3.5. 설치 문제 해결
3.5.1. 설치 프로그램 워크플로 문제 해결
설치 환경의 문제를 해결하기 전에 베어 메탈에서 설치 프로그램이 제공하는 설치의 전체 흐름을 이해하는 것이 중요합니다. 다음 다이어그램은 환경에 대한 단계별 분석과 함께 문제 해결 흐름을 보여줍니다.
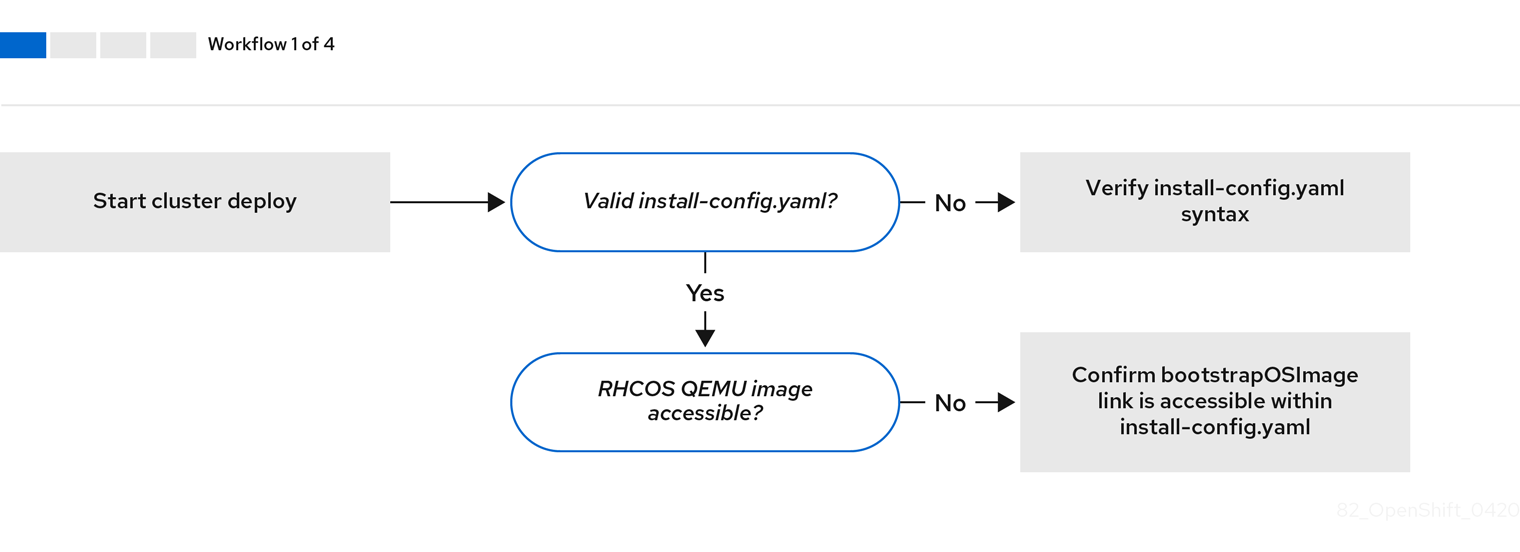
워크 플로우 1/4은 install-config.yaml 파일에 오류가 있거나 RHCOS (Red Hat Enterprise Linux CoreOS) 이미지에 액세스할 수 없는 경우 문제 해결의 워크 플로우를 보여줍니다. 문제 해결 제안 사항은 install-config.yaml 문제 해결을 참조하십시오.

워크 플로우 2/4는 부트스트랩 VM 문제, 클러스터 노드를 부팅할 수 없는 부트스트랩 VM 및 로그 검사에 대한 문제 해결 워크 플로우를 보여줍니다. provisioning 네트워크없이 OpenShift Container Platform 클러스터를 설치할 때 이 워크플로가 적용되지 않습니다.

워크 플로우 3/4은 PXE 부팅이 되지 않는 클러스터 노드에 대한 문제 해결의 워크 플로우를 보여줍니다. RedFish Virtual Media를 사용하여 설치하는 경우 각 노드가 노드를 배포하는 데 필요한 최소 펌웨어 요구 사항을 충족해야 합니다. 자세한 내용은 사전 요구 사항 섹션에서 가상 미디어를 사용하여 설치를 위한 펌웨어 요구 사항을 참조하십시오.

워크 플로우 4/4는 액세스할 수 없는 API부터 검증된 설치까지의 문제 해결 워크 플로우를 보여줍니다.
3.5.2. install-config.yaml 문제 해결
install-config.yaml 설정 파일은 OpenShift Container Platform 클러스터의 일부인 모든 노드를 나타냅니다. 이 파일에는 apiVersion, baseDomain, imageContentSources 및 가상 IP 주소로 구성되지만 이에 국한되지 않는 필수 옵션이 포함되어 있습니다. OpenShift Container Platform 클러스터 배포 초기에 오류가 발생하면 install-config.yaml 구성 파일에 오류가 있을 수 있습니다.
프로세스
- YAML-tips의 지침을 사용합니다.
- syntax-check를 사용하여 YAML 구문이 올바른지 확인합니다.
RHCOS (Red Hat Enterprise Linux CoreOS) QEMU 이미지가 올바르게 정의되어 있고
install-config.yaml에서 제공되는 URL을 통해 액세스할 수 있는지 확인합니다. 예를 들면 다음과 같습니다.$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7출력이
200이면 부트스트랩 VM 이미지를 저장하는 웹 서버의 유효한 응답이 있습니다.
3.5.3. 부트스트랩 VM 문제 해결
OpenShift Container Platform 설치 프로그램은 OpenShift Container Platform 클러스터 노드의 프로비저닝을 처리하는 부트스트랩 노드 가상 머신을 시작합니다.
프로세스
설치 프로그램을 트리거한 후 약 10~15 분 후에
virsh명령을 사용하여 부트스트랩 VM이 작동하는지 확인합니다.$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running참고부트스트랩 VM의 이름은 항상 클러스터 이름으로 시작하여 그 뒤에 임의의 문자 집합이 있고 "bootstrap"이라는 단어로 끝납니다.
부트스트랩 VM이 10-15 분 후에 실행되지 않는 경우 다음 명령을 실행하여 시스템에서
libvirtd가 실행되고 있는지 확인합니다.$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtd부트스트랩 VM이 작동하는 경우 해당 VM에 로그인합니다.
virsh console명령을 사용하여 부트스트랩 VM의 IP 주소를 찾습니다.$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:중요provisioning네트워크없이 OpenShift Container Platform 클러스터를 배포하는 경우172.22.0.2와 같은 개인 IP 주소가 아닌 공용 IP 주소를 사용해야 합니다.IP 주소를 가져온 후
ssh명령을 사용하여 부트스트랩 VM에 로그인합니다.참고이전 단계의 콘솔 출력에서
ens3에서 제공되는 IPv6 IP 주소 또는ens4에서 제공되는 IPv4 IP를 사용할 수 있습니다.$ ssh core@172.22.0.2
부트스트랩 VM에 성공적으로 로그인하지 못한 경우 다음 시나리오 중 하나가 발생했을 가능성이 있습니다.
-
172.22.0.0/24네트워크에 연결할 수 없습니다. 프로비저너와provisioning네트워크 브리지 간의 네트워크 연결을 확인합니다. 이 문제는provisioning네트워크를 사용하는 경우 발생할 수 있습니다. -
공용 네트워크를 통해 부트스트랩 VM에 연결할 수 없습니다.
baremetal네트워크에서 SSH를 시도할 때provisioner호스트, 특히baremetal네트워크 브리지의 연결을 확인합니다. -
Permission denied (publickey, password, keyboard-interactive)문제가 발생했습니다. 부트스트랩 VM에 액세스하려고하면Permission denied오류가 발생할 수 있습니다. VM에 로그인하려는 사용자의 SSH 키가 install-config.yaml 파일에 설정되어 있는지 확인합니다.
3.5.3.1. 부트스트랩 VM은 클러스터 노드를 부팅할 수 없습니다.
배포 중에 부트스트랩 VM이 클러스터 노드를 부팅하지 못하여 VM이 RHCOS 이미지로 노드를 프로비저닝하지 못할 수 있습니다. 이 시나리오는 다음과 같은 이유로 발생할 수 있습니다.
-
install-config.yaml파일 관련 문제 - baremetal 네트워크를 사용할 때 대역 외 네트워크 액세스 문제
이 문제를 확인하기 위해 ironic과 관련된 세 가지 컨테이너를 사용할 수 있습니다.
-
Ironic -
ironic-inspector
프로세스
부트스트랩 VM에 로그인합니다.
$ ssh core@172.22.0.2컨테이너 로그를 확인하려면 다음을 실행합니다.
[core@localhost ~]$ sudo podman logs -f <container_name><
;container_name>을ironic또는ironic-inspector중 하나로 바꿉니다. 컨트롤 플레인 노드가 PXE에서 부팅되지 않는 문제가 발생하면ironicpod를 확인합니다.ironicpod에는 IPMI를 통해 노드에 로그인을 시도하기 때문에 클러스터 노드를 부팅하려는 시도에 대한 정보가 포함되어 있습니다.
가능한 이유
배포가 시작되면 클러스터 노드가 ON 상태 일 수 있습니다.
해결책
IPMI를 통해 설치를 시작하기 전에 OpenShift Container Platform 클러스터 노드의 전원을 끄십시오.
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off3.5.3.2. 로그 검사
RHCOS 이미지를 다운로드하거나 액세스하는 데 문제가 발생하면 먼저 install-config.yaml 구성 파일에서 URL이 올바른지 확인합니다.
RHCOS 이미지를 호스팅하는 내부 웹 서버의 예
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader 컨테이너는 install-config.yaml 구성 파일에서 지정하는 외부 quay.io 레지스트리 또는 웹 서버 또는 외부 quay.io 레지스트리에서 리소스를 다운로드합니다. coreos-downloader 컨테이너가 실행 중인지 확인하고 필요에 따라 로그를 검사합니다.
프로세스
부트스트랩 VM에 로그인합니다.
$ ssh core@172.22.0.2다음 명령을 실행하여 부트스트랩 VM 내에서
coreos-downloader컨테이너의 상태를 확인합니다.[core@localhost ~]$ sudo podman logs -f coreos-downloader부트스트랩 VM이 이미지의 URL에 액세스할 수 없는 경우
curl명령을 사용하여 VM이 이미지에 액세스할 수 있는지 확인합니다.배포 단계에서 모든 컨테이너가 시작되었는지 여부를 나타내는
bootkube로그를 검사하려면 다음을 실행합니다.[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.servicednsmasq,mariadb,httpd및ironic를 포함한 모든 Pod가 실행 중인지 확인합니다.[core@localhost ~]$ sudo podman psPod에 문제가 있는 경우 문제가있는 컨테이너의 로그를 확인합니다.
ironic서비스의 로그를 확인하려면 다음 명령을 실행합니다.[core@localhost ~]$ sudo podman logs ironic
3.5.5. 클러스터를 초기화하지 못한 문제 해결
설치 프로그램은 Cluster Version Operator를 사용하여 OpenShift Container Platform 클러스터의 모든 구성 요소를 생성합니다. 설치 프로그램이 클러스터를 초기화하지 못하면 ClusterVersion 및 ClusterOperator 오브젝트에서 가장 중요한 정보를 검색할 수 있습니다.
프로세스
다음 명령을 실행하여
ClusterVersion오브젝트를 검사합니다.$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion -o yaml출력 예
apiVersion: config.openshift.io/v1 kind: ClusterVersion metadata: creationTimestamp: 2019-02-27T22:24:21Z generation: 1 name: version resourceVersion: "19927" selfLink: /apis/config.openshift.io/v1/clusterversions/version uid: 6e0f4cf8-3ade-11e9-9034-0a923b47ded4 spec: channel: stable-4.1 clusterID: 5ec312f9-f729-429d-a454-61d4906896ca status: availableUpdates: null conditions: - lastTransitionTime: 2019-02-27T22:50:30Z message: Done applying 4.1.1 status: "True" type: Available - lastTransitionTime: 2019-02-27T22:50:30Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:30Z message: Cluster version is 4.1.1 status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:24:31Z message: 'Unable to retrieve available updates: unknown version 4.1.1 reason: RemoteFailed status: "False" type: RetrievedUpdates desired: image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a version: 4.1.1 history: - completionTime: 2019-02-27T22:50:30Z image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a startedTime: 2019-02-27T22:24:31Z state: Completed version: 4.1.1 observedGeneration: 1 versionHash: Wa7as_ik1qE=다음 명령을 실행하여 조건을 확인합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion version \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'가장 중요한 조건 중 일부는
Failing,Available,Progressing입니다.출력 예
Available True Done applying 4.1.1 Failing False Progressing False Cluster version is 4.0.0-0.alpha-2019-02-26-194020 RetrievedUpdates False Unable to retrieve available updates: unknown version 4.1.1다음 명령을 실행하여
ClusterOperator오브젝트를 검사합니다.$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator명령은 클러스터 Operator의 상태를 반환합니다.
출력 예
NAME VERSION AVAILABLE PROGRESSING FAILING SINCE cluster-baremetal-operator True False False 17m cluster-autoscaler True False False 17m cluster-storage-operator True False False 10m console True False False 7m21s dns True False False 31m image-registry True False False 9m58s ingress True False False 10m kube-apiserver True False False 28m kube-controller-manager True False False 21m kube-scheduler True False False 25m machine-api True False False 17m machine-config True False False 17m marketplace-operator True False False 10m monitoring True False False 8m23s network True False False 13m node-tuning True False False 11m openshift-apiserver True False False 15m openshift-authentication True False False 20m openshift-cloud-credential-operator True False False 18m openshift-controller-manager True False False 10m openshift-samples True False False 8m42s operator-lifecycle-manager True False False 17m service-ca True False False 30m다음 명령을 실행하여 개별 클러스터 Operator를 검사합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> -oyaml1 - 1
- &
lt;operator>를 클러스터 Operator의 이름으로 바꿉니다. 이 명령은 클러스터 Operator가Available상태를 얻지 못했거나Failed상태에 있는 이유를 식별하는 데 유용합니다.
출력 예
apiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:47:04Z generation: 1 name: monitoring resourceVersion: "24677" selfLink: /apis/config.openshift.io/v1/clusteroperators/monitoring uid: 9a6a5ef9-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:49:10Z message: Successfully rolled out the stack. status: "True" type: Available - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Failing extension: null relatedObjects: null version: ""클러스터 Operator의 상태 조건을 가져오려면 다음 명령을 실행합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'&
lt;operator>를 위의 Operator 중 하나의 이름으로 바꿉니다.출력 예
Available True Successfully rolled out the stack Progressing False Failing False클러스터 Operator가 소유한 오브젝트 목록을 검색하려면 다음 명령을 실행합니다.
oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator kube-apiserver \ -o=jsonpath='{.status.relatedObjects}'출력 예
[map[resource:kubeapiservers group:operator.openshift.io name:cluster] map[group: name:openshift-config resource:namespaces] map[group: name:openshift-config-managed resource:namespaces] map[group: name:openshift-kube-apiserver-operator resource:namespaces] map[group: name:openshift-kube-apiserver resource:namespaces]]
3.5.6. 콘솔 URL을 가져오지 못하는 문제 해결
설치 프로그램은 openshift-console 네임스페이스 내에서 [route][route-object] 를 사용하여 OpenShift Container Platform 콘솔의 URL을 검색합니다. 설치 프로그램이 콘솔에 대한 URL을 검색하지 못하면 다음 절차를 사용하십시오.
프로세스
다음 명령을 실행하여 콘솔 라우터가
Available또는Failing상태에 있는지 확인합니다.$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator console -oyamlapiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:46:57Z generation: 1 name: console resourceVersion: "19682" selfLink: /apis/config.openshift.io/v1/clusteroperators/console uid: 960364aa-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:46:58Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:12Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:50:12Z status: "True" type: Available - lastTransitionTime: 2019-02-27T22:46:57Z status: "True" type: Upgradeable extension: null relatedObjects: - group: operator.openshift.io name: cluster resource: consoles - group: config.openshift.io name: cluster resource: consoles - group: oauth.openshift.io name: console resource: oauthclients - group: "" name: openshift-console-operator resource: namespaces - group: "" name: openshift-console resource: namespaces versions: null다음 명령을 실행하여 콘솔 URL을 수동으로 검색합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get route console -n openshift-console \ -o=jsonpath='{.spec.host}' console-openshift-console.apps.adahiya-1.devcluster.openshift.com
3.5.7. kubeconfig에 수신 인증서를 추가하지 못한 문제 해결
설치 프로그램은 기본 수신 인증서를 ${INSTALL_DIR}/auth/kubeconfig 의 신뢰할 수 있는 클라이언트 인증 기관 목록에 추가합니다. 설치 프로그램이 kubeconfig 파일에 Ingress 인증서를 추가하지 못하면 클러스터에서 인증서를 검색하여 추가할 수 있습니다.
프로세스
다음 명령을 사용하여 클러스터에서 인증서를 검색합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get configmaps default-ingress-cert \ -n openshift-config-managed -o=jsonpath='{.data.ca-bundle\.crt}'-----BEGIN CERTIFICATE----- MIIC/TCCAeWgAwIBAgIBATANBgkqhkiG9w0BAQsFADAuMSwwKgYDVQQDDCNjbHVz dGVyLWluZ3Jlc3Mtb3BlcmF0b3JAMTU1MTMwNzU4OTAeFw0xOTAyMjcyMjQ2Mjha Fw0yMTAyMjYyMjQ2MjlaMC4xLDAqBgNVBAMMI2NsdXN0ZXItaW5ncmVzcy1vcGVy YXRvckAxNTUxMzA3NTg5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA uCA4fQ+2YXoXSUL4h/mcvJfrgpBfKBW5hfB8NcgXeCYiQPnCKblH1sEQnI3VC5Pk 2OfNCF3PUlfm4i8CHC95a7nCkRjmJNg1gVrWCvS/ohLgnO0BvszSiRLxIpuo3C4S EVqqvxValHcbdAXWgZLQoYZXV7RMz8yZjl5CfhDaaItyBFj3GtIJkXgUwp/5sUfI LDXW8MM6AXfuG+kweLdLCMm3g8WLLfLBLvVBKB+4IhIH7ll0buOz04RKhnYN+Ebw tcvFi55vwuUCWMnGhWHGEQ8sWm/wLnNlOwsUz7S1/sW8nj87GFHzgkaVM9EOnoNI gKhMBK9ItNzjrP6dgiKBCQIDAQABoyYwJDAOBgNVHQ8BAf8EBAMCAqQwEgYDVR0T AQH/BAgwBgEB/wIBADANBgkqhkiG9w0BAQsFAAOCAQEAq+vi0sFKudaZ9aUQMMha CeWx9CZvZBblnAWT/61UdpZKpFi4eJ2d33lGcfKwHOi2NP/iSKQBebfG0iNLVVPz vwLbSG1i9R9GLdAbnHpPT9UG6fLaDIoKpnKiBfGENfxeiq5vTln2bAgivxrVlyiq +MdDXFAWb6V4u2xh6RChI7akNsS3oU9PZ9YOs5e8vJp2YAEphht05X0swA+X8V8T C278FFifpo0h3Q0Dbv8Rfn4UpBEtN4KkLeS+JeT+0o2XOsFZp7Uhr9yFIodRsnNo H/Uwmab28ocNrGNiEVaVH6eTTQeeZuOdoQzUbClElpVmkrNGY0M42K0PvOQ/e7+y AQ== -----END CERTIFICATE------
${INSTALL_DIR}/auth/kubeconfig파일의client-certificate-authority-data필드에 인증서를 추가합니다.
3.5.8. 클러스터 노드에 대한 SSH 액세스 문제 해결
보안을 강화하기 위해 기본적으로 클러스터 외부에서 클러스터에 SSH를 수행할 수 없습니다. 그러나 프로비저너 노드에서 컨트롤 플레인 및 작업자 노드에 액세스할 수 있습니다. 프로비저너 노드에서 클러스터 노드에 SSH를 수행할 수 없는 경우 노드가 부트스트랩 VM에서 대기 중일 수 있습니다. 컨트롤 플레인 노드는 부트스트랩 VM에서 부팅 구성을 검색하고 부팅 구성을 검색하지 않으면 성공적으로 부팅할 수 없습니다.
프로세스
- 노드에 대한 물리적 액세스 권한이 있는 경우 콘솔 출력을 확인하여 성공적으로 부팅되었는지 확인합니다. 노드가 부팅 구성을 계속 검색하는 경우 부트스트랩 VM에 문제가 있을 수 있습니다.
-
install-config.yaml파일에서sshKey: '<ssh_pub_key>'설정을 구성해야 합니다. 여기서 <ssh_pub_key>는 프로비저너 노드에서kni사용자의 공개 키입니다.
3.5.9. 클러스터 노드는 PXE 부팅 불가능
OpenShift Container Platform 클러스터 노드가 PXE 부팅을 하지 않는 경우 PXE 부팅이 되지 않는 클러스터 노드에서 다음 검사를 실행합니다. 이 절차는 provisioning 네트워크없이 OpenShift Container Platform 클러스터를 설치할 때 적용되지 않습니다.
프로세스
-
provisioning네트워크에 대한 네트워크 연결을 확인하십시오. -
provisioning네트워크의 NIC에서 PXE가 활성화되어 있고 다른 모든 NIC에 대해 PXE가 비활성화되어 있는지 확인합니다. install-config.yaml구성 파일에provisioning네트워크에 연결된 NIC의rootDeviceHints매개변수 및 부팅 MAC 주소가 포함되어 있는지 확인합니다. 예를 들면 다음과 같습니다.컨트롤 플레인 노드 설정
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC작업자 노드 설정
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC
3.5.10. 설치 시 작업자 노드가 생성되지 않음
설치 프로그램은 작업자 노드를 직접 프로비저닝하지 않습니다. 대신 Machine API Operator는 지원되는 플랫폼에서 노드를 확장 및 축소합니다. 클러스터의 인터넷 연결 속도에 따라 작업자 노드가 15~20분 후에 생성되지 않는 경우 Machine API Operator를 조사합니다.
프로세스
다음 명령을 실행하여 Machine API Operator를 확인합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api get deployments환경에
${INSTALL_DIR}이 설정되어 있지 않은 경우 값을 설치 디렉터리의 이름으로 교체합니다.출력 예
NAME READY UP-TO-DATE AVAILABLE AGE cluster-autoscaler-operator 1/1 1 1 86m cluster-baremetal-operator 1/1 1 1 86m machine-api-controllers 1/1 1 1 85m machine-api-operator 1/1 1 1 86m다음 명령을 실행하여 머신 컨트롤러 로그를 확인합니다.
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api logs deployments/machine-api-controllers \ --container=machine-controller
3.5.11. Cluster Network Operator 문제 해결
Cluster Network Operator는 네트워킹 구성 요소를 배포합니다. 컨트롤 플레인 노드가 시작된 후 설치 프로그램이 부트스트랩 컨트롤 플레인을 제거하기 전에 설치 프로세스 초기에 실행됩니다. 이 Operator의 문제는 설치 프로그램 문제를 나타낼 수 있습니다.
프로세스
다음 명령을 실행하여 네트워크 구성이 있는지 확인합니다.
$ oc get network -o yaml cluster존재하지 않는 경우 설치 프로그램이 이를 생성하지 않았습니다. 이유를 확인하려면 다음 명령을 실행합니다.
$ openshift-install create manifests매니페스트를 검토하여 설치 프로그램에서 네트워크 구성을 생성하지 않은 이유를 확인합니다.
다음 명령을 입력하여 네트워크가 실행 중인지 확인합니다.
$ oc get po -n openshift-network-operator
3.5.12. BMC를 사용하여 새 베어 메탈 호스트를 찾을 수 없음
경우에 따라 설치 프로그램에서 새 베어 메탈 호스트를 검색하고 원격 가상 미디어 공유를 마운트할 수 없기 때문에 오류를 발행할 수 없습니다.
예를 들면 다음과 같습니다.
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST
https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia
returned code 400.
Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information
Extended information: [
{
"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.",
"MessageArgs": [
"https://<ironic_address>/redfish/boot-<uuid>.iso"
],
"MessageArgs@odata.count": 1,
"MessageId": "IDRAC.2.5.RAC0720",
"RelatedProperties": [
"#/Image"
],
"RelatedProperties@odata.count": 1,
"Resolution": "Retry the operation.",
"Severity": "Informational"
}
].이 경우 알 수 없는 인증 기관이 있는 가상 미디어를 사용하는 경우 이 오류를 방지하기 위해 알 수 없는 인증 기관을 신뢰하도록 BMC(Baseboard Management Controller) 원격 파일 공유 설정을 구성할 수 있습니다.
이 확인은 Dell iDRAC 9 및 펌웨어 버전 5.10.50이 있는 OpenShift Container Platform 4.11에서 테스트되었습니다.
3.5.13. 클러스터에 참여할 수 없는 작업자 노드 문제 해결
설치 관리자 프로비저닝 클러스터는 api-int.<cluster_name>.<base_domain > URL에 대한 DNS 항목을 포함하는 DNS 서버와 함께 배포됩니다. 클러스터 내의 노드가 외부 또는 업스트림 DNS 서버를 사용하여 api-int.<cluster_name>.<base_domain > URL을 확인하면 작업자 노드가 클러스터에 참여하지 못할 수 있습니다. 클러스터의 모든 노드가 도메인 이름을 확인할 수 있는지 확인합니다.
프로세스
DNS A/AAAA 또는 CNAME 레코드를 추가하여 내부적으로 API 로드 밸런서를 식별합니다. 예를 들어 dnsmasq를 사용하는 경우
dnsmasq.conf구성 파일을 수정합니다.$ sudo nano /etc/dnsmasq.confaddress=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334내부적으로 API 로드 밸런서를 식별하는 DNS PTR 레코드를 추가합니다. 예를 들어 dnsmasq를 사용하는 경우
dnsmasq.conf구성 파일을 수정합니다.$ sudo nano /etc/dnsmasq.confptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.comDNS 서버를 다시 시작합니다. 예를 들어 dnsmasq를 사용하는 경우 다음 명령을 실행합니다.
$ sudo systemctl restart dnsmasq
이 레코드는 클러스터 내의 모든 노드에서 확인할 수 있어야 합니다.
3.5.14. 이전 설치 정리
이전 배포에 실패한 경우 OpenShift Container Platform을 다시 배포하기 전에 실패한 시도에서 아티팩트를 제거합니다.
프로세스
다음 명령을 사용하여 OpenShift Container Platform 클러스터를 설치하기 전에 모든 베어 메탈 노드의 전원을 끕니다.
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off다음 스크립트를 사용하여 이전 배포 시도에서 남아 있는 경우 이전 부트스트랩 리소스를 모두 제거합니다.
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done다음 명령을 사용하여 이전 설치에서 생성한 아티팩트를 삭제합니다.
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json다음 명령을 사용하여 OpenShift Container Platform 매니페스트를 다시 생성합니다.
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
3.5.15. 레지스트리 생성 문제
비 연결 레지스트리를 만들 때 레지스트리 미러링을 시도하는 경우 "User Not Authorized" 오류가 발생할 수 있습니다. 이 오류는 기존 pull-secret.txt 파일에 새 인증을 추가할 수 없는 경우 발생할 수 있습니다.
프로세스
인증이 성공했는지 확인합니다.
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO참고설치 이미지 미러링에 사용되는 변수의 출력 예:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'RELEASE_IMAGE및VERSION의 값은 OpenShift 설치 환경 설정 섹션의 OpenShift 설치 프로그램 가져오기 단계에서 설정됩니다.레지스트리를 미러링 후 연결이 끊긴 환경에서 이에 액세스할 수 있는지 확인합니다.
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}
3.5.16. 기타 문제
3.5.16.1. runtime network not ready 오류 해결
클러스터 배포 후 다음과 같은 오류가 발생할 수 있습니다.
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator 설치 프로그램이 생성한 특수 개체에 대응하여 네트워킹 구성 요소를 배포해야 합니다. 컨트롤 플레인 (마스터) 노드가 시작된 후 부트스트랩 컨트롤 플레인이 중지되기 전에 설치 프로세스 초기에 실행됩니다. 컨트롤 플레인 (마스터) 노드를 시작할 때 오랜 지연이나 apiserver 통신 문제와 같은 미묘한 설치 프로그램 문제가 표시될 수 있습니다.
프로세스
openshift-network-operator네임 스페이스에서 Pod를 검사합니다.$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149mprovisioner노드에서 네트워크 구성이 존재하는지 확인합니다.$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OVNKubernetes존재하지 않는 경우 설치 프로그램이 이를 생성하지 않았습니다. 설치 프로그램이 생성하지 않은 이유를 확인하려면 다음을 실행합니다.
$ openshift-install create manifestsnetwork-operator가 실행되고 있는지 확인합니다.$ kubectl -n openshift-network-operator get pods로그를 검색합니다.
$ kubectl -n openshift-network-operator logs -l "name=network-operator"3 개 이상의 컨트롤 플레인 (마스터) 노드가 있는 고가용성 클러스터에서 Operator는 리더의 선택을 실행하고 다른 Operator는 절전 모드로 전환합니다. 자세한 내용은 Troubleshooting을 참조하십시오.
클러스터를 배포한 후 다음과 같은 오류 메시지가 표시될 수 있습니다.
No disk found with matching rootDeviceHints
rootDeviceHints 오류 메시지와 일치하는 No disk found 를 해결하기 위해 임시 해결 방법은 rootDeviceHints 를 minSizeGigabytes: 300 로 변경하는 것입니다.
rootDeviceHints 설정을 변경한 후 CoreOS를 부팅한 다음 다음 명령을 사용하여 디스크 정보를 확인합니다.
$ udevadm info /dev/sda
DL360keygen 10 서버를 사용하는 경우 /dev/sda 장치 이름이 할당될 수 있는 SD 카드 슬롯이 있다는 점에 유의하십시오. 서버에 SD 카드가 없으면 충돌이 발생할 수 있습니다. 서버의 BIOS 설정에서 SD 카드 슬롯이 비활성화되어 있는지 확인합니다.
minSizeGigabytes 해결방법이 요구 사항을 충족하지 않는 경우 rootDeviceHints 를 /dev/sda 로 되돌려야 할 수 있습니다. 이러한 변경을 통해 ironic 이미지를 성공적으로 부팅할 수 있습니다.
이 문제를 해결하기 위한 대체 방법은 디스크의 직렬 ID를 사용하는 것입니다. 그러나 직렬 ID를 찾는 것은 어려울 수 있으며 구성 파일을 읽을 수 없게 만들 수 있습니다. 이 경로를 선택하는 경우 이전에 문서화한 명령을 사용하여 직렬 ID를 수집하여 구성에 통합해야 합니다.
3.5.16.3. DHCP를 통해 올바른 IPv6 주소를 얻지 못하는 클러스터 노드
클러스터 노드가 DHCP를 통해 올바른 IPv6 주소를 얻지 못하는 경우 다음을 확인합니다.
- 예약 된 IPv6 주소가 DHCP 범위 밖에 있는지 확인합니다.
DHCP 서버의 IP 주소 예약에서 예약에 올바른 DHCP 고유 식별자 (DUID)가 지정되어 있는지 확인합니다. 예를 들면 다음과 같습니다.
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- 경로 알림 (Route Announcement)이 제대로 작동하는지 확인합니다.
- DHCP 서버가 IP 주소 범위를 제공하는 데 필요한 인터페이스에서 수신하고 있는지 확인합니다.
3.5.16.4. DHCP를 통해 올바른 호스트 이름을 얻지 못하는 클러스터 노드
IPv6 배포 중에 클러스터 노드는 DHCP를 통해 호스트 이름을 검색해야 합니다. 경우에 따라 NetworkManager가 호스트 이름을 즉시 할당하지 않을 수 있습니다. 컨트롤 플레인 (마스터) 노드는 다음과 같은 오류를 보고할 수 있습니다.
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
이 오류는 클러스터 노드가 DHCP 서버에서 호스트 이름을 받지 않고 부팅되었을 가능성이 있음을 나타냅니다. 이로 인해 kubelet이 localhost.localdomain 호스트 이름으로 부팅됩니다. 이 문제를 해결하려면 노드가 호스트 이름을 업데이트하도록 합니다.
프로세스
hostname을 검색합니다.[core@master-X ~]$ hostname호스트 이름이
localhost인 경우 다음 단계를 진행합니다.참고여기서
X는 컨트롤 플레인 노드 번호입니다.클러스터 노드가 DHCP 임대를 갱신하도록 합니다.
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"<bare-metal-nic>을baremetal네트워크에 해당하는 유선 연결로 바꿉니다.hostname다시 확인하십시오.[core@master-X ~]$ hostname호스트 이름이 여전히
localhost.localdomain인 경우NetworkManager를 다시 시작합니다.[core@master-X ~]$ sudo systemctl restart NetworkManager-
호스트 이름이 여전히
localhost.localdomain인 경우 몇 분 기다린 후 다시 확인하십시오. 호스트 이름이localhost.localdomain으로 남아 있으면 이전 단계를 반복합니다. nodeip-configuration서비스를 다시 시작합니다.[core@master-X ~]$ sudo systemctl restart nodeip-configuration.service이 서비스는 올바른 호스트 이름 참조를 사용하여
kubelet서비스를 재구성합니다.이전 단계에서 kubelet이 변경되었으므로 단위 파일 정의를 다시 로드하십시오.
[core@master-X ~]$ sudo systemctl daemon-reloadkubelet서비스를 다시 시작합니다.[core@master-X ~]$ sudo systemctl restart kubelet.servicekubelet이 올바른 호스트 이름으로 부팅되었는지 확인합니다.[core@master-X ~]$ sudo journalctl -fu kubelet.service
클러스터 가동 후 (예: 클러스터를 다시 시작) 클러스터 노드가 DHCP를 통해 올바른 호스트 이름을 얻지 못하는 경우 클러스터에 csr은 보류 처리됩니다. csr을 승인 하지 마십시오. 그렇지 않으면 다른 문제가 발생할 수 있습니다.
CSR 처리
클러스터에서 CSR을 가져옵니다.
$ oc get csr보류중인
CSR에Subject Name: localhost.localdomain이 포함되어 있는지 확인합니다.$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -textSubject Name: localhost.localdomain이 포함된 모든csr을 제거합니다.$ oc delete csr <wrong_csr>
3.5.16.5. 루트가 엔드 포인트에 도달하지 않음
설치 프로세스 중에 VRRP (Virtual Router Redundancy Protocol) 충돌이 발생할 수 있습니다. 특정 클러스터 이름을 사용하여 클러스터 배포의 일부였던 이전에 사용된 OpenShift Container Platform 노드가 여전히 실행 중이지만 동일한 클러스터 이름을 사용하는 현재 OpenShift Container Platform 클러스터 배포의 일부가 아닌 경우 이러한 충돌이 발생할 수 있습니다. 예를 들어 클러스터는 클러스터 이름 openshift를 사용하여 3 개의 컨트롤 플레인 (마스터) 노드와 3 개의 작업자 노드를 배포합니다. 나중에 다른 설치에서 동일한 클러스터 이름 openshift를 사용하지만 이 재배포에서는 3 개의 컨트롤 플레인 (마스터) 노드 만 설치하여 이전 배포의 작업자 노드 3 개를 ON 상태로 유지합니다. 이로 인해 VRID (Virtual Router Identifier) 충돌 및 VRRP 충돌이 발생할 수 있습니다.
루트를 가져옵니다.
$ oc get route oauth-openshift서비스 엔드 포인트를 확인합니다.
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59m컨트롤 플레인 (마스터) 노드에서 서비스에 연결을 시도합니다.
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403provisioner노드에서authentication-operator오류를 식별합니다.$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
해결책
- 모든 배포의 클러스터 이름이 고유한지 확인하여 충돌이 발생하지 않도록합니다.
- 동일한 클러스터 이름을 사용하는 클러스터 배포의 일부가 아닌 잘못된 노드 모두를 종료합니다. 그렇지 않으면 OpenShift Container Platform 클러스터의 인증 pod가 정상적으로 시작되지 않을 수 있습니다.
3.5.16.6. Firstboot 동안 Ignition 실패
Firstboot 중에 Ignition 설정이 실패할 수 있습니다.
프로세스
Ignition 설정이 실패한 노드에 연결합니다.
Failed Units: 1 machine-config-daemon-firstboot.servicemachine-config-daemon-firstboot서비스를 다시 시작합니다.[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
3.5.16.7. NTP가 동기화되지 않음
OpenShift Container Platform 클러스터를 배포하려면 클러스터 노드 간의 NTP 시계가 동기화되어야합니다. 동기화된 시계가 없으면 시간 차이가 2 초보다 크면 클럭 드리프트로 인해 배포 실패할 수 있습니다.
프로세스
클러스터 노드의
AGE차이를 확인하십시오. 예를 들면 다음과 같습니다.$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.32.3 master-1.cloud.example.com Ready master 135m v1.32.3 master-2.cloud.example.com Ready master 145m v1.32.3 worker-2.cloud.example.com Ready worker 100m v1.32.3클럭 드리프트로 인한 일관성없는 시간 지연을 확인하십시오. 예를 들면 다음과 같습니다.
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out_of_band_ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
기존 클러스터에서 클럭 드리프트 처리
노드에 전송할
chrony.conf파일의 내용을 포함하여 Butane 구성 파일을 만듭니다. 다음 예제에서99-master-chrony.bu를 생성하여 파일을 컨트롤 플레인 노드에 추가합니다. 작업자 노드의 파일을 변경하거나 작업자 역할에 대해 이 절차를 반복할 수 있습니다.참고Butane에 대한 자세한 내용은 “Butane 을 사용하여 머신 구성 생성”을 참조하십시오.
variant: openshift version: 4.19.0 metadata: name: 99-master-chrony labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | server <NTP_server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
<NTP-server>를 NTP 서버의 IP 주소로 바꿉니다.
Butane을 사용하여 노드에 전달할 구성이 포함된
MachineConfig파일99-master-chrony.yaml을 생성합니다.$ butane 99-master-chrony.bu -o 99-master-chrony.yamlMachineConfig오브젝트를 적용합니다.$ oc apply -f 99-master-chrony.yamlSystem clock synchronized값이 yes 인지 확인하십시오.$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: no배포 전에 클럭 동기화를 설정하려면 매니페스트 파일을 생성하고이 파일을
openshift디렉터리에 추가합니다. 예를 들면 다음과 같습니다.$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yaml그런 다음 계속해서 클러스터를 만듭니다.
3.5.17. 설치 확인
설치 후 설치 프로그램이 노드와 Pod를 성공적으로 배포했는지 확인합니다.
프로세스
OpenShift Container Platform 클러스터 노드가 적절하게 설치되면
STATUS열에Ready상태가 표시됩니다.$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.32.3 master-1.example.com Ready master,worker 4h v1.32.3 master-2.example.com Ready master,worker 4h v1.32.3설치 프로그램이 모든 pod를 성공적으로 배포했는지 확인합니다. 다음 명령은 아직 실행 중이거나 출력의 일부로 완료된 모든 pod를 제거합니다.
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete