이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 12. Java Persistence API (JPA)
12.1. About Java Persistence API (JPA)
The Java Persistence API (JPA) is a Java specification for accessing, persisting, and managing data between Java objects or classes and a relational database. The JPA specification recognizes the interest and the success of the transparent object or relational mapping paradigm. It standardizes the basic APIs and the metadata needed for any object or relational persistence mechanism.
JPA itself is just a specification, not a product; it cannot perform persistence or anything else by itself. JPA is just a set of interfaces, and requires an implementation.
12.2. About Hibernate Core
Hibernate Core is an object-relational mapping framework for the Java language. It provides a framework for mapping an object-oriented domain model to a relational database, allowing applications to avoid direct interaction with the database. Hibernate solves object-relational impedance mismatch problems by replacing direct, persistent database accesses with high-level object handling functions.
12.3. Hibernate EntityManager
Hibernate EntityManager implements the programming interfaces and lifecycle rules as defined by the Java Persistence 2.1 specification. Together with Hibernate Annotations, this wrapper implements a complete (and standalone) JPA persistence solution on top of the mature Hibernate Core. You may use a combination of all three together, annotations without JPA programming interfaces and lifecycle, or even pure native Hibernate Core, depending on the business and technical needs of your project. You can at all times fall back to Hibernate native APIs, or if required, even to native JDBC and SQL. It provides JBoss EAP with a complete Java Persistence solution.
JBoss EAP is 100% compliant with the Java Persistence 2.1 specification. Hibernate also provides additional features to the specification. To get started with JPA and JBoss EAP, see the bean-validation, greeter, and kitchensink quickstarts that ship with JBoss EAP. For information about how to download and run the quickstarts, see Using the Quickstart Examples.
Persistence in JPA is available in containers like EJB 3 or the more modern CDI, Java Context and Dependency Injection, as well as in standalone Java SE applications that execute outside of a particular container. The following programming interfaces and artifacts are available in both environments.
- EntityManagerFactory
- An entity manager factory provides entity manager instances, all instances are configured to connect to the same database, to use the same default settings as defined by the particular implementation, etc. You can prepare several entity manager factories to access several data stores. This interface is similar to the SessionFactory in native Hibernate.
- EntityManager
- The EntityManager API is used to access a database in a particular unit of work. It is used to create and remove persistent entity instances, to find entities by their primary key identity, and to query over all entities. This interface is similar to the Session in Hibernate.
- Persistence context
- A persistence context is a set of entity instances in which for any persistent entity identity there is a unique entity instance. Within the persistence context, the entity instances and their lifecycle is managed by a particular entity manager. The scope of this context can either be the transaction, or an extended unit of work.
- Persistence unit
- The set of entity types that can be managed by a given entity manager is defined by a persistence unit. A persistence unit defines the set of all classes that are related or grouped by the application, and which must be collocated in their mapping to a single data store.
- Container-managed entity manager
- An entity manager whose lifecycle is managed by the container.
- Application-managed entity manager
- An entity manager whose lifecycle is managed by the application.
- JTA entity manager
- Entity manager involved in a JTA transaction.
- Resource-local entity manager
- Entity manager using a resource transaction (not a JTA transaction).
12.4. Create a Simple JPA Application
Follow the procedure below to create a simple JPA application in Red Hat Developer studio.
Create a JPA project in JBoss Developer Studio.
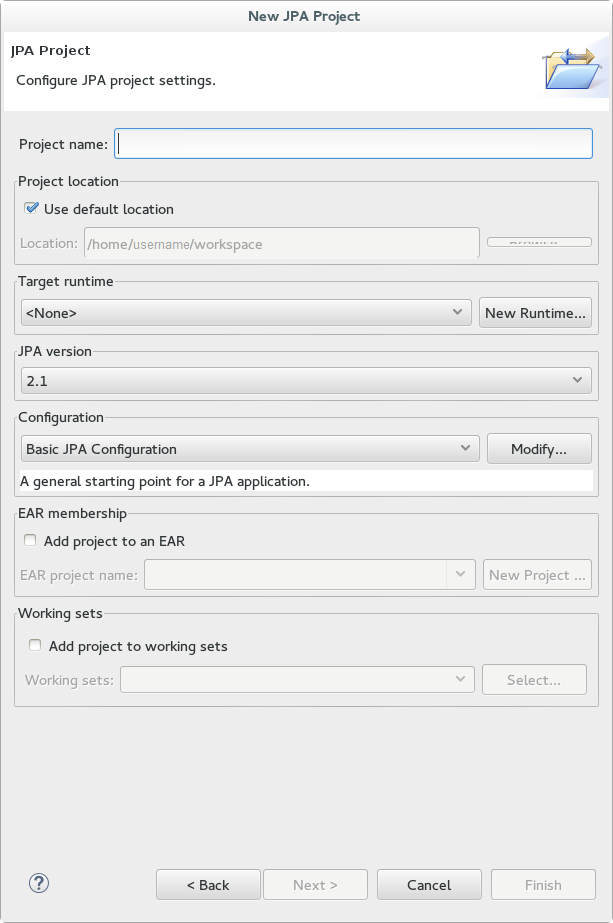
In Red Hat JBoss Developer Studio, click File-→ New -→ Project. Find JPA in the list, expand it, and select JPA Project. You are presented with the following dialog.
Figure 12.1. New JPA Project Dialog
- Enter a Project name.
- Select a Target runtime. If no target runtime is available, follow these instructions to define a new server and runtime: Add the JBoss EAP Server Using Define New Server .
- Under JPA version, ensure 2.1 is selected.
- Under Configuration, choose Basic JPA Configuration.
- Click Finish.
- If prompted, choose whether you wish to associate this type of project with the JPA perspective window.
Create and configure a new persistence settings file.
- Open an EJB 3.x project in Red Hat JBoss Developer Studio.
- Right click the project root directory in the Project Explorer panel.
-
Select New
Other…. - Select XML File from the XML folder and click Next.
-
Select the
ejbModule/META-INF/folder as the parent directory. -
Name the file
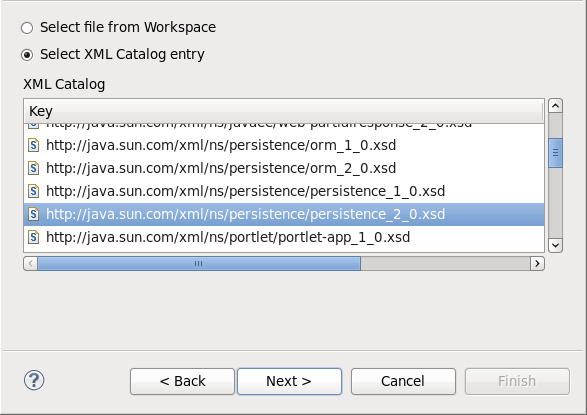
persistence.xmland click Next. - Select Create XML file from an XML schema file and click Next.
Select http://java.sun.com/xml/ns/persistence/persistence_2.0.xsd from the Select XML Catalog entry list and click Next.
Figure 12.2. Persistence XML Schema
Click Finish to create the file. The
persistence.xmlhas been created in theMETA-INF/folder and is ready to be configured.Example: Persistence Settings File
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.5. Hibernate Configuration
The configuration for entity managers both inside an application server and in a standalone application reside in a persistence archive. A persistence archive is a JAR file which must define a persistence.xml file that resides in the META-INF/ folder.
You can connect to the database using the persistence.xml file. There are two ways of doing this:
Specifying a data source which is configured in the
datasourcessubsystem in JBoss EAP.The
jta-data-sourcepoints to the JNDI name of the data source this persistence unit maps to. Thejava:jboss/datasources/ExampleDShere points to theH2 DBembedded in the JBoss EAP.Example of
object-relational-mappingin thepersistence.xmlFileCopy to Clipboard Copied! Toggle word wrap Toggle overflow Explicitly configuring the
persistence.xmlfile by specifying the connection properties.Example of Specifying Connection Properties in the
persistence.xmlfile<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver"/> <property name="javax.persistence.jdbc.user" value="sa"/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:."/>
<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver"/> <property name="javax.persistence.jdbc.user" value="sa"/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:."/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the complete list of connection properties, see Connection Properties Configurable in the
persistence.xmlFile.
There are a number of properties that control the behavior of Hibernate at runtime. All are optional and have reasonable default values. These Hibernate properties are all used in the persistence.xml file. For the complete list of all configurable Hibernate properties, see Hibernate Properties in the appendix of this guide.
12.6. Second-Level Caches
12.6.1. About Second-Level Caches
A second-level cache is a local data store that holds information persisted outside the application session. The cache is managed by the persistence provider, improving run-time by keeping the data separate from the application.
JBoss EAP supports caching for the following purposes:
- Web Session Clustering
- Stateful Session Bean Clustering
- SSO Clustering
- Hibernate Second Level Cache
Each cache container defines a "repl" and a "dist" cache. These caches should not be used directly by user applications.
12.6.2. Configure a Second-level Cache for Hibernate
The configuration of Infinispan to act as the second-level cache for Hibernate can be done in two ways:
-
It is recommended to configure the second-level cache through JPA applications, using the
persistence.xmlfile. -
Alternatively, you can configure the second-level cache through Hibernate native applications, using the
hibernate.cfg.xmlfile.
Configuring a Second-level Cache for Hibernate Using JPA Applications
- See Create a Simple JPA Application for details on how to create a Hibernate configuration file in Red Hat JBoss Developer Studio.
Add the following to the
persistence.xmlfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteThe following can be value of
$SHARED_CACHE_MODE:- ALL - All entities should be considered cacheable.
- ENABLE_SELECTIVE - Only entities marked as cacheable should be considered cacheable.
- DISABLE_SELECTIVE - All entities except the ones explicitly marked as not cacheable, should be considered cacheable.
Configuring a Second-level Cache for Hibernate Using Hibernate Native Applications
-
Create the
hibernate.cfg.xmlfile in the deployment’s class path. Add the following XML to the
hibernate.cfg.xmlfile. The XML needs to be within the<session-factory>tag:<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property> <property name="hibernate.cache.region.factory_class">org.jboss.as.jpa.hibernate5.infinispan.InfinispanRegionFactory</property>
<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property> <property name="hibernate.cache.region.factory_class">org.jboss.as.jpa.hibernate5.infinispan.InfinispanRegionFactory</property>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.7. Hibernate Annotations
The org.hibernate.annotations package contains some annotations which are offered by Hibernate, on top of the standard JPA annotations.
| Annotation | Description |
|---|---|
|
| Arbitrary SQL check constraints which can be defined at the class, property or collection level. |
|
| Mark an Entity or a Collection as immutable. No annotation means the element is mutable. An immutable entity may not be updated by the application. Updates to an immutable entity will be ignored, but no exception is thrown.
|
| Annotation | Description |
|---|---|
|
| Add caching strategy to a root entity or a collection. |
| Annotation | Description |
|---|---|
|
| Defines the type of key of a persistent map. |
|
|
Defines a |
|
| Order a collection using SQL ordering (not HQL ordering). |
|
|
Strategy to use on collections, arrays and on joined subclasses delete. |
|
| Specify a custom persister. |
|
| Collection sort (Java level sorting). |
|
| Where clause to add to the element Entity or target entity of a collection. The clause is written in SQL. |
|
| Where clause to add to the collection join table. The clause is written in SQL. |
| Annotation | Description |
|---|---|
|
|
Overwrites Hibernate default |
|
|
Overwrites the Hibernate default |
|
|
Overwrites the Hibernate default |
|
|
Overwrites the Hibernate default |
|
|
Overwrites the Hibernate default |
|
| Maps an immutable and read-only entity to a given SQL subselect expression. |
|
|
Ensures that auto-flush happens correctly and that queries against the derived entity do not return stale data. Mostly used with |
| Annotation | Description |
|---|---|
|
| Apply a cascade strategy on an association. |
|
|
Adds additional metadata that may be needed beyond what is defined in the standard
|
|
| Used to define the type of polymorphism Hibernate will apply to entity hierarchies. |
|
| Lazy and proxy configuration of a particular class. |
|
| Complementary information to a table either primary or secondary. |
|
| Plural annotation of Table. |
|
| Defines an explicit target, avoiding reflection and generics resolving. |
|
| Defines a tuplizer for an entity or a component. |
|
| Defines a set of tuplizers for an entity or a component. |
| Annotation | Description |
|---|---|
|
| Batch size for SQL loading. |
|
| Defines the fetching strategy profile. |
|
|
Plural annotation for |
| Annotation | Description |
|---|---|
|
| Adds filters to an entity or a target entity of a collection. |
|
| Filter definition. |
|
| Array of filter definitions. |
|
| Adds filters to a join table collection. |
|
|
Adds multiple |
|
|
Adds multiple |
|
| A parameter definition. |
| Annotation | Description |
|---|---|
|
| This annotated property is generated by the database. |
|
| Generator annotation describing any kind of Hibernate generator in a detyped manner. |
|
| Array of generic generator definitions. |
|
| Specifies that a property is part of the natural id of the entity. |
|
| Key/value pattern. |
|
|
Support for |
| Annotation | Description |
|---|---|
|
| Discriminator formula to be placed at the root entity. |
|
| Optional annotation to express Hibernate specific discriminator properties. |
|
| Maps a given discriminator value to the corresponding entity type. |
| Annotation | Description |
|---|---|
|
|
Extends |
|
|
Extends |
|
|
Extends |
|
|
Extends |
| Annotation | Description |
|---|---|
|
| Property Access type. |
|
| Support an array of columns. Useful for component user type mappings. |
|
| Custom SQL expression used to read the value from and write a value to a column. Use for direct object loading/saving as well as queries. The write expression must contain exactly one '?' placeholder for the value. |
|
|
Plural annotation for |
| Annotation | Description |
|---|---|
|
|
To be used as a replacement for |
|
| Defines a database index. |
|
|
To be used as a replacement for |
|
| Reference the property as a pointer back to the owner (generally the owning entity). |
|
| Hibernate Type. |
|
| Hibernate Type definition. |
|
| Hibernate Type definition array. |
| Annotation | Description |
|---|---|
|
| Defines a ToOne association pointing to several entity types. Matching the according entity type is done through a metadata discriminator column. This kind of mapping should be only marginal. |
|
|
Defines |
|
|
Defines |
|
| Defines the fetching strategy used for the given association. |
|
| Defines the lazy status of a collection. |
|
|
Defines the lazy status of a ToOne association (i.e. |
|
| Action to do when an element is not found on an association. |
| Annotation | Description |
|---|---|
|
| Whether or not a change of the annotated property will trigger an entity version increment. If the annotation is not present, the property is involved in the optimistic lock strategy (default). |
|
| Used to define the style of optimistic locking to be applied to an entity. In a hierarchy, only valid on the root entity. |
|
| Optional annotation in conjunction with Version and timestamp version properties. The annotation value decides where the timestamp is generated. |
12.8. Hibernate Query Language
12.8.1. About Hibernate Query Language
Introduction to JPQL
The Java Persistence Query Language (JPQL) is a platform-independent object-oriented query language defined as part of the Java Persistence API (JPA) specification. JPQL is used to make queries against entities stored in a relational database. It is heavily inspired by SQL, and its queries resemble SQL queries in syntax, but operate against JPA entity objects rather than directly with database tables.
Introduction to HQL
The Hibernate Query Language (HQL) is a powerful query language, similar in appearance to SQL. Compared with SQL, however, HQL is fully object-oriented and understands notions like inheritance, polymorphism and association.
HQL is a superset of JPQL. An HQL query is not always a valid JPQL query, but a JPQL query is always a valid HQL query.
Both HQL and JPQL are non-type-safe ways to perform query operations. Criteria queries offer a type-safe approach to querying.
12.8.2. About HQL Statements
Both HQL and JPQL allow SELECT, UPDATE, and DELETE statements. HQL additionally allows INSERT statements, in a form similar to a SQL INSERT-SELECT.
Care should be taken when executing bulk update or delete operations because they may result in inconsistencies between the database and the entities in the active persistence context. In general, bulk update and delete operations should only be performed within a transaction in a new persistence context or before fetching or accessing entities whose state might be affected by such operations.
| Statement | Description |
|---|---|
|
| The BNF for SELECT statements in HQL is: |
|
| The BNF for UPDATE statement in HQL is the same as it is in JPQL |
|
| The BNF for DELETE statements in HQL is the same as it is in JPQL |
12.8.3. About the INSERT Statement
HQL adds the ability to define INSERT statements. There is no JPQL equivalent to this. The BNF for an HQL INSERT statement is:
insert_statement ::= insert_clause select_statement insert_clause ::= INSERT INTO entity_name (attribute_list) attribute_list ::= state_field[, state_field ]*
insert_statement ::= insert_clause select_statement
insert_clause ::= INSERT INTO entity_name (attribute_list)
attribute_list ::= state_field[, state_field ]*
The attribute_list is analogous to the column specification in the SQL INSERT statement. For entities involved in mapped inheritance, only attributes directly defined on the named entity can be used in the attribute_list. Superclass properties are not allowed and subclass properties do not make sense. In other words, INSERT statements are inherently non-polymorphic.
The select_statement can be any valid HQL select query, with the caveat that the return types must match the types expected by the insert. Currently, this is checked during query compilation rather than allowing the check to relegate to the database. This can cause problems with Hibernate Types that are equivalent as opposed to equal. For example, this might cause mismatch issues between an attribute mapped as an org.hibernate.type.DateType and an attribute defined as a org.hibernate.type.TimestampType, even though the database might not make a distinction or might be able to handle the conversion.
For the id attribute, the insert statement gives you two options. You can either explicitly specify the id property in the attribute_list, in which case its value is taken from the corresponding select expression, or omit it from the attribute_list in which case a generated value is used. This latter option is only available when using id generators that operate "in the database"; attempting to use this option with any "in memory" type generators will cause an exception during parsing.
For optimistic locking attributes, the insert statement again gives you two options. You can either specify the attribute in the attribute_list in which case its value is taken from the corresponding select expressions, or omit it from the attribute_list in which case the seed value defined by the corresponding org.hibernate.type.VersionType is used.
Example. INSERT Query Statements
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ..."; int createdEntities = s.createQuery( hqlInsert ).executeUpdate();
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ...";
int createdEntities = s.createQuery( hqlInsert ).executeUpdate();12.8.4. About the FROM Clause
The FROM clause is responsible defining the scope of object model types available to the rest of the query. It also is responsible for defining all the "identification variables" available to the rest of the query.
12.8.5. About the WITH Clause
HQL defines a WITH clause to qualify the join conditions. This is specific to HQL; JPQL does not define this feature.
Example. With Clause
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
The important distinction is that in the generated SQL the conditions of the with clause are made part of the on clause in the generated SQL as opposed to the other queries in this section where the HQL/JPQL conditions are made part of the where clause in the generated SQL. The distinction in this specific example is probably not that significant. The with clause is sometimes necessary in more complicated queries.
Explicit joins may reference association or component/embedded attributes. In the case of component/embedded attributes, the join is logical and does not correlate to a physical (SQL) join.
12.8.6. About HQL Ordering
The results of the query can also be ordered. The ORDER BY clause is used to specify the selected values to be used to order the result. The types of expressions considered valid as part of the order-by clause include:
- state fields
- component/embeddable attributes
- scalar expressions such as arithmetic operations, functions, etc.
- identification variable declared in the select clause for any of the previous expression types
HQL does not mandate that all values referenced in the order-by clause must be named in the select clause, but it is required by JPQL. Applications desiring database portability should be aware that not all databases support referencing values in the order-by clause that are not referenced in the select clause.
Individual expressions in the order-by can be qualified with either ASC (ascending) or DESC (descending) to indicate the desired ordering direction.
Example. Order-by Examples
12.8.7. About Bulk Update, Insert and Delete
Hibernate allows the use of Data Manipulation Language (DML) to bulk insert, update and delete data directly in the mapped database through the Hibernate Query Language.
Using DML may violate the object/relational mapping and may affect object state. Object state stays in memory and by using DML, the state of an in-memory object is not affected depending on the operation that is performed on the underlying database. In-memory data must be used with care if DML is used.
The pseudo-syntax for UPDATE and DELETE statements is:
( UPDATE | DELETE ) FROM? EntityName (WHERE where_conditions)?.
The FROM keyword and the WHERE Clause are optional.
The result of execution of a UPDATE or DELETE statement is the number of rows that are actually affected (updated or deleted).
Example. Bulk Update Statement
Example. Bulk Delete Statement
The int value returned by the Query.executeUpdate() method indicates the number of entities within the database that were affected by the operation.
Internally, the database might use multiple SQL statements to execute the operation in response to a DML Update or Delete request. This might be because of relationships that exist between tables and the join tables that may need to be updated or deleted.
For example, issuing a delete statement (as in the example above) may actually result in deletes being executed against not just the Company table for companies that are named with oldName, but also against joined tables. Thus, a Company table in a BiDirectional ManyToMany relationship with an Employee table, would lose rows from the corresponding join table Company_Employee as a result of the successful execution of the previous example.
The int deletedEntries value above will contain a count of all the rows affected due to this operation, including the rows in the join tables.
The pseudo-syntax for INSERT statements is: INSERT INTO EntityName properties_list select_statement.
Only the INSERT INTO … SELECT … form is supported; not the INSERT INTO … VALUES … form.
Example. Bulk Insert Statement
If you do not supply the value for the id attribute via the SELECT statement, an identifier is generated for you, as long as the underlying database supports auto-generated keys. The return value of this bulk insert operation is the number of entries actually created in the database.
12.8.8. About Collection Member References
References to collection-valued associations actually refer to the values of that collection.
Example. Collection References
In the example, the identification variable o actually refers to the object model type Order which is the type of the elements of the Customer#orders association.
The example also shows the alternate syntax for specifying collection association joins using the IN syntax. Both forms are equivalent. Which form an application chooses to use is simply a matter of taste.
12.8.9. About Qualified Path Expressions
It was previously stated that collection-valued associations actually refer to the values of that collection. Based on the type of collection, there are also available a set of explicit qualification expressions.
| Expression | Description |
|---|---|
|
| Refers to the collection value. Same as not specifying a qualifier. Useful to explicitly show intent. Valid for any type of collection-valued reference. |
|
|
According to HQL rules, this is valid for both Maps and Lists which specify a javax.persistence.OrderColumn annotation to refer to the Map key or the List position (aka the OrderColumn value). JPQL however, reserves this for use in the List case and adds |
|
| Valid only for Maps. Refers to the map’s key. If the key is itself an entity, can be further navigated. |
|
|
Only valid only for Maps. Refers to the Map’s logical java.util.Map.Entry tuple (the combination of its key and value). |
Example. Qualified Collection References
12.8.10. About Scalar Functions
HQL defines some standard functions that are available regardless of the underlying database in use. HQL can also understand additional functions defined by the dialect and the application.
12.8.11. About HQL Standardized Functions
The following functions are available in HQL regardless of the underlying database in use.
| Function | Description |
|---|---|
|
| Returns the length of binary data. |
|
| Performs a SQL cast. The cast target should name the Hibernate mapping type to use. |
|
| Performs a SQL extraction on datetime values. An extraction extracts parts of the datetime (the year, for example). See the abbreviated forms below. |
|
| Abbreviated extract form for extracting the second. |
|
| Abbreviated extract form for extracting the minute. |
|
| Abbreviated extract form for extracting the hour. |
|
| Abbreviated extract form for extracting the day. |
|
| Abbreviated extract form for extracting the month. |
|
| Abbreviated extract form for extracting the year. |
|
| Abbreviated form for casting a value as character data. |
Application developers can also supply their own set of functions. This would usually represent either custom SQL functions or aliases for snippets of SQL. Such function declarations are made by using the addSqlFunction method of org.hibernate.cfg.Configuration
12.8.12. About the Concatenation Operation
HQL defines a concatenation operator in addition to supporting the concatenation (CONCAT) function. This is not defined by JPQL, so portable applications should avoid using it. The concatenation operator is taken from the SQL concatenation operator - ||.
Example. Concatenation Operation Example
select 'Mr. ' || c.name.first || ' ' || c.name.last from Customer c where c.gender = Gender.MALE
select 'Mr. ' || c.name.first || ' ' || c.name.last
from Customer c
where c.gender = Gender.MALE12.8.13. About Dynamic Instantiation
There is a particular expression type that is only valid in the select clause. Hibernate calls this "dynamic instantiation". JPQL supports some of this feature and calls it a "constructor expression".
Example. Dynamic Instantiation Example - Constructor
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offspr
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offsprSo rather than dealing with the Object[] here we are wrapping the values in a type-safe java object that will be returned as the results of the query. The class reference must be fully qualified and it must have a matching constructor.
The class here need not be mapped. If it does represent an entity, the resulting instances are returned in the NEW state (not managed!).
This is the part JPQL supports as well. HQL supports additional "dynamic instantiation" features. First, the query can specify to return a List rather than an Object[] for scalar results:
Example. Dynamic Instantiation Example - List
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offsprThe results from this query will be a List<List> as opposed to a List<Object[]>
HQL also supports wrapping the scalar results in a Map.
Example. Dynamic Instantiation Example - Map
The results from this query will be a List<Map<String,Object>> as opposed to a List<Object[]>. The keys of the map are defined by the aliases given to the select expressions.
12.8.14. About HQL Predicates
Predicates form the basis of the where clause, the having clause and searched case expressions. They are expressions which resolve to a truth value, generally TRUE or FALSE, although boolean comparisons involving NULL values generally resolve to UNKNOWN.
HQL Predicates
Null Predicate
Check a value for null. Can be applied to basic attribute references, entity references and parameters. HQL additionally allows it to be applied to component/embeddable types.
Null Check Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Like Predicate
Performs a like comparison on string values. The syntax is:
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]Copy to Clipboard Copied! Toggle word wrap Toggle overflow The semantics follow that of the SQL like expression. The
pattern_valueis the pattern to attempt to match in thestring_expression. Just like SQL,pattern_valuecan use_(underscore) and%(percent) as wildcards. The meanings are the same. The_matches any single character. The%matches any number of characters.The optional
escape_characteris used to specify an escape character used to escape the special meaning of_and%in thepattern_value. This is useful when needing to search on patterns including either_or%.Like Predicate Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Between Predicate
Analogous to the SQL
BETWEENexpression. Perform an evaluation that a value is within the range of 2 other values. All the operands should have comparable types.Between Predicate Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow IN Predicate
The
INpredicate performs a check that a particular value is in a list of values. Its syntax is:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The types of the
single_valued_expressionand the individual values in thesingle_valued_listmust be consistent. JPQL limits the valid types here to string, numeric, date, time, timestamp, and enum types. In JPQL,single_valued_expressioncan only refer to:- "state fields", which is its term for simple attributes. Specifically this excludes association and component/embedded attributes.
entity type expressions.
In HQL,
single_valued_expressioncan refer to a far more broad set of expression types. Single-valued association are allowed. So are component/embedded attributes, although that feature depends on the level of support for tuple or "row value constructor syntax" in the underlying database. Additionally, HQL does not limit the value type in any way, though application developers should be aware that different types may incur limited support based on the underlying database vendor. This is largely the reason for the JPQL limitations.The list of values can come from a number of different sources. In the
constructor_expressionandcollection_valued_input_parameter, the list of values must not be empty; it must contain at least one value.In Predicate Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.8.15. About Relational Comparisons
Comparisons involve one of the comparison operators - =, >, >=, <, ⇐, <>. HQL also defines != as a comparison operator synonymous with <>. The operands should be of the same type.
Example. Relational Comparison Examples
Comparisons can also involve subquery qualifiers - ALL, ANY, SOME. SOME and ANY are synonymous.
The ALL qualifier resolves to true if the comparison is true for all of the values in the result of the subquery. It resolves to false if the subquery result is empty.
Example. ALL Subquery Comparison Qualifier Example
The ANY/SOME qualifier resolves to true if the comparison is true for some of (at least one of) the values in the result of the subquery. It resolves to false if the subquery result is empty.
12.9. Hibernate Services
12.9.1. About Hibernate Services
Services are classes that provide Hibernate with pluggable implementations of various types of functionality. Specifically they are implementations of certain service contract interfaces. The interface is known as the service role; the implementation class is known as the service implementation. Generally speaking, users can plug in alternate implementations of all standard service roles (overriding); they can also define additional services beyond the base set of service roles (extending).
12.9.2. About Service Contracts
The basic requirement for a service is to implement the marker interface org.hibernate.service.Service. Hibernate uses this internally for some basic type safety.
Optionally, the service can also implement the org.hibernate.service.spi.Startable and org.hibernate.service.spi.Stoppable interfaces to receive notifications of being started and stopped. Another optional service contract is org.hibernate.service.spi.Manageable which marks the service as manageable in JMX provided the JMX integration is enabled.
12.9.3. Types of Service Dependencies
Services are allowed to declare dependencies on other services using either of 2 approaches:
- @org.hibernate.service.spi.InjectService
-
Any method on the service implementation class accepting a single parameter and annotated with
@InjectServiceis considered requesting injection of another service. -
By default the type of the method parameter is expected to be the service role to be injected. If the parameter type is different than the service role, the
serviceRoleattribute of theInjectServiceshould be used to explicitly name the role. -
By default injected services are considered required, that is the start up will fail if a named dependent service is missing. If the service to be injected is optional, the required attribute of the
InjectServiceshould be declared asfalse(default istrue). - org.hibernate.service.spi.ServiceRegistryAwareService
-
The second approach is a pull approach where the service implements the optional service interface
org.hibernate.service.spi.ServiceRegistryAwareServicewhich declares a singleinjectServicesmethod. -
During startup, Hibernate will inject the
org.hibernate.service.ServiceRegistryitself into services which implement this interface. The service can then use theServiceRegistryreference to locate any additional services it needs.
12.9.4. The Service Registry
12.9.4.1. About the ServiceRegistry
The central service API, aside from the services themselves, is the org.hibernate.service.ServiceRegistry interface. The main purpose of a service registry is to hold, manage and provide access to services.
Service registries are hierarchical. Services in one registry can depend on and utilize services in that same registry as well as any parent registries.
Use org.hibernate.service.ServiceRegistryBuilder to build a org.hibernate.service.ServiceRegistry instance.
Example Using ServiceRegistryBuilder to Create a ServiceRegistry
ServiceRegistryBuilder registryBuilder =
new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
ServiceRegistryBuilder registryBuilder =
new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();12.9.5. Custom Services
12.9.5.1. About Custom Services
Once a org.hibernate.service.ServiceRegistry is built it is considered immutable; the services themselves might accept reconfiguration, but immutability here means adding or replacing services. So another role provided by the org.hibernate.service.ServiceRegistryBuilder is to allow tweaking of the services that will be contained in the org.hibernate.service.ServiceRegistry generated from it.
There are two means to tell a org.hibernate.service.ServiceRegistryBuilder about custom services.
-
Implement a
org.hibernate.service.spi.BasicServiceInitiatorclass to control on-demand construction of the service class and add it to theorg.hibernate.service.ServiceRegistryBuilderusing itsaddInitiatormethod. -
Just instantiate the service class and add it to the
org.hibernate.service.ServiceRegistryBuilderusing itsaddServicemethod.
Either approach is valid for extending a registry, such as adding new service roles, and overriding services, such as replacing service implementations.
Example. Use ServiceRegistryBuilder to Replace an Existing Service with a Custom Service
12.9.6. The Boot-Strap Registry
12.9.6.1. About the Boot-strap Registry
The boot-strap registry holds services that absolutely have to be available for most things to work. The main service here is the ClassLoaderService which is a perfect example. Even resolving configuration files needs access to class loading services i.e. resource look ups. This is the root registry, no parent, in normal use.
Instances of boot-strap registries are built using the org.hibernate.service.BootstrapServiceRegistryBuilder class.
Using BootstrapServiceRegistryBuilder
Example. Using BootstrapServiceRegistryBuilder
12.9.6.2. BootstrapRegistry Services
org.hibernate.service.classloading.spi.ClassLoaderServiceHibernate needs to interact with class loaders. However, the manner in which Hibernate, or any library, should interact with class loaders varies based on the runtime environment that is hosting the application. Application servers, OSGi containers, and other modular class loading systems impose very specific class loading requirements. This service provides Hibernate an abstraction from this environmental complexity. And just as importantly, it does so in a single-swappable-component manner.
In terms of interacting with a class loader, Hibernate needs the following capabilities:
- the ability to locate application classes
- the ability to locate integration classes
- the ability to locate resources, such as properties files and XML files
the ability to load
java.util.ServiceLoaderNoteCurrently, the ability to load application classes and the ability to load integration classes are combined into a single load class capability on the service. That may change in a later release.
org.hibernate.integrator.spi.IntegratorServiceApplications, add-ons and other modules need to integrate with Hibernate. The previous approach required a component, usually an application, to coordinate the registration of each individual module. This registration was conducted on behalf of each module’s integrator.
This service focuses on the discovery aspect. It leverages the standard Java
java.util.ServiceLoadercapability provided by theorg.hibernate.service.classloading.spi.ClassLoaderServicein order to discover implementations of theorg.hibernate.integrator.spi.Integratorcontract.Integrators would simply define a file named
/META-INF/services/org.hibernate.integrator.spi.Integratorand make it available on the class path.This file is used by the
java.util.ServiceLoadermechanism. It lists, one per line, the fully qualified names of classes which implement theorg.hibernate.integrator.spi.Integratorinterface.
12.9.7. SessionFactory Registry
While it is best practice to treat instances of all the registry types as targeting a given org.hibernate.SessionFactory, the instances of services in this group explicitly belong to a single org.hibernate.SessionFactory.
The difference is a matter of timing in when they need to be initiated. Generally they need access to the org.hibernate.SessionFactory to be initiated. This special registry is org.hibernate.service.spi.SessionFactoryServiceRegistry
12.9.7.1. SessionFactory Services
org.hibernate.event.service.spi.EventListenerRegistry
- Description
- Service for managing event listeners.
- Initiator
-
org.hibernate.event.service.internal.EventListenerServiceInitiator - Implementations
-
org.hibernate.event.service.internal.EventListenerRegistryImpl
12.9.8. Integrators
The org.hibernate.integrator.spi.Integrator is intended to provide a simple means for allowing developers to hook into the process of building a functioning SessionFactory. The org.hibernate.integrator.spi.Integrator interface defines two methods of interest:
-
integrateallows us to hook into the building process -
disintegrateallows us to hook into aSessionFactoryshutting down.
There is a third method defined in org.hibernate.integrator.spi.Integrator, an overloaded form of integrate, accepting a org.hibernate.metamodel.source.MetadataImplementor instead of org.hibernate.cfg.Configuration.
In addition to the discovery approach provided by the IntegratorService, applications can manually register Integrator implementations when building the BootstrapServiceRegistry.
12.9.8.1. Integrator use-cases
The main use cases for an org.hibernate.integrator.spi.Integrator are registering event listeners and providing services, see org.hibernate.integrator.spi.ServiceContributingIntegrator.
Example. Registering Event Listeners
12.10. Envers
12.10.1. About Hibernate Envers
Hibernate Envers is an auditing and versioning system, providing JBoss EAP with a means to track historical changes to persistent classes. Audit tables are created for entities annotated with @Audited, which store the history of changes made to the entity. The data can then be retrieved and queried.
Envers allows developers to:
- audit all mappings defined by the JPA specification,
- audit all hibernate mappings that extend the JPA specification,
- audit entities mapped by or using the native Hibernate API
- log data for each revision using a revision entity, and
- query historical data.
12.10.2. About Auditing Persistent Classes
Auditing of persistent classes is done in JBoss EAP through Hibernate Envers and the @Audited annotation. When the annotation is applied to a class, a table is created, which stores the revision history of the entity.
Each time a change is made to the class, an entry is added to the audit table. The entry contains the changes to the class, and is given a revision number. This means that changes can be rolled back, or previous revisions can be viewed.
12.10.3. Auditing Strategies
12.10.3.1. About Auditing Strategies
Auditing strategies define how audit information is persisted, queried and stored. There are currently two audit strategies available with Hibernate Envers:
- Default Audit Strategy
- This strategy persists the audit data together with a start revision. For each row that is inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, along with the start revision of its validity.
- Rows in the audit tables are never updated after insertion. Queries of audit information use subqueries to select the applicable rows in the audit tables, which are slow and difficult to index.
- Validity Audit Strategy
- This strategy stores the start revision, as well as the end revision of the audit information. For each row that is inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, along with the start revision of its validity.
- At the same time, the end revision field of the previous audit rows (if available) is set to this revision. Queries on the audit information can then use between start and end revision, instead of subqueries. This means that persisting audit information is a little slower because of the extra updates, but retrieving audit information is a lot faster.
- This can also be improved by adding extra indexes.
For more information on auditing, refer to About Auditing Persistent Classes. To set the auditing strategy for the application, refer here: Set the Auditing Strategy .
12.10.3.2. Set the Auditing Strategy
There are two audit strategies supported by JBoss EAP:
- The default audit strategy
- The validity audit strategy
Define an Auditing Strategy
Configure the org.hibernate.envers.audit_strategy property in the persistence.xml file of the application. If the property is not set in the persistence.xml file, then the default audit strategy is used.
Set the Default Audit Strategy
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>Set the Validity Audit Strategy
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>12.10.4. Adding Auditing Support to a JPA Entity
JBoss EAP uses entity auditing, through About Hibernate Envers, to track the historical changes of a persistent class. This topic covers adding auditing support for a JPA entity.
Add Auditing Support to a JPA Entity
- Configure the available auditing parameters to suit the deployment: Configure Envers Parameters .
- Open the JPA entity to be audited.
-
Import the
org.hibernate.envers.Auditedinterface. Apply the
@Auditedannotation to each field or property to be audited, or apply it once to the whole class.Example: Audit Two Fields
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Audit an entire Class
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Once the JPA entity has been configured for auditing, a table called _AUD will be created to store the historical changes.
12.10.5. Configuration
12.10.5.1. Configure Envers Parameters
JBoss EAP uses entity auditing, through Hibernate Envers, to track the historical changes of a persistent class.
Configuring the Available Envers Parameters
-
Open the
persistence.xmlfile for the application. Add, remove or configure Envers properties as required. For a list of available properties, refer to Envers Configuration Properties .
Example: Envers Parameters
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.10.5.2. Enable or Disable Auditing at Runtime
Enable or Disable Entity Version Auditing at Runtime
-
Subclass the
AuditEventListenerclass. Override the following methods that are called on Hibernate events:
-
onPostInsert -
onPostUpdate -
onPostDelete -
onPreUpdateCollection -
onPreRemoveCollection -
onPostRecreateCollection
-
- Specify the subclass as the listener for the events.
- Determine if the change should be audited.
- Pass the call to the superclass if the change should be audited.
12.10.5.3. Configure Conditional Auditing
Hibernate Envers persists audit data in reaction to various Hibernate events, using a series of event listeners. These listeners are registered automatically if the Envers jar is in the class path.
Implement Conditional Auditing
-
Set the
hibernate.listeners.envers.autoRegisterHibernate property to false in thepersistence.xmlfile. - Subclass each event listener to be overridden. Place the conditional auditing logic in the subclass, and call the super method if auditing should be performed.
-
Create a custom implementation of
org.hibernate.integrator.spi.Integrator, similar toorg.hibernate.envers.event.EnversIntegrator. Use the event listener subclasses created in step two, rather than the default classes. -
Add a
META-INF/services/org.hibernate.integrator.spi.Integratorfile to the jar. This file should contain the fully qualified name of the class implementing the interface.
12.10.5.4. Envers Configuration Properties
| Property Name | Default Value | Description |
|---|---|---|
|
| It has is no default value | A string that is prepended to the name of an audited entity, to create the name of the entity that will hold the audit information. |
|
| _AUD |
A string that is appended to the name of an audited entity to create the name of the entity that will hold the audit information. For example, if an entity with a table name of |
|
| REV | The name of the field in the audit entity that holds the revision number. |
|
| REVTYPE |
The name of the field in the audit entity that holds the type of revision. The current types of revisions possible are: |
|
| true |
This property determines if a revision should be generated if a relation field that is not owned changes. This can either be a collection in a one-to-many relation, or the field using the |
|
| true |
When true, properties used for optimistic locking (annotated with |
|
| false | This property defines whether or not entity data should be stored in the revision when the entity is deleted, instead of only the ID, with all other properties marked as null. This is not usually necessary, as the data is present in the last-but-one revision. Sometimes, however, it is easier and more efficient to access it in the last revision. However, this means the data the entity contained before deletion is stored twice. |
|
| null (same as normal tables) |
The default schema name used for audit tables. Can be overridden using the |
|
| null (same as normal tables) |
The default catalog name that should be used for audit tables. Can be overridden using the |
|
|
|
This property defines the audit strategy that should be used when persisting audit data. By default, only the revision where an entity was modified is stored. Alternatively, |
|
| REVEND | The column name that will hold the end revision number in audit entities. This property is only valid if the validity audit strategy is used. |
|
| false |
This property defines whether the timestamp of the end revision, where the data was last valid, should be stored in addition to the end revision itself. This is useful to be able to purge old audit records out of a relational database by using table partitioning. Partitioning requires a column that exists within the table. This property is only evaluated if the |
|
| REVEND_TSTMP |
Column name of the timestamp of the end revision at which point the data was still valid. Only used if the |
12.10.6. Retrieve Auditing Information through Queries
Hibernate Envers provides the functionality to retrieve audit information through queries.
Queries on the audited data will be, in many cases, much slower than corresponding queries on live data, as they involve correlated subselects.
Querying for Entities of a Class at a Given Revision
The entry point for this type of query is:
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
Constraints can then be specified, using the AuditEntity factory class. The query below only selects entities where the name property is equal to John:
query.add(AuditEntity.property("name").eq("John"));
query.add(AuditEntity.property("name").eq("John"));The queries below only select entities that are related to a given entity:
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));The results can then be ordered, limited, and have aggregations and projections (except grouping) set. The example below is a full query.
Query Revisions where Entities of a Given Class Changed
The entry point for this type of query is:
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);Constraints can be added to this query in the same way as the previous example. There are additional possibilities for this query:
AuditEntity.revisionNumber()- Specify constraints, projections and order on the revision number in which the audited entity was modified.
AuditEntity.revisionProperty(propertyName)- Specify constraints, projections and order on a property of the revision entity, corresponding to the revision in which the audited entity was modified.
AuditEntity.revisionType()- Provides accesses to the type of the revision (ADD, MOD, DEL).
The query results can then be adjusted as necessary. The query below selects the smallest revision number at which the entity of the MyEntity class, with the entityId ID has changed, after revision number 42:
Queries for revisions can also minimize/maximize a property. The query below selects the revision at which the value of the actualDate for a given entity was larger than a given value, but as small as possible:
The minimize() and maximize() methods return a criteria, to which constraints can be added, which must be met by the entities with the maximized/minimized properties.
There are two boolean parameters passed when creating the query.
selectEntitiesOnly-
This parameter is only valid when an explicit projection is not set.
Iftrue, the result of the query will be a list of entities that changed at revisions satisfying the specified constraints.
Iffalse, the result will be a list of three element arrays. The first element will be the changed entity instance. The second will be an entity containing revision data. If no custom entity is used, this will be an instance ofDefaultRevisionEntity. The third element array will be the type of the revision (ADD, MOD, DEL). selectDeletedEntities-
This parameter specifies if revisions in which the entity was deleted must be included in the results. If true, the entities will have the revision type
DEL, and all fields, except id, will have the valuenull.
Query Revisions of an Entity that Modified a Given Property
The query below will return all revisions of MyEntity with a given id, where the actualDate property has been changed.
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
The hasChanged condition can be combined with additional criteria. The query below will return a horizontal slice for MyEntity at the time the revisionNumber was generated. It will be limited to the revisions that modified prop1, but not prop2.
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
The result set will also contain revisions with numbers lower than the revisionNumber. This means that this query cannot be read as "Return all MyEntities changed in revisionNumber with prop1 modified and prop2 untouched."
The query below shows how this result can be returned, using the forEntitiesModifiedAtRevision query:
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());Query Entities Modified in a Given Revision
The example below shows the basic query for entities modified in a given revision. It allows entity names and corresponding Java classes changed in a specified revision to be retrieved:
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);There are a number of other queries that are also accessible from org.hibernate.envers.CrossTypeRevisionChangesReader:
List<Object> findEntities(Number)-
Returns snapshots of all audited entities changed (added, updated and removed) in a given revision. Executes
n+1SQL queries, wherenis a number of different entity classes modified within the specified revision. List<Object> findEntities(Number, RevisionType)-
Returns snapshots of all audited entities changed (added, updated or removed) in a given revision filtered by modification type. Executes
n+1SQL queries, wherenis a number of different entity classes modified within specified revision. Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)-
Returns a map containing lists of entity snapshots grouped by modification operation (e.g. addition, update and removal). Executes
3n+1SQL queries, wherenis a number of different entity classes modified within specified revision.
12.11. Performance Tuning
12.11.1. Alternative Batch Loading Algorithms
Hibernate allows you to load data for associations using one of four fetching strategies: join, select, subselect and batch. Out of these four strategies, batch loading allows for the biggest performance gains as it is an optimization strategy for select fetching. In this strategy, Hibernate retrieves a batch of entity instances or collections in a single SELECT statement by specifying a list of primary or foreign keys. Batch fetching is an optimization of the lazy select fetching strategy.
There are two ways to configure batch fetching: per-class level or per-collection level.
Per-Class Level
When Hibernate loads data on a per-class level, it requires the batch size of the association to pre-load when queried. For example, consider that at runtime you have 30 instances of a
carobject loaded in session. Eachcarobject belongs to anownerobject. If you were to iterate through all thecarobjects and request their owners, withlazyloading, Hibernate will issue 30 select statements - one for each owner. This is a performance bottleneck.You can instead, tell Hibernate to pre-load the data for the next batch of owners before they have been sought via a query. When an
ownerobject has been queried, Hibernate will query many more of these objects in the same SELECT statement.The number of
ownerobjects to query in advance depends upon thebatch-sizeparameter specified at configuration time:<class name="owner" batch-size="10"></class>
<class name="owner" batch-size="10"></class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This tells Hibernate to query at least 10 more
ownerobjects in expectation of them being needed in the near future. When a user queries theownerofcar A, theownerofcar Bmay already have been loaded as part of batch loading. When the user actually needs theownerofcar B, instead of going to the database (and issuing a SELECT statement), the value can be retrieved from the current session.In addition to the
batch-sizeparameter, Hibernate 4.2.0 has introduced a new configuration item to improve in batch loading performance. The configuration item is calledBatch Fetch Styleconfiguration and specified by thehibernate.batch_fetch_styleparameter.Three different batch fetch styles are supported: LEGACY, PADDED and DYNAMIC. To specify which style to use, use
org.hibernate.cfg.AvailableSettings#BATCH_FETCH_STYLE.LEGACY: In the legacy style of loading, a set of pre-built batch sizes based on
ArrayHelper.getBatchSizes(int)are utilized. Batches are loaded using the next-smaller pre-built batch size from the number of existing batchable identifiers.Continuing with the above example, with a
batch-sizesetting of 30, the pre-built batch sizes would be [30, 15, 10, 9, 8, 7, .., 1]. An attempt to batch load 29 identifiers would result in batches of 15, 10, and 4. There will be 3 corresponding SQL queries, each loading 15, 10 and 4 owners from the database.PADDED - Padded is similar to LEGACY style of batch loading. It still utilizes pre-built batch sizes, but uses the next-bigger batch size and pads the extra identifier placeholders.
As with the example above, if 30 owner objects are to be initialized, there will only be one query executed against the database.
However, if 29 owner objects are to be initialized, Hibernate will still execute only 1 SQL select statement of batch size 30, with the extra space padded with a repeated identifier.
Dynamic - While still conforming to batch-size restrictions, this style of batch loading dynamically builds its SQL SELECT statement using the actual number of objects to be loaded.
For example, for 30 owner objects, and a maximum batch size of 30, a call to retrieve 30 owner objects will result in one SQL SELECT statement. A call to retrieve 35 will result in two SQL statements, of batch sizes 30 and 5 respectively. Hibernate will dynamically alter the second SQL statement to keep at 5, the required number, while still remaining under the restriction of 30 as the batch-size. This is different to the PADDED version, as the second SQL will not get PADDED, and unlike the LEGACY style, there is no fixed size for the second SQL statement - the second SQL is created dynamically.
For a query of less than 30 identifiers, this style will dynamically only load the number of identifiers requested.
Per-Collection Level
Hibernate can also batch load collections honoring the batch fetch size and styles as listed in the per-class section above.
To reverse the example used in the previous section, consider that you need to load all the
carobjects owned by eachownerobject. If 10ownerobjects are loaded in the current session iterating through all owners will generate 10 SELECT statements, one for every call togetCars()method. If you enable batch fetching for the cars collection in the mapping of Owner, Hibernate can pre-fetch these collections, as shown below.<class name="Owner"><set name="cars" batch-size="5"></set></class>
<class name="Owner"><set name="cars" batch-size="5"></set></class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Thus, with a batch-size of 5 and using legacy batch style to load 10 collections, Hibernate will execute two SELECT statements, each retrieving 5 collections.
12.11.2. Second Level Caching of Object References for Non-mutable Data
Hibernate automatically caches data within memory for improved performance. This is accomplished by an in-memory cache which reduces the number of times that database lookups are required, especially for data that rarely changes.
Hibernate maintains two types of caches. The primary cache (also called the first-level cache) is mandatory. This cache is associated with the current session and all requests must pass through it. The secondary cache (also called the second-level cache) is optional, and is only consulted after the primary cache has been consulted first.
Data is stored in the second-level cache by first disassembling it into a state array. This array is deep copied, and that deep copy is put into the cache. The reverse is done for reading from the cache. This works well for data that changes (mutable data), but is inefficient for immutable data.
Deep copying data is an expensive operation in terms of memory usage and processing speed. For large data sets, memory and processing speed become a performance-limiting factor. Hibernate allows you to specify that immutable data be referenced rather than copied. Instead of copying entire data sets, Hibernate can now store the reference to the data in the cache.
This can be done by changing the value of the configuration setting hibernate.cache.use_reference_entries to true. By default, hibernate.cache.use_reference_entries is set to false.
When hibernate.cache.use_reference_entries is set to true, an immutable data object that does not have any associations is not copied into the second-level cache, and only a reference to it is stored.
When hibernate.cache.use_reference_entries is set to true, immutable data objects with associations are still deep copied into the second-level cache.