이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 9. Configuring transactions
Data that resides on a distributed system is vulnerable to errors that can arise from temporary network outages, system failures, or just simple human error. These external factors are uncontrollable but can have serious consequences for quality of your data. The effects of data corruption range from lower customer satisfaction to costly system reconciliation that results in service unavailability.
Data Grid can carry out ACID (atomicity, consistency, isolation, durability) transactions to ensure the cache state is consistent.
9.1. Transactions
Data Grid can be configured to use and to participate in JTA compliant transactions.
Alternatively, if transaction support is disabled, it is equivalent to using autocommit in JDBC calls, where modifications are potentially replicated after every change (if replication is enabled).
On every cache operation Data Grid does the following:
- Retrieves the current Transaction associated with the thread
- If not already done, registers XAResource with the transaction manager to be notified when a transaction commits or is rolled back.
In order to do this, the cache has to be provided with a reference to the environment’s TransactionManager. This is usually done by configuring the cache with the class name of an implementation of the TransactionManagerLookup interface. When the cache starts, it will create an instance of this class and invoke its getTransactionManager() method, which returns a reference to the TransactionManager.
Data Grid ships with several transaction manager lookup classes:
Transaction manager lookup implementations
- EmbeddedTransactionManagerLookup: This provides with a basic transaction manager which should only be used for embedded mode when no other implementation is available. This implementation has some severe limitations to do with concurrent transactions and recovery.
-
JBossStandaloneJTAManagerLookup: If you’re running Data Grid in a standalone environment, or in JBoss AS 7 and earlier, and WildFly 8, 9, and 10, this should be your default choice for transaction manager. It’s a fully fledged transaction manager based on JBoss Transactions which overcomes all the deficiencies of the
EmbeddedTransactionManager. - WildflyTransactionManagerLookup: If you’re running Data Grid in WildFly 11 or later, this should be your default choice for transaction manager.
-
GenericTransactionManagerLookup: This is a lookup class that locate transaction managers in the most popular Java EE application servers. If no transaction manager can be found, it defaults on the
EmbeddedTransactionManager.
Once initialized, the TransactionManager can also be obtained from the Cache itself:
//the cache must have a transactionManagerLookupClass defined
Cache cache = cacheManager.getCache();
//equivalent with calling TransactionManagerLookup.getTransactionManager();
TransactionManager tm = cache.getAdvancedCache().getTransactionManager();9.1.1. Configuring transactions
Transactions are configured at cache level. Below is the configuration that affects a transaction behaviour and a small description of each configuration attribute.
<locking
isolation="READ_COMMITTED"/>
<transaction
locking="OPTIMISTIC"
auto-commit="true"
complete-timeout="60000"
mode="NONE"
notifications="true"
reaper-interval="30000"
recovery-cache="__recoveryInfoCacheName__"
stop-timeout="30000"
transaction-manager-lookup="org.infinispan.transaction.lookup.GenericTransactionManagerLookup"/>or programmatically:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.locking()
.isolationLevel(IsolationLevel.READ_COMMITTED);
builder.transaction()
.lockingMode(LockingMode.OPTIMISTIC)
.autoCommit(true)
.completedTxTimeout(60000)
.transactionMode(TransactionMode.NON_TRANSACTIONAL)
.useSynchronization(false)
.notifications(true)
.reaperWakeUpInterval(30000)
.cacheStopTimeout(30000)
.transactionManagerLookup(new GenericTransactionManagerLookup())
.recovery()
.enabled(false)
.recoveryInfoCacheName("__recoveryInfoCacheName__");-
isolation- configures the isolation level. Check section Isolation Levels for more details. Default isREPEATABLE_READ. -
locking- configures whether the cache uses optimistic or pessimistic locking. Check section Transaction Locking for more details. Default isOPTIMISTIC. -
auto-commit- if enable, the user does not need to start a transaction manually for a single operation. The transaction is automatically started and committed. Default istrue. -
complete-timeout- the duration in milliseconds to keep information about completed transactions. Default is60000. mode- configures whether the cache is transactional or not. Default isNONE. The available options are:-
NONE- non transactional cache -
FULL_XA- XA transactional cache with recovery enabled. Check section Transaction recovery for more details about recovery. -
NON_DURABLE_XA- XA transactional cache with recovery disabled. -
NON_XA- transactional cache with integration via Synchronization instead of XA. Check section Enlisting Synchronizations for details. -
BATCH- transactional cache using batch to group operations. Check section Batching for details.
-
-
notifications- enables/disables triggering transactional events in cache listeners. Default istrue. -
reaper-interval- the time interval in millisecond at which the thread that cleans up transaction completion information kicks in. Defaults is30000. -
recovery-cache- configures the cache name to store the recovery information. Check section Transaction recovery for more details about recovery. Default isrecoveryInfoCacheName. -
stop-timeout- the time in millisecond to wait for ongoing transaction when the cache is stopping. Default is30000. -
transaction-manager-lookup- configures the fully qualified class name of a class that looks up a reference to ajakarta.transaction.TransactionManager. Default isorg.infinispan.transaction.lookup.GenericTransactionManagerLookup.
For more details on how Two-Phase-Commit (2PC) is implemented in Data Grid and how locks are being acquired see the section below. More details about the configuration settings are available in Configuration reference.
9.1.2. Isolation levels
Data Grid offers two isolation levels - READ_COMMITTED and REPEATABLE_READ.
These isolation levels determine when readers see a concurrent write, and are internally implemented using different subclasses of MVCCEntry, which have different behaviour in how state is committed back to the data container.
Here’s a more detailed example that should help understand the difference between READ_COMMITTED and REPEATABLE_READ in the context of Data Grid. With READ_COMMITTED, if between two consecutive read calls on the same key, the key has been updated by another transaction, the second read may return the new updated value:
Thread1: tx1.begin()
Thread1: cache.get(k) // returns v
Thread2: tx2.begin()
Thread2: cache.get(k) // returns v
Thread2: cache.put(k, v2)
Thread2: tx2.commit()
Thread1: cache.get(k) // returns v2!
Thread1: tx1.commit()
With REPEATABLE_READ, the final get will still return v. So, if you’re going to retrieve the same key multiple times within a transaction, you should use REPEATABLE_READ.
However, as read-locks are not acquired even for REPEATABLE_READ, this phenomena can occur:
cache.get("A") // returns 1
cache.get("B") // returns 1
Thread1: tx1.begin()
Thread1: cache.put("A", 2)
Thread1: cache.put("B", 2)
Thread2: tx2.begin()
Thread2: cache.get("A") // returns 1
Thread1: tx1.commit()
Thread2: cache.get("B") // returns 2
Thread2: tx2.commit()9.1.3. Transaction locking
9.1.3.1. Pessimistic transactional cache
From a lock acquisition perspective, pessimistic transactions obtain locks on keys at the time the key is written.
- A lock request is sent to the primary owner (can be an explicit lock request or an operation)
The primary owner tries to acquire the lock:
- If it succeed, it sends back a positive reply;
- Otherwise, a negative reply is sent and the transaction is rollback.
As an example:
transactionManager.begin();
cache.put(k1,v1); //k1 is locked.
cache.remove(k2); //k2 is locked when this returns
transactionManager.commit();
When cache.put(k1,v1) returns, k1 is locked and no other transaction running anywhere in the cluster can write to it. Reading k1 is still possible. The lock on k1 is released when the transaction completes (commits or rollbacks).
For conditional operations, the validation is performed in the originator.
9.1.3.2. Optimistic transactional cache
With optimistic transactions locks are being acquired at transaction prepare time and are only being held up to the point the transaction commits (or rollbacks). This is different from the 5.0 default locking model where local locks are being acquire on writes and cluster locks are being acquired during prepare time.
- The prepare is sent to all the owners.
The primary owners try to acquire the locks needed:
- If locking succeeds, it performs the write skew check.
- If the write skew check succeeds (or is disabled), send a positive reply.
- Otherwise, a negative reply is sent and the transaction is rolled back.
As an example:
transactionManager.begin();
cache.put(k1,v1);
cache.remove(k2);
transactionManager.commit(); //at prepare time, K1 and K2 is locked until committed/rolled back.For conditional commands, the validation still happens on the originator.
9.1.3.3. What do I need - pessimistic or optimistic transactions?
From a use case perspective, optimistic transactions should be used when there is not a lot of contention between multiple transactions running at the same time. That is because the optimistic transactions rollback if data has changed between the time it was read and the time it was committed (with write skew check enabled).
On the other hand, pessimistic transactions might be a better fit when there is high contention on the keys and transaction rollbacks are less desirable. Pessimistic transactions are more costly by their nature: each write operation potentially involves a RPC for lock acquisition.
9.1.4. Write Skews
Write skews occur when two transactions independently and simultaneously read and write to the same key. The result of a write skew is that both transactions successfully commit updates to the same key but with different values.
Data Grid automatically performs write skew checks to ensure data consistency for REPEATABLE_READ isolation levels in optimistic transactions. This allows Data Grid to detect and roll back one of the transactions.
When operating in LOCAL mode, write skew checks rely on Java object references to compare differences, which provides a reliable technique for checking for write skews.
9.1.4.1. Forcing write locks on keys in pessimitic transactions
To avoid write skews with pessimistic transactions, lock keys at read-time with Flag.FORCE_WRITE_LOCK.
-
In non-transactional caches,
Flag.FORCE_WRITE_LOCKdoes not work. Theget()call reads the key value but does not acquire locks remotely. -
You should use
Flag.FORCE_WRITE_LOCKwith transactions in which the entity is updated later in the same transaction.
Compare the following code snippets for an example of Flag.FORCE_WRITE_LOCK:
// begin the transaction
if (!cache.getAdvancedCache().lock(key)) {
// abort the transaction because the key was not locked
} else {
cache.get(key);
cache.put(key, value);
// commit the transaction
}// begin the transaction
try {
// throws an exception if the key is not locked.
cache.getAdvancedCache().withFlags(Flag.FORCE_WRITE_LOCK).get(key);
cache.put(key, value);
} catch (CacheException e) {
// mark the transaction rollback-only
}
// commit or rollback the transaction9.1.5. Dealing with exceptions
If a CacheException (or a subclass of it) is thrown by a cache method within the scope of a JTA transaction, then the transaction is automatically marked for rollback.
9.1.6. Enlisting Synchronizations
By default Data Grid registers itself as a first class participant in distributed transactions through XAResource. There are situations where Data Grid is not required to be a participant in the transaction, but only to be notified by its lifecycle (prepare, complete): e.g. in the case Data Grid is used as a 2nd level cache in Hibernate.
Data Grid allows transaction enlistment through Synchronization. To enable it just use NON_XA transaction mode.
Synchronizations have the advantage that they allow TransactionManager to optimize 2PC with a 1PC where only one other resource is enlisted with that transaction (last resource commit optimization). E.g. Hibernate second level cache: if Data Grid registers itself with the TransactionManager as a XAResource than at commit time, the TransactionManager sees two XAResource (cache and database) and does not make this optimization. Having to coordinate between two resources it needs to write the tx log to disk. On the other hand, registering Data Grid as a Synchronization makes the TransactionManager skip writing the log to the disk (performance improvement).
9.1.7. Batching
Batching allows atomicity and some characteristics of a transaction, but not full-blown JTA or XA capabilities. Batching is often a lot lighter and cheaper than a full-blown transaction.
Generally speaking, one should use batching API whenever the only participant in the transaction is an Data Grid cluster. On the other hand, JTA transactions (involving TransactionManager) should be used whenever the transactions involves multiple systems. E.g. considering the "Hello world!" of transactions: transferring money from one bank account to the other. If both accounts are stored within Data Grid, then batching can be used. If one account is in a database and the other is Data Grid, then distributed transactions are required.
You do not have to have a transaction manager defined to use batching.
9.1.7.1. API
Once you have configured your cache to use batching, you use it by calling startBatch() and endBatch() on Cache. E.g.,
Cache cache = cacheManager.getCache();
// not using a batch
cache.put("key", "value"); // will replicate immediately
// using a batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k2", "value");
cache.endBatch(true); // This will now replicate the modifications since the batch was started.
// a new batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(false); // This will "discard" changes made in the batch9.1.7.2. Batching and JTA
Behind the scenes, the batching functionality starts a JTA transaction, and all the invocations in that scope are associated with it. For this it uses a very simple (e.g. no recovery) internal TransactionManager implementation. With batching, you get:
- Locks you acquire during an invocation are held until the batch completes
- Changes are all replicated around the cluster in a batch as part of the batch completion process. Reduces replication chatter for each update in the batch.
- If synchronous replication or invalidation are used, a failure in replication/invalidation will cause the batch to roll back.
- All the transaction related configurations apply for batching as well.
9.1.8. Transaction recovery
Recovery is a feature of XA transactions, which deal with the eventuality of a resource or possibly even the transaction manager failing, and recovering accordingly from such a situation.
9.1.8.1. When to use recovery
Consider a distributed transaction in which money is transferred from an account stored in an external database to an account stored in Data Grid. When TransactionManager.commit() is invoked, both resources prepare successfully (1st phase). During the commit (2nd) phase, the database successfully applies the changes whilst Data Grid fails before receiving the commit request from the transaction manager. At this point the system is in an inconsistent state: money is taken from the account in the external database but not visible yet in Data Grid (since locks are only released during 2nd phase of a two-phase commit protocol). Recovery deals with this situation to make sure data in both the database and Data Grid ends up in a consistent state.
9.1.8.2. How does it work
Recovery is coordinated by the transaction manager. The transaction manager works with Data Grid to determine the list of in-doubt transactions that require manual intervention and informs the system administrator (via email, log alerts, etc). This process is transaction manager specific, but generally requires some configuration on the transaction manager.
Knowing the in-doubt transaction ids, the system administrator can now connect to the Data Grid cluster and replay the commit of transactions or force the rollback. Data Grid provides JMX tooling for this - this is explained extensively in the Transaction recovery and reconciliation section.
9.1.8.3. Configuring recovery
Recovery is not enabled by default in Data Grid. If disabled, the TransactionManager won’t be able to work with Data Grid to determine the in-doubt transactions. The Transaction configuration section shows how to enable it.
NOTE: recovery-cache attribute is not mandatory and it is configured per-cache.
For recovery to work, mode must be set to FULL_XA, since full-blown XA transactions are needed.
9.1.8.3.1. Enable JMX support
In order to be able to use JMX for managing recovery JMX support must be explicitly enabled.
9.1.8.4. Recovery cache
In order to track in-doubt transactions and be able to reply them, Data Grid caches all transaction state for future use. This state is held only for in-doubt transaction, being removed for successfully completed transactions after when the commit/rollback phase completed.
This in-doubt transaction data is held within a local cache: this allows one to configure swapping this info to disk through cache loader in the case it gets too big. This cache can be specified through the recovery-cache configuration attribute. If not specified Data Grid will configure a local cache for you.
It is possible (though not mandated) to share same recovery cache between all the Data Grid caches that have recovery enabled. If the default recovery cache is overridden, then the specified recovery cache must use a TransactionManagerLookup that returns a different transaction manager than the one used by the cache itself.
9.1.8.5. Integration with the transaction manager
Even though this is transaction manager specific, generally a transaction manager would need a reference to a XAResource implementation in order to invoke XAResource.recover() on it. In order to obtain a reference to an Data Grid XAResource following API can be used:
XAResource xar = cache.getAdvancedCache().getXAResource();It is a common practice to run the recovery in a different process from the one running the transaction.
9.1.8.6. Reconciliation
The transaction manager informs the system administrator on in-doubt transaction in a proprietary way. At this stage it is assumed that the system administrator knows transaction’s XID (a byte array).
A normal recovery flow is:
- STEP 1: The system administrator connects to an Data Grid server through JMX, and lists the in doubt transactions. The image below demonstrates JConsole connecting to an Data Grid node that has an in doubt transaction.
Figure 9.1. Show in-doubt transactions
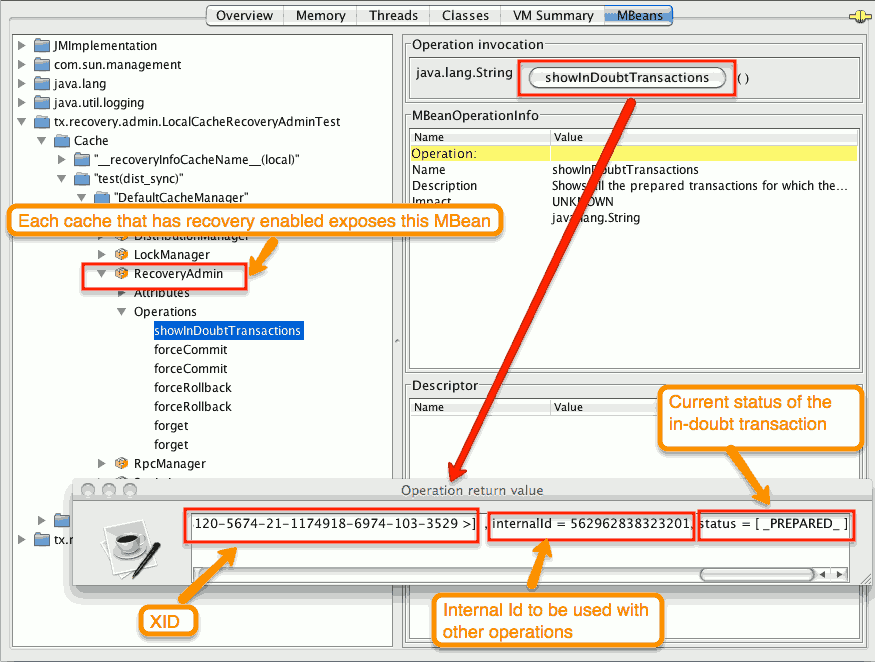
The status of each in-doubt transaction is displayed(in this example " PREPARED "). There might be multiple elements in the status field, e.g. "PREPARED" and "COMMITTED" in the case the transaction committed on certain nodes but not on all of them.
- STEP 2: The system administrator visually maps the XID received from the transaction manager to an Data Grid internal id, represented as a number. This step is needed because the XID, a byte array, cannot conveniently be passed to the JMX tool (e.g. JConsole) and then re-assembled on Data Grid’s side.
- STEP 3: The system administrator forces the transaction’s commit/rollback through the corresponding jmx operation, based on the internal id. The image below is obtained by forcing the commit of the transaction based on its internal id.
Figure 9.2. Force commit
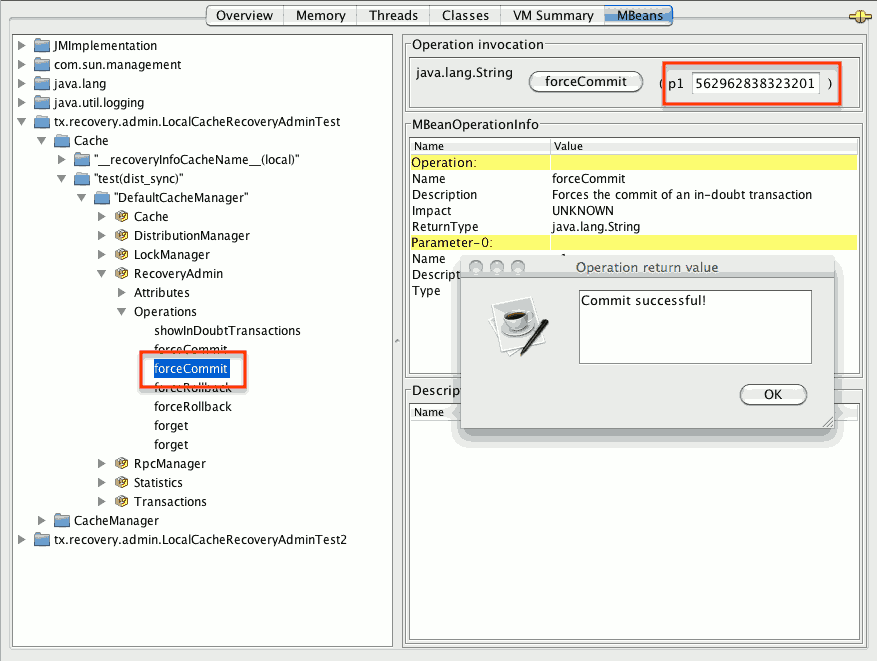
All JMX operations described above can be executed on any node, regardless of where the transaction originated.
9.1.8.6.1. Force commit/rollback based on XID
XID-based JMX operations for forcing in-doubt transactions' commit/rollback are available as well: these methods receive byte[] arrays describing the XID instead of the number associated with the transactions (as previously described at step 2). These can be useful e.g. if one wants to set up an automatic completion job for certain in-doubt transactions. This process is plugged into transaction manager’s recovery and has access to the transaction manager’s XID objects.