1장. 관찰 기능 서비스 도입
관찰 기능을 사용하면 추가 테스트 및 지원 없이 성능 문제를 식별하고 평가할 수 있습니다. Red Hat Advanced Cluster Management for Kubernetes 관찰 기능 구성 요소는 클러스터의 상태 및 사용률과 플릿의 워크로드를 이해하는 데 사용할 수 있는 서비스입니다. 관찰 기능 서비스를 사용하면 관찰 기능 내에 있는 구성 요소를 자동화하고 관리할 수 있습니다.
관찰 기능 서비스는 오픈 소스 커뮤니티의 기존 및 널리 채택된 관찰 툴을 사용합니다. 기본적으로 다중 클러스터 관찰 기능 Operator는 Red Hat Advanced Cluster Management를 설치하는 동안 활성화됩니다. Thanos는 장기 메트릭 스토리지를 위해 허브 클러스터 내에 배포됩니다. observability-endpoint-operator 는 가져온 각 관리 클러스터에 자동으로 배포됩니다. 이 컨트롤러는 Red Hat OpenShift Container Platform Prometheus에서 데이터를 수집하는 메트릭 수집기를 시작한 다음 해당 데이터를 Red Hat Advanced Cluster Management Hub 클러스터로 전송합니다.
관찰 구성 요소에 대한 자세한 내용은 다음 문서를 참조하십시오.
1.1. 관찰 기능 아키텍처
multiclusterhub-operator 는 기본적으로 multicluster-observability-operator Pod를 활성화합니다. multicluster-observability-operator Pod를 구성해야 합니다.
1.1.1. 관찰 기능 오픈 소스 구성 요소
관찰 기능 서비스는 커뮤니티의 오픈 소스 관찰 툴을 사용합니다. 제품 관찰 서비스 이외의 툴에 대한 다음 설명을 확인하십시오.
- Thanos: 여러 Prometheus 인스턴스에서 글로벌 쿼리를 수행하는 데 사용할 수 있는 구성 요소의 툴킷입니다. Prometheus 데이터의 장기 스토리지의 경우 S3 호환 스토리지에 유지합니다. 고가용성 및 확장 가능한 메트릭 시스템을 구성할 수도 있습니다.
- Prometheus: 애플리케이션에서 지표를 수집하고 이러한 지표를 시계열 데이터로 저장하는 데 사용할 수 있는 모니터링 및 경고 툴입니다. 스크랩된 모든 샘플을 로컬에 저장하고, 규칙을 실행하여 기존 데이터의 새 시계열을 집계하고 기록하며 경고를 생성합니다.
- Alertmanager: Prometheus에서 경고를 관리하고 수신하는 툴입니다. 이메일, Slack, PagerDuty와 같은 통합에 경고를 중복, 그룹화 및 라우팅합니다. 특정 경고를 음소거하고 차단하도록 Alertmanager를 구성합니다.
1.1.2. 관찰 기능 아키텍처 다이어그램
다음 다이어그램은 관찰 가능성의 구성 요소를 보여줍니다.
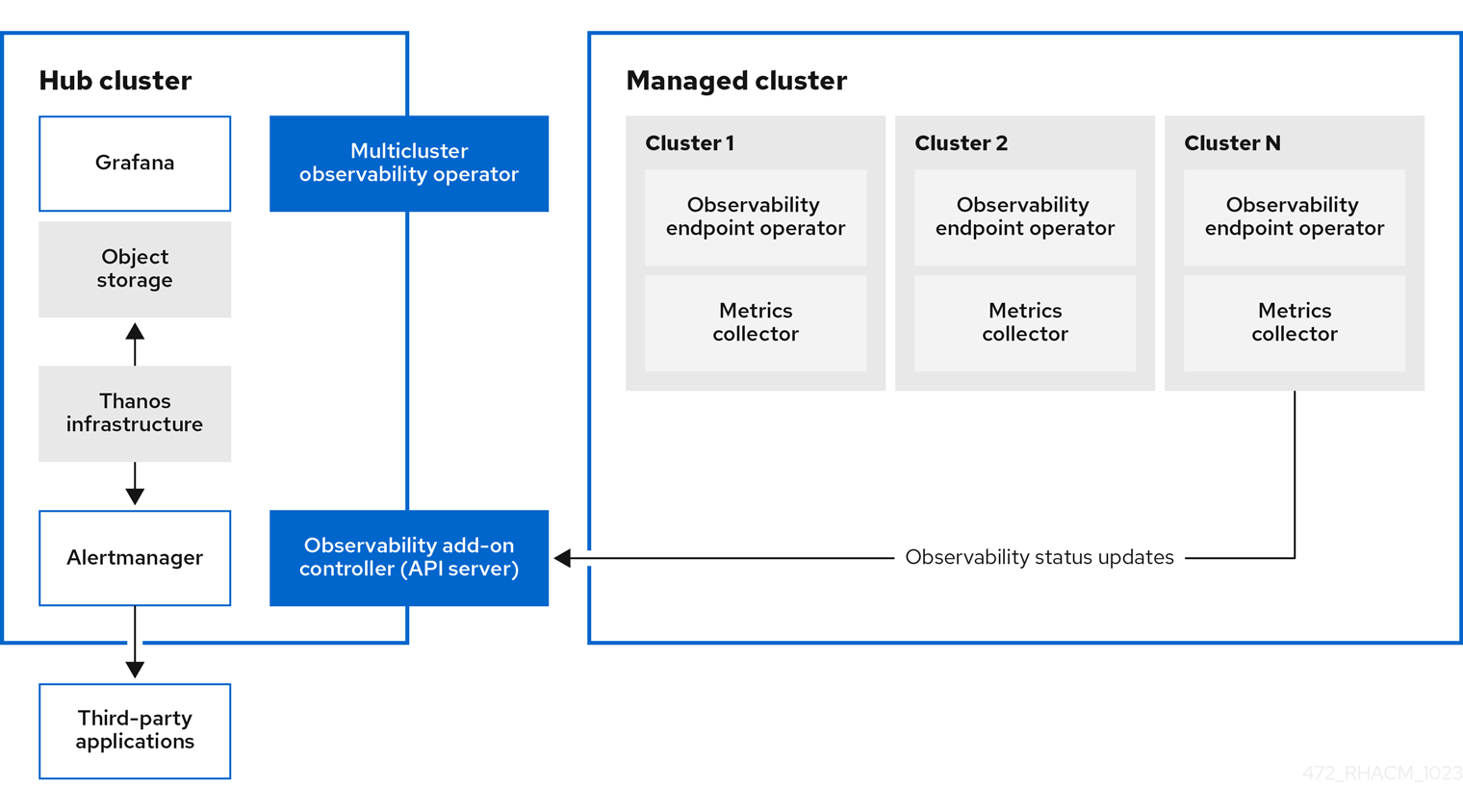
관찰 기능 아키텍처의 구성 요소에는 다음 항목이 포함됩니다.
-
multiclusterhub-operatorPod라고도 하는 다중 클러스터 허브 Operator는multicluster-observability-operatorPod를 배포합니다. 허브 클러스터 데이터를 관리 클러스터에 보냅니다. - 관찰 기능 애드온 컨트롤러는 관리 클러스터의 로그를 자동으로 업데이트하는 API 서버입니다.
Thanos 인프라에는
multicluster-observability-operatorPod에서 배포한 Thanos Cryostator가 포함되어 있습니다. Thanos Cryostator는 보존 구성을 사용하고 스토리지의 데이터를 압축하여 쿼리가 제대로 수행되도록 합니다.Thanos Cryostator에 문제가 발생할 때 이를 식별하는 데 도움이 되도록 상태를 모니터링하는 4개의 기본 경고를 사용합니다. 다음 기본 경고 테이블을 읽습니다.
Expand 표 1.1. 기본 Thanos 경고 테이블 경고 심각도 설명 ACMThanosCompactHalted심각
compactor가 중지되면 경고가 전송됩니다.
ACMThanosCompactHighCompactionFailures경고
압축 실패 비율이 5%보다 크면 경고가 전송됩니다.
ACMThanosCompactBucketHighOperationFailures경고
버킷 작업 실패 비율이 5%보다 크면 경고가 전송됩니다.
ACMThanosCompactHasNotRun경고
압축기가 지난 24시간 동안 아무것도 업로드하지 않으면 경고가 전송됩니다.
- 관찰 기능 구성 요소는 Grafana 인스턴스를 배포하여 대시보드(static) 또는 데이터 무관을 사용하여 데이터 시각화를 활성화합니다. Red Hat Advanced Cluster Management는 Grafana의 8.5.20 버전을 지원합니다. Grafana 대시보드를 설계할 수도 있습니다. 자세한 내용은 Grafana 대시보드 설계를 참조하십시오.
- Prometheus Alertmanager 를 사용하면 타사 애플리케이션과 함께 경고를 전달할 수 있습니다. 사용자 정의 레코딩 규칙 또는 경고 규칙을 생성하여 관찰 기능 서비스를 사용자 지정할 수 있습니다. Red Hat Advanced Cluster Management는 Prometheus Alertmanager의 버전 0.25를 지원합니다.
1.1.3. observability 서비스에 사용되는 영구 저장소
중요: 영구 스토리지에 로컬 볼륨을 사용하는 로컬 스토리지 Operator 또는 스토리지 클래스를 사용하지 마십시오. 재시작 후 Pod가 다른 노드에서 다시 시작되면 데이터가 손실될 수 있습니다. 이 경우 Pod는 더 이상 노드의 로컬 스토리지에 액세스할 수 없습니다. 데이터 손실을 방지하기 위해 수신 및 규칙 포드의 영구 볼륨에 액세스할 수 있는지 확인합니다.
Red Hat Advanced Cluster Management를 설치할 때 PVC(영구 볼륨 클레임)가 자동으로 연결할 수 있도록 다음과 같은 PV(영구 볼륨)를 생성해야 합니다. 기본 스토리지 클래스가 지정되지 않았거나 기본 스토리지 클래스를 사용하여 PV를 호스팅하려는 경우 MultiClusterObservability 사용자 정의 리소스에 스토리지 클래스를 정의해야 합니다. Prometheus에서 사용하는 것과 유사하게 Block Storage를 사용하는 것이 좋습니다. 또한 alertmanager,thanos-compactor,thanos-ruler,thanos-receive-default 및 thanos-store-shard 의 각 복제본에는 자체 PV가 있어야 합니다. 다음 표를 참조하십시오.
| 영구 볼륨 이름 | 목적 |
| alertmanager |
Alertmanager는 |
| Thanos-compact | compactor에는 처리를 위한 중간 데이터와 버킷 상태 캐시를 저장하기 위해 로컬 디스크 공간이 필요합니다. 필요한 공간은 기본 블록의 크기에 따라 다릅니다. compactor는 모든 소스 블록을 다운로드할 수 있는 충분한 공간이 있어야 하고 디스크에 압축된 블록을 빌드해야 합니다. 디스크상의 데이터는 재시작 중에 삭제할 수 있으며 크래시 루프 콤팩트러를 가장 먼저 시도해야 합니다. 그러나 다시 시작 사이에 버킷 상태 캐시를 효과적으로 사용하려면 compactor 영구 디스크를 제공하는 것이 좋습니다. |
| Thanos-rule |
thanos 룰러는 고정된 간격으로 쿼리를 실행하여 선택한 쿼리 API에 대해 Prometheus 기록 및 경고 규칙을 평가합니다. 규칙 결과는 Prometheus 2.0 스토리지 형식으로 디스크에 다시 작성됩니다. 이 상태 저장 세트에 유지되는 시간 또는 일수의 데이터는 API 버전 |
| Thanos-receive-default |
Thanos receiver는 수신 데이터(Prometheus 원격 쓰기 요청)를 수락하고 이를 Prometheus TSDB의 로컬 인스턴스에 씁니다. 주기적으로 (각 2시간), TSDB 블록은 장기 저장 및 압축을 위해 오브젝트 스토리지에 업로드됩니다. 로컬 캐시를 작동하는 이 상태 저장 세트에 유지되는 시간 또는 데이터의 양은 API 버전 |
| Thanos-store-shard | 기본적으로 API 게이트웨이 역할을 하므로 상당한 양의 로컬 디스크 공간이 필요하지 않습니다. 시작 시 Thanos 클러스터에 가입하고 액세스할 수 있는 데이터를 알립니다. 로컬 디스크의 모든 원격 블록에 대한 약간의 정보를 유지하고 버킷과 동기화되도록 유지합니다. 이 데이터는 일반적으로 시작 시간이 늘어남에 따라 다시 시작할 때마다 삭제하는 것이 안전합니다. |
참고: 시계열 기록 데이터는 오브젝트 저장소에 저장됩니다. Thanos는 오브젝트 스토리지를 지표 및 메타데이터의 기본 스토리지로 사용합니다. 오브젝트 스토리지 및 다운스ampling에 대한 자세한 내용은 관찰 기능 활성화를 참조하십시오.
1.1.4. 추가 리소스
관찰 기능 및 통합 구성 요소에 대한 자세한 내용은 다음 항목을 참조하십시오.
- Observability 서비스 소개참조
- Observability 구성참조
- 관찰 기능 서비스 활성화를참조하십시오.
- Thanos 설명서 를 참조하십시오.
- Prometheus 개요 를 참조하십시오.
- Alertmanager 설명서 를 참조하십시오.