4.5. 데이터가 컬렉션에 있을 때의 통합 동작
경우에 따라 연결에서 동일한 유형의 여러 값을 포함하는 컬렉션을 반환합니다. 연결이 컬렉션을 반환하면 다음을 포함하여 여러 가지 방법으로 컬렉션에서 흐름이 작동할 수 있습니다.
- 컬렉션에 대해 각 단계를 한 번 실행합니다.
- 컬렉션의 각 요소에 대해 각 단계를 한 번 실행합니다.
- 컬렉션에 대해 일부 단계를 한 번 실행하고 컬렉션의 각 요소에 대해 한 번 다른 단계를 실행합니다.
흐름에서 컬렉션에 대해 작동하는 방법을 결정하려면 흐름이 연결되는 애플리케이션, 컬렉션을 처리할 수 있는지 여부 및 흐름에 달성하려는 애플리케이션을 알아야 합니다. 그런 다음 다음 항목의 정보를 사용하여 컬렉션을 처리하는 흐름에 단계를 추가할 수 있습니다.
4.5.1. 데이터 매퍼의 데이터 유형 및 컬렉션 정보
데이터 매퍼에서 필드는 다음과 같습니다.
-
단일 값을 저장하는 기본 형식입니다. 기본 유형의 예로는 부울 ,
char, byte , short , int , long , float 및 double이 있습니다.Examples of primitive types includeboolean, char ,byte,short,int,long,float, anddouble. 기본 유형은 단일 필드이므로 확장할 수 없습니다. - 다양한 유형의 여러 필드로 구성된 복잡한 유형입니다. 디자인 타임에 복잡한 유형의 하위 필드를 정의합니다. 데이터 매퍼에서는 하위 필드를 볼 수 있도록 복잡한 유형을 확장할 수 있습니다.
각 유형의 필드(primitive 및 complex)도 컬렉션이 될 수 있습니다. 컬렉션은 여러 값을 가질 수 있는 단일 필드입니다. 컬렉션의 항목 수는 런타임에 결정됩니다. 설계 시 데이터 매퍼에서 컬렉션은
![]() 로 표시됩니다. 데이터 매퍼 인터페이스에서 컬렉션을 확장할 수 있는지 여부는 해당 유형에 따라 결정됩니다. 컬렉션이 기본 형식인 경우 확장할 수 없습니다. 컬렉션이 복잡한 유형인 경우 데이터 매퍼는 컬렉션의 하위 필드를 표시하도록 확장할 수 있습니다. 각 필드에서 매핑할 수 있습니다.
로 표시됩니다. 데이터 매퍼 인터페이스에서 컬렉션을 확장할 수 있는지 여부는 해당 유형에 따라 결정됩니다. 컬렉션이 기본 형식인 경우 확장할 수 없습니다. 컬렉션이 복잡한 유형인 경우 데이터 매퍼는 컬렉션의 하위 필드를 표시하도록 확장할 수 있습니다. 각 필드에서 매핑할 수 있습니다.
다음은 몇 가지 예입니다.
-
ID는 기본 유형 필드(int)입니다. 런타임 시, 직원은 하나의ID만 가질 수 있습니다. 예를 들면ID=823입니다. 따라서ID는 컬렉션도 아닌 기본 유형입니다. 데이터 매퍼에서ID는 확장할 수 없습니다. -
email은 기본 유형 필드(문자열)입니다. 런타임 시 직원은 여러이메일값을 가질 수 있습니다. 예를 들어email<0>=aslan@home.com및email<1>=aslan@business.com. 따라서이메일은 컬렉션이기도 하는 기본 유형입니다. 데이터 매퍼는 를 사용하여
를 사용하여 이메일필드가 컬렉션이지만 기본 유형(하위 필드가 없음)이므로 확장할 수 없음을 나타냅니다. -
employee는ID및이메일을포함한 여러 하위 필드가 있는 복잡한 오브젝트 필드입니다. 런타임에는 회사에 많은직원이있기 때문에 직원도 컬렉션입니다.
설계 시 데이터 매퍼는
를 사용하여 직원이컬렉션임을 나타냅니다.employee필드는 하위 필드가 있는 복잡한 유형이므로 확장할 수 있습니다.
4.5.2. 처리 컬렉션 정보
컬렉션을 처리하는 흐름이 가장 쉬운 방법은 데이터 매퍼를 사용하여 소스 컬렉션에 있는 필드를 대상 컬렉션에 있는 필드에 매핑하는 것입니다. 많은 흐름의 경우 이 모든 것이 필요합니다. 예를 들어 흐름은 데이터베이스에서 직원 레코드 컬렉션을 가져온 다음 해당 레코드를 제도에 삽입할 수 있습니다.For example, a flow might obtain a collection of employee records from a database and then insert those records into a font. 데이터베이스 연결과 Google의 연결 간에 데이터 매퍼 단계는 데이터베이스 필드를 Google Cryostat 필드에 매핑합니다. 소스와 대상은 모두 컬렉션이므로 Fuse Online에서 흐름을 실행할 때 Google 연결을 한 번 호출합니다. 이 호출에서 Fuse Online은 레코드를 반복하고 축소를 올바르게 채웁니다.
일부 흐름에서는 컬렉션을 개별 오브젝트로 분할해야 할 수 있습니다. 예를 들어 데이터베이스에 연결하고 특정 날짜 이전에 사용하지 않는 경우 할당된 시간이 손실되는 직원 컬렉션을 가져오는 흐름을 고려해 보십시오. 그런 다음 흐름은 각 직원에게 이메일 알림을 보내야 합니다. 이 흐름에서는 데이터베이스 연결 후 분할 단계를 추가합니다. 그런 다음 직원 레코드의 소스 필드를 message를 전송하는 GPO 연결의 대상 필드에 매핑하는 데이터 매퍼 단계를 추가합니다. Fuse Online에서 흐름을 실행할 때 데이터 매퍼 단계와 각 직원에 대해 한 번의 controlPlane 연결을 실행합니다.
흐름에서 컬렉션을 분할한 후 흐름이 컬렉션에 있는 각 요소에 대해 한 번 일부 단계를 실행한 후 컬렉션에서 흐름이 다시 작동하도록 합니다. 이전 단락의 예제를 고려하십시오. 각 직원에 게 메시지를 전송 한 후, 지금, you want to add a list of the employees who were notified to a picture. 이 시나리오에서는 GPO 연결 후 집계 단계를 추가하여 직원 이름 컬렉션을 생성합니다. 그런 다음 소스 컬렉션의 필드를 대상 Google Cryostat 연결의 필드에 매핑하는 데이터 매퍼 단계를 추가합니다. Fuse Online에서 흐름을 실행할 때 컬렉션에 대해 새 데이터 매퍼 단계와 Google의 연결을 한 번 실행합니다.
이러한 시나리오는 흐름에서 컬렉션을 처리하는 가장 일반적인 시나리오입니다. 그러나 훨씬 더 복잡한 처리도 가능합니다. 예를 들어 컬렉션의 요소가 자체 컬렉션인 경우 다른 분할 및 집계 단계 내부의 분할 및 집계 단계를 중첩할 수 있습니다.For example, when the elements in a collection are themselves collections, you can nest split and aggregate steps inside other split and aggregate steps.
4.5.3. 데이터 매퍼를 사용하여 컬렉션 처리
흐름에서 단계가 컬렉션을 출력하고 흐름에 있는 후속 연결이 컬렉션을 입력으로 예상하는 경우 데이터 매퍼를 사용하여 컬렉션을 처리할 방법을 지정할 수 있습니다.
단계가 컬렉션을 출력하면 흐름 시각화가 단계에 대한 세부 정보에 컬렉션을 표시합니다. 예를 들면 다음과 같습니다.

컬렉션을 제공하는 단계와 매핑이 필요한 단계 앞에 데이터 매퍼 단계를 추가합니다. 흐름에서 이 데이터 매퍼 단계는 흐름의 다른 단계에 따라 달라집니다. 다음 이미지는 소스 컬렉션 필드에서 대상 컬렉션 필드로의 매핑을 보여줍니다.
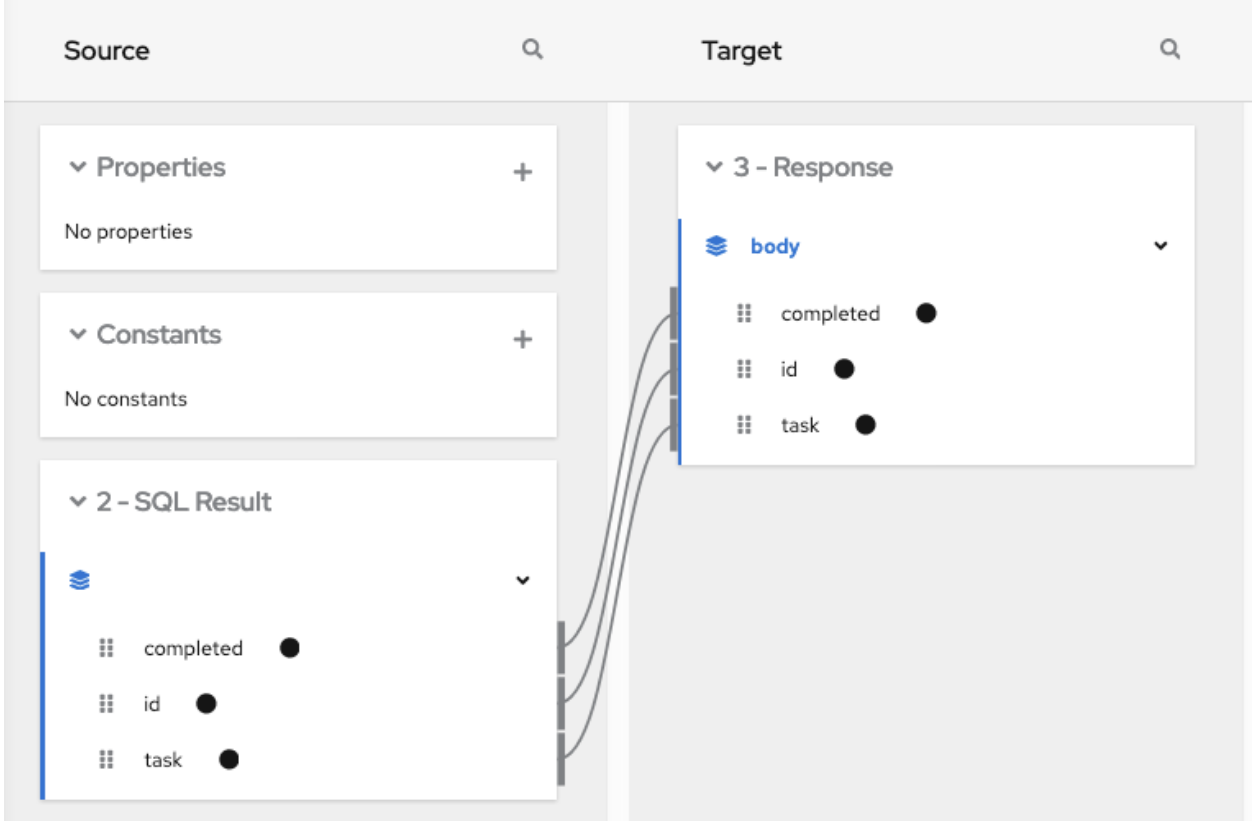
소스 및 대상 패널에서 데이터 매퍼는
![]() 를 표시하여 컬렉션을 나타냅니다.
를 표시하여 컬렉션을 나타냅니다.
컬렉션이 복잡한 유형인 경우 데이터 매퍼는 컬렉션의 하위 필드를 표시합니다. 각 필드에서 매핑할 수 있습니다.
소스 필드가 여러 컬렉션에 중첩된 경우 다음 조건 중 하나를 충족하는 대상 필드에 매핑할 수 있습니다.
target 필드는 소스 필드와 동일한 수의 컬렉션에 중첩되어 있습니다. 예를 들어 이러한 매핑이 허용됩니다.
-
/A<>/B<>/C
/D<>/E<>/F -
/A<>/B<>/C
/G<>/H/I<>/J
-
/A<>/B<>/C
대상 필드는 하나의 컬렉션에만 중첩됩니다. 예를 들어 이 매핑은 허용됩니다.
/A<>/B<>/C
/K<>/L 이 경우 데이터 매퍼는 깊이 우선 알고리즘을 사용하여 소스의 모든 값을 반복합니다. 데이터 매퍼는 발생 순서대로 소스 값을 단일 대상 컬렉션에 배치합니다.
다음 매핑은 허용되지 않습니다.
/A<>/B<>/C cannot-map-to /M<>/N/O<>/P<>/Q
Fuse Online에서 흐름을 실행하면 소스 컬렉션 요소를 반복하여 대상 컬렉션 요소를 채웁니다. 하나 이상의 소스 컬렉션 필드를 대상 컬렉션 또는 대상 컬렉션 필드에 매핑하는 경우 대상 컬렉션 요소에는 매핑된 필드에 대한 값만 포함됩니다.
소스 컬렉션의 소스 컬렉션 또는 필드를 컬렉션에 없는 대상 필드에 매핑하는 경우 Fuse Online에서 흐름을 실행할 때 소스 컬렉션의 마지막 요소 값만 할당합니다. 컬렉션의 다른 요소는 해당 매핑 단계에서 무시됩니다. 그러나 후속 매핑 단계는 소스 컬렉션의 모든 요소에 액세스할 수 있습니다.
연결에서 JSON 또는 Java 문서에 정의된 컬렉션을 반환하는 경우 데이터 매퍼는 일반적으로 소스 문서를 컬렉션으로 처리할 수 있습니다.
4.5.4. 분할 단계 추가
흐름을 실행하는 동안 연결이 개체 컬렉션을 반환하면 Fuse Online은 컬렉션에 대해 한 번 후속 단계를 실행합니다. 컬렉션에 있는 각 오브젝트에 대해 후속 단계를 한 번 실행하려면 분할 단계를 추가합니다. 예를 들어 Google의 연결에서는 행 오브젝트 컬렉션을 반환합니다. 각 행에 대해 후속 단계를 한 번 실행하려면 Google recording 연결 후 분할 단계를 추가합니다.
분할 단계에 대한 입력이 항상 컬렉션인지 확인합니다. 분할 단계가 컬렉션 유형이 아닌 소스 문서를 가져오는 경우 단계는 각 공간에 입력을 분할합니다. 예를 들어, Fuse Online은 "Hello" 및 "world!"의 두 요소로 "Hello world!"를 분할하고 흐름의 다음 단계에 이 두 요소를 전달합니다. 특히 XML 데이터는 컬렉션 유형이 아닙니다.
사전 요구 사항
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 이미 있습니다.
- 흐름 시각화에서 원본 데이터를 가져오는 연결은 데이터가 (Collection)임을 나타냅니다.In the flow visualization, the connection that obtains the source data indicates that the data is a (Collection).
절차
-
흐름 시각화에서 분할 단계를 추가할 위치에서
 를 클릭합니다.
를 클릭합니다.
- 분할 을 클릭합니다. 이 단계에는 구성이 필요하지 않습니다.
- 다음을 클릭합니다.
추가 정보
일반적으로 데이터 매퍼 단계를 추가하기 전에 분할 단계와 집계 단계를 추가하려고 합니다. 이는 데이터가 컬렉션인지 또는 개별 개체가 매핑에 영향을 미치든 때문입니다. 데이터 매퍼 단계를 추가한 다음 분할 단계를 추가하는 경우 일반적으로 매핑을 다시 수행해야 합니다. 마찬가지로 분할 또는 집계 단계를 제거하는 경우 매핑을 다시 실행해야 합니다.
4.5.5. 집계 단계 추가
흐름에서 Fuse Online을 사용하여 개별 개체에서 컬렉션을 생성하려는 집계 단계를 추가합니다. 실행 중에 집계 단계 후 각 개체에 대해 후속 단계를 한 번 실행하지 않고 Fuse Online은 컬렉션에 대해 한 번 후속 단계를 실행합니다.
흐름에 집계 단계를 추가할지 여부를 결정할 때 흐름의 연결을 고려하십시오. 분할 단계 이후 각 후속 연결에 대해 Fuse Online은 흐름 데이터의 각 요소에 대해 한 번 해당 애플리케이션에 연결합니다. 일부 연결의 경우 여러 번 연결하는 것이 좋습니다.
사전 요구 사항
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 이미 있습니다.
- 이전 단계에서는 컬렉션을 개별 오브젝트로 나눕니다.
절차
-
흐름 시각화에서 흐름에 집계 단계를 추가하려면
를 클릭합니다.
- 집계 를 클릭합니다. 이 단계에는 구성이 필요하지 않습니다.
- 다음을 클릭합니다.
추가 정보
일반적으로 데이터 매퍼 단계를 추가하기 전에 분할 및 집계 단계를 추가하려고 합니다. 이는 데이터가 컬렉션인지 또는 개별 개체가 매핑에 영향을 미치든 때문입니다. 데이터 매퍼 단계를 추가한 다음 집계 단계를 추가하는 경우 일반적으로 매핑을 다시 수행해야 합니다. 마찬가지로 집계 단계를 제거하는 경우 매핑을 다시 수행해야 합니다.
4.5.6. 흐름에서 컬렉션을 처리하는 예
이 간단한 통합은 Fuse Online에서 제공되는 샘플 데이터베이스에서 작업 컬렉션을 가져옵니다. 흐름은 컬렉션을 개별 작업 오브젝트로 분할한 다음 이러한 오브젝트를 필터링하여 수행된 작업을 찾습니다. 그런 다음 흐름은 컬렉션의 완료된 작업을 집계하고, 해당 컬렉션의 필드를 제도의 필드에 매핑하고, 완료된 작업 목록을 document에 추가하여 완료합니다.
아래 절차에서는 이 간단한 통합을 생성하는 방법을 설명합니다.
사전 요구 사항
- Google connection을 생성했습니다.
- Google이 액세스하는 계정에는 데이터베이스 레코드를 수신하기 위한 정보 표시가 있습니다.
절차
- 통합 생성을 클릭합니다.
시작 연결을 추가합니다.
- 연결 선택 페이지에서 PostgresDB 를 클릭합니다.
- 작업 선택 페이지에서 Periodic SQL Invocation 을 선택합니다.
-
SQL 문 필드에
Select * fromdo를입력하고 Next 를 클릭합니다.
이 연결은 작업 오브젝트 컬렉션을 반환합니다.
완료 연결을 추가합니다.
- 연결 선택 페이지에서 Google Connect를 클릭합니다.
- 작업 선택 페이지에서 시트에 대한 앱 값을 선택합니다.
- SpreadsheetId 필드에 작업 목록을 추가하려면 프로젝트 ID를 입력합니다.
-
Range 필드에 값을 추가할 대상 열로
A:B를 입력합니다. 첫 번째 열인 A 는 작업 ID에 대한 것입니다. 두 번째 열인 B 는 작업 이름에 사용됩니다. - 주요 Cryostat 및 값 입력 옵션에 대한 기본값을 수락하고 Next 를 클릭합니다.
Google#159s 연결은 컬렉션의 각 요소를 제도에 추가하여 흐름을 완료합니다.
흐름에 분할 단계를 추가합니다.
- 흐름 시각화에서 더하기 기호를 클릭합니다.
- 분할 을 클릭합니다.
흐름이 분할 단계를 실행한 후 결과는 개별 작업 오브젝트 세트입니다. Fuse Online은 개별 작업 오브젝트에 대해 흐름의 후속 단계를 한 번 실행합니다.
흐름에 필터 단계를 추가합니다.
- 흐름 시각화에서 분할 단계 후 더하기 기호를 클릭합니다.
기본 필터 를 클릭하고 다음과 같이 필터를 구성합니다.
-
첫 번째 필드를 클릭하고 평가할 데이터가 포함된 필드의 이름인
completed를 선택합니다. - 두 번째 필드에서 완료된 필드 값이 충족되어야 하는 조건으로 선택합니다.
-
세 번째 필드에서 완료된 필드에 있어야 하는 값으로
1을 지정합니다.1은 작업이 완료되었음을 나타냅니다.
-
첫 번째 필드를 클릭하고 평가할 데이터가 포함된 필드의 이름인
- 다음을 클릭합니다.
실행 중에 흐름은 각 작업 오브젝트에 대해 필터 단계를 한 번 실행합니다. 결과는 개별 완료된 작업 오브젝트 세트입니다.
흐름에 집계 단계를 추가합니다.
- 흐름 시각화에서 필터 단계 후 더하기 기호를 클릭합니다.
- 집계 를 클릭합니다.
이제 결과 집합에는 각 완료된 작업의 요소가 포함된 하나의 컬렉션이 포함됩니다.
흐름에 데이터 매퍼 단계를 추가합니다.
- 흐름 시각화에서 집계 단계 후 더하기 기호를 클릭합니다.
데이터 매퍼 를 클릭하고 SQL 결과 소스 컬렉션의 다음 필드를 Google Cryostat 대상 컬렉션에 매핑합니다.
- ID A
- 작업 B
- Done 을 클릭합니다.
- 게시 를 클릭합니다.
결과
통합이 실행되면 1분마다 샘플 데이터베이스에서 작업을 얻은 다음 완료된 작업을 조각 모음의 첫 번째 시트에 추가합니다. 통합은 작업 ID를 첫 번째 열인 A 에 매핑하고 작업 이름을 두 번째 열인 B 에 매핑합니다.