此内容没有您所选择的语言版本。
Chapter 1. Overview of AMQ Streams
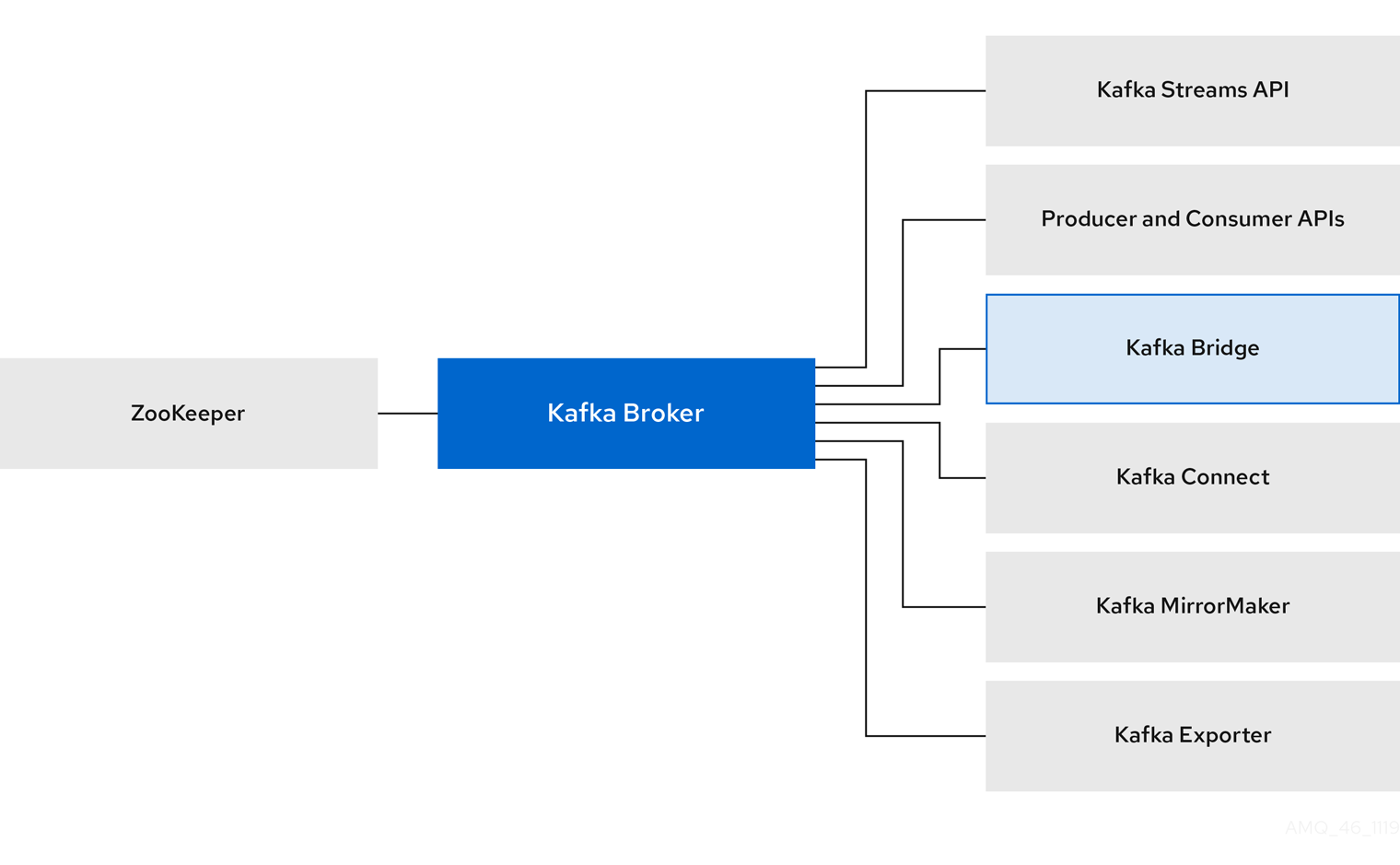
Red Hat AMQ Streams is a massively-scalable, distributed, and high-performance data streaming platform based on the Apache ZooKeeper and Apache Kafka projects.
The main components comprise:
- Kafka Broker
Messaging broker responsible for delivering records from producing clients to consuming clients.
Apache ZooKeeper is a core dependency for Kafka, providing a cluster coordination service for highly reliable distributed coordination.
- Kafka Streams API
- API for writing stream processor applications.
- Producer and Consumer APIs
- Java-based APIs for producing and consuming messages to and from Kafka brokers.
- Kafka Bridge
- AMQ Streams Kafka Bridge provides a RESTful interface that allows HTTP-based clients to interact with a Kafka cluster.
- Kafka Connect
- A toolkit for streaming data between Kafka brokers and other systems using Connector plugins.
- Kafka MirrorMaker
- Replicates data between two Kafka clusters, within or across data centers.
- Kafka Exporter
- An exporter used in the extraction of Kafka metrics data for monitoring.
- Kafka Cruise Control
- Rebalances a Kafka cluster based on a set of optimization goals and capacity limits.
A cluster of Kafka brokers is the hub connecting all these components. The broker uses Apache ZooKeeper for storing configuration data and for cluster coordination. Before running Apache Kafka, an Apache ZooKeeper cluster has to be ready.
Figure 1.1. AMQ Streams architecture
1.1. Kafka capabilities
The underlying data stream-processing capabilities and component architecture of Kafka can deliver:
- Microservices and other applications to share data with extremely high throughput and low latency
- Message ordering guarantees
- Message rewind/replay from data storage to reconstruct an application state
- Message compaction to remove old records when using a key-value log
- Horizontal scalability in a cluster configuration
- Replication of data to control fault tolerance
- Retention of high volumes of data for immediate access
1.2. Kafka use cases
Kafka’s capabilities make it suitable for:
- Event-driven architectures
- Event sourcing to capture changes to the state of an application as a log of events
- Message brokering
- Website activity tracking
- Operational monitoring through metrics
- Log collection and aggregation
- Commit logs for distributed systems
- Stream processing so that applications can respond to data in real time
1.3. Supported Configurations
In order to be running in a supported configuration, AMQ Streams must be running in one of the following JVM versions and on one of the supported operating systems.
| Java Virtual Machine | Version |
|---|---|
| OpenJDK | 1.8, 11 |
| OracleJDK | 1.8, 11 |
| IBM JDK | 1.8 |
| Operating System | Architecture | Version |
|---|---|---|
| Red Hat Enterprise Linux | x86_64 | 7.x, 8.x |
1.4. Document conventions
Replaceables
In this document, replaceable text is styled in monospace, with italics, uppercase, and hyphens.
For example, in the following code, you will want to replace BOOTSTRAP-ADDRESS and TOPIC-NAME with your own address and topic name:
bin/kafka-console-consumer.sh --bootstrap-server BOOTSTRAP-ADDRESS --topic TOPIC-NAME --from-beginning