此内容没有您所选择的语言版本。
9.5.3. Replicated Caches With Only One Cache Having A Store
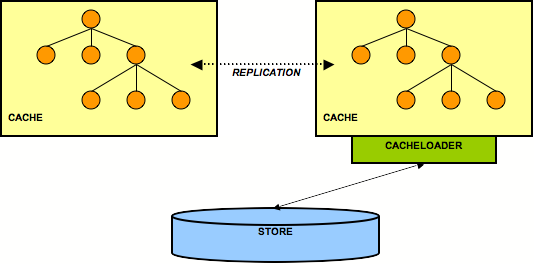
Figure 9.3. 2 nodes but only one accesses the back end store
This is a similar case to the previous one, but here only one node in the cluster interacts with a back end store via its cache loader. All other nodes perform in-memory replication. The idea here is all application state is kept in memory in each node, with the existence of multiple caches making the data highly available. (This assumes that a client that needs the data is able to somehow fail over from one cache to another.) The single persistent back end store then provides a backup copy of the data in case all caches in the cluster fail or need to be restarted.
Note that here it may make sense for the cache loader to store changes asynchronously, that is not on the caller's thread, in order not to slow down the cluster by accessing (for example) a database. This is a non-issue when using asynchronous replication.
A weakness with this architecture is that the cache with access to the cache loader becomes a single point of failure. Furthermore, if the cluster is restarted, the cache with the cache loader must be started first (easy to forget). A solution to the first problem is to configure a cache loader on each node, but set the
singletonStore configuration to true. With this kind of setup, one but only one node will always be writing to a persistent store. However, this complicates the restart problem, as before restarting you need to determine which cache was writing before the shutdown/failure and then start that cache first.