此内容没有您所选择的语言版本。
Chapter 3. Configuring the JBoss EAP for OpenShift Image for Your Java Application
The JBoss EAP for OpenShift image is preconfigured for basic use with your Java applications. However, you can configure the JBoss EAP instance inside the image. The recommended method is to use the OpenShift S2I process, together with application template parameters and environment variables.
Any configuration changes made on a running container will be lost when the container is restarted or terminated.
This includes any configuration changes made using scripts that are included with a traditional JBoss EAP installation, for example add-user.sh or the management CLI.
It is strongly recommended that you use the OpenShift S2I process, together with application template parameters and environment variables, to make any configuration changes to the JBoss EAP instance inside the JBoss EAP for OpenShift image.
3.1. How the JBoss EAP for OpenShift S2I Process Works
The variable EAP_HOME is used to denote the path to the JBoss EAP installation inside the JBoss EAP for OpenShift image.
The S2I process for JBoss EAP for OpenShift works as follows:
If a
pom.xmlfile is present in the source code repository, a Maven build process is triggered that uses the contents of the$MAVEN_ARGSenvironment variable.Although you can specify custom Maven arguments or options with the
$MAVEN_ARGSenvironment variable, Red Hat recommends that you use the$MAVEN_ARGS_APPENDenvironment variable to do this. The$MAVEN_ARGS_APPENDvariable takes the default arguments from$MAVEN_ARGSand appends the options from$MAVEN_ARGS_APPENDto it.By default, the OpenShift profile uses the Maven
packagegoal, which includes system properties for skipping tests (-DskipTests) and enabling the Red Hat GA repository (-Dcom.redhat.xpaas.repo).NoteTo use Maven behind a proxy on JBoss EAP for OpenShift image, set the
$HTTP_PROXY_HOSTand$HTTP_PROXY_PORTenvironment variables. Optionally, you can also set the$HTTP_PROXY_USERNAME,HTTP_PROXY_PASSWORD, andHTTP_PROXY_NONPROXYHOSTSvariables.-
The results of a successful Maven build are copied to the
EAP_HOME/standalone/deployments/directory inside the JBoss EAP for OpenShift image. This includes all JAR, WAR, and EAR files from the source repository specified by the$ARTIFACT_DIRenvironment variable. The default value of$ARTIFACT_DIRis the Maven target directory. -
All files in the
configurationsource repository directory are copied to theEAP_HOME/standalone/configuration/directory inside the JBoss EAP for OpenShift image. If you want to use a custom JBoss EAP configuration file, it should be namedstandalone-openshift.xml. -
All files in the
modulessource repository directory are copied to theEAP_HOME/modules/directory inside the JBoss EAP for OpenShift image.
See Artifact Repository Mirrors for additional guidance on how to instruct the S2I process to utilize the custom Maven artifacts repository mirror.
Using environment variables is the recommended method of configuring the JBoss EAP for OpenShift image. See the OpenShift documentation for instructions on specifying environment variables for application containers and build containers.
For example, you can set the JBoss EAP instance’s management username and password using environment variables when creating your OpenShift application:
Available environment variables for the JBoss EAP for OpenShift image are listed in Reference Information.
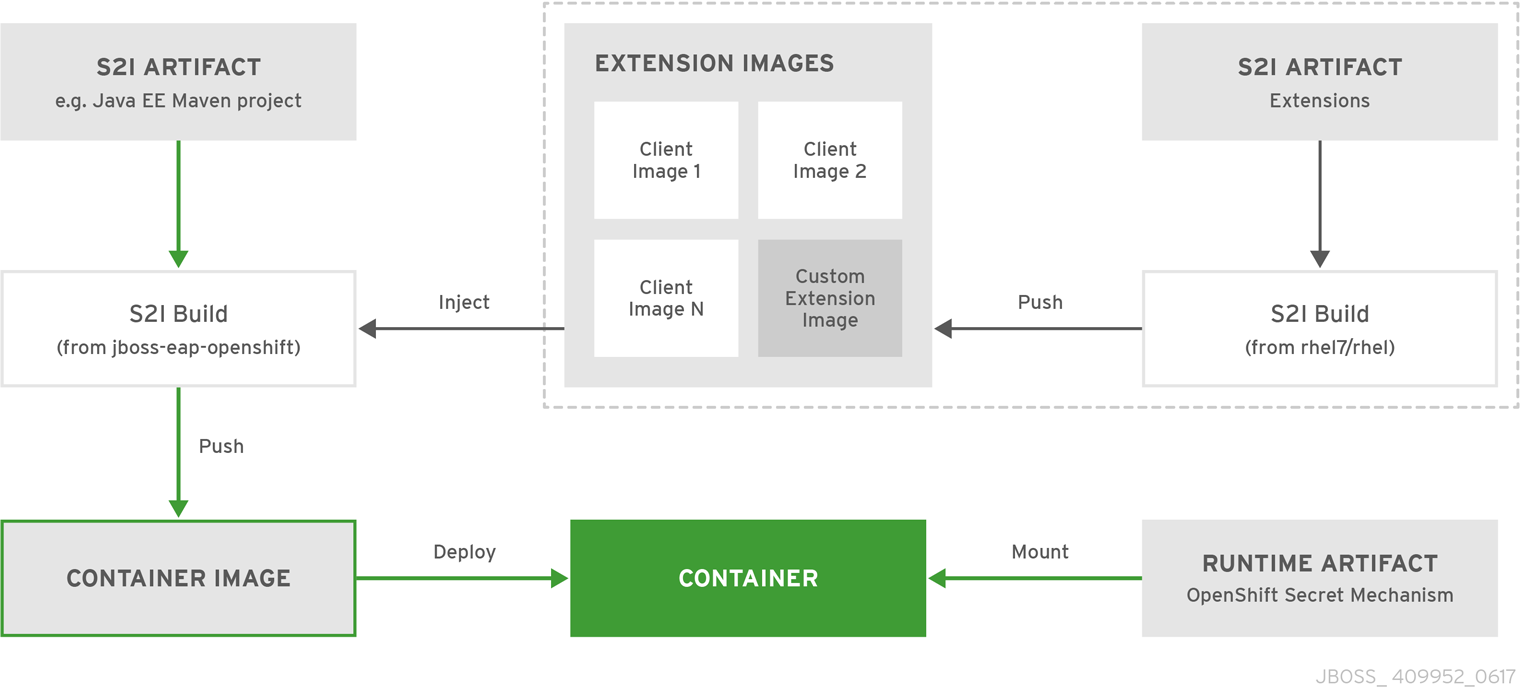
3.3. Build Extensions and Project Artifacts
The JBoss EAP for OpenShift image extends database support in OpenShift using various artifacts. These artifacts are included in the built image through different mechanisms:
- S2I artifacts that are injected into the image during the S2I process.
- Runtime artifacts from environment files provided through the OpenShift Secret mechanism.
Support for using the Red Hat-provided internal datasource drivers with the JBoss EAP for OpenShift image is now deprecated for JDK 8 image streams. It is recommended that you use JDBC drivers obtained from your database vendor for your JBoss EAP applications.
The following internal datasources are no longer provided with the JBoss EAP for OpenShift JDK 11 image:
- MySQL
- PostgreSQL
For more information about installing drivers, see Modules, Drivers, and Generic Deployments.
For more information on configuring JDBC drivers with JBoss EAP, see JDBC drivers in the JBoss EAP Configuration Guide.
3.3.1. S2I Artifacts
The S2I artifacts include modules, drivers, and additional generic deployments that provide the necessary configuration infrastructure required for the deployment. This configuration is built into the image during the S2I process so that only the datasources and associated resource adapters need to be configured at runtime.
See Artifact Repository Mirrors for additional guidance on how to instruct the S2I process to utilize the custom Maven artifacts repository mirror.
3.3.1.1. Modules, Drivers, and Generic Deployments
There are a few options for including these S2I artifacts in the JBoss EAP for OpenShift image:
- Include the artifact in the application source deployment directory. The artifact is downloaded during the build and injected into the image. This is similar to deploying an application on the JBoss EAP for OpenShift image.
Include the
CUSTOM_INSTALL_DIRECTORIESenvironment variable, a list of comma-separated list of directories used for installation and configuration of artifacts for the image during the S2I process. There are two methods for including this information in the S2I:An
install.shscript in the nominated installation directory. The install script executes during the S2I process and operates with impunity.install.shScript ExampleCopy to Clipboard Copied! Toggle word wrap Toggle overflow The
install.shscript is responsible for customizing the base image using APIs provided byinstall-common.sh.install-common.shcontains functions that are used by theinstall.shscript to install and configure the modules, drivers, and generic deployments.Functions contained within
install-common.sh:-
install_modules -
configure_drivers install_deploymentsModules
A module is a logical grouping of classes used for class loading and dependency management. Modules are defined in the
EAP_HOME/modules/directory of the application server. Each module exists as a subdirectory, for exampleEAP_HOME/modules/org/apache/. Each module directory then contains a slot subdirectory, which defaults to main and contains themodule.xmlconfiguration file and any required JAR files.For more information about configuring
module.xmlfiles for MySQL and PostgreSQL JDBC drivers, see the Datasource Configuration Examples in the JBoss EAP Configuration Guide.Example
module.xmlFileCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
module.xmlFile for PostgreSQL DatasourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
module.xmlFile for MySQL Connect/J 8 DatasourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow NoteThe ".Z" in
mysql-connector-java-8.0.Z.jarindicates the version of theJARfile downloaded. The file can be renamed, but the name must match the name in themodule.xmlfile.The
install_modulesfunction ininstall.shcopies the respective JAR files to the modules directory in JBoss EAP, along with themodule.xml.Drivers
Drivers are installed as modules. The driver is then configured in
install.shby theconfigure_driversfunction, the configuration properties for which are defined in a runtime artifact environment file.Example
drivers.envFileCopy to Clipboard Copied! Toggle word wrap Toggle overflow The MySQL and PostgreSQL datasources are no longer provided as pre-configured internal datasources. However, these drivers can still be installed as modules as described in Modules, Drivers, and Generic Deployments.
The mechanism follows the
Derbydriver example and uses S2I artifacts. Create adrivers.envfile for each datasource to be installed.Example
drivers.envFile for MySQL DatasourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example
drivers.envFile for PostgreSQL DatasourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow For information about download locations for various drivers, such as MySQL or PostgreSQL, see JDBC Driver Download Locations in the Configuration Guide.
-
Generic Deployments
Deployable archive files, such as JARs, WARs, RARs, or EARs, can be deployed from an injected image using the install_deployments function supplied by the API in install-common.sh.
If the
CUSTOM_INSTALL_DIRECTORIESenvironment variable has been declared but noinstall.shscripts are found in the custom installation directories, the following artifact directories will be copied to their respective destinations in the built image:-
modules/*copied to$JBOSS_HOME/modules/system/layers/openshift -
configuration/*copied to$JBOSS_HOME/standalone/configuration -
deployments/*copied to$JBOSS_HOME/standalone/deployments
This is a basic configuration approach compared to the
install.shalternative, and requires the artifacts to be structured appropriately.-
3.3.2. Runtime Artifacts
3.3.2.1. Datasources
There are three types of datasources:
- Default internal datasources. These are PostgreSQL, MySQL, and MongoDB. These datasources are available on OpenShift by default through the Red Hat Registry and do not require additional environment files to be configured for JDK 8 image streams. Set the DB_SERVICE_PREFIX_MAPPING environment variable to the name of the OpenShift service for the database to be discovered and used as a datasource.
- Other internal datasources. These are datasources not available by default through the Red Hat Registry but run on OpenShift. Configuration of these datasources is provided by environment files added to OpenShift Secrets.
- External datasources that are not run on OpenShift. Configuration of external datasources is provided by environment files added to OpenShift Secrets.
Example: Datasource Environment File
The DATASOURCES property is a comma-separated list of datasource property prefixes. These prefixes are then appended to all properties for that datasource. Multiple datasources can then be included in a single environment file. Alternatively, each datasource can be provided in separate environment files.
Datasources contain two types of properties: connection pool-specific properties and database driver-specific properties. Database driver-specific properties use the generic XA_CONNECTION_PROPERTY, because the driver itself is configured as a driver S2I artifact. The suffix of the driver property is specific to the particular driver for the datasource.
In the above example, ACCOUNTS is the datasource prefix, XA_CONNECTION_PROPERTY is the generic driver property, and DatabaseName is the property specific to the driver.
The datasources environment files are added to the OpenShift Secret for the project. These environment files are then called within the template using the ENV_FILES environment property, the value of which is a comma-separated list of fully qualified environment files as shown below.
{
“Name”: “ENV_FILES”,
“Value”: “/etc/extensions/datasources1.env,/etc/extensions/datasources2.env”
}
{
“Name”: “ENV_FILES”,
“Value”: “/etc/extensions/datasources1.env,/etc/extensions/datasources2.env”
}3.3.2.2. Resource Adapters
Configuration of resource adapters is provided by environment files added to OpenShift Secrets.
| Attribute | Description |
|---|---|
| PREFIX_ID | The identifier of the resource adapter as specified in the server configuration file. |
| PREFIX_ARCHIVE | The resource adapter archive. |
| PREFIX_MODULE_SLOT |
The slot subdirectory, which contains the |
| PREFIX_MODULE_ID | The JBoss Module ID where the object factory Java class can be loaded from. |
| PREFIX_CONNECTION_CLASS | The fully qualified class name of a managed connection factory or admin object. |
| PREFIX_CONNECTION_JNDI | The JNDI name for the connection factory. |
| PREFIX_PROPERTY_ParentDirectory | Directory where the data files are stored. |
| PREFIX_PROPERTY_AllowParentPaths |
Set |
| PREFIX_POOL_MAX_SIZE | The maximum number of connections for a pool. No more connections will be created in each sub-pool. |
| PREFIX_POOL_MIN_SIZE | The minimum number of connections for a pool. |
| PREFIX_POOL_PREFILL | Specifies if the pool should be prefilled. Changing this value requires a server restart. |
| PREFIX_POOL_FLUSH_STRATEGY |
How the pool should be flushed in case of an error. Valid values are: |
The RESOURCE_ADAPTERS property is a comma-separated list of resource adapter property prefixes. These prefixes are then appended to all properties for that resource adapter. Multiple resource adapter can then be included in a single environment file. In the example below, MYRA is used as the prefix for a resource adapter. Alternatively, each resource adapter can be provided in separate environment files.
Example: Resource Adapter Environment File
The resource adapter environment files are added to the OpenShift Secret for the project namespace. These environment files are then called within the template using the ENV_FILES environment property, the value of which is a comma-separated list of fully qualified environment files as shown below.
{
"Name": "ENV_FILES",
"Value": "/etc/extensions/resourceadapter1.env,/etc/extensions/resourceadapter2.env"
}
{
"Name": "ENV_FILES",
"Value": "/etc/extensions/resourceadapter1.env,/etc/extensions/resourceadapter2.env"
}3.4.1. Scaling Up and Persistent Storage Partitioning
There are two methods for deploying JBoss EAP with persistent storage: single-node partitioning, and multi-node partitioning.
Single-node partitioning stores the JBoss EAP data store directory, including transaction data, in the storage volume.
Multi-node partitioning creates additional, independent split-n directories to store the transaction data for each JBoss EAP pod, where n is an incremental integer. This communication is not altered if a JBoss EAP pod is updated, goes down unexpectedly, or is redeployed. When the JBoss EAP pod is operational again, it reconnects to the associated split directory and continues as before. If a new JBoss EAP pod is added, a corresponding split-n directory is created for that pod.
To enable the multi-node configuration you must set the SPLIT_DATA parameter to true. This results in the server creating independent split-n directories for each instance within the persistent volume which are used as their data store.
This is now the default setting in the eap72-tx-recovery-s2i template.
Due to the different storage methods of single-node and multi-node partitioning, changing a deployment from single-node to multi-node results in the application losing all data previously stored in the data directory, including messages, transaction logs, and so on. This is also true if changing a deployment from multi-node to single-node, as the storage paths will not match.
3.4.2. Scaling Down and Transaction Recovery
When the JBoss EAP for OpenShift image is deployed using a multi-node configuration, it is possible for unexpectedly terminated transactions to be left in the data directory of a terminating pod if the cluster is scaled down.
In order to prevent transactions from remaining within the data store of the terminating pod until the cluster next scales up, the eap72-tx-recovery-s2i JBoss EAP template creates a second deployment containing a migration pod that is responsible for managing the migration of transactions. The migration pod scans each independent split-n directory within the JBoss EAP persistent volume, identifies data stores associated with the pods that are terminating, and continues to run until all transactions on the terminating pod are completed.
Since the persistent volume needs to be accessed in read-write mode by both the JBoss EAP application pod and the migration pod, it needs to be created with the ReadWriteMany access mode. This access mode is currently only supported for persistent volumes using GlusterFS and NFS plug-ins. For details, see the Supported Access Modes for Persistent Volumes table.
For more information, see Example Workflow: Automated Transaction Recovery Feature When Scaling Down a Cluster, which demonstrates the automated transaction recovery feature of the JBoss EAP for OpenShift image when scaling down a cluster.