4.11. 高可用性和消息迁移
4.11.1. 高可用性
术语 高可用性 指的是该系统的一部分或关闭系统也可以保持操作的系统。对于 OpenShift Container Platform 上的 AMQ Broker,这意味着在代理 Pod 失败时确保消息传递数据的完整性和可用性,或者因为部署的有意扩展而关闭。
要允许 OpenShift Container Platform 上 AMQ Broker 的高可用性,您可以在代理集群中运行多个代理 Pod。每个代理 Pod 将其消息数据写入您声明用于 PVC 的可用持久性卷(PV)。如果代理 Pod 失败或关闭,保存在 PV 的消息数据会迁移到代理集群中的另一个可用代理 Pod。其他代理 Pod 将消息数据存储在自己的 PV 中。
下图显示了基于 StatefulSet 的代理部署。在这种情况下,代理集群中的两个代理 Pod 仍然在运行。
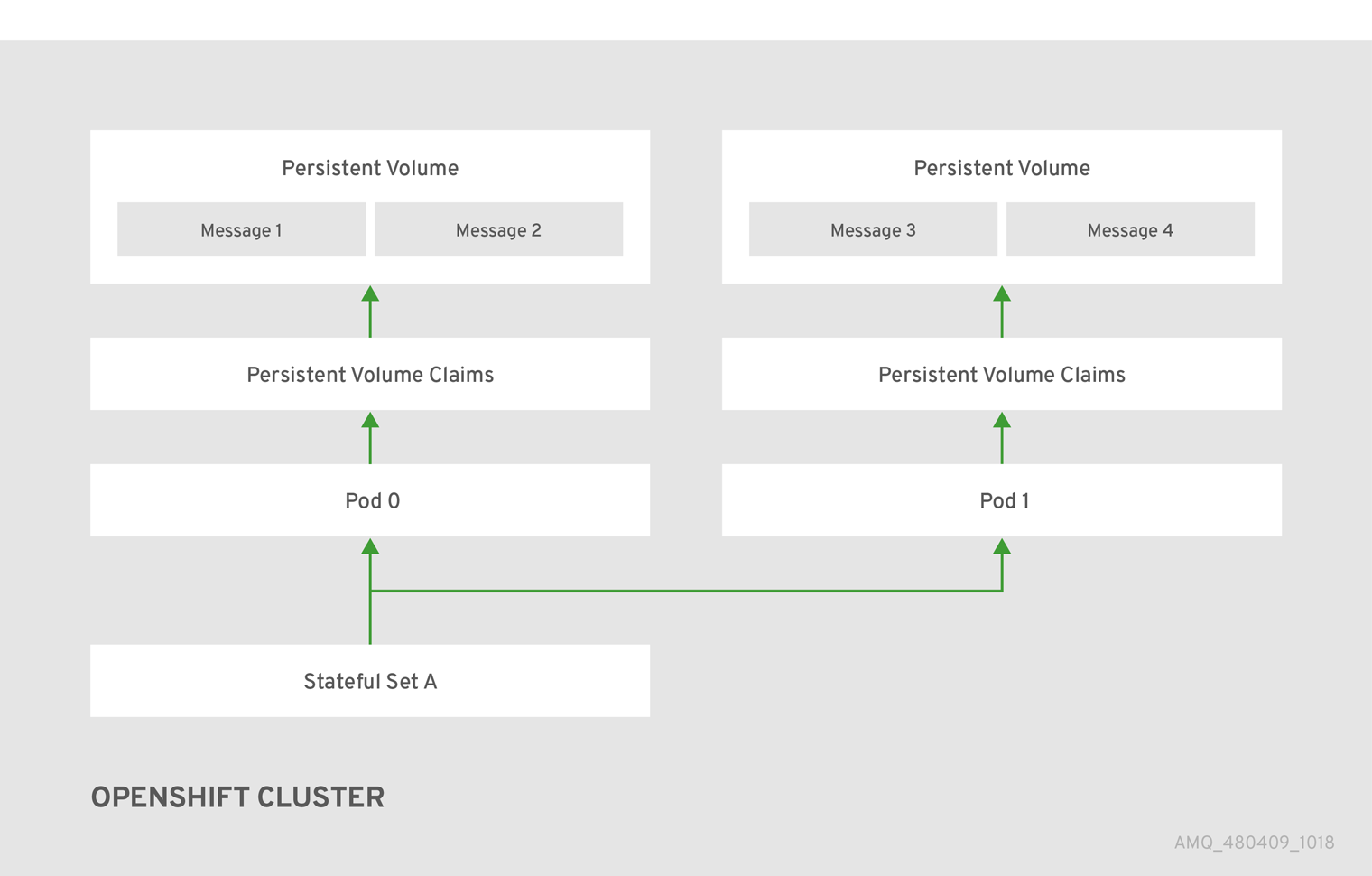
当代理 Pod 关闭时,AMQ Broker Operator 会自动启动一个 scaledown 控制器,它将执行消息迁移到仍在代理集群中运行的另一个代理 Pod。此消息迁移过程也称为 Pod draining。下面的部分描述了消息迁移。
4.11.2. 消息迁移
消息迁移是由于部署的意图缩减,如何在集群部署中代理关闭时确保消息传递数据的完整性。也称为 Pod 排空,此过程指的是从已关闭的代理 Pod 中删除和重新分发消息。
- 执行消息迁移的 scaledown 控制器只能在单个 OpenShift 项目中操作。控制器无法在单独的项目中的代理之间迁移信息。
- 要使用消息迁移,您的部署中必须至少有两个代理。默认集群带有两个或多个代理的代理。
对于基于 Operator 的代理部署,您可以在用于部署的主代理自定义资源中将 messageMigration 设置为 true 来启用消息迁移。
消息迁移过程遵循以下步骤:
- 当部署中的代理 Pod 因部署的意图而关闭时,Operator 会自动启动缩减控制器以准备消息迁移。scaledown 控制器在与代理集群相同的 OpenShift 项目名称中运行。
- scaledown 控制器注册自己,并侦听项目中与持久性卷声明(PVC)相关的 Kubernetes 事件。
要检查已经孤立的持久性卷(PV),扩展控制器会在卷声明上查看 或dinal。控制器将卷声明上的 ordinal 与项目中仍然在 StatefulSet 中运行的代理 Pod(即代理集群)进行比较。
如果卷声明上的 ordinal 大于仍在代理集群中任何代理 Pod 的 ordinal,则 scaledown 控制器会确定代理 Pod 已关闭,且消息传递数据必须迁移到另一个代理 Pod。
scaledown 控制器启动一个 drainer Pod。drainer Pod 运行代理并执行消息迁移。然后,drainer Pod 标识可迁移到孤立消息的替代代理 Pod。
注意部署中必须至少有一个代理 Pod 仍在部署中运行,才能进行消息迁移。
下图演示了 scaledown 控制器(也称为 drain controller)如何将消息迁移到正在运行的代理 Pod。
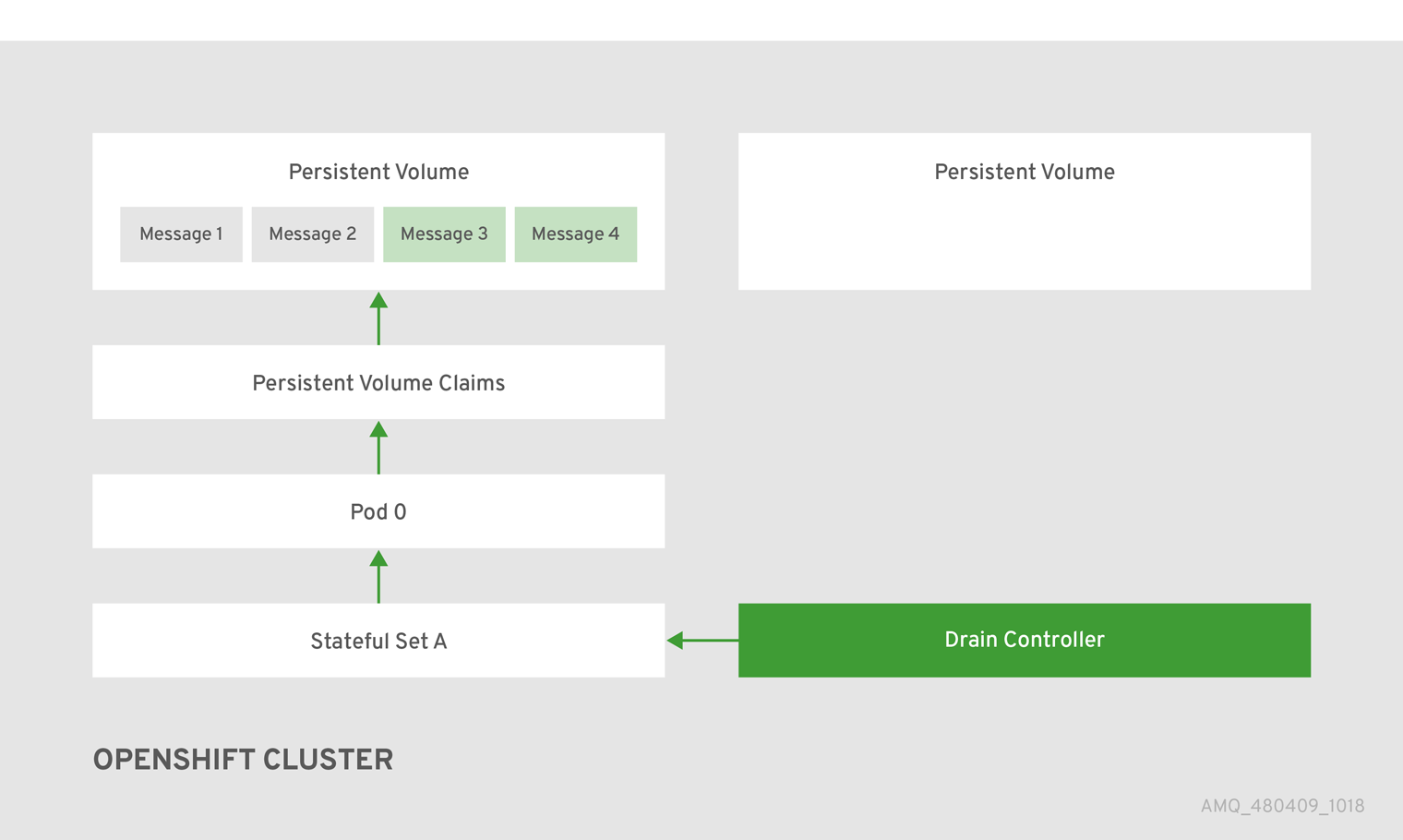
当信息成功迁移到可操作的代理 Pod 后,排空器 Pod 会关闭,扩展控制器会删除孤立 PV 的 PVC。PV 返回为"Released"状态。
如果您将代理部署缩减为 0(零),则不会发生消息迁移,因为没有正在运行的代理 Pod 可以迁移到哪个代理数据。但是,如果您将部署缩减到零,然后再备份小于原始部署的大小,则为保持关闭的代理启动排空 Pod。
其他资源
- 有关缩减代理部署时的消息迁移示例,请参阅 大规模迁移信息。
4.11.3. 在缩减时迁移消息
要在代理部署时迁移消息,请使用主代理自定义资源(CR)来启用消息迁移。当您缩小集群代理部署时,AMQ Broker Operator 会自动运行专用的扩展控制器来执行消息迁移。
启用消息迁移后,Operator 中的 scaledown 控制器会检测到代理 Pod 的关闭,并启动 drainer Pod 来执行消息迁移。drainer Pod 连接到集群中的其他 live 代理 Pod,并将信息迁移到该实时代理 Pod。迁移完成后,scaledown 控制器将关闭。
- 缩减控制器仅在单一 OpenShift 项目中运行。控制器无法在单独的项目中的代理之间迁移信息。
- 如果您将代理部署缩减为 0(零),则不会发生消息迁移,因为没有运行可将消息传递数据迁移到的代理 Pod。但是,如果您将部署缩减到零代理,然后备份到原始部署中的一些代理,排空 Pod 会在保持关闭的代理中启动。
以下示例步骤显示 scaledown 控制器的行为。
先决条件
- 您已有基本的代理部署。请参阅 第 3.4.1 节 “部署基本代理实例”。
- 您应该了解消息迁移的工作原理。更多信息请参阅 第 4.11.2 节 “消息迁移”。
流程
-
在您最初下载并提取的 Operator 存储库的
deploy/crs目录中,打开主代理 CRbroker_activemqartemis_cr.yaml。 在主代理 CR 中,将
messageMigration和persistenceEnabled设置为true。这些设置意味着,当您稍后缩减集群代理部署的大小时,Operator 会自动启动扩展控制器,并将信息迁移到仍然运行的代理 Pod。
在现有代理部署中,验证哪些 Pod 正在运行。
$ oc get pods您会看到类似如下的输出。
activemq-artemis-operator-8566d9bf58-9g25l 1/1 Running 0 3m38s ex-aao-ss-0 1/1 Running 0 112s ex-aao-ss-1 1/1 Running 0 8s前面的输出显示,有三个 Pod 正在运行:一个用于 broker Operator 本身,以及部署中每个代理一个单独的 Pod。
登录到每个 Pod,并将一些消息发送到每个代理。
作为 Pod
ex-aao-s-0 的补充,其集群 IP 地址为172.17.0.6,运行以下命令:$ /opt/amq/bin/artemis producer --url tcp://172.17.0.6:61616 --user admin --password admin作为 Pod
ex-aao-s-1 的补充,集群 IP 地址为172.17.0.7,运行以下命令:$ /opt/amq/bin/artemis producer --url tcp://172.17.0.7:61616 --user admin --password admin前面的命令在每个代理上创建一个名为
TEST的队列,并将 1000 个消息添加到每个队列。
将集群从两个代理缩减为一个。
-
打开主代理 CR,
broker_activemqartemis_cr.yaml。 -
在 CR 中,将
deploymentPlan.size设置为1。 在命令行中应用更改:
$ oc apply -f deploy/crs/broker_activemqartemis_cr.yaml您会看到 Pod
ex-aao-s-1开始关闭。scaledown 控制器会启动同一名称的新 drainer Pod。这个 drainer Pod 也会在将信息从代理 Podex-ao-s-1中迁移到集群(ex-aao-ss-0)中的其他代理 Pod 中后关闭。
-
打开主代理 CR,
-
当 drainer Pod 关闭时,检查 broker Pod
ex-aao-ss-0的TEST队列的消息数。您会看到队列中的消息数量为 2000,表示 drainer Pod 已成功迁移了关闭的代理 Pod 中的 1000 信息。