15.3. Red Hat Ceph Storage 클러스터 구성
다음 예제 절차에서는 내결함성을 위해 Red Hat Ceph 스토리지 클러스터를 구성하는 방법을 설명합니다. OSD(Object Storage Device) 노드를 실제 물리적 설치를 반영하는 데이터 센터로 집계하기 위해 CloudEvent 버킷을 생성합니다. 또한 스토리지 풀에서 데이터를 복제하는 방법을 CloudEvent에 알리는 규칙을 생성합니다. 이 단계는 Ceph 설치에 의해 생성된 기본 CloudEvent 맵이 업데이트되었습니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터가 이미 설치되어 있습니다. 자세한 내용은 Red Hat Ceph Storage 설치를 참조하십시오.
- Red Hat Ceph Storage가 PG(배치 그룹)를 사용하여 풀에서 많은 수의 데이터 오브젝트를 구성하는 방법과 풀에서 사용할 PG 수를 계산하는 방법을 이해해야 합니다. 자세한 내용은 PG(배치 그룹)를 참조하십시오.
- 풀에서 오브젝트 복제본 수를 설정하는 방법을 이해해야 합니다. 자세한 내용은 오브젝트 복제본 수를 설정합니다.
절차
CloudEvent 버킷을 생성하여 OSD 노드를 구성합니다. 버킷은 데이터 센터와 같은 물리적 위치를 기반으로 하는 OSD 목록입니다. Ceph에서 이러한 물리적 위치를 장애 도메인 이라고 합니다.
ceph osd crush add-bucket dc1 datacenter ceph osd crush add-bucket dc2 datacenterOSD 노드의 호스트 시스템을 사용자가 생성한 데이터 센터 CloudEvent 버킷으로 이동합니다. 호스트 이름
host1-host4를 호스트 시스템의 이름으로 바꿉니다.ceph osd crush move host1 datacenter=dc1 ceph osd crush move host2 datacenter=dc1 ceph osd crush move host3 datacenter=dc2 ceph osd crush move host4 datacenter=dc2생성한 CloudEvent 버킷이
기본CloudEvent 트리에 포함되어 있는지 확인합니다.ceph osd crush move dc1 root=default ceph osd crush move dc2 root=default데이터 센터에서 스토리지 오브젝트 복제본을 매핑하는 규칙을 생성합니다. 이를 통해 데이터 손실을 방지하고 단일 데이터 센터 중단 시 클러스터가 계속 실행될 수 있습니다.
규칙을 생성하는 명령은 다음 구문을 사용합니다.
ceph osd crush 규칙 create-replicated <rule-name> <root> <failure-domain> <class>. 예는 다음과 같습니다.ceph osd crush rule create-replicated multi-dc default datacenter hdd참고이전 명령에서 스토리지 클러스터가 SSD(솔리드 스테이트 드라이브)를 사용하는 경우
hdd(하드 디스크 드라이브) 대신ssd를 지정합니다.생성한 규칙을 사용하도록 Ceph 데이터 및 메타데이터 풀을 구성합니다. 처음에 이로 인해 CloudEvent 알고리즘에 의해 결정된 스토리지 대상에 데이터가 다시 입력될 수 있습니다.
ceph osd pool set cephfs_data crush_rule multi-dc ceph osd pool set cephfs_metadata crush_rule multi-dc메타데이터 및 데이터 풀의 PG(배치 그룹) 및 PG(배치 그룹) 수를 지정합니다. PGP 값은 PG 값과 같아야 합니다.
ceph osd pool set cephfs_metadata pg_num 128 ceph osd pool set cephfs_metadata pgp_num 128 ceph osd pool set cephfs_data pg_num 128 ceph osd pool set cephfs_data pgp_num 128데이터 및 메타데이터 풀에서 사용할 복제본 수를 지정합니다.
ceph osd pool set cephfs_data min_size 1 ceph osd pool set cephfs_metadata min_size 1 ceph osd pool set cephfs_data size 2 ceph osd pool set cephfs_metadata size 2
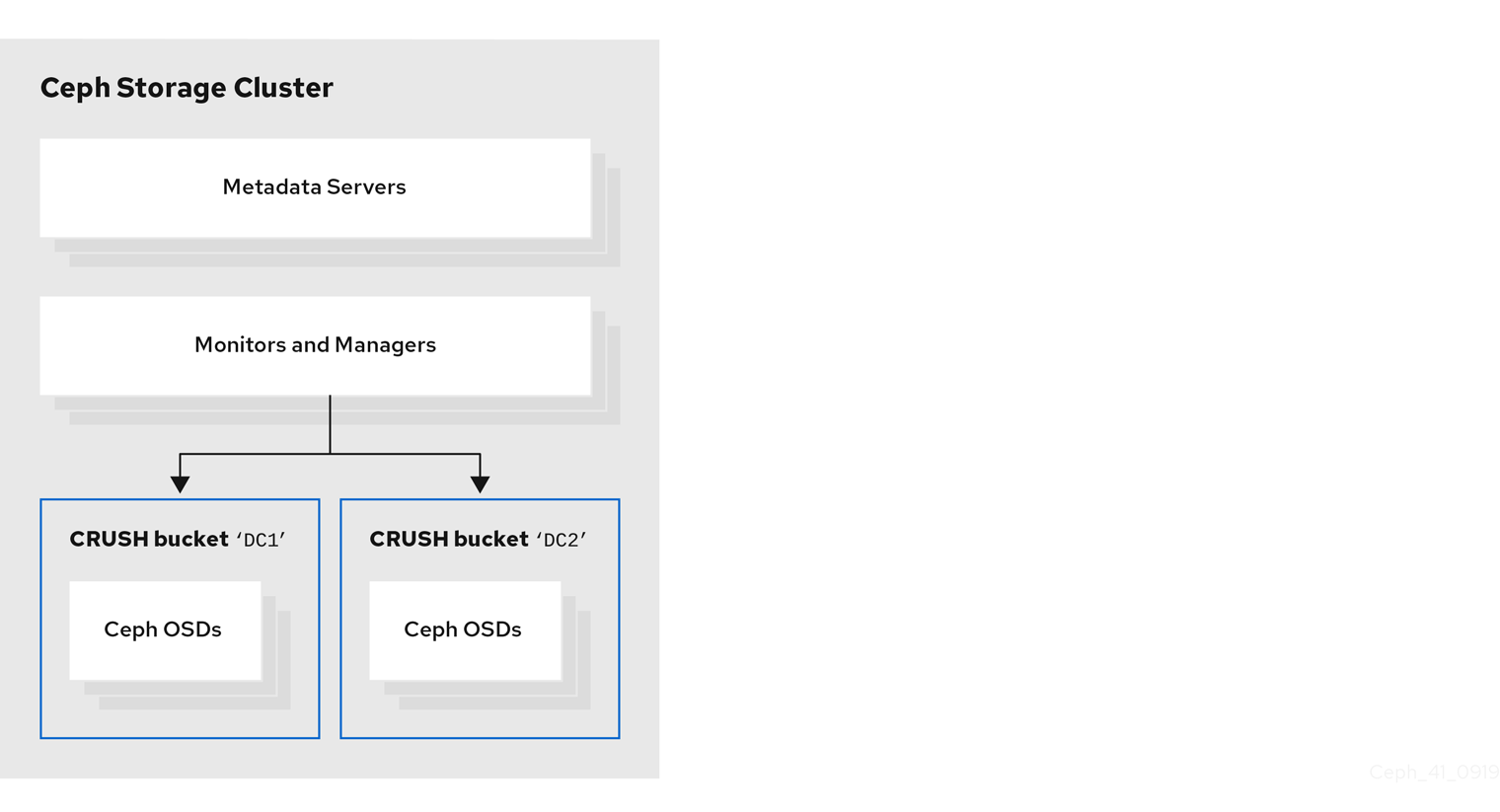
다음 그림은 이전 예제 프로시저에서 생성한 Red Hat Ceph Storage 클러스터를 보여줍니다. 스토리지 클러스터에는 데이터 센터에 해당하는 CloudEvent 버킷으로 구성된 OSD가 있습니다.
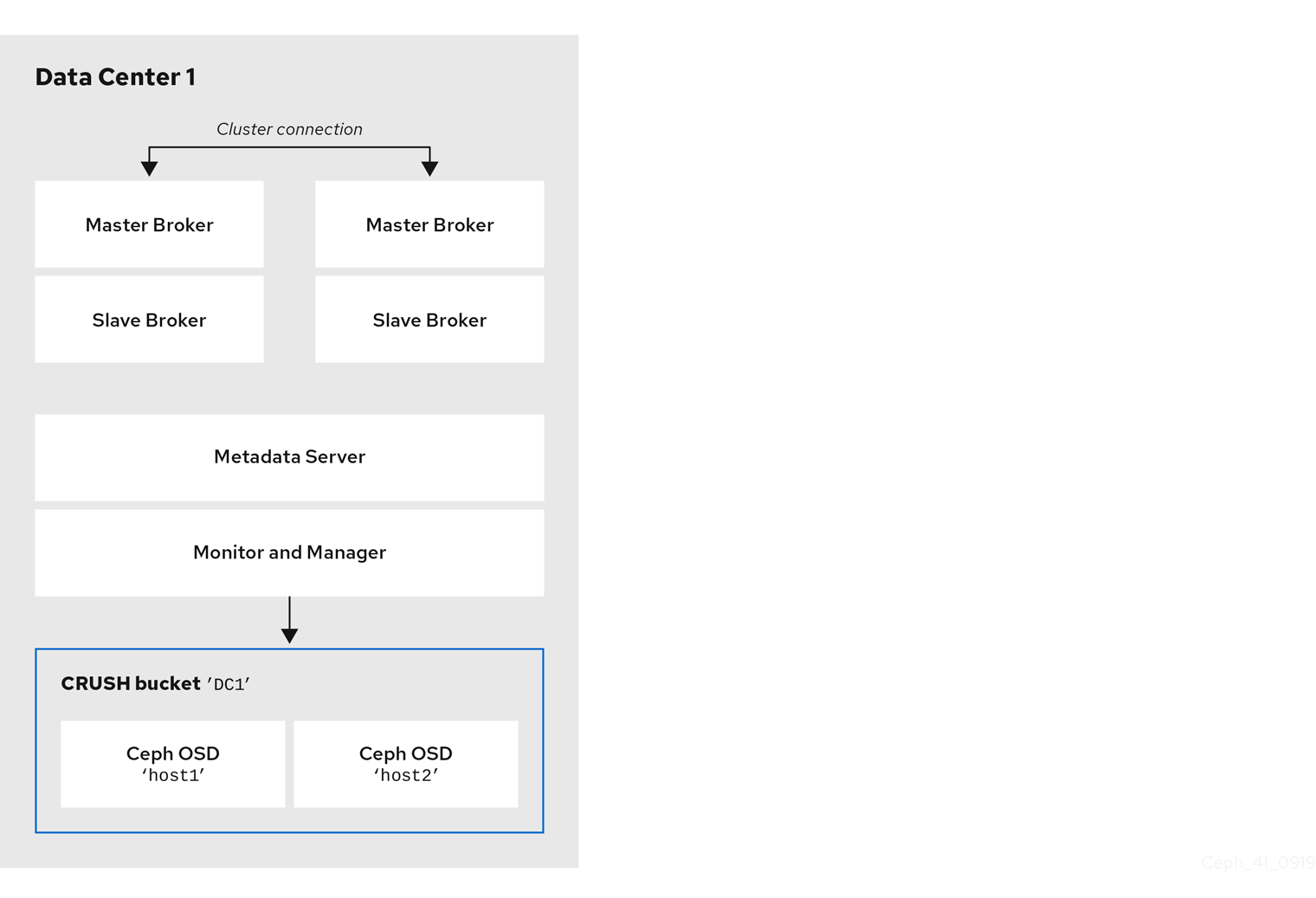
다음 그림은 브로커 서버를 포함하여 첫 번째 데이터 센터의 가능한 레이아웃을 보여줍니다. 특히 데이터 센터 호스트는 다음과 같습니다.
- 두 개의 라이브 백업 브로커 쌍의 서버
- 이전 절차의 첫 번째 데이터 센터에 할당한 OSD 노드
- 단일 메타데이터 서버, 모니터 및 관리자 노드. 모니터 노드와 Manager 노드는 일반적으로 동일한 시스템에 배치됩니다.
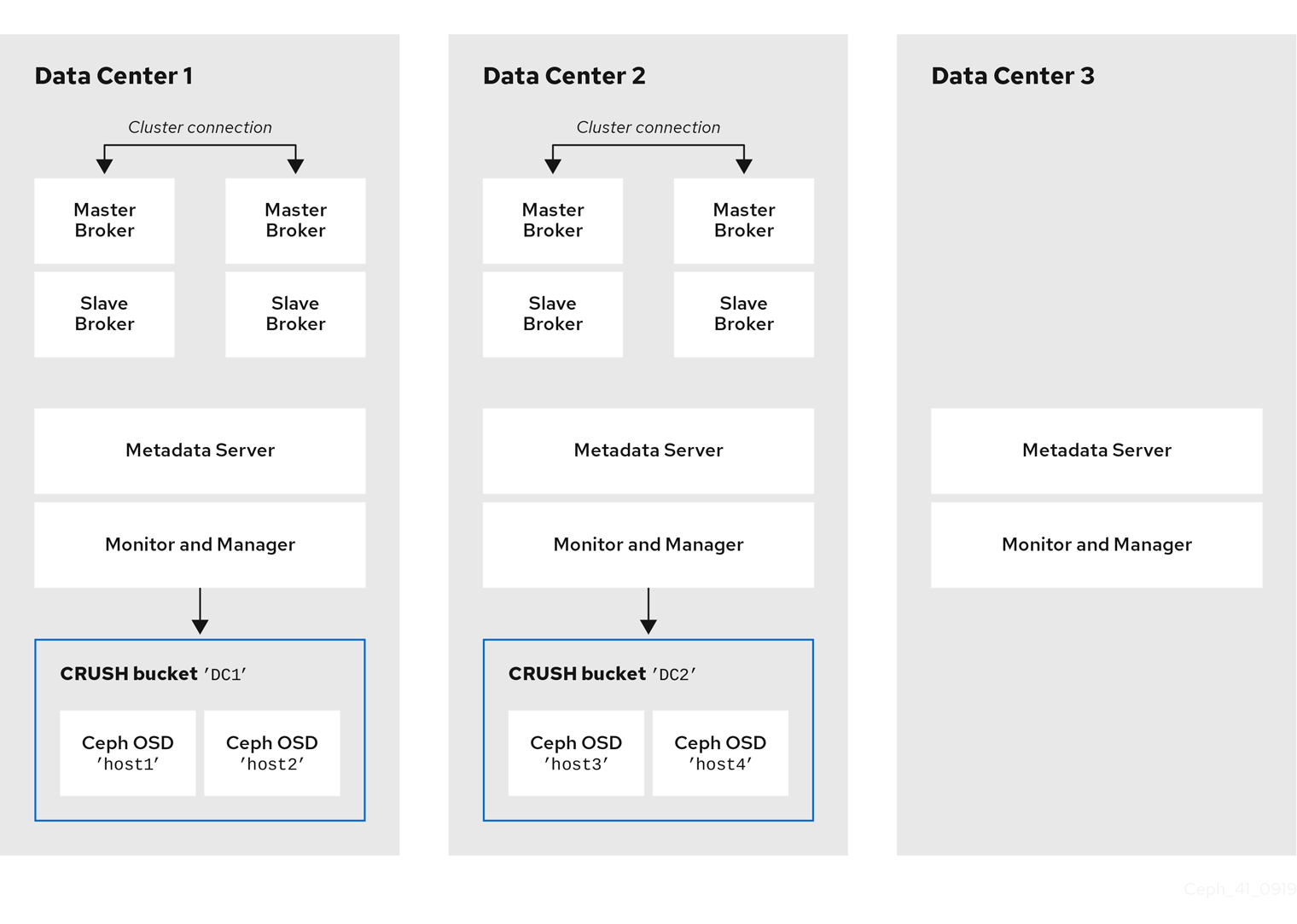
동일한 물리적 또는 가상 머신에서 OSD, MON, MGR 및 MDS 노드를 실행할 수 있습니다. 그러나 Red Hat Ceph Storage 클러스터 내에서 내결함성을 보장하기 위해 이러한 유형의 각 노드를 별도의 데이터 센터에 배포하는 것이 좋습니다. 특히 단일 데이터 센터 중단 시 최소 두 개의 사용 가능한 MON 노드가 있는지 확인해야 합니다. 따라서 클러스터에 MON 노드가 3개인 경우 이러한 각 노드는 별도의 데이터 센터의 별도의 호스트 시스템에서 실행해야 합니다.
다음 그림은 전체 예제 토폴로지를 보여줍니다. 스토리지 클러스터에서 내결함성을 보장하기 위해 MON, MGR 및 MDS 노드는 세 개의 별도의 데이터 센터에 배포됩니다.
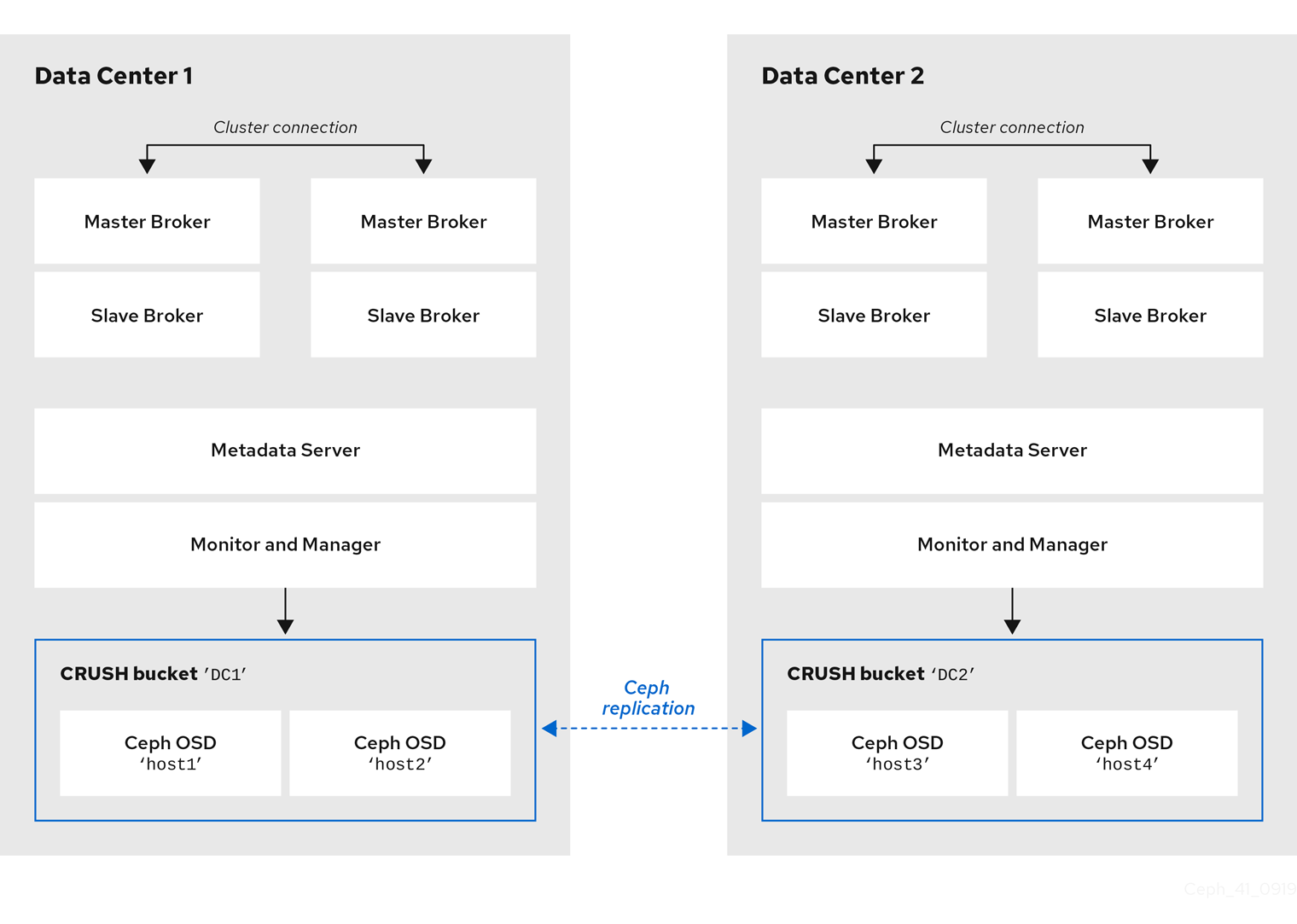
브로커 서버와 동일한 데이터 센터에 있는 특정 OSD 노드의 호스트 시스템을 배치해도 특정 OSD 노드에 메시징 데이터를 저장하는 것은 아닙니다. 메시징 데이터를 Ceph 파일 시스템의 지정된 디렉터리에 저장하도록 브로커를 구성합니다. 그런 다음 클러스터의 메타데이터 서버 노드는 저장된 데이터를 데이터 센터에서 사용 가능한 모든 OSD에 배포하고 이 데이터의 복제를 처리하는 방법을 결정합니다. 다음 섹션에서는 Ceph 파일 시스템에 메시징 데이터를 저장하도록 브로커를 구성하는 방법을 보여줍니다.
아래 그림은 브로커 서버가 있는 두 데이터 센터 간 데이터 복제를 보여줍니다.
추가 리소스
다음에 대한 자세한 내용은 다음을 참조하십시오.
- Red Hat Ceph Storage 클러스터에 대한 ReadWriteMany를 관리하는 방법은 CloudEvent 관리 를 참조하십시오.
- 스토리지 풀에서 설정할 수 있는 전체 속성 세트는 풀 값을 참조하십시오.