3.5. 自动扩展放置组
池中放置组(PG)的数量对于集群如何对等、分布数据和重平衡操作起非常重要的作业。
自动扩展 PG 数量可以更轻松地管理集群。pg-autoscaling 命令提供扩展 PG 的建议,或根据集群的使用方式自动扩展 PG。
- 要了解更多有关自动扩展如何工作的信息,请参阅 第 3.5.1 节 “放置组自动扩展”。
- 要启用或禁用自动扩展,请参阅 第 3.5.3 节 “设置放置组自动扩展模式”。
- 要查看放置组扩展建议,请参阅 第 3.5.4 节 “查看放置组扩展建议”。
- 要设置放置组自动扩展,请参阅 第 3.5.5 节 “设置放置组自动扩展”。
-
要全局更新自动扩展,请查看 第 3.5.6 节 “更新
noautoscale标记” - 要设置目标池大小,请参阅 第 3.5.7 节 “指定目标池大小”。
3.5.1. 放置组自动扩展
auto-scaler 的工作原理
自动缩放器会根据每个子树分析池并调整。由于每个池都可以映射到不同的 CRUSH 规则,并且每个规则可以在不同的设备间分布数据,Ceph 都将独立使用每个子树。例如,映射到类 ssd 的 OSD 的池以及映射到类 hdd 的 OSD 的池,各自具有取决于这些对应设备类型的最优 PG 数量。
3.5.2. 放置组分割和合并
splitting
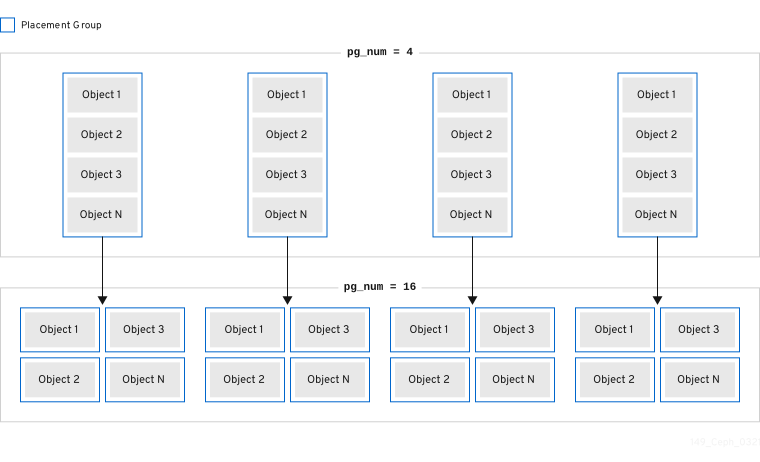
Red Hat Ceph Storage 可将现有放置组(PG)分成较小的 PG,这会增加给定池的 PG 总数。分割现有放置组(PG)使得红帽 Ceph 存储集群在存储要求增加时随时间进行扩展。PG 自动扩展功能可以增加 pg_num 值,这会导致现有 PG 分割为存储集群扩展。如果 PG 自动扩展功能被禁用,您可以手动增加 pg_num 值,这样可触发 PG 分割进程以开始。例如,将 pg_num 值从 4 增加到 16,则会分成四个部分:增加 pg_num 值也将增加 pgp_num 值,但 pgp_num 值会递增递增阶段。逐步增加是为了最大程度降低存储集群性能和客户端工作负载的影响,因为迁移对象数据给系统带来显著的负载。默认情况下,Ceph 队列,移动不超过 5% 的对象数据,这些数据处于"实际"状态。可以使用 target_max_misplaced_ratio 选项调整这个默认百分比。
合并
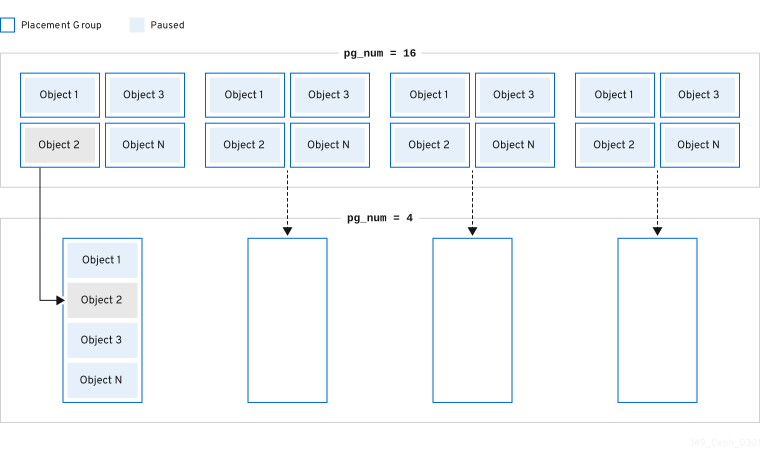
Red Hat Ceph Storage 也可以将两个现有 PG 合并到一个较大的 PG 中,这样可以减少 PG 的总数。将两个 PG 合并在一起会很有用,特别是当池中对象的相对量逐渐下降时,或者选择初始的 PG 数量太大时。合并 PG 可能很有用,但它也是一个复杂和委派的过程。在进行合并时,到 PG 的 I/O 会暂停,一次只合并一个 PG,从而最大程度降低对存储集群性能的影响。Ceph 在合并对象数据时缓慢工作,直到达到新的 pg_num 值。
3.5.3. 设置放置组自动扩展模式
Red Hat Ceph Storage 集群中的每个池都有一个 pg_autoscale_mode 属性,而 PG 的 PG 可以设置为 off、上的、或 warn。
-
off:禁用池的自动扩展。管理员最多可为每个池选择适当的 PG 数。如需更多信息,请参阅 PG 数量 部分。 -
在 上:为给定池启用自动调整 PG 数量。 -
Warn:当 PG 数量需要调整时,处理健康状态警报。
在 Red Hat Ceph Storage 5.0 及更新的版本中,pg_autoscale_mode 默认为 开启。升级的存储集群会保留现有的 pg_autoscale_mode 设置。对于新创建的池,pg_auto_scale 模式为 on。PG 数量自动调整,ceph 状态 可能会在 PG 计数调整期间显示恢复状态。
自动缩放器使用 bulk 标志来确定哪个池应当以完整补充的 PG 开头,并且仅在池之间的使用量比率不会被缩减。但是,如果池没有 bulk 标记,池以最少的 PG 开头,并且仅在池中有更多使用量时才会开始。
自动扩展程序(autoscaler)会识别任何重叠的根,并防止扩展带有重叠根的池,因为重叠的根可能会导致扩展过程出现问题。
流程
在现有池中启动自动扩展:
语法
ceph osd pool set POOL_NAME pg_autoscale_mode on示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_autoscale_mode on在新创建的池中启用自动扩展:
语法
ceph config set global osd_pool_default_pg_autoscale_mode MODE示例
[ceph: root@host01 /]# ceph config set global osd_pool_default_pg_autoscale_mode on使用
批量标记创建池:语法
ceph osd pool create POOL_NAME --bulk示例
[ceph: root@host01 /]# ceph osd pool create testpool --bulk为现有池设置或取消设置
批量标记:重要该值必须写为
true、false、1或0。1等同于true,0相当于false。如果使用不同的大写或其它内容编写,则会发出错误。以下是使用错误语法编写的命令示例:
[ceph: root@host01 /]# ceph osd pool set ec_pool_overwrite bulk True Error EINVAL: expecting value 'true', 'false', '0', or '1'语法
ceph osd pool set POOL_NAME bulk true/false/1/0示例
[ceph: root@host01 /]# ceph osd pool set testpool bulk true获取现有池
批量标记:语法
ceph osd pool get POOL_NAME bulk示例
[ceph: root@host01 /]# ceph osd pool get testpool bulk bulk: true
3.5.4. 查看放置组扩展建议
您可以查看池,它的相对利用率以及存储集群中 PG 数量的建议更改。
先决条件
- 正在运行的 Red Hat Ceph Storage 集群
- 所有节点的根级别访问权限。
流程
您可以使用以下命令查看每个池、其相对利用率以及对 PG 计数所做的任何更改:
[ceph: root@host01 /]# ceph osd pool autoscale-status输出类似如下:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK device_health_metrics 0 3.0 374.9G 0.0000 1.0 1 on False cephfs.cephfs.meta 24632 3.0 374.9G 0.0000 4.0 32 on False cephfs.cephfs.data 0 3.0 374.9G 0.0000 1.0 32 on False .rgw.root 1323 3.0 374.9G 0.0000 1.0 32 on False default.rgw.log 3702 3.0 374.9G 0.0000 1.0 32 on False default.rgw.control 0 3.0 374.9G 0.0000 1.0 32 on False default.rgw.meta 382 3.0 374.9G 0.0000 4.0 8 on False
SIZE 是池中存储的数据量。
如果存在 TARGET SIZE,则管理员指定的数据量是管理员最终在此池中存储的数据量。系统在计算时会使用这两个值中的较大的值。
RATE 是决定池使用的原始存储容量的池的倍数。例如,一个 3 副本池的比率为 3.0,而 k=4,m=2 纠删代码池的比例为 1.5。
RAW CAPACITY 是 OSD 上原始存储容量的总量,它们负责存储池的数据。
RATIO 是池消耗的总容量的比例,即 ratio = 大小,即 * 速率/原始容量。
TARGET RATIO (如果存在)是管理员指定的存储比率,是与带有目标比率的其他池相对应的期望池的消耗。如果同时指定了目标大小字节和比例,则比率将具有优先权。TARGET RATIO 的默认值为 0, 除非在创建池时指定。您向池中提供的 --target_ratio 越大,您希望池具有的大量 PG。
EFFECTIVE RATIO 是在以两种方式调整后的目标比率:1。减少设定目标大小的池预期使用容量。2. 在带有目标比率设置的池之间规范化目标比率,以便它们一起处理剩余空间。例如,目标 ratio 1.0 的 4 池具有 0.25 的有效比例。系统使用的较大的实际比率,以及计算的有效比率。
BIAS 被视为一个倍数,根据之前有关特定池应有的 PG 量的信息,手动调整池的 PG。默认情况下,如果 1.0,否则值(除非在创建池时已指定)。您提供的池中提供的 --bias 越多,您希望池拥有的 PG 大。
PG_NUM 是池的当前 PG 数量,或者当 pg_num 更改正在进行时,池工作的 PG 数量的当前 PG 数量。NEW PG_NUM (若存在)是建议的 PG 数量(pg_num)。它始终是 2 的指数,它只有在建议的值与因当前值的不同大于 3 倍时才存在。
AUTOSCALE,是池 pg_autoscale_mode,可以为 on, off, 或 warn。
BULK 用于确定哪个池应以 PG 的完整补充开头。BULK 仅在使用量在池中的使用比率不平衡时进行缩减。如果池没有此标志,池以最少的 PG 开始,且仅在池中有更多使用量时才使用。
BULK 的值为 true, false, 1, 或 0, 其中 1 等同于 true,0 等同于 false。默认值为 false。
BULK 值可以在池创建过程中或之后设置 。
有关使用 bulk 标记的更多信息,请参阅 创建池 和设置放置组自动扩展模式。
3.5.5. 设置放置组自动扩展
允许集群根据集群使用量自动扩展 PG,是扩展 PG 的最简单方法。Red Hat Ceph Storage 使用整个系统的可用存储和 PG 的目标数量,比较每个池中存储的数据数量,并相应地应用 PG。该命令仅更改其当前 PG 数 (pg_num) 大于计算出的或建议的 PG 数的 3 倍的池。
每个 OSD 的目标 PG 数量基于 mon_target_pg_per_osd 可配置。默认值为 100。
流程
调整
mon_target_pg_per_osd:ceph config set global mon_target_pg_per_osd number例如:
$ ceph config set global mon_target_pg_per_osd 150
3.5.5.1. 为池设置最小和最大放置组数量
指定放置组(PG)的最小和最大值,以限制自动扩展范围。
如果设置了最小值,Ceph 不会自动减少或建议减少,PG 的数量为设置最小值下的值。
如果设置了最小值,Ceph 不会自动增加或推荐增加的 PG 数量,则值超过设置的最大值。
最小和最大值可以一起设置,或者单独设置。
除了此流程外,ceph osd pool create 命令还有两个命令行选项,可用于在创建池时指定最小或最大 PG 数量。
语法
ceph osd pool create --pg-num-min NUMBER
ceph osd pool create --pg-num-max NUMBER示例
ceph osd pool create --pg-num-min 50
ceph osd pool create --pg-num-max 150先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
为池设置最小 PG 数量:
语法
ceph osd pool set POOL_NAME pg_num_min NUMBER示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_num_min 50为池设置最大 PG 数量:
语法
ceph osd pool set POOL_NAME pg_num_max NUMBER示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_num_max 150
3.5.6. 更新 noautoscale 标记
如果要同时为所有池启用或禁用自动扩展器,您可以使用 noautoscale 全局标志。当某些 OSD 被退回或集群处于维护状态时,这个全局标志很有用。您可以在任何活动前设置标志,并在活动完成后取消设置它。
默认情况下,noautoscale 标志设置为 off。当设置这个标记时,所有池 都为 off,并且所有池都禁用自动扩展器。
先决条件
- 正在运行的 Red Hat Ceph Storage 集群
- 所有节点的根级别访问权限。
流程
获取
noautoscale标志的值:示例
[ceph: root@host01 /]# ceph osd pool get noautoscale在任何活动前设置
noautoscale标志:示例
[ceph: root@host01 /]# ceph osd pool set noautoscale在完成活动时取消设置
noautoscale标志:示例
[ceph: root@host01 /]# ceph osd pool unset noautoscale
3.5.7. 指定目标池大小
新创建的池消耗少量集群容量,并出现在需要少量的 PG 的系统中。然而,在大多数情形中,集群管理员知道哪些池预期消耗了大多数系统容量。如果提供此信息,称为 Red Hat Ceph Storage 的目标大小,此类池可以从头开始使用更合适的 PG 数(pg_num)。此方法可防止 pg_num 中的后续更改,并在进行这些调整时与移动数据相关的开销。
您可以使用以下方法指定池 的目标大小 :
3.5.7.1. 使用池的绝对大小指定目标大小
流程
使用池的绝对
大小(以字节为单位)设置目标大小:ceph osd pool set pool-name target_size_bytes value例如,要指示
mypool的系统预期消耗 100T 空间:$ ceph osd pool set mypool target_size_bytes 100T
您还可以通过将可选的 --target-size-bytes <bytes> 参数添加到 ceph osd pool create 命令中,来设置池创建的目标大小。
3.5.7.2. 使用集群容量总量指定目标大小
流程
使用集群容量总数来设置
目标大小:ceph osd pool set pool-name target_size_ratio ratio例如:
$ ceph osd pool set mypool target_size_ratio 1.0告诉系统,池
mypool期望消耗 1.0,相对于其他设置了target_size_ratio的池。如果mypool是集群中唯一的池,这意味着预期使用总容量的 100%。如果存在第二个池,其target_size_ratio为 1.0,两个池都希望使用 50% 的集群容量。
您还可以通过将可选的 --target-size-ratio <ratio> 参数添加到 ceph osd pool create 命令,在创建时设置池的目标大小。
如果您指定了无法达到的目标大小值,例如:大于总集群的容量,或者设置比例的总和大于 1.0,集群会引发 POOL_TARGET_SIZE_RATIO_OVERCOMMITTED 或 POOL_TARGET_SIZE_BYTES_OVERCOMMITTED 健康警告。
如果您同时为池指定 target_size_ratio 和 target_size_bytes,集群只会考虑比例,并引发 POOL_HAS_TARGET_BYTES_AND_RATIO 健康警告。