2.3. 클러스터
2.3.1. 클러스터 소개
클러스터는 동일한 스토리지 도메인을 공유하고 동일한 유형의 CPU(Intel 또는 AMD)를 갖는 호스트의 논리적 그룹화입니다. 호스트에 다른 CPU 모델이 있는 경우 모든 모델에 있는 기능만 사용합니다.
시스템의 각 클러스터는 데이터 센터에 속해야 하며 시스템의 각 호스트가 클러스터에 속해야 합니다. 가상 시스템은 클러스터의 모든 호스트에 동적으로 할당되며, 가상 시스템의 클러스터 및 설정에 정의된 정책에 따라 클러스터 간에 마이그레이션할 수 있습니다. 클러스터는 전원 및 로드 공유 정책을 정의할 수 있는 최상위 수준입니다.
클러스터에 속하는 호스트 수와 가상 시스템 수는 각각 Host Count(호스트 개수) 및 VM Count (VM 개수) 아래의 결과 목록에 표시됩니다.
클러스터는 가상 시스템 또는 Red Hat Gluster Storage 서버를 실행합니다. 이 두 가지 목적은 함께 사용할 수 없습니다. 단일 클러스터는 가상화 및 스토리지 호스트를 함께 지원할 수 없습니다.
Red Hat Virtualization은 설치 중에 기본 데이터 센터에 기본 클러스터를 생성합니다.
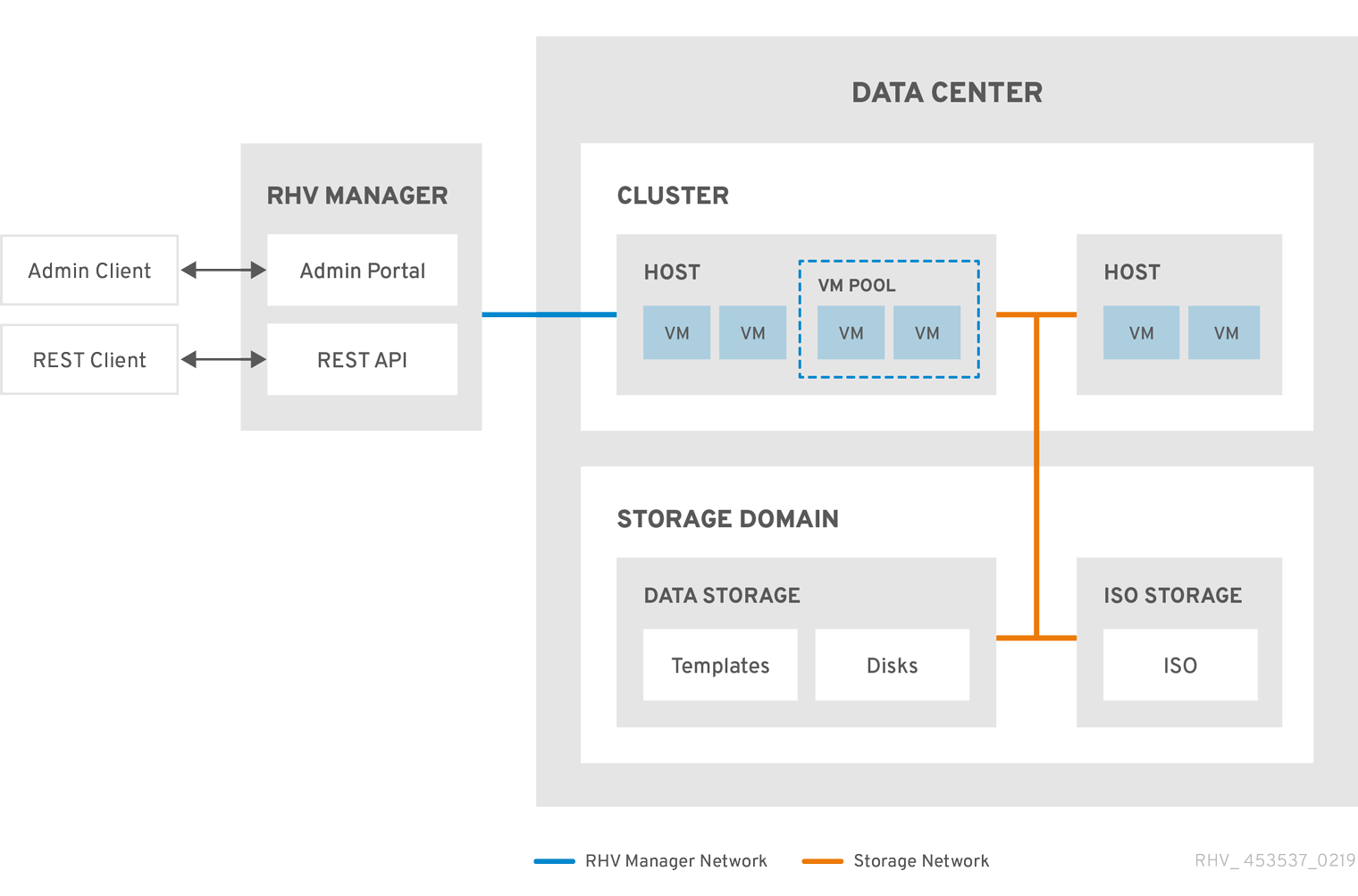
그림 2.2. Cluster
2.3.2. 클러스터 작업
일부 클러스터 옵션은 Gluster 클러스터에 적용되지 않습니다. Red Hat Virtualization과 함께 Red Hat Gluster Storage 사용에 대한 자세한 내용은 Red Hat Gluster Storage를 사용하여 Red Hat Virtualization 구성을 참조하십시오.
2.3.2.1. 새 클러스터 생성
데이터 센터에 여러 클러스터를 포함할 수 있으며 클러스터에 여러 호스트가 포함될 수 있습니다. 클러스터의 모든 호스트에는 동일한 CPU 아키텍처가 있어야 합니다. CPU 유형을 최적화하려면 클러스터를 생성하기 전에 호스트를 생성합니다. 클러스터를 생성한 후 Guide Me (안내) 버튼을 사용하여 호스트를 구성할 수 있습니다.
절차
- 를 클릭합니다.
- New (새로 만들기)를 클릭합니다.
- 드롭다운 목록에서 클러스터가 속할 Data Center (데이터 센터)를 선택합니다.
- 클러스터의 Name (이름) 및 Description (설명)을 입력합니다.
- Management Network (관리 네트워크) 드롭다운 목록에서 네트워크를 선택하여 관리 네트워크 역할을 할당합니다.
- CPU Architecture (CPU 아키텍처)를 선택합니다.
CPU Type (CPU 유형) 의 경우 이 클러스터의 일부가 될 호스트 중 가장 오래된 CPU 프로세서 제품군 을 선택합니다. CPU 유형은 가장 오래된 유형부터 최신 순으로 나열됩니다.
중요CPU 프로세서 제품군이 CPU 유형으로 지정한 호스트보다 오래된 호스트는 이 클러스터의 일부가 될 수 없습니다. 자세한 내용은 Whath ich CPU family should a RHEV3 or RHV4 cluster be set to?를 참조하십시오.
- 드롭다운 목록에서 클러스터의 FIPS 모드를 선택합니다.
- 드롭다운 목록에서 클러스터의 Compatibility Version (호환 버전)을 선택합니다.
- 드롭다운 목록에서 Switch Type (스위치 유형)을 선택합니다.
클러스터에서 Firewalld (default) 또는 iptables 중 하나를 선택합니다.
참고iptables 는 호환성 버전 4.2 또는 4.3이 있는 클러스터에서만 Red Hat Enterprise Linux 7 호스트에서만 지원됩니다. 방화벽 유형 firewalld가 있는 클러스터에만 Red Hat Enterprise Linux 8 호스트를 추가할 수 있습니다.
- Enable Virt Service (가상 서비스 사용) 또는 Enable Gluster Service (Gluster 서비스 활성화) 확인란을 선택하여 클러스터가 가상 시스템 호스트 또는 Gluster 지원 노드로 채워질지 여부를 정의합니다.
- 선택적으로 Enable to set VM maintenance reason (VM 유지 관리 이유 설정) 확인란을 선택하여 Manager에서 가상 시스템을 종료할 때 선택적 reason 필드를 활성화하여 관리자가 유지 관리에 대한 설명을 제공할 수 있습니다.
- 선택적으로 Enable to set Host maintenance reason (호스트 유지 관리 이유 설정) 확인란을 선택하여 Manager에서 호스트를 유지 관리 모드로 전환할 때 선택적 reason 필드를 활성화하여 관리자가 유지 관리에 대한 설명을 제공할 수 있습니다.
- 선택적으로 /dev/hwrng 소스 (외부 하드웨어 장치) 확인란을 선택하여 클러스터의 모든 호스트에서 사용할 임의 번호 생성기 장치를 지정합니다. /dev/urandom 소스 (Linux 제공 장치)는 기본적으로 활성화되어 있습니다.
- Optimization( 최적화 ) 탭을 클릭하여 클러스터의 임계값을 공유하는 메모리 페이지를 선택하고, 클러스터의 호스트에서 CPU 스레드 처리 및 메모리 증대를 선택적으로 활성화합니다.
- Migration Policy(마이그레이션 정책 ) 탭을 클릭하여 클러스터의 가상 시스템 마이그레이션 정책을 정의합니다.
- 선택 사항으로 스케줄링 정책을 구성하고, 스케줄러 최적화 설정을 구성하고, 클러스터에서 호스트에 대해 신뢰할 수 있는 서비스를 활성화하고, HA 예약을 활성화하고, 일련 번호 정책을 선택하려면 Scheduling Policy (스케줄링 정책) 탭을 클릭합니다.
- Console(콘솔 ) 탭을 클릭하여 글로벌 SPICE 프록시(있는 경우 선택적으로 재정의)를 클릭하고 클러스터의 호스트에 대한 SPICE 프록시 주소를 지정합니다.
- 펜싱 정책 탭을 클릭하여 클러스터에서 펜싱을 활성화하거나 비활성화하고 펜싱 옵션을 선택합니다.
- MAC Address Pool(MAC 주소 풀 ) 탭을 클릭하여 클러스터의 기본 풀 이외의 MAC 주소 풀을 지정합니다. MAC 주소 풀 생성, 편집 또는 제거에 대한 자세한 내용은 MAC Address Pools 를 참조하십시오.
- )를 클릭하여 클러스터를 생성하고 Cluster - Guide Me(클러스터 - 안내 ) 창을 엽니다.
-
Guide Me (안내) 창에는 클러스터에 대해 구성해야 하는 엔터티가 나열됩니다. Configure Later(나중에 구성) 버튼을 클릭하여 이러한 엔터티 또는 postpone 구성을 구성합니다. 클러스터를 선택하고 추가 작업 (
 )을 클릭한 다음 가이드를 클릭하여 구성을 다시 시작할 수 있습니다.
)을 클릭한 다음 가이드를 클릭하여 구성을 다시 시작할 수 있습니다.
2.3.2.2. 설명된 일반 클러스터 설정
아래 표는 New Cluster(새 클러스터) 및 Edit Cluster (클러스터 편집) 창의 General(일반 ) 탭에 대한 설정을 설명합니다. )를 클릭하면 유효하지 않은 항목이 노란색으로 설명되어 변경 사항이 수락되지 않습니다. 또한 필드 프롬프트는 예상 값 또는 값 범위를 나타냅니다.
| 필드 | 설명/액션 |
|---|---|
| 데이터 센터 | 클러스터를 포함할 데이터 센터입니다. 클러스터를 추가하기 전에 데이터 센터를 생성해야 합니다. |
| 이름 | 클러스터의 이름입니다. 이 텍스트 필드에는 40자 제한이 있으며 대문자와 소문자, 숫자, 하이픈, 밑줄이 조합된 고유한 이름이어야 합니다. |
| 설명/주석 | 클러스터 또는 추가 노트에 대한 설명입니다. 이러한 필드는 권장되지만 필수는 아닙니다. |
| 관리 네트워크 | 관리 네트워크 역할이 할당될 논리적 네트워크입니다. 기본값은 ovirtmgmt 입니다. 마이그레이션 네트워크가 소스 또는 대상 호스트에 올바르게 연결되지 않은 경우에도 이 네트워크가 가상 머신을 마이그레이션하는 데 사용됩니다. 기존 클러스터에서 관리 네트워크는 세부 정보 보기의 Logical Networks(논리 네트워크) 탭에서 Manage Networks (네트워크 관리) 버튼을 사용해서만 변경할 수 있습니다. |
| CPU 아키텍처 | 클러스터의 CPU 아키텍처입니다. 클러스터의 모든 호스트는 지정한 아키텍처를 실행해야 합니다. 선택한 CPU 아키텍처에 따라 다양한 CPU 유형을 사용할 수 있습니다.
|
| CPU 유형 | 클러스터에서 가장 오래된 CPU 제품군. CPU 유형 목록은 계획 및 사전 요구 사항 가이드의 CPU 요구 사항을 참조하십시오. 중요한 중단 없이 클러스터를 생성한 후에는 이를 변경할 수 없습니다. CPU 유형을 클러스터에서 가장 오래된 CPU 모델로 설정합니다. 모든 모델에 있는 기능만 사용할 수 있습니다. Intel 및 AMD CPU 유형의 경우 나열된 CPU 모델은 가장 오래된 CPU 모델에서 최신 버전까지 논리적 순서로 되어 있습니다. |
| 칩셋/방지 유형 | 이 설정은 클러스터의 CPU 아키텍처 가 x86_64 로 설정된 경우에만 사용할 수 있습니다. 이 설정은 칩셋 및 펌웨어 유형을 지정합니다. 옵션은 다음과 같습니다.
자세한 내용은 관리 가이드 의 UEFI 및 Q35 칩셋 을 참조하십시오. |
| BIOS를 사용하여 기존 VM/Templates를 1440fx에서 Q35 Chipset으로 변경 | 클러스터의 칩셋이 I440FX에서 Q35로 변경될 때 이 확인란을 선택하여 기존 워크로드를 변경합니다. |
| FIPS 모드 | 클러스터에서 사용하는 FIPS 모드입니다. 클러스터의 모든 호스트는 사용자가 지정하는 FIPS 모드를 실행해야 합니다. 그렇지 않으면 작동하지 않습니다.
|
| Compatibility Version | Red Hat Virtualization의 버전. 데이터 센터에 지정된 버전보다 이전에 버전을 선택할 수 없습니다. |
| 스위치 유형 | 클러스터에서 사용하는 스위치 유형입니다. Linux Bridge 는 표준 Red Hat Virtualization 스위치입니다. OVS 는 Open vSwitch 네트워킹 기능을 지원합니다. |
| 방화벽 유형 | 클러스터의 호스트 방화벽 유형을 firewalld (기본값) 또는 iptables로 지정합니다. iptables 는 호환성 버전 4.2 또는 4.3이 있는 클러스터에서만 Red Hat Enterprise Linux 7 호스트에서만 지원됩니다. 방화벽 유형 firewalld 가 있는 클러스터에만 Red Hat Enterprise Linux 8 호스트를 추가할 수 있습니다. 기존 클러스터의 방화벽 유형을 변경하는 경우 변경 사항을 적용하려면 클러스터의 모든 호스트를 다시 설치해야 합니다. |
| 기본 네트워크 공급자 | 클러스터가 사용할 기본 외부 네트워크 공급자를 지정합니다. OVN(Open Virtual Network)을 선택하면 클러스터에 추가된 호스트가 OVN 공급자와 통신하도록 자동으로 구성됩니다. 기본 네트워크 공급자를 변경하는 경우 변경 사항을 적용하려면 클러스터의 모든 호스트를 다시 설치해야 합니다. |
| 최대 로그 메모리 임계값 |
최대 메모리 사용량의 로깅 임계값을 백분율로 지정하거나 절대 값으로 MB로 지정합니다. 호스트의 메모리 사용량이 백분율 값을 초과하거나 호스트의 사용 가능한 메모리가 절대 값(MB)보다 낮은 경우 메시지가 기록됩니다. 기본값은 |
| 가상 서비스 활성화 | 이 확인란을 선택하면 이 클러스터의 호스트를 사용하여 가상 시스템을 실행합니다. |
| Gluster 서비스 활성화 | 이 확인란을 선택하면 이 클러스터의 호스트가 Red Hat Gluster Storage Server 노드로 사용되며 가상 시스템 실행에 대해서는 사용되지 않습니다. |
| 기존 Gluster 구성 가져오기 | 이 확인란은 Enable Gluster Service (Gluster 서비스 활성화) 라디오 버튼을 선택한 경우에만 사용할 수 있습니다. 이 옵션을 사용하면 기존 Gluster 지원 클러스터 및 연결된 모든 호스트를 Red Hat Virtualization Manager에 가져올 수 있습니다. 가져온 클러스터의 각 호스트에는 다음 옵션이 필요합니다.
|
| 추가 임의 번호 생성기 소스 | 확인란을 선택하면 클러스터의 모든 호스트에 사용 가능한 추가 임의 번호 생성기 장치가 있습니다. 따라서 난수 생성기 장치에서 가상 머신으로 엔트로피의 패스스루를 사용할 수 있습니다. |
| Gluster Tuned 프로필 | 이 확인란은 Gluster Service 사용 확인란이 선택된 경우에만 사용할 수 있습니다. 이 옵션은 호스트 성능에 도움이 되는 더러운 메모리 페이지를 더 적극적으로 쓸 수 있도록 virtual-host 튜닝 프로필을 지정합니다. |
2.3.2.3. 최적화 설정 설명
메모리 고려 사항
메모리 페이지 공유를 통해 가상 머신은 다른 가상 시스템에서 사용하지 않는 메모리를 활용하여 할당된 메모리의 최대 200%를 사용할 수 있습니다. 이 프로세스는 Red Hat Virtualization 환경의 가상 머신이 모두 동시에 실행되는 것이 아니라는 가정을 기반으로 하며, 미사용 메모리를 특정 가상 시스템에 일시적으로 할당할 수 있다는 가정을 토대로 합니다.
CPU 고려 사항
CPU 집약적이 아닌 워크로드의 경우 호스트의 코어 수보다 큰 총 프로세서 코어 수를 사용하여 가상 머신을 실행할 수 있습니다(단일 가상 머신의 프로세서 코어 수는 호스트의 코어 수를 초과하지 않아야 함). 다음과 같은 이점을 얻을 수 있습니다.
- 더 많은 수의 가상 시스템을 실행하여 하드웨어 요구 사항을 줄일 수 있습니다.
- 가상 코어 수가 호스트 코어 수와 호스트 스레드 수 사이의 경우와 같이 가능하지 않은 CPU 토폴로지를 사용하여 가상 시스템을 구성할 수 있습니다.
- 최상의 성능, 특히 CPU 사용량이 많은 워크로드 의 경우 호스트와 가상 시스템의 동일한 토폴로지를 사용해야 하므로 호스트와 가상 시스템에 동일한 캐시 사용량이 필요합니다. 호스트에 하이퍼 스레딩이 활성화된 경우 QEMU는 호스트의 하이퍼 스레드를 코어로 처리하므로 가상 시스템이 여러 스레드가 있는 단일 코어에서 실행되고 있음을 인식하지 못합니다. 이 동작은 가상 시스템의 성능에 영향을 줄 수 있습니다. 호스트 코어의 하이퍼스레드에 실제로 해당하는 가상 코어는 동일한 호스트 코어의 다른 하이퍼스레드와 단일 캐시를 공유할 수 있기 때문입니다. 가상 시스템은 이를 별도의 코어로 취급합니다.
아래 표는 New Cluster(새 클러스터) 및 Edit Cluster (클러스터 편집) 창의 Optimization (최적화) 탭에 대한 설정을 설명합니다.
| 필드 | 설명/액션 |
|---|---|
| 메모리 최적화 |
|
| CPU 스레드 | Count Threads as Cores 확인란을 선택하면 호스트에서 호스트의 코어 수보다 큰 총 프로세서 코어 수를 사용하여 가상 머신을 실행할 수 있습니다(단일 가상 시스템의 프로세서 코어 수는 호스트의 코어 수를 초과할 수 없음). 이 확인란을 선택하면 노출된 호스트 스레드가 가상 시스템에서 사용할 수 있는 코어로 처리됩니다. 예를 들어 코어당 2개 스레드(총 48개 스레드)가 있는 24코어 시스템은 각각 48개 코어의 가상 시스템을 실행할 수 있으며 호스트 CPU 부하를 계산하기 위한 알고리즘은 사용 가능한 코어 수의 두 배에 비해 부하를 비교합니다. |
| 메모리 증대 | Enable Memory balloon Optimization 확인란을 선택하면 이 클러스터의 호스트에서 실행되는 가상 시스템에서 메모리 과다 할당이 활성화됩니다. 이 확인란을 선택하면 메모리 과다 할당 관리자(MoM)가 가능한 경우 모든 가상 시스템의 메모리 크기가 보장된 메모리 크기 제한으로 ballooning을 시작합니다.
balloon을 실행하려면 가상 시스템에 관련 드라이버가 있는 balloon 장치가 있어야 합니다. 특히 제거되지 않는 한 각 가상 시스템에는 balloon 장치가 포함되어 있습니다. 이 클러스터의 각 호스트는 상태가 일부 시나리오에서 증대는 KSM과 충돌할 수 있다는 점을 이해하는 것이 중요합니다. 이러한 경우 MoM은 충돌을 최소화하기 위해 balloon 크기를 조정하려고 합니다. 또한 일부 시나리오에서는 가상 시스템의 하위 최적화 성능을 유발할 수 있습니다. 관리자는 ballooning 최적화를 주의해서 사용하는 것이 좋습니다. |
| KSM 제어 | Enable KSM( KSM 활성화) 확인란을 선택하면 MoM이 필요할 때 KSM(Kernel Same-page Merging)을 실행하고 CPU 비용을 초과하는 메모리 절약 효과를 얻을 수 있습니다. |
2.3.2.4. 마이그레이션 정책 설정 설명
마이그레이션 정책은 호스트 장애 발생 시 가상 시스템을 실시간 마이그레이션하기 위한 조건을 정의합니다. 이러한 조건에는 마이그레이션 중 가상 머신 가동 중지 시간, 네트워크 대역폭, 가상 시스템의 우선 순위 지정 방법이 포함됩니다.
| policy | 설명 |
|---|---|
| 클러스터 기본값(최소 다운타임) |
|
| 가동 중지 시간 최소화 | 일반적인 상황에서 가상 시스템을 마이그레이션할 수 있는 정책입니다. 가상 시스템에는 다운타임이 발생하지 않아야 합니다. 가상 머신 마이그레이션이 오랜 시간 후에 수렴되지 않으면 마이그레이션이 중단됩니다(최대 500밀리초의 QEMU 반복에 종속됨). 게스트 에이전트 후크 메커니즘이 활성화되어 있습니다. |
| 복사 후 마이그레이션 | 사용 시 사후 복사 마이그레이션은 소스 호스트에서 가상 시스템 vCPU 마이그레이션 일시 중단, 최소 메모리 페이지만 전송하고, 대상 호스트에서 가상 시스템 vCPU를 활성화하며, 가상 시스템이 대상 호스트에서 실행 중인 동안 나머지 메모리 페이지를 전송합니다. 사후 복사 정책은 먼저 사전 복사를 시도하여 수렴이 발생할 수 있는지 확인합니다. 오랜 시간 후에 가상 머신 마이그레이션이 수렴되지 않으면 마이그레이션이 사후 복사로 전환됩니다. 따라서 마이그레이션된 가상 시스템의 다운타임을 크게 줄이고 소스 가상 시스템의 메모리 페이지 변경 속도와 관계없이 마이그레이션을 완료할 수 있습니다. 표준 사전 복사 마이그레이션을 통해 마이그레이션할 수 없는 지속적인 사용으로 가상 시스템을 마이그레이션하는 것이 최적입니다. 이 정책의 단점은 복사 후 단계에서 누락된 메모리 부분이 호스트 간에 전송되므로 가상 시스템이 상당히 느려질 수 있다는 것입니다. 주의 사후 복사 프로세스를 완료하기 전에 네트워크 연결이 끊어지면 Manager가 실행 중인 가상 시스템을 일시 중지한 다음 종료합니다. 가상 머신 가용성이 중요하거나 마이그레이션 네트워크가 불안정한 경우에는 사후 복사 마이그레이션을 사용하지 마십시오. |
| 필요한 경우 워크로드 일시 중단 | 워크로드가 많은 가상 시스템을 포함하여 대부분의 상황에서 가상 시스템을 마이그레이션할 수 있는 정책입니다. 이로 인해 가상 머신에 다른 일부 설정보다 더 중요한 다운 타임이 발생할 수 있습니다. 극심한 워크로드로 인해 마이그레이션이 중단될 수 있습니다. 게스트 에이전트 후크 메커니즘이 활성화되어 있습니다. |
대역폭 설정은 호스트당 나가는 마이그레이션과 들어오는 마이그레이션의 최대 대역폭을 정의합니다.
| policy | 설명 |
|---|---|
| auto | 대역폭은 데이터 센터 Host Network QoS 의 Rate Limit [Mbps] 설정에서 복사됩니다. 속도 제한이 정의되지 않은 경우 네트워크 인터페이스를 보내고 받는 최소 링크 속도로 계산됩니다. 속도 제한을 설정하지 않고 링크 속도를 사용할 수 없는 경우 호스트 전송 시 로컬 VDSM 설정에 의해 결정됩니다. |
| 하이퍼바이저 기본값 | 대역폭은 호스트 전송 시 로컬 VDSM 설정을 통해 제어됩니다. |
| 사용자 지정 | 사용자 정의(Mbps). 이 값은 동시 마이그레이션 수로 나뉩니다(기본값은 진행 중 및 나가는 마이그레이션을 고려하는 2). 따라서 사용자 정의 대역폭은 모든 동시 마이그레이션을 수용할 수 있을 만큼 충분히 커야 합니다.
예를 들어 |
복원력 정책은 가상 시스템이 마이그레이션의 우선 순위를 지정하는 방법을 정의합니다.
| 필드 | 설명/액션 |
|---|---|
| 가상 머신 마이그레이션 | 정의된 우선 순위에 따라 모든 가상 시스템을 마이그레이션합니다. |
| Migrate only Highly Available Virtual Machines | 다른 호스트 과부하를 방지하기 위해 고가용성 가상 시스템만 마이그레이션합니다. |
| 가상 머신을 마이그레이션하지 않음 | 가상 시스템이 마이그레이션되지 않도록 합니다. |
| 필드 | 설명/액션 |
|---|---|
| 마이그레이션 암호화 활성화 | 마이그레이션 중에 가상 시스템을 암호화할 수 있습니다.
|
| 병렬 마이그레이션 | 사용할 병렬 마이그레이션 연결의 여부와 수를 지정할 수 있습니다.
|
| VM 마이그레이션 연결 수 | 이 설정은 Custom 을 선택한 경우에만 사용할 수 있습니다. 2에서 255 사이의 사용자 정의 병렬 마이그레이션 수입니다. |
2.3.2.5. 설명된 스케줄링 정책 설정
스케줄링 정책을 사용하면 사용 가능한 호스트 간에 가상 시스템의 사용 및 배포를 지정할 수 있습니다. 클러스터의 호스트 전체에서 자동 로드 밸런싱을 활성화하도록 스케줄링 정책을 정의합니다. 스케줄링 정책에 관계없이 과부하된 CPU가 있는 호스트에서 가상 시스템이 시작되지 않습니다. 기본적으로 5분 동안 80% 이상의 부하가 있는 경우 호스트의 CPU가 과부하로 간주되지만 스케줄링 정책을 사용하여 이러한 값을 변경할 수 있습니다. 자세한 내용은 관리 가이드 의 스케줄링 정책을 참조하십시오.
| 필드 | 설명/액션 |
|---|---|
| 정책 선택 | 드롭다운 목록에서 정책을 선택합니다.
|
| 속성 | 다음 속성은 선택한 정책에 따라 표시됩니다. 필요한 경우 편집합니다.
|
| 스케줄러 최적화 | 호스트 가중치/주문에 대한 스케줄링을 최적화합니다.
|
| 신뢰할 수 있는 서비스 활성화 |
OpenAttestation 서버와의 통합을 활성화합니다. 이를 활성화하기 전에 |
| HA 예약 활성화 | Manager를 활성화하여 고가용성 가상 시스템의 클러스터 용량을 모니터링합니다. Manager는 기존 호스트가 예기치 않게 실패하는 경우 마이그레이션하기 위해 고가용성으로 지정된 가상 시스템을 위해 적절한 용량이 클러스터 내에 있도록 합니다. |
| 일련 번호 정책 | 클러스터의 각 새 가상 머신에 일련 번호를 할당하기 위한 정책을 구성합니다.
|
| 사용자 정의 직렬 번호 | 클러스터의 새 가상 머신에 적용할 사용자 정의 일련 번호를 지정합니다. |
호스트의 사용 가능한 메모리가 20% 미만으로 떨어지면 metal .Controllers.Balloon - INFO ballooning guest:half1 from 1096400~172580 과 같은 ballooning 명령이 /var/log/vdsm/mom.log 에 기록됩니다./var/log/vdsm/mom.log 는 Memory Overcommit Manager 로그 파일입니다.
2.3.2.6. MaxFreeMemoryForOverUtilized 및 MinFreeMemoryForUnderUtilized 클러스터 스케줄링 정책 속성
스케줄러에는 현재 클러스터 스케줄링 정책 및 해당 매개 변수에 따라 가상 시스템을 마이그레이션하는 백그라운드 프로세스가 있습니다. 정책의 다양한 기준과 상대적 가중치에 따라 스케줄러는 호스트를 소스 호스트 또는 대상 호스트로 계속 분류하고 개별 가상 시스템을 이전에서 후자로 마이그레이션합니다.
다음 설명은 evenly_distributed 및 power_ saving 클러스터 스케줄링 정책이 MaxFreeMemoryForOverUtilized 및 MinFreeMemoryForUnderUtilized 속성과 상호 작용하는 방법을 설명합니다. 두 정책 모두 CPU 및 메모리 로드를 고려하지만 CPU 로드는 MaxFreeMemoryForOverUtilized 및 MinFreeMemoryForUnderUtilized 속성과 관련이 없습니다.
MaxFreeMemoryForOverUtilized 및 MinFreeMemoryForUnderUtilized 속성을 evenly_distributed 정책의 일부로 정의하는 경우:
- MaxFreeMemoryForOverUtilized 보다 사용 가능한 메모리가 적은 호스트는 활용도가 높으며 소스 호스트가 됩니다.
- MinFreeMemoryForUnderUtilized 보다 사용 가능한 메모리가 더 많은 호스트는 활용도가 떨어지고 대상 호스트가 됩니다.
- MaxFreeMemoryForOverUtilized 가 정의되지 않은 경우 스케줄러는 메모리 로드를 기반으로 가상 머신을 마이그레이션하지 않습니다. (CPU 로드와 같은 정책의 다른 기준에 따라 가상 머신을 계속 마이그레이션합니다.)
- MinFreeMemoryForUnderUtilized 가 정의되지 않은 경우 스케줄러는 대상 호스트가 될 수 있는 모든 호스트를 고려합니다.
power_saving 정책의 일부로 MaxFreeMemoryForOver Utilized 및 MinFreeMemoryForUnderUtilized 속성을 정의하는 경우:
- MaxFreeMemoryForOverUtilized 보다 사용 가능한 메모리가 적은 호스트는 활용도가 높으며 소스 호스트가 됩니다.
- MinFreeMemoryForUnderUtilized 보다 사용 가능한 메모리가 많은 호스트는 활용도가 떨어지고 소스 호스트가 됩니다.
- MaxFreeMemoryForOverUtilized 보다 사용 가능한 메모리가 많은 호스트는 활용도가 높지 않고 대상 호스트가 됩니다.
- MinFreeMemoryForUnderUtilized 보다 사용 가능한 메모리가 적은 호스트는 충분히 활용되지 않으며 대상 호스트가 됩니다.
- 스케줄러는 활용도가 떨어지거나 활용도가 낮은 호스트로 가상 시스템을 마이그레이션하는 것을 선호합니다. 이러한 호스트가 충분하지 않은 경우 스케줄러는 가상 시스템을 활용도가 낮은 호스트로 마이그레이션할 수 있습니다. 활용도가 낮은 호스트가 이러한 용도로 필요하지 않은 경우 스케줄러는 전원을 끌 수 있습니다.
- MaxFreeMemoryForOverUtilized 가 정의되지 않은 경우 호스트가 과도하게 사용되지 않습니다. 따라서 활용도가 낮은 호스트만 소스 호스트이며 대상 호스트에는 클러스터의 모든 호스트가 포함됩니다.
- MinFreeMemoryForUnderUtilized 가 정의되지 않은 경우 활용도가 높은 호스트만 소스 호스트이며 활용도가 높은 호스트는 대상 호스트입니다.
호스트가 모든 물리적 CPU를 과도하게 사용하지 않도록 하려면 가상 CPU를 물리적 CPU와 물리적 CPU 비율 - 0.1~2.9 사이의 값으로 가상 CPU를 정의합니다. 이 매개변수를 설정하면 가상 머신을 예약할 때 CPU 사용률이 더 낮은 호스트가 선호됩니다.
가상 머신을 추가하면 비율이 제한을 초과할 경우, CloudEvent puToPhysicalCpuRatio 와 CPU 사용률이 모두 고려됩니다.
실행 중인 환경에서 호스트가 2.5를 초과하면 일부 가상 머신이 로드 밸런싱이 되고 더 낮은ical CpuRatio 가 있는 호스트로 이동할 수 있습니다.
추가 리소스
2.3.2.7. 설명된 클러스터 콘솔 설정
아래 표는 New Cluster(새 클러스터) 및 Edit Cluster (클러스터 편집) 창의 Console(콘솔 ) 탭에 대한 설정을 설명합니다.
| 필드 | 설명/액션 |
|---|---|
| 클러스터용 SPICE 프록시 정의 | 글로벌 구성에 정의된 SPICE 프록시 재정의를 사용하려면 이 확인란을 선택합니다. 이 기능은 사용자가(예: VM 포털을 통해 연결) 하이퍼바이저가 있는 네트워크 외부에 있는 경우 유용합니다. |
| 재정의된 SPICE 프록시 주소 | SPICE 클라이언트가 가상 머신에 연결되는 프록시. 주소는 다음과 같은 형식이어야 합니다. |
2.3.2.8. 설명된 펜싱 정책 설정
아래 표는 New Cluster(새 클러스터) 및 Edit Cluster (클러스터 편집) 창의 Fencing Policy(펜싱 정책 ) 탭의 설정을 설명합니다.
| 필드 | 설명/액션 |
|---|---|
| 펜싱 활성화 | 클러스터에서 펜싱을 활성화합니다. 펜싱은 기본적으로 활성화되어 있지만 필요한 경우 비활성화할 수 있습니다. 예를 들어 임시 네트워크 문제가 발생하거나 필요한 경우 관리자는 진단 또는 유지 관리 작업이 완료될 때까지 펜싱을 비활성화할 수 있습니다. 펜싱이 비활성화된 경우 무응답 호스트에서 실행 중인 고가용성 가상 시스템은 다른 위치에서는 재시작되지 않습니다. |
| 호스트에 스토리지에 라이브 리스가 있는 경우 펜싱을 건너뜁니다 | 이 확인란을 선택하면 무응답인 클러스터의 모든 호스트가 펜싱되지 않고 스토리지에 연결된 호스트는 펜싱되지 않습니다. |
| 클러스터 연결 문제에서 펜싱 건너 뛰기 | 이 확인란을 선택하면 연결 문제가 발생한 클러스터의 호스트 백분율이 정의된 임계값 보다 크거나 같은 경우 펜싱이 일시적으로 비활성화됩니다. 임계값 은 드롭다운 목록에서 선택되며 사용 가능한 값은 25,50,75, 100 입니다. |
| gluster brick이 작동 중인 경우 펜싱을 건너뜁니다 | 이 옵션은 Red Hat Gluster Storage 기능이 활성화된 경우에만 사용할 수 있습니다. 이 확인란을 선택하면 brick이 실행 중이고 다른 피어에서 도달할 수 있는 경우 펜싱을 건너뜁니다. 섀퍼 2를 참조하십시오. Fencing Policies(펜싱 정책) 및 부록 A를 사용하여 고가용성을 구성합니다. 자세한 내용은 Red Hat Hyperconverged Infrastructure를 유지 관리하는 Red Hat Gluster Storage용 펜싱 정책 입니다. |
| gluster 쿼럼이 충족되지 않는 경우 펜싱을 건너뜁니다. | 이 옵션은 Red Hat Gluster Storage 기능이 활성화된 경우에만 사용할 수 있습니다. 이 확인란을 선택하면 brick이 실행 중이고 호스트를 종료하면 펜싱을 건너뛰면 쿼럼이 손실됩니다. 섀퍼 2를 참조하십시오. Fencing Policies(펜싱 정책) 및 부록 A를 사용하여 고가용성을 구성합니다. 자세한 내용은 Red Hat Hyperconverged Infrastructure를 유지 관리하는 Red Hat Gluster Storage용 펜싱 정책 입니다. |
2.3.2.9. 클러스터에서 호스트의 로드 및 전원 관리 정책 설정
evenly_distributed 및 power_saving 스케줄링 정책을 사용하면 허용 가능한 메모리 및 CPU 사용량 값을 지정할 수 있으며, 가상 시스템을 호스트로 또는 호스트에서 마이그레이션해야 하는 시점을 지정할 수 있습니다. vm_evenly_distributed 스케줄링 정책은 가상 시스템 수에 따라 호스트 간에 가상 시스템을 균등하게 배포합니다. 클러스터의 호스트 전체에서 자동 로드 밸런싱을 활성화하도록 스케줄링 정책을 정의합니다. 각 스케줄링 정책에 대한 자세한 내용은 클러스터 스케줄링 정책 설정을 참조하십시오.
절차
-
(클러스터)를 클릭하고 클러스터를 선택합니다. - Edit(편집 )를 클릭합니다.
- Scheduling Policy(스케줄링 정책 ) 탭을 클릭합니다.
다음 정책 중 하나를 선택합니다.
- none
vm_evenly_distributed
- HighVmCount 필드에서 부하 분산을 활성화하려면 하나 이상의 호스트에서 실행해야 하는 최소 가상 시스템 수를 설정합니다.
- 가장 활용도가 높은 호스트의 가상 시스템 수와 MigrationThreshold(마이그레이션Threshold ) 필드에서 가장 활용도가 가장 적은 호스트의 가상 시스템 수 간의 허용 가능한 최대 차이를 정의합니다.
- SpmVmGrace 필드의 SPM 호스트에 예약할 가상 시스템의 슬롯 수를 정의합니다.
- 선택적으로 HeSparesCount 필드에 마이그레이션하거나 종료하는 경우 Manager 가상 머신을 시작하기에 충분한 여유 메모리를 예약하는 추가 자체 호스팅 엔진 노드 수를 입력합니다. 자세한 내용은 Configuring Memory Slots Reserved for the self-hosted engine 에서 참조하십시오.
evenly_distributed
- 스케줄링 정책이 CpuOverCommitDurationMinutes 필드에서 작업을 수행하기 전에 호스트가 정의된 사용률 값 외부에서 CPU 부하를 실행할 수 있는 시간(분 단위)을 설정합니다.
- HighUtilization (고유률) 필드의 다른 호스트로 마이그레이션하기 시작하는 CPU 사용률을 입력합니다.
- 선택적으로 HeSparesCount 필드에 마이그레이션하거나 종료하는 경우 Manager 가상 머신을 시작하기에 충분한 여유 메모리를 예약하는 추가 자체 호스팅 엔진 노드 수를 입력합니다. 자세한 내용은 Configuring Memory Slots Reserved for the self-hosted engine 에서 참조하십시오.
선택적으로 호스트가 모든 물리적 CPU를 과도하게 사용하지 않도록 하려면 가상 CPU를 물리적 CPU와 물리적 CPU 비율 - 0.1에서 2.9 사이의 값을 사용하여 가상 CPU를 정의합니다. 이 매개변수를 설정하면 가상 머신을 예약할 때 CPU 사용률이 더 낮은 호스트가 선호됩니다.
가상 머신을 추가하면 비율이 제한을 초과할 경우, CloudEvent puToPhysicalCpuRatio 와 CPU 사용률이 모두 고려됩니다.
실행 중인 환경에서 호스트가 2.5를 초과하면 일부 가상 머신이 로드 밸런싱이 되고 더 낮은ical CpuRatio 가 있는 호스트로 이동할 수 있습니다.
power_saving
- 스케줄링 정책이 CpuOverCommitDurationMinutes 필드에서 작업을 수행하기 전에 호스트가 정의된 사용률 값 외부에서 CPU 부하를 실행할 수 있는 시간(분 단위)을 설정합니다.
- 호스트가 LowUtilization (낮음) 필드에서 활용도가 낮은 것으로 간주될 CPU 사용률을 입력합니다.
- HighUtilization (고유률) 필드의 다른 호스트로 마이그레이션하기 시작하는 CPU 사용률을 입력합니다.
- 선택적으로 HeSparesCount 필드에 마이그레이션하거나 종료하는 경우 Manager 가상 머신을 시작하기에 충분한 여유 메모리를 예약하는 추가 자체 호스팅 엔진 노드 수를 입력합니다. 자세한 내용은 Configuring Memory Slots Reserved for the self-hosted engine 에서 참조하십시오.
클러스터의 스케줄러 최적화 로 다음 중 하나를 선택합니다.
- 최적의 선택을 위해 weight 모듈을 스케줄링에 포함하려면 Optimize for Utilization (사용률 최적화)을 선택합니다.
- 보류 중인 요청이 10개를 초과하는 경우 Optimize for Speed 를 선택하여 호스트 가중치를 건너뜁니다.
-
OpenAttestation 서버를 사용하여 호스트를 확인하고
engine-config도구를 사용하여 서버의 세부 정보를 설정한 경우 Enable Trusted Service (신뢰할 수 있는 서비스 활성화) 확인란을 선택합니다.
OpenAttestation 및 Intel Trusted Execution Technology(Intel TXT)는 더 이상 사용할 수 없습니다.
- 선택적으로 관리자가 고가용성 가상 시스템의 클러스터 용량을 모니터링할 수 있도록 Enable HA reserved(HA 예약 사용) 확인란을 선택합니다.
클러스터의 가상 머신에 대한 직렬 번호 정책을 선택적으로 선택합니다.
-
시스템 기본값: 엔진 구성 도구 및
DefaultSerialNumberPolicy 및키 이름을 사용하여 Manager 데이터베이스에 구성된 시스템 전체 기본값을 사용합니다.DefaultCustomSerialNumberDefaultSerialNumberPolicy의 기본값은 호스트 ID를 사용하는 것입니다. 자세한 내용은 관리 가이드 의 스케줄링 정책을 참조하십시오. - 호스트 ID: 각 가상 시스템의 일련 번호를 호스트의 UUID로 설정합니다.
- Vm ID: 각 가상 머신의 일련 번호를 가상 머신의 UUID로 설정합니다.
- 사용자 정의 일련 번호: 각 가상 머신의 일련 번호를 다음 Custom Serial Number 매개변수에서 지정한 값으로 설정합니다.
-
시스템 기본값: 엔진 구성 도구 및
- 클릭합니다.
2.3.2.10. 클러스터의 호스트에서 MoM 정책 업데이트
Memory Overcommit Manager는 호스트에서 메모리 balloon 및 KSM 기능을 처리합니다. 클러스터의 이러한 기능에 대한 변경 사항은 다음에 호스트가 재부팅된 후 또는 유지 관리 모드로 Up 상태로 이동할 때 호스트에 전달합니다. 그러나 필요한 경우 호스트가 Up 인 동안 MoM 정책을 동기화하여 호스트에 중요한 변경 사항을 즉시 적용할 수 있습니다. 다음 절차는 각 호스트에서 개별적으로 수행해야 합니다.
절차
- 를 클릭합니다.
- 클러스터 이름을 클릭합니다. 그러면 세부 정보 보기가 열립니다.
- Hosts(호스트 ) 탭을 클릭하고 업데이트된 MoM 정책이 필요한 호스트를 선택합니다.
- Sync MoM Policy(모M 정책 동기화)를 클릭합니다.
호스트를 유지 관리 모드로 이동하고 백업할 필요 없이 호스트의 MoM 정책이 업데이트됩니다 .
2.3.2.11. CPU 프로필 생성
CPU 프로필은 클러스터의 가상 시스템이 실행되는 호스트에서 액세스할 수 있는 최대 처리 기능을 정의합니다. 이는 해당 호스트에서 사용할 수 있는 총 처리 기능의 백분율로 표시됩니다. CPU 프로필은 데이터 센터에 정의된 CPU 프로필을 기반으로 생성되며 클러스터의 모든 가상 시스템에 자동으로 적용되지 않습니다. 프로필을 적용하려면 개별 가상 시스템에 수동으로 할당해야 합니다.
이 절차에서는 클러스터가 속한 데이터 센터 아래에 하나 이상의 CPU 품질을 이미 정의했다고 가정합니다.
절차
- 를 클릭합니다.
- 클러스터 이름을 클릭합니다. 그러면 세부 정보 보기가 열립니다.
- CPU Profiles(CPU 프로필 ) 탭을 클릭합니다.
- New (새로 만들기)를 클릭합니다.
- CPU 프로필에 Name (이름)과 Description (설명)을 입력합니다.
- QoS (QoS) 목록에서 CPU 프로필에 적용할 서비스 품질을 선택합니다.
- 클릭합니다.
2.3.2.12. CPU 프로필 제거
Red Hat Virtualization 환경에서 기존 CPU 프로필을 제거합니다.
절차
- 를 클릭합니다.
- 클러스터 이름을 클릭합니다. 그러면 세부 정보 보기가 열립니다.
- CPU Profiles(CPU 프로필 ) 탭을 클릭하고 제거할 CPU 프로필을 선택합니다.
- Remove(제거)를 클릭합니다.
- 클릭합니다.
CPU 프로필이 모든 가상 시스템에 할당되면 해당 가상 시스템에 기본 CPU 프로필이 자동으로 할당됩니다.
2.3.2.13. 기존 Red Hat Gluster Storage 클러스터 가져오기
Red Hat Gluster Storage 클러스터와 클러스터에 속하는 모든 호스트를 Red Hat Virtualization Manager로 가져올 수 있습니다.
클러스터에 있는 모든 호스트의 IP 주소 또는 호스트 이름 및 암호와 같은 세부 정보를 제공하면 gluster 피어 상태 명령이 SSH를 통해 해당 호스트에서 실행된 다음 클러스터의 일부인 호스트 목록을 표시합니다. 각 호스트의 지문을 수동으로 확인하고 암호를 제공해야 합니다. 클러스터의 호스트 중 하나가 다운되거나 연결할 수 없는 경우 클러스터를 가져올 수 없습니다. 새로 가져온 호스트에 VDSM이 설치되지 않으므로 부트스트랩 스크립트는 가져온 후 호스트에 필요한 모든 VDSM 패키지를 설치하고 재부팅합니다.
절차
- 를 클릭합니다.
- New (새로 만들기)를 클릭합니다.
- 클러스터가 속할 Data Center (데이터 센터)를 선택합니다.
- 클러스터의 Name (이름) 및 Description (설명)을 입력합니다.
Enable Gluster Service (Gluster 서비스 사용) 확인란을 선택하고 Import existing gluster configuration (기존 Gluster 구성 가져오기) 확인란을 선택합니다.
Import existing Gluster configuration (기존 Gluster 구성 가져오기) 필드는 Enable Gluster Service (Gluster 서비스 활성화)가 선택된 경우에만 표시됩니다.
Hostname(호스트 이름 ) 필드에 클러스터에 있는 서버의 호스트 이름 또는 IP 주소를 입력합니다.
호스트 SSH Fingerprint 가 올바른 호스트와 연결되도록 표시됩니다. 호스트에 연결할 수 없거나 네트워크 오류가 있는 경우 Error in fetching fingerprint 가 Fingerprint 필드에 표시됩니다.
- 서버의 암호를 입력하고 )를 클릭합니다.
- Add Hosts(호스트 추가) 창이 열리고 클러스터의 일부인 호스트 목록이 표시됩니다.
- 각 호스트에 대해 Name (이름) 및 Root Password(루트 암호) 를 입력합니다.
모든 호스트에 대해 동일한 암호를 사용하려면 Use a Common Password (일반 암호 사용) 확인란을 선택하여 제공된 텍스트 필드에 암호를 입력합니다.
Apply(적용 )를 클릭하여 입력한 암호를 모든 호스트를 설정합니다.
지문이 유효한지 확인하고 OK(확인 )를 클릭하여 변경 사항을 제출합니다.
부트스트랩 스크립트는 가져온 후 호스트에 필요한 모든 VDSM 패키지를 설치하고 재부팅합니다. 이제 기존 Red Hat Gluster Storage 클러스터를 Red Hat Virtualization Manager로 성공적으로 가져왔습니다.
2.3.2.14. 호스트 추가 창의 설정 설명
Add Hosts(호스트 추가) 창을 사용하면 Gluster 지원 클러스터의 일부로 가져온 호스트의 세부 정보를 지정할 수 있습니다. 이 창은 New Cluster (새 클러스터 ) 창에서 Enable Gluster Service ( Gluster 서비스 활성화) 확인란을 선택하고 필요한 호스트 세부 정보를 제공한 후에 나타납니다.
| 필드 | 설명 |
|---|---|
| 공통 암호 사용 | 클러스터에 속하는 모든 호스트에 대해 동일한 암호를 사용하려면 이 확인란을 선택하십시오. Password (암호) 필드에 암호를 입력한 다음 Apply (적용) 버튼을 클릭하여 모든 호스트에서 암호를 설정합니다. |
| 이름 | 호스트 이름을 입력합니다. |
| 호스트 이름/IP | 이 필드는 New Cluster (새 클러스터) 창에서 제공한 호스트의 정규화된 도메인 이름 또는 IP로 자동으로 채워집니다. |
| Root 암호 | 각 호스트에 다른 루트 암호를 사용하려면 이 필드에 암호를 입력합니다. 이 필드는 클러스터의 모든 호스트에 제공된 공통 암호를 재정의합니다. |
| 지문 | 호스트 지문이 표시되어 올바른 호스트와 연결 중인지 확인합니다. 이 필드는 New Cluster (새 클러스터) 창에서 제공한 호스트의 지문으로 자동으로 채워집니다. |
2.3.2.15. 클러스터 제거
제거하기 전에 모든 호스트를 클러스터에서 이동합니다.
Blank 템플릿을 보유하고 있으므로 Default 클러스터를 제거할 수 없습니다. 그러나 Default 클러스터의 이름을 변경하고 새 데이터 센터에 추가할 수 있습니다.
절차
-
(클러스터)를 클릭하고 클러스터를 선택합니다. - 클러스터에 호스트가 없는지 확인합니다.
- Remove(제거)를 클릭합니다.
2.3.2.16. 메모리 최적화
호스트에서 가상 시스템 수를 늘리려면 가상 시스템에 할당한 메모리가 RAM을 초과하고 스왑 공간을 사용하는 메모리 과다 할당을 사용할 수 있습니다.
그러나 메모리 과다 할당에 잠재적인 문제가 있습니다.
- 스왑 성능 - 스왑 공간이 더 느리고 RAM보다 많은 CPU 리소스를 소비하므로 가상 시스템 성능에 영향을 미칩니다. 과도한 스왑으로 인해 CPU 스래싱이 발생할 수 있습니다.
- OOM(메모리 부족) 킬러 - 호스트에 스왑 공간이 부족하면 새 프로세스를 시작할 수 없으며 커널의 OOM 킬러 데몬이 가상 시스템 게스트와 같은 활성 프로세스 종료를 시작합니다.
이러한 단점을 극복하기 위해 다음을 수행할 수 있습니다.
- Memory Optimization 설정 및 Memory Overcommit Manager(MoM) 를 사용하여 메모리 과다 할당을 제한합니다.
- 가상 메모리에 대한 최대 잠재적인 수요를 수용하고 안전 마진을 유지할 수 있을 만큼 충분한 스왑 공간을 만듭니다.
- 메모리 증대 및 KSM( Kernel Same-page Merging) 을 활성화하여 가상 메모리 크기를 줄입니다.
2.3.2.17. 메모리 최적화 및 메모리 과다 할당
Memory Optimization 설정 중 하나를 선택하여 메모리 과다 할당 양을 제한할 수 있습니다. 없음 (0%), 150% 또는 200%.
각 설정은 RAM의 백분율을 나타냅니다. 예를 들어 64GB RAM이 있는 호스트를 사용하면 150% 를 선택하면 총 가상 메모리에서 총 96GB의 메모리를 추가로 32GB까지 과다 할당할 수 있습니다. 호스트가 총 4GB를 사용하는 경우 나머지 92GB를 사용할 수 있습니다. 대부분의 가상 머신(시스템의Memory Size (메모리 크기 ) )을 가상 머신에 할당할 수 있지만 일부 할당되지 않은 상태로 두는 것을 안전한 여백으로 두는 것이 좋습니다.
가상 메모리에 대한 수요가 급증하면 MoM, 메모리 증대 및 KSM이 가상 메모리를 다시 최적화하기 전에 성능에 영향을 미칠 수 있습니다. 해당 영향을 줄이려면 실행 중인 애플리케이션 및 워크로드 유형에 적합한 제한을 선택합니다.
- 메모리 수요 증가를 유발하는 워크로드의 경우 200% 또는 150% 와 같이 더 높은 백분율을 선택합니다.
- 메모리 수요 증가를 유발하는 중요한 애플리케이션 또는 워크로드의 경우 150% 또는 None (0%)과 같이 더 낮은 백분율을 선택합니다. None 을 선택하면 메모리 과다 할당을 방지할 수 있지만 MoM, 메모리 증대 장치 및 KSM이 가상 메모리를 계속 최적화할 수 있습니다.
항상 구성을 프로덕션에 배포하기 전에 광범위한 조건 하에서 스트레스 테스트를 통해 메모리 최적화 설정을 테스트합니다.
Memory Optimization (메모리 최적화) 설정을 구성하려면 New Cluster(새 클러스터) 또는 Edit Cluster (클러스터 편집) 창에서 Optimization (최적화) 탭을 클릭합니다. 클러스터 최적화 설정 설명을 참조하십시오.
추가 코멘트 :
- Host Statistics(호스트 통계) 뷰에 는 오버 커밋 비율의 크기를 조정하는 데 유용한 기록 정보가 표시됩니다.
- KSM에서 달성한 메모리 최적화 양과 메모리 증대(Memory ballooning) 변경이 지속적으로 이루어지기 때문에 실제 메모리는 실시간으로 결정할 수 없습니다.
- 가상 머신이 가상 메모리 제한에 도달하면 새 앱을 시작할 수 없습니다.
- 호스트에서 실행할 가상 시스템 수를 계획하는 경우 최대 가상 메모리(물리 메모리 크기 및 메모리 최적화 설정)를 시작점으로 사용합니다. 메모리 증대 및 KSM과 같은 메모리 최적화에 의해 달성되는 더 작은 가상 메모리를 고려하지 마십시오.
2.3.2.18. 스왑 공간 및 메모리 과다 할당
Red Hat은 스왑 공간을 구성하기 위한 권장 사항을 제공합니다.
이러한 권장 사항을 적용하는 경우 지침에 따라 스왑 공간의 크기를 최악의 경우 "마지막 작업 메모리"로 조정합니다. 실제 메모리 크기 및 메모리 최적화 설정을 총 가상 메모리 크기를 추정하기 위해 기준으로 사용합니다. MoM, 메모리 증대 및 KSM에 의해 최적화된 가상 메모리 크기 감소를 제외합니다.
OOM 조건을 방지하려면 스왑 공간을 활용하여 최악의 시나리오를 처리할 수 있으며 여전히 안전한 여백을 사용할 수 있습니다. 프로덕션에 배포하기 전에 항상 광범위한 조건 하에서 구성을 과부하 테스트를 수행하십시오.
2.3.2.19. 메모리 과다 할당 관리자 (MoM)
MM (Memory Overcommit Manager) 은 다음 두 가지를 수행합니다.
- 이전 섹션에 설명된 대로 Memory Optimization (메모리 최적화) 설정을 클러스터의 호스트에 적용하여 메모리 과다 할당을 제한합니다.
- 다음 섹션에 설명된 대로 메모리 ballooning 및 KSM 을 관리하여 메모리를 최적화합니다.
MoM을 활성화 또는 비활성화할 필요가 없습니다.
호스트의 사용 가능한 메모리가 20% 미만으로 떨어지면 ballooning 명령(예: ballooning). Controllers.Ballooning - INFO ballooning guest:half1 from 1096400~172580 은 /var/log/vdsm/mom.log 에 기록되며 Memory Overcommit Manager 로그 파일입니다.
2.3.2.20. 메모리 증대
가상 머신은 가상 메모리에 할당한 전체 양의 가상 메모리로 시작합니다. 가상 메모리 사용량이 RAM을 초과하므로 호스트는 스왑 공간에 더 많이 의존합니다. 메모리 증대 기능을 사용하면 가상 머신에서 사용하지 않는 메모리 부분을 포기할 수 있습니다. 사용 가능한 메모리는 호스트의 다른 프로세스 및 가상 시스템에서 재사용할 수 있습니다. 메모리 점유율이 감소하면 스왑 가능성이 줄어들고 성능이 향상됩니다.
메모리 증대 장치 및 드라이버를 제공하는 virtio-balloon 패키지는 로드 가능한 커널 모듈(LKM)으로 제공됩니다. 기본적으로 자동으로 로드되도록 구성됩니다. 거부 또는 언로드에 모듈을 추가하면 풍선이 비활성화됩니다.
메모리 증대 장치는 서로 직접 조정되지 않습니다. 호스트의 MOM(메모리 과다 할당 관리자) 프로세스를 사용하여 각 가상 시스템의 요구 사항을 지속적으로 모니터링하고 balloon 장치에 가상 메모리를 늘리거나 줄이도록 지시합니다.
성능 고려 사항:
- Red Hat은 지속적인 고성능과 짧은 대기 시간이 필요한 워크로드에 대해 메모리 증대 및 과다 할당을 권장하지 않습니다. 고성능 가상 머신, 템플릿 및 풀 구성을 참조하십시오.
- 가상 시스템 밀도(ecographic)를 늘릴 때 메모리 증대를 사용하는 것이 성능보다 더 중요합니다.
- 메모리 증대는 CPU 사용률에 큰 영향을 미치지 않습니다. (KSM은 일부 CPU 리소스를 사용하지만 사용량은 지속적으로 부족합니다.)
메모리 증대를 사용하려면 New Cluster(새 클러스터) 또는 Edit Cluster (클러스터 편집) 창에서 Optimization (최적화) 탭을 클릭합니다. 그런 다음 Enable Memory balloon Optimization(메모리 balloon 최적화 활성화) 확인란을 선택합니다. 이 설정을 사용하면 이 클러스터의 호스트에서 실행되는 가상 머신의 메모리 과다 할당이 가능합니다. 이 확인란을 선택하면 MoM은 모든 가상 시스템의 메모리 크기 보장된 제한과 함께 가능한 경우 ballooning을 시작합니다. 클러스터 최적화 설정 설명을 참조하십시오.
이 클러스터의 각 호스트는 상태가 Up으로 변경되면 balloon 정책 업데이트를 수신합니다. 필요한 경우 상태를 변경하지 않고도 호스트에서 balloon 정책을 수동으로 업데이트할 수 있습니다. 클러스터의 호스트에서 MoM 정책 업데이트를 참조하십시오.
2.3.2.21. KSM(Kernel Same-page Merging)
가상 시스템이 실행되면 공통 라이브러리 및 사용량이 많은 데이터와 같은 항목에 대한 중복 메모리 페이지를 생성하는 경우가 많습니다. 또한 유사한 게스트 운영 체제 및 애플리케이션을 실행하는 가상 머신은 가상 메모리에서 중복 메모리 페이지를 생성합니다.
활성화된 경우 KSM(Kernel Same-page Merging )은 호스트에서 가상 메모리를 검사하고 중복 메모리 페이지를 제거하고 여러 애플리케이션과 가상 시스템에서 나머지 메모리 페이지를 공유합니다. 이러한 공유 메모리 페이지는 COW(Copy-On-Write)로 표시됩니다. 가상 시스템이 페이지에 변경 사항을 작성해야 하는 경우 해당 복사본에 수정 사항을 작성하기 전에 먼저 복사본을 만듭니다.
KSM이 활성화되는 동안 MoM은 KSM을 관리합니다. KSM을 수동으로 구성하거나 제어할 필요가 없습니다.
KSM은 두 가지 방식으로 가상 메모리 성능을 향상시킵니다. 공유 메모리 페이지가 더 자주 사용되므로 호스트는 캐시 또는 주 메모리에 저장할 가능성이 높기 때문에 메모리 액세스 속도가 향상됩니다. 또한 메모리 과다 할당을 통해 KSM은 가상 메모리 공간을 줄여 스왑을 줄이고 성능을 개선할 수 있습니다.
KSM은 메모리 증대기보다 더 많은 CPU 리소스를 사용합니다. CPU KSM 소비 양은 계속 압박을 받고 있습니다. 호스트에서 동일한 가상 머신 및 애플리케이션을 실행하면 KSM이 다른 가상 시스템보다 더 많은 메모리 페이지를 병합할 수 있습니다. 대부분 다른 가상 시스템 및 애플리케이션을 실행하는 경우 KSM 사용의 CPU 비용이 그 이점을 상쇄할 수 있습니다.
성능 고려 사항:
- KSM 데몬이 많은 메모리를 병합한 후 커널 메모리 계정 통계가 결국 서로 모순될 수 있습니다. 시스템에 사용 가능한 메모리가 많은 경우 KSM을 비활성화하여 성능을 향상시킬 수 있습니다.
- Red Hat은 지속적인 고성능과 짧은 대기 시간이 필요한 워크로드에 KSM 및 과다 할당을 권장하지 않습니다. 고성능 가상 머신, 템플릿 및 풀 구성을 참조하십시오.
- KSM을 성능보다 더 중요시하는 가상 머신 밀도(보안)를 늘리는 경우 KSM을 사용합니다.
KSM을 활성화하려면 New Cluster(새 클러스터) 또는 Edit Cluster (클러스터 편집) 창에서 Optimization (최적화) 탭을 클릭합니다. 그런 다음 Enable KSM 확인란을 선택합니다. 이 설정을 사용하면 필요한 경우 MoM이 KSM을 실행할 수 있으며 CPU 비용보다 더 큰 메모리를 절약할 수 있습니다. 클러스터 최적화 설정 설명을 참조하십시오.
2.3.2.22. UEFI 및 Q35 칩셋
새 가상 시스템의 기본 칩셋인 Intel Q35 칩셋에는 레거시 BIOS를 대체하는 UEFI(Unified Extensible Firmware Interface) 지원이 포함되어 있습니다.
또는 UEFI를 지원하지 않는 레거시 Intel i440fx 칩셋을 사용하도록 가상 시스템 또는 클러스터를 구성할 수도 있습니다.
UEFI는 다음을 포함하여 기존 BIOS에 비해 몇 가지 이점을 제공합니다.
- 최신 부트 로더
- SecureBoot: 부트 로더의 디지털 서명을 인증
- 2TB보다 큰 디스크를 활성화하는 GUID 파티션 테이블 (GPT)
가상 머신에서 UEFI를 사용하려면 4.4 이상의 호환성을 위해 가상 머신의 클러스터를 구성해야 합니다. 그런 다음 기존 가상 시스템에 대해 UEFI를 설정하거나 클러스터의 새 가상 시스템의 기본 BIOS 유형으로 설정할 수 있습니다. 다음 옵션을 사용할 수 있습니다.
| BIOS 유형 | 설명 |
|---|---|
| Legacy BIOS를 사용한 Q35set | UEFI가 없는 레거시 BIOS (호환 버전 4.4가 있는 클러스터의 경우기본값) |
| UEFI BIOS를 사용한 Q35œset | UEFI 사용 BIOS |
| SecureBoot를 사용한 Q35œset | UEFI SecureBoot와 함께, 부트 로더의 디지털 서명을 인증 |
| 레거시 | 레거시 BIOS가 있는 i440fx 칩셋 |
운영 체제를 설치하기 전에 BIOS 유형 설정
운영 체제를 설치하기 전에 Q35 칩셋 및 UEFI를 사용하도록 가상 머신을 구성할 수 있습니다. 운영 체제를 설치한 후에는 가상 시스템을 레거시 BIOS에서 UEFI로 변환하는 것은 지원되지 않습니다.
2.3.2.23. Q35œset 및 UEFI를 사용하도록 클러스터 구성
클러스터를 Red Hat Virtualization 4.4로 업그레이드한 후 클러스터의 모든 가상 머신은 4.4 버전의 VDSM을 실행합니다. 해당 클러스터에서 생성한 새 가상 시스템의 기본 BIOS 유형을 결정하는 클러스터의 기본 BIOS 유형을 구성할 수 있습니다. 필요한 경우 가상 머신을 생성할 때 다른 BIOS 유형을 지정하여 클러스터의 기본 BIOS 유형을 재정의할 수 있습니다.
절차
-
VM 포털 또는 관리 포털에서
(클러스터) 를 클릭합니다. - 클러스터를 선택하고 Edit(편집 )를 클릭합니다.
- General(일반 )을 클릭합니다.
BIOS Type(OSOS 유형) 드롭다운 메뉴를 클릭하고 다음 중 하나를 선택하여 클러스터에서 새 가상 머신의 기본 BIOS 유형을 정의합니다.
- 레거시
- Legacy BIOS를 사용한 Q35set
- UEFI BIOS를 사용한 Q35œset
- SecureBoot를 사용한 Q35œset
- Compatibility Version(호환 버전 ) 드롭다운 메뉴에서 4.4 를 선택합니다. 관리자는 실행 중인 모든 호스트가 4.4와 호환되는지 확인하고, 해당 호스트가 있는 경우 관리자는 4.4 기능을 사용합니다.
- 클러스터의 기존 가상 시스템이 새 BIOS 유형을 사용해야 하는 경우 이를 수행하도록 구성합니다. BIOS 유형 클러스터 기본값 을 사용하도록 구성된 클러스터의 새 가상 머신은 이제 선택한 BIOS 유형을 사용합니다. 자세한 내용은 Q35œset 및 UEFI를 사용하도록 가상 머신 구성을 참조하십시오.
운영 체제를 설치하기 전에만 BIOS 유형을 변경할 수 있으므로 BIOS 유형 클러스터 기본값 을 사용하도록 구성된 기존 가상 머신에 대해 BIOS 유형을 이전 기본 클러스터 BIOS 유형으로 변경합니다. 그렇지 않으면 가상 시스템이 부팅되지 않을 수 있습니다. 또는 가상 시스템의 운영 체제를 다시 설치할 수 있습니다.
2.3.2.24. Q35œset 및 UEFI를 사용하도록 가상 머신 구성
운영 체제를 설치하기 전에 Q35 칩셋 및 UEFI를 사용하도록 가상 머신을 구성할 수 있습니다. 가상 시스템을 레거시 BIOS에서 UEFI로 변환하거나 UEFI에서 레거시 BIOS로 변환하면 가상 시스템이 부팅되지 않을 수 있습니다. 기존 가상 머신의 BIOS 유형을 변경하는 경우 운영 체제를 다시 설치합니다.
가상 시스템의 BIOS 유형이 클러스터 기본값으로 설정된 경우 클러스터의 BIOS 유형을 변경하면 가상 시스템의 BIOS 유형이 변경됩니다. 가상 시스템에 운영 체제가 설치되어 있는 경우 클러스터 BIOS 유형을 변경하면 가상 시스템이 부팅되지 않을 수 있습니다.
절차
Q35 칩셋 및 UEFI를 사용하도록 가상 머신을 구성하려면 다음을 수행합니다.
- VM 포털 또는 관리 포털에서 를 클릭합니다.
- 가상 시스템을 선택하고 Edit(편집 )를 클릭합니다.
- General(일반 ) 탭에서 Show Advanced Options(고급 옵션 표시 )를 클릭합니다.
-
(시스템 고급 매개 변수)를 클릭합니다. BIOS 유형 드롭다운 메뉴에서 다음 중 하나를 선택합니다.
- 클러스터 기본값
- Legacy BIOS를 사용한 Q35set
- UEFI BIOS를 사용한 Q35œset
- SecureBoot를 사용한 Q35œset
- 클릭합니다.
- 가상 시스템 포털 또는 관리 포털에서 가상 시스템의 전원을 끕니다. 다음에 가상 시스템을 시작하면 선택한 새 BIOS 유형으로 실행됩니다.
2.3.2.25. 클러스터 호환성 버전 변경
Red Hat Virtualization 클러스터에는 호환성 버전이 있습니다. 클러스터 호환성 버전은 클러스터의 모든 호스트에서 지원하는 Red Hat Virtualization의 기능을 나타냅니다. 클러스터 호환성은 클러스터에서 가장 적게 사용할 수 있는 호스트 운영 체제 버전에 따라 설정됩니다.
사전 요구 사항
- 클러스터 호환성 수준을 변경하려면 먼저 클러스터의 모든 호스트를 원하는 호환성 수준을 지원하는 수준으로 업데이트해야 합니다. 호스트 옆에 업데이트를 사용할 수 있음을 나타내는 아이콘이 있는지 확인합니다.
제한
VirtIO NIC는 클러스터 호환성 수준을 4.6으로 업그레이드한 후 다른 장치로 열거됩니다. 따라서 NIC를 재구성해야 할 수 있습니다. Red Hat은 가상 머신에서 클러스터 호환성 수준을 4.6으로 설정하고 네트워크 연결을 확인하여 클러스터를 업그레이드하기 전에 가상 머신을 테스트하는 것이 좋습니다.
가상 시스템의 네트워크 연결이 실패하면 클러스터를 업그레이드하기 전에 현재 에뮬레이트된 시스템과 일치하는 사용자 지정 에뮬레이트 시스템(예: 4.5 호환성 버전의 pc-q35-rhel8.3.0)을 사용하여 가상 머신을 구성합니다.
절차
- 관리 포털에서 를 클릭합니다.
- 변경할 클러스터를 선택하고 )를 클릭합니다.
- General(일반 ) 탭에서 Compatibility Version (호환 버전)을 원하는 값으로 변경합니다.
- 클릭합니다. 클러스터 호환성 버전 변경 확인 대화 상자가 열립니다.
- )를 클릭하여 확인합니다.
일부 가상 시스템 및 템플릿이 잘못 구성되었다고 경고하는 오류 메시지가 표시될 수 있습니다. 이 오류를 수정하려면 각 가상 시스템을 수동으로 편집합니다. Edit Virtual Machine(가상 시스템 편집 ) 창에서 수정할 항목을 보여주는 추가 검증 및 경고를 제공합니다. 문제가 자동으로 수정되고 가상 시스템의 구성을 다시 저장하면 되는 경우가 있습니다. 각 가상 시스템을 편집한 후 클러스터 호환성 버전을 변경할 수 있습니다.
클러스터 호환성 버전을 업데이트한 후 관리 포털에서 재부팅하거나 REST API를 사용하거나 게스트 운영 체제 내에서 실행 중인 모든 가상 머신의 클러스터 호환성 버전을 업데이트해야 합니다. 재부팅이 필요한 가상 머신은 보류 중인 변경 아이콘(
 )으로 표시됩니다. 미리 보기 중인 가상 머신 스냅샷의 클러스터 호환성 버전을 변경할 수 없습니다. 먼저 프리뷰를 커밋하거나 실행 취소해야 합니다.
)으로 표시됩니다. 미리 보기 중인 가상 머신 스냅샷의 클러스터 호환성 버전을 변경할 수 없습니다. 먼저 프리뷰를 커밋하거나 실행 취소해야 합니다.
자체 호스팅 엔진 환경에서는 Manager 가상 시스템을 다시 시작할 필요가 없습니다.
편리한 시간에 가상 시스템을 재부팅할 수 있지만 가상 시스템이 최신 구성을 사용하도록 즉시 재부팅하는 것이 좋습니다. 업데이트되지 않은 가상 시스템은 이전 구성으로 실행되며 재부팅하기 전에 가상 시스템을 다른 변경하면 새 구성을 덮어쓸 수 있습니다.
데이터 센터에서 모든 클러스터 및 가상 시스템의 호환성 버전을 업데이트한 후에는 데이터 센터 자체의 호환성 버전을 변경할 수 있습니다.