 이 기능은FlowCollector리소스를 수동으로 구성하지 않고도 클러스터 수신 및 송신 트래픽에 대한 높은 수준의 트래픽을 제공합니다.중요OpenShift Container Platform 4.19 이상에서 게이트웨이 API와의 통합을 사용할 수 있습니다.
OpenShift Container Platform 웹 콘솔의 Observe → 네트워크 트래픽 보기에서 네트워크 흐름의 자동 매핑을 확인할 수 있습니다. Owner 열에는 게이트웨이 이름이 표시되고 연결된 게이트웨이 리소스 페이지에 대한 직접 링크가 제공됩니다.
- 개요 및 토폴로지 보기에서 데이터 복원력 개선
이번 릴리스에서는 일부 백그라운드 쿼리가 실패하더라도 개요 및 토폴로지 보기에 기능 데이터가 계속 표시됩니다. 이번 개선된 기능을 통해 부분적인 서비스 중단 중에 토폴로지 보기의 범위 및 그룹 드롭다운 메뉴에 액세스할 수 있습니다.
또한 개요 페이지에 문제 해결을 지원하기 위해 활성 오류 메시지가 표시되어 모니터링 워크플로를 중단하지 않고 시스템 상태를 보다 효과적으로 파악할 수 있습니다.
- 알 수 없는 네트워크 흐름 분류 개선
이번 릴리스에서는 알 수 없는 소스의 네트워크 흐름이 외부, 알 수 없는 서비스, 알 수 없는 노드 및 알 수 없는 Pod의 네 가지 그룹으로 분류됩니다.
이번 개선된 기능을 통해 서브넷 레이블을 사용하여 알 수 없는 IP 서브넷을 분리하여 더 명확한 네트워크 토폴로지를 제공합니다. 개선된 가시성은 잠재적인 보안 위협을 식별하는 데 도움이 되며 클러스터 내에서 알 수 없는 요소에 대한 대상 분석을 허용합니다.
- 새로운 네트워크 Observability 설치를 위한 성능 개선
새 설치를 위해 Network Observability Operator의 기본 성능이 향상되었습니다.
cacheActiveTimeout의 기본값은 5초에서 15초로 증가하며cacheMaxFlows값은 더 높은 흐름 볼륨을 수용하기 위해 100,000에서 120,000으로 증가합니다.중요이러한 새 기본값은 새 설치에만 적용되며 기존 설치는 현재 구성을 유지합니다.
이러한 변경으로 CPU 부하를 최대 40%까지 줄일 수 있습니다.
- LokiStack 상태 모니터링 및 보고 개선
이번 릴리스에서는 Network Observability Operator가
LokiStack리소스의 상태를 모니터링하고 오류 또는 구성 문제를 보고합니다. Network Observability Operator는 보류 중 또는 실패한 Pod 및 특정 경고 조건을 포함하여LokiStack조건을 확인합니다.이번 개선된 기능을 통해
FlowCollector상태에서 더 많은 실행 가능한 정보가 제공되어 네트워크 관찰 기능 내에서LokiStack구성 요소를 보다 효과적으로 해결할 수 있습니다.- 필터 메뉴에서 Loki 인덱싱된 필드에 대한 시각적 표시
이번 릴리스에서는 일부 백그라운드 쿼리가 실패하더라도 개요 및 토폴로지 보기에 기능 데이터가 계속 표시됩니다. 이번 개선된 기능을 통해 부분적인 서비스 중단 중에 토폴로지 보기의 범위 및 그룹 드롭다운 메뉴에 액세스할 수 있습니다.
이번 개선된 기능을 통해 더 빠른 데이터 검색을 위해 인덱싱되는 필드를 표시하여 쿼리 성능이 향상됩니다. 데이터를 필터링할 때 인덱싱된 필드를 사용하면 콘솔 내에서 네트워크 흐름을 검색하고 분석하는 데 필요한 시간이 줄어듭니다.
1.6. Network Observability Operator 1.11 알려진 문제
다음 알려진 문제는 Network Observability Operator 1.11 릴리스에 영향을 미칩니다.
lowVolumeThreshold로 인해 샘플링 속도가 증가할 때 상태 규칙이 트리거되지 않음높은 샘플링 속도로 인해 볼륨이
lowVolumeThreshold필터 미만인 경우 네트워크 관찰 기능 경고가 트리거되지 않을 수 있습니다. 이로 인해 평가되거나 표시되는 경고가 줄어듭니다.이 문제를 해결하려면 샘플링 속도와 일치하도록
lowVolumeThreshold값을 조정하여 일관된 경고 평가를 보장합니다.- Loki가 비활성화된 경우 DNS 메트릭을 사용할 수 없음
"Loki-less" 설치에서
DNSTracking기능이 활성화되면 DNS 그래프에 필요한 지표를 사용할 수 없습니다. 결과적으로 대시보드에서 DNS 대기 시간 및 응답 코드를 볼 수 없습니다.이 문제를 해결하려면
spec.loki.enable을 true로 설정하여DNSTracking옵션을 비활성화하거나FlowCollector리소스에서 Loki를 활성화해야 합니다.
1.7. Network Observability Operator 1.11 문제 해결
Network Observability Operator 1.11 릴리스에는 성능 및 사용자 환경을 개선하는 몇 가지 수정된 문제가 포함되어 있습니다.
- 차트에서 누락된 날짜
이번 업데이트 이전에는 종속성 변경으로 인해 차트 툴팁 날짜가 의도한 대로 표시되지 않았습니다. 결과적으로 OpenShift Container Platform 웹 콘솔 플러그인의 개요 탭 차트에서 데이터 컨텍스트에 영향을 미치는 날짜 정보가 누락되었습니다.
이번 릴리스에서는 차트 툴팁 날짜 표시가 복원됩니다.
- 확장 후 직접 모드에 대한 경고 메시지가 새로 고쳐지지 않음
이번 업데이트 이전에는 스케일링 후 클러스터 정보가 새로 고쳐지지 않아 변경 사항으로 업데이트되지 않고 대규모 클러스터에서 경고 메시지가 유지되었습니다.
이번 릴리스에서는 변경 시 클러스터 정보가 새로 고쳐 클러스터 크기가 변경되어 사용자 가시성을 개선할 수 있는
직접모드의 대규모 클러스터에 대한 경고 메시지가 표시됩니다.- 풍부한 OVN IP
이번 업데이트 이전에는 OVN-Kubernetes에서 선언한 일부 IP가 보강되지 않아
100.64.0.x와 같은 불충분한 IP가머신네트워크에 표시되지 않았습니다. 그 결과 IP가 강화되지 않아 사용자에게 잘못된 네트워크 가시성이 발생했습니다.이번 릴리스에서는 OVN-Kubernetes에서 누락된 IP가 강화되었습니다. 결과적으로 OVN-Kubernetes에서 선언한 IP는 올바르게 보강되고
머신네트워크에 표시되고 머신 네트워크의 네트워크 트래픽 소스 가시성이 향상됩니다.- Operator API 검색 안정성 개선
이번 업데이트 이전에는 Network Observability Operator 시작 중에 경쟁 조건으로 인해 API 검색이 자동으로 실패할 수 있었습니다. 결과적으로 Operator가 OpenShift Container Platform 클러스터를 인식하지 못하여 필수
ClusterRoleBinding리소스가 누락되어 구성 요소가 제대로 작동하지 않을 수 있었습니다.이번 릴리스에서는 Network Observability Operator에서 시간이 지남에 따라 API 가용성을 계속 확인하고 검색에 실패하면 조정이 차단됩니다. 결과적으로 Operator는 환경을 올바르게 식별하고 필요한 모든 역할이 생성되었는지 확인합니다.
- IPFIX 내보내기에 누락된 변환 필드 추가
이번 업데이트 이전에는 IPFIX 내보내기 프로세스 중에 일부 네트워크 흐름 필드에 번역이 누락되었습니다. 그 결과 내보낸 IPFIX 데이터가 불완전하거나 외부 수집기에서 해석하기 어려웠습니다.
이번 릴리스에서는
flowlogs-pipelineIPFIX 내보내기에 누락된 변환 필드(xlat)가 추가되었습니다. IPFIX 내보내기에서는 일관된 네트워크 관찰 기능을 위해 번역된 전체 필드 세트를 제공합니다.- 수정된 FlowMetric 양식 생성 링크 및 기본값
이번 업데이트 이전에는
FlowMetric사용자 정의 리소스를 생성하는 링크가 의도한 양식 뷰 대신 YAML 편집기로 잘못 전달되었습니다. 또한 편집기가 잘못된 기본값으로 미리 입력되었습니다.이번 릴리스에서는 링크가 예상되는 기본 설정으로
FlowMetric리소스 생성 양식으로 올바르게 연결됩니다. 결과적으로 사용자 인터페이스를 통해FlowMetric리소스를 쉽게 생성할 수 있습니다.- 토폴로지 보기의 가상 머신 리소스 유형 아이콘
이번 업데이트 이전에는 VM(가상 머신) 소유자 유형에 토폴로지 보기에 일반 물음표(?) 아이콘이 잘못 표시되었습니다.
이번 릴리스에서는 사용자 인터페이스에 이제 VM 리소스에 대한 특정 아이콘이 포함됩니다. 결과적으로 사용자는 네트워크 토폴로지 내에서 VM 트래픽을 보다 쉽게 식별하고 구분할 수 있습니다.
- DNS 최적화, DNS 경고 업데이트
이번 업데이트 이전에는 네트워크 관찰 기능에서 사용되는 모호한 URL로 인해 많은 DNS "NXDOMAIN" 오류가 반환되었습니다.
이번 릴리스에서는 이러한 URL을 모호하게 하여 DNS를 보다 효과적으로 사용합니다.
2장. 네트워크 관찰 운영자 릴리스 노트 보관소
2.1. 네트워크 관찰 운영자 릴리스 노트 보관소
이 릴리스 노트는 OpenShift 컨테이너 플랫폼의 네트워크 관찰 연산자에 대한 과거 개발 사항을 추적합니다. 이는 참고 목적으로만 사용됩니다.
네트워크 관찰 연산자를 통해 관리자는 OpenShift Container Platform 클러스터의 네트워크 트래픽 흐름을 관찰하고 분석할 수 있습니다.
2.1.1. 네트워크 관측 가능성 운영자 1.10.1 권고 사항
네트워크 관찰 가능성 운영자 1.10.1 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.2. 네트워크 관측 가능성 운영자 1.10.1 CVE
네트워크 관찰 가능성 운영자 1.10.1 릴리스의 CVE를 검토할 수 있습니다.
2.1.3. 네트워크 관측 가능성 운영자 1.10.1 버전에서 수정된 문제점들
네트워크 관찰 가능성 운영자 1.10.1 릴리스에는 성능 및 사용자 경험을 개선하는 여러 수정 사항이 포함되어 있습니다.
- 15개 이상의 노드로 구성된 클러스터에서 직접 모드를 사용할 때 경고가 발생했습니다.
이번 업데이트 이전에는 대규모 클러스터에서
직접배포 모델을 사용하지 말라는 권장 사항은 문서에서만 확인할 수 있었습니다.이번 릴리스를 통해 네트워크 관찰 가능성 운영자는 15개 이상의 노드로 구성된 클러스터에서 직접 배포 모드를 사용할 경우 경고를 생성합니다.
- OpenShiftSDN에서 네트워크 정책 배포가 비활성화되었습니다.
이번 업데이트 이전에는 OpenShift SDN이 클러스터 네트워크 플러그인이었을 때
FlowCollector네트워크 정책을 활성화하면 네트워크 관찰 가능성 Pod 간의 통신이 중단되는 문제가 있었습니다. 이 문제는 기본 지원 네트워크 플러그인인 OVN-Kubernetes에서는 발생하지 않습니다.이번 릴리스부터 네트워크 관찰 가능성 운영자는 OpenShift SDN이 감지될 때 더 이상 네트워크 정책을 배포하려고 시도하지 않고 대신 경고를 표시합니다. 또한 네트워크 정책 활성화의 기본값이 수정되었습니다. 이제 OVN-Kubernetes가 클러스터 네트워크 플러그인으로 감지된 경우에만 기본적으로 활성화됩니다.
- 서브넷 레이블 문자에 대한 유효성 검사가 추가되었습니다.
이번 업데이트 이전에는 서브넷 레이블의 "이름" 구성에 허용되는 문자에 대한 제한이 없었으므로 사용자는 공백이나 특수 문자가 포함된 텍스트를 입력할 수 있었습니다. 이로 인해 사용자가 필터를 적용하려고 할 때 웹 콘솔 플러그인에서 오류가 발생했으며, 서브넷 레이블에 대한 필터 아이콘을 클릭하는 작업이 종종 실패했습니다.
이번 릴리스에서는
FlowCollector사용자 지정 리소스에 서브넷 레이블 이름을 구성할 때 즉시 유효성 검사가 수행됩니다. 유효성 검사를 통해 이름에 영숫자, 콜론(:),밑줄(_), 하이픈(-)만 포함되어 있는지 확인합니다. 그 결과, 웹 콘솔 플러그인에서 서브넷 레이블을 기준으로 필터링하는 기능이 이제 예상대로 작동합니다.- Network Observability CLI는 실행 시마다 고유한 임시 디렉터리를 사용합니다.
이번 업데이트 이전에는 네트워크 관찰 가능성 CLI가 현재 작업 디렉터리에 하나의 임시(
tmp) 디렉터리를 생성하거나 재사용했습니다. 이로 인해 서로 다른 실행 간에 충돌이나 데이터 손상이 발생할 수 있습니다.이번 릴리스를 통해 네트워크 관찰 가능성 CLI는 실행할 때마다 고유한 임시 디렉터리를 생성하여 잠재적인 충돌을 방지하고 파일 관리의 효율성을 향상시켰습니다.
2.1.4. 네트워크 관찰성 운영자 1.10 권고
Network Observability Operator 1.10 릴리스에 대한 권고를 검토할 수 있습니다.
2.1.5. 네트워크 관찰 연산자 1.10의 새로운 기능 및 향상된 기능
Network Observability Operator 1.10 릴리스에서는 보안이 강화되고, 성능이 개선되었으며, 더 나은 네트워크 흐름 관리를 위한 새로운 CLI UI 도구가 도입되었습니다.
2.1.5.1. 네트워크 정책 업데이트
네트워크 관찰 운영자는 이제 포드 트래픽을 제어하기 위해 유입 및 유출 네트워크 정책을 모두 구성할 수 있습니다. 이러한 개선으로 보안이 강화되었습니다.
기본적으로 spec.NetworkPolicy.enable 사양은 이제 true 로 설정됩니다. 즉, Loki 또는 Kafka를 사용하는 경우 Loki Operator와 Kafka 인스턴스를 전용 네임스페이스에 배포하는 것이 좋습니다. 이를 통해 모든 구성 요소 간의 통신을 허용하도록 네트워크 정책을 올바르게 구성할 수 있습니다.
2.1.5.2. 네트워크 관찰성 운영자 CLI UI 업데이트
이 릴리스에서는 네트워크 관찰 운영자 CLI( oc netobserv ) 사용자 인터페이스(UI)에 다음과 같은 새로운 기능과 업데이트가 추가되었습니다.
테이블 뷰 개선
- 사용자 정의 가능한 열: 열 관리를 클릭하여 표시할 열을 선택하고 필요에 맞게 표를 맞춤 설정합니다.
- 스마트 필터링: 라이브 필터에 자동 제안 기능이 추가되어 올바른 키와 값을 더 쉽게 선택할 수 있습니다.
-
패킷 미리보기: 패킷을 캡처할 때 행을 클릭하면
pcap콘텐츠를 직접 검사할 수 있습니다.
터미널 기반 선형 차트 개선
- 지표 시각화: 실시간 그래프가 CLI에서 직접 렌더링됩니다.
- 패널 선택: 미리 정의된 보기에서 선택하거나 패널 관리 팝업 메뉴를 사용하여 보기를 사용자 정의하여 특정 지표의 차트를 선택적으로 볼 수 있습니다.
2.1.5.3. 네트워크 관찰 콘솔 개선
네트워크 관찰 콘솔 플러그인에는 FlowCollector 사용자 정의 리소스(CR)를 구성하기 위한 새로운 뷰가 포함되어 있습니다. 이 보기에서 다음 작업을 완료할 수 있습니다.
-
FlowCollectorCR을 구성합니다. - 자원 발자국을 계산해 보세요.
- 구성 경고나 높은 메트릭 카디널리티와 같은 문제가 증가했습니다.
2.1.5.4. 성능 개선
Network Observability Operator 1.10에서는 Operator의 성능과 메모리 사용량이 개선되었으며, 특히 대규모 클러스터에서 눈에 띄게 향상되었습니다.
2.1.6. 네트워크 관찰 연산자 1.10 기술 미리보기 기능
Network Observability Operator 1.10 릴리스의 기술 프리뷰 기능을 검토할 수 있습니다.
2.1.6.1. 네트워크 관찰 운영자 사용자 정의 알림(기술 미리 보기)
이 릴리스에서는 새로운 알림 기능과 사용자 정의 알림 구성이 도입되었습니다. 이러한 기능은 기술 미리 보기 기능이므로 명시적으로 활성화해야 합니다.
새로운 알림을 보려면 OpenShift Container Platform 웹 콘솔에서 관찰 → 알림 → 알림 규칙을 클릭합니다.
2.1.6.2. 네트워크 관찰 운영자 네트워크 상태 대시보드(기술 미리보기)
Network Observability Operator에서 기술 프리뷰 경고 기능을 활성화하면 Observe 를 클릭하여 OpenShift Container Platform 웹 콘솔에서 새 Network Health 대시보드를 볼 수 있습니다.
네트워크 상태 대시보드는 중요, 경고, 사소한 문제를 구분하여 발생한 알림에 대한 요약을 제공하며 보류 중인 알림도 표시합니다.
2.1.7. Network Observability Operator 1.10에서 제거된 기능
Network Observability Operator 1.10 릴리스 사용에 영향을 줄 수 있는 제거된 기능을 검토하세요.
2.1.7.1. FlowCollector API 버전 v1beta1이 제거되었습니다.
FlowCollector 사용자 정의 리소스(CR) API 버전 v1beta1 이 제거되었으며 더 이상 지원되지 않습니다. v1beta2 버전을 사용하세요.
2.1.8. 네트워크 관찰 연산자 1.10 알려진 문제
Network Observability Operator 1.10 릴리스 사용에 영향을 줄 수 있는 알려진 문제와 권장되는 해결 방법(사용 가능한 경우)을 검토하세요.
2.1.8.1. OpenShift Container Platform 4.14 이하 버전에서 1.10으로 업그레이드가 실패합니다.
OpenShift Container Platform 4.14 및 이전 버전에서 Network Observability Operator 1.10으로 업그레이드하면 소프트웨어 카탈로그의 FlowCollector 사용자 정의 리소스 정의(CRD) 유효성 검사 오류로 인해 실패할 수 있습니다.
이 문제를 해결하려면 다음을 수행해야 합니다.
OpenShift Container Platform 웹 콘솔의 소프트웨어 카탈로그에서 Network Observability Operator의 두 버전을 모두 제거합니다.
-
FlowCollectorCRD를 설치해 두면 유량 수집 프로세스가 중단되지 않습니다.
-
다음 명령을 실행하여
FlowCollectorCRD의 현재 이름을 확인하세요.$ oc get crd flowcollectors.flows.netobserv.io -o jsonpath='{.spec.versions[0].name}'예상 출력
v1beta1다음 명령을 실행하여
FlowCollectorCRD의 현재 제공 상태를 확인하세요.$ oc get crd flowcollectors.flows.netobserv.io -o jsonpath='{.spec.versions[0].served}'예상 출력
true다음 명령을 실행하여
v1beta1버전의제공플래그를false로 설정합니다.$ oc patch crd flowcollectors.flows.netobserv.io --type='json' -p "[{'op': 'replace', 'path': '/spec/versions/0/served', 'value': false}]"다음 명령을 실행하여
제공된플래그가false로 설정되었는지 확인하세요.$ oc get crd flowcollectors.flows.netobserv.io -o jsonpath='{.spec.versions[0].served}'예상 출력
false- Network Observability Operator 1.10을 설치합니다.
2.1.8.2. 이전 OpenShift Container Platform 버전과 eBPF 에이전트 호환성
네트워크 관찰 명령줄 인터페이스(CLI) 패킷 캡처 기능에 사용되는 eBPF 에이전트는 OpenShift Container Platform 버전 4.16 이하와 호환되지 않습니다.
이러한 제한으로 인해 eBPF 기반 패킷 캡처 에이전트(PCA)가 이전 클러스터에서 올바르게 작동하지 않습니다.
이 문제를 해결하려면 이전의 호환 가능한 eBPF 에이전트 컨테이너 이미지를 사용하도록 PCA를 수동으로 구성해야 합니다. 자세한 내용은 Network Observability CLI 1.10+에서 이전 Openshift 버전과 Red Hat Knowledgebase Solution eBPF 에이전트의 호환성을 참조하세요.
2.1.8.3. NetworkPolicy가 활성화된 경우 eBPF 에이전트가 OpenShiftSDN으로 흐름을 보내지 못합니다.
OpenShiftSDN CNI 플러그인을 사용하는 OpenShift Container Platform 4.14 클러스터에서 Network Observability Operator 1.10을 실행할 때 eBPF 에이전트는 flowlogs-pipeline 구성 요소에 흐름 레코드를 보낼 수 없습니다. 이는 NetworkPolicy가 활성화된( spec.networkPolicy.enable: true ) FlowCollector 사용자 정의 리소스가 생성될 때 발생합니다.
결과적으로, 흐름 데이터는 flowlogs-pipeline 구성 요소에 의해 처리되지 않으며 네트워크 트래픽 대시 보드나 구성된 저장소(Loki)에 나타나지 않습니다. eBPF 에이전트 포드 로그는 수집기에 연결을 시도할 때 I/O 시간 초과 오류를 표시합니다.
time="2025-10-17T13:53:44Z" level=error msg="couldn't send flow records to collector" collector="10.0.68.187:2055" component=exporter/GRPCProto error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing: dial tcp 10.0.68.187:2055: i/o timeout\""
이 문제를 해결하려면 spec.networkPolicy.enable을 false 로 설정하여 Network Observability Operator 1.10의 FlowCollector 리소스에서 NetworkPolicy를 비활성화합니다.
이를 통해 eBPF 에이전트는 자동으로 배포된 네트워크 정책의 간섭 없이 flowlogs-pipeline 구성 요소와 통신할 수 있습니다.
2.1.9. Network Observability Operator 1.10에서 수정된 문제
Network Observability Operator 1.10 릴리스에는 성능과 사용자 경험을 개선하는 여러 가지 문제가 수정되었습니다.
2.1.9.1. MetricName 및 Remap 필드가 검증되었습니다.
이 업데이트 이전에는 사용자가 잘못된 메트릭 이름으로 FlowMetric 사용자 지정 리소스(CR)를 만들 수 있었습니다. FlowMetric CR이 성공적으로 생성되었지만 기본 메트릭은 사용자에게 오류 피드백을 제공하지 않고 아무런 오류도 발생하지 않았습니다.
이번 릴리스에서는 FlowMetric , metricName 및 remap 필드가 생성 전에 검증되므로 사용자가 잘못된 이름을 입력하면 즉시 알림을 받게 됩니다.
2.1.9.2. HTML-이미지 내보내기 성능 향상
이 업데이트 이전에는 기본 라이브러리의 성능 문제로 인해 HTML을 이미지로 내보내는 기능에 시간이 오래 걸려 브라우저가 멈추는 현상이 발생했습니다.
이번 릴리스에서는 html-to-image 라이브러리의 성능이 개선되어 내보내기 대기 시간이 줄어들고 이미지 생성 중 브라우저가 멈추는 현상이 없어졌습니다.
2.1.9.3. eBPF 권한 모드에 대한 경고 개선
이 업데이트 이전에는 사용자가 권한 모드가 필요한 eBPF 기능을 선택하면 권한 모드가 없거나 활성화해야 한다는 사실을 사용자에게 명확하게 알리지 않고 기능이 실패하는 경우가 많았습니다.
이 릴리스에서는 구성에 일관성이 없는 경우 유효성 검사 후크가 사용자에게 즉시 경고합니다. 이를 통해 사용자의 이해를 높이고 잘못된 구성을 방지할 수 있습니다.
2.1.9.4. OpenTelemetry 내보내기에 서브넷 레이블이 추가되었습니다.
이 업데이트 이전에는 OpenTelemetry 메트릭 내보내기 도구에 네트워크 흐름 레이블인 SrcSubnetLabel 과 DstSubnetLabel 이 없어서 비어 있는 것으로 표시되었습니다.
이번 릴리스에서는 이러한 레이블이 이제 내보내기 프로그램에서 올바르게 제공됩니다. 또한 OpenTelemetry 표준과의 일관성과 명확성을 높이기 위해 source.subnet.label 과 destination.subnet.label 로 이름이 변경되었습니다.
2.1.9.5. 네트워크 관찰성 구성 요소에 대한 기본 허용 범위가 감소되었습니다.
이 업데이트 이전에는 모든 네트워크 관찰 구성 요소에 기본 허용 범위가 설정되어 NoSchedule 로 오염된 노드를 포함하여 모든 노드에서 예약이 가능했습니다. 이로 인해 클러스터 업그레이드가 차단될 가능성이 있습니다.
이 릴리스에서는 기본 허용 범위가 직접 모드로 구성된 경우 eBPF 에이전트와 Flowlogs-Pipeline에 대해서만 유지됩니다. Kafka 모드로 구성된 경우 OpenShift Container Platform 웹 콘솔 플러그인과 Flowlogs-Pipeline 에서 허용이 제거되었습니다.
또한, FlowCollector 사용자 정의 리소스(CR)에서 항상 허용 범위를 구성할 수 있었지만 이전에는 허용 범위를 빈 목록으로 바꾸는 것이 불가능했습니다. 이제 허용 범위를 빈 목록으로 바꿀 수 있습니다.
2.1.10. 네트워크 관찰성 운영자 1.9.3 권고
Network Observability Operator 1.9.3 릴리스에 대한 권고를 검토할 수 있습니다.
2.1.11. 네트워크 관찰 운영자 1.9.2 권고
Network Observability Operator 1.9.2 릴리스에 대한 권고를 검토할 수 있습니다.
2.1.12. 네트워크 관찰성 1.9.2 버그 수정
Network Observability Operator 1.9.1 릴리스의 해결된 문제를 검토할 수 있습니다.
-
이 업데이트 이전에는 OpenShift Container Platform 버전 4.15 이하에서는
TC_ATTACH_MODE구성을 지원하지 않았습니다. 이로 인해 명령줄 인터페이스(CLI) 오류가 발생하고 패킷과 흐름을 관찰할 수 없게 되었습니다. 이번 릴리스에서는 Traffic Control eXtension(TCX) 후크 부착 모드가 이전 버전에 맞게 조정되었습니다. 이렇게 하면tcx후크 오류가 제거되고 흐름과 패킷 관찰이 가능해집니다.
2.1.13. 네트워크 관찰성 운영자 1.9.1 권고
Network Observability Operator 1.9.1 릴리스에 대한 권고 사항을 검토할 수 있습니다.
다음 권고 사항은 Network Observability Operator 1.9.1에 대해 제공됩니다.
2.1.14. Network Observability Operator 1.9.1에서 문제가 해결되었습니다.
Network Observability Operator 1.9.1 릴리스의 해결된 문제를 검토할 수 있습니다.
-
이 업데이트 이전에는 잘못된 연결 모드 설정으로 인해 OpenShift Container Platform 4.15에서 네트워크 흐름이 관찰되지 않았습니다. 이로 인해 사용자는 특히 특정 카탈로그에서 네트워크 흐름을 올바르게 모니터링하지 못했습니다. 이 릴리스에서는 4.16.0보다 이전 버전의 OpenShift Container Platform에 대한 기본 연결 모드가
tc로 설정되어 이제 OpenShift Container Platform 4.15에서 흐름이 관찰됩니다. ( 네트옵서버-2333 ) - 이 업데이트 이전에는 IPFIX 수집기가 다시 시작되면 IPFIX 내보내기를 구성하면 연결이 끊어지고 수집기로 네트워크 흐름 전송이 중단될 수 있었습니다. 이 릴리스에서는 연결이 복구되었으며 네트워크 흐름은 계속 수집기로 전송됩니다. ( NETOBSERV-2315 )
- 이 업데이트 이전에는 IPFIX 내보내기를 구성할 때 포트 정보가 없는 흐름(예: ICMP 트래픽)이 무시되어 로그에 오류가 발생했습니다. IPFIX 내보내기에서 TCP 플래그와 ICMP 데이터도 누락되었습니다. 이번 릴리스에서는 이러한 세부 정보가 포함되었습니다. 누락된 필드(예: 포트)는 더 이상 오류를 발생시키지 않으며 내보낸 데이터의 일부입니다. (NETOBSERV-2307)
- 이 업데이트 이전에는 사용자 정의 네트워크(UDN) 매핑 기능이 OpenShift Container Platform 4.18에서 구성 문제와 경고가 발생했는데, 이는 코드에서 OpenShift 버전이 잘못 설정되었기 때문입니다. 이는 사용자 경험에 영향을 미쳤습니다. 이 릴리스부터 UDN 매핑은 이제 경고 없이 OpenShift Container Platform 4.18을 지원하여 원활한 사용자 경험을 제공합니다. (NETOBSERV-2305)
-
이 업데이트 이전에는 네트워크 트래픽 페이지의 확장 기능이 OpenShift Container Platform Console 4.19와 호환성 문제가 있었습니다. 이로 인해 확장 시 메뉴 공간이 비어 있고 사용자 인터페이스가 일관되지 않았습니다. 이번 릴리스에서는
NetflowTraffic부분과테마 후크의 호환성 문제가 해결되었습니다. 네트워크 트래픽 보기의 사이드 메뉴가 이제 제대로 관리되어 사용자 인터페이스와의 상호 작용 방식이 개선되었습니다. (NETOBSERV-2304)
2.1.15. 네트워크 관찰성 운영자 1.9.0 권고
Network Observability Operator 1.9.0 릴리스에 대한 권고 사항을 검토할 수 있습니다.
- Network Observability Operator 1.3.0
2.1.16. Network Observability Operator 1.9.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.9.0 릴리스의 새로운 기능과 향상된 기능을 검토할 수 있습니다.
2.1.16.1. 네트워크 관찰이 가능한 사용자 정의 네트워크
이번 릴리스를 통해 user-defined networks (UDN) 기능이 Network Observability에서 일반적으로 사용 가능해졌습니다. 네트워크 관찰에서 UDNMapping 기능이 활성화되면 트래픽 흐름 테이블에 UDN 레이블 열이 생깁니다. 소스 네트워크 이름 및 대상 네트워크 이름 정보에 대한 로그를 필터링할 수 있습니다.
2.1.16.2. 섭취 시 필터 플로우로그
이 릴리스를 사용하면 필터를 생성하여 생성된 네트워크 흐름 수와 네트워크 관찰 구성 요소의 리소스 사용량을 줄일 수 있습니다. 다음 필터를 구성할 수 있습니다.
- eBPF 에이전트 필터
- Flowlogs-파이프라인 필터
2.1.16.3. IPsec 지원
이 업데이트는 OpenShift Container Platform에서 IPsec이 활성화된 경우 네트워크 관찰성을 다음과 같이 향상시킵니다.
- IPsec 상태 라는 새 열이 네트워크 관찰 트래픽 흐름 보기에 표시되어 흐름이 성공적으로 IPsec 암호화되었는지 또는 암호화/복호화 중에 오류가 발생했는지 여부를 보여줍니다.
- 암호화된 트래픽의 비율을 보여주는 새로운 대시보드가 생성됩니다.
2.1.16.4. 네트워크 관찰 CLI
패킷, 흐름 및 메트릭 캡처에 대해 다음 필터링 옵션을 사용할 수 있습니다.
-
--sampling옵션을 사용하여 샘플링되는 패킷의 비율을 구성합니다. -
--query옵션을 사용하여 사용자 정의 쿼리를 사용하여 흐름을 필터링합니다. -
--interfaces옵션을 사용하여 모니터링할 인터페이스를 지정합니다. -
--exclude_interfaces옵션을 사용하여 제외할 인터페이스를 지정합니다. -
--include_list옵션을 사용하여 생성할 메트릭 이름을 지정합니다.
자세한 내용은 다음을 참조하세요.
2.1.17. Network Observability Operator 릴리스 노트 1.9.0 주요 기술 변경 사항
Network Observability Operator 1.6.0 릴리스의 주요 기술적 변경 사항을 검토할 수 있습니다.
-
네트워크 관찰 기능 1.9의
NetworkEvents기능이 OpenShift Container Platform 4.19의 최신 Linux 커널에서 작동하도록 업데이트되었습니다. 이 업데이트로 인해 이전 커널과의 호환성이 끊어집니다. 따라서NetworkEvents기능은 OpenShift Container Platform 4.19에서만 사용할 수 있습니다. Network Observability 1.8 및 OpenShift Container Platform 4.18과 함께 이 기능을 사용하는 경우 Network Observability 업그레이드를 피하거나 Network Observability 1.9 및 OpenShift Container Platform을 4.19로 업그레이드하는 것이 좋습니다. -
netobserv-reader클러스터 역할의 이름이netobserv-loki-reader로 변경되었습니다. - eBPF 에이전트의 CPU 성능이 향상되었습니다.
2.1.18. 네트워크 관찰 연산자 1.9.0 기술 미리보기 기능
Network Observability Operator 1.9.0 릴리스의 기술 미리 보기 기능을 검토할 수 있습니다.
이 릴리스의 일부 기능은 현재 기술 프리뷰 단계에 있습니다. 이러한 실험적 기능은 프로덕션용이 아닙니다. 해당 기능은 Red Hat Customer Portal의 지원 범위를 참조하십시오.
2.1.18.1. 네트워크 관찰이 가능한 eBPF 관리자 운영자
eBPF 관리자 운영자는 모든 eBPF 프로그램을 관리하여 공격 표면을 줄이고 규정 준수, 보안 및 충돌 방지를 보장합니다. 네트워크 관찰은 eBPF 관리자 연산자를 사용하여 후크를 로드할 수 있습니다. 이렇게 하면 eBPF 에이전트에 권한 모드나 CAP_BPF 및 CAP_PERFMON 과 같은 추가 Linux 기능을 제공할 필요가 없습니다. 네트워크 관찰 기능을 갖춘 eBPF 관리자 연산자는 64비트 AMD 아키텍처에서만 지원됩니다.
2.1.19. 네트워크 관찰성 운영자 1.9.0 CVE
Network Observability Operator 1.9.0 릴리스에 대한 CVE를 검토할 수 있습니다.
2.1.20. Network Observability Operator 1.9.0에서 문제가 해결되었습니다.
Network Observability Operator 1.9.0 릴리스의 해결된 문제를 검토할 수 있습니다.
-
이전에는 콘솔 플러그인에서 소스 또는 대상 IP로 필터링할 때
10.128.0.0/24와 같은 CIDR(Classless Inter-Domain Routing) 표기법을 사용하면 작동하지 않아 필터링해야 할 결과가 반환되었습니다. 이 업데이트를 통해 이제 CIDR 표기법을 사용할 수 있으며, 결과가 예상대로 필터링됩니다. ( NETOBSERV-2276 ) -
이전에는 네트워크 흐름이 사용 중인 네트워크 인터페이스를 잘못 식별했을 수 있으며, 특히
eth0와ens5를혼동할 위험이 있었습니다. 이 문제는 eBPF 에이전트가Privileged로 구성된 경우에만 발생했습니다. 이번 업데이트를 통해 문제가 부분적으로 해결되었으며, 거의 모든 네트워크 인터페이스가 올바르게 식별되었습니다. 자세한 내용은 아래의 알려진 문제를 참조하세요. (NETOBSERV-2257) - 이전에는 Operator가 동작을 조정하기 위해 사용 가능한 Kubernetes API를 확인했을 때 오래된 API가 있으면 Operator가 정상적으로 시작되지 못하게 하는 오류가 발생했습니다. 이 업데이트를 적용하면 Operator는 관련 없는 API의 오류를 무시하고, 관련 API의 오류를 기록하며 정상적으로 실행됩니다. (NETOBSERV-2240)
- 이전에는 사용자가 콘솔 플러그인의 트래픽 흐름 보기에서 바이트 또는 패킷 별로 흐름을 정렬할 수 없었습니다. 이 업데이트를 통해 사용자는 Bytes 와 Packets 별로 흐름을 정렬할 수 있습니다. ( NETOBSERV-2239 )
-
이전에는 IPFIX 내보내기 기능으로
FlowCollector리소스를 구성할 때 IPFIX 흐름의 MAC 주소가 처음 2바이트로 잘렸습니다. 이 업데이트를 통해 MAC 주소가 IPFIX 흐름에 완전히 표현되었습니다. (NETOBSERV-2208) - 이전에는 Operator 검증 웹훅에서 보낸 일부 경고에 수행해야 할 작업에 대한 명확한 설명이 부족했습니다. 이번 업데이트를 통해 일부 메시지가 검토되고 수정되어 더욱 실행 가능하게 되었습니다. ( NETOBSERV-2178 )
-
이전에는
FlowCollector리소스에서LokiStack을참조할 때 입력 오류 등의 문제가 있는지 알아내는 것이 명확하지 않았습니다. 이 업데이트를 통해FlowCollector상태에서 해당LokiStack을찾을 수 없다는 사실이 명확하게 나타납니다. ( NETOBSERV-2174 ) - 이전에는 콘솔 플러그인 트래픽 흐름 보기에서 텍스트 오버플로가 발생할 경우 텍스트 생략 부호로 인해 표시될 텍스트의 대부분이 가려지는 경우가 있었습니다. 이 업데이트를 통해 가능한 한 많은 텍스트를 표시합니다. ( 네트옵저브-2119 )
- 이전에는 네트워크 관찰 기능 1.8.1 및 이전 버전의 콘솔 플러그인이 OpenShift Container Platform 4.19 웹 콘솔에서 작동하지 않아 네트워크 트래픽 페이지에 접근할 수 없었습니다. 이 업데이트를 통해 콘솔 플러그인이 호환되고 네트워크 트래픽 페이지에 네트워크 관찰 기능 1.9.0에서 접근할 수 있습니다. (NETOBSERV-2046)
-
이전에는 대화 추적(
FlowCollector리소스의logTypes: Conversations또는logTypes: All)을 사용할 때 대시보드에 표시되는 트래픽 비율 측정항목에 결함이 있어 트래픽이 통제 불능적으로 증가했다고 잘못 표시했습니다. 이제 측정항목에서 더 정확한 트래픽 비율을 보여줍니다. 그러나Conversations및EndedConversations모드에서는 이러한 측정 항목이 오랫동안 지속된 연결을 포함하지 않으므로 여전히 완전히 정확하지는 않습니다. 이 정보는 문서에 추가되었습니다. 이러한 부정확성을 피하기 위해 기본 모드logTypes: Flows를 사용하는 것이 좋습니다. ( NETOBSERV-1955 )
2.1.21. Network Observability Operator 1.9.0 알려진 문제
Network Observability Operator 1.9.0 릴리스의 알려진 문제를 검토할 수 있습니다.
- 사용자 정의 네트워크(UDN) 기능은 지원됨에도 불구하고 OpenShift Container Platform 4.18과 함께 사용할 경우 구성 문제와 경고가 표시됩니다. 이 경고는 무시해도 됩니다. (NETOBSERV-2305)
-
드물지만, 여러 네트워크 네임스페이스가 있는
privileged모드에서 실행할 때 eBPF 에이전트가 관련 인터페이스와 흐름을 적절하게 연관시키지 못하는 경우가 있습니다. 이러한 문제 중 상당 부분은 이번 릴리스에서 확인되어 해결되었지만, 특히ens5인터페이스와 관련하여 일부 불일치 사항은 여전히 남아 있습니다. ( NETOBSERV-2287 )
2.1.22. 네트워크 관찰 운영자 1.8.1 권고
Network Observability Operator 1.8.1 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.23. 네트워크 관찰성 운영자 1.8.1 CVE
Network Observability Operator 1.8.1 릴리스에 대한 CVE를 검토할 수 있습니다.
2.1.24. Network Observability Operator 1.8.1에서 문제가 해결되었습니다.
Network Observability Operator 1.8.1 릴리스의 해결된 문제를 검토할 수 있습니다.
- 이 수정을 통해 OpenShift Container Platform의 향후 버전에서는 관찰 메뉴가 한 번만 나타나도록 할 수 있습니다. (NETOBSERV-2139)
2.1.25. 네트워크 관찰성 운영자 1.8.0 권고
Network Observability Operator 1.8.0 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.26. Network Observability Operator 1.8.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.8.0 릴리스의 새로운 기능과 향상된 기능을 검토할 수 있습니다.
2.1.26.1. 패킷 번역
이제 번역된 엔드포인트 정보로 네트워크 흐름을 풍부하게 하여 서비스뿐만 아니라 특정 백엔드 Pod도 표시하여 어떤 Pod가 요청을 처리했는지 확인할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.26.2. OVN-Kubernetes 네트워킹 이벤트 추적
OVN-Kubernetes 네트워킹 이벤트 추적은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
이제 네트워크 관찰 기능에서 네트워크 이벤트 추적을 사용하여 네트워크 정책, 관리자 네트워크 정책, 송신 방화벽을 비롯한 OVN-Kubernetes 이벤트에 대한 통찰력을 얻을 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.26.3. 1.8에서 eBPF 성능 개선
- 네트워크 관찰은 이제 CPU별 맵 대신 해시 맵을 사용합니다. 즉, 네트워크 흐름 데이터는 이제 커널 공간에서 추적되고 새로운 패킷도 거기에서 집계됩니다. 이제 네트워크 흐름의 중복 제거가 커널에서 수행될 수 있으므로 커널과 사용자 공간 간의 데이터 전송 크기가 더 작아져 성능이 향상됩니다. 이러한 eBPF 성능 개선을 통해 eBPF 에이전트에서 CPU 리소스가 40~57% 감소할 가능성이 있습니다.
2.1.26.4. 네트워크 관찰 CLI
이번 릴리스에서는 다음과 같은 새로운 기능, 옵션 및 필터가 Network Observability CLI에 추가되었습니다.
-
oc netobserv metrics명령을 실행하여 필터가 활성화된 상태에서 메트릭을 캡처합니다. -
--background옵션과 함께 플로우 및 패킷 캡처를 사용하여 백그라운드에서 CLI를 실행하고,oc netobserv follow를실행하여 백그라운드 실행의 진행 상황을 확인하고,oc netobserv copy를실행하여 생성된 로그를 다운로드합니다. -
--get-subnets옵션을 사용하여 머신, 포드, 서비스 서브넷으로 흐름과 메트릭 캡처를 강화합니다. 패킷, 흐름 및 메트릭 캡처에 사용할 수 있는 새로운 필터링 옵션:
- IP, 포트, 프로토콜, 작업, TCP 플래그 등에 대한 eBPF 필터
-
--node-selector를사용한 사용자 정의 노드 -
--drops만 사용하여 삭제합니다. -
--regexes를사용하는 모든 필드
자세한 내용은 다음을 참조하세요.
2.1.27. Network Observability Operator 릴리스 노트 1.8.0 수정된 문제
Network Observability Operator 1.8.0 릴리스의 해결된 문제를 검토할 수 있습니다.
- 이전에는 네트워크 관찰 운영자가 메트릭 서버의 RBAC를 관리하기 위해 "kube-rbac-proxy" 컨테이너와 함께 제공되었습니다. 이 외부 구성 요소는 더 이상 사용되지 않으므로 제거해야 했습니다. 이제 사이드카 프록시가 필요 없이 Kubernetes 컨트롤러 런타임을 통한 직접적인 TLS 및 RBAC 관리로 대체되었습니다. (NETOBSERV-1999)
- 이전에는 OpenShift Container Platform 콘솔 플러그인에서 여러 값과 같지 않은 키를 필터링해도 아무것도 필터링되지 않았습니다. 이 수정을 통해 예상한 결과, 즉 필터링된 값이 하나도 없는 모든 흐름이 반환됩니다. (NETOBSERV-1990)
- 이전에는 Loki가 비활성화된 OpenShift Container Platform 콘솔 플러그인에서 호환되지 않는 필터 및 집계 집합을 선택하여 "쿼리를 작성할 수 없습니다" 오류가 발생할 가능성이 매우 컸습니다. 이제 사용자에게 필터 비호환성을 알리는 동시에 호환되지 않는 필터를 자동으로 비활성화하여 이러한 오류를 방지할 수 있습니다. (NETOBSERV-1977)
- 이전에는 콘솔 플러그인에서 흐름 세부 정보를 볼 때 ICMP 정보가 항상 측면 패널에 표시되어 ICMP가 아닌 흐름에 대한 "정의되지 않음" 값이 표시되었습니다. 이 수정 사항을 적용하면 ICMP가 아닌 흐름에 대한 ICMP 정보가 표시되지 않습니다. (NETOBSERV-1969)
- 이전에는 트래픽 흐름 보기의 "데이터 내보내기" 링크가 의도한 대로 작동하지 않아 빈 CSV 보고서가 생성되었습니다. 이제 내보내기 기능이 복구되어 비어 있지 않은 CSV 데이터가 생성됩니다. (NETOBSERV-1958)
-
이전에는
loki.enable을false로 설정하여process.logTypesConversations,EndedConversations또는All로FlowCollector를구성할 수 있었지만, 대화 로그는 Loki가 활성화된 경우에만 유용했습니다. 이로 인해 자원 낭비가 발생했습니다. 현재 이 구성은 유효하지 않으며 검증 웹훅에서 거부됩니다. (NETOBSERV-1957) -
Processor.logTypes를All로 설정하여FlowCollector를구성하면 다른 옵션보다 CPU, 메모리, 네트워크 대역폭 등의 리소스가 훨씬 더 많이 소모됩니다. 이런 사실은 이전에는 기록되지 않았습니다. 이 문제는 이제 문서화되었으며, 검증 웹훅에서 경고가 발생합니다. (NETOBSERV-1956) - 이전에는 높은 스트레스 상황에서 eBPF 에이전트가 생성한 일부 흐름이 실수로 무시되어 트래픽 대역폭이 과소평가되는 경우가 있었습니다. 이제 생성된 흐름은 해제되지 않습니다. (NETOBSERV-1954)
-
이전에는
FlowCollector구성에서 네트워크 정책을 활성화하면 Operator 웹훅에 대한 트래픽이 차단되어FlowMetricsAPI 유효성 검사가 중단되었습니다. 이제 웹후크에 대한 트래픽이 허용됩니다. (NETOBSERV-1934) -
이전에는 기본 네트워크 정책을 배포할 때
additionalNamespaces필드에openshift-console및openshift-monitoring네임스페이스가 기본적으로 설정되어 중복된 규칙이 발생했습니다. 이제 기본적으로 추가 네임스페이스가 설정되지 않아 중복된 규칙을 방지하는 데 도움이 됩니다.( NETOBSERV-1933 ) - 이전에는 OpenShift Container Platform 콘솔 플러그인에서 TCP 플래그를 필터링하면 원하는 플래그가 정확히 포함된 흐름만 일치했습니다. 이제 원하는 플래그 이상을 갖는 모든 흐름이 필터링된 흐름에 나타납니다. (NETOBSERV-1890)
- eBPF 에이전트가 권한 모드에서 실행되고 포드가 지속적으로 추가되거나 삭제되면 파일 설명자(FD) 누수가 발생합니다. 이 수정은 네트워크 네임스페이스가 삭제될 때 FD가 적절하게 닫히도록 보장합니다. (NETOBSERV-2063)
-
이전에는 CLI 에이전트
DaemonSet이마스터 노드에 배포되지 않았습니다. 이제 에이전트DaemonSet에 허용 범위가 추가되어 오염이 설정될 때마다 모든 노드에서 일정을 예약할 수 있습니다. 이제 CLI 에이전트DaemonSetPod가 모든 노드에서 실행됩니다. (NETOBSERV-2030) - 이전에는 Prometheus 스토리지만 사용할 때 Source Resource 및 Source Destination 필터가 자동 완성되지 않았습니다. 이제 이 문제는 해결되었고 제안은 예상대로 표시됩니다. (NETOBSERV-1885)
- 이전에는 여러 IP를 사용하는 리소스가 토폴로지 보기에서 별도로 표시되었습니다. 이제 리소스가 보기에서 단일 토폴로지 노드로 표시됩니다. (NETOBSERV-1818)
- 이전에는 마우스 포인터를 열 위에 올려놓으면 콘솔에서 네트워크 트래픽 표 보기 내용이 새로 고쳐졌습니다. 이제 디스플레이가 고정되어 마우스를 올려도 행 높이가 일정하게 유지됩니다. (NETOBSERV-2049)
2.1.28. Network Observability Operator 릴리스 노트 1.8.0 알려진 문제
Network Observability Operator 1.8.0 릴리스의 알려진 문제를 검토할 수 있습니다.
- 클러스터에 중복되는 서브넷을 사용하는 트래픽이 있는 경우 eBPF 에이전트가 중복된 IP의 흐름을 섞을 위험이 약간 있습니다. 이는 서로 다른 연결이 정확히 동일한 소스 및 대상 IP를 갖고 포트와 프로토콜이 5초 시간 프레임 내에 있고 동일한 노드에서 발생하는 경우 발생할 수 있습니다. 보조 네트워크나 UDN을 구성하지 않는 한 이는 가능하지 않습니다. 그런 경우에도 일반적인 트래픽에서는 발생할 가능성이 매우 낮습니다. 소스 포트가 일반적으로 좋은 구분 기준이기 때문입니다. (NETOBSERV-2115)
-
OpenShift Container Platform 웹 콘솔 양식 보기의
FlowCollector리소스spec.exporters섹션에서 구성할 내보내기 유형을 선택한 후 해당 유형에 대한 자세한 구성이 양식에 표시되지 않습니다. 해결 방법은 YAML을 직접 구성하는 것입니다. (NETOBSERV-1981)
2.1.29. 네트워크 관찰성 운영자 1.7.0 권고
Network Observability Operator 1.7.0 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.30. 네트워크 관찰 연산자 1.7.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.7.0 릴리스의 새로운 기능과 향상된 기능을 검토할 수 있습니다.
2.1.30.1. OpenTelemetry 지원
이제 OpenTelemetry의 Red Hat 빌드와 같은 호환 가능한 OpenTelemetry 엔드포인트로 강화된 네트워크 흐름을 내보낼 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.2. 네트워크 관찰성 개발자 관점
이제 개발자 관점에서 네트워크 관찰 기능을 사용할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.3. TCP 플래그 필터링
이제 tcpFlags 필터를 사용하여 eBPF 프로그램에서 처리하는 패킷 볼륨을 제한할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.4. OpenShift 가상화를 위한 네트워크 관찰성
OVN(Open Virtual Network)-Kubernetes 등을 통해 보조 네트워크에 연결된 VM에서 나오는 eBPF가 강화된 네트워크 흐름을 식별하여 OpenShift 가상화 설정에서 네트워킹 패턴을 관찰할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.5. 네트워크 정책은 FlowCollector 사용자 지정 리소스(CR)에 배포됩니다.
이 릴리스를 사용하면 네트워크 관찰을 위한 네트워크 정책을 배포하도록 FlowCollector 사용자 지정 리소스(CR)를 구성할 수 있습니다. 이전에는 네트워크 정책이 필요한 경우 수동으로 만들어야 했습니다. 네트워크 정책을 수동으로 생성하는 옵션은 여전히 사용할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.6. FIPS 컴플라이언스
FIPS 모드에서 실행되는 OpenShift Container Platform 클러스터에 Network Observability Operator를 설치하여 사용할 수 있습니다.
중요FIPS 모드를 활성화하려면 FIPS 모드에서 작동하도록 구성된 RHEL(Red Hat Enterprise Linux) 컴퓨터에서 설치 프로그램을 실행해야 합니다. RHEL에서 FIPS 모드를 구성하는 방법에 대한 자세한 내용은 RHEL을 FIPS 모드로 전환을 참조하세요.
FIPS 모드로 부팅된 Red Hat Enterprise Linux(RHEL) 또는 Red Hat Enterprise Linux CoreOS(RHCOS)를 실행할 때 OpenShift Container Platform 핵심 구성 요소는 x86_64, ppc64le 및 s390x 아키텍처에서만 FIPS 140-2/140-3 검증을 위해 NIST에 제출된 RHEL 암호화 라이브러리를 사용합니다.
2.1.30.7. eBPF 에이전트 개선 사항
eBPF 에이전트에는 다음과 같은 향상된 기능이 제공됩니다.
-
DNS 서비스가
53이아닌 다른 포트에 매핑되는 경우spec.agent.ebpf.advanced.env.DNS_TRACKING_PORT를 사용하여 이 DNS 추적 포트를 지정할 수 있습니다. - 이제 전송 프로토콜(TCP, UDP 또는 SCTP) 필터링 규칙에 두 개의 포트를 사용할 수 있습니다.
- 이제 프로토콜 필드를 비워두면 와일드카드 프로토콜을 사용하여 전송 포트를 필터링할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.30.8. 네트워크 관찰 CLI
네트워크 관찰 CLI( oc netobserv )가 이제 일반적으로 사용 가능합니다. 1.6 Technology Preview 릴리스 이후 다음과 같은 개선 사항이 적용되었습니다.
- 이제 패킷 캡처를 위한 플로우 캡처와 유사한 eBPF 강화 필터가 있습니다.
-
이제 흐름과 패킷 캡처 모두에 필터
tcp_flags를사용할 수 있습니다. - 자동 해제 옵션은 max-bytes 또는 max-time에 도달하면 사용할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.31. Network Observability Operator 1.7.0에서 문제가 해결되었습니다.
Network Observability Operator 1.7.0 릴리스에 대해 해결된 다음 문제를 검토할 수 있습니다.
-
이전에는 RHEL 9.2 실시간 커널을 사용할 때 일부 웹훅이 작동하지 않았습니다. 이제 RHEL 9.2 실시간 커널이 사용되고 있는지 확인하는 수정 방법이 마련되었습니다. 커널을 사용하는 경우 패킷 삭제 및
s390x아키텍처를 사용할 때 왕복 시간과 같은 작동하지 않는 기능에 대한 경고가 표시됩니다. 해당 문제는 OpenShift 4.16 이상에서 해결되었습니다. (NETOBSERV-1808) - 이전에는 개요 탭의 패널 관리 대화 상자에서 총계 , 막대형 , 도넛형 또는 선형을 필터링해도 결과가 표시되지 않았습니다. 이제 사용 가능한 패널이 올바르게 필터링되었습니다. (NETOBSERV-1540)
-
이전에는 높은 스트레스 하에서 eBPF 에이전트가 거의 응집되지 않은 수많은 작은 흐름을 생성하는 상태에 빠지기 쉬웠습니다. 이 수정을 통해 높은 스트레스 하에서도 집계 프로세스가 유지되어 생성되는 흐름이 줄어듭니다. 이 수정 사항은 eBPF 에이전트뿐만 아니라
flowlogs-pipeline과 Loki에서도 리소스 소비를 개선합니다. (NETOBSERV-1564) -
이전에는
workload_flows_total메트릭이namespace_flows_total메트릭 대신 활성화되었을 때 상태 대시보드에서네임스페이스별 흐름 차트가 표시되지 않았습니다. 이 수정 사항을 적용하면workload_flows_total이 활성화된 경우에도 상태 대시보드에 흐름 차트가 표시됩니다. (NETOBSERV-1746) -
이전에는
FlowMetricsAPI를 사용하여 사용자 지정 메트릭을 생성한 후 나중에 레이블을 수정(예: 새 레이블 추가)하면 메트릭이 더 이상 채워지지 않고flowlogs-pipeline로그에 오류가 표시되었습니다. 이 수정을 통해 레이블을 수정할 수 있으며,flowlogs-pipeline로그에서 오류가 더 이상 발생하지 않습니다. (NETOBSERV-1748) -
이전에는 기본 Loki
WriteBatchSize구성에 불일치가 있었습니다.FlowCollectorCRD 기본값에서는 100KB로 설정되었지만 OLM 샘플 또는 기본 구성에서는 10MB로 설정되었습니다. 이제 둘 다 10MB에 맞게 조정되어 일반적으로 더 나은 성능과 리소스 공간을 줄일 수 있습니다. (NETOBSERV-1766) - 이전에는 프로토콜을 지정하지 않으면 포트의 eBPF 흐름 필터가 무시되었습니다. 이 수정 사항을 사용하면 포트 및 프로토콜에서 eBPF 흐름 필터를 독립적으로 설정할 수 있습니다. (NETOBSERV-1779)
- 이전에는 Pod에서 서비스로의 트래픽이 토폴로지 보기 에서 숨겨졌습니다. 서비스에서 Pod로의 반환 트래픽만 표시되었습니다. 이 수정을 통해 해당 트래픽이 올바르게 표시됩니다. (NETOBSERV-1788)
- 이전에는 네트워크 관찰 기능에 액세스할 수 있는 클러스터 관리자가 아닌 사용자가 네임스페이스 등 자동 완성을 트리거하는 항목을 필터링하려고 하면 콘솔 플러그인에서 오류가 발생했습니다. 이 수정을 적용하면 오류가 표시되지 않고 자동 완성이 예상한 결과를 반환합니다. (NETOBSERV-1798)
- 2차 인터페이스 지원이 추가되었을 때는 인터페이스 알림에 대해 알아보기 위해 네트워크별 네임스페이스를 netlink에 등록하기 위해 여러 번 반복해야 했습니다. 동시에, 실패한 핸들러로 인해 파일 기술자 누수가 발생했습니다. TCX 후크의 경우 TC와 달리 인터페이스가 다운되면 핸들러를 명시적으로 제거해야 했기 때문입니다. 또한, 네트워크 네임스페이스가 삭제되었을 때 netlink 고루틴 소켓을 종료하는 Go 닫기 채널 이벤트가 없었고, 이로 인해 Go 스레드가 누수되었습니다. 이제 Pod를 생성하거나 삭제할 때 파일 설명자나 Go 스레드가 누출되는 일이 더 이상 발생하지 않습니다. (NETOBSERV-1805)
- 이전에는 관련 데이터가 흐름 JSON에 있는 경우에도 ICMP 유형과 값이 트래픽 흐름 표에서 'n/a'로 표시되었습니다. 이 수정 사항을 적용하면 ICMP 열이 흐름 테이블에서 예상대로 관련 값을 표시합니다. (NETOBSERV-1806)
- 이전 콘솔 플러그인에서는 설정되지 않은 필드(예: 설정되지 않은 DNS 지연 시간)를 필터링하는 것이 항상 가능하지는 않았습니다. 이 수정 사항을 통해 이제 설정되지 않은 필드에 대한 필터링이 가능해졌습니다. (NETOBSERV-1816)
- 이전에는 OpenShift 웹 콘솔 플러그인에서 필터를 지운 후 다른 페이지로 이동한 후 필터가 있는 페이지로 돌아오면 필터가 다시 나타나는 경우가 있었습니다. 이 수정 사항을 적용하면 필터를 지운 후 예기치 않게 다시 나타나는 일이 없어집니다. (NETOBSERV-1733)
2.1.32. 네트워크 관찰 연산자 1.7.0 알려진 문제
Network Observability Operator 1.7.0 릴리스에 대한 알려진 문제는 다음과 같습니다.
- 네트워크 관찰 기능을 갖춘 must-gather 도구를 사용하는 경우 클러스터에 FIPS가 활성화되어 있으면 로그가 수집되지 않습니다. (NETOBSERV-1830)
FlowCollector에서spec.networkPolicy가활성화되어netobserv네임스페이스에 네트워크 정책이 설치되면FlowMetricsAPI를 사용할 수 없습니다. 네트워크 정책은 검증 웹훅에 대한 호출을 차단합니다. 해결 방법으로 다음 네트워크 정책을 사용하세요.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-from-hostnetwork namespace: netobserv spec: podSelector: matchLabels: app: netobserv-operator ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/host-network: '' policyTypes: - Ingress
2.1.33. 네트워크 관찰 운영자 릴리스 노트 1.6.2 권고
Network Observability Operator 1.6.2 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.34. 네트워크 관찰 운영자 릴리스 노트 1.6.2 CVE
Network Observability Operator 1.6.2 릴리스에 대한 CVE를 검토할 수 있습니다.
2.1.35. Network Observability Operator 릴리스 노트 1.6.2 수정된 문제
Network Observability Operator 1.6.2 릴리스의 해결된 문제를 검토할 수 있습니다.
- 2차 인터페이스 지원이 추가되었을 때, 인터페이스 알림에 대해 알아보기 위해 네트워크별 네임스페이스를 netlink에 등록하기 위해 여러 번 반복해야 할 필요가 있었습니다. 동시에, 실패한 핸들러로 인해 파일 기술자 누수가 발생했습니다. TCX 후크의 경우 TC와 달리 인터페이스가 다운되면 핸들러를 명시적으로 제거해야 했기 때문입니다. 이제 Pod를 생성하고 삭제할 때 파일 설명자가 누출되는 일이 더 이상 발생하지 않습니다. (NETOBSERV-1805)
2.1.36. Network Observability Operator 릴리스 노트 1.6.2 알려진 문제
Network Observability Operator 1.6.2 릴리스의 알려진 문제를 검토할 수 있습니다.
- OpenShift Container Platform 클러스터의 향후 버전에 네트워크 관찰 기능을 설치하는 것을 방해하는 콘솔 플러그인 호환성 문제가 있었습니다. 1.6.2로 업그레이드하면 호환성 문제가 해결되고 예상대로 네트워크 관찰 기능을 설치할 수 있습니다. (NETOBSERV-1737)
2.1.37. 네트워크 관찰 운영자 릴리스 노트 1.6.1 권고
Network Observability Operator 1.6.1 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.38. 네트워크 관찰 운영자 릴리스 노트 1.6.1 CVE
Network Observability Operator 1.6.1 릴리스에 대한 CVE를 검토할 수 있습니다.
2.1.39. Network Observability Operator 릴리스 노트 1.6.1 수정된 문제
Network Observability Operator 1.6.1 릴리스의 해결된 문제를 검토할 수 있습니다.
- 이전에는 패킷 삭제에 대한 정보(원인 및 TCP 상태 등)를 Loki 데이터 저장소에서만 사용할 수 있었고 Prometheus에서는 사용할 수 없었습니다. 이러한 이유로 OpenShift 웹 콘솔 플러그인 개요 의 삭제 통계는 Loki에서만 사용할 수 있었습니다. 이 수정 사항을 적용하면 패킷 삭제에 대한 정보도 메트릭에 추가되어 Loki가 비활성화되어 있을 때도 삭제 통계를 볼 수 있습니다. (NETOBSERV-1649)
-
eBPF 에이전트
PacketDrop기능이 활성화되고 샘플링이1보다 큰 값으로 구성된 경우, 손실된 바이트가 보고되고 손실된 패킷은 샘플링 구성을 무시합니다. 이는 한 방울도 놓치지 않기 위해 의도적으로 이루어졌지만, 부작용으로 보고된 방울의 비율과 방울이 없는 비율에 차이가 생겼습니다. 예를 들어,1:1000과 같이 매우 높은 샘플링 속도에서는 콘솔 플러그인에서 관찰했을 때 거의 모든 트래픽이 삭제된 것처럼 보일 가능성이 높습니다. 이 수정 사항을 적용하면 샘플링 구성에 따라 바이트와 패킷이 삭제됩니다. (NETOBSERV-1676) - 이전에는 인터페이스가 먼저 생성된 후 eBPF 에이전트가 배포된 경우 SR-IOV 보조 인터페이스가 감지되지 않았습니다. 에이전트가 먼저 배포된 후 SR-IOV 인터페이스가 생성된 경우에만 감지되었습니다. 이 수정 사항을 적용하면 배포 순서에 관계없이 SR-IOV 보조 인터페이스가 감지됩니다. (NETOBSERV-1697)
- 이전에는 Loki가 비활성화되었을 때 OpenShift 웹 콘솔의 토폴로지 뷰에서 네트워크 토폴로지 다이어그램 옆 슬라이더에 클러스터 및 영역 집계 옵션이 표시되었는데, 이는 관련 기능이 활성화되어 있지 않은 경우에도 마찬가지였습니다. 이 수정 사항을 적용하면 이제 슬라이더는 활성화된 기능에 따라서만 옵션을 표시합니다. (NETOBSERV-1705)
-
이전에는 Loki가 비활성화되어 있고 OpenShift 웹 콘솔이 처음 로드될 때
"요청이 상태 코드 400으로 실패했습니다. Loki가 비활성화되었습니다."라는 오류가 발생했습니다. 이 수정을 통해 해당 오류는 더 이상 발생하지 않습니다. (NETOBSERV-1706) - 이전에는 OpenShift 웹 콘솔의 토폴로지 보기에서 그래프 노드 옆에 있는 Step into 아이콘을 클릭하면 선택한 그래프 노드에 초점을 맞추기 위해 필요한 필터가 적용되지 않아 OpenShift 웹 콘솔에서 토폴로지 보기가 넓게 표시되었습니다. 이 수정을 통해 필터가 올바르게 설정되어 토폴로지가 효과적으로 좁혀졌습니다. 이 변경 사항의 일환으로 이제 노드 에서 단계별 실행 아이콘을 클릭하면 네임스페이스 범위 대신 리소스 범위로 이동합니다. (NETOBSERV-1720)
- 이전에는 Loki가 비활성화되었을 때 OpenShift 웹 콘솔의 토폴로지 뷰에서 범위가 소유자 로 설정된 상태에서 그래프 노드 옆에 있는 단계별 실행 아이콘을 클릭하면 범위가 리소스 로 전환되었습니다. 이는 Loki가 없으면 사용할 수 없으므로 오류 메시지가 표시되었습니다. 이 수정을 통해 Loki가 비활성화되면 단계별 실행 아이콘이 소유자 범위에 숨겨지므로 이 시나리오는 더 이상 발생하지 않습니다.( NETOBSERV-1721 ) (NETOBSERV-980)
- 이전에는 Loki가 비활성화되었을 때 그룹이 설정되었지만 범위가 변경되어 그룹이 무효화되면 OpenShift 웹 콘솔의 토폴로지 보기에 오류가 표시되었습니다. 이 수정을 통해 잘못된 그룹이 제거되어 오류가 방지됩니다. (NETOBSERV-1722)
-
YAML 뷰 가 아닌 OpenShift 웹 콘솔 Form 뷰 에서
FlowCollector리소스를 생성할 때, 다음 설정이 웹 콘솔에서 잘못 관리되었습니다:agent.ebpf.metrics.enable및processor.subnetLabels.openShiftAutoDetect. 이러한 설정은 YAML 보기 에서만 비활성화할 수 있으며, Form 보기 에서는 비활성화할 수 없습니다. 혼란을 피하기 위해 이러한 설정은 양식 보기 에서 제거되었습니다. YAML 뷰 에서는 여전히 접근이 가능합니다. (NETOBSERV-1731) - 이전에는 eBPF 에이전트가 SIGTERM 신호로 인한 충돌 등 비정상적인 충돌이 발생하기 전에 설치된 트래픽 제어 흐름을 정리할 수 없었습니다. 이전 필터가 제거되지 않았기 때문에 동일한 이름을 가진 여러 개의 교통 제어 흐름 필터가 생성되었습니다. 이 수정 사항을 적용하면 에이전트가 시작될 때 새 트래픽 제어 흐름이 설치되기 전에 이전에 설치된 모든 트래픽 제어 흐름이 정리됩니다. (NETOBSERV-1732)
- 이전에는 사용자 정의 서브넷 레이블을 구성하고 OpenShift 서브넷 자동 감지를 활성화한 경우 OpenShift 서브넷이 사용자 정의 서브넷보다 우선하여 클러스터 서브넷에서 사용자 정의 레이블을 정의할 수 없었습니다. 이 수정 사항을 적용하면 사용자 정의 서브넷이 우선적으로 적용되어 클러스터 서브넷에 대한 사용자 정의 레이블을 정의할 수 있습니다. (NETOBSERV-1734)
2.1.40. 네트워크 관찰 운영자 릴리스 노트 1.6.0 권고
Network Observability Operator 1.6.0 릴리스에 대한 권고 사항을 검토할 수 있습니다.
2.1.41. Network Observability Operator 1.6.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.6.0의 새로운 기능과 향상된 기능을 살펴보세요.
2.1.41.1. Loki 없이 Network Observability Operator의 향상된 사용
이제 Network Observability Operator를 사용하면 Prometheus 메트릭을 사용할 수 있고 저장소를 위해 Loki에 덜 의존할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.41.2. 사용자 정의 메트릭 API
FlowMetrics API를 사용하면 플로우로그 데이터에서 사용자 정의 메트릭을 만들 수 있습니다. Flowlogs 데이터는 Prometheus 레이블과 함께 사용하여 대시보드의 클러스터 정보를 사용자 지정할 수 있습니다. 흐름과 메트릭에서 식별하려는 모든 서브넷에 사용자 정의 레이블을 추가할 수 있습니다. 이러한 개선 사항은 흐름 로그와 메트릭 모두에 존재하는 새로운 레이블인 SrcSubnetLabel 및 DstSubnetLabel 을 사용하여 외부 트래픽을 보다 쉽게 식별하는 데에도 사용할 수 있습니다. 이러한 필드는 외부 트래픽이 있을 때 비어 있으므로 이를 식별하는 방법이 제공됩니다.
자세한 내용은 다음을 참조하세요.
2.1.41.3. eBPF 성능 향상
다음 업데이트를 통해 CPU와 메모리 측면에서 eBPF 에이전트의 성능이 향상되었습니다.
- eBPF 에이전트는 이제 TC 대신 TCX 웹훅을 사용합니다.
NetObserv/Health 대시보드에 eBPF 지표를 보여주는 새로운 섹션이 추가되었습니다.
- 새로운 eBPF 메트릭을 기반으로 eBPF 에이전트가 흐름을 삭제할 때 알림이 표시됩니다.
- 중복된 흐름이 제거되었으므로 이제 로키 저장소 수요가 크게 감소합니다. 네트워크 인터페이스당 여러 개의 개별 중복된 흐름이 있는 대신, 관련 네트워크 인터페이스 목록이 있는 중복이 제거된 흐름이 하나 있습니다.
복제된 흐름이 업데이트되면서 네트워크 트래픽 테이블의 Interface 및 Interface Direction 필드의 이름이 Interfaces 및 Interface Directions 로 바뀌었습니다. 따라서 이러한 필드를 사용하는 북마크된 빠른 필터 쿼리는 interfaces 및 ifdirections 로 업데이트해야 합니다.
자세한 내용은 다음을 참조하세요.
2.1.41.4. eBPF 수집 규칙 기반 필터링
규칙 기반 필터링을 사용하면 생성된 흐름의 볼륨을 줄일 수 있습니다. 이 옵션을 활성화하면 eBPF 에이전트 통계의 Netobserv/Health 대시보드에 필터링된 흐름 비율 보기가 표시됩니다.
자세한 내용은 다음을 참조하세요.
2.1.42. Network Observability Operator 1.6.0에서 문제가 해결되었습니다.
Network Observability Operator 1.6.0에 대해 해결된 다음 문제를 검토할 수 있습니다.
-
이전에는
FlowMetricsAPI 생성을 위한 Operator Lifecycle Manager(OLM) 양식에 OpenShift Container Platform 설명서에 대한 끊어진 링크가 표시되었습니다. 이제 링크가 유효한 페이지를 가리키도록 업데이트되었습니다. (NETOBSERV-1607) - 이전에는 Operator Hub의 Network Observability Operator 설명에 설명서로 가는 링크가 끊어져 표시되었습니다. 이 수정을 통해 해당 링크가 복구되었습니다. (NETOBSERV-1544)
-
이전에는 Loki가 비활성화되고 Loki
모드가LokiStack으로 설정되었거나 Loki 수동 TLS 구성이 구성된 경우에도 네트워크 관찰 운영자는 여전히 Loki CA 인증서를 읽으려고 시도했습니다. 이 수정 사항을 적용하면 Loki가 비활성화된 경우 Loki 구성에 설정이 있더라도 Loki 인증서가 읽히지 않습니다. (NETOBSERV-1647) -
이전에는 Network Observability Operator를 위한
ocmust-gather플러그인이amd64아키텍처에서만 작동했고 다른 모든 아키텍처에서는 실패했습니다. 그 이유는 해당 플러그인이oc바이너리에amd64를사용했기 때문입니다. 이제 Network Observability Operatorocmust-gather플러그인은 모든 아키텍처 플랫폼에서 로그를 수집합니다. -
이전에는
not equal to를사용하여 IP 주소를 필터링할 때 네트워크 관찰 연산자가 요청 오류를 반환했습니다. 이제 IP 필터링은 IP 주소 및 범위에 대해동일하거나동일하지 않은경우 모두에서 작동합니다. (NETOBSERV-1630) -
이전에는 사용자가 관리자가 아닌 경우 오류 메시지가 웹 콘솔의 네트워크 트래픽 보기에서 선택한 탭과 일치하지 않았습니다. 이제 개선된 디스플레이를 통해 모든 탭에
사용자가 관리자가 아니라는오류가 표시됩니다.( NETOBSERV-1621 )
2.1.43. Network Observability Operator 1.6.0 알려진 문제
Network Observability Operator 1.6.0에 대해 알려진 문제는 다음과 같습니다.
-
eBPF 에이전트
PacketDrop기능이 활성화되어 있고 샘플링이1보다 큰 값으로 구성된 경우, 보고된 손실된 바이트와 손실된 패킷은 샘플링 구성을 무시합니다. 이는 한 방울도 놓치지 않기 위해 의도적으로 수행되지만, 부작용으로 보고된 방울의 비율이 방울이 없는 비율에 비해 편향된다는 것입니다. 예를 들어,1:1000과 같이 매우 높은 샘플링 속도에서는 콘솔 플러그인에서 관찰할 때 거의 모든 트래픽이 삭제된 것처럼 보일 가능성이 높습니다. (NETOBSERV-1676) - 개요 탭의 패널 관리 창에서 총계 , 막대형 , 도넛형 또는 선형을 필터링해도 결과가 표시되지 않습니다. (NETOBSERV-1540)
- SR-IOV 보조 인터페이스는 인터페이스가 먼저 생성된 다음 eBPF 에이전트가 배포된 경우 감지되지 않습니다. 에이전트가 먼저 배포된 후 SR-IOV 인터페이스가 생성된 경우에만 감지됩니다. (NETOBSERV-1697)
- Loki가 비활성화되어 있으면 OpenShift 웹 콘솔의 토폴로지 보기에서 네트워크 토폴로지 다이어그램 옆 슬라이더에 클러스터 및 영역 집계 옵션이 항상 표시됩니다. 관련 기능이 활성화되어 있지 않은 경우에도 마찬가지입니다. 이러한 슬라이더 옵션을 무시하는 것 외에는 특별한 해결 방법이 없습니다. (NETOBSERV-1705)
-
Loki가 비활성화되어 있고 OpenShift 웹 콘솔이 처음 로드되면
"요청이 상태 코드 400으로 실패했습니다. Loki가 비활성화되었습니다."라는 오류가 표시될 수 있습니다. 해결 방법으로, 토폴로지 와 개요 탭 사이를 클릭하는 등 네트워크 트래픽 페이지에서 콘텐츠를 계속 전환할 수 있습니다. 오류는 사라져야 합니다. (NETOBSERV-1706)
2.1.44. 네트워크 관찰성 운영자 1.5.0 권고
Network Observability Operator 1.5 릴리스에 대한 다음 권고 사항을 볼 수 있습니다.
2.1.45. Network Observability Operator 1.5.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.5 릴리스의 새로운 기능과 향상된 기능은 다음과 같습니다.
2.1.45.1. DNS 추적 향상
1.5에서는 UDP 외에도 TCP 프로토콜이 지원됩니다. 새 대시보드는 네트워크 트래픽 페이지의 개요 보기에도 추가됩니다.
자세한 내용은 다음을 참조하세요.
2.1.45.2. 왕복 시간(RTT)
fentry/tcp_rcv_established 확장 버클리 패킷 필터(eBPF) 후크포인트에서 캡처한 TCP 핸드셰이크 왕복 시간(RTT)을 사용하여 평활화된 왕복 시간(SRTT)을 읽고 네트워크 흐름을 분석할 수 있습니다. 웹 콘솔의 개요 , 네트워크 트래픽 및 토폴로지 페이지에서 네트워크 트래픽을 모니터링하고 RTT 메트릭, 필터링 및 에지 레이블링을 사용하여 문제를 해결할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.45.3. 메트릭, 대시보드 및 알림 기능 향상
Observe → Dashboards → NetObserv 의 네트워크 관찰성 메트릭 대시보드에는 Prometheus 알림을 생성하는 데 사용할 수 있는 새로운 메트릭 유형이 있습니다. 이제 includeList 사양에서 사용 가능한 메트릭을 정의할 수 있습니다. 이전 릴리스에서는 이러한 지표가 ignoreTags 사양에 정의되어 있습니다.
이러한 지표의 전체 목록은 다음을 참조하세요.
2.1.45.4. Loki 없이 네트워크 관찰성 개선
Loki를 사용하지 않더라도 DNS, 패킷 손실, RTT 메트릭을 사용하여 Netobserv 대시보드에 대한 Prometheus 알림을 생성할 수 있습니다. 네트워크 관찰 기능의 이전 버전인 1.4에서는 이러한 측정항목을 네트워크 트래픽 , 개요 및 토폴로지 보기에서의 쿼리 및 분석에만 사용할 수 있었으며, Loki가 없으면 이러한 보기를 사용할 수 없습니다.
자세한 내용은 다음을 참조하세요.
2.1.45.5. 가용성 영역
FlowCollector 리소스를 구성하여 클러스터 가용성 영역에 대한 정보를 수집할 수 있습니다. 이 구성은 노드에 적용된 topology.kubernetes.io/zone 레이블 값으로 네트워크 흐름 데이터를 풍부하게 만듭니다.
자세한 내용은 다음을 참조하세요.
2.1.45.6. 주요 개선 사항
Network Observability Operator의 1.5 릴리스에서는 OpenShift Container Platform 웹 콘솔 플러그인과 Operator 구성에 개선 사항과 새로운 기능이 추가되었습니다.
2.1.45.7. 성능 향상
Kafka를 사용할 때 eBPF 성능을 향상시키기 위해
spec.agent.ebpf.kafkaBatchSize기본값이10MB에서1MB로 변경되었습니다.중요기존 설치에서 업그레이드하는 경우 이 새로운 값은 구성에 자동으로 설정되지 않습니다. 업그레이드 후 eBPF 에이전트 메모리 소비로 인한 성능 회귀를 모니터링하는 경우
kafkaBatchSize를 새 값으로 줄이는 것을 고려할 수 있습니다.
2.1.45.8. 웹 콘솔 개선 사항:
- DNS 및 RTT에 대한 개요 보기에 최소, 최대, P90, P99라는 새로운 패널이 추가되었습니다.
새로운 패널 디스플레이 옵션이 추가되었습니다.
- 한 패널에 초점을 맞추는 동시에 다른 패널은 작게 초점을 맞춰서 볼 수 있도록 합니다.
- 그래프 유형을 전환합니다.
- 상위 및 전체 보기.
- 사용자 지정 시간 범위 창에 수집 지연 경고가 표시됩니다.
- 패널 관리 및 열 관리 팝업 창의 내용에 대한 가시성이 향상됩니다.
- 송신 QoS에 대한 DSCP(Differentiated Services Code Point) 필드는 웹 콘솔 네트워크 트래픽 페이지에서 QoS DSCP를 필터링하는 데 사용할 수 있습니다.
2.1.45.9. 구성 개선 사항:
-
spec.loki.mode사양의LokiStack모드는 URL, TLS, 클러스터 역할 및 클러스터 역할 바인딩은 물론authToken값을 자동으로 설정하여 설치를 간소화합니다.수동모드를 사용하면 이러한 설정의 구성을 더욱 세부적으로 제어할 수 있습니다. -
API 버전이
flows.netobserv.io/v1beta1에서flows.netobserv.io/v1beta2로 변경되었습니다.
2.1.46. Network Observability Operator 1.5.0에서 문제가 해결되었습니다.
Network Observability Operator 1.5 릴리스에 대한 다음 해결된 문제를 확인할 수 있습니다.
-
이전에는 콘솔 플러그인의 자동 등록이 비활성화된 경우 웹 콘솔 인터페이스에서 콘솔 플러그인을 수동으로 등록할 수 없었습니다.
FlowCollector리소스에서spec.console.register값이false로 설정된 경우 Operator가 플러그인 등록을 재정의하고 삭제합니다. 이 수정 사항을 적용하면spec.console.register값을false로 설정해도 콘솔 플러그인 등록이나 등록 제거에 영향을 미치지 않습니다. 결과적으로 플러그인을 수동으로 안전하게 등록할 수 있습니다. (NETOBSERV-1134) -
이전에는 기본 메트릭 설정을 사용할 때 NetObserv/Health 대시보드에 Flows Overhead 라는 이름의 빈 그래프가 표시되었습니다. 이 메트릭은
ignoreTags목록에서 "namespaces-flows"와 "namespaces"를 제거해야만 사용할 수 있습니다. 이 수정 사항을 적용하면 기본 메트릭 설정을 사용할 때 이 메트릭이 표시됩니다. (NETOBSERV-1351) - 이전에는 eBPF 에이전트가 실행 중인 노드가 특정 클러스터 구성을 확인하지 못했습니다. 이로 인해 일부 트래픽 측정 항목을 제공하지 못하는 결과가 발생했습니다. 이 수정을 통해 eBPF 에이전트의 노드 IP가 포드 상태에서 추론되어 운영자에 의해 안전하게 제공됩니다. 이제 누락된 지표가 복원되었습니다. (NETOBSERV-1430)
- 이전에는 Loki Operator의 '입력 크기가 너무 깁니다' 오류에 문제를 해결하기 위한 추가 정보가 포함되지 않았습니다. 이 수정 사항을 적용하면 오류 옆에 있는 웹 콘솔에 도움말이 직접 표시되고 자세한 안내를 위한 직접 링크가 제공됩니다. (NETOBSERV-1464)
-
이전에는 콘솔 플러그인 읽기 시간 초과가 30초로 강제 적용되었습니다.
FlowCollectorv1beta2API 업데이트를 사용하면spec.loki.readTimeout사양을 구성하여 Loki OperatorqueryTimeout제한에 따라 이 값을 업데이트할 수 있습니다. (NETOBSERV-1443) -
이전에는 Operator 번들이
features.operators.openshift.io/…와 같이 CSV 주석으로 지원되는 일부 기능을 예상대로 표시하지 않았습니다. 이번 수정을 통해 이러한 주석이 예상대로 CSV에 설정됩니다. (NETOBSERV-1305) -
이전에는 조정 중에
FlowCollector상태가 가끔씩DeploymentInProgress와Ready상태 사이를 오가곤 했습니다. 이 수정 사항을 적용하면 모든 기본 구성 요소가 완전히 준비된 경우에만 상태가준비로변경됩니다. (NETOBSERV-1293)
2.1.47. Network Observability Operator 1.5.0 알려진 문제
Network Observability Operator 1.5 릴리스에 대한 알려진 문제는 다음과 같습니다.
-
웹 콘솔에 접속하려고 할 때 OCP 4.14.10의 캐시 문제로 인해 Observe 뷰에 접속할 수 없습니다. 웹 콘솔에 다음 오류 메시지가 표시됩니다:
/api/plugins/monitoring-plugin/에서 유효한 플러그인 매니페스트를 가져오지 못했습니다. 권장되는 해결 방법은 클러스터를 최신 마이너 버전으로 업데이트하는 것입니다. 이 방법이 효과가 없으면 Red Hat Knowledgebase 문서 에 설명된 해결 방법을 적용해야 합니다.( NETOBSERV-1493 ) -
Network Observability Operator 1.3.0이 릴리스된 이후, Operator를 설치하면 커널 오염 경고가 나타납니다. 이 오류의 원인은 네트워크 관찰 eBPF 에이전트에 메모리 제약이 있어 해시맵 테이블 전체를 미리 할당할 수 없기 때문입니다. Operator eBPF 에이전트는 해시맵의 메모리가 너무 많이 필요할 때 사전 할당이 비활성화되도록
BPF_F_NO_PREALLOC플래그를 설정합니다.
2.1.48. 네트워크 관찰 운영자 1.4.2 권고
다음 권고 사항은 Network Observability Operator 1.4.2에 대해 제공됩니다.
2.1.49. 네트워크 관찰성 운영자 1.4.2 CVE
Network Observability Operator 1.4.2 릴리스에서 다음 CVE를 검토할 수 있습니다.
2.1.50. 네트워크 관찰 운영자 1.4.1 권고
네트워크 관찰 운영자 1.4.1에 대한 다음 권고 사항을 검토할 수 있습니다.
2.1.51. 네트워크 관찰 운영자 릴리스 1.4.1 CVE
Network Observability Operator 1.4.1 릴리스에서 다음 CVE를 검토할 수 있습니다.
2.1.52. Network Observability Operator 릴리스 노트 1.4.1 수정된 문제
Network Observability Operator 1.4.1 릴리스에서 해결된 다음 문제를 검토할 수 있습니다.
- 1.4에서는 Kafka로 네트워크 흐름 데이터를 전송할 때 알려진 문제가 있었습니다. Kafka 메시지 키가 무시되어 연결 추적 오류가 발생했습니다. 이제 키는 분할에 사용되므로 동일한 연결의 각 흐름은 동일한 프로세서로 전송됩니다. (NETOBSERV-926)
-
1.4에서는 동일한 노드에서 실행되는 포드 간의 흐름을 설명하기 위해
내부흐름 방향이 도입되었습니다.내부방향의 흐름은 흐름에서 파생된 Prometheus 메트릭에서 고려되지 않아 바이트와 패킷 속도가 과소평가되었습니다. 이제 파생된 지표에는내부방향의 흐름이 포함되어 정확한 바이트와 패킷 속도를 제공합니다. (NETOBSERV-1344)
2.1.53. 네트워크 관찰성 릴리스 노트 1.4.0 권고
Network Observability Operator 1.4.0 릴리스에 대한 다음 권고 사항을 검토할 수 있습니다.
2.1.54. 네트워크 관찰성 릴리스 노트 1.4.0 새로운 기능 및 향상된 기능
Network Observability Operator 1.4.0 릴리스에서는 다음과 같은 새로운 기능과 향상된 기능을 검토할 수 있습니다.
2.1.54.1. 주요 개선 사항
Network Observability Operator의 1.4 릴리스에서는 OpenShift Container Platform 웹 콘솔 플러그인과 Operator 구성에 개선 사항과 새로운 기능이 추가되었습니다.
2.1.54.2. 웹 콘솔 개선 사항:
- 쿼리 옵션 에서 중복된 흐름을 표시할지 여부를 선택할 수 있는 중복된 흐름 확인란이 추가되었습니다.
-
 One-way,
One-way,
 Back-and-forth, 스왑 필터를 사용하여 소스 및 대상 트래픽을 필터링할 수 있습니다.
Back-and-forth, 스왑 필터를 사용하여 소스 및 대상 트래픽을 필터링할 수 있습니다.
Observe → Dashboards → NetObserv 및 NetObserv/Health 의 네트워크 관찰성 측정 항목 대시보드는 다음과 같이 수정되었습니다.
- NetObserv 대시보드는 상위 바이트, 전송된 패킷, 노드당 수신된 패킷, 네임스페이스 및 워크로드를 보여줍니다. 이 대시보드에서 흐름 그래프가 제거되었습니다.
- NetObserv/Health 대시보드는 노드, 네임스페이스, 워크로드당 최대 흐름 속도뿐만 아니라 흐름 오버헤드도 보여줍니다.
- 인프라 및 애플리케이션 메트릭은 네임스페이스와 워크로드에 대한 분할 보기로 표시됩니다.
자세한 내용은 다음을 참조하세요.
2.1.54.3. 구성 개선 사항:
- 이제 인증서 구성과 같이 구성된 ConfigMap이나 Secret 참조에 대해 다른 네임스페이스를 지정할 수 있는 옵션이 제공됩니다.
-
spec.processor.clusterName매개변수가 추가되어 클러스터 이름이 흐름 데이터에 나타납니다. 이는 다중 클러스터 컨텍스트에서 유용합니다. OpenShift Container Platform을 사용하는 경우, 자동으로 결정되도록 비워 두세요.
자세한 내용은 다음을 참조하세요.
2.1.54.4. Loki 없이도 네트워크 관찰 가능
네트워크 관찰 연산자는 이제 Loki 없이도 작동하고 사용할 수 있습니다. Loki가 설치되지 않은 경우 KAFKA 또는 IPFIX 형식으로만 흐름을 내보내고 네트워크 관찰성 메트릭 대시보드에서 메트릭을 제공할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.54.5. DNS 추적
1.4에서는 네트워크 관찰 연산자가 eBPF 추적점 후크를 사용하여 DNS 추적을 활성화합니다. 웹 콘솔의 네트워크 트래픽 및 개요 페이지에서 네트워크를 모니터링하고, 보안 분석을 수행하고, DNS 문제를 해결할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.54.6. SR-IOV 지원
이제 SR-IOV(Single Root I/O Virtualization) 장치를 사용하여 클러스터에서 트래픽을 수집할 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.54.7. IPFIX 수출 지원
이제 eBPF가 강화된 네트워크 흐름을 IPFIX 수집기로 내보낼 수 있습니다.
자세한 내용은 다음을 참조하세요.
2.1.54.8. 패킷 삭제
Network Observability Operator의 1.4 릴리스에서는 패킷 삭제 추적을 활성화하기 위해 eBPF 추적점 후크가 사용되었습니다. 이제 패킷 손실의 원인을 감지하고 분석하여 네트워크 성능을 최적화하기 위한 결정을 내릴 수 있습니다. OpenShift Container Platform 4.14 이상에서는 호스트 삭제와 OVS 삭제가 모두 감지됩니다. OpenShift Container Platform 4.13에서는 호스트 삭제만 감지됩니다.
자세한 내용은 다음을 참조하세요.
2.1.54.9. s390x 아키텍처 지원
네트워크 관찰 연산자는 이제 s390x 아키텍처에서 실행될 수 있습니다. 이전에는 amd64, ppc64le, arm64에서 실행되었습니다.
2.1.55. 네트워크 관찰성 릴리스 노트 1.4.0에서 제거된 기능
Network Observability Operator 1.4.0 릴리스에서 제거된 다음 기능을 검토할 수 있습니다.
2.1.55.1. 채널 제거
최신 운영자 업데이트를 받으려면 채널을 v1.0.x 에서 stable 로 전환해야 합니다. v1.0.x 채널은 이제 제거되었습니다.
2.1.56. 네트워크 관찰성 릴리스 노트 1.4.0 수정된 문제
Network Observability Operator 1.4.0 릴리스에서 해결된 다음 문제를 검토할 수 있습니다.
- 이전에는 네트워크 관찰을 통해 내보낸 Prometheus 메트릭이 잠재적으로 중복된 네트워크 흐름에서 계산되었습니다. 관련 대시보드에서 관찰 → 대시보드를 선택하면 요금이 두 배로 증가할 가능성이 있습니다. 네트워크 트래픽 보기의 대시보드는 영향을 받지 않았습니다. 이제 메트릭 계산 전에 네트워크 흐름을 필터링하여 중복을 제거하고, 그 결과 대시보드에 정확한 트래픽 속도가 표시됩니다. (NETOBSERV-1131)
-
이전에는 Network Observability Operator 에이전트가 Multus 또는 SR-IOV, 기본이 아닌 네트워크 네임스페이스로 구성된 경우 네트워크 인터페이스에서 트래픽을 캡처할 수 없었습니다. 이제 사용 가능한 모든 네트워크 네임스페이스가 인식되어 흐름 캡처에 사용되므로 SR-IOV에 대한 트래픽을 캡처할 수 있습니다. 트래픽을 수집하려면
FlowCollector및SRIOVnetwork사용자 지정 리소스에 대한 구성이 필요합니다. (NETOBSERV-1283)
-
이전에는 Network Observability Operator에서 Operators → 설치된 Operators의 세부 정보에서
FlowCollectorStatus 필드에 배포 상태에 대한 잘못된 정보가 보고되었을 수 있었습니다. 이제 상태 필드에는 개선된 메시지와 함께 적절한 조건이 표시됩니다. 이벤트 기록은 이벤트 날짜별로 정리되어 보관됩니다. (NETOBSERV-1224) -
이전에는 네트워크 트래픽 부하가 급증하는 동안 특정 eBPF 포드가 OOM으로 종료되어
CrashLoopBackOff상태로 전환되었습니다. 이제eBPF에이전트 메모리 사용량이 개선되어 포드가 OOM으로 종료되거나CrashLoopBackOff상태로 전환되지 않습니다. (NETOBSERV-975) -
이전에는
processor.metrics.tls가PROVIDED로 설정되었을 때insecureSkipVerify옵션 값이 반드시true가 되도록 강제되었습니다. 이제insecureSkipVerify를true또는false로 설정하고 필요한 경우 CA 인증서를 제공할 수 있습니다. (NETOBSERV-1087)
2.1.57. 네트워크 관찰성 릴리스 노트 1.4.0 알려진 문제
Network Observability Operator 1.4.0 릴리스에서 알려진 문제는 다음과 같습니다.
-
Loki Operator 5.6을 사용하는 Network Observability Operator 1.2.0 릴리스 이후, Loki 인증서 변경이 주기적으로
flowlogs-pipeline포드에 영향을 미쳐 Loki에 흐름이 기록되는 대신 흐름이 삭제됩니다. 이 문제는 시간이 지나면서 자체적으로 해결되지만 Loki 인증서를 변경하는 동안 여전히 일시적인 흐름 데이터 손실이 발생합니다. 이 문제는 120개 이상의 노드가 있는 대규모 환경에서만 관찰되었습니다. (NETOBSERV-980) -
현재
spec.agent.ebpf.features에 DNSTracking이 포함되어 있는 경우, 더 큰 DNS 패킷의 경우eBPF에이전트가 1차 소켓 버퍼(SKB) 세그먼트 외부에서 DNS 헤더를 찾아야 합니다. 이를 지원하기 위해 새로운eBPF에이전트 도우미 기능을 구현해야 합니다. 현재로선 이 문제에 대한 해결 방법이 없습니다. (NETOBSERV-1304) -
현재
spec.agent.ebpf.features에서 DNSTracking이 포함된 경우, TCP 패킷을 통한 DNS를 사용하려면eBPF에이전트가 첫 번째 SKB 세그먼트 외부에서 DNS 헤더를 찾아야 합니다. 이를 지원하기 위해 새로운eBPF에이전트 도우미 기능을 구현해야 합니다. 현재로선 이 문제에 대한 해결 방법이 없습니다. (NETOBSERV-1245) -
현재
KAFKA배포 모델을 사용할 때 대화 추적이 구성된 경우 대화 이벤트가 Kafka 소비자 간에 중복되어 대화 추적이 일관되지 않고 볼륨 데이터가 잘못될 수 있습니다. 이러한 이유로,deploymentModel이KAFKA로 설정된 경우 대화 추적을 구성하지 않는 것이 좋습니다. (NETOBSERV-926) -
현재,
processor.metrics.server.tls.type이제공된인증서를 사용하도록 구성된 경우, 운영자는 성능과 리소스 소비에 영향을 줄 수 있는 불안정한 상태에 들어갑니다. 이 문제가 해결될 때까지제공된인증서를 사용하지 않고 대신 자동 생성된 인증서를 사용하고,processor.metrics.server.tls.type을AUTO로 설정하는 것이 좋습니다. (NETOBSERV-1293 -
Network Observability Operator 1.3.0이 릴리스된 이후, Operator를 설치하면 커널 오염 경고가 나타납니다. 이 오류의 원인은 네트워크 관찰 eBPF 에이전트에 메모리 제약이 있어 해시맵 테이블 전체를 미리 할당할 수 없기 때문입니다. Operator eBPF 에이전트는 해시맵의 메모리가 너무 많이 필요할 때 사전 할당이 비활성화되도록
BPF_F_NO_PREALLOC플래그를 설정합니다.
2.1.58. 네트워크 관찰성 운영자 1.3.0 권고
다음 권고 사항은 Network Observability Operator 1.3.0 릴리스에서 검토할 수 있습니다.
2.1.59. Network Observability Operator 1.3.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.3.0 릴리스에서는 다음과 같은 새로운 기능과 향상된 기능을 검토할 수 있습니다.
2.1.59.1. 네트워크 관찰의 다중 테넌시
- 시스템 관리자는 Loki에 저장된 흐름에 대한 개별 사용자 액세스 또는 그룹 액세스를 허용하고 제한할 수 있습니다. 자세한 내용은 "네트워크 관찰의 다중 테넌시"를 참조하세요.
2.1.59.2. 흐름 기반 메트릭 대시보드
- 이 릴리스에서는 OpenShift Container Platform 클러스터의 네트워크 흐름에 대한 개요를 제공하는 새로운 대시보드가 추가되었습니다. 자세한 내용은 "네트워크 관찰성 지표 대시보드"를 참조하세요.
2.1.59.3. 필수 수집 도구를 사용한 문제 해결
- 이제 네트워크 관찰 운영자에 대한 정보를 문제 해결을 위한 필수 수집 데이터에 포함할 수 있습니다. 자세한 내용은 "네트워크 관찰성 필수 수집"을 참조하세요.
2.1.59.4. 이제 여러 아키텍처가 지원됩니다.
-
Network Observability Operator는 이제
amd64,ppc64le, 또는arm64아키텍처에서 실행할 수 있습니다. 이전에는amd64에서만 실행되었습니다.
2.1.60. 네트워크 관찰 연산자 1.3.0 더 이상 사용되지 않는 기능
Network Observability Operator 1.3.0 릴리스에서 더 이상 사용되지 않는 다음 기능을 검토할 수 있습니다.
2.1.60.1. 채널 지원 중단
향후 운영자 업데이트를 받으려면 채널을 v1.0.x 에서 안정 버전 으로 전환해야 합니다. v1.0.x 채널은 더 이상 사용되지 않으며 다음 릴리스에서 삭제될 예정입니다.
2.1.60.2. 더 이상 사용되지 않는 구성 매개변수 설정
Network Observability Operator 1.3이 출시되면서 spec.Loki.authToken HOST 설정이 더 이상 사용되지 않습니다. Loki Operator를 사용할 때는 이제 FORWARD 설정만 사용해야 합니다.
2.1.61. Network Observability Operator 1.3.0에서 문제가 해결되었습니다.
Network Observability Operator 1.3.0 릴리스에서 해결된 다음 문제를 검토할 수 있습니다.
-
이전에는 CLI에서 Operator를 설치했을 때 클러스터 모니터링 Operator가 메트릭을 읽는 데 필요한
Role과RoleBinding이예상대로 설치되지 않았습니다. 웹 콘솔에서 Operator를 설치할 때 문제가 발생하지 않았습니다. 이제, 어떤 방법으로 Operator를 설치하든 필요한Role과RoleBinding이설치됩니다. (NETOBSERV-1003) -
1.2 버전부터 네트워크 관찰 운영자는 흐름 수집에 문제가 발생하면 경고를 발생시킬 수 있습니다. 이전에는 버그로 인해 알림을 비활성화하는 관련 구성인
spec.processor.metrics.disableAlerts가예상대로 작동하지 않았고 때로는 효과가 없었습니다. 이제 이 구성이 수정되어 알림을 비활성화할 수 있게 되었습니다. (NETOBSERV-976) -
이전에는
spec.loki.authToken을DISABLED로 설정하여 네트워크 관찰 기능을 구성한 경우kubeadmin클러스터 관리자만 네트워크 흐름을 볼 수 있었습니다. 다른 유형의 클러스터 관리자는 권한 부여 실패를 받았습니다. 이제 모든 클러스터 관리자가 네트워크 흐름을 볼 수 있습니다. (NETOBSERV-972) -
이전에는 버그로 인해 사용자가
spec.consolePlugin.portNaming.enable을false로 설정할 수 없었습니다. 이제 이 설정을false로 설정하여 포트-서비스 이름 변환을 비활성화할 수 있습니다. (NETOBSERV-971) - 이전에는 잘못된 구성으로 인해 콘솔 플러그인에서 노출된 메트릭이 클러스터 모니터링 운영자(Prometheus)에서 수집되지 않았습니다. 이제 구성이 수정되어 콘솔 플러그인 메트릭이 OpenShift Container Platform 웹 콘솔에서 올바르게 수집되고 액세스할 수 있습니다. (NETOBSERV-765)
-
이전에는
FlowCollector에서processor.metrics.tls가AUTO로 설정된 경우flowlogs-pipeline servicemonitor가적절한 TLS 체계를 적용하지 않아 웹 콘솔에서 메트릭이 표시되지 않았습니다. 이제 AUTO 모드에 대한 문제가 해결되었습니다. (NETOBSERV-1070) -
이전에는 Kafka 및 Loki에 사용되는 인증서 구성에서 네임스페이스 필드를 지정할 수 없었기 때문에 인증서는 네트워크 관찰 기능이 배포된 동일한 네임스페이스에 있어야 했습니다. 게다가 TLS/mTLS와 함께 Kafka를 사용할 경우 사용자는
eBPF에이전트 포드가 배포된 권한 있는 네임스페이스에 인증서를 수동으로 복사하고 인증서 로테이션과 같은 경우 인증서 업데이트를 수동으로 관리해야 했습니다. 이제FlowCollector리소스에 인증서에 대한 네임스페이스 필드를 추가하여 네트워크 관찰 설정이 간소화되었습니다. 결과적으로 사용자는 네트워크 관찰 네임스페이스에 인증서를 수동으로 복사하지 않고도 다른 네임스페이스에 Loki나 Kafka를 설치할 수 있습니다. 원본 증명서를 보관하여 필요할 때 사본을 자동으로 업데이트합니다. (NETOBSERV-773) - 이전에는 SCTP, ICMPv4 및 ICMPv6 프로토콜이 네트워크 관찰 에이전트에서 다루어지지 않아 네트워크 흐름에 대한 포괄적인 범위가 부족했습니다. 이러한 프로토콜은 이제 흐름 범위를 개선하는 데 도움이 되는 것으로 알려져 있습니다. (NETOBSERV-934)
2.1.62. 네트워크 관찰 연산자 1.3.0 알려진 문제
Network Observability Operator 1.3.0 릴리스와 관련된 문제를 해결하려면 다음 문제와 해결 방법(있는 경우)을 검토하세요.
-
FlowCollector에서processor.metrics.tls가PROVIDED로 설정된 경우flowlogs-pipeline서비스 모니터가TLS 체계에 맞게 조정되지 않습니다. (NETOBSERV-1087) -
Loki Operator 5.6을 사용하는 Network Observability Operator 1.2.0 릴리스 이후, Loki 인증서 변경이 주기적으로
flowlogs-pipeline포드에 영향을 미쳐 Loki에 흐름이 기록되는 대신 흐름이 삭제됩니다. 이 문제는 시간이 지나면서 자체적으로 해결되지만 Loki 인증서를 변경하는 동안 여전히 일시적인 흐름 데이터 손실이 발생합니다. 이 문제는 120개 이상의 노드가 있는 대규모 환경에서만 관찰되었습니다.( NETOBSERV-980 ) -
Operator를 설치하면 경고 커널 테인트가 표시될 수 있습니다. 이 오류의 원인은 네트워크 관찰 eBPF 에이전트에 메모리 제약이 있어 해시맵 테이블 전체를 미리 할당할 수 없기 때문입니다. Operator eBPF 에이전트는 해시맵의 메모리가 너무 많이 필요할 때 사전 할당이 비활성화되도록
BPF_F_NO_PREALLOC플래그를 설정합니다.
2.1.63. 네트워크 관찰성 릴리스 노트 1.2.0 다음 업데이트를 준비 중입니다.
향후 릴리스 및 업데이트를 계속 받으려면 Network Observability Operator의 업데이트 채널을 더 이상 사용되지 않는 v1.0.x 에서 안정적인 채널로 전환하세요.
설치된 운영자의 구독은 운영자에 대한 업데이트를 추적하고 수신하는 업데이트 채널을 지정합니다. Network Observability Operator가 1.2 버전으로 출시되기 전까지는 v1.0.x 채널만 사용할 수 있었습니다. 네트워크 관찰 연산자 1.2 릴리스에서는 업데이트를 추적하고 수신하기 위한 안정적인 업데이트 채널이 도입되었습니다. 향후 운영자 업데이트를 받으려면 채널을 v1.0.x 에서 안정 버전 으로 전환해야 합니다. v1.0.x 채널은 더 이상 사용되지 않으며 다음 릴리스에서 삭제될 예정입니다.
2.1.64. 네트워크 관찰성 운영자 1.2.0 권고
Network Observability Operator 1.2.0 릴리스에 대한 다음 권고 사항을 볼 수 있습니다.
2.1.65. Network Observability Operator 1.2.0의 새로운 기능 및 향상된 기능
Network Observability Operator 1.2.0 릴리스에 대한 다음과 같은 새로운 기능과 향상된 기능을 확인할 수 있습니다.
2.1.65.1. 트래픽 흐름 보기의 히스토그램
이제 시간 경과에 따른 흐름의 히스토그램을 표시하도록 선택할 수 있습니다. 히스토그램을 사용하면 Loki 쿼리 제한에 도달하지 않고도 흐름의 기록을 시각화할 수 있습니다. 자세한 내용은 "히스토그램 사용"을 참조하세요.
2.1.65.2. 대화 추적
이제 로그 유형별 로 흐름을 쿼리할 수 있으며, 이를 통해 동일한 대화에 속하는 네트워크 흐름을 그룹화할 수 있습니다. 자세한 내용은 "대화 작업"을 참조하세요.
2.1.65.3. 네트워크 관찰 상태 알림
이제 네트워크 관찰 연산자는 쓰기 단계에서 오류가 발생하거나 Loki 수집 속도 제한에 도달한 경우 flowlogs-pipeline에서 흐름이 삭제되는 경우 자동으로 알림을 생성합니다. 자세한 내용은 "상태 대시보드"를 참조하세요.
2.1.66. 네트워크 관찰 연산자 1.2.0 버그 수정
Network Observability Operator 1.2.0 릴리스에 대한 다음 해결된 문제를 확인할 수 있습니다.
-
이전에는 FlowCollector 사양에서
네임스페이스값을 변경한 후 이전 네임스페이스에서 실행 중인eBPF에이전트 포드가 적절하게 삭제되지 않았습니다. 이제 이전 네임스페이스에서 실행 중이던 포드가 적절하게 삭제되었습니다. (NETOBSERV-774) -
이전에는 FlowCollector 사양(예: Loki 섹션)에서
caCert.name값을 변경한 후 FlowLogs-Pipeline 포드와 Console 플러그인 포드가 다시 시작되지 않아 구성 변경 사항을 인식하지 못했습니다. 이제 포드가 재시작되어 구성이 변경됩니다. (NETOBSERV-772) - 이전에는 서로 다른 노드에서 실행되는 포드 간의 네트워크 흐름이 서로 다른 네트워크 인터페이스에 의해 캡처되기 때문에 중복으로 올바르게 식별되지 않는 경우가 있었습니다. 이로 인해 콘솔 플러그인에 과대평가된 지표가 표시되었습니다. 이제 흐름이 중복으로 올바르게 식별되고 콘솔 플러그인이 정확한 지표를 표시합니다. (NETOBSERV-755)
- 콘솔 플러그인의 "리포터" 옵션은 소스 노드나 대상 노드의 관찰 지점을 기준으로 흐름을 필터링하는 데 사용됩니다. 이전에는 이 옵션이 노드 관찰 지점에 관계없이 흐름을 혼합했습니다. 이는 노드 수준에서 네트워크 흐름이 Ingress 또는 Egress로 잘못 보고되었기 때문입니다. 이제 네트워크 흐름 방향 보고가 정확합니다. "리포터" 옵션은 예상대로 소스 관찰 지점이나 목적지 관찰 지점을 필터링합니다. (NETOBSERV-696)
- 이전에는 gRPC+protobuf 요청으로 프로세서에 직접 흐름을 보내도록 구성된 에이전트의 경우 제출된 페이로드가 너무 커서 프로세서의 GRPC 서버에서 거부되었습니다. 이 문제는 매우 높은 부하 시나리오에서 일부 에이전트 구성에서만 발생했습니다. 에이전트는 다음과 같은 오류 메시지를 기록했습니다: grpc: 최대값보다 큰 메시지를 받았습니다 . 결과적으로 해당 흐름에 대한 정보 손실이 발생했습니다. 이제 gRPC 페이로드가 크기가 임계값을 초과하면 여러 메시지로 나뉩니다. 결과적으로 서버는 연결을 유지합니다. (NETOBSERV-617)
2.1.67. Network Observability Operator 1.2.0 알려진 문제
Network Observability Operator 1.2.0 릴리스와 관련된 문제를 해결하려면 다음 문제와 해결 방법(있는 경우)을 검토하세요.
-
Network Observability Operator의 1.2.0 릴리스에서 Loki Operator 5.6을 사용하면 Loki 인증서 전환이 주기적으로
flowlogs-pipeline포드에 영향을 미쳐 Loki에 흐름이 기록되는 대신 흐름이 삭제됩니다. 이 문제는 시간이 지나면서 자체적으로 해결되지만 Loki 인증서 전환 중에 여전히 일시적인 흐름 데이터 손실이 발생합니다. (NETOBSERV-980)
2.1.68. Network Observability Operator 1.2.0의 주요 기술적 변경 사항
새로운 기술적 변경으로 인해 Network Observability Operator 1.2.0 릴리스는 openshift-netobserv-operator 네임스페이스에 설치해야 합니다. 이전에 사용자 정의 네임스페이스를 사용했던 사용자는 이전 인스턴스를 삭제하고 Operator를 다시 설치해야 합니다.
이전에는 사용자 정의 네임스페이스를 사용하여 Network Observability Operator를 설치할 수 있었습니다. 이 릴리스에서는 ClusterServiceVersion 을 변경하는 변환 웹훅이 도입되었습니다. 이러한 변경으로 인해 사용 가능한 네임스페이스가 모두 나열되지 않습니다. 또한, Operator 메트릭 수집을 활성화하려면 openshift-operators 네임스페이스와 같이 다른 Operator와 공유되는 네임스페이스를 사용할 수 없습니다.
이제 Operator는 openshift-netobserv-operator 네임스페이스에 설치되어야 합니다.
이전에 사용자 지정 네임스페이스를 사용하여 Network Observability Operator를 설치한 경우 새 Operator 버전으로 자동으로 업그레이드할 수 없습니다. 이전에 사용자 정의 네임스페이스를 사용하여 Operator를 설치한 경우, 설치된 Operator 인스턴스를 삭제하고 openshift-netobserv-operator 네임스페이스에 Operator를 다시 설치해야 합니다. 일반적으로 사용되는 netobserv 네임스페이스와 같은 사용자 정의 네임스페이스는 FlowCollector , Loki, Kafka 및 기타 플러그인에서도 여전히 가능하다는 점에 유의하는 것이 중요합니다.
2.1.69. 네트워크 관찰 연산자 1.1.0 개선 사항
Network Observability Operator 1.1.0에 대한 다음 권고 사항을 볼 수 있습니다.
네트워크 관찰 연산자는 이제 안정적이며 릴리스 채널은 v1.1.0 으로 업그레이드되었습니다.
2.1.70. Network Observability Operator 1.1.0에서 문제가 해결되었습니다.
Network Observability Operator 1.1.0 릴리스에 대한 다음 해결된 문제를 확인할 수 있습니다.
-
이전에는 Loki
authToken구성이FORWARD모드로 설정되지 않으면 인증이 적용되지 않아 권한이 없는 사용자가 흐름을 검색할 수 있었습니다. 이제 LokiauthToken모드와 관계없이 클러스터 관리자만 흐름을 검색할 수 있습니다. (BZ#2169468)
3장. 네트워크 관찰성에 관하여
네트워크 관찰 연산자를 사용하면 eBPF 기술을 통해 네트워크 트래픽을 관찰하고 Prometheus 메트릭과 Loki 로그를 통해 문제 해결에 대한 통찰력을 얻을 수 있습니다.
OpenShift Container Platform 콘솔에서 저장된 정보를 보고 분석하여 추가적인 통찰력을 얻고 문제를 해결할 수 있습니다.
3.1. Network Observability Operator
네트워크 관찰 가능성 운영자는 클러스터 범위의 FlowCollector API 사용자 지정 리소스를 제공하며, 이 리소스는 Loki 또는 Prometheus에 네트워크 흐름을 수집, 보강 및 저장하는 eBPF 에이전트 및 서비스 파이프라인을 관리합니다.
FlowCollector 인스턴스는 모니터링 파이프라인을 구성하는 파드와 서비스를 배포합니다.
eBPF 에이전트는 데몬셋 객체로 배포되어 네트워크 흐름을 생성합니다. 파이프라인은 Loki에 저장하거나 Prometheus 메트릭을 생성하기 전에 Kubernetes 메타데이터로 네트워크 흐름을 수집하고 강화합니다.
3.2. 네트워크 관찰 연산자의 선택적 종속성
흐름 저장을 위한 Loki Operator 및 탄력적이고 대규모 데이터 처리 및 확장성을 위한 AMQ Streams(Kafka)와 같은 선택적 종속성을 사용하여 네트워크 관찰 가능성 연산자를 통합합니다.
지원되는 선택적 종속성에는 흐름 저장을 위한 Loki Operator와 Kafka를 통한 대규모 데이터 처리를 위한 AMQ Streams가 포함됩니다.
- 로키 오퍼레이터
- Loki를 백엔드로 사용하면 수집된 모든 흐름을 최대한 세부적으로 저장할 수 있습니다. Loki를 설치하려면 Red Hat에서 지원하는 Loki Operator를 사용하는 것이 좋습니다. Loki 없이 네트워크 관찰 기능을 사용할 수도 있지만, 몇 가지 요소를 고려해야 합니다. 자세한 내용은 "Network Observability without Loki"를 참조하십시오.
- AMQ 스트림 운영자
Kafka는 대규모 배포를 위해 OpenShift Container Platform 클러스터에서 확장성, 복원성 및 고가용성을 제공합니다.
참고Kafka를 사용하기로 선택한 경우 Red Hat에서 지원하는 AMQ Streams Operator를 사용하는 것이 좋습니다.
3.3. OpenShift 컨테이너 플랫폼 콘솔 통합
네트워크 관찰 가능성 운영자는 OpenShift 컨테이너 플랫폼 콘솔과 통합되어 개요, 토폴로지 보기 및 트래픽 흐름 테이블을 제공합니다.
관찰 → 대시보드의 네트워크 관찰성 지표 대시보드 는 관리자 액세스 권한이 있는 사용자만 사용할 수 있습니다.
개발자 액세스와 네임스페이스에 대한 액세스가 제한된 관리자에게 다중 테넌시를 활성화하려면 역할을 정의하여 권한을 지정해야 합니다. 자세한 내용은 "네트워크 관찰에서 다중 테넌시 활성화"를 참조하세요.
3.3.1. 네트워크 관찰성 지표 대시보드
OpenShift Container Platform 콘솔에서 네트워크 관찰 가능성 메트릭 대시보드를 검토해 보세요. 이 대시보드는 전반적인 트래픽 흐름 집계, 필터링 옵션, 그리고 운영자 상태 모니터링을 위한 전용 대시보드를 제공합니다.
OpenShift Container Platform 콘솔의 개요 탭에서 클러스터의 네트워크 트래픽 흐름에 대한 전체 집계된 지표를 볼 수 있습니다. 클러스터, 노드, 네임스페이스, 소유자, 포드, 서비스별로 정보를 표시하도록 선택할 수 있습니다. 필터 및 표시 옵션은 메트릭을 추가로 구체화할 수 있습니다. 자세한 내용은 개요 보기에서 네트워크 트래픽 모니터를 참조하세요.
Observe → 대시보드 에서 Netobserv 대시보드는 OpenShift Container Platform 클러스터의 네트워크 흐름에 대한 빠른 개요를 제공합니다. Netobserv/Health 대시보드는 운영자의 상태에 대한 측정 항목을 제공합니다. 자세한 내용은 "네트워크 관찰성 측정항목" 및 "상태 정보 보기"를 참조하세요.
3.3.2. 네트워크 관찰 토폴로지 뷰
OpenShift Container Platform 콘솔의 네트워크 관찰 가능성 토폴로지 보기에는 구성 요소 간의 트래픽 흐름이 그래픽으로 표시되며, 다양한 필터 및 표시 옵션을 사용하여 세부적으로 확인할 수 있습니다.
OpenShift Container Platform 콘솔은 OpenShift Container Platform 구성 요소 간의 트래픽을 네트워크 그래프로 나타내는 토폴로지 탭을 제공합니다. 필터와 표시 옵션을 사용하여 그래프를 세부적으로 조정할 수 있습니다. 클러스터, 영역, udn, 노드, 네임스페이스, 소유자, 포드, 서비스에 대한 정보에 액세스할 수 있습니다.
3.3.3. 교통 흐름표
OpenShift Container Platform 웹 콘솔의 트래픽 흐름 테이블은 원시 네트워크 흐름에 대한 자세한 보기를 제공하며, 심층 분석을 위해 강력한 필터링 옵션과 구성 가능한 열을 제공합니다.
OpenShift Container Platform 웹 콘솔의 트래픽 흐름 탭에는 네트워크 흐름 데이터와 트래픽 양이 표시됩니다.
3.4. 네트워크 관찰 CLI
네트워크 관찰 가능성 CLI( oc netobserv )는 전체 네트워크 관찰 가능성 운영자 설치 없이도 네트워크 문제를 신속하게 실시간으로 파악할 수 있도록 흐름 및 패킷 데이터를 스트리밍하는 경량 도구입니다.
네트워크 관찰 CLI는 eBPF 에이전트를 사용하여 수집된 데이터를 임시 수집기 포드로 스트리밍하는 흐름 및 패킷 시각화 도구입니다. 캡처하는 동안 지속적인 저장이 필요하지 않습니다. 실행 후 출력이 로컬 컴퓨터로 전송됩니다. 이를 통해 네트워크 관찰 운영자를 설치하지 않고도 패킷과 흐름 데이터에 대한 빠르고 실시간 통찰력을 얻을 수 있습니다.
4장. 네트워크 관찰 연산자 설치
Network Observability Operator를 사용하기 전에 Loki Operator를 설치하는 것이 좋습니다. Loki 없이도 네트워크 관찰 기능을 사용할 수 있지만, 메트릭이나 외부 내보내기만 필요한 경우 특별한 고려 사항이 적용됩니다.
Loki Operator는 데이터 흐름 저장을 위해 Loki와 다중 테넌시 및 인증을 구현하는 게이트웨이를 통합합니다. LokiStack 리소스는 확장 가능하고 가용성이 높은 다중 테넌트 로그 집계 시스템인 Loki와 OpenShift Container Platform 인증을 갖춘 웹 프록시를 관리합니다. LokiStack 프록시는 OpenShift Container Platform 인증을 사용하여 다중 테넌시를 적용하고 Loki 로그 저장소에서 데이터의 저장 및 인덱싱을 용이하게 합니다.
4.1. Loki 없이도 네트워크 관찰 가능
Loki Operator를 설치한 경우와 설치하지 않은 경우 네트워크 관찰 기능을 통해 사용할 수 있는 기능을 비교해 보세요.
Kafka 소비자나 IPFIX 수집기로만 흐름을 내보내려는 경우나 대시보드 메트릭만 필요한 경우, Loki를 설치하거나 Loki에 대한 저장소를 제공할 필요가 없습니다. 다음 표는 Loki가 있는 경우와 없는 경우 사용 가능한 기능을 비교합니다.
| 로키와 함께 | 로키 없이 | |
|---|---|---|
| 내보내기 | X | X |
| Multi-tenancy | X | X |
| 완벽한 필터링 및 집계 기능 [1] | X | |
| 부분 필터링 및 집계 기능 [2] | X | X |
| 흐름 기반 메트릭 및 대시보드 | X | X |
| 트래픽 흐름 보기 개요 [3] | X | X |
| 교통 흐름 보기 표 | X | |
| Topology view | X | X |
| OpenShift 컨테이너 플랫폼 콘솔 네트워크 트래픽 탭 통합 | X | X |
- 예를 들어 포드당.
- 예를 들어, 워크로드나 네임스페이스별로.
- 패킷 드롭의 통계는 Loki에서만 사용할 수 있습니다.
4.2. Loki Operator 설치
네트워크 관찰을 위한 자동 클러스터 내 인증 및 권한 부여를 제공하는 안전한 LokiStack 인스턴스를 활성화하려면 소프트웨어 카탈로그에서 지원되는 Loki Operator 버전을 설치하세요.
Loki Operator 버전 6.0+ 은 네트워크 관찰을 위해 지원되는 Loki Operator 버전입니다. 이 버전은 openshift-network 테넌트 구성 모드를 사용하여 LokiStack 인스턴스를 생성하는 기능을 제공하고 네트워크 관찰을 위한 완전 자동화된 클러스터 내 인증 및 권한 부여 지원을 제공합니다.
사전 요구 사항
- 관리자 권한이 있습니다.
- OpenShift Container Platform 웹 콘솔에 액세스할 수 있습니다.
- 지원되는 오브젝트 저장소에 액세스할 수 있습니다. 예를 들어 AWS S3, Google Cloud Storage, Azure, Swift, Minio 또는 OpenShift Data Foundation이 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 사용 가능한 Operator 목록에서 Loki Operator를 선택하고 설치를 클릭합니다.
- 설치 모드에서 클러스터의 모든 네임스페이스를 선택합니다.
검증
- Loki Operator를 설치했는지 확인합니다. Operators → 설치된 Operators 페이지를 방문하여 Loki Operator 를 찾습니다.
- Loki Operator 가 모든 프로젝트에 Succeeded 상태로 나열되어 있는지 확인합니다.
Loki를 제거하려면 Loki를 설치하는 데 사용한 방법에 해당하는 제거 프로세스를 참조하세요. 제거해야 할 ClusterRole 과 ClusterRoleBinding , 객체 저장소에 저장된 데이터, 영구 볼륨이 남아 있을 수 있습니다.
4.2.1. 로키 저장소에 대한 비밀 만들기
Amazon Web Services(AWS)와 같은 클라우드 스토리지 자격 증명을 사용하여 비밀을 생성하면 Loki Operator가 로그 지속성에 필요한 개체 저장소에 액세스할 수 있습니다.
Loki Operator는 AWS S3, Google Cloud Storage, Azure, Swift, Minio, OpenShift Data Foundation 등 몇 가지 로그 저장 옵션을 지원합니다. 다음 예제에서는 AWS S3 저장소에 대한 비밀을 생성하는 방법을 보여줍니다. 이 예제에서 생성된 비밀인 loki-s3 은 "LokiStack 사용자 정의 리소스 생성"에서 참조됩니다. 웹 콘솔이나 CLI에서 이 비밀을 만들 수 있습니다.
프로세스
- 웹 콘솔을 사용하여 프로젝트 → 모든 프로젝트 드롭다운으로 이동하여 프로젝트 생성을 선택합니다.
-
프로젝트 이름을
netobserv로지정하고 만들기를 클릭합니다. 오른쪽 상단 모서리에 있는 가져오기 아이콘( + )으로 이동합니다. YAML 파일을 편집기에 붙여넣습니다.
다음은 S3 스토리지에 대한 비밀 YAML 파일의 예를 보여줍니다.
apiVersion: v1 kind: Secret metadata: name: loki-s3 namespace: netobserv-loki stringData: access_key_id: QUtJQUlPU0ZPRE5ON0VYQU1QTEUK access_key_secret: d0phbHJYVXRuRkVNSS9LN01ERU5HL2JQeFJmaUNZRVhBTVBMRUtFWQo= bucketnames: s3-bucket-name endpoint: https://s3.eu-central-1.amazonaws.com region: eu-central-1다음과 같습니다.
metadata.namespace-
Loki S3 시크릿의 네임스페이스를 지정합니다. 이 예제에서는
netobserv-loki를 사용하지만 다른 구성 요소에 다른 네임스페이스를 사용할 수 있습니다. stringData.access_key_id- S3 버킷의 액세스 키 ID를 지정합니다.
stringData.access_key_secret- S3 버킷의 시크릿 액세스 키를 지정합니다.
stringData.bucketnames- S3 버킷의 이름을 지정합니다.
stringData.endpoint- S3 서비스의 끝점 URL을 지정합니다.
stringData.region- 버킷이 있는 AWS 리전을 지정합니다.
검증
- 비밀을 만든 후에는 웹 콘솔의 워크로드 → 비밀 아래에 나열된 비밀을 볼 수 있습니다.
4.2.2. LokiStack 사용자 정의 리소스 생성
웹 콘솔이나 OpenShift CLI( oc )를 사용하여 LokiStack 사용자 정의 리소스를 배포하고, Loki 개체 스토리지에 대한 올바른 네임스페이스, 배포 크기 및 비밀 이름을 구성합니다.
LokiStack 사용자 정의 리소스(CR)를 배포하여 네임스페이스나 새 프로젝트를 만들 수 있습니다.
프로세스
- Operators → 설치된 Operators로 이동하여 프로젝트 드롭다운에서 모든 프로젝트를 확인합니다.
- Loki Operator를 찾으세요. 세부 정보의 제공된 API 아래에서 LokiStack을 선택합니다.
- LokiStack 만들기를 클릭합니다.
다음 필드가 Form View 또는 YAML View 에 지정되어 있는지 확인하세요.
apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv-loki spec: size: 1x.small storage: schemas: - version: v13 effectiveDate: '2022-06-01' secret: name: loki-s3 type: s3 storageClassName: gp3 tenants: mode: openshift-network다음과 같습니다.
metadata.namespace-
LokiStack리소스의 네임스페이스를 지정합니다. 이 예제에서는netobserv-loki를 사용하지만 다른 구성 요소에 다른 네임스페이스를 사용할 수 있습니다. spec.size배포 크기를 지정합니다. Loki Operator 5.8 이상 버전에서 Loki의 프로덕션 인스턴스에 지원되는 크기 옵션은
1x.extra-#159 ,1x.tekton 또는1x.medium입니다.중요배포 크기의 숫자
1x를 변경할 수 없습니다.spec.storageClassNameReadWriteOnce액세스 모드에서 클러스터에서 사용할 수 있는 스토리지 클래스 이름을 지정합니다. 최상의 성능을 위해서는 블록 스토리지를 할당하는 스토리지 클래스를 지정합니다.oc get storageclasses명령을 사용하여 클러스터에서 사용 가능한 스토리지 클래스를 확인합니다.중요로깅에 사용되는 동일한
LokiStack사용자 정의 리소스를 재사용해서는 안 됩니다.
- 생성을 클릭합니다.
4.2.3. 클러스터 관리자 사용자 역할에 대한 새 그룹 만들기
클러스터 관리자 사용자로서 여러 네임스페이스에 대한 애플리케이션 로그를 쿼리할 때 클러스터의 모든 네임스페이스의 문자 합계가 5120을 초과하면 Parse error: input size too long (XXXX > 5120) 오류가 발생합니다. LokiStack에서 로그에 대한 액세스를 더 잘 제어하려면 cluster-admin 사용자를 cluster-admin 그룹의 멤버로 만드세요. cluster-admin 그룹이 존재하지 않으면 그룹을 만들고 원하는 사용자를 추가합니다.
다음 절차에 따라 cluster-admin 권한이 있는 사용자를 위한 새 그룹을 생성합니다.
프로세스
다음 명령을 입력하여 새 그룹을 생성합니다.
$ oc adm groups new cluster-admincluster-admin그룹에 원하는 사용자를 추가하려면 다음 명령을 입력하세요.$ oc adm groups add-users cluster-admin <username>다음 명령을 입력하여 그룹에
cluster-admin사용자 역할을 추가합니다.$ oc adm policy add-cluster-role-to-group cluster-admin cluster-admin
4.2.4. 사용자 정의 관리자 그룹 액세스
반드시 관리자 없이 클러스터 전체 로그를 확인해야 하거나 여기에서 사용하려는 그룹이 이미 정의되어 있는 경우 adminGroup 필드를 사용하여 사용자 지정 그룹을 지정할 수 있습니다. LokiStack CR(사용자 정의 리소스)의 adminGroups 필드에 지정된 그룹의 멤버인 사용자는 관리자와 동일한 읽기 액세스 권한을 갖습니다.
관리자 사용자는 클러스터 전체의 모든 네트워크 로그에 액세스할 수 있습니다.
LokiStack CR의 예
apiVersion: loki.grafana.com/v1
kind: LokiStack
metadata:
name: loki
namespace: netobserv
spec:
tenants:
mode: openshift-network
openshift:
adminGroups:
- cluster-admin
- custom-admin-group 4.2.5. Loki 배포 크기 조정
Loki의 크기 조정은 1x.<size> 형식을 따릅니다. 여기서 값 1x 는 인스턴스 수이고 <size> 는 성능 용량을 지정합니다.
배포 크기의 숫자 1x 를 변경할 수 없습니다.
| 1x.demo | 1x.extra-small | 1x.small | 1x.medium | |
|---|---|---|---|---|
| 데이터 전송 | 데모용으로만 사용 가능 | 100GB/일 | 500GB/day | 2TB/day |
| 초당 쿼리 수(QPS) | 데모용으로만 사용 가능 | 200ms에서 1-25 QPS | 200ms에서 25-50 QPS | 200ms에서 25-75 QPS |
| 복제 인자 | 없음 | 2 | 2 | 2 |
| 총 CPU 요청 수 | 없음 | 14 vCPUs | 34 vCPUs | 54 vCPUs |
| 총 메모리 요청 수 | 없음 | 31Gi | 67Gi | 139Gi |
| 총 디스크 요청 수 | 40Gi | 430Gi | 430Gi | 590Gi |
4.2.6. LokiStack 섭취 한도 및 상태 알림
LokiStack 인스턴스에는 관리자가 성능을 관리하고 시스템 경고나 오류를 방지하기 위해 재정의할 수 있는 기본 수집 및 쿼리 제한이 포함되어 있습니다.
콘솔 플러그인이나 flowlogs-pipeline 로그에 Loki 오류가 표시되는 경우 수집 및 쿼리 제한을 업데이트하는 것이 좋습니다.
구성된 제한의 예는 다음과 같습니다.
spec:
limits:
global:
ingestion:
ingestionBurstSize: 40
ingestionRate: 20
maxGlobalStreamsPerTenant: 25000
queries:
maxChunksPerQuery: 2000000
maxEntriesLimitPerQuery: 10000
maxQuerySeries: 3000이러한 설정에 대한 자세한 내용은 LokiStack API 참조를 확인하세요.
4.3. 네트워크 관찰 연산자 설치
Network Observability Operator를 설치하고 설정 마법사를 사용하여 FlowCollector 사용자 정의 리소스 정의(CRD)를 만들어 초기 구성을 완료합니다.
FlowCollector를 생성할 때 웹 콘솔에서 사양을 설정할 수 있습니다.
Operator의 실제 메모리 소비량은 클러스터 크기와 배포된 리소스 수에 따라 달라집니다. 그에 따라 메모리 사용을 조정해야 할 수 있습니다. 자세한 내용은 "중요한 Flow Collector 구성 고려 사항" 섹션의 "네트워크 관찰 컨트롤러 관리자 Pod의 메모리가 부족합니다"를 참조하세요.
사전 요구 사항
- Loki를 사용하기로 선택한 경우 Loki Operator 버전 5.7 이상을 설치하세요.
-
cluster-admin권한이 있어야 합니다. -
지원되는 아키텍처 중 하나는
amd64,ppc64le,arm64, 또는s390x입니다. - Red Hat Enterprise Linux (RHEL) 9에서 지원하는 모든 CPU.
- OVN-Kubernetes를 기본 네트워크 플러그인으로 구성해야 하며, 선택적으로 Multus 및 SR-IOV와 함께 보조 인터페이스를 사용해야 합니다.
또한, 이 설치 예제에서는 모든 구성 요소에서 사용되는 netobserv 네임스페이스를 사용합니다. 선택적으로 다른 네임스페이스를 사용할 수 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- OperatorHub 에서 사용 가능한 운영자 목록에서 Network Observability Operator를 선택하고 설치를 클릭합니다.
-
이 네임스페이스에서 운영자가 권장하는 클러스터 모니터링을 활성화하는확인란을 선택합니다. - Operators → 설치된 Operator로 이동합니다. 네트워크 관찰을 위한 제공된 API에서 Flow Collector 링크를 선택합니다.
- Network Observability FlowCollector 설정 마법사를 따르세요.
- 생성을 클릭합니다.
검증
이것이 성공했는지 확인하려면 Observe 로 이동하면 옵션에 네트워크 트래픽이 나열되어 있어야 합니다.
OpenShift Container Platform 클러스터 내에 애플리케이션 트래픽이 없으면 기본 필터에 "결과가 없음"이 표시되어 시각적 흐름이 발생하지 않을 수 있습니다. 필터 선택 옆에 있는 모든 필터 지우기를 선택하면 흐름을 확인할 수 있습니다.
4.4. 네트워크 관찰성에서 다중 테넌시 활성화
Loki와 Prometheus의 흐름과 메트릭에 대한 세부적이고 제한된 액세스 권한을 프로젝트 관리자와 개발자에게 부여하기 위해 클러스터 역할과 네임스페이스 역할을 구성하여 네트워크 관찰성에서 다중 테넌시를 활성화합니다.
프로젝트 관리자의 접근이 활성화되었습니다. 일부 네임스페이스에 대한 액세스가 제한된 프로젝트 관리자는 해당 네임스페이스의 흐름에만 액세스할 수 있습니다.
개발자의 경우 Loki와 Prometheus 모두에서 멀티 테넌시를 사용할 수 있지만 다른 액세스 권한이 필요합니다.
사전 요구 사항
- Loki를 사용하는 경우 최소한 Loki Operator 버전 5.7을 설치해야 합니다.
- 프로젝트 관리자로 로그인해야 합니다.
프로세스
테넌트별 액세스를 위해서는 개발자 관점을 사용하려면
netobserv-loki-reader클러스터 역할과netobserv-metrics-reader네임스페이스 역할이 있어야 합니다. 이 액세스 수준에 대해 다음 명령을 실행합니다.$ oc adm policy add-cluster-role-to-user netobserv-loki-reader <user_group_or_name>$ oc adm policy add-role-to-user netobserv-metrics-reader <user_group_or_name> -n <namespace>클러스터 전체에 액세스하려면 클러스터 관리자가 아닌 사용자에게
netobserv-loki-reader,cluster-monitoring-view,netobserv-metrics-reader클러스터 역할이 있어야 합니다. 이 시나리오에서는 관리자 관점이나 개발자 관점을 사용할 수 있습니다. 이 액세스 수준에 대해 다음 명령을 실행합니다.$ oc adm policy add-cluster-role-to-user netobserv-loki-reader <user_group_or_name>$ oc adm policy add-cluster-role-to-user cluster-monitoring-view <user_group_or_name>$ oc adm policy add-cluster-role-to-user netobserv-metrics-reader <user_group_or_name>
4.5. 중요한 Flow Collector 구성 고려 사항
이후 재구성으로 인한 Pod 중단을 방지하기 위해 초기 배포 전에 필수 FlowCollector 구성 옵션을 검토하십시오. 주요 설정에는 Kafka 통합, 보강된 흐름 데이터 내보내기, SR-IOV 트래픽 모니터링 및 DNS 및 패킷 드롭에 대한 고급 추적이 포함됩니다.
FlowCollector 인스턴스를 생성하면 재구성할 수 있지만 Pod가 종료되고 다시 생성되어 손상될 수 있습니다.
따라서 처음으로 FlowCollector 를 만들 때 다음 옵션을 구성할 수 있습니다.
4.5.1. 삭제된 버전의 FlowCollector CRD 마이그레이션
업그레이드 오류를 방지하고 Network Observability Operator 1.6으로 성공적으로 마이그레이션하려면 FlowCollector 사용자 정의 리소스 정의(CRD) storedVersion 목록에서 더 이상 사용되지 않는 v1alpha1 버전을 수동으로 제거하세요.
저장된 버전을 제거하는 방법은 다음 두 가지가 있습니다.
- 스토리지 버전 Migrator Operator를 사용합니다.
- Network Observability Operator를 설치 제거하고 다시 설치하여 설치가 정리되었는지 확인합니다.
사전 요구 사항
-
이전 버전의 Operator가 설치되어 있으며 최신 버전의 Operator를 설치할 클러스터를 준비하려고 합니다. 또는 Network Observability Operator 1.6을 설치하고 오류 발생:
데이터 손실 위험 "flowcollectors.flows.netobserv.io": 새 CRD는 기존 CRD에 저장된 버전으로 나열된 버전 v1alpha1을 제거합니다.
프로세스
이전
FlowCollectorCRD 버전이storedVersion에서 계속 참조되는지 확인합니다.$ oc get crd flowcollectors.flows.netobserv.io -ojsonpath='{.status.storedVersions}'결과 목록에
v1alpha1이 표시되면 Step a 를 진행하여 Kubernetes Storage Version Migrator 또는 Step b 를 사용하여 CRD와 Operator를 설치 제거하고 다시 설치합니다.옵션 1: Kubernetes Storage 버전 Migrator :
StorageVersionMigration 오브젝트를 정의하는 YAML을 만듭니다(예:migrate-flowcollector-v1alpha1.yaml).apiVersion: migration.k8s.io/v1alpha1 kind: StorageVersionMigration metadata: name: migrate-flowcollector-v1alpha1 spec: resource: group: flows.netobserv.io resource: flowcollectors version: v1alpha1- 파일을 저장합니다.
다음 명령을 실행하여
StorageVersionMigration을 적용합니다.$ oc apply -f migrate-flowcollector-v1alpha1.yamlstoredVersion에서v1alpha1을 수동으로 제거하도록FlowCollectorCRD를 업데이트합니다.$ oc edit crd flowcollectors.flows.netobserv.io
옵션 2: Reinstall:
FlowCollectorCR의 Network Observability Operator 1.5 버전을 파일에 저장합니다(예:flowcollector-1.5.yaml).$ oc get flowcollector cluster -o yaml > flowcollector-1.5.yaml-
Operator를 제거하고 기존
FlowCollectorCRD를 제거하는 "Network Observability Operator 제거"의 단계를 따릅니다. - Network Observability Operator 최신 버전 1.6.0을 설치합니다.
-
b 단계에 저장된 백업을 사용하여
FlowCollector를 만듭니다.
-
Operator를 제거하고 기존
검증
다음 명령을 실행합니다.
$ oc get crd flowcollectors.flows.netobserv.io -ojsonpath='{.status.storedVersions}'결과 목록에 더 이상
v1alpha1이 표시되지 않아야 하며 최신 버전v1beta1만 표시되어야 합니다.
4.6. Kafka 설치(선택 사항)
Kafka Operator는 대규모 환경에서 지원됩니다. 카프카는 보다 탄력적이고 확장 가능한 방식으로 네트워크 흐름 데이터를 전달하기 위해 높은 처리량과 낮은 지연 시간의 데이터 피드를 제공합니다.
Loki Operator와 Network Observability Operator를 설치한 것처럼 Operator Hub에서 Red Hat AMQ Streams 로 Kafka Operator를 설치할 수 있습니다. Kafka를 스토리지 옵션으로 구성하려면 "Kafka를 사용하여 FlowCollector 리소스 구성"을 참조하세요.
Kafka를 제거하려면 설치에 사용한 방법에 해당하는 제거 프로세스를 참조하세요.
4.7. 네트워크 관찰 연산자 제거
OpenShift Container Platform 웹 콘솔 Operator Hub의 Ecosystem → Installed Operators 영역에서 Network Observability Operator를 제거합니다.
프로세스
FlowCollector사용자 정의 리소스를 제거합니다.- 제공된 API 열에서 Network Observability Operator 옆에 있는 흐름 수집기 를 클릭합니다.
-
클러스터 의 옵션 메뉴
 를 클릭하고 FlowCollector 삭제 를 선택합니다.
를 클릭하고 FlowCollector 삭제 를 선택합니다.
네트워크 관찰 연산자를 제거합니다.
- Operator → 설치된 Operator 영역으로 돌아갑니다.
-
Network Observability Operator 옆에 있는 옵션 메뉴
를 클릭하고 Operator 설치 제거를 선택합니다.
-
홈 → 프로젝트 및
openshift-netobserv-operator선택 - 작업 으로 이동하여 프로젝트 삭제를 선택하세요.
FlowCollector사용자 정의 리소스 정의(CRD)를 제거합니다.- 관리 → 클러스터 리소스 정의로 이동합니다.
-
FlowCollector 를 찾고
옵션 메뉴를 클릭합니다.
CustomResourceDefinition 삭제를 선택합니다.
중요Loki Operator와 Kafka는 설치된 경우 그대로 유지되므로 별도로 제거해야 합니다. 또한, 개체 저장소에 남아 있는 데이터가 있을 수도 있고, 제거해야 하는 영구 볼륨이 있을 수도 있습니다.
5장. OpenShift 컨테이너 플랫폼의 네트워크 관찰 연산자
OpenShift Container Platform의 네트워크 관찰 운영자는 모니터링 파이프라인을 배포합니다. 이 파이프라인은 eBPF 에이전트가 생성한 네트워크 트래픽 흐름을 수집하고 강화합니다.
5.1. 상태 보기
`oc get` 명령어를 사용하여 FlowCollector 리소스 상태는 물론 eBPF 에이전트 , flowlogs-pipeline 및 콘솔 플러그인 Pod의 상태를 확인하여 네트워크 관찰 가능성 운영자의 작동 상태를 볼 수 있습니다.
네트워크 관찰 연산자는 Flow Collector API를 제공합니다. Flow Collector 리소스가 생성되면 Loki 로그 저장소에 네트워크 흐름을 생성하고 저장하기 위해 Pod와 서비스를 배포하고, OpenShift Container Platform 웹 콘솔에 대시보드, 메트릭 및 흐름을 표시합니다.
프로세스
FlowCollector의 상태를 보려면 다음 명령을 실행하세요.$ oc get flowcollector/cluster출력 예
NAME AGENT SAMPLING (EBPF) DEPLOYMENT MODEL STATUS cluster EBPF 50 DIRECT Ready다음 명령을 입력하여
netobserv네임스페이스에서 실행 중인 포드의 상태를 확인하세요.$ oc get pods -n netobserv출력 예
NAME READY STATUS RESTARTS AGE flowlogs-pipeline-56hbp 1/1 Running 0 147m flowlogs-pipeline-9plvv 1/1 Running 0 147m flowlogs-pipeline-h5gkb 1/1 Running 0 147m flowlogs-pipeline-hh6kf 1/1 Running 0 147m flowlogs-pipeline-w7vv5 1/1 Running 0 147m netobserv-plugin-cdd7dc6c-j8ggp 1/1 Running 0 147mflowlogs-pipeline포드는 흐름을 수집하고, 수집된 흐름을 풍부하게 한 다음, 흐름을 Loki 저장소로 보냅니다.netobserv-pluginpod는 OpenShift Container Platform Console을 위한 시각화 플러그인을 생성합니다.다음 명령을 입력하여
netobserv-privileged네임스페이스에서 실행 중인 포드의 상태를 확인하세요.$ oc get pods -n netobserv-privileged출력 예
NAME READY STATUS RESTARTS AGE netobserv-ebpf-agent-4lpp6 1/1 Running 0 151m netobserv-ebpf-agent-6gbrk 1/1 Running 0 151m netobserv-ebpf-agent-klpl9 1/1 Running 0 151m netobserv-ebpf-agent-vrcnf 1/1 Running 0 151m netobserv-ebpf-agent-xf5jh 1/1 Running 0 151mnetobserv-ebpf-agent포드는 노드의 네트워크 인터페이스를 모니터링하여 흐름을 가져와flowlogs-pipeline포드로 전송합니다.Loki Operator를 사용하는 경우 다음 명령을 입력하여
netobserv네임스페이스에서LokiStack사용자 지정 리소스의componentpod 상태를 확인하세요.$ oc get pods -n netobserv출력 예
NAME READY STATUS RESTARTS AGE lokistack-compactor-0 1/1 Running 0 18h lokistack-distributor-654f87c5bc-qhkhv 1/1 Running 0 18h lokistack-distributor-654f87c5bc-skxgm 1/1 Running 0 18h lokistack-gateway-796dc6ff7-c54gz 2/2 Running 0 18h lokistack-index-gateway-0 1/1 Running 0 18h lokistack-index-gateway-1 1/1 Running 0 18h lokistack-ingester-0 1/1 Running 0 18h lokistack-ingester-1 1/1 Running 0 18h lokistack-ingester-2 1/1 Running 0 18h lokistack-querier-66747dc666-6vh5x 1/1 Running 0 18h lokistack-querier-66747dc666-cjr45 1/1 Running 0 18h lokistack-querier-66747dc666-xh8rq 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-b2xfb 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-jm94f 1/1 Running 0 18h
5.2. 네트워크 관찰성 연산자 아키텍처
FlowCollector 리소스가 eBPF 에이전트를 관리하는 방식을 자세히 검토하십시오. 이 에이전트는 플로우를 수집하고 보강하여 Loki에 저장하거나 Prometheus에 메트릭을 전송합니다.
네트워크 관찰 연산자는 FlowCollector API를 제공하는데, 이는 설치 시 인스턴스화되고 eBPF 에이전트 , flowlogs-pipeline 및 netobserv-plugin 구성 요소를 조정하도록 구성됩니다. 클러스터당 하나의 FlowCollector 만 지원됩니다.
eBPF 에이전트는 각 클러스터 노드에서 실행되며 네트워크 흐름을 수집하는 일부 권한을 가지고 있습니다. flowlogs-pipeline은 네트워크 흐름 데이터를 수신하고 Kubernetes 식별자로 데이터를 보강합니다. Loki를 사용하기로 선택한 경우, flowlogs-pipeline은 저장 및 인덱싱을 위해 Loki로 흐름 로그 데이터를 전송합니다. 동적 OpenShift Container Platform 웹 콘솔 플러그인인 netobserv-plugin은 Loki에 쿼리를 보내 네트워크 흐름 데이터를 가져옵니다. 클러스터 관리자는 웹 콘솔에서 데이터를 볼 수 있습니다.
Loki를 사용하지 않으면 Prometheus를 사용하여 메트릭을 생성할 수 있습니다. 해당 지표와 관련 대시보드는 웹 콘솔에서 접근할 수 있습니다. 자세한 내용은 "Network Observability without Loki"를 참조하십시오.
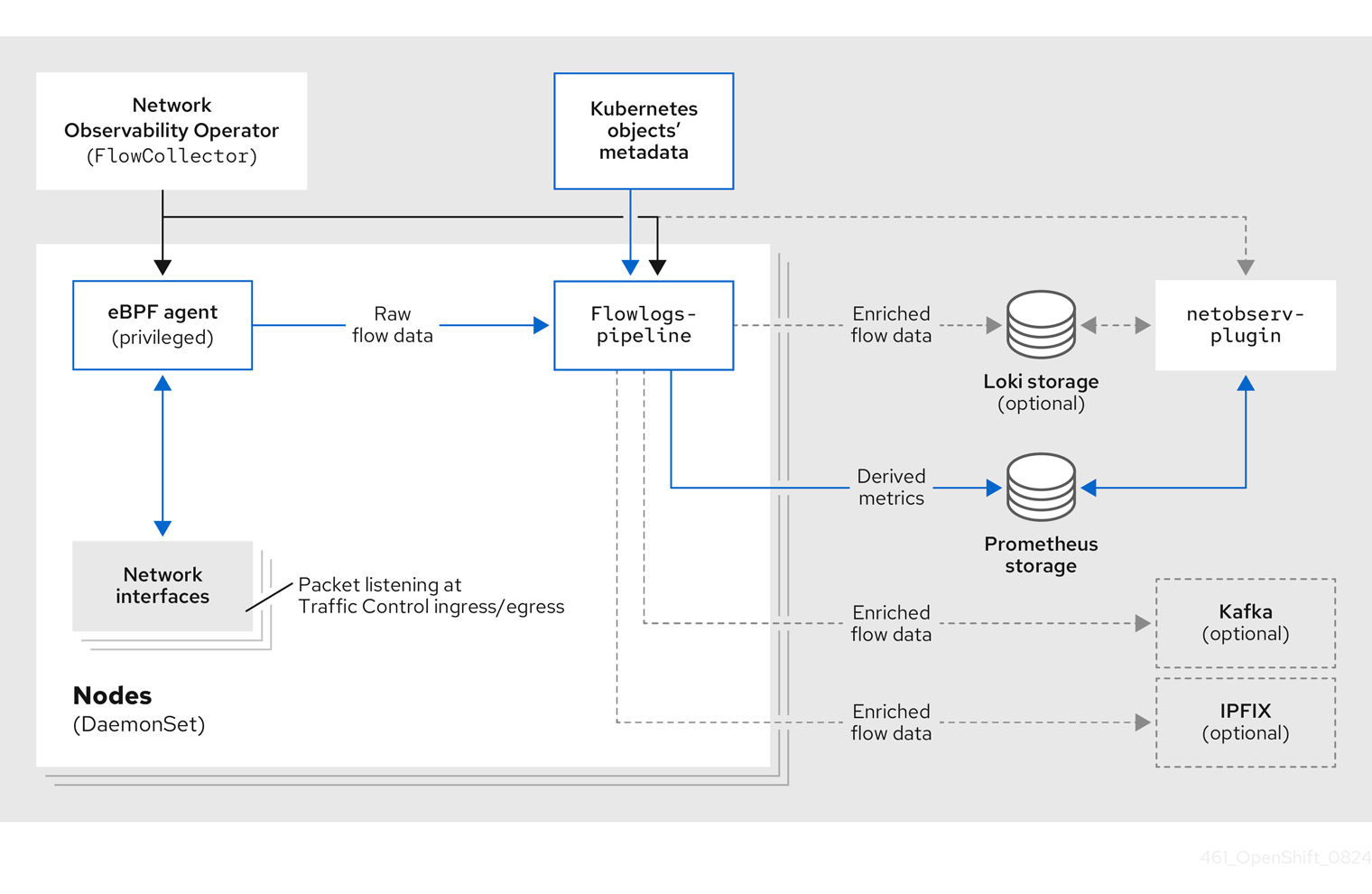
Network Observability Operator에는 세 가지 배포 모델 옵션이 있습니다.
Network Observability Operator는 Loki 또는 기타 데이터 저장소를 관리하지 않습니다. Loki Operator를 사용하여 Loki를 별도로 설치해야 합니다. Kafka를 사용하는 경우 Kafka Operator를 사용하여 별도로 설치해야 합니다.
- 서비스 배포 모델
-
FlowCollector리소스의spec.deploymentModel필드가Service로 설정되면 노드별로 데몬 세트로 배포됩니다.flowlogs-pipeline은 서비스가 포함된 표준 배포입니다.spec.processor.consumerReplicas필드를 사용하여flowlogs-pipeline구성 요소를 확장할 수 있습니다. - 직접 배포 모델
-
spec.deploymentModel필드가Direct로 설정되면 agent 및flowlogs-pipeline이 둘 다 노드당 데몬 세트로 배포됩니다. 이 모델은 기술 평가 및 소규모 클러스터에 적합합니다. 그러나flowlogs-pipeline의 각 인스턴스가 동일한 클러스터 정보를 캐시하므로 대규모 클러스터에서 메모리 효율이 줄어듭니다. - Kafka 배포 모델 (선택 사항)
Kafka 옵션을 사용하는 경우
eBPF 에이전트는 네트워크 흐름 데이터를 Kafka로 보냅니다.spec.processor.consumerReplicas필드를 사용하여flowlogs-pipeline구성 요소를 확장할 수 있습니다.flowlogs-pipeline구성 요소는 다음 다이어그램에 표시된 대로 데이터를 Loki로 보내기 전에 Kafka 주제에서 읽습니다.
5.3. 네트워크 관찰 운영자 상태 및 구성 보기
oc describe flowcollector/cluster 명령을 사용하여 네트워크 관찰 가능성 운영자의 현재 상태, 구성 세부 정보 및 생성된 리소스를 검사합니다.
프로세스
다음 명령을 실행하여 Network Observability Operator의 상태 및 구성을 확인합니다.
$ oc describe flowcollector/cluster
6장. 네트워크 관찰 연산자 구성
클러스터 전체 FlowCollector API 리소스(클러스터)를 업데이트하여 네트워크 관찰 운영자를 구성하고 구성 요소 구성 및 흐름 수집 설정을 관리합니다.
설치 중에 FlowCollector 가 명시적으로 생성됩니다. 이 리소스는 클러스터 전체에서 작동하기 때문에 단일 FlowCollector 만 허용되며 cluster 라는 이름을 지정해야 합니다. 자세한 내용은 FlowCollector API 참조를 참조하십시오.
6.1. FlowCollector 리소스 보기
통합 설정, 고급 양식을 통해 OpenShift Container Platform 웹 콘솔에서 FlowCollector 리소스를 보고 수정하거나 YAML을 직접 편집하여 Network Observability Operator를 구성합니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
-
클러스터를 선택한 다음 YAML 탭을 선택합니다. 여기에서
FlowCollector리소스를 수정하여 네트워크 관찰 연산자를 구성할 수 있습니다.
6.1.1. FlowCollector 리소스의 예
eBPF 샘플링, 대화 추적, Loki 통합 및 콘솔 빠른 필터에 대한 구성을 보여주는 FlowCollector 사용자 정의 리소스의 포괄적인 주석이 있는 예를 검토합니다.
6.1.1.1. 샘플 FlowCollector 리소스
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Service
networkPolicy:
enable: true
agent:
type: eBPF
ebpf:
sampling: 50
privileged: false
features: []
processor:
addZone: false
subnetLabels:
openShiftAutoDetect: true
customLabels: []
consumerReplicas: 3
loki:
enable: true
mode: LokiStack
lokiStack:
name: loki
namespace: netobserv-loki
consolePlugin:
enable: true
exporters: []다음과 같습니다.
spec.agent.type-
eBPF가 지원되는 유일한 OpenShift Container Platform 옵션이므로 eBPF여야 합니다. spec.agent.ebpf.sampling-
샘플링 간격을 지정합니다. 기본적으로 eBPF 샘플링은
50으로 설정되므로 패킷은 샘플링될 가능성이 50개에서 1입니다. 샘플링 간격 값이 낮을수록 더 많은 계산, 메모리, 저장 리소스가 필요합니다. 값이0또는1이면 모든 패킷이 샘플링됩니다. 기본값으로 시작한 후 경험을 통해 값을 조정하여 클러스터에 가장 적합한 설정을 찾는 것이 좋습니다. spec.agent.ebpf.privileged- eBPF 에이전트 Pod가 권한으로 실행되는지 여부를 지정합니다. 기본이 아닌 네트워크 모니터링 및 패킷 추적과 같은 여러 기능에는 privileged를 실행해야 합니다. 보안을 위해 최소 권한 원칙에 따라 이러한 기능 중 일부가 필요한 경우에만 활성화해야 합니다. true로 설정하지 않고 권한 있는 모드를 활성화한 경우 경고가 표시됩니다.
spec.processor.addZone- 네트워크 흐름에 클라우드 가용성 영역을 삽입하는 데 사용됩니다.
spec.processor.subnetLabels- 일치하는 CIDR에 따라 네트워크 흐름에 삽입할 사용자 지정 라벨 목록을 지정합니다.
spec.processor.consumerReplicas- 프로세서 포드의 복제본 수(flowlogs-pipeline)를 지정합니다. 클러스터 크기에 따른 권장 사항은 리소스 관리 및 성능 고려 사항을 참조하십시오.
spec.loki.mode-
설치 모드에 따라 Loki에 대한 연결을 구성하는 방법을 지정합니다. " Loki Operator 설치"에 설명된 설치 경로를 사용하는 경우 모드를
LokiStack으로 설정하고spec.loki.lokiStack은 설치된LokiStack리소스 이름과 네임스페이스를 참조해야 합니다. spec.loki.lokistack.namespace-
LokiStack리소스의 네임스페이스를 지정합니다. 이 값은LokiStack사용자 정의 리소스에 정의된metadata.namespace와 일치해야 합니다. 이 예제에서는netobserv-loki를 사용하지만 다른 구성 요소에 다른 네임스페이스를 사용할 수 있습니다.
6.2. Kafka를 사용하여 FlowCollector 리소스 구성
처리량이 높고 대기 시간이 짧은 데이터 피드에 Kafka를 사용하도록 FlowCollector 리소스를 구성합니다.
실행 중인 Kafka 인스턴스가 있어야 하며 OpenShift Container Platform 네트워크 Observability 전용 해당 인스턴스에 Kafka 주제를 생성해야 합니다. 자세한 내용은 AMQ Streams를 사용한 Kafka 문서를 참조하십시오.
사전 요구 사항
- Kafka를 설치했습니다. Red Hat은 AMQ Streams Operator를 사용하여 Kafka를 지원합니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- Network Observability Operator의 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 클릭합니다.
다음 샘플 YAML에 표시된 대로 OpenShift Container Platform Network Observability Operator의
FlowCollector리소스를 변경하여 Kafka를 사용합니다.FlowCollector리소스의 샘플 Kafka 구성apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: deploymentModel: Kafka kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: network-flows tls: enable: false다음과 같습니다.
spec.deploymentModel-
배포 모델을 지정합니다.
Kafka배포 모델을 활성화하려면Service대신 Kafka로 설정합니다. spec.kafka.address-
Kafka 부트스트랩 서버 주소를 지정합니다. 필요한 경우 포트 9093에서 TLS를 사용하기 위해
kafka-cluster-kafka-bootstrap.netobserv:9093과 같이 포트를 지정할 수 있습니다. spec.kafka.topic- Kafka에서 생성된 주제의 이름을 지정합니다. Kafka에서 생성된 주제의 이름과 일치해야 합니다.
spec.kafka.tls-
통신 암호화를 지정합니다. 이 설정을 사용하여 TLS 또는 mTLS를 사용하여 Kafka로의 모든 통신을 암호화합니다. 활성화된 경우 Kafka CA 인증서를 ConfigMap 또는 두 네임스페이스에서 Secret으로 사용할 수 있어야 합니다.
flowlogs-pipeline프로세서 구성 요소(기본값:netobserv)를 배포하는 네임스페이스와 eBPF 에이전트(기본값:netobserv-privileged)를 배포하는 네임스페이스입니다.spec.kafka.tls.caCert를 사용하여 인증서를 참조합니다. mTLS를 사용하는 경우 이러한 네임스페이스에서 클라이언트 시크릿을 사용할 수 있도록 합니다. Red Hat AMQ Streams User Operator를 사용하여 시크릿을 생성할 수 있습니다.spec.kafka.tls.userCert를 사용하여 시크릿을 참조합니다.
6.3. 강화된 네트워크 흐름 데이터 내보내기
Splunk 또는 Prometheus와 같은 툴을 통해 외부 소비를 위해 보강된 네트워크 흐름 데이터를 Kafka, IPFIX 또는 OpenTelemetry 엔드포인트에 동시에 내보내도록 FlowCollector 리소스를 구성합니다.
Kafka 또는 IPFIX의 경우 Splunk, Elasticsearch, Fluentd 등 해당 입력을 지원하는 모든 프로세서나 스토리지는 강화된 네트워크 흐름 데이터를 사용할 수 있습니다.
OpenTelemetry의 경우 네트워크 흐름 데이터와 메트릭을 OpenTelemetry의 Red Hat 빌드나 Prometheus와 같은 호환 가능한 OpenTelemetry 엔드포인트로 내보낼 수 있습니다.
구성 후 네트워크 흐름 데이터를 사용 가능한 출력으로 전송할 수 있습니다. 자세한 내용은 "네트워크 흐름 형식 참조"를 참조하세요.
사전 요구 사항
-
Kafka, IPFIX 또는 OpenTelemetry 수집기 엔드포인트는 Network Observability
flowlogs-pipelinepod에서 사용할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
FlowCollector를편집하여 다음과 같이spec.exporters를구성합니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: exporters: - type: Kafka kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: netobserv-flows-export tls: enable: false - type: IPFIX ipfix: targetHost: "ipfix-collector.ipfix.svc.cluster.local" targetPort: 4739 transport: tcp - type: OpenTelemetry openTelemetry: targetHost: my-otelcol-collector-headless.otlp.svc targetPort: 4317 type: grpc logs: enable: true metrics: enable: true prefix: netobserv pushTimeInterval: 20s expiryTime: 2m # fieldsMapping: # input: SrcAddr # output: source.address다음과 같습니다.
spec.exporters.type-
내보내기 유형을 지정합니다.
IPFIX,OpenTelemetry및Kafka로 개별적으로 또는 동시에 흐름을 내보낼 수 있습니다. spec.exporters.kafka.topic- Network Observability Operator에서 모든 흐름을 내보내는 Kafka 주제를 지정합니다.
spec.exporters.kafka.tls.enable-
SSL/TLS 또는 mTLS를 사용하여 Kafka 간 통신을 암호화할지 여부를 지정합니다. 활성화된 경우 Kafka CA 인증서를
ConfigMap또는flowlogs-pipeline프로세서 구성 요소가 배포된 네임스페이스에서Secret으로 사용할 수 있어야 합니다(기본값:netobserv).spec.exporters.tls.caCert를 사용하여 인증서를 참조합니다. mTLS의 경우 이러한 네임스페이스에서 클라이언트 시크릿도 사용할 수 있어야 하며spec.exporters.tls.userCert에서 참조해야 합니다. spec.exporters.ipfix.transport-
전송 프로토콜을 지정합니다. 기본값은
tcp이지만udp를 지정할 수도 있습니다. spec.exporters.openTelemetry.type-
OpenTelemetry 연결 프로토콜을 지정합니다. 사용 가능한 옵션은
http와grpc입니다. spec.exporters.openTelemetry.logs- 로그 내보내기에 대한 OpenTelemetry 구성을 지정합니다. 이 구성은 Loki용으로 생성된 로그와 동일합니다.
spec.exporters.openTelemetry.metrics-
지표 내보내기에 대한 OpenTelemetry 구성을 지정합니다. 이는 Prometheus에 대해 생성된 지표와 동일합니다. 이는
FlowCollector리소스의spec.processor.metrics.includeList매개변수 또는FlowMetrics리소스를 통해 정의됩니다. spec.exporters.openTelemetry.metrics.pushTimeInterval- OpenTelemetry 수집기로 메트릭을 전송하는 시간 간격을 지정합니다.
spec.exporters.openTelemetry.fieldsMapping-
OpenTelemetry 형식 출력을 사용자 지정하는 선택적 매핑을 지정합니다. 네트워크 Observability 흐름 형식의 이름은 자동으로 OpenTelemetry 호환 형식으로 이름이 지정되지만 이 매개변수를 사용하면 사용자 지정 덮어쓰기가 가능합니다. 예를 들어 YAML 샘플에서
SrcAddr는 Network Observability 입력 필드이며 OpenTelemetry 출력에서source.address로 이름이 변경됩니다. "네트워크 흐름 형식 참조"에서 네트워크 관찰성과 OpenTelemetry 형식을 모두 볼 수 있습니다.
6.4. FlowCollector 리소스 업데이트
웹 콘솔을 사용하는 대신 oc patch 명령을 flowcollector 사용자 정의 리소스와 함께 사용하여 eBPF 샘플링과 같은 특정 사양을 신속하게 업데이트합니다.
프로세스
다음 명령을 실행하여
flowcollectorCR을 패치하고spec.agent.ebpf.sampling값을 업데이트합니다.$ oc patch flowcollector cluster --type=json -p "[{"op": "replace", "path": "/spec/agent/ebpf/sampling", "value": <new value>}] -n netobserv"
6.5. 섭취 시 네트워크 흐름 필터링
필터를 생성하여 생성된 네트워크 흐름 수를 줄입니다. 네트워크 흐름을 필터링하면 네트워크 관찰 구성 요소의 리소스 사용량을 줄일 수 있습니다.
두 가지 종류의 필터를 구성할 수 있습니다.
- eBPF 에이전트 필터
- Flowlogs-파이프라인 필터
6.5.1. eBPF 에이전트 필터
eBPF 에이전트 필터는 네트워크 흐름 수집 프로세스의 가장 초기 단계에서 적용되므로 성능을 극대화합니다.
네트워크 관찰 연산자로 eBPF 에이전트 필터를 구성하려면 "여러 규칙을 사용하여 eBPF 흐름 데이터 필터링"을 참조하세요.
6.5.2. Flowlogs-파이프라인 필터
Flowlogs 파이프라인 필터는 네트워크 흐름 수집 프로세스에서 나중에 적용되므로 트래픽 선택에 대한 제어력이 더 뛰어납니다. 이는 주로 데이터 저장을 개선하는 데 사용됩니다.
Flowlogs 파이프라인 필터는 다음 예에서 볼 수 있듯이 간단한 쿼리 언어를 사용하여 네트워크 흐름을 필터링합니다.
(srcnamespace="netobserv" OR (srcnamespace="ingress" AND dstnamespace="netobserv")) AND srckind!="service"쿼리 언어는 다음 구문을 사용합니다.
| 카테고리 | Operator |
|---|---|
| 논리적 부울 연산자(대소문자 구분 없음) |
|
| 비교 연산자 |
|
| 단항 연산 |
|
FlowCollector 리소스의 spec.processor.filters 섹션에서 flowlogs-pipeline 필터를 구성할 수 있습니다. 예를 들면 다음과 같습니다.
YAML Flowlogs-파이프라인 필터 예시
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
agent:
processor:
filters:
- query: |
(SrcK8S_Namespace="netobserv" OR (SrcK8S_Namespace="openshift-ingress" AND DstK8S_Namespace="netobserv"))
outputTarget: Loki
sampling: 10다음과 같습니다.
spec.processor.filters.outputTarget-
Loki,Prometheus또는 외부 시스템과 같은 일치하는 흐름의 출력 대상을 지정합니다. 이 매개변수를 생략하면 시스템은 모든 구성된 출력으로 흐름을 보냅니다. spec.processor.filters.sampling-
저장 또는 내보낸 일치하는 흐름 수를 제한하는 선택적 샘플링 간격을 지정합니다. 예를 들어 값
10은 흐름이 유지될 가능성이 10분의 1임을 의미합니다.
6.6. 빠른 필터 구성
사용 가능한 소스, 대상 및 범용 필터 키 목록을 사용하여 FlowCollector 리소스 내에서 빠른 필터를 수정합니다.
값을 큰따옴표로 묶으면 정확한 일치가 가능합니다. 그렇지 않은 경우 텍스트 값에 대한 부분 일치가 사용됩니다. 키의 끝에 붙는 뱅(!) 문자는 부정을 의미합니다. YAML 수정에 대한 자세한 내용은 샘플 FlowCollector 리소스를 참조하십시오.
"모두" 또는 "아무거나"와 일치하는 필터는 사용자가 쿼리 옵션에서 수정할 수 있는 UI 설정입니다. 이 리소스는 이 리소스 구성의 일부가 아닙니다.
다음은 사용 가능한 모든 필터 키 목록입니다.
| Universal* | 소스 | 대상 | 설명 |
|---|---|---|---|
| 네임스페이스 |
|
| 특정 네임스페이스와 관련된 트래픽을 필터링합니다. |
| name |
|
| 호스트-네트워크 트래픽의 경우 특정 포드, 서비스 또는 노드와 같은 주어진 리프 리소스 이름과 관련된 트래픽을 필터링합니다. |
| kind |
|
| 주어진 리소스 종류와 관련된 트래픽을 필터링합니다. 리소스 종류에는 리프 리소스(Pod, 서비스 또는 노드)나 소유자 리소스(배포 및 StatefulSet)가 포함됩니다. |
| owner_name |
|
| 지정된 리소스 소유자(즉, 워크로드 또는 포드 세트)와 관련된 트래픽을 필터링합니다. 예를 들어, 배포 이름, StatefulSet 이름 등이 될 수 있습니다. |
| resource |
|
|
정식 이름으로 표시되는 특정 리소스와 관련된 트래픽을 필터링하여 해당 리소스를 고유하게 식별합니다. 정식 표기법은 네임스페이스 종류의 경우 |
| address |
|
| IP 주소와 관련된 트래픽을 필터링합니다. IPv4와 IPv6가 지원됩니다. CIDR 범위도 지원됩니다. |
| mac |
|
| MAC 주소와 관련된 트래픽을 필터링합니다. |
| port |
|
| 특정 포트와 관련된 트래픽을 필터링합니다. |
| host_address |
|
| 포드가 실행 중인 호스트 IP 주소와 관련된 트래픽을 필터링합니다. |
| protocol | 해당 없음 | 해당 없음 | TCP나 UDP와 같은 프로토콜과 관련된 트래픽을 필터링합니다. |
-
모든 소스 및 대상에 대한 범용 키 필터링. 예를 들어,
name: 'my-pod'를 필터링하는 것은 모든 트래픽의 모든 트래픽을my-pod및my-pod로의 Match all 또는 Match any를 의미합니다.
6.7. 리소스 관리 및 성능 고려 사항
성능 기준을 관리하고 네트워크 관찰을 위해 리소스 소비를 최적화하는 데 필요한 eBPF 샘플링, 기능 활성화 및 리소스 제한을 포함한 주요 구성 설정을 검토합니다.
네트워크 관찰에 필요한 리소스 양은 클러스터의 크기와 클러스터가 관찰 데이터를 수집하고 저장하기 위한 요구 사항에 따라 달라집니다. 클러스터의 리소스를 관리하고 성능 기준을 설정하려면 다음 설정을 구성하는 것이 좋습니다. 이러한 설정을 구성하면 최적의 설정 및 관찰성 요구 사항을 충족할 수 있습니다.
다음 설정은 처음부터 리소스와 성과를 관리하는 데 도움이 될 수 있습니다.
- eBPF 샘플링
-
샘플링 사양인
spec.agent.ebpf.sampling을 설정하여 리소스를 관리할 수 있습니다. 기본적으로 eBPF 샘플링은50으로 설정되어 있으므로 흐름이 샘플링될 확률은 50분의 1입니다. 샘플링 간격 값이 낮을수록 더 많은 계산, 메모리, 저장 리소스가 필요합니다.0또는1의 값은 모든 흐름이 샘플링됨을 의미합니다. 기본값으로 시작한 후 경험을 통해 값을 조정하여 클러스터에 가장 적합한 설정을 찾는 것이 좋습니다. - eBPF 기능
- 더 많은 기능을 활성화할수록 CPU와 메모리에 영향을 주는 양도 늘어납니다. 이러한 기능의 전체 목록은 "네트워크 트래픽 관찰"을 참조하세요.
- 로키 없이
- Loki를 사용하지 않고 대신 Prometheus를 사용하면 네트워크 관찰에 필요한 리소스 양을 줄일 수 있습니다. 예를 들어, Loki 없이 네트워크 관찰 기능을 구성하면 메모리 사용량을 총 20~65% 절감할 수 있으며, 샘플링 간격 값에 따라 CPU 사용률은 10~30% 낮아집니다. 자세한 내용은 "Network Observability without Loki"를 참조하십시오.
- 인터페이스 제한 또는 제외
-
spec.agent.ebpf.interfaces및spec.agent.ebpf.excludeInterfaces에 대한 값을 설정하여 관찰된 전체 트래픽을 줄입니다. 기본적으로 에이전트는excludeInterfaces및lo(로컬 인터페이스)에 나열된 인터페이스를 제외한 시스템의 모든 인터페이스를 가져옵니다. 인터페이스 이름은 사용되는 컨테이너 네트워크 인터페이스(CNI)에 따라 다를 수 있습니다. - 성능 미세 조정
다음 설정은 네트워크 관찰 기능을 일정 시간 동안 실행한 후 성능을 미세 조정하는 데 사용할 수 있습니다.
-
리소스 요구 사항 및 제한 사항 :
spec.agent.ebpf.resources및spec.processor.resources사양을 사용하여 클러스터에서 예상되는 부하와 메모리 사용량에 맞게 리소스 요구 사항 및 제한 사항을 조정합니다. 대부분의 중간 규모 클러스터에는 기본 제한인 800MB가 충분할 수 있습니다. -
캐시 최대 흐름 시간 초과 : eBPF 에이전트의
spec.agent.ebpf.cacheMaxFlows및spec.agent.ebpf.cacheActiveTimeout사양을 사용하여 에이전트가 흐름을 보고하는 빈도를 제어합니다. 값이 클수록 에이전트에서 생성되는 트래픽이 줄어들어 CPU 부하가 낮아집니다. 그러나 값이 클수록 메모리 소모가 약간 더 많아지고 흐름 수집 시 지연 시간이 길어질 수 있습니다.
-
리소스 요구 사항 및 제한 사항 :
6.7.1. 리소스 고려 사항
Network Observability Operator 구성은 클러스터 워크로드 크기에 따라 조정할 수 있습니다. 다음 기준 예제를 사용하여 환경에 대한 적절한 리소스 제한 및 구성 설정을 확인합니다.
표에 나와 있는 예는 특정 작업 부하에 맞춰진 시나리오를 보여줍니다. 각 예시는 업무량 요구에 맞게 조정할 수 있는 기준선으로만 생각하세요.
이러한 권장 사항에 사용되는 테스트 베드는 다음과 같습니다.
-
추가 small: 10-node 클러스터, 작업자당 4개의 vCPU 및 16GiB 메모리,
LokiStack크기1x.extra-undercloud 에서는 AWS M6i 인스턴스에서 테스트합니다. -
small: 25-node 클러스터, 작업자당 16개의 vCPU 및 64GiB 메모리,
LokiStack크기1x.undercloud 에서는 AWS M6i 인스턴스에서 테스트합니다. -
Large: 250-node 클러스터, 작업자당 16개의 vCPU 및 64GiB 메모리,
LokiStack크기1x.medium은 AWS M6i 인스턴스에서 테스트합니다. 작업자 및 컨트롤러 노드 외에도 3개의 인프라 노드(크기M6i.12xlarge)와 워크로드 노드(M6i.8xlarge크기)를 테스트했습니다.
| 기준 | 매우 작음(10개 노드) | 소형(25개 노드) | 대규모(250 노드) |
|---|---|---|---|
|
Operator 메모리 제한: |
|
|
|
|
eBPF 에이전트 샘플링 간격: |
|
|
|
|
eBPF 에이전트 메모리 제한: |
|
|
|
|
eBPF 에이전트 캐시 크기: |
|
|
|
|
프로세서 메모리 제한: |
|
|
|
|
프로세서 복제본: |
|
|
|
|
배포 모델: |
|
|
|
| Kafka 파티션: Kafka 설치 | 해당 없음 |
|
|
| Kafka 브로커: Kafka 설치 | 해당 없음 |
|
|
6.7.2. 총 평균 메모리 및 CPU 사용량
다른 eBPF 샘플링 값에서 두 개의 개별 트래픽 시나리오(테스트 1 및 )에서 네트워크 관찰 가능성 구성 요소의 총 평균 CPU 및 메모리 사용량을 자세히 검토하십시오.
테스트2
다음 표는 두 가지 테스트( 테스트 1 및 테스트 2) 에 대한 샘플링 값이 1 과 50인 클러스터의 총 리소스 사용량 평균을 간략하게 보여줍니다. 테스트는 다음과 같은 점에서 다릅니다.
-
테스트 1은OpenShift Container Platform 클러스터의 총 네임스페이스, 포드 및 서비스 수 외에도 높은 유입 트래픽 볼륨을 고려하고, eBPF 에이전트에 부하를 주며, 주어진 클러스터 크기에 대해 많은 작업 부하가 있는 사용 사례를 나타냅니다. 예를 들어,테스트 1은76개의 네임스페이스, 5,153개의 Pod, 2,305개의 서비스로 구성되며 네트워크 트래픽 규모는 약 350MB/s입니다. -
테스트 2에서는OpenShift Container Platform 클러스터의 총 네임스페이스, 포드 및 서비스 수 외에도 높은 유입 트래픽 볼륨을 고려하고 주어진 클러스터 크기에 대해 많은 수의 워크로드가 있는 사용 사례를 나타냅니다. 예를 들어,테스트 2는553개의 네임스페이스, 6998개의 Pod, 2508개의 서비스로 구성되며 네트워크 트래픽 규모는 ~950MB/s입니다.
다양한 테스트에서 다양한 유형의 클러스터 사용 사례가 예시되었기 때문에 이 표의 숫자는 나란히 비교했을 때 선형적으로 증가하지 않습니다. 대신, 이는 개인의 클러스터 사용을 평가하기 위한 벤치마크로 사용되도록 의도되었습니다. 표에 나와 있는 예는 특정 작업 부하에 맞춰진 시나리오를 보여줍니다. 각 예시는 업무량 요구에 맞게 조정할 수 있는 기준선으로만 생각하세요.
Prometheus로 내보낸 메트릭은 리소스 사용량에 영향을 미칠 수 있습니다. 메트릭의 기수 값은 리소스가 얼마나 영향을 받는지 확인하는 데 도움이 될 수 있습니다. 자세한 내용은 추가 리소스 섹션의 "네트워크 흐름 형식"을 참조하세요.
| 샘플링 값 | 사용된 리소스 | 테스트 1(25개 노드) | 테스트 2(250개 노드) |
|---|---|---|---|
| Sampling = 50 | 총 NetObserv CPU 사용량 | 1.35 | 5.39 |
| 총 NetObserv RSS(메모리) 사용량 | 16GB | 63 GB | |
| Sampling = 1 | 총 NetObserv CPU 사용량 | 1.82 | 11.99 |
| 총 NetObserv RSS(메모리) 사용량 | 22 GB | 87 GB |
요약: 이 표는 모든 기능이 활성화된 에이전트, FLP, Kafka, Loki를 포함한 네트워크 관찰의 평균 총 리소스 사용량을 보여줍니다. 어떤 기능이 활성화되어 있는지에 대한 자세한 내용은 "네트워크 트래픽 관찰"에서 다루는 기능을 참조하세요. 여기에는 이 테스트에서 활성화된 모든 기능이 포함되어 있습니다.
7장. 테넌트당 네트워크 관찰 기능 모델
글로벌 클러스터 거버넌스를 유지하면서 FlowCollectorSlice 리소스를 사용하여 네트워크 트래픽 분석 관리를 프로젝트 관리자에게 위임합니다.
7.1. 테넌트별 계층 거버넌스 및 테넌트 autonomy
클러스터 관리자는 글로벌 거버넌스를 유지하면서 프로젝트 관리자가 특정 네임스페이스 내에서 네트워크 트래픽 관찰 기능을 관리할 수 있습니다.
Network Observability Operator는 계층적 구성 모델을 사용하여 멀티 테넌시를 지원합니다. 이 아키텍처는 클러스터 관리자 개입 없이 개별 팀에 셀프 서비스 가시성이 필요한 대규모 배포 및 호스팅된 컨트롤 플레인 환경에 유용합니다.
계층적 모델은 다음 구성 요소로 구성됩니다.
- 글로벌 거버넌스
-
클러스터 관리자는 글로벌
FlowCollector리소스를 관리합니다. 이 리소스는 관찰 가능 인프라를 정의하고 테넌트별 구성이 허용되는지 여부를 결정합니다. - 테넌트 autonomy
-
프로젝트 관리자는
FlowCollectorSlice리소스를 관리합니다. 이 네임스페이스 범위의 CR(사용자 정의 리소스)을 사용하면 팀이 워크로드에 대한 특정 관찰 기능 설정을 정의할 수 있습니다.
7.2. 세분화된 흐름 수집을 위한 FlowCollectorSlice 리소스
FlowCollectorSlice 는 세분화된 다중 테넌트 네트워크 흐름 컬렉션을 가능하게 하는 CRD(사용자 정의 리소스 정의)입니다. 네임스페이스 또는 서브넷을 기반으로 논리 슬라이스를 정의하면 트래픽을 선택적으로 수집하고 전체 클러스터가 아닌 특정 워크로드에 사용자 정의 샘플링을 적용할 수 있습니다.
모든 트래픽에 균일하게 적용되는 단일 글로벌 구성 대신 세분화된 선택 및 다중 테넌트 인식 흐름 컬렉션을 활성화하여 기존 FlowCollector 사용자 지정 리소스를 보완합니다.
슬라이스 기반 컬렉션이 활성화되면 하나 이상의 FlowCollectorSlice 와 일치하는 트래픽만 수집되어 관리자가 모니터링되는 네트워크 흐름을 정확하게 제어할 수 있습니다.
7.2.1. FlowCollectorSlice의 이점
기본적으로 네트워크 흐름 컬렉션은 클러스터의 모든 트래픽에 균일하게 적용됩니다. 이로 인해 과도한 데이터 볼륨과 유연성이 제한될 수 있습니다.
FlowCollectorSlice 를 사용하면 다음과 같은 이점이 있습니다.
- 특정 네임스페이스 또는 워크로드에 대해 선택적 흐름 컬렉션을 활성화합니다.
- 멀티 테넌트 및 환경 기반 관찰 기능 지원
- 관련 트래픽을 필터링하여 스토리지 및 처리 비용을 줄입니다.
- 옵트인 구성을 통해 이전 버전과의 호환성을 유지합니다.
7.2.2. FlowCollector와 FlowCollectorSlice 간의 관계
FlowCollector 리소스는 클러스터에 대한 글로벌 흐름 수집 동작을 정의하지만, FlowCollectorSlice 리소스는 슬라이스 기반 필터링이 활성화된 경우 컬렉션에 적합한 트래픽을 정의합니다.
FlowCollector.spec.slicesConfig 필드는 슬라이스 정의가 적용되는 방법을 제어합니다.
7.2.3. 컬렉션 모드
슬라이스 동작은 FlowCollector.spec.slicesConfig.collectionMode 필드에 의해 관리됩니다. 필드를 다음 컬렉션 모드 중 하나로 설정합니다.
- AlwaysCollect
- 모든 클러스터 네임스페이스에서 네트워크 흐름을 수집합니다.
-
FlowCollectorSlice리소스에 정의된 서브넷 및 샘플링 구성을 적용합니다. -
FlowCollectorSlice리소스의 네임스페이스 선택 논리를 무시합니다. - 이전 버전과의 호환성을 위해 기본 컬렉션 동작을 유지 관리합니다.
- allowlist
-
하나 이상의
FlowCollectorSlice리소스와 일치하는 트래픽만 수집합니다. - 선택적 네임스페이스 허용 목록에는 컬렉션에서 선택한 네임스페이스가 포함됩니다.
-
하나 이상의
7.2.4. FlowCollectorSlice 상태
각 FlowCollectorSlice 리소스는 다음을 보고하는 상태 하위 리소스를 노출합니다.
- 검증 결과.
- 조정 상태.
- 슬라이스가 성공적으로 적용되었는지 여부입니다.
이 상태를 통해 관리자는 슬라이스 정의가 활성 상태이고 예상대로 작동하는지 확인할 수 있습니다.
7.3. Network Observability Operator FlowCollectorSlice 활성화
FlowCollector Slicor 리소스에서 FlowCollectorSlice 기능을 활성화하면 클러스터 관리자가 흐름 수집 및 데이터 강화 관리를 특정 네임스페이스에 위임할 수 있습니다.
프로젝트 관리자가 고유한 설정을 관리하려면 클러스터 관리자가 FlowCollector 사용자 지정 리소스를 활성화하여 FlowCollectorSlice 사용자 지정 리소스를 조사해야 합니다.
사전 요구 사항
- Network Observability Operator가 설치되어 있습니다.
-
클러스터에
FlowCollector사용자 지정 리소스가 있습니다. -
cluster-admin권한이 있어야 합니다.
프로세스
다음 명령을 실행하여
FlowCollector사용자 지정 리소스를 편집합니다.$ oc edit flowcollector cluster슬라이스를 사용할 수 있는 네임스페이스를 정의하도록
spec.processor.slicesConfig필드를 구성합니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: slicesConfig: enable: true collectionMode: AllowList namespacesAllowList: - /openshift-.*|netobserv.*/다음과 같습니다.
spec.processor.sliceConfig.enable-
FlowCollectorSlice기능이 활성화되어 있는지 여부를 지정합니다. 그렇지 않으면FlowCollectorSlice의 모든 리소스가 무시됩니다. spec.processor.sliceConfig.collectionMode-
FlowCollectorSlice사용자 지정 리소스가 흐름 컬렉션 프로세스에 영향을 미치는 방법을 지정합니다.AlwaysCollect로 설정하면FlowCollectorSlice의 존재 여부에 관계없이 모든 흐름이 수집됩니다.AllowList로 설정하면FlowCollectorSlice리소스가 있거나 글로벌namespacesAllowList를 통해 구성된 네임스페이스와 관련된 흐름만 수집됩니다. spec.processor.sliceConfig.namespacesAllowList해당 네임스페이스에
FlowCollectorSlice의 존재 여부에 관계없이 항상 흐름이 수집되는 네임스페이스 목록을 지정합니다.참고namespacesAllowList필드는/openshift-.*/와 같은 정규식을 지원하여 여러 네임스페이스를 캡처하거나netobserv와 같은 엄격한 일치를 특정 네임스페이스와 일치시킬 수 있습니다.
- 변경 사항을 저장하고 편집기를 종료합니다.
검증
-
openshift-로 시작하는netobserv네임스페이스 및 네임스페이스에서 네트워크 흐름만 웹 콘솔의 네트워크 트래픽 페이지에 표시되는지 확인합니다.
7.3.1. Network Observability Operator FlowCollectorSlice 비활성화
Network Observability Operator에서 슬라이스 기반 필터링을 비활성화하여 기존 FlowCollectorSlice 리소스를 보존하면서 글로벌 흐름 컬렉션을 재개합니다.
프로세스
다음 명령을 실행하여
FlowCollector리소스를 편집합니다.$ oc edit flowcollector clusterspec.processor.slicesConfig.collectionMode필드를AlwaysCollect:로 설정합니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: slicesConfig: enable: true collectionMode: AlwaysCollect ...변경 사항을 저장합니다.
흐름 컬렉션은 모든 트래픽에 대해 재개되며 기존
FlowCollectorSlice리소스는 향후 사용할 수 있도록 계속 사용할 수 있습니다.
7.4. 프로젝트 관리자로 FlowCollectorSlice 구성
프로젝트 관리자는 분산된 네트워크 트래픽 분석을 위해 FlowCollectorSlice 사용자 정의 리소스를 구성하여 자체 네임스페이스 내에서 흐름 수집 및 데이터 강화를 관리할 수 있습니다.
사전 요구 사항
- Network Observability Operator가 설치되어 있습니다.
-
네임스페이스에 대한
project-admin권한이 있습니다.
프로세스
flowCollectorSlice.yaml이라는 YAML 파일을 생성합니다.apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollectorSlice metadata: name: flowcollectorslice-sample namespace: my-app spec: sampling: 1 subnetLabels: - name: EXT:Database cidrs: - 192.168.50.0/24다음 명령을 실행하여 구성을 적용합니다.
$ oc apply -f flowCollectorSlice.yaml
검증
- OpenShift Container Platform 콘솔에서 모니터링 → 네트워크 트래픽 으로 이동합니다.
-
EXT:Database레이블을 사용하여192.168.50.0/24서브넷으로의 흐름이 관찰되는지 확인합니다.
7.5. FlowCollectorSlice [flows.netobserv.io/v1alpha1]
- 설명
- FlowCollectorSlice는 네임스페이스 테넌트당 일부 FlowCollector 구성을 분산할 수 있는 API입니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| APIVersion은 버전이 지정된 이 오브젝트 표현의 스키마를 정의합니다. 서버는 인식된 스키마를 최신 내부 값으로 변환해야 하며, 인식되지 않는 값을 거부할 수 있습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| kind는 이 오브젝트가 나타내는 REST 리소스에 해당하는 문자열 값입니다. 서버는 클라이언트에서 요청을 제출한 끝점에서 이를 유추할 수 있습니다. CamelCase로 업데이트할 수 없습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
| FlowCollectorSliceSpec은 원하는 FlowCollectorSlice 상태를 정의합니다. |
7.5.1. .metadata
- 설명
- 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- 유형
-
object
7.5.2. .spec
- 설명
- FlowCollectorSliceSpec은 원하는 FlowCollectorSlice 상태를 정의합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
FlowCollectorSlice에 구성된 서브넷 레이블은 관련 네임스페이스의 흐름으로 제한되지 않습니다. 전체 클러스터의 흐름은 이 구성을 사용하여 레이블을 지정할 수 있습니다. 그러나 클러스터 범위의 FlowCollector에 정의된 서브넷 레이블은 규칙이 충돌하는 경우 우선합니다. |
7.5.3. .spec.subnetLabels
- 설명
subnetLabels를 사용하면 클러스터 외부 워크로드 또는 웹 서비스를 식별하기 위해 서브넷 및 IP 레이블을 사용자 지정할 수 있습니다. 기본 빠른 필터 및 제공된 일부 메트릭 예제에서 작업하려면 외부 서브넷에EXT:접두사 , 레이블이 지정되거나 전혀 레이블이 지정되지 않아야 합니다.
FlowCollectorSlice에 구성된 서브넷 레이블은 관련 네임스페이스의 흐름으로 제한되지 않습니다. 전체 클러스터의 흐름은 이 구성을 사용하여 레이블을 지정할 수 있습니다. 그러나 클러스터 범위의 FlowCollector에 정의된 서브넷 레이블은 규칙이 충돌하는 경우 우선합니다.
- 유형
-
array
7.5.4. .spec.subnetLabels[]
- 설명
- SubnetLabel을 사용하면 클러스터 외부 작업 부하나 웹 서비스를 식별하기 위해 서브넷과 IP에 레이블을 지정할 수 있습니다.
- 유형
-
object - 필수 항목
-
cidrs -
name
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
레이블 이름은 일치하는 흐름을 표시하는 데 사용됩니다. 기본 빠른 필터 및 제공된 일부 메트릭 예제에서 작업하려면 외부 서브넷에 |
8장. Network Policy
관리자는 netobserv 네임스페이스에 대한 네트워크 정책을 만들 수 있습니다. 이 정책은 네트워크 관찰 운영자에 대한 인바운드 및 아웃바운드 액세스를 보호합니다.
8.1. FlowCollector 사용자 정의 리소스를 사용하여 네트워크 정책 구성
Pod 트래픽을 제어하기 위해 수신 및 송신 네트워크 정책을 설정할 수 있습니다. 이를 통해 보안이 강화되고 필요한 네트워크 흐름 데이터만 수집됩니다. 이를 통해 노이즈가 줄어들고, 규정 준수가 지원되며, 네트워크 통신에 대한 가시성이 향상됩니다.
FlowCollector 사용자 정의 리소스(CR)를 구성하여 네트워크 관찰을 위해 송신 및 수신 네트워크 정책을 배포할 수 있습니다. 기본적으로 spec.NetworkPolicy.enable 사양은 true 로 설정됩니다.
네트워크 정책이 있는 다른 네임스페이스에 Loki, Kafka 또는 내보내기 프로그램을 설치한 경우 네트워크 관찰 구성 요소가 해당 구성 요소와 통신할 수 있는지 확인해야 합니다. 설정에 관해 다음 사항을 고려하세요.
-
Loki에 대한 연결(
FlowCollectorCRspec.loki매개변수에 정의된 대로) -
Kafka에 대한 연결(
FlowCollectorCRspec.kafka매개변수에 정의된 대로) -
모든 내보내기 프로그램에 대한 연결(FlowCollector CR
spec.exporters매개변수에 정의된 대로) -
Loki를 사용하고 정책 대상에 포함하는 경우 외부 개체 저장소(
LokiStack관련 비밀에 정의된 대로)에 연결
프로세스
- 웹 콘솔에서 Operator → 설치된 Operator 로 이동합니다.
- Network Observability에 대해 제공된 API에서 Flow Collector 를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
FlowCollectorCR을 구성합니다. 샘플 구성은 다음과 같습니다.네트워크 정책을 위한
FlowCollectorCR 예시apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv networkPolicy: enable: true additionalNamespaces: ["openshift-console", "openshift-monitoring"] # ...다음과 같습니다.
spec.networkPolicy.enable-
네트워크 정책 관리를 활성화할지 여부를 지정합니다. 기본값은
true입니다. spec.networkPolicy.additionalNamespaces-
네트워크 정책에 포함할 네임스페이스를 지정합니다. 기본값은
["openshift-console", "openshift-monitoring"]입니다.
9장. 네트워크 관찰 기능 DNS 확인 분석
DNS 확인 분석에서 eBPF 기반 디코딩을 사용하여 서비스 검색 문제를 식별하고 단계를 수행하여 FlowCollector 리소스에서 DNS 추적을 활성화하여 도메인 이름으로 네트워크 흐름 레코드를 강화할 수 있습니다.
9.1. DNS 확인 분석의 전략적 이점
DNS 확인 분석을 사용하여 도메인 이름 및 상태 코드로 eBPF 흐름 레코드를 강화하여 네트워크 전송 실패와 서비스 검색 문제를 구분합니다.
표준 흐름 로그는 포트 53에서 트래픽이 발생한 경우에만 표시됩니다. DNS 확인 분석을 사용하면 다음 작업을 완료할 수 있습니다.
-
식별할 시간 단축(Mtti):
NXDOMAIN오류와 같은 네트워크 라우팅 실패와 DNS 확인 실패 사이에 즉시 해제됩니다. -
내부 서비스 대기 시간 측정: CoreDNS가 특정 내부 조회(예:
my-service.namespace.svc.cluster.local)에 응답하는 데 걸리는 시간을 추적합니다. - 감사 외부 종속성: 사이드카 또는 수동 패킷 캡처 없이도 워크로드가 통신하는 외부 API 또는 타사 도메인을 감사합니다.
- 향상된 보안 상태: 내부 워크로드에서 쿼리하는 FQDN(정규화된 도메인 이름)을 감사하여 잠재적인 데이터 유출 또는 명령 및 제어(C2) 활동을 감지합니다.
9.1.1. DNS 흐름 강화
이 기능이 활성화되면 eBPF 에이전트는 흐름 레코드를 강화합니다. 이 메타데이터를 사용하면 소스 IP뿐만 아니라 연결(도메인)의 의도로 트래픽을 그룹화하고 필터링할 수 있습니다.
향상된 DNS 디코딩을 사용하면 eBPF 에이전트가 DNS 요청에 대한 쿼리 이름과 함께 포트 53에서 UDP 및 TCP DNS 트래픽을 검사할 수 있습니다.
9.2. 네트워크 관찰 기능에 대한 DNS 도메인 추적 구성
Network Observability Operator에서 DNS 추적을 활성화하여 클러스터 내에서 네트워크 흐름에 대한 DNS 쿼리 이름, 응답 코드 및 대기 시간을 모니터링합니다.
사전 요구 사항
- Network Observability Operator가 설치되어 있습니다.
-
cluster-admin권한이 있어야 합니다. -
FlowCollector사용자 지정 리소스에 대해 잘 알고 있습니다.
프로세스
다음 명령을 실행하여
FlowCollector리소스를 편집합니다.$ oc edit flowcollector clusterDNS 추적 기능을 활성화하도록 eBPF 에이전트를 구성합니다.
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: eBPF ebpf: features: - DNSTracking다음과 같습니다.
spec.agent.type.ebpf.features-
eBPF 에이전트에 사용할 기능 목록을 지정합니다. DNS 추적을 활성화하려면
DNSTracking을 이 목록에 추가합니다.
- 저장하고 편집기를 종료합니다.
검증
- OpenShift Container Platform 웹 콘솔에서 모니터링 → 네트워크 트래픽 으로 이동합니다.
- 트래픽 흐름 보기에서 열 관리 아이콘을 클릭합니다.
- DNS 쿼리 이름, DNS 응답 코드 및 DNS 대기 시간 열이 선택되어 있는지 확인합니다.
-
Port to
53을 설정하여 결과를 필터링합니다. - 흐름 테이블 열이 도메인 이름 및 DNS 메타데이터로 채워져 있는지 확인합니다.
9.3. DNS 흐름 강화 및 분석 참조
네트워크 흐름에 추가된 메타데이터를 식별하고, 네트워크 최적화를 위해 DNS 데이터를 활용하고, 클러스터에 미치는 성능 및 스토리지 영향을 파악합니다.
다음 표에서는 DNS 추적을 활성화할 때 네트워크 흐름에 추가된 메타데이터 필드를 설명합니다.
압축 포인터 또는 캐시 제한으로 인해 쿼리 이름이 없거나 잘릴 수 있습니다.
| 필드 | 설명 | 예 |
|---|---|---|
|
| 쿼리되는 FQDN(정규화된 도메인 이름)입니다. |
|
|
| DNS 서버에서 반환한 상태 코드입니다. |
|
|
| 쿼리와 응답 일치에 사용되는 트랜잭션 ID입니다. |
|
9.3.1. 네트워크 최적화를 위해 DNS 데이터 활용
다음 운영 결과에 대해 캡처된 DNS 메타데이터를 사용합니다.
- 감사 외부 종속 항목: 권한이 없는 외부 API 또는 고위험 도메인에 워크로드가 도달하지 않도록 합니다.
-
성능 튜닝:
CoreDNSPod에 추가 확장이 필요한지 또는 업스트림DNS 공급자가 지연되는지 확인하기 위해 DNS 대기시간을 모니터링합니다.
9.3.2. 잘못된 구성 오류 확인
높은 빈도의 NXDOMAIN 응답은 일반적으로 애플리케이션 코드 또는 오래된 환경 변수에서 서비스 검색 오류를 나타냅니다.
서비스 및 Pod에서 DNS 검색으로 인해 Kubernetes에서 NXDOMAIN 오류가 발생할 수 있습니다. 이러한 결과는 반드시 잘못된 URL 또는 손상된 URL을 나타내는 것은 아니지만 성능에 부정적인 영향을 미칠 수 있습니다.
my-svc.my-namespace.svc 와 같은 유효한 서비스 또는 Pod 호스트 이름에도 NXDOMAIN 오류가 반환되면 확인자가 다른 접미사에 대해 DNS를 쿼리하도록 구성됩니다. 정규화된 도메인 이름에 후행 점을 추가하여 이름을 모호하지 않음을 확인자에게 알릴 수 있습니다.
예를 들어 https://my-svc.my-namespace.svc 대신 https://my-svc.my-namespace.svc.cluster.local 를 후행 점과 함께 사용합니다.
9.3.3. Loki 스토리지 고려 사항
DNS 추적은 레이블 수와 흐름당 메타데이터 양을 늘립니다. Loki 스토리지 크기가 증가된 로그 볼륨을 수용하도록 조정되었는지 확인합니다.
10장. 네트워크 트래픽 관찰
관리자는 OpenShift Container Platform 웹 콘솔에서 네트워크 트래픽을 관찰하여 자세한 문제 해결 및 분석을 수행할 수 있습니다. 이 기능을 사용하면 교통 흐름을 다양한 그래픽으로 표현하여 통찰력을 얻을 수 있습니다.
10.1. 개요 보기에서 네트워크 트래픽 관찰
네트워크 트래픽 개요 보기는 집계된 흐름 지표와 애플리케이션 통신에 대한 시각적 통찰력을 제공합니다. 관리자는 메트릭을 사용하여 데이터 볼륨을 모니터링하고 연결 문제를 해결하며 클러스터 전체에서 비정상적인 트래픽 패턴을 감지할 수 있습니다.
개요 보기에는 OpenShift Container Platform 클러스터에서 집계 네트워크 트래픽이 표시되어 통신 중인 애플리케이션 및 전송되는 데이터를 확인할 수 있습니다. 최상위 트래픽 흐름 및 평균 바이트 비율과 함께 소스, 대상 및 흐름 유형별로 자세한 통찰력을 제공합니다.
관리자는 연결 문제를 해결하고 비정상적인 트래픽 패턴을 감지하고 애플리케이션 성능을 최적화할 수 있습니다. 네트워크 동작에 대한 간략한 개요를 제공하여 작업을 더 쉽게 우선시하고 리소스 사용량을 효율적으로 수행할 수 있습니다.
10.1.1. 개요 보기 작업
OpenShift Container Platform 콘솔에서 네트워크 트래픽 개요 보기로 이동하여 흐름 속도 통계의 그래픽 표시를 확인하고 사용 가능한 옵션을 사용하여 표시 범위를 구성합니다.
사전 요구 사항
- 관리자 권한으로 클러스터에 액세스합니다.
프로세스
- 모니터링 → 네트워크 트래픽 으로 이동합니다.
- 네트워크 트래픽 페이지에서 개요 탭을 클릭합니다.
- 메뉴 아이콘을 클릭하여 각 흐름 속도 데이터의 범위를 구성합니다.
10.1.2. 개요 보기에 대한 고급 옵션 구성
흐름 속도 통계 및 트래픽 데이터 표시를 구체화하도록 그래프 범위, 라벨 잘림 및 패널 관리와 같은 고급 옵션을 구성하여 네트워크 트래픽 개요 보기를 사용자 지정합니다.
고급 옵션에 액세스하려면 고급 옵션 표시를 클릭하세요. 표시 옵션 드롭다운 메뉴를 사용하여 그래프의 세부 정보를 구성할 수 있습니다. 사용 가능한 옵션은 다음과 같습니다.
- 범위 : 네트워크 트래픽이 흐르는 구성 요소를 보려면 선택합니다. Node, Namespace, Owner, Zones, Cluster 또는 Resource로 리소스 범위를 설정할 수 있습니다. 소유자 는 리소스의 집합체입니다. 리소스는 호스트 네트워크 트래픽의 경우 포드, 서비스, 노드이거나 알 수 없는 IP 주소일 수 있습니다. 기본값은 Namespace 입니다.
- 라벨 자르기 : 드롭다운 목록에서 라벨의 필요한 너비를 선택합니다. 기본값은 M 입니다.
10.1.2.1. 패널 및 디스플레이 관리
표시할 필요한 패널을 선택하고, 패널 순서를 바꾸고, 특정 패널에 집중할 수 있습니다. 패널을 추가하거나 제거하려면 패널 관리를 클릭하세요.
기본적으로 다음 패널이 표시됩니다.
- 상위 X 평균 바이트 속도
- 전체와 함께 쌓인 상위 X 바이트 속도
패널 관리에서 다른 패널을 추가할 수 있습니다.
- 상위 X 평균 패킷 속도
- 전체와 함께 쌓인 상위 X 패킷 속도
쿼리 옵션을 사용하면 Top 5, Top 10, Top 15 개 비율을 표시할지 여부를 선택할 수 있습니다.
10.1.3. 패킷 삭제 추적
드롭 위치를 식별하고 호스트 또는 OVS별 드롭인 이유를 감지하고, 개요 보기에서 전용 그래픽 패널을 제공하는 eBPF 기반 패킷 드롭 추적을 사용하여 네트워크 패킷 손실을 모니터링하고 분석합니다.
개요 보기에서 패킷 손실이 발생한 네트워크 흐름 기록의 그래픽 표현을 구성할 수 있습니다. eBPF 추적점 후크를 사용하면 TCP, UDP, SCTP, ICMPv4 및 ICMPv6 프로토콜에 대한 패킷 삭제에 대한 귀중한 통찰력을 얻을 수 있으며, 이는 다음과 같은 작업을 초래할 수 있습니다.
- 식별: 패킷 손실이 발생하는 정확한 위치와 네트워크 경로를 파악합니다. 특정 장치, 인터페이스 또는 경로가 삭제될 가능성이 더 높은지 확인합니다.
- 근본 원인 분석: eBPF 프로그램에서 수집한 데이터를 조사하여 패킷 손실의 원인을 파악합니다. 예를 들어, 혼잡, 버퍼 문제 또는 특정 네트워크 이벤트로 인해 발생합니까?
- 성능 최적화: 패킷 손실에 대한 더 명확한 그림을 통해 버퍼 크기 조정, 라우팅 경로 재구성, 서비스 품질(QoS) 조치 구현 등 네트워크 성능을 최적화하기 위한 조치를 취할 수 있습니다.
패킷 삭제 추적이 활성화되면 기본적으로 개요 에서 다음 패널을 볼 수 있습니다.
- 상위 X 패킷은 드롭 상태가 총으로 누적됨
- 상위 X 패킷이 삭제되어 총합이 쌓였습니다.
- 상위 X 평균 패킷 손실률
- 전체와 함께 누적된 상위 X개의 패킷 삭제율
패널 관리에서 다른 패킷 드롭 패널을 추가할 수 있습니다.
- 상위 X 평균 바이트 삭제율
- 총합과 함께 쌓인 상위 X개의 바이트 삭제율
10.1.3.1. 패킷 삭제 유형
네트워크 관찰 기능에서 패킷 드롭 다운의 두 가지 종류(호스트 드롭 및 OVS 드롭)로 감지됩니다. 호스트 드롭에는 SKB_DROP 이라는 접두사가 붙고 OVS 드롭에는 OVS_DROP 이라는 접두사가 붙습니다. 삭제된 흐름은 트래픽 흐름 표의 측면 패널에 표시되며 각 삭제 유형에 대한 설명에 대한 링크도 함께 표시됩니다. 호스트 삭제 이유의 예는 다음과 같습니다.
-
SKB_DROP_REASON_NO_SOCKET: 소켓이 없어서 패킷이 삭제되었습니다. -
SKB_DROP_REASON_TCP_CSUM: TCP 체크섬 오류로 인해 패킷이 삭제되었습니다.
OVS가 삭제되는 이유의 예는 다음과 같습니다.
-
OVS_DROP_LAST_ACTION: 구성된 네트워크 정책 등으로 인해 암묵적인 삭제 작업으로 인해 삭제된 OVS 패킷입니다. -
OVS_DROP_IP_TTL: IP TTL이 만료되어 OVS 패킷이 삭제되었습니다.
패킷 삭제 추적을 활성화하고 사용하는 방법에 대한 자세한 내용은 이 섹션의 추가 리소스를 참조하세요.
10.1.4. DNS 추적
eBPF 기반 DNS 추적을 사용하여 DNS 활동을 모니터링하여 쿼리 패턴에 대한 인사이트를 얻고, 보안 위협을 감지하고, 개요 보기의 전용 그래픽 패널을 통해 대기 시간 문제를 해결합니다.
개요 보기에서 네트워크 흐름의 DNS(도메인 이름 시스템) 추적에 대한 그래픽 표현을 구성할 수 있습니다. 확장된 Berkeley Packet Filter(eBPF) 추적점 후크와 함께 DNS 추적을 사용하면 다양한 목적을 달성할 수 있습니다.
- 네트워크 모니터링: DNS 쿼리와 응답에 대한 통찰력을 얻어 네트워크 관리자가 비정상적인 패턴, 잠재적 병목 현상 또는 성능 문제를 식별하는 데 도움이 됩니다.
- 보안 분석: 맬웨어가 사용하는 도메인 이름 생성 알고리즘(DGA)과 같은 의심스러운 DNS 활동을 감지하거나 보안 위반을 나타낼 수 있는 승인되지 않은 DNS 확인을 식별합니다.
- 문제 해결: DNS 확인 단계를 추적하고, 지연 시간을 추적하고, 잘못된 구성을 식별하여 DNS 관련 문제를 디버깅합니다.
기본적으로 DNS 추적이 활성화된 경우 개요 에서 도넛형 또는 선형 차트로 표현된 다음과 같은 비어 있지 않은 메트릭을 볼 수 있습니다.
- 상위 X DNS 응답 코드
- 전체 평균 DNS 대기 시간 상위 X개
- 상위 X 90번째 백분위수 DNS 대기 시간
패널 관리에 다른 DNS 추적 패널을 추가할 수 있습니다.
- 하단 X 최소 DNS 대기 시간
- 상위 X 최대 DNS 대기 시간
- 상위 X 99번째 백분위수 DNS 대기 시간
이 기능은 IPv4 및 IPv6 UDP 및 TCP 프로토콜에서 지원됩니다.
이 보기를 활성화하고 사용하는 방법에 대한 자세한 내용은 이 섹션의 추가 리소스를 참조하세요.
10.1.5. 왕복 시간
eBPF 후크 포인트를 사용하여 성능 병목 현상을 식별하고 개요 보기의 전용 패널을 통해 TCP 관련 문제를 해결하는 TCP Round-Trip Time (RTT) 지표를 사용하여 네트워크 흐름 대기 시간을 분석합니다.
TCP 평활화 왕복 시간(sRTT)을 사용하여 네트워크 흐름 지연을 분석할 수 있습니다. fentry/tcp_rcv_established eBPF 후크포인트에서 캡처한 RTT를 사용하여 TCP 소켓에서 sRTT를 읽어 다음 작업에 도움을 줄 수 있습니다.
- 네트워크 모니터링: TCP 지연 시간에 대한 통찰력을 얻어 네트워크 관리자가 비정상적인 패턴, 잠재적 병목 현상 또는 성능 문제를 식별하는 데 도움을 줍니다.
- 문제 해결: 지연 시간을 추적하고 잘못된 구성을 식별하여 TCP 관련 문제를 디버깅합니다.
기본적으로 RTT가 활성화된 경우 개요 에 다음과 같은 TCP RTT 메트릭이 표시됩니다.
- 전체 TCP 왕복 시간 중 상위 X 90번째 백분위수
- 전반적인 상위 X 평균 TCP 왕복 시간
- 전체에 대한 최소 TCP 왕복 시간(최소 X)
패널 관리에서 다른 RTT 패널을 추가할 수 있습니다.
- 전체와 함께 상위 X 최대 TCP 왕복 시간
- 전체 TCP 왕복 시간 중 상위 X 99번째 백분위수
이 보기를 활성화하고 사용하는 방법에 대한 자세한 내용은 이 섹션의 추가 리소스를 참조하세요.
10.1.6. eBPF 흐름 규칙 필터
eBPF 흐름 규칙 필터링을 사용하여 포트 및 CIDR 표기법을 기반으로 캡처 기준을 지정하고 전용 상태 대시보드 및 Prometheus 지표를 통해 필터 성능을 모니터링하여 패킷 캡처 볼륨을 제어합니다.
규칙 기반 필터링을 사용하면 eBPF 흐름 테이블에 캐시된 패킷 볼륨을 제어할 수 있습니다. 예를 들어, 필터는 포트 100에서 들어오는 패킷만 캡처하도록 지정할 수 있습니다. 그러면 필터와 일치하는 패킷만 캡처되고 나머지는 삭제됩니다.
여러 개의 필터 규칙을 적용할 수 있습니다.
10.1.6.1. 유입 및 유출 트래픽 필터링
CIDR(Classless Inter-Domain Routing) 표기법은 기본 IP 주소와 접두사 길이를 결합하여 IP 주소 범위를 효율적으로 나타냅니다. 유입 및 유출 트래픽 모두에 대해 소스 IP 주소는 CIDR 표기법으로 구성된 필터 규칙과 일치하도록 먼저 사용됩니다. 일치하는 항목이 있는 경우 필터링이 진행됩니다. 일치하는 항목이 없으면 대상 IP를 사용하여 CIDR 표기법으로 구성된 필터 규칙을 일치시킵니다.
소스 IP 또는 대상 IP CIDR을 일치시킨 후 peerIP를 사용하여 특정 엔드포인트를 지정하고 패킷의 대상 IP 주소를 구별할 수 있습니다. 프로비저닝된 작업에 따라, 플로우 데이터는 eBPF 플로우 테이블에 캐시되거나 캐시되지 않습니다.
10.1.6.2. 대시보드 및 메트릭 통합
이 옵션을 활성화하면 eBPF 에이전트 통계 의 Netobserv/Health 대시보드에 필터링된 흐름 비율 보기가 표시됩니다. 또한 Observe → Metrics 에서 netobserv_agent_filtered_flows_total을 쿼리하여 FlowFilterAcceptCounter , FlowFilterNoMatchCounter 또는 FlowFilterRecjectCounter 에 대한 이유로 메트릭을 관찰할 수 있습니다.
10.1.6.3. 흐름 필터 구성 매개변수
CIDR 범위, 필터 작업, 프로토콜 및 특정 포트 구성을 포함하여 FlowCollector 리소스에서 흐름 필터 규칙을 구성하는 데 필요한 및 선택적 매개 변수를 참조합니다.
| 매개변수 | 설명 |
|---|---|
|
|
eBPF 흐름 필터링 기능을 활성화하려면 |
|
|
흐름 필터 규칙에 대한 IP 주소와 CIDR 마스크를 제공합니다. IPv4 및 IPv6 주소 형식을 모두 지원합니다. 모든 IP에 대해 일치시키려면 IPv4의 경우 |
|
|
흐름 필터 규칙에 대해 수행되는 작업을 설명합니다. 가능한 값은
|
| 매개변수 | 설명 |
|---|---|
|
|
흐름 필터 규칙의 방향을 정의합니다. 가능한 값은 |
|
|
흐름 필터 규칙의 프로토콜을 정의합니다. 가능한 값은 |
|
|
흐름을 필터링하기 위한 TCP 플래그를 정의합니다. 가능한 값은 |
|
|
흐름 필터링에 사용할 포트를 정의합니다. 출발지 포트나 목적지 포트에 모두 사용할 수 있습니다. 단일 포트를 필터링하려면 단일 포트를 정수 값으로 설정합니다. 예를 들어 |
|
|
흐름 필터링에 사용할 소스 포트를 정의합니다. 단일 포트를 필터링하려면 단일 포트를 정수 값으로 설정합니다(예: |
|
|
DestPorts는 흐름 필터링에 사용할 대상 포트를 정의합니다. 단일 포트를 필터링하려면 단일 포트를 정수 값으로 설정합니다(예 |
|
| 흐름 필터링에 사용할 ICMP 유형을 정의합니다. |
|
| 흐름 필터링에 사용할 ICMP 코드를 정의합니다. |
|
|
흐름 필터링에 사용할 IP 주소를 정의합니다(예: |
10.1.7. 사용자 정의 네트워크
유연한 네트워크 분할에 UDN(사용자 정의 네트워크)을 사용하고 Network Observability Operator를 활용하여 트래픽 흐름 테이블의 전용 라벨 및 이름 필터를 통해 이러한 세그먼트를 모니터링하는 방법을 알아봅니다.
사용자 정의 네트워크(UDN)는 모든 세그먼트가 기본적으로 격리되는 사용자 정의 레이어 2 및 레이어 3 네트워크 세그먼트를 활성화하여 Kubernetes Pod 네트워크의 기본 레이어 3 토폴로지의 유연성과 세분화 기능을 개선합니다. 이러한 세그먼트는 기본 OVN-Kubernetes CNI 플러그인을 사용하는 컨테이너 포드와 가상 머신의 기본 또는 보조 네트워크 역할을 합니다.
UDN은 광범위한 네트워크 아키텍처와 토폴로지를 지원하여 네트워크의 유연성, 보안, 성능을 향상시킵니다.
네트워크 관찰 기능과 함께 UDNMapping 기능이 활성화되면 트래픽 흐름 테이블에 UDN 레이블 열이 생깁니다. 소스 네트워크 이름 과 대상 네트워크 이름 으로 필터링할 수 있습니다.
10.1.8. OVN-Kubernetes 네트워킹 이벤트
OVN-Kubernetes 네트워크 이벤트 추적을 사용하여 클러스터에서 네트워크 정책, 관리 네트워크 정책 및 송신 방화벽 규칙을 모니터링하고 감사합니다.
OVN-Kubernetes 네트워킹 이벤트 추적은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
네트워크 이벤트 추적에서 얻은 통찰력을 활용하여 다음 작업을 수행할 수 있습니다.
- 네트워크 모니터링: 허용 및 차단된 트래픽을 모니터링하고, 네트워크 정책과 관리자 네트워크 정책에 따라 패킷이 허용 또는 차단되었는지 감지합니다.
- 네트워크 보안: 아웃바운드 트래픽을 추적하고 송신 방화벽 규칙을 준수하는지 확인할 수 있습니다. 허가되지 않은 아웃바운드 연결을 감지하고, 이탈 규칙을 위반하는 아웃바운드 트래픽을 표시합니다.
이 보기를 활성화하고 사용하는 방법에 대한 자세한 내용은 이 섹션의 추가 리소스를 참조하세요.
10.2. 트래픽 흐름 보기에서 네트워크 트래픽 관찰
클러스터 구성 요소 간 실시간 및 기록 네트워크 통신을 모니터링하려면 트래픽 흐름 보기를 사용합니다. eBPF를 통해 수집된 세분화된 흐름 데이터를 분석하면 네트워크 트래픽을 감사하고 네트워크 정책을 검증하고 외부 보고 및 분석을 위해 데이터를 내보낼 수 있습니다.
Network Observability Operator의 트래픽 흐름 보기는 OpenShift Container Platform 클러스터 전체에서 네트워크 활동을 세부적으로 표현합니다. eBPF 기술을 활용하여 흐름 데이터를 수집함으로써 관리자는 Pod, 서비스 및 노드 간의 실시간 및 기록 통신을 모니터링할 수 있습니다. 이러한 가시성은 네트워크 트래픽을 감사하고, 네트워크 정책을 검증하고, 클러스터 인프라 내에서 예기치 않은 통신 패턴을 식별하는 데 중요합니다.
트래픽 흐름 인터페이스에서 개별 행과 상호 작용하여 자세한 흐름 정보를 검색하여 특정 연결 세부 정보를 분석할 수 있습니다. 보기는 행 밀도를 조정하고 열을 관리할 수 있는 표시 옵션 메뉴를 통해 고급 사용자 지정을 지원합니다. 특정 열을 선택하고 다시 정렬하면 테이블을 조정하여 소스 및 대상 끝점 또는 트래픽 볼륨과 같이 해당 환경의 가장 관련 데이터 지점을 강조 표시할 수 있습니다.By selecting and reordering specific columns, you can tailor the table to highlight the most relevant data points for your environment, such as source and destination endpoints or traffic volume.
외부 분석 및 보고를 지원하기 위해 트래픽 흐름 보기에는 데이터 내보내기 기능이 포함됩니다. 전체 데이터 세트를 내보내거나 특정 필드를 선택하여 네트워크 활동에 대한 대상 보고서를 생성할 수 있습니다. 이 기능을 통해 장기 감사 또는 타사 모니터링 툴에서 사용하기 위해 네트워크 흐름 데이터에 액세스할 수 있으므로 OpenShift Container Platform 환경의 네트워크 상태를 문서화하고 분석할 수 있는 유연한 방법을 제공합니다.
10.2.1. 트래픽 흐름 보기 작업
트래픽 흐름 테이블을 사용하여 자세한 네트워크 흐름 정보를 보고 분석합니다.
관리자는 트래픽 흐름 표로 이동하여 네트워크 흐름 정보를 볼 수 있습니다.
사전 요구 사항
- 관리자 액세스 권한이 있습니다.
프로세스
- 모니터링 → 네트워크 트래픽 으로 이동합니다.
- 네트워크 트래픽 페이지에서 트래픽 흐름 탭을 클릭합니다.
- 각 행을 클릭하여 해당 흐름 정보를 가져옵니다.
10.2.2. 트래픽 흐름 표시 설정
트래픽 흐름 보기에는 디스플레이 밀도, 데이터 열 및 데이터 내보내기 옵션을 사용자 지정하는 설정이 포함되어 있습니다.
10.2.2.1. 표시 옵션
다음 요소는 트래픽 흐름 보기에서 사용할 수 있습니다.
- 고급 옵션 표시
- 현재 뷰를 사용자 지정하고 내보낼 메뉴를 지정합니다.
- 디스플레이 옵션 드롭다운
- 데이터 테이블의 행 크기를 지정합니다. 기본값은 Normal 입니다.
- 열 관리
- 트래픽 흐름 테이블에 표시된 열을 선택하고 재정렬하는 대화 상자를 지정합니다.
10.2.3. 트래픽 흐름 데이터 내보내기
트래픽 흐름 보기에서 네트워크 흐름 데이터를 외부 분석 또는 보고를 위해 CSV 파일로 내보냅니다.
프로세스
- 데이터 내보내기 를 클릭합니다.
- 창에서 모든 데이터를 내보내려면 Export all data 확인란을 선택하고, 내보낼 필수 필드를 선택하려면 확인란을 지웁니다.
- 내보내기를 클릭합니다.
10.2.4. FlowCollector 사용자 지정 리소스로 IPsec 구성
FlowCollector 리소스에서 IPsec 추적을 활성화하여 암호화된 트래픽을 모니터링하고, IPsec 상태 열을 트래픽 흐름 보기에 추가하고, 전용 암호화 대시보드를 생성합니다.
OpenShift Container Platform에서는 IPsec이 기본적으로 비활성화되어 있습니다. "IPsec 암호화 구성"의 지침에 따라 IPsec을 활성화할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform에서 IPsec 암호화를 활성화했습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
IPsec에 대한
FlowCollector사용자 지정 리소스를 구성합니다.IPsec을 위한
FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - "IPSec"
검증
IPsec이 활성화된 경우:
- IPsec 상태 라는 새 열이 네트워크 관찰 트래픽 흐름 보기에 표시되어 흐름이 성공적으로 IPsec 암호화되었는지 또는 암호화/복호화 중에 오류가 발생했는지 여부를 보여줍니다.
- 암호화된 트래픽의 비율을 보여주는 새로운 대시보드가 생성됩니다.
10.2.5. 대화 추적 작업
웹 콘솔에서 관련 네트워크 흐름을 그룹화하고 분석하기 위한 대화 추적을 사용하도록 FlowCollector 사용자 지정 리소스를 구성합니다.
관리자는 동일한 대화에 속하는 네트워크 흐름을 그룹화할 수 있습니다. 대화는 IP 주소, 포트, 프로토콜로 식별되는 피어 그룹으로 정의되며, 고유한 대화 ID가 생성됩니다. 웹 콘솔에서 대화 이벤트를 쿼리할 수 있습니다. 이러한 이벤트는 웹 콘솔에서 다음과 같이 표시됩니다.
- 대화 시작 : 이 이벤트는 연결이 시작되거나 TCP 플래그가 가로채질 때 발생합니다.
-
대화 틱 : 이 이벤트는 연결이 활성화되어 있는 동안
FlowCollectorspec.processor.conversationHeartbeatInterval매개변수에 정의된 각 지정 간격에서 발생합니다. -
대화 종료 : 이 이벤트는
FlowCollectorspec.processor.conversationEndTimeout매개변수에 도달하거나 TCP 플래그가 가로채질 때 발생합니다. - 흐름: 지정된 간격 내에 발생하는 네트워크 트래픽 흐름입니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
spec.processor.logTypes,conversationEndTimeout,conversationHeartbeatInterval매개변수가 관찰 요구 사항에 맞게 설정되도록FlowCollector사용자 정의 리소스를 구성합니다. 샘플 구성은 다음과 같습니다.대화 추적을 위해
FlowCollector구성apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: logTypes: Flows advanced: conversationEndTimeout: 10s conversationHeartbeatInterval: 30s다음과 같습니다.
spec.processor.logTypes-
내보낼 이벤트 유형을 지정합니다.
Flows로 설정하면 Flow 이벤트만 내보내집니다.All으로 설정하면 대화 및 흐름 이벤트가 모두 내보내 네트워크 트래픽 페이지에 표시됩니다. 대화 이벤트에만 집중하려면 Conversation start,Conversation tick, Conversation end events를 지정합니다.대화 끝 이벤트만 내보내려면EndedConversations를 지정합니다.EndedConversations의 경우 스토리지 요구 사항이All및 lowest에서 가장 높습니다. spec.processor.advanced.conversationEndTimeout- 시간 초과에 도달하거나 TCP 플래그를 가로채면 Conversation end 이벤트가 트리거되는 기간을 지정합니다.
spec.processor.advanced.conversationHeartbeatInterval네트워크 연결이 활성화된 동안 Conversation tick 이벤트 간격을 지정합니다.
참고logType옵션을 업데이트하면 이전 선택의 흐름이 콘솔 플러그인에서 지워지지 않습니다. 예를 들어, 처음에logType을오전 10시까지의 시간 범위에 대한Conversations로 설정한 다음EndedConversations로 변경하면 콘솔 플러그인은 오전 10시 이전의 모든 대화 이벤트를 표시하고 오전 10시 이후에 종료된 대화만 표시합니다.
-
트래픽 흐름 탭에서 네트워크 트래픽 페이지를 새로 고칩니다. 이벤트/유형 과 대화 ID라는 두 개의 새로운 열이 있다는 점에 주목하세요. 흐름이 선택된 쿼리 옵션인 경우 모든 이벤트/유형 필드는
흐름입니다. - 쿼리 옵션을 선택하고 로그 유형 , 대화를 선택합니다. 이제 이벤트/유형에 원하는 대화 이벤트가 모두 표시됩니다.
- 다음으로, 측면 패널에서 특정 대화 ID로 필터링하거나 대화 및 흐름 로그 유형 옵션 간에 전환할 수 있습니다.
10.2.6. 패킷 삭제 작업
웹 콘솔에서 네트워크 데이터 손실을 모니터링하고 시각화하도록 FlowCollector 리소스를 구성하여 Network Observability Operator에서 패킷 드롭 추적을 활성화합니다.
패킷 손실은 하나 이상의 네트워크 흐름 데이터 패킷이 목적지에 도달하지 못할 때 발생합니다. 다음 YAML 예제의 사양에 따라 FlowCollector를 편집하여 이러한 감소를 추적할 수 있습니다.
이 기능을 활성화하면 CPU와 메모리 사용량이 증가합니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
패킷 삭제를 위해
FlowCollector사용자 정의 리소스를 구성합니다(예:FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - PacketDrop privileged: true다음과 같습니다.
spec.agent.ebpf.features-
활성화할 기능을 지정합니다. 각 네트워크 흐름에 대한 패킷 드롭을 시작하기 위해
PacketDrop을 포함합니다. spec.agent.ebpf.privileged-
권한 모드가 활성화되었는지 여부를 지정합니다. 패킷 드롭 추적에 대해
true로 설정해야 합니다.
검증
네트워크 트래픽 페이지를 새로 고치면 개요 , 트래픽 흐름 및 토폴로지 보기에 패킷 삭제에 대한 새로운 정보가 표시됩니다.
- 관리 패널 에서 새로운 선택 사항을 선택하여 개요 에 표시할 패킷 삭제의 그래픽 시각화를 선택합니다.
열 관리 에서 새 선택 사항을 선택하여 트래픽 흐름 표에 표시할 패킷 삭제 정보를 선택합니다.
-
트래픽 흐름 보기에서 측면 패널을 확장하여 패킷 삭제에 대한 자세한 정보를 볼 수도 있습니다. 호스트 드롭에는
SKB_DROP접두사가 붙고 OVS 드롭에는OVS_DROP접두사가 붙습니다.
-
트래픽 흐름 보기에서 측면 패널을 확장하여 패킷 삭제에 대한 자세한 정보를 볼 수도 있습니다. 호스트 드롭에는
- 토폴로지 보기에서는 방울이 있는 곳에 빨간색 선이 표시됩니다.
10.2.7. DNS 추적 작업
웹 콘솔에서 네트워크 성능, 보안 분석 및 DNS 문제 해결을 위해 DNS 추적을 사용하도록 FlowCollector 사용자 지정 리소스를 구성합니다.
다음 YAML 예제의 사양에 따라 FlowCollector를 편집하여 DNS를 추적할 수 있습니다.
이 기능을 활성화하면 eBPF 에이전트에서 CPU 및 메모리 사용량이 증가하는 것이 관찰됩니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- Network Observability에 대해 제공된 API에서 Flow Collector 를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
FlowCollector사용자 정의 리소스를 구성합니다. 샘플 구성은 다음과 같습니다.DNS 추적을 위한
FlowCollector구성apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - DNSTracking sampling: 1-
웹 콘솔에서 각 네트워크 흐름의 DNS 추적을 활성화하려면
spec.agent.ebpf.features매개변수 목록을 설정할 수 있습니다. -
더욱 정확한 측정 항목을 얻고 DNS 지연 시간을 파악하려면
샘플링값을1로 설정할 수 있습니다. 1보다 큰샘플링값의 경우 DNS 응답 코드 및 DNS Id 를 사용하여 흐름을 확인할 수 있으며 DNS Latency 시간을 확인할 수 없습니다.
-
웹 콘솔에서 각 네트워크 흐름의 DNS 추적을 활성화하려면
네트워크 트래픽 페이지를 새로 고치면 개요 및 트래픽 흐름 보기에서 볼 수 있는 새로운 DNS 표현과 적용할 수 있는 새로운 필터가 표시됩니다.
- 관리 패널 에서 새로운 DNS 선택 사항을 선택하여 개요 에 그래픽 시각화와 DNS 메트릭을 표시합니다.
- 트래픽 흐름 보기에 DNS 열을 추가하려면 열 관리 에서 새 선택 사항을 선택합니다.
DNS ID , DNS 오류 DNS 대기 시간 및 DNS 응답 코드 와 같은 특정 DNS 메트릭을 필터링하고 측면 패널에서 자세한 정보를 확인하세요. DNS 대기 시간 및 DNS 응답 코드 열은 기본적으로 표시됩니다.
참고TCP 핸드셰이크 패킷에는 DNS 헤더가 없습니다. DNS 헤더가 없는 TCP 프로토콜 흐름은 트래픽 흐름 데이터에 "n/a"의 DNS 대기 시간 , ID 및 응답 코드 값으로 표시됩니다. 일반 필터 "DNSError"가 "0"인 경우 DNS 헤더가 있는 흐름만 보려면 흐름 데이터를 필터링할 수 있습니다.
10.2.8. RTT 추적 작업
웹 콘솔을 사용하여 클러스터 전체에서 네트워크 대기 시간을 모니터링하고 분석하도록 FlowCollector 사용자 지정 리소스를 구성하여 RTT(Round Trip Time) 추적을 활성화합니다.
다음 YAML 예제의 사양에 따라 FlowCollector를 편집하여 RTT를 추적할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
예를 들어 RTT 추적을 위해
FlowCollector사용자 정의 리소스를 구성합니다.FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - FlowRTT다음과 같습니다.
spec.agent.ebpf.features-
활성화할 eBPF 기능 목록을 지정합니다. 이 목록에
FlowRTT를 추가하여 RTT(Round-trip Time) 네트워크 흐름 추적을 시작합니다.
검증
네트워크 트래픽 페이지가 새로 고쳐지면 개요,트래픽 흐름 및 토폴로지 보기에 RTT 정보가 표시됩니다.
- 개요 보기에서 패널 관리를 클릭하여 표시할 RTT 그래픽 시각화를 선택합니다.
- 트래픽 흐름 테이블에서 Flow RTT 열이 기본적으로 표시되는지 확인합니다. 열을 관리하려면 열 관리를 클릭합니다.
트래픽 흐름 보기에서 측면 패널을 확장하여 RTT 메타데이터를 확인합니다.
-
필터 검색 창에
protocol= TCP를 입력하여 TCP 프로토콜의 흐름 데이터를 필터링합니다. -
모든 TCP 필터링된 흐름에 FlowRTT 값이
0보다 큰지 확인합니다. -
필터 검색 창에
time_flow_rtt>=10000000을 입력하여10,000,000나노초(10ms)보다 큰 FlowRTT 값을 필터링합니다. - 필터를 제거합니다.
-
필터 검색 창에
- 토폴로지 보기에서 표시 옵션 드롭다운 메뉴를 클릭합니다. 에지 라벨 목록에서 RTT 를 선택합니다.
10.2.9. eBPF 관리자 운영자와 함께 작업하기
eBPF Manager Operator를 Network Observability와 통합하여 eBPF 프로그램을 관리하고 권한 있는 에이전트 권한의 필요성을 줄입니다.
eBPF 관리자 운영자는 모든 eBPF 프로그램을 관리하여 공격 표면을 줄이고 규정 준수, 보안 및 충돌 방지를 보장합니다. 네트워크 관찰은 eBPF 관리자 연산자를 사용하여 후크를 로드할 수 있습니다. 결과적으로 더 이상 eBPF 에이전트에 권한 모드나 CAP_BPF 및 CAP_PERFMON 과 같은 추가 Linux 기능을 제공할 필요가 없습니다. 네트워크 관찰 기능을 갖춘 eBPF 관리자 연산자는 64비트 AMD 아키텍처에서만 지원됩니다.
네트워크 관찰 기능을 갖춘 eBPF 관리자 운영자는 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
프로세스
- 웹 콘솔에서 운영자 → 운영자 허브 로 이동합니다.
- eBPF 관리자를 설치합니다.
-
bpfman네임스페이스의 워크로드 → 포드를 확인하여 모두 제대로 작동하고 있는지 확인합니다. eBPF Manager Operator를 사용하도록
FlowCollector사용자 정의 리소스를 구성합니다.FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: agent: ebpf: features: - EbpfManager
검증
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
eBPF 관리자 운영자 → 모든 인스턴스 탭을 클릭합니다.
각 노드에 대해
netobserv라는 이름의BpfApplication과 트래픽 제어(TCx) 수신용과 TCx 송신용의BpfProgram객체 쌍이 있는지 확인합니다. 다른 eBPF 에이전트 기능을 활성화하면 더 많은 개체가 생길 수 있습니다.
10.2.10. 히스토그램을 사용하여
히스토그램은 트래픽 볼륨 추세를 분석하고 특정 시간 간격에 따라 흐름 데이터를 필터링하는 데 사용할 수 있는 네트워크 흐름 로그를 시각화합니다.
'히스토그램 표시'를 클릭하면 흐름 기록을 막대 차트로 시각화하는 도구 모음 보기가 표시됩니다. 히스토그램은 시간에 따른 로그 수를 보여줍니다. 도구 모음 다음에 나오는 표에서 네트워크 흐름 데이터를 필터링하려면 히스토그램의 일부를 선택할 수 있습니다.
10.2.11. 가용성 영역 작업
가용성 영역 데이터를 수집하도록 FlowCollector 사용자 지정 리소스를 구성하여 웹 콘솔의 여러 클러스터 영역에서 네트워크 트래픽을 시각화하고 분석할 수 있습니다.
FlowCollector를 구성하여 클러스터 가용성 영역에 대한 정보를 수집할 수 있습니다. 이를 통해 노드에 적용된 topology.kubernetes.io/zone 레이블 값으로 네트워크 흐름 데이터를 풍부하게 만들 수 있습니다.
프로세스
- 웹 콘솔에서 Operator → 설치된 Operator 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
FlowCollector사용자 정의 리소스를 구성하여spec.processor.addZone매개변수가true로 설정되도록 합니다. 샘플 구성은 다음과 같습니다.가용성 영역 수집을 위해
FlowCollector구성apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: # ... processor: addZone: true # ...
검증
네트워크 트래픽 페이지를 새로 고치면 개요 , 트래픽 흐름 및 토폴로지 보기에 가용성 영역에 대한 새로운 정보가 표시됩니다.
- 개요 탭에서 사용 가능한 범위 로 영역을 볼 수 있습니다.
- 네트워크 트래픽 → 트래픽 흐름 에서 SrcK8S_Zone 및 DstK8S_Zone 필드 아래에서 영역을 볼 수 있습니다.
- 토폴로지 보기에서 영역을 범위 또는 그룹 으로 설정할 수 있습니다.
10.2.12. 여러 규칙을 사용하여 eBPF 흐름 데이터 필터링
IP 주소 및 패킷 조건을 기반으로 특정 eBPF 흐름을 수락하거나 거부하여 네트워크 트래픽 데이터 수집을 구체화하도록 FlowCollector 사용자 지정 리소스에서 여러 필터링 규칙을 구성합니다.
- 필터 규칙에서는 중복된 CIDR(Classless Inter-Domain Routing)을 사용할 수 없습니다.
- IP 주소가 여러 필터 규칙과 일치하는 경우 가장 구체적인 CIDR 접두사(가장 긴 접두사)가 있는 규칙이 우선합니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- Network Observability에 대해 제공된 API에서 Flow Collector 를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
-
FlowCollector사용자 정의 리소스를 구성합니다.
10.2.13. eBPF 흐름 데이터 필터링 예
이러한 FlowCollector 사용자 지정 리소스 예제를 사용하여 eBPF 흐름을 필터링하여 eBPF 흐름 테이블에 캐시된 패킷의 흐름을 제어합니다.
10.2.13.1. 모든 남북 교통과 1:50 동서 교통을 샘플링하기 위한 YAML 예제
기본적으로 다른 모든 흐름은 거부됩니다.
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Service
agent:
type: eBPF
ebpf:
flowFilter:
enable: true
rules:
- action: Accept
cidr: 0.0.0.0/0
sampling: 1
- action: Accept
cidr: 10.128.0.0/14
peerCIDR: 10.128.0.0/14
- action: Accept
cidr: 172.30.0.0/16
peerCIDR: 10.128.0.0/14
sampling: 50다음과 같습니다.
spec.agent.ebpf.flowFilter.enable-
eBPF흐름 필터링을 활성화할지 여부를 지정합니다. 흐름 필터링을 활성화하려면true로 설정합니다. spec.agent.ebpf.flowFilter.rules.action-
흐름 필터 규칙에 대한 작업을 지정합니다. 유효한 값은
Accept또는Reject입니다. spec.agent.ebpf.flowFilter.rules.cidr-
흐름 필터 규칙의 IP 주소 및
CIDR마스크를 지정합니다. 이 매개변수는IPv4및IPv6주소 형식을 모두 지원합니다.IPv4의 경우0.0.0.0/0을 사용하거나::/0을 사용하여 모든 IP 주소와 일치하도록IPv6에 대해 를 사용합니다. spec.agent.ebpf.flowFilter.rules.peerCIDR-
흐름을 필터링하는 데 사용되는 피어 IP
CIDR을 지정합니다. spec.agent.ebpf.flowFilter.rules.sampling-
일치하는 흐름의 샘플링 간격을 지정합니다. 이 값은
spec.agent.ebpf.sampling에 정의된 글로벌 샘플링 설정을 재정의합니다.
10.2.13.2. 패킷 삭제로 흐름을 필터링하는 YAML 예제
기본적으로 다른 모든 흐름은 거부됩니다.
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Service
agent:
type: eBPF
ebpf:
privileged: true
features:
- PacketDrop
flowFilter:
enable: true
rules:
- action: Accept
cidr: 172.30.0.0/16
pktDrops: true다음과 같습니다.
spec.agent.ebpf.privileged- 패킷 드롭 보고에 필요한 권한 모드를 활성화할지 여부를 지정합니다.
spec.agent.ebpf.features-
활성화할 eBPF 기능 목록을 지정합니다. 이 목록에
PacketDrop값을 추가하면 각 네트워크 흐름에 대한 패킷 드롭이 보고됩니다. spec.agent.ebpf.flowFilter.enable-
eBPF흐름 필터링을 활성화할지 여부를 지정합니다. spec.agent.ebpf.flowFilter.rules.action-
흐름 필터 규칙에 대한 작업을 지정합니다. 유효한 값은
Accept또는Reject입니다. spec.agent.ebpf.flowFilter.rules.pktDrops- 패킷 드롭을 포함하는 흐름을 필터링할지 여부를 지정합니다.
10.2.14. 엔드포인트 번역(xlat)
엔드포인트 변환(xlat)은 eBPF를 사용하여 변환된 Pod 수준 메타데이터로 네트워크 흐름 로그를 강화하여 서비스 또는 로드 밸런서 뒤의 트래픽을 제공하는 특정 백엔드 Pod에 대한 가시성을 제공합니다.
네트워크 관찰 기능과 확장된 Berkeley Packet Filter(eBPF)를 사용하면 통합된 보기에서 트래픽을 처리하는 엔드포인트에 대한 가시성을 얻을 수 있습니다. 일반적으로 트래픽이 서비스, 출구 IP 또는 로드 밸런서를 통과할 때 트래픽 흐름 정보는 사용 가능한 포드 중 하나로 라우팅되면서 추상화됩니다. 트래픽에 대한 정보를 얻으려고 하면 서비스 IP 및 포트와 같은 서비스 관련 정보만 볼 수 있으며, 요청을 처리하는 특정 포드에 대한 정보는 볼 수 없습니다. 서비스 트래픽과 가상 서비스 엔드포인트에 대한 정보가 두 개의 별도 흐름으로 수집되는 경우가 많아 문제 해결이 복잡해집니다.
이 문제를 해결하기 위해 Endpoint xlat은 다음과 같은 방법으로 도움을 줄 수 있습니다.
- 성능에 미치는 영향을 최소화하기 위해 커널 수준에서 네트워크 흐름을 캡처합니다.
- 번역된 엔드포인트 정보로 네트워크 흐름을 풍부하게 하면 서비스뿐만 아니라 특정 백엔드 포드도 표시되므로 어떤 포드가 요청을 처리했는지 확인할 수 있습니다.
네트워크 패킷이 처리됨에 따라 eBPF 후크는 변환된 엔드포인트에 대한 메타데이터로 흐름 로그를 강화합니다. 여기에는 네트워크 트래픽 페이지에서 단일 행으로 볼 수 있는 다음 정보가 포함됩니다.
- 소스 포드 IP
- 소스 포트
- 목적지 포드 IP
- destination.port
- Conntrack 존 ID
10.2.15. 엔드포인트 번역(xlat) 작업
FlowCollector 리소스에서 엔드포인트 변환(xlat)을 활성화하여 변환된 패킷 정보를 사용하여 네트워크 흐름을 강화합니다. 이 정보를 사용하여 전용 xlat 열을 통해 서비스 트래픽을 제공하는 특정 Pod 및 오브젝트를 식별할 수 있습니다.
네트워크 관찰성과 eBPF를 사용하면 번역된 엔드포인트 정보로 Kubernetes 서비스의 네트워크 흐름을 강화하고 트래픽을 처리하는 엔드포인트에 대한 통찰력을 얻을 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
예를 들어,
PacketTranslation에 대한FlowCollector사용자 정의 리소스를 구성합니다.FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - PacketTranslation-
spec.agent.ebpf.features사양 목록에PacketTranslation매개변수를 나열하면 변환된 패킷 정보로 네트워크 흐름을 풍부하게 만들 수 있습니다.
-
네트워크 트래픽 페이지를 새로 고침하여 변환된 패킷에 대한 정보를 필터링합니다.
- 대상 종류(서비스)를 기준으로 네트워크 흐름 데이터를 필터링합니다.
번역된 정보가 표시되는 위치를 구분하는 xlat 열과 다음과 같은 기본 열을 볼 수 있습니다.
- xlat_zone_id
- Xlat Src Kubernetes 객체
- Xlat Dst Kubernetes 객체
- 추가 xlat 열의 표시는 열 관리 에서 관리할 수 있습니다.
10.2.16. 사용자 정의 네트워크 작업
UDN(사용자 정의 네트워크) 매핑을 사용하도록 FlowCollector 사용자 정의 리소스를 구성하여 웹 콘솔 내의 사용자 지정 네트워크 인터페이스 간 트래픽을 시각화할 수 있습니다.
네트워크 관찰 리소스에서 사용자 정의 네트워크(UDN)를 활성화할 수 있습니다. 다음 예에서는 FlowCollector 리소스에 대한 구성을 보여줍니다.
사전 요구 사항
- Red Hat OpenShift Networking에서 UDN을 구성했습니다. 자세한 내용은 "CLI를 사용하여 UserDefinedNetwork 만들기" 또는 "웹 콘솔을 사용하여 UserDefinedNetwork 만들기"를 참조하세요.
프로세스
다음 명령을 실행하여 네트워크 관찰
FlowCollector리소스를 편집합니다.$ oc edit flowcollectorFlowCollector리소스의ebpf섹션을 구성합니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: agent: ebpf: sampling: 1 privileged: true features: - UDNMapping다음과 같습니다.
spec.agent.ebpf.sampling-
네트워크 이벤트에 대한 샘플링 속도를 지정합니다. 모든 네트워크 이벤트를 캡처하려면
1값으로 설정합니다. 샘플링1에리소스가 너무 많이 필요한 경우, 필요에 맞게 샘플링을 더 적합한 것으로 설정하세요. spec.agent.ebpf.privileged-
권한 모드가 활성화되었는지 여부를 지정합니다. 사용자 정의 네트워크 매핑에 대해
true로 설정해야 합니다.
검증
트래픽 흐름 및 토폴로지 보기에서 업데이트된 UDN 정보를 보려면 네트워크 트래픽 페이지를 새로 고칩니다.
-
네트워크 트래픽 > 트래픽 흐름 에서
SrcK8S_NetworkName및DstK8S_NetworkName필드 아래에서 UDN을 볼 수 있습니다. - 토폴로지 보기에서 네트워크를 범위 또는 그룹 으로 설정할 수 있습니다.
-
네트워크 트래픽 > 트래픽 흐름 에서
10.2.17. 네트워크 이벤트 보기
보안 정책, 방화벽 및 격리 규칙이 웹 콘솔의 트래픽 흐름에 미치는 영향을 감사하기 위해 네트워크 이벤트 추적을 사용하도록 FlowCollector 사용자 지정 리소스를 구성합니다.
OVN-Kubernetes 네트워킹 이벤트 추적은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
FlowCollector를 편집하여 다음 리소스에 의해 삭제되거나 허용된 네트워크 흐름 등 네트워크 트래픽 이벤트에 대한 정보를 볼 수 있습니다.
-
NetworkPolicy -
AdminNetworkPolicy -
BaselineNetworkPolicy -
egressFirewall -
사용자 정의 네트워크격리 - 멀티캐스트 ACL
사전 요구 사항
-
FeatureGate사용자 정의 리소스(CR)의cluster라는 이름의TechPreviewNoUpgrade기능 세트를 설정하여OVNObservability를활성화해야 합니다. 자세한 내용은 "CLI를 사용하여 기능 세트 활성화" 및 "CLI를 사용하여 OVS 샘플링으로 OVN-Kubernetes 네트워크 트래픽 확인"을 참조하세요. -
다음 네트워크 API 중 하나 이상을 생성했습니다:
NetworkPolicy,AdminNetworkPolicy,BaselineNetworkPolicy,UserDefinedNetworkisolation, multicast 또는EgressFirewall.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
예를 들어
NetworkEvents보기를 활성화하려면FlowCollectorCR을 구성하세요.FlowCollector구성 예apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: agent: type: eBPF ebpf: # sampling: 1 privileged: true features: - "NetworkEvents"다음과 같습니다.
spec.agent.ebpf.sampling-
네트워크 이벤트의 샘플링 속도를 지정합니다. 모든 네트워크 이벤트를 캡처하려면
1값으로 설정합니다. 샘플링1의 리소스가 너무 많은 경우 샘플링을 요구 사항에 더 적합한 것으로 설정합니다. 이 값은 선택 사항입니다. spec.agent.ebpf.privileged-
eBPF 에이전트가 권한 있는 모드에서 실행되는지 여부를 지정합니다. OVN 관찰 기능 라이브러리에서 로컬 OVS(Open vSwitch) 소켓 및 OVN(Open Virtual Network) 데이터베이스에 액세스해야 하므로
true로 설정합니다.
검증
- 네트워크 트래픽 보기로 이동하여 트래픽 흐름 표를 선택합니다.
다음 네트워크 API 중 하나가 활성화한 경우, 해당 API의 영향에 대한 정보를 볼 수 있는 새 열인 네트워크 이벤트가 표시됩니다.
NetworkPolicy,AdminNetworkPolicy,BaselineNetworkPolicy,UserDefinedNetwork격리, 멀티캐스트 또는 송신 방화벽입니다.이 칼럼에서 볼 수 있는 이벤트 종류의 예는 다음과 같습니다.
네트워크 이벤트 출력 예
<Dropped_or_Allowed> by <network_event_and_event_name>, direction <Ingress_or_Egress>
10.3. 토폴로지 뷰에서 네트워크 트래픽 관찰
네트워크 트래픽 페이지의 토폴로지 보기에는 OpenShift Container Platform 클러스터의 네트워크 흐름 및 트래픽 볼륨이 그래픽으로 표시됩니다. 관리자는 이 보기를 사용하여 애플리케이션 트래픽 데이터를 모니터링하고 다양한 네트워크 구성 요소 간의 관계를 시각화할 수 있습니다.
시각화는 네트워크 엔터티를 노드 및 트래픽 흐름으로 나타냅니다. 그래프 내에서 개별 구성 요소를 선택하면 해당 리소스에 대한 특정 메트릭 및 상태 세부 정보가 포함된 측면 패널에 액세스할 수 있습니다. 이러한 대화형 접근 방식을 사용하면 클러스터 내에서 트래픽 패턴 및 연결 문제를 신속하게 식별할 수 있습니다.
복잡한 환경을 관리하기 위해 토폴로지 보기에는 레이아웃 및 데이터 밀도를 사용자 지정할 수 있는 고급 구성 옵션이 포함되어 있습니다. 뷰 범위를 조정하고 리소스 소유권을 나타내기 위해 그룹을 적용하고, 다른 레이아웃 알고리즘을 선택하여 그래픽 표시를 최적화할 수 있습니다. 또한 Edge 레이블을 사용하여 흐름 라인에서 직접 평균 바이트 비율과 같은 실시간 측정을 표시할 수 있습니다.
보고 또는 외부 분석을 위해 토폴로지 보기에 내보내기 기능이 있습니다. 현재 그래픽 표시를 PNG 이미지로 다운로드하거나 다른 관리자와 공유할 특정 보기 구성에 대한 직접 링크를 생성할 수 있습니다. 이러한 툴을 사용하면 네트워크 인사이트에 액세스하고 문서화할 수 있습니다.
10.3.1. 토폴로지 보기 작업
토폴로지 보기에 액세스하여 클러스터 네트워크 관계를 시각적으로 검사하고 개별 구성 요소를 선택하여 자세한 트래픽 지표 및 메타데이터를 확인합니다.
관리자는 토폴로지 보기로 이동하여 구성 요소의 세부 정보 및 지표를 확인할 수 있습니다.
사전 요구 사항
- 관리자 액세스 권한이 있습니다.
프로세스
- 모니터링 → 네트워크 트래픽 으로 이동합니다.
- 네트워크 트래픽 페이지에서 토폴로지 탭을 클릭합니다.
- 토폴로지 탭에서 각 구성 요소를 클릭하여 세부 정보 및 지표를 확인합니다.
10.3.2. 토폴로지 보기의 고급 옵션 구성
토폴로지 보기에서 사용 가능한 고급 옵션을 검토하여 표시 설정을 사용자 지정하고, 구성 요소 그룹화 및 레이아웃을 구성하고, 네트워크 그래프를 이미지로 내보냅니다.
고급 옵션 표시를 사용하여 보기를 사용자 지정하고 내보낼 수 있습니다. 고급 옵션 보기에는 다음과 같은 기능이 있습니다.
- 보기에서 찾기: 뷰에서 필요한 구성 요소를 검색하려면 다음을 수행합니다.
Display options: 다음 옵션을 구성하려면 다음을 수행합니다.
- Edge 라벨: 지정된 측정값을 에지 레이블로 표시하려면 다음을 수행합니다. 기본값은 Average rate in Cryostats를 표시하는 것입니다.
- scope: 네트워크 트래픽이 이동하는 구성 요소의 범위를 선택합니다. 기본값은 Namespace 입니다.
- groups: 구성 요소를 그룹화하여 소유권에 대한 이해를 강화합니다. 기본값은 nil입니다.
- Layout: 그래픽 표현의 레이아웃을 선택합니다. 기본값은 ColaNoForce 입니다.
- show: 표시할 필요가 있는 세부 정보를 선택합니다. 모든 옵션은 기본적으로 확인됩니다. 사용 가능한 옵션은 Edges,Edges 레이블 및 Badges 입니다.
- truncate 레이블: 드롭다운 목록에서 레이블의 필요한 너비를 선택합니다. 기본값은 M 입니다.
- 그룹 축소: 그룹을 확장하거나 축소합니다. 그룹은 기본적으로 확장됩니다. group의 값이 None 인 경우 이 옵션이 비활성화됩니다.
10.3.2.1. 토폴로지 보기 내보내기
뷰를 내보내려면 토폴로지 보기 내보내기 를 클릭합니다. 보기는 PNG 형식으로 다운로드됩니다.
10.4. 네트워크 트래픽 필터링
Network Traffic 보기에서 사용 가능한 쿼리 옵션 및 필터링 매개변수를 검토하여 데이터 검색을 최적화하고 특정 로그 유형을 분석하며 방향 트래픽 가시성을 관리합니다.
기본적으로 네트워크 트래픽 페이지에는 FlowCollector 인스턴스에 구성된 기본 필터를 기반으로 클러스터의 트래픽 흐름 데이터가 표시됩니다. 필터 옵션을 사용하여 사전 설정 필터를 변경하여 필요한 데이터를 관찰할 수 있습니다.
또는 해당 집계의 필터링된 데이터를 제공하는 네임스페이스,서비스,경로,노드, 워크로드 페이지의 네트워크 트래픽 탭에서 트래픽 흐름 데이터에 액세스할 수 있습니다.
- 쿼리 옵션
다음과 같이 쿼리 옵션을 사용하여 검색 결과를 최적화할 수 있습니다.
- 사용 가능한 옵션 대화 및 흐름은 흐름 로그, 새 대화, 완료된 대화 및 하트비트와 같은 로그 유형 별로 흐름을 쿼리하는 기능을 제공합니다. 이 기능은 긴 대화에 대한 업데이트가 포함된 주기적인 레코드입니다. 대화는 동일한 피어 간의 흐름을 집계하는 것입니다.
- Match filters: 고급 필터에서 선택한 다양한 필터 매개변수 간의 관계를 확인할 수 있습니다. 사용 가능한 옵션은 all 및 match any와 일치합니다. Match all은 모든 값과 일치하는 결과를 제공하며 Match any는 입력한 값과 일치하는 결과를 제공합니다. 기본값은 all과 일치합니다.
- 데이터 소스: Loki,Prometheus 또는 Auto 와 같은 쿼리에 사용할 데이터 소스를 선택할 수 있습니다. 중요 한 성능 개선은 Loki가 아닌 데이터 소스로 Prometheus를 사용할 때 실현할 수 있지만 Prometheus는 제한된 필터 및 집계 집합을 지원합니다. 기본 데이터 소스는 지원되는 쿼리에 Prometheus를 사용하거나 쿼리에서 Prometheus를 지원하지 않는 경우 Loki를 사용하는 Auto 입니다.
drops filter: 다음 쿼리 옵션을 사용하여 삭제된 패킷의 다른 수준을 볼 수 있습니다.
- 완전히 삭제된 패킷은 완전히 삭제된 흐름 레코드를 표시합니다.
- 포함 된 삭제 에는 드롭을 포함하지만 보낼 수 있는 흐름 레코드가 표시됩니다.
- drop을 사용하지 않으면 전송된 패킷이 포함된 레코드가 표시됩니다.
- 모두 앞서 언급한 모든 레코드를 보여줍니다.
- Limit: 내부 백엔드 쿼리의 데이터 제한입니다. 일치 및 필터 설정에 따라 트래픽 흐름 데이터 수가 지정된 제한 내에 표시됩니다.
- 빠른 필터
-
빠른 필터 드롭다운 메뉴의 기본값은
FlowCollector구성에 정의되어 있습니다. 콘솔에서 옵션을 수정할 수 있습니다. - 고급 필터
- 드롭다운 목록에서 필터링할 매개변수를 선택하여 고급 필터, 공통,소스 또는 대상 을 설정할 수 있습니다. 흐름 데이터는 선택 사항에 따라 필터링됩니다. 적용된 필터를 활성화하거나 비활성화하려면 필터 옵션 아래에 나열된 적용된 필터를 클릭하면 됩니다.
![]() 에서 한 가지 방법과
에서 한 가지 방법과 ![]() 뒤로
뒤로 ![]() 필터링을 전환할 수 있습니다.
필터링을 전환할 수 있습니다.
![]() 한 가지 방법 필터는 필터 선택에 따라 소스 및 대상 트래픽만 표시합니다. 스왑을 사용하여 소스 및 대상 트래픽의 방향 보기를 변경할 수 있습니다.
한 가지 방법 필터는 필터 선택에 따라 소스 및 대상 트래픽만 표시합니다. 스왑을 사용하여 소스 및 대상 트래픽의 방향 보기를 변경할 수 있습니다.
![]()
![]() Back and forth 필터에는 소스 및 대상 필터가 있는 반환 트래픽이 포함됩니다. 네트워크 트래픽의 방향 흐름은 트래픽의 Direction 열에
Back and forth 필터에는 소스 및 대상 필터가 있는 반환 트래픽이 포함됩니다. 네트워크 트래픽의 방향 흐름은 트래픽의 Direction 열에 Ingress' 또는 'Egress for inter-node traffic 및 ' Inner' 트래픽의 경우 단일 노드 내의 트래픽으로 표시됩니다.
기본값 재설정 을 클릭하여 기존 필터를 제거하고 FlowCollector 구성에 정의된 필터를 적용할 수 있습니다.
텍스트 값을 지정하는 규칙을 이해하려면 자세히 알아보기 를 클릭합니다.
11장. 네트워크 관찰 기능 상태 규칙
Network Observability Operator는 기본 제공 메트릭과 OpenShift Container Platform 모니터링 스택을 사용하여 클러스터 네트워크 상태를 보고하여 경고를 제공합니다.
네트워크 관찰 기능 상태 경고에는 OpenShift Container Platform 4.16 이상이 필요합니다.
11.1. 상태 및 성능에 대한 네트워크 관찰 기능 규칙
네트워크 관찰 기능에는 Prometheus 기반 규칙을 관리하는 시스템이 포함됩니다. 이러한 규칙을 사용하여 OpenShift Container Platform 애플리케이션 및 인프라의 상태 및 성능을 모니터링합니다.
Network Observability Operator는 이러한 규칙을 PrometheusRule 리소스로 변환합니다. Network Observability Operator는 다음 규칙 유형을 지원합니다.
-
경고 규칙: Prometheus
AlertManager에서 관리하는 규칙을 지정하여 네트워크 anomalies 또는 인프라 실패에 대한 알림을 제공합니다. - 기록 규칙: 대시보드 성능 및 시각화를 개선하기 위해 미리 계산된 복잡한 Prometheus Query Language(PromQL) 표현식을 새 시계열로 지정합니다.
다음 명령을 실행하여 netobserv 네임스페이스에서 PrometheusRule 리소스를 확인합니다.
$ oc get prometheusrules -n netobserv -o yaml11.1.1. 네트워크 상태 모니터링 및 경고 규칙
Network Observability Operator에는 네트워크 이상 및 인프라 오류를 감지하는 규칙 기반 시스템이 포함되어 있습니다. Operator는 구성을 경고 규칙으로 변환하여 OpenShift Container Platform 웹 콘솔을 통해 자동화된 모니터링 및 문제 해결을 활성화합니다.
11.1.1.1. 결과 모니터링
Network Observability Operator는 다음 영역에서 네트워크 상태를 표시합니다.
- 경고 UI
-
특정 경고가 Prometheus
AlertManager를 통해 관리되는 Observe → Alerting 에 표시됩니다. - 네트워크 상태 대시보드
- Observe → Network Health 의 특수 대시보드는 클러스터 네트워크 상태에 대한 높은 수준의 요약을 제공합니다.
네트워크 상태 대시보드는 위반을 탭으로 분류하여 문제 범위를 격리합니다.
- Global: 전체 클러스터의 집계 상태
- 노드: 인프라 노드에 고유합니다.
- 네임스페이스: 개별 네임스페이스와 관련된 위반입니다.
-
워크로드:
Deployments또는DaemonSets와 같은 리소스에 고유합니다.
11.1.1.2. 사전 정의된 상태 규칙
Network Observability Operator는 일반적인 네트워킹 시나리오에 대한 기본 규칙을 제공합니다. 이러한 규칙은 FlowCollector CR(사용자 정의 리소스)에서 해당 기능이 활성화된 경우에만 활성화됩니다.
다음 목록에는 사용 가능한 기본 규칙의 서브 세트가 포함되어 있습니다.
PacketDropsByDevice-
높은 비율의 패킷의 트리거는 네트워크 장치에서 삭제됩니다. 표준 node-exporter 메트릭을 기반으로 하며
PacketDrop에이전트 기능이 필요하지 않습니다. PacketDropsByKernel-
커널로 인해 높은 비율의 패킷에 대한 트리거가 삭제됩니다.
PacketDrop에이전트 기능이 필요합니다. IPsec 오류-
IPsec 암호화 오류가 감지되면 트리거됩니다.
IPSec에이전트 기능이 필요합니다. NetpolDenied-
네트워크 정책에서 거부된 트래픽이 감지될 때 트리거됩니다.
NetworkEvents에이전트 기능이 필요합니다. LatencyHighTrend-
TCP 대기 시간이 크게 증가할 때 트리거가 검색됩니다.
FlowRTT에이전트 기능이 필요합니다. DNS 오류-
DNS 오류가 감지되면 트리거됩니다.
DNSTracking에이전트 기능이 필요합니다.
Network Observability Operator에 대한 운영 경고:
NetObservNoFlows- 파이프라인이 활성화되지만 흐름이 관찰되지 않을 때 트리거됩니다.
NetObservLokiError- Loki 오류로 인해 흐름이 삭제될 때 트리거됩니다.
전체 규칙 및 실행북 목록은 Network Observability Operator runbooks 를 참조하십시오.
11.1.1.3. 규칙 종속성 및 기능 요구 사항
Network Observability Operator는 FlowCollector CR(사용자 정의 리소스)에서 활성화된 기능을 기반으로 규칙을 생성합니다.
예를 들어 패킷 드롭 관련 규칙은 PacketDrop 에이전트 기능이 활성화된 경우에만 생성됩니다. 규칙은 메트릭을 기반으로 빌드됩니다. 필요한 메트릭이 누락된 경우 구성 경고가 표시될 수 있습니다. FlowCollector 리소스의 spec.processor.metrics.includeList 오브젝트에서 메트릭을 구성합니다.
11.2. 레코딩 규칙을 사용한 성능 최적화
대규모 클러스터의 경우 레코딩 규칙은 Prometheus가 네트워크 데이터를 처리하는 방법을 최적화합니다. 규칙을 기록하면 대시보드 응답성이 향상되고 복잡한 쿼리의 계산 오버헤드가 줄어듭니다.
11.2.1. 최적화 이점
복잡한 Prometheus Query Language(PromQL) 표현식을 사전 계산하고 결과를 새 시계열로 저장합니다. 경고 규칙과 달리 기록 규칙은 임계값을 모니터링하지 않습니다.
레코딩 규칙을 사용하면 다음과 같은 이점이 있습니다.
- 성능 개선
- 사전 컴퓨팅 Prometheus 쿼리를 사용하면 장기적인 추세에 대한 온디맨드 계산을 방지하여 대시보드를 더 빠르게 로드할 수 있습니다.
- 리소스 효율성
- 고정된 간격으로 데이터를 계산하면 모든 대시보드 새로 고침에서 데이터를 다시 계산하는 것보다 Prometheus 서버의 CPU 로드가 줄어듭니다.
- 간소화된 쿼리
-
cluster:network_traffic:rate_5m과 같은 짧은 메트릭 이름을 사용하면 사용자 정의 대시보드에서 복잡한 집계 계산이 간소화됩니다.
11.2.2. 규칙 모드 비교
다음 표에서는 예상되는 결과에 따라 규칙 모드를 비교합니다.
| 설명 | 경고 규칙 | 기록 규칙 |
|---|---|---|
| 목표 | 문제 알림. | 높은 수준의 메트릭의 기록을 저장합니다. |
| 데이터 결과 | 경고 상태를 생성합니다. | 영구 지표를 생성합니다. |
| 가시성 | 경고 UI 및 네트워크 상태 보기. | 메트릭 Explorer 및 네트워크 상태 보기. |
| 알림 |
| 알림을 트리거하지 않습니다. |
11.3. 네트워크 관찰 기능 상태 규칙 구조 및 사용자 정의
Network Observability Operator의 상태 규칙은 FlowCollector CR(사용자 정의 리소스)의 spec.processor.metrics.healthRules 오브젝트에서 규칙 템플릿 및 변형을 사용하여 정의됩니다. 기본 템플릿과 변형을 사용자 정의하여 유연하고 세부적인 알림을 제공할 수 있습니다.
각 템플릿에 대해 고유한 임계값과 그룹화 구성을 갖는 변형 목록을 정의할 수 있습니다. 자세한 내용은 "기본 경고 템플릿 목록"을 참조하십시오.
다음 예제에서는 경고를 보여줍니다.
apiVersion: flows.netobserv.io/v1beta1
kind: FlowCollector
metadata:
name: flow-collector
spec:
processor:
metrics:
healthRules:
- template: PacketDropsByKernel
mode: Alert # or Recording
variants:
# triggered when the whole cluster traffic (no grouping) reaches 10% of drops
- thresholds:
critical: "10"
# triggered when per-node traffic reaches 5% of drops, with gradual severity
- thresholds:
critical: "15"
warning: "10"
info: "5"
groupBy: Node다음과 같습니다.
spec.processor.metrics.healthRules.template- 사전 정의된 규칙 템플릿의 이름을 지정합니다.
spec.processor.metrics.healthRules.mode-
규칙 기능이
경고또는레코드규칙으로 작동하는지 여부를 지정합니다. 이 설정은 변형별로 정의하거나 전체 템플릿에 대해 정의할 수 있습니다. spec.processor.metrics.healthRules.variants.thresholds-
규칙을 트리거하는 숫자 값을 지정합니다. 단일 변형에서
중요한보안 수준,경고또는정보와같은 여러 심각도 수준을 정의할 수 있습니다. 클러스터 전체 변형-
groupBy설정없이 정의된 변형을 지정합니다. 제공된 예에서 이 변형은 전체 클러스터 트래픽이 10% 드롭에 도달하면 트리거됩니다. spec.processor.metrics.healthRules.variants.groupBy- 메트릭을 집계하는 데 사용되는 차원을 지정합니다. 제공된 예에서 경고는 각 *노드8에 대해 독립적으로 평가됩니다.
규칙을 사용자 정의하면 해당 템플릿의 기본 구성이 교체됩니다. 기본 구성을 유지하려면 수동으로 복제해야 합니다.
11.3.1. 상태 규칙에 대한 PromQL 표현식 및 메타데이터
Prometheus Query Language( PromQL )의 기본 쿼리에 대해 알아보고, 특정 요구 사항에 맞게 네트워크 관찰 알림을 구성할 수 있도록 사용자 정의하는 방법을 알아보세요.
네트워크 관찰 가능성 FlowCollector CR(사용자 정의 리소스)의 상태 규칙 API는 Prometheus Operator API에 매핑되어 PrometheusRule 을 생성합니다. 다음 명령을 실행하면 기본 netobserv 네임스페이스에서 PrometheusRule 을 볼 수 있습니다.
$ oc get prometheusrules -n netobserv -oyaml11.3.1.1. 유입 트래픽 급증 시 경고에 대한 예제 쿼리
이 예제에서는 유입 트래픽 급증에 대한 알림에 대한 기본 PromQL 쿼리 패턴을 제공합니다.
sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m])) by (DstK8S_Namespace)
이 쿼리는 지난 30분 동안 openshift-ingress 네임스페이스에서 모든 워크로드 네임스페이스로 들어오는 바이트 전송률을 계산합니다.
일부 요금만 유지하고, 특정 기간 동안 쿼리를 실행하고, 최종 임계값을 설정하는 등 쿼리를 사용자 지정할 수 있습니다.
- 노이즈 필터링
이 쿼리에
1000 이상을추가하면1KB/s보다 큰 속도만 관찰되어 대역폭이 낮은 소비자의 노이즈가 제거됩니다.(SrcK8S_Namespace="openshift-ingress"}[30m]의 합계 비율(netobserv_workload_ingress_bytes_total)) (DstK8S_Namespace) > 1000)바이트 속도는
FlowCollector사용자 정의 리소스(CR) 구성에서 정의된 샘플링 간격을 기준으로 합니다. 샘플링 간격이1:100이면 실제 트래픽은 보고된 지표보다 약 100배 더 높을 수 있습니다.- 시간 비교
오프셋수정자를 사용하면 특정 기간 동안 동일한 쿼리를 실행할 수 있습니다. 예를 들어, 하루 전의 쿼리는오프셋 1d를사용하여 실행할 수 있고, 5시간 전의 쿼리는오프셋 5h를사용하여 실행할 수 있습니다.sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m] 오프셋 1d)) (DstK8S_Namespace))100 * (<현재 쿼리> - <전날 쿼리>) / <전날 쿼리>공식을 사용하면 전날 대비 증가율을 계산할 수 있습니다. 오늘의 바이트 속도가 전날보다 낮으면 이 값은 음수가 될 수 있습니다.- 최종 임계값
-
원하는 백분율보다 낮은 증가를 필터링하기 위해 최종 임계값을 적용할 수 있습니다. 예를 들어,
> 100은100%보다 낮은 증가를 제거합니다.
PrometheusRule 에 대한 완전한 표현식은 다음과 같습니다.
...
expr: |-
(100 *
(
(sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m])) by (DstK8S_Namespace) > 1000)
- sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m] offset 1d)) by (DstK8S_Namespace)
)
/ sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m] offset 1d)) by (DstK8S_Namespace))
> 10011.3.1.2. 알림 메타데이터 필드
네트워크 관찰 운영자는 모니터링 스택과 같은 다른 OpenShift 컨테이너 플랫폼 기능의 구성 요소를 사용하여 네트워크 트래픽에 대한 가시성을 향상시킵니다. 자세한 내용은 "스택 아키텍처 모니터링"을 참조하세요.
규칙 정의에 맞게 일부 메타데이터를 구성해야 합니다. 이 메타데이터는 모니터링 스택의 Prometheus와 Alertmanager 서비스 또는 네트워크 상태 대시 보드에서 사용됩니다.
다음 예에서는 구성된 메타데이터가 포함된 AlertingRule 리소스를 보여줍니다.
apiVersion: monitoring.openshift.io/v1
kind: AlertingRule
metadata:
name: netobserv-alerts
namespace: openshift-monitoring
spec:
groups:
- name: NetObservAlerts
rules:
- alert: NetObservIncomingBandwidth
annotations:
netobserv_io_network_health: '{"namespaceLabels":["DstK8S_Namespace"],"threshold":"100","unit":"%","upperBound":"500"}'
message: |-
NetObserv is detecting a surge of incoming traffic: current traffic to {{ $labels.DstK8S_Namespace }} has increased by more than 100% since yesterday.
summary: "Surge in incoming traffic"
expr: |-
(100 *
(
(sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m])) by (DstK8S_Namespace) > 1000)
- sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m] offset 1d)) by (DstK8S_Namespace)
)
/ sum(rate(netobserv_workload_ingress_bytes_total{SrcK8S_Namespace="openshift-ingress"}[30m] offset 1d)) by (DstK8S_Namespace))
> 100
for: 1m
labels:
app: netobserv
netobserv: "true"
severity: warning다음과 같습니다.
spec.groups.rules.alert.labels.netobserv-
true로 설정된 경우 네트워크 상태 대시 보드에서 감지할 알림을 지정합니다. spec.groups.rules.alert.labels.severity-
경고의 심각도를 지정합니다. 유효한 값은 다음과 같습니다:
critical,warning,info.
정의된 PromQL 표현식의 출력 레이블을 메시지 주석에 활용할 수 있습니다. 이 예에서 결과는 DstK8S_Namespace 별로 그룹화되므로 메시지 텍스트에서 {{ $labels.DstK8S_Namespace }}라는 표현식이 사용됩니다.
netobserv_io_network_health 주석은 선택 사항이며, 네트워크 상태 페이지에서 알림이 렌더링되는 방식을 제어합니다.
netobserv_io_network_health 주석은 다음 필드로 구성된 JSON 문자열입니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
| 문자열 목록입니다. | 네임스페이스를 보유하는 하나 이상의 레이블입니다. 제공된 경우 알림은 네임스페이스 탭에 나타납니다. |
|
| 문자열 목록입니다. | 노드 이름을 저장하는 하나 이상의 레이블입니다. 제공된 경우 알림은 노드 탭 아래에 나타납니다. |
|
| 문자열 목록입니다. |
소유자/워크로드 이름을 보유하는 하나 이상의 레이블입니다. |
|
| 문자열 목록입니다. |
소유자/워크로드 종류를 보유하는 하나 이상의 레이블입니다. |
| 임계값 | 문자열 |
|
|
| 문자열 | 표시 목적으로만 사용되는 데이터 단위입니다. |
|
| 문자열 | 폐쇄된 척도에서 점수를 계산하는 데 사용되는 상한값입니다. 이 경계를 초과하는 메트릭 값은 고정됩니다. |
|
| 개체 목록. |
알림과 함께 상황에 맞게 표시할 링크 목록입니다. 각 링크에는 |
|
| 문자열 |
URL 빌드를 위한 네트워크 트래픽 페이지에 대한 링크와 관련된 정보입니다. 일부 필터는 |
namespaceLabels 와 nodeLabels는 상호 배타적입니다. 둘 다 제공되지 않으면 알림은 글로벌 탭에 나타납니다.
| 필드 | 설명 |
|---|---|
|
| 삽입할 추가 필터(예: DNS 관련 경고의 DNS 응답 코드) |
|
|
필터에 반환 트래픽이 포함되어야 하는지 여부( |
|
|
필터에서 소스 대신 트래픽 대상을 대상으로 지정하는지 여부( |
11.3.2. 사용자 정의 상태 규칙 구성
Prometheus 쿼리 언어( PromQL )를 사용하여 특정 네트워크 측정항목(예: 트래픽 급증)에 따라 알림을 트리거하는 사용자 지정 AlertingRule 리소스를 정의합니다.
사전 요구 사항
-
PromQL에 대한 지식. - OpenShift Container Platform 4.16 이상을 설치했습니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - 네트워크 관찰 연산자를 설치했습니다.
프로세스
-
AlertingRule리소스가 포함된custom-alert.yaml이라는 YAML 파일을 만듭니다. 다음 명령을 실행하여 사용자 지정 알림 규칙을 적용합니다.
$ oc apply -f custom-alert.yaml
검증
다음 명령을 실행하여
PrometheusRule리소스가netobserv네임스페이스에 생성되었는지 확인하세요.$ oc get prometheusrules -n netobserv -oyaml출력에는 방금 만든
netobserv-alerts규칙이 포함되어야 하며, 이를 통해 리소스가 올바르게 생성되었음을 확인할 수 있습니다.- OpenShift Container Platform 웹 콘솔의 네트워크 상태 대시보드를 확인하여 규칙이 활성화되었는지 확인합니다. → 관찰합니다 .
11.4. 사전 정의된 규칙 비활성화
FlowCollector CR(사용자 정의 리소스)의 spec.processor.metrics.disableAlerts 필드에서 규칙 템플릿을 비활성화할 수 있습니다. 이 설정은 규칙 템플릿 이름 목록을 허용합니다. 경고 템플릿 이름 목록은 "기본 규칙 목록"을 참조하십시오.
spec.processor.metrics.healthRules 필드에서 템플릿을 비활성화하고 재정의하는 경우 disable 설정이 우선하며 경고 규칙이 생성되지 않습니다.
12장. 대시보드 및 경고로 메트릭 사용
네트워크 관찰 연산자는 flowlogs-pipeline 구성 요소를 사용하여 흐름 로그에서 메트릭을 생성합니다. 이러한 측정 항목을 사용하여 사용자 정의 알림을 설정하고 네트워크 활동 분석을 위한 대시보드를 확인하세요.
12.1. 네트워크 관찰성 지표 대시보드 보기
OpenShift Container Platform 콘솔의 개요 탭을 사용하여 네트워크 관찰 가능성 메트릭 대시보드를 보고 전체 트래픽 흐름 및 시스템 상태를 모니터링할 수 있으며, 노드, 네임스페이스, 소유자, 파드 및 서비스별로 메트릭을 필터링할 수 있습니다.
프로세스
- 웹 콘솔 Observe → Dashboards 에서 Netobserv 대시보드를 선택합니다.
다음 카테고리에서 네트워크 트래픽 지표를 확인합니다. 각각 노드, 네임스페이스, 소스 및 대상당 하위 집합을 갖습니다.
- 바이트 비율
- 패킷 드롭
- DNS
- RTT
- Netobserv/Health 대시보드를 선택합니다.
다음 카테고리에서 Operator의 상태에 대한 메트릭을 표시하고 각 카테고리에는 노드, 네임스페이스, 소스 및 대상당 하위 집합이 있습니다.
- flows
- 흐름 오버 헤드
- 유량
- 에이전트
- 프로세서
Operator
인프라 및 애플리케이션 메트릭은 네임스페이스 및 워크로드에 대한 분할 보기에 표시됩니다.
12.2. 네트워크 관찰성 지표
FlowCollector 리소스에서 구성하고 트래픽을 모니터링하고 Prometheus 경고를 생성하는 데 사용할 수 있는 netobserv_ 접두사가 붙은 네트워크 관찰 가능성 메트릭의 전체 목록을 검토하십시오.
flowlogs-pipeline 에서 생성한 지표는 지표를 추가하거나 제거하기 위해 FlowCollector 사용자 정의 리소스의 spec.processor.metrics.includeList 에서 구성할 수 있습니다.
예제 "경고 생성"과 같이 Prometheus 규칙에 includeList 지표를 사용하여 경고를 생성할 수도 있습니다.
Observe → Metrics 를 통해 콘솔에서와 같이 Prometheus에서 이러한 지표를 찾을 때 또는 경고를 정의할 때 모든 메트릭 이름 앞에 netobserv_ 접두사가 지정됩니다. 예를 들어 netobserv_namespace_flows_total. 사용 가능한 지표 이름은 다음과 같습니다.
- includeList 지표 이름
이름 뒤에 별표
*는 기본적으로 활성화되어 있습니다.-
namespace_egress_bytes_total -
namespace_egress_packets_total -
namespace_ingress_bytes_total -
namespace_ingress_packets_total -
namespace_flows_total* -
node_egress_bytes_total -
node_egress_packets_total -
node_ingress_bytes_total* -
node_ingress_packets_total -
node_flows_total -
workload_egress_bytes_total -
workload_egress_packets_total -
workload_ingress_bytes_total* -
workload_ingress_packets_total -
workload_flows_total
-
- PacketDrop 메트릭 이름
spec.agent.ebpf.features(특권모드)에서PacketDrop기능이 활성화된 경우 다음과 같은 추가 메트릭을 사용할 수 있습니다.-
namespace_drop_bytes_total -
namespace_drop_packets_total* -
node_drop_bytes_total -
node_drop_packets_total -
workload_drop_bytes_total -
workload_drop_packets_total
-
- DNS 메트릭 이름
spec.agent.ebpf.features에서DNSTracking기능이 활성화되면 다음과 같은 추가 메트릭을 사용할 수 있습니다.-
namespace_dns_latency_seconds* -
node_dns_latency_seconds -
workload_dns_latency_seconds
-
- FlowRTT 메트릭 이름
spec.agent.ebpf.features에서FlowRTT기능이 활성화되면 다음과 같은 추가 메트릭을 사용할 수 있습니다.-
namespace_rtt_seconds* -
node_rtt_seconds -
workload_rtt_seconds
-
- 네트워크 이벤트 메트릭 이름
NetworkEvents기능이 활성화되면 기본적으로 다음 메트릭을 사용할 수 있습니다.-
namespace_network_policy_events_total
-
12.3. 알림 생성
Netobserv 대시보드 메트릭을 기반으로 사용자 지정 AlertingRule 리소스를 생성하여 OpenShift Container Platform 콘솔에서 경고를 트리거하는 조건을 정의할 수 있습니다.
사전 요구 사항
- cluster-admin 역할이 있는 사용자 또는 모든 프로젝트에 대한 보기 권한이 있는 사용자로 클러스터에 액세스할 수 있습니다.
- 네트워크 관찰 연산자가 설치되어 있습니다.
프로세스
- 가져오기 아이콘 + 을 클릭하여 YAML 파일을 만듭니다.
YAML 파일에 경고 규칙 구성을 추가합니다. 다음 YAML 샘플에서는 클러스터 수신 트래픽이 대상 워크로드당 10MBps의 임계값에 도달하면 알림이 생성됩니다.
apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: netobserv-alerts namespace: openshift-monitoring spec: groups: - name: NetObservAlerts rules: - alert: NetObservIncomingBandwidth annotations: message: |- {{ $labels.job }}: incoming traffic exceeding 10 MBps for 30s on {{ $labels.DstK8S_OwnerType }} {{ $labels.DstK8S_OwnerName }} ({{ $labels.DstK8S_Namespace }}). summary: "High incoming traffic." expr: sum(rate(netobserv_workload_ingress_bytes_total {SrcK8S_Namespace="openshift-ingress"}[1m])) by (job, DstK8S_Namespace, DstK8S_OwnerName, DstK8S_OwnerType) > 10000000 for: 30s labels: severity: warning-
netobserv_workload_ingress_bytes_total메트릭은spec.processor.metrics.includeList에서 기본적으로 활성화됩니다.
-
- 클러스터에 구성 파일을 적용하려면 만들기를 클릭합니다.
12.4. 사용자 정의 메트릭
FlowMetric API를 사용하여 플로우로그 데이터에서 사용자 지정 메트릭을 정의하고, 로그 필드를 Prometheus 레이블로 활용하여 대시보드 정보를 사용자 지정하고 특정 클러스터 데이터를 모니터링할 수 있습니다.
수집된 모든 플로우로그 데이터에는 소스 이름, 대상 이름 등 로그별로 레이블이 지정된 여러 필드가 있습니다. 이러한 필드는 Prometheus 레이블로 활용하여 대시보드에서 클러스터 정보를 사용자 정의할 수 있습니다.
12.5. FlowMetric API를 사용하여 사용자 정의 메트릭 구성
FlowMetric API를 구성하여 특정 모니터링 요구 사항을 충족하도록 플로우 로그 필드를 레이블로 매핑함으로써 사용자 지정 Prometheus 메트릭을 생성할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 FlowMetric을 선택합니다.
- 프로젝트: 드롭다운 목록에서 Network Observability Operator 인스턴스의 프로젝트를 선택합니다.
- FlowMetric 만들기를 클릭합니다.
-
FlowMetric리소스를 구성합니다. "Custom metrics configuration examples"를 참조하십시오.
검증
- Pod가 새로 고쳐지면 모니터링 → 메트릭 으로 이동합니다.
-
Expression 필드에서 메트릭 이름을 입력하여 해당 결과를 볼 수 있습니다.
topk(5, sum(rate(netobserv_cluster_external_ingress_bytes_total{DstK8S_Namespace="my-namespace"}[2m])) by (DstK8S_HostName, DstK8S_OwnerName, DstK8S_OwnerType))와 같은 표현식을 입력할 수도 있습니다.
12.5.1. 사용자 정의 메트릭 구성 예
외부 트래픽 볼륨 또는 대기 시간 급증과 같은 기본 메트릭에서 다루지 않는 특정 네트워크 동작을 모니터링하려면 FlowMetric CR(사용자 정의 리소스)을 사용합니다. 이 예제에서는 네트워크 흐름에서 대상 Prometheus 지표를 생성하는 데 필요한 구성을 제공합니다.
12.5.1.1. 클러스터 외부 소스에서 수신 바이트 추적
외부 네트워크에서 클러스터를 입력하는 데이터 볼륨을 측정하려면 다음 FlowMetric 구성을 사용합니다. 이 메트릭은 잠재적인 대역폭 문제 또는 예기치 않은 외부 데이터 전송 비용을 식별하는 데 도움이 됩니다.
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-traffic
namespace: netobserv
spec:
metricName: cluster_external_ingress_bytes_total
type: Counter
valueField: Bytes
direction: Ingress
labels: [DstK8S_HostName,DstK8S_Namespace,DstK8S_OwnerName,DstK8S_OwnerType]
filters:
- field: SrcSubnetLabel
matchType: Absence다음과 같습니다.
metadata.namespace-
FlowMetric리소스가 생성되는 네임스페이스를 지정합니다. 이는 기본적으로netobserv인FlowCollector리소스spec.namespace필드에 정의된 네임스페이스와 일치해야 합니다. spec.metricName-
OpenShift Container Platform 웹 콘솔에
netobserv-<metricName> 접두사가 표시되는 Prometheus 지표의 이름을 지정합니다. spec.type-
메트릭 유형을 지정합니다. Cryo
stat유형은 바이트 또는 패킷을 계산하는 데 유용합니다. spec.direction- 캡처할 트래픽 방향을 지정합니다. 지정하지 않으면 유입과 유출이 모두 캡처되어 중복 계산이 발생할 수 있습니다.
spec.labels-
지표의 모양과 다른 엔티티 간의 관계 및 메트릭 카디널리티를 정의하는 레이블을 지정합니다. 예를 들어,
SrcK8S_Name은 높은 카디널리티 메트릭입니다. spec.filters-
나열된 기준에 따라 결과를 구체화하는 기준을 지정합니다. 이 예에서 클러스터 외부 트래픽만 선택하는 것은
SrcSubnetLabel이없는 흐름만 일치시켜 수행됩니다. 이는 기본적으로 서브넷 레이블 기능이 (spec.processor.subnetLabels를 통해) 활성화되어 있다고 가정합니다.
12.5.1.2. 클러스터 외부 수신 트래픽의 RTT 대기 시간 모니터링
외부 연결의 성능을 분석하고 대기 시간이 긴 경로를 확인하려면 다음 FlowMetric 구성을 사용합니다. 이 메트릭은 표준 Prometheus 대기 시간 대시보드와 일치하도록 나노초를 초로 변환합니다.
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-rtt
namespace: netobserv
spec:
metricName: cluster_external_ingress_rtt_seconds
type: Histogram
valueField: TimeFlowRttNs
direction: Ingress
labels: [DstK8S_HostName,DstK8S_Namespace,DstK8S_OwnerName,DstK8S_OwnerType]
filters:
- field: SrcSubnetLabel
matchType: Absence
- field: TimeFlowRttNs
matchType: Presence
divider: "1000000000"
buckets: [".001", ".005", ".01", ".02", ".03", ".04", ".05", ".075", ".1", ".25", "1"]다음과 같습니다.
metadata.namespace-
FlowMetric리소스가 생성되는 네임스페이스를 지정합니다. 이는 기본적으로netobserv인FlowCollector리소스spec.namespace필드에 정의된 네임스페이스와 일치해야 합니다. spec.type-
메트릭 유형을 지정합니다.
histogram 유형은TimeFlowRttNs와 같은 대기 시간 값에 유용합니다. spec.divider- 지표를 분할하는 데 사용되는 값을 지정합니다. RTT(Round-trip Time)는 흐름에서 나노초로 제공되므로 1,000,000,000의 분할기를 사용하여 Prometheus 지침의 표준인 초 단위로 값을 변환합니다.
spec.buckets- RTT 정확도에 대한 사용자 지정 버킷을 지정합니다. 최적의 전체 정확도 범위는 5ms에서 250ms 사이입니다.
12.6. 트래픽 흐름 테이블의 중첩 또는 배열 필드에서 메트릭 생성
FlowMetric 사용자 지정 리소스를 생성하여 트래픽 흐름 테이블의 중첩 필드 또는 배열 필드(예: 네트워크 이벤트 또는 인터페이스) 에 대한 메트릭을 생성합니다.
OVN 관찰/ NetworkEvents 보기는 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
OVN 관찰 기능과 네트워크 이벤트를 보고 추적하는 기능은 OpenShift Container Platform 4.17 및 4.18에서만 사용할 수 있습니다.
다음 예는 네트워크 정책 이벤트에 대한 네트워크 이벤트 필드에서 메트릭을 생성하는 방법을 보여줍니다.
사전 요구 사항
-
NetworkEvents 기능을활성화합니다. 이 작업을 수행하는 방법은 추가 리소스를 참조하십시오. - 네트워크 정책이 지정되었습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 FlowMetric을 선택합니다.
- 프로젝트 드롭다운 목록에서 Network Observability Operator 인스턴스의 프로젝트를 선택합니다.
- FlowMetric 만들기를 클릭합니다.
FlowMetric리소스를 생성하여 다음 구성을 추가합니다.정책 이름 및 네임스페이스당 네트워크 정책 이벤트 계산 구성
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: network-policy-events namespace: netobserv spec: metricName: network_policy_events_total type: Counter labels: [NetworkEvents>Type, NetworkEvents>Namespace, NetworkEvents>Name, NetworkEvents>Action, NetworkEvents>Direction] filters: - field: NetworkEvents>Feature value: acl flatten: [NetworkEvents] remap: "NetworkEvents>Type": type "NetworkEvents>Namespace": namespace "NetworkEvents>Name": name "NetworkEvents>Direction": direction다음과 같습니다.
spec.labels-
트래픽 흐름 테이블의 네트워크 이벤트 의 중첩된 필드를 나타내는 레이블을 지정합니다. 각 네트워크 이벤트에는 특정 유형, 네임스페이스, 이름, 작업 및 방향이 있습니다. OpenShift Container Platform 버전에서
NetworkEvents를 사용할 수 없는 경우Interfaces를 지정할 수도 있습니다. spec.flatten- 고유한 항목으로 표시할 항목 목록을 포함하는 선택적 필드를 지정합니다.
spec.remap- Prometheus에서 이름을 바꿀 선택적 필드 세트를 지정합니다.
검증
- 웹 콘솔에서 관찰 → 대시보드 로 이동한 다음 아래로 스크롤하여 네트워크 정책 탭을 확인합니다.
- 네트워크 정책 사양과 함께 생성한 메트릭을 기반으로 메트릭 필터링이 적용되는 것을 확인할 수 있습니다.
12.7. FlowMetric API를 사용하여 사용자 정의 차트 구성
FlowMetric 사용자 지정 리소스의 차트 섹션을 정의하여 OpenShift Container Platform 웹 콘솔 대시보드용 사용자 지정 차트를 생성합니다.
관리자는 대시보드 메뉴에서 사용자 지정 차트를 볼 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 FlowMetric을 선택합니다.
- 프로젝트: 드롭다운 목록에서 Network Observability Operator 인스턴스의 프로젝트를 선택합니다.
- FlowMetric 만들기를 클릭합니다.
-
FlowMetric리소스를 구성합니다. "Flowmetric 차트 구성 예제"를 참조하십시오.
검증
- Pod가 새로 고쳐지면 모니터링 → 대시보드 로 이동합니다.
NetObserv/메인 대시 보드를 검색하세요. NetObserv/Main 대시보드 아래에 두 개의 패널이 표시되거나, 선택적으로 사용자가 만든 대시보드 이름이 표시됩니다.
- 모든 차원에 걸쳐 합산된 글로벌 외부 유입률을 보여주는 텍스트 단일 통계
- 대상 작업 부하당 동일한 메트릭을 보여주는 시계열 그래프
쿼리 언어에 대한 자세한 내용은 Prometheus 문서를 참조하세요.
12.7.1. Flowmetric 차트 구성 예
이러한 FlowMetric 사용자 정의 리소스 예제에서는 외부 인그레스 트래픽 및 RTT(Round-trip Time) 대기 시간을 추적하기 위해 OpenShift Container Platform 웹 콘솔에서 차트를 정의하는 방법을 보여줍니다.
12.7.1.1. 클러스터 외부 소스에 대한 Ingress 바이트 차트
다음 구성을 사용하여 클러스터 외부 소스의 수신 트래픽 속도를 추적합니다. 이러한 차트는 워크로드당 대역폭 사용량을 식별하는 데 도움이 됩니다.
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-traffic
namespace: netobserv
# ...
charts:
- dashboardName: Main
title: External ingress traffic
unit: Bps
type: SingleStat
queries:
- promQL: "sum(rate($METRIC[2m]))"
legend: ""
- dashboardName: Main
sectionName: External
title: Top external ingress traffic per workload
unit: Bps
type: StackArea
queries:
- promQL: "sum(rate($METRIC{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace, DstK8S_OwnerName)"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
# ...다음과 같습니다.
metadata.namespace-
FlowMetric리소스가 생성되는 네임스페이스를 지정합니다. 이는 기본적으로netobserv인FlowCollectorspec.namespace에 정의된 네임스페이스와 일치해야 합니다. spec.charts.dashboardName-
대시보드 이름을 지정합니다. 다른
대시보드 이름을사용하면Netobserv로 시작하는 새로운 대시보드가 생성됩니다. 예를 들어, Netobserv / <대시보드_이름> .
12.7.1.2. 클러스터 외부 수신 트래픽의 RTT 대기 시간 차트
다음 구성을 사용하여 클러스터 외부 수신 트래픽에 대해 RTT(Round-trip Time)를 모니터링합니다. 이 예에서는 히스토그램_quantile 함수를 사용하여 50번째 및 99번째 백분위수(p50 및 p99)를 표시합니다.
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-traffic
namespace: netobserv
# ...
charts:
- dashboardName: Main
title: External ingress TCP latency
unit: seconds
type: SingleStat
queries:
- promQL: "histogram_quantile(0.99, sum(rate($METRIC_bucket[2m])) by (le)) > 0"
legend: "p99"
- dashboardName: Main
sectionName: External
title: "Top external ingress sRTT per workload, p50 (ms)"
unit: seconds
type: Line
queries:
- promQL: "histogram_quantile(0.5, sum(rate($METRIC_bucket{DstK8S_Namespace!=\"\"}[2m])) by (le,DstK8S_Namespace,DstK8S_OwnerName))*1000 > 0"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
- dashboardName: Main
sectionName: External
title: "Top external ingress sRTT per workload, p99 (ms)"
unit: seconds
type: Line
queries:
- promQL: "histogram_quantile(0.99, sum(rate($METRIC_bucket{DstK8S_Namespace!=\"\"}[2m])) by (le,DstK8S_Namespace,DstK8S_OwnerName))*1000 > 0"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
# ...다음과 같습니다.
metadata.namespace-
FlowMetric리소스가 생성되는 네임스페이스를 지정합니다. 이는 기본적으로netobserv인FlowCollectorspec.namespace에 정의된 네임스페이스와 일치해야 합니다. spec.charts.dashboardName-
대시보드 이름을 지정합니다. 다른
대시보드 이름을사용하면Netobserv로 시작하는 새로운 대시보드가 생성됩니다. 예를 들어, Netobserv / <대시보드_이름> .
12.7.1.3. 히스토그램 평균 계산
히스토그램을 생성할 때 자동으로 생성되는메트릭 $METRIC_sum을 메트릭 $METRIC_count로 나누어 히스토그램의 평균을 표시할 수 있습니다. 앞의 예에서 이를 수행하기 위한 Prometheus 쿼리는 다음과 같습니다.
promQL: "(sum(rate($METRIC_sum{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace,DstK8S_OwnerName) / sum(rate($METRIC_count{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace,DstK8S_OwnerName))*1000"12.8. FlowMetric API 및 TCP 플래그를 사용하여 SYN 플러딩 감지
사용자 지정 AlertingRule 및 FlowMetric 구성을 배포하여 TCP 플래그를 모니터링하고 클러스터에 대한 SYN 플러딩 공격을 실시간으로 감지하고 경고할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목에서 FlowMetric을 선택합니다.
- 프로젝트 드롭다운 목록에서 Network Observability Operator 인스턴스의 프로젝트를 선택합니다.
- FlowMetric 만들기를 클릭합니다.
FlowMetric리소스를 생성하여 다음 구성을 추가합니다.TCP 플래그를 사용하여 대상 호스트 및 리소스당 흐름 계산 구성
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flows-with-flags-per-destination spec: metricName: flows_with_flags_per_destination_total type: Counter labels: [SrcSubnetLabel,DstSubnetLabel,DstK8S_Name,DstK8S_Type,DstK8S_HostName,DstK8S_Namespace,Flags]TCP 플래그를 사용하여 소스 호스트 및 리소스당 흐름 계산 구성
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flows-with-flags-per-source spec: metricName: flows_with_flags_per_source_total type: Counter labels: [DstSubnetLabel,SrcSubnetLabel,SrcK8S_Name,SrcK8S_Type,SrcK8S_HostName,SrcK8S_Namespace,Flags]SYN 플러딩에 대한 경고를 위해 다음
AlertingRule리소스를 배포합니다.SYN 플러딩에 대한
경고 규칙apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: netobserv-syn-alerts namespace: openshift-monitoring # ... spec: groups: - name: NetObservSYNAlerts rules: - alert: NetObserv-SYNFlood-in annotations: message: |- {{ $labels.job }}: incoming SYN-flood attack suspected to Host={{ $labels.DstK8S_HostName}}, Namespace={{ $labels.DstK8S_Namespace }}, Resource={{ $labels.DstK8S_Name }}. This is characterized by a high volume of SYN-only flows with different source IPs and/or ports. summary: "Incoming SYN-flood" expr: sum(rate(netobserv_flows_with_flags_per_destination_total{Flags="2"}[1m])) by (job, DstK8S_HostName, DstK8S_Namespace, DstK8S_Name) > 300 for: 15s labels: severity: warning app: netobserv - alert: NetObserv-SYNFlood-out annotations: message: |- {{ $labels.job }}: outgoing SYN-flood attack suspected from Host={{ $labels.SrcK8S_HostName}}, Namespace={{ $labels.SrcK8S_Namespace }}, Resource={{ $labels.SrcK8S_Name }}. This is characterized by a high volume of SYN-only flows with different source IPs and/or ports. summary: "Outgoing SYN-flood" expr: sum(rate(netobserv_flows_with_flags_per_source_total{Flags="2"}[1m])) by (job, SrcK8S_HostName, SrcK8S_Namespace, SrcK8S_Name) > 300 for: 15s labels: severity: warning app: netobserv # ...이 예에서 알림에 대한 임계값은
300입니다. 하지만 경험적으로 이 값을 조정할 수 있습니다. 임계값이 너무 낮으면 거짓 양성 결과가 나올 수 있고, 임계값이 너무 높으면 실제 공격을 놓칠 수 있습니다.
검증
- 웹 콘솔에서 네트워크 트래픽 테이블 보기의 열 관리를 클릭하고 TCP 플래그를 클릭합니다.
- 네트워크 트래픽 테이블 보기에서 TCP 프로토콜 SYN TCPFlag를 필터링합니다. 동일한 byteSize를 가진 많은 수의 흐름은 SYN 플러드를 나타냅니다.
- 모니터링 → 경고로 이동하여 경고 규칙 탭을 선택합니다.
- netobserv-synflood-in 경고 에 대한 필터링. SYN 플러딩이 발생하면 경고가 실행됩니다.
13장. 네트워크 관찰성 운영자 모니터링
OpenShift Container Platform 웹 콘솔을 사용하여 네트워크 관찰 운영자의 상태와 관련된 알림을 모니터링합니다. 이를 통해 시스템 안정성을 유지하고 운영 문제를 신속하게 감지할 수 있습니다.
13.1. 건강 대시보드
OpenShift Container Platform 웹 콘솔에서 네트워크 관찰 가능성 운영자 상태 대시보드를 확인하여 운영자와 해당 구성 요소의 상태, 리소스 사용량 및 내부 통계를 모니터링할 수 있습니다.
메트릭은 OpenShift Container Platform 웹 콘솔의 관찰 → 대시보드 페이지에서 확인할 수 있습니다. 네트워크 관찰 가능성 운영자의 상태에 대한 지표는 다음 범주에서 확인할 수 있습니다.
- 초당 흐름
- sampling:
- 마지막 순간 오류 발생
- 초당 감소된 흐름
- Flowlogs-파이프라인 통계
- Flowlogs-파이프라인 통계 뷰
- eBPF 에이전트 통계 보기
- 운영자 통계
- 리소스 사용량
13.2. 건강 알림
Loki 데이터 수집 오류, 데이터 수집 없음 또는 eBPF 데이터 흐름 손실과 같은 상황이 발생할 때 배너를 표시하는 네트워크 관찰 가능성 운영자가 생성하는 상태 경고를 이해하십시오.
알림이 발생하면 대시보드로 이동하는 건강 알림 배너가 네트워크 트래픽 및 홈페이지 에 나타날 수 있습니다. 다음과 같은 경우 알림이 생성됩니다.
-
NetObservLokiError경고는 Loki 오류(예: Loki 수집 속도 제한에 도달한 경우)로 인해flowlogs-pipeline작업 부하가 흐름을 삭제하는 경우 발생합니다. -
NetObservNoFlows경고는 특정 시간 동안 흐름이 수집되지 않으면 발생합니다. -
NetObservFlowsDropped경고는 Network Observability eBPF 에이전트 해시맵 테이블이 가득 차고 eBPF 에이전트가 성능이 저하된 상태로 흐름을 처리하거나 용량 제한이 트리거되는 경우 발생합니다.
13.3. 건강 정보 보기
OpenShift Container Platform 웹 콘솔 내의 Netobserv/Health 대시보드를 통해 네트워크 관찰 가능성 운영자(Network Observability Operator) 및 해당 구성 요소의 상태와 리소스 사용량을 모니터링할 수 있습니다.
사전 요구 사항
- 네트워크 관찰 연산자가 설치되어 있습니다.
-
cluster-admin역할 또는 모든 프로젝트에 대한 보기 권한이 있는 사용자로 클러스터에 액세스할 수 있습니다.
프로세스
- 웹 콘솔의 관리자 관점에서 관찰 → 대시보드 로 이동합니다.
- 대시보드 드롭다운에서 Netobserv/Health를 선택합니다.
- 페이지에 표시되는 운영자 상태에 대한 측정 항목을 확인하세요.
13.3.1. 건강 알림 비활성화
FlowCollector 리소스를 편집하고 spec.processor.metrics.disableAlerts 사양을 사용하여 NetObservLokiError 또는 NetObservNoFlows 와 같은 특정 상태 알림을 비활성화할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
다음 YAML 샘플과 같이
spec.processor.metrics.disableAlerts를추가하여 상태 알림을 비활성화합니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: metrics: disableAlerts: [NetObservLokiError, NetObservNoFlows]다음과 같습니다.
spec.processor.metrics.disableAlerts- 비활성화할 경고 유형을 하나 이상 지정합니다.
13.4. NetObserv 대시보드에 대한 Loki 속도 제한 알림 생성
Loki 메트릭을 기반으로 하는 사용자 지정 AlertingRule 리소스를 생성하여 HTTP 429 오류로 표시되는 Loki 데이터 수집 속도 제한에 도달할 때 알림을 감지하고 트리거합니다.
Netobserv 대시보드 메트릭에 대한 사용자 정의 알림 규칙을 만들어 Loki 속도 제한에 도달했을 때 알림을 트리거할 수 있습니다.
사전 요구 사항
- cluster-admin 역할이 있는 사용자 또는 모든 프로젝트에 대한 보기 권한이 있는 사용자로 클러스터에 액세스할 수 있습니다.
- 네트워크 관찰 연산자가 설치되어 있습니다.
프로세스
- 가져오기 아이콘 + 을 클릭하여 YAML 파일을 만듭니다.
YAML 파일에 경고 규칙 구성을 추가합니다. 다음 YAML 샘플에서는 Loki 속도 제한에 도달했을 때 알림이 생성됩니다.
apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: loki-alerts namespace: openshift-monitoring spec: groups: - name: LokiRateLimitAlerts rules: - alert: LokiTenantRateLimit annotations: message: |- {{ $labels.job }} {{ $labels.route }} is experiencing 429 errors. summary: "At any number of requests are responded with the rate limit error code." expr: sum(irate(loki_request_duration_seconds_count{status_code="429"}[1m])) by (job, namespace, route) / sum(irate(loki_request_duration_seconds_count[1m])) by (job, namespace, route) * 100 > 0 for: 10s labels: severity: warning- 클러스터에 구성 파일을 적용하려면 만들기를 클릭합니다.
13.5. eBPF 에이전트 알림 사용
eBPF 에이전트 해시맵이 가득 찼을 때 발생하는 NetObservAgentFlowsDropped 경고를 해결하려면 FlowCollector 사용자 지정 리소스에서 spec.agent.ebpf.cacheMaxFlows 값을 늘리십시오.
용량 제한기가 작동되면 NetObservAgentFlowsDropped 라는 경고도 발생합니다. 이 경고가 표시되면 다음 예와 같이 FlowCollector 에서 cacheMaxFlows를 늘리는 것을 고려하세요.
cacheMaxFlows를 늘리면 eBPF 에이전트의 메모리 사용량이 늘어날 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- Network Observability Operator 의 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
다음 YAML 샘플에 표시된 대로
spec.agent.ebpf.cacheMaxFlows값을 늘립니다.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Service agent: type: eBPF ebpf: cacheMaxFlows: 200000다음과 같습니다.
spec.agent.ebpf.cacheMaxFlows-
캐시할 최대 흐름 수를 지정합니다.
NetObservAgentFlowsDropped경고가 발생하면 이 값을 현재 수준에서 늘립니다.
14장. 리소스 스케줄링
오염과 허용은 어떤 노드가 특정 포드를 호스팅하는지 제어하는 데 도움이 됩니다. 이러한 도구를 노드 선택기와 함께 사용하여 네트워크 관찰 구성 요소의 배치를 안내합니다.
노드 선택기는 노드의 사용자 정의 레이블과 포드에 지정된 선택기를 사용하여 정의된 키/값 쌍의 맵을 지정합니다.
노드에서 Pod를 실행하려면 노드의 라벨과 동일한 키/값 노드 선택기가 Pod에 있어야 합니다.
14.1. 특정 노드에서의 네트워크 관찰성 배포
NodeSelector , Tolerations 및 Affinity 를 포함한 스케줄링 사양을 사용하여 FlowCollector 리소스를 구성하면 특정 노드에 네트워크 관찰 가능성 구성 요소가 배포되는 방식을 제어할 수 있습니다.
spec.agent.ebpf.advanced.scheduling , spec.processor.advanced.scheduling 및 spec.consolePlugin.advanced.scheduling 사양에는 다음과 같은 구성 가능한 설정이 있습니다.
- <nodeSelector>
-
허용 오차 -
유사성 -
PriorityClassName
spec.<component>.advanced.scheduling의 샘플 FlowCollector 리소스
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
# ...
advanced:
scheduling:
tolerations:
- key: "<taint key>"
operator: "Equal"
value: "<taint value>"
effect: "<taint effect>"
nodeSelector:
<key>: <value>
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- app-worker-node
priorityClassName: """
# ...15장. 2차 네트워크
SR-IOV 및 OVN-Kubernetes 와 같은 보조 네트워크에서 네트워크 흐름 데이터를 수집하고 보강하도록 네트워크 관찰 연산자를 구성할 수 있습니다.
15.1. 사전 요구 사항
- 보조 인터페이스나 L2 네트워크와 같은 추가 네트워크 인터페이스가 있는 OpenShift Container Platform 클러스터에 액세스합니다.
15.2. SR-IOV 인터페이스 트래픽에 대한 모니터링 구성
FlowCollector 리소스를 구성하여 SR-IOV(Single Root I/O Virtualization) 장치의 트래픽을 모니터링하려면 spec.agent.ebpf.privileged 필드를 true 로 설정하십시오. 이렇게 하면 eBPF 에이전트가 다른 네트워크 네임스페이스를 모니터링할 수 있습니다.
eBPF 에이전트는 기본적으로 모니터링되는 호스트 네트워크 네임스페이스 외에도 다른 네트워크 네임스페이스를 모니터링합니다. 가상 기능(VF) 인터페이스가 있는 포드가 생성되면 새로운 네트워크 네임스페이스가 생성됩니다. SRIOVNetwork 정책 IPAM 구성이 지정되면 VF 인터페이스는 호스트 네트워크 네임스페이스에서 포드 네트워크 네임스페이스로 마이그레이션됩니다.
사전 요구 사항
- SR-IOV 장치가 있는 OpenShift Container Platform 클러스터에 액세스합니다.
-
SRIOVNetwork사용자 정의 리소스(CR)사양.ipam구성은 인터페이스가 나열한 범위나 다른 플러그인의 IP 주소로 설정해야 합니다.
프로세스
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
FlowCollector사용자 정의 리소스를 구성합니다. 샘플 구성은 다음과 같습니다.SR-IOV 모니터링을 위한
FlowCollector구성apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Service agent: type: eBPF ebpf: privileged: true-
SR-IOV 모니터링을 활성화하려면
spec.agent.ebpf.privileged필드 값을true로 설정해야 합니다.
-
SR-IOV 모니터링을 활성화하려면
15.3. 네트워크 관찰을 위한 가상 머신(VM) 보조 네트워크 인터페이스 구성
FlowCollector를 구성하여 VM 보조 네트워크 트래픽을 모니터링하려면 eBPF 에이전트를 권한 모드로 설정하고 보조 네트워크에 대한 인덱싱을 정의하여 OpenShift 가상화에서 발생하는 흐름을 캡처하고 보강할 수 있도록 합니다.
기본 내부 포드 네트워크에 연결된 VM에서 발생하는 네트워크 흐름은 네트워크 관찰 기능을 통해 자동으로 캡처됩니다.
프로세스
다음 명령을 실행하여 가상 머신 런처 포드에 대한 정보를 가져옵니다. 이 정보는 5단계에서 사용됩니다.
$ oc get pod virt-launcher-<vm_name>-<suffix> -n <namespace> -o yamlapiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/network-status: |- [{ "name": "ovn-kubernetes", "interface": "eth0", "ips": [ "10.129.2.39" ], "mac": "0a:58:0a:81:02:27", "default": true, "dns": {} }, { "name": "my-vms/l2-network", "interface": "podc0f69e19ba2", "ips": [ "10.10.10.15" ], "mac": "02:fb:f8:00:00:12", "dns": {} }] name: virt-launcher-fedora-aqua-fowl-13-zr2x9 namespace: my-vms spec: # ... status: # ...다음과 같습니다.
name- 보조 네트워크의 이름을 지정합니다.
interface- 보조 네트워크의 네트워크 인터페이스를 지정합니다.
ips- 보조 네트워크에서 사용하는 IP 주소 목록을 지정합니다.
mac- 보조 네트워크에 사용되는 MAC 주소를 지정합니다.
- 웹 콘솔에서 Operators → 설치된 Operators 로 이동합니다.
- NetObserv Operator 에 대한 제공된 API 제목 아래에서 Flow Collector를 선택합니다.
- 클러스터를 선택한 다음 YAML 탭을 선택합니다.
추가 네트워크 조사에서 찾은 정보를 기반으로
FlowCollector를구성하세요.apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: agent: ebpf: privileged: true processor: advanced: secondaryNetworks: - index: - MAC name: my-vms/l2-network # ...다음과 같습니다.
spec.agent.ebpf.privileged-
eBPF 에이전트가
권한 있는모드에서 실행되도록 지정합니다. 이 모드는 가상 머신 시작 관리자 Pod의 보조 네트워크 인터페이스에서 흐름을 수집하는 데 필요합니다. spec.processor.advanced.secondaryNetworks.index-
가상 머신 시작 관리자 Pod를 인덱싱하는 데 사용할 필드를 지정합니다. 2차 인터페이스의 네트워크 흐름을 강화하려면
MAC주소를 인덱싱 필드로 사용하는 것이 좋습니다. Pod 간에 MAC 주소가 겹치는 경우IP및 인터페이스와 같은 추가 인덱싱 필드를 추가하여 정확한 보강을 보장할 수 있습니다. MAC-
MAC 주소를 인덱싱 필드 값으로 지정합니다. 추가 네트워크 정보에
MAC주소가 포함된 경우인덱스필드 목록에 MAC을 추가합니다. spec.processor.advanced.secondaryNetworks.name-
가상 머신 시작 관리자 Pod의
k8s.v1.cni.cncf.io/network-status주석에 있는 보조 네트워크의 이름을 지정합니다. 형식은 일반적으로 <namespace>/<network_attachment_definition_name>입니다.
검증
VM 트래픽을 관찰하세요.
- 네트워크 트래픽 페이지로 이동합니다.
-
k8s.v1.cni.cncf.io/network-status주석에서 찾은 가상 머신 IP를 사용하여 소스 IP로 필터링합니다. - 보강해야 할 소스 및 대상 필드를 모두 보고 VM 런처 포드와 VM 인스턴스를 소유자로 식별합니다.
16장. 네트워크 관찰 CLI
16.1. 네트워크 Observability CLI 설치
네트워크 관찰 CLI( oc netobserv )는 네트워크 관찰 연산자와 별도로 배포됩니다. CLI는 OpenShift CLI( oc ) 플러그인으로 사용할 수 있습니다. 네트워크 관찰을 통해 빠르게 디버깅하고 문제를 해결할 수 있는 가벼운 방법을 제공합니다.
16.1.1. 네트워크 관찰 CLI에 관하여
네트워크 관찰 CLI( oc netobserv )를 사용하면 네트워크 문제를 빠르게 디버깅하고 해결할 수 있습니다. 이 도구는 네트워크 관찰 운영자를 설치하지 않고도 흐름과 패킷에 대한 즉각적이고 실시간적인 통찰력을 제공합니다.
네트워크 관찰 CLI는 eBPF 에이전트를 사용하여 수집된 데이터를 임시 수집기 포드로 스트리밍하는 흐름 및 패킷 시각화 도구입니다. 캡처하는 동안 지속적인 저장이 필요하지 않습니다. 실행 후 출력이 로컬 컴퓨터로 전송됩니다.
CLI 캡처는 8~10분 정도의 짧은 기간 동안만 실행되도록 설계되었습니다. 너무 오래 실행되는 경우 실행 중인 프로세스를 삭제하기 어려울 수 있습니다.
16.1.2. 네트워크 Observability CLI 설치
네트워크 관찰 CLI를 사용하면 네트워크 관찰을 빠르게 디버깅하고 문제를 해결할 수 있는 가벼운 방법을 제공합니다. 별도로 설치해야 합니다.
네트워크 관찰 CLI( oc netobserv )를 설치하는 것은 네트워크 관찰 운영자 설치와 별도의 절차입니다. 즉, Operator를 소프트웨어 카탈로그에서 설치하더라도 CLI는 별도로 설치해야 합니다.
사용자는 선택적으로 Krew를 사용하여 netobserv CLI 플러그인을 설치할 수 있습니다. 자세한 내용은 "Krew로 CLI 플러그인 설치"를 참조하세요.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치해야 합니다. - macOS 또는 Linux 운영 체제가 있어야 합니다.
-
docker또는podman을설치해야 합니다.
podman 이나 docker를 사용하여 설치 명령을 실행할 수 있습니다. 이 절차에서는 podman을 사용합니다.
프로세스
다음 명령을 실행하여 Red Hat 레지스트리 에 로그인합니다.
$ podman login registry.redhat.io다음 명령을 실행하여 이미지에서
oc-netobserv파일을 추출합니다.$ podman create --name netobserv-cli registry.redhat.io/network-observability/network-observability-cli-rhel9:1.11 $ podman cp netobserv-cli:/oc-netobserv . $ podman rm netobserv-cli다음 명령을 실행하여 추출된 파일을 시스템의
PATH에 있는 디렉토리(예:/usr/local/bin/)로 이동합니다.$ sudo mv oc-netobserv /usr/local/bin/
검증
oc netobserv를사용할 수 있는지 확인하세요.$ oc netobserv version이 명령을 실행하면 다음 예와 비슷한 결과가 나옵니다.
Netobserv CLI version <version>16.2. 네트워크 Observability CLI 정리
터미널에서 직접 흐름과 패킷 데이터를 시각화하고 필터링하여 특정 포트를 사용하는 사람을 식별하는 등 구체적인 사용량을 확인할 수 있습니다. 네트워크 관찰 CLI는 흐름을 JSON으로 수집하고 데이터베이스 파일이나 패킷을 PCAP 파일로 수집하는데, 이는 타사 도구와 함께 사용할 수 있습니다.
16.2.1. 흐름 캡처
CLI에서 직접 네트워크 흐름을 캡처하고 리소스나 영역을 기반으로 필터를 적용합니다. 이를 통해 두 개의 서로 다른 영역 간의 왕복 시간(RTT)을 시각화하는 등 복잡한 사용 사례를 해결하는 데 도움이 됩니다.
CLI에서 테이블 시각화를 통해 보기 및 흐름 검색 기능을 제공합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
네트워크 관찰 CLI(
oc netobserv) 플러그인을 설치합니다.
프로세스
다음 명령을 실행하여 필터가 활성화된 흐름을 캡처합니다.
$ oc netobserv flows --enable_filter=true --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=49051터미널의
라이브 테이블 필터프롬프트에 필터를 추가하여 유입 흐름을 더욱 세분화합니다. 예를 들면 다음과 같습니다.live table filter: [SrcK8S_Zone:us-west-1b] press enter to match multiple regular expressions at once- PageUp 및 PageDown 키를 사용하여 None , Resource , Zone , Host , Owner 및 그 이상의 모든 항목 사이를 전환합니다.
-
캡처를 중지하려면 Ctrl+C 를 누르세요. 캡처된 데이터는 CLI를 설치하는 데 사용된 경로와 동일한 경로에 있는
./output디렉토리의 두 개의 별도 파일에 기록됩니다. ./output/flow/<capture_date_time>.jsonJSON 파일에서 캡처된 데이터를 볼 수 있습니다. 이 파일에는 캡처된 데이터의 JSON 배열이 포함되어 있습니다.JSON 파일 예시
{ "AgentIP": "10.0.1.76", "Bytes": 561, "DnsErrno": 0, "Dscp": 20, "DstAddr": "f904:ece9:ba63:6ac7:8018:1e5:7130:0", "DstMac": "0A:58:0A:80:00:37", "DstPort": 9999, "Duplicate": false, "Etype": 2048, "Flags": 16, "FlowDirection": 0, "IfDirection": 0, "Interface": "ens5", "K8S_FlowLayer": "infra", "Packets": 1, "Proto": 6, "SrcAddr": "3e06:6c10:6440:2:a80:37:b756:270f", "SrcMac": "0A:58:0A:80:00:01", "SrcPort": 46934, "TimeFlowEndMs": 1709741962111, "TimeFlowRttNs": 121000, "TimeFlowStartMs": 1709741962111, "TimeReceived": 1709741964 }SQLite를 사용하여
./output/flow/<capture_date_time>.db데이터베이스 파일을 검사할 수 있습니다. 예를 들면 다음과 같습니다.다음 명령을 실행하여 파일을 엽니다.
$ sqlite3 ./output/flow/<capture_date_time>.db예를 들어, SQLite
SELECT문을 실행하여 데이터를 쿼리합니다.sqlite> SELECT DnsLatencyMs, DnsFlagsResponseCode, DnsId, DstAddr, DstPort, Interface, Proto, SrcAddr, SrcPort, Bytes, Packets FROM flow WHERE DnsLatencyMs >10 LIMIT 10;출력 예
12|NoError|58747|10.128.0.63|57856||17|172.30.0.10|53|284|1 11|NoError|20486|10.128.0.52|56575||17|169.254.169.254|53|225|1 11|NoError|59544|10.128.0.103|51089||17|172.30.0.10|53|307|1 13|NoError|32519|10.128.0.52|55241||17|169.254.169.254|53|254|1 12|NoError|32519|10.0.0.3|55241||17|169.254.169.254|53|254|1 15|NoError|57673|10.128.0.19|59051||17|172.30.0.10|53|313|1 13|NoError|35652|10.0.0.3|46532||17|169.254.169.254|53|183|1 32|NoError|37326|10.0.0.3|52718||17|169.254.169.254|53|169|1 14|NoError|14530|10.0.0.3|58203||17|169.254.169.254|53|246|1 15|NoError|40548|10.0.0.3|45933||17|169.254.169.254|53|174|1
16.2.2. 패킷 캡처
네트워크 관찰 CLI를 사용하여 네트워크 패킷을 캡처합니다. 터미널에서 필터를 적용하고 실시간으로 세부 조정하여 정확하고 실시간 디버깅을 수행할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
네트워크 관찰 CLI(
oc netobserv) 플러그인을 설치합니다.
프로세스
필터를 활성화하여 패킷 캡처를 실행합니다.
$ oc netobserv packets --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=49051터미널의
라이브 테이블 필터프롬프트에 필터를 추가하여 수신 패킷을 세분화합니다. 필터 예는 다음과 같습니다.live table filter: [SrcK8S_Zone:us-west-1b] press enter to match multiple regular expressions at once- PageUp 및 PageDown 키를 사용하여 None , Resource , Zone , Host , Owner 및 그 이상의 모든 항목 사이를 전환합니다.
- 캡처를 중지하려면 Ctrl+C 를 누르세요.
CLI를 설치하는 데 사용된 경로와 동일한 경로에 있는
./output/pcap디렉토리의 단일 파일에 기록된 캡처된 데이터를 확인합니다.-
./output/pcap/<capture_date_time>.pcap파일은 Wireshark로 열 수 있습니다.
-
16.2.3. 메트릭 캡처
서비스 모니터를 사용하여 Prometheus에서 주문형 네트워크 관찰 대시보드를 생성합니다. 이를 통해 네트워크 지표를 빠르게 보고 분석할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
네트워크 관찰 CLI(
oc netobserv) 플러그인을 설치합니다.
프로세스
다음 명령을 실행하여 필터가 활성화된 메트릭을 캡처합니다.
출력 예
$ oc netobserv metrics --enable_filter=true --cidr=0.0.0.0/0 --protocol=TCP --port=49051터미널에 제공된 링크를 열어 NetObserv/On-Demand 대시보드를 확인하세요.
예시 URL
https://console-openshift-console.apps.rosa...openshiftapps.com/monitoring/dashboards/netobserv-cli참고활성화되지 않은 기능은 빈 그래프로 표시됩니다.
16.2.4. 네트워크 Observability CLI 정리
oc netobserv cleanup을 사용하여 Network Observability CLI에서 설치한 모든 구성 요소를 클러스터에서 수동으로 제거합니다. 캡처 후 클라이언트가 자동으로 이 명령을 실행하지만, 연결 문제가 발생하면 수동으로 실행해야 할 수도 있습니다.
프로세스
다음 명령을 실행합니다.
$ oc netobserv cleanup
추가 리소스
16.3. 네트워크 관찰 CLI(oc netobserv) 참조
네트워크 관찰 CLI( oc netobserv )에는 네트워크 관찰 연산자에서 사용할 수 있는 대부분의 기능과 필터링 옵션이 있습니다. 명령줄 인수를 전달하여 기능이나 필터링 옵션을 활성화할 수 있습니다.
16.3.1. 네트워크 관찰 CLI 사용법
네트워크 관찰 CLI( oc netobserv )를 사용하면 명령줄 인수를 전달하여 흐름 데이터, 패킷 데이터 및 메트릭을 캡처하고 추가 분석을 수행하고 네트워크 관찰 운영자가 지원하는 기능을 활성화할 수 있습니다.
16.3.1.1. 구문
oc netobserv 명령의 기본 구문:
oc netobserv 구문
$ oc netobserv [<command>] [<feature_option>] [<command_options>] - 1
- 기능 옵션은
oc netobserv flows명령과 함께만 사용할 수 있습니다.oc netobserv packets명령과 함께 사용할 수 없습니다.
16.3.1.2. 기본 명령
| 명령 | 설명 |
|---|---|
| 흐름 | 흐름 정보를 수집합니다. 하위 명령에 대해서는 "흐름 캡처 옵션" 표를 참조하세요. |
| 패킷 | 패킷 데이터를 캡처합니다. 하위 명령에 대해서는 "패킷 캡처 옵션" 표를 참조하세요. |
| metrics | 측정항목 데이터를 수집합니다. 하위 명령에 대해서는 "메트릭 캡처 옵션" 표를 참조하세요. |
| 팔로우 | 백그라운드에서 실행할 때 수집기 로그를 따르세요. |
| 중지 | 에이전트 데몬셋을 제거하여 수집을 중지합니다. |
| 복사 | 수집기에서 생성된 파일을 로컬로 복사합니다. |
| cleanup | 네트워크 관찰 CLI 구성 요소를 제거합니다. |
| version | 소프트웨어 버전을 인쇄하세요. |
| help | 도움을 보여주세요. |
16.3.1.3. 흐름 캡처 옵션
흐름 캡처에는 필수 명령은 물론 패킷 삭제, DNS 지연, 왕복 시간, 필터링 등에 대한 추가 기능을 활성화하는 등의 추가 옵션도 있습니다.
oc netobserv 흐름 구문
$ oc netobserv flows [<feature_option>] [<command_options>]| 옵션 | 설명 | 기본 |
|---|---|---|
| --enable_all | 모든 eBPF 기능 활성화 | false |
| --enable_dns | DNS 추적 활성화 | false |
| --enable_ipsec | IPsec 추적 활성화 | false |
| --enable_network_events | 네트워크 이벤트 모니터링 활성화 | false |
| --enable_pkt_translation | 패킷 변환 활성화 | false |
| --enable_pkt_drop | 패킷 삭제 활성화 | false |
| --enable_rtt | RTT 추적 활성화 | false |
| --enable_udn_mapping | 사용자 정의 네트워크 매핑 활성화 | false |
| --get-subnets | 서브넷 정보 가져오기 | false |
| --privileged | eBPF 에이전트 권한 모드 강제 적용 | auto |
| sampling: | 패킷 샘플링 간격 | 1 |
| 배경 | 백그라운드에서 실행 | false |
| --copy | 출력 파일을 로컬로 복사합니다 | prompt |
| --log-level | 구성 요소 로그 | info |
| --max-time | 최대 캡처 시간 | 5m |
| --max-bytes | 최대 캡처 바이트 | 50000000 = 50MB |
| --action | 필터 동작 | accept |
| --cidr | 필터 CIDR | 0.0.0.0/0 |
| --direction | 필터 방향 | - |
| --dport | 필터 대상 포트 | - |
| --dport_range | 필터 대상 포트 범위 | - |
| --dports | 두 개의 대상 포트 중 하나를 필터링합니다. | - |
| --drops | 삭제된 패킷만 포함하는 필터 흐름 | false |
| --icmp_code | ICMP 코드 필터링 | - |
| --icmp_type | ICMP 유형 필터링 | - |
| --node-selector | 특정 노드에서 캡처 | - |
| --peer_ip | 피어 IP 필터링 | - |
| --peer_cidr | 필터 피어 CIDR | - |
| --port_range | 필터 포트 범위 | - |
| --port | 필터 포트 | - |
| <ports> | 두 포트 중 하나에 필터 설치 | - |
| --protocol | 필터 프로토콜 | - |
| query | 사용자 정의 쿼리를 사용하여 흐름 필터링 | - |
| --sport_range | 필터 소스 포트 범위 | - |
| --sport | 필터 소스 포트 | - |
| --sports | 두 소스 포트 중 하나에 필터 적용 | - |
| --tcp_flags | TCP 플래그 필터링 | - |
| --interfaces | 모니터링할 인터페이스 목록(쉼표로 구분) | - |
| --exclude_interfaces | 제외할 인터페이스 목록(쉼표로 구분) | lo |
PacketDrop 및 RTT 기능이 활성화된 TCP 프로토콜 및 포트 49051에서 흐름 캡처를 실행하는 예:
$ oc netobserv flows --enable_pkt_drop --enable_rtt --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=4905116.3.1.4. 패킷 캡처 옵션
필터를 사용하여 패킷 캡처 데이터를 플로우 캡처와 동일하게 필터링할 수 있습니다. 패킷 삭제, DNS, RTT, 네트워크 이벤트와 같은 특정 기능은 흐름 및 메트릭 캡처에만 사용할 수 있습니다.
oc netobserv 패킷 구문
$ oc netobserv packets [<option>]| 옵션 | 설명 | 기본 |
|---|---|---|
| 배경 | 백그라운드에서 실행 | false |
| --copy | 출력 파일을 로컬로 복사합니다 | prompt |
| --log-level | 구성 요소 로그 | info |
| --max-time | 최대 캡처 시간 | 5m |
| --max-bytes | 최대 캡처 바이트 | 50000000 = 50MB |
| --action | 필터 동작 | accept |
| --cidr | 필터 CIDR | 0.0.0.0/0 |
| --direction | 필터 방향 | - |
| --dport | 필터 대상 포트 | - |
| --dport_range | 필터 대상 포트 범위 | - |
| --dports | 두 개의 대상 포트 중 하나를 필터링합니다. | - |
| --drops | 삭제된 패킷만 포함하는 필터 흐름 | false |
| --icmp_code | ICMP 코드 필터링 | - |
| --icmp_type | ICMP 유형 필터링 | - |
| --node-selector | 특정 노드에서 캡처 | - |
| --peer_ip | 피어 IP 필터링 | - |
| --peer_cidr | 필터 피어 CIDR | - |
| --port_range | 필터 포트 범위 | - |
| --port | 필터 포트 | - |
| <ports> | 두 포트 중 하나에 필터 설치 | - |
| --protocol | 필터 프로토콜 | - |
| query | 사용자 정의 쿼리를 사용하여 흐름 필터링 | - |
| --sport_range | 필터 소스 포트 범위 | - |
| --sport | 필터 소스 포트 | - |
| --sports | 두 소스 포트 중 하나에 필터 적용 | - |
| --tcp_flags | TCP 플래그 필터링 | - |
TCP 프로토콜 및 포트 49051에서 패킷 캡처를 실행하는 예:
$ oc netobserv packets --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=4905116.3.1.5. 메트릭 캡처 옵션
흐름 캡처와 마찬가지로 메트릭 캡처에 기능을 활성화하고 필터를 사용할 수 있습니다. 생성된 그래프는 대시보드에 적절히 채워집니다.
oc netobserv 메트릭 구문
$ oc netobserv metrics [<option>]| 옵션 | 설명 | 기본 |
|---|---|---|
| --enable_all | 모든 eBPF 기능 활성화 | false |
| --enable_dns | DNS 추적 활성화 | false |
| --enable_ipsec | IPsec 추적 활성화 | false |
| --enable_network_events | 네트워크 이벤트 모니터링 활성화 | false |
| --enable_pkt_translation | 패킷 변환 활성화 | false |
| --enable_pkt_drop | 패킷 삭제 활성화 | false |
| --enable_rtt | RTT 추적 활성화 | false |
| --enable_udn_mapping | 사용자 정의 네트워크 매핑 활성화 | false |
| --get-subnets | 서브넷 정보 가져오기 | false |
| --privileged | eBPF 에이전트 권한 모드 강제 적용 | auto |
| sampling: | 패킷 샘플링 간격 | 1 |
| 배경 | 백그라운드에서 실행 | false |
| --log-level | 구성 요소 로그 | info |
| --max-time | 최대 캡처 시간 | 1시간 |
| --action | 필터 동작 | accept |
| --cidr | 필터 CIDR | 0.0.0.0/0 |
| --direction | 필터 방향 | - |
| --dport | 필터 대상 포트 | - |
| --dport_range | 필터 대상 포트 범위 | - |
| --dports | 두 개의 대상 포트 중 하나를 필터링합니다. | - |
| --drops | 삭제된 패킷만 포함하는 필터 흐름 | false |
| --icmp_code | ICMP 코드 필터링 | - |
| --icmp_type | ICMP 유형 필터링 | - |
| --node-selector | 특정 노드에서 캡처 | - |
| --peer_ip | 피어 IP 필터링 | - |
| --peer_cidr | 필터 피어 CIDR | - |
| --port_range | 필터 포트 범위 | - |
| --port | 필터 포트 | - |
| <ports> | 두 포트 중 하나에 필터 설치 | - |
| --protocol | 필터 프로토콜 | - |
| query | 사용자 정의 쿼리를 사용하여 흐름 필터링 | - |
| --sport_range | 필터 소스 포트 범위 | - |
| --sport | 필터 소스 포트 | - |
| --sports | 두 소스 포트 중 하나에 필터 적용 | - |
| --tcp_flags | TCP 플래그 필터링 | - |
| --include_list | 생성할 메트릭 이름 목록(쉼표로 구분) | namespace_flows_total,node_ingress_bytes_total,node_egress_bytes_total,workload_ingress_bytes_total |
| --interfaces | 모니터링할 인터페이스 목록(쉼표로 구분) | - |
| --exclude_interfaces | 제외할 인터페이스 목록(쉼표로 구분) | lo |
TCP 삭제에 대한 실행 메트릭 캡처 예시
$ oc netobserv metrics --enable_pkt_drop --protocol=TCP17장. FlowCollector API 참조
FlowCollector API는 네트워크 흐름 수집을 위한 배포를 시범 운영하고 구성하는 데 사용되는 기본 스키마입니다. 이 참조 가이드는 중요한 설정을 관리하는 데 도움이 됩니다.
17.1. FlowCollector API 사양
- 설명
-
FlowCollector는기본 배포를 시범 운영하고 구성하는 네트워크 흐름 수집 API의 스키마입니다. - 유형
-
object
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| APIVersion은 버전이 지정된 이 오브젝트 표현의 스키마를 정의합니다. 서버는 인식된 스키마를 최신 내부 값으로 변환해야 하며, 인식되지 않는 값을 거부할 수 있습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| kind는 이 오브젝트가 나타내는 REST 리소스에 해당하는 문자열 값입니다. 서버는 클라이언트에서 요청을 제출한 끝점에서 이를 유추할 수 있습니다. CamelCase로 업데이트할 수 없습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
|
FlowCollector 리소스의 원하는 상태를 정의합니다. *: 이 문서 전반에 걸쳐 기능에 대해 "지원되지 않음" 또는 "더 이상 지원되지 않음"이 언급된 경우 해당 기능은 Red Hat에서 공식적으로 지원하지 않음을 의미합니다. 예를 들어, 커뮤니티에서 기여한 후 유지 관리에 대한 공식적인 합의 없이 수용되었을 수도 있습니다. 제품 유지 관리자는 최선의 노력으로만 이러한 기능에 대한 일부 지원을 제공할 수 있습니다. |
17.1.1. .metadata
- 설명
- 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- 유형
-
object
17.1.2. .spec
- 설명
FlowCollector 리소스의 원하는 상태를 정의합니다.
*: 이 문서 전반에 걸쳐 기능에 대해 "지원되지 않음" 또는 "더 이상 지원되지 않음"이 언급된 경우 해당 기능은 Red Hat에서 공식적으로 지원하지 않음을 의미합니다. 예를 들어, 커뮤니티에서 기여한 후 유지 관리에 대한 공식적인 합의 없이 수용되었을 수도 있습니다. 제품 유지 관리자는 최선의 노력으로만 이러한 기능에 대한 일부 지원을 제공할 수 있습니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 흐름 추출을 위한 에이전트 구성. |
|
|
|
|
|
|
|
- 흐름 프로세서가 확장 가능한 배포에서 지원하는 Kubernetes 서비스로 수신 대기하도록 하는
-
- 흐름 프로세서가 DaemonSet에서 지원하는 호스트 네트워크를 사용하여 에이전트에서 직접 수신하도록 합니다.
Kafka는 더 나은 확장성, 복원력 및 고가용성을 제공할 수 있습니다(자세한 내용은 https://www.redhat.com/en/topics/integration/what-is-apache-kafka)를 참조하십시오.
메모리 효율이 낮기 때문에 대규모 클러스터에서 |
|
|
|
|
|
|
|
카프카 구성을 사용하면 카프카를 플로우 수집 파이프라인의 일부로 브로커로 사용할 수 있습니다. |
|
|
|
|
|
|
| 네트워크 관찰 포드가 배포되는 네임스페이스입니다. |
|
|
|
|
|
|
|
|
|
|
|
|
17.1.3. .spec.agent
- 설명
- 흐름 추출을 위한 에이전트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
17.1.4. .spec.agent.ebpf
- 설명
-
eBPF는spec.agent.type이eBPF로 설정된 경우 eBPF 기반 흐름 보고기와 관련된 설정을 설명합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
추가로 활성화할 수 있는 기능 목록입니다. 이러한 기능은 모두 기본적으로 비활성화되어 있습니다. 추가 기능을 활성화하면 성능에 영향을 미칠 수 있습니다. 가능한 값은 다음과 같습니다:
-
-
-
-
-
-
-
이 기능을 사용하려면 커널 디버그 파일 시스템을 마운트해야 하므로 eBPF 에이전트 포드는
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
eBPF 에이전트 컨테이너의 권한 모드입니다. |
|
|
|
|
|
|
| eBPF 프로브의 샘플링 간격. 100은 100개의 패킷이 전송된다는 것을 의미합니다. 0 또는 1은 모든 패킷이 샘플링됨을 의미합니다. |
17.1.5. .spec.agent.ebpf.advanced
- 설명
-
Advanced를 사용하면 eBPF 에이전트의 내부 구성의 일부 측면을 설정할 수 있습니다. 이 섹션은 주로GOGC및GOMAXPROCS환경 변수와 같은 디버깅 및 세부적인 성능 최적화를 목표로 합니다. 이러한 값을 설정하는 것은 사용자의 책임입니다. 거기에서 기본 Linux 기능을 재정의할 수도 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 특권 모드로 실행하지 않을 경우 Linux 기능이 재정의됩니다. 기본 기능은 BPF, PERFMON 및 NET_ADMIN입니다. |
|
|
|
|
|
|
| 스케줄링은 노드에서 Pod를 예약하는 방법을 제어합니다. |
17.1.6. .spec.agent.ebpf.advanced.scheduling
- 설명
- 스케줄링은 노드에서 Pod를 예약하는 방법을 제어합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. |
|
|
|
|
|
|
| 지정된 경우 Pod의 우선순위를 나타냅니다. 자세한 내용은 https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption 을 참조하세요. 지정하지 않으면 기본 우선순위가 사용되거나 기본값이 없는 경우 0이 사용됩니다. |
|
|
|
|
17.1.7. .spec.agent.ebpf.advanced.scheduling.affinity
- 설명
- 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요.
- 유형
-
object
17.1.8. .spec.agent.ebpf.advanced.scheduling.tolerations
- 설명
-
tolerations는포드가 일치하는 taint가 있는 노드에 스케줄을 지정할 수 있도록 하는 tolerations 목록입니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. - 유형
-
array
17.1.9. .spec.agent.ebpf.flowFilter
- 설명
-
flowFilter는 흐름 필터링과 관련된 eBPF 에이전트 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
eBPF 흐름 필터링 기능을 활성화하려면 |
|
|
|
|
|
|
|
ICMP 트래픽의 경우 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
17.1.10. .spec.agent.ebpf.flowFilter.rules
- 설명
-
규칙은eBPF 에이전트의 필터링 규칙 목록을 정의합니다. 필터링이 활성화된 경우 기본적으로 어떤 규칙과도 일치하지 않는 흐름은 거부됩니다. 기본값을 변경하려면 모든 것을 허용하는 규칙을 정의합니다.{ action: "Accept", cidr: "0.0.0.0/0" }, 그런 다음 거부 규칙을 세부적으로 지정합니다. - 유형
-
array
17.1.11. .spec.agent.ebpf.flowFilter.rules[]
- 설명
-
EBPFFlowFilterRule은흐름 필터링 규칙과 관련된 원하는 eBPF 에이전트 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ICMP 트래픽의 경우 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
17.1.12. .spec.agent.ebpf.metrics
- 설명
-
메트릭은메트릭과 관련된 eBPF 에이전트 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
eBPF 에이전트에서 패킷이나 흐름이 누락된 경우(예: BPF 해시맵이 사용 중이거나 가득 찬 경우 또는 용량 제한이 트리거되는 경우)에 트리거되는 |
|
|
|
eBPF 에이전트 메트릭 수집을 비활성화하려면 |
|
|
| Prometheus 스크래퍼를 위한 메트릭 서버 엔드포인트 구성. |
17.1.13. .spec.agent.ebpf.metrics.server
- 설명
- Prometheus 스크래퍼를 위한 메트릭 서버 엔드포인트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 메트릭 서버 HTTP 포트. |
|
|
| TLS 구성입니다. |
17.1.14. .spec.agent.ebpf.metrics.server.tls
- 설명
- TLS 구성입니다.
- 유형
-
object - 필수 항목
-
type
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TLS 구성 유형을 선택하세요:
- |
17.1.15. .spec.agent.ebpf.metrics.server.tls.provided
- 설명
-
유형이제공됨으로 설정된 경우의 TLS 구성입니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.16. .spec.agent.ebpf.metrics.server.tls.providedCaFile
- 설명
-
유형이제공됨으로 설정된 경우 CA 파일에 대한 참조입니다. - 유형
-
object
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조: |
17.1.17. .spec.agent.ebpf.resources
- 설명
-
리소스는이 컨테이너에 필요한 컴퓨팅 리소스입니다. 자세한 내용은 https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/를 참조하세요. - 유형
-
object
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| 제한은 허용되는 최대 컴퓨팅 리소스 양을 나타냅니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| 요청은 필요한 최소 컴퓨팅 리소스 양을 설명합니다. 컨테이너에 대한 요청이 생략되면 명시적으로 지정되어 있으면 제한이 기본값으로 설정되고, 그렇지 않으면 구현에서 정의한 값이 기본값으로 설정됩니다. 요청은 한도를 초과할 수 없습니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
17.1.18. .spec.consolePlugin
- 설명
-
consolePlugin은사용 가능한 경우 OpenShift Container Platform Console 플러그인과 관련된 설정을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
플러그인 배포에 설정할 수평 Pod |
|
|
| 콘솔 플러그인 배포를 활성화합니다. |
|
|
|
|
|
|
|
콘솔 플러그인 백엔드의 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
이 컨테이너에 필요한 컴퓨팅 리소스 측면에서 |
|
|
| OpenShift Container Platform 콘솔 대신 독립 실행형 콘솔로 배포합니다. 통합 환경을 제공하지 않으므로 OpenShift Container Platform과 함께 사용하는 것은 권장되지 않습니다. [지원되지 않음(*)]. |
|
|
|
|
17.1.19. .spec.consolePlugin.advanced
- 설명
-
고급을사용하면 콘솔 플러그인의 내부 구성의 일부 측면을 설정할 수 있습니다. 이 섹션은 주로GOGC및GOMAXPROCS환경 변수와 같은 디버깅 및 세부적인 성능 최적화를 목표로 합니다. 이러한 값을 설정하는 것은 사용자의 책임입니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
17.1.20. .spec.consolePlugin.advanced.scheduling
- 설명
-
scheduling은 노드에서 pod가 어떻게 스케줄링되는지 제어합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. |
|
|
|
|
|
|
| 지정된 경우 Pod의 우선순위를 나타냅니다. 자세한 내용은 https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption 을 참조하세요. 지정하지 않으면 기본 우선순위가 사용되거나 기본값이 없는 경우 0이 사용됩니다. |
|
|
|
|
17.1.21. .spec.consolePlugin.advanced.scheduling.affinity
- 설명
- 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요.
- 유형
-
object
17.1.22. .spec.consolePlugin.advanced.scheduling.tolerations
- 설명
-
tolerations는포드가 일치하는 taint가 있는 노드에 스케줄을 지정할 수 있도록 하는 tolerations 목록입니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. - 유형
-
array
17.1.23. .spec.consolePlugin.autoscaler
- 설명
-
플러그인 배포에 설정할 수평 Pod
자동 스케일러의 자동 스케일러 [더 이상 사용되지 않음 (*)] 사양입니다. 사용 중단 알림: 관리형 자동 스케일러는 향후 버전에서 제거됩니다. 선택한 자동 스케일러를 대신 구성하고spec.consolePlugin.unmanagedReplicas를true로 설정할 수 있습니다. HorizontalPodAutoscaler 문서(자동 확장/v2)를 참조하세요. - 유형
-
object
17.1.24. .spec.consolePlugin.portNaming
- 설명
-
portNaming은 port-to-service 이름 변환의 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 콘솔 플러그인 포트-서비스 이름 변환을 활성화합니다. |
|
|
|
|
17.1.25. .spec.consolePlugin.quickFilters
- 설명
-
quickFilters는 Console 플러그인에 대한 빠른 필터 사전 설정을 구성합니다. 외부 트래픽의 필터는 서브넷 레이블이 내부 및 외부 트래픽을 구분하도록 구성되어 있다고 가정합니다(spec.processor.subnetLabels참조). - 유형
-
array
17.1.26. .spec.consolePlugin.quickFilters[]
- 설명
-
QuickFilter는 콘솔의 빠른 필터에 대한 사전 설정 구성을 정의합니다. - 유형
-
object - 필수 항목
-
filter -
name
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 콘솔에 표시되는 필터의 이름 |
17.1.27. .spec.consolePlugin.resources
- 설명
-
이 컨테이너에 필요한 컴퓨팅 리소스 측면에서
리소스입니다. 자세한 내용은 https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ 을 참조하십시오. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 제한은 허용되는 최대 컴퓨팅 리소스 양을 나타냅니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| 요청은 필요한 최소 컴퓨팅 리소스 양을 설명합니다. 컨테이너에 대한 요청이 생략되면 명시적으로 지정되어 있으면 제한이 기본값으로 설정되고, 그렇지 않으면 구현에서 정의한 값이 기본값으로 설정됩니다. 요청은 한도를 초과할 수 없습니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
17.1.28. .spec.exporters
- 설명
-
exporters는 사용자 정의 사용 또는 스토리지에 대한 추가 선택적 내보내기를 정의합니다. - 유형
-
array
17.1.29. .spec.exporters[]
- 설명
-
FlowCollectorExporter는강화된 흐름을 보낼 추가적인 내보내기 도구를 정의합니다. - 유형
-
object - 필수 항목
-
type
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| IPFIX 구성(풍부한 IPFIX 흐름을 보낼 IP 주소 및 포트 등) |
|
|
| 풍요한 흐름을 보내기 위한 주소 및 주제와 같은 Kafka 구성입니다. |
|
|
| 강화된 로그 또는 메트릭을 전송하는 IP 주소 및 포트와 같은 OpenTelemetry 구성입니다. |
|
|
|
|
17.1.30. .spec.exporters[].ipfix
- 설명
- IPFIX 구성(풍부한 IPFIX 흐름을 보낼 IP 주소 및 포트 등)
- 유형
-
object - 필수 항목
-
enterpriseID -
targetHost -
targetPort
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| EnterpriseID 또는 개인 엔터프라이즈 번호(PEN). 지금까지 Network Observability는 할당된 번호를 소유하지 않으므로 구성에 대해 열린 상태로 유지됩니다. PEN은 Kubernetes 이름, RTT 등과 같은 표준 데이터를 수집하는 데 필요합니다. |
|
|
| IPFIX 외부 수신자의 주소입니다. |
|
|
| IPFIX 외부 수신자용 포트입니다. |
|
|
|
IPFIX 연결에 사용되는 전송 프로토콜( |
17.1.31. .spec.exporters[].kafka
- 설명
- 풍요한 흐름을 보내기 위한 주소 및 주제와 같은 Kafka 구성입니다.
- 유형
-
object - 필수 항목
-
address -
topic
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 카프카 서버의 주소 |
|
|
| SASL 인증 구성. [지원되지 않음(*)]. |
|
|
| TLS 클라이언트 구성. TLS를 사용하는 경우 주소가 TLS에 사용되는 Kafka 포트(일반적으로 9093)와 일치하는지 확인합니다. |
|
|
| 사용할 카프카 주제. 그것은 반드시 존재해야 합니다. 네트워크 관찰성이 이를 생성하지 않습니다. |
17.1.32. .spec.exporters[].kafka.sasl
- 설명
- SASL 인증 구성. [지원되지 않음(*)].
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 클라이언트 ID를 포함하는 비밀 또는 구성 맵에 대한 참조 |
|
|
| 클라이언트 비밀을 포함하는 비밀 또는 구성 맵에 대한 참조 |
|
|
|
사용할 SASL 인증 유형 또는 SASL을 사용하지 않는 경우 |
17.1.33. .spec.exporters[].kafka.sasl.clientIDReference
- 설명
- 클라이언트 ID를 포함하는 비밀 또는 구성 맵에 대한 참조
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조: |
17.1.34. .spec.exporters[].kafka.sasl.clientSecretReference
- 설명
- 클라이언트 비밀을 포함하는 비밀 또는 구성 맵에 대한 참조
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조: |
17.1.35. .spec.exporters[].kafka.tls
- 설명
- TLS 클라이언트 구성. TLS를 사용하는 경우 주소가 TLS에 사용되는 Kafka 포트(일반적으로 9093)와 일치하는지 확인합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.36. .spec.exporters[].kafka.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.37. .spec.exporters[].kafka.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.38. .spec.exporters[].openTelemetry
- 설명
- 강화된 로그 또는 메트릭을 전송하는 IP 주소 및 포트와 같은 OpenTelemetry 구성입니다.
- 유형
-
object - 필수 항목
-
targetHost -
targetPort
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| OpenTelemetry 규격 형식에 매핑되는 사용자 정의 필드입니다. 기본적으로 네트워크 관찰성 형식 제안이 사용됩니다: https://github.com/rhobs/observability-data-model/blob/main/network-observability.md#format-proposal . 현재 L3 또는 L4 강화 네트워크 로그에 대한 허용되는 표준이 없으므로 자유롭게 사용자 고유의 표준으로 재정의할 수 있습니다. |
|
|
| 메시지에 추가할 헤더(선택 사항) |
|
|
| 로그에 대한 OpenTelemetry 구성. |
|
|
| 메트릭을 위한 OpenTelemetry 구성. |
|
|
|
OpenTelemetry 연결의 프로토콜입니다. 사용 가능한 옵션은 |
|
|
| OpenTelemetry 수신기의 주소입니다. |
|
|
| OpenTelemetry 수신기용 포트입니다. |
|
|
| TLS 클라이언트 구성. |
17.1.39. .spec.exporters[].openTelemetry.fieldsMapping
- 설명
- OpenTelemetry 규격 형식에 매핑되는 사용자 정의 필드입니다. 기본적으로 네트워크 관찰성 형식 제안이 사용됩니다: https://github.com/rhobs/observability-data-model/blob/main/network-observability.md#format-proposal . 현재 L3 또는 L4 강화 네트워크 로그에 대한 허용되는 표준이 없으므로 자유롭게 사용자 고유의 표준으로 재정의할 수 있습니다.
- 유형
-
array
17.1.40. .spec.exporters[].openTelemetry.fieldsMapping[]
- 설명
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
17.1.41. .spec.exporters[].openTelemetry.logs
- 설명
- 로그에 대한 OpenTelemetry 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
로그를 OpenTelemetry 수신기로 보내려면 |
17.1.42. .spec.exporters[].openTelemetry.metrics
- 설명
- 메트릭을 위한 OpenTelemetry 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
OpenTelemetry 수신기에 메트릭을 전송하려면 |
|
|
| 메트릭이 수집기에 전송되는 빈도를 지정합니다. |
17.1.43. .spec.exporters[].openTelemetry.tls
- 설명
- TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.44. .spec.exporters[].openTelemetry.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.45. .spec.exporters[].openTelemetry.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.46. .spec.kafka
- 설명
-
카프카 구성을 사용하면 카프카를 플로우 수집 파이프라인의 일부로 브로커로 사용할 수 있습니다.
spec.deploymentModel이Kafka인 경우 사용 가능합니다. - 유형
-
object - 필수 항목
-
address -
topic
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 카프카 서버의 주소 |
|
|
| SASL 인증 구성. [지원되지 않음(*)]. |
|
|
| TLS 클라이언트 구성. TLS를 사용하는 경우 주소가 TLS에 사용되는 Kafka 포트(일반적으로 9093)와 일치하는지 확인합니다. |
|
|
| 사용할 카프카 주제. 그것은 반드시 존재해야 합니다. 네트워크 관찰성이 이를 생성하지 않습니다. |
17.1.47. .spec.kafka.sasl
- 설명
- SASL 인증 구성. [지원되지 않음(*)].
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 클라이언트 ID를 포함하는 비밀 또는 구성 맵에 대한 참조 |
|
|
| 클라이언트 비밀을 포함하는 비밀 또는 구성 맵에 대한 참조 |
|
|
|
사용할 SASL 인증 유형 또는 SASL을 사용하지 않는 경우 |
17.1.48. .spec.kafka.sasl.clientIDReference
- 설명
- 클라이언트 ID를 포함하는 비밀 또는 구성 맵에 대한 참조
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조에 대한 유형: |
17.1.49. .spec.kafka.sasl.clientSecretReference
- 설명
- 클라이언트 비밀을 포함하는 비밀 또는 구성 맵에 대한 참조
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조에 대한 유형: |
17.1.50. .spec.kafka.tls
- 설명
- TLS 클라이언트 구성. TLS를 사용하는 경우 주소가 TLS에 사용되는 Kafka 포트(일반적으로 9093)와 일치하는지 확인합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.51. .spec.kafka.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.52. .spec.kafka.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.53. .spec.loki
- 설명
-
로키, 플로우 스토어, 클라이언트 설정. - 유형
-
object - 필수 항목
-
mode
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
Loki에 흐름을 저장하려면 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Loki Operator를 사용하여 Loki를 관리하는 경우
- Loki가 모놀리식 작업으로 설치된 경우
- Loki가 마이크로서비스로 설치되었지만 Loki Operator가 없는 경우
- 위의 옵션 중 어느 것도 설정과 일치하지 않으면 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
17.1.54. .spec.loki.advanced
- 설명
-
고급을사용하면 Loki 클라이언트의 내부 구성의 일부 측면을 설정할 수 있습니다. 이 섹션은 주로 디버깅과 세부적인 성능 최적화를 목표로 합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
17.1.55. .spec.loki.lokiStack
- 설명
-
LokiStack모드를 위한 Loki 구성. 이는 Loki Operator를 쉽게 구성하는 데 유용합니다. 다른 모드에서는 무시됩니다. - 유형
-
object - 필수 항목
-
name
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 사용할 기존 LokiStack 리소스의 이름입니다. |
|
|
|
이 |
17.1.56. .spec.loki.manual
- 설명
-
수동모드를 위한 Loki 구성. 이것은 가장 유연한 구성입니다. 다른 모드에서는 무시됩니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
-
-
-
Loki Operator를 사용하는 경우 이 값을 |
|
|
|
|
|
|
|
|
|
|
| Loki 상태 URL에 대한 TLS 클라이언트 구성. |
|
|
|
|
|
|
|
|
|
|
| Loki URL에 대한 TLS 클라이언트 구성. |
17.1.57. .spec.loki.manual.statusTls
- 설명
- Loki 상태 URL에 대한 TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.58. .spec.loki.manual.statusTls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.59. .spec.loki.manual.statusTls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.60. .spec.loki.manual.tls
- 설명
- Loki URL에 대한 TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.61. .spec.loki.manual.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.62. .spec.loki.manual.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.63. .spec.loki.microservices
- 설명
-
마이크로서비스모드를 위한 Loki 구성. Loki가 마이크로서비스 배포 모드( https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#microservices-mode )를 사용하여 설치된 경우 이 옵션을 사용합니다. 다른 모드에서는 무시됩니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Loki URL에 대한 TLS 클라이언트 구성. |
17.1.64. .spec.loki.microservices.tls
- 설명
- Loki URL에 대한 TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.65. .spec.loki.microservices.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.66. .spec.loki.microservices.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.67. .spec.loki.monolithic
- 설명
-
모노리식모드를 위한 Loki 구성. Loki가 모놀리식 배포 모드( https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#monolithic-mode )를 사용하여 설치된 경우 이 옵션을 사용하세요. 다른 모드에서는 무시됩니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Loki URL에 대한 TLS 클라이언트 구성. |
|
|
|
|
17.1.68. .spec.loki.monolithic.tls
- 설명
- Loki URL에 대한 TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.69. .spec.loki.monolithic.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.70. .spec.loki.monolithic.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.71. .spec.networkPolicy
- 설명
-
networkPolicy는네트워크 관찰 구성 요소 격리에 대한 네트워크 정책 설정을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| 네트워크 관찰 기능에서 사용하는 네임스페이스(기본 및 권한 있는 네임스페이스)에 네트워크 정책을 배포합니다. 이러한 네트워크 정책은 네트워크 관찰 가능성 구성 요소를 더 잘 격리하여 원치 않는 연결이 발생하는 것을 방지합니다. 이 옵션은 OVNKubernetes와 함께 사용할 경우 기본적으로 활성화되고, 그렇지 않은 경우에는 비활성화됩니다(다른 CNI와의 호환성은 테스트되지 않았습니다). 이 기능을 비활성화하면 네트워크 관찰 가능성 구성 요소에 대한 네트워크 정책을 수동으로 생성할 수 있습니다. |
17.1.72. .spec.processor
- 설명
-
프로세서는에이전트로부터 흐름을 수신하고, 이를 풍부하게 하고, 메트릭을 생성하고, 이를 Loki 지속성 계층 및/또는 사용 가능한 모든 내보내기 도구로 전달하는 구성 요소의 설정을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
프로세서 런타임의 |
|
|
|
- 정기적인 네트워크 흐름을 내보내는
- 시작된 대화에 대한 이벤트를 생성하는
-
- 네트워크 흐름과 모든 대화 이벤트 |
|
|
|
|
|
|
|
다중 클러스터 기능을 활성화하려면 |
|
|
|
|
|
|
| FlowCollectorSlices 사용자 지정 리소스를 관리하는 글로벌 구성입니다. |
|
|
|
|
|
|
|
|
17.1.73. .spec.processor.advanced
- 설명
-
고급 기능을사용하면 플로우 프로세서의 내부 구성의 일부 측면을 설정할 수 있습니다. 이 섹션은 주로GOGC및GOMAXPROCS환경 변수와 같은 디버깅 및 세부적인 성능 최적화를 목표로 합니다. 이러한 값을 설정하는 것은 사용자의 책임입니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 유량 수집기의 포트(호스트 포트). 관례상 일부 값은 금지되어 있습니다. 1024보다 커야 하며 4500, 4789, 6081과 달라야 합니다. |
|
|
|
|
|
|
| 스케줄링은 노드에서 Pod를 예약하는 방법을 제어합니다. |
|
|
| 리소스 식별을 위해 검사할 보조 네트워크를 정의합니다. 정확한 식별을 보장하려면 인덱스된 값이 클러스터 전체에서 고유한 식별자를 형성해야 합니다. 동일한 인덱스가 여러 리소스에 의해 사용되는 경우 해당 리소스에 잘못된 레이블이 지정될 수 있습니다. |
17.1.74. .spec.processor.advanced.scheduling
- 설명
- 스케줄링은 노드에서 Pod를 예약하는 방법을 제어합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. |
|
|
|
|
|
|
| 지정된 경우 Pod의 우선순위를 나타냅니다. 자세한 내용은 https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption 을 참조하세요. 지정하지 않으면 기본 우선순위가 사용되거나 기본값이 없는 경우 0이 사용됩니다. |
|
|
|
|
17.1.75. .spec.processor.advanced.scheduling.affinity
- 설명
- 지정된 경우, 포드의 스케줄링 제약 조건이 적용됩니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요.
- 유형
-
object
17.1.76. .spec.processor.advanced.scheduling.tolerations
- 설명
-
tolerations는포드가 일치하는 taint가 있는 노드에 스케줄을 지정할 수 있도록 하는 tolerations 목록입니다. 자세한 내용은 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling 을 참조하세요. - 유형
-
array
17.1.77. .spec.processor.advanced.secondaryNetworks
- 설명
- 리소스 식별을 위해 검사할 보조 네트워크를 정의합니다. 정확한 식별을 보장하려면 인덱스된 값이 클러스터 전체에서 고유한 식별자를 형성해야 합니다. 동일한 인덱스가 여러 리소스에 의해 사용되는 경우 해당 리소스에 잘못된 레이블이 지정될 수 있습니다.
- 유형
-
array
17.1.78. .spec.processor.advanced.secondaryNetworks[]
- 설명
- 유형
-
object - 필수 항목
-
인덱스 -
name
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
17.1.79. .spec.processor.deduper
- 설명
-
deduper를사용하면 중복으로 식별된 흐름을 샘플링하거나 삭제하여 리소스 사용량을 절약할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
프로세서 중복 제거 모드를 설정합니다. 에이전트는 다른 노드에서 보고된 동일한 흐름을 중복 제거할 수 없으므로, 이 기능은 에이전트 기반 중복 제거에 추가됩니다.
-
-
- 프로세서 기반 중복 제거를 끄려면 |
|
|
|
|
17.1.80. .spec.processor.filters
- 설명
-
필터를사용하면 사용자 정의 필터를 정의하여 생성된 흐름의 양을 제한할 수 있습니다. 이러한 필터는 eBPF 에이전트 필터(spec.agent.ebpf.flowFilter)보다 더 많은 유연성을 제공합니다. 예를 들어 Kubernetes 네임스페이스로 필터링할 수 있지만 성능 향상 폭은 적습니다. - 유형
-
array
17.1.81. .spec.processor.filters[]
- 설명
-
CryostatPFilterSet은 모든 조건을 충족하는 CryostatP 기반 필터링에 대해 원하는 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
지정된 경우 이러한 필터는 |
|
|
| 유지할 네트워크 흐름을 선택하는 쿼리입니다. 이 쿼리 언어에 대한 자세한 내용은 https://github.com/netobserv/flowlogs-pipeline/blob/main/docs/filtering.md 에서 확인하세요. |
|
|
|
|
17.1.82. .spec.processor.kafkaConsumerAutoscaler
- 설명
-
kafkaConsumerAutoscaler[deprecated (*)]는 Kafka 메시지를 사용하는flowlogs-pipeline-transformer에 대해 설정하는 수평 Pod 자동 스케일러의 사양입니다. Kafka가 비활성화된 경우 이 설정은 무시됩니다. 사용 중단 알림: 관리형 자동 스케일러는 향후 버전에서 제거됩니다. 선택한 자동 스케일러를 대신 구성하고spec.processor.unmanagedReplicas를true로 설정할 수 있습니다. HorizontalPodAutoscaler 문서(자동 확장/v2)를 참조하세요. - 유형
-
object
17.1.83. .spec.processor.metrics
- 설명
-
메트릭은메트릭과 관련된 프로세서 구성을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Prometheus 스크래퍼를 위한 메트릭 서버 엔드포인트 구성 |
17.1.84. .spec.processor.metrics.healthRules
- 설명
-
healthRules는 Prometheus에 대해 생성할 상태 규칙 목록으로, 템플릿 및 변형으로 구성됩니다. 각 상태 규칙은 mode 필드를 기반으로 경고 또는 레코딩 규칙을 생성하도록 구성할 수 있습니다. 건강 규칙에 대한 자세한 내용은 https://github.com/netobserv/network-observability-operator/blob/main/docs/HealthRules.md - 유형
-
array
17.1.85. .spec.processor.metrics.healthRules[]
- 설명
- 유형
-
object - 필수 항목
-
템플릿 -
변종
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
mode는 이 상태 규칙을 경고 또는 레코딩 규칙으로 생성해야 하는지 여부를 정의합니다. 가능한 값은 |
|
|
|
상태 규칙 템플릿 이름. 가능한 값은 다음과 같습니다. |
|
|
| 이 템플릿의 변형 목록 |
17.1.86. .spec.processor.metrics.healthRules[].variants
- 설명
- 이 템플릿의 변형 목록
- 유형
-
array
17.1.87. .spec.processor.metrics.healthRules[].variants[]
- 설명
- 유형
-
object - 필수 항목
-
thresholds
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
선택적인 그룹화 기준, 가능한 값은 다음과 같습니다: |
|
|
| 낮은 볼륨 임계값을 사용하면 신호 대 잡음비를 개선하기 위해 트래픽 볼륨이 너무 낮은 메트릭을 무시할 수 있습니다. 이는 절대 속도(맥락에 따라 초당 바이트 또는 초당 패킷)로 제공됩니다. 제공되는 경우 float로 구문 분석할 수 있어야 합니다. |
|
|
|
mode는 이 특정 변형에 대한 상태 규칙 모드를 재정의합니다. 지정하지 않으면 상위 상태 규칙의 모드에서 상속됩니다. 가능한 값은 |
|
|
| 심각도별로 상태 규칙의 임계값입니다. 이는 경고가 발생하는 오류의 백분율로 표시됩니다. 이는 부동 소수점으로 구문 분석 가능해야 합니다. 경고 및 레코딩 모드 모두에 필요합니다. |
|
|
| 상태 규칙 추세를 위해 기준 비교의 기간 간격입니다. 예를 들어, "2h"는 2시간 평균과 비교하는 것을 의미합니다. 기본값은 2시간입니다. |
|
|
| 상태 규칙 추세를 위해 기준 비교에 대한 시간 오프셋입니다. 예를 들어, "1d"는 어제와 비교하는 것을 의미합니다. 기본값은 1d입니다. |
17.1.88. .spec.processor.metrics.healthRules[].variants[].thresholds
- 설명
- 심각도별로 상태 규칙의 임계값입니다. 이는 경고가 발생하는 오류의 백분율로 표시됩니다. 이는 부동 소수점으로 구문 분석 가능해야 합니다. 경고 및 레코딩 모드 모두에 필요합니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
심각도 임계값이 |
|
|
|
심각도 |
|
|
|
심각도 |
17.1.89. .spec.processor.metrics.server
- 설명
- Prometheus 스크래퍼를 위한 메트릭 서버 엔드포인트 구성
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 메트릭 서버 HTTP 포트. |
|
|
| TLS 구성입니다. |
17.1.90. .spec.processor.metrics.server.tls
- 설명
- TLS 구성입니다.
- 유형
-
object - 필수 항목
-
type
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TLS 구성 유형을 선택하세요:
- |
17.1.91. .spec.processor.metrics.server.tls.provided
- 설명
-
유형이제공됨으로 설정된 경우의 TLS 구성입니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.92. .spec.processor.metrics.server.tls.providedCaFile
- 설명
-
유형이제공됨으로 설정된 경우 CA 파일에 대한 참조입니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 구성 맵 또는 시크릿 내의 파일 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 이름입니다. |
|
|
| 해당 파일을 포함하는 구성 맵 또는 비밀의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
파일 참조에 대한 유형: |
17.1.93. .spec.processor.resources
- 설명
-
리소스는이 컨테이너에 필요한 컴퓨팅 리소스입니다. 자세한 내용은 https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/를 참조하세요. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 제한은 허용되는 최대 컴퓨팅 리소스 양을 나타냅니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| 요청은 필요한 최소 컴퓨팅 리소스 양을 설명합니다. 컨테이너에 대한 요청이 생략되면 명시적으로 지정되어 있으면 제한이 기본값으로 설정되고, 그렇지 않으면 구현에서 정의한 값이 기본값으로 설정됩니다. 요청은 한도를 초과할 수 없습니다. 자세한 정보: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
17.1.94. .spec.processor.slicesConfig
- 설명
- FlowCollectorSlices 사용자 지정 리소스를 관리하는 글로벌 구성입니다.
- 유형
-
object - 필수 항목
-
enable
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
-
- |
|
|
|
FlowCollectorSlice 기능이 활성화되어 있는지 여부를 결정합니다. |
|
|
|
|
17.1.95. .spec.processor.subnetLabels
- 설명
-
subnetLabels는 서브넷 및 IP에 사용자 지정 레이블을 정의하거나 클러스터 외부 트래픽을 식별하는 데 사용되는 OpenShift Container Platform에서 인식된 서브넷의 자동 레이블을 활성화할 수 있습니다. 서브넷이 흐름의 소스 또는 대상 IP와 일치하면 해당 필드인SrcSubnetLabel또는DstSubnetLabel이추가됩니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
17.1.96. .spec.processor.subnetLabels.customLabels
- 설명
customLabels를 사용하면 클러스터 외부 워크로드 또는 웹 서비스를 식별하기 위해 서브넷 및 IP 레이블을 사용자 지정할 수 있습니다. 기본 빠른 필터 및 제공된 일부 메트릭 예제에서 작업하려면 외부 서브넷에EXT:접두사 , 레이블이 지정되거나 전혀 레이블이 지정되지 않아야 합니다.
openShiftAuto detect가 비활성화되었거나 OpenShift Container Platform을 사용하지 않는 경우 내부 트래픽을 외부 트래픽과 구분하기 위해 클러스터 서브넷에 대한 라벨을 수동으로 구성하는 것이 좋습니다.
openShiftAutoDetect가 활성화된 경우customLabels는 겹치는 경우 감지된 서브넷을 덮어씁니다.
- 유형
-
array
17.1.97. .spec.processor.subnetLabels.customLabels[]
- 설명
- SubnetLabel을 사용하면 클러스터 외부 작업 부하나 웹 서비스를 식별하기 위해 서브넷과 IP에 레이블을 지정할 수 있습니다.
- 유형
-
object - 필수 항목
-
cidrs -
name
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
레이블 이름은 일치하는 흐름을 표시하는 데 사용됩니다. 기본 빠른 필터 및 제공된 일부 메트릭 예제에서 작업하려면 외부 서브넷에 |
17.1.98. .spec.prometheus
- 설명
-
prometheus는콘솔 플러그인에서 메트릭을 가져오는 데 사용되는 쿼리어 구성과 같은 Prometheus 설정을 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 콘솔 플러그인에서 사용되는 클라이언트 설정 등의 Prometheus 쿼리 구성입니다. |
17.1.99. .spec.prometheus.querier
- 설명
- 콘솔 플러그인에서 사용되는 클라이언트 설정 등의 Prometheus 쿼리 구성입니다.
- 유형
-
object - 필수 항목
-
mode
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
-
- |
|
|
|
|
17.1.100. .spec.prometheus.querier.manual
- 설명
-
수동모드를 위한 Prometheus 구성. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| Alertmanager 구성입니다. 이는 콘솔에서 상태 정보를 표시하기 위해 음소거된 경고를 쿼리하는 데 사용됩니다. OpenShift Container Platform에서 사용하는 경우 대신 Console API를 사용하도록 비워 둘 수 있습니다. [지원되지 않음(*)]. |
|
|
|
Prometheus에 대한 쿼리에서 로그인한 사용자 토큰을 전달하려면 |
|
|
| Prometheus URL에 대한 TLS 클라이언트 구성. |
|
|
|
|
17.1.101. .spec.prometheus.querier.manual.alertManager
- 설명
- Alertmanager 구성입니다. 이는 콘솔에서 상태 정보를 표시하기 위해 음소거된 경고를 쿼리하는 데 사용됩니다. OpenShift Container Platform에서 사용하는 경우 대신 Console API를 사용하도록 비워 둘 수 있습니다. [지원되지 않음(*)].
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| Prometheus AlertManager URL에 대한 TLS 클라이언트 구성 |
|
|
|
|
17.1.102. .spec.prometheus.querier.manual.alertManager.tls
- 설명
- Prometheus AlertManager URL에 대한 TLS 클라이언트 구성
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.103. .spec.prometheus.querier.manual.alertManager.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.104. .spec.prometheus.querier.manual.alertManager.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.105. .spec.prometheus.querier.manual.tls
- 설명
- Prometheus URL에 대한 TLS 클라이언트 구성.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| TLS 활성화 |
|
|
|
|
|
|
|
|
17.1.106. .spec.prometheus.querier.manual.tls.caCert
- 설명
-
caCert는인증 기관에 대한 인증서 참조를 정의합니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
17.1.107. .spec.prometheus.querier.manual.tls.userCert
- 설명
-
userCert는사용자 인증서 참조를 정의하며 mTLS에 사용됩니다. 단방향 TLS를 사용하는 경우 이 속성을 무시할 수 있습니다. - 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 이름입니다. |
|
|
| 인증서가 포함된 구성 맵 또는 시크릿의 네임스페이스입니다. 생략하면 기본적으로 Network Observability가 배포된 것과 동일한 네임스페이스를 사용합니다. 네임스페이스가 다르면 구성 맵이나 비밀이 복사되어 필요에 따라 마운트될 수 있습니다. |
|
|
|
인증서 참조 유형: |
18장. FlowMetric 구성 매개변수
FlowMetric API는 수집된 네트워크 흐름 로그에서 사용자 정의 관찰성 지표를 생성하는 데 사용됩니다.
18.1. FlowMetric [flows.netobserv.io/v1alpha1]
- 설명
- FlowMetric은 수집된 흐름 로그에서 사용자 지정 지표를 생성할 수 있는 API입니다.
- 유형
-
object
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| APIVersion은 버전이 지정된 이 오브젝트 표현의 스키마를 정의합니다. 서버는 인식된 스키마를 최신 내부 값으로 변환해야 하며, 인식되지 않는 값을 거부할 수 있습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| kind는 이 오브젝트가 나타내는 REST 리소스에 해당하는 문자열 값입니다. 서버는 클라이언트에서 요청을 제출한 끝점에서 이를 유추할 수 있습니다. CamelCase로 업데이트할 수 없습니다. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
|
FlowMetricSpec은 FlowMetric의 원하는 상태를 정의합니다. 제공된 API를 사용하면 이러한 지표를 사용자의 요구 사항에 맞게 사용자 정의할 수 있습니다.
새로운 지표를 추가하거나 기존 레이블을 수정할 때는 Prometheus 워크로드의 메모리 사용량을 주의 깊게 모니터링해야 합니다. 이는 잠재적으로 큰 영향을 미칠 수 있기 때문입니다. https://rhobs-handbook.netlify.app/products/openshiftmonitoring/telemetry.md/#what-is-the-cardinality-of-a-metric 참조
모든 네트워크 관찰성 지표의 기수를 확인하려면 |
18.1.1. .metadata
- 설명
- 표준 객체의 메타데이터. 자세한 정보: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- 유형
-
object
18.1.2. .spec
- 설명
FlowMetricSpec은 FlowMetric의 원하는 상태를 정의합니다. 제공된 API를 사용하면 이러한 지표를 사용자의 요구 사항에 맞게 사용자 정의할 수 있습니다.
새로운 지표를 추가하거나 기존 레이블을 수정할 때는 Prometheus 워크로드의 메모리 사용량을 주의 깊게 모니터링해야 합니다. 이는 잠재적으로 큰 영향을 미칠 수 있기 때문입니다. https://rhobs-handbook.netlify.app/products/openshiftmonitoring/telemetry.md/#what-is-the-cardinality-of-a-metric 참조
모든 네트워크 관찰성 지표의 기수를 확인하려면
promql:count({ name =~"netobserv.*"}) by ( name )을 실행합니다.- 유형
-
object - 필수 항목
-
type
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
|
|
|
| 대시보드 메뉴의 관리자 보기에서 OpenShift Container Platform Console에 대한 차트 구성입니다. |
|
|
|
유입, 유출 또는 모든 방향의 흐름을 필터링합니다. |
|
|
| 0이 아닌 경우 값의 스케일 인수(divider)입니다. 메트릭 값 = 흐름 값 / 분배기. |
|
|
|
|
|
|
|
|
|
|
| Prometheus에 표시되는 지표의 도움말 텍스트입니다. |
|
|
|
|
|
|
|
지표의 이름입니다. Prometheus에서는 자동으로 "netobserv_"라는 접두사가 붙습니다. |
|
|
|
생성된 메트릭 레이블에 흐름 필드와 다른 이름을 사용하려면 |
|
|
| 지표 유형: "카운터", "히스토그램" 또는 "게이지". 시간이 지남에 따라 증가하고 비율을 계산할 수 있는 값(예: 바이트 또는 패킷)에 대해 "카운터"를 사용합니다. 대기 시간과 같이 독립적으로 샘플링해야 하는 값에는 "히스토그램"을 사용합니다. 시간 경과에 따른 정확성이 필요하지 않은 다른 값에는 "게이지"를 사용합니다(게이지는 Prometheus가 메트릭을 가져올 때 N초마다 샘플링됩니다). |
|
|
|
|
18.1.3. .spec.charts
- 설명
- 대시보드 메뉴의 관리자 보기에서 OpenShift Container Platform Console에 대한 차트 구성입니다.
- 유형
-
array
18.1.4. .spec.charts[]
- 설명
- 메트릭과 관련된 차트/대시보드 생성을 구성합니다.
- 유형
-
object - 필수 항목
-
dashboardName -
queries -
title -
type
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
| 포함된 대시보드의 이름입니다. 이 이름이 기존 대시보드를 참조하지 않으면 새 대시보드가 생성됩니다. |
|
|
|
이 차트에 표시할 쿼리 목록입니다. |
|
|
|
포함된 대시보드 섹션의 이름입니다. 이 이름이 기존 섹션을 참조하지 않으면 새 섹션이 생성됩니다. |
|
|
| 차트의 제목. |
|
|
| 차트의 유형. |
|
|
| 이 차트의 단위입니다. 현재 지원되는 유닛은 일부에 불과합니다. 일반 번호를 사용하려면 비워 두세요. |
18.1.5. .spec.charts[].queries
- 설명
-
이 차트에 표시할 쿼리 목록입니다.
유형이SingleStat이고 여러 개의 쿼리가 제공되는 경우, 이 차트는 자동으로 여러 패널(쿼리당 하나)로 확장됩니다. - 유형
-
array
18.1.6. .spec.charts[].queries[]
- 설명
- PromQL 쿼리를 구성합니다.
- 유형
-
object - 필수 항목
-
전설 -
promQL -
top
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
이 차트에 표현된 각 시계열에 적용되는 쿼리 범례입니다. 여러 시계열이 표시되는 경우 각 시계열을 구별하는 범례를 설정해야 합니다. 다음 형식으로 수행할 수 있습니다: |
|
|
|
Prometheus에 대해 실행할 |
|
|
|
타임스탬프별로 표시할 상위 N개 시리즈입니다. |
18.1.7. .spec.filters
- 설명
-
필터는어떤 흐름을 고려할지 제한하는 데 사용되는 필드와 값의 목록입니다. 사용 가능한 필드 목록은 다음 문서를 참조하세요: https://docs.redhat.com/en/documentation/openshift_container_platform/latest/html/network_observability/json-flows-format-reference . - 유형
-
array
18.1.8. .spec.filters[]
- 설명
- 유형
-
object - 필수 항목
-
field -
matchType
-
| 재산 | 유형 | 설명 |
|---|---|---|
|
|
|
필터링할 필드의 이름(예: |
|
|
| 적용할 매칭 유형 |
|
|
|
필터링할 값입니다. |
19장. 네트워크 흐름 형식 참조
Kafka로 흐름 데이터를 내보내는 데 사용되는 내부적으로 사용되는 네트워크 흐름 형식에 대한 사양을 검토합니다.
19.1. 네트워크 흐름 형식 참조.
이는 네트워크 흐름 형식의 사양입니다. 이 형식은 Kafka 내보내기 기능이 구성될 때, Prometheus 메트릭 레이블에 사용될 때, 그리고 Loki 저장소에 내부적으로 사용될 때 사용됩니다.
"필터 ID" 열은 빠른 필터를 정의할 때 사용할 관련 이름을 보여줍니다( FlowCollector 사양의 spec.consolePlugin.quickFilters 참조).
"Loki 레이블" 열은 Loki를 직접 쿼리할 때 유용합니다. 레이블 필드는 스트림 선택기를 사용하여 선택해야 합니다.
"Cardinality" 열은 이 필드가 FlowMetrics API에서 Prometheus 레이블로 사용될 경우 암시적인 메트릭 카디널리티에 대한 정보를 제공합니다. 이 API 사용에 대한 자세한 내용은 FlowMetrics 문서를 참조하세요.
| 이름 | 유형 | 설명 | 필터 ID | 로키 라벨 | 기수 | OpenTelemetry |
|---|---|---|---|---|---|---|
|
| number | 바이트 수 | 해당 없음 | 제공되지 않음 | avoid | 바이트 |
|
| number | DNS 추적기 ebpf 후크 함수에서 반환된 오류 번호 |
| 제공되지 않음 | 괜찮은 | dns.errno |
|
| number | DNS 레코드에 대한 DNS 플래그 | 해당 없음 | 제공되지 않음 | 괜찮은 | dns.flags |
|
| string | 구문 분석된 DNS 헤더 RCODE 이름 |
| 제공되지 않음 | 괜찮은 | dns.responsecode |
|
| number | DNS 레코드 ID |
| 제공되지 않음 | avoid | dns.id |
|
| number | DNS 요청과 응답 사이의 시간(밀리초) |
| 제공되지 않음 | avoid | dns.latency |
|
| string | DNS 쿼리 이름 |
| 제공되지 않음 | 주의 깊은 | 해당 없음 |
|
| number | DSCP(Differentiated Services Code Point) 값 |
| 제공되지 않음 | 괜찮은 | dscp |
|
| string | 목적지 IP 주소(ipv4 또는 ipv6) |
| 제공되지 않음 | avoid | destination.address |
|
| string | 대상 노드 IP |
| 제공되지 않음 | 괜찮은 | destination.k8s.host.address |
|
| string | 목적지 노드 이름 |
| 제공되지 않음 | 괜찮은 | destination.k8s.host.name |
|
| string | Pod 이름, 서비스 이름 또는 노드 이름과 같은 대상 Kubernetes 객체의 이름입니다. |
| 제공되지 않음 | 주의 깊은 | destination.k8s.name |
|
| string | 대상 네임스페이스 |
| 제공됨 | 괜찮은 | destination.k8s.namespace.name |
|
| string | 대상 네트워크 이름 |
| 제공되지 않음 | 괜찮은 | 해당 없음 |
|
| string | 배포 이름, StatefulSet 이름 등 대상 소유자의 이름입니다. |
| 제공됨 | 괜찮은 | destination.k8s.owner.name |
|
| string | 배포, StatefulSet 등과 같은 대상 소유자의 종류 |
| 제공되지 않음 | 괜찮은 | 목적지.k8s.소유자.종류 |
|
| string | Pod, Service 또는 Node와 같은 대상 Kubernetes 객체의 종류입니다. |
| 제공됨 | 괜찮은 | destination.k8s.kind |
|
| string | 목적지 가용성 영역 |
| 제공됨 | 괜찮은 | destination.zone |
|
| string | 대상 MAC 주소 |
| 제공되지 않음 | avoid | destination.mac |
|
| number | destination.port |
| 제공되지 않음 | 주의 깊은 | destination.port |
|
| string | 대상 서브넷 레이블 |
| 제공되지 않음 | 괜찮은 | destination.subnet.label |
|
| string[] |
RFC-9293에 따른 흐름에 포함된 TCP 플래그 목록과 다음 패킷별 조합을 나타내는 추가 사용자 정의 플래그입니다. |
| 제공되지 않음 | 주의 깊은 | tcp.flags |
|
| number |
흐름은 노드 관찰 지점에서 해석되는 방향입니다. |
| 제공됨 | 괜찮은 | host.direction |
|
| string | IPsec 암호화 상태(커널 xfrm_output 함수에서 제공) 또는 복호화 상태(xfrm_input을 통해 수신 시) |
| 제공되지 않음 | 괜찮은 | 해당 없음 |
|
| number | --icmp_code |
| 제공되지 않음 | 괜찮은 | icmp.code |
|
| number | --icmp_type |
| 제공되지 않음 | 괜찮은 | icmp.type |
|
| number[] |
네트워크 인터페이스 관찰 지점의 흐름 방향입니다. |
| 제공되지 않음 | 괜찮은 | interface.directions |
|
| string[] | 네트워크 인터페이스 |
| 제공되지 않음 | 주의 깊은 | interface.names |
|
| string | 클러스터 이름 또는 식별자 |
| 제공됨 | 괜찮은 | k8s.cluster.name |
|
| string | 흐름 계층: 'app' 또는 'infra' |
| 제공됨 | 괜찮은 | k8s.layer |
|
| object[] |
네트워크 정책 작업과 같은 중첩된 필드로 구성된 네트워크 이벤트: |
| 제공되지 않음 | avoid | 해당 없음 |
|
| number | 패킷 수 | 해당 없음 | 제공되지 않음 | avoid | 패킷 |
|
| number | 커널에 의해 삭제된 바이트 수 | 해당 없음 | 제공되지 않음 | avoid | drops.bytes |
|
| string | 최근 하락 원인 |
| 제공되지 않음 | 괜찮은 | drops.latestcause |
|
| number | 마지막으로 삭제된 패킷의 TCP 플래그 | 해당 없음 | 제공되지 않음 | 괜찮은 | drops.latestflags |
|
| string | 마지막으로 삭제된 패킷의 TCP 상태 |
| 제공되지 않음 | 괜찮은 | drops.lateststate |
|
| number | 커널에 의해 삭제된 패킷 수 | 해당 없음 | 제공되지 않음 | avoid | drops.packets |
|
| number | L4 프로토콜 |
| 제공되지 않음 | 괜찮은 | protocol |
|
| number | 이 흐름에 사용된 샘플링 간격 | 해당 없음 | 제공되지 않음 | 괜찮은 | 해당 없음 |
|
| string | 소스 IP 주소(ipv4 또는 ipv6) |
| 제공되지 않음 | avoid | source.address |
|
| string | 소스 노드 IP |
| 제공되지 않음 | 괜찮은 | source.k8s.host.address |
|
| string | 소스 노드 이름 |
| 제공되지 않음 | 괜찮은 | source.k8s.host.name |
|
| string | Pod 이름, 서비스 이름 또는 노드 이름과 같은 소스 Kubernetes 객체의 이름입니다. |
| 제공되지 않음 | 주의 깊은 | source.k8s.name |
|
| string | 소스 네임스페이스 |
| 제공됨 | 괜찮은 | source.k8s.namespace.name |
|
| string | 소스 네트워크 이름 |
| 제공되지 않음 | 괜찮은 | 해당 없음 |
|
| string | 배포 이름, StatefulSet 이름 등 소스 소유자의 이름입니다. |
| 제공됨 | 괜찮은 | source.k8s.owner.name |
|
| string | 배포, StatefulSet 등과 같은 소스 소유자의 종류 |
| 제공되지 않음 | 괜찮은 | source.k8s.owner.kind |
|
| string | Pod, Service 또는 Node와 같은 소스 Kubernetes 객체의 종류입니다. |
| 제공됨 | 괜찮은 | source.k8s.kind |
|
| string | 소스 가용성 영역 |
| 제공됨 | 괜찮은 | source.zone |
|
| string | 소스 MAC 주소 |
| 제공되지 않음 | avoid | source.mac |
|
| number | 소스 포트 |
| 제공되지 않음 | 주의 깊은 | source.port |
|
| string | 소스 서브넷 레이블 |
| 제공되지 않음 | 괜찮은 | source.subnet.label |
|
| number | 이 흐름의 종료 타임스탬프(밀리초) | 해당 없음 | 제공되지 않음 | avoid | 시간의 흐름 끝 |
|
| number | TCP Smoothed Round Trip Time(SRTT), 나노초 단위 |
| 제공되지 않음 | avoid | tcp.rtt |
|
| number | 이 흐름의 시작 타임스탬프(밀리초) | 해당 없음 | 제공되지 않음 | avoid | timeflowstart |
|
| number | 이 흐름이 흐름 수집기에 의해 수신되고 처리된 타임스탬프(초) | 해당 없음 | 제공되지 않음 | avoid | 시간 수신 |
|
| string[] | 사용자 정의 네트워크 목록 |
| 제공되지 않음 | 주의 깊은 | 해당 없음 |
|
| string | 패킷 변환 대상 주소 |
| 제공되지 않음 | avoid | 해당 없음 |
|
| number | 패킷 변환 대상 포트 |
| 제공되지 않음 | 주의 깊은 | 해당 없음 |
|
| string | 패킷 변환 소스 주소 |
| 제공되지 않음 | avoid | 해당 없음 |
|
| number | 패킷 변환 소스 포트 |
| 제공되지 않음 | 주의 깊은 | 해당 없음 |
|
| number | 패킷 변환 영역 ID |
| 제공되지 않음 | avoid | 해당 없음 |
|
| string | 대화 추적에서 대화 식별자 |
| 제공되지 않음 | avoid | 해당 없음 |
|
| string |
레코드 유형: 일반 흐름 로그의 경우 |
| 제공됨 | 괜찮은 | 해당 없음 |
20장. 네트워크 관찰성 문제 해결
네트워크 관찰 운영자 및 해당 구성 요소와 관련된 일반적인 문제를 해결하기 위한 진단 작업을 수행합니다.
20.1. must-gather 툴 사용
must-gather 툴을 사용하여 클러스터 문제 해결을 지원하기 위해 Pod 로그 및 구성 세부 정보를 포함하여 Network Observability Operator 리소스에 대한 진단 정보를 수집합니다.
프로세스
- must-gather 데이터를 저장하려는 디렉터리로 이동합니다.
클러스터 전체의 필수 수집 리소스를 수집하려면 다음 명령을 실행하세요.
$ oc adm must-gather --image-stream=openshift/must-gather \ --image=quay.io/netobserv/must-gather
20.2. OpenShift Container Platform 콘솔에서 네트워크 트래픽 메뉴 항목 구성
FlowCollector 리소스 및 콘솔 운영자 구성에 콘솔 플러그인을 수동으로 등록하여 OpenShift Container Platform 콘솔의 Observe 메뉴에서 누락된 네트워크 트래픽 메뉴 항목을 복원합니다.
사전 요구 사항
- OpenShift Container Platform 버전 4.10 이상을 설치했습니다.
프로세스
다음 명령을 실행하여
spec.consolePlugin.register필드가true로 설정되었는지 확인하세요.$ oc -n netobserv get flowcollector cluster -o yaml출력 예
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: false선택 사항: Console Operator 구성을 수동으로 편집하여
netobserv-plugin플러그인을 추가합니다.$ oc edit console.operator.openshift.io cluster출력 예
... spec: plugins: - netobserv-plugin ...선택 사항: 다음 명령을 실행하여
spec.consolePlugin.register필드를true로 설정합니다.$ oc -n netobserv edit flowcollector cluster -o yaml출력 예
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: true다음 명령을 실행하여 콘솔 포드의 상태가
실행중인지 확인하세요.$ oc get pods -n openshift-console -l app=console다음 명령을 실행하여 콘솔 포드를 다시 시작합니다.
$ oc delete pods -n openshift-console -l app=console- 브라우저 캐시와 기록을 지우세요.
다음 명령을 실행하여 네트워크 관찰 플러그인 포드의 상태를 확인하세요.
$ oc get pods -n netobserv -l app=netobserv-plugin출력 예
NAME READY STATUS RESTARTS AGE netobserv-plugin-68c7bbb9bb-b69q6 1/1 Running 0 21s다음 명령을 실행하여 네트워크 관찰 플러그인 포드의 로그를 확인하세요.
$ oc logs -n netobserv -l app=netobserv-plugin출력 예
time="2022-12-13T12:06:49Z" level=info msg="Starting netobserv-console-plugin [build version: , build date: 2022-10-21 15:15] at log level info" module=main time="2022-12-13T12:06:49Z" level=info msg="listening on https://:9001" module=server
20.3. Kafka 설치 후 Flowlogs-Pipeline이 네트워크 흐름을 사용하지 않습니다.
흐름 수집기와 Kafka 배포 간의 연결을 복원하기 위해 flow-pipeline 포드를 수동으로 다시 시작하여 Kafka에서 네트워크 흐름을 사용하지 못하는 문제를 해결합니다.
먼저 deploymentModel: KAFKA 로 플로우 수집기를 배포한 다음 Kafka를 배포한 경우, 플로우 수집기가 Kafka에 올바르게 연결되지 않을 수 있습니다. Kafka에서 네트워크 흐름을 사용하지 않는 Flowlogs-pipeline 포드를 수동으로 다시 시작합니다.
프로세스
다음 명령을 실행하여 flow-pipeline 포드를 삭제하고 다시 시작합니다.
$ oc delete pods -n netobserv -l app=flowlogs-pipeline-transformer
20.4. br-int 및 br-ex 인터페이스 모두에서 네트워크 흐름을 볼 수 없음
br-int 및 br-ex 와 같은 가상 브릿지 장치에 대한 인터페이스 제한을 제거하여 네트워크 흐름이 누락된 문제를 해결하여 eBPF 에이전트가 적절한 계층 3 인터페이스에 연결할 수 있도록 합니다.
br-ex 및 br-int 는 OSI 계층 2에서 작동하는 가상 브릿지 장치입니다. eBPF 에이전트는 IP 및 TCP 레벨(각각 3계층과 4계층)에서 작동합니다. eBPF 에이전트는 네트워크 트래픽이 물리적 호스트 또는 가상 pod 인터페이스와 같은 다른 인터페이스에서 처리할 때 br-ex 및 br-int 를 통과하는 네트워크 트래픽을 캡처할 수 있습니다. eBPF 에이전트 네트워크 인터페이스를 br-ex 및 br-int 에만 연결하도록 제한하면 네트워크 흐름이 표시되지 않습니다.
br-int 및 br-ex 로 네트워크 인터페이스를 제한하는 interfaces 또는 excludeInterfaces 부분을 수동으로 제거합니다.
프로세스
인터페이스 [ 'br-int', 'br-ex' ]필드를 제거합니다. 이를 통해 에이전트는 모든 인터페이스에서 정보를 가져올 수 있습니다. 또는eth0과 같이 Layer-3 인터페이스를 지정할 수 있습니다. 다음 명령을 실행합니다.$ oc edit -n netobserv flowcollector.yaml -o yaml출력 예
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: EBPF ebpf: interfaces: [ 'br-int', 'br-ex' ]1 - 1
- 네트워크 인터페이스를 지정합니다.
20.5. 네트워크 관찰 컨트롤러 관리자 Pod의 메모리가 부족합니다.
컨트롤러 관리자 Pod가 메모리가 부족하지 않도록 Subscription 오브젝트의 메모리 제한을 늘려 Network Observability Operator의 메모리 문제를 해결합니다.
Subscription 객체의 spec.config.resources.limits.memory 사양을 편집하여 Network Observability Operator의 메모리 한도를 늘릴 수 있습니다.
프로세스
- 웹 콘솔에서 Operator → 설치된 Operator로 이동합니다.
- 네트워크 관찰성을 클릭한 다음 구독을 선택합니다.
작업 메뉴에서 구독 편집을 클릭합니다.
또는 다음 명령을 실행하여 CLI를 사용하여
Subscription개체에 대한 YAML 구성을 열 수 있습니다.$ oc edit subscription netobserv-operator -n openshift-netobserv-operator
구독객체를 편집하여config.resources.limits.memory사양을 추가하고 메모리 요구 사항을 고려하여 값을 설정합니다. 리소스 고려 사항에 대한 자세한 내용은 추가 리소스를 참조하세요.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: netobserv-operator namespace: openshift-netobserv-operator spec: channel: stable config: resources: limits: memory: 800Mi1 requests: cpu: 100m memory: 100Mi installPlanApproval: Automatic name: netobserv-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: <network_observability_operator_latest_version>2
20.6. Loki에 대한 사용자 정의 쿼리 실행
명령줄 인터페이스를 사용하여 사용 가능한 레이블을 검색하거나 소스 네임스페이스와 같은 특정 기준으로 로그를 필터링하도록 사용자 정의 Loki 쿼리를 실행하여 네트워크 흐름 데이터의 문제를 해결합니다.
이를 수행하는 방법에는 두 가지 예가 있으며, <api_token>을 사용자 정의 토큰으로 바꿔서 필요에 맞게 조정할 수 있습니다.
이러한 예제에서는 Network Observability Operator와 Loki 배포에 netobserv 네임스페이스를 사용합니다. 또한, 이 예제에서는 LokiStack의 이름이 loki 라고 가정합니다. 선택적으로 예제, 특히 -n netobserv 또는 loki-gateway URL을 적용하여 다른 네임스페이스 및 이름을 사용할 수 있습니다.
사전 요구 사항
- Network Observability Operator에서 사용할 Loki Operator를 설치합니다.
프로세스
사용 가능한 모든 레이블을 가져오려면 다음 명령을 실행합니다.
$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/labels | jq소스 네임스페이스인
my-namespace에서 모든 흐름을 가져오려면 다음 명령을 실행합니다.$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/query --data-urlencode 'query={SrcK8S_Namespace="my-namespace"}' | jq
20.7. Loki ResourceExhausted 오류 문제 해결
FlowCollector 리소스에서 batchSize 또는 Loki 구성의 최대 메시지 크기 설정을 조정하여 Loki ResourceExhausted 오류를 해결하여 흐름 데이터가 메모리 제한 내에 유지되도록 합니다.
네트워크 관찰을 통해 전송된 네트워크 흐름 데이터가 구성된 최대 메시지 크기를 초과하는 경우 Loki는 ResourceExhausted 오류를 반환할 수 있습니다. Red Hat Loki Operator를 사용하는 경우 최대 메시지 크기는 100MiB로 구성됩니다.
프로세스
- Operators → 설치된 Operators로 이동하여 프로젝트 드롭다운 메뉴에서 모든 프로젝트를 확인합니다.
- 제공된 API 목록에서 네트워크 관찰 연산자를 선택합니다.
Flow Collector를 클릭한 다음 YAML 보기 탭을 클릭합니다.
-
Loki Operator를 사용하는 경우
spec.loki.batchSize값이 98MiB를 초과하지 않는지 확인하세요. -
Grafana Loki와 같이 Red Hat Loki Operator와 다른 Loki 설치 방법을 사용하는 경우 Grafana Loki 서버 설정의
grpc_server_max_recv_msg_size가FlowCollector리소스spec.loki.batchSize값보다 높은지 확인하세요. 그렇지 않은 경우grpc_server_max_recv_msg_size값을 늘리거나spec.loki.batchSize값을 줄여서 한도보다 낮게 설정해야 합니다.
-
Loki Operator를 사용하는 경우
- FlowCollector 를 편집한 경우 저장을 클릭합니다.
20.8. 로키 빈 반지 오류
Pod 상태를 확인하거나, 이전 영구 볼륨 클레임을 지우거나, 포드를 다시 시작하여 연결을 복원하고 네트워크 흐름이 올바르게 저장 및 표시되는지 확인하여 Loki "빈 링" 오류를 조사하고 해결합니다.
Loki "빈 링" 오류는 흐름이 Loki에 저장되지 않고 웹 콘솔에 표시되지 않는 결과를 낳습니다. 이 오류는 다양한 상황에서 발생할 수 있습니다. 이 모든 문제를 해결할 수 있는 단일한 해결책은 존재하지 않습니다. Loki Pod의 로그를 조사하고 LokiStack 이 정상이고 준비되었는지 확인하기 위해 취할 수 있는 몇 가지 조치가 있습니다.
이 오류가 관찰되는 상황 중 일부는 다음과 같습니다.
LokiStack을제거한 후 같은 네임스페이스에 다시 설치하면 이전 PVC가 제거되지 않아 이 오류가 발생할 수 있습니다.-
조치 :
LokiStack을다시 제거하고 PVC를 제거한 다음LokiStack을다시 설치해보세요.
-
조치 :
인증서 회전 후 이 오류로 인해
flowlogs-pipeline및console-plugin포드와의 통신이 방해받을 수 있습니다.- 조치 : 포드를 다시 시작하여 연결을 복구할 수 있습니다.
20.9. LokiStack 속도 제한 오류
Loki 속도 제한 오류를 해결하고 LokiStack 리소스를 업데이트하여 네트워크 관찰 기능 데이터 스트림에 대한 수집 속도 및 버스트 제한을 늘려 데이터 손실을 방지합니다.
Loki 테넌트에 속도 제한을 적용하면 데이터가 일시적으로 손실될 가능성이 있으며 429 오류가 발생할 수 있습니다. 스트림을 수집하려고 시도하는 동안 스트림당 속도 제한(limit:xMB/sec)을 초과했습니다 . 이 오류가 발생하면 알림을 받도록 알림을 설정하는 것이 좋습니다. 자세한 내용은 이 섹션의 추가 리소스의 "NetObserv 대시보드에 대한 Loki 속도 제한 경고 생성"을 참조하십시오.
다음 절차에 표시된 대로 perStreamRateLimit 및 perStreamRateLimitBurst 사양을 사용하여 LokiStack CRD를 업데이트할 수 있습니다.
프로세스
- Operators → 설치된 Operators로 이동하여 프로젝트 드롭다운에서 모든 프로젝트를 확인합니다.
- Loki Operator를 찾아 LokiStack 탭을 선택하세요.
YAML 뷰를 사용하여 기존 LokiStack 인스턴스를 만들거나 편집하여
perStreamRateLimit및perStreamRateLimitBurst사양을 추가합니다.apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv spec: limits: global: ingestion: perStreamRateLimit: 61 perStreamRateLimitBurst: 302 tenants: mode: openshift-network managementState: Managed- 저장을 클릭합니다.
검증
perStreamRateLimit 및 perStreamRateLimitBurst 사양을 업데이트하면 클러스터의 포드가 다시 시작되고 429 속도 제한 오류가 더 이상 발생하지 않습니다.
20.10. 대규모 쿼리를 실행하면 Loki 오류가 발생합니다.
인덱싱된 필터를 사용하여 대규모 쿼리를 실행할 때 Loki 시간 초과 및 요청 오류를 완화하고, Prometheus를 긴 시간 범위로 사용하거나, 사용자 지정 메트릭을 생성하거나, Loki 및 FlowCollector 성능 설정을 조정하는 방법을 설명합니다.
장시간 동안 큰 쿼리를 실행하면 시간 초과나 처리되지 않은 요청이 너무 많아지는 등의 Loki 오류가 발생할 수 있습니다. 이 문제에 대한 완벽한 해결책은 없지만, 이를 완화할 수 있는 방법은 여러 가지가 있습니다.
- 인덱스 필터를 추가하려면 쿼리를 조정하세요.
-
Loki 쿼리를 사용하면 인덱싱된 필드나 레이블과 인덱싱되지 않은 필드나 레이블을 모두 쿼리할 수 있습니다. 레이블에 필터가 포함된 쿼리는 더 나은 성능을 보입니다. 예를 들어, 인덱싱된 필드가 아닌 특정 Pod를 쿼리하는 경우 쿼리에 해당 네임스페이스를 추가할 수 있습니다. 인덱싱된 필드 목록은
Loki 레이블열의 "네트워크 흐름 형식 참조"에서 찾을 수 있습니다. - Loki보다는 Prometheus에 쿼리를 보내는 것을 고려하세요.
- Prometheus는 Loki보다 넓은 시간 범위에 대한 쿼리를 처리하는 데 더 적합합니다. 하지만 Loki 대신 Prometheus를 사용할 수 있는지 여부는 사용 사례에 따라 달라집니다. 예를 들어, Prometheus의 쿼리는 Loki의 쿼리보다 훨씬 빠르며, 긴 시간 범위는 성능에 영향을 미치지 않습니다. 그러나 Prometheus 메트릭에는 Loki의 흐름 로그만큼 많은 정보가 포함되어 있지 않습니다. Network Observability OpenShift 웹 콘솔은 쿼리가 호환되는 경우 Loki보다 Prometheus를 자동으로 선호합니다. 호환되지 않는 경우 기본적으로 Loki를 사용합니다. 쿼리가 Prometheus에서 실행되지 않으면 일부 필터나 집계를 변경하여 전환할 수 있습니다. OpenShift 웹 콘솔에서 Prometheus 사용을 강제할 수 있습니다. 호환되지 않는 쿼리가 실패하면 오류 메시지가 표시되며, 이를 통해 쿼리를 호환 가능하게 만들기 위해 어떤 레이블을 변경해야 할지 파악하는 데 도움이 됩니다. 예를 들어, 필터나 집계를 Resource 또는 Pods 에서 Owner 로 변경합니다.
- FlowMetrics API를 사용하여 고유한 메트릭을 생성하는 것을 고려하세요.
- 필요한 데이터를 Prometheus 지표로 사용할 수 없는 경우 FlowMetrics API를 사용하여 사용자 고유의 지표를 만들 수 있습니다. 자세한 내용은 "FlowMetrics API 참조" 및 "FlowMetric API를 사용하여 사용자 지정 메트릭 구성"을 참조하세요.
- 쿼리 성능을 개선하기 위해 Loki를 구성하세요
문제가 지속되면 Loki를 구성하여 쿼리 성능을 개선하는 것을 고려해 보세요. 일부 옵션은 Loki에 사용한 설치 모드(Operator 및
LokiStack사용,Monolithic모드,Microservices모드 등)에 따라 달라집니다.-
LokiStack또는Microservices모드에서 쿼리어 복제본의 수를 늘려 보세요. -
쿼리 시간 초과를 늘립니다.
FlowCollectorspec.loki.readTimeout에서 Loki에 대한 네트워크 관찰 읽기 시간 제한도 늘려야 합니다.
-