4.13. 启用消息迁移来支持集群缩减
如果要缩减集群中的代理数量,并将信息迁移到集群中剩余的 Pod,您必须启用消息迁移。
当您缩减启用了消息迁移的集群时,缩减控制器会管理消息迁移过程。
4.13.1. 消息迁移过程中的步骤
消息迁移过程遵循以下步骤:
- 当部署中的代理 Pod 因部署的意图缩减而关闭时,Operator 会自动部署 scaledown 自定义资源以准备消息迁移。
要检查已孤立的持久性卷(PV),scaledown 控制器会查看卷声明的 等级。控制器将卷声明的 ordinal 与项目中仍在 StatefulSet (即代理集群)中运行的代理 Pod 进行比较。
如果卷声明上的 ordinal 大于代理集群中仍在运行的任何代理 Pod 上的 ordinal,则 scaledown 控制器会决定该等级上的代理 Pod 已关闭,且该消息传递数据必须迁移到另一个代理 Pod。
- scaledown 控制器启动一个 drainer Pod。drainer Pod 连接到集群中的其他实时代理 Pod 之一,并将信息迁移到该实时代理 Pod。
下图演示了 scaledown 控制器(也称为 drain 控制器)如何将消息迁移到正在运行的代理 Pod。
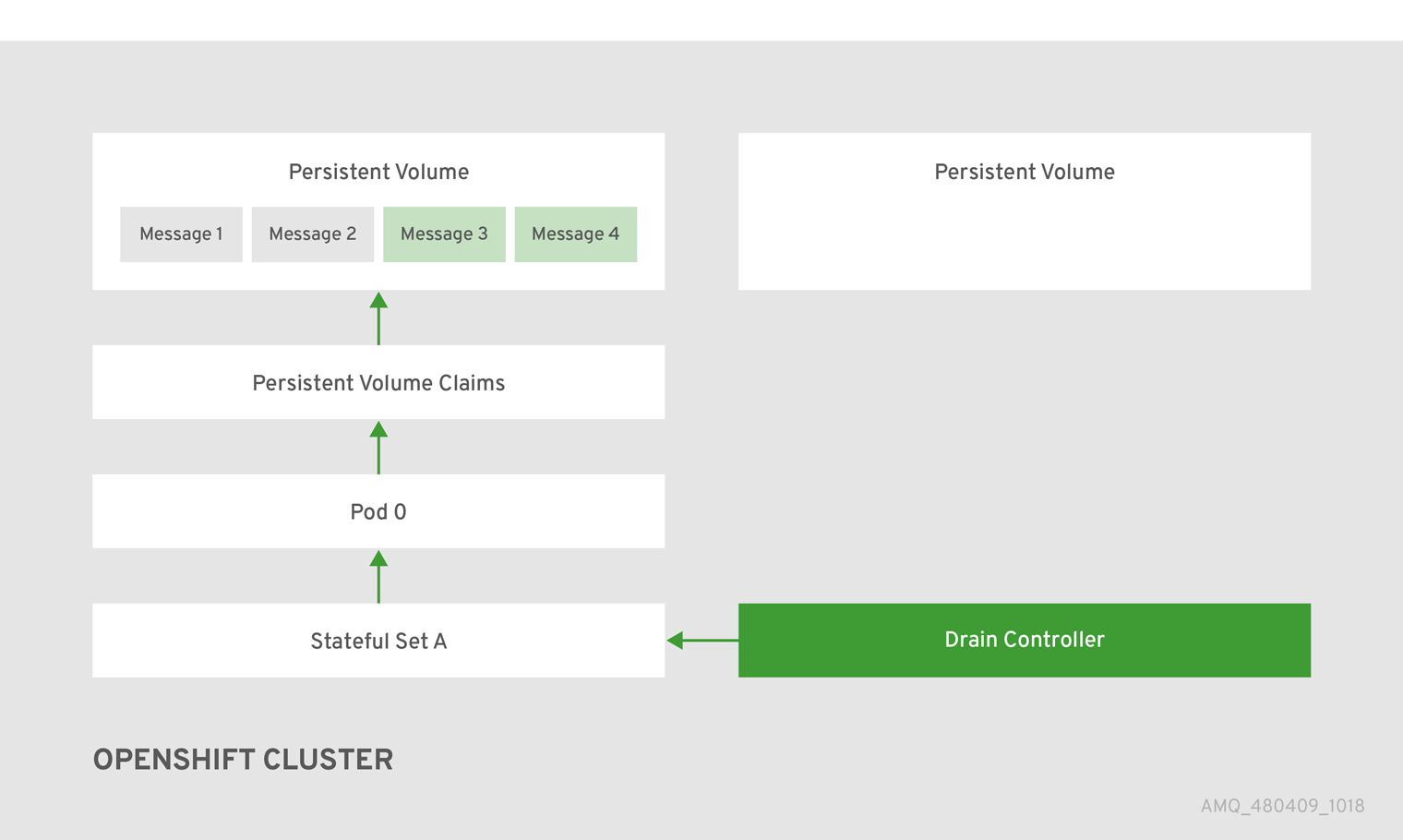
当消息成功迁移到可正常工作的代理 Pod 后,排空器 Pod 会关闭,缩减控制器会删除孤立 PV 的 PVC。PV 返回到 "Released" 状态。
如果将 PV 的 reclaim 策略设置为 保留,则 PV 无法供另一个 Pod 使用,直到您删除并重新创建 PV。例如,如果您在缩减后扩展集群,则 PV 将无法供 Pod 启动,直到删除并重新创建 PV。
其他资源
- 有关缩减代理部署时的消息迁移示例,请参阅 第 4.13.2 节 “启用消息迁移”。
4.13.2. 启用消息迁移
您可以在 ActiveMQArtemis 自定义资源(CR)中启用消息迁移。
先决条件
- 您已有一个基本的代理部署。请参阅 第 3.4.1 节 “部署基本代理实例”。
- 您了解消息迁移的工作原理。更多信息请参阅 第 4.13.1 节 “消息迁移过程中的步骤”。
- 缩减控制器仅在单一 OpenShift 项目中运行。控制器无法在独立项目中的代理之间迁移信息。
- 如果您将代理部署缩减为 0 (零),则不会进行消息迁移,因为没有正在运行的代理 Pod 可迁移到哪些消息传递数据。但是,如果您将部署缩减为零,然后备份到小于原始部署的大小,则会为保持关闭的代理启动 drainer Pod。
流程
编辑代理部署的 CR 实例。
使用 OpenShift 命令行界面:
- 以具有特权在项目中为代理部署 CR 的用户身份登录 OpenShift Container Platform。
编辑部署的 CR。
oc edit ActiveMQArtemis <CR instance name> -n <namespace>
使用 OpenShift Container Platform Web 控制台:
- 以具有特权在项目中为代理部署 CR 的用户身份登录 OpenShift Container Platform。
-
在左侧窗格中,点
。 - 单击 ActiveMQArtemis CRD。
- 点 实例 选项卡。
- 点代理部署的实例。
点 YAML 标签。
在控制台中,会打开 YAML 编辑器,供您编辑 CR 实例。
在 CR 的
deploymentPlan部分中,添加一个messageMigration属性,并设置为true。如果尚未配置,请添加persistenceEnabled属性,并设置为true。例如:spec: deploymentPlan: messageMigration: true persistenceEnabled: true ...这些设置意味着,当您稍后缩减集群代理部署的大小时,Operator 会自动启动缩减控制器,并将信息迁移到仍在运行的代理 Pod 中。
- 保存 CR。
(可选)完成以下步骤来缩减集群并查看消息迁移过程。
在现有代理部署中,验证哪个 Pod 正在运行。
$ oc get pods您会看到类似如下的输出。
activemq-artemis-operator-8566d9bf58-9g25l 1/1 Running 0 3m38s ex-aao-ss-0 1/1 Running 0 112s ex-aao-ss-1 1/1 Running 0 8s前面的输出显示有三个 Pod 正在运行:一个用于代理 Operator 本身,以及部署中每个代理的独立 Pod。
登录到每个 Pod,并将一些信息发送到每个代理。
Pod
ex-aao-ss-0具有集群 IP 地址172.17.0.6,运行以下命令:$ /opt/amq/bin/artemis producer --url tcp://172.17.0.6:61616 --user admin --password admin
Pod
ex-aao-ss-1具有集群 IP 地址172.17.0.7,运行以下命令:$ /opt/amq/bin/artemis producer --url tcp://172.17.0.7:61616 --user admin --password admin上述命令在每个代理上创建一个名为
TEST的队列,并将 1000 个消息添加到每个队列中。将集群从两个代理缩减为一。
-
打开主代理 CR
broker_activemqartemis_cr.yaml。 -
在 CR 中,将
deploymentPlan.size设置为1。 在命令行中应用更改:
$ oc apply -f deploy/crs/broker_activemqartemis_cr.yaml您会看到 Pod
ex-aao-ss-1开始关闭。scaledown 控制器启动相同名称的新 drainer Pod。这个 drainer Pod 也会在将信息从代理 Podex-ao-s-1中迁移到集群(ex-aao-ss-0)中的其他代理 Pod 中后关闭。
-
打开主代理 CR
-
当 drainer Pod 关闭时,检查代理 Pod
ex-aao-ss-0的TEST队列中的消息计数。您会看到队列中的消息数量为 2000,这表示 drainer Pod 已成功从关闭的代理 Pod 中迁移了 1000 个信息。