31.4. 性能测试过程
本节的目标是构建安装了 VDO 的设备的性能配置集。每个测试都应该使用且未安装 VDO 的情况下运行,以便根据基本系统性能评估 VDO 的性能。
31.4.1. 阶段 1:I/O Depth 的影响,修正了 4 KB 块
复制链接链接已复制到粘贴板!
此测试的目标是确定为设备产生最佳吞吐量和最低延迟的 I/O 深度。VDO 使用 4 KB 扇区大小,而不是传统 512 B 在传统存储设备中使用。较大的扇区大小允许其支持更高容量存储、提高性能,并与大多数操作系统使用的缓存缓冲区大小匹配。
- 执行 4 KB I/O 和 I/O 深度为 1, 8, 16, 32, 64, 128, 256, 512, 1024 的四级测试:
- 顺序 100% 读取,在固定 4 KB * 中
- 顺序 100% 写入,在固定 4 KB
- 随机 100% 读取,在固定 4 KB * 中
- 随机 100% 写入,在固定 4 KB **
* 通过首先执行写 fio 作业,在读取测试过程中预先填充任何可能读取的区域** 在 4 KB 随机写入 I/O 运行后重新创建 VDO 卷shell 测试输入模拟器(写入)示例:# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write --bs=4096 --name=vdo --filename=/dev/mapper/vdo0 \ --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300\ --direct=1 --iodepth=$depth --scramble_buffers=1 --offset=0 \ --size=100g done - 在各个数据点记录吞吐量和延迟,然后记录图形。
- 重复测试以完成四级测试:
--rw=randwrite、--rw=read和--rw=randread。
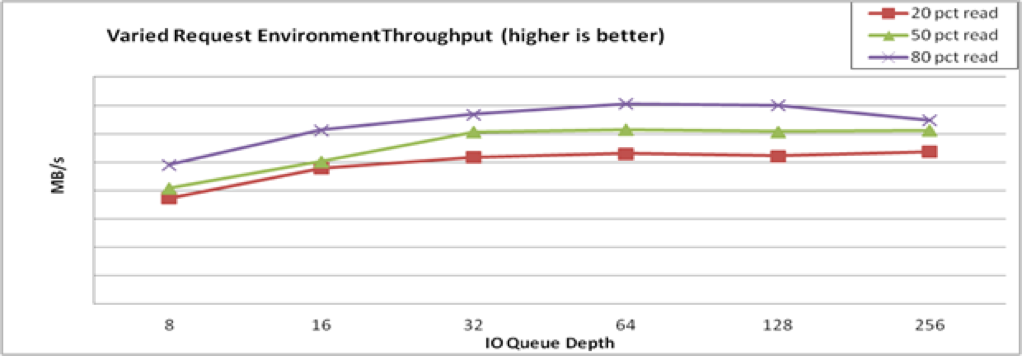
结果为图表,如下所示。感兴趣的点是跨范围的行为和 inflection 的点,其中增加了 I/O 深度,以降低吞吐量收益。顺序访问和随机访问将以不同值进行峰值,但适用于所有类型的存储配置。在 图 31.1 “I/O Depth Analysis” 中,注意每个性能曲线中的 "knee"。标记 1 标识 X 点的峰值顺序吞吐量,标记 2 标识 Z 点的峰值随机 4 KB 吞吐量。
- 这个特定设备不会从顺序 4 KB I/O depth > X 中受益。请注意,带宽带宽收益减少,平均请求延迟将增加每个额外 I/O 请求的 1:1。
- 这个特定设备不会从随机 4 KB I/O depth > Z 中获益。请注意,带宽收益会减少,平均请求延迟会增加每个额外 I/O 请求的 1:1。
图 31.1. I/O Depth Analysis
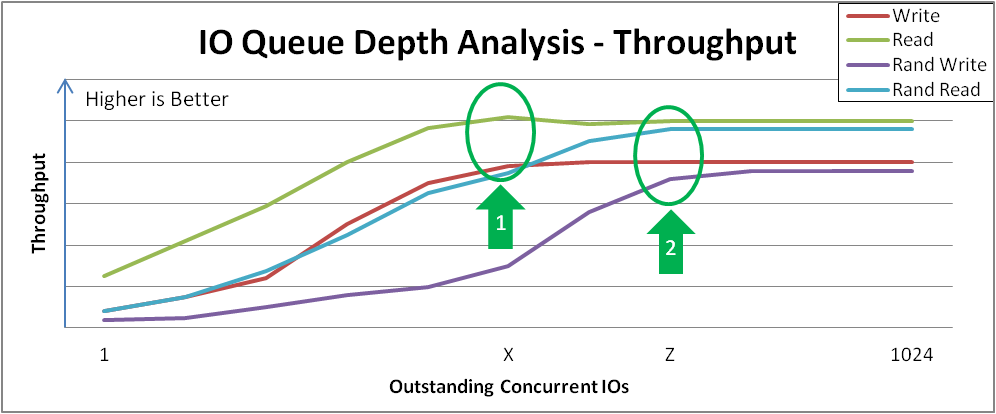
图 31.2 “为 Random Writes 增加 I/O 的延迟响应” 显示 图 31.1 “I/O Depth Analysis” 中 curve 的 "knee" 后随机写入延迟的示例。基准测试实践应在这些点上测试,以达到最低响应时间损失的最大吞吐量。当我们在这个示例设备的测试计划中转发时,我们将使用 I/O depth = Z 来收集其他数据
图 31.2. 为 Random Writes 增加 I/O 的延迟响应
31.4.2. 阶段 2: I/O 请求大小的影响
复制链接链接已复制到粘贴板!
此测试的目标是了解在上一步中确定的最佳 I/O 深度下测试下系统性能的块大小。
- 在固定 I/O 深度中执行四级测试,在范围 8 KB 到 1 MB 时,块大小有不同(2 的指数为 2)。请记住,要预先填充要读取的区域,并在测试之间重新创建卷。
- 将 I/O Depth 设置为 第 31.4.1 节 “阶段 1:I/O Depth 的影响,修正了 4 KB 块” 中决定的值。测试输入模拟器(写入)示例:
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 在各个数据点记录吞吐量和延迟,然后记录图形。
- 重复测试以完成四级测试:
--rw=randwrite、--rw=read和--rw=randread。
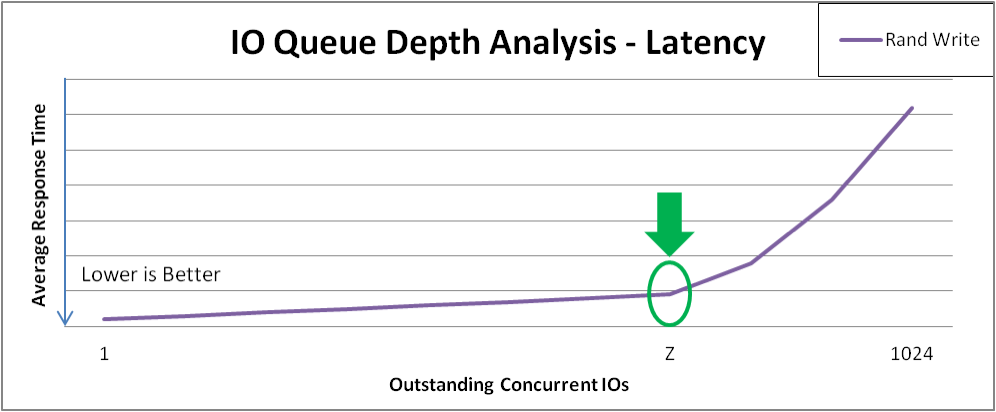
您可以发现结果有几点。在本例中:
- 顺序写入在请求大小 Y 时达到峰值吞吐量。此 curve 演示了可配置或自然地由特定请求大小划分的应用程序可能会感知性能。更大的请求大小通常会提供更多吞吐量,因为 4 KB I/O 可能会从合并中受益。
- 顺序读取在 Z 点达到类似的峰值吞吐量。请记住,在 I/O 完成后,I/O 完成后会增加一个类似的峰值吞吐量,而不会增加额外的吞吐量。将设备调优为不接受大于这个大小的 I/O 是明智的。
- 随机读取在 X 点达到峰值吞吐量。有些设备可能会在大型请求大小随机访问时达到近似的吞吐量率,而其他设备会在与纯顺序访问不同时受到更多的损失。
- 随机写入在 Y 点达到峰值吞吐量。随机写入涉及对去除重复设备的大多数交互,VDO 则实现高性能,特别是在请求大小和/或 I/O 深度较大时。
此测试 图 31.3 “请求大小与.吞吐量分析和密钥检查点” 的结果可帮助了解存储设备的特性以及特定应用程序的用户体验。向红帽销售工程师咨询,以确定是否有进一步调整,以在不同请求大小上提高性能。
图 31.3. 请求大小与.吞吐量分析和密钥检查点
31.4.3. 阶段 3:减少密集读和写 I/O 的影响
复制链接链接已复制到粘贴板!
此测试的目的是了解您的带有 VDO 的设备在混合 I/O 加载时的行为方式(读/写),分析读/写混合在最佳随机队列深度和请求大小从 4 KB 到 1 MB。您应该根据您的具体情况使用任何合适的内容。
- 在固定 I/O 深度中执行四级测试,在 8 KB 到 256 KB 的块大小(2 的指数)上进行四个测试,并以 10% 的增量设置读取百分比,从 0% 开始。请记住,要预先填充要读取的区域,并在测试之间重新创建卷。
- 将 I/O Depth 设置为 第 31.4.1 节 “阶段 1:I/O Depth 的影响,修正了 4 KB 块” 中决定的值。测试输入模拟(读/写混合)示例:
# z=[see previous step] # for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw --rwmixread=$readmix --bs=$iosize\k --name=vdo \ --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \ --norandommap --runtime=300 --direct=0 --iodepth=$z --scramble_buffers=1 \ --offset=0 --size=100g done done - 在各个数据点记录吞吐量和延迟,然后记录图形。
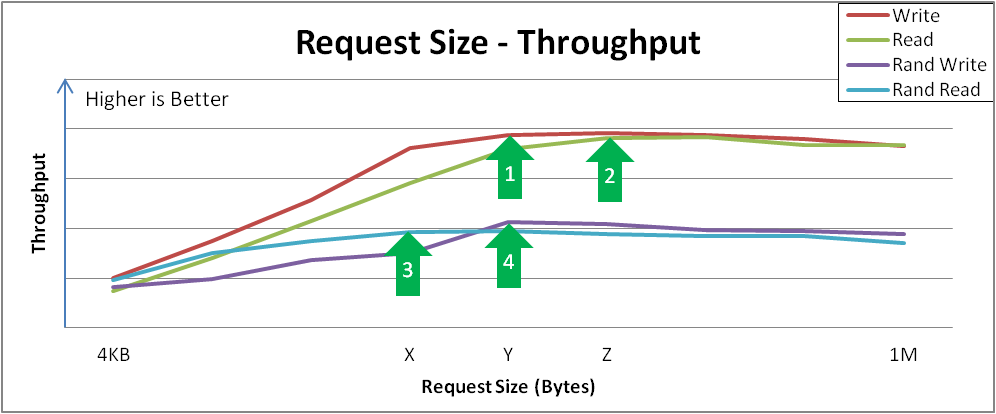
图 31.4 “跨 Varying Read/Write Mixes 的性能下降” 显示 VDO 如何响应 I/O 负载的示例:
图 31.4. 跨 Varying Read/Write Mixes 的性能下降
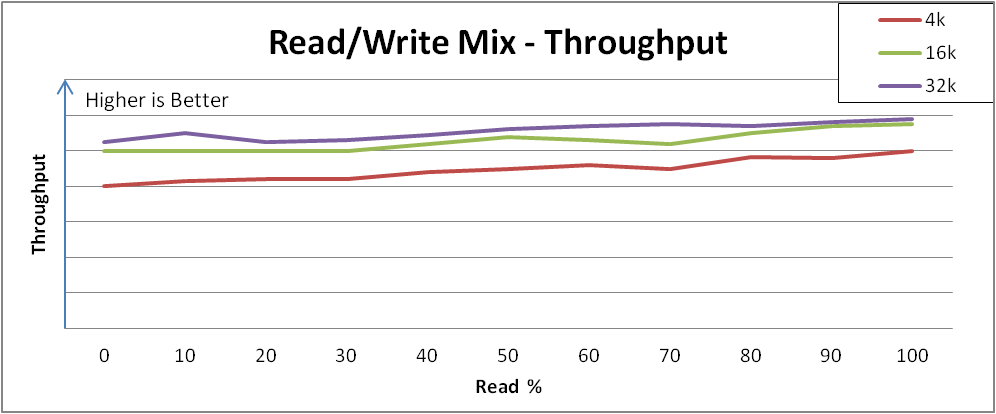
性能(aggregate)和延迟(aggregate)在混合的读取和写入范围之间相对一致,从较低最大写入吞吐量到更高的最大读吞吐量。
这个行为可能因不同的存储而异,但重要的观察是,在不同负载和/或下性能是,您可以了解演示特定读/写混合的应用程序的性能期望。如果您发现任何意外的结果,红帽销售工程师将可以帮助您了解它是否是 VDO 还是需要修改的存储设备。
注意: 没有呈现类似的响应一致性的系统通常会表示一个子优化配置。如果出现这种情况,请联络您的红帽销售工程师。
31.4.4. 阶段 4:应用程序环境
复制链接链接已复制到粘贴板!
这些最终测试的目的是了解在实际应用程序环境中部署时,使用 VDO 的系统的行为方式。如果可能,请使用实际应用程序并使用目前所学的知识;请考虑限制设备上允许的队列深度,如果可能,请调优应用以对这些块大小最有益于 VDO 性能的请求。
请求大小、I/O 负载、读/写模式等一般很难预测,因为它们会因应用程序用例(如文件与虚拟桌面与数据库)而异,并且应用程序通常因特定操作或多租户访问而不同。
最终测试显示了混合环境中的通用 VDO 性能。如果对预期环境有更具体的信息,还要测试这些设置。
测试输入模拟(读/写混合)示例:
# for readmix in 20 50 80; do
for iosize in 4 8 16 32 64 128 256 512 1024; do
fio --rw=rw --rwmixread=$readmix --bsrange=4k-256k --name=vdo \
--filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \
--norandommap --runtime=300 --direct=0 --iodepth=$iosize \
--scramble_buffers=1 --offset=0 --size=100g
done
done
在各个数据点记录吞吐量和延迟,然后记录图表(图 31.5 “混合环境性能”)。
图 31.5. 混合环境性能