이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 5. Kafka configuration
A deployment of Kafka components to an OpenShift cluster using AMQ Streams is highly configurable through the application of custom resources. Custom resources are created as instances of APIs added by Custom resource definitions (CRDs) to extend OpenShift resources.
CRDs act as configuration instructions to describe the custom resources in an OpenShift cluster, and are provided with AMQ Streams for each Kafka component used in a deployment, as well as users and topics. CRDs and custom resources are defined as YAML files. Example YAML files are provided with the AMQ Streams distribution.
CRDs also allow AMQ Streams resources to benefit from native OpenShift features like CLI accessibility and configuration validation.
In this chapter we look at how Kafka components are configured through custom resources, starting with common configuration points and then important configuration considerations specific to components.
5.1. Custom resources
After a new custom resource type is added to your cluster by installing a CRD, you can create instances of the resource based on its specification.
The custom resources for AMQ Streams components have common configuration properties, which are defined under spec.
In this fragment from a Kafka topic custom resource, the apiVersion and kind properties identify the associated CRD. The spec property shows configuration that defines the number of partitions and replicas for the topic.
Kafka topic custom resource
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
# ...There are many additional configuration options that can be incorporated into a YAML definition, some common and some specific to a particular component.
5.2. Common configuration
Some of the configuration options common to resources are described here. Security and metrics collection might also be adopted where applicable.
- Bootstrap servers
Bootstrap servers are used for host/port connection to a Kafka cluster for:
- Kafka Connect
- Kafka Bridge
- Kafka MirrorMaker producers and consumers
- CPU and memory resources
You request CPU and memory resources for components. Limits specify the maximum resources that can be consumed by a given container.
Resource requests and limits for the Topic Operator and User Operator are set in the
Kafkaresource.- Logging
- You define the logging level for the component. Logging can be defined directly (inline) or externally using a config map.
- Healthchecks
- Healthcheck configuration introduces liveness and readiness probes to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- JVM options
- JVM options provide maximum and minimum memory allocation to optimize the performance of the component according to the platform it is running on.
- Pod scheduling
- Pod schedules use affinity/anti-affinity rules to determine under what circumstances a pod is scheduled onto a node.
Example YAML showing common configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-cluster
spec:
# ...
bootstrapServers: my-cluster-kafka-bootstrap:9092
resources:
requests:
cpu: 12
memory: 64Gi
limits:
cpu: 12
memory: 64Gi
logging:
type: inline
loggers:
connect.root.logger.level: "INFO"
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
template:
pod:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-type
operator: In
values:
- fast-network
# ...5.3. Kafka cluster configuration
A kafka cluster comprises one or more brokers. For producers and consumers to be able to access topics within the brokers, Kafka configuration must define how data is stored in the cluster, and how the data is accessed. You can configure a Kafka cluster to run with multiple broker nodes across racks.
- Storage
Kafka and ZooKeeper store data on disks.
AMQ Streams requires block storage provisioned through
StorageClass. The file system format for storage must be XFS or EXT4. Three types of data storage are supported:- Ephemeral (Recommended for development only)
- Ephemeral storage stores data for the lifetime of an instance. Data is lost when the instance is restarted.
- Persistent
- Persistent storage relates to long-term data storage independent of the lifecycle of the instance.
- JBOD (Just a Bunch of Disks, suitable for Kafka only)
- JBOD allows you to use multiple disks to store commit logs in each broker.
The disk capacity used by an existing Kafka cluster can be increased if supported by the infrastructure.
- Listeners
Listeners configure how clients connect to a Kafka cluster.
By specifying a unique name and port for each listener within a Kafka cluster, you can configure multiple listeners.
The following types of listener are supported:
- Internal listeners for access within OpenShift
- External listeners for access outside of OpenShift
You can enable TLS encryption for listeners, and configure authentication.
Internal listeners are specified using an
internaltype.External listeners expose Kafka by specifying an external
type:-
routeto use OpenShift routes and the default HAProxy router -
loadbalancerto use loadbalancer services -
nodeportto use ports on OpenShift nodes -
ingressto use OpenShift Ingress and the NGINX Ingress Controller for Kubernetes
If you are using OAuth 2.0 for token-based authentication, you can configure listeners to use the authorization server.
- Rack awareness
- Rack awareness is a configuration feature that distributes Kafka broker pods and topic replicas across racks, which represent data centers or racks in data centers, or availability zones.
Example YAML showing Kafka configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external1
port: 9094
type: route
tls: true
authentication:
type: tls
# ...
storage:
type: persistent-claim
size: 10000Gi
# ...
rack:
topologyKey: topology.kubernetes.io/zone
# ...5.4. Kafka MirrorMaker configuration
To set up MirrorMaker, a source and target (destination) Kafka cluster must be running.
You can use AMQ Streams with MirrorMaker 2.0, although the earlier version of MirrorMaker continues to be supported.
MirrorMaker 2.0
MirrorMaker 2.0 is based on the Kafka Connect framework, connectors managing the transfer of data between clusters.
MirrorMaker 2.0 uses:
- Source cluster configuration to consume data from the source cluster
- Target cluster configuration to output data to the target cluster
Cluster configuration
You can use MirrorMaker 2.0 in active/passive or active/active cluster configurations.
- In an active/active configuration, both clusters are active and provide the same data simultaneously, which is useful if you want to make the same data available locally in different geographical locations.
- In an active/passive configuration, the data from an active cluster is replicated in a passive cluster, which remains on standby, for example, for data recovery in the event of system failure.
You configure a KafkaMirrorMaker2 custom resource to define the Kafka Connect deployment, including the connection details of the source and target clusters, and then run a set of MirrorMaker 2.0 connectors to make the connection.
Topic configuration is automatically synchronized between the source and target clusters according to the topics defined in the KafkaMirrorMaker2 custom resource. Configuration changes are propagated to remote topics so that new topics and partitions are detected and created. Topic replication is defined using regular expression patterns to include or exclude topics.
The following MirrorMaker 2.0 connectors and related internal topics help manage the transfer and synchronization of data between the clusters.
- MirrorSourceConnector
- A MirrorSourceConnector creates remote topics from the source cluster.
- MirrorCheckpointConnector
- A MirrorCheckpointConnector tracks and maps offsets for specified consumer groups using an offset sync topic and checkpoint topic. The offset sync topic maps the source and target offsets for replicated topic partitions from record metadata. A checkpoint is emitted from each source cluster and replicated in the target cluster through the checkpoint topic. The checkpoint topic maps the last committed offset in the source and target cluster for replicated topic partitions in each consumer group.
- MirrorHeartbeatConnector
- A MirrorHeartbeatConnector periodically checks connectivity between clusters. A heartbeat is produced every second by the MirrorHeartbeatConnector into a heartbeat topic that is created on the local cluster. If you have MirrorMaker 2.0 at both the remote and local locations, the heartbeat emitted at the remote location by the MirrorHeartbeatConnector is treated like any remote topic and mirrored by the MirrorSourceConnector at the local cluster. The heartbeat topic makes it easy to check that the remote cluster is available and the clusters are connected. If things go wrong, the heartbeat topic offset positions and time stamps can help with recovery and diagnosis.
Figure 5.1. Replication across two clusters
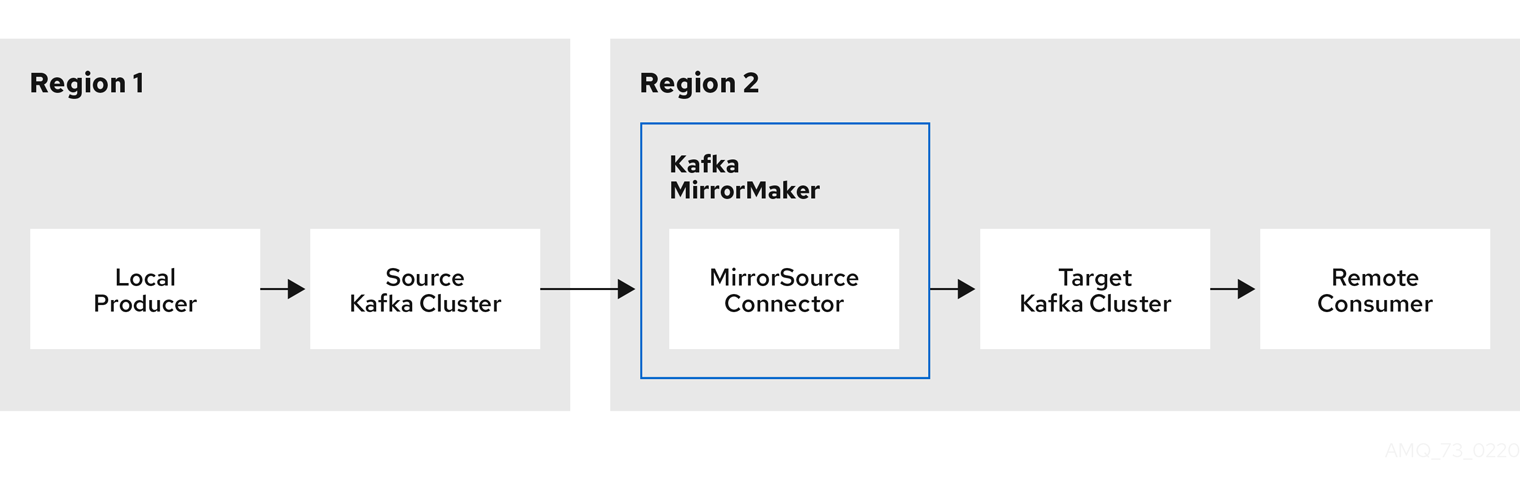
Bidirectional replication across two clusters
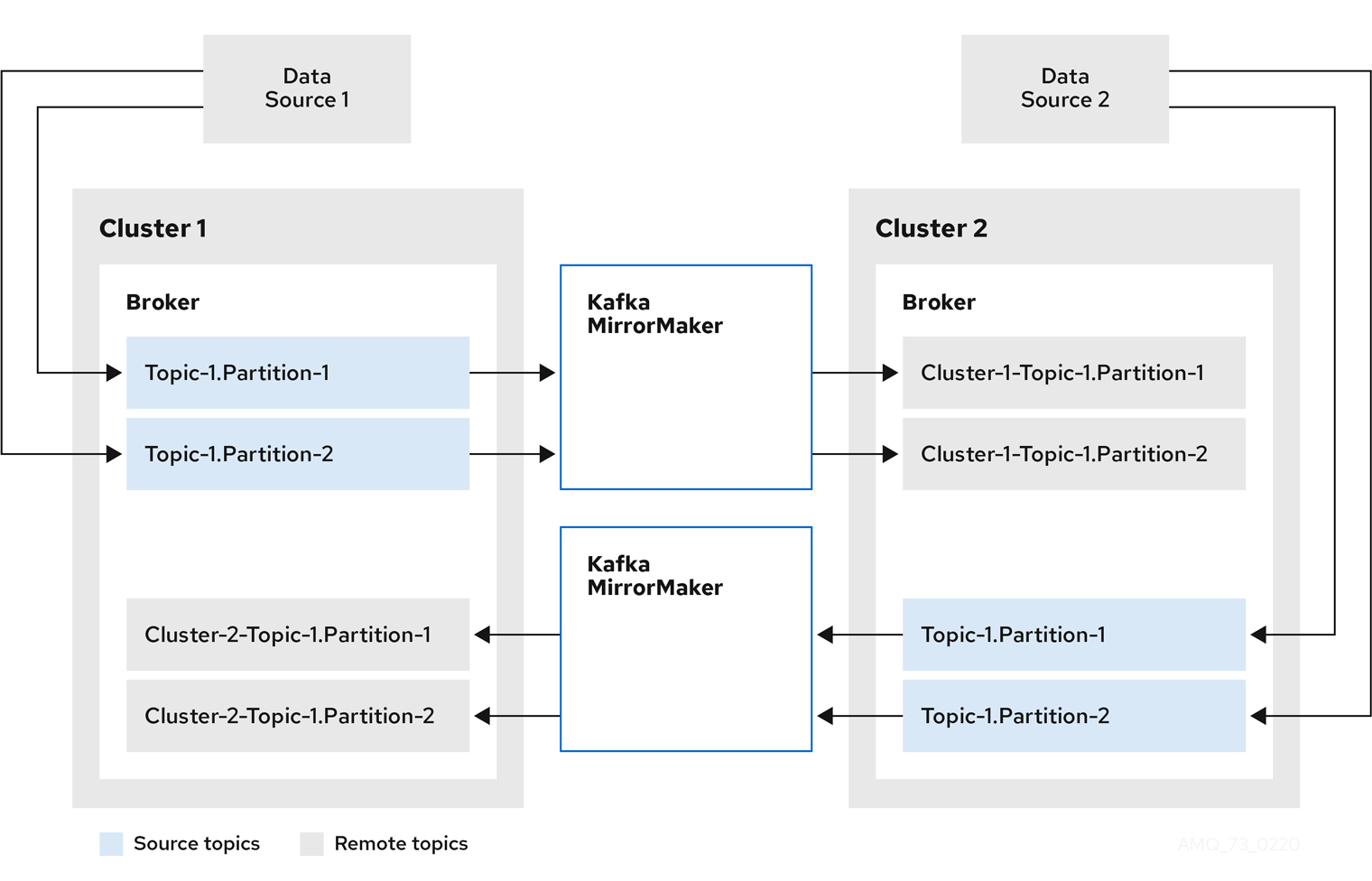
The MirrorMaker 2.0 architecture supports bidirectional replication in an active/active cluster configuration, so both clusters are active and provide the same data simultaneously. A MirrorMaker 2.0 cluster is required at each target destination.
Remote topics are distinguished by automatic renaming that prepends the name of cluster to the name of the topic. This is useful if you want to make the same data available locally in different geographical locations.
However, if you want to backup or migrate data in an active/passive cluster configuration, you might want to keep the original names of the topics. If so, you can configure MirrorMaker 2.0 to turn off automatic renaming.
Figure 5.2. Bidirectional replication
Example YAML showing MirrorMaker 2.0 configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.8.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}
topicsPattern: ".*"
groupsPattern: "group1|group2|group3"MirrorMaker
The earlier version of MirrorMaker uses producers and consumers to replicate data across clusters.
MirrorMaker uses:
- Consumer configuration to consume data from the source cluster
- Producer configuration to output data to the target cluster
Consumer and producer configuration includes any authentication and encryption settings.
The include field defines the topics to mirror from a source to a target cluster.
Key Consumer configuration
- Consumer group identifier
- The consumer group ID for a MirrorMaker consumer so that messages consumed are assigned to a consumer group.
- Number of consumer streams
- A value to determine the number of consumers in a consumer group that consume a message in parallel.
- Offset commit interval
- An offset commit interval to set the time between consuming and committing a message.
Key Producer configuration
- Cancel option for send failure
- You can define whether a message send failure is ignored or MirrorMaker is terminated and recreated.
Example YAML showing MirrorMaker configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker
metadata:
name: my-mirror-maker
spec:
# ...
consumer:
bootstrapServers: my-source-cluster-kafka-bootstrap:9092
groupId: "my-group"
numStreams: 2
offsetCommitInterval: 120000
# ...
producer:
# ...
abortOnSendFailure: false
# ...
include: "my-topic|other-topic"
# ...5.5. Kafka Connect configuration
A basic Kafka Connect configuration requires a bootstrap address to connect to a Kafka cluster, and encryption and authentication details.
Kafka Connect instances are configured by default with the same:
- Group ID for the Kafka Connect cluster
- Kafka topic to store the connector offsets
- Kafka topic to store connector and task status configurations
- Kafka topic to store connector and task status updates
If multiple different Kafka Connect instances are used, these settings must reflect each instance.
Example YAML showing Kafka Connect configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
# ...Connectors
Connectors are configured separately from Kafka Connect. The configuration describes the source input data and target output data to feed into and out of Kafka Connect. The external source data must reference specific topics that will store the messages.
Kafka provides two built-in connectors:
-
FileStreamSourceConnectorstreams data from an external system to Kafka, reading lines from an input source and sending each line to a Kafka topic. -
FileStreamSinkConnectorstreams data from Kafka to an external system, reading messages from a Kafka topic and creating a line for each in an output file.
You can add other connectors using connector plugins, which are a set of JAR files or TGZ archives that define the implementation required to connect to certain types of external system.
You create a custom Kafka Connect image that uses new connector plugins.
To create the image, you can use:
- Kafka Connect configuration so that AMQ Streams creates the new image automatically.
- A Kafka container image on Red Hat Ecosystem Catalog as a base image.
- OpenShift builds and the Source-to-Image (S2I) framework to create new container images.
For AMQ Streams to create the new image automatically, a build configuration requires output properties to reference a container registry that stores the container image, and plugins properties to list the connector plugins and their artifacts to add to the image.
The output properties describe the type and name of the image, and optionally the name of the Secret containing the credentials needed to access the container registry. The plugins properties describe the type of artifact and the URL from which the artifact is downloaded. Additionally, you can specify a SHA-512 checksum to verify the artifact before unpacking it.
Example Kafka Connect configuration to create a new image automatically
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
# ...
build:
output:
type: docker
image: my-registry.io/my-org/my-connect-cluster:latest
pushSecret: my-registry-credentials
plugins:
- name: debezium-postgres-connector
artifacts:
- type: tgz
url: https://ARTIFACT-ADDRESS.tgz
sha512sum: HASH-NUMBER-TO-VERIFY-ARTIFACT
# ...
#...Managing connectors
You can use the KafkaConnector resource or the Kafka Connect REST API to create and manage connector instances in a Kafka Connect cluster. The KafkaConnector resource offers an OpenShift-native approach, and is managed by the Cluster Operator.
The spec for the KafkaConnector resource specifies the connector class and configuration settings, as well as the maximum number of connector tasks to handle the data.
Example YAML showing KafkaConnector configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-source-connector
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.kafka.connect.file.FileStreamSourceConnector
tasksMax: 2
config:
file: "/opt/kafka/LICENSE"
topic: my-topic
# ...
You enable KafkaConnectors by adding an annotation to the KafkaConnect resource. KafkaConnector resources must be deployed to the same namespace as the Kafka Connect cluster they link to.
Example YAML showing annotation to enable KafkaConnector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
annotations:
strimzi.io/use-connector-resources: "true"
# ...5.6. Kafka Bridge configuration
A Kafka Bridge configuration requires a bootstrap server specification for the Kafka cluster it connects to, as well as any encryption and authentication options required.
Kafka Bridge consumer and producer configuration is standard, as described in the Apache Kafka configuration documentation for consumers and Apache Kafka configuration documentation for producers.
HTTP-related configuration options set the port connection which the server listens on.
CORS
The Kafka Bridge supports the use of Cross-Origin Resource Sharing (CORS). CORS is a HTTP mechanism that allows browser access to selected resources from more than one origin, for example, resources on different domains. If you choose to use CORS, you can define a list of allowed resource origins and HTTP methods for interaction with the Kafka cluster through the Kafka Bridge. The lists are defined in the http specification of the Kafka Bridge configuration.
CORS allows for simple and preflighted requests between origin sources on different domains.
- A simple request is a HTTP request that must have an allowed origin defined in its header.
- A preflighted request sends an initial OPTIONS HTTP request before the actual request to check that the origin and the method are allowed.
Example YAML showing Kafka Bridge configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
bootstrapServers: my-cluster-kafka:9092
http:
port: 8080
cors:
allowedOrigins: "https://strimzi.io"
allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH"
consumer:
config:
auto.offset.reset: earliest
producer:
config:
delivery.timeout.ms: 300000
# ...Additional resources
- Fetch CORS specification