이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 9. Using AMQ Streams with MirrorMaker 2.0
MirrorMaker 2.0 is used to replicate data between two or more active Kafka clusters, within or across data centers.
Data replication across clusters supports scenarios that require:
- Recovery of data in the event of a system failure
- Aggregation of data for analysis
- Restriction of data access to a specific cluster
- Provision of data at a specific location to improve latency
MirrorMaker 2.0 has features not supported by the previous version of MirrorMaker. However, you can configure MirrorMaker 2.0 to be used in legacy mode.
Additional resources
9.1. MirrorMaker 2.0 data replication
MirrorMaker 2.0 consumes messages from a source Kafka cluster and writes them to a target Kafka cluster.
MirrorMaker 2.0 uses:
- Source cluster configuration to consume data from the source cluster
- Target cluster configuration to output data to the target cluster
MirrorMaker 2.0 is based on the Kafka Connect framework, connectors managing the transfer of data between clusters. A MirrorMaker 2.0 MirrorSourceConnector replicates topics from a source cluster to a target cluster.
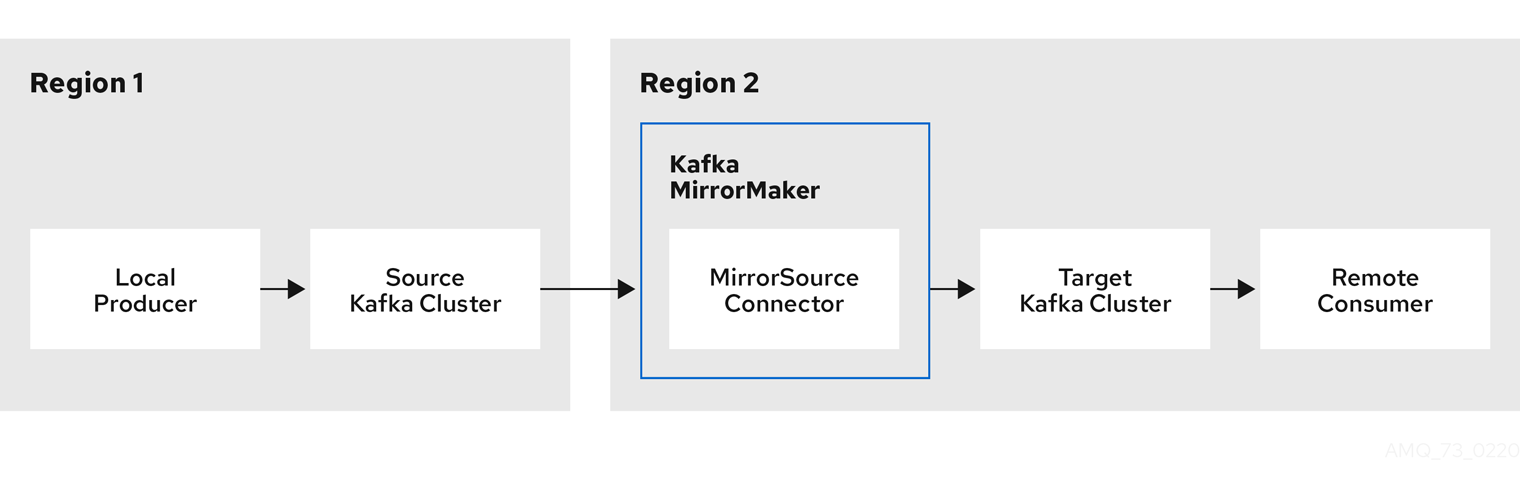
The process of mirroring data from one cluster to another cluster is asynchronous. The recommended pattern is for messages to be produced locally alongside the source Kafka cluster, then consumed remotely close to the target Kafka cluster.
MirrorMaker 2.0 can be used with more than one source cluster.
Figure 9.1. Replication across two clusters
9.2. Cluster configuration
You can use MirrorMaker 2.0 in active/passive or active/active cluster configurations.
- In an active/passive configuration, the data from an active cluster is replicated in a passive cluster, which remains on standby, for example, for data recovery in the event of system failure.
- In an active/active configuration, both clusters are active and provide the same data simultaneously, which is useful if you want to make the same data available locally in different geographical locations.
The expectation is that producers and consumers connect to active clusters only.
9.2.1. Bidirectional replication
The MirrorMaker 2.0 architecture supports bidirectional replication in an active/active cluster configuration. A MirrorMaker 2.0 cluster is required at each target destination.
Each cluster replicates the data of the other cluster using the concept of source and remote topics. As the same topics are stored in each cluster, remote topics are automatically renamed by MirrorMaker 2.0 to represent the source cluster.
Figure 9.2. Topic renaming
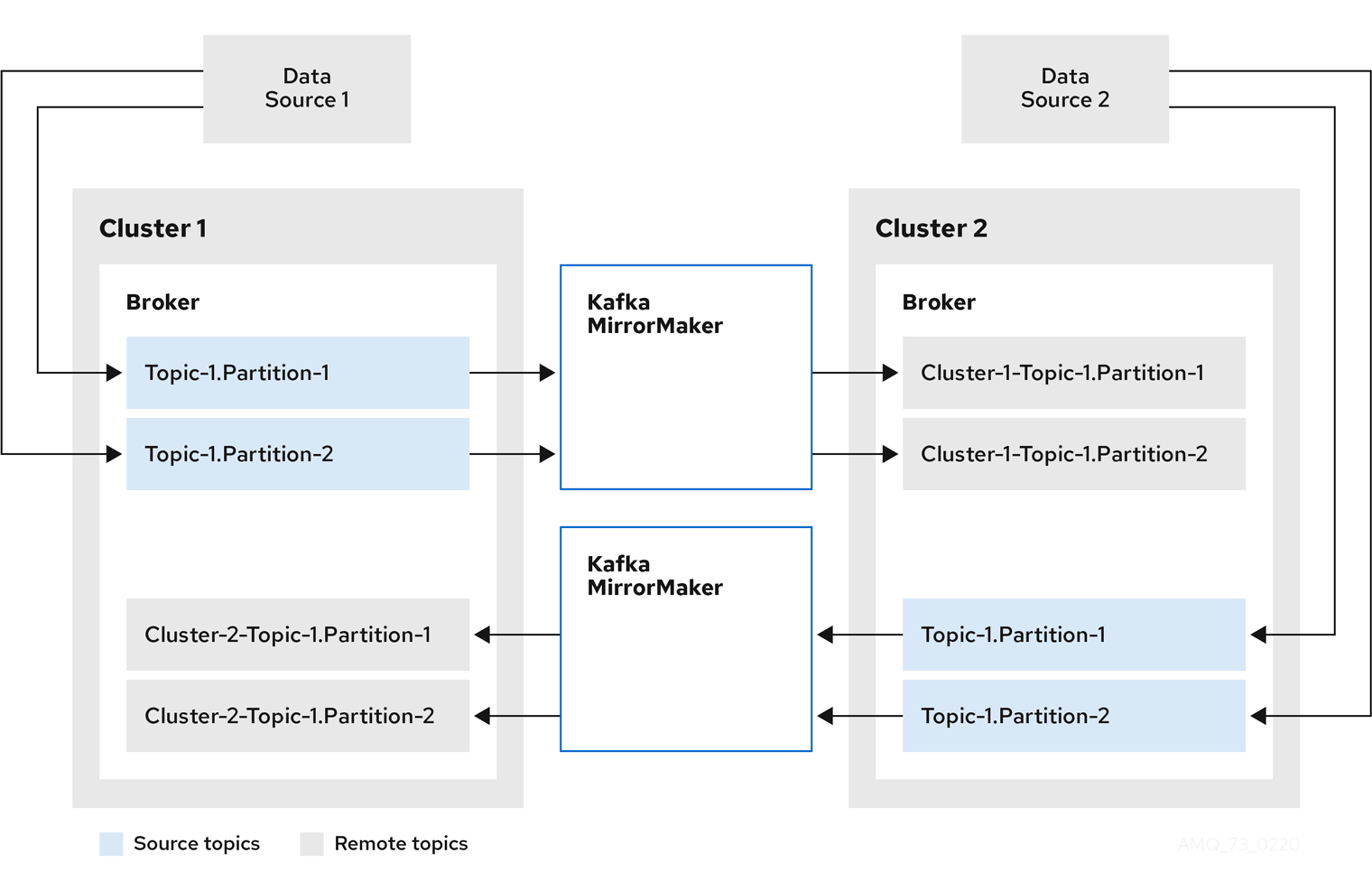
By flagging the originating cluster, topics are not replicated back to that cluster.
The concept of replication through remote topics is useful when configuring an architecture that requires data aggregation. Consumers can subscribe to source and remote topics within the same cluster, without the need for a separate aggregation cluster.
9.2.2. Topic configuration synchronization
Topic configuration is automatically synchronized between source and target clusters. By synchronizing configuration properties, the need for rebalancing is reduced.
9.2.3. Data integrity
MirrorMaker 2.0 monitors source topics and propagates any configuration changes to remote topics, checking for and creating missing partitions. Only MirrorMaker 2.0 can write to remote topics.
9.2.4. Offset tracking
MirrorMaker 2.0 tracks offsets for consumer groups using internal topics.
- The offset sync topic maps the source and target offsets for replicated topic partitions from record metadata
- The checkpoint topic maps the last committed offset in the source and target cluster for replicated topic partitions in each consumer group
Offsets for the checkpoint topic are tracked at predetermined intervals through configuration. Both topics enable replication to be fully restored from the correct offset position on failover.
MirrorMaker 2.0 uses its MirrorCheckpointConnector to emit checkpoints for offset tracking.
9.2.5. Connectivity checks
A heartbeat internal topic checks connectivity between clusters.
The heartbeat topic is replicated from the source cluster.
Target clusters use the topic to check:
- The connector managing connectivity between clusters is running
- The source cluster is available
MirrorMaker 2.0 uses its MirrorHeartbeatConnector to emit heartbeats that perform these checks.
9.3. ACL rules synchronization
If SimpleAclAuthorizer is being used, ACL rules that manage access to brokers also apply to remote topics. Users that can read a source topic can read its remote equivalent.
OAuth 2.0 authorization does not support access to remote topics in this way.
9.4. Synchronizing data between Kafka clusters using MirrorMaker 2.0
Use MirrorMaker 2.0 to synchronize data between Kafka clusters through configuration.
The previous version of MirrorMaker continues to be supported, by running MirrorMaker 2.0 in legacy mode.
The configuration must specify:
- Each Kafka cluster
- Connection information for each cluster, including TLS authentication
The replication flow and direction
- Cluster to cluster
- Topic to topic
- Replication rules
- Committed offset tracking intervals
This procedure describes how to implement MirrorMaker 2.0 by creating the configuration in a properties file, then passing the properties when using the MirrorMaker script file to set up the connections.
MirrorMaker 2.0 uses Kafka Connect to make the connections to transfer data between clusters. Kafka provides MirrorMaker sink and source connectors for data replication. If you wish to use the connectors instead of the MirrorMaker script, the connectors must be configured in the Kafka Connect cluster. For more information, refer to the Apache Kafka documentation.
Before you begin
A sample configuration properties file is provided in ./config/connect-mirror-maker.properties.
Prerequisites
- You need AMQ Streams installed on the hosts of each Kafka cluster node you are replicating.
Procedure
Open the sample properties file in a text editor, or create a new one, and edit the file to include connection information and the replication flows for each Kafka cluster.
The following example shows a configuration to connect two clusters, cluster-1 and cluster-2, bidirectionally. Cluster names are configurable through the
clustersproperty.clusters=cluster-1,cluster-21 cluster-1.bootstrap.servers=<my-cluster>-kafka-bootstrap-<my-project>:4432 cluster-1.security.protocol=SSL3 cluster-1.ssl.truststore.password=<my-truststore-password> cluster-1.ssl.truststore.location=<path-to-truststore>/truststore.cluster-1.jks cluster-1.ssl.keystore.password=<my-keystore-password> cluster-1.ssl.keystore.location=<path-to-keystore>/user.cluster-1.p12 cluster-2.bootstrap.servers=<my-cluster>-kafka-bootstrap-<my-project>:4434 cluster-2.security.protocol=SSL5 cluster-2.ssl.truststore.password=<my-truststore-password> cluster-2.ssl.truststore.location=<path-to-truststore>/truststore.cluster-2.jks cluster-2.ssl.keystore.password=<my-keystore-password> cluster-2.ssl.keystore.location=<path-to-keystore>/user.cluster-2.p12 cluster-1->cluster-2.enabled=true6 cluster-1->cluster-2.topics=.*7 cluster-2->cluster-1.enabled=true8 cluster-2->cluster-1B->C.topics=.*9 replication.policy.separator=-10 sync.topic.acls.enabled=false11 refresh.topics.interval.seconds=6012 refresh.groups.interval.seconds=6013 - 1
- Each Kafka cluster is identified with its alias
- 2
- Connection information for cluster-1, using the bootstrap address and port 443. Both clusters use port 443 to connect to Kafka using OpenShift Routes
- 3
- The
ssl.properties define TLS configuration for cluster-1. - 4
- Connection information for cluster-2.
- 5
- The
ssl.properties define the TLS configuration for cluster-2. - 6
- Replication flow enabled from the cluster-1 cluster to the cluster-2 cluster
- 7
- Replicates all topics from the cluster-1 cluster to the cluster-2 cluster
- 8
- Replication flow enabled from the cluster-2 cluster to the cluster-1 cluster
- 9
- Replicates specific topics from the cluster-2 cluster to the cluster-1 cluster
- 10
- Policy to declare the reserved character used as the topic name separator.
- 11
- When enabled, ACLs are applied to synchronized topics. The default is
false. - 12
- The period between checks for new topics to synchronize.
- 13
- The period between checks for new consumer groups to synchronize.
Start MirrorMaker with the cluster connection configuration and replication policies you defined in your properties file:
su - kafka /opt/kafka/bin/kafka-mirror-maker.sh /config/connect-mirror-maker.propertiesMirrorMaker sets up connections between the clusters.
Start ZooKeeper and Kafka in the target clusters:
su - kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.propertiessu - kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.propertiesFor each target cluster, verify that the topics are being replicated:
/bin/kafka-topics.sh --zookeeper <ZooKeeperAddress> --list
9.5. Using MirrorMaker 2.0 in legacy mode
This procedure describes how to configure MirrorMaker 2.0 to use it in legacy mode. Legacy mode supports the previous version of MirrorMaker.
The MirrorMaker script /opt/kafka/bin/kafka-mirror-maker.sh can run MirrorMaker 2.0 in legacy mode.
Prerequisites
You need the properties files you currently use with the legacy version of MirrorMaker.
-
/opt/kafka/config/consumer.properties -
/opt/kafka/config/producer.properties
Procedure
Edit the MirrorMaker
consumer.propertiesandproducer.propertiesfiles to turn off MirrorMaker 2.0 features.For example:
replication.policy.class=org.apache.kafka.mirror.LegacyReplicationPolicy1 refresh.topics.enabled=false2 refresh.groups.enabled=false emit.checkpoints.enabled=false emit.heartbeats.enabled=false sync.topic.configs.enabled=false sync.topic.acls.enabled=falseSave the changes and restart MirrorMaker with the properties files you used with the previous version of MirrorMaker:
su - kafka /opt/kafka/bin/kafka-mirror-maker.sh \ --consumer.config /opt/kafka/config/consumer.properties \ --producer.config /opt/kafka/config/producer.properties \ --num.streams=2The
consumerproperties provide the configuration for the source cluster and theproducerproperties provide the target cluster configuration.MirrorMaker sets up connections between the clusters.
Start ZooKeeper and Kafka in the target cluster:
su - kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.propertiessu - kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.propertiesFor the target cluster, verify that the topics are being replicated:
/bin/kafka-topics.sh --zookeeper <ZooKeeperAddress> --list