2.3. Ceph 배치 그룹
클러스터에 수백만 개의 오브젝트를 저장하고 개별적으로 관리하는 것은 리소스 집약적입니다. 따라서 Ceph는 배치 그룹(PG)을 사용하여 대규모 오브젝트를 보다 효율적으로 관리합니다.
PG는 개체 컬렉션을 포함하는 데 사용되는 풀의 하위 집합입니다. Ceph는 풀을 일련의 PG로 분할합니다. 그런 다음 CRUSH 알고리즘은 클러스터 맵과 클러스터의 상태를 고려하여 PG를 균등하게 및 의사 무작위로 클러스터의 OSD에 배포합니다.
이것이 작동하는 방식은 다음과 같습니다.
시스템 관리자가 풀을 생성할 때 CRUSH는 사용자가 정의한 풀 PG 수를 생성합니다. 일반적으로 PG 수는 데이터의 합리적으로 세분화된 하위 집합이어야 합니다. 예를 들어 풀당 OSD당 100개의 PG는 각 PG가 풀 데이터의 약 1%를 차지함을 의미합니다.
Ceph가 하나의 OSD에서 다른 OSD로 PG를 이동해야 하는 경우 PG 수가 성능에 영향을 미칩니다. 풀에 PG가 너무 적으면 Ceph는 많은 양의 데이터를 동시에 이동하고 네트워크 로드는 클러스터 성능에 부정적인 영향을 미칩니다. 풀에 PG가 너무 많은 경우 Ceph는 데이터의 백분율을 낮게 이동할 때 CPU와 RAM을 너무 많이 사용하므로 클러스터 성능에 부정적인 영향을 미칩니다. 최적의 성능을 얻기 위해 PG 수를 계산하는 방법에 대한 자세한 내용은 배치 그룹 수 를 참조하십시오.
Ceph는 오브젝트의 복제본을 저장하거나 오브젝트의 삭제 코드 청크를 저장하여 데이터 손실을 방지합니다. Ceph는 PG 내에 오브젝트 또는 삭제 코드 청크를 저장하므로, Ceph는 각 PG를 오브젝트 복사본 또는 오브젝트의 각 삭제 코드 청크에 대해 "Acting Set"이라고 하는 OSD 세트에 복제합니다. 시스템 관리자는 풀의 PG 수와 복제본 또는 삭제 코드 청크 수를 결정할 수 있습니다. 그러나 CRUSH 알고리즘은 특정 PG에 대해 설정된 OSD를 계산합니다.
CRUSH 알고리즘과 PG는 Ceph 동적입니다. 클러스터 맵 또는 클러스터 상태를 변경하면 Ceph가 하나의 OSD에서 다른 OSD로 PG를 자동으로 이동할 수 있습니다.
다음은 몇 가지 예입니다.
- 클러스터 확장: 클러스터에 새 호스트와 해당 OSD를 추가하면 클러스터 맵이 변경됩니다. CRUSH와 의사 무작위적으로 클러스터 전체에서 PG를 OSD에 배포하므로 새 호스트와 해당 OSD를 추가하면 CRUSH가 새 OSD에 일부 풀 배치 그룹을 다시 할당합니다. 즉, 시스템 관리자는 클러스터를 수동으로 재조정할 필요가 없습니다. 또한 새 OSD에는 다른 OSD와 거의 동일한 양의 데이터가 포함됩니다. 또한 새 OSD에는 새로 작성된 OSD가 포함되어 있지 않아 클러스터에서 "hot spots"가 방지됩니다.
- OSD Fails: OSD가 실패하면 클러스터 상태가 변경됩니다. Ceph는 일시적으로 복제본 또는 삭제 코드 청크 중 하나를 손실하므로 다른 사본을 만들어야 합니다. 동작 세트의 기본 OSD가 실패하면 동작 세트의 다음 OSD가 기본이 되고 CRUSH는 추가 복사 또는 삭제 코드 청크를 저장할 새 OSD를 계산합니다.
Ceph 스토리지 클러스터는 수백 ~ 수천 개의 PG 환경에서 수백만 개의 오브젝트를 관리함으로써 장애를 효율적으로 확장, 축소 및 복구할 수 있습니다.
Ceph 클라이언트의 경우 librados 를 통한 CRUSH 알고리즘을 사용하면 오브젝트를 읽고 쓰는 프로세스가 매우 간단합니다. Ceph 클라이언트는 개체를 풀에 작성하거나 풀에서 오브젝트를 읽기만 하면 됩니다. 작동 중인 세트의 기본 OSD는 오브젝트의 복제본 또는 오브젝트 삭제 코드 청크를 Ceph 클라이언트를 대신하여 작업 세트의 보조 OSD에 작성할 수 있습니다.
클러스터 맵 또는 클러스터 상태가 변경되면 PG를 저장하는 OSD의 CRUSH 계산도 변경됩니다. 예를 들어 Ceph 클라이언트는 오브젝트 foo 를 풀 바에 작성할 수 있습니다. CRUSH는 PG 1.a 에 오브젝트를 할당하고 OSD 5 에 저장하므로 OSD 10 및 OSD 15 의 복제본을 각각 생성합니다. OSD 5 가 실패하면 클러스터 상태가 변경됩니다. Ceph 클라이언트가 pool bar 에서 오브젝트 foo 를 읽을 때 librados 를 통해 클라이언트는 새 기본 OSD로 OSD 10 에서 자동으로 검색합니다.
librados 를 통해 Ceph 클라이언트는 오브젝트를 작성하고 읽을 때 작동 세트 내의 기본 OSD에 직접 연결합니다. I/O 작업은 중앙 집중식 브로커를 사용하지 않기 때문에 일반적으로 네트워크 초과 서브스크립션은 Ceph의 문제가 아닙니다.
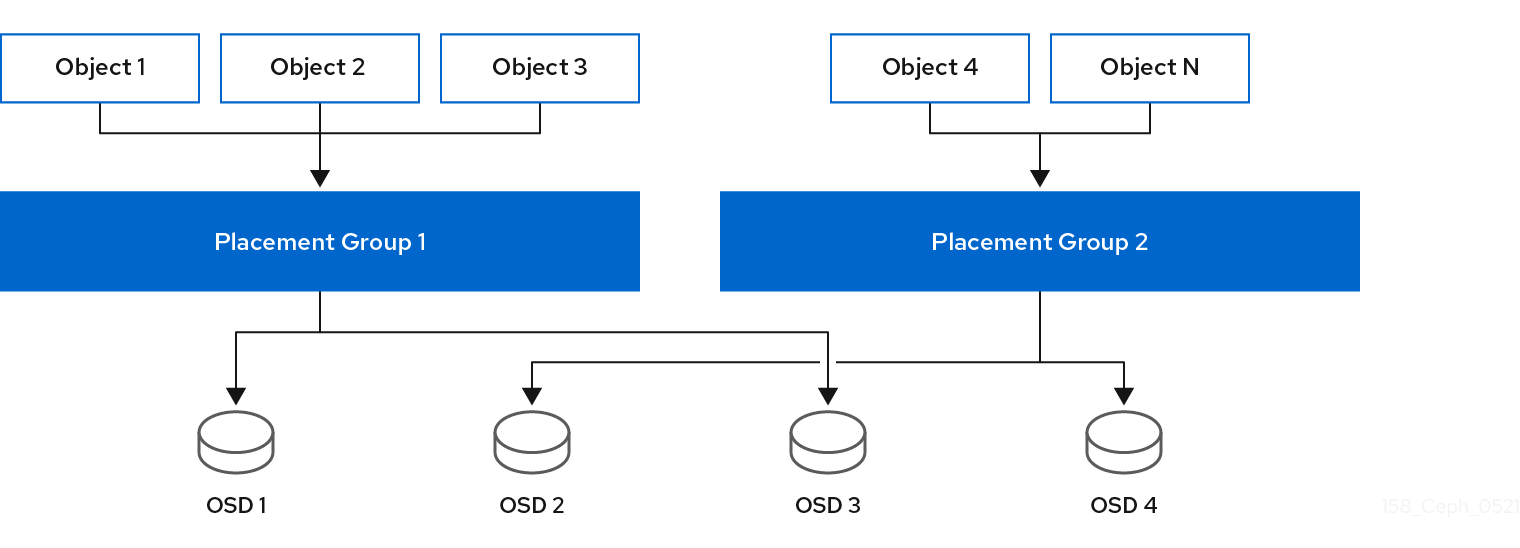
다음 다이어그램에서는 CRUSH가 PG에 오브젝트를 할당하고 PG를 OSD에 할당하는 방법을 보여줍니다. CRUSH 알고리즘은 작동 세트의 각 OSD가 별도의 장애 도메인에 있도록 OSD에 PG를 할당합니다. 이는 일반적으로 OSD가 항상 별도의 서버 호스트에 있고 경우에 따라 별도의 랙에 있어야 함을 의미합니다.